Код [программы] — компьютерная программа или часть программы: последовательность команд, данных и описаний данных, из которых она состоит.
У меня есть подозрение, что данное определение несколько устарело. Лет так на тридцать. 30 лет назад такое определение было совершенно верным и отражало существующий тогда порядок вещей. Код программы действительно состоял из последовательности команд и данных, всё было предельно просто:
int Foo()
{
return 2 * 2;
}
Что же изменилось с тех пор? Давайте посмотрим:
class Bar
{
int Foo()
{
return 2 * 2;
}
}
За 30 лет развития традиционных языков программирования (Fortran, PL/1, COBOL, Pascal, C/C++, Java, C#) принципиально изменился только мир вокруг метода. Мы получили наследование, инкапсуляцию и полиморфизм, компонентность и контрактность, шаблоны/дженерики и атрибуты, массу паттернов проектирования, подходов и отходов, методологий и прочих вещей, призванных организовать код в нечто более менее управляемое.
Что же изменилось внутри метода? Да почти ничего. Как и 30 лет назад мы имеем if/else/switch, несколько циклов, команды выхода из цикла и метода, операции, присваивание и ещё немного по мелочёвке. Было только одно существенное новшество – замыкания в C# 2.0 в 2005-м году, и те приобрели человеческое лицо только в 2008-м в C# 3.0 с введением лямбд. Может быть ещё с натяжкой вывод типов из инициализации. И это всё! Всё! За 30, блин (в грубой форме), лет!
Фактически, 30 лет развитие шло только снаружи метода и сегодня мы имеем полный мыслимый набор инструментов для организации кода и управления им. По развитию снаружи метода мы уже давно вышли в космос и осваиваем другие планеты. А внутри метода? Внутри мы всё ещё в той же пещере, с тем же каменным топором в руках, что и 30 лет назад. Ни письменности, ни колеса, ни железа.
Думаю, именно в этом заключается природа предпочтений многих разработчиков. Все хотят быть архитекторами, никто не хочет быть кодером. Ведь кто такой архитектор? Это стратег, командир космической эскадры, бороздящей просторы вселенной. А кто такой кодер? Пещерный человек с каменным топором в руке, пусть даже его пещера и находится внутри одного из кораблей эскадры. Жуткий дисбаланс. Иметь такой дисбаланс в стратегических и тактических средствах не просто глупо, а уже даже не смешно. Только представьте себе ситуацию – космический десант в виде волосатого безграмотного сброда в шкурах с каменными топорами и костяными ножами. А ведь это и есть истинный портрет современных коммандос от IT. Мы сильно преуспели в стратегии, но при этом являемся абсолютными ламерами в тактике.
В результате часто следствием такого дисбаланса становится смена приоритетов – архитектура всё, код ничто. Много ли у нас обсуждений на тему жизни внутри метода? А чему у нас учат в вузах? Есть ли у нас хотя бы один предмет, рассказывающий как правильно писать код внутри метода? Скорее всего нет. А о чём там рассказывать? Вот и получается на уровне кода бескультурье, самопал и дурь. Но ведь это просто чудовищная несправедливость. Без кода внутри метода, без кодера программа работать не будет, точнее её просто не будет. Без внешней обвязки и архитектора хоть как-то, но можно обойтись.
Но так ли всё плохо? Есть ли надежда на просветление? Конечно, есть. Имя этому просветлению – (кто бы мог подумать) functional programming.
Как это ни странно, но всё это время, в отличии от традиционных языков программирования, развитие на планете FP шло по пути наращивания возможностей внутри функции и манипуляции функциями. В результате было наработано множество техник и паттернов не относящихся напрямую к FP: pattern matching, algebraic types, tuples, type inference, immutability. Всё это спокойно можно использовать вообще без знания, что такое функция высшего порядка. Более того, если попытаться применить FP в традиционном программировании, то окажется, что и ФВП и любые другие возможности FP вообще никак не конфликтуют ни с ООП, ни с АОП, ни с компонентностью, вообще ни с чем. Причина в том, что они применимы и улучшают жизнь внутри метода, практически никак не проявляя себя и не влияя на то, что происходит снаружи, что отлично демонстрируется новыми возможностями C# 3.0.
Казалось бы, причём тут Немерле? А вы думали я о чём? Не дождётесь!
Немерле – это удачная попытка совмещения традиционного программирования и FP. Практически все, что наработано в FP поддерживается в Немерле и уже сейчас готово к использованию. Можно отложить в сторону каменный топор (if/else) и взять в руки охринительной мощности базуку (match). Кривизну out/ref параметров можно заменить на tuples, а зоопарк из приватных методов на удобные локальные функции. Много чего. И главное больше нет необходимости компенсировать скудность тактических средств стратегией.
Это путь в другой мир, в другую жизнь внутри всё того же метода. Примерно как разница между структурным C и современным C# с точки зрения организации архитектуры приложения. Вспомните, как вы изучали ООП или COM/компонентность, точно так же и здесь напрочь рушатся устоявшиеся представления о существующем порядке вещей. Код, получив стероиды от FP, становится мощнее, выразительнее, компактнее, понятнее и интереснее одновременно. Здесь есть куда приложить мозги и есть от чего получить эффект. Кодер здесь уже не троглодит в поеденной молью шкуре, а боец спецназа в нано-костюме из Crysis , способный в одиночку выполнять самые сложные задания.
Впрочем, это всё лирика. На практике получается, что код внутри и снаружи – это два разных кода, два мира, внешний и внутренний. Это хорошо видно при рефакторинге, когда код алгоритма не трогается, но его компоновка полностью меняется. Из этого, кстати, напрашивается ещё один вывод.
Людей принято делить по темпераменту на сангвиников, холериков, флегматиков и меланхоликов. Программистов можно условно поделить на (в примере выше я назвал метод Foo, а класс Bar) фуриков и бариков, на тех, чей код растёт из методов и тех, кто проектирует приложение от иерархий классов. Попробуйте ответить для себя на вопрос кто вы. Представьте, что вы пишите небольшое консольное приложение строчек на 300. Я – однозначно фурик. Я сразу начну писать код прямо в методе Main и только когда почувствую дискомфорт, озабочусь иерархией классов. Делать это сразу я не стану, т.к. считаю это бесполезной тратой времени, потому что не знаю, что меня ждёт впереди. Потом, если понадобится, будет всё, и иерархии, и паттерны, и компоненты. Но это потом, а пока главное – код, главное – функционал.
Смею предположить, что именно поэтому Немерле произвёл на меня столь сильное впечатление. И, наоборот, для бариков все эти фенечки вторичны. А мега-архитекторам так вообще глубоко до лампочки. Представим себе такого условного мега-архитектора. Вот взял он Немерле, покопался в нём и ничего интересного для себя не обнаружил. И правильно. Ведь с точки зрения архитектуры приложения в целом Немерле не привносит ничего нового. Вообще ничего. Все фичи на уровне методов, а методы у нас удел кодеров, затупятся каменные топоры, настругают ещё. В общем, нафига такой козе такой баян? Непонятно.
Собственно, всё. Теперь можно и пофлеймить
Сразу хочу обозначить несколько моментов для предотвращения ненужного флейма.
— Я умышленно не стал трогать МП, так эта вещь идёт в параллель с обсуждаемой темой.
— Я знаю про F# и другие функциональные языки. Моё мнение – у них нет будущего в мэйнстриме даже на платформе .NET по причине необходимости переселения на другую планету.
— Все имена и совпадения в тексте случайны.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, IT, Вы писали:
IT>Казалось бы, причём тут Немерле? А вы думали я о чём? Не дождётесь!
Почему то после прочтения первой строчки я уже в этом не сомневался.
IT> Попробуйте ответить для себя на вопрос кто вы. Представьте, что вы пишите небольшое консольное приложение строчек на 300.
Не смог. Ответить, в смысле . Пишу и то и другое одновременно.
Я так понимаю, это обещаное объяснение, почему мне не нравится Немерле? Тогда мимо. Я как раз таки очень положительно отношусь к ФП, и даже первый готов воткнуть Хейлсбергу вилку в глаз за то, что в шарпе до сих пор нет паттерн матчинга . Скептическое отношение у меня как раз таки к МП, а точнее к его реализации в Немерле.
Ну и еще, хоть я и стараюсь с собой бороться, местный неуемный немерлевый пиар, приправленный изрядной порцией демагогии, периодически переходящей в хамство, вызывает чисто инстинктивное раздражение и отторжение.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, IT, Вы писали:
IT>Но так ли всё плохо? Есть ли надежда на просветление? Конечно, есть. Имя этому просветлению – (кто бы мог подумать) functional programming.
Понимаете, есть один очень серьёзный камень преткновения и его имя -- деструктивные присваивания. Не знаю как вам а лично мне очень сложно обойтись без деструктивных присваиваний. Основной рабочий инструмент для меня C, но я много изучал Haskell и много пытался на нём писать. Вы когда-нибудь пробовали написать на этом языке двусвязный список например? А вы попробуйте... А потом слить два отсортированных двусвязных списка с сохранением сортировки... верёвка и мыло в магазине за углом кстати. Диссер Окасаки по чисто функциональным структурам данных на мой взгляд просто хоронит эти структуры с точки зрения практики.
Так вот любая попытка смешать снотворное со слабительным неизбежно заканчивается тем, что обычный человек в своей жизни мыслит императивно, деструктивными ходами. Типа взять ложку положить в ящик. Потом вынуть ложку положить вилку. Вам мама в детстве записки на столе наверняка оставляла. Типа возьми крупу, свари кашу, съешь её и иди в школу. Чисто императивный алгоритм. А функциональные фичи в языке требуют функциональной чистоты и высокой математической культуры (я месяц въезжал в монады и до сих пор не уверен, что въехал). Что до метапрограммирования, то напишите этот марсианский кошмар и вы увидите что его некому поддерживать.
В то же время у меня есть опыт редукции офигительной объектно-ориентированной иерархии на C++ из десятка шаблонных классов и активным использованием STL и Boost на полсотни килобайт кода в одну (!) функцию на C из сорока строчек, *не использующую даже CRT*. И я совершенно уверен из всего своего опыта -- любая "сложность" программирования на простых языках без лишних фич во многом надумана. C is really enough.
Сейчас все эти сишарпы и немерле выплывают только на растущей производительности компов, которая пока растёт быстрее чем все их сборщики мусора тормозят. Надолго ли?
Здравствуйте, Pzz, Вы писали:
Pzz>А вот внутри самих алгоритмов if'ы и while'ы — вполне себе адекватный инструмент. Во всяком случае, все классические алгоритмы описаны в литературе именно в этих терминах.
Ай, неправда Ваша, уважаемый. if и while — ересь бесовская, для лохов, реальные пацаны и девчонки пишут на ассемблере, который есть самый адекватный инструмент. Во всяком случае, все самые классические алгоритмы описаны в самом классическом трехтомнике Кнуте не именно в терминах if-ов, а на ассемблере выдуманной им угребищной машины (открываем ветхий завет, и приобщаемся к истинной, ортодоксальной вере).
ЗЫ: Удивительно дурацкие флеймы пошли. Как на подбор. Кошмар просто. Казалось бы, причем здесь пропаганда Немерле?
Здравствуйте, IT, Вы писали:
IT>Но так ли всё плохо? Есть ли надежда на просветление? Конечно, есть. Имя этому просветлению – (кто бы мог подумать) functional programming.
Ну, ёптыть. Более забористой травы, чем FP в области программирования я пока не встречал. Кто ни попробует -- у всех бошку сносит напрочь.
SObjectizer: <микро>Агентно-ориентированное программирование на C++.
В целом совсем неплохо, но я не согласен с основным пойнтом того, что нужно скрещивать ООП + ФП и получится всемирное счастье. Попробую пояснить. Раньше я сам тоже был такого же мнения, увидев OCaml и позже Nemerle, думал как же это круто. На первый взгляд все вроде бы отлично, на внешнем более высоком уровне мы используем ООП, а внутри методов ФП. Но чем больше я стал углубляться в ФП, дошел до изучения языка Haskell. Пришел так называемый enlightment! Нет вру, он пришел позже, я все продолжал писать микс ООП и ФП, но уже начали влиять последствия изучения Haskell'а. Внутри методов я все активнее начал применять функциональную декомпозицию, создавать на месте функции, передавать их как аргумент, возвращать их как результат из функции. Таким образом я избавился от многократного дублирования кода (который я хотел кстати убрать макросами), весь объем кода уменьшился в 6-7 раз! Это все я рефакторил одну из моих подсистем. В итоге от ООП остались только описание класса и внешние интерфейсы. Все. Далее, остальные подсистемы подверглись такому же процессу рефакторинга, ну кроме мордочек.
Из всего этого вывод я делаю такой, что ООП в принципе и не нужен, ФП более чем достаточно. Ну разве, что если ООП будет средством модульности. Т.е. от ООП в классическом понимании останется совсем мало.
Lisp is not dead. It’s just the URL that has changed: http://clojure.org
Здравствуйте, IT, Вы писали:
IT>Фактически, 30 лет развитие шло только снаружи метода и сегодня мы имеем полный мыслимый набор инструментов для организации кода и управления им. По развитию снаружи метода мы уже давно вышли в космос и осваиваем другие планеты. А внутри метода? Внутри мы всё ещё в той же пещере, с тем же каменным топором в руках, что и 30 лет назад. Ни письменности, ни колеса, ни железа.
Внутри метода — алгоритмы. Те самые сортировки и поиски, о которых книжки пишут. А снаружи — клей и упаковка.
Граждан, способных нагородить иерархую классов, из которой, если ее нарисовать на бумажке разноцветными карандашами, можно обои сделать — пруд пруди. А много вы знаете граждан, способных написать самостоятельно RB-дерево? Или сделать недостающий в системе примитив синхронизации из того, что в системе есть? Много ли вы вообще знаете граждан, которые знают, что в системе может недоставать каких-то примитивов синхронизации?
Дело в том, что проектировать клей и упаковку фундаментально проще, чем проектировать структуры данных и алгоритмы. Кроме того, не все понимают, зачем вообще нужно проектировать алгоритмы, когда полно готовых компонент. А без клея и упаковки 30 человек не посадишь колупать одну большую программу, это же понятно. А без 30 человек ну никак невозможно наваять в срок все эти красивые всплывающие полупрозрачные окна. А без них кто же купит такую программу, только разве лохи безденежные?
Так что совершенно понятно, что архитектор, вооруженный иерархией классов, гораздо более важный для бизнеса человек, чем 30 кодеров, вместе взятые — ведь именно он соединяет их труд воедино, делая одновременно их всех взаимозаменяемыми, а себя — единым и неповторимым (это пройдет, когда изобретут метод, позволяющий засадить за один проект 30 архитекторов).
И получается печальная картина: все мечтают наслаивать классы, слой за слоем, а простую сортировку, если что, и написать-то некому.
IT>Думаю, именно в этом заключается природа предпочтений многих разработчиков. Все хотят быть архитекторами, никто не хочет быть кодером. Ведь кто такой архитектор? Это стратег, командир космической эскадры, бороздящей просторы вселенной. А кто такой кодер? Пещерный человек с каменным топором в руке, пусть даже его пещера и
Осталось еще небольшое количество просто программистов — людей, способных и разрабатывать архитектуру, и наполнять ее кодом. Но увы, это вымирающий вид...
IT>- Я знаю про F# и другие функциональные языки. Моё мнение – у них нет будущего в мэйнстриме даже на платформе .NET по причине необходимости переселения на другую планету.
Обратите внимание, что тот дикий язык, на котором в C++ пишут темплейты, тоже является функциональным языком. Причем чисто функциональным, с ленивыми вычислениями и выводом типов.
Здравствуйте, netch80, Вы писали:
N>>>А при чём тут, откуда оно зародилось? ГВ>>Откуда зародилось, свойства того органично и унаследовало. Но это ни в коем случае не инструмент менеджера. Инструмент менеджера — это нормативная база, ресурсы, деньги, планы, организационные подходы... А не ООП.
N>Так это кроме прочего и организационный подход. Определим и формализуем, как именно связаны между собой работы разных групп и людей, и тем самым уменьшим затраты на взаимодействие при разработке. Разумеется, этот подход заметно некорректен, ну так не он же один используется...
Погоди. Вот опять, не ставь лошадь позади телеги. Сначала инженеры определяют структуру проекта, потом они же определяют структуру работ по проекту. Полученный граф передаётся менеджеру, который отдаёт под козырёк и начинает следить за исполнением графика. Если инженеры определят структуру исходя из принципов функционального программирования, то менеджер точно так же "сделает под козырёк" и будет отслеживать движение работ. Менеджер, в общем, инвариантен структуре интерфейсов.
Чуть-чуть вольных рассуждений:
В истории ООП было много всего интересного и неинтересного, но ИМХО, лучше всех подсуетился на ниве популяризации (читай: продажи) принципов ООП небезызвестный Гради Буч сотоварищи. Его RUP (унифицированный процесс фирмы Rational) настолько плотно поселился в индустрии, что сейчас почитается чуть ли не за нечто само собой разумеющееся. На мой взгляд, это связано прежде всего с тем, что RUP очень удачно оседлал терминологию. По-моему, нет такого слова, относящегося к IT-индустрии, которое не встречалось бы в полной спецификации RUP. "Роли", code review, test case, use case, это вот всё как раз было объединено под крылом RUP. Поскольку Буч параллельно проталкивал именно объектно-ориентированное программирование, то вполне естественно и то, что раньше или позже ООП и RUP должны были превратиться в сиамских близнецов в мозгах пресловутого "среднего менеджера". И таки да, так и произошло. Чуть позже начала активной раскрутки ООП его стали повсеместно называть "методом анализа", а потом уже и "способом организации работ". Больше того, даже итеративную разработку (по принципу: сделали-посмотрели-переделали) намертво связали именно с ООП, хотя в сущности, связи тут никакой, кроме того, что RUP определил "итерацию", как шаг развития проекта.
N>>>Фактически, разделение объектов — то, что позднее назвали "контрактным программированием", с ограничением тем, что "контракт" проводится по границе объекта ("пуля вылетает — проблемы не на моей стороне"). ГВ>>Ты путаешь объектную декомпозицию и спецификацию.
N>Я не путаю, я упрощаю до уровня такого менеджера Спецификация взаимодействия (как при выполнении, так и разработке) является следствием декомпозиции. Это в принципе всё, что ему нужно, чтобы подход работал.
Прости, но этому подходу лет больше, чем ООП. Совершенно классический способ реализации крупных программных проектов: разделить систему на подсистемы, формализовать и зафиксировать интерфейсы, дальше — поскакали. Относительное новшество языков спецификаций, встроенных в язык программирования заключается в том, что появилась возможность автоматически (компилятором) верифицировать спецификации. Спрашивается, при чём тут менеджмент?
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Блин, я вас читал-читал, а как все банально заканчивается
Понятно, что не все на свете задачи можно решить с помощью дотнета — хотя бы потому, что не везде этот самый дотнет "влезет". Но разве вы об этом спорили?
Правда жизни в том, что таких задач становится все меньше и меньше. Вон, помнится, была статья — причем год или два назад — даже луноход какой-то под управлением джавы работал. Все-таки сейчас немного меняются представления о производительности, оптимизации и пр.
Сейчас в большинстве случаев не надо байты и тики считать — приложения тормозят не потому что какой-то алгоритм на си-шарпе написан, а не асме, а из-за кривой архитектуры. Что в осном народ-то пишет? Бизнес-приложения, распределенные приложения, всякие там корпоративные шины и проч., веб-сервисы и другую подобную дрянь. Там совсем другие проблемы возникают, на другом уровне. Если, к примеру, у тебя плохо продумана связь с каким-нибудь нодом, идет слишком частый обмен пакетами, некорректно обрабатывается таймаут нода, нет кэширования и пр. — тебе тут не поможет переделка твоего приложения на более низкоуровневый асм.
А теперь представь — вот люди пишут всякие ESB, передают тонны ХМЛя (ХМЛя, понимаешь? ), а ты их пытаешься убедить, что "существуют задачи, для решения которых использование высокоуровневых средств... неэффективно и нецелесообразно". Как на фиг высокоуровневые средства, у нас сплошной ХМЛ, блин
И в итоге чего ты хочешь добиться? Никто не отрицает, что в принципе да, есть задачи для которых подходят более низкоуровневые средства. Но вы разве это обсуждаете? Статистику использования технологий что ли составляете? Речь-то о перспективах, о развитии, о тенденциях. И тенденция такова, что таких задач становится все меньше. Гораздно меньше. Причем в тех областях, в которых использования какого-нибудь дотнета раньше даже помыслить было нельзя.
И будет еще меньше. Сейчас у банальной игровой приставки — под которую игры выпускают, кстати, в "обрезанном" по сравнению с PC варианте — прозводительность терафлопами мерится. О чем тут можно говорить-то? Какой асм?
Собственно, такова позиция твоих оппонентов, как я ее понимаю. И я с ней согласен. А вот твою позицию я не очень понимаю. Какой смысл все сводить к тому, что "есть задачи для к-х асм подходит"? Ну да, пока еще есть. Но мне действительно кажется, что ты переоцениваешь роль и количество таких задач. Им недолго осталось жить. Через пять-десят лет китайская кофеварка с многоядерным процессором производительностью в несколько терафлоп будет доставать мне из интернета рецепты кофе. Это реальность
IT>>Вот здесь два примера того, как правильные высокоуровневые конструкции могут сделать код в разы проще, понятнее и эффективнее.
Полностью абстрагируясь от эффективного вычисления процентов , отмечу лишь, что сделать код с помощью каких-то высокоуровненвых конструкций проще — можно, понятнее — тоже можно, а вот эффективнее — дудки. Потому что предельно эффективная программа — это наилучшим образом оптимизированная программа, написанная на ассемблере. А в этом самом ассемблере есть только презренные присваивания, if, с грехом пополам циклы, и ни одной лямбды
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Может объяснишь в чем принципиальное отличие?
Чего от чего? HTML от XAML? Такое же, как HTML от SOAP, к примеру. XAML сам по себе никакой семантики не содержит, это просто формат сериализации графа компонентов в терминах специальной компонентной модели. HTML же подразумевает вполне конкретную сематику и абсолютно нерасширяем.
ВВ>>>Только вот в итоге все равно непонятно, что в вин-формс не нравится. Уровень абстракции недостаточно высок? AVK>>Убогий дизайн.
ВВ>Где именно?
А ты сам не видишь? Во-первых, практически единственный способ расширения функционала контролов — наследование. Почему плохо наследование реализации здесь уже обсуждалось не раз. Кроме того, использование наследования для расширения функционала это нарушение LSP. Использование же, скажем, агрегации практически невозможно ввиду того самого дизайна и подвязки на виндовый хендл.
Во-вторых, взгляни на публичный контракт Control. Он имеет огромный размер и содержит большое количество грубейших нарушений SRP. В WPF он в разы меньше, хотя и там в этом плане косяков предостаточно.
В-третьих, крайне убогие средства реюза готовых кусков UI. UserControl это все, что на эту тебу имеется. Даже нелюбимые тобой вебформсы в этом плане куда богаче.
В-четвертых, убогий, запутанный и крайне плохо расширяемый механизм баиндинга данных.
В-пятых, крайне примитивная компонентная модель, которую правда, в отличие от, по месту подкрутить все таки можно.
В-шестых, большинство контролов имеют неудобный и примитивный API для взаимодействия с состоянием. Виртуальный режим кое где со скрипом появился, но почти всегда с кривизной.
Ну и куча всего по мелочи.
Итого, дизайн винформсов весьма неоднородный и, в среднем, находится на уровне начала 90-х.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Ну-ну. Предложи разработчиками Windows заменить потоки в процессе System на файберы. То-то весело будет
Видишь ли Павел... Напомню тебе, что речь у вас шла об эффективности. И здесь Антон абсолютно прав, конкурентная многозадачность показывает существенно большую эффективность, чем вытесняющая.
В Windows планировщик вытесняющий не потому что он производительнее, а потому, что это безопаснее. При вытесняющей многозадачности у неправильно написанного кода меньше шансов уронить все приложение, вместе с OS, и исключительно по этой причине в OS реализована именно она. То есть, производительность приносится в жертву безопастности, как раз тот расклад, который тебе так не нравится.
В тех же случаях, когда безопасность можно обеспечить каким-либо другим способом, например, когда заранее известно все множество возможных операций и можно гарантировать, что никакая комбинация этих операций не приведет к зависаню всего приложения, включая планировщик, кооперативная многозадачность демонстрирует себя во всей красе. Характерные примеры Антон как раз и привел — lightttpd, SQL Server.
MS SQL Server — вообще, классический пример. Там внутри реализована практически полноценная операционка для управления нагрузкой, собственно, эта часть сиквельного движка так и называется — SQL OS, и одна из основных задач этой OS, обеспечивать non-preemptive schedulind. Опять-таки, ты же любишь ссылаться на операционки? Вот тебе пример OS с кооперативной многозадачностью, как раз из тех соображений, чтобы выжать максимум производительности.
PD>Читать классиков надо. Вдумчиво, не спеша. С толком, с расстановкой.
Так вот Павел, не торопись и задумайся, из каких соображений они дают именно такие советы.
Здравствуйте, AndrewVK, Вы писали:
F>>Правда, надо сделать одно важное извиняющее замечание — если человеку так не повезло, что ему не приходилось решать по настоящему сложных (а, значит, интересных) задач, то тогда, действительно, к чему засорять мозг
AVK>О да, без пенисометрии никак. Знаешь только, в чем проблема, особенно в этом форуме? По результатам измерений запросто может оказаться, что у кого то из твоих оппонентов длиннее.
Угу, особенно если учесть тот факт, что сравнивают тут обычно не первичные половые признаки (если следовать физиологической аналогии), а пальцы рук. И получаются занятные посылы типа "мой большой палец левой руки, длиннее и толще твоего мизинца на правой, поэтому я круче". А вот, если бы заявляющий такое, попробовал бы поковырять своим суперским большим пальцем на левой руке в своей же правой ноздре, то глядишь и проникся бы важной ролью правых мизинцев в нелегкой судьбе местных спорщиков.
Важно не насколько длинные / толстые у человека пальцы, а насколько он умеет их применять по делу и к месту. А про пенисы, я вообще — молчу
Здравствуйте, Sinclair, Вы писали:
ВВ>>И что мне от этого понимания? C# крут, потому что теоретически возможно написать супер-компилятор? Теоретически много чего возможно. S>Совершенно верно. Я и говорю — теоретически можно и Http Handler на ассемблере написать.
Мне теоретический "суперкомплятор" неинтересен.
S>Лучший — это по результатам моего личного опыта. Сравнивали с JSP, ASP, PHP, Python. С наколеночными CGI на C и С++. Тесты проводили самые разнообразные. Кроме того, я немножко представляю себе, как все эти фреймворки устроены внутри. А у вас какие основания клеймить ASP.NET?
Опыт использования.
Вернее, давайте я поправлюсь — тот ASP.NET, который начинается и заканчивается на IHttpHandler/IHttpModule — это отличная штука. А вот все что сверху...
Развитие ASP.NETа — причем заметьте в понятие ASP.NET обычно вкладывается не технология "интеграции конвеера с IIS", а собственно web forms — это постепенное превращение его в чистой воды конструктор. Программирование мышкой. В свое время над Дельфи за этой посмеивались. То же самое в ASP.NET — как вы сказали? — высокотехнлогичность или как там? Неувязочка получается, нет?
Во-первых, сама по себе концепция веб-форм ущербна изначально. Это была попытка сделать программирование под веб похожим на windows forms — причем абсолютно непонятно зачем, учитывая принципиально разную модель работы приложений. Они даже св-ва к контролам типа BackColor и проч. поначалу прикрутили — чтобы на вин-формс было похоже. Тоже вот как бы уровень абстракции. А то, что там CSS-ы есть — это до них только потом дошло. В итоге сохраняем "уши" от ASP, aspCompat, мастерскую вставку, гениальный разбор самой ASPX страницы через регулярные выражения — но зато "где-то там" у нас "комплируемый" код. Ну это ладно.
Но что принпиально новое в нес ASP.NET? Чего добились создатели ASP.NET? Разделения логики и представления? Как бы не так. Ничем в сущности ASP.NET приложение не отличается от того же PHP. И там, и там одинаковая по большому счету свалка — только несколько иначе организованная. И там и там можно писать нормально, если уж очень захочется.
Далее. что у нас еще есть? Богатые библиотеки контролов? Берем ГридВью. Нет проблем! Бросили на форму, пару движений мышкой — все работает. Нужна двунаправленная сортировка, чтобы еще и в заголовка направление сортировки показывать? Без проблем, темплейт-column. Нужно чтобы выглядело по-красивее? Без проблем, еще пару движений мышкой. Ох, надо чтобы совсем-совсем по-красивее? Ой, а надо чтобы весь столбец, по к-му происходит сортировка подсвечивался? Ну что ж придется изменить рендеринг HTML — что ж делаем темплейт колонки (количества кода на странице начинает ох как расти). Хотите чтобы работать даже тривиальные функции ГридВью — не вздумайте отключить вью-стейт, ибо ни фига работать не будет. Ну ладно, вроде прикрутили, сделали. Завтра приходит клиент и говорит — о, а давайте это сделаем в виде вложенного грида, который по плюсику будет распахиваться, а эту и и эту колонку будем мержить когда такая-то информация выводится.
И вот смотрим мы — реально на кучу разметки и кода, которую пришлось — смотрим, и выбрасываем на фиг весь это грид, и переписываем все на XSLT. И — о чудо! — на XSLT кода получается даже меньше, а все наши фичи учтены. И выглядит аккуратнее. И работает быстрее.
И таких примеров можно много привести, и не только с контролами. Чуть-чуть сходишь с "рельс" — и все, приехали. Написав приложение на IHttpHandler/IHttpModule + XSLT, ты:
— получишь чистый код с нормальным разделением данных (XML), правил валидации (XSD) и представления (XSLT)
— получишь более производительный код
— и даже потратишь меньше времени (если приложение не хоум-пейдж)
Какой вывод после этого можно сделать о веб-формах? Но зато да, веб-формы это абстракция.
А ведь в описанной выше технике не используется ничего специфичного для АСП.НЕТ. Ее при желании можно реализовать и на ПХП.
S>Неумение с ним работать? Незнание того, как его конвеер проинтегрирован с IIS7? Или просто незнакомство с предметом?
Я так смотрю хамство — это нынче модный тренд на RSDN.
ВВ>>Ну да, а сравнить ассемблер и ASP.NET — это видимо правила хорошего тона. S>При чем здесь хороший тон? S>Просто веб-сервер — это типичный пример высоконагруженного приложения.
Еще раз повторяю — причем здесь вообще ASP.NET? Каким образом ASP.NET вообще возникает при разговоре об ассемблере?
Я в принципе понимаю, в чем ваша проблема. Не "ваша" конкретно, а вообще. Почему в принципе при разговоре об ассемблере возникает предложение написать на нем аналог ASP.NET приложения? Или мы исходим из принципа — все или ничего?
А правда в том, что есть задачи, в к-х abstraction не дает никаких gain-ов, одни penalty. И такие ситуации также реалистичны как и те, где введение уровня абстракции позволяет сделать приложение более производительным.
S>Математика в наши дни встречается редко; большинство десктопного софта в принципе никогда не сталкивается с ситуацией нехватки производительности.
Я этого никогда не отрицал.
S>Как зачем? Чтобы рассуждения "теоретически, самый быстрый код — это написанный вручную на ассемблере" перестали быть голословными.
Большинство рассуждений здесь голословны. Про суперкомпляторы, которые никто не видел в глаза, про производительность кода на C#.
Напишите с 0 на C#, без всяких managed direct x, 3D-движок, полностью дублирующий CryEngine 2 и при этом работающий по крайней мере с такой же скоростью?
S>Пока что никаких доказательств этому в топике не прозвучало. Главный адвокат ручной сборки Дворкин продолжает удивлять примерами на С++. S>А до тех порк, пока вы настаиваете на присутствии в рассуждениях "теоретического ассемблерщика", я настаиваю на соревновании его с "теоретическим компилятором".
Люди, который пишут на ассемблере, есть. Задачи, который пока еще приходится реализовывать на самом низком уровне есть.
Но я никогда не слышал, чтобы кто-нибудь компилировал си-шарп "суперкомпилятором".
Здравствуйте, Pavel Dvorkin, Вы писали: PD>Полностью абстрагируясь от эффективного вычисления процентов , отмечу лишь, что сделать код с помощью каких-то высокоуровненвых конструкций проще — можно, понятнее — тоже можно, а вот эффективнее — дудки. Потому что предельно эффективная программа — это наилучшим образом оптимизированная программа, написанная на ассемблере. А в этом самом ассемблере есть только презренные присваивания, if, с грехом пополам циклы, и ни одной лямбды
Как и следовало ожидать, провокационная тема ушла в глубокий флейм, перемежаемый пенисометрией.
Поскольку никто из нормальных людей в такие глубины веток не ныряет, напишу правильный ответ здесь.
Итак, не отвлекаясь на фигню, отвечаем на вопрос: "можно ли сделать код эффективнее с помошью каких-то высокоуровневых конструкций?".
Во-первых, нужно отметить, что вопрос про то, какой код исполняется эффективнее — ассемблерный или еще какой — не стоит. Как ты верно подметил в глубинах флейма, "процессор всё равно не умеет исполнять никакого другого кода, кроме ассемблерного".
Отлично, тогда что же мы сравниваем и с чем? Вот у нас одна программа (очевидно, ассемблерная), и вот другая программа. Очевидно, тоже ассемблерная. Одна из них может оказаться эффективнее другой. Какая же программа будет именно такой?
Для начала, нужно понять, что такое "более эффективная". Это не такой тривиальный вопрос, как кажется. Дело даже не столько в том, что количество тактов, потребляемое некоторой программой для решения некоторой задачи, зависит от массы сторонних факторов (например, насколько часто процессору приходится отвлекаться от нее на обслуживание чего-то другого), а в том, что сначала нужно определиться с тем, что такое "решение задачи".
В стародавние времена программы (и задачи) были одноразовыми. Нужно вам, скажем, посчитать число Пи до тысячного знака. Ок, пишем программу, которая считает число Пи; запускаем, дожидаемся результата — ок, задача решена. Очевидно, что второй раз нам считать число Пи уже не надо. (Если, конечно, мы не забыли вывести куда-то результат вычислений ). Опять же очевидно, что при многократном запуске расчета числа Пи эффективнее всех прочих будет программа, которая устроена примерно так (в терминах C++):
сout << "3.1415926...";
(Производители процессоров об этом в курсе; поэтому инструкция fldpi выполняется значительно быстрее, чем самый оптимизированный расчет суммы несложного ряда)
Cейчас мы подразумеваем под "задачей" семейство задач в том древнем смысле. То есть когда мы говорим "нужна программа для сортировки массива" мы подразумеваем, что одна и та же программа будет использоваться для сортировки различных массивов. А вовсе не для сортировки конкретного массива.
В чем сложность? В том, что раньше мы могли рассуждать об эффективности в терминах расходов памяти и тактов процессора, нужных для решения конкретной задачи. Нужно тебе X знаков после запятой в разложении Пи? Ок, это будет стоить N(X) тактов и потребует P(X) байт памяти.
Теперь так рассуждать нельзя — затраты в тактах и байтах существенным образом зависят от того, какие именно данные мы подали на вход. На пальцах: пузырек, запущенный на отсортированном массиве длины N выполнит N сравнений, 0 обменов и успокоится. На обратно отсортированных данных он выполнит N^2/2 сравнений и обменов.
Поэтому, говоря об эффективности, мы говорим о матожидании затрат при некотором распределении входных данных. Очень немногие программисты задумываются об этом распределении. К примеру, асимптотические оценки алгоритмов сортировки традиционно даются для равномерного распределения: все перестановки значений во входных данных считаются равновероятными.
Конечно же, в природе задач с равномерным распределением не существует.
На данном этапе мы уже поняли, что если мы беремся сравнивать две программы по эффективности, то нам нужно задатсья некоторым распределением входных данных. Если мы этого не сделаем, то сравнение не имеет смысла — в одних условиях выиграет программа А, в других — программа B.
Итак, критерий сравнения эффективности программ — это матожидание затрат памяти и тактов на решение одной из задач, заданных некоторым распределением.
Поговорим об идеальной эффективности.
В идеальном мире мы можем получить информацию о предполагаемом распределении, и выбрать ту программу, которая покажет наилучшие результаты именно для него.
В реальном мире такие оценки очень редко можно получить заранее, до запуска программы.
Как же нам быть в таком случае? Выбирать программу случайно?
Способ, очевидно, есть. Вместо того, чтобы подготовить одну программу, мы можем подготовить семейство программ, которые имеют одну и ту же семантику (например, все они сортируют любой массив), но отличаются характеристиками производительности для различных входных данных.
И только тогда, когда мы узнаем, какие же данные поступают к нам на вход, мы выбираем ту из программ, которая лучше подходит для конкретного случая.
Этот подход замечателен тем, что он не требует полной априорной информации о свойствах будущей задачи. Очевидно, что он обеспечит не худшую производительность, чем фиксированная программа на все случаи жизни.
Осталось понять, можно ли применить этот подход, оставаясь в рамках "наилучшим образом оптимизированной программы, написанной на ассемблере", и "можно ли сделать код эффективнее с помошью каких-то высокоуровневых конструкций". Об этом я напишу завтра, потому что сегодня пора домой
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, fplab, Вы писали:
_FR>>Вот что ты скажешь о кодере, которому за девять с лишним лет ни разу не пришлось самому писать сортировку Не то, что строить деревья или создавать примитив синхронизации? Что он должен сгореть от горя или позора?
F>Да, однозначно. Ничто не может служить оправданием халтуры. Конечно, на практике нужно использовать оптимизированные и проверенные библиотечные функции. Но это не значит, что нет необходимости знать основные алгоритмы. Пусть пузырьковая сортировка не оптимальна: она дает навык работы с массивами. А быстрая сортировка — навык работы с рекурсией. Или, по вашему, это лишнее ?
Если человеку ни разу не приходилось писать сортировку, это не значит, что он не сможет это сделать, если понадобится. Измерять профессионализм тем, что человеку приходилось или не приходилось делать — это пустое дело. Единственный объективный индикатор профессионализма — это уровень зарплаты.
Здравствуйте, McSeem2, Вы писали:
MS>Здравствуйте, IT, Вы писали:
IT>>Я сразу начну писать код прямо в методе Main и только когда почувствую дискомфорт, озабочусь иерархией классов.
MS>Слушай, Игорь, но почему именно "озабочусь иерархией классов"? Что, без наследования в современном мире не прожить? Лично я считаю парадигму наследования самым противоестественным самодурством какого-то одного горе-теоретика, типа авторитета, которому удалось запудрить мозги всем и надолго. Я это уже говорил что инкапсуляция и полиморфизм — 256 раз да! Наследованию — отказать. Парадигма наследования в программировании компьютеров — это пожалуй второй по величине фуфлоид.
IT>>Делать это сразу я не стану, т.к. считаю это бесполезной тратой времени, потому что не знаю, что меня ждёт впереди.
MS>Согласен! Лично для меня первична алгортмическая сущность — на уровне получится или нет и что можно выжать из этого именно на алгортмическом уровне. Это для меня — самая сложная и самая интересная часть задачи. А уж обернуть в классы и иерархии, плюс кодовая оптимизация — это рутина, этим пусть мальчики-архитекторы и мальчики-кодеры занимаются. Я всегда готов их проконсультировать и объяснить сущность алгоритма.
самый большой проект, в котором ты когда-либо участвовал?
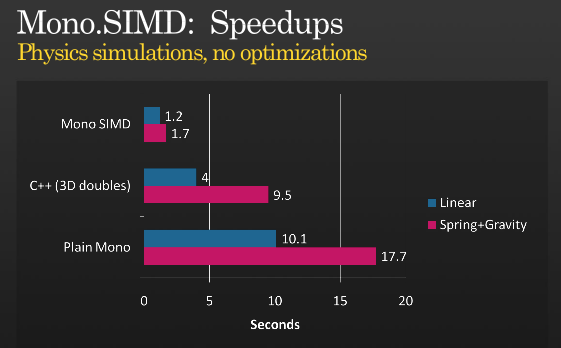
When we were measuring the performance improvement of the SIMD extensions we wrote our own home-grown tests and they showed some nice improvements. But I wanted to implement a real game workload and compare it to the non-accelerated case.
I picked a C++ implementation and did a straight-forward port to Mono.Simd without optimizing anything to compare Simd vs Simd. The result was surprising, as it was even faster than the C++ version:
Based on the C++ code from F# for Game Development
The source code for the above tests is available here.
I use the C++ version just because it peeked my curiosity. If you use compiler-specific features in C++ to use SIMD instructions you will likely improve the C++ performance (please post the updated version and numbers if you do).
I would love to see whether Johann Deneux from the F# for Game Development Blog could evaluate the performance of Mono.Simd in his scenarios.
If you are curious and want to look at the assembly code generated with or without the SIMD optimizations, you want to call Mono's runtime with the -v -v flags (yes, twice) and use -O=simd and -O=-simd to enable or disable it.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, netch80, Вы писали:
N>Здравствуйте, samius, Вы писали:
S>>Здравствуйте, netch80, Вы писали:
N>>>Какой ответ на этот вопрос Вы хотите? Можно ответить цинически — мол, есть клавишное мясо, которое не способно даже осознать, что оно теряет и почему. А можно — что пусть себе и дальше продолжает, но пусть осознаёт, где его потолок. В принципе, оба ответа правильны.
S>>У меня один знакомый считает, что тот не программист, кто не написал ни одного драйвера устройства. S>>Весьма ограниченная точка зрения, как впрочем и Ваша.
N>Вы ещё ничего не поняли толком про мою точку зрения, но уже успели приравнять её к "одному знакомому" и унизить сравнением.
Думаю что понял. Она примерно следующая: есть те, кому приходилось иметь дело с сортировкой с выкрутасами, и есть клавишное мясо. Ну или мягче — версия с потолком. По части унижения — я унизил только Вас, а Вы — всех тех, кто не писал свою сортировку.
Если я не понял Вашу точку зрения — поправьте.
N>Не думаю, что такой метод дискутирования адекватен теме.
Не думаете — не начинайте.
Здравствуйте, Pzz, Вы писали:
Pzz>>>Внутри метода — алгоритмы. Те самые сортировки и поиски, о которых книжки пишут. А снаружи — клей и упаковка. _FR>>Я как-то всегда думал, что как раз алгоритмы — это то, что очень неплохо поддаётся "библиотизации", то есть вынесением в многократно используемые кирпичи. И задумываться над алгоритмами лишний раз не приходится. Pzz>В библиотеках содержатся стандартные алгоритмы. Куда вы пойдете, если вам нужна не просто сортировка, а сортировка с преподвывертом? Готовую именно с нужными вам свойствами вы не найдете, свою написать вы не умеете, т.к. всегда использовали готовую.
Уметь по памяти и суметь на рабочем месте — две разные задачи.
_FR>>В первую очередь из-за того, что редко, очень редко встречаются сейчас такие задачи. Pzz>Принесут вам код, написанный для UNIX'а и активно использующий read/write lock'и, и попросят запустить его на Windows XP. А в XP нет read/write lock'ов. Ваши дальнейшие действия?
Сяду читать или пойду пить пиво с юниксойдами, или нет, сначала пойду колоть юниксойдов, а потом сяду читать… нет, сначала почитаю, потом пойду пить пиво с юниксойдами Или попросту скажу, что это "не мой профиль" Зачем "это" (read/write lock) знать заранее? Именно: только в силу специфики решаемых задач. Если человеку каждый день надо писать под UNIX с учётом многопоточности, то он, наверное, должен это знать. Если человеку каждый день приходится писать запросы к базе данных, то он должен представлять себе, как работает её оптимизатор. Для "абстрактного" програмиста, для которого не определена специфика решаемых задач эти вопросы безсмысленны.
В том числе и сортировка, потому что (внимание) абстрактному програмисту не придётся её писать самому. Максимум — придётся научиться выбирать между сортировкой А и сортировкой Б, так этому научиваешься быстро, когда решаешь реальные задачи.
Если говорить конкретно о програмисте XYZ, то тогда можно с него потребовать и X, и Y и Z.
Pzz>>>И получается печальная картина: все мечтают наслаивать классы, слой за слоем, а простую сортировку, если что, и написать-то некому. _FR>>Вот что ты скажешь о кодере, которому за девять с лишним лет ни разу не пришлось самому писать сортировку Не то, что строить деревья или создавать примитив синхронизации? Что он должен сгореть от горя или позора? Pzz>Ну скорее я посоветую такому кодеру освоить другую профессию. Потому что произойдет очередная "смена технологий", C# заменят на C#$#%, и такой кодер останется без работы: кому нужен в качестве кодера 50-летний дядька, владеющий только устаревшими методами?
Из этих слов не ясно, почему пришедшие новые технологии потребуют навыков в рукопашной сортировке Скорее, я буду прав, предположив, что с течением времени (при условии использования новых и новых технологий) всё реже и реже придётся придётся самостоятельно разбираться с такими вещами, как реализация быстрой сортировки.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111>>
Help will always be given at Hogwarts to those who ask for it.
Предлагаю всем, кто согласен, подписать следующую декларацию. Я один раз такое уже делал, несколько лет назад, но ничего, хуже не будет, повторим.
1. Существуют задачи, для решения которых использование низкоуровневых средств, таких как C/C++ или ассемблер, неэффективно и нецелесообразно, а применение высокоуровневых средств, таких как C# (включая LinQ), языки ФП и т.д. — оправданно и наиболее эффективно.
2. Существуют задачи, для решения которых использование высокоуровневых средств, таких как C# (включая LinQ), языки ФП и т.д., неэффективно и нецелесообразно, а применение низкоуровневых средств, таких как C/C++ или ассемблер — оправданно и наиболее эффективно.
Слова "неэффективно и нецелесообразно" и "оправданно и наиболее эффективно" понимаются в некотором общем смысле, без конкретной расшифровки. Просто — стоит такое использовать или же нет в реальной жизни.
Я, Дворкин П.Л., настоящим подписываюсь под этой декларацией и призываю моих оппонентов подписаться под ней.
Подпись под этой декларацией можно осуществить двумя способами. Либо поставьте мне на это сообщение плюс, либо ответьте на это сообщение своим со словом "согласен".
Несогласные с этой декларацией могут поставить мне минус или же ответить со словом "не согласен". Объяснение причин несогласия желательно, но не обязательно.
Персонально приглашаю AndrewVK и Sinclair подписаться под этой декларацией
Здравствуйте, IT, Вы писали:
IT>Этот топик как раз о том, что не у всех и я долго не мог понять почему
Наверное потому-что пару десятков лет "бошку" пытались снести на объектно-ориентированный лад. Хотя классики предупреждали:
"Object-oriented programming is an exceptionally bad idea" (Edsger Dijkstra)
"I find OOP technically unsound" (Alex Stepanov, здесь)
IMHO ФП и ООП несовместимы.
PS. Похоже в математике нет ничего, на чем могло бы основываться ООП, в то время как функциональное программирование просто пропитано идеями из математики. А ведь давно известно, что
"В каждой естественной науке заключено столько истины, сколько в ней математики" (Иммануил Кант)
Здравствуйте, Pzz, Вы писали:
Pzz>А много вы знаете граждан, способных написать самостоятельно RB-дерево?
ну дык слава богу выясняется не зря программисты несколько десятков лет работали и не нужно уже в каждом проекте реализовывать свои списки, деревья, сортировки и проч. фигню
Здравствуйте, FR, Вы писали:
FR>Угу совместимы тот же Ocaml да и величайший из языков на букву N это демонстрируют. Но совместимы только на том уровне который ты сейчас рекламируешь, а вот если идти выше то уже нет, притом скорее и не отрицают и не дополняют друг — друга а просто совершено различны.
Уровень выше это для тех кто всосал FP с молоком матери, а особо продвинутым оно передалось вообще по трубочке ещё в чреве. Я к ним, к счастью, не отношусь.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, Sinclair, Вы писали:
PD>>Да. Но не более эффективно, чем собственно ассемблер. В лучшем случае (см. выделенное мной) — не хуже. А ведь обещали на порядок — вот я и смеюсь. S>Неочевидно, кто будет смеяться последним. Представления вашего поколения об эффективности программ оказались плохо совместимыми с реальностью.
#pragma flame on
Напротив. Просто потребность в эффективности программ стала не общепринятой, а нишевой. Когда возникает необходимость спроектировать сервер, обслуживающий большое количество клиентов, или коробочку, выдающую осмысленную производительность на слабом железе, то тут некуда деваться от традиционных представлений о производительности (разве что tradeoff между процессором и памятью заметно сместился в сторону памяти). Ваше поколение оказывается довольно беспомощным при решении такого рода задач, и плохо обучаемым, потому как у вас происходит разрыв шаблона при соприкосновении с реальностью
#pragma flame off
S>Помимо abstraction penalty есть еще и abstraction gain. S>В реальной жизни вручную оптимизировать мало-мальски сложный алгоритм на ассемблере не получится — слишком мала емкость головы. И это даже если задаться конкретным целевым процессором и параметрами окружения.
У вас на слово "ассемблер" невротическая реакция. Павел не предлагал все писать на ассемблере, или даже что-либо писать на ассемблере, он произнес слово "ассемблер", чтобы очертить некоторый теоретический предел эффективности, достижимой на данном железе.
Здравствуйте, Lazy Cjow Rhrr, Вы писали:
IT>>Это всё будет работать очень и очень медленно. Это просто в принципе не может работать быстро.
LCR>верно
Вот!
LCR>Так что с "в принципе" не согласен.
Ты не понимаешь. Быстро может работать только написанное на ассемблере или его высокоуровневых аналогах вроде C. У тебя же только GC будет отрабатывать столько, сколько нормально написанная программа на ассемблере будет работать всего.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Да. Но не более эффективно, чем собственно ассемблер. В лучшем случае (см. выделенное мной) — не хуже. А ведь обещали на порядок — вот я и смеюсь.
Неочевидно, кто будет смеяться последним. Представления вашего поколения об эффективности программ оказались плохо совместимыми с реальностью.
Помимо abstraction penalty есть еще и abstraction gain.
В реальной жизни вручную оптимизировать мало-мальски сложный алгоритм на ассемблере не получится — слишком мала емкость головы. И это даже если задаться конкретным целевым процессором и параметрами окружения.
Наточить вручную программу, которая будет эффективна на широком классе условий эксплуатации — вообще малореально. В том смысле, что всё-таки придется вводить абстракции высокого уровня. Ну, например, придется делать подменяемый алгоритм сортировки чего-нибудь, чтобы выбирать его в зависимости от количества ядер процессора.
А то и вообще придется точить свой кодогенератор, который будет инлайнить оптимальный для данного RegEx целевой код непосредственно перед вызовом.
В итоге, если потратить достаточное время и усилия, то скорее всего получится та самая управляемая среда, jit, hot-spotting, query plan evaluation, и прочие техники, с успехом применяющиеся там, где некоторые упертые программисты до сих пор думают, что ассемблер лучше.
... << RSDN@Home 1.2.0 alpha rev. 677>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Pzz, Вы писали:
Pzz>Я имел ввиду, что поскольку знания, в которые вы вкладываетесь, в основном состоят из перечня интерфейсов той технологии, которую вы сейчас считаете современной, то они по природе своей полностью устаревают за несколько лет, и вам приходится переучиваться. В 50 лет это будет сделать значительно сложнее. В том числе и по организационным причинам: никто не возьмет 50-летнего дядьку "на вырост", лучше возьмут студента.
Очень сильное утверждение. А какие знания вы считаете несводимыми к перечню интерфейсов технологии?
Я вот регулярно спорю в этих же форумах со "старой гвардией", которая делает аналогичные высказывания. А потом выясняется, что для этой гвардии интерфейс строки — это ровно ASCIIZ. И человек, гордящийся умением написать по памяти поиск бойер-мура, совершенно не в состоянии написать эффективный алгоритм конкатенации строк, потому что в его ментальной модели не у всех строк есть длина. Я понятно объясняю?
Или, к примеру, совершенно невозможно объяснить такому человеку, что сравнение двух строк не сводится к сравнению байт, потому что есть суррогаты, есть нормализация, есть case sensitivity, есть accent sensitivity, и что пунктуация должна сравниваться с другим приоритетом, чем alphanumeric.
Тем не менее, такой человек считает себя безмерно круче окружающих и позволяет себе смеяться над людьми, которые выучили только интерфейс к string.Compare().
Тем не менее, с точки зрения, скажем, менеджера, эти наивные молодые люди куда полезнее старой гвардии: они, по крайней мере, могут правильно сравнить строки, когда нужно.
... << RSDN@Home 1.2.0 alpha rev. 677>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Павел Лазаревич,
PD>Лет так 30 назад была такая система программирования Альфа, сделана была в Новосибирске Ершовым, поттосиным и др. На базе языка Алгол, но с расширениями. Так вот, там сложение матриц делалось еще проще PD>real array a[1:n][1:m],b[1:n][1:m], c[1:n][1:m]; PD>// инициализация PD>c := a + b; PD>Проще некуда.
PD>Второе ИМХО выглядит так — если речь идет о чем-то стандартном, это может быть сделано очень хорошо, потому что писали реализацию грамотные люди. Но все стандартные задачи не переберешь, а когда что-то нестандартное потребуется, то будет уже и сложнее, и менее понятно, и менее эффективно.
Вот, по-моему это и есть ключевая фраза. Все задачи не переберёшь, следовательно экстенсивный путь уже обречён на неудачу. Мы можем реализовать сложение, умножение, инвертирование матриц, матрицы могут быть ленточные, треугольные, разряжённые, но этого всё-равно ничтожно мало, за бортом по-прежнему множество алгоритмов счётной мощности, куда уже не сунешься, потому что выразительных средств недостаточно.
На данный момент необходимо иметь такой базовый набор выразительных средств (нотацию, язык — назовите как угодно), которая
1. Позволяет реализовать любой алгоритм в принципе
2. Позволяет реализовать любой алгоритм практически, причём реализация была или как можно более эффективной (учитывала конкретное окружение включая кэши, конвейеры, наличие нескольких ядер), или давала гарантии по эффективности или затратам памяти.
Несложный анализ показывает, что вышеназванная Альфа никак укладывается в требования выше. Чтобы попытаться накрыть ладонью всё множество алгоритмов, выделения кусочка кода и возможность обозвать его "+" явно недостаточно. Нужна модульность, много модульности, больше чем сейчас. Поясню на примере.
Допустим, вы реализовали умножение матриц, причём учли и кэши, и многопроцессорность, и учли специфику Intel/AMD и ещё много чего. То есть, ваш алгоритм стал очень очень быстрым, так что на любой машине это оказалась самая эффективная реализация.
Я делаю преобразование Лапласа, (или решаю нелинейные уравнения, или делаю какой-нибудь комбинаторный алгоритм), и теперь мне тоже надо его сделать как можно быстрее. Я запрограммировал его в виде функции laplas_transform, и теперь как мне выделить из вашего алгоритма отражение знания об архитектуре и использовать с моей функцией? Как вообще сделать так, чтобы это было возможно?
А Вася, например, хочет взять ваш алгоритм, и сделать так, чтобы вместо вещественных чисел можно было использовать символьные значения (ему нужны символьные алгебраические преобразования).
А Таня, вдобавок, хочет взять ваш алгорить, и сделать так, чтобы вместо вещественных чисел были функции, да ещё и на комплексном пространстве.
И, наконец, Алиса, взяв ваш алгоритм в качестве процедуры, вдруг осознала, что он и является главным пожирателем процессорного времени, но специфика задачи позволяет вычислять всё произведение не сразу, а по немножку. И её осенило, что если в вашем алгоритме использовать ленивые for-ы, то всё становится замечательно.
Единственный разумный путь сделать счастливыми всех четырёх человек, как мне видится, это декларативно описать алгоритм и возложить знание об архитектуре и окружение на компилятор (так что компилятор и будет модулем optimize, можно считать что каждая функция описана как f = optimize f_). Такое декларативное описание присутствует в коде на Хаскеле, и в подавляющем большинстве случаев отсутствует в коде на C++, так что бедные Вася, Таня, Алиса и ваш покорный ученик должны заново изобретать свои многоугольные колёса.
Здравствуйте, konsoletyper, Вы писали:
K>Тут надо не книжки читать. Тут надо прежде всего инструмент соответствующий. А то на while/if реализация даже простых алгритмов превращается в кошмар. А чтение того, что получилось — ещё ужаснее.
Никак не могу согласиться. Одному дай топор — он комплекс в Кижах сделает, а другой — замочит кучу народа. Так же и с инструментами.
Инструмент у программиста — прежде всего голова. Когда в голове бардак, то реализация даже простейшего алгоритма будет нечитаемой. Когда голова в порядке — реализация даже сложных алгоритмов весьма хорошо читается.
Приходиться заниматься гадостью — зарабатывать на жизнь честным трудом (Б.Шоу)
Здравствуйте, Andrei F., Вы писали:
AF>Мне очень интересно послушать, какие в ней есть реальные проблемы.
А мне уже нет. Я уже мильен раз об этом говорил, и поднимать старый флейм нет никакого желания.
AF>Угм. "Сниму шапку, пусть назло бабушке уши отмерзнут нахрен". Всё таки странно слышать такую аргументацию от взрослого человека.
Это не аргументация. Это констатация факта. Если непонятно — могу проиллюстрировать: когда зовут обедать криком "жрать, суки", у меня почему то аппетит пропадает.
Ну и насчет взрослого человека — давай все таки обходится без хамства.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, IT, Вы писали:
IT>Я сразу начну писать код прямо в методе Main и только когда почувствую дискомфорт, озабочусь иерархией классов.
Слушай, Игорь, но почему именно "озабочусь иерархией классов"? Что, без наследования в современном мире не прожить? Лично я считаю парадигму наследования самым противоестественным самодурством какого-то одного горе-теоретика, типа авторитета, которому удалось запудрить мозги всем и надолго. Я это уже говорил что инкапсуляция и полиморфизм — 256 раз да! Наследованию — отказать. Парадигма наследования в программировании компьютеров — это пожалуй второй по величине фуфлоид.
IT>Делать это сразу я не стану, т.к. считаю это бесполезной тратой времени, потому что не знаю, что меня ждёт впереди.
Согласен! Лично для меня первична алгортмическая сущность — на уровне получится или нет и что можно выжать из этого именно на алгортмическом уровне. Это для меня — самая сложная и самая интересная часть задачи. А уж обернуть в классы и иерархии, плюс кодовая оптимизация — это рутина, этим пусть мальчики-архитекторы и мальчики-кодеры занимаются. Я всегда готов их проконсультировать и объяснить сущность алгоритма.
McSeem
Я жертва цепи несчастных случайностей. Как и все мы.
По моему тут только ты единственный его неправильно понял.
PD>А в смысле работы программиста — вот тебе самое эффективное решение из незабвенного "Hello, World"
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>В этом смысле — мб, и да, если знать Хаскель, конечно. Но меня вообще-то больше интересует эффективность его выполнения
Ключевым моментом, которого пока не касались в этой дискуссии, является высокоуровневая оптимизация, про которую никакой ассемблер не знает. Например, в Хаскелле есть дефорестация (list fusion). Вася взял список, применил к его элементам функцию f, получив другой список:
vasja lst = map f lst
Петя взял васин код, и поэлементно применил к возвращаемому этим кодом списку функцию g
petja lst = map g (vasja lst)
Оля взяла петин код, поэлементно применила к возвращаемому этим кодом списку функцию h
olja lst = map h (petja lst)
Компилятор Хаскеля взял эту конструкцию с кучей промежуточных списков и оптимизировал в
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Я вот об одном думаю иногда. Взять бы этих специалистов по паттернам, фреймворкам и интерфейсам, назначить им хорошую зарплату, да только поручить им спроектировать и написать www.microsoft.com , с тем количеством запросов, которое он реально обслуживает. А потом, когда время ответа будет порядка десятков секунд, уволить всех с распубликованием их имен
При мне про высоконагруженные системы даже не заикайся.
Я на них не одну свору собак сожрал.
Так что порву на тряпки по любому.
... << RSDN@Home 1.2.0 alpha rev. 745>>
Пусть это будет просто:
просто, как только можно,
но не проще.
(C) А. Эйнштейн
Здравствуйте, Pzz, Вы писали:
Pzz>И не забывайте еще одно. Вот выйдет новый процессор Интел, а мелкософт скажет, что ему не интересно. И не будет его специальным образом поддерживать. Дворкин-то выматерится и руками все соптимизирует. А вы куда пойдете?
В плане эффективных оптимизаций я доверяю компиляторам гораздо больше, чем Дворкину.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, Sinclair, Вы писали:
S>Бред какой-то. Мы что, начали с обсуждения веба? Нет, начали с производительности и возможностей по оптимизации. АСП.НЕТ здесь — только пример. Что тут непонятного?
Ну, тут многие так спорят:
А> ... и буду нем как рыба ...
В> А, рыба? Это та самая, у которой нет шерсти? А, следовательно, блох тоже нет? Так вот, ты нифига не понимаешь в блохах, ведь блохи ...
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Sinclair, Вы писали:
ВВ>>Да я уже, понял. Я сам с собой разговариваю. Зачем мне вообще отвечать? У меня и так прекрасно получается. S>Совершенно верно. Ну где хоть один аргумент от твоих противников в защиту WebForms?
Лень ветку почитать?
ВВ>>
ВВ>>Здравствуте, Воронков Василий, Вы писали:
ВВ>>>>ASP.NET — говно.
ВВ>>Это все от ламерства и полного бескультурия! Как ASP.NET может быть говном — ведь он же включает в себя все достоинства .NET, а следовательно и WPF. WPF — это самая мощная технология построения интранет-приложений, которая существует на настоящий момент. И которая как раз и предлагает мощный метаязык для описания представления — XAML. Какой человек в здравом уме скажет после этого, что ASP.NET — говно?
ВВ>>АSP.NET просто невменяемо рулит!
S>Этот понос — он к чему?
Этот "понос" писался не для тебя. Раз уж ты так бестактно влез в мою дискуссию с самим собой, объясни мне в таком случае, где у нас вообще "кончается" ASP.NET? Ты же в достоинства ASP.NET приписываешь все возможности .NET? Даже Рихтеровский power threading тут всуе помянул. Так, извините, почему бы и WPF сюда не засунуть? WPF — часть .NET, позволяет разрабатывать приложения доступные через веб, ну значит часть ASP.NET, очевидно.
Этот "понос" — ваша манера вести дискуссию. Что, пахнет?
ВВ>>А то, может, WindowsForms тоже говно, а я и не заметил. S>Вообще-то да, говно. У неё тоже модель GUI совершенно не соответствующая современным реалиям. Поэтому нормальный десктопный интерфейс на ней делать весьма и весьма тяжко. Что, собственно, и привело к изобретению WPF. Но это никакого отношения к веб не имеет.
У WindowForms модель полностью отвечает архитектуре Win32 и является прекрасной надстройкой над user32. То, что сама по себе эта модель уже устарела, разумеется, очевидно. Но WPF (в отличие от того разрекламированного тут ASP.NET MVC) представляет собой не другую абстракцию, а принципиально другую технологию.
Если стоит задача разработки именно под Win32, то WindowsForms — пожалуй, одно из лучших решений. Особенно в свете детских болячек WPF.
ВВ>>У месье богатый опыт работы консьержем? Предлагаю на досуге помедитировать над значением аббревиатуры ASP. S>Аббревиатура совершенно ни при чем. Это становится очевидно, если сравнить архитектуру ASP.NET и ASP, у которых вроде бы она одна и та же.
Само название ASP.NET говорит о то, что это реализация active server pages на .NET. Реализация, active server pages на .NET — это ASPX, класс Page, реализующий IHttpHandler и все, что тянется за ним. И все, что на настоящий момент предлагается в качестве реализации — это WebForms.
ВВ>>кому вообще нужен ассемблер, если на нем нельзя написать эффективное веб-приложение?! Да еще за разумные сроки! S>Этот понос — он к чему? К тому, что есть какие-то узкоспециальные приложения, где ассемблер всё еще может справиться? S>Много ли кому интересны эти ниши, кроме ассемблерщиков, неспособных освоить ничего нового?
Т.е. те области, в которых ассемблер может справиться, никому не интересны, кроме самих программистов да и то их интерес возникает лишь в силу того, что они не способны освоить ничего нового? А были бы способны, так может и областей бы таких не было?
Юношеским максимализмом попахивает.
S>Я говорю о сложностях реализации настоящих высоконагруженных систем, где важна производительность. И о том, что она на ассемблере недостижима, что в точности противоположно точке зрения апологетов ассемблера. S>Вон непдалеку кто-то мне грозил разрывом шаблонов в случае написания высоконагруженного сервера. Павел Дворкин искренне полагает, что microsof.com не может работать на ASP.NET. Твоя точка зрения мне вообще остается непонятной.
ВВ>>Можно было и без "очень простого примера" это сказать. С этим даже Дворкин согласится. S>Это вряд ли. У него та часть личности, которая отвечает за "ой, извините, это я протупил" отключена за неуплату.
А у меня вот аналогичное впечатление от вашей партии.
ВВ>>И поэтому мы говорим об ASP.NET приложении на ассемблере? Железная логика ВВ>>Кстати, было бы очень интересно обсудить пример веб-приложения, в котором правильно применяются хорошие фреймворки, разработанного MS. S>Примером хорошего приложения является сайт microsoft.com и значительная часть msdn.microsoft.com.
Ты знаком с архитектурой этих приложений? Не мог бы рассказать, какие именно хорошие фреймворки там использует и как же именно они правильно применяются.
ВВ>>Предлагаешь производителям ждать XBox370 вместо того, чтобы делать игры? Чур-чур! S>Предлагаю не делать вид, что инвестиции в ручную оптимизацию под конкретную железку гарантированно не будут выброшены на ветер.
Т.е. компании, вкладывающие десятки миллионов в разработку игр под XBox360, "гарантированно" выбрасывают деньги на ветер?
Pavel Dvorkin,
PD>Все же, если не сложно, сделай, пожалуйста, в разы проще, понятнее и эффективнее сортировку — любую. Или, скажем, какой-нибудь графический фильтр. Или создание и управление неким сложно организованным файлом на диске. Или математический алгоритм — матричную алгебру, к примеру.
В сортировках, графических фильтрах и сложных файлах на дисках увы дас вайст их нихт.
А вот про матричную алгебру — это пожалуйста:
Скалярное умножение вектора-строки на вектор-столбец:
bra_ket u v =
sum_product u (map coupled v)
Сложение матриц:
add_matrices :: (Num a) => t -> t1 -> [[a]] -> [[a]] -> [[a]]
add_matrices _ _ = matrix_zipWith (+) where
matrix_zipWith f a b = [zipWith f ak bk | (ak,bk) <- zip a b]
Транспонирование:
transposed a
| null (head a) = []
| otherwise = ([head mi| mi <- a])
:transposed ([tail mi| mi <- a])
Умножение матрички на скаляр:
scalar_matrix alpha a =
[[alpha*aij| aij <- ai] | ai<-a]
Умножение матрички на матричку:
matrix_matrix a b
| null a = []
| otherwise = ([sum_product (head a) bi | bi <- b])
: matrix_matrix (tail a) b
orthogonals :: (Scalar a, Fractional a) => [a] -> [[a]]
orthogonals x =
orth [x] size (next (-1))
where
orth a n m
| n == 1 = drop 1 (reverse a)
| otherwise = orth ((gram_schmidt a u ):a) (n-1) (next m)
where
u = unit_vector m size
size = length x
next i = if (i+1) == k then (i+2) else (i+1)
k = length (takeWhile (== 0) x)
gram_schmidt :: (Scalar a, Fractional a) => [[a]] -> [a] -> [a]
gram_schmidt a u =
gram_schmidt' a u u
where
gram_schmidt' [] _ w = w
gram_schmidt' (b:bs) v w
| all (== 0) b = gram_schmidt' bs v w
| otherwise = gram_schmidt' bs v w'
where
w' = vectorCombination w (-(bra_ket b v)/(bra_ket b b)) b
vectorCombination x c y
| null x = []
| null y = []
| otherwise = (head x + c * (head y))
: (vectorCombination (tail x) c (tail y))
Ну и решение СЛАУ методом выделения треугольной матрицы:
one_ket_triangle a b
| null a = []
| otherwise = (p,q):(one_ket_triangle a' b')
where
p = [bra_ket u ak | ak <- a]
q = bra_ket u b
a' = [[bra_ket ck ai | ck <- orth] | ai <- v]
b' = [ bra_ket ck b | ck <- orth]
orth = orthogonals u
u = head a
v = tail a
one_ket_solution :: (Fractional a, Scalar a) => [[a]] -> [a] -> [a]
one_ket_solution a b =
solve' (unzip (reverse (one_ket_triangle a b))) []
where
solve' (d, c) xs
| null d = xs
| otherwise = solve' ((tail d), (tail c)) (x:xs)
where
x = (head c - (sum_product (tail u) xs))/(head u)
u = head d
Представьте себе, и это всё, да. В последний раз, когда я видел решение СЛАУ (моё) оно было минимум 5 экранов — и for-ы, for-ы, много for-ов... Выбор несколько других примитивов позволяет, даже в такой "цыкло-насыщенной" задаче, избежать явного применения оператора цикла. Казалось бы, согласно маэстро Дейкстре, основополагающего примитива.
PD>Слишком уж разные у нас с вами задачи, господа...
Из ваших сообщениях в тематических форумах подозреваю что нет. Просто у меня другое отношение к заточке инструмента
Andrei F.,
AVK>>UI то, конечно, делать можно. Проблема в дизайн-тайме, причем не только этого самого UI. Сколько я ни спрашивал, никто не смог мне продемонстрировать чисто функциональную компонентную модель. Что, впрочем, не мешает при этом какими то элементами ФП пользоваться.
AF>Любой интерфейс должен иметь состояние — просто потому, что пользователь так устроен Так что делать его в идеологии ФП — все равно что бегать в ластах.
Нет.
Состояние может существовать просто согласно постановке задачи (например, stateful протокол). Для того, чтобы состояние не рассыпалось, конечно достаточно линеаризации мутаторов и аксессоров, и так делают все императивные языки. Однако, это не необходимое условие. Для корректного сохранения состояния достаточно соблюдать относительный порядок вызовов мутаторов и аксессоров.
Один из подходов — это монады, о них ты уже много раз слышал. Формируется ФВП, связывающая аргумент и цепочку мутаторов/аксессоров, таким образом сохраняющая относительный порядок и таким образом поддерживающая состояние в корректном гхм... состоянии Итоговая конструкция скорее не "последовательная", а "вложенная", и обладает несимметричностью (слева значение, а справа функцию (условно говоря, ибо функции тоже значения)).
Другой подход. Теперь мы говорим, что эти обращения к состоянию образуют поток (то есть вводим понятие функционального потока). Мы можем, если хотим, производить различные операции над такими потоками, эти операции будут порождать другие потоки. Операции над потоками обобщаются до стрелок (в случае хаскеля просто класс типов Arrow). В деталях эта абстракция довольно сложна, но пользоваться ею (при наличии необходимых примитивов) вполне нормально:
Здравствуйте, fplab, Вы писали:
F>Здравствуйте, _FRED_, Вы писали:
_FR>>Вот что ты скажешь о кодере, которому за девять с лишним лет ни разу не пришлось самому писать сортировку Не то, что строить деревья или создавать примитив синхронизации? Что он должен сгореть от горя или позора?
F>Да, однозначно. Ничто не может служить оправданием халтуры. Конечно, на практике нужно использовать оптимизированные и проверенные библиотечные функции. Но это не значит, что нет необходимости знать основные алгоритмы. Пусть пузырьковая сортировка не оптимальна: она дает навык работы с массивами. А быстрая сортировка — навык работы с рекурсией. Или, по вашему, это лишнее ?
Т.е. так как я сейчас не могу написать быструю сортировку по памяти — я не умею работать с рекурсией?
Вам не кажется, что вполне возможно оттачивать навыки и на других задачах?
Здравствуйте, eao197, Вы писали:
E>PS. В начале 90-х в Союзе у многих крышу срывало Прологом. С тех пор я думал, что именно Пролог самая крутая трава. Но, видимо, FP еще круче.
Пролог трава более крутая, но к сожалению плохо совместимая с жизнью, так как создать эффективные реализации практически невозможно, и с императивными языками не стыкуется.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Воронков Василий, Вы писали: ВВ>И что мне с ней делать? Молиться на нее?
Ну, например понять, что применение той же техники для C# принципиальных проблем не имеет.
S>>В таком случае, нужно отказаться от муссирования рассуждений типа "теоретически программист может вручную на ассемблере заоптимизировать всё насмерть" ВВ>Ну правильно, ведь на ассемблере никто ничего не пишет, им пугают детей на ночь, а мы тут уже вовсю дотнет-приложения "суперкомпляторами" компилируем.
Этот понос — он к чему?
ВВ>Да, ослиный ASP.NET — это гениальный пример для сравнения. Ничего лучше чем дебильный конструктор сайтов и подобрать нельзя.
А что в нём ослиного? Это не дебильный конструктор сайтов, а лучший в мире фреймворк для построения высокопроизводительных веб-приложений. Это так, к слову о.
ВВ>Может, лучше программирование на асме вообще сравнить с InfoPath-ом? Ведь какие там формочки, какие абстракции.
Ну, с таким уровнем представлений вы можете асм хоть с копченой рыбой сравнивать.
ВВ>А может, это — давайте тогда все на свете на АСП-НЕТ писать? Ведь АСП-НЕТ рвет на части асм по своей эффективности. Чет мужики еще не доперли что надо все на АСП-НЕТ переводить.
Еще раз медленно повторяю: пусть твои мужики воспроизведут на асме хотя бы один пример из самплов к Рихтеровской Power Threading Library. И посмотрим, кто кого порвёт по эффективности. ВВ>Abstraction gain — он в голове. И это хорошо, что он в голове, а не в другом месте. И не надо его из головы куда-то перекладывать.
Еще раз, медленно, поясняю: abstraction gain — вполне конкретная штука, и она существует. В частности специализация абстрактного кода под аппаратную платформу в момент исполнения, она же JIT. В частности, специализация абстрактного кода под реальные данные в момент сборки, она же суперкомпиляция.
Поменьше эмоций, побольше мыслей.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, igna, Вы писали:
IT>>Этот топик как раз о том, что не у всех и я долго не мог понять почему I>Наверное потому-что пару десятков лет "бошку" пытались снести на объектно-ориентированный лад. Хотя классики предупреждали:
За цитаты — респект
А вот как из процетированно следует, что I>IMHO ФП и ООП несовместимы.
неясно Или это только IMHO?
... << RSDN@Home 1.2.0 alpha 4 rev. 1111>>
Help will always be given at Hogwarts to those who ask for it.
Здравствуйте, _FRED_, Вы писали:
_FR>Вот что ты скажешь о кодере, которому за девять с лишним лет ни разу не пришлось самому писать сортировку Не то, что строить деревья или создавать примитив синхронизации? Что он должен сгореть от горя или позора?
Да, однозначно. Ничто не может служить оправданием халтуры. Конечно, на практике нужно использовать оптимизированные и проверенные библиотечные функции. Но это не значит, что нет необходимости знать основные алгоритмы. Пусть пузырьковая сортировка не оптимальна: она дает навык работы с массивами. А быстрая сортировка — навык работы с рекурсией. Или, по вашему, это лишнее ?
Приходиться заниматься гадостью — зарабатывать на жизнь честным трудом (Б.Шоу)
Здравствуйте, _FRED_, Вы писали:
Pzz>>Внутри метода — алгоритмы. Те самые сортировки и поиски, о которых книжки пишут. А снаружи — клей и упаковка. _FR>Я как-то всегда думал, что как раз алгоритмы — это то, что очень неплохо поддаётся "библиотизации", то есть вынесением в многократно используемые кирпичи. И задумываться над алгоритмами лишний раз не приходится.
Приходится задумываться, очень даже. Вот возьмём ту же пресловутую сортировку. Кто из кодеров вообще слышал о каком-то методе кроме "quick sort" (и то — под его маркетинговым названием)? А условия применимости? Вот завтра придут данные с определённым на них частичным порядком вместо линейного, и опаньки — условия применимости не выполняются. А если сравнения очень дорогие и их надо минимизировать? А если данных никогда не больше 8 элементов и quicksort просто дорог в раскачке, простейший метод вставок сработает быстрее? А если надо выполнить сортировку параллельно? А если дали 100 миллиардов элементов и они даже в виртуальную память не влезут (я уж молчу, что сортировать данные толще физической памяти такой сортировкой — самоубийство независимо от того, влезло оно в виртуалку или нет)? Всё, такой кодер сдулся, независимо от того, насколько он хорошо знает STL и может задавать сортировку его средствами.
"Библиотизация", конечно, возможна — до определённой степени. И грустно то, что факт самих ограничений многим недоступен просто по недостатку образования и желания их узнать и осознать.
Pzz>>Граждан, способных нагородить иерархую классов, из которой, если ее нарисовать на бумажке разноцветными карандашами, можно обои сделать — пруд пруди. А много вы знаете граждан, способных написать самостоятельно RB-дерево? Или сделать недостающий в системе примитив синхронизации из того, что в системе есть? Много ли вы вообще знаете граждан, которые знают, что в системе может недоставать каких-то примитивов синхронизации? :-) _FR>В первую очередь из-за того, что редко, очень редко встречаются сейчас такие задачи.
Угу, именно так. Фактически, можно тупо рубить бабло на минимальном базисе. Впрочем, для этого нужно соответствующее усердие, которое тоже нечастый скилл.;(
Pzz>>И получается печальная картина: все мечтают наслаивать классы, слой за слоем, а простую сортировку, если что, и написать-то некому. _FR>Вот что ты скажешь о кодере, которому за девять с лишним лет ни разу не пришлось самому писать сортировку :???: Не то, что строить деревья или создавать примитив синхронизации? Что он должен сгореть от горя или позора?
Какой ответ на этот вопрос Вы хотите? Можно ответить цинически — мол, есть клавишное мясо:), которое не способно даже осознать, что оно теряет и почему. А можно — что пусть себе и дальше продолжает, но пусть осознаёт, где его потолок. В принципе, оба ответа правильны.
Здравствуйте, netch80, Вы писали:
N>А описанные Вами знания "есть такое, а есть сякое" без подкрепления забудутся после первого экзамена. N>Поэтому я с сомнением отношусь к тем архитекторам, которые давно сами не кодируют, и к тем кодерам, которые способны только применить указанное им решение.
Вот пример из личной жизни: пока писал на VB, приходилось вручную реализовывать бинарный поиск (ну нет его в стандартной библиотеке), и с обобщением написанного кода нет так всё просто в этом языке. Так вот несколько лет уже пишу на C# и, наверное, не вспомню, как его реализовать.
Знания забываются от отсутствия практики, а вовсе не от понимания сути. И закономерно, что в некоторых областях, где от определённых знаний толку чуть (я не говорю "совсем нет"), уровень "базы" снижается.
Например, вспоминаю анекдот про то, как старого програмиста спросили, как записать некие данные на диск, а он начал ответ со слов о том, что "перво-наперво нужно спозиционировать головку устройства". И life is good что подобного не требуется знать сейчас.
_FR>>Гхм… попробую так: в каком проценте задач сортировки данных вам не достаточно библиотечных реализаций? Мне кажется, эта цифра вполне подойдёт под описание "очень редкно". N>У меня лично статистики недостаточно. Но вот случай, когда обычная сортировка крайне невыгодна — каждый рабочий день на глазах, это таймерное дерево в движке событий. Оно сделано на пирамиде.
В отдельных случаях может быть (и даже имеет право быть) всё что угодно. Но вот спрашивать веб-програмиста про объекты синхронизации на юниксе — гхм..? Вот я и говорю, что "база" у програмистов в общем смысле не в алгоритмах сортировки и прочих деталях реализации.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111>>
Help will always be given at Hogwarts to those who ask for it.
Здравствуйте, Pzz, Вы писали:
Pzz>Да помилте, какой еще нужен струмент для написаныя простых алгоритмов, кроме как раз тех самых if'ов и while'ов? Откройте любую книжку про алгоритмы, обратите внимание, на каком языке в этих книжках алгоритны расписывают.
См. квиксорт на Хаскеле и на С. Классический пример. Или там использование паттерн матчинга для красно-черных деревьев.
Оно реально выглядит красивше и понятнее.
Здравствуйте, AndrewVK, Вы писали:
AVK>Скептическое отношение у меня как раз таки к МП, а точнее к его реализации в Немерле.
Мне очень интересно послушать, какие в ней есть реальные проблемы.
AVK>Ну и еще, хоть я и стараюсь с собой бороться, местный неуемный немерлевый пиар, приправленный изрядной порцией демагогии, периодически переходящей в хамство, вызывает чисто инстинктивное раздражение и отторжение.
Угм. "Сниму шапку, пусть назло бабушке уши отмерзнут нахрен". Всё таки странно слышать такую аргументацию от взрослого человека.
Здравствуйте, AndrewVK, Вы писали:
AVK>ФП не отрицает состояния
In computer science, functional programming is a programming paradigm that treats computation as the evaluation of mathematical functions and avoids state and mutable data
AVK>А устроенность мира заменяется в ФП копированием. Это ж, блин, азы.
Я, блин, в курсе, как работает ФП.
"Все вокруг тупицы, один я д'Артаньян" — это ты молодец. Не надо обвинять фанатичных немерлистов, источник флейма явно в тебе.
Здравствуйте, IT, Вы писали:
IT>Уровень выше это для тех кто всосал FP с молоком матери, а особо продвинутым оно передалось вообще по трубочке ещё в чреве. Я к ним, к счастью, не отношусь.
Достаточно чтобы ООП не был впитан с молоком матери или еще раньше
Я как раз и отношусь к таким (большое влияние форта на неокрепший еще мозг ).
Здравствуйте, yumi, Вы писали:
Y>Здравствуйте, D. Mon, Вы писали:
DM>>Например, у меня есть несколько алгоритмов компенсации движения, отличающиеся лишь способом поиска похожего блока. Наследование позволило обойтись без дублирования кода, лишних if'ов и указателей на функции (которые, по сути, изоморфны VMT).
Y>Если я правильно тебя понял, то нужно было написать один generic алгоритм компенсации движения, и в него при создании конкретного экземпяра передавать функцию поиска похожего блока.
А на практике окажется, что из ~100 методов отличаются у потомков 20, и этого достаточно, чтобы действие "передать функцию поиска похожего блока" вылилось в извращение типа "передать структуру функций, специфичных именно для этой реализации". И всё это с костылями вроде приведения типов.
Нет, конечно, использовать такое порой можно и нужно. Но в общую практику я бы рекомендовал наследование. Конечно, у него есть свои проблемы (вспомним множественное наследование и его эффекты). Но это проблема любого подобного механизма — можно загнать в ситуацию, когда перестанет работать.
Здравствуйте, McSeem2, Вы писали:
MS>Слушай, Игорь, но почему именно "озабочусь иерархией классов"? Что, без наследования в современном мире не прожить? Лично я считаю парадигму наследования самым противоестественным самодурством какого-то одного горе-теоретика, типа авторитета, которому удалось запудрить мозги всем и надолго.
Проблемы обычно встречаются при наследовании реализации. А какие проблемы у наследования интерфейса? К тому же иерархия объектов — это не обязательно наследование.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, netch80, Вы писали:
N>... "quick sort" ...
Во, IT, ты удивляешься почему не у всех FP крышу сносит? У людей крыша занята. Одни ее занимают мыслями о том как писать quick sort-ты и где их лучше применять. Другие о том как бы не пропустить новые революции от Майкрософ. Третие еще чем-мто...
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Pzz, Вы писали:
ГВ>>Цирк. Для тех кто в это верит, поясню: привлекать неквалифицированных пользователей к формализации задачи — хорошо, привлекать неквалифицированных программистов (именно их ты имеешь в виду, говоря об индусах, правда?) — очень плохо.
Pzz>Их привлекают не к формализации, а к реализации. Хорошо ли это, плохо ли, но вот привлекают. Наверное потому, что свободных квалифицированных уже почти не осталось.
Это и есть — плохо.
ГВ>>Вообще-то ООП зародилось из фреймов-слотов, это такой ма-а-а-алепусенький кусочек инструментария ИИ по формализации знаний. Менеджеры софтостроения там если и стояли рядом, то только стояли. Pzz>Вообще-то ООП зародилось из Симулы, языка. предназначенного для компутерного моделирования.
О точных прародителях ООП и календаре его развития можно спорить, но это не слишком важно. Важно то, что к менеджменту ООП не имеет никакого отношения. К структуризации знаний — да, к менеджменту — нет.
Pzz>А в индустрию пришло и разрослось именно потому, что помогает раскидывать задачу по большому количеству исполнителей. Фича эта сама по себе очень ценная, но имеет отношение скорее к управлению проектом, чем собственно к программированию.
Всё не так. Первоначально рассуждали о том, что ООП позволяет существенно расширить возможности одного программиста, благодаря тому, что способ представления абстракций лучше адаптирован к человеческому мышлению, чем, скажем, процедурная абстракция. То есть один из тезисов, послуживших распространению ООП прямо противоположен приведённому тобой: предполагалось в некотором роде сокращение числа программистов. Понимаешь? А распределять программирование на массу народу умели задолго до появления даже языков высокого уровня. Почитай того же Брукса.
ГВ>>Свежо предание... Только паттерн, это не "готовое решение", а некое собирательное название разных по существу решений. Хотя примеры могут быть и вполне определёнными. А каким же им ещё быть?! Pzz>Это, признаюсь, не моя мысль, а Пола Грэхема. В оригинале она звучала примерно в том духе, что наличие паттернов проектирования свидетельствует об отсутствии в языке нормальных макросов. Потому что если приходится из проекта в проект делать похожие телодвижения, это повод написать макрос, который эти телодвижения автоматизирует.
Ну, Грэхем в своём репертуаре. Только нужно, как бы, это... Разделять призывы и "идеологемы", и технически реализуемые штучки. Корни паттернов на самом деле в особенностях мышления человека вообще и технических специалистов в частности. Они выходят очень далеко за пределы языков программирования.
Pzz>Я, в общем, отчасти согласен, но с той оговоркой, что некоторые вещи очень просто рассказать человеку, но при этом очень трудно формализовать до такой степени, чтобы их можно было сказать компьютеру.
Ну, я тоже согласен с тем, что повторяющиеся действия нужно загонять в компьютер. Другое дело, что не все действия туда загоняемы и кроме того, даже будучи загнанными они снова упорядочиваются в некие паттерны и так до бесконечности.
Pzz>>>А вот внутри самих алгоритмов if'ы и while'ы — вполне себе адекватный инструмент. ГВ>>Это не просто "адекватный инструмент", if — это блин, базисная конструкция императивного стиля. Pzz>Я как-то не уловил, почему базисная конструкция императивного стиля не может быть адекватным инструментом? Какое слово является ругательным, "базисная" или "императивного"?
"адекватный инструмент" Абсурдна сама формулировка. Ну, что-то вроде: "капли — адекватный инструмент дождика". Вот такое же.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, IT, Вы писали:
IT>За 30 лет развития традиционных языков программирования (Fortran, PL/1, COBOL, Pascal, C/C++, Java, C#) принципиально изменился только мир вокруг метода. Мы получили наследование, инкапсуляцию и полиморфизм, компонентность и контрактность, шаблоны/дженерики и атрибуты, массу паттернов проектирования, подходов и отходов, методологий и прочих вещей, призванных организовать код в нечто более менее управляемое.
Ничего мы не получили. Все вышесказанное относится к организации кода и только. А сам код каким был, таким и остался. И если не согласен — напиши, пожалуйста, какой-либо более или менее серьезный алгоритм иным способом. Ну, к примеру, ту же сортировку, хоть быструю, хоть пузырьковую. Сам напиши, а не метод вызови.. Тут как-то сразу забываешь про инкапсуляцию с полиморфизмом и про все паттерны, потому что надо код писать, а не организовать. Алгоритм реализовать то есть.
А вот роль организации кода резко повысилась по сравнению с фортрановскими временами, да. Но это не столько с новыми приемами связано, сколько с характером задач. В значительной степени нынешний код — код без алгоритма . Это не реализация какого-то алгоритма, заложенного в задачу, а набор обработчиков разных событий. Программу для обработки битовых карт не превратишь в программу для обработки текста, алгоритмы тут совсем разные. А программа типа — ввести данные с формы — записать в БД практически индифферентна к тому, что вводить с формы и что писать в БД. Отсюда и все эти паттерны, фреймворки, библиотеки и т.д.
IT>Что же изменилось внутри метода? Да почти ничего. Как и 30 лет назад мы имеем if/else/switch, несколько циклов, команды выхода из цикла и метода, операции, присваивание и ещё немного по мелочёвке.
А не возникала ли у тебя мысль — а может, ничего и не надо ? Базовые конструкции потому и называются базовыми, что они , во-первых, не упрощаются, а во-вторых, их набор минимален и не всякое туда пустят, просто для того, чтобы не нарушать стройность и логику — иными словами, по принципу бритвы Оккама. Это как аксиомы Евклида — за 2000 лет никаких новых аксиом туда не добавили и не добавят . И три классические формы — следование, выбор, повторение — так и остались, и четвертому Риму похоже, не бывать
Здравствуйте, AndrewVK, Вы писали:
VD>>Вот если бы я был АВК, то сказал бы "опять С++
AVK>Фи, как грубо и неумело. Не переноси свои фобии на других.
Какие фобии? Как только где-то появляется слово Nemerle, так то час мы видим тебя с громкими воплями "опять этот Nemerle...". Право, реакция совершенно не адекватная. Если в Nemerle ничего нет, то что так на него реагировать то? (вопрос риторический)
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>А это не обсуждалось. Вот что писал IT
IT>>Вот здесь два примера того, как правильные высокоуровневые конструкции могут сделать код в разы проще, понятнее и эффективнее
А почему "могут" не выделил? Я же знал с кем имею дело и специально так сформулировал
На самом деле ты будешь неприятно удивлён, но я знаю о чём говорю. Тот же самый алгоритм расчёта нелюбимых тобой процентов, который я привёл, ускоряется в разы в зависимости от количества ядер путём внесения маленького изменения в код, состоящего из вызова одного метода AsParallel. Распаралеливание императивного алгоритма потребует больше времени, чем написание самого алгоритма и сделает его в конце концов окончательно безнадёжным.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, WolfHound, Вы писали:
WH>При мне про высоконагруженные системы даже не заикайся.
Ик... WH>Я на них не одну свору собак сожрал.
Говорят очень полезно от туберкулеза, болеете да? Выздоравливайте WH>Так что порву на тряпки по любому.
Не пойму я вас, то собак жрете, то тряпки рвете...
Lisp is not dead. It’s just the URL that has changed: http://clojure.org
Здравствуйте, Sinclair, Вы писали:
S>Сосал почтовый сервер, весь из себя написанный на плюсах и работавший поверх файлухи. (а то! ведь СУБД — это тормоза, они не дают прямого управления IO). S>После переписывания на Java, поверх MS SQL, на той же машинке почтовый сервер стал выгребать не 200000 писем в сутки, а 1000000. S>Второй боттлнек устранить не удалось: это был Interbase, тоже ясное дело, не на сишарпе писанный. Увы, он никак не хотел жрать больше 1 СPU на четырехпроцессорной машине, и кластеризовываться тоже не умел.
Не собираюсь оспаривать твои высказывания, но объясни мне, пожалуйста, почему тогда абсолютное большинство десктопного софта, написанного на яве работает в разы медленее, чем его аналоги на C/C++? Почему mcirosoft-овский MSDN работает быстро, а IBM-овская справка (на Java) — из рук вон медленно? Почему та же история повторяется с парочкой OpenOffice/MS Office? UML-рисовалки, это вообще мрак. Если сравнивать Eclipse и MSVC 6.0 — это попросту не смешно. Если ява с такой уверенностью "рвёт" плюсовый код?
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Sinclair, Вы писали:
S>Сосал почтовый сервер, весь из себя написанный на плюсах и работавший поверх файлухи. (а то! ведь СУБД — это тормоза, они не дают прямого управления IO).
Вот что значат тормозные FS в Винде...
Здравствуйте, Pzz, Вы писали:
Pzz>Я вообще не понимаю этот дискурс, "у нас тут над задачей крутится мега-кластер из миллиона серверов".
Ты просто начал наезжать на новое поколение что это новое поколение в жизни не осилит большой сервер.
Вот я тебе и расказал что не тебе об этом говорить ибо про большие серверы ты ничего не знаешь.
... << RSDN@Home 1.2.0 alpha rev. 745>>
Пусть это будет просто:
просто, как только можно,
но не проще.
(C) А. Эйнштейн
Здравствуйте, Pavel Dvorkin, Вы писали:
AVK>>Нет.
PD>Ну что же, все ясно.
Смешно. Потрясающий ты человек, Павел Дворкин.
PD> Ответ свой я дал в ответе IT.
Нет, там ты тоже его не дал. Итого — доказать, что ты в императивном стиле напишешь не хуже функционального ты не смог. Вот и весь итог.
PD>Еще раз (на этот раз тебе) объясняю — требовать от меня чего-либо ни ты, ни он не можешь.
Да я и не требую. Только выглядят после этого твои слова, как бы это помягче, неубедительно.
AVK>>Я хочу не кашу из звездочек и стрелочек, а вменяемое описание алгоритма.
PD>Ну насчет каши — не нравится язык — дело твое. Я другой язык использовать не буду.
Кто бы сомневался.
PD> А описание — мне казалось , что я его дал.
Вот именно что казалось.
>>поэтому я просто распараллелил вычисление сумм красных компонент по столбцам окна.
Компонент чего, rакого окна? О чем вообще речь? Сравни свое "описание" с описанием IT. Ну хотя бы по объему. А с таким описанием я тебе могу дать точно такой же ответ:
Из комментариев еще можно понять, что у тебя там вроде бы есть еще и непараллельный алгоритм, но AsParallel реально параллелит только если есть несколько ядер. Впрочем, явно указать тоже не проблема:
А теперь сравни со своей простыней. Что там у нас осталось? Параллелить вкривь и вкось различными способами? Все это задается начальными итераторами, теми, которые на вход AsParallel поступают. И тут тоже у шарпа с его итераторами возможностей по понятной и эффективной реализации всяких причудей будет больше, чем ты сможешь на С++ изобразить. Впрочем, это уже не ФП.
PD>Дано окно Windows с неким рисунком в нем. Пройти по всем пиксельным столбцам клиентской области этого окна и найти для каждого столбца сумму R (красных) компонент пикселей , записать результаты в массив columnSum. Две реализации — в лоб без распараллеливания, и с распараллеливанием PD>Реализация с распараллеливанием — создаются N потоков, где N — число процессоров (возвращает GetSystemInfo). Если процессоров 2, то один поток займется левой половиной окна, а другой правой. Если 3 — левой, средней и правой соответственно. И т.д.
Если это все, тогда в первый вариант вместо things подставляем:
Здравствуйте, Andrei F., Вы писали:
AF>Избавленный от побочных эффектов GUI — это феноменально. Изобретатель обезжиренного сала удавился от зависти. Все корифеи ФП рыдают от тоски, что не додумались до такой простой и гениальной идеи.
GUI даже в чистых ФП языках есть уже ндцать лет. По делу есть что сказать?
AVK>>Рылом не вышел?
AF>Нет, не рылом. Но хотя бы немного думать, прежде чем писать — это очень желательно.
Аналогично. Если ты чего то не понял, это не означает, что оппонент дурак.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
S>Осталось понять, можно ли применить этот подход, оставаясь в рамках "наилучшим образом оптимизированной программы, написанной на ассемблере", и "можно ли сделать код эффективнее с помошью каких-то высокоуровневых конструкций". Об этом я напишу завтра, потому что сегодня пора домой
Итак, продолжаем разрывать шаблоны. Но перед тем, как перейти к основному обсуждению, сделаю два уточнения:
1. Напомню, что речь идет именно о сферических программах в вакууме. Мы не собираемся обсуждать возможности реально доступных компиляторов и сред исполнения. Во-первых, потому, что изначально вопрос формулировался именно в абстрактно-теоретических терминах, а во-вторых, потому, что иначе нам придется сравнивать реальные компиляторы с реальными программистами-ассемблерщиками, и тут совершенно неясно, слон кита заборет или всё-таки наоборот
2. Как совершенно верно заметил Pzz, моё утверждение про эффективность адаптивного алгоритма слишком сильное. Действительно, нужно оговориться: мы выиграем только в том случае, когда цена выбора оптимального решения не превышает проигрыш от применения неоптимального.
Тем не менее, на справедливость остальных умозаключений это не влияет: дело в том, что мне не нужно доказывать, что этот подход будет пределом эффективности. Мне достаточно показать, что существуют задачи, на которых он эффективнее.
Итак, вернемся к нашим "высокоуровневым конструкциям".
Пока что мы получили интуитивное представление о том, что неплохо бы выбирать решение в зависимости от свойств поступающих задач. Ассемблер достаточно гибок для того, чтобы помочь нам в простых случаях. Под простыми случаями я имею в виду такие, когда количество вариантов решения невелико. Ну вот сколько у нас алгоритмов сортировки для массива? В таком случае, расходы памяти на одновременное хранение всех этих программ не выходят за пределы разумного, а выбор сводится к традиционному conditional statement.
К сожалению, у этого подхода имеются свои ограничения.
Если "размеры" семейства программ-решений выходят за разумные пределы, то их суммарный объем становится препятствием для статической реализации. Это не такая уж редкая ситуация: как правило, некоторая задача делится на более мелкие подзадачи. Если у подзадач A1 и A2 — по четыре решения, то у задачи A, которая является суперпозицией этих двух задач, получается 16 решений.
В более сложных случаях мы можем наблюдать экспоненциальный взрыв пространства возможных решений. Реальный пример желающие могут пронаблюдать здесь.
Есть ли способ "ускорить" решение таких задач, при этом не заплатив мегабайтами различных комбинаций ассемблерных инструкций?
Для машин с фон-Неймановской архитектурой есть. Поскольку программа — это те же данные, никто не мешает нам генерировать новый код (или модифицировать имеющийся) "на лету", в процессе выполнения программы.
И вот тут-то у нас и возникает спецэффект. Если мы проведем водораздел там, где начинается генерация кода, то как раз и окажется, что она всё-таки помогает сделать код эффективнее.
В принципе, вопрос можно считать решенным, но на всякий случай я продолжу разжевывание — практика показала, что даже высокообразованные люди совершенно неспособны самостоятельно строить логические цепочки, особенно когда им этого не хочется.
Итак, изначальный вопрос пользовался "высокоуровневыми конструкциями", а не "runtime code generation".
Поясняю логическую взаимосвязь: вот у нас есть та часть программы, которая не меняется в процессе ее работы. И вот есть другая часть программы, которая таки меняется в процессе работы. На чем написана эта вторая часть? Я имею в виду — до того, как мы начали программу выполнять?
На ассемблере? Нет, это не лучшая идея.
На ассемблере ее написать нельзя — потому, что сам ассемблер не содержит достаточно информации о том, какие трансформации можно над ним проводить. Ну, если быть точным, то для ограниченного количества вырожденных случаев всё-таки можно обойтись ассемблером — соблюдая специальные конвенции, чтобы обеспечить "совместимость" кусочков программы, из которых собирается конечное решение.
Но в общем случае помимо собственно ассемблерного "образца" статической части программы понадобится какая-то еще информация о его устройстве: какие части образца можно менять, куда их можно встраивать, и так далее. Эта информация как раз эквивалентна более высокоуровневым конструкциям, чем сам язык ассемблера.
Вот, собственно, и всё. Sapienti Sat.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
LCR>Вот, по-моему это и есть ключевая фраза. Все задачи не переберёшь, следовательно экстенсивный путь уже обречён на неудачу. Мы можем реализовать сложение, умножение, инвертирование матриц, матрицы могут быть ленточные, треугольные, разряжённые, но этого всё-равно ничтожно мало, за бортом по-прежнему множество алгоритмов счётной мощности, куда уже не сунешься, потому что выразительных средств недостаточно.
Если использовать крупноблочное строительство, то всегда найдется проект, для которого ни один набор выпускаемых крупных блоков не подходит. Если строить из кирпичей, то можно построить все, что угодно — от утепленной собачьей будки до собора святого Петра.
LCR>На данный момент необходимо иметь такой базовый набор выразительных средств (нотацию, язык — назовите как угодно), которая LCR>1. Позволяет реализовать любой алгоритм в принципе
Из кирпичей можно все построить.
LCR>2. Позволяет реализовать любой алгоритм практически, причём реализация была или как можно более эффективной (учитывала конкретное окружени
е включая кэши, конвейеры, наличие нескольких ядер), или давала гарантии по эффективности или затратам памяти.
И будет это здание наиболее эффективным. Некоторые их них уже 2000 лет стоят. И все там учитывают , если надо — от сейсмостойкости до розы ветров.
LCR>Несложный анализ показывает, что вышеназванная Альфа никак укладывается в требования выше.
Коля, вы что говорите! Эта Альфа 1968 г.р.
>Чтобы попытаться накрыть ладонью всё множество алгоритмов, выделения кусочка кода и возможность обозвать его "+" явно недостаточно. Нужна модульность, много модульности, больше чем сейчас. Поясню на примере.
LCR>Допустим, вы реализовали умножение матриц, причём учли и кэши, и многопроцессорность, и учли специфику Intel/AMD и ещё много чего. То есть, ваш алгоритм стал очень очень быстрым, так что на любой машине это оказалась самая эффективная реализация.
LCR>Я делаю преобразование Лапласа, (или решаю нелинейные уравнения, или делаю какой-нибудь комбинаторный алгоритм), и теперь мне тоже надо его сделать как можно быстрее. Я запрограммировал его в виде функции laplas_transform, и теперь как мне выделить из вашего алгоритма отражение знания об архитектуре и использовать с моей функцией? Как вообще сделать так, чтобы это было возможно?
А так же, как делали умножение. С учетом кэшей, и многопроцессорности, и специфики Intel/AMD и ещё много чего. Наверняка многие решения совпадут, но, в общем, это разные алгоритмы, и оптимизировать их надо по -разному.
LCR>А Вася, например, хочет взять ваш алгоритм, и сделать так, чтобы вместо вещественных чисел можно было использовать символьные значения (ему нужны символьные алгебраические преобразования).
Что-то я не понял. Вы собрались матрицы в символьном виде перемножать ? Задача достойная, но это не арифметика, а обработка текста в основном. И оптимизация совсем другого, мб, понадобится — рабботы со строками, к примеру.
LCR>А Таня, вдобавок, хочет взять ваш алгорить, и сделать так, чтобы вместо вещественных чисел были функции, да ещё и на комплексном пространстве.
LCR>И, наконец, Алиса, взяв ваш алгоритм в качестве процедуры, вдруг осознала, что он и является главным пожирателем процессорного времени, но специфика задачи позволяет вычислять всё произведение не сразу, а по немножку. И её осенило, что если в вашем алгоритме использовать ленивые for-ы, то всё становится замечательно.
Что-то много у вас знакомых, и все они чего-то хотят
LCR>Единственный разумный путь сделать счастливыми всех четырёх человек, как мне видится, это декларативно описать алгоритм и возложить знание об архитектуре и окружение на компилятор (так что компилятор и будет модулем optimize, можно считать что каждая функция описана как f = optimize f_). Такое декларативное описание присутствует в коде на Хаскеле, и в подавляющем большинстве случаев отсутствует в коде на C++, так что бедные Вася, Таня, Алиса и ваш покорный ученик должны заново изобретать свои многоугольные колёса.
К сожалению, если поручить это все оптимизатору компилятора, то этот компилятор должен будет быть попросту гениальным, то есть включать в себя знание всех и всяческих техник, трюков и т.п, связанных и с кэшами, и с многопроцессорностью и с характером задачи. Увы, это вряд ли реально. Компилятор будет в лучшем случае оптимизировать "в среднем", то есть в расчете на некую среднюю задачу. И чем выше уровень абстракций, тем хуже он это будет делать. Оптимизировать цикл можно очень хорошо, а оптимизировать задачу "сделай вот это" — можно лишь на бвзе некоторых правил оптимизации общего порядка. Как только попадется нечто, что под эти правила не подходят — результат будет плохим.
Оптимизировать задачу "построите мне автоматически жилой дом" — можно. Выбираем подходящие блоки, стыкуем их, определяем , в каком порядке их ставить, ставим, замазываем щели — дом готов.
Оптимизировать задачу "постройте мне автоматически собор святого Петра" — нельзя. Для этого Браманте и Микеланджело нужны. А если эту задачу оптимизировать автоматически, то в итоге получится утепленная собачья будка размером с собор святого Петра.
Здравствуйте, IB, Вы писали:
IB>В Windows планировщик вытесняющий не потому что он производительнее, а потому, что это безопаснее. При вытесняющей многозадачности у неправильно написанного кода меньше шансов уронить все приложение, вместе с OS, и исключительно по этой причине в OS реализована именно она. То есть, производительность приносится в жертву безопастности, как раз тот расклад, который тебе так не нравится.
Гм... Вообще-то шансы уронить ОС (насчет того, чтобы уронить приложение , промолчу — это не так уж сложно сделать при обоих видах многозадачности определяются не тем, какая многозадачность, а тем, отделен ли код ядра от кода пользователя. В корректно написанной системе шансы нулевые, независимо от того, какая тут многозадачность. Я, признаться, никак не вижу связи между тем, как приложения (потоки и т.д.) уступают друг другу процессор и защищенностью OS. Более того, ИМХО кооперативная модель является более защищенной, так как передача управления происходит в строго фиксированных местах, а не где угодно.
И второй момент. Кооперативная многозадачность в Windows ведь была, 3.1. Но в NT от нее полностью отказались. И дело тут не в Windows. И OS IBM/360-370 всех сортов, и RT-11 — RSX-11, и VAX VMS, и другие OS — используют именно вытесняющую многозадачность. Я вообще до Windows 3.x о кооперативной мультизадачности не слышал, а узнав — был, просто скажу, удивлен. Кто-то, кстати, назвал ее "решением для бедных".
Видишь ли, суть проблемы в том, что мы о разных вещах говорим. Если внутри MS SQL и есть некая псевдо- OS, и если эта псевдо-OS работает именно так, как я сказал — это означает, что для тех задач, которые там решаются, авторы признали кооперативную мультизадачность лучшим решением. Причин для этого может быть много. Но все же это не OS, а лишь приложение, хоть и сколь угодно сложное. В настоящей ОС твое требование "например, когда заранее известно все множество возможных операций и можно гарантировать, что никакая комбинация этих операций не приведет к зависаню всего приложения, включая планировщик" — просто вряд ли выполнимо.
То, что кооперативная мультизадачность может быть эффективнее — согласен, в общем-то, я тут погорячился. Но только для определенного круга задач. В общем случае нет.
Здравствуйте, AndrewVK, Вы писали:
ВВ>>Хочется узнать, что конкретно делалось. AVK>Янус устроит? На войну с гридом немало времени убито, а глюков все одно навалом.
Что-то я не увидел там никакого "запаивания".
ВВ>>Я помню, с кем я беседовал. А ты на что возражал? AVK>На то, что я процитировал. ВВ>> На заключительную часть предложения? По-моему, это как раз выдергивание слов из контекста. AVK>А по мне, так совершенно законченная мысль. ВВ>>Что конкретно не нравится в этой фразе? AVK>Смысл.
Правда глаза режет?
ВВ>> Дизайн большинства классов дотнета довольно говнистый. AVK>Нет.
Ага, вин-формс единственная прям ложка говна в огромной бочке меда. Самому-то не смешно?
ВВ>> C# тоже, знаешь, большой внутренней красотой не отличается. AVK>Нет.
Язык, который лепился в спешке по принципу "с мира по нитке"? В 1.0 я вообще не вижу практически ни одной светлой мысли, многое просто тупо скопировано с J++. И до сих пор нет внятного понимания, в какую сторону он движется.
Да можно даже и не о языке. Наследование всего от System.Object и возникший в результате этого изящнейший боксинг/анбоксинг тоже мега-красивое решение?
ВВ>> Мораль-то какая, запаивать все надо?
AVK>Тоже простой вопрос. Мораль такова: AVK>1) Дизайн винформсов — унылое гавно AVK>2) Если не запаивать — в результате получится унылое гавно
ВВ>> Должны быть разумные пределы.
AVK>Конечно. Дизайн винформсов — за рамками этих пределов.
ВВ>>Фраза, кстати, относилась к тому, что с необходимостью написания адапатеров для вин-формс контролов в конкретном случае вполне можно смириться AVK>Если нет альтернативы — можно. Я этого никогда не отрицал. Только это никак не исключает того простого факта, что дизайн винформсов ..., ну ты понял. ВВ>>, хотя о большой красоте архитектуры эта необходимость не говорит. AVK>Так речь тут изначально именно о красоте архитектуры шла, а не о том что винформсы применять нельзя. Последнее ты выдумал исключительно самостоятельно.
Это даже не смешно. У кого речь шла о красоте архитектуры? Может, стоит отличать красоту от принципиальных ошибок в дизайне, из-за которых всю эту "архитектуру" во многих случаях просто нельзя нормально использовать.
ВВ>>Ага, бинарный. ВВ>>Рассказать видимо не получится никак? AVK>Получится, если я от тебя услышу конкретные вопросы, а не "расскажи, как оно".
А ты ничего конкретного, кроме этого "запаивать" так и не сказал.
ВВ>>- Каким образом ты запаивал вин-формс? ВВ>>- Не скажу. AVK>Я этого не говорил. Оно конечно просто — сочинять за собеседника и потом с сочиненным спорить, удобно. Но демагогия есть.
А что ты говорил? Ничего. Вопрос неконкретный — и типа иди на фиг. Я вот не вижу проблемы в описании общего подхода.
ВВ>>И что это значит? AVK>Это значит, что, если я начну в твоем стиле разговаривать, будет очень весело. Или ты думаешь, я хуже тебя умею демагогией пользоваться?
Да нет, судя по твоим ответам — лучше.
ВВ>>Ну и где я вру? AVK>А вот прям тут и врешь. Рассказываешь сказки, что не ты про винформсы разговор завел, хотя именно ты этот разговор начал. ВВ>> Я с самого начала предлагал ее рассматривать как надстройку над юзер32 AVK>Врешь. Ни слова ни про надстройки, ни про user32 в первых сообщениях нету. user32 ты вспомнил, уже отвечая на мое сообщение, а я его в цитатах этих даже не приводил, потому что оно было позже.
Отличная тактика — сказать собеседнику, что он врет и приписывать ему всякий бред. А что я про вин-формс говорил "в первых сообщениях", можно полюбопытствовать?
Я вообще-то по поводу вин-формс изначально не с тобой общался.
А без проблем, восстановим беседу:
ВВ->S: (первое упоминание вин-форм в треде )
Интересно, а WindowsForms включает в себя разработку под веб? А то, может, WindowsForms тоже говно, а я и не заметил.
S->ВВ:
Вообще-то да, говно. У неё тоже модель GUI совершенно не соответствующая современным реалиям. Поэтому нормальный десктопный интерфейс на ней делать весьма и весьма тяжко. Что, собственно, и привело к изобретению WPF.
ВВ->S: (второе упоминание)
У WindowForms модель полностью отвечает архитектуре Win32 и является прекрасной надстройкой над user32. То, что сама по себе эта модель уже устарела, разумеется, очевидно. Но WPF (в отличие от того разрекламированного тут ASP.NET MVC) представляет собой не другую абстракцию, а принципиально другую технологию.
Так что боюсь титул "вруна" мне придется уступить тебе.
AVK>Ты про вебформсы? Таки да, тоже гавно. А что, кто то с этим спорит?
Почитай ветку, спорят.
ВВ>>Вообще если уж вспомнить, то речь была о том, что не все абстракции одинаково полезны. AVK>Не, речь была про то, что не все абстракции одинаково вредны
Угу, в поддержку чего я изначально писал. Только что-то упоминание того, что абстракция может и помешать привело к весьма своеобразной реакции.
ВВ>> Почему в рамках этой темы надо сравнивать вин-формс с WPF, а не с "низким уровнем" этого самого вин-формс? AVK>Потому что сравнивать надо с лучшими решениями, а не с худшими. Это так сложно понять?
Так сложно понять, что я не сравниваю ГУИ-фреймворки?
ВВ>> А как же политкорректность? AVK>Ее кто то обещал?
Правила сайта вообще-то. Но, бесспорно, тебе виднее
ВВ>>>> Мне тоже не очень нравится получать советы в стиле "учись сынок, и ты поймешь, что кривая архитектура это плохо". AVK>>>Я тебе такие советы давал? ВВ>>Ну знаешь, многие из твоих реплик звучат именно в таком ключе. AVK>Ты ошибся. Ни имею никакого желания тебя обучать без твоей воли.
У меня даже и в мыслях не было, что у тебя есть такое желание. Я вообще ничего конкретного от тебя не слышу. А общие слова мало кому помогают.
ВВ>> Я, конечно, понимаю, что у тебя может быть другой опыт, но это не значит, что он применим везде, и все кто думают иначе... как ты там говорил? AVK>Золотые слова. Вывод какой?
Да все тот же. Винформс — говно. Какой еще может быть вывод?
AVK>>>В чем? Только надо, чтобы эта тема логически сочеталась с твоими словами. ВВ>>О том, что вин-формс как надстройка над юзер32 значительно лучше, чем веб-формс как надстройка над прямой работой с HTTP и куда меньше мешает жить. AVK>Теперь неплохо бы это обосновать.
Я этим вообще-то довольно долго тут занимался, можешь почитать.
ВВ>>Ты же не работал в интеграторе, откуда такие выводы? AVK>У меня есть несколько хороших знакомых, которые подробно рассказывали.
А мне ты не веришь?
ВВ>>А мы не работаем с клиентами, которые не готовы к серьезным инвестициям AVK>Видимо, у нас серьезность разная. Под серьезностью я понимаю готовность потратить хотя бы несколько сотен килобаксов (только на разработку, а не на желески и консалтинг) и год работы команды программистов.
Видимо, разная. Никогда не считал несколько сотен килобаксов серьезными инвестициями. "Год работы команды программистов", "ивестиции в несколько сотен" — странная у вас арифметика.
Причем вывод сделан молниеносно — а, да у вас проекты маленькие.
AVK>А если общий бюджет большой, но основаня его масса уходит на железки, коробочное ПО и консалтинг, так это ни о чем не говорит.
Тот же MOSS МС сама хорошо умеет продавать. А внедрение как раз и предполагает разработку да переработку всего что можно под MOSS. И поверь мне, речь там не о сотнях тысяч и не о годе.
Например, один из проектов, на котором я сейчас работаю — и где слава богу нет МОССа — длится уже 6 лет.
AVK>О, о чем я и говорил. Деньги платятся за "внедрение какого-нибудь MOSS или Hummingbird".
А что такое внедрение какого-нибудь "MOSS или Hummingbird" по-твоему? Коробку купил и свободен?
ВВ>> И это вовсе не означает, что весь некоробочный софт хуже коробочного. AVK>И этого я тоже не говорил. Горазд ты сочинять. С кем споришь то? Сам с собой?
Ну да, давай действительно в таком стиле общаться. А я где-то говорил, что ты это говорил?
ВВ>> Но и коробочный софт тоже бывает говном. AVK>Бывает. Вопрос другой — бывает ли не говном софт, сделаный по принципу "обычно не до "красоты".
Бывает. Особенно когда принцип "обычно не до красоты" понимается именно в том ключе, в котором я его употреблил. А не то, что ты сам там додумал.
Здравствуйте, Геннадий Васильев, Вы писали:
ГВ>Не собираюсь оспаривать твои высказывания, но объясни мне, пожалуйста, почему тогда абсолютное большинство десктопного софта, написанного на яве работает в разы медленее, чем его аналоги на C/C++?
Вкратце: потому, что десктопный софт работает совершенно по-другому, чем серверный.
Более длинно:
1. в серверном коде важнее не responsiveness, а throughput. Задержка реакции в 500 мс для веб-сервера — норма, благодаря тому, что UI обслуживается отдельным агентом на клиентской стороне. В десктопном приложении задержка реакции в 500мс — это ощутимые тормоза.
2. в десктопном коде важную роль играют операции с графикой, а bit-crunching по историческим причинам в управляемых платформах не слишком-то оптимизирован. Это не то чтобы их неотъемлемая особенность, это скорее вопросы приоритетов, выбранных при разработке платформ.
ГВ>Почему mcirosoft-овский MSDN работает быстро, а IBM-овская справка (на Java) — из рук вон медленно? Почему та же история повторяется с парочкой OpenOffice/MS Office? UML-рисовалки, это вообще мрак. Если сравнивать Eclipse и MSVC 6.0 — это попросту не смешно. Если ява с такой уверенностью "рвёт" плюсовый код?
Однако visual studio, несмотря на значительную долю управляемого кода, работает вполне себе приемлемо. Это, грубо говоря, означает, что дело не столько в языке, сколько в прямизне рук разработчика.
Да, это несколько подтачивает тезис о том, что хороший перформанс на средствах высокого уровня достигается меньшей ценой разработки, чем с низким уровнем, но не опровергает его окончательно.
Просто пока что баланс abstraction penalty / abstraction gain в среднем проходит чуть ниже уровня, доступного прикладным программистам управляемых сред. В стародавние времена и C++ безнадежно сливал C по производительности — однако время прошло, и сейчас редкий ассемблерщик порвет плюсы. Точно так же дело обстоит и в управляемых средах: улучшения Execution Runtime позволяют выигрывать всем программам, даже написанным до этих улучшений, и чем более высокоуровневые средства применяются, тем больше будет этот abstraction gain.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Pzz, Вы писали:
Pzz>Здравствуйте, samius, Вы писали:
S>>Вы думаете, что я облажаюсь с пузырьком?
Pzz>А на квиксорте не облажаетесь?
Облажаюсь ли я на квиксорте?
Справлюсь ли я с поиском в ширину
Смогу ли перемножить матрицы
К счастью (моему), у меня и у моих работодателей вопросы интереснее. Чего и Вам желаю.
Не беспокойтесь, пока справляюсь.
З.Ы. Сортировку я возможно писал. Не отложилось в памяти. Не считаю это занимательным фактом, достойным биографии.
BSP дерево — писал. Ток не на интерес, а в рамках курсового. Задача курсового, кстати была не в том, чтобы написать BSP. И это я запомнил вовсе не потому, что написал BSP и офанарел от этого.
Здравствуйте, Воронков Василий, Вы писали: ВВ>На фига мне "подключать" браузер к БД? Что вообще значит "подключить" браузер к БД? У меня десктоп-приложение, браузер — не более чем контрол для отображения данных. Его использования в данном случае аналогично какому-нибудь текст-боксу. SetText или там SetHtml и все. Работает с базой код на джава.
Ключевой момент — вот этот "SetHtml". Общепринятого стандарта на него нету, в отличие от "NavigateTo".
Поэтому действительно, самый кроссплатформенный способ — это сделать NavigateTo на соответствующий адрес.
В IE применяют специальные трюки для того, чтобы не поднимать честный HTTP-сервер: например, регистрируют свой псевдопротокол.
Или пользуются интерфейсом принудительной загрузки из IStream. Но это не кросс-браузерное решение.
Резюме тут примерно такое: встроить в себя браузер — нетривиальное занятие. А держать локальный HTTP-сервер стоит не слишком дорого.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, _FRED_, Вы писали:
_FR>>>и факториал как пример рекурсии T>>Убивать за такие примеры рекурсии. _FR>За что? Только за то, что "навязло" в зубах?
За методическую некорректность. Показывание рекурсии на примере факториала, при том, что рядом он считается просто и тривиально обычным циклом — это способ показать "а вот можно ещё через левое ухо, если очень захотеть и совсем нечего делать". Этот способ годится по отношению к тем, кто интересуется математическими диковинками, или к тем, кто заранее _сознательно_ готов принимать все методические принципы преподавателя. И много Вы таких сейчас видели? обычно 1-2 на сотню. остальные — сдадут и забудут.
Если бы я показывал рекурсию на каком-то примере, первый пример был бы взят максимально практический, причём такой, чтобы его нельзя было в одной функции свести в цикл. А уже после этого — числа Фибоначчи, а собственно факториал — уже в качестве упражнения (если на лекции — вызвать кого-то к доске и заставить преобразовать).
И ещё одно — размахивание факториалом является косвенным указанием на то, что "рекурсия — это очень просто". Когда же выучивший такое сталкивается с реальной жизнью, когда перекладка алгоритма на рекурсивный лад в первую очередь крайне громоздка — следует шок.
Здравствуйте, AndrewVK, Вы писали: AVK>А какой надо? Все желающие давно уже приобрели себе тарелку с тем самым цифровым телевидением, благо стоит оно сейчас копейки.
Я лично совершенно не верю в отказ от broadcast-модели доставки медиаконтента по двум причинам:
1. Usability.
Далеко не всем хочется заниматься каким-то выбором. Вещание удобно тем, что оно поставляет тебе контент, не требуя вмешательства.
К примеру, вместо имения и поддержки огромного плейлиста в машине, многие до сих пор предпочтут включить радио. Аналогом этого является интернет-радио.
2. Эффективность
Бродкастинг позволяет одним каналом накормить очень много народу. Пока что у нас полоса пропускания не настолько велика, чтобы вещать каждому лично.
3. В итоге, скорее всего останется смешанная модель.
То есть хочешь — включаешь канал "Youtube News 24x7" и сиотришь/слушаешь то, что там тебе течёт в реальном времени.
Не хочешь — каждый раз сам лазишь по каталогу и тыкаешь "watch on demand".
Лень лазить — подписываешься на один или несколько фидов (наприер, на Channel 9, или на "Battlestar Galactica"), телевизор сливает эпизоды асинхронно, ты их высматриваешь как тебе удобно (в отличие от прямого вещания можно ставить на паузу и пересматривать повторно).
Вот этот третий вид, имхо, и есть телевидение будущего. Эффективность достигается благодаря использованию пиринговых сетей (то есть распределению нагрузки на канал между потребителями), юзабилити достигается за счет минимизации пользовательского выбора.
Предоставляются богатейшие маркетинговые возможности — можно предоставлять контент за деньги; можно впаривать в него рекламу, как сейчас в ящике; можно применять смешанную модель.
... << RSDN@Home 1.2.0 alpha rev. 677>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, _FRED_, Вы писали:
Pzz>>В библиотеках содержатся стандартные алгоритмы. Куда вы пойдете, если вам нужна не просто сортировка, а сортировка с преподвывертом? Готовую именно с нужными вам свойствами вы не найдете, свою написать вы не умеете, т.к. всегда использовали готовую.
_FR>Уметь по памяти и суметь на рабочем месте — две разные задачи.
Владение в совершенстве счетными палочками очень мало помогает в решении дифференциальных уровнений — тут требуется, э, несколько другой уровень математической культуры.
Точно так же умение в совершенстве склеивать готовые компоненты совершенно не помогает сочинять алгоритмы, напоминающие классические алгоритмы. Понять их устройство глядя на интерфейс тоже невозможно, как невозможно понять принципы работы двигателя внутреннего сгорания, в совершенстве овладев рулем и педалями.
Вы это либо умеете, либо нет. Если никогда не занимались, то, скорее всего, не умеете. Наверное, потратив время, вы сможете научиться, но у вас никогда не найдется на это времени. Поэтому когда встанет задача, в которой надо не просто скрестить XML с HTML'ем, а изобрести что-нибудь необычное, вас к ней никогда не привлекут. Это и есть тот самый ваш потолок, о котором говорил Валентин Нечаев. Заметьте, это ваш добровольный выбор.
Pzz>>Принесут вам код, написанный для UNIX'а и активно использующий read/write lock'и, и попросят запустить его на Windows XP. А в XP нет read/write lock'ов. Ваши дальнейшие действия?
_FR>Сяду читать или пойду пить пиво с юниксойдами, или нет, сначала пойду колоть юниксойдов, а потом сяду читать… нет, сначала почитаю, потом пойду пить пиво с юниксойдами Или попросту скажу, что это "не мой профиль" Зачем "это" (read/write lock) знать заранее? Именно: только в силу специфики решаемых задач. Если человеку каждый день надо писать под UNIX с учётом многопоточности, то он, наверное, должен это знать. Если человеку каждый день приходится писать запросы к базе данных, то он должен представлять себе, как работает её оптимизатор. Для "абстрактного" програмиста, для которого не определена специфика решаемых задач эти вопросы безсмысленны.
Есть знание специфическое, и есть знание фундаментальное. Специалист по географии, который не знает климатические особенности какого-нибудь никому неизвестного острова размером 2х2 метра в Тихом окене — явление вполне нормальное. Специалист по географии, который не знает, что такое остров вообще, потому что всю жизнь изучал только сушу — нонсенс.
Read/write lock — это классический примитив синхронизации, а не что-то UNIX-специфическое. Его нету в API Windows XP по чистому недоразумению (в Висте он уже появился), но аналогичные конструкции попадаются на каждом шагу. Так что я не понимаю, что вы собираетесь обсуждать с юниксоидами, и довольно печально, что вы по этому вопросу вообще собираетесь с ними что-то обсуждать — это свидетельствует о том, что вы не поняли вопрос.
Pzz>>Ну скорее я посоветую такому кодеру освоить другую профессию. Потому что произойдет очередная "смена технологий", C# заменят на C#$#%, и такой кодер останется без работы: кому нужен в качестве кодера 50-летний дядька, владеющий только устаревшими методами?
_FR>Из этих слов не ясно, почему пришедшие новые технологии потребуют навыков в рукопашной сортировке Скорее, я буду прав, предположив, что с течением времени (при условии использования новых и новых технологий) всё реже и реже придётся придётся самостоятельно разбираться с такими вещами, как реализация быстрой сортировки.
Я имел ввиду, что поскольку знания, в которые вы вкладываетесь, в основном состоят из перечня интерфейсов той технологии, которую вы сейчас считаете современной, то они по природе своей полностью устаревают за несколько лет, и вам приходится переучиваться. В 50 лет это будет сделать значительно сложнее. В том числе и по организационным причинам: никто не возьмет 50-летнего дядьку "на вырост", лучше возьмут студента.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Ну по-моему реально странно все это. Мы, к примеру, создаем коллекции, скажем так, "векторного" типа, которые предполагают, что для осуществления групповых операций придется пользоваться банальным перебором — а потом начинаем придумывать наиболее "красивые" формы этого перебора.
Вот в этом месте не понял. Недавно набрел на linq-проект, который прозрачным образом использует индексы на In-memory коллекциях. Вот он, небанальный перебор за счет декларативности программирования. Может, другой пример подберем?
... << RSDN@Home 1.2.0 alpha rev. 677>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Sinclair, Вы писали:
S>А вот у компании Ericsson был пример другой задачи, когда C++ оказался тупо непригоден потому, что стоимость разработки и отладки софта на нём превысила доступный бюджет. В итоге его выкинули и заменили самым медленным из промышленных ФП-языков; при этом, естественно, микропроизводительность упала со страшной силой. Но свитч заработал, и его надежность компенсирует все претензии к его производительности. Это — правое плечо графика.
Ты просто плохо разобрался в том, что и зачем делали в Эриксоне.
На самом деле они как раз средством в чем-то аналогичном ПЛинку решили задачу котору и правда решить на плюсах было просто невозможно.
Им был нужен массовый параллелизм. Причем параллелизм был нужен на на тысячах физических процессоров, а на одном (ну, или нескольких). Так вот они подумали и пришли к выводу, что основные затраты при массовмо параллелизме вызываются двумя банальнешими факторами:
1. Синхронизацией разделяемых структур данных.
2. Дороговизной переключения контекста.
Далее ход их мысли был примерно таким... ФП позволяет сложить почти все состояние программы на стек. Это позволяет сделать переключение контекста очень дешёвой операцией... ФП позволяет не использовать глобальные данные которые нужно синхронизировать.
Далее они подумали, что можно организовать множество параллельно выполняемых процессов общение между которыми производится с помощью сообщений. За чёт того, что ЯП функциональный удалось сократить время переключения контекста и отказаться от синхронизации отличной от очереди сообщений процесса. Это позволило оптимизировать данную очередь.
В итоге в Эриксоне получили решение которое рвет любую реализацию хоть на ассемблере хоть на С++ просто потому, что их модель вычислений позволяет обойтись без накладных расходов которые обязательны для "обычного кода". При этом, если начать считать на Эрланге некий последовательный (когда следующее вычисление зависит от результата предыдущего) алгоритм, то мы получим дикие тормоза, так как "чудес не бывает" и любой интерпретатор минимум в 10 раз медленнее машинного кода. Но если задача хорошо параллелится или просто требует проведения множества (сотен тысяч) параллельных вычислений, то Эрланг начинает рвать обычный код как грелку.
Кстати, именно по этому эффективно воспроизвести модель Эрланга на виртуальной машине (без затачивания оной под модель вычислений) — это крайне трудная (если вообще разрешимая) задача.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, AndrewVK, Вы писали:
AVK>Здравствуйте, fplab, Вы писали:
F>>Наконец-то — дождались ! Вот оно — ключевое слово: "проще".
AVK>Ключевое слово — "к чему знание деталей реализации"
Ага. Теоретически я знаю, как пилотировать самолет, но практически — предпочту обратиться к тому, кто в деталях знает как это делается. Ну извините — опять "некорректный" прием !
F>> Зачем нам обезболивающие ? Деревянным молотком по голове, как в средние века: пока пациент очухается, мы ему немножко вырежем здесь и подрихтуем там
AVK>А без некорректных приемов выразить свою точку зрения никак?
Так живее. Многое проще объяснить на пальцах, чем строить строгое доказательство. Тем более в такой области, где сколько голов — столько и мнений.
F>>Факториал — это да, это классика. Но именно как пример. Наверное процентов 90 всех книг по программированию объясняют рекурсию на примере именно факториала. Но между теорией и практикой дистанция немалого размера.
AVK>Ну да. И что?
И ничего. Я же написал "именно как пример", поскольку на императивных языках обычный цикл эффективнее.
F>> Интересно, а если надо построить дерево, а потом сделать его обход ? Понятно, что можно и без рекурсии, но вот вопрос — а стоит ли ?
AVK>Иногда очень даже стоит. Только вот, сдается мне, как раз таки нерекурсивный обход дерева может вызвать у новичков затруднение, а не рекурсия.
А что, программист не должен знать (или хотя бы предполагать) где и в чем могут возникнуть затруднения и уметь их либо обходить, либо решать ? Но для этого, думается мне, надо все же знать и детали реализации.
AVK>А еще иногда нужно рекурсивный обход замаскировать под нерекурсивный. И вот тут то уже частенько у знатоков быстрой сортировки начинаются проблемы.
Не понял — а зачем маскировать ? Ясность — лучшее "украшение" программы (после, понятно, эффективности, т.е. быстродействия и расхода памяти).
F>>А линейный поиск — вообще прелесть. Понятно, что в массиве из 100 записей "при современном развитии печатного дела на Западе" (О.Бендер) — просмотреть их плевое дело. Дураки они, что ли компиляторщики — сортируют таблицу символов, чтобы потом в ней быстро искать ? А то и вообще хэш-функции втыкают
AVK>Только вот, как оказалось, на современных компьютерах линейный поиск на очень коротких списках может оказаться самым быстрым решением. Вот ведь незадача.
Незадача, да только у кого ? Ведь я и привел пример короткого списка 100 элементов в массиве — это разве много ? Для него, действительно, практически никогда не надо осуществлять дополнительных телодвижений.
F>>Правда, надо сделать одно важное извиняющее замечание — если человеку так не повезло, что ему не приходилось решать по настоящему сложных (а, значит, интересных) задач, то тогда, действительно, к чему засорять мозг
AVK>О да, без пенисометрии никак. Знаешь только, в чем проблема, особенно в этом форуме? По результатам измерений запросто может оказаться, что у кого то из твоих оппонентов длиннее.
Вот тут, коллега, вы сами себе противоречите Выше, если не ошибаюсь, вы указали мне на использование некорректных приемов. Может, будем последовательными ?
В общем, я понял — минусов я себе заработал
Приходиться заниматься гадостью — зарабатывать на жизнь честным трудом (Б.Шоу)
Здравствуйте, Pzz, Вы писали:
IT>>В плане эффективных оптимизаций я доверяю компиляторам гораздо больше, чем Дворкину.
Pzz>А компиляторы что, какие-то небожители пишут что ли?
Им я тоже доверяю больше, чем Дворкину.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, Tilir, Вы писали:
T>В то же время у меня есть опыт редукции офигительной объектно-ориентированной иерархии на C++ из десятка шаблонных классов и активным использованием STL и Boost на полсотни килобайт кода в одну (!) функцию на C из сорока строчек, *не использующую даже CRT*.
дьявол как всегда в деталях — сохранена ли при этом _вся_ функциональность исходного кода, или половину выкинули (пусть даже за ненадобностью), сохранена ли та же безопасность по отношению к внешним параметрам и т.д., без этого судить о крутости "редукции" не представляется возможным
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Ну в каких терминах происходит мышление это отдельный, так сказать, философский вопрос. Речь даже не в "каких терминах" оно происходит, а чем оно детерминируется. Можно думать "по-другому" используя любой язык программирования, но что-то должно в итоге заставить думать по-другому?
На мой взгляд, в первую очередь мышление детерминируется неким общим образованием (не обязательно вузовским). Ну не конструкциями же языка программирования, в самом деле.
ВВ>Мне вот интересно посмотреть на альтернативу ООП — альтернативу в том плане, что это будет концепция способная полноценно заменить ООП, хотя бы теоретически. Возможно, это ФП. Возможно, это не ФП. ВВ>Но это точно не должен быть ОО язык, в котором "до кучи" напихивают противоречащих этому самому ОО концепций.
Ну, если считать, что FP, в некотором роде, является базисом ООП, то... Сложный это получается вопрос: кто на ком стоял.
ВВ>>>ФП не в детерминированность ф-ций упирается, а в иной подход к созданию абстракций. ГВ>>Как это ни удивительно, но именно об этом я с самого начала и говорю. ВВ>В таком случае "гибридный" стиль и у тебя наверное не должен вызывать особого восторга, нет?
Да нет как раз... Любой стиль, ИМХО, хорош к своему месту. Структурный (процедурный) — в своих случаях, ОО — в своих, FP — в своих.
Если так, немного отвлечённо порассуждать, то мне кажется примерно так:
Процедурный — то, что касается обработки структур данных. Какие-то цельные запутанные блоки данных с не очень сложными алгоритмами. Уж точно с простейшими эвристиками.
ОО — хорош для композиции, когда нужно завязать много агрегатов. Здесь, думается, влияет стереотип "агрегатов", которые "соединяются". Ещё ООП неплох для игр случаев, когда можно разобрать задачу на атрибутированные сущности. Кстати, "агрегаты" и "соединения" — как раз такие сущности. ИМХО, как раз поэтому ООП и прижилось в этой области — очень уж похожи "классы" на "устройства", милые сердцу технарей.
FP — очень хорошо, когда нужно решить задачи анализа и разбора чего-то. Ну то есть, когда мы можем естественно выразить задачу в терминах x = f(y) и сопутствующего перебора (привет, pattern matching!). Просто компактно записывается, компактнее, чем в предыдущих случаях. Хотя в распространённых языках, ИМХО, FP на данный момент не лишено недостатков реализации — порой слишком вольно обходится с ресурсами.
Решение задачи параллелизации вычислений я, скорее, жду от компиляторов, нежели от стилей программирования. Ну это так, на полях и в свете соседних флеймов.
Ну и разумеется, смесь оных стилей я горячо приветствую — в разумных пределах, конечно. Например, в стиле FP хорошо записывать какой-нибудь анализ разветвлённых объектных структур.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Pzz, Вы писали:
IT>>Фактически, 30 лет развитие шло только снаружи метода и сегодня мы имеем полный мыслимый набор инструментов для организации кода и управления им. По развитию снаружи метода мы уже давно вышли в космос и осваиваем другие планеты. А внутри метода? Внутри мы всё ещё в той же пещере, с тем же каменным топором в руках, что и 30 лет назад. Ни письменности, ни колеса, ни железа.
Pzz>Внутри метода — алгоритмы. Те самые сортировки и поиски, о которых книжки пишут. А снаружи — клей и упаковка.
Я как-то всегда думал, что как раз алгоритмы — это то, что очень неплохо поддаётся "библиотизации", то есть вынесением в многократно используемые кирпичи. И задумываться над алгоритмами лишний раз не приходится.
Pzz>Граждан, способных нагородить иерархую классов, из которой, если ее нарисовать на бумажке разноцветными карандашами, можно обои сделать — пруд пруди. А много вы знаете граждан, способных написать самостоятельно RB-дерево? Или сделать недостающий в системе примитив синхронизации из того, что в системе есть? Много ли вы вообще знаете граждан, которые знают, что в системе может недоставать каких-то примитивов синхронизации?
В первую очередь из-за того, что редко, очень редко встречаются сейчас такие задачи.
Pzz>И получается печальная картина: все мечтают наслаивать классы, слой за слоем, а простую сортировку, если что, и написать-то некому.
Вот что ты скажешь о кодере, которому за девять с лишним лет ни разу не пришлось самому писать сортировку Не то, что строить деревья или создавать примитив синхронизации? Что он должен сгореть от горя или позора?
... << RSDN@Home 1.2.0 alpha 4 rev. 1111>>
Help will always be given at Hogwarts to those who ask for it.
Здравствуйте, fplab, Вы писали:
_FR>>Мне больше нравится линейный поиск как навык работы с массивами и факториал как пример рекурсии. Они проще И что мы получаем: есть знания и про массивы и про рекурсию, но никакого отношения к сортировке это не имеет.
F>Наконец-то — дождались ! Вот оно — ключевое слово: "проще". Зачем нам обезболивающие ? Деревянным молотком по голове, как в средние века: пока пациент очухается, мы ему немножко вырежем здесь и подрихтуем там
Не согласен с аналогией. Зачем мне таскать тяжеленный сундук, когда у меня есть удобный рюкзачёк? Объясни, зачем для понимания рекурсии необходимо именно возиться с сортировкой и не подойдёт факториал?
F>между теорией и практикой дистанция немалого размера.
Это и есть ответ? Гхм, мне одному кажется это нелогичным? Например, правила сложения гораздо легче объяснять на примере натуральных силел, нежели комплексных (да ещё и в показательном представлении). Так и тут: для объяснения рекурсии — факториал.
F>Интересно, а если надо построить дерево, а потом сделать его обход ? Понятно, что можно и без рекурсии, но вот вопрос — а стоит ли ?
Это большой вопрос. Например, может зависеть от используемого компилятора. Где-то я с удовольствием предпочитаю рекурсии цикл.
F>А линейный поиск — вообще прелесть. Понятно, что в массиве из 100 записей "при современном развитии печатного дела на Западе" (О.Бендер) — просмотреть их плевое дело.
А если в массиве всего четыре элемента?
F>Дураки они, что ли компиляторщики — сортируют таблицу символов, чтобы потом в ней быстро искать ? А то и вообще хэш-функции втыкают
Если поиск в большом массиве делается один раз, то зачем его перед этим сортировать?
F>Правда, надо сделать одно важное извиняющее замечание — если человеку так не повезло, что ему не приходилось решать по настоящему сложных (а, значит, интересных) задач, то тогда, действительно, к чему засорять мозг
Как видишь, обсуждаемый вопрос (необходимость знания некоторых, пусть и часто используемых, алгоритмов) многогранен. Не менее многогранен и вопрос о "настоящности" и "сложности" тех или иных задач. А раз, то категоричные высказывания о необходимости того или иного — ни что иное как заносчивость.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111>>
Help will always be given at Hogwarts to those who ask for it.
Y>Из всего этого вывод я делаю такой, что ООП в принципе и не нужен, ФП более чем достаточно. Ну разве, что если ООП будет средством модульности. Т.е. от ООП в классическом понимании останется совсем мало.
Смотря, что считать классическим понимание ООП Если "черные ящики, обменивающиеся сообщениями"(с)Алан Кей, то ООП остается
Здравствуйте, AndrewVK, Вы писали:
AVK>О да, без пенисометрии никак. Знаешь только, в чем проблема, особенно в этом форуме? По результатам измерений запросто может оказаться, что у кого то из твоих оппонентов длиннее.
Эххх, ну когда же все поймете, важна ведь не длина, а диаметр!
Lisp is not dead. It’s just the URL that has changed: http://clojure.org
Здравствуйте, Константин Л., Вы писали:
КЛ>со всем более-менее согласен кроме IT>>…а зоопарк из приватных методов на удобные локальные функции.…
КЛ>локальная функция, если она не захватывает контекст, ничем не лучше private static, а может быть и хуже, тк захламляет код оснофной функции. Если же захватывает, то надо быть очень осторожным. Тут по работе пришлось насмотреться на локальные функции в delphi.net — ппц.
Ага, уж лучше замусорить тело класса пачкой функций-хелперов, чем тело одной единственной функции
... << RSDN@Home 1.2.0 alpha 4 rev. 1111>>
Help will always be given at Hogwarts to those who ask for it.
Здравствуйте, Andrei F., Вы писали:
AVK>>ФП не отрицает состояния
AF>
In computer science, functional programming is a programming paradigm that treats computation as the evaluation of mathematical functions and avoids state and mutable data
Кривое определение непонятно откуда, что я еще могу сказать. Автомат без состояния это тупая КС, на ней много не построишь.
Слабо написать функциональную программу для машины только с ПЗУ?
AF>"Все вокруг тупицы, один я д'Артаньян" — это ты молодец. Не надо обвинять фанатичных немерлистов, источник флейма явно в тебе.
А может в тебе?
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Pzz, Вы писали:
Pzz>А вообще да, ФП предоставляет очень гибкий набор средств для выражения сложных структур данных и итераторов по ним. Но не более того. Те вещи, которые не сводятся к хитроунмой итерации сложной структуры данных, на ФП и на Фортране будут выглядеть совершенно одинаково
ФП предоставляет расширяемый набор средств. Не на столько хорошо расширяемый, как в случае с метапрограммированием, но всё же. Взять хотя бы тот же Parsec. Он же не использует сторонних утилит. И не пользуется средствами метапрограммирования. Он целиком сделан поверх языка. А вот если бы в Хаскелле были средства расширения синтаксиса, Parsec выглядел бы красиво.
Даже какая-нибудь троица map/filter/reduce в "традиционном" ИЯ тянула бы на полноценную конструкцию языка. А дальше — больше. Таких "конструкций" я могу понаделать вдоволь. Жаль только, что синтаксис не всегда будет замечательным. Вообще, тот факт, что функция является первоклассным объектом в языке и что эти самые функции удобно описывать, есть большое подспорье в смысле увеличения выразительности языка на порядки.
Здравствуйте, _FRED_, Вы писали:
_FR>Точно! Но с каикх это пор область прогармирования ограничивается "изобретением что-нибудь необычного"? Если хотя бы каждый сотый програмист на Земле начнёт этим "изобретением" заниматься, во что превратится мир [програмирования]?
Ну как вам сказать. Среднее техническое образование подразумевает умение грамотно применять изученные в техникуме приемы для решения типовых задач. Высшее техническое образование подразумевает умение подбирать подходы для решения нетиповых задач. Мне как-то хочется все же видеть программирование среди профессий, которые подразумевают высокую степень квалификации. Хотя я понимаю, что многие сегодняшние программисты не имеют профессиональных знаний даже в эквиаваленте техникума.
Если говорить о более практических вещах, то по-моему как-то справедливо, что если у программиста знаний примерно как у хорошего слесяря-сантехника, то и зарплата у него должна быть, как у хорошего слесаря-сантехника. И к этому, безусловно, со временем придет, т.к. готовить программистов-техников не сложно.
Pzz>>Есть знание специфическое, и есть знание фундаментальное.
_FR>Я по-прежнему не понимаю (из Ваших слов), для чего веб-програмисту обладать фундоментальными знаниями о примитивах синхронизации? Давайте тогда определим, что для "тех-то" нужно "то-то", а для "этих" "вон то". Только ограничить уж очень не просто получится, вплоть до того, что обоснованная работа на эту тему сможет стоитьь дисера.
Ну это как спросить, зачем начальнику домоуправления знать формы глаголов. Чтобы грамотно писать, вот зачем.
Pzz>>Я имел ввиду, что поскольку знания, в которые вы вкладываетесь, в основном состоят из перечня интерфейсов той технологии, которую вы сейчас считаете современной, то они по природе своей полностью устаревают за несколько лет,
_FR>С чего Вы это взяли? Это как-то следует из того, что я не могу написать сортировку?
Нет, это следует из подхода, за который вы агитируете. Который заключается в том, что знать надо только специфические для своей области вещи.
Здравствуйте, IT, Вы писали:
IT>Здравствуйте, _DAle_, Вы писали:
_DA>>Есть такие программисты вроде меня, которые просто не могут понять, ну как можно "не вспомнить", как реализовывать бинарный поиск.
IT>Можно не вспомнить как релизовать бинарный поиск, а можно просто не помнить, что такое бинарный поиск. Между этими вещами большая разница, что, тем не менее, не мешает многим их путать.
Я хотел сказать, что я лично не понимаю, как можно помнить, что такое бинарный поиск, и не выразить это в коде без особых усилий.
Здравствуйте, Pzz, Вы писали:
IT>>Так и для организации кода достаточно одних структур и методов. Зачем ООП придумали и кучу других паттернов? Непонятно
Pzz>ООП придумали для того, чтобы можно было структуруровать программу в терминах довольно больших блоков. Это нужно, в первую очередь, в связи с индустриальными методами разработки, когда над одной программой работают 50 индусов, и надо как-то провести границы, чтобы они не наступали друг другу на пятки.
Цирк. Для тех кто в это верит, поясню: привлекать неквалифицированных пользователей к формализации задачи — хорошо, привлекать неквалифицированных программистов (именно их ты имеешь в виду, говоря об индусах, правда?) — очень плохо.
Pzz>Т.е., в первую очередь ООП — это инструмент для менеджера проекта, а не для программиста.
Вообще-то ООП зародилось из фреймов-слотов, это такой ма-а-а-алепусенький кусочек инструментария ИИ по формализации знаний. Менеджеры софтостроения там если и стояли рядом, то только стояли.
Pzz>Что касается паттернов, их существование объясняется только тем, что люди решают похожие проблемы похожими способами, и похожих проблем встречается довольно много. В принципе, никаких паттернов быть не должно, раз уж люди постоянно делают одно и тоже, готовое решение должно стать библиотечной функцией (макросом, классом, темплейтом, ... — не важно).
Свежо предание... Только паттерн, это не "готовое решение", а некое собирательное название разных по существу решений. Хотя примеры могут быть и вполне определёнными. А каким же им ещё быть?!
Pzz>А вот внутри самих алгоритмов if'ы и while'ы — вполне себе адекватный инструмент. Во всяком случае, все классические алгоритмы описаны в литературе именно в этих терминах.
Это не просто "адекватный инструмент", if — это блин, базисная конструкция императивного стиля. Ну, вернее, не if, а goto. if — это уже структурный подход. Уж куда "адекватнее"!
P.S.: Не ставьте лошадь позади телеги, коллеги. Совсем уже свихнулись на "инструментах", "адекватности" и прочих "проблемах". Хех, ООП — инструмент менеджеров. Насмешил, спасибо.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, FR, Вы писали:
FR>Так обратное еще вернее там где можно применить рекурсию циклы часто невозможны или слишком сложны FR>Тем более часто рекурсия и читабельнее даже когда заменяет простой цикл. Ну и учитывая что современные FR>компиляторы (C++ про шарп и ява не в курсе) нормально оптимизируют хвостовую рекурсию, то и для оптимизации FR>циклы не так уж и нужны.
Вот если бы я был АВК, то сказал бы "опять С++ ". А так...
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Константин Л., Вы писали:
КЛ>Это сарказм? Если удается сделать правильную пачку хэлперов, то это повышает читабельность основного метода,
Дык, так оно и есть. Только если эти хэлперы локальны специфичны для конкретного метода, то лучше калькулироваться их в этом самом методе, а уж если они универсальны, то мм самое место в отдельном классе/модуле.
КЛ>плюс от к захвату контекста все-же лучше прибегать с осторожностью.
Это предрассудок. Другое дело, что нужны некоторые инструменты позволяющие упростить рефаторинг локальных функций. Так разумно было бы иметь фичу (в IDE) позволяющую выявить все захваченные переменные, фичу позволяющую переносить захваченные переменные в параметры, и фичу позволяющую вынести локальную функцию в отдельный метод.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, IT, Вы писали:
IT>Знаешь что ты только что сказал? Примерно следующее:
IT>(я) — я думаю, что 2 * 2 = 4 IT>(ты) — нифига ты, мужик, не понимаешь. 2 * 2 — ЭТО ЧЕТЫРЕ!!!!! Запомни, будешь знать!
Что-то чересчур много экспрессии и мало смысла.
IT>Даже не хочется на это отвечать. Знаешь, если всё же открыть дверь, то мир может оказаться совсем не таким, каким он видится через замочную скважину.
Ну и не отвечал бы.
IT>Вот здесь два примера того, как правильные высокоуровневые конструкции могут сделать код в разы проще, понятнее и эффективнее.
IT>1. http://www.rsdn.ru/forum/message/2102148.aspx
Все же, если не сложно, сделай, пожалуйста, в разы проще, понятнее и эффективнее сортировку — любую. Или, скажем, какой-нибудь графический фильтр. Или создание и управление неким сложно организованным файлом на диске. Или математический алгоритм — матричную алгебру, к примеру. Или что угодно еще, но только не использование классов, а написание методов класса с нуля, и при этом желательно ну хоть на порядок сложнее вычисления процентов Вот тогда и поговорим. А пока в качестве аргумента приводится вычисление процентов — говорить не о чем, потому как меня совсем не интересует, как сделать вычисление их в разы проще, понятнее и эффективнее.
Здравствуйте, McSeem2, Вы писали:
MS>Здравствуйте, Константин Л., Вы писали:
КЛ>>может быть после того, как поучаствуешь, будешь говорить про мальчиков-архитекторов?
[]
от твоей манеры общения пропадает все желание тебе отвечать
VD>Как ни одного? А тогда к чему вся эта пышная демагогия?
Шикарно. Предлогаю переименовать форум в "Демагагия программирования", как более соответствующее духу дискуссий
Здравствуйте, D. Mon, Вы писали:
DM>А вот тут подробнее, пожалуйста. Как упомянутые фишки изменят дело, кроме более удобного синтаксиса? DM>Вот задачка: есть семейство алгоритмов (та же компенсация, допустим), которые теперь отличаются не одной функцией, а пятью (при этом имеют по 10 общих). В случае ООП и наследования все просто — общие функции в базовый класс, различные — в наследников.
Вот эти "если" — это все выдумки. На практике если для алгоритма требуется передавать более трех функций, то что-то не так в самой функции. Когда код исходно пишется в функциональном стиле, то функция пишется не как монолит с "настройками", а собирается из других более общих функций. При этом происходит нечто вроде IoC (разворот управления). Вместо того чтобы создавать функцию-монстра и потом передавать ей тонну детализирующих функций, нужная функция собирается из кусков. Примером тут может служить LINQ. В нем нет одной супер-функции типа Query, а есть несколько функций: Where, OrderBy, ThenBy, Join, Group, Select и т.п. Каждая из них принимает одну-две лямбды и возвращает некий обект-контекст к которому можно применять другие функции из приведённого списка.
Ну, и если, что то гибридный язык позволяет использовать для обледенения набора функций и интерфейсы с реализациями. На программу (если ее пишут не долболомы) таки случаев должно быть не много, за то случаев где требуется передать одну-две функции море. Это сэкономит массу времени сил и избавит код от не нужных типов (баласта).
DM>А что в этом случае делают в Хаскеле и Лиспе?
Ты бы попробовал на них по программировать, а потом бы уже вопросы задавал. А то тебе ведь ничего объяснить нельзя просто по определнию. Ты думаешь другими категориями.
DM>Первое, приходящее мне на ум решение, — функция-конструктор, которая получает на вход охапку тех функций, что отличают конкретный алгоритм, и выдает в качестве результата одну функцию, его реализующую. Последняя уже вызывается когда надо. Т.е. все детали специализации пошли в замыкание, и по сути, мы получили некий аналог объекта из ООП, но с меньшим числом степеней свободы.
Есть разные пути. В конце концов не трудно функции поместить в кортеж. Но на самом деле сама постановка задачи — это выдумка.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, konsoletyper, Вы писали:
K>Гм, ну вообще-то повторение тоже разное бывает. Я вот уже давно for-ом в C# не пользуюсь. А в Питоне, например, for вообще имеет семантику C#-ского foreach, и ничего. Во-вторых, про труъ базовые конструкции я уже писал. В-третьих, туда не только не добавили аксиомы, но и изъяли одну, и получили теории, гораздо более мощные. Ну и наконец, никто не заставляет строить геометрию аки Евклид. Можно выбрать и другой набор аксиом, правда он будет не столь удобен. Так вот в случае с программированием мне известны три такие альтернативные системы аксиом. И не факт, что они чем-то уступают машине Тьюринга.
Со всем этим можно было бы согласиться, если бы процессор мог непосредственно выполнять код на Хаскеле/C#... Тогда я бы снял свои возражения. А пока что, что там не делай, а закончится все mov, add, jmp и т.д. И вот это есть абсолютный теоретический предел при данном алгоритме, если его идеально эффективно запрограммировать. Улучшить можно, только если алгоритм поменять (или доступ к данным ускорить или распараллелить и т.д.).
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Полностью абстрагируясь от эффективного вычисления процентов , отмечу лишь, что сделать код с помощью каких-то высокоуровненвых конструкций проще — можно, понятнее — тоже можно, а вот эффективнее — дудки.
Я могу тебе ещё раз посоветовать перестать подглядывать за миром через замочную скважину и наконец-то распахнуть дверь. Приведённый мною алгоритм ускоряется пропорционально количеству ядер за время меньшее, чем тебе потребовалось на прочтение этого сообщения.
Что касается первого примера с pattern matching, то для леквидации своей безграмотности можешь полистать на досуге вот этот документик. Это алгоритм компиляции pattern matching, который используется в Nemerle. Код, который получается в результате, не просто полностью отжат и максимально эффективен, он ещё и генерируется так, что повторить его столько же эффективно на if-ах просто невозможно. Refletor в большинстве случаев такой код не восстанавливает, пишет что метод обфусцирован.
Ассемблер рулил 20 лет назад. И то с переменным успехом. Сегодня компиляторы вытворяют такие оптимизации, которые человек не станет использовать хотя бы потому, что написанный им код должен оставаться элементарно читаемым. При этом чем более высокоуровневые средства используются, тем больше у компилятора свободы для оптимизаций.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, IT, Вы писали:
IT>Здравствуйте, Pavel Dvorkin, Вы писали:
PD>>А это не обсуждалось. Вот что писал IT
IT>>>Вот здесь два примера того, как правильные высокоуровневые конструкции могут сделать код в разы проще, понятнее и эффективнее
IT>А почему "могут" не выделил?
А потому что я выделил то, на что считаю нужным обратить внимание читающих. А остально они и сами прочитать могут — я твое высказывание не изменял.
>Я же знал с кем имею дело и специально так сформулировал
К сожалению, вынужден констатировать, что ты выходишь за пределы корректности. Я не позволял себе личных выпадов в твой адрес. И делая эти личные выпады, ты ни в коей мере не доказываешь свои постулаты, а только демонстрируешь свою, мягко выражаясь, своеобразную культуру общения.
IT>На самом деле ты будешь неприятно удивлён, но я знаю о чём говорю. Тот же самый алгоритм расчёта нелюбимых тобой процентов, который я привёл, ускоряется в разы в зависимости от количества ядер путём внесения маленького изменения в код, состоящего из вызова одного метода AsParallel.
Я действительно удивлен, но не этим. Я удивлен, как можно обсуждать оптимизацию на примере вычисление процентов. Я не спорю, что дело это нужное и полезное , но алгоритмическая сложность этой задачи близка к нулю. Если хочешь что-то доказать — приведи более или менее серьезную задачу, а не подобные пустяки.
>Распаралеливание императивного алгоритма потребует больше времени, чем написание самого алгоритма и сделает его в конце концов окончательно безнадёжным.
Ну не знаю. Если уж распараллеливание императивного алгоритма вычисления процентов — дело безнадежное, то, наверное, все, приехали, надо забыть про все, что есть на свете. Windows уж точно работать не должна — там внутри сплошное распараллеливание и никакой декларативности. А задачи там на несколько порядков сложнее вычисления процентов.
Вся беда твоя (и не только), что вы со своими простенькими задачами решили, что выводы, которые на базе этих простеньких задач можно сделать (мб, вполне для этих задач и верные) — могут обобщаться для программирования в целом.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Я вот об одном думаю иногда. Взять бы этих специалистов по паттернам, фреймворкам и интерфейсам, назначить им хорошую зарплату, да только поручить им спроектировать и написать www.microsoft.com , с тем количеством запросов, которое он реально обслуживает. А потом, когда время ответа будет порядка десятков секунд, уволить всех с распубликованием их имен
ASP.NET, который оно использует, спроектировали как раз таки "специалисты по паттернам, фреймворкам и интерфейсам".
А еще, я конечно не большой спец в проектировании высоконагруженных серверов, но того что я знаю хватает, чтобы предполагать, что ты очень сильно удивишься мягко говоря, когда увидишь их архитектуру и код. Никаких ассемблеров и экономии на спичках там сроду нет. Наоборот, их код, если его исполнять при нагрузке в единицы пользователей, будет чудовищно неэффективен.
Да, еще рекомендую почитать про MapReduce.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Pzz, Вы писали:
Pzz>Угу. И получишь программу, которая на вид как живая, все вроде работает, только данные никуда не ходят. Потому что сети нет. Перманентные сокеты — это то, что Джоел называет Leaky Abstractions.
Скажи пожалуйста, а что, введение абстракций является прерогативой исключительно ООП?
Pzz> А методология ООП подразумевает
Методология ООП ничего не подразумевает, потому что нет в природе никакой методологии ООП. Есть RUP, есть agile семейство, есть MSF, а методологии ООП нет.
Pzz>Поэтому да, тривиальное знание, типа того, как открыть сокет и как в него писать, в ООП описать относительно удобно. А для нетривиального знания — типа того, что сеть по природе своей штука динамическая — опаньки, никакой готовой методологии и нет.
Какая то каша у тебя выходит. Сокеты, методологии, динамические сети — все в одном горшке. Ни черта не понятно.
Pzz>ООП и есть метод структурирования программы посредством модульности.
Хм. Модульность и ООП ортогональны. Вот, к примеру, С++ ООПнутый, но, обычно, нифига не модульный, а Виртовский Оберон модульный, но нифига не ООПнутый, в джаве модуль действительно совпадает с классом, а в дотнете классы и модули (ака сборки) друг другу ортогональны (за одним маленьким исключением).
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, FR, Вы писали:
FR>Здравствуйте, Pavel Dvorkin, Вы писали:
PD>>Ну уж нет. Читай внимательно. Выделено мной.
IT>>>Вот здесь два примера того, как правильные высокоуровневые конструкции могут сделать код в разы проще, понятнее и эффективнее
PD>>Код!
FR>Это
FR>
Задача придолбаться?;)) Проще, понятнее — верю. Эффективнее — сомнительно. Реально, фильтрация на списках будет занимать дохрена копирований, рекурсия может переполнить стек при кривой реализации... в общем, эффективность такого должна быть не выше (а то и ниже) эффективности пузырька, который пишется не менее просто и понятно.:)) Или докажите обратное (желательно на практике;))
Здравствуйте, D. Mon, Вы писали:
DM>Некоторый опыт ФП у меня есть, просто вдруг я что-то важное пропустил, что хорошо заменяет ООП, вот и решил спросить. Пока вижу, что не ничего не пропустил, ответы предсказуемые.
.........
DM>Ручная имитация VMT.
Пока ты будешь думать в таких терминах, (туда же и замыкание как объект) польза от изучения функциональщины для тебя будет близка к нулю.
Здравствуйте, Pzz, Вы писали:
Pzz>#pragma flame on
Pzz>Напротив. Просто потребность в эффективности программ стала не общепринятой, а нишевой. Когда возникает необходимость спроектировать сервер, обслуживающий большое количество клиентов, или коробочку, выдающую осмысленную производительность на слабом железе, то тут некуда деваться от традиционных представлений о производительности (разве что tradeoff между процессором и памятью заметно сместился в сторону памяти). Ваше поколение оказывается довольно беспомощным при решении такого рода задач, и плохо обучаемым, потому как у вас происходит разрыв шаблона при соприкосновении с реальностью
Боюсь тебя разочаровать, но я таки имею некоторый опыт проектирования серверов, обслуживающих большое количество клиентов.
Скажем так, одна из систем, которую я проектировал, выдерживала впятеро большую нагрузку по клиентам, чем RSDN.RU. И было это почти десять лет назад, на тогдашней аппаратуре. Мое поколение справилось вполне успешно.
Разрыв шаблонов, действительно, произошел. Оказалось, что узкими местами в системе были вовсе не JSP странички. Они-то как раз летали, как трофейный мессершмит.
Сосал почтовый сервер, весь из себя написанный на плюсах и работавший поверх файлухи. (а то! ведь СУБД — это тормоза, они не дают прямого управления IO).
После переписывания на Java, поверх MS SQL, на той же машинке почтовый сервер стал выгребать не 200000 писем в сутки, а 1000000.
Второй боттлнек устранить не удалось: это был Interbase, тоже ясное дело, не на сишарпе писанный. Увы, он никак не хотел жрать больше 1 СPU на четырехпроцессорной машине, и кластеризовываться тоже не умел.
До того проекта я придерживался ровно таких же взглядов, как и Павел Дворкин сейчас. Стандартный набор шаблонов: "Ассемблер порвать невозможно; плюсы — единственный приемлемый язык" и так далее. Разрыв был таким, что я днями смотрел в профайлер и не верил себе.
Ничего, потом всё зажило. Павлу повезло — ему не удалось столкнуться с человеком, который бы столь же наглядно продемонстрировал ему ущербность его взглядов.
Вот, он рядом пишет про сайт microsoft.сom. Ну это же просто праздник какой-то!
Pzz>#pragma flame off
Pzz>У вас на слово "ассемблер" невротическая реакция. Павел не предлагал все писать на ассемблере, или даже что-либо писать на ассемблере, он произнес слово "ассемблер", чтобы очертить некоторый теоретический предел эффективности, достижимой на данном железе.
У меня с реакцией на ассемблер всё в порядке. У меня невротическая реакция как раз на "теоретический предел эффективности", который устроен вовсе не так, как думает Павел. Но объяснить ему это нереально: шаблоны слишком прочны.
... << RSDN@Home 1.2.0 alpha rev. 677>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, geniepro, Вы писали:
G>Расширяемые записи есть -- вот и основа для ООП. Ну а то, что методы нужно вручную прописывать в процедурные переменные (поля этих записей) -- ну так на то он и "ассемблер ООП"...
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Со всем этим можно было бы согласиться, если бы процессор мог непосредственно выполнять код на Хаскеле/C#... Тогда я бы снял свои возражения. А пока что, что там не делай, а закончится все mov, add, jmp и т.д. И вот это есть абсолютный теоретический предел при данном алгоритме, если его идеально эффективно запрограммировать. Улучшить можно, только если алгоритм поменять (или доступ к данным ускорить или распараллелить и т.д.).
Ну прикол-то в том, что если программа сформулирована в терминах mov, add, jmp и т.д, то простор для ее оптимизации крайне мал. Да, процессоры сейчас выжимают максимум из этого, но у них есть существенные ограничения как по ресурсам, которые можно на это потратить, так и по возможным действиям, которые они могут выполнить.
А вот если задача сформулирована декларативно, то как раз можно и алгоритм поменять, и доступ к данным ускорить, и распараллелить и всё что угодно.
Более того, во многих задачах невозможно заранее предложить оптимальное решение в терминах mov, add, jmp и т.д. Просто потому, что еще нет информации о том, в каких условиях будет алгоритм выполняться. Потому, что, к примеру, параллелить на 1 ядре — это гарантированная потеря производительности. И непараллелить при 4 ядрах — тоже гарантированная потеря. А никакого способа автоматически трансформировать mov/add/jmp так, чтобы они были оптимальны для 1/2/4 ядер наука не знает. Зато знает способы делать это в том случае, если программа написана в декларативном стиле.
Ты в курсе, как работают оптимизаторы в современных компиляторах? Именно так и делают: переписывают Control Flow Graph в виде SSA/SSI, то есть практически в функциональном, а потом уже применяют всякие трансформации, учитывая дополнительную информацию.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Sinclair, Вы писали:
C>>Вот что значат тормозные FS в Винде... S>А, ну да, конечно. А сиквел сервер, значит, не поверх них работает, а божьей милостью впятеро быстрее шарашит. S>Дело не в FS, а в правильности подхода. Смею полагать, что мы с тем же успехом могли бы поднять тот сервер и поверх Оракла на линухе, и всё равно джава порвала бы нативную реализацию поверх файлухи.
Обычно "взрослые" SQL-сервера стараются общаться с диском напрямую, насколько это возможно. Вплоть до использования своей собственной партиции, на которой нет никакой файловой системы.
Это как раз пример, опровергающий вашу точку зрения. Нормальная файловая система старается оптимизировать доступ к диску — используя кеши, опережающее чтение и т.п. В среднем это дает выигрыш, но у SQL-серверов своя собственная идея, как наиболее эффективно работать с диском, так что обычная автоматическая оптимизация им только мешает.
Т.е., SQL-сервер работает с диском быстрее именно благодаря тому, что он работает с ним на более низком уровне.
Совершенно аналогично, есть код, которому поможет рантаймовая оптимизация, встроенная в дотнет, а есть, которому только помешает.
P.S. Что до самой идеи держать почту в файлах, а не в SQL-базе, в ней есть свои преимущества. Такая конструкция значительно проще и прозрачнее, и если в ней что-то сломается, проще починить, что немаловажно для администрирования. К тому же, юниксовские файловые системы довольно быстрые при таком паттерне использования, в отличии от.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Вообще-то такое называется провокацией . Ладно. Будем считать, что провокация твоя удалась
Это не провокация и уж тем более не удавшаяся. С заданием ты не справился, а подменил его своим, подогнанными под себя.
PD>Но процентами и провайдерами я все же заниматься не буду.
И совершенно напрасно. Эта примитивная задачка достаточно сложна для того, чтобы на распаралеливание её в императивном стиле на неё потратить не 20 минут, а несколько больше. При этом мы бы увидели как 80 строк императивного кода лекго превращаются в 150-200. И ещё бы мы увидели, что задеревьями лес потерялся бы окончательно. В примере с Linq 90% кода — это алгоритм. В императивном от алгоритма примерно процентов 20%. Оптимизации уменьшают эту долю ещё в разы. А теперь предположим, что такого кода как 25 строк на linq у меня 2000 строк. Императив + оптимизации увеличат этот код минимум раз в 5, если не больше. Итого 10000+ строк. Full time job по поддержке такого кода для какого-нибудь индуса — это обычное дело. Ещё на забудем про QA team и тогда уж точно манагеров. Куча народа, на внесение изменений тикет за пол года вперёд и поехали.
PD>Насколько я понимаю, AsParallel — это из .Net 4.0, так ?
Это PLinq, CTP доступен здесь.
PD>Ray Tracer мне изучать недосуг, поэтому я просто распараллелил вычисление сумм красных компонент по столбцам окна. Зачем там эти суммы — а просто, чтобы было что делать .
Ну и зачем это надо? Тебя же просили распаралелить конкретный код, чтобы потом сравнить с существующим. А с чем мы теперь будем сравнивать? Опять с твоими домыслами?
PD>Вот код
Свят, свят, свят. Давненько я не видел C. Жуть. От звёздочек и кучи конвенций аж в глазах рябит.
PD>А теперь вопросы к тебе.
Ты сначала сделай то, что тебя просили и мы это обсудим, а потом будешь свою мерялку доставать.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, IT, Вы писали:
PD>>А теперь вопросы к тебе.
IT>Ты сначала сделай то, что тебя просили
Ну вот что, уважаемый IT. Давать мне задания и требовать их выполнения у тебя права нет. Я сделал то, что нашел нужным. Принципиально это мало чем отличается от того, что ты хочешь. У меня реальная работа есть, и ты ее за меня делать не будешь.
>и мы это обсудим
Ты уж прямо на себя функции верховного арбитра взял. Ты мол, сделай, а мы тут посмотрим и решим. Не слишком ли много на себя берешь ?
А ответов на мои вопросы нет. Ну хоть, если нет времени, напиши на словах, как будешь делать. Ну хоть не на все 5, хоть на 2-3 из них
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Ну вот что, уважаемый IT. Давать мне задания и требовать их выполнения у тебя права нет. Я сделал то, что нашел нужным. Принципиально это мало чем отличается от того, что ты хочешь. У меня реальная работа есть, и ты ее за меня делать не будешь.
Слив защитан. Другого я и не ожидал. Трындеть, оно понятно, не мешки таскать.
PD>Ты уж прямо на себя функции верховного арбитра взял. Ты мол, сделай, а мы тут посмотрим и решим. Не слишком ли много на себя берешь ?
Не много. Ты влез в это обсуждение со своим несогласным с другими мнением. Всё, что я прощу — это свои слова подкрепить делом. Приведённый мной код был написан за 20 минут для разъяснения моей позиции. Если я имею позиции и мнение, то я её стараюсь разъяснить и наглядно продемонстрировать. Тебе предлагается всего лишь сделать тоже самое — разъясниь и прдемонстрировать. Вместо этого ты приводишь какой-то левый код, задаёшь какие-то вопросы и ссылаешься на занятость. Думаешь это сильно доказывает твою правоту? Сначала приведи распараллеливание приведённого алгоритма, в нём нет ничего сложного (он, кстати, не только выражен в коде, но ещё и доступно описан на словах). Затем мы сравним его с двумя первыми реализациями, выявим достоинства и недостатки всех подходов. Ну, а потом, если у нас останутся непрояснённые моменты, мы попробуем ответить на твои вопросы.
PD>А ответов на мои вопросы нет.
Воспитанные люди не отвечают вопросами на вопросы.
PD>Ну хоть, если нет времени, напиши на словах, как будешь делать. Ну хоть не на все 5, хоть на 2-3 из них
Ты проценты распараллелил? Нет? Ну так иди параллель. До тех пор разговор окончен и своё особое мнение может написать на заборе. Или нашкрябать не сиденье в маршрутке.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, Pavel Dvorkin, Вы писали:
S>>Ну прикол-то в том, что если программа сформулирована в терминах mov, add, jmp и т.д, то простор для ее оптимизации крайне мал. PD>Ты когда-нибудь видел задачу, которая могла бы быть сформулирована в терминах mov, add, jmp и т.д ? Я таких задач в предметной области не встречал, разумееется, драйверы и прочие средства доступа к железу не в счет.
PD>На тебе банальную задачу умножения матриц и сформулируй ее в терминах mov, add, jmp и т.д. Подчеркиваю, сформулируй, а не напиши програму. А мы посмотрим, что из этого вышло
Повторяю специально для альтернативно одаренных: речь о том, в каких абстракциях сформулирована программа. А не исходную задачу.
>>Да, процессоры сейчас выжимают максимум из этого PD>Из чего они выжимают, ты что говоришь-то ? Из себя, что ли ? Или из своих собственных команд add. mov и т.д. ? Вот сижу и вижу — процессор пытается из самого себя выжать максимум. Меня это даже пугает немного — а вдруг чего-то выжмет
Да, Павел, всё именно так плохо. Процессор пытается выжать максимум именно из add, mov и так далее. Тебе вообще знакома хотя бы поверхностно архитектура современных процессоров? Термин "предсказание переходов" тебе что-нибудь говорит? Это как раз и есть попытка изменить стратегию исполнения ассемблерного кода так, чтобы увеличить throughput. Потому что формально любое ветвление обязано приводить к простою конвеера: на ассемблере ясно написано "пока не сравнишь содержимое EAX с EBX, непонятно куда переходить".
Далее, я тебе открою страшную тайну: реально никаких EAX и EBX в процессоре нету. Есть внутренние регистры, и маппинг "внешних" регистров на внутреннние определяется только в момент исполнения программы. Более того, процессор переупорядочивает команды для обеспечения лучшей производительности. Добро пожаловать в реальный мир, Павел.
Все эти трюки призваны исправить глупости, допущенные программистом ассемблера. Потому, что если бы он был умным, то он бы сам переупорядочил командны так, чтобы обеспечить максимальную микропараллельность. Вот только возможности процессора в этом ограничены.
>> но у них есть существенные ограничения как по ресурсам, которые можно на это потратить, так и по возможным действиям, которые они могут выполнить. PD>Это у процессоров ограничения по действиям, которые они могут выполнить ? Ну , кажется, приехали. У процессоров , значит, ограничения, а вот если на этих процессорах исполнять управляемый код со всеми наворотами, то эти ограничения куда-то исчезают и открываются у процессоров дополнительные возможности, так , что ли ? Ну и ну!
Совершенно верно. Для человека, который декларирует стремление к оптимальности, ты последовательно демонстрируешь потрясающую некомпетентность в вопросах оптимизации. На любом, причем, уровне. Поясняю еще раз: у процессора очень маленькое "окно просмотра кода", внутри которого он пытается понять намерения программиста, и обеспечить их выполнение с наилучшей производительностью. У него очень мало прав по внесению изменений в код, т.к. ему неясна семантика.
Вот простейший пример: ты пишешь код, вычисляющий сумму целых чисел в массиве. По какой-то причине на каждой итерации цикла ты выполняешь запись в определенную ячейку памяти.
Процессору совершенно непонятно, зачем ты это делаешь. То ли ты просто забыл, что можно использовать регистр, то ли есть другой поток, который наблюдает за этой ячейкой. В итоге, процессор честно выполняет обращение к памяти.
Если та же программа написана в терминах языка высокого уровня, типа того же С++, то по ней можно гораздо лучше понять, что именно происходит.
В частности, например, компилятор может выбрать хранение промежуточных результатов в регистре, потому что это эффективнее.
Далее, если процессор видит вызов в ассемблерном коде, он попытается предсказать переход и накормить конвейер. Но он не может выполнить инлайнинг кода, потому что у него нет такого права. А инлайнинг позволяет массу других оптимизаций. Тебе понятно, что сам по себе инлайнинг требует размеченного кода? Мы вроде уже обсуждали LTCG. Жаль, что ты ничего из этого не запомнил.
PD>Можно. Алгоритм всегда поменять можно, было бы на что менять. И доступ тоже поменять можно. И распараллелить. Поверь, все это вполне можно и без всяких управляемых сред. Это еще лет 20 назад умели и даже раньше.
Да-да. Я как бы в курсе.
S>>Более того, во многих задачах невозможно заранее предложить оптимальное решение в терминах mov, add, jmp и т.д.
PD>И неоптимальное тоже — см. выше, потому что так никто задачи не формулирует.
Еще раз повторяю для альтернативно одаренных: я говорю не о формулировке задачи, а о формулировке решения.
PD>И зря ты пытаешься доказать, что я это утверждаю. Я лишь одно утверждал — есть некий теоретический предел, им является идеально написанная программа на ассемблере. На любом языке с любыми средствами лучше сделать нельзя. При этом я вовсе не утверждаю, что знаю, как такую программу написать. Это лишь теорема о существовании. Но теорема верная. И из нее вовсе не следует, что программы надо писать на ассемблере.
