Р>Кто-нибудь понимает суть отказа от зависимостей?
Мой любимый способ разработки. Когда кто-нибудь приходит с очередной гениальной идеей "а давайте впупыжим еще пять микросервисов на критическом пути", я применяю данный паттерн, и говорю "нафиг-нафиг".
Здравствуйте, Разраб, Вы писали:
Р>Кто-нибудь понимает суть отказа от зависимостей? Р>Можете привести пример кода? Р>Или доклад/статью на русском хотя бы
Несколько лет назад я написал книгу «Внедрение зависимостей в .NET», и, так как название этого доклада гласит «От внедрения зависимостей к отказу от зависимостей», возможно, вы ждете, что я отрекусь от всего, что написал в этой книге, но этого не произойдет. Я доволен содержанием книги и думаю, что она предоставляет хорошее руководство по написанию объектно-ориентированных программ.
Отказ от зависимостей — это про способ работы зависимостями в функциональных языках
Несколько лет назад я написал книгу «Внедрение зависимостей в .NET», и, так как название этого доклада гласит «От внедрения зависимостей к отказу от зависимостей», возможно, вы ждете, что я отрекусь от всего, что написал в этой книге, но этого не произойдет. Я доволен содержанием книги и думаю, что она предоставляет хорошее руководство по написанию объектно-ориентированных программ.
Б>Отказ от зависимостей — это про способ работы зависимостями в функциональных языках
Что-то я не понял прикол. Обычный "грязный" код MaitreD в начале, хоть был и грязным, но его можно было хорошо протестировать и бизнес-логика была сосредоточена в одном месте — прочитали список и репозитория, выполнили вычисления, проверили условия, сохранили результат, дали ответ — это всё пишется как слышится по бизнес-требованиям. Соответствующий тест будет тестировать именно бизнес-логику и тест написать легко — запихиваем мок репозитория и ассертим что репозиторий используется ожидаемым образом в разных сценариях.
А "образцово-показательный" код в конце статьи разрывает бизнес-логику посередине — чтение и создание. Выносит чистую функцию (которая настолько проста, что там даже тестировать-то нечего) и код работы с базой в tryAcceptComposition — который тестами уже никак нормально не покрывается, т.к. там connectionString и глобальный DB. И даже теряется тот факт, что чтение и запись данных происходит из того же репозитория.
Ещё "ух! Мы заменили целый класс MaitreD на всего одну функцию tryAccept" — тоже какая-то странная риторика. В реальности MaitreD будет иметь ещё cancelReservation/reschedule/etc и опять же соответствовать вполне реальной бизнес-сущности. Как логически объединять пачку разрозненных функций — тоже неясно.
И если бизнес-логика обрастёт подробностями (например, добавить аудит, посылку емейла о результате, и т.п.) то вообще вся логика раскрошится в пыль и понять что к чему, протетсировать всё как целое — станет совсем сложно.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
·>Что-то я не понял прикол. Обычный "грязный" код MaitreD в начале, хоть был и грязным, но его можно было хорошо протестировать и бизнес-логика была сосредоточена в одном месте — прочитали список и репозитория, выполнили вычисления, проверили условия, сохранили результат, дали ответ — это всё пишется как слышится по бизнес-требованиям ·> Соответствующий тест будет тестировать именно бизнес-логику и тест написать легко — запихиваем мок репозитория и ассертим что репозиторий используется ожидаемым образом в разных сценариях.
Сейчас это называется плохо протестировать — вместо простых и дешовых юнит-тестов вам надо обмазываться моками, и писать хрупкие тесты вида "вызвали функцию репозитория"
То есть, это тесты "как написано", тавтологические
·>А "образцово-показательный" код в конце статьи разрывает бизнес-логику посередине — чтение и создание.
Из бизнес логики здесь только создание. Вот это и тестируем юнит-тестами безо всяких моков. Что там будет в чтении-дело — дело десятое. Отделили мух от котлет.
> Выносит чистую функцию (которая настолько проста, что там даже тестировать-то нечего)
Вот-вот, именно это и есть тренд последних десяти лет, при чем не только в функциональных языках.
> и код работы с базой в tryAcceptComposition — который тестами уже никак нормально не покрывается, т.к. там connectionString и глобальный DB. И даже теряется тот факт, что чтение и запись данных происходит из того же репозитория.
Это интеграционный код, он покрывается интеграционным тестом. не надо мокать базу, что бы убедиться что туда приходит коннекшн стринг. однострочный интеграционный тест даст нам куда более сильную гарантию
·>Ещё "ух! Мы заменили целый класс MaitreD на всего одну функцию tryAccept" — тоже какая-то странная риторика. В реальности MaitreD будет иметь ещё cancelReservation/reschedule/etc и опять же соответствовать вполне реальной бизнес-сущности. Как логически объединять пачку разрозненных функций — тоже неясно. ·>И если бизнес-логика обрастёт подробностями (например, добавить аудит, посылку емейла о результате, и т.п.) то вообще вся логика раскрошится в пыль и понять что к чему, протетсировать всё как целое — станет совсем сложно.
Ничего не крошится. все функции будут сделаны по одной и той же схеме. Аудит, емейл о результате — какую вы здесь проблему видите?
Несколько лет назад я написал книгу «Внедрение зависимостей в .NET», и, так как название этого доклада гласит «От внедрения зависимостей к отказу от зависимостей», возможно, вы ждете, что я отрекусь от всего, что написал в этой книге, но этого не произойдет. Я доволен содержанием книги и думаю, что она предоставляет хорошее руководство по написанию объектно-ориентированных программ.
Б>Отказ от зависимостей — это про способ работы зависимостями в функциональных языках
У автора статьи подмена понятий. Для демонстрации ооп он выбрал дурацкий подход, когда зависимости протаскиваются на всю глубину, а иерархия связывания у него глубокая.
А для хорошести фп он взял другой подход — вместо глубокой взял широкую, и показал как там всё просто.
На самом деле его подход якобы функциональный и есть тот самый, что нужно применять вообще везде, независимо от парадигмы.
Правило большого пальца — длинные, глубокие иерархии, будь то связывание, наследование, определение, заменяем на широкие, когда все дочерние растут из одного рута.
То есть, если привести его ООП код в порядок, используя тот же дизайн, что и во второй части статьи, получим ровно тот же эффект — код станет проще, тестировать его станет легче, протаскивать зависимости будет легче.
Здравствуйте, Pauel, Вы писали:
P>·>Что-то я не понял прикол. Обычный "грязный" код MaitreD в начале, хоть был и грязным, но его можно было хорошо протестировать и бизнес-логика была сосредоточена в одном месте — прочитали список и репозитория, выполнили вычисления, проверили условия, сохранили результат, дали ответ — это всё пишется как слышится по бизнес-требованиям P>·> Соответствующий тест будет тестировать именно бизнес-логику и тест написать легко — запихиваем мок репозитория и ассертим что репозиторий используется ожидаемым образом в разных сценариях. P>Сейчас это называется плохо протестировать — вместо простых и дешовых юнит-тестов вам надо обмазываться моками, и писать хрупкие тесты вида "вызвали функцию репозитория" P>То есть, это тесты "как написано", тавтологические
Технически то же самое. Вместо передачи параметров проверки результатов пюрешки (pure function), прогоняются данные через моки. Тестируется ровно то же, ровно так же. Разница же лишь семантическая — в случае пюрешки у тебя некий абстрактный кусок кода, который как-то преобразует данные которые неясно откуда берутся и куда деваются. В случае моков — готовый к использованию неделимый юнит, один-к-одному отражающий бизнес-требования. В бизнес-требованиях никакого пюре нет, там именно грязная модификация реального мира.
P>·>А "образцово-показательный" код в конце статьи разрывает бизнес-логику посередине — чтение и создание. P>Из бизнес логики здесь только создание. Вот это и тестируем юнит-тестами безо всяких моков. Что там будет в чтении-дело — дело десятое. Отделили мух от котлет.
Создание на основе именно прочитанных данных, а не чего попало. Чтение данных согласуется с созданием.
>> Выносит чистую функцию (которая настолько проста, что там даже тестировать-то нечего) P>Вот-вот, именно это и есть тренд последних десяти лет, при чем не только в функциональных языках.
Тренд в объединении подходов: глобально — грязный ооп (т.е. на уровне больших частей системы) бизнеса, локально — функциональное пюре (на уровне методов) технической реализации.
>> и код работы с базой в tryAcceptComposition — который тестами уже никак нормально не покрывается, т.к. там connectionString и глобальный DB. И даже теряется тот факт, что чтение и запись данных происходит из того же репозитория. P>Это интеграционный код, он покрывается интеграционным тестом. не надо мокать базу, что бы убедиться что туда приходит коннекшн стринг. однострочный интеграционный тест даст нам куда более сильную гарантию
Покажи мне этот однострочный интеграционный тест для tryAcceptComposition. Авторы статьи — "забыли".
Пока итог такой. Был грязный метод tryAccept на 4 строки, который требует только один юнит-тест, хотя с моком.
Они это преобразовали в пюрешный tryAccept на 3 строки, который вроде как легко покрывается юнит-тестом, но без мока. Ура. Но замели сложность в ещё один tryAcceptComposition на 3 строки (притом довольно хитрый! со всякими магическими заклинаниями liftIO, $, return, flip, .), для которого теперь требуется писать ещё и интеграционный тест. Удвоили кол-во кода, усложнили тестирование... а в чём выгода — я ну никак понять не могу.
P>·>Ещё "ух! Мы заменили целый класс MaitreD на всего одну функцию tryAccept" — тоже какая-то странная риторика. В реальности MaitreD будет иметь ещё cancelReservation/reschedule/etc и опять же соответствовать вполне реальной бизнес-сущности. Как логически объединять пачку разрозненных функций — тоже неясно. P>·>И если бизнес-логика обрастёт подробностями (например, добавить аудит, посылку емейла о результате, и т.п.) то вообще вся логика раскрошится в пыль и понять что к чему, протетсировать всё как целое — станет совсем сложно. P>Ничего не крошится. все функции будут сделаны по одной и той же схеме.
Как эти разрозненные функции будут объединяться в единую определяемую бизнесом сущность MaitreD?
P>Аудит, емейл о результате — какую вы здесь проблему видите?
В том, что результатом tryAccept может быть пачка несвязных результатов, которые должны быть распределены соответсвующим образом: результат резервации — клиенту, аудит — сервису аудита, емейл — smtp-серверу и т.п. Если это переделывать в пюре, придётся конструировать какие-то сложные результирующие объекты, которые потом надо будет ещё потом правильно разбирать на части. Или как ты это видишь?
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Любая развитая идея формирует группу антаго(в)нистов, воспринимаю это диалектически. Любой постулат рано или поздно становится объектом критики и так идет по кругу.
Здравствуйте, ·, Вы писали:
P>>Сейчас это называется плохо протестировать — вместо простых и дешовых юнит-тестов вам надо обмазываться моками, и писать хрупкие тесты вида "вызвали функцию репозитория" P>>То есть, это тесты "как написано", тавтологические ·>Технически то же самое.
Тесты "как написано", технически не дают никаких гарантий — вызвал другой метод репозитория, результат тот же, а тесты сломались. Вот вам и "то же самое"
> Вместо передачи параметров проверки результатов пюрешки (pure function), прогоняются данные через моки.
И это проблема, т.к. моки так или иначе искажают действительность. Т.к. всегда есть риск, что с моками работает, а без моков — ни гу-гу. При росте сложности приложения эти риски начинают срабатывать регулярно.
Например, научить новичка внятно пользоваться моками да правильно покрывать тесты используя такой подход довольно трудно, на это уходят годы. А потому рано или поздно будете ловить последствия в проде.
> Тестируется ровно то же, ровно так же. Разница же лишь семантическая
Вы сейчас играете в слова. В одном случае вы получаете проблемы из за моков, а в другом случае просто тестируете ключевую функцию юнит-тестами без моков.
Обмазываетесь моками — значит время на разработку тестов больше, тк тесты хрупкие.
Моки это инструмент решения проблем, а не способ выражения намерений. А раз так, то нужно сперва решить проблему, тогда и отпадет необходимость применять этот инструмент.
P>>Из бизнес логики здесь только создание. Вот это и тестируем юнит-тестами безо всяких моков. Что там будет в чтении-дело — дело десятое. Отделили мух от котлет. ·>Создание на основе именно прочитанных данных, а не чего попало. Чтение данных согласуется с созданием.
Эти вещи связаны исключительно конкретным пайплайном. А вот логически это разные вещи. Тестировать сам пайплайн удобнее интеграционными тестам — прогнал один, значит пайпалайн работает. А вот отдельные части пайплайна — дешовыми юнит-тестами, их можно настрочить тыщи, хоть генерируй по спеке, время на запуск все равно 0 секунд.
А вот если вы обмазываетесь моками, то пишете тесты "как написано" и другого варианта у вас нет.
P>>Вот-вот, именно это и есть тренд последних десяти лет, при чем не только в функциональных языках. ·>Тренд в объединении подходов: глобально — грязный ооп (т.е. на уровне больших частей системы) бизнеса, локально — функциональное пюре (на уровне методов) технической реализации.
Именно! А вы предлагаете грязный ооп использовать на уровне методов технической реализации. Потому вам и нужны моки. ООП это парадигма для управления сложностью взаимодействия. ФП — для управления сложностью вычислений. Отсюда ясно, что нам надо и то, и другое — склеить взаимодействие с вычислениями. Создание — тупо вычисления, а вы сюда втискиваете зависимость на БД и вещаете что это хорошо.
Опомнитесь — ваш подход из 80х-90х, когда TurboVision в MSDOS встречали на ура.
·>Покажи мне этот однострочный интеграционный тест для tryAcceptComposition. Авторы статьи — "забыли".
·>Пока итог такой. Был грязный метод tryAccept на 4 строки, который требует только один юнит-тест, хотя с моком.
Неверно — была монолитная иерархия вызовов во главе с tryAccept который только сам по себе 4 строки.
И тестировать нужно всю эту иерархию, для чего вам и нужны моки.
·>Они это преобразовали в пюрешный tryAccept на 3 строки, который вроде как легко покрывается юнит-тестом, но без мока. Ура.
Именно!
> Но замели сложность в ещё один tryAcceptComposition на 3 строки (притом довольно хитрый! со всякими магическими заклинаниями liftIO, $, return, flip, .), для которого теперь требуется писать ещё и интеграционный тест. Удвоили кол-во кода, усложнили тестирование... а в чём выгода — я ну никак понять не могу.
Вы по прежнему думаете, что моки избавляют от интеграционных тестов. Ровно наоборот — сверх обычных юнитов вам надо понаписывать моки на все кейсы, и всё равно придется писать интеграционные тесты.
P>>Ничего не крошится. все функции будут сделаны по одной и той же схеме. ·>Как эти разрозненные функции будут объединяться в единую определяемую бизнесом сущность MaitreD?
MaitreD это метафора уровня реализации, никакой бизнес это не определяет. Бизнесу надо что бы работали юз-кейсы вида "зарезервировать столик на 10 мест на 31е декабря между баром и сценой". Используете вы MaitreD или нет, дело десятое.
На основе коротких функций мы можем менять компоновку уже по ходу пьесы подстраиваясь под изменения треботваний, а не бетонировать код на все времена.
P>>Аудит, емейл о результате — какую вы здесь проблему видите? ·>В том, что результатом tryAccept может быть пачка несвязных результатов, которые должны быть распределены соответсвующим образом: результат резервации — клиенту, аудит — сервису аудита, емейл — smtp-серверу и т.п. Если это переделывать в пюре, придётся конструировать какие-то сложные результирующие объекты, которые потом надо будет ещё потом правильно разбирать на части. Или как ты это видишь?
Похоже, вы просто не в курсе, как подобное реализуется в функциональном стиле, а потому порете чушь. Нам нужен аудит не вызова tryAccept, а аудит всей транзации которая изначально будет грязной, принципиально. Т.е. вещи вида "третьего дня разместили заявку xxx(детали) ... статус успешно, детали(...)"
То есть, к известным эффектам мы всего то добавляем еще один. И емейл это ровно такой же эффект. Т.е. нам нужна всего то парочка мидлвар, которые и берут на себя все что надо.
Более того, и запись в очередь это снова такой же эффект
Здравствуйте, Pauel, Вы писали:
P>>>Сейчас это называется плохо протестировать — вместо простых и дешовых юнит-тестов вам надо обмазываться моками, и писать хрупкие тесты вида "вызвали функцию репозитория" P>>>То есть, это тесты "как написано", тавтологические P>·>Технически то же самое. P>Тесты "как написано", технически не дают никаких гарантий — вызвал другой метод репозитория, результат тот же, а тесты сломались. Вот вам и "то же самое"
Это уже детали реализации — что именно тестируют тесты. Если я хочу тестировать факт вызова определённого метода, то тест и должен сломаться. Что именно покрывает тест — это должен решать программист. Моки к этому отношения не имеют вообще никакого. >> Вместо передачи параметров проверки результатов пюрешки (pure function), прогоняются данные через моки. P>И это проблема, т.к. моки так или иначе искажают действительность. Т.к. всегда есть риск, что с моками работает, а без моков — ни гу-гу. При росте сложности приложения эти риски начинают срабатывать регулярно. P>Например, научить новичка внятно пользоваться моками да правильно покрывать тесты используя такой подход довольно трудно, на это уходят годы. А потому рано или поздно будете ловить последствия в проде.
Это всё риторика. Любые тесты искажают действительность, просто по определению. Моки — тут вообще не при чём. >> Тестируется ровно то же, ровно так же. Разница же лишь семантическая P>Вы сейчас играете в слова. В одном случае вы получаете проблемы из за моков, а в другом случае просто тестируете ключевую функцию юнит-тестами без моков.
Моки это всего лишь механизм передачи данных от одного участка кода другому. Пюрешки могут использовать только передачу параметров и возвращаемое значение. Моки — дополнительно позволяют передавать инфу через вызовы методов. Вот и вся разница. P>Обмазываетесь моками — значит время на разработку тестов больше, тк тесты хрупкие.
Моки лишь дополнительный инструмент. Можно им всё сломать, а можно сделать красиво. P>Моки это инструмент решения проблем, а не способ выражения намерений. А раз так, то нужно сперва решить проблему, тогда и отпадет необходимость применять этот инструмент.
Решения каких проблем? P>·>Создание на основе именно прочитанных данных, а не чего попало. Чтение данных согласуется с созданием. P>Эти вещи связаны исключительно конкретным пайплайном. А вот логически это разные вещи. Тестировать сам пайплайн удобнее интеграционными тестам — прогнал один, значит пайпалайн работает. А вот отдельные части пайплайна — дешовыми юнит-тестами, их можно настрочить тыщи, хоть генерируй по спеке, время на запуск все равно 0 секунд.
Я о чём и говорю. Шило на мыло меняешь, правда ценой удвоения количества кода. P>А вот если вы обмазываетесь моками, то пишете тесты "как написано" и другого варианта у вас нет.
Варианта чего? Вынести пюрешку можно банальным extract method refactoring и покрыть отдельно — если это имеет хоть какую-то практическую пользу. Мой поинт в том, что в статье практической пользы делать закат вручную мне не удалось увидеть. P>·>Тренд в объединении подходов: глобально — грязный ооп (т.е. на уровне больших частей системы) бизнеса, локально — функциональное пюре (на уровне методов) технической реализации. P>Именно! А вы предлагаете грязный ооп использовать на уровне методов технической реализации. Потому вам и нужны моки. ООП это парадигма для управления сложностью взаимодействия. ФП — для управления сложностью вычислений. Отсюда ясно, что нам надо и то, и другое — склеить взаимодействие с вычислениями. Создание — тупо вычисления, а вы сюда втискиваете зависимость на БД и вещаете что это хорошо.
Я предлагаю использовать ооп. На минутку — что требует бизнес? Реализацию сущности MaitreD. Это такой дядька, который стоит на входе в ресторан и взаимодействует с клиентами обслуживая запросы (притом разные — accept/cancel/reschedule/etc) на резервацию столиков. Т.е. прямое соответствие интерфейсу class MaitreD {int? tryAccept(Reservation r){...}; boolean tryReschdedule(Reservation r, DateTime newTime){...}; ....} — ничего лишнего, как слышится, так и пишется — это и есть описание системы в целом.
В статье на замену предложено вычленить локальное нутро реализации метода, вынести наружу, чтобы получилось вот это: int -> (DateTimeOffset -> Reservation list) -> (Reservation -> int) -> Reservation — это вообще чо??!. P>·>Покажи мне этот однострочный интеграционный тест для tryAcceptComposition. Авторы статьи — "забыли".
Напиши однострочный интеграционный тест для tryAcceptComposition. Именно этот метод напрямую соответствует рассматриваемому в начале статьи методу "public int? TryAccept(Reservation)" который очень легко тестировать, но с моком. P>·>Пока итог такой. Был грязный метод tryAccept на 4 строки, который требует только один юнит-тест, хотя с моком. P>Неверно — была монолитная иерархия вызовов во главе с tryAccept который только сам по себе 4 строки. P>И тестировать нужно всю эту иерархию, для чего вам и нужны моки.
Не понял ты о чём. Я о "главном герое" статьи, вот этом классе:
P>·>Они это преобразовали в пюрешный tryAccept на 3 строки, который вроде как легко покрывается юнит-тестом, но без мока. Ура. P>Именно!
С моком он так же покрывается на ура. >> Но замели сложность в ещё один tryAcceptComposition на 3 строки (притом довольно хитрый! со всякими магическими заклинаниями liftIO, $, return, flip, .), для которого теперь требуется писать ещё и интеграционный тест. Удвоили кол-во кода, усложнили тестирование... а в чём выгода — я ну никак понять не могу. P> Вы по прежнему думаете, что моки избавляют от интеграционных тестов. Ровно наоборот — сверх обычных юнитов вам надо понаписывать моки на все кейсы, и всё равно придется писать интеграционные тесты.
Зачем писать моки на все кейсы? Моки делаются не для кейсов, а для зависимостей. Тут одна зависимость — репозиторий — значит один мок. Неважно сколько кейсов.
Юнит-тестов нужно только два — успешная и неуспешная резервация. Интеграционный тест только один — что MaitreD успешно интегрируется со всеми своими зависимостями. P>·>Как эти разрозненные функции будут объединяться в единую определяемую бизнесом сущность MaitreD? P>MaitreD это метафора уровня реализации, никакой бизнес это не определяет. Бизнесу надо что бы работали юз-кейсы вида "зарезервировать столик на 10 мест на 31е декабря между баром и сценой". Используете вы MaitreD или нет, дело десятое. P>На основе коротких функций мы можем менять компоновку уже по ходу пьесы подстраиваясь под изменения треботваний, а не бетонировать код на все времена.
"зарезервировать столик" — это Responsibility выполняемое Actor-ом MaitreD. Это понятно бизнесу. И бизнесу понятно, что клиентов надо направлять именно к MaitreD для резервации, а не к Actor-у Повар. Что резервация должна записываться в Репозитории, а не на стене туалета. И т.п. P>>>Аудит, емейл о результате — какую вы здесь проблему видите? P>·>В том, что результатом tryAccept может быть пачка несвязных результатов, которые должны быть распределены соответсвующим образом: результат резервации — клиенту, аудит — сервису аудита, емейл — smtp-серверу и т.п. Если это переделывать в пюре, придётся конструировать какие-то сложные результирующие объекты, которые потом надо будет ещё потом правильно разбирать на части. Или как ты это видишь? P>Похоже, вы просто не в курсе, как подобное реализуется в функциональном стиле, а потому порете чушь. Нам нужен аудит не вызова tryAccept, а аудит всей транзации которая изначально будет грязной, принципиально. Т.е. вещи вида "третьего дня разместили заявку xxx(детали) ... статус успешно, детали(...)"
Это не аудит, это просто лог для дебага. Аудит это требуемый аудиторами record-keeping процесс определённого формата с определёнными требованиями с целью контролировать business conduct — по тому как происходят различные бизнес-операции с т.з. legal compliance. С т.з. реального мира — тот дядька у входа в ресторан, например, обязан секретно уведомлять полицию если к нему пришёл клиент с признаками наркотического отравления. P>То есть, к известным эффектам мы всего то добавляем еще один. И емейл это ровно такой же эффект. Т.е. нам нужна всего то парочка мидлвар, которые и берут на себя все что надо. P>Более того, и запись в очередь это снова такой же эффект
Ты не отвлекайся. Код в статье рассматривай. Расскажи куда там воткнуть это всё в tryAcceptComposition или куда там получится. Я хочу рассмотреть пример когда у метода будет больше одной зависимости. А ты мне предлагаешь зависимости внедрять неявно через аннотации и глобальные переменные. P>@useAudit(Schema.arrange, Schema.arranged) P>@useEvent(Schema.arranged) P>@validate(Schema.arrange) P>@presenter(Schema.arranged)
Ужас. annotation-driven development. Прям Spring, AOP, ejb, 00-е, application container, framework, middleware. Закопай обратно.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>>>Сейчас это называется плохо протестировать — вместо простых и дешовых юнит-тестов вам надо обмазываться моками, и писать хрупкие тесты вида "вызвали функцию репозитория" P>>>>То есть, это тесты "как написано", тавтологические P>>·>Технически то же самое. P>>Тесты "как написано", технически не дают никаких гарантий — вызвал другой метод репозитория, результат тот же, а тесты сломались. Вот вам и "то же самое" ·>Это уже детали реализации — что именно тестируют тесты. Если я хочу тестировать факт вызова определённого метода, то тест и должен сломаться. Что именно покрывает тест — это должен решать программист. Моки к этому отношения не имеют вообще никакого.
Забавный плюрализм в одной голове — в одном треде вы клеймите позором "тесты как написано", тк "они ничего не тестируют", а здесь это уже "детали реализации"
Как вас понимать, какая версия вашего мнения считается более актуальной?
P>>Например, научить новичка внятно пользоваться моками да правильно покрывать тесты используя такой подход довольно трудно, на это уходят годы. А потому рано или поздно будете ловить последствия в проде. ·>Это всё риторика. Любые тесты искажают действительность, просто по определению. Моки — тут вообще не при чём.
Любые и все по разному, в разной степени. Моки по своей сути сильнее всего этому подвержены. Пол-приложения не работает при зеленых тестах — обычное дело с моками.
P>>Вы сейчас играете в слова. В одном случае вы получаете проблемы из за моков, а в другом случае просто тестируете ключевую функцию юнит-тестами без моков. ·>Моки это всего лишь механизм передачи данных от одного участка кода другому. Пюрешки могут использовать только передачу параметров и возвращаемое значение. Моки — дополнительно позволяют передавать инфу через вызовы методов. Вот и вся разница.
Не вся — моки могут добавлять то чего в природе нет, не водится, или выворачивать наизнанку. Соответствие моков реальному поведению системы всегда остаётся на совести разработчика, а следовательно человеческий фактор в его максимальном проявлении.
P>>Обмазываетесь моками — значит время на разработку тестов больше, тк тесты хрупкие. ·>Моки лишь дополнительный инструмент. Можно им всё сломать, а можно сделать красиво.
У вас моки стали какой то панацеей. Вас послушать так у моков одни преимущества, без каких либо недостатков.
P>>Моки это инструмент решения проблем, а не способ выражения намерений. А раз так, то нужно сперва решить проблему, тогда и отпадет необходимость применять этот инструмент. ·>Решения каких проблем?
Зависимости. Моки отрезают зависимости во время тестирования. Что характерно, моки далеко это не единственный инструмент решения этой поблемы, и далеко не самый эффективный.
А у вас он стал панацеей
P>>Эти вещи связаны исключительно конкретным пайплайном. А вот логически это разные вещи. Тестировать сам пайплайн удобнее интеграционными тестам — прогнал один, значит пайпалайн работает. А вот отдельные части пайплайна — дешовыми юнит-тестами, их можно настрочить тыщи, хоть генерируй по спеке, время на запуск все равно 0 секунд. ·>Я о чём и говорю. Шило на мыло меняешь, правда ценой удвоения количества кода.
Если есть выбор, моком или простым юнит-тестом, то юнит-тест всегда эффективнее. Удвоение количества — это как раз про моки. При одинаковом покрытии кейсов мокам нужно больше кода.
P>>А вот если вы обмазываетесь моками, то пишете тесты "как написано" и другого варианта у вас нет. ·>Варианта чего? Вынести пюрешку можно банальным extract method refactoring и покрыть отдельно — если это имеет хоть какую-то практическую пользу. Мой поинт в том, что в статье практической пользы делать закат вручную мне не удалось увидеть.
Так вы хотели, что бы вам в трех словах все тайны мироздания раскрыли? Все статьи такие, что там можно найти частный случай и заткнуть всё сразу.
P>>Именно! А вы предлагаете грязный ооп использовать на уровне методов технической реализации. Потому вам и нужны моки. ООП это парадигма для управления сложностью взаимодействия. ФП — для управления сложностью вычислений. Отсюда ясно, что нам надо и то, и другое — склеить взаимодействие с вычислениями. Создание — тупо вычисления, а вы сюда втискиваете зависимость на БД и вещаете что это хорошо. ·>Я предлагаю использовать ооп. На минутку — что требует бизнес? Реализацию сущности MaitreD.
Нет, не требует. Бизнесу до ваших сущностей никакого дела нет. А потому разработчик имеет право выбирать, нужна ли ему такая сущность, и как он её будет моделировать — объектами, классами, актерами итд итд итд Хоть набором переменных, абы это имело практическое обоснование
·>В статье на замену предложено вычленить локальное нутро реализации метода, вынести наружу, чтобы получилось вот это: int -> (DateTimeOffset -> Reservation list) -> (Reservation -> int) -> Reservation — это вообще чо??!.
Это описание конкретного пайплайна. В ооп подходе у вас будет примерно такая же штукенция. Покрасивее будет, т.к. именованая. Но принципиально всё сохранится. В том и то и бенефит.
Проблема с самой статье
1. в ооп стоит делать так, как автор показывает для фп варианта — больше контроля, меньше моков, больше юнит-тестов
2. если в фп задаться целью сделать как автор для ооп вариана — можно просто убиться
Это правило для работы с глубокоми иерахиями чего угодно — глубокую запутанную превращаем в плоскую одноуровневую. методы становятся длиннее, но зависимостями управлять легче тк иерархия неглубокая.
>>> Но замели сложность в ещё один tryAcceptComposition на 3 строки (притом довольно хитрый! со всякими магическими заклинаниями liftIO, $, return, flip, .), для которого теперь требуется писать ещё и интеграционный тест. Удвоили кол-во кода, усложнили тестирование... а в чём выгода — я ну никак понять не могу. P>> Вы по прежнему думаете, что моки избавляют от интеграционных тестов. Ровно наоборот — сверх обычных юнитов вам надо понаписывать моки на все кейсы, и всё равно придется писать интеграционные тесты. ·>Зачем писать моки на все кейсы? Моки делаются не для кейсов, а для зависимостей. Тут одна зависимость — репозиторий — значит один мок. Неважно сколько кейсов.
Ваш мок должен поддерживать все эти кейсы, что очевидно. Думаете мок сам догадается, какие кейсы ему поддерживать?
·>Юнит-тестов нужно только два — успешная и неуспешная резервация. Интеграционный тест только один — что MaitreD успешно интегрируется со всеми своими зависимостями.
Юнит-тестов нужно гораздо больше — в зависимости от того, сколько у нас параметров, состояний итд.
P>>На основе коротких функций мы можем менять компоновку уже по ходу пьесы подстраиваясь под изменения треботваний, а не бетонировать код на все времена. ·>"зарезервировать столик" — это Responsibility выполняемое Actor-ом MaitreD. Это понятно бизнесу.
Бизнесу до этого никакого дела нет. MaitreD это абстракция уровня реализации.
·>Это не аудит, это просто лог для дебага. Аудит это требуемый аудиторами record-keeping процесс определённого формата с определёнными требованиями с целью контролировать business conduct — по тому как происходят различные бизнес-операции с т.з. legal compliance. С т.з. реального мира — тот дядька у входа в ресторан, например, обязан секретно уведомлять полицию если к нему пришёл клиент с признаками наркотического отравления.
·>Ты не отвлекайся. Код в статье рассматривай. Расскажи куда там воткнуть это всё в tryAcceptComposition или куда там получится. Я хочу рассмотреть пример когда у метода будет больше одной зависимости. А ты мне предлагаешь зависимости внедрять неявно через аннотации и глобальные переменные.
Это ваши фантазии. Я ничего не предлагаю внедрать неявно, тем более с глобальными переменными. Это вы с голосами в голове спорите.
P>>@useAudit(Schema.arrange, Schema.arranged) P>>@useEvent(Schema.arranged) P>>@validate(Schema.arrange) P>>@presenter(Schema.arranged) ·>Ужас. annotation-driven development. Прям Spring, AOP, ejb, 00-е, application container, framework, middleware. Закопай обратно.
Здравствуйте, Pauel, Вы писали:
P>>>Тесты "как написано", технически не дают никаких гарантий — вызвал другой метод репозитория, результат тот же, а тесты сломались. Вот вам и "то же самое" P>·>Это уже детали реализации — что именно тестируют тесты. Если я хочу тестировать факт вызова определённого метода, то тест и должен сломаться. Что именно покрывает тест — это должен решать программист. Моки к этому отношения не имеют вообще никакого. P>Забавный плюрализм в одной голове — в одном треде вы клеймите позором "тесты как написано", тк "они ничего не тестируют", а здесь это уже "детали реализации"
Это потому что ты сам с собой споришь и с темы спрыгиваешь.
P>Как вас понимать, какая версия вашего мнения считается более актуальной?
Разжевываю:
"тесты как написано", тк "они ничего не тестируют" — позор. Не важно с моками они или нет.
Использование моков или нет — "детали реализации".
P>>>Например, научить новичка внятно пользоваться моками да правильно покрывать тесты используя такой подход довольно трудно, на это уходят годы. А потому рано или поздно будете ловить последствия в проде. P>·>Это всё риторика. Любые тесты искажают действительность, просто по определению. Моки — тут вообще не при чём. P>Любые и все по разному, в разной степени. Моки по своей сути сильнее всего этому подвержены. Пол-приложения не работает при зеленых тестах — обычное дело с моками.
Ещё раз повторюсь. Моки — инструмент. Если ты молотком пользоваться не умеешь и постоянно попадаешь по пальцам, то правильным решением будет научиться пользоваться молотком, а не продолжать закручивать гвозди отвёрткой.
P>·>Моки это всего лишь механизм передачи данных от одного участка кода другому. Пюрешки могут использовать только передачу параметров и возвращаемое значение. Моки — дополнительно позволяют передавать инфу через вызовы методов. Вот и вся разница. P>Не вся — моки могут добавлять то чего в природе нет, не водится, или выворачивать наизнанку. Соответствие моков реальному поведению системы всегда остаётся на совести разработчика, а следовательно человеческий фактор в его максимальном проявлении.
В параметры тоже можно передавать то чего в природе нет. И что?
P>>>Обмазываетесь моками — значит время на разработку тестов больше, тк тесты хрупкие. P>·>Моки лишь дополнительный инструмент. Можно им всё сломать, а можно сделать красиво. P>У вас моки стали какой то панацеей. Вас послушать так у моков одни преимущества, без каких либо недостатков.
Это твои фантазии.
P>>>Моки это инструмент решения проблем, а не способ выражения намерений. А раз так, то нужно сперва решить проблему, тогда и отпадет необходимость применять этот инструмент. P>·>Решения каких проблем? P>Зависимости. Моки отрезают зависимости во время тестирования. Что характерно, моки далеко это не единственный инструмент решения этой поблемы, и далеко не самый эффективный.
Ты так и не показал как ты предлагаешь решать эту проблему, только заявил, что решается одной строчкой, но не показал как. Проигнорировал вопрос дважды: Напиши однострочный интеграционный тест для tryAcceptComposition.
P>А у вас он стал панацеей
Не панацеей, а конкретным решением твоей конкретной проблемы.
P>>>Эти вещи связаны исключительно конкретным пайплайном. А вот логически это разные вещи. Тестировать сам пайплайн удобнее интеграционными тестам — прогнал один, значит пайпалайн работает. А вот отдельные части пайплайна — дешовыми юнит-тестами, их можно настрочить тыщи, хоть генерируй по спеке, время на запуск все равно 0 секунд. P>·>Я о чём и говорю. Шило на мыло меняешь, правда ценой удвоения количества кода. P>Если есть выбор, моком или простым юнит-тестом, то юнит-тест всегда эффективнее.
Классика же — у каждой проблемы есть простое, ясное, эффективное, но неправильное решение.
P>Удвоение количества — это как раз про моки. При одинаковом покрытии кейсов мокам нужно больше кода.
Я говорю конкретно о статье. Там кол-во кода удвоилось. Тестовое покрытие упало в несколько раз, зато Без Моков™.
P>·>Варианта чего? Вынести пюрешку можно банальным extract method refactoring и покрыть отдельно — если это имеет хоть какую-то практическую пользу. Мой поинт в том, что в статье практической пользы делать закат вручную мне не удалось увидеть. P>Так вы хотели, что бы вам в трех словах все тайны мироздания раскрыли? Все статьи такие, что там можно найти частный случай и заткнуть всё сразу.
Я хотел, чтобы мне разъяснили нераскрытый вопрос в статье.
P>·>Я предлагаю использовать ооп. На минутку — что требует бизнес? Реализацию сущности MaitreD. P>Нет, не требует. Бизнесу до ваших сущностей никакого дела нет. А потому разработчик имеет право выбирать, нужна ли ему такая сущность, и как он её будет моделировать — объектами, классами, актерами итд итд итд Хоть набором переменных, абы это имело практическое обоснование
Ясен пень, можно хоть на brainfuck писать, без этого вашего ООП. Но чем модель ближе — тем лучше. ООП как раз направлено на моделирование бизнес-требований как можно более похожим образом — именованная сущность там — именованная сущность здесь. Набор переменных это круто, конечно, но обычно только как практическое обоснование для жоп-секьюрити.
P>·>В статье на замену предложено вычленить локальное нутро реализации метода, вынести наружу, чтобы получилось вот это: int -> (DateTimeOffset -> Reservation list) -> (Reservation -> int) -> Reservation — это вообще чо??!. P>Это описание конкретного пайплайна. В ооп подходе у вас будет примерно такая же штукенция. Покрасивее будет, т.к. именованая. Но принципиально всё сохранится. В том и то и бенефит.
Какова цель этой штуки? Зачем нам описывать конкретный пайплайн? Что можно полезного делать с этим описанием? Как проверить, что писание верное? Откуда взялось, что "принципиально всё сохранится"?
P>Проблема с самой статье P>1. в ооп стоит делать так, как автор показывает для фп варианта — больше контроля, меньше моков, больше юнит-тестов
И кода стало больше, и бОльшая часть нетривиального кода не протестирована.
P>2. если в фп задаться целью сделать как автор для ооп вариана — можно просто убиться
А какой целью надо задаваться-то?
P>Это правило для работы с глубокоми иерахиями чего угодно — глубокую запутанную превращаем в плоскую одноуровневую. методы становятся длиннее, но зависимостями управлять легче тк иерархия неглубокая.
Ну так внедрение зависимостей DI+CI это и есть плоская иерархия. В конструкторе все зависимости, методы — целевая бизнес-логика. В статье это и было показано, что такой подход эквивалентен частичному применению функций — код под капотом идентичный получается.
P>>> Вы по прежнему думаете, что моки избавляют от интеграционных тестов. Ровно наоборот — сверх обычных юнитов вам надо понаписывать моки на все кейсы, и всё равно придется писать интеграционные тесты. P>·>Зачем писать моки на все кейсы? Моки делаются не для кейсов, а для зависимостей. Тут одна зависимость — репозиторий — значит один мок. Неважно сколько кейсов. P>Ваш мок должен поддерживать все эти кейсы, что очевидно. Думаете мок сам догадается, какие кейсы ему поддерживать?
Ещё раз повторюсь — мок это лишь способ передачи данных внуть метода. В твоём случае ровно то же придётся делать, но передавать через параметры, а не через мок, вот и вся разница.
P>·>Юнит-тестов нужно только два — успешная и неуспешная резервация. Интеграционный тест только один — что MaitreD успешно интегрируется со всеми своими зависимостями. P>Юнит-тестов нужно гораздо больше — в зависимости от того, сколько у нас параметров, состояний итд.
Сосредоточься на обсуждаемой теме. Я говорю конкретно о коде в статье. Там видно сколько конкретно параметров, состояний и т.д.
P>>>На основе коротких функций мы можем менять компоновку уже по ходу пьесы подстраиваясь под изменения треботваний, а не бетонировать код на все времена. P>·>"зарезервировать столик" — это Responsibility выполняемое Actor-ом MaitreD. Это понятно бизнесу. P>Бизнесу до этого никакого дела нет. MaitreD это абстракция уровня реализации.
Слова Responsibility и Actor — это из словаря FRD. Т.е. именно эта терминология используется бизнесом для общения с девами.
P>·>Ты не отвлекайся. Код в статье рассматривай. Расскажи куда там воткнуть это всё в tryAcceptComposition или куда там получится. Я хочу рассмотреть пример когда у метода будет больше одной зависимости. А ты мне предлагаешь зависимости внедрять неявно через аннотации и глобальные переменные. P>Это ваши фантазии. Я ничего не предлагаю внедрать неявно, тем более с глобальными переменными. Это вы с голосами в голове спорите.
Аннотации именно так и работают.
P>·>Ужас. annotation-driven development. Прям Spring, AOP, ejb, 00-е, application container, framework, middleware. Закопай обратно. P>Это то куда идут по большому счету все платформы.
Когда отдают на аутсорс в индию, да. Именно такое рассуждение я как-то слышал "у нас требование покрытия тестами >90%. Аннотации в покрытии не участвуют. Давайте программировать на аннотациях".
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
·>Что-то я не понял прикол. Обычный "грязный" код MaitreD в начале, хоть был и грязным, но его можно было хорошо протестировать и бизнес-логика была сосредоточена в одном месте...
Да, ты не понял. Чувак — специались, он написал мильён блог постов. Твои проблемы ему не интересны.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, IT, Вы писали:
IT>·>Что-то я не понял прикол. Обычный "грязный" код MaitreD в начале, хоть был и грязным, но его можно было хорошо протестировать и бизнес-логика была сосредоточена в одном месте... IT>Да, ты не понял. Чувак — специались, он написал мильён блог постов. Твои проблемы ему не интересны.
К чему эта апелляция к авторитетам? По делу есть что сказать?
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>Как вас понимать, какая версия вашего мнения считается более актуальной? ·>Разжевываю: ·>"тесты как написано", тк "они ничего не тестируют" — позор. Не важно с моками они или нет. ·>Использование моков или нет — "детали реализации".
"деталь реализации" означает что разница в свойствах несущественна и инструменты взаимозаменяемы, т.к. эквивалентны
Моки и сравнения вовзращаемого значения не эквивалентны. Это следует хотя бы из того факта, что их приходится использовать совместно.
То есть, это инструменты которые решают разные классы задач — вместо "assert x = y" тестируем "унутре вызвали вон тот метод с такими параметрами"
Собственно, уже 20 лет как известно, что особенностью тестов на моках является их хрупкость, т.к. привязываемся буквально к "как написано"
P>>·>Это всё риторика. Любые тесты искажают действительность, просто по определению. Моки — тут вообще не при чём. P>>Любые и все по разному, в разной степени. Моки по своей сути сильнее всего этому подвержены. Пол-приложения не работает при зеленых тестах — обычное дело с моками. ·>Ещё раз повторюсь. Моки — инструмент. Если ты молотком пользоваться не умеешь и постоянно попадаешь по пальцам, то правильным решением будет научиться пользоваться молотком, а не продолжать закручивать гвозди отвёрткой.
Есть два подхода к покрытию — на моках, и классический. У каждого есть и достоинства, и недостатки.
А вы вместо обсуждения конкретных свойств каждого подхода пытаетесь переходить на личности и обсуждать мою квалификацию.
P>>Не вся — моки могут добавлять то чего в природе нет, не водится, или выворачивать наизнанку. Соответствие моков реальному поведению системы всегда остаётся на совести разработчика, а следовательно человеческий фактор в его максимальном проявлении. ·>В параметры тоже можно передавать то чего в природе нет. И что?
Именно. Для классических тестов вы просто берете и покрываете входы по таблице истинности, покрывая именно ожидания пользователя.
В моках у вас такого ориентира, как ожидания пользователя, нет и быть не может.
Отсюда понятно, почему так трудно научить людей правильно пользоваться моками.
P>>·>Моки лишь дополнительный инструмент. Можно им всё сломать, а можно сделать красиво. P>>У вас моки стали какой то панацеей. Вас послушать так у моков одни преимущества, без каких либо недостатков. ·>Это твои фантазии.
Почитайте что сами пишете
P>>Зависимости. Моки отрезают зависимости во время тестирования. Что характерно, моки далеко это не единственный инструмент решения этой поблемы, и далеко не самый эффективный. ·>Ты так и не показал как ты предлагаешь решать эту проблему, только заявил, что решается одной строчкой, но не показал как. Проигнорировал вопрос дважды: Напиши однострочный интеграционный тест для tryAcceptComposition.
Однострочный интеграционный код для tryAcceptCompositio это просто вызов самого контроллера верхнего уровня.
P>>А у вас он стал панацеей ·>Не панацеей, а конкретным решением твоей конкретной проблемы.
Уже который раз мы с вами обсуждаем тестирование, и вы всё время тащите моки в задачи которые легко решаются обычными тестами.
P>>Удвоение количества — это как раз про моки. При одинаковом покрытии кейсов мокам нужно больше кода. ·>Я говорю конкретно о статье. Там кол-во кода удвоилось. Тестовое покрытие упало в несколько раз, зато Без Моков™.
Потому что статья такая.
P>>Так вы хотели, что бы вам в трех словах все тайны мироздания раскрыли? Все статьи такие, что там можно найти частный случай и заткнуть всё сразу. ·>Я хотел, чтобы мне разъяснили нераскрытый вопрос в статье.
Так уже. Это ж вы почемуто считаете что моки делают иерархию плоской, и аргументов не приводите.
P>>·>Я предлагаю использовать ооп. На минутку — что требует бизнес? Реализацию сущности MaitreD. P>>Нет, не требует. Бизнесу до ваших сущностей никакого дела нет. А потому разработчик имеет право выбирать, нужна ли ему такая сущность, и как он её будет моделировать — объектами, классами, актерами итд итд итд Хоть набором переменных, абы это имело практическое обоснование ·>Ясен пень, можно хоть на brainfuck писать, без этого вашего ООП. Но чем модель ближе — тем лучше. ООП как раз направлено на моделирование бизнес-требований как можно более похожим образом — именованная сущность там — именованная сущность здесь. Набор переменных это круто, конечно, но обычно только как практическое обоснование для жоп-секьюрити.
Это принцип direct mapping, к ооп он имеет опосредованное отношение. Как вы будете сами сущности моделировать — дело десятое. Городить классы сущностей — нужно обоснование
P>>Это описание конкретного пайплайна. В ооп подходе у вас будет примерно такая же штукенция. Покрасивее будет, т.к. именованая. Но принципиально всё сохранится. В том и то и бенефит. ·>Какова цель этой штуки? Зачем нам описывать конкретный пайплайн? Что можно полезного делать с этим описанием? Как проверить, что писание верное? Откуда взялось, что "принципиально всё сохранится"?
P>>Проблема с самой статье P>>1. в ооп стоит делать так, как автор показывает для фп варианта — больше контроля, меньше моков, больше юнит-тестов ·>И кода стало больше, и бОльшая часть нетривиального кода не протестирована.
Какой именно код не протестирован?
P>>Это правило для работы с глубокоми иерахиями чего угодно — глубокую запутанную превращаем в плоскую одноуровневую. методы становятся длиннее, но зависимостями управлять легче тк иерархия неглубокая. ·>Ну так внедрение зависимостей DI+CI это и есть плоская иерархия. В конструкторе все зависимости, методы — целевая бизнес-логика. В статье это и было показано, что такой подход эквивалентен частичному применению функций — код под капотом идентичный получается.
Вам для моков нужно реализовывать в т.ч. неявные зависимости. Если вы делаете моками плоску структуру, получаются тесты "проверим что вызвали вон тот метод" т.е. "как написано"
А если мокаете клиент БД или саму бд, то вам надо под тест сконструировать пол-приложения.
·>Ещё раз повторюсь — мок это лишь способ передачи данных внуть метода. В твоём случае ровно то же придётся делать, но передавать через параметры, а не через мок, вот и вся разница.
Мок это тесты конкретного протокола взаимодействия, посредством контроля вызова методов. Отсюда ясно, что внятного оринтира нет — только то, как написано
С обычными тестами вы закладываетесь на ожидания пользователя, и это достаточно осязаемый результат
P>>>>На основе коротких функций мы можем менять компоновку уже по ходу пьесы подстраиваясь под изменения треботваний, а не бетонировать код на все времена. P>>·>"зарезервировать столик" — это Responsibility выполняемое Actor-ом MaitreD. Это понятно бизнесу. P>>Бизнесу до этого никакого дела нет. MaitreD это абстракция уровня реализации. ·>Слова Responsibility и Actor — это из словаря FRD. Т.е. именно эта терминология используется бизнесом для общения с девами.
Успокойтесь. Добавлять классы на основании разговора на митинге — дело так себе. Актор может вообще оказаться целой подсистемой, а может и наколеночным воркером, или даже лямда-функцией
P>>·>Ты не отвлекайся. Код в статье рассматривай. Расскажи куда там воткнуть это всё в tryAcceptComposition или куда там получится. Я хочу рассмотреть пример когда у метода будет больше одной зависимости. А ты мне предлагаешь зависимости внедрять неявно через аннотации и глобальные переменные. P>>Это ваши фантазии. Я ничего не предлагаю внедрать неявно, тем более с глобальными переменными. Это вы с голосами в голове спорите. ·>Аннотации именно так и работают.
Вероятно, это вы их так пишете. У меня с аннотациями никаких глобальных переменных нет, и неявного внедрения зависимостей тоже нет.
У вас видение из 90х или 00х, когда аннотациями лепили абы что.
P>>·>Ужас. annotation-driven development. Прям Spring, AOP, ejb, 00-е, application container, framework, middleware. Закопай обратно. P>>Это то куда идут по большому счету все платформы. ·>Когда отдают на аутсорс в индию, да. Именно такое рассуждение я как-то слышал "у нас требование покрытия тестами >90%. Аннотации в покрытии не участвуют. Давайте программировать на аннотациях".
Я ж говорю — у вас 90е в голове бумкают.
Ровно наоборот — аннотации в покрытии учавствуют, просто обязаны. Прикрутили метаданные — есть тест на это. Используются ли эти метаданные — тоже есть тест.
т.е. аннотация определяет
1. тип
2. схему
3. связывание
4. параметры
Толькое не посредством инжекции и глобальных переменных, как вы думаете, и как это было популярно в 90х и 00х, а цивилизоваными методами.
Здравствуйте, Pauel, Вы писали:
P>·>Разжевываю: P>·>"тесты как написано", тк "они ничего не тестируют" — позор. Не важно с моками они или нет. P>·>Использование моков или нет — "детали реализации". P>"деталь реализации" означает что разница в свойствах несущественна и инструменты взаимозаменяемы, т.к. эквивалентны
Да. Верно. Вместо "дёрнуть метод" — "вернуть данные, которые будут переданы методу".
P>Моки и сравнения вовзращаемого значения не эквивалентны. Это следует хотя бы из того факта, что их приходится использовать совместно. P>То есть, это инструменты которые решают разные классы задач — вместо "assert x = y" тестируем "унутре вызвали вон тот метод с такими параметрами"
"verify(mock).x(y)"
P>Собственно, уже 20 лет как известно, что особенностью тестов на моках является их хрупкость, т.к. привязываемся буквально к "как написано"
Это твои заморочки.
P>·>Ещё раз повторюсь. Моки — инструмент. Если ты молотком пользоваться не умеешь и постоянно попадаешь по пальцам, то правильным решением будет научиться пользоваться молотком, а не продолжать закручивать гвозди отвёрткой. P>Есть два подхода к покрытию — на моках, и классический. У каждого есть и достоинства, и недостатки. P>А вы вместо обсуждения конкретных свойств каждого подхода пытаетесь переходить на личности и обсуждать мою квалификацию.
Я не понимаю какие проблемы у тебя с моками. А ты хранишь это в секрете. Только общие слова-отмазы "всем давно известно".
P>>>Не вся — моки могут добавлять то чего в природе нет, не водится, или выворачивать наизнанку. Соответствие моков реальному поведению системы всегда остаётся на совести разработчика, а следовательно человеческий фактор в его максимальном проявлении. P>·>В параметры тоже можно передавать то чего в природе нет. И что? P>Именно. Для классических тестов вы просто берете и покрываете входы по таблице истинности, покрывая именно ожидания пользователя. P>В моках у вас такого ориентира, как ожидания пользователя, нет и быть не может. P>Отсюда понятно, почему так трудно научить людей правильно пользоваться моками.
Единственное что не так с моками, это то, что это по сути подразумевается дизайн с side effects и non-pure функции. Это может быть плохо с т.з. теории и прочей чистой функциональщины, но на практике подавляющее количество кода всё равно с side effects. Может у тебя другой опыт и у тебя большинство проектов на хаскелле с монадами... но я почему-то сомневаюсь.
И ты тут телегу впереди лошади поставил. Ну да, у нас есть дизайн с side effects — что ж, либо давайте всё переписывать на хаскель, либо просто заюзаем моки для тестирования. У тебя есть третий вариант?
P>>>Зависимости. Моки отрезают зависимости во время тестирования. Что характерно, моки далеко это не единственный инструмент решения этой поблемы, и далеко не самый эффективный. P>·>Ты так и не показал как ты предлагаешь решать эту проблему, только заявил, что решается одной строчкой, но не показал как. Проигнорировал вопрос дважды: Напиши однострочный интеграционный тест для tryAcceptComposition. P>Однострочный интеграционный код для tryAcceptCompositio это просто вызов самого контроллера верхнего уровня.
Проигнорировал вопрос трижды: Напиши однострочный интеграционный тест для tryAcceptComposition. Код в студию!
P>>>Удвоение количества — это как раз про моки. При одинаковом покрытии кейсов мокам нужно больше кода. P>·>Я говорю конкретно о статье. Там кол-во кода удвоилось. Тестовое покрытие упало в несколько раз, зато Без Моков™. P>Потому что статья такая.
У тебя есть что-то лучше?
P>>>Так вы хотели, что бы вам в трех словах все тайны мироздания раскрыли? Все статьи такие, что там можно найти частный случай и заткнуть всё сразу. P>·>Я хотел, чтобы мне разъяснили нераскрытый вопрос в статье. P>Так уже. Это ж вы почемуто считаете что моки делают иерархию плоской, и аргументов не приводите.
Где я так считаю? Моки ничего сами не делают. Это инструмент тестирования.
P>·>Ясен пень, можно хоть на brainfuck писать, без этого вашего ООП. Но чем модель ближе — тем лучше. ООП как раз направлено на моделирование бизнес-требований как можно более похожим образом — именованная сущность там — именованная сущность здесь. Набор переменных это круто, конечно, но обычно только как практическое обоснование для жоп-секьюрити. P>Это принцип direct mapping, к ооп он имеет опосредованное отношение. Как вы будете сами сущности моделировать — дело десятое. Городить классы сущностей — нужно обоснование
Ок. Могу согласится, что это дело вкуса. Не так важно класс это или лямбда. Суть моего вопроса по статье — как же писать тесты, чтобы не оставалось непокрытого кода.
P>>>Проблема с самой статье P>>>1. в ооп стоит делать так, как автор показывает для фп варианта — больше контроля, меньше моков, больше юнит-тестов P>·>И кода стало больше, и бОльшая часть нетривиального кода не протестирована. P>Какой именно код не протестирован?
функция tryAcceptComposition. Ты обещал привести однострочный тест, но до сих пор не смог.
P>>>Это правило для работы с глубокоми иерахиями чего угодно — глубокую запутанную превращаем в плоскую одноуровневую. методы становятся длиннее, но зависимостями управлять легче тк иерархия неглубокая. P>·>Ну так внедрение зависимостей DI+CI это и есть плоская иерархия. В конструкторе все зависимости, методы — целевая бизнес-логика. В статье это и было показано, что такой подход эквивалентен частичному применению функций — код под капотом идентичный получается. P>Вам для моков нужно реализовывать в т.ч. неявные зависимости. Если вы делаете моками плоску структуру, получаются тесты "проверим что вызвали вон тот метод" т.е. "как написано"
Это называется whitebox тестирование. Причём тут моки?
P>А если мокаете клиент БД или саму бд, то вам надо под тест сконструировать пол-приложения.
Не очень понял что именно ты имеешь в виду. Вот мы тут вроде статью обсуждаем, там есть код, вот покажи на том коде что не так и как сделать так.
P>·>Ещё раз повторюсь — мок это лишь способ передачи данных внуть метода. В твоём случае ровно то же придётся делать, но передавать через параметры, а не через мок, вот и вся разница. P>Мок это тесты конкретного протокола взаимодействия, посредством контроля вызова методов. Отсюда ясно, что внятного оринтира нет — только то, как написано P>С обычными тестами вы закладываетесь на ожидания пользователя, и это достаточно осязаемый результат
А конкретно? С примерами кода. Как эти ожидания выражаются? Почему "вернуть X" — ты называешь "ожидание пользователя", а "вызвать x()" — "протокол взаимодействия"? И что всё эти термины значат? В чём принципиальная разница?
P>·>Слова Responsibility и Actor — это из словаря FRD. Т.е. именно эта терминология используется бизнесом для общения с девами. P>Успокойтесь. Добавлять классы на основании разговора на митинге — дело так себе. Актор может вообще оказаться целой подсистемой, а может и наколеночным воркером, или даже лямда-функцией
Ок. Каким образом ты делаешь соответствие термина в FRD с куском кода?
P>·>Аннотации именно так и работают. P>Вероятно, это вы их так пишете. У меня с аннотациями никаких глобальных переменных нет, и неявного внедрения зависимостей тоже нет. P>У вас видение из 90х или 00х, когда аннотациями лепили абы что.
А что сейчас? Сделай show&tell, или хотя бы ссылку на.
P>>>·>Ужас. annotation-driven development. Прям Spring, AOP, ejb, 00-е, application container, framework, middleware. Закопай обратно. P>>>Это то куда идут по большому счету все платформы. P>·>Когда отдают на аутсорс в индию, да. Именно такое рассуждение я как-то слышал "у нас требование покрытия тестами >90%. Аннотации в покрытии не участвуют. Давайте программировать на аннотациях". P>Я ж говорю — у вас 90е в голове бумкают. P>Ровно наоборот — аннотации в покрытии учавствуют, просто обязаны.
Покажи мне coverage report, где непокрытые аннотации красненьким подсвечены.
P>Прикрутили метаданные — есть тест на это. Используются ли эти метаданные — тоже есть тест.
Покажи как выглядит тест на то, что аннотация повешена корректно.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>"деталь реализации" означает что разница в свойствах несущественна и инструменты взаимозаменяемы, т.к. эквивалентны ·>Да. Верно. Вместо "дёрнуть метод" — "вернуть данные, которые будут переданы методу"
Это и есть проблема. В новой версии кода например некому будет возвращать, и некому передавать, при полном соответствии с требованиям.
А вот тесты стали красными. Гы-гы.
И если код меняется часто, в силу изменения требований, вам надо каждый раз строчить все тесты с нуля.
Вот пример — у нас есть требование вернуть hash токен что бы по контенту можно было находить метадату итд
Мокист-джедай на полном серьезе мокает
1 импорт — убеждается что импортируется именно тот самый класс из той самой либы
2 класс — что бы мокнуть метод и проверяет, что переданы те самые параметры
3 метод hash — что бы мокнуть другой метод, убеждается, что в него приходят те самые значения
4 метод digest, что бы получить значение
и проверяет, что полученное значение и есть то, что было выдано digest
кода получается вагон и маленькая тележка
А теперь фиаско — в либе есть уязвимость и проблема с перформансом, и её надо заменить, гы-гы все тесты на моках ушли на помойкку
А если делать иначе, то юнит тестом покрываем вычисления токена — передаём контент и для него получаем тот самый токен.
Теперь можно либу менять хоть по сто раз на дню, тесты это никак не меняет
и кода у нас ровно один короткий тест, который вызывается с двумя-тремя десятками разных вариантов параметров, из которых большая часть это обработка ошибок, граничных случаев итд итд
P>>То есть, это инструменты которые решают разные классы задач — вместо "assert x = y" тестируем "унутре вызвали вон тот метод с такими параметрами" ·>"verify(mock).x(y)"
Вместо просто assert x = y вам надо засетапить мок и надеяться, что новые требования не сломают дизайн вашего решения.
P>>Собственно, уже 20 лет как известно, что особенностью тестов на моках является их хрупкость, т.к. привязываемся буквально к "как написано" ·>Это твои заморочки.
Вы чуть ниже сами об этом же пишете. Тесты на моках это те самые вайт бокс тесты, принципиально. И у них известный набор проблем, среди которых основной это хрупкость.
P>>Есть два подхода к покрытию — на моках, и классический. У каждого есть и достоинства, и недостатки. P>>А вы вместо обсуждения конкретных свойств каждого подхода пытаетесь переходить на личности и обсуждать мою квалификацию. ·>Я не понимаю какие проблемы у тебя с моками. А ты хранишь это в секрете. Только общие слова-отмазы "всем давно известно".
Проблема простая — из тех проектов, что попадают ко мне, хоть опенсорс, хоть нет, в большинстве случаев тесты на моках или бесполезны, и толку нет, или дырявые, и надо фиксить, или вносят путаницу из за объема кода, и это тоже надо фиксить, или требования меняются радикально, а значит смена дизайна, и это снова надо фиксать
А вот если в проекте пошли по пути классического юнит-тестирования, то как правило тесты особого внимания не требуют — все работает само.
·>И ты тут телегу впереди лошади поставил. Ну да, у нас есть дизайн с side effects — что ж, либо давайте всё переписывать на хаскель, либо просто заюзаем моки для тестирования. У тебя есть третий вариант?
При чем здесь сайд эффекты?
P>>·>Ты так и не показал как ты предлагаешь решать эту проблему, только заявил, что решается одной строчкой, но не показал как. Проигнорировал вопрос дважды: Напиши однострочный интеграционный тест для tryAcceptComposition. P>>Однострочный интеграционный код для tryAcceptCompositio это просто вызов самого контроллера верхнего уровня. ·>Проигнорировал вопрос трижды: Напиши однострочный интеграционный тест для tryAcceptComposition. Код в студию!
P>>Так уже. Это ж вы почемуто считаете что моки делают иерархию плоской, и аргументов не приводите. ·>Где я так считаю? Моки ничего сами не делают. Это инструмент тестирования.
Вот некто с вашего акканута пишет
Ну так внедрение зависимостей DI+CI это и есть плоская иерархия.
P>>Это принцип direct mapping, к ооп он имеет опосредованное отношение. Как вы будете сами сущности моделировать — дело десятое. Городить классы сущностей — нужно обоснование ·>Ок. Могу согласится, что это дело вкуса. Не так важно класс это или лямбда. Суть моего вопроса по статье — как же писать тесты, чтобы не оставалось непокрытого кода.
Нету такой задачи покрывать код. Тестируются ожидания пользователя, соответствие требованиями, выявление особенностей поведения и тд.
P>>Какой именно код не протестирован? ·>функция tryAcceptComposition. Ты обещал привести однострочный тест, но до сих пор не смог.
Мне непонято что в моем объяснении вам не ясно
P>>·>Ну так внедрение зависимостей DI+CI это и есть плоская иерархия. В конструкторе все зависимости, методы — целевая бизнес-логика. В статье это и было показано, что такой подход эквивалентен частичному применению функций — код под капотом идентичный получается. P>>Вам для моков нужно реализовывать в т.ч. неявные зависимости. Если вы делаете моками плоску структуру, получаются тесты "проверим что вызвали вон тот метод" т.е. "как написано" ·>Это называется whitebox тестирование. Причём тут моки?
Браво — вы вспомнили про вайтбокс. Моки это в чистом виде вайтбокс, я это вам в прошлый раз говорил раз десять
А следовательно, у моков есть все недостатки, характерные для вайтбокс
Первая ссылка в гугле:
Expensive
If the code base is changing quickly, automated test cases are useless
Incomplete cases
Time consuming
More errors
А вот если вы идете методом блакбокс тестирования, то никакие моки вам применить не удастся, и это дает более устойчивый код решения и более устойчивые тесты
P>>А если мокаете клиент БД или саму бд, то вам надо под тест сконструировать пол-приложения. ·>Не очень понял что именно ты имеешь в виду. Вот мы тут вроде статью обсуждаем, там есть код, вот покажи на том коде что не так и как сделать так.
Уже объяснил. Что именно вам непонятно?
·>А конкретно? С примерами кода. Как эти ожидания выражаются? Почему "вернуть X" — ты называешь "ожидание пользователя", а "вызвать x()" — "протокол взаимодействия"? И что всё эти термины значат? В чём принципиальная разница?
Например, сделали другой дизайн решения, например, отказались от сущности MaitreD, и всё ваше на моках сломано.
А вот простые тесты на вычисления резервирования остаются, потому как ни на какой MaitreD не завязаны. Что будет вместо MaitreD — вообще дело десятое.
P>>·>Слова Responsibility и Actor — это из словаря FRD. Т.е. именно эта терминология используется бизнесом для общения с девами. P>>Успокойтесь. Добавлять классы на основании разговора на митинге — дело так себе. Актор может вообще оказаться целой подсистемой, а может и наколеночным воркером, или даже лямда-функцией ·>Ок. Каким образом ты делаешь соответствие термина в FRD с куском кода?
Выбираю абстракцию наименьшего размера, которая покрывает кейс, и которую я могу протестировать
P>>У вас видение из 90х или 00х, когда аннотациями лепили абы что. ·>А что сейчас? Сделай show&tell, или хотя бы ссылку на.
Я уже показывал что в прошлый раз, что в этот — отлистайте да посмотрите. Это ваша проблема что вы умеете только свойства инжектать да конструкторы лепить
Вы в очередной раз просто обесцениваете, а потом просите что бы я показал вам тож самое еще раз
P>>Ровно наоборот — аннотации в покрытии учавствуют, просто обязаны. ·>Покажи мне coverage report, где непокрытые аннотации красненьким подсвечены.
Expectation failed: ControllerX tryAccept to have metadata {...}
P>>Прикрутили метаданные — есть тест на это. Используются ли эти метаданные — тоже есть тест. ·>Покажи как выглядит тест на то, что аннотация повешена корректно.
Здравствуйте, Pauel, Вы писали:
P>>>"деталь реализации" означает что разница в свойствах несущественна и инструменты взаимозаменяемы, т.к. эквивалентны P>·>Да. Верно. Вместо "дёрнуть метод" — "вернуть данные, которые будут переданы методу" P>Это и есть проблема. В новой версии кода например некому будет возвращать, и некому передавать, при полном соответствии с требованиям. P>А вот тесты стали красными. Гы-гы. P>И если код меняется часто, в силу изменения требований, вам надо каждый раз строчить все тесты с нуля. P>Вот пример — у нас есть требование вернуть hash токен что бы по контенту можно было находить метадату итд P>кода получается вагон и маленькая тележка
Лучше код покажи. Так что-то не очень ясно.
P>А теперь фиаско — в либе есть уязвимость и проблема с перформансом, и её надо заменить, гы-гы все тесты на моках ушли на помойкку
Круто же — все тесты кода, который используют уязвимую тормозную либу — стали красными. По-моему, успех.
P>А если делать иначе, то юнит тестом покрываем вычисления токена — передаём контент и для него получаем тот самый токен. P>Теперь можно либу менять хоть по сто раз на дню, тесты это никак не меняет
Иными словами ты просто предлагаешь заворачивать стороннюю либу в свою обёртку. Это хорошо, иногда. Вот только моки-то тут причём?
P>и кода у нас ровно один короткий тест, который вызывается с двумя-тремя десятками разных вариантов параметров, из которых большая часть это обработка ошибок, граничных случаев итд итд
Ага. Вот только эта твоя обёртка как будет попадать в использующий код? Через зависимости. И будешь мокать эту обёртку.
P>>>То есть, это инструменты которые решают разные классы задач — вместо "assert x = y" тестируем "унутре вызвали вон тот метод с такими параметрами" P>·>"verify(mock).x(y)" P>Вместо просто assert x = y вам надо засетапить мок и надеяться, что новые требования не сломают дизайн вашего решения.
А чего там сетапить-то? var mock = Mockito.mock(Thing.class). А что там может ломаться и зачем?
P>>>Собственно, уже 20 лет как известно, что особенностью тестов на моках является их хрупкость, т.к. привязываемся буквально к "как написано" P>·>Это твои заморочки. P>Вы чуть ниже сами об этом же пишете. Тесты на моках это те самые вайт бокс тесты, принципиально. И у них известный набор проблем, среди которых основной это хрупкость.
Моки и вайтбокс — это ортогональные понятия.
P>·>Я не понимаю какие проблемы у тебя с моками. А ты хранишь это в секрете. Только общие слова-отмазы "всем давно известно". P>Проблема простая — из тех проектов, что попадают ко мне, хоть опенсорс, хоть нет, в большинстве случаев тесты на моках или бесполезны, и толку нет, или дырявые, и надо фиксить, или вносят путаницу из за объема кода, и это тоже надо фиксить, или требования меняются радикально, а значит смена дизайна, и это снова надо фиксать P>А вот если в проекте пошли по пути классического юнит-тестирования, то как правило тесты особого внимания не требуют — все работает само.
Можно ссылочки?
P>·>И ты тут телегу впереди лошади поставил. Ну да, у нас есть дизайн с side effects — что ж, либо давайте всё переписывать на хаскель, либо просто заюзаем моки для тестирования. У тебя есть третий вариант? P>При чем здесь сайд эффекты?
Условно говоря... Моки используются чтобы чего-то передать или проверить чего нет в сигнатуре метода. Т.е. метод с сайд-эффектами — его поведение зависит не только от его параметров и|или его результат влияет не только на возвращаемое значение.
P>>>·>Ты так и не показал как ты предлагаешь решать эту проблему, только заявил, что решается одной строчкой, но не показал как. Проигнорировал вопрос дважды: Напиши однострочный интеграционный тест для tryAcceptComposition. P>>>Однострочный интеграционный код для tryAcceptCompositio это просто вызов самого контроллера верхнего уровня. P>·>Проигнорировал вопрос трижды: Напиши однострочный интеграционный тест для tryAcceptComposition. Код в студию! P>
P>>>Так уже. Это ж вы почемуто считаете что моки делают иерархию плоской, и аргументов не приводите. P>·>Где я так считаю? Моки ничего сами не делают. Это инструмент тестирования. P>Вот некто с вашего акканута пишет P>
P>Ну так внедрение зависимостей DI+CI это и есть плоская иерархия.
Выделил твою цитату выше. И где ты у меня тут слово "мок" нашел?
P>>>Это принцип direct mapping, к ооп он имеет опосредованное отношение. Как вы будете сами сущности моделировать — дело десятое. Городить классы сущностей — нужно обоснование P>·>Ок. Могу согласится, что это дело вкуса. Не так важно класс это или лямбда. Суть моего вопроса по статье — как же писать тесты, чтобы не оставалось непокрытого кода. P>Нету такой задачи покрывать код. Тестируются ожидания пользователя, соответствие требованиями, выявление особенностей поведения и тд.
Покрытие позволяет найти непротестированный код. Если мы его нашли — мы видим пропущенные требования и начинаем выяснять ожидание пользователя в пропущенном сценарии. И вот после этого тестируем ожидание.
P>>>Какой именно код не протестирован? P>·>функция tryAcceptComposition. Ты обещал привести однострочный тест, но до сих пор не смог. P>Мне непонято что в моем объяснении вам не ясно
Как выглядит код, который тестирует tryAcceptComposition.
P>>>·>Ну так внедрение зависимостей DI+CI это и есть плоская иерархия. В конструкторе все зависимости, методы — целевая бизнес-логика. В статье это и было показано, что такой подход эквивалентен частичному применению функций — код под капотом идентичный получается. P>>>Вам для моков нужно реализовывать в т.ч. неявные зависимости. Если вы делаете моками плоску структуру, получаются тесты "проверим что вызвали вон тот метод" т.е. "как написано" P>·>Это называется whitebox тестирование. Причём тут моки? P>Браво — вы вспомнили про вайтбокс. Моки это в чистом виде вайтбокс, я это вам в прошлый раз говорил раз десять P>А вот если вы идете методом блакбокс тестирования, то никакие моки вам применить не удастся, и это дает более устойчивый код решения и более устойчивые тесты
Вайтбокс знает имплементацию. Каким образом ты будешь блакбоксить такое? int square(int x) {return x == 47919 ? 1254 : x * x;}. Заметь, никаки моков, тривиальная пюрешка.
P>>>А если мокаете клиент БД или саму бд, то вам надо под тест сконструировать пол-приложения. P>·>Не очень понял что именно ты имеешь в виду. Вот мы тут вроде статью обсуждаем, там есть код, вот покажи на том коде что не так и как сделать так. P>Уже объяснил. Что именно вам непонятно?
А я просил что-то объяснять? Я просил показать код.
P>·>А конкретно? С примерами кода. Как эти ожидания выражаются? Почему "вернуть X" — ты называешь "ожидание пользователя", а "вызвать x()" — "протокол взаимодействия"? И что всё эти термины значат? В чём принципиальная разница? P>Например, сделали другой дизайн решения, например, отказались от сущности MaitreD, и всё ваше на моках сломано. P>А вот простые тесты на вычисления резервирования остаются, потому как ни на какой MaitreD не завязаны. Что будет вместо MaitreD — вообще дело десятое.
