Здравствуйте, hi_octane, Вы писали:
_>Ну во-первых детям очень рано показывают настоящих животных в движении. Это буквально сотни-тысячи кадров стерео-видео в минуту. Обучать детей только на статических фотографиях никто не пробовал. Возможно, в обучении на 2D-статике, мы уже хуже ИИ.
Да, показывают. Да, сотни-тысячи кадров. Но одного или нескольких котов. А не сотен тысяч. А с собаками еще хуже. Кошки все друг на друга, в общем, похожи, а вот такса на бульдога не очень.
PD>>Есть такие ? _>А ты читал мои примеры? Ведь каждый что я приводил — однозначно говорит о том что фундаментально ограничение "нужны миллионы фоток/видео/звуков" уже давно пройдено. И для фото, и для звуков, и для видео. Дай современной ИИ-хе типа qwen3 vl на вход две картинки — на одной выдуманное животное, а на другой фото на котором оно или есть или нет (в другом ракурсе), и попроси найти это животное. С огромной вероятностью она сделает это правильно. Более того, тот же qwen edit 2509 или Wan 2.2 i2v, возьмёт картинку с твоим выдуманным животным (которое она никогда не видела), и сделает следующие кадры с сохранением деталей. Т.е. буквально с одного предъявления поймёт ключевые фичи твоего выдуманного существа, с глубиной, достаточной для воспроизведения.
Это опять же операции надо имеющимися данными, пусть и трансформация их сколь угодно сложная. Или сравнение двух экземпляров данных. Найти какие-то фичи, определяющие эти данные. Это понятно как делать, хотя бы в принципе. А я говорю о произвольном заранее не заданном наборе данных, который нужно отнести к одному из двух классов.
Простое упрощение.
Твои примеры.
На входе строка, на втором входе текст, который ее содержит. Найти, есть он там или нет. Простая задача.
Модифицировать эту строку по каким-то алгоритмам. Ну не так просто, но понятно.
А моя задача
Даны строка. Классифицировать ее как относящуюся к одному из двух классов при том, что экземпляров этих классов было дано до этого штук 20-30. И больше ничего не использовать. А по каким критериям эти 2 референтных набора сформированы — не знаю. Решай сам, как хочешь.
В общем, пока я не увижу сайт (или что угодно), где будет почти 100% опознание кошек от собак — не поверю. И чтобы там не было обучения на сотнях тысяч . Будет такое, смогу попробовать и проверить — тогда поверю. Тестовых данных у меня сколько угодно
_>Ты сейчас рассуждаешь на уровне "ваш паровой двигатель фигня, потому что не обгоняет самую быструю лошадь". В то время как теоретическая возможность обогнать любую лошадь инженерам уже очевидна (всегда есть 10-15% непредвиденных проблем). Именно от уверенности в результате, такая безумная гонка бюджетов и строек дата-центров.
И тем не менее пока он не обгоняет лошадь я имею право оставаться при своем мнении насчет его возможностей. Бог его знает, обгонит или нет, несмотря на все теоретические возможности. Вот обгонит — поменяю мнение. Но не раньше.
PD>>Но никакой ребенок не будет под микроскопом или даже без него пристально эту структуру рассматривать. Просто взглянет и скажет — кис-кис. _>А ещё часть детей и взрослых шарахается от всего похожего на змею под ногами и боится пауков. А ещё вспомним что у нас с рождения захардкожены алгоритмы распознавания человеческих лиц, эмоций, отслеживания направления чужого взгляда. Вполне может быть что мы и собачек с кошечками, и птичек, и вообще типовую фауну очень даже распознаём "от природы", хардкодом. А быстрое обучение сводится к тому какими звуками обозначать "ощущение кота".
Тут не знаю, что и сказать. Нет у меня уверенности, что такое захардкожено, но и противоположное отстаивать уверенно нет оснований.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>А моя задача
PD>Даны строка. Классифицировать ее как относящуюся к одному из двух классов при том, что экземпляров этих классов было дано до этого штук 20-30. И больше ничего не использовать. А по каким критериям эти 2 референтных набора сформированы — не знаю. Решай сам, как хочешь.
Ключевое заблуждение, которое вы настойчиво продолжаете исповедовать — это "и больше ничего не использовать".
Вот я дам вам два класса строк:
1: рей, ичи, хито, ни, сан, йон, ши, го, року, шичи, хачи, ку, джу
2: ака, ao, сиро, мидори, кииро, мурасаки, гурээ, тяиро, ханада
Это, естественно, не полные описания классов.
Слово "куро" к какому из этих классов относится — сможете угадать, "ничего больше не используя"?