Эта теорема неверна. Попробуй ее доказать
>>Просто потому, что еще нет информации о том, в каких условиях будет алгоритм выполняться.
PD>Если он на нетипичном процессоре или на иной архитектуре может выполняться — я со скрипом, но соглашусь. Потому что не знаю. что там хорошо, а что плохо. (В скобках : если буду знать — не соглашусь)
PD>Если же речь идет об обычной архитектуре, то не соглашусь. Windows NT-Vista, как тебе известно должно быть, написана так, что кроме HAL, все остальное от архитектуры не зависит. И работает она на x86, x64, а до этого были Alpha, MIPS, Power PC.
И почему ты думаешь, что Windows NT — это теоретический предел быстродействия???
>>Потому, что, к примеру, параллелить на 1 ядре — это гарантированная потеря производительности.
PD>Грандиозная мысль! Я бы сам никак не догадался . Но , к твоему сведению, узнать число процессоров через Win32 совсем не сложно. См. мой ответ IT с примером программы. PD>А вот до этого я не догадался. Я как-то до сих пор считал, что параллелить можно либо распараллеливаемые алгоритмы, либо массовые операции. А ты, похоже, дай тебе 4 ядра — возьмешься параллелить все, что угодно. Успехов >>А никакого способа автоматически трансформировать mov/add/jmp так, чтобы они были оптимальны для 1/2/4 ядер наука не знает. Зато знает способы делать это в том случае, если программа написана в декларативном стиле. PD>Посмотри мой пример. Там хоть и не mov и не add (опять борьба с ветряными мельницами), но вполне-таки распараллелено, и без всякого декларативного стиля. Без LINQ. Без интерфейсов. И даже (о ужас!) без классов. Кошмар просто
Павел, это даже смешно. Во-первых, твоя программа тупо делает два прохода: один в последовательном режиме, второй в параллельном.
Давай ты приведешь ту программу, которая просто старается сделать один проход, но как можно быстрее. В том числе и в зависимости от количества процессоров. И мы сразу убедимся, что теоретического предела она не достигает.
Во-вторых, Павел, ты же против лишнего уровня абстракции, так? Давай-ка, приведи код сразу на ассемблере; посмотрим, насколько он порвет высокоабстрактные плюсы.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Pzz, Вы писали:
Pzz>Забудьте на секундочку о SQL-сервере как о продукте, готовом к употреблению. Я привожу его в качестве примера программы, которую тоже кто-то разрабатывает.
То есть ты признаешься в том, что сознательно уводишь от темы, так как Антон привел его именно в качестве примера продукта, готового к употреблению?
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Sinclair, Вы писали:
S>Здравствуйте, Pavel Dvorkin, Вы писали:
S>Продолжаю пояснять, несмотря на очевидные проблемы с восприятием. Вот то, что ты называешь "написать", это и есть "сформулировать".
. Теперь на игру понятий переведем.
S>Еще раз, на пальцах: пишешь ты add eax, [ebp+8]. Это означает: "нужно увеличить значение регистра EAX на значение, лежащее в четырех байтах памяти по такому-то адресу". Вот такая, значит, у нас формулировка решения некоторой задачи.
Спаси меня господи и помилуй и от такой формулировки задачи и от тех, кто так задачи формулирует. Похоже, они уже потеряли всякую человеческую сущность и полностью окомпьютеризировались. И поэтому их нужно не кормить, а просто включать в сеть 220В
S>Во-вторых, я ничего не обещал выжать из отдельной команды add. Я писал про то, что процессор выжимает максимум производительности из программы, сформулированной в терминах ассемблерных команд.
Ну что же, сравним
>Да, Павел, всё именно так плохо. Процессор пытается выжать максимум именно из add, mov и так далее.
PD>>Очень сильно похоже на ребенка, который узнал, откуда дети берутся и спешит сообщить своим друзьям по песочнице эту страшную тайну. Поверь, эта тайна — тайна только для тебя, всем остальным она давным-давно известна. В общем, почитай приличное руководство по архитектуре процессора, там есть и другие тайны, о которых можешь тоже всех оповестить S>Очень рад, что ты тоже читал руководство по архитектуре процессора (кстати, какого?). Жаль, что оно ничего не дало твоему развитию.
Ты по прежнему уверен, что таким способом тебе удастся что-то добиться в этой дискуссии ? Единственное, что ты демонстрируешь — это свое неумение вести ее. То у меня с восприятием что-то не так, то развитие не то, то про особо одаренных речь идет. Успокойся , вывести меня из себя тебе не удастся, хамством я не отвечаю, а аргументы такого рода лишь характеризуют соответствующим образом того, кто их употребляет. Я же все эти выпады просто сериализую в Гольфстрим
PD>>Ну и ну! Не вдаваясь в суть этого утверждения ( а оно совсем не верно, но объяснять почему просто нет времени), могу лишь сделать вывод — программист на асме глупый, а вот компилятор — умный, он видимо, такое делать не будет. Остается лишь ответить на вопрос, умные ли те, кто писал этот компилятор. S>Ну почему сразу "глупый"? С логикой проблемы? Поясняю еще раз, специально для альтернативно начитанных: программист на ассемблере не глупый. Просто он писал программу тогда, когда "руководства" еще и в помине не было. Откуда он мог знать, сколько будет конвееров?
Давай дальше, интересно, что еще будет. Еще одно открытие — программисты на ассемблере пишут без руководства, ясно.
PD>>А если серьезнее — почитай про penalty, про конвейеры, про рекомендации Intel, какие команды следует и в каком порядке выполнять, чтобы добиться наилучшего распараллеливания. VTune, наконец, загрузи и запусти, пусть она твою программу оценит. Может, перестанешь после этого нести ахинею насчет априорно глупых программистов на ассемблере. S>Павел, я всё это знаю. Какое отношение имеет VTune к интеллекту программистов?
Самое прямое. имеющие такой интеллект используют эту программу для нахождения своих не лучших решений. Не имеющие — не используют и подпадают под твои комментарии
PD>>В огороде бузина, а в Киеве дядька. Никто от процессора и не требует, чтобы он вдруг начал изображать собой твой любимый JIT и пытаться что-то понять. S>Он уже это делает. Внутри процессора как раз и работает микро-JIT, который превращает суперскалярные команды во внутренний микрокод, выполняющийся на RISC-ядре.
. Сравнил!
PD>>Не его это задача, а задача программиста на ассемблере — писать программу так, чтобы учесть специфику выполнения команд процессором. S>А мужики-то не знали!
Насчет мужиков — не знаю, а насчет рекомендаций Интел на этот счет для x86 — поищи, найдешь. У меня где-то дома книжка валялась.
PD>>И не только процессором, кстати, а еще и продумать, как доступ к ОП лучше организовать, чтобы не было проблем с кэшем и т.п. S>Ну так вот это — неразрешимая задача.
Угу. Вот сегодня я как раз в 2.5 раза повысил скорость работы, только за счет иного размещения в памяти, ничего в алгоритме не менял (и без ассемблера)Еще в 8 раз повысить — и все, задача решена.
>Чем быстрее ты это поймешь, тем лучше для твоих студентов.
Еще один выпад. Продолжай.
>Например, потому, что ты не знаешь заранее, какой именно будет кэш.
PD>>Устал я уже отвечать. Резюме твои высказываниям — компилятор умнее человека. Компилятор может такой код соорудить, что человек его соорудить не может. Остается только одно понять — кто же этот компилятор написал — сверхчеловеки? S>Совершенно неважно, кто написал компилятор. Компилятор не устает и не ошибается
Свершилось, господа — написана программа, которая не ошибается.
"О сколько нам открытий чудных
Готовит просвещенья дух"
особенно когда этот дух на тебя нисходит.
>у него нет проблем выполнить глобальные оптимизации
Это мы летом обсуждали, там выяснилось, как обстоят дела с глобальной оптимизацией
PD>>А то, что компилятор может сделать код лучше, чем средний программист на ассемблере — вполне мб и верно. Но я-то говорил про идеально написанную программу на ассемблере как некий теоретический предел, как теорему о существовании. S>Ты ее всё еще даже не попробовал толком сформулировать, не то что доказать.
Да зачем мне ее формулировать, если ты обещал мою программу сравнить и доказать, что она этому критерию не удовлетворяет. Критерий давай сюда, эталон, с которым сравнивать будешь!
PD>>Параллелить на одном ядре — это совершенно обычная практика, существующая уже лет так 30-40. S>Нерелевантный спам поскипан. Поясняю подробнее: я не имел в виду "параллелить ожидание", я имел в виду "параллелить задачу, которая полностью нагружает одно ядро". В частности, твоя числодробилка, приведенная в примере, явно даст худший результат, если запустить даже один лишний поток.
PD>>Ну и бери ее. Выкинь кусок без распараллеливаняи и бери второй. S>Отлично. Именно об этом я и говорил. Берем второй кусок, и что мы видим?
PD>>Как, кстати, ты этот предел вычислять собираешься, если не секрет Я готов попробовать доказать теорему о его существовании, а ты готов , видимо, дать прямо-таки методику его вычислкния ? . Давай сюда ее, обсудим S>Достаточно показать возможности по дальнейшей оптимизации. Понятно, почему?
Нет, давай критерий. Ты же мою программу хочешь сравнить, так что давай критерий, а не слова. Это я на слова имею право, если буду доказывать теорему о существовании — она по определению не говорит, как это найти. А ты готов программу сравнивать. Критерий давай!
S>Показываю, следим за руками: S>При запуске на 1 (одном) ядре, эта программа тратит X вычислительных ресурсов (временем я оперировать не буду, т.к. оно зависит много от чего еще). S>При этом непараллельная версия, которую ты привел, тратит X-delta ресурсов (например, потому что в ней нет WaitforMultipleObjects, нет динамического распределения памяти, да и вообще обращений к структурам chunk).
S>Значит, она заведомо хуже, чем теоретически достижимый предел.
Дай сначала определение ресурса (время тебя не устраивает, тогда что же это ?), тогда и поговорим. А пока это попытка доказать что-то с неопределенными утверждениями , используемыми для доказательства.
>Еще вопросы? Хочешь еще раз попробовать приблизиться к теоретическому пределу, или прямо сейчас сольешь?
Сливаешь именно ты. Но сдается мне, просто прикидываешься. Ну да все равно.
А кстати, как все же насчет распараллеливания на одном процессоре ? Ты по-прежнему готов похоронить всю вычмслительную технику или пусть она все же живет, вопреки твоим воззрениям ? Или просто лучше не отвечать, когда тебя поймали ?
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Здравствуйте, Pzz, Вы писали:
Pzz>>А если так: для любой программы на языке высокого уровня существует эквиавалентная программа на ассемблере, которая работает не хуже?
PD>А может, проще — для любой программы на языке ВУ существует эквивалентная программа на ассемблере, которая работает так же.
Я точно так же могу доказать, что для любой программы, написанной на чем угодно, существует программа, составленная из байтов на коленке, или более того, полученная с помощью rnd.Next() (понадобится достаточно большое кол-во попыток), которая работает так же как данная.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Ты не понял. На шарпе это 1:1 можно сделать, никто и не спорит. Я просил это на LinQ реализовать.
По первым двум пунктам реализовать это на PLInq не составит труда. Мы любую коллекцию данные IEnumerable можем обрабатывать как AsParallel. а как энумератор будет бегать по элементам — хошь задом наперед хошь по диагонали это вопрос третий.
Но этот подход работает там, где потоки равноправны. Как только появляются извращения с приоритетами потоков у меня есть подозрение что Plinq с этим не справится. по крайней мере в текущей версии.
Другой вопрос в том, что принципиальная возможность имеется.
допустим так AsParallel(for_even_processes_set_priority_low)
или допустим сделать 2 потока
в одном будут выполняться все AsParallel вычисления с приоритетом какой укажешь, а в другом основной поток. Опять же с произвольно выбранным приоритетом.
а по поводу ассемблера. Таки да. Любой код рано или поздно будет переведен в ассемблер. Но есть нюанс. Человек не сможет написать такой же эффективный ассемблер как компилятор просто физически. Делать на асме кроссмодульные оптимизации хотя бы дестятка двух модулей это чревато вывихом мозга как минимум.
Поэтому чисто теоретически — да, эффективнее ассемблера ничего нет. Но в практическом плане использование высокоуровневых абстракций позволяет генерировать более эффективный код исключитлеьно за счет того, что компилятору намного проще анализировать весь граф вызовов n модулей и сделать JIT код конкретный процессор с оптимизациями, чем человеку.
конечно JIT не панацея. И высокоуровневые вещи вроде Plinq не настолько универсальны как ручное управление потоками. Но они дают возможность избавиться от туевой хучи головной боли и тупых задач вроде оптимизации кода на асме под новый процессор с немного другим размером кеша. Есть такое подозрение, что в 80 случаях из 100, а то и больше JIT+Plinq позволяют решить задачу проще и одновреенно эффективнее. А в остальных 20 случаях может быть и наоборот.
Здравствуйте, konsoletyper, Вы писали:
K>Оптимизация тут вот где. Есть у нас один общий алгоритм для вычисления произведения матриц над кольцом P, где само кольцо передаётся в качестве параметра. При этом кольцо представляет из себя интерфейс. Далее, пишем реализации этого интерфейса для понятий "целые числа", "действительные числа", "выражение". Если бы это компилировали в C++, то на каждое сложение/умножение пришлось бы вызывать виртуальный метод, что не быстро. В случае с нормальным языком (тот же C#) вызов может заинлайниться.
На С++ в таких случаях пишется шаблон, реализация которого прекрасно инлайнится, причем возможности инлайнинга у современных компиляторов С++ заметно выше дотнетного или джавовского джита.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Предлагаю всем, кто согласен, подписать следующую декларацию. Я один раз такое уже делал, несколько лет назад, но ничего, хуже не будет, повторим.
<skipped>
PD>Слова "неэффективно и нецелесообразно" и "оправданно и наиболее эффективно" понимаются в некотором общем смысле, без конкретной расшифровки. Просто — стоит такое использовать или же нет в реальной жизни.
Павел! понятия эффективности и целесообразности без специальных оговорок весьма субъективны.
Подпись под такой декларацией позволит и дальше оппонентам иметь разные мнения об эффективных и целесообразных мерах для решения одной конкретной задачи. А факт существования таких задач из пунктов 1) и 2), где по поводу эффективности сойдутся большинство мнений — не интересен.
Здравствуйте, Воронков Василий, Вы писали: ВВ>Мне теоретический "суперкомплятор" неинтересен.
В таком случае я в очередной раз предлагаю отказаться от обсуждения теоретического ассемблерщика.
ВВ>Опыт использования. ВВ>Вернее, давайте я поправлюсь — тот ASP.NET, который начинается и заканчивается на IHttpHandler/IHttpModule — это отличная штука.
Совершенно верно. И далеко не всё, что сверху, так плохо как кажется. ВВ>Развитие ASP.NETа — причем заметьте в понятие ASP.NET обычно вкладывается не технология "интеграции конвеера с IIS", а собственно web forms — это постепенное превращение его в чистой воды конструктор.
Мне всё равно, что именно вкладывается в это понятие обычно. Точно так же, как и то, что среднестатистический программист обычно только ухудшает код при первых попытках вставить что-то на ассемблере. ВВ>Программирование мышкой. В свое время над Дельфи за этой посмеивались. То же самое в ASP.NET — как вы сказали? — высокотехнлогичность или как там? Неувязочка получается, нет?
Программирование мышкой здесь ни при чем. Можно хоть подмышкой программировать, вопрос в том, какие возможности дает фреймворк, какой объем кода при этом нужно писать вручную, и какая при этом получается эффективность конечного решения.
ВВ>Во-первых, сама по себе концепция веб-форм ущербна изначально.
Да. ВВ>Но что принпиально новое в нес ASP.NET? Чего добились создатели ASP.NET? Разделения логики и представления? Как бы не так. Ничем в сущности ASP.NET приложение не отличается от того же PHP. И там, и там одинаковая по большому счету свалка — только несколько иначе организованная. И там и там можно писать нормально, если уж очень захочется.
Щас прямо. PHP рядом не валялся.
ВВ>Далее. что у нас еще есть? Богатые библиотеки контролов?
Нет. Библиотеки контролов меня интересуют меньше всего — это собственно даже не надводная часть айсберга, а гуано чаек на его поверхности. ВВ>И вот смотрим мы — реально на кучу разметки и кода, которую пришлось — смотрим, и выбрасываем на фиг весь это грид, и переписываем все на XSLT. И — о чудо! — на XSLT кода получается даже меньше, а все наши фичи учтены. И выглядит аккуратнее. И работает быстрее.
ВВ>И таких примеров можно много привести, и не только с контролами. Чуть-чуть сходишь с "рельс" — и все, приехали. Написав приложение на IHttpHandler/IHttpModule + XSLT, ты: ВВ>- получишь чистый код с нормальным разделением данных (XML), правил валидации (XSD) и представления (XSLT) ВВ>- получишь более производительный код ВВ>- и даже потратишь меньше времени (если приложение не хоум-пейдж) ВВ>Какой вывод после этого можно сделать о веб-формах? Но зато да, веб-формы это абстракция.
ВВ>А ведь в описанной выше технике не используется ничего специфичного для АСП.НЕТ. Ее при желании можно реализовать и на ПХП.
А ты попробуй — реализуй. И посмотри на то, сколько кода тебе для этого потребуется, и какое будет быстродействие.
ВВ>Я так смотрю хамство — это нынче модный тренд на RSDN.
А ты перечитай свой предыдущий постинг, эстет ты наш. S>>Просто веб-сервер — это типичный пример высоконагруженного приложения. ВВ>Еще раз повторяю — причем здесь вообще ASP.NET? Каким образом ASP.NET вообще возникает при разговоре об ассемблере?
При том, что ASP.NET — лучший в мире фреймворк для веб-приложений.
ВВ>Я в принципе понимаю, в чем ваша проблема. Не "ваша" конкретно, а вообще. Почему в принципе при разговоре об ассемблере возникает предложение написать на нем аналог ASP.NET приложения?
Ну а почему как начинается речь об управляемых языках — так сразу давайте матрицы умножать?
ВВ>А правда в том, что есть задачи, в к-х abstraction не дает никаких gain-ов, одни penalty. И такие ситуации также реалистичны как и те, где введение уровня абстракции позволяет сделать приложение более производительным.
С этим никто и не спорил. На всякий случай напомню, что местная притча во языцех — Павел Дворкин, с юношеским задором объявлял повышение производительности за счет введения уровней абстракции нереалистичными. S>>Как зачем? Чтобы рассуждения "теоретически, самый быстрый код — это написанный вручную на ассемблере" перестали быть голословными. ВВ>Большинство рассуждений здесь голословны. Про суперкомпляторы, которые никто не видел в глаза
Идем по ссылке, смотрим на суперкомпилятор джавы. В чем проблема?
ВВ>Напишите с 0 на C#, без всяких managed direct x, 3D-движок, полностью дублирующий CryEngine 2 и при этом работающий по крайней мере с такой же скоростью?
Только после того, как мне покажут CryEngine на ассемблере.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, IT, Вы писали:
Y>>STL, Boost.
IT>Это библиотеки, а не языковые конструкции. Если там и есть претензии на FP, то дальше претензий оно никуда не ушло.
FP — это стиль, ничего больше. ООП — тоже. В принципе, функциональную абстракцию можно воплотить и средствами структурного программирования. Будет сложновато, спору нет, но можно.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Воронков Василий, Вы писали:
ВВ>>>Да не выгоднее. Никто не разрабатывает "уникальные" программы с повышенными требованиями к железу. PD>>Я. И еще какие повышенные требования! ВВ>Ну да ради бога, только ты в меньшистве.
О! Вот она — сила логики!
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Геннадий Васильев, Вы писали:
ГВ>Но я имел в виду другое. FP, ООП, СП — это всё стили структурирования предметной области. Если хочешь — подходы. Можно даже "парадигмами" назвать. От возможностей компилятора реализация этих подходов до какой-то степени зависит, но только до какой-то.
От компилятора это зависит ровно до той степени будут эти стили использоваться или нет. Те же лямбды в C# 3.0 являются чистым сахаром над анонимными методами C# 2.0. И надо же, о чудо, их стали использовать широко и повсеместно. Делегаты таким похвастаться не могли. Ещё пример про стиль? Пожалуйста. Сейчас много говорят о параллельном программировании, о том, что если писать в соответствующем стиле, то компиляторы смогут автоматически распараллеливать выполнение задачи. Я об immutable стиле написания кода. Так вот. В C# нет средств заставить программиста писать код в таком стиле, а в том же Nemerle это делается по умолчанию. В результате после небольшой настройки мозгов immutable код на Nemerle получается сам собой. А вот на C# так стараться делать не будет никто и никогда. Компилятору по барабану, а уж программистам тем более.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, IT, Вы писали:
IT>Здравствуйте, FR, Вы писали:
IT>>>Это не совсем так. Есть вещи, которые невозможно сделать без поддержки компилятора/среды. Например, в ООП это перегрузка методов, в FP замыкания.
IT>Вот тебе перегрузка:
IT>
Здравствуйте, IT, Вы писали:
IT>Здравствуйте, Геннадий Васильев, Вы писали:
IT>>>Переписать всё на N? Да без проблем. У тебя кошелёк достаточно большого размера?
ГВ>>А... То есть, будучи написанными на Немерле они автоматически станут более серьёзными. Ясно.
IT>Т.е. кошелёк у нас небольшого размера.
Можно ещё так сказать:
т.е. переписанными они не будут.
Насколько серьёзен ненаписанный проект (и не собирающийся писаться в виду того, что денег никто выделять не будет) по сравнению с написанным и работающим?
Или так:
Да, небольшого, и что? Ты же утверждение сделал.
А то опять религия начинается:
— Если бы они были написаны с использованием FP, то они были бы ещё серьёзней.
— Докажи
— Ты не можешь доказать, что я неправ!!!!!!! // дай денег, перепишу, убедишься. денег не дашь? ну и всё тогда, я прав
Во логика.
Больше всего, конечно, меня удивляет, почему надо выставить себя правым любым способом.
Здравствуйте, VladD2, Вы писали:
VD>А жаль. Потому как какому числу людей ты будущее загубил только Бог может судить.
М-да. Что тут скажешь. Все, что я могу в твой адрес сказать — выходит за рамки допустимого не только правилами RSDN, но и обычными правилами, принятыми в среде порядочных людей.
Здравствуйте, IT, Вы писали:
IT> Я думал, ты всё же не станешь опускаться до такого уровня. Впрочем, смешно получилось. Надо будет этот код добавить себе в избранное. Топик я уже переименовал.
Ну не совсем бред, та же эмуляция ООП на Си для очень многих задач вполне окупается. Также и написанние в стиле ФП даже на языках совсем для этого не предназначеных тоже бывает иногда лучше других вариантов.
Здравствуйте, IT, Вы писали:
IT>Кривизна решения, которую нам великолепно продемонстрировал FR.
FR взял текущий Си. Я говорил о другом. Чтобы присобачить виртуальные методы, надо компилятор научить классам, наследованию, ну и всему ООП.
Чтобы присобачить нормальные замыкания, переделывать надо тоже достаточно.
Добавление же перегрузки функций никакого знания об ООП не требует.
Я так понял, что ты отнёс её к ООП по той причине, что в тех языках, где она есть, есть также и ООП?
Ок.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Здравствуйте, Sinclair, Вы писали:
S>>Эмм, а что такое "волновое телевидение"? Каким образом, интересно, контент попадет ко мне в тойоту? ВВ>А как интересно люди в интернет из самолетов выходят? ВВ>И ты представляешь — уже сейчас есть города с практически 100% wifi покрытием.
wifi = волновой интернет...
ВВ>Мы же о будущем говорим? Если ширина канала не позволяет, то как пиринговая сеть поможет? Она мне канал не увеличит, она позволяет бороться не с узостью моего канала, а с узостью канала сервера при классической доставке контента сервер-клиент.
Там много каналов — у поставщика фильма, у тебя в доме, у твоего дома к локальному провайдеру, от твоего провайдера к более крупному.
Пиринговая сеть позволяет распределить нагрузку и уменьшить число узких мест. Например, частый случай — локалка внутри дома и один выход к провайдеру от всего дома. За счет пиринговой сети как толкьо один кто-то скачал, дальше распространение идет внутри дома гораздо быстрее чем если бы все пытались через узкий канал скачивать извне.
Аналогично прямое соединение пользователей одного провайдера может оказаться быстрее, чем качать с другой стороны земного шара через всех посредников (банально может быть перегружен уже внешний канал самого провайдера).
ВВ>В целом — это спор о деталях, но я лично не очень люблю пиринговые сети. Я вот, например, хочу посмотреть "Последнего императора" Бертолуччи. Так, сколько человек его держат в активе и отдают? Что, ноль?!
Предполагается, что это "пиринг" только для улучшения, но не замены раздачи от производителя. Т.е. "вещатель" будет раздавать этот фильм всегда (ну, пока не решит, что это более не выгодно).
Остальные пользователи просто "стоят на подхвате" и ускоряют загрузку для других пользователей.
ВВ>Вторая проблема пиринговых сетей — отдача. Зачем мне, скачав контент, сидеть и отдавать его, а? В нынешних пиринговых сетях причина одна — рейтинг. Маленький рейтинг — ничего не могу скачать. Хочешь или не хочешь, а отдавать придется. Но я его, извините, нахаляву ведь получаю, так что претензий нет. ВВ>А с коммерческой пиринговой сетью как будет? Я денежку заплатил да еще надо сидеть отдавать, чтобы "кислород" не отключили?
Во-первых — раздавать — несложно, большинство может раздавать даже не задумываясь об этом.
Во-вторых, это может быть частью соглашения.
В-третьих, нет проблем ввести такой же рейтинг, только с переводом на коммерческие рельсы. Например — за раздачу фильмов вещателя начисляются "очки", которые можно использовать для бесплатного просмотра других фильмов того же вещателя.
Можно ввести систему бонусов для активных участников, таких как уменьшенная стоимость абонентской платы или раздача призов. И т.д. и т.п., можно разных стимулов придумать, приятных для пользователей и необременительных для издателей.
Здравствуйте, Воронков Василий, Вы писали:
S>>>>Эмм, а что такое "волновое телевидение"? Каким образом, интересно, контент попадет ко мне в тойоту? ВВ>>>А как интересно люди в интернет из самолетов выходят? ВВ>>>И ты представляешь — уже сейчас есть города с практически 100% wifi покрытием. F>>wifi = волновой интернет...
ВВ>"Волновое" телевидение — это такая кочерга на крыше. Вот этот протокол умрет думаю наверняка.
Да неужели?
Не надо путать "волновое" и "кабельное"
"аналоговое" и "цифровое".
"видео-по-запросу" и "видео-по-подписке"
Это совершенно разные вещи, и могут существовать в разных комбинациях.
У меня стоит спутниковая тарелка. Вещает в точности те же каналы на тех же основаниях, что "кочерга на крыше". И способ распространения аналогичный — поставить ее можно на территории всей России и будет принимать.
Но качество изображения — лучше по сравнению с "кочергой" в моем же доме. Потому что передаваемый цифровой сигнал более устойчив к помехам, ну и сама антенна более чувствительная.
Не вижу, с чего бы это ей вдруг умирать.
Единственное чего тут нет — это видео-по-запросу. Но оно не всем и нужно...
"Кочергу" тоже можно допилить, передавая на нее оцифрованный сигнал и заодно поставив железку получше.
С другой стороны, у моего коллеги НТВ+ дома показывается через кабельное телевидение... По кабелю доходит то, что к дргим доходит через волны со спутника...
Здравствуйте, Sinclair, Вы писали:
ВВ>>Этот "понос" писался не для тебя. Раз уж ты так бестактно влез в мою дискуссию с самим собой, объясни мне в таком случае, где у нас вообще "кончается" ASP.NET? S>Ну, вообще-то его основное преимущество в том, что он, собственно, нигде не кончается. S>Это как бы из области базового образования, если что. S>Поясняю: WPF вебу строго ортогонален.
Да, ты прав. Базовое образование. Логику в институте преподают.
S>Если непонятно, почему, то я, пожалуй, столь же бестактно покину топик.
Сделай милость, а? Пока тебя не было, дискуссия шла спокойно, никакого "поноса" не было. Дворкин, которому там "что-то за неуплату отключили", ведет себя как взрослый и культурный человек. Поэтому у меня к нему уважительное отношение, независимо от того, какие у нас там разногласия.
А ваша "партия" что-то вся на нервах. Чуть что — так сразу в бой, все недоучки, LOL да RTFM, ничего в жизни не понимают и вообще скоро будут полы подметать. Что ж так нервничаете, господа? "Высокоуровневое" программирование с абстракциями все нервы истрепало?
S>Потому как при таком уровне представлений можно и ассемблер с копченой рыбой сравнивать.
Уровень ваших представлений я уже понял, благодаря живописному и до невозможности наглядному примеру реализовать ASP.NET приложение на ассемблере.
ВВ>>То, что сама по себе эта модель уже устарела, разумеется, очевидно. Но WPF (в отличие от того разрекламированного тут ASP.NET MVC) представляет собой не другую абстракцию, а принципиально другую технологию. ВВ>>Если стоит задача разработки именно под Win32, то WindowsForms — пожалуй, одно из лучших решений. Особенно в свете детских болячек WPF. S>Я бы подчеркнул — под user32. Я как-то не склонен преувеличивать значение окон в win32.
А к чему это сказано? Чтобы покрасоваться? Речь идет о ГУИ-фреймворке, а ты "не склонен преувеличивать значение окон в win32". Сказать было нечего больше?
ВВ>>Само название ASP.NET говорит о то, что это реализация active server pages на .NET. Реализация, active server pages на .NET — это ASPX, класс Page, реализующий IHttpHandler и все, что тянется за ним. S>Эту глупость тебе кто сказал? Или ты сделал вывод самостоятельно, на основании наличия слова Page? S>Я не думаю, что имеет смысл вести архитектурные дискуссии с аргументацией такого уровня.
Архитектурные дискуссии вообще нельзя вести о терминах, о чем я уже говорил. Но все твои, гм, "полемические высказывания" посвящены именно что терминам. Ну что ж, видимо "такой" уровень.
[Понос поскрипан]
ВВ>>Т.е. компании, вкладывающие десятки миллионов в разработку игр под XBox360, "гарантированно" выбрасывают деньги на ветер? S>Я совершенно не уверен, что они пишут эти игры на ассемблере, который пойдет в корзину при незначительной смене характеристик платформы.
А может, стоит ознакомиться с предметом? Эти игры как раз и пойдут в корзину при смене платформы, которая "незначительной" в принципе быть не может. Сейчас максимальная совместимость — это то, что некоторые игры со старых консолей запускаются на новых через эмулятор.
Здравствуйте, IT, Вы писали:
ГВ>>По-моему, всё как раз наоборот — если есть некоторая, скажем так, теоретическая база, то никто не мешает ей пользоваться "чисто практически" даже "в Си". Вернее — мешает, но эти помехи к особенностям языков программирования не относятся.
IT>Выше я тебе уже всё объяснил в примерах на immutable.
В immutable-стиле как раз можно писать на Си. Здесь скорее мешают некоторые стереотипы и устоявшиеся подходы к проектированию, иных больших препятствия я не вижу. Но, правда, подозреваю, что распространение многоядерных "настольных процессоров" сильно поспособствует изменению подходов.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Sinclair, Вы писали:
ВВ>>Уровень ваших представлений я уже понял, благодаря живописному и до невозможности наглядному примеру реализовать ASP.NET приложение на ассемблере. S>А в чем проблема?
У меня проблем нет, т.к. я не пытаюсь доказать, что какая-то одна технология, архитектура, модель программирования и проч. несравненно лучшем чем все остальные и подходит всегда и везде.
ВВ>>А к чему это сказано? Чтобы покрасоваться? Речь идет о ГУИ-фреймворке, а ты "не склонен преувеличивать значение окон в win32". Сказать было нечего больше? S>Ну почему — есть что сказать. Ок, если рассматривать только ГУИ-фреймворк, то в общем-то и так понятно, что модель деления плоскости экрана на независимые окошки с рисованием через оконную функцию безнадежно устарела. То есть сам по себе user32 предоставляет слишком низкий уровень абстракции. Это касается как GDI, так и Windowing. S>Единственный способ написать удачное GUI приложение — это захватить одно окно (в терминах user32), а внутри него выполнять отрисовку вручную. То есть, конечно же, не вручную, а при помощи некоторого совершенно другого фреймворка, у которого базовые примитивы устроены вовсе не так, как предлагают user32 и comctl32. S>В качестве недавних примеров таких приложений можно посмотреть на Chrome. S>В качестве примеров таких фреймворков можно посмотреть на HTMLayout.
А еще можно посмотреть на GDI+.
S>То есть, в WinForms мы имеем ровно ту же ситуацию, как и в ASP.NET — та часть, которая про Forms — полный отстой. Остается использовать только самый нижний уровень.
Та, часть которая про Forms реализуется по большей части на GDI+. Есть какие-то конкретные претензии к реализации?
Архитектура вин-форм *отвечает* архитектуре юзер32, представляя *достаточный* уровень абстракции, благодаря которому и разработка упрощается, и всегда можно спуститься на "ступеньку" ниже — причем это не будет выглядеть как хак. Утверждать, что вин-формс хуже чем WTL... очень я не уверен, что хуже.
А сравнивать ее, извините, с движком, который HTML рендерит. HTMLayout вообще идеологически ближе к WPF вообще-то.
С вин-формс разработка реально упрощается. Выбранная архитектура естестественна для "окошек". Всякий раз, когда ты упираешь в ограничения, ты упираешься в ограничения не собственно вин-формс, а именно этих самых "окошек".
Так в чем проблема?
S>Поэтому мне совершенно непонятно, почему WinForms позиционируется как что-то хорошее по сравнению с WebForms. ВВ>>Архитектурные дискуссии вообще нельзя вести о терминах, о чем я уже говорил. Но все твои, гм, "полемические высказывания" посвящены именно что терминам. Ну что ж, видимо "такой" уровень. S>А ты используй термины по назначению — я и не буду критиковать их использование.
"По назначению" — это, видимо, так, как используешь их ты.
S>>>Я совершенно не уверен, что они пишут эти игры на ассемблере, который пойдет в корзину при незначительной смене характеристик платформы. ВВ>>А может, стоит ознакомиться с предметом? Эти игры как раз и пойдут в корзину при смене платформы, которая "незначительной" в принципе быть не может. Сейчас максимальная совместимость — это то, что некоторые игры со старых консолей запускаются на новых через эмулятор. S>По прежнему продолжаю непонимать место ассемблера в приставочных играх. С предметом незнаком. Есть какие-то свидетельства того, что их пишут непереносимым образом?
То, что на PS3 запускаются только некоторые игры PS2 да и то под эмулятором не является свидетельством?
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Ты мне предлагаешь Linq изучать, кто-нибудь другой предложит, к примеру, Lisp или Prolog, а когда я работать-то буду ?
Удивительное дело: что Lisp, что Prolog — простейшие языки. Их долго изучать невозможно в принципе. С другой стороны, они оказались настолько значимыми, что игнорировать их существование... Преподавателю... Э-э-э...
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Здравствуйте, FR, Вы писали:
FR>>Совершенно кривая аналогия, если бы ты привел пример использования только сути ООП и ничего больше был бы коррекный пример. Но для ООП в стиле шарпа или С++ такое трудно сделать, в стиле же смалтака можно соорудить даже и на том же си.
ВВ>А в чем кривизна аналогии? ООП должно быть "всеобъемлющим" (что кстати нереализуемо вообще), а ФП — нет?
Нет.
ВВ>Со смолтолком не знаком, не знаю, что там было. А в рамках шарпа ОО предполагает что у тебя логика строится на полиморфизме классов — причем целиком и полностью это не делает никто, даже убежденный ООП-ист, ибо есть некоторый баг в концепции ВВ>Кстати, абсолютно идеальная ОО-программа будет содержать минимум императива. Только такой нет.
Это как?
ВВ>Только смысл-то ООП не в том, что мы начинаем кое-где лепить классы с виртуальными ф-циями, а в том, что саму структуру программы начинаешь описывать, воспринимать, "думать" по-другому. В категориях сущностей — не действий — обладающих поведением, состоянием и пр. Именно в этом соль ООП на самом деле, а не в том, что местами использовать "ее суть", а местами — забить.
Практика показывает что на низком уровне абстраций удобнее отделять данные от алгоритмов их обработки. тогда классы вырождаются в наборы методов и классы данных. Вот тут и приходит на помощь ФП.
ВВ>А ФП в каком-то плане ломает мозги покруче так, чем ООП. Серьезно покруче. Почему ж у вас он получает роль обвертки какой-то? Писать на ФП — это значит думать, что mutable это такая же исключительная ситуация как и static в шарпе (а скорее всего даже куда более исключительная ситуация).
Во всем должен быть прагматичный подход. Если mutable заметно упрощает\убыстряет реализацию, то стоит использовать его, но так чтобы сама функция при этом оставалась "чистой".Никто не говорит что все внетренности надо писать императивно.
PD>>Ты мне предлагаешь Linq изучать, кто-нибудь другой предложит, к примеру, Lisp или Prolog, а когда я работать-то буду ?
ГВ>Удивительное дело: что Lisp, что Prolog — простейшие языки. Их долго изучать невозможно в принципе. С другой стороны, они оказались настолько значимыми, что игнорировать их существование... Преподавателю... Э-э-э...
А с чего ты решил, что я игнорирую их существование ? Принципы и идеи их я знаю, а писать на них — не пишу. Я думаю, ты сам понимаешь, что есть разница между знанием языка и работой с конкретной системой программирования. С GCC я, к примеру, тоже не работаю, но из этого не следует, что я не знаю C++
А вот насчет значимости... Пролог, если помнишь, был объявлен базовым языком японского проекта ЭВМ 5 поколения. Проект блестяще провалился (кажется, ни один проект столь блистательно не проваливался), что ИМХО порядком-таки подорвало крединталии Пролога. Но это ИМХО.
Здравствуйте, AndrewVK, Вы писали:
ВВ>>Т.е. разница в том, что XAML более прост как язык разметки, чем HTML? AVK>Разница в том, что это не язык разметки, несмотря на ML в его названии. ВВ>> И там и там мы имеем описание именно представления, конкретного представления, стилей и пр. AVK>Нет. В WF, к примеру, никакого конкретного представления и стилей нет, однако XAML там присутствует в полной мере. ВВ>>XAML описывает структуры, используемые компоненты, их представление. Нет? AVK>Он не описывает их представление. Только компоненты и связи между ними. Любые компоненты. ВВ>>А для чего еще годен XAML кроме как быть "форматом сериализации" конкретного "документа"? AVK>Быть форматом сериализации любого документа и не только документа. Даже в рамках WPF XAML используется не только для описания конкретной странички/окошка, но и, к примеру, для декларативного описания приложения в целом.
Да, вот только HTML всплыл вообще при разговоре о HTMLLayout, где он как раз и используется как "формат сериализации компонентов" и весьма близок к XAML по сути.
AVK>>>Что, никогда не наследовался от контролов винформсов? А если наследовался, не скажешь с какой целью? ВВ>>Наследовался. Именно с этой целью. AVK>Понятно, значит это была игра на публику.
Тебе вероятно все-таки не известна разница между "всегда" и "иногда". "практически единственный способ расширения функционала контролов — наследование" — это была не игра на публику?
Это утверждение неверное. Наследование — один из способов расширения функционала, прибегать к которому приходится не так часто. В многих случаях удобнее использовать другие способы.
ВВ>> Но ты знаешь, не так уж и часто. AVK>А это уже не важно. Важно что это во многих случаях вынужденно приходится делать.
Т.е. версия уже поменялась?
ВВ>>Могу с тобой поменяться на учебник логики. AVK>Не хами.
У тебя эксклюзивное право на хамство?
ВВ>> Заодно разберешься, чем "вообще" отличается от "в частности". И если "в частности" надо наследоваться для расширения функционала, это не означается "вообще" это надо делать. AVK>Я нигде не писал про "вообще". Я писал конкретно про винформс и его архитектуру и ее проблемы. И если я не могу собрать декларативно нужный контрол из примитивов, не прибегая к наследованию, то это проблемы именно винформсов, а не моей логики.
Ты писал именно про "вообще". О "практически единственном способе". Стоило немножко покопаться в твоих аргументов, и оказалось все не так просто.
И да, я не вижу проблем "собрать декларативно нужный контрол из примитивов", не прибегая к наследованию.
AVK>>>Вот только, скажем, код отработки default button и ее modal result намертво прошит в код Form. ВВ>>И кто-то при этом мешает переопределить modal result? AVK>А ты попробуй. Сначало без наследования
А в чем проблема? Свойство DialogResult поменять?
AVK>>>Поздравляю. К сожалению, отдельные моменты не исключают общей печальной ситуации. ВВ>>Вот только эти "отдельные моменты" почему-то очень во многих случаях работают. AVK>Хреново они работают. Чтобы соорудить TreeList для януса, пришлось наворотить гору кода, при этом публичный контракт полученного контрола на редкость ужасен. А для того, чтобы сделать нормально, придется весь функционал ListView переписать с нуля, потому что агрегацию сделать не выйдет.
ListView — это стандартное такое окошко. Его масштабируемость ограничена возможностями этого окошка. Тут наверное претензии должны быть не к винформс, а конкретно выбранному контролу.
AVK>>>А ты попробуй отнаследовать свой контрол от Control и агрегировать в нем функционал, скажем, TreeView. ВВ>>1. Controls.Add ВВ>>2. override CreateParams AVK>А, ну ну
А в чем проблема? Ты предлагаешь для создания собственного контрола, "агрегирующего функционал" три-вью, наследоваться от три-вью?
Мне бы это и в голову не пришло.
AVK>>>Например когда шаблон UI не квадратный кусок, а состоит из разных частей, перемежаемых кастомным UI. В WPF это делается сравнительно просто, без привлечения тяжелой артиллерии. ВВ>>Что такое "состоит из разных частей, перемежаемых кастомным UI"? AVK>То и значит. Шапка стандартная, далее переменный кусок, но справа стандартный элемент, далее грид, в котором часть колонок стандартная, часть нет, далее переменный кусок и наконец стандартный подвал, но с возможностью добавления в линейку кнопок собственной, причем в любое место.
В чем проблема? У тебя внутри элемент, который меняется от случая к случаю. Выносим его в качестве свойства.
ВВ>> Я честно пытался представить, что это значит, но, увы, не получилось AVK>Это потому что у тебя мышление винформсоподобным дизайном ограничено
Выражаться надо яснее.
ВВ>>SplitContainer? И что там? AVK>А ты поизучай. ВВ>> То, что он убоговат с первого взгляда видно. AVK>Даже для этой убоговатости МС пришлось существенно доработать инфраструктуру дизайн-тайма и написать гору кода. ВВ>> Так напиши свой AVK>А ты пробовал?
Меня устраивал штатный. И да, мне нужна функциональность, а не красивый дизайн-тайм, я не продаю контролы. Аналог этого сплиттер-панели делается за 5 минут на коленке с помощью сплиттера и двух панелей — как собственно он и сделал, все мудрости там с дизайн-таймом.
ВВ>>Меня, кстати, он вполне устраивал. AVK>Дело не в том, устраивает или нет. Это пример того, как убогость архитектуры винформсов привела к кривым решенияв в конкретном случае. Необходимость в контролах, у которых поведение отлично от "панелька с абсолютным позиционированием контролов внутри и рамкой" не редкость, и вызывает немаленькие танцы с бубном даже в ситуациях, когда таких панелек просто 2 штуки.
ВВ>>Мне вот интересно — вы все серьезно считаете, что сравнение кросс-платформенного фреймворка и надстройки над конкретной платформой — это корректно? AVK>Серьезно считаю. Потому что проблема не в кроссплатформенности, а в дизайне. ВВ>> И непонятно какие преимущества дает "одноплатформенный" фреймворк? AVK>Это не имеет отношения к дизайну винформсов.
Это имеет самое прямое отношение. Принципы дизайн таких фреймворков разные. Вин-формс не ставит перед собой задачи скрыть юзер32, он всегда позволяет спуститься на ступеньку ниже и дает больше возможностей по изменению поведений окошек, по использованию особенностей именно окошек. Этим он и выгодно отличается от "абстрактных" фреймворков.
ВВ>>Не знаю, как у вас там со свингами и прочими джазами, но в вин-среде и в 2002 вин-формс выглядел весьма и весьма внушительно. AVK>Ну, если ты ничего другого не видел, то может и внушительно. А по факту — нет. И среда тут не причем. ВВ>> По сравнению с тем, что предлагала МС до этого — огромный прогресс. AVK>И то, что МС не умела делать нормальный дизайн, тоже не делает винформсы лучше. Совершенно не интересно, какое тогда на рынке было УГ. Куда интереснее сравнивать с тем, что не является УГ.
Да, на момент выхода вин-формс я имел реальный опыт работы с только VB6 и MFC. "Видел" J++ и Swing.
Что, надо было пройти курс молодого бойца перед тем, как с вин-формами начинать общаться? Для вин-среды это был все-таки большой прогресс. И причем тут кроссплатформенный библиотеки для Джава я не понимаю.
ВВ>> Архитектура завязанная на модель событий — очень логичная для юзер32. AVK>Заметь, я ни слова не написал в притензиях про модель событий. В свинге тоже "модель событий". И в WPF тоже оно.
А я говорю именно про модель событий. Про инкапсуляцию окошек через контролы.
Потому что это — основное. Это — база, на которой строится приложение. Все остальное "навешивается" сверху.
ВВ>>Ты перечислил проблемы в стиле "примитивная компонентная модель" или "неудобный и примитивный АПИ для взаимодействия с состоянием". В таком стиле эту тему можно перетирать бесконечно. AVK>Ну, если "баба яга против", то конечно. А если цель — действительно понять, что не так с дизайном, то нет.
Чтобы понять, что не так с дизайном нужно наверное обсуждать более конкретные вещи.
ВВ>> А вот конкретные примеры что-то не выглядят убедительно.
AVK>То есть ты считаешь, что коллекция DataBindings в интерфейсе Control это вполне нормально? Что коллекция Items или свойство SelectedItems, если он в виртуальном режиме в ListView ничего не содержат и вызывают исключение при доступе это тоже нормально? Что у контрола есть полный комплект методов и свойств для работы с фокусом, даже если этот контрол не предполагает клавиатурного ввода?
Избыточность контракта имеет двоякий эффект. Во-первых, для юзер32 эта избыточность естестественна, потом, во многих случаях она удобна. Да, это некрасиво с т.з. дизайна и может привести также и к негативным эффектом. Но вот не факт, что в "одноплатформенной" библиотеке, к-я не ставит перед собой задачи скрывать детали реализации юзер32 минималистичный контракт оказался бы более удачным.
AVK>Что для создания office 2003 style тулбаров приходится выкидывать весь твой любимый user32 и реализовывать все с нуля?
В то же время при создании рендерера не нужно ни от каких контролов наследоваться, как ты и любишь.
К тому же Strip-ы это с нуля "нарисованные" контролы изначально, они вроде как не расшируют стандартные тулбары и менюшки, что в общем-то по их поведению заметно. Что тут удвивительного?
AVK>Ты вот писал про то, что есть механика, позволяющая добавлять в дизайн тайме свойства, которой пользуется Tooltip. В скольких еще местах эта механика используется? В одном? Двух. А в скольких ее можно использовать с положительным эффектом для дизайна?
В двух по крайней мере
И никто кстати не мешает использовать эту практику куда чаще при разработке собственного функционала.
AVK>Зачем понадобилась явная заплатка BindingSource, дублирующая часть уже существующего функционала, если с дизайном байндинга все было хорошо?
Ну дата биндинг не очень удачен в принципе. Мы сейчас будем перечислять все решения вин-формс и "оценки" им выставлять?
ВВ>>А базовая архитектура — это обработка сообщений через события, и она хороша. AVK>И все? То есть единственное, что делает винформс полезного, это крякеры виндовых мессаджей и увязка окон с экземплярами классов CLR? Спасибо, порадовал. К сожалению, MFC и OWL делали это не сильно хуже лет на 10 раньше его рождения. AVK>Возможности современного GUI-фреймворка ушли от тех времен очень далеко. Даже в 2002 году. AVK>>>Опять же, еще большая кривизна user32 никак не делает дизайн винформсов хорошим. ВВ>>Делает. AVK>Нет, не делает. ВВ>> Делает его лучше чем работа напрямую с юзер32. AVK>Тут кто то утверждал обратное? Следуя твоей логике — user32 тоже лучше, чем рукопашная реализация окошек, сильно лучше, Следовательно, если сейчас выпустить похожий по уровню фреймворк, это будет вполне нормлаьно. Так?
А что ты мне пытаешься доказать? Я где-то утверждал, что вин-формс самый лучший ГУИ-фреймворк?
Само обсуждение о вин-формсах всплыло как очередное передергивание на тему "никто не защищает веб-формс".
Вин-формы хотя бы построены на основе правильных архитектурных решений. Да, на мой взгляд обработка сообщений через события — это важный момент, и он сделан удачно. Да, "маппинг" окошек на контролы — это хорошо. И это значительно удобнее того, что было в MFC. И это не мешает мне спуститься на более низкий уровень, когда это нужно.
Веб-формы построены изначально на в корне неверных архитектурных решениях. Хотя бы потому что они точно такие же, как в вин-формс И сама эта идея — неправильная. Более того, если даже сравнивать отдельные решения, использованные в веб-формс и вин-формс, то веб-формс пожалуй даже выиграет по сумме очков — вот только к чему это все, когда фундамент гнилой?
Ты с этим не согласен?
ВВ>А что ты мне пытаешься доказать? Я где-то утверждал, что вин-формс самый лучший ГУИ-фреймворк? ВВ>Само обсуждение о вин-формсах всплыло как очередное передергивание на тему "никто не защищает веб-формс".
Заметь — передергивание было с твоей стороны. Именно ты привлек в топик ВинФормз.
ВВ>Вин-формы хотя бы построены на основе правильных архитектурных решений. Да, на мой взгляд обработка сообщений через события — это важный момент, и он сделан удачно.
Совершенно неудачно. См. bubbling/sinking как правильный механизм обработки сообщений. ВВ>Да, "маппинг" окошек на контролы — это хорошо.
Это отвратительно. ВВ>И это значительно удобнее того, что было в MFC.
Ну, если слаще репы ничего не есть, то таки да. Но мы же не с MFC сравниваем винформз, нет? ВВ>И это не мешает мне спуститься на более низкий уровень, когда это нужно. ВВ>Веб-формы построены изначально на в корне неверных архитектурных решениях. Хотя бы потому что они точно такие же, как в вин-формс И сама эта идея — неправильная. Более того, если даже сравнивать отдельные решения, использованные в веб-формс и вин-формс, то веб-формс пожалуй даже выиграет по сумме очков — вот только к чему это все, когда фундамент гнилой? ВВ>Ты с этим не согласен?
Я согласен. Только вот у веб-форм фундамент как раз хороший; гнилая там — только малозначительная надстройка. Ее можно безболезненно заменить, и построить на том же фундаменте совершенно другое решение.
А в винФормах гнил сам фундамент; поэтому невозможно как-то починить этот фреймворк. Только выкинуть целиком — и тогда получится WPF.
... << RSDN@Home 1.2.0 alpha rev. 677>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Я пытаюсь рассматривать ее изолированно от конкретных технических задач — а как же иначе? Чтобы появились конкретные задачи, вся система должна быть сначала описана в бизнес-терминах, а затем, в качестве результата анализа бизнес требований, в технических терминах. В зависимости от того, что нам будет представляено в качестве бизнес-функций и, в зависимости, от того, какие решения будут выбраны при техническом анализе, и возникнет наш спектр собственно технических задач. ВВ>Скажем, использование чистых функций для распараллеливания логики — не заложено в задачу изначально, а является следствием той архитектуры, которую мы выбрали, которая предлагает использовать параллельные вычисления для решения какой-либо из бизнес-задач, а чистые функции в данном случае — средство, облегчающее реализацию оных.
Понятно. Но всё равно здесь теряется один важный фактор. Например, прежде, чем чистые функции будут явно использованы для распараллеливания обработки, эта самая задача параллельной обработки возникает, так скажем, на уровне проблемы, которую желательно разрешить. Пусть даже в виде интереса кого-то из разработчиков. Я думаю, тебя не удивит, что задача распараллеливания ставится очень давно. То есть это не "неожиданно открывшиеся возможности", а плод долгой и целенаправленной исследовательской, в частности, работы. Другое дело, что сейчас это вбрасывается, как нечто "принципиально новое", раскрывающее "новые горизонты", так и тому есть сугубо прагматическая причина — упёрлись в физические ограничения по повышению производительности процессора. ИМХО, это и есть ключевая проблема.
И ещё, такое рассмотрение системы (изолированно от технических задач) ставит тебя на скользкий путь, подверженный очень сильному влиянию спекуляций. Собственно, вся новейшая история ООП тому примером. В нашей работе опасно ставить лошадь позади телеги и пытаться найти в такой перестановке новые возможности — лошадь будет прыгать гораздо дальше и гораздо веселее, чем когда она запряжена, а телега не будет изнашиваться и скрипеть. Вот только она так и будет стоять на месте, под аккомпанемент весёлого ржания. Между прочим, именно это мы и наблюдаем вокруг.
ГВ>>Тут вот какой прикол, на самом деле. Явления имеют такую причинно-следственную связь (в формулировках): ГВ>>
Проблема --> Задача --> Система
ВВ>Правильно. При этом проблема как и задача формулируются в бизнес-терминах. Система — описание решения в технических терминах. Или лучше сказать постановка задач в технических терминах. ВВ>Рядовой разработчик вовлекается в проект как раз на той стадии, когда система описана. Соответственно, перед ним уже ставятся технические задачи.
Ага... Как я понимаю, как раз то самый "рядовой разработчик" и интересен тебе в первую очередь. Я прав?
ВВ>Но первоначально таких задач нет. Есть задача отконвертировать бизнес-описание в архитектуру.
Не забегай вперёд. Архитектура — суть вспомогательное явление. Если можно было бы без неё обойтись — обошлись бы и не вспомнили.
ГВ>>Так вот, новые способы описания систем могут появиться только при появлении новых задач. ВВ>С этим я не согласен. С точки зрения бизнеса задачи как правило не меняются. В общем-то сейчас мы решаем те же бизнес-задачи что и десять лет назад. По большей части по кр. мере.
Десять? Я бы сказал — сорок-пятьдесят.
ГВ>>Кардинально новые способы возникнут после формулировок кардинально новых задач.
ВВ>А вот тут уже зависит от нас — как мы будем формулировать технические задачи. Для того, чтобы их сформулировать, нужен язык, который, с одной стороны, близок к бизнес-терминах, с другой — может одновременно служить техническим описанием устройства системы.
Таких языков есть. Сложности обычно начинаются с того момента, когда дело доходит до точной формализации требований. Например, всё хорошо, пока у нас есть два отвлечённых описания, скажем, событий и ожидаемой реакции системы. Всё становится очень плохо, когда нужно "разобраться", что происходит в случае каких-то ошибок, и всё становится ещё хуже, когда эти два описания нужно привести к взаимно непротиворечивому виду.
С другой стороны, если вдруг те же описания появились в а) полном и б) непротиворечивом виде, то кодирование (построение системы) становится тривиальным занятием.
ВВ>На настоящий момент — это язык ООП, обладающий, так сказать, рядом характерных особенностей. И наши технические проблемы возникают не потому, как может показаться, что бизнес что-то захотел, а потому что мы сами так "отконвертировали" эти хотения.
Вот тут ты, ИМХО, ошибаешься. На настоящий момент язык описания бизнес-задач ближе всего к вариациям SADT (группа стандартов IDEF, например), то есть, проще говоря — квадратики и стрелочки. По совместительству, такая нотация близка к "языку" описания семантических сетей (атрибутированные сущности и т.п.), и по ещё более дальнему совместительству — к ООП, как к таковому. Применение других формализмов в этом контексте, безусловно, возможно, но к нему просто нечасто прибегают.
Так вот, принципиально новые языки описания системы, ИМХО, могут возникнуть только при условии, что изменится язык, которым описывают бизнес-задачи. Повторюсь, я допускаю такую возможность, хотя склонен считать, что это произойдёт не раньше, чем, ммм... соберётся рако-щучий фестиваль на Лысой Горе по фигурному свисту.
ВВ>Мне было бы интересно рассмотреть какое-нибудь принципиально иное средство описания.
Спору нет, было бы интересно. Но главная засада заключена в том, что любое описание (на данный момент) должно сочетать метафоры действий, условий, сущностей и ресурсов. С технической же точки зрения решение сводится к выбору структуры, оптимальной в смысле использования человеческих и машинных ресурсов.
ВВ>Описание устройства системы — ответ на бизнес-требования к системе. ВВ>Описание алгоритма — ответ на технические требования к системе.
Ясно.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Здравый смысл говорит, что при суммировании строк надо идти по строкам, а при суммировании столбцов — по столбцам. И с точки зрения абстракций — то же самое (суммирование вектора-строки или вектора-столбца). А на реальной машине, где есть кэш процессора и виртуальная память, оказывается, что проходить надо всегда по строкам. Хотя какая при этом абстракция получается — черт разберет.
Просто во-первых, представление должно быть адекватно преимущественному способу обхода. А во-вторых, что в общем-то следует из во-первых, абстрагируясь от способа обхода нужно абстрагироваться и от способа представления.
... << RSDN@Home 1.2.0 alpha 4 rev. 1110>>
'You may call it "nonsense" if you like, but I'VE heard nonsense, compared with which that would be as sensible as a dictionary!' (c) Lewis Carroll
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Андрей, мы что-то воду в ступе толчем. Не хочешь окна и пикселей — возьми массив двумерный произвольного происхождения с цветами в качестве элементов. Что изменится, кроме ожидания, конечно ?
Мне в такие моменты не жлако тестовых примеров написать. Суммирование столбцов матрицы, машина у меня двухпроцессорная.
На C++ по приведенному ранее коду:
const int matrixWidth = 1280;
const int matrixHeight = 1024;
struct CHUNK
{
unsigned int *matrix;//!int xStart, xEnd;
int nHeight;
};
unsigned* columnSum;
unsigned __stdcall ThreadFunc(void* arg)
{
CHUNK* pChunk = (CHUNK*) arg;
int xEnd = pChunk->xEnd;
int nHeight = pChunk->nHeight;
unsigned int* matrix = pChunk->matrix;//!for (int x = pChunk->xStart; x <= xEnd; x++)
{
unsigned s = 0;
for ( int y = 0; y < nHeight; y++)
{
s += matrix[x + y * matrixWidth];//!
}
columnSum[x] = s;
}
return 0;
}
int _tmain(int argc, _TCHAR* argv[])
{
unsigned int *matrix = new unsigned int[matrixWidth*matrixHeight];//!for(int i=0; i<matrixWidth*matrixHeight; i++)
{
matrix[i] = i;
}
int nHeight = matrixHeight;
int nWidth = matrixWidth;
columnSum = new unsigned[nWidth];
// без распараллеливания
DWORD nTime1, nTime2, dwTimeStart , dwTimeEnd;
dwTimeStart = GetTickCount();
for ( int x = 0; x < nWidth; x++)
{
unsigned s = 0;
for(int y = 0; y < nHeight; y++)
{
s += matrix[x + y * matrixWidth];//!
}
columnSum[x] = s;
}
dwTimeEnd = GetTickCount();
nTime1 = dwTimeEnd - dwTimeStart;
// а теперь распараллелим
SYSTEM_INFO si;
GetSystemInfo(&si);
unsigned nProcNumber = si.dwNumberOfProcessors;
int xChunkWidth = nWidth / nProcNumber;
CHUNK * pChunks = new CHUNK[nProcNumber];
HANDLE* hThread = new HANDLE[nProcNumber];
for ( unsigned i = 0; i < nProcNumber; i++)
{
pChunks[i].nHeight = nHeight;
pChunks[i].xStart = xChunkWidth * i;
pChunks[i].xEnd = xChunkWidth * (i + 1) - 1;
pChunks[i].matrix = matrix;//!
}
pChunks[si.dwNumberOfProcessors - 1].xEnd = nWidth - 1; // спишем на него остаток от деления
dwTimeStart = GetTickCount();
for ( unsigned i = 0; i < nProcNumber; i++)
{
hThread[i] = (HANDLE)_beginthreadex(NULL, 0, ThreadFunc,pChunks +i, 0, NULL);
}
WaitForMultipleObjects(nProcNumber, hThread, TRUE, INFINITE);
dwTimeEnd = GetTickCount();
nTime2 = dwTimeEnd - dwTimeStart;
std::cout << "nTime1 = " << nTime1 << " nTime2 = " << nTime2;
for ( unsigned i = 0; i < nProcNumber; i++)
CloseHandle(hThread[i]);
delete[] pChunks;
delete[] hThread;
delete[] columnSum;
delete[] matrix;
return 0;
}
Здравствуйте, AndrewVK, Вы писали:
AVK>Как так, специалист по Немерле, и не знает, как тамошний компилятор устроен? ЕМНИП там есть функциональное RB-tree, неплохо работающее в том числе и в таких сценариях. Опять же — если не страдать пуризмом, то можно использовать классы с изменяемым состоянием, если они хорошо оттестированы, и демонстрируют эту изменяемость в крайне ограниченных пределах. Вот статейка на эту тему.
Из нее следует что таки лучше страдать пуризмом.
Дешевле обойдется.
... << RSDN@Home 1.2.0 alpha rev. 745>>
Пусть это будет просто:
просто, как только можно,
но не проще.
(C) А. Эйнштейн
Здравствуйте, Воронков Василий, Вы писали:
ВВ>В эклипсе я справу запускал из самого эклипса — т.е. "внешняя" среда была. Да и справка сама по себе ведь не в мазиле какой-нибудь открывалась — т.е. была среда, которая автоматизировала браузер и пр.
ВВ>На вопрос (см. выделенное) ты мне так и не ответил
Думаю, им так проще было. Они этот же хелп через веб выставляют. Ничего менять не надо.
В последнем Eclipse хотя бы заменили Tomcat на нечто более легковесное.
Здравствуйте, Воронков Василий, Вы писали:
WF>>Думаю, им так проще было. Они этот же хелп через веб выставляют. Ничего менять не надо. WF>>В последнем Eclipse хотя бы заменили Tomcat на нечто более легковесное.
ВВ>Мне собственно интересен механизм реализации этого дела. У них что, получается устанавливается веб-сервер, на котором крутится — ну скажем JSP — который обрабатывает запросы и сам же, опять-таки возможно через некую легкую БД, осуществляет полнотекстовый поиск? Я это правильно понял или там все хитрее?
Как-то так. Вместо базы там Lucene, библиотека для построения полнотекстовых индексов.
ВВ>Если это так, то все равно ведь индексацию делает движок БД. Ну если даже там и не БД, а самописное что-то — то некие процедуры на Джава. Т.е. на десктопе получается, что приложение на джава использует веб-сервер, чтобы вызвать код на джава И это для того, чтобы упростить выставление хелпа на вебе.
Не только. Возможно, ещё что-то связанное со ссылками/распахиванием меню/и.т.д. Если бы браузер показывал только контент, а всё остальное (содержание/индекс, поисковый контрол, и.т.д) было бы сделано обычным UI-ем, то надо было бы всё это вместе как-то синхронизовать (например, там есть кнопка показать в иерархии слева текущую страницу). Для этого надо было бы как-то заинтегрироваться с браузером (иметь возможность из браузера вызывать Java-код, например), ловить события перехода между страницами, и.т.д. В общем, много разных сложностей. А ещё учти, что браузеры там могут встраиваться разные — IE, FF, Safari(?).
А так открыли окно с браузером, ткнули его на http://localhost:некийпорт/ и всё. А дальше — обычное веб приложение
В принципе, нормальный подход, если при этом сервер делать максимально легковесным. JavaScript нынче быстр, отдать страницу через локальный сокет тоже быстро, простенький сервлет для поиска.
ВВ>И в это в супер-пупер масштабируемом эклипсе, по архитектуре которого целые диссертации написаны.
Здравствуйте, gandjustas, Вы писали:
G>А можно работать напрямую с видеопамятью хоть где-нибудь под Windows? Ответ — нет.
Ответ да. DirectDraw создаешь поверхность в видеопамяти и вперед.
G>Да и наибольшие тормоза в графических движках вызывает не отрисовка и текстутрирование (они уже давно выполняются на видеокарте), а отсечение невидимых поверхностей, расчет столкновений итп.
Угу и часто эти алгоритмы требуют много памяти и оптимизации доступа к этой памяти с учетом кеша и т. п. что проще делать в средах без GC.
G>Используя более высокий уровень абстракциии можно написать код, который будет компилироваться в язык шейдеров и выполняться на видеокарте или на CPU, если видеокатра не поддерживает. .NET также позволяет достаточно просто распараллелить вычисления на несколько процессоров.
Для шейдеров не нужны и бесполезны более высокие уровни абстракций, слишком короткие и ограниченые "программы" они пока подерживают, и существующих сиобразных языков сейчас более чем достаточно.
G>Не ждите появления завтра сумер-мега управляемого 3d-движка на .NET, большенство технологий которые нужны для написания движка еще "сырые", ни в одном большом проекте пока не будут использоваться. Также многие игростудии пока что испытывают страх перед управляемыми платформами в 3d движках.
Игростудии пишут сейчас игры в основном для приставок, а там до сих пор всего 256 (512 вместе с видео) метров памяти на борту. Кроме того большая часть приставок не контролируются ms и там NET еще долго не появится.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>В пиринговых сетях, конечно, секции маленькие совсем и влетают очень быстро, но может быть ситуация, что какой-то секции просто нет пока — и будешь сидеть ждать ее. В общем, не знаю. Сложно как-то все это выглядит.
Зачем ждать? Грубо говоря, если вы пропустили кадр, надо плюнуть и ехать дальше. Должна быть разумная буферизация/избыточность, чтобы это не случалось слишком часто. И роутинг надо разумно строить, чтобы, грубо говоря, самые быстрые пиры были поближе к серверу.
Здравствуйте, Воронков Василий, Вы писали:
Pzz>>Слово Joost вам ничего не говорит?
ВВ>Собственно, как и ссылка, к сожалению.
Это ребята, которые сделали скайп, сделали после того пир-ту-пировый телевизор.
Сейчас они вроде и через бровсер научились раздавать свое кено, и непонятно, чем они собираются отличаться от ютьюба. А немного раньше смотреть можно было, только поставив ихний клиент. Вполне себе пир-ту-пировый.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>>>А это неправда. Я сам давеча играл на ПС3 в Shadow of Collosus и Okami. F>>Модель и год выпуска? F>>На последних моделях PS3 была убрана совместимость с рс2.
ВВ>Можно ссылочку на официальную информацию? Модель 60-гиговая, кажется, покупалась в районе года назад.
Официальная информация у меня дома стоит — 40Гб версия этого года
60ки японские поддерживали пс2 идеально (и GPU и CPU от двушки были добавлены), 60ки европейские — частично (только GPU, CPU на эмуляции). Новые 40-ки и 80-ки вообще не держат, поскольку эмулятор для GPU не написан, а сам чип убрали.
В свое время видел новости от Сони, но сейчас найти не могу. Однако здесь есть таблица моделей с описанием уровня совместимости.
F>>В последних — уже ничего нет. F>>Я этот вопрос изучал перед покупкой пс3. F>>В инете есть даже таблицы совместимости по версиям приставки
ВВ>Мне кажется, что ты что-то путаешь. Какой им смысл откручивать обратную совместимость, когда она была раньше?
Удешевление производства. Там не только эмулятор, но и некоторые чипы стояли от пс2.
На первых порах совместимость с пс2 была жизненно необходимо, т.к. не было игр под саму пс3. По мере появления родных игр пс3 необходимость в совместимости уменьшалась и уменьшалась. В какой-то момент времени приняли решение, что она не окупает себя.
Здравствуйте, MxKazan, Вы писали:
MK>Вот, кстати, очень интересный вопрос! Сколько смотрю на последние "жаркие" темы — учебный флейм и эту — всё пытаюсь представить, как же делать на ФП пользовательский интерфейс. Я пока что на ФП не пробовал ниче писать и вопрос скорее оффтопный, но мож кто чиркнет в общих чертах Вот как баттон на форму впихнуть?
module Main where
import Graphics.UI.WX
main :: IO ()
main
= start hello
hello :: IO ()
hello
= do f <- frame [text := "Hello!"]
quit <- button f [text := "Quit", on command := close f]
set f [layout := widget quit]
Здравствуйте, AndrewVK, Вы писали:
AVK>Ты не мог бы вкратце рассказать суть? Читать 22 страницы текста как то лень.
Disclaimer: Статью читал давно некоторые детали мог немного переврать.
Вкраце так:
Ребятишки начали писать компилятор С-- на окамле.
И подумали: У нас же окамл, а не хаскель какойнибудь. Будем использовать изменяемые данные в оптимизаторе.
И начали они их использовать.
Даже в конце концов оно у них заработало.
Но гемороя по накату и главное откату изменений было столько что они потонули в багах.
Решили попробовать переписать используя паттерн zipper. Позволяющий дешево "модифицировать" неизменяемые структуры.
По началу боялись что zipper'ы сильно прогрузят ГЦ. Но тк баги совсем заели делать было нечего.
Но о чудо! Когда переписали компилятор начал работать быстрее.
Да и кода стало почти в 3 раза меньше и проще.
Так как производилась "модификация" откат стал тривиален (просто возвращаемся к версии до "модификации"). И "модификации" начали использовать более агрессивно.
Как следствие добавили кучу оптимизаций на которые раньше они не решались.
... << RSDN@Home 1.2.0 alpha rev. 745>>
Пусть это будет просто:
просто, как только можно,
но не проще.
(C) А. Эйнштейн
Здравствуйте, D. Mon, Вы писали:
DM>Например, у меня есть несколько алгоритмов компенсации движения, отличающиеся лишь способом поиска похожего блока. Наследование позволило обойтись без дублирования кода, лишних if'ов и указателей на функции (которые, по сути, изоморфны VMT).
Ну я уже говорил где-то. Это классический пример полиморфного поведения — перегрузка виртуальных функций. Это нормально, но это не наследование, это, дети, называется специализация. Что не нормально, так это расширение функциональности. А особенным идиотизмом является наследование от классов типа std::string или std::vector.
MS>>Парадигма наследования в программировании компьютеров — это пожалуй второй по величине фуфлоид.
DM>А первый какой?
Первенство по идиотизму до сих пор устойчиво держит фуфлоид под названием Венгерская Нотация.
McSeem
Я жертва цепи несчастных случайностей. Как и все мы.
Здравствуйте, FR, Вы писали:
N>>Ну вот, вы, наверняка, и фразу "The God is real..." не продолжите FR>Нет не продолжу
..., unless declared integer
Старая как мир и не особенно смешная шутка. Кстати, в FORTRAN все еще хуже, чем можно судить по этой шутке.
Имя бога, как известно, это тетраграмматон IHVH — а раз уж это имя начинается с I то бог таки integer, unless declared real.
... << RSDN@Home 1.2.0 alpha 4 rev. 1110>>
'You may call it "nonsense" if you like, but I'VE heard nonsense, compared with which that would be as sensible as a dictionary!' (c) Lewis Carroll
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Здравствуйте, prVovik, Вы писали:
V>>Тем более, что и МС не гнушаются делать хелп в виде ASP.NET приложений. У них, правда, причины другие, но факт остается фактом.
ВВ>А где у MS такой хелп?
Здравствуйте, Sergey J. A., Вы писали:
SJA>Здравствуйте, samius, Вы писали:
S>>А я подразумевал ту задачу с процентами.
SJA>Можно ссылочку на задачу, или своими словами? А то все похоже знают, что за задача, кроме меня Отсюда
Здравствуйте, netch80, Вы писали:
_FR>>>>и факториал как пример рекурсии T>>>Убивать за такие примеры рекурсии. _FR>>За что? Только за то, что "навязло" в зубах? N>За методическую некорректность. Показывание рекурсии на примере факториала, при том, что рядом он считается просто и тривиально обычным циклом
Факториал — циклом? Реально считать надо таблицей (массивом), в котором индекс элемента — входное значение, а значение в массиве — результат. Но это так, ремарка, к делу отношения не имеющая.
N>Если бы я показывал рекурсию на каком-то примере, первый пример был бы взят максимально практический, причём такой, чтобы его нельзя было в одной функции свести в цикл. А уже после этого — числа Фибоначчи, а собственно факториал — уже в качестве упражнения (если на лекции — вызвать кого-то к доске и заставить преобразовать).
Например? Вот я точно знаю, что лично на меня лучше всего подействовал именно факториал, о нём и говорю. Какой может быть пример? Лучше сказать "такой-то", а я только слышу "какой-то не такой, другой" и т.п. Покажите, и дискуссия исчерпает себя. но помните, что про рекрсию надо рассказвать ещё школьникам (информатика в 10-11 классе).
N>И ещё одно — размахивание факториалом является косвенным указанием на то, что "рекурсия — это очень просто". Когда же выучивший такое сталкивается с реальной жизнью, когда перекладка алгоритма на рекурсивный лад в первую очередь крайне громоздка — следует шок.
Это уже к вопросу отношения не имеет: просто там вообще или нет. Бывает же по-разному.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111>>
Help will always be given at Hogwarts to those who ask for it.
Здравствуйте, Геннадий Васильев, Вы писали:
WF>>Eclipse просто слишком гибкая и навороченная платформа, да и есть у Java объективные проблемы на десктопе (нет ни кеширования нативного кода, ни AOT, JIT срабатывает не сразу, автоматическая настройка GC как-то неважно работает для монстров типа Eclipse, и.т.д).
ГВ>Ты хочешь сказать, что это приводит к замедлению где-то на порядок?
Думаю, первый пункт — запросто. А это уже не к Java, а к конкретному приложению относится. Например, IBM-овский хелп, насколько мне известно, написан на JSP+JS и поднимает на фоне Tomcat. Да ещё и при первом поиске начинает строить индекс Lucene-ом (или чем-то ещё). Из-за того, что Eclipse расширяем в каждую дырку, а VC 6.0 — нет, да и фич у Eclipse поболее будет. И так далее.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Если использовать крупноблочное строительство, то всегда найдется проект, для которого ни один набор выпускаемых крупных блоков не подходит. Если строить из кирпичей, то можно построить все, что угодно — от утепленной собачьей будки до собора святого Петра.
Отличный пример.
Расходы на строительство оказались столь велики, что для покрытия их папе Льву X пришлось за большую сумму денег передать право распространять индульгенции Альбрехту Брандербургскому. Злоупотребления индульгенциями в немецких землях вызвали протест Лютера, Реформацию и последующий раскол Европы.
PD>Из кирпичей можно все построить.
Ну да, попробуйте что-то вроде Salginatobel Bridge из кирпичей построить. Из кирпича не построить даже Flatiron Building, здания из кирпича имеют тенденцию расползаться под собственной тяжестью.
... << RSDN@Home 1.2.0 alpha 4 rev. 1110>>
'You may call it "nonsense" if you like, but I'VE heard nonsense, compared with which that would be as sensible as a dictionary!' (c) Lewis Carroll
Здравствуйте, Cyberax, Вы писали:
C>Если поле ввода, то хранится как простой String в модели страницы. Поля ввода синхронизируются при совершении действия, требующего вызов серверного события. Т.е. у тебя форма с 10 полями, ты их как-то редактируешь на клиенте, а когда нажимаешь кнопку "OK" изменённые поля уходят на сервер вместе с событием "кнопка нажата". На сервере изменения вливаются в модель, а потом вызывается обработчик.
C>Если повесить обработчик на событие "фокус потерян", то синхронизироваться будет после потери фокуса (для валидации, например).
WebForms работают по такой же схеме. Проблемы начинаются при усложнении взаимодействия с пользователем и необходимости в использовании нестандартных для данной технологии средств.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, fmiracle, Вы писали:
F>Так что компании, вбухивающие миллионы в жесткую ручную оптимизацию под Х-Бокс, возможно, делают это напрасно (например, не смогут соптимизировать в рамках бюджета и проект умрет, или, например(!), можно было соптимизировать проще, а они ступили)
Не напрасно, во первых это просто необходимо чтобы вообще получить разрешение на издание (есть жесткие нормативы по времени загрузки, фпс и т. п.) во вторых очень жескоконкурентный рынок в котором "победитель получает все" (20% хитов забирают 80% прибыли)
Здравствуйте, Pzz, Вы писали:
Pzz>Внутри метода — алгоритмы. Те самые сортировки и поиски, о которых книжки пишут. А снаружи — клей и упаковка.
Тут надо не книжки читать. Тут надо прежде всего инструмент соответствующий. А то на while/if реализация даже простых алгритмов превращается в кошмар. А чтение того, что получилось — ещё ужаснее.
Pzz>Обратите внимание, что тот дикий язык, на котором в C++ пишут темплейты, тоже является функциональным языком. Причем чисто функциональным, с ленивыми вычислениями и выводом типов.
Здравствуйте, IT, Вы писали:
IT>Сразу хочу обозначить несколько моментов для предотвращения ненужного флейма.
IT>- Я умышленно не стал трогать МП, так эта вещь идёт в параллель с обсуждаемой темой.
Если ты имеешь в виду метапрограммировние — то очень зря его "умышленно не трогаешь".
Сила декларативного программирования (и ФП в частности) — как раз в том, что внутренности метода могут являться метапрограммой, подвергать и подвергаться разнообразным трансформациям.
Паттерн-матчинг — это очень красивый if, всё-таки.
А вот трансформирующийся код — это реально круто.
Причём необязательно прибегать к мощи языков С++, Haskell и тем более Template Haskell.
Старые добрые паттерны ООП делают немножко чудес.
Например, банальная сериализация объекта
void serialize(Archive& ar)
{
ar & m_foo;
ar & m_bar;
ar & m_buz;
}
Здесь, благодаря полиморфизму всех участников соревнования (сам объект-подлежащее, его члены, и посетитель) мы написали метапрограмму, порождающую разные способы записи и чтения (смотря какой посетитель туда придёт), а то и генерирования кода для дальнейшей записи и чтения.
Что же касается фуриков-бариков, то для кодирования прямо в методе нужен достаточно богатый и выразительный фреймворк.
Не обязательно "супер-богатый и супер-выразительный", но всё-таки достаточный.
Почему так популярен Tk во всех его портах — там уже есть все классы окон с кучей точек кастомизации (причём колбеки там на функциях, а не на интерфейсах).
Здравствуйте, IT, Вы писали:
IT>Казалось бы, причём тут Немерле? А вы думали я о чём?
Если это такой чудесный и суперпродуктивный язык, то почему единственные условно известные проекты на нем — компилятор и интеграция — никак не могут дойти до версии 1.0?
Здравствуйте, _FRED_, Вы писали:
Pzz>>Внутри метода — алгоритмы. Те самые сортировки и поиски, о которых книжки пишут. А снаружи — клей и упаковка.
_FR>Я как-то всегда думал, что как раз алгоритмы — это то, что очень неплохо поддаётся "библиотизации", то есть вынесением в многократно используемые кирпичи. И задумываться над алгоритмами лишний раз не приходится.
В библиотеках содержатся стандартные алгоритмы. Куда вы пойдете, если вам нужна не просто сортировка, а сортировка с преподвывертом? Готовую именно с нужными вам свойствами вы не найдете, свою написать вы не умеете, т.к. всегда использовали готовую.
_FR>В первую очередь из-за того, что редко, очень редко встречаются сейчас такие задачи.
Принесут вам код, написанный для UNIX'а и активно использующий read/write lock'и, и попросят запустить его на Windows XP. А в XP нет read/write lock'ов. Ваши дальнейшие действия?
Pzz>>И получается печальная картина: все мечтают наслаивать классы, слой за слоем, а простую сортировку, если что, и написать-то некому.
_FR>Вот что ты скажешь о кодере, которому за девять с лишним лет ни разу не пришлось самому писать сортировку Не то, что строить деревья или создавать примитив синхронизации? Что он должен сгореть от горя или позора?
Ну скорее я посоветую такому кодеру освоить другую профессию. Потому что произойдет очередная "смена технологий", C# заменят на C#$#%, и такой кодер останется без работы: кому нужен в качестве кодера 50-летний дядька, владеющий только устаревшими методами?
Здравствуйте, netch80, Вы писали:
N>Какой ответ на этот вопрос Вы хотите? Можно ответить цинически — мол, есть клавишное мясо, которое не способно даже осознать, что оно теряет и почему. А можно — что пусть себе и дальше продолжает, но пусть осознаёт, где его потолок. В принципе, оба ответа правильны.
У меня один знакомый считает, что тот не программист, кто не написал ни одного драйвера устройства.
Весьма ограниченная точка зрения, как впрочем и Ваша.
Здравствуйте, fplab, Вы писали:
_FR>>Вот что ты скажешь о кодере, которому за девять с лишним лет ни разу не пришлось самому писать сортировку Не то, что строить деревья или создавать примитив синхронизации? Что он должен сгореть от горя или позора?
F>Да, однозначно. Ничто не может служить оправданием халтуры. Конечно, на практике нужно использовать оптимизированные и проверенные библиотечные функции. Но это не значит, что нет необходимости знать основные алгоритмы.
Под "знать алгоритм" я понимаю наличие представления о том, для чего этот алгоритм нужен. Я не понимаю, к чему знание деталей реализации? В наиболее общем ключе, ка кговорим сейчас мы.
F>Пусть пузырьковая сортировка не оптимальна: она дает навык работы с массивами. А быстрая сортировка — навык работы с рекурсией. Или, по вашему, это лишнее ?
Мне больше нравится линейный поиск как навык работы с массивами и факториал как пример рекурсии. Они проще И что мы получаем: есть знания и про массивы и про рекурсию, но никакого отношения к сортировке это не имеет.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111>>
Help will always be given at Hogwarts to those who ask for it.
Здравствуйте, netch80, Вы писали:
N>Здравствуйте, _FRED_, Вы писали:
Pzz>>>Внутри метода — алгоритмы. Те самые сортировки и поиски, о которых книжки пишут. А снаружи — клей и упаковка. _FR>>Я как-то всегда думал, что как раз алгоритмы — это то, что очень неплохо поддаётся "библиотизации", то есть вынесением в многократно используемые кирпичи. И задумываться над алгоритмами лишний раз не приходится.
N>Приходится задумываться, очень даже. Вот возьмём ту же пресловутую сортировку. Кто из кодеров вообще слышал о каком-то методе кроме "quick sort" (и то — под его маркетинговым названием)? А условия применимости? Вот завтра придут данные с определённым на них частичным порядком вместо линейного, и опаньки — условия применимости не выполняются. А если сравнения очень дорогие и их надо минимизировать? А если данных никогда не больше 8 элементов и quicksort просто дорог в раскачке, простейший метод вставок сработает быстрее? А если надо выполнить сортировку параллельно? А если дали 100 миллиардов элементов и они даже в виртуальную память не влезут (я уж молчу, что сортировать данные толще физической памяти такой сортировкой — самоубийство независимо от того, влезло оно в виртуалку или нет)? Всё, такой кодер сдулся, независимо от того, насколько он хорошо знает STL и может задавать сортировку его средствами.
N>"Библиотизация", конечно, возможна — до определённой степени. И грустно то, что факт самих ограничений многим недоступен просто по недостатку образования и желания их узнать и осознать.
И как в решении описанных проблем поможет умение написать _реализацию алгоритма_? ИМХО, достаточно знаний о том, что есть вот такое, есть такое, которое хорошо тогда и тогда, а тут лучше это и это. Что бы провести подобные рассуждения и сделать правильный выбор для решения задачи, вовсе не требуется знание алгоритма. А уж узнав, каким молотком надо вбивать гвоздь, пойти и достать молоток (читай: разобраться с реализацией) совсем, мне кажется, не сложно.
_FR>>В первую очередь из-за того, что редко, очень редко встречаются сейчас такие задачи. N>Угу, именно так. Фактически, можно тупо рубить бабло на минимальном базисе. Впрочем, для этого нужно соответствующее усердие, которое тоже нечастый скилл.;(
Гхм… попробую так: в каком проценте задач сортировки данных вам не достаточно библиотечных реализаций? Мне кажется, эта цифра вполне подойдёт под описание "очень редкно".
... << RSDN@Home 1.2.0 alpha 4 rev. 1111>>
Help will always be given at Hogwarts to those who ask for it.
Здравствуйте, netch80, Вы писали:
ВВ>>Еще задолго до C# 2.0 я писал в самом банальном жабо-скрипте: N>Ну так где ECMAscript (который Netscape зачем-то назвал JavaScript), а где C#.
А где? Каждый на своем месте. И думаю на жабо-скрипте пишут даже больше людей чем на C#.
N>Кстати, "ещё задолго до C# 2.0" тривиально было в делегат поместить метод класса, а в класс вгрузить необходимые параметры — это было то же замыкание, только сконструированное вручную. Добавка синтаксического клея во 2-й и 3-й версии сделала этот процесс доступным ширнармассам, но кто хотел — умел и раньше.
Я собственно придираюсь к хронологии. А то выглядит так — все жили в пещерах, потом пришел C# и показал всем "свет разума", а Немерле превратил этот "свет" в пожарище. Я не специалист по истории ЯВУ, но сдается мне, что все этим "замыканиям" уже сто лет в обед, и C# тут как обычно выступает лишь в роли качественного подражателя.
Здравствуйте, fplab, Вы писали:
F>Наконец-то — дождались ! Вот оно — ключевое слово: "проще".
Ключевое слово — "к чему знание деталей реализации"
F> Зачем нам обезболивающие ? Деревянным молотком по голове, как в средние века: пока пациент очухается, мы ему немножко вырежем здесь и подрихтуем там
А без некорректных приемов выразить свою точку зрения никак?
F>Факториал — это да, это классика. Но именно как пример. Наверное процентов 90 всех книг по программированию объясняют рекурсию на примере именно факториала. Но между теорией и практикой дистанция немалого размера.
Ну да. И что?
F> Интересно, а если надо построить дерево, а потом сделать его обход ? Понятно, что можно и без рекурсии, но вот вопрос — а стоит ли ?
Иногда очень даже стоит. Только вот, сдается мне, как раз таки нерекурсивный обход дерева может вызвать у новичков затруднение, а не рекурсия.
А еще иногда нужно рекурсивный обход замаскировать под нерекурсивный. И вот тут то уже частенько у знатоков быстрой сортировки начинаются проблемы.
F>А линейный поиск — вообще прелесть. Понятно, что в массиве из 100 записей "при современном развитии печатного дела на Западе" (О.Бендер) — просмотреть их плевое дело. Дураки они, что ли компиляторщики — сортируют таблицу символов, чтобы потом в ней быстро искать ? А то и вообще хэш-функции втыкают
Только вот, как оказалось, на современных компьютерах линейный поиск на очень коротких списках может оказаться самым быстрым решением. Вот ведь незадача.
F>Правда, надо сделать одно важное извиняющее замечание — если человеку так не повезло, что ему не приходилось решать по настоящему сложных (а, значит, интересных) задач, то тогда, действительно, к чему засорять мозг
О да, без пенисометрии никак. Знаешь только, в чем проблема, особенно в этом форуме? По результатам измерений запросто может оказаться, что у кого то из твоих оппонентов длиннее.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
"Программист должен написать хотя бы пару сортировок, иначе его уровень программизма ниже, чем у тех, кто сортировки писал."
Если это то, что вы утверждаете, то:
A: уровень программиста ниже
B: написал сортировки
C: усвоил сортировки
Вы утверждаете:
!B => A // Не писал сортировок — плохой программист
что эквивалентно
!A => B // Хороший программист — писал сортироки
Обоснование, как я понял, вот такое:
B => C => !A // Писал сортировки, значит усвоил, значит хороший программист
Далее получаем:
B => !A // пропуская C
И потом делаем логическую ошибку:
!B => A // что явно неверно, т.о. вывод из предпосылок неверен
Т.о. либо у вас другие предпосылки, либо вы неправы.
Здравствуйте, fplab, Вы писали:
AVK>>Ключевое слово — "к чему знание деталей реализации" F>Ага. Теоретически я знаю, как пилотировать самолет, но практически — предпочту обратиться к тому, кто в деталях знает как это делается.
Либо пойти на курсы и получить 20 часов налета и корочку пилота-любителя.
F> Ну извините — опять "некорректный" прием !
Не извиню.
AVK>>А без некорректных приемов выразить свою точку зрения никак? F>Так живее.
Ничуть. Так — путь к разжиганию флейма и повышению градуса дисскуссии. Проходили уже. Сейчас твои оппоненты начнут тоже самое делать и понеслась.
F> Многое проще объяснить на пальцах, чем строить строгое доказательство.
Объяснение на пальцах != доказательство по аналогии. Второе выеденного яйца не стоит и ничего не аргументирует ни на капельку.
F> Тем более в такой области, где сколько голов — столько и мнений.
F>>>Факториал — это да, это классика. Но именно как пример. Наверное процентов 90 всех книг по программированию объясняют рекурсию на примере именно факториала. Но между теорией и практикой дистанция немалого размера.
AVK>>Ну да. И что? F>И ничего. Я же написал "именно как пример", поскольку на императивных языках обычный цикл эффективнее.
А чего ты вдруг про эффективность заговорил, если до этого речь шла о принципах и навыках? Ну и, в данном конкретном случае, факториал эффективнее вообще не считать и воспользоваться табличным преобразованием, там допустимый диапазон аргументов крошечный.
Только это опять все то же самое — увод спора в сторону.
AVK>>Иногда очень даже стоит. Только вот, сдается мне, как раз таки нерекурсивный обход дерева может вызвать у новичков затруднение, а не рекурсия. F>А что, программист не должен знать (или хотя бы предполагать) где и в чем могут возникнуть затруднения и уметь их либо обходить, либо решать ?
Должен. Но из этого никак не следует необходимость досконального знания большого количества алгоритмов сортировки.
F> Но для этого, думается мне, надо все же знать и детали реализации.
Не знаю. Вопрос в том, что это за затруднения. Если речь о производительности, то, об этом уже говорено не раз, начинать надо не с деталей алгоритмов, а с запуска профайлера.
AVK>>А еще иногда нужно рекурсивный обход замаскировать под нерекурсивный. И вот тут то уже частенько у знатоков быстрой сортировки начинаются проблемы. F>Не понял — а зачем маскировать ?
Нужно бывает. Попробуй, к примеру, сравнить два дерева.
F> Ясность — лучшее "украшение" программы (после, понятно, эффективности, т.е. быстродействия и расхода памяти).
Иногда ясность количеством деталей забивает основную суть алгоритма. Хороший пример — итераторы в шарпе (и не только в нем, впрочем).
AVK>>Только вот, как оказалось, на современных компьютерах линейный поиск на очень коротких списках может оказаться самым быстрым решением. Вот ведь незадача. F>Незадача, да только у кого ?
Догадайся
F> Ведь я и привел пример короткого списка 100 элементов в массиве — это разве много ?
Бывает и 10 элементов.
AVK>>О да, без пенисометрии никак. Знаешь только, в чем проблема, особенно в этом форуме? По результатам измерений запросто может оказаться, что у кого то из твоих оппонентов длиннее. F>Вот тут, коллега, вы сами себе противоречите Выше, если не ошибаюсь, вы указали мне на использование некорректных приемов. Может, будем последовательными ?
И где здесь некорректный прием? Я всего лишь указал на нежелательность выяснения, кто тут круче.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, igna, Вы писали:
I>IMHO ФП и ООП несовместимы.
Давай попробуем сделать так. Представим, что ФП и ООП это не целые парадигмы, а просто набор паттернов. Ну там ООП — это инкапсуляция, наследование и полиморфизм, а ФП даже лень перечислять. Так вот теперь ответь на вопрос, какие из этих паттернов между собой несовместимы.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, nikov, Вы писали:
N>Если человеку ни разу не приходилось писать сортировку, это не значит, что он не сможет это сделать, если понадобится. Измерять профессионализм тем, что человеку приходилось или не приходилось делать — это пустое дело.
Согласен. Именно это и есть моя точка зрения, но вот так выразить ее я не смог.
N>Единственный объективный индикатор профессионализма — это уровень зарплаты.
А здесь — не согласен.
Не все рвутся в центр. А на перифирии программисты оплачиваются дешевле. Кроме этого — не все стремятся к максимальной зарплате.
Не поверите наверное, но есть толковые ребята, которые сидят в каких-нить оборонных НИИ за проволокой и работают за еду. Я не утверждаю, что все там толковые. Я только утверждаю, что такие есть.
Здравствуйте, Константин Л., Вы писали:
КЛ>>>локальная функция, если она не захватывает контекст, ничем не лучше private static, а может быть и хуже, тк захламляет код оснофной функции. Если же захватывает, то надо быть очень осторожным. Тут по работе пришлось насмотреться на локальные функции в delphi.net — ппц. _FR>>Ага, уж лучше замусорить тело класса пачкой функций-хелперов, чем тело одной единственной функции
КЛ>Это сарказм? Если удается сделать правильную пачку хэлперов, то это повышает читабельность основного метода,
То есть можно жертвовать надёжностью, модульностью, локализацией ради "читабельности"? Это при том, что мнение "чем локальнее объявление, тем лучше" можно считать верным (или нет?), а "читабельность" — величина субъективная?
КЛ>плюс от к захвату контекста все-же лучше прибегать с осторожностью.
Вынося метод "наружу" ты позваляешь кому-то (а как ты запрещаешь? ага, никак!) к нему обратиться, тем самым увеличивая связаность. К лишней связаности надо относиться с ещё большим подозрением чем "к захвату контекста". Кстати, из за чего требуется осторожность? И, между прочим, мы же говорим о методах, не захватывающих контекст.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111>>
Help will always be given at Hogwarts to those who ask for it.
Здравствуйте, Tilir, Вы писали:
T>А функциональные фичи в языке требуют функциональной чистоты и высокой математической культуры (я месяц въезжал в монады и до сих пор не уверен, что въехал).
Лично мне плевать на чистоты и высокие культуры. Я беру от FP то, что мне надо, там где надо пишу императивно и сплю при этом абсолютно спокойно. Всё это только потому, что я рассматриваю FP не как религиозное учение, а как набор удобных паттернов, вполне совместимых с жизнью.
T> Что до метапрограммирования, то напишите этот марсианский кошмар и вы увидите что его некому поддерживать.
Метапрограммирования у меня целая библиотека — http://www.bltoolkit.net. Если бы она была написана на Немерле и для Немерле, то была бы в несколько раз короче и делала бы больше полезных вещей более прямыми способами.
T>В то же время у меня есть опыт редукции офигительной объектно-ориентированной иерархии на C++ из десятка шаблонных классов и активным использованием STL и Boost на полсотни килобайт кода в одну (!) функцию на C из сорока строчек, *не использующую даже CRT*. И я совершенно уверен из всего своего опыта -- любая "сложность" программирования на простых языках без лишних фич во многом надумана. C is really enough.
Нет таких алгоритмов, которые можно сделать на C и нельзя сделать на том же C# так же или проще. Обратное неверно. Возьми хотя бы замыкания.
T>Сейчас все эти сишарпы и немерле выплывают только на растущей производительности компов, которая пока растёт быстрее чем все их сборщики мусора тормозят. Надолго ли?
Это всё домысла. GC работает вполне приемлемо. А вот от объема того функционала, который делается сегодня современными средствами, любой C очень быстро захлебнётся в собственном дерь... простите в malloc, free и char*.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, Mirrorer, Вы писали:
M>См. квиксорт на Хаскеле и на С. Классический пример. Или там использование паттерн матчинга для красно-черных деревьев. M>Оно реально выглядит красивше и понятнее.
Квиксорт с хаскеля практически 1:1 переписывается в Си, с той поправкой, что в Си не сделаешь итератора по списку с помощью пары загадочных знаков препинания, приходится цикл руками расписывать.
А вообще да, ФП предоставляет очень гибкий набор средств для выражения сложных структур данных и итераторов по ним. Но не более того. Те вещи, которые не сводятся к хитроунмой итерации сложной структуры данных, на ФП и на Фортране будут выглядеть совершенно одинаково
Здравствуйте, Pzz, Вы писали:
IT>>Так и для организации кода достаточно одних структур и методов. Зачем ООП придумали и кучу других паттернов? Непонятно
Pzz>ООП придумали для того, чтобы можно было структуруровать программу в терминах довольно больших блоков.
Какая разница для чего его придумали. Без ООП можно обойтись? Можно. Но почему тогда не обходятся?
Pzz>Т.е., в первую очередь ООП — это инструмент для менеджера проекта, а не для программиста.
Даже так? Надо будет рассказать об этом своему менеджеру.
Pzz>А вот внутри самих алгоритмов if'ы и while'ы — вполне себе адекватный инструмент.
Ты сам пробовал что-нибудь ещё?
Pzz>Во всяком случае, все классические алгоритмы описаны в литературе именно в этих терминах.
Лучший язык для обучения — Паскаль. Давайте все писать на нём.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, AndrewVK, Вы писали:
AVK>UI то, конечно, делать можно. Проблема в дизайн-тайме, причем не только этого самого UI. Сколько я ни спрашивал, никто не смог мне продемонстрировать чисто функциональную компонентную модель. Что, впрочем, не мешает при этом какими то элементами ФП пользоваться.
Любой интерфейс должен иметь состояние — просто потому, что пользователь так устроен Так что делать его в идеологии ФП — все равно что бегать в ластах.
Здравствуйте, Odi$$ey, Вы писали:
OE>ну дык слава богу выясняется не зря программисты несколько десятков лет работали и не нужно уже в каждом проекте реализовывать свои списки, деревья, сортировки и проч. фигню
Ну да, в программировании вычислительных машин появились уже области, где не требуется высшее образование, достаточно знаний на уровне техникума
Здравствуйте, Andrei F., Вы писали:
AF>Ты написал "нет желания поднимать старый флейм" — я написал "ну и не надо его поднимать".
Ну так я и не поднимаю. В чем суть притензии?
AVK>>А я видел.
AF>ссылку, пожалуйста
Надеюсь, ты понимаешь, что мой пример — это иллюстрация мысли, а не точное описание происходящего. Что же касается ссылки — думаю, ты и без ссылки легко найдешь требуемое.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Pzz, Вы писали:
Pzz>Школьные сочинения преследуют 2 цели: научить человека писать синтаксически грамотно, и научить внятно излагать свои мысли в письменном виде. Вероятно и тому и другому можно научиться, не написав в жизни не одного сочинения. Но на практике такое встречается нечасто.
(нИ одного)
Т.е. Вы утверждаете, что написание велосипеда-сортировки эквивалентно совокупности всех сочинений в школе?
На мой взляд — написание сортировки эквивалентно лишь одному изложению. И если кто-то не написал одно изложение, то нельзя говорить что он не освоил школьную программу.
Здравствуйте, IT, Вы писали:
IT>Давай попробуем сделать так. Представим, что ФП и ООП это не целые парадигмы, а просто набор паттернов. Ну там ООП — это инкапсуляция, наследование и полиморфизм, а ФП даже лень перечислять. Так вот теперь ответь на вопрос, какие из этих паттернов между собой несовместимы.
Угу совместимы тот же Ocaml да и величайший из языков на букву N это демонстрируют. Но совместимы только на том уровне который ты сейчас рекламируешь, а вот если идти выше то уже нет, притом скорее и не отрицают и не дополняют друг — друга а просто совершено различны.
Здравствуйте, D. Mon, Вы писали:
DM>Например, у меня есть несколько алгоритмов компенсации движения, отличающиеся лишь способом поиска похожего блока. Наследование позволило обойтись без дублирования кода, лишних if'ов и указателей на функции (которые, по сути, изоморфны VMT).
Если я правильно тебя понял, то нужно было написать один generic алгоритм компенсации движения, и в него при создании конкретного экземпяра передавать функцию поиска похожего блока.
Lisp is not dead. It’s just the URL that has changed: http://clojure.org
Здравствуйте, netch80, Вы писали:
N>А на практике окажется, что из ~100 методов отличаются у потомков 20, и этого достаточно, чтобы действие "передать функцию поиска похожего блока" вылилось в извращение типа "передать структуру функций, специфичных именно для этой реализации". И всё это с костылями вроде приведения типов.
Если на практике ~100 методов, то эту практику нужно прекращать немедленно
А костыли эти появляются из-за того, что языки не поддерживают higher-order functions & functions as first class objects. Вы кажется про С++, да, он этого не поддерживает, придется обходиться функторами, а это действительно костыли. А в C# 3 уже есть некоторая поддержка ФП и этих костылей не будет, не говоря уже о более развитых языках.
N>Нет, конечно, использовать такое порой можно и нужно. Но в общую практику я бы рекомендовал наследование. Конечно, у него есть свои проблемы (вспомним множественное наследование и его эффекты). Но это проблема любого подобного механизма — можно загнать в ситуацию, когда перестанет работать.
Наследование реализации сама по себе одна большая проблема.
Lisp is not dead. It’s just the URL that has changed: http://clojure.org
Здравствуйте, IT, Вы писали:
T>>В то же время у меня есть опыт редукции офигительной объектно-ориентированной иерархии на C++ из десятка шаблонных классов и активным использованием STL и Boost на полсотни килобайт кода в одну (!) функцию на C из сорока строчек, *не использующую даже CRT*. И я совершенно уверен из всего своего опыта -- любая "сложность" программирования на простых языках без лишних фич во многом надумана. C is really enough. IT>Нет таких алгоритмов, которые можно сделать на C и нельзя сделать на том же C# так же или проще. Обратное неверно. Возьми хотя бы замыкания.
Обратное верно, если учесть хотя бы низкоуровневую специфику, которую часто на C# или реализовать нельзя, или только unmanaged кодом (который лучше считать диверсией, а не C#, по крайней мере в рамках данной дискуссии). Но и замыкания — ни капельки не rocket science. Везде, где интерфейс написан нормально (а не через двуединую сущность с вертикальной улыбкой) и есть передача указателя на callback, есть и передача произвольного параметра (как правило, void*) к этому коллбэку. Если мы подменим и функцию (на свою) и данные (заведя структуру с исходным указателем и сохранёнными данными), получим то же замыкание. Да, это "закат солнца вручную" и грабли этого подхода известны. Но тем не менее — работает и используется.
Я подобный механизм использовал на C, и мне его понять было значительно легче, чем замыкания, в которых косвенным и изначально неочевидным образом фиксируются значения переменных. Фактически, замыкания в известных ФЯ и приближенных к них, таких, как Perl, Python... — хак на основании того, что ссылка на копию значения запоминается через неявное средство обеспечения уникальной копии (для процедурно функционально-обогащённых;)) языков это персональный стековый фрейм).
(О, какой термин прикольный родился на ходу — надо запомнить.)
T>>Сейчас все эти сишарпы и немерле выплывают только на растущей производительности компов, которая пока растёт быстрее чем все их сборщики мусора тормозят. Надолго ли? IT>Это всё домысла. GC работает вполне приемлемо. А вот от объема того функционала, который делается сегодня современными средствами, любой C очень быстро захлебнётся в собственном дерь... простите в malloc, free и char*.
С этим полностью согласен — сила современных языков не столько в том, что они позволяют, сколько в том, что они не позволяют и в какие рамки укладывают применяемые средства.
Здравствуйте, McSeem2, Вы писали:
MS>Ну я уже говорил где-то. Это классический пример полиморфного поведения — перегрузка виртуальных функций. Это нормально, но это не наследование, это, дети, называется специализация. Что не нормально, так это расширение функциональности.
Так это не в наследовании проблема, а в его использовании. Если нарушать LSP, естественно добра от этого не жди. Классическая ситуация, описываемая присказкой про альтернативно одаренного человека и детородный орган из стекла.
Вообще, тут все намешали в одну кучу — наследование интерфейсов, наследование реализаций и LSP. В результате — каждый говорит о своем.
MS>Первенство по идиотизму до сих пор устойчиво держит фуфлоид под названием Венгерская Нотация.
Не отрывай труп, пусть покоится с миром.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, samius, Вы писали:
S>К счастью (моему), у меня и у моих работодателей вопросы интереснее. Чего и Вам желаю.
Вы не представляете, насколько они у меня интереснее
S>BSP дерево — писал. Ток не на интерес, а в рамках курсового. Задача курсового, кстати была не в том, чтобы написать BSP. И это я запомнил вовсе не потому, что написал BSP и офанарел от этого.
Интересная, кстати, структура. Я и не знал про такую, спасибо...
Здравствуйте, D. Mon, Вы писали:
DM>А вот тут подробнее, пожалуйста. Как упомянутые фишки изменят дело, кроме более удобного синтаксиса? DM>Вот задачка: есть семейство алгоритмов (та же компенсация, допустим), которые теперь отличаются не одной функцией, а пятью (при этом имеют по 10 общих). В случае ООП и наследования все просто — общие функции в базовый класс, различные — в наследников.
А у тебя тут не ожидается комбинаторного взрыва наследников?
DM>А что в этом случае делают в Хаскеле и Лиспе? DM>Не передают же при каждом вызове "вагон колбеков", как тут его назвали.
Нет конечно, они обычно осмысленно комбинируется в промежуточные сущности.
DM>Первое, приходящее мне на ум решение, — функция-конструктор, которая получает на вход охапку тех функций, что отличают конкретный алгоритм, и выдает в качестве результата одну функцию, его реализующую. Последняя уже вызывается когда надо. Т.е. все детали специализации пошли в замыкание, и по сути, мы получили некий аналог объекта из ООП, но с меньшим числом степеней свободы.
В общем да так и будет, только наоборот на объектах и будет корявое подобие с ограниченым числом степеней свободы
Здравствуйте, netch80, Вы писали:
IT>>Нет таких алгоритмов, которые можно сделать на C и нельзя сделать на том же C# так же или проще. Обратное неверно. Возьми хотя бы замыкания.
N>Обратное верно, если учесть хотя бы низкоуровневую специфику,
Для низкоуровневой специфики лучше всего использовать ассемблер. Впрочем, C это и есть почти ассемблер, вот пусть он этими спецификами и занимается. А тягаться с высокоуровневой логикой на C даже не смешно.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, _DAle_, Вы писали:
_DA>Казалось бы, при чем тут рекурсия и цикл? Там, где можно обойтись просто циклом, рекурсия обычно не нужна и не используется.
Это вопрос предпочтений. Мне тоже так раньше казалось. Сегодня же при наличии хвостовой рекурсии я скорее всего выберу рекурсию, кроме ну уж совсем примитивных случаев.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, _DAle_, Вы писали:
_DA>Есть такие программисты вроде меня, которые просто не могут понять, ну как можно "не вспомнить", как реализовывать бинарный поиск.
Можно не вспомнить как релизовать бинарный поиск, а можно просто не помнить, что такое бинарный поиск. Между этими вещами большая разница, что, тем не менее, не мешает многим их путать.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, FR, Вы писали:
N>>Ну вот, вы, наверняка, и фразу "The God is real..." не продолжите :) FR>Нет не продолжу :???:
И после этого комментируете Фортран. Понятно, "не читал, но осуждаю".
FR>>>Угу сами себе придумал 20 ФВП и сами себе отвечаем не надо? N>>Хотел бы я, чтобы это оказалось только своей придумкой... да вот увы — практика. FR>Угу бытие определяет сознание :) FR>А сама практика такая потому-что ничего кромее ООП ты не видишь и не хочешь видеть.
В данном случае практика иная: а именно, Вы не хотите видеть ничего кроме ФП. Вы уже который постинг подряд только и делаете, что агитируете "за советскую власть" совершенно не представляя себе специфики задач, ограничений механизма, придумываете любые фишки лишь бы доказать одно — "ФП рулез, всё остальное сакс". Вы наобум приписываете собеседникам чужие свойства (как мне что "кромее ООП ты не видишь и не хочешь видеть" — это мне-то, который до массового распространения ООП уже лет 7 был "в системе" и успел писать на всём что только тогда было), не дав себе даже минимального труда проанализировать адекватность своих "назначений".
Я с Вами не хочу больше спорить. Когда Вы научитесь вести действительно дискуссию, а не выливать потоки религиозного гона — возвращайтесь, поговорим.
Нет.
"писать на бейсике можно используя любой язык."
Суть же в том что недостаточно выучить синтаксис языка программирования чтобы научится на нем нормально писать.
FR>>Ужас меня уже записали в злобные функциональщики
N>Как себя ведёте — туда и записываем.
Это ты просто не видел как себя ведут настоящие злобные функциональщики
FR>>Однако если вернутся к теме к локальному коду, то преимущества ФП и сопутствующего ему сахара может не видеть только слепой.
N>Вот именно — злобный функциональщик и есть, сами согласились.
Нет и стиль и суть совсем не соответствуют
FR>>Если хочешь померятся то лучше покажи небольшой законченный кусочек кода который по твоему продемонстрирует неоспоримые преимущества наследования для задачи специализации алгоритмов, я же перепишу его в ФП стиле и сравним.
N>На "небольшом законченном" и я одной левой смогу. Это не реальная задача.
Так в топике же обсуждается именно локальный код, он по определению небольшой и соответственно совершено нетрудно привести вполне практичный примерчик.
Здравствуйте, McSeem2, Вы писали:
MS>Здравствуйте, Константин Л., Вы писали:
КЛ>>самый большой проект, в котором ты когда-либо участвовал?
MS>Я не участвую в так называемых "больших проектах", мне это не интересно.
может быть после того, как поучаствуешь, будешь говорить про мальчиков-архитекторов?
Здравствуйте, netch80, Вы писали:
N>Я что-то не смог найти в постинге Певзнера стремления привлечь индусов к _формализации_ задачи. Где Вы это вычитали?
Я имел в виду, конечно, привлечение неквалифицированных программистов к реализации, а не к формализации. Спасибо, что заметил неточность.
Pzz>>>Т.е., в первую очередь ООП — это инструмент для менеджера проекта, а не для программиста. ГВ>>Вообще-то ООП зародилось из фреймов-слотов, это такой ма-а-а-алепусенький кусочек инструментария ИИ по формализации знаний. Менеджеры софтостроения там если и стояли рядом, то только стояли.
N>А при чём тут, откуда оно зародилось?
Откуда зародилось, свойства того органично и унаследовало. Но это ни в коем случае не инструмент менеджера. Инструмент менеджера — это нормативная база, ресурсы, деньги, планы, организационные подходы... А не ООП.
N>Современная практика совсем иная, и от тех времён, когда оно рождалось — несколько крупных логических переходов (например, насколько ООП формата Simula & Smalltalk отличается от того, что из него сделали даже в Objective C, я уж не говорю про развития C и Паскаля).
Интересно, в чём же состоит крупный логический переход?
N>Фактически, разделение объектов — то, что позднее назвали "контрактным программированием", с ограничением тем, что "контракт" проводится по границе объекта ("пуля вылетает — проблемы не на моей стороне").
Ты путаешь объектную декомпозицию и спецификацию.
N>Другой вопрос, что такое разделение нормально возможно только при статичных спецификациях. Если они меняются — приходится пересматривать места проведения границ. А вот тут уже начинаются нюансы.
Что-то я не пойму — к чему ты это? Спецификации — это спецификации, объектная декомпозиция — это объектная декомпозиция. От того, что спецификация, например, будет комбинироваться в runtime ничего принципиально не меняется, кроме того, что исполняющая машина языка программирования будет подставлять не только реализацию, но ещё и спецификацию. Принципы те же, что и для абстрактных типов данных.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, AndrewVK, Вы писали:
AF>>Мне очень интересно послушать, какие в ней есть реальные проблемы.
AVK>А мне уже нет. Я уже мильен раз об этом говорил, и поднимать старый флейм нет никакого желания.
Раз миллион, то не составит труда найти ссылку хоть на одно внятное объяснение?
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Pzz, Вы писали:
Pzz>А вот внутри самих алгоритмов if'ы и while'ы — вполне себе адекватный инструмент. Во всяком случае, все классические алгоритмы описаны в литературе именно в этих терминах.
Для тупых и ленивых индокодеров — да. Для людей с мозгами — нет.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, VladD2, Вы писали:
VD>Раз миллион, то не составит труда найти ссылку хоть на одно внятное объяснение?
Лень искать, если честно. Если тебе действительно интересно, пошукай тему с названием то ли "Nemerle vs все остальное", то ли "Nemerle vs весь мир". Смотреть сообщения мои, IB, Синклера.
Ну а насчет внятного — для тебя любое объяснение, отличное от Nemerle рулиззз, как показывает практика, будет невнятным, вредничанием и прочая. Ты уж извини, но другого у меня нет. Не все мыслят так же, как ты.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, D. Mon, Вы писали:
DM>Например, у меня есть несколько алгоритмов компенсации движения, отличающиеся лишь способом поиска похожего блока. Наследование позволило обойтись без дублирования кода, лишних if'ов и указателей на функции (которые, по сути, изоморфны VMT).
Здравствуйте, netch80, Вы писали:
N>Здравствуйте, VoidEx, Вы писали:
VE>>А сам вон сначала "программист должен уметь писать сортировку", а потом VE>>"Если он при этом учится и ошибка замечена вовремя — то почему бы и нет?"
N>Здесь нет противоречия.
Т.е. потолок есть у обоих (так как у первых он есть). И что же, вы с рождения знали сортировку? Или что, потолок сначала есть, а потом по изучении сортировки исчезает? Тогда в чём суть потолка, если он вроде есть, а на самом деле при достижении — отдаляется?
Здравствуйте, AndrewVK, Вы писали:
AVK>Здравствуйте, VladD2, Вы писали:
VD>>Раз миллион, то не составит труда найти ссылку хоть на одно внятное объяснение?
AVK>Лень искать, если честно. Если тебе действительно интересно, пошукай тему с названием то ли "Nemerle vs все остальное", то ли "Nemerle vs весь мир". Смотреть сообщения мои, IB, Синклера. AVK>Ну а насчет внятного — для тебя любое объяснение, отличное от Nemerle рулиззз, как показывает практика, будет невнятным, вредничанием и прочая. Ты уж извини, но другого у меня нет. Не все мыслят так же, как ты.
Ясно. Опять много слов и никакого дела. Другого и не ожидал, если честно.
ЗЫ
За других тоже не стоит говорить. Особенно за Синклера. Может быть мне конечно и показалось, но он в некоторый момент как-то резко переменил риторику.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, VladD2, Вы писали:
VD>Вопрос к головастому товарищу, много ли он на ваяет современных многоэтажных домов если ему дать один топор? VD>Как ни одного? А тогда к чему вся эта пышная демагогия?
Вопрос к другому головастому товарищу — сколько комплексов в Кижах ему удастся сделать с помощью крупнопанельных блоков ?
У меня нет Хаскеля, проверить не могу.
Пожалуйста, приведи данные по скорости работы алгоритма на Хаскеле и на С, если они есть. Обещано же (хоть и не вами обоими) — эффективнее
"Мы обслужим вас быстро, дешево и качественно. Выберите любые два из этих трех слов"
Здравствуйте, _DAle_, Вы писали:
_DA>Есть такие программисты вроде меня, которые просто не могут понять, ну как можно "не вспомнить", как реализовывать бинарный поиск. Ну это же простейший кирпичик, который многие дети придумывают сами в школе на уроках информатики.
Как можно не помнить письмо Татьяны! Как можно не суметь выпить двадцать кружек пива за вечер! И т.д.… Про Холмса читали?
... << RSDN@Home 1.2.0 alpha 4 rev. 1111>>
Help will always be given at Hogwarts to those who ask for it.
Здравствуйте, D. Mon, Вы писали:
DM>Здравствуйте, Pavel Dvorkin, Вы писали:
PD>>а вот эффективнее — дудки.
Уф, хоть один нормальный ответ
DM>Тут вопрос: эффективнее чем что? Чем идеально оптимизированная программа — действительно вряд ли. А чем обычная — легко.
Все зависит от того, что делаем. Если употребить неэффективный алгоритм, то, конечно, да, но язык тут ни при чем. Если неэффективно кодировать — тоже да (например, лишние ненужные действия). Если же обычная программа написана как следует (ты же не будешь утверждать, что обычняа == плохо написанная), то тут уже зависит от оптимизирующих возможносте компилятора.
DM>Чем выше уровнем конструкция, тем ближе она к смыслу операции, а не деталям реализации ("что?" вместо "как?"), и тем больше шансов, что хороший компилятор найдет более удачное решение.
Черт знает. Чем выше уровень, тем больше вероятность, что этот самый компилятор применит стандартное решение, которое как раз в этом случае лучше бы и не применять, может быть. Либо в нем должны быть зашиты эти самые "что" (это в конечном счете эквивалентно набору встроенных высокоэффективных решений). Но все "что" не встроишь, а вот оптимизировать детали можно всегда — на то они и детали, их немного.
Здравствуйте, Sinclair, Вы писали:
S>В итоге, если потратить достаточное время и усилия, то скорее всего получится та самая управляемая среда, jit, hot-spotting, query plan evaluation, и прочие техники, с успехом применяющиеся там, где некоторые упертые программисты до сих пор думают, что ассемблер лучше.
Я что-то одно не понял. Я вроде говорил, что сделать лучше, чем на ассемблере , да и то предельно оптимизировав, не получится, а не то, что ассемблер лучше. Разницу чувствуешь или объяснить ?
Конечно, проще спорить , если предварительно приписать оппоненту то, что хотелось бы от него слышать... Впрочем, этот твой стиль мне давно знаком.
Меж тем я уже не раз слышал от Синклера, что "язык ему очень нравится".
AVK>Просто предложил почитать его сообщения, бо с его точкой зрения в тех флеймах я в общем и целом согласен.
Я их читал. Потому и говорю.
VD>>Может быть мне конечно и показалось, но он в некоторый момент как-то резко переменил риторику.
AVK>Ну и кто из нас тут говорит за Синклера?
А я как раз за него и не говорю. Он сам за себя довольно не двусмысленно сказал.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Pavel Dvorkin, Вы писали:
IT>>>Вот здесь два примера того, как правильные высокоуровневые конструкции могут сделать код в разы проще, понятнее и эффективнее.
PD>Полностью абстрагируясь от эффективного вычисления процентов , отмечу лишь, что сделать код с помощью каких-то высокоуровненвых конструкций проще — можно, понятнее — тоже можно, а вот эффективнее — дудки. Потому что предельно эффективная программа — это наилучшим образом оптимизированная программа, написанная на ассемблере. А в этом самом ассемблере есть только презренные присваивания, if, с грехом пополам циклы, и ни одной лямбды
Дворкин, а что ты тогда делаешь в форуме по дотнету, да и здесь? Ты же должен писать софт на асме. И по сему, времени у тебя свободного остаться не должно. Вот у меня и возникает вопрос, ты просто: ты нас обманываешь или заказчиков?
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, VladD2, Вы писали:
VD>Дворкин, а что ты тогда делаешь в форуме по дотнету, да и здесь? Ты же должен писать софт на асме. И по сему, времени у тебя свободного остаться не должно. Вот у меня и возникает вопрос, ты просто: ты нас обманываешь или заказчиков?
Вообще-то на вопросы, заданные в таком тоне, лучше не отвечать, но так и быть, отвечу.
1. В форуме по дотнету я задаю вопросы, связанные с небольшой утилиткой, которую я написал. А мне на эти вопросы вместо ответов по существу дают советы, как правильно делать и учат уму-разуму.
2. На асме мне писать, возможно, придется. Очередная задача — есть некий код автора алгоритма, работает 5 сек, коммерческий софт на эту тему работает тоже примерно 5 сек, а заказчик хочет, чтобы уложилось в 200 мсек. Как ускорить быстродействие раза в 3-4 — понимаю, а вот в 20 — нет. Хотя предпочел бы обойтись без асма, но, возможно, придется. И не так уж это сложно, поверь.
3.И поскольку я это не понимаю пока, и заказчик тоже понимает, что я это за мгновение не сделаю, то мне надо думать, и заказчик меня не торопит. Думать надо, понимаешь ? Не оптимизировать вычисление процентов и не искать синтаксический сахар или аттическую соль, а думать, что с алгоритмом сделать. И думать я могу в самых разных местах, например, в маршрутке по дороге из дома/домой (почти час в один конец, увы). И я не знаю, сколько времени мне понадобится на то, чтобы что-то радикальное придумать. Был случай — две недели думал, ни одной строчки не написал, потом придумал и за пару дней реализовал.
Вот поэтому мне и забавно, когда серьезные вроде бы люди на полном серьезе обсуждают, как оптимизировать вычисление процентов или как контрол должен с родителем общаться. Мне бы ваши проблемы, господа.
4. А сегодня у меня университетский день был, между прочим. И писалось все это в основном в двухчасовом перерыве, а немного рано утром, пока студенты меня еще в оборот не взяли.
5. А обманывать тебя или других — в чем, собственно, этот обман мог бы заключаться ?
Надеюсь, я удовлетворил твое любопытство ?
А теперь позволь вопрос к тебе. Я не буду указывать, на чем ты должен писать софт, а вопрос такой — ты его вообще пишешь или только рассуждаешь здесь о преимуществах того или иного языка/среды/сахара/соли ? Дело в том, что у меня довольно давно сложилось устойчивое впечатление — те, кто очень любят обсуждать синтаксические конструкции и т.п. — люди, которые сами уже ничего серьезного не пишут.
Здравствуйте, AndrewVK, Вы писали:
PD>>Ну не знаю. Если уж распараллеливание императивного алгоритма вычисления процентов — дело безнадежное, то, наверное, все, приехали, надо забыть про все, что есть на свете.
AVK>Чего воду в ступе толочь? Реализуй описанный алгоритмв императивном стиле, и чтобы распараллеливался, вот мы и посмотрим.
Думаю, мы сейчас будет свидетелями очередного слива
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Он на P4 выполняется или нет ? Если да — берем ассемблерный код, который в конце концов получился хоть от Немерле, хоть от духа святого. Вот тебе эти самые if'ы и т.д.
Ну так возьми, давай. Не надо нас пугать своими магаалгоритмами, возьми этот простенький и распаралель. Можешь взять ассемблер, который получился от Немерле. Вперёд.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, Pzz, Вы писали: Pzz>Отвечу вопросом на вопрос , а какие вы считаете сводимыми?
Я — все.
Pzz>Угу. И настойчиво продолжают их сравнивать, когда не нужно. Но зато правильно, с учетом пунктуации
Сарказм уловлен, но не понят.
Pzz>Вы говорите ровно то же, что и я: люди, привыкшие изучать интерфейсы без понимания того, что "под капотом" у этих интерфейсов, оказываются в неудобном положении, когда интерфейсы меняются. Через несколько лет string.Compare() будет смотреться столь же ограниченным частным случаем, как сейчас смотрится интерфейс к строке в виде последовательности байт в кодировке ASCII.
Ну, на мой взгляд, всегда нужно смотреть как минимум на +-1 уровень. То есть когда пишешь страничку на ASP.NET, то нужно как минимум
а) знать, для чего эта страничка нужна (а не просто "положи сюда грид, а сюда кнопку в панели")
б) знать, во что превращается разметка, которую ты пишешь (а не просто "упа, я заменил = на # и оно заработало")
В целом, чем дальше по уровням от текущей задачи смотрит разработчик, тем лучше (только вот недавно был аналогичный флейм). То есть можно смотреть +-2 уровня, 3, и так далее.
Но ваши-то утверждения формулируются не в относительных терминах, а в абсолютных. Грубо говоря, та самая страничка находится на 12 уровне абстракции. Я предлагаю смотреть на 11 и 13й, а вы хотите — чтоб прямо от нулевого.
Вот я и говорю про старую гвардию, которая знает ровно два уровня абстракции: язык Си и ассемблер. И им невозможно рассказать даже про 5й уровень, тем более про 13й. Для них это пустой звук.
... << RSDN@Home 1.2.0 alpha rev. 677>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, geniepro, Вы писали:
G>В смысле? Оберон вполне себе ООП-язык, только ООП там немного низкоуровневый... G>Ну так ООПы разные бывают, друг на друга непохожие совсем...
Виртовский же это первый оберон, там вроде ООП практически и нет.
Здравствуйте, Sinclair, Вы писали:
S>Сосал почтовый сервер, весь из себя написанный на плюсах и работавший поверх файлухи. (а то! ведь СУБД — это тормоза, они не дают прямого управления IO).
CommuniGate, что ли? Его автор одно время сюда заходил, и расставлял пальцы до плеч. Или не сюда, а в ФИДО?..
S>У меня с реакцией на ассемблер всё в порядке. У меня невротическая реакция как раз на "теоретический предел эффективности", который устроен вовсе не так, как думает Павел. Но объяснить ему это нереально: шаблоны слишком прочны.
Вы пытаетесь доказать удивительные вещи: что программа, между которой и железом несколько слоев абстракции, может работать быстрее, чем программа, которая работает прямо на железе.
А почему бы эти слои абстракции не запустить поверх себя, и так далее до бесконечности, каждый раз увеличивая производительность
Если ослабить ваше утверждение до "плохо написанная программа на ассемблере может работать медленнее, чем хорошо написанная программа на C#", с таким утверждением несложно согласиться. Но только оно тривиально и верно для любой пары языков.
Здравствуйте, FR, Вы писали:
FR>Здравствуйте, netch80, Вы писали:
N>>Задача придолбаться?;)) Проще, понятнее — верю. Эффективнее — сомнительно. Реально, фильтрация на списках будет занимать дохрена копирований, рекурсия может переполнить стек при кривой реализации... в общем, эффективность такого должна быть не выше (а то и ниже) эффективности пузырька, который пишется не менее просто и понятно.:)) Или докажите обратное (желательно на практике;))
FR>Очень полезно дочитать тему перед тем как придплбливатся :)
Там нет сравнения с C или даже C++.
FR>Так что все мимо.
Здравствуйте, D. Mon, Вы писали:
VD>>Вот эти "если" — это все выдумки. На практике если для алгоритма требуется передавать более трех функций, то что-то не так в самой функции. Когда код исходно пишется в функциональном стиле, то функция пишется не как монолит с "настройками", а собирается из других более общих функций. При этом происходит нечто вроде IoC (разворот управления). Вместо того чтобы создавать функцию-монстра и потом передавать ей тонну детализирующих функций, нужная функция собирается из кусков. Примером тут может служить LINQ. В нем нет одной супер-функции типа Query, а есть несколько функций: Where, OrderBy, ThenBy, Join, Group, Select и т.п. Каждая из них принимает одну-две лямбды и возвращает некий обект-контекст к которому можно применять другие функции из приведённого списка.
DM>Понятно. То же замыкание, только создающееся в несколько шагов.
Понятно только одно — ничего тебе не понятно.
VD>>Ты бы попробовал на них по программировать, а потом бы уже вопросы задавал. А то тебе ведь ничего объяснить нельзя просто по определнию. Ты думаешь другими категориями.
DM>Хамишь. DM>Некоторый опыт ФП у меня есть, просто вдруг я что-то важное пропустил, что хорошо заменяет ООП, вот и решил спросить. Пока вижу, что не ничего не пропустил, ответы предсказуемые.
Если бы у тебя был реальный опыт, ты бы такого не городил. Можешь считать хамством все, что угодно — это ничего не изменит. Дело в тебе, точнее в твоих знания и опыте. Научись использовать то что пытаешся обсуждать, а потом поговорим еще раз.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Во-первых, поправлюсь: встраиваемая БД ВВ>Во-вторых, "неповторимость" януса ведь не из-за этого происходит.
А чем ты собираешься на этом зоопарке ОС просматривать помощь? У них даже нет общего оконного тулкита и браузера!
Но какой-нибудь браузер в том или ином виде есть везде.
ВВ>А так — берем например очень легкий и кроссплатформенный движок sqlite (http://sqlite.org), поддерживающий full-text search и выпускаемый под лицензией public domain... Продолжать?
SQLite НЕ поддерживает полнотекстовый поиск.
Для справки: полнотекстовый поиск это не линейный поиск по SQL LIKE, а поиск по специальному индексу. Таких систем не так уж много, кстати. Из качественных свободных, пожалуй, только Lucene и остаётся.
C>>Как ты из браузера планируешь его делать без спецплугинов или без внешней программы? ВВ>В эклипсе я справу запускал из самого эклипса — т.е. "внешняя" среда была. Да и справка сама по себе ведь не в мазиле какой-нибудь открывалась — т.е. была среда, которая автоматизировала браузер и пр.
Ну да, для Windows сделали особые красявости. В Линуксе их долгое время не было — прямо браузер запускался.
ВВ>На вопрос (см. выделенное) ты мне так и не ответил
Ответил. Я не понимаю чем тебе особо встраиваемая БД подойдёт. Из неё данные надо ещё и показывать.
Здравствуйте, Cyberax, Вы писали:
C>А чем ты собираешься на этом зоопарке ОС просматривать помощь? У них даже нет общего оконного тулкита и браузера! C>Но какой-нибудь браузер в том или ином виде есть везде.
На "каком-нибудь" браузере.
ВВ>>А так — берем например очень легкий и кроссплатформенный движок sqlite (http://sqlite.org), поддерживающий full-text search и выпускаемый под лицензией public domain... Продолжать? C>SQLite НЕ поддерживает полнотекстовый поиск.
Ты знаешь, я вот обычно не считаю a priori, что мой собеседник идиот. Может, тоже стоит взять на вооружение?
ВВ>>На вопрос (см. выделенное) ты мне так и не ответил C>Ответил. Я не понимаю чем тебе особо встраиваемая БД подойдёт. Из неё данные надо ещё и показывать.
На вопрос мне ответил WFraq. А ты, извини, устроил какой-то спор непонятный, хотя у меня не было целей что-то кому-то доказывать.
Здравствуйте, Lazy Cjow Rhrr, Вы писали:
LCR>Не понял. Ты предлагаешь локальные бинды обзывать my_favourite_name. Или что? Если так, то это контрпродуктивно.
Я предлагаю использовать примеры, которые ближе к реальности, и писать их так, чтобы они не напоминали птичью тропку на снегу. Обсуждаемый тут пример IT как раз такой.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Pzz, Вы писали:
Pzz>Это очень неоднозначное утверждение. Можно ли, например, понимать его так: "разница в эффективности скомпилированного кода при включенной и выключенной оптимизации гораздо заметнее у декларативной программы, чем императивной. И она тем больше, чем ниже уровень императивной программы. В частности, для программ, написаных на ассемблере, эта разница практически не заметна"?
Не совсем, но уже ближе к истине.
А дальше начинаются вопросы практической применимости. Если ты писал свой алгоритм на ассемблере, а через полгода тебе заказчик сказал "опа, вышел новый процессор от Интел, мы будем гонять это на нём", то тебе останется только рвать растительность на различных частях тела. Вон неподалеку, Павел Дворкин в качестве аргумента в защиту ассемблера приводит
Напиши аналогичное со свои любимым AsParallel, только не вертикальными полосами, а прямоугольно-гнездовыми кусками. Мне, как понимаешь, это на пять минут работы — массив columnSum превратить в двумерный, а в CHUNK вместо nHeight ввести yStart, yEnd.
Я бы посмотрел на этого рыцаря меча и орала, если бы код был на ассемблере. Превратить массив в двумерный, и ввести вместо nHeight yStart и yEnd. А потом то же самое по диагонали.
В итоге, у тебя очень хорошие шансы получить в итоге программу на ассемблере, которая уже не является оптимальной. Не потому, что ты ее плохо написал, а потому, что условия изменились. Твоя программа — бесполезна, ее надо оптимизировать заново. Развернутые циклы сворачивать, заинлайненный код выносить обратно, чтобы сократить длину цикла, менять выравнивание данных под новый размер линейки кэша.
Хуже того: есть задачи, в которых заранее неизвестны условия исполнения. Максимум, что может себе позволить классическая ассемблерная программа — это сделать условный либо косвенный вызов в зависимости от некоего условия. Например, в зависимости от количества доступных ядер вызвать разные версии подпрограмм для расчета.
Современные процессоры даже постараются предсказать результат ветвления. Тем не менее, эта оптимизация никогда не порвет по производительности код, в котором уже заинлайнена версия, оптимальная для текущей ситуации.
Динамический инлайнинг в классическом ассемблере делать нельзя. Для того, чтобы он был возможен, нужен не целевой код, а специальным образом подготовленный. Что мы получаем? Правильно, получаем JIT (если это во время исполнения) или LTCG (если во время линковки).
Ну так это же как раз тот самый уровень абстракции, который мы полагали лишним! Парадокс? Или закономерность?
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, geniepro, Вы писали:
FR>>Ну тогда и в Си есть ООП G>В этом случае понятие ООП уж слишком сильно размывается...
А не надо пытаться определять ООП через язык программирования.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Sinclair, Вы писали:
S>Здравствуйте, Pavel Dvorkin, Вы писали:
S>>>Ну прикол-то в том, что если программа сформулирована в терминах mov, add, jmp и т.д, то простор для ее оптимизации крайне мал. PD>>Ты когда-нибудь видел задачу, которая могла бы быть сформулирована в терминах mov, add, jmp и т.д ? Я таких задач в предметной области не встречал, разумееется, драйверы и прочие средства доступа к железу не в счет.
PD>>На тебе банальную задачу умножения матриц и сформулируй ее в терминах mov, add, jmp и т.д. Подчеркиваю, сформулируй, а не напиши програму. А мы посмотрим, что из этого вышло S>Повторяю специально для альтернативно одаренных: речь о том, в каких абстракциях сформулирована программа. А не исходную задачу.
А не может ли уважаемый сэр, хоть и допускающий невежливые высказывания (чтобы не сказать больше) пояснить, как это можно сформулировать хотя бы программу на уровне абстракций типа mov — jmp. Мне это все же кажется странным. Написать ее с применением mov, jmp — или if, for — это понятно, а вот сформулировать в абстракциях хоть тех, хоть других — нет. Формулируют обычно в абстракциях структур данных и алгоритмов, а уж потом кодируют с помощью mov или for. Это курсе так на 1-2 объясняют вообще-то.
S>Да, Павел, всё именно так плохо. Процессор пытается выжать максимум именно из add, mov и так далее. Тебе вообще знакома хотя бы поверхностно архитектура современных процессоров?
И даже очень неплохо.
>Термин "предсказание переходов" тебе что-нибудь говорит?
Примерно так лет 10 назад с ним ознакомился. При появлении Pentium
>Это как раз и есть попытка изменить стратегию исполнения ассемблерного кода так, чтобы увеличить throughput.Потому что формально любое ветвление обязано приводить к простою конвеера: на ассемблере ясно написано "пока не сравнишь содержимое EAX с EBX, непонятно куда переходить".
Батенька, не морочь людям голову и не путай божий дар с яичницей. Предсказание переходов, конвейер и внутренние регистры — это одно, а время выполнения команды add, взятой самой по себе, от конвейера и предсказания переходов не зависит. А ты обещал выжать что-то из самой add
S>Далее, я тебе открою страшную тайну: реально никаких EAX и EBX в процессоре нету.Есть внутренние регистры, и маппинг "внешних" регистров на внутреннние определяется только в момент исполнения программы. Более того, процессор переупорядочивает команды для обеспечения лучшей производительности. Добро пожаловать в реальный мир, Павел.
Очень сильно похоже на ребенка, который узнал, откуда дети берутся и спешит сообщить своим друзьям по песочнице эту страшную тайну. Поверь, эта тайна — тайна только для тебя, всем остальным она давным-давно известна. В общем, почитай приличное руководство по архитектуре процессора, там есть и другие тайны, о которых можешь тоже всех оповестить
S>Все эти трюки призваны исправить глупости, допущенные программистом ассемблера. Потому, что если бы он был умным, то он бы сам переупорядочил командны так, чтобы обеспечить максимальную микропараллельность. Вот только возможности процессора в этом ограничены.
Ну и ну! Не вдаваясь в суть этого утверждения ( а оно совсем не верно, но объяснять почему просто нет времени), могу лишь сделать вывод — программист на асме глупый, а вот компилятор — умный, он видимо, такое делать не будет. Остается лишь ответить на вопрос, умные ли те, кто писал этот компилятор.
А если серьезнее — почитай про penalty, про конвейеры, про рекомендации Intel, какие команды следует и в каком порядке выполнять, чтобы добиться наилучшего распараллеливания. VTune, наконец, загрузи и запусти, пусть она твою программу оценит. Может, перестанешь после этого нести ахинею насчет априорно глупых программистов на ассемблере.
>>> но у них есть существенные ограничения как по ресурсам, которые можно на это потратить, так и по возможным действиям, которые они могут выполнить. PD>>Это у процессоров ограничения по действиям, которые они могут выполнить ? Ну , кажется, приехали. У процессоров , значит, ограничения, а вот если на этих процессорах исполнять управляемый код со всеми наворотами, то эти ограничения куда-то исчезают и открываются у процессоров дополнительные возможности, так , что ли ? Ну и ну! S>Совершенно верно. Для человека, который декларирует стремление к оптимальности, ты последовательно демонстрируешь потрясающую некомпетентность в вопросах оптимизации. На любом, причем, уровне. Поясняю еще раз: у процессора очень маленькое "окно просмотра кода", внутри которого он пытается понять намерения программиста, и обеспечить их выполнение с наилучшей производительностью. У него очень мало прав по внесению изменений в код, т.к. ему неясна семантика.
В огороде бузина, а в Киеве дядька. Никто от процессора и не требует, чтобы он вдруг начал изображать собой твой любимый JIT и пытаться что-то понять. Не его это задача, а задача программиста на ассемблере — писать программу так, чтобы учесть специфику выполнения команд процессором. И не только процессором, кстати, а еще и продумать, как доступ к ОП лучше организовать, чтобы не было проблем с кэшем и т.п.
S>Вот простейший пример: ты пишешь код, вычисляющий сумму целых чисел в массиве. По какой-то причине на каждой итерации цикла ты выполняешь запись в определенную ячейку памяти. S>Процессору совершенно непонятно, зачем ты это делаешь. То ли ты просто забыл, что можно использовать регистр, то ли есть другой поток, который наблюдает за этой ячейкой. В итоге, процессор честно выполняет обращение к памяти.
А по какой, собственно , причине ты это делаешь (я это не делаю без надобности и про регисты не забываю — про все.). Причин две — либо твое неумение писать на ассемблере как следует, либо volatile. Второе вполне разумно, хотя и странно при сумировании, а если первое — иди учись.
S>Если та же программа написана в терминах языка высокого уровня, типа того же С++, то по ней можно гораздо лучше понять, что именно происходит.
Вот это верно.
S>В частности, например, компилятор может выбрать хранение промежуточных результатов в регистре, потому что это эффективнее.
И грамотный программист тоже. В общем, изобрел ты себе некий образ неграмотного программиста, не умеющего писать как следует на ассемблере и успешно с ним расправился. Бога ради, но какое это отношение к делу имеет ?
S>Далее, если процессор видит вызов в ассемблерном коде, он попытается предсказать переход и накормить конвейер. Но он не может выполнить инлайнинг кода, потому что у него нет такого права. А инлайнинг позволяет массу других оптимизаций. Тебе понятно, что сам по себе инлайнинг требует размеченного кода? Мы вроде уже обсуждали LTCG. Жаль, что ты ничего из этого не запомнил.
Устал я уже отвечать. Резюме твои высказываниям — компилятор умнее человека. Компилятор может такой код соорудить, что человек его соорудить не может. Остается только одно понять — кто же этот компилятор написал — сверхчеловеки ?
А то, что компилятор может сделать код лучше, чем средний программист на ассемблере — вполне мб и верно. Но я-то говорил про идеально написанную программу на ассемблере как некий теоретический предел, как теорему о существовании. А ты это понять не хочешь, а вместо это рассказываешь мне банальные истины под видом страшной тайны для маленьких детей.
S>>>Более того, во многих задачах невозможно заранее предложить оптимальное решение в терминах mov, add, jmp и т.д.
Все ясно. Человек не может, а вот компилятор может. Приехали.
PD>>И зря ты пытаешься доказать, что я это утверждаю. Я лишь одно утверждал — есть некий теоретический предел, им является идеально написанная программа на ассемблере. На любом языке с любыми средствами лучше сделать нельзя. При этом я вовсе не утверждаю, что знаю, как такую программу написать. Это лишь теорема о существовании. Но теорема верная. И из нее вовсе не следует, что программы надо писать на ассемблере. S>Эта теорема неверна. Попробуй ее доказать
Подумаю, сейчас нет времени.
>>>Просто потому, что еще нет информации о том, в каких условиях будет алгоритм выполняться.
PD>>Если он на нетипичном процессоре или на иной архитектуре может выполняться — я со скрипом, но соглашусь. Потому что не знаю. что там хорошо, а что плохо. (В скобках : если буду знать — не соглашусь)
PD>>Если же речь идет об обычной архитектуре, то не соглашусь. Windows NT-Vista, как тебе известно должно быть, написана так, что кроме HAL, все остальное от архитектуры не зависит. И работает она на x86, x64, а до этого были Alpha, MIPS, Power PC. S>И почему ты думаешь, что Windows NT — это теоретический предел быстродействия???
>>>Потому, что, к примеру, параллелить на 1 ядре — это гарантированная потеря производительности.
А вот на этот пункт я тебе вчера неверно ответил. Исправляюсь.
Параллелить на одном ядре — это совершенно обычная практика, существующая уже лет так 30-40. Тебе , видимо, просто неизвестны такие понятия как состояния потоков, переходы между этим состояниями, ожидание и т.д. И имея 10 потоков, каждый из которых по своему характеру может работать 10% времени, а 90% должен ожидать, скажем, завершения операции ввода-вывода, можно получить десятикратное (в пределе) ускорение работы при одном ядре. Это все азбучные истины, и их изучают на средних курсах института. Я студентам об этом в спецкурсе рассказываю. Приезжай, послушаешь
Да больше скажу — ты ведь своим высказыванием просто похоронил всю вычислительную технику, начиная с 60-х-70-х годов. Все мультпрограммирование похоронил — оно начиналось, когда о нескольких процессорах и речи не было. Windows похоронил — она внутри себя асинхронна и распараллелена. Зачем ей потоки, если при одном ядре параллелить — это гарантированная потеря производительности ?
Ты уж хоть думай следующий раз, прежде чем такое писать. И почитай хотя бы тут в форумах, это много раз обсуждалось в самых разных аспектах. А то решили — AsParallel и ура, пусть умный компилятор все остальное за нас сделает
S>Павел, это даже смешно. Во-первых, твоя программа тупо делает два прохода: один в последовательном режиме, второй в параллельном.
Ты хоть посмотри на нее как следует и почитай что я написал. Там есть тест без распараллеливания (для сравнения времени только) и тест, когда каждый поток берет себе 1/N работы, гдк N- число процессоров. И в обоих случаях один проход — по всем столбцам окна. Только в параллельном тесте это проход разделен на N частей.
S>Давай ты приведешь ту программу, которая просто старается сделать один проход, но как можно быстрее.
Что быстрее ? Пиксели с окна считывать ?
>В том числе и в зависимости от количества процессоров.
Ну и бери ее. Выкинь кусок без распараллеливаняи и бери второй.
>И мы сразу убедимся, что теоретического предела она не достигает.
Ну и аргументы!. Сначала IT меня подначил, требуя от меня доказать, что я умею писать распараллеливание. А теперь от меня требуют, чтобы этот простенький тест, написанный за 20 минут, выдал прямо-таки теоретический предел. Да еще с GetPixel внутри цикла . И подай мне эту программу, и мы все убедимся, что твоя программа не достигает теоретического предела .
Как, кстати, ты этот предел вычислять собираешься, если не секрет Я готов попробовать доказать теорему о его существовании, а ты готов , видимо, дать прямо-таки методику его вычислкния ? . Давай сюда ее, обсудим
S>Во-вторых, Павел, ты же против лишнего уровня абстракции, так? Давай-ка, приведи код сразу на ассемблере; посмотрим, насколько он порвет высокоабстрактные плюсы.
Это точно! Правильное замечание, с примесью демагогии, конечно, но правильное. Еще надо будет Windows выкинуть, вернуться к MS-DOS, напрямую читать из видеопамяти (думаю, не забыл еще , запретить все прерывания, оптимизировать донельзя код — вот тогда мы и получим этот самый теоретический предел
Забавно с вами спорить, господа (и не с тобой одним). Из кожи лезете вон, готовы всякую чепуху писать, противника в незнании элементарных вещей обвинять, передергивать, демагогией заниматься и т.д. — и все лишь ради одного — доказать, что мой Спартак — это круто, а ваше Динамо никуда не годится. А когда вам говорят — да, есть в Спартаке хорошие игроки, но в Динамо тоже есть — получаем в ответ — Спартак рулез, Динамо маст дай.
Здравствуйте, IT, Вы писали:
IT>Здравствуйте, Pavel Dvorkin, Вы писали:
PD>>Ну вот что, уважаемый IT. Давать мне задания и требовать их выполнения у тебя права нет. Я сделал то, что нашел нужным. Принципиально это мало чем отличается от того, что ты хочешь. У меня реальная работа есть, и ты ее за меня делать не будешь.
IT>Слив защитан. Другого я и не ожидал. Трындеть, оно понятно, не мешки таскать.
Естественно, демагогией заниматься легче, чем ответить. Никакой принципиальной разницы в том, чтобы читать писксели и суммировать их в массиве или читать значения из коллекции и вычислять проценты, нет, и ты это сам прекрасно понимаешь. Не согласен — объясни, в чем разница — только принципиальная, а не по мелочам.
PD>>Ты уж прямо на себя функции верховного арбитра взял. Ты мол, сделай, а мы тут посмотрим и решим. Не слишком ли много на себя берешь ?
IT>Не много. Ты влез в это обсуждение со своим несогласным с другими мнением. Всё, что я прощу — это свои слова подкрепить делом. Приведённый мной код был написан за 20 минут для разъяснения моей позиции. Если я имею позиции и мнение, то я её стараюсь разъяснить и наглядно продемонстрировать. Тебе предлагается всего лишь сделать тоже самое — разъясниь и прдемонстрировать.
Я предложил свой код и продемонстрировал. Это мое право — предложить код, который я хочу для демонстрации. А вот права требовать, чтобы я делал то, что тебе хочется, у тебя нет. Можешь от своих подчиненных требовать, если они у тебя есть.
>Вместо этого ты приводишь какой-то левый код, задаёшь какие-то вопросы и ссылаешься на занятость.
Ну насчет того, чей код левый, а чей правый — опустим.
>Думаешь это сильно доказывает твою правоту? Сначала приведи распараллеливание приведённого алгоритма, в нём нет ничего сложного (он, кстати, не только выражен в коде, но ещё и доступно описан на словах). Затем мы сравним его с двумя первыми реализациями, выявим достоинства и недостатки всех подходов. Ну, а потом, если у нас останутся непрояснённые моменты, мы попробуем ответить на твои вопросы.
Ну надо же! Почти как господь бог — мы решим, правы вы или нет. А не допускаешь, что кто-то может и о вас такое же решить ?
PD>>А ответов на мои вопросы нет.
IT>Воспитанные люди не отвечают вопросами на вопросы.
Воспитанные люди не требуют от других, чтобы они писали программы по заказанному ими алгоритму. В лучшем случае просят, а получив отказ — принимают его как должное.
PD>>Ну хоть, если нет времени, напиши на словах, как будешь делать. Ну хоть не на все 5, хоть на 2-3 из них
IT>Ты проценты распараллелил? Нет? Ну так иди параллель. До тех пор разговор окончен и своё особое мнение может написать на заборе. Или нашкрябать не сиденье в маршрутке.
Да уж. Не помню, кто сказал — когда аргументов иных нет, остается только ругаться. Впрочем, если это очередная провокация — то не жди от меня неадекватной реакции. Я всегда остаюсь политкорретен, даже если приходится отвечать на такие вот "аргументы".
Ладно. Остальное не к тебе, а просто для сведения читающих. Поскольку ответа на мои вопросы нет, скажу сам.
Те пять вопросов, которые я задал, выбраны не случайно. Я вовсе не утверждаю, что в рамках .Net или LINQ на все из них нет ответов. На некоторые ИМХО нет, но я вовсе не специалист в LINQ, чтобы это утверждать точно. Их особенность в том, что нужно выполнить некоторое действие, которое требует не крупноблочного строительства, а тонкой настройки. Выбрать по строкам — хорошо, по столбцам — тоже (там пример есть, ссылку я выше по треду приводил), а вот квадратно-гнездовым — там же и объясняется, что параллелить по двум измерениям нельзя. Почти наверняка это можно как-то обойти, но это будет уже не так уж просто и совсем не очевидно. То же касается и диагоналей. И т.д. Вот и все. Пока стандартные действия — легко, просто и понятно, может быть, даже и эффективно (зависит от того, что там под спудом в этом AsParallel делается), а как только надо что-то нестандартное сделать — увы...
Здравствуйте, Cyberax, Вы писали: C>Если у тебя туча файлов — такой трюк не проходит. Ну а если у тебя один большой файл — то проще, действительно, взять БД и не мучаться.
Так ведь это ж не индексер контента — это почтовый сервер. Никого не интересует, что у него унутре — куча файлов, одно хранилище, или несколько.
S>>Увы, мы ничего не знаем про то, какая была CУБД, какие были блобы, и каким кодом ты отдавал их по HTTP. C>PostgreSQL и Oracle. Код был самый тупой — проверяем права пользователя (один простой SQL-запрос), делаем запрос в хранилище по ID файла, получаем blob и отдаём по HTTP. Тупее некуда. Логи лайти смотрели? Сколько он отдает 304 Not Modified?
C>На самом деле, это весьма важный пункт. В Линуксе я реально могу использовать файловые системы с сотнями тысяч файлов в каталоге, и оно будет приемлимо работать. На Windows такое решение не будет работать вообще — сдохнет просто на простейших операциях, как ты ни бейся головой об стену. Это просто ещё одна разница между разными ОС.
Еще раз повторяю для тех, кто не читает: речь не идет про сравнение винды и линукса. Хочешь поговорить об этом — иди в КСВ и бейся там до упаду. Мы сравниваем "рукопашную" реализацию с "высокоабстрактной".
C>Кстати, тот же лайти элементарно прикрутился к файловой системе — там внутри всего стека сейчас получается поный zero-copy для данных. Ядро прямо из буффера файловой системы в сеть пакеты пихает. Стомегабитная сеть в результате засвечивается почти без видимой нагрузки на CPU. Это позволило на эти ноды воткнуть ещё и другую логику.
Ну, это не совсем то, что доктор прописал. К примеру, gzip компрессию так применить не получится а это может увеличить скорость отдачи (естественно, при использовании кэширования с zero-copy) еще серъезнее, чем просто zero-copy.
C>Такое сделать с БД — просто не получится. Если не организовать, конечно, файловый кэш для полученных из БД данных.
Смотря какая БД. Вон, команда SQL Server обещает получить производительность линейного чтения blob из БД сравнимой с голой файлухой. А это означает, что буфера db-client можно отдавать прямо в сокет, и результаты будут удивительными
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Lazy Cjow Rhrr, Вы писали:
LCR>А вот про матричную алгебру — это пожалуйста:
<местами skipped>
LCR>Скалярное умножение вектора-строки на вектор-столбец: LCR>Сложение матриц: LCR>Представьте себе, и это всё, да. В последний раз, когда я видел решение СЛАУ (моё) оно было минимум 5 экранов — и for-ы, for-ы, много for-ов... Выбор несколько других примитивов позволяет, даже в такой "цыкло-насыщенной" задаче, избежать явного применения оператора цикла. Казалось бы, согласно маэстро Дейкстре, основополагающего примитива.
Лет так 30 назад была такая система программирования Альфа, сделана была в Новосибирске Ершовым, поттосиным и др. На базе языка Алгол, но с расширениями. Так вот, там сложение матриц делалось еще проще
real array a[1:n][1:m],b[1:n][1:m], c[1:n][1:m];
// инициализация
c := a + b;
Проще некуда. И это во времена, когда ни о каком функциональном программировании и речи не было.
Но за эту простоту заплачено. В данном случае — куском компилятора, который разобрался, что эти массивы одинакового размера и создал код, который реализует это двойной цикл. В вашем примере — средствами иной системы. А в конечном счете их будет реализовать процессор P4, которому до матриц столько же дела, сколько мне до китайского языка .
Так что весь вопрос в цене этой платы — это раз, и в том, насколько хорошо это сделано — это два. Второе ИМХО выглядит так — если речь идет о чем-то стандартном, это может быть сделано очень хорошо, потому что писали реализацию грамотные люди. Но все стандартные задачи не переберешь, а когда что-то нестандартное потребуется, то будет уже и сложнее, и менее понятно, и менее эффективно. Это, кстати, хорошо демонстрируют приведенные примеры. По строкам и по столбцам (сложения, умножения) — очень ясно и просто, а что касается решения СЛАУ — не намного короче кода на С++. Не понял, кстати, для чего требуется 5 экранов для СЛАУ — ИМХО инвертирование матрицы по Гауссу-Жордану занимает строк 30-40. Не без циклов, правда. Но они и здесь есть — так же, как и в том примере сложения матриц, с которого я начал.
Здравствуйте, Sinclair, Вы писали:
S>А дальше начинаются вопросы практической применимости. Если ты писал свой алгоритм на ассемблере, а через полгода тебе заказчик сказал "опа, вышел новый процессор от Интел, мы будем гонять это на нём", то тебе останется только рвать растительность на различных частях тела.
Возьметесь ли вы утверждать, что чисто вычислительный код, например, криптографика или обработка изображений, могут выигрывать или хотя бы быть сравнимы с кодом, оптимизированным вручную с помощью более низкоуровнего инструмента?
А на невычислительных задачах это выжимание последнего такта никому нафиг не нужно. Все равно ждать придется окончания дисковой операции или приема/отправки пакета в сеть.
И не забывайте еще одно. Вот выйдет новый процессор Интел, а мелкософт скажет, что ему не интересно. И не будет его специальным образом поддерживать. Дворкин-то выматерится и руками все соптимизирует. А вы куда пойдете?
S>Я бы посмотрел на этого рыцаря меча и орала, если бы код был на ассемблере. Превратить массив в двумерный, и ввести вместо nHeight yStart и yEnd. А потом то же самое по диагонали.
А причем здесь? Павел не защищает ассемблер, а опровергает ваш тезис об однозначных преимуществах автоматической оптимизации перед ручной.
S>В итоге, у тебя очень хорошие шансы получить в итоге программу на ассемблере, которая уже не является оптимальной. Не потому, что ты ее плохо написал, а потому, что условия изменились. Твоя программа — бесполезна, ее надо оптимизировать заново. Развернутые циклы сворачивать, заинлайненный код выносить обратно, чтобы сократить длину цикла, менять выравнивание данных под новый размер линейки кэша.
Обычно нужна не программа, которая выжимает 100% из процессора, а программа, которая на разумном имеющемся железе успевает.
Если на новом процессоре ваша программа выжимает не 100% CPU, а лишь 30, но сам CPU в 4 раза быстрее старого, то задачу вы по-прежнему решили: ваша программа успевает и на старом, и на новом процессоре.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Проще некуда. И это во времена, когда ни о каком функциональном программировании и речи не было.
Ну чисто для справки: функциональное программирование придумано раньше Алгола. ЛИСП называется. Говорят, были очень хорошие оптимизирующие компиляторы лиспа, хотя в обычной реализации как правило ограничивались интерпретатором.
Здравствуйте, Andrei F., Вы писали:
AF>Допустим, у нас есть некоторый GUI с деревом. Развесистым таким деревом, на 10^n элементов. И пользователь где-то в глубине иерархии поменял название одного элемента. Как это будет выглядеть в рамках ФП?
Допустим, у нас есть некоторый компилятор с деревом (AST). Развесистым таким деревом, на 10^n элементов. И в процессе компиляции где-то в глубине иерархии поменяли тип одного элемента. Как это будет выглядеть в рамках ФП?
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Pzz, Вы писали:
Pzz>А если так: для любой программы на языке высокого уровня существует эквиавалентная программа на ассемблере, которая работает не хуже?
Существует где? В воображении? Тогда запросто.
Бессмысленно выводить абстрактные теоремы, когда речь идет о практическом программировании.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Andrei F., Вы писали:
AF>Ты это у меня спрашиваешь?
Как так, специалист по Немерле, и не знает, как тамошний компилятор устроен? ЕМНИП там есть функциональное RB-tree, неплохо работающее в том числе и в таких сценариях. Опять же — если не страдать пуризмом, то можно использовать классы с изменяемым состоянием, если они хорошо оттестированы, и демонстрируют эту изменяемость в крайне ограниченных пределах.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>А может, проще — для любой программы на языке ВУ существует эквивалентная программа на ассемблере, которая работает так же. Потому что программа на языке ВУ не работает вообще, а работает в конечном счете ассемблерный (машинный) код, порожденный из нее с помощью компиляторов. линкеров и прочих JIT'ов. Вот и возьмем эту эквивалентную программу в машинных кодах.
В какой момент времени? Она может меняться в процессе выполнения, оптимизироваться с учётом каких-то параметров, зависящих, в частности, от входных данных. Спекулятивный инлайнинг к примеру.
Здравствуйте, IB, Вы писали:
Pzz>>Если бы это было никому не нужно, зачем бы в линухе это стали делать? IB>Писать в обход кеша? нужно, только непонятно какое это имеет отношение к обсуждаемому вопросу.
В качестве дидактического примера. Сколько раз вы еще зададите этот вопрос?
Pzz>>Так же непонятно, с чего речь шла только о венде. IB>"поверх MS SQL"
Мы давно уже отошли от обсуждения, почему одна реализация почтового сервера медленнее другой. Обсуждение MS SQL осталось уже позади, забудьте.
Pzz>>Вы мне рассказываете, что есть такой слоистый мир, в котором программа на каждом уровне пользуется предыдущим слоем, а что ниже ее не касается. IB>Нет. Я рассказываю, что есть разные уровни абстракции, и более высокий уровень абстракции в состоянии дать более эффективный результат, чем более низкий. А уж пользуются ли более высокие уровни, нижележащими реализациями, или не пользуются — малосущественные подробности.
Программа, написанная с использованием более высокоуровнего API может работать эффективнее, чем программа, написанная с использованием более низкоуровнего API. Это как-бы очевидное утверждение. А может и менее эффективно — смотря как написана
То, что использование более высокоуровнего API всегда и по волшебству дает более эффективный результат — это неверное утверждение. Я вам привел опровергающий пример.
Pzz>>Я вам привел пример программы, которая живет не так, как принято в рамках этого вашего слоистого мира. IB>Нет не привел. Не смотря на то, что промышленные СУБД действительно оборудованы возможностю работать с голым диском в обход FS, процент практического использования такого сценария стремится к нулю. Более того, в конкретной обсуждаемой задаче MSSQL работал поверх FS, пользуясь ее публичным API.
А я говорю, что привел. Что дальше делать будем?
Pzz>>На что смотреть, простите? IB>На то что архитектурные особенности сиквела не имеют никакого отношения к обсуждаемому вопросу.
Почему? Мы говорим о философии программирования. Почему бы не говорить об этом на примере SQL-сервера?
Pzz>>Шансов восстановить, хотя бы частично, сломанную ФС значительно больше, чем восстановить аналогично поломаную БД. IB>Это заблуждение. БД гораздо более устойчива чем FS и возможности по повышению устойчивости БД тоже существенно больше.
Еще одно волшебство.
То у вас высокоуровневые конструкции работают быстрее, чем то сочетание низкоуровневых конструкций, на которые они раскладываются. Теперь вот БД, живущая в файле, оказывается более живучей, чем сам файл.
Наверное, в случае смерти файловой системы жившая на нем БД становится ангелом, который потом вселяется в файл назад, после его починки
Pzz>>Уже потому, что у ФС структура значительно проще. IB>Ну и что?
Здравствуйте, Pzz, Вы писали:
Pzz>Мы давно уже отошли от обсуждения, почему одна реализация почтового сервера медленнее другой. Обсуждение MS SQL осталось уже позади, забудьте.
Мне кажется, это только ты постоянно пытаешься соскочить с темы. А вот твои собеседники все таки говорят все о том же.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, AndrewVK, Вы писали:
AVK>Мне кажется, это только ты постоянно пытаешься соскочить с темы. А вот твои собеседники все таки говорят все о том же.
А вам не кажется, что если все участники будут продолжать говорить о том же, то мы вряд ли далеко продвинемся в нашем разговоре относительно начальных позиций?
Я не пытаюсь соскочить с темы, я пытаюсь развить тему.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Здравствуйте, Pzz, Вы писали:
Pzz>>А если так: для любой программы на языке высокого уровня существует эквиавалентная программа на ассемблере, которая работает не хуже?
PD>А может, проще — для любой программы на языке ВУ существует эквивалентная программа на ассемблере, которая работает так же. Потому что программа на языке ВУ не работает вообще, а работает в конечном счете ассемблерный (машинный) код, порожденный из нее с помощью компиляторов. линкеров и прочих JIT'ов. Вот и возьмем эту эквивалентную программу в машинных кодах. Теперь одно из двух — либо ее нельзя улучшить (когда она уже в кодах), либо можно. Если верно первое — это значит, что компилятор и прочие создали такой код, который является идеальным, его же нельзя улучшить, так ? Из этого утверждения логически следует, что разрабатывать новые версии компилятора по крайней мере для этого процессора незачем, так как существующий компилятор уже создает идеальную программу. Если второе — доказано как минимум то, что существует программа, лучшая, чем создает компилятор. Это не помешает, конечно, улучшить компилятор, но после этого мы опять вернемся к исходной позиции. Вот и все доказательство теоремы.
Как написал IT это утверждение частично верно для одного наперед взятого компьютера/окружения.
Более того вы не учли что оптимальность машинного кода может зависить не только от программы, но и от входных данных. Яркий пример этому генерация сборок в ORMах для маппинга.
Здравствуйте, IB, Вы писали:
Pzz>> В том, что мейлер, хорошо написаный на C# работает быстрее, чем мейлер, плохо написаный на C++. Ок. Работает. Быстрее. И чо? IB>Нет. В том что мейлер написанный с применением высокоуровневых абстракций работает быстрее, чем написанный в рукопашную с применением хардкорных оптимизаций.
Ну я и говорю, хорошо написаный работает лучше, чем плого написаный, не важно, на чем написан.
Pzz>>А что именно вы утверждаете? IB>1. Что пример Антона опровергает тезис Павла о неприменимости высокоуровневых абстракций при решении практических задач.
Я что-то не припомню, чтобы Павел такое утверждал.
Вы тут граждане хором пытаетесь отстоять ту точки зрения, что низкоуровневые абстракции не применимы при решении практических задач. Вот с этой точкой зрения мы спорим. Ну во всяком случае, я
Если же вы ослабите свою позицию до применимости высокоуровневых абстракций при решении практических задач, то тут и спорить по-моему не о чем.
Здравствуйте, Pzz, Вы писали: Pzz>Какая разница, о разработчиках чего идет речь? Факт в том, что SQL реализует весьма высокоуровневую штуку, а пользоваться при реализации приходится уровнем абстракции даже более низким, чем то, с чем имеют дело обычные программы: не файлами, а блоками на диске.
Еще раз повторяю: ни с какими блоками на диске никто не возится. Сиквел использует ровно те же примитивы файловой системы, что и обычная прикладная программа.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Ну каждый дает описание исходя из своего понимания того, как это дают. Если бы я это в форуме по Win32 написал — уверен, меня бы с полуслова поняли бы.
Проблема в аудитории, то есть? Понятно.
>>О чем вообще речь? Сравни свое "описание" с описанием IT. Ну хотя бы по объему. А с таким описанием я тебе могу дать точно такой же ответ: AVK>>
PD>Нет, не пойдет этот аргумент. Пусть даже ты прав, и можно было уточнить. Но текст программы приведен, и в нем (по крайней мере в непаралельной части) разберется любой мой студент за 1 минуту, даже если я вообще никакого описания не дам.
Логично, на то он и пример.
PD> несерьезно это.
Несерьезно, это не понимать, что читаемость кода и его близость к формулировке задачи — это самый важный параметр оценки качества этого самого кода. Конечно, на таком игрушечном кусочке вроде как можно и пережить то, что ты продемонстрировал, но когда кусочки станут побольше, соотношение объема изапутанности сохранится, если не увеличится, и вот тут то это будет совсем уже не фигня.
PD> Ну а потом — я же дал тебе после этого более развернутое описание задачи, зачем опять муссировать это ?
Ну а я — более подробное решение. В чем проблема то?
AVK>>Из комментариев еще можно понять, что у тебя там вроде бы есть еще и непараллельный алгоритм, но AsParallel реально параллелит только если есть несколько ядер. Впрочем, явно указать тоже не проблема:
PD>Если ты не очень понимаешь Win32, это еще не причина, чтобы жаловаться.
Вот, кстати, характерная твоя ошибка — говорим о дизайне кода, а ты даже не в состоянии привести пример без использования специфики Win32. Все я прекрасно понимаю, но разбираться в этом принципиально не хочу, потому что к обсуждаемому вопросу это отношения не имеет.
PD> Я не лучше тебя знаю LinQ
Ты вообще понимаешь разницу между конструкциями языка и API операционной системы? Мы здесь, еще раз напоминаю, обсуждаем именно конструкции языка, и ничто иное. Обойтись без LINQ для демонстрации возможностей ФП на шарпе нельзя в принципе, обойтись без Win32 для демонстрации того, что LINQ ничего не дает можно, и даже нужно.
PD>, но я не заявлял, что не пойму этот SELECT, что IT привел.
Конечно, в том и суть, что ты, ничего не зная ни про ФП, ни про LINQ, тем не менее понимаешь код, который IT привел.
AVK>>А теперь сравни со своей простыней. Что там у нас осталось? Параллелить вкривь и вкось различными способами?
PD>Если не сложно, объясни , почему вкривь и вкось, это раз
Не знаю, тебе захотелось по диагонали или еще как то там пиксели обсчитывать.
PD>, и откуда там различные способы, если там всего один.
В конце у тебя там вопросы под пунктами.
PD> А второй вопрос — ты хоть понимаешь, что внутри твоего AsParallel зашита работа с потоками примерно так, как я и сделал.
Понимаю. И что? Я тебе в который раз напоминаю — речь не о библиотеках и их возможностях, речь о языке программирования. AsParallel просто демонстрирует эти возможности, не более того.
PD> Не обязательно так, конечно, скорее там пул потоков, посмотрю как-нибудь. Ну нет в Win32 иного способа параллелить и нет в Windows ничего, что не проходио бы через Win32 (про OS/2 и POSIX умолчим).
Оторвись от замочной скважины и открой наконец дверь.
PD>Итераторы в С++ существуют, а вообще это понятие языково-независимо.
Под итераторами в C# здесь подразумеваются специальные возможности языка. Это частный случай продолжений (continuations), предназначенный для легкого и удобного создания сложных итераторов. В С++ такое эмулируют при помощи макросов, но качество решения получается при этом ниже плинтуса.
PD> Вот ответь прямо — да или нет ?
Отвечаю прямо — неважно. Не уводи от темы. Распараллеливание здесь в качестве примера, а не самоцель. Если не можешь съехать с Win32, я могу в примере заменить распараллеливание на, скажем, кеширование.
PD>Честно говоря, не слишком понял — что ты суммируешь и куда. Если это реализация моей задачи
Она.
PD> — где массив сумм по столбцам ?
Вот тебе с массивом, это еще проще:
return
(
from x in Enumerable.Range(0, Width)
select Enumerable.Range(0, Height).Sum(y => pixels[x, y])
)
.AsParallel()
.ToArray();
Обрати внимание, насколько просто оказывается поменять код.
PD>Ты все же попробуй те 5 вопросов осилить.
Смысл? Игрища с приоритетами потоков в контексте вопроса малоинтересны и непринципиальны (ну будет там какой нибудь доп.параметр у AsParallel()). А хитрые итераторы, как я уже сказал, не проблема вовсе.
PD> А это суммирование, конечно, распараллелить можно, задачка-то пустяковая.
Только даже на такой пустяковой задачке прекрасно видно, насколько твой императивнй код запутаннее.
AVK>>А теперь я поработаю чуток предсказателем — ты все равно не напишешь пример IT в императивной форме.
PD>Вообще-то я не очень понимаю — в чем разница. Он какие-то проценты считает на баз неких коллекций, а я суммы считаю на базе тоже, если хочешь, "коллекций — столбцов пикселей.
У него алгоритм намного сложнее, а, главное, там уровень косвенности выше.
PD> Делить я не делю и не суммирую, верно, но так ли это важно ? Есть распараллеливание алгоритма, что тут особого-то.
Ты сделай сперва без распараллеливания, и мы обсудим результат.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Sinclair, Вы писали:
S>То есть тебе не очевидно, что твоя программа "с параллельностью", запущенная на одном ядре, будет менее эффективной, чем твоя же программа "без параллельности"?
Не только не очевидно, но в общем случае и неверно. И, возможно, даже в этом конкретном случае. Да, именно на одном ядре, будет более эффективна параллельная . Я же тебе уже объяснял — если потоки большую часть времени проводят в ожидании, распараллеливание на одном ядре может дать вплоть до N-кратного улучшения — просто потому, что когда один поток ждет, другой работает, а при одном потоке придется ждать.
Вот смотри — 10 временных единиц я суммирую, а потом читаю с диска, на это уходит 90 временных единиц. Пока не прочитается, суммировать не могу. И цикл по всему этому. Итого я загружаю процессор на 10%. А теперь 2 потока. 10 временных единиц каждый поток суммирует, 90 единиц ждет. Теперь оба потока вместе могут загрузить процессор на 20%. И т.д. Конечно, при 10 потоках 100% не получится, вмешаются другие факторы, которыми я тут пренебрег, но тенденция именно такая.
В данной же программе сидит GetPixel в цикле. GetPixel — это вызов ядра Windows (точнее, win32k.sys), int 2eh. Что там в ядре в этой ситуации делается — точно я , конечно, не знаю, но вот что могу сказать точно — при запуске моей программы в той части, где идет параллельная обработка, загрузка процессорв по Taskman составила всего лишь 53%. Поскольку мой код готов загрузить его на 100% (там только суммирование), то, очевидно, ожидание на GetPixel занимает почти половину времени. Что там за ожидание и чего — это не ко мне вопрос, я могу лишь предполагать. А пока что мой код хоть и готов загрузить оба ядра на 100%, да GetPixel не дает. Поэтому не исключаю, что даже на одном процессоре он будет быстрее, чем нераспараллеленный код. А может, нет, так как hdc я обоим потокам подсунул один и тот же (а мог бы и разный дать), и если на нем стоит мютекс, то ничего не выйдет. Такие вопросы надо конкретно решать, с учетом специфики задачи. Почитай форум по Win32, там это обсуждалось ИМХО, да и здесь тоже.
И вообще распараллеливание — это совсем не очевидное действие, где можно сказать — AsParallel и ждать, когда галушки в рот посыпятся. Много здесь факторов, которые могут сделать теоретически совершенно правильное решение никуда не годным. И наоборот тоже.
>В каких бы терминах мы ни мерили — в секундах, в тактах, в байтах или еще в чем?
Нет уж, давай определись. Секунды (время) — ты вчера сказал, что тебя не устраивает. Такты — это те же секунды с учетом числа ядер. Байты — это совсем другая опера, надеюсь, тебе не надо напоминать, что память и время — конкуренты, это на 1 курсе рассказывают. У компилятора С++, кстати, есть оптимизация по времени и оптимизация по размеру. Так что сначала определи точно, потом и обсудим.
S>Ты уже определись — то ли ты крутой специалист по оптимизации программ, то ли необученный новичок.
Лучше ты ознакомься сначала с основами параллельных вычислений и состояниями потоков, их переходами и т.д. А то ты вдруг взял да и похоронил все мультипрограммирование, а после того, как я тебе это пояснил, признать свои ошибки не только не хочешь, но еще и повторяешь их. Честно говоря, меня это просто поражает. Я тебя все же считал (да и считаю) неплохим специалистом, а ты вдруг такие вещи говоришь, что студенту непростительно. Как ты при таком понимании параллельной работы потоков можешь что-то проектировать и писать — мне решительно непонятно. Это же азы. Ну Рихтера хоть почитай, что ли.
S>Если первое — то непонятно, зачем тебе разжевывать, куда деваются такты и байты памяти при лишних вызовах WaitForMultipleObjects и new[].
О господи! Это уж за всякие пределы выходит. Придется ликбез провести.
WaitForMultipleObjects практически никаких тактов вообще не требует в user mode. Все, что делается при ее вызове — засылка параметров в стек и int 2eh. Все. Поток больше делать ничего не может, так как спит сном праведника и сам себя разбудить не может. Просто в ядре Windows он теперь добавлен в список тех потоков, которые на этом ивенте/мютексе... ждут. Он спит. И когда мютекс сей освободится — ядро проверит его (потока) приоритет, и если он выше приоритета текущего потока, даст ему управление, а если нет — в очередь готовых потоков. Так что WaitFor... работает почти целиком в kernel-mode. А в этом kernel mode этот поток — лишь один из многих, котррыми система управляет. Это все называется накладные расходы, если их не хочешь — возвращайся в DOS. И вопрос в том, перекрывает ли ожидаемый выигрыш от распараллеливания эти расходы или нет.
А new — это тоже накладные расходы, хоть и (чаше всего) не в ядре. В идеале наилучшее по времени распределение памяти было в Фортране -4, так как там вообще динамического распределения памяти не было. Но это шутка, а реально мы ее вынуждены выделять. Опять-таки — как эти накладные расходы соотносятся с ожидаемым эффектом ? Тут и так все ясно — количество chunk равно числу процессоров, а количество new — числу chunk, то есть 2-4-8..., но не тысячи. И на фоне тех 1-2 сек, что требуется для циклов с GetPixel — это все равно, что монетку положить на автомобильные весы
Здравствуйте, WolfHound, Вы писали:
WH>Но о чудо! Когда переписали компилятор начал работать быстрее. WH>Да и кода стало почти в 3 раза меньше и проще.
Как показывает практика, при переписываниях обычно именно так и происходит, причём независимо от используемых технологий
Здравствуйте, AndrewVK, Вы писали:
AVK>GUI даже в чистых ФП языках есть уже ндцать лет. По делу есть что сказать?
Я в курсе, что он там есть. Про чудаков которые устраивают соревнования по бегу в ластах, я тоже слышал.
Побочные эффекты в виде вывода на экран — это цель создания GUI. Использовать ФП чтобы создавать побочные эффекты — такое же извращение.
AVK>Аналогично. Если ты чего то не понял, это не означает, что оппонент дурак.
А когда этот оппонент доказывает мне одно, а в соседней ветке проталкивает прямо противоположное — вот тогда сомнения уже закрадываются...
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>К сожалению, если поручить это все оптимизатору компилятора, то этот компилятор должен будет быть попросту гениальным, то есть включать в себя знание всех и всяческих техник, трюков и т.п, связанных и с кэшами, и с многопроцессорностью и с характером задачи. Увы, это вряд ли реально.
Но теоретически возможно. Что и требовалось доказать.
PD>Компилятор будет в лучшем случае оптимизировать "в среднем", то есть в расчете на некую среднюю задачу. И чем выше уровень абстракций, тем хуже он это будет делать. Оптимизировать цикл можно очень хорошо, а оптимизировать задачу "сделай вот это" — можно лишь на бвзе некоторых правил оптимизации общего порядка. Как только попадется нечто, что под эти правила не подходят — результат будет плохим.
Можно не писать то, что под эти правила не подходит. Или язык будет запрещать так писать.
PD>Оптимизировать задачу "построите мне автоматически жилой дом" — можно. Выбираем подходящие блоки, стыкуем их, определяем , в каком порядке их ставить, ставим, замазываем щели — дом готов. PD>Оптимизировать задачу "постройте мне автоматически собор святого Петра" — нельзя. Для этого Браманте и Микеланджело нужны. А если эту задачу оптимизировать автоматически, то в итоге получится утепленная собачья будка размером с собор святого Петра.
