PD>Люди тоже. Нельзя объять необъятное, и один человек, будь он хоть гений в своей области, может не понять или не принять. Тут опять Эйнштейн появляется, который, как известно, не принял квантовую механику ("бог не играет в кости"). Не понял — вряд ли, а вот не принял — факт. Ну а кто-то и не поймет. Не беда. Найдутся иные, которые поймут.
Мы не можем объять необъятное по нескольким причинам, которые все связаны с нашей кожаностью и временем:
1) Ограниченность часов в сутках — если человек А изучает только физику, а человек B и физику и, допустим, геологию; предполагая, что их умственные способности абсолютно равны, человек A в итоге будет лучшим в физике. Просто потому что больше данных по физике "получил на вход"
2) Ограниченность "окна эффективного обучения" — условно до 14 лет обучение ещё не эффективно (нет нужной концентрации на выбранном предмете), после 30 — эффективность обучения уже падает, относительно "пика формы". Получается, в топе людей, в любой науке, неизбежно оказываются только те, кто весь "пик формы" занимались одним делом
3) Ограниченность времени жизни. Причём не факт что бесконечная жизнь поможет изучить всё, ведь все науки двигают множество отдельных людей, и даже читать чужие работы в одной области может требовать больше времени, чем есть в сутках.
У ИИ нет ни одного из этих ограничений. Нет проблем со временем жизни. Нет гормональных или каких-то других ограничений на нейропластичность, нет ограничений даже на потребление информации в сутки — больше мощностей = больше токенов 'съел'. По ощущениям среднего человека, ИИ уже объял необъятное, ведь в большинстве тем, для большинства людей, ответы ИИ уже лучше, чем они ответили бы сами. Именно поэтому у ИИ и спрашивают.
Поэтому, рассчитывать что ИИ будет подвержен нашим ограничениям на компетентность и необъятность не могу. Возможно, у ИИ будут какие-то свои ограничения, но пока единственное которое нам известно — сложность научить отвечать "не знаю".
PD>Пока еще не вышли, но, видимо, скоро выйдут. Ну и за нанометры бороться можно, а вот на ангстремы не перейти — физика не позволит, это уже размер атома. Так что я не думаю, что тут будет большой прогресс.
Нанометры сейчас один сплошной маркетинг. До 32 года у TSMC есть вполне чёткий план на уменьшение тем же темпом что и раньше. Плюс ещё рост кристаллов. Плюс вынос самых важных простых математических операций прямо в чипы памяти. Плюс новые архитектуры для TPU. За это раньше просто не платили вообще. Сейчас деньги летят за каждый процент ускорения.
PD>>Это существенно изменит и саму модель ИИ как явления. Вместо одного универсального ИИ в огромном датацентре можно будет иметь сотни и тысячи (а может, сотни тысяч) специализированных ИИ, взаимодействующих между собой и расположенных на относительно некрупных серверах относительно небольших организаций.
Тут вопрос эффективности/пользы буквально такой же как и с людьми. Что лучше — один Эйнштейн/Ньютон/Галилей или тысяч умеющих сносно читать и писать? Маленькие модели могут тупо не понять задачу целиком, сколько ты их не собери. Гонять огромную модель ради вопроса "что мне одеть по погоде?" — а люди реально так начали использовать ИИ, тоже безумие.
PD>Вот этого пока, насколько я знаю, нет.
Внутри OpenAI и других контор, в своих датацентрах и для своих исследований, они гоняют сотни над одной задачей. Технически можно и самому такое запустить — API есть, только успевай посылать запросы. Но по коммерческим тарифам это запускать денег не хватит.
Обычные люди тоже работают в этом направлении постоянно — агенты, протоколы для агентов, фреймворки типа LangChain/LangGraph/n8n, алгоритмы автоматического выбора лучшего из N параллельных решений, и так далее. Уже можно насобирать некий граф-конвейер, который будет вполне нормально что-то делать, и даже на разных компах — не проблема. Разве что в типичном графе не сотни или тысячи. Видел десятки. Но, думаю, десятки, в основном потому, что большинство моделей (ещё?) достаточно универсальны, чтобы сотни подключать не имело большого смысла.
PD>И кстати, если уж продолжать аналогию. Выход из строя ЭВМ тогда — ЧП. Заменить ее нечем. И сейчас, если вдруг сдохнет ChatGPT — тоже заменить нечем (конечно, есть другие ИИ, но именно этот не заменишь). А если бы все было децентрализовано, то выход из строя одного узкоспециализированного ИИ — проблема не большая, чем выход из строя одного сайта в Интернете.
Увы. Неделю назад вылет одного CloudFlare положил пол-интернета. А ведь они вроде как даже не сайт и не ИИ.
Сейчас основная проблема — недоступное даже мелким компаниям, уж не говорю про домашних потребителей, железо. Оно внезапно и абсолютно не поспевает за потребностями. Буквально до сегодняшнего дня не было сценария, при котором обычному домашнему пользователю кровь из носу нужно 512 Гб памяти, и процессор способный буквально по всей этой памяти пробежаться за секунду, пусть делая и простые операции сложить-умножить. Модели есть, исходники на github/hugging face, но потребительского железа нет. Недавно читал историю успеха, как чувак собрал у себя из б/у комплектующих для датацентра комп, на котором может запускать (не учить, только запускать) полный DeepSeek. Думал о! темка! попробую повторить — фигвам, я перепаивать охлаждение и патчить линух для загрузки каких-то особенных дров, не готов, лол
Подтянутся производители железа, и всё придёт. Всё идёт к тому что на каждом телефоне будет крутиться мелкая модель, и отвечать на запросы на которые сейчас отвечает ChatGPT. А сложные запросы будет сама же определять и отправлять в большую GPT. Собственно внутри OpenAI подобный роутер уже работает. А будет многостадийный и на всех устройствах.
Здравствуйте, Sinclair, Вы писали:
S>Вот я дам вам два класса строк: S>1: рей, ичи, хито, ни, сан, йон, ши, го, року, шичи, хачи, ку, джу S>2: ака, ao, сиро, мидори, кииро, мурасаки, гурээ, тяиро, ханада S>Это, естественно, не полные описания классов.
S>Слово "куро" к какому из этих классов относится — сможете угадать, "ничего больше не используя"?
Ничего больше не используя: куро относится к 2 классу, в котором сиро, кииро.
Думаю что угадал моё предположение верно с точностью 66 к 44.
S>Хорошо, а теперь так: S>1: воробей, утка, ворона, галка, дрозд S>2: скарабей, богомол, паук, муравей, пчела S>К какому классу относится "муха"?
Я видел мух. Муха относится к муравьям, богомолам, пчелам и др. перепончатокрыльчатым. (у птиц в крыльях оперение)
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>И вот этой модифицированной версии ChatGPT дают ту же пару десятков картинок , на которых изображены коала и кенгуру. Больше ничего не дают, как и тому человеку 1850 года. А потом предлагают их опознать на тестовом наборе фотографий, где они есть.
PD>Будет почти 100% ? Не думаю.
Будет. Может на практике для высокого качества не с пары десятков, а с пары сотен изображений, но точно не с петабайт. Это обучение без учителя (Self Supervised Learning), когда модель обучается в принципе различать картинки с какими-то объектами. Функцию потерь (лосс-функцию) для такого обучения выбирают такой, чтобы происходила кластеризация эмбеддингов (векторов на выходе) для картинок с разными объектами. Например, Barlow Twins В результате можно затем добавить к обученной модели классификатор (которым может быть даже тривиальный персептрон с 1-2 слоями) и натренировать модель+классификатор на малом количестве изображений.
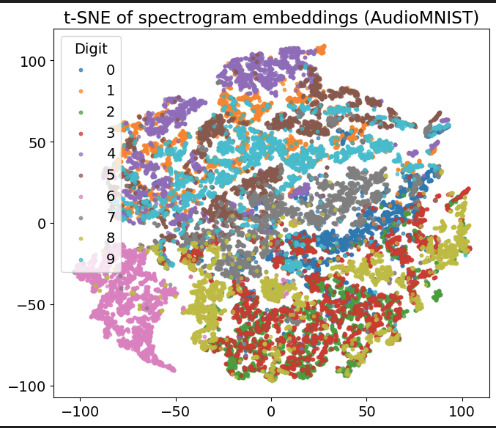
У меня под рукой как раз оказался результат экспериментов с простенькой моделью с распознаванием не изображений, а звуков на наборе данных AudioMNIST (наговоренные разными людьми вслух цифры от 0 до 9). После самообучения видно, что модель натренировалась кластеризовать цифры. Для визуализации применен метод t-SNE для уменьшения размерности до 2-х и построения диаграммы.
Эксперимент, не совсем конечно в тему коалы и кенгуру, было бы интереснее, если бы ее натренировали, например, на произнесении цифр от нуля до 7, а 8 и 9 она потом смогла легко освоить, но боюсь модель слишком простая для такого фокуса, мало исходно объектов (0-9 или 0-7 и вообще audiomnist небольшой), чтобы выработать универсальное умение, хотя любопытно будет попробовать. Но в общем, принцип именно такой.
Подозреваю, что и у ЕИ примерно также. Мозг человека или изначально умеет классифицировать объекты или обучается этому в первые несколько недель-месяцев своей жизни, а потом уже просто быстро дополняет свой "классификатор". Косвенно на обучение указывает, что младенец не сразу может узнавать других людей и вообще узнавать предметы.
Здравствуйте, TheBeginner, Вы писали:
PD>>Представьте себе, что ИИ организован по-другому. Вместо универсального ChatGPT или DeepSeek имеется большое количество узкоспециализированных ИИ, но таких, которые очень хорошо ориентируются в своей области...