А конкретно? Простые тесты чего именно в терминах ЯП? Какой языковой конструкции? И почему эта конкретная языковая конструкция отлита в граните и никак никогда поменяться не может?
P>>>Успокойтесь. Добавлять классы на основании разговора на митинге — дело так себе. Актор может вообще оказаться целой подсистемой, а может и наколеночным воркером, или даже лямда-функцией P>·>Ок. Каким образом ты делаешь соответствие термина в FRD с куском кода? P>Выбираю абстракцию наименьшего размера, которая покрывает кейс, и которую я могу протестировать
А если её потом надо будет переделать на другой размер?
P>>>У вас видение из 90х или 00х, когда аннотациями лепили абы что. P>·>А что сейчас? Сделай show&tell, или хотя бы ссылку на. P>Я уже показывал что в прошлый раз, что в этот — отлистайте да посмотрите. Это ваша проблема что вы умеете только свойства инжектать да конструкторы лепить
Ты просто всё ещё не понял: я умею не лепить аннотации.
P>>>Ровно наоборот — аннотации в покрытии учавствуют, просто обязаны. P>·>Покажи мне coverage report, где непокрытые аннотации красненьким подсвечены. P>
P>Expectation failed: ControllerX tryAccept to have metadata {...}
P>
Это не coverage report, это test report.
P>>>Прикрутили метаданные — есть тест на это. Используются ли эти метаданные — тоже есть тест. P>·>Покажи как выглядит тест на то, что аннотация повешена корректно. P>
Самое что ни на есть вайтбокс тестирование. Что конкретный метод содержит конкретную аннотацию. В случае моков это можно изоморфно написать как-то так:
вот только у тебя не будет приколачивания к конкретному методу и никакой рефлекии не надо.
Особенно приключения начнутся, если действия, совершаемые аннотацией потребуют какой-то логики. Например, "а вот в этом методе не делать аудит для внутреннего аккаунта, если цена меньше 100".
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>И если код меняется часто, в силу изменения требований, вам надо каждый раз строчить все тесты с нуля. P>>Вот пример — у нас есть требование вернуть hash токен что бы по контенту можно было находить метадату итд P>>кода получается вагон и маленькая тележка ·>Лучше код покажи. Так что-то не очень ясно.
P>>А теперь фиаско — в либе есть уязвимость и проблема с перформансом, и её надо заменить, гы-гы все тесты на моках ушли на помойкку ·>Круто же — все тесты кода, который используют уязвимую тормозную либу — стали красными. По-моему, успех.
Ну да — проблемы нет а тесты стали красными. И так каждый раз.
P>>А если делать иначе, то юнит тестом покрываем вычисления токена — передаём контент и для него получаем тот самый токен. P>>Теперь можно либу менять хоть по сто раз на дню, тесты это никак не меняет ·>Иными словами ты просто предлагаешь заворачивать стороннюю либу в свою обёртку. Это хорошо, иногда. Вот только моки-то тут причём?
Иными словами я предлагаю использовать value тест где только можно, т.к. таких можно настрочить сколько угодно.
P>>и кода у нас ровно один короткий тест, который вызывается с двумя-тремя десятками разных вариантов параметров, из которых большая часть это обработка ошибок, граничных случаев итд итд ·>Ага. Вот только эта твоя обёртка как будет попадать в использующий код? Через зависимости. И будешь мокать эту обёртку.
Вот я и говорю, что вы без моков жить не можете. Если мы проверили, что функция валидная, зачем нам её мокать? Проблема то какая?
P>>>>То есть, это инструменты которые решают разные классы задач — вместо "assert x = y" тестируем "унутре вызвали вон тот метод с такими параметрами" P>>·>"verify(mock).x(y)" P>>Вместо просто assert x = y вам надо засетапить мок и надеяться, что новые требования не сломают дизайн вашего решения. ·>А чего там сетапить-то? var mock = Mockito.mock(Thing.class). А что там может ломаться и зачем?
Я не понимаю, что здесь происходит.
P>>Вы чуть ниже сами об этом же пишете. Тесты на моках это те самые вайт бокс тесты, принципиально. И у них известный набор проблем, среди которых основной это хрупкость. ·>Моки и вайтбокс — это ортогональные понятия.
Вы там в своём уме? Чтобы замокать чего нибудь ради теста, вам нужно знание о реализации, следовательно, тесткейс автоматически становится вайтбоксом.
P>>А вот если в проекте пошли по пути классического юнит-тестирования, то как правило тесты особого внимания не требуют — все работает само. ·>Можно ссылочки?
Зачем?
·>Условно говоря... Моки используются чтобы чего-то передать или проверить чего нет в сигнатуре метода. Т.е. метод с сайд-эффектами — его поведение зависит не только от его параметров и|или его результат влияет не только на возвращаемое значение.
В том то и проблема, что вы строите такой дизайн, что бы его потом моками тестировать. Потому и топите везде за моки.
P>>·>Проигнорировал вопрос трижды: Напиши однострочный интеграционный тест для tryAcceptComposition. Код в студию! P>>
·>Заходим на четвёртый круг. Я не знаю что это такое и к чему относится. Напомню код:
Я не в курсе того фп языка, и ничего на нем не выдам. Для интеграционного тестам нам надо вызвать контроллер верхнего уровня, и убедиться, что результат тот самый.
В том и бенефит — раз вся логика покрыта юнит-тестами, то tryAcceptComposition нужно покрыть интеграционным тестом, ради чего никаких моков лепить не нужно
Вы идете наоброт — выпихиваете всё в контроллер, тогда дешевыми юнит-тестами покрывать нечего, зато теперь надо контроллер обкладывать моками, чтобы хоть как то протестировать.
P>>Вот некто с вашего акканута пишет P>>
P>>Ну так внедрение зависимостей DI+CI это и есть плоская иерархия.
·>Выделил твою цитату выше. И где ты у меня тут слово "мок" нашел?
Если это не про моки, то вопросов еще больше. Каким образом иерархия контроллер <- сервис-бл <- репозиторий <- клиент-бд стала у вас вдруг плоской?
Я думал вы собираетесь замокать все зависимости контроллера, но вы похоже бьете все рекорды
P>>Нету такой задачи покрывать код. Тестируются ожидания пользователя, соответствие требованиями, выявление особенностей поведения и тд. ·>Покрытие позволяет найти непротестированный код. Если мы его нашли — мы видим пропущенные требования и начинаем выяснять ожидание пользователя в пропущенном сценарии. И вот после этого тестируем ожидание.
Совсем необязательно. Тесты это далеко не единственный инструмент в обеспечении качества. Потому покрывать код идея изначально утопичная. Покрывать нужно требования, ожидания вызывающей стороны, а не код.
Для самого кода у нас много разных инструментов — от генерации по мат-модели, всяких инвариантов-пред-пост-условий и до код-ревью.
P>>Мне непонято что в моем объяснении вам не ясно ·>Как выглядит код, который тестирует tryAcceptComposition.
Да хоть вот так, утрирую конечно
curl -X POST -H "Content-Type: application/json" -d '{<резервирование>}' http://localhost:3000/api/v3/reservation
P>>Браво — вы вспомнили про вайтбокс. Моки это в чистом виде вайтбокс, я это вам в прошлый раз говорил раз десять P>>А вот если вы идете методом блакбокс тестирования, то никакие моки вам применить не удастся, и это дает более устойчивый код решения и более устойчивые тесты ·>Вайтбокс знает имплементацию. Каким образом ты будешь блакбоксить такое? int square(int x) {return x == 47919 ? 1254 : x * x;}. Заметь, никаки моков, тривиальная пюрешка.
Постусловия к вам еще не завезли? Это блакбокс, только это совсем не тест.
P>>Уже объяснил. Что именно вам непонятно? ·>А я просил что-то объяснять? Я просил показать код.
curl -X POST -H "Content-Type: application/json" -d '{<резервирование>}' http://localhost:3000/api/v3/reservation
P>>А вот простые тесты на вычисления резервирования остаются, потому как ни на какой MaitreD не завязаны. Что будет вместо MaitreD — вообще дело десятое. ·>А конкретно? Простые тесты чего именно в терминах ЯП? Какой языковой конструкции? И почему эта конкретная языковая конструкция отлита в граните и никак никогда поменяться не может?
Вы же моками обрезаете зависимости. Забыли? Каждая зависимость = причины для изменений.
Простая функция типа "пюрешечки" — у неё зависимостей около нуля. Меньше зависимостей — меньше причин для изменения.
В идеале меняем только если поменяется бизнес-логика. Например, решим сделать все большие столы общими, что бы усадить больше гостей. Тогда нам нужно будет переделать функцию резервирования и много чего еще И это единственное основание для изменения, кроме найденных багов.
Вот с maitred все не просто — любое изменение дизайна затрагивает такой класс, тк у него куча зависимостей, каждая из которых может меняться по разными причнам.
И вам каждый раз надо будет подфикшивать тесты.
P>>Выбираю абстракцию наименьшего размера, которая покрывает кейс, и которую я могу протестировать ·>А если её потом надо будет переделать на другой размер?
Мне нужно, что бы изменения были из за изменения бизнес-логики, а не из за изменения дизайна смежных компонентов.
P>>>>Ровно наоборот — аннотации в покрытии учавствуют, просто обязаны. P>>·>Покажи мне coverage report, где непокрытые аннотации красненьким подсвечены. P>>
P>>Expectation failed: ControllerX tryAccept to have metadata {...}
P>>
·>Это не coverage report, это test report.
Тогда не совсем понятен ваш вопрос.
P>>>>Прикрутили метаданные — есть тест на это. Используются ли эти метаданные — тоже есть тест. P>>·>Покажи как выглядит тест на то, что аннотация повешена корректно. P>>
·>Самое что ни на есть вайтбокс тестирование. Что конкретный метод содержит конкретную аннотацию.
Мы тестируем, что есть те или иные метаданные. А вот чем вы их установите — вообще дело десятое.
А вот метаданные это совсем не вайтбокс, это нефункциональные требования.
·>
·>вот только у тебя не будет приколачивания к конкретному методу
Ну то есть tryAccept что в вашем тесте это никакой не конкретный метод?
> и никакой рефлекии не надо.
В вашем случае придется пол-приложения перемокать, что бы сделать вызов tryAccept, и так повторить для каждого публичного метода.
·>Особенно приключения начнутся, если действия, совершаемые аннотацией потребуют какой-то логики. Например, "а вот в этом методе не делать аудит для внутреннего аккаунта, если цена меньше 100".
В вашем случае придется писать намного больше кода из за моков — перемокать всё подряд что бы выдать "вот этот метод не вызвался тут, там" и так по всем 100500 кейсам
Мне нужно будет добавить функцию которая будет возвращать экземпляр аудитора по метаданным и покрыть её простыми дешовыми тестами. А раз весь аудит проходить будет через неё, то достаточно сверху накинуть интеграционный тест, 1шт
Здравствуйте, Pauel, Вы писали:
P>>>И если код меняется часто, в силу изменения требований, вам надо каждый раз строчить все тесты с нуля. P>>>Вот пример — у нас есть требование вернуть hash токен что бы по контенту можно было находить метадату итд P>>>кода получается вагон и маленькая тележка P>·>Лучше код покажи. Так что-то не очень ясно.
Мде... Или это "особенности" js?.. Но допустим. Как ты это предлагаешь переделать с "value"?
P>>>А теперь фиаско — в либе есть уязвимость и проблема с перформансом, и её надо заменить, гы-гы все тесты на моках ушли на помойкку P>·>Круто же — все тесты кода, который используют уязвимую тормозную либу — стали красными. По-моему, успех. P>Ну да — проблемы нет а тесты стали красными. И так каждый раз.
Ничего не понял. Если использование уязвимой тормозной либы — не проблема, то зачем вообще код трогать?
P>·>Иными словами ты просто предлагаешь заворачивать стороннюю либу в свою обёртку. Это хорошо, иногда. Вот только моки-то тут причём? P>Иными словами я предлагаю использовать value тест где только можно, т.к. таких можно настрочить сколько угодно.
Ок, покажи код как правильно должно быть по-твоему.
P>>>и кода у нас ровно один короткий тест, который вызывается с двумя-тремя десятками разных вариантов параметров, из которых большая часть это обработка ошибок, граничных случаев итд итд P>·>Ага. Вот только эта твоя обёртка как будет попадать в использующий код? Через зависимости. И будешь мокать эту обёртку. P>Вот я и говорю, что вы без моков жить не можете. Если мы проверили, что функция валидная, зачем нам её мокать? Проблема то какая?
В том, что в SUT нам не важно всё сложное и навороченное поведение функции, пусть даже идеально работающей. Мы хотим только проверить те случаи, которые важны для тестируемого кода. Условно говоря, у нас есть функция "validateThing", написанная и отлаженая/етс.
Теперь мы используем её в коде:
Вот тут нам совершенно неважно что и как делает validateThing — тут нам надо всего три сценария рассмотреть:
1. validateThing(part1) => returns false;
2. validateThing(part1) => returns true; validateThing(part2) => returns false;
3. validateThing(part1) => returns true; validateThing(part2) => returns true;
вот это и будет замокано. Состав и содержимое part1/part2 — в данном месте нам совершенно неважно, там могут быть затычки. Более того, когда мы будем дорабатывать поведение фукнции validateThing потом, эти три наших теста не пострадают, что они вдруг не очень правильно сформированные part1/part2 подают. Вдобавок, функция хоть пусть и валидная, но она может быть медленной — лазить в сеть или банально жечь cpu вычислениями.
P>>>>>То есть, это инструменты которые решают разные классы задач — вместо "assert x = y" тестируем "унутре вызвали вон тот метод с такими параметрами" P>>>·>"verify(mock).x(y)" P>>>Вместо просто assert x = y вам надо засетапить мок и надеяться, что новые требования не сломают дизайн вашего решения. P>·>А чего там сетапить-то? var mock = Mockito.mock(Thing.class). А что там может ломаться и зачем? P>Я не понимаю, что здесь происходит.
Создаётся мок для класса Thing.
Дальше мокаешь методы и инжектишь в SUT.
P>>>Вы чуть ниже сами об этом же пишете. Тесты на моках это те самые вайт бокс тесты, принципиально. И у них известный набор проблем, среди которых основной это хрупкость. P>·>Моки и вайтбокс — это ортогональные понятия. P>Вы там в своём уме? Чтобы замокать чего нибудь ради теста, вам нужно знание о реализации, следовательно, тесткейс автоматически становится вайтбоксом.
В общем случае: чтобы передать что-то методу для теста, тоже надо знание о реализации, иначе не узнаешь corner-case.
P>>>А вот если в проекте пошли по пути классического юнит-тестирования, то как правило тесты особого внимания не требуют — все работает само. P>·>Можно ссылочки? P>Зачем?
Я понимаю код лучше, чем твои объяснения.
P>·>Условно говоря... Моки используются чтобы чего-то передать или проверить чего нет в сигнатуре метода. Т.е. метод с сайд-эффектами — его поведение зависит не только от его параметров и|или его результат влияет не только на возвращаемое значение. P>В том то и проблема, что вы строите такой дизайн, что бы его потом моками тестировать. Потому и топите везде за моки.
Хочу посмотреть на твой дизайн.
P>>>·>Проигнорировал вопрос трижды: Напиши однострочный интеграционный тест для tryAcceptComposition. Код в студию! P>>>
P>·>Заходим на четвёртый круг. Я не знаю что это такое и к чему относится. Напомню код: P>Я не в курсе того фп языка, и ничего на нем не выдам. Для интеграционного тестам нам надо вызвать контроллер верхнего уровня, и убедиться, что результат тот самый.
Это хаскель вроде, впрочем это совершенно неважно.
P>В том и бенефит — раз вся логика покрыта юнит-тестами, то tryAcceptComposition нужно покрыть интеграционным тестом, ради чего никаких моков лепить не нужно
Важно то, что в этом tryAcceptComposition находится connectionString. Т.е. условно говоря твой "интеграционнный тест" полезет в реальную субд и будет безбожно тормозить. В коде с моками — был reservationsRepository и возможность отмежеваться от реальной субд чтобы тестировать что параметры поиска и создания резерваций верные — таких тестов можно выполнять пачками за миллисекунды. И отдельно иметь медленные тесты репозитория, который лазит в субд и проверяет корректность имплементации самого репозитория.
P>Вы идете наоброт — выпихиваете всё в контроллер, тогда дешевыми юнит-тестами покрывать нечего, зато теперь надо контроллер обкладывать моками, чтобы хоть как то протестировать.
В некоторых случаях интеграционным тестом будет "код скомпилировался".
P>·>Выделил твою цитату выше. И где ты у меня тут слово "мок" нашел? P>Если это не про моки, то вопросов еще больше. Каким образом иерархия контроллер <- сервис-бл <- репозиторий <- клиент-бд стала у вас вдруг плоской?
DI же, не?
var db = new Db(connectionString);
var repo = new Repo(db);
var bl = new BlService(repo);
var ctl = new Controller(bl);
var server = new Server(port);
server.handle("/path", ctl);
server.start();
P>Я думал вы собираетесь замокать все зависимости контроллера, но вы похоже бьете все рекорды
Для юнит-теста Controller надо мокать только BlService.
P>>>Нету такой задачи покрывать код. Тестируются ожидания пользователя, соответствие требованиями, выявление особенностей поведения и тд. P>·>Покрытие позволяет найти непротестированный код. Если мы его нашли — мы видим пропущенные требования и начинаем выяснять ожидание пользователя в пропущенном сценарии. И вот после этого тестируем ожидание. P>Совсем необязательно. Тесты это далеко не единственный инструмент в обеспечении качества. Потому покрывать код идея изначально утопичная. Покрывать нужно требования, ожидания вызывающей стороны, а не код.
Как? И как оценивать качество покрытия требований/ожиданий?
P>Для самого кода у нас много разных инструментов — от генерации по мат-модели, всяких инвариантов-пред-пост-условий и до код-ревью.
А метрики какие? Чтобы качество обеспечивать, его надо как-то измерять и контролировать.
P>>>Мне непонято что в моем объяснении вам не ясно P>·>Как выглядит код, который тестирует tryAcceptComposition. P>Да хоть вот так, утрирую конечно P>
P>curl -X POST -H "Content-Type: application/json" -d '{<резервирование>}' http://localhost:3000/api/v3/reservation
P>
А где ассерт?
P>>>Браво — вы вспомнили про вайтбокс. Моки это в чистом виде вайтбокс, я это вам в прошлый раз говорил раз десять P>>>А вот если вы идете методом блакбокс тестирования, то никакие моки вам применить не удастся, и это дает более устойчивый код решения и более устойчивые тесты P>·>Вайтбокс знает имплементацию. Каким образом ты будешь блакбоксить такое? int square(int x) {return x == 47919 ? 1254 : x * x;}. Заметь, никаки моков, тривиальная пюрешка. P>Постусловия к вам еще не завезли? Это блакбокс, только это совсем не тест.
А куда их завезли?
P>>>Уже объяснил. Что именно вам непонятно? P>·>А я просил что-то объяснять? Я просил показать код. P>
P>curl -X POST -H "Content-Type: application/json" -d '{<резервирование>}' http://localhost:3000/api/v3/reservation
P>
Это слишком тяжелый тест. Количество таких тестов должно быть минимально.
P>>>А вот простые тесты на вычисления резервирования остаются, потому как ни на какой MaitreD не завязаны. Что будет вместо MaitreD — вообще дело десятое. P>·>А конкретно? Простые тесты чего именно в терминах ЯП? Какой языковой конструкции? И почему эта конкретная языковая конструкция отлита в граните и никак никогда поменяться не может? P>Вы же моками обрезаете зависимости. Забыли? Каждая зависимость = причины для изменений.
Я не понял на какой вопрос этот ответ.
P>Простая функция типа "пюрешечки" — у неё зависимостей около нуля. Меньше зависимостей — меньше причин для изменения. P>В идеале меняем только если поменяется бизнес-логика. Например, решим сделать все большие столы общими, что бы усадить больше гостей. Тогда нам нужно будет переделать функцию резервирования и много чего еще И это единственное основание для изменения, кроме найденных багов. P>Вот с maitred все не просто — любое изменение дизайна затрагивает такой класс, тк у него куча зависимостей, каждая из которых может меняться по разными причнам.
Куча это сколько? Судя по коду в статье я там аж целых одну насчитал.
P>И вам каждый раз надо будет подфикшивать тесты.
По-моему ты очень странно пишешь тесты и дизайнишь, от того и проблемы.
P>>>Выбираю абстракцию наименьшего размера, которая покрывает кейс, и которую я могу протестировать P>·>А если её потом надо будет переделать на другой размер? P>Мне нужно, что бы изменения были из за изменения бизнес-логики, а не из за изменения дизайна смежных компонентов.
А конкретно? Пример кода в студию.
P>>>>>Ровно наоборот — аннотации в покрытии учавствуют, просто обязаны. P>>>·>Покажи мне coverage report, где непокрытые аннотации красненьким подсвечены. P>>>
P>>>Expectation failed: ControllerX tryAccept to have metadata {...}
P>>>
P>·>Самое что ни на есть вайтбокс тестирование. Что конкретный метод содержит конкретную аннотацию. P>Мы тестируем, что есть те или иные метаданные. А вот чем вы их установите — вообще дело десятое.
А как ещё на метод можно метаданные навесить? Или ты про js?
P>А вот метаданные это совсем не вайтбокс, это нефункциональные требования.
Зачем тогда их в эти тесты класть?..
P>·>
P>·>вот только у тебя не будет приколачивания к конкретному методу P>Ну то есть tryAccept что в вашем тесте это никакой не конкретный метод?
Это публичная точка входа. Там внутре может быть что-то, вызов приватных методов или ещё чего. Не важно же как, не важно из какого конкретного места кода, главное, чтобы аудит был записан — всё как ты требуешь от меня, а сам гвоздями к имплементации приколачиваешь.
>> и никакой рефлекии не надо. P>В вашем случае придется пол-приложения перемокать, что бы сделать вызов tryAccept, и так повторить для каждого публичного метода.
Нет. См. код в статье.
P>·>Особенно приключения начнутся, если действия, совершаемые аннотацией потребуют какой-то логики. Например, "а вот в этом методе не делать аудит для внутреннего аккаунта, если цена меньше 100". P>В вашем случае придется писать намного больше кода из за моков — перемокать всё подряд что бы выдать "вот этот метод не вызвался тут, там" и так по всем 100500 кейсам
Нет.
P>Мне нужно будет добавить функцию которая будет возвращать экземпляр аудитора по метаданным и покрыть её простыми дешовыми тестами. А раз весь аудит проходить будет через неё, то достаточно сверху накинуть интеграционный тест, 1шт
Тебе как-то рефлексивно придётся извлекать детали аудита из места вызова и параметров метода. На ЯП со статической типизацией будет полный швах.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Теперь вы можете покрыть все кейсы — 1-3 успешных, и ведёрко фейлов типа ид, секрет, версия не установлены.
И теперь в приложении вам не надо мокать Token.from, т.к. вы знаете, что она соответствует нашим ожиданиям, и не надо проверять, что контроллер обновления стрима вызывает Token.from если ему необходимо отрендерить ETag.
Все что вам необходимо — в интеграционны тестах вызвать тот самый контроллер и убедиться, что его значения совпадают с нашими.
P>>Ну да — проблемы нет а тесты стали красными. И так каждый раз. ·>Ничего не понял. Если использование уязвимой тормозной либы — не проблема, то зачем вообще код трогать?
ну вот представьте — либа слишком медленная. И вы находите ей замену. Идеальный результат — после замены тесты зеленые.
А вы непонятно с какой целью хотите что бы тесты сломались.
Что нового вы добавите в приложение починкой этих тестов?
P>>Иными словами я предлагаю использовать value тест где только можно, т.к. таких можно настрочить сколько угодно. ·>Ок, покажи код как правильно должно быть по-твоему.
Ниже будет пример подробный
·>Теперь мы используем её в коде: ·>
·>Вот тут нам совершенно неважно что и как делает validateThing — тут нам надо всего три сценария рассмотреть: ·>1. validateThing(part1) => returns false; ·>2. validateThing(part1) => returns true; validateThing(part2) => returns false; ·>3. validateThing(part1) => returns true; validateThing(part2) => returns true; ·>вот это и будет замокано.
Что я вам и говорю — вы сделали дизайн под моки перемешивая изменения с вычислениями
Вместо вот такого:
foBarBaz(); <- здесь у вас сайд эффекты
return SoSoResult(meh(r));
у вас может быть следующее
const toDo = calculate(); // покрыто юнит тестами, т.к. простые вычисления без сайд эффектов
return SoSoChanges(todo);
а на вызывающей стороне вы вызываете какой нибудь result.applyTo(ctx)
Соответсвенно, все изменения у вас будут в конце, на самом верху, а до того — вычисления, которые легко тестируются.
·>Создаётся мок для класса Thing. ·>Дальше мокаешь методы и инжектишь в SUT.
Вот-вот, еще чтото надо куда то инжектить, вызывать, проверять, а вызвалось ли замоканое нужное количество раз, в нужной последовательности, итд итд итд
Итого — вы прибили тесты к реализации
P>>Вы там в своём уме? Чтобы замокать чего нибудь ради теста, вам нужно знание о реализации, следовательно, тесткейс автоматически становится вайтбоксом. ·>В общем случае: чтобы передать что-то методу для теста, тоже надо знание о реализации, иначе не узнаешь corner-case.
На мой взгляд это не нужно — самый минимум это ожидания вызывающей стороны. Всё остальное это если время некуда девать.
P>>Зачем? ·>Я понимаю код лучше, чем твои объяснения.
Я только-только поменял работу, к сожалению физически не могу показать типичный пример.
P>>В том то и проблема, что вы строите такой дизайн, что бы его потом моками тестировать. Потому и топите везде за моки. ·>Хочу посмотреть на твой дизайн.
Мой дизайн в основном в закрытых репозиториях. Пока что так. Опенсорсные проекты я только исследую или использую.
·>Важно то, что в этом tryAcceptComposition находится connectionString. Т.е. условно говоря твой "интеграционнный тест" полезет в реальную субд и будет безбожно тормозить.
Во первых — таких тестов у нас будет пару штук
Во вторых — моки не избавляют от необхидимости интеграционных тестов, в т.ч. запуска на реальной субд
>В коде с моками — был reservationsRepository и возможность отмежеваться от реальной субд чтобы тестировать что параметры поиска и создания резерваций верные
Вот я и говорю — вы сделали в бл зависимость от бд, а потом в тестах изолируетесь от нее. Можно ж и иначе пойти — изолироваться на этапе дизайна, тогда ничего мокать не надо
P>>Вы идете наоброт — выпихиваете всё в контроллер, тогда дешевыми юнит-тестами покрывать нечего, зато теперь надо контроллер обкладывать моками, чтобы хоть как то протестировать. ·>В некоторых случаях интеграционным тестом будет "код скомпилировался".
Если у вас много зависимостей — статическая типизация помогает слабовато.
P>>Если это не про моки, то вопросов еще больше. Каким образом иерархия контроллер <- сервис-бл <- репозиторий <- клиент-бд стала у вас вдруг плоской? ·>DI же, не? ·>
·>var db = new Db(connectionString);
·>var repo = new Repo(db);
·>var bl = new BlService(repo);
·>var ctl = new Controller(bl);
·>var server = new Server(port);
·>server.handle("/path", ctl);
·>server.start();
·>
Я вижу, что здесь вы создаёте ту самую глубокую иерархию — у вас сервис bl зависит от репозитория который зависит от bd.
Есть другой вариант — не вы передаете репозиторий в bl, а вызываете bl внутри т.н. use-case в терминологии clean architecture
тогда получается иерархия плоская — у контроллера кучка зависимостей, но репозиторий не зависит от бд, бл не зависит от репозитория
controller зависит от
* db
* repositotory
* bl
Вот наш юз кейс — интеграционный код, покрывается интеграционным тестом
P>>Я думал вы собираетесь замокать все зависимости контроллера, но вы похоже бьете все рекорды ·>Для юнит-теста Controller надо мокать только BlService.
вот это и проблема — у вас тест "как написано", т.к. далеко не факт, что ваш мок этого бл-сервиса соответствует реальному блсервису. Эта часть вообще никак не контролируется — и крайне трудно научить этому разработчикв.
Типичная проблема — моки крайне слабо напоминают тот самый класс.
P>>Совсем необязательно. Тесты это далеко не единственный инструмент в обеспечении качества. Потому покрывать код идея изначально утопичная. Покрывать нужно требования, ожидания вызывающей стороны, а не код. ·>Как? И как оценивать качество покрытия требований/ожиданий?
А как это QA делают? Строчка требований — список тестов, где она фигурирует.
P>>Для самого кода у нас много разных инструментов — от генерации по мат-модели, всяких инвариантов-пред-пост-условий и до код-ревью. ·>А метрики какие? Чтобы качество обеспечивать, его надо как-то измерять и контролировать.
Строчки это плохие метрики, т.к. цикломатическая сложность может зашкаливать как угодно
P>>Да хоть вот так, утрирую конечно P>>
P>>curl -X POST -H "Content-Type: application/json" -d '{<резервирование>}' http://localhost:3000/api/v3/reservation
P>>
·>А где ассерт?
Это я так трохи пошутил — идея в том, что нам всего то нужен один тест верхнего уровня. он у нас тупой как доска — буквально как http реквест-респонс
P>>Постусловия к вам еще не завезли? Это блакбокс, только это совсем не тест. ·>А куда их завезли?
Много где завезли, в джава коде я такое много где видел. А еще есть сравнение логов — если у вас вдруг появится лишний аудит, он обязательно сломает выхлоп. Это тоже блекбокс
·>Это слишком тяжелый тест. Количество таких тестов должно быть минимально.
Разумеется — таких у нас по несколько штук на каждый роут
P>>Вы же моками обрезаете зависимости. Забыли? Каждая зависимость = причины для изменений. ·>Я не понял на какой вопрос этот ответ.
Вы спрашивали, почему короткая функция более устойчива по сравнению с maitred — потому, что у ней зависимостей меньше. Каждая зависимость, прямая или нет, это причина для изменения.
Например, ваш бл-сервис неявно зависит от бд-клиента, через репозиторий. А это значит, смена бд сначала сломает ваш репозиторий, а это сломает ваш бл сервис.
А раз вы его замокали для теста контроллера, то вам надо перебулшитить все тесты
P>>Вот с maitred все не просто — любое изменение дизайна затрагивает такой класс, тк у него куча зависимостей, каждая из которых может меняться по разными причнам. ·>Куча это сколько? Судя по коду в статье я там аж целых одну насчитал.
прямых — одна, а непрямых — все дочерние от того же репозитория
P>>И вам каждый раз надо будет подфикшивать тесты. ·>По-моему ты очень странно пишешь тесты и дизайнишь, от того и проблемы.
Я не знаю, в чем вы проблему видите. В жээс аннотация это обычный код, который инструментируется, и будет светиться или красным, или зеленым
P>>·>Самое что ни на есть вайтбокс тестирование. Что конкретный метод содержит конкретную аннотацию. P>>Мы тестируем, что есть те или иные метаданные. А вот чем вы их установите — вообще дело десятое. ·>А как ещё на метод можно метаданные навесить? Или ты про js?
разными способами
1. аннотации метода
2. аннотации класса
3. аннотации контекста класса
4. скриптованием, например, на старте
5. конфигурация приложения
6. переменные окружения
P>>А вот метаданные это совсем не вайтбокс, это нефункциональные требования. ·>Зачем тогда их в эти тесты класть?..
затем и класть, что это часть требований. фиксируем капабилити
P>>Мне нужно будет добавить функцию которая будет возвращать экземпляр аудитора по метаданным и покрыть её простыми дешовыми тестами. А раз весь аудит проходить будет через неё, то достаточно сверху накинуть интеграционный тест, 1шт ·>Тебе как-то рефлексивно придётся извлекать детали аудита из места вызова и параметров метода. На ЯП со статической типизацией будет полный швах.
Зачем? Есть трассировка и правило — результат аудита можно сравнивать
Здравствуйте, Pauel, Вы писали:
P>·>Мде... Или это "особенности" js?.. Но допустим. Как ты это предлагаешь переделать с "value"?
В общем я плохо знаю что есть в js, но тот код в jest действительно туфта какая-то, не надо так делать. Если не задаваться вопросом, зачем вообще вдруг понадобилось мокать hmac, то подобное с сохранением возможностей api библиотеки crypto в java будет выглядеть как-то так:
@Test void shouldVerify()
{
// depsvar console = mock(Console.class);
var crypto = mock(Crypto.class);
var hmac = mock(Hmac.class);
// set up
when(crypto.createHmac("sha256", "API_TOKEN")).thenReturn(hmac);//factory pattern
when(hmac.digest("hex")).thenReturn("123");
//sutvar app = new App(console, crypto);// dependency injection
app.main();
//verify
verify(hmac).update("{}");
verify(console).log("verified successfully. Implement next logic");
//тут ещё не хватает проверок, что "123" где-то правильно использовалось в результатах.
}
P>Например, нам нужно считать токен для стрима, нас интересует ид класса, ид сущность, версия сущность b секрет.
Не очень ясно в чём идея. У тебя есть библотека которая умеет несколько алгоритмов, апдейт по частям с приведением типов, формирование дайджеста в разных форматах. И ты это оборачиваешь в свою обёртку, которая умеет только одно — конкретный алгоритм упакованный в отдельный метод Token.from, который содержит конкретные параметры и т.п. И что в этом такого особенного? Называется частичное применение функции. И причём тут моки?
Проблема такого подхода в том, что это работает только в тривиальных случаях. Когда в твоём приложении понадобятся много разных комбинаций, то у тебя количество частично применённых функций пойдёт по экспоненте. У тебя получатся ApiTokenAsHex.from, ApiTokenAsBytes.from, ApiTokenAsB64.from, HashedPassword.from, HashedPasswordAsBytes.from и пошло поехало.
И это только _два_ метода из целой библиотеки crypto уже даёт кучу комбинаций.
P>
P>Теперь вы можете покрыть все кейсы — 1-3 успешных, и ведёрко фейлов типа ид, секрет, версия не установлены.
Т.е. вынесли кусочек кода в метод и его протестировали отдельно. И? Моки тут причём?
P>И теперь в приложении вам не надо мокать Token.from, т.к. вы знаете, что она соответствует нашим ожиданиям, и не надо проверять, что контроллер обновления стрима вызывает Token.from если ему необходимо отрендерить ETag. Ты изобрёл функции? Конечно, если у тебя из нескольких мест используется конкретно sha256 hex hmac, то это имеет смысл вынести в отдельный переиспользуемый метод. Но если у тебя оно нужно конкретно в одном месте для etag, то это уже оверкилл.
В этом случае тогда непонятно как изменение формата etag может все тесты сделать красными. Могу объяснить лишь тем как ты дизайнишь тесты. Потому что "обязательно сломает выхлоп"? Потому что тестов много, проверяют они очень много. И изменения бьют по многим целям одновременно.
P>Все что вам необходимо — в интеграционны тестах вызвать тот самый контроллер и убедиться, что его значения совпадают с нашими.
Я о чём и говорю — пишешь обёртки стороннего кода. Моки тут вообще никаким боком.
P>>>Ну да — проблемы нет а тесты стали красными. И так каждый раз. P>·>Ничего не понял. Если использование уязвимой тормозной либы — не проблема, то зачем вообще код трогать? P>ну вот представьте — либа слишком медленная. И вы находите ей замену. Идеальный результат — после замены тесты зеленые.
Оборачивать каждую стороннюю либу — т.к. её _возможно_ нужно будет заменить — это оверинжиниринг в большинстве случаев.
P>А вы непонятно с какой целью хотите что бы тесты сломались. P>Что нового вы добавите в приложение починкой этих тестов?
Нет, я пытаюсь понять причём тут моки. Ты с таким же успехом можешь оборачивать либу своей обёрткой и свою обёртку мочить.
P>а на вызывающей стороне вы вызываете какой нибудь result.applyTo(ctx)
А какая разница? Ведь эту конструкцию надо будет тоже каким-то тестом покрыть.
P>Соответсвенно, все изменения у вас будут в конце, на самом верху, а до того — вычисления, которые легко тестируются.
То что ты логику в коде куда-то переносишь, не означает, что её вдруг можно не тестировать.
P>·>Создаётся мок для класса Thing. P>·>Дальше мокаешь методы и инжектишь в SUT. P>Вот-вот, еще чтото надо куда то инжектить, вызывать, проверять, а вызвалось ли замоканое нужное количество раз, в нужной последовательности, итд итд итд
Это надо не для моков как таковых (если validateThing — тривиальна, то зачем её вообще мочить? Всегда можно запихать реальную имплементацию), а для разделения компонент и независимого их тестирования.
Я тебе уже написал когда это _надо_, но ты как-то тихо проигнорировал: Более того, когда мы будем дорабатывать поведение фукнции validateThing потом, эти три наших теста не пострадают, что они вдруг не очень правильно сформированные part1/part2 подают. Вдобавок, функция хоть пусть и валидная, но она может быть медленной — лазить в сеть или банально жечь cpu вычислениями.
То что это _надо_ именно для моков — это ты сам придумал. Тут зависимость в противоположную сторону — есть проблема использовать какой-то кусок из тестов, т.к. он делает слишком много, мы описываем только интересные нам аспекты поведения куска кода и фиксируем их в виде моков.
P>Итого — вы прибили тесты к реализации
В js принято валить всё в Global и сплошные синглтоны? DI не слышали?
P>>>Вы там в своём уме? Чтобы замокать чего нибудь ради теста, вам нужно знание о реализации, следовательно, тесткейс автоматически становится вайтбоксом. P>·>В общем случае: чтобы передать что-то методу для теста, тоже надо знание о реализации, иначе не узнаешь corner-case. P>На мой взгляд это не нужно — самый минимум это ожидания вызывающей стороны. Всё остальное это если время некуда девать.
Так пиши ожидания когда они известны, если ты их знаешь. Анализ вайтбокс, покрытие кода — именно поиск неизвестных ожиданий.
"Мы тут написали все ожидания по спеке, но вот в тот else почему-то ни разу не попали ни разу. Разбираемся почему."
P>·>Я понимаю код лучше, чем твои объяснения. P>Я только-только поменял работу, к сожалению физически не могу показать типичный пример.
Да мне не нужен код с реального проекта. Небольшой пример достаточно.
P>·>Важно то, что в этом tryAcceptComposition находится connectionString. Т.е. условно говоря твой "интеграционнный тест" полезет в реальную субд и будет безбожно тормозить. P>Во первых — таких тестов у нас будет пару штук
Это только для tryAcceptComposition. А таких врапперов придётся написать под каждый метод контроллера. И на каждый пару тестов.
P>Во вторых — моки не избавляют от необхидимости интеграционных тестов, в т.ч. запуска на реальной субд
Такой тест может быть один на всю систему. Запустилось, соединения установлены, версии совпадают, пинги идут. Готово.
>>В коде с моками — был reservationsRepository и возможность отмежеваться от реальной субд чтобы тестировать что параметры поиска и создания резерваций верные P>Вот я и говорю — вы сделали в бл зависимость от бд, а потом в тестах изолируетесь от нее. Можно ж и иначе пойти — изолироваться на этапе дизайна, тогда ничего мокать не надо
В бл зависимость от репы.
P>>>Вы идете наоброт — выпихиваете всё в контроллер, тогда дешевыми юнит-тестами покрывать нечего, зато теперь надо контроллер обкладывать моками, чтобы хоть как то протестировать. P>·>В некоторых случаях интеграционным тестом будет "код скомпилировался". P>Если у вас много зависимостей — статическая типизация помогает слабовато.
Гораздо больше, чем динамическая.
P>Есть другой вариант — не вы передаете репозиторий в bl, а вызываете bl внутри т.н. use-case в терминологии clean architecture P>тогда получается иерархия плоская — у контроллера кучка зависимостей, но репозиторий не зависит от бд, бл не зависит от репозитория
А какие типы у объектов getUser/updateUser? И примерная реализация всех методов?
> const updateUser = repository.updateUser(oldUser, newUser);
А если я случайно напишу
const updateUser = repository.updateUser(newUser, oldUser);
где что когда упадёт?
P>·>Для юнит-теста Controller надо мокать только BlService. P>вот это и проблема — у вас тест "как написано", т.к. далеко не факт, что ваш мок этого бл-сервиса соответствует реальному блсервису. Эта часть вообще никак не контролируется — и крайне трудно научить этому разработчикв.
А как контролиоруется что newUser возвращённый из бл обработается так как мы задумали в репе?
У тебя какое-то странное понимание моков. Цель мока не чтобы максимально точно описать поведение мокируемого, а чтобы описать различные возможные сценарии поведения мокируемого, на которые мы реагируем различным способом в sut.
P>Типичная проблема — моки крайне слабо напоминают тот самый класс.
Не очень понимаю проблему. Что можно нереального сделать в моке bl.modifyUser(id, newUserData) не так? Суть в том, что контроллер зовёт modifyUser и конвертирует результат:
class UserController {
Response update(Request r) {
var id = extractId(r);
var data = extractData(r);
var result = bl.modifyUser(id, data);
return result.isSuccess ? Response(r.correlationId, prepare(result)) : Failure("sorry");
}
}
Т.е. при тестировании контроллера совершенно неважно, что именно делает реальный modifyUser. Важно какие варианты результата он может вернуть и что на них реагируем в sut в соответствии с ожиданиями.
P>>>Совсем необязательно. Тесты это далеко не единственный инструмент в обеспечении качества. Потому покрывать код идея изначально утопичная. Покрывать нужно требования, ожидания вызывающей стороны, а не код. P>·>Как? И как оценивать качество покрытия требований/ожиданий? P>А как это QA делают? Строчка требований — список тестов, где она фигурирует.
А как узнать, что требования покрывают как можно больше возможных сценариев, а не только те, о которых не забыли подумать?
P>>>Для самого кода у нас много разных инструментов — от генерации по мат-модели, всяких инвариантов-пред-пост-условий и до код-ревью. P>·>А метрики какие? Чтобы качество обеспечивать, его надо как-то измерять и контролировать. P>Строчки это плохие метрики, т.к. цикломатическая сложность может зашкаливать как угодно
Чтобы она не зашкаливала — разделяют на части и мокают. Тогда как бы ни повёл себя одна часть, другая знает что делать.
P>Это я так трохи пошутил — идея в том, что нам всего то нужен один тест верхнего уровня. он у нас тупой как доска — буквально как http реквест-респонс
Ага. Но он, в лучшем случае, покроет только один xxxComposition. А их будет на каждый метод контроллера.
P>>>Постусловия к вам еще не завезли? Это блакбокс, только это совсем не тест. P>·>А куда их завезли? P>Много где завезли, в джава коде я такое много где видел. А еще есть сравнение логов — если у вас вдруг появится лишний аудит, он обязательно сломает выхлоп. Это тоже блекбокс
Это означает, что небольшое изменение в формате аудита ломает все тесты с образцами логов. Вот и представь, добавление небольшой штучки в аудит поломает все твои "несколько штук" тестов на каждый роут.
P>·>Это слишком тяжелый тест. Количество таких тестов должно быть минимально. P>Разумеется — таких у нас по несколько штук на каждый роут
Именно. А должно быть несколько штук на весь сервис. Роутов может быть сотни. А достаточно потрогать каждое соединение между зависимостями. Например, если MaitreD может успешно дёрнуть метод getReservation у Repository, то это автоматически означает репо работает, что можно дёргать любые методы этого же Repository из любого метода MaitreD. Поэтому тяжелые и-тесты для find/create/delete/modify/etc уже не нужны.
P>>>Вы же моками обрезаете зависимости. Забыли? Каждая зависимость = причины для изменений. P>·>Я не понял на какой вопрос этот ответ. P>Вы спрашивали, почему короткая функция более устойчива по сравнению с maitred — потому, что у ней зависимостей меньше. Каждая зависимость, прямая или нет, это причина для изменения.
Я не о конкретной функции рассуждаю, а о системе. Если у неё зависимостей меньше, в ней меньше логики. А это значит, что эта логика была перенесена куда-то. И теперь это что-то тоже приходится тестировать. И плюс ещё тестировать что это что-то соединяется с этой функцией верно.
В этом у меня и основная претензия к статье. Был код, который делал X. Его заменили на "чистую красивую маленькую функцию", которая делает Y и теперь её легче тестировать. Но факт, что Y<X — замели под коврик. А эту разницу X-Y — запихали в страхолюдный xxxComposition метод и сделали вид, что он скучный и неинтересный, и можно его даже не тестировать.
P>Например, ваш бл-сервис неявно зависит от бд-клиента, через репозиторий. А это значит, смена бд сначала сломает ваш репозиторий, а это сломает ваш бл сервис.
Не понял, что значит "сломает"? Что за такая "смена бд"?
P>А раз вы его замокали для теста контроллера, то вам надо перебулшитить все тесты
Зачем? В тесте контрллера используется бл, поэтому моки только для него. И что творится в репе с т.з. контроллера — совершенно неважно.
P>>>Вот с maitred все не просто — любое изменение дизайна затрагивает такой класс, тк у него куча зависимостей, каждая из которых может меняться по разными причнам. P>·>Куча это сколько? Судя по коду в статье я там аж целых одну насчитал. P> прямых — одна, а непрямых — все дочерние от того же репозитория
Неясно как "непрямые" зависимости влияют на _дизайн_ класса. Он их вообще никак не видит. Никак. Вообще. Ок... Есть, конечно, вероятность, что т.к. класс есть в скопе, то кто-то в конструктор MaitreD впишет Db и connectionString. От такого можно отмежеваться интерфейсами и разделением на модули, но обычно оверкилл — проще на ревью такое резать.
P>>>И вам каждый раз надо будет подфикшивать тесты. P>·>По-моему ты очень странно пишешь тесты и дизайнишь, от того и проблемы. P>Ничего странного — вы как то прошли мимо clean architecture.
Я как-то мимо rest и ui прошел в принципе... если есть какая ссылка "clean architecture for morons", давай.
P>>>Тогда не совсем понятен ваш вопрос. P>·>https://en.wikipedia.org/wiki/Code_coverage P>Я не знаю, в чем вы проблему видите. В жээс аннотация это обычный код, который инструментируется, и будет светиться или красным, или зеленым
В js вроде вообще нет аннотаций. Не знаю что именно ты зовёшь аннотацией тогда.
P>>>·>Самое что ни на есть вайтбокс тестирование. Что конкретный метод содержит конкретную аннотацию. P>>>Мы тестируем, что есть те или иные метаданные. А вот чем вы их установите — вообще дело десятое. P>·>А как ещё на метод можно метаданные навесить? Или ты про js? P>разными способами P>1. аннотации метода P>2. аннотации класса P>3. аннотации контекста класса P>4. скриптованием, например, на старте P>5. конфигурация приложения P>6. переменные окружения
И это всё юнит-тестится как ты обещал?! expext(Metadata.from(ControllerX, 'tryAccept')).metadata.to.match({...})?
P>>>Мне нужно будет добавить функцию которая будет возвращать экземпляр аудитора по метаданным и покрыть её простыми дешовыми тестами. А раз весь аудит проходить будет через неё, то достаточно сверху накинуть интеграционный тест, 1шт P>·>Тебе как-то рефлексивно придётся извлекать детали аудита из места вызова и параметров метода. На ЯП со статической типизацией будет полный швах. P>Зачем? Есть трассировка и правило — результат аудита можно сравнивать
Не понял к чему ты это говоришь. На вход метода подаются какие-то парамы. У тебя на нём висит аннотация. Откуда аннотация узнает что/как извлечь из каких парамов чтобы записать что-то в аудит?
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>Например, нам нужно считать токен для стрима, нас интересует ид класса, ид сущность, версия сущность b секрет. ·>Не очень ясно в чём идея. У тебя есть библотека которая умеет несколько алгоритмов, апдейт по частям с приведением типов, формирование дайджеста в разных форматах. И ты это оборачиваешь в свою обёртку, которая умеет только одно — конкретный алгоритм упакованный в отдельный метод Token.from, который содержит конкретные параметры и т.п. И что в этом такого особенного? Называется частичное применение функции. И причём тут моки?
Это я вам пример привел, для чего вообще люди мокают, когда всё прекрасно тестируется и без моков.
·>Проблема такого подхода в том, что это работает только в тривиальных случаях. Когда в твоём приложении понадобятся много разных комбинаций, то у тебя количество частично применённых функций пойдёт по экспоненте. У тебя получатся ApiTokenAsHex.from, ApiTokenAsBytes.from, ApiTokenAsB64.from, HashedPassword.from, HashedPasswordAsBytes.from и пошло поехало.
А зачем вам эти AsHex, AsBytes? Это же просто преставление. У вас есть токен — это значение. Его можно создать парой-тройкой способов, и сохранить так же. Отсюда ясно, что нет нужды плодить те функции, что вы предложили, а следовательно и тестировать их тоже не нужно.
Всех дел — отделить данные от представления, и количество тестов уменьшается.
P>>Теперь вы можете покрыть все кейсы — 1-3 успешных, и ведёрко фейлов типа ид, секрет, версия не установлены. ·>Т.е. вынесли кусочек кода в метод и его протестировали отдельно. И? Моки тут причём?
Насколько я понимаю, я вам показываю, как разные люди понимают моки. Вы же всё приписываете лично мне.
·>Но если у тебя оно нужно конкретно в одном месте для etag, то это уже оверкилл.
Вас всё тянет любое высказывание к абсурду свести. Естетсвенно, что городить вагон абстракций, ради того, что бы вычислить етаг не нужно.
При этом и моки тоже не нужны для этого случая.
У нас будет функция getEtag(content) которую можно проверить разными значениями.
Тем не менее, пример на моках что я вам показал, он именно отсюда взят.
P>>ну вот представьте — либа слишком медленная. И вы находите ей замену. Идеальный результат — после замены тесты зеленые. ·>Оборачивать каждую стороннюю либу — т.к. её _возможно_ нужно будет заменить — это оверинжиниринг в большинстве случаев.
При чем здесь оборачивание? У вас есть функционал — верификация jwt токена.
Объясните внятно, почему замена jsonwebtoken на jose должна сломать тесты?
А вот если вы замокали jsonwebtoken, то ваши тесты сломаются. И причина только в том, что вы замокали там где этого не надо делать.
P>>А вы непонятно с какой целью хотите что бы тесты сломались. P>>Что нового вы добавите в приложение починкой этих тестов? ·>Нет, я пытаюсь понять причём тут моки. Ты с таким же успехом можешь оборачивать либу своей обёрткой и свою обёртку мочить.
Не надо здесь вообще ничего мокать, и ничего не сломается.
P>>а на вызывающей стороне вы вызываете какой нибудь result.applyTo(ctx) ·>А какая разница? Ведь эту конструкцию надо будет тоже каким-то тестом покрыть.
Для этого есть интеграционный тест
P>>Соответсвенно, все изменения у вас будут в конце, на самом верху, а до того — вычисления, которые легко тестируются. ·>То что ты логику в коде куда-то переносишь, не означает, что её вдруг можно не тестировать.
Там где логика — там юнит-тесты, без моков, а там где интеграция — там интеграционные тесты, тоже без моков.
P>>Вот-вот, еще чтото надо куда то инжектить, вызывать, проверять, а вызвалось ли замоканое нужное количество раз, в нужной последовательности, итд итд итд ·>Это надо не для моков как таковых (если validateThing — тривиальна, то зачем её вообще мочить? Всегда можно запихать реальную имплементацию), а для разделения компонент и независимого их тестирования.
А задизайнить компоненты, что бы они не зависели друг от друга?
·>Я тебе уже написал когда это _надо_, но ты как-то тихо проигнорировал: Более того, когда мы будем дорабатывать поведение фукнции validateThing потом, эти три наших теста не пострадают, что они вдруг не очень правильно сформированные part1/part2 подают. Вдобавок, функция хоть пусть и валидная, но она может быть медленной — лазить в сеть или банально жечь cpu вычислениями.
Это ваш выбор дизайна — на самом низу стека вы вдруг вызываете чтение из сети-базы-итд, или начинаете жечь cpu.
А если этого не делать, то и моки не нужны.
P>>Итого — вы прибили тесты к реализации ·>В js принято валить всё в Global и сплошные синглтоны? DI не слышали?
Зачем global? DI можно по разному использовать — речь же об этом. Посмотрите framework as a detail или clean architecture, сразу станет понятнее.
Вместо выстраивания глубокой иерархии, где на самом низу стека идет чтение из бд, делаем иначе — вычисляем, что читать из бд, следующим шагом выполняем чтение.
Итого — самое важное тестируется плотно юнит-тестами, а остальное — интеграционными
С вашими моками покрытие будет хуже, кода больше, а интеграционные всё равно нужны
P>>На мой взгляд это не нужно — самый минимум это ожидания вызывающей стороны. Всё остальное это если время некуда девать. ·>Так пиши ожидания когда они известны, если ты их знаешь. Анализ вайтбокс, покрытие кода — именно поиск неизвестных ожиданий. ·>"Мы тут написали все ожидания по спеке, но вот в тот else почему-то ни разу не попали ни разу. Разбираемся почему."
С моками чаще получается так — моками некто заставил попасть в этот else, а на проде этот else срабатывает совсем в другом контексте, и все валится именно там где покрыто тестом.
P>>Я только-только поменял работу, к сожалению физически не могу показать типичный пример. ·>Да мне не нужен код с реального проекта. Небольшой пример достаточно.
Я ж вам его и дал, дважды
·>Это только для tryAcceptComposition. А таких врапперов придётся написать под каждый метод контроллера. И на каждый пару тестов.
Именно! И никакие моки этого не отменяют!
P>>Во вторых — моки не избавляют от необхидимости интеграционных тестов, в т.ч. запуска на реальной субд ·>Такой тест может быть один на всю систему. Запустилось, соединения установлены, версии совпадают, пинги идут. Готово.
Если у вас система из одного единственного роута и без зависимостей входящих-исходящих, то так и будет. А если роутов много, и есть зависимости, то надо интеграционными тестами покрыть весь входящий и исходящий трафик.
P>>Вот я и говорю — вы сделали в бл зависимость от бд, а потом в тестах изолируетесь от нее. Можно ж и иначе пойти — изолироваться на этапе дизайна, тогда ничего мокать не надо ·>В бл зависимость от репы.
А следовательно и от бд. Например, вечная проблема с репозиториями, как туда фильтры передавать и всякие параметры, что бы не плодить сотни методов. Сменили эту механику — и весь код где прокидываются фильтры, издох — начинай переписывать тесты.
P>>Если у вас много зависимостей — статическая типизация помогает слабовато. ·>Гораздо больше, чем динамическая.
Этого недостаточно. Нужен внятный интеграционный тест, его задача — следить что подсистема с правильными зависимостями соответствует ожиданиям
P>>тогда получается иерархия плоская — у контроллера кучка зависимостей, но репозиторий не зависит от бд, бл не зависит от репозитория ·>А какие типы у объектов getUser/updateUser? И примерная реализация всех методов?
getUser — чистая функция, выдает объект-реквест, например select * from users where id=? + параметры + трансформации. UpdateUser — чистая функция, вычисляет все что нужно для операции. execute — принимает объект-реквест, возвращает трансформированый результат.
>> const updateUser = repository.updateUser(oldUser, newUser); ·>А если я случайно напишу ·>const updateUser = repository.updateUser(newUser, oldUser); ·>где что когда упадёт?
Упадет интеграционный тест, тест вида "выполним операцию и проверим, что состояние юзера соответствует ожиданиям".
·>А как контролиоруется что newUser возвращённый из бл обработается так как мы задумали в репе?
Метод репозитория тоже тестируется юнитами, без моков — его задача сгенерировать правильный реквест.
Проблему может вызвать ветвление в контроллере — он должен быть линейным.
·>У тебя какое-то странное понимание моков. Цель мока не чтобы максимально точно описать поведение мокируемого, а чтобы описать различные возможные сценарии поведения мокируемого, на которые мы реагируем различным способом в sut.
Я вам пишу про разные кейсы из того что вижу, а вы все пытаетесь причину во мне найти
·>Т.е. при тестировании контроллера совершенно неважно, что именно делает реальный modifyUser. Важно какие варианты результата он может вернуть и что на них реагируем в sut в соответствии с ожиданиями.
А моки вам зачем для этого?
P>>·>Как? И как оценивать качество покрытия требований/ожиданий? P>>А как это QA делают? Строчка требований — список тестов, где она фигурирует. ·>А как узнать, что требования покрывают как можно больше возможных сценариев, а не только те, о которых не забыли подумать?
Если мы очем то забыли, то никакой кавередж не спасет. Например, если вы забыли, что вам могут приходить данные разной природы, то всё, приплыли.
P>>Строчки это плохие метрики, т.к. цикломатическая сложность может зашкаливать как угодно ·>Чтобы она не зашкаливала — разделяют на части и мокают. Тогда как бы ни повёл себя одна часть, другая знает что делать.
Это можно делать и без моков.
P>>Это я так трохи пошутил — идея в том, что нам всего то нужен один тест верхнего уровня. он у нас тупой как доска — буквально как http реквест-респонс ·>Ага. Но он, в лучшем случае, покроет только один xxxComposition. А их будет на каждый метод контроллера.
Это в любом случае так — e2e тесты должны покрыть весь входящий и исходящий трафик.
P>>Много где завезли, в джава коде я такое много где видел. А еще есть сравнение логов — если у вас вдруг появится лишний аудит, он обязательно сломает выхлоп. Это тоже блекбокс ·>Это означает, что небольшое изменение в формате аудита ломает все тесты с образцами логов. Вот и представь, добавление небольшой штучки в аудит поломает все твои "несколько штук" тестов на каждый роут.
Похоже, вы незнакомы с acceptance driven тестированием. В данном случае нам нужно просмотреть логи, и сделать коммит, если всё хорошо.
·>Именно. А должно быть несколько штук на весь сервис. Роутов может быть сотни.
Тесты верхнего уровня в любом случае должны покрывать весь апи. Вы же своими моками пытаетесь искусственно уровень тестирования понизить.
P>>Например, ваш бл-сервис неявно зависит от бд-клиента, через репозиторий. А это значит, смена бд сначала сломает ваш репозиторий, а это сломает ваш бл сервис. ·>Не понял, что значит "сломает"? Что за такая "смена бд"?
Как ваш репозиторий фильтры принимает ?
·>Зачем? В тесте контрллера используется бл, поэтому моки только для него. И что творится в репе с т.з. контроллера — совершенно неважно.
Если у вас полная изоляция, то так и будет. А если неполная, что чаще всего, то будет всё сломано.
Собственно — что бы добиться этой самой хорошей изоляции в коде девелопера надо тренировать очень долго.
P>> прямых — одна, а непрямых — все дочерние от того же репозитория ·>Неясно как "непрямые" зависимости влияют на _дизайн_ класса. Он их вообще никак не видит. Никак.
Я вот регулярно вижу такое — контроллер вызывает сервис, передает тому объекты http request response. А вот сервис, чья задача это бл, вычитывает всё из req, res, лезет в базу пополам с репозиторием, и еще собственно бл считает, плюс кеширование итд.
То есть, типичный разработчик не умеет пользоваться абстракциями и изоляцией, а пишет прямолинейный низкоуровневый код. И у него нет ни единого шанса протестировать такое чудовище кроме как моками.
P>>Ничего странного — вы как то прошли мимо clean architecture. ·>Я как-то мимо rest и ui прошел в принципе... если есть какая ссылка "clean architecture for morons", давай.
·>И это всё юнит-тестится как ты обещал?! expext(Metadata.from(ControllerX, 'tryAccept')).metadata.to.match({...})?
Смотря что — валидатор, это юнит-тест. А вот чтото нужна или нет авторизация, это можно переопределить конфигом или переменными окружения.
P>>Зачем? Есть трассировка и правило — результат аудита можно сравнивать ·>Не понял к чему ты это говоришь. На вход метода подаются какие-то парамы. У тебя на нём висит аннотация. Откуда аннотация узнает что/как извлечь из каких парамов чтобы записать что-то в аудит?
Кое что надо и в самом методе вызывать, без этого работать не будет. Видите нужные строчки — аудит работает, выхлоп совпадает с предыдущим забегом — точно все отлично. Не совпадает — точно есть проблемы.
Здравствуйте, Pauel, Вы писали:
P>вот наш контроллер — интеграционный код, покрывается интеграционным тестом
Хочу тоже подключиться к вашему обсуждению.
1. Про контроллер
С тестированием контроллера все понятно. В нем редко есть сложная логика, а если и есть, то легко разбить на две части — до вызова логики и после, и соответственно, выделить в чистые функции.
Кстати, что делаете если параметров много (как в примере)? Выделяете под них структуру для хранения?
http_handler(request):
v1, v2, v3 = parse_and_validate(request) // pure
result = do_logic(v1, v2, v3)
return serialize(result) // pure
2. Про логику
Ниже пример того, что хотим протестировать. Есть обращение к БД и внешним сервисам. Как это будет протестировано?
Самый главный вопрос — как будет протестировано ветвление (if-ы, их может быть много).
do_logic(v1, v2, v3):
// работаем с БД
p = repo.get(v1)
// получаем дополнительные данные из внешнего источника
if что-то(p):
p2 = external_service.request(v2)
p = update(p, p2)
// отправляем в БД и условную кафку
if что-то(p):
repo.put(v3)
another_external_service.send(v3)
result = serialize(p) // pure
return result
Здравствуйте, Pauel, Вы писали:
P>>>Например, нам нужно считать токен для стрима, нас интересует ид класса, ид сущность, версия сущность b секрет. P>·>Не очень ясно в чём идея. У тебя есть библотека которая умеет несколько алгоритмов, апдейт по частям с приведением типов, формирование дайджеста в разных форматах. И ты это оборачиваешь в свою обёртку, которая умеет только одно — конкретный алгоритм упакованный в отдельный метод Token.from, который содержит конкретные параметры и т.п. И что в этом такого особенного? Называется частичное применение функции. И причём тут моки? P>Это я вам пример привел, для чего вообще люди мокают, когда всё прекрасно тестируется и без моков.
Т.е. проблема не в моках как таковых, а в том, что некоторые люди используют некоторые подходы и пишут корявый код? Это проблема ликбеза, а не моков. Ровно та же проблема есть в любых подходах тестирования.
P>·>Проблема такого подхода в том, что это работает только в тривиальных случаях. Когда в твоём приложении понадобятся много разных комбинаций, то у тебя количество частично применённых функций пойдёт по экспоненте. У тебя получатся ApiTokenAsHex.from, ApiTokenAsBytes.from, ApiTokenAsB64.from, HashedPassword.from, HashedPasswordAsBytes.from и пошло поехало. P>А зачем вам эти AsHex, AsBytes? Это же просто преставление. У вас есть токен — это значение. Его можно создать парой-тройкой способов, и сохранить так же.
Именно. 3 способа создания x 3 способа представления — уже девять комбинаций. У тебя будет либо девять функций, либо своя обёртка над сторонним api, изоморфная по сложности тому же api.
P> Отсюда ясно, что нет нужды плодить те функции, что вы предложили, а следовательно и тестировать их тоже не нужно.
Нужда идёт из кода, из требований. Если у тебя достаточно сложная система, у тебя будет там все 9 комбинаций, а то и больше.
P>Всех дел — отделить данные от представления, и количество тестов уменьшается.
Количество может быть уменьшено, только если ты какое-то требование перестал тестировать.
P>>>Теперь вы можете покрыть все кейсы — 1-3 успешных, и ведёрко фейлов типа ид, секрет, версия не установлены. P>·>Т.е. вынесли кусочек кода в метод и его протестировали отдельно. И? Моки тут причём? P>Насколько я понимаю, я вам показываю, как разные люди понимают моки. Вы же всё приписываете лично мне.
Что лично тебе я приписал?
P>·>Но если у тебя оно нужно конкретно в одном месте для etag, то это уже оверкилл. P>Вас всё тянет любое высказывание к абсурду свести. Естетсвенно, что городить вагон абстракций, ради того, что бы вычислить етаг не нужно.
А ты таки предложил новую абстракцию ввести в виде ApiToken.from.
P>При этом и моки тоже не нужны для этого случая. P>У нас будет функция getEtag(content) которую можно проверить разными значениями.
Именно. Зачем нам тогда нужен ApiToken.from?
P>Тем не менее, пример на моках что я вам показал, он именно отсюда взят.
Пример на то и пример, чтобы показать как использовать моки. А в твоём примере было показано как _не надо_ писать код. Я показал как надо писать код при использовании моков. И мой код был вполне вменяемым. Оправданы ли они в данном случае моки — вопрос другой.
P>>>ну вот представьте — либа слишком медленная. И вы находите ей замену. Идеальный результат — после замены тесты зеленые. P>·>Оборачивать каждую стороннюю либу — т.к. её _возможно_ нужно будет заменить — это оверинжиниринг в большинстве случаев. P>При чем здесь оборачивание? У вас есть функционал — верификация jwt токена. P>Объясните внятно, почему замена jsonwebtoken на jose должна сломать тесты? P>А вот если вы замокали jsonwebtoken, то ваши тесты сломаются. И причина только в том, что вы замокали там где этого не надо делать.
В примере никакого jwt токена не было. Я не знаю ты о чём, у тебя где-то в голове какая-то более широкая картина, но к сожалению, я не очень хороший телепат.
P>>>а на вызывающей стороне вы вызываете какой нибудь result.applyTo(ctx) P>·>А какая разница? Ведь эту конструкцию надо будет тоже каким-то тестом покрыть. P>Для этого есть интеграционный тест
Жуть. Т.е. ты не можешь что-то протестировать быстрыми тестами, приходится плодить медленные интеграционные и тривиальные ошибки обнаруживать только после запуска всего приложения. Спасибо, не хочу.
P>>>Соответсвенно, все изменения у вас будут в конце, на самом верху, а до того — вычисления, которые легко тестируются. P>·>То что ты логику в коде куда-то переносишь, не означает, что её вдруг можно не тестировать. P>Там где логика — там юнит-тесты, без моков, а там где интеграция — там интеграционные тесты, тоже без моков.
Слишком тяжелый подход. Только на мелких приложениях работает.
P>>>Вот-вот, еще чтото надо куда то инжектить, вызывать, проверять, а вызвалось ли замоканое нужное количество раз, в нужной последовательности, итд итд итд P>·>Это надо не для моков как таковых (если validateThing — тривиальна, то зачем её вообще мочить? Всегда можно запихать реальную имплементацию), а для разделения компонент и независимого их тестирования. P>А задизайнить компоненты, что бы они не зависели друг от друга?
Это как? То что зависимости неявные — это не означает, что их нет.
P>·>Я тебе уже написал когда это _надо_, но ты как-то тихо проигнорировал: Более того, когда мы будем дорабатывать поведение фукнции validateThing потом, эти три наших теста не пострадают, что они вдруг не очень правильно сформированные part1/part2 подают. Вдобавок, функция хоть пусть и валидная, но она может быть медленной — лазить в сеть или банально жечь cpu вычислениями. P>Это ваш выбор дизайна — на самом низу стека вы вдруг вызываете чтение из сети-базы-итд, или начинаете жечь cpu. P>А если этого не делать, то и моки не нужны.
Ага-ага. Но тогда нужны ещё более медленные и неуклюжие интеграционные тесты, много.
P>>>Итого — вы прибили тесты к реализации P>·>В js принято валить всё в Global и сплошные синглтоны? DI не слышали? P>Зачем global? DI можно по разному использовать — речь же об этом. Посмотрите framework as a detail или clean architecture, сразу станет понятнее.
require это нифига не DI, это SL.
P>Вместо выстраивания глубокой иерархии, где на самом низу стека идет чтение из бд, делаем иначе — вычисляем, что читать из бд, следующим шагом выполняем чтение. P>Итого — самое важное тестируется плотно юнит-тестами, а остальное — интеграционными P>С вашими моками покрытие будет хуже, кода больше, а интеграционные всё равно нужны
Интеграционные тесты тестируют интеграцию крупных, тяжелых компонент. А у тебя они тестируют всю мелкую функциональность.
P>>>На мой взгляд это не нужно — самый минимум это ожидания вызывающей стороны. Всё остальное это если время некуда девать. P>·>Так пиши ожидания когда они известны, если ты их знаешь. Анализ вайтбокс, покрытие кода — именно поиск неизвестных ожиданий. P>·>"Мы тут написали все ожидания по спеке, но вот в тот else почему-то ни разу не попали ни разу. Разбираемся почему." P>С моками чаще получается так — моками некто заставил попасть в этот else, а на проде этот else срабатывает совсем в другом контексте, и все валится именно там где покрыто тестом.
Очень вряд-ли, но допустим даже что-то вальнулось в проде. Изучив логи прода, ты с моками сможешь быстро воспроизвести сценарий и получить быстрый красный тест, который можно спокойно отлаживать и фиксить, без всякой интеграции.
P>·>Это только для tryAcceptComposition. А таких врапперов придётся написать под каждый метод контроллера. И на каждый пару тестов. P>Именно! И никакие моки этого не отменяют!
Они отменяют необходимость написания тучи этих самых xxxComposition, нет кода — нечего тестировать.
P>>>Во вторых — моки не избавляют от необхидимости интеграционных тестов, в т.ч. запуска на реальной субд P>·>Такой тест может быть один на всю систему. Запустилось, соединения установлены, версии совпадают, пинги идут. Готово. P>Если у вас система из одного единственного роута и без зависимостей входящих-исходящих, то так и будет. А если роутов много, и есть зависимости, то надо интеграционными тестами покрыть весь входящий и исходящий трафик.
Не весь, а только покрывающий интеграцию компонент.
P>>>Вот я и говорю — вы сделали в бл зависимость от бд, а потом в тестах изолируетесь от нее. Можно ж и иначе пойти — изолироваться на этапе дизайна, тогда ничего мокать не надо P>·>В бл зависимость от репы. P>А следовательно и от бд. Например, вечная проблема с репозиториями, как туда фильтры передавать и всякие параметры, что бы не плодить сотни методов. Сменили эту механику — и весь код где прокидываются фильтры, издох — начинай переписывать тесты.
Это какая-то специфичная проблема в твоих проектах, я не в курсе.
P>·>Гораздо больше, чем динамическая. P>Этого недостаточно. Нужен внятный интеграционный тест, его задача — следить что подсистема с правильными зависимостями соответствует ожиданиям
Задача инеграционного теста — тестировать места взаимодействия компонент, а не сценарии поведения.
P>>>тогда получается иерархия плоская — у контроллера кучка зависимостей, но репозиторий не зависит от бд, бл не зависит от репозитория P>·>А какие типы у объектов getUser/updateUser? И примерная реализация всех методов? P>getUser — чистая функция, выдает объект-реквест, например select * from users where id=? + параметры + трансформации. UpdateUser — чистая функция, вычисляет все что нужно для операции. execute — принимает объект-реквест, возвращает трансформированый результат.
Как ассертить такую функцию в юнит-тесте? Как проверить, что текст запроса хотя бы синтаксически корректен? И как ассертить что параметры куда надо положены и транформация верна?
И далее, ну допустим ты как-то написал кучу тестов что getUser выглядит правильно. А дальше? Как убедиться, что настоящая субд будет работать с getUser именно так, как ты описал в ожиданиях теста репы?
>>> const updateUser = repository.updateUser(oldUser, newUser); P>·>А если я случайно напишу P>·>const updateUser = repository.updateUser(newUser, oldUser); P>·>где что когда упадёт? P>Упадет интеграционный тест, тест вида "выполним операцию и проверим, что состояние юзера соответствует ожиданиям".
Плохо, это функциональная бизнес-логика, а не интеграция. Это должно ловиться юнит-тестом, а не интеграционным.
P>·>А как контролиоруется что newUser возвращённый из бл обработается так как мы задумали в репе? P>Метод репозитория тоже тестируется юнитами, без моков — его задача сгенерировать правильный реквест. P>Проблему может вызвать ветвление в контроллере — он должен быть линейным.
Т.е. нужно писать интеграционный тест как минимум для каждого метода контроллера. Это слишком дохрена.
P>·>У тебя какое-то странное понимание моков. Цель мока не чтобы максимально точно описать поведение мокируемого, а чтобы описать различные возможные сценарии поведения мокируемого, на которые мы реагируем различным способом в sut. P>Я вам пишу про разные кейсы из того что вижу, а вы все пытаетесь причину во мне найти
Т.е. ты пытаешься своё "Я так вижу" за какой-то объективный факт.
P>·>Т.е. при тестировании контроллера совершенно неважно, что именно делает реальный modifyUser. Важно какие варианты результата он может вернуть и что на них реагируем в sut в соответствии с ожиданиями. P>А моки вам зачем для этого?
Чтобы описать варианты результата что может вернуть modifyUser.
P>>>А как это QA делают? Строчка требований — список тестов, где она фигурирует. P>·>А как узнать, что требования покрывают как можно больше возможных сценариев, а не только те, о которых не забыли подумать? P>Если мы очем то забыли, то никакой кавередж не спасет. Например, если вы забыли, что вам могут приходить данные разной природы, то всё, приплыли.
Это наверное для js актуально, где всё есть Object и где угодно может быть что угодно. При статической типизации вариантов разной природы не так уж много. Если modifyUser возвращает boolean, то тут только два варианта данных. А вот в js оно внезапно может выдать "FileNotFound" — и приехали.
P>>>Это я так трохи пошутил — идея в том, что нам всего то нужен один тест верхнего уровня. он у нас тупой как доска — буквально как http реквест-респонс P>·>Ага. Но он, в лучшем случае, покроет только один xxxComposition. А их будет на каждый метод контроллера. P>Это в любом случае так — e2e тесты должны покрыть весь входящий и исходящий трафик.
Вот тут тебе и аукнется цикломатическая сложность. Чтобы покрыть весть трафик — надо будет выполнить все возможные пути выполнения. Что просто дофига и очень долго.