Метафора строительства зданий далеко не всегда адекватна для программирования.
В случае декларативного описания решения алгоритмической задачи такая метаформа совсем неадекватна.
Здравствуйте, Sinclair, Вы писали:
S> Я уж не говорю про то, что твой лишний поток сожрал 1 мегабайт адресного пространства ни за хрен собачий, что могло кого-то вытеснить в своп.
Ну зачем же так подставляться. Павел, ИМХО, совершенно сознательно переводит любой разговор на обсуждение тонкостей Win32, а ты ему такой подарок делаешь.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Здравствуйте, gandjustas, Вы писали:
G>>Здравствуйте, Pavel Dvorkin, Вы писали:
PD>>>К сожалению, если поручить это все оптимизатору компилятора, то этот компилятор должен будет быть попросту гениальным, то есть включать в себя знание всех и всяческих техник, трюков и т.п, связанных и с кэшами, и с многопроцессорностью и с характером задачи. Увы, это вряд ли реально. G>>Но теоретически возможно. Что и требовалось доказать.
PD>Я пытаюсь эту ситуацию сейчас понять. В общем, видимо, с идеальной программой я не совсем прав. При бесконечном количестве ресурсов ее не может быть. При ограниченном количестве она все же существует. Додумать надо.
PD>>>Компилятор будет в лучшем случае оптимизировать "в среднем", то есть в расчете на некую среднюю задачу. И чем выше уровень абстракций, тем хуже он это будет делать. Оптимизировать цикл можно очень хорошо, а оптимизировать задачу "сделай вот это" — можно лишь на бвзе некоторых правил оптимизации общего порядка. Как только попадется нечто, что под эти правила не подходят — результат будет плохим. G>>Можно не писать то, что под эти правила не подходит.
PD>Так я об этом и говорю. Каждому инструменту — свое назначение. Где Linq, где ассемблер. кесарю кесарево, слесарю — слесарево
Из всего вышесказанного следует что программа написанная на более высоком уровне лучше поддается оптимизации.
Здравствуйте, AndrewVK, Вы писали:
PD>>и результаты его меня просто пугают.
AVK>welcome to real world
"Этот прекрасный новый мир" (О.Хаксли) не читал ? Кстати, управляемый
PD>>А где там запутанность ? Нормальный код, как все на Win32 пишут.
AVK>Самому не смешно?
Ну тогда зайди в форум по Win32 и объяви во всеуслышание — все, что вы тут делаете — смешно. Потому что там именно такой код и пишут, и мой — не лучше и не хуже. Зайди и напиши, честное слово. Посмотрим на реакцию.
AVK>>>Вот, кстати, характерная твоя ошибка — говорим о дизайне кода, а ты даже не в состоянии привести пример без использования специфики Win32.
PD>>Опять ? Я же привел тебе описание задачи!
AVK>Тогда забудь в этом топике про слово Win32, ты же его через абзац упоминаешь.
А ты готов забыть в этом топике про C#, .Net. LinQ ? Либо уж оба забудем, либо оба нет
PD>> Ну не могу же я его привести, не упоминая окна и пикселей, если задача именно с окном и именно с пикселями.
AVK>Вот об этом и речь.
Андрей, мы что-то воду в ступе толчем. Не хочешь окна и пикселей — возьми массив двумерный произвольного происхождения с цветами в качестве элементов. Что изменится, кроме ожидания, конечно ?
PD>>Да никто и не заставляет. Ну не нравится тебе мое описание — сказал, я согласился, дал другое.
AVK>Нук а я тебе дал ответ. Что тебя еще не устраивает?
Да меня все устраивает, только, ей-богу, я уже не пойму, о каком ответе и каком вопрос речь идет
PD>> Впрочем, чтобы IT-ские проценты сравнить в AsParallel и без, то же придется сделать. Но все же никак не пойму — чего ты к пустякам придираешься ? Ну какое отношение к распараллеливанию имеет вопрос откуда и как брать эту матрицу ?
AVK>Win32, Win32, Win32, Win32. Напоминаю — обсуждать тут пытались конструкции языков программирования. Я понимаю, тебе про этот Win32 каждый день приходится студентам рассказывать, но надо хоть чуть чуть абстрагироваться, если тема разговора никакого отношения к Win32 не имеет.
Андрей, ну некорректные же аргументы. Не хочешь Win32 — не надо, но зачем педалировать-то ? Там распараллеливание алгоритма, это главное, остальное второстепенное. А про конструкции vs бмблиотеки я уже сказал.
PD>>Вообще-то нет. Про ФП я могу не знать, про LinQ тоже, а вот SQL знать надо, иначе я его этот SELECT и GROUP в нем не пойму.
AVK>А ты SQL не знаешь?
Знаю А если бы нет ? Вот предстваь себе — пишет некий X математическую обработку, ему SQL совсем не нужен. А матрицы по диагоналям он сплошь и рядом проходит — в линейной алгебре диагональных, трехдиагональных и нижне- или верхне- треугольных матриц хоть пруд пруди.
PD>>Андрей, это уж никуда не годится. Я привел этот пример именно, чтобы показать, что когда мне надо не в "горизонтально-вертикальном", а в произвольном направлении ходить, ваш подход ИМХО пробуксовывает.
AVK>Нигде он не пробуксовывает. Тебе уже два человека написали — начальные итераторы (в моем коде Enumerable.Range) можно написать какими угодно, причем код будет короче за счет наличия в шарпе специальных конструкций для этого.
Ну и прекрасно. Примем, что это сделать можно. Я же с самого начала писал — я вовсе не утверждаю, что это сделать нельзя.
PD>>Я вот одно понять не могу. Ну что стоит признать, что для определенной ситуации этот подход не очень хорош ?
AVK>О, вот очень удачно ты это спросил. Ты сам, лично, ни разу здесь не признал, что был не прав, даже если, порой, тебе приводили абсолютно неопровержимые аргументы. Зато с других ты это требуешь.
Прекрасно. Вот на этом месте я и закончу, иначе можно продолжать до бесконечности. Продолжение см. в моем следующем письме, поскольку хочу выделить это с отдельным заголовком.
PD>>>>Компилятор будет в лучшем случае оптимизировать "в среднем", то есть в расчете на некую среднюю задачу. И чем выше уровень абстракций, тем хуже он это будет делать. Оптимизировать цикл можно очень хорошо, а оптимизировать задачу "сделай вот это" — можно лишь на бвзе некоторых правил оптимизации общего порядка. Как только попадется нечто, что под эти правила не подходят — результат будет плохим.G>>>Можно не писать то, что под эти правила не подходит.
PD>>Так я об этом и говорю. Каждому инструменту — свое назначение. Где Linq, где ассемблер. кесарю кесарево, слесарю — слесарево
G>Из всего вышесказанного следует что программа написанная на более высоком уровне лучше поддается оптимизации.
ИМХО следует наоборот. Я же ясно сказал — см. выделенное.
Здравствуйте, AndrewVK, Вы писали:
Pzz>>О как. Интересно, где это они нашли для UNIX'а такую threading library, и серверные аппликации, на ней написаные, которые имеет смысл "make it easy to port"?
AVK>http://en.wikipedia.org/wiki/Setcontext
В унихе есть, конечно, загадочный API. Но я не слышал ни об одной полезной программе, которая им бы пользовалась. Впрочем, возможно что мне просто повезло.
Вообще, POSIX threads существуют уже давно, и их модель мира примерно такая же, как у вендовых потоков. Под капотом они могут использовать ручное переключение контекстов полностью в user space, полностью полагаться на ядро или использовать смешанную модель, но если программа корректно использует примитивы синхронизации, ей должно быть все равно. Ранние имплементации обходились без помощи ядра, но по-моему рост популярности посиксных потоков как раз совпал с появлением и широким распостранением соответствующей поддержки в ядре.
Кроме того, если кому уж очень приперло сэмулировать в венде setcontext, то сделать это несложно и безо всяких фиберов.
В общем, я думаю, фиберы в венду попали не для эмуляции setcontext/getcontext. А как альтернатива потокам, которая 1) дешевая 2) с ручным управлением, что бывает удобно — не обязательно защищаться критическими секциями.
А я понимаю эту дискуссию несколько иначе.
Оппоненты Дворкина утверждают, что высокоуровневый код вроде такого:
[1 .. 5]
легче оптимизировать, чем низкоуровневый код вроде такого:
+>++>+++>++++>+++++<<<<
потому, что семантика в высокоуровневом коде явно выражена. В первом случае, например, мы (и компилятор) видим последовательность чисел от 1 до 5и, во втором же случае за деревьями перемещений ленты и инкрементов не видно леса.
... << RSDN@Home 1.2.0 alpha 4 rev. 1110>>
'You may call it "nonsense" if you like, but I'VE heard nonsense, compared with which that would be as sensible as a dictionary!' (c) Lewis Carroll
Здравствуйте, D. Mon, Вы писали:
DM>Как я и сказал: DM>"The places where NASA scientists have used Java for this mission is all on the ground side right now." DM>"The Rover itself has a computer onboard. There's no Java in that computer now."
Ты целиком процитируй, а не вырывай из контекста:
Q:Are they actually commanding the Mars Rover with Java?
A: For the command and control system, big parts of it are this rather large Java application. There are a lot of parts involved in this. The Rover itself has a computer onboard. There's no Java in that computer now. But on the ground-side, there are a number of parts of the whole command and control chain that goes out to the Rover that's done in Java. It's not like every last piece of every subsystem is based on the Java code. Great big pieces of it are. In particular, all the data visualization, user interface front-end stuff and I believe a whole lot of the database stuff is.
Из чего следует, что софт на джава используется для управления марсоходом (хотя конечно же и не только он).
О чем я собственно и написал.
А про то, что джаву "послали в космос" я и не говорил.
PD>Проблема же в том, что адепты этих новых технологий претендуют на их универсальность для всех задач. Тому же AndrewYK просто смешно смотреть на Win32 код — именно потому, что он не те средства (язык, АПИ) использует, что ему надо. Если бы он сказал — для твоей задачи это хорошо, для других — не годится — я бы немедленно согласился, тут и сказке конец. Я разве предлагал web-сайты на С++ писать или XML на ассемблере парсить ? Но нет, подайте им все, они на меньшее не согласны, а поэтому все, что под их методы не подходит — им смешно. Вот я и пытаюсь побудить их просто зафиксировать это простенькое утверждение — независимо от того, какие сферы покрывает то или иное направление.
Есть такая штука, как правила и исключения. Так вот, правило универсально, даже если из него есть исключения. Если новая технология покрывает 90% задач или больше — она универсальна, а всё не попавшее в область покрытия — это исключения.
И, да, смешно, когда пытаются сделать то, что мы можем сделать одной строкой кода — листингом на две страницы на асме. При этом, человек, который пишет на асме сам загоняет себя в угол — ему больше некуда оптимизировать. Всё, точка. А нам — есть куда. Мы сначала можем посмотреть на С++ или Erlang. А потом и на ассемблер. Если вдруг это понадобится.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Здравствуйте, samius, Вы писали:
S>>Не совсем так. Фигурально выражаясь, они пытаются усадить Вас за BMW с тем чтобы Вы могли сравнить ее с ВАЗ-ом, но Вы отказываетесь, аппелируя тем, что у BMW больше расход и что надо просто уметь ездить на ВАЗ-е.
PD>Сравнение некорректно. Если уж сравнивать, то надо сравнивать BMW с неким автомобилем, который хорошая фирма могла бы сделать ручной сборкой, а не на конвейере, и с деталями, сделаннными специально для этого автомобиля, а не отштапованными. Иными словами, сравнить BMW с неким гоночным автомобилем. Это и будет вполне подходящее сравнение — BMW штука хорошая, но выжать из двигателя внутреннего сгорания и прочего то, что они могут сейчас дать, он и близко не может.
Я сравнивал не для того, чтобы провести аналогию с технологиями. Я сравивал для того, чтобы дать Вам понять, чего же от Вас хотят оппоненты — что бы Вы попробовали (а уж ВАЗ и BMW или BMW и F1 — не важно).
И попробовать лучше пройти один и тот же путь разными способами. Путь, который упирается в Win32 не лучший в данном сравнении.
Здравствуйте, samius, Вы писали: S>Мне все же кажется, что это не так. Оппоненты пытаются донести что использование высокоуровневых средств более эффективно в большинстве задач, если речь идет не о железе. Эффективно — значит при схожей или чуть меньшей производительности решения оно будет дешевле и быстрее по срокам.
Это не так. Если бы мы хотели доказать именно это, то мечта Павла вполне бы сбылась.
Просто он подменяет понятия: сначала делает некое абстрактно-теоретическое утверждение, которое не может доказать. Все опровержения этого абстрактно-теоретического утверждения он последовательно игнорирует, пытаясь сделать вид, что его кто-то заставляет писать на C#.
На всякий случай напомню, что про шарп речь вообще не шла. Никто даже не пытается убедить Павла попробовать шарп (ну, кроме тебя). Речь шла о том, что Павел посмеялся над утверждением Игоря про способность ФП в теории получать более эффективный код, чем ассемблер. Вот и весь хрен до копейки.
А как только мы отстаем от этого абстрактно-теоретического рассуждения про сферические компиляторы в вакууме, сразу начинается суровая реальность. Со слабо проработанными оптимизаторами в реальных JIT, с отсутствием production quality оптимизаторов для ФП-языков и так далее.
В итоге, действительно, шкала ровно такая: максимальная производительность реального рантайм кода лежит в области максимальных же затрат на ручную оптимизацию.
Весь вопрос только в том, где проходит граница допустимых расходов на оптимизацию, и где проходит граница допустимой неэффективности.
Вот Павел приводит пример задачи, где нужно выжать 200мс вместо 15с. Я с легкостью поверю, что никакой компилятор сейчас не даст этого результата автоматически: те, у кого хорошие теоретические способности, не оборудованы бэкендами с поддержкой SSE и прочих хардкорных фич. А те, у кого хороший бэкенд, компилируют с таких языков, где нет возможности проводить хитрые оптимизации автоматом. Вот Павел и занимается ручным выравниванием структур и выпиливанием по интринсикам.
А вот у компании Ericsson был пример другой задачи, когда C++ оказался тупо непригоден потому, что стоимость разработки и отладки софта на нём превысила доступный бюджет. В итоге его выкинули и заменили самым медленным из промышленных ФП-языков; при этом, естественно, микропроизводительность упала со страшной силой. Но свитч заработал, и его надежность компенсирует все претензии к его производительности. Это — правое плечо графика.
В середине, в общем-то, можно использовать оба подхода. Никаких проблем. Никто никому ничего не запрещает. Пишите хоть сразу в микрокоде. Но только не нужно питать иллюзий про перспективы таких разработок. Как только управляемые среды дорастят до нужного уровня, ассемблер станет практически ненужным.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Можно ссылку на суперкомпилятор для C#?
Ccылку на джаву дали. ВВ>Честно, не вижу много смысла муссировать рассуждения типа "теоретически возможно написать такой компилятор, который заоптимизирует все насмерть".
В таком случае, нужно отказаться от муссирования рассуждений типа "теоретически программист может вручную на ассемблере заоптимизировать всё насмерть" ВВ>Когда напишут — тогда и поговорим. А пока все абстракции — реализуемые средствами языков на .NET — о которых здесь и речь неизбежно несут оверхед.
Вот-вот. Когда напишет — тогда и поговорим. А пока на ассемблере воспроизвести банальную ASP.NET страничку, которая обращается к базе, веб-сервису и локальной файлухе — совершенно нереально. Я имею в виду — со сравнимой с ASP.NET эффективностью: то есть везде IO Completion Ports, тред пул по максимуму и т.п.
А пока все эти суперомтизации — реализуемые трюками с регистрами, SSE, и переупорядочиванием команд — о которых здесь и речь неизбежно несут оверхед в стоимости разработки.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Pavel Dvorkin, Вы писали:
ВВ>>Мне вот непонятно, что за задача такая — помножение матриц. И, думаю, не только мне. Для чего/для кого она делается? PD>Не обижайся на то, что я сейчас скажу, ладно ? Я вовсе не хочу ни тебя, ни кого-то еще обидеть. Я с уважением отношусь к любым задачам. PD>В этом твоем ответе — суть проблемы. Тебе и другим — действительно непонятно. В задачах бизнеса (как я их определил) — это действительно не нужно. Если речь идет о создании сайта — это скорее всего не нужно. Если речь идет о системе управления заводом — может быть, тоже. И т.д.А поскольку большинство этим бизнес-задачами и занимается, то ему (большинству) это действительно непонятно. Оно как-то подсознательно уверено, что то, чем они занимаются — и есть единственно верное программирование, а то, что ему не нужно — вообще не нужно. PD>О чисто научных задачах я говорить не буду. То. что там оно нужно — думаю, спорить не будешь, но об этих задачах не говорим сейчас.
PD>Вернемся к бизнесу. Ну а если это не сайт и не АСУ (не к ночи будь помянута). О своих нынешних делах рассказывать не буду, а вот о том. что делал лет 10 назад — расскажу. А была это задача натягивания некоей текстуры на фотографию человека.
Вот в последнем предложении описана бизнес-задача.
А перемножение матриц — это не бизнес задача, это кусочек ее решения. Отдельная техническая задача, так сказать
Заказчику же не особо важно, как технически решается его задача.
И оппоненты тебе пытаются сказать, что задачи надо рассматривать именно глобально, а не только в отдельных деталях. Может быть можно провести оптимизацию где-то выше, чтобы уменьшить количество перемножений матриц.
Я ведь тоже могу рассказать, какая это жуткая задача строить веб страницы — у меня сотни запросов в секунду, на каждый запрос надо подготовить данные по 20000 сущностей, а их все надо взять из базы, а для этого мне надо 200 запросов, а потом все эти данные обработать непростым алгоритмом ( 300 мс на каждую сущность) и все это нужно уложиться в полсекунды для каждого пользователя (которых тысячи). Это же уму непостижимо какая сложная вычислительная задача!!!
А потом рассказать, как я жутко оптимизирую алгоритм, и он уже не 300мс тратит, а всего 50мс (но 20000 объектов —
это все равно слишком долго обрабатывается). Ах, какие стали ужасные неэффективные средства.
Только если посмотреть по ограничениям самой задачи, то получается, что их можно закешировать в уже обработанном виде и вуаля, уложились в полсекунды на запрос.
И самая главная техническая (не бизнес!!!!) задача внезапно преобразуется в совершенно другую — вместо проблемы оптимизации алгоритма встает проблема правильности обновления и синхронизации кеша. Это тоже задача, и она тоже требует серьезного решения. Но другими средствами.
А вот бизнес-задача остается при этом той же самой.
Ты часто путаешь технические задачи и отдельные детали решения с собственно бизнес-задачами.
Да, бывают бизнес-задачи, где все упрется в один алгоритм и нет никаких способов решить бизнес-задачу, кроме как заоптимизировать этот алгоритм по самое немогу.
Но бывают и бизнес-задачи, где все упирается в один алгоритм, но все же есть способы решить бизнес-задачу, отойдя от оптимизации собственно прямого выполения алгоритма (например, дополнительно предобрпботав входные данные или закешировав частичные решения).
А бывают и бизнес-задачи, где все, кажется, упирается в один алгоритм, а на самом деле можно решить и несколькими другими, более или менее подходящими в разных условиях. И решение, отличное в одних случаях (скажем, один слабый компьютер) может оказаться плохоим в других (скажем, кластер мощных компьютеров)
Все.
Это я просто про разницу между "бизнес-" и "вообще-" задачами высказался, более ничего. Про твои задачи я ничего не знаю.
Но не стоит считать других глупее себя, даже если они пишут веб-приложения для всякого бизнеса.
Мы, на самом деле, многое понимаем.
Да еще и высказать можем
Здравствуйте, Sinclair, Вы писали:
ВВ>>Можно ссылку на суперкомпилятор для C#? S>Ccылку на джаву дали.
И что мне с ней делать? Молиться на нее?
ВВ>>Честно, не вижу много смысла муссировать рассуждения типа "теоретически возможно написать такой компилятор, который заоптимизирует все насмерть". S>В таком случае, нужно отказаться от муссирования рассуждений типа "теоретически программист может вручную на ассемблере заоптимизировать всё насмерть"
Ну правильно, ведь на ассемблере никто ничего не пишет, им пугают детей на ночь, а мы тут уже вовсю дотнет-приложения "суперкомпляторами" компилируем.
ВВ>>Когда напишут — тогда и поговорим. А пока все абстракции — реализуемые средствами языков на .NET — о которых здесь и речь неизбежно несут оверхед. S>Вот-вот. Когда напишет — тогда и поговорим. А пока на ассемблере воспроизвести банальную ASP.NET страничку, которая обращается к базе, веб-сервису и локальной файлухе — совершенно нереально. Я имею в виду — со сравнимой с ASP.NET эффективностью: то есть везде IO Completion Ports, тред пул по максимуму и т.п.
Да, ослиный ASP.NET — это гениальный пример для сравнения. Ничего лучше чем дебильный конструктор сайтов и подобрать нельзя. Может, лучше программирование на асме вообще сравнить с InfoPath-ом? Ведь какие там формочки, какие абстракции.
А может, это — давайте тогда все на свете на АСП-НЕТ писать? Ведь АСП-НЕТ рвет на части асм по своей эффективности. Чет мужики еще не доперли что надо все на АСП-НЕТ переводить.
Abstraction gain — он в голове. И это хорошо, что он в голове, а не в другом месте. И не надо его из головы куда-то перекладывать.
S>А пока все эти суперомтизации — реализуемые трюками с регистрами, SSE, и переупорядочиванием команд — о которых здесь и речь неизбежно несут оверхед в стоимости разработки.
Здравствуйте, Воронков Василий, Вы писали:
S>>Лучший — это по результатам моего личного опыта. Сравнивали с JSP, ASP, PHP, Python. С наколеночными CGI на C и С++. Тесты проводили самые разнообразные. Кроме того, я немножко представляю себе, как все эти фреймворки устроены внутри. А у вас какие основания клеймить ASP.NET? ВВ>Опыт использования.
Судя по всему хреновый опыт. ASP.NET MVC видели?
ВВ>Вернее, давайте я поправлюсь — тот ASP.NET, который начинается и заканчивается на IHttpHandler/IHttpModule — это отличная штука. А вот все что сверху...
Расширяемая модель провайдеров? Dynamic Data?
ВВ>Развитие ASP.NETа — причем заметьте в понятие ASP.NET обычно вкладывается не технология "интеграции конвеера с IIS", а собственно web forms — это постепенное превращение его в чистой воды конструктор. Программирование мышкой. В свое время над Дельфи за этой посмеивались. То же самое в ASP.NET — как вы сказали? — высокотехнлогичность или как там? Неувязочка получается, нет?
Тем не менее на делфи делалась большая часть Enterprise софта в СНГ до появления C# 2.0
ВВ>Далее. что у нас еще есть? Богатые библиотеки контролов? Берем ГридВью. Нет проблем! Бросили на форму, пару движений мышкой — все работает. Нужна двунаправленная сортировка, чтобы еще и в заголовка направление сортировки показывать? Без проблем, темплейт-column. Нужно чтобы выглядело по-красивее? Без проблем, еще пару движений мышкой. Ох, надо чтобы совсем-совсем по-красивее? Ой, а надо чтобы весь столбец, по к-му происходит сортировка подсвечивался? Ну что ж придется изменить рендеринг HTML — что ж делаем темплейт колонки (количества кода на странице начинает ох как расти). Хотите чтобы работать даже тривиальные функции ГридВью — не вздумайте отключить вью-стейт, ибо ни фига работать не будет. Ну ладно, вроде прикрутили, сделали. Завтра приходит клиент и говорит — о, а давайте это сделаем в виде вложенного грида, который по плюсику будет распахиваться, а эту и и эту колонку будем мержить когда такая-то информация выводится.
Для сильно кастомной разметки используйте ListView.
ВВ>И вот смотрим мы — реально на кучу разметки и кода, которую пришлось — смотрим, и выбрасываем на фиг весь это грид, и переписываем все на XSLT. И — о чудо! — на XSLT кода получается даже меньше, а все наши фичи учтены. И выглядит аккуратнее. И работает быстрее. ВВ>И таких примеров можно много привести, и не только с контролами. Чуть-чуть сходишь с "рельс" — и все, приехали. Написав приложение на IHttpHandler/IHttpModule + XSLT, ты: ВВ>- получишь чистый код с нормальным разделением данных (XML), правил валидации (XSD) и представления (XSLT) ВВ>- получишь более производительный код ВВ>- и даже потратишь меньше времени (если приложение не хоум-пейдж) ВВ>Какой вывод после этого можно сделать о веб-формах? Но зато да, веб-формы это абстракция.
Не могу удержаться. Код на в студию! XML+XSLT, повторяющий функциональность GridView: темплейты, пейджинг, сортировка, инплейс редактирование.
ВВ>А ведь в описанной выше технике не используется ничего специфичного для АСП.НЕТ. Ее при желании можно реализовать и на ПХП.
Компилируемое XSLT-преобразование есть в PHP?
Более того никто не мешает использовать ASP.NET MVC и XSLTViewEngine.
ВВ>Еще раз повторяю — причем здесь вообще ASP.NET? Каким образом ASP.NET вообще возникает при разговоре об ассемблере?
Ассемблер — это условно говоря самый низкий уровень абстракции, а ASP.NET — самый высокий.
ВВ>Люди, который пишут на ассемблере, есть. Задачи, который пока еще приходится реализовывать на самом низком уровне есть.
Вы уверены что эти люди напишут код, который всегда эффективнее кода на высокоуровневом языке?
Здравствуйте, gandjustas, Вы писали:
G>Судя по всему хреновый опыт. ASP.NET MVC видели?
Давайте вы не будете судить о моем опыте, и я тоже не буду переходить на личности? Хамство не лучшее подспорье в беседе.
И я писал конкретно о веб-формах, если вы не заметили. А технологию в бета-версии, которую как раз и внедрили для того, чтобы прикрыть убожество веб-форм, я в промышленных проектах использовать пока не намерен.
ВВ>>Вернее, давайте я поправлюсь — тот ASP.NET, который начинается и заканчивается на IHttpHandler/IHttpModule — это отличная штука. А вот все что сверху... G>Расширяемая модель провайдеров? Dynamic Data?
Dynamic Data — для хоум-пейджей. Для хоум-пейджей и веб-форм подходит отлично.
ВВ>>Развитие ASP.NETа — причем заметьте в понятие ASP.NET обычно вкладывается не технология "интеграции конвеера с IIS", а собственно web forms — это постепенное превращение его в чистой воды конструктор. Программирование мышкой. В свое время над Дельфи за этой посмеивались. То же самое в ASP.NET — как вы сказали? — высокотехнлогичность или как там? Неувязочка получается, нет? G>Тем не менее на делфи делалась большая часть Enterprise софта в СНГ до появления C# 2.0
А я против дельфи ничего не имею.
ВВ>>Далее. что у нас еще есть? Богатые библиотеки контролов? Берем ГридВью. Нет проблем! Бросили на форму, пару движений мышкой — все работает. Нужна двунаправленная сортировка, чтобы еще и в заголовка направление сортировки показывать? Без проблем, темплейт-column. Нужно чтобы выглядело по-красивее? Без проблем, еще пару движений мышкой. Ох, надо чтобы совсем-совсем по-красивее? Ой, а надо чтобы весь столбец, по к-му происходит сортировка подсвечивался? Ну что ж придется изменить рендеринг HTML — что ж делаем темплейт колонки (количества кода на странице начинает ох как расти). Хотите чтобы работать даже тривиальные функции ГридВью — не вздумайте отключить вью-стейт, ибо ни фига работать не будет. Ну ладно, вроде прикрутили, сделали. Завтра приходит клиент и говорит — о, а давайте это сделаем в виде вложенного грида, который по плюсику будет распахиваться, а эту и и эту колонку будем мержить когда такая-то информация выводится. G>Для сильно кастомной разметки используйте ListView.
Угу, потратить кучу времени на лист-вью, а потом выкинуть и его тоже. Отличная перспектива.
G>Не могу удержаться. Код на в студию! XML+XSLT, повторяющий функциональность GridView: темплейты, пейджинг, сортировка, инплейс редактирование.
А вы попробуйте сами как-нибудь. Там все куда проще чем может показаться.
ВВ>>А ведь в описанной выше технике не используется ничего специфичного для АСП.НЕТ. Ее при желании можно реализовать и на ПХП. G>Компилируемое XSLT-преобразование есть в PHP?
Это как-то влияет на ф-ность XSLT-процессора? В ПХП вообще нет ничего комплируемого. Что не мешает на ПХП написать приложение с лучшим перформансом чем на АСП.НЕТ+веб-форм.
G>Более того никто не мешает использовать ASP.NET MVC и XSLTViewEngine. ВВ>>Еще раз повторяю — причем здесь вообще ASP.NET? Каким образом ASP.NET вообще возникает при разговоре об ассемблере? G>Ассемблер — это условно говоря самый низкий уровень абстракции, а ASP.NET — самый высокий.
Поэтому надо сравнивать ассемблер с АСП.НЕТ? Логика железная!
ВВ>>Люди, который пишут на ассемблере, есть. Задачи, который пока еще приходится реализовывать на самом низком уровне есть. G>Вы уверены что эти люди напишут код, который всегда эффективнее кода на высокоуровневом языке?
Я специально для тех в танке написал до этого — принцип "все или ничего" тут не действует.
Здравствуйте, gandjustas, Вы писали:
ВВ>>А вы будете начинать новый проект прям на Бете? G>Я уже сделал пару проектов на ASP.NET MVC(еще Preview версии), на бете один сейчас в разработке.
А я не могу "продать", скажем, крупному мобильному оператору проект на непонятно какой бете, которая не поддерживается.
ВВ>>"Хоум-пейдж" это относительно простое приложение, с БД, которая вообще может создаваться с нуля и пр. ВВ>>А как поможет Dynamic Data в приложении, где лет за пять до вас написали оракловую базу, где под сотню таблиц (про количество полей в этих таблицах я вообще промолчу)? А теперь еще представьте формы, работающие с этой БД. А еще данные из этой БД надо экспортировать в другую БД, которую разрабатывают вообще в другой строне и у нас execute right на несколько процедур всего. Это real world application. G>Это вообще проблемы другого уровня. Сделйте на EF модель поверх того что вам доступно и сможете пользоваться Dynamic Data.
Да того, того уровня. Представьте как будет происходить работа с такой базой — джойн там по парочке таблиц уже трагедия. Там не до Linq.
ВВ>>Время по настройке пейджинга в том же дата-гриде аналогично времени на реализацию этого пейджинга в XSLT. Да, да, не надо делать круглые глаза. Если клиентский пейджинг — вставляешь 1 строку сортировку и 1 if. Ну да еще сам блок "пейджера" надо описать — при этом пейджер может выглядеть как угодно, и ты не будешь ломать голову как бы настроить его также как на mock-up нарисовано, используя все три св-ва в датагриде. ВВ>>Опять-таки как будет работать пейджит — через GET или не через GET — как хочешь так и сделай. Сортировка через GET — две строчки кода фактически. Причем это масштабируется блин. G>А инплейсное редактирование?
Ну а какие проблемы? Нажали на кнопочку, перерисовали грид через XSLT — для строк соотв. используются просто другой XSLT-шаблон — нажали на кнопочку сохранить — функция на джаваскрипте отсылает данные на сервер — порядка 10 строк кода — грид перерисовывается.
А если например нужно *все* строки по умолчанию показывать в режиме редактирования? Вот нехочется людям каждый раз "кликать" на эдит. А еще хочется например поменять значение в столбце Х и чтобы во всех столбцах с *аналогичными* значениями тоже значение поменялось? На XSLT я эту фичу прикручу, веб-контрол — в recycle bin.
ВВ>>Технология, особенно "крутая" современная технология должна хотя бы поощрят писать хорошо. Лучше — давать минимальные возможности писать плохо. Web Forms этого не делает. G>Это сильно зависит от того что такое хорошо. Иногда "хорошо" значит написать быстро, WebForms это обеспечивает. Для "правильного" писания веб-приложений вебформы не подходят.
"Хорошо" — это чтобы в принципе работало, не глючило, чтобы в срок и чтобы деньги за проект заплатили, а я свои бонусы за проект получил. Это хорошо. Остальное, если честно, не [censored].
А таким понятием как "маленькое веб-приложение" я давно по работе не сталкивался. Везде сплошные корпоративные интранеты, а там рулят портальные решения, а что у нас у МС в качестве портального решения? MOSS? О, нет, не "открывайте", я же только что поел!
ВВ>>А Шарепоинт вы видели, который на основе веб-форм построен? И во что там мастер-пейджи превращаются, когда нужно их дизайн перетачивать под нарисованные картинки. Причем иначе и не сделаешь фактически. Пусть вот эти клоуны сначала туда MVC прикрутят. G>Мне слава богу не доводилось таким заниматься. Да и шарепоинт не для этого нужен.
А для чего нужен MOSS? Поведайте нам. А лучше парням из МС которые продают его кому ни попадя, как отличное портальное решение. А потом интеграторы по программе парнер-шипа с ним [censored].
ВВ>>Как думаешь, на момент презентации, скажем, ASP.NET 2.0 это было официальной позицией MS? G>Архитекторы ASP.NET неправльно представляли себе web.
И о чем тогда спорим, казалось бы?
ВВ>>А ведь веб-формс — просто уровень абстракции над прямой работой с HTTP. G>Не, HttpHandler — уровень абстракции над выводом в stdout для формирования страницы. А вебформы находятся на 3-4 условных уровня выше.
Ну как сказать... class Page : IHttpHandler. Впрочем, не суть.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>А мне вот неизвестно изначально, что клиент захочет. Я хочу чтобы технология была гибкой и позволяла легко вносить изменения, если они требуются. Или мне под каждый requirement все с нуля переписывать?
Зачем с нуля? Купить контролы сторонних производителей.
ВВ>Как объяснить бизнесу, что реализация фичи Х занимает 3 часа, а для фичи У надо все на фиг переписать? С т.з. клиента это совершенно нелогично.
А вот так и приходится. Постоянно. Жизнь у айтишников такая.
ВВ>Я уж не говорю о производительности всего этого добра, которое по малейшему чиху тянет вью-стейт, а если его отключить, то контролы теряют все свои замечательные фишки.
ВВ>Вот кстати в вин-формах ситуация значительно лучше. Я там контрол могу хоть раком поставить. При этом "отрисовать все самому" мне в голову придет в последнюю очередь. Есть конечно ограничения, но в значительно меньшей степени.
В Windows Forms точно такая же проблема. И ограничения там мешают в неменьшей степени. Самой гибкой "технологией" оказалась бы "попиксельный рендеринг с помощью XSLT".
Здравствуйте, minorlogic, Вы писали:
M>Если существуют методологии позволяющие очень сильно повысить читабельность, уменьшить к-во, улучшить сопровождение и т.п. Я бы очень хотел об этом подробнее узнать.
См. FP.
M>Но я оцениваю вероятность такой ситуации близкой к нулю , потому что не встречал написанных революционно проектв типа FFMPEG или openCV или декодер jpeg2000.
А как ООП революционно работает для проектов типа FFMPEG или openCV или декодер jpeg2000? Никак? Давайте откажемся от ООП!
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Проблема тех же контролов в том, что с одной стороны это "шаблоны", уровень некоторой абстракции над HTML
Контролы и HTML связаны лишь тем, что контролы занимаются рендерингом HTML. Этим всё равно должен кто-то заниматься. У тебя есть притензии к контролам, что они плохо рендерят HTML?
ВВ>- с другой, стоит чуть сойти с проторенных рельс, и вокруг этих самых шаблонов вырастают тонны HTML-я.
Пиши свои контролы, в чём проблема?
ВВ>Потом ты вот говоришь, что тебе не нравится как организована работа с состоянием. А ведь viewstate — одна из основных фишек контролов. Причем он всегда или есть или нет. Т.е. я не могу его отключить частично, если мне нет нужны дублировать данные контрола и перегружать страницу.
ViewState — это как раз и есть затычка, призванная упростить работу с состоянием. Но получается это по-любому хреново из за того, что состоянию распределённость противопоказана.
ВВ>А AJAX тоже не панацея. Особенно то, как это сделано в ASP.NET.
UpdatePanel — это обманка. Проблему состояния такой AJAX не решает никак.
ВВ>ИМХО дело не в технологии "передачи" состояния — ибо все равно ты его будешь передавать на сервер в конечно счете. Проблема в том, что построив "абстракцию" над HTTP, внутри АСП.НЕТ все те же формы, поля и пр. — т.е. методы работы с данными самые что ни на есть древние.
Ты явно путаешь HTTP с чем-то другим. Формы не являются надстройкой над HTTP. HTTP — это всего лишь протокол передачи данных.
ВВ>Интереснее было бы, мне кажется, структировать сам формат состояния да и вообще данные, которые гоняются туда сюда. Например, чтобы это была не форма вида key=value&k2=value2..., а XML документ, который в свою очередь можно всегда проверить по XML-схеме, всегда можно показать используя различные стайлшиты (XSLT), а уж технология передачи — это мне кажется дело вторичное.
Повторяю ещё раз. Состоянию противопоказан распределённость. Если попытаться распределить состояние между UI (WPF/WinForms) приложением и сервером, то ты мгновено получишь теже самы проблемы, с точностью до изобретения ViewState. Это не проблема конкретно WebForms, это проблема подхода.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, FR, Вы писали:
FR>Пока просто нет нужной массовости, но ситуация уже меняется, в общем ждем релиза F# и доведение до ума Scala скорее всего на них появятся первые серъезные приложения. Хотя последние версии Haskell'а тоже радуют.
А я считаю что дело не в массовости , потому что FFMPEG ядро делают несколько человек. Я уверен, что если бы использование FP дало бы хоть 5% к производительности программы ядро бы уже переписали.
M>>>Почему по твоему мнению , серезные приложения которые я перечислял FFMPEG — JASPER написанны без использования FP ? на традиционных C/C++. ?
IT>>Если бы они были написаны с использованием FP, то они были бы ещё серьёзней.
M>Попробую еще раз , а почему они не написанны с использованием FP ?
Потому что для подобных вещей важна не эффективность разработки а эффективность работы готового кода. Пока FP компиляторы не достигли уровня хороших C++ компиляторов.
Здравствуйте, Pzz, Вы писали:
Pzz>Компилятор ocaml выплевывает код, сравнимый по быстродействию с тем, что выплевывает g++. Иногда даже более быстрый — за счет более оптимальной реализации вызова функции.
Я тестировал и смотрел асм выход от Ocaml'а, по сравнению с хорошими C++ компиляторами все-таки слабавато.
Здравствуйте, AndrewVK, Вы писали:
AVK>Не надо фантазировать. Смотреть мне не смешно, а, скорее, грусто.
Недавно было смешно, теперь грустно. А нельзя ли вообще без эмоций обойтись ?
PD>>Но нет, подайте им все, они на меньшее не согласны
AVK>Цитату в студию, где я предлагал все писать в функциональном стиле.
Напоминаю целиком фразу, часть которой ты процитировал. Кое-что выделил
PD>Проблема же в том, что адепты этих новых технологий претендуют на их универсальность для всех задач. Тому же AndrewYK просто смешно смотреть на Win32 код — именно потому, что он не те средства (язык, АПИ) использует, что ему надо. Если бы он сказал — для твоей задачи это хорошо, для других — не годится — я бы немедленно согласился, тут и сказке конец. Я разве предлагал web-сайты на С++ писать или XML на ассемблере парсить ? Но нет, подайте им все, они на меньшее не согласны, а поэтому все, что под их методы не подходит — им смешно. Вот я и пытаюсь побудить их просто зафиксировать это простенькое утверждение — независимо от того, какие сферы покрывает то или иное направление.
Приведи в этой фразе место, где речь идет именно о ФП. Для меня это — лишь часть проблемы, а речь идет о более важном — о претензии на универсальность для всех задач. А Linq — это лишь часть.
Здравствуйте, Sinclair, Вы писали:
ВВ>>Мне теоретический "суперкомплятор" неинтересен. S>В таком случае я в очередной раз предлагаю отказаться от обсуждения теоретического ассемблерщика.
Я никогда и не писал, что "теоретического ассемблерщик" всех порвет по производительности. А писал, кстати, прямо противоположное. Ни с кем меня не путаете?
ВВ>>Развитие ASP.NETа — причем заметьте в понятие ASP.NET обычно вкладывается не технология "интеграции конвеера с IIS", а собственно web forms — это постепенное превращение его в чистой воды конструктор. S>Мне всё равно, что именно вкладывается в это понятие обычно. Точно так же, как и то, что среднестатистический программист обычно только ухудшает код при первых попытках вставить что-то на ассемблере.
А может, стоит вообще забыть об ассемблере? Речь изначально о том, всегда ли есть abstraction gain, как вы говорите. А тут не надо далеко ходить — можно оставаться в рамках того же C#.
ВВ>>Программирование мышкой. В свое время над Дельфи за этой посмеивались. То же самое в ASP.NET — как вы сказали? — высокотехнлогичность или как там? Неувязочка получается, нет? S>Программирование мышкой здесь ни при чем. Можно хоть подмышкой программировать, вопрос в том, какие возможности дает фреймворк, какой объем кода при этом нужно писать вручную, и какая при этом получается эффективность конечного решения.
"Программирование мышкой" — это практика, которая неизбежно влияет на квалификацию программиста. А объем кода, который необходимо писать вручную, в случае с АСП.НЕТ все равно остается немаленький, стоить лишь только отойти от стандартного способа работы с компонентами, что случается довольно часто. При этом получается забавная ситуация, что среднестатистический асп.нет-чик может не знать ни базовые вещи по работе с HTTP, не уметь работать с джава-скриптом и пр. Я человек сто наверное прособеседовал, так что можно уже статистику составлять.
ВВ>>Во-первых, сама по себе концепция веб-форм ущербна изначально. S>Да. ВВ>>Но что принпиально новое в нес ASP.NET? Чего добились создатели ASP.NET? Разделения логики и представления? Как бы не так. Ничем в сущности ASP.NET приложение не отличается от того же PHP. И там, и там одинаковая по большому счету свалка — только несколько иначе организованная. И там и там можно писать нормально, если уж очень захочется. S>Щас прямо. PHP рядом не валялся. ВВ>>А ведь в описанной выше технике не используется ничего специфичного для АСП.НЕТ. Ее при желании можно реализовать и на ПХП. S>А ты попробуй — реализуй. И посмотри на то, сколько кода тебе для этого потребуется, и какое будет быстродействие.
А в чем проблема? Ты пробовал и получилось слишком медленно? И что являлось "бутылочным горлышком"? Типа база летала, странички были заоптимизированы, скрипты клиентские не тормозили, а тормозил конкретно интерпретируемый PHP?
А что с "количеством" кода? Надо много писать, чтобы вызвать XSLT-преобразование? В каких конкретно частях системы, при решение каких задач пришлось писать много кода?
ВВ>>Я так смотрю хамство — это нынче модный тренд на RSDN. S>А ты перечитай свой предыдущий постинг, эстет ты наш.
А ты перечитай всю ветку сообщений, до как ты мне "отписался". Я утверждал, что abstraction gain есть не всегда, abstraction penalty — всегда. В ответ началось, извините, передергивание на тему теоретического комплятора, который "заоптимизирует" все насмерть, и АСП.НЕТ-а, который на ассемблере реализовать невозможно.
Говорите, Дворкин плохой? Утверждает, что абстракции это всегда плохо? А линия вашей партии чем отличается? Абстракции это всегда хорошо? Ну молодцы, да Я высказал более нейтральную точку зрения в постинге, который был, кстати, возражением Дворкину — и, что называется, "понеслась".
Что-то вместо "философии" программирования тут больше попахивает "религией".
S>>>Просто веб-сервер — это типичный пример высоконагруженного приложения. ВВ>>Еще раз повторяю — причем здесь вообще ASP.NET? Каким образом ASP.NET вообще возникает при разговоре об ассемблере? S>При том, что ASP.NET — лучший в мире фреймворк для веб-приложений.
Угу, при архитектуре, которая ущербна изначально. В каком страшном мире мы живем
Даже если он и лучший, это никак не отменяет того факта, что ASP.NET — [censored]. А про "инкарнации" ASP.NET в виде MOSS цензурно вообще ничего написать не получится.
ВВ>>Я в принципе понимаю, в чем ваша проблема. Не "ваша" конкретно, а вообще. Почему в принципе при разговоре об ассемблере возникает предложение написать на нем аналог ASP.NET приложения? S>Ну а почему как начинается речь об управляемых языках — так сразу давайте матрицы умножать? ВВ>>А правда в том, что есть задачи, в к-х abstraction не дает никаких gain-ов, одни penalty. И такие ситуации также реалистичны как и те, где введение уровня абстракции позволяет сделать приложение более производительным. S>С этим никто и не спорил. На всякий случай напомню, что местная притча во языцех — Павел Дворкин, с юношеским задором объявлял повышение производительности за счет введения уровней абстракции нереалистичными.
И что мне с этого? Причем тут Дворкин? Я ему не родственник и не занимаюсь его апологией. Может, вместо того, чтобы приписывать мне чужие утверждения стоит мои сначала прочитать?
S>>>Как зачем? Чтобы рассуждения "теоретически, самый быстрый код — это написанный вручную на ассемблере" перестали быть голословными. ВВ>>Большинство рассуждений здесь голословны. Про суперкомпляторы, которые никто не видел в глаза S>Идем по ссылке, смотрим на суперкомпилятор джавы. В чем проблема?
Дело не ассемблере или C#. Игры, пожалуй, единственный софт, который я знаю, который имеет тенденцию выживать самый максимум из железа, несмотря даже на мощность этого самого железа. И от того, насколько удачно они смогут провести это "соковыживание" зависит их конкурентноспособность, ибо встречают-то все-таки по одежке.
А в таких случаях "абстракции" противопоказаны.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Здравствуйте, gandjustas, Вы писали:
PD>>>Ничего себе! В одном (твоем случае) речь идет об операциях в памяти. В другом (моем) — системные вызовы. И массива как такового в памяти, между прочим, нет вообще G>>Алгоритм от этого не меняется. Адерстенд? PD>Если ты готов алгоритм без анализа применять где угодно — что тут скажешь...
Такое барахло как этот код сумрования я бы вообще в продакшн ен пустил.
G>>Я думаю считать все пиксели в память а потом суммировать будет лучше. PD>А я так думаю, что введение лишнего массива без всякого обоснования не есть лучшее.
Добро пожаловать в настоящее, копромис время-память уже давно сместился в сторону времени, память теперь никто не жалеет. Ну может кроме тебя.
G>>Это мелочи. Измерять время можно с помощью rdtsc, программа от этого не изменится. PD>Программа не изменится. Изменятся выводы, так как их нельзя делать на данных, которые не позволяют делать эти выводы. В общем,см. курс матстатистики — сравнение двух средних и т.д.
Это нельяз делать потому что нельзя... смешно.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Здравствуйте, gandjustas, Вы писали:
G>>Такое барахло как этот код сумрования я бы вообще в продакшн ен пустил. PD>Чудненько. Можешь еще заявить, что суммирование вообще есть барахло, а поэтому его и не надо делать. Или придумай другой способ суммирования.
Пустая риторика, низачот.
G>>>>Я думаю считать все пиксели в память а потом суммировать будет лучше. PD>>>А я так думаю, что введение лишнего массива без всякого обоснования не есть лучшее. G>>Добро пожаловать в настоящее, копромис время-память уже давно сместился в сторону времени, память теперь никто не жалеет. Ну может кроме тебя. PD>И поэтому надо без всякого смысла создавать новый массив и тратить время на его заполнение. Когда выбор идет между временем и памятью — это имеет смысл и решение может быть и в ту и в другую пользу. Когда же увеличивают и то и другое без всякого смысла — это уже иначе называется.
Напряги свои знания WinAPI, может впомнишь что есть функция считывание всего битмапа из DC, что будет гораздо быстрее считывания отдельных пикселей.
PD>>>Программа не изменится. Изменятся выводы, так как их нельзя делать на данных, которые не позволяют делать эти выводы. В общем,см. курс матстатистики — сравнение двух средних и т.д. G>>Это нельяз делать потому что нельзя... смешно. PD>Да не смешно, а очень грустно, что элементарные понятия из матстатистики для тебя тайна за семью печатями.
Меня эти понятия. Мне достаточно сравнить два числа.
Если тебе для сравнения двух чисел надо привлекать матстатистику, то мне тебя очень жаль.
Здравствуйте, fmiracle, Вы писали:
F>Или наоборот — на фоне их и так немалых требований к ОЗУ оверхед от дотнета будет просто незаметен
Нет проблема в том что в той же приставке всего 256 метров памяти, а игра требует гораздо большего объема и в таких условиях ручное управление на порядки эффективнее чем GC
F>Такая вот диалектика, как про грязного мужика и баню
Угу только не в бане а очень тесной душевой кабине
Здравствуйте, AndrewVK, Вы писали:
FR>>Какой теории?
AVK>
проблема в том что в той же приставке всего 256 метров памяти, а игра требует гораздо большего объема и в таких условиях ручное управление на порядки эффективнее чем GC
Ты очень невнимательно читал, я выделил нужное.
В условиях нехватки памяти теория очень даже верна.
Здравствуйте, AndrewVK, Вы писали:
AVK>Автоматическое управление памятью — это внешний механизм. Разумеется, работа с ним это более высокий уровень. Но это самое управление памятью никаким образом не имеет отношения к работе с видеопамятью. Просто параллельна ей. И никак не мешает. То, что в С++ одна и та же механика используется для того и другого, совсем не означает, что это идентичные вещи. По факту — для управления созданием/удалением объектов в куче механика есть, для работы с поверхностями DirectX механики нету. Просто нету. И не потому что абстракции при этом противопоказаны, а потому что никто не озаботился.
Да дело даже не в видео-памяти. Если даже рассматривать только PC как платформу, то мне кажется сборка мусора может вносить довольно критический оверхед даже при работе с обычной ОЗУ. Памяти-то с одной стороны хоть и много, но с другой — ее постоянно не хватает. Игрушка спокойно может скушать гиг оперативы, и не только не подавится, но и еще попросит. Запаса-то особо не чувствуется. А память кончится — упремся в жесткий диск, и прощай производительность.
А теперь представим, что мы не только хотим написать движок на дотнете, но и сделать его более "абстрактным", упростить модификацию и добавление новых фич... Мне кажется, в таком случае выжать соки из железа совсем не получится.
А если взять приставки — то там вообще все тяжко. Железки-то по современным мерках уже не ахти какие, а ведь пользователи с каждой новой частью сериала закономерно ожидают каких-нибудь улучшений и новых красивостей. Это ж не PC, где мы добавили красивостей, задрали системные требования, пришили лейбл "best played on nvidia" — и шито крыто, заодно и железо продавать помогаем. С приставкой по определению приходится жить с тем, что есть.
Здравствуйте, FR, Вы писали:
FR>На PC все гораздо проще, объем доступной памяти намного больше, есть подкачка из виртуального файла для обычной памяти и отображение на системную для видео. В приставках же память очень даже ресурс. Вот тут http://www.dtf.ru/articles/print.php?id=4071 неплохо описана типичная работа с памятью в приставках.
Судя по тому же Кризису — память для PC это тоже ресурс. А подкачка из свопа == тормоза. Как и использование системной памяти вместо видео. Игра ведь это не слайдшоу
Здравствуйте, gandjustas, Вы писали:
ВВ>>А теперь представим, что мы не только хотим написать движок на дотнете, но и сделать его более "абстрактным", упростить модификацию и добавление новых фич... Мне кажется, в таком случае выжать соки из железа совсем не получится. G>Почему?
Ну соки-то ты, конечно, выжмешь, но результат может оказаться не таким уж впечатляющим. Зачем вводить дополнительный оверхед, прямым образом влияющий на ресурс, которого и так не хватает?
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Я, видимо, неточно выразился. Я имел в виду, не то, сольются ли они технически, а сольются ли в массовом масштабе.
Смотря что понимать под массовым масштабом.
PD> Иными словами, закончится ли зоопарк ОС на мобильниках переходом к некоей ОС, единой для мобильников и настольных (или как минимум неким интеграционным пакетом).
При чем тут ОС? И что такое интеграционный пакет? Давным давно проблемы написания разного софта определяются не ОС и загадочными пакетами (и линух для мелких дивайсов давно доступен, и WM твой любимый Win32 предоставляет в очень приличном объеме), а принципиальными ограничениями железа, размером экрана прежде всего и разными моделями применения (наличие тачскринов, GPS, но при этом отсутствие быстрых и скоростных дисков).
PD> А про телевидение — — останется ли вариант "вещания" или выживет только вариант "запроса" ?
Останется.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, IT, Вы писали:
IT>Это не совсем так. Есть вещи, которые невозможно сделать без поддержки компилятора/среды. Например, в ООП это перегрузка методов, в FP замыкания.
Оба эмулируются даже на си.
И к тому и замыкания и перегрузка методов это не более чем вкусности, они не являются необходимыми чтобы программировать в соответствующем стиле.
Здравствуйте, IT, Вы писали:
ГВ>>FP — это стиль, ничего больше. ООП — тоже.
IT>Это не совсем так. Есть вещи, которые невозможно сделать без поддержки компилятора/среды. Например, в ООП это перегрузка методов, в FP замыкания.
Я бы сказал так: невозможно так же компактно записать, как при наличии компилятора с соответствующими возможностями.
Но я имел в виду другое. FP, ООП, СП — это всё стили структурирования предметной области. Если хочешь — подходы. Можно даже "парадигмами" назвать. От возможностей компилятора реализация этих подходов до какой-то степени зависит, но только до какой-то.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Здравствуйте, Константин Б., Вы писали:
PD>>>Можно ссылочку на источник, где говорится, что они вызывают BitBlt ? Куда она копирует ? Где второй HDC ? КБ>>http://www.rsdn.ru/res/book/mmedia/yuan.xml
PD>Ссылку дают на конкретный текст, а не на оглавление какой-то книги. Пожалуйста, ссылку на то место, где сказано, что GetPixel вызывает BitBlt.
Когда вам дают ссылку, надо сказать "Спасибо, обязательно ознакомлюсь.". А если вы решили что я собираюсь с вами спорить, то вы ошиблись. Можете и дальше писать тормозной код с использованием GetPixel.
S>Тем не менее, мне ты продолжаешь твердить, что ASP.NET в целом — отстой. Мне как-то не очень хочется следить за раздвоениями личности и пытаться скомпоновать удобные мне утверждения из нескольких независимых постингов. S>Вот ты там поправился, с этим все согласились.
Тем не менее продолжается обсуждение в защиту веб-формс.
S>Потом ты продолжаешь сравнивать ASP.NET с PHP, при этом, похоже, имеешь в виду WebForms против XSLT.
А ты под АСП.НЕТ понимаешь все прелести, которые дает стандартная библиотка? Для меня если я разрабатываю приложение используя лишь низкоуровневые надстройки над ИЗАПИ — то не АСП.НЕТ. А АСП.НЕТ для меня эквивалентен веб-формс. Возможно, это неверное утверждение, но тогда это уже получается спор о терминах, который бесперспективен.
Большинство асп.нет приложений сейчас разрабатываются именно на веб-формс. И веб-формс как раз пример той самой абстракции, — по сравнению с более "традиционными" технологиями вроде ПХП (к-й кстати не столь уж и убог как может показаться) — которая не только не помогает, но — если задачи несколько отличаются от тривиальных — только усложняют жизнь. Для меня это пример случая, когда abstraction gain очевидно нету.
К тому же МС сама ведь не позиционирует веб-формс (по кр. мере до недавнего времени) как средство для конструирования хоум-пейджей — это блин энтерпрайз левел технология. И сама разрабатывает на ней приложения именно такого "левела". Что из этого получается, я уже неоднократно писал.
У меня вот перед глазами есть два примера — МОСС внедренный в одной немаленькой компании и портал собственной разработки, внедренный в совсем не маленькой компании, архитектуру которого я разрабатывал 3.5 года назад. Да, там дотнет 1.1, а не ПХП. Решают они примерно одинаковые задачи, хотя конечно же совокупные возможности МОСС заметно превосходят нашу разработку — "лицо интранета", быстрое конструирование портальных сайтов, CMS, всякие там орг. структуры, простенькое хранилище документов ну и разумеется интеграция в портал существующих и новых веб-приложений. И я прекрасно вижу во что это выливается в одном и другом случае. И сколько времени уходит на МОСС.
S>Напомню, что ASP.NET всплыл не потому, что вебФормз. А потому, что Рихтер прикрутил к дотнету Power Threading Library, которая позволяет писать офигенно высокопроизводительный код, не слишком жертвуя читаемостью. И потому, что использование IO Completion Ports, которое Рихтер облегчил, крайне важно как раз в серверах массового обслуживания, в частности в веб серверах. В десктопном приложении лишний десяток потоков — тьфу, семечки. А в сервере каждый поток на счету; неэффективные примитивы синхронизации способны убить производительность куда быстрее, чем проверки выхода за границы массивов.
Все это прямого отношения к вебу не имеет. И почему казалось бы тут "всплыл" асп.нет?
S>Здесь, конечно, никакого abstraction gain нету. S>Аналогичную реализацию теоретически можно получить "на ассемблере". Вот только из местных апологетов микрооптимизаций ни один чего-то не спешит представить доказательство в студию. Всё больше рассуждают о теории. Поэтому я настаиваю на эквивалентной честности к обеим сторонам. S>Потому, что теоретически abstraction gain таки не сводится к "голове". Я писал тут неподалеку, каким именно способом абстрактный код может обгонять ассемблер.
Это как раз и говорит о том, что в голове. В голове не значит, что его нет. В голове значит, что это "человеческий" фактор. Конечно же, если упираться в "крайние" примеры — то тут можно сказать только то, что "на ассемблере" их не только нельзя сделать более эффективно, но вообще чисто физически нельзя сделать.
А вот интересные примеры появляются, когда речь далеко не об ассемблере и не о разработке на нем асп.нет приложения, а о куда более приземленных вещах вроде веб-формс.
S>А если мы говорим об этом в том смысле, как имеет в виду Дворкин ("платформа у нас одна — win32"), то это просто ламерство.
Здравствуйте, Геннадий Васильев, Вы писали:
M>>>Почему по твоему мнению , серезные приложения которые я перечислял FFMPEG — JASPER написанны без использования FP ? на традиционных C/C++. ? IT>>Если бы они были написаны с использованием FP, то они были бы ещё серьёзней.
ГВ>Докажи.
Переписать всё на N? Да без проблем. У тебя кошелёк достаточно большого размера?
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
IT>Func<int,int> Foo(int x)
IT>{
IT> return y => x + y;
IT>}
IT>
IT>Эмулируй.
typedef struct TFoo
{
int (*Call)(struct TFoo*, int);
int x;
} Foo;
int Add(Foo *Self, int y)
{
return Self->x + y;
}
void Create(Foo *Self, int x)
{
Self->Call = Add;
Self->x = x;
}
FR>>И к тому и замыкания и перегрузка методов это не более чем вкусности, они не являются необходимыми чтобы программировать в соответствующем стиле.
IT>А этот топик о чём? Именно о вкусностях. А ты о чём думал?
Ну я то понимаю, но пока не попробуешь объяснять бесполезно
Здравствуйте, FR, Вы писали:
FR>Оба эмулируются даже на си. FR>И к тому и замыкания и перегрузка методов это не более чем вкусности, они не являются необходимыми чтобы программировать в соответствующем стиле.
Опять пошла подмена понятий. Они не являются необходимыми чтобы порвав задницу хоть что-то изобразить. Но можно ли назвать программированием эмуляцию приводящую к ужасному нагромождению кода?
Так что эмулировать конечно можно, а программировать нельзя.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, VoidEx, Вы писали:
VE>Больше всего, конечно, меня удивляет, почему надо выставить себя правым любым способом.
Хоть правым, хоть левым, лично мне без разницы. Мой код FP техники делают более серьёзным и мне самому себе доказывать ничего не надо. Если вы хотите, чтобы я это доказывал на ваших задачах, да ещё на достаточно объёмных, и если это вам действительно нужно, то я просто предлагаю заплатить мне за моё потраченное время. Ведь это будет работа не на час и не на два, в возможно на неделю, месяц, год. Я пока без понятия. Требовать от меня переписывания этого кода, конечно же, можно. Но тогда нужно будет подумать о компенсации моего времени. Что в этой логике не так?
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Здравствуйте, gandjustas, Вы писали:
G>>Здравствуйте, Pavel Dvorkin, Вы писали: G>>Это и надо, детали не волнуют. PD>Если это и надо, то надо именно это и делать, а не нести чушь насчет получения битов с помощью BitBlt.
Где я говорил такое?
PD>>>Уф! Ну как еще объяснять ? Не знаю. Не хватает моих педагогических способностей. Человеку говоришь — для сравнения двух приближенных чисел, полученных как результаты измерений, необходимо учитывать точность измерений. А он в ответ — да не надо, и так можно. В общем, 8.000001 всегда больше чем 8.00000, даже если точность измерения плюс-минус 0.001 G>>Не надо разводить демагогию без конкретных чисел. Какова погрешность измерения Time Stamp Counter? PD>А самому посмотреть можно ? Для GetTickCount — примерно 15 мсек. Что там в .Net — не знаю, выясни сам. Но при той точности моих данных (15 мсек) — делать какие бы то ни было выводы нельзя, даже если в .Net используется QueryPerfomanceCounter с хорошей точностью. Как минимум в этом случае надо перемерить мои данные с той же точностью.
Тогда к чему были несколько постов про матстатистику?
>>Какая разница значений будет на измеряемом коде? PD>Посмотри свое собственное сообщение, где ты утверждаешь, что тебе удалось на C# сделать лучше, чем мне на С++. Ты там сам эти значения приводишь. Разница измеряется путем вычитания одного из другого, полученное значение сравнивается с 15 мсек
В обоих случаях сравниваются милисекунды, измеренные с одинаковой точностью.
PD>Если немного серьезнее. Как преподаватель уже (не как программист) скажу вот что. Не знать что-то не стыдно. Но вот упорствовать в своем незнании не стоит. В конце концов от этого хуже тебе самому будет, не мне же.
Ну тогда изучай ФП, .NET вообще и PLinq в частности, а потом возвращайся.
Здравствуйте, Pavel Dvorkin, Вы писали:
AVK>>Россия в этом плане понятие отдельное ввиду территории
PD>Канада ? Китай ?
В Канаде почти все население сосредоточено по узкой полосе вдоль южной границы, а в Китае в деревнях даже канализация не всегда имеется, какой уж там triple play.
PD>Они примерно так же доступны, как в годы моей молодости телевизор был доступен.
Смотря где. В Москве они доступны кому угодно без особых проблем.
AVK>>Что "то же самое"? Наличие небольшого количества стандартных операционок? Так уже давно. Наличие идентичных с десктопом программ? Невозможно в принципе.
PD>Идентичных — да. Близких — нет.
Что значит близких? По внутренней архитектуре — легко. По user experience — даже близкие невозможны в принципе.
AVK>>У тебя смартфон? Если нет, то при чем тут компьютеры?
PD>При том, что при любом телефоне вопросы его подключения не должны меня заботить.
При чем тут вопросы подключения?
PD>Впечатление такое, что многие наши разногласия определяются взаимным непониманием. При чем тут твой мобильник ? Я имею в виду твой уровень понимания этой области vs понимание ее же обычным пользователем.
А при чем тут мой уровень понимания?
AVK>>У меня в профиле город, вроде как, указан.
PD>Сорри. Почему-то считал, что ты москвич. Но ИМХО разница небольшая.
Ну да, подумаешь, мегаполис с населением в 20 миллионов, и районный городок с населением чуть больше 100 тыс. Одна фигня
AVK>>Нет, не только для них. Старые телепреемники есть в огромных количествах. За 10 лет полного изменения ситуации не будет.
PD>Полного и не надо.
А какой надо? Все желающие давно уже приобрели себе тарелку с тем самым цифровым телевидением, благо стоит оно сейчас копейки.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Sinclair, Вы писали:
S>Здравствуйте, Воронков Василий, Вы писали: ВВ>>Тем не менее продолжается обсуждение в защиту веб-формс. S>Нет нигде обсуждения в защиту веб-формс.
Да я уже, понял. Я сам с собой разговариваю. Зачем мне вообще отвечать? У меня и так прекрасно получается.
Здравствуте, Воронков Василий, Вы писали:
ВВ>>ASP.NET — говно.
Это все от ламерства и полного бескультурия! Как ASP.NET может быть говном — ведь он же включает в себя все достоинства .NET, а следовательно и WPF. WPF — это самая мощная технология построения интранет-приложений, которая существует на настоящий момент. И которая как раз и предлагает мощный метаязык для описания представления — XAML. Какой человек в здравом уме скажет после этого, что ASP.NET — говно?
АSP.NET просто невменяемо рулит!
ВВ>>А ты под АСП.НЕТ понимаешь все прелести, которые дает стандартная библиотка? S>Естественно.
Интересно, а WindowsForms включает в себя разработку под веб? А то, может, WindowsForms тоже говно, а я и не заметил.
ВВ>>Для меня если я разрабатываю приложение используя лишь низкоуровневые надстройки над ИЗАПИ — то не АСП.НЕТ. А АСП.НЕТ для меня эквивалентен веб-формс. S>И в третий раз повторяю: очень плохо, что ты не можешь отделить вебФормз от АСП.НЕТ. Тренируйся, иначе так и будешь ключи подавать.
У месье богатый опыт работы консьержем? Предлагаю на досуге помедитировать над значением аббревиатуры ASP.
S>>>Напомню, что ASP.NET всплыл не потому, что вебФормз. А потому, что Рихтер прикрутил к дотнету Power Threading Library, которая позволяет писать офигенно высокопроизводительный код, не слишком жертвуя читаемостью. И потому, что использование IO Completion Ports, которое Рихтер облегчил, крайне важно как раз в серверах массового обслуживания, в частности в веб серверах. В десктопном приложении лишний десяток потоков — тьфу, семечки. А в сервере каждый поток на счету; неэффективные примитивы синхронизации способны убить производительность куда быстрее, чем проверки выхода за границы массивов. ВВ>>Все это прямого отношения к вебу не имеет. И почему казалось бы тут "всплыл" асп.нет? S>Бред какой-то. Мы что, начали с обсуждения веба? Нет, начали с производительности и возможностей по оптимизации. АСП.НЕТ здесь — только пример. Что тут непонятного?
"Мы" как раз и начали с обсуждения веба. Предложение написать ASP.NET-приложение на ассемблере и послужило начало дискуссии, если можно так выразиться. Видно, это было задумано как мощный аргумент, призванный свалить всех оппонентов "одним выстрелом".
Нет, ну правда, мы такие идиоты, кому вообще нужен ассемблер, если на нем нельзя написать эффективное веб-приложение?! Да еще за разумные сроки!
S>>>Здесь, конечно, никакого abstraction gain нету. S>>>Аналогичную реализацию теоретически можно получить "на ассемблере". Вот только из местных апологетов микрооптимизаций ни один чего-то не спешит представить доказательство в студию. Всё больше рассуждают о теории. Поэтому я настаиваю на эквивалентной честности к обеим сторонам. S>>>Потому, что теоретически abstraction gain таки не сводится к "голове". Я писал тут неподалеку, каким именно способом абстрактный код может обгонять ассемблер. ВВ>>Это как раз и говорит о том, что в голове. В голове не значит, что его нет. В голове значит, что это "человеческий" фактор. S>Еще раз: я писал не про человеческий, а про машинный фактор.
А я про человеческий. Машинный фактор — это 100110100110010001010.
ВВ>>Конечно же, если упираться в "крайние" примеры — то тут можно сказать только то, что "на ассемблере" их не только нельзя сделать более эффективно, но вообще чисто физически нельзя сделать. S>Ну какие же они крайние. Я привел очень простой пример. Там 30 строчек кода всё демонстрируют.
"Все" — это наверное то, что есть области, в которых ассемблер неприменим
Можно было и без "очень простого примера" это сказать. С этим даже Дворкин согласится.
ВВ>>А вот интересные примеры появляются, когда речь далеко не об ассемблере и не о разработке на нем асп.нет приложения, а о куда более приземленных вещах вроде веб-формс. S>Не понимаю, почему для интересных примеров нужно привлекать неправильное использование плохих фреймворков S>Вот мне интересны примеры, где правильно применяются хорошие фреймворки.
И поэтому мы говорим об ASP.NET приложении на ассемблере? Железная логика
Кстати, было бы очень интересно обсудить пример веб-приложения, в котором правильно применяются хорошие фреймворки, разработанного MS.
S>>>А если мы говорим об этом в том смысле, как имеет в виду Дворкин ("платформа у нас одна — win32"), то это просто ламерство. ВВ>>А если "одна платформа" — это XBox 360? S>Во-первых, в предыдущей фразе я об этом упомянул. Во-вторых, где у вас гарантия невыхода XBox370?
Предлагаешь производителям ждать XBox370 вместо того, чтобы делать игры? Чур-чур!
Здравствуйте, Sinclair, Вы писали:
S>Предоставляются богатейшие маркетинговые возможности — можно предоставлять контент за деньги; можно впаривать в него рекламу,
И можно написать софт, который более или менее надежно эту рекламу вырезает . Исполняться-то все это будет на PC, а тут опыт есть.
Здравствуйте, fmiracle, Вы писали:
F>Так что компании, вбухивающие миллионы в жесткую ручную оптимизацию под Х-Бокс, возможно, делают это напрасно (например, не смогут соптимизировать в рамках бюджета и проект умрет, или, например(!), можно было соптимизировать проще, а они ступили)
Консоль рано или поздно приходит к своему пределу. А железки там не обновишь. Да и жизненный цикл у консоли довольно длинный. Года два только нужно, чтобы она "раскрутилась" по-человечески.
Опять-таки логично, что пользователи в каждой новой игре хотят, чтобы стало по-красивее. Вот игры на PS2 до сих пор продаются лучше чем на PS3. А ты представляешь какое там железо? Пещерный век. И при этом сравни игры под PS2 первого поколения и последние эксклюзивы. Разница колоссальная — от "я не могу смотреть на это убожество" до "вполне сносно".
Здравствуйте, FR, Вы писали:
FR>Здравствуйте, fmiracle, Вы писали:
F>>Так что компании, вбухивающие миллионы в жесткую ручную оптимизацию под Х-Бокс, возможно, делают это напрасно (например, не смогут соптимизировать в рамках бюджета и проект умрет, или, например(!), можно было соптимизировать проще, а они ступили)
FR>Не напрасно, во первых это просто необходимо чтобы вообще получить разрешение на издание (есть жесткие нормативы по времени загрузки, фпс и т. п.) во вторых очень жескоконкурентный рынок в котором "победитель получает все" (20% хитов забирают 80% прибыли)
И это никак не говорит о том что нужно именно вручную оптимизировать на ассемблере...
Я же не спорю, что нужно заботиться о производительности и эффективности. Я не согласен только с утверждением, что достаточной производительности всегда можно получить только хардкорной оптимизацией на самом низком уровне.
(прошу обратить внимание на выделенное)
А то может получиться как у Павла в Юморе — делал сложную обработку массива, а потом выяснилось, что если его вообще убрать нафиг, то разница-то почти незаметна, и ей можно пренебречь.
P.S.
Кстати, жесткая ручная оптимизация под приставки сильно легче оптимизации под ПК или сервера — именно из-за того, что железо гарантированно одно и то же у всех пользователей.
Это обратная сторона медали ограниченности и фиксированности железа. Да, нельзя поднять требования, но с другой стороны не нужно рассматривать различные случаи возможных комбинаций оборудования у пользователя.
Здравствуйте, Sinclair, Вы писали:
S>>>Предоставляются богатейшие маркетинговые возможности — можно предоставлять контент за деньги; можно впаривать в него рекламу, PD>>И можно написать софт, который более или менее надежно эту рекламу вырезает . Исполняться-то все это будет на PC, а тут опыт есть. S>Ну, вопрос, конечно, интересный. Вот ты сериалы смотришь с какого-нибудь lostfilm.tv?
Я вообще никакие сериалы не смотрю . Объясянть почему — не буду, а то кто-нибудь обидится
>Обрати внимание, что в них врезана реклама "смотрите далее на нашем канале". Как ты собираешься ее вырезать? Это ж не HTML, где честно написано "а вот здесь идет баннер".
Поскольку не смотрю, то не могу судить, как именно там это сделано. Но реклама на обычном ТВ практически часто сопровождается повышением силы звука, что вполне можно программно отловить. Менее уверен, что можно отловить тот истерический тон, в котором она ведется, т.е. отличить его (скажем, анализом частот и амплитуд звука), но не исключено, что и это возможно. Ну а против реккламы без звука я ничего против не имею, так как можно просто не смотреть. Вот реклама со звуком меня раздражает — приходится держать все время рядом пульт, чтобы это издевательство прекратить.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Поскольку не смотрю, то не могу судить, как именно там это сделано. Но реклама на обычном ТВ практически часто сопровождается повышением силы звука, что вполне можно программно отловить.
Вот начали какие-нибудь живописные взрывы показывать, "повышение звука" произошло, а твой вырезальщик взял да вырезал самый кульминационный момент
Здравствуйте, _FRED_, Вы писали:
VD>>Тогда те кто работают в США большие профессионалы чем те кто работает Москве. А те кто работает в Малых Васюках вообще ламеры.
_FR>Речь шла об "уровне", то есть некой относительной величине. Только вот не ясно, как её мерять.
Уровень, как зарплаты, так и знаний определяется тучей факторов. Скажем уровень зарплаты определяется в частности востребованностью кокретных скилов и наличием предложения на рынке. Простой пример. 1С-ники были низкоплачиваемой раб. силой до тех пор пока не прошел слух, что С1 завязывает с поддержкой 7-ой версии. Сразу после этого зарплаты у 1С-ников взлетели до уровня высококвалифицированных программистов. При это умнее или работоспособнее никто из 1С-ников не стал.
Что до уровня занний, то это вообще субъективная оценка. Скажем многие преподаватели сильно переоценивают свои реальные знания. И почти все преподаватели недооценены с точки зрения зарплаты (даже те что действительно являются отличными программистами).
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Pavel Dvorkin, Вы писали:
VD>>А жаль. Потому как какому числу людей ты будущее загубил только Бог может судить.
PD>М-да. Что тут скажешь. Все, что я могу в твой адрес сказать — выходит за рамки допустимого не только правилами RSDN, но и обычными правилами, принятыми в среде порядочных людей.
В моей среде принято говорить правду. Ты уж не серчай.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, IT, Вы писали:
ГВ>>Очень хорошо, но это тоже из другой оперы. От того, что язык заставляет определённым образом структурировать программу стили построения абстракций не перестают быть стилями, не находишь?
IT>Конечно, чисто теоретически FP и OOP в C такой же стиль как и в Nemerle. А чисто практически его там нет напрочь и никогда в жизни не будет.
По-моему, всё как раз наоборот — если есть некоторая, скажем так, теоретическая база, то никто не мешает ей пользоваться "чисто практически" даже "в Си". Вернее — мешает, но эти помехи к особенностям языков программирования не относятся.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Геннадий Васильев, Вы писали:
ГВ>Ну или давай поставим вопрос — что же такое "серьёзность" кода?
Это вопрос не ко мне, а к тому кто этот термин ввернул в дискуссию.
ГВ>Ты говоришь, что у тебя код становится серьёзней, когда ты его пишешь не Немерле.
Я это утверждаю со всей ответственностью.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, Геннадий Васильев, Вы писали:
IT>>Я это утверждаю со всей ответственностью.
ГВ>Ответственность за правомерность термина, смысл которого ещё кто-то должен разъяснить? Лихо.
Не кто-то, а тот кто его ввёл в этой ветке. Все свои притензии туда.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, Геннадий Васильев, Вы писали:
IT>>Выше я тебе уже всё объяснил в примерах на immutable.
ГВ>В immutable-стиле как раз можно писать на Си. Здесь скорее мешают некоторые стереотипы и устоявшиеся подходы к проектированию, иных больших препятствия я не вижу. Но, правда, подозреваю, что распространение многоядерных "настольных процессоров" сильно поспособствует изменению подходов.
От блин Объясняю на пальцах в третий и последний раз. Теоретико-гепотетическая возможность на практике совершенно никого не интересует. Никто и никогда писать immutable код на C# не станет. Вот ты сам много написал такого кода? А я пишу, но только на N, потому что он к этому принуждает. Раньше сильно противился, потом въехал. Но даже сейчас на C# я такой код не пишу по простой причине. Это хоть и просто принцип, но в N он кроме принуждения ещё и отлично поддержвается компилятором, в частности наличием туплов, pattern matching, тем, что if, match и практически все остальные конструкции языка возращают значения и пр. Без такой поддержки immutable стиль создаёт больше проблем, чем их решает. Попробуй сам. Возьми, какой-нибудь не очень сложный алгоритм и попробуй его переписать в этом стиле.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, Геннадий Васильев, Вы писали:
IT>>От блин Объясняю на пальцах в третий и последний раз. Теоретико-гепотетическая возможность на практике совершенно никого не интересует.
ГВ>Меня интересует, соответственно — спрячь пальцы и не колоти молотком по компьютеру. Почти наверняка интересует и ещё кого-то (хотя это и не особо важно).
Я вот тут подумал и понял, что на самом деле без поддержки компилятором immutable style невозможен даже теоретически.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, FR, Вы писали:
FR>Ну не совсем бред, та же эмуляция ООП на Си для очень многих задач вполне окупается. Также и написанние в стиле ФП даже на языках совсем для этого не предназначеных тоже бывает иногда лучше других вариантов.
Вспомнить тот же STL стыренный у Лиспа.
Lisp is not dead. It’s just the URL that has changed: http://clojure.org
Здравствуйте, IT, Вы писали:
IT>Здравствуйте, Геннадий Васильев, Вы писали:
ГВ>>Ну или давай поставим вопрос — что же такое "серьёзность" кода?
IT>Это вопрос не ко мне, а к тому кто этот термин ввернул в дискуссию.
Вот только беда, что ты сам его и ввернул, да?
Чтобы не быть голословным:
IT> Мой код FP техники делают более серьёзным и мне самому себе доказывать ничего не надо.
M> Почему по твоему мнению , серезные приложения которые я перечислял FFMPEG — JASPER написанны без использования FP ? на традиционных C/C++. ?
Ну-с и повторяем тогда вопрос, что же такое "серьёзность" кода?
Здравствуйте, AndrewVK, Вы писали:
ВВ>>"Волновое" телевидение — это такая кочерга на крыше. AVK>Инженеры, блин, обсуждают технический вопрос.
Положь колдобину со стороны загогулины... (с)
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
ВВ>Через канал шириной 1Gbit фильм будет качаться со скоростью 10Gbit? Какие-нибудь средства наркотические надо будет принимать для этого?
Гм. Когда мы говорим об интернете, речь идет о нескольких каналах.
Поясняю: дело в том, что у протокола TCP/IP нет управления качеством сервиса. Поэтому, вообще говоря, ширина канала от точки A до точки B равна ширине "самого узкого звена".
В итоге, иметь локальный канал в 10Gbit — это совсем не то же самое, что иметь канал до провайдера шириной в 10Gbit.
Об этом я и говорю: вместо того, чтобы тянуть от провайдера со скоростью в 1Gbit ты будешь тянуть от N ретрансляторов с суммарной скоростью выше 1Gbit.
ВВ>А какие? Чем будут отличаться?
Они будут отличаться тем, что контроль за расшаренным контентом будет осуществляться не тобой, а провайдером.
Ты не сможешь ничего опубликовать в такую сеть — точно так же, как сейчас не можешь ничего транслировать по первому каналу.
ВВ>Сейчас пиринг — это тот же lostfilm.tv, novafilm.tv, animereactor и пр. Они работают именно по такому принципу.
Они работают по принципу нарушения копирайта. Это ненормально. Брать с тебя тридцать долларов за диск, который ты даже не имеешь права посмотреть с друзьями — тоже ненормально.
Нормально — когда ты пользуешься контентом за скромные деньги, но при этом правообладатель получает за это свою долю.
Одну из таких моделей я тебе как раз и описываю.
ВВ>Раздача предполагает и мое косвенное участие. Я должен держать контент на винте. Я должен держать сам девайс включенным. Я должен терпеть деградацию по скорости и пр. ВВ>К тому же у пиринга есть и еще одна проблема — стриминг идет лесом.
Опять же — это существующее положение вещей. Мы же говорим про телевидение будущего, не так ли?
Вот одна из самых жизнеспособных моделей телевидения on-demand — это построение сети из приемников, которые всё делают автоматически.
С твоей точки зрения всё будет выглядеть неотличимо от стриминга — ты нажал play, оно заиграло. А как оно там использует встроенный винчестер и сетевой провод — дело техническое и малоинтересное. Весь пиринг и прочее — это обеспечение эффективной широкой полосы дешевыми средствами.
... << RSDN@Home 1.2.0 alpha rev. 677>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
AVK>Тебя клинит на Москве, что ли? У меня на даче, что в 130 км от МКАД тоже Москва, что там вся деревня в тарелках? То, что у вас тарелок нет, скорее всего говорит о том, что развиты кабельные сети. А до кабельной сети контент наверняка доставляется через те же самые тарельки.
Сложность в том, что в 130км от МКАДа видны те же спутники, что и в 13. А в 3500 от МКАДа с этим как-то очень плохо.
Продавцы тарелок у нас на вопрос "а что через них у нас принимают" начинают мяться и говорить, что надо бы ставить двухметровую.
... << RSDN@Home 1.2.0 alpha rev. 677>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, IT, Вы писали:
ГВ>>Например — цикл. IT>Например, if и switch.
С if и switch, как раз понятно: они вполне укладываются в функциональный стиль — выбор и выбор. Можно выбирать функции, можно — значения. Можно унифицировать возращаемые типы по всем веткам и получить некий "типизованный" if.
ГВ>>Что он должен возвращать? IT>Цикл тоже хороший пример конструкции с изменяемым состоянием. В FP он обычно заменяется функциями с хвостовой рекурсией, которые, ты не поверишь, возвращают значения.
Ты уходишь от ответа. Так что же должен возвращать цикл? Особено это интересно в контексте обсуждения immutable-стиля.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Sinclair, Вы писали:
S>Здравствуйте, Воронков Василий, Вы писали: ВВ>>У меня проблем нет, т.к. я не пытаюсь доказать, что какая-то одна технология, архитектура, модель программирования и проч. несравненно лучшем чем все остальные и подходит всегда и везде. S>А кто-то пытается?
А о чем тогда спор?
ВВ>>А еще можно посмотреть на GDI+. S>Можно, но смысла нет. Ничего фундаментально нового он не дает. Так, немножко улучшенная модель GDI.
А на WTL смысл есть смотреть? Каким образом тут Хром всплыл, мне интересно?
ВВ>>Та, часть которая про Forms реализуется по большей части на GDI+. Есть какие-то конкретные претензии к реализации? S>К обертке? Нет, к обертке претензий нету. Ну, кроме того, что стандартные контролы из WinForms — жуткое убожество, а свои нормальные писать крайне неудобно. S>По сравнению, естественно, с полноценными фреймворками.
А можно по-конкретнее? Что там неудобно? Что сложно реализовать?
Реализация одного и того же функционала — допустим контрол, с большим кол-вом owner draw — на GDI+ и на WPF занимает почему-то весьма и весьма схожее время. Реализация этого функционала на WPF получается никак не "проще". При этом еще и АА в итоге кривой
ВВ>>Архитектура вин-форм *отвечает* архитектуре юзер32, представляя *достаточный* уровень абстракции, благодаря которому и разработка упрощается, и всегда можно спуститься на "ступеньку" ниже — причем это не будет выглядеть как хак. Утверждать, что вин-формс хуже чем WTL... очень я не уверен, что хуже. S>Я такого не утверждал.
В таком случая определишь, что ты утверждаешь.
ВВ>>А сравнивать ее, извините, с движком, который HTML рендерит. S>О, я так и знал, что именно этот аргумент прозвучит из уст человека, который все выводы строит на основе знакомых слов в названии технологии. Если ASP — значит про странички, если win32 — значит про окошки, если HTMLayout — значит про HTML.
Вообще-то я игрался с HTMLayout, правда не очень недавно. И он именно, что HTML и рендерит Причем на тот момент не дружил с XHTML и CSS.
ВВ>>HTMLayout вообще идеологически ближе к WPF вообще-то. S>Cовершенно верною Ну то есть он идеологически ближе к нормальной платформе для построения GUI. В которой логика отделена от представления, а представление — от отрисовки.
Ну правильно. HTML + браузер. Вот с одной стороны язык разметки, описывающий представления и в то же время отделенный — я бы даже сказал "отдаленный" — от отрисовки. HTML в данном случае можно понимать как некий язык разметки, к которому тот же XAML довольно близок идеологически.
Но если все так просто, то почему ж классические веб-технологии, где как раз и есть что работа с HTML врукопашную, приводят к такой каше в коде?
ВВ>>С вин-формс разработка реально упрощается. Выбранная архитектура естестественна для "окошек". Всякий раз, когда ты упираешь в ограничения, ты упираешься в ограничения не собственно вин-формс, а именно этих самых "окошек". ВВ>>Так в чем проблема? S>Да нет никакой проблемы. Точно так же, как в ASP.NET — выкидываем всё из System.Windows.Forms и пользуемся своим.
Только вот в итоге все равно непонятно, что в вин-формс не нравится. Уровень абстракции недостаточно высок?
Помнится, несколько постов назад ты утверждал, что "никто не защищает веб-формс". Теперь тактика поменялась? Решил путем аналогий начать, так сказать, апологию веб-форм? А смысл?
У меня вот складывается ощущение, что ты не какую-то точку зрения пытаешься доказать, потому что судя по всему ее нет — или ты ее по крайней мере очень хорошо скрываешь — а то, что твой оппонент идиот.
S>>>А ты используй термины по назначению — я и не буду критиковать их использование. ВВ>>"По назначению" — это, видимо, так, как используешь их ты. S>Нет, это так, как их используют все.
"Все", значит, считают, что ASP.NET "нигде не кончается", т.е. практически эквивалентент понятию .NET, но при этом WPF к ASP.NET не имеет никакого отношения.
ВВ>>То, что на PS3 запускаются только некоторые игры PS2 да и то под эмулятором не является свидетельством? S>А производители не предлагают PS3-аналоги своих PS2 игр? Я, честно, не в курсе — никогда не увлекался приставками.
Что такое PS3-аналог PS2-игры?
Игра может выйти одновременно на PS3 и PS2 — но почему-то такие игры всегда заметны "с первого взгляда". Причем когда некст-ген вошел в полную силу, они практически изсчезли, ибо не конкурентноспособны.
Игры с бокса, где 512МБ памяти и дохлая по современным меркам карта, с никакой пропускной способностью, умудряются тормозить на PC с 4ГБ шустрой оперативы и 8800GTX, хотя по мощность такой комп превосходит бокс чуть ли не на порядок. Т.е. тут речь даже не о том, что в 2 раза медленнее оказывается игра, а о куда более страшных цифрах. Почему же они так портируются-то хреново, интересно? А ведь у бокса еще близкая к PC архитектура. А что уж тут говорить про PS3 где 9-ядерный Cell.
Здравствуйте, Aen Sidhe, Вы писали:
ВВ>>Это из области "все мы сидим в локалке"? Под локальной сетью обычно имеется в виду все-таки некоторая "сеть", где доступны другие ноды, контент и пр. У меня ADSL2, у меня нет никакой внутренней сети. Причем на самом деле необходимости в ней и не возникает. AS>У меня тоже АДСЛ2 и локалка есть. Иногда полезна — внутренний канал несколько ширше внешнего пока.
Ну я уже говорил. Я не думаю, что прям всем кроме меня одного очевидны преимущества локальной сети, пиринга и проч. Мне удобнее платный файл-сервер, чем пиринг, хотя я пользуюсь и тем и другим. А для того, чтобы пиринг захватил мир, нужна "критическая масса".
Здравствуйте, Pavel Dvorkin, Вы писали:
ВВ>>Да не дадут тебе этого на PC. PD>Речь шла об интеграции ТВ и PC. Как это мне чего-то не дадут на IBM PC ? Не дадут — сами возьмем >>Или дадут через дикие ограничение ОС, которую надо будет в специальный "медиа-режим" вводить, чтобы можно было высококачественный контент смотреть. А скаченное через какой-нибудь торрент вообще не будут запускаться. PD>Не верю. Расхакают в конечном счете все что угодно.
"Расхакать" все что угодно можно. Чем больше совершенствуются методы пиратства, тем жестче становятся методы борьбы с пиратством и наоборот. Приставки игровые вот существуют каким-то образом — а там ограничения похожей природы.
>>ВВ>ИМХО как только в полную силу развернется цифровая дистрибьюция, и доходы больших компаний будут зависеть от того, сможешь ли прокрутить рекламу или нет — ужесточения появятся просто дикие.
PD>Посмотрим .
Здравствуйте, IT, Вы писали:
ГВ>>С if и switch, как раз понятно: они вполне укладываются в функциональный стиль — выбор и выбор. IT>Ты о чём? Ни в C#, ни в C/C++ ни if, ни switch ничего не возвращают и никогда не будут возвращать. Так что про immutable стиль в этих языках забудь.
if/switch не предполагают изменения состояния. Pattern matching это что по-твоему, как не завуалированный if?
IT>Так я же тебе как раз и объясняю или ты опять не понял Функциональный аналог цикла — это функция с хвостовой рекурсией.
Да нет, это я как раз понял. Мне по-прежнему непонятно, что должно мешать программировать в FP-стиле на языках семейства С? Семантика if/switch здесь точно не помеха. Цикл — зависит от способности компилятора выделять хвостовую рекурсию, да и с другой стороны — не всегда его нужно преобразовывать в рекурсию.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Геннадий Васильев, Вы писали:
ГВ>if/switch не предполагают изменения состояния. Pattern matching это что по-твоему, как не завуалированный if?
if/switch не возвращающие значение и не меняющие состояния бесполезны и безсмысленны.
ГВ>Да нет, это я как раз понял. Мне по-прежнему непонятно, что должно мешать программировать в FP-стиле на языках семейства С? Семантика if/switch здесь точно не помеха.
Самая что ни на есть помеха. Любой алгоритм, выполняющий полезную работу, производит действия над определёнными данными. В императиве эти действия производятся непосредственно над самими данными, меняя тем самым их текущее состояние. В FP текущее состояние не меняется, оно каждый раз воссоздаётся заново. Это состояние хранится в передаваемых параметрах и передаётся в возвращаемых значениях как эстафетная палочка следующей части алгоритма. Если конструкция не возвращает значения, то в immutable стиле она перестаёт работать как часть процесса вычисления и становится бесполезной.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, IT, Вы писали:
IT>if/switch не возвращающие значение и не меняющие состояния бесполезны и безсмысленны.
А вот тут ты явно подменяешь понятия, в том же си ничто ни мешает писать так чтобы if или switch всегда возвращали значения, кроме того если уж совсем до маразма доходить то никто еще тернарный оператор "?" не отменял.
ГВ>>Да нет, это я как раз понял. Мне по-прежнему непонятно, что должно мешать программировать в FP-стиле на языках семейства С? Семантика if/switch здесь точно не помеха.
IT>Самая что ни на есть помеха. Любой алгоритм, выполняющий полезную работу, производит действия над определёнными данными. В императиве эти действия производятся непосредственно над самими данными, меняя тем самым их текущее состояние. В FP текущее состояние не меняется, оно каждый раз воссоздаётся заново. Это состояние хранится в передаваемых параметрах и передаётся в возвращаемых значениях как эстафетная палочка следующей части алгоритма. Если конструкция не возвращает значения, то в immutable стиле она перестаёт работать как часть процесса вычисления и становится бесполезной.
Нисколько ни помеха. Чтобы функциональнй стиль нормально работал, достаточно чтобы функция не меняла никакие внешние состояния и не имела мутабельного внутренего сохраняемого между вызовами состояния. Что происходит внутри нее при этом совершенно неважно, даже без проблем допустимо чтобы внутри она использовала и мутабельные переменные и циклы или любую другую имеративщину.
FR>>А вот тут ты явно подменяешь понятия, в том же си ничто ни мешает писать так чтобы if или switch всегда возвращали значения, кроме того если уж совсем до маразма доходить то никто еще тернарный оператор "?" не отменял.
IT>Это сейчас ты начнёшь подменять понятия, если я попрошу тебя привести код, где if и switch возвращают значения.
Я уже приводил, но мне не трудно повторить:
int fib_r(int n, int a, int b)
{
if(n == 0)
return a;
return fib_r(n - 1, b, a + b);
}
здесь if всегда возвращает значения, код чисто функционален, написан на си.
Могу еще и так повторить
int fib_r(int n, int a, int b)
{
return n == 0 ? a : fib_r(n - 1, b, a + b);
}
FR>>Нисколько ни помеха. Чтобы функциональнй стиль нормально работал, достаточно чтобы функция не меняла никакие внешние состояния и не имела мутабельного внутренего сохраняемого между вызовами состояния. Что происходит внутри нее при этом совершенно неважно, даже без проблем допустимо чтобы внутри она использовала и мутабельные переменные и циклы или любую другую имеративщину.
IT>Это кому не важно? Тебе? Ну с этим я спорить не буду. Но и функциональным стилем это назвать не могу.
Не важно для того чтобы программировать в ФП стиле, и писать при этом чисто функционально даже на си.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Здравствуйте, gandjustas, Вы писали:
ВВ>>>Ну таким образом "функциональщина" — это что, по твоему мнению? Просто когда часть кода написана в ф-ном стиле, а часть как угодно? G>>Писать ВСЕ в функциональном стиле а)неэффективно б)не всегда возможно. Практически в любом проекте на функ. языке будет немного императивного кода.
ВВ>А в данном случае речь о том, что "функциональность" соблюдается только снаружи. "Распарелливать" и "оптимизировать" можно и без нее. Пишите "красиво" на ООП.
Вообще любую программу можно написать на ассемблере, выше уже обсуждали. Только трудозатраты слишком велики. Так и распараллеливанием. Композиция чистых функций распараллеливается декларативно (может даже автоматически, но это не нужно), для императивного кода так сделать не получается.
Что касается оптимизации, то для чистых функций результат работы можно заменить на константу, если функция в программе или подпрограмме вызывается на небольшом конечном множестве аргуметнов. Для императивного кода такое выполнить в большенстве случаев невозможно.
ВВ>>>Ты вот ратуешь за "чистоту" функций — т.е. внутри что угодно, а внешне все должно быть stateless, immutable и проч. — но для чего нужна эта "чистота"? Для того, чтобы код в других фукнциях выглядел функционально? При это часть кода у тебя проекте по-прежнему будет в императивном стиле. G>>Чем больше чистых функций, тем проще создавать из них другие чистые функции, тем проще распараллеливать и оптимизировать код. ВВ>>>Мне казалось, что ФП предполагает нечто иное. G>>Что именно?
ВВ>Изменение стереотипов. Можно, конечно, рассуждать, что императивность не искоренима в принципе и везде есть чуточку "императива" — пожалуй и так, но суть-то не в этом. ВВ>Если новая концепция программирования не заставляет тебя думать и писать по-другому, а лишь помогает что-то там "распараллелить", то в recycle bin эту концепцию.
ФП заставляет думать и писать по-другому. Простота распараллеливания и оптимизации чистого функционального кода — это следствие.
ВВ>У вас же получается, что мы думаем по-старому, пишем по-старому ("по-старому" кстати далеко не эквивалетно "плохо"), и при этом используем какие-то "фишки" функционального стиля, при этом считая, что "функциональщина" больше ничего не дает.
Такой подход тоде может использоваться. Иногда очень оправданно.
Здравствуйте, AndrewVK, Вы писали:
AVK>То и значит. Каждый тег имеет вполне конкретное, присущее самому HTML значение. Тег же в XAML несет в себе довольно мало семантики, в основном это увязка с его компонентной моделью, которая неизмеримо более примитивна, нежели HTML. Все остальное навешивает уже конкретный фреймворк, который XAMLом пользуется.
Т.е. разница в том, что XAML более прост как язык разметки, чем HTML? В чем "конкретность" HTML? Его описания могут транслироваться и транслируются во что угодно, от окошек вин32 до "нарисованных красивостей". И там и там мы имеем описание именно представления, конкретного представления, стилей и пр.
ВВ>> Конкретную для кого? AVK>Для всех. ВВ>> Кроме общих слов есть что-нибудь сказать? AVK>Это не общие слова, это вполне себе конкретика. ВВ>>HTML — язык разметки, описывающий структуру страницы, используемые на ней элементы и их визуальное представление. AVK>Ну вот видишь, ты сам все знаешь. ВВ>> XAML делает то же самое абсолютно. AVK>Нет. Ничего этого в XAML нет. Термины XAML это: меппинг пространства имен, компоненты, свойства, присоединенные свойства, контент.
XAML описывает структуры, используемые компоненты, их представление. Нет?
ВВ>> Можешь называть это "форматом сериализации" или как-то иначе — суть от этого не изменится. AVK>Суть конечно не изменится, чего бы я не называл. Главное, что эта суть по факту совсем не та суть, что в HTML. ВВ>> Про HTML я тоже могу сказать, что это формат сериализации объектной модели документа, и что?
AVK>И все. Даже если это так (а это не так), то это не просто формат сериализации документа, это формат вполне конкретного документа. Ни для чего другого он не годен.
А для чего еще годен XAML кроме как быть "форматом сериализации" конкретного "документа"?
ВВ>>Мы вообще о контролах говорим? Или как? Я с таким явлением как способ расширения функционала контролов "вообще" не знаком. AVK>Что, никогда не наследовался от контролов винформсов? А если наследовался, не скажешь с какой целью?
Наследовался. Именно с этой целью. Но ты знаешь, не так уж и часто.
ВВ>> И что такое расширение? AVK>Словарик руского языка подарить?
Могу с тобой поменяться на учебник логики. Заодно разберешься, чем "вообще" отличается от "в частности". И если "в частности" надо наследоваться для расширения функционала, это не означается "вообще" это надо делать.
ВВ>>Чтобы "расширить" DataGridView — я напишу собственный тип ячейки/колонки. AVK>Ага, это единственный контрол, который хоть что то из себя в плане дизайна представляет. ВВ>>Для изменения поведения некоторых контролов — например при валидации ошибок — я буду использовать совершенно отдельный такой проперти-провайдер. AVK>Вот только, скажем, код отработки default button и ее modal result намертво прошит в код Form.
И кто-то при этом мешает переопределить modal result?
ВВ>>Да и еще помнится только взяв в руки вин-формс в году этак 2003 я делал owner-draw меню без всякого наследования, а через отдельный такой класс-адаптер. AVK>Поздравляю. К сожалению, отдельные моменты не исключают общей печальной ситуации.
Вот только эти "отдельные моменты" почему-то очень во многих случаях работают.
ВВ>>Слушай, а для того, чтобы красивый тултип к контролу добавить — тоже небось наследоваться придется? AVK>Если ты будешь разговаривать в таком тоне, я общение с тобой закончу. Не надо дурачка изображать, ты все прекрасно понял.
Не знаю, кто тут изображает "дурачка". Ты когда ScintillaWrapper как там конкретно контрол создавал, не вспомнишь?
ВВ>>Как хендл связан с агрегацией, а? AVK>А ты попробуй отнаследовать свой контрол от Control и агрегировать в нем функционал, скажем, TreeView.
1. Controls.Add
2. override CreateParams
ВВ>>Расскажи какие сценарии реюза тебе требовались, и ты не смог их реализовать на вин-формс.
AVK>Например когда шаблон UI не квадратный кусок, а состоит из разных частей, перемежаемых кастомным UI. В WPF это делается сравнительно просто, без привлечения тяжелой артиллерии.
Что такое "состоит из разных частей, перемежаемых кастомным UI"? Я честно пытался представить, что это значит, но, увы, не получилось
AVK>Да, для развлекухи могу предложить поизучать дизайнер (и дизайн) SplitterContainer, познавательно.
SplitContainer? И что там? То, что он убоговат с первого взгляда видно. Так напиши свой
Меня, кстати, он вполне устраивал.
ВВ>> Вин-формс, при всей его "неоднородности", "убогости" и проч. — огромный прогресс по сравнению с тем, что было до этого. AVK>Во-первых это его в современных условиях лучше не делает, во-вторых на момент его релиза свинг уже порядочно времени как был зарелизен, а по сравнению с ним, ты уж извини, это все таки регресс.
Мне вот интересно — вы все серьезно считаете, что сравнение кросс-платформенного фреймворка и надстройки над конкретной платформой — это корректно? И непонятно какие преимущества дает "одноплатформенный" фреймворк?
AVK>Винформс, выйди он году в 95, был бы вполне адекватен времени, но в 2002 он явно устарел.
Не знаю, как у вас там со свингами и прочими джазами, но в вин-среде и в 2002 вин-формс выглядел весьма и весьма внушительно. По сравнению с тем, что предлагала МС до этого — огромный прогресс. Архитектура завязанная на модель событий — очень логичная для юзер32.
ВВ>> Его убогость и неоднородность является отличной надстройкой над юзер32. AVK>Оно тут не причем. Почти все пакости user32 легко замазываются. Опять же, обрати внимание, большинство тех проблем, что я перечислил, никакого отношения к user32 не имеют. К примеру, байндинга в нем просто нет. Отсутствует как класс. Что не помешало вкрячить коллекцию DataBindings в интерфейс базового контрола.
Ты перечислил проблемы в стиле "примитивная компонентная модель" или "неудобный и примитивный АПИ для взаимодействия с состоянием". В таком стиле эту тему можно перетирать бесконечно. А вот конкретные примеры что-то не выглядят убедительно.
ВВ>> Да, он неидеален в деталях, но базовая архитектура для "окошек" там хороша. AVK>Детали фигня, благо поставщики компонентов переписывают чуть ли не все контролы. Проблема именно в базовой архитектуре. Главное чудовище это класс Control, а не куча его наследников.
Да нормально там все с классом Контрол. Да он перегружен, но сделано так было не в последнюю очередь для удобства. И не припомню, чтобы у меня возникали какие-то специфические проблемы связанные именно с "перегруженностью" Контрола.
А базовая архитектура — это обработка сообщений через события, и она хороша.
ВВ>>И у меня ни разу не возникало желание выбросить на фиг вин-формс как ненужный уровень абстракции и вернуться "обратно", сообщения обрабатывать. AVK>Это, видимо, потому что опыт ковыряния у тебя в этой каке небольшой.
Любое мнение отличное от вашего возможно лишь в силу незнания, ограниченности или недостаточного опыта. Это несомненно.
AVK>Опять же, еще большая кривизна user32 никак не делает дизайн винформсов хорошим.
Делает. Делает его лучше чем работа напрямую с юзер32. Что уже хорошо. Хотя бы то, что в худшем случае не мешает. Чего я не могу сказать про веб-формс и тамошний "низкий уровень" в виде обработки реквестов напрямую.
Здравствуйте, AndrewVK, Вы писали:
AVK>Мне нужно, чтобы ты осознал, что Россия №1 по площади и всего лишь №9 по населению.
Осознал
PD>>>>Сдается мне, что о персональных компьютерах в 1981 году говорили примерно то же самое.
AVK>>>Нет, не говорил.
PD>>Ты, может , и не говорил, но при чем здесь ты ?
AVK>А при том, что ты со мной беседуешь. Если кто то там что то говорил — все вопросы к нему.
См. выше выделенное. В 1981 говорили. Не ты. А ты почему-то решил, что я о тебе говорю.
AVK>Означает. Ты попробуй ради интереса хоть что нибудь под мелкий дивайс написать, а потом мы с тобой поговорим, чем их UI от UI десктопа отличается.
Нет, не буду. Не мое это дело
AVK>Затем, что ты считаешь что вся Россия как твой Омск, тогда как в плане телекоммуникаций Россия за Уралом как раз таки нехарактерная ситуация, а вот европейская территория — характерная, просто потому что там живет значительно больше половины населения.
Последнее — верно, а первое — не то, чтобы очень. Был я в ряде городов Европейской России. Весьма похоже на Омск.
PD>>В огороде бузина, а в Киеве дядька. Что-то скучно становится с тобой обсуждать.
AVK>Чего, не ведусь на твои приемчики?
Слушай, у тебя уже просто какая-то реакция на мои слова. Ты просто подозреваешь, что что бы я ни сказал, это обязательно какой-то приемчик. Ей-богу, несерьезно
PD>> Ну написал я , что не был там, и все дела.
AVK>Нет, не все. Ты заявил, что между Коломной и Москвой разница небольшая (а ближнее и дальнее подмосковье, так вообще одно и тоже), и все это нехарактерно для России.
Да, я по-прежнему так считаю.
PD>> Так нет, надо глубокие выводы делать.
AVK>Глубокие выводы здесь ты в основном делаешь.
PD>>А Москва не Россия, верно. Я в ней 5 лет прожил, так что могу судить.
AVK>Ага. Замучался я уже лапшу с ушей снимать.
Которую в основном сам и повесил
AVK>То и смешно, что за Уралом таких городов совсем не десятки. А вот таких как Коломна — их даже не десятки, сотни. Классический провинциальный городок, не богаче соседней Рязани.
AVK>>>Павел, 130 км это уже далеко не ближнее подмосковье. Это самая натуральная провинция, там до Рязани в 2 раза ближе, чем до Москвы.
PD>>Ну не знаю, ты там живешь, тебе в конце концов виднее.
AVK>Ну вот тогда и не надо мне тут рассказывать, что Москва не Россия.
Что-то я уже совсем запутался. Так Москва или Коломна ?
AVK>>>И как же ты телевизер смотришь?
PD>>Антенна на крыше стоит. Коллективная. 17 каналов. Представь себе, 95% Омска живет именно так.
AVK>А антенна откуда сигнал принимает. Прямо из Останкина?
Нет, с омского телецентра. Но если это называется кабельным телевидением, то уж извини... У меня несколько иное представление о том. что такое кабельное ТВ
PD>>Увы. Пока что твое высказывание насчет кабельного ТВ в Омске
AVK>Я не знаю что там у вас конкретно в Омске. Наличие кабелей весьма характерно для европейской части, по крайней мере для небольших городов, которым советская власть строительством телецентров не озаботилась. Но суть то не в кабелях, суть в том, что несмотря на аналоговый местный канал доставки (будь то кабель или местный телецентр), в локальный хаб контент доставляется давно уже в цифровой форме.
Я что-то не понял. Куда в цифровой форме, какой хаб контент ? Из Останкина в местный телецентр ? Если об этом речь, то это не мое дело, как там они доставляют. Но вот с местного телецентра на мой телевизор уж точно не в цифровой форме.
>Просто потому что втыкать MPEG декодер в каждый телеприемник пока еще дороговато и заметно сказывается на цене недорогих телевисеров. Но не мне тебе расказывать, что эти декодеры дешевеют и будут продолжать дешеветь в обозримом будущем, что уже немалый процент телеприемников продается с поддержкой DVB-T/DVB-C. Так что, как только это станет оправданным, трансляцию переведут в параллеть на этот самый DVB-T, просто потому что диапазон используется эффективнее и меньше гемороя со стабильностью приема. При этом принципиально ничего не поменяется. У меня вот на даче тарелька, дома аналоговый кабель, разницы для юзеря практически нет, разве что тарелька сама программу транслирует, а для аналогового кабеля приходится из инета качать.
Вполне согласен.
PD>> мне напомнило высказывание Марии-Антуанетты (кажется) "Если крестьяне жалуются, что им не хватает хлеба, то почему они не едят пирожные" ?
AVK>Тарелька со всеми прибамбасами мне обошлась в 5000 р. и час работы. Не думаю, что это такие уж огромные деньги даже для Омска.
Нет, не большие. Но тарелки тем не менее слабо распространены. Если проехаться по городу, их можно увидеть , но о массовом явлении говорить не приходится. Я года 3 назад хотел себе тарелку завести и интересовался этим. Есть штук 5-7 компаний, которые готовы поставить все оборудование (я сам на крышу не полезу, а больше ее ставить некуда, у меня балкона нет, 1 этаж). Но в итоге все это кончилось ничем.
Может, психология иная. Российские телеканалы и так все доступны. А смотреть импортное ТВ — нет у нас такой культуры. Провинция
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Т.е. разница в том, что XAML более прост как язык разметки, чем HTML?
Разница в том, что это не язык разметки, несмотря на ML в его названии.
ВВ> И там и там мы имеем описание именно представления, конкретного представления, стилей и пр.
Нет. В WF, к примеру, никакого конкретного представления и стилей нет, однако XAML там присутствует в полной мере.
ВВ>XAML описывает структуры, используемые компоненты, их представление. Нет?
Он не описывает их представление. Только компоненты и связи между ними. Любые компоненты.
ВВ>А для чего еще годен XAML кроме как быть "форматом сериализации" конкретного "документа"?
Быть форматом сериализации любого документа и не только документа. Даже в рамках WPF XAML используется не только для описания конкретной странички/окошка, но и, к примеру, для декларативного описания приложения в целом.
AVK>>Что, никогда не наследовался от контролов винформсов? А если наследовался, не скажешь с какой целью?
ВВ>Наследовался. Именно с этой целью.
Понятно, значит это была игра на публику.
ВВ> Но ты знаешь, не так уж и часто.
А это уже не важно. Важно что это во многих случаях вынужденно приходится делать.
ВВ>Могу с тобой поменяться на учебник логики.
Не хами.
ВВ> Заодно разберешься, чем "вообще" отличается от "в частности". И если "в частности" надо наследоваться для расширения функционала, это не означается "вообще" это надо делать.
Я нигде не писал про "вообще". Я писал конкретно про винформс и его архитектуру и ее проблемы. И если я не могу собрать декларативно нужный контрол из примитивов, не прибегая к наследованию, то это проблемы именно винформсов, а не моей логики.
AVK>>Вот только, скажем, код отработки default button и ее modal result намертво прошит в код Form.
ВВ>И кто-то при этом мешает переопределить modal result?
А ты попробуй. Сначало без наследования
AVK>>Поздравляю. К сожалению, отдельные моменты не исключают общей печальной ситуации.
ВВ>Вот только эти "отдельные моменты" почему-то очень во многих случаях работают.
Хреново они работают. Чтобы соорудить TreeList для януса, пришлось наворотить гору кода, при этом публичный контракт полученного контрола на редкость ужасен. А для того, чтобы сделать нормально, придется весь функционал ListView переписать с нуля, потому что агрегацию сделать не выйдет.
ВВ>Не знаю, кто тут изображает "дурачка".
Ты.
ВВ> Ты когда ScintillaWrapper как там конкретно контрол создавал, не вспомнишь?
При чем тут это?
AVK>>А ты попробуй отнаследовать свой контрол от Control и агрегировать в нем функционал, скажем, TreeView.
ВВ>1. Controls.Add ВВ>2. override CreateParams
А, ну ну
AVK>>Например когда шаблон UI не квадратный кусок, а состоит из разных частей, перемежаемых кастомным UI. В WPF это делается сравнительно просто, без привлечения тяжелой артиллерии.
ВВ>Что такое "состоит из разных частей, перемежаемых кастомным UI"?
То и значит. Шапка стандартная, далее переменный кусок, но справа стандартный элемент, далее грид, в котором часть колонок стандартная, часть нет, далее переменный кусок и наконец стандартный подвал, но с возможностью добавления в линейку кнопок собственной, причем в любое место.
ВВ> Я честно пытался представить, что это значит, но, увы, не получилось
Это потому что у тебя мышление винформсоподобным дизайном ограничено
ВВ>SplitContainer? И что там?
А ты поизучай.
ВВ> То, что он убоговат с первого взгляда видно.
Даже для этой убоговатости МС пришлось существенно доработать инфраструктуру дизайн-тайма и написать гору кода.
ВВ> Так напиши свой
А ты пробовал?
ВВ>Меня, кстати, он вполне устраивал.
Дело не в том, устраивает или нет. Это пример того, как убогость архитектуры винформсов привела к кривым решенияв в конкретном случае. Необходимость в контролах, у которых поведение отлично от "панелька с абсолютным позиционированием контролов внутри и рамкой" не редкость, и вызывает немаленькие танцы с бубном даже в ситуациях, когда таких панелек просто 2 штуки.
ВВ>Мне вот интересно — вы все серьезно считаете, что сравнение кросс-платформенного фреймворка и надстройки над конкретной платформой — это корректно?
Серьезно считаю. Потому что проблема не в кроссплатформенности, а в дизайне.
ВВ> И непонятно какие преимущества дает "одноплатформенный" фреймворк?
Это не имеет отношения к дизайну винформсов.
ВВ>Не знаю, как у вас там со свингами и прочими джазами, но в вин-среде и в 2002 вин-формс выглядел весьма и весьма внушительно.
Ну, если ты ничего другого не видел, то может и внушительно. А по факту — нет. И среда тут не причем.
ВВ> По сравнению с тем, что предлагала МС до этого — огромный прогресс.
И то, что МС не умела делать нормальный дизайн, тоже не делает винформсы лучше. Совершенно не интересно, какое тогда на рынке было УГ. Куда интереснее сравнивать с тем, что не является УГ.
ВВ> Архитектура завязанная на модель событий — очень логичная для юзер32.
Заметь, я ни слова не написал в притензиях про модель событий. В свинге тоже "модель событий". И в WPF тоже оно.
ВВ>Ты перечислил проблемы в стиле "примитивная компонентная модель" или "неудобный и примитивный АПИ для взаимодействия с состоянием". В таком стиле эту тему можно перетирать бесконечно.
Ну, если "баба яга против", то конечно. А если цель — действительно понять, что не так с дизайном, то нет.
ВВ> А вот конкретные примеры что-то не выглядят убедительно.
То есть ты считаешь, что коллекция DataBindings в интерфейсе Control это вполне нормально? Что коллекция Items или свойство SelectedItems, если он в виртуальном режиме в ListView ничего не содержат и вызывают исключение при доступе это тоже нормально? Что у контрола есть полный комплект методов и свойств для работы с фокусом, даже если этот контрол не предполагает клавиатурного ввода? Что для создания office 2003 style тулбаров приходится выкидывать весь твой любимый user32 и реализовывать все с нуля?
Ты вот писал про то, что есть механика, позволяющая добавлять в дизайн тайме свойства, которой пользуется Tooltip. В скольких еще местах эта механика используется? В одном? Двух. А в скольких ее можно использовать с положительным эффектом для дизайна?
Зачем понадобилась явная заплатка BindingSource, дублирующая часть уже существующего функционала, если с дизайном байндинга все было хорошо?
ВВ>Да нормально там все с классом Контрол.
Нет, не нормально. Катастрофически ненормально.
ВВ> Да он перегружен, но сделано так было не в последнюю очередь для удобства.
В жопу такое индусское удобство.
ВВ> И не припомню, чтобы у меня возникали какие-то специфические проблемы связанные именно с "перегруженностью" Контрола.
.
ВВ>А базовая архитектура — это обработка сообщений через события, и она хороша.
И все? То есть единственное, что делает винформс полезного, это крякеры виндовых мессаджей и увязка окон с экземплярами классов CLR? Спасибо, порадовал. К сожалению, MFC и OWL делали это не сильно хуже лет на 10 раньше его рождения.
Возможности современного GUI-фреймворка ушли от тех времен очень далеко. Даже в 2002 году.
AVK>>Опять же, еще большая кривизна user32 никак не делает дизайн винформсов хорошим.
ВВ>Делает.
Нет, не делает.
ВВ> Делает его лучше чем работа напрямую с юзер32.
Тут кто то утверждал обратное? Следуя твоей логике — user32 тоже лучше, чем рукопашная реализация окошек, сильно лучше, Следовательно, если сейчас выпустить похожий по уровню фреймворк, это будет вполне нормлаьно. Так?
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Геннадий Васильев, Вы писали:
ГВ> Пролог, ИМХО, хорош чистотой метода резолюций, который в нём реализован.
Пролог для обучения хорош тем, что намного дальше по идеологии и внутренней логике отстоит от императивного программирования, нежели, скажем, ФП. Отличная возможность понять, что в замочную скважину можно увидеть не весь мир.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Классы не ради ОО-стиля делают, а потому что мыслят саму структуру программы в терминах сущностей, их взаимосвязей и пр. Когда пишут на ОО-языке, то мыслят в ОО-стиле. Разве это не очевидно?
Опять двадцать пять. Очевидно только то, что программа проектируется и записывается в ОО-стиле. Это единственное, что может быть очевидно. Остальное — дешёвые домыслы. Спешу дать добрый совет: забудь про выражения, апеллирующие к свойствам субъекта — они изначально неправомерны. И не читай википедию, особенно статью про "парадигму".
ВВ>А правила по принципу — "давайте все ф-ции делать детерминированными, и тогда у нас получится ФП" — это ни фига ФП, это просто старое хорошое правило декомпизиции функций, к-е еще в СП рулило.
Я имел в виду не только детерминированость функций. В детерминированность не очень умещаются, например, функции высших порядков.
ВВ>Вопрос не в стиле. Вопрос в полной, так сказать, очередной ломке мозгов, необходимость в которой ИМХО назрела. Попробуйте думать не в ОО-ключе. Возможно, вам понравится
Блин, это ж как узко надо мыслить, чтобы смена языка программирования превращалась в ломку мозга?! И эти люди... Это ты у Влада нахватался, что ли? Так не учись плохому.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Ну вот другие товарищи практически такие функции и считают "чистыми". Хотя ни фига они не чистые в смысле ФП.
Они чистые в смысле ФП.
Они полностью удовлетворяют определению чистоты например из "Функционального программирования" Харрисона-Филда.
Здравствуйте, Воронков Василий, Вы писали:
FR>>Они чистые в смысле ФП. FR>>Они полностью удовлетворяют определению чистоты например из "Функционального программирования" Харрисона-Филда.
ВВ>Что, любая детерминированная ф-ция удовлетворяет определению чистоты?
Да любая детерминированная функция без побочных эффектов чистая. Добавив сюда прозрачность по ссылкам, получаем необходимый минимум чтобы программировать в функциональном стиле.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>У тебя проекты на винформс начинались с того, что ты принимался эти винформсы куда-то "запаивать"?
Серьезные? Да, как только дело доходило до GUI.
ВВ> Или другие задачи были?
Были, не связаные с винформсами.
ВВ> А если их не "запаивать", то будет говно?
Их это винформс? Да, будет гавно.
ВВ>Я понимаю, конечно, всю привлекательность позиции этакого "гурмана"
Это позиция не гурмана, а практика. Ошибки в архитектуре стоят слишком дорого.
ВВ> особенно, кстати, удобно это делаеть, когда обязанности уже далеко не связаны с разработкой
Это ты по своему опыту, что ли, судишь?
ВВ> — но, может, стоит быть поближе к реальности?
Стоит. Приближайся .
Слушай, может хватит уже считать других глупее себя? Или нет?
ВВ>Я не против обсудить достоинства и недостатки ГУИ-фреймворков, но я вообще-то не об этом писал.
А я об этом.
ВВ> user32 сам по себе не отличается высоким изяществом
Я тебе больше скажу — х86 тоже не отличается высоким изяществом. Однако это совершенно не повод плодить УГ. Надо желать качественный продукт, а не лепить говнокод лишь бы впарить. Впрочем, возможно для интеграторов второй вариант в финансовом плане более выгодный. Поэтому, скорее всего, я никогда не буду там работать.
ВВ>, тем не менее большинство приложений, которые я использую, написаны именно под user32 с помощью библиотек, для которых, скажем так, тебе пришлось бы подбирать еще более ядреные метафоры.
Ну и что?
ВВ> И они не становятся от этого говном.
А я этого и не утверждал.
ВВ>В том, что приложения становятся говном вовсе не фреймворки виноваты.
Безусловно. Виноват подход к разработке.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, AndrewVK, Вы писали:
ВВ>>У тебя проекты на винформс начинались с того, что ты принимался эти винформсы куда-то "запаивать"? AVK>Серьезные? Да, как только дело доходило до GUI.
Помнится, тебе не нравились аналогии. Так давай говорить конкретнее.
Ты возвражал на мой пост, в котором я писал, что при необходимости интегрировать одну и ту же логику — отображение температуры в виде графического градусника, взятое в качестве примера — вовсе необязательно эту самую логику дублировать. Да, винформс не предлагает единую систему расширения функциональности ГУИ-элементов, что бесспорно является недостатком. В данном случае это приведет к тому, что необходимо будет сделать несколько "адаптеров" — где-то весьма минималистичных, где-то чуть менее минималистичных.
Судя по твоему возвражению, ты считаешь такую практику порочной и неизбежно приводящей к говно-коду. В свете этого мне интересно узнать, как происходило это самое запаивание вин-формс когда ты начинал работать над серьезными проектами?
И приходилось ли тебе тебе работать над серьезными проектами на веб-формс? И каким образом ты "запаивал" веб-формс?
ВВ> А если их не "запаивать", то будет говно? AVK>Их это винформс? Да, будет гавно.
Предлагаю использовать альтернативный термин — гОвно.
ВВ>>Я понимаю, конечно, всю привлекательность позиции этакого "гурмана" AVK>Это позиция не гурмана, а практика. Ошибки в архитектуре стоят слишком дорого.
Наши дискуссии последнее время строятся по принципу — ты берешь какую-нибудь мою фразу из контекста и возражаешь на нее в стиле "кривая архитектура приводит к говну".
А в итоге оказывается, что я считаю других глупее себя.
Цель-то какая? Зачем было втягивать меня в спор о ГУИ-фреймворках, который я вообще-то не начинал, и вин-формс был упомянут совсем по другим причинам. Я рассматривал его как надстройку на юзер32. Точка. И не столько в разрезе его основной функции, а именно как абстракцию над юзер32, которая упрощает с ней работу.
Сдается мне, что мы далеко ушли от этого.
ВВ>> особенно, кстати, удобно это делаеть, когда обязанности уже далеко не связаны с разработкой AVK>Это ты по своему опыту, что ли, судишь?
Эээ, "обязанности уже далеко не связаны с разработкой" — это прозвучало обидно? Вот уж, не думал.
Да, сужу по своему опыту общения с людьми, обязанности которых "уже далеко не связаны с разработкой".
ВВ>> — но, может, стоит быть поближе к реальности? AVK>Стоит. Приближайся . AVK>Слушай, может хватит уже считать других глупее себя? Или нет?
Наверное, это должно быть взаимно? Мне тоже не очень нравится получать советы в стиле "учись сынок, и ты поймешь, что кривая архитектура это плохо".
ВВ>>Я не против обсудить достоинства и недостатки ГУИ-фреймворков, но я вообще-то не об этом писал. AVK>А я об этом.
А я НЕ об этом. Тема была о другом. В разрезе обсуждения ГУИ-фреймворков, даже еще на "философский" манер, мне вин-формс вообще неинтересен.
ВВ>> user32 сам по себе не отличается высоким изяществом AVK>Я тебе больше скажу — х86 тоже не отличается высоким изяществом. Однако это совершенно не повод плодить УГ.
Кто-то утверждал обратное?
AVK>Надо желать качественный продукт, а не лепить говнокод лишь бы впарить. AVK>Впрочем, возможно для интеграторов второй вариант в финансовом плане более выгодный. Поэтому, скорее всего, я никогда не буду там работать.
Большинство интеграторов не занимается постоянной сменой клиентов, которым можно что-нибудь "впарить". Есть несколько крупных заказчиков, с которыми приходится работать годами, и если постоянно "впаривать им говнокод", то при наличии нехилой такой конкуренции можно в итоге остаться без работы.
Мне вот нравится работать в интеграторе. За последние годы я познакомился с "внутренними делами" такого количества компаний, что можно, пожалуй, мемуары писать. Да, не всегда есть возможность начать проект с замызывания вин-формс или чего-то там еще — да, могут дать в зубы готовую систему с тем самым "говнокодом", причем уже внедренную, и ее надо как-то развивать, и "переписать все" не получится, как бы ни хотелось. А часто и невозможно в принципе, если этот самый "говнокод" написала какая-нибудь компания с "большим" именем.
Да, это не всем понравится. Но это challenge. И заставить говно нормально работать тоже ох как непросто.
А в создании злонамеренного говнокода "лишь бы впарить" я не учавствовал никогда. Тут ты не попал, извини.
ВВ>>, тем не менее большинство приложений, которые я использую, написаны именно под user32 с помощью библиотек, для которых, скажем так, тебе пришлось бы подбирать еще более ядреные метафоры. AVK>Ну и что?
И правда, а что? Ты какую идею сейчас продвигаешь?
ВВ>> И они не становятся от этого говном. AVK>А я этого и не утверждал. ВВ>>В том, что приложения становятся говном вовсе не фреймворки виноваты. AVK>Безусловно. Виноват подход к разработке.
Виноват может быть кто угодно, например, идиот-аналитик.
А я не спорю. Я просто говорю, что из двух вариантов: WebForms vs. PHP(Perl/Python/Ruby)+XSLT ручками я выберу первый вариант. Это в случае, если выбора нету. Если есть выбор, заюзаю что-то более удачное (если из предложенного выбора есть что-то более удачное). Вариант с ручной генерацией — ещё большее унылое говно, чем всё остальное (разве что, ручная генерация HTML-я на брейнфаке).
Здравствуйте, Воронков Василий, Вы писали:
ГВ>>Как это ни странно, но такое соединение даёт некие новые возможности: таким выразительным инструментарием можно несколько проще реализовать задачи, для решения которых хорошо подходит FP и ООП.
ВВ>Да, честно говоря, мне неинтересно проще ли можно реализовать задачу или сложнее. Мне интересно ВВ>- а можно ли было избежать вообще появления данной технической задачи?
Это прямое следствие сложнее-проще.
ВВ>- не появилась ли эта задача вследствие ошибки дизайна?
Дык. "Ошибки дизайна" появляются как раз в результате изменения требований к системе. "Абсолютно правильного" дизайна не бывает.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, eao197, Вы писали:
E>Ну, ёптыть. Более забористой травы, чем FP в области программирования я пока не встречал. Кто ни попробует -- у всех бошку сносит напрочь.
Этот топик как раз о том, что не у всех и я долго не мог понять почему
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
IT>Что же изменилось внутри метода? Да почти ничего. Как и 30 лет назад мы имеем if/else/switch, несколько циклов, команды выхода из цикла и метода, операции, присваивание и ещё немного по мелочёвке.
"Мясо" все равно сейчас писать намного проще, чем раньше. Появились фреймворки и это главное. Если раньше надо было все писать самому, то сейчас можно использовать готовое.
IT>Фактически, 30 лет развитие шло только снаружи метода и сегодня мы имеем полный мыслимый набор инструментов для организации кода и управления им. По развитию снаружи метода мы уже давно вышли в космос и осваиваем другие планеты. А внутри метода? Внутри мы всё ещё в той же пещере, с тем же каменным топором в руках, что и 30 лет назад. Ни письменности, ни колеса, ни железа.
Взять например web-программирование. Тогда каменный топор — это когда html код надо формировать плюсованием строк. От этого очевидно очень далеко ушли.
IT>Много ли у нас обсуждений на тему жизни внутри метода?
Загляните в форум по .NET'у, там только такие вопросы и есть.
Здравствуйте, russian_bear, Вы писали:
IT>>Много ли у нас обсуждений на тему жизни внутри метода?
_>Загляните в форум по .NET'у, там только такие вопросы и есть.
Ты, ИМХО, не правильно IT понял. Он о форме, а ты о содержании.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, russian_bear, Вы писали:
_>"Мясо" все равно сейчас писать намного проще, чем раньше.
Мясо как писалось раньше на if/else/while, так и сейчас пишется на if/else/while.
_>Появились фреймворки и это главное. Если раньше надо было все писать самому, то сейчас можно использовать готовое.
Если бы фреймворки решали всё, то всё уже было бы давно написано и мы были бы без работы. Тем не менее мне почему-то приходится каждый день писать код не покладая рук.
_>Взять например web-программирование. Тогда каменный топор — это когда html код надо формировать плюсованием строк. От этого очевидно очень далеко ушли.
В ASP.NET эта проблема решается средствами метапрограммирования, конкретно precompile time генерацией. А дальше практически как ты сказал, правда не конкатенация, а вывод в stream. Но сути дела это не меняет. Придумали парни из MS DSL для типовой задачи, очень хорошо. Но как мы уже выяснили типовыми задачами жизнь не ограничивается. Почему-то работодатели когда ищут ASP.NET программиста включают в графу skills C#. А значит придётся писать ifs & whiles.
IT>>Много ли у нас обсуждений на тему жизни внутри метода?
_>Загляните в форум по .NET'у, там только такие вопросы и есть.
Дай ссылку хатя бы на один.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Много ли у нас обсуждений на тему жизни внутри метода? А чему у нас учат в вузах? Есть ли у нас хотя бы один предмет, рассказывающий как правильно писать код внутри метода? Скорее всего нет. А о чём там рассказывать? Вот и получается на уровне кода бескультурье, самопал и дурь. Но ведь это просто чудовищная несправедливость. Без кода внутри метода, без кодера программа работать не будет, точнее её просто не будет. Без внешней обвязки и архитектора хоть как-то, но можно обойтись.
Вопрос не столько в том — есть именно такой предмет или нет. Вопрос в системе подготовки программистов. В вузах элементарно отсутствуют преподаватели. Те, кто действительно что-то знает, работают в других местах. Ибо решиться получать 7..10 тыс.руб. за эту весьма тяжкую и нервную работу способны далеко не все, а альтруистов как обычно на всех не хватает.
А старые кадры (еще советских времен) — в подавляющем большинстве так и остались на уровне "времен Очаковских и покоренья Крыма". Научить ассемблеру ЕС-ЭВМ они еще могут. Те, кто продвинутей, вспомнят PDP-11. От практики такие "учителя" оторвались безнадежно (да, наверное, никогда ею и не занимались).
Отдельные вузы (наверное, штук 5-7 на всю Расею) не в счет: по большому счету они, к сожалению, погоды не делают. Вот вам и бескультурье. Добро, если начинающему программисту встретится на пути добрый человек и посоветует почитать, к примеру "Практику программирования" (Б.Керниган и Р.Пайк), "Дисциплину программирования" (Э.Дейкстра) или "Жемчужины программирования" (Дж.Бентли).
Только, боюсь, подавляющее большинство неофитов сие премудрые книжки "ни асилит" — проще ваять псевдомудреный код с кучей абсолютно лишних наворотов
Приходиться заниматься гадостью — зарабатывать на жизнь честным трудом (Б.Шоу)
Здравствуйте, igna, Вы писали:
I>PS. Похоже в математике нет ничего, на чем могло бы основываться ООП, в то время как функциональное программирование просто пропитано идеями из математики. A Theory of Objects как теоретический фундамент не прокатит?
На citeseer есть прорва статей в которых OO выражают средствами FP.
И у небезывестного Олега что-то видел на эту тему.
Здравствуйте, IT, Вы писали:
E>>Ну, ёптыть. Более забористой травы, чем FP в области программирования я пока не встречал. Кто ни попробует -- у всех бошку сносит напрочь.
IT>Этот топик как раз о том, что не у всех и я долго не мог понять почему
В стартовом сообщении темы ты как раз и не ответил на вопрос "почему же бошку сносит не у всех".
PS. В начале 90-х в Союзе у многих крышу срывало Прологом. С тех пор я думал, что именно Пролог самая крутая трава. Но, видимо, FP еще круче.
SObjectizer: <микро>Агентно-ориентированное программирование на C++.
Здравствуйте, fplab, Вы писали:
F>Здравствуйте, _FRED_, Вы писали:
_FR>>Вот что ты скажешь о кодере, которому за девять с лишним лет ни разу не пришлось самому писать сортировку Не то, что строить деревья или создавать примитив синхронизации? Что он должен сгореть от горя или позора?
F>Да, однозначно. Ничто не может служить оправданием халтуры. Конечно, на практике нужно использовать оптимизированные и проверенные библиотечные функции. Но это не значит, что нет необходимости знать основные алгоритмы. Пусть пузырьковая сортировка не оптимальна: она дает навык работы с массивами. А быстрая сортировка — навык работы с рекурсией. Или, по вашему, это лишнее ?
Навыки работы с массивами приобретаются не только при написании своего пузырька.
А в языках без поддержки хвостовой рекурсии гораздо полезнее навыки работы без рекурсии.
Здравствуйте, konsoletyper, Вы писали:
Pzz>>Внутри метода — алгоритмы. Те самые сортировки и поиски, о которых книжки пишут. А снаружи — клей и упаковка.
K>Тут надо не книжки читать. Тут надо прежде всего инструмент соответствующий. А то на while/if реализация даже простых алгритмов превращается в кошмар. А чтение того, что получилось — ещё ужаснее.
Да помилте, какой еще нужен струмент для написаныя простых алгоритмов, кроме как раз тех самых if'ов и while'ов? Откройте любую книжку про алгоритмы, обратите внимание, на каком языке в этих книжках алгоритны расписывают.
ФП, кстати, надо понимать, для описания именно алгоритмов ничуть не лучше. Но ФП предоставляет гораздо более удобные способы представления сложных структур данных.
Здравствуйте, netch80, Вы писали:
N>Здравствуйте, _FRED_, Вы писали:
Pzz>>>Внутри метода — алгоритмы. Те самые сортировки и поиски, о которых книжки пишут. А снаружи — клей и упаковка. _FR>>Я как-то всегда думал, что как раз алгоритмы — это то, что очень неплохо поддаётся "библиотизации", то есть вынесением в многократно используемые кирпичи. И задумываться над алгоритмами лишний раз не приходится.
N>Приходится задумываться, очень даже. Вот возьмём ту же пресловутую сортировку. Кто из кодеров вообще слышал о каком-то методе кроме "quick sort" (и то — под его маркетинговым названием)? А условия применимости? Вот завтра придут данные с определённым на них частичным порядком вместо линейного, и опаньки — условия применимости не выполняются. А если сравнения очень дорогие и их надо минимизировать? А если данных никогда не больше 8 элементов и quicksort просто дорог в раскачке, простейший метод вставок сработает быстрее? А если надо выполнить сортировку параллельно? А если дали 100 миллиардов элементов и они даже в виртуальную память не влезут (я уж молчу, что сортировать данные толще физической памяти такой сортировкой — самоубийство независимо от того, влезло оно в виртуалку или нет)? Всё, такой кодер сдулся, независимо от того, насколько он хорошо знает STL и может задавать сортировку его средствами.
Мне очень завидно, если у вас такие задачи появляются чаще, чем раз в пять лет. У меня пока такие задачи были только на собеседованиях, в реальности всё гораздо проще.
Здравствуйте, fplab, Вы писали:
F>Вопрос не столько в том — есть именно такой предмет или нет. Вопрос в системе подготовки программистов. В вузах элементарно отсутствуют преподаватели. Те, кто действительно что-то знает, работают в других местах. Ибо решиться получать 7..10 тыс.руб. за эту весьма тяжкую и нервную работу способны далеко не все, а альтруистов как обычно на всех не хватает. F>А старые кадры (еще советских времен) — в подавляющем большинстве так и остались на уровне "времен Очаковских и покоренья Крыма". Научить ассемблеру ЕС-ЭВМ они еще могут. Те, кто продвинутей, вспомнят PDP-11. От практики такие "учителя" оторвались безнадежно (да, наверное, никогда ею и не занимались). F>Отдельные вузы (наверное, штук 5-7 на всю Расею) не в счет: по большому счету они, к сожалению, погоды не делают. Вот вам и бескультурье. Добро, если начинающему программисту встретится на пути добрый человек и посоветует почитать, к примеру "Практику программирования" (Б.Керниган и Р.Пайк), "Дисциплину программирования" (Э.Дейкстра) или "Жемчужины программирования" (Дж.Бентли).
Так, может, что-то делать по сути? Например, я думаю, что Вам надоедает таки 8 часов в день сидеть за монитором, а свои мысли надо уложить в систему.
Объявите на фирме семинар для студентов, где-то так в пятницу 17:00-18:30, с приходом всех желающих, и рассказывайте хоть что-то, но свежее и актуальное, а тех, кто показывает понимание, заманивайте на пиво и затем на работу:)) В принципе, неважно, что именно будете рассказывать — лишь бы умели это делать. Развесить объявления в ближайших профильных вузах и смотреть, кто приходит... После этого всерьёз воспринимать тех титанов мысли XIX века с ассемблером ЕС ЭВМ уже не станут.
F>Только, боюсь, подавляющее большинство неофитов сие премудрые книжки "ни асилит" — проще ваять псевдомудреный код с кучей абсолютно лишних наворотов :xz:
Ну и не надо книжки, надо с людьми работать. Книжки потом будут.
Здравствуйте, samius, Вы писали:
S>Здравствуйте, netch80, Вы писали:
N>>Какой ответ на этот вопрос Вы хотите? Можно ответить цинически — мол, есть клавишное мясо:), которое не способно даже осознать, что оно теряет и почему. А можно — что пусть себе и дальше продолжает, но пусть осознаёт, где его потолок. В принципе, оба ответа правильны.
S>У меня один знакомый считает, что тот не программист, кто не написал ни одного драйвера устройства. S>Весьма ограниченная точка зрения, как впрочем и Ваша.
Вы ещё ничего не поняли толком про мою точку зрения, но уже успели приравнять её к "одному знакомому" и унизить сравнением.
Не думаю, что такой метод дискутирования адекватен теме.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Здравствуйте, IT, Вы писали:
IT>>Было только одно существенное новшество – замыкания в C# 2.0 в 2005-м году
ВВ>Еще задолго до C# 2.0 я писал в самом банальном жабо-скрипте:
Ну так где ECMAscript (который Netscape зачем-то назвал JavaScript), а где C#.
Кстати, "ещё задолго до C# 2.0" тривиально было в делегат поместить метод класса, а в класс вгрузить необходимые параметры — это было то же замыкание, только сконструированное вручную. Добавка синтаксического клея во 2-й и 3-й версии сделала этот процесс доступным ширнармассам, но кто хотел — умел и раньше.
Здравствуйте, samius, Вы писали:
S>>>У меня один знакомый считает, что тот не программист, кто не написал ни одного драйвера устройства. S>>>Весьма ограниченная точка зрения, как впрочем и Ваша. N>>Вы ещё ничего не поняли толком про мою точку зрения, но уже успели приравнять её к "одному знакомому" и унизить сравнением. S>Думаю что понял. Она примерно следующая: есть те, кому приходилось иметь дело с сортировкой с выкрутасами, и есть клавишное мясо.
Неверно. Попробуйте ещё.
N>>Не думаю, что такой метод дискутирования адекватен теме. S>Не думаете — не начинайте.
Здравствуйте, _FRED_, Вы писали:
_FR>Здравствуйте, fplab, Вы писали:
_FR>Мне больше нравится линейный поиск как навык работы с массивами и факториал как пример рекурсии. Они проще И что мы получаем: есть знания и про массивы и про рекурсию, но никакого отношения к сортировке это не имеет.
Наконец-то — дождались ! Вот оно — ключевое слово: "проще". Зачем нам обезболивающие ? Деревянным молотком по голове, как в средние века: пока пациент очухается, мы ему немножко вырежем здесь и подрихтуем там
Факториал — это да, это классика. Но именно как пример. Наверное процентов 90 всех книг по программированию объясняют рекурсию на примере именно факториала. Но между теорией и практикой дистанция немалого размера. Интересно, а если надо построить дерево, а потом сделать его обход ? Понятно, что можно и без рекурсии, но вот вопрос — а стоит ли ?
А линейный поиск — вообще прелесть. Понятно, что в массиве из 100 записей "при современном развитии печатного дела на Западе" (О.Бендер) — просмотреть их плевое дело. Дураки они, что ли компиляторщики — сортируют таблицу символов, чтобы потом в ней быстро искать ? А то и вообще хэш-функции втыкают
Правда, надо сделать одно важное извиняющее замечание — если человеку так не повезло, что ему не приходилось решать по настоящему сложных (а, значит, интересных) задач, то тогда, действительно, к чему засорять мозг
Приходиться заниматься гадостью — зарабатывать на жизнь честным трудом (Б.Шоу)
Вообще-то вопросы границ применимости встречаются постоянно. Простейший пример: парни проектируют систему миграции из инфраструктуры A в инфраструктуру B. Архитектурная идея — проста как грабли, и при этом хорошо идет в струе технологического совершенства: экспортируем все данные из A в XML, трансформируем его в понятный системе B XML при помощи XSLT, и радуемся жизни.
И тут (через, грубо говоря, полгода разработки) вдруг возникает грустный эффект: трансформация подразумевает работу с DOM моделью, а далеко не все из интересных нам систем A генерируют документы, которые умещаются в 3GB RAM. Я доступно объясняю?
... << RSDN@Home 1.2.0 alpha rev. 677>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Кстати, у тебя присутствует фактически следующая классификация: сам ООП это ультрамодный космический корабль, а то, что мы пишем в методах — пещерный век.
А мне кажется, что ООП — это не космический корабль. Это ржавая подводная лодка, которая медленно идет ко дну
Вот неужели ООП не предлагает средств, чтобы избавиться от всех этих switch, if/else и прочая? Разве нельзя спроектировать систему — именно спроектировать — чтобы практически избавиться от всех этих "пережитков" вкупе с out/ref и другими неприглядными вещами? Так почему же мы это не делаем?
А ответ простой. Потому что последовательно и полностью реализованная ООП концепция в большом приложении — это просто кошмар. По сравнению с этим все "неприглядности" старого структурного программирования покажутся просто детскими шалостями. Я видел, как люди, "дорвавшиеся" до всяких ООП фенек, начинали проектировать системы — вполне в соответствии со всеми, паттернами — и когда я смотрел на их творчество мне хотелось выблевать на монитор, извините. При этом я с удовольствием читал код, скажем, Sqlite — хотя мои знания C# на настоящий момент несколько лучше, мягко говоря, чем plain C.
Собственно, почему я не "проникся" Немерле. Не из-за того, что я "барик", не из-за того, что не могу оценить все прелести ФП, а из-за того, что все это очень сильно похоже на "припарки" мертвому. Я не понимаю, почему "внешняя" архитектура должны быть ООП, а "внутренняя", скажем, ФП. Если та или иная концепция не позволяет реализовать ее последовательно во всех частях программы — так ли эта самая концепция хороша? И может стоит вообще пересесть с этой подводной лодки на что-нибудь другое?
Здравствуйте, netch80, Вы писали:
N>Так, может, что-то делать по сути? Например, я думаю, что Вам надоедает таки 8 часов в день сидеть за монитором, а свои мысли надо уложить в систему. N>Объявите на фирме семинар для студентов, где-то так в пятницу 17:00-18:30, с приходом всех желающих, и рассказывайте хоть что-то, но свежее и актуальное, а тех, кто показывает понимание, заманивайте на пиво и затем на работу В принципе, неважно, что именно будете рассказывать — лишь бы умели это делать. Развесить объявления в ближайших профильных вузах и смотреть, кто приходит... После этого всерьёз воспринимать тех титанов мысли XIX века с ассемблером ЕС ЭВМ уже не станут.
F>>Только, боюсь, подавляющее большинство неофитов сие премудрые книжки "ни асилит" — проще ваять псевдомудреный код с кучей абсолютно лишних наворотов
N>Ну и не надо книжки, надо с людьми работать. Книжки потом будут.
Да стараюсь как могу За трех человек, кто прошел через наставничество, не стыдно. Одно печалит — выход мал: это все достижения за 15 лет. Оставшихся стараюсь хоть чему-нибудь да поднатаскивать.
Приходиться заниматься гадостью — зарабатывать на жизнь честным трудом (Б.Шоу)
Здравствуйте, _FRED_, Вы писали:
_FR>И как в решении описанных проблем поможет умение написать _реализацию алгоритма_? ИМХО, достаточно знаний о том, что есть вот такое, есть такое, которое хорошо тогда и тогда, а тут лучше это и это.
Напрямую — никак. Но так уж человек устроен, что чтобы помнить о том, что есть разные методы — ему нужно с ними столкнуться лично и желательно написать хотя бы простейшую реализацию. Собственно, поэтому метод пузырька до сих остаётся в книгах, хотя он худший из того, что может быть. Альтернатива — умение запоминать большое количество абстрактных данных, с которыми не сталкиваешься и которые остаются пустым звуком, а затем через много лет — вытащить эти данные из памяти, когда нужно. Это редкое умение, противоречащее всей природе человеческой памяти, и поэтому на него ориентироваться нельзя.
А описанные Вами знания "есть такое, а есть сякое" без подкрепления забудутся после первого экзамена.
Поэтому я с сомнением отношусь к тем архитекторам, которые давно сами не кодируют, и к тем кодерам, которые способны только применить указанное им решение.
_FR>>>В первую очередь из-за того, что редко, очень редко встречаются сейчас такие задачи. N>>Угу, именно так. Фактически, можно тупо рубить бабло на минимальном базисе. Впрочем, для этого нужно соответствующее усердие, которое тоже нечастый скилл.;( _FR>Гхм… попробую так: в каком проценте задач сортировки данных вам не достаточно библиотечных реализаций? Мне кажется, эта цифра вполне подойдёт под описание "очень редкно".
У меня лично статистики недостаточно. Но вот случай, когда обычная сортировка крайне невыгодна — каждый рабочий день на глазах, это таймерное дерево в движке событий. Оно сделано на пирамиде.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Если та или иная концепция не позволяет реализовать ее последовательно во всех частях программы — так ли эта самая концепция хороша?
так ли хороша концепция подводной лодки если на ней неудобно ездить по пустыне?
ВВ>И может стоит вообще пересесть с этой подводной лодки на что-нибудь другое?
Здравствуйте, netch80, Вы писали:
N>Приходится задумываться, очень даже.
Вы всего лишь сказали одну банальную истину. Что выбор того или иного алгоритма должен быть осознанным, т.е. надо разобраться в _характеристиках_ и выбрать то, что подходит.
Но это не значит, что я должен уметь писать каждую сортировку (и тем более, что я должен был их когда-то писать), но знать их характеристики — должен. Но и то, только тогда, когда эта сортировка мне понадобится.
Вы же не берёте для проекта библиотеку U% только потому, что она единственная вам известная. Плюсы-минусы-то надо взешивать, так это никто не отрицал.
Здравствуйте, Pzz, Вы писали:
Pzz>В библиотеках содержатся стандартные алгоритмы. Куда вы пойдете, если вам нужна не просто сортировка, а сортировка с преподвывертом? Готовую именно с нужными вам свойствами вы не найдете, свою написать вы не умеете, т.к. всегда использовали готовую.
Ваша фраза применима к любой области и любой библиотеке. Однако, вы не станете требовать от человека знание всех ГУИ библиотек, всех библиотек для работы с сетью и т.п.?
Важно, чтобы человек не бездумно брал первую попавшуюся, а выбирал лучшую, и, если таковой не нашлось, 10 раз подумать и таки написать самому.
Только причём тут важность уметь писать самому всё изначально? Понадобится — будем разбираться.
Pzz>Принесут вам код, написанный для UNIX'а и активно использующий read/write lock'и, и попросят запустить его на Windows XP. А в XP нет read/write lock'ов. Ваши дальнейшие действия?
Гоги, ты чей друг? Мой или медведя?
Почитаю соответствующую документацию, выберу решение. Или я должен всё знать заранее?
Здравствуйте, netch80, Вы писали:
_FR>>И как в решении описанных проблем поможет умение написать _реализацию алгоритма_? ИМХО, достаточно знаний о том, что есть вот такое, есть такое, которое хорошо тогда и тогда, а тут лучше это и это.
N>Напрямую — никак. Но так уж человек устроен, что чтобы помнить о том, что есть разные методы — ему нужно с ними столкнуться лично и желательно написать хотя бы простейшую реализацию.
Т.е. я правильно понял вашу точку зрения:
1. Программист(инженер) должен учитывать характеристики составных частей при проектировании более сложной системы. Если существующие составные части не подходят, можно использовать специальные нестандартные детали.
2. Большинство программист(инженер) ленивые и потому берут первую попавшуюся деталь, если не бились ранее лбом по этой теме. Если бились, то обычно разбираются в вопросе и сразу думают, какую деталь лучше взять.
3. Если программист(инженер) не имеет знаний о сортировках, то он относится к пункту 2
3.a [с большой вероятностью].
?
С 1-м пунктом не согласиться сложно. Этой банальности учат на всех инженерных специальностях.
Со 2-м пунктом тоже сложно не согласиться. И правда ленивых немало.
C 3-им пунктом я не согласен. Во-первых, вывод просто неверен. Это логика. Множество ленивых инженеров и не знающих сортировки пересекаются, но ни одно из них не включает другое.
Во-вторых, если даже он относится к пункту 2, то он сталкивался. И либо он сразу сделал осознанный вывод (что опровергает пункт 3, так как изначально знаний он не имел), либо он таки напортачил. Зачем вам программист, который на неизвестной задаче сначала портачит, а потом разбирается?
Если вы имели в виду пункт 3.а (большинство/многие/некоторые, а не все), то я не понимаю требования знания сортировок.
Это лишь значит, что при прочих равных инженер, знающий сортировку, вероятнее окажется лучшим.
Но знание сортировок не является для этого ни достаточным, ни необходимым.
Здравствуйте, Sinclair, Вы писали:
S>Здравствуйте, Aen Sidhe, Вы писали:
S>Вообще-то вопросы границ применимости встречаются постоянно. Простейший пример: парни проектируют систему миграции из инфраструктуры A в инфраструктуру B. Архитектурная идея — проста как грабли, и при этом хорошо идет в струе технологического совершенства: экспортируем все данные из A в XML, трансформируем его в понятный системе B XML при помощи XSLT, и радуемся жизни. S>И тут (через, грубо говоря, полгода разработки) вдруг возникает грустный эффект: трансформация подразумевает работу с DOM моделью, а далеко не все из интересных нам систем A генерируют документы, которые умещаются в 3GB RAM. Я доступно объясняю?
Конечно понятно. Моё сообщение не было издёвкой. Это было сугубо про мой опыт работы, который невелик (всего три года).
А сложные задачки интереснее, чем обычные банальные вещи, поэтому я и завидую, да.
Здравствуйте, VoidEx, Вы писали:
VE>Т.е. я правильно понял вашу точку зрения: VE>1. Программист(инженер) должен учитывать характеристики составных частей при проектировании более сложной системы. Если существующие составные части не подходят, можно использовать специальные нестандартные детали. VE>2. Большинство программист(инженер) ленивые и потому берут первую попавшуюся деталь, если не бились ранее лбом по этой теме. Если бились, то обычно разбираются в вопросе и сразу думают, какую деталь лучше взять. VE>3. Если программист(инженер) не имеет знаний о сортировках, то он относится к пункту 2 VE> 3.a [с большой вероятностью]. VE>?
Да.
VE>С 1-м пунктом не согласиться сложно. Этой банальности учат на всех инженерных специальностях. VE>Со 2-м пунктом тоже сложно не согласиться. И правда ленивых немало.
VE>C 3-им пунктом я не согласен. Во-первых, вывод просто неверен. Это логика. Множество ленивых инженеров и не знающих сортировки пересекаются, но ни одно из них не включает другое.
Речь не идёт о знании, как писать конкретную сортировку. Но о знании граничных и оптимальных условий их применения, хотя бы минимальных оценок эффективности. И о том, что лучший способ усвоения этих знаний — написать в порядке обучения хотя бы парочку.
Пусть сортировка только классический показательный пример, но программист, который решил применить quicksort на множестве ключей без линейного порядка — мягко говоря, поступает некорректно.
VE>Во-вторых, если даже он относится к пункту 2, то он сталкивался.
Почему?
VE> И либо он сразу сделал осознанный вывод (что опровергает пункт 3, так как изначально знаний он не имел), либо он таки напортачил. Зачем вам программист, который на неизвестной задаче сначала портачит, а потом разбирается?
Если он при этом учится и ошибка замечена вовремя — то почему бы и нет?
VE>Если вы имели в виду пункт 3.а (большинство/многие/некоторые, а не все), то я не понимаю требования знания сортировок. VE>Это лишь значит, что при прочих равных инженер, знающий сортировку, вероятнее окажется лучшим. VE>Но знание сортировок не является для этого ни достаточным, ни необходимым.
Точно так же как любое другое отдельно взятое знание. Реальная оценка будет идти по их совокупности.
Здравствуйте, VoidEx, Вы писали:
VE>Вы всего лишь сказали одну банальную истину. Что выбор того или иного алгоритма должен быть осознанным, т.е. надо разобраться в _характеристиках_ и выбрать то, что подходит. VE>Но это не значит, что я должен уметь писать каждую сортировку (и тем более, что я должен был их когда-то писать), но знать их характеристики — должен. Но и то, только тогда, когда эта сортировка мне понадобится.
Если я правильно понял, он утверждает что человеку без знания подробного алгоритма запомнить характеристики невозможно, и что иное встречается крайне редко.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, netch80, Вы писали:
N>Здравствуйте, VoidEx, Вы писали:
VE>>Т.е. я правильно понял вашу точку зрения: VE>>1. Программист(инженер) должен учитывать характеристики составных частей при проектировании более сложной системы. Если существующие составные части не подходят, можно использовать специальные нестандартные детали. VE>>2. Большинство программист(инженер) ленивые и потому берут первую попавшуюся деталь, если не бились ранее лбом по этой теме. Если бились, то обычно разбираются в вопросе и сразу думают, какую деталь лучше взять. VE>>3. Если программист(инженер) не имеет знаний о сортировках, то он относится к пункту 2 VE>> 3.a [с большой вероятностью]. VE>>?
N>Речь не идёт о знании, как писать конкретную сортировку. Но о знании граничных и оптимальных условий их применения, хотя бы минимальных оценок эффективности. И о том, что лучший способ усвоения этих знаний — написать в порядке обучения хотя бы парочку.
С этим никто не спорит.
Ясно, добавим пункт 4 (чтобы ссылаться).
4. Лучший способ усвоить знания — проверить на практике. Т.е. если инженер пробовал на практике — велика вероятность, что усвоил.
Но насколько я понял, вы утверждали, что инженер обязан написать хотя бы пару сортировок, или он клавишное мясо.
Так вот.
* Почему именно сортировок? Требуйте знание всего абсолютно. Или есть некая специфика? Ну так она у каждого инженера своя. Ясное дело, что оптик должен про линзы и аберрации знать. Но это не значит, что если он не знает, то он плохой инженер. Оптик плохой. Программист — это не только написатель алгоритмов. Писатель алгоритмов должен знать сортировки. Обобщённый программист — нет.
* Пока я не понимаю, откуда следует вывод, что если инженер не писал сортировок, то он их не усвоил. Ибо
(A => B) =/> (!A => !B) // =/> — не следует
A: писал сортировки
B: усвоил их
N>Пусть сортировка только классический показательный пример, но программист, который решил применить quicksort на множестве ключей без линейного порядка — мягко говоря, поступает некорректно.
Этого никто не отрицал.
Отрицают, что абстрактный программист должен знать сортировки, иначе он программист уровня ниже, нежели тот, кто писал.
VE>>Во-вторых, если даже он относится к пункту 2, то он сталкивался.
N>Почему?
Потому что именно это утверждает пункт 2: B (берут первую попавшуюся деталь), если A (не бились ранее лбом по этой теме). !A => !B, !B => !A. Если берёт осознанно — бился лбом. При условии, если программист относится к множеству (2), разумеется.
Здравствуйте, yumi, Вы писали:
Y>Здравствуйте, AndrewVK, Вы писали:
AVK>>О да, без пенисометрии никак. Знаешь только, в чем проблема, особенно в этом форуме? По результатам измерений запросто может оказаться, что у кого то из твоих оппонентов длиннее.
Y>Эххх, ну когда же все поймете, важна ведь не длина, а диаметр!
Здравствуйте, AndrewVK, Вы писали:
AVK>Если я правильно понял, он утверждает что человеку без знания подробного алгоритма запомнить характеристики невозможно, и что иное встречается крайне редко.
Я тоже так понял. И чтобы исключить недопонимание, я предлагаю ввести таки буквенные логические утверждения и пользоваться логикой, что частично сделал
Здравствуйте, VoidEx, Вы писали:
VE>Но насколько я понял, вы утверждали, что инженер обязан написать хотя бы пару сортировок, или он клавишное мясо.
Именно сортировка была показательным примером. В каждой суботрасли свой набор таких ключевых знаний.
VE>Так вот. VE> * Почему именно сортировок?
Уже отвечено много раз.
VE> Требуйте знание всего абсолютно. Или есть некая специфика? Ну так она у каждого инженера своя.
Я так и говорил. Вы почему-то не хотите это прочитать.
VE> * Пока я не понимаю, откуда следует вывод, что если инженер не писал сортировок, то он их не усвоил. Ибо VE>(A => B) =/> (!A => !B) // =/> — не следует VE>A: писал сортировки VE>B: усвоил их
По общей логике — да, не следует. Но практика показывает заметную корреляцию, а психология её обосновывает.
VE>Отрицают, что абстрактный программист должен знать сортировки, иначе он программист уровня ниже, нежели тот, кто писал.
Я не знаю, кто это отрицает — я его не поддерживаю (или поддерживаю с сильными ограничениями).
VE>>>Во-вторых, если даже он относится к пункту 2, то он сталкивался. N>>Почему? VE>Потому что именно это утверждает пункт 2: B (берут первую попавшуюся деталь), если A (не бились ранее лбом по этой теме). !A => !B, !B => !A. Если берёт осознанно — бился лбом. При условии, если программист относится к множеству (2), разумеется.
со всем более-менее согласен кроме
IT>Немерле – это удачная попытка совмещения традиционного программирования и FP. Практически все, что наработано в FP поддерживается в Немерле и уже сейчас готово к использованию. Можно отложить в сторону каменный топор (if/else) и взять в руки охринительной мощности базуку (match). Кривизну out/ref параметров можно заменить на tuples, а зоопарк из приватных методов на удобные локальные функции. Много чего. И главное больше нет необходимости компенсировать скудность тактических средств стратегией.
локальная функция, если она не захватывает контекст, ничем не лучше private static, а может быть и хуже, тк захламляет код оснофной функции. Если же захватывает, то надо быть очень осторожным. Тут по работе пришлось насмотреться на локальные функции в delphi.net — ппц.
Здравствуйте, netch80, Вы писали:
N>По общей логике — да, не следует. Но практика показывает заметную корреляцию, а психология её обосновывает.
Вот именно, что заметную, а не абсолютную.
Утверждение же "должен был писать пару сортировок, иначе его уровень ниже" неверно.
Правильно так: "если не писал пары сортировок, вероятно, его уровень ниже".
Чтобы не было демагогии и искажения собственных слов, я приведу цитату:
_FR>Вот что ты скажешь о кодере, которому за девять с лишним лет ни разу не пришлось самому писать сортировку Не то, что строить деревья или создавать примитив синхронизации? Что он должен сгореть от горя или позора?
Какой ответ на этот вопрос Вы хотите? Можно ответить цинически — мол, есть клавишное мясо, которое не способно даже осознать, что оно теряет и почему. А можно — что пусть себе и дальше продолжает, но пусть осознаёт, где его потолок. В принципе, оба ответа правильны.
Т.е. фактически это равносильно вашему утверждению "Не писал сортировок => клавишное мясо с потолком"
Здравствуйте, _FRED_, Вы писали:
_FR>Здравствуйте, Константин Л., Вы писали:
КЛ>>со всем более-менее согласен кроме IT>>>…а зоопарк из приватных методов на удобные локальные функции.…
КЛ>>локальная функция, если она не захватывает контекст, ничем не лучше private static, а может быть и хуже, тк захламляет код оснофной функции. Если же захватывает, то надо быть очень осторожным. Тут по работе пришлось насмотреться на локальные функции в delphi.net — ппц.
_FR>Ага, уж лучше замусорить тело класса пачкой функций-хелперов, чем тело одной единственной функции
Это сарказм? Если удается сделать правильную пачку хэлперов, то это повышает читабельность основного метода, плюс от к захвату контекста все-же лучше прибегать с осторожностью.
Здравствуйте, VoidEx, Вы писали:
VE>Чтобы не было демагогии и искажения собственных слов, я приведу цитату:
VE>
_FR>>Вот что ты скажешь о кодере, которому за девять с лишним лет ни разу не пришлось самому писать сортировку Не то, что строить деревья или создавать примитив синхронизации? Что он должен сгореть от горя или позора?
VE>Какой ответ на этот вопрос Вы хотите? Можно ответить цинически — мол, есть клавишное мясо, которое не способно даже осознать, что оно теряет и почему. А можно — что пусть себе и дальше продолжает, но пусть осознаёт, где его потолок. В принципе, оба ответа правильны.
VE>Т.е. фактически это равносильно вашему утверждению "Не писал сортировок => клавишное мясо с потолком"
В совокупности со следующей фразой это немного странно смотрится
N>Именно сортировка была показательным примером. В каждой суботрасли свой набор таких ключевых знаний.
То ли netch80 быстро меняет свою точку зрения, то ли не до конца ее излагает. netch80!
Вы не хотите сформулировать свою позицию так, чтобы она не вызывала противоречий?
Здравствуйте, AndrewVK, Вы писали:
AVK>А мне уже нет. Я уже мильен раз об этом говорил, и поднимать старый флейм нет никакого желания.
Ну тогда не надо поднимать флейм, достаточно просто нейтрально написать — "я считаю, что вот такая-то вещь в реализации является проблемой вот в таких-то случаях".
AVK>Это не аргументация. Это констатация факта. Если непонятно — могу проиллюстрировать: когда зовут обедать криком "жрать, суки", у меня почему то аппетит пропадает.
Ни разу не видел ничего в духе "пользуйтесь Немерле с#%и"
AVK>Ну и насчет взрослого человека — давай все таки обходится без хамства.
Здравствуйте, AndrewVK, Вы писали:
AVK>>>О да, без пенисометрии никак. Знаешь только, в чем проблема, особенно в этом форуме? По результатам измерений запросто может оказаться, что у кого то из твоих оппонентов длиннее. F>>Вот тут, коллега, вы сами себе противоречите Выше, если не ошибаюсь, вы указали мне на использование некорректных приемов. Может, будем последовательными ?
AVK>И где здесь некорректный прием? Я всего лишь указал на нежелательность выяснения, кто тут круче.
Опуская всю пургу, что все мы — и я не исключение — по мере сил наваяли (видимо, пятница, финансовый кризис и прочая, прочая, прочая) я всего лишь скромно хотел обратить ваше внимание, что использование (простите!) слова "пени%%%%%рия" — это и есть некорректный прием Просматривая топик я не заметил, чтобы кто-то еще из уважаемых участников, не смотря на раздирающие душу эмоции, скатывался до гениталий
Пора, по-моему, завязывать, ибо — как обычно — хорошая тема смялась и перешла от собственно обсуждения к выплескиванию эмоций.
Всем хороших выходных чтобы там не происходило
Приходиться заниматься гадостью — зарабатывать на жизнь честным трудом (Б.Шоу)
Здравствуйте, eao197, Вы писали:
E>В стартовом сообщении темы ты как раз и не ответил на вопрос "почему же бошку сносит не у всех".
Не ответил? Странно. Ну ладно. Ответ тогда может звучать так: у людей разные предпочтения и тем, кто проектирует приложения от иерархий классов, то что происходит внутри методов глубоко вторично.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, AndrewVK, Вы писали:
IT>>Казалось бы, причём тут Немерле? А вы думали я о чём? Не дождётесь!
AVK>Почему то после прочтения первой строчки я уже в этом не сомневался.
Первая строчка была:
Из Лингвы:
Ну ты телепат!
IT>> Попробуйте ответить для себя на вопрос кто вы. Представьте, что вы пишите небольшое консольное приложение строчек на 300.
AVK>Не смог. Ответить, в смысле . Пишу и то и другое одновременно.
Я в этом ни секунды не сомневаюсь.
AVK>Я так понимаю, это обещаное объяснение, почему мне не нравится Немерле? Тогда мимо. Я как раз таки очень положительно отношусь к ФП, и даже первый готов воткнуть Хейлсбергу вилку в глаз за то, что в шарпе до сих пор нет паттерн матчинга .
В следующий раз будешь проездом в Редмонд я тебе выделю вилку из семейного серебра и специально её инкрустирую "за всех обиженных отсутствием паттерн матчинга"
AVK>Скептическое отношение у меня как раз таки к МП, а точнее к его реализации в Немерле.
Я не знаю огорчит это тебя или обрадует, но за два года работы с Немерле я написал ровно 0 макросов. Мне не надо было
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, yumi, Вы писали:
Y>В итоге от ООП остались только описание класса и внешние интерфейсы. Все. Далее, остальные подсистемы подверглись такому же процессу рефакторинга, ну кроме мордочек.
Всё верно, я как раз об этом говорил. Такое получилось потому, что ранее у тебя скудность тактических средств затыкалась стратегией.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, D. Mon, Вы писали:
DM>Если это такой чудесный и суперпродуктивный язык, то почему единственные условно известные проекты на нем — компилятор и интеграция — никак не могут дойти до версии 1.0?
Потому что всем и так хорошо
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, yumi, Вы писали:
Y>Из всего этого вывод я делаю такой, что ООП в принципе и не нужен, ФП более чем достаточно. Ну разве, что если ООП будет средством модульности. Т.е. от ООП в классическом понимании останется совсем мало.
Здравствуйте, Andrei F., Вы писали:
AF>Здравствуйте, yumi, Вы писали:
Y>>Из всего этого вывод я делаю такой, что ООП в принципе и не нужен, ФП более чем достаточно. Ну разве, что если ООП будет средством модульности. Т.е. от ООП в классическом понимании останется совсем мало.
AF>GUI на ФП тоже хорошо делается?
Вот, кстати, очень интересный вопрос! Сколько смотрю на последние "жаркие" темы — учебный флейм и эту — всё пытаюсь представить, как же делать на ФП пользовательский интерфейс. Я пока что на ФП не пробовал ниче писать и вопрос скорее оффтопный, но мож кто чиркнет в общих чертах Вот как баттон на форму впихнуть?
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Кстати, у тебя присутствует фактически следующая классификация: сам ООП это ультрамодный космический корабль, а то, что мы пишем в методах — пещерный век. ВВ>А мне кажется, что ООП — это не космический корабль. Это ржавая подводная лодка, которая медленно идет ко дну
Как вам угодно. Пусть это ржавая подводная лодка. Но это всё равно офигительный прогресс по сравнению с каменным топором.
ВВ>И может стоит вообще пересесть с этой подводной лодки на что-нибудь другое?
Предлагай. Насколько мне известно, на сегодняшний день всё уже придумано, но не всё пока реализовано в мэйнстриме. Если ты придумаешь что-то новое, что будет круче всего, что уже есть, то Нобелевская премия тебе гарантирована.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, IT, Вы писали:
Pzz>>Да помилте, какой еще нужен струмент для написаныя простых алгоритмов, кроме как раз тех самых if'ов и while'ов?
IT>Так и для организации кода достаточно одних структур и методов. Зачем ООП придумали и кучу других паттернов? Непонятно
ООП придумали для того, чтобы можно было структуруровать программу в терминах довольно больших блоков. Это нужно, в первую очередь, в связи с индустриальными методами разработки, когда над одной программой работают 50 индусов, и надо как-то провести границы, чтобы они не наступали друг другу на пятки.
Т.е., в первую очередь ООП — это инструмент для менеджера проекта, а не для программиста.
Что касается паттернов, их существование объясняется только тем, что люди решают похожие проблемы похожими способами, и похожих проблем встречается довольно много. В принципе, никаких паттернов быть не должно, раз уж люди постоянно делают одно и тоже, готовое решение должно стать библиотечной функцией (макросом, классом, темплейтом, ... — не важно).
А вот внутри самих алгоритмов if'ы и while'ы — вполне себе адекватный инструмент. Во всяком случае, все классические алгоритмы описаны в литературе именно в этих терминах.
Здравствуйте, Tilir, Вы писали:
T>Понимаете, есть один очень серьёзный камень преткновения и его имя -- деструктивные присваивания. Не знаю как вам а лично мне очень сложно обойтись без деструктивных присваиваний.
Они конечно нужны но намного реже чем ты думаешь.
T>Основной рабочий инструмент для меня C,
Заметно.
T>но я много изучал Haskell и много пытался на нём писать.
На хаскеле или таки на С с синтаксисом хаскеля?
T>Вы когда-нибудь пробовали написать на этом языке двусвязный список например? А вы попробуйте...
А зачем?
Лично мне двусвязные списки по делу так ни разу и не понодобились.
T>А потом слить два отсортированных двусвязных списка с сохранением сортировки... верёвка и мыло в магазине за углом кстати.
А зачем?
T>Диссер Окасаки по чисто функциональным структурам данных на мой взгляд просто хоронит эти структуры с точки зрения практики.
Если применять их по делу то нет.
T>Так вот любая попытка смешать снотворное со слабительным неизбежно заканчивается тем,
Демагогия.
T>что обычный человек в своей жизни мыслит императивно, деструктивными ходами.
Не обобщай свой ход мыслей на всех.
T>Типа взять ложку положить в ящик. Потом вынуть ложку положить вилку. Вам мама в детстве записки на столе наверняка оставляла. Типа возьми крупу, свари кашу, съешь её и иди в школу. Чисто императивный алгоритм.
Сколько раз твердили миру что нельзя тупо переносить опыт из реального мира на программирование и все тудаже...
T>А функциональные фичи в языке требуют функциональной чистоты и высокой математической культуры (я месяц въезжал в монады и до сих пор не уверен, что въехал).
Я въехал минут за нацать прочитав одну статью.
Концепция тупая как пробка. Никакой заумной матиматики для ее понимания не нужно.
T>Что до метапрограммирования, то напишите этот марсианский кошмар и вы увидите что его некому поддерживать.
Вот только это не соответствует действительности.
Например код на немерле буквально забит вызовами макросов. Они есть почти в каждой строке, а то и по нескульку раз. И никаких проблем это не создает.
Натворить конечно можно будь здоров сколько вот только натворить можно и на обычном языке. Вон посмотри индусячий код.
T>В то же время у меня есть опыт редукции офигительной объектно-ориентированной иерархии на C++ из десятка шаблонных классов и активным использованием STL и Boost на полсотни килобайт кода в одну (!) функцию на C из сорока строчек, *не использующую даже CRT*.
У меня есть обратный опыт из
и что? На функциональщене это будет еще короче.
Будешь и дальше обобщать один случай (скорей всего показывающий неопытность тех кто писал тот код) на все?
Это слишком простая демагогия. Тут такая не работает.
T>И я совершенно уверен из всего своего опыта -- любая "сложность" программирования на простых языках без лишних фич во многом надумана. C is really enough.
А я уверен прямо в противоположном.
T>Сейчас все эти сишарпы и немерле
Эти языки стоят на разных уровнях.
T>выплывают только на растущей производительности компов, которая пока растёт быстрее чем все их сборщики мусора тормозят. Надолго ли?
Навсегда.
Ибо сборщики мусора тормозят гораздо меньше чем ты думаешь и более того со временем тормозят все меньше и меньше.
А когда наконец сделают правильную ВМ (модель CLR и JVM мусор редкостный хрен чего докажешь почти как в С, а без доказательств агрессивную оптимизацию не сделать) у С начнутся очень тяжелые времена.
Сначала его загонят во встраиваимые железки, а потом кроскомпиляцией и оттуда выдавят.
... << RSDN@Home 1.2.0 alpha rev. 745>>
Пусть это будет просто:
просто, как только можно,
но не проще.
(C) А. Эйнштейн
_>>"Мясо" все равно сейчас писать намного проще, чем раньше. IT>Мясо как писалось раньше на if/else/while, так и сейчас пишется на if/else/while.
Вопрос в том сколько раньше этих if/else/while нужно было, чтобы написать что-то и сколько сейчас. Я прекрасно понимаю, что мы о разном говорим: вы про синтаксические конструкции внутри методов, а я про то насколько проще стало писать мясо используя готовые написанные компоненты. Но видимо не так уж важны эти синтаксические навороты...
_>>Появились фреймворки и это главное. Если раньше надо было все писать самому, то сейчас можно использовать готовое. IT>Если бы фреймворки решали всё, то всё уже было бы давно написано и мы были бы без работы. Тем не менее мне почему-то приходится каждый день писать код не покладая рук.
Хехе, вы оптимист. Что значит ВСЕ написано? Все нельзя написать и кстати любой фреймворк можно улучшить. Поэтому тут работа никогда не закончится.
_>>Взять например web-программирование. Тогда каменный топор — это когда html код надо формировать плюсованием строк. От этого очевидно очень далеко ушли.
IT>В ASP.NET эта проблема решается средствами метапрограммирования, конкретно precompile time генерацией. А дальше практически как ты сказал, правда не конкатенация, а вывод в stream. Но сути дела это не меняет. Придумали парни из MS DSL для типовой задачи, очень хорошо. Но как мы уже выяснили типовыми задачами жизнь не ограничивается. Почему-то работодатели когда ищут ASP.NET программиста включают в графу skills C#. А значит придётся писать ifs & whiles.
Да, внутри те же if/else/while. Но только если раньше это все приходилось писать самому, то теперь нет проблем: взял ASP.NET и ваяй сколько душе угодно. Надо использовать шаблоны? Пожалуйста тебе UserControl. Надо кеширование? Да нет проблем, выбирай что душе угодно.
Здравствуйте, Andrei F., Вы писали:
AF>Ну тогда не надо поднимать флейм, достаточно просто нейтрально написать — "я считаю, что вот такая-то вещь в реализации является проблемой вот в таких-то случаях".
Не вижу разницы и причин, почему ты посчитал что я начинаю флейм.
AF>Ни разу не видел ничего в духе "пользуйтесь Немерле с#%и"
А я видел.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, IT, Вы писали:
IT>Первая строчка была:
IT>
Из Лингвы:
IT>Ну ты телепат!
Первая строчка была сабжем Так что я еще круче телепат, чем ты думаешь
AVK>>Не смог. Ответить, в смысле . Пишу и то и другое одновременно.
IT>Я в этом ни секунды не сомневаюсь.
Тогда как быть с твоей классификацией?
IT>Я не знаю огорчит это тебя или обрадует, но за два года работы с Немерле я написал ровно 0 макросов. Мне не надо было
Отож. А дальше идеть скучная и нудная волынка про возможность использования Немерли в моей текущей и будущей работе.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, fplab, Вы писали:
F>использование (простите!) слова "пени%%%%%рия" — это и есть некорректный прием
ИМХО нет. ИМХО точный и в меру политкорректный термин.
F> Просматривая топик я не заметил, чтобы кто-то еще из уважаемых участников, не смотря на раздирающие душу эмоции, скатывался до гениталий
Гениталии тут не при чем, это аллегория.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, VoidEx, Вы писали:
VE>Ваша фраза применима к любой области и любой библиотеке. Однако, вы не станете требовать от человека знание всех ГУИ библиотек, всех библиотек для работы с сетью и т.п.? VE>Важно, чтобы человек не бездумно брал первую попавшуюся, а выбирал лучшую, и, если таковой не нашлось, 10 раз подумать и таки написать самому. VE>Только причём тут важность уметь писать самому всё изначально? Понадобится — будем разбираться.
Напротив, я призываю как раз к прямо противоположному: попытаться понять те принципы, которые у этих библиотек "под капотом", а не все 10 миллионов вариантов реализации, различающихся только деталями. Принципов на самом деле не так много, они медленно меняются и редко устаревают, в отличии от реализаций. Время, потраченное на обучение, лучше инвестировать в те знания, которые приносят долгосрочную помощь, а не устаревают раз в несколько лет.