TB>Возникает вопрос — как очертить границу знаний узкоспециализированной модели ИИ? TB>Задачу формулирует человек с использование синонимов, жаргонов, терминов из другой предметной области которых не будет в обучающем наборе данных узкоспециализированной модели. Если обучать условную модель "программист" только на специализированных книгах или исходных текстах, то эта модель просто не поймет что вы от нее хотите. То есть нужно добавлять некий "слой" общих знаний или использовать универсальную модель которая будет взаимодействовать со специализированными и отправлять им запрос в формальном и "доступном" для них виде. Например, пользователь делает запрос по написанию программы, требующей знания физики. Универсальной общая модель формализует запрос на понятном для "физической" модели языке, получает от неё формулы и... в каком виде передать эти формулы модели "программист", если эта модель кроме программирования ничего не знает?
Я об этом писал.
PD> которые очень хорошо ориентируются в своей области, так что на вопрос, относящийся к ней они дают всегда или почти всегда правильный ответ, а если вопрос выходит за пределы их компетенции — пытаются определить, к компетенции какого другого ИИ он относится и передаю вопрос ему. Иными словами, ведут себя как люди в этом плане. "Я в этой области плохо разбираюсь, но знаю Ивана Петрова, который вроде в этом разбирается, спрошу его". Возможно, что Иван Петров тоже окажется не специалистом и передаст вопрос Петру Сидорову, а возможно, что в итоге будет собрано совещание с участием всех троих, и совместными усилиями они найдут ответ. Вот и для ИИ могло бы быть аналогично.
Если тебе завтра придется писать программу для теорфизиков, то ты не сядешь за изучение курса Ландау-Лифшица. Вместо этого ты попросишь теорфизика дать нужные формулы или алгоритмы. Да даже в бизнес-задачах то же. Мне довелось в незапамятные времена писать программу расчет зарплаты в одном предприятии. Так мне дали бухгалтера, с которым мы просидели пару дней, и она мне дала все правила для начислений и удержаний. Сам бы я и за месяц не справился, особенно с учетом того, что Интернета тогда не было.
PD>Представьте себе, что ИИ организован по-другому. Вместо универсального ChatGPT или DeepSeek имеется большое количество узкоспециализированных ИИ, но таких, которые очень хорошо ориентируются в своей области, так что на вопрос, относящийся к ней они дают всегда или почти всегда правильный ответ, а если вопрос выходит за пределы их компетенции — пытаются определить, к компетенции какого другого ИИ он относится и передаю вопрос ему.
Даже не знаю чему больше удивляться, Крош, твоей изобретательности или твоей неинформированности (с) Ежик из м/ф Смешарики
Насколько можно собрать информацию из утечек или публикаций, все современные модели так или иначе или именно такие, или используют ещё более лучшие варианты этой идеи. Gemini 3 — MoE. DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model — прямо у них на гитхабе. GPT-5 tech reports — тоже MoE. И даже маленькая GPT-OSS — тоже MoE.
MoE — Mixture of Experts, ровненько то что ты описываешь — несколько "экспертов" внутри одной модели. Детали разнятся: от 8 экспертов в Mistral, которая в декабре 2023-го года вышла в опен-сорс; до неизвестно скольки экспертов у закрытых моделей. Сам термин "mixture of experts" (мне вряд ли поверят, ведь тогда наверное не было даже GPT-1) родом вообще из года 2017-го. Вышли на идею подсмотрев внутрь нейросетей, у которых в процессе обучения нейроны сами группировались (логически, физически понятное дело нет), по областям знаний. И активация одних означала мышление в одной области, а других в другой. Просто с явным делением на MoE и всякими трюками, вроде заморозки посторонних областей (чтобы сохранить уже изученное), обучение идёт быстрее и надёжнее.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>>Это существенно изменит и саму модель ИИ как явления. Вместо одного универсального ИИ в огромном датацентре можно будет иметь сотни и тысячи (а может, сотни тысяч) специализированных ИИ, взаимодействующих между собой и расположенных на относительно некрупных серверах относительно небольших организаций. PD>Вот этого пока, насколько я знаю, нет.
В целом, такое или есть, или к этому движется мир. ИИ-агенты — это как раз движение в эту сторону. Многие говорят, что AGI или даже ASI будет как раз не одной супер-моделью, а набором агентов, способных решить практически любую проблему.
Есть ещё мнение, что ЕИ — это не AGI, а что-то более специализированное.
Здравствуйте, Stanislaw K, Вы писали:
PD>>На мой взгляд, сравнение ИИ с ЕИ любого возраста некорректно. Это существенно разные явления.
SK>Но ведь ты сам первым проводишь такое сравнение ("знает ОТО или экономические модели"). Противоречишь сам себе.
Я неточно, видимо, выразился. Не имеет смысла сравнивать ИИ с ЕИ в его возрастном развитии, то есть говорить, что вот этот ИИ на уровне пятилетнего ребенка, а вот этот уже на уровне десятилетнего.
SK>Конечно не корректно, у ИИ нет основной человеческой черты ЕИ — синтезирования нового. и. по собственной инициативы.
Не только это. У них разный, видимо, подход. ЕИ не перерабатывает терабайты или петабайты для нахождения решения пусть и известной задачи. Он как-то иначе действует. А как — непонятно.
Я этот пример уже как-то приводил, приведу еще раз.
Чтобы ЕИ научился отличать кошку от собаки, достаточно ему показать с десяток особей того и другого вида, хоть живых, хоть на картинке. После этого он (пятилетний ЕИ) практически никогда не будет ошибаться. Мяу-мяу или гав-гав.
Чтобы ЕИ запомнил, что такое дикобраз, достаточно ему показать одно фото дикобраза. После этого он практически безошибочно будет его определять.
PD>20-30 фотографий домашних кошек PD>20-30 фотографий собак разных пород. От пуделя до бульдога.
PD>Никакую иную информацию она использовать не имеет права.
Ну во-первых детям очень рано показывают настоящих животных в движении. Это буквально сотни-тысячи кадров стерео-видео в минуту. Обучать детей только на статических фотографиях никто не пробовал. Возможно, в обучении на 2D-статике, мы уже хуже ИИ.
PD>Есть такие ?
А ты читал мои примеры? Ведь каждый что я приводил — однозначно говорит о том что фундаментально ограничение "нужны миллионы фоток/видео/звуков" уже давно пройдено. И для фото, и для звуков, и для видео. Дай современной ИИ-хе типа qwen3 vl на вход две картинки — на одной выдуманное животное, а на другой фото на котором оно или есть или нет (в другом ракурсе), и попроси найти это животное. С огромной вероятностью она сделает это правильно. Более того, тот же qwen edit 2509 или Wan 2.2 i2v, возьмёт картинку с твоим выдуманным животным (которое она никогда не видела), и сделает следующие кадры с сохранением деталей. Т.е. буквально с одного предъявления поймёт ключевые фичи твоего выдуманного существа, с глубиной, достаточной для воспроизведения.
То что у нас есть отдельные модели для звука, фото, видео, текста — это лишь нехватка мощностей. Именно поэтому все ключевые AI-конторы рассуждают про World Model, и наперегонки строят дата-центры. Их world model это не про наш мир. Это про любой мир, включая выдуманные, игровые, книжные, и т.д.
Ты сейчас рассуждаешь на уровне "ваш паровой двигатель фигня, потому что не обгоняет самую быструю лошадь". В то время как теоретическая возможность обогнать любую лошадь инженерам уже очевидна (всегда есть 10-15% непредвиденных проблем). Именно от уверенности в результате, такая безумная гонка бюджетов и строек дата-центров.
PD>Но никакой ребенок не будет под микроскопом или даже без него пристально эту структуру рассматривать. Просто взглянет и скажет — кис-кис.
А ещё часть детей и взрослых шарахается от всего похожего на змею под ногами и боится пауков. А ещё вспомним что у нас с рождения захардкожены алгоритмы распознавания человеческих лиц, эмоций, отслеживания направления чужого взгляда. Вполне может быть что мы и собачек с кошечками, и птичек, и вообще типовую фауну очень даже распознаём "от природы", хардкодом. А быстрое обучение сводится к тому какими звуками обозначать "ощущение кота".
Здравствуйте, hi_octane, Вы писали:
_>А ещё часть детей и взрослых шарахается от всего похожего на змею под ногами и боится пауков. А ещё вспомним что у нас с рождения захардкожены алгоритмы распознавания человеческих лиц, эмоций, отслеживания направления чужого взгляда. Вполне может быть что мы и собачек с кошечками, и птичек, и вообще типовую фауну очень даже распознаём "от природы", хардкодом. А быстрое обучение сводится к тому какими звуками обозначать "ощущение кота".
Подумал. Возможно, где-то и да, но в общем случае нет.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Не думаю. От того, что пятилетний ребенок может со 100% надежностью отличить кошку от собаки, пример с "куро" ничего не меняет. Я же уже писал, что отнюдь не утверждаю, что ЕИ будет не всегда так легко классифицировать, это Вы почему-то игнорируете, зря. А мой пример остается — здесь он исключительно надежно работает.
Пример остаётся, но он ничего не иллюстрирует.
PD>Я лишь в очередной раз вынужден повторить — пока я не увижу у ИИ тех же результатов по распознаванию кошек и собак, коал и кенгуру, причем во втором случае — после обучения на 20 картинках (и при любом предварительном обучении хоть на петабайтах чего угодно, но не включающего коал и кенгуру ни прямо ни косвенно) — я останусь при своем мнении.