P>>>Много где завезли, в джава коде я такое много где видел. А еще есть сравнение логов — если у вас вдруг появится лишний аудит, он обязательно сломает выхлоп. Это тоже блекбокс P>·>Это означает, что небольшое изменение в формате аудита ломает все тесты с образцами логов. Вот и представь, добавление небольшой штучки в аудит поломает все твои "несколько штук" тестов на каждый роут. P>Похоже, вы незнакомы с acceptance driven тестированием. В данном случае нам нужно просмотреть логи, и сделать коммит, если всё хорошо.
Это для игрушечных проектов ещё может только заработать. В более менее реальном проекте этих логов будут десятки тысяч. И просмотреть всё просто нереально. После тысячной строки диффа ты задолбаешься смотреть дальеш и тупо всё закоммитишь, незаметив особый случай в тысячепервой строке.
P>·>Именно. А должно быть несколько штук на весь сервис. Роутов может быть сотни. P>Тесты верхнего уровня в любом случае должны покрывать весь апи. Вы же своими моками пытаетесь искусственно уровень тестирования понизить.
Нет. Интеграционные тесты должны протестировать интеграцию, а не весь апи.
P>>>Например, ваш бл-сервис неявно зависит от бд-клиента, через репозиторий. А это значит, смена бд сначала сломает ваш репозиторий, а это сломает ваш бл сервис. P>·>Не понял, что значит "сломает"? Что за такая "смена бд"? P>Как ваш репозиторий фильтры принимает ?
Не очень знаком с этой терминологией.
P>·>Зачем? В тесте контрллера используется бл, поэтому моки только для него. И что творится в репе с т.з. контроллера — совершенно неважно. P>Если у вас полная изоляция, то так и будет. А если неполная, что чаще всего, то будет всё сломано. P>Собственно — что бы добиться этой самой хорошей изоляции в коде девелопера надо тренировать очень долго.
Если изоляция нужна, можно использовать интерфейсы.
P>>> прямых — одна, а непрямых — все дочерние от того же репозитория P>·>Неясно как "непрямые" зависимости влияют на _дизайн_ класса. Он их вообще никак не видит. Никак. P>Я вот регулярно вижу такое — контроллер вызывает сервис, передает тому объекты http request response. А вот сервис, чья задача это бл, вычитывает всё из req, res, лезет в базу пополам с репозиторием, и еще собственно бл считает, плюс кеширование итд. P>То есть, типичный разработчик не умеет пользоваться абстракциями и изоляцией, а пишет прямолинейный низкоуровневый код. И у него нет ни единого шанса протестировать такое чудовище кроме как моками.
Ну ликбез же.
P>>>Ничего странного — вы как то прошли мимо clean architecture. P>·>Я как-то мимо rest и ui прошел в принципе... если есть какая ссылка "clean architecture for morons", давай. P>https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html
Похоже это просто N-ая итерация очередной вариации самой правильной организации трёх слоёв типичного веб-приложения. MVC, MVP, MVI, MVVM, MVVM-C, VIPER, и ещё куча...
Причём тут моки — неясно.
Я вообще в последние N лет редко занимаюсь UI/web. У меня всякая поточка, очереди, сообщения, low/zero gc и прочее. Как там этот getUser сделать с zero gc — тот ещё вопрос.
Моки же общий инструмент, от деталей архитектуры зависит мало.
P>>>Я не знаю, в чем вы проблему видите. В жээс аннотация это обычный код, который инструментируется, и будет светиться или красным, или зеленым P>·>В js вроде вообще нет аннотаций. Не знаю что именно ты зовёшь аннотацией тогда. P>
А что за версия яп? Ну не важно. Это ещё можно простить, это просто маппинг урлов на объекты при отсутствии схемы REST. Как туда запихать аудит? Как аудит-аннотация будет описывать что, куда, когда и как аудитить?
P>·>И это всё юнит-тестится как ты обещал?! expext(Metadata.from(ControllerX, 'tryAccept')).metadata.to.match({...})? P>Смотря что — валидатор, это юнит-тест. А вот чтото нужна или нет авторизация, это можно переопределить конфигом или переменными окружения.
P>>>Зачем? Есть трассировка и правило — результат аудита можно сравнивать P>·>Не понял к чему ты это говоришь. На вход метода подаются какие-то парамы. У тебя на нём висит аннотация. Откуда аннотация узнает что/как извлечь из каких парамов чтобы записать что-то в аудит? P>Кое что надо и в самом методе вызывать, без этого работать не будет.
Именно! И накой тогда аннотация нужна для этого?
P> Видите нужные строчки — аудит работает, выхлоп совпадает с предыдущим забегом — точно все отлично. Не совпадает — точно есть проблемы.
Строчки где видим? Аудит может сообщения куда-нибудь в сокет слать или в бд отдельную писать.
И где валидировать, что для данных сценариев записываются нужная инфа в аудит?
Суть в том, что детали аудита каждой бизнес-операции можно покрывать туевой хучей отдельных юнит-тестов с моками на каждое возможное ожидание. И тут аннотации будут только мешаться. Интеграционный тест же можно написать один — что хоть какая-то бизнес-операция записала хоть какой-то аудит.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, Буравчик, Вы писали:
Б>Кстати, что делаете если параметров много (как в примере)? Выделяете под них структуру для хранения?
Выделяю. Так проще добавлять чего нибудь в будущем.
Б>2. Про логику
Б>Ниже пример того, что хотим протестировать. Есть обращение к БД и внешним сервисам. Как это будет протестировано?
Если дизайн именно такой, и надо вдруг покрыть это тестами, то вариантов не много
1. интеграционные тесты с какой то базой
2. разного сорта моки
для п.2 для разработчиков очень трудно не скатиться в тавтологические тесты вида "метод вызывает другой метод"
Б>Самый главный вопрос — как будет протестировано ветвление (if-ы, их может быть много).
Это ничего не меняет — вашем дизайне вариантов нету, и наличие ветвлений их не увеличит.
Проблема в самих зависимостях, их много, и в том, что ваш дизайн мутабельный
Попробуйте отказаться от мутабельного дизайна. Как минимум, три эффекта из четырех легко отделяются. Так что можно упростить до безобразия.
Здравствуйте, Pauel, Вы писали:
P>Если дизайн именно такой, и надо вдруг покрыть это тестами, то вариантов не много P>1. интеграционные тесты с какой то базой P>2. разного сорта моки
Что значит дизайн такой? Это логика приложения такая, как ее по другому задизайнить?
P>для п.2 для разработчиков очень трудно не скатиться в тавтологические тесты вида "метод вызывает другой метод"
С моками можно по-разному тестировать. Правильно — в моках возвращаемое значение фиксировать, а не тестировать факт вызовы.
Хотя в некоторых случаях и факт вызова тоже может быть важен
P>Это ничего не меняет — вашем дизайне вариантов нету, и наличие ветвлений их не увеличит.
Не понял, что понимается под вариантами. И почему ветвления не влияют.
P>Проблема в самих зависимостях, их много, и в том, что ваш дизайн мутабельный P>Попробуйте отказаться от мутабельного дизайна. Как минимум, три эффекта из четырех легко отделяются. Так что можно упростить до безобразия.
Я как раз и хочу понять, как эту логику сделать иммутабельной, чтобы все варианты протестить.
Как выделить эффекты, можно продемонстрировать?
С моками (стабами) я понимаю как это сделать — сайд-эффекты выделяются в интерфейсы (repo, external_service), мокаются, и далее вся логика проверяется как обычный юнит-тест.
Здравствуйте, Буравчик, Вы писали:
P>>Если дизайн именно такой, и надо вдруг покрыть это тестами, то вариантов не много P>>1. интеграционные тесты с какой то базой P>>2. разного сорта моки
Б>Что значит дизайн такой? Это логика приложения такая, как ее по другому задизайнить?
То и значит — вы приняли решениче, что все будет в одной функции мутабельным вперемешку с тяжелыми зависимостями.это и есть ваш дизайн
P>>для п.2 для разработчиков очень трудно не скатиться в тавтологические тесты вида "метод вызывает другой метод"
Б>С моками можно по-разному тестировать. Правильно — в моках возвращаемое значение фиксировать, а не тестировать факт вызовы.
Похоже, что моки про которые вы говорите, это фаулеровские стабы
Читайте фаулера
Mocks are objects pre-programmed with expectations which form a specification of the calls they are expected to receive
Мок в фаулеровской терминологии вещь бесполезная, хотя именно их чаще всего и лепят
P>>Это ничего не меняет — вашем дизайне вариантов нету, и наличие ветвлений их не увеличит.
Б>Не понял, что понимается под вариантами. И почему ветвления не влияют.
Варианты подходов к тестированию, я их вам показал. Ветвления влияют на количество тестов, но не на подход к тестированию
А вот конкретное оформление этого ветвления определяет то, какими могут быть тесты
P>>Проблема в самих зависимостях, их много, и в том, что ваш дизайн мутабельный P>>Попробуйте отказаться от мутабельного дизайна. Как минимум, три эффекта из четырех легко отделяются. Так что можно упростить до безобразия.
Б>Я как раз и хочу понять, как эту логику сделать иммутабельной, чтобы все варианты протестить.
Гнаться за иммутабельностью не сильно нужно, главное отделить зависимости, эффекты
Б>Как выделить эффекты, можно продемонстрировать?
У вас их 4 — чтение из бд, вызов сервиса, запись в бд, вызов кафки
Общий подход — эффекты преобразовать в вызовы интерфейса, инстанц которого приходит с параметрами
Потом преобразуете метод в класс, v1,v2,v3 уходят в члены класса
class Logic(v1, v2, v3): // параметры-значения в конструкторе
def run(load, load2, commit): // эффекты-зависимости здесь, эдакий аналог импорта
p = ctx.load(self.v1)
if что-то(p):
p2 = ctx.load2(self.v2) // load2 - абстракция так себе, должно быть хорошее имя
p = update(p, p2)
if что-то(p):
ctx.commit(self.v3)
return p
Теперь в тестах вы можете создать n троек значений, m результатов операций
И покроется все одной таблицей тестов n x m
И вам не надо мокать репозитории, запись в кафку, хттп вызов сервиса итд
def do_logic(v1,v2,v3):
l = Logic(v1,v2,v3)
p = l.run(
load = ..., repo // здесь и ниже хватит простой лямбды
load2 = ...., svc
commit = ..., repo+kafka // как вариант, для кафки можно протащить доп. имя, например event
);
Return serialize(p)
Теперь do-logic стал линейным, его покроет любой интеграционный код, который в любом случае должен быть
Любители моков правда очень обрадуются, умножат(sic!) Количество тестов за счет проверок "commit вызывается после двух load"
Потом небольшое изменение кода, сломает все такие тесты, даже если результат p у нас гарантированно сохранится
Теперь смотрите, что будет, если вы напрямую мокаете репозиторий в своем предыдущем коде
do_logic(v1, v2, v3):
p = repo.get(v1)
if что-то(p):
arg = repo.get(v2) // появился доп параметр, который надо вытащить из бд
p2 = external_service.request(v2, arg)
p = update(p, p2)
...
Теперь ваш мок repo.get должен считать вызовы — что его вызвали первый раз с v1, второй раз с v2, и это важно, т.к на втором разе вы должны вернуть кое что другое
И это именно то, чего делать не стоит — в сложной логике ваш мок репозитория будет чудовищем, которое мало будет походить на реальную часть системы
Чем более унивесальная зависимость, тем труднее её мокать, и тем выше шансы на ошибку
Если не хотите возиться с интерфейсом — можно вытащить repo.get и подобное в методы рядом с do_logic. Идея на самом деле так себе, этот подход стоит применять если у вас не сильно много зависимостей
do_logic(v1, v2, v3):
p = self.load(v1)
if что-то(p):
p2 = self.load2(v2)
p = update(p, p2)
if что-то(p):
self.commit(v3)
result = serialize(p)
return result
Выглядит компактно — только штука в том, что вам придется мокать сам класс, ну хотя бы через наследника под тесты или сетать все методы и надеятся что ничего не пропустите.
А вот зависимости как параметры вы можете понасоздвать или нагенерить на все случаи жизни
1 ошибки всех сортов
2 пустой результат
3 куча вариантов ответа
4 куча сочетаний того и этого
Здравствуйте, ·, Вы писали:
P>>Это я вам пример привел, для чего вообще люди мокают, когда всё прекрасно тестируется и без моков. ·>Т.е. проблема не в моках как таковых, а в том, что некоторые люди используют некоторые подходы и пишут корявый код?
Хорошесть инструмента это именно то как другие его понимают и умеют применять. Если код на моках в основном кривой — значит моки за 20 лет индустрия так и не осилила.
Вы вот сами путаете моки и стабы
> Это проблема ликбеза, а не моков. Ровно та же проблема есть в любых подходах тестирования.
Даем слово Фаулеру:
Mocks are objects pre-programmed with expectations which form a specification of the calls they are expected to receive
Видите — моки это про описание вызовов и связаные с этим ожидания
Вы же говорите про стабы. Если ваши утверждения в предыдущих постах поправить,заменив моки на стабы, будет более-менее понятно.
Но и наличие стабов это никакой не бенефит, а безысходность — там, где все обходится параметром, вам в тестах надо подкинуть метод нужной системы
P>>А зачем вам эти AsHex, AsBytes? Это же просто преставление. У вас есть токен — это значение. Его можно создать парой-тройкой способов, и сохранить так же. ·>Именно. 3 способа создания x 3 способа представления — уже девять комбинаций. У тебя будет либо девять функций, либо своя обёртка над сторонним api, изоморфная по сложности тому же api.
Ну так в джаве и пишут — перемножают сущности и радуются. Я портировал довольно много кода с джавы в тайпскрипт, и охренел от тамошних привычек.
Не нужны никакие "9 комбинаций" — нужно отделить создание и представление.
P>> Отсюда ясно, что нет нужды плодить те функции, что вы предложили, а следовательно и тестировать их тоже не нужно. ·>Нужда идёт из кода, из требований. Если у тебя достаточно сложная система, у тебя будет там все 9 комбинаций, а то и больше.
Это у вас так будет, тут я охотно верю.
P>>Всех дел — отделить данные от представления, и количество тестов уменьшается. ·>Количество может быть уменьшено, только если ты какое-то требование перестал тестировать.
Количество может быть уменьшено за счет подхода к дизайну.
Например, у нас есть Date, Time, DateTime, DateTimeOffset, LocalDateTime, Instant, Absolute, и целый набор всякой всячины.
Так вот, для создания DateTimeOffset нам не надо перебирать всё множество вариантов, как вы предлагаете
Можно свести ровно к одному DateTimeOffset.from({day, month, year, hour, minute, seconds, offset})
И каждый тип должен уметь две базовые операции
1. создание из примитивов
2. деструктурирование в примитивы
Соответсвенно вместо N! комбинаций нам надо протестировать всего 2N
А операция конверсии в прикладном коде будет вот такой DateTimeOffset.from({...date.toFields(), ...time.toFields, offset: serverOffset});
А если вы решили понасоздавать N! комбинаций — удачи, внятного покрытия вам не видеть, как своих ушей, хоть с моками, хоть без них.
P>>Насколько я понимаю, я вам показываю, как разные люди понимают моки. Вы же всё приписываете лично мне. ·>Что лично тебе я приписал?
Читайте себя внимательно — вы регулярно утверждаете, что именно у меня проблемы с моками, что именно у меня квалификация под сомнением.
Прекратите заниматься ерундой — я пишу о том, что вижу в т.ч. в джава коде.
Кто его писал этот джава код, может вы и ваши друзья?
P>>Вас всё тянет любое высказывание к абсурду свести. Естетсвенно, что городить вагон абстракций, ради того, что бы вычислить етаг не нужно. ·>А ты таки предложил новую абстракцию ввести в виде ApiToken.from.
ну да, ваше taraparam куда лучшая абстракция, не подкопаешься.
·>Именно. Зачем нам тогда нужен ApiToken.from?
Затем, зачем и ваш taraparam
P>>Тем не менее, пример на моках что я вам показал, он именно отсюда взят. ·>Пример на то и пример, чтобы показать как использовать моки. А в твоём примере было показано как _не надо_ писать код.
Именно — так не надо, но именно так пишут и это типичный пример, к сожалению
P>>А вот если вы замокали jsonwebtoken, то ваши тесты сломаются. И причина только в том, что вы замокали там где этого не надо делать. ·>В примере никакого jwt токена не было. Я не знаю ты о чём, у тебя где-то в голове какая-то более широкая картина, но к сожалению, я не очень хороший телепат.
Я вам привел конкретный пример — одну библиотеку для jwt заменили другой. Один клиент для бд, заменили другим. Один хттп клиент заменили другим...
P>>·>А какая разница? Ведь эту конструкцию надо будет тоже каким-то тестом покрыть. P>>Для этого есть интеграционный тест ·>Жуть. Т.е. ты не можешь что-то протестировать быстрыми тестами, приходится плодить медленные интеграционные и тривиальные ошибки обнаруживать только после запуска всего приложения. Спасибо, не хочу.
Интеграционные тесты это все выше уровня простых юнит тестов. Далеко не все интеграционные автоматически медленные. Условно, чистая функция вызывает десяток других чистых — опаньки, тест такой штуки будет интеграционным. Но нам это по барабану — они быстрые, можно обзапускаться хоть до посинения.
P>>Там где логика — там юнит-тесты, без моков, а там где интеграция — там интеграционные тесты, тоже без моков. ·>Слишком тяжелый подход. Только на мелких приложениях работает.
Наоборот. Большое количество дешовых тестов, тысячи минимум, и десятки-сотни интеграционных, самых тяжелых тестов по одному на каждый сценарий приложения — десяток другой.
P>>А задизайнить компоненты, что бы они не зависели друг от друга? ·>Это как? То что зависимости неявные — это не означает, что их нет.
Ну так вам это все в тестах надо отражать. Идете через моки — будьте добры отразить все неявные зависимости вида "а если на прошлом разе большой пейлоад, то сначала будем доедать выхлоп с предыдущей итерации"
P>>А если этого не делать, то и моки не нужны. ·>Ага-ага. Но тогда нужны ещё более медленные и неуклюжие интеграционные тесты, много
Интеграционные всех уровней нужны всегда. Их количество определяется
1. апи
2. сценариями
Большой апи — будет много тестов апи, иначе никак.
Много сценариев — будет много тестов e2e, и этого тоже не избежать.
P>>Зачем global? DI можно по разному использовать — речь же об этом. Посмотрите framework as a detail или clean architecture, сразу станет понятнее. ·>require это нифига не DI, это SL
В огороде бузина, а в киеве дядька. При чем здесь require ? framework as a detail и clean architecture это подходы к дизайну, архитектуре.
P>>С вашими моками покрытие будет хуже, кода больше, а интеграционные всё равно нужны ·>Интеграционные тесты тестируют интеграцию крупных, тяжелых компонент. А у тебя они тестируют всю мелкую функциональность.
Интеграционные тесты начинаются после самых простых юнит-тестов. компонентные тесты — это уже интеграционные. Функциональные — снова интеграционные. Апи — они же.
Приложение — снова они же. Система — снова интеграционные. E2E, acceptance — интеграционнее некуда.
P>>С моками чаще получается так — моками некто заставил попасть в этот else, а на проде этот else срабатывает совсем в другом контексте, и все валится именно там где покрыто тестом. ·>Очень вряд-ли, но допустим даже что-то вальнулось в проде. Изучив логи прода, ты с моками сможешь быстро воспроизвести сценарий и получить быстрый красный тест, который можно спокойно отлаживать и фиксить, без всякой интеграции.
С учетом того, что покрывали логированием вы под ваши моки из другой реальности, на проде может и не оказаться тех самых логов, что вам нужны в том самом месте.
P>>·>Это только для tryAcceptComposition. А таких врапперов придётся написать под каждый метод контроллера. И на каждый пару тестов. P>>Именно! И никакие моки этого не отменяют! ·>Они отменяют необходимость написания тучи этих самых xxxComposition, нет кода — нечего тестировать.
Неверно — тестируется не код, а соответствие ожиданиям, требованиями. какой бы дизайн у вас ни был — все равно нужны тесты апи, сценариев итд.
P>>Если у вас система из одного единственного роута и без зависимостей входящих-исходящих, то так и будет. А если роутов много, и есть зависимости, то надо интеграционными тестами покрыть весь входящий и исходящий трафик. ·>Не весь, а только покрывающий интеграцию компонент.
Тесты апи — интеграционные, и их должны быть минимум на количество ваших методов контроллеров, которые торчат наружу.
Мало ли по какой причине тот или иной контролер перестал вызываться снаружи — конфиг, переменные окружения, версия ос, рантайма, итд итд
А вы тут сказки рассказыете, что это делать не надо
P>>А следовательно и от бд. Например, вечная проблема с репозиториями, как туда фильтры передавать и всякие параметры, что бы не плодить сотни методов. Сменили эту механику — и весь код где прокидываются фильтры, издох — начинай переписывать тесты. ·>Это какая-то специфичная проблема в твоих проектах, я не в курсе.
Покажите как вы в репозиторий метод getAll передаете фильтры, сортировку итд
P>>Этого недостаточно. Нужен внятный интеграционный тест, его задача — следить что подсистема с правильными зависимостями соответствует ожиданиям ·>Задача инеграционного теста — тестировать места взаимодействия компонент, а не сценарии поведения.
Именно — кто даст гарантию что с тем или иным конфигом, рантаймом, переменными окружения, тот самый метод контролера не начнет вдруг гарантировано валиться ?
·>Как ассертить такую функцию в юнит-тесте? Как проверить, что текст запроса хотя бы синтаксически корректен? И как ассертить что параметры куда надо положены и транформация верна?
expect(query).to.deep.eq(pattern)
·>И далее, ну допустим ты как-то написал кучу тестов что getUser выглядит правильно. А дальше? Как убедиться, что настоящая субд будет работать с getUser именно так, как ты описал в ожиданиях теста репы?
вот, вы начинате понимать, для чего нужны интеграционные Здесь вам понадобится тест компонента с подклееной реальной бд. И без этого никак.
P>>Упадет интеграционный тест, тест вида "выполним операцию и проверим, что состояние юзера соответствует ожиданиям". ·>Плохо, это функциональная бизнес-логика, а не интеграция. Это должно ловиться юнит-тестом, а не интеграционным.
Это типичный пример интеграция — вы соединяете выходы одного со входами другого.
P>>Проблему может вызвать ветвление в контроллере — он должен быть линейным. ·>Т.е. нужно писать интеграционный тест как минимум для каждого метода контроллера. Это слишком дохрена.
Это в любом случае необходимо — у контролера всегда хрензнаетсколькилион зависимостей прямых и косвенных, и чтото да может пойти не так.
P>>Я вам пишу про разные кейсы из того что вижу, а вы все пытаетесь причину во мне найти ·>Т.е. ты пытаешься своё "Я так вижу" за какой-то объективный факт.
Для начала это вы пользуетесь местечковым понимаем моков, а не смотрите как это определено ну у того же Фаулера.
P>>А моки вам зачем для этого? ·>Чтобы описать варианты результата что может вернуть modifyUser.
Это называется стаб, а не мок
·>Это наверное для js актуально, где всё есть Object и где угодно может быть что угодно. При статической типизации вариантов разной природы не так уж много. Если modifyUser возвращает boolean, то тут только два варианта данных. А вот в js оно внезапно может выдать "FileNotFound" — и приехали.
И в джаве, и в дотнете полно разновидностей — ждете одно, приходит того же типа, похоже на то что надо, но чуточку другое. Бу-га-га.
А там где используют object, то отличий от js никакого нет
P>>Это в любом случае так — e2e тесты должны покрыть весь входящий и исходящий трафик. ·>Вот тут тебе и аукнется цикломатическая сложность. Чтобы покрыть весть трафик — надо будет выполнить все возможные пути выполнения. Что просто дофига и очень долго.
Это вы бы так делали. А здесь стоит вспомнить что такое апи тесты, и покрыть все что описании этого апи — как минимум роуты.
Иначе есть шанс что тот самый роут в нужный момент не сможет быть вызван, т.к. он просто задизаблен в конфиге
P>>Похоже, вы незнакомы с acceptance driven тестированием. В данном случае нам нужно просмотреть логи, и сделать коммит, если всё хорошо. ·>Это для игрушечных проектов ещё может только заработать. В более менее реальном проекте этих логов будут десятки тысяч. И просмотреть всё просто нереально. После тысячной строки диффа ты задолбаешься смотреть дальеш и тупо всё закоммитишь, незаметив особый случай в тысячепервой строке.
Вы там что, на каждый коммит всю систему переписываете?
P>>Тесты верхнего уровня в любом случае должны покрывать весь апи. Вы же своими моками пытаетесь искусственно уровень тестирования понизить. ·>Нет. Интеграционные тесты должны протестировать интеграцию, а не весь апи.
Апи это именно про интеграцию — вызов контроллера в конкретном окружении, что есть в чистом виде интеграция, т.к. у контроллера всегда есть хрензнаетсколькилион зависимостей, прямых и косвенных.
P>>Как ваш репозиторий фильтры принимает ? ·>Не очень знаком с этой терминологией.
Типичная функциональность —
дай всё по страницам по фильтру на дату отсортированым
Вот здесь пространство решений чудовищное.
P>>Собственно — что бы добиться этой самой хорошей изоляции в коде девелопера надо тренировать очень долго. ·>Если изоляция нужна, можно использовать интерфейсы.
Нужно. И девелопера на такое тренировать очень долго.
P>>То есть, типичный разработчик не умеет пользоваться абстракциями и изоляцией, а пишет прямолинейный низкоуровневый код. И у него нет ни единого шанса протестировать такое чудовище кроме как моками. ·>Ну ликбез же.
Ага, от ликбеза сразу в голове у разраба нарастут абстракции, как грибы. Забавляют курсы что пихают многие конторы "как правильно писать код" а потом удивляются, что разрабы понимают их рекоммендации буквально.
Абстракции выращиваются годами, к сожалению. Вспомните себя — абстракция агрегирование у вас начала расти в детском саду и сформировалась после окончания университета.
·>Похоже это просто N-ая итерация очередной вариации самой правильной организации трёх слоёв типичного веб-приложения. MVC, MVP, MVI, MVVM, MVVM-C, VIPER, и ещё куча... ·>Причём тут моки — неясно.
Старый подход — контролер вызывает сервис БД который вызывает БЛ через репозиторий итд. Моками надо обрезать зависимости на БД у БЛ.
Т.е. БЛ это клиент к БД, по факту.
В новом подходе БЛ, модель не имеет зависимости ни на репозиторий, на на БД. А раз так, то и моки не нужны.
Т.е. в центре у нас БЛ, модель, а вызывающий код является её клиентом, и именно там зависимости на БД итд.
Т.е. у нас слои поменялись местами.
·>Я вообще в последние N лет редко занимаюсь UI/web. У меня всякая поточка, очереди, сообщения, low/zero gc и прочее. Как там этот getUser сделать с zero gc — тот ещё вопрос. ·>Моки же общий инструмент, от деталей архитектуры зависит мало.
Актуальность моков зависит от вашей архитектуры. Если мы делаем БЛ, модель без зависимостей к БД, то и моки не нужны для тестирования.
·>А что за версия яп? Ну не важно. Это ещё можно простить, это просто маппинг урлов на объекты при отсутствии схемы REST. Как туда запихать аудит? Как аудит-аннотация будет описывать что, куда, когда и как аудитить?
Покажите ваш типичный код с аудитом.
P>>Кое что надо и в самом методе вызывать, без этого работать не будет. ·>Именно! И накой тогда аннотация нужна для этого?
Базовые гарантии. Некоторые из них можно выключить или доопределить конфигом итд.
·>Строчки где видим? Аудит может сообщения куда-нибудь в сокет слать или в бд отдельную писать. ·>И где валидировать, что для данных сценариев записываются нужная инфа в аудит?
Разумеется, это интеграция — что аудит интегрирован с тем или иным стораджем. 1 тест.
·>Суть в том, что детали аудита каждой бизнес-операции можно покрывать туевой хучей отдельных юнит-тестов с моками на каждое возможное ожидание. И тут аннотации будут только мешаться. Интеграционный тест же можно написать один — что хоть какая-то бизнес-операция записала хоть какой-то аудит.
Вот-вот. Только не ясно, чем вам мешают аннотации и зачем моки
Здравствуйте, Pauel, Вы писали:
P>>>Это я вам пример привел, для чего вообще люди мокают, когда всё прекрасно тестируется и без моков. P>·>Т.е. проблема не в моках как таковых, а в том, что некоторые люди используют некоторые подходы и пишут корявый код? P>Хорошесть инструмента это именно то как другие его понимают и умеют применять. Если код на моках в основном кривой — значит моки за 20 лет индустрия так и не осилила. P>Вы вот сами путаете моки и стабы
Ок, пусть. Не вижу, в чём важность этой терминологии. Я использую название "мок", потому что библиотека называется mockito и создаются эти штуки функцией mock или аннотацией @Mock. Если тебе комфортнее стаб, пусть. Хоть горшком назови, только в печку не ставь.
>> Это проблема ликбеза, а не моков. Ровно та же проблема есть в любых подходах тестирования. P>Даем слово Фаулеру: P>
P>Mocks are objects pre-programmed with expectations which form a specification of the calls they are expected to receive
P>Видите — моки это про описание вызовов и связаные с этим ожидания
Я увидел главное: в твоём примере использовался некий jest mock и судя по его доке там, честно говоря, неясно как писать вменяемый код.
P>Вы же говорите про стабы. Если ваши утверждения в предыдущих постах поправить,заменив моки на стабы, будет более-менее понятно.
Ок, гуд.
P>Но и наличие стабов это никакой не бенефит, а безысходность — там, где все обходится параметром, вам в тестах надо подкинуть метод нужной системы
Параметр подразумевает другую сигнатуру метода. Передавая парам через конструктор, просто шаришь его между несколькими методами.
P>>>А зачем вам эти AsHex, AsBytes? Это же просто преставление. У вас есть токен — это значение. Его можно создать парой-тройкой способов, и сохранить так же. P>·>Именно. 3 способа создания x 3 способа представления — уже девять комбинаций. У тебя будет либо девять функций, либо своя обёртка над сторонним api, изоморфная по сложности тому же api. P>Ну так в джаве и пишут — перемножают сущности и радуются.
Причём тут перемножают? Это диктуется требованиями. Если в json тебе нужен b64, а аналогичном месте protobuf тебе нужен Bytes, то хоть на bf пиши, у тебя будут комбинации.
P>Я портировал довольно много кода с джавы в тайпскрипт, и охренел от тамошних привычек.
Портировал это значит, как минимум, ты по ходу удалял гору легаси кода, совместимость с устаревшим, етс.
P>Не нужны никакие "9 комбинаций" — нужно отделить создание и представление.
Так в изначальном дизайне crypto так и было — создаём hmac нужного алгоритма, потом выводим в нужном представлении. Ты почему-то упаковал это в одну функцию и назвал успехом.
P>>> Отсюда ясно, что нет нужды плодить те функции, что вы предложили, а следовательно и тестировать их тоже не нужно. P>·>Нужда идёт из кода, из требований. Если у тебя достаточно сложная система, у тебя будет там все 9 комбинаций, а то и больше. P>Это у вас так будет, тут я охотно верю.
У кого "у нас"? Если бы никому не требовались разные виды токенов в разном представлении, то в библиотеке crypto был бы "makeToken" с ровно одним парамом.
Такое ощущение, что ты говоришь о дизайне какой-то домашней странички, а не о сложной системе.
P>>>Всех дел — отделить данные от представления, и количество тестов уменьшается. P>·>Количество может быть уменьшено, только если ты какое-то требование перестал тестировать. P>Количество может быть уменьшено за счет подхода к дизайну.
Я не понял, разговор был о crypto, теперь на какой-то time-api переключился. Я за твоим полётом мысли не успеваю.
P>А операция конверсии в прикладном коде будет вот такой DateTimeOffset.from({...date.toFields(), ...time.toFields, offset: serverOffset});
Это только на js годится такое писать. Со статической типизацией такое не прокатит.
P>А если вы решили понасоздавать N! комбинаций — удачи, внятного покрытия вам не видеть, как своих ушей, хоть с моками, хоть без них.
Я вроде рассказал, как упрощать тестирование комбинаций.
P>>>Насколько я понимаю, я вам показываю, как разные люди понимают моки. Вы же всё приписываете лично мне. P>·>Что лично тебе я приписал? P>Читайте себя внимательно — вы регулярно утверждаете, что именно у меня проблемы с моками, что именно у меня квалификация под сомнением.
Так ты сам откровенно пишешь: "за 20 лет индустрия так и не осилила". Я сталкивался с другой индустрией, в которой с моками (или стабами?) проблем таких нет.
P>Прекратите заниматься ерундой — я пишу о том, что вижу в т.ч. в джава коде. P>Кто его писал этот джава код, может вы и ваши друзья?
Не знаю о котором коде ты говоришь.
P>>>Вас всё тянет любое высказывание к абсурду свести. Естетсвенно, что городить вагон абстракций, ради того, что бы вычислить етаг не нужно. P>·>А ты таки предложил новую абстракцию ввести в виде ApiToken.from. P>ну да, ваше taraparam куда лучшая абстракция, не подкопаешься.
Чё? Абстракция уже была, в crypto api. Но тебе она показалась слишком сложной и ты сделал partial application.
P>·>Именно. Зачем нам тогда нужен ApiToken.from? P>Затем, зачем и ваш taraparam
Чё?
P>>>Тем не менее, пример на моках что я вам показал, он именно отсюда взят. P>·>Пример на то и пример, чтобы показать как использовать моки. А в твоём примере было показано как _не надо_ писать код. P>Именно — так не надо, но именно так пишут и это типичный пример, к сожалению
Может в твоей индустрии. В java так не пишут, ну если только совсем вчерашние студенты, но PR такое не пройдёт.
P>>>А вот если вы замокали jsonwebtoken, то ваши тесты сломаются. И причина только в том, что вы замокали там где этого не надо делать. P>·>В примере никакого jwt токена не было. Я не знаю ты о чём, у тебя где-то в голове какая-то более широкая картина, но к сожалению, я не очень хороший телепат. P>Я вам привел конкретный пример — одну библиотеку для jwt заменили другой. Один клиент для бд, заменили другим. Один хттп клиент заменили другим...
Где что и как замокали — я не знаю. О чём ты тут споришь — вообще непонятно.
P>>>·>А какая разница? Ведь эту конструкцию надо будет тоже каким-то тестом покрыть. P>>>Для этого есть интеграционный тест P>·>Жуть. Т.е. ты не можешь что-то протестировать быстрыми тестами, приходится плодить медленные интеграционные и тривиальные ошибки обнаруживать только после запуска всего приложения. Спасибо, не хочу. P>Интеграционные тесты это все выше уровня простых юнит тестов. Далеко не все интеграционные автоматически медленные. Условно, чистая функция вызывает десяток других чистых — опаньки, тест такой штуки будет интеграционным. Но нам это по барабану — они быстрые, можно обзапускаться хоть до посинения.
Ты куда-то мимо пошел. Не хочу вдаваться в подробности терминологии юнит-инт. Суть в том, что в твоём предложенном тесте появляется connectionString, значит "приходится плодить медленные тесты и тривиальные ошибки обнаруживать только после запуска всего приложения".
P>>>Там где логика — там юнит-тесты, без моков, а там где интеграция — там интеграционные тесты, тоже без моков. P>·>Слишком тяжелый подход. Только на мелких приложениях работает. P>Наоборот. Большое количество дешовых тестов, тысячи минимум, и десятки-сотни интеграционных, самых тяжелых тестов по одному на каждый сценарий приложения — десяток другой.
Какой тесто обнаружит ошибку в коде "repository.updateUser(newUser, oldUser)" и как? Вот это "выполним операцию и проверим, что состояние юзера соответствует ожиданиям"? Что должно быть поднято для прогона такого теста?
P>>>А задизайнить компоненты, что бы они не зависели друг от друга? P>·>Это как? То что зависимости неявные — это не означает, что их нет. P>Ну так вам это все в тестах надо отражать. Идете через моки — будьте добры отразить все неявные зависимости вида "а если на прошлом разе большой пейлоад, то сначала будем доедать выхлоп с предыдущей итерации"
Ничего не понял.
P>>>А если этого не делать, то и моки не нужны. P>·>Ага-ага. Но тогда нужны ещё более медленные и неуклюжие интеграционные тесты, много P>Интеграционные всех уровней нужны всегда. Их количество определяется P>1. апи P>2. сценариями P>Большой апи — будет много тестов апи, иначе никак. P>Много сценариев — будет много тестов e2e, и этого тоже не избежать.
Под интеграцией я понимал в данном случае твоё "curl -X POST". Это плохой тест, медленный, неуклюжий. Число таких тестов надо стараться минимизировать.
P>>>Зачем global? DI можно по разному использовать — речь же об этом. Посмотрите framework as a detail или clean architecture, сразу станет понятнее. P>·>require это нифига не DI, это SL P>В огороде бузина, а в киеве дядька. При чем здесь require ? framework as a detail и clean architecture это подходы к дизайну, архитектуре.
В том, что в твоём коде jest подменял код внутри глобального реестра require.
P>>>С вашими моками покрытие будет хуже, кода больше, а интеграционные всё равно нужны P>·>Интеграционные тесты тестируют интеграцию крупных, тяжелых компонент. А у тебя они тестируют всю мелкую функциональность. P>Интеграционные тесты начинаются после самых простых юнит-тестов. компонентные тесты — это уже интеграционные. Функциональные — снова интеграционные. Апи — они же. P>Приложение — снова они же. Система — снова интеграционные. E2E, acceptance — интеграционнее некуда.
whatever, не хочу в буквоедство играть.
P>>>С моками чаще получается так — моками некто заставил попасть в этот else, а на проде этот else срабатывает совсем в другом контексте, и все валится именно там где покрыто тестом. P>·>Очень вряд-ли, но допустим даже что-то вальнулось в проде. Изучив логи прода, ты с моками сможешь быстро воспроизвести сценарий и получить быстрый красный тест, который можно спокойно отлаживать и фиксить, без всякой интеграции. P>С учетом того, что покрывали логированием вы под ваши моки из другой реальности, на проде может и не оказаться тех самых логов, что вам нужны в том самом месте.
Это твои фантазии.
P>>>Именно! И никакие моки этого не отменяют! P>·>Они отменяют необходимость написания тучи этих самых xxxComposition, нет кода — нечего тестировать. P>Неверно — тестируется не код, а соответствие ожиданиям, требованиями. какой бы дизайн у вас ни был — все равно нужны тесты апи, сценариев итд.
Опять буквоедство какое-то. Что по-твоему тестируется на соответствие ожиданиям, требованиям?
P>>>Если у вас система из одного единственного роута и без зависимостей входящих-исходящих, то так и будет. А если роутов много, и есть зависимости, то надо интеграционными тестами покрыть весь входящий и исходящий трафик. P>·>Не весь, а только покрывающий интеграцию компонент. P>Тесты апи — интеграционные, и их должны быть минимум на количество ваших методов контроллеров, которые торчат наружу. P>Мало ли по какой причине тот или иной контролер перестал вызываться снаружи — конфиг, переменные окружения, версия ос, рантайма, итд итд P>А вы тут сказки рассказыете, что это делать не надо
Суть в том, что тесты апи можно тестировать без реальной субд|кафки и т.п. И описывать ожидания, что updateUser сделан именно с (newUser, oldUser), а не наоборот.
P>>>А следовательно и от бд. Например, вечная проблема с репозиториями, как туда фильтры передавать и всякие параметры, что бы не плодить сотни методов. Сменили эту механику — и весь код где прокидываются фильтры, издох — начинай переписывать тесты. P>·>Это какая-то специфичная проблема в твоих проектах, я не в курсе. P>Покажите как вы в репозиторий метод getAll передаете фильтры, сортировку итд
Не знаю, не припомню где у нас есть такое. Но наверное был бы какой-нибдуь value object, который передаёт необходимые настройки фильтров и сортировок.
P>>>Этого недостаточно. Нужен внятный интеграционный тест, его задача — следить что подсистема с правильными зависимостями соответствует ожиданиям P>·>Задача инеграционного теста — тестировать места взаимодействия компонент, а не сценарии поведения. P>Именно — кто даст гарантию что с тем или иным конфигом, рантаймом, переменными окружения, тот самый метод контролера не начнет вдруг гарантировано валиться ?
Никто.
P>·>Как ассертить такую функцию в юнит-тесте? Как проверить, что текст запроса хотя бы синтаксически корректен? И как ассертить что параметры куда надо положены и транформация верна? P>
P>expect(query).to.deep.eq(pattern)
P>
Ты не ответил ни на один заданный вопрос. Напомню: этот самый query был "select * from users where id=? + параметры + трансформации".
P>·>И далее, ну допустим ты как-то написал кучу тестов что getUser выглядит правильно. А дальше? Как убедиться, что настоящая субд будет работать с getUser именно так, как ты описал в ожиданиях теста репы? P>вот, вы начинате понимать, для чего нужны интеграционные Здесь вам понадобится тест компонента с подклееной реальной бд. И без этого никак.
Т.е. та же ж, вид в профиль, но теперь большинство логики без реальной бд не протестировать. В случае с репо реальная бд нужна только для тестирования самого слоя взаимодействия с бд, а остальное может мокаться (стабиться?). Ты же предлагаешь всё приложение тестировать с реальной бд.
P>>>Упадет интеграционный тест, тест вида "выполним операцию и проверим, что состояние юзера соответствует ожиданиям". P>·>Плохо, это функциональная бизнес-логика, а не интеграция. Это должно ловиться юнит-тестом, а не интеграционным. P>Это типичный пример интеграция — вы соединяете выходы одного со входами другого.
Ну да. Но это не означает, что для этого необходимо тестировать только с реальной бд.
P>>>Проблему может вызвать ветвление в контроллере — он должен быть линейным. P>·>Т.е. нужно писать интеграционный тест как минимум для каждого метода контроллера. Это слишком дохрена. P>Это в любом случае необходимо — у контролера всегда хрензнаетсколькилион зависимостей прямых и косвенных, и чтото да может пойти не так.
Для этого и объединяют толпу зависимостей в одну. Чтобы не N! было.
P>>>Я вам пишу про разные кейсы из того что вижу, а вы все пытаетесь причину во мне найти P>·>Т.е. ты пытаешься своё "Я так вижу" за какой-то объективный факт. P>Для начала это вы пользуетесь местечковым понимаем моков, а не смотрите как это определено ну у того же Фаулера.
Возможно, это всё терминология.
P>>>А моки вам зачем для этого? P>·>Чтобы описать варианты результата что может вернуть modifyUser. P>Это называется стаб, а не мок
Ок, пусть.
P>·>Это наверное для js актуально, где всё есть Object и где угодно может быть что угодно. При статической типизации вариантов разной природы не так уж много. Если modifyUser возвращает boolean, то тут только два варианта данных. А вот в js оно внезапно может выдать "FileNotFound" — и приехали. P>И в джаве, и в дотнете полно разновидностей — ждете одно, приходит того же типа, похоже на то что надо, но чуточку другое. Бу-га-га. P>А там где используют object, то отличий от js никакого нет
Ну обычно object стараются избегать использовать.
P>>>Это в любом случае так — e2e тесты должны покрыть весь входящий и исходящий трафик. P>·>Вот тут тебе и аукнется цикломатическая сложность. Чтобы покрыть весть трафик — надо будет выполнить все возможные пути выполнения. Что просто дофига и очень долго. P>Это вы бы так делали. А здесь стоит вспомнить что такое апи тесты, и покрыть все что описании этого апи — как минимум роуты. P>Иначе есть шанс что тот самый роут в нужный момент не сможет быть вызван, т.к. он просто задизаблен в конфиге
Не понял, ну раз задизаблен, значит и нельзя вызвать. Это является не ошибкой, а конфигурацией системы. Неясно что тут в принципе тестировать.
P>>>Похоже, вы незнакомы с acceptance driven тестированием. В данном случае нам нужно просмотреть логи, и сделать коммит, если всё хорошо. P>·>Это для игрушечных проектов ещё может только заработать. В более менее реальном проекте этих логов будут десятки тысяч. И просмотреть всё просто нереально. После тысячной строки диффа ты задолбаешься смотреть дальеш и тупо всё закоммитишь, незаметив особый случай в тысячепервой строке. P>Вы там что, на каждый коммит всю систему переписываете?
Я описываю ситуацию — добавили новое общее поле в аудит — везде в этих твоих логах каждого теста — строчка аудита выглядит чуть по-другому.
P>>>Тесты верхнего уровня в любом случае должны покрывать весь апи. Вы же своими моками пытаетесь искусственно уровень тестирования понизить. P>·>Нет. Интеграционные тесты должны протестировать интеграцию, а не весь апи. P>Апи это именно про интеграцию — вызов контроллера в конкретном окружении, что есть в чистом виде интеграция, т.к. у контроллера всегда есть хрензнаетсколькилион зависимостей, прямых и косвенных.
Апи это про интерфейс системы. Интеграция тут причём?
P>>>Как ваш репозиторий фильтры принимает ? P>·>Не очень знаком с этой терминологией. P>Типичная функциональность — P>
P>дай всё по страницам по фильтру на дату отсортированым
P>
P>Вот здесь пространство решений чудовищное.
Ну да. Поэтому "как ваш репозиторий принимает" зависит от столько всего, что даже не знаю с чего начать. И главное причём тут моки, неясно.
P>>>Собственно — что бы добиться этой самой хорошей изоляции в коде девелопера надо тренировать очень долго. P>·>Если изоляция нужна, можно использовать интерфейсы. P>Нужно. И девелопера на такое тренировать очень долго.
Зависит от. Интерфейсы плодить без повода, тоже не хорошо.
P>·>Похоже это просто N-ая итерация очередной вариации самой правильной организации трёх слоёв типичного веб-приложения. MVC, MVP, MVI, MVVM, MVVM-C, VIPER, и ещё куча... P>·>Причём тут моки — неясно. P>Старый подход — контролер вызывает сервис БД который вызывает БЛ через репозиторий итд. Моками надо обрезать зависимости на БД у БЛ. P>Т.е. БЛ это клиент к БД, по факту.
Моками (стабами?) обрезается БД и прочие внешние вещи от БЛ. Чтобы при тестировании БЛ можно было быстро тестировать логику кода, без всяких сетевых соединений и запуска всего приложения.
P>В новом подходе БЛ, модель не имеет зависимости ни на репозиторий, на на БД. А раз так, то и моки не нужны. P>Т.е. в центре у нас БЛ, модель, а вызывающий код является её клиентом, и именно там зависимости на БД итд. P>Т.е. у нас слои поменялись местами.
Да пофиг. Эти слои можно жонглировать как сейчас модно. Это меняется каждый год.
P>·>Я вообще в последние N лет редко занимаюсь UI/web. У меня всякая поточка, очереди, сообщения, low/zero gc и прочее. Как там этот getUser сделать с zero gc — тот ещё вопрос. P>·>Моки же общий инструмент, от деталей архитектуры зависит мало. P>Актуальность моков зависит от вашей архитектуры. Если мы делаем БЛ, модель без зависимостей к БД, то и моки не нужны для тестирования.
Лично для меня главное разделение — это конструкты ЯП и всё что снаружи от ЯП. Когда код не лезет куда-то наружу, без сокетов, файлов, да если ещё и без многопоточки, и т.п., то тестировать такой код — одно удовольствие.
А как компоненты называются, controller, presenter, interactor, как взаимодействуют — это мелочи жизни, не знаю зачем это всегда все так громко обсуждать любят.
P>·>А что за версия яп? Ну не важно. Это ещё можно простить, это просто маппинг урлов на объекты при отсутствии схемы REST. Как туда запихать аудит? Как аудит-аннотация будет описывать что, куда, когда и как аудитить? P>Покажите ваш типичный код с аудитом.
А что там показывать? В нужном месте стоит audit.send(new AuditMessage(....)) или типа того. Повторюсь, это всё не важно какие конкретно это компоненты, по итогу это просто всё сводится к вызовам методов с параметрами.
P>>>Кое что надо и в самом методе вызывать, без этого работать не будет. P>·>Именно! И накой тогда аннотация нужна для этого? P>Базовые гарантии. Некоторые из них можно выключить или доопределить конфигом итд.
Базовые гарантии чего?
P>·>Строчки где видим? Аудит может сообщения куда-нибудь в сокет слать или в бд отдельную писать. P>·>И где валидировать, что для данных сценариев записываются нужная инфа в аудит? P>Разумеется, это интеграция — что аудит интегрирован с тем или иным стораджем. 1 тест.
"для данных сценариев записываются нужная инфа". Это где-то нужно валидировать, что для некой бизнес-операции в соответвтующих условиях записывается соответвтующий требованиям сообщение аудита.
P>·>Суть в том, что детали аудита каждой бизнес-операции можно покрывать туевой хучей отдельных юнит-тестов с моками на каждое возможное ожидание. И тут аннотации будут только мешаться. Интеграционный тест же можно написать один — что хоть какая-то бизнес-операция записала хоть какой-то аудит. P>Вот-вот. Только не ясно, чем вам мешают аннотации и зачем моки
Как я понял скорее всего разница в том, что я обычно пишу на статике. Аннотации мешают тем, что их сложнее тестировать, контролировать типы. Приходится вместо простых вызовов методов поднимать очень много компонент и смотреть, что процессоры аннотаций сработали правильно. Т.е. вместо того, чтобы просто вызвать метод, мы пишем кучу слоёв какого-то мусора, чтобы вызывать ровно тот же метод.
А ты используешь динамические яп, и компилятор и так ничего делать не может, а значит и нечего терять.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>Вы вот сами путаете моки и стабы ·>Ок, пусть. Не вижу, в чём важность этой терминологии. Я использую название "мок", потому что библиотека называется mockito и создаются эти штуки функцией mock или аннотацией @Mock. Если тебе комфортнее стаб, пусть. Хоть горшком назови, только в печку не ставь.
Моки изначально предназначались для тестов вида "вызываем вон то, вон так, в такой последовательности"
P>>Ну так в джаве и пишут — перемножают сущности и радуются. ·>Причём тут перемножают? Это диктуется требованиями. Если в json тебе нужен b64, а аналогичном месте protobuf тебе нужен Bytes, то хоть на bf пиши, у тебя будут комбинации.
У вас — охотно верю. Я вам пример приводил, про время, вам он ожидаемо не понравился — язык не тот
P>>Я портировал довольно много кода с джавы в тайпскрипт, и охренел от тамошних привычек. ·>Портировал это значит, как минимум, ты по ходу удалял гору легаси кода, совместимость с устаревшим, етс.
С чего бы портирование стало означать удаление легаси ?
P>>Не нужны никакие "9 комбинаций" — нужно отделить создание и представление. ·>Так в изначальном дизайне crypto так и было — создаём hmac нужного алгоритма, потом выводим в нужном представлении. Ты почему-то упаковал это в одну функцию и назвал успехом.
В данном случае мне не надо переживать за поломаные тесты, если понадобится другой алгоритм, другая либа, итд.
Вот понадобился не hmac а что другое — в файлике samples поменял десяток значений, и всё
А ваша альтернатива этому — еще и тесты перебулшитить.
·>У кого "у нас"? Если бы никому не требовались разные виды токенов в разном представлении, то в библиотеке crypto был бы "makeToken" с ровно одним парамом. ·>Такое ощущение, что ты говоришь о дизайне какой-то домашней странички, а не о сложной системе.
Ну да, этож только у вас сложные системы.
P>>Количество может быть уменьшено за счет подхода к дизайну. ·>Я не понял, разговор был о crypto, теперь на какой-то time-api переключился. Я за твоим полётом мысли не успеваю.
У вас любой из примеров вызывает какой то негатив
P>>А операция конверсии в прикладном коде будет вот такой DateTimeOffset.from({...date.toFields(), ...time.toFields, offset: serverOffset}); ·>Это только на js годится такое писать. Со статической типизацией такое не прокатит.
Успокойтесь — это все статически контролируется, только в вашу джаву такие фичи еще не завезли.
P>>А если вы решили понасоздавать N! комбинаций — удачи, внятного покрытия вам не видеть, как своих ушей, хоть с моками, хоть без них. ·>Я вроде рассказал, как упрощать тестирование комбинаций.
Вы уже показали — перебулшитить все тесты, когда можно ограничиться десятком строчек на весь проект.
P>>Читайте себя внимательно — вы регулярно утверждаете, что именно у меня проблемы с моками, что именно у меня квалификация под сомнением. ·>Так ты сам откровенно пишешь: "за 20 лет индустрия так и не осилила". Я сталкивался с другой индустрией, в которой с моками (или стабами?) проблем таких нет.
Ну да — для вас перебулшитить тесты проблемой не является Еще и настаиваете, что так и надо.
P>>Именно — так не надо, но именно так пишут и это типичный пример, к сожалению ·>Может в твоей индустрии. В java так не пишут, ну если только совсем вчерашние студенты, но PR такое не пройдёт.
Проходит же. Вот я и интересуюсь, кто настрочил горы непотребства P>>Интеграционные тесты это все выше уровня простых юнит тестов. Далеко не все интеграционные автоматически медленные. Условно, чистая функция вызывает десяток других чистых — опаньки, тест такой штуки будет интеграционным. Но нам это по барабану — они быстрые, можно обзапускаться хоть до посинения. ·>Ты куда-то мимо пошел. Не хочу вдаваться в подробности терминологии юнит-инт. Суть в том, что в твоём предложенном тесте появляется connectionString, значит "приходится плодить медленные тесты и тривиальные ошибки обнаруживать только после запуска всего приложения".
Эта разновидность тестов нужна и вам.
P>>Наоборот. Большое количество дешовых тестов, тысячи минимум, и десятки-сотни интеграционных, самых тяжелых тестов по одному на каждый сценарий приложения — десяток другой. ·>Какой тесто обнаружит ошибку в коде "repository.updateUser(newUser, oldUser)" и как? Вот это "выполним операцию и проверим, что состояние юзера соответствует ожиданиям"? Что должно быть поднято для прогона такого теста?
да вобщем то ничего, какая нибудь ин-мемори дб и инстанц контроллера или юз-кейса.
P>>·>Ага-ага. Но тогда нужны ещё более медленные и неуклюжие интеграционные тесты, много P>>Интеграционные всех уровней нужны всегда. Их количество определяется P>>1. апи P>>2. сценариями P>>Большой апи — будет много тестов апи, иначе никак. P>>Много сценариев — будет много тестов e2e, и этого тоже не избежать. ·>Под интеграцией я понимал в данном случае твоё "curl -X POST". Это плохой тест, медленный, неуклюжий. Число таких тестов надо стараться минимизировать.
Такие тесты нужны в любом случае, моки-стабы от них не избавляют, это иллюзия.
P>>В огороде бузина, а в киеве дядька. При чем здесь require ? framework as a detail и clean architecture это подходы к дизайну, архитектуре. ·>В том, что в твоём коде jest подменял код внутри глобального реестра require.
Я вам пример привел, как применяют моки. Обмокать можно что угодно, в т.ч. и в джаве-дотнете
P>>·>Они отменяют необходимость написания тучи этих самых xxxComposition, нет кода — нечего тестировать. P>>Неверно — тестируется не код, а соответствие ожиданиям, требованиями. какой бы дизайн у вас ни был — все равно нужны тесты апи, сценариев итд. ·>Опять буквоедство какое-то. Что по-твоему тестируется на соответствие ожиданиям, требованиям?
Продукт, система, приложение, апи, компонент, модуль. Для теста именно кода у нас другие инструменты — код-ревью, линт, дизайн-ревью, статические анализаторы, итд.
P>>А вы тут сказки рассказыете, что это делать не надо ·>Суть в том, что тесты апи можно тестировать без реальной субд|кафки и т.п. И описывать ожидания, что updateUser сделан именно с (newUser, oldUser), а не наоборот.
Можно. И это делается без моков. Если мы заложимся на значение или состояние, то получим куда больше гарантий.
В функции средний девелопер может понаделывать ошибок куда больше, чем перепутать old и new.
P>>Покажите как вы в репозиторий метод getAll передаете фильтры, сортировку итд ·>Не знаю, не припомню где у нас есть такое. Но наверное был бы какой-нибдуь value object, который передаёт необходимые настройки фильтров и сортировок.
Вот вы и встряли Чем лучше изолируете, тем больше вам тестировать. Тут помогло бы использование какого dsl. В том же дотнете есть такое, и всё равно надо думать, что передать в репозиторий, быть в курсе, съест ли тамошний провайдер конкретную функцию или нет.
P>>Именно — кто даст гарантию что с тем или иным конфигом, рантаймом, переменными окружения, тот самый метод контролера не начнет вдруг гарантировано валиться ? ·>Никто.
Именно! А потому нам все контроллеры нужно тестировать в апи тестах — тем самым мы исключаем добрый десяток классов проблем.
P>>
P>>expect(query).to.deep.eq(pattern)
P>>
·>Ты не ответил ни на один заданный вопрос. Напомню: этот самый query был "select * from users where id=? + параметры + трансформации".
Что вас смущает? deep.eq проверит всё, что надо. query это не строка, объект с конкретной структурой, чтото навроде
{
sql: 'select * from users where id=?',
params: [id],
transformations: {
in: [fn1],
out: [fn2]
}
}
Сами трансформации тестируются отдельно, обычными юнитами, например expect(fn1(user)).to.eq(user.id);
P>>вот, вы начинате понимать, для чего нужны интеграционные Здесь вам понадобится тест компонента с подклееной реальной бд. И без этого никак. ·>Т.е. та же ж, вид в профиль, но теперь большинство логики без реальной бд не протестировать. В случае с репо реальная бд нужна только для тестирования самого слоя взаимодействия с бд, а остальное может мокаться (стабиться?). Ты же предлагаешь всё приложение тестировать с реальной бд.
Вы все думаете в единицах старого дизайна, когда БЛ прибита гвоздями к бд.
P>>Это типичный пример интеграция — вы соединяете выходы одного со входами другого. ·>Ну да. Но это не означает, что для этого необходимо тестировать только с реальной бд.
Нам нужна любая бд, что прогонять некоторые тесты, обычно небольшое количество.
P>>Это в любом случае необходимо — у контролера всегда хрензнаетсколькилион зависимостей прямых и косвенных, и чтото да может пойти не так. ·>Для этого и объединяют толпу зависимостей в одну. Чтобы не N! было.
Объединяйте что угодно — а контролер все равно придется вызвать в АПИ тестах.
P>>А там где используют object, то отличий от js никакого нет ·>Ну обычно object стараются избегать использовать.
Шота я этого за 4 года не заметил
P>>Иначе есть шанс что тот самый роут в нужный момент не сможет быть вызван, т.к. он просто задизаблен в конфиге ·>Не понял, ну раз задизаблен, значит и нельзя вызвать. Это является не ошибкой, а конфигурацией системы. Неясно что тут в принципе тестировать.
Юзеру так и скажете — мы не можем вернуть ваши деньги, потому что у нас в конфигурации возвраты отключены.
P>>Вы там что, на каждый коммит всю систему переписываете? ·>Я описываю ситуацию — добавили новое общее поле в аудит — везде в этих твоих логах каждого теста — строчка аудита выглядит чуть по-другому.
Добавили, посмотрели дифом, вкомитали. Вам же не надо сразу всё обрабатывать.
P>>Апи это именно про интеграцию — вызов контроллера в конкретном окружении, что есть в чистом виде интеграция, т.к. у контроллера всегда есть хрензнаетсколькилион зависимостей, прямых и косвенных. ·>Апи это про интерфейс системы. Интеграция тут причём?
Если апи возвращает то, что надо, это значит что у вас связка конфиг-di-sl-рантайм-переменные-итд склеено правильно.
P>>Старый подход — контролер вызывает сервис БД который вызывает БЛ через репозиторий итд. Моками надо обрезать зависимости на БД у БЛ. P>>Т.е. БЛ это клиент к БД, по факту. ·>Моками (стабами?) обрезается БД и прочие внешние вещи от БЛ. Чтобы при тестировании БЛ можно было быстро тестировать логику кода, без всяких сетевых соединений и запуска всего приложения.
Можно. Это старый подход.
P>>В новом подходе БЛ, модель не имеет зависимости ни на репозиторий, на на БД. А раз так, то и моки не нужны. P>>Т.е. в центре у нас БЛ, модель, а вызывающий код является её клиентом, и именно там зависимости на БД итд. P>>Т.е. у нас слои поменялись местами. ·>Да пофиг. Эти слои можно жонглировать как сейчас модно. Это меняется каждый год.
Это новый подход, позволяет обходиться без моков-стабов итд и свести тестирование ключевых вещей к дешовым юнит-тестам
P>>>>Кое что надо и в самом методе вызывать, без этого работать не будет. P>>·>Именно! И накой тогда аннотация нужна для этого? P>>Базовые гарантии. Некоторые из них можно выключить или доопределить конфигом итд. ·>Базовые гарантии чего?
Например, если вы аннотацией указываете что метод работает из под другого юзера, например Freemium, то базовая гарантия — вы будете получать Freemium юзера внутри этого метода. Ее можно модифицировать — отключить весь Freemium в конфиге приложения. Или навесить на Freemium юзера доп.свойства — свежегенеренное имя-емейл-баланс.
P>>Разумеется, это интеграция — что аудит интегрирован с тем или иным стораджем. 1 тест. ·>"для данных сценариев записываются нужная инфа". Это где-то нужно валидировать, что для некой бизнес-операции в соответвтующих условиях записывается соответвтующий требованиям сообщение аудита.
В этом случае можно сделать аудит через тесты состояния. Прогоняем операцию, сравниваем что в аудите. Тесты вида "вызываем аудит с параметрам" — это тесты "как написано"
·>Как я понял скорее всего разница в том, что я обычно пишу на статике. Аннотации мешают тем, что их сложнее тестировать, контролировать типы. Приходится вместо простых вызовов методов поднимать очень много компонент и смотреть, что процессоры аннотаций сработали правильно. Т.е. вместо того, чтобы просто вызвать метод, мы пишем кучу слоёв какого-то мусора, чтобы вызывать ровно тот же метод.
Вот эти вещи нужно выталкивать во фремворк, что бы там протестировать раз на все времена, и не надо было каждый раз перепроверять "а не отвалился ли процессор аннотации"
Вы же не проверяете, что джава выполняет циклы правильно? Так и здесь
Здравствуйте, Pauel, Вы писали:
P>>>Вы вот сами путаете моки и стабы P>·>Ок, пусть. Не вижу, в чём важность этой терминологии. Я использую название "мок", потому что библиотека называется mockito и создаются эти штуки функцией mock или аннотацией @Mock. Если тебе комфортнее стаб, пусть. Хоть горшком назови, только в печку не ставь. P>Моки изначально предназначались для тестов вида "вызываем вон то, вон так, в такой последовательности"
Может быть. Неясно какое это имеет значение сейчас, так исторические курьёзны. Даже если посмотреть на историю библиотек для тестов — за много лет много чего менялось и переделывалось.
P>>>Ну так в джаве и пишут — перемножают сущности и радуются. P>·>Причём тут перемножают? Это диктуется требованиями. Если в json тебе нужен b64, а аналогичном месте protobuf тебе нужен Bytes, то хоть на bf пиши, у тебя будут комбинации. P>У вас — охотно верю.
Потому что у нас не хелловорды, а не как у вас, да?
P>Я вам пример приводил, про время, вам он ожидаемо не понравился — язык не тот
Я не понял к чему ты скачешь с одного на другое. Обсуждали статью и MaitreD, потом crypto api, теперь вот ещё time api зачем-то...
P>>>Я портировал довольно много кода с джавы в тайпскрипт, и охренел от тамошних привычек. P>·>Портировал это значит, как минимум, ты по ходу удалял гору легаси кода, совместимость с устаревшим, етс. P>С чего бы портирование стало означать удаление легаси ?
С того. Когда код существует хотя бы десяток лет — там наслоения чего попало, когда что-то делалось и переделывалось, много накапливается мусора "по историческим причинам".
P>>>Не нужны никакие "9 комбинаций" — нужно отделить создание и представление. P>·>Так в изначальном дизайне crypto так и было — создаём hmac нужного алгоритма, потом выводим в нужном представлении. Ты почему-то упаковал это в одну функцию и назвал успехом. P>В данном случае мне не надо переживать за поломаные тесты, если понадобится другой алгоритм, другая либа, итд. P>Вот понадобился не hmac а что другое — в файлике samples поменял десяток значений, и всё
Почему десяток? У тебя только десяток операций в api?
P>А ваша альтернатива этому — еще и тесты перебулшитить.
Один, скорее всего. Ибо одного теста достаточно чтобы зафиксировать логику вычисления hmac. В остальных тестах достаточно ассертить его наличие, но не конкретный формат.
P>·>У кого "у нас"? Если бы никому не требовались разные виды токенов в разном представлении, то в библиотеке crypto был бы "makeToken" с ровно одним парамом. P>·>Такое ощущение, что ты говоришь о дизайне какой-то домашней странички, а не о сложной системе. P>Ну да, этож только у вас сложные системы.
Ну да, сам же сказал, что у тебя всё помещается в один файлик. Или он гиговый?
P>>>Количество может быть уменьшено за счет подхода к дизайну. P>·>Я не понял, разговор был о crypto, теперь на какой-то time-api переключился. Я за твоим полётом мысли не успеваю. P>У вас любой из примеров вызывает какой то негатив
Какой негатив? Вроде говорили об одном, теперь чего-то новое.
Вообще неясно причём тут time api и причём тут моки и тестирование вообще.
P>>>А операция конверсии в прикладном коде будет вот такой DateTimeOffset.from({...date.toFields(), ...time.toFields, offset: serverOffset}); P>·>Это только на js годится такое писать. Со статической типизацией такое не прокатит. P>Успокойтесь — это все статически контролируется, только в вашу джаву такие фичи еще не завезли.
Спасибо, но сводить всё к массиву из 7 чиселок — это фигня полная и издевательство. Даже такое DateTimeOffset.from({...time.toFields, ...date.toFields(), offset: serverOffset}); — и всё поехало. И где наносекуды, интересно?
Конструкторы удобнее и надёжнее с нужными типами, например, OffsetDateTime.of(date, time, offset), это хотя бы читабельно, и если что-то не так, не компиляется.
P>>>А если вы решили понасоздавать N! комбинаций — удачи, внятного покрытия вам не видеть, как своих ушей, хоть с моками, хоть без них. P>·>Я вроде рассказал, как упрощать тестирование комбинаций. P>Вы уже показали — перебулшитить все тесты, когда можно ограничиться десятком строчек на весь проект.
Это твои фантазии.
P>>>Читайте себя внимательно — вы регулярно утверждаете, что именно у меня проблемы с моками, что именно у меня квалификация под сомнением. P>·>Так ты сам откровенно пишешь: "за 20 лет индустрия так и не осилила". Я сталкивался с другой индустрией, в которой с моками (или стабами?) проблем таких нет. P>Ну да — для вас перебулшитить тесты проблемой не является Еще и настаиваете, что так и надо.
Я настаиваю, что так не надо.
P>>>Именно — так не надо, но именно так пишут и это типичный пример, к сожалению P>·>Может в твоей индустрии. В java так не пишут, ну если только совсем вчерашние студенты, но PR такое не пройдёт. P>Проходит же. Вот я и интересуюсь, кто настрочил горы непотребства
Вчерашние студенты?
P>>>Интеграционные тесты это все выше уровня простых юнит тестов. Далеко не все интеграционные автоматически медленные. Условно, чистая функция вызывает десяток других чистых — опаньки, тест такой штуки будет интеграционным. Но нам это по барабану — они быстрые, можно обзапускаться хоть до посинения. P>·>Ты куда-то мимо пошел. Не хочу вдаваться в подробности терминологии юнит-инт. Суть в том, что в твоём предложенном тесте появляется connectionString, значит "приходится плодить медленные тесты и тривиальные ошибки обнаруживать только после запуска всего приложения". P>Эта разновидность тестов нужна и вам.
Нужны, но не для проверки каждой строчки кода, что параметры вызова не перепутаны. А только для тестирования интеграции.
P>>>Наоборот. Большое количество дешовых тестов, тысячи минимум, и десятки-сотни интеграционных, самых тяжелых тестов по одному на каждый сценарий приложения — десяток другой. P>·>Какой тесто обнаружит ошибку в коде "repository.updateUser(newUser, oldUser)" и как? Вот это "выполним операцию и проверим, что состояние юзера соответствует ожиданиям"? Что должно быть поднято для прогона такого теста? P>да вобщем то ничего, какая нибудь ин-мемори дб и инстанц контроллера или юз-кейса.
Ясно, закопайте.
P>·>Под интеграцией я понимал в данном случае твоё "curl -X POST". Это плохой тест, медленный, неуклюжий. Число таких тестов надо стараться минимизировать. P>Такие тесты нужны в любом случае, моки-стабы от них не избавляют, это иллюзия.
Я знаю, что нужны, Я написал, что "Число таких тестов надо стараться минимизировать".
P>>>В огороде бузина, а в киеве дядька. При чем здесь require ? framework as a detail и clean architecture это подходы к дизайну, архитектуре. P>·>В том, что в твоём коде jest подменял код внутри глобального реестра require. P>Я вам пример привел, как применяют моки. Обмокать можно что угодно, в т.ч. и в джаве-дотнете
Я не знаю кто так применяет, но так делать не надо.
P>>>Неверно — тестируется не код, а соответствие ожиданиям, требованиями. какой бы дизайн у вас ни был — все равно нужны тесты апи, сценариев итд. P>·>Опять буквоедство какое-то. Что по-твоему тестируется на соответствие ожиданиям, требованиям? P>Продукт, система, приложение, апи, компонент, модуль. Для теста именно кода у нас другие инструменты — код-ревью, линт, дизайн-ревью, статические анализаторы, итд.
Я сказал "Они отменяют необходимость написания тучи этих самых xxxComposition, нет кода — нечего тестировать". Ты прикопаться решил к слову код? Ок, пусть будет не код, а модуль-компонент.
"Моки отменяют необходимость написания тучи этих самых xxxComposition, нет такого компонента|модуля — нечего тестировать." Так яснее?
P>>>А вы тут сказки рассказыете, что это делать не надо P>·>Суть в том, что тесты апи можно тестировать без реальной субд|кафки и т.п. И описывать ожидания, что updateUser сделан именно с (newUser, oldUser), а не наоборот. P>Можно. И это делается без моков. Если мы заложимся на значение или состояние, то получим куда больше гарантий.
Без моков ты предложил только полный запуск всей аппликухи, в лучшем случае с тестовой субд. Kafka/amps/lbm/solace/tibco/etc, кстати, тоже тестовую будешь пускать? Или как?
P>В функции средний девелопер может понаделывать ошибок куда больше, чем перепутать old и new.
Я в этом и до среднего не дотягиваю, дохрена таких ошибок делаю, но вся эта фигня на раз ловится тестами, c моками (стабами), да.
P>>>Покажите как вы в репозиторий метод getAll передаете фильтры, сортировку итд P>·>Не знаю, не припомню где у нас есть такое. Но наверное был бы какой-нибдуь value object, который передаёт необходимые настройки фильтров и сортировок. P>Вот вы и встряли Чем лучше изолируете, тем больше вам тестировать. Тут помогло бы использование какого dsl. В том же дотнете есть такое, и всё равно надо думать, что передать в репозиторий, быть в курсе, съест ли тамошний провайдер конкретную функцию или нет.
Пофиг. Я не знаю о чём ты говоришь и делаю wild guesses.
P>>>Именно — кто даст гарантию что с тем или иным конфигом, рантаймом, переменными окружения, тот самый метод контролера не начнет вдруг гарантировано валиться ? P>·>Никто. P>Именно! А потому нам все контроллеры нужно тестировать в апи тестах — тем самым мы исключаем добрый десяток классов проблем.
И эти тесты дадут тебе гарантию?
P>Что вас смущает? deep.eq проверит всё, что надо. query это не строка, объект с конкретной структурой, чтото навроде P>
Жуть. Ну ладно. Т.е. тут мы тестируем репозиторий и ассертим текст sql
Как проверить, что текст запроса хотя бы синтаксически корректен? И что он при выполнении выдаст то, что ожидается? И как ты собрался тут подменять субд? Ты обещал, что теперь эту хрень можно отдать любой db и оно выдаст одинаковый результат? Даже если эта субд это oracle или cassandra? Да там синтаксис банально другой.
P>Сами трансформации тестируются отдельно, обычными юнитами, например expect(fn1(user)).to.eq(user.id);
Так ведь надо трансформировать не некий user, а конкретно ResultSet возвращённый из "select *". Что колоночки в select местами не перепутаны, как минимум.
Ещё это всё "красиво" только на твоих хоумпейдж проектах. В реальном коде эти sql будут сотни строк с многоэтажными джойнами и подзапросами, и такие "тесты" станут даже немножечко вредить.
P>>>вот, вы начинате понимать, для чего нужны интеграционные Здесь вам понадобится тест компонента с подклееной реальной бд. И без этого никак. P>·>Т.е. та же ж, вид в профиль, но теперь большинство логики без реальной бд не протестировать. В случае с репо реальная бд нужна только для тестирования самого слоя взаимодействия с бд, а остальное может мокаться (стабиться?). Ты же предлагаешь всё приложение тестировать с реальной бд. P>Вы все думаете в единицах старого дизайна, когда БЛ прибита гвоздями к бд.
Не к бд прибита. БЛ прибивается к репе.
P>>>Это типичный пример интеграция — вы соединяете выходы одного со входами другого. P>·>Ну да. Но это не означает, что для этого необходимо тестировать только с реальной бд. P>Нам нужна любая бд, что прогонять некоторые тесты, обычно небольшое количество.
Любая бд даёт любой результат.