Pzz>>Принесут вам код, написанный для UNIX'а и активно использующий read/write lock'и, и попросят запустить его на Windows XP. А в XP нет read/write lock'ов. Ваши дальнейшие действия? VE>
Гоги, ты чей друг? Мой или медведя?
VE>Почитаю соответствующую документацию, выберу решение. Или я должен всё знать заранее?
По вашему ответу хорошо видно, что вы совсем не поняли вопроса. Что такое read/write lock, я вам и так расскажу, это несложно (кстати, это классический примитив синхронизации, печально, что вы про него не слышали). Вопрос в том, из чего вы будете его делать — готового-то в венде нет.
Тут надо не знать, а уметь думать. И не стесняться пользоваться этим умением.
Здравствуйте, MxKazan, Вы писали:
MK>Вот, кстати, очень интересный вопрос! Сколько смотрю на последние "жаркие" темы — учебный флейм и эту — всё пытаюсь представить, как же делать на ФП пользовательский интерфейс. Я пока что на ФП не пробовал ниче писать и вопрос скорее оффтопный, но мож кто чиркнет в общих чертах Вот как баттон на форму впихнуть?
xmonad — какие-то маньяки вообще сделали windows manager на haskell
Lisp is not dead. It’s just the URL that has changed: http://clojure.org
Здравствуйте, russian_bear, Вы писали:
_>Вопрос в том сколько раньше этих if/else/while нужно было, чтобы написать что-то и сколько сейчас. Я прекрасно понимаю, что мы о разном говорим: вы про синтаксические конструкции внутри методов, а я про то насколько проще стало писать мясо используя готовые написанные компоненты. Но видимо не так уж важны эти синтаксические навороты...
Здравствуйте, AndrewVK, Вы писали:
AVK>Не вижу разницы и причин, почему ты посчитал что я начинаю флейм.
Ты написал "нет желания поднимать старый флейм" — я написал "ну и не надо его поднимать".
Чтобы устроить флейм нужно как минимум две желающие этого стороны, не так ли?
AVK>А я видел.
Здравствуйте, russian_bear, Вы писали:
_>Да, внутри те же if/else/while. Но только если раньше это все приходилось писать самому, то теперь нет проблем: взял ASP.NET и ваяй сколько душе угодно. Надо использовать шаблоны? Пожалуйста тебе UserControl. Надо кеширование? Да нет проблем, выбирай что душе угодно.
Правильно я тебя понял: в процессе эволюции методы вовсе писать не понадобится?
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, samius, Вы писали:
S>Не поверите наверное, но есть толковые ребята, которые сидят в каких-нить оборонных НИИ за проволокой и работают за еду. Я не утверждаю, что все там толковые. Я только утверждаю, что такие есть.
IT в свое время на эту тему писал большое сообщение, породившее большой флейм.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Andrei F., Вы писали:
AF>GUI на ФП тоже хорошо делается?
UI то, конечно, делать можно. Проблема в дизайн-тайме, причем не только этого самого UI. Сколько я ни спрашивал, никто не смог мне продемонстрировать чисто функциональную компонентную модель. Что, впрочем, не мешает при этом какими то элементами ФП пользоваться.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Pzz, Вы писали:
Pzz>Тут надо не знать, а уметь думать. И не стесняться пользоваться этим умением.
Т.е. вы умение думать проверяете по тому, писал ли программист сортировки?
Или тогда потрудитесь разъяснить, какая вообще связь между тем, разбирался ли человек с сортировками, и умением думать.
_>>Да, внутри те же if/else/while. Но только если раньше это все приходилось писать самому, то теперь нет проблем: взял ASP.NET и ваяй сколько душе угодно. Надо использовать шаблоны? Пожалуйста тебе UserControl. Надо кеширование? Да нет проблем, выбирай что душе угодно.
AVK>Правильно я тебя понял: в процессе эволюции методы вовсе писать не понадобится?
Неправильно. В процессе эволюции не методы, а "примитивы" придется писать все реже и реже. Если раньше в программах на VB сортировка встречалась в каждом более-менее приличном проекте, то сейчас она идет в .NET Framework и никто (ну 99%) этим не заморачивается. Кроме сложных случаев, когда стандартная сортировка не оптимальна, но и это в итоге решится, если таких сложных случаев станет много.
Здравствуйте, Pzz, Вы писали:
Pzz>Есть знание специфическое, и есть знание фундаментальное. Специалист по географии, который не знает климатические особенности какого-нибудь никому неизвестного острова размером 2х2 метра в Тихом окене — явление вполне нормальное. Специалист по географии, который не знает, что такое остров вообще, потому что всю жизнь изучал только сушу — нонсенс.
Это что же, аналогия?
Не, ну если программист не знает, что такое сортировка вообще, то я соглашусь.
Только вы вроде о другом говорили.
Pzz>Так что я не понимаю, что вы собираетесь обсуждать с юниксоидами, и довольно печально, что вы по этому вопросу вообще собираетесь с ними что-то обсуждать — это свидетельствует о том, что вы не поняли вопрос.
Вы слишком хорошо развешиваете ярлыки. Самомнение что ли высокое.
Я понял ваш вопрос, он тоже. Однако ответили мы максимально общо, ибо вопрос был "например".
Здравствуйте, VoidEx, Вы писали:
Pzz>>Тут надо не знать, а уметь думать. И не стесняться пользоваться этим умением. VE>Т.е. вы умение думать проверяете по тому, писал ли программист сортировки? VE>Или тогда потрудитесь разъяснить, какая вообще связь между тем, разбирался ли человек с сортировками, и умением думать.
Школьные сочинения преследуют 2 цели: научить человека писать синтаксически грамотно, и научить внятно излагать свои мысли в письменном виде. Вероятно и тому и другому можно научиться, не написав в жизни не одного сочинения. Но на практике такое встречается нечасто.
Умение думать вообще от сортировок, конечно, не зависит. Вон узбеки на рынке какие умные , а сортировкок поди не писали. Но умение думать в приложении к программированую подразумевает определенную грамотность и умение внятно излагать свои мысли в виде програмного кода. Наверное, этому можно научитася безо всяких сортировок — с таким же примерно успехом, как научиться пользоваться письменной речью без школьных сочинений.
Здравствуйте, russian_bear, Вы писали:
_>Неправильно. В процессе эволюции не методы, а "примитивы" придется писать все реже и реже.
А что такое примитивы? И что, окромя таинственных примитивов, при этом останется внутри методов?
_> Если раньше в программах на VB сортировка встречалась в каждом более-менее приличном проекте, то сейчас она идет в .NET Framework и никто (ну 99%) этим не заморачивается.
Ну и чего? Это ж совсем не означает, что конструкция if тоже не используется. Еще раз повторюсь — речь о форме, а не о содержании.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Andrei F., Вы писали:
AF>Любой интерфейс должен иметь состояние — просто потому, что пользователь так устроен
ФП не отрицает состояния, ФП отрицает изменяемое состояние. А устроенность мира заменяется в ФП копированием. Это ж, блин, азы.
Еще раз — проблема не в UI, он то как раз в ФП стиле описывается, хотя о балансе плюсов и минусов такого способа я вывода сделать не готов. Проблема в другом — никакой альтернативы понятию компонента со стороны ФП нет. А вот уже компонент сделать неизменяемым, да так чтобы дизайн-тайм был нормальный — та еще задачка, в основном идеологического плана.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
я приводил пример того, как синтаксические навороты рвут if/else как тузик грелку.
Пример хороший и я согласен — преимущества у LINQ очевидные, но опять же есть одно но. Если исходные данные будут браться из базы данных, то надо очень четко следить, чтобы вот такой вот наворот:
var percents =
from percent in
from prov in
from p in providingVolumes
group p by p.Provider into pg
let total = pg.Sum(v => v.Volume)
from pp in pg
select new { pp, total }
join rec in
from r in receivingVolumes
group r by r.Account into rg
let total = rg.Sum(v => v.Volume)
from rr in rg
select new { rr, total }
on prov.pp.Account equals rec.rr.Account
select new Percent
{
Provider = prov.pp.Provider,
Receiver = rec.rr.Receiver,
Account = prov.pp.Account,
Value = prov.pp.Volume / prov.total * rec.rr.Volume / rec.total
}
group percent by percent.Provider;
не наворотил тучу запросов к базе данных вместо одного/нескольких. И частенько это будет снова решаться на уровне SQL и простейших операций в .NET.
Здравствуйте, _FRED_, Вы писали:
_FR>Здравствуйте, Константин Л., Вы писали:
КЛ>>>>локальная функция, если она не захватывает контекст, ничем не лучше private static, а может быть и хуже, тк захламляет код оснофной функции. Если же захватывает, то надо быть очень осторожным. Тут по работе пришлось насмотреться на локальные функции в delphi.net — ппц. _FR>>>Ага, уж лучше замусорить тело класса пачкой функций-хелперов, чем тело одной единственной функции
КЛ>>Это сарказм? Если удается сделать правильную пачку хэлперов, то это повышает читабельность основного метода,
_FR>То есть можно жертвовать надёжностью, модульностью, локализацией ради "читабельности"? Это при том, что мнение "чем локальнее объявление, тем лучше" можно считать верным (или нет?), а "читабельность" — величина субъективная?
где ты увидел что я ими жертвую? private static. ни стейта, ни открытости.
КЛ>>плюс от к захвату контекста все-же лучше прибегать с осторожностью.
_FR>Вынося метод "наружу" ты позваляешь кому-то (а как ты запрещаешь? ага, никак!) к нему обратиться, тем самым увеличивая связаность. К лишней связаности надо относиться с ещё большим подозрением чем "к захвату контекста". Кстати, из за чего требуется осторожность? И, между прочим, мы же говорим о методах, не захватывающих контекст.
связанность и там и там. только в одном случае по параметрам, в другом по локальным переменным. Наружу это куда? Я же написал — private.
_>>Неправильно. В процессе эволюции не методы, а "примитивы" придется писать все реже и реже. AVK>А что такое примитивы? И что, окромя таинственных примитивов, при этом останется внутри методов?
Все то, что входит в библиотеки. Как пример библиотеки — .NET Framework. Внутри как и всегда логика.
_>> Если раньше в программах на VB сортировка встречалась в каждом более-менее приличном проекте, то сейчас она идет в .NET Framework и никто (ну 99%) этим не заморачивается.
AVK>Ну и чего? Это ж совсем не означает, что конструкция if тоже не используется. Еще раз повторюсь — речь о форме, а не о содержании.
Ну так я уже сказал, что мы о разном говорим. Я говорю, что изменения есть и направлены они в сторону содержания.
Здравствуйте, russian_bear, Вы писали:
_>Все то, что входит в библиотеки. Как пример библиотеки — .NET Framework. Внутри как и всегда логика.
То есть внутри методов будут только вызовы методов фреймворка и больше никаких синтаксических конструкций, так?
AVK>>Ну и чего? Это ж совсем не означает, что конструкция if тоже не используется. Еще раз повторюсь — речь о форме, а не о содержании.
_>Ну так я уже сказал, что мы о разном говорим.
Ну и зачем тогда ты говоришь не по теме топика? С кем споришь?
_> Я говорю, что изменения есть и направлены они в сторону содержания.
Изменения чего? Языка программирования? Где?
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, VoidEx, Вы писали:
VE>Вы слишком хорошо развешиваете ярлыки. Самомнение что ли высокое. VE>Я понял ваш вопрос, он тоже. Однако ответили мы максимально общо, ибо вопрос был "например".
Меня очень удручает то, что вы оба собрались потопать к юниксоидам. Поскольку единственный содержательный вопрос, который вы можете им задать, это "что такое read/write lock?", я делаю вывод, что вы оба не знаете, что такое read/write lock.
Ума ни приложу, что вы при таком раскладе могли понять в моем вопросе...
Здравствуйте, Pzz, Вы писали:
Pzz>Меня очень удручает то, что вы оба собрались потопать к юниксоидам. Поскольку единственный содержательный вопрос, который вы можете им задать, это "что такое read/write lock?", я делаю вывод, что вы оба не знаете, что такое read/write lock.
Цитату, где я писал, что пойду к юниксойдам.
Здравствуйте, VoidEx, Вы писали:
Pzz>>Меня очень удручает то, что вы оба собрались потопать к юниксоидам. Поскольку единственный содержательный вопрос, который вы можете им задать, это "что такое read/write lock?", я делаю вывод, что вы оба не знаете, что такое read/write lock. VE>Цитату, где я писал, что пойду к юниксойдам.
Простите, я напутал. А какую документацию вы собрались читать, и что именно вы не знаете заранее?
Здравствуйте, samius, Вы писали:
S>На мой взляд — написание сортировки эквивалентно лишь одному изложению. И если кто-то не написал одно изложение, то нельзя говорить что он не освоил школьную программу.
Сочинению или изложению, не важно. Допустим, написание одной сортировки эквиавалентно одному изложению. Тогда ненаписание ни одной сортировки эквиавалентно ненаписанию ни одного изложения, не так ли? Логика, однако...
Я немного передергиваю, но не очень сильно. Замените слово "сортировка" словом "классический алгоритм". Просто так уж повелось, что сортировки оказываются первыми в списке кандидатов, наряду с поисками. Ну не на алгоритмах же IP-роутинга учить программированию, в самом деле
Здравствуйте, Pzz, Вы писали:
Pzz>Простите, я напутал. А какую документацию вы собрались читать, и что именно вы не знаете заранее?
Ещё раз, я отвечал максимально общо.
В данном случае я бы просто посмотрел текущие реализации, поискал бы их плюсы-минусы. И лишь в крайнем случае стал бы писать сам.
Здравствуйте, Pzz, Вы писали:
Pzz>Вы это либо умеете, либо нет. Если никогда не занимались, то, скорее всего, не умеете. Наверное, потратив время, вы сможете научиться, но у вас никогда не найдется на это времени. Поэтому когда встанет задача, в которой надо не просто скрестить XML с HTML'ем, а изобрести что-нибудь необычное, вас к ней никогда не привлекут. Это и есть тот самый ваш потолок, о котором говорил Валентин Нечаев. Заметьте, это ваш добровольный выбор.
Точно! Но с каикх это пор область прогармирования ограничивается "изобретением что-нибудь необычного"? Если хотя бы каждый сотый програмист на Земле начнёт этим "изобретением" заниматься, во что превратится мир [програмирования]?
Pzz>Есть знание специфическое, и есть знание фундаментальное.
Я по-прежнему не понимаю (из Ваших слов), для чего веб-програмисту обладать фундоментальными знаниями о примитивах синхронизации? Давайте тогда определим, что для "тех-то" нужно "то-то", а для "этих" "вон то". Только ограничить уж очень не просто получится, вплоть до того, что обоснованная работа на эту тему сможет стоитьь дисера.
Pzz>Я имел ввиду, что поскольку знания, в которые вы вкладываетесь, в основном состоят из перечня интерфейсов той технологии, которую вы сейчас считаете современной, то они по природе своей полностью устаревают за несколько лет,
С чего Вы это взяли? Это как-то следует из того, что я не могу написать сортировку?
Help will always be given at Hogwarts to those who ask for it.
Здравствуйте, Pzz, Вы писали:
Pzz>Здравствуйте, samius, Вы писали:
S>>На мой взляд — написание сортировки эквивалентно лишь одному изложению. И если кто-то не написал одно изложение, то нельзя говорить что он не освоил школьную программу.
Pzz>Сочинению или изложению, не важно. Допустим, написание одной сортировки эквиавалентно одному изложению. Тогда ненаписание ни одной сортировки эквиавалентно ненаписанию ни одного изложения, не так ли? Логика, однако...
С этой фразой я могу согласиться только, если слово "сортировка" здесь употреблено в фигуральном смысле. Потому как если человек что-то писал кроме сортировки в буквальном смысле, то это не эквивалентно ненаписанию ни одного изложения.
Pzz>Я немного передергиваю, но не очень сильно. Замените слово "сортировка" словом "классический алгоритм". Просто так уж повелось, что сортировки оказываются первыми в списке кандидатов, наряду с поисками. Ну не на алгоритмах же IP-роутинга учить программированию, в самом деле
В школе — может быть и с сортировки. Лично меня в ВУЗе учили на численных методах, уравнениях матфизики, методах дискретной оптимизации. После ВУЗ-а еще много чего было.
Вы думаете, что я облажаюсь с пузырьком?
Здравствуйте, samius, Вы писали:
Pzz>>Сочинению или изложению, не важно. Допустим, написание одной сортировки эквиавалентно одному изложению. Тогда ненаписание ни одной сортировки эквиавалентно ненаписанию ни одного изложения, не так ли? Логика, однако... S>С этой фразой я могу согласиться только, если слово "сортировка" здесь употреблено в фигуральном смысле. Потому как если человек что-то писал кроме сортировки в буквальном смысле, то это не эквивалентно ненаписанию ни одного изложения.
Я согласен заменить слово "сортировка" словосочетанием "классические алгоритмы". Квиксорт и бинарное дерево к ним относится, SQL-запрос на 3 экрана текста — нет.
Pzz>>Я немного передергиваю, но не очень сильно. Замените слово "сортировка" словом "классический алгоритм". Просто так уж повелось, что сортировки оказываются первыми в списке кандидатов, наряду с поисками. Ну не на алгоритмах же IP-роутинга учить программированию, в самом деле S>В школе — может быть и с сортировки. Лично меня в ВУЗе учили на численных методах, уравнениях матфизики, методах дискретной оптимизации. После ВУЗ-а еще много чего было.
Это вас основам математики учили. А основы програмизьма — это отдельная область знаний.
S>Вы думаете, что я облажаюсь с пузырьком?
Здравствуйте, fplab, Вы писали:
F>Опуская всю пургу, что все мы — и я не исключение — по мере сил наваяли (видимо, пятница, финансовый кризис и прочая, прочая, прочая) я всего лишь скромно хотел обратить ваше внимание, что использование (простите!) слова "пени%%%%%рия" — это и есть некорректный прием :)
Я знаю, что пребывание в Fido наносит необратимый отпечаток (это я про себя;)), но для меня это просто стандартный мем, давно потерявший свой буквальный смысл. Думаю, употребивший его собеседник понимает точно так же.
F> Просматривая топик я не заметил, чтобы кто-то еще из уважаемых участников, не смотря на раздирающие душу эмоции, скатывался до гениталий :xz:
Вы "гуртовщиков мыши" почитайте:) Там есть гениталии на гусеничном ходу:)
Здравствуйте, IT, Вы писали:
IT>Предлагай. Насколько мне известно, на сегодняшний день всё уже придумано, но не всё пока реализовано в мэйнстриме. Если ты придумаешь что-то новое, что будет круче всего, что уже есть, то Нобелевская премия тебе гарантирована.
Это вряд ли. Насколько мне известно, премия Нобеля не распространяется на математические области. Но это чисто так, придирка.
McSeem
Я жертва цепи несчастных случайностей. Как и все мы.
Здравствуйте, Pzz, Вы писали:
Pzz>Нет, это следует из подхода, за который вы агитируете. Который заключается в том, что знать надо только специфические для своей области вещи.
Вы флеймер? Не надо нам приписывать слова, которых никто не говорил.
И таки ответьте на моё сообщение, ссылку на которое я давал 2 раза.
Здравствуйте, AndrewVK, Вы писали:
_>>Все то, что входит в библиотеки. Как пример библиотеки — .NET Framework. Внутри как и всегда логика.
AVK>То есть внутри методов будут только вызовы методов фреймворка и больше никаких синтаксических конструкций, так?
Здравствуйте, McSeem2, Вы писали:
MS>Слушай, Игорь, но почему именно "озабочусь иерархией классов"? Что, без наследования в современном мире не прожить?
Прожить-то можно даже без рекурсии и динамической памяти, вопрос удобно ли.
Не поделишься удобным способом делать похожие по поведению (но слегка отличающиеся) сущности в императивных и функциональных языках?
Например, у меня есть несколько алгоритмов компенсации движения, отличающиеся лишь способом поиска похожего блока. Наследование позволило обойтись без дублирования кода, лишних if'ов и указателей на функции (которые, по сути, изоморфны VMT).
MS>Парадигма наследования в программировании компьютеров — это пожалуй второй по величине фуфлоид.
Здравствуйте, yumi, Вы писали:
Y>Здравствуйте, netch80, Вы писали:
N>>А на практике окажется, что из ~100 методов отличаются у потомков 20, и этого достаточно, чтобы действие "передать функцию поиска похожего блока" вылилось в извращение типа "передать структуру функций, специфичных именно для этой реализации". И всё это с костылями вроде приведения типов.
Y>Если на практике ~100 методов, то эту практику нужно прекращать немедленно :)
А давайте Вы немедленно прекратите:)) практику рассказывать подобные вещи тому, кто последние 4 года плотно писал на Питоне и разнообразными лямбдами, встроенными def'ами и list comprehensions пользуется куда лучше, чем STL'ем и прочими крестатостями.
Я пользуюсь разными средствами. И first class functions. И duck typing. И наследованием. Всему своё место, и у наследования — своё, заметное и положительное.
Y>А костыли эти появляются из-за того, что языки не поддерживают higher-order functions & functions as first class objects. Вы кажется про С++, да, он этого не поддерживает, придется обходиться функторами, а это действительно костыли. А в C# 3 уже есть некоторая поддержка ФП и этих костылей не будет, не говоря уже о более развитых языках.
Ну вот Вы только-только будете его осваивать, а для меня это как воздух. Так что рекомендую поверить мне, а не своему источнику, который может только ругать.
N>>Нет, конечно, использовать такое порой можно и нужно. Но в общую практику я бы рекомендовал наследование. Конечно, у него есть свои проблемы (вспомним множественное наследование и его эффекты). Но это проблема любого подобного механизма — можно загнать в ситуацию, когда перестанет работать. Y>Наследование реализации сама по себе одна большая проблема.
Нет, не проблема. Если не относиться к ней как к панацее.
Здравствуйте, netch80, Вы писали:
N>Я пользуюсь разными средствами. И first class functions. И duck typing. И наследованием. Всему своё место, и у наследования — своё, заметное и положительное.
Ну может расскажете где место наследованию?
Y>>А костыли эти появляются из-за того, что языки не поддерживают higher-order functions & functions as first class objects. Вы кажется про С++, да, он этого не поддерживает, придется обходиться функторами, а это действительно костыли. А в C# 3 уже есть некоторая поддержка ФП и этих костылей не будет, не говоря уже о более развитых языках.
N>Ну вот Вы только-только будете его осваивать, а для меня это как воздух. Так что рекомендую поверить мне, а не своему источнику, который может только ругать.
Верить я тебе на слово не буду, извини. Я незнаю как там в вашем Питоне, может там и действительно хреново получается делать функциональную декомпозицию, а вот по крайней мере в Хаскеле (и Лиспе тоже) это делается очень естесственно.
Lisp is not dead. It’s just the URL that has changed: http://clojure.org
Здравствуйте, yumi, Вы писали:
Y>Здравствуйте, netch80, Вы писали:
N>>Я пользуюсь разными средствами. И first class functions. И duck typing. И наследованием. Всему своё место, и у наследования — своё, заметное и положительное.
Y>Ну может расскажете где место наследованию?
Там, где у множества возможных реализаций общие черты, удобно реализуемые общим кодом.
Y>:)) Верить я тебе на слово не буду, извини. Я незнаю как там в вашем Питоне, может там и действительно хреново получается делать функциональную декомпозицию, а вот по крайней мере в Хаскеле (и Лиспе тоже) это делается очень естесственно.
Приведите пример. А я посмотрю, насколько он реален, а насколько — сферический в вакууме.
Здравствуйте, yumi, Вы писали:
Y> Верить я тебе на слово не буду, извини. Я незнаю как там в вашем Питоне, может там и действительно хреново получается делать функциональную декомпозицию, а вот по крайней мере в Хаскеле (и Лиспе тоже) это делается очень естесственно.
В питоне также естественно.
ФВП полноценные плюс динамика и утиная типизация.
И кстати как раз в питоне можно совсем без наследования прожить.
Здравствуйте, FR, Вы писали:
FR>Здравствуйте, yumi, Вы писали:
Y>>:)) Верить я тебе на слово не буду, извини. Я незнаю как там в вашем Питоне, может там и действительно хреново получается делать функциональную декомпозицию, а вот по крайней мере в Хаскеле (и Лиспе тоже) это делается очень естесственно.
FR>В питоне также естественно. FR>ФВП полноценные плюс динамика и утиная типизация. FR>И кстати как раз в питоне можно совсем без наследования прожить.
Можно, не спорю. Но удобно ли?
Не так давно добавлял одну функциональность к группе классов, прежде объединённых именно утиной типизацией (у них не было общего предка, были только одинаковые методы, но с заметно разной реализацией). Потребовалось добавить функциональность (асинхронная отработка вызова, причём с сериализацией адекватной задаче — несколько объектов фильтра могут использовать один прокси, но отрабатывать это должен тред, связанный с данным прокси). Оказалось, что надо писать почти один и тот же код (очень много общего) во всех классах фильтров. Вопрос — как это сделать?;)) Фактически получалось два варианта:
первый — как предлагает коллега yumi, примерно так:
class BasicFilter:
def ein(self):
...
def eout(self):
...
class Filter1(BasicFilter):
...
А теперь вопрос в студию — и нафига корячиться с явным списком по первому типу, опять-таки дублируя кучу кода с этими назначениями методов (или — как альтернатива — их явными вызовами в методах в каждом классе)? Второй вариант делает то же самое, требует минимальных затрат на понимание, проще в сопровождении, не даёт глупого дублирования, сокращает проблемы от описок. Я — всецело за него:))
А если кто-то хочет сказать, что это не наследование, а специализация — мне как-то здесь без разницы.:)
Здравствуйте, netch80, Вы писали:
N>Здравствуйте, FR, Вы писали:
FR>>Здравствуйте, yumi, Вы писали:
Y>>> Верить я тебе на слово не буду, извини. Я незнаю как там в вашем Питоне, может там и действительно хреново получается делать функциональную декомпозицию, а вот по крайней мере в Хаскеле (и Лиспе тоже) это делается очень естесственно.
FR>>В питоне также естественно. FR>>ФВП полноценные плюс динамика и утиная типизация. FR>>И кстати как раз в питоне можно совсем без наследования прожить.
N>Можно, не спорю. Но удобно ли?
Если пишешь в нужном стиле то вполне
N>Не так давно добавлял одну функциональность к группе классов, прежде объединённых именно утиной типизацией (у них не было общего предка, были только одинаковые методы, но с заметно разной реализацией). Потребовалось добавить функциональность (асинхронная отработка вызова, причём с сериализацией адекватной задаче — несколько объектов фильтра могут использовать один прокси, но отрабатывать это должен тред, связанный с данным прокси). Оказалось, что надо писать почти один и тот же код (очень много общего) во всех классах фильтров. Вопрос — как это сделать?) Фактически получалось два варианта:
Ну в питоне мог быть уместнее и третий вариант метапрограмирование, или через декораторы или для более сложных случаев через метаклассы.
Здравствуйте, FR, Вы писали:
FR>>>В питоне также естественно. FR>>>ФВП полноценные плюс динамика и утиная типизация. FR>>>И кстати как раз в питоне можно совсем без наследования прожить. N>>Можно, не спорю. Но удобно ли? FR>Если пишешь в нужном стиле то вполне :)
Гм, и зачем мне сначала вырабатывать стиль, а затем подгонять под него решение кровью и рашпилем? По-моему, мы пока что не в Бангалоре.
N>>Не так давно добавлял одну функциональность к группе классов, прежде объединённых именно утиной типизацией (у них не было общего предка, были только одинаковые методы, но с заметно разной реализацией). Потребовалось добавить функциональность (асинхронная отработка вызова, причём с сериализацией адекватной задаче — несколько объектов фильтра могут использовать один прокси, но отрабатывать это должен тред, связанный с данным прокси). Оказалось, что надо писать почти один и тот же код (очень много общего) во всех классах фильтров. Вопрос — как это сделать?;)) Фактически получалось два варианта: FR>Ну в питоне мог быть уместнее и третий вариант метапрограмирование, или через декораторы или для более сложных случаев через метаклассы.
Метаклассы — для сильно уж сложных случаев, концепция сильно громоздкая (одно описание порядка поиска метода в документации способно поднять волосы дыбом у полностью лысого). Остальные — требуют по-любому больше писанины, чем одно легкочитаемое упоминание базового класса в заголовке определения.
Здравствуйте, samius, Вы писали:
S>То ли netch80 быстро меняет свою точку зрения, то ли не до конца ее излагает. S>netch80! S>Вы не хотите сформулировать свою позицию так, чтобы она не вызывала противоречий?
Здравствуйте, VoidEx, Вы писали:
Pzz>>Нет, это следует из подхода, за который вы агитируете. Который заключается в том, что знать надо только специфические для своей области вещи.
VE>Вы флеймер? Не надо нам приписывать слова, которых никто не говорил. VE>И таки ответьте на моё сообщение, ссылку на которое я давал 2 раза.
Нет, я не флеймер. В том сообщении, ссылку на которое вы давали, вы там с Нечаевым спорите на уже довольно громких тонах, если я ничего не путаю. Вот и продолжайте себе, мне в ваш спор встревать неохота.
Если у вас есть чего у меня спросить, не поленитесь повторить свой вопрос лично для меня.
Здравствуйте, netch80, Вы писали:
N>Гм, и зачем мне сначала вырабатывать стиль, а затем подгонять под него решение кровью и рашпилем? По-моему, мы пока что не в Бангалоре.
Угу писать на фортране можно используя любой язык
Просто начнешь всеръез писать используя функциональщину нужный стиль сам собой выработается и окажется что наследование для специализации малополезная вещь.
N>Метаклассы — для сильно уж сложных случаев, концепция сильно громоздкая (одно описание порядка поиска метода в документации способно поднять волосы дыбом у полностью лысого). Остальные — требуют по-любому больше писанины, чем одно легкочитаемое упоминание базового класса в заголовке определения.
Зато декораторы очень просто и легко, и как раз для всяких прокси и т. п. предназначены.
А так как миксин конечно и наследование нормально.
Здравствуйте, FR, Вы писали:
FR>Здравствуйте, netch80, Вы писали:
N>>Гм, и зачем мне сначала вырабатывать стиль, а затем подгонять под него решение кровью и рашпилем? По-моему, мы пока что не в Бангалоре.
FR>Угу писать на фортране можно используя любой язык :)
Не любой. Арифметический IF не реализуется на языке без goto.
FR>Просто начнешь всеръез писать используя функциональщину нужный стиль сам собой выработается и окажется что наследование для специализации малополезная вещь.
Ну да, будем передавать вагон коллбэков. Так как всё-таки быть, если общего кода этак процентов 60? Ещё один вагон коллбэков?
N>>Метаклассы — для сильно уж сложных случаев, концепция сильно громоздкая (одно описание порядка поиска метода в документации способно поднять волосы дыбом у полностью лысого). Остальные — требуют по-любому больше писанины, чем одно легкочитаемое упоминание базового класса в заголовке определения. FR>Зато декораторы очень просто и легко, и как раз для всяких прокси и т. п. предназначены.
Вообще-то у меня словом "прокси" называлось совсем не то, что можно предположить исходя из контекста классов.:))
FR>>Угу писать на фортране можно используя любой язык
N>Не любой. Арифметический IF не реализуется на языке без goto.
switch, или таблица указателей на функции?
FR>>Просто начнешь всеръез писать используя функциональщину нужный стиль сам собой выработается и окажется что наследование для специализации малополезная вещь.
N>Ну да, будем передавать вагон коллбэков. Так как всё-таки быть, если общего кода этак процентов 60? Ещё один вагон коллбэков?
Угу, будем, только не коллбеков, а ФВП. И в этом стиле как раз обощаемость и повторное испрользование по моему повыще чем в ООП.
N>>>Метаклассы — для сильно уж сложных случаев, концепция сильно громоздкая (одно описание порядка поиска метода в документации способно поднять волосы дыбом у полностью лысого). Остальные — требуют по-любому больше писанины, чем одно легкочитаемое упоминание базового класса в заголовке определения. FR>>Зато декораторы очень просто и легко, и как раз для всяких прокси и т. п. предназначены.
N>Вообще-то у меня словом "прокси" называлось совсем не то, что можно предположить исходя из контекста классов.
Здравствуйте, Sinclair, Вы писали:
S>Вообще-то вопросы границ применимости встречаются постоянно. Простейший пример: парни проектируют систему миграции из инфраструктуры A в инфраструктуру B. Архитектурная идея — проста как грабли, и при этом хорошо идет в струе технологического совершенства: экспортируем все данные из A в XML, трансформируем его в понятный системе B XML при помощи XSLT, и радуемся жизни. S>И тут (через, грубо говоря, полгода разработки) вдруг возникает грустный эффект: трансформация подразумевает работу с DOM моделью, а далеко не все из интересных нам систем A генерируют документы, которые умещаются в 3GB RAM. Я доступно объясняю?
Испугал. Пишем для одной этой системы SAX трансформатор. Делов то
Здравствуйте, yumi, Вы писали:
N>>А на практике окажется, что из ~100 методов отличаются у потомков 20, и этого достаточно, чтобы действие "передать функцию поиска похожего блока" вылилось в извращение типа "передать структуру функций, специфичных именно для этой реализации". И всё это с костылями вроде приведения типов.
Y>Если на практике ~100 методов, то эту практику нужно прекращать немедленно Y>А костыли эти появляются из-за того, что языки не поддерживают higher-order functions & functions as first class objects.
А вот тут подробнее, пожалуйста. Как упомянутые фишки изменят дело, кроме более удобного синтаксиса?
Вот задачка: есть семейство алгоритмов (та же компенсация, допустим), которые теперь отличаются не одной функцией, а пятью (при этом имеют по 10 общих). В случае ООП и наследования все просто — общие функции в базовый класс, различные — в наследников.
А что в этом случае делают в Хаскеле и Лиспе?
Не передают же при каждом вызове "вагон колбеков", как тут его назвали.
Первое, приходящее мне на ум решение, — функция-конструктор, которая получает на вход охапку тех функций, что отличают конкретный алгоритм, и выдает в качестве результата одну функцию, его реализующую. Последняя уже вызывается когда надо. Т.е. все детали специализации пошли в замыкание, и по сути, мы получили некий аналог объекта из ООП, но с меньшим числом степеней свободы.
Здравствуйте, FR, Вы писали:
FR>>>Угу писать на фортране можно используя любой язык :) N>>Не любой. Арифметический IF не реализуется на языке без goto. FR>switch, или таблица указателей на функции?
Ну да, switch внутри while и переменная состояния условно эмулирующая счётчик команд — может спасти любую программу, когда её надо сдать преподавателю как выполненную по всем канонам структурного программирования:) Только уж если Вы вспомнили мой любимый Фортран (эх, тяжёлое детство, 32-битная игрушка ЕС1022-02...) — это уже будет не фортран. В классическом F-IV и циклов не было.
FR>>>Просто начнешь всеръез писать используя функциональщину нужный стиль сам собой выработается и окажется что наследование для специализации малополезная вещь. N>>Ну да, будем передавать вагон коллбэков. Так как всё-таки быть, если общего кода этак процентов 60? Ещё один вагон коллбэков? FR>Угу, будем, только не коллбеков, а ФВП. И в этом стиле как раз обощаемость и повторное испрользование по моему повыще чем в ООП.
... из коего и возникает синекдоха отвечания. Спасибо, я лучше "пешком постою". Передавать 20 ФВП мне как-то не очень нравится, когда есть разумная тому альтернатива. Всё равно громоздко.
FR>>>Зато декораторы очень просто и легко, и как раз для всяких прокси и т. п. предназначены. N>>Вообще-то у меня словом "прокси" называлось совсем не то, что можно предположить исходя из контекста классов.:)) FR>Не важно :)
Здравствуйте, _FRED_, Вы писали:
_FR>Не согласен с аналогией. Зачем мне таскать тяжеленный сундук, когда у меня есть удобный рюкзачёк? Объясни, зачем для понимания рекурсии необходимо именно возиться с сортировкой и не подойдёт факториал?
Хотя бы потому что нормальный человек, знающий, как вычислить факториал с помощью цикла, не оценит пример с факториалом и вспомнит что-нибудь про шашечки. Объяснение рекурсии на примере факториала — это сродни (утрирование) объяснению шаблонов с++ на примере вычисления того же факториала на этапе компиляции.
F>>Интересно, а если надо построить дерево, а потом сделать его обход ? Понятно, что можно и без рекурсии, но вот вопрос — а стоит ли ?
_FR>Это большой вопрос. Например, может зависеть от используемого компилятора. Где-то я с удовольствием предпочитаю рекурсии цикл.
Казалось бы, при чем тут рекурсия и цикл? Там, где можно обойтись просто циклом, рекурсия обычно не нужна и не используется. В той же (прости господи ) быстрой сортировке рекурсия обычно используется потому, что циклом не отделаешься.
Здравствуйте, IT, Вы писали:
_DA>>Есть такие программисты вроде меня, которые просто не могут понять, ну как можно "не вспомнить", как реализовывать бинарный поиск.
IT>Можно не вспомнить как релизовать бинарный поиск, а можно просто не помнить, что такое бинарный поиск.
Тем более что в школе его у нас называли поиском методом половинного деления.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, _FRED_, Вы писали:
_FR>Здравствуйте, netch80, Вы писали:
N>>А описанные Вами знания "есть такое, а есть сякое" без подкрепления забудутся после первого экзамена. N>>Поэтому я с сомнением отношусь к тем архитекторам, которые давно сами не кодируют, и к тем кодерам, которые способны только применить указанное им решение.
_FR>Вот пример из личной жизни: пока писал на VB, приходилось вручную реализовывать бинарный поиск (ну нет его в стандартной библиотеке), и с обобщением написанного кода нет так всё просто в этом языке. Так вот несколько лет уже пишу на C# и, наверное, не вспомню, как его реализовать.
_FR>Знания забываются от отсутствия практики, а вовсе не от понимания сути. И закономерно, что в некоторых областях, где от определённых знаний толку чуть (я не говорю "совсем нет"), уровень "базы" снижается.
Есть такие программисты вроде меня, которые просто не могут понять, ну как можно "не вспомнить", как реализовывать бинарный поиск. Ну это же простейший кирпичик, который многие дети придумывают сами в школе на уроках информатики. Не знаю, наверное, круг общения у меня исторически такой что ли среди программистов, но я действительно не могу понять, как люди, которые не могут написать бинарный поиск, могут написать маломальски сложный код. Ведь вроде бы это настолько просто..
Но, в общем-то, как там у Малдера.. "I want to believe", то есть я заставляю себя верить, что есть отличные программисты в своих областях, не знающие таких вещей, но понять этого не могу. И таких, как я, довольно много, и флеймам этим нет счета..
Здравствуйте, FR, Вы писали:
DM>>Вот задачка: есть семейство алгоритмов (та же компенсация, допустим), которые теперь отличаются не одной функцией, а пятью (при этом имеют по 10 общих). В случае ООП и наследования все просто — общие функции в базовый класс, различные — в наследников.
FR>А у тебя тут не ожидается комбинаторного взрыва наследников?
Если реализовывать все возможные комбинации — ожидается. К счастью, в данной задаче все возможные не нужны, достаточно нескольких определенных.
DM>> Т.е. все детали специализации пошли в замыкание, и по сути, мы получили некий аналог объекта из ООП, но с меньшим числом степеней свободы.
FR>В общем да так и будет, только наоборот на объектах и будет корявое подобие с ограниченым числом степеней свободы
Последнее мне пока неочевидно: и там, и там есть сочетание кода и данных, но в объекте данные могут быть доступны для чтения и даже изменения, а в замыкании — обычно нет. Т.е. с объектом можно больше всего делать.
Здравствуйте, D. Mon, Вы писали:
DM>Последнее мне пока неочевидно: и там, и там есть сочетание кода и данных, но в объекте данные могут быть доступны для чтения и даже изменения, а в замыкании — обычно нет. Т.е. с объектом можно больше всего делать.
Не вижу разницы. У замыканий есть другое название — захват контекста. Объект — это фактически контекст, замыкание тоже контекст. В чём разница?
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, netch80, Вы писали:
N>Ну да, switch внутри while и переменная состояния условно эмулирующая счётчик команд — может спасти любую программу, когда её надо сдать преподавателю как выполненную по всем канонам структурного программирования Только уж если Вы вспомнили мой любимый Фортран (эх, тяжёлое детство, 32-битная игрушка ЕС1022-02...) — это уже будет не фортран. В классическом F-IV и циклов не было.
К счастью меня фортран заднл только по касательной
FR>>Угу, будем, только не коллбеков, а ФВП. И в этом стиле как раз обощаемость и повторное испрользование по моему повыще чем в ООП.
N>... из коего и возникает синекдоха отвечания. Спасибо, я лучше "пешком постою". Передавать 20 ФВП мне как-то не очень нравится, когда есть разумная тому альтернатива. Всё равно громоздко.
Угу сами себе придумал 20 ФВП и сами себе отвечаем не надо?
Случаи когда имено нужно тупо сгрупировать кучу функций практически никогда на практике не встречаются, обычно все разбивается и групируется в осмысленные вещи.
Здравствуйте, _DAle_, Вы писали:
_DA>Казалось бы, при чем тут рекурсия и цикл? Там, где можно обойтись просто циклом, рекурсия обычно не нужна и не используется. В той же (прости господи ) быстрой сортировке рекурсия обычно используется потому, что циклом не отделаешься.
Так обратное еще вернее там где можно применить рекурсию циклы часто невозможны или слишком сложны
Тем более часто рекурсия и читабельнее даже когда заменяет простой цикл. Ну и учитывая что современные
компиляторы (C++ про шарп и ява не в курсе) нормально оптимизируют хвостовую рекурсию, то и для оптимизации
циклы не так уж и нужны.
Здравствуйте, D. Mon, Вы писали:
DM>Если реализовывать все возможные комбинации — ожидается. К счастью, в данной задаче все возможные не нужны, достаточно нескольких определенных.
Так тогда и для функции конструктора будет достаточно всего нескольких и никакой громоздкости не будет.
FR>>В общем да так и будет, только наоборот на объектах и будет корявое подобие с ограниченым числом степеней свободы
DM>Последнее мне пока неочевидно: и там, и там есть сочетание кода и данных, но в объекте данные могут быть доступны для чтения и даже изменения, а в замыкании — обычно нет. Т.е. с объектом можно больше всего делать.
Зато в замыкание можно засунуть абсолютно разное поведение, и легко комбинировать это замыкание с другими ФВП, например делать кеширование или фильтрацию не трогая основной код а просто применив к нашему замыканию стандартную ФВП. Кроме того рефакторинг для функционального стиля делается гораздо проще так как инкапсуляция выше.
Здравствуйте, IT, Вы писали:
IT>Не вижу разницы. У замыканий есть другое название — захват контекста. Объект — это фактически контекст, замыкание тоже контекст. В чём разница?
В доступных операциях.
После того, как мы передали в конструктор вагон колбеков и получили замыкание, реализующее наш сложный алгоритм, можем ли мы потом узнать, какие функции были переданы и что-то изменить? Обычно такие вещи совершенно непрозрачны, в отличие от объектов.
Здравствуйте, FR, Вы писали:
DM>>Если реализовывать все возможные комбинации — ожидается. К счастью, в данной задаче все возможные не нужны, достаточно нескольких определенных.
FR>Так тогда и для функции конструктора будет достаточно всего нескольких и никакой громоздкости не будет.
Согласен.
DM>>Последнее мне пока неочевидно: и там, и там есть сочетание кода и данных, но в объекте данные могут быть доступны для чтения и даже изменения, а в замыкании — обычно нет. Т.е. с объектом можно больше всего делать.
FR>Зато в замыкание можно засунуть абсолютно разное поведение, и легко комбинировать это замыкание с другими ФВП, например делать кеширование или фильтрацию не трогая основной код а просто применив к нашему замыканию стандартную ФВП.
Все то же самое можно делать с объектами, если они поддерживают нужные интерфейсы.
FR> Кроме того рефакторинг для функционального стиля делается гораздо проще так как инкапсуляция выше.
Здравствуйте, D. Mon, Вы писали:
FR>>Зато в замыкание можно засунуть абсолютно разное поведение, и легко комбинировать это замыкание с другими ФВП, например делать кеширование или фильтрацию не трогая основной код а просто применив к нашему замыканию стандартную ФВП.
DM>Все то же самое можно делать с объектами, если они поддерживают нужные интерфейсы.
Угу только писанины намного больше. И больше искусственных конструкций ненужных для непосредственного решения задачи, и что совем плохо эти исскуственные конструкции гораздо хуже обобщаются чем в случае с ФВП.
FR>> Кроме того рефакторинг для функционального стиля делается гораздо проще так как инкапсуляция выше.
DM>А можно обосновать?
Так выше уже обосновано — инкапсуляция плюс прозрачность по ссылкам, она позволяет легче менять реализации так как явного изменямого состояния нет.
Здравствуйте, D. Mon, Вы писали:
DM>Здравствуйте, IT, Вы писали:
IT>>Не вижу разницы. У замыканий есть другое название — захват контекста. Объект — это фактически контекст, замыкание тоже контекст. В чём разница?
DM>В доступных операциях.
Операций доступно одинаково, просто в ФП декомпозиция другая.
DM>После того, как мы передали в конструктор вагон колбеков и получили замыкание, реализующее наш сложный алгоритм, можем ли мы потом узнать, какие функции были переданы и что-то изменить? Обычно такие вещи совершенно непрозрачны, в отличие от объектов.
Угу и часто это плюс.
Хотя при желании можно без проблем возвращать несколько функций с нужными операциями для доступа к замыканию, или как в схеме и лиспе использовать вызов по имени, и получим те же объекты.
Здравствуйте, FR, Вы писали:
N>>Ну да, switch внутри while и переменная состояния условно эмулирующая счётчик команд — может спасти любую программу, когда её надо сдать преподавателю как выполненную по всем канонам структурного программирования:) Только уж если Вы вспомнили мой любимый Фортран (эх, тяжёлое детство, 32-битная игрушка ЕС1022-02...) — это уже будет не фортран. В классическом F-IV и циклов не было. FR>К счастью меня фортран заднл только по касательной :)
Ну вот, вы, наверняка, и фразу "The God is real..." не продолжите :)
FR>>>Угу, будем, только не коллбеков, а ФВП. И в этом стиле как раз обощаемость и повторное испрользование по моему повыще чем в ООП. N>>... из коего и возникает синекдоха отвечания. Спасибо, я лучше "пешком постою". Передавать 20 ФВП мне как-то не очень нравится, когда есть разумная тому альтернатива. Всё равно громоздко. FR>Угу сами себе придумал 20 ФВП и сами себе отвечаем не надо?
Хотел бы я, чтобы это оказалось только своей придумкой... да вот увы — практика.
FR>Случаи когда имено нужно тупо сгрупировать кучу функций практически никогда на практике не встречаются, обычно все разбивается и групируется в осмысленные вещи.
Здравствуйте, netch80, Вы писали:
N>Ну вот, вы, наверняка, и фразу "The God is real..." не продолжите
Нет не продолжу
FR>>Угу сами себе придумал 20 ФВП и сами себе отвечаем не надо?
N>Хотел бы я, чтобы это оказалось только своей придумкой... да вот увы — практика.
Угу бытие определяет сознание
А сама практика такая потому-что ничего кромее ООП ты не видишь и не хочешь видеть.
FR>>Случаи когда имено нужно тупо сгрупировать кучу функций практически никогда на практике не встречаются, обычно все разбивается и групируется в осмысленные вещи.
N>Вот я и группирую в подклассы.
Здравствуйте, Геннадий Васильев, Вы писали:
IT>>>Так и для организации кода достаточно одних структур и методов. Зачем ООП придумали и кучу других паттернов? Непонятно :xz: Pzz>>ООП придумали для того, чтобы можно было структуруровать программу в терминах довольно больших блоков. Это нужно, в первую очередь, в связи с индустриальными методами разработки, когда над одной программой работают 50 индусов, и надо как-то провести границы, чтобы они не наступали друг другу на пятки. ГВ>Цирк. Для тех кто в это верит, поясню: привлекать неквалифицированных пользователей к формализации задачи — хорошо, привлекать неквалифицированных программистов (именно их ты имеешь в виду, говоря об индусах, правда?) — очень плохо.
Я что-то не смог найти в постинге Певзнера стремления привлечь индусов к _формализации_ задачи. Где Вы это вычитали?
Pzz>>Т.е., в первую очередь ООП — это инструмент для менеджера проекта, а не для программиста. ГВ>Вообще-то ООП зародилось из фреймов-слотов, это такой ма-а-а-алепусенький кусочек инструментария ИИ по формализации знаний. Менеджеры софтостроения там если и стояли рядом, то только стояли.
А при чём тут, откуда оно зародилось? Современная практика совсем иная, и от тех времён, когда оно рождалось — несколько крупных логических переходов (например, насколько ООП формата Simula & Smalltalk отличается от того, что из него сделали даже в Objective C, я уж не говорю про развития C и Паскаля). Фактически, разделение объектов — то, что позднее назвали "контрактным программированием", с ограничением тем, что "контракт" проводится по границе объекта ("пуля вылетает — проблемы не на моей стороне").
Другой вопрос, что такое разделение нормально возможно только при статичных спецификациях. Если они меняются — приходится пересматривать места проведения границ. А вот тут уже начинаются нюансы.
Здравствуйте, _FRED_, Вы писали:
_FR>Здравствуйте, netch80, Вы писали:
N>>А описанные Вами знания "есть такое, а есть сякое" без подкрепления забудутся после первого экзамена. N>>Поэтому я с сомнением отношусь к тем архитекторам, которые давно сами не кодируют, и к тем кодерам, которые способны только применить указанное им решение. _FR>Вот пример из личной жизни: пока писал на VB, приходилось вручную реализовывать бинарный поиск (ну нет его в стандартной библиотеке), и с обобщением написанного кода нет так всё просто в этом языке. Так вот несколько лет уже пишу на C# и, наверное, не вспомню, как его реализовать.
В данном случае я не имел в виду конкретику. Но если — по Вашему же примеру — он веб-программист (кстати, какой именно? это очень обширный класс ролей) — то должен иметь свои, специфические базовые знания.
N>>У меня лично статистики недостаточно. Но вот случай, когда обычная сортировка крайне невыгодна — каждый рабочий день на глазах, это таймерное дерево в движке событий. Оно сделано на пирамиде. _FR>В отдельных случаях может быть (и даже имеет право быть) всё что угодно. Но вот спрашивать веб-програмиста про объекты синхронизации на юниксе — гхм..?
Ну а почему нет? Какой это веб-программист? Может, он программирует какую-то CMS, в которой хранится содержимое сайта (пардон, надо говорить "портала":)) и проблемы с модификацией данных ему очень даже существенны. Не надо зарекаться, случай всякий бывает...
_FR> Вот я и говорю, что "база" у програмистов в общем смысле не в алгоритмах сортировки и прочих деталях реализации.
База всегда в своих деталях реализации, и от этого не деться.
Здравствуйте, netch80, Вы писали:
N>И после этого комментируете Фортран. Понятно, "не читал, но осуждаю".
Я не комментировал фортран, просто привел известную поговорку, там фортран можно например заменить
бейсиком и суть от этого не изменится.
FR>>А сама практика такая потому-что ничего кромее ООП ты не видишь и не хочешь видеть.
N>В данном случае практика иная: а именно, Вы не хотите видеть ничего кроме ФП. Вы уже который постинг подряд только и делаете, что агитируете "за советскую власть" совершенно не представляя себе специфики задач, ограничений механизма, придумываете любые фишки лишь бы доказать одно — "ФП рулез, всё остальное сакс". Вы наобум приписываете собеседникам чужие свойства (как мне что "кромее ООП ты не видишь и не хочешь видеть" — это мне-то, который до массового распространения ООП уже лет 7 был "в системе" и успел писать на всём что только тогда было), не дав себе даже минимального труда проанализировать адекватность своих "назначений".
Ужас меня уже записали в злобные функциональщики
Однако если вернутся к теме к локальному коду, то преимущества ФП и сопутствующего ему сахара может не видеть только слепой.
Если хочешь померятся то лучше покажи небольшой законченный кусочек кода который по твоему продемонстрирует неоспоримые преимущества наследования для задачи специализации алгоритмов, я же перепишу его в ФП стиле и сравним.
N>Я с Вами не хочу больше спорить. Когда Вы научитесь вести действительно дискуссию, а не выливать потоки религиозного гона — возвращайтесь, поговорим.
Здравствуйте, FR, Вы писали:
N>>И после этого комментируете Фортран. Понятно, "не читал, но осуждаю". FR>Я не комментировал фортран, просто привел известную поговорку, там фортран можно например заменить FR>бейсиком и суть от этого не изменится.
Изменится.
FR>Ужас меня уже записали в злобные функциональщики :)))
Как себя ведёте — туда и записываем.
FR>Однако если вернутся к теме к локальному коду, то преимущества ФП и сопутствующего ему сахара может не видеть только слепой.
Вот именно — злобный функциональщик и есть, сами согласились.
FR>Если хочешь померятся то лучше покажи небольшой законченный кусочек кода который по твоему продемонстрирует неоспоримые преимущества наследования для задачи специализации алгоритмов, я же перепишу его в ФП стиле и сравним.
На "небольшом законченном" и я одной левой смогу. Это не реальная задача.
N>>Я с Вами не хочу больше спорить. Когда Вы научитесь вести действительно дискуссию, а не выливать потоки религиозного гона — возвращайтесь, поговорим. FR>У кого трава круче еще спорно.
Я в этом заранее сдаюсь, потому что обхожусь без травы. Играйте сами.
Здравствуйте, IT, Вы писали:
IT>Здравствуйте, Константин Л., Вы писали:
КЛ>>самый большой проект, в котором ты когда-либо участвовал?
IT>WPF для тебя большой проект, а WinForms? Так вот, если бы там не было наследования реализации, то жизнь у прикладников была бы немного веселей.
Ну для начала McSeem2 надо было уточнить какое наследование он имеет ввиду. Да и потом, наследование реализации не самое последнее зло.
Здравствуйте, VoidEx, Вы писали:
VE>А сам вон сначала "программист должен уметь писать сортировку", а потом VE>"Если он при этом учится и ошибка замечена вовремя — то почему бы и нет?"
Здравствуйте, Геннадий Васильев, Вы писали:
N>>Я что-то не смог найти в постинге Певзнера стремления привлечь индусов к _формализации_ задачи. Где Вы это вычитали? ГВ>Я имел в виду, конечно, привлечение неквалифицированных программистов к реализации, а не к формализации. Спасибо, что заметил неточность.
Тогда понятно.
N>>А при чём тут, откуда оно зародилось? ГВ>Откуда зародилось, свойства того органично и унаследовало. Но это ни в коем случае не инструмент менеджера. Инструмент менеджера — это нормативная база, ресурсы, деньги, планы, организационные подходы... А не ООП. :)
Так это кроме прочего и организационный подход. Определим и формализуем, как именно связаны между собой работы разных групп и людей, и тем самым уменьшим затраты на взаимодействие при разработке. Разумеется, этот подход заметно некорректен, ну так не он же один используется...
N>>Фактически, разделение объектов — то, что позднее назвали "контрактным программированием", с ограничением тем, что "контракт" проводится по границе объекта ("пуля вылетает — проблемы не на моей стороне"). ГВ>Ты путаешь объектную декомпозицию и спецификацию.
Я не путаю, я упрощаю до уровня такого менеджера:) Спецификация взаимодействия (как при выполнении, так и разработке) является следствием декомпозиции. Это в принципе всё, что ему нужно, чтобы подход работал.
Здравствуйте, FR, Вы писали:
N>>Изменится. FR>Нет. FR>"писать на бейсике можно используя любой язык." FR>Суть же в том что недостаточно выучить синтаксис языка программирования чтобы научится на нем нормально писать.
Неее, батенька, это Вы историю с географией путаете.:))) Когда кто-то из классиков сказал "Фортран-программу можно написать на любом языке" — это был ёмкий целенаправленный образ определённого стиля, который у тогдашних поклонников "структурного программирования" ассоциировался чуть ли не с пришествием Антихриста (при том, что тогда, можно считать, было три языка программирования — Fortran, LISP и APL;) ну и где-то рядом Алгол-60 маячил на задворках). Стиль, в котором паутина из GOTO покрывала программу так плотно, что невозможно было логически выделить ни одну явную структурную последовательность; с неявным объявлением переменных и трудноуловимыми ошибками типа "P вместо R"; с адскими хаками через COMMON и EQUIVALENCE... Это кошмар, но это Стиль с большой буквы. Вот по нему и проезжались чем только могли те, кто твёрдо решил избавить человечество от этого Стиля.
Вы вот в курсе, почему космическая станция улетела куда не следует? Поясняю: строка
DO100I=1,10
в классическом Fortran является оператором цикла (по I от 1 до 10 до метки 100 включительно), а строка
DO 100 I=1. 10
является присваиванием переменной DO100I значения 1.1.
Я не шучу. Пробелы в нём были незначимы везде кроме первых 6 колонок и текстовых (холлеритовых! никаких вам апострофов) констант.
А Вы говорите, мол, "писать на бейсике можно используя любой язык"... Да всё это жалкое эпигонство. Оригинал был только один, и замены ему нет. А то так можно договориться и до того, что "писать на Haskell можно используя любой язык"... Да, можно. Написав на нём интерпретатор.;))
FR>>>Ужас меня уже записали в злобные функциональщики :))) N>>Как себя ведёте — туда и записываем. FR>Это ты просто не видел как себя ведут настоящие злобные функциональщики :)
Ну, честно говоря, вести себя в стиле Луговского тут не позволят. Но я принимаю это как конструктивное предложение к продолжению диалога. Надеюсь, в дальнейшем без завлеканий типа "пока не попробуешь — не поймёшь" :))
FR>>>Если хочешь померятся то лучше покажи небольшой законченный кусочек кода который по твоему продемонстрирует неоспоримые преимущества наследования для задачи специализации алгоритмов, я же перепишу его в ФП стиле и сравним. N>>На "небольшом законченном" и я одной левой смогу. Это не реальная задача. FR>Так в топике же обсуждается именно локальный код, он по определению небольшой и соответственно совершено нетрудно привести вполне практичный примерчик.
Я, вероятно, слишком ленивый чтобы грамотно разделить код на части, но вот функция построения дерева раутинга в объектном виде по его сжатому представлению заняла 360 строк (бОльшая часть из них — игра со взаимовлияниями значений атрибутов), а функция генерации звонка по рауту — 213 строк. И как-то разумно сжать это пока не получается (да, заранее согласен, что это у меня руки кривые и можно целенаправленно надробить кучу мелких частей — только зачем?)
Здравствуйте, Геннадий Васильев, Вы писали:
ГВ>Цирк. Для тех кто в это верит, поясню: привлекать неквалифицированных пользователей к формализации задачи — хорошо, привлекать неквалифицированных программистов (именно их ты имеешь в виду, говоря об индусах, правда?) — очень плохо.
Их привлекают не к формализации, а к реализации. Хорошо ли это, плохо ли, но вот привлекают. Наверное потому, что свободных квалифицированных уже почти не осталось.
ГВ>Вообще-то ООП зародилось из фреймов-слотов, это такой ма-а-а-алепусенький кусочек инструментария ИИ по формализации знаний. Менеджеры софтостроения там если и стояли рядом, то только стояли.
Вообще-то ООП зародилось из Симулы, языка. предназначенного для компутерного моделирования. А в индустрию пришло и разрослось именно потому, что помогает раскидывать задачу по большому количеству исполнителей. Фича эта сама по себе очень ценная, но имеет отношение скорее к управлению проектом, чем собственно к программированию.
ГВ>Свежо предание... Только паттерн, это не "готовое решение", а некое собирательное название разных по существу решений. Хотя примеры могут быть и вполне определёнными. А каким же им ещё быть?!
Это, признаюсь, не моя мысль, а Пола Грэхема. В оригинале она звучала примерно в том духе, что наличие паттернов проектирования свидетельствует об отсутствии в языке нормальных макросов. Потому что если приходится из проекта в проект делать похожие телодвижения, это повод написать макрос, который эти телодвижения автоматизирует.
Я, в общем, отчасти согласен, но с той оговоркой, что некоторые вещи очень просто рассказать человеку, но при этом очень трудно формализовать до такой степени, чтобы их можно было сказать компьютеру.
Pzz>>А вот внутри самих алгоритмов if'ы и while'ы — вполне себе адекватный инструмент. Во всяком случае, все классические алгоритмы описаны в литературе именно в этих терминах.
ГВ>Это не просто "адекватный инструмент", if — это блин, базисная конструкция императивного стиля. Ну, вернее, не if, а goto. if — это уже структурный подход. Уж куда "адекватнее"!
Я как-то не уловил, почему базисная конструкция императивного стиля не может быть адекватным инструментом? Какое слово является ругательным, "базисная" или "императивного"?
Здравствуйте, netch80, Вы писали:
N>Здравствуйте, samius, Вы писали:
S>>Здравствуйте, netch80, Вы писали:
N>>>Какой ответ на этот вопрос Вы хотите? Можно ответить цинически — мол, есть клавишное мясо, которое не способно даже осознать, что оно теряет и почему. А можно — что пусть себе и дальше продолжает, но пусть осознаёт, где его потолок. В принципе, оба ответа правильны.
S>>У меня один знакомый считает, что тот не программист, кто не написал ни одного драйвера устройства. S>>Весьма ограниченная точка зрения, как впрочем и Ваша.
N>Вы ещё ничего не поняли толком про мою точку зрения, но уже успели приравнять её к "одному знакомому" и унизить сравнением.
netch80! Приношу извинения за сравнение Вашей точки зрения с мнением моего недалекого знакомого. Наблюдая за Вашими постами неоднократно убедился, что Вы человек опытный и очень разносторонний. После этого я переосмыслил высказывание про мясо и потолок. Мое несогласие с ним было обусловлено разницей восприятия термина мяса и уровня потолка.
Здравствуйте, Pzz, Вы писали:
Pzz>Обратите внимание, что тот дикий язык, на котором в C++ пишут темплейты, тоже является функциональным языком. Причем чисто функциональным, с ленивыми вычислениями и выводом типов.
Обратил. И с удивлением для себя обнаружил, что до конца понимают его десятые доли процента из тех кто считает, что знает С++.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, fplab, Вы писали:
F>Никак не могу согласиться. Одному дай топор — он комплекс в Кижах сделает, а другой — замочит кучу народа. Так же и с инструментами. F>Инструмент у программиста — прежде всего голова. Когда в голове бардак, то реализация даже простейшего алгоритма будет нечитаемой. Когда голова в порядке — реализация даже сложных алгоритмов весьма хорошо читается.
Вопрос к головастому товарищу, много ли он на ваяет современных многоэтажных домов если ему дать один топор?
Как ни одного? А тогда к чему вся эта пышная демагогия?
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Pzz, Вы писали:
Pzz>Квиксорт с хаскеля практически 1:1 переписывается в Си, с той поправкой, что в Си не сделаешь итератора по списку с помощью пары загадочных знаков препинания, приходится цикл руками расписывать.
Елы палы, так тебе об этом в теме и говорили. Все что пишется в функциональном стиле можно "один в дин" переписать на ИЯ, только вот появляется много НО и из понятной и краткой реализации получается засилье if-ов и гора мало понятного кода.
Pzz>А вообще да, ФП предоставляет очень гибкий набор средств для выражения сложных структур данных и итераторов по ним. Но не более того. Те вещи, которые не сводятся к хитроунмой итерации сложной структуры данных, на ФП и на Фортране будут выглядеть совершенно одинаково
Чушь это все. Нет никаких итераторв в ФП. И все это "просто" и есть огромная заслуга тех кто развивал ФП. О том речь.
А на Фортране просто пишется только 2 + 2.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, netch80, Вы писали:
N>Неее, батенька, это Вы историю с географией путаете. Когда кто-то из классиков сказал "Фортран-программу можно написать на любом языке" — это был ёмкий целенаправленный образ определённого стиля, который у тогдашних поклонников "структурного программирования" ассоциировался чуть ли не с пришествием Антихриста (при том, что тогда, можно считать, было три языка программирования — Fortran, LISP и APL ну и где-то рядом Алгол-60 маячил на задворках). Стиль, в котором паутина из GOTO покрывала программу так плотно, что невозможно было логически выделить ни одну явную структурную последовательность; с неявным объявлением переменных и трудноуловимыми ошибками типа "P вместо R"; с адскими хаками через COMMON и EQUIVALENCE... Это кошмар, но это Стиль с большой буквы. Вот по нему и проезжались чем только могли те, кто твёрдо решил избавить человечество от этого Стиля.
Фигня у фразы есть и более общий смысл, я использовал именно его.
N>Вы вот в курсе, почему космическая станция улетела куда не следует? Поясняю: строка
У меня конечно склероз, но как корабли бороздили оперный театр я еще помню
N>А Вы говорите, мол, "писать на бейсике можно используя любой язык"... Да всё это жалкое эпигонство. Оригинал был только один, и замены ему нет.
Нам не дано предугадать, Как слово наше отзовется.
N>А то так можно договориться и до того, что "писать на Haskell можно используя любой язык"... Да, можно. Написав на нём интерпретатор.)
Нет это уже у тебя склероз, правильнее было примерно так: "любая более менее сложная программа содержит в себе интерпретатор лиспа"
N>Ну, честно говоря, вести себя в стиле Луговского тут не позволят. Но я принимаю это как конструктивное предложение к продолжению диалога. Надеюсь, в дальнейшем без завлеканий типа "пока не попробуешь — не поймёшь"
Так от диалога пока только ты отказывался.
N>Я, вероятно, слишком ленивый чтобы грамотно разделить код на части, но вот функция построения дерева раутинга в объектном виде по его сжатому представлению заняла 360 строк (бОльшая часть из них — игра со взаимовлияниями значений атрибутов), а функция генерации звонка по рауту — 213 строк. И как-то разумно сжать это пока не получается (да, заранее согласен, что это у меня руки кривые и можно целенаправленно надробить кучу мелких частей — только зачем?)
И я бы восхитился, но извини, об этих алгоритмах ни имею ни малейшего представления. Так что без примеров никуда.
Здравствуйте, IT, Вы писали:
_DA>>Казалось бы, при чем тут рекурсия и цикл? Там, где можно обойтись просто циклом, рекурсия обычно не нужна и не используется.
IT>Это вопрос предпочтений. Мне тоже так раньше казалось. Сегодня же при наличии хвостовой рекурсии я скорее всего выберу рекурсию, кроме ну уж совсем примитивных случаев.
Да ну. Разворачивать рекурсию в хвостовую — неблагодарное занятие. Зачем велосипед изобретать? Функциональные языки на то и функциональные, чтобы в них можно было самым зверским образом комбинировать функции. Уже давно не писал рекурсию, которая бы принципиально разворачивалась в хвостовую. А при наличии ленивых списков в языке и умных оптимизаций в компиляторе (deforestation-а хватает) получается ещё и эффективный код.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Собственно, почему я не "проникся" Немерле. Не из-за того, что я "барик", не из-за того, что не могу оценить все прелести ФП, а из-за того, что все это очень сильно похоже на "припарки" мертвому. Я не понимаю, почему "внешняя" архитектура должны быть ООП, а "внутренняя", скажем, ФП. Если та или иная концепция не позволяет реализовать ее последовательно во всех частях программы — так ли эта самая концепция хороша? И может стоит вообще пересесть с этой подводной лодки на что-нибудь другое?
На что? Можно конкретнее?
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Согласен со всем сказанным по сути, но хочу заметить, что ты немного занижаешь заслуги ФП за пределами реализации методов.
Кроме отличного набора паттернов кодирования методов у ФП еще есть один два конька:
1. Неизменяемые структуры данных.
2. Аглебраические типы данных (variant в Nemerle).
Некоторые части приложения очень выигрывают если их писать на основе неизменяемых структур. При этом у нас получаются как бы слепки состояний и отладка (а значит и сопровождение) кода резко упрощается.
Алгебраические типы данных позволяют решать многие задачи вроде анализа или логического вывода на намного более высоком уровне абстракции (за счет того же паттерн-матчинга). Без них паттерн-матчинг был бы детской игрушкой.
Так что хочется сказать, что эти две фичи позволяют улучшить наш инструментарий и на уровне дизайна приложения (на уровне классов, если так проще).
ЗЫ
Ну, и про МП забывать тоже нельзя. Это действительно мощьнейшее оружее. Им проникся даже Хейльсберг...
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, netch80, Вы писали:
ГВ>> Менеджеры софтостроения там если и стояли рядом, то только стояли.
N>А при чём тут, откуда оно зародилось? Современная практика совсем иная, и от тех времён, когда оно рождалось — несколько крупных логических переходов (например, насколько ООП формата Simula & Smalltalk отличается от того, что из него сделали даже в Objective C, я уж не говорю про развития C и Паскаля). Фактически, разделение объектов — то, что позднее назвали "контрактным программированием", с ограничением тем, что "контракт" проводится по границе объекта ("пуля вылетает — проблемы не на моей стороне").
Что то я не улавливаю твою мысль. Можешь пояснить, как из всего того, что ты сказал, следует что менеджеры софтостроения там стояли рядом?
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, VladD2, Вы писали:
VD>Ясно. Опять много слов и никакого дела. Другого и не ожидал, если честно.
Ну а что я могу на подобное ответить? Учитывая, что "внятное" — характеристика в большей степени субъективная, то мне остается только признать — да, вероятно я не в состоянии дать внятное для тебя объяснение.
VD>ЗЫ
VD>За других тоже не стоит говорить. Особенно за Синклера.
А я за него нигде и не говорил, вообще то (в отличие от кое кого, кто тут решил поговорить за меня). Просто предложил почитать его сообщения, бо с его точкой зрения в тех флеймах я в общем и целом согласен.
VD>Может быть мне конечно и показалось, но он в некоторый момент как-то резко переменил риторику.
Ну и кто из нас тут говорит за Синклера?
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, VladD2, Вы писали:
VD>Здравствуйте, eao197, Вы писали:
E>>PS. В начале 90-х в Союзе у многих крышу срывало Прологом. С тех пор я думал, что именно Пролог самая крутая трава. Но, видимо, FP еще круче.
VD>Пролог трава более крутая, но к сожалению плохо совместимая с жизнью, так как создать эффективные реализации практически невозможно, и с императивными языками не стыкуется.
Это почему это не стыкуется? Очень даже стыкуется. Посмотри тот же интерфейс SWI Prolog. Всё стыкуется.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, fplab, Вы писали:
AVK>>О да, без пенисометрии никак. Знаешь только, в чем проблема, особенно в этом форуме? По результатам измерений запросто может оказаться, что у кого то из твоих оппонентов длиннее. F>Вот тут, коллега, вы сами себе противоречите Выше, если не ошибаюсь, вы указали мне на использование некорректных приемов. Может, будем последовательными ?
Правильно, давай будем последовательными и не будем заниматься пенисометрией и выяснением того, кто и насколько крутые задачи решал.
P.S.: А то глядишь, линейку на одно место намотают. Здесь с этим просто.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Геннадий Васильев, Вы писали:
Pzz>>Их привлекают не к формализации, а к реализации. Хорошо ли это, плохо ли, но вот привлекают. Наверное потому, что свободных квалифицированных уже почти не осталось.
ГВ>Это и есть — плохо.
Плохо. Предлагаете их взрывать целыми офисами? Никакого другого способа борьбы с этим печальным явлением я не вижу...
Хотя нет, можно вернуться к программированию на ассемблере. Тогда индусы вымрут сами собой
ГВ>О точных прародителях ООП и календаре его развития можно спорить, но это не слишком важно. Важно то, что к менеджменту ООП не имеет никакого отношения. К структуризации знаний — да, к менеджменту — нет.
Скорее для структуризации умений
Вот скажем, пишете вы сетевую программу. Всю возню с сокетами вы, конечно, засунете в какой-нибудь класс. Но вот знание о том, что сеть не всегда доступна и имеет тенденцию иногда отваливаться у вас будет распределено по всей программе. Не важно в каких терминах, в виде кода ошибки, который возвращает send(), или в виде нотификации о событии, на которое можно подписаться — это в любом случае знание, которым должны обладать многие части программы.
Зато ООП неплохо подходит, чтобы разграничить зону ответственности между людьми. При условии, что вы позаботитесь о том, что они обладают необходимыми общими знаниями. А разграничение зоны ответственности — это задача из области управления проектом, о чем я уже и говорил.
Я имею ввиду, конечно, техническое руководство, а не то, чтобы у всех были исправные стулья и соблюдались сроки
ГВ>Всё не так. Первоначально рассуждали о том, что ООП позволяет существенно расширить возможности одного программиста, благодаря тому, что способ представления абстракций лучше адаптирован к человеческому мышлению, чем, скажем, процедурная абстракция. То есть один из тезисов, послуживших распространению ООП прямо противоположен приведённому тобой: предполагалось в некотором роде сокращение числа программистов. Понимаешь? А распределять программирование на массу народу умели задолго до появления даже языков высокого уровня. Почитай того же Брукса.
И много программистов с тех пор сократилось? Давайте пропустим маркетинговый буллшит.
ООП как способ представления абстракции хорошо подходит для одних задач, средненько для других, и совсем не подходит для третьих. Например, для написания парсера гораздо лучше подходит BNF-грамматика, а не ООП, а для описания сетевого протокола вы бы предпочли инструмент, позволяющий описывать конечный автомат в естественных для него терминах состояний, событий и переходов между состояниями.
Сама организация человеческого мышления зависит и от мыслителя, и от предмета размышлений, и от дискурса. Слабость ООП заключается в том, что предлагается распихать все по коробочкам заранее, когда еще ничего не понятно, еще до начала, собственно, мышления. А к тому моменту, когда все становится понятно, ставки уже сделаны и уже поздно все перераспихивать. В то время как для человеческого мышления не является чем-то невозможным посмотреть на проблему по-другому, в других терминах.
Другая проблема ООП — оно хорошо работает, когда есть много относительно простых и понятных коробочек, но плохо работает, когда коробочек немного, но они сложны сами по себе. Например, ООП ничем вам не поможет, если ваша задача — разработать криптографический алгоритм.
ГВ>Ну, Грэхем в своём репертуаре. Только нужно, как бы, это... Разделять призывы и "идеологемы", и технически реализуемые штучки. Корни паттернов на самом деле в особенностях мышления человека вообще и технических специалистов в частности. Они выходят очень далеко за пределы языков программирования.
Да. Когда моя мама работала конструктором, это называлось "типовой проект". Теперь вот паттерны придумали, чтобы умнее казаться
Pzz>>>>А вот внутри самих алгоритмов if'ы и while'ы — вполне себе адекватный инструмент. ГВ>>>Это не просто "адекватный инструмент", if — это блин, базисная конструкция императивного стиля. Pzz>>Я как-то не уловил, почему базисная конструкция императивного стиля не может быть адекватным инструментом? Какое слово является ругательным, "базисная" или "императивного"?
ГВ>"адекватный инструмент" Абсурдна сама формулировка. Ну, что-то вроде: "капли — адекватный инструмент дождика". Вот такое же.
Ну это не моя формулировка, я реагирую на чью-то реплику выше по треду.
Здравствуйте, Pzz, Вы писали:
Pzz>>>Их привлекают не к формализации, а к реализации. Хорошо ли это, плохо ли, но вот привлекают. Наверное потому, что свободных квалифицированных уже почти не осталось.
ГВ>>Это и есть — плохо.
Pzz>Плохо. Предлагаете их взрывать целыми офисами? Никакого другого способа борьбы с этим печальным явлением я не вижу...
Нет. Я этого не предлагаю.
Pzz>Хотя нет, можно вернуться к программированию на ассемблере. Тогда индусы вымрут сами собой
И этого я тоже не предлагаю. Я только констатирую, что привлечение низкоквалифицированой "рабочей силы" не есть хорошо. А ориентация на неё в некотором идейном смысле — вообще ужасна.
ГВ>>О точных прародителях ООП и календаре его развития можно спорить, но это не слишком важно. Важно то, что к менеджменту ООП не имеет никакого отношения. К структуризации знаний — да, к менеджменту — нет. Pzz>Скорее для структуризации умений
То есть? (Просьба: обращайся ко мне на "ты", пожалуйста.)
Pzz>Вот скажем, пишете вы сетевую программу. Всю возню с сокетами вы, конечно, засунете в какой-нибудь класс. Но вот знание о том, что сеть не всегда доступна и имеет тенденцию иногда отваливаться у вас будет распределено по всей программе. Не важно в каких терминах, в виде кода ошибки, который возвращает send(), или в виде нотификации о событии, на которое можно подписаться — это в любом случае знание, которым должны обладать многие части программы.
Чего-чего? Во-первых, никто не мешает мне сделать какой-нибудь "permanent socket", который один раз получает параметры связи, а потом восстанавливает её по мере исчезновения. Во-вторых, распределено не знание, а управляющий сигнал от одной подсистемы к другой. Этих сигналов может быть ещё сто тыщ. В-третьих, если говорить о сокетах, то структурирование знаний здесь — само описание взаимодействия с сетью в виде "сокета".
Pzz>Зато ООП неплохо подходит, чтобы разграничить зону ответственности между людьми. При условии, что вы позаботитесь о том, что они обладают необходимыми общими знаниями. А разграничение зоны ответственности — это задача из области управления проектом, о чем я уже и говорил.
Ну так для этого подходит вообще любой метод структурирования программы, подразумевающий мало-мальскую модульность. По твоему выходит, что все они придуманы для загрузки больших коллективов?
"Управление проектом" только подхватывает эту самую структуризацию и придаёт ей некоторую административную силу. Ничего больше. В сущности, управление прекрасно справится со своими задачами и без ООП.
Pzz>Я имею ввиду, конечно, техническое руководство, а не то, чтобы у всех были исправные стулья и соблюдались сроки
Так ты не путай одно с другим. "Техническое руководство", это такая штука, которая к "менеджменту" вообще никакого отношения не имеет, кроме лексического подобия.
ГВ>>Всё не так. Первоначально рассуждали о том, что ООП позволяет существенно расширить возможности одного программиста, благодаря тому, что способ представления абстракций лучше адаптирован к человеческому мышлению, чем, скажем, процедурная абстракция. То есть один из тезисов, послуживших распространению ООП прямо противоположен приведённому тобой: предполагалось в некотором роде сокращение числа программистов. Понимаешь? А распределять программирование на массу народу умели задолго до появления даже языков высокого уровня. Почитай того же Брукса.
Pzz>И много программистов с тех пор сократилось? Давайте пропустим маркетинговый буллшит.
Нет, не пропустим. Соображение о повышении индивидуальных способностей программиста было весьма действенным фактором распространения ООП. И кстати, в некоторой части вполне подтвердилось. Естественно, что к рассуждениям о "сокращении количества" относились по большей части скептически, но если бы ООП проталкивалось под флагом вовлечения массы людей — сопротивление было бы сумасшедшим. Да ООП вообще бы из пробирки не вылезло, не смотря на все позывы индустрии.
Pzz>ООП как способ представления абстракции хорошо подходит для одних задач, средненько для других, и совсем не подходит для третьих. Например, для написания парсера гораздо лучше подходит BNF-грамматика, а не ООП, а для описания сетевого протокола вы бы предпочли инструмент, позволяющий описывать конечный автомат в естественных для него терминах состояний, событий и переходов между состояниями.
Никто и не говорит, что ООП — серебряная пуля. Да я и сам так не считаю. Я спорю с вот этой репликой:
А в индустрию пришло и разрослось именно потому, что помогает раскидывать задачу по большому количеству исполнителей. Фича эта сама по себе очень ценная, но имеет отношение скорее к управлению проектом, чем собственно к программированию.
Это не просто буллшит, это полная каша в голове. Вот я тебе и объясняю — кто на ком на самом деле стоял.
Pzz>Сама организация человеческого мышления зависит и от мыслителя, и от предмета размышлений, и от дискурса. Слабость ООП заключается в том, что предлагается распихать все по коробочкам заранее, когда еще ничего не понятно, еще до начала, собственно, мышления. А к тому моменту, когда все становится понятно, ставки уже сделаны и уже поздно все перераспихивать. В то время как для человеческого мышления не является чем-то невозможным посмотреть на проблему по-другому, в других терминах.
Ну, я уж не знаю, откуда ты извлёк мысль, что ООП предполагает "распихивание по коробочкам" до начала размышлений. По моему опыту и наблюдениям это далеко не так, а по моему убеждению это так и быть не может.
Pzz>Другая проблема ООП — оно хорошо работает, когда есть много относительно простых и понятных коробочек, но плохо работает, когда коробочек немного, но они сложны сами по себе. Например, ООП ничем вам не поможет, если ваша задача — разработать криптографический алгоритм.
Естественно, не поможет. К алгоритмическим задачам ООП имеет весьма слабое отношение. К криптографическим алгоритмам — в том числе. Но ты не учитываешь того, что IT-индустрия довольно таки сильно подвержена влиянию мифов и убеждений разных порядков. Вот ООП "разрослось" и пролезло во все щели как раз по тем соображениям, о которых я тебе сказал. Можешь мне не верить, твоё право, но именно так дела и обстояли.
ГВ>>Ну, Грэхем в своём репертуаре. Только нужно, как бы, это... Разделять призывы и "идеологемы", и технически реализуемые штучки. Корни паттернов на самом деле в особенностях мышления человека вообще и технических специалистов в частности. Они выходят очень далеко за пределы языков программирования. Pzz>Да. Когда моя мама работала конструктором, это называлось "типовой проект". Теперь вот паттерны придумали, чтобы умнее казаться
Аналогия довольно поверхностная, надо сказать. Типовой проект содержит уже просчитанные элементы конструкций, с паттернами немного не так. То есть паттерны — это не завершённые конструкции. Скорее, это просто графы, своего рода наброски структур.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Константин Л., Вы писали:
КЛ>может быть после того, как поучаствуешь, будешь говорить про мальчиков-архитекторов?
У тебя есть разум, надо только научиться им пользоваться. Почему все приходится разжевывать? Понимаешь, нет в этом моем высказывании ничего уничижительного. Я просто хотел сказать, что бывают разные задачи по самой сути. Для меня — это придумать алгоритм и отдать его "мальчикам-архитекторам" и прочим. И меня не интересует размер проекта, это их забота (про разделение труда слышал?) Поэтому, можно сказать, что я и не участвую в этом проекте. При этом архитекторы могут считать меня неким мальчиком-алгоритмистом и в этом тоже нет ничего уничижительного.
Бывали и казусы. Однажды архитекторы так запроектировали некий модуль обработки данных, что он требовал квадратичного времени выполнения как ты ни кодируй (а надо и можно было обойтись линейным.) В результате, по самым оптимистичным прогнозам, данная архитектура на реальных объемах данных требовала бы не меньше 500 лет для обработки. Зато все было очень красиво.
McSeem
Я жертва цепи несчастных случайностей. Как и все мы.
Здравствуйте, prVovik, Вы писали:
V>Испугал. Пишем для одной этой системы SAX трансформатор. Делов то
Ага. Только придется всю архитектуру перетряхивать
... << RSDN@Home 1.2.0 alpha rev. 677>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, McSeem2, Вы писали: MS>Это вряд ли. Насколько мне известно, премия Нобеля не распространяется на математические области. Но это чисто так, придирка.
Для придирчивых есть премия Тьюринга.
... << RSDN@Home 1.2.0 alpha rev. 677>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, russian_bear, Вы писали: _>Пример хороший и я согласен — преимущества у LINQ очевидные, но опять же есть одно но. Если исходные данные будут браться из базы данных, то надо очень четко следить, чтобы вот такой вот наворот: _>не наворотил тучу запросов к базе данных вместо одного/нескольких. Серъезно? Ну-ка, ну-ка, и как же нужно модифицировать этот запрос, чтобы он наворотил тучу SQL запросов? Хочется подтвердить эту небезынтересную гипотезу реальным ахтунг-примером.
... << RSDN@Home 1.2.0 alpha rev. 677>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Pavel Dvorkin, Вы писали:
IT>>За 30 лет развития традиционных языков программирования (Fortran, PL/1, COBOL, Pascal, C/C++, Java, C#) принципиально изменился только мир вокруг метода. Мы получили наследование, инкапсуляцию и полиморфизм, компонентность и контрактность, шаблоны/дженерики и атрибуты, массу паттернов проектирования, подходов и отходов, методологий и прочих вещей, призванных организовать код в нечто более менее управляемое.
PD>Ничего мы не получили. Все вышесказанное относится к организации кода и только. А сам код каким был, таким и остался. И если не согласен — напиши, пожалуйста, какой-либо более или менее серьезный алгоритм иным способом. Ну, к примеру, ту же сортировку, хоть быструю, хоть пузырьковую. Сам напиши, а не метод вызови.. Тут как-то сразу забываешь про инкапсуляцию с полиморфизмом и про все паттерны, потому что надо код писать, а не организовать. Алгоритм реализовать то есть.
PD>А вот роль организации кода резко повысилась по сравнению с фортрановскими временами, да.
Знаешь что ты только что сказал? Примерно следующее:
(я) — я думаю, что 2 * 2 = 4
(ты) — нифига ты, мужик, не понимаешь. 2 * 2 — ЭТО ЧЕТЫРЕ!!!!! Запомни, будешь знать!
IT>>Что же изменилось внутри метода? Да почти ничего. Как и 30 лет назад мы имеем if/else/switch, несколько циклов, команды выхода из цикла и метода, операции, присваивание и ещё немного по мелочёвке.
PD>А не возникала ли у тебя мысль — а может, ничего и не надо ? Базовые конструкции потому и называются базовыми, что они , во-первых, не упрощаются, а во-вторых, их набор минимален и не всякое туда пустят, просто для того, чтобы не нарушать стройность и логику — иными словами, по принципу бритвы Оккама. Это как аксиомы Евклида — за 2000 лет никаких новых аксиом туда не добавили и не добавят . И три классические формы — следование, выбор, повторение — так и остались, и четвертому Риму похоже, не бывать
Даже не хочется на это отвечать. Знаешь, если всё же открыть дверь, то мир может оказаться совсем не таким, каким он видится через замочную скважину.
Вот здесь два примера того, как правильные высокоуровневые конструкции могут сделать код в разы проще, понятнее и эффективнее.
Здравствуйте, Pavel Dvorkin, Вы писали:
IT>>>Вот здесь два примера того, как правильные высокоуровневые конструкции могут сделать код в разы проще, понятнее и эффективнее.
PD>Полностью абстрагируясь от эффективного вычисления процентов , отмечу лишь, что сделать код с помощью каких-то высокоуровненвых конструкций проще — можно, понятнее — тоже можно, а вот эффективнее — дудки. Потому что предельно эффективная программа — это наилучшим образом оптимизированная программа, написанная на ассемблере. А в этом самом ассемблере есть только презренные присваивания, if, с грехом пополам циклы, и ни одной лямбды
Если уж абстрагироваться полностью, то идеальный компилятор идеально (в плане эффективности) скомпилирует все наши лямбды и прочая в понятные процессору ифы и вайлы.
Здравствуйте, Aen Sidhe, Вы писали:
AS>Если уж абстрагироваться полностью, то идеальный компилятор идеально (в плане эффективности) скомпилирует все наши лямбды и прочая в понятные процессору ифы и вайлы.
Да. Но не более эффективно, чем собственно ассемблер. В лучшем случае (см. выделенное мной) — не хуже. А ведь обещали на порядок — вот я и смеюсь.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>У меня нет Хаскеля, проверить не могу. PD>Пожалуйста, приведи данные по скорости работы алгоритма на Хаскеле и на С, если они есть. Обещано же (хоть и не вами обоими) — эффективнее
Программа на хаскеле конечно эффективнее, в смысле производительности пишущего (и читающего) код программиста.
В смысле производительности работы готового она малоэффективна. Но можно оптимизировать http://en.literateprograms.org/Quicksort_(Haskell) и все равно код будет проще сишного в разы а по производительности вполне к нему приблизится.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Здравствуйте, Aen Sidhe, Вы писали:
AS>>Если уж абстрагироваться полностью, то идеальный компилятор идеально (в плане эффективности) скомпилирует все наши лямбды и прочая в понятные процессору ифы и вайлы.
PD>Да. Но не более эффективно, чем собственно ассемблер. В лучшем случае (см. выделенное мной) — не хуже. А ведь обещали на порядок — вот я и смеюсь.
Там шёл разговор о том, что эффективнее будет твоя работа, как программиста. Вместо написания 30 ифов и 50 вайлов — пара хайлевел инструкций.
ЗЫ: следует понимать, что про 30 и 50 — утрирование.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Да. Но не более эффективно, чем собственно ассемблер. В лучшем случае (см. выделенное мной) — не хуже. А ведь обещали на порядок — вот я и смеюсь.
Некторые современные компиляторы настолько хорошо оптимизируют, в том числе и в compile time что вручную на ассемблере их очень сложно обставить, особенно на нетривиальном коде.
А на порядок обещали поднять эффективность програмиста а не кода. Хотя я думаю на порядок не будет, но в разы да вполне возможно.
Здравствуйте, Константин Л., Вы писали:
_FR>>То есть можно жертвовать надёжностью, модульностью, локализацией ради "читабельности"? Это при том, что мнение "чем локальнее объявление, тем лучше" можно считать верным (или нет?), а "читабельность" — величина субъективная?
КЛ>где ты увидел что я ими жертвую? private static. ни стейта, ни открытости.
Ну представь себе такой не очень маленький класс. Кому-то понадобилось дописать в него некий метод, в котором понадобился какой-то хелпер. Он смотрит: ага! кто-то добрый уже такой написал! и берёт его. Вот связанность и получилась. Когда же хелпер объявлен локально, "случайно", поошибке, "не правильно" заиспользовать его невозможно, нужно явно постараться.
КЛ>>>плюс от к захвату контекста все-же лучше прибегать с осторожностью.
_FR>>Вынося метод "наружу" ты позваляешь кому-то (а как ты запрещаешь? ага, никак!) к нему обратиться, тем самым увеличивая связаность. К лишней связаности надо относиться с ещё большим подозрением чем "к захвату контекста". Кстати, из за чего требуется осторожность? И, между прочим, мы же говорим о методах, не захватывающих контекст.
КЛ>связанность и там и там. только в одном случае по параметрам, в другом по локальным переменным. Наружу это куда? Я же написал — private.
Связанность с параметрами — нормальное дело. Это всё равно что утверждать, что класс связан со своими членами: конечно связан, только это "положительная связь", в том смысле, что не причиняет вреда и которую легко порвать.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111>>
Help will always be given at Hogwarts to those who ask for it.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>а вот эффективнее — дудки.
Тут вопрос: эффективнее чем что? Чем идеально оптимизированная программа — действительно вряд ли. А чем обычная — легко.
Чем выше уровнем конструкция, тем ближе она к смыслу операции, а не деталям реализации ("что?" вместо "как?"), и тем больше шансов, что хороший компилятор найдет более удачное решение.
Здравствуйте, Aen Sidhe, Вы писали:
AS>Там шёл разговор о том, что эффективнее будет твоя работа, как программиста.
Ну уж нет. Читай внимательно. Выделено мной.
IT>Вот здесь два примера того, как правильные высокоуровневые конструкции могут сделать код в разы проще, понятнее и эффективнее
Здравствуйте, FR, Вы писали:
FR>Здравствуйте, Pavel Dvorkin, Вы писали:
PD>>У меня нет Хаскеля, проверить не могу. PD>>Пожалуйста, приведи данные по скорости работы алгоритма на Хаскеле и на С, если они есть. Обещано же (хоть и не вами обоими) — эффективнее
FR>Программа на хаскеле конечно эффективнее, в смысле производительности пишущего (и читающего) код программиста.
А это не обсуждалось. Вот что писал IT
IT>Вот здесь два примера того, как правильные высокоуровневые конструкции могут сделать код в разы проще, понятнее и эффективнее
А в смысле работы программиста — вот тебе самое эффективное решение из незабвенного "Hello, World"
Bob, could you please write me a program that prints "Hello,
world."? I need it by tomorrow.
Здравствуйте, FR, Вы писали:
FR>А на порядок обещали поднять эффективность програмиста а не кода. Хотя я думаю на порядок не будет, но в разы да вполне возможно.
Слушайте, господа, вы чего это все как будто сговорились ? Мне в третий раз приходится цитировать
IT>Вот здесь два примера того, как правильные высокоуровневые конструкции могут сделать код в разы проще, понятнее и эффективнее.
Где тут про эффективность труда программиста ? Тут именно про эффективность кода. Русским по белому.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Ну уж нет. Читай внимательно. Выделено мной.
IT>>Вот здесь два примера того, как правильные высокоуровневые конструкции могут сделать код в разы проще, понятнее и эффективнее
PD>Код!
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Здравствуйте, Aen Sidhe, Вы писали:
AS>>Там шёл разговор о том, что эффективнее будет твоя работа, как программиста.
PD>Ну уж нет. Читай внимательно. Выделено мной.
IT>>Вот здесь два примера того, как правильные высокоуровневые конструкции могут сделать код в разы проще, понятнее и эффективнее
PD>Код!
Придирки к словам, в случае, когда суть кристально понятна, вас не красит.
Здравствуйте, FR, Вы писали:
FR>Здравствуйте, Pavel Dvorkin, Вы писали:
PD>>Ну уж нет. Читай внимательно. Выделено мной.
IT>>>Вот здесь два примера того, как правильные высокоуровневые конструкции могут сделать код в разы проще, понятнее и эффективнее
PD>>Код!
FR>Это
FR>
Здравствуйте, FR, Вы писали:
FR>Здравствуйте, Pavel Dvorkin, Вы писали:
FR>>>по твоему не код?
PD>>А он эффективнее в разы ?
FR>В смысле читабельности и писабельности конечно.
В этом смысле — мб, и да, если знать Хаскель, конечно. Но меня вообще-то больше интересует эффективность его выполнения
Здравствуйте, FR, Вы писали:
FR>По моему тут только ты единственный его неправильно понял.
Если бы было сказано — кодирования — я бы еще засомненвался. Но эффективность кода — как еще можно понять ? Ладно, спишем — будем считать, что я проявил плохие телепатические способности, в отличие от вас всех
Здравствуйте, VladD2, Вы писали:
AVK>>Ну а что я могу на подобное ответить?
VD>Дать ссылку
Лень
VD> или признать, что внятного объяснения нет.
Я уже признал — для тебя внятного объяснения у меня нет.
AVK>>Учитывая, что "внятное" — характеристика в большей степени субъективная,
VD>А это уже судить тем кто будет смотреть ссылки.
И где я тут сказал за Синклера???
VD>Меж тем я уже не раз слышал от Синклера, что "язык ему очень нравится".
Наздоровье. Это не отменяет того простого факта, что те претензии к Немерле, что он высказывает, вполне соответствуют моим претензиям.
AVK>>Просто предложил почитать его сообщения, бо с его точкой зрения в тех флеймах я в общем и целом согласен.
VD>Я их читал.
Зачем тогда ссылки с меня требуешь?
AVK>>Ну и кто из нас тут говорит за Синклера?
VD>А я как раз за него и не говорю. Он сам за себя довольно не двусмысленно сказал.
Интересно, а ты ссылочку дашь?
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, IT, Вы писали:
VD>>1. Неизменяемые структуры данных. VD>>2. Аглебраические типы данных (variant в Nemerle).
IT>Я это не упомянул, т.к. это всё опять же работает на уровне кода. На компоновку кода и архитектуру приложения это никак не влияет.
Достаточно сравнить архитектуру компилятора написанного на ООЯ и на том же Немерле. Сразу видно, что два этих пункта сильно влияют на архитектуру. Так что тут я с тобой не соглашусь.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, VladD2, Вы писали:
VD>Достаточно сравнить архитектуру компилятора написанного на ООЯ и на том же Немерле. Сразу видно, что два этих пункта сильно влияют на архитектуру. Так что тут я с тобой не соглашусь.
В общем, я бы поправил твое высказывание следующим образом:
ФП с человеческим лицом офигительно улучшает и упрощает реализацию алгоритмов за счет встраивания в язык мощных фич вроде поддержки ФВП, паттерн-матчинга, возможности возвращать значение почти из любой конструкции языка, вывода типов и т.п., а так же позволяет, в некоторых случаях, существенно упростить проектирование отдельных частей приложения заменив классы алгебраическими типами данных и неизменяемыми структурами данных.
В таком описании соглашусь полностью.
Собственно проблема только в том, что тех кто придерживаются такого мнения окружают с двух сторон. С одной стороны те кто не хочет или не может (в силу своих особенностей) воспринять ФП, а с другой те кто кроме ФП ничего больше не видят и не приемлют.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, _FRED_, Вы писали:
_FR>Здравствуйте, Константин Л., Вы писали:
_FR>>>То есть можно жертвовать надёжностью, модульностью, локализацией ради "читабельности"? Это при том, что мнение "чем локальнее объявление, тем лучше" можно считать верным (или нет?), а "читабельность" — величина субъективная?
КЛ>>где ты увидел что я ими жертвую? private static. ни стейта, ни открытости.
_FR>Ну представь себе такой не очень маленький класс. Кому-то понадобилось дописать в него некий метод, в котором понадобился какой-то хелпер. Он смотрит: ага! кто-то добрый уже такой написал! и берёт его. Вот связанность и получилась. Когда же хелпер объявлен локально, "случайно", поошибке, "не правильно" заиспользовать его невозможно, нужно явно постараться.
Прости, но если это хелпер, который удовлетворяет его потребности, то это значит, что мы написали реюзабельный код, и его уже можно попробовать вынести наружу в common/utils. Чем лучше в данном случае подход "локальная функция на каждый чих"?
КЛ>>>>плюс от к захвату контекста все-же лучше прибегать с осторожностью.
_FR>>>Вынося метод "наружу" ты позваляешь кому-то (а как ты запрещаешь? ага, никак!) к нему обратиться, тем самым увеличивая связаность. К лишней связаности надо относиться с ещё большим подозрением чем "к захвату контекста". Кстати, из за чего требуется осторожность? И, между прочим, мы же говорим о методах, не захватывающих контекст.
КЛ>>связанность и там и там. только в одном случае по параметрам, в другом по локальным переменным. Наружу это куда? Я же написал — private.
_FR>Связанность с параметрами — нормальное дело. Это всё равно что утверждать, что класс связан со своими членами: конечно связан, только это "положительная связь", в том смысле, что не причиняет вреда и которую легко порвать.
Тогда еще раз повторюсь.
КЛ>плюс от к захвату контекста все-же лучше прибегать с осторожностью.
_FRВынося метод "наружу" ты позваляешь кому-то (а как ты запрещаешь? ага, никак!) к нему обратиться, тем самым увеличивая связаность. К лишней связаности надо относиться с ещё большим подозрением чем "к захвату контекста". Кстати, из за чего требуется осторожность? И, между прочим, мы же говорим о методах, не захватывающих контекст.
КЛ>>связанность и там и там. только в одном случае по параметрам, в другом по локальным переменным. Наружу это куда? Я же написал — private.
Здравствуйте, McSeem2, Вы писали:
MS>Здравствуйте, Константин Л., Вы писали:
КЛ>>может быть после того, как поучаствуешь, будешь говорить про мальчиков-архитекторов?
MS>У тебя есть разум, надо только научиться им пользоваться. Почему все приходится разжевывать? Понимаешь, нет в этом моем высказывании ничего уничижительного. Я просто хотел сказать, что бывают разные задачи по самой сути. Для меня — это придумать алгоритм и отдать его "мальчикам-архитекторам" и прочим. И меня не интересует размер проекта, это их забота (про разделение труда слышал?) Поэтому, можно сказать, что я и не участвую в этом проекте. При этом архитекторы могут считать меня неким мальчиком-алгоритмистом и в этом тоже нет ничего уничижительного.
Ну что за тон, право?
Понимаешь, обычно уменьшительно-ласкательные приставки это способ выразить насмешку, презрение. Мне вот было интересно, на каком основании ты всех архитекторов того, под общую гребенку, м? Я тебя спросил, я ты мне тут же "не участвовал, стремно; используй моск, приходится разжевывать". Твой тон очень резок и категоричен. Как ты хочешь, чтобы потом тебя нормально понимали?
MS>Бывали и казусы. Однажды архитекторы так запроектировали некий модуль обработки данных, что он требовал квадратичного времени выполнения как ты ни кодируй (а надо и можно было обойтись линейным.) В результате, по самым оптимистичным прогнозам, данная архитектура на реальных объемах данных требовала бы не меньше 500 лет для обработки. Зато все было очень красиво.
Как твоё "используй моск, я никого не хотел обидеть, бывали казусы" сочетается с вот этим высказыванием?
А уж обернуть в классы и иерархии, плюс кодовая оптимизация — это рутина, этим пусть мальчики-архитекторы и мальчики-кодеры занимаются. Я всегда готов их проконсультировать и объяснить сущность алгоритма.
1. Обосрал процесс создания архитектуры
2. Обосрал пару профессий вместе с ихними представителями
Здравствуйте, Константин Л., Вы писали:
КЛ>Ну что за тон, право?
КЛ>Понимаешь, обычно уменьшительно-ласкательные приставки это способ выразить насмешку, презрение.
ИМХО, вполне естественная, хоть и некорректная, реакция на попытку пенисометрии.
КЛ>1. Обосрал процесс создания архитектуры КЛ>2. Обосрал пару профессий вместе с ихними представителями
Это у него такая манера беседовать. Не только у него, кстати. Остается только либо забанить его навечно, либо терпеть, пока он совсем не выйдет за рамки.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, VladD2, Вы писали:
VD>На что? Можно конкретнее?
Для того, чтобы определиться "на что", надо в первую очередь понять "что" конкретно не устраивает. В интерпретации ИТ ситуация выглядит так:
"Снаружи" методов у нас все шоколадно. Иерархии классов, сплошное ООП, полиморфизм и прочие извращения. "Внутри" методов — пещерный век.
Мне вот это как раз и непонятно. Я об этом тут уже писал да потерли.
А "что" происходит внутри методов-то? Что за таинственная "жизнь" такая? Может сложиться впечатление, что "жизнь внутри методов" происходит как бы отдельно и сугубо автономно от всех этих внешних иерархий.
А фактически внутри методов и пишется как раз код, который использует все эти "иерархии". И если наши красивые объектно-ориентированные классы предполагают по своему дизайну, что работать с ними приходится пещерными методами — то чему тут можно удивляться?
Касательно Немерле. Вопроса метапрограммирования я нарочно не касаюсь — возьмем только сочетание ФП и ООП. Почему мне не нравится это? Потому что ФП в данном случае это не что иное как попытка облечь "пещерные методы" в более красивую форму. И все. Я тут не вижу никаких "кардинальных" изменений по сравнению с тем что раньше было. Да, раньше кололи дрова топором, теперь лесопилка — но "двора"-то по-прежнему нужны, мы от этого не ушли никуда.
Ну по-моему реально странно все это. Мы, к примеру, создаем коллекции, скажем так, "векторного" типа, которые предполагают, что для осуществления групповых операций придется пользоваться банальным перебором — а потом начинаем придумывать наиболее "красивые" формы этого перебора.
ООП, как тут многие более чем справедливо говорили, это фактически "кирпичи". Из них можно построить здание, но если мы хотим получить что-то более изящное, чем кондовую "хрущобу", то кирпичи не годятся. Весь "лес" из if-ов, foreach-ей, switch-ей и прочего возникает даже не потому, что ООП не предлагает нам других средств, но мы просто понимаем одним место, что если раскрутить весь наш великий полиморфизм, то мы получим не что иное как большое жилое здание, сделанное из конструктора Лего. Кирпичи они всегда кирпичи, независимо от размера.
Здравствуйте, AndrewVK, Вы писали:
AVK>Здравствуйте, Константин Л., Вы писали:
КЛ>>Ну что за тон, право?
КЛ>>Понимаешь, обычно уменьшительно-ласкательные приставки это способ выразить насмешку, презрение.
AVK>ИМХО, вполне естественная, хоть и некорректная, реакция на попытку пенисометрии.
Да никто с ним ничем меряться не собирается. Чем он занимается и насколько у него больше/меньше все прекрасно знают. Просто мимо его заявления про мальчиков-архитекторов и рутину я не смог пройти мимо. Вот и решил поинтересоваться, в каких проектах он участвовал, кроме своего AGG.
КЛ>>1. Обосрал процесс создания архитектуры КЛ>>2. Обосрал пару профессий вместе с ихними представителями
AVK>Это у него такая манера беседовать. Не только у него, кстати. Остается только либо забанить его навечно, либо терпеть, пока он совсем не выйдет за рамки.
Реплика в зал: не, ну что за мода пошла — понапридумывать аналогий, и потом считать, что это выглядит хоть в малейшей степени убедительным обоснованием собственной точки зрения?
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Константин Л., Вы писали:
КЛ>Да никто с ним ничем меряться не собирается.
А по мне, так ты вполне ясно продемонстрировал, что именно что собираешься. И не только по мне, судя по оценкам.
КЛ> Чем он занимается и насколько у него больше/меньше все прекрасно знают.
Ну так и не надо тут заниматься флеймогенераторством.
КЛ> Просто мимо его заявления про мальчиков-архитекторов и рутину я не смог пройти мимо.
Это не повод поступать точно так же.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, AndrewVK, Вы писали:
AVK>Реплика в зал: не, ну что за мода пошла — понапридумывать аналогий, и потом считать, что это выглядит хоть в малейшей степени убедительным обоснованием собственной точки зрения?
А что, на использование аналогий тоже нужны какие-то особые полномочия или мне тоже можно? К тому же как раз основную часть своей позиции я объяснил без всяких аналогий. Если есть что сказать по существу — буду рад подискутировать.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD> Тут как-то сразу забываешь про инкапсуляцию с полиморфизмом и про все паттерны, потому что надо код писать, а не организовать. Алгоритм реализовать то есть.
qsort [] = []
qsort h:t = qsort [e | e <- t, e < h] ++ [h] ++ qsort [e | e <- t, e >= h]
Предлагаю повторить то же самое на "базовых" if-ах и while-ах. Кстати, хочу заметить, что истинно базовыми являются jz, jnz, jc, jnc и т.п. Ну а вообще труъ — это когда таблица переходов для машины Тьюринга.
PD>А не возникала ли у тебя мысль — а может, ничего и не надо ? Базовые конструкции потому и называются базовыми, что они , во-первых, не упрощаются, а во-вторых, их набор минимален и не всякое туда пустят, просто для того, чтобы не нарушать стройность и логику — иными словами, по принципу бритвы Оккама. Это как аксиомы Евклида — за 2000 лет никаких новых аксиом туда не добавили и не добавят . И три классические формы — следование, выбор, повторение — так и остались, и четвертому Риму похоже, не бывать
Гм, ну вообще-то повторение тоже разное бывает. Я вот уже давно for-ом в C# не пользуюсь. А в Питоне, например, for вообще имеет семантику C#-ского foreach, и ничего. Во-вторых, про труъ базовые конструкции я уже писал. В-третьих, туда не только не добавили аксиомы, но и изъяли одну, и получили теории, гораздо более мощные. Ну и наконец, никто не заставляет строить геометрию аки Евклид. Можно выбрать и другой набор аксиом, правда он будет не столь удобен. Так вот в случае с программированием мне известны три такие альтернативные системы аксиом. И не факт, что они чем-то уступают машине Тьюринга.
Здравствуйте, FR, Вы писали:
FR>Программа на хаскеле конечно эффективнее, в смысле производительности пишущего (и читающего) код программиста. FR>В смысле производительности работы готового она малоэффективна. Но можно оптимизировать http://en.literateprograms.org/Quicksort_(Haskell) и все равно код будет проще сишного в разы а по производительности вполне к нему приблизится.
Кстати, для отдельно взятой функции сортировки Haskell может и проиграет в скорости. Но для реально больших программ компилятор делает такие оптимизации, что ручками то же делать на C — равносильно самоубийству.
Здравствуйте, deniok, Вы писали:
D>Ключевым моментом, которого пока не касались в этой дискуссии, является высокоуровневая оптимизация, про которую никакой ассемблер не знает. Например, в Хаскелле есть дефорестация (list fusion). Вася взял список, применил к его элементам функцию f, получив другой список:
А почему это обязательно list fusion? Есть же прекрасно описаный алгоритм fusion для алгебраических типов. Я его даже применял в своём компиляторе. Каково же было моё изумление, когда я до этого недели две убил на оптимизацию редуктора графов и сумел ускорить его всего в 2.5 раза, а потом добавил fusion и на исполнение тестового примера понадобилось в 30 раз меньше редукций (соответственно, и времени). Надо сказать, что код задачек для бенчмарка был крайне простеньким и запросто оптимизировался в случае с C. Но это же простой случай. Я по сей день когда пишу на С#, со страхом представляю, каких оптимизаций компилятор не будет делать. А в ручную сделать не возможно by design.
Кстати, слышал что то же fusion реализуется на хиломорфизмах. Но пока до этого не дорос.
Здравствуйте, Pzz, Вы писали:
Pzz>#pragma flame on
Pzz>Напротив. Просто потребность в эффективности программ стала не общепринятой, а нишевой. Когда возникает необходимость спроектировать сервер, обслуживающий большое количество клиентов, или коробочку, выдающую осмысленную производительность на слабом железе, то тут некуда деваться от традиционных представлений о производительности (разве что tradeoff между процессором и памятью заметно сместился в сторону памяти). Ваше поколение оказывается довольно беспомощным при решении такого рода задач, и плохо обучаемым, потому как у вас происходит разрыв шаблона при соприкосновении с реальностью
Pzz>#pragma flame off
Я вот об одном думаю иногда. Взять бы этих специалистов по паттернам, фреймворкам и интерфейсам, назначить им хорошую зарплату, да только поручить им спроектировать и написать www.microsoft.com , с тем количеством запросов, которое он реально обслуживает. А потом, когда время ответа будет порядка десятков секунд, уволить всех с распубликованием их имен
Ну а сайт первого заборостроительного завода имени второй половины шестой пятилетки — тут и без эффективности можно.
Здравствуйте, AndrewVK, Вы писали:
AVK>А если надо пройтись по индексированному списку и индекс использовать внутри — руками заводишь счетчик или делаешь foreach по Enumerable.Range()?
Правильнее было сказать, "уже давно for-ом практически не пользуюсь". Правда, чаще выбираю второй подход, нежели for. Потому что у меня есть свой индексированный список. И для работы с ним у меня есть Range. Я как правило не имею дело с парами индексов или длиной списка. У меня на это есть Range, который ещё реализует IEnumerable (например, пройтись по списку foreach (var i in list.All) { }. Разумеется, всё это только в тех проектах, где мне можно использовать свои библиотеки, и не надо взаимодейтстовать с кодом, который уже написан под List<T> или массивы.
Здравствуйте, deniok, Вы писали:
D>Компилятор Хаскеля взял эту конструкцию с кучей промежуточных списков и оптимизировал в D>
D>olja_oplimized lst = map (h . g. f) lst
D>
D>Без единого промежуточного списка.
Ты пойми, люди вроде Дворкина мыслят не так. Они когда пишут код, то представляют его в уже оптимизированном виде. У него не то что списка не будет (это же непроизводительные расходы памяти!). У него и функций в коде не будет. Он просто напишет один огромный "for" в тело которого он зафигачит все свои вычисления. В другом месте он зафигачит другой цикл, который будет похож на этот, но немножко другой. А для себя и окружающих от скажет (подумает), что дублирование кода неизбежно и определяется оно алгоритмами. В лучшем случае часть кода в цикле он вынесет в отдельные процедуры.
Ни о какой передаче ссылок на функции (функций) тем более с замыканиями, при этом и речи быть не может. Это же тоже трата драгоценного процессорного времени!
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Ну не знаю. Если уж распараллеливание императивного алгоритма вычисления процентов — дело безнадежное, то, наверное, все, приехали, надо забыть про все, что есть на свете.
Чего воду в ступе толочь? Реализуй описанный алгоритмв императивном стиле, и чтобы распараллеливался, вот мы и посмотрим.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, IT, Вы писали:
IT>Я могу тебе ещё раз посоветовать перестать подглядывать за миром через замочную скважину и наконец-то распахнуть дверь.
Слушай, а не хватит ? Так ведь ничего не докажешь!
>Приведённый мною алгоритм ускоряется пропорционально количеству ядер за время меньшее, чем тебе потребовалось на прочтение этого сообщения.
У меня есть подозрение, что любой алгоритм, допскающий истинное распараллеливание, ускоряется пропорционально количеству ядер . Впрочем, это только подозрение, так как если алгоритм оперирует данными, несколько более сложными, чем делимое и делитель при вычислении процентов, то начинают играть роль и иные факторы, как , например, время доступа к памяти и т.д. Тут это не раз обсуждалось.
IT>Что касается первого примера с pattern matching, то для леквидации своей безграмотности
Опять! Ну пойми же наконец — так ничего не докажешь.
>можешь полистать на досуге вот этот документик. Это алгоритм компиляции pattern matching, который используется в Nemerle. Код, который получается в результате, не просто полностью отжат и максимально эффективен, он ещё и генерируется так, что повторить его столько же эффективно на if-ах просто невозможно.
Он на P4 выполняется или нет ? Если да — берем ассемблерный код, который в конце концов получился хоть от Немерле, хоть от духа святого. Вот тебе эти самые if'ы и т.д.
Вот ответь прямо — можно написать код лучше, чем идеально написанный код на ассемблере ? Заметь, я вовсе не говорю, что знаю, как такой код написать. Но он теоретически существует — при данном алгоритме, конечно, и данном железе.
>Refletor в большинстве случаев такой код не восстанавливает, пишет что метод обфусцирован.
И что? какое это отношение к делу имеет ? В EXE с С++ все "обсфуцировано" и без всяких усилий с моей стороны
IT>Ассемблер рулил 20 лет назад. И то с переменным успехом. Сегодня компиляторы вытворяют такие оптимизации, которые человек не станет использовать хотя бы потому, что написанный им код должен оставаться элементарно читаемым.
Если я в своей задаче сделаю код слабочитаемым (о задаче я писал в ответе VladD2) — мне это простят. Если там будет нечто вроде блюда спагетти (не будет , конечно, но допустим) — простят. Ассемблер — не обсуждал с заказчиком, но , думаю, простят. Все простят, кроме одного — если я не уложусь в эти 200 мсек. И на фоне этого все прочие рассуждения меня интересуют, как прошлогодний снег. Потому что тут действительно сложная задача(и как ее решить — я пока не знаю), а не оптимизация вычисления процентов
>При этом чем более высокоуровневые средства используются, тем больше у компилятора свободы для оптимизаций.
Свободы больше, но при условии, что задачи стандартные, и компилятор знает, как их оптимизировать. Как только что-то нестандартное — будет плохо.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Я действительно удивлен, но не этим. Я удивлен, как можно обсуждать оптимизацию на примере вычисление процентов. Я не спорю, что дело это нужное и полезное , но алгоритмическая сложность этой задачи близка к нулю. Если хочешь что-то доказать — приведи более или менее серьезную задачу, а не подобные пустяки.
Эта задача была приведена в качестве примера, можно сказать ради забавы. Никто тебе здесь мегаалгоритмов приводить не будет, т.к. это никому не интересно. И так понятно, что если эффект получается на таких задачах, то на мегаалгоритмах всё будет ещё печальнее для твоего ассемблера.
>>Распаралеливание императивного алгоритма потребует больше времени, чем написание самого алгоритма и сделает его в конце концов окончательно безнадёжным.
PD>Ну не знаю. Если уж распараллеливание императивного алгоритма вычисления процентов — дело безнадежное, то, наверное, все, приехали, надо забыть про все, что есть на свете. Windows уж точно работать не должна — там внутри сплошное распараллеливание и никакой декларативности. А задачи там на несколько порядков сложнее вычисления процентов.
А ты попробуй. Возьми код, который я привёл (там же простенький алгоритм) и распаралель его на несколько ядер, а мы посмотрим. Ну давай, ради забавы. Там делов то.
PD>Вся беда твоя (и не только), что вы со своими простенькими задачами решили, что выводы, которые на базе этих простеньких задач можно сделать (мб, вполне для этих задач и верные) — могут обобщаться для программирования в целом.
Я думаю, что у тебя не хватит силёнок даже этот простенький алгоритм эффективно распаралелить. Просто даже в этом не сомневаюсь.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Вот ответь прямо — можно написать код лучше, чем идеально написанный код на ассемблере ? Заметь, я вовсе не говорю, что знаю, как такой код написать. Но он теоретически существует — при данном алгоритме, конечно, и данном железе.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>2. На асме мне писать, возможно, придется. Очередная задача — есть некий код автора алгоритма, работает 5 сек, коммерческий софт на эту тему работает тоже примерно 5 сек, а заказчик хочет, чтобы уложилось в 200 мсек. Как ускорить быстродействие раза в 3-4 — понимаю, а вот в 20 — нет. Хотя предпочел бы обойтись без асма, но, возможно, придется. И не так уж это сложно, поверь. PD>3.И поскольку я это не понимаю пока, и заказчик тоже понимает, что я это за мгновение не сделаю, то мне надо думать, и заказчик меня не торопит. Думать надо, понимаешь ? Не оптимизировать вычисление процентов и не искать синтаксический сахар или аттическую соль, а думать, что с алгоритмом сделать. И думать я могу в самых разных местах, например, в маршрутке по дороге из дома/домой (почти час в один конец, увы). И я не знаю, сколько времени мне понадобится на то, чтобы что-то радикальное придумать. Был случай — две недели думал, ни одной строчки не написал, потом придумал и за пару дней реализовал. PD>Вот поэтому мне и забавно, когда серьезные вроде бы люди на полном серьезе обсуждают, как оптимизировать вычисление процентов или как контрол должен с родителем общаться. Мне бы ваши проблемы, господа.
Дворкин, не смеши народ своими проблемами. 200 мс Мне вот тут нужно сократить время работы одного процесса, генерирующего десятки миллионов транзакций, с шести часов хотя бы до одного. Что бы люди спать могли по ночам. И как его сократить в десятки раз я знаю, только заказчик ждать не будет, т.к. это не день, не два, и даже не неделя как у тебя, а примерно год работы. И знаний одного ассемблера тут вовсе не достаточно. Нужно быть и алгоритмистом, и энтерпрайзным архитектором, и датабазным, а заодно и сетевым админом, и шарить в сетевых протоколах и местной инфраструктуре, и уметь распаралеливать вычисления не только на одной машине, но и на нескольких серверах, и писать читабельный код, который потом будут править будущие поколения, а не тяп-ляпать на ассемблере. И всё это нужно вчера. А ты говоришь 200 мс
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, Константин Л., Вы писали:
КЛ>Я тебя спросил, я ты мне тут же "не участвовал, стремно; используй моск, приходится разжевывать".
Не надо выдавать свои домыслы за мои высказывания. Где я говорил, что не участвовал, и где я говорил, что стремно?
Видишь, действительно приходится разжевывать. И все равно толку нету.
McSeem
Я жертва цепи несчастных случайностей. Как и все мы.
Здравствуйте, McSeem2, Вы писали:
MS>Здравствуйте, Константин Л., Вы писали:
КЛ>>Я тебя спросил, я ты мне тут же "не участвовал, стремно; используй моск, приходится разжевывать".
MS>Не надо выдавать свои домыслы за мои высказывания. Где я говорил, что не участвовал, и где я говорил, что стремно? MS>Видишь, действительно приходится разжевывать. И все равно толку нету.
Здравствуйте, VladD2, Вы писали:
DM>>Вот задачка: есть семейство алгоритмов (та же компенсация, допустим), которые теперь отличаются не одной функцией, а пятью (при этом имеют по 10 общих). В случае ООП и наследования все просто — общие функции в базовый класс, различные — в наследников.
VD>Вот эти "если" — это все выдумки. На практике если для алгоритма требуется передавать более трех функций, то что-то не так в самой функции. Когда код исходно пишется в функциональном стиле, то функция пишется не как монолит с "настройками", а собирается из других более общих функций. При этом происходит нечто вроде IoC (разворот управления). Вместо того чтобы создавать функцию-монстра и потом передавать ей тонну детализирующих функций, нужная функция собирается из кусков. Примером тут может служить LINQ. В нем нет одной супер-функции типа Query, а есть несколько функций: Where, OrderBy, ThenBy, Join, Group, Select и т.п. Каждая из них принимает одну-две лямбды и возвращает некий обект-контекст к которому можно применять другие функции из приведённого списка.
Понятно. То же замыкание, только создающееся в несколько шагов.
DM>>А что в этом случае делают в Хаскеле и Лиспе?
VD>Ты бы попробовал на них по программировать, а потом бы уже вопросы задавал. А то тебе ведь ничего объяснить нельзя просто по определнию. Ты думаешь другими категориями.
Хамишь.
Некоторый опыт ФП у меня есть, просто вдруг я что-то важное пропустил, что хорошо заменяет ООП, вот и решил спросить. Пока вижу, что не ничего не пропустил, ответы предсказуемые.
DM>>Первое, приходящее мне на ум решение, — функция-конструктор, которая получает на вход охапку тех функций, что отличают конкретный алгоритм, и выдает в качестве результата одну функцию, его реализующую. Последняя уже вызывается когда надо. Т.е. все детали специализации пошли в замыкание, и по сути, мы получили некий аналог объекта из ООП, но с меньшим числом степеней свободы.
VD>Есть разные пути. В конце концов не трудно функции поместить в кортеж.
Ручная имитация VMT.
VD>Но на самом деле сама постановка задачи — это выдумка.
Задачу я взял реальную из текущей работы, как первый попавшийся пример применения наследования.
Если что: я не защищаю ООП и не против ФП, только за. Просто хочу узнать получше.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Я вот об одном думаю иногда. Взять бы этих специалистов по паттернам, фреймворкам и интерфейсам, назначить им хорошую зарплату, да только поручить им спроектировать и написать www.microsoft.com , с тем количеством запросов, которое он реально обслуживает. А потом, когда время ответа будет порядка десятков секунд, уволить всех с распубликованием их имен
Наскока я понимаю, мелкософт.ком примерно так и спроектирован. Но с двумя оговорками: 1) у мелкософта бабла немеряно, поэтому они могут себе позволить поставить неограниченное количество серверов 2) перед мордой у мелкософтовского сайта висит акамаевский акселератор. Благодаря сочетанию этих двух факторов мелкософтовский сайт хоть как-то ворочается. А без них — получится как раз RSDN.ru
Здравствуйте, Pzz, Вы писали:
Pzz>Напротив. Просто потребность в эффективности программ стала не общепринятой, а нишевой. Когда возникает необходимость спроектировать сервер, обслуживающий большое количество клиентов, или коробочку, выдающую осмысленную производительность на слабом железе, то тут некуда деваться от традиционных представлений о производительности (разве что tradeoff между процессором и памятью заметно сместился в сторону памяти). Ваше поколение оказывается довольно беспомощным при решении такого рода задач, и плохо обучаемым, потому как у вас происходит разрыв шаблона при соприкосновении с реальностью
Ты хоть один большой сервер вернее кластер хотябы на несколько десятков машин которые стоят в разных дататцентрах и система должна маскировать сбои не только одной машины но и целого датацентра написал?
Вот тебе статистика с одного из серверов такой системы:
Здравствуйте, Sinclair, Вы писали:
Pzz>>Я имел ввиду, что поскольку знания, в которые вы вкладываетесь, в основном состоят из перечня интерфейсов той технологии, которую вы сейчас считаете современной, то они по природе своей полностью устаревают за несколько лет, и вам приходится переучиваться. В 50 лет это будет сделать значительно сложнее. В том числе и по организационным причинам: никто не возьмет 50-летнего дядьку "на вырост", лучше возьмут студента. S>Очень сильное утверждение. А какие знания вы считаете несводимыми к перечню интерфейсов технологии?
Отвечу вопросом на вопрос , а какие вы считаете сводимыми?
S>Тем не менее, такой человек считает себя безмерно круче окружающих и позволяет себе смеяться над людьми, которые выучили только интерфейс к string.Compare(). S>Тем не менее, с точки зрения, скажем, менеджера, эти наивные молодые люди куда полезнее старой гвардии: они, по крайней мере, могут правильно сравнить строки, когда нужно.
Угу. И настойчиво продолжают их сравнивать, когда не нужно. Но зато правильно, с учетом пунктуации
Вы говорите ровно то же, что и я: люди, привыкшие изучать интерфейсы без понимания того, что "под капотом" у этих интерфейсов, оказываются в неудобном положении, когда интерфейсы меняются. Через несколько лет string.Compare() будет смотреться столь же ограниченным частным случаем, как сейчас смотрится интерфейс к строке в виде последовательности байт в кодировке ASCII.
Здравствуйте, WolfHound, Вы писали:
WH>Ты хоть один большой сервер вернее кластер хотябы на несколько десятков машин которые стоят в разных дататцентрах и система должна маскировать сбои не только одной машины но и целого датацентра написал? WH>Вот тебе статистика с одного из серверов такой системы:
Справедливости ради, у тебя система заточена на быстрый отклик. Если нужна экономичность без очень быстрого отклика, то энергетически выгоднее загрузить на 100% меньшее число серверов.
Здравствуйте, Cyberax, Вы писали:
C>Справедливости ради, у тебя система заточена на быстрый отклик. Если нужна экономичность без очень быстрого отклика, то энергетически выгоднее загрузить на 100% меньшее число серверов.
Вообще согласно всем общепринятым нормам во втором листинге у него как раз практически предельная загрузка для продакшин-серверов, что и есть ~50%.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Вообще согласно всем общепринятым нормам во втором листинге у него как раз практически предельная загрузка для продакшин-серверов, что и есть ~50%.
А в первом типа не придельная? Ты на колонки с IO посмотри...
А во втором случае реально система может сожрать еще раза в 2-3 больше запросов на обработку картинок (так я ее не в пике и сфотографировал). Правда она там еще всякой ерундой занимается чтобы IO не простаивало.
... << RSDN@Home 1.2.0 alpha rev. 745>>
Пусть это будет просто:
просто, как только можно,
но не проще.
(C) А. Эйнштейн
Здравствуйте, Cyberax, Вы писали:
C>Справедливости ради, у тебя система заточена на быстрый отклик. Если нужна экономичность без очень быстрого отклика, то энергетически выгоднее загрузить на 100% меньшее число серверов.
Это совсем другая задача с совсем другими решениями.
... << RSDN@Home 1.2.0 alpha rev. 745>>
Пусть это будет просто:
просто, как только можно,
но не проще.
(C) А. Эйнштейн
Здравствуйте, Геннадий Васильев, Вы писали:
ГВ>И этого я тоже не предлагаю. Я только констатирую, что привлечение низкоквалифицированой "рабочей силы" не есть хорошо. А ориентация на неё в некотором идейном смысле — вообще ужасна.
Я не предлагаю на нее ориентироваться, я лишь описываю сложившуюся реальность.
ГВ>То есть? (Просьба: обращайся ко мне на "ты", пожалуйста.)
ОК, но могу забыть
ГВ>Чего-чего? Во-первых, никто не мешает мне сделать какой-нибудь "permanent socket", который один раз получает параметры связи, а потом восстанавливает её по мере исчезновения. Во-вторых, распределено не знание, а управляющий сигнал от одной подсистемы к другой. Этих сигналов может быть ещё сто тыщ. В-третьих, если говорить о сокетах, то структурирование знаний здесь — само описание взаимодействия с сетью в виде "сокета".
Угу. И получишь программу, которая на вид как живая, все вроде работает, только данные никуда не ходят. Потому что сети нет. Перманентные сокеты — это то, что Джоел называет Leaky Abstractions. А методология ООП подразумевает, что ты сначала придумаешь перманентные сокеты, а когда через полгода разработки тебя осенит, что это была совсем плохая идея, будет уже поздно, и придется изобретать какой-нибудь костыль.
Управляющие сигналы ты можешь описать и перечислить, хоть все сто тыщ. Беда лишь в том, что эти сто тысяч в совокупности — некоторый "алфавит", множество "символов". А программа твоя работает не с символами, а с "фразами" на этом языке. И за этим есть свои знания — например то, что disconnect приходит после connect'а, или то, что между disconnect'ом и следующим connect'ом никак не может прийти file_transmission_completed, потому что если сети нет, то какой уж тут completed. Теперь вопрос, где эти знания кодифицизованы в твоей программе? В лучшем случае — в конструкторской документации, в типичном — в голове у тех 2-3-х человек, которые на самом деле понимают, как оно работает.
Поэтому да, тривиальное знание, типа того, как открыть сокет и как в него писать, в ООП описать относительно удобно. А для нетривиального знания — типа того, что сеть по природе своей штука динамическая — опаньки, никакой готовой методологии и нет.
ГВ>Ну так для этого подходит вообще любой метод структурирования программы, подразумевающий мало-мальскую модульность. По твоему выходит, что все они придуманы для загрузки больших коллективов?
ООП и есть метод структурирования программы посредством модульности. Придуманы они могли бы быть для чего угодно, но в индустрии стали популярны стали потому, что позволяют капиталистам максимизировать прибыли при определенных условиях.
Pzz>>Я имею ввиду, конечно, техническое руководство, а не то, чтобы у всех были исправные стулья и соблюдались сроки
ГВ>Так ты не путай одно с другим. "Техническое руководство", это такая штука, которая к "менеджменту" вообще никакого отношения не имеет, кроме лексического подобия.
Это спор о терминах.
ГВ>>>Всё не так. Первоначально рассуждали о том, что ООП позволяет существенно расширить возможности одного программиста, благодаря тому, что способ представления абстракций лучше адаптирован к человеческому мышлению, чем, скажем, процедурная абстракция. То есть один из тезисов, послуживших распространению ООП прямо противоположен приведённому тобой: предполагалось в некотором роде сокращение числа программистов. Понимаешь? А распределять программирование на массу народу умели задолго до появления даже языков высокого уровня. Почитай того же Брукса.
Pzz>>И много программистов с тех пор сократилось? Давайте пропустим маркетинговый буллшит.
ГВ>Нет, не пропустим. Соображение о повышении индивидуальных способностей программиста было весьма действенным фактором распространения ООП. И кстати, в некоторой части вполне подтвердилось. Естественно, что к рассуждениям о "сокращении количества" относились по большей части скептически, но если бы ООП проталкивалось под флагом вовлечения массы людей — сопротивление было бы сумасшедшим. Да ООП вообще бы из пробирки не вылезло, не смотря на все позывы индустрии.
В свободном капиталистическом мире есть только один действенный фактор распостранения чего-бы то ни было: максимизация прибылей.
Не вовлечение массы людей, а линейное увеличение их совокупной производительности по мере увеличения их количества — именно это предлагает ООП. В современных коммерческих реалиях гораздо важнее успеть быстро, чем ограничиться минимумом сотрудников. Успешная программа может приносить миллион в месяц. Лишний десяток кодеров стоит гораздо дешевле.
ГВ>Ну, я уж не знаю, откуда ты извлёк мысль, что ООП предполагает "распихивание по коробочкам" до начала размышлений. По моему опыту и наблюдениям это далеко не так, а по моему убеждению это так и быть не может.
Здравствуйте, konsoletyper, Вы писали:
K>А почему это обязательно list fusion? Есть же прекрасно описаный алгоритм fusion для алгебраических типов. Я его даже применял в своём компиляторе.
Я привел простейший (но показательный) пример оптимизации, доступной компилятору функционального языка. Конечно это частный случай, исключительно с целью демонстрации идеи.
Здравствуйте, Pzz, Вы писали:
ГВ>>И этого я тоже не предлагаю. Я только констатирую, что привлечение низкоквалифицированой "рабочей силы" не есть хорошо. А ориентация на неё в некотором идейном смысле — вообще ужасна. Pzz>Я не предлагаю на нее ориентироваться, я лишь описываю сложившуюся реальность.
Ёшкин кот. Это чьи слова:
ООП придумали для того, чтобы можно было структуруровать программу в терминах довольно больших блоков. Это нужно, в первую очередь, в связи с индустриальными методами разработки, когда над одной программой работают 50 индусов, и надо как-то провести границы, чтобы они не наступали друг другу на пятки.
Гради Буча?
Ты ж, пытаешься свести причины распространение ООП к "индустриальным методам разработки", в которые (в методы, то бишь) ничтоже сумняшеся вписываешь десятки индусов. А я тебе пытаюсь объяснить, что такое почти никому в здравом уме и трезвой памяти в голову прийти не могло. Ну разве что IBM могла какой-нибудь финт отколоть в этом стиле, да и то — маловероятно.
Pzz>Поэтому да, тривиальное знание, типа того, как открыть сокет и как в него писать, в ООП описать относительно удобно. А для нетривиального знания — типа того, что сеть по природе своей штука динамическая — опаньки, никакой готовой методологии и нет.
Блин, ты не можешь чуть послабее шифровать то, что хотел сказать на самом деле? Никто здесь вроде, ООП серебряной пулей не считает. Это был раз.
Два, методология анализа в терминах ООП не просто "слабо развита", она вообще не развита. Нету надёжного метода определения того, что такое "объект". Это тоже ни для кого не новость. И это, тем не менее, никак не противоречит тому, что классы/методы — определённый способ записи знаний. Всего лишь определённый способ, ничего больше. Предоставляет русский язык специальные средства построения анекдотов? ИМХО — нет. Годится он, тем не менее, для выражения анекдотов? ИМХО — вполне. Он богаче наскальной письменности? Вроде как — да. Развивался ли он исключительно для руководства? Вроде как — нет. Вот и с ООП то же самое.
Не надо приписывать предметам те свойства, которыми они никогда не обладали, тогда и не придётся их ругать за несуществующие огрехи.
ГВ>>Ну так для этого подходит вообще любой метод структурирования программы, подразумевающий мало-мальскую модульность. По твоему выходит, что все они придуманы для загрузки больших коллективов?
Pzz>ООП и есть метод структурирования программы посредством модульности. Придуманы они могли бы быть для чего угодно, но в индустрии стали популярны стали потому, что позволяют капиталистам максимизировать прибыли при определенных условиях.
Странно, а как высказывание о повышении индивидуальных способностей противоречит прибыльности? По-моему — никак. Я тебе больше скажу. Сами по себе языки высокого уровня тоже повысили способности отдельно взятого программиста по сравнению с ассемблерами. Но что-то никому не приходит в голову называть языки высокого уровня "инструментом менеджера".
Pzz>>>Я имею ввиду, конечно, техническое руководство, а не то, чтобы у всех были исправные стулья и соблюдались сроки ГВ>>Так ты не путай одно с другим. "Техническое руководство", это такая штука, которая к "менеджменту" вообще никакого отношения не имеет, кроме лексического подобия. Pzz>Это спор о терминах.
Ну ни фига себе — спор о терминах. "Самолёт или подводная лодка — это всего лишь спор о терминах". Скажи ты про "техническое руководство" с самого начала, я бы и внимания на твой пассаж, может быть, не обратил.
Pzz>>>И много программистов с тех пор сократилось? Давайте пропустим маркетинговый буллшит. ГВ>>Нет, не пропустим. Соображение о повышении индивидуальных способностей программиста было весьма действенным фактором распространения ООП. И кстати, в некоторой части вполне подтвердилось. Естественно, что к рассуждениям о "сокращении количества" относились по большей части скептически, но если бы ООП проталкивалось под флагом вовлечения массы людей — сопротивление было бы сумасшедшим. Да ООП вообще бы из пробирки не вылезло, не смотря на все позывы индустрии.
Pzz>В свободном капиталистическом мире есть только один действенный фактор распостранения чего-бы то ни было: максимизация прибылей.
Где противоречие с:
Соображение о повышении индивидуальных способностей программиста... в некоторой части вполне подтвердилось.
?
Ты прибереги лучше банальности для других слушателей.
Pzz>Не вовлечение массы людей, а линейное увеличение их совокупной производительности по мере увеличения их количества — именно это предлагает ООП.
ГДЕ????? КОГДА???? АВТОРА!!! ШАМПАНСКОГО! Откуда ты взял этот бред?
Максимум, которого могли ожидать от распространения ООП — это некоторое замедление скорости роста потребности в программистах. Понимаешь, да? Производная и т.п. Сокращение численности — это была идеологема своего рода, этакое крайнее выражение пренебрежительности менеджеров к программистам. Потому никто на самом деле серьёзно оный тезис не воспринимал.
Больше того, IBM давно выяснила, что как ни крути, а производительность растёт пропорционально квадратному корню численности. Соответственно, линейного роста можно добиться только организационными мероприятиями. Как приятная конфетка от ООП — рост производительности отдельно взятого программиста, что позволило бы приостановить рост численности команд разработчиков. Понимаешь? А вот потом, уже очень сильно потом выросли химеры из переставленных лошадей и телег, вроде тех, о чём ты пишешь уже третий постинг кряду.
Pzz>В современных коммерческих реалиях гораздо важнее успеть быстро, чем ограничиться минимумом сотрудников. Успешная программа может приносить миллион в месяц. Лишний десяток кодеров стоит гораздо дешевле.
Тебе надо было на нобелевку номинироваться с такими высказываниями. Никогда ни один трезвомыслящий исследователь не ляпнул бы такого при вменяемых менеджерах ни одной компании. Потому что найм программистов всегда (вообще — всегда) был достаточно трудоёмким мероприятием с труднопредсказуемыми последствиями. Кроме того, кодеры-то, может быть, дешёвые, только вот управление ими ой, не дешёвое. Так что, не надо тут выдумками заниматься.
ГВ>>Ну, я уж не знаю, откуда ты извлёк мысль, что ООП предполагает "распихивание по коробочкам" до начала размышлений. По моему опыту и наблюдениям это далеко не так, а по моему убеждению это так и быть не может. Pzz>См. выше — сам же предложил перманантный сокет
А с чего ты взял, что я бы так вот и кинулся бы его реализовывать? Это ж я просто для иллюстрации предложил. Так, из серии "пальцем в небо". Можно было и что-нибудь другое ляпнуть, мы ж не о дизайне коммуникаций сейчас говорим.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Pavel Dvorkin, Вы писали:
VD>>Вопрос к головастому товарищу, много ли он на ваяет современных многоэтажных домов если ему дать один топор? VD>>Как ни одного? А тогда к чему вся эта пышная демагогия?
PD>Вопрос к другому головастому товарищу — сколько комплексов в Кижах ему удастся сделать с помощью крупнопанельных блоков ?
С начало сам на вопрос ответь, а потом свой задавай.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, WolfHound, Вы писали:
WH>Ты хоть один большой сервер вернее кластер хотябы на несколько десятков машин которые стоят в разных дататцентрах и система должна маскировать сбои не только одной машины но и целого датацентра написал? WH>Вот тебе статистика с одного из серверов такой системы: WH>
Гм, а мне расскажите, а как это у Вас так получается, что при avenrun (aka LA) > 2 такой idle? В него в данной системе считается сон над диском? Или там 16 ядер?
Отдача, что ни говори, красивая. Хотя собственно никакой особой кластерности не видно;))
WH>Короче проблемы в таких системах настолько другие что ты себе и представить не можешь.
Здравствуйте, netch80, Вы писали:
N>Гм, а мне расскажите, а как это у Вас так получается, что при avenrun (aka LA) > 2 такой idle?
Что такое LA я так и не уловил.
Уж очень мутные попугайчики.
N>В него в данной системе считается сон над диском? Или там 16 ядер?
Там 14 винтов по 700гектар каждый, а сколько ядер никогда не интересовался на этих машинах оно до лампочки.
У нас просто старое железо принципиально не закупают, а новые процессоры многоядерные...
N>Отдача, что ни говори, красивая.
Лично я предпочитаю менее красивую отдачу.
Ибо на этой красивости сисколы отвисают... хоть и не часто зато пачками.
N>Хотя собственно никакой особой кластерности не видно)
А оно должно быть видно из статистики одной машины?
В любом случае это лишь ответ на "традиционные представления об эффективности"...
... << RSDN@Home 1.2.0 alpha rev. 745>>
Пусть это будет просто:
просто, как только можно,
но не проще.
(C) А. Эйнштейн
Здравствуйте, Воронков Василий, Вы писали:
C>>Справедливости ради, у тебя система заточена на быстрый отклик. Если нужна экономичность без очень быстрого отклика, то энергетически выгоднее загрузить на 100% меньшее число серверов. ВВ>Вообще согласно всем общепринятым нормам во втором листинге у него как раз практически предельная загрузка для продакшин-серверов, что и есть ~50%.
Эти нормы для интерактивных сервисов (там и 50% может быть многовато). А если делать числодробилки — то нормы совсем уже и другие.
Здравствуйте, _FRED_, Вы писали:
_FR>Здравствуйте, netch80, Вы писали:
_FR>>>>>и факториал как пример рекурсии T>>>>Убивать за такие примеры рекурсии. _FR>>>За что? Только за то, что "навязло" в зубах? N>>За методическую некорректность. Показывание рекурсии на примере факториала, при том, что рядом он считается просто и тривиально обычным циклом
_FR>Факториал — циклом? Реально считать надо таблицей (массивом), в котором индекс элемента — входное значение, а значение в массиве — результат. Но это так, ремарка, к делу отношения не имеющая.
Вот именно что не имеющая:)) Данные-то откуда-то должны взяться? Или на "Феликсе" считать? ;))
N>>Если бы я показывал рекурсию на каком-то примере, первый пример был бы взят максимально практический, причём такой, чтобы его нельзя было в одной функции свести в цикл. А уже после этого — числа Фибоначчи, а собственно факториал — уже в качестве упражнения (если на лекции — вызвать кого-то к доске и заставить преобразовать). _FR>Например? Вот я точно знаю, что лично на меня лучше всего подействовал именно факториал, о нём и говорю.
Сочувствую. Не беспокойтесь, скоро доктор придёт и укольчик сделает:))
Свой первый пример я не помню. Что-то из преобразований списков, кажется...
_FR> Какой может быть пример? Лучше сказать "такой-то", а я только слышу "какой-то не такой, другой" и т.п. :xz: Покажите, и дискуссия исчерпает себя. но помните, что про рекрсию надо рассказвать ещё школьникам (информатика в 10-11 классе).
Дойдёт до этого — придумаем. Слава богу, есть с кем консультироваться. А что школьникам факториал не интересен — это я по себе ещё помню.
N>>И ещё одно — размахивание факториалом является косвенным указанием на то, что "рекурсия — это очень просто". Когда же выучивший такое сталкивается с реальной жизнью, когда перекладка алгоритма на рекурсивный лад в первую очередь крайне громоздка — следует шок. _FR>Это уже к вопросу отношения не имеет: просто там вообще или нет. Бывает же по-разному.
Здравствуйте, FR, Вы писали:
FR>Программа на хаскеле конечно эффективнее, в смысле производительности пишущего (и читающего) код программиста. FR>В смысле производительности работы готового она малоэффективна. Но можно оптимизировать http://en.literateprograms.org/Quicksort_(Haskell) и все равно код будет проще сишного в разы а по производительности вполне к нему приблизится.
Да уж... qsort3 из этого источника ничуть не проще хорошей сишной реализации. Наоборот, понять, что там творится, требует заметной подготовки.
А сравнение с C/C++ реализацией на чём-то вроде vector опущено сознательно?
Здравствуйте, WolfHound, Вы писали:
WH>Здравствуйте, netch80, Вы писали:
N>>Гм, а мне расскажите, а как это у Вас так получается, что при avenrun (aka LA) > 2 такой idle? WH>Что такое LA я так и не уловил. WH>Уж очень мутные попугайчики.
Среднее за энное время назад (обычно, 1, 5 и 15 минут, некоторым экспоненциально-кумулятивным механизмом) количество готовых к выполнению процессов. В зависимости от системы в это могут включаться или нет процессы, ждущие дискового ввода/вывода.
Попугай не мутный, но слишком уж усреднённый по больнице, включая морг и крематорий, за последний финансовый год.:))
N>>Отдача, что ни говори, красивая. WH>Лично я предпочитаю менее красивую отдачу. WH>Ибо на этой красивости сисколы отвисают... хоть и не часто зато пачками.
В каком смысле "отвисают"?
N>>Хотя собственно никакой особой кластерности не видно;)) WH>А оно должно быть видно из статистики одной машины?
Конечно, нет. Потому и не видно.
WH>В любом случае это лишь ответ на "традиционные представления об эффективности"...
Как по мне, он совершенно ничего не показал, отдача с видеосвалки средней паршивости может быть в разы больше и значительно дешевле.
Здравствуйте, Dog, Вы писали:
VD>>Как ни одного? А тогда к чему вся эта пышная демагогия? Dog>Шикарно. Предлогаю переименовать форум в "Демагагия программирования", как более соответствующее духу дискуссий
Батенька, вы не первый.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, WolfHound, Вы писали:
WH>Ты хоть один большой сервер вернее кластер хотябы на несколько десятков машин которые стоят в разных дататцентрах и система должна маскировать сбои не только одной машины но и целого датацентра написал?
Ну вообще-то, хвастаться надо не количеством затраченных ресурсов ("несколько десятков машин"), а достигнутым результатом — таким, как количество запросов/юзеров/не знаю чего и фотл-толерантностью.
Так вот, делал, но пиписьками с вами помериться не могу, потому что в моем случае в моих руках был и сетевой протокол, и разделение функционала между клиентом и сервером. В результате обработка одного запроса от клиента обходилась мне где-то в 3 сискола и немного вычислений, а массштабирование за счет добавления серверов было тривиально, поскольку серверам не о чем друг с другом общаться. Т.е., это совсем другой расклад, чем у вас.
Чем кончилось, я не знаю, я из той конторы ушел, когда юзеров было еще мало. Но судя по тому, что контора все еще на плаву, и никто пока не жаловался, все у них хорошо.
WH>Короче проблемы в таких системах настолько другие что ты себе и представить не можешь.
Это довольно смелое высказывание о моей способности представлять проблемы
Здравствуйте, VladD2, Вы писали:
VD>Пролог трава более крутая, но к сожалению плохо совместимая с жизнью, так как создать эффективные реализации практически невозможно, и с императивными языками не стыкуется.
Еще как стыкуется. Пролог-машинку можно использовать как "решатель", т.е. ставишь ей задачу (подаёшь данные), запускаешь, и забираешь результат. Сама по себе пролог-программа имеет глобальный контекст, поэтому для обхода этого все реализации embedded-прологов позволяют плодить независимые инстансы пролог-машин, вполне удобно и применимо.
Здравствуйте, IT, Вы писали:
IT>Здравствуйте, Pavel Dvorkin, Вы писали:
IT>Дворкин, не смеши народ своими проблемами. 200 мс Мне вот тут нужно сократить время работы одного процесса, генерирующего десятки миллионов транзакций, с шести часов хотя бы до одного.
Здравствуйте, netch80, Вы писали:
N>Задача придолбаться?) Проще, понятнее — верю. Эффективнее — сомнительно. Реально, фильтрация на списках будет занимать дохрена копирований, рекурсия может переполнить стек при кривой реализации... в общем, эффективность такого должна быть не выше (а то и ниже) эффективности пузырька, который пишется не менее просто и понятно. Или докажите обратное (желательно на практике)
Очень полезно дочитать тему перед тем как придплбливатся
Так что все мимо.
Здравствуйте, netch80, Вы писали:
N>Да уж... qsort3 из этого источника ничуть не проще хорошей сишной реализации. Наоборот, понять, что там творится, требует заметной подготовки.
Если на Си реализовать тот же алгоритм, будет сложнее.
N>А сравнение с C/C++ реализацией на чём-то вроде vector опущено сознательно?
Здравствуйте, AndrewVK, Вы писали:
AVK>Чего воду в ступе толочь? Реализуй описанный алгоритмв императивном стиле, и чтобы распараллеливался, вот мы и посмотрим.
Мне что, делать больше нечего, кроме как вычисление процентов распараллеливать ?
Здравствуйте, Геннадий Васильев, Вы писали:
ГВ>Не собираюсь оспаривать твои высказывания, но объясни мне, пожалуйста, почему тогда абсолютное большинство десктопного софта, написанного на яве работает в разы медленее, чем его аналоги на C/C++? Почему mcirosoft-овский MSDN работает быстро, а IBM-овская справка (на Java) — из рук вон медленно? Почему та же история повторяется с парочкой OpenOffice/MS Office? UML-рисовалки, это вообще мрак. Если сравнивать Eclipse и MSVC 6.0 — это попросту не смешно. Если ява с такой уверенностью "рвёт" плюсовый код?
Open Office не на Java, если что. C++. Java там так, какие-то плагины, что-ли.
Eclipse просто слишком гибкая и навороченная платформа, да и есть у Java объективные проблемы на десктопе (нет ни кеширования нативного кода, ни AOT, JIT срабатывает не сразу, автоматическая настройка GC как-то неважно работает для монстров типа Eclipse, и.т.д). Хотя 10 лет назад Java была ещё тормознее.
Здравствуйте, FR, Вы писали:
FR>Здравствуйте, geniepro, Вы писали:
G>>В смысле? Оберон вполне себе ООП-язык, только ООП там немного низкоуровневый... G>>Ну так ООПы разные бывают, друг на друга непохожие совсем...
FR>Виртовский же это первый оберон, там вроде ООП практически и нет.
Расширяемые записи есть -- вот и основа для ООП. Ну а то, что методы нужно вручную прописывать в процедурные переменные (поля этих записей) -- ну так на то он и "ассемблер ООП"...
Здравствуйте, VladD2, Вы писали:
VD>Ты пойми, люди вроде Дворкина мыслят не так. Они когда пишут код, то представляют его в уже оптимизированном виде. У него не то что списка не будет (это же непроизводительные расходы памяти!). У него и функций в коде не будет. Он просто напишет один огромный "for" в тело которого он зафигачит все свои вычисления.
Вот теперь понятно. Поскольку все это не имеет к моему стилю ни малейшего отношения, остается сделать простейший вывод. Люди вроде тебя сначала придумывают себе некий образ оппонента, причем именно такой образ, который хотелось бы видеть, а потом упорно с этим образом сражаются. С этим образом сражаться проще — он ведь специально для этой цели придуман. Ну а то, что это неэтично — не тебе же говорить об этике!
Не согласен ? Тогда, пожалуйста
1. Приведи , где и когда я говорил, что я вижу код уже в оптимизированном виде. Ссылку!
2. Приведи, где и когда я выступал против списков. Ссылку!
3. Приведи, где и когда я выступал против использования функций. Ссылку!
4. Приведи, где и когда я заявлял, что я все напишу в виде одного огромного for. Ссылку!
Жду. За свои слова надо отвечать — по крайней мере порядочные люди так себя ведут.
Здравствуйте, WFrag, Вы писали:
ГВ>>Не собираюсь оспаривать твои высказывания, но объясни мне, пожалуйста, почему тогда абсолютное большинство десктопного софта, написанного на яве работает в разы медленее, чем его аналоги на C/C++? Почему mcirosoft-овский MSDN работает быстро, а IBM-овская справка (на Java) — из рук вон медленно? Почему та же история повторяется с парочкой OpenOffice/MS Office? UML-рисовалки, это вообще мрак. Если сравнивать Eclipse и MSVC 6.0 — это попросту не смешно. Если ява с такой уверенностью "рвёт" плюсовый код?
WF>Open Office не на Java, если что. C++. Java там так, какие-то плагины, что-ли.
Да, верно. Про openoffice вопрос снимается.
WF>Eclipse просто слишком гибкая и навороченная платформа, да и есть у Java объективные проблемы на десктопе (нет ни кеширования нативного кода, ни AOT, JIT срабатывает не сразу, автоматическая настройка GC как-то неважно работает для монстров типа Eclipse, и.т.д).
Ты хочешь сказать, что это приводит к замедлению где-то на порядок?
WF>Хотя 10 лет назад Java была ещё тормознее.
Это я в курсе.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, FR, Вы писали:
FR>Здравствуйте, geniepro, Вы писали:
G>>Расширяемые записи есть -- вот и основа для ООП. Ну а то, что методы нужно вручную прописывать в процедурные переменные (поля этих записей) -- ну так на то он и "ассемблер ООП"...
FR>Ну тогда и в Си есть ООП
В этом случае понятие ООП уж слишком сильно размывается...
Здравствуйте, IT, Вы писали:
IT>Я думаю, что у тебя не хватит силёнок даже этот простенький алгоритм эффективно распаралелить. Просто даже в этом не сомневаюсь.
Вообще-то такое называется провокацией . Ладно. Будем считать, что провокация твоя удалась
Но процентами и провайдерами я все же заниматься не буду. Насколько я понимаю, AsParallel — это из .Net 4.0, так ? Во всяком случае MSDN 2008 о нем молчит. Ну вот, поискал я на Гугле и нашел вот это
Ray Tracer мне изучать недосуг, поэтому я просто распараллелил вычисление сумм красных компонент по столбцам окна. Зачем там эти суммы — а просто, чтобы было что делать . В остальном же делается именно то, о чем речь идет в этом примере — распараллеливание по кускам по ширине окна
Вот код
struct CHUNK
{
HDC hdc;
int xStart, xEnd;
int nHeight;
};
unsigned* columnSum;
unsigned __stdcall ThreadFunc(void* arg)
{
CHUNK* pChunk = (CHUNK*) arg;
int xEnd = pChunk->xEnd;
int nHeight = pChunk->nHeight;
HDC hdc = pChunk->hdc;
for (int x = pChunk->xStart; x <= xEnd; x++)
{
unsigned s = 0;
for ( int y = 0; y < nHeight; y++)
{
COLORREF cr = GetPixel(hdc, x, y); // сорри за такое безобразие, конечно
s+= GetRValue(cr);
}
columnSum[x] = s;
}
return 0;
}
///... а это где-нибудь для запуска
RECT r;
GetClientRect(hWnd, &r);
int nHeight = r.bottom - r.top;
int nWidth = r.right - r.left;
columnSum = new unsigned[nWidth];
// без распараллеливания
DWORD dwTimeStart , dwTimeEnd;
dwTimeStart = GetTickCount();
HDC hdc = GetDC(hWnd);
for ( int x = 0; x < nWidth; x++)
{
unsigned s = 0;
for(int y = 0; y < nHeight; y++)
{
COLORREF cr = GetPixel(hdc, x, y); // сорри за такое безобразие, конечно
s+= GetRValue(cr);
}
columnSum[x] = s;
}
dwTimeEnd = GetTickCount();
nTime1 = dwTimeEnd - dwTimeStart;
// а теперь распараллелим
SYSTEM_INFO si;
GetSystemInfo(&si);
unsigned nProcNumber = si.dwNumberOfProcessors;
int xChunkWidth = nWidth / nProcNumber;
CHUNK * pChunks = new CHUNK[nProcNumber];
HANDLE* hThread = new HANDLE[nProcNumber];
for ( unsigned i = 0; i < nProcNumber; i++)
{
pChunks[i].nHeight = nHeight;
pChunks[i].xStart = xChunkWidth * i;
pChunks[i].xEnd = xChunkWidth * (i + 1) - 1;
pChunks[i].hdc = hdc;
}
pChunks[si.dwNumberOfProcessors - 1].xEnd = nWidth - 1; // спишем на него остаток от деления
dwTimeStart = GetTickCount();
for ( unsigned i = 0; i < nProcNumber; i++)
hThread[i] = (HANDLE)_beginthreadex(NULL, 0, ThreadFunc,pChunks +i, 0, NULL);
WaitForMultipleObjects(nProcNumber, hThread, TRUE, INFINITE);
dwTimeEnd = GetTickCount();
nTime2 = dwTimeEnd - dwTimeStart;
for ( unsigned i = 0; i < nProcNumber; i++)
CloseHandle(hThread[i]);
delete[] pChunks;
delete[] hThread;
delete[] columnSum;
ReleaseDC(hWnd, hdc);
Вот и все. Писал минут 20. Не тестировал всерьез, так как нет времени, так что если есть ошибки — сорри. По этой же причине не сделана обработка ошибок
В релизе на моей машине (AMD Dual 4200+)
nTime1 == 2375
nTime2 = 1593
Не в 2 раза, но время уходит на инициализацию потоков. В реальной задаче я так, конечно, делать не буду — потоки (или пул) будут создаваться один раз, а потом им слаться work item или что-то в этом роде.
А теперь вопросы к тебе.
1. Напиши аналогичное со свои любимым AsParallel, только не вертикальными полосами, а прямоугольно-гнездовыми кусками. Мне, как понимаешь, это на пять минут работы — массив columnSum превратить в двумерный, а в CHUNK вместо nHeight ввести yStart, yEnd.
2. То же самое по диагоналям. Каждый тред занимается своей диагональю, параллельной главной (или побочной)
3. Сделай так, чтобы некоторые из процессоров не использовались этими потоками. Список этих процессоров дан. Мне это ничего не стоит — SetThreadAffinityMask — и все дела.
4. Сделай так, чтобы треды работали в фоне, то есть основной поток имел при этом больший приоритет — его работа для меня более важна, чем это суммирование. Иными словами, если я между
for ( unsigned i = 0; i < nProcNumber; i++)
hThread[i] = (HANDLE)_beginthreadex(NULL, 0, ThreadFunc,pChunks +i, 0, NULL);
и
WaitForMultipleObjects(nProcNumber, hThread, TRUE, INFINITE);
помещу еще некоторый код — должен исполняться он, а не поток — если процессоров не хватает.
5. Ну и напоследок. Сделай так, чтобы эти треды информировали периодически некий третий поток о том, как у них прогресс идет. Для меня тут, конечно, минут на 10 работы — еще один поток надо сделать, причем с петлей сообщений а потом просто PostThreadMessage когда надо.
А пока что мне пора к делу вернуться. Там мне распараллеливание если и поможет, то только при десятке процессоров, а их нет
Здравствуйте, Sinclair, Вы писали:
S>Вот в этом месте не понял. Недавно набрел на linq-проект, который прозрачным образом использует индексы на In-memory коллекциях. Вот он, небанальный перебор за счет декларативности программирования. Может, другой пример подберем?
Зачем другой пример? Ты, наверное, меня не до конца понял — я не отрицаю, что можно сделать по-другому. Причем для этого не нужен ни LINQ, ни прочие навороты последних ревизий си-шарпа. Собственно, первое что приходит в голову:
class Item
{
Item Next;
}
Уже модель работы с коллекцией изменяется — не будем рассматривать, в какую сторону
Речь-то не о том, как можно сделать, а как обычно делается. Ведь неужели корень зла в том, что в методах пару if-ов используется, и программа партии состоит в том, чтобы заменить эти if-ы на синтаксически что-нибудь другое? Проблема в том, что логика приложений фактически целиком строится на старых приемах и конструкциях, которым уже лет сто в обед. А почему так происходит?
Трактовка 1. "Внешняя" сторона, за которую отвечает ООП, все эти графы, полиморфизмы и прочая вроде как прогрессировала со времен царя гороха, а "внутреняя" нет. Так да здравствует же язык, который предоставляет средства, позволяющие, так сказать, поднять технологический уровень того, что в методах происходит.
Трактовка 2. Да, конечно, императивные конструкции стары. Но все старо в этом мире. Да и сам ООП в общем-то не молодчик. Проблема не в том, что мы в принципе используем эти конструкции, а в том что мы ими злоупотребляем. А почему злоупотребляем? Что мы делаем в этих методах? Пишем хитрые полностью изолированные от всего мира алгоритмы? Фига два. Мы используем "все эти графы, полиморфизмы и прочая". Никаких подозрений не возникает? Так где же у нас root of evil в таком случае?
Собственно, твой пример даже косвенно подтверждает то, о чем я писал.
ЗЫ. Аналогии по просьбе трудящихся не использовал.
Здравствуйте, Геннадий Васильев, Вы писали:
ГВ>Не собираюсь оспаривать твои высказывания, но объясни мне, пожалуйста, почему тогда абсолютное большинство десктопного софта, написанного на яве работает в разы медленее, чем его аналоги на C/C++? Почему mcirosoft-овский MSDN работает быстро, а IBM-овская справка (на Java) — из рук вон медленно?
IBMовская справка — она не на Java, а на HTML. Там локально запускается web-сервер по которому ходит браузер. Так что все претензии к браузеру на С++.
ГВ>Почему та же история повторяется с парочкой OpenOffice/MS Office?
Скажи, а где в OpenOffice используется Java?
ГВ>UML-рисовалки, это вообще мрак. Если сравнивать Eclipse и MSVC 6.0 — это попросту не смешно. Если ява с такой уверенностью "рвёт" плюсовый код?
Странно, а мы на GEF на Eclipse переписывали тормозючий проект с С++.
Здравствуйте, Cyberax, Вы писали:
C>IBMовская справка — она не на Java, а на HTML. Там локально запускается web-сервер по которому ходит браузер. Так что все претензии к браузеру на С++.
Эээ... Может, я немного не в тему. Видел я эту справку. Какой смысл запускать локальный веб-сервер для HTML?
Здравствуйте, Воронков Василий, Вы писали:
C>>IBMовская справка — она не на Java, а на HTML. Там локально запускается web-сервер по которому ходит браузер. Так что все претензии к браузеру на С++. ВВ>Эээ... Может, я немного не в тему. Видел я эту справку. Какой смысл запускать локальный веб-сервер для HTML?
Там не только статический HTML. Там ещё есть и активный полнотекстовый поиск (который, кстати, работает лучше чем убогий MSDNовский).
Здравствуйте, Pzz, Вы писали:
Pzz>Здравствуйте, Sinclair, Вы писали:
S>>Сосал почтовый сервер, весь из себя написанный на плюсах и работавший поверх файлухи. (а то! ведь СУБД — это тормоза, они не дают прямого управления IO).
Pzz>CommuniGate, что ли? Его автор одно время сюда заходил, и расставлял пальцы до плеч. Или не сюда, а в ФИДО?..
S>>У меня с реакцией на ассемблер всё в порядке. У меня невротическая реакция как раз на "теоретический предел эффективности", который устроен вовсе не так, как думает Павел. Но объяснить ему это нереально: шаблоны слишком прочны.
Pzz>Вы пытаетесь доказать удивительные вещи: что программа, между которой и железом несколько слоев абстракции, может работать быстрее, чем программа, которая работает прямо на железе.
нет, он говорит, что VM, в каждую следующую секунжу может нагенерить новый асм, которые будет оптимальнее предыдущего исходя из текущей ситуации. Т.е. VM может покрыть кучу случаев, изменяя машинный код налету, потимизируя, подстраиваясь под платформу, под погоду и настроение юзера. Как rdbms оптимайзят запросы, кароче.
Pzz>А почему бы эти слои абстракции не запустить поверх себя, и так далее до бесконечности, каждый раз увеличивая производительность
Pzz>Если ослабить ваше утверждение до "плохо написанная программа на ассемблере может работать медленнее, чем хорошо написанная программа на C#", с таким утверждением несложно согласиться. Но только оно тривиально и верно для любой пары языков.
Здравствуйте, Cyberax, Вы писали:
C>Там не только статический HTML. Там ещё есть и активный полнотекстовый поиск (который, кстати, работает лучше чем убогий MSDNовский).
Я спросил, зачем веб-сервер нужен Зачем веб-сервер для полнотекстового поиска?
Здравствуйте, Cyberax, Вы писали:
C>Вот что значат тормозные FS в Винде...
А, ну да, конечно. А сиквел сервер, значит, не поверх них работает, а божьей милостью впятеро быстрее шарашит.
Дело не в FS, а в правильности подхода. Смею полагать, что мы с тем же успехом могли бы поднять тот сервер и поверх Оракла на линухе, и всё равно джава порвала бы нативную реализацию поверх файлухи.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Pzz, Вы писали:
Pzz>CommuniGate, что ли? Его автор одно время сюда заходил, и расставлял пальцы до плеч. Или не сюда, а в ФИДО?..
Я, честно говоря, за восемь лет уже забыл, как назывался сервер, проработавший у нас два месяца.
Pzz>Вы пытаетесь доказать удивительные вещи: что программа, между которой и железом несколько слоев абстракции, может работать быстрее, чем программа, которая работает прямо на железе.
Совершенно верно, пытаюсь. Нужно просто понять, что "слои абстракции" не "между", а рядом. Я надеюсь, ты в курсе, что сам MSIL код никто не исполняет — он превращается в самый что ни на есть нативный, и исполняется "прямо на железе"?
Pzz>А почему бы эти слои абстракции не запустить поверх себя, и так далее до бесконечности, каждый раз увеличивая производительность
Есть старая байка про то, как оптимизирующий компилятор С++ скомпилировали на себе же. И получили 30% performance gain.
Я надеюсь, понятно, что еще один прогон не дал бы еще 30%?
Pzz>Если ослабить ваше утверждение до "плохо написанная программа на ассемблере может работать медленнее, чем хорошо написанная программа на C#", с таким утверждением несложно согласиться. Но только оно тривиально и верно для любой пары языков.
Это совсем другое утверждение, чем делал я.
Я защищаю примерно такое утверждение: "оптимизация декларативной программы дает больший выигрыш, чем императивной. И выигрыш тем больше, чем ниже уровень императивной программы". В частности, ассемблер улучшить почти что никак не удастся. Байки про "хорошо написанную программу на ассемблере" рассказывайте кому-нибудь другому.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
PD>>Мне что, делать больше нечего, кроме как вычисление процентов распараллеливать ?
AVK>Понятно. Тогда получается, что все твои утверждения получается рассматривать только как пустой звук.
Здравствуйте, FR, Вы писали:
FR>Здравствуйте, netch80, Вы писали:
N>>Да уж... qsort3 из этого источника ничуть не проще хорошей сишной реализации. Наоборот, понять, что там творится, требует заметной подготовки. FR>Если на Си реализовать тот же алгоритм, будет сложнее.
Держу перед глазами сишный код. По-моему, он проще.
N>>А сравнение с C/C++ реализацией на чём-то вроде vector опущено сознательно? FR>Так давай сравнивай никто ни мешает.
Не-а, это ведь ты агитируешь:) так покажи реально полезное сравнение, а не между хаскелем и хаскелем.
Здравствуйте, IT, Вы писали:
IT>В 20 и больше я знаю как. Только мне для этого не достаточно будет покататься в маршрутке.
А я в своей задаче не знаю. И не уверен, что этот способ существует вообще. Более того, практически уверен, что он не существует. Так что покамесь буду оптимизировать то, что есть, потом посмотрим, что из этого получилось, а потом... потом видно будет. . Распараллеливать придется, однако. Только не с помощью AsParallel .
S>Ну прикол-то в том, что если программа сформулирована в терминах mov, add, jmp и т.д, то простор для ее оптимизации крайне мал.
Ты когда-нибудь видел задачу, которая могла бы быть сформулирована в терминах mov, add, jmp и т.д ? Я таких задач в предметной области не встречал, разумееется, драйверы и прочие средства доступа к железу не в счет.
На тебе банальную задачу умножения матриц и сформулируй ее в терминах mov, add, jmp и т.д. Подчеркиваю, сформулируй, а не напиши програму. А мы посмотрим, что из этого вышло
>Да, процессоры сейчас выжимают максимум из этого
Из чего они выжимают, ты что говоришь-то ? Из себя, что ли ? Или из своих собственных команд add. mov и т.д. ? Вот сижу и вижу — процессор пытается из самого себя выжать максимум. Меня это даже пугает немного — а вдруг чего-то выжмет
> но у них есть существенные ограничения как по ресурсам, которые можно на это потратить, так и по возможным действиям, которые они могут выполнить.
Это у процессоров ограничения по действиям, которые они могут выполнить ? Ну , кажется, приехали. У процессоров , значит, ограничения, а вот если на этих процессорах исполнять управляемый код со всеми наворотами, то эти ограничения куда-то исчезают и открываются у процессоров дополнительные возможности, так , что ли ? Ну и ну!
S>А вот если задача сформулирована декларативно, то как раз можно и алгоритм поменять, и доступ к данным ускорить, и распараллелить и всё что угодно.
Можно. Алгоритм всегда поменять можно, было бы на что менять. И доступ тоже поменять можно. И распараллелить. Поверь, все это вполне можно и без всяких управляемых сред. Это еще лет 20 назад умели и даже раньше.
S>Более того, во многих задачах невозможно заранее предложить оптимальное решение в терминах mov, add, jmp и т.д.
И неоптимальное тоже — см. выше, потому что так никто задачи не формулирует. И зря ты пытаешься доказать, что я это утверждаю. Я лишь одно утверждал — есть некий теоретический предел, им является идеально написанная программа на ассемблере. На любом языке с любыми средствами лучше сделать нельзя. При этом я вовсе не утверждаю, что знаю, как такую программу написать. Это лишь теорема о существовании. Но теорема верная. И из нее вовсе не следует, что программы надо писать на ассемблере.
>Просто потому, что еще нет информации о том, в каких условиях будет алгоритм выполняться.
Если он на нетипичном процессоре или на иной архитектуре может выполняться — я со скрипом, но соглашусь. Потому что не знаю. что там хорошо, а что плохо. (В скобках : если буду знать — не соглашусь) Если же речь идет об обычной архитектуре, то не соглашусь. Windows NT-Vista, как тебе известно должно быть, написана так, что кроме HAL, все остальное от архитектуры не зависит. И работает она на x86, x64, а до этого были Alpha, MIPS, Power PC.
>Потому, что, к примеру, параллелить на 1 ядре — это гарантированная потеря производительности.
Грандиозная мысль! Я бы сам никак не догадался . Но , к твоему сведению, узнать число процессоров через Win32 совсем не сложно. См. мой ответ IT с примером программы.
>И непараллелить при 4 ядрах — тоже гарантированная потеря.
А вот до этого я не догадался. Я как-то до сих пор считал, что параллелить можно либо распараллеливаемые алгоритмы, либо массовые операции. А ты, похоже, дай тебе 4 ядра — возьмешься параллелить все, что угодно. Успехов
>А никакого способа автоматически трансформировать mov/add/jmp так, чтобы они были оптимальны для 1/2/4 ядер наука не знает. Зато знает способы делать это в том случае, если программа написана в декларативном стиле.
Посмотри мой пример. Там хоть и не mov и не add (опять борьба с ветряными мельницами), но вполне-таки распараллелено, и без всякого декларативного стиля. Без LINQ. Без интерфейсов. И даже (о ужас!) без классов. Кошмар просто
Здравствуйте, Воронков Василий, Вы писали:
C>>Там не только статический HTML. Там ещё есть и активный полнотекстовый поиск (который, кстати, работает лучше чем убогий MSDNовский). ВВ>Я спросил, зачем веб-сервер нужен Зачем веб-сервер для полнотекстового поиска?
А так проще всего. Предлагай другие варианты.
Здравствуйте, netch80, Вы писали:
N>Держу перед глазами сишный код. По-моему, он проще.
На си совсем другой алгоритм, несовпадающий кстати и с первым вариантом на хаскеле
N>>>А сравнение с C/C++ реализацией на чём-то вроде vector опущено сознательно? FR>>Так давай сравнивай никто ни мешает.
N>Не-а, это ведь ты агитируешь так покажи реально полезное сравнение, а не между хаскелем и хаскелем.
Я не агитирую, тем более за хаскель. Это тебе показалось что нужно сравнить еще и c C++,
пожалуйста я не мешаю. Хотя могу показать вариант на близком к C++ D
T[] qsort(T)(T[] t)
{
if(t.length == 0)
return [];
auto x = t[0];
auto xs = t[1 .. $];
return qsort(filter!((T a){return a < x;})(xs))
~ [x] ~
qsort(filter!((T a){return a >= x;})(xs));
}
Из которого видно что хаскелю он по выразительности уступает, на C++, будет еще чуть хуже.
Здравствуйте, Sinclair, Вы писали:
C>>Вот что значат тормозные FS в Винде... S>А, ну да, конечно. А сиквел сервер, значит, не поверх них работает, а божьей милостью впятеро быстрее шарашит.
А он работает с файлами на блоковом уровне, обходя почти все механизмы FS.
S>Дело не в FS, а в правильности подхода. Смею полагать, что мы с тем же успехом могли бы поднять тот сервер и поверх Оракла на линухе, и всё равно джава порвала бы нативную реализацию поверх файлухи.
У меня вот прямо сейчас есть хранилище документов на Линуксе, которое пользователи мучают в особо извращённой форме. После перехода с блобов в базе данных на хранилище в файловой система производительность поднялась в 4 раза. После того, как для отдачи этих файлов я подключил lighttppd — производительность поднялась во столько раз, что даже мерить лень.
Про сравнение производительности виндовых FS и линуксовых я тут как-то уже писал. Разница легко может быть в десятки раз, так что ничего удивительного.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Тогда и к тебе те же вопросы, что я задал IT в
Сначала я подожду, когда ты приведешь то, что тебя просили. Это во-первых. А во-вторых, как напишешь императивный аналог алгоритма, что IT описал, ты сделаешь точно такое же как у IT описание своего собственного алгоритма, который ты хочешь увидеть в функциональной форме.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, netch80, Вы писали:
N>В каком смысле "отвисают"?
В таком. Какойнибудь паршивый stat может думать десятки секунд.
N>Как по мне, он совершенно ничего не показал, отдача с видеосвалки средней паршивости может быть в разы больше и значительно дешевле.
Приверженци традиционных понятий считают что CPU в таких системах что-то решает... я показал что это не так.
... << RSDN@Home 1.2.0 alpha rev. 745>>
Пусть это будет просто:
просто, как только можно,
но не проще.
(C) А. Эйнштейн
Здравствуйте, Pzz, Вы писали:
Pzz>Ну вообще-то, хвастаться надо не количеством затраченных ресурсов ("несколько десятков машин"), а достигнутым результатом — таким, как количество запросов/юзеров/не знаю чего и фотл-толерантностью.
Юзверей очень не мало. И с фолттолерантностью тоже все в порядке. Вон недавно один из датацентров отключали. Моя подсистема это сразу просекла и все от пользователей спрятала.
Pzz>Так вот, делал, но пиписьками с вами помериться не могу, потому что в моем случае в моих руках был и сетевой протокол, и разделение функционала между клиентом и сервером. В результате обработка одного запроса от клиента обходилась мне где-то в 3 сискола и немного вычислений, а массштабирование за счет добавления серверов было тривиально, поскольку серверам не о чем друг с другом общаться. Т.е., это совсем другой расклад, чем у вас.
У меня тоже есть некоторое колличество одноранговых машин которые масштабируются также.
Вот только это настолько просто что даже не интересно.
Да и колличество сисколов я вобще ни разу не считал. Тем более что сискол сисколу рознь. Меня гораздо больше волнуют совсем другие вещи.
Pzz>Это довольно смелое высказывание о моей способности представлять проблемы
Ну пока что ты продемонстрировал полное не понимание больших серверов.
... << RSDN@Home 1.2.0 alpha rev. 745>>
Пусть это будет просто:
просто, как только можно,
но не проще.
(C) А. Эйнштейн
Здравствуйте, Cyberax, Вы писали:
C>Эти нормы для интерактивных сервисов (там и 50% может быть многовато). А если делать числодробилки — то нормы совсем уже и другие.
Это интерактивная числодробилка.
... << RSDN@Home 1.2.0 alpha rev. 745>>
Пусть это будет просто:
просто, как только можно,
но не проще.
(C) А. Эйнштейн
Здравствуйте, Sinclair, Вы писали:
S>Я защищаю примерно такое утверждение: "оптимизация декларативной программы дает больший выигрыш, чем императивной. И выигрыш тем больше, чем ниже уровень императивной программы". В частности, ассемблер улучшить почти что никак не удастся. Байки про "хорошо написанную программу на ассемблере" рассказывайте кому-нибудь другому.
Это очень неоднозначное утверждение. Можно ли, например, понимать его так: "разница в эффективности скомпилированного кода при включенной и выключенной оптимизации гораздо заметнее у декларативной программы, чем императивной. И она тем больше, чем ниже уровень императивной программы. В частности, для программ, написаных на ассемблере, эта разница практически не заметна"?