Хорошо, а теперь так:
1: воробей, утка, ворона, галка, дрозд
2: скарабей, богомол, паук, муравей, пчела
К какому классу относится "муха"?
PD>В общем, пока я не увижу сайт (или что угодно), где будет почти 100% опознание кошек от собак — не поверю. И чтобы там не было обучения на сотнях тысяч . Будет такое, смогу попробовать и проверить — тогда поверю. Тестовых данных у меня сколько угодно
Повторю очевидную для всех, кроме вас, мысль: без обучения ничего не получится.
PD>И тем не менее пока он не обгоняет лошадь я имею право оставаться при своем мнении насчет его возможностей.
Да вы и после этого имеете право оставаться при своём мнении .
PD>Тут не знаю, что и сказать. Нет у меня уверенности, что такое захардкожено, но и противоположное отстаивать уверенно нет оснований.
Это потому, что нужно не гадать, а читать исследования когнитивных психологов. В отличие от ваших воображаемых экспериментов с детьми, которые "никогда не видели никаких животных и после одной картинки отличают кошку от собаки", у них есть воспроизводимые, нетривиальные, и зачастую контр-интутивные результаты.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Sinclair, Вы писали:
S>Вот я дам вам два класса строк: S>1: рей, ичи, хито, ни, сан, йон, ши, го, року, шичи, хачи, ку, джу S>2: ака, ao, сиро, мидори, кииро, мурасаки, гурээ, тяиро, ханада S>Это, естественно, не полные описания классов.
S>Слово "куро" к какому из этих классов относится — сможете угадать, "ничего больше не используя"?
Этого языка я не знаю, если это слова вообще какого-то языка. Так что пример не годится. Я не предлагаю классифицировать незнакомое. Я предлагаю решить задачу отличить кошек от собак. Вполне реальные фото.
S>Хорошо, а теперь так: S>1: воробей, утка, ворона, галка, дрозд S>2: скарабей, богомол, паук, муравей, пчела S>К какому классу относится "муха"?
Отличный пример. Чтобы понять, что у них общего, нужно знать, что это представители классов птиц или членистоногих.
Вот только 5-летний ребенок, может, про птиц уже что-то знает, а про членистоногих пока что ничего. Зоологию , кажется, в 6 классе изучают. А уж отличия с точки зрения зоологии пауков и мух-пчел тем более. Да и само слово "зоология" тоже не знает.
Так что привлечь эти данные ребенок не сможет. А вот никого из (2) не отнесет к птицам, и наоборот. Хотя и не уверен, что всех (2) он объединит в нечто общее в своем сознании. Возможно, в его сознании это разные типы. Кстати, раков (если он их увидит), он к (2) не отнесет почти наверняка. Для меня , помню, было открытием в курсе зоологии, что, оказывается, раки и мухи одного класса.
PD>>В общем, пока я не увижу сайт (или что угодно), где будет почти 100% опознание кошек от собак — не поверю. И чтобы там не было обучения на сотнях тысяч . Будет такое, смогу попробовать и проверить — тогда поверю. Тестовых данных у меня сколько угодно S>Повторю очевидную для всех, кроме вас, мысль: без обучения ничего не получится.
Спокойно, спокойно . Я вовсе и не утверждаю, что можно без обучения. ЕИ именно на основе обучения и работает. Показали ему десятка два представителей кошек и столько же собак — он и обучился. И не надо ему было сотен тысяч и всяких гига и терабайт. Он прекрасно этому учился, когда не то , что байт не было, а и письменности тоже. Пещерные люди, думаю, их вполне отличать могли . А картинок тогда практически не было , да и кошек и собак в племени было хорошо если несколько десятков. Интернета тоже не было
PD>>И тем не менее пока он не обгоняет лошадь я имею право оставаться при своем мнении насчет его возможностей. S>Да вы и после этого имеете право оставаться при своём мнении .
Разумеется. Каждый вправе это делать
PD>>Тут не знаю, что и сказать. Нет у меня уверенности, что такое захардкожено, но и противоположное отстаивать уверенно нет оснований. S>Это потому, что нужно не гадать, а читать исследования когнитивных психологов. В отличие от ваших воображаемых экспериментов с детьми, которые "никогда не видели никаких животных и после одной картинки отличают кошку от собаки", у них есть воспроизводимые, нетривиальные, и зачастую контр-интутивные результаты.
Я и не гадаю. Я просто ответил — не знаю. На это я тоже имею право
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Этого языка я не знаю, если это слова вообще какого-то языка. Так что пример не годится. Я не предлагаю классифицировать незнакомое. Я предлагаю решить задачу отличить кошек от собак. Вполне реальные фото.