Ну так сходите и посмотрите. Ваши отмазки про то, что "придуманные животные всё равно будут напоминать настоящих" — ерунда. Коалы и кенгуру вполне себе напоминают "обычных" животных. Это вовсе не какая-то "неведомая хрень", которая вообще не пойми что.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Pavel Dvorkin, Вы писали:
S>>К какому классу относится "муха"?
PD>Отличный пример. Чтобы понять, что у них общего, нужно знать, что это представители классов птиц или членистоногих.
PD>Вот только 5-летний ребенок, может, про птиц уже что-то знает, а про членистоногих пока что ничего. Зоологию , кажется, в 6 классе изучают. А уж отличия с точки зрения зоологии пауков и мух-пчел тем более. Да и само слово "зоология" тоже не знает.
Да ну здрасьте! Это в какой такой (стерильной пробирке) рос ребенок, что к 5 годам не видел мух или комаров (или иных насекомых)?
или, если видел — почему не задавал вопросов "что это?"
Почему не в форум об ИИ — там в основном специальные вопросы, а это обсуждение общего плана.
Интеллект это или не интеллект — вопрос скорее философский. В общем, можно сказать, что это нечто, отчасти похожее на человеческий интеллект, но и существенно от него отличающееся. Тут можно многое сказать, но не буду.
Если считать его все же интеллектом, то вполне логично сравнить его с естественным интеллектом (ЕИ). И вот тут обнаруживаются существенные различия организационного характера.
Носители ЕИ, как правило, являются специалистами в одной, реже нескольких областях. Их знания в других областях поверхностны, и, как правило, не годятся для того, чтобы сделать серьезные экспертные заключения. За примерами ходить далеко не надо. Тут все более или менее являются специалистами в ИТ и могут дать компетентное заключение по какому-то вопросу, но послушаешь, что они высказывают в непрофильных форумах, например, по экономике — порой волосы становятся дыбом и уши вянут. И уж никакой серьезный экономист в здравом уме и твердой памяти не станет руководствоваться их высказываниями по экономике.
Более того. ЕИ (если конечно, речь не идет о личностях вроде Ноздрева) по большинству вопросов вне своей сферы компетенции даст ответ — не знаю. Ну действительно, что Вы можете ответить на узкоспециальный вопрос, скажем, по гетерогенному катализу ? Только одно — не знаю. Я как химик по образованию когда-то что-то знал, но давно забыл, так что и мой ответ, скорее всего, будет таким же.
Второй отличительный признак ЕИ — он децентрализован. Отдельные люди и являются его носителями, и их интеллект каким-то не вполне понятным образом и решает возникающие проблемы, дает ответ. С довольно высокой скоростью. Каналы же связи между носителями ЕИ имеют довольно низкую пропускную способность, как минимум не сравнимую с пропускной способностью внутренних интерфейсов ЕИ. Если необходимо получить ответ на вопрос, затрагивающий несколько сфер деятельности, то для ЕИ это приведет к созданию некоторой системы взаимодействующих ЕИ, являющихся специалистами в разных областях. Проще говоря, соберут совещание, на которое пригласят специалистов разного профиля, и они совместными усилиями будут пытаться решить эту проблему. При этом каждый участник , несомненно, будет хорошо понимать , что он сам говорит на эту тему и никаких недопониманий себя с самим собой не будет, а вот недопонимания и разногласия при взаимодействии участников будут почти обязательно, и их "утрясание" может занять большое время. За примерами опять же далеко ходить не надо — достаточно почитать дискуссии здесь на какую-то тему.
С ИИ все обстоит иначе. Он универсален и готов ответить на любой вопрос. А поскольку нельзя объять необъятное, то он начинает фантазировать, скрещивая данные из самых разных источников, и как результат, часто попадая впросак. Универсальный же ЕИ существует только в произведениях фантастов (вроде Лемовского Соляриса), реально его нет.
Может быть, в этом и (отчасти) кроются некоторые проблемы , связанные с ИИ ? Может быть, будь он организован иначе, эти проблемы бы ушли ?
Представьте себе, что ИИ организован по-другому. Вместо универсального ChatGPT или DeepSeek имеется большое количество узкоспециализированных ИИ, но таких, которые очень хорошо ориентируются в своей области, так что на вопрос, относящийся к ней они дают всегда или почти всегда правильный ответ, а если вопрос выходит за пределы их компетенции — пытаются определить, к компетенции какого другого ИИ он относится и передаю вопрос ему. Иными словами, ведут себя как люди в этом плане. "Я в этой области плохо разбираюсь, но знаю Ивана Петрова, который вроде в этом разбирается, спрошу его". Возможно, что Иван Петров тоже окажется не специалистом и передаст вопрос Петру Сидорову, а возможно, что в итоге будет собрано совещание с участием всех троих, и совместными усилиями они найдут ответ. Вот и для ИИ могло бы быть аналогично.
Ну и конечно, ИИ в данной области совсем не обязан быть в единственном экземпляре. Вполне можно допустить наличие нескольких экземпляров его, отличающихся заложенными для ответа данными или алгоритмами. Тогда окончательный ответ может быть дан путем "обсуждения" и последующего согласования ответов, данных отдельными экземплярами, либо же окончательный ответ будет сформулирован в виде "к сожалению, дать надежный ответ на этот вопрос не оказалось возможным, имеются разные точки зрения на то, что считать правильным". Возможно, что возникнет некоторая иерархическая система, в которой более авторитетные ИИ будет запрашивать мнение менее авторитетных и на основе их формировать окончательный ответ. В общем, как у ЕИ.
Это существенно изменит и саму модель ИИ как явления. Вместо одного универсального ИИ в огромном датацентре можно будет иметь сотни и тысячи (а может, сотни тысяч) специализированных ИИ, взаимодействующих между собой и расположенных на относительно некрупных серверах относительно небольших организаций.
Мне кажется, что ИИ сейчас проходит период развития, который можно назвать "очень большие и не слишком умные". Как динозавры. Или, если угодно, как ЭВМ до эпохи микропроцессоров и персональных компьютеров.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Представьте себе, что ИИ организован по-другому. Вместо универсального ChatGPT или DeepSeek имеется большое количество узкоспециализированных ИИ, но таких, которые очень хорошо ориентируются в своей области...
Возникает вопрос — как очертить границу знаний узкоспециализированной модели ИИ?
Задачу формулирует человек с использование синонимов, жаргонов, терминов из другой предметной области которых не будет в обучающем наборе данных узкоспециализированной модели. Если обучать условную модель "программист" только на специализированных книгах или исходных текстах, то эта модель просто не поймет что вы от нее хотите. То есть нужно добавлять некий "слой" общих знаний или использовать универсальную модель которая будет взаимодействовать со специализированными и отправлять им запрос в формальном и "доступном" для них виде. Например, пользователь делает запрос по написанию программы, требующей знания физики. Универсальной общая модель формализует запрос на понятном для "физической" модели языке, получает от неё формулы и... в каком виде передать эти формулы модели "программист", если эта модель кроме программирования ничего не знает?
Еще больше проблем возникнет при использовании предложенной вами модели взаимодействия по той же причине.
На самом деле, такой проблемы как перемешивание данных из разных областей со снижением качества результата почти нет. Проблема в том, что LLM должны выдать результат в любом случае, выбирая из наиболее статистически вероятных последующих в выдаче токенов(слов) даже в том случае, если хороших статистически вариантов ответа нет.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Что думаете ?
Думаем что искуственный может прожить значительно дольше чем естественный, да и размножается проще и пока не бунтует. Сплошные плюсы. Но как только его применят против людей будет жопа.
PD>Если тебе завтра придется писать программу для теорфизиков, то ты не сядешь за изучение курса Ландау-Лифшица. Вместо этого ты попросишь теорфизика дать нужные формулы или алгоритмы. Да даже в бизнес-задачах то же. Мне довелось в незапамятные времена писать программу расчет зарплаты в одном предприятии. Так мне дали бухгалтера, с которым мы просидели пару дней, и она мне дала все правила для начислений и удержаний. Сам бы я и за месяц не справился, особенно с учетом того, что Интернета тогда не было.
Вам конечно известно выражение не говорят на одном языке применительно к работе над проектом где участвуют специалисты в разных предметных областях и какие проблемы при этом возникают.
Узкоспециализированная модель ИИ может выглядеть как "json на входе с данными эхолокации а на выходе разведанные запасы нефти". Это конечно крайний случай и описанный вами подход предполагает, что модели ИИ являются универсальными (чтобы коммуницировать между собой) но специализирующимися на одной предметной области.
Представим такой пример запроса:
Найди ошибку:
N ← 20
mask ← (N⍴1)
mask[1] ← 0
i ← 2
:While i ≤ N
:If mask[i] = 1
mask[i×2↓⍳⌊N÷i] ← 0
:EndIf
i ← i + 1
:EndWhile
primes ← (mask)/⍳N
primes
Пользователь не уточнил о чем идет речь. Что это? Математика, программирование? Если программирование, то какой это язык. То есть наша модель ИИ должна обладать полнотой знаний, чтобы просто определить какой модели передать запрос, даже если речь идет об иерархической модели вида общая модель > программист > программист APL
Здравствуйте, TheBeginner, Вы писали:
TB>Представим такой пример запроса: TB>Найди ошибку:
<skipped>
Ну а если такой пример запроса адресован не ИИ, а просто мне или иному ЕИ ? Дали вот такое на чем-то вроде ЕГЭ , и попробуй ответь.
Мой ответ будет прост — без дополнительных данных я ответ дать не могу. И ИИ должен дать такой же ответ, а не фантазировать. Будут даны дополнительные данные — будет с кем связаться (другим ИИ или ЕИ) для уточнения.