Здравствуйте, WolfHound, Вы писали:
Pzz>>Это довольно смелое высказывание о моей способности представлять проблемы WH>Ну пока что ты продемонстрировал полное не понимание больших серверов.
Я вообще не понимаю этот дискурс, "у нас тут над задачей крутится мега-кластер из миллиона серверов".
Без понимания того, какую задачу они решают, это утверждение вообще ни о чем. С пониманием, оно может значить все что угодно в диапазоне "молодцы, что вообще решили такую задачу" и до "нашли чем гордиться — с какой задачей настольный калькулятор бы справился".
Здравствуйте, Воронков Василий, Вы писали:
C>>А так проще всего. Предлагай другие варианты. ВВ>Эээ... встраиваемая СУБД с full-text search? ВВ>Я вот, например, янусом пользуюсь — full-text search есть, веб-сервера нет.
А теперь повтори, пожалуйста, Янус на следующих ОС:
1) Linux.
2) Solaris.
3) AIX.
4) QNX.
5) *BSD.
6) Vax VMS.
ВВ>Ты мне объясни — я правда не понимаю — какое отношение вообще веб-сервер имеет к full-text search?
Как ты из браузера планируешь его делать без спецплугинов или без внешней программы?
Здравствуйте, WolfHound, Вы писали:
C>>Эти нормы для интерактивных сервисов (там и 50% может быть многовато). А если делать числодробилки — то нормы совсем уже и другие. WH>Это интерактивная числодробилка.
Ну так я не спорю
На интерактивных серверах часто неплохо иметь запас в 2-3 раза.
Здравствуйте, Pzz, Вы писали:
Pzz>Вплоть до использования своей собственной партиции, на которой нет никакой файловой системы.
Это официально не рекомендуемая экзотика, так что ""взрослые" SQL-сервера" как раз стараются работать поверх FS.
Pzz>Это как раз пример, опровергающий вашу точку зрения.
Именно что подтверждающий. Уровень абстракции сиквела гораздо выше абстракции файловой системы, при этом сиквел сработал поверх той же файловой системы эффективнее. Что, собственно, и требовалось доказать.
Pzz>Т.е., SQL-сервер работает с диском быстрее именно благодаря тому, что он работает с ним на более низком уровне.
Так что мешает самому работать на этом уровне? API-то файловой системы открытое, бери да пиши. Зачем привлекать немерянную абстракцию в виде сиквела, когда FS под рукой и ты точно знаешь, лучше всякого сиквела, что именно тебе нужно?
Pzz> Такая конструкция значительно проще и прозрачнее, и если в ней что-то сломается, проще починить,
Чем проще? Бакапов нет, поддержки согласованности нет, транзакций нет. Поэтому, во-первых, выше вероятносто того, что что-то сломается, а во-вторых, меньше шансов все корректно восстановить. В БД хотя бы средства автоматизированные есть.
Здравствуйте, Cyberax, Вы писали:
C>>>А так проще всего. Предлагай другие варианты. ВВ>>Эээ... встраиваемая СУБД с full-text search? ВВ>>Я вот, например, янусом пользуюсь — full-text search есть, веб-сервера нет. C>А теперь повтори, пожалуйста, Янус на следующих ОС: C>1) Linux. C>2) Solaris. C>3) AIX. C>4) QNX. C>5) *BSD. C>6) Vax VMS.
Во-первых, поправлюсь: встраиваемая БД
Во-вторых, "неповторимость" януса ведь не из-за этого происходит.
А так — берем например очень легкий и кроссплатформенный движок sqlite (http://sqlite.org), поддерживающий full-text search и выпускаемый под лицензией public domain... Продолжать?
ВВ>>Ты мне объясни — я правда не понимаю — какое отношение вообще веб-сервер имеет к full-text search? C>Как ты из браузера планируешь его делать без спецплугинов или без внешней программы?
В эклипсе я справу запускал из самого эклипса — т.е. "внешняя" среда была. Да и справка сама по себе ведь не в мазиле какой-нибудь открывалась — т.е. была среда, которая автоматизировала браузер и пр.
На вопрос (см. выделенное) ты мне так и не ответил
Здравствуйте, IB, Вы писали:
Pzz>>Вплоть до использования своей собственной партиции, на которой нет никакой файловой системы. IB>Это официально не рекомендуемая экзотика, так что ""взрослые" SQL-сервера" как раз стараются работать поверх FS.
Если не ошибаюсь, именно Оракл протолкал поддержку "сырых" дисков в linux 2.6 (в 2.4 их не было). Вероятно, ребята из Оракла забыли почитать официальные рекомендации
Pzz>>Это как раз пример, опровергающий вашу точку зрения. IB>Именно что подтверждающий. Уровень абстракции сиквела гораздо выше абстракции файловой системы, при этом сиквел сработал поверх той же файловой системы эффективнее. Что, собственно, и требовалось доказать.
А вы посмотрите на это не с точки зрения пользователя SQL-сервера, а с точки зрения его разработчика.
Казалось бы, ну зачем возиться со всем этим низкоуровневым доступом к диску, когда есть файловая система, которая все замечательно оптимизирует, да еще и автоматически. Ан нет, возятся. Наверное потому, что RSDN не читают
Pzz>>Т.е., SQL-сервер работает с диском быстрее именно благодаря тому, что он работает с ним на более низком уровне. IB>Так что мешает самому работать на этом уровне? API-то файловой системы открытое, бери да пиши. Зачем привлекать немерянную абстракцию в виде сиквела, когда FS под рукой и ты точно знаешь, лучше всякого сиквела, что именно тебе нужно?
SQL ващето это не только драйвер диска, но еще и реляционная алгебра.
Pzz>> Такая конструкция значительно проще и прозрачнее, и если в ней что-то сломается, проще починить, IB>Чем проще? Бакапов нет, поддержки согласованности нет, транзакций нет. Поэтому, во-первых, выше вероятносто того, что что-то сломается, а во-вторых, меньше шансов все корректно восстановить. В БД хотя бы средства автоматизированные есть.
Проще тем, что вот они письма, лежат на диске, каждое письмо в своем файле.
Здравствуйте, WFrag, Вы писали:
WF>Думаю, им так проще было. Они этот же хелп через веб выставляют. Ничего менять не надо. WF>В последнем Eclipse хотя бы заменили Tomcat на нечто более легковесное.
Мне собственно интересен механизм реализации этого дела. У них что, получается устанавливается веб-сервер, на котором крутится — ну скажем JSP — который обрабатывает запросы и сам же, опять-таки возможно через некую легкую БД, осуществляет полнотекстовый поиск? Я это правильно понял или там все хитрее?
Если это так, то все равно ведь индексацию делает движок БД. Ну если даже там и не БД, а самописное что-то — то некие процедуры на Джава. Т.е. на десктопе получается, что приложение на джава использует веб-сервер, чтобы вызвать код на джава И это для того, чтобы упростить выставление хелпа на вебе. И в это в супер-пупер масштабируемом эклипсе, по архитектуре которого целые диссертации написаны.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Вот теперь понятно. Поскольку все это не имеет к моему стилю ни малейшего отношения, остается сделать простейший вывод. Люди вроде тебя сначала придумывают себе некий образ оппонента, причем именно такой образ, который хотелось бы видеть, а потом упорно с этим образом сражаются. С этим образом сражаться проще — он ведь специально для этой цели придуман. Ну а то, что это неэтично — не тебе же говорить об этике!
Зачем мне что-то выдумывать?
PD>Не согласен ? Тогда, пожалуйста
PD>1. Приведи , где и когда я говорил, что я вижу код уже в оптимизированном виде. Ссылку! PD>2. Приведи, где и когда я выступал против списков. Ссылку! PD>3. Приведи, где и когда я выступал против использования функций. Ссылку! PD>4. Приведи, где и когда я заявлял, что я все напишу в виде одного огромного for. Ссылку!
Мне прийдется приводить все твои сообщения в которых речь идет об оптимизации. Собственно все твои рассуждения даже в этой ветке (вообще не имеющей отношения к оптимальности или оптимизациям) снова свелись к оптимизации. О чем еще можно говорить то?
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Воронков Василий, Вы писали:
C>>Но какой-нибудь браузер в том или ином виде есть везде. ВВ>На "каком-нибудь" браузере.
И как ты в него интегрируешь твою встроенную БД? Писать по отдельной интеграции на каждый браузер?
Missing features
The full-text module is still in an early development phase. The following features are missing but hopefully coming soon:
* We plan to support prefix queries (e.g. "foo*").
* Applications will be able to specify custom tokenizers.
И это в 2006 году, неудивительно, что я про него слышал. Eclipse был зарелизен в 2001-м году.
Здравствуйте, Cyberax, Вы писали:
C>И как ты в него интегрируешь твою встроенную БД? Писать по отдельной интеграции на каждый браузер? C>Да, и ради чего?
Браузер — это рисовалка. Точка. Все остальное — БД с full-text search и код на джава, который подгатавливает (генерирует) HTML страницы, подсвечивает в них "маркером" найденные слова и проч.
ВВ>>SQLite поддерживает полнотекстовый поиск: ВВ>>http://www.sqlite.org/cvstrac/wiki?p=FullTextIndex C>
C>Missing features
C>The full-text module is still in an early development phase. The following features are missing but hopefully coming soon:
C> * We plan to support prefix queries (e.g. "foo*").
C> * Applications will be able to specify custom tokenizers.
C>И это в 2006 году, неудивительно, что я про него слышал. Eclipse был зарелизен в 2001-м году.
Здравствуйте, Cyberax, Вы писали:
C>А чем ты собираешься на этом зоопарке ОС просматривать помощь? У них даже нет общего оконного тулкита и браузера!
Ты еще про Эклипс? В SWT ж вроде есть совсем простенький рендерер Html. Возможностей минимум, но для хелпа вполне достаточно.
C>Но какой-нибудь браузер в том или ином виде есть везде.
А хинты эклипс тоже через какой нибудь браузер показывает?
C>Для справки: полнотекстовый поиск это не линейный поиск по SQL LIKE, а поиск по специальному индексу. Таких систем не так уж много, кстати. Из качественных свободных, пожалуй, только Lucene и остаётся.
Янус ее и использует. Точнее ее порт на дотнет, кажется от Beagle.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Браузер — это рисовалка. Точка. Все остальное — БД с full-text search и код на джава, который подгатавливает (генерирует) HTML страницы, подсвечивает в них "маркером" найденные слова и проч.
КАК ты подключишь браузер к БД?
Самый простой способ — это запустить локальный сервер и законнектиться к нему. Что Eclipse и делает.
Естественно, там браузер используется как тупая рисовалка. Тормозит, в основном, крутое дерево категорий на JavaScript'е.
Здравствуйте, AndrewVK, Вы писали:
C>>А чем ты собираешься на этом зоопарке ОС просматривать помощь? У них даже нет общего оконного тулкита и браузера! AVK>Ты еще про Эклипс? В SWT ж вроде есть совсем простенький рендерер Html. Возможностей минимум, но для хелпа вполне достаточно.
В SWT есть Browser Control, требующий нативный браузер. Причём он портирован на Mac OS X/Linux был только в прошлом году.
C>>Но какой-нибудь браузер в том или ином виде есть везде. AVK>А хинты эклипс тоже через какой нибудь браузер показывает?
Нет, так как там очень ограниченный набор тэгов используется. Я посмотрел — оно там специальным рендерером рисует.
C>>Для справки: полнотекстовый поиск это не линейный поиск по SQL LIKE, а поиск по специальному индексу. Таких систем не так уж много, кстати. Из качественных свободных, пожалуй, только Lucene и остаётся. AVK>Янус ее и использует. Точнее ее порт на дотнет, кажется от Beagle.
Я это знаю.
Здравствуйте, Sinclair, Вы писали:
ГВ>>Не собираюсь оспаривать твои высказывания, но объясни мне, пожалуйста, почему тогда абсолютное большинство десктопного софта, написанного на яве работает в разы медленее, чем его аналоги на C/C++? S>Вкратце: потому, что десктопный софт работает совершенно по-другому, чем серверный. S>Более длинно: S>1. в серверном коде важнее не responsiveness, а throughput.
О! Спасибо. На этом, в принципе, можно и остановиться. Теперь всё ясно.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Cyberax, Вы писали:
C>КАК ты подключишь браузер к БД?
На фига мне "подключать" браузер к БД? Что вообще значит "подключить" браузер к БД? У меня десктоп-приложение, браузер — не более чем контрол для отображения данных. Его использования в данном случае аналогично какому-нибудь текст-боксу. SetText или там SetHtml и все. Работает с базой код на джава.
C>Самый простой способ — это запустить локальный сервер и законнектиться к нему. Что Eclipse и делает. C>Естественно, там браузер используется как тупая рисовалка. Тормозит, в основном, крутое дерево категорий на JavaScript'е. C>Что ты ещё предлагаешь улучшить и как именно?
Хочется уже перейти на нецензурный язык Я ничего не предлагаю улучшить. Я просил, зачем нужен веб-сервер. Мне ответили. Все.
Причем употребимость веб-сервера здесь оправдывается только тем, что это позволяет, грубо говоря, одну и ту же справку пихать и в веб, и в десктоп. В остальных случаях — это маразм.
Здравствуйте, Cyberax, Вы писали:
C>В SWT есть Browser Control, требующий нативный браузер. Причём он портирован на Mac OS X/Linux был только в прошлом году.
Я не про него. Там был обычный вьювер с поддержкой несложного форматирования, не браузер.
AVK>>А хинты эклипс тоже через какой нибудь браузер показывает? C>Нет, так как там очень ограниченный набор тэгов используется.
А нафига в хелпе неограниченный?
C> Я посмотрел — оно там специальным рендерером рисует.
Ну и кто мешал это рендерер использовать и для отображения хелпа?
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, AndrewVK, Вы писали:
C>>В SWT есть Browser Control, требующий нативный браузер. Причём он портирован на Mac OS X/Linux был только в прошлом году. AVK>Я не про него. Там был обычный вьювер с поддержкой несложного форматирования, не браузер.
Может ты со SWING'ом путаешь? В SWING'е, действительно, есть очень тупой нативный рендерер. Не помню я, чтоб в SWT было что-то похожее.
C>>Нет, так как там очень ограниченный набор тэгов используется. AVK>А нафига в хелпе неограниченный?
Всё же хочется побольше того, что есть в JavaDoc.
C>> Я посмотрел — оно там специальным рендерером рисует. AVK>Ну и кто мешал это рендерер использовать и для отображения хелпа?
Тупой уж слишком.
Здравствуйте, Cyberax, Вы писали:
ГВ>>Не собираюсь оспаривать твои высказывания, но объясни мне, пожалуйста, почему тогда абсолютное большинство десктопного софта, написанного на яве работает в разы медленее, чем его аналоги на C/C++? Почему mcirosoft-овский MSDN работает быстро, а IBM-овская справка (на Java) — из рук вон медленно? C>IBMовская справка — она не на Java, а на HTML. Там локально запускается web-сервер по которому ходит браузер. Так что все претензии к браузеру на С++.
ГВ>>Почему та же история повторяется с парочкой OpenOffice/MS Office? C>Скажи, а где в OpenOffice используется Java?
Меня уже поправили. Внимательней нужно было смотреть, ай-яй-яй мне.
ГВ>>UML-рисовалки, это вообще мрак. Если сравнивать Eclipse и MSVC 6.0 — это попросту не смешно. Если ява с такой уверенностью "рвёт" плюсовый код? C>Странно, а мы на GEF на Eclipse переписывали тормозючий проект с С++.
Может быть. Я только засвидетельствовал то, что видел неоднократно "своими собственными глазами". Я вполне допускаю, что много чего другого я не видел и где-то, получается, утрирую.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
AndrewVK,
LCR>>А вот про матричную алгебру — это пожалуйста:
AVK>Вот из-за таких примеров народ и бегает от ФП, как черт от ладана. Классика, блин — специфичные математические задачи, однобуквенные переменные.
Не понял. Ты предлагаешь локальные бинды обзывать my_favourite_name. Или что? Если так, то это контрпродуктивно.
Или сказывается просто отсутствие комментариев, которые я намеренно убрал, чтобы сообщение не получилось чересчур длинным, поскольку цель сообщения была дать представление о том, как может выглядеть другой способ решения. Реально нужно просто добавить удалённые комментарии
one_ket_triangle :: (Scalar a, Fractional a) => [[a]] -> [a] -> [([a],a)]
one_ket_triangle a b
--
-- Список пар (p, q) представляет собой
-- строки треугольной матрицы P и вектора-столбца q
-- в уравнении P x = q, которое было
-- получено через линейное преобразование
-- оригинального уравнения A x = b
--
| null a = []
| otherwise = (p,q):(one_ket_triangle a' b')
where
p = [bra_ket u ak | ak <- a]
q = bra_ket u b
a' = [[bra_ket ck ai | ck <- orth] | ai <- v]
b' = [ bra_ket ck b | ck <- orth]
orth = orthogonals u
u = head a
v = tail a
IT,
IT>Ты не понимаешь. Быстро может работать только написанное на ассемблере или его высокоуровневых аналогах вроде C. У тебя же только GC будет отрабатывать столько, сколько нормально написанная программа на ассемблере будет работать всего.
Здравствуйте, Воронков Василий, Вы писали:
C>>КАК ты подключишь браузер к БД? ВВ>На фига мне "подключать" браузер к БД? Что вообще значит "подключить" браузер к БД? У меня десктоп-приложение, браузер — не более чем контрол для отображения данных. Его использования в данном случае аналогично какому-нибудь текст-боксу. SetText или там SetHtml и все. Работает с базой код на джава.
Вот такого контрола в Eclipse для всех платформ не было до прошлого года. Так как не везде браузер можно было так встроить — в итоге на том же Mac OS X они для контрола стали использовать встроенный Mozilla, а не местный Safari.
ВВ>Причем употребимость веб-сервера здесь оправдывается только тем, что это позволяет, грубо говоря, одну и ту же справку пихать и в веб, и в десктоп. В остальных случаях — это маразм.
Это одна из причин. Но не единственная.
Здравствуйте, Cyberax, Вы писали: C>А он работает с файлами на блоковом уровне, обходя почти все механизмы FS.
Поинт не в этом. Поинт в том, что нативной аппликухе тоже никто не мешает "работать с файлами на блоковом уровне".
К тому же эта работа, в общем-то, сводится к выставлению флагов запрета кэширования при открытии файла, и тупом выравнивании обращений по 8к и 64к границе. Тем не менее, "не получилось".
C>У меня вот прямо сейчас есть хранилище документов на Линуксе, которое пользователи мучают в особо извращённой форме. После перехода с блобов в базе данных на хранилище в файловой система производительность поднялась в 4 раза. После того, как для отдачи этих файлов я подключил lighttppd — производительность поднялась во столько раз, что даже мерить лень.
Увы, мы ничего не знаем про то, какая была CУБД, какие были блобы, и каким кодом ты отдавал их по HTTP.
C>Про сравнение производительности виндовых FS и линуксовых я тут как-то уже писал. Разница легко может быть в десятки раз, так что ничего удивительного.
Вообще-то я ничего не писал про сравнение производительности линукса и винды. Да, наверное в моем случае почтовик писали криворукие люди, а сиквел — пряморукие. В твоем случае получилось наоборот: СУБД писали криворукие, а файлуху и лайти — нет.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, AndrewVK, Вы писали:
AVK>Здравствуйте, Pavel Dvorkin, Вы писали:
PD>>Тогда и к тебе те же вопросы, что я задал IT в
AVK>Сначала я подожду, когда ты приведешь то, что тебя просили. Это во-первых.
А все же, может, не дожидаясь моего ответа , ответишь на мои вопросы, а ? А то вы что-то оба с IT как будто сговорились, сначала требуете от меня, а сами даже сказать на словах не хотите, как будете делать. Я даже код не прошу — просто скажите. Ну что вам стоит . Хоть на 2-3 вопроса ответьте — вы же такие крутые специалисты
>А во-вторых, как напишешь императивный аналог алгоритма, что IT описал, ты сделаешь точно такое же как у IT описание своего собственного алгоритма, который ты хочешь увидеть в функциональной форме.
Эту фразу я так и не смог понять. Если уж я напишу алгоритм, то зачем еще его описание ? Или ты комментарии к нему хочешь ?
Здравствуйте, VladD2, Вы писали:
PD>>1. Приведи , где и когда я говорил, что я вижу код уже в оптимизированном виде. Ссылку! PD>>2. Приведи, где и когда я выступал против списков. Ссылку! PD>>3. Приведи, где и когда я выступал против использования функций. Ссылку! PD>>4. Приведи, где и когда я заявлял, что я все напишу в виде одного огромного for. Ссылку!
VD>Мне прийдется приводить все твои сообщения в которых речь идет об оптимизации. Собственно все твои рассуждения даже в этой ветке (вообще не имеющей отношения к оптимальности или оптимизациям) снова свелись к оптимизации. О чем еще можно говорить то?
Не надо все. Приведи по одной ссылке по каждому из 4 пунктов, перечисленных выше. Только найди, где я именно это говорил. Про списки, про функции и т.д. Можно даже не в этой ветки.
AndrewVK,
LCR>>Не понял. Ты предлагаешь локальные бинды обзывать my_favourite_name. Или что? Если так, то это контрпродуктивно.
AVK>Я предлагаю использовать примеры, которые ближе к реальности, и писать их так, чтобы они не напоминали птичью тропку на снегу. Обсуждаемый тут пример IT как раз такой.
К чьй реальности? К моей или к твоей? Или к некоей средневзвешенной реальности среди всех участников rsdn (которую лично я не имею наглости вычислять)?
Допустим, у нас есть некоторый GUI с деревом. Развесистым таким деревом, на 10^n элементов. И пользователь где-то в глубине иерархии поменял название одного элемента. Как это будет выглядеть в рамках ФП?
Здравствуйте, Sinclair, Вы писали:
PD>>И зря ты пытаешься доказать, что я это утверждаю. Я лишь одно утверждал — есть некий теоретический предел, им является идеально написанная программа на ассемблере. На любом языке с любыми средствами лучше сделать нельзя. При этом я вовсе не утверждаю, что знаю, как такую программу написать. Это лишь теорема о существовании. Но теорема верная. И из нее вовсе не следует, что программы надо писать на ассемблере. S>Эта теорема неверна. Попробуй ее доказать
А если так: для любой программы на языке высокого уровня существует эквиавалентная программа на ассемблере, которая работает не хуже?
Здравствуйте, VladD2, Вы писали:
VD>Ага... эмуляция эмперативщины на функциональном языке эмулиуемом в императивной машине.
Влад, ну это ж уже сто раз обсасывалось.
кто-то пользует mutable для изменяемых переменных, а кто-то State и IO.
где-то mutable захардкоженый элемент языка, а где-то это сделано на основе патттерна который применяется еще многими способами.
Допустим на той же идеологии монад в f# сделали красивые асинхронные вычисления. И software transactional memory. В Немерле допустим это можно было бы организовать макросами. разные подходы просто.
А где что кому лучше... Оно вопрос из серии "на вкус и цвет фломастеры разные".
Здравствуйте, Sinclair, Вы писали:
S>Поинт не в этом. Поинт в том, что нативной аппликухе тоже никто не мешает "работать с файлами на блоковом уровне". S>К тому же эта работа, в общем-то, сводится к выставлению флагов запрета кэширования при открытии файла, и тупом выравнивании обращений по 8к и 64к границе. Тем не менее, "не получилось".
Нет. В NTFS тормозит сам по себе поиск и открытие файла. Скажи, как ты это собираешься оптимизировать? MSSQL это делать часто не надо — он один раз открыл хранилище и работает дальше с ним уже напрямую.
Если у тебя туча файлов — такой трюк не проходит. Ну а если у тебя один большой файл — то проще, действительно, взять БД и не мучаться.
C>>У меня вот прямо сейчас есть хранилище документов на Линуксе, которое пользователи мучают в особо извращённой форме. После перехода с блобов в базе данных на хранилище в файловой система производительность поднялась в 4 раза. После того, как для отдачи этих файлов я подключил lighttppd — производительность поднялась во столько раз, что даже мерить лень. S>Увы, мы ничего не знаем про то, какая была CУБД, какие были блобы, и каким кодом ты отдавал их по HTTP.
PostgreSQL и Oracle. Код был самый тупой — проверяем права пользователя (один простой SQL-запрос), делаем запрос в хранилище по ID файла, получаем blob и отдаём по HTTP. Тупее некуда.
C>>Про сравнение производительности виндовых FS и линуксовых я тут как-то уже писал. Разница легко может быть в десятки раз, так что ничего удивительного. S>Вообще-то я ничего не писал про сравнение производительности линукса и винды.
На самом деле, это весьма важный пункт. В Линуксе я реально могу использовать файловые системы с сотнями тысяч файлов в каталоге, и оно будет приемлимо работать. На Windows такое решение не будет работать вообще — сдохнет просто на простейших операциях, как ты ни бейся головой об стену. Это просто ещё одна разница между разными ОС.
S>Да, наверное в моем случае почтовик писали криворукие люди, а сиквел — пряморукие. В твоем случае получилось наоборот: СУБД писали криворукие, а файлуху и лайти — нет.
Ну то же самое и с файловыми системами в Линукс и Виндоус
Кстати, тот же лайти элементарно прикрутился к файловой системе — там внутри всего стека сейчас получается поный zero-copy для данных. Ядро прямо из буффера файловой системы в сеть пакеты пихает. Стомегабитная сеть в результате засвечивается почти без видимой нагрузки на CPU. Это позволило на эти ноды воткнуть ещё и другую логику.
Такое сделать с БД — просто не получится. Если не организовать, конечно, файловый кэш для полученных из БД данных.
Здравствуйте, Pzz, Вы писали: Pzz>А если так: для любой программы на языке высокого уровня существует эквиавалентная программа на ассемблере, которая работает не хуже?
А вот для этого надо определиться, что значит "не хуже". И что значит "на ассемблере". Вот, к примеру, дотнет фреймворк — он на чём?
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Pzz, Вы писали:
Pzz>Если не ошибаюсь, именно Оракл протолкал поддержку "сырых" дисков в linux 2.6 (в 2.4 их не было). Вероятно, ребята из Оракла забыли почитать официальные рекомендации
Ага, чтобы хоть как-то оправдать наличие этих сырых дисков, пришлось поддержать их в ОС. Иначе вообще, не пришей кобыле хвост.
Pzz>А вы посмотрите на это не с точки зрения пользователя SQL-сервера, а с точки зрения его разработчика.
Зачем? Не о разработчиках сиквела речь. Преобразования из высокий абстракций в конкретные низкоуровневые реализации тоже кто-то пишет, они не святым байтом появляются.
Pzz>Казалось бы, ну зачем возиться со всем этим низкоуровневым доступом к диску, когда есть файловая система, которая все замечательно оптимизирует, да еще и автоматически. Ан нет, возятся.
В том-то и дело, что не возятся. Вся возня заключается в выставлении одного флага и выравнивании на границу страницы или экстента.
Опять-таки, даже если и возятся, к данному разговору это никакого отношения не имеет.
Pzz>SQL ващето это не только драйвер диска, но еще и реляционная алгебра.
И? Это как-то отменяет тезис о том, что уровень абстракции при работе с сиквелом выше, чем непосредственно с файловой системой? Как раз у этой самой алгебры уровень абстракции такой, что абстрактнее не придумаешь.
Pzz>Проще тем, что вот они письма, лежат на диске, каждое письмо в своем файле.
Ну вот они в табличке лежат, каждое в своей записи. Так чем проще-то?
Здравствуйте, VladD2, Вы писали:
N>>Единственный объективный индикатор профессионализма — это уровень зарплаты.
VD>Тогда те кто работают в США большие профессионалы чем те кто работает Москве. А те кто работает в Малых Васюках вообще ламеры.
Речь шла об "уровне", то есть некой относительной величине. Только вот не ясно, как её мерять.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111>>
Help will always be given at Hogwarts to those who ask for it.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>А не может ли уважаемый сэр, хоть и допускающий невежливые высказывания (чтобы не сказать больше) пояснить, как это можно сформулировать хотя бы программу на уровне абстракций типа mov — jmp. PD>Мне это все же кажется странным. Написать ее с применением mov, jmp — или if, for — это понятно, а вот сформулировать в абстракциях хоть тех, хоть других — нет. Формулируют обычно в абстракциях структур данных и алгоритмов, а уж потом кодируют с помощью mov или for. Это курсе так на 1-2 объясняют вообще-то.
Продолжаю пояснять, несмотря на очевидные проблемы с восприятием. Вот то, что ты называешь "написать", это и есть "сформулировать".
Еще раз, на пальцах: пишешь ты add eax, [ebp+8]. Это означает: "нужно увеличить значение регистра EAX на значение, лежащее в четырех байтах памяти по такому-то адресу". Вот такая, значит, у нас формулировка решения некоторой задачи. Если подумать головой, то окажется, что это решение — не единственно возможное. На самом деле решение можно сформулировать как-то по-другому, так, чтобы в нём не фигурировали регистры и адреса. К примеру, "увеличить значение целочисленной переменной a на значение целочисленной переменной b". Это по-прежнему часть решения той же самой задачи, но уже немножко более высокоуровневое. Оно допускает несколько различных формулировок в терминах регистров и памяти, но все эти формулировки продолжают оставаться эквивалентными. Проблема в том, что у нас нет способа доказать эквивалентность этих формулировок, глядя в их ассемблерное представление. Значит, мы не можем выбрать из множества семантически эквивалентных решений то, которое получает наилучшую производительность.
Если мы поднимем голову повыше, то окажется, что и это решение не единственное; оно часть решения еще более общей задачи, например "найти сумму целых чисел в массиве". Для такой формулировки есть масса эквивалентных представлений в терминах переменных и присваиваний; это, очевидным образом, резко увеличивает пространство выбора для оптимизации. Всё еще понятно?
PD>И даже очень неплохо.
PD>Батенька, не морочь людям голову и не путай божий дар с яичницей. Предсказание переходов, конвейер и внутренние регистры — это одно, а время выполнения команды add, взятой самой по себе, от конвейера и предсказания переходов не зависит. А ты обещал выжать что-то из самой add
Продолжаю, несмотря на очевидные проблемы с восприятием. Во-первых, "время выполнения команды add" зависит от конвеера и внутренних регистров, и еще как. Саму по себе эту команду выполнить за 1 такт невозможно. Но процессор, грубо говоря, делает так, чтобы за 500 тактов выполнялось 500 команд add.
Во-вторых, я ничего не обещал выжать из отдельной команды add. Я писал про то, что процессор выжимает максимум производительности из программы, сформулированной в терминах ассемблерных команд. Кстати, это далеко не для всех процессоров справедливо. К примеру, итаниум возлагал эти задачи на компиляторы.
PD>Очень сильно похоже на ребенка, который узнал, откуда дети берутся и спешит сообщить своим друзьям по песочнице эту страшную тайну. Поверь, эта тайна — тайна только для тебя, всем остальным она давным-давно известна. В общем, почитай приличное руководство по архитектуре процессора, там есть и другие тайны, о которых можешь тоже всех оповестить
Очень рад, что ты тоже читал руководство по архитектуре процессора (кстати, какого?). Жаль, что оно ничего не дало твоему развитию.
PD>Ну и ну! Не вдаваясь в суть этого утверждения ( а оно совсем не верно, но объяснять почему просто нет времени), могу лишь сделать вывод — программист на асме глупый, а вот компилятор — умный, он видимо, такое делать не будет. Остается лишь ответить на вопрос, умные ли те, кто писал этот компилятор.
Ну почему сразу "глупый"? С логикой проблемы? Поясняю еще раз, специально для альтернативно начитанных: программист на ассемблере не глупый. Просто он писал программу тогда, когда "руководства" еще и в помине не было. Откуда он мог знать, сколько будет конвееров?
PD>А если серьезнее — почитай про penalty, про конвейеры, про рекомендации Intel, какие команды следует и в каком порядке выполнять, чтобы добиться наилучшего распараллеливания. VTune, наконец, загрузи и запусти, пусть она твою программу оценит. Может, перестанешь после этого нести ахинею насчет априорно глупых программистов на ассемблере.
Павел, я всё это знаю. Какое отношение имеет VTune к интеллекту программистов? Ты предлагаешь программу отдельно оптимизировать под каждый целевой процессор?
PD>В огороде бузина, а в Киеве дядька. Никто от процессора и не требует, чтобы он вдруг начал изображать собой твой любимый JIT и пытаться что-то понять.
Он уже это делает. Внутри процессора как раз и работает микро-JIT, который превращает суперскалярные команды во внутренний микрокод, выполняющийся на RISC-ядре.
PD>Не его это задача, а задача программиста на ассемблере — писать программу так, чтобы учесть специфику выполнения команд процессором.
А мужики-то не знали! То, о чем ты говоришь — это итаниумная архитектура; была похоронена, в частности, потому, что не получилось написать компилятор, достаточно умный для полного учета "специфики выполнения команд процессора". PD>И не только процессором, кстати, а еще и продумать, как доступ к ОП лучше организовать, чтобы не было проблем с кэшем и т.п.
Ну так вот это — неразрешимая задача. Чем быстрее ты это поймешь, тем лучше для твоих студентов. Например, потому, что ты не знаешь заранее, какой именно будет кэш.
PD>Устал я уже отвечать. Резюме твои высказываниям — компилятор умнее человека. Компилятор может такой код соорудить, что человек его соорудить не может. Остается только одно понять — кто же этот компилятор написал — сверхчеловеки?
Совершенно неважно, кто написал компилятор. Компилятор не устает и не ошибается; у него нет проблем выполнить глобальные оптимизации и точно посчитать соотношение количества экземпляров каждого из классов в системе. Программист — устает и ошибается. Кроме того, его знания о целевой системе быстро устаревают.
PD>А то, что компилятор может сделать код лучше, чем средний программист на ассемблере — вполне мб и верно. Но я-то говорил про идеально написанную программу на ассемблере как некий теоретический предел, как теорему о существовании.
Ты ее всё еще даже не попробовал толком сформулировать, не то что доказать.
PD>А ты это понять не хочешь, а вместо это рассказываешь мне банальные истины под видом страшной тайны для маленьких детей.
Я как раз всё прекрасно понимаю. А вот ты почему-то упорно не можешь понять то, что тебе пишу я. S>>>>Более того, во многих задачах невозможно заранее предложить оптимальное решение в терминах mov, add, jmp и т.д. PD>Все ясно. Человек не может, а вот компилятор может. Приехали.
Нет, просто управляемой среде не обязательно делать это заранее.
PD>Параллелить на одном ядре — это совершенно обычная практика, существующая уже лет так 30-40.
Нерелевантный спам поскипан. Поясняю подробнее: я не имел в виду "параллелить ожидание", я имел в виду "параллелить задачу, которая полностью нагружает одно ядро". В частности, твоя числодробилка, приведенная в примере, явно даст худший результат, если запустить даже один лишний поток.
PD>Ну и бери ее. Выкинь кусок без распараллеливаняи и бери второй.
Отлично. Именно об этом я и говорил. Берем второй кусок, и что мы видим?
PD>Как, кстати, ты этот предел вычислять собираешься, если не секрет Я готов попробовать доказать теорему о его существовании, а ты готов , видимо, дать прямо-таки методику его вычислкния ? . Давай сюда ее, обсудим
Достаточно показать возможности по дальнейшей оптимизации. Понятно, почему?
Показываю, следим за руками:
При запуске на 1 (одном) ядре, эта программа тратит X вычислительных ресурсов (временем я оперировать не буду, т.к. оно зависит много от чего еще).
При этом непараллельная версия, которую ты привел, тратит X-delta ресурсов (например, потому что в ней нет WaitforMultipleObjects, нет динамического распределения памяти, да и вообще обращений к структурам chunk).
Значит, она заведомо хуже, чем теоретически достижимый предел. Еще вопросы? Хочешь еще раз попробовать приблизиться к теоретическому пределу, или прямо сейчас сольешь?
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, IB, Вы писали:
Pzz>>Если не ошибаюсь, именно Оракл протолкал поддержку "сырых" дисков в linux 2.6 (в 2.4 их не было). Вероятно, ребята из Оракла забыли почитать официальные рекомендации IB>Ага, чтобы хоть как-то оправдать наличие этих сырых дисков, пришлось поддержать их в ОС. Иначе вообще, не пришей кобыле хвост.
Я вообще не понял, что вы сказали. В линухе 2.4 нельзя было общаться с диском в обход системного кеша. В 2.6 стало можно. В других юниксах это было можно всегда, и этим базы данных пользовались. В линух добавили, чтобы можно было достичь высокой производительности.
Pzz>>А вы посмотрите на это не с точки зрения пользователя SQL-сервера, а с точки зрения его разработчика. IB>Зачем? Не о разработчиках сиквела речь. Преобразования из высокий абстракций в конкретные низкоуровневые реализации тоже кто-то пишет, они не святым байтом появляются.
Какая разница, о разработчиках чего идет речь? Факт в том, что SQL реализует весьма высокоуровневую штуку, а пользоваться при реализации приходится уровнем абстракции даже более низким, чем то, с чем имеют дело обычные программы: не файлами, а блоками на диске.
Вы же не будете утверждать, что SQL пишут небожители, а простому человеку это никогда не понадобится?
IB>В том-то и дело, что не возятся. Вся возня заключается в выставлении одного флага и выравнивании на границу страницы или экстента.
Плюс к этому самостоятельная реализация всей политики кеширования.
IB>Опять-таки, даже если и возятся, к данному разговору это никакого отношения не имеет.
Имеет. SQL-сервер это тоже программа.
Pzz>>SQL ващето это не только драйвер диска, но еще и реляционная алгебра. IB>И? Это как-то отменяет тезис о том, что уровень абстракции при работе с сиквелом выше, чем непосредственно с файловой системой? Как раз у этой самой алгебры уровень абстракции такой, что абстрактнее не придумаешь.
Забудьте на секундочку о SQL-сервере как о продукте, готовом к употреблению. Я привожу его в качестве примера программы, которую тоже кто-то разрабатывает.
Pzz>>Проще тем, что вот они письма, лежат на диске, каждое письмо в своем файле. IB>Ну вот они в табличке лежат, каждое в своей записи. Так чем проще-то?
Тем, что во-первых, файловую систему редко разносит до такого состояния, что ни одного файла нельзя отодрать. А во-вторых, есть миллион разных утилиток, позволяющих рассматривать файлы на файловой системе, даже на частично разрушенной файловой системе. А с базой, либо ваша SDBM заводится, и тогда у вас есть SELECT. Либо не заводится, и тогда вам только остается сосать лапти.
Здравствуйте, Sinclair, Вы писали:
Pzz>>А если так: для любой программы на языке высокого уровня существует эквиавалентная программа на ассемблере, которая работает не хуже? S>А вот для этого надо определиться, что значит "не хуже". И что значит "на ассемблере". Вот, к примеру, дотнет фреймворк — он на чём?
Мне нравится ход ваших мыслей. Вы ведь не будете утверждать, что фреймворк невозможно реализовать на ассемблере? Т.е., теорема существования доказана?
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Лет так 30 назад была такая система программирования Альфа, сделана была в Новосибирске Ершовым, поттосиным и др. На базе языка Алгол, но с расширениями. Так вот, там сложение матриц делалось еще проще
PD>real array a[1:n][1:m],b[1:n][1:m], c[1:n][1:m]; PD>// инициализация
PD>c := a + b;
PD>Проще некуда. И это во времена, когда ни о каком функциональном программировании и речи не было.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>А все же, может, не дожидаясь моего ответа , ответишь на мои вопросы, а ?
Нет.
PD> А то вы что-то оба с IT как будто сговорились, сначала требуете от меня, а сами даже сказать на словах не хотите
Мы с IT уже пмривели примеры кода в функциональном стиле и предложили тебе их повторить в императивном стиле. А ты все юлишь, как уж на сковородке.
>>А во-вторых, как напишешь императивный аналог алгоритма, что IT описал, ты сделаешь точно такое же как у IT описание своего собственного алгоритма, который ты хочешь увидеть в функциональной форме.
PD>Эту фразу я так и не смог понять. Если уж я напишу алгоритм, то зачем еще его описание ? Или ты комментарии к нему хочешь ?
Я хочу не кашу из звездочек и стрелочек, а вменяемое описание алгоритма.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, samius, Вы писали:
S>Здравствуйте, Pavel Dvorkin, Вы писали:
PD>>Лет так 30 назад была такая система программирования Альфа, сделана была в Новосибирске Ершовым, поттосиным и др. На базе языка Алгол, но с расширениями. Так вот, там сложение матриц делалось еще проще
Уточняю. Не 30, а 40 (книга от 1968 года, можно, кстати, отметить — когда-то у нас компиляторы делали . Впрочем, Лиспу 50. Я просто не знал, что у него такой почтенный возраст.
S>Кстати, посмотрите кто статью переводил
Здравствуйте, Andrei F., Вы писали:
AF>Допустим, у нас есть некоторый GUI с деревом. Развесистым таким деревом, на 10^n элементов. И пользователь где-то в глубине иерархии поменял название одного элемента. Как это будет выглядеть в рамках ФП?
Здравствуйте, Lazy Cjow Rhrr, Вы писали:
LCR>К чьй реальности? К моей или к твоей? Или к некоей средневзвешенной реальности среди всех участников rsdn (которую лично я не имею наглости вычислять)?
Последнее. И не надо никакой наглости, чтобы предположить, что с решениями СЛАУ или вычислением детерминанта матрицы на практике встречается ничтожное количество разработчиков. Еще раз предлагаю глянуть на пример IT.
Но, это, ты можешь продолжать и дальше, если хочешь. Я просто намекнул на крайне низкую, по моему мнению, эффективность подобных примеров при объяснении преимуществ ФП для неподготовленных людей.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Pzz, Вы писали:
Pzz>В линухе 2.4 нельзя было общаться с диском в обход системного кеша. В 2.6 стало можно.
Это исключительно проблемы линуха, и мне непонятно какое они имеют отношение к данному разговору.
Тем более, что речь шла о винде + MS SQL-е, где работать с диском в обход кеша можно было всегда и без особого напряжения.
Pzz> Факт в том, что SQL реализует весьма высокоуровневую штуку,
Именно. Мы взяли более высокоуровневую штуку и получили более эффективный результат — ЧТД.
Pzz>а пользоваться при реализации приходится уровнем абстракции даже более низким, чем то, с чем имеют дело обычные программы: не файлами, а блоками на диске.
Это уже детали реализации более высокоуровневой штуки, они не имеют никакого отношения к данному разговору.
Pzz>Плюс к этому самостоятельная реализация всей политики кеширования.
См. выше.
Pzz>Имеет. SQL-сервер это тоже программа.
Компилятор — тоже программа.
Pzz>Забудьте на секундочку о SQL-сервере как о продукте, готовом к употреблению. Я привожу его в качестве примера программы, которую тоже кто-то разрабатывает.
Компилятор тоже кто-то разрабатывает.
Pzz>Тем, что во-первых, файловую систему редко разносит до такого состояния, что ни одного файла нельзя отодрать.
Достаточно чтобы нелъзя было отодрать один.
Pzz>А во-вторых, есть миллион разных утилиток, позволяющих рассматривать файлы на файловой системе,
Данные в БД тоже.
Pzz> Либо не заводится, и тогда вам только остается сосать лапти.
Есть миллион утилит по восстановлению и обеспечению отказоустойчивости, с которыми никакая ФС не сравнится..
Здравствуйте, AndrewVK, Вы писали:
Pzz>>Забудьте на секундочку о SQL-сервере как о продукте, готовом к употреблению. Я привожу его в качестве примера программы, которую тоже кто-то разрабатывает.
AVK>То есть ты признаешься в том, что сознательно уводишь от темы, так как Антон привел его именно в качестве примера продукта, готового к употреблению?
А использование SQL-сервера в качестве примера готового продукта не может мирно сосуществовать с использованием его в качестве примера разрабатываемой программы?
Здравствуйте, IB, Вы писали:
Pzz>>В линухе 2.4 нельзя было общаться с диском в обход системного кеша. В 2.6 стало можно. IB>Это исключительно проблемы линуха, и мне непонятно какое они имеют отношение к данному разговору. IB>Тем более, что речь шла о винде + MS SQL-е, где работать с диском в обход кеша можно было всегда и без особого напряжения.
Pzz>Вплоть до использования своей собственной партиции, на которой нет никакой файловой системы.
Это официально не рекомендуемая экзотика, так что ""взрослые" SQL-сервера" как раз стараются работать поверх FS.
Если бы это было никому не нужно, зачем бы в линухе это стали делать?
Так же непонятно, с чего речь шла только о венде.
Pzz>> Факт в том, что SQL реализует весьма высокоуровневую штуку, IB>Именно. Мы взяли более высокоуровневую штуку и получили более эффективный результат — ЧТД.
Кто такие мы? Если для вас "мы" это те, кто пишет поделки на бейсике, а "они" — те, кто сделали бейсик, могу лишь посоветовать раздвинуть свои горизонты.
Pzz>>а пользоваться при реализации приходится уровнем абстракции даже более низким, чем то, с чем имеют дело обычные программы: не файлами, а блоками на диске. IB>Это уже детали реализации более высокоуровневой штуки, они не имеют никакого отношения к данному разговору.
Вы мне рассказываете, что есть такой слоистый мир, в котором программа на каждом уровне пользуется предыдущим слоем, а что ниже ее не касается.
Я вам привел пример программы, которая живет не так, как принято в рамках этого вашего слоистого мира. Вы ошибаетесь, если думаете, что эта программа — какое-то там особенное исключение.
Если после упоминания слова SQL у вас в голове случается короткое замыкание, и вы сразу начинаете мысленно выписывать SQL-запросы, могу только посочувствовать. Повторюсь еще раз, я использую SQL-сервер как пример программы, и обсуждаю использованное в ней архитектурное решение.
Pzz>>Плюс к этому самостоятельная реализация всей политики кеширования. IB>См. выше.
На что смотреть, простите?
Pzz>>Имеет. SQL-сервер это тоже программа. IB>Компилятор — тоже программа.
И что?
Pzz>>Забудьте на секундочку о SQL-сервере как о продукте, готовом к употреблению. Я привожу его в качестве примера программы, которую тоже кто-то разрабатывает. IB>Компилятор тоже кто-то разрабатывает.
Точно. И что?
Pzz>>Тем, что во-первых, файловую систему редко разносит до такого состояния, что ни одного файла нельзя отодрать. IB>Достаточно чтобы нелъзя было отодрать один.
Что лучше, потерять несколько писем, или потерять все письма?
Pzz>>А во-вторых, есть миллион разных утилиток, позволяющих рассматривать файлы на файловой системе, IB>Данные в БД тоже.
Они все упираются в одну — SDBM. Если она не работает с тем, что осталось от ваших данных, вам уже ничего не поможет.
Pzz>> Либо не заводится, и тогда вам только остается сосать лапти. IB>Есть миллион утилит по восстановлению и обеспечению отказоустойчивости, с которыми никакая ФС не сравнится..
Шансов восстановить, хотя бы частично, сломанную ФС значительно больше, чем восстановить аналогично поломаную БД. Уже потому, что у ФС структура значительно проще.
Потом поймите, я не призываю всех на свете использовать ФС в качестве базы данных. Я лишь объясняю, что этот подход имеет право на существование, и у него есть свои плюсы.
Здравствуйте, AndrewVK, Вы писали:
AVK>Здравствуйте, Pavel Dvorkin, Вы писали:
PD>>А все же, может, не дожидаясь моего ответа , ответишь на мои вопросы, а ?
AVK>Нет.
Ну что же, все ясно. Ответ свой я дал в ответе IT.
PD>> А то вы что-то оба с IT как будто сговорились, сначала требуете от меня, а сами даже сказать на словах не хотите
AVK>Мы с IT уже пмривели примеры кода в функциональном стиле и предложили тебе их повторить в императивном стиле. А ты все юлишь, как уж на сковородке.
Еще раз (на этот раз тебе) объясняю — требовать от меня чего-либо ни ты, ни он не можешь. И не стоит бросаться словами и ярлыками — это бессмысленно.
PD>>Эту фразу я так и не смог понять. Если уж я напишу алгоритм, то зачем еще его описание ? Или ты комментарии к нему хочешь ?
AVK>Я хочу не кашу из звездочек и стрелочек, а вменяемое описание алгоритма.
Ну насчет каши — не нравится язык — дело твое. Я другой язык использовать не буду. А описание — мне казалось , что я его дал.
>поэтому я просто распараллелил вычисление сумм красных компонент по столбцам окна.
Если этого недостаточно — пожалуйста.
Дано окно Windows с неким рисунком в нем. Пройти по всем пиксельным столбцам клиентской области этого окна и найти для каждого столбца сумму R (красных) компонент пикселей , записать результаты в массив columnSum. Две реализации — в лоб без распараллеливания, и с распараллеливанием
Реализация в лоб — пройти и отсуммировать.
Реализация с распараллеливанием — создаются N потоков, где N — число процессоров (возвращает GetSystemInfo). Если процессоров 2, то один поток займется левой половиной окна, а другой правой. Если 3 — левой, средней и правой соответственно. И т.д.
GetPixel взята специально — она медленная, так что время получается такое, что его можно сравнивать.
Здравствуйте, Pzz, Вы писали:
Pzz>И не забывайте еще одно. Вот выйдет новый процессор Интел, а мелкософт скажет, что ему не интересно. И не будет его специальным образом поддерживать. Дворкин-то выматерится и руками все соптимизирует. А вы куда пойдете?
Здравствуйте, Pzz, Вы писали:
Pzz>А использование SQL-сервера в качестве примера готового продукта не может мирно сосуществовать с использованием его в качестве примера разрабатываемой программы?
Может. В отдельном топике. А вот при обсуждении примера Антона — не может, если ты хочешь придерживаться корректности.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Pzz, Вы писали:
Pzz>А если так: для любой программы на языке высокого уровня существует эквиавалентная программа на ассемблере, которая работает не хуже?
А может, проще — для любой программы на языке ВУ существует эквивалентная программа на ассемблере, которая работает так же. Потому что программа на языке ВУ не работает вообще, а работает в конечном счете ассемблерный (машинный) код, порожденный из нее с помощью компиляторов. линкеров и прочих JIT'ов. Вот и возьмем эту эквивалентную программу в машинных кодах. Теперь одно из двух — либо ее нельзя улучшить (когда она уже в кодах), либо можно. Если верно первое — это значит, что компилятор и прочие создали такой код, который является идеальным, его же нельзя улучшить, так ? Из этого утверждения логически следует, что разрабатывать новые версии компилятора по крайней мере для этого процессора незачем, так как существующий компилятор уже создает идеальную программу. Если второе — доказано как минимум то, что существует программа, лучшая, чем создает компилятор. Это не помешает, конечно, улучшить компилятор, но после этого мы опять вернемся к исходной позиции. Вот и все доказательство теоремы.
Здравствуйте, Pzz, Вы писали:
Pzz>Если бы это было никому не нужно, зачем бы в линухе это стали делать?
Писать в обход кеша? нужно, только непонятно какое это имеет отношение к обсуждаемому вопросу.
Pzz>Так же непонятно, с чего речь шла только о венде.
"поверх MS SQL"
Pzz>Кто такие мы?
Это оборот речи такой.
Pzz> могу лишь посоветовать раздвинуть свои горизонты.
Могу посоветовать — не советовать.
Pzz>Вы мне рассказываете, что есть такой слоистый мир, в котором программа на каждом уровне пользуется предыдущим слоем, а что ниже ее не касается.
Нет. Я рассказываю, что есть разные уровни абстракции, и более высокий уровень абстракции в состоянии дать более эффективный результат, чем более низкий. А уж пользуются ли более высокие уровни, нижележащими реализациями, или не пользуются — малосущественные подробности.
Pzz>Я вам привел пример программы, которая живет не так, как принято в рамках этого вашего слоистого мира.
Нет не привел. Не смотря на то, что промышленные СУБД действительно оборудованы возможностю работать с голым диском в обход FS, процент практического использования такого сценария стремится к нулю. Более того, в конкретной обсуждаемой задаче MSSQL работал поверх FS, пользуясь ее публичным API.
Pzz>На что смотреть, простите?
На то что архитектурные особенности сиквела не имеют никакого отношения к обсуждаемому вопросу.
Pzz>И что?
И то. Онточно так же переводит высокоуровневые конструкции ФЯ в низкоуровневый ассемблер.
Pzz>Шансов восстановить, хотя бы частично, сломанную ФС значительно больше, чем восстановить аналогично поломаную БД.
Это заблуждение. БД гораздо более устойчива чем FS и возможности по повышению устойчивости БД тоже существенно больше.
Pzz>Уже потому, что у ФС структура значительно проще.
Ну и что?
Здравствуйте, Sinclair, Вы писали:
S>Ключевой момент — вот этот "SetHtml". Общепринятого стандарта на него нету, в отличие от "NavigateTo". S>Поэтому действительно, самый кроссплатформенный способ — это сделать NavigateTo на соответствующий адрес. S>В IE применяют специальные трюки для того, чтобы не поднимать честный HTTP-сервер: например, регистрируют свой псевдопротокол. S>Или пользуются интерфейсом принудительной загрузки из IStream. Но это не кросс-браузерное решение.
В MSIE насколько я помню вообще можно повеситься на событие Navigate и произвольно обрабатывать запросы даже без регистрации всяких псевдо-протоколов.
S>Резюме тут примерно такое: встроить в себя браузер — нетривиальное занятие. А держать локальный HTTP-сервер стоит не слишком дорого.
Может, я, конечно, сужу со своей колокольни, но мне казалось, что тот же Геко — достаточно кроссплатформенное решение. И о возможности встроить его в приложение на подобие MSIE я слышал уже давно — точно не год назад. А какой-нибудь аналог SetHtml там же явно есть.
Здравствуйте, Sinclair, Вы писали:
S>Так ведь это ж не индексер контента — это почтовый сервер. Никого не интересует, что у него унутре — куча файлов, одно хранилище, или несколько.
Не интересует. Но тем не менее, считать любой софт, не использующий MSSQL (или на худой конец Oracle) заведомо тормозным — тоже некорректно.
C>>PostgreSQL и Oracle. Код был самый тупой — проверяем права пользователя (один простой SQL-запрос), делаем запрос в хранилище по ID файла, получаем blob и отдаём по HTTP. Тупее некуда. S> Логи лайти смотрели? Сколько он отдает 304 Not Modified?
Почти нет совсем. Задача такая.
S>Еще раз повторяю для тех, кто не читает: речь не идет про сравнение винды и линукса. Хочешь поговорить об этом — иди в КСВ и бейся там до упаду. Мы сравниваем "рукопашную" реализацию с "высокоабстрактной".
А я тебе показываю, что разница в скорости между ними зависит, скорее, не от абстрактности, а от прямоты их реализации.
Если я буду запрашивать файлы через web-сервис с кодировкой base64, то это будет ещё более абстрактно. Какая будет скорость у этого счастья — сам понимаешь.
S>Ну, это не совсем то, что доктор прописал. К примеру, gzip компрессию так применить не получится а это может увеличить скорость отдачи (естественно, при использовании кэширования с zero-copy) еще серъезнее, чем просто zero-copy.
Там файлы уже сжатые (сканы документов).
C>>Такое сделать с БД — просто не получится. Если не организовать, конечно, файловый кэш для полученных из БД данных. S>Смотря какая БД. Вон, команда SQL Server обещает получить производительность линейного чтения blob из БД сравнимой с голой файлухой. А это означает, что буфера db-client можно отдавать прямо в сокет, и результаты будут удивительными
А у меня оно уже без обещаний работает
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Я предложил свой код и продемонстрировал. Это мое право — предложить код, который я хочу для демонстрации.
По этой логике моим ответом должно быть предложение ещё одного кода и задавание кучи не относящихся к теме вопросов. Извини, но это не диалог двух людей с высшим техническим образованием. Это тётки на базаре, кто кого перекричит. Я в этом участвовать не собираюсь.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>А может, проще — для любой программы на языке ВУ существует эквивалентная программа на ассемблере, которая работает так же.
JIT может пораждать разный код для разных железно/софтовых окружений. Отсюда следует простой вывод, что эквивалентная программа на ассемблере на твоём компьютере будет работать не так же на моём.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
не видел PlinQ и нет времени на него смотреть. Нету и двухядреной машины под рукой чтобы проверять многопоточный вариант, поэтому я его не писал. Может попозжа
public partial class Form1 : Form
{
[DllImport("user32.dll")]
static extern IntPtr GetDC(IntPtr hWnd);
[DllImport("user32.dll")]
static extern int ReleaseDC(IntPtr hWnd, IntPtr hDC);
[DllImport("gdi32.dll")]
static extern int GetPixel(IntPtr hDC, int x, int y);
public Form1()
{
InitializeComponent();
}
private void button1_Click(object sender, EventArgs e)
{
System.Diagnostics.Stopwatch sw = new System.Diagnostics.Stopwatch();
sw.Start();
var columnSum = new int[this.Width];
IntPtr hDC = GetDC(this.Handle);
foreach (var x in Enumerable.Range(0, this.Width))
{
int sum = 0;
foreach (var y in Enumerable.Range(0, this.Height))
{
int colorRef = GetPixel(hDC, x, y);
sum += (int)(colorRef & 0x000000FF);
}
columnSum[x] = sum;
}
ReleaseDC(this.Handle, hDC);
sw.Stop();
System.Console.WriteLine(sw.ElapsedMilliseconds.ToString());
}
PD>1. Напиши аналогичное со свои любимым AsParallel, только не вертикальными полосами, а прямоугольно-гнездовыми кусками. Мне, как понимаешь, это на пять минут работы — массив columnSum превратить в двумерный, а в CHUNK вместо nHeight ввести yStart, yEnd.
по поводу этого. просто foreach поменяется. Будет не для каждого игрека, а для только нужных.
PD>2. То же самое по диагоналям. Каждый тред занимается своей диагональю, параллельной главной (или побочной)
см. пункт 1
PD>3. Сделай так, чтобы некоторые из процессоров не использовались этими потоками. Список этих процессоров дан. Мне это ничего не стоит — SetThreadAffinityMask — и все дела.
если это апишная функция ничего не стоит дернуть ее из це шарпа. хотя может есть более красивое решение хз.
PD>4. Сделай так, чтобы треды работали в фоне, то есть основной поток имел при этом больший приоритет — его работа для меня более важна, чем это суммирование.
приоритеты можно ставть используя класс Thread. Наверное для этого придется отказаться от AsParallel.
PD>5. Ну и напоследок. Сделай так, чтобы эти треды информировали периодически некий третий поток о том, как у них прогресс идет. Для меня тут, конечно, минут на 10 работы — еще один поток надо сделать, причем с петлей сообщений а потом просто PostThreadMessage когда надо.
см.пункт 4
Здравствуйте, Sinclair, Вы писали:
S>Ключевой момент — вот этот "SetHtml". Общепринятого стандарта на него нету, в отличие от "NavigateTo". S>Поэтому действительно, самый кроссплатформенный способ — это сделать NavigateTo на соответствующий адрес. S>В IE применяют специальные трюки для того, чтобы не поднимать честный HTTP-сервер: например, регистрируют свой псевдопротокол. S>Или пользуются интерфейсом принудительной загрузки из IStream. Но это не кросс-браузерное решение.
S>Резюме тут примерно такое: встроить в себя браузер — нетривиальное занятие. А держать локальный HTTP-сервер стоит не слишком дорого.
Тем более, что и МС не гнушаются делать хелп в виде ASP.NET приложений. У них, правда, причины другие, но факт остается фактом.
Здравствуйте, Pzz, Вы писали:
Pzz>А вам не кажется, что если все участники будут продолжать говорить о том же, то мы вряд ли далеко продвинемся в нашем разговоре относительно начальных позиций?
Нет, не кажется. Если тебе нечего сказать по теме — ну так и скажи.
Pzz>Я не пытаюсь соскочить с темы, я пытаюсь развить тему.
А выглядит это именно как попытка опять раздуть очередной винилин. Могу посоветовать только воспользоваться советом Антона и пойти в КСВ, там у тебя найдутся более сговорчивые партнеры.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
AndrewVK,
AVK>Но, это, ты можешь продолжать и дальше, если хочешь. Я просто намекнул на крайне низкую, по моему мнению, эффективность подобных примеров при объяснении преимуществ ФП для неподготовленных людей.
Здравствуйте, Pzz, Вы писали:
AVK>>Нет, не кажется. Если тебе нечего сказать по теме — ну так и скажи.
Pzz>Хамить, мне кажется, совсем уж не обязательно.
Здесь нет никакого хамства.
Pzz> Если вам кажется, что я говорю не по теме, ну не читайте, кто ж просит?
Ты сам в этом признался
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Pzz, Вы писали:
Pzz>В качестве дидактического примера.
Плохой пример.
Pzz>Сколько раз вы еще зададите этот вопрос?
Столько, сколько раз ты попытаешься съехать с темы.
Pzz>Мы давно уже отошли от обсуждения,
"Мы — это кто?" (с) Лично я от обсуждения никуда не ухожу.
Pzz>То, что использование более высокоуровнего API всегда и по волшебству дает более эффективный результат — это неверное утверждение.
Кто такое утверждал и где?
Pzz>Я вам привел опровергающий пример.
А я доказал, что он не опровергающий.
Pzz>А я говорю, что привел. Что дальше делать будем?
Ну, приведи еще, с предыдущим у тебя промашка вышла.
Pzz>Почему?
По совокупности обстоятельств.
Pzz>Мы говорим о философии программирования.
Видимо, не со мной.
Pzz>Почему бы не говорить об этом на примере SQL-сервера?
Потому что реализация SQL-сервера не имеет к этому разговору отношения.
Pzz>Еще одно волшебство.
Удивительное рядом.
Pzz>То у вас высокоуровневые конструкции работают быстрее, чем то сочетание низкоуровневых конструкций, на которые они раскладываются.
Ты учись-учись, в жизни пригодится...
Pzz> Теперь вот БД, живущая в файле, оказывается более живучей, чем сам файл.
Именно так, просто она живет не в одном файле и реализует кучу механизмов обеспечения согласованности и отказоустойчивости.
Pzz>То, что ее чинить при необходимости проще.
Это тоже заблуждение. Вся индустрия БД на протяжении лет пятидесяти пахала на то, чтобы просто и качественно восстанавливаться после сбоя, тут наработок больше чем в любой другой области.
Здравствуйте, IB, Вы писали:
Pzz>>Мы давно уже отошли от обсуждения, IB>"Мы — это кто?" (с) Лично я от обсуждения никуда не ухожу.
Тогда в чем предмет нашего обсуждения? В том, что мейлер, хорошо написаный на C# работает быстрее, чем мейлер, плохо написаный на C++. Ок. Работает. Быстрее. И чо?
Pzz>>То, что использование более высокоуровнего API всегда и по волшебству дает более эффективный результат — это неверное утверждение. IB>Кто такое утверждал и где?
А что именно вы утверждаете?
Pzz>> Теперь вот БД, живущая в файле, оказывается более живучей, чем сам файл. IB>Именно так, просто она живет не в одном файле и реализует кучу механизмов обеспечения согласованности и отказоустойчивости.
Расскажите мне еще сказку. Про то, как данные можно волшебным образом растолкать по файлам так, что они способны пережить смерть underlying file system.
Pzz>>То, что ее чинить при необходимости проще. IB>Это тоже заблуждение. Вся индустрия БД на протяжении лет пятидесяти пахала на то, чтобы просто и качественно восстанавливаться после сбоя, тут наработок больше чем в любой другой области.
А индустрия ФС, наверное, все это время сухари сушила?
Здравствуйте, Pzz, Вы писали:
Pzz>Тогда в чем предмет нашего обсуждения?
В примере Синклера.
Pzz> В том, что мейлер, хорошо написаный на C# работает быстрее, чем мейлер, плохо написаный на C++. Ок. Работает. Быстрее. И чо?
Нет. В том что мейлер написанный с применением высокоуровневых абстракций работает быстрее, чем написанный в рукопашную с применением хардкорных оптимизаций.
Pzz>А что именно вы утверждаете?
1. Что пример Антона опровергает тезис Павла о неприменимости высокоуровневых абстракций при решении практических задач.
2. Что внутренне устройство сиквела не имеет к этому примеру никакого отношения.
Pzz>Расскажите мне еще сказку.
За сказками — не ко мне, добро пожаловать в реальный мир.
Здравствуйте, Pzz, Вы писали:
IB>>Нет. В том что мейлер написанный с применением высокоуровневых абстракций работает быстрее, чем написанный в рукопашную с применением хардкорных оптимизаций. Pzz>Ну я и говорю, хорошо написаный работает лучше, чем плого написаный, не важно, на чем написан.
Вот именно, сделать решение пользуясь высокоуровневой абстракцией качественнее и быстрее, чем выпиливать в ручную на низком уровне, оптимизируя все подряд.
Pzz>Я что-то не припомню, чтобы Павел такое утверждал.
Я в принципе подозревал, что ты не только меня не читаешь.
Pzz>Вы тут граждане хором пытаетесь отстоять ту точки зрения, что низкоуровневые абстракции не применимы при решении практических задач.
Иди, перечитывай топик сначала, приходи когда усвоишь о чем речь.
Здравствуйте, IB, Вы писали:
Pzz>>Ну я и говорю, хорошо написаный работает лучше, чем плого написаный, не важно, на чем написан. IB>Вот именно, сделать решение пользуясь высокоуровневой абстракцией качественнее и быстрее, чем выпиливать в ручную на низком уровне, оптимизируя все подряд.
А кто-то предлагает "выпиливать в ручную на низком уровне, оптимизируя все подряд"?
Здравствуйте, Pzz, Вы писали:
Pzz>А кто-то предлагает "выпиливать в ручную на низком уровне, оптимизируя все подряд"?
Да, Павел. И ты, судя по всему, активно отстаиваешь эту позицию, если конечно, внимательно прочитал за что споришь.
Здравствуйте, IB, Вы писали:
Pzz>>А кто-то предлагает "выпиливать в ручную на низком уровне, оптимизируя все подряд"? IB>Да, Павел. И ты, судя по всему, активно отстаиваешь эту позицию, если конечно, внимательно прочитал за что споришь.
Внимательно я не в состоянии прочитать — я как раз занят выпиливанием вручную того, что за меня ни один фреймворк не выпилит
Но насколько я понял его позицию, она примерно совпадает с моей.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Нет, давай критерий. Ты же мою программу хочешь сравнить, так что давай критерий, а не слова. Это я на слова имею право, если буду доказывать теорему о существовании — она по определению не говорит, как это найти. А ты готов программу сравнивать. Критерий давай!
S>>Показываю, следим за руками: S>>При запуске на 1 (одном) ядре, эта программа тратит X вычислительных ресурсов (временем я оперировать не буду, т.к. оно зависит много от чего еще). S>>При этом непараллельная версия, которую ты привел, тратит X-delta ресурсов (например, потому что в ней нет WaitforMultipleObjects, нет динамического распределения памяти, да и вообще обращений к структурам chunk).
S>>Значит, она заведомо хуже, чем теоретически достижимый предел.
PD>Дай сначала определение ресурса (время тебя не устраивает, тогда что же это ?), тогда и поговорим. А пока это попытка доказать что-то с неопределенными утверждениями , используемыми для доказательства.
Слив засчитан.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Sinclair, Вы писали:
S>Здравствуйте, Pavel Dvorkin, Вы писали:
PD>>Нет, давай критерий. Ты же мою программу хочешь сравнить, так что давай критерий, а не слова. Это я на слова имею право, если буду доказывать теорему о существовании — она по определению не говорит, как это найти. А ты готов программу сравнивать. Критерий давай!
S>>>Показываю, следим за руками: S>>>При запуске на 1 (одном) ядре, эта программа тратит X вычислительных ресурсов (временем я оперировать не буду, т.к. оно зависит много от чего еще). S>>>При этом непараллельная версия, которую ты привел, тратит X-delta ресурсов (например, потому что в ней нет WaitforMultipleObjects, нет динамического распределения памяти, да и вообще обращений к структурам chunk).
S>>>Значит, она заведомо хуже, чем теоретически достижимый предел.
PD>>Дай сначала определение ресурса (время тебя не устраивает, тогда что же это ?), тогда и поговорим. А пока это попытка доказать что-то с неопределенными утверждениями , используемыми для доказательства. S>Слив засчитан.
Твой ? Ты заявляешь, что программа тратит сколько-то ресурсов, а при этом отказываешься сказать, что же это такое — в твоем понимании. Что же она у тебя тратит в таком случае ? Пока ты это определение не дал, все твои разговоры о том, что она что-то тратит, выеденного яйца не стоят.
Здравствуйте, IT, Вы писали:
IT>Здравствуйте, Pavel Dvorkin, Вы писали:
PD>>А может, проще — для любой программы на языке ВУ существует эквивалентная программа на ассемблере, которая работает так же.
IT>JIT может пораждать разный код для разных железно/софтовых окружений. Отсюда следует простой вывод, что эквивалентная программа на ассемблере на твоём компьютере будет работать не так же на моём.
Хе-хе, батенька. А JIT — он что, дух святой ? Программа есть процесс (или несколько процессов), и в данном случае это неуправляемый процесс (потому что все процессы неуправляемые, других в Windows нет), частью которого является JIT, .Net FW или, к примеру, интерпретатор Бейсика древнего. И в этом смысле он ничем не отличается от некоей библиотечной функции, которую я могу вызвать. Эта функция мне данные каким-то образом преобразует, а JIT — тоже данные преобразует (байты IL) в другие данные, которые окажутся вдруг машинными командами , а поэтому он на них передаст управление.
Или ты считаешь, что я не могу без JIT написать самомодифицирующуюся программу ?
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Или ты считаешь, что я не могу без JIT написать самомодифицирующуюся программу ?
То есть вместо использования JIT ты напишеш свой?
Здравствуйте, prVovik, Вы писали:
V>Тем более, что и МС не гнушаются делать хелп в виде ASP.NET приложений. У них, правда, причины другие, но факт остается фактом.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Твой ? Ты заявляешь, что программа тратит сколько-то ресурсов, а при этом отказываешься сказать, что же это такое — в твоем понимании. Что же она у тебя тратит в таком случае ? Пока ты это определение не дал, все твои разговоры о том, что она что-то тратит, выеденного яйца не стоят.
То есть тебе не очевидно, что твоя программа "с параллельностью", запущенная на одном ядре, будет менее эффективной, чем твоя же программа "без параллельности"? В каких бы терминах мы ни мерили — в секундах, в тактах, в байтах или еще в чем?
Ты уже определись — то ли ты крутой специалист по оптимизации программ, то ли необученный новичок.
Если первое — то непонятно, зачем тебе разжевывать, куда деваются такты и байты памяти при лишних вызовах WaitForMultipleObjects и new[].
Если второе — то я могу разжевать, но тогда загибы пальцев в духе "я читал Intel Pentuim IV Programming Guide" и необоснованные предположения о моей некомпетентности в этих вопросах нужно спрятать подальше.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, AndrewVK, Вы писали:
AVK>Смешно. Потрясающий ты человек, Павел Дворкин.
Ну и смейся на здоровье. Я , собственно говоря, во всех этих дискуссиях порой с одной целью участвую — посмеяться над фанатиками чего бы то ни было
AVK>Да я и не требую.
Ты — нет, верно, сорри. Это IT вообразил, что он командовать может. Я как-то вас обоих перестал разделять, а напрасно. Учту
>Только выглядят после этого твои слова, как бы это помягче, неубедительно.
Да бога ради. Для тебя одно неубедительно, для меня другое, а третьи лица пусть сравнивают и убеждаются.
PD>>Ну насчет каши — не нравится язык — дело твое. Я другой язык использовать не буду.
AVK>Кто бы сомневался.
А зря, между прочим. Не буду — означало для данной задачи. А в остальном я вполне свободен в выборе. Надо будет — буду писать на C# (писал уже, хоть и совсем немного), надо будет — и на VBA напишу (тоже чуть-чуть приходилось), более того — если окажется, что в данном случае лучше всего GW-Basic — напишу на нем, хоть и чертыхнусь в душе.
А вот тебя заставить писать на C/C++ и Win32, похоже, можно только под дулом пистолета
Еще раз, Андрей, пойми наконец. Я вовсе не противник шарпа, LINQ или ФП. Там где они уместны — да бога ради. Я вовсе не предлагаю на ассемблере доступ к таблице БД писать. Не надо мне приписывать того, что я не говорил. Но когда мне начинают заявлять, что некие высокоуровненые средства ну никак нельзя реализовать на уровне ниже — я просто не знаю, смеяться или плакать. Потому что кто-то же их реализовал, ибо процессор не умеет ни LISP, ни LinQ обрабатывать. Вот и все.
PD>> А описание — мне казалось , что я его дал.
AVK>Вот именно что казалось.
Ну каждый дает описание исходя из своего понимания того, как это дают. Если бы я это в форуме по Win32 написал — уверен, меня бы с полуслова поняли бы.
>>>поэтому я просто распараллелил вычисление сумм красных компонент по столбцам окна.
AVK>Компонент чего, rакого окна?
Компонент пикселей окна, красных. Окна любого, Windows.
>О чем вообще речь? Сравни свое "описание" с описанием IT. Ну хотя бы по объему. А с таким описанием я тебе могу дать точно такой же ответ: AVK>
Нет, не пойдет этот аргумент. Пусть даже ты прав, и можно было уточнить. Но текст программы приведен, и в нем (по крайней мере в непаралельной части) разберется любой мой студент за 1 минуту, даже если я вообще никакого описания не дам. несерьезно это. Ну а потом — я же дал тебе после этого более развернутое описание задачи, зачем опять муссировать это ?
AVK>Из комментариев еще можно понять, что у тебя там вроде бы есть еще и непараллельный алгоритм, но AsParallel реально параллелит только если есть несколько ядер. Впрочем, явно указать тоже не проблема:
Если ты не очень понимаешь Win32, это еще не причина, чтобы жаловаться. Я не лучше тебя знаю LinQ, но я не заявлял, что не пойму этот SELECT, что IT привел. Если не понимаю — мои проблемы.
AVK>А теперь сравни со своей простыней. Что там у нас осталось? Параллелить вкривь и вкось различными способами?
Если не сложно, объясни , почему вкривь и вкось, это раз, и откуда там различные способы, если там всего один. А второй вопрос — ты хоть понимаешь, что внутри твоего AsParallel зашита работа с потоками примерно так, как я и сделал. Не обязательно так, конечно, скорее там пул потоков, посмотрю как-нибудь. Ну нет в Win32 иного способа параллелить и нет в Windows ничего, что не проходио бы через Win32 (про OS/2 и POSIX умолчим).
>Все это задается начальными итераторами, теми, которые на вход AsParallel поступают. И тут тоже у шарпа с его итераторами возможностей по понятной и эффективной реализации всяких причудей будет больше, чем ты сможешь на С++ изобразить.
Итераторы в С++ существуют, а вообще это понятие языково-независимо. Распараллеливание тоже (не в С++, а в Win32). И никак нельзя распараллелить иначе, чем Win32 (или на худой конец native API) позволит. С этим-то хоть ты согласен ? Вот ответь прямо — да или нет ?
PD>>Дано окно Windows с неким рисунком в нем. Пройти по всем пиксельным столбцам клиентской области этого окна и найти для каждого столбца сумму R (красных) компонент пикселей , записать результаты в массив columnSum. Две реализации — в лоб без распараллеливания, и с распараллеливанием PD>>Реализация с распараллеливанием — создаются N потоков, где N — число процессоров (возвращает GetSystemInfo). Если процессоров 2, то один поток займется левой половиной окна, а другой правой. Если 3 — левой, средней и правой соответственно. И т.д.
AVK>Если это все, тогда в первый вариант вместо things подставляем: AVK>
AVK>from x in Enumerable.Range(0, Width)
AVK>from y in Enumerable.Range(0, Height)
AVK>select pixels[x, y]
AVK>
AVK>Ну и все вместе: AVK>
AVK>return
AVK> (
AVK> from x in Enumerable.Range(0, Width)
AVK> from y in Enumerable.Range(0, Height)
AVK> select pixels[x, y].Red
AVK> )
AVK> .AsParallel()
AVK> .Sum();
AVK>
Честно говоря, не слишком понял — что ты суммируешь и куда. Если это реализация моей задачи — где массив сумм по столбцам ?
Но то, что эту задачу ты распараллелишь, я и не сомневаюсь. Ты все же попробуй те 5 вопросов осилить. А это суммирование, конечно, распараллелить можно, задачка-то пустяковая.
AVK>А теперь я поработаю чуток предсказателем — ты все равно не напишешь пример IT в императивной форме.
Вообще-то я не очень понимаю — в чем разница. Он какие-то проценты считает на баз неких коллекций, а я суммы считаю на базе тоже, если хочешь, "коллекций — столбцов пикселей. Делить я не делю и не суммирую, верно, но так ли это важно ? Есть распараллеливание алгоритма, что тут особого-то.
Ну а если тебе так уж нужны именно эти проценты — обещать не могу, что сделаю в ближайшее время, но так и быть, постараюсь сделать. Но не торопи. Не до этого мне сейчас.
Здравствуйте, IT, Вы писали:
IT>Здравствуйте, Pavel Dvorkin, Вы писали:
PD>>Я предложил свой код и продемонстрировал. Это мое право — предложить код, который я хочу для демонстрации.
IT>По этой логике моим ответом должно быть предложение ещё одного кода и задавание кучи не относящихся к теме вопросов. Извини, но это не диалог двух людей с высшим техническим образованием. Это тётки на базаре, кто кого перекричит. Я в этом участвовать не собираюсь.
Я тоже. Судя по всему, с тобой дискутировать лучше не надо.
Здравствуйте, Mirrorer, Вы писали:
M>Результаты в миллисекундах
M>478 M>489 M>487 M>492
M>машинка. Intel 1.73 ГГц
PD>>В релизе на моей машине (AMD Dual 4200+)
PD>>nTime1 == 2375 PD>>nTime2 = 1593
Приношу мои глубочайшие извинения, но мне и в голову не приходило, что кто-то станет сравнивать мои результаты со своими. Я привел их только для того, чтобы показать. что параллельный результат лучше, и насколько. Сравнивать же твои результаы с моими бессмысленно — сначала надо о размере окна договориться
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>И никак нельзя распараллелить иначе, чем Win32 (или на худой конец native API) позволит. С этим-то хоть ты согласен ? Вот ответь прямо — да или нет ?
Andrei F.,
AF>Допустим, у нас есть некоторый GUI с деревом. Развесистым таким деревом, на 10^n элементов. И пользователь где-то в глубине иерархии поменял название одного элемента. Как это будет выглядеть в рамках ФП?
Из сообщений z00n, я понял, что тебе недостаточно, что функциональные структуры данных существуют и работают. Тебя интересует, как будет происходить весь процесс, начиная с процедуры вндового цикла сообщений?
Здравствуйте, Lazy Cjow Rhrr, Вы писали:
LCR>Andrei F.,
AF>>Допустим, у нас есть некоторый GUI с деревом. Развесистым таким деревом, на 10^n элементов. И пользователь где-то в глубине иерархии поменял название одного элемента. Как это будет выглядеть в рамках ФП?
LCR>Из сообщений z00n, я понял, что тебе недостаточно, что функциональные структуры данных существуют и работают. Тебя интересует, как будет происходить весь процесс, начиная с процедуры вндового цикла сообщений?
Да, мне тоже. И хотя бы на примере кнопки, если можно.
Здравствуйте, Sergey J. A., Вы писали:
SJA>Здравствуйте, Pavel Dvorkin, Вы писали:
PD>>Или ты считаешь, что я не могу без JIT написать самомодифицирующуюся программу ? SJA>То есть вместо использования JIT ты напишеш свой?
Нет, конечно, зачем ? Я напоминаю, речь же шла о теореме существования.
Здравствуйте, IT, Вы писали:
IT>Здравствуйте, Pavel Dvorkin, Вы писали:
PD>>Или ты считаешь, что я не могу без JIT написать самомодифицирующуюся программу ?
IT>Картина Репина "Закат солнца в ручную". Ну-ну. Ты проценты распараллелить не в состоянии, какой нафиг JIT?
Ты же вроде обещал прекратить дискуссию, так ? Но почему-то продолжаешь ерничать. Причем с такой настойчивостью, что создается вречатление, что тебя сильно задели. Остынь и успокойся.
Здравствуйте, Sinclair, Вы писали:
S>Этот подход замечателен тем, что он не требует полной априорной информации о свойствах будущей задачи. Очевидно, что он обеспечит не худшую производительность, чем фиксированная программа на все случаи жизни.
При соблюдении двух услових:
в среднем автомат не ошибается, и выбирает правильный вариант программы
вычислительные ресурсы, потраченные на, собственно, выбор, не превышают экономии от правильно сделанного выбора
Здравствуйте, Lazy Cjow Rhrr, Вы писали:
LCR>Из сообщений z00n, я понял, что тебе недостаточно, что функциональные структуры данных существуют и работают.
Меня интересует, насколько хорошо они работают для данной конкретной задачи. Если на каждый чих пользователя будут копироваться целые пачки объектов — это точно не хорошо.
А еще меня интересует, какие преимущества дает использование идеологии ФП для данной задачи.
Вроде я не слишком многого хочу, не так ли?
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Сравнивать же твои результаы с моими бессмысленно — сначала надо о размере окна договориться
Не могу не согласиться
Здравствуйте, WolfHound, Вы писали:
AVK>>Ты не мог бы вкратце рассказать суть? Читать 22 страницы текста как то лень. WH>Disclaimer: Статью читал давно некоторые детали мог немного переврать. WH>Вкраце так: WH>Ребятишки начали писать компилятор С-- на окамле. WH>И подумали: У нас же окамл, а не хаскель какойнибудь. Будем использовать изменяемые данные в оптимизаторе. WH>И начали они их использовать. WH>Даже в конце концов оно у них заработало. WH>Но гемороя по накату и главное откату изменений было столько что они потонули в багах.
Но это же частный случай? Как из него следует, что всегда дешевле делать чисто функциональные структуры? С откатом все понятно. А если откат не нужен? За что мы будем платить повышенным расходом памяти и значительно более сложной реализацией самих структур (не говоря уж о том, что мутабельные структуры в фреймворке уже есть)?
Кроме того, есть всякие штуки вроде System.IO.Stream. Его нефункциональность прошита в базовые слои ОС. Можно его красиво обернуть, по крайней мере избавив от состояния, но с откатами один черт без большого оверхеда ничего не выйдет.
Вобщем, мораль всего этого простая — всегда надо включать голову, а не тупо следовать принципам и правилам. О чем, кстати, IT в заголовке топика явно упоминал.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Andrei F., Вы писали:
AF>Меня интересует, насколько хорошо они работают для данной конкретной задачи. Если на каждый чих пользователя будут копироваться целые пачки объектов — это точно не хорошо.
Зачем целые пачки? Копируются обычно только изменения. Вон, тот же string в дотнете, вполне себе сооответствует принципам ФП, что не мешает эффективно работать с громадным количеством его экземпляров.
AF>А еще меня интересует, какие преимущества дает использование идеологии ФП для данной задачи.
Именно для этой — точно такое же, как и для любой другой: надежный и хорошо читаемый код, отсутствие побочных эффектов, дешевизна распараллеливания на микроуровне и реализации in memory transaction.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Вот смотри — 10 временных единиц я суммирую, а потом читаю с диска, на это уходит 90 временных единиц. Пока не прочитается, суммировать не могу. И цикл по всему этому. Итого я загружаю процессор на 10%. А теперь 2 потока. 10 временных единиц каждый поток суммирует, 90 единиц ждет. Теперь оба потока вместе могут загрузить процессор на 20%. И т.д. Конечно, при 10 потоках 100% не получится, вмешаются другие факторы, которыми я тут пренебрег, но тенденция именно такая.
Это называет распараллеливанием ожидания. Все нормальные люди тут говорят про распараллеливание вычислений.
Достаточно вместо GetPixel взять массив точек в памяти (выдрать с помощью GetDIBits). Потом можно сравнить результаты.
Здравствуйте, AndrewVK, Вы писали:
AVK>Именно для этой — точно такое же, как и для любой другой: надежный и хорошо читаемый код, отсутствие побочных эффектов, дешевизна распараллеливания на микроуровне и реализации in memory transaction.
Избавленный от побочных эффектов GUI — это феноменально. Изобретатель обезжиренного сала удавился от зависти. Все корифеи ФП рыдают от тоски, что не додумались до такой простой и гениальной идеи.
AVK>Рылом не вышел?
Нет, не рылом. Но хотя бы немного думать, прежде чем писать — это очень желательно.
Здравствуйте, Pavel Dvorkin, Вы писали:
IT>>Картина Репина "Закат солнца в ручную". Ну-ну. Ты проценты распараллелить не в состоянии, какой нафиг JIT?
PD>Ты же вроде обещал прекратить дискуссию, так ?
Я и не дискутирую. Я констатирую факт.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, Pavel Dvorkin, Вы писали: S>>То есть тебе не очевидно, что твоя программа "с параллельностью", запущенная на одном ядре, будет менее эффективной, чем твоя же программа "без параллельности"? PD>Не только не очевидно, но в общем случае и неверно.
Павел, хватит придуриваться. Я говорю не про какой-то общий случай, а конкретно про твою конкретную программу.
PD>И, возможно, даже в этом конкретном случае. Да, именно на одном ядре, будет более эффективна параллельная . Я же тебе уже объяснял — если потоки большую часть времени проводят в ожидании, распараллеливание на одном ядре может дать вплоть до N-кратного улучшения — просто потому, что когда один поток ждет, другой работает, а при одном потоке придется ждать.
Павел, ты же такой крутой специалист. Что тебе непонятно? Что программа №1 делает всё в одном потоке — в том, в котором вызвали?
Или что программа номер 2 при вызове на 1 ядре занимается ерундой — выделяет память, создает объекты синхронизации, передает управление во второй поток и тупо садится ждать его выполнения?
S>>Ты уже определись — то ли ты крутой специалист по оптимизации программ, то ли необученный новичок.
PD>Лучше ты ознакомься сначала с основами параллельных вычислений и состояниями потоков, их переходами и т.д.
Павел, я с ними знаком.
S>>Если первое — то непонятно, зачем тебе разжевывать, куда деваются такты и байты памяти при лишних вызовах WaitForMultipleObjects и new[].
PD>О господи! Это уж за всякие пределы выходит. Придется ликбез провести.
PD>WaitForMultipleObjects практически никаких тактов вообще не требует в user mode. Все, что делается при ее вызове — засылка параметров в стек и int 2eh. Все. Поток больше делать ничего не может, так как спит сном праведника и сам себя разбудить не может. Просто в ядре Windows он теперь добавлен в список тех потоков, которые на этом ивенте/мютексе... ждут. Он спит. И когда мютекс сей освободится — ядро проверит его (потока) приоритет, и если он выше приоритета текущего потока, даст ему управление, а если нет — в очередь готовых потоков. Так что WaitFor... работает почти целиком в kernel-mode. А в этом kernel mode этот поток — лишь один из многих, котррыми система управляет. Это все называется накладные расходы, если их не хочешь — возвращайся в DOS. И вопрос в том, перекрывает ли ожидаемый выигрыш от распараллеливания эти расходы или нет. Я фигею.
PD>А new — это тоже накладные расходы, хоть и (чаше всего) не в ядре. В идеале наилучшее по времени распределение памяти было в Фортране -4, так как там вообще динамического распределения памяти не было. Но это шутка, а реально мы ее вынуждены выделять. Опять-таки — как эти накладные расходы соотносятся с ожидаемым эффектом ? Тут и так все ясно — количество chunk равно числу процессоров, а количество new — числу chunk, то есть 2-4-8..., но не тысячи. И на фоне тех 1-2 сек, что требуется для циклов с GetPixel — это все равно, что монетку положить на автомобильные весы
Павел, еще раз напомню, что ты имел смелость сделать абстрактно-теоретическое заявление. Я тебе показываю, что твоя мегапараллельная программа при запуске на 1 ядре будет делать 1 new, не 2-4-8, и будет делать WaitForMultipleObjects, который нифига не бесплатный (ты замерь, сколько времени занимает WaitForMultipleObjects в случае свободного объекта). Я уж не говорю про то, что твой лишний поток сожрал 1 мегабайт адресного пространства ни за хрен собачий, что могло кого-то вытеснить в своп. И всё это можно было не делать. Потому что ядро всё равно одно, и ты всё равно не получишь выигрыша на вычислительной задаче.
А теперь ты вдруг вспомнил про "практические соображения". Если мы перейдем к ним, то нам неизбежно придется вспомнить о том, что идеальных программистов и бесконечного времени на ручную оптимизацию не бывает.
По поводу мультипрограммирования тебе тут уже отвечали: речь не о распараллеливании ожидания. Хотя, конечно, опытным оптимизаторам известно, что даже для него применять потоки ядра — роскошь, а не средство передвижения. Если бы ты дал себе труд ознакомиться с архитектурой высокопроизводительных приложений, то убедился бы, что никто не выделяет "1 поток — 1 задача". Для распараллеливания ожидания эффективнее кооперативная многозадачность и программный параллелизм.
Причем опять же, пространство решений для неё слишком велико, чтобы покрыть его "оптимизированным кодом, написанным на ассемблере". Читать про свитч AXD-301. Там как раз задачи вроде тех, которые ты (как ты думаешь) любишь решать — ограниченная железка, чудовищная нагрузка. Наверное, там не должно быть места "высокоуровневым конструкциям" и "виртуальным машинам". Так? Увы. Всё как раз наоборот. Добро пожаловать в реальный мир.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, deniok, Вы писали:
D>Здравствуйте, Pavel Dvorkin, Вы писали:
PD>>И никак нельзя распараллелить иначе, чем Win32 (или на худой конец native API) позволит. С этим-то хоть ты согласен ? Вот ответь прямо — да или нет ?
D>Green threads
Это просто означает, что реального распараллеливания (то есть с квантованием времени и переключением в произвольный момент) там нет. Есть некое пседораспараллеливание, когда поток/процесс выполняет то одну часть кода, то другую. В любом случае OS может не дать этому потоку квант времени, и он будет спать и ждать, когда ему его дадут. И уж тем более здесь не удастся использовать те преимущества настоящей многопоточночти, как только речь пойдет об ожидании на объектах ядра. Стоит только начать ожидание — как блокируется поток Windows и все, ждите.
Кстати, для этого не надо никакой вирт. машины — посмотри фиберы.
И кстати, по твоей ссылке первая фраза
On a multi-core processor, native thread implementations can assign work to multiple processors, whereas green thread implementations cannot.
PD>И кстати, по твоей ссылке первая фраза
PD>On a multi-core processor, native thread implementations can assign work to multiple processors, whereas green thread implementations cannot.
В Хаскелле это не так. Там forkOS запускает поток OS, а forkIO — lightweight thread, причём
Just to clarify, forkOS is only necessary if you need to associate a Haskell thread with a particular OS thread. It is not necessary if you only need to make non-blocking foreign calls ... Neither is it necessary if you want to run threads in parallel on a multiprocessor: threads created with forkIO will be shared out amongst the running CPUs (using GHC, -threaded, and the +RTS -N runtime option).
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Это просто означает, что реального распараллеливания (то есть с квантованием времени и переключением в произвольный момент) там нет.
Почему? Переключать вполне может и VM. Да, это будет работать в пределах одного «тяжёловесного» потока, но, например, ожидание I/O можно таким образом распараллелить.
PD>Есть некое пседораспараллеливание, когда поток/процесс выполняет то одну часть кода, то другую. В любом случае OS может не дать этому потоку квант времени, и он будет спать и ждать, когда ему его дадут. И уж тем более здесь не удастся использовать те преимущества настоящей многопоточночти, как только речь пойдет об ожидании на объектах ядра. Стоит только начать ожидание — как блокируется поток Windows и все, ждите.
Не понятно, о что это за «преимущества». Вот например Erlang для массивной многопоточности (десятки и сотни тысяч процессов внутри VM) использует как раз что-то типа green threads. Процессы работают в рамках VM, и VM предоставляет им механизмы синхронизации (в случае Erlang это только посылка сообщения/приём). Т.е взять и заблокировать весь «тяжёлый» поток (предоставляемый OS) Erlang-овкий процесс не сможет.
Здравствуйте, AndrewVK, Вы писали:
AVK>Несерьезно, это не понимать, что читаемость кода и его близость к формулировке задачи — это самый важный параметр оценки качества этого самого кода.
и результаты его меня просто пугают. Но не хочу сейчас флейм на эту тему устраивать.
>Конечно, на таком игрушечном кусочке вроде как можно и пережить то, что ты продемонстрировал, но когда кусочки станут побольше, соотношение объема изапутанности сохранится, если не увеличится, и вот тут то это будет совсем уже не фигня.
А где там запутанность ? Нормальный код, как все на Win32 пишут.
AVK>Вот, кстати, характерная твоя ошибка — говорим о дизайне кода, а ты даже не в состоянии привести пример без использования специфики Win32.
Опять ? Я же привел тебе описание задачи! Ну не могу же я его привести, не упоминая окна и пикселей, если задача именно с окном и именно с пикселями.
>Все я прекрасно понимаю, но разбираться в этом принципиально не хочу, потому что к обсуждаемому вопросу это отношения не имеет.
Да никто и не заставляет. Ну не нравится тебе мое описание — сказал, я согласился, дал другое. Оно не нравится — скажи, уточню еще раз. Чего тему-то мусолить ?
AVK>Ты вообще понимаешь разницу между конструкциями языка и API операционной системы?
>Мы здесь, еще раз напоминаю, обсуждаем именно конструкции языка, и ничто иное. Обойтись без LINQ для демонстрации возможностей ФП на шарпе нельзя в принципе, обойтись без Win32 для демонстрации того, что LINQ ничего не дает можно, и даже нужно.
Согласен. Я вполне могу убрать оттуда и окно, и GetPixel, а просто предложить просуммировать столбцы некоего двумерного массива, каким-то образом заданного. Правда, чтобы время померить, придется либо в цикл это вставить, либо уж очень большой массив использовать. Впрочем, чтобы IT-ские проценты сравнить в AsParallel и без, то же придется сделать. Но все же никак не пойму — чего ты к пустякам придираешься ? Ну какое отношение к распараллеливанию имеет вопрос откуда и как брать эту матрицу ?
AVK>Конечно, в том и суть, что ты, ничего не зная ни про ФП, ни про LINQ, тем не менее понимаешь код, который IT привел.
Вообще-то нет. Про ФП я могу не знать, про LinQ тоже, а вот SQL знать надо, иначе я его этот SELECT и GROUP в нем не пойму.
AVK>>>А теперь сравни со своей простыней. Что там у нас осталось? Параллелить вкривь и вкось различными способами?
PD>>Если не сложно, объясни , почему вкривь и вкось, это раз
AVK>Не знаю, тебе захотелось по диагонали или еще как то там пиксели обсчитывать.
Андрей, это уж никуда не годится. Я привел этот пример именно, чтобы показать, что когда мне надо не в "горизонтально-вертикальном", а в произвольном направлении ходить, ваш подход ИМХО пробуксовывает. ИМХО, заметь — я же вопрос задал, а не утверждал, что нельзя. Если докажешь, что можно и логично при этом получится — признаю, конечно. Ну а насчет того, что , мол, вкривь и вкось — не будешь же ты утверждать всерьез, что матрицы только по строкам или по столбцам проходят
Я вот одно понять не могу. Ну что стоит признать, что для определенной ситуации этот подход не очень хорош ? Вот был бы я на вашем месте, ответил бы так — "да, для такого рода действий этот подход не годится или не очень эффективен (или еще что-то). Зато он очень хорош, для задач типа той, о которйк я написал". И все, вопрос исчерпан, и я тут же соглашусь — для заточки карандашей не годится топор, а дерево рубить не надо столовым ножиком. И обсуждать больше нечего, разве что детали и эффективность того или иного решения.
AVK>Понимаю. И что? Я тебе в который раз напоминаю — речь не о библиотеках и их возможностях, речь о языке программирования. AsParallel просто демонстрирует эти возможности, не более того.
Понимаешь, для меня большой разницы между языком и библиотекой нет. Реально для меня это два взаимосвязанных инструмента, и без одного из них, любого, я не обойдусь. Теоретически обойдусь, пока просто так думаю, а как сяду за компьютер — нет. Как ни страшно это для тебя звучит, но это так. Ну хорошо, давай оставим только язык. Linq твой останется, допустим, но ведь всех библиотек .NET FW я тебя лишу, если ты хочешь меня лишить Win32. И что ты сможешь сделать ? Или ты заявишь, что .Net FW — это часть языка, а Win32 — нет ? Массивы в C# — это часть языка или нет ? Безусловно да, входят в спецификацию. Но ведь без реализации класса Array в .Net FW не будет у тебя массивов!
PD>> Не обязательно так, конечно, скорее там пул потоков, посмотрю как-нибудь. Ну нет в Win32 иного способа параллелить и нет в Windows ничего, что не проходио бы через Win32 (про OS/2 и POSIX умолчим).
AVK>Оторвись от замочной скважины и открой наконец дверь.
Да пойми ты наконец, что все проходит через эту замочную скажину, если уж тебе такое сравнение нужно. Я абсолютно ниченго не знаю, скажем, про реализации ЛИСПА, да и сам ЛИСП не знаю, но если мне кто-то скажет, что в ЛИСПЕ можно записать файл, минуя в конечном счете WriteFile — это даже не смешно.
PD>>Итераторы в С++ существуют, а вообще это понятие языково-независимо.
AVK>Под итераторами в C# здесь подразумеваются специальные возможности языка. Это частный случай продолжений (continuations), предназначенный для легкого и удобного создания сложных итераторов. В С++ такое эмулируют при помощи макросов, но качество решения получается при этом ниже плинтуса.
Ну это обсуждать не будем, предлагаю так, а то мы еще один флейм устроим.
PD>> Вот ответь прямо — да или нет ?
AVK>Отвечаю прямо — неважно.
Не ответил
>Не уводи от темы. Распараллеливание здесь в качестве примера, а не самоцель.
А вот в этом не уверен. IT именно это и заявил — могу , мол, легко распараллелить.
>Если не можешь съехать с Win32, я могу в примере заменить распараллеливание на, скажем, кеширование.
Ты хочешь, чтобы мы еще флейм на тему кеширования завели ? Не надо
PD>>Честно говоря, не слишком понял — что ты суммируешь и куда. Если это реализация моей задачи
AVK>Она.
PD>> — где массив сумм по столбцам ?
AVK>Вот тебе с массивом, это еще проще: AVK>
AVK>return
AVK> (
AVK> from x in Enumerable.Range(0, Width)
AVK> select Enumerable.Range(0, Height).Sum(y => pixels[x, y])
AVK> )
AVK> .AsParallel()
AVK> .ToArray();
AVK>
AVK>Обрати внимание, насколько просто оказывается поменять код.
Да просто, кто спорит. Я еще раз говорю — я совсем не противник этого. Я не согласен, когда это за панацею выдается.
А все же, как с диагоналями ? . Мне-то несложно. PD>>Ты все же попробуй те 5 вопросов осилить.
AVK>Смысл? Игрища с приоритетами потоков в контексте вопроса малоинтересны и непринципиальны (ну будет там какой нибудь доп.параметр у AsParallel()).
Вот то-то и оно. IT уверен — напишу AsParallel и все, остается только сливки снимать. Ты уже засомневался, и это верно, хочешь какой-то параметр (в скобках — или метод, или аттрибут или еще что-то). Дело в том, что поручив все это системе(библиотеке, FW) и надеясь, что она сделает все наилучшим образом, ты очень скоро поймешь, что иногда да, это совсем неплохо, а иногда — ни в какие ворота. И тогда тебе придется изучать всю эту кухню (не обязательно на Win32, реализация Thread в С# в общем, повторяет Win32) и требовать, чтобы у AsParralel были какие-то возможности управления.
Хотя теоретически да, можно представить себе систему, которая сама примет решение о том, как и когда распараллеливать алгоритм. Но эта задача эквивалентна задаче автоматического распараллеливания произвольного алгоритма, а ее, насколько я понимаю, еще никто не решил. Впрочем, почитай здесь же в форуме, ИМХО с год назад тут большая дискуссия была о параллелизме.
PD>> А это суммирование, конечно, распараллелить можно, задачка-то пустяковая.
AVK>Только даже на такой пустяковой задачке прекрасно видно, насколько твой императивнй код запутаннее.
Андрей, не надо. Код как код, делает то, что ему положено, и запутанного там ничего нет. Ты просто мой код еще не знаешь — если уж я впрямь начну запутанный код писать, его никто, кроме меня, не распутает (Ох, какой козырь я тебе дал — но будь джентльменом, не воспользуйся им, прошу
PD>>Вообще-то я не очень понимаю — в чем разница. Он какие-то проценты считает на баз неких коллекций, а я суммы считаю на базе тоже, если хочешь, "коллекций — столбцов пикселей.
AVK>У него алгоритм намного сложнее, а, главное, там уровень косвенности выше.
У него в реальных его задачах — не сомневаюсь. И никаких сомнений в его качествах как специалиста я не высказывал, это ему очень хочется доказать, что я проценты считать не умею. Алгоритм вычисления процентов — мб и сложнее, чем вычисления сумм, но, по правде сказать, обоим (как алгоритмам) место в средней школе во втором-третьем месяце изучения программирования.
PD>> Делить я не делю и не суммирую, верно, но так ли это важно ? Есть распараллеливание алгоритма, что тут особого-то.
AVK>Ты сделай сперва без распараллеливания, и мы обсудим результат.
Здравствуйте, gandjustas, Вы писали:
G>Это называет распараллеливанием ожидания. Все нормальные люди тут говорят про распараллеливание вычислений.
G>Достаточно вместо GetPixel взять массив точек в памяти (выдрать с помощью GetDIBits). Потом можно сравнить результаты.
Да, конечно. Я просто хотел подчеркнуть, что распараллеливание — совсем не такое простое действие. Иногда и на одном процессоре можно, иногда — не имеет смысла. Иногда и то и другое
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Здравствуйте, gandjustas, Вы писали:
G>>Это называет распараллеливанием ожидания. Все нормальные люди тут говорят про распараллеливание вычислений.
G>>Достаточно вместо GetPixel взять массив точек в памяти (выдрать с помощью GetDIBits). Потом можно сравнить результаты.
PD>Да, конечно. Я просто хотел подчеркнуть, что распараллеливание — совсем не такое простое действие.
Это смотря как писать.
PD>Иногда и на одном процессоре можно, иногда — не имеет смысла. Иногда и то и другое
Еще раз: распараллеливание вычислений на одном процессоре только уменьшит быстродействие.
Распараллеливание ожидания лучше выполнять не с помощью ручного создания потоков.
Здравствуйте, Sinclair, Вы писали:
S>Здравствуйте, Pavel Dvorkin, Вы писали: S>>>То есть тебе не очевидно, что твоя программа "с параллельностью", запущенная на одном ядре, будет менее эффективной, чем твоя же программа "без параллельности"? PD>>Не только не очевидно, но в общем случае и неверно. S>Павел, хватит придуриваться.
Антон, хватит употреблять непарламентские выражения. Ты иначе не умеешь ?
S>Павел, ты же такой крутой специалист. Что тебе непонятно? Что программа №1 делает всё в одном потоке — в том, в котором вызвали? S>Или что программа номер 2 при вызове на 1 ядре занимается ерундой — выделяет память, создает объекты синхронизации, передает управление во второй поток и тупо садится ждать его выполнения?
Ах вот ты о чем! Извини, действительно не понял. Да, тут ты прав — код #2 потребует дополнительных расходов, верно. Но код #1 был просто приведен для сравнения скорости. Употреблять его вообще нельзя — он замораживает интерфейс. Это надо в поток выносить в любом случае.
S>Павел, я с ними знаком.
Не верится. Иначе не стал бы ты такое заявлять.
S>>>Если первое — то непонятно, зачем тебе разжевывать, куда деваются такты и байты памяти при лишних вызовах WaitForMultipleObjects и new[].
PD>>О господи! Это уж за всякие пределы выходит. Придется ликбез провести.
PD>>WaitForMultipleObjects практически никаких тактов вообще не требует в user mode. Все, что делается при ее вызове — засылка параметров в стек и int 2eh. Все. Поток больше делать ничего не может, так как спит сном праведника и сам себя разбудить не может. Просто в ядре Windows он теперь добавлен в список тех потоков, которые на этом ивенте/мютексе... ждут. Он спит. И когда мютекс сей освободится — ядро проверит его (потока) приоритет, и если он выше приоритета текущего потока, даст ему управление, а если нет — в очередь готовых потоков. Так что WaitFor... работает почти целиком в kernel-mode. А в этом kernel mode этот поток — лишь один из многих, котррыми система управляет. Это все называется накладные расходы, если их не хочешь — возвращайся в DOS. И вопрос в том, перекрывает ли ожидаемый выигрыш от распараллеливания эти расходы или нет. S> Я фигею.
Похоже, это твое основное состояние. Если ты фигееешь от того, что во всех руководствах написано (Еще раз — почтай Рихтера), и что я просто пересказал своими словами, не добавив от себя ничего — ну что же...
S>А теперь ты вдруг вспомнил про "практические соображения". Если мы перейдем к ним, то нам неизбежно придется вспомнить о том, что идеальных программистов и бесконечного времени на ручную оптимизацию не бывает.
А кто спорит ? Я же тысячу раз говорил — вопрос об идеальной программе есть теорема существования. А в реальности надо выбор делать. Если времени разработчика мало, а сроки поджимают, а производительность некритична — делай хоть на Linq, хоть на GW-Basic . Если наоборот — пиши на C++ или даже на ассемблере (отдельные куски).
S>По поводу мультипрограммирования тебе тут уже отвечали: речь не о распараллеливании ожидания. Хотя, конечно, опытным оптимизаторам известно, что даже для него применять потоки ядра — роскошь, а не средство передвижения.
Почитай Рихтера, особенно 2-й том. APC пользовательского режиа, порты ожидания, особенно им рекомендуемые, асинхронный ввод-вывод, процедуры завершения. Тогда не будешь такое говорить.
>Если бы ты дал себе труд ознакомиться с архитектурой высокопроизводительных приложений, то убедился бы, что никто не выделяет "1 поток — 1 задача".
Нет такого понятия в Windows — задача. Исключено при переходе Win16->Win32. Если речь идет о процессе, то он здесь ни при чем, так как Windows занимается квантованием времени на уровне потоков, а не процессов. Так что уж, будь добр, определи, что означает слово "задача" в твоем понимании, а тогда и обсудим, сколько потоков должно быть на задачу или задач на поток. Только все же сначала почитай Рихтера. Там эта архитектура подробно рассматривается.
>Для распараллеливания ожидания эффективнее кооперативная многозадачность и программный параллелизм.
Привет от Windows 3.11
Ожидания чего ? Ответа/запроса пользователя в каком-нибудь www-сервере ? Ожидание завершения операции ввода/вывода на диске ? Ожидание по таймеру ? И т.д. Это все совершенно разные действия, и методы тут разные. Где-то режим опроса (поллинга) эффективнее, где-то он совсем не годится. Представляю себе поллинг в ядре Windows
S>Причем опять же, пространство решений для неё слишком велико, чтобы покрыть его "оптимизированным кодом, написанным на ассемблере". Читать про свитч AXD-301.
Вот уж это читать не буду. У меня других дел хватает, чтобы еще свитчами заниматься.
Здравствуйте, Klapaucius, Вы писали:
K>Здравствуйте, Pavel Dvorkin, Вы писали:
PD>>Если использовать крупноблочное строительство, то всегда найдется проект, для которого ни один набор выпускаемых крупных блоков не подходит. Если строить из кирпичей, то можно построить все, что угодно — от утепленной собачьей будки до собора святого Петра.
K>Отличный пример. K>
K>Расходы на строительство оказались столь велики, что для покрытия их папе Льву X пришлось за большую сумму денег передать право распространять индульгенции Альбрехту Брандербургскому. Злоупотребления индульгенциями в немецких землях вызвали протест Лютера, Реформацию и последующий раскол Европы.
Верно!
Но построили же! Другого такого нет!
PD>>Из кирпичей можно все построить.
K>Ну да, попробуйте что-то вроде Salginatobel Bridge из кирпичей построить. Из кирпича не построить даже Flatiron Building, здания из кирпича имеют тенденцию расползаться под собственной тяжестью.
Здравствуйте, gandjustas, Вы писали:
G>Здравствуйте, Pavel Dvorkin, Вы писали:
PD>>К сожалению, если поручить это все оптимизатору компилятора, то этот компилятор должен будет быть попросту гениальным, то есть включать в себя знание всех и всяческих техник, трюков и т.п, связанных и с кэшами, и с многопроцессорностью и с характером задачи. Увы, это вряд ли реально. G>Но теоретически возможно. Что и требовалось доказать.
Я пытаюсь эту ситуацию сейчас понять. В общем, видимо, с идеальной программой я не совсем прав. При бесконечном количестве ресурсов ее не может быть. При ограниченном количестве она все же существует. Додумать надо.
PD>>Компилятор будет в лучшем случае оптимизировать "в среднем", то есть в расчете на некую среднюю задачу. И чем выше уровень абстракций, тем хуже он это будет делать. Оптимизировать цикл можно очень хорошо, а оптимизировать задачу "сделай вот это" — можно лишь на бвзе некоторых правил оптимизации общего порядка. Как только попадется нечто, что под эти правила не подходят — результат будет плохим. G>Можно не писать то, что под эти правила не подходит.
Так я об этом и говорю. Каждому инструменту — свое назначение. Где Linq, где ассемблер. кесарю кесарево, слесарю — слесарево
PD>А кто спорит ? Я же тысячу раз говорил — вопрос об идеальной программе есть теорема существования.
Подробное опровержение т.н. "теоремы существования" см. здесь
.
S>>По поводу мультипрограммирования тебе тут уже отвечали: речь не о распараллеливании ожидания. Хотя, конечно, опытным оптимизаторам известно, что даже для него применять потоки ядра — роскошь, а не средство передвижения.
PD>Почитай Рихтера, особенно 2-й том. APC пользовательского режиа, порты ожидания, особенно им рекомендуемые, асинхронный ввод-вывод, процедуры завершения. Тогда не будешь такое говорить.
Я продолжаю поражаться способностью некоторых людей смотреть в книгу, а видеть известную фигуру из трех пальцев. В том плане, что Рихтер как раз описывает способ минимизировать количество ядерных потоков для реализации асинхронных задач. Простой вопрос на понимание сути: для чего все эти припрыгивания с процедурами завершения, если можно тупо сделать блокирующий вызов в своем потоке?
>>Если бы ты дал себе труд ознакомиться с архитектурой высокопроизводительных приложений, то убедился бы, что никто не выделяет "1 поток — 1 задача".
PD>Нет такого понятия в Windows — задача. Исключено при переходе Win16->Win32. Если речь идет о процессе, то он здесь ни при чем, так как Windows занимается квантованием времени на уровне потоков, а не процессов. Так что уж, будь добр, определи, что означает слово "задача" в твоем понимании, а тогда и обсудим, сколько потоков должно быть на задачу или задач на поток. Только все же сначала почитай Рихтера. Там эта архитектура подробно рассматривается.
Задача здесь подразумевается пользовательская. К примеру, "прочитать 8192 байта с диска". Или, более крупно, скажем "обработать входящий http-запрос".
Очевидное решение — выделить каждое соединение в отдельный поток, чтобы обеспечить максимальный параллелизм. Вот только так никто не делает: слишком велики накладные расходы на управление сотнями потоков, так как они большую часть времени спят. Делают пул в пару десятков потоков на ядро, и его с запасом хватает для всех этих операций. Почитай Рихтера, там это хорошо описано
>>Для распараллеливания ожидания эффективнее кооперативная многозадачность и программный параллелизм. PD>Привет от Windows 3.11
Нет. Привет от файберов, lighttpd и SQL Server. Не стесняйся, Павел, учи матчасть.
PD>Ожидания чего ? Ответа/запроса пользователя в каком-нибудь www-сервере ? Ожидание завершения операции ввода/вывода на диске ? Ожидание по таймеру ? И т.д. Это все совершенно разные действия, и методы тут разные.
Это, Павел, от того, что твои знания — совершенно бессистемные. Ты не понимаешь, что JIT по отношению к x86 делает c MSIL то же самое, что Pentium делает с x86 кодом по отношению к своему микрокоду. Не понимаешь, что ожидание в www-сервере, файлового ввода-вывода, и таймера устроены совершенно одинаково. И методы везде применяются те же самые.
PD>Где-то режим опроса (поллинга) эффективнее, где-то он совсем не годится. Представляю себе поллинг в ядре Windows
Давненько я не видел задач, где поллинг был бы хоть как-то приемлем.
S>>Причем опять же, пространство решений для неё слишком велико, чтобы покрыть его "оптимизированным кодом, написанным на ассемблере". Читать про свитч AXD-301. PD>Вот уж это читать не буду. У меня других дел хватает, чтобы еще свитчами заниматься. Да здравствует упорствующее невежество.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Andrei F., Вы писали:
AF>Побочные эффекты в виде вывода на экран — это цель создания GUI.
На основании чего ты решил, что вывод на экран это побочный эффект?
AF>А когда этот оппонент доказывает мне одно, а в соседней ветке проталкивает прямо противоположное — вот тогда сомнения уже закрадываются...
Цитаты, конечно, будут?
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
welcome to real world
PD>А где там запутанность ? Нормальный код, как все на Win32 пишут.
Самому не смешно?
AVK>>Вот, кстати, характерная твоя ошибка — говорим о дизайне кода, а ты даже не в состоянии привести пример без использования специфики Win32.
PD>Опять ? Я же привел тебе описание задачи!
Тогда забудь в этом топике про слово Win32, ты же его через абзац упоминаешь.
PD> Ну не могу же я его привести, не упоминая окна и пикселей, если задача именно с окном и именно с пикселями.
Вот об этом и речь.
PD>Да никто и не заставляет. Ну не нравится тебе мое описание — сказал, я согласился, дал другое.
Нук а я тебе дал ответ. Что тебя еще не устраивает?
PD> Впрочем, чтобы IT-ские проценты сравнить в AsParallel и без, то же придется сделать. Но все же никак не пойму — чего ты к пустякам придираешься ? Ну какое отношение к распараллеливанию имеет вопрос откуда и как брать эту матрицу ?
Никакого. Только ты погляди на свои аргументы:
Если бы я это в форуме по Win32 написал ...
Если ты не очень понимаешь Win32 ...
Ну нет в Win32 иного способа параллелить и нет в Windows ничего, что не проходио бы через Win32
Распараллеливание тоже (не в С++, а в Win32)
И никак нельзя распараллелить иначе, чем Win32 ...
Win32, Win32, Win32, Win32. Напоминаю — обсуждать тут пытались конструкции языков программирования. Я понимаю, тебе про этот Win32 каждый день приходится студентам рассказывать, но надо хоть чуть чуть абстрагироваться, если тема разговора никакого отношения к Win32 не имеет.
PD>Вообще-то нет. Про ФП я могу не знать, про LinQ тоже, а вот SQL знать надо, иначе я его этот SELECT и GROUP в нем не пойму.
А ты SQL не знаешь?
AVK>>Не знаю, тебе захотелось по диагонали или еще как то там пиксели обсчитывать.
PD>Андрей, это уж никуда не годится. Я привел этот пример именно, чтобы показать, что когда мне надо не в "горизонтально-вертикальном", а в произвольном направлении ходить, ваш подход ИМХО пробуксовывает.
Нигде он не пробуксовывает. Тебе уже два человека написали — начальные итераторы (в моем коде Enumerable.Range) можно написать какими угодно, причем код будет короче за счет наличия в шарпе специальных конструкций для этого.
PD>Я вот одно понять не могу. Ну что стоит признать, что для определенной ситуации этот подход не очень хорош ?
О, вот очень удачно ты это спросил. Ты сам, лично, ни разу здесь не признал, что был не прав, даже если, порой, тебе приводили абсолютно неопровержимые аргументы. Зато с других ты это требуешь.
PD> Вот был бы я на вашем месте, ответил бы так — "да, для такого рода действий этот подход не годится или не очень эффективен (или еще что-то). Зато он очень хорош, для задач типа той, о которйк я написал".
У рыбы шерсти нет, а вот если бы была ...
PD>Понимаешь, для меня большой разницы между языком и библиотекой нет.
Вот вот.
PD> Linq твой останется, допустим, но ведь всех библиотек .NET FW я тебя лишу, если ты хочешь меня лишить Win32.
Я не хочу тебя лишать Win32 (боже упаси), я хочу чтобы в этой теме не присутствовало обсуждение особенностей этого самого Win32.
PD>Да пойми ты наконец, что все проходит через эту замочную скажину
PD>но если мне кто-то скажет, что в ЛИСПЕ можно записать файл, минуя в конечном счете WriteFile
А если не скажет? Сам выдумываешь оппонента и потом с ним споришь. Какая разница, через что там будет запись, если речь нге о механизмах записи файла, а о конструкциях языка?
PD>Ну это обсуждать не будем, предлагаю так, а то мы еще один флейм устроим.
Ну ты же настаиваешь, что для линка изменение порядка обхода — неразрешимая проблема.
PD>>> Вот ответь прямо — да или нет ?
AVK>>Отвечаю прямо — неважно.
PD>Не ответил
Ответил. И очень плохо, что ответ понят ты то ли не хочешь, то ли не можешь.
>>Не уводи от темы. Распараллеливание здесь в качестве примера, а не самоцель.
PD>А вот в этом не уверен.
А я уверен.
PD> IT именно это и заявил — могу , мол, легко распараллелить.
Он это заявил для того, чтобы продемонстрировать, как легко изменять функциональный код. Потому что именно наличие ФВП и возможности их комбинирования позволяет переместить в библиотеку не только конкретные алгоритмы, но и шаблоны кусков этих алгоритмов, не требуя при этом создания специальных классов или методов. Суть не в том, что это в Win32 обращается и что то там реально параллелит, а в сложности организации подобного в императивном коде.
Вот именно поэтому тебе и предлагают реализовать предложенный пример, чтобы ты понял, в чем именно преимущество ФП.
>>Если не можешь съехать с Win32, я могу в примере заменить распараллеливание на, скажем, кеширование.
PD>Ты хочешь, чтобы мы еще флейм на тему кеширования завели ? Не надо
Я хочу, чтобы ты наконец оглянулся вокруг и попытался думать чуть более абстрактно.
PD>Да просто, кто спорит.
Ты
PD> Я еще раз говорю — я совсем не противник этого.
Незаметно, если честно.
А не возникала ли у тебя мысль — а может, ничего и не надо ?
PD> Я не согласен, когда это за панацею выдается.
А кто тут выдавал ФП за панацею. Цитату можно? Вот кусочек сообщения IT, с которого эта нитка пошла:
Вот здесь два примера того, как правильные высокоуровневые конструкции могут сделать код ...
"Могут" это, по твоему, синоним панацеи? Причем, опять же, IT тебе на "могут" внимание уже обращал, так что на невнимательность списать не получится.
PD>А все же, как с диагоналями ? . Мне-то несложно.
Ну так привел бы.
PD> Ты уже засомневался
Я не засомневался, я просто указываю тебе на то, что управление приоритетами находится за рамками разговора. Никаких особенных возможностей языка оно ни при каком раскладе не требует.
PD>, и это верно, хочешь какой-то параметр (в скобках — или метод, или аттрибут или еще что-то).
Я не хочу, я просто указываю на то, что параметр, решающий твою проблему, добавить в метод AsParallel совсем не сложно (если его там уже нет) и это не приведет ни к какому ощутимому усложнению кода.
PD> Дело в том, что поручив все это системе(библиотеке, FW) и надеясь, что она сделает все наилучшим образом, ты очень скоро поймешь, что иногда да, это совсем неплохо, а иногда — ни в какие ворота.
То же можно сказать и о Win32. Но ты, я гляжу, упорно пытаешься увести разговор в сторону.
AVK>>Только даже на такой пустяковой задачке прекрасно видно, насколько твой императивнй код запутаннее.
PD>Андрей, не надо.
Надо. Именно в этом суть головного сообщения топика. Если ты этого понять не можешь — разговаривать, собственно, не о чем. Подробности Win32 обсуждай, пожалуйста, без меня, последние лет 5 меня сии знания не интересуют.
AVK>>У него алгоритм намного сложнее, а, главное, там уровень косвенности выше.
PD>У него в реальных его задачах — не сомневаюсь.
В примере тоже. Ты тут так красиво расписывал, что тебе какие то там проценты нипочем. А как до дела дошло — результата 0, одни слова.
PD> Алгоритм вычисления процентов — мб и сложнее, чем вычисления сумм, но, по правде сказать, обоим (как алгоритмам) место в средней школе во втором-третьем месяце изучения программирования.
Ну и отлично. Ждем код.
AVK>>Ты сделай сперва без распараллеливания, и мы обсудим результат.
PD>Ну опять
Конечно, а ты как думал? Ты уже неделю тут пытаешься что угодно обсудить, а кода все нет и нет.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, AndrewVK, Вы писали:
AF>>Побочные эффекты в виде вывода на экран — это цель создания GUI. AVK>На основании чего ты решил, что вывод на экран это побочный эффект?
На основании определения понятия "побочный эффект". Дальше можно точно не продолжать, ты уже сказал более чем достаточно.
PD>Что-то я не понял. Вы собрались матрицы в символьном виде перемножать ? Задача достойная, но это не арифметика, а обработка текста в основном. И оптимизация совсем другого, мб, понадобится — рабботы со строками, к примеру.
Ну-ну, вообще-то символьные вычисления — это не строки. Это деревья.
Оптимизация тут вот где. Есть у нас один общий алгоритм для вычисления произведения матриц над кольцом P, где само кольцо передаётся в качестве параметра. При этом кольцо представляет из себя интерфейс. Далее, пишем реализации этого интерфейса для понятий "целые числа", "действительные числа", "выражение". Если бы это компилировали в C++, то на каждое сложение/умножение пришлось бы вызывать виртуальный метод, что не быстро. В случае с нормальным языком (тот же C#) вызов может заинлайниться. Т.е. он не просто превратится в невиртуальный вызов, а вообще для сложения будет использоваться что-то вроде add eax, abx, тут же, по месту для случая целых чисел.
LCR>>А Таня, вдобавок, хочет взять ваш алгорить, и сделать так, чтобы вместо вещественных чисел были функции, да ещё и на комплексном пространстве.
LCR>>И, наконец, Алиса, взяв ваш алгоритм в качестве процедуры, вдруг осознала, что он и является главным пожирателем процессорного времени, но специфика задачи позволяет вычислять всё произведение не сразу, а по немножку. И её осенило, что если в вашем алгоритме использовать ленивые for-ы, то всё становится замечательно.
PD>Что-то много у вас знакомых, и все они чего-то хотят
А вот жизнь такая штука. Зачем по 100 раз писать один и тот же код, если его можно взять у другого, и заниматься решением _своей_ задачи, а не решать сотни других мелких подзадач? Платят же за задачу, а не за написание велосипедов.
PD>К сожалению, если поручить это все оптимизатору компилятора, то этот компилятор должен будет быть попросту гениальным, то есть включать в себя знание всех и всяческих техник, трюков и т.п, связанных и с кэшами, и с многопроцессорностью и с характером задачи. Увы, это вряд ли реально. Компилятор будет в лучшем случае оптимизировать "в среднем", то есть в расчете на некую среднюю задачу. И чем выше уровень абстракций, тем хуже он это будет делать. Оптимизировать цикл можно очень хорошо, а оптимизировать задачу "сделай вот это" — можно лишь на бвзе некоторых правил оптимизации общего порядка. Как только попадется нечто, что под эти правила не подходят — результат будет плохим.
Думаю, не стоит недооценивать компиляторы в этом аспекте. Кроме того, у них есть достоинство — они не ошибаются. Точнее, ошибаются, как и всякая программа. Но! На компилятор рано или поздно наложат заплатку, и он не будет ошибаться. Компилятор один раз пишут, а компилируют им миллионы человек миллионы раз. А человек, если ошибся один раз, не факт, что из-за своего невнимания не наступит на те же грабли в другой.
PD>Оптимизировать задачу "постройте мне автоматически собор святого Петра" — нельзя. Для этого Браманте и Микеланджело нужны. А если эту задачу оптимизировать автоматически, то в итоге получится утепленная собачья будка размером с собор святого Петра.
Здравствуйте, AndrewVK, Вы писали:
AVK>На С++ в таких случаях пишется шаблон, реализация которого прекрасно инлайнится, причем возможности инлайнинга у современных компиляторов С++ заметно выше дотнетного или джавовского джита.
Нужно уточнить что современные реализации С++ лучше инлайнят чем современный JIT но это не теоритическое ограничение.
Просто еще JIT'ы недоделали.
The choice of Java as a target for current supercompilation research is not coincidental. It was desired to choose a real-world programming language, in which there are numerous examples of large-scale programs needful of multifold optimization. C and C++ would seem to be the first choice; however, these languages are particularly unsuitable for global program optimization techniques, because of their use of pointers, which directly manipulate the memory heap. In order to do global program optimization on a C/C++ program, one would have to include in one's mathematical model of a program, a complete mathematical model of the memory heap and its interactions with the program. This is not impossible, but it would entail a huge increase in the complexity of the task involved.
То... кто кого порвет мы еще посмотрим.... шипела на тузика надутая до 100 атмосфер грелка.
... << RSDN@Home 1.2.0 alpha rev. 745>>
Пусть это будет просто:
просто, как только можно,
но не проще.
(C) А. Эйнштейн
Здравствуйте, WolfHound, Вы писали:
WH>А если предварительно пройтись сеперкомпилятором http://www.supercompilers.com/white_paper.shtml который для С++ реализовать мягко говоря не просто...
S> Серъезно? Ну-ка, ну-ка, и как же нужно модифицировать этот запрос, чтобы он наворотил тучу SQL запросов? Хочется подтвердить эту небезынтересную гипотезу реальным ахтунг-примером.
Здравствуйте, AndrewVK, Вы писали:
AVK>welcome to real world
Вот, кстати, про real world. Со мной уже все ясно — проценты я считать не умею, ладно . Но не я один такой. Оказывается, и суммы-то точно считать не умеют, и кто — страшно сказать!
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Вот, кстати, про real world. Со мной уже все ясно — проценты я считать не умею, ладно . Но не я один такой. Оказывается, и суммы-то точно считать не умеют, и кто — страшно сказать!
PD>Не иначе как они это суммирование распараллелили
K>Оптимизация тут вот где. Есть у нас один общий алгоритм для вычисления произведения матриц над кольцом P, где само кольцо передаётся в качестве параметра. При этом кольцо представляет из себя интерфейс. Далее, пишем реализации этого интерфейса для понятий "целые числа", "действительные числа", "выражение". Если бы это компилировали в C++, то на каждое сложение/умножение пришлось бы вызывать виртуальный метод, что не быстро.
Бог с тобой. Это темплейтами вполне делается, без всякой виртуальности.
>В случае с нормальным языком (тот же C#) вызов может заинлайниться. Т.е. он не просто превратится в невиртуальный вызов, а вообще для сложения будет использоваться что-то вроде add eax, abx, тут же, по месту для случая целых чисел.
Именно это и будет.
template <class T > class A
{
private:
T m_t;
public :
A(T t = 0)
{
m_t = t;
}
T operator+(A& a)
{
return m_t + a.m_t;
}
};
// глобальные - чтобы оптимизатор VC++ Release не выкинул весь этот код, как бесполезный. Он это умеет :-)
A<int> i1(10), i2(20), i3;
A<float> f1(10.5f), f2(20.8f), f3;
int _tmain(int argc, _TCHAR* argv[])
{
i3 = i1 + i2;
f3 = f1 + f2;
return 0;
}
Что там инлайнинг — он еще и порядок действий поменял.
K>А вот жизнь такая штука. Зачем по 100 раз писать один и тот же код, если его можно взять у другого, и заниматься решением _своей_ задачи, а не решать сотни других мелких подзадач? Платят же за задачу, а не за написание велосипедов.
Можно. Вот недавно взял. Исходный код работал 5 сек. Теперь у меня работает 1.5 секунды. А надо 200 мсек. Сделаю, теперь уже не сомненваюсь. Вот за это мне и платят
K>Думаю, не стоит недооценивать компиляторы в этом аспекте. Кроме того, у них есть достоинство — они не ошибаются. Точнее, ошибаются, как и всякая программа. Но! На компилятор рано или поздно наложат заплатку, и он не будет ошибаться. Компилятор один раз пишут, а компилируют им миллионы человек миллионы раз. А человек, если ошибся один раз, не факт, что из-за своего невнимания не наступит на те же грабли в другой.
Может, и наступит. Может , и нет. Но вот сделать то, благодаря чему мой код стал работать в 3 раза быстрее — компилятор не сможет. Ручаюсь. Потому что я там отнюдь не на ассемблере оптимизации проводил (и, надеюсь, не придется, хотя я там собираюсь SSE2 применить, но спасибо авторам C++ за intrinsic).
PD>>Оптимизировать задачу "постройте мне автоматически собор святого Петра" — нельзя. Для этого Браманте и Микеланджело нужны. А если эту задачу оптимизировать автоматически, то в итоге получится утепленная собачья будка размером с собор святого Петра.
K>Микеланжело лично клал кирпичи?
При чем здесь это ? Лично ты пишешь программу или руководишь группой программистов, которые пишут — какое это отношение к делу имеет ?
Здравствуйте, Sinclair, Вы писали:
S>Я продолжаю поражаться способностью некоторых людей смотреть в книгу, а видеть известную фигуру из трех пальцев. В том плане, что Рихтер как раз описывает способ минимизировать количество ядерных потоков для реализации асинхронных задач. Простой вопрос на понимание сути: для чего все эти припрыгивания с процедурами завершения, если можно тупо сделать блокирующий вызов в своем потоке?
Подумай сам, может, и поймешь. Хинт — процедура завершения никак не связана с созданием нового потока, она всегда выполняется в контексте потока, который начал эту операцию ввода-вывода. См. ReadFileEx. Хинт 2 — пока операция выполняется в ядре, в потоке, ее иницировавшем, можно успеть что-то сделать, прежде чем заснуть тревожным сном в ожидании вызова процедуры завершения.
Опять пальцем в небо попал
>>>Если бы ты дал себе труд ознакомиться с архитектурой высокопроизводительных приложений, то убедился бы, что никто не выделяет "1 поток — 1 задача".
PD>>Нет такого понятия в Windows — задача. Исключено при переходе Win16->Win32. Если речь идет о процессе, то он здесь ни при чем, так как Windows занимается квантованием времени на уровне потоков, а не процессов. Так что уж, будь добр, определи, что означает слово "задача" в твоем понимании, а тогда и обсудим, сколько потоков должно быть на задачу или задач на поток. Только все же сначала почитай Рихтера. Там эта архитектура подробно рассматривается. S>Задача здесь подразумевается пользовательская. К примеру, "прочитать 8192 байта с диска". Или, более крупно, скажем "обработать входящий http-запрос".
Вот это уже лучше. Насчет http — это не по моей части. А насчет прочитать 8192 байта с диска — зачем, по-твоему, асинхронный ввод/вывод существует ? Ну и читали бы себе последовательно по 8192 байта, так нет, зачем-то придумали асинхронный в/в, с процедурами завершения (а можно и без них, кстати, но все равно асинхронный — с ивентом). Зачем, как ты думаешь ?
S>Очевидное решение — выделить каждое соединение в отдельный поток, чтобы обеспечить максимальный параллелизм. Вот только так никто не делает: слишком велики накладные расходы на управление сотнями потоков, так как они большую часть времени спят. Делают пул в пару десятков потоков на ядро, и его с запасом хватает для всех этих операций. Почитай Рихтера, там это хорошо описано
Именно. Я же тебе и объяснил — почитай его , особенно насчет I/O Completion Port. На нем этот пул и сидит, возможно.
>>>Для распараллеливания ожидания эффективнее кооперативная многозадачность и программный параллелизм. PD>>Привет от Windows 3.11 S>Нет. Привет от файберов, lighttpd и SQL Server. Не стесняйся, Павел, учи матчасть.
Ну-ну. Предложи разработчиками Windows заменить потоки в процессе System на файберы. То-то весело будет
Кстати, маленький вопрос можно ? Соломон-Руссинович (а это классика по внутреннему устройству Windows) потоками посвящают массу страниц, а про файберы — вот все, что у них написано
Fibers allow an application to schedule its own "threads" of execution rather than rely on the priority-based scheduling mechanism built into Windows 2000. Fibers are often called "lightweight" threads, and in terms of scheduling, they're invisible to the kernel because they're implemented in user mode in Kernel32.dll. To use fibers, a call is first made to the Win32 ConvertThreadToFiber function. This function converts the thread to a running fiber. Afterward, the newly converted fiber can create additional fibers with the CreateFiber function. (Each fiber can have its own set of fibers.) Unlike a thread, however, a fiber doesn't begin execution until it's manually selected through a call to the SwitchToFiber function. The new fiber runs until it exits or until it calls SwitchToFiber, again selecting another fiber to run. For more information, see the Platform SDK documentation on fiber functions.
Все.
У Рихтера немного поинтереснее. Выделено мной
Microsoft added fibers to Windows to make it easy to port existing UNIX server applications to Windows. UNIX server applications are single-threaded (by the Windows definition) but can serve multiple clients. In other words, the developers of UNIX applications have created their own threading architecture library, which they use to simulate pure threads. This threading package creates multiple stacks, saves certain CPU registers, and switches among them to service the client requests.
Obviously, to get the best performance, these UNIX applications must be redesigned; the simulated threading library should be replaced with the pure threads offered by Windows. However, this redesign can take several months or longer to complete, so companies are first porting their existing UNIX code to Windows so they can ship something to the Windows market.
...
To help companies port their code more quickly and correctly to Windows, Microsoft added fibers to the operating system. In this chapter, we'll examine the concept of a fiber, the functions that manipulate fibers, and how to take advantage of fibers. Keep in mind, of course, that you should avoid fibers in favor of more properly designed applications that use Windows native threads.
Читать классиков надо. Вдумчиво, не спеша. С толком, с расстановкой.
S>Это, Павел, от того, что твои знания — совершенно бессистемные. Ты не понимаешь, что JIT по отношению к x86 делает c MSIL то же самое, что Pentium делает с x86 кодом по отношению к своему микрокоду. Не понимаешь, что ожидание в www-сервере, файлового ввода-вывода, и таймера устроены совершенно одинаково. И методы везде применяются те же самые.
М-да. Тут уже Рихтер не поможет. Тут надо про организацию файлового ввода/вывода в ядре читать. Про драйверы, про асинхронную модель ввода/вывода в ядре. Про списки ожидания, про потоки. Советую все же Соломона с Руссиновичем почитать, там много об этом. Правда, про www-сервер там ни слова.
S>>>Причем опять же, пространство решений для неё слишком велико, чтобы покрыть его "оптимизированным кодом, написанным на ассемблере". Читать про свитч AXD-301. PD>>Вот уж это читать не буду. У меня других дел хватает, чтобы еще свитчами заниматься. S> Да здравствует упорствующее невежество.
Глупо. Если я не собираюсь читать книги по ненужным мне свитчам — это есть упорствующее невежество
Здравствуйте, AndrewVK, Вы писали:
AVK>Ну зачем же так подставляться. Павел, ИМХО, совершенно сознательно переводит любой разговор на обсуждение тонкостей Win32
Да нет же, честное слово, Андрей!
> а ты ему такой подарок делаешь.
Не заметил. А жаль. ПО-джентльменски не воспользуюсь. А мог бы. Тут есть что сказать.
Здравствуйте, gandjustas, Вы писали:
PD>>Да, конечно. Я просто хотел подчеркнуть, что распараллеливание — совсем не такое простое действие. G>Это смотря как писать.
Разумеется
PD>>Иногда и на одном процессоре можно, иногда — не имеет смысла. Иногда и то и другое G>Еще раз: распараллеливание вычислений на одном процессоре только уменьшит быстродействие.
При условии, что ожиданий там нет вообще, то есть загрузка процессора на 100% — верно.
G>Распараллеливание ожидания лучше выполнять не с помощью ручного создания потоков.
Это я не понял. Thread pool ты предлагаешь, что ли ? Если да — это тема для отдельного разговора, скажу лишь, что это зависит от того, что и как ожидать. Если у меня нет массового обслуживания, а есть один рабочий code flow, которому периодически другие дают задания, а он спит и ждет эти задания — на что мне тут пул, зачем мне на него ресурсы тратить ? А в других случаях — пул, да.
Если не о пуле речь — поясни, что имеешь в виду.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Здравствуйте, gandjustas, Вы писали:
PD>>>>>Компилятор будет в лучшем случае оптимизировать "в среднем", то есть в расчете на некую среднюю задачу. И чем выше уровень абстракций, тем хуже он это будет делать. Оптимизировать цикл можно очень хорошо, а оптимизировать задачу "сделай вот это" — можно лишь на бвзе некоторых правил оптимизации общего порядка. Как только попадется нечто, что под эти правила не подходят — результат будет плохим. G>>>Можно не писать то, что под эти правила не подходит.
PD>>>Так я об этом и говорю. Каждому инструменту — свое назначение. Где Linq, где ассемблер. кесарю кесарево, слесарю — слесарево
G>>Из всего вышесказанного следует что программа написанная на более высоком уровне лучше поддается оптимизации.
PD>ИМХО следует наоборот. Я же ясно сказал — см. выделенное.
Увас с логикой проблемы. Не используем элементы, которые плохо оптимизируются => Получаем более оптимальный код. С другой стороны более высокоуровневые декларативные конструкции оптимизируются гораздо лучше низкоуровневых. Следовательно программа написанная на более высоком уровне лучше поддается оптимизации.
Здравствуйте, Mirrorer, Вы писали:
PD>>Сравнивать же твои результаы с моими бессмысленно — сначала надо о размере окна договориться M>Не могу не согласиться
А если серьезнее — ты делаешь то же самое, разница между скоростью суммирования в C++ и C# здесь скорее всего не проявится (подумаешь, задача — матрицу 500*500 просуммировать) на фоне ожидания в GetPixel. Так что результаты должны быть примерно одинаковы — на одной и той же машине, конечно.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>>>Иногда и на одном процессоре можно, иногда — не имеет смысла. Иногда и то и другое G>>Еще раз: распараллеливание вычислений на одном процессоре только уменьшит быстродействие.
PD>При условии, что ожиданий там нет вообще, то есть загрузка процессора на 100% — верно.
G>>Распараллеливание ожидания лучше выполнять не с помощью ручного создания потоков.
PD>Это я не понял. Thread pool ты предлагаешь, что ли ? Если да — это тема для отдельного разговора, скажу лишь, что это зависит от того, что и как ожидать. Если у меня нет массового обслуживания, а есть один рабочий code flow, которому периодически другие дают задания, а он спит и ждет эти задания — на что мне тут пул, зачем мне на него ресурсы тратить ?
Это и есть описание пула. Только с одним потоком, каждое следующее задание ждет завершения предыдущего. Если вруг станет надо обрабатывать задания пока есть свобоные ресурсы, то увеличим количество потоков, например до количества процессоров.
Реализация пула в неуправляемой среде — несложное дело, ресурсов хавает минимум.
PD>А в других случаях — пул, да.
В каких других?
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Здравствуйте, AndrewVK, Вы писали:
AVK>>welcome to real world
PD>Вот, кстати, про real world. Со мной уже все ясно — проценты я считать не умею, ладно . Но не я один такой. Оказывается, и суммы-то точно считать не умеют, и кто — страшно сказать!
если я не ошибаюсь — примерно пишут потому что есть страницы которые похожи друг на друга, но физически находятся на разных урлах. Гугль видит похожесть и скрывает копии страниц из поиска.
Здравствуйте, Pavel Dvorkin, Вы писали:
AVK>>welcome to real world
PD>"Этот прекрасный новый мир" (О.Хаксли) не читал ? Кстати, управляемый
Демагогия.
AVK>>Самому не смешно?
PD>Ну тогда зайди в форум по Win32 и объяви во всеуслышание — все, что вы тут делаете — смешно. Потому что там именно такой код и пишут, и мой — не лучше и не хуже. Зайди и напиши, честное слово. Посмотрим на реакцию.
Демагогия.
AVK>>Тогда забудь в этом топике про слово Win32, ты же его через абзац упоминаешь.
PD>А ты готов забыть в этом топике про C#, .Net. LinQ ? Либо уж оба забудем, либо оба нет
Уже два раза объяснял, почему твоя аналогия не годится.
PD>Андрей, мы что-то воду в ступе толчем.
Если пропускать мимо ушей половину того, что я пишу, так и будет.
PD> Не хочешь окна и пикселей — возьми массив двумерный произвольного происхождения с цветами в качестве элементов. Что изменится, кроме ожидания, конечно ?
Ты чего то попутал — у меня с абстрагированием от конкретики проблем нет, это ты все пытаешься на обсуждение Win32 свернуть.
PD>Андрей, ну некорректные же аргументы.
Некорректно, это когда ты упорно пытаешься сменить тему. Сразу скажу — со мной это не пройдет. Обсуждать здесь Win32 я не буду, и не надейся. Речь про функциональное программирование. Не нравится шарп — ОК, давай возьмем ML или Немерле, годится?
PD> Не хочешь Win32 — не надо, но зачем педалировать-то ?
Опять же, не переваливай с больной головы не здоровую. Все что я хочу — чтобы Win32 здесь не обсуждалось.
PD> Там распараллеливание алгоритма, это главное, остальное второстепенное. А про конструкции vs бмблиотеки я уже сказал.
Распараллеливание тоже не главное. Главное — конструкции языка, которые его использование позволяют упростить.
AVK>>А ты SQL не знаешь?
PD>Знаю
Ну вот и ладненько.
PD> А если бы нет ? Вот предстваь себе — пишет некий X математическую обработку, ему SQL совсем не нужен.
А мне этот Х не интересен. Мне интересно реальное положение дел. Как ты думаешь, сколько народу в этом форуме ничего не знают про SQL?
PD> А матрицы по диагоналям он сплошь и рядом проходит — в линейной алгебре диагональных, трехдиагональных и нижне- или верхне- треугольных матриц хоть пруд пруди.
При чем тут матрицы? Нить разговора потерял или специально? Претензии касались не матриц, а Win32.
PD>Прекрасно. Вот на этом месте я и закончу, иначе можно продолжать до бесконечности.
Вобщем понятно, кода так и не будет. Приятно, когда твои предсказания сбываются .
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Microsoft added fibers to Windows to make it easy to port existing UNIX server applications to Windows. UNIX server applications are single-threaded (by the Windows definition) but can serve multiple clients. In other words, the developers of UNIX applications have created their own threading architecture library, which they use to simulate pure threads. This threading package creates multiple stacks, saves certain CPU registers, and switches among them to service the client requests.
О как. Интересно, где это они нашли для UNIX'а такую threading library, и серверные аппликации, на ней написаные, которые имеет смысл "make it easy to port"?
Все-таки по-моему у виндовсных людей UNIX — это такая легенда, типа лешего, который живет (или жил когда-то) в лесу, и про него столько же примерно известно.
Здравствуйте, Pzz, Вы писали:
Pzz>Здравствуйте, Pavel Dvorkin, Вы писали:
PD>>Microsoft added fibers to Windows to make it easy to port existing UNIX server applications to Windows. UNIX server applications are single-threaded (by the Windows definition) but can serve multiple clients. In other words, the developers of UNIX applications have created their own threading architecture library, which they use to simulate pure threads. This threading package creates multiple stacks, saves certain CPU registers, and switches among them to service the client requests.
Pzz>О как. Интересно, где это они нашли для UNIX'а такую threading library, и серверные аппликации, на ней написаные, которые имеет смысл "make it easy to port"?
Pzz>Все-таки по-моему у виндовсных людей UNIX — это такая легенда, типа лешего, который живет (или жил когда-то) в лесу, и про него столько же примерно известно.
Сказать аналогичное про юниксоидов несложно. Вот только зачем?
Меня всегда удивляли заявления "виндузятники — не люди, а лемминги" и "юниксоиды — задроты". Этакие обобщения с нескольких встреченных особей на всех. Господа, смею напомнить, в общем случае, индукция — не метод доказательства.
Здравствуйте, Aen Sidhe, Вы писали:
AS>Меня всегда удивляли заявления "виндузятники — не люди, а лемминги" и "юниксоиды — задроты". Этакие обобщения с нескольких встреченных особей на всех. Господа, смею напомнить, в общем случае, индукция — не метод доказательства.
Я не сказал, что виндузятники лемминги. Я сказал, что виндузятники мало чего знают про UNIX.
Здравствуйте, Pzz, Вы писали:
Pzz>Здравствуйте, Aen Sidhe, Вы писали:
AS>>Меня всегда удивляли заявления "виндузятники — не люди, а лемминги" и "юниксоиды — задроты". Этакие обобщения с нескольких встреченных особей на всех. Господа, смею напомнить, в общем случае, индукция — не метод доказательства.
Pzz>Я не сказал, что виндузятники лемминги. Я сказал, что виндузятники мало чего знают про UNIX.
А я сказал, что индукция — неверный способ доказательства.
И, да, я не говорил, что ты сказал, что виндузятники — лемминги. Я сказал, что такие заявления существуют. Поиском по форуму вполне находятся.
Здравствуйте, Pzz, Вы писали:
Pzz>О как. Интересно, где это они нашли для UNIX'а такую threading library, и серверные аппликации, на ней написаные, которые имеет смысл "make it easy to port"?
По поводу оптимизации мне кажется интереснее пример, к-й Sinclair приводил. Переписали приложение на Java/MSSQL, и оно заработало быстрее, чем на более низкоуровневом С++. Выбор правильной архитектуры гораздо важнее того, насколько оптимально реализованы отдельные ее части.
А так — высокоуровневый код во всех в смыслах писать и поддерживать проще. И гораздо дешевле. Более того, многие современные системы практически невозможно писать на "низком уровне", потому что это выльется в такие сотни тысяч человекочасов — даже если речь идет просто о разработке — что окажется в принципе неподъемным.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>А так — высокоуровневый код во всех в смыслах писать и поддерживать проще. И гораздо дешевле. Более того, многие современные системы практически невозможно писать на "низком уровне", потому что это выльется в такие сотни тысяч человекочасов — даже если речь идет просто о разработке — что окажется в принципе неподъемным.
Ну так то, что высокоуровневость дает выигрыш при написании и поддержке — давно общепринято. Обсуждается то, что помимо abstraction penalty есть еще и abstraction gains, когда речь идет о производительности приложения. Дворкин же считает, что есть только penalty.
... << RSDN@Home 1.2.0 alpha 4 rev. 1110>>
'You may call it "nonsense" if you like, but I'VE heard nonsense, compared with which that would be as sensible as a dictionary!' (c) Lewis Carroll
Здравствуйте, Klapaucius, Вы писали:
K>Ну так то, что высокоуровневость дает выигрыш при написании и поддержке — давно общепринято. Обсуждается то, что помимо abstraction penalty есть еще и abstraction gains, когда речь идет о производительности приложения. Дворкин же считает, что есть только penalty.
Abstraction gain — в сущности всегда один — код более высокоуровневый, оперируется более высокоуровневыми понятиями, соответственно, в него проще "въехать" и как результат проще поддерживать. Это как раз и есть то, что "общепринято".
На это, конечно, всегда можно возразить, что я типа насколько глубоко разбираюсь в Х, что мне не нужен дополнительный уровень абстракции, чтобы я мог легко оптимизировать код на Х.
Теоретически это может быть правдой (если представить себе человека с таким имплантом в мозгах... в Систем Шок не играли? ) — потому что по факту дополнительные уровни абстракции неизбежно вносят оверхед, тут спорить нечего.
Но на практике имплантов для мозгов еще не изобрели Более того ИМХО на практике большинство оптимизаций ограничится изменением архитектуры, даже без вникания в то, что собственно происходит внутри методов (что косвенно и подводит нас к изначальной теме топика).
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Теоретически это может быть правдой (если представить себе человека с таким имплантом в мозгах... в Систем Шок не играли? ) — потому что по факту дополнительные уровни абстракции неизбежно вносят оверхед, тут спорить нечего.
Скажи это суперкомпиляторам...
... << RSDN@Home 1.2.0 alpha rev. 745>>
Пусть это будет просто:
просто, как только можно,
но не проще.
(C) А. Эйнштейн
Здравствуйте, Воронков Василий, Вы писали:
ВВ>А что "суперкомпилятор" сможет сделать с таким уровнем абстракции как делегат? Или с виртуальным вызовом?
Если ясно что именно будет вызвано то заинлайнить.
А искать что когда и зачем делают он умеет очень хорошо.
... << RSDN@Home 1.2.0 alpha rev. 745>>
Пусть это будет просто:
просто, как только можно,
но не проще.
(C) А. Эйнштейн
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Вон, помнится, была статья — причем год или два назад — даже луноход какой-то под управлением джавы работал.
Здравствуйте, WolfHound, Вы писали:
ВВ>>А что "суперкомпилятор" сможет сделать с таким уровнем абстракции как делегат? Или с виртуальным вызовом? WH>Если ясно что именно будет вызвано то заинлайнить. WH>А искать что когда и зачем делают он умеет очень хорошо.
Ну давай все-таки конкретнее говорить. Ты какой-то конкретный "суперкомплятор" имеешь в виду? Или может быть в свете здешних дискуссий уместнее сказать "суперджит"?
Мало того, что такая "хардкорная" оптимизация возможна даже теоретически далеко не всегда, так в для языков на .NET ее ведь все равно никто не делает.
Здравствуйте, D. Mon, Вы писали:
DM>Не было такого. Софт для всяких луно/марсо-ходов сейчас пишут на чистом С, даже от Ады отказались. Джава использовалась на Земле в какой-то утилитке, но в космос никогда не летала. DM>http://se-radio.net/podcast/2008-06/episode-100-software-space
Как я и сказал:
"The places where NASA scientists have used Java for this mission is all on the ground side right now."
"The Rover itself has a computer onboard. There's no Java in that computer now."
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Здравствуйте, Pavel Dvorkin, Вы писали:
ВВ>Блин, я вас читал-читал, а как все банально заканчивается
Устал
ВВ>Правда жизни в том, что таких задач становится все меньше и меньше. Вон, помнится, была статья — причем год или два назад — даже луноход какой-то под управлением джавы работал. Все-таки сейчас немного меняются представления о производительности, оптимизации и пр. ВВ>Сейчас в большинстве случаев не надо байты и тики считать — приложения тормозят не потому что какой-то алгоритм на си-шарпе написан, а не асме, а из-за кривой архитектуры.
Гм. Вообще-то не вижу связи между кривой архитектурой и языком.
>Что в осном народ-то пишет? Бизнес-приложения, распределенные приложения, всякие там корпоративные шины и проч., веб-сервисы и другую подобную дрянь. Там совсем другие проблемы возникают, на другом уровне. Если, к примеру, у тебя плохо продумана связь с каким-нибудь нодом, идет слишком частый обмен пакетами, некорректно обрабатывается таймаут нода, нет кэширования и пр. — тебе тут не поможет переделка твоего приложения на более низкоуровневый асм.
+100. Безусловно верно. Насчет "дряни" — я бы не стал так говорить, все задачи имеют право на существование.
ВВ>А теперь представь — вот люди пишут всякие ESB, передают тонны ХМЛя (ХМЛя, понимаешь? ), а ты их пытаешься убедить, что "существуют задачи, для решения которых использование высокоуровневых средств... неэффективно и нецелесообразно". Как на фиг высокоуровневые средства, у нас сплошной ХМЛ, блин
Со всем можно согласиться, но... Есть же задачи, в которых нет тонн XML и т.д. Пусть их становится меньше (меньше в каком смысле — меньше количество програмистов, ими занимающихся или меньше их роль ? со вторым не согласен, первое бесспорно).
Проблема же в том, что адепты этих новых технологий претендуют на их универсальность для всех задач. Тому же AndrewYK просто смешно смотреть на Win32 код — именно потому, что он не те средства (язык, АПИ) использует, что ему надо. Если бы он сказал — для твоей задачи это хорошо, для других — не годится — я бы немедленно согласился, тут и сказке конец. Я разве предлагал web-сайты на С++ писать или XML на ассемблере парсить ? Но нет, подайте им все, они на меньшее не согласны, а поэтому все, что под их методы не подходит — им смешно. Вот я и пытаюсь побудить их просто зафиксировать это простенькое утверждение — независимо от того, какие сферы покрывает то или иное направление.
ВВ>И в итоге чего ты хочешь добиться? Никто не отрицает, что в принципе да, есть задачи для которых подходят более низкоуровневые средства. Но вы разве это обсуждаете? Статистику использования технологий что ли составляете? Речь-то о перспективах, о развитии, о тенденциях. И тенденция такова, что таких задач становится все меньше. Гораздно меньше. Причем в тех областях, в которых использования какого-нибудь дотнета раньше даже помыслить было нельзя.
ВВ>И будет еще меньше. Сейчас у банальной игровой приставки — под которую игры выпускают, кстати, в "обрезанном" по сравнению с PC варианте — прозводительность терафлопами мерится. О чем тут можно говорить-то? Какой асм?
Не знаю насчет игровых приставок, а вот в моей задаче асм будет на днях. Не в чистом виде, а через intrinsic. Для реализации SSE2. Распараллеливание, так сказать, на одном процессоре, и даже без всяких потоков. Тест показал примерно 3.5- кратный выигрыш
ВВ>Собственно, такова позиция твоих оппонентов, как я ее понимаю. И я с ней согласен. А вот твою позицию я не очень понимаю. Какой смысл все сводить к тому, что "есть задачи для к-х асм подходит"? Ну да, пока еще есть. Но мне действительно кажется, что ты переоцениваешь роль и количество таких задач.
Из того, что большинство задач — это задачи бизнеса, еще не следует, что все остальное вымирает.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Проблема же в том, что адепты этих новых технологий претендуют на их универсальность для всех задач. Тому же AndrewYK просто смешно смотреть на Win32 код — именно потому, что он не те средства (язык, АПИ) использует, что ему надо.
Не надо фантазировать. Смотреть мне не смешно, а, скорее, грусто. Это во-первых. А во-вторых, и я тебе уже об этом говорил, всю специфику Win32 я игнорирую намеренно, потому что иначе ты тут же переведешь разговор на обсуждение технических мелочей, как ты в очередной раз продемонстрировал здесь же в разговоре с Синклером.
PD>Но нет, подайте им все, они на меньшее не согласны
Цитату в студию, где я предлагал все писать в функциональном стиле.
PD>, а поэтому все, что под их методы не подходит — им смешно.
Смешны твои попытки сменой темы и подтасовками доказать, что ты прав. Кода, кстати, от тебя мы так и не увидели, несмотря даже на то, что аналог твоего кода я тебе таки дал, хотя и этот твой ответ вопросом на вопрос выглядел так себе.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Aen Sidhe, Вы писали:
AS>Есть такая штука, как правила и исключения.
Есть.
>Так вот, правило универсально, даже если из него есть исключения. Если новая технология покрывает 90% задач или больше — она универсальна, а всё не попавшее в область покрытия — это исключения.
Таким образом ты слишком много задач в исключения запишешь. Тебе придется правило создавать, по которому ты будешь относить некую задачу к правилу или исключениям .
А кстати, такой вопрос. Ты утверждаешь 90:10. Я точных цифр не знаю, но пусть так. Но если из этих 90% исключить все приложения для www, которые никто никогда ни на асме, ни на С++ не предлагал писать , каково будет отношение между тем, что останется от этих 90% и тем, что сейчас входит в 10% ?
>При этом, человек, который пишет на асме сам загоняет себя в угол — ему больше некуда оптимизировать. Всё, точка. А нам — есть куда. Мы сначала можем посмотреть на С++ или Erlang. А потом и на ассемблер. Если вдруг это понадобится.
Прелесть! Умри Денис, лучше не скажешь.
Человек, который пишет на асме (в предположении, что он хорошо пишет) — загоняет себя в угол, потому что написав хорошо на асме, он действительно для данного железа ничего больше уже сделать не сможет — все, выжали все, что можно.
А вам — есть куда. Вы сначала нечто такое, что раз в N медленнее работает и в M раз больше памяти потребляет, напишете (не важно на чем, не будем уточнять). И, конечно, у вас теперь есть великолепные перспективы для улучшения — еще бы! Можно потом на С++ переписать и гордо заявить — вот, мы оптимизировали, какие мы молодцы. А потом и на асме переписать.
А зачем на асме-то переписать ? Правильно. Чтобы наконец загнать себя в угол!
Здравствуйте, samius, Вы писали:
S>Павел! понятия эффективности и целесообразности без специальных оговорок весьма субъективны.
Конечно, я это понимаю.
S>Подпись под такой декларацией позволит и дальше оппонентам иметь разные мнения об эффективных и целесообразных мерах для решения одной конкретной задачи.
Ну мнение-то никто не запрещате иметь какое-угодно, вне всякой связи с этой подписью.
>А факт существования таких задач из пунктов 1) и 2), где по поводу эффективности сойдутся большинство мнений — не интересен.
Мне не это интересно. Я другое имею в виду. Я-то согласен с тем, что писать с использованием низкоуровненвых средств не всегда имеет смысл. Иными словами, я на их мир не покушаюсь. А вот оппоненты мои на мой мир покушаются — они его попросту считают смешным.
Несколько более жестко высказываясь — если бы мне дали власть решать, что и где использовать, я бы отнюдь не стал запрещать им использовать C# , Linq , и т.д. Но , боюсь, дай им власть — они бы мне просто запретили бы C++ и asm.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Здравствуйте, Aen Sidhe, Вы писали:
AS>>Есть такая штука, как правила и исключения.
PD>Есть.
>>Так вот, правило универсально, даже если из него есть исключения. Если новая технология покрывает 90% задач или больше — она универсальна, а всё не попавшее в область покрытия — это исключения.
PD>Таким образом ты слишком много задач в исключения запишешь. Тебе придется правило создавать, по которому ты будешь относить некую задачу к правилу или исключениям .
Способ распределения задач нас сейчас не интересует — это некая абстракция.
PD>А кстати, такой вопрос. Ты утверждаешь 90:10. Я точных цифр не знаю, но пусть так. Но если из этих 90% исключить все приложения для www, которые никто никогда ни на асме, ни на С++ не предлагал писать , каково будет отношение между тем, что останется от этих 90% и тем, что сейчас входит в 10% ?
Однако, с чего вдруг, мы будем убирать www приложения? Новые технологии спокойно позволяют писать такие приложения с использованием тех же средств, что и для десктопных приложений. Более того, я лично видел несколько отлично работающих сайтов на С++ (ActiveX, COM, etc).
>>При этом, человек, который пишет на асме сам загоняет себя в угол — ему больше некуда оптимизировать. Всё, точка. А нам — есть куда. Мы сначала можем посмотреть на С++ или Erlang. А потом и на ассемблер. Если вдруг это понадобится.
PD>Прелесть! Умри Денис, лучше не скажешь.
PD>Человек, который пишет на асме (в предположении, что он хорошо пишет) — загоняет себя в угол, потому что написав хорошо на асме, он действительно для данного железа ничего больше уже сделать не сможет — все, выжали все, что можно.
Только вот проблема. Сменилось железо и всё переписывать? Ну удачи, я такого пути не понимаю.
PD>А вам — есть куда. Вы сначала нечто такое, что раз в N медленнее работает и в M раз больше памяти потребляет, напишете (не важно на чем, не будем уточнять). И, конечно, у вас теперь есть великолепные перспективы для улучшения — еще бы! Можно потом на С++ переписать и гордо заявить — вот, мы оптимизировали, какие мы молодцы. А потом и на асме переписать.
Вот только, есть мнение, память и процессор новые дешевле месяца твоей работы. Не так ли? Это раз. Два, N и M уже сейчас стремятся к 1, если использовать нормальные алгоритмы и архитектуры.
PD>А зачем на асме-то переписать ? Правильно. Чтобы наконец загнать себя в угол!
Я не видел ни одной задачи, где требовалось переписывать алгоритм на асме. Потому что задача, кроме "хочу" ПМа, должна быть обоснована экономически. А просто сделать выполнение какой-нибудь большой операции, запускаемой раз в год в два раза быстрее — трата денег, причём напрасная. Я не спорю, что такие задачи есть. Но они точно попадут в исключения из правил.
Во всех виденных мною "тормозах", "пожираниях памяти" так или иначе были проблемы с архитектурой и/или реализацией.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Здравствуйте, samius, Вы писали:
>>А факт существования таких задач из пунктов 1) и 2), где по поводу эффективности сойдутся большинство мнений — не интересен.
PD>Мне не это интересно. Я другое имею в виду. Я-то согласен с тем, что писать с использованием низкоуровненвых средств не всегда имеет смысл. Иными словами, я на их мир не покушаюсь. А вот оппоненты мои на мой мир покушаются — они его попросту считают смешным.
Мне все же кажется, что это не так. Оппоненты пытаются донести что использование высокоуровневых средств более эффективно в большинстве задач, если речь идет не о железе. Эффективно — значит при схожей или чуть меньшей производительности решения оно будет дешевле и быстрее по срокам.
PD>Несколько более жестко высказываясь — если бы мне дали власть решать, что и где использовать, я бы отнюдь не стал запрещать им использовать C# , Linq , и т.д. Но , боюсь, дай им власть — они бы мне просто запретили бы C++ и asm.
Не совсем так. Фигурально выражаясь, они пытаются усадить Вас за BMW с тем чтобы Вы могли сравнить ее с ВАЗ-ом, но Вы отказываетесь, аппелируя тем, что у BMW больше расход и что надо просто уметь ездить на ВАЗ-е. В свою очередь, оппонентам не будут интересны Ваши аргументы в пользу ВАЗ-а, пока вы как-следует не покатаетесь на BMW. Они не призывают Вас ездить на BMW, они просто хотят, чтобы Вы почувствовали разницу.
Здравствуйте, samius, Вы писали:
S>Мне все же кажется, что это не так. Оппоненты пытаются донести что использование высокоуровневых средств более эффективно в большинстве задач, если речь идет не о железе. Эффективно — значит при схожей или чуть меньшей производительности решения оно будет дешевле и быстрее по срокам.
Так я всего-то и хочу — чтобы они признали, что есть и другие задачи, где это неверно. А они не хотят . Похоже, в принципе не хотят.
S>Не совсем так. Фигурально выражаясь, они пытаются усадить Вас за BMW с тем чтобы Вы могли сравнить ее с ВАЗ-ом, но Вы отказываетесь, аппелируя тем, что у BMW больше расход и что надо просто уметь ездить на ВАЗ-е.
Сравнение некорректно. Если уж сравнивать, то надо сравнивать BMW с неким автомобилем, который хорошая фирма могла бы сделать ручной сборкой, а не на конвейере, и с деталями, сделаннными специально для этого автомобиля, а не отштапованными. Иными словами, сравнить BMW с неким гоночным автомобилем. Это и будет вполне подходящее сравнение — BMW штука хорошая, но выжать из двигателя внутреннего сгорания и прочего то, что они могут сейчас дать, он и близко не может.
Здравствуйте, Aen Sidhe, Вы писали:
PD>>А кстати, такой вопрос. Ты утверждаешь 90:10. Я точных цифр не знаю, но пусть так. Но если из этих 90% исключить все приложения для www, которые никто никогда ни на асме, ни на С++ не предлагал писать , каково будет отношение между тем, что останется от этих 90% и тем, что сейчас входит в 10% ?
AS>Однако, с чего вдруг, мы будем убирать www приложения? Новые технологии спокойно позволяют писать такие приложения с использованием тех же средств, что и для десктопных приложений. Более того, я лично видел несколько отлично работающих сайтов на С++ (ActiveX, COM, etc).
Да, есть, точнее, осталось от прошлых лет. Если специально поискать, то можно, наверное и CGI на C++ найти. Но это несерьехно.
Вот поэтому я и предложил их отложить в сторону и сравнить. В области www — я вам сразу первенство отдаю и ни на что не претендую. Давай остальное сравним.
AS>Только вот проблема. Сменилось железо и всё переписывать? Ну удачи, я такого пути не понимаю.
Не все. Конечно, при переходе 486 -> Pentium или P3->P4 кое-что меняется. Но отнюдь не полное переписывание.
А на С++ вообще не надо переписывать. Перекомпилировать надо, да.
AS>Вот только, есть мнение, память и процессор новые дешевле месяца твоей работы. Не так ли? Это раз.
Да. Только вот одна проблема — именно моя текущая работа требует выжать из этого железа максимум того, что можно. Не выжму — цена месяца моей работы будет равна 0. И что делать ?
>Два, N и M уже сейчас стремятся к 1, если использовать нормальные алгоритмы и архитектуры.
Вот тебе пример. Делал как-то приложение на C#. Ничего особенного, форма с табами, на них всякие листбоксы и т.д. За сценой никаких больших объектов (потом при работе они появятся, но до первого запроса их нет). 17 Мб вся эта прелесть занимает. Уверен, что больше 4-5 Мб она занимать не должна — на MFC. На чистом Win API — думаю, в 2-3 Мб уложился бы, но на это точно много моего времени уйдет.
Ну а насчет скорости — тут меня лучше не трогай, я именно этим сейчас и занимаюсь. И если меня лишить прямого доступа к памяти (указателей, выравнивания, иными словами) — все , что я сделал — коту под хвост. А так — уже в 6 раз быстрее.
AS>Я не видел ни одной задачи, где требовалось переписывать алгоритм на асме.
Не могу тебе про нее рассказать, но именно это мне и предстоит. Правда, без явного __asm я все же обйдусь — есть intrinsic в C++. Проще говоря — SSE2
>Потому что задача, кроме "хочу" ПМа, должна быть обоснована экономически.
Поверь, она так обоснована экономически, как немногие другие задачи
>А просто сделать выполнение какой-нибудь большой операции, запускаемой раз в год в два раза быстрее — трата денег, причём напрасная.
А если эта задача выполняется на сотнях компьютеров 24 часа в сутки каждый день ?
>Я не спорю, что такие задачи есть. Но они точно попадут в исключения из правил.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Здравствуйте, Aen Sidhe, Вы писали:
AS>>Только вот проблема. Сменилось железо и всё переписывать? Ну удачи, я такого пути не понимаю.
PD>Не все. Конечно, при переходе 486 -> Pentium или P3->P4 кое-что меняется. Но отнюдь не полное переписывание. PD>А на С++ вообще не надо переписывать. Перекомпилировать надо, да.
64 битные платформы не забываем. Хотя, если указатели к интам не приводить, проблем, по идее не будет. >>Два, N и M уже сейчас стремятся к 1, если использовать нормальные алгоритмы и архитектуры.
PD>Вот тебе пример. Делал как-то приложение на C#. Ничего особенного, форма с табами, на них всякие листбоксы и т.д. За сценой никаких больших объектов (потом при работе они появятся, но до первого запроса их нет). 17 Мб вся эта прелесть занимает. Уверен, что больше 4-5 Мб она занимать не должна — на MFC. На чистом Win API — думаю, в 2-3 Мб уложился бы, но на это точно много моего времени уйдет.
А есть разница для GUI приложения между 17 и 4 МБ? Сейчас браузеры по 100 отжирают и живём как-то.
PD>Ну а насчет скорости — тут меня лучше не трогай, я именно этим сейчас и занимаюсь. И если меня лишить прямого доступа к памяти (указателей, выравнивания, иными словами) — все , что я сделал — коту под хвост. А так — уже в 6 раз быстрее.
Ну, я вообще-то знаю, что такое прямой доступ к памяти, да. С С++ начинал в своё время
>>А просто сделать выполнение какой-нибудь большой операции, запускаемой раз в год в два раза быстрее — трата денег, причём напрасная.
PD>А если эта задача выполняется на сотнях компьютеров 24 часа в сутки каждый день ?
Значит, мы что-то делаем не так, имхо, если при этом забиты все ресурсы этих компов под 100% при этом. Хотя какое-нибудь сложное моделирование, которое заставит нас перебрать триллионы вариантов, или учитывающее пару десятков тысяч факторов — да, возможно. Но это всё же такая редкость, что я даже и не знаю.
Здравствуйте, Pavel Dvorkin, Вы писали:
AS>>Только вот проблема. Сменилось железо и всё переписывать? Ну удачи, я такого пути не понимаю. PD>Не все. Конечно, при переходе 486 -> Pentium или P3->P4 кое-что меняется. Но отнюдь не полное переписывание. PD>А на С++ вообще не надо переписывать. Перекомпилировать надо, да.
На .NET тоже не надо
AS>>Вот только, есть мнение, память и процессор новые дешевле месяца твоей работы. Не так ли? Это раз. PD>Да. Только вот одна проблема — именно моя текущая работа требует выжать из этого железа максимум того, что можно. Не выжму — цена месяца моей работы будет равна 0. И что делать ?
Я выше приводил тест, где не напрягаясь мой код на C# выжимает из железа больше, чем ваш на C.
PD>Вот тебе пример. Делал как-то приложение на C#. Ничего особенного, форма с табами, на них всякие листбоксы и т.д. За сценой никаких больших объектов (потом при работе они появятся, но до первого запроса их нет). 17 Мб вся эта прелесть занимает. Уверен, что больше 4-5 Мб она занимать не должна — на MFC. На чистом Win API — думаю, в 2-3 Мб уложился бы, но на это точно много моего времени уйдет.
Пусть лучше прога занимает больше памяти, но работает быстрее. Мне десяток мегов оперативки сейчас вообще не жалко.
PD>Ну а насчет скорости — тут меня лучше не трогай, я именно этим сейчас и занимаюсь. И если меня лишить прямого доступа к памяти (указателей, выравнивания, иными словами) — все , что я сделал — коту под хвост. А так — уже в 6 раз быстрее.
И вы наверное предпочитаете руками реализовывать файловое хранилище, вместо использования БД...
>>А просто сделать выполнение какой-нибудь большой операции, запускаемой раз в год в два раза быстрее — трата денег, причём напрасная. PD>А если эта задача выполняется на сотнях компьютеров 24 часа в сутки каждый день ? >>Я не спорю, что такие задачи есть. Но они точно попадут в исключения из правил. PD>Ну пусть будет исключение.
Для таких задач редко приходится сталкиваться с низкоуровневневой оптимизацией. Обычно производительность упирается в передачу данных.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Ну давай все-таки конкретнее говорить. Ты какой-то конкретный "суперкомплятор" имеешь в виду?
Суперкомпилятор это вполне конкретный давно усоявшейся термин. Появившейся еще в 70какомто году.
ВВ>Мало того, что такая "хардкорная" оптимизация возможна даже теоретически далеко не всегда, так в для языков на .NET ее ведь все равно никто не делает.
Если теоритичсеки возможно отследить зависимости суперкомпилятор сделает это всегда.
... << RSDN@Home 1.2.0 alpha rev. 745>>
Пусть это будет просто:
просто, как только можно,
но не проще.
(C) А. Эйнштейн
Здравствуйте, VoidEx, Вы писали:
WH>>Скажи это суперкомпиляторам... VE>С каких пор суперкомпилятор стал уровнем абстракции?
Ты вобще читаешь то на что отвечаешь?
... << RSDN@Home 1.2.0 alpha rev. 745>>
Пусть это будет просто:
просто, как только можно,
но не проще.
(C) А. Эйнштейн
Здравствуйте, Sinclair, Вы писали:
S>На всякий случай напомню, что про шарп речь вообще не шла. Никто даже не пытается убедить Павла попробовать шарп (ну, кроме тебя).
Я про шарп ни слова не написал ))) это Павел.
А я подразумевал ту задачу с процентами.
Здравствуйте, WolfHound, Вы писали:
WH>Здравствуйте, VoidEx, Вы писали:
WH>>>Скажи это суперкомпиляторам... VE>>С каких пор суперкомпилятор стал уровнем абстракции? WH>Ты вобще читаешь то на что отвечаешь?
И как же так суперконпелятор оптимизирует, зная только о самом верхнем уровне абстракции?
Или таки он знает не только о верхнем?
Здравствуйте, Aen Sidhe, Вы писали:
AS>Здравствуйте, Pavel Dvorkin, Вы писали:
PD>>Здравствуйте, Aen Sidhe, Вы писали:
AS>>>Только вот проблема. Сменилось железо и всё переписывать? Ну удачи, я такого пути не понимаю.
PD>>Не все. Конечно, при переходе 486 -> Pentium или P3->P4 кое-что меняется. Но отнюдь не полное переписывание. PD>>А на С++ вообще не надо переписывать. Перекомпилировать надо, да.
AS>64 битные платформы не забываем. Хотя, если указатели к интам не приводить, проблем, по идее не будет.
Не забываем, ох, не забываем
PD>>Вот тебе пример. Делал как-то приложение на C#. Ничего особенного, форма с табами, на них всякие листбоксы и т.д. За сценой никаких больших объектов (потом при работе они появятся, но до первого запроса их нет). 17 Мб вся эта прелесть занимает. Уверен, что больше 4-5 Мб она занимать не должна — на MFC. На чистом Win API — думаю, в 2-3 Мб уложился бы, но на это точно много моего времени уйдет.
AS>А есть разница для GUI приложения между 17 и 4 МБ? Сейчас браузеры по 100 отжирают и живём как-то.
Вот именно — как-то. Я совершенно убежден, что нынешнее ПО могло бы работать со скоростью раза в 3-4 больше и памяти кушать меньше. А пока что оно все тормозит, тормозит, тормозит и память ест, есть, ест. Отнюдь не только ПО под C#.
>>>А просто сделать выполнение какой-нибудь большой операции, запускаемой раз в год в два раза быстрее — трата денег, причём напрасная.
PD>>А если эта задача выполняется на сотнях компьютеров 24 часа в сутки каждый день ?
AS>Значит, мы что-то делаем не так, имхо, если при этом забиты все ресурсы этих компов под 100% при этом.
Все так. Просто есть такие задачи. Обработка огромных массивов данных при том, что эти данные поступают в реальном масштабе времени и отвечать нужно тоже в реальном масштабе. Я же говорил не раз — у нас разные совсем задачи.
Здравствуйте, WolfHound, Вы писали:
ВВ>>Ну давай все-таки конкретнее говорить. Ты какой-то конкретный "суперкомплятор" имеешь в виду? WH>Суперкомпилятор это вполне конкретный давно усоявшейся термин. Появившейся еще в 70какомто году.
Это как-нибудь применимо, скажем, к C#?
ВВ>>Мало того, что такая "хардкорная" оптимизация возможна даже теоретически далеко не всегда, так в для языков на .NET ее ведь все равно никто не делает. WH>Если теоритичсеки возможно отследить зависимости суперкомпилятор сделает это всегда.
Можно ссылку на суперкомпилятор для C#? Честно, не вижу много смысла муссировать рассуждения типа "теоретически возможно написать такой компилятор, который заоптимизирует все насмерть". Когда напишут — тогда и поговорим. А пока все абстракции — реализуемые средствами языков на .NET — о которых здесь и речь неизбежно несут оверхед.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Гм. Вообще-то не вижу связи между кривой архитектурой и языком.
А связи и нет. Приложение, которое тормозит, это в 99.99% случаев неправильно спроектированное приложение, а не приложение, к-е тормозит, потому что его реализовали с использованием средств разработки, вносящих большой "оверхед".
>>Что в осном народ-то пишет? Бизнес-приложения, распределенные приложения, всякие там корпоративные шины и проч., веб-сервисы и другую подобную дрянь. Там совсем другие проблемы возникают, на другом уровне. Если, к примеру, у тебя плохо продумана связь с каким-нибудь нодом, идет слишком частый обмен пакетами, некорректно обрабатывается таймаут нода, нет кэширования и пр. — тебе тут не поможет переделка твоего приложения на более низкоуровневый асм. PD>+100. Безусловно верно. Насчет "дряни" — я бы не стал так говорить, все задачи имеют право на существование.