Ну вот видите. А только что вы предлагали дословно следующее:
Дана строка. Классифицировать ее как относящуюся к одному из двух классов при том, что экземпляров этих классов было дано до этого штук 20-30. И больше ничего не использовать. А по каким критериям эти 2 референтных набора сформированы — не знаю. Решай сам, как хочешь.
Внезапно выясняется, что естественный интеллект категорически неспособен решить эту задачу. Что если у вас забрать ваш лингвистический опыт, то вы ничего не наклассифицируете.
Кстати, ИИ прекрасно решает задачку прямо в той формулировке, которую я процитировал.
PD>Отличный пример. Чтобы понять, что у них общего, нужно знать, что это представители классов птиц или членистоногих. PD>Вот только 5-летний ребенок, может, про птиц уже что-то знает, а про членистоногих пока что ничего. Зоологию , кажется, в 6 классе изучают. А уж отличия с точки зрения зоологии пауков и мух-пчел тем более. Да и само слово "зоология" тоже не знает. PD>Так что привлечь эти данные ребенок не сможет. PD>А вот никого из (2) не отнесет к птицам, и наоборот. Хотя и не уверен, что всех (2) он объединит в нечто общее в своем сознании. Возможно, в его сознании это разные типы. Кстати, раков (если он их увидит), он к (2) не отнесет почти наверняка. Для меня , помню, было открытием в курсе зоологии, что, оказывается, раки и мухи одного класса.
Задачки на "вычеркни лишнее" начинаются с детского сада. И даже в средней школе далеко не все дети способы верно "классифицировать строку". Потому что для этого требуется нетривиально обученная нейросеть.
Нет никаких чудес. Естественный интеллект пользуется не двумя наборами из 20 строк каждый, а всем своим колоссальным предыдущим опытом. Вы, Павел, почему-то недооцениваете этот опыт. Отсюда ваши иллюзии, что естественный интеллект какой-то магией способен миновать стадию обучения и сразу же начать классифицировать. Нет. Совершенно необязательно знать зоологию — но отличать "птиц" от "козявочек" всё же нужно.
PD>Спокойно, спокойно . Я вовсе и не утверждаю, что можно без обучения. ЕИ именно на основе обучения и работает. Показали ему десятка два представителей кошек и столько же собак — он и обучился.
НЕТ! Я же вам показал пример — почему вы не обучились языку на двух десятках представителей?
И ребёнок обучается не на двух десятках картинок, а на непрерывном потоке информации, который в него льётся всё время, пока он не спит.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Sinclair, Вы писали:
S>Задачки на "вычеркни лишнее" начинаются с детского сада. И даже в средней школе далеко не все дети способы верно "классифицировать строку". Потому что для этого требуется нетривиально обученная нейросеть. S>Нет никаких чудес. Естественный интеллект пользуется не двумя наборами из 20 строк каждый, а всем своим колоссальным предыдущим опытом. Вы, Павел, почему-то недооцениваете этот опыт. Отсюда ваши иллюзии, что естественный интеллект какой-то магией способен миновать стадию обучения и сразу же начать классифицировать. Нет. Совершенно необязательно знать зоологию — но отличать "птиц" от "козявочек" всё же нужно.
PD>>Спокойно, спокойно . Я вовсе и не утверждаю, что можно без обучения. ЕИ именно на основе обучения и работает. Показали ему десятка два представителей кошек и столько же собак — он и обучился. S>НЕТ! Я же вам показал пример — почему вы не обучились языку на двух десятках представителей?
Потому что я вовсе не утверждаю, что это всегда возможно. Я просто привел пример, когда это возможно. Кошки и собаки.
S>И ребёнок обучается не на двух десятках картинок, а на непрерывном потоке информации, который в него льётся всё время, пока он не спит.
На непрерывном потоке, говорите. Допустим. Вот Вам другой пример.
Представьте себе человека (пусть и не ребенка), который ничего не знает про Австралию. Сейчас такого человека найти сложно, ну пусть речь идет о человеке середины 19 века. Интеллект его был тот же, а вот информированность хуже намного. Едва ли сибирские крестьяне 1850 года что-то знали про Австралию.
И вот этому человеку, который прекрасно знает про кошек и собак, а также волков, медведей и рысей, овец и коз, показывают пару десятков картинок , на которых изображены коала и кенгуру. И говорят, что вот эти называются кенгуру, а эти — коала. Посмотрит он на них, и запомнит, как они выглядят. И если потом ему покажут еще одну картинку с ними, он без труда их опознает. Собственно, так оно и есть с нынешним человеком. Не помню, видел ли я живого кенгуру. Живого коала точно не видел.