P>>>Это в любом случае необходимо — у контролера всегда хрензнаетсколькилион зависимостей прямых и косвенных, и чтото да может пойти не так. P>·>Для этого и объединяют толпу зависимостей в одну. Чтобы не N! было. P>Объединяйте что угодно — а контролер все равно придется вызвать в АПИ тестах.
Не знаю что за апи тесты ты тут имеешь в виду, предполагаю, что это твой "curl". Если так, то достаточно позвать один метод для проверки интеграции всех компонент, а не для тестирования всей бизнес-логики апи.
P>>>А там где используют object, то отличий от js никакого нет P>·>Ну обычно object стараются избегать использовать. P>Шота я этого за 4 года не заметил
Может у тебя проекты написанные вайтишниками после курса ML, я не знаю. Но у тебя есть целый гитхаб, погляди насколько часто и для чего Object используют.
P>>>Иначе есть шанс что тот самый роут в нужный момент не сможет быть вызван, т.к. он просто задизаблен в конфиге P>·>Не понял, ну раз задизаблен, значит и нельзя вызвать. Это является не ошибкой, а конфигурацией системы. Неясно что тут в принципе тестировать. P>Юзеру так и скажете — мы не можем вернуть ваши деньги, потому что у нас в конфигурации возвраты отключены.
Для этого и есть L1 support — "проверьте, что ваш компьютер включен".
P>>>Вы там что, на каждый коммит всю систему переписываете? P>·>Я описываю ситуацию — добавили новое общее поле в аудит — везде в этих твоих логах каждого теста — строчка аудита выглядит чуть по-другому. P>Добавили, посмотрели дифом, вкомитали. Вам же не надо сразу всё обрабатывать.
А в дифе 10к строчек отличаются. И как это смотреть? Аудит же пишется для каждой операции, т.е. каждого теста, да ещё и не по разу.
P>>>Апи это именно про интеграцию — вызов контроллера в конкретном окружении, что есть в чистом виде интеграция, т.к. у контроллера всегда есть хрензнаетсколькилион зависимостей, прямых и косвенных. P>·>Апи это про интерфейс системы. Интеграция тут причём? P>Если апи возвращает то, что надо, это значит что у вас связка конфиг-di-sl-рантайм-переменные-итд склеено правильно.
И это ты предлагаешь гонять на каждый "updateUser(newUser, oldUser)"? Спасибо, не надо нам такого щастя.
P>>>Старый подход — контролер вызывает сервис БД который вызывает БЛ через репозиторий итд. Моками надо обрезать зависимости на БД у БЛ. P>>>Т.е. БЛ это клиент к БД, по факту. P>·>Моками (стабами?) обрезается БД и прочие внешние вещи от БЛ. Чтобы при тестировании БЛ можно было быстро тестировать логику кода, без всяких сетевых соединений и запуска всего приложения. P>Можно. Это старый подход.
Ты говоришь как будто это что-то плохое. Это разумный подход. Делить не по тому, что сейчас у фаулеров в моде, а по конкретному осязаемому критерию, т.к. это напрямую выражается во времени запуска и требуемых ресурсов для тестирования.
P>·>Да пофиг. Эти слои можно жонглировать как сейчас модно. Это меняется каждый год. P>Это новый подход, позволяет обходиться без моков-стабов итд и свести тестирование ключевых вещей к дешовым юнит-тестам
У тебя тривиальное updateUser(newUser, oldUser) не тестируется юнитами. Любая мелочёвка требует запуска всего, в лучшем случае с in-mem субд.
P>>>>>Кое что надо и в самом методе вызывать, без этого работать не будет. P>>>·>Именно! И накой тогда аннотация нужна для этого? P>>>Базовые гарантии. Некоторые из них можно выключить или доопределить конфигом итд. P>·>Базовые гарантии чего? P>Например, если вы аннотацией указываете что метод работает из под другого юзера, например Freemium, то базовая гарантия — вы будете получать Freemium юзера внутри этого метода. Ее можно модифицировать — отключить весь Freemium в конфиге приложения. Или навесить на Freemium юзера доп.свойства — свежегенеренное имя-емейл-баланс.
С такими же гарантиями можно и просто метод дёргать. Аннотации это только от плохого дизайна.
P>>>Разумеется, это интеграция — что аудит интегрирован с тем или иным стораджем. 1 тест. P>·>"для данных сценариев записываются нужная инфа". Это где-то нужно валидировать, что для некой бизнес-операции в соответвтующих условиях записывается соответвтующий требованиям сообщение аудита. P>В этом случае можно сделать аудит через тесты состояния. Прогоняем операцию, сравниваем что в аудите. Тесты вида "вызываем аудит с параметрам" — это тесты "как написано"
Не "вызываем аудит с параметрам", а "послано такое-то сообщение в аудит".
P>·>Как я понял скорее всего разница в том, что я обычно пишу на статике. Аннотации мешают тем, что их сложнее тестировать, контролировать типы. Приходится вместо простых вызовов методов поднимать очень много компонент и смотреть, что процессоры аннотаций сработали правильно. Т.е. вместо того, чтобы просто вызвать метод, мы пишем кучу слоёв какого-то мусора, чтобы вызывать ровно тот же метод. P>Вот эти вещи нужно выталкивать во фремворк, что бы там протестировать раз на все времена, и не надо было каждый раз перепроверять "а не отвалился ли процессор аннотации" P>Вы же не проверяете, что джава выполняет циклы правильно? Так и здесь
Фреймворк-ориентед программинг? Нет, спасибо.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>Моки изначально предназначались для тестов вида "вызываем вон то, вон так, в такой последовательности" ·>Может быть. Неясно какое это имеет значение сейчас, так исторические курьёзны. Даже если посмотреть на историю библиотек для тестов — за много лет много чего менялось и переделывалось.
И сейчас это основной кейс для моков. Вы и сами тащите "надо проверить old и new", и другого варианта не видите, как будто его нет. Можно же и дизайн поменять, что бы юнитами такое проверять. Но нет — вы топите за моки.
P>>·>Причём тут перемножают? Это диктуется требованиями. Если в json тебе нужен b64, а аналогичном месте protobuf тебе нужен Bytes, то хоть на bf пиши, у тебя будут комбинации. P>>У вас — охотно верю. ·>Потому что у нас не хелловорды, а не как у вас, да?
Потому, что вы используете дизайн, который плодит лишнее. Я вам на примере дата-время показал, как можно иначе, но вам любой пример не в вашу пользу надо забраковать.
P>>Я вам пример приводил, про время, вам он ожидаемо не понравился — язык не тот ·>Я не понял к чему ты скачешь с одного на другое. Обсуждали статью и MaitreD, потом crypto api, теперь вот ещё time api зачем-то...
Со статьё давно всё ясно. crypto api и time это пример, которые показывают, за счет можно отказаться от моков, и что будет, если этого не делать.
P>>·>Так в изначальном дизайне crypto так и было — создаём hmac нужного алгоритма, потом выводим в нужном представлении. Ты почему-то упаковал это в одну функцию и назвал успехом. P>>В данном случае мне не надо переживать за поломаные тесты, если понадобится другой алгоритм, другая либа, итд. P>>Вот понадобился не hmac а что другое — в файлике samples поменял десяток значений, и всё ·>Почему десяток? У тебя только десяток операций в api?
Это у вас на моках упадут все тесты всех операций апи. О том и речь. А на обычных юнит-тестах вы подкидываете новый набор значений, и всё путём.
P>>А ваша альтернатива этому — еще и тесты перебулшитить. ·>Один, скорее всего. Ибо одного теста достаточно чтобы зафиксировать логику вычисления hmac. В остальных тестах достаточно ассертить его наличие, но не конкретный формат.
"достаточно ассертить его наличие" — вот вам и привязка к "как написано"
Ага, тесты "как написано" Вам придется написать много больше, чем один тест — как минимум, пространство входов более-менее покрыть. Моками вы вспотеете это покрывать.
P>>Ну да, этож только у вас сложные системы. ·>Ну да, сам же сказал, что у тебя всё помещается в один файлик. Или он гиговый?
Вы там в телепатию заигрались? Что именно по вашему помещается в один файлик? Вся система, все тесты, вся система с тестами?
Вы чего то недопоняли, но вместо уточнения начинаете валять дурака?
·>Какой негатив? Вроде говорили об одном, теперь чего-то новое. ·>Вообще неясно причём тут time api и причём тут моки и тестирование вообще.
time api это пример дизайна, как можно уйти от комбинаторного взрыва.
P>>Успокойтесь — это все статически контролируется, только в вашу джаву такие фичи еще не завезли. ·>Спасибо, но сводить всё к массиву из 7 чиселок — это фигня полная и издевательство. Даже такое DateTimeOffset.from({...time.toFields, ...date.toFields(), offset: serverOffset}); — и всё поехало. И где наносекуды, интересно?
Где вы видите массив? Это объект, статически типизированый, наносекунды будут в time.toFields как fractionalSeconds. Вам телепатия еще не надоела?
·>Конструкторы удобнее и надёжнее с нужными типами, например, OffsetDateTime.of(date, time, offset), это хотя бы читабельно, и если что-то не так, не компиляется
Принципиальное отличе of вместо from
P>>Вы уже показали — перебулшитить все тесты, когда можно ограничиться десятком строчек на весь проект. ·>Это твои фантазии.
Вы сами пишите, что тестировать надо "как написано", это следует из того, как вы предлагаете решать задачу с hmac. Таких же задач будет не одна на проект, а целая куча. Вот и будут тесты "проверить что делает"
P>>Ну да — для вас перебулшитить тесты проблемой не является Еще и настаиваете, что так и надо. ·>Я настаиваю, что так не надо.
Если не надо, то должен быть другой подход к тестированию. А вы выбираете тесты на моках "проверим что вызывается hmac с нужными параметрами"
P>>Проходит же. Вот я и интересуюсь, кто настрочил горы непотребства ·>Вчерашние студенты?
Да не похоже.
P>>Эта разновидность тестов нужна и вам. ·>Нужны, но не для проверки каждой строчки кода, что параметры вызова не перепутаны. А только для тестирования интеграции.
АПИ и есть та самая интеграция.
P>>Продукт, система, приложение, апи, компонент, модуль. Для теста именно кода у нас другие инструменты — код-ревью, линт, дизайн-ревью, статические анализаторы, итд. ·>Я сказал "Они отменяют необходимость написания тучи этих самых xxxComposition, нет кода — нечего тестировать". Ты прикопаться решил к слову код? Ок, пусть будет не код, а модуль-компонент. ·>"Моки отменяют необходимость написания тучи этих самых xxxComposition, нет такого компонента|модуля — нечего тестировать." Так яснее?
Не отменяют. Когда вы укрупняете компонент, то тестировать его сложнее. Или ваше покрытие будет решетом, или вам придется понаписывать много моков вида "это вызывает то", которые сломаются даже при минорных изменения компоненты
P>>Можно. И это делается без моков. Если мы заложимся на значение или состояние, то получим куда больше гарантий. ·>Без моков ты предложил только полный запуск всей аппликухи, в лучшем случае с тестовой субд. Kafka/amps/lbm/solace/tibco/etc, кстати, тоже тестовую будешь пускать? Или как?
Вы додумываете. Это в вашем понадобился бы запуск всей апликухи. У меня же апликуха запускается только ради e2e тестов.
Кафка — это обычный эвент, как вариант, можно обойтись и простым юнитом, убедиться что функция возвращает объект-эвент.
Если у вас такой роскоши нет — добавьте мок ровно на нотификацию, а не на кафку.
P>>В функции средний девелопер может понаделывать ошибок куда больше, чем перепутать old и new. ·>Я в этом и до среднего не дотягиваю, дохрена таких ошибок делаю, но вся эта фигня на раз ловится тестами, c моками (стабами), да.
Если вы написали тест на old и new, то конечно же словится. Только откуда следует, что это единственные проблемы?
Проблем может быть сколько угодно, именно конечный результат говорит что правильно а что нет
Иногда без контроля вызовов не получится — см. пример у буравчика, но и там можно уйти от самих моков за счет максимально дешовых стабов.
P>>Именно! А потому нам все контроллеры нужно тестировать в апи тестах — тем самым мы исключаем добрый десяток классов проблем. ·>И эти тесты дадут тебе гарантию?
Разумеется, мы ради этого и пишем тесты. Не только что бы убедиться, что работает здесь и сейчас, но что бы можно было перепроверить это в т.ч. на живом окружении.
После билда работает, после деплоя — нет, опаньки!
Впрочем, в прошлом году вы рассказывали, что деплой трогать низя — он у вас хрупкий, не дай бог повалится от лишнего запроса.
P>>Что вас смущает? deep.eq проверит всё, что надо. query это не строка, объект с конкретной структурой, чтото навроде P>>
·>Жуть. Ну ладно. Т.е. тут мы тестируем репозиторий и ассертим текст sql
Здесь мы тестируем построение запроса
·>Как проверить, что текст запроса хотя бы синтаксически корректен?
Для этого нам всё равно придется выполнить его на реальной бд. Расскажите, как вы решите задачу вашими моками.
> И что он при выполнении выдаст то, что ожидается?
А здесь как вы моками обойдетесь?
> И как ты собрался тут подменять субд? Ты обещал, что теперь эту хрень можно отдать любой db и оно выдаст одинаковый результат? Даже если эта субд это oracle или cassandra? Да там синтаксис банально другой.
А разве я говорил, что бд можно менять любую на любую? Построение запросов мы можем тестировать для тех бд, которые поддерживаются нами.
P>>Сами трансформации тестируются отдельно, обычными юнитами, например expect(fn1(user)).to.eq(user.id); ·>Так ведь надо трансформировать не некий user, а конкретно ResultSet возвращённый из "select *". Что колоночки в select местами не перепутаны, как минимум.
Что вас смущает? трансформация результата принимает ResultSet и возвращает вам нужный объект.
·>Ещё это всё "красиво" только на твоих хоумпейдж проектах. В реальном коде эти sql будут сотни строк с многоэтажными джойнами и подзапросами, и такие "тесты" станут даже немножечко вредить.
Расскажите, как вы это моками решите
P>>Вы все думаете в единицах старого дизайна, когда БЛ прибита гвоздями к бд. ·>Не к бд прибита. БЛ прибивается к репе.
Это одно и то же, и в этом проблема. Я ж вам говорю, как можно иначе — но вы упорно видите только вариант из 90х-00х
В новом подходе не надо БЛ прибивать ни к какой репе, ни к бд, ни к стораджу, ни к кафе, ни к внешним сервисам
P>>Шота я этого за 4 года не заметил ·>Может у тебя проекты написанные вайтишниками после курса ML, я не знаю. Но у тебя есть целый гитхаб, погляди насколько часто и для чего Object используют.
Я как раз с гитхаба и брал, если что.
P>>Юзеру так и скажете — мы не можем вернуть ваши деньги, потому что у нас в конфигурации возвраты отключены. ·>Для этого и есть L1 support — "проверьте, что ваш компьютер включен".
Я именно это сказал — L1 support так и скажет юзеру, "в конфиге отключено, значит неположено"
Что бы такого не случалось, в тестах должен быть сценарий, который включает возврат. И так для всех апи которые вы выставляете.
P>>Добавили, посмотрели дифом, вкомитали. Вам же не надо сразу всё обрабатывать. ·>А в дифе 10к строчек отличаются. И как это смотреть? Аудит же пишется для каждой операции, т.е. каждого теста, да ещё и не по разу.
А почему 10к а не 10к миллионов?
P>>Если апи возвращает то, что надо, это значит что у вас связка конфиг-di-sl-рантайм-переменные-итд склеено правильно. ·>И это ты предлагаешь гонять на каждый "updateUser(newUser, oldUser)"? Спасибо, не надо нам такого щастя.
Да, я в курсе, у вас есть L1 суппорт, который скажет клиенту, что возвраты не положены.
Это не шутка — мне так L1 однажды залепил
Неделя бодания и перекинули проблему наверх, только когда я сослался на федеральный закон
Признавайтесь, ваша идея?
P>>Можно. Это старый подход. ·>Ты говоришь как будто это что-то плохое. Это разумный подход. Делить не по тому, что сейчас у фаулеров в моде, а по конкретному осязаемому критерию, т.к. это напрямую выражается во времени запуска и требуемых ресурсов для тестирования.
В данном случае вам нужно писать больше кода в тестах, и они будут хрупкими. Другого вы с моками не получите. Потому и убирают зависимости из БЛ целиком, что бы легче было покрывать тестами
P>>Это новый подход, позволяет обходиться без моков-стабов итд и свести тестирование ключевых вещей к дешовым юнит-тестам ·>У тебя тривиальное updateUser(newUser, oldUser) не тестируется юнитами. Любая мелочёвка требует запуска всего, в лучшем случае с in-mem субд.
Ага, сидим да годами ждём результаты одного теста. Вам самому не смешно?
P>>Например, если вы аннотацией указываете что метод работает из под другого юзера, например Freemium, то базовая гарантия — вы будете получать Freemium юзера внутри этого метода. Ее можно модифицировать — отключить весь Freemium в конфиге приложения. Или навесить на Freemium юзера доп.свойства — свежегенеренное имя-емейл-баланс. ·>С такими же гарантиями можно и просто метод дёргать. Аннотации это только от плохого дизайна.
Ну вот подергали вы метод. А потом вас попросили отразить всё такое в сваггере каком, что бы другим было понятно. Гы-гы. Ищите строчки в коде.
А с аннотациями взял да и отрендерил манифест.
P>>В этом случае можно сделать аудит через тесты состояния. Прогоняем операцию, сравниваем что в аудите. Тесты вида "вызываем аудит с параметрам" — это тесты "как написано" ·>Не "вызываем аудит с параметрам", а "послано такое-то сообщение в аудит".
Это непринципиально.
P>>Вы же не проверяете, что джава выполняет циклы правильно? Так и здесь ·>Фреймворк-ориентед программинг? Нет, спасибо.
Это ж классика — отделяем логику, которая меняется часто, от той, которая меняется редко. По этому пути индустрия идет последние 50 лет примерно.
Здравствуйте, Pauel, Вы писали:
Б>>Что значит дизайн такой? Это логика приложения такая, как ее по другому задизайнить?
P>То и значит — вы приняли решениче, что все будет в одной функции мутабельным вперемешку с тяжелыми зависимостями.это и есть ваш дизайн
Ну, у тебя (будем на ты?) то же самое написано. У тебя тяжелые зависимости вынесены в функции, а у меня вынесены в отдельные классы, закрыты интерфейсами (они в дальнейшем и мокаются), передаются как параметры.
Моки позволяют отрезать эти тяжелые вычисления и заменить их на простое поведение для теста.
P>Похоже, что моки про которые вы говорите, это фаулеровские стабы
Стабы/моки — вопрос терминологии. Я называю моками все разновидности моков, а стабами те, которые работают как "функция" — получили результат, обработали, вернули нужны.
Используются в основном стабы. Они просто заменяют в рамках теста тяжелое поведение на что-то легкое.
Моки, для которых проверяется факт вызова "с параметров а-б-в", тоже изредка могут применяться в основном для проверки отправки сообщений, где ответ не важен (в кафку, аудит).
P>Варианты подходов к тестированию, я их вам показал. Ветвления влияют на количество тестов, но не на подход к тестированию P>А вот конкретное оформление этого ветвления определяет то, какими могут быть тесты
Про дизайн. Подход с моками как раз не навязывает дизайн (не вынуждают выделять функции).
Где уместно, я создам чистую функцию и тесты (обычно для алгоритмов бизнес-логики). Где не уместно — буду использовать моки (обычно для логики приложения).
Т.е. любую сложную логику при желании могу протестить юнит-тестами
P>>>Проблема в самих зависимостях, их много, и в том, что ваш дизайн мутабельный P>>>Попробуйте отказаться от мутабельного дизайна. Как минимум, три эффекта из четырех легко отделяются. Так что можно упростить до безобразия.
Они у меня эти зависимости отделены. Выделены в отдельные классы (репозитории и т.п.), прокидываются как параметры.
P>Потом преобразуете метод в класс, v1,v2,v3 уходят в члены класса
P>
P>class Logic(v1, v2, v3): // параметры-значения в конструкторе
P> def run(load, load2, commit): // эффекты-зависимости здесь, эдакий аналог импорта
P> p = ctx.load(self.v1)
P> if что-то(p):
P> p2 = ctx.load2(self.v2) // load2 - абстракция так себе, должно быть хорошее имя
P> p = update(p, p2)
P> if что-то(p):
P> ctx.commit(self.v3)
P> return p
P>
P>Теперь в тестах вы можете создать n троек значений, m результатов операций P>И покроется все одной таблицей тестов n x m
Как тест будет написан? Как подготовлен, как будут передаваться эти n x m, как проверен?
P>Любители моков правда очень обрадуются, умножат(sic!) Количество тестов за счет проверок "commit вызывается после двух load"
Это твое (неправильное) понимание
P>Теперь ваш мок repo.get должен считать вызовы — что его вызвали первый раз с v1, второй раз с v2, и это важно, т.к на втором разе вы должны вернуть кое что другое P>И это именно то, чего делать не стоит — в сложной логике ваш мок репозитория будет чудовищем, которое мало будет походить на реальную часть системы P>Чем более унивесальная зависимость, тем труднее её мокать, и тем выше шансы на ошибку
Для этого теста (который будет проверять эту ветку логики) для операции repo.get будет написан такой стаб:
if v1:
return value1
else if v2:
return value2
else:
raise
P>Если не хотите возиться с интерфейсом — можно вытащить repo.get и подобное в методы рядом с do_logic. Идея на самом деле так себе, этот подход стоит применять если у вас не сильно много зависимостей P>
P>do_logic(v1, v2, v3):
P> p = self.load(v1)
P> if что-то(p):
P> p2 = self.load2(v2)
P> p = update(p, p2)
P> if что-то(p):
P> self.commit(v3)
P> result = serialize(p)
P> return result
P>
P>Выглядит компактно — только штука в том, что вам придется мокать сам класс, ну хотя бы через наследника под тесты или сетать все методы и надеятся что ничего не пропустите.
Да, выглядит компактно и понятно. И никто не заставляет наворачивать дизайн как у тебя — с дополнительными функциями, от которых код становится сложнее.
Да, часть сложности перекладывается на тесты, из-за моков, но не критично.
P>А вот зависимости как параметры вы можете понасоздвать или нагенерить на все случаи жизни P>1 ошибки всех сортов P>2 пустой результат P>3 куча вариантов ответа P>4 куча сочетаний того и этого
Зависимости отделены также, как и у тебя. В твоем случае в тесты ты передаешь их как параметры-функции, а я подменяю поведение через стаб (по-сути ту же функцию). И в обоих случаях проверяются все варианты
Здравствуйте, Буравчик, Вы писали:
Б>Ну, у тебя (будем на ты?) то же самое написано. У тебя тяжелые зависимости вынесены в функции, а у меня вынесены в отдельные классы, закрыты интерфейсами (они в дальнейшем и мокаются), передаются как параметры.
Почти то же самое. Вам нужно мокать репозиторий, а мне всего то лямду подкинуть.
Б>Моки позволяют отрезать эти тяжелые вычисления и заменить их на простое поведение для теста.
Вопрос в том, сколько вам кода для этих моков надо. Если у вас, скажем, три раза подряд идет вызов repo.get вам придется заниматься глупостями —
писать чтото навроде OnCall(3).Returnо(that) или писать кастомную вещь.
Собственно я вам привел пример, как вроде бы те же моки можно свести к простым тестам. Кода для моков около нуля, в отличие от вашего варианта.
Б>Стабы/моки — вопрос терминологии. Я называю моками все разновидности моков, а стабами те, которые работают как "функция" — получили результат, обработали, вернули нужны.
Стабы подкидывают значения. Моки — это тесты вида "проверить, что вызвали то и это"
Б>Моки, для которых проверяется факт вызова "с параметров а-б-в", тоже изредка могут применяться в основном для проверки отправки сообщений, где ответ не важен (в кафку, аудит).
Б>Про дизайн. Подход с моками как раз не навязывает дизайн (не вынуждают выделять функции).
Наоборон — моками вы бетонируете конкретный дизайн. Там где вы тестами на моках проверяете что repo.get вызвался с тем или иным параметром, изменить дизайн на другой вы можете только через поломку всех таких тестов. Даже если просто укажете, что "функция использует репозиторий", у вас будут поломки на ровном месте из за смены дизайна.
То еть — моки ограничивают вас в выборе
Б>Где уместно, я создам чистую функцию и тесты (обычно для алгоритмов бизнес-логики). Где не уместно — буду использовать моки (обычно для логики приложения). Б>Т.е. любую сложную логику при желании могу протестить юнит-тестами
И тесты и дизайн кода влияют друг на друга. Если вы избавитесь от моков, внезапно окажется, что можно менять дизайн, а не бояться, что надо перебулшитить все тесты.
Б>Они у меня эти зависимости отделены. Выделены в отдельные классы (репозитории и т.п.), прокидываются как параметры.
P>>Теперь в тестах вы можете создать n троек значений, m результатов операций P>>И покроется все одной таблицей тестов n x m
Б>Как тест будет написан? Как подготовлен, как будут передаваться эти n x m, как проверен?
Нам нужно описать все значения, табличкой. Часть значений протаскиваются через параметры, часть — через лямбды.
У нас их шесть штук, v1,v2,v3, repo1, svc, repo2,
Дальше у вас будет один параметризованый тест типа такого, не знаю как на вашем питоне это выглядит, напишу на жээсе
@test()
@params(
1,2,3,4,5,6 // и так на каждую строчку в табличке
)
@params(
8,4,2,1,3,5 // точно так же и исключения прокидывают
)
... сколько строчек, столько и тестов фактически выполнится
"a cool name test name" (v1, v2, v3, repo1, svc, repo2, result) {
let logic = Logic(v1,v2,v3);
let r = logic.run({
load: () => repo1,
load2: () => svc,
... и так прокидываем все что надо
})
expect(r).to.deep.eq(result)
}
P>>Любители моков правда очень обрадуются, умножат(sic!) Количество тестов за счет проверок "commit вызывается после двух load"
Б>Это твое (неправильное) понимание
Это типичная картина, к сожалению. Еще могут оставить только такие тесты.
P>>Теперь ваш мок repo.get должен считать вызовы — что его вызвали первый раз с v1, второй раз с v2, и это важно, т.к на втором разе вы должны вернуть кое что другое P>>И это именно то, чего делать не стоит — в сложной логике ваш мок репозитория будет чудовищем, которое мало будет походить на реальную часть системы P>>Чем более унивесальная зависимость, тем труднее её мокать, и тем выше шансы на ошибку
Б>Для этого теста (который будет проверять эту ветку логики) для операции repo.get будет написан такой стаб:
Б>
Б>Да, выглядит компактно и понятно. И никто не заставляет наворачивать дизайн как у тебя — с дополнительными функциями, от которых код становится сложнее.
А я вас и не заставляю Большей частью у меня получается избавиться от моков, заменить на проверку значения или состояния. Они самые дешовые, их можно за короткое время настрочить десятки и сотни.
Б>Зависимости отделены также, как и у тебя. В твоем случае в тесты ты передаешь их как параметры-функции, а я подменяю поведение через стаб (по-сути ту же функцию). И в обоих случаях проверяются все варианты
Ну так посмотрите — у меня две строчки, у вас шесть.
Здравствуйте, Pauel, Вы писали:
P>Здравствуйте, Буравчик, Вы писали:
P>Почти то же самое. Вам нужно мокать репозиторий, а мне всего то лямду подкинуть.
И мне лямбду прокинуть — через мок (стаб)
P>Вопрос в том, сколько вам кода для этих моков надо. Если у вас, скажем, три раза подряд идет вызов repo.get вам придется заниматься глупостями — P>писать чтото навроде OnCall(3).Returnо(that) или писать кастомную вещь.
Для repo.get будет использоваться стаб, т.е. лямбда с нужным поведением. И он сработает для любого количества вызовов.
А вот ваш подход не понял.
Если для каждого будет своя лямбда, то что произойдет, если добавится четвертый вызов get? Придется тесты переписывать?
А если код порефакторят и изменят вызовы?
P>Наоборон — моками вы бетонируете конкретный дизайн. Там где вы тестами на моках проверяете что repo.get вызвался с тем или иным параметром, изменить дизайн на другой вы можете только через поломку всех таких тестов. Даже если просто укажете, что "функция использует репозиторий", у вас будут поломки на ровном месте из за смены дизайна.
Уже сто раз сказал, что для repo.get не проверяется, что он "вызвался с тем или иным параметром".
P>Нам нужно описать все значения, табличкой. Часть значений протаскиваются через параметры, часть — через лямбды. P>У нас их шесть штук, v1,v2,v3, repo1, svc, repo2, P>Дальше у вас будет один параметризованый тест типа такого, не знаю как на вашем питоне это выглядит, напишу на жээсе
P>[code P>@test() P>@params( P> 1,2,3,4,5,6 // и так на каждую строчку в табличке P>) P>@params( P> 8,4,2,1,3,5 // точно так же и исключения прокидывают P>) P>... сколько строчек, столько и тестов фактически выполнится P>"a cool name test name" (v1, v2, v3, repo1, svc, repo2, result) { P> let logic = Logic(v1,v2,v3);
P> let r = logic.run({ P> load: () => repo1, P> load2: () => svc, P> ... и так прокидываем все что надо P> })
P> expect(r).to.deep.eq(result) P>} P>[/code]
Я не понял, тесты здесь используют реальные зависимости?
Или все же вместо них прокидываются лямбды. (лямбды с упрощенным поведением, т.е. стабы)
Здравствуйте, Буравчик, Вы писали:
Б>А вот ваш подход не понял. Б>Если для каждого будет своя лямбда, то что произойдет, если добавится четвертый вызов get? Придется тесты переписывать? Б>А если код порефакторят и изменят вызовы?
То же самое, что и у вас. Добавили 4й вызов — ваши моки, коих по количеству тестов, отвалятся.
Ведь не сам вызов добавился, а значение приходит или уходит.
А раз другого варианта, кроме как чере моки-стабы, не нашли, т.к. куча депенденсов, то тесты будут хрупкими.
Все что можно сделать — свести к минимуму код тестов. Я это сделал через лямбды.
Б>Уже сто раз сказал, что для repo.get не проверяется, что он "вызвался с тем или иным параметром".
Вы свой пример мока репозитория видите? Таких вам надо по количеству тестов.
Например "апдейт после гет кидает одно исключение, ожидаемый результат — другое исключение"
Вам все такое надо в своих моках предусмотреть
P>>Нам нужно описать все значения, табличкой. Часть значений протаскиваются через параметры, часть — через лямбды. P>>У нас их шесть штук, v1,v2,v3, repo1, svc, repo2, P>>Дальше у вас будет один параметризованый тест типа такого, не знаю как на вашем питоне это выглядит, напишу на жээсе
P>>
P>>@test()
P>>@params(
P>> 1,2,3,4,5,6 // и так на каждую строчку в табличке
P>>)
P>>@params(
P>> 8,4,2,1,3,5 // точно так же и исключения прокидывают
P>>)
P>>... сколько строчек, столько и тестов фактически выполнится
P>>"a cool name test name" (v1, v2, v3, repo1, svc, repo2, result) {
P>> let logic = Logic(v1,v2,v3);
P>> let r = logic.run({
P>> load: () => repo1,
P>> load2: () => svc,
P>> ... и так прокидываем все что надо
P>> })
P>> expect(r).to.deep.eq(result)
P>>}
P>>
Б>Я не понял, тесты здесь используют реальные зависимости?
Тестовые зависимости, @params это параметры-значения для тестов,
Т.е. у нас тест вызовется столько раз, сколько @params мы вкинули
Б>Или все же вместо них прокидываются лямбды. (лямбды с упрощенным поведением, т.е. стабы)
Здравствуйте, Pauel, Вы писали:
P>>>Моки изначально предназначались для тестов вида "вызываем вон то, вон так, в такой последовательности" P>·>Может быть. Неясно какое это имеет значение сейчас, так исторические курьёзны. Даже если посмотреть на историю библиотек для тестов — за много лет много чего менялось и переделывалось. P>И сейчас это основной кейс для моков.
Я не знаю где это основной кейс. Можешь посмотреть туториалы по тому же mockito, там такого треша нет.
P>Вы и сами тащите "надо проверить old и new", и другого варианта не видите, как будто его нет. Можно же и дизайн поменять, что бы юнитами такое проверять. Но нет — вы топите за моки.
Есть, конечно, но другие варианты хуже. Больше писать кода и сложнее тестировать.
P>>>У вас — охотно верю. P>·>Потому что у нас не хелловорды, а не как у вас, да? P>Потому, что вы используете дизайн, который плодит лишнее. Я вам на примере дата-время показал, как можно иначе, но вам любой пример не в вашу пользу надо забраковать.
По факту пока что кода лишнего больше у тебя. Притом "вот фаулер написал моки — плохо, давайте накрутим слоёв в прод коде!".
P>>>Я вам пример приводил, про время, вам он ожидаемо не понравился — язык не тот P>·>Я не понял к чему ты скачешь с одного на другое. Обсуждали статью и MaitreD, потом crypto api, теперь вот ещё time api зачем-то... P>Со статьё давно всё ясно. crypto api и time это пример, которые показывают, за счет можно отказаться от моков, и что будет, если этого не делать.
Ни для crypto api, ни для time моки не нужны обычно не потому что "дизайн", а потому что они быстрые, детерминированные, с нулём внешних зависимостей.
P>>>В данном случае мне не надо переживать за поломаные тесты, если понадобится другой алгоритм, другая либа, итд. P>>>Вот понадобился не hmac а что другое — в файлике samples поменял десяток значений, и всё P>·>Почему десяток? У тебя только десяток операций в api? P>Это у вас на моках упадут все тесты всех операций апи. О том и речь. А на обычных юнит-тестах вы подкидываете новый набор значений, и всё путём.
Почему десяток? У тебя только десяток операций в api? Откуда взялся десяток?
P>>>А ваша альтернатива этому — еще и тесты перебулшитить. P>·>Один, скорее всего. Ибо одного теста достаточно чтобы зафиксировать логику вычисления hmac. В остальных тестах достаточно ассертить его наличие, но не конкретный формат. P>"достаточно ассертить его наличие" — вот вам и привязка к "как написано"
Не понял. Наличие hmac — это ожидание, бизнес-требование.
P>Ага, тесты "как написано" Вам придется написать много больше, чем один тест — как минимум, пространство входов более-менее покрыть. Моками вы вспотеете это покрывать.
Я тебе показывал как надо моками покрывать.
P>>>Ну да, этож только у вас сложные системы. P>·>Ну да, сам же сказал, что у тебя всё помещается в один файлик. Или он гиговый? P>Вы там в телепатию заигрались? Что именно по вашему помещается в один файлик? Вся система, все тесты, вся система с тестами? P>Вы чего то недопоняли, но вместо уточнения начинаете валять дурака?
А толку уточнять. Я задал вопрос чего десяток — ответа так и не последовало.
P>·>Какой негатив? Вроде говорили об одном, теперь чего-то новое. P>·>Вообще неясно причём тут time api и причём тут моки и тестирование вообще. P>time api это пример дизайна, как можно уйти от комбинаторного взрыва.
Это не "дизайн". Это если ЯП умеет в duck typing и сооружать типы на ходу. Впрочем, тут явно фича применена не по месту.
P>>>Успокойтесь — это все статически контролируется, только в вашу джаву такие фичи еще не завезли. P>·>Спасибо, но сводить всё к массиву из 7 чиселок — это фигня полная и издевательство. Даже такое DateTimeOffset.from({...time.toFields, ...date.toFields(), offset: serverOffset}); — и всё поехало. И где наносекуды, интересно? P>Где вы видите массив? Это объект, статически типизированый, наносекунды будут в time.toFields как fractionalSeconds. Вам телепатия еще не надоела?
Ужас. Закопайте.
P>·>Конструкторы удобнее и надёжнее с нужными типами, например, OffsetDateTime.of(date, time, offset), это хотя бы читабельно, и если что-то не так, не компиляется P>Принципиальное отличе of вместо from
Принципиальное отличие что тут три разных типа Date, Time и Offset — и их никак не перепутать.
P>>>Вы уже показали — перебулшитить все тесты, когда можно ограничиться десятком строчек на весь проект. P>·>Это твои фантазии. P>Вы сами пишите, что тестировать надо "как написано", это следует из того, как вы предлагаете решать задачу с hmac. Таких же задач будет не одна на проект, а целая куча. Вот и будут тесты "проверить что делает"
Я предложил как решают задачу взаимодействия с неким абстрактным сложным API в тестах с моками (стабами?). То что это crypto — к сути дела не относится, я это сразу заявил в ответе на твой пример, перечитай. Так что это твои фантазии.
P>>>Ну да — для вас перебулшитить тесты проблемой не является Еще и настаиваете, что так и надо. P>·>Я настаиваю, что так не надо. P>Если не надо, то должен быть другой подход к тестированию. А вы выбираете тесты на моках "проверим что вызывается hmac с нужными параметрами"
У меня в примере не было "проверим что вызывается hmac с нужными параметрами". Это было у тебя, и я сказал, что так не надо.
P>>>Проходит же. Вот я и интересуюсь, кто настрочил горы непотребства P>·>Вчерашние студенты? P>Да не похоже.
Ок, пусть сорокалетние+ джуниоры.
P>>>Эта разновидность тестов нужна и вам. P>·>Нужны, но не для проверки каждой строчки кода, что параметры вызова не перепутаны. А только для тестирования интеграции. P>АПИ и есть та самая интеграция.
Нет.
P>>>Продукт, система, приложение, апи, компонент, модуль. Для теста именно кода у нас другие инструменты — код-ревью, линт, дизайн-ревью, статические анализаторы, итд. P>·>Я сказал "Они отменяют необходимость написания тучи этих самых xxxComposition, нет кода — нечего тестировать". Ты прикопаться решил к слову код? Ок, пусть будет не код, а модуль-компонент. P>·>"Моки отменяют необходимость написания тучи этих самых xxxComposition, нет такого компонента|модуля — нечего тестировать." Так яснее? P>Не отменяют. Когда вы укрупняете компонент, то тестировать его сложнее. Или ваше покрытие будет решетом, или вам придется понаписывать много моков вида "это вызывает то", которые сломаются даже при минорных изменения компоненты
Суть в том, что компонент содержит несколько частей функциональности и весь компонент покрывается со всей его функциональностью, с моками (стабами?) зависимостей. После этого достаточно одного интеграционного теста, что несколько компонент соединились вместе и взаимодействуют хотя бы по одной части функциональности. Условно говоря, если в классе 20 методов и все 20 протестированы сотней юнит-тестов, то для тестирования интеграции обычно достаточно одного и-теста. В качестве аналогии — когда ты вставляешь CPU в материнку — тебе достаточно по сути smoke test, а не прогонять те миллионы тестов, которые были сделаны на фабрике для каждого кристалла и конденсатора.
У тебя же будет дополнительных xxxComposition на каждый метод в прод-коде и это надо будет всё как-то тестииовать в полном сборе.
P>>>Можно. И это делается без моков. Если мы заложимся на значение или состояние, то получим куда больше гарантий. P>·>Без моков ты предложил только полный запуск всей аппликухи, в лучшем случае с тестовой субд. Kafka/amps/lbm/solace/tibco/etc, кстати, тоже тестовую будешь пускать? Или как? P>Вы додумываете. Это в вашем понадобился бы запуск всей апликухи. У меня же апликуха запускается только ради e2e тестов. P>Кафка — это обычный эвент, как вариант, можно обойтись и простым юнитом, убедиться что функция возвращает объект-эвент. P>Если у вас такой роскоши нет — добавьте мок ровно на нотификацию, а не на кафку.
Так вызов метода — это и есть по сути эвент. По крайней мере, изоморфное понятие.
P>>>В функции средний девелопер может понаделывать ошибок куда больше, чем перепутать old и new. P>·>Я в этом и до среднего не дотягиваю, дохрена таких ошибок делаю, но вся эта фигня на раз ловится тестами, c моками (стабами), да. P>Если вы написали тест на old и new, то конечно же словится. Только откуда следует, что это единственные проблемы? P>Проблем может быть сколько угодно, именно конечный результат говорит что правильно а что нет
Не знаю как у тебя, но у меня большинство ошибок именно логике в реалзиации методов, когда я тупо ошибаюсь в +1 вместо -1, from/to и т.п.
P>>>Именно! А потому нам все контроллеры нужно тестировать в апи тестах — тем самым мы исключаем добрый десяток классов проблем. P>·>И эти тесты дадут тебе гарантию? P>Разумеется, мы ради этого и пишем тесты. Не только что бы убедиться, что работает здесь и сейчас, но что бы можно было перепроверить это в т.ч. на живом окружении. P>После билда работает, после деплоя — нет, опаньки!
У меня такое редко бывает. Неделю мучаюсь, вылизываю corner cases, потом деплою и оно тупо работает. Ну или сразу грохается при запуске, т.к. новый парам забыл в конфиге определить и лечится за минуту.
P>Впрочем, в прошлом году вы рассказывали, что деплой трогать низя — он у вас хрупкий, не дай бог повалится от лишнего запроса.
Это ты фантазируешь. Не "повалится", а произойдёт реальная сделка.
P>·>Жуть. Ну ладно. Т.е. тут мы тестируем репозиторий и ассертим текст sql P>Здесь мы тестируем построение запроса
Ассерт-то в чём? Что текст запроса 'select * from users where id=?'? У тебя в тесте именно текст забит или что?
P>·>Как проверить, что текст запроса хотя бы синтаксически корректен? P>Для этого нам всё равно придется выполнить его на реальной бд. Расскажите, как вы решите задачу вашими моками.
Я уже рассказывал. Интеграционным тестом repo+db. Текстов запроса в тестах нет, и быть не должно. Как-то так:
var testSubject = new MyRepo("connectionString");// по возможности in-mem dbms, но может быть и реальнаяvar id = 42;
testSubject.save(new User(id, "Vasya")));
var actual = testSubject.getUser(id);
assert actual.getName().equals("Vasya");
>> И что он при выполнении выдаст то, что ожидается? P>А здесь как вы моками обойдетесь?
Тут и не надо. Здесь же интеграция с субд тестируется. Моки (стабы?) будут дальше — в бл, в контроллере, етс.
>> И как ты собрался тут подменять субд? Ты обещал, что теперь эту хрень можно отдать любой db и оно выдаст одинаковый результат? Даже если эта субд это oracle или cassandra? Да там синтаксис банально другой. P>А разве я говорил, что бд можно менять любую на любую? Построение запросов мы можем тестировать для тех бд, которые поддерживаются нами.
У тебя был такой код:
Этот код выглядит так, что getUser выдаваемый из репы не зависит от db (и как ты заявил обещано в clean) и repo покрывается тестами независимо. Но по сути всё то же самое. Просто зависимость стала неявной. "генерим любой результат, но только такой, который где-то как-то будет использоваться в db.execute и мы должны знать где и как". Иными словами, repo может генерить только такие результаты, которые можно использовать далее, пишем репу, но должны всё знать о db слое. И вот это никак не тестируется без запуска всего кода контроллера в котором живёт этот код. А чтобы запустить контроллер — надо обеспечить ему все зависимости, т.е. по сути запустить всё приложение.
В моём коде выше с MyRepo("connectionString") — мы тестируем только интеграцию двух частей repo + dbms. И ничего больше в таких тестах поднимать не надо.
P>>>Сами трансформации тестируются отдельно, обычными юнитами, например expect(fn1(user)).to.eq(user.id); P>·>Так ведь надо трансформировать не некий user, а конкретно ResultSet возвращённый из "select *". Что колоночки в select местами не перепутаны, как минимум. P>Что вас смущает? трансформация результата принимает ResultSet и возвращает вам нужный объект.
Так ведь надо не абы какой ResultSet, а именно тот, который реально возвращается из "select *". У тебя же эти по настоящему связанные сущности тестируются независимо. Что абсолютно бесполезно.
P>·>Ещё это всё "красиво" только на твоих хоумпейдж проектах. В реальном коде эти sql будут сотни строк с многоэтажными джойнами и подзапросами, и такие "тесты" станут даже немножечко вредить. P>Расскажите, как вы это моками решите
Моки (стабы) — это для отпиливания зависимостей в тестах. Репу тестируем медленными и-тестами с более-менее реальной субд, а дальше моки (стабы) для быстрого тестирования всего остального.
P>>>Вы все думаете в единицах старого дизайна, когда БЛ прибита гвоздями к бд. P>·>Не к бд прибита. БЛ прибивается к репе. P>Это одно и то же, и в этом проблема. Я ж вам говорю, как можно иначе — но вы упорно видите только вариант из 90х-00х
Ты показал это "иначе", но там всё ещё хуже прибито. Вплоть до побуквенного сравнения текста sql.
P>В новом подходе не надо БЛ прибивать ни к какой репе, ни к бд, ни к стораджу, ни к кафе, ни к внешним сервисам
Ага-ага.
P>>>Шота я этого за 4 года не заметил P>·>Может у тебя проекты написанные вайтишниками после курса ML, я не знаю. Но у тебя есть целый гитхаб, погляди насколько часто и для чего Object используют. P>Я как раз с гитхаба и брал, если что.
Ссылку давай.
P>>>Юзеру так и скажете — мы не можем вернуть ваши деньги, потому что у нас в конфигурации возвраты отключены. P>·>Для этого и есть L1 support — "проверьте, что ваш компьютер включен". P>Я именно это сказал — L1 support так и скажет юзеру, "в конфиге отключено, значит неположено" P>Что бы такого не случалось, в тестах должен быть сценарий, который включает возврат. И так для всех апи которые вы выставляете.
Не понял, если возврат отключен, то и тест должен тестировать, что возврат отключен.
P>>>Добавили, посмотрели дифом, вкомитали. Вам же не надо сразу всё обрабатывать. P>·>А в дифе 10к строчек отличаются. И как это смотреть? Аудит же пишется для каждой операции, т.е. каждого теста, да ещё и не по разу. P>А почему 10к а не 10к миллионов?
Примерное типичное кол-во сценариев реальной системе большего, чем хоумпейдж масштаба.
P>>>Если апи возвращает то, что надо, это значит что у вас связка конфиг-di-sl-рантайм-переменные-итд склеено правильно. P>·>И это ты предлагаешь гонять на каждый "updateUser(newUser, oldUser)"? Спасибо, не надо нам такого щастя. P>Да, я в курсе, у вас есть L1 суппорт, который скажет клиенту, что возвраты не положены. P>Это не шутка — мне так L1 однажды залепил P>Неделя бодания и перекинули проблему наверх, только когда я сослался на федеральный закон P>Признавайтесь, ваша идея?
Только не пытайся доказать, что это у них "не работало", потому что тесты у них неправильные. Уж поверь, у них всё работало как надо (им).
P>>>Можно. Это старый подход. P>·>Ты говоришь как будто это что-то плохое. Это разумный подход. Делить не по тому, что сейчас у фаулеров в моде, а по конкретному осязаемому критерию, т.к. это напрямую выражается во времени запуска и требуемых ресурсов для тестирования. P>В данном случае вам нужно писать больше кода в тестах, и они будут хрупкими. Другого вы с моками не получите. Потому и убирают зависимости из БЛ целиком, что бы легче было покрывать тестами
Но ведь не "убирают", а переносят. Что добавляет и количество прод-кода и число тестов.
P>>>Это новый подход, позволяет обходиться без моков-стабов итд и свести тестирование ключевых вещей к дешовым юнит-тестам P>·>У тебя тривиальное updateUser(newUser, oldUser) не тестируется юнитами. Любая мелочёвка требует запуска всего, в лучшем случае с in-mem субд. P>Ага, сидим да годами ждём результаты одного теста. Вам самому не смешно?
Думаю ваш хоум-пейдж за час тестируется, в лучшем случае.
P>·>С такими же гарантиями можно и просто метод дёргать. Аннотации это только от плохого дизайна. P>Ну вот подергали вы метод. А потом вас попросили отразить всё такое в сваггере каком, что бы другим было понятно. Гы-гы. Ищите строчки в коде. P>А с аннотациями взял да и отрендерил манифест.
Гы-гы. У тебя же, ты сам говорил, что попало где попало — и в переменных окружения, и в конфигах и где угодно эти "аннотации" висят. Сваггер у вас каждые 5 минут новый, да?
P>>>Вы же не проверяете, что джава выполняет циклы правильно? Так и здесь P>·>Фреймворк-ориентед программинг? Нет, спасибо. P>Это ж классика — отделяем логику, которая меняется часто, от той, которая меняется редко. По этому пути индустрия идет последние 50 лет
Ты любишь сложность на пустом месте, притом в прод-коде, я уже понял. Но это плохо. Фреймворк это совсем другая весовая категория. Для того что ты пишешь достаточно extract method refactoring, а не новая архитектура с фреймворками.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, Pauel, Вы писали:
Б>>А вот ваш подход не понял. Б>>Если для каждого будет своя лямбда, то что произойдет, если добавится четвертый вызов get? Придется тесты переписывать? Б>>А если код порефакторят и изменят вызовы? P>То же самое, что и у вас. Добавили 4й вызов — ваши моки, коих по количеству тестов, отвалятся.
Тебе уже раз тысячу написали, что НЕ НАДО ПИСАТЬ МОКИ по количеству. Моки (стабы?) пишутся по параметрам и условиям вызова. when(repo.get(v1)).thenReturn(r1); when(repo.get(v2)).thenReturn(r2);. Такой код OnCall(3) — это дичь полная. Так, мне кажется, писали может быть на заре изобретения фреймворков тестирования, лет 20-30 назад.
P>Все что можно сделать — свести к минимуму код тестов. Я это сделал через лямбды.
Любопытно, а что если "repo.get" дёргается в цикле? Заведёшь массив лямд?!
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
Б>>>А если код порефакторят и изменят вызовы? P>>То же самое, что и у вас. Добавили 4й вызов — ваши моки, коих по количеству тестов, отвалятся. ·>Тебе уже раз тысячу написали, что НЕ НАДО ПИСАТЬ МОКИ по количеству. Моки (стабы?) пишутся по параметрам и условиям вызова.
В этом случае вы воссоздаете ваше собственное видение мокируемой подсистемы, которое нечем проверить на соответствие с ожиданиями, ну разве что и моки тоже покрыть тестами OMG!
В таких моках вы должны отразить все неявные зависимости
Лямбдой это просто — симулируем любую ситуацию
Мок на тест — сложнее, но тоже возможно
Мок на все — приплызд, если у нас сотня кейсов, то вам понадобится довольно сложный мок
И теперь именно у вас проблема — а ну, как у нас чтото поменялось в дизайне, логике итд
Далеко не факт что ваш особо умный мок начнет валить тесты
В моем случае эти лямбды всего лишь помогают тестировать через возвращаемое значение
P>>Все что можно сделать — свести к минимуму код тестов. Я это сделал через лямбды. ·>Любопытно, а что если "repo.get" дёргается в цикле? Заведёшь массив лямд?!
Здравствуйте, Pauel, Вы писали:
P>>>То же самое, что и у вас. Добавили 4й вызов — ваши моки, коих по количеству тестов, отвалятся. P>·>Тебе уже раз тысячу написали, что НЕ НАДО ПИСАТЬ МОКИ по количеству. Моки (стабы?) пишутся по параметрам и условиям вызова. P>В этом случае вы воссоздаете ваше собственное видение мокируемой подсистемы, которое нечем проверить на соответствие с ожиданиями, ну разве что и моки тоже покрыть тестами OMG!
А твоя лямбда что возвращает?
P>В таких моках вы должны отразить все неявные зависимости P>Лямбдой это просто — симулируем любую ситуацию Хинт: Лямбда это и есть частный случай мока (стаба). Разница лишь в том, что лямбда это ровно один метод, а мок (стаб) — может быть больше одного. Поэтому у тебя и получается, что приходится плодить лямбды там, где можно обойтись одним классом/интерфейсом.
P>>>Все что можно сделать — свести к минимуму код тестов. Я это сделал через лямбды. P>·>Любопытно, а что если "repo.get" дёргается в цикле? Заведёшь массив лямд?! P>Лямбда которая возвращает значения по списку
Какому ещё списку? "repo.get" может дёргаться в цикле, несколько раз, в зависимости от условий и даже результатов предыдущих вызовов и погоды на марсе. Да там вообще внутре какая-нибудь рекурсия может быть, да что угодно. Или ты опять о своих хоумпейджах рассуждаешь?
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>Вы и сами тащите "надо проверить old и new", и другого варианта не видите, как будто его нет. Можно же и дизайн поменять, что бы юнитами такое проверять. Но нет — вы топите за моки. ·>Есть, конечно, но другие варианты хуже. Больше писать кода и сложнее тестировать.
Наоборот — юнит тесты дешевле некуда.
P>>>>У вас — охотно верю. P>>·>Потому что у нас не хелловорды, а не как у вас, да? P>>Потому, что вы используете дизайн, который плодит лишнее. Я вам на примере дата-время показал, как можно иначе, но вам любой пример не в вашу пользу надо забраковать. ·>По факту пока что кода лишнего больше у тебя. Притом "вот фаулер написал моки — плохо, давайте накрутим слоёв в прод коде!".
Это у вас телепатия разыгралась? С чего вы взяли, что у меня лишнего кода бОльше? У меня основной подход к разработке это как раз выбрасывать код и покрывать оставшееся максимально дешовыми юнит тестами.
Но вам конечно же виднее.
P>>Со статьё давно всё ясно. crypto api и time это пример, которые показывают, за счет можно отказаться от моков, и что будет, если этого не делать. ·>Ни для crypto api, ни для time моки не нужны обычно не потому что "дизайн", а потому что они быстрые, детерминированные, с нулём внешних зависимостей.
Вы сейчас сами себя отрицаете:
Во первых, вы сами недавно поделились решением для hmac — "моками проверим то и это"
Во вторых, чуть далее, тоже недавно, вы рассказывали, как моками отрезали Time.now
P>>Это у вас на моках упадут все тесты всех операций апи. О том и речь. А на обычных юнит-тестах вы подкидываете новый набор значений, и всё путём. ·>Почему десяток? У тебя только десяток операций в api? Откуда взялся десяток?
Десяток значений. Эти значения вы можете в каких угодно тестах использовать.
P>>·>Один, скорее всего. Ибо одного теста достаточно чтобы зафиксировать логику вычисления hmac. В остальных тестах достаточно ассертить его наличие, но не конкретный формат. P>>"достаточно ассертить его наличие" — вот вам и привязка к "как написано" ·>Не понял. Наличие hmac — это ожидание, бизнес-требование.
Это не повод моки тащить. Если значение hmac во всех кейсах совпадает с нашим, это куда лучшая проверка. Но вместо этого вы берете моки т.к. "это бизнес-требования"
P>>Ага, тесты "как написано" Вам придется написать много больше, чем один тест — как минимум, пространство входов более-менее покрыть. Моками вы вспотеете это покрывать. ·>Я тебе показывал как надо моками покрывать.
Я про это и говорю — вы предлагаете писать мок на все случаи жизни. Как убедиться что мокируемая система совпадает по поведению с вашим моком — не ясно.
P>>Вы чего то недопоняли, но вместо уточнения начинаете валять дурака? ·>А толку уточнять. Я задал вопрос чего десяток — ответа так и не последовало.
Десяток значений, что очевидно. Что для time, что для токенов. Вот если вы тестируете свою либу date-time или hmac, там будет побольше значений, до сотни, может и больше.
P>>time api это пример дизайна, как можно уйти от комбинаторного взрыва. ·>Это не "дизайн". Это если ЯП умеет в duck typing и сооружать типы на ходу. Впрочем, тут явно фича применена не по месту.
Это никакой не duck-typing. Это статически типизированые фичи — spread и destructuring. Если какого то филда не хватает — компилятор так и скажет. Если какой то филд будет иметь не тот тип — компилятор говорит об этом.
P>>Принципиальное отличе of вместо from ·>Принципиальное отличие что тут три разных типа Date, Time и Offset — и их никак не перепутать.
Запросто — local time и server time будут все равно Time, опаньки. Есть LocalTime, AbsoluteTime, итд. Ошалеете покрывать все кейсы
·>Я предложил как решают задачу взаимодействия с неким абстрактным сложным API в тестах с моками (стабами?). То что это crypto — к сути дела не относится, я это сразу заявил в ответе на твой пример, перечитай. Так что это твои фантазии.
Вы показываете выбор в пользу моков, а не в пользу сравнения результата. Вы сами то это видите? Если у нас сотня кейсов в апи, ваш моковый подход превращается в тавтологию, тесты "как написано"
Эту самую сотню кейсов всё равно надо покрыть внятными тестами.
·>Суть в том, что компонент содержит несколько частей функциональности и весь компонент покрывается со всей его функциональностью, с моками (стабами?) зависимостей. После этого достаточно одного интеграционного теста, что несколько компонент соединились вместе и взаимодействуют хотя бы по одной части функциональности. Условно говоря, если в классе 20 методов и все 20 протестированы сотней юнит-тестов, то для тестирования интеграции обычно достаточно одного и-теста.
В том то и дело — я именно это вам пишу уже второй месяц. Только моки здесь играют сильно вспомогательную роль, их обычно немного, только там, где дизайн дороже править чем накидать один мок.
> В качестве аналогии — когда ты вставляешь CPU в материнку — тебе достаточно по сути smoke test, а не прогонять те миллионы тестов, которые были сделаны на фабрике для каждого кристалла и конденсатора.
Недостаточно — полно причин, когда CPU проходит смок-тест. А вот загрузка операционки, что уже много больше смок теста, уже кое что гарантирует. И то полно случаев, когда в магазине пусканул систему, всё хорошо. Принес домой — комп уже не включется, а бибикает.
Вобщем, понятно, откуда вы берете невалидные идеи.
·>У тебя же будет дополнительных xxxComposition на каждый метод в прод-коде и это надо будет всё как-то тестииовать в полном сборе.
Вы там похоже вовсю фантазируете.
P>>Кафка — это обычный эвент, как вариант, можно обойтись и простым юнитом, убедиться что функция возвращает объект-эвент. P>>Если у вас такой роскоши нет — добавьте мок ровно на нотификацию, а не на кафку. ·>Так вызов метода — это и есть по сути эвент. По крайней мере, изоморфное понятие.
Эвент можно проверять как значение. А можно и моком. Значением дешевле.
P>>Проблем может быть сколько угодно, именно конечный результат говорит что правильно а что нет ·>Не знаю как у тебя, но у меня большинство ошибок именно логике в реалзиации методов, когда я тупо ошибаюсь в +1 вместо -1, from/to и т.п.
В том то и дело — и никакие моки этого не исправят. Потому и нужна проверка на результат.
P>>Здесь мы тестируем построение запроса ·>Ассерт-то в чём? Что текст запроса 'select * from users where id=?'? У тебя в тесте именно текст забит или что?
Я ж вам показал все что надо — deep equality + структура.
P>>·>Как проверить, что текст запроса хотя бы синтаксически корректен? P>>Для этого нам всё равно придется выполнить его на реальной бд. Расскажите, как вы решите задачу вашими моками. ·>Я уже рассказывал. Интеграционным тестом repo+db. Текстов запроса в тестах нет, и быть не должно. Как-то так:
Вот видите — вам тоже нужны такие тесты Только вы предпочитаете косвенную проверку.
Кстати, как вы собираетесь пагинацию да фильтры тестировать? Подозреваю, сгенерируете несколько тысяч значений, и так для каждой таблицы?
P>>А здесь как вы моками обойдетесь? ·>Тут и не надо. Здесь же интеграция с субд тестируется. Моки (стабы?) будут дальше — в бл, в контроллере, етс.
Ну да, раз вы протащили в БЛ репозиторий, то и отрезать надо там же. А вариант сделать БЛ иначе, что бы хватило юнитов, вы отбрасываете заранее с формулировкой "по старинке надёжнее"
P>>А разве я говорил, что бд можно менять любую на любую? Построение запросов мы можем тестировать для тех бд, которые поддерживаются нами. ·>У тебя был такой код: ·>
·>Этот код выглядит так, что getUser выдаваемый из репы не зависит от db (и как ты заявил обещано в clean) и repo покрывается тестами независимо.
Есть такое. Они конечно же должны быть согласованы. Моя идея была в том, что бы тестировать построение запроса, а не мокать всё подряд.
·>В моём коде выше с MyRepo("connectionString") — мы тестируем только интеграцию двух частей repo + dbms. И ничего больше в таких тестах поднимать не надо.
И у меня примерно так же, только моков не будет.
P>>Что вас смущает? трансформация результата принимает ResultSet и возвращает вам нужный объект. ·>Так ведь надо не абы какой ResultSet, а именно тот, который реально возвращается из "select *". У тебя же эти по настоящему связанные сущности тестируются независимо. Что абсолютно бесполезно.
1 раз тестируются в составе интеграционного теста, такого же, как у вас. и много раз — в составе юнит-тестов, где нас интересуют подробности
— а что если в колонке пусто
— а что если значение слишком длинное
— а что если значение слишком короткое
— ...
И это в любом случае нужно делать, и никакие моки от этого не избавляют. Можно просто отказаться от таких тестов типа "у нас смок тест бд". Тоже вариант, и собственно моки здесь снова никак не помогают
P>>Расскажите, как вы это моками решите ·>Моки (стабы) — это для отпиливания зависимостей в тестах. Репу тестируем медленными и-тестами с более-менее реальной субд, а дальше моки (стабы) для быстрого тестирования всего остального.
Вот — вам надо медленными тестами тестировать репу — каждый из её методов, раз вы её присобачили. А у меня репа это фактически билдер запросов, тестируется простыми юнит-тестами.
Зато мне нужно будет несколько медленных тестов самого useCase.
P>>Это одно и то же, и в этом проблема. Я ж вам говорю, как можно иначе — но вы упорно видите только вариант из 90х-00х ·>Ты показал это "иначе", но там всё ещё хуже прибито. Вплоть до побуквенного сравнения текста sql.
—
Вы так и не рассказали, чем это хуже. Вы предложили конский запрос тестировать косвенно
P>>В новом подходе не надо БЛ прибивать ни к какой репе, ни к бд, ни к стораджу, ни к кафе, ни к внешним сервисам ·>Ага-ага.
Похоже, вам ктото запрещает посмотреть как это делается
P>>Что бы такого не случалось, в тестах должен быть сценарий, который включает возврат. И так для всех апи которые вы выставляете. ·>Не понял, если возврат отключен, то и тест должен тестировать, что возврат отключен.
Очень даже понятно — вот некто неглядя вкомитал в конфиг что возвраты отключены. Ваши действия?
·>Примерное типичное кол-во сценариев реальной системе большего, чем хоумпейдж масштаба.
Из этого никак не следует, что и в тестах будет так же. Нам не нужно сравнивать трассы всех тестов вообще. Вы вы еще предложите трассы нагрузочных тестов сравнивать или трассы за весь спринт
Нас интересуют трассы конкретных тестов. Если вы можете такое выделить — акцептанс тесты для вас. Если у вас мешанина, и всё вызывает всё да помногу раз с аудитом вперемешку — акцептанс тесты вам не помогут.
P>>Неделя бодания и перекинули проблему наверх, только когда я сослался на федеральный закон P>>Признавайтесь, ваша идея? ·>Только не пытайся доказать, что это у них "не работало", потому что тесты у них неправильные. Уж поверь, у них всё работало как надо (им).
После ссылки на федеральный закон вдруг "заработало" как надо.
P>>В данном случае вам нужно писать больше кода в тестах, и они будут хрупкими. Другого вы с моками не получите. Потому и убирают зависимости из БЛ целиком, что бы легче было покрывать тестами ·>Но ведь не "убирают", а переносят. Что добавляет и количество прод-кода и число тестов.
Тестов БЛ — больше, т.к. теперь можно покрывать дешовыми тестами самые разные кейсы, для того и делается.
Интеграционных — столько же, как и раньше, — по количеству АПИ и сценариев.
P>>Ага, сидим да годами ждём результаты одного теста. Вам самому не смешно? ·>Думаю ваш хоум-пейдж за час тестируется, в лучшем случае.
Полтора часа только сборка идет.
P>>А с аннотациями взял да и отрендерил манифест. ·>Гы-гы. У тебя же, ты сам говорил, что попало где попало — и в переменных окружения, и в конфигах и где угодно эти "аннотации" висят. Сваггер у вас каждые 5 минут новый, да?
Вы снова из 90х? Манифест генерируется по запросу, обычно http. Отсюда ясно, что и переменные, и конфиги, и аннотации будут учтены. Еще тенантность будет учитывать — для одного тенанта один апи доступен, для другого — другой.
·>Ты любишь сложность на пустом месте, притом в прод-коде, я уже понял. Но это плохо. Фреймворк это совсем другая весовая категория. Для того что ты пишешь достаточно extract method refactoring, а не новая архитектура с фреймворками.
Ровно наоборот. Чем проще, тем лучше. Фремворковый код он не то что бы особо сложный — просто разновидности вы будете каждый раз писать по месту. Или же отделяете, покрываете сотней тестов, и используете через аннотации без оглядки "а вдруг не сработает"
Здравствуйте, Pauel, Вы писали:
P>>>Вы и сами тащите "надо проверить old и new", и другого варианта не видите, как будто его нет. Можно же и дизайн поменять, что бы юнитами такое проверять. Но нет — вы топите за моки. P>·>Есть, конечно, но другие варианты хуже. Больше писать кода и сложнее тестировать. P>Наоборот — юнит тесты дешевле некуда.
И? С моками (стабами) тесты такие же дешёвые. Т.к. мы мочим всё медленное и дорогое. В этом и цель моков (стабов) — удешевлять тесты.
P>>>Потому, что вы используете дизайн, который плодит лишнее. Я вам на примере дата-время показал, как можно иначе, но вам любой пример не в вашу пользу надо забраковать. P>·>По факту пока что кода лишнего больше у тебя. Притом "вот фаулер написал моки — плохо, давайте накрутим слоёв в прод коде!". P>Это у вас телепатия разыгралась? С чего вы взяли, что у меня лишнего кода бОльше?
В статье кода стало больше. Вот эти все getUser — это всё лишний код в проде. Твои "{...toFields}" — тоже лишний код, и это всё прод-код.
P>>>Со статьё давно всё ясно. crypto api и time это пример, которые показывают, за счет можно отказаться от моков, и что будет, если этого не делать. P>·>Ни для crypto api, ни для time моки не нужны обычно не потому что "дизайн", а потому что они быстрые, детерминированные, с нулём внешних зависимостей. P>Вы сейчас сами себя отрицаете: P>Во первых, вы сами недавно поделились решением для hmac — "моками проверим то и это"
Это твоё было решение. Я его просто сделал вменяемым.
P>Во вторых, чуть далее, тоже недавно, вы рассказывали, как моками отрезали Time.now
Ага. И это одна строчка кода. Ты взамен предложил _фреймворк_ для этого же.
P>>>Это у вас на моках упадут все тесты всех операций апи. О том и речь. А на обычных юнит-тестах вы подкидываете новый набор значений, и всё путём. P>·>Почему десяток? У тебя только десяток операций в api? Откуда взялся десяток? P>Десяток значений. Эти значения вы можете в каких угодно тестах использовать.
Значений чего? И почему они лежат в одном файлике?
P>>>"достаточно ассертить его наличие" — вот вам и привязка к "как написано" P>·>Не понял. Наличие hmac — это ожидание, бизнес-требование. P>Это не повод моки тащить.
Конечно, это я сразу тебе сказал. Моки для hmac — ты притащил. Перечитай топик, все ходы записаны.
P>Если значение hmac во всех кейсах совпадает с нашим, это куда лучшая проверка. Но вместо этого вы берете моки т.к. "это бизнес-требования"
Это плохая проверка. Т.к. при изменении формата/алгоритма этого hmac тебе придётся менять тестовые данные в этих самых всех кейсах.
P>>>Ага, тесты "как написано" Вам придется написать много больше, чем один тест — как минимум, пространство входов более-менее покрыть. Моками вы вспотеете это покрывать. P>·>Я тебе показывал как надо моками покрывать. P>Я про это и говорю — вы предлагаете писать мок на все случаи жизни.
Это твои фантазии.
P>Как убедиться что мокируемая система совпадает по поведению с вашим моком — не ясно.
Это не проблема моков. А проблема раздельного тестирования. У тебя ровно та же проблема: "Они конечно же должны быть согласованы".
P>>>Вы чего то недопоняли, но вместо уточнения начинаете валять дурака? P>·>А толку уточнять. Я задал вопрос чего десяток — ответа так и не последовало. P>Десяток значений, что очевидно. Что для time, что для токенов. Вот если вы тестируете свою либу date-time или hmac, там будет побольше значений, до сотни, может и больше.
Нет, совершенно не очевидно. И я всё равно не понял, какой time? каких токенов? какая своя либа?
P>>>time api это пример дизайна, как можно уйти от комбинаторного взрыва. P>·>Это не "дизайн". Это если ЯП умеет в duck typing и сооружать типы на ходу. Впрочем, тут явно фича применена не по месту. P>Это никакой не duck-typing. Это статически типизированые фичи — spread и destructuring. Если какого то филда не хватает — компилятор так и скажет. Если какой то филд будет иметь не тот тип — компилятор говорит об этом.
Насколько мне известно такое умеет только typescript из мейнстримовых яп.
P>>>Принципиальное отличе of вместо from P>·>Принципиальное отличие что тут три разных типа Date, Time и Offset — и их никак не перепутать. P>Запросто — local time и server time будут все равно Time, опаньки. Есть LocalTime, AbsoluteTime, итд. Ошалеете покрывать все кейсы
Я ничего не понял, но всё равно очень интересно. Если чё, то LocalTime/AbsoluteTime (это откуда кстати?) не просто так придумали, а потому что это действительно разные типы с разными свойствами, разной арифметикой и разными операциями. Это именно бизнес-область, календарь человеков — вещь такая, от которой если не достаточно ошалеть, будешь делать кучу ошибок.
P>·>Я предложил как решают задачу взаимодействия с неким абстрактным сложным API в тестах с моками (стабами?). То что это crypto — к сути дела не относится, я это сразу заявил в ответе на твой пример, перечитай. Так что это твои фантазии. P>Вы показываете выбор в пользу моков, а не в пользу сравнения результата. Вы сами то это видите? Если у нас сотня кейсов в апи, ваш моковый подход превращается в тавтологию, тесты "как написано" P>Эту самую сотню кейсов всё равно надо покрыть внятными тестами.
Я пытаюсь донести мысль, что пофиг — моки или результаты, это технические детали. Это ортогонально тестам "как написано", т.к. тесты это про семантику.
P>·>Суть в том, что компонент содержит несколько частей функциональности и весь компонент покрывается со всей его функциональностью, с моками (стабами?) зависимостей. После этого достаточно одного интеграционного теста, что несколько компонент соединились вместе и взаимодействуют хотя бы по одной части функциональности. Условно говоря, если в классе 20 методов и все 20 протестированы сотней юнит-тестов, то для тестирования интеграции обычно достаточно одного и-теста. P>В том то и дело — я именно это вам пишу уже второй месяц. Только моки здесь играют сильно вспомогательную роль, их обычно немного, только там, где дизайн дороже править чем накидать один мок.
Нет, ты предлагаешь всё разделять на лямбды и писать кучу composition кода, который тоже весь приходится тестировать.
>> В качестве аналогии — когда ты вставляешь CPU в материнку — тебе достаточно по сути smoke test, а не прогонять те миллионы тестов, которые были сделаны на фабрике для каждого кристалла и конденсатора. P>Недостаточно — полно причин, когда CPU проходит смок-тест. А вот загрузка операционки, что уже много больше смок теста, уже кое что гарантирует. И то полно случаев, когда в магазине пусканул систему, всё хорошо. Принес домой — комп уже не включется, а бибикает. P>Вобщем, понятно, откуда вы берете невалидные идеи.
Даже если так. Загрузка операционки это один тест. Кристалл и каждый компонент современного компьютера на фабриках тестируют тысячами-миллионами тестов.
P>·>У тебя же будет дополнительных xxxComposition на каждый метод в прод-коде и это надо будет всё как-то тестииовать в полном сборе. P>Вы там похоже вовсю фантазируете.
Вот это оно и есть:
{
load: () => repo1,
load2: () => svc,
... и так прокидываем все что надо
}
— эта лапша у тебя будет в каждом тесте, ещё такая же (почти!) копипастная лапша — и в прод-коде, которую придётся каждую покрывать отдельным и-тестом и это для каждого do_logic метода.
P>>>Кафка — это обычный эвент, как вариант, можно обойтись и простым юнитом, убедиться что функция возвращает объект-эвент. P>>>Если у вас такой роскоши нет — добавьте мок ровно на нотификацию, а не на кафку. P>·>Так вызов метода — это и есть по сути эвент. По крайней мере, изоморфное понятие. P>Эвент можно проверять как значение. А можно и моком. Значением дешевле.
Что значит "дешевле"? И то, и то выполняется микросекунды и никакой сети-диска не требует.
P>>>Проблем может быть сколько угодно, именно конечный результат говорит что правильно а что нет P>·>Не знаю как у тебя, но у меня большинство ошибок именно логике в реалзиации методов, когда я тупо ошибаюсь в +1 вместо -1, from/to и т.п. P>В том то и дело — и никакие моки этого не исправят. Потому и нужна проверка на результат.
Моки позволяют писать очень много быстрых и легковесных тестов и легко отлаживать.
P>>>Здесь мы тестируем построение запроса P>·>Ассерт-то в чём? Что текст запроса 'select * from users where id=?'? У тебя в тесте именно текст забит или что? P>Я ж вам показал все что надо — deep equality + структура.
deep equality чего с чем? Что написано в коде теста?
