Краткий пересказ — Интел выкатил мобильный чип, который жрёт как Макбук Про прошлогодний, по скорости ему сливает 15-80% (медленнее в тестах) и обдувает феном. Амейзинг!
Здравствуйте, Артём, Вы писали:
Аё>Краткий пересказ — Интел выкатил мобильный чип, который жрёт как Макбук Про прошлогодний, по скорости ему сливает 15-80% (медленнее в тестах) и обдувает феном. Амейзинг!
не впечатлят, против entry level lunar lake даже в подобранных на кастрированный мак синтетических тестах, толком преимуществ не видно. при этом очевидно, что чуть серьезней проекты и 8 gb ram макбуку не хватит и он будет нещадно сливать даже среднестатическому мобильному телефону.
не представляю кто может выложить денег за фигулину, где толком софта нет, игр нет и памяти меньше чем в телефоне. преклоняюсь перед яблочным маркетингом.
Здравствуйте, Gt_, Вы писали:
Gt_>Здравствуйте, Артём, Вы писали:
Аё>>Краткий пересказ — Интел выкатил мобильный чип, который жрёт как Макбук Про прошлогодний, по скорости ему сливает 15-80% (медленнее в тестах) и обдувает феном. Амейзинг!
Gt_>не впечатлят, против entry level lunar lake даже в подобранных на кастрированный мак синтетических тестах, толком преимуществ не видно. при этом очевидно, что чуть серьезней проекты и 8 gb ram макбуку не хватит и он будет нещадно сливать даже среднестатическому мобильному телефону. Gt_>не представляю кто может выложить денег за фигулину, где толком софта нет, игр нет и памяти меньше чем в телефоне. преклоняюсь перед яблочным маркетингом.
И главное, этот лунар будут засовывать и в 2-3 раза более дешевые девайсы чем зенбук.
Всё у вас лучше, всё у вас мощнее, всё у вас качественнее. А как реально садишься за мак РАБОТАТЬ, так какой-нибудь "CPU Thermal level: 172" или ещё какая-нибудь дрянь.
Это был MacBook pro 2019. До сих пор аж выворачивает.
Всё сказанное выше — личное мнение, если не указано обратное.
Здравствуйте, Артём, Вы писали:
Аё>Краткий пересказ — Интел выкатил мобильный чип, который жрёт как Макбук Про прошлогодний, по скорости ему сливает 15-80% (медленнее в тестах) и обдувает феном. Амейзинг!
Амейзинг тут то, Артемка, что переползать на закрытые железячные архитектуры теперь не нужно. И софт менять не нужно. И трахаться с эмуляторы тоже не нужно. А все это было очень близко. Спасибо, Intel, что вовремя проснулись.
Здравствуйте, novitk, Вы писали:
N>Амейзинг тут то, Артемка, что переползать на закрытые железячные архитектуры теперь не нужно. И софт менять не нужно. И трахаться с эмуляторы тоже не нужно. А все это было очень близко. Спасибо, Intel, что вовремя проснулись.
Сливает на 15-80% в тестах прошлогоднему процу и обдувает феном. M4 на подходе.
Насчёт что мало рамы в базовой модели- да есть такое. Можно взять на 36г/1тб прошку. У меня коллегам такие сейчас выдают взамен их прошлых m1-2 мак прошек.
Здравствуйте, Артём, Вы писали:
Аё>Сливает на 15-80% в тестах прошлогоднему процу и обдувает феном. M4 на подходе.
Про тесты надо смотреть на тесты, но что-то мне подсказывает что tpad P series/dell precision да с хорошей квадрой порвет проху. Ты в курсе, что в Intel NPU девственное кстати?
Про "обдувается феном" при одинаковой батарее... ну ты же в школу ходил в СССР на физику! Причем здесь INTC? Asus лаптопы делать не умеет, это и так всем известно.
Здравствуйте, novitk, Вы писали:
N>Про тесты надо смотреть на тесты, но что-то мне подсказывает что tpad P series/dell precision да с хорошей квадрой порвет проху.