"Дрянь" — это любя
ВВ>>А теперь представь — вот люди пишут всякие ESB, передают тонны ХМЛя (ХМЛя, понимаешь? ), а ты их пытаешься убедить, что "существуют задачи, для решения которых использование высокоуровневых средств... неэффективно и нецелесообразно". Как на фиг высокоуровневые средства, у нас сплошной ХМЛ, блин PD>Со всем можно согласиться, но... Есть же задачи, в которых нет тонн XML и т.д. Пусть их становится меньше (меньше в каком смысле — меньше количество програмистов, ими занимающихся или меньше их роль ? со вторым не согласен, первое бесспорно).
Меньше роль или больше роль — это философия. Таких задач становится меньше по количеству. То, что раньше реализовывали только на асме, сейчас могут делать на более высокоуровневых средствах, чуть ли не на C#.
Понятно, что те задачи, которые по-прежнему решают с помощью низкоуровневных средств супер важные. Управление буровыми, космическими кораблями и пр. — кто ж будет отрицать роль всего этого? Только вот надо понимать, что лет через -надцать та же джава действительно полетит в космос.
PD>Проблема же в том, что адепты этих новых технологий претендуют на их универсальность для всех задач.
Я не слышал заявления типа "что C# позволяет решить любую задачу по разработке". Может, пропустил? Но дело-то не в C#. Дело в том, что в перспективе ЯВУ типа C# или Немерле действительно позволит решать любую задачу.
ВВ>>И будет еще меньше. Сейчас у банальной игровой приставки — под которую игры выпускают, кстати, в "обрезанном" по сравнению с PC варианте — прозводительность терафлопами мерится. О чем тут можно говорить-то? Какой асм?
PD>Не знаю насчет игровых приставок, а вот в моей задаче асм будет на днях. Не в чистом виде, а через intrinsic. Для реализации SSE2. Распараллеливание, так сказать, на одном процессоре, и даже без всяких потоков. Тест показал примерно 3.5- кратный выигрыш
А что за задача? Можно по-подробнее? Только подробности не в стиле, что нужно писать используя опредленные инструкции процессора, а бизнес-формулировка задачи какая?
ВВ>>Собственно, такова позиция твоих оппонентов, как я ее понимаю. И я с ней согласен. А вот твою позицию я не очень понимаю. Какой смысл все сводить к тому, что "есть задачи для к-х асм подходит"? Ну да, пока еще есть. Но мне действительно кажется, что ты переоцениваешь роль и количество таких задач. PD>Из того, что большинство задач — это задачи бизнеса, еще не следует, что все остальное вымирает.
Павел, все задачи — это задачи бизнеса! Ты что, в стране ОЗ находишься? Это если, конечно, не рассматривать развлечения гиков по вечерам — но тут, как говорится, любые средства хороши. И бизнесу дешевле тратиться на железо, чем на разработку супер-производительного софта на этом железе. И это реальность. Софт на дотнете стоит дешево. Железо стоит дешево. Разработка/поддержка на асме — дорого. Зачем платить больше?
У меня кот есть. Он очень любит, когда его по шерсти гладят, и очень не любит, когда против шерсти или даже поперек шерсти
G> for (int x = pChunk->xStart; x <= xEnd; x++) G> { G> unsigned s = 0; G> for ( int y = 0; y < nHeight; y++) G> { G> s += matrix[x + y * matrixWidth];//! G> } G> columnSum[x] = s; G> }
Я-то в оригинальном своем примере GetPixel суммировал, там все равно, как суммировать, время, на GetPixel требуемое, все перекроет. А ты за память взялся. И расположил ты эту матрицу по строкам, как все сейчас делают. А вот доступ к ней оставил по столбцам, что в таком случае лучше не делать. Оптимзатору компилятора это нравится не более, чем моему коту, да и доступ к памяти тут тоже не ахти.
Заменим этот код на
for (int x = pChunk->xStart; x <= xEnd; x++)
columnSum[x] = 0;
for ( int y = 0; y < nHeight; y++)
for (int x = pChunk->xStart; x <= xEnd; x++)
columnSum[x] += matrix[x + y * matrixWidth];//!
ну и для непараллельного алгоритма тоже.
Кроме того, сравнивать значения, полученные по GetTickCount, при столь малых величинах, не очень корректно. У нее точность порядка 15 мсек, так что 60 и 70 — это одно и то же в пределах ошибки. Поэтому я увеличил
const int matrixWidth = 12800;
При этом.
С++, Release, VS 2005
по столбцам (твой то есть)
359 344
по строкам (мой)
16 15
Замечу в скобках, что и умножение в цикле там ни к чему, так как y * matrixWidth не меняется во внутреннем цикле, но не стал переделывать, компилятор разберется и сам.
В общем, ты выбрал наихудший способ из всех возможных .
G>На C# c Paralle Extension June CTP
Paralle Extension June CTP у меня нет, так что оставил только непараллельный алгоритм. Для него на моей машине 450.
Здравствуйте, gandjustas, Вы писали:
G>На .NET тоже не надо
Не надо
AS>>>Вот только, есть мнение, память и процессор новые дешевле месяца твоей работы. Не так ли? Это раз. PD>>Да. Только вот одна проблема — именно моя текущая работа требует выжать из этого железа максимум того, что можно. Не выжму — цена месяца моей работы будет равна 0. И что делать ? G>Я выше приводил тест, где не напрягаясь мой код на C# выжимает из железа больше, чем ваш на C.
Я твой тест не заметил, извини. Сейчас попробовал. Ответ да в ответе на то письмо.
PD>>Вот тебе пример. Делал как-то приложение на C#. Ничего особенного, форма с табами, на них всякие листбоксы и т.д. За сценой никаких больших объектов (потом при работе они появятся, но до первого запроса их нет). 17 Мб вся эта прелесть занимает. Уверен, что больше 4-5 Мб она занимать не должна — на MFC. На чистом Win API — думаю, в 2-3 Мб уложился бы, но на это точно много моего времени уйдет. G>Пусть лучше прога занимает больше памяти, но работает быстрее.
Если бы она работала быстрее — я бы согласился (не всегда).
>Мне десяток мегов оперативки сейчас вообще не жалко.
Тебе не жалко, другим не жалко, а в итоге...
PD>>Ну а насчет скорости — тут меня лучше не трогай, я именно этим сейчас и занимаюсь. И если меня лишить прямого доступа к памяти (указателей, выравнивания, иными словами) — все , что я сделал — коту под хвост. А так — уже в 6 раз быстрее. G>И вы наверное предпочитаете руками реализовывать файловое хранилище, вместо использования БД...
В этой задаче нет никаких файлов. А вообще было такое. И скорость работы была намного выше. Практически любой запрос делался за 15-20 мсек. Правда, одно но — вставки и изменения в этом хранилище не производились, оно было константым. Генерация его производилась один раз в 3 месяца и занимала 5 часов — вытаскивались все данные из БД и записывались в это хранилище.
G>Для таких задач редко приходится сталкиваться с низкоуровневневой оптимизацией. Обычно производительность упирается в передачу данных.
С передачей данных нет никаких проблем, 20-30 Мб передать можно со свистом. А вот потом ...
Здравствуйте, Воронков Василий, Вы писали:
WH>>Суперкомпилятор это вполне конкретный давно усоявшейся термин. Появившейся еще в 70какомто году. ВВ>Это как-нибудь применимо, скажем, к C#?
Для жабы уже даже реализовано. http://www.supercompilers.com/white_paper.shtml
Переделать это для C# дело техники.
... << RSDN@Home 1.2.0 alpha rev. 745>>
Пусть это будет просто:
просто, как только можно,
но не проще.
(C) А. Эйнштейн
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Я-то в оригинальном своем примере GetPixel суммировал, там все равно, как суммировать, время, на GetPixel требуемое, все перекроет. А ты за память взялся. И расположил ты эту матрицу по строкам, как все сейчас делают. А вот доступ к ней оставил по столбцам, что в таком случае лучше не делать. Оптимзатору компилятора это нравится не более, чем моему коту, да и доступ к памяти тут тоже не ахти.
Не я писал этот цикл.
PD>Кроме того, сравнивать значения, полученные по GetTickCount, при столь малых величинах, не очень корректно. У нее точность порядка 15 мсек, так что 60 и 70 — это одно и то же в пределах ошибки. Поэтому я увеличил
Не я придумал использовть GetTickCount.
PD>В общем, ты выбрал наихудший способ из всех возможных .
Вообще-то не я выбрал, а ты Я просто GetPixel заменил назначение из матрицы.
G>>На C# c Paralle Extension June CTP PD>Paralle Extension June CTP у меня нет, так что оставил только непараллельный алгоритм. Для него на моей машине 450. PD>Чудес на свете не бывает.
Конечно не бывает. Код на шарпе очень далек от оптимального.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>А связи и нет. Приложение, которое тормозит, это в 99.99% случаев неправильно спроектированное приложение, а не приложение, к-е тормозит, потому что его реализовали с использованием средств разработки, вносящих большой "оверхед".
Понимаешь, у меня нет приложения. Есть просто алгоритм некоторой обработки матрицы. Он может, и не наилучший, но лучше в мире нет, не нашел. А неправильно его спроектировать нельзя, потому что там нечего проектировать. А тормозит он потому, что там сотни миллионов операций. Вот и все. Так что оно тормозит, и , видимо, попадает в 0.01%. Впрочем, уже не торомозит.
ВВ>Я не слышал заявления типа "что C# позволяет решить любую задачу по разработке". Может, пропустил? Но дело-то не в C#. Дело в том, что в перспективе ЯВУ типа C# или Немерле действительно позволит решать любую задачу.
Улитка едет, когда-то будет
ВВ>А что за задача? Можно по-подробнее?
Увы, нет.
>Только подробности не в стиле, что нужно писать используя опредленные инструкции процессора, а бизнес-формулировка задачи какая?
А нет тут бизнес-формулировки вообще . Например, для умножения матриц — какая тут бизнес-формулировка ? И у меня примерно то же.
ВВ>Павел, все задачи — это задачи бизнеса!
Задачи бизнеса — да. В том смысле, что за это кто-то платит и это кому-то нужно. Но и только. Формулировка же задачи чисто математическая. Ну вот, к примеру, предложу я тебе задачу создания некоторого графического фильтра, который позарез кому-то нужен и за который кто-то готов заплатить. Но это все же математическая задача или, если угодно, задача из машинной графики, но не задача из бизнес-сферы. Вот в этом смысле и надо было понимать мое высказывание.
>Ты что, в стране ОЗ находишься?
Нет
>И бизнесу дешевле тратиться на железо, чем на разработку супер-производительного софта на этом железе.
Представь себе, не всегда. Иначе бы мне за это не платили.
>И это реальность. Софт на дотнете стоит дешево. Железо стоит дешево. Разработка/поддержка на асме — дорого. Зачем платить больше?
А просто — не работает тут экстенсивный метод. Не успевает, проще говоря. Нет возможности тратить 5 секунд на компьютере на один образец. А одну задачу распараллелить между компьютерами тоже нельзя, да и не даст это ничего. Это во-первых. А во-вторых, по сравнению с той экономией, что даст эта оптимизация, расходы на мою зарплату — копейки. Я на эту задачу потрачу месяц, ну пусть два, а работать это будет на сотнях компьютеров. Посчитай.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Понимаешь, у меня нет приложения. Есть просто алгоритм некоторой обработки матрицы. Он может, и не наилучший, но лучше в мире нет, не нашел. А неправильно его спроектировать нельзя, потому что там нечего проектировать. А тормозит он потому, что там сотни миллионов операций. Вот и все. Так что оно тормозит, и , видимо, попадает в 0.01%. Впрочем, уже не торомозит. PD>А нет тут бизнес-формулировки вообще . Например, для умножения матриц — какая тут бизнес-формулировка ? И у меня примерно то же.
Мне вот непонятно, что за задача такая — помножение матриц. И, думаю, не только мне. Для чего/для кого она делается?
ВВ>>Павел, все задачи — это задачи бизнеса! PD>Задачи бизнеса — да. В том смысле, что за это кто-то платит и это кому-то нужно. Но и только. Формулировка же задачи чисто математическая. Ну вот, к примеру, предложу я тебе задачу создания некоторого графического фильтра, который позарез кому-то нужен и за который кто-то готов заплатить. Но это все же математическая задача или, если угодно, задача из машинной графики, но не задача из бизнес-сферы. Вот в этом смысле и надо было понимать мое высказывание.
Математика, исследования, обучение студентов — это все понятно, тут базара нет
Но мы ведь говорили о промышленном программировании, разве нет? В противном случае вообще непонятно к чем тут проценты "распространенности" сравнивать — 90 там на 10 или 80 на 20. Собственно говоря, непонятно что мы вообще сравниваем.
>>И бизнесу дешевле тратиться на железо, чем на разработку супер-производительного софта на этом железе. PD>Представь себе, не всегда. Иначе бы мне за это не платили.
А я представляю. Именно поэтому асм еще не умер. Понятно, что до сих пор есть железки растираживанные сотнями тысяч экземпляров, на которых ну никак дотнет не встанет, и асм чуть ли единственное решение.
Но неужели ты считаешь, что через 5-10 лет эти железки не изменятся кардинально?
>>И это реальность. Софт на дотнете стоит дешево. Железо стоит дешево. Разработка/поддержка на асме — дорого. Зачем платить больше? PD>А просто — не работает тут экстенсивный метод. Не успевает, проще говоря. Нет возможности тратить 5 секунд на компьютере на один образец.
Ты представляешь скорость с которой железо развивается? Сегодня у тебя на старом компьютере твой алгоритм выполняется за 2 сек. на асме, завтра на новом компьютере тот же алгоритм с "абстракциями" на C# будет выполняться за 0.5 сек. Это реальность.
У меня вот нынешний проц на компе — Core2Duo E8500
Предыдущий — P4 Prescott 3.2 HT
Представляешь какая между ними разница по производительности?
А стоимость производства снижается с каждым годом. Процессоры становится меньше, холоднее, мощнее. На дешевых мобильниках теперь идут игры, о которых раньше мы на компах могли только мечтать. Это тенденция, разве нет?
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Чудес на свете не бывает.
Тоже мне, бином Ньютона.
Ускоряем код в 25 раз:
using System;
using System.Linq;
namespace linqbench
{
public static class SumHelper
{
// Sum для uint в стандартной библиотеке нет.public static uint Sum(this uint[] items)
{
var result = 0U;
for (int i = 0; i < items.Length; i++) result += items[i];
return result;
}
}
class Program
{
static void Main()
{
var matrix = new uint[128000, 1024];
var notParallel = from x in Enumerable.Range(0, matrix.GetLength(0) - 1)
select Enumerable.Range(0, matrix.GetLength(1) - 1).Sum(y => matrix[x, y]);
notParallel.ToArray(); //Чтобы выполнился JITvar matrix2 = new uint[128000][];
for (int i = 0; i < matrix2.Length; i++) matrix2[i] = new uint[1024];
var notparallel2 = from col in matrix2
select col.Sum();
notparallel2.ToArray();
var sw = new System.Diagnostics.Stopwatch();
sw.Start();
notParallel.ToArray();
sw.Stop();
var time1 = sw.ElapsedMilliseconds;
sw.Reset();
sw.Start();
notparallel2.ToArray();
sw.Stop();
var time2 = sw.ElapsedMilliseconds;
Console.WriteLine("time1={0} time2={1}", time1, time2);
}
}
}
Parallel Extensions у меня нет, но легко видеть, что легкость распараллеливания никуда не девается.
... << RSDN@Home 1.2.0 alpha 4 rev. 1110>>
'You may call it "nonsense" if you like, but I'VE heard nonsense, compared with which that would be as sensible as a dictionary!' (c) Lewis Carroll
Здравствуйте, gandjustas, Вы писали:
G>Здравствуйте, Pavel Dvorkin, Вы писали:
PD>>Я-то в оригинальном своем примере GetPixel суммировал, там все равно, как суммировать, время, на GetPixel требуемое, все перекроет. А ты за память взялся. И расположил ты эту матрицу по строкам, как все сейчас делают. А вот доступ к ней оставил по столбцам, что в таком случае лучше не делать. Оптимзатору компилятора это нравится не более, чем моему коту, да и доступ к памяти тут тоже не ахти. G>Не я писал этот цикл.
Но я-то его писал для других целей. Не могу же я отвечать за использование моего цикла в иной ситуации.
PD>>Кроме того, сравнивать значения, полученные по GetTickCount, при столь малых величинах, не очень корректно. У нее точность порядка 15 мсек, так что 60 и 70 — это одно и то же в пределах ошибки. Поэтому я увеличил G>Не я придумал использовть GetTickCount.
Да, но я ее использовал там, где время было 1500-2000 мсек
PD>>В общем, ты выбрал наихудший способ из всех возможных . G>Вообще-то не я выбрал, а ты Я просто GetPixel заменил назначение из матрицы.
Нет. Я выбрал не для матрицы, а для окна. Я за твой перенос этого на матрицу в ОП отвечать не намерен!
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Здравствуйте, gandjustas, Вы писали:
G>>Здравствуйте, Pavel Dvorkin, Вы писали:
PD>>>Я-то в оригинальном своем примере GetPixel суммировал, там все равно, как суммировать, время, на GetPixel требуемое, все перекроет. А ты за память взялся. И расположил ты эту матрицу по строкам, как все сейчас делают. А вот доступ к ней оставил по столбцам, что в таком случае лучше не делать. Оптимзатору компилятора это нравится не более, чем моему коту, да и доступ к памяти тут тоже не ахти. G>>Не я писал этот цикл.
PD>Но я-то его писал для других целей. Не могу же я отвечать за использование моего цикла в иной ситуации.
Какой иной ситуации. Ситуация та же — суммирование массива по столбцам. Только способ получения массива другой.
Вообще изначально код ущербный был. Надо получить весь массив пикселей, а потом сумировать вместо GetPixel на каждой итерации.
PD>>>Кроме того, сравнивать значения, полученные по GetTickCount, при столь малых величинах, не очень корректно. У нее точность порядка 15 мсек, так что 60 и 70 — это одно и то же в пределах ошибки. Поэтому я увеличил G>>Не я придумал использовть GetTickCount.
PD>Да, но я ее использовал там, где время было 1500-2000 мсек
Ну сегодня это 1500 мс, а послезавтра 15 мс.
PD>>>В общем, ты выбрал наихудший способ из всех возможных . G>>Вообще-то не я выбрал, а ты Я просто GetPixel заменил назначение из матрицы.
PD>Нет. Я выбрал не для матрицы, а для окна. Я за твой перенос этого на матрицу в ОП отвечать не намерен!
>Мы здесь, еще раз напоминаю, обсуждаем именно конструкции языка, и ничто иное. Обойтись без LINQ для демонстрации возможностей ФП на шарпе нельзя в принципе, обойтись без Win32 для демонстрации того, что LINQ ничего не дает можно, и даже нужно.
Согласен. Я вполне могу убрать оттуда и окно, и GetPixel, а просто предложить просуммировать столбцы некоего двумерного массива, каким-то образом заданного. Правда, чтобы время померить, придется либо в цикл это вставить, либо уж очень большой массив использовать. Впрочем, чтобы IT-ские проценты сравнить в AsParallel и без, то же придется сделать. Но все же никак не пойму — чего ты к пустякам придираешься ? Ну какое отношение к распараллеливанию имеет вопрос откуда и как брать эту матрицу ?
Кто же это писал???
PD>А резюме простое — истина конкретна
Здравствуйте, Klapaucius, Вы писали:
K>Здравствуйте, Pavel Dvorkin, Вы писали:
PD>>Чудес на свете не бывает.
K>Тоже мне, бином Ньютона.
Все правильно. Ты сделал проход по смежным адресам, по строкам, иными словами, поэтому быстро. А если надо по столбцам еще (а кстати, требовалось именно по столбцам) — что напишешь ?
K> var matrix2 = new uint[128000][]; K> for (int i = 0; i < matrix2.Length; i++) matrix2[i] = new uint[1024]; K> var notparallel2 = from col in matrix2 K> select col.Sum(); K> notparallel2.ToArray();
Кстати, почему ты считаешь, что здесь именно колонка суммируется ? ИМХО все же в массиве первый индекс — номер строки, а второй — колонки, так что у теяб массив из 128000 строк и 1024 колонок.
Можешь изменить так, чтобы получился не массив из 128000 элементов (сумм строк) , а из 1024 элементов — сумм столбцов ? Условие — расположение массива не менять!
Я-то смогу, потому что в любом случае пойду по смежным адресам — хоть при суммировании по строкам (это вообще просто), хоть по столбцам — см. мой пример в этой ветке, на который ты ответил.
Вот тебе пример на всякий случай. Здесь и суммы по строкам, и по столбцам.
#include"stdafx.h"#include"windows.h"int _tmain(int argc, _TCHAR* argv[])
{
DWORD dwTimeStart, dwTimeEnd;
unsigned rows = 128000, cols = 1024;
unsigned** p = new unsigned *[rows];
for (unsigned i = 0; i < rows; i++)
p[i] = new unsigned [cols];
// сорри, но мне нули никто не занесетfor (unsigned i = 0; i < rows; i++)
for (unsigned j = 0; j < cols; j++)
p[i][j] = i;
unsigned* colSum = new unsigned[cols];
unsigned* rowSum = new unsigned[rows];
// суммирую по столбцам
dwTimeStart = GetTickCount();
for (unsigned i = 0; i < cols; i++)
colSum[i] = 0;
for (unsigned i = 0; i < rows; i++) // а пойду по строкам во внешнем циклеfor (unsigned j = 0; j < cols; j++)
colSum[j] += p[i][j];
dwTimeEnd = GetTickCount();
printf("%d\n", dwTimeEnd - dwTimeStart);
for ( int i = 0; i < cols; i++)
printf("%d ", colSum[i]);
printf("\n");
// суммирую по строкам
dwTimeStart = GetTickCount();
for (unsigned i = 0; i < rows; i++) // тоже пойду по строкам во внешнем цикле
{
unsigned s = 0;
for (unsigned j = 0; j < cols; j++)
s += p[i][j];
rowSum[i] = s;
}
dwTimeEnd = GetTickCount();
printf("%d\n", dwTimeEnd - dwTimeStart);
for ( int i = 0; i < rows; i++)
printf("%d ", rowSum[i]);
printf("\n");
for (unsigned i = 0; i < rows; i++)
delete p[i];
delete [] p;
delete []colSum;
delete [] rowSum;
return 0;
}
P.S. Переполнения при суммировании игнорируются. Я не поставил __int64 для сумм, чтобы не давать повода для еще одного флейма
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Мне вот непонятно, что за задача такая — помножение матриц. И, думаю, не только мне. Для чего/для кого она делается?
Не обижайся на то, что я сейчас скажу, ладно ? Я вовсе не хочу ни тебя, ни кого-то еще обидеть. Я с уважением отношусь к любым задачам.
В этом твоем ответе — суть проблемы. Тебе и другим — действительно непонятно. В задачах бизнеса (как я их определил) — это действительно не нужно. Если речь идет о создании сайта — это скорее всего не нужно. Если речь идет о системе управления заводом — может быть, тоже. И т.д.А поскольку большинство этим бизнес-задачами и занимается, то ему (большинству) это действительно непонятно. Оно как-то подсознательно уверено, что то, чем они занимаются — и есть единственно верное программирование, а то, что ему не нужно — вообще не нужно.
О чисто научных задачах я говорить не буду. То. что там оно нужно — думаю, спорить не будешь, но об этих задачах не говорим сейчас.
Вернемся к бизнесу. Ну а если это не сайт и не АСУ (не к ночи будь помянута). О своих нынешних делах рассказывать не буду, а вот о том. что делал лет 10 назад — расскажу. А была это задача натягивания некоей текстуры на фотографию человека. Вот стоит он, одет в голубую рубашку, а еще ткань есть, клетчатая. И надо эту ткань на его рубашку наложить. Чтобы складки там остались, тени и т.д, но только чтобы он был не в голубом, а в клетчатом. Не помню, было ли там перемножение матриц, но, в общем, всяких алгоритмов там хватало.
Это задача бизнеса ? Еще как — заказчик — некая фирма, которая эти рубашки шьет и хочет моделировать процесс — натянуть новый материал и посмотреть, что получится. Без человека — модели.
Другая задача, в которой я участвовал, включала в себя обширный регрессионный анализ для предсказания в экономике... вот чего — не скажу, NDA. Там линейная алгебра в чистом виде и перемножений матриц сколько угодно.
ВВ>Математика, исследования, обучение студентов — это все понятно, тут базара нет ВВ>Но мы ведь говорили о промышленном программировании, разве нет? В противном случае вообще непонятно к чем тут проценты "распространенности" сравнивать — 90 там на 10 или 80 на 20. Собственно говоря, непонятно что мы вообще сравниваем.
Ну вот я тебе привел пару задач вполне промышленного программирования. И то, чем я сейчас занимаюсь, и тот проект, в котором я несколько лет участвовал — тоже промышленное программирование, поверь. И еще какое промышленное
ВВ>А я представляю. Именно поэтому асм еще не умер. Понятно, что до сих пор есть железки растираживанные сотнями тысяч экземпляров, на которых ну никак дотнет не встанет, и асм чуть ли единственное решение.
За милую душу он туда встанет. 4-ядерный процессор с 4 Гб — туда что хочешь встанет (это машина заказчика, у меня хуже). Но вот работать все это будет с такой скоростью, что меня просто уволят
Про свою задачу не скажу, а сделаю имитацию. Вот мы тут сложение матриц вдоль и поперек обсуждали чуть выше. Ну так вот — матриц таких 6 штук, одна входная, другая выходная, 4 промежуточных. Размеры их примерно так 5000 на 5000. А время на обработку дается 200 мсек. И там немного сложнее, чем суммирование по строкам или столбцам. Теперь считаем. 5000 на 5000 — 25 млн. элементов на матрицу. Их надо хотя бы заполнить, а матриц 5 (кроме входной), итого 125 млн. элементов. И действия совершить. А тактовая частота всего лишь 3 Ггц (3 млрд в сек) , а команды за один такт не все выполняются, а времени всего 200 мсек. Вот и все.
ВВ>Но неужели ты считаешь, что через 5-10 лет эти железки не изменятся кардинально?
ВВ>Ты представляешь скорость с которой железо развивается? Сегодня у тебя на старом компьютере твой алгоритм выполняется за 2 сек. на асме, завтра на новом компьютере тот же алгоритм с "абстракциями" на C# будет выполняться за 0.5 сек. Это реальность.
Во-первых, если я его не сделаю сейчас, то меня сейчас и уволят, не дожидаясь, когда с абстракциями будет 0.5 сек. Впрочем, за 0.5 сек уволят тоже сейчас, хоть с абстракциями, хоть без И обратно меня когда-нибудь не возьмут, сколько бы я им потом не говорил про абстракции.
Во-вторых, аппетит приходит во время еды. 200 мсек я еще не сделал, но 400 сделал, а у меня еще SSE2 есть, на 4-кратное ускорение я не надеюсь, но раза в 2 хочу. А заказчик пока что, увидев эти 400, написал мне, что он хотел бы уже не 200, а 20 мсек и предлагает попробовать здесь CUDA. Вот такие вот дела.
ВВ>У меня вот нынешний проц на компе — Core2Duo E8500 ВВ>Предыдущий — P4 Prescott 3.2 HT ВВ>Представляешь какая между ними разница по производительности? ВВ>А стоимость производства снижается с каждым годом. Процессоры становится меньше, холоднее, мощнее. На дешевых мобильниках теперь идут игры, о которых раньше мы на компах могли только мечтать. Это тенденция, разве нет?
Это тема отдельного флейма, не хочу его начинать, скажу лишь, что я в этом совсем не уверен. Железо становится лучше, да, но вот софт все больше и больше тормозит. Тебя скорость работы XP или Vista не раздражает ? Меня даже время их загрузки раздражает, что они там, черт побери, почти полминуты делают ? А ведь у процессора миллиарды операций в секунду. Миллиарды!
На самом деле мне и правда непонятно. Вот сегодня заказчик хочет чтобы у тебя было за 200 мс, завтра он передумал и хочет за 20 мс — т.е. так ни с того с сего требования по производительности изменились на порядок А что в действительности-то заказчику нужно? Это вообще похоже на какие-то упражнения для ума.
Ты вот сам пишешь — десять лет назад занимался "текстурированием" на асме. Сейчас есть куча движков написанных на С# — да, это конечно не мейн-стрим подход (пока) — но почему спустя еще 10 лет эта задача не должна выполняться на дотнете без всяких "но"? Я вот правда не вижу причин
Тезис "в перспективе любую задачу можно решить на ЯВУ" возникает не потому что все так ненавидят асм, а потому что непонятны те самые таинственные задачи, для которых он будет нужен всегда — ведь это основной тезис, не так ли? что асм никогда не умрет? Да ты и сам тумана напускаешь.
Помножение матриц — да, для меня это не задача. У меня мозг по-другому устроен И мне так кажется, что многие думают примерно также.
Здесь речь в первую очередь о мейнстриме. И тенденции мейнстрима у меня лично сомнений не вызывают. Код становится все более высокоуровневым. Я не удивлюсь, если через -надцать лет C# будет восприниматься как низкоуровневое средство разработки, а большинство программистов будут какие-нибудь UML-и компилить. И при этом доказывать "ветеранам" вроде меня, что C# уже почти мертв, а UML 6.0 — это видите ли супер-уровень абстракции, благодаря которому программы проще оптимизировать.
F>Вот в последнем предложении описана бизнес-задача. F>А перемножение матриц — это не бизнес задача, это кусочек ее решения. Отдельная техническая задача, так сказать F>Заказчику же не особо важно, как технически решается его задача.
+1
F>И оппоненты тебе пытаются сказать, что задачи надо рассматривать именно глобально, а не только в отдельных деталях. Может быть можно провести оптимизацию где-то выше, чтобы уменьшить количество перемножений матриц.
У меня нет "выше". На входе образец, его надо обработать, потом следующий и т.д. Между образцами — ничего общего, кешировать там нечего.
F>Я ведь тоже могу рассказать, какая это жуткая задача строить веб страницы — у меня сотни запросов в секунду, на каждый запрос надо подготовить данные по 20000 сущностей, а их все надо взять из базы, а для этого мне надо 200 запросов, а потом все эти данные обработать непростым алгоритмом ( 300 мс на каждую сущность) и все это нужно уложиться в полсекунды для каждого пользователя (которых тысячи). Это же уму непостижимо какая сложная вычислительная задача!!!
А я и не спорю.
F>А потом рассказать, как я жутко оптимизирую алгоритм, и он уже не 300мс тратит, а всего 50мс (но 20000 объектов — F>это все равно слишком долго обрабатывается). Ах, какие стали ужасные неэффективные средства.
Знакомо мне все это... Ох, как знакомо. Без БД, правда.
F>Только если посмотреть по ограничениям самой задачи, то получается, что их можно закешировать в уже обработанном виде и вуаля, уложились в полсекунды на запрос.
Твое счастье, что можно кешировать. А у меня абсолютно нет.
F>Ты часто путаешь технические задачи и отдельные детали решения с собственно бизнес-задачами.
А вот для меня лни просто равны. Задачи такие...
F>Да, бывают бизнес-задачи, где все упрется в один алгоритм и нет никаких способов решить бизнес-задачу, кроме как заоптимизировать этот алгоритм по самое немогу.
Вот именно
F>Но бывают и бизнес-задачи, где все упирается в один алгоритм, но все же есть способы решить бизнес-задачу, отойдя от оптимизации собственно прямого выполения алгоритма (например, дополнительно предобрпботав входные данные или закешировав частичные решения).
Бывают.
F>Все. F>Это я просто про разницу между "бизнес-" и "вообще-" задачами высказался, более ничего. Про твои задачи я ничего не знаю. F>Но не стоит считать других глупее себя, даже если они пишут веб-приложения для всякого бизнеса.
Упаси боже. Я же просил — не обижаться. У меня такого и в мыслях не было.
F>Мы, на самом деле, многое понимаем. F>Да еще и высказать можем
Здравствуйте, Sinclair, Вы писали:
ВВ>>И что мне с ней делать? Молиться на нее? S>Ну, например понять, что применение той же техники для C# принципиальных проблем не имеет.
И что мне от этого понимания? C# крут, потому что теоретически возможно написать супер-компилятор? Теоретически много чего возможно.
ВВ>>Да, ослиный ASP.NET — это гениальный пример для сравнения. Ничего лучше чем дебильный конструктор сайтов и подобрать нельзя. S>А что в нём ослиного? Это не дебильный конструктор сайтов, а лучший в мире фреймворк для построения высокопроизводительных веб-приложений. Это так, к слову о.
"Лучший" — это по результатам голосований на MSDN? С чем его сравнивали? Какие перформанс тесты проводили?
ВВ>>Может, лучше программирование на асме вообще сравнить с InfoPath-ом? Ведь какие там формочки, какие абстракции. S>Ну, с таким уровнем представлений вы можете асм хоть с копченой рыбой сравнивать.
Ну да, а сравнить ассемблер и ASP.NET — это видимо правила хорошего тона.
ВВ>>А может, это — давайте тогда все на свете на АСП-НЕТ писать? Ведь АСП-НЕТ рвет на части асм по своей эффективности. Чет мужики еще не доперли что надо все на АСП-НЕТ переводить. S>Еще раз медленно повторяю: пусть твои мужики воспроизведут на асме хотя бы один пример из самплов к Рихтеровской Power Threading Library. И посмотрим, кто кого порвёт по эффективности.
Зачем?
ВВ>>Abstraction gain — он в голове. И это хорошо, что он в голове, а не в другом месте. И не надо его из головы куда-то перекладывать. S>Еще раз, медленно, поясняю: abstraction gain — вполне конкретная штука, и она существует. В частности специализация абстрактного кода под аппаратную платформу в момент исполнения, она же JIT. В частности, специализация абстрактного кода под реальные данные в момент сборки, она же суперкомпиляция.
А если аппаратная платформа вообще всего одна и другой быть не может?
Или abstract gain он присутствует по определению, что бы мы не писали? Ну по фиг, да, есть проблем с производительностью? — добавить дополнительный уровень абстракции, и все станет шоколадно.
S>Поменьше эмоций, побольше мыслей.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>И что мне от этого понимания? C# крут, потому что теоретически возможно написать супер-компилятор? Теоретически много чего возможно.
Совершенно верно. Я и говорю — теоретически можно и Http Handler на ассемблере написать. S>>А что в нём ослиного? Это не дебильный конструктор сайтов, а лучший в мире фреймворк для построения высокопроизводительных веб-приложений. Это так, к слову о. ВВ>"Лучший" — это по результатам голосований на MSDN? С чем его сравнивали? Какие перформанс тесты проводили?
Лучший — это по результатам моего личного опыта. Сравнивали с JSP, ASP, PHP, Python. С наколеночными CGI на C и С++. Тесты проводили самые разнообразные. Кроме того, я немножко представляю себе, как все эти фреймворки устроены внутри. А у вас какие основания клеймить ASP.NET? Неумение с ним работать? Незнание того, как его конвеер проинтегрирован с IIS7? Или просто незнакомство с предметом?
ВВ>Ну да, а сравнить ассемблер и ASP.NET — это видимо правила хорошего тона.
При чем здесь хороший тон?
Просто веб-сервер — это типичный пример высоконагруженного приложения. Математика в наши дни встречается редко; большинство десктопного софта в принципе никогда не сталкивается с ситуацией нехватки производительности.
S>>Еще раз медленно повторяю: пусть твои мужики воспроизведут на асме хотя бы один пример из самплов к Рихтеровской Power Threading Library. И посмотрим, кто кого порвёт по эффективности. ВВ>Зачем?
Как зачем? Чтобы рассуждения "теоретически, самый быстрый код — это написанный вручную на ассемблере" перестали быть голословными. Пока что никаких доказательств этому в топике не прозвучало. Главный адвокат ручной сборки Дворкин продолжает удивлять примерами на С++.
А до тех порк, пока вы настаиваете на присутствии в рассуждениях "теоретического ассемблерщика", я настаиваю на соревновании его с "теоретическим компилятором".
ВВ>А если аппаратная платформа вообще всего одна и другой быть не может?
Тогда оба подхода, очевидно, дадут одинаковый результат. Еще раз намекну: можно и более вырожденный случай взять. Вон, задача получения числа Пи и вовсе без ассемблера решается. Если задача одна и другой быть не может, то таблицы брадиса порвут по производительности любой математический фреймворк.
ВВ>Или abstract gain он присутствует по определению, что бы мы не писали?
Нет, не по определению. Но он есть, и дается значительно дешевле, чем specialization gain, полученный вручную.
Поменьше эмоций, побольше мыслей.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Кстати, почему ты считаешь, что здесь именно колонка суммируется?
Потому, что так оно и есть. Я считаю суммы столбцов в матрице со 128000 столбцов и 1024 строками.
Т.к. мне нужно считать столбцы — я выбираю адекватное задаче представление матрицы. Она хранится транспонированной.
PD>Условие — расположение массива не менять!
Ход игры, в которой правила меняет в процессе только одна сторона слишком предсказуем, чтобы быть интересным.
С другой стороны, мне совершенно не понятно, какое отношение эти упражнения имеют к теме разговора и доказательству/опровержению тезиса о существовании abstraction gain?
... << RSDN@Home 1.2.0 alpha 4 rev. 1110>>
'You may call it "nonsense" if you like, but I'VE heard nonsense, compared with which that would be as sensible as a dictionary!' (c) Lewis Carroll
Здравствуйте, Sinclair, Вы писали:
S>Лучший — это по результатам моего личного опыта. Сравнивали с JSP, ASP, PHP, Python. С наколеночными CGI на C и С++.
JSP само по себе как бы не очень фреймворк. Это скорее только View, причем не единственно возможный и далеко не самый лучший. Аналог ASP.NET, как я понимаю, это что-нибудь вроде JSF/Tapestry/Wicket.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Вернемся к бизнесу. Ну а если это не сайт и не АСУ (не к ночи будь помянута). О своих нынешних делах рассказывать не буду, а вот о том. что делал лет 10 назад — расскажу. А была это задача натягивания некоей текстуры на фотографию человека. Вот стоит он, одет в голубую рубашку, а еще ткань есть, клетчатая. И надо эту ткань на его рубашку наложить. Чтобы складки там остались, тени и т.д, но только чтобы он был не в голубом, а в клетчатом. Не помню, было ли там перемножение матриц, но, в общем, всяких алгоритмов там хватало. PD>Это задача бизнеса ? Еще как — заказчик — некая фирма, которая эти рубашки шьет и хочет моделировать процесс — натянуть новый материал и посмотреть, что получится. Без человека — модели.
Ну вот, кстати, в тему "развития" этой задачи. Как ты думаешь, будет выглядеть эта задача, скажем, еще через 10 лет? Т.е. твоему заказчику будет нужно ровно то же самое, что в другом веке? Ну наверное ведь нет. И при реализации задачи придется рассчитывать честное освещение, "физику" ткани, завязанную на материал ткани опять же — и еще кучу всяких факторов. Алгоритмы еще более усложняются — и насколько реально — т.е. вообще в человеческих стилах — будет описывать все это на низком уровне?
Ведь, согласись, помимо производительности еще и не менее важный "ресурс" — время называется
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Здравствуйте, gandjustas, Вы писали:
G>>Судя по всему хреновый опыт. ASP.NET MVC видели?
ВВ>Давайте вы не будете судить о моем опыте, и я тоже не буду переходить на личности? Хамство не лучшее подспорье в беседе. ВВ>И я писал конкретно о веб-формах, если вы не заметили.
А разговор был об ASP.NET.
ВВ>А технологию в бета-версии, которую как раз и внедрили для того, чтобы прикрыть убожество веб-форм, я в промышленных проектах использовать пока не намерен.
Ваше право.
ВВ>>>Вернее, давайте я поправлюсь — тот ASP.NET, который начинается и заканчивается на IHttpHandler/IHttpModule — это отличная штука. А вот все что сверху... G>>Расширяемая модель провайдеров? Dynamic Data? ВВ>Dynamic Data — для хоум-пейджей. Для хоум-пейджей и веб-форм подходит отлично.
Что для хоум-пейджей дает Dynamic Data, вы его вообще использовали?
G>>Для сильно кастомной разметки используйте ListView. ВВ>Угу, потратить кучу времени на лист-вью, а потом выкинуть и его тоже. Отличная перспектива.
Ну если вы сразу планируете все выкинуть, то вам вообще ниче не поможет. В listView вы полностью контроллируете разметку, при этом остаются возможности пейдинга, сортировки, инплейс редактирвания. Пейджинг кстати на ListView можно сделать по GET запросу.
G>>Не могу удержаться. Код на в студию! XML+XSLT, повторяющий функциональность GridView: темплейты, пейджинг, сортировка, инплейс редактирование.
ВВ>А вы попробуйте сами как-нибудь. Там все куда проще чем может показаться.
Да я пробовал, но данные у меня не в XML гуляют туда-сюда.
ВВ>>>А ведь в описанной выше технике не используется ничего специфичного для АСП.НЕТ. Ее при желании можно реализовать и на ПХП. G>>Компилируемое XSLT-преобразование есть в PHP? ВВ>Это как-то влияет на ф-ность XSLT-процессора? В ПХП вообще нет ничего комплируемого. Что не мешает на ПХП написать приложение с лучшим перформансом чем на АСП.НЕТ+веб-форм.
Плохо написать можно на чем угодно. Это проблема писателей, а не технологии.
ВВ>Поэтому надо сравнивать ассемблер с АСП.НЕТ? Логика железная!
Да никто их не сравнивает. Просто хотят люди увидеть пример web страницы на ассемблере, по скорости сравнимой с ASP.NET. Это к вопросу об abstraction gain
Я сам очень недоволен тем, как работают веб-формы. Но сейчас webforms и dynamic data — наиболее удобный способ разработки базоморд, например админок сайта, мелки учетных приложеший итп. Для нормальных веб-приложений вебформы не подходят.
Здравствуйте, gandjustas, Вы писали:
ВВ>>Давайте вы не будете судить о моем опыте, и я тоже не буду переходить на личности? Хамство не лучшее подспорье в беседе. ВВ>>И я писал конкретно о веб-формах, если вы не заметили. G>А разговор был об ASP.NET.
Разговор между кем и кем? То, что я писал — относилось к веб-формс. Каким боком тут поднимается MVC, который во-первых не зарелизен, а во-вторых представляет собой по большому счету замену веб-формс (что уже наводит на мысли как бы)?
"Классический" ASP.NET сейчас это все-таки веб-формс, так широко разрекламированный во всяких презентациях, где человек рисует страничку мышкой, раскидывает контролы, связывают их с датасурсами. Это не MVC, если говорить о паттерне, это анти-MVC.
Давайте я выделю жирным:
ASP.NET супер, Web Forms — отстой
Так претензии ко мне сняты?
ВВ>>А технологию в бета-версии, которую как раз и внедрили для того, чтобы прикрыть убожество веб-форм, я в промышленных проектах использовать пока не намерен. G>Ваше право.
А вы будете начинать новый проект прям на Бете?
ВВ>>>>Вернее, давайте я поправлюсь — тот ASP.NET, который начинается и заканчивается на IHttpHandler/IHttpModule — это отличная штука. А вот все что сверху... G>>>Расширяемая модель провайдеров? Dynamic Data? ВВ>>Dynamic Data — для хоум-пейджей. Для хоум-пейджей и веб-форм подходит отлично. G>Что для хоум-пейджей дает Dynamic Data, вы его вообще использовали?
"Хоум-пейдж" это относительно простое приложение, с БД, которая вообще может создаваться с нуля и пр.
А как поможет Dynamic Data в приложении, где лет за пять до вас написали оракловую базу, где под сотню таблиц (про количество полей в этих таблицах я вообще промолчу)? А теперь еще представьте формы, работающие с этой БД. А еще данные из этой БД надо экспортировать в другую БД, которую разрабатывают вообще в другой строне и у нас execute right на несколько процедур всего. Это real world application.
А динамик дата — "украшательство", которое где-то подойдет, а где-то в принципе не подойдет. Как и linq2sql, впрочем. Тоже кстати еще одна красивая абстракция. Только вот хинты по-прежнему в запросах прописывать надо.
G>>>Для сильно кастомной разметки используйте ListView. ВВ>>Угу, потратить кучу времени на лист-вью, а потом выкинуть и его тоже. Отличная перспектива. G>Ну если вы сразу планируете все выкинуть, то вам вообще ниче не поможет. В listView вы полностью контроллируете разметку, при этом остаются возможности пейдинга, сортировки, инплейс редактирвания. Пейджинг кстати на ListView можно сделать по GET запросу.
Веб контролы не масштабируются в принципе. Есть область функционала, где они работают хорошо — выходишь за ее пределы, и использование контрола становится невозможным. Приходится переделывать.
А если уж нужно тупо генерить HTML, то уж извини это гораздо проще делать через XSLT. Время по настройке пейджинга в том же дата-гриде аналогично времени на реализацию этого пейджинга в XSLT. Да, да, не надо делать круглые глаза. Если клиентский пейджинг — вставляешь 1 строку сортировку и 1 if. Ну да еще сам блок "пейджера" надо описать — при этом пейджер может выглядеть как угодно, и ты не будешь ломать голову как бы настроить его также как на mock-up нарисовано, используя все три св-ва в датагриде.
Опять-таки как будет работать пейджит — через GET или не через GET — как хочешь так и сделай. Сортировка через GET — две строчки кода фактически. Причем это масштабируется блин.
G>>>Не могу удержаться. Код на в студию! XML+XSLT, повторяющий функциональность GridView: темплейты, пейджинг, сортировка, инплейс редактирование. ВВ>>А вы попробуйте сами как-нибудь. Там все куда проще чем может показаться. G>Да я пробовал, но данные у меня не в XML гуляют туда-сюда.
Пользовательский XPathNavigator поможет. Писали еще лет пять назад.
ВВ>>Это как-то влияет на ф-ность XSLT-процессора? В ПХП вообще нет ничего комплируемого. Что не мешает на ПХП написать приложение с лучшим перформансом чем на АСП.НЕТ+веб-форм. G>Плохо написать можно на чем угодно. Это проблема писателей, а не технологии.
Технология, особенно "крутая" современная технология должна хотя бы поощрят писать хорошо. Лучше — давать минимальные возможности писать плохо. Web Forms этого не делает.
Ну веб-форм реально хреновая штука. Мне нравятся веб-приложения, нравится работать с HTTP-протоколом, нравится в .NET реализован низкий уровень работы с HTTP, но даже сама изначальная концепция web forms — это же просто неправильно. И реальные (а не картинках) большие приложения на АСП.НЕТ приводят к тому, что уже рвотный рефлекс на все это вырабатывается.
И нас этим кормят уже почти семь лет.
А Шарепоинт вы видели, который на основе веб-форм построен? И во что там мастер-пейджи превращаются, когда нужно их дизайн перетачивать под нарисованные картинки. Причем иначе и не сделаешь фактически. Пусть вот эти клоуны сначала туда MVC прикрутят.
ВВ>>Поэтому надо сравнивать ассемблер с АСП.НЕТ? Логика железная! G>Да никто их не сравнивает. Просто хотят люди увидеть пример web страницы на ассемблере, по скорости сравнимой с ASP.NET. Это к вопросу об abstraction gain
А я хочу увидеть 3Д-движок, написанный с использование АСП-НЕТ разметки. Может, нам вместе с доктору записаться?
G>Я сам очень недоволен тем, как работают веб-формы. Но сейчас webforms и dynamic data — наиболее удобный способ разработки базоморд, например админок сайта, мелки учетных приложеший итп. Для нормальных веб-приложений вебформы не подходят.
Как думаешь, на момент презентации, скажем, ASP.NET 2.0 это было официальной позицией MS?
А ведь веб-формс — просто уровень абстракции над прямой работой с HTTP. И отличный пример того, как этот уровень абстракции для "нормальных веб-приложений" может не иметь никакого gain, а только penalty.
ВВ>А вы будете начинать новый проект прям на Бете?
Я уже сделал пару проектов на ASP.NET MVC(еще Preview версии), на бете один сейчас в разработке.
ВВ>"Хоум-пейдж" это относительно простое приложение, с БД, которая вообще может создаваться с нуля и пр. ВВ>А как поможет Dynamic Data в приложении, где лет за пять до вас написали оракловую базу, где под сотню таблиц (про количество полей в этих таблицах я вообще промолчу)? А теперь еще представьте формы, работающие с этой БД. А еще данные из этой БД надо экспортировать в другую БД, которую разрабатывают вообще в другой строне и у нас execute right на несколько процедур всего. Это real world application.
Это вообще проблемы другого уровня. Сделйте на EF модель поверх того что вам доступно и сможете пользоваться Dynamic Data.
ВВ>А динамик дата — "украшательство", которое где-то подойдет, а где-то в принципе не подойдет. Как и linq2sql, впрочем. Тоже кстати еще одна красивая абстракция. Только вот хинты по-прежнему в запросах прописывать надо.
Про ORMы был флейм в другой теме.
ВВ>Веб контролы не масштабируются в принципе. Есть область функционала, где они работают хорошо — выходишь за ее пределы, и использование контрола становится невозможным. Приходится переделывать.
В этом и есть суть контрола.
ВВ>А если уж нужно тупо генерить HTML, то уж извини это гораздо проще делать через XSLT.
Я бы предпочел возможность выбирать на чем тупо рендерить HTML без изменений в остальной программе.
ВВ>Время по настройке пейджинга в том же дата-гриде аналогично времени на реализацию этого пейджинга в XSLT. Да, да, не надо делать круглые глаза. Если клиентский пейджинг — вставляешь 1 строку сортировку и 1 if. Ну да еще сам блок "пейджера" надо описать — при этом пейджер может выглядеть как угодно, и ты не будешь ломать голову как бы настроить его также как на mock-up нарисовано, используя все три св-ва в датагриде. ВВ>Опять-таки как будет работать пейджит — через GET или не через GET — как хочешь так и сделай. Сортировка через GET — две строчки кода фактически. Причем это масштабируется блин.
А инплейсное редактирование?
ВВ>Технология, особенно "крутая" современная технология должна хотя бы поощрят писать хорошо. Лучше — давать минимальные возможности писать плохо. Web Forms этого не делает.
Это сильно зависит от того что такое хорошо. Иногда "хорошо" значит написать быстро, WebForms это обеспечивает. Для "правильного" писания веб-приложений вебформы не подходят.
ВВ>А Шарепоинт вы видели, который на основе веб-форм построен? И во что там мастер-пейджи превращаются, когда нужно их дизайн перетачивать под нарисованные картинки. Причем иначе и не сделаешь фактически. Пусть вот эти клоуны сначала туда MVC прикрутят.
Мне слава богу не доводилось таким заниматься. Да и шарепоинт не для этого нужен.
G>>Я сам очень недоволен тем, как работают веб-формы. Но сейчас webforms и dynamic data — наиболее удобный способ разработки базоморд, например админок сайта, мелки учетных приложеший итп. Для нормальных веб-приложений вебформы не подходят. ВВ> ВВ>Как думаешь, на момент презентации, скажем, ASP.NET 2.0 это было официальной позицией MS?
Архитекторы ASP.NET неправльно представляли себе web.
ВВ>А ведь веб-формс — просто уровень абстракции над прямой работой с HTTP.
Не, HttpHandler — уровень абстракции над выводом в stdout для формирования страницы. А вебформы находятся на 3-4 условных уровня выше.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Да того, того уровня. Представьте как будет происходить работа с такой базой — джойн там по парочке таблиц уже трагедия. Там не до Linq.
Не делайте джоины.
ВВ>Ну а какие проблемы? Нажали на кнопочку, перерисовали грид через XSLT — для строк соотв. используются просто другой XSLT-шаблон — нажали на кнопочку сохранить — функция на джаваскрипте отсылает данные на сервер — порядка 10 строк кода — грид перерисовывается.
Ну если потом все эти мелкие функции, ифы и проче собрать получится дофига кода.
Я такоеже мнение от программиста на ПХП слышал, типа все лего, там 10 строчек, тут 5... В итоге 2 недели делал, так и не сделал.
ВВ>А если например нужно *все* строки по умолчанию показывать в режиме редактирования? Вот нехочется людям каждый раз "кликать" на эдит.
Details\Form View?
Ну или совсем изврат в виде Repeater+Grid\ListView
ВВ>А еще хочется например поменять значение в столбце Х и чтобы во всех столбцах с *аналогичными* значениями тоже значение поменялось? На XSLT я эту фичу прикручу, веб-контрол — в recycle bin.
Не понял что надо, но понял что стандартные контролы на это не рассчитаны. Ну в таком случае ниче не поможет. Вы же не ругаете библиотеку контролов для десктомных приложений что там нельзя что-то сделать.
ВВ>"Хорошо" — это чтобы в принципе работало, не глючило, чтобы в срок и чтобы деньги за проект заплатили, а я свои бонусы за проект получил. Это хорошо. Остальное, если честно, не [censored].
На самом деле важно только выделенное.
ВВ>А для чего нужен MOSS? Поведайте нам. А лучше парням из МС которые продают его кому ни попадя, как отличное портальное решение. А потом интеграторы по программе парнер-шипа с ним [censored].
Я с ним только с точки зрения документооборота сталкивался.Интерфейс ковырять не приходилось.
ВВ>>>Как думаешь, на момент презентации, скажем, ASP.NET 2.0 это было официальной позицией MS? G>>Архитекторы ASP.NET неправльно представляли себе web. ВВ>И о чем тогда спорим, казалось бы?
О том что web-формы можно использовать... но далеко не везде.
ВВ>>>А ведь веб-формс — просто уровень абстракции над прямой работой с HTTP. G>>Не, HttpHandler — уровень абстракции над выводом в stdout для формирования страницы. А вебформы находятся на 3-4 условных уровня выше. ВВ>Ну как сказать... class Page : IHttpHandler. Впрочем, не суть.
Это значит что страница сама может обрабатывать запрос. Абстракция заключается в том как она его обрабатывает.
Здравствуйте, gandjustas, Вы писали:
ВВ>>Да того, того уровня. Представьте как будет происходить работа с такой базой — джойн там по парочке таблиц уже трагедия. Там не до Linq. G>Не делайте джоины.
А ну ради бога, если dynamic data и linq у вас подходит для всех случаев жизни, то я вас переубеждать не собираюсь.
ВВ>>Ну а какие проблемы? Нажали на кнопочку, перерисовали грид через XSLT — для строк соотв. используются просто другой XSLT-шаблон — нажали на кнопочку сохранить — функция на джаваскрипте отсылает данные на сервер — порядка 10 строк кода — грид перерисовывается. G>Ну если потом все эти мелкие функции, ифы и проче собрать получится дофига кода.
А его еще больше с веб-контролами получается, в том-то все и дело.
ВВ>>А если например нужно *все* строки по умолчанию показывать в режиме редактирования? Вот нехочется людям каждый раз "кликать" на эдит. G>Details\Form View? G>Ну или совсем изврат в виде Repeater+Grid\ListView ВВ>>А еще хочется например поменять значение в столбце Х и чтобы во всех столбцах с *аналогичными* значениями тоже значение поменялось? На XSLT я эту фичу прикручу, веб-контрол — в recycle bin. G>Не понял что надо, но понял что стандартные контролы на это не рассчитаны. Ну в таком случае ниче не поможет. Вы же не ругаете библиотеку контролов для десктомных приложений что там нельзя что-то сделать.
А мне вот неизвестно изначально, что клиент захочет. Я хочу чтобы технология была гибкой и позволяла легко вносить изменения, если они требуются. Или мне под каждый requirement все с нуля переписывать?
Как объяснить бизнесу, что реализация фичи Х занимает 3 часа, а для фичи У надо все на фиг переписать? С т.з. клиента это совершенно нелогично.
Я уж не говорю о производительности всего этого добра, которое по малейшему чиху тянет вью-стейт, а если его отключить, то контролы теряют все свои замечательные фишки.
Вот кстати в вин-формах ситуация значительно лучше. Я там контрол могу хоть раком поставить. При этом "отрисовать все самому" мне в голову придет в последнюю очередь. Есть конечно ограничения, но в значительно меньшей степени.
ВВ>>"Хорошо" — это чтобы в принципе работало, не глючило, чтобы в срок и чтобы деньги за проект заплатили, а я свои бонусы за проект получил. Это хорошо. Остальное, если честно, не [censored]. G>На самом деле важно только выделенное.
Да, ты знаешь, мне важно, чтобы компания на проекте заработала.
ВВ>>А для чего нужен MOSS? Поведайте нам. А лучше парням из МС которые продают его кому ни попадя, как отличное портальное решение. А потом интеграторы по программе парнер-шипа с ним [censored]. G>Я с ним только с точки зрения документооборота сталкивался.Интерфейс ковырять не приходилось.
Очень странно. Потому что шарепоинт решений для документооборота не предлагает.
ВВ>>>>Как думаешь, на момент презентации, скажем, ASP.NET 2.0 это было официальной позицией MS? G>>>Архитекторы ASP.NET неправльно представляли себе web. ВВ>>И о чем тогда спорим, казалось бы? G>О том что web-формы можно использовать... но далеко не везде.
А я с этим спорю? Да, для хоум-пейджей отличное решение. Но не более.
Здравствуйте, Klapaucius, Вы писали:
K>С другой стороны, мне совершенно не понятно, какое отношение эти упражнения имеют к теме разговора и доказательству/опровержению тезиса о существовании abstraction gain?
В этом и суть
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Вот тебе пример. Делал как-то приложение на C#. Ничего особенного, форма с табами, на них всякие листбоксы и т.д. За сценой никаких больших объектов (потом при работе они появятся, но до первого запроса их нет). 17 Мб вся эта прелесть занимает. Уверен, что больше 4-5 Мб она занимать не должна — на MFC. На чистом Win API — думаю, в 2-3 Мб уложился бы, но на это точно много моего времени уйдет.
Хм, кажется вопрос с отжиранием памяти дотнетом не раз обсуждался тут...
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Здравствуйте, Воронков Василий, Вы писали:
ВВ>>Мне вот непонятно, что за задача такая — помножение матриц. И, думаю, не только мне. Для чего/для кого она делается?
PD>Не обижайся на то, что я сейчас скажу, ладно ? Я вовсе не хочу ни тебя, ни кого-то еще обидеть. Я с уважением отношусь к любым задачам.
PD>В этом твоем ответе — суть проблемы. Тебе и другим — действительно непонятно. В задачах бизнеса (как я их определил) — это действительно не нужно. Если речь идет о создании сайта — это скорее всего не нужно. Если речь идет о системе управления заводом — может быть, тоже. И т.д.А поскольку большинство этим бизнес-задачами и занимается, то ему (большинству) это действительно непонятно. Оно как-то подсознательно уверено, что то, чем они занимаются — и есть единственно верное программирование, а то, что ему не нужно — вообще не нужно.
В задачах бизнеса без ЭТОГО никуда. Даже неразработчику программы, а пользователю. Закладыватся на прогноз полученный по непонятному алгоритму? Увольте-с. Так что если не уметь, то представление иметь следует обязательно.
Здравствуйте, konsoletyper, Вы писали:
ВВ>>Как объяснить бизнесу, что реализация фичи Х занимает 3 часа, а для фичи У надо все на фиг переписать? С т.з. клиента это совершенно нелогично. K>А вот так и приходится. Постоянно. Жизнь у айтишников такая.
Да ты что? У нас тут один "айтишник" бегает — мне казалось, он сервера чинит. Оказывается, вон у него жизнь какая.
Технология должна упрощать жизнь. Если она не упрощает, а наоборот усложняет, то на фиг нужна такая технология.
ВВ>>Вот кстати в вин-формах ситуация значительно лучше. Я там контрол могу хоть раком поставить. При этом "отрисовать все самому" мне в голову придет в последнюю очередь. Есть конечно ограничения, но в значительно меньшей степени. K>В Windows Forms точно такая же проблема. И ограничения там мешают в неменьшей степени. Самой гибкой "технологией" оказалась бы "попиксельный рендеринг с помощью XSLT".
Это какие ограничения в windows forms мешают? В Windows Forms довольно удачная для Win32 архитектура, построенная на событиях, инкапсулирующих сообщения Windows. Программировать под Windows Forms значительно проще и приятнее чем, скажем, под MFC. Да и "попиксельный рендеринг" через GDI+ реализован довольно удачно. В Web Forms попытались изобразить то же самое, что и Win Forms.
Если до кого-то не доходит, что веб-приложение не должно иметь такую же архитектуру как и вин-приложение, то это его проблемы — пусть и дальше изображает из себя "айтишника".
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Технология должна упрощать жизнь. Если она не упрощает, а наоборот усложняет, то на фиг нужна такая технология.
Ну-ну. Вот как раз Web Forms упрощает жизнь. В 99% случаев. А в 1% можно 1) найти workaround 2) сторонний контрол. Да, можно сказать, что самая крутая технология — это непосредственно генерить тексты на ассемблере. Там простор действий большой. Но удобно ли это? Может, лучше мириться с небольшими ограничениями ради того, чтобы разработка была простой?
Вот XSLT, за который ты цепляешься, при всей своей мощности, тоже обладает рядом недостатков. Году в 2004-м (я тогда ещё не работал в компании) народ у нас пытался заюзать XSLT для кодогенерации. В результате столкнулись с тем, что не получалось решить банальные проблемы, вроде генерации аналога имени в pascal и camel casing. В итоге пришлось написать свой кодогенаратор на основе своего XML-языка. Кстати, сейчас мы сходимся во мнении, что для подобных задач лучше иметь специальный язык шаблонизации, не основанный на XML.
ВВ>>>Вот кстати в вин-формах ситуация значительно лучше. Я там контрол могу хоть раком поставить. При этом "отрисовать все самому" мне в голову придет в последнюю очередь. Есть конечно ограничения, но в значительно меньшей степени. K>>В Windows Forms точно такая же проблема. И ограничения там мешают в неменьшей степени. Самой гибкой "технологией" оказалась бы "попиксельный рендеринг с помощью XSLT".
ВВ>Это какие ограничения в windows forms мешают? В Windows Forms довольно удачная для Win32 архитектура, построенная на событиях, инкапсулирующих сообщения Windows. Программировать под Windows Forms значительно проще и приятнее чем, скажем, под MFC. Да и "попиксельный рендеринг" через GDI+ реализован довольно удачно. В Web Forms попытались изобразить то же самое, что и Win Forms.
Это в Windows Forms нету ограничений? Тогда пример приведу. Вот есть TreeView. Он может отображать в узлах дерева иконку и текст (а ещё, если не ошибаюсь, checkbox). Чтобы отобразить в нём что-то нетривиальное (например, смарттеги к узлам добавить), приходится либо извращаться, либо выкидывать контрол и писать свой или брать сторонний. Вот если бы была возможность класть в узлы дерева любой контрол, то сам по себе TreeView решал бы гораздо более широкий класс задач. Но, к сожалению, в рамках WinForms этот недостаток непреодолим в силу Windows API. Так что нужно строить что-то поверх. Например, посмотреть в сторону WPF.
Попиксельный рендеринг — это хорошо. Вот только громоздко и неудобно. Я тебе так же могу предложить использовать твой любимый XSLT для того, чтобы рендерить свой WebForms контрол. Почему бы нет?
ВВ>Если до кого-то не доходит, что веб-приложение не должно иметь такую же архитектуру как и вин-приложение, то это его проблемы — пусть и дальше изображает из себя "айтишника".
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Вернее, давайте я поправлюсь — тот ASP.NET, который начинается и заканчивается на IHttpHandler/IHttpModule — это отличная штука. А вот все что сверху...
Всё, что сверху тоже клаcсная штука. Но есть одно "но". В интерактивных веб-приложениях сложность использования технологий, гоняющих состояние туда-сюда между клиентом и сервером, растёт пропорционально навороченности пользовательского интерфейса. Но это проблема не WebForms конкретно, а вообще подхода. Состояние должно быть в одном месте, либо на клиенте, либо на сервере. На сервере его хранить невозможно в принципе, т.к. весь диалог идёт на клиенте, соответственно, единственный рецепт — это держать состояние на клиенте, т.е. переходить на javascript (чего не очень хочется) и AJAX, либо на сервелады и xbap.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, IT, Вы писали:
IT>На сервере его хранить невозможно в принципе
Хорошо, что ты это не сказал ребятам из ZK (http://www.zkoss.org/), а то ведь бы они тогда не сделали свой фреймворк.
IT>т.к. весь диалог идёт на клиенте, соответственно, единственный рецепт — это держать состояние на клиенте, т.е. переходить на javascript (чего не очень хочется) и AJAX, либо на сервелады и xbap.
Держать состояние на клиенте — это тоже хорошая идея. И даже на JavaScript можно не переходить (см. Google Web Toolkit).
Здравствуйте, Cyberax, Вы писали:
IT>>На сервере его хранить невозможно в принципе C>Хорошо, что ты это не сказал ребятам из ZK (http://www.zkoss.org/), а то ведь бы они тогда не сделали свой фреймворк.
А как это у них работает в двух словах? Если это действительно возможно, то я легко откажусь от своих принципов
IT>>т.к. весь диалог идёт на клиенте, соответственно, единственный рецепт — это держать состояние на клиенте, т.е. переходить на javascript (чего не очень хочется) и AJAX, либо на сервелады и xbap. C>Держать состояние на клиенте — это тоже хорошая идея. И даже на JavaScript можно не переходить (см. Google Web Toolkit).
Можно, конечно, заниматься преобразованием серверного кода в javascript, но что-то мне пока не кажется этот путь наиболее эффективным.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, IT, Вы писали:
C>>Хорошо, что ты это не сказал ребятам из ZK (http://www.zkoss.org/), а то ведь бы они тогда не сделали свой фреймворк. IT>А как это у них работает в двух словах? Если это действительно возможно, то я легко откажусь от своих принципов
На сервере в сессии хранится реплика клиентского состояния. Обработчики событий на сервере поэтому работают "как будто на клиенте", а клиенту высылаются изменения в дереве контролов. Естественно, там учитывается, что может быть несколько окон браузера с несколькими табами и т.п.
С некоторыми оптимизациями работает даже вполне прилично. Хотя мне лично не нравится то, что сервер перестаёт быть stateless.
C>>Держать состояние на клиенте — это тоже хорошая идея. И даже на JavaScript можно не переходить (см. Google Web Toolkit). IT>Можно, конечно, заниматься преобразованием серверного кода в javascript, но что-то мне пока не кажется этот путь наиболее эффективным.
Конкретно GWT мне позволяет писать AJAX-приложения с такой же скоростью, что и обычные десктопные. Особо рулит использование автокомплита и обычного Java-отладчика внутри GWT-кода.
Здравствуйте, deniok, Вы писали:
D>Здравствуйте, Pavel Dvorkin, Вы писали:
PD>>В этом смысле — мб, и да, если знать Хаскель, конечно. Но меня вообще-то больше интересует эффективность его выполнения
D>Ключевым моментом, которого пока не касались в этой дискуссии, является высокоуровневая оптимизация, про которую никакой ассемблер не знает. Например, в Хаскелле есть дефорестация (list fusion). Вася взял список, применил к его элементам функцию f, получив другой список: D>
D>vasja lst = map f lst
D>
D>Петя взял васин код, и поэлементно применил к возвращаемому этим кодом списку функцию g D>
D>petja lst = map g (vasja lst)
D>
D>Оля взяла петин код, поэлементно применила к возвращаемому этим кодом списку функцию h D>
D>olja lst = map h (petja lst)
D>
D>Компилятор Хаскеля взял эту конструкцию с кучей промежуточных списков и оптимизировал в D>
D>olja_oplimized lst = map (h . g. f) lst
D>
D>Без единого промежуточного списка.
Довольно стандартная фича например для C++, это я недоразобрался или в плюсах есть потдержка функциональных фичей ? это не наезд , но например boost iterator adaptors именно так и работают.
Если существуют методологии позволяющие очень сильно повысить читабельность, уменьшить к-во, улучшить сопровождение и т.п. Я бы очень хотел об этом подробнее узнать.
Но я оцениваю вероятность такой ситуации близкой к нулю , потому что не встречал написанных революционно проектв типа FFMPEG или openCV или декодер jpeg2000.
Здравствуйте, Cyberax, Вы писали:
C>На сервере в сессии хранится реплика клиентского состояния.
Как хранится состояние строки ввода в браузере на сервере?
C>Обработчики событий на сервере поэтому работают "как будто на клиенте", а клиенту высылаются изменения в дереве контролов. Естественно, там учитывается, что может быть несколько окон браузера с несколькими табами и т.п.
C>С некоторыми оптимизациями работает даже вполне прилично. Хотя мне лично не нравится то, что сервер перестаёт быть stateless.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, IT, Вы писали:
IT>Всё, что сверху тоже клаcсная штука. Но есть одно "но". В интерактивных веб-приложениях сложность использования технологий, гоняющих состояние туда-сюда между клиентом и сервером, растёт пропорционально навороченности пользовательского интерфейса.
Ну вот скажи, тебе лично нравится идея сделать архитектуру веб-приложения по аналогии с Windows-приложением? Зачем WebForms делать по аналогии c WindowsForms?
Неужели и этот уровень абстракции тоже супер-полезен?
IT>Но это проблема не WebForms конкретно, а вообще подхода. Состояние должно быть в одном месте, либо на клиенте, либо на сервере.
Это особенность HTTP, и от нее никуда не уйдешь, ибо HTTP stateless.
Здравствуйте, IT, Вы писали:
IT>Здравствуйте, minorlogic, Вы писали:
M>>Если существуют методологии позволяющие очень сильно повысить читабельность, уменьшить к-во, улучшить сопровождение и т.п. Я бы очень хотел об этом подробнее узнать.
IT>См. FP.
Я читал предыдущий пост пере тем как ответить.
M>>Но я оцениваю вероятность такой ситуации близкой к нулю , потому что не встречал написанных революционно проектв типа FFMPEG или openCV или декодер jpeg2000.
IT>А как ООП революционно работает для проектов типа FFMPEG или openCV или декодер jpeg2000? Никак? Давайте откажемся от ООП!
ОПП просто восхитительно работает , см исходники Jasper или kakadu или JJ2000, это из тех что я точно знаю.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Ну вот скажи, тебе лично нравится идея сделать архитектуру веб-приложения по аналогии с Windows-приложением? Зачем WebForms делать по аналогии c WindowsForms? ВВ>Неужели и этот уровень абстракции тоже супер-полезен?
Что касается контролов, как средство инкапсуляции для рендеринга, то я не вижу в этом проблем. А вот с состоянием не получилось и это мне не нравится.
IT>>Но это проблема не WebForms конкретно, а вообще подхода. Состояние должно быть в одном месте, либо на клиенте, либо на сервере.
ВВ>Это особенность HTTP, и от нее никуда не уйдешь, ибо HTTP stateless.
Дело не в HTTP, дело в распределённости состояния.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, minorlogic, Вы писали:
M>>>Если существуют методологии позволяющие очень сильно повысить читабельность, уменьшить к-во, улучшить сопровождение и т.п. Я бы очень хотел об этом подробнее узнать.
IT>>См. FP.
M>Я читал предыдущий пост пере тем как ответить.
Тогда что именно не понятно?
M>>>Но я оцениваю вероятность такой ситуации близкой к нулю , потому что не встречал написанных революционно проектв типа FFMPEG или openCV или декодер jpeg2000.
IT>>А как ООП революционно работает для проектов типа FFMPEG или openCV или декодер jpeg2000? Никак? Давайте откажемся от ООП!
M>ОПП просто восхитительно работает , см исходники Jasper или kakadu или JJ2000, это из тех что я точно знаю.
И что там революционного?
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, IT, Вы писали:
IT>Здравствуйте, minorlogic, Вы писали:
M>>>>Если существуют методологии позволяющие очень сильно повысить читабельность, уменьшить к-во, улучшить сопровождение и т.п. Я бы очень хотел об этом подробнее узнать.
IT>>>См. FP.
M>>Я читал предыдущий пост пере тем как ответить.
IT>Тогда что именно не понятно?
Я не говорил что мне что то непонятно.
M>>>>Но я оцениваю вероятность такой ситуации близкой к нулю , потому что не встречал написанных революционно проектв типа FFMPEG или openCV или декодер jpeg2000.
IT>>>А как ООП революционно работает для проектов типа FFMPEG или openCV или декодер jpeg2000? Никак? Давайте откажемся от ООП!
M>>ОПП просто восхитительно работает , см исходники Jasper или kakadu или JJ2000, это из тех что я точно знаю.
IT>И что там революционного?
Понятия не имею с чего ты взял? на мой взгляд ничего революционного там нет? Я имел ввиду написаноого в революцыонном стиле (FP например) из подобного рода проектов не встречал.
Здравствуйте, minorlogic, Вы писали:
M>Довольно стандартная фича например для C++, это я недоразобрался или в плюсах есть потдержка функциональных фичей ? это не наезд , но например boost iterator adaptors именно так и работают.
Как "так"?
В GHC оптимизатор сначала прочитывает Rewriting Rules типа
{-# RULES
"map/map" forall f g xs . map f (map g xs) = map (f . g) xs
#-}
после чего проходясь по исходному коду заменяет левую часть на правую. Такие "синтаксические" трансформации допустимы поскольку функциональный код "чистый", то есть не имеет побочных эффектов. Можно забацать любую трансформацию — желательно, правда, доказать предварительно, что она не меняет семантики .
А для list fusion в GHC используют, конечно, не примитивный map/map, а
{-# RULES
"fold/build" forall k z (g::forall b. (a->b->b) -> b -> b) .
foldr k z (build g) = g k z
"foldr/augment" forall k z xs (g::forall b. (a->b->b) -> b -> b) .
foldr k z (augment g xs) = g k (foldr k z xs)
...
#-}
и ещё десяток более специальных правил. Причём библиотечные функции для списков реализованы таким образом, чтобы максимально облегчить deforestation при включённом оптимизаторе.
Здравствуйте, IT, Вы писали:
IT>Что касается контролов, как средство инкапсуляции для рендеринга, то я не вижу в этом проблем. А вот с состоянием не получилось и это мне не нравится.
Проблема тех же контролов в том, что с одной стороны это "шаблоны", уровень некоторой абстракции над HTML — с другой, стоит чуть сойти с проторенных рельс, и вокруг этих самых шаблонов вырастают тонны HTML-я. Т.е. в общем случае под видом контрола мы получаем... ну что-то вроде макроса в С, причем по своей функциональности и методу работы они практически аналогичны. А хочется ведь макросов как в Немерле
Потом ты вот говоришь, что тебе не нравится как организована работа с состоянием. А ведь viewstate — одна из основных фишек контролов. Причем он всегда или есть или нет. Т.е. я не могу его отключить частично, если мне нет нужны дублировать данные контрола и перегружать страницу.
А AJAX тоже не панацея. Особенно то, как это сделано в ASP.NET. Кол-во телодвижений для обновления некой части страницы через updatepanel примерно аналогично реализации того же самого через XMLHTTPRequest напрямую. И в чем фича?
Ну это ладно, вот "добавили" аякс, люди "в массе" своей решили, что у них приложения будут работать благодаря нему в разы быстрее, а в итоге все почему-то работает даже медленнее. Не видел например веб-морду у Remedy? Она целиком на аяксе (не асп-нет) и блин как она тормозит!
ИМХО дело не в технологии "передачи" состояния — ибо все равно ты его будешь передавать на сервер в конечно счете. Проблема в том, что построив "абстракцию" над HTTP, внутри АСП.НЕТ все те же формы, поля и пр. — т.е. методы работы с данными самые что ни на есть древние.
Интереснее было бы, мне кажется, структировать сам формат состояния да и вообще данные, которые гоняются туда сюда. Например, чтобы это была не форма вида key=value&k2=value2..., а XML документ, который в свою очередь можно всегда проверить по XML-схеме, всегда можно показать используя различные стайлшиты (XSLT), а уж технология передачи — это мне кажется дело вторичное.
Здравствуйте, IT, Вы писали:
C>>На сервере в сессии хранится реплика клиентского состояния. IT>Как хранится состояние строки ввода в браузере на сервере?
Адресной строки или поля ввода?
Если поле ввода, то хранится как простой String в модели страницы. Поля ввода синхронизируются при совершении действия, требующего вызов серверного события. Т.е. у тебя форма с 10 полями, ты их как-то редактируешь на клиенте, а когда нажимаешь кнопку "OK" изменённые поля уходят на сервер вместе с событием "кнопка нажата". На сервере изменения вливаются в модель, а потом вызывается обработчик.
Если повесить обработчик на событие "фокус потерян", то синхронизироваться будет после потери фокуса (для валидации, например).
Здравствуйте, minorlogic, Вы писали:
M>>>>>Если существуют методологии позволяющие очень сильно повысить читабельность, уменьшить к-во, улучшить сопровождение и т.п. Я бы очень хотел об этом подробнее узнать. IT>>>>См. FP. M>>>Я читал предыдущий пост пере тем как ответить. IT>>Тогда что именно не понятно? M>Я не говорил что мне что то непонятно.
Если всё понятно, то о чём тогда хочется подробнее узнать?
M>Понятия не имею с чего ты взял? на мой взгляд ничего революционного там нет? Я имел ввиду написаноого в революцыонном стиле (FP например) из подобного рода проектов не встречал.
Почему тогда от FP хочется именно чего-то революционного?
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, IT, Вы писали:
C>>Если повесить обработчик на событие "фокус потерян", то синхронизироваться будет после потери фокуса (для валидации, например). IT>WebForms работают по такой же схеме. Проблемы начинаются при усложнении взаимодействия с пользователем и необходимости в использовании нестандартных для данной технологии средств.
Проблемы везде бывают. Просто это было возражение про то, что на сервере состояние в принципе хранить нельзя.
Здравствуйте, IT, Вы писали:
IT>Контролы и HTML связаны лишь тем, что контролы занимаются рендерингом HTML. Этим всё равно должен кто-то заниматься. У тебя есть притензии к контролам, что они плохо рендерят HTML?
У меня есть претензии к контролам вообще, как к сущности. Мне кажется им не место в веб-приложении вообще, самой концепции контролов в принципе. В идеале должен быть некий мета-язык, которые позволит описывать структуру страниц.
Вот есть такая отличная штука — XForms называется. Наверняка ведь слышал. Почему бы МС его не реализовать?
ВВ>>Потом ты вот говоришь, что тебе не нравится как организована работа с состоянием. А ведь viewstate — одна из основных фишек контролов. Причем он всегда или есть или нет. Т.е. я не могу его отключить частично, если мне нет нужны дублировать данные контрола и перегружать страницу. IT>ViewState — это как раз и есть затычка, призванная упростить работу с состоянием. Но получается это по-любому хреново из за того, что состоянию распределённость противопоказана.
Как я и написал в самом начале состояние не может не быть распределенным. Да, это плохо. Но другого не дано.
ВВ>>А AJAX тоже не панацея. Особенно то, как это сделано в ASP.NET. IT>UpdatePanel — это обманка. Проблему состояния такой AJAX не решает никак.
Да он в любом виде не решает проблему состояния. Он лишь "откладывает" момент передачи данных и минимизирует кол-во передаваемых пакетов — при этом приносит свои собственные проблемы — кэширование, усложненную обработку ошибок и пр.
ВВ>>ИМХО дело не в технологии "передачи" состояния — ибо все равно ты его будешь передавать на сервер в конечно счете. Проблема в том, что построив "абстракцию" над HTTP, внутри АСП.НЕТ все те же формы, поля и пр. — т.е. методы работы с данными самые что ни на есть древние. IT>Ты явно путаешь HTTP с чем-то другим. Формы не являются надстройкой над HTTP. HTTP — это всего лишь протокол передачи данных.
Форма — это особой формат данных, который передается в теле HTTP-запроса. Собственно, о нем я говорю. Структура передаваемых данных абсолютно одинакова что а ПХП, что в АСП, что в АСП.НЕТ, и в этом мне кажется основная ошибка.
IT>Повторяю ещё раз. Состоянию противопоказан распределённость. Если попытаться распределить состояние между UI (WPF/WinForms) приложением и сервером, то ты мгновено получишь теже самы проблемы, с точностью до изобретения ViewState. Это не проблема конкретно WebForms, это проблема подхода.
А мне кажется проблема в том, как хранится состояние. Оно неорганизовано, представляет собой "кашу", которую в случае с АСП.НЕТ обрабатывается на уровне каждого отдельного контрола и рендеринге страницы снова собирается в "кашу". Мне кажется, если состояние описывать более структурировано, то это поможет решить проблемы. А с распределенностью ничего сделать не получится.
Здравствуйте, minorlogic, Вы писали:
M>Почему по твоему мнению , серезные приложения которые я перечислял FFMPEG — JASPER написанны без использования FP ? на традиционных C/C++. ?
А серьезное приложение Autocad написано с использованием FP. Какие из этого мы можем сделать выводы?
Здравствуйте, minorlogic, Вы писали:
M>Попробую зайти с другой стороны.
M>Почему по твоему мнению , серезные приложения которые я перечислял FFMPEG — JASPER написанны без использования FP ? на традиционных C/C++. ?
Как думаешь почему основная масса серъезных (и не очень серъезных тоже) приложений до года примерно 98 писалась в большинстве своем на си без использования ООП ?
Здравствуйте, minorlogic, Вы писали:
M>Почему по твоему мнению , серезные приложения которые я перечислял FFMPEG — JASPER написанны без использования FP ? на традиционных C/C++. ?
Если бы они были написаны с использованием FP, то они были бы ещё серьёзней.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, minorlogic, Вы писали:
M>Если существуют методологии позволяющие очень сильно повысить читабельность, уменьшить к-во, улучшить сопровождение и т.п. Я бы очень хотел об этом подробнее узнать.
Как уже сказали FP и связаные с ним вкусности и сахар.
M>Но я оцениваю вероятность такой ситуации близкой к нулю , потому что не встречал написанных революционно проектв типа FFMPEG или openCV или декодер jpeg2000.
Пока просто нет нужной массовости, но ситуация уже меняется, в общем ждем релиза F# и доведение до ума Scala скорее всего на них появятся первые серъезные приложения. Хотя последние версии Haskell'а тоже радуют.
Здравствуйте, Pzz, Вы писали:
Pzz>Здравствуйте, minorlogic, Вы писали:
M>>Почему по твоему мнению , серезные приложения которые я перечислял FFMPEG — JASPER написанны без использования FP ? на традиционных C/C++. ?
Pzz>А серьезное приложение Autocad написано с использованием FP. Какие из этого мы можем сделать выводы?
Исходников автокада у меня нет , я не могу оценить как и где там использовалось FP. Боюсь что аналогия не очень уместна , предполагаю что автокад стстоит и большого числа компонентов с различными требованиями.
Например критичные к эфективности компоненты могут быть написанны на C++, а высокоуровневая логика на языке с элементами FP.
Здравствуйте, FR, Вы писали:
FR>Здравствуйте, minorlogic, Вы писали:
M>>Попробую зайти с другой стороны.
M>>Почему по твоему мнению , серезные приложения которые я перечислял FFMPEG — JASPER написанны без использования FP ? на традиционных C/C++. ?
FR>Как думаешь почему основная масса серъезных (и не очень серъезных тоже) приложений до года примерно 98 писалась в большинстве своем на си без использования ООП ?
Вероятно предпочтение языку давалось исходя из функциональных требований к программе ?
Здравствуйте, IT, Вы писали:
IT>Здравствуйте, minorlogic, Вы писали:
M>>Почему по твоему мнению , серезные приложения которые я перечислял FFMPEG — JASPER написанны без использования FP ? на традиционных C/C++. ?
IT>Если бы они были написаны с использованием FP, то они были бы ещё серьёзней.
Попробую еще раз , а почему они не написанны с использованием FP ?
Здравствуйте, minorlogic, Вы писали:
M>Например критичные к эфективности компоненты могут быть написанны на C++, а высокоуровневая логика на языке с элементами FP.
По моему это вполне нормальная практика. Таким образом пишут приложения например на очень даже не шустром питоне, при этом эффективность разработки существенно выше чем на чистом C++.
Здравствуйте, FR, Вы писали:
FR>Здравствуйте, minorlogic, Вы писали:
M>>Например критичные к эфективности компоненты могут быть написанны на C++, а высокоуровневая логика на языке с элементами FP.
FR>По моему это вполне нормальная практика. Таким образом пишут приложения например на очень даже не шустром питоне, при этом эффективность разработки существенно выше чем на чистом C++.
Ну да , я полностью согласен. А почему ВСЕ приложение не пишется нв питоне?
Здравствуйте, minorlogic, Вы писали:
FR>>Как думаешь почему основная масса серъезных (и не очень серъезных тоже) приложений до года примерно 98 писалась в большинстве своем на си без использования ООП ?
M>Вероятно предпочтение языку давалось исходя из функциональных требований к программе ?
Нет чаще исходя из доступности разработчиков владеющих нужной технологией.
Здравствуйте, minorlogic, Вы писали:
M>А я считаю что дело не в массовости , потому что FFMPEG ядро делают несколько человек. Я уверен, что если бы использование FP дало бы хоть 5% к производительности программы ядро бы уже переписали.
Сейчас эти технологии могут ускорить разработку скажем в полтора-два раза (при сложной логике и побольше) и в эти же полтора-два раза замедлить (тот же Ocaml) работу готового кода.
Здравствуйте, FR, Вы писали:
FR>Здравствуйте, minorlogic, Вы писали:
M>>>>Почему по твоему мнению , серезные приложения которые я перечислял FFMPEG — JASPER написанны без использования FP ? на традиционных C/C++. ?
IT>>>Если бы они были написаны с использованием FP, то они были бы ещё серьёзней.
M>>Попробую еще раз , а почему они не написанны с использованием FP ?
FR>Потому что для подобных вещей важна не эффективность разработки а эффективность работы готового кода. Пока FP компиляторы не достигли уровня хороших C++ компиляторов.
Здравствуйте, minorlogic, Вы писали:
IT>>Если бы они были написаны с использованием FP, то они были бы ещё серьёзней.
M>Попробую еще раз , а почему они не написанны с использованием FP ?
Потому что в C/C++ нет ни одной фишки FP.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, minorlogic, Вы писали:
FR>>По моему это вполне нормальная практика. Таким образом пишут приложения например на очень даже не шустром питоне, при этом эффективность разработки существенно выше чем на чистом C++.
M>Ну да , я полностью согласен. А почему ВСЕ приложение не пишется нв питоне?
Потому что пока нет эффективных компиляторов питона выдающих код хотя бы на уровне плохих (хотя бы борландовского) компиляторов C++.
Но попытки есть, например тот же PyPy http://codespeak.net/pypy/dist/pypy/doc/home.html который дал очень неплохие вначале надежды.
Другой путь более успешный это язык со статической типизацией максимально похожий и имеющий многие вкусности от питона http://www.cython.org/
Здравствуйте, FR, Вы писали:
FR>Здравствуйте, minorlogic, Вы писали:
M>>А я считаю что дело не в массовости , потому что FFMPEG ядро делают несколько человек. Я уверен, что если бы использование FP дало бы хоть 5% к производительности программы ядро бы уже переписали.
FR>Сейчас эти технологии могут ускорить разработку скажем в полтора-два раза (при сложной логике и побольше) и в эти же полтора-два раза замедлить (тот же Ocaml) работу готового кода.
Именно , вот про цену которую придется заплатить за использование FP. Кажется никто и не сказал.
Здравствуйте, FR, Вы писали:
FR>Потому что для подобных вещей важна не эффективность разработки а эффективность работы готового кода. Пока FP компиляторы не достигли уровня хороших C++ компиляторов.
Компилятор ocaml выплевывает код, сравнимый по быстродействию с тем, что выплевывает g++. Иногда даже более быстрый — за счет более оптимальной реализации вызова функции.
Здравствуйте, minorlogic, Вы писали:
M>Именно , вот про цену которую придется заплатить за использование FP. Кажется никто и не сказал.
Ровно ту же цену приходится платить за любую высокоуровневость, за тот же ООП например. В те же 90ые годы эта цена в очень большом числе случаев была слишком дорогой, сейчас скорее наоборот, но это после 10 — 15 лет развития оптимизиторов и прогресса вычислительной техники.
Никто пока не занимался серъезной оптимизацией (на уровне хороших компиляторов для C++ ) для ФП языков. Но лед уже тронулся так что цена будет дешеветь.
Здравствуйте, minorlogic, Вы писали:
M>Именно , вот про цену которую придется заплатить за использование FP. Кажется никто и не сказал.
Ну и какова будет цена за использование tuples, например, immutable паттерна или pattern matching? Ты видимо не понял смысла основного поста. Там нет призыва переходить на FP и тем более на чистые FP языки. Там высказано желание получить арсенал FP фич в мэйнстрим языках.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, Klapaucius, Вы писали:
K>Потому, что так оно и есть. Я считаю суммы столбцов в матрице со 128000 столбцов и 1024 строками. K>Т.к. мне нужно считать столбцы — я выбираю адекватное задаче представление матрицы. Она хранится транспонированной.
Вообще-то об этом стоило бы сказать с самого начала.
PD>>Условие — расположение массива не менять!
K>Ход игры, в которой правила меняет в процессе только одна сторона слишком предсказуем, чтобы быть интересным.
Если даже согласиться с этим тезисом, то суть проблемы от этого не исчезнет. Здесь выбор "адекватного представления не пройдет". А если придется идти и так и так, скажем, в алгоритмах линейной алгебры ?
Кстати, вопрос без подвоха. А вообще это хоть как-то сделать можно с помощью LinQ ? Я просто не знаю, я с ним очень поверхностно знаком. Разумееется, без транспонирования матрицы и без заведения каких-бы то ни было дополнительных массивов любой размерности хоть явно, хоть неявно.
K>С другой стороны, мне совершенно не понятно, какое отношение эти упражнения имеют к теме разговора и доказательству/опровержению тезиса о существовании abstraction gain?
А никакого. Тебе захотелось показать, что можно ускорить вычисление. Я ответил. Вот и все. Инициатива твоя была
Здравствуйте, gandjustas, Вы писали:
PD>>Но я-то его писал для других целей. Не могу же я отвечать за использование моего цикла в иной ситуации. G>Какой иной ситуации. Ситуация та же — суммирование массива по столбцам. Только способ получения массива другой.
Ничего себе! В одном (твоем случае) речь идет об операциях в памяти. В другом (моем) — системные вызовы. И массива как такового в памяти, между прочим, нет вообще
G>Вообще изначально код ущербный был. Надо получить весь массив пикселей, а потом сумировать вместо GetPixel на каждой итерации.
Если не секрет, чем это лучше ? Я вижу в этой идее только дополнительный массив, который тут совсем не нужен, и никаких плюсов.
PD>>Да, но я ее использовал там, где время было 1500-2000 мсек G>Ну сегодня это 1500 мс, а послезавтра 15 мс.
Так в том-то и дело. Если замеряется время порядка 1500 мсек — точность в 15 мсек достаточна, чтобы делать какие-то выводы. Если же замеряется время порядка 70 мсек — недостаточна и выводы делать не стоит.
G>Согласен. Я вполне могу убрать оттуда и окно, и GetPixel, а просто предложить просуммировать столбцы некоего двумерного массива, каким-то образом заданного. Правда, чтобы время померить, придется либо в цикл это вставить, либо уж очень большой массив использовать. G>Кто же это писал???
Я писал и я выделил сейчас то, на что ты внимание не обратил
Здравствуйте, AndrewVK, Вы писали:
PD>>"Этот прекрасный новый мир" (О.Хаксли) не читал ? Кстати, управляемый
AVK>Демагогия.
А все же почитай.
AVK>>>Самому не смешно?
PD>>Ну тогда зайди в форум по Win32 и объяви во всеуслышание — все, что вы тут делаете — смешно. Потому что там именно такой код и пишут, и мой — не лучше и не хуже. Зайди и напиши, честное слово. Посмотрим на реакцию.
AVK>Демагогия.
Почему же ? Вот ответь прямо — имеет право программирование на Win32 право на существование или нет ? Да или нет ?
PD>>А ты готов забыть в этом топике про C#, .Net. LinQ ? Либо уж оба забудем, либо оба нет
AVK>Уже два раза объяснял, почему твоя аналогия не годится.
Почему ты считаешь, что если ты объяснял — это означает, что твое объяснение и есть истина в последней инстанции ? Я тоже объяснил, что для меня эта аналогия годится. Ты хочешь оставить себе все средства, а меня почему-то лишить части их и после этого требовать сравнения. В конце концов, если уж на то пошло, объясни, почему вызов метода некоего класса (AsParallel) есть корректное действие, а вызов библиотечной функции — нет ? Не кругло это как-то...
PD>> Не хочешь окна и пикселей — возьми массив двумерный произвольного происхождения с цветами в качестве элементов. Что изменится, кроме ожидания, конечно ?
AVK>Ты чего то попутал — у меня с абстрагированием от конкретики проблем нет, это ты все пытаешься на обсуждение Win32 свернуть.
????
PD>>Андрей, ну некорректные же аргументы.
AVK>Некорректно, это когда ты упорно пытаешься сменить тему. Сразу скажу — со мной это не пройдет.
>Обсуждать здесь Win32 я не буду, и не надейся.
Ну если мне понадобится что-то из Win32 обсуждать, я это буду делать в друом форуме и с другими людьми.
>Речь про функциональное программирование. Не нравится шарп — ОК, давай возьмем ML или Немерле, годится?
Упаси боже
PD>> Не хочешь Win32 — не надо, но зачем педалировать-то ?
AVK>Опять же, не переваливай с больной головы не здоровую. Все что я хочу — чтобы Win32 здесь не обсуждалось.
Да никто и не требует от тебя, чтобы ты его обсуждал.
PD>> Там распараллеливание алгоритма, это главное, остальное второстепенное. А про конструкции vs бмблиотеки я уже сказал.
AVK>Распараллеливание тоже не главное. Главное — конструкции языка, которые его использование позволяют упростить.
AVK>>>А ты SQL не знаешь?
PD>> А если бы нет ? Вот предстваь себе — пишет некий X математическую обработку, ему SQL совсем не нужен.
AVK>А мне этот Х не интересен. Мне интересно реальное положение дел. Как ты думаешь, сколько народу в этом форуме ничего не знают про SQL?
То , что интересно или нет тебе лично, есть не более, чем твое личное дело. Мне, к примеру, совсем не интересен Немерле, и я нигде в дискуссиях о нем не участвовал.
PD>> А матрицы по диагоналям он сплошь и рядом проходит — в линейной алгебре диагональных, трехдиагональных и нижне- или верхне- треугольных матриц хоть пруд пруди.
AVK>Вобщем понятно, кода так и не будет. Приятно, когда твои предсказания сбываются .
Здравствуйте, Воронков Василий, Вы писали:
ВВ>На самом деле мне и правда непонятно. Вот сегодня заказчик хочет чтобы у тебя было за 200 мс, завтра он передумал и хочет за 20 мс — т.е. так ни с того с сего требования по производительности изменились на порядок
Ну он понимает, что с этим железом такого не будет.
>А что в действительности-то заказчику нужно?
Массовая обработка входных данных большого размера в реальном масштабе времени. Это все. что я скажу.
>Это вообще похоже на какие-то упражнения для ума.
За упражнения для ума деньги не платят.
ВВ>Ты вот сам пишешь — десять лет назад занимался "текстурированием" на асме.
Насчет асма я не писал, его там не было. И вообще это было на Delphi
>Сейчас есть куча движков написанных на С# — да, это конечно не мейн-стрим подход (пока) — но почему спустя еще 10 лет эта задача не должна выполняться на дотнете без всяких "но"? Я вот правда не вижу причин
Я другое не понимаю. Почему, как только заходит речь о работе на пределе возможностей железа, так сразу начинается нечто в роде "да , сейчас это еще не очень, но вот лет через 10 будет..." Не знаю я, что через 10 лет будет, и мне это сейчас не так уж важно. Будет — тогда и говорить будем. А мне сейчас работать надо.
ВВ>Тезис "в перспективе любую задачу можно решить на ЯВУ" возникает не потому что все так ненавидят асм, а потому что непонятны те самые таинственные задачи, для которых он будет нужен всегда — ведь это основной тезис, не так ли? что асм никогда не умрет? Да ты и сам тумана напускаешь. ВВ>Помножение матриц — да, для меня это не задача. У меня мозг по-другому устроен И мне так кажется, что многие думают примерно также.
ВВ>Здесь речь в первую очередь о мейнстриме. И тенденции мейнстрима у меня лично сомнений не вызывают. Код становится все более высокоуровневым. Я не удивлюсь, если через -надцать лет C# будет восприниматься как низкоуровневое средство разработки, а большинство программистов будут какие-нибудь UML-и компилить.
Опять светлое будущее
>И при этом доказывать "ветеранам" вроде меня, что C# уже почти мертв, а UML 6.0 — это видите ли супер-уровень абстракции, благодаря которому программы проще оптимизировать.
Однажды у первобытного человека первобытный журналист взял первобытное интервью. На вопрос о том, что он ожидает от светлого будущего, интервьюируемый ответил — "огромных и великолепно обточенных кремней"
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Здравствуйте, Pavel Dvorkin, Вы писали:
ВВ>Ну вот, кстати, в тему "развития" этой задачи. Как ты думаешь, будет выглядеть эта задача, скажем, еще через 10 лет? Т.е. твоему заказчику будет нужно ровно то же самое, что в другом веке? Ну наверное ведь нет. И при реализации задачи придется рассчитывать честное освещение, "физику" ткани, завязанную на материал ткани опять же — и еще кучу всяких факторов. Алгоритмы еще более усложняются — и насколько реально — т.е. вообще в человеческих стилах — будет описывать все это на низком уровне?
Дело в том, что алгоритмы либо придется писать самому, либо брать их реализации откуда-то (а это тоже значит, что кто-то их писал сам). Физику ткани — ее что, автоматизировать можно ? Там свои вычислительные задачи, их хочешь не хочешь, а надо программировать. Либо уж такой ИИ тут задействовать, чтобы он смог это запрограммировать
И на чем это писать — не суть важно. И на С++, и на С# — это примерно одинаково по сложности и времени. Потому что здесь не дизайн и не сборка мусора главное, а программирование сложного расчета. Все равно на чем его писать, он от этого проще не станет.
А асм — да никто и не предлагает на нем писать все. Его используют только тогда, когда надо оптимизировать какой-то кусочек, вот и все. В той же программе для одежды, да, написал я свою реализацию дыойного цикла на асме — не понравилось мне, как Delphi его реализовал.
ВВ>Ведь, согласись, помимо производительности еще и не менее важный "ресурс" — время называется
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Здравствуйте, gandjustas, Вы писали:
PD>>>Но я-то его писал для других целей. Не могу же я отвечать за использование моего цикла в иной ситуации. G>>Какой иной ситуации. Ситуация та же — суммирование массива по столбцам. Только способ получения массива другой.
PD>Ничего себе! В одном (твоем случае) речь идет об операциях в памяти. В другом (моем) — системные вызовы. И массива как такового в памяти, между прочим, нет вообще
Алгоритм от этого не меняется. Адерстенд?
G>>Вообще изначально код ущербный был. Надо получить весь массив пикселей, а потом сумировать вместо GetPixel на каждой итерации. PD>Если не секрет, чем это лучше ? Я вижу в этой идее только дополнительный массив, который тут совсем не нужен, и никаких плюсов.
Я думаю считать все пиксели в память а потом суммировать будет лучше.
G>>Согласен. Я вполне могу убрать оттуда и окно, и GetPixel, а просто предложить просуммировать столбцы некоего двумерного массива, каким-то образом заданного. Правда, чтобы время померить, придется либо в цикл это вставить, либо уж очень большой массив использовать. G>>Кто же это писал???
PD>Я писал и я выделил сейчас то, на что ты внимание не обратил
Это мелочи. Измерять время можно с помощью rdtsc, программа от этого не изменится.
Здравствуйте, Pavel Dvorkin, Вы писали:
G>>Вообще изначально код ущербный был. Надо получить весь массив пикселей, а потом сумировать вместо GetPixel на каждой итерации.
PD>Если не секрет, чем это лучше ? Я вижу в этой идее только дополнительный массив, который тут совсем не нужен, и никаких плюсов.
Тем что быстрее. Функции GetPixel и SetPixel работают очень медленно, т.к. внутри себя вызвают BitBlt. Напрямую получить весь массив с той же BitBlt гораздо быстрее.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Вообще-то об этом стоило бы сказать с самого начала.
var notparallel2 = fromcolin matrix2
selectcol.Sum();
PD>А если придется идти и так и так, скажем, в алгоритмах линейной алгебры ?
Если задача будет другой, то и решение будет другим.
PD>А вообще это хоть как-то сделать можно с помощью LinQ ? Разумееется, без транспонирования матрицы и без заведения каких-бы то ни было дополнительных массивов любой размерности хоть явно, хоть неявно.
На этот вопрос уже отвечал AndrewVK. Можно. Пишете итератор и обходите. Хоть матрицу, хоть дерево, хоть граф. Отображаете, свертываете. Промежуточные массивы не создаются. Non strict семантика.
PD>А никакого.
Внезапно, прямой ответ. Благодарю.
... << RSDN@Home 1.2.0 alpha 4 rev. 1110>>
'You may call it "nonsense" if you like, but I'VE heard nonsense, compared with which that would be as sensible as a dictionary!' (c) Lewis Carroll
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Я другое не понимаю. Почему, как только заходит речь о работе на пределе возможностей железа, так сразу начинается нечто в роде "да , сейчас это еще не очень, но вот лет через 10 будет..." Не знаю я, что через 10 лет будет, и мне это сейчас не так уж важно. Будет — тогда и говорить будем. А мне сейчас работать надо.
А с чего вообще все это обсуждение началось? Какой смысл говорить о том, что есть здесь и сейчас. Тут вообще никакого обсуждения не будет, голая статистика. Мы же говорим о "перспективе". И все наши "войны" в таком конктексте и начинаются — вытеснит ли C# через 10 лет С++? вытеснит ли Немерле через 10 лет C#? вытеснит ли юникс винду? и пр.
С твоей стороны можно было бы например показать что такая задача как "работа на пределе возможностей железа" будет существовать всегда, независимо от уровня развития этого железа (для меня, например, это далеко не очевидно).
ВВ>А с чего вообще все это обсуждение началось? Какой смысл говорить о том, что есть здесь и сейчас. Тут вообще никакого обсуждения не будет, голая статистика. Мы же говорим о "перспективе". И все наши "войны" в таком конктексте и начинаются — вытеснит ли C# через 10 лет С++?
Вообще-то обсуждение началось в текущем контексте, то есть как это сейчас хорошо. Что будет через 10 лет — это ИМХО обсуждать не стоит. Спроецируйся назад на 10 лет (1998г) и попробуй предсказать будущее. Я не уверен, что в этом предсказании .Net вообще бы оказалась.
>вытеснит ли Немерле через 10 лет C#?
>вытеснит ли юникс винду?
какого размера кремни будут в продаже ?
Если уж вопрос о 10 годах ставить, то я бы другое обсудить предложил
1. Сольются ли мобильные девайсы и настольные системы ?
2. Сольются ли телевидение и персональные компьютеры ? Останется ли "волновое" телевидение или только цифровое будет ?
И т.д. Впрочем, все равно получатся великолепно обточенные кремни
А прогнозы насчет языков и их будущего на 10 лет — дело ИМХО пустое. Придет время — увидим.
ВВ>С твоей стороны можно было бы например показать что такая задача как "работа на пределе возможностей железа" будет существовать всегда, независимо от уровня развития этого железа (для меня, например, это далеко не очевидно).
Будет ли она существовать всегда — не знаю. "Мне не нужна вечная игла, я не намерен жить вечно". Пока что как мощности ни росли, всегда находились задачи, которым этих мощностей не хватало. В науке их полно, а научные задачи имеют свойство превращаться в производственные. Но вообще эта тема слишком серьезная, чтобы за 5 минут дать развернутое объяснение.
Здравствуйте, gandjustas, Вы писали:
PD>>Ничего себе! В одном (твоем случае) речь идет об операциях в памяти. В другом (моем) — системные вызовы. И массива как такового в памяти, между прочим, нет вообще G>Алгоритм от этого не меняется. Адерстенд?
Если ты готов алгоритм без анализа применять где угодно — что тут скажешь...
G>Я думаю считать все пиксели в память а потом суммировать будет лучше.
А я так думаю, что введение лишнего массива без всякого обоснования не есть лучшее.
G>Это мелочи. Измерять время можно с помощью rdtsc, программа от этого не изменится.
Программа не изменится. Изменятся выводы, так как их нельзя делать на данных, которые не позволяют делать эти выводы. В общем,см. курс матстатистики — сравнение двух средних и т.д.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Вообще-то обсуждение началось в текущем контексте, то есть как это сейчас хорошо. Что будет через 10 лет — это ИМХО обсуждать не стоит.
Ну с позицией, что введение высокоуровневых абстракций рулит всегда и в любом случае я и сам не согласен. Эта проблема в общем-то не столько даже к асму сводится. Но очень частно они действительно рулят. И необязательно только в веб-приложениях
Высокоуровневый код легко написать и проще поддерживать, его проще масштабировать. А соответственно проще реализовать другое архитектурное решение, которое поможет нам улучшить производительность системы в целом. Ведь если наше приложение, скажем, не зависит от способа работы с хранилищем данных, то мы всегда сможем подменить это хранилище — скажем, прикрутить базу данных вместо файловой системы "напрямую" и пр. Причем "снаружи", для клиентского кода, эти изменения вообще останутся незаметными. И это нормальная ситуация, когда действительно проще "оптимизировать" высокоуровневую систему.
И такие ситуация происходят очень часто. А часто бывают и ситуации когда дешевле купить железо, а не заниматься оптимизацией криво спроектированного приложения. Причем все это может касаться также и систем с достаточно высокими требованиями к производительности. Причем даже безотносительно к "оптимизации" — удешевление разработки и поддержки это ведь реально круто. Часто выгоднее продать систему + наши железки, чем заоптимизированную до смерти систему на *ваши* железки.
И разговор о "тенденциях" возникает потому, что такой подход потихоньку распространяется. И даже появляется другой подход — описание программы в средствах бизнес-нотаций — как в каком-нибудь биз-толке — соединил стрелочками пару квадратиков — а на выходе у тебя уже соотвествующий код на "низкоуровневом" C#.
Здравствуйте, gandjustas, Вы писали:
G>Такое барахло как этот код сумрования я бы вообще в продакшн ен пустил.
Чудненько. Можешь еще заявить, что суммирование вообще есть барахло, а поэтому его и не надо делать. Или придумай другой способ суммирования.
G>>>Я думаю считать все пиксели в память а потом суммировать будет лучше. PD>>А я так думаю, что введение лишнего массива без всякого обоснования не есть лучшее. G>Добро пожаловать в настоящее, копромис время-память уже давно сместился в сторону времени, память теперь никто не жалеет. Ну может кроме тебя.
И поэтому надо без всякого смысла создавать новый массив и тратить время на его заполнение. Когда выбор идет между временем и памятью — это имеет смысл и решение может быть и в ту и в другую пользу. Когда же увеличивают и то и другое без всякого смысла — это уже иначе называется.
PD>>Программа не изменится. Изменятся выводы, так как их нельзя делать на данных, которые не позволяют делать эти выводы. В общем,см. курс матстатистики — сравнение двух средних и т.д. G>Это нельяз делать потому что нельзя... смешно.
Да не смешно, а очень грустно, что элементарные понятия из матстатистики для тебя тайна за семью печатями.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Ну с позицией, что введение высокоуровневых абстракций рулит всегда и в любом случае я и сам не согласен. Эта проблема в общем-то не столько даже к асму сводится. Но очень частно они действительно рулят. И необязательно только в веб-приложениях
Да не надо чересчур много про асм. Я вовсе не предлагаю на асме писать все. И на С++ не предлагаю. Вот попробуй найди, где я предлагаю сайты на C++ писать . Не говоря уж об асме . Это мои оппоненты предлагают C++ и асм похоронить.
ВВ>Высокоуровневый код легко написать и проще поддерживать, его проще масштабировать.
+1.
>А соответственно проще реализовать другое архитектурное решение, которое поможет нам улучшить производительность системы в целом.
Может быть, да. Но только может быть. Не всегда.
>Ведь если наше приложение, скажем, не зависит от способа работы с хранилищем данных, то мы всегда сможем подменить это хранилище — скажем, прикрутить базу данных вместо файловой системы "напрямую" и пр.
+1
>Причем "снаружи", для клиентского кода, эти изменения вообще останутся незаметными. И это нормальная ситуация, когда действительно проще "оптимизировать" высокоуровневую систему.
+1
Как видишь, я согласился почти со всеми твоими доводами. А теперь начинается "но"
Все это верно — но до поры до времени. А точнее — когда есть запас подкожного жира. Иными словами, если работать можно не на пределе, а как бы это скахать... слегка помягче. Можно лишних 20-50 Мб скушать. Можно скорость иметь не 100%, а только 70, скажем. И т.д.
Если так — можно себе позволить несколько проиграть в настоящем, рассчитывая при этом получить некие преимущества в будущем. Реализовать не лучшее, зато более гибкое решение, которое в случае чего (новая аппаратура, новое ПО) позволит легче перейти к иному решению. Оно, это иное решение, опять-таки будет не оптимальным, но и его легче будет заменить решением 3 поколения. И т.д.
Если же подкожного жира нет, то всем этим приходится пренебречь. Решение будет плохо масштабируемо и плохо сопровождаемо — не потому, что оно плохо написано, а потому, что оно уж больно конкретно. К БД не перейдешь, там стоит явное чтение из файла да еще асинхронное, , а то и MMF, вместо абстракций НезнаюЧтоReader. Снаружи это будет очень даже заметным, так как придется и снаружи менять, и как бы не все. В общем, плохо во всем, кроме одного — это сейчас единственно возможное решение, потому что все остальные не дают нужной производительности.
И вот обстановка сложилась такая, что у вас этого подкожного жира много. Если что-то из нижесказанного будет обидным — заранее прошу извинения, я не хочу обижать.
Вот такой вопрос задам . Большинство сайтов , разрабатываемых средними программистскими группами — на каком числе физических компьютеров это работать будет ( я имею в виду, конечно, серверную часть, а на JS). Боюсь, что во многих случаях ответ будет прост — на одном. На сайте этой самой фирмы. И если это не Газпром и не IBM, то скорее всего у них будет один сервер, где все это и будет крутиться. Ну в крайнем случае кластер на несколько машин. И эти машины будут хорошими (подумаешь, выложить несколько тыс. долларов) и на них, вполне возможно, ничего, кроме этого сайта, и не будет работать.
А теперь второй вопрос — а сколько запросов-то будет. Оценитт их число я не могу,, пусть другие сделают. Но если это сайт некоей средненькой фирмы, то не думаю, что очень уж много. Тем более на запись. Тут и для серьезных фирм почти ничего нет — разве что форму могу заполнить да письмо им отослать.
И в этих условиях вы можете себе позволить от максимальной производительности отступить. Может даже аргументировать — мол, дешевле новый компьютер поставить. Можете про abstraction gain рассуждать. Верно. Есть у вас подкожный жир, можете позволить. И позволяя себе это, вы начинаете распространять свое видение на всю остальную область. А автор драйвера, к примеру, не имеет этого жира и не может себе ничего позволить — вторая машина тут ничего не даст, напишет он драйвер неэффективно — будет тормозить, и все. И я не могу.
Это раз. Но есть и два. Отношение к сопровождаемости и поддержке вообще зависит от того, о чем речь идет. В одном случае (те же сайты) — это очень важно, так как , действительно, кому нужен сайт. в котором нельзя произвести легко даже простое изменение при том. что автор давно уволился. Но есть и другие задачи, в которых это далеко не так важно. Иногда задача формулируется так, что по сути не предполагает модификаций, иногда модификации в ней легко предсказуемы и могут быть заложены как TODO еще при ее разработке. Мне кажется. что и в этом многие перегибают палку — пытаются распространить принципы, хорошо себя зарекомендовавшие, скажем, при разработке www-сайтов, на весь остальной программистский мир. Да, вас большинство, но из этого отнюдь не следует, что ваши боги есть боги для всех остальных
ВВ>И такие ситуация происходят очень часто. А часто бывают и ситуации когда дешевле купить железо, а не заниматься оптимизацией криво спроектированного приложения.
Я же тебе предлагал посчитать, что будет, если программа работает на сотне компьютеров, а ее работу удастся ускороить хотя бы в 5 раз. Ладно, посчитаю сам. Это значит, что вместо 100 компьютеров можно поставить 20. Считая стоимость компьютера за $1000, имеем 80 тыс долларов. Кому это 80 тыс за месяц работы платят ?
А если их не 100 ? А если вообще число компьютеров увеличить нельзя ? Под 1000 компьютеров придется ведь здание новое строить... А если и не надо все их в одном месте собирать, но придется к программе писать такое требование — RAM не менее 4 Гб, как минммум четырехядерный процессор ? Многие готовы выложить еще 1.5 тыс долларов , чтобы иметь возможность эту программу запустить ? На их компьютере она же не пойдет!
ВВ>И разговор о "тенденциях" возникает потому, что такой подход потихоньку распространяется. И даже появляется другой подход — описание программы в средствах бизнес-нотаций — как в каком-нибудь биз-толке — соединил стрелочками пару квадратиков — а на выходе у тебя уже соотвествующий код на "низкоуровневом" C#.
Еще раз повторю — ты делаешь попытку перенести принципы, пригодные для одного круга задач, на весь мир. Все же попробуй отвлечься от своей родной сферы и посмотри на остальные задачи непредвзято. И ты сразу поймешь, что то, что хорошо здесь, там просто не имеет смысла. Ну пойди, к примеру, к автору программы расчета погоды или свойств веществ и предложи ему соединять стрелочкой и ждать на выходе соответствующий код .
Здравствуйте, Pavel Dvorkin, Вы писали:
AVK>>Вобщем понятно, кода так и не будет. Приятно, когда твои предсказания сбываются .
PD>Очень дешевый прием, ты уж меня извини.
Дешевый примем это свалить в кусты вместо признания собственной неправоты.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Если же подкожного жира нет, то всем этим приходится пренебречь. Решение будет плохо масштабируемо и плохо сопровождаемо — не потому, что оно плохо написано, а потому, что оно уж больно конкретно. К БД не перейдешь, там стоит явное чтение из файла да еще асинхронное, , а то и MMF, вместо абстракций НезнаюЧтоReader. Снаружи это будет очень даже заметным, так как придется и снаружи менять, и как бы не все. В общем, плохо во всем, кроме одного — это сейчас единственно возможное решение, потому что все остальные не дают нужной производительности.
Довод твоих оппонентов в том, что даже в таком случае высокоуровневое приложение может быть производительнее. Что если ты упрешься в ограничения "файлухи"? И она станет узким горлышком? А чтобы переделать все на БД, придется "все переписать", а сделать ты это не сможешь.
На мой взгляд эта одна из "крупиц истины" в вашем споре
PD>Вот такой вопрос задам . Большинство сайтов , разрабатываемых средними программистскими группами — на каком числе физических компьютеров это работать будет ( я имею в виду, конечно, серверную часть, а на JS). Боюсь, что во многих случаях ответ будет прост — на одном. На сайте этой самой фирмы. И если это не Газпром и не IBM, то скорее всего у них будет один сервер, где все это и будет крутиться. Ну в крайнем случае кластер на несколько машин. И эти машины будут хорошими (подумаешь, выложить несколько тыс. долларов) и на них, вполне возможно, ничего, кроме этого сайта, и не будет работать.
Ну вот тут ты не очень прав. Могу рассказать о своем опыте. Я архитектор. Контора в основном специализируется на крупных клиентах (ибо с ними банально работать проще). Один клиент, с к-м я работал, крупный мобильный оператор. Там интранет, интеграция MOSS. Load balancing на всех staging серверах. При этом приложение глобальное — доступно всем сотрудникам компании в т.ч. и в регионах. MOSS — это ASP.NET в худшем его проявлении.
Вторая компания — нефтяной гигант с английскими корнями. Число только прямых сотрудников более 100 тыс. С "непрямыми", к к-м отношусь и я, больше, пожалуй, на порядок. Разрабатывали портальный движок, он внедрен в нескольких странах. Даже количество внедрений в рамках одной стороны сейчас уже приближается к десяткам — "внедрение" означение среду с всей цепочкой staging серверов. Портальный движок реализован еще на .NET 1.1. Основной "паттерн" использования — что-то вроде веб-десктопа для пользователя. Т.е. у сотен тысяч пользователей он грузится всякий раз когда они открывают браузер в кач. домашней страницы.
По производительности — тестили — тупо упиравается в оракловый кластер.
PD>А теперь второй вопрос — а сколько запросов-то будет. Оценитт их число я не могу,, пусть другие сделают. Но если это сайт некоей средненькой фирмы, то не думаю, что очень уж много. Тем более на запись. Тут и для серьезных фирм почти ничего нет — разве что форму могу заполнить да письмо им отослать.
А что по твоему в крупных компаниях? В крупных компаниях WebShpere портал, Sharepoint и пр. В компанию на букву "Г" тоже недавно продали приложение под MOSS, кстати. И ничего, крутится у них все.
PD>И в этих условиях вы можете себе позволить от максимальной производительности отступить. Может даже аргументировать — мол, дешевле новый компьютер поставить. Можете про abstraction gain рассуждать. Верно. Есть у вас подкожный жир, можете позволить. И позволяя себе это, вы начинаете распространять свое видение на всю остальную область. А автор драйвера, к примеру, не имеет этого жира и не может себе ничего позволить — вторая машина тут ничего не даст, напишет он драйвер неэффективно — будет тормозить, и все. И я не могу.
А мы еще и железо продаем Если подкожного жира нет, то его надо нарастить.
PD>Это раз. Но есть и два. Отношение к сопровождаемости и поддержке вообще зависит от того, о чем речь идет. В одном случае (те же сайты) — это очень важно, так как , действительно, кому нужен сайт. в котором нельзя произвести легко даже простое изменение при том. что автор давно уволился. Но есть и другие задачи, в которых это далеко не так важно. Иногда задача формулируется так, что по сути не предполагает модификаций, иногда модификации в ней легко предсказуемы и могут быть заложены как TODO еще при ее разработке. Мне кажется. что и в этом многие перегибают палку — пытаются распространить принципы, хорошо себя зарекомендовавшие, скажем, при разработке www-сайтов, на весь остальной программистский мир. Да, вас большинство, но из этого отнюдь не следует, что ваши боги есть боги для всех остальных
Честно, ни разу не встречался с "сайтами", которые не предполагают модификаций.
ВВ>>И такие ситуация происходят очень часто. А часто бывают и ситуации когда дешевле купить железо, а не заниматься оптимизацией криво спроектированного приложения. PD>Я же тебе предлагал посчитать, что будет, если программа работает на сотне компьютеров, а ее работу удастся ускороить хотя бы в 5 раз. Ладно, посчитаю сам. Это значит, что вместо 100 компьютеров можно поставить 20. Считая стоимость компьютера за $1000, имеем 80 тыс долларов. Кому это 80 тыс за месяц работы платят ?
Компания-интегратор далеко не такие счеты тебе выставит И далеко не месяц насчитает
Ты правда думаешь, что в Газпроме сто компов не купят?
PD>А если их не 100 ? А если вообще число компьютеров увеличить нельзя ? Под 1000 компьютеров придется ведь здание новое строить...
Здание не надо строить. Купил сервера у IBM, ну там и запарковал их. У IBM места хватит, это их бизнес.
PD>А если и не надо все их в одном месте собирать, но придется к программе писать такое требование — RAM не менее 4 Гб, как минммум четырехядерный процессор ? Многие готовы выложить еще 1.5 тыс долларов , чтобы иметь возможность эту программу запустить ? На их компьютере она же не пойдет!
Ни к одному из приложений, к-е мы разрабатывали не приходилось такие требования писать. Мы все еще о вебе говорим?
PD>Еще раз повторю — ты делаешь попытку перенести принципы, пригодные для одного круга задач, на весь мир. Все же попробуй отвлечься от своей родной сферы и посмотри на остальные задачи непредвзято. И ты сразу поймешь, что то, что хорошо здесь, там просто не имеет смысла. Ну пойди, к примеру, к автору программы расчета погоды или свойств веществ и предложи ему соединять стрелочкой и ждать на выходе соответствующий код .
Не знаю о программах расчета погоды, но сдается мне, что представлениях о многих типах задач у тебя не совсем верное.
Здравствуйте, AndrewVK, Вы писали:
ВВ>>А в таких случаях "абстракции" противопоказаны. AVK>Прочитай то, что я процитировал, еще раз. На всякий случай, если непонятно — Mono.Simd это та самая абстракция, которая, якобы, противопоказана.
А такая абстракция как отсутствие прямого доступа к памяти не помешает в реализации движка, как думаешь?
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Довод твоих оппонентов в том, что даже в таком случае высокоуровневое приложение может быть производительнее. Что если ты упрешься в ограничения "файлухи"? И она станет узким горлышком? А чтобы переделать все на БД, придется "все переписать", а сделать ты это не сможешь.
Ну во-первых, еще вопрос, что тут быстрее будет. Лично мне как раз пришлось свой файл писать, так как с SQL скорости были недостаточны. Почему ты считаешь, что я должен в них упереться ? Я , в общем-то, знаю, что от нее можно ожидать. Кстати, когда я этот свой собственный файл писал (псевдо-БД) подход мой был таков — я не могу сделать время чтения с диска сколь угодно малым, не от меня это зависит, но остальное от меня зависит, и время должно быть сведено почти к нулю. Что я и сделал, 10-20 мсек. Так что это решение станет неэффектиынм только если резко изменится скорость работы БД vs скорость файловой системы, что маловероятно, так как БД все же поверх ФС работают.
Но не в этом даже дело. Мне надо было максимальную скорость обеспечить. Сейчас. А через 5 лет — не так уж важно. Такая вот ситуация.
ВВ>На мой взгляд эта одна из "крупиц истины" в вашем споре
. задачи сильно отличаются. вот мы и не можем к общему знаменателю придти. Проще говоря, аргументы моих оппонентов для меня маловажны, и мои для них — тоже.
ВВ>Ну вот тут ты не очень прав. Могу рассказать о своем опыте. Я архитектор.
<skipped>
Я же не говорю — все. Я лишь о некоторой средней ситуации говорю. Мне прилось около года участвовать в создании нескольких сайтов небольших компаний, вот и все.
ВВ>Вторая компания — нефтяной гигант с английскими корнями.
Так гигант все же . Я не спорю, есть и такие задачи. Но увы, большинство все же не работает с гигантами в 100000 человек
ВВ>А что по твоему в крупных компаниях? В крупных компаниях WebShpere портал, Sharepoint и пр. В компанию на букву "Г" тоже недавно продали приложение под MOSS, кстати. И ничего, крутится у них все. ВВ>А мы еще и железо продаем Если подкожного жира нет, то его надо нарастить.
Я не против, но вроде мы не тебя обсуждаем и не твою фирму
PD>>Это раз. Но есть и два. Отношение к сопровождаемости и поддержке вообще зависит от того, о чем речь идет. В одном случае (те же сайты) — это очень важно, так как , действительно, кому нужен сайт. в котором нельзя произвести легко даже простое изменение при том. что автор давно уволился. Но есть и другие задачи, в которых это далеко не так важно. Иногда задача формулируется так, что по сути не предполагает модификаций, иногда модификации в ней легко предсказуемы и могут быть заложены как TODO еще при ее разработке. Мне кажется. что и в этом многие перегибают палку — пытаются распространить принципы, хорошо себя зарекомендовавшие, скажем, при разработке www-сайтов, на весь остальной программистский мир. Да, вас большинство, но из этого отнюдь не следует, что ваши боги есть боги для всех остальных
ВВ>Честно, ни разу не встречался с "сайтами", которые не предполагают модификаций.
Василий, прочти внимательно. что я написал. Я же именно это и сказал — что такой сайт не нужен.
ВВ>>>И такие ситуация происходят очень часто. А часто бывают и ситуации когда дешевле купить железо, а не заниматься оптимизацией криво спроектированного приложения. PD>>Я же тебе предлагал посчитать, что будет, если программа работает на сотне компьютеров, а ее работу удастся ускороить хотя бы в 5 раз. Ладно, посчитаю сам. Это значит, что вместо 100 компьютеров можно поставить 20. Считая стоимость компьютера за $1000, имеем 80 тыс долларов. Кому это 80 тыс за месяц работы платят ?
ВВ>Компания-интегратор далеко не такие счеты тебе выставит И далеко не месяц насчитает
И что ? Это как-то опровергает мой расчет ?
ВВ>Ты правда думаешь, что в Газпроме сто компов не купят?
Ну здравствуйте! Я же не об этом, нетрудно же понять. Я просто о том. что в данном случае оптимизировать программу куда выгоднее, чем 100 компов купить.
PD>>А если их не 100 ? А если вообще число компьютеров увеличить нельзя ? Под 1000 компьютеров придется ведь здание новое строить...
ВВ>Здание не надо строить. Купил сервера у IBM, ну там и запарковал их. У IBM места хватит, это их бизнес.
Психология web-программирования неистребима . Предложи Газпрому поставить свои компьютеры в IBM
PD>>А если и не надо все их в одном месте собирать, но придется к программе писать такое требование — RAM не менее 4 Гб, как минммум четырехядерный процессор ? Многие готовы выложить еще 1.5 тыс долларов , чтобы иметь возможность эту программу запустить ? На их компьютере она же не пойдет!
ВВ>Ни к одному из приложений, к-е мы разрабатывали не приходилось такие требования писать. Мы все еще о вебе говорим?
Нет. О моих задачах.
PD>>Еще раз повторю — ты делаешь попытку перенести принципы, пригодные для одного круга задач, на весь мир. Все же попробуй отвлечься от своей родной сферы и посмотри на остальные задачи непредвзято. И ты сразу поймешь, что то, что хорошо здесь, там просто не имеет смысла. Ну пойди, к примеру, к автору программы расчета погоды или свойств веществ и предложи ему соединять стрелочкой и ждать на выходе соответствующий код .
ВВ>Не знаю о программах расчета погоды, но сдается мне, что представлениях о многих типах задач у тебя не совсем верное.
О веб-программах — может быть, я в них не специалист. Но вот о других видах программ — возвращаю тебе твой упрек. Потому что одной из таких задач я и занимаюсь, а поэтому у меня о ней представление все же есть
Здравствуйте, Pavel Dvorkin, Вы писали:
ВВ>>Довод твоих оппонентов в том, что даже в таком случае высокоуровневое приложение может быть производительнее. Что если ты упрешься в ограничения "файлухи"? И она станет узким горлышком? А чтобы переделать все на БД, придется "все переписать", а сделать ты это не сможешь.
PD>Ну во-первых, еще вопрос, что тут быстрее будет. Лично мне как раз пришлось свой файл писать, так как с SQL скорости были недостаточны. Почему ты считаешь, что я должен в них упереться ?
Задачи есть разные. Где-то будет БД быстрее, где прямая работа с файлухой. Но это даже неважно. Можем "перевернуть" пример. Вот написал ты приложение через БД, а потом понимаешь что напрямую через ФС будет побыстрее.
PD>Я же не говорю — все. Я лишь о некоторой средней ситуации говорю. Мне прилось около года участвовать в создании нескольких сайтов небольших компаний, вот и все.
То, что творится в небольших компаниях одному богу известно. Я вот завтра организую фирмы и поставлю сотрудникам 386-е.
ВВ>>Вторая компания — нефтяной гигант с английскими корнями. PD>Так гигант все же . Я не спорю, есть и такие задачи. Но увы, большинство все же не работает с гигантами в 100000 человек
А с какими "гигантами" работает большинство? Это крупные предприятия, банки и пр. Ну не 100, но тысячи человек.
ВВ>>А что по твоему в крупных компаниях? В крупных компаниях WebShpere портал, Sharepoint и пр. В компанию на букву "Г" тоже недавно продали приложение под MOSS, кстати. И ничего, крутится у них все. ВВ>>А мы еще и железо продаем Если подкожного жира нет, то его надо нарастить. PD>Я не против, но вроде мы не тебя обсуждаем и не твою фирму
А любая фирма поступит также. Мы что ли свою уникальную нишу нашли? Или уж по крайней мере вендоры софта и железа будут рука об руку. Потому что, ты представляешь, вендорам железа тоже надо как-то свои железки продавать.
PD>>>Это раз. Но есть и два. Отношение к сопровождаемости и поддержке вообще зависит от того, о чем речь идет. В одном случае (те же сайты) — это очень важно, так как , действительно, кому нужен сайт. в котором нельзя произвести легко даже простое изменение при том. что автор давно уволился. Но есть и другие задачи, в которых это далеко не так важно. Иногда задача формулируется так, что по сути не предполагает модификаций, иногда модификации в ней легко предсказуемы и могут быть заложены как TODO еще при ее разработке. Мне кажется. что и в этом многие перегибают палку — пытаются распространить принципы, хорошо себя зарекомендовавшие, скажем, при разработке www-сайтов, на весь остальной программистский мир. Да, вас большинство, но из этого отнюдь не следует, что ваши боги есть боги для всех остальных ВВ>>Честно, ни разу не встречался с "сайтами", которые не предполагают модификаций.
PD>Василий, прочти внимательно. что я написал. Я же именно это и сказал — что такой сайт не нужен.
Тогда я не понял. Ты говоришь, что есть задачи, в которые не обязательно должна закладываться возможность модификаций, и масштабируемость для них не так важна?
ВВ>>>>И такие ситуация происходят очень часто. А часто бывают и ситуации когда дешевле купить железо, а не заниматься оптимизацией криво спроектированного приложения. PD>>>Я же тебе предлагал посчитать, что будет, если программа работает на сотне компьютеров, а ее работу удастся ускороить хотя бы в 5 раз. Ладно, посчитаю сам. Это значит, что вместо 100 компьютеров можно поставить 20. Считая стоимость компьютера за $1000, имеем 80 тыс долларов. Кому это 80 тыс за месяц работы платят ? ВВ>>Компания-интегратор далеко не такие счеты тебе выставит И далеко не месяц насчитает PD>И что ? Это как-то опровергает мой расчет ?
Железо купить дешевле.
ВВ>>Ты правда думаешь, что в Газпроме сто компов не купят? PD>Ну здравствуйте! Я же не об этом, нетрудно же понять. Я просто о том. что в данном случае оптимизировать программу куда выгоднее, чем 100 компов купить.
Да не выгоднее. Никто не разрабатывает "уникальные" программы с повышенными требованиями к железу. 99% решений для корпоративного обладают такими требованиями. Эксчендж-сервер, шарепоинт и пр. Ты предлагаешь весь софт переделывать под древние железки? И считаешь, что это будет дешевле?
PD>>>А если их не 100 ? А если вообще число компьютеров увеличить нельзя ? Под 1000 компьютеров придется ведь здание новое строить... ВВ>>Здание не надо строить. Купил сервера у IBM, ну там и запарковал их. У IBM места хватит, это их бизнес. PD>Психология web-программирования неистребима . Предложи Газпрому поставить свои компьютеры в IBM
Ну да. BP вот религия позволяет сервера у IBM парковать. Видимо, там "веб-программисты" руководящие посты занимают
Здравствуйте, AndrewVK, Вы писали:
ВВ>>А такая абстракция как отсутствие прямого доступа к памяти не помешает в реализации движка, как думаешь? AVK>Так он присутствует.
Где присутствует? То, что отдельные функции и даже отдельные библиотеки, и даже такие важные вещи как расчет физики, можно реализовать с использованием управляемой среды, не теряя в эффективности практически, я не отрицаю.
Но вот как написать целиком и полностью 3D-движок только с использованием управляемой среды я уже представляю с трудом. Возможно, я недостаточно знаком с предметной областью. Можно вот как-нибудь напрямую работать с видео-памятью в дотнете?
Здравствуйте, Воронков Василий, Вы писали:
ВВ>>>А такая абстракция как отсутствие прямого доступа к памяти не помешает в реализации движка, как думаешь? AVK>>Так он присутствует.
ВВ>Где присутствует?
В дотнете и языке C# присутствует прямой доступ к памяти.
ВВ> Можно вот как-нибудь напрямую работать с видео-памятью в дотнете?
Напрямую с видеопамятью так просто, как в ДОСе, давно уже не работают. Работают, к примеру, с плоскостями DirectX. Выделяешь плоскость, получаешь ее адрес и вперед. А уж как потом все это видеокарте достанется — забота драйвера.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Pavel Dvorkin, Вы писали:
PD> Спроецируйся назад на 10 лет (1998г) и попробуй предсказать будущее. Я не уверен, что в этом предсказании .Net вообще бы оказалась.
Java в 98 уже три года как была доступна, в 97 уже началась ругачка между Саном и МС по поводу нее, а два года спуста уже была доступна первая бета-версия, так что появление в 2001 году дотнета, вобщем то, предсказать было вполне реально.
PD>1. Сольются ли мобильные девайсы и настольные системы ?
Они уже слились.
PD>2. Сольются ли телевидение и персональные компьютеры ?
Уже слилось.
PD> Останется ли "волновое" телевидение или только цифровое будет ?
Останется. Мир большой.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Воронков Василий, Вы писали:
ВВ>>>Где присутствует? AVK>>В дотнете и языке C# присутствует прямой доступ к памяти.
ВВ>Т.е. мы не отрицаем, что такая красивая абстракция как опосредованный доступ к памяти
Не понимаю. Сейф-режим идет лесом при прямом доступе к памяти, только потому что современное железо не в состоянии обеспечить сейфнутость такого доступа. Все абстракции платформы при этом остаются на своих местах.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, AndrewVK, Вы писали:
AVK>Не понимаю. Сейф-режим идет лесом при прямом доступе к памяти, только потому что современное железо не в состоянии обеспечить сейфнутость такого доступа. Все абстракции платформы при этом остаются на своих местах.
А сейф-режим разве это не абстракция платформы? Собственно, почему он сейфом-то называется.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>А сейф-режим разве это не абстракция платформы?
Нет. это признак того, что код можно статически проконтроллировать верификатором. Дополнительных абстракций в саму платформу верификатор не вносит. А IL один и тот же.
ВВ> Собственно, почему он сейфом-то называется.
Потому что может быть верифицирован.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, AndrewVK, Вы писали:
AVK>Java в 98 уже три года как была доступна, в 97 уже началась ругачка между Саном и МС по поводу нее, а два года спуста уже была доступна первая бета-версия, так что появление в 2001 году дотнета, вобщем то, предсказать было вполне реально.
Кстати, да. В 98-м была уже доступна "первая попытка дотнета" — J++. И я даже с ней возился, хотя и несколько позже.
Здравствуйте, AndrewVK, Вы писали:
AVK>Нет. это признак того, что код можно статически проконтроллировать верификатором. Дополнительных абстракций в саму платформу верификатор не вносит. А IL один и тот же.
Ну извините. Я же не работаю с указателями, не оперирую понятиями типа "адрес объекта", не удаляю объекты вручную. В CLI даже синтаксис разный:
MyObject* o = new Object;
и
MyObject^ o = gcnew Object();
Причем второй пример более высокоуровневый чем первый.
ВВ>> Собственно, почему он сейфом-то называется. AVK>Потому что может быть верифицирован.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Здравствуйте, Константин Б., Вы писали:
КБ>>Тем что быстрее. Функции GetPixel и SetPixel работают очень медленно, т.к. внутри себя вызвают BitBlt.
PD>Можно ссылочку на источник, где говорится, что они вызывают BitBlt ? Куда она копирует ? Где второй HDC ? http://www.rsdn.ru/res/book/mmedia/yuan.xml
>>Напрямую получить весь массив с той же BitBlt гораздо быстрее.
PD>BitBlt все-таки копирует битовую карту , а вовсе не возвращает биты. А получить биты можно, GetBitmapBits / GetDIBIts, но это совсем другая история
Вот копируем на off-screen DC и оттуда забираем биты. Вы что первый раз c GDI работаете?
Здравствуйте, Воронков Василий, Вы писали:
AVK>>Прочитай то, что я процитировал, еще раз. На всякий случай, если непонятно — Mono.Simd это та самая абстракция, которая, якобы, противопоказана. ВВ>А такая абстракция как отсутствие прямого доступа к памяти не помешает в реализации движка, как думаешь?
Нет. Уже много лет никто ничего напрямую в видео память не пишет.
Видюхе просто данные подготавливают, а она сама все рендерит.
Так на порядки быстрее получается чем рендерить при помощи CPU и пиать в видео память.
... << RSDN@Home 1.2.0 alpha rev. 745>>
Пусть это будет просто:
просто, как только можно,
но не проще.
(C) А. Эйнштейн
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Здравствуйте, AndrewVK, Вы писали:
ВВ>>>А такая абстракция как отсутствие прямого доступа к памяти не помешает в реализации движка, как думаешь? AVK>>Так он присутствует.
ВВ>Где присутствует? То, что отдельные функции и даже отдельные библиотеки, и даже такие важные вещи как расчет физики, можно реализовать с использованием управляемой среды, не теряя в эффективности практически, я не отрицаю. ВВ>Но вот как написать целиком и полностью 3D-движок только с использованием управляемой среды я уже представляю с трудом. Возможно, я недостаточно знаком с предметной областью. Можно вот как-нибудь напрямую работать с видео-памятью в дотнете?
А можно работать напрямую с видеопамятью хоть где-нибудь под Windows? Ответ — нет.
Да и наибольшие тормоза в графических движках вызывает не отрисовка и текстутрирование (они уже давно выполняются на видеокарте), а отсечение невидимых поверхностей, расчет столкновений итп.
Используя более высокий уровень абстракциии можно написать код, который будет компилироваться в язык шейдеров и выполняться на видеокарте или на CPU, если видеокатра не поддерживает. .NET также позволяет достаточно просто распараллелить вычисления на несколько процессоров.
Не ждите появления завтра сумер-мега управляемого 3d-движка на .NET, большенство технологий которые нужны для написания движка еще "сырые", ни в одном большом проекте пока не будут использоваться. Также многие игростудии пока что испытывают страх перед управляемыми платформами в 3d движках.
Здравствуйте, gandjustas, Вы писали:
G>А можно работать напрямую с видеопамятью хоть где-нибудь под Windows? Ответ — нет.
Это я уже понял. Ступанул.
G>Да и наибольшие тормоза в графических движках вызывает не отрисовка и текстутрирование (они уже давно выполняются на видеокарте), а отсечение невидимых поверхностей, расчет столкновений итп.
Мне вот кажется, что требования к потреблении памяти — как обычной, так и видео — в 3Д движках должны более жесткие, чем в других приложениях. Посмотрите на системные требования игрушек, ужаснуться можно. Сколько всякого добра им приходится кэшировать в ОЗУ. И тут дополнительный "оверхед", который вносит дотнет, может сыграть не самую лучшую роль.
minorlogic,
M>Довольно стандартная фича например для C++, это я недоразобрался или в плюсах есть потдержка функциональных фичей ? это не наезд , но например boost iterator adaptors именно так и работают.
Чтобы компиляторы грязных C++ или Java имели возможность полноценного применения дефорестейшна, компилятор должен знать, когда вызывается функция над коллекцией и имеет ли она или нет побочные эффекты. Это весьма трудная задача для компилятора, если конечно язык не содержит явного описания операции над коллекциями. А вот например, система типов Хаскеля позволяет выяснить как первое, так и второе.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Мне вот кажется, что требования к потреблении памяти — как обычной, так и видео — в 3Д движках должны более жесткие, чем в других приложениях. Посмотрите на системные требования игрушек, ужаснуться можно. Сколько всякого добра им приходится кэшировать в ОЗУ. И тут дополнительный "оверхед", который вносит дотнет, может сыграть не самую лучшую роль.
Или наоборот — на фоне их и так немалых требований к ОЗУ оверхед от дотнета будет просто незаметен
Такая вот диалектика, как про грязного мужика и баню
P.S. где-то тут на форуме видел ссылку на разрабатываемый эффективный и качественный (по уверениям разработчиков) 3D-движок для дотнета. Который еще в бете, но скоро зарелизят. И пока что можно его бесплатно скачать-посмотреть.
Незнаю насколько он управляеый, а насколько просто обертка над нативом, но это не важно. Будет движок — можно ожидать появления игр, где дотнет будет основной средой.
Если первые проекты окажутся достаточно удачными — будут и другие.
Не так много людей готовы рискнуть деньгами на необычной для данного направления технологии. Но рано или поздно находятся. И если у них все удается, то и остальные подтягиваются.
Здравствуйте, FR, Вы писали:
FR>Здравствуйте, gandjustas, Вы писали:
G>>А можно работать напрямую с видеопамятью хоть где-нибудь под Windows? Ответ — нет. FR>Ответ да. DirectDraw создаешь поверхность в видеопамяти и вперед.
А причем тут 3d?
G>>Да и наибольшие тормоза в графических движках вызывает не отрисовка и текстутрирование (они уже давно выполняются на видеокарте), а отсечение невидимых поверхностей, расчет столкновений итп. FR>Угу и часто эти алгоритмы требуют много памяти и оптимизации доступа к этой памяти с учетом кеша и т. п. что проще делать в средах без GC.
Бред. Все эти оптимизации дадут максимум 20%, при этом оптимизация алгоритма может в разы увеличить скорость.
G>>Используя более высокий уровень абстракциии можно написать код, который будет компилироваться в язык шейдеров и выполняться на видеокарте или на CPU, если видеокатра не поддерживает. .NET также позволяет достаточно просто распараллелить вычисления на несколько процессоров. FR>Для шейдеров не нужны и бесполезны более высокие уровни абстракций, слишком короткие и ограниченые "программы" они пока подерживают, и существующих сиобразных языков сейчас более чем достаточно.
Ключевое слово "пока" — выделено.
Уже сейчас есть возможность написать на F# код, который будет выполняться как на CPU, так и на видеокарте. В неуправляемой среде можно сделать такое?
G>>Не ждите появления завтра сумер-мега управляемого 3d-движка на .NET, большенство технологий которые нужны для написания движка еще "сырые", ни в одном большом проекте пока не будут использоваться. Также многие игростудии пока что испытывают страх перед управляемыми платформами в 3d движках.
FR>Игростудии пишут сейчас игры в основном для приставок, а там до сих пор всего 256 (512 вместе с видео) метров памяти на борту. Кроме того большая часть приставок не контролируются ms и там NET еще долго не появится.
Для большенства приставок и DirectX нету, там вообще другие "законы".
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Мне вот кажется, что требования к потреблении памяти — как обычной, так и видео — в 3Д движках должны более жесткие, чем в других приложениях. Посмотрите на системные требования игрушек, ужаснуться можно. Сколько всякого добра им приходится кэшировать в ОЗУ. И тут дополнительный "оверхед", который вносит дотнет, может сыграть не самую лучшую роль.
.NET вносит очень малый оверхед по памяти в больших приложениях.
Кстати создатели движков на C++ часто используют кастомные аллокаторы, которые работают быстрее, но при этом вносят дополнительный оверхед по памяти.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Ну извините. Я же не работаю с указателями, не оперирую понятиями типа "адрес объекта", не удаляю объекты вручную.
Непринципиально.
ВВ> В CLI даже синтаксис разный:
Ну и что?
ВВ>Причем второй пример более высокоуровневый чем первый.
Ничуть. Уровень один и тот же.
ВВ>Угу. А за счет чего он может быть верифицирован?
За счет сознательного исключения возможностей, которые верифицировать не получается. При чем тут уровни? Вот, скажем, Сингулярити не может гарантировать верификацию для DMA, потому что аппаратура не позволяет его нужным образом контроллировать. Это, по твоему, означает, что механизм DMA более низкоуровневый, чем обращение к портам IO или отображение в адресное пространство?
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, AndrewVK, Вы писали:
FR>>Нет проблема в том что в той же приставке всего 256 метров памяти, а игра требует гораздо большего объема
AVK>А мужики то не знают.
Здравствуйте, gandjustas, Вы писали:
G>Здравствуйте, FR, Вы писали:
FR>>Здравствуйте, gandjustas, Вы писали:
G>>>А можно работать напрямую с видеопамятью хоть где-нибудь под Windows? Ответ — нет. FR>>Ответ да. DirectDraw создаешь поверхность в видеопамяти и вперед. G>А причем тут 3d?
Утверждалось то что выделено, а это неправда.
G>>>Да и наибольшие тормоза в графических движках вызывает не отрисовка и текстутрирование (они уже давно выполняются на видеокарте), а отсечение невидимых поверхностей, расчет столкновений итп. FR>>Угу и часто эти алгоритмы требуют много памяти и оптимизации доступа к этой памяти с учетом кеша и т. п. что проще делать в средах без GC. G>Бред. Все эти оптимизации дадут максимум 20%, при этом оптимизация алгоритма может в разы увеличить скорость.
Я писал эти алгоритмы так что не надо теоретических ихвышлений, одна только оптиизация мапов под память у меня дала больше 50% выигрыша.
FR>>Для шейдеров не нужны и бесполезны более высокие уровни абстракций, слишком короткие и ограниченые "программы" они пока подерживают, и существующих сиобразных языков сейчас более чем достаточно. G>Ключевое слово "пока" — выделено. G>Уже сейчас есть возможность написать на F# код, который будет выполняться как на CPU, так и на видеокарте. В неуправляемой среде можно сделать такое?
Конечно какая разница управляемый код или нет, это ничем ни отличается от написания любого транслятора.
G>>>Не ждите появления завтра сумер-мега управляемого 3d-движка на .NET, большенство технологий которые нужны для написания движка еще "сырые", ни в одном большом проекте пока не будут использоваться. Также многие игростудии пока что испытывают страх перед управляемыми платформами в 3d движках.
FR>>Игростудии пишут сейчас игры в основном для приставок, а там до сих пор всего 256 (512 вместе с видео) метров памяти на борту. Кроме того большая часть приставок не контролируются ms и там NET еще долго не появится. G>Для большенства приставок и DirectX нету, там вообще другие "законы".
Здравствуйте, AndrewVK, Вы писали:
AVK>А мужики то не знают.
Кстати подобные игры без проблем пишутся на смеси питон (или луа) (80%) С++ (20%) сам работал
в этой отрасли.
Но для больших и не PC игр это уже не проходит. Те же питон и луа кстати в них тоже для скриптования
предпочтительней чем управляемые ява или шарп из-за легкого и полного контроля над выделением памяти.
Здравствуйте, FR, Вы писали:
FR>Здравствуйте, gandjustas, Вы писали:
G>>Здравствуйте, FR, Вы писали:
FR>>>Здравствуйте, gandjustas, Вы писали:
G>>>>А можно работать напрямую с видеопамятью хоть где-нибудь под Windows? Ответ — нет. FR>>>Ответ да. DirectDraw создаешь поверхность в видеопамяти и вперед. G>>А причем тут 3d?
FR>Утверждалось то что выделено, а это неправда.
В контексте разработки 3d движков очень даже правда.
Можете еще драйвера вспомнить.
G>>>>Да и наибольшие тормоза в графических движках вызывает не отрисовка и текстутрирование (они уже давно выполняются на видеокарте), а отсечение невидимых поверхностей, расчет столкновений итп. FR>>>Угу и часто эти алгоритмы требуют много памяти и оптимизации доступа к этой памяти с учетом кеша и т. п. что проще делать в средах без GC. G>>Бред. Все эти оптимизации дадут максимум 20%, при этом оптимизация алгоритма может в разы увеличить скорость.
FR> FR>Я писал эти алгоритмы так что не надо теоретических ихвышлений, одна только оптиизация мапов под память у меня дала больше 50% выигрыша.
Значит до этого алгоритм далеко неоптимальный был.
Я имел счатье один раз оптимизировать на ассемблере код, скомпилированный на C. При всех выкрустах удалось вытянуть только 20% процентов. Потом поменяли алгоритм и получили прирост в 2 с чем-то раза.
FR>>>Для шейдеров не нужны и бесполезны более высокие уровни абстракций, слишком короткие и ограниченые "программы" они пока подерживают, и существующих сиобразных языков сейчас более чем достаточно. G>>Ключевое слово "пока" — выделено. G>>Уже сейчас есть возможность написать на F# код, который будет выполняться как на CPU, так и на видеокарте. В неуправляемой среде можно сделать такое? FR>Конечно какая разница управляемый код или нет, это ничем ни отличается от написания любого транслятора.
Ну напишите транслятор С++ или его подмножества в язык шейдеров.
G>>>>Не ждите появления завтра сумер-мега управляемого 3d-движка на .NET, большенство технологий которые нужны для написания движка еще "сырые", ни в одном большом проекте пока не будут использоваться. Также многие игростудии пока что испытывают страх перед управляемыми платформами в 3d движках. FR>>>Игростудии пишут сейчас игры в основном для приставок, а там до сих пор всего 256 (512 вместе с видео) метров памяти на борту. Кроме того большая часть приставок не контролируются ms и там NET еще долго не появится. G>>Для большенства приставок и DirectX нету, там вообще другие "законы". FR>Угу, вот поэтому успеха NET там долго не будет.
Да, только "там" постоянно сокращается.
Здравствуйте, Aen Sidhe, Вы писали:
AS>В новом стандарте — лямбды. МС обещала в 2010 студии сделать их в С++. Ну я С++ не сильно интересуюсь — больше не вспомню.
Здравствуйте, gandjustas, Вы писали:
FR>>Утверждалось то что выделено, а это неправда. G>В контексте разработки 3d движков очень даже правда.
В этом контексте тоже неправда, доступ к видеопамяти без проблем доступен и из D3D
IDirect3DVertexBuffer9::Lock
G>Можете еще драйвера вспомнить.
При чем тут драйвера.
FR>> FR>>Я писал эти алгоритмы так что не надо теоретических ихвышлений, одна только оптиизация мапов под память у меня дала больше 50% выигрыша. G>Значит до этого алгоритм далеко неоптимальный был.
Тут уже выше был аналог моей ситуации суммирование массива по строкам и столбцам занимает разное время.
Алгоритм при этом не меняется. У меня менялись аллокоторы памяти и была сделана локализация доступа.
G>Я имел счатье один раз оптимизировать на ассемблере код, скомпилированный на C. При всех выкрустах удалось вытянуть только 20% процентов. Потом поменяли алгоритм и получили прирост в 2 с чем-то раза.
Алгоритм не всегда можно поменять.
G>>>Уже сейчас есть возможность написать на F# код, который будет выполняться как на CPU, так и на видеокарте. В неуправляемой среде можно сделать такое? FR>>Конечно какая разница управляемый код или нет, это ничем ни отличается от написания любого транслятора. G>Ну напишите транслятор С++ или его подмножества в язык шейдеров.
А зачем мне писать подмножество C++ на C++ может мне инетереснее подмножество Ocaml'ана этом же самом Ocaml'е.
И давай не виляй покажи преимущества именно управляемого кода в этом вопросе.
FR>>Угу, вот поэтому успеха NET там долго не будет. G>Да, только "там" постоянно сокращается.
Здравствуйте, AndrewVK, Вы писали:
AVK>За счет сознательного исключения возможностей, которые верифицировать не получается. При чем тут уровни? Вот, скажем, Сингулярити не может гарантировать верификацию для DMA, потому что аппаратура не позволяет его нужным образом контроллировать. Это, по твоему, означает, что механизм DMA более низкоуровневый, чем обращение к портам IO или отображение в адресное пространство?
На мой взгляд автоматическое управление памятью — это более высокий уровень по сравнению с прямой работой с указателями.
Здравствуйте, FR, Вы писали:
ВВ>>На боксе кстати 512, причем разделения на видео и не-видео нет. +10 МБ (кажется) кэш. FR>Угу. Только текстуры и другие видеоданные как раз и сожрут большую ее часть.
А как иначе-то? Это и к немногим игрушкам, написанным специально под PC, тоже относится. Текстурки-то там почетче будут.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>На мой взгляд автоматическое управление памятью — это более высокий уровень по сравнению с прямой работой с указателями.
Автоматическое управление памятью — это внешний механизм. Разумеется, работа с ним это более высокий уровень. Но это самое управление памятью никаким образом не имеет отношения к работе с видеопамятью. Просто параллельна ей. И никак не мешает. То, что в С++ одна и та же механика используется для того и другого, совсем не означает, что это идентичные вещи. По факту — для управления созданием/удалением объектов в куче механика есть, для работы с поверхностями DirectX механики нету. Просто нету. И не потому что абстракции при этом противопоказаны, а потому что никто не озаботился.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, FR, Вы писали:
AVK>>Даже один факт способен опровергнуть теорию.
FR>Какой теории?
проблема в том что в той же приставке всего 256 метров памяти, а игра требует гораздо большего объема и в таких условиях ручное управление на порядки эффективнее чем GC
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Воронков Василий, Вы писали:
ВВ>А как иначе-то? Это и к немногим игрушкам, написанным специально под PC, тоже относится. Текстурки-то там почетче будут.
На PC все гораздо проще, объем доступной памяти намного больше, есть подкачка из виртуального файла для обычной памяти и отображение на системную для видео. В приставках же память очень даже ресурс. Вот тут http://www.dtf.ru/articles/print.php?id=4071 неплохо описана типичная работа с памятью в приставках.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Да дело даже не в видео-памяти.
Пример оказался неудачным? Я так понимаю, насчет уровня абстракции и прямого доступа к памяти больше вопросов нет?
ВВ> Если даже рассматривать только PC как платформу, то мне кажется
А мне нет.
ВВ> Мне кажется, в таком случае выжать соки из железа совсем не получится.
А мне нет.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, FR, Вы писали:
FR>Здравствуйте, gandjustas, Вы писали:
FR>>>Утверждалось то что выделено, а это неправда. G>>В контексте разработки 3d движков очень даже правда. FR>В этом контексте тоже неправда, доступ к видеопамяти без проблем доступен и из D3D FR>IDirect3DVertexBuffer9::Lock
Это память вертекс-буффера. Из .NET можно с такими буфером работать.
FR>>> FR>>>Я писал эти алгоритмы так что не надо теоретических ихвышлений, одна только оптиизация мапов под память у меня дала больше 50% выигрыша. G>>Значит до этого алгоритм далеко неоптимальный был. FR>Тут уже выше был аналог моей ситуации суммирование массива по строкам и столбцам занимает разное время. FR>Алгоритм при этом не меняется. У меня менялись аллокоторы памяти и была сделана локализация доступа. G>>Я имел счатье один раз оптимизировать на ассемблере код, скомпилированный на C. При всех выкрустах удалось вытянуть только 20% процентов. Потом поменяли алгоритм и получили прирост в 2 с чем-то раза. FR>Алгоритм не всегда можно поменять.
G>>>>Уже сейчас есть возможность написать на F# код, который будет выполняться как на CPU, так и на видеокарте. В неуправляемой среде можно сделать такое? FR>>>Конечно какая разница управляемый код или нет, это ничем ни отличается от написания любого транслятора. G>>Ну напишите транслятор С++ или его подмножества в язык шейдеров. FR>А зачем мне писать подмножество C++ на C++ может мне инетереснее подмножество Ocaml'ана этом же самом Ocaml'е. FR>И давай не виляй покажи преимущества именно управляемого кода в этом вопросе.
Еще раз: сейчас таких преимуществ не увидете. Большенство технологий, позволяющих получить значителньный прирост производительности, еще сырые. Но потенциал очень большой, надеюсь его будут использовать.
FR>>>Угу, вот поэтому успеха NET там долго не будет. G>>Да, только "там" постоянно сокращается. FR>В этом конкретном "там" и не думает сокращатся.
Цифры в студию.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>А теперь представим, что мы не только хотим написать движок на дотнете, но и сделать его более "абстрактным", упростить модификацию и добавление новых фич... Мне кажется, в таком случае выжать соки из железа совсем не получится.
Почему?
Здравствуйте, AndrewVK, Вы писали:
ВВ>>Да дело даже не в видео-памяти. AVK>Пример оказался неудачным?
Да как скажете. Хотя вопрос, каким образом будет осуществляться эффективная работа с видео-девайсом без MDX, по-прежнему остался.
AVK>Я так понимаю, насчет уровня абстракции и прямого доступа к памяти больше вопросов нет?
Здравствуйте, gandjustas, Вы писали:
G>Это память вертекс-буффера. Из .NET можно с такими буфером работать.
Конечно можно только это уже будет unsafe или будет оверхед
FR>>А зачем мне писать подмножество C++ на C++ может мне инетереснее подмножество Ocaml'ана этом же самом Ocaml'е. FR>>И давай не виляй покажи преимущества именно управляемого кода в этом вопросе. G>Еще раз: сейчас таких преимуществ не увидете. Большенство технологий, позволяющих получить значителньный прирост производительности, еще сырые. Но потенциал очень большой, надеюсь его будут использовать.
Угу все ясно
FR>>В этом конкретном "там" и не думает сокращатся. G>Цифры в студию.
NET доступен на одной приставке которая отнюдь не доминирует на рынке, при этом даже на этой приставке он позиционируется как средство разработки небольших малобюджетных проектов. Срок жизни приставок 5 — 7 лет, так что ближаюшую пятилетку вряд-ли что существенно поменяется.
Здравствуйте, Воронков Василий, Вы писали: ВВ>Я никогда и не писал, что "теоретического ассемблерщик" всех порвет по производительности. А писал, кстати, прямо противоположное. Ни с кем меня не путаете?
Ну вот я и удивился, что это ты вдруг переключился с критики ассемблера на критику abstraction.
ВВ>А может, стоит вообще забыть об ассемблере? Речь изначально о том, всегда ли есть abstraction gain, как вы говорите.
Я еще раз повторяю: изначально о "всегдашности" abstraction gain никто, кроме тебя, не говорил. Очень удобно приписать собеседнику ложное утверждение и потом его развеивать.
ВВ>"Программирование мышкой" — это практика, которая неизбежно влияет на квалификацию программиста.
Ничего подобного. На квалификацию программиста влияет не способ программирования, а те задачи, которые он решает.
Я провел под Delphi несколько не самых плохих лет. Никаких тяжких последствий VCL на себе не ощущаю. Что я делал не так?
Наверное, я мало пользовался стандартными контролами, зато много писал своих. Много читал исходников VCL и занимался отладкой.
ВВ>А объем кода, который необходимо писать вручную, в случае с АСП.НЕТ все равно остается немаленький, стоить лишь только отойти от стандартного способа работы с компонентами, что случается довольно часто.
Это у вас от незнакомства с предметом. Вся прелесть аспнета — в его сквозной интегрированности и расширяемости. Совершенно необязательно выбрасывать его целиком: можно расширять его ровно в нужном месте. Вот, к примеру, тот же MVC Framework. Он совершенно не требует отказа от WebForms. У тебя полприложения может быть написано на говнопостбеках, а половина — на MVC. И всё вместе будет прекрасно работать; будут работать SiteMapProviders, MembershipProvider, безопасность, логгирование, и прочее.
Вот, в частности, если у тебя вырисовывается свой фреймворк, к примеру, основанный на XML/XSLT, то можно наколбасить BuildProvider и вместо того, чтобы лепить однообразные хэндлеры, получить минимум лишнего кода, и при этом прекрасную производительность. Что там PHP от жизни хотел?
ВВ>При этом получается забавная ситуация, что среднестатистический асп.нет-чик может не знать ни базовые вещи по работе с HTTP, не уметь работать с джава-скриптом и пр. Я человек сто наверное прособеседовал, так что можно уже статистику составлять.
Меня совершенно не волнуют проблемы среднестатистических дотнетчиков. Меня волнуют возможности, предоставляемые движком тем, кто знает HTTP и умеет работать с JavaScript, DOM, CSS и так далее.
ВВ>А в чем проблема? Ты пробовал и получилось слишком медленно? ВВ>А то!
И что являлось "бутылочным горлышком"?
Как что? То, что в PHP невозможно закэшировать XsltCompiledTransform, конечно же. ВВ>Типа база летала, странички были заоптимизированы, скрипты клиентские не тормозили, а тормозил конкретно интерпретируемый PHP? ВВ>А что с "количеством" кода? Надо много писать, чтобы вызвать XSLT-преобразование? В каких конкретно частях системы, при решение каких задач пришлось писать много кода?
Отсутствие Build Providers требует всякий раз приседать вручную для вызова XSLT. Отлаживать всё это крайне неудобно, особенно когда есть цепочка из XSLT преобразований. ВВ>>>Я так смотрю хамство — это нынче модный тренд на RSDN.
S>>При том, что ASP.NET — лучший в мире фреймворк для веб-приложений. ВВ>Угу, при архитектуре, которая ущербна изначально. В каком страшном мире мы живем
А какие претензии к архитектуре ASP.NET? Вот только не надо мне рассказывать про мышку и стандартные контролы. Это не архитектура, а самый верхний её слой.
Вон какой-нибудь супермодный Джанго в Питоне архитектурно на порядок хуже ASP.NET, именно из-за чрезмерной жесткости и заточенности под конкретное убогое применение.
ВВ>Даже если он и лучший, это никак не отменяет того факта, что ASP.NET — [censored].
С таким фактом я не знаком.
Демагогия поскипана.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, FR, Вы писали:
FR>Здравствуйте, gandjustas, Вы писали:
G>>Это память вертекс-буффера. Из .NET можно с такими буфером работать. FR>Конечно можно только это уже будет unsafe или будет оверхед
Тем не менее это не видеопамять.
FR>>>В этом конкретном "там" и не думает сокращатся. G>>Цифры в студию.
FR>NET доступен на одной приставке которая отнюдь не доминирует на рынке, при этом даже на этой приставке он позиционируется как средство разработки небольших малобюджетных проектов. Срок жизни приставок 5 — 7 лет, так что ближаюшую пятилетку вряд-ли что существенно поменяется.
Ну-ну, за последние 7 лет много чего изменилось.
Здравствуйте, Sinclair, Вы писали:
ВВ>>А может, стоит вообще забыть об ассемблере? Речь изначально о том, всегда ли есть abstraction gain, как вы говорите. S>Я еще раз повторяю: изначально о "всегдашности" abstraction gain никто, кроме тебя, не говорил. Очень удобно приписать собеседнику ложное утверждение и потом его развеивать.
ВВ>>"Программирование мышкой" — это практика, которая неизбежно влияет на квалификацию программиста. S>Ничего подобного. На квалификацию программиста влияет не способ программирования, а те задачи, которые он решает. S>Я провел под Delphi несколько не самых плохих лет. Никаких тяжких последствий VCL на себе не ощущаю. Что я делал не так? S>Наверное, я мало пользовался стандартными контролами, зато много писал своих. Много читал исходников VCL и занимался отладкой.
Инструмент создается под задачи, а задачи придумываются для инструмента. И речь, наверное, не конкретно о тебе, а об общей картине, которую я себе представляю.
ВВ>>А объем кода, который необходимо писать вручную, в случае с АСП.НЕТ все равно остается немаленький, стоить лишь только отойти от стандартного способа работы с компонентами, что случается довольно часто.
S>Это у вас от незнакомства с предметом.
А может быть наоборот? Излишняя лояльность к ASP.NET от недостаточно полного знакомства с ним?
Кстати, мне интересно, переключение на личность собеседеника теперь "узаконенный" прием? Я теперь могу в дискуссии писать в стиле — "Любишь ООП? Это от незнакомства с предметом"?
S>Вся прелесть аспнета — в его сквозной интегрированности и расширяемости.
Расширяемость хороша, когда сама по себе платформа архитектурно удачна. Если платформа архитектурно неудачна, что мне от ее расширяемости?
S>Совершенно необязательно выбрасывать его целиком: можно расширять его ровно в нужном месте. Вот, к примеру, тот же MVC Framework. Он совершенно не требует отказа от WebForms.
А должна бы требовать.
Потом я не понимаю — зачем нужен очередной велосипед? Microsoft никак не может опуститься до реализации уже существующих стандартов?
S>У тебя полприложения может быть написано на говнопостбеках, а половина — на MVC.
А зачем это? Зачем мне "говнопостбеки"? Я должен устроить зоопарк в своем приложении, только потому что технология эта позволяет?
Сама архитектура WebForms ушербна для веб-приложения, что весьма живописно себя показывает в более или менее сложных проектах. Потому что, я уже сотый раз повторяю, веб-приложение не должно иметь архитектуру аналогичную вин-приложению. То, что хорошо в вин-формах и служит прекрасной замене какой-нибудь карте сообщений, на вебе может оказаться не такой уж и хорошей идеей.
Сама концепция контролов вообще — а не какие-то контролы в частности — ущербна. На вебе не нужны контролы, нужен гибкий метаязык для описания представления веб-страницы. Сама концепция построения веб-страниц кардинально отличается от вин-формс, и использовать те же принципы по крайней мере странно. "Шаблоны", которыми пытаются казаться веб-контролы, быстро превращаются в кучу HTML-разметки, стоить лишь чуть-чуть сойти с проторенной дорожки.
Модель сохранения состояния ущербна.
Модель событий, завязанная на состоянии, так хорошо работающая в вин-формс, ущербна также. Про аякс, прикрученный к веб-формах, даже говорить не хочется.
Что есть в веб-формах такого ценного, что стоило бы "сохранять"?
А, кстати, еще представь как расширяется стандартное такое веб-форм приложение. У тебя есть иерархия мастер-пейджей, внутри них стандартный "понос" из контролов и разметки — и того и другого много, т.е. есть ценный функционал который никаким образом нельзя поломать, а есть тупая разметка, которую нужно выкинуть. И соответственно, задача полностью перекрутить дизайн.
S>И всё вместе будет прекрасно работать; будут работать SiteMapProviders, MembershipProvider, безопасность, логгирование, и прочее.
Давай не будет "растекаться мыслью по древу", ок? Тот же RoleProvider вообще ортогонален WebForms — неудивительно, что ты сможешь его использовать, даже если пошлешь WebForms куда подальше. А то так можно всю BCL к достоинствам WebForms приписать.
S>Вот, в частности, если у тебя вырисовывается свой фреймворк, к примеру, основанный на XML/XSLT, то можно наколбасить BuildProvider и вместо того, чтобы лепить однообразные хэндлеры, получить минимум лишнего кода, и при этом прекрасную производительность.
"Однообразный хэндлер" обычно получается в единственном числе, и кода лишнего там совсем немного. Значительно меньше чем на средней aspx-страничке.
ВВ>>При этом получается забавная ситуация, что среднестатистический асп.нет-чик может не знать ни базовые вещи по работе с HTTP, не уметь работать с джава-скриптом и пр. Я человек сто наверное прособеседовал, так что можно уже статистику составлять. S>Меня совершенно не волнуют проблемы среднестатистических дотнетчиков.
А меня волнуют.
S>Меня волнуют возможности, предоставляемые движком тем, кто знает HTTP и умеет работать с JavaScript, DOM, CSS и так далее.
Возможности предоставляются низкоуровневой архитектурой ASP.NET. Все, что начинается от реализации конкретного обработчика запроса к *.aspx в виде класса Page — это именно реализация этих возможностей. Причем далеко не самая удачная.
ВВ>>А в чем проблема? Ты пробовал и получилось слишком медленно? ВВ>>А то! S>И что являлось "бутылочным горлышком"? S>Как что? То, что в PHP невозможно закэшировать XsltCompiledTransform, конечно же.
Да вот прям в этом вся проблема. В 1.0 да и 1.1, кажется, XSLT-преобразование, построенное еще на основе старой версии MSXML работало где-то раза в 4 медленнее, чем в 2.0 — и никаких проблем не было даже близко. Упирались как все нормальные люди в перформанс БД.
А в PHP прям так сразу отсутствие XsltCompiledTransform убивает весь перформанс. Может стоит действительно сравнить, сколько времени уходит на преобразование, а сколько на все остальное?
Я вот делал преобразование прямо на клиенте, и знаешь во что приложение упиралось на страничках с большим количеством контента? В скорость, с которой браузер это дело отрисовывал.
ВВ>>Типа база летала, странички были заоптимизированы, скрипты клиентские не тормозили, а тормозил конкретно интерпретируемый PHP? ВВ>>А что с "количеством" кода? Надо много писать, чтобы вызвать XSLT-преобразование? В каких конкретно частях системы, при решение каких задач пришлось писать много кода? S>Отсутствие Build Providers требует всякий раз приседать вручную для вызова XSLT. Отлаживать всё это крайне неудобно, особенно когда есть цепочка из XSLT преобразований.
Ты серьезно? "Приседать", блин. Ты представляешь работу с XSLT в PHP? Там примерно то же количество приседаний, что и в .NET, даже чуть меньше.
И да, если тупо копипастить весь код, то наверное будут проблемы, причем далеко не только в PHP.
Это называется — давайте придумаем проблемы, а потом покажем для нее красивое решение.
И кстати, что ты собрался отлаживать? XSLT? И какое это имеет вообще отношение к PHP/WebForms?
S>>>При том, что ASP.NET — лучший в мире фреймворк для веб-приложений. ВВ>>Угу, при архитектуре, которая ущербна изначально. В каком страшном мире мы живем S>А какие претензии к архитектуре ASP.NET? Вот только не надо мне рассказывать про мышку и стандартные контролы. Это не архитектура, а самый верхний её слой.
ВВ>То, что творится в небольших компаниях одному богу известно. Я вот завтра организую фирмы и поставлю сотрудникам 386-е.
Разбегутся
ВВ>>>Вторая компания — нефтяной гигант с английскими корнями. PD>>Так гигант все же . Я не спорю, есть и такие задачи. Но увы, большинство все же не работает с гигантами в 100000 человек
ВВ>А с какими "гигантами" работает большинство? Это крупные предприятия, банки и пр. Ну не 100, но тысячи человек.
Маловато
ВВ>А любая фирма поступит также. Мы что ли свою уникальную нишу нашли? Или уж по крайней мере вендоры софта и железа будут рука об руку. Потому что, ты представляешь, вендорам железа тоже надо как-то свои железки продавать.
Сорри, но мы о чем-то ? Похоже, от обсужденяи проблем написания кода ты как-то к маркетингу перешел. Здесь я не специалист, обсуждать не буду.
PD>>>>Это раз. Но есть и два. Отношение к сопровождаемости и поддержке вообще зависит от того, о чем речь идет. В одном случае (те же сайты) — это очень важно, так как , действительно, кому нужен сайт. в котором нельзя произвести легко даже простое изменение при том. что автор давно уволился. Но есть и другие задачи, в которых это далеко не так важно. Иногда задача формулируется так, что по сути не предполагает модификаций, иногда модификации в ней легко предсказуемы и могут быть заложены как TODO еще при ее разработке. Мне кажется. что и в этом многие перегибают палку — пытаются распространить принципы, хорошо себя зарекомендовавшие, скажем, при разработке www-сайтов, на весь остальной программистский мир. Да, вас большинство, но из этого отнюдь не следует, что ваши боги есть боги для всех остальных ВВ>>>Честно, ни разу не встречался с "сайтами", которые не предполагают модификаций.
PD>>Василий, прочти внимательно. что я написал. Я же именно это и сказал — что такой сайт не нужен.
ВВ>Тогда я не понял. Ты говоришь, что есть задачи, в которые не обязательно должна закладываться возможность модификаций, и масштабируемость для них не так важна?
Именно, но отнюдь не сайты. См. выделенное выше.
ВВ>>>>>И такие ситуация происходят очень часто. А часто бывают и ситуации когда дешевле купить железо, а не заниматься оптимизацией криво спроектированного приложения. PD>>>>Я же тебе предлагал посчитать, что будет, если программа работает на сотне компьютеров, а ее работу удастся ускороить хотя бы в 5 раз. Ладно, посчитаю сам. Это значит, что вместо 100 компьютеров можно поставить 20. Считая стоимость компьютера за $1000, имеем 80 тыс долларов. Кому это 80 тыс за месяц работы платят ? ВВ>>>Компания-интегратор далеко не такие счеты тебе выставит И далеко не месяц насчитает PD>>И что ? Это как-то опровергает мой расчет ?
ВВ>Железо купить дешевле.
Ну это я уже не понимаю. Я тебе привел конкретный числовой пример, где дополнительное железо стоит $80К, а я (допустим) могу сделать так, чтобы оно не потребовалось. А ты опять — железо дешевле. Если так — бери меня на работу и плати $80K в месяц
ВВ>Да не выгоднее. Никто не разрабатывает "уникальные" программы с повышенными требованиями к железу.
Я. И еще какие повышенные требования!
>99% решений для корпоративного обладают такими требованиями. Эксчендж-сервер, шарепоинт и пр.
Почему ты считаешь, что бизнес — это только задачи обмена информацией ? Там еще и обработка ее есть. И она порой намного сложнее, чем форматирование текста
>Ты предлагаешь весь софт переделывать под древние железки?
Ну если P4 Quad 4 Гб или NVidia 8,9 серий это древняя железка — тогда найди поновее . А и их не хватает.
>И считаешь, что это будет дешевле?
Я же привел расчет. Ты его опровергнуть можешь ?
PD>>>>А если их не 100 ? А если вообще число компьютеров увеличить нельзя ? Под 1000 компьютеров придется ведь здание новое строить... ВВ>>>Здание не надо строить. Купил сервера у IBM, ну там и запарковал их. У IBM места хватит, это их бизнес. PD>>Психология web-программирования неистребима . Предложи Газпрому поставить свои компьютеры в IBM
ВВ>Ну да. BP вот религия позволяет сервера у IBM парковать. Видимо, там "веб-программисты" руководящие посты занимают
Религия может что угодно позволять, но то, что Газпром свои конфиденциальные данные разместит на сервере , находящемся в США — извини, не поверю.
Здравствуйте, gandjustas, Вы писали:
G>Тем не менее это не видеопамять.
Самая что ни на есть видео да еще и с прямым доступом по указателю.
FR>>>>В этом конкретном "там" и не думает сокращатся. G>>>Цифры в студию.
FR>>NET доступен на одной приставке которая отнюдь не доминирует на рынке, при этом даже на этой приставке он позиционируется как средство разработки небольших малобюджетных проектов. Срок жизни приставок 5 — 7 лет, так что ближаюшую пятилетку вряд-ли что существенно поменяется. G>Ну-ну, за последние 7 лет много чего изменилось.
Здравствуйте, AndrewVK, Вы писали:
AVK>Здравствуйте, Pavel Dvorkin, Вы писали:
PD>> Спроецируйся назад на 10 лет (1998г) и попробуй предсказать будущее. Я не уверен, что в этом предсказании .Net вообще бы оказалась.
AVK>Java в 98 уже три года как была доступна
И в 1998 именно мы сайт с апплетом делали, он и посейчас жив
>в 97 уже началась ругачка между Саном и МС по поводу нее
И это помню.
>, а два года спуста уже была доступна первая бета-версия, так что появление в 2001 году дотнета, вобщем то, предсказать было вполне реально.
мб.
PD>>1. Сольются ли мобильные девайсы и настольные системы ?
AVK>Они уже слились.
PD>>2. Сольются ли телевидение и персональные компьютеры ?
AVK>Уже слилось.
Я, видимо, неточно выразился. Я имел в виду, не то, сольются ли они технически, а сольются ли в массовом масштабе. Иными словами, закончится ли зоопарк ОС на мобильниках переходом к некоей ОС, единой для мобильников и настольных (или как минимум неким интеграционным пакетом). А про телевидение — — останется ли вариант "вещания" или выживет только вариант "запроса" ?
Здравствуйте, Pavel Dvorkin, Вы писали:
ВВ>>То, что творится в небольших компаниях одному богу известно. Я вот завтра организую фирмы и поставлю сотрудникам 386-е. PD>Разбегутся
Почему? Как разница на чем в "солитер" играть?