И не перепутает он коала с бурым медведем, а кенгуру с козой. Хотя они в чем-то похожи.
На каком непрерывном потоке он обучился в данном конкретном случае ? Да, он давно обучился на непрерывном потоке понимать, что такое животное, какие у него повадки и т.д. И если бы я сказал, что он их определит как животных — тут да, можно было бы возразить, что он использует ранее накопленные знания. Но я не об этом. Я о том, что он их теперь опознает именно как коала и кенгуру.
И генная память, если она есть, тут тоже не поможет. Ни один из предков этого человека 1850 года никогда ничего не слышал ни про коала, ни про кенгуру. И не видел их.
А теперь рассмотрим иной пример. Мысленно, конечно.
Предположим, что создана версия ChatGPT, обученная на тех же терабайтах и петабайтах, но с одним отличием. При обучении жестко отсекались все источники, которые хоть прямо, хоть косвенно относятся к Австралии.
Эта версия, в общем, будет владеть почти той же информацией, что и реальная, во всем остальном. Если бы я предложил Европу или США исключить — получилась бы явно ущербная версия, да. А исключить Австралию — в основном останется почти то же. Она не центр мира. Если бы ее вообще не было — мир был бы примерно тем же.
И вот этой модифицированной версии ChatGPT дают ту же пару десятков картинок , на которых изображены коала и кенгуру. Больше ничего не дают, как и тому человеку 1850 года. А потом предлагают их опознать на тестовом наборе фотографий, где они есть.
Здравствуйте, hi_octane, Вы писали:
_>А ещё часть детей и взрослых шарахается от всего похожего на змею под ногами и боится пауков. А ещё вспомним что у нас с рождения захардкожены алгоритмы распознавания человеческих лиц, эмоций, отслеживания направления чужого взгляда. Вполне может быть что мы и собачек с кошечками, и птичек, и вообще типовую фауну очень даже распознаём "от природы", хардкодом. А быстрое обучение сводится к тому какими звуками обозначать "ощущение кота".
Подумал. Возможно, где-то и да, но в общем случае нет.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>На непрерывном потоке, говорите. Допустим. Вот Вам другой пример.
PD>Представьте себе человека (пусть и не ребенка), который ничего не знает про Австралию. Сейчас такого человека найти сложно, ну пусть речь идет о человеке середины 19 века. Интеллект его был тот же, а вот информированность хуже намного. Едва ли сибирские крестьяне 1850 года что-то знали про Австралию.
PD>И вот этому человеку, который прекрасно знает про кошек и собак, а также волков, медведей и рысей, овец и коз, показывают пару десятков картинок , на которых изображены коала и кенгуру. И говорят, что вот эти называются кенгуру, а эти — коала. Посмотрит он на них, и запомнит, как они выглядят. И если потом ему покажут еще одну картинку с ними, он без труда их опознает. Собственно, так оно и есть с нынешним человеком. Не помню, видел ли я живого кенгуру. Живого коала точно не видел.
PD>И не перепутает он коала с бурым медведем, а кенгуру с козой. Хотя они в чем-то похожи.
PD>На каком непрерывном потоке он обучился в данном конкретном случае ? Да, он давно обучился на непрерывном потоке понимать, что такое животное, какие у него повадки и т.д. И если бы я сказал, что он их определит как животных — тут да, можно было бы возразить, что он использует ранее накопленные знания. Но я не об этом. Я о том, что он их теперь опознает именно как коала и кенгуру.
Конечно же он использует ранее накопленные знания. Эти знания, в первую очередь, позволяют ему видеть не "картинку" в виде мешанины мегапикселов, а сразу набор фич. Вроде длины и цвета шерсти, формы головы, конечностей, и так далее. Пара десятков картинок — как раз достаточно для того, чтобы выделить значимые признаки и подавить незначимые.
Точно так же, как при классификации слов вы используете все свои предыдущие знания.
PD>Будет почти 100% ? Не думаю.
Павел, мысленные эксперименты можно проводить только на заведомо исправном оборудовании
Вы лучше попробуйте. Сгенерируйте наборы картинок для зверей, несуществующих в природе, и проверьте.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
PD>>На каком непрерывном потоке он обучился в данном конкретном случае ? Да, он давно обучился на непрерывном потоке понимать, что такое животное, какие у него повадки и т.д. И если бы я сказал, что он их определит как животных — тут да, можно было бы возразить, что он использует ранее накопленные знания. Но я не об этом. Я о том, что он их теперь опознает именно как коала и кенгуру. S>Конечно же он использует ранее накопленные знания. Эти знания, в первую очередь, позволяют ему видеть не "картинку" в виде мешанины мегапикселов, а сразу набор фич. Вроде длины и цвета шерсти, формы головы, конечностей, и так далее. Пара десятков картинок — как раз достаточно для того, чтобы выделить значимые признаки и подавить незначимые.