Еще раз поясню суть того, о чем я говорю. ИИ должен действовать так же, как ЕИ. А для ЕИ такой подход работает. Получив ответ, о чем идет речь, я смогу связаться с кем-то (ЕИ2) и спросить его ну хотя бы о том, какие алгоритмы используются в этой области. Возможно, что ЕИ2 разбирается в этом плохо, но выведет меня на ЕИ3, который разбирается лучше. И т.д. В конце концов ответ будет, возможно, дан. А может, и нет...
TB>Пользователь не уточнил о чем идет речь. Что это? Математика, программирование? Если программирование, то какой это язык.
Ну вот первый вопрос, который я задам — это математика или программирование ? Второй (если ответ на первый — программирование) — на каком языке. Ты выбрал пример текста, где можно заподозрить и то и другое (алгоритмическое описание в математике или же код на APL. Тут схожее. Если бы текст был кодом на Java , C++ или C#, я бы опознал его сам сразу и эти 2 вопроса задавать не стал. А может, и задал бы все же, потому что Java и C# по короткому фрагменту не всегда можно отличить. Далее последуют иные вопросы — например, для чего этот код. И т.д.
А что мне еще делать ? Искать ошибку, не понимая, о чем идет речь ? Если это APL, то ошибку надо искать по правилам APL. Если это чисто математическая нотация, то по правилам ее, которые могут от правил APL отличаться.
Кстати, вот контрпример. Дан некий текст на естественном языке, найти в нем грамматические или стилистические ошибки.
Если текст на кириллице и я его опознаю как русский — отвечу сам в меру своего знания правил русского языка . Если он на кириллице, но явно не русский — попробую опознать язык и свяжусь с тем, кто его хорошо знает, пусть он ответит. Если текст на латинице и я его опознаю как английский — попробую ответить сам, но все же скорее всего обращусь к кому-то из нативов или хотя бы к преподавателю английского, поскольку тут я совсем не уверен, что дам корректный ответ. Если на латинице и явно не английский — попробую определить, какой это язык (такие алгоритмы есть, по наличию диакритических знаков, специфическим парам и т.д.), после чего обращусь к нативу. Если не кириллица и не латиница — ну тогда надо каким-то способом опознать язык (и возможно, я это сделаю неверно, хотя Google Translate мне в помощь), после чего опять же обратиться к нативу. Разница лишь в том, что если я его опознаю неверно, то натив мне даст ответ — "это не суахили", после чего придется найти следующий язык- кандидат и обратиться к его нативу и т.д.
Здравствуйте, hi_octane, Вы писали:
_>Даже не знаю чему больше удивляться, Крош, твоей изобретательности или твоей неинформированности (с) Ежик из м/ф Смешарики
_>MoE — Mixture of Experts, ровненько то что ты описываешь — несколько "экспертов" внутри одной модели.
Я понимаю, что внутри так и сделано — несколько экспертов. Но я акцентировал внимание на другом
PD>Это существенно изменит и саму модель ИИ как явления. Вместо одного универсального ИИ в огромном датацентре можно будет иметь сотни и тысячи (а может, сотни тысяч) специализированных ИИ, взаимодействующих между собой и расположенных на относительно некрупных серверах относительно небольших организаций.
Вот этого пока, насколько я знаю, нет.
В целом ситуация сильно напоминает ту, что была до эры персональных компьютеров. Большие и дорогие ЭВМ, десятки их или максимум сотни на крупный город, связи между ними или совсем отсутствуют или в зачаточном состоянии. Это до. А теперь сравни с тем, что сейчас.
И кстати, если уж продолжать аналогию. Выход из строя ЭВМ тогда — ЧП. Заменить ее нечем. И сейчас, если вдруг сдохнет ChatGPT — тоже заменить нечем (конечно, есть другие ИИ, но именно этот не заменишь). А если бы все было децентрализовано, то выход из строя одного узкоспециализированного ИИ — проблема не большая, чем выход из строя одного сайта в Интернете.
Здравствуйте, hi_octane, Вы писали:
_>Тут вопрос эффективности/пользы буквально такой же как и с людьми. Что лучше — один Эйнштейн/Ньютон/Галилей или тысяч умеющих сносно читать и писать?
Не очень корректное сравнение. Эйнштейн — гений, но только в физике. Более того, в теоретической физике. Не знаю, как у него обстояло дело с экспериментальной физикой, но вот Паули был крупным теорфизиком, а в экспериментах у него все валилось из рук, так что в итоге, наряду с принципом Паули был сформулирован шутливый "эффект Паули"
И уж никто обоих не стал бы привлекать в качестве экспертов по биологии или машиностроению.
А тут и сравнения нет. Нет такого универсального разума. Разве что в научно-фантастических романах (Солярис). Ну и господь бог еще
>Маленькие модели могут тупо не понять задачу целиком, сколько ты их не собери. Гонять огромную модель ради вопроса "что мне одеть по погоде?" — а люди реально так начали использовать ИИ, тоже безумие.
Люди тоже. Нельзя объять необъятное, и один человек, будь он хоть гений в своей области, может не понять или не принять. Тут опять Эйнштейн появляется, который, как известно, не принял квантовую механику ("бог не играет в кости"). Не понял — вряд ли, а вот не принял — факт. Ну а кто-то и не поймет. Не беда. Найдутся иные, которые поймут.
PD>>И кстати, если уж продолжать аналогию. Выход из строя ЭВМ тогда — ЧП. Заменить ее нечем. И сейчас, если вдруг сдохнет ChatGPT — тоже заменить нечем (конечно, есть другие ИИ, но именно этот не заменишь). А если бы все было децентрализовано, то выход из строя одного узкоспециализированного ИИ — проблема не большая, чем выход из строя одного сайта в Интернете. _>Увы. Неделю назад вылет одного CloudFlare положил пол-интернета. А ведь они вроде как даже не сайт и не ИИ.
Это лишь говорит о том, что не все в Интернете верно сделано. Если помнишь, для исходной ArpaNet один из основных принципов был — сеть должна продолжить функционирование даже если значительная часть ее вышла из строя. Это, в общем, так и осталось. И то, что вылет CloudFlare привел к таким результатам, говорит лишь о том, что должно было бы быть N таких "CloudFlare", так что выход из строя одного или даже нескольких не привел бы к таким последствиям.
_>Сейчас основная проблема — недоступное даже мелким компаниям, уж не говорю про домашних потребителей, железо. Оно внезапно и абсолютно не поспевает за потребностями. Буквально до сегодняшнего дня не было сценария, при котором обычному домашнему пользователю кровь из носу нужно 512 Гб памяти, и процессор способный буквально по всей этой памяти пробежаться за секунду, пусть делая и простые операции сложить-умножить. Модели есть, исходники на github/hugging face, но потребительского железа нет. Недавно читал историю успеха, как чувак собрал у себя из б/у комплектующих для датацентра комп, на котором может запускать (не учить, только запускать) полный DeepSeek. Думал о! темка! попробую повторить — фигвам, я перепаивать охлаждение и патчить линух для загрузки каких-то особенных дров, не готов, лол
А черт его знает. Я совершенно убежден в том, что большинство задач, которые решаются на рабочих станциях пользователей, вполне решались бы, если бы рост производительности закончился на 4 Гб и 1 ГГц. Просто в условиях меньших ресурсов писали бы более эффективно. Вот, например, у меня банковский клиент на телефоне сейчас занимает 345 Мбайт. А между тем все мои данные в этом банке, да не только на клиенте, но и на сервер, скорее всего, имеют объем не более 100 Кбайт, а то и меньше. Больше просто нет. И вполне можно было такой клиент (ну пусть менее красиво, но почти с тем же функционалом) написать для MS-DOS. Сам писал когда-то программу для расчета зарплаты предприятия на несколько сот человек, на СМ-1420 с памятью 256 Кбайт. И даже мысли не возникало, что памяти мало.
Конечно, сейчас вернуться к эффективному использованию ресурсов в стиле MS-DOS , а то и машин с памятью 64 Кбайт уже невозможно. Но более эффективно писать код все же можно. И если понадобится — напишут. Хотя..., может и не смогут понять, что более эффективно можно — привыкли уже к расточительству.
_>Подтянутся производители железа, и всё придёт.
А вот тут большие сомнения. Настольные компьютеры вышли на плато лет 10+ назад, с тех пор прогресс незначителен. А сейчас, похоже, на плато выходят и мобильные девайсы. Пока еще не вышли, но, видимо, скоро выйдут. Ну и за нанометры бороться можно, а вот на ангстремы не перейти — физика не позволит, это уже размер атома. Так что я не думаю, что тут будет большой прогресс.
>Всё идёт к тому что на каждом телефоне будет крутиться мелкая модель, и отвечать на запросы на которые сейчас отвечает ChatGPT. А сложные запросы будет сама же определять и отправлять в большую GPT. Собственно внутри OpenAI подобный роутер уже работает. А будет многостадийный и на всех устройствах.
Ну в общем, это вполне согласно с тем, о чем я написал. Действительно, наличие множества мелких ИИ отнюдь не исключает наличия и крупного, к которому они обращаются, если сами не могут.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Почему не в форум об ИИ — там в основном специальные вопросы, а это обсуждение общего плана.
PD>С ИИ все обстоит иначе. Он универсален и готов ответить на любой вопрос. А поскольку нельзя объять необъятное, то он начинает фантазировать, скрещивая данные из самых разных источников, и как результат, часто попадая впросак. Универсальный же ЕИ существует только в произведениях фантастов (вроде Лемовского Соляриса), реально его нет.