Нвидия карта порвёт встройку m3. Кому-то такой вариант лучше подходит, но мне подходит встройка в тонком ноуте. И ещё удар ниже пояса нвидии- на инференсе LLM нужно много-много VRAM, которых в просьюмерских картах наидиа простл нет. А у M — рама унифицированная, т.е. даже 120Gb VRAM — не проблема для соответствующей конфы макпро.
N> Ты в курсе, что в Intel NPU девственное кстати?
В макпро давно есть NPU. Интел здесь в догоняющих, причём боюсь тоже сливают.
N>Про "обдувается феном" при одинаковой батарее... Причем здесь INTC?
При том, что интел и амд лаптопы обдувают феном, а m лапторы ябла- нет. Причём, если взять старый интел-макпро, то тот обдувает феном шо песец.
Здравствуйте, Артём, Вы писали:
Аё>на инференсе LLM нужно много-много VRAM
для трейнинга нужно много-много VRAM, а не для инференц.
Аё>В макпро давно есть NPU. Интел здесь в догоняющих, причём боюсь тоже сливают.
Именно, то есть софт еще не адаптирован. Когда адаптируют, тесты изменятся.
Аё>При том, что интел и амд лаптопы обдувают феном, а m лапторы ябла- нет. Причём, если взять старый интел-макпро, то тот обдувает феном шо песец.
А у меня не обдувается и это даже не LLake. Потому что лаптоп сделан правильно.
Здравствуйте, Артём, Вы писали:
Аё>Краткий пересказ — Интел выкатил мобильный чип, который жрёт как Макбук Про прошлогодний, по скорости ему сливает 15-80% (медленнее в тестах) и обдувает феном. Амейзинг!
Теперь нет смысла гнаться за арм, уже метеор лейк работает целый день и в конце остается треть батареи.
Этот ноут не является аналогом Mac Pro. Насколько я знаю, у него тдп смешной, до 28 ватт максимум, вот вам и просадка в производительности.
Здравствуйте, novitk, Вы писали:
Аё>>на инференсе LLM нужно много-много VRAM N>для трейнинга нужно много-много VRAM, а не для инференц.
Для инференнса тоже. Модель Llama 3.1 8B говорит, что у неё 8 миллиардов параметров. Если она сохранена во float16, то потребуется не меньше 16 Гб памяти, поэтому квантуют и в uint8 (8 Гб памяти), и меньше, теряя при этом в качестве. А есть ещё модели и 70B, и 400B. Короче, ппамяти мало не бывает, ведь ещё и работать при этом надо на ноуте.
Здравствуйте, Nuzhny, Вы писали:
N>>для трейнинга нужно много-много VRAM, а не для инференц.
N>Для инференнса тоже. Модель Llama 3.1 8B говорит, что у неё 8 миллиардов параметров. Если она сохранена во float16, то потребуется не меньше 16 Гб памяти, поэтому квантуют и в uint8 (8 Гб памяти), и меньше, теряя при этом в качестве. А есть ещё модели и 70B, и 400B. Короче, ппамяти мало не бывает, ведь ещё и работать при этом надо на ноуте.
Я в курсе, капитан. Artem растекся мыслью по дереву, а я привязался к двойному"много" и 120GB. Речь идет про ноуты, то есть мы говорим о какой-нибудь Phi-2 с inference <8GB.
Здравствуйте, novitk, Вы писали:
N>Я в курсе, капитан. Artem растекся мыслью по дереву, а я привязался к двойному"много" и 120GB. Речь идет про ноуты, то есть мы говорим о какой-нибудь Phi-2 с inference <8GB.
Ну вот не надо обобщать. Ноуты без GPU в принципе не годятся на сколько-то полезную LLM, ноуты с 4070, 4080, 4090 — вот эти уже норм. Ну или уже Макбцки, которые не сильно уступают в этом ноутам с дискретной.
Так что я согласен с Артёмом — Интел сосёт и сильно.
Здравствуйте, Nuzhny, Вы писали:
N>>Я в курсе, капитан. Artem растекся мыслью по дереву, а я привязался к двойному"много" и 120GB. Речь идет про ноуты, то есть мы говорим о какой-нибудь Phi-2 с inference <8GB. N>Ну вот не надо обобщать. Ноуты без GPU в принципе не годятся на сколько-то полезную LLM, ноуты с 4070, 4080, 4090 — вот эти уже норм.