C этим вполне согласен. Именно так. А вот как именно это он делает — непонятно. Более того, совсем не уверен, что это вообще делается им алгоритмически, а значит, в принципе алгоритмизируемо.
PD>>Будет почти 100% ? Не думаю. S>Павел, мысленные эксперименты можно проводить только на заведомо исправном оборудовании
Уходите от ответа. Такую версию ChatGPT создать вполне можно.
Почему все же этот человек 1850 года, используя весь свой накопленный опыт, сможет на двух десятках картинок обучиться и давать потом почти 100% надежные ответы, а ChatGPT не сможет ?
В этом-то и вопрос.
S>Вы лучше попробуйте. Сгенерируйте наборы картинок для зверей, несуществующих в природе, и проверьте.
А вот об этом я не говорил, и ничего не утверждал. Хотя... Единорога он (человек) тоже опознает, хоть он и не существует. И дракона, хотя тут сложнее — драконы бывают разные
Сгенерированные не совсем подходят. Единорог сгенерирован человеческим интеллектом, так что он очень похож на реальное существо. Дракон тоже, хотя тут более буйная фантазия ЕИ. А сгенерировать машинным интеллектом — это порочный круг, так как в основу генерации будут заложены те же по сути алгоритмы.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>C этим вполне согласен. Именно так. А вот как именно это он делает — непонятно. Более того, совсем не уверен, что это вообще делается им алгоритмически, а значит, в принципе алгоритмизируемо.
Вполне себе алгоритмически. Магии не существует.
PD>Уходите от ответа. Такую версию ChatGPT создать вполне можно. PD>Почему все же этот человек 1850 года, используя весь свой накопленный опыт, сможет на двух десятках картинок обучиться и давать потом почти 100% надежные ответы, а ChatGPT не сможет ? PD>В этом-то и вопрос.
Нет такого вопроса. S>>Вы лучше попробуйте. Сгенерируйте наборы картинок для зверей, несуществующих в природе, и проверьте. PD>А вот об этом я не говорил, и ничего не утверждал. Хотя... Единорога он (человек) тоже опознает, хоть он и не существует. И дракона, хотя тут сложнее — драконы бывают разные
Вы придумали себе реальность, вместо того, чтобы изучать реальность существующую.
Вот вам пример из области "австралии": в прошлом году у нас ребята занимались классификацией волчьего воя. Как обычно, две противоположные задачи — опознать "индивидуальный голос" конкретного волка, независимо от "семантики", и опознать "семантику" независимо от конкретного волка.
Внезапно оказывается, что нейросети, обученные для распознавания человеческой речи, гораздо лучше и быстрее обучаются распознавать волчий вой.
То есть два важных факта:
1. Нейросеть плохо распознаёт голоса волков, если её обучать с нуля только на размеченном датасете с волками.
2. Нейросеть хорошо распознаёт голоса волков, если взять готовую нейросетку для распознавания человеческой речи, и дообучить её на датасете с волками.
Это и есть ровно ваш пример с коалами и кенгуру — несмотря на то, что конкретная нейросеть никогда не "видела" волков, опыт распознавания человеческой речи ей почему-то очень сильно помогает. Так и тут — человек, "обученный" на европейских животных (и ещё на огромном количестве более абстрактных примеров), прекрасно различает коалу и кенгуру. Даже если ему показать всего две фотки в анфас, а потом фотку "сзади" или "сверху", он прекрасно поймёт, о каком из зверей идёт речь. И точно так же нейросетки ухитряются отвечать на вопросы, ответов на которые нет в публичном домене. И "на пальцах" совершенно понятно, как это происходит — нейросетка, которая учится классифицировать речь, автоматически формирует "feature detectors", которые выделяют из потока звука важные для распознавания особенности.
Так что вы одновременно делаете две систематических ошибки: завышаете способности человека (я вас в третий раз тыкаю носом в "куро"), и занижаете способности ИИ.
Вот вам ещё пример: если вам дать прочесть один раз какое-то слово, а потом показывать это же самое слово среди похожих на него других слов, то ваша способность правильно угадать образец сильно зависит от того, сколько фиче детекторов сработало на исходном слове. Если это будет случайный набор букв и его длина превысит ёмкость вашей системы-1, то вы покажете весьма средненький результат. Если это будет знакомое вам слово — то у вас будет близкий к 100% уровень успеха, даже если писать всякий раз разными шрифтами. Если вам показать эти слова вверх ногами, то даже при том же шрифте вам потребуется гораздо больше времени на опознание правильного варианта.