ВВ>>>>Вторая компания — нефтяной гигант с английскими корнями. PD>>>Так гигант все же . Я не спорю, есть и такие задачи. Но увы, большинство все же не работает с гигантами в 100000 человек ВВ>>А с какими "гигантами" работает большинство? Это крупные предприятия, банки и пр. Ну не 100, но тысячи человек. PD>Маловато
Да уж, прям так маловато
Для того, чтобы заниматься многогодовыми внедрениями какой-нибудь очередной хреновины обычно хватает.
ВВ>>А любая фирма поступит также. Мы что ли свою уникальную нишу нашли? Или уж по крайней мере вендоры софта и железа будут рука об руку. Потому что, ты представляешь, вендорам железа тоже надо как-то свои железки продавать. PD>Сорри, но мы о чем-то ? Похоже, от обсужденяи проблем написания кода ты как-то к маркетингу перешел. Здесь я не специалист, обсуждать не буду.
Разработка софта — это коммерческий продукт. Такой же как тушь для ресниц или автомобили. Разве нет? Ты в любом случае упрешься в маркетинг, это нормально.
Даже как человек не слишком-то близкий к собственно бизнесу я в первую очередь определяю, что нам выгоднее будет продать. А потом уже идет архитектура, проблемы написания кода и проч.
ВВ>>>>>>И такие ситуация происходят очень часто. А часто бывают и ситуации когда дешевле купить железо, а не заниматься оптимизацией криво спроектированного приложения. PD>>>>>Я же тебе предлагал посчитать, что будет, если программа работает на сотне компьютеров, а ее работу удастся ускороить хотя бы в 5 раз. Ладно, посчитаю сам. Это значит, что вместо 100 компьютеров можно поставить 20. Считая стоимость компьютера за $1000, имеем 80 тыс долларов. Кому это 80 тыс за месяц работы платят ? ВВ>>>>Компания-интегратор далеко не такие счеты тебе выставит И далеко не месяц насчитает PD>>>И что ? Это как-то опровергает мой расчет ? ВВ>>Железо купить дешевле.
PD>Ну это я уже не понимаю. Я тебе привел конкретный числовой пример, где дополнительное железо стоит $80К, а я (допустим) могу сделать так, чтобы оно не потребовалось. А ты опять — железо дешевле. Если так — бери меня на работу и плати $80K в месяц
Ты сам себе человек-оркестр что ли? Я тебе говорю, стандартный такой скромный интегратор высосет из клиента куда больше денег на оптимизации, чем тот заплатил бы за железо. Ты один может быть и составишь конкуренцию альтернативе "поменять все железо".
Потом, что за программа такая? Клиентское приложение, разворачивается на всех компах фирмы? Мы опять получается о какой-нибудь специфической нише говорим. Я тебе много раз уже говорил, что согласен с тем, что такие задачи есть, что есть такие приложение и пр. Только есть и другие приложения. И это не только всякие там веб-сайты да хоум-пейджи.
А в общем случае мне вообще сложно представить, что за приложение должно быть такое, что у него требования будут зашкалировать по сравнению, скажем, с Office 2007
ВВ>>Да не выгоднее. Никто не разрабатывает "уникальные" программы с повышенными требованиями к железу. PD>Я. И еще какие повышенные требования!
Ну да ради бога, только ты в меньшистве.
>>99% решений для корпоративного обладают такими требованиями. Эксчендж-сервер, шарепоинт и пр. PD>Почему ты считаешь, что бизнес — это только задачи обмена информацией ? Там еще и обработка ее есть. И она порой намного сложнее, чем форматирование текста
И что? Какие в большинстве случаев ты представляешь задачи для обработки информации, что с ними никак не справляется железо?
>>Ты предлагаешь весь софт переделывать под древние железки? PD>Ну если P4 Quad 4 Гб или NVidia 8,9 серий это древняя железка — тогда найди поновее . А и их не хватает.
P4 Quad — это что? Четырехядерный пентиум 4?
Упоминание NVidia 8,9 — это или 3D или [censored] математика. Ну по поводу 3D я и сам согласен, а [censored] математика она на то и [censored].
>>И считаешь, что это будет дешевле? PD>Я же привел расчет. Ты его опровергнуть можешь ?
Я тебе еще раз говорю — компания за месячную разработку возьмет больше.
ВВ>>Ну да. BP вот религия позволяет сервера у IBM парковать. Видимо, там "веб-программисты" руководящие посты занимают PD>Религия может что угодно позволять, но то, что Газпром свои конфиденциальные данные разместит на сервере , находящемся в США — извини, не поверю.
И правда — IBM периферийная контрола с одним офисом в США. И весь небось серверами завален.
Здравствуйте, fmiracle, Вы писали:
F>Sinclair говорит тебе, что ASP.NET и WebForms — это отнють не синонимы, и WebForms это только составная, но не обязательная часть ASP.NET. F>У тебя же претензии к WebForms, но при этом упорно утверждаешь, что ASP.NET вообще — полнейший отстой. F>Это как-то вроде того, что аргументировать ущербность архитектуры Windows тем, что explorer — далеко не самый мощный файловый менеджер...
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Я, видимо, неточно выразился. Я имел в виду, не то, сольются ли они технически, а сольются ли в массовом масштабе. Иными словами, закончится ли зоопарк ОС на мобильниках переходом к некоей ОС, единой для мобильников и настольных (или как минимум неким интеграционным пакетом). А про телевидение — — останется ли вариант "вещания" или выживет только вариант "запроса" ?
Вставлю свои пять копеек — думаю, вещание таки умрет все-таки. Хотя, возможно, и не через десять лет. Через десять лет у нас дай бог HDTV появится.
Вариант "запроса" вообще значительно удобнее и позволяет решить много проблем, связанных с вещанием. Кстати, уже сейчас есть варианты реализации такого телевидения "по запросу" — XBox 360.
Тем не менее, мне ты продолжаешь твердить, что ASP.NET в целом — отстой. Мне как-то не очень хочется следить за раздвоениями личности и пытаться скомпоновать удобные мне утверждения из нескольких независимых постингов.
Вот ты там поправился, с этим все согласились. Потом ты продолжаешь сравнивать ASP.NET с PHP, при этом, похоже, имеешь в виду WebForms против XSLT.
Напомню, что ASP.NET всплыл не потому, что вебФормз. А потому, что Рихтер прикрутил к дотнету Power Threading Library, которая позволяет писать офигенно высокопроизводительный код, не слишком жертвуя читаемостью. И потому, что использование IO Completion Ports, которое Рихтер облегчил, крайне важно как раз в серверах массового обслуживания, в частности в веб серверах. В десктопном приложении лишний десяток потоков — тьфу, семечки. А в сервере каждый поток на счету; неэффективные примитивы синхронизации способны убить производительность куда быстрее, чем проверки выхода за границы массивов.
В свете этого набор используемых контролов не имеет никакого значения. Речь идет о том, что легко построить реализацию IHttpHandler, которая не блокирует поток из пула на время выполнения асинхронных операций. И вообще никакой не блокирует, в отличие от предлагаемой в MSDN реализации "Async Handler".
Здесь, конечно, никакого abstraction gain нету.
Аналогичную реализацию теоретически можно получить "на ассемблере". Вот только из местных апологетов микрооптимизаций ни один чего-то не спешит представить доказательство в студию. Всё больше рассуждают о теории. Поэтому я настаиваю на эквивалентной честности к обеим сторонам.
Потому, что теоретически abstraction gain таки не сводится к "голове". Я писал тут неподалеку, каким именно способом абстрактный код может обгонять ассемблер.
Суперкомпилятор, кстати, к этой теории отношения не имеет (в отличие от HotSpot). Потому, что результат суперкомпилятора — это один хрен некоторая "жесткая" программа, которую можно превратить в ассемблер и забыть про суперкомпилятор. А супероптимизатор обязан работать в рантайме, чтобы подстроиться под фактическую платформу и условия задачи и обогнать ассемблер.
Да, опять же к слову: всякие предположения типа "а если платформа ровно одна и заведомо не изменится" нужно делать очень осторожно. Ты как-то задавал такой вопрос. Ну так надо уточнить, что понимается под "одной платформой". Если это встраиваемый контроллер — то да, перспективой смены платформы нужно пренебречь. Ну, и, для супероптимизатора может тупо не хватить ресурсов, и придется все оптимизации делать статически (что, в свою очередь, возможно вручную).
А если мы говорим об этом в том смысле, как имеет в виду Дворкин ("платформа у нас одна — win32"), то это просто ламерство. Потому, что оптимальные алгоритмы синхронизации сильно отличаются для, к примеру, одноядерного процессора, HT, и многопроцессорной машины. В итоге, код, скомпилированный в расчете на одну архитектуру, будет сосать на другой. А код, оборудованный рантайм-проверками, будет сливать коду, который динамически компилируется с высокого уровня в низкий.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Почему? Как разница на чем в "солитер" играть?
В Quake не поиграешь
ВВ>>>А с какими "гигантами" работает большинство? Это крупные предприятия, банки и пр. Ну не 100, но тысячи человек. PD>>Маловато
ВВ>Да уж, прям так маловато
Не мои масштабы
ВВ>Разработка софта — это коммерческий продукт. Такой же как тушь для ресниц или автомобили. Разве нет? Ты в любом случае упрешься в маркетинг, это нормально.
Да, но это не ко мне. Пусть заказчик этим занимается, а с меня и программирования хватит
ВВ>Даже как человек не слишком-то близкий к собственно бизнесу я в первую очередь определяю, что нам выгоднее будет продать. А потом уже идет архитектура, проблемы написания кода и проч.
Это все не мои проблемы. Я получаю задачу и решаю ее. Все. Я только программист
ВВ>>>Железо купить дешевле.
PD>>Ну это я уже не понимаю. Я тебе привел конкретный числовой пример, где дополнительное железо стоит $80К, а я (допустим) могу сделать так, чтобы оно не потребовалось. А ты опять — железо дешевле. Если так — бери меня на работу и плати $80K в месяц
ВВ>Потом, что за программа такая? Клиентское приложение, разворачивается на всех компах фирмы?
Почти
>Мы опять получается о какой-нибудь специфической нише говорим.
И даже очень
>Я тебе много раз уже говорил, что согласен с тем, что такие задачи есть, что есть такие приложение и пр. Только есть и другие приложения. И это не только всякие там веб-сайты да хоум-пейджи.
А я и не спорю, что они есть. И ты согласен, что и другие есть. Мы оба согласны друг с другом
ВВ>А в общем случае мне вообще сложно представить, что за приложение должно быть такое, что у него требования будут зашкалировать по сравнению, скажем, с Office 2007
Ну я же тебе привел пример с обработкой матриц 5000 * 5000. Куда там офису, у него загрузка процессора большую часть времени близка к 0, а у меня (вот сейчас как раз смотрел — около 60%-70% на двухядерном проце все время. Мало. Буду думать, как до 90 хотя бы довести.
ВВ>>>Да не выгоднее. Никто не разрабатывает "уникальные" программы с повышенными требованиями к железу. PD>>Я. И еще какие повышенные требования!
ВВ>Ну да ради бога, только ты в меньшистве.
А мне в меньшинстве совсем не плохо . Во всяком случае конкурентов гораздо меньше — это у вас можно заменить ну пусть не любого, но многих. А меня гораздо труднее заменить
ВВ>И что? Какие в большинстве случаев ты представляешь задачи для обработки информации, что с ними никак не справляется железо?
Я же тебе говорил про матрицы уже не раз. Ну не хочу я раскрывать суть задачи
ВВ>P4 Quad — это что? Четырехядерный пентиум 4?
Да. У заказчика есть еще и 8-ядерный.
ВВ>Упоминание NVidia 8,9 — это или 3D или [censored] математика.
Нет, это не математика. Это распараллеливание обработки. Под видом видеокарты там фактически матричный процессор на 512 аппаратных потоков. См. CUDA.
>Ну по поводу 3D я и сам согласен, а [censored] математика она на то и [censored].
К 3D моя задача отношения не имеет, а математика там простенькая.
>>>И считаешь, что это будет дешевле? PD>>Я же привел расчет. Ты его опровергнуть можешь ?
ВВ>Я тебе еще раз говорю — компания за месячную разработку возьмет больше.
За разработку какого-нибудь простенького сайта , используя существующий фреймворк и посадив 2-3 программиста на месяц, компания получит >80 K ? Из них она пусть $10K заплатит программистам, а остальное себе возьмет ? Если так, то это грабеж среди бела дня. Но что-то сомнительно...
А впрочем, компания — ладно, ты лучше мне $80K заплати
ВВ>>>Ну да. BP вот религия позволяет сервера у IBM парковать. Видимо, там "веб-программисты" руководящие посты занимают PD>>Религия может что угодно позволять, но то, что Газпром свои конфиденциальные данные разместит на сервере , находящемся в США — извини, не поверю.
ВВ>И правда — IBM периферийная контрола с одним офисом в США. И весь небось серверами завален.
Не понял юмора. Хоть где у них офисы, даже в России, все равно там Газпром ИМХО свои конфиденциальные данные хранить не будет.
Здравствуйте, AndrewVK, Вы писали:
AVK>Здравствуйте, Pavel Dvorkin, Вы писали:
PD>>Я, видимо, неточно выразился. Я имел в виду, не то, сольются ли они технически, а сольются ли в массовом масштабе.
AVK>Смотря что понимать под массовым масштабом.
Ну хотя бы общедоступность в городах с населением от 200,000. Общедоступность на том же уровне, как сейчас в них доступно обычное ТВ.
PD>> Иными словами, закончится ли зоопарк ОС на мобильниках переходом к некоей ОС, единой для мобильников и настольных (или как минимум неким интеграционным пакетом).
AVK>При чем тут ОС? И что такое интеграционный пакет? Давным давно проблемы написания разного софта определяются не ОС и загадочными пакетами (и линух для мелких дивайсов давно доступен, и WM твой любимый Win32 предоставляет в очень приличном объеме), а принципиальными ограничениями железа, размером экрана прежде всего и разными моделями применения (наличие тачскринов, GPS, но при этом отсутствие быстрых и скоростных дисков).
Что такое интеграционный пакет -я и сам не знаю, а имею в виду я просто следующее. Сажусь я за любую машину с Windows — и мне сразу ясно, что делать. Вот и на мобильниках должно быть то же самое. А сейчас каждый из них изучать надо. И, скажем, связь между ними и PC — тоже не всегда тривиальна. Я для своего мобильника кабель по всему Омску искал, нет, говорят, под такой разъем,а когда наконец нашел — он инсталлироваться не захотел
1. Не суди по своему уровню, а суди по уровню массового пользователя.
2. Не суди по Москве.
PD>> А про телевидение — — останется ли вариант "вещания" или выживет только вариант "запроса" ?
AVK>Останется.
Опять-таки вопрос — соотношение между. Если только для медвежьих уголков (впрочем, спутники есть) — это одно. Если оно останется в массовом масштабе — другое.
Здравствуйте, gandjustas, Вы писали:
G>Пустая риторика, низачот.
. Зачеты я только сам ставлю, от других не принимаю
G>Напряги свои знания WinAPI, может впомнишь что есть функция считывание всего битмапа из DC, что будет гораздо быстрее считывания отдельных пикселей.
Нет функции считывания битмапа из DC. Нету такой, уважаемый. Есть функция, выбирающая битмап в DC (SelectObject). Есть функция, возвращающая текущий в DC битмап (GetCurrentObject). И знаешь почему нет ? Потому что в DC нет битов, а есть они в битовой карте только.
Ну а если речь шла о том, что можно , имея HDC, получить HBITMAP и GetBitmapBits, то это верно. И действительно будет быстрее. Но посмотри мой исходный постинг с первоначальной программой, я там извинился за использование GetPixel. Это специально было сделано, чтобы продемонстрировать распараллеливание при одновременном обращении потоков к нулевому кольцу.
G>Меня эти понятия. Мне достаточно сравнить два числа. G>Если тебе для сравнения двух чисел надо привлекать матстатистику, то мне тебя очень жаль.
Уф! Ну как еще объяснять ? Не знаю. Не хватает моих педагогических способностей. Человеку говоришь — для сравнения двух приближенных чисел, полученных как результаты измерений, необходимо учитывать точность измерений. А он в ответ — да не надо, и так можно. В общем, 8.000001 всегда больше чем 8.00000, даже если точность измерения плюс-минус 0.001
Здравствуйте, Константин Б., Вы писали:
PD>>Можно ссылочку на источник, где говорится, что они вызывают BitBlt ? Куда она копирует ? Где второй HDC ? КБ>http://www.rsdn.ru/res/book/mmedia/yuan.xml
Ссылку дают на конкретный текст, а не на оглавление какой-то книги. Пожалуйста, ссылку на то место, где сказано, что GetPixel вызывает BitBlt. Дело в том. что это чушь.
>>>Напрямую получить весь массив с той же BitBlt гораздо быстрее.
PD>>BitBlt все-таки копирует битовую карту , а вовсе не возвращает биты. А получить биты можно, GetBitmapBits / GetDIBIts, но это совсем другая история КБ>Вот копируем на off-screen DC и оттуда забираем биты. Вы что первый раз c GDI работаете?
Я с ним лет так 20 работаю, а вот ты, похоже, даже с понятиями не разобрался как следует. Нет на DC битов. Они есть в битовой карте, выбранной в этом DC (а впрочем, и в битовой карте, не выбранной ни в каком DC). Поэтому биты карты (если уж не через GetPixel работать), можно получить из этой карты (GetBitmapBits,GetDIBits или даже GetObject с DIBSECTION, если, конечно, это дибсекция). Что же касается BitBlt, то она копирует эти биты из битовой карты, выбранной в одном DC, в битовую карту, выбранную в другом DC, и при этом никакие биты не возвращает (нам), поскольку не ее дело. Вот и все. Учите матчасть!
Здравствуйте, AndrewVK, Вы писали:
PD>>Очень дешевый прием, ты уж меня извини.
AVK>Дешевый примем это свалить в кусты вместо признания собственной неправоты.
М-да. Сначала мне предлагают в ультимативном порядке написать некоторую программу, что само по себе не есть особо вежливое действие. Когда я этого не делаю, мне заявляют, что я , мол, и не мог ее написать, а вместо этого свалил в кусты. Чудная логика.
Впрочем, спроецируй на себя. Представь себе, что я что-то утверждаю , а ты с этим не согласен (было такое ? . Ну вот, в ответ я требую от тебя в ультимативной форме что-то написать. Будешь ?
А вообще-то раньще в этом отношении нравы были более разумными. Когда вызывали на дуэль — право выбора оружия предоставлялось всегда тому, кого вызывали. Так что уж если от меня требуют участия в каком-то соревновании — право выбора теста за мной .
Здравствуйте, IT, Вы писали:
M>>Почему по твоему мнению , серезные приложения которые я перечислял FFMPEG — JASPER написанны без использования FP ? на традиционных C/C++. ? IT>Если бы они были написаны с использованием FP, то они были бы ещё серьёзней.
Докажи.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Pavel Dvorkin, Вы писали:
G>>Напряги свои знания WinAPI, может впомнишь что есть функция считывание всего битмапа из DC, что будет гораздо быстрее считывания отдельных пикселей.
PD>Нет функции считывания битмапа из DC. Нету такой, уважаемый. Есть функция, выбирающая битмап в DC (SelectObject). Есть функция, возвращающая текущий в DC битмап (GetCurrentObject). И знаешь почему нет ? Потому что в DC нет битов, а есть они в битовой карте только. PD>Ну а если речь шла о том, что можно , имея HDC, получить HBITMAP и GetBitmapBits, то это верно.
Это и надо, детали не волнуют.
PD>И действительно будет быстрее. Но посмотри мой исходный постинг с первоначальной программой, я там извинился за использование GetPixel. Это специально было сделано, чтобы продемонстрировать распараллеливание при одновременном обращении потоков к нулевому кольцу.
На любом надуманном примере можно показать что угодно.
G>>Меня эти понятия. Мне достаточно сравнить два числа. G>>Если тебе для сравнения двух чисел надо привлекать матстатистику, то мне тебя очень жаль.
PD>Уф! Ну как еще объяснять ? Не знаю. Не хватает моих педагогических способностей. Человеку говоришь — для сравнения двух приближенных чисел, полученных как результаты измерений, необходимо учитывать точность измерений. А он в ответ — да не надо, и так можно. В общем, 8.000001 всегда больше чем 8.00000, даже если точность измерения плюс-минус 0.001
Не надо разводить демагогию без конкретных чисел. Какова погрешность измерения Time Stamp Counter? Какая разница значений будет на измеряемом коде?
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Здравствуйте, Константин Б., Вы писали:
PD>>>Можно ссылочку на источник, где говорится, что они вызывают BitBlt ? Куда она копирует ? Где второй HDC ? КБ>>http://www.rsdn.ru/res/book/mmedia/yuan.xml
PD>Ссылку дают на конкретный текст, а не на оглавление какой-то книги. Пожалуйста, ссылку на то место, где сказано, что GetPixel вызывает BitBlt. Дело в том. что это чушь.
Глава 7. Пикселы.
Страница 417
Разобраться в том, как реализованы функции вывода пикселов, особенно интересно, поскольку речь идет о самой простой графической операции. Кроме
того, это поможет вам лучше понять, с какими затратами связано выполнение некоторых графических команд в GDI.
В Windows NT/2000 обе функции, SetPixel и SetPixelV, обслуживаются одной и той же системной функцией _NtGdiSetPixel@16, вызываемой после проверки параметров по манипулятору контекста устройства. Имя _NtGdiSetPixel016 означает, что при вызове функции передаются четыре параметра. При этом инициируется программное прерывание, которое обрабатывается одноименной функцией механизма GDI режима ядра (win32k.sys). Функция ядра NtGdiSetPixel блокирует контекст устройства, отображает логические координаты в физические, выполняет простую проверку границ, при необходимости преобразует COLORREF в индекс и вызывает функцию драйвера DrvBitBlt (если она поддерживается) или функцию EngBitBlt. При необходимости цветовое значение транслируется в формат RGB. Перед возвращением из функции контекст устройства разблокируется.
Функция GetPixel обрабатывается системной функцией _NtGdiGetPixel012. Эта функция создает временный растр и копирует в него пиксел вызовом DrvCopyBits/EngCopyBits.
Главное, на что необходимо обратить внимание в этой процедуре — это быстродействие. Для каждого вызова GetPixel, SetPixel или SetPixelV графическая система должна инициировать программное прерывание, переключиться в режим ядра и обратно, отобразить координаты, преобразовать индекс палитры, постро
ить временный растр и затем вызвать функцию блиттинга драйвера устройства. Для одного пиксела объем работы получается довольно большим.
Да память меня немного подвела. Это SetPixel работает через BitBlt. GetPixel работает через CopyBits.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Ну хотя бы общедоступность в городах с населением от 200,000. Общедоступность на том же уровне, как сейчас в них доступно обычное ТВ.
Россия в этом плане понятие отдельное ввиду территории, но и в ней услуги triple play доступны во многих городах уже сейчас.
PD>Что такое интеграционный пакет -я и сам не знаю, а имею в виду я просто следующее. Сажусь я за любую машину с Windows — и мне сразу ясно, что делать. Вот и на мобильниках должно быть то же самое.
Что "то же самое"? Наличие небольшого количества стандартных операционок? Так уже давно. Наличие идентичных с десктопом программ? Невозможно в принципе.
PD> И, скажем, связь между ними и PC — тоже не всегда тривиальна. Я для своего мобильника кабель по всему Омску искал, нет, говорят, под такой разъем,а когда наконец нашел — он инсталлироваться не захотел
У тебя смартфон? Если нет, то при чем тут компьютеры?
PD>1. Не суди по своему уровню, а суди по уровню массового пользователя.
Масовый пользователь в этом плане намного круче меня. У меня мобильнику 2.5 года и менять ы обозримом будущем я его не собираюсь.
PD>2. Не суди по Москве.
У меня в профиле город, вроде как, указан.
PD>Опять-таки вопрос — соотношение между. Если только для медвежьих уголков (впрочем, спутники есть) — это одно.
Нет, не только для них. Старые телепреемники есть в огромных количествах. За 10 лет полного изменения ситуации не будет.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Константин Б., Вы писали:
КБ>Когда вам дают ссылку, надо сказать "Спасибо, обязательно ознакомлюсь.". А если вы решили что я собираюсь с вами спорить, то вы ошиблись. Можете и дальше писать тормозной код с использованием GetPixel.
Мне кажется споришь именно ты, человек уже десять раз объяснил зачем именно он использовал GetPixel
А, ну так это ж бубль-гум!
Классический пример того, что Lazy Load — великое зло. Если бы парни воспользовались именно Join, а не дурацкими хинтами "дай мне всё", то всё получилось бы гораздо лучше
_>Когда есть join'ы надо быть с LINQ очень аккуратным.
Точнее, когда их нет. Когда начинаются игры с навигационным доступом — велкам ту хелл.
... << RSDN@Home 1.2.0 alpha rev. 677>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, FR, Вы писали:
IT>>Это не совсем так. Есть вещи, которые невозможно сделать без поддержки компилятора/среды. Например, в ООП это перегрузка методов, в FP замыкания.
FR>Оба эмулируются даже на си.
Эмулируй.
FR>И к тому и замыкания и перегрузка методов это не более чем вкусности, они не являются необходимыми чтобы программировать в соответствующем стиле.
А этот топик о чём? Именно о вкусностях. А ты о чём думал?
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, IT, Вы писали:
M>>>>Почему по твоему мнению , серезные приложения которые я перечислял FFMPEG — JASPER написанны без использования FP ? на традиционных C/C++. ? IT>>>Если бы они были написаны с использованием FP, то они были бы ещё серьёзней. ГВ>>Докажи.
IT>Переписать всё на N? Да без проблем. У тебя кошелёк достаточно большого размера?
А... То есть, будучи написанными на Немерле они автоматически станут более серьёзными. Ясно.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, IT, Вы писали:
ГВ>>От возможностей компилятора реализация этих подходов до какой-то степени зависит, но только до какой-то.
IT>От компилятора это зависит ровно до той степени будут эти стили использоваться или нет. [...]
Если это было возражение, то из какой-то смежной области.
IT>Ещё пример про стиль? Пожалуйста. Сейчас много говорят о параллельном программировании, о том, что если писать в соответствующем стиле, то компиляторы смогут автоматически распараллеливать выполнение задачи. Я об immutable стиле написания кода. [...]
Очень хорошо, но это тоже из другой оперы. От того, что язык заставляет определённым образом структурировать программу стили построения абстракций не перестают быть стилями, не находишь?
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, FR, Вы писали:
FR>Ну я то понимаю, но пока не попробуешь объяснять бесполезно
Я думал, ты всё же не станешь опускаться до такого уровня. Впрочем, смешно получилось. Надо будет этот код добавить себе в избранное. Топик я уже переименовал.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, VoidEx, Вы писали:
VE>Т.е. перегрузка функций — это прерогатива ООП
Точно так же как замыкания — прерогатива платформ с автоматической сборкой мусора. Тот бред, который привёл FR даже комментировать не хочется. У нас тут как-то был большой флейм на тему замыканий в C/C++.
VE>Я лично про виртуальность подумал, тем более раз методы.
Ну вообще-то есть overloading, а есть overriding.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, Геннадий Васильев, Вы писали:
ГВ>Очень хорошо, но это тоже из другой оперы. От того, что язык заставляет определённым образом структурировать программу стили построения абстракций не перестают быть стилями, не находишь?
Конечно, чисто теоретически FP и OOP в C такой же стиль как и в Nemerle. А чисто практически его там нет напрочь и никогда в жизни не будет.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, Геннадий Васильев, Вы писали:
IT>>Переписать всё на N? Да без проблем. У тебя кошелёк достаточно большого размера?
ГВ>А... То есть, будучи написанными на Немерле они автоматически станут более серьёзными. Ясно.
Т.е. кошелёк у нас небольшого размера.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, IT, Вы писали:
IT>Точно так же как замыкания — прерогатива платформ с автоматической сборкой мусора. Тот бред, который привёл FR даже комментировать не хочется. У нас тут как-то был большой флейм на тему замыканий в C/C++.
Для замыканий есть объяснение. А что мешает сделать перегрузку в Си?
Т.е. в принципе-то она может там быть вообще без каких-либо изменений, или нет?
IT>Ну вообще-то есть overloading, а есть overriding.
Здравствуйте, Воронков Василий, Вы писали: ВВ>Тем не менее продолжается обсуждение в защиту веб-формс.
Нет нигде обсуждения в защиту веб-формс.
ВВ>А ты под АСП.НЕТ понимаешь все прелести, которые дает стандартная библиотка?
Естественно. ВВ>Для меня если я разрабатываю приложение используя лишь низкоуровневые надстройки над ИЗАПИ — то не АСП.НЕТ. А АСП.НЕТ для меня эквивалентен веб-формс.
И в третий раз повторяю: очень плохо, что ты не можешь отделить вебФормз от АСП.НЕТ. Тренируйся, иначе так и будешь ключи подавать.
S>>Напомню, что ASP.NET всплыл не потому, что вебФормз. А потому, что Рихтер прикрутил к дотнету Power Threading Library, которая позволяет писать офигенно высокопроизводительный код, не слишком жертвуя читаемостью. И потому, что использование IO Completion Ports, которое Рихтер облегчил, крайне важно как раз в серверах массового обслуживания, в частности в веб серверах. В десктопном приложении лишний десяток потоков — тьфу, семечки. А в сервере каждый поток на счету; неэффективные примитивы синхронизации способны убить производительность куда быстрее, чем проверки выхода за границы массивов.
ВВ>Все это прямого отношения к вебу не имеет. И почему казалось бы тут "всплыл" асп.нет?
Бред какой-то. Мы что, начали с обсуждения веба? Нет, начали с производительности и возможностей по оптимизации. АСП.НЕТ здесь — только пример. Что тут непонятного?
S>>Здесь, конечно, никакого abstraction gain нету. S>>Аналогичную реализацию теоретически можно получить "на ассемблере". Вот только из местных апологетов микрооптимизаций ни один чего-то не спешит представить доказательство в студию. Всё больше рассуждают о теории. Поэтому я настаиваю на эквивалентной честности к обеим сторонам. S>>Потому, что теоретически abstraction gain таки не сводится к "голове". Я писал тут неподалеку, каким именно способом абстрактный код может обгонять ассемблер. ВВ>Это как раз и говорит о том, что в голове. В голове не значит, что его нет. В голове значит, что это "человеческий" фактор.
Еще раз: я писал не про человеческий, а про машинный фактор.
ВВ>Конечно же, если упираться в "крайние" примеры — то тут можно сказать только то, что "на ассемблере" их не только нельзя сделать более эффективно, но вообще чисто физически нельзя сделать.
Ну какие же они крайние. Я привел очень простой пример. Там 30 строчек кода всё демонстрируют.
ВВ>А вот интересные примеры появляются, когда речь далеко не об ассемблере и не о разработке на нем асп.нет приложения, а о куда более приземленных вещах вроде веб-формс.
Не понимаю, почему для интересных примеров нужно привлекать неправильное использование плохих фреймворков
Вот мне интересны примеры, где правильно применяются хорошие фреймворки.
S>>А если мы говорим об этом в том смысле, как имеет в виду Дворкин ("платформа у нас одна — win32"), то это просто ламерство. ВВ>А если "одна платформа" — это XBox 360?
Во-первых, в предыдущей фразе я об этом упомянул. Во-вторых, где у вас гарантия невыхода XBox370?
... << RSDN@Home 1.2.0 alpha rev. 677>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>К сожалению, если поручить это все оптимизатору компилятора, то этот компилятор должен будет быть попросту гениальным, то есть включать в себя знание всех и всяческих техник, трюков и т.п, связанных и с кэшами, и с многопроцессорностью и с характером задачи. Увы, это вряд ли реально. Компилятор будет в лучшем случае оптимизировать "в среднем", то есть в расчете на некую среднюю задачу. И чем выше уровень абстракций, тем хуже он это будет делать. Оптимизировать цикл можно очень хорошо, а оптимизировать задачу "сделай вот это" — можно лишь на бвзе некоторых правил оптимизации общего порядка. Как только попадется нечто, что под эти правила не подходят — результат будет плохим.
Всё обстоит ровно с точностью до наоборот: современные компиляторы включают в себя знание всяческих техник, связанных с кэшами и многпроцессорностью.
Причем эти знания в них имеются по поводу достаточно широкого набора целевых платформ. Этот набор значительно шире, чем кругозор среднестатистического программиста.
Далее, среды, которые занимаются оптимизацией в рантайме, гораздо больше знают о реальном характере задачи, чем любой программист. По очевидной причине: у них эти знания получены экспериментальным путём, а, значит, они надежнее, чем медитативные практики и теоретические предсказания.
В итоге, мы имеем относительно небольшой набор техник оптимизации, который применим к достаточно высокоуровневым алгоритмам. Компилятору не нужно быть гениальным. Ему достаточно быть просто очень терпеливым в применении этих техник.
В отличие от навыков программиста, которому проще знать фиксированный набор решений задач типа "сделай вот это", чем в уме перебирать все возможные сочетания различных техник, компилятору проще как раз не затачиваться на высокоуровневые прикладные задачи.
И чем выше уровень абстракции, тем лучше он будет это делать. Потому что нужно меньше правил, и меньше шансов, что "попадется нечто, что под эти правила не подходит".
Вот, в частности, оптимизаторы баз данных начинались именно с эвристических методов — это именно то, о чем ты говоришь как об оптимизации на основе частных правил. Типв, "если идет join, то скорее всего его результат будет непустым". Практика показала, что методы динамического программирования и cost-based optimization дают значительно лучшие результаты.
В частности, хороший оптимизатор строит разные планы для одинаковых запросов с разными параметрами. Программист вряд ли сможет заранее предсказать реальное распределение данных; а вот оптимизатор видит статистику, и ему всё понятно.
Основные трудности с оптимизацией SQL запросов, требующие ручного вмешательства, относятся к одному из двух случаев:
1. Семантическая оптимизация. Т.е. есть некоторые факты о реальной задаче, которые отсутствуют у оптимизатора, но есть у программиста.
2. Слишком большой объем пространства решений. У СУБД мало времени на то, чтобы заниматься оптимизацией; поэтому она выбирает первое решение, которое кажется ей достаточно приличным. В интегрированной исполняющей среде, где есть информация о частотах встречаемости запросов, можно добиться значительного улучшения.
Аналогичные техники применяются сейчас и для оптимизации классических императивных программ: чтобы получить информацию о "характере задачи", компилятор использует информацию от профайлера. См.тж. "Profile-guided optimization".
В общем, любому программисту крайне полезно для саморазвития почитать хотя бы Аппеля. Чтобы знать, что такое оптимизирующий компилятор, что он делает, как, и почему.
... << RSDN@Home 1.2.0 alpha rev. 677>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, gandjustas, Вы писали:
G>Здравствуйте, Pavel Dvorkin, Вы писали:
G>Это и надо, детали не волнуют.
Если это и надо, то надо именно это и делать, а не нести чушь насчет получения битов с помощью BitBlt.
PD>>Уф! Ну как еще объяснять ? Не знаю. Не хватает моих педагогических способностей. Человеку говоришь — для сравнения двух приближенных чисел, полученных как результаты измерений, необходимо учитывать точность измерений. А он в ответ — да не надо, и так можно. В общем, 8.000001 всегда больше чем 8.00000, даже если точность измерения плюс-минус 0.001 G>Не надо разводить демагогию без конкретных чисел. Какова погрешность измерения Time Stamp Counter?
А самому посмотреть можно ? Для GetTickCount — примерно 15 мсек. Что там в .Net — не знаю, выясни сам. Но при той точности моих данных (15 мсек) — делать какие бы то ни было выводы нельзя, даже если в .Net используется QueryPerfomanceCounter с хорошей точностью. Как минимум в этом случае надо перемерить мои данные с той же точностью.
>Какая разница значений будет на измеряемом коде?
Посмотри свое собственное сообщение, где ты утверждаешь, что тебе удалось на C# сделать лучше, чем мне на С++. Ты там сам эти значения приводишь. Разница измеряется путем вычитания одного из другого, полученное значение сравнивается с 15 мсек
Если немного серьезнее. Как преподаватель уже (не как программист) скажу вот что. Не знать что-то не стыдно. Но вот упорствовать в своем незнании не стоит. В конце концов от этого хуже тебе самому будет, не мне же.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Напишите с 0 на C#, без всяких managed direct x, 3D-движок, полностью дублирующий CryEngine 2 и при этом работающий по крайней мере с такой же скоростью?
А как ты себе это видишь то? CryEngine 2 как и CryEngine реализованы поверх DX или OpenGL. Те в свою очередь упираются в дрова апаратных акселераторов.
Будет аналогичный управляемый АПИ, будет и возможность это все написать.
Кстати, глючит этот CryEngine 2 очень сильно. И я бы не отказался чтобы он жрал в два раза больше памяти и работал процентов на 10% медленнее, но чтобы при этом я бы все же мог дойти Кризис до конца без вылетов.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, IT, Вы писали:
IT>Здравствуйте, Геннадий Васильев, Вы писали:
M>>>>Почему по твоему мнению , серезные приложения которые я перечислял FFMPEG — JASPER написанны без использования FP ? на традиционных C/C++. ? IT>>>Если бы они были написаны с использованием FP, то они были бы ещё серьёзней.
ГВ>>Докажи.
IT>Переписать всё на N? Да без проблем. У тебя кошелёк достаточно большого размера?
Абсолютно уверен что написать на N хотя бы не хуже не получится. Если считаешь обратное , то ты заблуждаешься. Доказывать ничего не собираюсь.
Здравствуйте, AndrewVK, Вы писали:
AVK>Россия в этом плане понятие отдельное ввиду территории
Канада ? Китай ?
>но и в ней услуги triple play доступны во многих городах уже сейчас.
Они примерно так же доступны, как в годы моей молодости телевизор был доступен. Тогда к соседям, у которых он был, ходили его смотреть. Усаживались все вместе, человек 5-7 и смотрели
PD>>Что такое интеграционный пакет -я и сам не знаю, а имею в виду я просто следующее. Сажусь я за любую машину с Windows — и мне сразу ясно, что делать. Вот и на мобильниках должно быть то же самое.
AVK>Что "то же самое"? Наличие небольшого количества стандартных операционок? Так уже давно. Наличие идентичных с десктопом программ? Невозможно в принципе.
Идентичных — да. Близких — нет.
PD>> И, скажем, связь между ними и PC — тоже не всегда тривиальна. Я для своего мобильника кабель по всему Омску искал, нет, говорят, под такой разъем,а когда наконец нашел — он инсталлироваться не захотел
AVK>У тебя смартфон? Если нет, то при чем тут компьютеры?
При том, что при любом телефоне вопросы его подключения не должны меня заботить.
PD>>1. Не суди по своему уровню, а суди по уровню массового пользователя.
AVK>Масовый пользователь в этом плане намного круче меня. У меня мобильнику 2.5 года и менять ы обозримом будущем я его не собираюсь.
Впечатление такое, что многие наши разногласия определяются взаимным непониманием. При чем тут твой мобильник ? Я имею в виду твой уровень понимания этой области vs понимание ее же обычным пользователем.
PD>>2. Не суди по Москве.
AVK>У меня в профиле город, вроде как, указан.
Сорри. Почему-то считал, что ты москвич. Но ИМХО разница небольшая.
PD>>Опять-таки вопрос — соотношение между. Если только для медвежьих уголков (впрочем, спутники есть) — это одно.
AVK>Нет, не только для них. Старые телепреемники есть в огромных количествах. За 10 лет полного изменения ситуации не будет.
Полного и не надо. У меня до сих пор дома стоит Океан (радиоприемник такой, размером с дисплей), купленный на первую в жизни зарплату . Но все остально — 3-5 летней давнсти максимум.
Здравствуйте, VladD2, Вы писали: VD>Опять пошла подмена понятий. Они не являются необходимыми чтобы порвав задницу хоть что-то изобразить. Но можно ли назвать программированием эмуляцию приводящую к ужасному нагромождению кода?
Я опять влезу со своим напоминанием про то, что все тьюринг-полные языки функционально эквивалентны. Что позволяет эмулировать что угодно на чем угодно.
Поэтому основное значение имеет количество кода, потребное для такой эмуляции. А также умение компилятора настучать по рукам, если эмуляция нарушает контракты.
Вот, к примеру, дотнет не даст создать делегат из метода, несовместимого по сигнатуре. Таким образом, среда и компилятор следят за тем, что за указатель я кладу в структурку. Я, конечно, могу эмулировать ровно то же хоть на C, хоть на asm, но любые ошибки будут отложены до рантайма.
А вот, к примеру, проследить, чтобы я не забыл сделать EndXXX() с IAsyncResult, полученным из BeginXXX(), компилятор C# пока не может. И это очень плохо, потому что чревато всякими занятными ошибками и утечками.
По идее, тот же Немерле мог бы делать что-то типа Рихтеровского AsyncEnumerator, только с человеческим лицом.
И чтобы семантика, соответственно, совпадала с Рихтеровской. То есть вместо блокировки вызываюшего потока он возвращался бы в пул, а в момент окончания async из пула бы брался другой поток и начинал с того же места.
... << RSDN@Home 1.2.0 alpha rev. 677>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, VladD2, Вы писали:
VD>Далее ход их мысли был примерно таким... ФП позволяет сложить почти все состояние программы на стек. Это позволяет сделать переключение контекста очень дешёвой операцией... ФП позволяет не использовать глобальные данные которые нужно синхронизировать.
Ход мысли был таким, но ФП там вряд ли был на уме. Скорее всего они пошерстили по научным работам по исследованию параллельных вычислений, и конечно же нашли, т.к. эти работы ведутся еще с 70-х годов.
VD>Далее они подумали, что можно организовать множество параллельно выполняемых процессов общение между которыми производится с помощью сообщений. За чёт того, что ЯП функциональный удалось сократить время переключения контекста и отказаться от синхронизации отличной от очереди сообщений процесса. Это позволило оптимизировать данную очередь.
В Ерланге крутой параллелизм не потому, что он ФП, а потому что на верхнем уровне у него другая вычислительная модель — актеры, отличная от лямбда-исчисления и машины Тьюринга.
В чистом виде модель никак не ограничивает внутренюю механику актеров, Ерланг например использует для нее ФП, pattern matching сильно помогает разбирать сообщения, но это может быть любая другая форма языка, хоть ассемблер.
Здравствуйте, VladD2, Вы писали:
ВВ>>Напишите с 0 на C#, без всяких managed direct x, 3D-движок, полностью дублирующий CryEngine 2 и при этом работающий по крайней мере с такой же скоростью? VD>А как ты себе это видишь то?
Никак
VD>Будет аналогичный управляемый АПИ, будет и возможность это все написать. VD>Кстати, глючит этот CryEngine 2 очень сильно. И я бы не отказался чтобы он жрал в два раза больше памяти и работал процентов на 10% медленнее, но чтобы при этом я бы все же мог дойти Кризис до конца без вылетов.
Не знаю, у меня стабильно работал, под Вистой. Если не считать тормозов в конце.
Здравствуйте, Sinclair, Вы писали:
S>Здравствуйте, AndrewVK, Вы писали: AVK>>А какой надо? Все желающие давно уже приобрели себе тарелку с тем самым цифровым телевидением, благо стоит оно сейчас копейки. S>Я лично совершенно не верю в отказ от broadcast-модели доставки медиаконтента по двум причинам: S>1. Usability. S>Далеко не всем хочется заниматься каким-то выбором. Вещание удобно тем, что оно поставляет тебе контент, не требуя вмешательства. S>К примеру, вместо имения и поддержки огромного плейлиста в машине, многие до сих пор предпочтут включить радио. Аналогом этого является интернет-радио.
А как это конфликтует с моделью выбора? Выбрал себе шоу "Горячая 20-ка" или там "Утро с черным перцем" — и слушай себе на здоровье.
"Выбора" тут будет не больше чем при перещелкивании радиостанций в машине.
S>2. Эффективность S>Бродкастинг позволяет одним каналом накормить очень много народу. Пока что у нас полоса пропускания не настолько велика, чтобы вещать каждому лично.
Какой бродкастинг? Речь о том, что волновое телевидение вообще отомрет. Модель выбора есть в XBox360 — видео-прокат фильмов, мультиков и передач в обычном и HD-качестве. Выбрал то, что тебе нужно, скачал, с момента начала просмотра у тебя есть три дня, после этого контент-удаляется.
S>3. В итоге, скорее всего останется смешанная модель. S>То есть хочешь — включаешь канал "Youtube News 24x7" и сиотришь/слушаешь то, что там тебе течёт в реальном времени.
"Горячие новости" и даже прямой эфир модель выбора тоже не отменяет. Вот, на страничке лайва висят баннеры с "горячими" новинками. Так и тут. "Сейчас в эфире репортаж с..." Включил, и тебе его стримят в реальном времени. Не вижу проблемы.
Волновое вещание, нынешний кабель тут вообще не нужно. Интернет-телевидение спокойно все это заменит, причем заменяет уже сейчас.
Сколько вот каналов у тебя доступно дома? А так будут многие сотни. Как только их станет настолько много полагаться на реальное время уже не получится. Пока каналы "перещелкаешь" поседеть успеешь
S>Вот этот третий вид, имхо, и есть телевидение будущего. Эффективность достигается благодаря использованию пиринговых сетей (то есть распределению нагрузки на канал между потребителями), юзабилити достигается за счет минимизации пользовательского выбора.
А пиринговые сети зачем?
S>Предоставляются богатейшие маркетинговые возможности — можно предоставлять контент за деньги; можно впаривать в него рекламу, как сейчас в ящике; можно применять смешанную модель.
А вот это как раз и мощный бенефит "заказа". За денежки — последнюю новинку без рекламы. Совсем дешево — не очень новое или с рекламой.
Здравствуйте, AndrewVK, Вы писали:
AVK>В Канаде почти все население сосредоточено по узкой полосе вдоль южной границы,
В Азиатской части России почти все население сосредоточено по узкой полосе вдоль Транссиба.
>а в Китае в деревнях даже канализация не всегда имеется
И в России тоже
PD>>Они примерно так же доступны, как в годы моей молодости телевизор был доступен.
AVK>Смотря где. В Москве они доступны кому угодно без особых проблем.
Я же говорю — не суди по Москве.
AVK>Что значит близких? По внутренней архитектуре — легко. По user experience — даже близкие невозможны в принципе.
Если речь идет об ограничениях, связанных с размером дисплея — да. Но они не везде существенны. Просмотр сайтов все же возможен, например.
PD>>При том, что при любом телефоне вопросы его подключения не должны меня заботить.
AVK>При чем тут вопросы подключения?
Да это просто один момент. Если все это интегрируется — не должно быть таких проблем. Значит, пока не интегрировано , хотя бы для этого телефона.
PD>>Впечатление такое, что многие наши разногласия определяются взаимным непониманием. При чем тут твой мобильник ? Я имею в виду твой уровень понимания этой области vs понимание ее же обычным пользователем.
AVK>А при чем тут мой уровень понимания?
При том, что он у тебя несколько выше , чем у среднего пользователя.
AVK>>>У меня в профиле город, вроде как, указан.
PD>>Сорри. Почему-то считал, что ты москвич. Но ИМХО разница небольшая.
AVK>Ну да, подумаешь, мегаполис с населением в 20 миллионов, и районный городок с населением чуть больше 100 тыс. Одна фигня
Неубедительно. В Коломне я не был. Но был в Протвино, Пущино, Троицке. Пешком обойти за час-два город можно. И тем не менее они и тогда, когда я там был (конец 80-х) были гораздо ближе по духу к Москве, чем мой Омск.
AVK>А какой надо? Все желающие давно уже приобрели себе тарелку с тем самым цифровым телевидением, благо стоит оно сейчас копейки.
Опять по Москве судишь. У нас тарелки есть, но до массовой "тарелкизации" еще как до Москвы.
Здравствуйте, Pavel Dvorkin, Вы писали:
S>>Предоставляются богатейшие маркетинговые возможности — можно предоставлять контент за деньги; можно впаривать в него рекламу,
PD>И можно написать софт, который более или менее надежно эту рекламу вырезает . Исполняться-то все это будет на PC, а тут опыт есть.
Почему на PC?
На видео-декодере, который будет подключен к телевизору и инету. Шифрование данных, чтобы не уперли, проверка лицензий, и запрет на вмешательство извне.
Да, внутри там своя операционка, софт и т.д., как на ПК, но пользователя туда пускать не будут. Именно чтобы не вырезали
Ну это как вариант, но логичный.
Пускать фильм с рекламой и предоставлять возможности пользователю ее на лету вырезать — несколько неумно.
Здравствуйте, fmiracle, Вы писали:
F>Здравствуйте, Pavel Dvorkin, Вы писали:
S>>>Предоставляются богатейшие маркетинговые возможности — можно предоставлять контент за деньги; можно впаривать в него рекламу,
PD>>И можно написать софт, который более или менее надежно эту рекламу вырезает . Исполняться-то все это будет на PC, а тут опыт есть.
F>Почему на PC? F>На видео-декодере, который будет подключен к телевизору и инету. Шифрование данных, чтобы не уперли, проверка лицензий, и запрет на вмешательство извне. F>Да, внутри там своя операционка, софт и т.д., как на ПК, но пользователя туда пускать не будут. Именно чтобы не вырезали
F>Ну это как вариант, но логичный. F>Пускать фильм с рекламой и предоставлять возможности пользователю ее на лету вырезать — несколько неумно.
btw, мне кажется, что брать абонентку или разовую плату за просмотр фильма (а-ля билет в кино, но смотрим дома) и без рекламы будет всем удобнее и проще к внедрению. Благо, кредиток щас только у ленивых, хотя и тем уже их на работе выдают.
Здравствуйте, IT, Вы писали:
IT>Здравствуйте, VoidEx, Вы писали:
IT>Хоть правым, хоть левым, лично мне без разницы. Мой код FP техники делают более серьёзным и мне самому себе доказывать ничего не надо. Если вы хотите, чтобы я это доказывал на ваших задачах, да ещё на достаточно объёмных, и если это вам действительно нужно, то я просто предлагаю заплатить мне за моё потраченное время. Ведь это будет работа не на час и не на два, в возможно на неделю, месяц, год. Я пока без понятия. Требовать от меня переписывания этого кода, конечно же, можно. Но тогда нужно будет подумать о компенсации моего времени. Что в этой логике не так?
Не так то, что ты сам себе придумал, что от тебя хотят.
Тебя попросили доказать. Писать ничего не просили. Судя по твоему ответу (явно с издёвкой, ты вряд ли ожидал, что тебе и правда заплатят), единственный способ доказать — это всё переписать. Логичный напрашивается вывод, что переписывание является достаточным, чтобы проект стал более серьёзным, раз именно при помощи этого ты и "хотел" доказать?
Ну так и к чему потом издёвочная фраза про малый кошелёк?
Не можешь доказать, так и скажи, зачем сам флейм провоцируешь?
И самое главное, нормально ты таки ответил, но только после моего поста. Сразу, конечно же, нельзя было сказать, что доказать не можешь, но твой код делается серьёзнее и именно на этом основании ты так и утверждаешь.
Я лично с minorlogic в изначальном вопросе тоже не согласен, так как всегда существует период, когда инструмент ещё не был задействован, что никак не говорит о его качествах, поэтому отсутствие существования серьёзных проектов ничего не значит. Ну разве что если ФП так и канет в летах (что вряд ли), а серьёзных проектов мы так и не увидим.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Да я уже, понял. Я сам с собой разговариваю. Зачем мне вообще отвечать? У меня и так прекрасно получается.
Совершенно верно. Ну где хоть один аргумент от твоих противников в защиту WebForms?
ВВ>
ВВ>Здравствуте, Воронков Василий, Вы писали:
ВВ>>>ASP.NET — говно.
ВВ>Это все от ламерства и полного бескультурия! Как ASP.NET может быть говном — ведь он же включает в себя все достоинства .NET, а следовательно и WPF. WPF — это самая мощная технология построения интранет-приложений, которая существует на настоящий момент. И которая как раз и предлагает мощный метаязык для описания представления — XAML. Какой человек в здравом уме скажет после этого, что ASP.NET — говно?
ВВ>АSP.NET просто невменяемо рулит!
Этот понос — он к чему?
ВВ>Интересно, а WindowsForms включает в себя разработку под веб?
Не очень понятен вопрос. Я так понимаю, что нет.
ВВ>А то, может, WindowsForms тоже говно, а я и не заметил.
Вообще-то да, говно. У неё тоже модель GUI совершенно не соответствующая современным реалиям. Поэтому нормальный десктопный интерфейс на ней делать весьма и весьма тяжко. Что, собственно, и привело к изобретению WPF. Но это никакого отношения к веб не имеет.
ВВ>У месье богатый опыт работы консьержем? Предлагаю на досуге помедитировать над значением аббревиатуры ASP.
Аббревиатура совершенно ни при чем. Это становится очевидно, если сравнить архитектуру ASP.NET и ASP, у которых вроде бы она одна и та же.
ВВ>"Мы" как раз и начали с обсуждения веба. Предложение написать ASP.NET-приложение на ассемблере и послужило начало дискуссии, если можно так выразиться.
А, у тебя какая-то отдельная дискуссия?
Хорошо, давайте пообсуждаем веб. ВВ> Видно, это было задумано как мощный аргумент, призванный свалить всех оппонентов "одним выстрелом". ВВ>Нет, ну правда, мы такие идиоты,
Заметьте, не я это сказал. ВВ>кому вообще нужен ассемблер, если на нем нельзя написать эффективное веб-приложение?! Да еще за разумные сроки!
Этот понос — он к чему? К тому, что есть какие-то узкоспециальные приложения, где ассемблер всё еще может справиться?
Много ли кому интересны эти ниши, кроме ассемблерщиков, неспособных освоить ничего нового?
Я говорю о сложностях реализации настоящих высоконагруженных систем, где важна производительность. И о том, что она на ассемблере недостижима, что в точности противоположно точке зрения апологетов ассемблера.
Вон непдалеку кто-то мне грозил разрывом шаблонов в случае написания высоконагруженного сервера. Павел Дворкин искренне полагает, что microsof.com не может работать на ASP.NET. Твоя точка зрения мне вообще остается непонятной.
ВВ>Можно было и без "очень простого примера" это сказать. С этим даже Дворкин согласится.
Это вряд ли. У него та часть личности, которая отвечает за "ой, извините, это я протупил" отключена за неуплату.
ВВ>И поэтому мы говорим об ASP.NET приложении на ассемблере? Железная логика ВВ>Кстати, было бы очень интересно обсудить пример веб-приложения, в котором правильно применяются хорошие фреймворки, разработанного MS.
Примером хорошего приложения является сайт microsoft.com и значительная часть msdn.microsoft.com.
ВВ>Предлагаешь производителям ждать XBox370 вместо того, чтобы делать игры? Чур-чур!
Предлагаю не делать вид, что инвестиции в ручную оптимизацию под конкретную железку гарантированно не будут выброшены на ветер.
... << RSDN@Home 1.2.0 alpha rev. 677>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Воронков Василий, Вы писали: ВВ>Какой бродкастинг? Речь о том, что волновое телевидение вообще отомрет.
Эмм, а что такое "волновое телевидение"? Каким образом, интересно, контент попадет ко мне в тойоту?
ВВ>Модель выбора есть в XBox360 — видео-прокат фильмов, мультиков и передач в обычном и HD-качестве. Выбрал то, что тебе нужно, скачал, с момента начала просмотра у тебя есть три дня, после этого контент-удаляется.
S>>3. В итоге, скорее всего останется смешанная модель. S>>То есть хочешь — включаешь канал "Youtube News 24x7" и сиотришь/слушаешь то, что там тебе течёт в реальном времени.
ВВ>А пиринговые сети зачем?
Для того, чтобы обойти ограничение ширины канала. У тебя сейчас интернет позволяет HD в реальном времени смотреть, или ты всё-таки его скачиваешь за ночь?
Если весь 16-этажный дом попробует слить себе какой-нибудь Квант Милосердия напрямую с сайта издателя, то канал по-любому ляжет.
Поэтому грамотные собаководы инвестируют в систему доставки, построенную на пиринге: жильцы скачают себе один экземпляр на всех и поделят трафик.
S>>Предоставляются богатейшие маркетинговые возможности — можно предоставлять контент за деньги; можно впаривать в него рекламу, как сейчас в ящике; можно применять смешанную модель. ВВ>А вот это как раз и мощный бенефит "заказа". За денежки — последнюю новинку без рекламы. Совсем дешево — не очень новое или с рекламой.
... << RSDN@Home 1.2.0 alpha rev. 677>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Pavel Dvorkin, Вы писали: S>>Предоставляются богатейшие маркетинговые возможности — можно предоставлять контент за деньги; можно впаривать в него рекламу, PD>И можно написать софт, который более или менее надежно эту рекламу вырезает . Исполняться-то все это будет на PC, а тут опыт есть.
Ну, вопрос, конечно, интересный. Вот ты сериалы смотришь с какого-нибудь lostfilm.tv? Обрати внимание, что в них врезана реклама "смотрите далее на нашем канале". Как ты собираешься ее вырезать? Это ж не HTML, где честно написано "а вот здесь идет баннер".
... << RSDN@Home 1.2.0 alpha rev. 677>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Aen Sidhe, Вы писали:
AS>btw, мне кажется, что брать абонентку или разовую плату за просмотр фильма (а-ля билет в кино, но смотрим дома) и без рекламы будет всем удобнее и проще к внедрению. Благо, кредиток щас только у ленивых, хотя и тем уже их на работе выдают.
Ну чуть выше Sinclair подробно объяснил как "просмотр по заказу" и "просмотр канала" могут отлично уживаться вместе не мешая, но дополняя друг друга.
Каналы по абоненткам — это хорошо, но не надо недооценивать жадность среднестатистического человка. Ради халявы люди готовы даже платить большие деньги
Потому "бесплатные" каналы — всегда будут хорошим источником дохода. Либо самостоятельного (реклама) либо связанного — как первый шаг к платным каналам того же поставщика.
Здравствуйте, Sinclair, Вы писали:
S>Здравствуйте, Воронков Василий, Вы писали: ВВ>>Какой бродкастинг? Речь о том, что волновое телевидение вообще отомрет. S>Эмм, а что такое "волновое телевидение"? Каким образом, интересно, контент попадет ко мне в тойоту?
А как интересно люди в интернет из самолетов выходят?
И ты представляешь — уже сейчас есть города с практически 100% wifi покрытием.
ВВ>>Модель выбора есть в XBox360 — видео-прокат фильмов, мультиков и передач в обычном и HD-качестве. Выбрал то, что тебе нужно, скачал, с момента начала просмотра у тебя есть три дня, после этого контент-удаляется. S>>>3. В итоге, скорее всего останется смешанная модель. S>>>То есть хочешь — включаешь канал "Youtube News 24x7" и сиотришь/слушаешь то, что там тебе течёт в реальном времени.
ВВ>>А пиринговые сети зачем? S>Для того, чтобы обойти ограничение ширины канала. У тебя сейчас интернет позволяет HD в реальном времени смотреть, или ты всё-таки его скачиваешь за ночь?
Мы же о будущем говорим? Если ширина канала не позволяет, то как пиринговая сеть поможет? Она мне канал не увеличит, она позволяет бороться не с узостью моего канала, а с узостью канала сервера при классической доставке контента сервер-клиент.
Сейчас выход в интернет со скоростью 100Mbs — это уже реальность, а не фантастика. В предудыщих постах, если обратишь внимание, назывался срок в 10 лет. Мне вот кажется, что ширина каналов таки обгонит и перегонит "разрешение" видео-контента.
Фильм в SD, например, я могу смотреть в реальном времени сейчас.
S>Если весь 16-этажный дом попробует слить себе какой-нибудь Квант Милосердия напрямую с сайта издателя, то канал по-любому ляжет. S>Поэтому грамотные собаководы инвестируют в систему доставки, построенную на пиринге: жильцы скачают себе один экземпляр на всех и поделят трафик.
С рапиды не качаешь никогда? Сколько, интересно, народу качает с рапиды одновременно? Тем не менее — я всегда качаю с высокой скоростью.
И какая ферма серверов может быть у сайта издателя.
В целом — это спор о деталях, но я лично не очень люблю пиринговые сети. Я вот, например, хочу посмотреть "Последнего императора" Бертолуччи. Так, сколько человек его держат в активе и отдают? Что, ноль?!
Вот в каких-нибудь торрентах — это частая проблема. Контент не самой последней свежести и уже не такая запредельная скорость, как хотелось бы. А вот рапида и днем и ночью сосет стабильно
Т.е. в пиринговую сеть все равно придется вводить "свои" сервера, которые будут заниматься раздачей непопулярного контента.
Вторая проблема пиринговых сетей — отдача. Зачем мне, скачав контент, сидеть и отдавать его, а? В нынешних пиринговых сетях причина одна — рейтинг. Маленький рейтинг — ничего не могу скачать. Хочешь или не хочешь, а отдавать придется. Но я его, извините, нахаляву ведь получаю, так что претензий нет.
А с коммерческой пиринговой сетью как будет? Я денежку заплатил да еще надо сидеть отдавать, чтобы "кислород" не отключили?
В общем я не особо себе такую схему представляю, если честно.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>>>Предлагаешь производителям ждать XBox370 вместо того, чтобы делать игры? Чур-чур! S>>Предлагаю не делать вид, что инвестиции в ручную оптимизацию под конкретную железку гарантированно не будут выброшены на ветер.
ВВ>Т.е. компании, вкладывающие десятки миллионов в разработку игр под XBox360, "гарантированно" выбрасывают деньги на ветер?
Налицо явный логический разрыв между этими фразами.
!(точно не А) = !точно или !А
но никак не
!(точно не А) = точно !А
Так что компании, вбухивающие миллионы в жесткую ручную оптимизацию под Х-Бокс, возможно, делают это напрасно (например, не смогут соптимизировать в рамках бюджета и проект умрет, или, например(!), можно было соптимизировать проще, а они ступили)
Здравствуйте, fmiracle, Вы писали:
S>>>Эмм, а что такое "волновое телевидение"? Каким образом, интересно, контент попадет ко мне в тойоту? ВВ>>А как интересно люди в интернет из самолетов выходят? ВВ>>И ты представляешь — уже сейчас есть города с практически 100% wifi покрытием. F>wifi = волновой интернет...
"Волновое" телевидение — это такая кочерга на крыше. Вот этот протокол умрет думаю наверняка.
F>Предполагается, что это "пиринг" только для улучшения, но не замены раздачи от производителя. Т.е. "вещатель" будет раздавать этот фильм всегда (ну, пока не решит, что это более не выгодно). F>Остальные пользователи просто "стоят на подхвате" и ускоряют загрузку для других пользователей.
Я не говорю, что пиринг умрет. Как улучшение возможно. Но это не исключает мощные и скорее всего централизованные фермы, ориентированные на раздачу контента. Помимо собственно популярности p2p есть и тендиция формирование таких систем также. Вон, игрушки можно покупать через steam или direct2drive — и все они выступают в качестве своего рода интернет-издателя. Вот, думаю, первичной доставкой контента будут заниматься именно такие системы. Ну а то, что там будет происходить внутри локальной сети...
Да и с нагрузкой, думаю, справятся спокойно. Лайв же вот справляется, когда миллионы человек начинают качать демку какой-нибудь ожидаемой игрушки.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Лень ветку почитать?
Да.
ВВ>Этот "понос" писался не для тебя. Раз уж ты так бестактно влез в мою дискуссию с самим собой, объясни мне в таком случае, где у нас вообще "кончается" ASP.NET?
Ну, вообще-то его основное преимущество в том, что он, собственно, нигде не кончается. В него можно много чего добавить, и многим в нём не обязательно пользоваться. Вот, к примеру, WebForms можно вообще не трогать, а можно трогать, но постбеками не пользоваться. Можно написать полностью свой UI слой, и при этом он будет прекрасно интероперировать с другими частями того же приложения, не построенными на нём же.
Это как бы из области базового образования, если что.
ВВ>Ты же в достоинства ASP.NET приписываешь все возможности .NET? Даже Рихтеровский power threading тут всуе помянул. Так, извините, почему бы и WPF сюда не засунуть?
Поясняю: WPF вебу строго ортогонален. Если непонятно, почему, то я, пожалуй, столь же бестактно покину топик. Потому как при таком уровне представлений можно и ассемблер с копченой рыбой сравнивать.
ВВ>У WindowForms модель полностью отвечает архитектуре Win32 и является прекрасной надстройкой над user32.
Ну, наверное да.
ВВ>То, что сама по себе эта модель уже устарела, разумеется, очевидно. Но WPF (в отличие от того разрекламированного тут ASP.NET MVC) представляет собой не другую абстракцию, а принципиально другую технологию. ВВ>Если стоит задача разработки именно под Win32, то WindowsForms — пожалуй, одно из лучших решений. Особенно в свете детских болячек WPF.
Я бы подчеркнул — под user32. Я как-то не склонен преувеличивать значение окон в win32.
ВВ>Само название ASP.NET говорит о то, что это реализация active server pages на .NET. Реализация, active server pages на .NET — это ASPX, класс Page, реализующий IHttpHandler и все, что тянется за ним.
Эту глупость тебе кто сказал? Или ты сделал вывод самостоятельно, на основании наличия слова Page?
Я не думаю, что имеет смысл вести архитектурные дискуссии с аргументацией такого уровня. ВВ> И все, что на настоящий момент предлагается в качестве реализации — это WebForms.
В качестве реализации чего? На всякий случай напомню, что мы говорим о веб-приложениях. А это далеко не только странички.
В частности, веб-сервисы, несмотря на явное отсутствие каких-либо классов с именем Page, являются ASP.NET приложениями.
S>>Много ли кому интересны эти ниши, кроме ассемблерщиков, неспособных освоить ничего нового? ВВ>Т.е. те области, в которых ассемблер может справиться, никому не интересны, кроме самих программистов да и то их интерес возникает лишь в силу того, что они не способны освоить ничего нового?
Всё наоборот. Одни программисты ищут подходящие инструменты для областей, в которых они решают задачу.
А другие — ищут области, в которых их инструменты еще как-то применимы.
Вот и получается разговор глухого со слепым.
Намример, некто ПД делает утверждение типа "да ну, эти управляемые среды медленно память выделяют".
Ему говорят: "нет, наоборот, они ее быстро выделяют".
Он: "а, ну тогда они наверное не смогут высоконагруженные вебсайты поддерживать"
Ему: "нет, как раз наоборот, смогут гораздо лучше нативных"
Он: "а вот игрушки, игрушки они могут делать?"
Ему: "да, вот посмотри примеры, иногда даже лучше нативы выходит"
Он: "ну всё равно, вот у меня такие-растакие задачи, где дотнет уж наверняка не справился бы."
Ему: "ну давай свои задачи, посмотрим, что для них лучше всего подходит".
Он: "Нет, не покажу. У меня NDA. И вообще, я в прошлый раз задачу показал — так весь форум ржал и говорил, что я ее неправильно решил"
ВВ>А у меня вот аналогичное впечатление от вашей партии.
ВВ>Ты знаком с архитектурой этих приложений? Не мог бы рассказать, какие именно хорошие фреймворки там использует и как же именно они правильно применяются.
Поверхностно — знаком. Читать про IHttpHandler, BuildProvider
ВВ>Т.е. компании, вкладывающие десятки миллионов в разработку игр под XBox360, "гарантированно" выбрасывают деньги на ветер?
Я совершенно не уверен, что они пишут эти игры на ассемблере, который пойдет в корзину при незначительной смене характеристик платформы.
... << RSDN@Home 1.2.0 alpha rev. 677>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Воронков Василий, Вы писали: ВВ>А как интересно люди в интернет из самолетов выходят? ВВ>И ты представляешь — уже сейчас есть города с практически 100% wifi покрытием.
Я думаю, там таки используются некие радиоволны
ВВ>Мы же о будущем говорим? Если ширина канала не позволяет, то как пиринговая сеть поможет?
Я уже написал, как она поможет. См. ниже.
ВВ>Она мне канал не увеличит, она позволяет бороться не с узостью моего канала, а с узостью канала сервера при классической доставке контента сервер-клиент. ВВ>Сейчас выход в интернет со скоростью 100Mbs — это уже реальность, а не фантастика. В предудыщих постах, если обратишь внимание, назывался срок в 10 лет. Мне вот кажется, что ширина каналов таки обгонит и перегонит "разрешение" видео-контента.
Помимо ширины есть еще и цена.
Вот тебе ГМэйл дает гигабайты места в инбоксе не потому, что винчестеры дешевые. А потому, что это виртуальное пространство.
Так и тут: канал у тебя, допустим, будет 1Gbit, а пиринг обеспечит его наличие через провод шириной 100Mbps.
Или наоборот: фильм будет качаться со скоростью 10Gbit.
S>>Если весь 16-этажный дом попробует слить себе какой-нибудь Квант Милосердия напрямую с сайта издателя, то канал по-любому ляжет. S>>Поэтому грамотные собаководы инвестируют в систему доставки, построенную на пиринге: жильцы скачают себе один экземпляр на всех и поделят трафик. ВВ>С рапиды не качаешь никогда? ВВ>Сколько, интересно, народу качает с рапиды одновременно? Тем не менее — я всегда качаю с высокой скоростью. ВВ>И какая ферма серверов может быть у сайта издателя. ВВ>В целом — это спор о деталях, но я лично не очень люблю пиринговые сети. Я вот, например, хочу посмотреть "Последнего императора" Бертолуччи. Так, сколько человек его держат в активе и отдают? Что, ноль?!
Это будут не те пиринговые сети. ВВ>Вот в каких-нибудь торрентах — это частая проблема. Контент не самой последней свежести и уже не такая запредельная скорость, как хотелось бы. А вот рапида и днем и ночью сосет стабильно ВВ>Т.е. в пиринговую сеть все равно придется вводить "свои" сервера, которые будут заниматься раздачей непопулярного контента.
А так и будет.
ВВ>Вторая проблема пиринговых сетей — отдача. Зачем мне, скачав контент, сидеть и отдавать его, а?
А ты по другому и не сможешь. Телевизор будет отдавать контент за тебя, просто потому, что он его скачал. ВВ>А с коммерческой пиринговой сетью как будет? Я денежку заплатил да еще надо сидеть отдавать, чтобы "кислород" не отключили?
Совершенно верно. А тебе-то что? Ты денежку заплатил за провод из стены. Какая тебе разница, что по нему реально идет и в какую сторону, если тебя качество устраивает?
... << RSDN@Home 1.2.0 alpha rev. 677>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, fmiracle, Вы писали:
F>Здравствуйте, Pavel Dvorkin, Вы писали:
S>>>Предоставляются богатейшие маркетинговые возможности — можно предоставлять контент за деньги; можно впаривать в него рекламу,
PD>>И можно написать софт, который более или менее надежно эту рекламу вырезает . Исполняться-то все это будет на PC, а тут опыт есть.
F>Почему на PC?
Речь-то изначально шла о слиянии ТВ и PC.
F>На видео-декодере, который будет подключен к телевизору и инету. Шифрование данных, чтобы не уперли, проверка лицензий, и запрет на вмешательство извне. F>Да, внутри там своя операционка, софт и т.д., как на ПК, но пользователя туда пускать не будут. Именно чтобы не вырезали
F>Ну это как вариант, но логичный. F>Пускать фильм с рекламой и предоставлять возможности пользователю ее на лету вырезать — несколько неумно.
Не поможет. Вся фишка в том. что у нынешнего ТВ нет процессора. Поставь процессор — и его кто-нибудь да запрограммирует как надо
Здравствуйте, fmiracle, Вы писали:
F>Я же не спорю, что нужно заботиться о производительности и эффективности. Я не согласен только с утверждением, что достаточной производительности всегда можно получить только хардкорной оптимизацией на самом низком уровне. F>(прошу обратить внимание на выделенное)
А что такое "достаточная" производительность? Для чего или для кого она достаточно?
Пример консоли довольно удачен — потому что перед нами фиксированная платформа, с долгим сроком жизни, ограниченными ресурсами, под которую надо делать продукты, причем постоянно пытаясь переплюнуть конкурентов. А визуальная составляющая — первое, что продает игру, как это ни печально. При этом удачные проекты вполне могут сорвать немаленький куш — там прибыли сейчас как у американских блокбастеров, а то и больше. Тираж в 4-5 млн копий в первые недели продажи — реальность.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Не поможет. Вся фишка в том. что у нынешнего ТВ нет процессора. Поставь процессор — и его кто-нибудь да запрограммирует как надо
дааа?
Блин, а у меня в телевизоре есть процессор
(да и вообще он есть уже в большинстве телевизоров хотя бы для просто обработки сигнала. А еще уже есть телевизоры которые умеют ходить в инет и показывать фильмы с флешек или из сети).
А перепрограммировать его? Можно, наверное, специалисту с оборудованием.
Далее, сейчас платное спутниковое и кабельное телевидение работает через специальный аппаратный декодер. Их иногда ломают, а иногда не могут.
И декодер уже точно имеет процессор и перелопачивает внутри себя сигнал. А перепрограммировать его не так-то просто и, скорее всего, оборудование нужно, да и возможности у него ограничены наверняка.
Видео-по-запросу-из-инета запросто может работать через такую же коробку (потенциально, возможно, встроенную в сам телевизор).
Здравствуйте, VladD2, Вы писали:
VD>Уровень, как зарплаты, так и знаний определяется тучей факторов. Скажем уровень зарплаты определяется в частности востребованностью кокретных скилов и наличием предложения на рынке. Простой пример. 1С-ники были низкоплачиваемой раб. силой до тех пор пока не прошел слух, что С1 завязывает с поддержкой 7-ой версии. Сразу после этого зарплаты у 1С-ников взлетели до уровня высококвалифицированных программистов. При это умнее или работоспособнее никто из 1С-ников не стал.
Обижаешь. А я вот все умнее и умнее. И краёв умности не видно. Для 1С большее значение имеет предметная область. А она может быть те только бухгалтерией, экономикой, логистикой, статистикой, линейной алгеброй и прочеих производственных и технологических прибамбасов.
и солнце б утром не вставало, когда бы не было меня
Здравствуйте, Кодёнок, Вы писали:
Кё>Ход мысли был таким, но ФП там вряд ли был на уме. Скорее всего они пошерстили по научным работам по исследованию параллельных вычислений, и конечно же нашли, т.к. эти работы ведутся еще с 70-х годов.
Тут нечего домысливать. Человек создавший Эрланг опубликовал ряд научных работ доступных в Интернете (ссылок у меня нет, но их легко можно попросить в "Декларативном программировании"). Я одну из них когда-то прочел поперек. Так что это не мои домыслы, а моя интерпретация прочитанного.
Кё>В Ерланге крутой параллелизм не потому, что он ФП, а потому что на верхнем уровне у него другая вычислительная модель — актеры, отличная от лямбда-исчисления и машины Тьюринга.
Ну, что я могу сказать? В общем-то я уже все сказал.
Кё>В чистом виде модель никак не ограничивает внутренюю механику актеров, Ерланг например использует для нее ФП, pattern matching сильно помогает разбирать сообщения, но это может быть любая другая форма языка, хоть ассемблер.
Актеры фигеры дело десятое. Вжно, что без языка и рантайма заточенного под мультипараллельность и работу с событиями создать эффетивную реализацию очень сложно. Если бы это было не так, то скажем актеры Скалы работали бы быстрее Эрланговых просто потому, что компилируются джитом.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>В Азиатской части России почти все население сосредоточено по узкой полосе вдоль Транссиба.
Во-первых далеко не все, во-вторых транссиб ой какой длинный.
>>а в Китае в деревнях даже канализация не всегда имеется
PD>И в России тоже
Разница, все таки, определенная имеется. Китайская деревня это как крупный российский город, а не 20 дворов.
AVK>>Смотря где. В Москве они доступны кому угодно без особых проблем.
PD>Я же говорю — не суди по Москве.
А чего так? Это не меньше 10% населения РФ, вполне себе значимая величина. А еще есть Питер и несколько крупных городов.
PD>Если речь идет об ограничениях, связанных с размером дисплея — да.
И о разрешении дисплея, и об отсутствии клавиатуры, и, главное, о предъявляемых требованиях. Никто в здравом уме и твердой памяти не будет программировать на таких малютках всерьез, к примеру.
PD> Но они не везде существенны. Просмотр сайтов все же возможен, например.
Но ограничен размером экрана .
PD>Да это просто один момент. Если все это интегрируется — не должно быть таких проблем.
А у меня,к примеру, никаких проблем и нет. Я свою нокию подключаю по BT и вуаля, без дополнительных телодвижений имею на ноуте интернет. Но я так и не понял, при чем здесь это.
PD> Значит, пока не интегрировано , хотя бы для этого телефона.
Что куда не интегрировано?
AVK>>А при чем тут мой уровень понимания?
PD>При том, что он у тебя несколько выше , чем у среднего пользователя.
Ну и что? С точки зрения использования всяких мелкогаджетов я такой же юзер.
AVK>>Ну да, подумаешь, мегаполис с населением в 20 миллионов, и районный городок с населением чуть больше 100 тыс. Одна фигня
PD>Неубедительно.
Именно.
PD> В Коломне я не был.
Значит ее не существует?
PD> Но был в Протвино, Пущино, Троицке.
На карту взгляни , да?
PD> И тем не менее они и тогда, когда я там был (конец 80-х) были гораздо ближе по духу к Москве, чем мой Омск.
Так если по Москве судить нельзя, то по Омску тем более.
AVK>>А какой надо? Все желающие давно уже приобрели себе тарелку с тем самым цифровым телевидением, благо стоит оно сейчас копейки.
PD>Опять по Москве судишь.
Тебя клинит на Москве, что ли? У меня на даче, что в 130 км от МКАД тоже Москва, что там вся деревня в тарелках? То, что у вас тарелок нет, скорее всего говорит о том, что развиты кабельные сети. А до кабельной сети контент наверняка доставляется через те же самые тарельки.
PD> У нас тарелки есть, но до массовой "тарелкизации" еще как до Москвы.
А в Москве нет массовой тарелькизации, оно там нафик не нужно. Как и в Коломне. Тарельки это решение в основном для глухомани.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Sinclair, Вы писали:
S>Примером хорошего приложения является сайт microsoft.com и значительная часть msdn.microsoft.com.
Здесь имеется в виду хорошее с точки зрения исключительно применения технологии или со стороны конечного пользователя?
Здравствуйте, IT, Вы писали:
IT>Здравствуйте, VoidEx, Вы писали:
VE>>Я так понял, что ты отнёс её к ООП по той причине, что в тех языках, где она есть, есть также и ООП?
IT>Мне не интересно выяснять что к чему относится. Я продемонстрировал два примера, которые без поддержки компилятора/среды не реализуются.
Зато мне интересно. Я удивился, увидев перегрузку функций отнесённую к ООП, потому и спросил.
Тебе сложно ответить или ты во всём видишь провокацию бурного флейма?
Я даже подскажу с ответами, которые меня удовлеворят и дискуссия закончится:
1. Нет, я отнёс их к ООП по ошибке
2. Да, именно поэтому
Здравствуйте, Sinclair, Вы писали:
S>Помимо ширины есть еще и цена. S>Вот тебе ГМэйл дает гигабайты места в инбоксе не потому, что винчестеры дешевые. А потому, что это виртуальное пространство. S>Так и тут: канал у тебя, допустим, будет 1Gbit, а пиринг обеспечит его наличие через провод шириной 100Mbps. S>Или наоборот: фильм будет качаться со скоростью 10Gbit.
Через канал шириной 1Gbit фильм будет качаться со скоростью 10Gbit? Какие-нибудь средства наркотические надо будет принимать для этого?
ВВ>>Сколько, интересно, народу качает с рапиды одновременно? Тем не менее — я всегда качаю с высокой скоростью. ВВ>>И какая ферма серверов может быть у сайта издателя. ВВ>>В целом — это спор о деталях, но я лично не очень люблю пиринговые сети. Я вот, например, хочу посмотреть "Последнего императора" Бертолуччи. Так, сколько человек его держат в активе и отдают? Что, ноль?! S>Это будут не те пиринговые сети.
А какие? Чем будут отличаться?
Сейчас пиринг — это тот же lostfilm.tv, novafilm.tv, animereactor и пр. Они работают именно по такому принципу.
ВВ>>Вторая проблема пиринговых сетей — отдача. Зачем мне, скачав контент, сидеть и отдавать его, а? S>А ты по другому и не сможешь. Телевизор будет отдавать контент за тебя, просто потому, что он его скачал.
Раздача предполагает и мое косвенное участие. Я должен держать контент на винте. Я должен держать сам девайс включенным. Я должен терпеть деградацию по скорости и пр.
К тому же у пиринга есть и еще одна проблема — стриминг идет лесом.
Здравствуйте, IT, Вы писали:
IT>>>Переписать всё на N? Да без проблем. У тебя кошелёк достаточно большого размера? ГВ>>А... То есть, будучи написанными на Немерле они автоматически станут более серьёзными. Ясно. IT>Т.е. кошелёк у нас небольшого размера.
Ещё аргументы имеются?
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, IT, Вы писали:
VE>>Больше всего, конечно, меня удивляет, почему надо выставить себя правым любым способом. IT>Требовать от меня переписывания этого кода, конечно же, можно. Но тогда нужно будет подумать о компенсации моего времени. Что в этой логике не так?
В этой логике "не так" то, что ты сам предложил "переписать всё на Немереле", как единственный метод доказательства. Проблема в том, что это ничего не докажет.
Ну или давай поставим вопрос — что же такое "серьёзность" кода? Ты говоришь, что у тебя код становится серьёзней, когда ты его пишешь не Немерле.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Раздача предполагает и мое косвенное участие. Я должен держать контент на винте. Я должен держать сам девайс включенным. Я должен терпеть деградацию по скорости и пр.
Да. Но если вы получаете таким образом контент или услуги в несколько раз дешевле, чем традиционным методом, то по-моему можно и потерпеть.
ВВ>К тому же у пиринга есть и еще одна проблема — стриминг идет лесом.
Здравствуйте, VoidEx, Вы писали:
VE>Тебе сложно ответить или ты во всём видишь провокацию бурного флейма?
Поверь, мне всё равно куда это относится Overriding и overloading часто рассматривают вместе в рамках ООП, противопоставляют и т.п. Но главное, ни того, ни другого нет ни в одном структурном языке. Это паттерн, который пришёл вместе с ООП.
Я ответил на твой вопрос?
А теперь ты мне ответь. Тебе доставляет большое удовольствие смотреть не в суть проблемы, а смаковать отдельные, не относящиеся к делу детали? Большое или небольшое?
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, Геннадий Васильев, Вы писали:
ГВ>По-моему, всё как раз наоборот — если есть некоторая, скажем так, теоретическая база, то никто не мешает ей пользоваться "чисто практически" даже "в Си". Вернее — мешает, но эти помехи к особенностям языков программирования не относятся.
Выше я тебе уже всё объяснил в примерах на immutable.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, IT, Вы писали:
ГВ>>Ну или давай поставим вопрос — что же такое "серьёзность" кода?
IT>Это вопрос не ко мне, а к тому кто этот термин ввернул в дискуссию.
ГВ>>Ты говоришь, что у тебя код становится серьёзней, когда ты его пишешь не Немерле.
IT>Я это утверждаю со всей ответственностью.
Ответственность за правомерность термина, смысл которого ещё кто-то должен разъяснить? Лихо.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Воронков Василий, Вы писали:
Pzz>>Ошибаетесь. ВВ>А можно поподробнее? Каким образом он будет работать при секционном скачивании файла?
Кэшируем пару минут и раздаём их — это если live-streaming. Для передачи запрограммированого видео — так вообще проблем никаких.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Здравствуйте, Pzz, Вы писали:
ВВ>>>К тому же у пиринга есть и еще одна проблема — стриминг идет лесом. Pzz>>Ошибаетесь.
ВВ>А можно поподробнее? Каким образом он будет работать при секционном скачивании файла?
Мухи отдельно, котлеты отдельно. В смысле, стриминг отдельно, пиринг отдельно. Плюс, есть пиринговые алгоритмы, которые качают файл последовательно. Да, посекционно, но последовательно. И если 3го куска нет, то 4й кусок не качают.
Здравствуйте, Cyberax, Вы писали:
Pzz>>>Ошибаетесь. ВВ>>А можно поподробнее? Каким образом он будет работать при секционном скачивании файла? C>Кэшируем пару минут и раздаём их — это если live-streaming.
Ну т.е. мы пытаемся скачивать файл последовательно, а не хватаем все что есть. И такая схема реально работает? Я вот неоднократно замечал, что у меня может быть 90%, а при этом до сих пор нет начала, к примеру.
Да и смысл пиринга тогда? Ведь подобная техника приведет к падению скорости по сравнению с классическим "берем все что есть".
Это вообще в реале существует? Можно, например, поэкспериментировать с такой закачкой используя торрент какой-нибудь?
C>Для передачи запрограммированого видео — так вообще проблем никаких.
Здравствуйте, Aen Sidhe, Вы писали:
AS>Мухи отдельно, котлеты отдельно. В смысле, стриминг отдельно, пиринг отдельно. Плюс, есть пиринговые алгоритмы, которые качают файл последовательно. Да, посекционно, но последовательно. И если 3го куска нет, то 4й кусок не качают.
Гм, ну они же не синхронно их качают. Я вот писал многопоточную закачку — делим единый файл на сервере на секции, открывается 5 соединений одновременно и как бы при такой схеме и 3 кусок есть, и 4-ый, и 5 — но выкачиваются-то они одновременно.
Т.е. у меня будет половина первой секции, половина второй и так далее. Пока все не высосем единой последовательности длиннее чем 1 секция не получится.
В пиринговых сетях, конечно, секции маленькие совсем и влетают очень быстро, но может быть ситуация, что какой-то секции просто нет пока — и будешь сидеть ждать ее. В общем, не знаю. Сложно как-то все это выглядит.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>>>К тому же у пиринга есть и еще одна проблема — стриминг идет лесом. Pzz>>Ошибаетесь.
ВВ>А можно поподробнее? Каким образом он будет работать при секционном скачивании файла?
Здравствуйте, Pzz, Вы писали:
ВВ>>А можно поподробнее? Каким образом он будет работать при секционном скачивании файла? Pzz>Волной от центра до окраин.
И? Я ссылку в плеер скопировал, хочу смотреть. Что эта "волна" будет делать.
Pzz>Слово Joost вам ничего не говорит?
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Это вообще в реале существует? Можно, например, поэкспериментировать с такой закачкой используя торрент какой-нибудь?
Здравствуйте, Pzz, Вы писали:
ВВ>>Это вообще в реале существует? Можно, например, поэкспериментировать с такой закачкой используя торрент какой-нибудь? Pzz>Существует: http://www.joost.com/
Здравствуйте, Pzz, Вы писали:
Pzz>Это ребята, которые сделали скайп, сделали после того пир-ту-пировый телевизор. Pzz>Сейчас они вроде и через бровсер научились раздавать свое кено, и непонятно, чем они собираются отличаться от ютьюба. А немного раньше смотреть можно было, только поставив ихний клиент. Вполне себе пир-ту-пировый.
Понятно. Честно, мне кажется довольно заморченная схема все-таки да и с побочными эффектами к тому же, ведь пропуски-то все-таки будут. А в данном случае речь же не о лайв телевизоре, а о высококачественном HD контенте будущего
Я вот в принципе особой проблемы с централизованными файловыми фермами не вижу. Живет ведь та же рапида, и сколько народу с нее качает.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Понятно. Честно, мне кажется довольно заморченная схема все-таки да и с побочными эффектами к тому же, ведь пропуски-то все-таки будут. А в данном случае речь же не о лайв телевизоре, а о высококачественном HD контенте будущего
Схема довольно замороченная, но оно того стоит. Пропуски можно сделать сколь угодно редкими, используя разумную буферизацию и кодирование с избыточностью. А совсем уж редкие пропуски вы не заметите. Что до HD контента будущего, думаю со временем интернет станет достаточно быстрым, и его можно будет стримить со скоростью просмотра.
ВВ>Я вот в принципе особой проблемы с централизованными файловыми фермами не вижу. Живет ведь та же рапида, и сколько народу с нее качает.
Поинтересуйтесь как-нибудь, сколько она платит за траффик.
Здравствуйте, IT, Вы писали:
IT>От блин Объясняю на пальцах в третий и последний раз. Теоретико-гепотетическая возможность на практике совершенно никого не интересует.
Меня интересует, соответственно — спрячь пальцы и не колоти молотком по компьютеру. Почти наверняка интересует и ещё кого-то (хотя это и не особо важно).
IT>Никто и никогда [...]
А вот это совершенно не важно.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, IT, Вы писали:
IT>Поверь, мне всё равно куда это относится Overriding и overloading часто рассматривают вместе в рамках ООП, противопоставляют и т.п. Но главное, ни того, ни другого нет ни в одном структурном языке. Это паттерн, который пришёл вместе с ООП.
IT>Я ответил на твой вопрос?
Ура.
IT>А теперь ты мне ответь. Тебе доставляет большое удовольствие смотреть не в суть проблемы, а смаковать отдельные, не относящиеся к делу детали? Большое или небольшое?
Небольшое.
Большое доставляет, когда по сути проблемы ещё внятно отвечают, без флейма, ухода в сторону и других типичных приёмов, которые всё равно к результату не приводят.
Здравствуйте, Pzz, Вы писали:
ВВ>>Понятно. Честно, мне кажется довольно заморченная схема все-таки да и с побочными эффектами к тому же, ведь пропуски-то все-таки будут. А в данном случае речь же не о лайв телевизоре, а о высококачественном HD контенте будущего Pzz>Схема довольно замороченная, но оно того стоит. Пропуски можно сделать сколь угодно редкими, используя разумную буферизацию и кодирование с избыточностью. А совсем уж редкие пропуски вы не заметите. Что до HD контента будущего, думаю со временем интернет станет достаточно быстрым, и его можно будет стримить со скоростью просмотра.
ВВ>>Я вот в принципе особой проблемы с централизованными файловыми фермами не вижу. Живет ведь та же рапида, и сколько народу с нее качает. Pzz>Поинтересуйтесь как-нибудь, сколько она платит за траффик.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>>>Я вот в принципе особой проблемы с централизованными файловыми фермами не вижу. Живет ведь та же рапида, и сколько народу с нее качает. Pzz>>Поинтересуйтесь как-нибудь, сколько она платит за траффик.
ВВ>У кого? Явно ж она не в убыток себе работает.
Рапида отдает файлы либо за бапки, либо очень медленно и с кучей рекламы. Не представляю, как она собирается конкурировать с пир-ту-пировыми файлшарингами, у которых прямая пересылка вообще бесплатная и работает со скоростью интернета, да еще они до кучи пару гигов забесплатно дают на дисках своих серверов, а деньги собираются зарабатывать на дополнительных услугах.
Про счета рапиды я ничего не знаю. Ютьюб, говорят, платил за интернет что-то типа лимона в месяц, только за траффик.
Здравствуйте, Pzz, Вы писали:
Pzz>Про счета рапиды я ничего не знаю. Ютьюб, говорят, платил за интернет что-то типа лимона в месяц, только за траффик.
(по секрету: примерно на порядок больше Ютуб платит).
Здравствуйте, IT, Вы писали:
IT>Я вот тут подумал и понял, что на самом деле без поддержки компилятором immutable style невозможен даже теоретически.
Почему? По-моему, тут цена не выше, чем некоторая потеря производительности. В том смысле, что компилятор не заточенный под immutable оперирует более широким набором предположений, следовательно, не может породить настолько же эффективный код immutable-styled программы, как минимум, без хинтования. А-ля устранение хвостовой рекурсии, которую умели уже стародавние лиспы и не умел более молодой паскаль на каком-то этапе.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Pzz, Вы писали:
ВВ>>У кого? Явно ж она не в убыток себе работает. Pzz>Рапида отдает файлы либо за бапки, либо очень медленно и с кучей рекламы.
Я вот плачу за премиум 10 баксов в месяц, не напрягает совершенно. Причем часто упираюсь в дневной лимит (10ГБ). Так что эти 10 баксов себя окупают двести раз
Скорость кстати офигенная, качать можно хоть в пять потоков с разных зеркал.
Pzz>Не представляю, как она собирается конкурировать с пир-ту-пировыми файлшарингами, у которых прямая пересылка вообще бесплатная и работает со скоростью интернета,
Если что-то доступно через рапиду и торрент, скажем, я буду качать через рапиду в первую очередь. Скачал, ушел, ничего никому не должен. Скорость стабильна всегда и не зависит от популярности контента.
Pzz>да еще они до кучи пару гигов забесплатно дают на дисках своих серверов, а деньги собираются зарабатывать на дополнительных услугах. Pzz>Про счета рапиды я ничего не знаю. Ютьюб, говорят, платил за интернет что-то типа лимона в месяц, только за траффик.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Если что-то доступно через рапиду и торрент, скажем, я буду качать через рапиду в первую очередь. Скачал, ушел, ничего никому не должен. Скорость стабильна всегда и не зависит от популярности контента.
Вы рассуждаете о том, чего не видели
Попробуйте какой-нибудь, ну microsoft live mesh, хотя бы. Это все совсем не похоже на торрент...
Здравствуйте, VladD2, Вы писали:
FR>>Оба эмулируются даже на си. FR>>И к тому и замыкания и перегрузка методов это не более чем вкусности, они не являются необходимыми чтобы программировать в соответствующем стиле.
VD>Опять пошла подмена понятий. Они не являются необходимыми чтобы порвав задницу хоть что-то изобразить. Но можно ли назвать программированием эмуляцию приводящую к ужасному нагромождению кода?
Что-то тут не так. Что тогда программирование? Программирование это процесс, в результате которого получается программное обеспечение. А если эмуляция позволяет сократить время разработки и повысить качество продукта, то почему бы и нет? Все зависит от целесообразности применения тех или иных эмуляций
VD>Так что эмулировать конечно можно, а программировать нельзя.
Скажи это всем тем, кто использует STL.
Lisp is not dead. It’s just the URL that has changed: http://clojure.org
Здравствуйте, IT, Вы писали:
IT>Здравствуйте, Геннадий Васильев, Вы писали:
IT>>>Я это утверждаю со всей ответственностью.
ГВ>>Ответственность за правомерность термина, смысл которого ещё кто-то должен разъяснить? Лихо.
IT>Не кто-то, а тот кто его ввёл в этой ветке. Все свои притензии туда.
Да какие у меня претензии? Ты говоришь, что твой код становится "более серьёзным", а потом:
ГВ>>Ну или давай поставим вопрос — что же такое "серьёзность" кода?
IT>Это вопрос не ко мне, а к тому кто этот термин ввернул в дискуссию.
Но ты же сам говоришь, что твой код становится более серьёзным, значит, как минимум, понимаешь, что это такое — эта самая "серьёзность".
Я где-то читал такую историю про Марата (ключевое слово: французская революция):
Однажды Марат был у парикмахера (в общем, не суть не важно, где именно). Мимо окна, выходившего на улицу, пробежали какие-то люди, выкрикивая лозунги и размахивая флагами. Марат немедленно вскочил и рванулся к дверям заведения:
— Я их поведу!
— Но ты ведь даже не представляешь, куда они направляются! — резонно заметили его друзья.
— Да какая разница!
Ну или: "все претензии — туда". Точно до изморфизма.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Здравствуйте, Aen Sidhe, Вы писали:
AS>>Мухи отдельно, котлеты отдельно. В смысле, стриминг отдельно, пиринг отдельно. Плюс, есть пиринговые алгоритмы, которые качают файл последовательно. Да, посекционно, но последовательно. И если 3го куска нет, то 4й кусок не качают.
ВВ>Гм, ну они же не синхронно их качают. Я вот писал многопоточную закачку — делим единый файл на сервере на секции, открывается 5 соединений одновременно и как бы при такой схеме и 3 кусок есть, и 4-ый, и 5 — но выкачиваются-то они одновременно.
Ну можно и так. В общем, была бы задача, а решить уже можно.
ВВ>Т.е. у меня будет половина первой секции, половина второй и так далее. Пока все не высосем единой последовательности длиннее чем 1 секция не получится.
В ТВ, я подозреваю, секции будут небольшими. На 5-10 секунд передачи по какому-нибудь "каналу стандартной пропускной способности".
ВВ>В пиринговых сетях, конечно, секции маленькие совсем и влетают очень быстро, но может быть ситуация, что какой-то секции просто нет пока — и будешь сидеть ждать ее. В общем, не знаю. Сложно как-то все это выглядит.
DС++ так работает и ничего. Живёт почти наравне с торрентами.
Здравствуйте, Геннадий Васильев, Вы писали:
ГВ>Но ты же сам говоришь, что твой код становится более серьёзным, значит, как минимум, понимаешь, что это такое — эта самая "серьёзность".
Конечно, я догадываюсь что это такое. И ты тоже догадываешься. И я могу от тебя потребовать дать определение этому точно также как и ты от меня. Поэтому, чтобы не возникало неопределённостей и домыслов лучше всего будет, если определение этому понятия даст тот, кто его ввёл. Так что ты знаешь куда обращаться.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, IT, Вы писали:
ГВ>>Почему? IT>Потому что для поддержки такого стиля нужно, чтобы основные языковые конструкции возвращали значения.
Например — цикл. Что он должен возвращать?
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, IT, Вы писали:
IT>Здравствуйте, VoidEx, Вы писали:
VE>>Вот только беда, что ты сам его и ввернул, да?
IT>Чтобы мне ещё такого ввернуть, чтоб занять тебя на день на два?
Кстати, раз уж спросил. Вверни-таки определение фразы "серьёзность кода".
Здравствуйте, Геннадий Васильев, Вы писали:
ГВ>Например — цикл.
Например, if и switch.
ГВ>Что он должен возвращать?
Цикл тоже хороший пример конструкции с изменяемым состоянием. В FP он обычно заменяется функциями с хвостовой рекурсией, которые, ты не поверишь, возвращают значения.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, IT, Вы писали:
IT>Здравствуйте, VoidEx, Вы писали:
VE>>Кстати, раз уж спросил. Вверни-таки определение фразы "серьёзность кода".
IT>Для альтернативно одарённых повторяю ещё раз — за определением к тому, кто эту фразу ввёл.
Для альтернативно одарённых повторяю ещё раз — её ввёл ты. Можешь по сообщениям пробежаться.
Здравствуйте, AndrewVK, Вы писали:
AVK>Здравствуйте, Pavel Dvorkin, Вы писали:
PD>>В Азиатской части России почти все население сосредоточено по узкой полосе вдоль Транссиба.
AVK>Во-первых далеко не все, во-вторых транссиб ой какой длинный.
И полоса в Канаде тоже . Пусть и не столь.
PD>>Я же говорю — не суди по Москве.
AVK>А чего так? Это не меньше 10% населения РФ, вполне себе значимая величина. А еще есть Питер и несколько крупных городов.
А потому что есть существенная разница между жизнью в Москве или в каком-нибудь областном городе.
AVK>И о разрешении дисплея, и об отсутствии клавиатуры, и, главное, о предъявляемых требованиях. Никто в здравом уме и твердой памяти не будет программировать на таких малютках всерьез, к примеру.
Сдается мне, что о персональных компьютерах в 1981 году говорили примерно то же самое. Никто всерьез не будет. BASIC вам встроенный в руки — и вперед
PD>> Но они не везде существенны. Просмотр сайтов все же возможен, например.
AVK>Но ограничен размером экрана .
Сдается мне, что и на ПК он тоже ограничен. И хорошо еще, если скроллинг только вертикальный
PD>>Да это просто один момент. Если все это интегрируется — не должно быть таких проблем.
AVK>А у меня,к примеру, никаких проблем и нет. Я свою нокию подключаю по BT и вуаля, без дополнительных телодвижений имею на ноуте интернет. Но я так и не понял, при чем здесь это.
Ну значит я объяснять разучился.
AVK>>>А при чем тут мой уровень понимания?
PD>>При том, что он у тебя несколько выше , чем у среднего пользователя.
AVK>Ну и что? С точки зрения использования всяких мелкогаджетов я такой же юзер.
PD>> В Коломне я не был.
AVK>Значит ее не существует?
Что за чушь ?
PD>> Но был в Протвино, Пущино, Троицке.
AVK>На карту взгляни , да?
???
PD>> И тем не менее они и тогда, когда я там был (конец 80-х) были гораздо ближе по духу к Москве, чем мой Омск.
AVK>Так если по Москве судить нельзя, то по Омску тем более.
По Омску скорее можно. Дело в том, что Омск — вполне типичный областной центр, таких десятки.
PD>>Опять по Москве судишь.
AVK>Тебя клинит на Москве, что ли? У меня на даче, что в 130 км от МКАД тоже Москва, что там вся деревня в тарелках?
Я же тебе уже сказал — ближнее Подмосковье по духу скорее Москва.
>То, что у вас тарелок нет, скорее всего говорит о том, что развиты кабельные сети. А до кабельной сети контент наверняка доставляется через те же самые тарельки.
"Мы раскопали десяток курганов и не обнаружили ни куска проволоки. Совершенно очевидно, что древние скифы пользовались беспроволочной радиосвязью"
Не смеши. Кабельных сетей в Омске практически нет. Есть в каком-то микрорайоне кабельное ТВ, вот и все.
Как вы далеки от понимания реальной жизни в России...
Здравствуйте, gandjustas, Вы писали:
PD>>Если это и надо, то надо именно это и делать, а не нести чушь насчет получения битов с помощью BitBlt. G>Где я говорил такое?
Извини. Я тебя с Константин Б. перепутал.
>>>Какая разница значений будет на измеряемом коде? PD>>Посмотри свое собственное сообщение, где ты утверждаешь, что тебе удалось на C# сделать лучше, чем мне на С++. Ты там сам эти значения приводишь. Разница измеряется путем вычитания одного из другого, полученное значение сравнивается с 15 мсек G>В обоих случаях сравниваются милисекунды, измеренные с одинаковой точностью.
Опять двадцать пять. Я тебе в который раз уже объясняю, что точность там такова, что разница этих значений укладывается в пределы погрешности измерения, и именно поэтому выводы там делать нельзя, а ты опять за свое. Ну не веришь мне — возьми любой учебник по теории вероятности и почитай, тебе же самому будет потом стыдно за свои высказывания.
PD>>Если немного серьезнее. Как преподаватель уже (не как программист) скажу вот что. Не знать что-то не стыдно. Но вот упорствовать в своем незнании не стоит. В конце концов от этого хуже тебе самому будет, не мне же. G>Ну тогда изучай ФП, .NET вообще и PLinq в частности, а потом возвращайся.
Дело в том, что основные принципы их я знаю, а для .Net даже кое-что пишу . Детали же Linq, к примеру, изучать я не буду, так как мне это просто сейчас не надо. В конце концов есть масса вещей, которых я не знаю. Ты мне предлагаешь Linq изучать, кто-нибудь другой предложит, к примеру, Lisp или Prolog, а когда я работать-то буду ?
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Вот начали какие-нибудь живописные взрывы показывать, "повышение звука" произошло, а твой вырезальщик взял да вырезал самый кульминационный момент
Вообще говоря, подумав, я понял, что и этого не надо. По очень простой причине — если работаем в режиме "запроса", то в большинстве случаев онлайн-скачивание и не требуется. Новости, спорт — да, а фильмы и постановки — вовсе нет. Ну вот я и запрограммирую утром свой компьютер-телевизор, чтобы он мне к вечеру скачал фильм А и спектакль Б. Приду вечером домой, включу фильм, и как только там реклама — стрелку вправо и нет ее .
Реклама ведь не тем раздражает, что она есть. Когда она ненавязчивая, я ничего против нее не имею. Мне домой приносят две рекламные газетки, и я их обычно просматриваю — вдруг там что-то интересное есть ? Раздражает реклама, которая пытается действовать на мое подсознание, которая навязчиво пытается меня заставить купить то, что я вовсе и не хочу. И такая реклама возможна только в режиме вещания, когда все идет онлайн. Уберите онлайн — и от этой рекламы и следов не останется.
Здравствуйте, Klapaucius, Вы писали:
K>На этот вопрос уже отвечал AndrewVK. Можно. Пишете итератор и обходите. Хоть матрицу, хоть дерево, хоть граф. Отображаете, свертываете. Промежуточные массивы не создаются. Non strict семантика.
Ну что же, если при этом итератор будет итерировать по строкам, а суммы считаться по столбцам, то результат может быть неплохим. В сущности здесь ведь вопрос не в том, какими средствами суммировать , а в том, как именно проходить матрицу. Здравый смысл говорит, что при суммировании строк надо идти по строкам, а при суммировании столбцов — по столбцам. И с точки зрения абстракций — то же самое (суммирование вектора-строки или вектора-столбца). А на реальной машине, где есть кэш процессора и виртуальная память, оказывается, что проходить надо всегда по строкам. Хотя какая при этом абстракция получается — черт разберет.
Здравствуйте, EvilChild, Вы писали: EC>Здесь имеется в виду хорошее с точки зрения исключительно применения технологии или со стороны конечного пользователя?
И то и другое.
... << RSDN@Home 1.2.0 alpha rev. 677>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Уровень ваших представлений я уже понял, благодаря живописному и до невозможности наглядному примеру реализовать ASP.NET приложение на ассемблере.
А в чем проблема?
ВВ>А к чему это сказано? Чтобы покрасоваться? Речь идет о ГУИ-фреймворке, а ты "не склонен преувеличивать значение окон в win32". Сказать было нечего больше?
Ну почему — есть что сказать. Ок, если рассматривать только ГУИ-фреймворк, то в общем-то и так понятно, что модель деления плоскости экрана на независимые окошки с рисованием через оконную функцию безнадежно устарела. То есть сам по себе user32 предоставляет слишком низкий уровень абстракции. Это касается как GDI, так и Windowing.
Единственный способ написать удачное GUI приложение — это захватить одно окно (в терминах user32), а внутри него выполнять отрисовку вручную. То есть, конечно же, не вручную, а при помощи некоторого совершенно другого фреймворка, у которого базовые примитивы устроены вовсе не так, как предлагают user32 и comctl32.
В качестве недавних примеров таких приложений можно посмотреть на Chrome.
В качестве примеров таких фреймворков можно посмотреть на HTMLayout.
То есть, в WinForms мы имеем ровно ту же ситуацию, как и в ASP.NET — та часть, которая про Forms — полный отстой. Остается использовать только самый нижний уровень.
Поэтому мне совершенно непонятно, почему WinForms позиционируется как что-то хорошее по сравнению с WebForms.
ВВ>Архитектурные дискуссии вообще нельзя вести о терминах, о чем я уже говорил. Но все твои, гм, "полемические высказывания" посвящены именно что терминам. Ну что ж, видимо "такой" уровень.
А ты используй термины по назначению — я и не буду критиковать их использование.
S>>Я совершенно не уверен, что они пишут эти игры на ассемблере, который пойдет в корзину при незначительной смене характеристик платформы. ВВ>А может, стоит ознакомиться с предметом? Эти игры как раз и пойдут в корзину при смене платформы, которая "незначительной" в принципе быть не может. Сейчас максимальная совместимость — это то, что некоторые игры со старых консолей запускаются на новых через эмулятор.
По прежнему продолжаю непонимать место ассемблера в приставочных играх. С предметом незнаком. Есть какие-то свидетельства того, что их пишут непереносимым образом?
... << RSDN@Home 1.2.0 alpha rev. 677>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Геннадий Васильев, Вы писали:
ГВ>В immutable-стиле как раз можно писать на Си.
А толку-то? Компилятор не сможет извлечь из твоей иммутабельности никаких выгод. Грубо говоря, каждый раз, как он видит обращение p->test1, он обязан пройти по ссылке, а каждый раз на p->test2() он обязан сделать вызов.
Несмотря на константность test1 и отсутствие побочных эффектов от test2().
А если ты будешь вручную заниматься constant propagation и memoizing, то рехнёшся на мало-мальски сложной задаче.
... << RSDN@Home 1.2.0 alpha rev. 677>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Sinclair, Вы писали:
ГВ>>В immutable-стиле как раз можно писать на Си. S>А толку-то? Компилятор не сможет извлечь из твоей иммутабельности никаких выгод. Грубо говоря, каждый раз, как он видит обращение p->test1, он обязан пройти по ссылке, а каждый раз на p->test2() он обязан сделать вызов. S>Несмотря на константность test1 и отсутствие побочных эффектов от test2().
.
S>А если ты будешь вручную заниматься constant propagation и memoizing, то рехнёшся на мало-мальски сложной задаче.
Вопрос в разнице цен на итоговый тикет.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Опять двадцать пять. Я тебе в который раз уже объясняю, что точность там такова, что разница этих значений укладывается в пределы погрешности измерения, и именно поэтому выводы там делать нельзя, а ты опять за свое. Ну не веришь мне — возьми любой учебник по теории вероятности и почитай, тебе же самому будет потом стыдно за свои высказывания.
Да расслабься. Сдал я теорию вероятности и статистику еще на третьем курсе и мне не стыдно за мои высказывания. С точки зрения статистики вполне нормальные измерения были.
PD>>>Если немного серьезнее. Как преподаватель уже (не как программист) скажу вот что. Не знать что-то не стыдно. Но вот упорствовать в своем незнании не стоит. В конце концов от этого хуже тебе самому будет, не мне же. G>>Ну тогда изучай ФП, .NET вообще и PLinq в частности, а потом возвращайся.
PD>Дело в том, что основные принципы их я знаю, а для .Net даже кое-что пишу.
Как показывают сообщения в форумах — это не так.
PD>Детали же Linq, к примеру, изучать я не буду, так как мне это просто сейчас не надо.
Детали не нужны, нужна идея, которую ты не понимаешь.
PD>В конце концов есть масса вещей, которых я не знаю.
Очень зря.
PD>Ты мне предлагаешь Linq изучать, кто-нибудь другой предложит, к примеру, Lisp или Prolog, а когда я работать-то буду ?
Иногда час изучения чего-то нового помогает сократить работу в несколько раз.
Про лисп и пролого — http://www.softcraft.ru/paradigm/dp/index.shtml. Можно прям сейчас начинать.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Здравствуйте, Sinclair, Вы писали:
S>>>>Предоставляются богатейшие маркетинговые возможности — можно предоставлять контент за деньги; можно впаривать в него рекламу, PD>>>И можно написать софт, который более или менее надежно эту рекламу вырезает . Исполняться-то все это будет на PC, а тут опыт есть. S>>Ну, вопрос, конечно, интересный. Вот ты сериалы смотришь с какого-нибудь lostfilm.tv?
PD>Я вообще никакие сериалы не смотрю . Объясянть почему — не буду, а то кто-нибудь обидится
scrubs посмотри если конечно время свободное есть немного
Здравствуйте, Геннадий Васильев, Вы писали:
ГВ>>>Почему? IT>>Потому что для поддержки такого стиля нужно, чтобы основные языковые конструкции возвращали значения.
ГВ>Например — цикл. Что он должен возвращать?
Здравствуйте, Кодёнок, Вы писали:
ГВ>>Например — цикл. Что он должен возвращать?
Кё>Список:
Кё>numbers = for (i in 1..10) { i*i }
while(!keypressed()){ ... }
Где список?
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Sinclair, Вы писали:
AVK>>Тебя клинит на Москве, что ли? У меня на даче, что в 130 км от МКАД тоже Москва, что там вся деревня в тарелках? То, что у вас тарелок нет, скорее всего говорит о том, что развиты кабельные сети. А до кабельной сети контент наверняка доставляется через те же самые тарельки. S>Сложность в том, что в 130км от МКАДа видны те же спутники, что и в 13. А в 3500 от МКАДа с этим как-то очень плохо. S>Продавцы тарелок у нас на вопрос "а что через них у нас принимают" начинают мяться и говорить, что надо бы ставить двухметровую.
Покрывает всю Россию, но в какой-то момент за Уралом надо ставить тарелки диаметром 90 вместо диаметром 60.
Несколько большая дура, конечно, но не смертельно (я и в Москве и Подмосковье часто такие вижу), а в цене тут разница должна быть вообще никакая (стоимость самой тарелки в комплекте оборудования — мелочи, рублей 200-300 вместе с крепежом).
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>И полоса в Канаде тоже . Пусть и не столь.
Ага, подумаешь в 2 раза короче
AVK>>И о разрешении дисплея, и об отсутствии клавиатуры, и, главное, о предъявляемых требованиях. Никто в здравом уме и твердой памяти не будет программировать на таких малютках всерьез, к примеру.
PD>Сдается мне, что о персональных компьютерах в 1981 году говорили примерно то же самое.
Нет, не говорил.
AVK>>Но ограничен размером экрана .
PD>Сдается мне, что и на ПК он тоже ограничен.
Ну хватит уже передергиванием заниматься. Не может быть UI одинаковым на устройствах, отличающихся по площади минимум раз в 15.
PD>Ну значит я объяснять разучился.
Нет, ты в принципе разучился признавать свою неправоту и споришь даже в абсолютно феерических ситуациях.
PD>>> В Коломне я не был.
AVK>>Значит ее не существует?
PD>Что за чушь ?
А к чему тогда эта вечная демагогия про "Мааасква не Россия"?
AVK>>Так если по Москве судить нельзя, то по Омску тем более.
PD>По Омску скорее можно. Дело в том, что Омск — вполне типичный областной центр, таких десятки.
AVK>>Тебя клинит на Москве, что ли? У меня на даче, что в 130 км от МКАД тоже Москва, что там вся деревня в тарелках?
PD>Я же тебе уже сказал — ближнее Подмосковье по духу скорее Москва.
Павел, 130 км это уже далеко не ближнее подмосковье. Это самая натуральная провинция, там до Рязани в 2 раза ближе, чем до Москвы.
PD>Не смеши. Кабельных сетей в Омске практически нет.
И как же ты телевизер смотришь?
PD>Как вы далеки от понимания реальной жизни в России...
Ну ну.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Sinclair, Вы писали:
S>Сложность в том, что в 130км от МКАДа видны те же спутники, что и в 13. А в 3500 от МКАДа с этим как-то очень плохо.
Да ну брось ты. Тот же триколор при помощи Eutelsat W4 и Бонум-1 перекрывает почти всю РФ, за исключением части Дальнего Востока.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, fmiracle, Вы писали:
F>Покрывает всю Россию, но в какой-то момент за Уралом надо ставить тарелки диаметром 90 вместо диаметром 60. F>Несколько большая дура, конечно, но не смертельно (я и в Москве и Подмосковье часто такие вижу), а в цене тут разница должна быть вообще никакая (стоимость самой тарелки в комплекте оборудования — мелочи, рублей 200-300 вместе с крепежом).
F>С того же спутника вещает НТВ+
Я в вопрос пока не погружался. Так, беглые разговоры с продавцами.
... << RSDN@Home 1.2.0 alpha rev. 677>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
ГВ>>Где список?
AVK>В функциональном стиле будет бескоечный ленивый список нажатых клавиш.
Да, согласен. Слона, как водится...
Тогда да — цикл определяется списком (в частном случае — ленивым) управляющих параметров. Конечный он или бесконечный, можно определять изнутри самой функции, реализующей тело цикла. Контексты, естественно, будут копироваться...
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, AndrewVK, Вы писали: AVK>В функциональном стиле будет бескоечный ленивый список нажатых клавиш.
Вроде бы наоборот — бесконечного списка не будет, т.к. цикл выходит по первому нажатию.
Будет бесконечный ленивый список результатов вычисления выражения, стоящего внутри фигурных скобок.
... << RSDN@Home 1.2.0 alpha rev. 677>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Вообще говоря, подумав, я понял, что и этого не надо. По очень простой причине — если работаем в режиме "запроса", то в большинстве случаев онлайн-скачивание и не требуется. Новости, спорт — да, а фильмы и постановки — вовсе нет. Ну вот я и запрограммирую утром свой компьютер-телевизор, чтобы он мне к вечеру скачал фильм А и спектакль Б. Приду вечером домой, включу фильм, и как только там реклама — стрелку вправо и нет ее .
А "стрелку вправо" могут и отключить
Вот я наверное всех задолбал уже с Икс-боксом но конкретный пример — берешь на прокат фильм в Иксбокс-лайв, скачиваешь его на локальный диск — через три дня после начала просмотра он автоматически удаляется!
Т.е. тут речь не о компьютере в обычном понимании идет. Думай в сторону некой медиа-приставки, вроде игровой консоли, у которой своя операционка, естественно не предоставляющая никакого прямого доступа к контенту. А модификация такой консоли, попытка установить на нее другой софт — преступление согласно EULA.
PD>Реклама ведь не тем раздражает, что она есть. Когда она ненавязчивая, я ничего против нее не имею. Мне домой приносят две рекламные газетки, и я их обычно просматриваю — вдруг там что-то интересное есть ? Раздражает реклама, которая пытается действовать на мое подсознание, которая навязчиво пытается меня заставить купить то, что я вовсе и не хочу. И такая реклама возможна только в режиме вещания, когда все идет онлайн. Уберите онлайн — и от этой рекламы и следов не останется.
Я думаю останется. Но появится возможность, заплатив деньги, скачать вариант без рекламы.
Здравствуйте, Sinclair, Вы писали:
ВВ>>Через канал шириной 1Gbit фильм будет качаться со скоростью 10Gbit? Какие-нибудь средства наркотические надо будет принимать для этого? S>Гм. Когда мы говорим об интернете, речь идет о нескольких каналах. S>Поясняю: дело в том, что у протокола TCP/IP нет управления качеством сервиса. Поэтому, вообще говоря, ширина канала от точки A до точки B равна ширине "самого узкого звена". S>В итоге, иметь локальный канал в 10Gbit — это совсем не то же самое, что иметь канал до провайдера шириной в 10Gbit. S>Об этом я и говорю: вместо того, чтобы тянуть от провайдера со скоростью в 1Gbit ты будешь тянуть от N ретрансляторов с суммарной скоростью выше 1Gbit.
А что такое локальный канал? А если у меня выделенная линия например? Да, имея локалку в 100Мб и выход в интернет в 10Мб я увеличу свою скорость на порядок, если контент ко мне будет приходить "изнутри". Но это будет работать, если все сядут в локальные сети и пиринг станет основным способом доставки контента.
Да и не решаем ли мы проблему, которой нет? У меня канал в 10Мбит и меня скорость скачки устраивает практически всегда — что через пиринг, что без него. Какой канал у меня будет через 10 лет?
ВВ>>А какие? Чем будут отличаться? S>Они будут отличаться тем, что контроль за расшаренным контентом будет осуществляться не тобой, а провайдером. S>Ты не сможешь ничего опубликовать в такую сеть — точно так же, как сейчас не можешь ничего транслировать по первому каналу.
Да ради бога, сейчас любой мало мальски уважающий себя трекер не позволит первому встречному что-то публиковать. А на некоторых такая возможность закрыта в принципе — публикует только "тим".
ВВ>>Сейчас пиринг — это тот же lostfilm.tv, novafilm.tv, animereactor и пр. Они работают именно по такому принципу. S>Они работают по принципу нарушения копирайта. Это ненормально. Брать с тебя тридцать долларов за диск, который ты даже не имеешь права посмотреть с друзьями — тоже ненормально. S>Нормально — когда ты пользуешься контентом за скромные деньги, но при этом правообладатель получает за это свою долю. S>Одну из таких моделей я тебе как раз и описываю.
Ты описываешь модель доставки контента. Каким образом тут возникают вопросы нарушения копирайта и проч.? Пользоваться контентом за скромные деньги — значит брать его напрокат, к примеру. Какая разница каким именно способом это дело упадет мне на винт?
ВВ>>Раздача предполагает и мое косвенное участие. Я должен держать контент на винте. Я должен держать сам девайс включенным. Я должен терпеть деградацию по скорости и пр. ВВ>>К тому же у пиринга есть и еще одна проблема — стриминг идет лесом. S>Опять же — это существующее положение вещей. Мы же говорим про телевидение будущего, не так ли? S>Вот одна из самых жизнеспособных моделей телевидения on-demand — это построение сети из приемников, которые всё делают автоматически. S>С твоей точки зрения всё будет выглядеть неотличимо от стриминга — ты нажал play, оно заиграло. А как оно там использует встроенный винчестер и сетевой провод — дело техническое и малоинтересное. Весь пиринг и прочее — это обеспечение эффективной широкой полосы дешевыми средствами.
Мне непонятно одно — что вам этот пиринг так сдался? Есть сейчас пиринг, через к-й распространяется коммерческий контент? А централизованных систем, позволяющих покупать фильмы/игры онлайн, уже довольно много.
Что дает пиринг в принципе? Позволяет экономить траффик дистрибьютору. Но если даже та же рапида вполне себе выживает с 10-долларовых месячных сборов, то что-то мне кажется, что крупный интернет-издатель вообще не будут особенно по этому вопросу париться.
Здравствуйте, Sinclair, Вы писали:
S>Здравствуйте, AndrewVK, Вы писали: AVK>>В функциональном стиле будет бескоечный ленивый список нажатых клавиш. S>Вроде бы наоборот — бесконечного списка не будет, т.к. цикл выходит по первому нажатию. S>Будет бесконечный ленивый список результатов вычисления выражения, стоящего внутри фигурных скобок.
На входе — бесконечный список соcтояний клавиатуры. На выходе может быть этот же список. Хотя вообще-то вопрос интересный.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Воронков Василий, Вы писали: ВВ>У меня проблем нет, т.к. я не пытаюсь доказать, что какая-то одна технология, архитектура, модель программирования и проч. несравненно лучшем чем все остальные и подходит всегда и везде.
А кто-то пытается?
ВВ>А еще можно посмотреть на GDI+.
Можно, но смысла нет. Ничего фундаментально нового он не дает. Так, немножко улучшенная модель GDI.
ВВ>Та, часть которая про Forms реализуется по большей части на GDI+. Есть какие-то конкретные претензии к реализации?
К обертке? Нет, к обертке претензий нету. Ну, кроме того, что стандартные контролы из WinForms — жуткое убожество, а свои нормальные писать крайне неудобно.
По сравнению, естественно, с полноценными фреймворками.
ВВ>Архитектура вин-форм *отвечает* архитектуре юзер32, представляя *достаточный* уровень абстракции, благодаря которому и разработка упрощается, и всегда можно спуститься на "ступеньку" ниже — причем это не будет выглядеть как хак. Утверждать, что вин-формс хуже чем WTL... очень я не уверен, что хуже.
Я такого не утверждал.
ВВ>А сравнивать ее, извините, с движком, который HTML рендерит.
О, я так и знал, что именно этот аргумент прозвучит из уст человека, который все выводы строит на основе знакомых слов в названии технологии. Если ASP — значит про странички, если win32 — значит про окошки, если HTMLayout — значит про HTML.
ВВ>HTMLayout вообще идеологически ближе к WPF вообще-то.
Cовершенно верною Ну то есть он идеологически ближе к нормальной платформе для построения GUI. В которой логика отделена от представления, а представление — от отрисовки. ВВ>С вин-формс разработка реально упрощается. Выбранная архитектура естестественна для "окошек". Всякий раз, когда ты упираешь в ограничения, ты упираешься в ограничения не собственно вин-формс, а именно этих самых "окошек". ВВ>Так в чем проблема?
Да нет никакой проблемы. Точно так же, как в ASP.NET — выкидываем всё из System.Windows.Forms и пользуемся своим.
S>>А ты используй термины по назначению — я и не буду критиковать их использование. ВВ>"По назначению" — это, видимо, так, как используешь их ты.
Нет, это так, как их используют все.
ВВ>То, что на PS3 запускаются только некоторые игры PS2 да и то под эмулятором не является свидетельством?
А производители не предлагают PS3-аналоги своих PS2 игр? Я, честно, не в курсе — никогда не увлекался приставками.
... << RSDN@Home 1.2.0 alpha rev. 677>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>А что такое локальный канал?
Это твой канал от машины до ближайшего выхода в internet backbone.
ВВ>А если у меня выделенная линия например?
И куда упирается твоя выделенная линия ? ВВ>Да, имея локалку в 100Мб и выход в интернет в 10Мб я увеличу свою скорость на порядок, если контент ко мне будет приходить "изнутри". Но это будет работать, если все сядут в локальные сети и пиринг станет основным способом доставки контента.
Совершенно верно.
ВВ>Да и не решаем ли мы проблему, которой нет? У меня канал в 10Мбит и меня скорость скачки устраивает практически всегда — что через пиринг, что без него. Какой канал у меня будет через 10 лет?
Неизвестно. Известно только одно — твое субъективное восприятие этого канала никак не изменится. Пойми, что даже существующие предложения контента способны забить любой канал.
Вот, опять же, к примеру. Когда-то размер CD людям казался бесконечно большим. Попробуй объяснить кому-то в 1991 году, что игра в 2008 будет продаваться на трех DVD — ведь засмеяли бы. "Такой игры не может быть, потому что ее написание потребует бесконечного времени".
ВВ>Да ради бога, сейчас любой мало мальски уважающий себя трекер не позволит первому встречному что-то публиковать. А на некоторых такая возможность закрыта в принципе — публикует только "тим".
ВВ>Ты описываешь модель доставки контента. Каким образом тут возникают вопросы нарушения копирайта и проч.? Пользоваться контентом за скромные деньги — значит брать его напрокат, к примеру. Какая разница каким именно способом это дело упадет мне на винт?
Очень простая — речь о себестоимости этого способа, которая напрямую влияет на цену сервиса. Цитирую слова Скотта Гатри про Silverlight:
NOS representative reported that they were able to serve 100,000 concurrent users using Silverlight and 40 Windows Media Servers, whereas it would have required 270 servers if they had used Flash Media Servers.
Вроде бы изменилась только модель доставки контента; парни сэкономили 85% TCO благодаря выбору правильной технологии.
Применяем p2p — и экономим еще 14%.
ВВ>Мне непонятно одно — что вам этот пиринг так сдался? Есть сейчас пиринг, через к-й распространяется коммерческий контент?
Есть. Joost. ВВ>А централизованных систем, позволяющих покупать фильмы/игры онлайн, уже довольно много. ВВ>Что дает пиринг в принципе? Позволяет экономить траффик дистрибьютору. Но если даже та же рапида вполне себе выживает с 10-долларовых месячных сборов, то что-то мне кажется, что крупный интернет-издатель вообще не будут особенно по этому вопросу париться.
Посмотрим. Мы пока что рассуждаем о совершенно гипотетических вещах. Возможно, мы оба окажемся неправы. В нашей области адски трудно давать сколь-нибудь корректные предсказания.
... << RSDN@Home 1.2.0 alpha rev. 677>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>А "стрелку вправо" могут и отключить
Если речь идет о PC, мы ее как-нибудь да включим обратно. В конце концов это просто .avi или .mpg, неужели не разберемся ?
ВВ>Т.е. тут речь не о компьютере в обычном понимании идет. Думай в сторону некой медиа-приставки, вроде игровой консоли, у которой своя операционка, естественно не предоставляющая никакого прямого доступа к контенту. А модификация такой консоли, попытка установить на нее другой софт — преступление согласно EULA.
Если так — да. Но исходно речь шла все же об интеграции PC-ТВ. Не надо мне этой приставки, я просто хочу по PC смотреть ТВ.
PD>>Реклама ведь не тем раздражает, что она есть. Когда она ненавязчивая, я ничего против нее не имею. Мне домой приносят две рекламные газетки, и я их обычно просматриваю — вдруг там что-то интересное есть ? Раздражает реклама, которая пытается действовать на мое подсознание, которая навязчиво пытается меня заставить купить то, что я вовсе и не хочу. И такая реклама возможна только в режиме вещания, когда все идет онлайн. Уберите онлайн — и от этой рекламы и следов не останется.
ВВ>Я думаю останется. Но появится возможность, заплатив деньги, скачать вариант без рекламы.
Если все же PC — в нынешнем виде ИМХО нет. Но они что-то другое придумают
Здравствуйте, gandjustas, Вы писали:
G>Да расслабься. Сдал я теорию вероятности и статистику еще на третьем курсе и мне не стыдно за мои высказывания. С точки зрения статистики вполне нормальные измерения были.
PD>>>>Если немного серьезнее. Как преподаватель уже (не как программист) скажу вот что. Не знать что-то не стыдно. Но вот упорствовать в своем незнании не стоит. В конце концов от этого хуже тебе самому будет, не мне же. G>>>Ну тогда изучай ФП, .NET вообще и PLinq в частности, а потом возвращайся.
PD>>Дело в том, что основные принципы их я знаю, а для .Net даже кое-что пишу. G>Как показывают сообщения в форумах — это не так.
Что не так ? Программу тебе показать ? Не могу. Но у заказчика она работает, вроде не жалуется.
PD>>Детали же Linq, к примеру, изучать я не буду, так как мне это просто сейчас не надо. G>Детали не нужны, нужна идея, которую ты не понимаешь.
PD>>В конце концов есть масса вещей, которых я не знаю. G>Очень зря.
"Нельзя объять необъятное" (С) К. Прутков. Покажи мне человека, который имеет право такое про себя не сказать.
PD>>Ты мне предлагаешь Linq изучать, кто-нибудь другой предложит, к примеру, Lisp или Prolog, а когда я работать-то буду ? G>Иногда час изучения чего-то нового помогает сократить работу в несколько раз. G>Про лисп и пролого — http://www.softcraft.ru/paradigm/dp/index.shtml. Можно прям сейчас начинать.
Спасибо, но мне работать все же надо. И от моей работы до Лиспа и Пролога — пости так же как до Полярной звезды .
Здравствуйте, Sinclair, Вы писали:
S>Это твой канал от машины до ближайшего выхода в internet backbone. ВВ>>А если у меня выделенная линия например? S>И куда упирается твоя выделенная линия ?
Это из области "все мы сидим в локалке"? Под локальной сетью обычно имеется в виду все-таки некоторая "сеть", где доступны другие ноды, контент и пр. У меня ADSL2, у меня нет никакой внутренней сети. Причем на самом деле необходимости в ней и не возникает.
Любой мало-мальски приличный торрент, когда разгонится, начинает качать со скоростью более 1Мбайта в сек. Представляем сколько чего можно скачать за ночь. Или за день. Оставив комп включенным.
ВВ>>Да, имея локалку в 100Мб и выход в интернет в 10Мб я увеличу свою скорость на порядок, если контент ко мне будет приходить "изнутри". Но это будет работать, если все сядут в локальные сети и пиринг станет основным способом доставки контента. S>Совершенно верно.
ВВ>>Да и не решаем ли мы проблему, которой нет? У меня канал в 10Мбит и меня скорость скачки устраивает практически всегда — что через пиринг, что без него. Какой канал у меня будет через 10 лет? S>Неизвестно. Известно только одно — твое субъективное восприятие этого канала никак не изменится. Пойми, что даже существующие предложения контента способны забить любой канал.
Я уже высказывал мысль, что скорость каналов должна обогнать рост разрешения видео контента. Потому что последний упирается в пока еще живущие физические носители — тот же блю-рей, который еще и на рынок-то нормально выйти не успел и наверняка проживет довольно долго. А там чего-то сильно отличного от 1960х1080 ты не увидишь, ибо не влезет.
С другой стороны могут конечно перейти от всяких Mp2 на использование других алгоритмов. Ибо я, честно, последнее время в упор не вижу разницы между "аналогом" и каким-нибудь хорошим XVid. Но с другой стороны смысл? Какое разрешение у твоего монитора? А у телевизора? А каково сейчас соотношение SD-телевизоров и HD-телевизоров?
Все-таки эта отрасль достаточно инертна, а вот рост интернет-каналов вширь никакие факторы не сдерживают.
S>Вот, опять же, к примеру. Когда-то размер CD людям казался бесконечно большим. Попробуй объяснить кому-то в 1991 году, что игра в 2008 будет продаваться на трех DVD — ведь засмеяли бы. "Такой игры не может быть, потому что ее написание потребует бесконечного времени".
В то же время сейчас-то меня не удивит, если скажут, что в будущем игра будет занимать несколько террабайт. Причем я спокойно будут скачивать ее через какой-нибудь steam. Как не удивит и то, что физические носители вообще скорее всего отойдут на второй план.
Все равно же тенденции можно прослеживать. Вот сейчас есть четкая тенденция — цифровая дистрибьюция.
ВВ>>Да ради бога, сейчас любой мало мальски уважающий себя трекер не позволит первому встречному что-то публиковать. А на некоторых такая возможность закрыта в принципе — публикует только "тим".
ВВ>>Ты описываешь модель доставки контента. Каким образом тут возникают вопросы нарушения копирайта и проч.? Пользоваться контентом за скромные деньги — значит брать его напрокат, к примеру. Какая разница каким именно способом это дело упадет мне на винт? S>Очень простая — речь о себестоимости этого способа, которая напрямую влияет на цену сервиса. Цитирую слова Скотта Гатри про Silverlight: S>
NOS representative reported that they were able to serve 100,000 concurrent users using Silverlight and 40 Windows Media Servers, whereas it would have required 270 servers if they had used Flash Media Servers.
S>Вроде бы изменилась только модель доставки контента; парни сэкономили 85% TCO благодаря выбору правильной технологии. S>Применяем p2p — и экономим еще 14%.
Мне кажется тут будет рулить не технология, которая позволит сэкономить "еще 14%", а та, которая позволит максимально эффективно бороться с пиратством. Ибо благодаря нему потери будут посильнее.
И вот тут мне кажется, что централизованная доставка позволит сделать это эффективнее, чем пиринг. Хотя, возможно, я не прав, и все как раз наоборот.
ВВ>>Мне непонятно одно — что вам этот пиринг так сдался? Есть сейчас пиринг, через к-й распространяется коммерческий контент? S>Есть. Joost.
Он разве коммерческий?
ВВ>>А централизованных систем, позволяющих покупать фильмы/игры онлайн, уже довольно много. ВВ>>Что дает пиринг в принципе? Позволяет экономить траффик дистрибьютору. Но если даже та же рапида вполне себе выживает с 10-долларовых месячных сборов, то что-то мне кажется, что крупный интернет-издатель вообще не будут особенно по этому вопросу париться. S>Посмотрим. Мы пока что рассуждаем о совершенно гипотетических вещах. Возможно, мы оба окажемся неправы. В нашей области адски трудно давать сколь-нибудь корректные предсказания.
Ну если не даваться в детали, то можно, почему нет? Есть же несколько довольно явных тенденций, как мне кажется:
— уход на покой физических носителей, переход на цифровую дистрибьюцию
— объедение различных медиа-устройсв вроде видео-плеера, игровой приставки и пр. в единое развлекательное устройство (что уже почти произошло), через которое будет и телевидение "с кочергой", и видео, и игры. А также музыка и многое другое. Причем это устройство не будут по факту эквивалентно PC и не заменит его.
Здравствуйте, Воронков Василий, Вы писали:
S>>По прежнему продолжаю непонимать место ассемблера в приставочных играх. С предметом незнаком. Есть какие-то свидетельства того, что их пишут непереносимым образом?
ВВ>То, что на PS3 запускаются только некоторые игры PS2 да и то под эмулятором не является свидетельством?
Естественно, игра, скомпилированная под PS2 не будет запускаться на PS3, поскольку сильно другая архитектура.
Эмулятор нужен для проигрывания на ps3 игр от ps1/ps2, но это проблемы совместимости, а не переносимости.
Но это не значит, что они не могут быть перенесены на ps3, т.е. откомпилированы заново под нее. И переизданы соответственно.
Однако тут надо не забывать, что:
1. Переиздание игры — это расходы. Окупятся ли они?
2. Да вот не факт, что окупятся, игры-то уже "староваты",под ps3 можно ведь выпустить гораздо более "крутые" современные игры.
3. Надо очень помнить, что на руках населения сейчас уйма ps2, и она до сих пор производится и продается, причем вполне неплохо (цена низкая стала) , то есть издетель вполне себе получает доход и от ps2-игр не дергаясь с их переизданием.
Собственно, Сони убрала из ps3 совместимость с ps2 (все, теперь и через эмулятор нельзя, ибо эмулировался только ЦП, а графических процессороров раньше в соньке было 2 — новый и оставленный для совместимости с ps2). Совместимость убрали с обоснованием, что данная возможность была мало интересна пользователям, а понижение стоимости приставки — гораздо интереснее.
С другой стороны, посмотри на новые игры. Многие игры выходят мультиплатформой. PC, PS3, X-BOX — это очень разные платформы, а игры делают сразу подо все.
Не все, есть и эксклюзивы, про них можно поговорить отдельно. Например, что да, мультиплатформа не может максимально использовать возможности конкретной приставки (вспомнить хоть пресловутый процессор у PS3 — замечательная вещь, только полностью другая чем PC/XBox и глубоко ориентирован на параллельные вычисления).
И ручная оптимизация под Xbox не даст ничего (а то и ухудшит даже) для PS3, и наоборот.
Ладно, дальше к переносимости. Интересно посмотреть на новые "сиюминутные" игры. Ну, типа по популярным фильмам. Это обычно достаточно примитивные игры, которые надо выпустить очень быстро и накрыть максимальную аудиторию. Загляни в любой дисковый магазин, и ты увидишь одновременно продаваемые диски с полностью одной и той же игрой для
1. РС
2. XBox,
3. PS3
4. PS2
Так что без проблем делать одну игру под ps2 и ps3 если она достаточно проста чтобы работать на ps2 (как более слабой платформе).
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Если речь идет о PC, мы ее как-нибудь да включим обратно. В конце концов это просто .avi или .mpg, неужели не разберемся ?
Да не дадут тебе этого на PC. Или дадут через дикие ограничение ОС, которую надо будет в специальный "медиа-режим" вводить, чтобы можно было высококачественный контент смотреть. А скаченное через какой-нибудь торрент вообще не будут запускаться.
ИМХО как только в полную силу развернется цифровая дистрибьюция, и доходы больших компаний будут зависеть от того, сможешь ли прокрутить рекламу или нет — ужесточения появятся просто дикие.
Так что надо бы припасти VHS-плеер на "черный день"
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Здравствуйте, Sinclair, Вы писали:
S>>Это твой канал от машины до ближайшего выхода в internet backbone. ВВ>>>А если у меня выделенная линия например? S>>И куда упирается твоя выделенная линия ?
ВВ>Это из области "все мы сидим в локалке"? Под локальной сетью обычно имеется в виду все-таки некоторая "сеть", где доступны другие ноды, контент и пр. У меня ADSL2, у меня нет никакой внутренней сети. Причем на самом деле необходимости в ней и не возникает.
У меня тоже АДСЛ2 и локалка есть. Иногда полезна — внутренний канал несколько ширше внешнего пока.
Здравствуйте, fmiracle, Вы писали:
F>Естественно, игра, скомпилированная под PS2 не будет запускаться на PS3, поскольку сильно другая архитектура. F>Эмулятор нужен для проигрывания на ps3 игр от ps1/ps2, но это проблемы совместимости, а не переносимости. F>Но это не значит, что они не могут быть перенесены на ps3, т.е. откомпилированы заново под нее. И переизданы соответственно.
Там не все так просто. Сони вообще вначале планировала "включить" в ПС3 потраха о ПС2, чтобы старые игры запускались. Так что видать все же в совместимости дело.
F>Собственно, Сони убрала из ps3 совместимость с ps2 (все, теперь и через эмулятор нельзя, ибо эмулировался только ЦП, а графических процессороров раньше в соньке было 2 — новый и оставленный для совместимости с ps2). Совместимость убрали с обоснованием, что данная возможность была мало интересна пользователям, а понижение стоимости приставки — гораздо интереснее.
А это неправда. Я сам давеча играл на ПС3 в Shadow of Collosus и Okami.
F>С другой стороны, посмотри на новые игры. Многие игры выходят мультиплатформой. PC, PS3, X-BOX — это очень разные платформы, а игры делают сразу подо все.
Игр, которые выходят сразу на всех платформах, далеко не большинство. На боксе традиционный вариант — вышла на боксе, через годик на PC. Причем за этот годик PC успевают "подрасти". И по сравнению с боксом предоставляют просто огромное преимущество по мощности. Причем игры на них по сравнению с боксом тормозят.
F>Не все, есть и эксклюзивы, про них можно поговорить отдельно. Например, что да, мультиплатформа не может максимально использовать возможности конкретной приставки (вспомнить хоть пресловутый процессор у PS3 — замечательная вещь, только полностью другая чем PC/XBox и глубоко ориентирован на параллельные вычисления).
Вот зачем PS3 этот процессор, если никто не собирается писать с учетом его возможностей.
F>И ручная оптимизация под Xbox не даст ничего (а то и ухудшит даже) для PS3, и наоборот.
Это так. Но основной рынок для того же бокса — эксклюзивные проекты, console sellers. Всякие там Gears of Way, Mass Effect на соньке не выходят.
F>Ладно, дальше к переносимости. Интересно посмотреть на новые "сиюминутные" игры. Ну, типа по популярным фильмам. Это обычно достаточно примитивные игры, которые надо выпустить очень быстро и накрыть максимальную аудиторию. Загляни в любой дисковый магазин, и ты увидишь одновременно продаваемые диски с полностью одной и той же игрой для F>1. РС F>2. XBox, F>3. PS3 F>4. PS2 F>Так что без проблем делать одну игру под ps2 и ps3 если она достаточно проста чтобы работать на ps2 (как более слабой платформе).
Такие игры есть, и они всегда определяются наиболее слабой платформой. И как я уже говорил, они и выглядят соответствующе.
Ты вот лучше мне объясни почему боксовые игры на компьютере далеко не летают?
Здравствуйте, Геннадий Васильев, Вы писали:
ГВ>С if и switch, как раз понятно: они вполне укладываются в функциональный стиль — выбор и выбор.
Ты о чём? Ни в C#, ни в C/C++ ни if, ни switch ничего не возвращают и никогда не будут возвращать. Так что про immutable стиль в этих языках забудь.
ГВ>>>Что он должен возвращать? IT>>Цикл тоже хороший пример конструкции с изменяемым состоянием. В FP он обычно заменяется функциями с хвостовой рекурсией, которые, ты не поверишь, возвращают значения.
ГВ>Ты уходишь от ответа. Так что же должен возвращать цикл? Особено это интересно в контексте обсуждения immutable-стиля.
Так я же тебе как раз и объясняю или ты опять не понял Функциональный аналог цикла — это функция с хвостовой рекурсией. Вот сейчас специально глянул на свой первый попавшийся проект на Немерле. На 1000+ строк кода ни одного for/while/foreach. Да и в самом языке они реализуются как макросы через функции с хвостовой рекурсией. Т.е. это просто сахарок для императивщиков.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Да не дадут тебе этого на PC.
Речь шла об интеграции ТВ и PC. Как это мне чего-то не дадут на IBM PC ? Не дадут — сами возьмем
>Или дадут через дикие ограничение ОС, которую надо будет в специальный "медиа-режим" вводить, чтобы можно было высококачественный контент смотреть. А скаченное через какой-нибудь торрент вообще не будут запускаться.
Не верю. Расхакают в конечном счете все что угодно.
>ВВ>ИМХО как только в полную силу развернется цифровая дистрибьюция, и доходы больших компаний будут зависеть от того, сможешь ли прокрутить рекламу или нет — ужесточения появятся просто дикие.
Посмотрим .
ВВ>Так что надо бы припасти VHS-плеер на "черный день"
Лежит дома. Купил гибрид DVD + VHS (у меня много лент), а старый VHS лежит себе, не знаю куда девать.
ВВ>Там не все так просто. Сони вообще вначале планировала "включить" в ПС3 потраха о ПС2, чтобы старые игры запускались. Так что видать все же в совместимости дело.
...
F>>Собственно, Сони убрала из ps3 совместимость с ps2 (все, теперь и через эмулятор нельзя, ибо эмулировался только ЦП, а графических процессороров раньше в соньке было 2 — новый и оставленный для совместимости с ps2). Совместимость убрали с обоснованием, что данная возможность была мало интересна пользователям, а понижение стоимости приставки — гораздо интереснее.
ВВ>А это неправда. Я сам давеча играл на ПС3 в Shadow of Collosus и Okami.
Модель и год выпуска?
На последних моделях PS3 была убрана совместимость с рс2.
Включали графический процессор, т.к. его эмулировать было сложно. И вроде в самых первых еще какие-то компоненты были, может и ЦП, во всяком случае там была вообще 99.9% совместимость. В более массовых версиях приставки обещалось "почти все игры отличны, ингда возможны глюки"
В последних — уже ничего нет.
Я этот вопрос изучал перед покупкой пс3.
В инете есть даже таблицы совместимости по версиям приставки
Но это ничего не значит о переносимости игр.
ВВ>Игр, которые выходят сразу на всех платформах, далеко не большинство. На боксе традиционный вариант — вышла на боксе, через годик на PC. Причем за этот годик PC успевают "подрасти". И по сравнению с боксом предоставляют просто огромное преимущество по мощности. Причем игры на них по сравнению с боксом тормозят.
1. я же не писал ВСЕ игры. Но есть такие. Соответственно переносимость возможна. Это уже решение разработчика — замахнуться на более широкий рынок или вложиться в оптимизацию под одну платформу.
2. Какой отсюда вывод? Что оптимизация на низком уровне сильно невыгодна — чтобы сделать качественную игру для трех платформ приходится утраивать бюджет Но использовать приходится, поскольку (пока?) других возможностей нет...
ВВ>Вот зачем PS3 этот процессор, если никто не собирается писать с учетом его возможностей.
Ну для тех же эксклюзивов (вообще-то и у пс3 есть эксклюзивы).
ВВ>Такие игры есть, и они всегда определяются наиболее слабой платформой. И как я уже говорил, они и выглядят соответствующе.
Вот поскольку они "выглядят соответствующе" никто и не переносит старые хиты пс2 на пс3.
ВВ>Ты вот лучше мне объясни почему боксовые игры на компьютере далеко не летают?
Вроде бы очевидно.
Продажи под РС меньше, бюджет "оптимизаторов" — меньше.
Была бы возможна качественная автоматическая оптимизация — работало бы под РС лучше. Но подходящих компиляторов, видимо, нет, а ручная оптимизация под ХБокс убивает работу под РС. Либо делать чуть ли не две программы с различной оптимизацией, но это черевато удвоением бюджета (а с ps3 утроение).
Выбирается "приоритетная" платформа, под которую идет заточка, для остальных делается "лишь бы работало".
Собственно, это именно то, про что говорит Sinclair — жесткой ручной оптимизацией можно получить отличные результаты для конкретной платформы, но при этом для другой платформы — будет работать гораздо хуже чем могла бы.
В консолях хорошо — 1 жесткая платформа (для эксклюзивов), может быть две-с-половиной для мультиплатформы (ПС менее приоритетный рынок, и можно положиться на хорошее железо у геймеров).
Можно сделать и три версии программы. Можно даже утроить бюджет и сделать хорошо оптимизированную под все 3 платформы.
А в каком-либо серверном коде? Вариаций комплектации серверов масса, и постоянно появляются новые, под которые, как ожидается, программа будет работать, причем гораздо лучше, нежели под старые. И тут уже не получится сделать 23243 версий программы под все возможные разные сервера — уже совсем нереально.
А динамическая компиляция и оптимизация может очень даже помочь (это даже не говоря про оптимизации по результатам работы).
Здравствуйте, Sinclair, Вы писали:
EC>>Здесь имеется в виду хорошее с точки зрения исключительно применения технологии или со стороны конечного пользователя? S>И то и другое.
В фаерфоксе работает отвратно.
Здравствуйте, AndrewVK, Вы писали:
AVK>Здравствуйте, Pavel Dvorkin, Вы писали:
PD>>И полоса в Канаде тоже . Пусть и не столь.
AVK>Ага, подумаешь в 2 раза короче
А тебе таки нужно от Бомбея и до Лондона ?
PD>>Сдается мне, что о персональных компьютерах в 1981 году говорили примерно то же самое.
AVK>Нет, не говорил.
Ты, может , и не говорил, но при чем здесь ты ?
AVK>>>Но ограничен размером экрана .
PD>>Сдается мне, что и на ПК он тоже ограничен.
AVK>Ну хватит уже передергиванием заниматься. Не может быть UI одинаковым на устройствах, отличающихся по площади минимум раз в 15.
Не может. Но это не значет , что нечто аналогичное может.
PD>>Ну значит я объяснять разучился.
AVK>Нет, ты в принципе разучился признавать свою неправоту и споришь даже в абсолютно феерических ситуациях.
ИМХО это именно ты делаешь. Например, зачем тебе понадобилось спорить на мое вполне нейтральное замечание, что я не был в Коломне ?
PD>>>> В Коломне я не был.
AVK>>>Значит ее не существует?
PD>>Что за чушь ?
AVK>А к чему тогда эта вечная демагогия про "Мааасква не Россия"?
В огороде бузина, а в Киеве дядька. Что-то скучно становится с тобой обсуждать. Ну написал я , что не был там, и все дела. Так нет, надо глубокие выводы делать.
А Москва не Россия, верно. Я в ней 5 лет прожил, так что могу судить.
AVK>>>Так если по Москве судить нельзя, то по Омску тем более.
PD>>По Омску скорее можно. Дело в том, что Омск — вполне типичный областной центр, таких десятки.
AVK>
И что тут смешного ? Он действительно типичный областной центр.
AVK>>>Тебя клинит на Москве, что ли? У меня на даче, что в 130 км от МКАД тоже Москва, что там вся деревня в тарелках?
PD>>Я же тебе уже сказал — ближнее Подмосковье по духу скорее Москва.
AVK>Павел, 130 км это уже далеко не ближнее подмосковье. Это самая натуральная провинция, там до Рязани в 2 раза ближе, чем до Москвы.
Ну не знаю, ты там живешь, тебе в конце концов виднее. У меня сложилось иное представление. Предлагаю признать (хоть в этом, это же не LinQ , что у нас мнения на этот счет разные и согласиться, что каждый имеет право на свое. Устраивает ? Честно говоря, все это очень уж далеко от философии программирования
PD>>Не смеши. Кабельных сетей в Омске практически нет.
AVK>И как же ты телевизер смотришь?
Антенна на крыше стоит. Коллективная. 17 каналов. Представь себе, 95% Омска живет именно так. Если не больше. Технически отличие от 1980 года только в том, что тогда каналов было 3, ну и часть каналов теперь — дециметровые (кстати, у меня дома доступны стали 2-3 года назад)
PD>>Как вы далеки от понимания реальной жизни в России...
AVK>Ну ну.
Увы. Пока что твое высказывание насчет кабельного ТВ в Омске мне напомнило высказывание Марии-Антуанетты (кажется) "Если крестьяне жалуются, что им не хватает хлеба, то почему они не едят пирожные" ?
Здравствуйте, Pavel Dvorkin, Вы писали:
>>Или дадут через дикие ограничение ОС, которую надо будет в специальный "медиа-режим" вводить, чтобы можно было высококачественный контент смотреть. А скаченное через какой-нибудь торрент вообще не будут запускаться.
PD>Не верю. Расхакают в конечном счете все что угодно.
Расхакайте PS3 Пока что-то ни у кого не выходит. Платформа далеко не новая.
Здравствуйте, fmiracle, Вы писали:
ВВ>>А это неправда. Я сам давеча играл на ПС3 в Shadow of Collosus и Okami. F>Модель и год выпуска? F>На последних моделях PS3 была убрана совместимость с рс2.
Можно ссылочку на официальную информацию? Модель 60-гиговая, кажется, покупалась в районе года назад.
F>В последних — уже ничего нет. F>Я этот вопрос изучал перед покупкой пс3. F>В инете есть даже таблицы совместимости по версиям приставки
Мне кажется, что ты что-то путаешь. Какой им смысл откручивать обратную совместимость, когда она была раньше?
F>Но это ничего не значит о переносимости игр. ВВ>>Игр, которые выходят сразу на всех платформах, далеко не большинство. На боксе традиционный вариант — вышла на боксе, через годик на PC. Причем за этот годик PC успевают "подрасти". И по сравнению с боксом предоставляют просто огромное преимущество по мощности. Причем игры на них по сравнению с боксом тормозят.
F>1. я же не писал ВСЕ игры. Но есть такие. Соответственно переносимость возможна. Это уже решение разработчика — замахнуться на более широкий рынок или вложиться в оптимизацию под одну платформу. F>2. Какой отсюда вывод? Что оптимизация на низком уровне сильно невыгодна — чтобы сделать качественную игру для трех платформ приходится утраивать бюджет Но использовать приходится, поскольку (пока?) других возможностей нет...
Сдается мне, что бюджет если и не утраивается, что увеличивается серьезно так. Причем версии под разные платформы могут делать разные команды.
ВВ>>Вот зачем PS3 этот процессор, если никто не собирается писать с учетом его возможностей. F>Ну для тех же эксклюзивов (вообще-то и у пс3 есть эксклюзивы).
Кто ж спорит Но после того, как она ни с того ни с сего сломалась не взлюбил я ее сильно.
Вот только разработка такого "заточенного под ПС3" эксклюзива как раз и приведет к фактически непортируемой игре.
ВВ>>Такие игры есть, и они всегда определяются наиболее слабой платформой. И как я уже говорил, они и выглядят соответствующе. F>Вот поскольку они "выглядят соответствующе" никто и не переносит старые хиты пс2 на пс3.
А я утверждал обратное?
ВВ>>Ты вот лучше мне объясни почему боксовые игры на компьютере далеко не летают? F>Вроде бы очевидно. F>Продажи под РС меньше, бюджет "оптимизаторов" — меньше. F>Была бы возможна качественная автоматическая оптимизация — работало бы под РС лучше. Но подходящих компиляторов, видимо, нет, а ручная оптимизация под ХБокс убивает работу под РС. Либо делать чуть ли не две программы с различной оптимизацией, но это черевато удвоением бюджета (а с ps3 утроение). F>Выбирается "приоритетная" платформа, под которую идет заточка, для остальных делается "лишь бы работало".
Ну все верно. На что ты в таком случае возражал изначально?
F>Собственно, это именно то, про что говорит Sinclair — жесткой ручной оптимизацией можно получить отличные результаты для конкретной платформы, но при этом для другой платформы — будет работать гораздо хуже чем могла бы.
Я не знаю, что Синклер говорит. Лучше у него уточнить.
Я привел пример приставки — как той самой платформу, под которую часто приходится оптимизировать софт, используя все особенности этой платформы и делай этот самый софт практически непортабельным.
F>В консолях хорошо — 1 жесткая платформа (для эксклюзивов), может быть две-с-половиной для мультиплатформы (ПС менее приоритетный рынок, и можно положиться на хорошее железо у геймеров). F>Можно сделать и три версии программы. Можно даже утроить бюджет и сделать хорошо оптимизированную под все 3 платформы. F>А в каком-либо серверном коде? Вариаций комплектации серверов масса, и постоянно появляются новые, под которые, как ожидается, программа будет работать, причем гораздо лучше, нежели под старые. И тут уже не получится сделать 23243 версий программы под все возможные разные сервера — уже совсем нереально. F>А динамическая компиляция и оптимизация может очень даже помочь (это даже не говоря про оптимизации по результатам работы).
Речь о том, что оптимизация под конкретная железо имеет место быть. И пока даже не видно перспективы ее полного исчезновения. А не о том, что она нужна и полезна везде.
Здравствуйте, Воронков Василий, Вы писали:
Pzz>>да еще они до кучи пару гигов забесплатно дают на дисках своих серверов, а деньги собираются зарабатывать на дополнительных услугах. Pzz>>Про счета рапиды я ничего не знаю. Ютьюб, говорят, платил за интернет что-то типа лимона в месяц, только за траффик.
ВВ>Ну видно зарабатывают они куда больше.
Я слышал, что это убыточный сервис.
Здравствуйте, EvilChild, Вы писали:
Pzz>>>да еще они до кучи пару гигов забесплатно дают на дисках своих серверов, а деньги собираются зарабатывать на дополнительных услугах. Pzz>>>Про счета рапиды я ничего не знаю. Ютьюб, говорят, платил за интернет что-то типа лимона в месяц, только за траффик. ВВ>>Ну видно зарабатывают они куда больше. EC>Я слышал, что это убыточный сервис.
Ютьюб? Вроде бы его Гугл же купил недавно за кругленькую сумму. Смысл тогда тратиться на убыточный сервис? Может, я, конечно, что-то не понимаю
Ну или та же рапида — не может же она быть убыточной. Ибо смысл тогда какой, последний оплот пиратства? Мне кажется, что вполне она живет за счет этих своих премиум аккаунтов.
Здравствуйте, IT, Вы писали:
ГВ>>if/switch не предполагают изменения состояния. Pattern matching это что по-твоему, как не завуалированный if? IT>if/switch не возвращающие значение и не меняющие состояния бесполезны и безсмысленны.
Упс. Так они и не возвращают значение, и не меняют состояние. Состояние меняется операторами присвоения значения, а это совсем не if/switch. Хотя "возврат значения" им приписать можно — в некоторых рамках.
ГВ>>Да нет, это я как раз понял. Мне по-прежнему непонятно, что должно мешать программировать в FP-стиле на языках семейства С? Семантика if/switch здесь точно не помеха.
IT>Самая что ни на есть помеха. Любой алгоритм, выполняющий полезную работу, производит действия над определёнными данными. В императиве эти действия производятся непосредственно над самими данными, меняя тем самым их текущее состояние.
Ну, закрутилась шарманка. С чего ты взял, что в императиве входные данные обязательно модифицируются? Ничего подобного. Они могут модифицироваться, но это совершенно не обязательно.
IT>В FP текущее состояние не меняется, оно каждый раз воссоздаётся заново. Это состояние хранится в передаваемых параметрах и передаётся в возвращаемых значениях как эстафетная палочка следующей части алгоритма.
Угу, угу.
IT>Если конструкция не возвращает значения, то в immutable стиле она перестаёт работать как часть процесса вычисления и становится бесполезной.
Расскажи это авторам pattern matching, COND.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>А тебе таки нужно от Бомбея и до Лондона ?
Мне нужно, чтобы ты осознал, что Россия №1 по площади и всего лишь №9 по населению.
PD>>>Сдается мне, что о персональных компьютерах в 1981 году говорили примерно то же самое.
AVK>>Нет, не говорил.
PD>Ты, может , и не говорил, но при чем здесь ты ?
А при том, что ты со мной беседуешь. Если кто то там что то говорил — все вопросы к нему.
AVK>>Ну хватит уже передергиванием заниматься. Не может быть UI одинаковым на устройствах, отличающихся по площади минимум раз в 15.
PD>Не может. Но это не значет , что нечто аналогичное может.
Означает. Ты попробуй ради интереса хоть что нибудь под мелкий дивайс написать, а потом мы с тобой поговорим, чем их UI от UI десктопа отличается.
AVK>>Нет, ты в принципе разучился признавать свою неправоту и споришь даже в абсолютно феерических ситуациях.
PD>ИМХО это именно ты делаешь. Например, зачем тебе понадобилось спорить на мое вполне нейтральное замечание, что я не был в Коломне ?
Затем, что ты считаешь что вся Россия как твой Омск, тогда как в плане телекоммуникаций Россия за Уралом как раз таки нехарактерная ситуация, а вот европейская территория — характерная, просто потому что там живет значительно больше половины населения.
PD>В огороде бузина, а в Киеве дядька. Что-то скучно становится с тобой обсуждать.
Чего, не ведусь на твои приемчики?
PD> Ну написал я , что не был там, и все дела.
Нет, не все. Ты заявил, что между Коломной и Москвой разница небольшая (а ближнее и дальнее подмосковье, так вообще одно и тоже), и все это нехарактерно для России.
PD> Так нет, надо глубокие выводы делать.
Глубокие выводы здесь ты в основном делаешь.
PD>А Москва не Россия, верно. Я в ней 5 лет прожил, так что могу судить.
Ага. Замучался я уже лапшу с ушей снимать.
AVK>>
PD>И что тут смешного ?
То и смешно, что за Уралом таких городов совсем не десятки. А вот таких как Коломна — их даже не десятки, сотни. Классический провинциальный городок, не богаче соседней Рязани.
AVK>>Павел, 130 км это уже далеко не ближнее подмосковье. Это самая натуральная провинция, там до Рязани в 2 раза ближе, чем до Москвы.
PD>Ну не знаю, ты там живешь, тебе в конце концов виднее.
Ну вот тогда и не надо мне тут рассказывать, что Москва не Россия.
AVK>>И как же ты телевизер смотришь?
PD>Антенна на крыше стоит. Коллективная. 17 каналов. Представь себе, 95% Омска живет именно так.
А антенна откуда сигнал принимает. Прямо из Останкина?
PD>Увы. Пока что твое высказывание насчет кабельного ТВ в Омске
Я не знаю что там у вас конкретно в Омске. Наличие кабелей весьма характерно для европейской части, по крайней мере для небольших городов, которым советская власть строительством телецентров не озаботилась. Но суть то не в кабелях, суть в том, что несмотря на аналоговый местный канал доставки (будь то кабель или местный телецентр), в локальный хаб контент доставляется давно уже в цифровой форме. Просто потому что втыкать MPEG декодер в каждый телеприемник пока еще дороговато и заметно сказывается на цене недорогих телевисеров. Но не мне тебе расказывать, что эти декодеры дешевеют и будут продолжать дешеветь в обозримом будущем, что уже немалый процент телеприемников продается с поддержкой DVB-T/DVB-C. Так что, как только это станет оправданным, трансляцию переведут в параллеть на этот самый DVB-T, просто потому что диапазон используется эффективнее и меньше гемороя со стабильностью приема. При этом принципиально ничего не поменяется. У меня вот на даче тарелька, дома аналоговый кабель, разницы для юзеря практически нет, разве что тарелька сама программу транслирует, а для аналогового кабеля приходится из инета качать.
PD> мне напомнило высказывание Марии-Антуанетты (кажется) "Если крестьяне жалуются, что им не хватает хлеба, то почему они не едят пирожные" ?
Тарелька со всеми прибамбасами мне обошлась в 5000 р. и час работы. Не думаю, что это такие уж огромные деньги даже для Омска.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Геннадий Васильев, Вы писали:
ГВ>Тогда да — цикл определяется списком
Иногда списком, иногда рекурсией. С моей точки зрения первое все таки читабельнее и лучше совместимо с современный мейнстримом, но и рекурсия вполне работоспособна.
ГВ>(в частном случае — ленивым) управляющих параметров. Конечный он или бесконечный, можно определять изнутри самой функции, реализующей тело цикла.
Бесконечный список, если он возможен, более универсален — можно задавать любое условие его окончания снаружи.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Геннадий Васильев, Вы писали:
ГВ>>>if/switch не предполагают изменения состояния. Pattern matching это что по-твоему, как не завуалированный if? IT>>if/switch не возвращающие значение и не меняющие состояния бесполезны и безсмысленны.
ГВ>Упс. Так они и не возвращают значение, и не меняют состояние.
Вот именно. Т.е. они вообще ничего не делают. И поэтому бесполезны.
ГВ>Ну, закрутилась шарманка. С чего ты взял, что в императиве входные данные обязательно модифицируются? Ничего подобного. Они могут модифицироваться, но это совершенно не обязательно.
А почему именно входные данные. Модифицируется контекст, а в императиве это не только входные данные.
IT>>Если конструкция не возвращает значения, то в immutable стиле она перестаёт работать как часть процесса вычисления и становится бесполезной.
ГВ>Расскажи это авторам pattern matching, COND.
Pattern matching как раз великолепно возвращает данные. Аж со свистом.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, FR, Вы писали:
IT>>if/switch не возвращающие значение и не меняющие состояния бесполезны и безсмысленны.
FR>А вот тут ты явно подменяешь понятия, в том же си ничто ни мешает писать так чтобы if или switch всегда возвращали значения, кроме того если уж совсем до маразма доходить то никто еще тернарный оператор "?" не отменял.
Это сейчас ты начнёшь подменять понятия, если я попрошу тебя привести код, где if и switch возвращают значения.
FR>Нисколько ни помеха. Чтобы функциональнй стиль нормально работал, достаточно чтобы функция не меняла никакие внешние состояния и не имела мутабельного внутренего сохраняемого между вызовами состояния. Что происходит внутри нее при этом совершенно неважно, даже без проблем допустимо чтобы внутри она использовала и мутабельные переменные и циклы или любую другую имеративщину.
Это кому не важно? Тебе? Ну с этим я спорить не буду. Но и функциональным стилем это назвать не могу.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, IT, Вы писали:
IT>Это кому не важно? Тебе? Ну с этим я спорить не буду. Но и функциональным стилем это назвать не могу.
Для функционального стиля единственное что нужно чистота функций, все остальное шашечки, так что можешь не называть, но это будет самый что ни на есть функциональный стиль.
Вообще похоже тема скоро скатится в тупой терминологический спор как было с сахором
Здравствуйте, FR, Вы писали:
FR>Для функционального стиля единственное что нужно чистота функций, все остальное шашечки, так что можешь не называть, но это будет самый что ни на есть функциональный стиль. FR>Вообще похоже тема скоро скатится в тупой терминологический спор как было с сахором
В твоих рассуждениях есть один косяк. Ты можешь написать ф-цию которая будет вести себя в функциональном стиле, но при этом быть написанной в императивном стиле. Но смысл такой ф-ции? Получается, что у тебя часть кода в императивном стиле, часть кода — как бы клиентская — в фукциональном стиле. А где граница-то между тем и другим?
Здравствуйте, IT, Вы писали:
FR>>Не важно для того чтобы программировать в ФП стиле, и писать при этом чисто функционально даже на си.
IT>Что-то подобное я и ожидал. Было бы забавно посмотреть на реальный код хотя строк в 500 в подобном стиле.
Ничего страшного и ужасного, если конечно алгоритм ложится нормально на функциональщину.
Я бы спокойно и без проблем некторые вещи (на C++ там еще const и функторы здорово помогают)
писал в чисто таком стиле, но работодатель к сожалению не поймет, приходится поэтому писать
в более гибридном стиле.
IT>Удивительно, насколько люди могут далеко зайти в попытках отстаивания своих заблуждений.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>В твоих рассуждениях есть один косяк. Ты можешь написать ф-цию которая будет вести себя в функциональном стиле, но при этом быть написанной в императивном стиле. Но смысл такой ф-ции? Получается, что у тебя часть кода в императивном стиле, часть кода — как бы клиентская — в фукциональном стиле. А где граница-то между тем и другим?
Нет никакого косяка единственно что требуется чтобы писать в функциональном стиле это чистота функций. При этом минимальная сущность которой мы в ФП оперируем это именно функция, поэтому внутри нее вполне допустима и императивная грязь, но на эту императивщину есть ограничение, она не долнжа влиять на чистоту функции, и поэтому например нельзя изменять глобальные (или статические внутри функций в С++) переменные. Здесь http://www.digitalmars.com/d/2.0/accu-functional.pdf подробно все описано.
Здравствуйте, FR, Вы писали:
FR>Нет никакого косяка единственно что требуется чтобы писать в функциональном стиле это чистота функций. При этом минимальная сущность которой мы в ФП оперируем это именно функция, поэтому внутри нее вполне допустима и императивная грязь, но на эту императивщину есть ограничение, она не долнжа влиять на чистоту функции, и поэтому например нельзя изменять глобальные (или статические внутри функций в С++) переменные. Здесь http://www.digitalmars.com/d/2.0/accu-functional.pdf подробно все описано.
А где ты оперируешь такой сущностью как функция? В других функциях?
Здравствуйте, FR, Вы писали:
ВВ>>А где ты оперируешь такой сущностью как функция? В других функциях? FR>Угу. По сути в функциональщине больше ничего и нету.
Ну таким образом "функциональщина" — это что, по твоему мнению? Просто когда часть кода написана в ф-ном стиле, а часть как угодно?
Ты вот ратуешь за "чистоту" функций — т.е. внутри что угодно, а внешне все должно быть stateless, immutable и проч. — но для чего нужна эта "чистота"? Для того, чтобы код в других фукнциях выглядел функционально? При это часть кода у тебя проекте по-прежнему будет в императивном стиле.
Мне казалось, что ФП предполагает нечто иное. При твоем подходе ты всю логику можешь описать в императивном стиле с лесом if-ов, свитчей и проч. — собственно, с чем и боремся, кстати говоря — при этом какая-то внешняя часть проекта будет оформлена "красиво".
Действительно "функциональщина" какая-то получается.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Ну таким образом "функциональщина" — это что, по твоему мнению? Просто когда часть кода написана в ф-ном стиле, а часть как угодно?
Так в любых даже самых что ни на есть функциональных строгих языках часть кода всегда императивна
ВВ>Ты вот ратуешь за "чистоту" функций — т.е. внутри что угодно, а внешне все должно быть stateless, immutable и проч. — но для чего нужна эта "чистота"? Для того, чтобы код в других фукнциях выглядел функционально? При это часть кода у тебя проекте по-прежнему будет в императивном стиле.
Во первых я за это не ратую, я как раз за то чтобы и внутри было все функционально. Я просто демонстрирую что для написания в функциональном стиле шашечки не необходимы.
ВВ>Мне казалось, что ФП предполагает нечто иное. При твоем подходе ты всю логику можешь описать в императивном стиле с лесом if-ов, свитчей и проч. — собственно, с чем и боремся, кстати говоря — при этом какая-то внешняя часть проекта будет оформлена "красиво".
Императивный стиль ни имеет никакого отношения к лесу ифов, их без проблем можно нагородить и в чисто функциональных языках. Вообще у меня уже возникает впечатление что немерлисты уже тут так промыли всем мозги что люди уже принимают за ФП только сахар из немерле.
ВВ>Действительно "функциональщина" какая-то получается.
Угу и она уже дает кучу преимуществ из функциональных языков, а именно модульность и инкапсуляцию кода, упрощение отладки, легкое распаралеливание.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Здравствуйте, FR, Вы писали:
ВВ>>>А где ты оперируешь такой сущностью как функция? В других функциях? FR>>Угу. По сути в функциональщине больше ничего и нету.
ВВ>Ну таким образом "функциональщина" — это что, по твоему мнению? Просто когда часть кода написана в ф-ном стиле, а часть как угодно?
Писать ВСЕ в функциональном стиле а)неэффективно б)не всегда возможно. Практически в любом проекте на функ. языке будет немного императивного кода.
ВВ>Ты вот ратуешь за "чистоту" функций — т.е. внутри что угодно, а внешне все должно быть stateless, immutable и проч. — но для чего нужна эта "чистота"? Для того, чтобы код в других фукнциях выглядел функционально? При это часть кода у тебя проекте по-прежнему будет в императивном стиле.
Чем больше чистых функций, тем проще создавать из них другие чистые функции, тем проще распараллеливать и оптимизировать код.
ВВ>Мне казалось, что ФП предполагает нечто иное.
Что именно?
Здравствуйте, gandjustas, Вы писали:
ВВ>>Ну таким образом "функциональщина" — это что, по твоему мнению? Просто когда часть кода написана в ф-ном стиле, а часть как угодно? G>Писать ВСЕ в функциональном стиле а)неэффективно б)не всегда возможно. Практически в любом проекте на функ. языке будет немного императивного кода.
А в данном случае речь о том, что "функциональность" соблюдается только снаружи. "Распарелливать" и "оптимизировать" можно и без нее. Пишите "красиво" на ООП.
ВВ>>Ты вот ратуешь за "чистоту" функций — т.е. внутри что угодно, а внешне все должно быть stateless, immutable и проч. — но для чего нужна эта "чистота"? Для того, чтобы код в других фукнциях выглядел функционально? При это часть кода у тебя проекте по-прежнему будет в императивном стиле. G>Чем больше чистых функций, тем проще создавать из них другие чистые функции, тем проще распараллеливать и оптимизировать код. ВВ>>Мне казалось, что ФП предполагает нечто иное. G>Что именно?
Изменение стереотипов. Можно, конечно, рассуждать, что императивность не искоренима в принципе и везде есть чуточку "императива" — пожалуй и так, но суть-то не в этом.
Если новая концепция программирования не заставляет тебя думать и писать по-другому, а лишь помогает что-то там "распараллелить", то в recycle bin эту концепцию.
У вас же получается, что мы думаем по-старому, пишем по-старому ("по-старому" кстати далеко не эквивалетно "плохо"), и при этом используем какие-то "фишки" функционального стиля, при этом считая, что "функциональщина" больше ничего не дает.
А вы пробовали взять?
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Ютьюб? Вроде бы его Гугл же купил недавно за кругленькую сумму. Смысл тогда тратиться на убыточный сервис? Может, я, конечно, что-то не понимаю
Вот от гугловцев это и слышал.
У них денег много (было как минимум до последнего времени), так, что могут себе позволить держать некоторые убыточные сервисы так, на перспективу. ВВ>Ну или та же рапида — не может же она быть убыточной. Ибо смысл тогда какой, последний оплот пиратства? Мне кажется, что вполне она живет за счет этих своих премиум аккаунтов.
Про рапиду не в курсе, но думаю они в плюсе.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>А в данном случае речь о том, что "функциональность" соблюдается только снаружи. "Распарелливать" и "оптимизировать" можно и без нее. Пишите "красиво" на ООП.
ООП также как чистые функции распаралелвать как раз не дает. Почитай pdf на который я выше дал ссылку.
ВВ>Изменение стереотипов. Можно, конечно, рассуждать, что императивность не искоренима в принципе и везде есть чуточку "императива" — пожалуй и так, но суть-то не в этом. ВВ>Если новая концепция программирования не заставляет тебя думать и писать по-другому, а лишь помогает что-то там "распараллелить", то в recycle bin эту концепцию.
Изменение стереотипов и "заставление думать" нужно когда ты осваиваешь функциональщину, и поэтому учится ей да очень желательно на функциональном или даже чисто функциональном языке. А вот дальше зачем себя ограничивать в использовании концепции? Почему нельзя применять ее и в языках для нее не приспособленных?
ВВ>У вас же получается, что мы думаем по-старому, пишем по-старому ("по-старому" кстати далеко не эквивалетно "плохо"), и при этом используем какие-то "фишки" функционального стиля, при этом считая, что "функциональщина" больше ничего не дает. ВВ>А вы пробовали взять?
Конечно пробовали, и пишем и думаем не по старому, хотя и приходится писать на старых язках.
Вообще, извините за аналогию, но то, что вы говорите похоже, скажем, на рассуждения об ООП в C# в стиле — вот я нафигачу кучу статических классов, причем всю логику напишу в них, потом "сверху" создам несколько инстансных, и это все будет ООП. И ничего, кроме этого, я в ООП не вижу. Причем если использовать ООП везде, то это будет а)неэффективно б)не всегда возможно (что, кстати, абсолютная правда).
Здравствуйте, FR, Вы писали:
ВВ>>А в данном случае речь о том, что "функциональность" соблюдается только снаружи. "Распарелливать" и "оптимизировать" можно и без нее. Пишите "красиво" на ООП. FR>ООП также как чистые функции распаралелвать как раз не дает. Почитай pdf на который я выше дал ссылку.
ПДФ-ом не проникся, извини Потом смысл оперировать понятиями ФП вроде "чистых ф-ций", если ты сам в них вкладываешь несколько иной смысл чем в ФП?
ВВ>>Изменение стереотипов. Можно, конечно, рассуждать, что императивность не искоренима в принципе и везде есть чуточку "императива" — пожалуй и так, но суть-то не в этом. ВВ>>Если новая концепция программирования не заставляет тебя думать и писать по-другому, а лишь помогает что-то там "распараллелить", то в recycle bin эту концепцию. FR>Изменение стереотипов и "заставление думать" нужно когда ты осваиваешь функциональщину, и поэтому учится ей да очень желательно на функциональном или даже чисто функциональном языке. А вот дальше зачем себя ограничивать в использовании концепции? Почему нельзя применять ее и в языках для нее не приспособленных?
Обычно "изменение стереотипов" приводит к тому, что по-старому уже думать не хочется. Да, всем нам приходится писать на старых языках, но мы же при этом не делаем вид, что в них доступны все прелести ФП. Да и применять ФП-техники можно. Точно также я в свое время применял некоторые ОО-техники в ВБ6, когда приходилось писать на нем. Но ведь он от этого не становился объектно-ориентированным?