Мне кажется, что вы с Артемом обсуждаете "сферических коней". Ты реально гоняешь 13B на ноуте? Если да, то зачем?
N>Так что я согласен с Артёмом — Интел сосёт и сильно.
В "вакууме" возможно, а в реалии надо смотреть. 100+ TOPS > 38 TOPS.
Другое дело, что 32ГБ это имхо мало для дева.
Здравствуйте, novitk, Вы писали: N>>Ну вот не надо обобщать. Ноуты без GPU в принципе не годятся на сколько-то полезную LLM, ноуты с 4070, 4080, 4090 — вот эти уже норм. N>Мне кажется, что вы с Артемом обсуждаете "сферических коней". Ты реально гоняешь 13B на ноуте? Если да, то зачем?
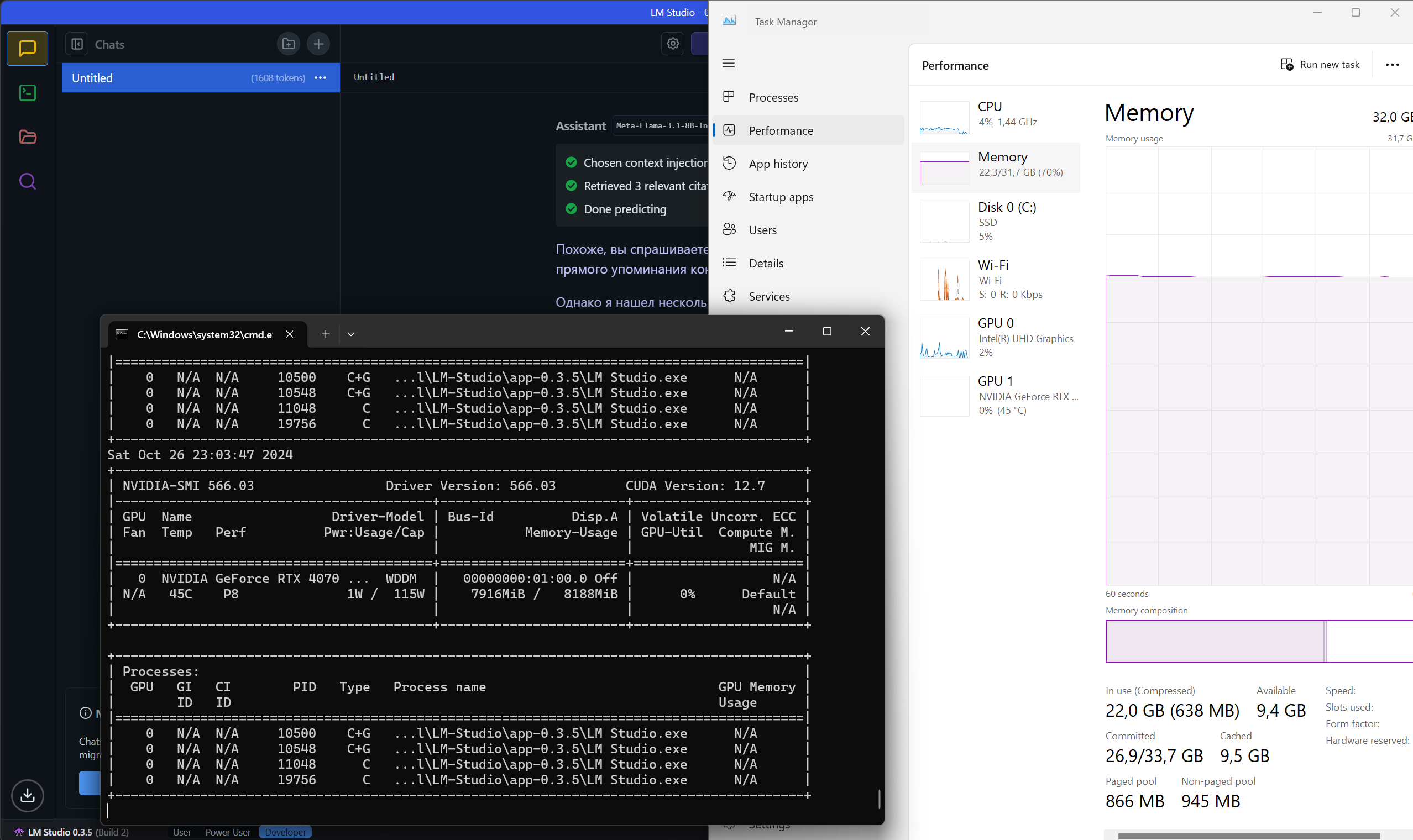
У меня сейчас Meta Llama 3.1 8B Q8. И, блин, видеопамять вся занята.