Если мы дадим незнакомое вам слово, но сгенерированное в соответствии с привычной вам морфологией, то уровень успеха снизится. По мере увеличения расстояния от знакомых вам слов и перехода к случайным цепочкам, уровень успеха будет снижаться. А если вам показать слова из тайского или грузинского языка, вы вообще скорее всего продемонстрируете примерно тот же уровень, что и при случайном выборе варианта.
Хотя казалось бы — вон, вы прекрасно коалу от кенгуру научились отличать с одного взгляда.
А вот так — у вас распознавание слов устроено не на битовом уровне, а на уровне "фич". Слово "симплектоматический" вы разбираете на знакомые вам слоги (вы даже, скорее всего, сможете осознать семантическую область, к которой относится этот выдуманный термин), а не анализируете отдельные штрихи отдельных глифов. А вот если вам дать слово "ปัญญา", то ваш накопленный опыт ничем вам не поможет — нет в вашей нейросети готовых фиче-детекторов достаточно высокого уровня. Вам придётся долго вглядываться в это слово, чтобы при помощи системы-2 разобрать его на фичи "вручную", и то результат не гарантирован.
Это всё в точности соответствует наблюдаемому поведению нейросетей вообще и LLM в частности.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Sinclair, Вы писали:
S>Вы придумали себе реальность, вместо того, чтобы изучать реальность существующую.
Ну вообще-то мне как-то больно считать, что кошки и собаки не есть реальность существующая. Как, впрочем, и коалы с кенгуру.
S>Внезапно оказывается, что нейросети, обученные для распознавания человеческой речи, гораздо лучше и быстрее обучаются распознавать волчий вой.
Вполне допускаю. Есть у них что-то общее. Homo homini lupus est, как было давно сказано
S>То есть два важных факта:
<skipped>
S>Так что вы одновременно делаете две систематических ошибки: завышаете способности человека (я вас в третий раз тыкаю носом в "куро"), и занижаете способности ИИ.
Не думаю. От того, что пятилетний ребенок может со 100% надежностью отличить кошку от собаки, пример с "куро" ничего не меняет. Я же уже писал, что отнюдь не утверждаю, что ЕИ будет не всегда так легко классифицировать, это Вы почему-то игнорируете, зря. А мой пример остается — здесь он исключительно надежно работает.
S>Вот вам ещё пример:
<skipped>
Вы зачем-то ломитесь в открытую дверь. Доказываете мне, что накопленный ранее опыт помогает классифицировать, и даете примеры, где его отсутствие не дает нужного результата. Я с этим не спорю. Я вполне согласен с тем, что для того, чтобы отличить кошек от собак, ребенок использует ту информацию, что он накопил за 5 лет своей жизни. Взрослый человек — для обучения распознавания коала и кенгуру. Тут не о чем спорить, все верно.
Я лишь в очередной раз вынужден повторить — пока я не увижу у ИИ тех же результатов по распознаванию кошек и собак, коал и кенгуру, причем во втором случае — после обучения на 20 картинках (и при любом предварительном обучении хоть на петабайтах чего угодно, но не включающего коал и кенгуру ни прямо ни косвенно) — я останусь при своем мнении.
И никакие рассуждения никакого рода тут ничего не докажут. Почти 100% результат в студию, тогда и признаю.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Не думаю. От того, что пятилетний ребенок может со 100% надежностью отличить кошку от собаки, пример с "куро" ничего не меняет. Я же уже писал, что отнюдь не утверждаю, что ЕИ будет не всегда так легко классифицировать, это Вы почему-то игнорируете, зря. А мой пример остается — здесь он исключительно надежно работает.
Пример остаётся, но он ничего не иллюстрирует.
PD>Я лишь в очередной раз вынужден повторить — пока я не увижу у ИИ тех же результатов по распознаванию кошек и собак, коал и кенгуру, причем во втором случае — после обучения на 20 картинках (и при любом предварительном обучении хоть на петабайтах чего угодно, но не включающего коал и кенгуру ни прямо ни косвенно) — я останусь при своем мнении.
Ну так сходите и посмотрите. Ваши отмазки про то, что "придуманные животные всё равно будут напоминать настоящих" — ерунда. Коалы и кенгуру вполне себе напоминают "обычных" животных. Это вовсе не какая-то "неведомая хрень", которая вообще не пойми что.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Sinclair, Вы писали:
S>Вот я дам вам два класса строк: S>1: рей, ичи, хито, ни, сан, йон, ши, го, року, шичи, хачи, ку, джу S>2: ака, ao, сиро, мидори, кииро, мурасаки, гурээ, тяиро, ханада S>Это, естественно, не полные описания классов.