PD>Может быть, в этом и (отчасти) кроются некоторые проблемы , связанные с ИИ ? Может быть, будь он организован иначе, эти проблемы бы ушли ?
PD>Что думаете ?
Думаю что проблема ИИ надумана. И ответственность за это прямо лежит на писателях-фантастах. (1) Благодаря живописанию ИИ в произведениях люди заранее считают ИИ всезнающим и непогрешимым. а "не большие оплошности" не замечают или списывают "с кем не бывает" и т.п.
(2) Человеческими чертами ИИ наделяют потому, что способ общения с ИИ не отличим от способа общения с реальными людьми (чат, беседы голосом). и опять-же — это было предсказано писателями-фантастами, что ещё больше усиливает (1) веру в ИИ, которая в свою очередь придает больше (2) человеческих черт.
То есть "ваши ожидания — это ваши проблемы".
Всё остальное — технологический вопрос. Сейчас ИИ сравним со смышленым 3-5 летним ребенком, лет через несколько, рывком, поднимется до уровня подростка. со всеми сюрпризами пубертата.
Здравствуйте, Stanislaw K, Вы писали:
SK>Всё остальное — технологический вопрос. Сейчас ИИ сравним со смышленым 3-5 летним ребенком, лет через несколько, рывком, поднимется до уровня подростка. со всеми сюрпризами пубертата.
Хм. 3-5 летний ребенок может писать хоть какой-то, но все же код ? И знает что-то, скажем, про теорию относительности или экономические модели и законы ?
На мой взгляд, сравнение ИИ с ЕИ любого возраста некорректно. Это существенно разные явления.
Здравствуйте, Pavel Dvorkin, Вы писали:
SK>>Всё остальное — технологический вопрос. Сейчас ИИ сравним со смышленым 3-5 летним ребенком, лет через несколько, рывком, поднимется до уровня подростка. со всеми сюрпризами пубертата.
PD>Хм. 3-5 летний ребенок может писать хоть какой-то, но все же код ?
Ну а почему нет? Тысяча обезьян с печатными машинками написали же войну и мир линукс.
PD>И знает что-то, скажем, про теорию относительности или экономические модели и законы ?
У ИИ тоже нет знания.
PD>На мой взгляд, сравнение ИИ с ЕИ любого возраста некорректно. Это существенно разные явления.
Но ведь ты сам первым проводишь такое сравнение ("знает ОТО или экономические модели"). Противоречишь сам себе.
Конечно не корректно, у ИИ нет основной человеческой черты ЕИ — синтезирования нового. и. по собственной инициативы.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>>>На мой взгляд, сравнение ИИ с ЕИ любого возраста некорректно. Это существенно разные явления.
SK>>Но ведь ты сам первым проводишь такое сравнение ("знает ОТО или экономические модели"). Противоречишь сам себе.
PD>Я неточно, видимо, выразился. Не имеет смысла сравнивать ИИ с ЕИ в его возрастном развитии, то есть говорить, что вот этот ИИ на уровне пятилетнего ребенка, а вот этот уже на уровне десятилетнего.
Конечно, линейно их сравнить невозможно. Но есть общие черты, характерные для пятилетних детей и текущих ИИ.
SK>>Конечно не корректно, у ИИ нет основной человеческой черты ЕИ — синтезирования нового. и. по собственной инициативы.
PD>Не только это. У них разный, видимо, подход. ЕИ не перерабатывает терабайты или петабайты для нахождения решения пусть и известной задачи. Он как-то иначе действует. А как — непонятно.
PD>Я этот пример уже как-то приводил, приведу еще раз.
PD>Чтобы ЕИ научился отличать кошку от собаки, достаточно ему показать с десяток особей того и другого вида, хоть живых, хоть на картинке. После этого он (пятилетний ЕИ) практически никогда не будет ошибаться. Мяу-мяу или гав-гав.
PD>Чтобы ЕИ запомнил, что такое дикобраз, достаточно ему показать одно фото дикобраза. После этого он практически безошибочно будет его определять.
Это смелое обобщение. многие ЕИ на это не способны, или способны ограниченно. Ты просто за средний ЕИ берешь пример из своего окружения, с достаточно высоким интеллектом, забывая что в среднем по популяции интеллект особей значительно ниже среднего.
PD>Чтобы ЕИ запомнил, что такое дикобраз, достаточно ему показать одно фото дикобраза. После этого он практически безошибочно будет его определять.
Так новым графическим моделькам, которые запускаются на потребительской видюхе, достаточно одной фото человека, чтобы они нарисовали другое фото этого же человека в совершенной другой одежде и обстановке (PullId, InstantId, и даже Qwen Edit). Люди такое могут только после долгих лет обучения в художке.
Современные модели zero shot voice cloning могут послушать одну фразу, 5-30 секунд, голоса человека и синтезировать неотличимую речь. На сотне языков. Сколько человек на планете так смогут?
Вчера вышло обновление модельки ИИ, которая с одного фото делает полноценную 3D-модель для 3d-печати/игры. Это как если бы ребёнок увидел одно фото дикобраза, и запилил его скульптуру во всех деталях. Сколько человек на планете смогут также?
Это всё домашние модели, работающие на потребительских видеокартах. Железо для игр сделанное. Когда выходили видеокарты 4090 никто и не думал о таких применениях. Оказалось что это всё можно, просто не было понимания архитектуры таких штук и математики для этого. Не более.
Здравствуйте, hi_octane, Вы писали:
_>Так новым графическим моделькам, которые запускаются на потребительской видюхе, достаточно одной фото человека, чтобы они нарисовали другое фото этого же человека в совершенной другой одежде и обстановке (PullId, InstantId, и даже Qwen Edit). Люди такое могут только после долгих лет обучения в художке.
Ну в разработке такой программы я сам принимал участие еще в конце 90-х. Посмотреть, как на этом человеке будет выглядеть рубашка из данной ткани. Там чистая машинная графика и никакого ИИ не нужно было, и даже GPU мы не использовали. Вот насчет обстановки — не знаю, не делал, да и обстановка — понятие растяжимое.
_>Современные модели zero shot voice cloning могут послушать одну фразу, 5-30 секунд, голоса человека и синтезировать неотличимую речь. На сотне языков. Сколько человек на планете так смогут?
_>Вчера вышло обновление модельки ИИ, которая с одного фото делает полноценную 3D-модель для 3d-печати/игры. Это как если бы ребёнок увидел одно фото дикобраза, и запилил его скульптуру во всех деталях. Сколько человек на планете смогут также?
_>Это всё домашние модели, работающие на потребительских видеокартах. Железо для игр сделанное. Когда выходили видеокарты 4090 никто и не думал о таких применениях. Оказалось что это всё можно, просто не было понимания архитектуры таких штук и математики для этого. Не более.
И все же это немного другое. Генерация на базе имеющихся данных, а не обобщение.
Я и не спорю, что человек многое не может сделать, что может машина. Тут спорить глупо.
Но все же хотелось бы посмотреть на программу, которой дается
20-30 фотографий домашних кошек
20-30 фотографий собак разных пород. От пуделя до бульдога.
Никакую иную информацию она использовать не имеет права.
После чего она по любой фотографии с почти 100% надежностью говорить, кто на ней изображен — кошка или собака. Причем на фото это животное может быть в профиль, в фас и даже со спины.
Любой ребенок 5 лет со средним интеллектом это сделает.
Есть такие ?
Ну и из личного опыта. Попался мне лет 5 назад сайт, где обещали примерно такое — определить, что за животное на фото. Конечно, не ИИ там был, а просто какой-то алгоритм. Скормил я ему фото моего тогдашнего кота, а он был совершенно белый и длинношерстный. Ну и оказался он на 40% кроликом, и только на 20% котом. Судя по всему, исследовали структуру шерсти, а они и впрямь похожи. Но никакой ребенок не будет под микроскопом или даже без него пристально эту структуру рассматривать. Просто взглянет и скажет — кис-кис.
Здравствуйте, hi_octane, Вы писали:
_>Ну во-первых детям очень рано показывают настоящих животных в движении. Это буквально сотни-тысячи кадров стерео-видео в минуту. Обучать детей только на статических фотографиях никто не пробовал. Возможно, в обучении на 2D-статике, мы уже хуже ИИ.
Да, показывают. Да, сотни-тысячи кадров. Но одного или нескольких котов. А не сотен тысяч. А с собаками еще хуже. Кошки все друг на друга, в общем, похожи, а вот такса на бульдога не очень.
PD>>Есть такие ? _>А ты читал мои примеры? Ведь каждый что я приводил — однозначно говорит о том что фундаментально ограничение "нужны миллионы фоток/видео/звуков" уже давно пройдено. И для фото, и для звуков, и для видео. Дай современной ИИ-хе типа qwen3 vl на вход две картинки — на одной выдуманное животное, а на другой фото на котором оно или есть или нет (в другом ракурсе), и попроси найти это животное. С огромной вероятностью она сделает это правильно. Более того, тот же qwen edit 2509 или Wan 2.2 i2v, возьмёт картинку с твоим выдуманным животным (которое она никогда не видела), и сделает следующие кадры с сохранением деталей. Т.е. буквально с одного предъявления поймёт ключевые фичи твоего выдуманного существа, с глубиной, достаточной для воспроизведения.
Это опять же операции надо имеющимися данными, пусть и трансформация их сколь угодно сложная. Или сравнение двух экземпляров данных. Найти какие-то фичи, определяющие эти данные. Это понятно как делать, хотя бы в принципе. А я говорю о произвольном заранее не заданном наборе данных, который нужно отнести к одному из двух классов.