P>>>·>Как проверить, что текст запроса хотя бы синтаксически корректен? P>>>Для этого нам всё равно придется выполнить его на реальной бд. Расскажите, как вы решите задачу вашими моками. P>·>Я уже рассказывал. Интеграционным тестом repo+db. Текстов запроса в тестах нет, и быть не должно. Как-то так: P>Вот видите — вам тоже нужны такие тесты Только вы предпочитаете косвенную проверку.
В чём косвенность?
P>Кстати, как вы собираетесь пагинацию да фильтры тестировать? Подозреваю, сгенерируете несколько тысяч значений, и так для каждой таблицы?
Зачем несколько тысяч? Тысячи нужны для перф-тестов. Для тестирования логики достаточно нескольких значений. Но, впрочем, если тебе очень хочется — сгенерировать тысячу значений — есть такая штука как for-loop, например.
P>>>А здесь как вы моками обойдетесь? P>·>Тут и не надо. Здесь же интеграция с субд тестируется. Моки (стабы?) будут дальше — в бл, в контроллере, етс. P>Ну да, раз вы протащили в БЛ репозиторий, то и отрезать надо там же. А вариант сделать БЛ иначе, что бы хватило юнитов, вы отбрасываете заранее с формулировкой "по старинке надёжнее"
Так ведь юниты и "делать не по старинке" — это не самоцель. Целью может быть — писать поменьше прод кода, ловить баги как можно раньше и быстрее, упрощать разработку, отладку, етс.
P>·>У тебя был такой код: P>·>
P>·>Этот код выглядит так, что getUser выдаваемый из репы не зависит от db (и как ты заявил обещано в clean) и repo покрывается тестами независимо. P>Есть такое. Они конечно же должны быть согласованы. Моя идея была в том, что бы тестировать построение запроса, а не мокать всё подряд.
Зачем тебе тестировать построение запроса? С т.з. "ожидаемого результата", за который ты так ратуешь, совершенно пофиг какой запрос построился. Главное, что если его выполнить и распарсить recordset — вернётся ожидаемый результат.
P>·>В моём коде выше с MyRepo("connectionString") — мы тестируем только интеграцию двух частей repo + dbms. И ничего больше в таких тестах поднимать не надо. P>И у меня примерно так же, только моков не будет.
В этом моём коде выше не было моков.
P>>>Что вас смущает? трансформация результата принимает ResultSet и возвращает вам нужный объект. P>·>Так ведь надо не абы какой ResultSet, а именно тот, который реально возвращается из "select *". У тебя же эти по настоящему связанные сущности тестируются независимо. Что абсолютно бесполезно. P>1 раз тестируются в составе интеграционного теста, такого же, как у вас. и много раз — в составе юнит-тестов, где нас интересуют подробности P>- а что если в колонке пусто
Именно. А по итогу получится, что при вставке бд пустую колонку заменяет на дефолтное значение и при выборке там пусто быть просто не может; и окажется, что это дефолтное значение не очень правильное. Получается, что твои тесты тестируют какую-то хрень, "как написано".
P>И это в любом случае нужно делать, и никакие моки от этого не избавляют. Можно просто отказаться от таких тестов типа "у нас смок тест бд". Тоже вариант, и собственно моки здесь снова никак не помогают
Ещё раз повторю. Это и-тесты репо+бд. А моки избавляют от необходимости иметь бд при тестировании всего остального.
P>>>Расскажите, как вы это моками решите P>·>Моки (стабы) — это для отпиливания зависимостей в тестах. Репу тестируем медленными и-тестами с более-менее реальной субд, а дальше моки (стабы) для быстрого тестирования всего остального. P>Вот — вам надо медленными тестами тестировать репу — каждый из её методов, раз вы её присобачили. А у меня репа это фактически билдер запросов, тестируется простыми юнит-тестами.
Толку правда никакого от таких юнит-тестов, т.к. они тестируют "как написано".
P>Зато мне нужно будет несколько медленных тестов самого useCase.
Не несколько, а дофига.
P>>>Это одно и то же, и в этом проблема. Я ж вам говорю, как можно иначе — но вы упорно видите только вариант из 90х-00х P>·>Ты показал это "иначе", но там всё ещё хуже прибито. Вплоть до побуквенного сравнения текста sql. P>- P>Вы так и не рассказали, чем это хуже. Вы предложили конский запрос тестировать косвенно
Тем, что тесты пишутся в первую очередь для людей. Может я просто недостаточно профессионал, но я не умею в уме исполнять sql-запросы и уж точно запросто пропущу мелкие синтаксические ошибки. Вот user.getName() == "Vasya" — мой мозг понять способен, а вот "select * from users where id=?" — я не понимаю эти все закорючки, тем более с учётом того, что каждая субд любит это немного по-разному. Может надо было "from user where" написать? Или "from [user] where"? А фиг знает... Я понятия не имею какой sql правильный.
P>>>Что бы такого не случалось, в тестах должен быть сценарий, который включает возврат. И так для всех апи которые вы выставляете. P>·>Не понял, если возврат отключен, то и тест должен тестировать, что возврат отключен. P>Очень даже понятно — вот некто неглядя вкомитал в конфиг что возвраты отключены. Ваши действия?
Ни разу такой проблемы не припомню. Это как "неглядя"? Конфиг, если что, бизнес/operations правят. Если это не должно отключаться, так я просто конфиг грохну.
P>·>Примерное типичное кол-во сценариев реальной системе большего, чем хоумпейдж масштаба. P>Из этого никак не следует, что и в тестах будет так же. Нам не нужно сравнивать трассы всех тестов вообще. Вы вы еще предложите трассы нагрузочных тестов сравнивать или трассы за весь спринт P>Нас интересуют трассы конкретных тестов. Если вы можете такое выделить — акцептанс тесты для вас. Если у вас мешанина, и всё вызывает всё да помногу раз с аудитом вперемешку — акцептанс тесты вам не помогут.
Что за трассы тестов? Мы об аудите говорим. Аудит пишется практически каждым действием, т.е. почти каждым тестом бл. Значит при изменении формата аудита — изменится результат всех таких тестов.
P>·>Только не пытайся доказать, что это у них "не работало", потому что тесты у них неправильные. Уж поверь, у них всё работало как надо (им). P>После ссылки на федеральный закон вдруг "заработало" как надо.
Именно. И причём тут тесты?
P>>>В данном случае вам нужно писать больше кода в тестах, и они будут хрупкими. Другого вы с моками не получите. Потому и убирают зависимости из БЛ целиком, что бы легче было покрывать тестами P>·>Но ведь не "убирают", а переносят. Что добавляет и количество прод-кода и число тестов. P>Тестов БЛ — больше, т.к. теперь можно покрывать дешовыми тестами самые разные кейсы, для того и делается. P>Интеграционных — столько же, как и раньше, — по количеству АПИ и сценариев.
АПИ и сценарии — это и есть БЛ.
P>>>Ага, сидим да годами ждём результаты одного теста. Вам самому не смешно? P>·>Думаю ваш хоум-пейдж за час тестируется, в лучшем случае. P>Полтора часа только сборка идет.
Ээээ. шутишь? А тесты сколько времени занимают?
P>>>А с аннотациями взял да и отрендерил манифест. P>·>Гы-гы. У тебя же, ты сам говорил, что попало где попало — и в переменных окружения, и в конфигах и где угодно эти "аннотации" висят. Сваггер у вас каждые 5 минут новый, да? P>Вы снова из 90х? Манифест генерируется по запросу, обычно http. Отсюда ясно, что и переменные, и конфиги, и аннотации будут учтены.
Сваггер — это спека для клиентов. Она статическая и меняться должна в идеале никогда.
P>Еще тенантность будет учитывать — для одного тенанта один апи доступен, для другого — другой.
Жуть.
P>·>Ты любишь сложность на пустом месте, притом в прод-коде, я уже понял. Но это плохо. Фреймворк это совсем другая весовая категория. Для того что ты пишешь достаточно extract method refactoring, а не новая архитектура с фреймворками. P>Ровно наоборот. Чем проще, тем лучше. Фремворковый код он не то что бы особо сложный — просто разновидности вы будете каждый раз писать по месту. Или же отделяете, покрываете сотней тестов, и используете через аннотации без оглядки "а вдруг не сработает"
Есть такая штука, называется code reuse.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
·>Не очень понимаю проблему. Что можно нереального сделать в моке bl.modifyUser(id, newUserData) не так? Суть в том, что контроллер зовёт modifyUser и конвертирует результат: ·>
·>class UserController {
·> Response update(Request r) {
·> var id = extractId(r);
·> var data = extractData(r);
·> var result = bl.modifyUser(id, data);
·> return result.isSuccess ? Response(r.correlationId, prepare(result)) : Failure("sorry");
·> }
·>}
·>
·>Т.е. при тестировании контроллера совершенно неважно, что именно делает реальный modifyUser. Важно какие варианты результата он может вернуть и что на них реагируем в sut в соответствии с ожиданиями.
Хочу вот здесь уточнить про тестирование контроллера
Правильно понимаю, что отдельно тестируете контроллер (мокаете bl) и отдельно тестируете bl (мокаете repo)?
Я придерживаюсь такого подхода, но некоторые тестируют сразу контоллер+логику вместе (мокая repo и не мокая БЛ).
Хочу понять плюсы и минусы подходов. На мой взгляд так:
Плюсы если тестировать вместе: тестируется видимое поведение системы, типа "входной json -> выходной json", а также не ломаются тесты во время рефакторинга связки контроллер-action (хотя здесь редко что-то изменяется).
Плюсы если тестировать отдельно контроллер: тесты bl описываются в рамках сущностей БЛ, получаются более "бизнесовыми".
Или может как-то по-другому тестируете контроллер, например, выделяя логику валидации и сериализации в чистые функции.
В общем, есть какие-то принципы?
Здравствуйте, Буравчик, Вы писали:
Б>Хочу вот здесь уточнить про тестирование контроллера Б>Правильно понимаю, что отдельно тестируете контроллер (мокаете bl) и отдельно тестируете bl (мокаете repo)?
Тут зависит от приложения. Контроллер и бл — это слои нужные в случае если у тебя есть несколько разных представлений. Назначение контроллера — разбирать входные запросы, что-то делать внутре, и формировать ответы. В мире микросервисов выделение отдельного слоя далеко не всегда нужно. Т.к. контроллер один и в него можно сразу запрятать всю бл, оттуда сразу ходить в репо.
Отдельный слой бл нужен если у тебя есть несколько представлений. Например, контроллер http с request-response и тут же контроллер каких-нибудь protobuf с асинхронными сообщениями. А бизнес-логика — шарится общая.
Б>Я придерживаюсь такого подхода, но некоторые тестируют сразу контоллер+логику вместе (мокая repo и не мокая БЛ).
Можно. Собираешь wiring-модуль, в котором компоненты бл и контроллеры соединяются в единое и в тестах туда инжектится мок репы, а в проде — реальный репо с субд.
Б>В общем, есть какие-то принципы?
Я думаю надо выбирать не по каким-то принципам, а по тому где сколько кода и насколько его легко тестировать. Если и в контроллере, и в бл много логики, то по частям тестировать может быть проще. А если контроллер простой, то писать тривиальные тесты скучно и бесполезно.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>Наоборот — юнит тесты дешевле некуда. ·>И? С моками (стабами) тесты такие же дешёвые. Т.к. мы мочим всё медленное и дорогое. В этом и цель моков (стабов) — удешевлять тесты.
Для начала это вы сами сделали тесты дорогими, когда поместили БЛ прямо в контроллер
P>>Это у вас телепатия разыгралась? С чего вы взяли, что у меня лишнего кода бОльше? ·>В статье кода стало больше. Вот эти все getUser — это всё лишний код в проде. Твои "{...toFields}" — тоже лишний код, и это всё прод-код.
Вы все еще про статью, тут я ничем помочь не могу.
P>>Во первых, вы сами недавно поделились решением для hmac — "моками проверим то и это" ·>Это твоё было решение. Я его просто сделал вменяемым.
Мое решение — просто сравнивать по значению. А вы все моки тащите.
P>>Во вторых, чуть далее, тоже недавно, вы рассказывали, как моками отрезали Time.now ·>Ага. И это одна строчка кода. Ты взамен предложил _фреймворк_ для этого же.
Не одна — для каждого из тестов вам нужен будет этот мок
Проще передавать время как значение и тестировать дешовыми юнит тестами
А если вам трудно время прокидывать с контроллера — можете брать его из фремворковой части, это почти все фремворки умеют.
P>>Десяток значений. Эти значения вы можете в каких угодно тестах использовать. ·>Значений чего? И почему они лежат в одном файлике?
hmac, time, итд. В одном файле — что бы чинить не 100 тестов, а всего 10 значений когда вы поменяете hmac 256 на 512.
Т.е. вместо того, что бы хардкодить константы по всем тестами, складываем их в один файл, что бы сразу видеть всю картину
И из этого файла таскаете паттерны и тд
P>>Это не повод моки тащить. ·>Конечно, это я сразу тебе сказал. Моки для hmac — ты притащил. Перечитай топик, все ходы записаны.
У вас требование hmac стало основанием моки протаскивать. Вот это непонятно. Значением проверить никак нельзя, да?
P>>Если значение hmac во всех кейсах совпадает с нашим, это куда лучшая проверка. Но вместо этого вы берете моки т.к. "это бизнес-требования" ·>Это плохая проверка. Т.к. при изменении формата/алгоритма этого hmac тебе придётся менять тестовые данные в этих самых всех кейсах.
1 При изменении алгоритма, формата итд, сломаются ваши моки
2 Тестовые данные не размазываются по кейсам, а хранятся в файле тестовые-данные.json
P>>Как убедиться что мокируемая система совпадает по поведению с вашим моком — не ясно. ·>Это не проблема моков. А проблема раздельного тестирования. У тебя ровно та же проблема: "Они конечно же должны быть согласованы".
Эта согласованность проверится любым интеграционным тестом который вызовет контроллер.
P>>Десяток значений, что очевидно. Что для time, что для токенов. Вот если вы тестируете свою либу date-time или hmac, там будет побольше значений, до сотни, может и больше. ·>Нет, совершенно не очевидно. И я всё равно не понял, какой time? каких токенов? какая своя либа?
Ну вот нам нужен тест nextFriday() — функция, которая возвращает дату следующей пятницы
1 вариант, как вы любите, с моками — мокаем Time.now, делаем свои вычисления и проверяем, что наши вычисления совпадают с теми, что возвращает функция
Поздравляю, это классика тавтологических тестов
2 вариант, кладем в файлик тестовы-данные.json "время", "правильный результат", штуки 10 строчк. Меняем дизайн на nextFriday(now) и теперь у нас простой юнит-тест
@params(samples.nextFiday); // вот здесь все наши константы
"next friday"(now, result) {
expect(nextFriday(now)).to.deep.eq(result)
}
P>>Эту самую сотню кейсов всё равно надо покрыть внятными тестами. ·>Я пытаюсь донести мысль, что пофиг — моки или результаты, это технические детали. Это ортогонально тестам "как написано", т.к. тесты это про семантику.
Это неверное упрощение. Моки и тесты результатов это разные классы задач, с разными свойствами, а отсюда — разные гарантии, проблемы итд
Это для менджера и то и то есть тесты. Но гарантии они предоставляют не эквивалентные.
P>>В том то и дело — я именно это вам пишу уже второй месяц. Только моки здесь играют сильно вспомогательную роль, их обычно немного, только там, где дизайн дороже править чем накидать один мок. ·>Нет, ты предлагаешь всё разделять на лямбды и писать кучу composition кода, который тоже весь приходится тестировать.
1. сводить все к простым вычислениям
2. если нет другого варианта, как в примере Буравчика, изолировать от зависимостей, что бы логика всё равно зависела от своих параметров.
P>>Вобщем, понятно, откуда вы берете невалидные идеи. ·>Даже если так. Загрузка операционки это один тест. Кристалл и каждый компонент современного компьютера на фабриках тестируют тысячами-миллионами тестов.
Загрузка операционки это выполнение несколько миллионов операций на процессоре и связанных с ним устройствах.
·>- эта лапша у тебя будет в каждом тесте, ещё такая же (почти!) копипастная лапша — и в прод-коде, которую придётся каждую покрывать отдельным и-тестом и это для каждого do_logic метода.
Этот самый и-тест по любому нужен, для каждого do_login метода. Как бы вы не выкручивались. У меня метод do_logic будет линейным, заниматься только связыванием.
С моками вам нужно делать или то же самое, по моку на метод
Или написать мок на все случаи жизни, что бы промоделировать все неявные зависимости
P>>Эвент можно проверять как значение. А можно и моком. Значением дешевле. ·>Что значит "дешевле"? И то, и то выполняется микросекунды и никакой сети-диска не требует.
Дешевле с точки зрения разработки. Например, я могу менять дизай свободно, не оглядываясь "а вдруг надо моки править"
P>>В том то и дело — и никакие моки этого не исправят. Потому и нужна проверка на результат. ·>Моки позволяют писать очень много быстрых и легковесных тестов и легко отлаживать.
Простые юнит тесты еше проще и быстрее. Как вы с моками будете дизайн менять?
P>>Я ж вам показал все что надо — deep equality + структура. ·>deep equality чего с чем? Что написано в коде теста?
Я ж вам все показал. Код теста почти полностью состоит из
1. вызов нужной функции которая строит запрос
2. паттерн запроса
3. expect(buildRequest(params)).to.deep.eq(pattern)
P>>·>Я уже рассказывал. Интеграционным тестом repo+db. Текстов запроса в тестах нет, и быть не должно. Как-то так: P>>Вот видите — вам тоже нужны такие тесты Только вы предпочитаете косвенную проверку. ·>В чём косвенность?
Вы вместо проверки построения бд тестируете весь пайплан — связывание, построение, вызов бд клиента, получение промежуточных результатов, обработка, возвращение окончательного
Это и есть косвенная проверка. Например, если запрос у вас не тот, но из за вашей бд будет выдавать нужные данные, вы проблему из за косвенности не найдете
P>>Кстати, как вы собираетесь пагинацию да фильтры тестировать? Подозреваю, сгенерируете несколько тысяч значений, и так для каждой таблицы? ·>Зачем несколько тысяч? Тысячи нужны для перф-тестов. Для тестирования логики достаточно нескольких значений. Но, впрочем, если тебе очень хочется — сгенерировать тысячу значений — есть такая штука как for-loop, например.
Много фильтров и их комбинаций, да еще и пагинация
P>>Ну да, раз вы протащили в БЛ репозиторий, то и отрезать надо там же. А вариант сделать БЛ иначе, что бы хватило юнитов, вы отбрасываете заранее с формулировкой "по старинке надёжнее" ·>Так ведь юниты и "делать не по старинке" — это не самоцель. Целью может быть — писать поменьше прод кода, ловить баги как можно раньше и быстрее, упрощать разработку, отладку, етс.
Так вы думаете я юнит-тесты пишу что бы работы себе доваить? Я их пишу, что бы избавиться от лишнего когда, как в тестах, так и в приложении.
P>>Есть такое. Они конечно же должны быть согласованы. Моя идея была в том, что бы тестировать построение запроса, а не мокать всё подряд. ·>Зачем тебе тестировать построение запроса? С т.з. "ожидаемого результата", за который ты так ратуешь, совершенно пофиг какой запрос построился. Главное, что если его выполнить и распарсить recordset — вернётся ожидаемый результат.
Затем, что самое сложное в БД это построение или запроса к ORM, или SQL. Слишком много запросов похожих на тот, что нам нужен, но нерабочих.
Вот на той неделе был случай — некто заимплементил фильтры, которые на некоторых наборах параметров вырождаются в пустую строку, и запрос каждый раз булшитит десятки миллионов записей в таблице
Зато на тестовой бд всё хорошо
P>>- а что если в колонке пусто ·>Именно. А по итогу получится, что при вставке бд пустую колонку заменяет на дефолтное значение и при выборке там пусто быть просто не может; и окажется, что это дефолтное значение не очень правильное. Получается, что твои тесты тестируют какую-то хрень, "как написано".
Смотрите выше, пример про десятки миллионов записей как раз для вас.
P>>И это в любом случае нужно делать, и никакие моки от этого не избавляют. Можно просто отказаться от таких тестов типа "у нас смок тест бд". Тоже вариант, и собственно моки здесь снова никак не помогают ·>Ещё раз повторю. Это и-тесты репо+бд. А моки избавляют от необходимости иметь бд при тестировании всего остального.
А можно поменять дизайн. Но для вас это не вариант, вы по старинке!
P>>Вот — вам надо медленными тестами тестировать репу — каждый из её методов, раз вы её присобачили. А у меня репа это фактически билдер запросов, тестируется простыми юнит-тестами. ·>Толку правда никакого от таких юнит-тестов, т.к. они тестируют "как написано".
Они тестируют построение запроса, например, построение тех самых фильтров.
·>Тем, что тесты пишутся в первую очередь для людей. Может я просто недостаточно профессионал, но я не умею в уме исполнять sql-запросы и уж точно запросто пропущу мелкие синтаксические ошибки. Вот user.getName() == "Vasya" — мой мозг понять способен, а вот "select * from users where id=?" — я не понимаю эти все закорючки, тем более с учётом того, что каждая субд любит это немного по-разному. Может надо было "from user where" написать? Или "from [user] where"? А фиг знает... Я понятия не имею какой sql правильный.
Если понятия не имеете, то скорее всего и запросы ваши будут работать приблизительно. Например, фильтры будут работать только на тестовых данных
P>>Очень даже понятно — вот некто неглядя вкомитал в конфиг что возвраты отключены. Ваши действия? ·>Ни разу такой проблемы не припомню. Это как "неглядя"? Конфиг, если что, бизнес/operations правят. Если это не должно отключаться, так я просто конфиг грохну.
Знакомая ситуация — какую проблему ни назови, у вас она принципиально невозможна.
P>>Нас интересуют трассы конкретных тестов. Если вы можете такое выделить — акцептанс тесты для вас. Если у вас мешанина, и всё вызывает всё да помногу раз с аудитом вперемешку — акцептанс тесты вам не помогут. ·>Что за трассы тестов? Мы об аудите говорим. Аудит пишется практически каждым действием, т.е. почти каждым тестом бл. Значит при изменении формата аудита — изменится результат всех таких тестов.
Если вы протащили аудит прямо в бл, то так и будет. А если бл не имеет зависимостей на репу и бд, то для аудита у нас только одно место — там где применяем изменения. И таких тестов у нас много быть не может.
P>>Интеграционных — столько же, как и раньше, — по количеству АПИ и сценариев. ·>АПИ и сценарии — это и есть БЛ.
У вас уже и API стал бизнес логикой
P>>Полтора часа только сборка идет. ·>Ээээ. шутишь? А тесты сколько времени занимают?
Процентов 30-40 от сборки.
P>>Вы снова из 90х? Манифест генерируется по запросу, обычно http. Отсюда ясно, что и переменные, и конфиги, и аннотации будут учтены. ·>Сваггер — это спека для клиентов. Она статическая и меняться должна в идеале никогда.
Вы что, в первой версии приложения знаете, какие фичи понадобятся в течении следующих 10 лет? АПИ всегда эволюционирует
Если манифест держать кодом, то это хорошая заявочка на рассинхронизацию — у нас работает, а у клиентов — нет.
Здравствуйте, Pauel, Вы писали:
P>·>Т.к. контроллер один и в него можно сразу запрятать всю бл, оттуда сразу ходить в репо P>Это и есть основная причина для моков — называется монолитный дизайн.
С опытом понимаешь, что важно не то как оно называется или что на сегодня модно у фаулеров, а то что лучше всего подходит для конкретной разрабатываемой системы. Для простенького микросервиса проще запилить всё в трёх классах, а не накручивать десять слоёв на пять фреймворков.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, Буравчик, Вы писали:
P>>Это и есть основная причина для моков — называется монолитный дизайн.
Б>Проблемы обычно кроются в зависимостях, которые трудно разорвать. Эту проблему решает DI. Моки ортогональны.
Моки это привязка к конкретным вызовам, параметрам, последовательностям.
То есть — тавтологические тесты.
Монолитный — посмотрите ваш первый вариант, логика и зависимости вперемешку. Потому полностью уйти от моков не выйдет. У меня почти во всех случаях получается избавиться от такого дизайна и свести к простым юнит тестам.
Но если вы изначально считаете моки чем то хороши, естественно, более простой вариант в голову и не придет
Здравствуйте, Pauel, Вы писали:
P>Моки это привязка к конкретным вызовам, параметрам, последовательностям.
Ты также привязываешься к конкретным вызовам, параметрам, последовательностям, но не моками, а лямбдами. Нет разницы в этом.
Но ты усложняешь логику, добавляя лишние лямбды, которые просто оборачивают зависимости (как говорится, фабрика на фабрике, в твоем случае адаптер на адаптере).
P>Монолитный — посмотрите ваш первый вариант, логика и зависимости вперемешку. Потому полностью уйти от моков не выйдет. У меня почти во всех случаях получается избавиться от такого дизайна и свести к простым юнит тестам.
Если говорить про внешние зависимости, твои лямбды это и есть моки. Никуда от них не ушел.
P>Но если вы изначально считаете моки чем то хороши, естественно, более простой вариант в голову и не придет
Я стараюсь выбирать подходящий инструмент (более простой).
Если я вижу сложную логику, то выделяю ее в отдельную функцию и тестирую как чистую функцию (входные параметры -> результат)
Если я вижу много взаимодействия с внешними зависимостями, то использую моки. Это позволяет протестировать поведение как обычную функцию (входные параметры + "мок-данные из внешних систем" -> результат)
Здравствуйте, Pauel, Вы писали:
P>·>Любопытно, а что если "repo.get" дёргается в цикле? Заведёшь массив лямд?!
P>Лямбда которая возвращает значения по списку
Здравствуйте, Pauel, Вы писали:
P>>>Наоборот — юнит тесты дешевле некуда. P>·>И? С моками (стабами) тесты такие же дешёвые. Т.к. мы мочим всё медленное и дорогое. В этом и цель моков (стабов) — удешевлять тесты. P>Для начала это вы сами сделали тесты дорогими, когда поместили БЛ прямо в контроллер
Ты опять скрываешь что ты понимаешь под дороговизной.
P>>>Это у вас телепатия разыгралась? С чего вы взяли, что у меня лишнего кода бОльше? P>·>В статье кода стало больше. Вот эти все getUser — это всё лишний код в проде. Твои "{...toFields}" — тоже лишний код, и это всё прод-код. P>Вы все еще про статью, тут я ничем помочь не могу.
getUser и toFields это не про статью.
P>·>Это твоё было решение. Я его просто сделал вменяемым. P>Мое решение — просто сравнивать по значению. А вы все моки тащите.
У тебя было expect...toBeCalledWith — это было совершенно неправильное решение. Я просто попытался объяснить, что так делать не надо и показал как надо, сделав оговорку "Если не задаваться вопросом, зачем вообще вдруг понадобилось мокать hmac".
P>>>Во вторых, чуть далее, тоже недавно, вы рассказывали, как моками отрезали Time.now P>·>Ага. И это одна строчка кода. Ты взамен предложил _фреймворк_ для этого же. P>Не одна — для каждого из тестов вам нужен будет этот мок
Зачем для каждого? Этот мок можно куда-нибудь в setUp вынести.
P>Проще передавать время как значение и тестировать дешовыми юнит тестами
Конечно, проще. Но не везде же.
P>А если вам трудно время прокидывать с контроллера — можете брать его из фремворковой части, это почти все фремворки умеют.
В топку фреймворки. Мне не нужен фреймворк ради экономии одной строчки в _тестовом_ коде.
P>>>Десяток значений. Эти значения вы можете в каких угодно тестах использовать. P>·>Значений чего? И почему они лежат в одном файлике? P>hmac, time, итд. В одном файле — что бы чинить не 100 тестов, а всего 10 значений когда вы поменяете hmac 256 на 512.
Я может что-то не знаю, но обычно hmac зависит от каждого теста — контрольная сумма сериализованного тела ответа. У тебя в твоём хоумпейдже на всю функциональность хватает 10 тестов?
P>>>Это не повод моки тащить. P>·>Конечно, это я сразу тебе сказал. Моки для hmac — ты притащил. Перечитай топик, все ходы записаны. P>У вас требование hmac стало основанием моки протаскивать. Вот это непонятно. Значением проверить никак нельзя, да?
Ты врёшь. Цитирую себя: "Если не задаваться вопросом, зачем вообще вдруг понадобилось мокать hmac". Моки в hmac притащил ты сам. Так что с собой спорь.
P>>>Если значение hmac во всех кейсах совпадает с нашим, это куда лучшая проверка. Но вместо этого вы берете моки т.к. "это бизнес-требования" P>·>Это плохая проверка. Т.к. при изменении формата/алгоритма этого hmac тебе придётся менять тестовые данные в этих самых всех кейсах. P>1 При изменении алгоритма, формата итд, сломаются ваши моки
Не сломаются.
P>2 Тестовые данные не размазываются по кейсам, а хранятся в файле тестовые-данные.json
Не размазываются.
P>>>Как убедиться что мокируемая система совпадает по поведению с вашим моком — не ясно. P>·>Это не проблема моков. А проблема раздельного тестирования. У тебя ровно та же проблема: "Они конечно же должны быть согласованы". P>Эта согласованность проверится любым интеграционным тестом который вызовет контроллер.
Не любым.
P>>>Десяток значений, что очевидно. Что для time, что для токенов. Вот если вы тестируете свою либу date-time или hmac, там будет побольше значений, до сотни, может и больше. P>·>Нет, совершенно не очевидно. И я всё равно не понял, какой time? каких токенов? какая своя либа? P>Ну вот нам нужен тест nextFriday() — функция, которая возвращает дату следующей пятницы P>1 вариант, как вы любите, с моками — мокаем Time.now, делаем свои вычисления и проверяем, что наши вычисления совпадают с теми, что возвращает функция P>Поздравляю, это классика тавтологических тестов P>2 вариант, кладем в файлик тестовы-данные.json "время", "правильный результат", штуки 10 строчк. Меняем дизайн на nextFriday(now) и теперь у нас простой юнит-тест
Ты подменил задание, а не дизайн. Вначале была функция nextFriday(), потом вдруг стала nextFriday(now). Если твоя система должна по контракту клиентам выдавать операцию nextFriday(), то поменять сигнатуру ты не можешь.
P>>>Эту самую сотню кейсов всё равно надо покрыть внятными тестами. P>·>Я пытаюсь донести мысль, что пофиг — моки или результаты, это технические детали. Это ортогонально тестам "как написано", т.к. тесты это про семантику. P>Это неверное упрощение. Моки и тесты результатов это разные классы задач, с разными свойствами, а отсюда — разные гарантии, проблемы итд
Верно. Но почему-то ты считаешь, что задачи из других классов не существует.
P>>>В том то и дело — я именно это вам пишу уже второй месяц. Только моки здесь играют сильно вспомогательную роль, их обычно немного, только там, где дизайн дороже править чем накидать один мок. P>·>Нет, ты предлагаешь всё разделять на лямбды и писать кучу composition кода, который тоже весь приходится тестировать. P>1. сводить все к простым вычислениям
Но не всё сводится.
P>2. если нет другого варианта, как в примере Буравчика, изолировать от зависимостей, что бы логика всё равно зависела от своих параметров.
У тебя зависимости не изолировались, просто перелилось из пустого в порожнее. Кода стало больше.
P>>>Вобщем, понятно, откуда вы берете невалидные идеи. P>·>Даже если так. Загрузка операционки это один тест. Кристалл и каждый компонент современного компьютера на фабриках тестируют тысячами-миллионами тестов. P>Загрузка операционки это выполнение несколько миллионов операций на процессоре и связанных с ним устройствах.
И? Это всё равно на порядки меньше, чем проверок при изготовлении какого-нибудь чипа.
P>·>- эта лапша у тебя будет в каждом тесте, ещё такая же (почти!) копипастная лапша — и в прод-коде, которую придётся каждую покрывать отдельным и-тестом и это для каждого do_logic метода. P>Этот самый и-тест по любому нужен, для каждого do_login метода. Как бы вы не выкручивались. У меня метод do_logic будет линейным, заниматься только связыванием.
Не по любому. Я тебе уже рассказывал как.
P>С моками вам нужно делать или то же самое, по моку на метод P>Или написать мок на все случаи жизни, что бы промоделировать все неявные зависимости
Это твои фантазии. Судя по тому коду, который ты привёл, ты не понимаешь как пользоваться моками и придумываешь себе страшилки.
P>>>Эвент можно проверять как значение. А можно и моком. Значением дешевле. P>·>Что значит "дешевле"? И то, и то выполняется микросекунды и никакой сети-диска не требует. P>Дешевле с точки зрения разработки. Например, я могу менять дизай свободно, не оглядываясь "а вдруг надо моки править"
Страшилки.
P>>>В том то и дело — и никакие моки этого не исправят. Потому и нужна проверка на результат. P>·>Моки позволяют писать очень много быстрых и легковесных тестов и легко отлаживать. P>Простые юнит тесты еше проще и быстрее. Как вы с моками будете дизайн менять?
Ещё раз повторюсь — разница чисто техническая.
P>>>Я ж вам показал все что надо — deep equality + структура. P>·>deep equality чего с чем? Что написано в коде теста? P>Я ж вам все показал. Код теста почти полностью состоит из P>1. вызов нужной функции которая строит запрос P>2. паттерн запроса P>3. expect(buildRequest(params)).to.deep.eq(pattern)
Что за паттерн-то? Полный код можешь написать? Вот ты рассказал, что оно выглядит так:
{
sql: 'select * from users where id=?',
params: [id],
transformations: {
in: [fn1],
out: [fn2]
}
}
Какой код будет в тесте для проверки этого?
P>>>·>Я уже рассказывал. Интеграционным тестом repo+db. Текстов запроса в тестах нет, и быть не должно. Как-то так: P>>>Вот видите — вам тоже нужны такие тесты Только вы предпочитаете косвенную проверку. P>·>В чём косвенность? P>Вы вместо проверки построения бд тестируете весь пайплан — связывание, построение, вызов бд клиента, получение промежуточных результатов, обработка, возвращение окончательного
Именно, всё как ты хочешь "соответствует ожиданиям", и как ты любишь "блакбокс". Ожидаем, что если мы сохранили запись, то потом её можем найти и загрузить. А что там происходит за кулисами — совершенно неважно.
P>Это и есть косвенная проверка. Например, если запрос у вас не тот, но из за вашей бд будет выдавать нужные данные, вы проблему из за косвенности не найдете
Что значит "не тот"? Как проверить тот он или не тот? Как в принципе узнать как должен выглядеть тот?
P>>>Кстати, как вы собираетесь пагинацию да фильтры тестировать? Подозреваю, сгенерируете несколько тысяч значений, и так для каждой таблицы? P>·>Зачем несколько тысяч? Тысячи нужны для перф-тестов. Для тестирования логики достаточно нескольких значений. Но, впрочем, если тебе очень хочется — сгенерировать тысячу значений — есть такая штука как for-loop, например. P>Много фильтров и их комбинаций, да еще и пагинация
И? зачем для этого несколько тысяч значений? У тебя там комбинаторно рвануло, да?
P>>>Ну да, раз вы протащили в БЛ репозиторий, то и отрезать надо там же. А вариант сделать БЛ иначе, что бы хватило юнитов, вы отбрасываете заранее с формулировкой "по старинке надёжнее" P>·>Так ведь юниты и "делать не по старинке" — это не самоцель. Целью может быть — писать поменьше прод кода, ловить баги как можно раньше и быстрее, упрощать разработку, отладку, етс. P>Так вы думаете я юнит-тесты пишу что бы работы себе доваить? Я их пишу, что бы избавиться от лишнего когда, как в тестах, так и в приложении.
Пока ты продемонстрировал лишь добавление кода.
P>>>Есть такое. Они конечно же должны быть согласованы. Моя идея была в том, что бы тестировать построение запроса, а не мокать всё подряд. P>·>Зачем тебе тестировать построение запроса? С т.з. "ожидаемого результата", за который ты так ратуешь, совершенно пофиг какой запрос построился. Главное, что если его выполнить и распарсить recordset — вернётся ожидаемый результат. P>Затем, что самое сложное в БД это построение или запроса к ORM, или SQL. Слишком много запросов похожих на тот, что нам нужен, но нерабочих.
Построение запроса это детали реализации, важно что построенный запрос вернёт.
P>Вот на той неделе был случай — некто заимплементил фильтры, которые на некоторых наборах параметров вырождаются в пустую строку, и запрос каждый раз булшитит десятки миллионов записей в таблице P>Зато на тестовой бд всё хорошо
Если эти наборы параметров забыли протестировать, то чем твой getUser поможет?
P>>>- а что если в колонке пусто P>·>Именно. А по итогу получится, что при вставке бд пустую колонку заменяет на дефолтное значение и при выборке там пусто быть просто не может; и окажется, что это дефолтное значение не очень правильное. Получается, что твои тесты тестируют какую-то хрень, "как написано". P>Смотрите выше, пример про десятки миллионов записей как раз для вас.
Было у вас, а тебе хочется верить, что про нас... опять фантазии.
P>·>Тем, что тесты пишутся в первую очередь для людей. Может я просто недостаточно профессионал, но я не умею в уме исполнять sql-запросы и уж точно запросто пропущу мелкие синтаксические ошибки. Вот user.getName() == "Vasya" — мой мозг понять способен, а вот "select * from users where id=?" — я не понимаю эти все закорючки, тем более с учётом того, что каждая субд любит это немного по-разному. Может надо было "from user where" написать? Или "from [user] where"? А фиг знает... Я понятия не имею какой sql правильный. P>Если понятия не имеете, то скорее всего и запросы ваши будут работать приблизительно. Например, фильтры будут работать только на тестовых данных
У тебя тоже.
P>>>Очень даже понятно — вот некто неглядя вкомитал в конфиг что возвраты отключены. Ваши действия? P>·>Ни разу такой проблемы не припомню. Это как "неглядя"? Конфиг, если что, бизнес/operations правят. Если это не должно отключаться, так я просто конфиг грохну. P>Знакомая ситуация — какую проблему ни назови, у вас она принципиально невозможна.
Ты не поверишь, но некоторые классы проблем легко и гарантированно решаются. Проще не создавать себе трудности, чем их героически решать немоками.
P>>>Нас интересуют трассы конкретных тестов. Если вы можете такое выделить — акцептанс тесты для вас. Если у вас мешанина, и всё вызывает всё да помногу раз с аудитом вперемешку — акцептанс тесты вам не помогут. P>·>Что за трассы тестов? Мы об аудите говорим. Аудит пишется практически каждым действием, т.е. почти каждым тестом бл. Значит при изменении формата аудита — изменится результат всех таких тестов. P>Если вы протащили аудит прямо в бл, то так и будет. А если бл не имеет зависимостей на репу и бд, то для аудита у нас только одно место — там где применяем изменения. И таких тестов у нас много быть не может.
Аудит это и есть бл. Аудит — прямое требование бизнеса. Ты ведь надеюсь, уже перестал путать логи и аудит?
P>>>Интеграционных — столько же, как и раньше, — по количеству АПИ и сценариев. P>·>АПИ и сценарии — это и есть БЛ. P>У вас уже и API стал бизнес логикой
Если я правильно понял, то тут под API подразумевался интерфейс системы для внешних клиентов. Т.е. то, о чём бизнес договаривается с клиентами.
А у вас уже и сценарии перестали быть бизнес логикой
P>>>Полтора часа только сборка идет. P>·>Ээээ. шутишь? А тесты сколько времени занимают? P>Процентов 30-40 от сборки.
А что потом после сборки?
P>>>Вы снова из 90х? Манифест генерируется по запросу, обычно http. Отсюда ясно, что и переменные, и конфиги, и аннотации будут учтены. P>·>Сваггер — это спека для клиентов. Она статическая и меняться должна в идеале никогда. P>Вы что, в первой версии приложения знаете, какие фичи понадобятся в течении следующих 10 лет? АПИ всегда эволюционирует
Как правило, он расширяется, а не эволюционирует. И чем реже, тем лучше.
P>Если манифест держать кодом, то это хорошая заявочка на рассинхронизацию — у нас работает, а у клиентов — нет.
Я вообще за contract-first.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, Буравчик, Вы писали:
P>>·>Любопытно, а что если "repo.get" дёргается в цикле? Заведёшь массив лямд?! P>>Лямбда которая возвращает значения по списку Б>Здесь я тоже не понял. Можно пример?
Было class Repo{ User get(int id)} он гениально предлагает class Repo{ List<User> get(List<int> id)}, иначе ведь в лямбду не заворачивается...
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>·>И? С моками (стабами) тесты такие же дешёвые. Т.к. мы мочим всё медленное и дорогое. В этом и цель моков (стабов) — удешевлять тесты. P>>Для начала это вы сами сделали тесты дорогими, когда поместили БЛ прямо в контроллер ·>Ты опять скрываешь что ты понимаешь под дороговизной.
Я ж сказал — если я поменяю внутреннюю реализацию, никакие тесты падать не должны.
Мы покрываем ожидания вызывающей стороны, а у неё как раз нету ожиданий "вызовем crypto hmac вот таким макаром"
А у вас видение "раз hmac в требованиях, то нужны моки"
А следовательно, вам придется фиксить тесты -> удорожание
P>>Вы все еще про статью, тут я ничем помочь не могу. ·>getUser и toFields это не про статью.
Разумеется. Зачем продолжать мусолить заведомо однобокую статью?
·>У тебя было expect...toBeCalledWith — это было совершенно неправильное решение. Я просто попытался объяснить, что так делать не надо и показал как надо, сделав оговорку "Если не задаваться вопросом, зачем вообще вдруг понадобилось мокать hmac".
Ну ок — если вы не предлагаете мокать hmac, то всё в порядке.
P>>Не одна — для каждого из тестов вам нужен будет этот мок ·>Зачем для каждого? Этот мок можно куда-нибудь в setUp вынести.
Он будет везде использоваться. А раз так, то ваш мок надо или посать под каждый тест. Или запилить в ём поддержку всех кейсов.
Если под каждый тест — очевидно, дороже чем сравнение значений
Если один на всё — вы затачиваете тесты об синтетику
P>>hmac, time, итд. В одном файле — что бы чинить не 100 тестов, а всего 10 значений когда вы поменяете hmac 256 на 512. ·>Я может что-то не знаю, но обычно hmac зависит от каждого теста — контрольная сумма сериализованного тела ответа. У тебя в твоём хоумпейдже на всю функциональность хватает 10 тестов?
А нам не надо везде тащить этот hmac и тестировать это в каждом тесте. юнит-тестами покрываем вычисление hmac по конкретному контенту, и всё. Остальное — в интеграционных, коих на порядок меньше чем юнит-тестов.
P>>1 При изменении алгоритма, формата итд, сломаются ваши моки ·>Не сломаются.
Вот пример — вы решили изменить сигнатуру getAll у вашего repository, добавить-убрать фильры-сортировку-итд.
getAll у вас покрыт моками.
Вопрос — надо ли их фиксить, если поменялась сигнатура getAll? Если нет — покажите это чудо примером
P>>Эта согласованность проверится любым интеграционным тестом который вызовет контроллер. ·>Не любым.
Покажите пример.
P>>Поздравляю, это классика тавтологических тестов P>>2 вариант, кладем в файлик тестовы-данные.json "время", "правильный результат", штуки 10 строчк. Меняем дизайн на nextFriday(now) и теперь у нас простой юнит-тест ·>Ты подменил задание, а не дизайн. Вначале была функция nextFriday(), потом вдруг стала nextFriday(now). Если твоя система должна по контракту клиентам выдавать операцию nextFriday(), то поменять сигнатуру ты не можешь.
Разве я сказал, что nextFriday это функция системы? Это одна из операций в самой БЛ, вопрос только в том, как её тестировать — моками или без них
P>>Это неверное упрощение. Моки и тесты результатов это разные классы задач, с разными свойствами, а отсюда — разные гарантии, проблемы итд ·>Верно. Но почему-то ты считаешь, что задачи из других классов не существует.
Я ж прямо пишу — разные классы задач. Для одних используем моки, их совсем немного, от безвыходности, для других — тесты чем дешевле тем лучше.
P>>2. если нет другого варианта, как в примере Буравчика, изолировать от зависимостей, что бы логика всё равно зависела от своих параметров. ·>У тебя зависимости не изолировались, просто перелилось из пустого в порожнее. Кода стало больше.
А вы свой пример покажите, что бы можно было тестировать на разных наборах данных-входов итд, вот и сравним.
P>>Этот самый и-тест по любому нужен, для каждого do_login метода. Как бы вы не выкручивались. У меня метод do_logic будет линейным, заниматься только связыванием. ·>Не по любому. Я тебе уже рассказывал как.
Вы или будете апи дергать в тестах, или надеетесь, что моки от этого избавляют. Не избавляют.
P>>Или написать мок на все случаи жизни, что бы промоделировать все неявные зависимости ·>Это твои фантазии. Судя по тому коду, который ты привёл, ты не понимаешь как пользоваться моками и придумываешь себе страшилки.
Пока что от вас ни одного примера не было.
P>>3. expect(buildRequest(params)).to.deep.eq(pattern) ·>Что за паттерн-то? Полный код можешь написать? Вот ты рассказал, что оно выглядит так: ·>
P>>Вы вместо проверки построения бд тестируете весь пайплан — связывание, построение, вызов бд клиента, получение промежуточных результатов, обработка, возвращение окончательного ·>Именно, всё как ты хочешь "соответствует ожиданиям", и как ты любишь "блакбокс". Ожидаем, что если мы сохранили запись, то потом её можем найти и загрузить. А что там происходит за кулисами — совершенно неважно.
Ну вот выполняете запрос на проде, прод падает. Ваши действия? Смотрите и видите, что ваши фильтры в конкретной комбинации вырождаются в пустую строку, и прод пытается вгрузить всю таблицу где десятки млн записей
После этого идете и юнит-тестами покрываете построение запроса к бд/орм/итд
P>>Это и есть косвенная проверка. Например, если запрос у вас не тот, но из за вашей бд будет выдавать нужные данные, вы проблему из за косвенности не найдете ·>Что значит "не тот"? Как проверить тот он или не тот? Как в принципе узнать как должен выглядеть тот?
Для этого нужно знать, какие запросы кому вы отправляете. ORM — пишите тест на построение запроса к ORM. Если же ORM такого не умеет — вот он случай для косвенных проверок, и для моков.
P>>Много фильтров и их комбинаций, да еще и пагинация ·>И? зачем для этого несколько тысяч значений? У тебя там комбинаторно рвануло, да?
Смотря сколько фильтров и значений. Если у вас один филд и один простой фильтр <> — хватит десятка.
P>>Так вы думаете я юнит-тесты пишу что бы работы себе доваить? Я их пишу, что бы избавиться от лишнего когда, как в тестах, так и в приложении. ·>Пока ты продемонстрировал лишь добавление кода.
Вы пока вообще ничего не продемонстрировали.
P>>Затем, что самое сложное в БД это построение или запроса к ORM, или SQL. Слишком много запросов похожих на тот, что нам нужен, но нерабочих. ·>Построение запроса это детали реализации, важно что построенный запрос вернёт.
Нам нужны гарантии, что этот запрос не повалит нам прод, когда в него пойдут произвольные комбинации фильтров и всего остального
P>>Вот на той неделе был случай — некто заимплементил фильтры, которые на некоторых наборах параметров вырождаются в пустую строку, и запрос каждый раз булшитит десятки миллионов записей в таблице P>>Зато на тестовой бд всё хорошо ·>Если эти наборы параметров забыли протестировать, то чем твой getUser поможет?
Тут мы возвращаемся к тем нескольким тысячам значений. Нам нужны все значения в фильтрах, и всех их ркомбинации, =, <>, like итд.
P>>Если понятия не имеете, то скорее всего и запросы ваши будут работать приблизительно. Например, фильтры будут работать только на тестовых данных ·>У тебя тоже.
Я вам примеры беру из своей практики. На новом проекте именно такая проблема, я это как раз и исправляю.
P>>Если вы протащили аудит прямо в бл, то так и будет. А если бл не имеет зависимостей на репу и бд, то для аудита у нас только одно место — там где применяем изменения. И таких тестов у нас много быть не может. ·>Аудит это и есть бл. Аудит — прямое требование бизнеса. Ты ведь надеюсь, уже перестал путать логи и аудит?
Ну да — раз аудит и бл нужны бизнесу, значит во всех функциях должны быть зависимости на репозиторий, бд, и кафку
Функция может просто вернуть изменение состояния, и запись для аудита. А сохранять новое состояние и писать аудит вы будете снаружи. Но вы почему то такой вариант не рассматривает
P>>Процентов 30-40 от сборки. ·>А что потом после сборки?
После сборки — тесты.
P>>Вы что, в первой версии приложения знаете, какие фичи понадобятся в течении следующих 10 лет? АПИ всегда эволюционирует ·>Как правило, он расширяется, а не эволюционирует. И чем реже, тем лучше.
у вас вероятно только расширяется. Откройте любое взрослое апи — v1, v2, v3, deprecated итд.
P>>Если манифест держать кодом, то это хорошая заявочка на рассинхронизацию — у нас работает, а у клиентов — нет. ·>Я вообще за contract-first.
Вот аннотации и есть тот самый контракт — в нем указано всё, что надо. Кода еще нет, а интеграция уже готова и можно начинать одновременно писать и клиента, и тесты, и сам код бакенда.
Здравствуйте, Pauel, Вы писали:
P>>>·>И? С моками (стабами) тесты такие же дешёвые. Т.к. мы мочим всё медленное и дорогое. В этом и цель моков (стабов) — удешевлять тесты. P>>>Для начала это вы сами сделали тесты дорогими, когда поместили БЛ прямо в контроллер P>·>Ты опять скрываешь что ты понимаешь под дороговизной. P>Я ж сказал — если я поменяю внутреннюю реализацию, никакие тесты падать не должны.
Т.е. если ты поменяешь 'select * from users where id=?' на 'select id, name, email from users where id=?' у тебя тесты и посыпятся.
P>Мы покрываем ожидания вызывающей стороны, а у неё как раз нету ожиданий "вызовем crypto hmac вот таким макаром"
Я уже показал как пишутся тесты с моками для hmac. Там не должно быть такого.
P>А у вас видение "раз hmac в требованиях, то нужны моки"
Ты врёшь.
P>>>Вы все еще про статью, тут я ничем помочь не могу. P>·>getUser и toFields это не про статью. P>Разумеется. Зачем продолжать мусолить заведомо однобокую статью?
Ок. Наконец-то ты согласился, что таки да, у тебя прод-кода больше. Нам такого не надо.
P>·>У тебя было expect...toBeCalledWith — это было совершенно неправильное решение. Я просто попытался объяснить, что так делать не надо и показал как надо, сделав оговорку "Если не задаваться вопросом, зачем вообще вдруг понадобилось мокать hmac". P>Ну ок — если вы не предлагаете мокать hmac, то всё в порядке.
С чего ты взял, что я в принципе мог такое предложить — я не знаю.
P>>>Не одна — для каждого из тестов вам нужен будет этот мок P>·>Зачем для каждого? Этот мок можно куда-нибудь в setUp вынести. P>Он будет везде использоваться. А раз так, то ваш мок надо или посать под каждый тест. Или запилить в ём поддержку всех кейсов.
Нет, только те тесты, в которых ассертится логика, зависящая от текущего времени. В остальных может чего-нибудь дефолтное возвращаться.
P>>>hmac, time, итд. В одном файле — что бы чинить не 100 тестов, а всего 10 значений когда вы поменяете hmac 256 на 512. P>·>Я может что-то не знаю, но обычно hmac зависит от каждого теста — контрольная сумма сериализованного тела ответа. У тебя в твоём хоумпейдже на всю функциональность хватает 10 тестов? P>А нам не надо везде тащить этот hmac и тестировать это в каждом тесте. юнит-тестами покрываем вычисление hmac по конкретному контенту, и всё. Остальное — в интеграционных, коих на порядок меньше чем юнит-тестов.
Что значит не надо? У тебя там deep equals и сравнение логов. А интеграционных у тебя тоже дофига, т.к. они покрывают каждый do_logic.
P>>>1 При изменении алгоритма, формата итд, сломаются ваши моки P>·>Не сломаются. P>Вот пример — вы решили изменить сигнатуру getAll у вашего repository, добавить-убрать фильры-сортировку-итд. P>getAll у вас покрыт моками. P>Вопрос — надо ли их фиксить, если поменялась сигнатура getAll? Если нет — покажите это чудо примером
Это типичный рефакторинг add-remove method parameter. Если добавляем парам, то тот прод-код, который мы меняем, ведь теперь надо передавать какое-то значение в такой параметр — надо и в тесте зафиксировать изменение в поведении. Удаление парама — так вообще тривиально, IDE автоматом везде подчистит, тест-не тест, не важно.
P>>>Эта согласованность проверится любым интеграционным тестом который вызовет контроллер. P>·>Не любым. P>Покажите пример.
Ну ты там ю-тест упоминал "а что если в колонке пусто". Вот такой соответствующий и-тест тоже придётся писать. Т.е. ю-тест бесполезен, ибо такое можно полноценно протестировать только и-тестом repo-dbms. Как я понял, ты здесь под и-тестом имеешь в виду тест вида "curl".
P>>>Поздравляю, это классика тавтологических тестов P>>>2 вариант, кладем в файлик тестовы-данные.json "время", "правильный результат", штуки 10 строчк. Меняем дизайн на nextFriday(now) и теперь у нас простой юнит-тест P>·>Ты подменил задание, а не дизайн. Вначале была функция nextFriday(), потом вдруг стала nextFriday(now). Если твоя система должна по контракту клиентам выдавать операцию nextFriday(), то поменять сигнатуру ты не можешь. P>Разве я сказал, что nextFriday это функция системы? Это одна из операций в самой БЛ, вопрос только в том, как её тестировать — моками или без них
По сути это не столь важно. Если у тебя в бл будет nextFriday(now), то во всех контроллерах где зовётся этот метод придётся передавать туда это самое now. И придётся писать полные интеграционные тесты, что туда передаётся именно серверное текущее время, а не что-то другое.
Т.е. вместо одного легковесного ю-теста с моком для данного конкретного метода бл, нам теперь приходится писать туеву хучу тяжёлых и-тестов на каждый вызов этого метода из разных контроллеров. Ещё интересно послушать как именно ты собираешься в "curl" и-тестах ассертить, что туда передаётся именно текущее время.
P>>>Это неверное упрощение. Моки и тесты результатов это разные классы задач, с разными свойствами, а отсюда — разные гарантии, проблемы итд P>·>Верно. Но почему-то ты считаешь, что задачи из других классов не существует. P>Я ж прямо пишу — разные классы задач. Для одних используем моки, их совсем немного, от безвыходности, для других — тесты чем дешевле тем лучше.
У тебя появляются "дешевые", но бесполезные ю-тесты, т.к. и-тесты всё равно нужны, практически в том же количестве.
P>>>2. если нет другого варианта, как в примере Буравчика, изолировать от зависимостей, что бы логика всё равно зависела от своих параметров. P>·>У тебя зависимости не изолировались, просто перелилось из пустого в порожнее. Кода стало больше. P>А вы свой пример покажите, что бы можно было тестировать на разных наборах данных-входов итд, вот и сравним.
Ну я не знаю что именно показать. Ну допустим хотим nextFriday() потестировать:
var clock = mock(InstantSource.class);
var testSubject = new CalendarLogic(clock);
when(clock.instant()).thenReturn(Instant.of("2023-12-28T12:27:00Z"));
assertThat(testSubject.nextFriday()).equalTo(LocalDate.of("2023-12-29"));
when(clock.instant()).thenReturn(Instant.of("2023-12-29T23:59:59Z"));
assertThat(testSubject.nextFriday()).equalTo(LocalDate.of("2023-12-29"));
when(clock.instant()).thenReturn(Instant.of("2023-12-30T00:00:00Z"));
assertThat(testSubject.nextFriday()).equalTo(LocalDate.of("2024-01-05"));
Я вполне допускаю, что внутри CalendarLogic отрефакторить nextFriday() так, чтобы оно звало какой-нибудь static nextFriday(now) который можно потестирвать как пюрешку, но зачем? Если у нас конечная цель иметь именно nextFriday(), то рисовать ещё один слой, увеличивать количество прод-кода ради "единственно верного дизайна" — только энтропию увеличивать.
P>>>Или написать мок на все случаи жизни, что бы промоделировать все неявные зависимости P>·>Это твои фантазии. Судя по тому коду, который ты привёл, ты не понимаешь как пользоваться моками и придумываешь себе страшилки. P>Пока что от вас ни одного примера не было.
Было несколько. Погляди сниппеты кода в моих сообщениях.
P>·>Какой код будет в тесте для проверки этого? P>Вот, что нового вы здесь открыли для себя? const pattern = ?
Появилась возможность пальчиком тыкнуть в то, что у тебя в коде теста полный кусок текста запроса 'select * from users where id=?', а не какой-то магический паттерн, проверяющий что запрос "тот". Т.е. по большому счёту ты никак не можешь знать что запрос хотя бы синтаксически корректен. Пишутся такие тесты обычно копипастой текста запроса из прод-кода в тест-код и тестируют "как написано", а не ожидания. И валятся только после полной сборки и запуска всего приложения, нередко только в проде.
P>
Что такое "fn1" и "fn2"? Как deep.eq будет это сравнивать?
P>>>Вы вместо проверки построения бд тестируете весь пайплан — связывание, построение, вызов бд клиента, получение промежуточных результатов, обработка, возвращение окончательного P>·>Именно, всё как ты хочешь "соответствует ожиданиям", и как ты любишь "блакбокс". Ожидаем, что если мы сохранили запись, то потом её можем найти и загрузить. А что там происходит за кулисами — совершенно неважно. P>Ну вот выполняете запрос на проде, прод падает. Ваши действия?
Воспроизвожу сценарий в тесте и фиксю код.
P>>>Это и есть косвенная проверка. Например, если запрос у вас не тот, но из за вашей бд будет выдавать нужные данные, вы проблему из за косвенности не найдете P>·>Что значит "не тот"? Как проверить тот он или не тот? Как в принципе узнать как должен выглядеть тот? P>Для этого нужно знать, какие запросы кому вы отправляете. ORM — пишите тест на построение запроса к ORM. Если же ORM такого не умеет — вот он случай для косвенных проверок, и для моков.
Как это можно знать, что запрос "тот"? Единственный вменяемый вариант — выполнить запрос и поглядеть что вернулось. Полагаю ты делаешь это ручками, копипастишь текст запроса в консоль субд, вручную подставляешь парамы, выполняешь, глазками смотришь на результат, что похоже вроде бы на правду. Я предлагаю поручить это дело и-тестам repo+dbms. Пишем тест, он запускает построенный запрос с парамами и ассертит результат.
P>>>Много фильтров и их комбинаций, да еще и пагинация P>·>И? зачем для этого несколько тысяч значений? У тебя там комбинаторно рвануло, да? P>Смотря сколько фильтров и значений. Если у вас один филд и один простой фильтр <> — хватит десятка.
Не понял. Достаточно иметь одно значение и слать разные фильтры.
Ок... ну может для сортировки и пагинации может понадобиться чуть больше одного значения.
P>·>Пока ты продемонстрировал лишь добавление кода. P>Вы пока вообще ничего не продемонстрировали.
Я продемонстрировал как удалить код в твоём примере с hmac, например.
P>>>Затем, что самое сложное в БД это построение или запроса к ORM, или SQL. Слишком много запросов похожих на тот, что нам нужен, но нерабочих. P>·>Построение запроса это детали реализации, важно что построенный запрос вернёт. P>Нам нужны гарантии, что этот запрос не повалит нам прод, когда в него пойдут произвольные комбинации фильтров и всего остального
И как ты эти гарантии собрался обеспечивать? Неиспользованием моков?
P>·>Если эти наборы параметров забыли протестировать, то чем твой getUser поможет? P>Тут мы возвращаемся к тем нескольким тысячам значений. Нам нужны все значения в фильтрах, и всех их ркомбинации, =, <>, like итд.
Для этого нужны комбинации фильтров, а не комбинации значений.
P>>>Если понятия не имеете, то скорее всего и запросы ваши будут работать приблизительно. Например, фильтры будут работать только на тестовых данных P>·>У тебя тоже. P>Я вам примеры беру из своей практики. На новом проекте именно такая проблема, я это как раз и исправляю.
Т.е. ты находишь баги и непротестированные сценарии. И?
P>>>Если вы протащили аудит прямо в бл, то так и будет. А если бл не имеет зависимостей на репу и бд, то для аудита у нас только одно место — там где применяем изменения. И таких тестов у нас много быть не может. P>·>Аудит это и есть бл. Аудит — прямое требование бизнеса. Ты ведь надеюсь, уже перестал путать логи и аудит? P>Ну да — раз аудит и бл нужны бизнесу, значит во всех функциях должны быть зависимости на репозиторий, бд, и кафку
Нет. Я тебе уже рассказывал что от чего зависит.
P>Функция может просто вернуть изменение состояния, и запись для аудита. А сохранять новое состояние и писать аудит вы будете снаружи. Но вы почему то такой вариант не рассматривает
Я уже рассказал. Это делает больше прод-кода, усложняет его и начинает требовать дополнительных тестов о том, что аудит таки пишется снаружи как надо куда надо.
P>>>Процентов 30-40 от сборки. P>·>А что потом после сборки? P>После сборки — тесты.
Т.е. сборка без тестов 1.5 часа, потом ещё тесты час?
P>>>Вы что, в первой версии приложения знаете, какие фичи понадобятся в течении следующих 10 лет? АПИ всегда эволюционирует P>·>Как правило, он расширяется, а не эволюционирует. И чем реже, тем лучше. P>у вас вероятно только расширяется. Откройте любое взрослое апи — v1, v2, v3, deprecated итд.
v1,v2,v3 — это разные спеки, практически новое api.
P>>>Если манифест держать кодом, то это хорошая заявочка на рассинхронизацию — у нас работает, а у клиентов — нет. P>·>Я вообще за contract-first. P>Вот аннотации и есть тот самый контракт — в нем указано всё, что надо. Кода еще нет, а интеграция уже готова и можно начинать одновременно писать и клиента, и тесты, и сам код бакенда.
Аннотации — часть кода. Если вы захотите переписать свой сервис на другой ЯП, ну там с js на rust — что вы будете делать со своими аннотациями?
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>Я ж сказал — если я поменяю внутреннюю реализацию, никакие тесты падать не должны. ·>Т.е. если ты поменяешь 'select * from users where id=?' на 'select id, name, email from users where id=?' у тебя тесты и посыпятся.
Посыплются. Есть такой недостаток. Потому нужно всегда писать осмысленные вещи,ш а не затыкать хренью. select * появится в том случае, если некто вместо построения запроса так и захардкодит.
P>>Мы покрываем ожидания вызывающей стороны, а у неё как раз нету ожиданий "вызовем crypto hmac вот таким макаром" ·>Я уже показал как пишутся тесты с моками для hmac. Там не должно быть такого.
Я шота не могу найти. Не могли бы вы ссылкой поделиться?
P>>А у вас видение "раз hmac в требованиях, то нужны моки" ·>Ты врёшь.
Очевидно, это я так вас понял. Вы слишком много таких аргументов тащите
P>>Разумеется. Зачем продолжать мусолить заведомо однобокую статью? ·>Ок. Наконец-то ты согласился, что таки да, у тебя прод-кода больше. Нам такого не надо.
Я согласился с тем, что статья кривая, а вы читаете что у меня прод-кода больше. Вы там что курите?
P>>Он будет везде использоваться. А раз так, то ваш мок надо или посать под каждый тест. Или запилить в ём поддержку всех кейсов. ·>Нет, только те тесты, в которых ассертится логика, зависящая от текущего времени. В остальных может чего-нибудь дефолтное возвращаться.
Я примерно так и имел ввиду.
P>>А нам не надо везде тащить этот hmac и тестировать это в каждом тесте. юнит-тестами покрываем вычисление hmac по конкретному контенту, и всё. Остальное — в интеграционных, коих на порядок меньше чем юнит-тестов. ·>Что значит не надо? У тебя там deep equals и сравнение логов. А интеграционных у тебя тоже дофига, т.к. они покрывают каждый do_logic.
У вас тут мешанина — интеграционных тестов по количеству методов в апи, + сценарии.
Сравнение логов только там, где вы это используете.
А чем deep equals не угодил я без понятия
P>>Вопрос — надо ли их фиксить, если поменялась сигнатура getAll? Если нет — покажите это чудо примером ·>Это типичный рефакторинг add-remove method parameter. Если добавляем парам, то тот прод-код, который мы меняем, ведь теперь надо передавать какое-то значение в такой параметр — надо и в тесте зафиксировать изменение в поведении. Удаление парама — так вообще тривиально, IDE автоматом везде подчистит, тест-не тест, не важно.
Не совсем понятно, почему этот типичный рефакторинг должен ломать тесты. Вы в этом видите какуюто пользу, но никак не расскажете, что за она
·>Ну ты там ю-тест упоминал "а что если в колонке пусто". Вот такой соответствующий и-тест тоже придётся писать.
Непонятно, что за проблему хотите решить этим дополнительным тестом. Перепроверить, что юнит-тест таки валидный?
·>По сути это не столь важно. Если у тебя в бл будет nextFriday(now), то во всех контроллерах где зовётся этот метод придётся передавать туда это самое now. И придётся писать полные интеграционные тесты, что туда передаётся именно серверное текущее время, а не что-то другое. ·>Т.е. вместо одного легковесного ю-теста с моком для данного конкретного метода бл, нам теперь приходится писать туеву хучу тяжёлых и-тестов на каждый вызов этого метода из разных контроллеров. Ещё интересно послушать как именно ты собираешься в "curl" и-тестах ассертить, что туда передаётся именно текущее время.
Количество тестов будет одинаковым. Только вам нужно будет везде указывать свой мок. Вы почему то верите, что моки избавляют от интеграционных. Это разные вещи. Интеграционный тест проверяет 1) что сама склейка валидная, а не 2) способность к ней. Моки проверяют второе, а нам надо — первое.
·>У тебя появляются "дешевые", но бесполезные ю-тесты, т.к. и-тесты всё равно нужны, практически в том же количестве.
В том то и дело, что тесты как раз полезные. А количество интеграционных зависит от апи и сценариев.
·>Ну я не знаю что именно показать. Ну допустим хотим nextFriday() потестировать:
Вот и сравните разницу
var testSubject = new CalendarLogic();
var now = Samples.nextFriday.case1.in;
assertThat(testSubject.nextFriday(now)).equalTo(Samples.nextFriday.result);
В вашем случае точно так же нужно предусмотреть все кейсы, только у вас будет везде на 5 строчек больше
·>Я вполне допускаю, что внутри CalendarLogic отрефакторить nextFriday() так, чтобы оно звало какой-нибудь static nextFriday(now) который можно потестирвать как пюрешку, но зачем? Если у нас конечная цель иметь именно nextFriday(), то рисовать ещё один слой, увеличивать количество прод-кода ради "единственно верного дизайна" — только энтропию увеличивать.
Ну да, вы только и думаете в терминах моков
P>>·>Какой код будет в тесте для проверки этого? P>>Вот, что нового вы здесь открыли для себя? const pattern = ? ·>Появилась возможность пальчиком тыкнуть в то, что у тебя в коде теста полный кусок текста запроса 'select * from users where id=?', а не какой-то магический паттерн, проверяющий что запрос "тот". Т.е. по большому счёту ты никак не можешь знать что запрос хотя бы синтаксически корректен. Пишутся такие тесты обычно копипастой текста запроса из прод-кода в тест-код и тестируют "как написано", а не ожидания. И валятся только после полной сборки и запуска всего приложения, нередко только в проде.
Расскажите, как вы вашими косвенными тестами дадите гарантию, что на проде никогда не случится ситуация, что запрос выродится в select * from users и у нас будут сотни тысяч записей вгружаться разом.
Подробнее пожалуйста.
Это вероятно вы тестируете чтото копируя чтото с прода. А я тестирую построение запроса, например, те самые фильтры. И логики в методе довольно много, т.к. в зависимости от разных фильтров у нас могут быть разные вещи.
·>Что такое "fn1" и "fn2"? Как deep.eq будет это сравнивать?
По ссылке.
P>>Ну вот выполняете запрос на проде, прод падает. Ваши действия? ·>Воспроизвожу сценарий в тесте и фиксю код.
Непросто код а в т.ч. и построение запроса к орм или бд.
P>>Для этого нужно знать, какие запросы кому вы отправляете. ORM — пишите тест на построение запроса к ORM. Если же ORM такого не умеет — вот он случай для косвенных проверок, и для моков. ·>Как это можно знать, что запрос "тот"? Единственный вменяемый вариант — выполнить запрос и поглядеть что вернулось.
Что вы так думаете — это я помню. Вы никак не расскажете, как побороть data complexity, т.е. как убедиться что ваш запрос не выдаст какой нибудь вырожденный кейс и вгрузит всё.
P>>Смотря сколько фильтров и значений. Если у вас один филд и один простой фильтр <> — хватит десятка. ·>Не понял. Достаточно иметь одно значение и слать разные фильтры. ·>
·>Ок... ну может для сортировки и пагинации может понадобиться чуть больше одного значения.
У вас здесь та самая data complexity. Вам нужно обосновать внятно, почему ваш фильтр никогда не вернет пустое выражение, и запрос не выродится в "вгрузить всё"
Кроме того, если фильтров много, то количество данных будет расти экспоненциально.
P>>Вы пока вообще ничего не продемонстрировали. ·>Я продемонстрировал как удалить код в твоём примере с hmac, например.
Я нашел только тот вариант, где вы мокаете hmac. У вас есть что лучше?
P>>Нам нужны гарантии, что этот запрос не повалит нам прод, когда в него пойдут произвольные комбинации фильтров и всего остального ·>И как ты эти гарантии собрался обеспечивать? Неиспользованием моков?
Здесь тесты не дают полного контроля над ситуацией. Нам нужно спроектировать запрос и доказать его корректность, а построение фильтров итд покрыть юнит-тестами.
P>>Функция может просто вернуть изменение состояния, и запись для аудита. А сохранять новое состояние и писать аудит вы будете снаружи. Но вы почему то такой вариант не рассматривает ·>Я уже рассказал. Это делает больше прод-кода, усложняет его и начинает требовать дополнительных тестов о том, что аудит таки пишется снаружи как надо куда надо.
Нет, не делает. И тестов становится меньше. Аудит пишется снаружи как надо — это в любом случае задача интеграционного теста, что у нас всё в сборе поддерживает аудит
P>>После сборки — тесты. ·>Т.е. сборка без тестов 1.5 часа, потом ещё тесты час?
Чото конкретно вас смущает?
P>>у вас вероятно только расширяется. Откройте любое взрослое апи — v1, v2, v3, deprecated итд. ·>v1,v2,v3 — это разные спеки, практически новое api.
Забавно, что ту часть, где deprecated вы скромно опустили. Вы так в слова играете?
P>>Вот аннотации и есть тот самый контракт — в нем указано всё, что надо. Кода еще нет, а интеграция уже готова и можно начинать одновременно писать и клиента, и тесты, и сам код бакенда. ·>Аннотации — часть кода. Если вы захотите переписать свой сервис на другой ЯП, ну там с js на rust — что вы будете делать со своими аннотациями?
Вы из какого века пишете? Если по аннотациям можно получить клиентский код, серверный, да еще и тесты с документацией, то почему нельзя для rust это проделать?
Смена стека технологий встречается куда реже, чем смена бд или изменения в апи.
Вы бы еще метеориты вспомнили
Здравствуйте, Буравчик, Вы писали:
Б>Ты также привязываешься к конкретным вызовам, параметрам, последовательностям, но не моками, а лямбдами. Нет разницы в этом.
Про ваш пример я сразу сказал, что проблемы из за зависимостей, потому полностью от моков не избавиться.
Я всего лишь предложил вариант, как уменьшить количество кода в тестах.
Б>Но ты усложняешь логику, добавляя лишние лямбды, которые просто оборачивают зависимости (как говорится, фабрика на фабрике, в твоем случае адаптер на адаптере).
Связывание усложняется ради того, что бы, а в тестах можно было задешево покрыть все ключевые комбинации.
Самое главное — свести тесты функции к таблице истинности, а не продираться через нагромождения моков.
P>> Потому полностью уйти от моков не выйдет.
Б>Если говорить про внешние зависимости, твои лямбды это и есть моки. Никуда от них не ушел.
Цитирую себя "Потому полностью уйти от моков не выйдет." Причина в зависимостях, т.е. ваш пример он почти идеально подходит под моки.
P>>Но если вы изначально считаете моки чем то хороши, естественно, более простой вариант в голову и не придет
Б>Я стараюсь выбирать подходящий инструмент (более простой).
Более простой — понятие растяжимое. Я сюда включаю и тесты. Если мне писать в тестах больше кода, это значит, что мне придется или покрыть выборочно, или потратить намного больше времени, да еще потом спотыкаться о разные кейсы.
Б>Если я вижу сложную логику, то выделяю ее в отдельную функцию и тестирую как чистую функцию (входные параметры -> результат) Б>Если я вижу много взаимодействия с внешними зависимостями, то использую моки. Это позволяет протестировать поведение как обычную функцию (входные параметры + "мок-данные из внешних систем" -> результат
Примерно так, да. Только взаимодействие со внешними зависимостями тоже разное бывает. Например, мы делаем так
1. вычисляем какие измнения-вызовы нужны, чистая часть, много логики
2. выполняем все нужные изменения-вызовы итд, грязная, обычно линейная
В вашем примере такой фокус провернуть не получится
Здравствуйте, Pauel, Вы писали:
P>>>Я ж сказал — если я поменяю внутреннюю реализацию, никакие тесты падать не должны. P>·>Т.е. если ты поменяешь 'select * from users where id=?' на 'select id, name, email from users where id=?' у тебя тесты и посыпятся. P>Посыплются. Есть такой недостаток. Потому нужно всегда писать осмысленные вещи,ш а не затыкать хренью. select * появится в том случае, если некто вместо построения запроса так и захардкодит.