S>Слово "куро" к какому из этих классов относится — сможете угадать, "ничего больше не используя"?
Ничего больше не используя: куро относится к 2 классу, в котором сиро, кииро.
Думаю что угадал моё предположение верно с точностью 66 к 44.
S>Хорошо, а теперь так: S>1: воробей, утка, ворона, галка, дрозд S>2: скарабей, богомол, паук, муравей, пчела S>К какому классу относится "муха"?
Я видел мух. Муха относится к муравьям, богомолам, пчелам и др. перепончатокрыльчатым. (у птиц в крыльях оперение)
Здравствуйте, Pavel Dvorkin, Вы писали:
S>>К какому классу относится "муха"?
PD>Отличный пример. Чтобы понять, что у них общего, нужно знать, что это представители классов птиц или членистоногих.
PD>Вот только 5-летний ребенок, может, про птиц уже что-то знает, а про членистоногих пока что ничего. Зоологию , кажется, в 6 классе изучают. А уж отличия с точки зрения зоологии пауков и мух-пчел тем более. Да и само слово "зоология" тоже не знает.
Да ну здрасьте! Это в какой такой (стерильной пробирке) рос ребенок, что к 5 годам не видел мух или комаров (или иных насекомых)?
или, если видел — почему не задавал вопросов "что это?"
PD>>Вот только 5-летний ребенок, может, про птиц уже что-то знает, а про членистоногих пока что ничего. Зоологию , кажется, в 6 классе изучают. А уж отличия с точки зрения зоологии пауков и мух-пчел тем более. Да и само слово "зоология" тоже не знает.
SK>Да ну здрасьте! Это в какой такой (стерильной пробирке) рос ребенок, что к 5 годам не видел мух или комаров (или иных насекомых)? SK>или, если видел — почему не задавал вопросов "что это?"
Однако! Я же ясно написал — он про членистоногих не знает ничего. Про зоологический тип. Про понятие. А не про мух или пчел.
Вот про тип "птицы" знает, скорее всего. "Мама, птичка летит".
Иными словами, abstract class Bird у него уже выделен, а abstract class Arthropod еще нет
PD>>>Вот только 5-летний ребенок, может, про птиц уже что-то знает, а про членистоногих пока что ничего. Зоологию , кажется, в 6 классе изучают. А уж отличия с точки зрения зоологии пауков и мух-пчел тем более. Да и само слово "зоология" тоже не знает.
SK>>Да ну здрасьте! Это в какой такой (стерильной пробирке) рос ребенок, что к 5 годам не видел мух или комаров (или иных насекомых)? SK>>или, если видел — почему не задавал вопросов "что это?"
PD>Однако! Я же ясно написал — он про членистоногих не знает ничего.
Вот я, в принципе, знал о существовании каких-то-там членистоногих, но в быту, летающих крыльями мух (и даже мух ползающих) к этому классу не отношу. только пауков. И, может быть муравьев, но этих скорее к хитиновым, за их хитиновый внешний скилет.
PD>Про зоологический тип. Про понятие. А не про мух или пчел.
Мне в быту такая, академическая, точность нафиг не нужна. Подозреваю что и 99,95% людей, тоже, достаточно знания каким тапком устраняется назойливая помеха.
PD>Вот про тип "птицы" знает, скорее всего. "Мама, птичка летит".
Летит = птичка, ползёт на ногах = членистоногие. всё логично.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD> Представьте себе человека (пусть и не ребенка), который ничего не знает про Австралию. Сейчас такого человека найти сложно, ну пусть речь идет о человеке середины
Сложный какой-то эксперимент. Заведи себе ребёнка, и примерно в год-два обучай его отличать животных, например. И обращай внимание как он путается. Например, у меня путал голову коровы и жирафа. Ведь там у обоих рожки.
А ещё на детские рисунки погляди, и посчитай сколько там пальцев, отсмеявшись над AI-generated images.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>И вот этой модифицированной версии ChatGPT дают ту же пару десятков картинок , на которых изображены коала и кенгуру. Больше ничего не дают, как и тому человеку 1850 года. А потом предлагают их опознать на тестовом наборе фотографий, где они есть.
PD>Будет почти 100% ? Не думаю.