Простое упрощение.
Твои примеры.
На входе строка, на втором входе текст, который ее содержит. Найти, есть он там или нет. Простая задача.
Модифицировать эту строку по каким-то алгоритмам. Ну не так просто, но понятно.
А моя задача
Даны строка. Классифицировать ее как относящуюся к одному из двух классов при том, что экземпляров этих классов было дано до этого штук 20-30. И больше ничего не использовать. А по каким критериям эти 2 референтных набора сформированы — не знаю. Решай сам, как хочешь.
В общем, пока я не увижу сайт (или что угодно), где будет почти 100% опознание кошек от собак — не поверю. И чтобы там не было обучения на сотнях тысяч . Будет такое, смогу попробовать и проверить — тогда поверю. Тестовых данных у меня сколько угодно
_>Ты сейчас рассуждаешь на уровне "ваш паровой двигатель фигня, потому что не обгоняет самую быструю лошадь". В то время как теоретическая возможность обогнать любую лошадь инженерам уже очевидна (всегда есть 10-15% непредвиденных проблем). Именно от уверенности в результате, такая безумная гонка бюджетов и строек дата-центров.
И тем не менее пока он не обгоняет лошадь я имею право оставаться при своем мнении насчет его возможностей. Бог его знает, обгонит или нет, несмотря на все теоретические возможности. Вот обгонит — поменяю мнение. Но не раньше.
PD>>Но никакой ребенок не будет под микроскопом или даже без него пристально эту структуру рассматривать. Просто взглянет и скажет — кис-кис. _>А ещё часть детей и взрослых шарахается от всего похожего на змею под ногами и боится пауков. А ещё вспомним что у нас с рождения захардкожены алгоритмы распознавания человеческих лиц, эмоций, отслеживания направления чужого взгляда. Вполне может быть что мы и собачек с кошечками, и птичек, и вообще типовую фауну очень даже распознаём "от природы", хардкодом. А быстрое обучение сводится к тому какими звуками обозначать "ощущение кота".
Тут не знаю, что и сказать. Нет у меня уверенности, что такое захардкожено, но и противоположное отстаивать уверенно нет оснований.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>А моя задача
PD>Даны строка. Классифицировать ее как относящуюся к одному из двух классов при том, что экземпляров этих классов было дано до этого штук 20-30. И больше ничего не использовать. А по каким критериям эти 2 референтных набора сформированы — не знаю. Решай сам, как хочешь.
Ключевое заблуждение, которое вы настойчиво продолжаете исповедовать — это "и больше ничего не использовать".
Вот я дам вам два класса строк:
1: рей, ичи, хито, ни, сан, йон, ши, го, року, шичи, хачи, ку, джу
2: ака, ao, сиро, мидори, кииро, мурасаки, гурээ, тяиро, ханада
Это, естественно, не полные описания классов.
Слово "куро" к какому из этих классов относится — сможете угадать, "ничего больше не используя"?
Хорошо, а теперь так:
1: воробей, утка, ворона, галка, дрозд
2: скарабей, богомол, паук, муравей, пчела
К какому классу относится "муха"?
PD>В общем, пока я не увижу сайт (или что угодно), где будет почти 100% опознание кошек от собак — не поверю. И чтобы там не было обучения на сотнях тысяч . Будет такое, смогу попробовать и проверить — тогда поверю. Тестовых данных у меня сколько угодно
Повторю очевидную для всех, кроме вас, мысль: без обучения ничего не получится.
PD>И тем не менее пока он не обгоняет лошадь я имею право оставаться при своем мнении насчет его возможностей.
Да вы и после этого имеете право оставаться при своём мнении .
PD>Тут не знаю, что и сказать. Нет у меня уверенности, что такое захардкожено, но и противоположное отстаивать уверенно нет оснований.
Это потому, что нужно не гадать, а читать исследования когнитивных психологов. В отличие от ваших воображаемых экспериментов с детьми, которые "никогда не видели никаких животных и после одной картинки отличают кошку от собаки", у них есть воспроизводимые, нетривиальные, и зачастую контр-интутивные результаты.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Sinclair, Вы писали:
S>Вот я дам вам два класса строк: S>1: рей, ичи, хито, ни, сан, йон, ши, го, року, шичи, хачи, ку, джу S>2: ака, ao, сиро, мидори, кииро, мурасаки, гурээ, тяиро, ханада S>Это, естественно, не полные описания классов.
S>Слово "куро" к какому из этих классов относится — сможете угадать, "ничего больше не используя"?
Этого языка я не знаю, если это слова вообще какого-то языка. Так что пример не годится. Я не предлагаю классифицировать незнакомое. Я предлагаю решить задачу отличить кошек от собак. Вполне реальные фото.
S>Хорошо, а теперь так: S>1: воробей, утка, ворона, галка, дрозд S>2: скарабей, богомол, паук, муравей, пчела S>К какому классу относится "муха"?
Отличный пример. Чтобы понять, что у них общего, нужно знать, что это представители классов птиц или членистоногих.
Вот только 5-летний ребенок, может, про птиц уже что-то знает, а про членистоногих пока что ничего. Зоологию , кажется, в 6 классе изучают. А уж отличия с точки зрения зоологии пауков и мух-пчел тем более. Да и само слово "зоология" тоже не знает.
Так что привлечь эти данные ребенок не сможет. А вот никого из (2) не отнесет к птицам, и наоборот. Хотя и не уверен, что всех (2) он объединит в нечто общее в своем сознании. Возможно, в его сознании это разные типы. Кстати, раков (если он их увидит), он к (2) не отнесет почти наверняка. Для меня , помню, было открытием в курсе зоологии, что, оказывается, раки и мухи одного класса.
PD>>В общем, пока я не увижу сайт (или что угодно), где будет почти 100% опознание кошек от собак — не поверю. И чтобы там не было обучения на сотнях тысяч . Будет такое, смогу попробовать и проверить — тогда поверю. Тестовых данных у меня сколько угодно S>Повторю очевидную для всех, кроме вас, мысль: без обучения ничего не получится.
Спокойно, спокойно . Я вовсе и не утверждаю, что можно без обучения. ЕИ именно на основе обучения и работает. Показали ему десятка два представителей кошек и столько же собак — он и обучился. И не надо ему было сотен тысяч и всяких гига и терабайт. Он прекрасно этому учился, когда не то , что байт не было, а и письменности тоже. Пещерные люди, думаю, их вполне отличать могли . А картинок тогда практически не было , да и кошек и собак в племени было хорошо если несколько десятков. Интернета тоже не было
PD>>И тем не менее пока он не обгоняет лошадь я имею право оставаться при своем мнении насчет его возможностей. S>Да вы и после этого имеете право оставаться при своём мнении .
Разумеется. Каждый вправе это делать
PD>>Тут не знаю, что и сказать. Нет у меня уверенности, что такое захардкожено, но и противоположное отстаивать уверенно нет оснований. S>Это потому, что нужно не гадать, а читать исследования когнитивных психологов. В отличие от ваших воображаемых экспериментов с детьми, которые "никогда не видели никаких животных и после одной картинки отличают кошку от собаки", у них есть воспроизводимые, нетривиальные, и зачастую контр-интутивные результаты.
Я и не гадаю. Я просто ответил — не знаю. На это я тоже имею право
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Этого языка я не знаю, если это слова вообще какого-то языка. Так что пример не годится. Я не предлагаю классифицировать незнакомое. Я предлагаю решить задачу отличить кошек от собак. Вполне реальные фото.
Ну вот видите. А только что вы предлагали дословно следующее:
Дана строка. Классифицировать ее как относящуюся к одному из двух классов при том, что экземпляров этих классов было дано до этого штук 20-30. И больше ничего не использовать. А по каким критериям эти 2 референтных набора сформированы — не знаю. Решай сам, как хочешь.
Внезапно выясняется, что естественный интеллект категорически неспособен решить эту задачу. Что если у вас забрать ваш лингвистический опыт, то вы ничего не наклассифицируете.
Кстати, ИИ прекрасно решает задачку прямо в той формулировке, которую я процитировал.
PD>Отличный пример. Чтобы понять, что у них общего, нужно знать, что это представители классов птиц или членистоногих. PD>Вот только 5-летний ребенок, может, про птиц уже что-то знает, а про членистоногих пока что ничего. Зоологию , кажется, в 6 классе изучают. А уж отличия с точки зрения зоологии пауков и мух-пчел тем более. Да и само слово "зоология" тоже не знает. PD>Так что привлечь эти данные ребенок не сможет. PD>А вот никого из (2) не отнесет к птицам, и наоборот. Хотя и не уверен, что всех (2) он объединит в нечто общее в своем сознании. Возможно, в его сознании это разные типы. Кстати, раков (если он их увидит), он к (2) не отнесет почти наверняка. Для меня , помню, было открытием в курсе зоологии, что, оказывается, раки и мухи одного класса.
Задачки на "вычеркни лишнее" начинаются с детского сада. И даже в средней школе далеко не все дети способы верно "классифицировать строку". Потому что для этого требуется нетривиально обученная нейросеть.
Нет никаких чудес. Естественный интеллект пользуется не двумя наборами из 20 строк каждый, а всем своим колоссальным предыдущим опытом. Вы, Павел, почему-то недооцениваете этот опыт. Отсюда ваши иллюзии, что естественный интеллект какой-то магией способен миновать стадию обучения и сразу же начать классифицировать. Нет. Совершенно необязательно знать зоологию — но отличать "птиц" от "козявочек" всё же нужно.