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Здравствуйте, gandjustas, Вы писали:
ВВ>Вообще, извините за аналогию, но то, что вы говорите похоже, скажем, на рассуждения об ООП в C# в стиле — вот я нафигачу кучу статических классов, причем всю логику напишу в них, потом "сверху" создам несколько инстансных, и это все будет ООП. И ничего, кроме этого, я в ООП не вижу. Причем если использовать ООП везде, то это будет а)неэффективно б)не всегда возможно (что, кстати, абсолютная правда).
ВВ>Ну все-таки что-то не то, нет?
Совершенно кривая аналогия, если бы ты привел пример использования только сути ООП и ничего больше был бы коррекный пример. Но для ООП в стиле шарпа или С++ такое трудно сделать, в стиле же смалтака можно соорудить даже и на том же си.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>ПДФ-ом не проникся, извини Потом смысл оперировать понятиями ФП вроде "чистых ф-ций", если ты сам в них вкладываешь несколько иной смысл чем в ФП?
Я как раз совершенно не отклоняюсь от смысла ФП. Вот IT даже уже вкладывает свой смысл основанный на особенностях реализации немерле и ML образных языков.
FR>>Изменение стереотипов и "заставление думать" нужно когда ты осваиваешь функциональщину, и поэтому учится ей да очень желательно на функциональном или даже чисто функциональном языке. А вот дальше зачем себя ограничивать в использовании концепции? Почему нельзя применять ее и в языках для нее не приспособленных?
ВВ>Обычно "изменение стереотипов" приводит к тому, что по-старому уже думать не хочется. Да, всем нам приходится писать на старых языках, но мы же при этом не делаем вид, что в них доступны все прелести ФП. Да и применять ФП-техники можно. Точно также я в свое время применял некоторые ОО-техники в ВБ6, когда приходилось писать на нем. Но ведь он от этого не становился объектно-ориентированным?
Так я нигде не утверждал что в них доступны все прелести ФП. Я просто сказал что при необходимости на них вполне можно писать и в ФП стиле. Да это будет в большинстве случаев коряво и неуклюже, но вполне возможно и иногда даже выгодно.
Здравствуйте, FR, Вы писали:
FR>Совершенно кривая аналогия, если бы ты привел пример использования только сути ООП и ничего больше был бы коррекный пример. Но для ООП в стиле шарпа или С++ такое трудно сделать, в стиле же смалтака можно соорудить даже и на том же си.
А в чем кривизна аналогии? ООП должно быть "всеобъемлющим" (что кстати нереализуемо вообще), а ФП — нет?
Со смолтолком не знаком, не знаю, что там было. А в рамках шарпа ОО предполагает что у тебя логика строится на полиморфизме классов — причем целиком и полностью это не делает никто, даже убежденный ООП-ист, ибо есть некоторый баг в концепции
Кстати, абсолютно идеальная ОО-программа будет содержать минимум императива. Только такой нет.
Только смысл-то ООП не в том, что мы начинаем кое-где лепить классы с виртуальными ф-циями, а в том, что саму структуру программы начинаешь описывать, воспринимать, "думать" по-другому. В категориях сущностей — не действий — обладающих поведением, состоянием и пр. Именно в этом соль ООП на самом деле, а не в том, что местами использовать "ее суть", а местами — забить.
А ФП в каком-то плане ломает мозги покруче так, чем ООП. Серьезно покруче. Почему ж у вас он получает роль обвертки какой-то? Писать на ФП — это значит думать, что mutable это такая же исключительная ситуация как и static в шарпе (а скорее всего даже куда более исключительная ситуация).
Здравствуйте, FR, Вы писали:
FR>Так я нигде не утверждал что в них доступны все прелести ФП. Я просто сказал что при необходимости на них вполне можно писать и в ФП стиле. Да это будет в большинстве случаев коряво и неуклюже, но вполне возможно и иногда даже выгодно.
Но при этом сам же говоришь, что "по сути в функциональщине больше ничего и нету", кроме описанного тобой подхода
Там есть другой образ мысли, при котором нам не придет в голову строчить такие ПДФ-ы как тот, на который ты мне ссылку дал.
Здравствуйте, IT, Вы писали:
IT>Ты о чём? Ни в C#, ни в C/C++ ни if, ни switch ничего не возвращают и никогда не будут возвращать. Так что про immutable стиль в этих языках забудь.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>А в чем кривизна аналогии? ООП должно быть "всеобъемлющим" (что кстати нереализуемо вообще), а ФП — нет?
Кривизна в том что я взял имено суть ФП, а ты суть ООП оставил полностью за скобками.
В стиле смалталка ООП как раз и всеобъемлющий.
ВВ>Со смолтолком не знаком, не знаю, что там было. А в рамках шарпа ОО предполагает что у тебя логика строится на полиморфизме классов — причем целиком и полностью это не делает никто, даже убежденный ООП-ист, ибо есть некоторый баг в концепции
В ОО в стиле смалталка такого бага нет. Там вся логика строится только на объектах и посылках сообщений этим объектам.
ВВ>Кстати, абсолютно идеальная ОО-программа будет содержать минимум императива. Только такой нет.
Главный признак императива изменяемое состояние будет.
ВВ>Только смысл-то ООП не в том, что мы начинаем кое-где лепить классы с виртуальными ф-циями, а в том, что саму структуру программы начинаешь описывать, воспринимать, "думать" по-другому. В категориях сущностей — не действий — обладающих поведением, состоянием и пр. Именно в этом соль ООП на самом деле, а не в том, что местами использовать "ее суть", а местами — забить.
Не местами, главное чистота, если она соблюдена ФП уже есть.
ВВ>А ФП в каком-то плане ломает мозги покруче так, чем ООП. Серьезно покруче. Почему ж у вас он получает роль обвертки какой-то? Писать на ФП — это значит думать, что mutable это такая же исключительная ситуация как и static в шарпе (а скорее всего даже куда более исключительная ситуация).
ФП ломает мозги покруче только потому что сначала ты изучал ООП.
Еще раз повторю, все это важно только при обучении.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Но при этом сам же говоришь, что "по сути в функциональщине больше ничего и нету", кроме описанного тобой подхода
Если совсем по сути то там еще меньше, но на Unlambda писать также приятно как и на Brainfuck
ВВ>Там есть другой образ мысли, при котором нам не придет в голову строчить такие ПДФ-ы как тот, на который ты мне ссылку дал.
Если есть цель внедрить безболезнено функциональщину (и в особености бонусы для распаралелвания которые она дает) в досточно нискоуровневый язык очень похожий на C++ то очень даже придет
Здравствуйте, minorlogic, Вы писали:
IT>>Ты о чём? Ни в C#, ни в C/C++ ни if, ни switch ничего не возвращают и никогда не будут возвращать. Так что про immutable стиль в этих языках забудь.
M>i ==5 ? 5 : 7
И много ты immutable кода такими конструкциями написал? Только честно.
Неясность изложения обычно происходит от путаницы в мыслях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, Воронков Василий, Вы писали:
ВВ> HTML в данном случае можно понимать как некий язык разметки, к которому тот же XAML довольно близок идеологически.
Ничего общего, кроме угловых скобочек. XAML это просто формат сериализации, удобный для написания человеком. А идеология у WPF вполне себе классическая десктопная.
ВВ>Только вот в итоге все равно непонятно, что в вин-формс не нравится. Уровень абстракции недостаточно высок?
Убогий дизайн.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, AndrewVK, Вы писали:
ВВ>> HTML в данном случае можно понимать как некий язык разметки, к которому тот же XAML довольно близок идеологически. AVK>Ничего общего, кроме угловых скобочек. XAML это просто формат сериализации, удобный для написания человеком. А идеология у WPF вполне себе классическая десктопная.
Может объяснишь в чем принципиальное отличие?
ВВ>>Только вот в итоге все равно непонятно, что в вин-формс не нравится. Уровень абстракции недостаточно высок? AVK>Убогий дизайн.
Здравствуйте, Воронков Василий, Вы писали:
AVK>>Убогий дизайн. ВВ>Где именно?
Везде. Скажем, так и не появилось нормальных систем layout'ов, хотя бы как в SWING'е в Java.
Здравствуйте, Cyberax, Вы писали:
AVK>>>Убогий дизайн. ВВ>>Где именно? C>Везде. Скажем, так и не появилось нормальных систем layout'ов, хотя бы как в SWING'е в Java.
TableLayoutPanel, FlowLayoutPanel — совсем ненормальные? Причем и то и другое в любом случае реализуется самостоятельно, в качестве контрола.
Мне вот интересно какие есть претензии именно к дизайну, архитектуре вин-формс, с учетом того, что это фреймворк построенный над юзер32. Приводить тут в качестве аргумента какие-то контролы не совсем в кассу мне кажется.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>>>Где именно? C>>Везде. Скажем, так и не появилось нормальных систем layout'ов, хотя бы как в SWING'е в Java. ВВ>TableLayoutPanel, FlowLayoutPanel — совсем ненормальные? Причем и то и другое в любом случае реализуется самостоятельно, в качестве контрола.
Нет, не нормальные. Они появились, AFAIR, далеко не в первой версии WinForms.
Ещё очень не хватает нормального разделения модель/вид.
ВВ>Мне вот интересно какие есть претензии именно к дизайну, архитектуре вин-формс, с учетом того, что это фреймворк построенный над юзер32. Приводить тут в качестве аргумента какие-то контролы не совсем в кассу мне кажется.
Это не "контролы", а дизайн самой системы. Поверх user32 прекрасно строятся вполне нормальные графические системы. См.: SWT+JFace.
WPF реально сделан более правильно, чем почти все остальные оконные системы.
Здравствуйте, AndrewVK, Вы писали:
C>> Скажем, так и не появилось нормальных систем layout'ов, хотя бы как в SWING'е в Java. AVK>Это уже большей частью не дизайн, это реализация.
Как сказать... Благодаря layout'ам большинство не совсем уж криворуких приложений на SWINGе имеют resolution independence и нормальный resize. Это заранее закладывалось в дизайн самого SWINGа. Различие в архитектуре тут, ИМХО, вполне есть.
Здравствуйте, Cyberax, Вы писали:
C>Как сказать... Благодаря layout'ам большинство не совсем уж криворуких приложений на SWINGе имеют resolution independence и нормальный resize.
Нормальный ресайз можно обеспечить и сейчас. Что же касается resolution independence, то никаких фундаментальных ограничений к тому дизайн винформсов не вносит. Я бы еще понял, если бы вопросы были к отсутствию сменных единиц измерения размера, но в свинге, емнип, в этом плане ситуация точно такая же.
C> Различие в архитектуре тут, ИМХО, вполне есть.
Я пока что существенных различий в архитектуре не вижу. Даже getX и getY в свинге умудрились вкрячит в базовый JComponent.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, AndrewVK, Вы писали:
ВВ>>Может объяснишь в чем принципиальное отличие? AVK>Чего от чего? HTML от XAML? Такое же, как HTML от SOAP, к примеру. XAML сам по себе никакой семантики не содержит, это просто формат сериализации графа компонентов в терминах специальной компонентной модели. HTML же подразумевает вполне конкретную сематику и абсолютно нерасширяем.
Что значит — HTML содержит "вполне конкретную" семантику? Конкретную для кого? Кроме общих слов есть что-нибудь сказать?
HTML — язык разметки, описывающий структуру страницы, используемые на ней элементы и их визуальное представление. XAML делает то же самое абсолютно. Можешь называть это "форматом сериализации" или как-то иначе — суть от этого не изменится. Про HTML я тоже могу сказать, что это формат сериализации объектной модели документа, и что?
ВВ>>>>Только вот в итоге все равно непонятно, что в вин-формс не нравится. Уровень абстракции недостаточно высок? AVK>>>Убогий дизайн. ВВ>>Где именно?
AVK>А ты сам не видишь? Во-первых, практически единственный способ расширения функционала контролов — наследование.
Мы вообще о контролах говорим? Или как? Я с таким явлением как способ расширения функционала контролов "вообще" не знаком. И что такое расширение?
Чтобы "расширить" DataGridView — я напишу собственный тип ячейки/колонки.
Для изменения поведения некоторых контролов — например при валидации ошибок — я буду использовать совершенно отдельный такой проперти-провайдер.
Да и еще помнится только взяв в руки вин-формс в году этак 2003 я делал owner-draw меню без всякого наследования, а через отдельный такой класс-адаптер. Глупый тогда был, не знал, что наследоваться надо.
Слушай, а для того, чтобы красивый тултип к контролу добавить — тоже небось наследоваться придется?
AVK>Почему плохо наследование реализации здесь уже обсуждалось не раз. Кроме того, использование наследования для расширения функционала это нарушение LSP. Использование же, скажем, агрегации практически невозможно ввиду того самого дизайна и подвязки на виндовый хендл.
Как хендл связан с агрегацией, а?
AVK>Во-вторых, взгляни на публичный контракт Control. Он имеет огромный размер и содержит большое количество грубейших нарушений SRP. В WPF он в разы меньше, хотя и там в этом плане косяков предостаточно. AVK>В-третьих, крайне убогие средства реюза готовых кусков UI. UserControl это все, что на эту тебу имеется. Даже нелюбимые тобой вебформсы в этом плане куда богаче.
Расскажи какие сценарии реюза тебе требовались, и ты не смог их реализовать на вин-формс. Может, вместе сообразим что
AVK>В-четвертых, убогий, запутанный и крайне плохо расширяемый механизм баиндинга данных. AVK>В-пятых, крайне примитивная компонентная модель, которую правда, в отличие от, по месту подкрутить все таки можно. AVK>В-шестых, большинство контролов имеют неудобный и примитивный API для взаимодействия с состоянием. Виртуальный режим кое где со скрипом появился, но почти всегда с кривизной. AVK>Ну и куча всего по мелочи. AVK>Итого, дизайн винформсов весьма неоднородный и, в среднем, находится на уровне начала 90-х.
Скажи, а на чем ты раньше писал? Вин-формс, при всей его "неоднородности", "убогости" и проч. — огромный прогресс по сравнению с тем, что было до этого. Его убогость и неоднородность является отличной надстройкой над юзер32. Да, он неидеален в деталях, но базовая архитектура для "окошек" там хороша. Чего вот как раз про веб-формс я сказать не могу.
И у меня ни разу не возникало желание выбросить на фиг вин-формс как ненужный уровень абстракции и вернуться "обратно", сообщения обрабатывать.
Да и по поводу "большинство контролов имеют неудобный и примитивный API для взаимодействия с состоянием" — это вы, батенька, зажрались. У меня вот культурный шок был, когда я увидел ту же модель событий в вин-формс. Ибо это было настолько удобнее и *понятнее* того, что было... И как раз в вин-формс она абсолютно к месту.
Сейчас это конечно уже не так воспринимается. Но сам юзер32 архаичен, олё! Вы хотите увидеть модный фреймворк на его основе? Это вряд ли. Но вин-формс это ИМХО лучшая надстройка над юзер32 что есть сейчас.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Что значит — HTML содержит "вполне конкретную" семантику?
То и значит. Каждый тег имеет вполне конкретное, присущее самому HTML значение. Тег же в XAML несет в себе довольно мало семантики, в основном это увязка с его компонентной моделью, которая неизмеримо более примитивна, нежели HTML. Все остальное навешивает уже конкретный фреймворк, который XAMLом пользуется.
ВВ> Конкретную для кого?
Для всех.
ВВ> Кроме общих слов есть что-нибудь сказать?
Это не общие слова, это вполне себе конкретика.
ВВ>HTML — язык разметки, описывающий структуру страницы, используемые на ней элементы и их визуальное представление.
Ну вот видишь, ты сам все знаешь.
ВВ> XAML делает то же самое абсолютно.
Нет. Ничего этого в XAML нет. Термины XAML это: меппинг пространства имен, компоненты, свойства, присоединенные свойства, контент.
ВВ> Можешь называть это "форматом сериализации" или как-то иначе — суть от этого не изменится.
Суть конечно не изменится, чего бы я не называл. Главное, что эта суть по факту совсем не та суть, что в HTML.
ВВ> Про HTML я тоже могу сказать, что это формат сериализации объектной модели документа, и что?
И все. Даже если это так (а это не так), то это не просто формат сериализации документа, это формат вполне конкретного документа. Ни для чего другого он не годен.
ВВ>Мы вообще о контролах говорим? Или как? Я с таким явлением как способ расширения функционала контролов "вообще" не знаком.
Что, никогда не наследовался от контролов винформсов? А если наследовался, не скажешь с какой целью?
ВВ> И что такое расширение?
Словарик руского языка подарить?
ВВ>Чтобы "расширить" DataGridView — я напишу собственный тип ячейки/колонки.
Ага, это единственный контрол, который хоть что то из себя в плане дизайна представляет.
ВВ>Для изменения поведения некоторых контролов — например при валидации ошибок — я буду использовать совершенно отдельный такой проперти-провайдер.
Вот только, скажем, код отработки default button и ее modal result намертво прошит в код Form.
ВВ>Да и еще помнится только взяв в руки вин-формс в году этак 2003 я делал owner-draw меню без всякого наследования, а через отдельный такой класс-адаптер.
Поздравляю. К сожалению, отдельные моменты не исключают общей печальной ситуации.
ВВ>Слушай, а для того, чтобы красивый тултип к контролу добавить — тоже небось наследоваться придется?
Если ты будешь разговаривать в таком тоне, я общение с тобой закончу. Не надо дурачка изображать, ты все прекрасно понял.
ВВ>Как хендл связан с агрегацией, а?
А ты попробуй отнаследовать свой контрол от Control и агрегировать в нем функционал, скажем, TreeView.
ВВ>Расскажи какие сценарии реюза тебе требовались, и ты не смог их реализовать на вин-формс.
Например когда шаблон UI не квадратный кусок, а состоит из разных частей, перемежаемых кастомным UI. В WPF это делается сравнительно просто, без привлечения тяжелой артиллерии.
Да, для развлекухи могу предложить поизучать дизайнер (и дизайн) SplitterContainer, познавательно.
ВВ>Скажи, а на чем ты раньше писал?
Много на чем, если ты про UI фреймворки. Начинал с TV, потом какой то сишный графический фреймворк с названием на букву Z, уже запамятовал, потом паскалевый OWL, потом он же, но сишный, потом VCL, потом Swing.
ВВ> Вин-формс, при всей его "неоднородности", "убогости" и проч. — огромный прогресс по сравнению с тем, что было до этого.
Во-первых это его в современных условиях лучше не делает, во-вторых на момент его релиза свинг уже порядочно времени как был зарелизен, а по сравнению с ним, ты уж извини, это все таки регресс.
Винформс, выйди он году в 95, был бы вполне адекватен времени, но в 2002 он явно устарел.
ВВ> Его убогость и неоднородность является отличной надстройкой над юзер32.
Оно тут не причем. Почти все пакости user32 легко замазываются. Опять же, обрати внимание, большинство тех проблем, что я перечислил, никакого отношения к user32 не имеют. К примеру, байндинга в нем просто нет. Отсутствует как класс. Что не помешало вкрячить коллекцию DataBindings в интерфейс базового контрола.
ВВ> Да, он неидеален в деталях, но базовая архитектура для "окошек" там хороша.
Детали фигня, благо поставщики компонентов переписывают чуть ли не все контролы. Проблема именно в базовой архитектуре. Главное чудовище это класс Control, а не куча его наследников.
ВВ>И у меня ни разу не возникало желание выбросить на фиг вин-формс как ненужный уровень абстракции и вернуться "обратно", сообщения обрабатывать.
Это, видимо, потому что опыт ковыряния у тебя в этой каке небольшой. Опять же, еще большая кривизна user32 никак не делает дизайн винформсов хорошим.
ВВ>Да и по поводу "большинство контролов имеют неудобный и примитивный API для взаимодействия с состоянием" — это вы, батенька, зажрались.
Ничуть. На дворе конец 2008 года. Мы тут всякие линки обсуждаем, asp.net mvc, а в винформсах все каменный век.
ВВ> У меня вот культурный шок был, когда я увидел ту же модель событий в вин-формс.
Ну, видимо мое предположение было верным.
ВВ>Сейчас это конечно уже не так воспринимается.
Еще раз повторяю — в 2002 оно тоже воспринималось "не так".
ВВ>Вы хотите увидеть модный фреймворк на его основе?
Я хотел его увидеть в 2002, а сейчас есть WPF.
ВВ> Это вряд ли. Но вин-формс это ИМХО лучшая надстройка над юзер32 что есть сейчас.
Cyberax утверждает, что не лучшая. Ну и того, что я знаю про wxWidgets, тоже хватает, чтобы усомнится в этом утверждении.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Мне казалось, что ФП предполагает нечто иное. При твоем подходе ты всю логику можешь описать в императивном стиле с лесом if-ов, свитчей и проч. — собственно, с чем и боремся, кстати говоря — при этом какая-то внешняя часть проекта будет оформлена "красиво". Действительно "функциональщина" какая-то получается.
Ты удивишься, но с лесом if-ов и свитчей "боролись" посредством виртуальных функций не далее, как лет 10-12 назад. Что-то победы так и не случилось. Сейчас есть новая игрушка для решения этой проблемы, только это не pattern matching, конечно. Я имею в виду функции высших порядков. Проблемы будут ровно те же самые, что и с виртуальными функциями — тоже придётся дробить код на кусочки, с той лишь разницей, что в случае ОО-стиля мы оперируем "классами", а в FP — функциями. Функции, само собой, несколько мельче, чем классы, но проблема разбиения абстракции, в которую, в общем-то, мейнстрим и ткнулся, остаётся той же самой.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, IT, Вы писали:
ГВ>>>>if/switch не предполагают изменения состояния. Pattern matching это что по-твоему, как не завуалированный if? IT>>>if/switch не возвращающие значение и не меняющие состояния бесполезны и безсмысленны. ГВ>>Упс. Так они и не возвращают значение, и не меняют состояние. IT>Вот именно. Т.е. они вообще ничего не делают. И поэтому бесполезны.
На колу мочало, начинай сначала.
ГВ>>Ну, закрутилась шарманка. С чего ты взял, что в императиве входные данные обязательно модифицируются? Ничего подобного. Они могут модифицироваться, но это совершенно не обязательно. IT>А почему именно входные данные. Модифицируется контекст, а в императиве это не только входные данные.
Опять таки, это вовсе не обязательно.
ГВ>>Расскажи это авторам pattern matching, COND. IT>Pattern matching как раз великолепно возвращает данные. Аж со свистом.
Да ну? Я-то, грешным делом, привык думать, что pattern matching — это только подсахаривание выбора тела функции в зависимости от параметров. Где ты там нашёл возвращаемое значение? Я тоже хочу!
P.S.: Разговор начинает напоминать апологию ОО — тогда процедурному стилю тоже приписывались все мыслимые и немыслимые негативные качества, которые ему, якобы, имманентны.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Геннадий Васильев, Вы писали:
ГВ>Да ну? Я-то, грешным делом, привык думать, что pattern matching — это только подсахаривание выбора тела функции в зависимости от параметров. Где ты там нашёл возвращаемое значение? Я тоже хочу!
ПМ назвать подсахариванием можно только с большой натяжкой. А возвращаемое значение — преставь себе, что в switch в каждом case стоит return. Осталось только превратить полученную функцию в локальный кусок кода и ты получишь ответ.
ГВ>P.S.: Разговор начинает напоминать апологию ОО — тогда процедурному стилю тоже приписывались все мыслимые и немыслимые негативные качества, которые ему, якобы, имманентны.
Возвращаемые значения у if или switch это совсем не признаки функционального стиля, а очень даже особенности синтаксиса конкретных языков. И никто, кстати, не мешает один раз написать функцию R If<R>(Func<bool> predicate, Func<R> then, Func<R> else), если уж в языке if не возвращает значения и тернарного оператора нет. В PL/SQL, кажись, так и сделали.
Опять же, есть ведь еще и итераторы (привет лиспу), где if заменяется when/filter/как-там-еще.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, AndrewVK, Вы писали:
ГВ>>Да ну? Я-то, грешным делом, привык думать, что pattern matching — это только подсахаривание выбора тела функции в зависимости от параметров. Где ты там нашёл возвращаемое значение? Я тоже хочу!
AVK>ПМ назвать подсахариванием можно только с большой натяжкой.
Ну а что там ещё сверх if?
AVK>А возвращаемое значение — преставь себе, что в switch в каждом case стоит return. Осталось только превратить полученную функцию в локальный кусок кода и ты получишь ответ.
Да я это представляю вполне.
ГВ>>P.S.: Разговор начинает напоминать апологию ОО — тогда процедурному стилю тоже приписывались все мыслимые и немыслимые негативные качества, которые ему, якобы, имманентны.
AVK>Возвращаемые значения у if или switch это совсем не признаки функционального стиля, а очень даже особенности синтаксиса конкретных языков. И никто, кстати, не мешает один раз написать функцию R If<R>(Func<bool> predicate, Func<R> then, Func<R> else), если уж в языке if не возвращает значения и тернарного оператора нет. В PL/SQL, кажись, так и сделали.
Я примерно это и имел в виду, когда говорил, что if/switch несложно приписать возвращаемые значения.
AVK>Опять же, есть ведь еще и итераторы (привет лиспу), где if заменяется when/filter/как-там-еще.
Что-то не догоняю, а при чём они здесь?
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Геннадий Васильев, Вы писали:
ГВ>Ты удивишься, но с лесом if-ов и свитчей "боролись" посредством виртуальных функций не далее, как лет 10-12 назад.
Вообще полиморфизм классов теоретически действительно позволяет выкинуть это барахло. А вот на практике — да, не получится. Тут и пробовать особо не надо. Ибо очень уж тяжеловесен ООП для этого.
ГВ>Что-то победы так и не случилось. Сейчас есть новая игрушка для решения этой проблемы, только это не pattern matching, конечно. Я имею в виду функции высших порядков. Проблемы будут ровно те же самые, что и с виртуальными функциями — тоже придётся дробить код на кусочки, с той лишь разницей, что в случае ОО-стиля мы оперируем "классами", а в FP — функциями.
ГВ>Функции, само собой, несколько мельче, чем классы, но проблема разбиения абстракции, в которую, в общем-то, мейнстрим и ткнулся, остаётся той же самой.
Она не той же самой остается, она становится "несколько мельче" . Ф-ция производит впечатление более "масштабируемого" что ли кирпичика. Возможно, это будет лучше чем ОО подход. Возможно, нет. Но пока мне кажется судить об этом рановато
Здравствуйте, Воронков Василий, Вы писали:
ВВ>>>Мне казалось, что ФП предполагает нечто иное. G>>Что именно? ВВ>Изменение стереотипов. Можно, конечно, рассуждать, что императивность не искоренима в принципе и везде есть чуточку "императива" — пожалуй и так, но суть-то не в этом.
Ну как всегда — как же без апелляции к стереотипам, которые "надо менять" почему-то. Освободи свой разум, ж... освободится сама! (c) Для сведения: императивность неискоренима вовсе не из-за каких-то надуманных стереотипов, а из-за того, что компьютер в своей основе — сугубо императивный агрегат, бесконечно разрушающий свою собственную память. Понимаешь? До тех пор, пока ЦПУ не станет чисто функциональным, а RAM не начнёт возникать из космической пыли по мановению волшебной палочки — императивщина останется неискоренимой в принципе.
В то же время, функциональный стиль, как облегчающий распараллеливание (это едва ли не единственное значимое преимущество FP) именно сейчас оказался на пике моды из-за того, что развитие процессоров упёрлось в физические ограничения, поэтому-то в майнстрим понеслась идея FP. Не только поэтому, разумеется, но в некоторой немалой части, ИМХО.
ВВ>Если новая концепция программирования не заставляет тебя думать и писать по-другому, а лишь помогает что-то там "распараллелить", то в recycle bin эту концепцию.
Парадокс в том, что FP — это чудовищно не новая концепция. Просто до невероятности не новая. Не новая настолько, что называть её новой — это нарываться на шутки в свой адрес. "Новое" сейчас только жужжание вокруг FP и повсеместное внедрение лямбд с сопутствующими замыканиями. Больше новизны — ни на грош.
ВВ>У вас же получается, что мы думаем по-старому, пишем по-старому ("по-старому" кстати далеко не эквивалетно "плохо"), и при этом используем какие-то "фишки" функционального стиля, при этом считая, что "функциональщина" больше ничего не дает. ВВ>А вы пробовали взять?
Да что там брать-то, кроме способа разбиения абстракций и некоторого сокращения записи из-за возможности определения функций "по месту", присущего FP-языкам? А, нет. Ещё можно "взять" относительную близость сугубо математической нотации. Правда, что тут от кого "берётся" — математика от FP или FP от математики — вопрос спорный.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Воронков Василий, Вы писали:
FR>>Изменение стереотипов и "заставление думать" нужно когда ты осваиваешь функциональщину, и поэтому учится ей да очень желательно на функциональном или даже чисто функциональном языке. А вот дальше зачем себя ограничивать в использовании концепции? Почему нельзя применять ее и в языках для нее не приспособленных?
ВВ>Обычно "изменение стереотипов" приводит к тому, что по-старому уже думать не хочется.
Менять стереотипы неприятно потому, что замена одного стереотипа на другой раньше или позже выливается в замену шила на мыло. Меняешь одни шоры на другие — в чём кайф?
ВВ>Да, всем нам приходится писать на старых языках, но мы же при этом не делаем вид, что в них доступны все прелести ФП. Да и применять ФП-техники можно. Точно также я в свое время применял некоторые ОО-техники в ВБ6, когда приходилось писать на нем. Но ведь он от этого не становился объектно-ориентированным?
ВБ6, как раз — вполне ОО-язык. Пусть и ограниченный в некотором роде.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Воронков Василий, Вы писали:
ВВ>В твоих рассуждениях есть один косяк. Ты можешь написать ф-цию которая будет вести себя в функциональном стиле, но при этом быть написанной в императивном стиле. Но смысл такой ф-ции?
Очевидно, что смысл такой функции заключён в её использовании ради реализации определённых абстракций. Я надеюсь, ты не думаешь, что классы/объекты делают только ради ОО-стиля, а процедуры — только ради императивного стиля самого по себе.
ВВ>Получается, что у тебя часть кода в императивном стиле, часть кода — как бы клиентская — в фукциональном стиле. А где граница-то между тем и другим?
А зачем она, эта самая граница? ИМХО, всё ограничивается удобством/очевидностью/другими практическими аспектами использования. Стиль ради стиля, это, как-то, неправильно.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Воронков Василий, Вы писали:
ГВ>>Ты удивишься, но с лесом if-ов и свитчей "боролись" посредством виртуальных функций не далее, как лет 10-12 назад. ВВ>Вообще полиморфизм классов теоретически действительно позволяет выкинуть это барахло. А вот на практике — да, не получится. Тут и пробовать особо не надо. Ибо очень уж тяжеловесен ООП для этого.
Ерунда. Дроблению абстракции мешают, как это ни странно, организационные моменты, а не тяжеловесность ООП.
ГВ>>Функции, само собой, несколько мельче, чем классы, но проблема разбиения абстракции, в которую, в общем-то, мейнстрим и ткнулся, остаётся той же самой.
ВВ>Она не той же самой остается, она становится "несколько мельче" . Ф-ция производит впечатление более "масштабируемого" что ли кирпичика. Возможно, это будет лучше чем ОО подход. Возможно, нет. Но пока мне кажется судить об этом рановато
Я не знаю, как именно отразится FP на мейнстриме, я руководствуюсь только соображениями общего характера. Условия "скорей-скорей" и "что тут думать, это же не шахматы" никогда не способствовали построению глубоких абстракций. А как раз эти условия мутному потому по имени мейнстрим и характерны. Будь там хоть какой мегапродвинутый стиль.
Сейчас я вижу ситуацию, с точностью до деталей повторяющую вакханалию вокруг ООП. Вот всё один в один то же самое: точно так же предлагается выбросить всё и переписать на [новый язык], которому приписываются мистические свойства и точно так же "старый" [язык, стиль, подход] объявляется [исчадие ада, след Ктулху, зашоренность мозга]. Совершенно же аналогично истории с ООП есть свой набор success stories.
То есть, чисто внешне ситуация выглядит повторяющей то, что уже происходило не раз. Курьёзный момент, что во времена распространения ООП вузы преподавали как раз функциональные языки, а сейчас положение склоняется к зеркальному: в вузах ООП, на практике — FP. Совсем не курьёзный момент — это то, что людей со специальным образованием становится банально меньше, что как раз служит аргументом в пользу сомнений относительно применимости чисто математических фишек FP.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Воронков Василий, Вы писали:
ВВ>А о чем тогда спор?
Ну, раньше был о производительности и методах ее достижения.
Ты с какой-то непонятной мне целью свернул его на UI-фреймворки.
ВВ>А на WTL смысл есть смотреть?
Нет, нету. ВВ>Каким образом тут Хром всплыл, мне интересно?
У тебя трудности с памятью или с восприятием? Цитирую место, где всплыл хром:
Единственный способ написать удачное GUI приложение — это захватить одно окно (в терминах user32), а внутри него выполнять отрисовку вручную. То есть, конечно же, не вручную, а при помощи некоторого совершенно другого фреймворка, у которого базовые примитивы устроены вовсе не так, как предлагают user32 и comctl32.
В качестве недавних примеров таких приложений можно посмотреть на Chrome.
Что тут непонятно? Что у хрома всего два user32-окна? Ну так запусти Spy++ и посмотри.
ВВ>А можно по-конкретнее? Что там неудобно? Что сложно реализовать?
Любая анимация состояния — это pain. Любые игры с выходом за пределы своего clip rect типа теней, обводки, и прочих glow — pain. Масштабирование — pain. Композитные контролы — тройной pain.
Cкорее возникает вопрос — а что там реализовать легко и удобно. Практика показывает, что легко и удобно делать только примеры для книжек "как не должен быть устроен UI". Более-менее нормальные решения делать уже сложно. Для хороших, повторюсь, нужно выкидывать весь стандартный стек и брать свой.
ВВ>Реализация одного и того же функционала — допустим контрол, с большим кол-вом owner draw — на GDI+ и на WPF занимает почему-то весьма и весьма схожее время. Реализация этого функционала на WPF получается никак не "проще". При этом еще и АА в итоге кривой
Мы с WPF играли мало, но наши эксперименты показывают ровно обратную ситуацию. Большое количество Owner Draw в жизненных примерах достигается не выпиливанием по пикселам, а выбором правильных векторных примитивов. К тому же их рисует дизайнер, у которого рука набита, а не программист.
ВВ>В таком случая определишь, что ты утверждаешь.
Я вообще про WTL ни слова не говорил. Откуда появился WTL?
ВВ>Вообще-то я игрался с HTMLayout, правда не очень недавно. И он именно, что HTML и рендерит Причем на тот момент не дружил с XHTML и CSS.
То, что он рендерит — это не HTML. Это его близкий родственник, конечно, но это язык разметки UI, а не гипертекста. Вон посмотри на терраинформатике примеры приложений, UI которых построен на HTMLayout.
ВВ>Ну правильно. HTML + браузер. Вот с одной стороны язык разметки, описывающий представления и в то же время отделенный — я бы даже сказал "отдаленный" — от отрисовки. HTML в данном случае можно понимать как некий язык разметки, к которому тот же XAML довольно близок идеологически. ВВ>Но если все так просто, то почему ж классические веб-технологии, где как раз и есть что работа с HTML врукопашную, приводят к такой каше в коде?
У кого они к этому приводят? У нормальных пацанов никакой каши в коде нету. См. jQuery. А у тех, у кого каша в голове, она же всегда будет в коде. Независимо от платформы. Раньше они писали логику в Button1Click, теперь — в a.onclick.
ВВ>Только вот в итоге все равно непонятно, что в вин-формс не нравится.
Убогая архитектура. Я уже три дня рассказываю, что в нем плохо. Это для кого? ВВ>Помнится, несколько постов назад ты утверждал, что "никто не защищает веб-формс". Теперь тактика поменялась? Решил путем аналогий начать, так сказать, апологию веб-форм?
Нет. Я, в отличие от некоторых участников данной дискуссии, что думаю, то и пишу. Никаких скрытых мотивов у меня нету. Поясняю еще раз, медленно и без намеков:
1. ВебФормз — отстой.
2. ВинФормз — отстой.
Еще вопросы? ВВ>У меня вот складывается ощущение, что ты не какую-то точку зрения пытаешься доказать, потому что судя по всему ее нет — или ты ее по крайней мере очень хорошо скрываешь — а то, что твой оппонент идиот.
Я ничего не скрываю. Это ты почему-то хочешь найти в моих словах какой-то неожиданный смысл. Нет, они означают ровно то, что означают. Когда я пишу, что ASP.NET — хорошая платформа, я имею в виду именно то, что это хорошая платформа. А не то, что размещение бизнес-логики в System.Web.UI.Page.OnLoad — хорошая идея. Когда я пишу, что винФормз предлагает хреновую модель для построения GUI — я именно это и имею в виду.
Причем к user32 у меня претензий, в общем-то, нету. Потому что она, в отличие от comctl32, не навязывает идею строить UI из микроокон. Критиковать user32 за плохую модель UI — то же самое, что критиковать сокеты за неудачную модель постбеков.
ВВ>"Все", значит, считают, что ASP.NET "нигде не кончается", т.е. практически эквивалентент понятию .NET,
Главное — это то, что все считают, что ASP.NET не сводится к System.Web.UI.Page. ВВ>но при этом WPF к ASP.NET не имеет никакого отношения.
До тех пор, пока он ортогонален ASP.NET — да, не имеет.
... << RSDN@Home 1.2.0 alpha rev. 677>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Это из области "все мы сидим в локалке"? Под локальной сетью обычно имеется в виду все-таки некоторая "сеть", где доступны другие ноды, контент и пр. У меня ADSL2, у меня нет никакой внутренней сети. Причем на самом деле необходимости в ней и не возникает. ВВ>Любой мало-мальски приличный торрент, когда разгонится, начинает качать со скоростью более 1Мбайта в сек. Представляем сколько чего можно скачать за ночь. Или за день. Оставив комп включенным.
Ну так торрент как раз и использует много поставщиков. С точки зрения провайдера, главное — это его личные расходы на трафик и организацию сети.
Тебе хорошо, у тебя толстый канал. В России есть еще места, где такой канал — один на территорию размером с Данию, и его делят все потребители.
ВВ>Я уже высказывал мысль, что скорость каналов должна обогнать рост разрешения видео контента. Потому что последний упирается в пока еще живущие физические носители — тот же блю-рей, который еще и на рынок-то нормально выйти не успел и наверняка проживет довольно долго. А там чего-то сильно отличного от 1960х1080 ты не увидишь, ибо не влезет.
А вот я как раз думаю наоборот. Такая ситуация связана с возрастными проблемами среди издателей: они до сих пор мыслят категориями "вот Д.Доу покупает видеокассету, тьфу, то есть диск...". Распространение контента через сеть резко снижает важность конкретного формата, и тем более конкретного носителя.
ВВ>С другой стороны могут конечно перейти от всяких Mp2 на использование других алгоритмов. Ибо я, честно, последнее время в упор не вижу разницы между "аналогом" и каким-нибудь хорошим XVid. Но с другой стороны смысл? Какое разрешение у твоего монитора? А у телевизора? А каково сейчас соотношение SD-телевизоров и HD-телевизоров?
Правильно, рост разрешения сейчас по факту сдерживается исключительно возможностями воспроизводящих устройств. Я не в курсе, бывают ли проекторы с более чеем FullHD разрешением. Наращивать разрешение контента на снимающей стороне вполне себе есть куда. ВВ>Все-таки эта отрасль достаточно инертна, а вот рост интернет-каналов вширь никакие факторы не сдерживают.
Вот это мне непонятно. Ты себе вообще представляешь характерные стоимости проводных каналов?
Маленький пример: в Северомуйском тоннеле стоимость всего компютерного обрудования пренебрежимо мала по сравнению со стоимостью кабелей, которые к нему подключены.
Инертность области телевизоров меня, конечно же, угнетает со страшной силой. Потому что я не успеваю прицениться к девайсу, как кто-нибудь выпускает более классный. Вон, Панасоник освоил 42" плазму в FullHD. А LCD вообще без проблем сделать еще в два раза больше — было бы что смотреть.
ВВ>В то же время сейчас-то меня не удивит, если скажут, что в будущем игра будет занимать несколько террабайт. Причем я спокойно будут скачивать ее через какой-нибудь steam. Как не удивит и то, что физические носители вообще скорее всего отойдут на второй план.
Да, я тоже думаю, что физические носители отойдут подальше. Или, по крайней мере, станут значительно более простыми. В том плане, что все эти припрыгивания с медиа-форматами — бред собачий. Зачем это всё, когда можно просто положить на диск нормальную файлуху, а в ней положить медиа-контент? ВВ>Все равно же тенденции можно прослеживать. Вот сейчас есть четкая тенденция — цифровая дистрибьюция.
Совершенно верно, есть. Аналог еще долго будет держаться в местностях, труднодоступных для цифровых каналов. Но в местах с высокой плотностью населения востребованность аналога будет только падать.
ВВ>Мне кажется тут будет рулить не технология, которая позволит сэкономить "еще 14%", а та, которая позволит максимально эффективно бороться с пиратством. Ибо благодаря нему потери будут посильнее.
Основной способ борьбы с пиратством — отмена сверхприбылей. Сейчас приобретать нелегальный контент удобнее и дешевле, чем легальный.
Поэтому как ни борись, а плетью обуха не перешибешь. Достаточно сделать легальный контент удобнее, и пираты отомрут. Грубо говоря, зачем тебе качать камрип из сети, когда ты за $12 в месяц имеешь доступ к нормальному медиа-провайдеру, который отдает тебе FullHD 7.1 с раздельными дорожками для языков? При этом найти нужный фильм, посмотреть связанную с ним информацию и прочее ты можешь прямо там же; сервис подсказывает тебе на основе твоего же опыта, какие фильмы отстой, а какие нет; помимо самого фильма валяется масса материалов типа интервью с командой, текст книги, прочая дополнительная информация. Ну то есть этакая помесь IMDB с Amazon, только круче
Круче это будет потому, что у Амазона прибыль возникает только в момент продажи чего-то. А медиа-провайдер живет на подписках, то есть у него стабильный и хорошо прогнозируемый доход (ну, до тех пор, пока конкурент не вызовет массовый отток клиентов). ВВ>>>Мне непонятно одно — что вам этот пиринг так сдался? Есть сейчас пиринг, через к-й распространяется коммерческий контент? S>>Есть. Joost. ВВ>Он разве коммерческий?
Контент? Конечно же коммерческий. А ты думаешь, там только опен-сорсные фильмы раздают?
ВВ>Ну если не даваться в детали, то можно, почему нет? Есть же несколько довольно явных тенденций, как мне кажется: ВВ>- уход на покой физических носителей, переход на цифровую дистрибьюцию ВВ>- объедение различных медиа-устройсв вроде видео-плеера, игровой приставки и пр. в единое развлекательное устройство (что уже почти произошло), через которое будет и телевидение "с кочергой", и видео, и игры. А также музыка и многое другое. Причем это устройство не будут по факту эквивалентно PC и не заменит его.
Всё может быть. Проблема с таким устройством — невозможность апгрейда по частям.
... << RSDN@Home 1.2.0 alpha rev. 677>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Pavel Dvorkin, Вы писали:
ГВ>>Удивительное дело: что Lisp, что Prolog — простейшие языки. Их долго изучать невозможно в принципе. С другой стороны, они оказались настолько значимыми, что игнорировать их существование... Преподавателю... Э-э-э...
PD>А с чего ты решил, что я игнорирую их существование ?
Ну, значит, просто показалось, что ты их и в самом деле считаешь чем-то новым.
PD>А вот насчет значимости... Пролог, если помнишь, был объявлен базовым языком японского проекта ЭВМ 5 поколения. Проект блестяще провалился (кажется, ни один проект столь блистательно не проваливался), что ИМХО порядком-таки подорвало крединталии Пролога. Но это ИМХО.
ЭВМ 5-го поколения, ИМХО, не показатель. Этот проект блистательно провалился во всех ипостасях: что в Европе с Лиспом (или в Штатах с Лиспом играли, не помню), что в Японии. Пролог, ИМХО, хорош чистотой метода резолюций, который в нём реализован. Примерно как Лисп — он тоже привлекателен своей минимальностью.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Pavel Dvorkin, Вы писали:
AVK>>Означает. Ты попробуй ради интереса хоть что нибудь под мелкий дивайс написать, а потом мы с тобой поговорим, чем их UI от UI десктопа отличается.
PD>Нет, не буду. Не мое это дело
Я пробовал. Первая мысль "ну твою мать, и как сюда запихать то всё?". Бросил.
AVK>>Затем, что ты считаешь что вся Россия как твой Омск, тогда как в плане телекоммуникаций Россия за Уралом как раз таки нехарактерная ситуация, а вот европейская территория — характерная, просто потому что там живет значительно больше половины населения.
PD>Последнее — верно, а первое — не то, чтобы очень. Был я в ряде городов Европейской России. Весьма похоже на Омск.
В последнее время (буквально год-полтора) идёт бум кабельных сетей, дешёвых анлимов. Как показывает практика, через 2-3 года цены будут как сейчас в Мск.
PD>>>Увы. Пока что твое высказывание насчет кабельного ТВ в Омске
AVK>>Я не знаю что там у вас конкретно в Омске. Наличие кабелей весьма характерно для европейской части, по крайней мере для небольших городов, которым советская власть строительством телецентров не озаботилась. Но суть то не в кабелях, суть в том, что несмотря на аналоговый местный канал доставки (будь то кабель или местный телецентр), в локальный хаб контент доставляется давно уже в цифровой форме.
PD>Я что-то не понял. Куда в цифровой форме, какой хаб контент ? Из Останкина в местный телецентр ? Если об этом речь, то это не мое дело, как там они доставляют. Но вот с местного телецентра на мой телевизор уж точно не в цифровой форме.
Он к тому, что не в каждом городе есть телецентр. Где нет — всё раздавалось и раздаётся по кабелю.
PD>>> мне напомнило высказывание Марии-Антуанетты (кажется) "Если крестьяне жалуются, что им не хватает хлеба, то почему они не едят пирожные" ?
AVK>>Тарелька со всеми прибамбасами мне обошлась в 5000 р. и час работы. Не думаю, что это такие уж огромные деньги даже для Омска.
PD>Нет, не большие. Но тарелки тем не менее слабо распространены. Если проехаться по городу, их можно увидеть , но о массовом явлении говорить не приходится. Я года 3 назад хотел себе тарелку завести и интересовался этим. Есть штук 5-7 компаний, которые готовы поставить все оборудование (я сам на крышу не полезу, а больше ее ставить некуда, у меня балкона нет, 1 этаж). Но в итоге все это кончилось ничем. PD>Может, психология иная. Российские телеканалы и так все доступны. А смотреть импортное ТВ — нет у нас такой культуры. Провинция
У нас тоже провинция, а по НТВ+ футбола больше, к примеру. Поэтому тарелок много достаточно. Почти на каждом доме есть. Ну, т.е. их где-то тысяч 10-20 по городу, я думаю.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Здравствуйте, Alexey Voytsehovich, Вы писали:
AV>>scrubs посмотри если конечно время свободное есть немного
PD>какой канал ?
у меня источником была локалка. тебе скорее всего торрент.
Здравствуйте, Воронков Василий, Вы писали:
F>>Выбирается "приоритетная" платформа, под которую идет заточка, для остальных делается "лишь бы работало".
ВВ>Ну все верно. На что ты в таком случае возражал изначально?
На то, что игры под игровую консоль непортируемы.
Они по возможности пишутся на достаточно высоком уровне и только по необходимости оптимизируются на более низком под уже конкретную приставку. Иначе бюджет и сроки будут неадекватно разрастаться.
Для некоторых игр необходимости опускаться на более низкий уровень вообще нет. Пишутся все на С с одним алгоритмом и компилируются просто под разные платформы.
Еще лучше было бы писать все время на еще более высоком уровне, и чтобы уже компилятор правильно оптимизировал код (в том числе отдельные алгоритмы) под конкретную платформу. Теоретически высокий уровень абстракции позволяет подобное делать. Практически — нет такого компилятора. Но это направление развития.
Здравствуйте, Геннадий Васильев, Вы писали:
ГВ>Ну а что там ещё сверх if?
Под натяжкой я понимаю то, что, в принципе, можно все фичи компилятора назвать подсахариванием поверх ассемблера. Все таки ПМ привносит довольно много нового функционала, а не просто чуть чуть упрощает написание if.
AVK>>Опять же, есть ведь еще и итераторы (привет лиспу), где if заменяется when/filter/как-там-еще.
ГВ>Что-то не догоняю, а при чём они здесь?
А при том, что if, возвращающий значение — далеко не единственный вариант.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, AndrewVK, Вы писали:
ГВ>> Пролог, ИМХО, хорош чистотой метода резолюций, который в нём реализован. AVK>Пролог для обучения хорош тем, что намного дальше по идеологии и внутренней логике отстоит от императивного программирования, нежели, скажем, ФП. Отличная возможность понять, что в замочную скважину можно увидеть не весь мир.
Да, и с этой стороны тоже.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Геннадий Васильев, Вы писали:
ВВ>>Обычно "изменение стереотипов" приводит к тому, что по-старому уже думать не хочется. ГВ>Менять стереотипы неприятно потому, что замена одного стереотипа на другой раньше или позже выливается в замену шила на мыло. Меняешь одни шоры на другие — в чём кайф?
А в чем кайф не менять ничего и оставаться в плену представлений, которым уже сто лет в обед?
ОО-программированию необходима серьезная встряска. Почему ФП ее не устроить? И я не знаю, будет ли это "шилом" или очередным "мылом", но тот же ОО привнес много нового да и в принципе дал серьезный прогресс по сравнению с СП.
Если у ФП будет хотя бы вполовину такая роль — это уже хорошо.
ВВ>>Да, всем нам приходится писать на старых языках, но мы же при этом не делаем вид, что в них доступны все прелести ФП. Да и применять ФП-техники можно. Точно также я в свое время применял некоторые ОО-техники в ВБ6, когда приходилось писать на нем. Но ведь он от этого не становился объектно-ориентированным? ГВ>ВБ6, как раз — вполне ОО-язык. Пусть и ограниченный в некотором роде.
Там нет полноценного полиморфизма классов через виртуальные функции, а есть ли его имитация через КОМ-интерфейсы. На мой взгляд этого ничтожно мало, чтобы считать его "вполне ОО-языком". Большая часть ОО паттернов на нем нереализуема.
Здравствуйте, Геннадий Васильев, Вы писали:
ГВ>>>Ты удивишься, но с лесом if-ов и свитчей "боролись" посредством виртуальных функций не далее, как лет 10-12 назад. ВВ>>Вообще полиморфизм классов теоретически действительно позволяет выкинуть это барахло. А вот на практике — да, не получится. Тут и пробовать особо не надо. Ибо очень уж тяжеловесен ООП для этого. ГВ>Ерунда. Дроблению абстракции мешают, как это ни странно, организационные моменты, а не тяжеловесность ООП.
Что такое организационные моменты? Борьба со свитчами "посредством виртуальных функций" приведет к тому, что у тебя будут такие развернутые объектные модели, что в них сам черт ногу сломит.
ГВ>>>Функции, само собой, несколько мельче, чем классы, но проблема разбиения абстракции, в которую, в общем-то, мейнстрим и ткнулся, остаётся той же самой. ВВ>>Она не той же самой остается, она становится "несколько мельче" . Ф-ция производит впечатление более "масштабируемого" что ли кирпичика. Возможно, это будет лучше чем ОО подход. Возможно, нет. Но пока мне кажется судить об этом рановато
ГВ>Я не знаю, как именно отразится FP на мейнстриме, я руководствуюсь только соображениями общего характера.
Мне кажется, эти соображения общего характера звучат как "мы не хотим ничего нового". Или я ошибаюсь?
ГВ>Условия "скорей-скорей" и "что тут думать, это же не шахматы" никогда не способствовали построению глубоких абстракций.
А кто выдвигает такие условия?
ГВ>А как раз эти условия мутному потому по имени мейнстрим и характерны. Будь там хоть какой мегапродвинутый стиль.
Разве? Мейнстрим рвется куда-то срочно переходить и все переделывать?
ГВ>Сейчас я вижу ситуацию, с точностью до деталей повторяющую вакханалию вокруг ООП. Вот всё один в один то же самое: точно так же предлагается выбросить всё и переписать на [новый язык], которому приписываются мистические свойства и точно так же "старый" [язык, стиль, подход] объявляется [исчадие ада, след Ктулху, зашоренность мозга]. Совершенно же аналогично истории с ООП есть свой набор success stories. ГВ>То есть, чисто внешне ситуация выглядит повторяющей то, что уже происходило не раз. Курьёзный момент, что во времена распространения ООП вузы преподавали как раз функциональные языки, а сейчас положение склоняется к зеркальному: в вузах ООП, на практике — FP. Совсем не курьёзный момент — это то, что людей со специальным образованием становится банально меньше, что как раз служит аргументом в пользу сомнений относительно применимости чисто математических фишек FP.
Вакханалия вокруг ООП способствовала развитию как раз того самого мейнстрим-программирования. В итоге.
Здравствуйте, Геннадий Васильев, Вы писали:
ВВ>>В твоих рассуждениях есть один косяк. Ты можешь написать ф-цию которая будет вести себя в функциональном стиле, но при этом быть написанной в императивном стиле. Но смысл такой ф-ции? ГВ>Очевидно, что смысл такой функции заключён в её использовании ради реализации определённых абстракций. Я надеюсь, ты не думаешь, что классы/объекты делают только ради ОО-стиля, а процедуры — только ради императивного стиля самого по себе.
Классы не ради ОО-стиля делают, а потому что мыслят саму структуру программы в терминах сущностей, их взаимосвязей и пр. Когда пишут на ОО-языке, то мыслят в ОО-стиле. Разве это не очевидно?
А правила по принципу — "давайте все ф-ции делать детерминированными, и тогда у нас получится ФП" — это ни фига ФП, это просто старое хорошое правило декомпизиции функций, к-е еще в СП рулило.
ВВ>>Получается, что у тебя часть кода в императивном стиле, часть кода — как бы клиентская — в фукциональном стиле. А где граница-то между тем и другим? ГВ>А зачем она, эта самая граница? ИМХО, всё ограничивается удобством/очевидностью/другими практическими аспектами использования. Стиль ради стиля, это, как-то, неправильно.
Вопрос не в стиле. Вопрос в полной, так сказать, очередной ломке мозгов, необходимость в которой ИМХО назрела. Попробуйте думать не в ОО-ключе. Возможно, вам понравится
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Что такое организационные моменты?
См. ниже.
ВВ>Борьба со свитчами "посредством виртуальных функций" приведет к тому, что у тебя будут такие развернутые объектные модели, что в них сам черт ногу сломит.
Правильно, модели получаются большими. Но это естественное следствие такого подхода к проектированию, обусловленного, кстати, вполне прагматическими причинами. И (по секрету) совсем не всегда в таких моделях черти ноги ломают. У них другой недостаток — увеливается время на первоначальную разработку, что вступает в противоречие с... См. ниже.
ГВ>>Я не знаю, как именно отразится FP на мейнстриме, я руководствуюсь только соображениями общего характера. ВВ>Мне кажется, эти соображения общего характера звучат как "мы не хотим ничего нового". Или я ошибаюсь?
Ошибаешься. Дело не в новизне, а в благовоспитанном иммунитете от панацей.
ГВ>>Условия "скорей-скорей" и "что тут думать, это же не шахматы" никогда не способствовали построению глубоких абстракций. ВВ>А кто выдвигает такие условия?
Менеджмент, вестимо. Его зачастую можно понять, но сами по себе условия от этого не меняются. Как и неприятные последствия от оных. И как раз этого бардака в пресловутом мейнстриме хватает за глаза и за уши.
ГВ>>А как раз эти условия мутному потому по имени мейнстрим и характерны. Будь там хоть какой мегапродвинутый стиль. ВВ>Разве? Мейнстрим рвется куда-то срочно переходить и все переделывать?
Я написал про другие условия. Прочти предложение выше.
ВВ>Вакханалия вокруг ООП способствовала развитию как раз того самого мейнстрим-программирования. В итоге.
Не забывай, что была ещё масса дополнительных благоприятных условий. Одно из них то, что вдруг неимоверно раскрутившийся C++ попал на, в общем, очень благодатную почву — в среду "сишников". Сейчас обстановка малость другая.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, fmiracle, Вы писали:
F>Официальная информация у меня дома стоит — 40Гб версия этого года F>60ки японские поддерживали пс2 идеально (и GPU и CPU от двушки были добавлены), 60ки европейские — частично (только GPU, CPU на эмуляции). Новые 40-ки и 80-ки вообще не держат, поскольку эмулятор для GPU не написан, а сам чип убрали. F>В свое время видел новости от Сони, но сейчас найти не могу. Однако здесь есть таблица моделей с описанием уровня совместимости.
Маразм-то какой
Не ожидал такой гадости от Сони. Я ее во многом купил из-за того, что было интересно погонять некоторые интересные ПС2-эксклюзивы.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>>>Обычно "изменение стереотипов" приводит к тому, что по-старому уже думать не хочется. ГВ>>Менять стереотипы неприятно потому, что замена одного стереотипа на другой раньше или позже выливается в замену шила на мыло. Меняешь одни шоры на другие — в чём кайф? ВВ>А в чем кайф не менять ничего и оставаться в плену представлений, которым уже сто лет в обед?
Я, вообще-то, имел в виду, что к языкам имеет смысл подходить с более прагматической точки зрения, не ограничивая мозги стереотипами, которые воспитываются языком программирования.
ГВ>>ВБ6, как раз — вполне ОО-язык. Пусть и ограниченный в некотором роде. ВВ>Там нет полноценного полиморфизма классов через виртуальные функции, а есть ли его имитация через КОМ-интерфейсы. На мой взгляд этого ничтожно мало, чтобы считать его "вполне ОО-языком". Большая часть ОО паттернов на нем нереализуема.
Тем не менее, ОО-языком его можно назвать по критерию наличия явной поддержки хоть какого-то ООП.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Sinclair, Вы писали:
ВВ>>Это из области "все мы сидим в локалке"? Под локальной сетью обычно имеется в виду все-таки некоторая "сеть", где доступны другие ноды, контент и пр. У меня ADSL2, у меня нет никакой внутренней сети. Причем на самом деле необходимости в ней и не возникает. ВВ>>Любой мало-мальски приличный торрент, когда разгонится, начинает качать со скоростью более 1Мбайта в сек. Представляем сколько чего можно скачать за ночь. Или за день. Оставив комп включенным. S>Ну так торрент как раз и использует много поставщиков. С точки зрения провайдера, главное — это его личные расходы на трафик и организацию сети. S>Тебе хорошо, у тебя толстый канал. В России есть еще места, где такой канал — один на территорию размером с Данию, и его делят все потребители.
Ну лет пять назад и у меня канал был далеко не такой толстый. Налицо, так сказать, тенденция по расширению каналов.
ВВ>>Я уже высказывал мысль, что скорость каналов должна обогнать рост разрешения видео контента. Потому что последний упирается в пока еще живущие физические носители — тот же блю-рей, который еще и на рынок-то нормально выйти не успел и наверняка проживет довольно долго. А там чего-то сильно отличного от 1960х1080 ты не увидишь, ибо не влезет. S>А вот я как раз думаю наоборот. Такая ситуация связана с возрастными проблемами среди издателей: они до сих пор мыслят категориями "вот Д.Доу покупает видеокассету, тьфу, то есть диск...". Распространение контента через сеть резко снижает важность конкретного формата, и тем более конкретного носителя.
Снижает. Если мы вообще перейдем на цифровую дистрибьюцию, т.е. физические носители отомрут. Это рано или поздно случится — но пока это не так.
ВВ>>С другой стороны могут конечно перейти от всяких Mp2 на использование других алгоритмов. Ибо я, честно, последнее время в упор не вижу разницы между "аналогом" и каким-нибудь хорошим XVid. Но с другой стороны смысл? Какое разрешение у твоего монитора? А у телевизора? А каково сейчас соотношение SD-телевизоров и HD-телевизоров? S>Правильно, рост разрешения сейчас по факту сдерживается исключительно возможностями воспроизводящих устройств. Я не в курсе, бывают ли проекторы с более чеем FullHD разрешением. Наращивать разрешение контента на снимающей стороне вполне себе есть куда.
Есть, но смысл это делать, когда нет аппаратуры, к-я позволит оценит все прелести такого высокого разрешения?
ВВ>>Все-таки эта отрасль достаточно инертна, а вот рост интернет-каналов вширь никакие факторы не сдерживают. S>Вот это мне непонятно. Ты себе вообще представляешь характерные стоимости проводных каналов? S>Маленький пример: в Северомуйском тоннеле стоимость всего компютерного обрудования пренебрежимо мала по сравнению со стоимостью кабелей, которые к нему подключены.
А тут все просто. Я не говорю, что расширять каналы легко, дешево и пр. Я говорю — что нет сдерживающих факторов, как в случае с ростом разрешений видео. И уже по факту этот рост происходит быстрее, чем, скажем, переход с ДВД на блюрей.
S>Инертность области телевизоров меня, конечно же, угнетает со страшной силой. Потому что я не успеваю прицениться к девайсу, как кто-нибудь выпускает более классный. Вон, Панасоник освоил 42" плазму в FullHD. А LCD вообще без проблем сделать еще в два раза больше — было бы что смотреть.
У меня плазма 46", купленная чуть ли не в 2000 году, матрица которой физически тянет разрешение 1240х1024. Да, ты знаешь, мне кажется некоторая "инертность" имеет место быть
ВВ>>Мне кажется тут будет рулить не технология, которая позволит сэкономить "еще 14%", а та, которая позволит максимально эффективно бороться с пиратством. Ибо благодаря нему потери будут посильнее. S>Основной способ борьбы с пиратством — отмена сверхприбылей. Сейчас приобретать нелегальный контент удобнее и дешевле, чем легальный. S>Поэтому как ни борись, а плетью обуха не перешибешь. Достаточно сделать легальный контент удобнее, и пираты отомрут. Грубо говоря, зачем тебе качать камрип из сети, когда ты за $12 в месяц имеешь доступ к нормальному медиа-провайдеру, который отдает тебе FullHD 7.1 с раздельными дорожками для языков? При этом найти нужный фильм, посмотреть связанную с ним информацию и прочее ты можешь прямо там же; сервис подсказывает тебе на основе твоего же опыта, какие фильмы отстой, а какие нет; помимо самого фильма валяется масса материалов типа интервью с командой, текст книги, прочая дополнительная информация. Ну то есть этакая помесь IMDB с Amazon, только круче
Ну знаешь, мне кажется всегда останется актуальной ситуация "этот контент недоступен в вашем регионе".
Я вот, например, люблю смотреть фильмы на русском, ну не нравятся мне без перевода, не потому что не понимаю, просто не нравятся.
А сколько, скажем, интересных сериалов доступно только в каком-нибудь лостфильмовском переводе? Я бы с удовольствием купил бы лицензию, даже несмотря на неудобный по сравнению с HDD носитель, но так нет ее. И я не вижу предпосылок к тому, чтобы эта ситуация поменялась кардинально. Ну будет продавать очередной BSG на английском. А я хочу на русском. Вот тебе и вотчина для пиратов.
ВВ>>Ну если не даваться в детали, то можно, почему нет? Есть же несколько довольно явных тенденций, как мне кажется: ВВ>>- уход на покой физических носителей, переход на цифровую дистрибьюцию ВВ>>- объедение различных медиа-устройсв вроде видео-плеера, игровой приставки и пр. в единое развлекательное устройство (что уже почти произошло), через которое будет и телевидение "с кочергой", и видео, и игры. А также музыка и многое другое. Причем это устройство не будут по факту эквивалентно PC и не заменит его. S>Всё может быть. Проблема с таким устройством — невозможность апгрейда по частям.
Это для пользователя проблема Для производителя даже бенефит. Например, XBox вообще говоря не продается, а дается "на прокат", при этом ты не имеешь права как-либо модифицировать его согласно EULA. Получается даже не XBox, а этакий BlackBox. Зато можно вытворять всякие штуки, вроде автоматического удаления контента с винта. На PC такие вещи будет сложнее замутить.
Здравствуйте, Геннадий Васильев, Вы писали:
ВВ>>Классы не ради ОО-стиля делают, а потому что мыслят саму структуру программы в терминах сущностей, их взаимосвязей и пр. Когда пишут на ОО-языке, то мыслят в ОО-стиле. Разве это не очевидно? ГВ>Опять двадцать пять. Очевидно только то, что программа проектируется и записывается в ОО-стиле. Это единственное, что может быть очевидно. Остальное — дешёвые домыслы. Спешу дать добрый совет: забудь про выражения, апеллирующие к свойствам субъекта — они изначально неправомерны. И не читай википедию, особенно статью про "парадигму".
К чему написано все вышесказанное? Это возражение на что-то? Что конкретно я домысливал?
ВВ>>А правила по принципу — "давайте все ф-ции делать детерминированными, и тогда у нас получится ФП" — это ни фига ФП, это просто старое хорошое правило декомпизиции функций, к-е еще в СП рулило. ГВ>Я имел в виду не только детерминированость функций. В детерминированность не очень умещаются, например, функции высших порядков.
Ну вот другие товарищи практически такие функции и считают "чистыми". Хотя ни фига они не чистые в смысле ФП.
ВВ>>Вопрос не в стиле. Вопрос в полной, так сказать, очередной ломке мозгов, необходимость в которой ИМХО назрела. Попробуйте думать не в ОО-ключе. Возможно, вам понравится ГВ>Блин, это ж как узко надо мыслить, чтобы смена языка программирования превращалась в ломку мозга?!
Речь не о смене языка, а о смене концепции программирования вообще-то.
ГВ>И эти люди... Это ты у Влада нахватался, что ли? Так не учись плохому.
Я с Владом за последний год парочкой постов всего обменялся. Думаешь, это так заразно?
Здравствуйте, Геннадий Васильев, Вы писали:
ГВ>Тем не менее, ОО-языком его можно назвать по критерию наличия явной поддержки хоть какого-то ООП.
Ну в этом твои аргументы схожи с тем же FR. Эти вот ребята тоже считают, что С# можно назвать ФП-языком благодаря "наличию явной поддержки хоть какого-то ФП".
Странный критерий, мне кажется
Здравствуйте, Воронков Василий, Вы писали:
ВВ>>>Классы не ради ОО-стиля делают, а потому что мыслят саму структуру программы в терминах сущностей, их взаимосвязей и пр. Когда пишут на ОО-языке, то мыслят в ОО-стиле. Разве это не очевидно? ГВ>>Опять двадцать пять. Очевидно только то, что программа проектируется и записывается в ОО-стиле. Это единственное, что может быть очевидно. Остальное — дешёвые домыслы. Спешу дать добрый совет: забудь про выражения, апеллирующие к свойствам субъекта — они изначально неправомерны. И не читай википедию, особенно статью про "парадигму".
ВВ>К чему написано все вышесказанное? Это возражение на что-то? Что конкретно я домысливал?
Всё, что касается особеностей мышления собеседника изначально неправомерно.
В терминах ОО-языка можно записать массу всяческих мыслей. В терминах функционального языка — тоже. Язык — это только язык, он влияет до какой-то степени на выбор абстракций, но только до какой-то. Хм. По-моему, я уже где-то об этом говорил, совсем недавно.
ВВ>>>А правила по принципу — "давайте все ф-ции делать детерминированными, и тогда у нас получится ФП" — это ни фига ФП, это просто старое хорошое правило декомпизиции функций, к-е еще в СП рулило. ГВ>>Я имел в виду не только детерминированость функций. В детерминированность не очень умещаются, например, функции высших порядков. ВВ>Ну вот другие товарищи практически такие функции и считают "чистыми". Хотя ни фига они не чистые в смысле ФП.
Что-то у тебя всё перепутано. Хоть по словам оспаривай, ёлки зелёные. С одной стороны, я что-то не припомню, чтобы кто-то сводил FP-стиль к детерминированным функциям, а с другой — детерминированные функции вполне себе годятся на "pure FP".
ВВ>>>Вопрос не в стиле. Вопрос в полной, так сказать, очередной ломке мозгов, необходимость в которой ИМХО назрела. Попробуйте думать не в ОО-ключе. Возможно, вам понравится ГВ>>Блин, это ж как узко надо мыслить, чтобы смена языка программирования превращалась в ломку мозга?! ВВ>Речь не о смене языка, а о смене концепции программирования вообще-то.
Только не парадигма! Только не парадигма!
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Воронков Василий, Вы писали:
ГВ>>Тем не менее, ОО-языком его можно назвать по критерию наличия явной поддержки хоть какого-то ООП. ВВ>Ну в этом твои аргументы схожи с тем же FR. Эти вот ребята тоже считают, что С# можно назвать ФП-языком благодаря "наличию явной поддержки хоть какого-то ФП". ВВ>Странный критерий, мне кажется
А где это FR называл C# именно функциональным языком?
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Геннадий Васильев, Вы писали:
ГВ>Всё, что касается особеностей мышления собеседника изначально неправомерно. ГВ>В терминах ОО-языка можно записать массу всяческих мыслей. В терминах функционального языка — тоже. Язык — это только язык, он влияет до какой-то степени на выбор абстракций, но только до какой-то. Хм. По-моему, я уже где-то об этом говорил, совсем недавно.
Для этого надо сначала признать, что именно есть эти самые "термины ФП", и они также отличны от того, что было раньше, как ООП от СП.
ГВ>Что-то у тебя всё перепутано. Хоть по словам оспаривай, ёлки зелёные. С одной стороны, я что-то не припомню, чтобы кто-то сводил FP-стиль к детерминированным функциям, а с другой — детерминированные функции вполне себе годятся на "pure FP".
Забавная ситуация получается. С одной стороны "мы это все уже проходили" и "нас ничем не удивить", а уж какой-нибудь там "ломке мозгов" и говорить даже не приходится — типа это все по неопытности и незнанию. С другой стороны — налицо какое-то явное непонимание ФП, раз рождаются такие заявления о детерминированных ф-циях.
ФП не в детерминированность ф-ций упирается, а в иной подход к созданию абстракций. Именно поэтому гибридные языки, пытающиеся соединить в себе "the best of two worlds" и вызывают у меня некоторые сомнения.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Мы вообще о контролах говорим? Или как? Я с таким явлением как способ расширения функционала контролов "вообще" не знаком. И что такое расширение? ВВ>Чтобы "расширить" DataGridView — я напишу собственный тип ячейки/колонки.
Ага, только колонки и можно расширять, и то весьма примитивно. А что если я захочу: группировку строк; строку с суммой/средним по строкам; объединённые ячейчки, грид, вложенный в ячейку; сложные заголовки? Всё это делается методом выкидывания DataGridView.
Помню, даже для такой простой фичи, как автофильтры в заголовках столбцов, пришлось изрядно попотеть, и то вышло далеко не идеальное решение. Причём, хлопот доставил как сам DataGridView, так и кривая модель байндинга в WinForms.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Ну в этом твои аргументы схожи с тем же FR. Эти вот ребята тоже считают, что С# можно назвать ФП-языком благодаря "наличию явной поддержки хоть какого-то ФП". ВВ>Странный критерий, мне кажется
Угу особенно учитывая что это твои фантазии, ничего подобного я не утверждал. Я говорил что на таких языках можно писать в функциональном стиле.
Здравствуйте, FR, Вы писали:
FR>Они чистые в смысле ФП. FR>Они полностью удовлетворяют определению чистоты например из "Функционального программирования" Харрисона-Филда.
Что, любая детерминированная ф-ция удовлетворяет определению чистоты?
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Забавная ситуация получается. С одной стороны "мы это все уже проходили" и "нас ничем не удивить", а уж какой-нибудь там "ломке мозгов" и говорить даже не приходится — типа это все по неопытности и незнанию. С другой стороны — налицо какое-то явное непонимание ФП, раз рождаются такие заявления о детерминированных ф-циях.
Это у зомбированных немерле свое понимание, из которого выходит что если управляющие конструкции устроены иначе чем в немерле то такой язык не пригоден для ФП. Я же просто показал что для для программирования в ФП стиле нужна совсем малость.
ВВ>ФП не в детерминированность ф-ций упирается, а в иной подход к созданию абстракций. Именно поэтому гибридные языки, пытающиеся соединить в себе "the best of two worlds" и вызывают у меня некоторые сомнения.
То есть такие языки как Ocaml, F#, ML, Scheme, Nemerle, Scala сомнительны?
Здравствуйте, FR, Вы писали:
ВВ>>Забавная ситуация получается. С одной стороны "мы это все уже проходили" и "нас ничем не удивить", а уж какой-нибудь там "ломке мозгов" и говорить даже не приходится — типа это все по неопытности и незнанию. С другой стороны — налицо какое-то явное непонимание ФП, раз рождаются такие заявления о детерминированных ф-циях. FR>Это у зомбированных немерле свое понимание, из которого выходит что если управляющие конструкции устроены иначе чем в немерле то такой язык не пригоден для ФП. Я же просто показал что для для программирования в ФП стиле нужна совсем малость.
Тогда проясни в чем отличия программирования в ФП стиле и собственно ФП-программирования.
ВВ>>ФП не в детерминированность ф-ций упирается, а в иной подход к созданию абстракций. Именно поэтому гибридные языки, пытающиеся соединить в себе "the best of two worlds" и вызывают у меня некоторые сомнения. FR>То есть такие языки как Ocaml, F#, ML, Scheme, Nemerle, Scala сомнительны?
Соединение ООП и ФП лично у меня — да, вызывает некоторое сомнение в том, что это правильный путь. И в первую очередь мне на ум приходит тот же самый немерле.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Тогда проясни в чем отличия программирования в ФП стиле и собственно ФП-программирования.
Программирование в ФП стиле это программирование с использованием функциональной декомпозиции, с использованием преимуществ которые дают чистота и прозрачность по ссылкам и ФВП. Многое из этого можно применить даже в C++, еще больше в шарпе, питоне или D.
ВВ>>>ФП не в детерминированность ф-ций упирается, а в иной подход к созданию абстракций. Именно поэтому гибридные языки, пытающиеся соединить в себе "the best of two worlds" и вызывают у меня некоторые сомнения. FR>>То есть такие языки как Ocaml, F#, ML, Scheme, Nemerle, Scala сомнительны?
ВВ>Соединение ООП и ФП лично у меня — да, вызывает некоторое сомнение в том, что это правильный путь. И в первую очередь мне на ум приходит тот же самый немерле.
У меня кстати тоже, например при написании хоть и небольших утилиток на окамле даже мысли не возникало использовать тамошний ООП. С другой стороны тот же эрланг показывает что ОО и функциональный стиль могут дополнять и усиливать друг друга
Здравствуйте, Sinclair, Вы писали:
ВВ>>А что ты мне пытаешься доказать? Я где-то утверждал, что вин-формс самый лучший ГУИ-фреймворк? ВВ>>Само обсуждение о вин-формсах всплыло как очередное передергивание на тему "никто не защищает веб-формс". S>Заметь — передергивание было с твоей стороны. Именно ты привлек в топик ВинФормз.
Ты знаешь — случайно упомянул. Ей-богу, уже страшно писать что-то — чуть что, сразу начинается какой-то флейм. Этак можно выцепить любую фразу — и понеслась.
ВВ>>Вин-формы хотя бы построены на основе правильных архитектурных решений. Да, на мой взгляд обработка сообщений через события — это важный момент, и он сделан удачно. S>Совершенно неудачно. См. bubbling/sinking как правильный механизм обработки сообщений. ВВ>>Да, "маппинг" окошек на контролы — это хорошо. S>Это отвратительно.
Обосновать можешь? В контексте именно ГУИ-фреймворка.
ВВ>>И это значительно удобнее того, что было в MFC. S>Ну, если слаще репы ничего не есть, то таки да. Но мы же не с MFC сравниваем винформз, нет?
"Мы" — это кто? Я сравниваю именно с МФС вообще-то. В мире вин32 вин-формс были неплохим таким шагом вперед. По-моему странно обсуждать это. И странно критиковать их сейчас, когда собственно то, над чем они строятся уходит на покой.
Я же для веб-формс не искал каких-то особенно "крутых" соперников. Меня устраивало любое сравнение. Хотите ПХП, хотите АСП. Я вот не знаю SWT или wxWidgets. Ну и как мне реагировать на всякие "вот в wxWidgets это сделано лучше". Да ради бога, может и лучше.
Собственно, если бы даже вин-формс были самым неудачным ГУИ-фреймворков (что абсолютно неправда на самом деле), это как бы не исключало того факта, что архитектурно они более правильны чем веб-формс.
ВВ>>И это не мешает мне спуститься на более низкий уровень, когда это нужно. ВВ>>Веб-формы построены изначально на в корне неверных архитектурных решениях. Хотя бы потому что они точно такие же, как в вин-формс И сама эта идея — неправильная. Более того, если даже сравнивать отдельные решения, использованные в веб-формс и вин-формс, то веб-формс пожалуй даже выиграет по сумме очков — вот только к чему это все, когда фундамент гнилой? ВВ>>Ты с этим не согласен? S>Я согласен. Только вот у веб-форм фундамент как раз хороший; гнилая там — только малозначительная надстройка. Ее можно безболезненно заменить, и построить на том же фундаменте совершенно другое решение.
А какой фундамент у веб-форм? Может, еще к архитектуре ИИС обратимся, и ее в плюсы веб-форм запишем? Всякие хендлеры — это практически тривиальная обвертка над ИЗАПИ, не более.
Потом это опять спор о терминах. Фундамент, не фундамент. Есть концепция заложенная в веб-форм. Та же обработка пост-бека через события. Это одна из основных концепций программирования на веб-формс. Эта концепция неудачная. Аналогичная концепция в вин-формс куда более удачно ложится на "предметную область". Вот, собственно, и все.
Здравствуйте, Sinclair, Вы писали:
S>Здравствуйте, Воронков Василий, Вы писали:
ВВ>>А о чем тогда спор? S>Ну, раньше был о производительности и методах ее достижения. S>Ты с какой-то непонятной мне целью свернул его на UI-фреймворки.
Ну первым страшное слово АСП.НЕТ сказал ты. Точно также как и я первым сказал страшное слово ВинФормс. Так что виноват в этом флейме ты
ВВ>>А на WTL смысл есть смотреть? S>Нет, нету. ВВ>>Каким образом тут Хром всплыл, мне интересно? S>У тебя трудности с памятью или с восприятием? Цитирую место, где всплыл хром: S>
S>Единственный способ написать удачное GUI приложение — это захватить одно окно (в терминах user32), а внутри него выполнять отрисовку вручную. То есть, конечно же, не вручную, а при помощи некоторого совершенно другого фреймворка, у которого базовые примитивы устроены вовсе не так, как предлагают user32 и comctl32.
S>В качестве недавних примеров таких приложений можно посмотреть на Chrome.
S>Что тут непонятно? Что у хрома всего два user32-окна? Ну так запусти Spy++ и посмотри.
Да знаешь, на вид там вообще одно окно
Хром вообще такое типичное WTL-ное приложение, они там даже какие-то фишки узают, которые еще в репозитории только доступны.
ВВ>>А можно по-конкретнее? Что там неудобно? Что сложно реализовать? S>Любая анимация состояния — это pain.
Это в юзер32 всегда так.
S>Любые игры с выходом за пределы своего clip rect типа теней, обводки, и прочих glow — pain.
И опять-таки. Чтобы обойти все это, надо фактически не использовать "окошки". Но какая же это тогда надстройка над окошками, а?
S>Композитные контролы — тройной pain.
А тут-то в чем проблема?
S>Cкорее возникает вопрос — а что там реализовать легко и удобно.
Все, что нормально ложится на юзер32 + кое-что еще.
Вот рисование через примитивы ГДИ+ вполне себе легко и удобно, например.
S>Практика показывает, что легко и удобно делать только примеры для книжек "как не должен быть устроен UI".
Может быть "не" стоит убрать? Вин-интерфейс вообще-то должен отвечать определенным стандартам, быть *шаблонным* (за исключение редких программ). Сама вин сделана на "окошках". Так что для "шаблонного" вин UI там всего достаточно.
S>Более-менее нормальные решения делать уже сложно. Для хороших, повторюсь, нужно выкидывать весь стандартный стек и брать свой. ВВ>>Реализация одного и того же функционала — допустим контрол, с большим кол-вом owner draw — на GDI+ и на WPF занимает почему-то весьма и весьма схожее время. Реализация этого функционала на WPF получается никак не "проще". При этом еще и АА в итоге кривой S>Мы с WPF играли мало, но наши эксперименты показывают ровно обратную ситуацию. Большое количество Owner Draw в жизненных примерах достигается не выпиливанием по пикселам, а выбором правильных векторных примитивов. К тому же их рисует дизайнер, у которого рука набита, а не программист.
Что за "выпиливание по пикселям"? В ГДИ+ вполне удобные примитивы, не припомню, чтобы я там что-то "выпиливал".
Попробуйте нарисовать какой-нибудь нетривиальный контрол — например, показывающий температуру в виде градусника. Или там скорость ветра в виде спидометра. Вот недавно такую хрень рисовали как раз.
На WPF — по трудозатрам — ну практически те же яйца.
ВВ>>Вообще-то я игрался с HTMLayout, правда не очень недавно. И он именно, что HTML и рендерит Причем на тот момент не дружил с XHTML и CSS. S>То, что он рендерит — это не HTML. Это его близкий родственник, конечно, но это язык разметки UI, а не гипертекста. Вон посмотри на терраинформатике примеры приложений, UI которых построен на HTMLayout.
Ради бога. Но мне показалось, что это очень похоже на ХТМЛ
ВВ>>"Все", значит, считают, что ASP.NET "нигде не кончается", т.е. практически эквивалентент понятию .NET, S>Главное — это то, что все считают, что ASP.NET не сводится к System.Web.UI.Page.
А мне интересно обсудить именно System.Web.UI.Page и все с ним сопряженное. А не то, к чему он там сводится или не сводится.
Здравствуйте, FR, Вы писали:
FR>У меня кстати тоже, например при написании хоть и небольших утилиток на окамле даже мысли не возникало использовать тамошний ООП. С другой стороны тот же эрланг показывает что ОО и функциональный стиль могут дополнять и усиливать друг друга
Ну, собственно, даже бескомпромиссный Хаскель вполне себе ОО.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Воронков Василий, Вы писали:
S>>Совершенно неудачно. См. bubbling/sinking как правильный механизм обработки сообщений. ВВ>>>Да, "маппинг" окошек на контролы — это хорошо. S>>Это отвратительно. ВВ>Обосновать можешь? В контексте именно ГУИ-фреймворка.
Конечно могу. Пример на пальцах: делаем композитный контрол. В идеологии окошко=контрол он обязан иметь оконный хендл, а все его компоненты обязаны быть его дочерними окнами. Что абсолютно никак не требуется по логике самого контрола — ни рисование, ни event processing не пострадают, если запчасти от контрола будут разнесены. А я, может быть, хочу линию вертикальную нарисовать между label и input. Упс, только наследоваться и сабкласситься.
ВВ>"Мы" — это кто? Я сравниваю именно с МФС вообще-то.
Вопрос — зачем? Берем говно, сравниваем с ним другое говно. Поверь, никому это не интересно. ВВ>В мире вин32 вин-формс были неплохим таким шагом вперед. По-моему странно обсуждать это. И странно критиковать их сейчас, когда собственно то, над чем они строятся уходит на покой. ВВ>Я же для веб-формс не искал каких-то особенно "крутых" соперников. Меня устраивало любое сравнение. Хотите ПХП, хотите АСП.
ВВ>Я вот не знаю SWT или wxWidgets. Ну и как мне реагировать на всякие "вот в wxWidgets это сделано лучше".
Как на повод повысить свою квалификацию. . Если тебе неинтересен вопрос "как должен быть устроен хороший GUI-framework", то не надо было поднимать эту тему в этом форуме. Если интересен — забей на устаревший отстой; смотри на лучшие достижения.
ВВ>Да ради бога, может и лучше. ВВ>Собственно, если бы даже вин-формс были самым неудачным ГУИ-фреймворков (что абсолютно неправда на самом деле), это как бы не исключало того факта, что архитектурно они более правильны чем веб-формс.
Знаешь, мне трудно сравнивать два отстоя на предмет большей или меньшей правильности. Их надо не сравнивать, а выкидывать на помойку.
S>>Я согласен. Только вот у веб-форм фундамент как раз хороший; гнилая там — только малозначительная надстройка. Ее можно безболезненно заменить, и построить на том же фундаменте совершенно другое решение.
ВВ>А какой фундамент у веб-форм?
И в четвертый раз разжевываю: IHttpHandler/IHttpModule/BuildProvider. Вот основной фундамент.
Дальше мы увидим еще N провайдеров, которые можно считать фундаментом, а можно — подвалом. Всё это сделано очень хорошо. ВВ>Может, еще к архитектуре ИИС обратимся, и ее в плюсы веб-форм запишем? Всякие хендлеры — это практически тривиальная обвертка над ИЗАПИ, не более. Тривиальная? Ну-ну. Я бы вот так с налёту не смог написать аналог инфраструктуры ASP.NET. Ты вообще смотрел на классы ISAPI*? Или так, понты колотишь?
ВВ>Потом это опять спор о терминах. Фундамент, не фундамент. Есть концепция заложенная в веб-форм. Та же обработка пост-бека через события. Это одна из основных концепций программирования на веб-формс. ВВ>Эта концепция неудачная.
С этим никто не спорит. Точка. По-прежнему продолжаю не понимать, зачем заниматься копрофагией.
ВВ>Аналогичная концепция в вин-формс куда более удачно ложится на "предметную область".
Ты имел в виду наоборот — "на нижележащую технологию", надо полагать? Потому как на предметную область это ложится плохо. Простейший пример из предметной области: делаем композитный контрол с большим количеством child controls. Из-за отсутствия bubbling, композитный контрол вынужден заниматься ретрансляцией событий от детей путем подписывания на события каждого из них. Никак не могу назвать эту концепцию удачной — язык не поворачивается. ВВ>Вот, собственно, и все.
... << RSDN@Home 1.2.0 alpha rev. 677>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Воронков Василий, Вы писали:
ГВ>>Всё, что касается особеностей мышления собеседника изначально неправомерно. ГВ>>В терминах ОО-языка можно записать массу всяческих мыслей. В терминах функционального языка — тоже. Язык — это только язык, он влияет до какой-то степени на выбор абстракций, но только до какой-то. Хм. По-моему, я уже где-то об этом говорил, совсем недавно.
ВВ>Для этого надо сначала признать, что именно есть эти самые "термины ФП", и они также отличны от того, что было раньше, как ООП от СП.
Странно. Раз есть функциональный (объектный, логический...) язык программирования (я имел в виду именно язык программирования), то безусловно есть и термины этого языка. Или ты хочешь сказать, что нужно непременно признать, что мышление человека происходит непосредственно в терминах языка?
ГВ>>Что-то у тебя всё перепутано. Хоть по словам оспаривай, ёлки зелёные. С одной стороны, я что-то не припомню, чтобы кто-то сводил FP-стиль к детерминированным функциям, а с другой — детерминированные функции вполне себе годятся на "pure FP".
ВВ>Забавная ситуация получается. С одной стороны "мы это все уже проходили" и "нас ничем не удивить", а уж какой-нибудь там "ломке мозгов" и говорить даже не приходится — типа это все по неопытности и незнанию. С другой стороны — налицо какое-то явное непонимание ФП, раз рождаются такие заявления о детерминированных ф-циях.
Я оговорился. Следует читать как: "...некоторые детерминированные функции вполне...".
ВВ>ФП не в детерминированность ф-ций упирается, а в иной подход к созданию абстракций.
Как это ни удивительно, но именно об этом я с самого начала и говорю.
ВВ>Именно поэтому гибридные языки, пытающиеся соединить в себе "the best of two worlds" и вызывают у меня некоторые сомнения.
Ну что тут поделаешь.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Геннадий Васильев, Вы писали:
ГВ>>>Удивительное дело: что Lisp, что Prolog — простейшие языки. Их долго изучать невозможно в принципе. С другой стороны, они оказались настолько значимыми, что игнорировать их существование... Преподавателю... Э-э-э...
PD>>А с чего ты решил, что я игнорирую их существование ?
ГВ>Ну, значит, просто показалось, что ты их и в самом деле считаешь чем-то новым.
Новым ? Я ? Лисп и Пролог ? У меня дома по ним книжки лежат года так примерно 1985 года выпуска, прочитанные примерно тогда же
ГВ>ЭВМ 5-го поколения, ИМХО, не показатель. Этот проект блистательно провалился во всех ипостасях: что в Европе с Лиспом (или в Штатах с Лиспом играли, не помню), что в Японии. Пролог, ИМХО, хорош чистотой метода резолюций, который в нём реализован. Примерно как Лисп — он тоже привлекателен своей минимальностью.
Просто я не любитель маргинальных направлений. И Лисп и Пролог живут и не помирают, но отнюдь не составляют конкуренции мэйнфреймовским языкам. Поэтому с меня хватит знать, что они есть, и иметь представление, что они собой представляют, а больше не хочу.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Что за "выпиливание по пикселям"? В ГДИ+ вполне удобные примитивы, не припомню, чтобы я там что-то "выпиливал". ВВ>Попробуйте нарисовать какой-нибудь нетривиальный контрол — например, показывающий температуру в виде градусника. Или там скорость ветра в виде спидометра. Вот недавно такую хрень рисовали как раз. ВВ>На WPF — по трудозатрам — ну практически те же яйца.
В WPF эти трудозатраты будут сделаны один раз. Далее этот градусник можно будет засунуть куда угодно. В WindowsForms тебе придётся нарисовать градусник для контрола "градусник", градусник для кастомного типа столбцов в гриде, градусник внутри своего контрола TreeView, выпиленного целиком с нуля, ради того, чтобы он умел показывать градусник.
Здравствуйте, Sinclair, Вы писали:
S>>>Совершенно неудачно. См. bubbling/sinking как правильный механизм обработки сообщений. ВВ>>>>Да, "маппинг" окошек на контролы — это хорошо. S>>>Это отвратительно. ВВ>>Обосновать можешь? В контексте именно ГУИ-фреймворка. S>Конечно могу. Пример на пальцах: делаем композитный контрол. В идеологии окошко=контрол он обязан иметь оконный хендл, а все его компоненты обязаны быть его дочерними окнами. Что абсолютно никак не требуется по логике самого контрола — ни рисование, ни event processing не пострадают, если запчасти от контрола будут разнесены. А я, может быть, хочу линию вертикальную нарисовать между label и input. Упс, только наследоваться и сабкласситься.
Причем тут непосредственно вин-форм?
Кто мешает нарисовать эту линию без сабклассинга?
ВВ>>Я вот не знаю SWT или wxWidgets. Ну и как мне реагировать на всякие "вот в wxWidgets это сделано лучше". S>Как на повод повысить свою квалификацию. . Если тебе неинтересен вопрос "как должен быть устроен хороший GUI-framework", то не надо было поднимать эту тему в этом форуме. Если интересен — забей на устаревший отстой; смотри на лучшие достижения.
Я не поднимал тему "как должен быть устроен хороший GUI-framework". Помимо рассуждений о высоких вопросах стиля, людям еще работать надо. Причем на разных фреймворках.
ВВ>>Да ради бога, может и лучше. ВВ>>Собственно, если бы даже вин-формс были самым неудачным ГУИ-фреймворков (что абсолютно неправда на самом деле), это как бы не исключало того факта, что архитектурно они более правильны чем веб-формс. S>Знаешь, мне трудно сравнивать два отстоя на предмет большей или меньшей правильности. Их надо не сравнивать, а выкидывать на помойку.
Да, да, да, сотни приложений написаны на веб-форм, шарепоинт, продвигаемый всеми силами МС, написан на веб-форм, 99.99% ГУИ-приложений на дотнете написаны на вин-формах — чего мелочиться, давайте это все выкинем!
S>>>Я согласен. Только вот у веб-форм фундамент как раз хороший; гнилая там — только малозначительная надстройка. Ее можно безболезненно заменить, и построить на том же фундаменте совершенно другое решение. ВВ>>А какой фундамент у веб-форм? S>И в четвертый раз разжевываю: IHttpHandler/IHttpModule/BuildProvider. Вот основной фундамент. S>Дальше мы увидим еще N провайдеров, которые можно считать фундаментом, а можно — подвалом. Всё это сделано очень хорошо. ВВ>>Может, еще к архитектуре ИИС обратимся, и ее в плюсы веб-форм запишем? Всякие хендлеры — это практически тривиальная обвертка над ИЗАПИ, не более. S>Тривиальная? Ну-ну. Я бы вот так с налёту не смог написать аналог инфраструктуры ASP.NET. Ты вообще смотрел на классы ISAPI*? Или так, понты колотишь?
Здравствуйте, konsoletyper, Вы писали:
K>Ага, только колонки и можно расширять, и то весьма примитивно. А что если я захочу: группировку строк; строку с суммой/средним по строкам; объединённые ячейчки, грид, вложенный в ячейку; сложные заголовки? Всё это делается методом выкидывания DataGridView. K>Помню, даже для такой простой фичи, как автофильтры в заголовках столбцов, пришлось изрядно попотеть, и то вышло далеко не идеальное решение. Причём, хлопот доставил как сам DataGridView, так и кривая модель байндинга в WinForms.
Здравствуйте, konsoletyper, Вы писали:
K>В WPF эти трудозатраты будут сделаны один раз. Далее этот градусник можно будет засунуть куда угодно. В WindowsForms тебе придётся нарисовать градусник для контрола "градусник", градусник для кастомного типа столбцов в гриде, градусник внутри своего контрола TreeView, выпиленного целиком с нуля, ради того, чтобы он умел показывать градусник.
Правда что ли? Пиксели тогда не надо пилить, нарисуйте вектор.
Здравствуйте, Воронков Василий, Вы писали: ВВ>Причем тут непосредственно вин-форм? ВВ>Кто мешает нарисовать эту линию без сабклассинга?
Как кто??? В идеологии контрол == окно только контрол отвечает за рисование того, что в пределах его clip region.
ВВ>Я не поднимал тему "как должен быть устроен хороший GUI-framework". Помимо рассуждений о высоких вопросах стиля, людям еще работать надо. Причем на разных фреймворках.
А это какое отношение к теме имеет? И к какой?
ВВ>Да, да, да, сотни приложений написаны на веб-форм, шарепоинт, продвигаемый всеми силами МС, написан на веб-форм, 99.99% ГУИ-приложений на дотнете написаны на вин-формах — чего мелочиться, давайте это все выкинем!
Давайте. На Коболе написано значительно больше кода, чем на вин- и веб-формах вместе взятых. Это как-то влияет на наше желание и дальше разрабатывать на Коболе?
Вон МС в новой студии переписывает редактор на WPF. Видать, канонический RichEdit их не устраивает.
S>>Тривиальная? Ну-ну. Я бы вот так с налёту не смог написать аналог инфраструктуры ASP.NET. Ты вообще смотрел на классы ISAPI*? Или так, понты колотишь? ВВ>Архитектурно — да, тривиальная.
То есть всё же понты.
... << RSDN@Home 1.2.0 alpha rev. 677>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Здравствуйте, konsoletyper, Вы писали:
K>>В WPF эти трудозатраты будут сделаны один раз. Далее этот градусник можно будет засунуть куда угодно. В WindowsForms тебе придётся нарисовать градусник для контрола "градусник", градусник для кастомного типа столбцов в гриде, градусник внутри своего контрола TreeView, выпиленного целиком с нуля, ради того, чтобы он умел показывать градусник.
ВВ>Правда что ли? Пиксели тогда не надо пилить, нарисуйте вектор.
Ну и зачем? Все равно вместо одного класса "мой клёвый редактор ктулхов" надо будет завести:
сам редактор
редактор для грида
....
Градусники:
градусник
градусник для грида
градусник для тривью
....
Здравствуйте, Sinclair, Вы писали:
S>Здравствуйте, Воронков Василий, Вы писали: ВВ>>Причем тут непосредственно вин-форм? ВВ>>Кто мешает нарисовать эту линию без сабклассинга? S>Как кто??? В идеологии контрол == окно только контрол отвечает за рисование того, что в пределах его clip region.
Ну и что? Все контролы находятся внутри родительского окна, вот в нем и рисуй.
Да и вообще какая-то надуманная проблема. Линия — это что? Часть "заголовка" контрола? Рисуй в заголовке. Это "разметка" самой формы, на которой контролы расположены? Рисуй по форме.
ВВ>>Я не поднимал тему "как должен быть устроен хороший GUI-framework". Помимо рассуждений о высоких вопросах стиля, людям еще работать надо. Причем на разных фреймворках. S>А это какое отношение к теме имеет? И к какой?
Прямое. Мы технологии обсуждаем разве не в разрезе их реального использования?
ВВ>>Да, да, да, сотни приложений написаны на веб-форм, шарепоинт, продвигаемый всеми силами МС, написан на веб-форм, 99.99% ГУИ-приложений на дотнете написаны на вин-формах — чего мелочиться, давайте это все выкинем! S>Давайте. На Коболе написано значительно больше кода, чем на вин- и веб-формах вместе взятых. Это как-то влияет на наше желание и дальше разрабатывать на Коболе?
Мне казалось, это вопрос практики, а не высокой теории и наших желаний. В разрезе желаний я бы вообще поговорил о чем-то другом, а не о всяких зловонных УИ-фреймворках.
S>Вон МС в новой студии переписывает редактор на WPF. Видать, канонический RichEdit их не устраивает.
Лучше бы они шарепоинт переделали.
Да, и RichEdit-то тут причем?
S>>>Тривиальная? Ну-ну. Я бы вот так с налёту не смог написать аналог инфраструктуры ASP.NET. Ты вообще смотрел на классы ISAPI*? Или так, понты колотишь? ВВ>>Архитектурно — да, тривиальная. S>То есть всё же понты.
Для того, чтобы написать ISAPI эстеншин еще в 6 вижуалке не надо было быть гуру. Там даже визард был специальный
И по "интерфейсу" получалось — те же яйца, вид сбоку.
Да, поэтому я и не хочу, считать, что прям IHttpHandler/IHttpModule — это прям вся соль асп-нета. Ибо нового в них ноль. И они ничего не дают такого, что не было бы доступно раньше. Просто еще одна удобная реализация. А билд-провайдеры позднее появились да и не везде нужны.
Здравствуйте, Aen Sidhe, Вы писали:
ВВ>>Здравствуйте, konsoletyper, Вы писали: K>>>В WPF эти трудозатраты будут сделаны один раз. Далее этот градусник можно будет засунуть куда угодно. В WindowsForms тебе придётся нарисовать градусник для контрола "градусник", градусник для кастомного типа столбцов в гриде, градусник внутри своего контрола TreeView, выпиленного целиком с нуля, ради того, чтобы он умел показывать градусник. ВВ>>Правда что ли? Пиксели тогда не надо пилить, нарисуйте вектор.
AS>Ну и зачем?
Для того, чтобы картинка была легко масштабируемой и вставлялась куда угодно. Ведь на это уйдет основное время разработки, нет?
AS>Все равно вместо одного класса "мой клёвый редактор ктулхов" надо будет завести:
А кто мешает написать один класс "мой клёвый редактор ктулхов"? Вин-формс конечно довольно примитивен по сравнению с WPF, но ведь это не значит, что мозг надо совсем отключать. Если логику можно сделать reusable, то ее можно сделать reusable независимо от того, какой УИ-фреймворк используется. Вин-формс в данном случае лишь обязует реализовать несколько разных "контрактов". Вот собственно и все. И вся трагедия.
AS>
AS>сам редактор AS>редактор для грида AS>.... AS>AS>Градусники: AS>
AS>градусник AS>градусник для грида AS>градусник для тривью AS>.... AS>
Универсальная модель расширения — это очень хорошо. Это упрощает расширение контролов. Но это никак не упрощает создание самого градусника, который в большинстве случаях все-таки нужен в единственной форме, а не в виде "мы интегрируемся во все контролы подряд".
Здравствуйте, Воронков Василий, Вы писали:
ВВ>А кто мешает написать один класс "мой клёвый редактор ктулхов"? Вин-формс конечно довольно примитивен по сравнению с WPF, но ведь это не значит, что мозг надо совсем отключать. Если логику можно сделать reusable, то ее можно сделать reusable независимо от того, какой УИ-фреймворк используется. Вин-формс в данном случае лишь обязует реализовать несколько разных "контрактов". Вот собственно и все. И вся трагедия.
Ну так я так и делаю. В результате у меня какая мысля возникла: а зачем делать какой-то невнятный helper-класс для отрисовки/обработки мыши/клавиатуры, а потом его ещё и пристёгивать к каждому конкретному случаю по-своему? А не проще ли сделать один на все случаи жизни MyControl, который содержал бы общий код для отрисовки и обработки ввода? А потом сделаю грид (наследующийся от MyControl, а не от Control), в котором в ячейках будут MyControl и TreeView (так же наследник MyControl), в котором так же в узлах дерева будут MyControl? Тогда из WindowsForms мне понадобятся только классы Control, на котором я буду отрисовывать корневой MyControl (очевидно — панелька со всем UT) и формочка, куда я буду класть этот Control. Мне даже этот тормоз GDI+ не понадобится, т.к. если я всё своими силами делаю, то и рендерер свой могу сделать, который будет основан на DirectX. Стоп! А зачем мне тратить n человеколет на такую непростую задачу, если я могу взять WPF?
Собственно, ты начал с того, что заявил, будто Web Forms — говно, Windows Forms — рулит. Я же, аналогично Синклеру, доказываю что говно и то и другое. Собственно, не то чтобы это говно во всех отношениях. Какие-то простенькие повседневные задачки они решают хорошо. В этом смысле Web Forms не проигрывает Windows Forms в плане удобства.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Интересно, а в WPF какой грид?
Никакого. Но чисто теоретически можно написать такой, чтобы в ячейках отображались произвольные контролы. И это будет работать хорошо. В Windows Forms если такое и сделаешь, то будет очень и очень плохо (в качестве упражнения предлагаю положить на формочку 400 кнопочек в виде таблицы 20x20 и посмотреть, что из этого выйдет).
Остальные вещи, да, достигаются за счёт правильного дизайна грида, а не за счёт WPF. Но! Ты как раз и говорил об убогости Web Form на примере того, что у тебя что-то не получилось расширить в стандартном DataGrid'е. Так что мешает для Web Forms взять нормальный грид?
Здравствуйте, konsoletyper, Вы писали:
K>Ну так я так и делаю. В результате у меня какая мысля возникла: а зачем делать какой-то невнятный helper-класс для отрисовки/обработки мыши/клавиатуры, а потом его ещё и пристёгивать к каждому конкретному случаю по-своему? А не проще ли сделать один на все случаи жизни MyControl, который содержал бы общий код для отрисовки и обработки ввода? А потом сделаю грид (наследующийся от MyControl, а не от Control),
Ну да, и получится еще что-то более уродливое, чем Control.
K>в котором в ячейках будут MyControl и TreeView (так же наследник MyControl), в котором так же в узлах дерева будут MyControl? Тогда из WindowsForms мне понадобятся только классы Control, на котором я буду отрисовывать корневой MyControl (очевидно — панелька со всем UT) и формочка, куда я буду класть этот Control.
А можно проще — пошел и купил готовый набор компонент. Только вот в отличие от веб-форм тут ты в итоге не упрешься в то, что сама концепция контролов и событий принципиально ущербно, мешает тебе работать и ее вообще надо выкинуть на хрен и напрямую с сообщениями работать.
K>Мне даже этот тормоз GDI+ не понадобится, т.к. если я всё своими силами делаю, то и рендерер свой могу сделать, который будет основан на DirectX.
Угу, "тормоз GDI+" просто летает по сравнению с софтварным рендерером у WPF.
K>Собственно, ты начал с того, что заявил, будто Web Forms — говно, Windows Forms — рулит.
Я не говорил, что "Windows Forms — рулит". Но Windows Forms — это говно в куда меньшей степени, чем Web Forms.
K>Я же, аналогично Синклеру, доказываю что говно и то и другое.
Неубедительно. Да и вместо того, чтобы что-то доказывать попробовал бы лучше лет пять поработать и с тем, и с другим. И посмотреть во что это реально выливается. Windows Forms хотя бы не мешает, в отличие от. Да и нормы построения вин и веб интерфейса несколько отличаются.
K>Собственно, не то чтобы это говно во всех отношениях. Какие-то простенькие повседневные задачки они решают хорошо. В этом смысле Web Forms не проигрывает Windows Forms в плане удобства.
Проигрывает. Потому что опраданий на построение веб-приложение по аналогии в вин-приложением нет никаких. Вообще.
"Простенькие повседневные задачи" можно и на ПХП решать. Там сейчас тоже библиотек хватает.
Здравствуйте, konsoletyper, Вы писали:
K>Никакого.
А я-то думал, ты мне про WPF Toolkit расскажешь, и начнется спор — говно этот тулкит или нет
Да, обломал
K>Но чисто теоретически можно написать такой
Теоретик блин
А чисто практически можно пойти и купить грид у Инфрагистика.
Причем покупали грид у Инфрагистика, когда писали на Актив-Икс.
Покупали грид у Инфрагистика, когда писали на вин-формс.
И будут покупать грид у Инфрагистика для WPF.
K>, чтобы в ячейках отображались произвольные контролы.
Не вижу в этом проблемы даже со стандартным ГридВью (который, кстати, очень неплох для стандартного контрола, а ждать какого-то супер-грида от МС — это утопия). Другим компаниям тоже кушать хочется.
K>И это будет работать хорошо. В Windows Forms если такое и сделаешь, то будет очень и очень плохо (в качестве упражнения предлагаю положить на формочку 400 кнопочек в виде таблицы 20x20 и посмотреть, что из этого выйдет).
Если ты таким образом тулбары делаешь, то неудивительно, что тебе вин-формс не нравится.
Вообще надо бы отделять представление данных, для которого никаких новых окошек делать не надо, и редактирование данных.
K>Остальные вещи, да, достигаются за счёт правильного дизайна грида, а не за счёт WPF. Но! Ты как раз и говорил об убогости Web Form на примере того, что у тебя что-то не получилось расширить в стандартном DataGrid'е. Так что мешает для Web Forms взять нормальный грид?
Пример грида показывает не убогость грида, а убогость контрола на вебе вообще. Контролы на вебе не нужны. Нужен полноценный метаязык. Вин != Веб. Задачи разные. Попробуйте подумайть над этим не только в ключе "что бы тут возразить".
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Здравствуйте, Aen Sidhe, Вы писали:
ВВ>>>Здравствуйте, konsoletyper, Вы писали: K>>>>В WPF эти трудозатраты будут сделаны один раз. Далее этот градусник можно будет засунуть куда угодно. В WindowsForms тебе придётся нарисовать градусник для контрола "градусник", градусник для кастомного типа столбцов в гриде, градусник внутри своего контрола TreeView, выпиленного целиком с нуля, ради того, чтобы он умел показывать градусник. ВВ>>>Правда что ли? Пиксели тогда не надо пилить, нарисуйте вектор.
AS>>Ну и зачем?
ВВ>Для того, чтобы картинка была легко масштабируемой и вставлялась куда угодно. Ведь на это уйдет основное время разработки, нет?
Масштабируемость контролов при зуме — конечно красиво, но далеко не всегда необходима. Или я неправильно понял?
AS>>Все равно вместо одного класса "мой клёвый редактор ктулхов" надо будет завести:
ВВ>А кто мешает написать один класс "мой клёвый редактор ктулхов"? Вин-формс конечно довольно примитивен по сравнению с WPF, но ведь это не значит, что мозг надо совсем отключать. Если логику можно сделать reusable, то ее можно сделать reusable независимо от того, какой УИ-фреймворк используется. Вин-формс в данном случае лишь обязует реализовать несколько разных "контрактов". Вот собственно и все. И вся трагедия.
Речь как раз об этом. Зачем делать сто тысяч разных хелпер-контролов? Какая ж это реюзабельность? Реюзабельность (в моём понимании) — "взял, заюзал", а не "взял, допилил напильником, отполировал нулёвкой, заюзал".
Посмотрите, кстати, любую библиотеку с контролами коммерческую. 99% используют только Control. И выстраивают всю иерархию заново. Наверно неспроста.
ВВ>Универсальная модель расширения — это очень хорошо. Это упрощает расширение контролов. Но это никак не упрощает создание самого градусника, который в большинстве случаях все-таки нужен в единственной форме, а не в виде "мы интегрируемся во все контролы подряд".
В WPF, насколько мне известно, мы один раз рисуем градусник. Вроде бы это не слишком сложно. А потом вставляем куда надо. Будь то грид или форма, или текстбокс. Вставляем без тысяч хелпер классов.
Здравствуйте, Aen Sidhe, Вы писали:
ВВ>>Для того, чтобы картинка была легко масштабируемой и вставлялась куда угодно. Ведь на это уйдет основное время разработки, нет? AS>Масштабируемость контролов при зуме — конечно красиво, но далеко не всегда необходима. Или я неправильно понял?
Не знаю, правильно или нет, но для того, чтобы отрисовать градусник и в ячейке, и в "крупноформатном" варианте, наверное, нужна масштабируемость.
AS>>>Все равно вместо одного класса "мой клёвый редактор ктулхов" надо будет завести:
ВВ>>А кто мешает написать один класс "мой клёвый редактор ктулхов"? Вин-формс конечно довольно примитивен по сравнению с WPF, но ведь это не значит, что мозг надо совсем отключать. Если логику можно сделать reusable, то ее можно сделать reusable независимо от того, какой УИ-фреймворк используется. Вин-формс в данном случае лишь обязует реализовать несколько разных "контрактов". Вот собственно и все. И вся трагедия. AS>Речь как раз об этом. Зачем делать сто тысяч разных хелпер-контролов? Какая ж это реюзабельность? Реюзабельность (в моём понимании) — "взял, заюзал", а не "взял, допилил напильником, отполировал нулёвкой, заюзал".
Сто тысяч — это легкое преувеличение
Ну да, несколько — не хелперов, а именно формальных реализаций вин-формых "контрактов" — сделать придется. И да, я не вижу в этом трагедии, хотя без них было бы конечно лучше.
И "внутренней красоты" при таком подходе бесспорно не хватает. Но обычно не до "красоты".
AS>Посмотрите, кстати, любую библиотеку с контролами коммерческую. 99% используют только Control. И выстраивают всю иерархию заново. Наверно неспроста.
Действительно, неспроста они, видимо, Control используют, несмотря на всю "уродливость" его контракта.
ВВ>>Универсальная модель расширения — это очень хорошо. Это упрощает расширение контролов. Но это никак не упрощает создание самого градусника, который в большинстве случаях все-таки нужен в единственной форме, а не в виде "мы интегрируемся во все контролы подряд".
AS>В WPF, насколько мне известно, мы один раз рисуем градусник.
В вин-формс тоже один раз рисуем.
О чем спор вообще? О том, что WPF "круче", чем вин-формс? Я разве это отрицал где-то?
Речь про "градусник" вообще зашла в разрезе того, что ГДИ+ — отстой, и в нем надо все по пикселям выпилить. А вот в WPF нарисовать все куда проще.
Да не так уж чтобы проще. Если мы именно про "рисование" говорим. И "выпиливать по пикселям" ничего в ГДИ+ не надо — это очередной перл из области, что "в вин-формс для расширения функционала надо всегда наследоваться". Возможно, в WPF это и удобнее. Но речь не об этом.
Я вообще не хочу спорить на тему вин-формс версус WPF, ибо это будет действительно глупо К тому же у меня промышленного опыта использования WPF, а именно он мне и интересен, банальная практика, а не "внутренняя красота" и прочая. Так что тут вообще непонятно что с чем сравнивать.
Да, WPF предлагает принципиально другой подход, да он совершеннее в плане архитектуры и многие задачи в нем решаются проще. Да, постепенно все перейдут с вин-формс на WPF — но пока этот процесс еще далек от завершения. И работать надо с тем, что есть.
AS>Вроде бы это не слишком сложно. А потом вставляем куда надо. Будь то грид или форма, или текстбокс. Вставляем без тысяч хелпер классов.
Здравствуйте, Воронков Василий, Вы писали:
K>>Но чисто теоретически можно написать такой
ВВ>А чисто практически можно пойти и купить грид у Инфрагистика. ВВ>Причем покупали грид у Инфрагистика, когда писали на Актив-Икс. ВВ>Покупали грид у Инфрагистика, когда писали на вин-формс. ВВ>И будут покупать грид у Инфрагистика для WPF. ВВ>
А чисто практически никто и не говорил. Чисто практически есть и Инфрагистик, и ДевЭкспресс и так далее. Я говорю про чисто теоретическую возможность написать грид, у которого в ячейках находились бы произвольные контролы. Так вот для Windows Forms этого сделать нельзя. Для WPF — можно (и сделано)
K>>, чтобы в ячейках отображались произвольные контролы.
ВВ>Не вижу в этом проблемы даже со стандартным ГридВью (который, кстати, очень неплох для стандартного контрола, а ждать какого-то супер-грида от МС — это утопия). Другим компаниям тоже кушать хочется.
Нет-нет. Если ты в каждой ячейке покажешь по контролу, то начнутся жуткие тормоза. Заметь, я говорю про контролы, находящиеся внутри ячеек всегда, а не только в момент редактирования. Кстати, а что там насчёт контролов, встраиваемых в заголовки?
K>>И это будет работать хорошо. В Windows Forms если такое и сделаешь, то будет очень и очень плохо (в качестве упражнения предлагаю положить на формочку 400 кнопочек в виде таблицы 20x20 и посмотреть, что из этого выйдет).
ВВ> Если ты таким образом тулбары делаешь, то неудивительно, что тебе вин-формс не нравится.
Вот уже хватит, надоел этот снисходительный тон. Ты не думал, что у человека, с которым ты общаешься, может быть опыт не меньший, чем у тебя?
ВВ>Вообще надо бы отделять представление данных, для которого никаких новых окошек делать не надо, и редактирование данных.
Здравствуйте, Воронков Василий, Вы писали:
K>>Ну так я так и делаю. В результате у меня какая мысля возникла: а зачем делать какой-то невнятный helper-класс для отрисовки/обработки мыши/клавиатуры, а потом его ещё и пристёгивать к каждому конкретному случаю по-своему? А не проще ли сделать один на все случаи жизни MyControl, который содержал бы общий код для отрисовки и обработки ввода? А потом сделаю грид (наследующийся от MyControl, а не от Control),
ВВ>Ну да, и получится еще что-то более уродливое, чем Control.
В большинстве случаев — да. Если же руки прямые и написание подобного фреймворка ставится как самоцель профессионалами, то получается нечто хорошее.
K>>в котором в ячейках будут MyControl и TreeView (так же наследник MyControl), в котором так же в узлах дерева будут MyControl? Тогда из WindowsForms мне понадобятся только классы Control, на котором я буду отрисовывать корневой MyControl (очевидно — панелька со всем UT) и формочка, куда я буду класть этот Control.
ВВ>А можно проще — пошел и купил готовый набор компонент. Только вот в отличие от веб-форм тут ты в итоге не упрешься в то, что сама концепция контролов и событий принципиально ущербно, мешает тебе работать и ее вообще надо выкинуть на хрен и напрямую с сообщениями работать.
Сама концепция контролов в WindowsForms, в том виде, в котором она есть, не позволяет сделать описанного, даже если закупить супер-мега контролов. Ты вообще читаешь, что тебе пишут?
K>>Мне даже этот тормоз GDI+ не понадобится, т.к. если я всё своими силами делаю, то и рендерер свой могу сделать, который будет основан на DirectX.
ВВ>Угу, "тормоз GDI+" просто летает по сравнению с софтварным рендерером у WPF.
Никто не говорил про софтварный рендерер. Нле я сказал про это?
K>>Я же, аналогично Синклеру, доказываю что говно и то и другое.
ВВ>Неубедительно. Да и вместо того, чтобы что-то доказывать попробовал бы лучше лет пять поработать и с тем, и с другим. И посмотреть во что это реально выливается. Windows Forms хотя бы не мешает, в отличие от. Да и нормы построения вин и веб интерфейса несколько отличаются.
А что, из моих слов следует, что я вообще ни с тем ни с другим не работал и месяца? Не говоря уж о других технологиях?
K>>Собственно, не то чтобы это говно во всех отношениях. Какие-то простенькие повседневные задачки они решают хорошо. В этом смысле Web Forms не проигрывает Windows Forms в плане удобства.
ВВ>Проигрывает. Потому что опраданий на построение веб-приложение по аналогии в вин-приложением нет никаких. Вообще. ВВ>"Простенькие повседневные задачи" можно и на ПХП решать. Там сейчас тоже библиотек хватает.
Твоя аргументация? Всё, что я видел до этого "вот тут неудобно, тут неудобно, приходится переписывать на XSLT". Когда я использую Windows Forms у меня тоже возникает чёс в руках выкинуть всё нафиг и рендерить через GDI+ самому. Чего именно в аналогии не так?
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Здравствуйте, Aen Sidhe, Вы писали:
ВВ>>>Для того, чтобы картинка была легко масштабируемой и вставлялась куда угодно. Ведь на это уйдет основное время разработки, нет? AS>>Масштабируемость контролов при зуме — конечно красиво, но далеко не всегда необходима. Или я неправильно понял?
ВВ>Не знаю, правильно или нет, но для того, чтобы отрисовать градусник и в ячейке, и в "крупноформатном" варианте, наверное, нужна масштабируемость.
А, ну да. Протупил, бывает.
AS>>>>Все равно вместо одного класса "мой клёвый редактор ктулхов" надо будет завести:
ВВ>>>А кто мешает написать один класс "мой клёвый редактор ктулхов"? Вин-формс конечно довольно примитивен по сравнению с WPF, но ведь это не значит, что мозг надо совсем отключать. Если логику можно сделать reusable, то ее можно сделать reusable независимо от того, какой УИ-фреймворк используется. Вин-формс в данном случае лишь обязует реализовать несколько разных "контрактов". Вот собственно и все. И вся трагедия. AS>>Речь как раз об этом. Зачем делать сто тысяч разных хелпер-контролов? Какая ж это реюзабельность? Реюзабельность (в моём понимании) — "взял, заюзал", а не "взял, допилил напильником, отполировал нулёвкой, заюзал".
ВВ>Сто тысяч — это легкое преувеличение
На каждый чих (читай, новый композитный контрол) — новый хелпер.
ВВ>Ну да, несколько — не хелперов, а именно формальных реализаций вин-формых "контрактов" — сделать придется. И да, я не вижу в этом трагедии, хотя без них было бы конечно лучше.
Трагедии нет. Есть кривизна
ВВ>И "внутренней красоты" при таком подходе бесспорно не хватает. Но обычно не до "красоты".
Кому как.
AS>>Посмотрите, кстати, любую библиотеку с контролами коммерческую. 99% используют только Control. И выстраивают всю иерархию заново. Наверно неспроста.
ВВ>Действительно, неспроста они, видимо, Control используют, несмотря на всю "уродливость" его контракта.
Наверно это потому, что его нельзя не использовать в винформах, не находите? А не от его замечательной архитектуры. И смотреть надо на то, что заменены даже такие простые контролы как текстбокс или комбобокс (дерьмо то ещё, кстати)
Здравствуйте, konsoletyper, Вы писали:
K>>>Ну так я так и делаю. В результате у меня какая мысля возникла: а зачем делать какой-то невнятный helper-класс для отрисовки/обработки мыши/клавиатуры, а потом его ещё и пристёгивать к каждому конкретному случаю по-своему? А не проще ли сделать один на все случаи жизни MyControl, который содержал бы общий код для отрисовки и обработки ввода? А потом сделаю грид (наследующийся от MyControl, а не от Control), ВВ>>Ну да, и получится еще что-то более уродливое, чем Control. K>В большинстве случаев — да. Если же руки прямые и написание подобного фреймворка ставится как самоцель профессионалами, то получается нечто хорошее.
Золотые слова. Хоть на стенку вешай
ВВ>>А можно проще — пошел и купил готовый набор компонент. Только вот в отличие от веб-форм тут ты в итоге не упрешься в то, что сама концепция контролов и событий принципиально ущербно, мешает тебе работать и ее вообще надо выкинуть на хрен и напрямую с сообщениями работать. K>Сама концепция контролов в WindowsForms, в том виде, в котором она есть, не позволяет сделать описанного, даже если закупить супер-мега контролов. Ты вообще читаешь, что тебе пишут?
Сделать "описанного" — это что? Я пока никакой конкретной проблемы вообще не услышал.
K>>>Мне даже этот тормоз GDI+ не понадобится, т.к. если я всё своими силами делаю, то и рендерер свой могу сделать, который будет основан на DirectX. ВВ>>Угу, "тормоз GDI+" просто летает по сравнению с софтварным рендерером у WPF. K>Никто не говорил про софтварный рендерер. Нле я сказал про это?
Ах, да, я забыл, мы ведь сравниваем user32 и DirectX
K>>>Я же, аналогично Синклеру, доказываю что говно и то и другое.
ВВ>>Неубедительно. Да и вместо того, чтобы что-то доказывать попробовал бы лучше лет пять поработать и с тем, и с другим. И посмотреть во что это реально выливается. Windows Forms хотя бы не мешает, в отличие от. Да и нормы построения вин и веб интерфейса несколько отличаются. K>А что, из моих слов следует, что я вообще ни с тем ни с другим не работал и месяца? Не говоря уж о других технологиях?
Ты знаешь, я предпочитаю не обсуждать чужой опыт. Тебе бы лично посоветал не доказывать что-то, "аналогично Синклеру", а найти в этом флейме свою, уникальную нишу А по поводу того, что "все говно" я уж тогда лучше с "первоисточником" пособачусь.
K>>>Собственно, не то чтобы это говно во всех отношениях. Какие-то простенькие повседневные задачки они решают хорошо. В этом смысле Web Forms не проигрывает Windows Forms в плане удобства. ВВ>>Проигрывает. Потому что опраданий на построение веб-приложение по аналогии в вин-приложением нет никаких. Вообще. ВВ>>"Простенькие повседневные задачи" можно и на ПХП решать. Там сейчас тоже библиотек хватает.
K>Твоя аргументация?
Того, что веб-контролы не нужны на вебе? Во-первых, почитай всю ветку, мне переписывать одно и то же лень.
А во-вторых, как ни странно, с этим-то как раз никто не спорит
K>Всё, что я видел до этого "вот тут неудобно, тут неудобно, приходится переписывать на XSLT". Когда я использую Windows Forms у меня тоже возникает чёс в руках выкинуть всё нафиг и рендерить через GDI+ самому. Чего именно в аналогии не так?
Как бы сказать... всё.
Есть такая штука — подмена понятий. Разговор изначально был о том, все ли абстракции полезны. Пример веб-формса возник как абстракции (над прямой обработкой реквеста), которая НЕ полезна.
Потом притянули сюда Вин-формс. Вин-формс — это надстройка над Юзер32. И в данном контексте она рассматривается именно с этой точки зрения — насколько она удачна именно как надстройка над Юзер32. Да, даже не "удачна", а удобнее ли работать напрямую через Юзер32 или через вин-формс. Вся тема в стиле вин-формс версус WPF, Свинг, wxWidgets, ГДИ+ против Бэтмена — это вообще что-то из области "поворота не туда". Но поспорить можно
Заявление, что я типа сам все буду рендерить через ГДИ+, который сам по себе высокоуровневый по самое не могу, это вообще как-то не в тему "Пиксели-то точить" каждый дурак может Особенно когда эти самые "пиксели" такие как в ГДИ+.
Давай даже не напрямую, давай на МФС попробуешь ГУЙ пописать, потом то же самое на вин-формс и расскажешь где и что тебе выбросить хотелось?
А вот веб-формс в определенных проектах просто *приходится* выбрасывать, ибо он просто конкретно мешает. Или получится очередной Шарепоинт, мать его. И выбрасывая веб-формс — все что у тебя остается это тоненькая надстройка над ISAPI и stateless HTTP в зубы. И вот в больших проектах это самое "HTTP в зубы" оказывается как ни странно проще и удобнее.
Здравствуйте, Геннадий Васильев, Вы писали:
ВВ>>Для этого надо сначала признать, что именно есть эти самые "термины ФП", и они также отличны от того, что было раньше, как ООП от СП. ГВ>Странно. Раз есть функциональный (объектный, логический...) язык программирования (я имел в виду именно язык программирования), то безусловно есть и термины этого языка. Или ты хочешь сказать, что нужно непременно признать, что мышление человека происходит непосредственно в терминах языка?
Ну в каких терминах происходит мышление это отдельный, так сказать, философский вопрос. Речь даже не в "каких терминах" оно происходит, а чем оно детерминируется. Можно думать "по-другому" используя любой язык программирования, но что-то должно в итоге заставить думать по-другому?
Мне вот интересно посмотреть на альтернативу ООП — альтернативу в том плане, что это будет концепция способная полноценно заменить ООП, хотя бы теоретически. Возможно, это ФП. Возможно, это не ФП.
Но это точно не должен быть ОО язык, в котором "до кучи" напихивают противоречащих этому самому ОО концепций.
ВВ>>ФП не в детерминированность ф-ций упирается, а в иной подход к созданию абстракций. ГВ>Как это ни удивительно, но именно об этом я с самого начала и говорю.
В таком случае "гибридный" стиль и у тебя наверное не должен вызывать особого восторга, нет?
ВВ>>Именно поэтому гибридные языки, пытающиеся соединить в себе "the best of two worlds" и вызывают у меня некоторые сомнения. ГВ>Ну что тут поделаешь.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Ну в каких терминах происходит мышление это отдельный, так сказать, философский вопрос. Речь даже не в "каких терминах" оно происходит, а чем оно детерминируется. Можно думать "по-другому" используя любой язык программирования, но что-то должно в итоге заставить думать по-другому?
Вернее, я поправлюсь. "Как" и "чем" мы там думаем неважно Важно то, что та или иная концепция предоставляет определенные средства для выражения мыслей. Как бы там ни были широко раздвинуты "горизонты", ты так или иначе упрешься в конкретные средства выражения, которые эти самые "горизонты" несколько подрежут. И сама идея соединения ФП и ООП не предоставит тебе новые "термины" для описания архитектуры, как мне кажется. Она решает другую проблему — которую ИТ описывал в теме "Жизнь внутри метода". Но я вот даже не уверен, что эта проблема существует — по крайней мере в том виде, в котором она была описана.
Здравствуйте, Геннадий Васильев, Вы писали:
ВВ>>Ну в каких терминах происходит мышление это отдельный, так сказать, философский вопрос. Речь даже не в "каких терминах" оно происходит, а чем оно детерминируется. Можно думать "по-другому" используя любой язык программирования, но что-то должно в итоге заставить думать по-другому? ГВ>На мой взгляд, в первую очередь мышление детерминируется неким общим образованием (не обязательно вузовским). Ну не конструкциями же языка программирования, в самом деле.
Ну вот, к примеру, мне часто приходится говорить по-английски. Английский я знаю неплохо, но гораздо хуже чем русский. Поэтому английский как язык неизбежно ограничивает меня в средствах выражения. Так как разговор, даже сугубо технический, строится не по законам формальной логики, и от меня требуется не высказывать какие-то силлогизмы, мне в итоге приходится строить всю беседу несколько иначе, чем если бы я говорил по-русски. Что-то я не буду говорить вообще, что-то скажу по-другому и так далее.
В итоге не столь и важно, что у меня творилось в голове, ибо этого никто не увидел, а увидели то, что попало, так сказать, в stdout. Да, мое мышление бесспорно продиктовано образованием (кстати, философским ), жизненным опытом, мировоззрением, но результат, сказанное, не в последнюю очередь было определено теми средствами выражения, которые я использовал.
Причем английский — тут просто пример. Даже когда я говорю по-русски, я неизбежно соотношу изначальную мысль с тем, насколько она адекватно она будет звучать будучи сказанной, насколько правильно она будет понята. И судя по всему не всегда удачно
ВВ>>Мне вот интересно посмотреть на альтернативу ООП — альтернативу в том плане, что это будет концепция способная полноценно заменить ООП, хотя бы теоретически. Возможно, это ФП. Возможно, это не ФП. ВВ>>Но это точно не должен быть ОО язык, в котором "до кучи" напихивают противоречащих этому самому ОО концепций. ГВ>Ну, если считать, что FP, в некотором роде, является базисом ООП, то... Сложный это получается вопрос: кто на ком стоял. ВВ>>>>ФП не в детерминированность ф-ций упирается, а в иной подход к созданию абстракций. ГВ>>>Как это ни удивительно, но именно об этом я с самого начала и говорю. ВВ>>В таком случае "гибридный" стиль и у тебя наверное не должен вызывать особого восторга, нет? ГВ>Да нет как раз... Любой стиль, ИМХО, хорош к своему месту. Структурный (процедурный) — в своих случаях, ОО — в своих, FP — в своих.
Стиль хорош к месту — бесспорно. Но мне интересен "стиль" не в рамках решения конкретной задачи, а в рамках описания устройства системы в целом. Все новвоведения в тот же C# в итоге не дают мне новых средств, которые позволили бы мне выразить устройство системы иначе, чем бы я делал это в самой первой версии.
Мне интересно использовать ФП — да и не обязательно ФП, любую новую для мейнстрима концепцию — не для того, чтобы решать задачи, возникающие в результате того, что основая структура была писана с использованием привычных средств, а для того, чтобы получить принципиально иные средства для описания этой самой основной структуры, в результате которого отдельные задачи — те самые, для которых сейчас так хорошо подходит ФП — могут не появиться вовсе или же появиться совсем в другом качестве.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>И "внутренней красоты" при таком подходе бесспорно не хватает. Но обычно не до "красоты".
Ага, а потом у одних выходит УГ под названием CodeRush, а у других Resharper. Вот и вся разница.
ВВ>Действительно, неспроста они, видимо, Control используют, несмотря на всю "уродливость" его контракта.
Ага. И в результате возникает вопрос — что будет, если в бочку меда добавить ложку гавна. Ответ знаешь?
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, AndrewVK, Вы писали:
ВВ>>И "внутренней красоты" при таком подходе бесспорно не хватает. Но обычно не до "красоты".
AVK>Ага, а потом у одних выходит УГ под названием CodeRush, а у других Resharper. Вот и вся разница.
ВВ>>Действительно, неспроста они, видимо, Control используют, несмотря на всю "уродливость" его контракта.
AVK>Ага. И в результате возникает вопрос — что будет, если в бочку меда добавить ложку гавна. Ответ знаешь?
Дай-ка я угадаю... Ты, видно, предлагаешь все переписать, да?
Здравствуйте, AndrewVK, Вы писали:
ВВ>>Дай-ка я угадаю... Ты, видно, предлагаешь все переписать, да? AVK>Нет, я просто рассказывают, что бывает, когда не до красоты, трясти надо.
Т.е. любой проект на WindowsForms обречен превратиться в говно?
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Т.е. любой проект на WindowsForms обречен превратиться в говно?
Я этого не говорил. Просто в случае винформсов приходится тратить массу усилий для обмазки этих самых винформсов. Пользуясь метафорой, запаивать ложку с гавном в полиэтиленовый пакет.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, AndrewVK, Вы писали:
ВВ>>Т.е. любой проект на WindowsForms обречен превратиться в говно? AVK>Я этого не говорил. Просто в случае винформсов приходится тратить массу усилий для обмазки этих самых винформсов. Пользуясь метафорой, запаивать ложку с гавном в полиэтиленовый пакет.
У тебя проекты на винформс начинались с того, что ты принимался эти винформсы куда-то "запаивать"? Или другие задачи были? А если их не "запаивать", то будет говно?
Я понимаю, конечно, всю привлекательность позиции этакого "гурмана", который свысока смотрит на технологии и рассуждает об их внутренней красоте — особенно, кстати, удобно это делаеть, когда обязанности уже далеко не связаны с разработкой — но, может, стоит быть поближе к реальности?
Я не против обсудить достоинства и недостатки ГУИ-фреймворков, но я вообще-то не об этом писал. user32 сам по себе не отличается высоким изяществом, тем не менее большинство приложений, которые я использую, написаны именно под user32 с помощью библиотек, для которых, скажем так, тебе пришлось бы подбирать еще более ядреные метафоры. И они не становятся от этого говном.
В том, что приложения становятся говном вовсе не фреймворки виноваты.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Здравствуйте, AndrewVK, Вы писали:
ВВ>>>Т.е. любой проект на WindowsForms обречен превратиться в говно? AVK>>Я этого не говорил. Просто в случае винформсов приходится тратить массу усилий для обмазки этих самых винформсов. Пользуясь метафорой, запаивать ложку с гавном в полиэтиленовый пакет.
ВВ>В том, что приложения становятся говном вовсе не фреймворки виноваты.
Если фреймворк плох/крив/недоделан — он предрасполагает к появлению кривых приложений. А то так можно вспомнить кучу замечательных программ написанных на pure C. От этого самопальная отрисовка элементов управления и ручная обработка всех WM_ событий не станет замечательной практикой программирования GUI.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Помнится, тебе не нравились аналогии.
Они мне и сейчас не нравятся. А что?
ВВ> Так давай говорить конкретнее.
Ты на свой вопрос получил конкретный ответ. Куда уж конкретнее.
ВВ>Ты возвражал на мой пост, в котором я писал, что при необходимости интегрировать одну и ту же логику — отображение температуры в виде графического градусника
У тебя в голове все запуталось. Про градусник — это ты не со мной беседовал. То, на что я отвечаю, я всегда привожу в цитатах.
ВВ>Судя по твоему возвражению, ты считаешь такую практику порочной
Порочным я считаю вполне конкретную вещь, а именно "но обычно не до "красоты".
ВВ> и неизбежно приводящей к говно-коду. В свете этого мне интересно узнать, как происходило это самое запаивание вин-формс когда ты начинал работать над серьезными проектами?
Что значит как? Тебе код привести надо, что ли?
ВВ>И приходилось ли тебе тебе работать над серьезными проектами на веб-формс?
Да.
ВВ> И каким образом ты "запаивал" веб-формс?
Похожим.
AVK>>Это позиция не гурмана, а практика. Ошибки в архитектуре стоят слишком дорого.
ВВ>Наши дискуссии последнее время строятся по принципу — ты берешь какую-нибудь мою фразу из контекста и возражаешь на нее в стиле "кривая архитектура приводит к говну".
Не, я просто пытаюсь отвечать на то то, содержащее конструктивные возражения, а не очередные передергивания. На передергивания отвечать бессмыслено.
ВВ>А в итоге оказывается, что я считаю других глупее себя.
Ок. Воронков on.
ВВ>Цель-то какая? Зачем было втягивать меня в спор о ГУИ-фреймворках, который я вообще-то не начинал
А врать то некрасиво. Вот тебе сообщение твое собственное — Re[51]: декларация
. Попробуй найти выше по ветке упоминание винформсов.
ВВ>, и вин-формс был упомянут совсем по другим причинам.
Ой, да ладно уже изворачиваться, все было довольно тривиально. Началось с твоего вопроса:
А то, может, WindowsForms тоже говно, а я и не заметил.
На что был получен конкретный ответ без каких либо рассусоливаний:
Вообще-то да, говно.
После чего ты взялся защищать винформсы
У WindowForms модель полностью отвечает архитектуре Win32 и является прекрасной надстройкой над user32.
И теперь ты тут нам забиваешь баки про какие то другие причины. Выглядит со стороны забавно.
ВВ> Я рассматривал его как надстройку на юзер32. Точка.
Тю, так с тобой об этом никто и не спорит. Все очень просто — винформс это унылое гавно. Точка. А надстройка это или пристройка — наеважно.
ВВ>Сдается мне, что мы далеко ушли от этого.
Лично я никуда не уходил. Я все о том же, а именно — винформс унылое гавно Я это еще в 2002 году говорил. Тогда же, кстати, я и про вебформсы говорил, что это тоже УГ, тока на меня тогда толпой накинулись, дескать, ничего ты не понимаешь в колбасных обрезках, неме..., тьфу ты, вебформсы это последнее слово науки и техники.
ВВ>Эээ, "обязанности уже далеко не связаны с разработкой" — это прозвучало обидно?
Да нет, не обидно. Это прозвучало как демагогия.
ВВ>Да, сужу по своему опыту общения с людьми, обязанности которых "уже далеко не связаны с разработкой".
Ну, мое мнение по этому поводу я тоже не скрываю. Эксперты в области дизайна ПО в общем, и архитекты в частности, которые не то что не занимаются разработкой, не пишут код — унылое гавно
Да, если тебе интересно — за деньги я занимаюсь на 90% именно разработкой и в обозримом будущем менять что то в этом плане не планирую.
ВВ>Наверное, это должно быть взаимно?
Конечно.
ВВ> Мне тоже не очень нравится получать советы в стиле "учись сынок, и ты поймешь, что кривая архитектура это плохо".
Я тебе такие советы давал?
ВВ>>>Я не против обсудить достоинства и недостатки ГУИ-фреймворков, но я вообще-то не об этом писал. AVK>>А я об этом.
ВВ>А я НЕ об этом.
Ну не отвечай тогда.
ВВ> Тема была о другом.
В чем? Только надо, чтобы эта тема логически сочеталась с твоими словами.
ВВ> В разрезе обсуждения ГУИ-фреймворков, даже еще на "философский" манер, мне вин-формс вообще неинтересен.
Ну так не пиши о нем. К чему тогда все эти рассусоливания на тему надстроек? Самый лучший способ избежать ухода от темы — отвечать только на те вопросы, которые к теме имеют отношение. Если таких вопросов совсем нет — не отвечать совсем. Лично я так и поступаю обычно.
ВВ>Большинство интеграторов не занимается постоянной сменой клиентов, которым можно что-нибудь "впарить".
А это не так важно. Просто у интегратора есть возможность отыграть в другом направлении. А вот у производителя коробки такой возможности нет.
ВВ>А в создании злонамеренного говнокода "лишь бы впарить" я не учавствовал никогда. Тут ты не попал, извини.
Не извиню. Я не писал о злонамеренном создании. Просто рамки и бюджеты зачастую позволяют только залатать дыры на скорую руку. Клиент частенько не готов к серьезным инвестициям в развитие ПО, а интегратор просто удовлетворяет потребности клиента. Какая уж тут злонамеренность.
ВВ>>>, тем не менее большинство приложений, которые я использую, написаны именно под user32 с помощью библиотек, для которых, скажем так, тебе пришлось бы подбирать еще более ядреные метафоры. AVK>>Ну и что?
ВВ>И правда, а что? Ты какую идею сейчас продвигаешь?
О, это простой вопрос, и у меня есть на него чиста канкретный ответ. Идея в том, что винформс в плане дизайна — унылое гавно.
ВВ>Виноват может быть кто угодно, например, идиот-аналитик.
Это следствие подхода к разработке.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, AndrewVK, Вы писали:
ВВ>>Помнится, тебе не нравились аналогии. AVK>Они мне и сейчас не нравятся. А что?
Мне вот тоже не нравится "запаивание ложки с дерьмом куда-то там". Хочется узнать, что конкретно делалось. Без под... И обычно это не предполагает написание кода.
ВВ>> Так давай говорить конкретнее. AVK>Ты на свой вопрос получил конкретный ответ. Куда уж конкретнее.
Ага.
— И получится говно.
— Т.е. точно получится говно?
— Да, точно получится говно.
ВВ>>Ты возвражал на мой пост, в котором я писал, что при необходимости интегрировать одну и ту же логику — отображение температуры в виде графического градусника AVK>У тебя в голове все запуталось. Про градусник — это ты не со мной беседовал. То, на что я отвечаю, я всегда привожу в цитатах.
Я помню, с кем я беседовал. А ты на что возражал? На заключительную часть предложения? По-моему, это как раз выдергивание слов из контекста.
Речь была про градусник. И ты это, не уходи от темы, я хочу услышать про градусник
ВВ>>Судя по твоему возвражению, ты считаешь такую практику порочной AVK>Порочным я считаю вполне конкретную вещь, а именно "но обычно не до "красоты".
Что конкретно не нравится в этой фразе? То как она звучит? Дизайн большинства классов дотнета довольно говнистый. C# тоже, знаешь, большой внутренней красотой не отличается. Мораль-то какая, запаивать все надо? Должны быть разумные пределы.
Фраза, кстати, относилась к тому, что с необходимостью написания адапатеров для вин-формс контролов в конкретном случае вполне можно смириться, хотя о большой красоте архитектуры эта необходимость не говорит.
ВВ>> и неизбежно приводящей к говно-коду. В свете этого мне интересно узнать, как происходило это самое запаивание вин-формс когда ты начинал работать над серьезными проектами? AVK>Что значит как? Тебе код привести надо, что ли?
Ага, бинарный.
Рассказать видимо не получится никак?
ВВ>>И приходилось ли тебе тебе работать над серьезными проектами на веб-формс? AVK>Да. ВВ>> И каким образом ты "запаивал" веб-формс? AVK>Похожим.
— Каким образом ты запаивал вин-формс?
— Не скажу.
— А каким образом ты запаивал веб-формс?
— Похожим.
ВВ>>А в итоге оказывается, что я считаю других глупее себя. AVK>Ок. Воронков on.
И что это значит?
ВВ>>Цель-то какая? Зачем было втягивать меня в спор о ГУИ-фреймворках, который я вообще-то не начинал
AVK>А врать то некрасиво. Вот тебе сообщение твое собственное — Re[51]: декларация
. Попробуй найти выше по ветке упоминание винформсов. ВВ>>, и вин-формс был упомянут совсем по другим причинам. AVK>Ой, да ладно уже изворачиваться, все было довольно тривиально. Началось с твоего вопроса: AVK>
А то, может, WindowsForms тоже говно, а я и не заметил.
AVK>На что был получен конкретный ответ без каких либо рассусоливаний: AVK>
Вообще-то да, говно.
AVK>После чего ты взялся защищать винформсы AVK>
У WindowForms модель полностью отвечает архитектуре Win32 и является прекрасной надстройкой над user32.
AVK>И теперь ты тут нам забиваешь баки про какие то другие причины. Выглядит со стороны забавно.
Ну и где я вру? Я с самого начала предлагал ее рассматривать как надстройку над юзер32, а не сравнивать с WPF и директ-икс. Да, возможно, у нас разное понимание "говна", но если вин-формс — говно, то что можно сказать о технологии, которая ей подражает, несмотря на что решения из вин-формс для нее подходят значительно в меньшей степени?
ВВ>> Я рассматривал его как надстройку на юзер32. Точка. AVK>Тю, так с тобой об этом никто и не спорит. Все очень просто — винформс это унылое гавно. Точка. А надстройка это или пристройка — наеважно.
Ну да, все говно, кроме мочи.
Вообще если уж вспомнить, то речь была о том, что не все абстракции одинаково полезны. Почему в рамках этой темы надо сравнивать вин-формс с WPF, а не с "низким уровнем" этого самого вин-формс? Как я это и делал в отношении веб-формс.
ВВ>>Сдается мне, что мы далеко ушли от этого. AVK>Лично я никуда не уходил. Я все о том же, а именно — винформс унылое гавно Я это еще в 2002 году говорил. Тогда же, кстати, я и про вебформсы говорил, что это тоже УГ, тока на меня тогда толпой накинулись, дескать, ничего ты не понимаешь в колбасных обрезках, неме..., тьфу ты, вебформсы это последнее слово науки и техники.
Вообще-то насколько я помню, твоя критика в адрес вин-форсов была относительно спокойной, а вот по поводу асп.нета целый буйный флейм разгорелся. И кстати если уж я совсем ничего не путаю, ты его как раз с обычным АСП сравнивал.
Да, и я тогда не считал веб-формс говном. Теперь считаю. Да, да, да, ты был прав
ВВ>>Да, сужу по своему опыту общения с людьми, обязанности которых "уже далеко не связаны с разработкой". AVK>Ну, мое мнение по этому поводу я тоже не скрываю. Эксперты в области дизайна ПО в общем, и архитекты в частности, которые не то что не занимаются разработкой, не пишут код — унылое гавно
Заниматься разработкой и писать код — не одно и то же. А как же политкорректность? Вдруг нас читают люди, которые "не пишут" код?
ВВ>> Мне тоже не очень нравится получать советы в стиле "учись сынок, и ты поймешь, что кривая архитектура это плохо". AVK>Я тебе такие советы давал?
Ну знаешь, многие из твоих реплик звучат именно в таком ключе. Я, конечно, понимаю, что у тебя может быть другой опыт, но это не значит, что он применим везде, и все кто думают иначе... как ты там говорил?
AVK>В чем? Только надо, чтобы эта тема логически сочеталась с твоими словами.
О том, что вин-формс как надстройка над юзер32 значительно лучше, чем веб-формс как надстройка над прямой работой с HTTP и куда меньше мешает жить.
ВВ>> В разрезе обсуждения ГУИ-фреймворков, даже еще на "философский" манер, мне вин-формс вообще неинтересен. AVK>Ну так не пиши о нем. К чему тогда все эти рассусоливания на тему надстроек? Самый лучший способ избежать ухода от темы — отвечать только на те вопросы, которые к теме имеют отношение. Если таких вопросов совсем нет — не отвечать совсем. Лично я так и поступаю обычно.
Да, это дельный совет
ВВ>>Большинство интеграторов не занимается постоянной сменой клиентов, которым можно что-нибудь "впарить". AVK>А это не так важно. Просто у интегратора есть возможность отыграть в другом направлении. А вот у производителя коробки такой возможности нет.
Ты же не работал в интеграторе, откуда такие выводы? "Другое направление" обычно тесно связано с первым.
ВВ>>А в создании злонамеренного говнокода "лишь бы впарить" я не учавствовал никогда. Тут ты не попал, извини. AVK>Не извиню. Я не писал о злонамеренном создании. Просто рамки и бюджеты зачастую позволяют только залатать дыры на скорую руку. Клиент частенько не готов к серьезным инвестициям в развитие ПО, а интегратор просто удовлетворяет потребности клиента. Какая уж тут злонамеренность.
А мы не работаем с клиентами, которые не готовы к серьезным инвестициям С маленькими клиентами вообще работать нереально — 1) надо уметь и 2) очень дорого. А если клиент большой, да еще готов к внедрению какого-нибудь MOSS или Hummingbird — неважно, в общем какого-нибудь говна — то тут про "не готов к серьезным инвестициям" уже говорить не приходится.
А так, да, надо удовлетворять потребности клиента. И это вовсе не означает, что весь некоробочный софт хуже коробочного. Да, возвникает много проблем не связанных напярмую с написанием кода. Но и коробочный софт тоже бывает говном.
ВВ>>>>, тем не менее большинство приложений, которые я использую, написаны именно под user32 с помощью библиотек, для которых, скажем так, тебе пришлось бы подбирать еще более ядреные метафоры. AVK>>>Ну и что? ВВ>>И правда, а что? Ты какую идею сейчас продвигаешь? AVK>О, это простой вопрос, и у меня есть на него чиста канкретный ответ. Идея в том, что винформс в плане дизайна — унылое гавно.
Ради бога, а веб-формс еще большее говно.
ВВ>>Виноват может быть кто угодно, например, идиот-аналитик. AVK>Это следствие подхода к разработке.
Методология не исключает того, что аналитик окажется идиотом. Да даже не "идиотом"... Ну просто не получится у него из конкретного клиента "выжать" что-то внятное, в итоге клиент вспомнит о том, что ему нужно уже когда далеко не до анализа.
Вообще да, это тоже следствие подхода к разработке. Проблема только в том, что один подход на все случаи жизни использовать не получится. Так кто, получается, виноват в конечном счете? Мне кажется, уж точно не вин-формс
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Мне вот тоже не нравится "запаивание ложки с дерьмом куда-то там".
Ну так пропускай вовсе, там, помимо этой метафоры, есть и прямое описание.
ВВ>Хочется узнать, что конкретно делалось.
Янус устроит? На войну с гридом немало времени убито, а глюков все одно навалом.
ВВ>Я помню, с кем я беседовал. А ты на что возражал?
На то, что я процитировал.
ВВ> На заключительную часть предложения? По-моему, это как раз выдергивание слов из контекста.
А по мне, так совершенно законченная мысль.
ВВ>Что конкретно не нравится в этой фразе?
Смысл.
ВВ> Дизайн большинства классов дотнета довольно говнистый.
Нет.
ВВ> C# тоже, знаешь, большой внутренней красотой не отличается.
Нет.
ВВ> Мораль-то какая, запаивать все надо?
Тоже простой вопрос. Мораль такова:
1) Дизайн винформсов — унылое гавно
2) Если не запаивать — в результате получится унылое гавно
ВВ> Должны быть разумные пределы.
Конечно. Дизайн винформсов — за рамками этих пределов.
ВВ>Фраза, кстати, относилась к тому, что с необходимостью написания адапатеров для вин-формс контролов в конкретном случае вполне можно смириться
Если нет альтернативы — можно. Я этого никогда не отрицал. Только это никак не исключает того простого факта, что дизайн винформсов ..., ну ты понял.
ВВ>, хотя о большой красоте архитектуры эта необходимость не говорит.
Так речь тут изначально именно о красоте архитектуры шла, а не о том что винформсы применять нельзя. Последнее ты выдумал исключительно самостоятельно.
ВВ>Ага, бинарный. ВВ>Рассказать видимо не получится никак?
Получится, если я от тебя услышу конкретные вопросы, а не "расскажи, как оно".
ВВ>- Каким образом ты запаивал вин-формс? ВВ>- Не скажу.
Я этого не говорил. Оно конечно просто — сочинять за собеседника и потом с сочиненным спорить, удобно. Но демагогия есть.
ВВ>- А каким образом ты запаивал веб-формс?
Путем написания кода, который нивелирует кривость архитектуры путем введения дополнительного слоя абстракции. Какой вопрос (обо всем) — такой и ответ.
ВВ>И что это значит?
Это значит, что, если я начну в твоем стиле разговаривать, будет очень весело. Или ты думаешь, я хуже тебя умею демагогией пользоваться?
ВВ>Ну и где я вру?
А вот прям тут и врешь. Рассказываешь сказки, что не ты про винформсы разговор завел, хотя именно ты этот разговор начал.
ВВ> Я с самого начала предлагал ее рассматривать как надстройку над юзер32
Врешь. Ни слова ни про надстройки, ни про user32 в первых сообщениях нету. user32 ты вспомнил, уже отвечая на мое сообщение, а я его в цитатах этих даже не приводил, потому что оно было позже.
ВВ> но если вин-формс — говно
Говно, не сомневайся
ВВ>, то что можно сказать о технологии, которая ей подражает, несмотря на что решения из вин-формс для нее подходят значительно в меньшей степени?
Ты про вебформсы? Таки да, тоже гавно. А что, кто то с этим спорит?
ВВ>Ну да, все говно, кроме мочи.
Нет, не все.
ВВ>Вообще если уж вспомнить, то речь была о том, что не все абстракции одинаково полезны.
Не, речь была про то, что не все абстракции одинаково вредны
ВВ> Почему в рамках этой темы надо сравнивать вин-формс с WPF, а не с "низким уровнем" этого самого вин-формс?
Потому что сравнивать надо с лучшими решениями, а не с худшими. Это так сложно понять?
ВВ>Вообще-то насколько я помню, твоя критика в адрес вин-форсов была относительно спокойной
А у меня почти что вся критика спокойная, не вижу смысла устраивать истерики.
ВВ>, а вот по поводу асп.нета целый буйный флейм разгорелся
Ну а я тут причем?
ВВ>. И кстати если уж я совсем ничего не путаю, ты его как раз с обычным АСП сравнивал.
Путаешь. Хотя бы потому что с обычным ASP я никогда дела не имел. А сравнивал я тогда с сервлетами и JSP.
ВВ>Да, и я тогда не считал веб-формс говном.
Так о том и речь
ВВ>Заниматься разработкой и писать код — не одно и то же.
Не одно. Но "писать код" означает "заниматься разработкой". Обратное, разумеется, не верно.
ВВ> А как же политкорректность?
Ее кто то обещал?
ВВ> Вдруг нас читают люди, которые "не пишут" код?
Наздоровье.
ВВ>>> Мне тоже не очень нравится получать советы в стиле "учись сынок, и ты поймешь, что кривая архитектура это плохо". AVK>>Я тебе такие советы давал?
ВВ>Ну знаешь, многие из твоих реплик звучат именно в таком ключе.
Ты ошибся. Ни имею никакого желания тебя обучать без твоей воли.
ВВ> Я, конечно, понимаю, что у тебя может быть другой опыт, но это не значит, что он применим везде, и все кто думают иначе... как ты там говорил?
Золотые слова. Вывод какой?
AVK>>В чем? Только надо, чтобы эта тема логически сочеталась с твоими словами.
ВВ>О том, что вин-формс как надстройка над юзер32 значительно лучше, чем веб-формс как надстройка над прямой работой с HTTP и куда меньше мешает жить.
Теперь неплохо бы это обосновать.
ВВ>Ты же не работал в интеграторе, откуда такие выводы?
У меня есть несколько хороших знакомых, которые подробно рассказывали.
ВВ>А мы не работаем с клиентами, которые не готовы к серьезным инвестициям
Видимо, у нас серьезность разная. Под серьезностью я понимаю готовность потратить хотя бы несколько сотен килобаксов (только на разработку, а не на желески и консалтинг) и год работы команды программистов. А если общий бюджет большой, но основаня его масса уходит на железки, коробочное ПО и консалтинг, так это ни о чем не говорит.
ВВ> С маленькими клиентами
Опять ты читаешь не то, что я писал. Я про маленьких клиентов ничего не говорил.
ВВ> вообще работать нереально — 1) надо уметь и 2) очень дорого. А если клиент большой, да еще готов к внедрению какого-нибудь MOSS или Hummingbird
О, о чем я и говорил. Деньги платятся за "внедрение какого-нибудь MOSS или Hummingbird".
ВВ> И это вовсе не означает, что весь некоробочный софт хуже коробочного.
И этого я тоже не говорил. Горазд ты сочинять. С кем споришь то? Сам с собой?
ВВ> Но и коробочный софт тоже бывает говном.
Бывает. Вопрос другой — бывает ли не говном софт, сделаный по принципу "обычно не до "красоты".
ВВ>Методология не исключает того, что аналитик окажется идиотом.
Уважаемый. При чем тут методология? Хватит уже придумывать. Я сказал именно то, что сказал. Если руководствоваться принципом "обычно не до красоты", то обычно получается унылое гавно. Вот такая простая мысль, и не надо ничего к ней додумывать.
ВВ>Вообще да, это тоже следствие подхода к разработке. Проблема только в том, что один подход на все случаи жизни использовать не получится.
Не получится. Все никак не могу понять — с кем, все же, ты споришь. Пока так выходит, что сам с собой.
ВВ> Так кто, получается, виноват в конечном счете? Мне кажется, уж точно не вин-формс
Виноваты, разумеется, те, кто относится к выполняемой работе халатно. Ничего нового я тут сказать не хочу.
... << RSDN@Home 1.2.0 alpha 4 rev. 1111 on Windows Vista 6.0.6001.65536>>
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Здравствуйте, AndrewVK, Вы писали:
AVK>>Ты про вебформсы? Таки да, тоже гавно. А что, кто то с этим спорит?
ВВ>Почитай ветку, спорят.
Никто не спорил. Спорили с тезисами ASP.NET = гавно и ASP.NET = WebForms, AFAIR
Здравствуйте, Воронков Василий, Вы писали:
ВВ>Причем английский — тут просто пример. Даже когда я говорю по-русски, я неизбежно соотношу изначальную мысль с тем, насколько она адекватно она будет звучать будучи сказанной, насколько правильно она будет понята. И судя по всему не всегда удачно
Вот-вот. Не нужно путать владение языком и мысли, которые ты хочешь выразить.
ГВ>>Да нет как раз... Любой стиль, ИМХО, хорош к своему месту. Структурный (процедурный) — в своих случаях, ОО — в своих, FP — в своих.
ВВ>Стиль хорош к месту — бесспорно. Но мне интересен "стиль" не в рамках решения конкретной задачи, а в рамках описания устройства системы в целом.
Так любая система — есть решение какой-то задачи. Если принять это во внимание, то вот это твоё рассуждение:
ВВ>Все новвоведения в тот же C# в итоге не дают мне новых средств, которые позволили бы мне выразить устройство системы иначе, чем бы я делал это в самой первой версии. Мне интересно использовать ФП — да и не обязательно ФП, любую новую для мейнстрима концепцию — не для того, чтобы решать задачи, возникающие в результате того, что основая структура была писана с использованием привычных средств, а для того, чтобы получить принципиально иные средства для описания этой самой основной структуры, в результате которого отдельные задачи — те самые, для которых сейчас так хорошо подходит ФП — могут не появиться вовсе или же появиться совсем в другом качестве.
...получается построенным на глубоком внутреннем противоречии, которое вызвано неверной исходной посылкой.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Геннадий Васильев, Вы писали:
ВВ>>Причем английский — тут просто пример. Даже когда я говорю по-русски, я неизбежно соотношу изначальную мысль с тем, насколько она адекватно она будет звучать будучи сказанной, насколько правильно она будет понята. И судя по всему не всегда удачно ГВ>Вот-вот. Не нужно путать владение языком и мысли, которые ты хочешь выразить.
Наверное, можно не учитывать сам факт существования неформализуемого мышления, когда речь идет не о высоких материях, а о программировании?
ГВ>>>Да нет как раз... Любой стиль, ИМХО, хорош к своему месту. Структурный (процедурный) — в своих случаях, ОО — в своих, FP — в своих. ВВ>>Стиль хорош к месту — бесспорно. Но мне интересен "стиль" не в рамках решения конкретной задачи, а в рамках описания устройства системы в целом. ГВ>Так любая система — есть решение какой-то задачи. Если принять это во внимание, то вот это твоё рассуждение ...получается построенным на глубоком внутреннем противоречии, которое вызвано неверной исходной посылкой.
А в чем противоречие, можешь сказать? Или просто нашел способ прицепиться к формулировке? "Описание устройства системы целом" — вполне себе "какая-то" задача. И по качеству она несколько отличается, скажем, от задачи написания конкретного алгоритма. И вот в ее рамках соединение ФП и ООП не дает чего-то существенно нового.
Здравствуйте, Воронков Василий, Вы писали:
ВВ>>>Причем английский — тут просто пример. Даже когда я говорю по-русски, я неизбежно соотношу изначальную мысль с тем, насколько она адекватно она будет звучать будучи сказанной, насколько правильно она будет понята. И судя по всему не всегда удачно ГВ>>Вот-вот. Не нужно путать владение языком и мысли, которые ты хочешь выразить.
ВВ>Наверное, можно не учитывать сам факт существования неформализуемого мышления, когда речь идет не о высоких материях, а о программировании?
Интересно, для чего? Чтобы доказать, что язык программирования определяющим образом влияет на мышление программиста?
ГВ>>>>Да нет как раз... Любой стиль, ИМХО, хорош к своему месту. Структурный (процедурный) — в своих случаях, ОО — в своих, FP — в своих. ВВ>>>Стиль хорош к месту — бесспорно. Но мне интересен "стиль" не в рамках решения конкретной задачи, а в рамках описания устройства системы в целом. ГВ>>Так любая система — есть решение какой-то задачи. Если принять это во внимание, то вот это твоё рассуждение ...получается построенным на глубоком внутреннем противоречии, которое вызвано неверной исходной посылкой.
ВВ>А в чем противоречие, можешь сказать?
В том и противоречие, что ты говоришь о системе, но пытаешься рассматривать её изолированно от задачи, ради которой система создана. Во всяком случае, мне показалось именно так.
Тут вот какой прикол, на самом деле. Явления имеют такую причинно-следственную связь (в формулировках):
Проблема --> Задача --> Система
Если мы начнём рассуждать о способах описания систем (новизне, преимуществах, недостатках), то будем рассуждать ни о чём, поскольку в это обсуждение нужно непременно внести описание задач и проблем, которые решаются обсуждаемыми системами. Тогда обсуждение будет конечным и имеющим тенденцию к порождению некоего позитивного результата.
Так вот, новые способы описания систем могут появиться только при появлении новых задач. Кардинально новые способы возникнут после формулировок кардинально новых задач. Я не пытаюсь сказать, что таких задач не может появиться, заметь.
ВВ>Или просто нашел способ прицепиться к формулировке?
Туманная у тебя формулировка, мягко говоря. Было бы сформулировано яснее, вот и не "прицепился" бы. И ещё, чтобы уж быть совсем честным, остался после неё какой-то карамельный привкус. У меня такое бывает, когда я натыкаюсь на залакированную чепух... "глубокое заблуждение автора", я хотел сказать. Это к вопросу о мышлении, кстати.
ВВ>"Описание устройства системы целом" — вполне себе "какая-то" задача. И по качеству она несколько отличается, скажем, от задачи написания конкретного алгоритма. И вот в ее рамках соединение ФП и ООП не дает чего-то существенно нового.
Ну раскрой тогда, будь добр, что такое "описание устройства системы в целом". Я понимаю, что речь идёт о программной системе, но всё же. И ещё — чем оно отличается от описания алгоритма? Я могу додумать сам, но хочу услышать формулировку от тебя.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Воронков Василий, Вы писали:
ВВ>"Описание устройства системы целом" — вполне себе "какая-то" задача. И по качеству она несколько отличается, скажем, от задачи написания конкретного алгоритма. И вот в ее рамках соединение ФП и ООП не дает чего-то существенно нового.
Как это ни странно, но такое соединение даёт некие новые возможности: таким выразительным инструментарием можно несколько проще реализовать задачи, для решения которых хорошо подходит FP и ООП.
Обрати внимание, что иной раз шкала "проще-сложнее" интерпретируется как "нельзя-можно".
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
ГВ>Обрати внимание, что иной раз шкала "проще-сложнее" интерпретируется как "нельзя-можно".
"можно-нельзя", разумеется.
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Геннадий Васильев, Вы писали:
ВВ>>Наверное, можно не учитывать сам факт существования неформализуемого мышления, когда речь идет не о высоких материях, а о программировании? ГВ>Интересно, для чего? Чтобы доказать, что язык программирования определяющим образом влияет на мышление программиста?
Если вопрос о том, что там конкретно влияет на мышление программиста был поднят в связи с каким-либо из моих постов, то можешь считать я забираю свои слова назад
Язык программирования влияет на результат, так сказать, мышления программиста. А то, что там творится в голове программиста тема глубоко нетехническая и, мне кажется, не стоит ее тут развивать
ГВ>В том и противоречие, что ты говоришь о системе, но пытаешься рассматривать её изолированно от задачи, ради которой система создана. Во всяком случае, мне показалось именно так.
Я пытаюсь рассматривать ее изолированно от конкретных технических задач — а как же иначе? Чтобы появились конкретные задачи, вся система должна быть сначала описана в бизнес-терминах, а затем, в качестве результата анализа бизнес требований, в технических терминах. В зависимости от того, что нам будет представляено в качестве бизнес-функций и, в зависимости, от того, какие решения будут выбраны при техническом анализе, и возникнет наш спектр собственно технических задач.
Скажем, использование чистых функций для распараллеливания логики — не заложено в задачу изначально, а является следствием той архитектуры, которую мы выбрали, которая предлагает использовать параллельные вычисления для решения какой-либо из бизнес-задач, а чистые функции в данном случае — средство, облегчающее реализацию оных.
ГВ>Тут вот какой прикол, на самом деле. Явления имеют такую причинно-следственную связь (в формулировках): ГВ>
Проблема --> Задача --> Система
Правильно. При этом проблема как и задача формулируются в бизнес-терминах. Система — описание решения в технических терминах. Или лучше сказать постановка задач в технических терминах.
Рядовой разработчик вовлекается в проект как раз на той стадии, когда система описана. Соответственно, перед ним уже ставятся технические задачи.
Но первоначально таких задач нет. Есть задача отконвертировать бизнес-описание в архитектуру.
ГВ>Так вот, новые способы описания систем могут появиться только при появлении новых задач.
С этим я не согласен. С точки зрения бизнеса задачи как правило не меняются. В общем-то сейчас мы решаем те же бизнес-задачи что и десять лет назад. По большей части по кр. мере.
ГВ>Кардинально новые способы возникнут после формулировок кардинально новых задач.
А вот тут уже зависит от нас — как мы будем формулировать технические задачи. Для того, чтобы их сформулировать, нужен язык, который, с одной стороны, близок к бизнес-терминах, с другой — может одновременно служить техническим описанием устройства системы.
На настоящий момент — это язык ООП, обладающий, так сказать, рядом характерных особенностей. И наши технические проблемы возникают не потому, как может показаться, что бизнес что-то захотел, а потому что мы сами так "отконвертировали" эти хотения.
Мне было бы интересно рассмотреть какое-нибудь принципиально иное средство описания.
ГВ>Ну раскрой тогда, будь добр, что такое "описание устройства системы в целом". Я понимаю, что речь идёт о программной системе, но всё же. И ещё — чем оно отличается от описания алгоритма? Я могу додумать сам, но хочу услышать формулировку от тебя.
Описание устройства системы — ответ на бизнес-требования к системе.
Описание алгоритма — ответ на технические требования к системе.
Здравствуйте, Геннадий Васильев, Вы писали:
ГВ>Как это ни странно, но такое соединение даёт некие новые возможности: таким выразительным инструментарием можно несколько проще реализовать задачи, для решения которых хорошо подходит FP и ООП.
Да, честно говоря, мне неинтересно проще ли можно реализовать задачу или сложнее. Мне интересно
— а можно ли было избежать вообще появления данной технической задачи?
— не появилась ли эта задача вследствие ошибки дизайна?
и пр.
ГВ>Обрати внимание, что иной раз шкала "проще-сложнее" интерпретируется как "нельзя-можно".
Здравствуйте, Геннадий Васильев, Вы писали:
ГВ>Понятно. Но всё равно здесь теряется один важный фактор. Например, прежде, чем чистые функции будут явно использованы для распараллеливания обработки, эта самая задача параллельной обработки возникает, так скажем, на уровне проблемы, которую желательно разрешить. Пусть даже в виде интереса кого-то из разработчиков. Я думаю, тебя не удивит, что задача распараллеливания ставится очень давно. То есть это не "неожиданно открывшиеся возможности", а плод долгой и целенаправленной исследовательской, в частности, работы. Другое дело, что сейчас это вбрасывается, как нечто "принципиально новое", раскрывающее "новые горизонты", так и тому есть сугубо прагматическая причина — упёрлись в физические ограничения по повышению производительности процессора. ИМХО, это и есть ключевая проблема.
ГВ>И ещё, такое рассмотрение системы (изолированно от технических задач) ставит тебя на скользкий путь, подверженный очень сильному влиянию спекуляций. Собственно, вся новейшая история ООП тому примером. В нашей работе опасно ставить лошадь позади телеги и пытаться найти в такой перестановке новые возможности —
Гм, по-моему это ты все перевернул. Каким образом лошадь позади телеги оказалась? Технических задач нет изначально, есть бизнес-задачи. Как бы ни рассматривал программную систему, на самой первой стадии она все равно будет в каком-то смысле "изолирована" от технических задач, ибо последние еще не поставлены. Требование, скажем, извещать пользователя по емейлу об изменении статус заказа — это чистое бизнес-требования. При этом нет некоего "стандартного набора технических задач", в которое это требование переводится. В одном случае этом будет один набор задач, в другом — совершенной другой, а третьем случае вообще окажется, что с текущей инфраструктурой это нереализуемо.
Но всему это предшествует понимание системы в бизнес-терминах и ее перевод в технические термины. Причем чем ближе тот же ОО язык к бизнесу, тем проще осуществлять этот перевод. Т.е. у меня есть сущность "Заказ", обладающая некоторым поведением и пр. Есть такое понятие как Статус, есть процесс Изменение Статуса и так далее. Вот, у нас уже и классы какие-то на бумажке нарисованы.
А техническая задача... Ну в итоге все может закончиться тем, что триггер какой-нибудь надо будет дописать При этом нет никакой связи между "известить пользователя об изменении статуса" и "переписать триггер" — эту связь мы сами придумываем.
ВВ>>Правильно. При этом проблема как и задача формулируются в бизнес-терминах. Система — описание решения в технических терминах. Или лучше сказать постановка задач в технических терминах. ВВ>>Рядовой разработчик вовлекается в проект как раз на той стадии, когда система описана. Соответственно, перед ним уже ставятся технические задачи. ГВ>Ага... Как я понимаю, как раз то самый "рядовой разработчик" и интересен тебе в первую очередь. Я прав?
Ну, честно говоря, не совсем. Разработчик — не очень. Не в рамках данной темы. Ежу понятно, что "рядовой разработчик" получит кучу наикрутейших инструментов, когда перейдет, скажем, на Немерле.
Вот только если сами его задачи сформулированы неверно — это, к сожалению, не поможет.
ВВ>>Но первоначально таких задач нет. Есть задача отконвертировать бизнес-описание в архитектуру. ГВ>Не забегай вперёд. Архитектура — суть вспомогательное явление. Если можно было бы без неё обойтись — обошлись бы и не вспомнили.
Мне кажется, ты все время забегаешь вперед
В том-то и дело, что без нее обойтись нельзя. Не нравится термин "архитектура" замени его на "техническое планирование". Это так или иначе есть. И это есть наш способ интерпретации бизнес-задачи — применительно к существующей системе, к срокам, людям, возможностям и пр.
ГВ>>>Так вот, новые способы описания систем могут появиться только при появлении новых задач. ВВ>>С этим я не согласен. С точки зрения бизнеса задачи как правило не меняются. В общем-то сейчас мы решаем те же бизнес-задачи что и десять лет назад. По большей части по кр. мере. ГВ>Десять? Я бы сказал — сорок-пятьдесят.
Я так долго не живу
ГВ>>>Кардинально новые способы возникнут после формулировок кардинально новых задач. ВВ>>А вот тут уже зависит от нас — как мы будем формулировать технические задачи. Для того, чтобы их сформулировать, нужен язык, который, с одной стороны, близок к бизнес-терминах, с другой — может одновременно служить техническим описанием устройства системы. ГВ>Таких языков есть.
Разумеется. Кто ж спорит с этим.
ГВ>Сложности обычно начинаются с того момента, когда дело доходит до точной формализации требований. Например, всё хорошо, пока у нас есть два отвлечённых описания, скажем, событий и ожидаемой реакции системы. Всё становится очень плохо, когда нужно "разобраться", что происходит в случае каких-то ошибок, и всё становится ещё хуже, когда эти два описания нужно привести к взаимно непротиворечивому виду. ГВ>С другой стороны, если вдруг те же описания появились в а) полном и б) непротиворечивом виде, то кодирование (построение системы) становится тривиальным занятием.
Непротиворечивость собственно бизнес-требований не означает то, что они могут однозначно переведены в технические задачи. Как это ни печально.
ВВ>>На настоящий момент — это язык ООП, обладающий, так сказать, рядом характерных особенностей. И наши технические проблемы возникают не потому, как может показаться, что бизнес что-то захотел, а потому что мы сами так "отконвертировали" эти хотения.
ГВ>Вот тут ты, ИМХО, ошибаешься. На настоящий момент язык описания бизнес-задач ближе всего к вариациям SADT (группа стандартов IDEF, например), то есть, проще говоря — квадратики и стрелочки. По совместительству, такая нотация близка к "языку" описания семантических сетей (атрибутированные сущности и т.п.), и по ещё более дальнему совместительству — к ООП, как к таковому. Применение других формализмов в этом контексте, безусловно, возможно, но к нему просто нечасто прибегают.
Я не самом деле не про язык описания бизнес-задач, это немного другое. Я именно про тот, скажем так, "набор терминов", в котором мы уже начинаем описывать технические задачи — на основе анализа бизнес-задач. И тут-то начинается самое веселье. До этого нет никакой задачи распараллеливания чего-то там, тут она появляется. Т.е. мы имеет такую схему (весьма тривиальную же на самом деле):
Бизнес-задачи --> Технические задачи
И вот тут ИМХО (Имею Мнение Хрен Оспоришь ) то, что мы используем при проектировании — ООП там или не ООП — начинает играть весьма весомую роль при определении набора задач.
ГВ>Так вот, принципиально новые языки описания системы, ИМХО, могут возникнуть только при условии, что изменится язык, которым описывают бизнес-задачи. Повторюсь, я допускаю такую возможность, хотя склонен считать, что это произойдёт не раньше, чем, ммм... соберётся рако-щучий фестиваль на Лысой Горе по фигурному свисту.
ВВ>>Мне было бы интересно рассмотреть какое-нибудь принципиально иное средство описания. ГВ>Спору нет, было бы интересно. Но главная засада заключена в том, что любое описание (на данный момент) должно сочетать метафоры действий, условий, сущностей и ресурсов. С технической же точки зрения решение сводится к выбору структуры, оптимальной в смысле использования человеческих и машинных ресурсов.
Описание системы в терминах ООП как взаимосвязи классов, обладающих поведением, состоянием и пр. — это уже техническое описание, и оно-то как раз и загонит тебя в рамки, когда будут приниматься технические решения уже на более низком уровне.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Со всем этим можно было бы согласиться, если бы процессор мог непосредственно выполнять код на Хаскеле/C#... Тогда я бы снял свои возражения. А пока что, что там не делай, а закончится все mov, add, jmp и т.д. И вот это есть абсолютный теоретический предел при данном алгоритме, если его идеально эффективно запрограммировать. Улучшить можно, только если алгоритм поменять (или доступ к данным ускорить или распараллелить и т.д.).
Вы рассматриваете ассемблер на котором человеку программировать достаточно легко. Поинтересуйтесь программированием цифровых сигнальных процессоров TMS. Там распараллеливание по конвейерам выполняется вручную (архитектура VLIW).
Мне удавалось бороться с C++ компилятором при одновременном выполнении двух итераций цикла. Дальше просто швах. А у него получается до 8 параллельных итераций.
Так что, заявления о ручной ассемблерной оптимизации прокатывают только для морально устаревшей системы команд x86.
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Ну и ну! Не вдаваясь в суть этого утверждения ( а оно совсем не верно, но объяснять почему просто нет времени), могу лишь сделать вывод — программист на асме глупый, а вот компилятор — умный, он видимо, такое делать не будет. Остается лишь ответить на вопрос, умные ли те, кто писал этот компилятор.
Компилятор, это инструмент, который позволяет автоматизировать рутинные действия по генерации машинного кода из исходной задачи. Возможности компилятора в этом плане намного выше возможностей человека, которые ограничены в силу его физиологии. Например, сможете ли вы держать в памяти, скажем 200 или 300 переменных состояния. Нет? А компилятор может. Очень многое также зависит от особенностей конкретного процессора. Есть процессоры, система команд которых не преспособлена для написания программ человеком. Он просто не сможет тупо перебрать такое количество вариантов.



 Если нам не помогут, то мы тоже никого не пощадим.
Если нам не помогут, то мы тоже никого не пощадим.











 Мы уже победили, просто это еще не так заметно...
Мы уже победили, просто это еще не так заметно...










 quicksort =: (($:@(<#[),(=#[),$:@(>#[)) ({~ ?@#)) ^: (1<#)
quicksort =: (($:@(<#[),(=#[),$:@(>#[)) ({~ ?@#)) ^: (1<#)



























 Перекуём баги на фичи!
Перекуём баги на фичи!






Не то, что строить деревья или создавать примитив синхронизации? Что он должен сгореть от горя или позора?