Будет. Может на практике для высокого качества не с пары десятков, а с пары сотен изображений, но точно не с петабайт. Это обучение без учителя (Self Supervised Learning), когда модель обучается в принципе различать картинки с какими-то объектами. Функцию потерь (лосс-функцию) для такого обучения выбирают такой, чтобы происходила кластеризация эмбеддингов (векторов на выходе) для картинок с разными объектами. Например, Barlow Twins В результате можно затем добавить к обученной модели классификатор (которым может быть даже тривиальный персептрон с 1-2 слоями) и натренировать модель+классификатор на малом количестве изображений.
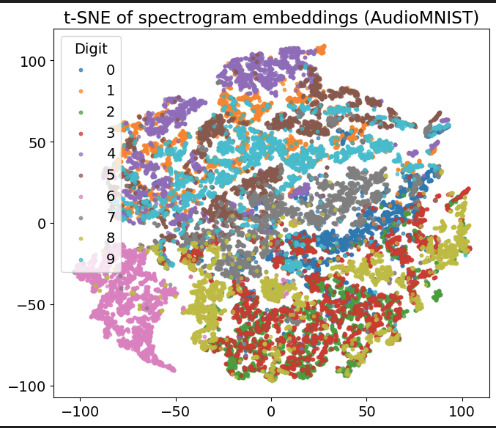
У меня под рукой как раз оказался результат экспериментов с простенькой моделью с распознаванием не изображений, а звуков на наборе данных AudioMNIST (наговоренные разными людьми вслух цифры от 0 до 9). После самообучения видно, что модель натренировалась кластеризовать цифры. Для визуализации применен метод t-SNE для уменьшения размерности до 2-х и построения диаграммы.
Эксперимент, не совсем конечно в тему коалы и кенгуру, было бы интереснее, если бы ее натренировали, например, на произнесении цифр от нуля до 7, а 8 и 9 она потом смогла легко освоить, но боюсь модель слишком простая для такого фокуса, мало исходно объектов (0-9 или 0-7 и вообще audiomnist небольшой), чтобы выработать универсальное умение, хотя любопытно будет попробовать. Но в общем, принцип именно такой.
Подозреваю, что и у ЕИ примерно также. Мозг человека или изначально умеет классифицировать объекты или обучается этому в первые несколько недель-месяцев своей жизни, а потом уже просто быстро дополняет свой "классификатор". Косвенно на обучение указывает, что младенец не сразу может узнавать других людей и вообще узнавать предметы.
M>У меня под рукой как раз оказался результат экспериментов с простенькой моделью с распознаванием не изображений, а звуков на наборе данных AudioMNIST (наговоренные разными людьми вслух цифры от 0 до 9). После самообучения видно, что модель натренировалась кластеризовать цифры. Для визуализации применен метод t-SNE для уменьшения размерности до 2-х и построения диаграммы.
Мне кажется, что эта задача существенно проще. Цифр всего 10, да и звуки ИМХО проще изображений, их еще и в докомпьютерную эру умели классифицировать, и даже с индивидуальными отличиями (см. "В круге первом") . А в варианте коала и кенгуру отличать их надо на фоне неопределенно большого набора изображений, где нет ни тех, ни других, а есть все, что угодно. Про леопардовый ковер, наверное, слышал ? Ссылку сейчас не дам, суть простая — некий распознаватель определил ковер (или плед, не помню) леопардовой раскраски как леопарда.
Так что для твоего примера с цифрами надо , чтобы этот распознаватель опознал слова-цифры на фоне 100500 других слов.
PD>Вместо универсального ChatGPT или DeepSeek имеется большое количество узкоспециализированных ИИ, но таких, которые очень хорошо ориентируются в своей области
ChatGPT и DeepSeek вполне узкоспециализированны и хорошо ориентируются в своей области (а именно в развлечении аудитории). Цель же — не научить чему-то пользователей, а развлечь (сэкономив на писателях, актёрах, художниках...). А нужно было бы научить — тогда ИИ обучается не на интернет-мусоре, а на точных проверенных данных: на единственно верной энциклопедии, на утверждённых минобразованием учебниках и т.п.
Здравствуйте, L.K., Вы писали:
LK>ChatGPT и DeepSeek вполне узкоспециализированны и хорошо ориентируются в своей области (а именно в развлечении аудитории). Цель же — не научить чему-то пользователей, а развлечь (сэкономив на писателях, актёрах, художниках...). А нужно было бы научить — тогда ИИ обучается не на интернет-мусоре, а на точных проверенных данных: на единственно верной энциклопедии, на утверждённых минобразованием учебниках и т.п.
Нет, не поможет. Он порой берет вполне надежные данные, но комбинирует их так, что в итоге получается неверно. И при нынешних алгоритмах это едва ли устранимо.