PD>Спокойно, спокойно . Я вовсе и не утверждаю, что можно без обучения. ЕИ именно на основе обучения и работает. Показали ему десятка два представителей кошек и столько же собак — он и обучился.
НЕТ! Я же вам показал пример — почему вы не обучились языку на двух десятках представителей?
И ребёнок обучается не на двух десятках картинок, а на непрерывном потоке информации, который в него льётся всё время, пока он не спит.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Sinclair, Вы писали:
S>Задачки на "вычеркни лишнее" начинаются с детского сада. И даже в средней школе далеко не все дети способы верно "классифицировать строку". Потому что для этого требуется нетривиально обученная нейросеть. S>Нет никаких чудес. Естественный интеллект пользуется не двумя наборами из 20 строк каждый, а всем своим колоссальным предыдущим опытом. Вы, Павел, почему-то недооцениваете этот опыт. Отсюда ваши иллюзии, что естественный интеллект какой-то магией способен миновать стадию обучения и сразу же начать классифицировать. Нет. Совершенно необязательно знать зоологию — но отличать "птиц" от "козявочек" всё же нужно.
PD>>Спокойно, спокойно . Я вовсе и не утверждаю, что можно без обучения. ЕИ именно на основе обучения и работает. Показали ему десятка два представителей кошек и столько же собак — он и обучился. S>НЕТ! Я же вам показал пример — почему вы не обучились языку на двух десятках представителей?
Потому что я вовсе не утверждаю, что это всегда возможно. Я просто привел пример, когда это возможно. Кошки и собаки.
S>И ребёнок обучается не на двух десятках картинок, а на непрерывном потоке информации, который в него льётся всё время, пока он не спит.
На непрерывном потоке, говорите. Допустим. Вот Вам другой пример.
Представьте себе человека (пусть и не ребенка), который ничего не знает про Австралию. Сейчас такого человека найти сложно, ну пусть речь идет о человеке середины 19 века. Интеллект его был тот же, а вот информированность хуже намного. Едва ли сибирские крестьяне 1850 года что-то знали про Австралию.
И вот этому человеку, который прекрасно знает про кошек и собак, а также волков, медведей и рысей, овец и коз, показывают пару десятков картинок , на которых изображены коала и кенгуру. И говорят, что вот эти называются кенгуру, а эти — коала. Посмотрит он на них, и запомнит, как они выглядят. И если потом ему покажут еще одну картинку с ними, он без труда их опознает. Собственно, так оно и есть с нынешним человеком. Не помню, видел ли я живого кенгуру. Живого коала точно не видел.
И не перепутает он коала с бурым медведем, а кенгуру с козой. Хотя они в чем-то похожи.
На каком непрерывном потоке он обучился в данном конкретном случае ? Да, он давно обучился на непрерывном потоке понимать, что такое животное, какие у него повадки и т.д. И если бы я сказал, что он их определит как животных — тут да, можно было бы возразить, что он использует ранее накопленные знания. Но я не об этом. Я о том, что он их теперь опознает именно как коала и кенгуру.
И генная память, если она есть, тут тоже не поможет. Ни один из предков этого человека 1850 года никогда ничего не слышал ни про коала, ни про кенгуру. И не видел их.
А теперь рассмотрим иной пример. Мысленно, конечно.
Предположим, что создана версия ChatGPT, обученная на тех же терабайтах и петабайтах, но с одним отличием. При обучении жестко отсекались все источники, которые хоть прямо, хоть косвенно относятся к Австралии.
Эта версия, в общем, будет владеть почти той же информацией, что и реальная, во всем остальном. Если бы я предложил Европу или США исключить — получилась бы явно ущербная версия, да. А исключить Австралию — в основном останется почти то же. Она не центр мира. Если бы ее вообще не было — мир был бы примерно тем же.
И вот этой модифицированной версии ChatGPT дают ту же пару десятков картинок , на которых изображены коала и кенгуру. Больше ничего не дают, как и тому человеку 1850 года. А потом предлагают их опознать на тестовом наборе фотографий, где они есть.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>На непрерывном потоке, говорите. Допустим. Вот Вам другой пример.
PD>Представьте себе человека (пусть и не ребенка), который ничего не знает про Австралию. Сейчас такого человека найти сложно, ну пусть речь идет о человеке середины 19 века. Интеллект его был тот же, а вот информированность хуже намного. Едва ли сибирские крестьяне 1850 года что-то знали про Австралию.
PD>И вот этому человеку, который прекрасно знает про кошек и собак, а также волков, медведей и рысей, овец и коз, показывают пару десятков картинок , на которых изображены коала и кенгуру. И говорят, что вот эти называются кенгуру, а эти — коала. Посмотрит он на них, и запомнит, как они выглядят. И если потом ему покажут еще одну картинку с ними, он без труда их опознает. Собственно, так оно и есть с нынешним человеком. Не помню, видел ли я живого кенгуру. Живого коала точно не видел.
PD>И не перепутает он коала с бурым медведем, а кенгуру с козой. Хотя они в чем-то похожи.
PD>На каком непрерывном потоке он обучился в данном конкретном случае ? Да, он давно обучился на непрерывном потоке понимать, что такое животное, какие у него повадки и т.д. И если бы я сказал, что он их определит как животных — тут да, можно было бы возразить, что он использует ранее накопленные знания. Но я не об этом. Я о том, что он их теперь опознает именно как коала и кенгуру.
Конечно же он использует ранее накопленные знания. Эти знания, в первую очередь, позволяют ему видеть не "картинку" в виде мешанины мегапикселов, а сразу набор фич. Вроде длины и цвета шерсти, формы головы, конечностей, и так далее. Пара десятков картинок — как раз достаточно для того, чтобы выделить значимые признаки и подавить незначимые.
Точно так же, как при классификации слов вы используете все свои предыдущие знания.
PD>Будет почти 100% ? Не думаю.
Павел, мысленные эксперименты можно проводить только на заведомо исправном оборудовании
Вы лучше попробуйте. Сгенерируйте наборы картинок для зверей, несуществующих в природе, и проверьте.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
PD>>На каком непрерывном потоке он обучился в данном конкретном случае ? Да, он давно обучился на непрерывном потоке понимать, что такое животное, какие у него повадки и т.д. И если бы я сказал, что он их определит как животных — тут да, можно было бы возразить, что он использует ранее накопленные знания. Но я не об этом. Я о том, что он их теперь опознает именно как коала и кенгуру. S>Конечно же он использует ранее накопленные знания. Эти знания, в первую очередь, позволяют ему видеть не "картинку" в виде мешанины мегапикселов, а сразу набор фич. Вроде длины и цвета шерсти, формы головы, конечностей, и так далее. Пара десятков картинок — как раз достаточно для того, чтобы выделить значимые признаки и подавить незначимые.
C этим вполне согласен. Именно так. А вот как именно это он делает — непонятно. Более того, совсем не уверен, что это вообще делается им алгоритмически, а значит, в принципе алгоритмизируемо.
PD>>Будет почти 100% ? Не думаю. S>Павел, мысленные эксперименты можно проводить только на заведомо исправном оборудовании
Уходите от ответа. Такую версию ChatGPT создать вполне можно.
Почему все же этот человек 1850 года, используя весь свой накопленный опыт, сможет на двух десятках картинок обучиться и давать потом почти 100% надежные ответы, а ChatGPT не сможет ?
В этом-то и вопрос.
S>Вы лучше попробуйте. Сгенерируйте наборы картинок для зверей, несуществующих в природе, и проверьте.
А вот об этом я не говорил, и ничего не утверждал. Хотя... Единорога он (человек) тоже опознает, хоть он и не существует. И дракона, хотя тут сложнее — драконы бывают разные
Сгенерированные не совсем подходят. Единорог сгенерирован человеческим интеллектом, так что он очень похож на реальное существо. Дракон тоже, хотя тут более буйная фантазия ЕИ. А сгенерировать машинным интеллектом — это порочный круг, так как в основу генерации будут заложены те же по сути алгоритмы.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>C этим вполне согласен. Именно так. А вот как именно это он делает — непонятно. Более того, совсем не уверен, что это вообще делается им алгоритмически, а значит, в принципе алгоритмизируемо.
Вполне себе алгоритмически. Магии не существует.
PD>Уходите от ответа. Такую версию ChatGPT создать вполне можно. PD>Почему все же этот человек 1850 года, используя весь свой накопленный опыт, сможет на двух десятках картинок обучиться и давать потом почти 100% надежные ответы, а ChatGPT не сможет ? PD>В этом-то и вопрос.
Нет такого вопроса. S>>Вы лучше попробуйте. Сгенерируйте наборы картинок для зверей, несуществующих в природе, и проверьте. PD>А вот об этом я не говорил, и ничего не утверждал. Хотя... Единорога он (человек) тоже опознает, хоть он и не существует. И дракона, хотя тут сложнее — драконы бывают разные
Вы придумали себе реальность, вместо того, чтобы изучать реальность существующую.
Вот вам пример из области "австралии": в прошлом году у нас ребята занимались классификацией волчьего воя. Как обычно, две противоположные задачи — опознать "индивидуальный голос" конкретного волка, независимо от "семантики", и опознать "семантику" независимо от конкретного волка.
Внезапно оказывается, что нейросети, обученные для распознавания человеческой речи, гораздо лучше и быстрее обучаются распознавать волчий вой.
То есть два важных факта:
1. Нейросеть плохо распознаёт голоса волков, если её обучать с нуля только на размеченном датасете с волками.
2. Нейросеть хорошо распознаёт голоса волков, если взять готовую нейросетку для распознавания человеческой речи, и дообучить её на датасете с волками.