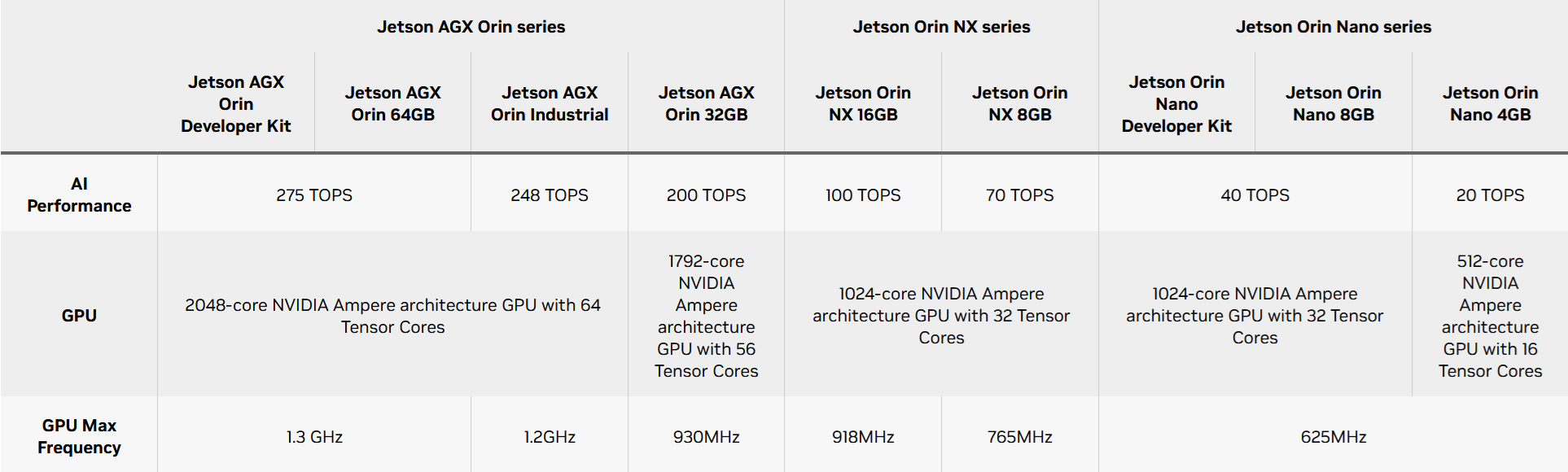
Ну, 45 или 100 TOPs — это уровень Джетсонов, причём не самых мощных.
картинка
Типа, ок, неплохо по сравнению с тем, что было, но... У меня есть Orin NX на 100 TOPs, посмотрю, как на нём можно запуститься. Через недельку-другую, сейчас совсем не до этого. Сравню с текущим ноутом с 4070 и компом с 4090.
Здравствуйте, novitk, Вы писали:
N>Я в курсе, капитан. Artem растекся мыслью по дереву, а я привязался к двойному"много" и 120GB. Речь идет про ноуты, то есть мы говорим о какой-нибудь Phi-2 с inference <8GB.
Для LLM рамы много не бывает — см. с 1мин- про мак студию. А у 4090 всего 24G- это оч далеко от NVidia A100, которая для облачных LLM.
Здравствуйте, Артём, Вы писали:
Аё>Для LLM рамы много не бывает — см. с 1мин- про мак студию. А у 4090 всего 24G- это оч далеко от NVidia A100, которая для облачных LLM.
Артем, ты реально инферируешь Llama 13B на своем ноуте или собираешься?