Именно, и это просто один из примеров. Тысячи их. Небольшое изменение стиля во внутренней реализации — и твои безмокные тесты сыплются. И см. что ты заявил выше, подчёркнутое. У меня, кстати, такие проблемы только в твоих фантазиях.
P>>>Мы покрываем ожидания вызывающей стороны, а у неё как раз нету ожиданий "вызовем crypto hmac вот таким макаром" P>·>Я уже показал как пишутся тесты с моками для hmac. Там не должно быть такого. P>Я шота не могу найти. Не могли бы вы ссылкой поделиться? Тут
.
P>>>Разумеется. Зачем продолжать мусолить заведомо однобокую статью? P>·>Ок. Наконец-то ты согласился, что таки да, у тебя прод-кода больше. Нам такого не надо. P>Я согласился с тем, что статья кривая, а вы читаете что у меня прод-кода больше. Вы там что курите?
Это просто ты так внимательно читаешь. Я написал три предложения "В статье кода стало больше. Вот эти все getUser — это всё лишний код в проде. Твои "{...toFields}" — тоже лишний код, и это всё прод-код.". Ты только от первого открестился, а на вторые два сделал вид, что их не было.
P>>>Он будет везде использоваться. А раз так, то ваш мок надо или посать под каждый тест. Или запилить в ём поддержку всех кейсов. P>·>Нет, только те тесты, в которых ассертится логика, зависящая от текущего времени. В остальных может чего-нибудь дефолтное возвращаться. P>Я примерно так и имел ввиду.
Почему тогда под "каждый тест" или "всех кейсов"?
Тебе ровно то же надо, там где есть зависимость от now, будешь его передавать как парам. Разница лишь в том, что я буду передавать не через парам, а через мок.
И, самое главное, у меня это всё будет тестовый код. А ты взамен этого предлагаешь усложнять ещё и прод-код своими фреймворками.
P>>>А нам не надо везде тащить этот hmac и тестировать это в каждом тесте. юнит-тестами покрываем вычисление hmac по конкретному контенту, и всё. Остальное — в интеграционных, коих на порядок меньше чем юнит-тестов. P>·>Что значит не надо? У тебя там deep equals и сравнение логов. А интеграционных у тебя тоже дофига, т.к. они покрывают каждый do_logic. P>У вас тут мешанина — интеграционных тестов по количеству методов в апи, + сценарии.
Верно, у вас интеграционные должны быть для всех сценариев, т.е. дохрена. А у меня интеграционных — гораздо меньше. Т.к. интеграционные тесты тестируют интеграцию компонент, а не сценарии. Компоненты, как правило, отвечают сразу за группу сценариев.
P>Сравнение логов только там, где вы это используете.
Эээ. "Это" что? Логи, обычно, используются везде.
P>А чем deep equals не угодил я без понятия
Тем, что он сравнивает очень много. А не то, что конкретно тест тестирует.
P>>>Вопрос — надо ли их фиксить, если поменялась сигнатура getAll? Если нет — покажите это чудо примером P>·>Это типичный рефакторинг add-remove method parameter. Если добавляем парам, то тот прод-код, который мы меняем, ведь теперь надо передавать какое-то значение в такой параметр — надо и в тесте зафиксировать изменение в поведении. Удаление парама — так вообще тривиально, IDE автоматом везде подчистит, тест-не тест, не важно. P>Не совсем понятно, почему этот типичный рефакторинг должен ломать тесты. Вы в этом видите какуюто пользу, но никак не расскажете, что за она
Почему ломать? Вот был у тебя nextFriday(now), и вдруг теперь ты это меняешь на nextFriday(now, tz) — у тебя весь код как-то магически будет работать как раньше? Не верю.
P>·>Ну ты там ю-тест упоминал "а что если в колонке пусто". Вот такой соответствующий и-тест тоже придётся писать. P>Непонятно, что за проблему хотите решить этим дополнительным тестом. Перепроверить, что юнит-тест таки валидный?
Что юнит тест тестит не "как написано в коде", а некое реально возможное ожидание.
P>·>По сути это не столь важно. Если у тебя в бл будет nextFriday(now), то во всех контроллерах где зовётся этот метод придётся передавать туда это самое now. И придётся писать полные интеграционные тесты, что туда передаётся именно серверное текущее время, а не что-то другое. P>·>Т.е. вместо одного легковесного ю-теста с моком для данного конкретного метода бл, нам теперь приходится писать туеву хучу тяжёлых и-тестов на каждый вызов этого метода из разных контроллеров. Ещё интересно послушать как именно ты собираешься в "curl" и-тестах ассертить, что туда передаётся именно текущее время. P>Количество тестов будет одинаковым. Только вам нужно будет везде указывать свой мок. Вы почему то верите, что моки избавляют от интеграционных. Это разные вещи. Интеграционный тест проверяет 1) что сама склейка валидная, а не 2) способность к ней. Моки проверяют второе, а нам надо — первое.
Не моки избавляют, а дизайн. Если ты себя заставил использовать nextFriday(now), то у тебя будет куча мест склейки, которые теперь _приходится_ тестировать дополнительными тестами. В случае nextFriday() — у тебя склейка происходит в одном месте и тестов становится меньше. Ещё раз напомню, nextFriday() — это же просто трюк для снижения копипасты, называется "частичное применение функции". А каждая копипаста — это отдельный кусок кода, который надо покрывать отдельными тестами.
Так как именно ты собираешься в "curl" и-тестах ассертить, что туда передаётся именно текущее время?
P>·>У тебя появляются "дешевые", но бесполезные ю-тесты, т.к. и-тесты всё равно нужны, практически в том же количестве. P>В том то и дело, что тесты как раз полезные. А количество интеграционных зависит от апи и сценариев.
В чём полезность? В том, что посыпаться могут от малейших изменений?
P>·>Ну я не знаю что именно показать. Ну допустим хотим nextFriday() потестировать: P>Вот и сравните разницу P>
P>var testSubject = new CalendarLogic();
P>var now = Samples.nextFriday.case1.in;
P>assertThat(testSubject.nextFriday(now)).equalTo(Samples.nextFriday.result);
P>
P>В вашем случае точно так же нужно предусмотреть все кейсы, только у вас будет везде на 5 строчек больше
Каких ещё пять строчек? Разница пока в одной строчке, на все тесты, не надо mock(InstantSource.class) делать. Если ты не понял, у меня было три различных тестовых сценария, для трёх разных now, у тебя — один.
И ты как всегда "забыл" что теперь тебе помимо _одной_ сэкономленной строчки в тест-коде придётся писать ещё по отдельному тесту на каждое место склейки nextFriday и now. Т.е. одну строчку экономишь и сотню добавляешь.
P>·>Я вполне допускаю, что внутри CalendarLogic отрефакторить nextFriday() так, чтобы оно звало какой-нибудь static nextFriday(now) который можно потестирвать как пюрешку, но зачем? Если у нас конечная цель иметь именно nextFriday(), то рисовать ещё один слой, увеличивать количество прод-кода ради "единственно верного дизайна" — только энтропию увеличивать. P>Ну да, вы только и думаете в терминах моков
Опять фантазии.
P>>>·>Какой код будет в тесте для проверки этого? P>>>Вот, что нового вы здесь открыли для себя? const pattern = ? P>·>Появилась возможность пальчиком тыкнуть в то, что у тебя в коде теста полный кусок текста запроса 'select * from users where id=?', а не какой-то магический паттерн, проверяющий что запрос "тот". Т.е. по большому счёту ты никак не можешь знать что запрос хотя бы синтаксически корректен. Пишутся такие тесты обычно копипастой текста запроса из прод-кода в тест-код и тестируют "как написано", а не ожидания. И валятся только после полной сборки и запуска всего приложения, нередко только в проде. P>Расскажите, как вы вашими косвенными тестами дадите гарантию, что на проде никогда не случится ситуация, что запрос выродится в select * from users и у нас будут сотни тысяч записей вгружаться разом. P>Подробнее пожалуйста.
Начни с себя, как ты с вашими супер-тестами дадите гарантию.
P>Это вероятно вы тестируете чтото копируя чтото с прода. А я тестирую построение запроса, например, те самые фильтры. И логики в методе довольно много, т.к. в зависимости от разных фильтров у нас могут быть разные вещи.
Как ты тестируешь что построенный запрос хотя бы синтаксически корректен?
P>>>
P>·>Что такое "fn1" и "fn2"? Как deep.eq будет это сравнивать? P>По ссылке.
По ссылке куда? Неужели fn1/fn2 — публично выставленные внутренности? И как тогда ты будешь знать, что нужно именно fn2, а не fn3?
P>>>Ну вот выполняете запрос на проде, прод падает. Ваши действия? P>·>Воспроизвожу сценарий в тесте и фиксю код. P>Непросто код а в т.ч. и построение запроса к орм или бд.
Не знаю что за такой "непросто код". Код он и в африке код. Чем код построения запроса принципиально отличается от другого кода?
P>>>Для этого нужно знать, какие запросы кому вы отправляете. ORM — пишите тест на построение запроса к ORM. Если же ORM такого не умеет — вот он случай для косвенных проверок, и для моков. P>·>Как это можно знать, что запрос "тот"? Единственный вменяемый вариант — выполнить запрос и поглядеть что вернулось. P>Что вы так думаете — это я помню. Вы никак не расскажете, как побороть data complexity, т.е. как убедиться что ваш запрос не выдаст какой нибудь вырожденный кейс и вгрузит всё.
Выполнить и заасертить, что было вружено то, что ожидается, а не всё.
На вопрос "Как это можно знать, что запрос "тот"?" ты так и не ответил.
P>·>Ок... ну может для сортировки и пагинации может понадобиться чуть больше одного значения. P>У вас здесь та самая data complexity. Вам нужно обосновать внятно, почему ваш фильтр никогда не вернет пустое выражение, и запрос не выродится в "вгрузить всё"
А почему ваш не выродится?
P>Кроме того, если фильтров много, то количество данных будет расти экспоненциально.
Почему данных-то? Просто разные фильтры для тех же данных.
P>>>Вы пока вообще ничего не продемонстрировали. P>·>Я продемонстрировал как удалить код в твоём примере с hmac, например. P>Я нашел только тот вариант, где вы мокаете hmac. У вас есть что лучше?
Так говорил же — ну не мокать hmac, неясно зачем его вообще мокать. Тесты от этого медленнее не становятся.
P>>>Нам нужны гарантии, что этот запрос не повалит нам прод, когда в него пойдут произвольные комбинации фильтров и всего остального P>·>И как ты эти гарантии собрался обеспечивать? Неиспользованием моков? P>Здесь тесты не дают полного контроля над ситуацией. Нам нужно спроектировать запрос и доказать его корректность, а построение фильтров итд покрыть юнит-тестами.
Противоречивые параграфы детектед.
Как доказывать корректность запроса?
P>>>Функция может просто вернуть изменение состояния, и запись для аудита. А сохранять новое состояние и писать аудит вы будете снаружи. Но вы почему то такой вариант не рассматривает P>·>Я уже рассказал. Это делает больше прод-кода, усложняет его и начинает требовать дополнительных тестов о том, что аудит таки пишется снаружи как надо куда надо. P>Нет, не делает. И тестов становится меньше. Аудит пишется снаружи как надо — это в любом случае задача интеграционного теста, что у нас всё в сборе поддерживает аудит
Мест снаружи — больше, чем одно место внутри. И каждое место снаружи надо покрывать отдельным тестом. А для одного места внутри будет один тест.
P>>>После сборки — тесты. P>·>Т.е. сборка без тестов 1.5 часа, потом ещё тесты час? P>Чото конкретно вас смущает?
Слишком долго.
P>>>у вас вероятно только расширяется. Откройте любое взрослое апи — v1, v2, v3, deprecated итд. P>·>v1,v2,v3 — это разные спеки, практически новое api. P>Забавно, что ту часть, где deprecated вы скромно опустили. Вы так в слова играете?
Дык deprecated это часть "только расширяется". Что старое не удаляется, а добавляется новое.
P>>>Вот аннотации и есть тот самый контракт — в нем указано всё, что надо. Кода еще нет, а интеграция уже готова и можно начинать одновременно писать и клиента, и тесты, и сам код бакенда. P>·>Аннотации — часть кода. Если вы захотите переписать свой сервис на другой ЯП, ну там с js на rust — что вы будете делать со своими аннотациями? P>Вы из какого века пишете? Если по аннотациям можно получить клиентский код, серверный, да еще и тесты с документацией, то почему нельзя для rust это проделать?
Можно. Но придётся и все эти аннотации как-то переписывать.
P>Смена стека технологий встречается куда реже, чем смена бд или изменения в апи. P>Вы бы еще метеориты вспомнили
Смотря как долго проект живёт.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>>>Мы покрываем ожидания вызывающей стороны, а у неё как раз нету ожиданий "вызовем crypto hmac вот таким макаром" P>>·>Я уже показал как пишутся тесты с моками для hmac. Там не должно быть такого. P>>Я шота не могу найти. Не могли бы вы ссылкой поделиться? ·>Тут
Именно здесь вы и демонстрируете чудеса моков — все прибито гвоздями к "как написано". А значит, если вместо crypto взяли другую эквивалентную либу — тесты насмарку
И вы видите в этом какой то бенефит.
> Твои "{...toFields}" — тоже лишний код, и это всё прод-код.". Ты только от первого открестился, а на вторые два сделал вид, что их не было.
{...toFields} экономит вам десяток другой методов и тестов для них. Если у вас нет такого метода, вам придется или по месту колбасить код, намного больше, или создавать все возможные методы для конверсии.
P>>·>Нет, только те тесты, в которых ассертится логика, зависящая от текущего времени. В остальных может чего-нибудь дефолтное возвращаться. P>>Я примерно так и имел ввиду. ·>Почему тогда под "каждый тест" или "всех кейсов"?
Потому, что одного теста на моках, как вы показываете, недостаточно. Вам придется вместо таблицы инстинности приседать с моками.
·>Тебе ровно то же надо, там где есть зависимость от now, будешь его передавать как парам. Разница лишь в том, что я буду передавать не через парам, а через мок.
Вы уже показали — кода в тестах в вашем исполнении больше.
·>Верно, у вас интеграционные должны быть для всех сценариев, т.е. дохрена. А у меня интеграционных — гораздо меньше. Т.к. интеграционные тесты тестируют интеграцию компонент, а не сценарии. Компоненты, как правило, отвечают сразу за группу сценариев.
У вас какая то мешанина — интерграционные это все что выше юнитов. Сценарии — это на самом верху, уровень приложения или всей системы. Не ясно, за счет чего у вас будет меньше интеграционных — похоже, вы верите, что моки здесь чего то решают.
P>>Сравнение логов только там, где вы это используете. ·>Эээ. "Это" что? Логи, обычно, используются везде.
Это ж не значит, что и применять данных подход нужно везде. В некоторых интеграционных тестах, которых обычно немного.
P>>А чем deep equals не угодил я без понятия ·>Тем, что он сравнивает очень много. А не то, что конкретно тест тестирует.
deep equals проверяет значение, всё разом, если у вас чтото больше чем инт или строка
P>>Не совсем понятно, почему этот типичный рефакторинг должен ломать тесты. Вы в этом видите какуюто пользу, но никак не расскажете, что за она ·>Почему ломать? Вот был у тебя nextFriday(now), и вдруг теперь ты это меняешь на nextFriday(now, tz) — у тебя весь код как-то магически будет работать как раньше? Не верю.
Поломаются тесты не там, где вы обмокали, а ровно по месту — меняется таблица истинности функции
В вашем случае далеко не факт, что найдете в моках все нужные места, и сделаете что бы соответствовало
P>>Непонятно, что за проблему хотите решить этим дополнительным тестом. Перепроверить, что юнит-тест таки валидный? ·>Что юнит тест тестит не "как написано в коде", а некое реально возможное ожидание
Тест проверяет построение запроса. Построение запроса зависит от многих параметров — вот это связывание надо как то проверить.
Косвенные проверки, как вы любите, работают в простых кейсах типа key-value
Если у вас будет подсчет статистики, вы вспотеете покрывать тестами "из базы"
P>>Количество тестов будет одинаковым. Только вам нужно будет везде указывать свой мок. Вы почему то верите, что моки избавляют от интеграционных. Это разные вещи. Интеграционный тест проверяет 1) что сама склейка валидная, а не 2) способность к ней. Моки проверяют второе, а нам надо — первое. ·>Не моки избавляют, а дизайн. Если ты себя заставил использовать nextFriday(now), то у тебя будет куча мест склейки, которые теперь _приходится_ тестировать дополнительными тестами.
Не дополнительными, а теми же самыми интеграционными, что есть и у вас. Интеграционные тесты не пишутся на все вещи вида "проверим что где то внутре передается параметр". Если такое критично — выносится в юниты.
Если у нас код контролера линейный, а в моем случае это именно так, то нам нужен ровно один интеграционный тест, который нужен и вам
·>Так как именно ты собираешься в "curl" и-тестах ассертить, что туда передаётся именно текущее время?
Никак.
P>>·>У тебя появляются "дешевые", но бесполезные ю-тесты, т.к. и-тесты всё равно нужны, практически в том же количестве. P>>В том то и дело, что тесты как раз полезные. А количество интеграционных зависит от апи и сценариев. ·>В чём полезность? В том, что посыпаться могут от малейших изменений?
У вас причин для изменения гораздо больше — любое измение дизайна означает поломку ваших тестов на моках.
P>>·>Ну я не знаю что именно показать. Ну допустим хотим nextFriday() потестировать: P>>Вот и сравните разницу
var testSubject = new CalendarLogic();
assertThat(testSubject.nextFriday(Samples.nextFriday.case1.in)).equalTo(Samples.nextFriday.case1.result);
assertThat(testSubject.nextFriday(Samples.nextFriday.case2.in)).equalTo(Samples.nextFriday.case2.result);
assertThat(testSubject.nextFriday(Samples.nextFriday.case3.in)).equalTo(Samples.nextFriday.case3.result);
P>>В вашем случае точно так же нужно предусмотреть все кейсы, только у вас будет везде на 5 строчек больше ·>Каких ещё пять строчек? Разница пока в одной строчке, на все тесты, не надо mock(InstantSource.class) делать. Если ты не понял, у меня было три различных тестовых сценария, для трёх разных now, у тебя — один.
ок — на 4.
P>>Ну да, вы только и думаете в терминах моков ·>Опять фантазии.
Смотрите выше — я вас просил хороший вариант тестирования кода с hmac. Вы во второй раз показали моки, хотя и сами пишете, что так делать не надо.
Похоже, что "как надо" у вас там не прописано
P>>Расскажите, как вы вашими косвенными тестами дадите гарантию, что на проде никогда не случится ситуация, что запрос выродится в select * from users и у нас будут сотни тысяч записей вгружаться разом. P>>Подробнее пожалуйста. ·>Начни с себя, как ты с вашими супер-тестами дадите гарантию.
И не собираюсь — data complexity решается совсем другими инструментами. Количество перестановок в фильтрах спокойно может исчисляться чудовищным количеством кейсов. Если некто поправит запрос, и забудет нагенерерить сотню другую данных — приплыли.
т.е. вы снова притягиваете решение которое зависит от человеческого фактора
P>>Это вероятно вы тестируете чтото копируя чтото с прода. А я тестирую построение запроса, например, те самые фильтры. И логики в методе довольно много, т.к. в зависимости от разных фильтров у нас могут быть разные вещи. ·>Как ты тестируешь что построенный запрос хотя бы синтаксически корректен?
тот самый интеграционный тест, на некорретном запросе он упадет
P>>По ссылке. ·>По ссылке куда? Неужели fn1/fn2 — публично выставленные внутренности? И как тогда ты будешь знать, что нужно именно fn2, а не fn3?
а как вы знаете, синус нуля это 0 ? fn1 и fn2 должны быть видны в тестах, а не публично
P>>Непросто код а в т.ч. и построение запроса к орм или бд. ·>Не знаю что за такой "непросто код". Код он и в африке код. Чем код построения запроса принципиально отличается от другого кода?
Тем, что у вас в тестовой бд может не оказаться тех самых значений, которые ломают один из сотен-тысяч кейсов
P>>Что вы так думаете — это я помню. Вы никак не расскажете, как побороть data complexity, т.е. как убедиться что ваш запрос не выдаст какой нибудь вырожденный кейс и вгрузит всё. ·>Выполнить и заасертить, что было вружено то, что ожидается, а не всё.
Для этого вам надо перебрать все возможные сочетания фильтров -> здесь счет тестов идет на десятки тысяч по скромной оценке
·>На вопрос "Как это можно знать, что запрос "тот"?" ты так и не ответил.
Выборочные тесты. Поскольку я знаю, как строятся фильтры, мне нужно убедиться, что они таки вызываются. И не надо проверять всё перестановки.
P>>·>Ок... ну может для сортировки и пагинации может понадобиться чуть больше одного значения. P>>У вас здесь та самая data complexity. Вам нужно обосновать внятно, почему ваш фильтр никогда не вернет пустое выражение, и запрос не выродится в "вгрузить всё" ·>А почему ваш не выродится?
Например, на это тест написан, который гарантирует, что никакой ввод не дает пустой комбинации.
P>>Кроме того, если фильтров много, то количество данных будет расти экспоненциально. ·>Почему данных-то? Просто разные фильтры для тех же данных.
И вы уверены, что в тестовой бд всегда будет полный фарш? Вы что, один работаете?
P>>Я нашел только тот вариант, где вы мокаете hmac. У вас есть что лучше? ·>Так говорил же — ну не мокать hmac, неясно зачем его вообще мокать. Тесты от этого медленнее не становятся.
Вы так и не показали, как надо тестировать, как дать гарантии что hmac той системы
P>>Здесь тесты не дают полного контроля над ситуацией. Нам нужно спроектировать запрос и доказать его корректность, а построение фильтров итд покрыть юнит-тестами. ·>Противоречивые параграфы детектед.
Противоречие у вас в голове. Сказано — полного контроля не дают.
·>Как доказывать корректность запроса?
Да как обычно это делается с алгоритмами.
P>>Нет, не делает. И тестов становится меньше. Аудит пишется снаружи как надо — это в любом случае задача интеграционного теста, что у нас всё в сборе поддерживает аудит ·>Мест снаружи — больше, чем одно место внутри. И каждое место снаружи надо покрывать отдельным тестом. А для одного места внутри будет один тест.
Вы себя превзошли — по вашему, если все сунуть в один main, понадобится ровно один тест
P>>Чото конкретно вас смущает? ·>Слишком долго.
Откуда у вас знание "слишком" или "не слишком" ? Вы даже не в курсе, что за проект, но делаете какие то суждения. Для того проекта — нет, не слишком.
P>>Вы из какого века пишете? Если по аннотациям можно получить клиентский код, серверный, да еще и тесты с документацией, то почему нельзя для rust это проделать? ·>Можно. Но придётся и все эти аннотации как-то переписывать.
Переписывать то зачем? Чем они вам мешают?
P>>Смена стека технологий встречается куда реже, чем смена бд или изменения в апи. P>>Вы бы еще метеориты вспомнили ·>Смотря как долго проект живёт.
Чем дольше, тем меньше шансов на переписывание, проще заново напилить новое.
. P>Именно здесь вы и демонстрируете чудеса моков — все прибито гвоздями к "как написано". А значит, если вместо crypto взяли другую эквивалентную либу — тесты насмарку P>И вы видите в этом какой то бенефит.
Бенефит не вижу, я сразу это заявил. Я просто увидел, что твой код с моками был как писать не надо. Я показал как надо писать код с моками.
>> Твои "{...toFields}" — тоже лишний код, и это всё прод-код.". Ты только от первого открестился, а на вторые два сделал вид, что их не было. P>{...toFields} экономит вам десяток другой методов и тестов для них. Если у вас нет такого метода, вам придется или по месту колбасить код, намного больше, или создавать все возможные методы для конверсии.
Не экономит. Конкретные типы и конструкторы с ними соответствуют конкретным арифметическим операциям с календарём. Твоё toFields — какое-то месиво, неясно о чём и чревато багами. Скажем, если у тебя тип time окажется какого-то не того типа, то эта твоя ... начнёт давать странное месиво с неясным результатом из=за перекрытия одноимённых полей. Не надо так делать.
P>>>Я примерно так и имел ввиду. P>·>Почему тогда под "каждый тест" или "всех кейсов"? P>Потому, что одного теста на моках, как вы показываете, недостаточно. Вам придется вместо таблицы инстинности приседать с моками.
Недостаточно для чего? Почему недостаточно? Причём тут таблица истинности?
P>·>Тебе ровно то же надо, там где есть зависимость от now, будешь его передавать как парам. Разница лишь в том, что я буду передавать не через парам, а через мок. P>Вы уже показали — кода в тестах в вашем исполнении больше.
Больше, т.к. код делает больше.
P>·>Верно, у вас интеграционные должны быть для всех сценариев, т.е. дохрена. А у меня интеграционных — гораздо меньше. Т.к. интеграционные тесты тестируют интеграцию компонент, а не сценарии. Компоненты, как правило, отвечают сразу за группу сценариев. P>У вас какая то мешанина — интерграционные это все что выше юнитов. Сценарии — это на самом верху, уровень приложения или всей системы. Не ясно, за счет чего у вас будет меньше интеграционных — похоже, вы верите, что моки здесь чего то решают.
Меньше интеграционных за счёт того, что они тестируют интеграцию. А не всю копипасту, которую ты предлагаешь плодить.
P>>>Сравнение логов только там, где вы это используете. P>·>Эээ. "Это" что? Логи, обычно, используются везде. P>Это ж не значит, что и применять данных подход нужно везде. В некоторых интеграционных тестах, которых обычно немного.
Как немного? Ты пишешь по интеграционному тесту для каждого do_logic. Т.к. именно там происходит склейка.
P>>>А чем deep equals не угодил я без понятия P>·>Тем, что он сравнивает очень много. А не то, что конкретно тест тестирует. P>deep equals проверяет значение, всё разом, если у вас чтото больше чем инт или строка
Я знаю. И это плохо, особенно для юнит-тестов.
P>>>Не совсем понятно, почему этот типичный рефакторинг должен ломать тесты. Вы в этом видите какуюто пользу, но никак не расскажете, что за она P>·>Почему ломать? Вот был у тебя nextFriday(now), и вдруг теперь ты это меняешь на nextFriday(now, tz) — у тебя весь код как-то магически будет работать как раньше? Не верю. P>Поломаются тесты не там, где вы обмокали, а ровно по месту — меняется таблица истинности функции
Так функция может использоваться из множества мест.
P>В вашем случае далеко не факт, что найдете в моках все нужные места, и сделаете что бы соответствовало
Какие места? Зачем их искать?
P>>>Непонятно, что за проблему хотите решить этим дополнительным тестом. Перепроверить, что юнит-тест таки валидный? P>·>Что юнит тест тестит не "как написано в коде", а некое реально возможное ожидание P>Тест проверяет построение запроса. Построение запроса зависит от многих параметров — вот это связывание надо как то проверить. P>Косвенные проверки, как вы любите, работают в простых кейсах типа key-value P>Если у вас будет подсчет статистики, вы вспотеете покрывать тестами "из базы"
Ты потерял контекст. Тут шла речь о ю-тест упоминал "а что если в колонке пусто". В колонке, внезапно окажется, будет не пусто а дефолтное значение из бд. Багу такую поймаешь только на проде, т.к. и-тесты для таких подробных мелочей явно писать не будешь.
Я эту багу поймаю на и-тесте repo+dbms — пытаясь воспроизвести пустую колонку.
P>>>Количество тестов будет одинаковым. Только вам нужно будет везде указывать свой мок. Вы почему то верите, что моки избавляют от интеграционных. Это разные вещи. Интеграционный тест проверяет 1) что сама склейка валидная, а не 2) способность к ней. Моки проверяют второе, а нам надо — первое. P>·>Не моки избавляют, а дизайн. Если ты себя заставил использовать nextFriday(now), то у тебя будет куча мест склейки, которые теперь _приходится_ тестировать дополнительными тестами. P>Не дополнительными, а теми же самыми интеграционными, что есть и у вас. Интеграционные тесты не пишутся на все вещи вида "проверим что где то внутре передается параметр". Если такое критично — выносится в юниты.
Ты не в тему споришь. Ты заявил "Интеграционный тест проверяет 1) что сама склейка валидная". Мест склейки now и nextFriday(now) у тебя будет полно. У меня такое место — одно. Какие такие "внутре передается параметр" ты имеешь в виду — я понятия не имею.
P>Если у нас код контролера линейный, а в моем случае это именно так, то нам нужен ровно один интеграционный тест, который нужен и вам
_Такой_ интеграционный тест мне не нужен. Я могу обойтись одним ю-тестом с моком о том, что nextFriday() действительно возвращает правильные даты для разных моментов времени. И ещё соответсвующими ю-тестами в местах использования nextFriday(), там можно моком просто возвращать хоть семь пятниц на неделе.
P>·>Так как именно ты собираешься в "curl" и-тестах ассертить, что туда передаётся именно текущее время? P>Никак.
Именно. Т.е. усложняешь прод-код, теряешь возможность протестировать и ловишь баги в проде. Нам такого не надо.
P>>>В том то и дело, что тесты как раз полезные. А количество интеграционных зависит от апи и сценариев. P>·>В чём полезность? В том, что посыпаться могут от малейших изменений? P>У вас причин для изменения гораздо больше — любое измение дизайна означает поломку ваших тестов на моках.
Это страшилки.
P>>>·>Ну я не знаю что именно показать. Ну допустим хотим nextFriday() потестировать: P>>>Вот и сравните разницу P>
P> var testSubject = new CalendarLogic();
P> assertThat(testSubject.nextFriday(Samples.nextFriday.case1.in)).equalTo(Samples.nextFriday.case1.result);
P> assertThat(testSubject.nextFriday(Samples.nextFriday.case2.in)).equalTo(Samples.nextFriday.case2.result);
P> assertThat(testSubject.nextFriday(Samples.nextFriday.case3.in)).equalTo(Samples.nextFriday.case3.result);
P>
Мде. Если хочешь строчки считать по честному, показывай изменения в прод коде и тест на каждый вызов nextFriday.
P>>>В вашем случае точно так же нужно предусмотреть все кейсы, только у вас будет везде на 5 строчек больше P>·>Каких ещё пять строчек? Разница пока в одной строчке, на все тесты, не надо mock(InstantSource.class) делать. Если ты не понял, у меня было три различных тестовых сценария, для трёх разных now, у тебя — один. P>ок — на 4.
Я тоже так умею:
var clock = mock(InstantSource.class);
var testSubject = new CalendarLogic(clock);
when(clock.instant()).thenReturn(Instant.of("2023-12-28T12:27:00Z"));assertThat(testSubject.nextFriday()).equalTo(LocalDate.of("2023-12-29"));
when(clock.instant()).thenReturn(Instant.of("2023-12-29T23:59:59Z"));assertThat(testSubject.nextFriday()).equalTo(LocalDate.of("2023-12-29"));
when(clock.instant()).thenReturn(Instant.of("2023-12-30T00:00:00Z"));assertThat(testSubject.nextFriday()).equalTo(LocalDate.of("2024-01-05"));
Сейчас начнёшь символы считать, да?
P>>>Ну да, вы только и думаете в терминах моков P>·>Опять фантазии. P>Смотрите выше — я вас просил хороший вариант тестирования кода с hmac. Вы во второй раз показали моки, хотя и сами пишете, что так делать не надо.
А что там хочешь увидеть, я не понял. Для каждого теста hmac будет известным и фиксированным. Ассертишь по значению, да и всё.
P>>>Расскажите, как вы вашими косвенными тестами дадите гарантию, что на проде никогда не случится ситуация, что запрос выродится в select * from users и у нас будут сотни тысяч записей вгружаться разом. P>>>Подробнее пожалуйста. P>·>Начни с себя, как ты с вашими супер-тестами дадите гарантию. P>И не собираюсь — data complexity решается совсем другими инструментами. Количество перестановок в фильтрах спокойно может исчисляться чудовищным количеством кейсов. Если некто поправит запрос, и забудет нагенерерить сотню другую данных — приплыли.
Именно. Так что неясно зачем ты делаешь эти предъявы о гарантиях. У тебя аргументация вида "Раз ваш подход не умеет кофе варить и тапочки приносить — значит это плохо и надо делать как фаулер завещал".
P>т.е. вы снова притягиваете решение которое зависит от человеческого фактора
А у тебя есть решение независящее от человеческого фактора?
P>>>Это вероятно вы тестируете чтото копируя чтото с прода. А я тестирую построение запроса, например, те самые фильтры. И логики в методе довольно много, т.к. в зависимости от разных фильтров у нас могут быть разные вещи. P>·>Как ты тестируешь что построенный запрос хотя бы синтаксически корректен? P>тот самый интеграционный тест, на некорретном запросе он упадет
Т.е. у тебя интеграционные тесты будет тестировать всё "чудовищное количество кейсов"? Накой тогда ю-тесты?
P>>>По ссылке. P>·>По ссылке куда? Неужели fn1/fn2 — публично выставленные внутренности? И как тогда ты будешь знать, что нужно именно fn2, а не fn3? P>а как вы знаете, синус нуля это 0 ?
Я это знаю из тригонометрии, от моего кода не зависящей. А вот то, что fn2 — правильно, а fn3 — неправильно ты знаешь только из "как в коде написано". Т.е. твой код тестирует самого себя, порочный круг называется.
P>fn1 и fn2 должны быть видны в тестах, а не публично
А тесты должны, по уму, тестировать публичный контракт. @VisibleForTesting — это очень хороший сигнал code smells.
P>>>Непросто код а в т.ч. и построение запроса к орм или бд. P>·>Не знаю что за такой "непросто код". Код он и в африке код. Чем код построения запроса принципиально отличается от другого кода? P>Тем, что у вас в тестовой бд может не оказаться тех самых значений, которые ломают один из сотен-тысяч кейсов
И у вас в тестах может не оказаться тех самых значений для построения того самого ломающего запроса. Опять "тапочки не приносит"?
P>>>Что вы так думаете — это я помню. Вы никак не расскажете, как побороть data complexity, т.е. как убедиться что ваш запрос не выдаст какой нибудь вырожденный кейс и вгрузит всё. P>·>Выполнить и заасертить, что было вружено то, что ожидается, а не всё. P>Для этого вам надо перебрать все возможные сочетания фильтров -> здесь счет тестов идет на десятки тысяч по скромной оценке
Нам — не надо.
Кстати, 10 значений в базе это тебе уже есть где разгуляться, более трёх миллионов комбинаций. Не нужно никаких тысяч значений в таких тестах.
P>·>На вопрос "Как это можно знать, что запрос "тот"?" ты так и не ответил. P>Выборочные тесты. Поскольку я знаю, как строятся фильтры, мне нужно убедиться, что они таки вызываются. И не надо проверять всё перестановки.
Ага. Именно то самое whitebox, котором ты ещё недавно меня попрекал.
P>>>·>Ок... ну может для сортировки и пагинации может понадобиться чуть больше одного значения. P>>>У вас здесь та самая data complexity. Вам нужно обосновать внятно, почему ваш фильтр никогда не вернет пустое выражение, и запрос не выродится в "вгрузить всё" P>·>А почему ваш не выродится? P>Например, на это тест написан, который гарантирует, что никакой ввод не дает пустой комбинации.
Ух ты. У тебя что-то тест гарантирует. Поздравляю.
P>>>Кроме того, если фильтров много, то количество данных будет расти экспоненциально. P>·>Почему данных-то? Просто разные фильтры для тех же данных. P>И вы уверены, что в тестовой бд всегда будет полный фарш? Вы что, один работаете?
"Тапочки не приносит".
P>>>Я нашел только тот вариант, где вы мокаете hmac. У вас есть что лучше? P>·>Так говорил же — ну не мокать hmac, неясно зачем его вообще мокать. Тесты от этого медленнее не становятся. P>Вы так и не показали, как надо тестировать, как дать гарантии что hmac той системы
Я не знаю что такое "hmac той системы" и как давать гарантии тестами.
P>>>Здесь тесты не дают полного контроля над ситуацией. Нам нужно спроектировать запрос и доказать его корректность, а построение фильтров итд покрыть юнит-тестами. P>·>Противоречивые параграфы детектед. P>Противоречие у вас в голове. Сказано — полного контроля не дают.
Именно. Зачем же тогда покрыть юнит-тестами?
P>·>Как доказывать корректность запроса? P>Да как обычно это делается с алгоритмами.
И что мешает это же делать в repo+dbms?
P>>>Нет, не делает. И тестов становится меньше. Аудит пишется снаружи как надо — это в любом случае задача интеграционного теста, что у нас всё в сборе поддерживает аудит P>·>Мест снаружи — больше, чем одно место внутри. И каждое место снаружи надо покрывать отдельным тестом. А для одного места внутри будет один тест. P>Вы себя превзошли — по вашему, если все сунуть в один main, понадобится ровно один тест
Нет. Ты что-то не так прочитал. Перечитай что я написал. Под местом я понимал call site. У меня один call site, который склеивает календарную логику с текущим временем и потом во всех call site пишется просто nextFriday(). У тебя таких мест склейки будет в call site каждого nextFriday(now). ЧПФ, помнишь?
P>>>Чото конкретно вас смущает? P>·>Слишком долго. P>Откуда у вас знание "слишком" или "не слишком" ? Вы даже не в курсе, что за проект, но делаете какие то суждения. Для того проекта — нет, не слишком.
Это значит, что изменение в коде занимает как минимум день для выкатки в прод. Значит глобально архитектура выбрана плохо. Возможно надо резать на независимые компоненты.
P>>>Вы из какого века пишете? Если по аннотациям можно получить клиентский код, серверный, да еще и тесты с документацией, то почему нельзя для rust это проделать? P>·>Можно. Но придётся и все эти аннотации как-то переписывать. P>Переписывать то зачем? Чем они вам мешают?
Тем, что они написаны на конкретном ЯП.
P>>>Смена стека технологий встречается куда реже, чем смена бд или изменения в апи. P>>>Вы бы еще метеориты вспомнили P>·>Смотря как долго проект живёт. P>Чем дольше, тем меньше шансов на переписывание, проще заново напилить новое.
Но при сохранении контракта, который у вас описан на аннотациях конкретного ЯП. В общем гугли ликбез, например, тут https://swagger.io/blog/code-first-vs-design-first-api/
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
>>> Твои "{...toFields}" — тоже лишний код, и это всё прод-код.". Ты только от первого открестился, а на вторые два сделал вид, что их не было. P>>{...toFields} экономит вам десяток другой методов и тестов для них. Если у вас нет такого метода, вам придется или по месту колбасить код, намного больше, или создавать все возможные методы для конверсии. ·>Не экономит. Конкретные типы и конструкторы с ними соответствуют конкретным арифметическим операциям с календарём. Твоё toFields — какое-то месиво, неясно о чём и чревато багами. Скажем, если у тебя тип time окажется какого-то не того типа, то эта твоя ... начнёт давать странное месиво с неясным результатом из=за перекрытия одноимённых полей. Не надо так делать.
Ваша альтернатива — понасоздавать вагон методов для конверсии "всё во всё" что дает вагон кода и вагон тестов. Или же вместо однострочной конверсии у вас будет несколько строчек кода точно так же без полного контроля.
P>>Потому, что одного теста на моках, как вы показываете, недостаточно. Вам придется вместо таблицы инстинности приседать с моками. ·>Недостаточно для чего? Почему недостаточно? Причём тут таблица истинности?
Логику, вычисления мы тестируем по таблице истинности. И чем меньше дополнительного кода сверх этой таблицы истинности, тем лучше. А вам надо все поразмазывать по мокам
P>>Вы уже показали — кода в тестах в вашем исполнении больше. ·>Больше, т.к. код делает больше.
Функционально — ровно столько же.
P>>У вас какая то мешанина — интерграционные это все что выше юнитов. Сценарии — это на самом верху, уровень приложения или всей системы. Не ясно, за счет чего у вас будет меньше интеграционных — похоже, вы верите, что моки здесь чего то решают. ·>Меньше интеграционных за счёт того, что они тестируют интеграцию. А не всю копипасту, которую ты предлагаешь плодить.
Моки не тестируют интеграцию. Моком вы можете проверить, а что будет, если подкинуть ту или иную зависимость. А нам надо совсем другое — готовый компонент работает как нам надо.
Это разные вещи и вы продолжаете путать.
Количество интеграционных тестов моки уменьшить никак не могут. Моки — это фактически понижение уровня тестирования за счет обрезания зависимостей. Нам же надо не понижение, а повышение.
P>>Это ж не значит, что и применять данных подход нужно везде. В некоторых интеграционных тестах, которых обычно немного. ·>Как немного? Ты пишешь по интеграционному тесту для каждого do_logic. Т.к. именно там происходит склейка.
Есть метод — его нужно вызвать в тестах. И у вас будет ровно то же. Просто вас тянет тестировать код, а не ожидания вызывающей стороны.
Склейка или нет дело десятое — вызывающая сторона никаких ожиданий на этот счет не имеет, ей про это неизвестно.
Проверка конкретной склейки — это вайтбокс, тест "как написано", классика тавтологии.
Вместо проверки конкретной склейки делаем интеграционный код линейным, буквально, а интеграцию осуществляем на самом верху.
P>>deep equals проверяет значение, всё разом, если у вас чтото больше чем инт или строка ·>Я знаю. И это плохо, особенно для юнит-тестов.
Простите, вы мапперы из одной структуры в другую как тестировать собираетесь? А парсинг? А как вы проверите, что ваш репозиторий на конкретный запрос вернет ту самую структуру? Например, нам нужен order + order items + customer + delivery + billing
Как вы собираетесь протестировать результат?
P>>Поломаются тесты не там, где вы обмокали, а ровно по месту — меняется таблица истинности функции ·>Так функция может использоваться из множества мест.
Пусть используется. Что вас смущает ?
P>>В вашем случае далеко не факт, что найдете в моках все нужные места, и сделаете что бы соответствовало ·>Какие места? Зачем их искать?
Читайте себя "Так функция может использоваться из множества мест."
У вас в тех самых тестах все будет обмокано. Как узнаете, что там, в моках, должно вызываться не "то", а "это"?
P>>Если у вас будет подсчет статистики, вы вспотеете покрывать тестами "из базы" ·>Ты потерял контекст. Тут шла речь о ю-тест упоминал "а что если в колонке пусто". В колонке, внезапно окажется, будет не пусто а дефолтное значение из бд. Багу такую поймаешь только на проде, т.к. и-тесты для таких подробных мелочей явно писать не будешь.
Наоборот — именно для таких мелочей юнит-тесты и нужны.
·>Я эту багу поймаю на и-тесте repo+dbms — пытаясь воспроизвести пустую колонку.
Вы пытаетесь таблицу истинности запихать куда подальше, в данном случае в бд. А она должна быть прямо рядом с тестом как можно ближе к коду.
Что там будет с бд, когда другой девелопер чего нибудь фиксанет — а хрен его знает.
А если таблица истинности рядом с тестами и тестируемой функцией, шансов намного больше что проблему заметят еще во время код ревью.
P>>Не дополнительными, а теми же самыми интеграционными, что есть и у вас. Интеграционные тесты не пишутся на все вещи вида "проверим что где то внутре передается параметр". Если такое критично — выносится в юниты. ·>Ты не в тему споришь. Ты заявил "Интеграционный тест проверяет 1) что сама склейка валидная". Мест склейки now и nextFriday(now) у тебя будет полно. У меня такое место — одно.
Интеграционный тест проверяет всю интеграцию разом, а вас тянет проверить каждую строчку. Каждая строчка — это про юнит-тестирование.
P>>Если у нас код контролера линейный, а в моем случае это именно так, то нам нужен ровно один интеграционный тест, который нужен и вам ·>_Такой_ интеграционный тест мне не нужен. Я могу обойтись одним ю-тестом с моком о том, что nextFriday() действительно возвращает правильные даты для разных моментов времени. И ещё соответсвующими ю-тестами в местах использования nextFriday(), там можно моком просто возвращать хоть семь пятниц на неделе.
Какой такой? Вам всё равно нужен интеграционный тест. Задачи интеграционных тестов не каждую склейку проверять по отдельности, а проверять работает ли компонент собраный целиком. Что там унутре — для интеграционного тестирования по барабану — нужная функция работает, значит всё хорошо.
P>>Никак. ·>Именно. Т.е. усложняешь прод-код, теряешь возможность протестировать и ловишь баги в проде. Нам такого не надо.
Забавная телепатия.
P>>У вас причин для изменения гораздо больше — любое измение дизайна означает поломку ваших тестов на моках. ·>Это страшилки.
Это следует из ваших примеров.
·>Мде. Если хочешь строчки считать по честному, показывай изменения в прод коде и тест на каждый вызов nextFriday.
Тест на каждый вызов это классика тавтологичного тестирования
P>>ок — на 4. ·>Я тоже так умею: ·>
Обычное правило — 1 инструкция на строку. Вы втюхали минимум две. А поскольку у вас значения захардкожены, то между разными тестами согласованность никак не проверяется, т.к. везде хардкодите значения.
P>>Смотрите выше — я вас просил хороший вариант тестирования кода с hmac. Вы во второй раз показали моки, хотя и сами пишете, что так делать не надо. ·>А что там хочешь увидеть, я не понял. Для каждого теста hmac будет известным и фиксированным. Ассертишь по значению, да и всё.
Ну ок.
P>>И не собираюсь — data complexity решается совсем другими инструментами. Количество перестановок в фильтрах спокойно может исчисляться чудовищным количеством кейсов. Если некто поправит запрос, и забудет нагенерерить сотню другую данных — приплыли. ·>Именно. Так что неясно зачем ты делаешь эти предъявы о гарантиях. У тебя аргументация вида "Раз ваш подход не умеет кофе варить и тапочки приносить — значит это плохо и надо делать как фаулер завещал".
Вы забыли, что именно вы претендуете что решите это всё тестами.
P>>т.е. вы снова притягиваете решение которое зависит от человеческого фактора ·>А у тебя есть решение независящее от человеческого фактора?
Его можно ограничить контролируя построение запроса + таблицу истинности храним не абы где, а рядом. Вы же все хотите таблицу истинности или размазать, или запихать куда подальше.
P>>тот самый интеграционный тест, на некорретном запросе он упадет ·>Т.е. у тебя интеграционные тесты будет тестировать всё "чудовищное количество кейсов"? Накой тогда ю-тесты?
Интеграционные тесты не проверяют варианты склейки — они проверяют функционирование в сборе. Юнит-тесты проверяют работоспособность примитивов.
·>Я это знаю из тригонометрии, от моего кода не зависящей. А вот то, что fn2 — правильно, а fn3 — неправильно ты знаешь только из "как в коде написано". Т.е. твой код тестирует самого себя, порочный круг
называется.
Не из кода, а из требований вызывающей стороны.
P>>fn1 и fn2 должны быть видны в тестах, а не публично ·>А тесты должны, по уму, тестировать публичный контракт. @VisibleForTesting — это очень хороший сигнал code smells.
Это ваша фантазия — эдак у вас юнит-тесты станут code smell, тк они принципиально по своей сути видят слишком много.
P>>Тем, что у вас в тестовой бд может не оказаться тех самых значений, которые ломают один из сотен-тысяч кейсов ·>И у вас в тестах может не оказаться тех самых значений для построения того самого ломающего запроса. Опять "тапочки не приносит"?
В моем случае таблица истинности рядом с тестом и функцией. Вы же ее пихаете куда подальше — прямо в бд.
Скажите честно — у вас есть требование по процессу во время код ревью обязательно смотреть содержимое тестовой бд? Те самые десятки-сотни-тысячи записей
P>>Для этого вам надо перебрать все возможные сочетания фильтров -> здесь счет тестов идет на десятки тысяч по скромной оценке ·>Нам — не надо.
Вероятно, это особенность вашего проекта. Любая более-менее внятная статистика-аналитика по бд это довольно сложные алгоритмы, и здесь нужно чтото лучше, чем смотреть в бд и думать, что же должно быть на выходе.
P>>Выборочные тесты. Поскольку я знаю, как строятся фильтры, мне нужно убедиться, что они таки вызываются. И не надо проверять всё перестановки. ·>Ага. Именно то самое whitebox, котором ты ещё недавно меня попрекал.
Раскройте глаза — здесь блекбокс. Выборочно вызываем бд нашим кодом, проверяется весь пайплайн в сборе, косвенно. Только нам не надо проверять всё на свете таким образом, т.к. есть и другие инструменты.
P>>И вы уверены, что в тестовой бд всегда будет полный фарш? Вы что, один работаете? ·>"Тапочки не приносит".
Вы никак не можете объяснить преимущества размазывания таблицы истинности по тестами и бд, чем это лучше хранения таблицы истинности рядом с кодом и функцией с тестом.
P>>Противоречие у вас в голове. Сказано — полного контроля не дают. ·>Именно. Зачем же тогда покрыть юнит-тестами?
—
Затем, что доказательство корректности — это необходимое условие. А такое доказательство + тесты + код ревью, необходимое и достаточное.
P>>·>Как доказывать корректность запроса? P>>Да как обычно это делается с алгоритмами. ·>И что мешает это же делать в repo+dbms?
Вы же сами говорите,что про это не думаете, верите только в результаты. Вот вы и нашли, кто мешает.
P>>Откуда у вас знание "слишком" или "не слишком" ? Вы даже не в курсе, что за проект, но делаете какие то суждения. Для того проекта — нет, не слишком. ·>Это значит, что изменение в коде занимает как минимум день для выкатки в прод. Значит глобально архитектура выбрана плохо. Возможно надо резать на независимые компоненты.
Нет, не значит.
Вы не в курсе, ни что за проект, ни какие требования, итд. Далеко не все проекты могут протаскивать изменения в прод прям сразу.
Во вторых, я вам сказал, что это полная сборка, все платформы, всё-всё-всё. Кто вам сказал, что нет сборки отдельных модулей?
И так у вас всё — вместо вопросов занимаетесь телепатией.
P>>Переписывать то зачем? Чем они вам мешают? ·>Тем, что они написаны на конкретном ЯП.
Я ж сказал — если по аннотации можно сгенерировать 4 артефакта, то почему нельзя сгенерировать 5й, 6й, 7й?
Вы же видите только переписывание
P>>·>Смотря как долго проект живёт. P>>Чем дольше, тем меньше шансов на переписывание, проще заново напилить новое. ·>Но при сохранении контракта, который у вас описан на аннотациях конкретного ЯП. В общем гугли ликбез, например, тут https://swagger.io/blog/code-first-vs-design-first-api/
Вы путаете code-first и design-first. design first — означает, что первое деливери это апи, а не реализация. code-first — наоборот. А какой файл вы в начале редактируете, json или java и yaml, дело десяток
Я ж сразу сказал — апи уже есть, а реализации нету, зато можно и тесты писать, и клиентский код, и документацию прикручивать
Здравствуйте, Pauel, Вы писали:
P>·>Не экономит. Конкретные типы и конструкторы с ними соответствуют конкретным арифметическим операциям с календарём. Твоё toFields — какое-то месиво, неясно о чём и чревато багами. Скажем, если у тебя тип time окажется какого-то не того типа, то эта твоя ... начнёт давать странное месиво с неясным результатом из=за перекрытия одноимённых полей. Не надо так делать. P>Ваша альтернатива — понасоздавать вагон методов для конверсии "всё во всё" что дает вагон кода и вагон тестов. Или же вместо однострочной конверсии у вас будет несколько строчек кода точно так же без полного контроля.
Моя альтернатива аккуратно реализовать реальную модель календаря с аккуратной арифметикой различных типов. Конверсия "всё во всё" — это полное непонимание предметной области.
P>·>Недостаточно для чего? Почему недостаточно? Причём тут таблица истинности? P>Логику, вычисления мы тестируем по таблице истинности. И чем меньше дополнительного кода сверх этой таблицы истинности, тем лучше. А вам надо все поразмазывать по мокам
Ну тестируй. Моки тебе ничем не мешают.
P>>>Вы уже показали — кода в тестах в вашем исполнении больше. P>·>Больше, т.к. код делает больше. P>Функционально — ровно столько же.
Нет. Он у меня ещё и содержит склейку. У тебя склейки нет.
P>>>У вас какая то мешанина — интерграционные это все что выше юнитов. Сценарии — это на самом верху, уровень приложения или всей системы. Не ясно, за счет чего у вас будет меньше интеграционных — похоже, вы верите, что моки здесь чего то решают. P>·>Меньше интеграционных за счёт того, что они тестируют интеграцию. А не всю копипасту, которую ты предлагаешь плодить. P>Моки не тестируют интеграцию. Моком вы можете проверить, а что будет, если подкинуть ту или иную зависимость. А нам надо совсем другое — готовый компонент работает как нам надо.
Ты читать умеешь? Ты где увидел в моём предложении выше слово "моки"? Хинт: моки вообще ничего не тестируют. Тесты — тестируют.
P>Количество интеграционных тестов моки уменьшить никак не могут. Моки — это фактически понижение уровня тестирования за счет обрезания зависимостей. Нам же надо не понижение, а повышение.
Могут, т.к. большинство логики тестируется ю-тестами. А и-тесты нужны только чтобы тестировать интеграцию уже протестированных компонент.
P>>>Это ж не значит, что и применять данных подход нужно везде. В некоторых интеграционных тестах, которых обычно немного. P>·>Как немного? Ты пишешь по интеграционному тесту для каждого do_logic. Т.к. именно там происходит склейка. P>Есть метод — его нужно вызвать в тестах. И у вас будет ровно то же. Просто вас тянет тестировать код, а не ожидания вызывающей стороны.
У меня такого метода просто не будет. Следовательно и тестов писать просто не для чего.
P>Склейка или нет дело десятое — вызывающая сторона никаких ожиданий на этот счет не имеет, ей про это неизвестно. P>Проверка конкретной склейки — это вайтбокс, тест "как написано", классика тавтологии. P>Вместо проверки конкретной склейки делаем интеграционный код линейным, буквально, а интеграцию осуществляем на самом верху.
Чем выше, тем больше мест. Функция nextFriday() осуществляет склейку у себя внутри. И покрывается одним тестом. У тебя будет nextFriday(now) — и на самом верху будет множество call site для этого накопипастено. Код линейный, да, но накопипастен в кучу мест.
P>>>deep equals проверяет значение, всё разом, если у вас чтото больше чем инт или строка P>·>Я знаю. И это плохо, особенно для юнит-тестов. P>Простите, вы мапперы из одной структуры в другую как тестировать собираетесь?
В ю-тестах — по частям. Иначе изменение логики маппинга одного поля сломает все deep.equal тесты, где это поле есть.
P>>>Поломаются тесты не там, где вы обмокали, а ровно по месту — меняется таблица истинности функции P>·>Так функция может использоваться из множества мест. P>Пусть используется. Что вас смущает ?
Что в каждое из этих мест тебе понадобится копипастить склейку nextFriday(now) с источником текущего времени и покрывать это ещё одним тестом. Хотя, как я понял, ты вообще заявил, что такое протестировать ты просто не сможешь.
Ещё раз. nextFriday() ≡ nextFriday(now) ∘ timeSource.now(). Если ты отказываешься использовать в call site готовый и протестированный nextFriday(), значит тебе в каждый call site придётся протаскивать timeSource и копипастить композицию с nextFriday(now). Это увеличивает кол-во прод-кода и требует больше более тяжеловесных тестов для покрытия всей копипасты.
P>>>В вашем случае далеко не факт, что найдете в моках все нужные места, и сделаете что бы соответствовало P>·>Какие места? Зачем их искать? P>Читайте себя "Так функция может использоваться из множества мест."
И?
P>У вас в тех самых тестах все будет обмокано. Как узнаете, что там, в моках, должно вызываться не "то", а "это"?
Эээ.. Ты рефакторингом точно умеешь пользоваться? Компилятор и IDE всё покажет, подскажет и подправит.
P>>>Если у вас будет подсчет статистики, вы вспотеете покрывать тестами "из базы" P>·>Ты потерял контекст. Тут шла речь о ю-тест упоминал "а что если в колонке пусто". В колонке, внезапно окажется, будет не пусто а дефолтное значение из бд. Багу такую поймаешь только на проде, т.к. и-тесты для таких подробных мелочей явно писать не будешь. P>Наоборот — именно для таких мелочей юнит-тесты и нужны.
Ты не читаешь, что тебе пишут.
P>·>Я эту багу поймаю на и-тесте repo+dbms — пытаясь воспроизвести пустую колонку. P>Вы пытаетесь таблицу истинности запихать куда подальше, в данном случае в бд. А она должна быть прямо рядом с тестом как можно ближе к коду. P>Что там будет с бд, когда другой девелопер чего нибудь фиксанет — а хрен его знает. P>А если таблица истинности рядом с тестами и тестируемой функцией, шансов намного больше что проблему заметят еще во время код ревью.
Нет, не пытаюсь, ты опять фантазируешь. Я пытаюсь донести мысль, что надо проверять что код делает, а не как он выглядит.
P>>>Не дополнительными, а теми же самыми интеграционными, что есть и у вас. Интеграционные тесты не пишутся на все вещи вида "проверим что где то внутре передается параметр". Если такое критично — выносится в юниты. P>·>Ты не в тему споришь. Ты заявил "Интеграционный тест проверяет 1) что сама склейка валидная". Мест склейки now и nextFriday(now) у тебя будет полно. У меня такое место — одно. P>Интеграционный тест проверяет всю интеграцию разом, а вас тянет проверить каждую строчку. Каждая строчка — это про юнит-тестирование.
Твой один интеграционный тест проверяет интеграцию одного do_logic. Таких do_logic у тебя будет дофига, и каждого надо будет проверить.
P>>>Если у нас код контролера линейный, а в моем случае это именно так, то нам нужен ровно один интеграционный тест, который нужен и вам P>·>_Такой_ интеграционный тест мне не нужен. Я могу обойтись одним ю-тестом с моком о том, что nextFriday() действительно возвращает правильные даты для разных моментов времени. И ещё соответсвующими ю-тестами в местах использования nextFriday(), там можно моком просто возвращать хоть семь пятниц на неделе. P>Какой такой? Вам всё равно нужен интеграционный тест. Задачи интеграционных тестов не каждую склейку проверять по отдельности, а проверять работает ли компонент собраный целиком. Что там унутре — для интеграционного тестирования по барабану — нужная функция работает, значит всё хорошо.
Интеграционный тест чего?
P>>>Никак. P>·>Именно. Т.е. усложняешь прод-код, теряешь возможность протестировать и ловишь баги в проде. Нам такого не надо. P>Забавная телепатия.
Никакая не телепатия. Если ты никак не можешь протестировать, то проблемы будут обнаруживаться в проде. Ок, возможно, ещё при ручном тестировании.
P>>>У вас причин для изменения гораздо больше — любое измение дизайна означает поломку ваших тестов на моках. P>·>Это страшилки. P>Это следует из ваших примеров.
Не следует.
P>·>Мде. Если хочешь строчки считать по честному, показывай изменения в прод коде и тест на каждый вызов nextFriday. P>Тест на каждый вызов это классика тавтологичного тестирования
Я имею в виду писать тест, который покроет код каждого вызова и заасертит, что ожидания выполняются.
Я всё ещё жду требуемые изменения в прод коде для твоего дизайна.
P>·>Сейчас начнёшь символы считать, да? P>Обычное правило — 1 инструкция на строку. Вы втюхали минимум две.
И что? Небо на землю упадёт?
P>А поскольку у вас значения захардкожены, то между разными тестами согласованность никак не проверяется, т.к. везде хардкодите значения.
Ну ввести константу — не проблема.
P>>>И не собираюсь — data complexity решается совсем другими инструментами. Количество перестановок в фильтрах спокойно может исчисляться чудовищным количеством кейсов. Если некто поправит запрос, и забудет нагенерерить сотню другую данных — приплыли. P>·>Именно. Так что неясно зачем ты делаешь эти предъявы о гарантиях. У тебя аргументация вида "Раз ваш подход не умеет кофе варить и тапочки приносить — значит это плохо и надо делать как фаулер завещал". P>Вы забыли, что именно вы претендуете что решите это всё тестами.
Опять фантазии. Давай в следующий раз когда ты решишь что я думаю, на что я претендую, и т.п., подкрепляй моими цитатами.
P>>>т.е. вы снова притягиваете решение которое зависит от человеческого фактора P>·>А у тебя есть решение независящее от человеческого фактора? P>Его можно ограничить контролируя построение запроса + таблицу истинности храним не абы где, а рядом. Вы же все хотите таблицу истинности или размазать, или запихать куда подальше.
Не знаю где ты собрался размазывать и запихивать таблицы, просто не делай так, я разрешаю. Но это не отвечает на вопрос, куда делся человеческий фактор-то?
P>>>тот самый интеграционный тест, на некорретном запросе он упадет P>·>Т.е. у тебя интеграционные тесты будет тестировать всё "чудовищное количество кейсов"? Накой тогда ю-тесты? P>Интеграционные тесты не проверяют варианты склейки — они проверяют функционирование в сборе. Юнит-тесты проверяют работоспособность примитивов.
У тебя плодится много точек сборки, которые теперь приходится проверять. Ты решил терминов наизобретать? Что такое "работоспособность"? Чем она отличается от функционирования?
P>·>Я это знаю из тригонометрии, от моего кода не зависящей. А вот то, что fn2 — правильно, а fn3 — неправильно ты знаешь только из "как в коде написано". Т.е. твой код тестирует самого себя, порочный круг называется. P>Не из кода, а из требований вызывающей стороны.
Что за требования вызывающей стороны, которые диктуют, что должен быть написан код с fn2, а не fn3? Вызывающая сторона это вообще что и где?
P>>>fn1 и fn2 должны быть видны в тестах, а не публично P>·>А тесты должны, по уму, тестировать публичный контракт. @VisibleForTesting — это очень хороший сигнал code smells. P>Это ваша фантазия — эдак у вас юнит-тесты станут code smell, тк они принципиально по своей сути видят слишком много.
У нас юнит-тесты видят те же публичные методы, что и используются из других мест прод-кода. Тестировать то, что видно только тестам — это и есть твоё "как написано", завязка тестов на детали внутренней реализации.
P>>>Тем, что у вас в тестовой бд может не оказаться тех самых значений, которые ломают один из сотен-тысяч кейсов P>·>И у вас в тестах может не оказаться тех самых значений для построения того самого ломающего запроса. Опять "тапочки не приносит"? P>В моем случае таблица истинности рядом с тестом и функцией. Вы же ее пихаете куда подальше — прямо в бд. P>Скажите честно — у вас есть требование по процессу во время код ревью обязательно смотреть содержимое тестовой бд? Те самые десятки-сотни-тысячи записей
Я не знаю что такое содержимое тестовой бд и накой оно вообще нужно. Я код теста уже показывал
, хватит фантазировать. Делается save и тут же find для только что сохранённых записей. Я уже писал, что тысячи записей не нужны в подавляющем большинстве случаев. А там где нужны — создаются программно в этом же тесте.
P>>>Для этого вам надо перебрать все возможные сочетания фильтров -> здесь счет тестов идет на десятки тысяч по скромной оценке P>·>Нам — не надо. P>Вероятно, это особенность вашего проекта. Любая более-менее внятная статистика-аналитика по бд это довольно сложные алгоритмы, и здесь нужно чтото лучше, чем смотреть в бд и думать, что же должно быть на выходе.
Верно. Я уже показал что лучше — сохранить данные в бд и поискать их разными фильтрами.
P>>>Выборочные тесты. Поскольку я знаю, как строятся фильтры, мне нужно убедиться, что они таки вызываются. И не надо проверять всё перестановки. P>·>Ага. Именно то самое whitebox, котором ты ещё недавно меня попрекал. P>Раскройте глаза — здесь блекбокс. Выборочно вызываем бд нашим кодом, проверяется весь пайплайн в сборе, косвенно. Только нам не надо проверять всё на свете таким образом, т.к. есть и другие инструменты.
"я знаю, как строятся фильтры" — это и есть whitebox, не лукавь.
P>>>И вы уверены, что в тестовой бд всегда будет полный фарш? Вы что, один работаете? P>·>"Тапочки не приносит". P>Вы никак не можете объяснить преимущества размазывания таблицы истинности по тестами и бд, чем это лучше хранения таблицы истинности рядом с кодом и функцией с тестом.
Размазывание таблицы истинности придумал ты сам, сам и спорь со своими фантазиями.
P>>>Противоречие у вас в голове. Сказано — полного контроля не дают. P>·>Именно. Зачем же тогда покрыть юнит-тестами? P>- P>Затем, что доказательство корректности — это необходимое условие. А такое доказательство + тесты + код ревью, необходимое и достаточное.
Если у тебя есть доказательство корректности кода, то тесты уже не нужны. Это и есть идея доказательного программирования.
P>·>И что мешает это же делать в repo+dbms? P>Вы же сами говорите,что про это не думаете, верите только в результаты. Вот вы и нашли, кто мешает.
Опять мои мысли читаешь... Тебя не затруднит привести цитату, где я так говорю?
P>·>Это значит, что изменение в коде занимает как минимум день для выкатки в прод. Значит глобально архитектура выбрана плохо. Возможно надо резать на независимые компоненты. P>Нет, не значит.
Ты сказал, что процесс билда и тестов занимает 2.5 часа. Это уже пол дня.
P>Вы не в курсе, ни что за проект, ни какие требования, итд. Далеко не все проекты могут протаскивать изменения в прод прям сразу.
Я знаю, но это обычно недостаток, а не повод для гордости.
P>Во вторых, я вам сказал, что это полная сборка, все платформы, всё-всё-всё. Кто вам сказал, что нет сборки отдельных модулей? P>И так у вас всё — вместо вопросов занимаетесь телепатией.
Я задал вопрос — ты ответил 1.5ч + 40%, если надо, могу тебя процитировать, если ты запамятовал. Если ты умолчал важную инфу, релевантную для ответа на мой вопрос — это не моя вина.
P>>>Переписывать то зачем? Чем они вам мешают? P>·>Тем, что они написаны на конкретном ЯП. P>Я ж сказал — если по аннотации можно сгенерировать 4 артефакта, то почему нельзя сгенерировать 5й, 6й, 7й? P>Вы же видите только переписывание
Вопрос в том, что является источником — прога на конкретном яп или language agnostic описание контракта.
P>>>·>Смотря как долго проект живёт. P>>>Чем дольше, тем меньше шансов на переписывание, проще заново напилить новое. P>·>Но при сохранении контракта, который у вас описан на аннотациях конкретного ЯП. В общем гугли ликбез, например, тут https://swagger.io/blog/code-first-vs-design-first-api/ P>Вы путаете code-first и design-first. design first — означает, что первое деливери это апи, а не реализация. code-first — наоборот. А какой файл вы в начале редактируете, json или java и yaml, дело десяток
Не десятое, а первое. Погляди в словаре что означает слово "first".
P>Я ж сразу сказал — апи уже есть, а реализации нету, зато можно и тесты писать, и клиентский код, и документацию прикручивать
А начался разговор, что у тебя аннотации хитрые и сложные, зависят от переменных окружения и погоды на марсе.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>·>Недостаточно для чего? Почему недостаточно? Причём тут таблица истинности? P>>Логику, вычисления мы тестируем по таблице истинности. И чем меньше дополнительного кода сверх этой таблицы истинности, тем лучше. А вам надо все поразмазывать по мокам ·>Ну тестируй. Моки тебе ничем не мешают.
Мешают — хрупкие тесты, т.к. вайтбоксы, и дополнительный приседания что бы обмокать зависимости
P>>Функционально — ровно столько же. ·>Нет. Он у меня ещё и содержит склейку. У тебя склейки нет.
Нету такой функции как склейка. Вы все еще думаете вайтбоксом.
P>>·>Меньше интеграционных за счёт того, что они тестируют интеграцию. А не всю копипасту, которую ты предлагаешь плодить. P>>Моки не тестируют интеграцию. Моком вы можете проверить, а что будет, если подкинуть ту или иную зависимость. А нам надо совсем другое — готовый компонент работает как нам надо. ·>Ты читать умеешь? Ты где увидел в моём предложении выше слово "моки"? Хинт: моки вообще ничего не тестируют. Тесты — тестируют.
Тесты на моках интеграцию не тестируют, и не могут. Тест интеграции — проверка функционирования в сборе, а не с отрезаными зависимостями.
P>>Количество интеграционных тестов моки уменьшить никак не могут. Моки — это фактически понижение уровня тестирования за счет обрезания зависимостей. Нам же надо не понижение, а повышение. ·>Могут, т.к. большинство логики тестируется ю-тестами. А и-тесты нужны только чтобы тестировать интеграцию уже протестированных компонент.
Вот у вас снова из за моков почему то интеграционных тестов становится меньше. Вы путаете два противоположных случая — тест со включенными зависимостями и с обрезанными.
P>>·>Как немного? Ты пишешь по интеграционному тесту для каждого do_logic. Т.к. именно там происходит склейка. P>>Есть метод — его нужно вызвать в тестах. И у вас будет ровно то же. Просто вас тянет тестировать код, а не ожидания вызывающей стороны. ·>У меня такого метода просто не будет. Следовательно и тестов писать просто не для чего.
Куда ни ткни у вас "таких проблем у меня не может быть".
P>>Вместо проверки конкретной склейки делаем интеграционный код линейным, буквально, а интеграцию осуществляем на самом верху. ·>Чем выше, тем больше мест. Функция nextFriday() осуществляет склейку у себя внутри. И покрывается одним тестом. У тебя будет nextFriday(now) — и на самом верху будет множество call site для этого накопипастено. Код линейный, да, но накопипастен в кучу мест.
Нужно проверять все эти call site вне зависимости от способа доставки депенденсов, каждая функция должна быть вызвана в тестах минимум один раз.
P>>Простите, вы мапперы из одной структуры в другую как тестировать собираетесь? ·>В ю-тестах — по частям. Иначе изменение логики маппинга одного поля сломает все deep.equal тесты, где это поле есть.
Вы наверное не в курсе, то в джаве типизация хилая — не позволяет внятно типизировать согласованые значения, например "если ид = 0" то "created = null"
А раз так, то вы будете выписать такие согласованые значения руками.
Следовательно, и тестировать нужно ровно так же, а не размазывать значение по разным тестам
Будь у вас фукнциональный язык, можно было бы типизировать чуть не все подряд, но у вас такого фокуса нет.
P>>Пусть используется. Что вас смущает ? ·>Что в каждое из этих мест тебе понадобится копипастить склейку nextFriday(now) с источником текущего времени и покрывать это ещё одним тестом. Хотя, как я понял, ты вообще заявил, что такое протестировать ты просто не сможешь.
Вы кроме как вайтбоксом думать не хотите. "тестировть склейку" — это тупой вайтбокс, со всеми его недостатками. Вайтбокс в мейнтенансе дороже блакбокса. Вам это каждая ссылка в гугле скажет.
Не надо тестировать склейку — нужно тестировать результат той или иной функции. И тут по барабану, что откуда вызываете — есть функция, её нужно связать с таблицей истинности и покрыть тестом.
Вы же все время намекаете, что ваши моки от этого избавляют.
·>Ещё раз. nextFriday() ≡ nextFriday(now) ∘ timeSource.now(). Если ты отказываешься использовать в call site готовый и протестированный nextFriday(), значит тебе в каждый call site придётся протаскивать timeSource и копипастить композицию с nextFriday(now). Это увеличивает кол-во прод-кода и требует больше более тяжеловесных тестов для покрытия всей копипасты.
Вам точно так же нужно протаскивать timeSource, только без параметра. И тестировать нужно ровно столько же, т.к. нужно знать, как ведет себя вся интеграция разом.
P>>Читайте себя "Так функция может использоваться из множества мест." ·>И?
Вы же все эти места обмокали. Вот новый девелопер пришел на проект, откуда ему знать, должно его изменение повлечь правки моков или нет?
P>>У вас в тех самых тестах все будет обмокано. Как узнаете, что там, в моках, должно вызываться не "то", а "это"? ·>Эээ.. Ты рефакторингом точно умеешь пользоваться? Компилятор и IDE всё покажет, подскажет и подправит.
Вы здесь жульничаете — по факту вы мне задали тот же вопрос, что и я вам. Но у меня, по вашему, будут проблемы и ни компилер, ни иде не помогут, а вот вам в аналогичной ситуации будут помогать
Я же вижу, что с чистыми функциями помощи от компилятора кратно выше
В некоторых случаях кода писать больше, за счет того, что в других — намного меньше, и бОльшую часть можно переложить на компилятор и иде.
Например, нужно заинлайнить функцию
с чистой функцией это нажал на кнопку и получил результат
с вашими зависимостями компилер говорит "приплыли" потому что в текущий блок зависимость не подложена, и компилер не в курсе, как правильно её привязать.
Ровно так же дела с переносом кода куда угодно, выделение наследника, сплющивание иерархии, конверсии класса в функцию и обратно
А вам всегда будет мешать та самая зависимость
Если вы не согласны — покажите как ваша иде инлайнит код nextFriday по месту каждого из call site. Явите же чудо, про которое вещаете тут годами
P>>·>Ты потерял контекст. Тут шла речь о ю-тест упоминал "а что если в колонке пусто". В колонке, внезапно окажется, будет не пусто а дефолтное значение из бд. Багу такую поймаешь только на проде, т.к. и-тесты для таких подробных мелочей явно писать не будешь. P>>Наоборот — именно для таких мелочей юнит-тесты и нужны. ·>Ты не читаешь, что тебе пишут.
Наоборот. Я как раз для подробных мелочей и пишу юниты-тесты. Вероятно, вы делаете иначе.