Это и есть ровно ваш пример с коалами и кенгуру — несмотря на то, что конкретная нейросеть никогда не "видела" волков, опыт распознавания человеческой речи ей почему-то очень сильно помогает. Так и тут — человек, "обученный" на европейских животных (и ещё на огромном количестве более абстрактных примеров), прекрасно различает коалу и кенгуру. Даже если ему показать всего две фотки в анфас, а потом фотку "сзади" или "сверху", он прекрасно поймёт, о каком из зверей идёт речь. И точно так же нейросетки ухитряются отвечать на вопросы, ответов на которые нет в публичном домене. И "на пальцах" совершенно понятно, как это происходит — нейросетка, которая учится классифицировать речь, автоматически формирует "feature detectors", которые выделяют из потока звука важные для распознавания особенности.
Так что вы одновременно делаете две систематических ошибки: завышаете способности человека (я вас в третий раз тыкаю носом в "куро"), и занижаете способности ИИ.
Вот вам ещё пример: если вам дать прочесть один раз какое-то слово, а потом показывать это же самое слово среди похожих на него других слов, то ваша способность правильно угадать образец сильно зависит от того, сколько фиче детекторов сработало на исходном слове. Если это будет случайный набор букв и его длина превысит ёмкость вашей системы-1, то вы покажете весьма средненький результат. Если это будет знакомое вам слово — то у вас будет близкий к 100% уровень успеха, даже если писать всякий раз разными шрифтами. Если вам показать эти слова вверх ногами, то даже при том же шрифте вам потребуется гораздо больше времени на опознание правильного варианта.
Если мы дадим незнакомое вам слово, но сгенерированное в соответствии с привычной вам морфологией, то уровень успеха снизится. По мере увеличения расстояния от знакомых вам слов и перехода к случайным цепочкам, уровень успеха будет снижаться. А если вам показать слова из тайского или грузинского языка, вы вообще скорее всего продемонстрируете примерно тот же уровень, что и при случайном выборе варианта.
Хотя казалось бы — вон, вы прекрасно коалу от кенгуру научились отличать с одного взгляда.
А вот так — у вас распознавание слов устроено не на битовом уровне, а на уровне "фич". Слово "симплектоматический" вы разбираете на знакомые вам слоги (вы даже, скорее всего, сможете осознать семантическую область, к которой относится этот выдуманный термин), а не анализируете отдельные штрихи отдельных глифов. А вот если вам дать слово "ปัญญา", то ваш накопленный опыт ничем вам не поможет — нет в вашей нейросети готовых фиче-детекторов достаточно высокого уровня. Вам придётся долго вглядываться в это слово, чтобы при помощи системы-2 разобрать его на фичи "вручную", и то результат не гарантирован.
Это всё в точности соответствует наблюдаемому поведению нейросетей вообще и LLM в частности.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Sinclair, Вы писали:
S>Вы придумали себе реальность, вместо того, чтобы изучать реальность существующую.
Ну вообще-то мне как-то больно считать, что кошки и собаки не есть реальность существующая. Как, впрочем, и коалы с кенгуру.
S>Внезапно оказывается, что нейросети, обученные для распознавания человеческой речи, гораздо лучше и быстрее обучаются распознавать волчий вой.
Вполне допускаю. Есть у них что-то общее. Homo homini lupus est, как было давно сказано
S>То есть два важных факта:
<skipped>
S>Так что вы одновременно делаете две систематических ошибки: завышаете способности человека (я вас в третий раз тыкаю носом в "куро"), и занижаете способности ИИ.
Не думаю. От того, что пятилетний ребенок может со 100% надежностью отличить кошку от собаки, пример с "куро" ничего не меняет. Я же уже писал, что отнюдь не утверждаю, что ЕИ будет не всегда так легко классифицировать, это Вы почему-то игнорируете, зря. А мой пример остается — здесь он исключительно надежно работает.
S>Вот вам ещё пример:
<skipped>
Вы зачем-то ломитесь в открытую дверь. Доказываете мне, что накопленный ранее опыт помогает классифицировать, и даете примеры, где его отсутствие не дает нужного результата. Я с этим не спорю. Я вполне согласен с тем, что для того, чтобы отличить кошек от собак, ребенок использует ту информацию, что он накопил за 5 лет своей жизни. Взрослый человек — для обучения распознавания коала и кенгуру. Тут не о чем спорить, все верно.
Я лишь в очередной раз вынужден повторить — пока я не увижу у ИИ тех же результатов по распознаванию кошек и собак, коал и кенгуру, причем во втором случае — после обучения на 20 картинках (и при любом предварительном обучении хоть на петабайтах чего угодно, но не включающего коал и кенгуру ни прямо ни косвенно) — я останусь при своем мнении.
И никакие рассуждения никакого рода тут ничего не докажут. Почти 100% результат в студию, тогда и признаю.
PD>>Вот только 5-летний ребенок, может, про птиц уже что-то знает, а про членистоногих пока что ничего. Зоологию , кажется, в 6 классе изучают. А уж отличия с точки зрения зоологии пауков и мух-пчел тем более. Да и само слово "зоология" тоже не знает.
SK>Да ну здрасьте! Это в какой такой (стерильной пробирке) рос ребенок, что к 5 годам не видел мух или комаров (или иных насекомых)? SK>или, если видел — почему не задавал вопросов "что это?"
Однако! Я же ясно написал — он про членистоногих не знает ничего. Про зоологический тип. Про понятие. А не про мух или пчел.
Вот про тип "птицы" знает, скорее всего. "Мама, птичка летит".
Иными словами, abstract class Bird у него уже выделен, а abstract class Arthropod еще нет
PD>>>Вот только 5-летний ребенок, может, про птиц уже что-то знает, а про членистоногих пока что ничего. Зоологию , кажется, в 6 классе изучают. А уж отличия с точки зрения зоологии пауков и мух-пчел тем более. Да и само слово "зоология" тоже не знает.
SK>>Да ну здрасьте! Это в какой такой (стерильной пробирке) рос ребенок, что к 5 годам не видел мух или комаров (или иных насекомых)? SK>>или, если видел — почему не задавал вопросов "что это?"
PD>Однако! Я же ясно написал — он про членистоногих не знает ничего.
Вот я, в принципе, знал о существовании каких-то-там членистоногих, но в быту, летающих крыльями мух (и даже мух ползающих) к этому классу не отношу. только пауков. И, может быть муравьев, но этих скорее к хитиновым, за их хитиновый внешний скилет.
PD>Про зоологический тип. Про понятие. А не про мух или пчел.
Мне в быту такая, академическая, точность нафиг не нужна. Подозреваю что и 99,95% людей, тоже, достаточно знания каким тапком устраняется назойливая помеха.
PD>Вот про тип "птицы" знает, скорее всего. "Мама, птичка летит".
Летит = птичка, ползёт на ногах = членистоногие. всё логично.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD> Представьте себе человека (пусть и не ребенка), который ничего не знает про Австралию. Сейчас такого человека найти сложно, ну пусть речь идет о человеке середины
Сложный какой-то эксперимент. Заведи себе ребёнка, и примерно в год-два обучай его отличать животных, например. И обращай внимание как он путается. Например, у меня путал голову коровы и жирафа. Ведь там у обоих рожки.
А ещё на детские рисунки погляди, и посчитай сколько там пальцев, отсмеявшись над AI-generated images.
M>У меня под рукой как раз оказался результат экспериментов с простенькой моделью с распознаванием не изображений, а звуков на наборе данных AudioMNIST (наговоренные разными людьми вслух цифры от 0 до 9). После самообучения видно, что модель натренировалась кластеризовать цифры. Для визуализации применен метод t-SNE для уменьшения размерности до 2-х и построения диаграммы.
Мне кажется, что эта задача существенно проще. Цифр всего 10, да и звуки ИМХО проще изображений, их еще и в докомпьютерную эру умели классифицировать, и даже с индивидуальными отличиями (см. "В круге первом") . А в варианте коала и кенгуру отличать их надо на фоне неопределенно большого набора изображений, где нет ни тех, ни других, а есть все, что угодно. Про леопардовый ковер, наверное, слышал ? Ссылку сейчас не дам, суть простая — некий распознаватель определил ковер (или плед, не помню) леопардовой раскраски как леопарда.
Так что для твоего примера с цифрами надо , чтобы этот распознаватель опознал слова-цифры на фоне 100500 других слов.
PD>Вместо универсального ChatGPT или DeepSeek имеется большое количество узкоспециализированных ИИ, но таких, которые очень хорошо ориентируются в своей области
ChatGPT и DeepSeek вполне узкоспециализированны и хорошо ориентируются в своей области (а именно в развлечении аудитории). Цель же — не научить чему-то пользователей, а развлечь (сэкономив на писателях, актёрах, художниках...). А нужно было бы научить — тогда ИИ обучается не на интернет-мусоре, а на точных проверенных данных: на единственно верной энциклопедии, на утверждённых минобразованием учебниках и т.п.
Здравствуйте, L.K., Вы писали:
LK>ChatGPT и DeepSeek вполне узкоспециализированны и хорошо ориентируются в своей области (а именно в развлечении аудитории). Цель же — не научить чему-то пользователей, а развлечь (сэкономив на писателях, актёрах, художниках...). А нужно было бы научить — тогда ИИ обучается не на интернет-мусоре, а на точных проверенных данных: на единственно верной энциклопедии, на утверждённых минобразованием учебниках и т.п.
Нет, не поможет. Он порой берет вполне надежные данные, но комбинирует их так, что в итоге получается неверно. И при нынешних алгоритмах это едва ли устранимо.