P>>Что там будет с бд, когда другой девелопер чего нибудь фиксанет — а хрен его знает. P>>А если таблица истинности рядом с тестами и тестируемой функцией, шансов намного больше что проблему заметят еще во время код ревью. ·>Нет, не пытаюсь, ты опять фантазируешь. Я пытаюсь донести мысль, что надо проверять что код делает, а не как он выглядит.
Еще раз — у меня нет буквально в коде того или иного запроса целиком, а есть конструирование его. Я ж прямо пишу — построение запроса по фильтрам.
Это значит, что у нас
1. связывание
2. маппер туда
3. маппер обратно
+ шаблоны запроса, шаблоны фильтров итд
То есть, у нас в наличии обычные вычисления вида object -> sql которые идеально покрываются юнит-тестами
P>>Интеграционный тест проверяет всю интеграцию разом, а вас тянет проверить каждую строчку. Каждая строчка — это про юнит-тестирование. ·>Твой один интеграционный тест проверяет интеграцию одного do_logic. Таких do_logic у тебя будет дофига, и каждого надо будет проверить.
Этот do_logic по одному на юз кейс. Сколько юз кейсов — столько и таких методов, а значит столько будет и интеграционных тестов. И у вас будет ровно то же. И никаие моки этого не отменят.
Даже если вы вообще удалите зависимость от Time.now, это ничего не изменит — количество интеграционных тестов останется прежним
P>>Какой такой? Вам всё равно нужен интеграционный тест. Задачи интеграционных тестов не каждую склейку проверять по отдельности, а проверять работает ли компонент собраный целиком. Что там унутре — для интеграционного тестирования по барабану — нужная функция работает, значит всё хорошо. ·>Интеграционный тест чего?
Чего угодно — хоть системы, хоть приложения, хоть компонента.
P>>·>Именно. Т.е. усложняешь прод-код, теряешь возможность протестировать и ловишь баги в проде. Нам такого не надо. P>>Забавная телепатия. ·>Никакая не телепатия. Если ты никак не можешь протестировать, то проблемы будут обнаруживаться в проде. Ок, возможно, ещё при ручном тестировании.
Я и говорю — телепатия. Вы лучше меня знаете, что у меня в коде, что у меня за проект, где больше всего проблем возникает, сколько должен длиться билд
P>>>>У вас причин для изменения гораздо больше — любое измение дизайна означает поломку ваших тестов на моках. P>>·>Это страшилки. P>>Это следует из ваших примеров. ·>Не следует.
Именно что следует. Вы топите за вайтбокс тесты, а у них известное свойство — поломки при изменении внутреннего дизайна.
У вас выходят вайтбокс тесты без недостатков свойственных вайтбокс тестам.
Чудо, которое можно объяснить только вашими фантазиями
P>>Обычное правило — 1 инструкция на строку. Вы втюхали минимум две. ·>И что? Небо на землю упадёт?
Выглядит так, что вы отрицаете недостатки моков и вайтбокс тестов, даже посредтством такой вот дешовой детской подтасовки.
P>>А поскольку у вас значения захардкожены, то между разными тестами согласованность никак не проверяется, т.к. везде хардкодите значения. ·>Ну ввести константу — не проблема.
Её нужно вводить, хотя бы для того, что бы обеспечить согласованность некоторых тестов.
А все лишние из тестов нужно убрать, что бы ничего не мешало делать ревью
Чем больше, тем лучше. Если моки можно убрать — их нужно убрать
P>>·>Именно. Так что неясно зачем ты делаешь эти предъявы о гарантиях. У тебя аргументация вида "Раз ваш подход не умеет кофе варить и тапочки приносить — значит это плохо и надо делать как фаулер завещал". P>>Вы забыли, что именно вы претендуете что решите это всё тестами. ·>Опять фантазии. Давай в следующий раз когда ты решишь что я думаю, на что я претендую, и т.п., подкрепляй моими цитатами.
Вы же пишете, что вам на проверку любой сложности фильтров хватит одной тестовой бд с ничтожным количетсвом записей.
P>>Его можно ограничить контролируя построение запроса + таблицу истинности храним не абы где, а рядом. Вы же все хотите таблицу истинности или размазать, или запихать куда подальше. ·>Не знаю где ты собрался размазывать и запихивать таблицы, просто не делай так, я разрешаю. Но это не отвечает на вопрос, куда делся человеческий фактор-то?
Если вы таблицу истинности размазали по бд, вам нужны административные меры, что бы заставить девелоперов собирать всё в кучку на код-ревью или для разработки.
Нет такогого — значит часть изменений будут идти на авось
А если таблица истинности рядом — проверить её обычно секундное дело. Можно даже тестировщиков привлечь, и бизнес-аналитиков — кого угодно, в отличие от вашей схемы с бд
P>>Интеграционные тесты не проверяют варианты склейки — они проверяют функционирование в сборе. Юнит-тесты проверяют работоспособность примитивов. ·>У тебя плодится много точек сборки, которые теперь приходится проверять.
Проверять нужно не точки сборки, а всю сборку целиком. Точки сборки — та самая вайтбоксовость с её недостатками, которые вы отрицаете уже минимум несколько лет
> Ты решил терминов наизобретать? Что такое "работоспособность"? Чем она отличается от функционирования?
Функционирование и работоспособность это слова-синонимы. В руссокм языке это уже давно изобретено.
P>>Не из кода, а из требований вызывающей стороны. ·>Что за требования вызывающей стороны, которые диктуют, что должен быть написан код с fn2, а не fn3? Вызывающая сторона это вообще что и где?
Например, те самые требования. Если нам вернуть нужно User, то очевидно, что fn2 должна возвращать User, а не абы что.
Вызывающая сторона — в русском языке это значит та сторона, которая делает конкретный вызов.
P>>Это ваша фантазия — эдак у вас юнит-тесты станут code smell, тк они принципиально по своей сути видят слишком много. ·>У нас юнит-тесты видят те же публичные методы, что и используются из других мест прод-кода. Тестировать то, что видно только тестам — это и есть твоё "как написано", завязка тестов на детали внутренней реализации.
Вы снова додумываете вместо того, что бы задать простой вопрос.
·>Я не знаю что такое содержимое тестовой бд и накой оно вообще нужно.
Во первых, врете, см ниже
Ну как же — вы собирались фильтры тестировать посредством выполнения запросов на бд, те самые "репозитории" которые вы тестируете косвенно, через БД. Или у вас фильтрация вне репозитория сделана? Ну-ну.
P>>Вероятно, это особенность вашего проекта. Любая более-менее внятная статистика-аналитика по бд это довольно сложные алгоритмы, и здесь нужно чтото лучше, чем смотреть в бд и думать, что же должно быть на выходе. ·>Верно. Я уже показал что лучше — сохранить данные в бд и поискать их разными фильтрами.
А вот и доказательство, что врете — здесь вы знаете что такое содержимое бд и накой оно нужно.
P>>Раскройте глаза — здесь блекбокс. Выборочно вызываем бд нашим кодом, проверяется весь пайплайн в сборе, косвенно. Только нам не надо проверять всё на свете таким образом, т.к. есть и другие инструменты. ·>"я знаю, как строятся фильтры" — это и есть whitebox, не лукавь.
Как строятся — какой должен получиться в итоге запрос. А вот подробности того, какого цвета унутре неонки(связывание, конверсия, маппинг, итд) — мне не надо.
Чем сложнее логика построения запросов — тем больше тестов придется писать. Косвенные проверки не смогут побороть data complexity
P>>Вы никак не можете объяснить преимущества размазывания таблицы истинности по тестами и бд, чем это лучше хранения таблицы истинности рядом с кодом и функцией с тестом. ·>Размазывание таблицы истинности придумал ты сам, сам и спорь со своими фантазиями.
Ну как же, смотрите выше — "лучше — сохранить данные в бд и поискать их разными фильтрами."
P>>Затем, что доказательство корректности — это необходимое условие. А такое доказательство + тесты + код ревью, необходимое и достаточное. ·>Если у тебя есть доказательство корректности кода, то тесты уже не нужны. Это и есть идея доказательного программирования.
Ну и дичь Каким чудом ваше доказательство сработает, если в код влезет другой ?
Дональд Кнут на линии: "Остерегайтесь ошибок коде; я только доказал его правильность, но не проверял его."
P>>·>Это значит, что изменение в коде занимает как минимум день для выкатки в прод. Значит глобально архитектура выбрана плохо. Возможно надо резать на независимые компоненты. P>>Нет, не значит. ·>Ты сказал, что процесс билда и тестов занимает 2.5 часа. Это уже пол дня.
P>>Вы не в курсе, ни что за проект, ни какие требования, итд. Далеко не все проекты могут протаскивать изменения в прод прям сразу. ·>Я знаю, но это обычно недостаток, а не повод для гордости.
А еще чаще это признак огромного проекта
P>>Я ж сказал — если по аннотации можно сгенерировать 4 артефакта, то почему нельзя сгенерировать 5й, 6й, 7й? P>>Вы же видите только переписывание ·>Вопрос в том, что является источником — прога на конкретном яп или language agnostic описание контракта.
language agnostic описания, если вы про json, это отстой, т.к. удлинняет цикл разработки — есть шанс написать такой манифест, который хрен знает как заимплементить
Такое описание далеко не всегда нужно:
1. например, у нас всё на джаве — джава, скала, котлин, итд.
2. например, у нас нет внешних консумеров
3. например, мы связываем части своего собственного проекта — здесь вообще может быть один и тот же яп
P>>·>Но при сохранении контракта, который у вас описан на аннотациях конкретного ЯП. В общем гугли ликбез, например, тут https://swagger.io/blog/code-first-vs-design-first-api/ P>>Вы путаете code-first и design-first. design first — означает, что первое деливери это апи, а не реализация. code-first — наоборот. А какой файл вы в начале редактируете, json или java и yaml, дело десяток ·>Не десятое, а первое. Погляди в словаре что означает слово "first".
design-first означает, что в первую очередь деливерится апи, а не абы что. А вот как вы его сформулируете — json, idl, grapql, grpc, интерфейсы на псевдокоде, java классы без реализации — вообще дело десятое, хоть plantuml или curl.
Здесь самое главное, что бы мы могли отдать описание всем, кто будет с ним взаимодействовать. А уже потом начнем работать над реализацией.
P>>Я ж сразу сказал — апи уже есть, а реализации нету, зато можно и тесты писать, и клиентский код, и документацию прикручивать ·>А начался разговор, что у тебя аннотации хитрые и сложные, зависят от переменных окружения и погоды на марсе.
Основа апи остаётся. Переменные окружения и конфиги не могут поменять параметры метода, типы, результат итд. Но могут скрыть этот метод, или добавить метаданные, например, метод начнет требовать авторизацию, или наоборот, будет работать без авторизации.
Здравствуйте, Pauel, Вы писали:
P>>>Логику, вычисления мы тестируем по таблице истинности. И чем меньше дополнительного кода сверх этой таблицы истинности, тем лучше. А вам надо все поразмазывать по мокам P>·>Ну тестируй. Моки тебе ничем не мешают. P>Мешают — хрупкие тесты, т.к. вайтбоксы, и дополнительный приседания что бы обмокать зависимости
Хрупкость тестов с моками — это твои фантазии и страшилки. Конечно, в том виде как ты показывал способ использования моков — делает тесты хрупкими. Просто не используй моки так.
P>>>Функционально — ровно столько же. P>·>Нет. Он у меня ещё и содержит склейку. У тебя склейки нет. P>Нету такой функции как склейка. Вы все еще думаете вайтбоксом.
Частичное применение функции — даёт функцию.
P>>>Моки не тестируют интеграцию. Моком вы можете проверить, а что будет, если подкинуть ту или иную зависимость. А нам надо совсем другое — готовый компонент работает как нам надо. P>·>Ты читать умеешь? Ты где увидел в моём предложении выше слово "моки"? Хинт: моки вообще ничего не тестируют. Тесты — тестируют. P>Тесты на моках интеграцию не тестируют, и не могут. Тест интеграции — проверка функционирования в сборе, а не с отрезаными зависимостями.
Я не знаю к чему ты это всё рассказываешь, с чем споришь. Впрочем, тоже слишком общее, поэтому неверное утверждение. Можно тестировать интеграцию двух компонент, мокая третий. Например, можно тестировать интеграцию контроллера с бизнес-логикой, замокав репу.
P>>>Количество интеграционных тестов моки уменьшить никак не могут. Моки — это фактически понижение уровня тестирования за счет обрезания зависимостей. Нам же надо не понижение, а повышение. P>·>Могут, т.к. большинство логики тестируется ю-тестами. А и-тесты нужны только чтобы тестировать интеграцию уже протестированных компонент. P>Вот у вас снова из за моков почему то интеграционных тестов становится меньше. Вы путаете два противоположных случая — тест со включенными зависимостями и с обрезанными.
Моки позволяют упростить дизайн, снизить тяжеловесность тестов, уменьшить количество интеграционного кода, и соответственно — меньше кода — меньше тестов.
P>>>Есть метод — его нужно вызвать в тестах. И у вас будет ровно то же. Просто вас тянет тестировать код, а не ожидания вызывающей стороны. P>·>У меня такого метода просто не будет. Следовательно и тестов писать просто не для чего. P>Куда ни ткни у вас "таких проблем у меня не может быть".
Потому что для данной конкретной проблемы существует подход, чтобы эта проблема не возникала. Если ты не хочешь использовать этот подход, тебе приходится бороться с этой проблемой.
P>>>Вместо проверки конкретной склейки делаем интеграционный код линейным, буквально, а интеграцию осуществляем на самом верху. P>·>Чем выше, тем больше мест. Функция nextFriday() осуществляет склейку у себя внутри. И покрывается одним тестом. У тебя будет nextFriday(now) — и на самом верху будет множество call site для этого накопипастено. Код линейный, да, но накопипастен в кучу мест. P>Нужно проверять все эти call site вне зависимости от способа доставки депенденсов, каждая функция должна быть вызвана в тестах минимум один раз.
Проверять на что и каким тестом? В call site я могу использовать мок nextFriday() и проверять поведение ю-тестами.
P>>>Простите, вы мапперы из одной структуры в другую как тестировать собираетесь? P>·>В ю-тестах — по частям. Иначе изменение логики маппинга одного поля сломает все deep.equal тесты, где это поле есть. P>Вы наверное не в курсе, то в джаве типизация хилая — не позволяет внятно типизировать согласованые значения, например "если ид = 0" то "created = null" P>А раз так, то вы будете выписать такие согласованые значения руками. P>Следовательно, и тестировать нужно ровно так же, а не размазывать значение по разным тестам P>Будь у вас фукнциональный язык, можно было бы типизировать чуть не все подряд, но у вас такого фокуса нет.
Не очень понял. Наверное мы говорим о разных вещах. Покажи код где там какой типизации не хватает в java.
P>>>Пусть используется. Что вас смущает ? P>·>Что в каждое из этих мест тебе понадобится копипастить склейку nextFriday(now) с источником текущего времени и покрывать это ещё одним тестом. Хотя, как я понял, ты вообще заявил, что такое протестировать ты просто не сможешь. P>Вы кроме как вайтбоксом думать не хотите. "тестировть склейку" — это тупой вайтбокс, со всеми его недостатками. Вайтбокс в мейнтенансе дороже блакбокса. Вам это каждая ссылка в гугле скажет. P>Не надо тестировать склейку — нужно тестировать результат той или иной функции. И тут по барабану, что откуда вызываете — есть функция, её нужно связать с таблицей истинности и покрыть тестом. P>Вы же все время намекаете, что ваши моки от этого избавляют.
Так я это и тестирую результат, что он зависит от nextFriday() правильным способом. Разговор о другом.
nextFriday(now) — это функция возвращающая пятницу для данного момента времени. А nextFriday() — это функция возвращающая пятницу для текущего момента времени. В первом случае мы по месту использования должны откуда-то брать некий момент времени, а для второго — мы знаем, что это текущий момент.
В функциональных яп — это частичное применение функции. У нас просто разная семантика функции "текущее время" vs "данный момент времени". Причём тут white/black — вообще неясно.
P>·>Ещё раз. nextFriday() ≡ nextFriday(now) ∘ timeSource.now(). Если ты отказываешься использовать в call site готовый и протестированный nextFriday(), значит тебе в каждый call site придётся протаскивать timeSource и копипастить композицию с nextFriday(now). Это увеличивает кол-во прод-кода и требует больше более тяжеловесных тестов для покрытия всей копипасты. P>Вам точно так же нужно протаскивать timeSource, только без параметра. И тестировать нужно ровно столько же, т.к. нужно знать, как ведет себя вся интеграция разом.
Не нужно его протаскивать. Он уже "частично применён" в CalendarLogic. Ты вообще понимаешь что такое ЧПФ?!
P>>>Читайте себя "Так функция может использоваться из множества мест." P>·>И? P>Вы же все эти места обмокали. Вот новый девелопер пришел на проект, откуда ему знать, должно его изменение повлечь правки моков или нет?
Компилятор расскажет.
P>·>Эээ.. Ты рефакторингом точно умеешь пользоваться? Компилятор и IDE всё покажет, подскажет и подправит. P>Вы здесь жульничаете — по факту вы мне задали тот же вопрос, что и я вам. Но у меня, по вашему, будут проблемы и ни компилер, ни иде не помогут, а вот вам в аналогичной ситуации будут помогать P>Я же вижу, что с чистыми функциями помощи от компилятора кратно выше P>В некоторых случаях кода писать больше, за счет того, что в других — намного меньше, и бОльшую часть можно переложить на компилятор и иде. P>Например, нужно заинлайнить функцию P>с чистой функцией это нажал на кнопку и получил результат P>с вашими зависимостями компилер говорит "приплыли" потому что в текущий блок зависимость не подложена, и компилер не в курсе, как правильно её привязать.
Ровно то же и с частично применёнными функциями.
P>Ровно так же дела с переносом кода куда угодно, выделение наследника, сплющивание иерархии, конверсии класса в функцию и обратно P>А вам всегда будет мешать та самая зависимость
Вам зависимость тоже будет мешаться всегда, просто в других местах.
P>Если вы не согласны — покажите как ваша иде инлайнит код nextFriday по месту каждого из call site. Явите же чудо, про которое вещаете тут годами
А ты можешь заинлайнить, например, хотя бы str.length()? Или тоже "тапочки не приносит"?
P>>>·>Ты потерял контекст. Тут шла речь о ю-тест упоминал "а что если в колонке пусто". В колонке, внезапно окажется, будет не пусто а дефолтное значение из бд. Багу такую поймаешь только на проде, т.к. и-тесты для таких подробных мелочей явно писать не будешь. P>>>Наоборот — именно для таких мелочей юнит-тесты и нужны. P>·>Ты не читаешь, что тебе пишут. P>Наоборот. Я как раз для подробных мелочей и пишу юниты-тесты. Вероятно, вы делаете иначе.
Ты не понял, что я тебе написал. Попробую объяснить ещё раз.
"а что если в колонке пусто" — это не реальное возможное ожидание, а тестовые параметры, которые ты подсовываешь своей "чистой функции" в своём ю-тесте. А на самом деле никакого "в колонке пусто" может просто не быть, т.к. dbms заменяет его на дефолтное значение. Твой ю-тест тестирует "как написано в коде". И эту "подробную мелочь" ты тестировать в и-тесте не собираешься, а значит будешь ловить баг на проде.
P>>>Что там будет с бд, когда другой девелопер чего нибудь фиксанет — а хрен его знает. P>>>А если таблица истинности рядом с тестами и тестируемой функцией, шансов намного больше что проблему заметят еще во время код ревью. P>·>Нет, не пытаюсь, ты опять фантазируешь. Я пытаюсь донести мысль, что надо проверять что код делает, а не как он выглядит. P>Еще раз — у меня нет буквально в коде того или иного запроса целиком, а есть конструирование его.
Цитирую тебя:
Что вас смущает? deep.eq проверит всё, что надо. query это не строка, объект с конкретной структурой, чтото навроде
sql: 'select * from users where id=?',
Это не буквально?!
P>Я ж прямо пишу — построение запроса по фильтрам. P>+ шаблоны запроса, шаблоны фильтров итд P>То есть, у нас в наличии обычные вычисления вида object -> sql которые идеально покрываются юнит-тестами
То что они идеально покрываются ю-тестами, не означает, что их надо покрывать ю-тестами. Цель тестирования репо не то, как запросы выглядят, какие буковки сидят в твоих шаблонах фильтров, а то что выдаёт субд для конкретных данных.
P>>>Интеграционный тест проверяет всю интеграцию разом, а вас тянет проверить каждую строчку. Каждая строчка — это про юнит-тестирование. P>·>Твой один интеграционный тест проверяет интеграцию одного do_logic. Таких do_logic у тебя будет дофига, и каждого надо будет проверить. P>Этот do_logic по одному на юз кейс. Сколько юз кейсов — столько и таких методов, а значит столько будет и интеграционных тестов. И у вас будет ровно то же. И никаие моки этого не отменят. P>Даже если вы вообще удалите зависимость от Time.now, это ничего не изменит — количество интеграционных тестов останется прежним
А у меня этих твоих do_logic — по нулю на юз-кейс. Чуешь разницу?
P>>>·>Именно. Т.е. усложняешь прод-код, теряешь возможность протестировать и ловишь баги в проде. Нам такого не надо. P>>>Забавная телепатия. P>·>Никакая не телепатия. Если ты никак не можешь протестировать, то проблемы будут обнаруживаться в проде. Ок, возможно, ещё при ручном тестировании. P>Я и говорю — телепатия. Вы лучше меня знаете, что у меня в коде, что у меня за проект, где больше всего проблем возникает, сколько должен длиться билд
Ты вроде прямо заявил, что некий аспект поведения ты не можешь протестировать. И время билда ты сам рассказал. Я телепатией пользоваться не умею, могу привести твои цитаты.
P>·>Не следует. P>Именно что следует. Вы топите за вайтбокс тесты, а у них известное свойство — поломки при изменении внутреннего дизайна.
Я топлю за вайтбокс в том смысле, что тест-кейсы пишутся со знанием что происходит внутри, чтобы понимать какие могут быть corner-cases. Но сами входные данные и ассерты теста должны соответствовать бизнес-требованиям (для данного id возвращается правильно сконструированный User). Следовательно, изменение имплементации всё ещё должно сохранять тесты зелёными.
Вот твой код "{sql: 'select * from users where id=?', params: [id], transformations: {in: [fn1],out: [fn2]}" — таким свойством не обладает, т.к. проверяет детали реализации (текст запроса, порядок ?-парамов, имена приватных функций), а не поведение. Этот тест будет ломаться от каждого чиха.
P>У вас выходят вайтбокс тесты без недостатков свойственных вайтбокс тестам. P>Чудо, которое можно объяснить только вашими фантазиями
Допускаю, что я неправильно терминологию использую white/black box...
P>>>Обычное правило — 1 инструкция на строку. Вы втюхали минимум две. P>·>И что? Небо на землю упадёт? P>Выглядит так, что вы отрицаете недостатки моков и вайтбокс тестов, даже посредтством такой вот дешовой детской подтасовки.
Я отрицаю недостатки, которые ты придумал, основываясь на непонимании как надо использовать моки.
P>·>Ну ввести константу — не проблема. P>Её нужно вводить, хотя бы для того, что бы обеспечить согласованность некоторых тестов. P>А все лишние из тестов нужно убрать, что бы ничего не мешало делать ревью
Это всё мелочи жизни, применимо к любому коду. В любом коде хорошо вводить константы, если они означают одно и то же в разных частях кода. Любой код надо делать так, чтобы было проще читать/ревьювить. При чём тут сабж?
P>Чем больше, тем лучше. Если моки можно убрать — их нужно убрать
Это уже твои личные заморочки от неумения пользоваться моками.
P>>>Вы забыли, что именно вы претендуете что решите это всё тестами. P>·>Опять фантазии. Давай в следующий раз когда ты решишь что я думаю, на что я претендую, и т.п., подкрепляй моими цитатами. P>Вы же пишете, что вам на проверку любой сложности фильтров хватит одной тестовой бд с ничтожным количетсвом записей.
Нет, ты врёшь, я такое не писал. Ты опять приписываешь мне какие-то свои фантазии, вместо прямой моей цитаты.
P>·>Не знаю где ты собрался размазывать и запихивать таблицы, просто не делай так, я разрешаю. Но это не отвечает на вопрос, куда делся человеческий фактор-то? P>Если вы таблицу истинности размазали по бд, вам нужны административные меры, что бы заставить девелоперов собирать всё в кучку на код-ревью или для разработки.
Опять фантазии. Я не размазывал таблицу истинности по бд.
P>>>Интеграционные тесты не проверяют варианты склейки — они проверяют функционирование в сборе. Юнит-тесты проверяют работоспособность примитивов. P>·>У тебя плодится много точек сборки, которые теперь приходится проверять. P>Проверять нужно не точки сборки, а всю сборку целиком. Точки сборки — та самая вайтбоксовость с её недостатками, которые вы отрицаете уже минимум несколько лет
Ок, переформулирую. В сборке целиком тебе нужно проверять все точки . Тебе надо будет проверить, что где-то в твоём склеивающем коде do_logic_742 в качестве now в nextFriday(now) подставилось время сервера, а не клиента, например. И так для каждого do_logic_n, где используется nextFriday.
>> Ты решил терминов наизобретать? Что такое "работоспособность"? Чем она отличается от функционирования? P>Функционирование и работоспособность это слова-синонимы. В руссокм языке это уже давно изобретено.
Тогда неясно зачем тебе и юнит тесты, и интеграционные, если и те, и те проверяют функционирование, и что тебе в твоих и-тестах приходится проверять всю функциональность.
P>>>Не из кода, а из требований вызывающей стороны. P>·>Что за требования вызывающей стороны, которые диктуют, что должен быть написан код с fn2, а не fn3? Вызывающая сторона это вообще что и где? P>Например, те самые требования. Если нам вернуть нужно User, то очевидно, что fn2 должна возвращать User, а не абы что.
Ерунда какая-то.
Во-первых, это очень слабая проверка, т.к. такое работает если только у тебя _каждая_ функция имеет уникальный тип результата.
Во-вторых, вспомним код:
const getUser = repository.getUser(id);
const oldUser = db.execute(getUser);
const newUser = bl.modifyUser(oldUser); // вот тут у тебя должен быть compilation error, если getUser будет возвращать что-то отличное от User.
Ты своими тестами компилятор тестируешь что-ли? Или у тебя настолько "типизация нехилая", что каждый тип приходится тестом покрывать?!
P>>>Это ваша фантазия — эдак у вас юнит-тесты станут code smell, тк они принципиально по своей сути видят слишком много. P>·>У нас юнит-тесты видят те же публичные методы, что и используются из других мест прод-кода. Тестировать то, что видно только тестам — это и есть твоё "как написано", завязка тестов на детали внутренней реализации. P>Вы снова додумываете вместо того, что бы задать простой вопрос.
Вопрос о чём? Ты сам сказал, что fn2 видно только для тестов. Цитата: "fn1 и fn2 должны быть видны в тестах, а не публично". Я просто пытаюсь донести мысль, что это code smells, т.к. тесты завязаны на непубличный контракт компонента, иными словами, на внутренние детали реализации.
P>·>Я не знаю что такое содержимое тестовой бд и накой оно вообще нужно. P>Во первых, врете, см ниже
Мимо.
P>Ну как же — вы собирались фильтры тестировать посредством выполнения запросов на бд, те самые "репозитории" которые вы тестируете косвенно, через БД.
Да.
P>Или у вас фильтрация вне репозитория сделана?
Нет.
P>>>Вероятно, это особенность вашего проекта. Любая более-менее внятная статистика-аналитика по бд это довольно сложные алгоритмы, и здесь нужно чтото лучше, чем смотреть в бд и думать, что же должно быть на выходе. P>·>Верно. Я уже показал что лучше — сохранить данные в бд и поискать их разными фильтрами. P>А вот и доказательство, что врете — здесь вы знаете что такое содержимое бд и накой оно нужно.
С т.з. тестов репы нет никакого "содержимого тестовой бд". "сохранить данные в бд" == вызов метода save репы, "поискать их разными фильтрами" == вызов метода find. Я же в пример кода уже дважы тыкал. С т.з. теста впрочем и бд как таковой тоже нет, можно сказать, есть просто класс с пачкой методов, которые тест дёргает и ассертит результаты.
P>>>Раскройте глаза — здесь блекбокс. Выборочно вызываем бд нашим кодом, проверяется весь пайплайн в сборе, косвенно. Только нам не надо проверять всё на свете таким образом, т.к. есть и другие инструменты. P>·>"я знаю, как строятся фильтры" — это и есть whitebox, не лукавь. P>Как строятся — какой должен получиться в итоге запрос.
P>А вот подробности того, какого цвета унутре неонки(связывание, конверсия, маппинг, итд) — мне не надо.
Но вот тут "params: [id], { [fn1],out: [fn2]}" ты именно это и тестируешь. Ты уж определись надо оно тебе или не надо... Или ты тестируешь то, что тебе не надо?!!
P>Чем сложнее логика построения запросов — тем больше тестов придется писать. Косвенные проверки не смогут побороть data complexity
Ну да. Больше логики — больше тестов. Причём тут "косвенность" проверок?
P>>>Вы никак не можете объяснить преимущества размазывания таблицы истинности по тестами и бд, чем это лучше хранения таблицы истинности рядом с кодом и функцией с тестом. P>·>Размазывание таблицы истинности придумал ты сам, сам и спорь со своими фантазиями. P>Ну как же, смотрите выше — "лучше — сохранить данные в бд и поискать их разными фильтрами."
И? Я код же показал. Где там размазывание чего?
P>>>Затем, что доказательство корректности — это необходимое условие. А такое доказательство + тесты + код ревью, необходимое и достаточное. P>·>Если у тебя есть доказательство корректности кода, то тесты уже не нужны. Это и есть идея доказательного программирования. P>Ну и дичь Каким чудом ваше доказательство сработает, если в код влезет другой ? P>Дональд Кнут на линии: "Остерегайтесь ошибок коде; я только доказал его правильность, но не проверял его."
Ты либо крестик, либо трусы. Док.программирование это спеки, контракты и верификаторы. Тесты тут непричём.
P>>>Вы не в курсе, ни что за проект, ни какие требования, итд. Далеко не все проекты могут протаскивать изменения в прод прям сразу. P>·>Я знаю, но это обычно недостаток, а не повод для гордости. P>А еще чаще это признак огромного проекта
Огромного проекта в плохом состоянии, да. Впрочем, не раз наблюдал и маленькие проекты на неск. сот строк билдятся час — сразу видно, писали по всем канонам и заветам дядек из интернета!
P>·>Вопрос в том, что является источником — прога на конкретном яп или language agnostic описание контракта. P>language agnostic описания, если вы про json, это отстой, т.к. удлинняет цикл разработки — есть шанс написать такой манифест, который хрен знает как заимплементить
Написать такой корявый манифест немного сложнее, чем сгенерить.
P>Такое описание далеко не всегда нужно: P>1. например, у нас всё на джаве — джава, скала, котлин, итд. P>2. например, у нас нет внешних консумеров P>3. например, мы связываем части своего собственного проекта — здесь вообще может быть один и тот же яп
Тогда нафиг и не нужны аннотации, и уж тем более манифесты.
P>·>Не десятое, а первое. Погляди в словаре что означает слово "first". P>design-first означает, что в первую очередь деливерится апи, а не абы что. А вот как вы его сформулируете — json, idl, grapql, grpc, интерфейсы на псевдокоде, java классы без реализации — вообще дело десятое, хоть plantuml или curl. P>Здесь самое главное, что бы мы могли отдать описание всем, кто будет с ним взаимодействовать. А уже потом начнем работать над реализацией.
Так у тебя же в начале (first) пишется/меняется code и потом из него генерится описание, которые ты отдаёшь всем. Да ещё и разное описание, в зависимости от фазы луны. Т.е. ты в первую очередь кодишь свои переменные, конфиги, логику тенантов, и лишь потом у тебя появляется описание.
P>>>Я ж сразу сказал — апи уже есть, а реализации нету, зато можно и тесты писать, и клиентский код, и документацию прикручивать P>·>А начался разговор, что у тебя аннотации хитрые и сложные, зависят от переменных окружения и погоды на марсе. P>Основа апи остаётся. Переменные окружения и конфиги не могут поменять параметры метода, типы, результат итд. Но могут скрыть этот метод, или добавить метаданные, например, метод начнет требовать авторизацию, или наоборот, будет работать без авторизации.
И на чём эта вся логика написана? На grpc, да?
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>Мешают — хрупкие тесты, т.к. вайтбоксы, и дополнительный приседания что бы обмокать зависимости ·>Хрупкость тестов с моками — это твои фантазии и страшилки. Конечно, в том виде как ты показывал способ использования моков — делает тесты хрупкими. Просто не используй моки так.
Вы уже показывали, когда мокали репозиторий ради тестов контролера, а потом скромно замолчали на вопрос, что делать, если меняется дизайн
P>>Нету такой функции как склейка. Вы все еще думаете вайтбоксом. ·>Частичное применение функции — даёт функцию.
Я вам про функциональные требования, а вы мне про функции в коде. Проверка склейки — это вайтбокс тест уровня юнит-тестов. В интеграционных тестах мы проверяем ожидания вызывающей стороны. А её точно ничего про склейку не известно.
P>>Тесты на моках интеграцию не тестируют, и не могут. Тест интеграции — проверка функционирования в сборе, а не с отрезаными зависимостями. ·>Я не знаю к чему ты это всё рассказываешь, с чем споришь. Впрочем, тоже слишком общее, поэтому неверное утверждение. Можно тестировать интеграцию двух компонент, мокая третий. Например, можно тестировать интеграцию контроллера с бизнес-логикой, замокав репу.
Есть такая штука. От безысходности — если вы такой дизайн построили. Искусственное понижение уровня тестирования.
P>>Вот у вас снова из за моков почему то интеграционных тестов становится меньше. Вы путаете два противоположных случая — тест со включенными зависимостями и с обрезанными. ·>Моки позволяют упростить дизайн, снизить тяжеловесность тестов, уменьшить количество интеграционного кода, и соответственно — меньше кода — меньше тестов.
Наоборот — моки это инструмент тестирования тяжелого, монолитного кода перемешанного с зависимостями. Например, когда физически невозможно выделить логику в простые вычисления. Тогда приходят на помощь моки — как вы сами и сказали, замокали один компонент, что бы проверить остальные два. Или как у Буравчика — мутабельные вычисления, кучка зависимостей да два ифа.
И если вы предпочитаете моки, то и дизайн кода будет тяжелым.
P>>Куда ни ткни у вас "таких проблем у меня не может быть". ·>Потому что для данной конкретной проблемы существует подход, чтобы эта проблема не возникала. Если ты не хочешь использовать этот подход, тебе приходится бороться с этой проблемой.
Я вам вобщем то ровно то же говорю.
P>>Нужно проверять все эти call site вне зависимости от способа доставки депенденсов, каждая функция должна быть вызвана в тестах минимум один раз. ·>Проверять на что и каким тестом? В call site я могу использовать мок nextFriday() и проверять поведение ю-тестами.
Каким угодно, абы гарантии были, и тестирование было дешовым. Если мы выталкиваем связывание наверх, в контролер, очевидно, что юнит-тесты будет писать легче. В противном случае такой дизайн применять не стоит. И ежу понятно.
P>>Следовательно, и тестировать нужно ровно так же, а не размазывать значение по разным тестам P>>Будь у вас фукнциональный язык, можно было бы типизировать чуть не все подряд, но у вас такого фокуса нет. ·>Не очень понял. Наверное мы говорим о разных вещах. Покажи код где там какой типизации не хватает в java.
Джава умеет пересечения, объединения типов, условную типизацию, алгебраические типы?
Ы-ы-ы — всё это придется затыкать юнит-тестами, компилер вам не помощник.
·>Так я это и тестирую результат, что он зависит от nextFriday() правильным способом. Разговор о другом. ·>nextFriday(now) — это функция возвращающая пятницу для данного момента времени. А nextFriday() — это функция возвращающая пятницу для текущего момента времени. В первом случае мы по месту использования должны откуда-то брать некий момент времени, а для второго — мы знаем, что это текущий момент. ·>В функциональных яп — это частичное применение функции. У нас просто разная семантика функции "текущее время" vs "данный момент времени". Причём тут white/black — вообще неясно.
whitebox — это ваше желание протестировать каждый вызов функции.
blackbox — тестируем исходя из функциональных требований.
P>>Вам точно так же нужно протаскивать timeSource, только без параметра. И тестировать нужно ровно столько же, т.к. нужно знать, как ведет себя вся интеграция разом. ·>Не нужно его протаскивать. Он уже "частично применён" в CalendarLogic. Ты вообще понимаешь что такое ЧПФ?!
о
Вы сейчас в слова играете. Если не протаскивать зависимости, в CalendarLogic будет null во время вызова, буквально. Это значит, вы всю мелочевку повесите на dependency injection.
А вот вам кейс — трохи поменяли архитектуру, и БЛ начала вызываться через очередь, с задержкой от часов до дней. А время должно отсчитываться с момента когда юзер нажал кнопку.
И теперь ваша стройная система моков ляснулась.
В моем случае всех изменений — вместо прямого вызова делаем отложеный.
Интересно, что может быть и так и так — часть вещей считаем сейчас, часть — потом, а время используется и там и там, как текущее, так и предзаписанное.
Это вам пример, как изменение дизайна вносит хаос именно в моковую часть тестов.
P>>Вы же все эти места обмокали. Вот новый девелопер пришел на проект, откуда ему знать, должно его изменение повлечь правки моков или нет? ·>Компилятор расскажет.
Ога — каким чудом компилер узнает, что в отложеном процессинге время в той самой функции надо брать с момента инициирования запроса, а в аудите и то, и другое?
P>>Ровно так же дела с переносом кода куда угодно, выделение наследника, сплющивание иерархии, конверсии класса в функцию и обратно P>>А вам всегда будет мешать та самая зависимость ·>Вам зависимость тоже будет мешаться всегда, просто в других местах.
Ровно там, где у нас связывание, а таких мест
1 немного
2 код в них тривиальный, линейный
P>>Если вы не согласны — покажите как ваша иде инлайнит код nextFriday по месту каждого из call site. Явите же чудо, про которое вещаете тут годами ·>А ты можешь заинлайнить, например, хотя бы str.length()? Или тоже "тапочки не приносит"?
Вы только что говорили о чудесной поддержке иде именно вашего дизайна. Покажите это чудо. Мне вот ИДЕ спокойно может заинлайнить любое из мест вызова nextFriday(now)
·>"а что если в колонке пусто" — это не реальное возможное ожидание, а тестовые параметры, которые ты подсовываешь своей "чистой функции" в своём ю-тесте. А на самом деле никакого "в колонке пусто" может просто не быть, т.к. dbms заменяет его на дефолтное значение. Твой ю-тест тестирует "как написано в коде". И эту "подробную мелочь" ты тестировать в и-тесте не собираешься, а значит будешь ловить баг на проде.
Это с любыми юнит-тестами так. Для того нам и нужна таблица истинности рядом с кодом и его тестами — такое можно только другими методами проверять
У вас будет ровно то же — только косвенные проверки и больше кода.
P>>Еще раз — у меня нет буквально в коде того или иного запроса целиком, а есть конструирование его. ·>Цитирую тебя: ·>
·>Что вас смущает? deep.eq проверит всё, что надо. query это не строка, объект с конкретной структурой, чтото навроде
·> sql: 'select * from users where id=?',
·>Это не буквально?!
Это выхлоп билдера. С чего вы взяли, что такой код надо руками выписывать?
P>>То есть, у нас в наличии обычные вычисления вида object -> sql которые идеально покрываются юнит-тестами ·>То что они идеально покрываются ю-тестами, не означает, что их надо покрывать ю-тестами. Цель тестирования репо не то, как запросы выглядят, какие буковки сидят в твоих шаблонах фильтров, а то что выдаёт субд для конкретных данных.
В данном случае мы имеем дело с метапрограммированием — любое построение запроса любым методом именно оно и есть.
Соответсвенно, и тестировать нужно соответствующим методом
Ваша альтернатива — забить на data complexity, так себе идея.
P>>Даже если вы вообще удалите зависимость от Time.now, это ничего не изменит — количество интеграционных тестов останется прежним ·>А у меня этих твоих do_logic — по нулю на юз-кейс. Чуешь разницу?
do_logic и есть или юз-кейс, или контроллер.
P>>Я и говорю — телепатия. Вы лучше меня знаете, что у меня в коде, что у меня за проект, где больше всего проблем возникает, сколько должен длиться билд ·>Ты вроде прямо заявил, что некий аспект поведения ты не можешь протестировать. И время билда ты сам рассказал. Я телепатией пользоваться не умею, могу привести твои цитаты.
Все аспекты никто никогда не тестирует, у вас солнце погаснет раньше. Выбирая стратегию тестирования мы решаем что самое важно, а что нет.
Вы вот предпочитаете забить на data complexity, но продолжаете отрицать это
P>>Именно что следует. Вы топите за вайтбокс тесты, а у них известное свойство — поломки при изменении внутреннего дизайна. ·>Я топлю за вайтбокс в том смысле, что тест-кейсы пишутся со знанием что происходит внутри, чтобы понимать какие могут быть corner-cases. Но сами входные данные и ассерты теста должны соответствовать бизнес-требованиям (для данного id возвращается правильно сконструированный User). Следовательно, изменение имплементации всё ещё должно сохранять тесты зелёными.
Нет, не должно. Смотрите про тривиальный перенос вызова из одного места в другое — ваш nextFriday поломал вообще всё
·>Вот твой код "{sql: 'select * from users where id=?', params: [id], transformations: {in: [fn1],out: [fn2]}" — таким свойством не обладает, т.к. проверяет детали реализации (текст запроса, порядок ?-парамов, имена приватных функций), а не поведение. Этот тест будет ломаться от каждого чиха.
Кое что сломается. Поскольку это метапрограммирование, то это ожидаемый результат. Что бы от каждого чиха — такого нету. Запросы меняются с изменением бизнес логики.
P>>Выглядит так, что вы отрицаете недостатки моков и вайтбокс тестов, даже посредтством такой вот дешовой детской подтасовки. ·>Я отрицаю недостатки, которые ты придумал, основываясь на непонимании как надо использовать моки.
Из того кода, что приходит ко мне, моки большей частью создают проблемы. Вероятно, вы большей частью сидите в своем коде.
P>>Проверять нужно не точки сборки, а всю сборку целиком. Точки сборки — та самая вайтбоксовость с её недостатками, которые вы отрицаете уже минимум несколько лет ·>Ок, переформулирую. В сборке целиком тебе нужно проверять все точки . Тебе надо будет проверить, что где-то в твоём склеивающем коде do_logic_742 в качестве now в nextFriday(now) подставилось время сервера, а не клиента, например. И так для каждого do_logic_n, где используется nextFriday.
В интеграционных тестах мы не проверяем точки — мы проверяем саму сборку. То, что вы пишете — именно вайтбокс тест, тавтологичный "проверим что подставилось время клиента" — это и есть суть проблемы.
Вызовем как то иначе, но обеспечим результат тот же, ваш тест сломается т.к. он по прежнему будет долбить "проверим что подставилось время клиента"
P>>Функционирование и работоспособность это слова-синонимы. В руссокм языке это уже давно изобретено. ·>Тогда неясно зачем тебе и юнит тесты, и интеграционные, если и те, и те проверяют функционирование, и что тебе в твоих и-тестах приходится проверять всю функциональность.
Функции приложения никакие юнит-тесты не проверяют. Функции компонента никакие юнит-тесты не проверяют. А вот вычисление nextFriday — ровно то, что нужно .
P>>Например, те самые требования. Если нам вернуть нужно User, то очевидно, что fn2 должна возвращать User, а не абы что. ·>Ерунда какая-то. ·>Во-первых, это очень слабая проверка, т.к. такое работает если только у тебя _каждая_ функция имеет уникальный тип результата.
Это лучше, чем покрывать конское количество вычислений косвенными проверками
P>>Вы снова додумываете вместо того, что бы задать простой вопрос. ·>Вопрос о чём? Ты сам сказал, что fn2 видно только для тестов. Цитата: "fn1 и fn2 должны быть видны в тестах, а не публично". Я просто пытаюсь донести мысль, что это code smells, т.к. тесты завязаны на непубличный контракт компонента, иными словами, на внутренние детали реализации.
Для юнит-тестов это как раз нормально, их предназначение — тестировать всю мелочевку, из за которой у вас вообще что угодно можно происходить
Во многих фремворках для тестирования вы юнит-тесты можете размещать прямо в том же файле, или вообще привязывать аннотациями.
P>>Ну как же — вы собирались фильтры тестировать посредством выполнения запросов на бд, те самые "репозитории" которые вы тестируете косвенно, через БД. ·>Да.
Вот вот.
P>>Или у вас фильтрация вне репозитория сделана? ·>Нет.
И как же вы решаете проблемы с data complexity которая тестами не решается используя исключительно косвенные тесты?
P>>А вот и доказательство, что врете — здесь вы знаете что такое содержимое бд и накой оно нужно. ·>С т.з. тестов репы нет никакого "содержимого тестовой бд". "сохранить данные в бд" == вызов метода save репы, "поискать их разными фильтрами" == вызов метода find. Я же в пример кода уже дважы тыкал. С т.з. теста впрочем и бд как таковой тоже нет, можно сказать, есть просто класс с пачкой методов, которые тест дёргает и ассертит результаты.
Для простых кейсов сгодится.
P>>А вот подробности того, какого цвета унутре неонки(связывание, конверсия, маппинг, итд) — мне не надо. ·>Но вот тут "params: [id], { [fn1],out: [fn2]}" ты именно это и тестируешь. Ты уж определись надо оно тебе или не надо... Или ты тестируешь то, что тебе не надо?!!
Это выхлоп билдера — в нем связывание, конверсия, маппинг и тд. Т.е. у нас кейс с метапрограммированием — результат фукнции это код другой функции. И я использую ровно тот же подход что и везде — сравнение результата. Только в данном случае наш результат это код.
P>>Чем сложнее логика построения запросов — тем больше тестов придется писать. Косвенные проверки не смогут побороть data complexity ·>Ну да. Больше логики — больше тестов. Причём тут "косвенность" проверок?
Я ж вам пример привел с фильтрами. Одними проверками по результату побороть data complexity не получится. А у вас ничего кроме этого и нет.
т.е. вы не сможете различить два кейса — правильный запрос, и запрос на некотором множеств результатов выдает данные похожие на нужные
Например — фильтр вырождается в true. А вот если мы накладываем ограничения на результирующий запрос, у нас эта часть исключается принципиально.
P>>Дональд Кнут на линии: "Остерегайтесь ошибок коде; я только доказал его правильность, но не проверял его." ·>Ты либо крестик, либо трусы. Док.программирование это спеки, контракты и верификаторы. Тесты тут непричём.
Простой вопрос был — как ваше доказательство проверит само себя если другой коллега начнет писать код как ему вздумается?
С тестами всё просто — в пулреквесте будут видны закомменченые тесты, или же билд не соберется и не попадёт на прод
P>>А еще чаще это признак огромного проекта ·>Огромного проекта в плохом состоянии, да. Впрочем, не раз наблюдал и маленькие проекты на неск. сот строк билдятся час — сразу видно, писали по всем канонам и заветам дядек из интернета!
Да, ваша телепатия похоже прогрессирует
P>>language agnostic описания, если вы про json, это отстой, т.к. удлинняет цикл разработки — есть шанс написать такой манифест, который хрен знает как заимплементить ·>Написать такой корявый манифест немного сложнее, чем сгенерить.
Наоборот. Руками затейники выдают такое, что ни один генератор проглотить не может. А если вы начинаете с аннотаций или хотя бы интерфейсов, то уж точно ясно, что это реализуемо.
P>>3. например, мы связываем части своего собственного проекта — здесь вообще может быть один и тот же яп ·>Тогда нафиг и не нужны аннотации, и уж тем более манифесты.
Наоборот. АПИ то никуда не делся, только работаем мы с ним немного не так, как вы привыкли. Тесты всё равно остаются. И их надо не ногой писать, а согласно определению апи. И документирование, и клиентский код, и много чего еще.
P>>design-first означает, что в первую очередь деливерится апи, а не абы что. А вот как вы его сформулируете — json, idl, grapql, grpc, интерфейсы на псевдокоде, java классы без реализации — вообще дело десятое, хоть plantuml или curl. P>>Здесь самое главное, что бы мы могли отдать описание всем, кто будет с ним взаимодействовать. А уже потом начнем работать над реализацией. ·>Так у тебя же в начале (first) пишется/меняется code
АПИ. Его формат непринципиален — интерфейс с аннотациями, json, idl, curl, абстрактные классы, просто набор функций. Главное, что бы реализации нет.
> и потом из него генерится описание, которые ты отдаёшь всем. Да ещё и разное описание, в зависимости от фазы луны.
Вы вместо вопроса слишком злоупотребляете телепатией. АПИ, если отдаётся, то в большинстве случаев уже ничего генерить не надо. Например, согласовали интерфейс, зафиксировали, и каждый пошел работать над своей реализацией.
> Т.е. ты в первую очередь кодишь свои переменные, конфиги, логику тенантов, и лишь потом у тебя появляется описание.
Вы похоже не вдупляте — design-first = вначале деливерим АПИ, а потом уже реализация, куда входят переменные, конфиги, логика тенантов итд.
P>>Основа апи остаётся. Переменные окружения и конфиги не могут поменять параметры метода, типы, результат итд. Но могут скрыть этот метод, или добавить метаданные, например, метод начнет требовать авторизацию, или наоборот, будет работать без авторизации. ·>И на чём эта вся логика написана? На grpc, да?
На чем хотите. grpc возможно не всё умеет, я не сильно в ём понимаю, но принципиальных проблем не вижу.
Здравствуйте, Pauel, Вы писали: P>>>Мешают — хрупкие тесты, т.к. вайтбоксы, и дополнительный приседания что бы обмокать зависимости P>·>Хрупкость тестов с моками — это твои фантазии и страшилки. Конечно, в том виде как ты показывал способ использования моков — делает тесты хрупкими. Просто не используй моки так. P>Вы уже показывали, когда мокали репозиторий ради тестов контролера, а потом скромно замолчали на вопрос, что делать, если меняется дизайн
Вопрос я не понял, мол что делать если что-то меняется, ответил как мог — если что-то меняется, то эээ... надо что-то менять. Если тебя интересует конкретная проблема, сформулируй с примерами кода. P>>>Нету такой функции как склейка. Вы все еще думаете вайтбоксом. P>·>Частичное применение функции — даёт функцию. P>Я вам про функциональные требования, а вы мне про функции в коде. Проверка склейки — это вайтбокс тест уровня юнит-тестов. В интеграционных тестах мы проверяем ожидания вызывающей стороны. А её точно ничего про склейку не известно.
"следующая пятница текущего времени" — вполне функциональное требование. В интеграционных тестах ты прямо заявил, что никак не сможешь проверить это ожидание. P>>>Тесты на моках интеграцию не тестируют, и не могут. Тест интеграции — проверка функционирования в сборе, а не с отрезаными зависимостями. P>·>Я не знаю к чему ты это всё рассказываешь, с чем споришь. Впрочем, тоже слишком общее, поэтому неверное утверждение. Можно тестировать интеграцию двух компонент, мокая третий. Например, можно тестировать интеграцию контроллера с бизнес-логикой, замокав репу. P>Есть такая штука. От безысходности — если вы такой дизайн построили. Искусственное понижение уровня тестирования.
Ну да, верно. Ты так говоришь, как будто что-то плохое. Чем больше мы можем проверять низкоуровневыми тестами, тем лучше. "Искусственно" — тоже верно, мы режем зависимости там, где они самые тяжелые, требуют больше ресурсов, замедляют билд. "Безысходность" — потому что альтернативы — хуже. P>>>Вот у вас снова из за моков почему то интеграционных тестов становится меньше. Вы путаете два противоположных случая — тест со включенными зависимостями и с обрезанными. P>·>Моки позволяют упростить дизайн, снизить тяжеловесность тестов, уменьшить количество интеграционного кода, и соответственно — меньше кода — меньше тестов. P>Наоборот — моки это инструмент тестирования тяжелого, монолитного кода перемешанного с зависимостями. Например, когда физически невозможно выделить логику в простые вычисления.
Что за "физически"? Тезис Чёрча знаешь? Любой код можно переписать на чистый, хаскель неплохо это доказывает. Вопрос — накой?! P> Тогда приходят на помощь моки — как вы сами и сказали, замокали один компонент, что бы проверить остальные два.
Замокали "плохой", тяжёлый компонент, требующий файловой системы, сети, многопоточки, чтобы хорошо и легко проверить остальные два на саму логику и бизнес-требования. P>Или как у Буравчика — мутабельные вычисления, кучка зависимостей да два ифа.
Ну "правильного" дизайна ты предолжить просто не смог. Т.к. это более менее реальный проект с нетривиальной бизнес-логикой. А твои штуки вменяемо работают только на хоумпейджах. P>И если вы предпочитаете моки, то и дизайн кода будет тяжелым.
Я не знаю что за такое "тяжелый дизайн". P>>>Куда ни ткни у вас "таких проблем у меня не может быть". P>·>Потому что для данной конкретной проблемы существует подход, чтобы эта проблема не возникала. Если ты не хочешь использовать этот подход, тебе приходится бороться с этой проблемой. P>Я вам вобщем то ровно то же говорю.
И? Что такого, что я знаю как некоторые проблемы решаются? Магией для тебя что-ли выглядит? P>>>Нужно проверять все эти call site вне зависимости от способа доставки депенденсов, каждая функция должна быть вызвана в тестах минимум один раз. P>·>Проверять на что и каким тестом? В call site я могу использовать мок nextFriday() и проверять поведение ю-тестами. P>Каким угодно, абы гарантии были, и тестирование было дешовым. Если мы выталкиваем связывание наверх, в контролер, очевидно, что юнит-тесты будет писать легче. В противном случае такой дизайн применять не стоит. И ежу понятно.
Связывание находится в wiring code. Контроллер это просто ещё один компонент, ничем принципиальным от других не отличается. P>>>Следовательно, и тестировать нужно ровно так же, а не размазывать значение по разным тестам P>>>Будь у вас фукнциональный язык, можно было бы типизировать чуть не все подряд, но у вас такого фокуса нет. P>·>Не очень понял. Наверное мы говорим о разных вещах. Покажи код где там какой типизации не хватает в java. P>Джава умеет пересечения, объединения типов, условную типизацию, алгебраические типы? P>Ы-ы-ы — всё это придется затыкать юнит-тестами, компилер вам не помощник.
Покажи код где там какой типизации не хватает в java. И не просто общие слова, а не забывай про контекст обсуждения. P>·>Так я это и тестирую результат, что он зависит от nextFriday() правильным способом. Разговор о другом. P>·>nextFriday(now) — это функция возвращающая пятницу для данного момента времени. А nextFriday() — это функция возвращающая пятницу для текущего момента времени. В первом случае мы по месту использования должны откуда-то брать некий момент времени, а для второго — мы знаем, что это текущий момент. P>·>В функциональных яп — это частичное применение функции. У нас просто разная семантика функции "текущее время" vs "данный момент времени". Причём тут white/black — вообще неясно. P>whitebox — это ваше желание протестировать каждый вызов функции. P>blackbox — тестируем исходя из функциональных требований.
И? "текущее время" vs "данный момент времени" — это функциональные требования. Причём тут вызовы функций? P>>>Вам точно так же нужно протаскивать timeSource, только без параметра. И тестировать нужно ровно столько же, т.к. нужно знать, как ведет себя вся интеграция разом. P>·>Не нужно его протаскивать. Он уже "частично применён" в CalendarLogic. Ты вообще понимаешь что такое ЧПФ?! P>о P>Вы сейчас в слова играете. Если не протаскивать зависимости, в CalendarLogic будет null во время вызова, буквально. Это значит, вы всю мелочевку повесите на dependency injection.
Что за ерунда? Откуда там null возьмётся? Что за "повесите на dependency injection"? источник времени — это зависимость CalendarLogic, инжектится через конструктор. ЧПФ, забыл опять? P>А вот вам кейс — трохи поменяли архитектуру, и БЛ начала вызываться через очередь, с задержкой от часов до дней. А время должно отсчитываться с момента когда юзер нажал кнопку.
Поменяется InstantSource, будет добывать время не из system clock, а из таймстампа в очереди. Это вообще никакое не архитектурное изменение, а одна строчка в wiring code — что инжектить как источник времени. P>И теперь ваша стройная система моков ляснулась.
Опять страшилки какие-то. В каком месте что ляснулось? P>В моем случае всех изменений — вместо прямого вызова делаем отложеный.
Что за отложенный вызов? Вызов где? P>Интересно, что может быть и так и так — часть вещей считаем сейчас, часть — потом, а время используется и там и там, как текущее, так и предзаписанное.
Ну будет два InstantSource в разных местах. P>Это вам пример, как изменение дизайна вносит хаос именно в моковую часть тестов.
В моках надо будет просто сделать два источника времени, у и ассертить, что в нужных местах используется время из ожидаемого источника. P>>>Вы же все эти места обмокали. Вот новый девелопер пришел на проект, откуда ему знать, должно его изменение повлечь правки моков или нет? P>·>Компилятор расскажет. P>Ога — каким чудом компилер узнает, что в отложеном процессинге время в той самой функции надо брать с момента инициирования запроса, а в аудите и то, и другое?
Это будет две функции. ЧПФ, слышал? P>·>Вам зависимость тоже будет мешаться всегда, просто в других местах. P>Ровно там, где у нас связывание, а таких мест P>1 немного
У тебя много, на каждый сценарий. P>2 код в них тривиальный, линейный
Да, но кода этого много накопипасчено. P>>>Если вы не согласны — покажите как ваша иде инлайнит код nextFriday по месту каждого из call site. Явите же чудо, про которое вещаете тут годами P>·>А ты можешь заинлайнить, например, хотя бы str.length()? Или тоже "тапочки не приносит"? P>Вы только что говорили о чудесной поддержке иде именно вашего дизайна. Покажите это чудо. Мне вот ИДЕ спокойно может заинлайнить любое из мест вызова nextFriday(now)
Круто, но зачем? Задачу-то какую решаем? P>·>"а что если в колонке пусто" — это не реальное возможное ожидание, а тестовые параметры, которые ты подсовываешь своей "чистой функции" в своём ю-тесте. А на самом деле никакого "в колонке пусто" может просто не быть, т.к. dbms заменяет его на дефолтное значение. Твой ю-тест тестирует "как написано в коде". И эту "подробную мелочь" ты тестировать в и-тесте не собираешься, а значит будешь ловить баг на проде. P>Это с любыми юнит-тестами так.
Не с любыми, а только с теми, которые тестируют детали имплементации, а не логику. Поэтому я и говорю, что _эти_ ю-тесты — не нужны. Ибо всё ровно то же придётся покрывать и-тестами с субд. Ты можешь объяснить зачем ты пишешь такие ю-тесты? Повторюсь, эти тесты не только бесполезны, но и вредны, т.к. хрупкие и усложняют внесение изменений. P>Для того нам и нужна таблица истинности рядом с кодом и его тестами — такое можно только другими методами проверять
Дело в том, что в случае субд у тебя кода субд нет. P>У вас будет ровно то же — только косвенные проверки и больше кода.
Я код уже показывал, не фантазируй. P>>>Еще раз — у меня нет буквально в коде того или иного запроса целиком, а есть конструирование его. P>·>Цитирую тебя: P>·>
P>·>Что вас смущает? deep.eq проверит всё, что надо. query это не строка, объект с конкретной структурой, чтото навроде
P>·> sql: 'select * from users where id=?',
P>·>
P>·>Это не буквально?! P>Это выхлоп билдера. С чего вы взяли, что такой код надо руками выписывать?
Это какой-то небуквальный выхлоп или что? Выхлоп какого билдера?
Тесты обычно пишут люди для людей. А вы генерите тесты?! P>·>То что они идеально покрываются ю-тестами, не означает, что их надо покрывать ю-тестами. Цель тестирования репо не то, как запросы выглядят, какие буковки сидят в твоих шаблонах фильтров, а то что выдаёт субд для конкретных данных. P>В данном случае мы имеем дело с метапрограммированием — любое построение запроса любым методом именно оно и есть. P>Соответсвенно, и тестировать нужно соответствующим методом
Ты вроде сам заявлял, что тестировать нужно ожидания. Какое отношение метапрограммирование имеет к бизнес-требованиям или ожиданиям? P>Ваша альтернатива — забить на data complexity, так себе идея.
Цитату в студию или признавайся, что опять соврал. P>>>Даже если вы вообще удалите зависимость от Time.now, это ничего не изменит — количество интеграционных тестов останется прежним P>·>А у меня этих твоих do_logic — по нулю на юз-кейс. Чуешь разницу? P>do_logic и есть или юз-кейс, или контроллер.
Я имею в виду вот этот твой do_logic. Это не юзкейс. Это код-лапша.
def do_logic(v1,v2,v3):
l = Logic(v1,v2,v3)
p = l.run(
load = ..., repo // здесь и ниже хватит простой лямбды
load2 = ...., svc
commit = ..., repo+kafka // как вариант, для кафки можно протащить доп. имя, например event
);
Return serialize(p)
P>>>Я и говорю — телепатия. Вы лучше меня знаете, что у меня в коде, что у меня за проект, где больше всего проблем возникает, сколько должен длиться билд P>·>Ты вроде прямо заявил, что некий аспект поведения ты не можешь протестировать. И время билда ты сам рассказал. Я телепатией пользоваться не умею, могу привести твои цитаты. P>Все аспекты никто никогда не тестирует, у вас солнце погаснет раньше. Выбирая стратегию тестирования мы решаем что самое важно, а что нет.
Ты читать умеешь? Я пишу "некий аспект", ты возражаешь "Все аспекты". Я где-то требовал тестировать все аспекты, кроме как в твоих фантазиях? Я спросил как тестировать один конкретный тривиальный аспект, который элементарно тестируется с моим дизайном, а ты не смог, у тебя солнце погасло. P>Вы вот предпочитаете забить на data complexity, но продолжаете отрицать это
Ты врёшь опять. Цитаты ведь не будет. P>>>Именно что следует. Вы топите за вайтбокс тесты, а у них известное свойство — поломки при изменении внутреннего дизайна. P>·>Я топлю за вайтбокс в том смысле, что тест-кейсы пишутся со знанием что происходит внутри, чтобы понимать какие могут быть corner-cases. Но сами входные данные и ассерты теста должны соответствовать бизнес-требованиям (для данного id возвращается правильно сконструированный User). Следовательно, изменение имплементации всё ещё должно сохранять тесты зелёными. P>Нет, не должно.
Должно, т.к. это тестирование бизнес-требования. P>Смотрите про тривиальный перенос вызова из одного места в другое — ваш nextFriday поломал вообще всё
Куда смотреть? Поломал что? P>·>Вот твой код "{sql: 'select * from users where id=?', params: [id], transformations: {in: [fn1],out: [fn2]}" — таким свойством не обладает, т.к. проверяет детали реализации (текст запроса, порядок ?-парамов, имена приватных функций), а не поведение. Этот тест будет ломаться от каждого чиха. P>Кое что сломается. Поскольку это метапрограммирование, то это ожидаемый результат.
Ожидаемый кем/зачем? P>Что бы от каждого чиха — такого нету. Запросы меняются с изменением бизнес логики.
Я тебе приводил пример — заменить звёздочку на список полей — это чих, а не изменение бизнес логики. P>>>Выглядит так, что вы отрицаете недостатки моков и вайтбокс тестов, даже посредтством такой вот дешовой детской подтасовки. P>·>Я отрицаю недостатки, которые ты придумал, основываясь на непонимании как надо использовать моки. P>Из того кода, что приходит ко мне, моки большей частью создают проблемы. Вероятно, вы большей частью сидите в своем коде.
У нас вообще нет никакого своего кода... "вы" — это примерно пол сотни девов... ну да, сидим. P>>>Проверять нужно не точки сборки, а всю сборку целиком. Точки сборки — та самая вайтбоксовость с её недостатками, которые вы отрицаете уже минимум несколько лет P>·>Ок, переформулирую. В сборке целиком тебе нужно проверять все точки . Тебе надо будет проверить, что где-то в твоём склеивающем коде do_logic_742 в качестве now в nextFriday(now) подставилось время сервера, а не клиента, например. И так для каждого do_logic_n, где используется nextFriday. P>В интеграционных тестах мы не проверяем точки — мы проверяем саму сборку.
Если сборка идёт в трёх точках — проверить легко. Если сборка идёт в трёхсот точках — проверить сложно. P>То, что вы пишете — именно вайтбокс тест, тавтологичный "проверим что подставилось время клиента" — это и есть суть проблемы.
Почему вайтбокс? Тест бизнес-требования — "в ответе приходит правильное время". P>Вызовем как то иначе, но обеспечим результат тот же, ваш тест сломается т.к. он по прежнему будет долбить "проверим что подставилось время клиента"
Как ты _проверишь_, что результат тот же и соответствует ожиданиям? P>>>Функционирование и работоспособность это слова-синонимы. В руссокм языке это уже давно изобретено. P>·>Тогда неясно зачем тебе и юнит тесты, и интеграционные, если и те, и те проверяют функционирование, и что тебе в твоих и-тестах приходится проверять всю функциональность. P>Функции приложения никакие юнит-тесты не проверяют. Функции компонента никакие юнит-тесты не проверяют. А вот вычисление nextFriday — ровно то, что нужно .
Я не знаю что ты сейчас такое написал и к чему. Напомню, тут речь идёт о:
·>Как ты тестируешь что построенный запрос хотя бы синтаксически корректен?
тот самый интеграционный тест, на некорретном запросе он упадет
Т.е. у тебя есть туева хуча ю-тестов для каждого сценария, которые проверяют _тексты_ запросов, но для проверки, что текст запроса хотя бы корректен — приходится ещё и и-тестом каждый запрос проверить для ровно тех же сценариев. P>>>Например, те самые требования. Если нам вернуть нужно User, то очевидно, что fn2 должна возвращать User, а не абы что. P>·>Ерунда какая-то. P>·>Во-первых, это очень слабая проверка, т.к. такое работает если только у тебя _каждая_ функция имеет уникальный тип результата. P>Это лучше, чем покрывать конское количество вычислений косвенными проверками
Это хуже, т.к. это нереально, по крайней мере для любого проекта, хоть чуть больше хоумпейджа.
А про "во-вторых" ты сделал вид, что этого даже не было. Ловко. Вот только надо было бы ещё и "во-первых" не квотить, я бы может и не вспомнил.. P>>>Вы снова додумываете вместо того, что бы задать простой вопрос. P>·>Вопрос о чём? Ты сам сказал, что fn2 видно только для тестов. Цитата: "fn1 и fn2 должны быть видны в тестах, а не публично". Я просто пытаюсь донести мысль, что это code smells, т.к. тесты завязаны на непубличный контракт компонента, иными словами, на внутренние детали реализации. P>Для юнит-тестов это как раз нормально, их предназначение — тестировать всю мелочевку, из за которой у вас вообще что угодно можно происходить
Дело не в мелочёвке-большичёвке, а в том, что ты тестируешь код как написано, а не ожидания/бизнес-требования. Ровно то, чем ты меня пытался попрекать. P>Во многих фремворках для тестирования вы юнит-тесты можете размещать прямо в том же файле, или вообще привязывать аннотациями.
Мрак. P>>>Ну как же — вы собирались фильтры тестировать посредством выполнения запросов на бд, те самые "репозитории" которые вы тестируете косвенно, через БД. P>·>Да. P>Вот вот.
Ты так говоришь, как будто это что-то плохое. P>>>Или у вас фильтрация вне репозитория сделана? P>·>Нет. P>И как же вы решаете проблемы с data complexity которая тестами не решается используя исключительно косвенные тесты?
А конкретнее? С примером кода. P>>>А вот и доказательство, что врете — здесь вы знаете что такое содержимое бд и накой оно нужно. P>·>С т.з. тестов репы нет никакого "содержимого тестовой бд". "сохранить данные в бд" == вызов метода save репы, "поискать их разными фильтрами" == вызов метода find. Я же в пример кода уже дважы тыкал. С т.з. теста впрочем и бд как таковой тоже нет, можно сказать, есть просто класс с пачкой методов, которые тест дёргает и ассертит результаты. P>Для простых кейсов сгодится.
А сложные будем упрощать. Или у тебя есть конкретный пример когда не сгодится? P>>>А вот подробности того, какого цвета унутре неонки(связывание, конверсия, маппинг, итд) — мне не надо. P>·>Но вот тут "params: [id], { [fn1],out: [fn2]}" ты именно это и тестируешь. Ты уж определись надо оно тебе или не надо... Или ты тестируешь то, что тебе не надо?!! P>Это выхлоп билдера — в нем связывание, конверсия, маппинг и тд. Т.е. у нас кейс с метапрограммированием — результат фукнции это код другой функции. И я использую ровно тот же подход что и везде — сравнение результата. Только в данном случае наш результат это код.
Зачем нам тестировать выхлоп билдера? У билдера должны быть свои тесты. Ты сомневаешься, что какой-нибудь linq/jooq что-то не так нагенерит? И как это относится к тестированию ожиданий, а не кода "как написано"? P>>>Чем сложнее логика построения запросов — тем больше тестов придется писать. Косвенные проверки не смогут побороть data complexity P>·>Ну да. Больше логики — больше тестов. Причём тут "косвенность" проверок? P>Я ж вам пример привел с фильтрами. Одними проверками по результату побороть data complexity не получится. А у вас ничего кроме этого и нет. P>т.е. вы не сможете различить два кейса — правильный запрос, и запрос на некотором множеств результатов выдает данные похожие на нужные P>Например — фильтр вырождается в true. А вот если мы накладываем ограничения на результирующий запрос, у нас эта часть исключается принципиально.
Не понимаю проблему. Если фильтр выродится в true, то субд вернёт те записи, которые мы не ожидаем, тест провалится. P>>>Дональд Кнут на линии: "Остерегайтесь ошибок коде; я только доказал его правильность, но не проверял его." P>·>Ты либо крестик, либо трусы. Док.программирование это спеки, контракты и верификаторы. Тесты тут непричём. P>Простой вопрос был — как ваше доказательство проверит само себя если другой коллега начнет писать код как ему вздумается?
Верификатор выдаст ошибку. Почитай про какой-нибудь coq что-ли. P>С тестами всё просто — в пулреквесте будут видны закомменченые тесты, или же билд не соберется и не попадёт на прод
Ну будет в коммите одном из десятка тестов вырожденный фильтр... И? Особенно весёлые штуки типа "A = B OR A <> B" из-за немножко не так поставленных скобочкек. Ты как равьювер будешь смотреть тесты и в уме интерпретировать sql запросы? P>>>language agnostic описания, если вы про json, это отстой, т.к. удлинняет цикл разработки — есть шанс написать такой манифест, который хрен знает как заимплементить P>·>Написать такой корявый манифест немного сложнее, чем сгенерить. P>Наоборот. Руками затейники выдают такое, что ни один генератор проглотить не может. А если вы начинаете с аннотаций или хотя бы интерфейсов, то уж точно ясно, что это реализуемо.
Верно, но называется это code-first со всеми последствиями. P>>>3. например, мы связываем части своего собственного проекта — здесь вообще может быть один и тот же яп P>·>Тогда нафиг и не нужны аннотации, и уж тем более манифесты. P>Наоборот. АПИ то никуда не делся, только работаем мы с ним немного не так, как вы привыкли. Тесты всё равно остаются. И их надо не ногой писать, а согласно определению апи. И документирование, и клиентский код, и много чего еще.
Апи будет просто набор интерфейсов и/или модели данных. С нулевой логикой. P>>>design-first означает, что в первую очередь деливерится апи, а не абы что. А вот как вы его сформулируете — json, idl, grapql, grpc, интерфейсы на псевдокоде, java классы без реализации — вообще дело десятое, хоть plantuml или curl. P>>>Здесь самое главное, что бы мы могли отдать описание всем, кто будет с ним взаимодействовать. А уже потом начнем работать над реализацией. P>·>Так у тебя же в начале (first) пишется/меняется code P>АПИ. Его формат непринципиален — интерфейс с аннотациями, json, idl, curl, абстрактные классы, просто набор функций. Главное, что бы реализации нет.
Главнее, чтобы логики не было. >> и потом из него генерится описание, которые ты отдаёшь всем. Да ещё и разное описание, в зависимости от фазы луны. P>Вы вместо вопроса слишком злоупотребляете телепатией. АПИ, если отдаётся, то в большинстве случаев уже ничего генерить не надо. Например, согласовали интерфейс, зафиксировали, и каждый пошел работать над своей реализацией.
Ты опять врёшь. Не телепатией, а из твоих слов: "Манифест генерируется по запросу, обычно http", противоречие выделил жирным. Или ты похоже просто в прыжке переобуваешься. >> Т.е. ты в первую очередь кодишь свои переменные, конфиги, логику тенантов, и лишь потом у тебя появляется описание. P>Вы похоже не вдупляте — design-first = вначале деливерим АПИ, а потом уже реализация, куда входят переменные, конфиги, логика тенантов итд.
http-сервер это такой АПИ... Угу-угу.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>Вы уже показывали, когда мокали репозиторий ради тестов контролера, а потом скромно замолчали на вопрос, что делать, если меняется дизайн ·>Вопрос я не понял, мол что делать если что-то меняется, ответил как мог — если что-то меняется, то эээ... надо что-то менять. Если тебя интересует конкретная проблема, сформулируй с примерами кода.
Вы мок затачивали на все тесты, или по моку на каждый?
1. На все — все ваши тесты неявно теперь зависят от мока. И если вы закостылили мок, то заточили тесты под синтетику, код — под такие тесты.
2. Если по моку на каждый — можно хоть ревью сделать. Кода больше, но и контроля больше.
P>>Я вам про функциональные требования, а вы мне про функции в коде. Проверка склейки — это вайтбокс тест уровня юнит-тестов. В интеграционных тестах мы проверяем ожидания вызывающей стороны. А её точно ничего про склейку не известно. ·>"следующая пятница текущего времени" — вполне функциональное требование. В интеграционных тестах ты прямо заявил, что никак не сможешь проверить это ожидание.
Проверка склейки — такого не будет. А вот поддерживает ли приложение такую функцию — нужно проверять интеграционным тестым.
И ваши моки не избавляют этого.
P>>Есть такая штука. От безысходности — если вы такой дизайн построили. Искусственное понижение уровня тестирования. ·>Ну да, верно. Ты так говоришь, как будто что-то плохое. Чем больше мы можем проверять низкоуровневыми тестами, тем лучше. "Искусственно" — тоже верно, мы режем зависимости там, где они самые тяжелые, требуют больше ресурсов, замедляют билд. "Безысходность" — потому что альтернативы — хуже.
Самосбывающееся пророчество — обычно безысходность очень быстро наступает в том случае, когда изначально заложились на моки b монолитный дизайн.
Вариантов дизайна всегда больше одного
P>>Наоборот — моки это инструмент тестирования тяжелого, монолитного кода перемешанного с зависимостями. Например, когда физически невозможно выделить логику в простые вычисления. ·>Что за "физически"? Тезис Чёрча знаешь? Любой код можно переписать на чистый, хаскель неплохо это доказывает. Вопрос — накой?!
Есть же пример Буравчика. Вам мало, надо к абсурду свести?
P>> Тогда приходят на помощь моки — как вы сами и сказали, замокали один компонент, что бы проверить остальные два. ·>Замокали "плохой", тяжёлый компонент, требующий файловой системы, сети, многопоточки, чтобы хорошо и легко проверить остальные два на саму логику и бизнес-требования.
В стиле ТДД — написали тесты на моках, а потом и дизайн вышел соответствующим
P>>Или как у Буравчика — мутабельные вычисления, кучка зависимостей да два ифа. ·>Ну "правильного" дизайна ты предолжить просто не смог. Т.к. это более менее реальный проект с нетривиальной бизнес-логикой. А твои штуки вменяемо работают только на хоумпейджах.
Какой еще "правильный"? Я продемонстрировал, что минимальными усилиями можно свести тесты к таблице истинности и хранить все это максимально близко к коду.
P>>И если вы предпочитаете моки, то и дизайн кода будет тяжелым. ·>Я не знаю что за такое "тяжелый дизайн".
Это тот, который вы демонстрируете
·>Связывание находится в wiring code. Контроллер это просто ещё один компонент, ничем принципиальным от других не отличается.
Связывание и есть wiring код. Основная обязанность контроллера — именно это. И тестировать связку, как следствие.
Если же вы сторонник жирных контроллеров, конечно же вам придется мокать всё на свете. Не только time, а еще и sin и cos
P>>Ы-ы-ы — всё это придется затыкать юнит-тестами, компилер вам не помощник. ·>Покажи код где там какой типизации не хватает в java. И не просто общие слова, а не забывай про контекст обсуждения.
Я ж вам перечислил. Вы хотите еще и фичи статической типизации докинуть к нынешней теме?
P>>blackbox — тестируем исходя из функциональных требований. ·>И? "текущее время" vs "данный момент времени" — это функциональные требования. Причём тут вызовы функций?
Вы тестируете, что результат зависит от конкретного вызова. Сами же про это и пишете.
P>>Вы сейчас в слова играете. Если не протаскивать зависимости, в CalendarLogic будет null во время вызова, буквально. Это значит, вы всю мелочевку повесите на dependency injection. ·>Что за ерунда? Откуда там null возьмётся? Что за "повесите на dependency injection"? источник времени — это зависимость CalendarLogic, инжектится через конструктор. ЧПФ, забыл опять?
Сами спросили — сами ответили.
P>>А вот вам кейс — трохи поменяли архитектуру, и БЛ начала вызываться через очередь, с задержкой от часов до дней. А время должно отсчитываться с момента когда юзер нажал кнопку. ·>Поменяется InstantSource, будет добывать время не из system clock, а из таймстампа в очереди. Это вообще никакое не архитектурное изменение, а одна строчка в wiring code — что инжектить как источник времени.
О — InstantSource появился. Значит инжектиться может не один единственный вариант с Now, а минимум два. Где у вас тестирование инжекции? А ну как на проде все инжектиться будет по старому?
P>>В моем случае всех изменений — вместо прямого вызова делаем отложеный. ·>Что за отложенный вызов? Вызов где?
А как вы понимаете, что такое отложеный вызов? Недавно вам непонятно было что такое dependency injection, потом выяснилось, что все вам известно. Тут похоже вам снова надо с самим собой поговорить
P>>Интересно, что может быть и так и так — часть вещей считаем сейчас, часть — потом, а время используется и там и там, как текущее, так и предзаписанное. ·>Ну будет два InstantSource в разных местах.
Вот-вот. Как вы отличите что первый и второй не перепутаны? Это ж ваша любимая тема — надо проверить, что передали то самое!
P>>Это вам пример, как изменение дизайна вносит хаос именно в моковую часть тестов. ·>В моках надо будет просто сделать два источника времени, у и ассертить, что в нужных местах используется время из ожидаемого источника.
А еще можно обойтись без моков И свести к таблице истинности, поскольку интеграционный тест всё равно понадобится.
P>>Ога — каким чудом компилер узнает, что в отложеном процессинге время в той самой функции надо брать с момента инициирования запроса, а в аудите и то, и другое? ·>Это будет две функции. ЧПФ, слышал?
Я в курсе: "ассертим что вызываем с тем параметром а не этим"
P>>Ровно там, где у нас связывание, а таких мест P>>1 немного ·>У тебя много, на каждый сценарий.
Не всё так страшно — мы упрощаем не только бл, но и связывание. Посколько у вас больше одного провайдера для зависимости, всё может играть по разному в зависимости от сценария.
В одном сценарии у вас один провайдер времени, в другом — другой. Опаньки! Только вы это размазали по коду.
P>>2 код в них тривиальный, линейный ·>Да, но кода этого много накопипасчено.
Ну и что?
P>>Вы только что говорили о чудесной поддержке иде именно вашего дизайна. Покажите это чудо. Мне вот ИДЕ спокойно может заинлайнить любое из мест вызова nextFriday(now) ·>Круто, но зачем? Задачу-то какую решаем?
Затем, что признак хорошего кода это его гибкость, которая проявляется в т.ч. в том, что код можно трансформировать, инлайнить, итд, да хоть вовсе от него избавиться.
·>Не с любыми, а только с теми, которые тестируют детали имплементации, а не логику. Поэтому я и говорю, что _эти_ ю-тесты — не нужны. Ибо всё ровно то же придётся покрывать и-тестами с субд. Ты можешь объяснить зачем ты пишешь такие ю-тесты? Повторюсь, эти тесты не только бесполезны, но и вредны, т.к. хрупкие и усложняют внесение изменений.
Вы так и не рассказали, как будете решать ту самую задачу с фильтрами.
P>>Для того нам и нужна таблица истинности рядом с кодом и его тестами — такое можно только другими методами проверять ·>Дело в том, что в случае субд у тебя кода субд нет.
И не надо.
P>>Это выхлоп билдера. С чего вы взяли, что такой код надо руками выписывать? ·>Это какой-то небуквальный выхлоп или что? Выхлоп какого билдера?
Билдера запросов к базе данных. Вы что думаете, все sql запросы руками пишутся? Кое что, для аналитики — возможно. Но это большей частью всё равно перегоняется в орм или билдер. Есть орм — можно проверять построение логики запросов орм.
P>>Соответсвенно, и тестировать нужно соответствующим методом ·>Ты вроде сам заявлял, что тестировать нужно ожидания. Какое отношение метапрограммирование имеет к бизнес-требованиям или ожиданиям?
Запрос к базе должен соответсвовать бизнес-требованиям. Только проверяем мы это в т.ч. посредством метапрограммирования.
P>>Ваша альтернатива — забить на data complexity, так себе идея. ·>Цитату в студию или признавайся, что опять соврал.
Вы до сих пор не привели решение кроме "ищем в бд"
P>>do_logic и есть или юз-кейс, или контроллер. ·>Я имею в виду вот этот твой do_logic. Это не юзкейс. Это код-лапша.
Сравнивать нужно не как выглядит, а всё цельные решения, включая моки всех сортов, dependency injection, размазаную и скрытую, тесты которые без таблицы истинности итд.
P>>>>Я и говорю — телепатия. Вы лучше меня знаете, что у меня в коде, что у меня за проект, где больше всего проблем возникает, сколько должен длиться билд P>>·>Ты вроде прямо заявил, что некий аспект поведения ты не можешь протестировать. И время билда ты сам рассказал. Я телепатией пользоваться не умею, могу привести твои цитаты. P>>Все аспекты никто никогда не тестирует, у вас солнце погаснет раньше. Выбирая стратегию тестирования мы решаем что самое важно, а что нет. ·>Ты читать умеешь? Я пишу "некий аспект", ты возражаешь "Все аспекты". Я где-то требовал тестировать все аспекты, кроме как в твоих фантазиях? Я спросил как тестировать один конкретный тривиальный аспект, который элементарно тестируется с моим дизайном, а ты не смог, у тебя солнце погасло.
У вас плохо с логикой — если нет возможности тестировать все аспекты, а это невозможно, значит в каждом конкретном случае какие то аспекты будут непротестированы.
Ваш тривиальный аспект это "вызываем с нужным параметром" ?
о. P>>·>Я топлю за вайтбокс в том смысле, что тест-кейсы пишутся со знанием что происходит внутри, чтобы понимать какие могут быть corner-cases. Но сами входные данные и ассерты теста должны соответствовать бизнес-требованиям (для данного id возвращается правильно сконструированный User). Следовательно, изменение имплементации всё ещё должно сохранять тесты зелёными. P>>Нет, не должно. ·>Должно, т.к. это тестирование бизнес-требования.
Должно, только ваш nextFriday поломал вообще всё, т.к. ему надо прописать другие значения, а без этого или все тесты красные, или зелены при гарантировано нерабочей системе.
P>>Смотрите про тривиальный перенос вызова из одного места в другое — ваш nextFriday поломал вообще всё ·>Куда смотреть? Поломал что?
Вам надо мок подфиксить, что бы время было той системы
P>>·>Вот твой код "{sql: 'select * from users where id=?', params: [id], transformations: {in: [fn1],out: [fn2]}" — таким свойством не обладает, т.к. проверяет детали реализации (текст запроса, порядок ?-парамов, имена приватных функций), а не поведение. Этот тест будет ломаться от каждого чиха. P>>Кое что сломается. Поскольку это метапрограммирование, то это ожидаемый результат. ·>Ожидаемый кем/зачем?
Наша задача гарантировать что запросы соответствуют бизнес-требованиям. Что бы это гарантировать, я выбрал реализацию с метапрограммированием. Вы, очевидно, выбрали другое — гонять горстку данных к базе и обратно, и у вас кейс с вырожденным фильром до сих пор не покрыт тестом.
P>>Что бы от каждого чиха — такого нету. Запросы меняются с изменением бизнес логики. ·>Я тебе приводил пример — заменить звёздочку на список полей — это чих, а не изменение бизнес логики.
Не знаю, что у вас с этим за проблема, тут рукописные логи годами ходят в одном и том же виде, тригерят эвенты, и ничего. А гарантировать сохранность стиля генерируемого кода почему то вам кажется рокетсаенсом.
P>>В интеграционных тестах мы не проверяем точки — мы проверяем саму сборку. ·>Если сборка идёт в трёх точках — проверить легко. Если сборка идёт в трёхсот точках — проверить сложно.
Вы почемуто забываете про dependency injection — это такой код, который труднее всего покрыть тестами, а между тем у него чудовищное влияние на систему.
Потому и стоит менять дизайн что бы это контролировать, а через di протаскивать только технологические зависимости.
P>>То, что вы пишете — именно вайтбокс тест, тавтологичный "проверим что подставилось время клиента" — это и есть суть проблемы. ·>Почему вайтбокс? Тест бизнес-требования — "в ответе приходит правильное время".
Если это про некоторую сборку, когда вы проверяете результат, то все годится. Только вам здесь надо вбросить "время клиента" каким то раком. А потом проверить, что вбросили удачно.
P>>Вызовем как то иначе, но обеспечим результат тот же, ваш тест сломается т.к. он по прежнему будет долбить "проверим что подставилось время клиента" ·>Как ты _проверишь_, что результат тот же и соответствует ожиданиям?
Очень просто — у нас уже есть тесты, одни должны сохраниться без каких либо изменений. Раз мы их спроектировали, а не наструячили от балды, убедились в этом, то они рассматриваются, как корректные.
Теперь изменение реализации должно сохранить тесты зелеными
·>
·>·>Как ты тестируешь что построенный запрос хотя бы синтаксически корректен?
·>тот самый интеграционный тест, на некорретном запросе он упадет
·>Т.е. у тебя есть туева хуча ю-тестов для каждого сценария, которые проверяют _тексты_ запросов, но для проверки, что текст запроса хотя бы корректен — приходится ещё и и-тестом каждый запрос проверить для ровно тех же сценариев.
интеграционные тесты строятся по функциям, а не по запросам к базе.
А вот запросы к базе вещь слишком сложная и ответственная, потому стоит использовать разные инструменты, а не рассказывать, что вам запретили метапрограммирование
P>>Для юнит-тестов это как раз нормально, их предназначение — тестировать всю мелочевку, из за которой у вас вообще что угодно можно происходить ·>Дело не в мелочёвке-большичёвке, а в том, что ты тестируешь код как написано, а не ожидания/бизнес-требования. Ровно то, чем ты меня пытался попрекать.
Похоже, что вам действительно ктото запретил метапрограммирование
P>>Во многих фремворках для тестирования вы юнит-тесты можете размещать прямо в том же файле, или вообще привязывать аннотациями. ·>Мрак.
Видите — не так, как вы привыкли и сразу ужос-ужос-мрак-и-смэрть
P>>>>Ну как же — вы собирались фильтры тестировать посредством выполнения запросов на бд, те самые "репозитории" которые вы тестируете косвенно, через БД. P>>·>Да. P>>Вот вот. ·>Ты так говоришь, как будто это что-то плохое.
Хорошего в этом как то маловато.
P>>И как же вы решаете проблемы с data complexity которая тестами не решается используя исключительно косвенные тесты? ·>А конкретнее? С примером кода.
Это я вам вопрос задал, вообще говоря. Те самые фильтры — вполне себе хороший пример.
P>>Это выхлоп билдера — в нем связывание, конверсия, маппинг и тд. Т.е. у нас кейс с метапрограммированием — результат фукнции это код другой функции. И я использую ровно тот же подход что и везде — сравнение результата. Только в данном случае наш результат это код. ·>Зачем нам тестировать выхлоп билдера? У билдера должны быть свои тесты.
Это и есть тесты билдера. Только конкретного, в котором заложено много различных вырожденных кейсов. linq не в курсе, что вы вытаскиваете всю базу, ему по барабану. Мне — нет.
P>>Например — фильтр вырождается в true. А вот если мы накладываем ограничения на результирующий запрос, у нас эта часть исключается принципиально. ·>Не понимаю проблему. Если фильтр выродится в true, то субд вернёт те записи, которые мы не ожидаем, тест провалится.
Ну так найдите эту комбинацию. А их, мягко говоря, немало. Как будете искать?
P>>Простой вопрос был — как ваше доказательство проверит само себя если другой коллега начнет писать код как ему вздумается? ·>Верификатор выдаст ошибку. Почитай про какой-нибудь coq что-ли.
И вы так прямо и втащите coq в любом проект на джаве?
·>Ну будет в коммите одном из десятка тестов вырожденный фильтр... И? Особенно весёлые штуки типа "A = B OR A <> B" из-за немножко не так поставленных скобочкек. Ты как равьювер будешь смотреть тесты и в уме интерпретировать sql запросы?
Еще раз — фильтр не хардкодится, а строится.
P>>Наоборот. Руками затейники выдают такое, что ни один генератор проглотить не может. А если вы начинаете с аннотаций или хотя бы интерфейсов, то уж точно ясно, что это реализуемо. ·>Верно, но называется это code-first со всеми последствиями.
Нет, не называется. Разница между code-first и design-first не формате и расширении файла, как вам кажется, а в очередности деливери.
P>>Наоборот. АПИ то никуда не делся, только работаем мы с ним немного не так, как вы привыкли. Тесты всё равно остаются. И их надо не ногой писать, а согласно определению апи. И документирование, и клиентский код, и много чего еще. ·>Апи будет просто набор интерфейсов и/или модели данных. С нулевой логикой.
В том то и дело — ваша задача накидать интерфейсы-модели так, что бы имплементации было 0. Тогда можно деливерить сразу, а вот будет ли деливериться имплементация, и когда — уже дело десятое.
Посмотрите grapql, grpc — API и есть код, вопрос в том, что вы деливерите. Полурабочий каркас приложения — это code-first. А если описание, которое могут взять другие команды, и работать независимо — design first
P>>Вы вместо вопроса слишком злоупотребляете телепатией. АПИ, если отдаётся, то в большинстве случаев уже ничего генерить не надо. Например, согласовали интерфейс, зафиксировали, и каждый пошел работать над своей реализацией. ·>Ты опять врёшь. Не телепатией, а из твоих слов: "Манифест генерируется по запросу, обычно http", противоречие выделил жирным. Или ты похоже просто в прыжке переобуваешься.
Вы вместо уточнения пытаетесь в телепатию играть. Если у нас готовое приложение, то конечно же генерируется — и странно было бы иначе делать.
А если у нас ничего нет, только АПИ, то пишите АПИ сразу так, что бы быстрее его заделиверить и цикл разработки был максимально короткий.
P>>Вы похоже не вдупляте — design-first = вначале деливерим АПИ, а потом уже реализация, куда входят переменные, конфиги, логика тенантов итд. ·>http-сервер это такой АПИ... Угу-угу.
Я вам про интерфейсы, а вы сюда http-server тащите. Дурака валяете.
Здравствуйте, Pauel, Вы писали:
P>>>Вы уже показывали, когда мокали репозиторий ради тестов контролера, а потом скромно замолчали на вопрос, что делать, если меняется дизайн P>·>Вопрос я не понял, мол что делать если что-то меняется, ответил как мог — если что-то меняется, то эээ... надо что-то менять. Если тебя интересует конкретная проблема, сформулируй с примерами кода. P>Вы мок затачивали на все тесты, или по моку на каждый? P>1. На все — все ваши тесты неявно теперь зависят от мока. И если вы закостылили мок, то заточили тесты под синтетику, код — под такие тесты. P>2. Если по моку на каждый — можно хоть ревью сделать. Кода больше, но и контроля больше.
Я не понимаю что такое заточка мока. Код с моками это просто код. Там где код общий, там он переиспользуется из разных мест. Там где не общий, там не переиспользуется. Мок это просто механизм передачи данных. Ровно такой же вопрос я могу спросить про твои параметры.
P>>>Я вам про функциональные требования, а вы мне про функции в коде. Проверка склейки — это вайтбокс тест уровня юнит-тестов. В интеграционных тестах мы проверяем ожидания вызывающей стороны. А её точно ничего про склейку не известно. P>·>"следующая пятница текущего времени" — вполне функциональное требование. В интеграционных тестах ты прямо заявил, что никак не сможешь проверить это ожидание. P>Проверка склейки — такого не будет. А вот поддерживает ли приложение такую функцию — нужно проверять интеграционным тестым.
Не всегда нужно, в этом и суть. Интеграционный тест проверяет интеграцию, что компоненты работают вместе. А не каждую функцию приложения.
P>И ваши моки не избавляют этого.
Моки не избавляют. А помогают избавляться. Избавляет дизайн. Вместо того, чтобы всё распылять на мелкие кусочки, которые теперь надо скурпулёзно инетгрировать, можно делать относительно крупные компоненты, которые проще интегрировать вместе.
P>>>Есть такая штука. От безысходности — если вы такой дизайн построили. Искусственное понижение уровня тестирования. P>·>Ну да, верно. Ты так говоришь, как будто что-то плохое. Чем больше мы можем проверять низкоуровневыми тестами, тем лучше. "Искусственно" — тоже верно, мы режем зависимости там, где они самые тяжелые, требуют больше ресурсов, замедляют билд. "Безысходность" — потому что альтернативы — хуже. P>Самосбывающееся пророчество — обычно безысходность очень быстро наступает в том случае, когда изначально заложились на моки b монолитный дизайн. P>Вариантов дизайна всегда больше одного
Именно. Это всё субъективщина. Эти варианты у тебя меняются каждые год два, как женские шляпки. А вот требование ресурсов, использование сети-тредов-диска — это объективные критерии. На них я и ориентируюсь, а не на последние веяния моды.
P>>>Наоборот — моки это инструмент тестирования тяжелого, монолитного кода перемешанного с зависимостями. Например, когда физически невозможно выделить логику в простые вычисления. P>·>Что за "физически"? Тезис Чёрча знаешь? Любой код можно переписать на чистый, хаскель неплохо это доказывает. Вопрос — накой?! P>Есть же пример Буравчика. Вам мало, надо к абсурду свести?
В смысле ты хочешь сказать, что его пример на хаскель не переписывается? Переписыватеся, с монадами и т.п. Но проще он не станет. Поэтому вопрос и остаётся — накой. Твои предложения "улучшить" я не понял в чём же улучшение.
P>>> Тогда приходят на помощь моки — как вы сами и сказали, замокали один компонент, что бы проверить остальные два. P>·>Замокали "плохой", тяжёлый компонент, требующий файловой системы, сети, многопоточки, чтобы хорошо и легко проверить остальные два на саму логику и бизнес-требования. P>В стиле ТДД — написали тесты на моках, а потом и дизайн вышел соответствующим
Нет.
P>>>Или как у Буравчика — мутабельные вычисления, кучка зависимостей да два ифа. P>·>Ну "правильного" дизайна ты предолжить просто не смог. Т.к. это более менее реальный проект с нетривиальной бизнес-логикой. А твои штуки вменяемо работают только на хоумпейджах. P>Какой еще "правильный"? Я продемонстрировал, что минимальными усилиями можно свести тесты к таблице истинности и хранить все это максимально близко к коду.
Я видимо не понял. Где какие таблицы?
P>·>Связывание находится в wiring code. Контроллер это просто ещё один компонент, ничем принципиальным от других не отличается. P>Связывание и есть wiring код. Основная обязанность контроллера — именно это. И тестировать связку, как следствие.
Нет, обязанность контрллера связывать входящие запросы с бизнес-логикой. wiring code — это отдельный код для связывания компонент друг с другом.
P>Если же вы сторонник жирных контроллеров, конечно же вам придется мокать всё на свете. Не только time, а еще и sin и cos
Это твои фантазии, спорить не буду.
P>>>Ы-ы-ы — всё это придется затыкать юнит-тестами, компилер вам не помощник. P>·>Покажи код где там какой типизации не хватает в java. И не просто общие слова, а не забывай про контекст обсуждения. P>Я ж вам перечислил. Вы хотите еще и фичи статической типизации докинуть к нынешней теме?
Мне пофиг на общие слова и перечисления. Я прошу код. Что с чем ты собираешься согласовывать, зачем, и причём тут система типов.
P>>>blackbox — тестируем исходя из функциональных требований. P>·>И? "текущее время" vs "данный момент времени" — это функциональные требования. Причём тут вызовы функций? P>Вы тестируете, что результат зависит от конкретного вызова. Сами же про это и пишете.
В следующий раз когда ты мне будешь приписывать очередную фантазию, цитируй.
P>>>Вы сейчас в слова играете. Если не протаскивать зависимости, в CalendarLogic будет null во время вызова, буквально. Это значит, вы всю мелочевку повесите на dependency injection. P>·>Что за ерунда? Откуда там null возьмётся? Что за "повесите на dependency injection"? источник времени — это зависимость CalendarLogic, инжектится через конструктор. ЧПФ, забыл опять? P>Сами спросили — сами ответили.
Откуда _у тебя_ null берётся? У меня никаких null тут нет.
P>>>А вот вам кейс — трохи поменяли архитектуру, и БЛ начала вызываться через очередь, с задержкой от часов до дней. А время должно отсчитываться с момента когда юзер нажал кнопку. P>·>Поменяется InstantSource, будет добывать время не из system clock, а из таймстампа в очереди. Это вообще никакое не архитектурное изменение, а одна строчка в wiring code — что инжектить как источник времени. P>О — InstantSource появился. Значит инжектиться может не один единственный вариант с Now, а минимум два.
А ты вообще код мой читал? В первой строчке код-сниппета
. Ты по-моему сам со своими фантазиями споришь, я тебе только мешаю.
P>Где у вас тестирование инжекции? А ну как на проде все инжектиться будет по старому?
В прод-classpath не видны моки и вообще вся тестовая белиберда. Код не скомпилится просто, если туда правильную зависимость не вписать.
P>>>В моем случае всех изменений — вместо прямого вызова делаем отложеный. P>·>Что за отложенный вызов? Вызов где? P>А как вы понимаете, что такое отложеный вызов? Недавно вам непонятно было что такое dependency injection, потом выяснилось, что все вам известно.
Мне не было понятно, что ты под этим понимаешь.
P>Тут похоже вам снова надо с самим собой поговорить
Ну ссылку на вики дай.
P>>>Интересно, что может быть и так и так — часть вещей считаем сейчас, часть — потом, а время используется и там и там, как текущее, так и предзаписанное. P>·>Ну будет два InstantSource в разных местах. P>Вот-вот. Как вы отличите что первый и второй не перепутаны? Это ж ваша любимая тема — надо проверить, что передали то самое!
Устанавливаем в тестах, что "у нас на сервере now это 21:00:01, а на клиенте "21:00:02". И в тестах можно ассертить что в нужных случаях ожидаемое время. Что ты будешь делать со своим синлтоном Time.Now — ты так и не рассказал. Вообще я не понимаю как ты такое можешь использовать и тем более тестировать, просвети.
Что синглтоны — плохо учат ещё в детском садике, ясельной группе.
P>>>Это вам пример, как изменение дизайна вносит хаос именно в моковую часть тестов. P>·>В моках надо будет просто сделать два источника времени, у и ассертить, что в нужных местах используется время из ожидаемого источника. P>А еще можно обойтись без моков И свести к таблице истинности, поскольку интеграционный тест всё равно понадобится.
Ты заявил, что никак не сможешь время протестировать.
P>>>Ога — каким чудом компилер узнает, что в отложеном процессинге время в той самой функции надо брать с момента инициирования запроса, а в аудите и то, и другое? P>·>Это будет две функции. ЧПФ, слышал? P>Я в курсе: "ассертим что вызываем с тем параметром а не этим"
Бред.
P>·>У тебя много, на каждый сценарий. P>Не всё так страшно — мы упрощаем не только бл, но и связывание. Посколько у вас больше одного провайдера для зависимости, всё может играть по разному в зависимости от сценария. P>В одном сценарии у вас один провайдер времени, в другом — другой. Опаньки! Только вы это размазали по коду.
Опять фантазируешь что-то.
P>>>2 код в них тривиальный, линейный P>·>Да, но кода этого много накопипасчено. P>Ну и что?
Что каждую копию надо покрывать тестом. Ты правда сейчас собираешься копи-пасту продвигать как правильный дизайн?
P>>>Вы только что говорили о чудесной поддержке иде именно вашего дизайна. Покажите это чудо. Мне вот ИДЕ спокойно может заинлайнить любое из мест вызова nextFriday(now) P>·>Круто, но зачем? Задачу-то какую решаем? P>Затем, что признак хорошего кода это его гибкость, которая проявляется в т.ч. в том, что код можно трансформировать, инлайнить, итд, да хоть вовсе от него избавиться.
Если при этом нужно плодить копипасту, то это явно что-то не то. И неясно причём тут инлайн и гибкость кода. str.length() — это негибкий код?!
P>·>Не с любыми, а только с теми, которые тестируют детали имплементации, а не логику. Поэтому я и говорю, что _эти_ ю-тесты — не нужны. Ибо всё ровно то же придётся покрывать и-тестами с субд. Ты можешь объяснить зачем ты пишешь такие ю-тесты? Повторюсь, эти тесты не только бесполезны, но и вредны, т.к. хрупкие и усложняют внесение изменений. P>Вы так и не рассказали, как будете решать ту самую задачу с фильтрами.
Рассказал и даже код показал,
насколько понял твою задачу. Если ещё остались вопросы, спрашивай.
P>>>Для того нам и нужна таблица истинности рядом с кодом и его тестами — такое можно только другими методами проверять P>·>Дело в том, что в случае субд у тебя кода субд нет. P>И не надо.
Надо, если хотим тестировать поведение, а не детали имплементации.
P>>>Это выхлоп билдера. С чего вы взяли, что такой код надо руками выписывать? P>·>Это какой-то небуквальный выхлоп или что? Выхлоп какого билдера? P>Билдера запросов к базе данных. Вы что думаете, все sql запросы руками пишутся?
Да похрен как они пишутся, хоть левой пяткой. Это всё детали реализации. Главное что они работают ожидаемым способом.
P> Кое что, для аналитики — возможно. Но это большей частью всё равно перегоняется в орм или билдер. Есть орм — можно проверять построение логики запросов орм.
В смысле ты в своих тестах linq/etc тестируешь? Зачем? У linq свои тесты есть.
P>>>Соответсвенно, и тестировать нужно соответствующим методом P>·>Ты вроде сам заявлял, что тестировать нужно ожидания. Какое отношение метапрограммирование имеет к бизнес-требованиям или ожиданиям? P>Запрос к базе должен соответсвовать бизнес-требованиям. Только проверяем мы это в т.ч. посредством метапрограммирования.
Что за бред? У тебя в FRD прописаны тексты запросов??! Прям где-то у вас есть бизнес-требование "select * from users where id=?" и "in: [fn1]"?! Приходит к вам клиент и говорит "а мне очень нужно чтобы out: [fn2], когда можете сделать?"
P>>>Ваша альтернатива — забить на data complexity, так себе идея. P>·>Цитату в студию или признавайся, что опять соврал.
Цитаты нет. Т.е. соврал.
P>Вы до сих пор не привели решение кроме "ищем в бд"
Я код
привёл. Что не устраивает-то??! "ищем" — это "find", английский язык знаешь?
P>>>do_logic и есть или юз-кейс, или контроллер. P>·>Я имею в виду вот этот твой do_logic. Это не юзкейс. Это код-лапша. P>Сравнивать нужно не как выглядит, а всё цельные решения, включая моки всех сортов, dependency injection, размазаную и скрытую, тесты которые без таблицы истинности итд.
Я уже всё рассказал и показал. _Всё_. Нет ничего скрытого.
P>·>Ты читать умеешь? Я пишу "некий аспект", ты возражаешь "Все аспекты". Я где-то требовал тестировать все аспекты, кроме как в твоих фантазиях? Я спросил как тестировать один конкретный тривиальный аспект, который элементарно тестируется с моим дизайном, а ты не смог, у тебя солнце погасло. P>У вас плохо с логикой — если нет возможности тестировать все аспекты, а это невозможно, значит в каждом конкретном случае какие то аспекты будут непротестированы. P>Ваш тривиальный аспект это "вызываем с нужным параметром" ?
Нет. Код смотри.
P>>>·>Я топлю за вайтбокс в том смысле, что тест-кейсы пишутся со знанием что происходит внутри, чтобы понимать какие могут быть corner-cases. Но сами входные данные и ассерты теста должны соответствовать бизнес-требованиям (для данного id возвращается правильно сконструированный User). Следовательно, изменение имплементации всё ещё должно сохранять тесты зелёными. P>>>Нет, не должно. P>·>Должно, т.к. это тестирование бизнес-требования. P>Должно, только ваш nextFriday поломал вообще всё, т.к. ему надо прописать другие значения, а без этого или все тесты красные, или зелены при гарантировано нерабочей системе.
Фантазии.
P>>>Смотрите про тривиальный перенос вызова из одного места в другое — ваш nextFriday поломал вообще всё P>·>Куда смотреть? Поломал что? P>Вам надо мок подфиксить, что бы время было той системы
Чё?
P>>>·>Вот твой код "{sql: 'select * from users where id=?', params: [id], transformations: {in: [fn1],out: [fn2]}" — таким свойством не обладает, т.к. проверяет детали реализации (текст запроса, порядок ?-парамов, имена приватных функций), а не поведение. Этот тест будет ломаться от каждого чиха. P>>>Кое что сломается. Поскольку это метапрограммирование, то это ожидаемый результат. P>·>Ожидаемый кем/зачем? P>Наша задача гарантировать что запросы соответствуют бизнес-требованиям. Что бы это гарантировать, я выбрал реализацию с метапрограммированием. Вы, очевидно, выбрали другое — гонять горстку данных к базе и обратно,
Покажи пример бизнес-требования.
P>и у вас кейс с вырожденным фильром до сих пор не покрыт тестом.
Я не видел этого кейса, и не могу нафантазировать какие у тебя возникли проблемы его покрыть.
P>>>Что бы от каждого чиха — такого нету. Запросы меняются с изменением бизнес логики. P>·>Я тебе приводил пример — заменить звёздочку на список полей — это чих, а не изменение бизнес логики. P>Не знаю, что у вас с этим за проблема, тут рукописные логи годами ходят в одном и том же виде, тригерят эвенты, и ничего. А гарантировать сохранность стиля генерируемого кода почему то вам кажется рокетсаенсом.
Да причём тут стиль? Это мелкий чих. Я могу переписать например "SELECT ... X OR Y" на "UNION SELECT ... X ... SELECT ... Y" для оптитмизации. У тебя все тесты посыпятся и любая ошибка — увидишь после деплоя и прогона многочасовых тестов, в лучшем случае (а скорее всего только в проде). А у меня только те тесты грохнутся, если я реально ошибусь и что-то поломаю в поведении, ещё до коммита.
P>>>В интеграционных тестах мы не проверяем точки — мы проверяем саму сборку. P>·>Если сборка идёт в трёх точках — проверить легко. Если сборка идёт в трёхсот точках — проверить сложно. P>Вы почемуто забываете про dependency injection — это такой код, который труднее всего покрыть тестами, а между тем у него чудовищное влияние на систему. P>Потому и стоит менять дизайн что бы это контролировать, а через di протаскивать только технологические зависимости.
Зато этот код очень простой, линейный и на 99% покрывается компилятором. Остальной 1% покрывается стартом приложения.
P>>>То, что вы пишете — именно вайтбокс тест, тавтологичный "проверим что подставилось время клиента" — это и есть суть проблемы. P>·>Почему вайтбокс? Тест бизнес-требования — "в ответе приходит правильное время". P>Если это про некоторую сборку, когда вы проверяете результат, то все годится. Только вам здесь надо вбросить "время клиента" каким то раком. А потом проверить, что вбросили удачно.
Ну да, но только не раком, а моком.
P>>>Вызовем как то иначе, но обеспечим результат тот же, ваш тест сломается т.к. он по прежнему будет долбить "проверим что подставилось время клиента" P>·>Как ты _проверишь_, что результат тот же и соответствует ожиданиям? P>Очень просто — у нас уже есть тесты, одни должны сохраниться без каких либо изменений.
Я спросил как сделать так, чтобы такие тесты были, ты ответил
"Никак.". Т.е. тестов у вас таких просто нет.
P>Раз мы их спроектировали, а не наструячили от балды, убедились в этом, то они рассматриваются, как корректные. P>Теперь изменение реализации должно сохранить тесты зелеными
Эээ.. ну да... верно. После любого такого изменения ни один тест не покраснеет. no matter what, т.к. с тестами это тестирующих у вас "никак".
P>·>
P>·>·>Как ты тестируешь что построенный запрос хотя бы синтаксически корректен?
P>·>тот самый интеграционный тест, на некорретном запросе он упадет
P>·>
P>·>Т.е. у тебя есть туева хуча ю-тестов для каждого сценария, которые проверяют _тексты_ запросов, но для проверки, что текст запроса хотя бы корректен — приходится ещё и и-тестом каждый запрос проверить для ровно тех же сценариев. P>интеграционные тесты строятся по функциям, а не по запросам к базе.
Я о чём и говорю. В каких-то случаях у тебя могут меняться запросы. Ты уже сам говорил о случае с пустым значением, которое ты заявил, что и-тестами тестировать не собираешься.
И это могут быть нефункиональные требования, а какие-то технические детали, оптимизации. Простой пример. Скажем, если идёт выборка по небольшому списку параметров, то строится запрос с "IN (?,?)", иначе создаётся временная табличка и с ней джойнится.
P>А вот запросы к базе вещь слишком сложная и ответственная, потому стоит использовать разные инструменты, а не рассказывать, что вам запретили метапрограммирование
Именно. Поэтому надо их выполнять и проверять результаты, неважно мета там или фета. Никто вам ничего не запрещает, а мой поинт в том, что важно что запросы делают, а не какие инструменты используются.
P>>>Для юнит-тестов это как раз нормально, их предназначение — тестировать всю мелочевку, из за которой у вас вообще что угодно можно происходить P>·>Дело не в мелочёвке-большичёвке, а в том, что ты тестируешь код как написано, а не ожидания/бизнес-требования. Ровно то, чем ты меня пытался попрекать. P>Похоже, что вам действительно ктото запретил метапрограммирование
Фантазируешь.
P>>>Во многих фремворках для тестирования вы юнит-тесты можете размещать прямо в том же файле, или вообще привязывать аннотациями. P>·>Мрак. P>Видите — не так, как вы привыкли и сразу ужос-ужос-мрак-и-смэрть
Ну вроде это уже вс проходили и забили. Заталкивать тесты в прод-код... зачем??!
P>>>И как же вы решаете проблемы с data complexity которая тестами не решается используя исключительно косвенные тесты? P>·>А конкретнее? С примером кода.
Именно. Примера кода я так и не дождусь.
P>Это я вам вопрос задал, вообще говоря. Те самые фильтры — вполне себе хороший пример.
Для тебя — хороший. Потому что у тебя оно в голове, т.к. ты с этим трахаешься последние пол года, не меньше, похоже. Я вообще плохо понимаю о чём идёт речь и с какими конкретными проблемами ты столкнулся. Я ведь не телепат... А подробностей от тебя не дождёшься. Приведи код, сформулируй проблему, я может и погляжу подробнее.
P>>>Это выхлоп билдера — в нем связывание, конверсия, маппинг и тд. Т.е. у нас кейс с метапрограммированием — результат фукнции это код другой функции. И я использую ровно тот же подход что и везде — сравнение результата. Только в данном случае наш результат это код. P>·>Зачем нам тестировать выхлоп билдера? У билдера должны быть свои тесты. P>Это и есть тесты билдера. Только конкретного, в котором заложено много различных вырожденных кейсов. linq не в курсе, что вы вытаскиваете всю базу, ему по барабану. Мне — нет.
Linq выдаёт список результатов — вот и проверяй, что в этом списке — вся база или не вся.
P>>>Например — фильтр вырождается в true. А вот если мы накладываем ограничения на результирующий запрос, у нас эта часть исключается принципиально. P>·>Не понимаю проблему. Если фильтр выродится в true, то субд вернёт те записи, которые мы не ожидаем, тест провалится. P>Ну так найдите эту комбинацию. А их, мягко говоря, немало. Как будете искать?
Анализом требовний, кода, данных, етс. Обычный corner case analysis. А как вы будете искать?
P>>>Простой вопрос был — как ваше доказательство проверит само себя если другой коллега начнет писать код как ему вздумается? P>·>Верификатор выдаст ошибку. Почитай про какой-нибудь coq что-ли. P>И вы так прямо и втащите coq в любом проект на джаве?
Нет. А вы таки втащили доказательное программированипе в js?
P>·>Ну будет в коммите одном из десятка тестов вырожденный фильтр... И? Особенно весёлые штуки типа "A = B OR A <> B" из-за немножко не так поставленных скобочкек. Ты как равьювер будешь смотреть тесты и в уме интерпретировать sql запросы? P>Еще раз — фильтр не хардкодится, а строится.
Я потерял суть. О чём речь вообще? Пример в студи. КОД!
P>>>Наоборот. Руками затейники выдают такое, что ни один генератор проглотить не может. А если вы начинаете с аннотаций или хотя бы интерфейсов, то уж точно ясно, что это реализуемо. P>·>Верно, но называется это code-first со всеми последствиями. P>Нет, не называется. Разница между code-first и design-first не формате и расширении файла, как вам кажется, а в очередности деливери.
Верно. В design-first деливерится манифест first. А не http-приложение, генерящее манифест.
P>В том то и дело — ваша задача накидать интерфейсы-модели так, что бы имплементации было 0. Тогда можно деливерить сразу, а вот будет ли деливериться имплементация, и когда — уже дело десятое.
Ну да. Откуда же берутся конфиги/тенанты/http-запросы?
P>Посмотрите grapql, grpc — API и есть код, вопрос в том, что вы деливерите. Полурабочий каркас приложения — это code-first. А если описание, которое могут взять другие команды, и работать независимо — design first
Расскажи где в graphql/grpc можно найти конфиги/аннотации/переменные окружения?
P>>>Вы вместо вопроса слишком злоупотребляете телепатией. АПИ, если отдаётся, то в большинстве случаев уже ничего генерить не надо. Например, согласовали интерфейс, зафиксировали, и каждый пошел работать над своей реализацией. P>·>Ты опять врёшь. Не телепатией, а из твоих слов: "Манифест генерируется по запросу, обычно http", противоречие выделил жирным. Или ты похоже просто в прыжке переобуваешься. P>Вы вместо уточнения пытаетесь в телепатию играть. Если у нас готовое приложение, то конечно же генерируется — и странно было бы иначе делать.
Угу. ЧТД. "готовое приложение" == "code-first".
P>А если у нас ничего нет, только АПИ, то пишите АПИ сразу так, что бы быстрее его заделиверить и цикл разработки был максимально короткий.
Откуда в апи у тебя возьмутся тенаты? Или ты просто словоблудием занимаешься? Когда удобно имеешь в виду gprc, а когда удобно вкидываешь про готовое приложение — лишь бы собеседника переспорить.
P>>>Вы похоже не вдупляте — design-first = вначале деливерим АПИ, а потом уже реализация, куда входят переменные, конфиги, логика тенантов итд. P>·>http-сервер это такой АПИ... Угу-угу. P>Я вам про интерфейсы, а вы сюда http-server тащите. Дурака валяете.
Не ври. http втащил ты. Цитиую: "по запросу, обычно http".
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>1. На все — все ваши тесты неявно теперь зависят от мока. И если вы закостылили мок, то заточили тесты под синтетику, код — под такие тесты. P>>2. Если по моку на каждый — можно хоть ревью сделать. Кода больше, но и контроля больше. ·>Я не понимаю что такое заточка мока. Код с моками это просто код. Там где код общий, там он переиспользуется из разных мест. Там где не общий, там не переиспользуется. Мок это просто механизм передачи данных. Ровно такой же вопрос я могу спросить про твои параметры.
Это я имею ввиду начинку — то, что вы заложите в мок. С параметрами у нас ровно самый минимум — только таблица истинности, и сам код. У вас к этому добавляются еще и моки.
P>>Проверка склейки — такого не будет. А вот поддерживает ли приложение такую функцию — нужно проверять интеграционным тестым. ·>Не всегда нужно, в этом и суть. Интеграционный тест проверяет интеграцию, что компоненты работают вместе. А не каждую функцию приложения.
То-то и оно. Вот вы снова сами себе и ответили
P>>И ваши моки не избавляют этого. ·>Моки не избавляют. А помогают избавляться.
Нисколько. Моки прибивают вас к конкретному дизайну — см пример про инлайн кода. Этот пример демонстрирует особенность — даже ИДЕ перестает помогать.
А вот если вы отказываетесь от моков, соотвественно, ИДЕ вам в помощник — вдруг рефакторинг inline начинает работать сам собой
P>>Вариантов дизайна всегда больше одного ·>Именно. Это всё субъективщина. Эти варианты у тебя меняются каждые год два, как женские шляпки. А вот требование ресурсов, использование сети-тредов-диска — это объективные критерии. На них я и ориентируюсь, а не на последние веяния моды.
Дизайн вообще должен меняться постоянно, непрерывно. А вы выбираете такой подход, что изменения раз в год-два. О том я и говорю — вы пилите монолит.
P>>Есть же пример Буравчика. Вам мало, надо к абсурду свести? ·>В смысле ты хочешь сказать, что его пример на хаскель не переписывается? Переписыватеся, с монадами и т.п. Но проще он не станет. Поэтому вопрос и остаётся — накой. Твои предложения "улучшить" я не понял в чём же улучшение.
Я ж объяснил — таблица истинности рядом с тестом и кодом, моки-стабы тоньше некуда. Вы рассматриваете систему в отрыве от тестов. Это категрически неверно. Даже конкретный деплоймент не имеет смысла без тестов — чемодан без ручки. Нужно проверить, а все ли путём, без тестов это никак. Более того — поменялись внешние зависимости — снова нужны тесты.
Соответсвенно нужно выбирать такое решение, которое проще мейнтейнить, с учетом тестов.
P>>В стиле ТДД — написали тесты на моках, а потом и дизайн вышел соответствующим ·>Нет.
У вас похоже особое видение каждого термина, который мы обсуждаем. ТДД по Кенту Беку целиком про дизайн.
Вот код теста — как только вы его написали, решение о том, как будут протягиваться зависимости, уже принято
const calendar = new CalendarLogic(Predefined.Now);
expect(nextFriday()).to.eq(Predefined.Friday);
P>>·>Ну "правильного" дизайна ты предолжить просто не смог. Т.к. это более менее реальный проект с нетривиальной бизнес-логикой. А твои штуки вменяемо работают только на хоумпейджах. P>>Какой еще "правильный"? Я продемонстрировал, что минимальными усилиями можно свести тесты к таблице истинности и хранить все это максимально близко к коду. ·>Я видимо не понял. Где какие таблицы?
@test()
@params(
1,2,3,4,5,6 // и так на каждую строчку в табличке
)
@params(
8,4,2,1,3,5 // точно так же и исключения прокидывают
)
... сколько строчек, столько и тестов фактически выполнится
"a cool name test name" (v1, v2, v3, repo1, svc, repo2, result) {
let logic = Logic(v1,v2,v3);
let r = logic.run({
load: () => repo1,
load2: () => svc,
... и так прокидываем все что надо
})
expect(r).to.deep.eq(result)
}
P>>Связывание и есть wiring код. Основная обязанность контроллера — именно это. И тестировать связку, как следствие. ·>Нет, обязанность контрллера связывать входящие запросы с бизнес-логикой. wiring code — это отдельный код для связывания компонент друг с другом.u
Вы сейчас в слова играете. Сами же пишете — "обязанность контроллера связывать" Только еще вводите понятие wiring code.
Часть кода связывания будет вне контролера, и правила вы водите сами, это и есть тот дизайн. Прокидываете через dependency injection — значит внутри контролера этого не будет.
Прокидываете now в контролере — эту часть логично исключить из dependency injection.
Смысл помещения кода связывания в контроллер в том, что бы легче было интеграцию тестировать, делая самое важно явным.
P>>·>Что за ерунда? Откуда там null возьмётся? Что за "повесите на dependency injection"? источник времени — это зависимость CalendarLogic, инжектится через конструктор. ЧПФ, забыл опять? P>>Сами спросили — сами ответили. ·>Откуда _у тебя_ null берётся? У меня никаких null тут нет.
У вас CalendarLogic принимает зависимость к конструкторе. Технически, эта зависимость может быть и null, и предзаписаной, и привязаной к контексту — не принципиально. Ваша задача — сделать так, что бы в контролер этот CalendarLogic пришел с нужной завимостью, а не произвольной. Соответсвенно, гарантии фиксируем через интеграционный тест — конкретный use case собран как положено. И вот здесь внутренности реализации вообще роли не играют — проверяется интеграция, а не внутреннее устройство.
P>>О — InstantSource появился. Значит инжектиться может не один единственный вариант с Now, а минимум два. ·>А ты вообще код мой читал? В первой строчке код-сниппета
. Ты по-моему сам со своими фантазиями споришь, я тебе только мешаю.
Вы похоже сами свой код не читали, т.к. у вас недоумение, откуда может быть null. И ежу понятно — будет передан в конструктор или явно, или неявно. Правильно это или нет — скажут тесты.
P>>Где у вас тестирование инжекции? А ну как на проде все инжектиться будет по старому? ·>В прод-classpath не видны моки и вообще вся тестовая белиберда. Код не скомпилится просто, если туда правильную зависимость не вписать.
Успокойтесь — у вас есть провайдер time, вам нужно больше одной реализации — время может тащиться из разных источников. И ваш CalendarLogic работает с любой из таких зависимостей.
А щас вы расказываете басню, что компилер как то отличит один провайдер времени от другого времени с таким же интерфейсом
P>>А как вы понимаете, что такое отложеный вызов? Недавно вам непонятно было что такое dependency injection, потом выяснилось, что все вам известно. ·>Мне не было понятно, что ты под этим понимаешь.
Прямой вызов — ваша функция вызовется прямо сейчас. Отложеный — потом. Например, вы сначала делаете запись, что за функция вызовется, с какими параметрами и тд, а в нужный момент сервис делает собственно сам вызов.
P>>Вот-вот. Как вы отличите что первый и второй не перепутаны? Это ж ваша любимая тема — надо проверить, что передали то самое! ·>Устанавливаем в тестах, что "у нас на сервере now это 21:00:01, а на клиенте "21:00:02". И в тестах можно ассертить что в нужных случаях ожидаемое время. Что ты будешь делать со своим синлтоном Time.Now — ты так и не рассказал. Вообще я не понимаю как ты такое можешь использовать и тем более тестировать, просвети.
Просто разные аргументы.
·>Что синглтоны — плохо учат ещё в детском садике, ясельной группе.
Вы наверное не поняли — никаких синглтонов, только параметры.
P>>·>В моках надо будет просто сделать два источника времени, у и ассертить, что в нужных местах используется время из ожидаемого источника. P>>А еще можно обойтись без моков И свести к таблице истинности, поскольку интеграционный тест всё равно понадобится. ·>Ты заявил, что никак не сможешь время протестировать.
Мне не надо время тестировать. Мне нужно тестировать логику, в которой один или несколько параметров — время. Вы это время протаскиваете через конструктор косвенно, в виде провайдера. Я протаскиваю через параметр функции, явно.
P>>·>Да, но кода этого много накопипасчено. P>>Ну и что? ·>Что каждую копию надо покрывать тестом. Ты правда сейчас собираешься копи-пасту продвигать как правильный дизайн?
Интеграционным, которых ровно столько же, сколько и у вас.
P>>Затем, что признак хорошего кода это его гибкость, которая проявляется в т.ч. в том, что код можно трансформировать, инлайнить, итд, да хоть вовсе от него избавиться. ·>Если при этом нужно плодить копипасту, то это явно что-то не то. И неясно причём тут инлайн и гибкость кода. str.length() — это негибкий код?!
Вы сейчас перевираете. Речь про инлайн вашего nextFriday(). Об ваш супер-крутой подход почему то ИДЕ спотыкается и вы проблемы в этом не видите.
P>>Вы так и не рассказали, как будете решать ту самую задачу с фильтрами. ·>Рассказал и даже код показал,
насколько понял твою задачу. Если ещё остались вопросы, спрашивай.
Ваши тесты проверяют только тривиальные кейсы, на которых все зелено. В проде как правило кучка всего подряд.
P>>·>Дело в том, что в случае субд у тебя кода субд нет. P>>И не надо. ·>Надо, если хотим тестировать поведение, а не детали имплементации.
Тестируйте базу, я ж не мешаю. Можете еще и операционку и джава рантайм сюда добавить
P>>Билдера запросов к базе данных. Вы что думаете, все sql запросы руками пишутся? ·>Да похрен как они пишутся, хоть левой пяткой. Это всё детали реализации. Главное что они работают ожидаемым способом.
Работают ожидаемым способом — это вы на примитивных фильтрах, что вы продемонстрировали, не проверите. О том, что фильтр может вернуть много записей, вам может сказать или сам запрос, или его результат.
Второй вариант у вас отпадает, т.к. в тестах у вас не будет хрензнаетсколькилион записей в тестах
P>> Кое что, для аналитики — возможно. Но это большей частью всё равно перегоняется в орм или билдер. Есть орм — можно проверять построение логики запросов орм. ·>В смысле ты в своих тестах linq/etc тестируешь? Зачем? У linq свои тесты есть.
Это вы собираетесь базу тестировать и топите за поведение. А мне надо всего лишь построение запроса к орм проверить. Если орм не позволяет такого — надо смотреть его sql выхлоп, если и такого нету, значит придется делать так, как вы предлагаете.
P>>Запрос к базе должен соответсвовать бизнес-требованиям. Только проверяем мы это в т.ч. посредством метапрограммирования. ·>Что за бред? У тебя в FRD прописаны тексты запросов??! Прям где-то у вас есть бизнес-требование "select * from users where id=?" и "in: [fn1]"?! Приходит к вам клиент и говорит "а мне очень нужно чтобы out: [fn2], когда можете сделать?"
Что вас смущает? Запрос к бд должен возвращать именно те данные, что прописаны в бл или непосредственно следуют из бл, нефункциональных требований итд. Вас почему то тянет всё к абсурду сводить.
Кроме бизнес требований, у нас куча важных вещей — те самые нефункциональные. Их на порядок больше чем бизнес-требований.
И всё это нужно покрывать тестами, иначе любой дядел поломает цивилизацию
P>>·>Цитату в студию или признавайся, что опять соврал. ·>Цитаты нет. Т.е. соврал.
Смотрите выше — вы фильтры предлагаете тестировать однострочными вырожденными кейсами. Как вы будете ловить те самые комбинации, не ясно.
P>>Вы до сих пор не привели решение кроме "ищем в бд" ·>Я код
привёл. Что не устраивает-то??! "ищем" — это "find", английский язык знаешь?
Смотрите сами: assertThat(testSubject.find(new Filter.byEqual("Vasya"))).isPresent();
У вас testSubject это или репозиторий, который вы предлагаете с подключеной бд тестировать, или компонент, который дергает мок репозитория
Ни то, ни другое проблему с фильтрами не найдут.
P>>>>Смотрите про тривиальный перенос вызова из одного места в другое — ваш nextFriday поломал вообще всё P>>·>Куда смотреть? Поломал что? P>>Вам надо мок подфиксить, что бы время было той системы ·>Чё?
Смотрите — первая версия — вызываем бл прямо из контролера.
Ваши тесты — вы обмокали провайдер времени, передаете туда-сюда, включая тесты контролера
т.е. тесты контролера зависят от мока
Вторая — вызываем бл при чтении из очереди, при этом время должно быть клиенское.
А контролер занят всего лишь тем, что кладет запрос в очередь.
А это значит, что ваши тесты контролера идут в топку, как и моки которые вы под это дело прикрутили.
P>>Наша задача гарантировать что запросы соответствуют бизнес-требованиям. Что бы это гарантировать, я выбрал реализацию с метапрограммированием. Вы, очевидно, выбрали другое — гонять горстку данных к базе и обратно, ·>Покажи пример бизнес-требования.
зачем?
P>>и у вас кейс с вырожденным фильром до сих пор не покрыт тестом. ·>Я не видел этого кейса, и не могу нафантазировать какие у тебя возникли проблемы его покрыть.
А он и не виден, т.к. проблема тупо в количестве вариантов которые могут порождать фильтры. Та самая data complexity.
P>>Не знаю, что у вас с этим за проблема, тут рукописные логи годами ходят в одном и том же виде, тригерят эвенты, и ничего. А гарантировать сохранность стиля генерируемого кода почему то вам кажется рокетсаенсом. ·>Да причём тут стиль? Это мелкий чих. Я могу переписать например "SELECT ... X OR Y" на "UNION SELECT ... X ... SELECT ... Y" для оптитмизации. У тебя все тесты посыпятся и любая ошибка — увидишь после деплоя и прогона многочасовых тестов, в лучшем случае (а скорее всего только в проде). А у меня только те тесты грохнутся, если я реально ошибусь и что-то поломаю в поведении, ещё до коммита.
Очевидно, посыплются не все. Ну нет такой ситуации что бы билдер на каждый запрос лепил UNION. Отвалится скорее всего несколько кейсов, ради которых это все и затевается.
P>>Потому и стоит менять дизайн что бы это контролировать, а через di протаскивать только технологические зависимости. ·>Зато этот код очень простой, линейный и на 99% покрывается компилятором.
Не проверяется. Ваш CalendarLogic может принимать разные экземпляры — с текущим временем, клиентским, серверным, из параметра, итд. Всё что вам компилятор скажет, что типы нужные.
Ну и что?
Кто даст гарантию, что в проде вы правильно прописали зависимости для CalendarLogic? Интерфейс то один и то же
> Остальной 1% покрывается стартом приложения.
Еще меньшая гарантия.
P>>Очень просто — у нас уже есть тесты, одни должны сохраниться без каких либо изменений. ·>Я спросил как сделать так, чтобы такие тесты были, ты ответил
Вы вопрос свой прочитать в состоянии? как именно ты собираешься в "curl" и-тестах ассертить
Буквально curl тест все что может, это сравнить выхлоп, и всё. Если там время не фигурирует, то никак.
Если же вы имеете ввиду интеграционные, то будет все ровно как и у вас.
·>Я о чём и говорю. В каких-то случаях у тебя могут меняться запросы. Ты уже сам говорил о случае с пустым значением, которое ты заявил, что и-тестами тестировать не собираешься. ·>И это могут быть нефункиональные требования, а какие-то технические детали, оптимизации. Простой пример. Скажем, если идёт выборка по небольшому списку параметров, то строится запрос с "IN (?,?)", иначе создаётся временная табличка и с ней джойнится.
Бинго! Оптимизация, нефункциональные требования, технические особенности — все это имеет чудовищное влияние, намного больше, чем сама бизнес-логика.
Если вы потеряете оптимизацию — приплызд. и тест нужен зафиксировать эту особенность что бы сохранить при изменениях.
P>>А вот запросы к базе вещь слишком сложная и ответственная, потому стоит использовать разные инструменты, а не рассказывать, что вам запретили метапрограммирование ·>Именно. Поэтому надо их выполнять и проверять результаты, неважно мета там или фета. Никто вам ничего не запрещает, а мой поинт в том, что важно что запросы делают, а не какие инструменты используются.
См выше — все нефунциональные вещи нужно проверять и фиксировать тестами.
P>>Видите — не так, как вы привыкли и сразу ужос-ужос-мрак-и-смэрть ·>Ну вроде это уже вс проходили и забили. Заталкивать тесты в прод-код... зачем??!
Затем, что это быстрый, дешовый и надежный способ узнавать о проблемах с приложением в целом
1. поменялись зависимости на той стороне — убедились, что все в порядке, или сообщили о проблеме, вкатили хотфикс
2. поменялась инфраструктура — убедились, что все в порядке
3. протух-обновился сертификат — оно же
4. обновили часть системы — оно же, тестируем всю
5. высокая нагрузка — снимаем наши собственные значения, получаем ту инфу которую другим способом никак не получить. Например — некоторые юзеры под высокой нагрузкой получают некорретные данные.
Покажите, как вы все эти кейсы обнаруживать будете. Полагаю ответ будет "у нас багов на проде нету" ?
P>>>>И как же вы решаете проблемы с data complexity которая тестами не решается используя исключительно косвенные тесты? P>>·>А конкретнее? С примером кода. ·>Именно. Примера кода я так и не дождусь.
насколько я понимаю, это я все еще жду вашего примера про фильтры, который решает ту самую data complexity
P>>Это и есть тесты билдера. Только конкретного, в котором заложено много различных вырожденных кейсов. linq не в курсе, что вы вытаскиваете всю базу, ему по барабану. Мне — нет. ·>Linq выдаёт список результатов — вот и проверяй, что в этом списке — вся база или не вся.
Вход на фильтры полным перебором подавать или магией воздействовать?
P>>Ну так найдите эту комбинацию. А их, мягко говоря, немало. Как будете искать? ·>Анализом требовний, кода, данных, етс. Обычный corner case analysis. А как вы будете искать?
Вот-вот. Анализом. Только результаты нужно зафиксировать тестами таким образом, что бы следующиее изменение не сломало всё подряд втихую.
P>>И вы так прямо и втащите coq в любом проект на джаве? ·>Нет. А вы таки втащили доказательное программированипе в js?
Зачем? Доказывать свойства можно и без coq, только результаты нужно выражать в дизайне и подкреплять тестами.
P>>Еще раз — фильтр не хардкодится, а строится. ·>Я потерял суть. О чём речь вообще? Пример в студи. КОД!
Вы когда нибудь видели дашборды где фильтры можно выбирать хрензнаетсколькилионом кнопочек и полей ввода?
P>>Нет, не называется. Разница между code-first и design-first не формате и расширении файла, как вам кажется, а в очередности деливери. ·>Верно. В design-first деливерится манифест first.
Не просто манифест — а любое описание, абы ваши пиры могли его понять и цикл разработки был быстрым.
P>>В том то и дело — ваша задача накидать интерфейсы-модели так, что бы имплементации было 0. Тогда можно деливерить сразу, а вот будет ли деливериться имплементация, и когда — уже дело десятое. ·>Ну да. Откуда же берутся конфиги/тенанты/http-запросы?
Появятся после того, как вы заделивирите АПИ, например спустя год, когда у вас уже версия 1.x. И вот здесь вы решите перейти на rust, то в этот момент крайне странно топить за design-first — у нас уже готовое приложение версии 1.x, и нужно сделать так, что бы манифест отрендерился — с учетом тенантов и прочих вещей, включая not implemented. Или вы собираетесь бегать по отделам и рассказывать "а чо вы это делаете — мы же на джаве год назад это решили не делать" ?
P>>·>Ты опять врёшь. Не телепатией, а из твоих слов: "Манифест генерируется по запросу, обычно http", противоречие выделил жирным. Или ты похоже просто в прыжке переобуваешься. P>>Вы вместо уточнения пытаетесь в телепатию играть. Если у нас готовое приложение, то конечно же генерируется — и странно было бы иначе делать. ·>Угу. ЧТД. "готовое приложение" == "code-first".
Я вам говорю откуда возьмется апи в готовом, если вы решите уже готовое переписать на другом языке.
Здравствуйте, Pauel, Вы писали:
P>·>Я не понимаю что такое заточка мока. Код с моками это просто код. Там где код общий, там он переиспользуется из разных мест. Там где не общий, там не переиспользуется. Мок это просто механизм передачи данных. Ровно такой же вопрос я могу спросить про твои параметры. P>Это я имею ввиду начинку — то, что вы заложите в мок. С параметрами у нас ровно самый минимум — только таблица истинности, и сам код. У вас к этому добавляются еще и моки.
И пусть добавляются. Это просто способ передачи значений.
P>>>Проверка склейки — такого не будет. А вот поддерживает ли приложение такую функцию — нужно проверять интеграционным тестым. P>·>Не всегда нужно, в этом и суть. Интеграционный тест проверяет интеграцию, что компоненты работают вместе. А не каждую функцию приложения. P>То-то и оно. Вот вы снова сами себе и ответили
Причём тут тогда "такую функцию"? Интеграция это не "такая функция".
P>>>И ваши моки не избавляют этого. P>·>Моки не избавляют. А помогают избавляться. P>Нисколько. Моки прибивают вас к конкретному дизайну — см пример про инлайн кода.
Вас может прибивают, нас — не прибивают.
P>Этот пример демонстрирует особенность — даже ИДЕ перестает помогать.
Помогать в чём? Ещё раз — инлайнинг и т.п. — это средство, а не цель. С какой целью что инлайнить-то?
P>А вот если вы отказываетесь от моков, соотвественно, ИДЕ вам в помощник — вдруг рефакторинг inline начинает работать сам собой
Ок, расскажи от каких моков надо избавиться, чтобы рефакторинг inline для str.length() заработал?
P>>>Вариантов дизайна всегда больше одного P>·>Именно. Это всё субъективщина. Эти варианты у тебя меняются каждые год два, как женские шляпки. А вот требование ресурсов, использование сети-тредов-диска — это объективные критерии. На них я и ориентируюсь, а не на последние веяния моды. P>Дизайн вообще должен меняться постоянно, непрерывно. А вы выбираете такой подход, что изменения раз в год-два. О том я и говорю — вы пилите монолит.
Зачем?! Это ты из мира js говоришь, где каждую неделю новый фреймворк выходит и надо всё переписать? А каждые пол года очередной самый правильный дизайн появляется от фаулеров и надо срочно всю архитектуру перекраивать?!
P>>>Есть же пример Буравчика. Вам мало, надо к абсурду свести? P>·>В смысле ты хочешь сказать, что его пример на хаскель не переписывается? Переписыватеся, с монадами и т.п. Но проще он не станет. Поэтому вопрос и остаётся — накой. Твои предложения "улучшить" я не понял в чём же улучшение. P>Я ж объяснил — таблица истинности рядом с тестом и кодом, моки-стабы тоньше некуда. Вы рассматриваете систему в отрыве от тестов. Это категрически неверно. Даже конкретный деплоймент не имеет смысла без тестов — чемодан без ручки. Нужно проверить, а все ли путём, без тестов это никак. Более того — поменялись внешние зависимости — снова нужны тесты.
Это мы уже обсуждали, в проде мы не тестируем, это дичь какая-то из прошлого века.
P>Соответсвенно нужно выбирать такое решение, которое проще мейнтейнить, с учетом тестов.
Угу. И моки тут помогают.
P>>>В стиле ТДД — написали тесты на моках, а потом и дизайн вышел соответствующим P>·>Нет. P>У вас похоже особое видение каждого термина, который мы обсуждаем. ТДД по Кенту Беку целиком про дизайн. P>Вот код теста — как только вы его написали, решение о том, как будут протягиваться зависимости, уже принято
ТДД диктует необходимость того, чтобы код был тестируемый, а не про то куда как тянуть зависимости. Единственно что он может диктовать, что зависимостями надо управлять явно, чтобы можно было прокидывать тестовые.
P>>>·>Ну "правильного" дизайна ты предолжить просто не смог. Т.к. это более менее реальный проект с нетривиальной бизнес-логикой. А твои штуки вменяемо работают только на хоумпейджах. P>>>Какой еще "правильный"? Я продемонстрировал, что минимальными усилиями можно свести тесты к таблице истинности и хранить все это максимально близко к коду. P>·>Я видимо не понял. Где какие таблицы? P> 1,2,3,4,5,6 // и так на каждую строчку в табличке
Не понимаю. Ты, похоже, стиль кода путаешь с дизайном. А дизайн с управлением зависимостями. Ну сделай себе таблицу истинности и с моками, и с параметрами:
void truthTable(int x, int y, int z) {
when(dep.getX()).thenReturn(x);
assert testSubject.doSomething(y) == z;
}
@Test withTableAsYouWish() {
truthTable(1, 2, 5);
truthTable(10, 3, 42);
}
Можешь и аннотации забабахать как у тебя выше. Или цикл. Или на разные тесты (чтобы имена давать осмысленные).
@params(
1,2,3,4,5,6 // и так на каждую строчку в табличке
)
@params(
8,4,2,1,3,5 // точно так же и исключения прокидывают
)
@Test withTableAsYouWish(x, y, z) {
when(dep.getX()).thenReturn(x);
assert testSubject.doSomething(y) == z;
}
Аннотации мне не нравятся, т.к., например, отладчиком сложно пройтись.
P>>>Связывание и есть wiring код. Основная обязанность контроллера — именно это. И тестировать связку, как следствие. P>·>Нет, обязанность контрллера связывать входящие запросы с бизнес-логикой. wiring code — это отдельный код для связывания компонент друг с другом.u P>Вы сейчас в слова играете. Сами же пишете — "обязанность контроллера связывать"
Ну не просто "связывать", а _что_ связывать. Шнурки связывать, контроллер, например, не умеет, хоть с моками, хоть без.
Связывание компонент это не то же, что связывание запросов с логикой.
P> Только еще вводите понятие wiring code.
Ок. Возможно я использовал неизвестную тебе терминологию. Это из мира управления зависимостей. "wiring up dependencies", "autowiring", под я под wiring code здесь имел в виду "composition root".
P>Часть кода связывания будет вне контролера, и правила вы водите сами, это и есть тот дизайн. Прокидываете через dependency injection — значит внутри контролера этого не будет.
Да похрен на дизайн. Это лишь меняет место где "волшебство" происходить будет.
P>Прокидываете now в контролере — эту часть логично исключить из dependency injection.
В контроллере now откуда возьмётся?
P>Смысл помещения кода связывания в контроллер в том, что бы легче было интеграцию тестировать, делая самое важно явным.
Не понял, чем легче?
P>>>·>Что за ерунда? Откуда там null возьмётся? Что за "повесите на dependency injection"? источник времени — это зависимость CalendarLogic, инжектится через конструктор. ЧПФ, забыл опять? P>>>Сами спросили — сами ответили. P>·>Откуда _у тебя_ null берётся? У меня никаких null тут нет. P>У вас CalendarLogic принимает зависимость к конструкторе. Технически, эта зависимость может быть и null, и предзаписаной, и привязаной к контексту — не принципиально.
Это тут причём? Технически передавая через параметр твой now — тоже может быть null и т.п. Всё то же самое.
Но есть очень важная разница в том, что конструктор таких зависимостей (по крайней мере подавляющего большинства зависимостей) вызывается в момент старта приложения, в composition root. И банальная requireNotNull (если яп не поддерживает not-null типы на этапе компиляции) в худшем случае будет железно ронять деплоймент, если конфиги плохие.
В твоём же случае впихивание null будет происходить только при вызове функции приложения. Поэтому вам и требуются тесты всего уже после "успешгого" деплоя в проде.
P>Ваша задача — сделать так, что бы в контролер этот CalendarLogic пришел с нужной завимостью, а не произвольной. Соответсвенно, гарантии фиксируем через интеграционный тест — конкретный use case собран как положено. И вот здесь внутренности реализации вообще роли не играют — проверяется интеграция, а не внутреннее устройство.
А как ты будешь такой и-тест писать, если у тебя будет Time.Now? Что ассертить-то будешь? Как отличать два разных вызова Time.Now — клиентский от серверного? Впрочем, ты уже ответил "никак". Или я что-то пропустил?
P>>>О — InstantSource появился. Значит инжектиться может не один единственный вариант с Now, а минимум два. P>·>А ты вообще код мой читал? В первой строчке код-сниппета
. Ты по-моему сам со своими фантазиями споришь, я тебе только мешаю. P>Вы похоже сами свой код не читали, т.к. у вас недоумение, откуда может быть null. И ежу понятно — будет передан в конструктор или явно, или неявно. Правильно это или нет — скажут тесты.
Так же можно явно или неявно передать now=null в твой nextFriday(now). Ты опять вместо того, чтобы сравнивать два подхода начинаешь общие слова говорить.
P>>>Где у вас тестирование инжекции? А ну как на проде все инжектиться будет по старому? P>·>В прод-classpath не видны моки и вообще вся тестовая белиберда. Код не скомпилится просто, если туда правильную зависимость не вписать. P>Успокойтесь — у вас есть провайдер time, вам нужно больше одной реализации — время может тащиться из разных источников. И ваш CalendarLogic работает с любой из таких зависимостей. P>А щас вы расказываете басню, что компилер как то отличит один провайдер времени от другого времени с таким же интерфейсом
Компилятор может отличать имена символов. Это же в коде видно и на ревью всё очень очевидно — где какое поле куда передаётся. Впрочем, если у тебя всё равно паранойя по этому поводу, лечится просто. Заводим что-то вроде
class TimeProviders
{
private final EventTimestampSource etSource;
InstantSource systemClock() { return Clock.systemUTC(); }
InstantSource eventTimestampClock() { return etSource; }
}
Это, мягко говоря, немного другая ситуация, чем с modify(oldUser, newUser) — т.к. тут по строчке кода никак не видно что куда передаётся и не перепутаны ли параметры.
P>>>А как вы понимаете, что такое отложеный вызов? Недавно вам непонятно было что такое dependency injection, потом выяснилось, что все вам известно. P>·>Мне не было понятно, что ты под этим понимаешь. P>Прямой вызов — ваша функция вызовется прямо сейчас. Отложеный — потом. Например, вы сначала делаете запись, что за функция вызовется, с какими параметрами и тд, а в нужный момент сервис делает собственно сам вызов.
Какое это имеет отношение к разговору?
P>·>Устанавливаем в тестах, что "у нас на сервере now это 21:00:01, а на клиенте "21:00:02". И в тестах можно ассертить что в нужных случаях ожидаемое время. Что ты будешь делать со своим синлтоном Time.Now — ты так и не рассказал. Вообще я не понимаю как ты такое можешь использовать и тем более тестировать, просвети. P>Просто разные аргументы.
Аргументы чего? Откуда ты знаешь, что значения этих аргументов именно Time.Now и как это проверишь в тесте?
P>·>Что синглтоны — плохо учат ещё в детском садике, ясельной группе. P>Вы наверное не поняли — никаких синглтонов, только параметры.
Откуда возьмутся значения этих параметров во всех местах вызова?
P>>>А еще можно обойтись без моков И свести к таблице истинности, поскольку интеграционный тест всё равно понадобится. P>·>Ты заявил, что никак не сможешь время протестировать. P>Мне не надо время тестировать. Мне нужно тестировать логику, в которой один или несколько параметров — время. Вы это время протаскиваете через конструктор косвенно, в виде провайдера. Я протаскиваю через параметр функции, явно.
Надо где-то тестировать, что ты протаскиваешь именно Time.Now а не что-то другое.
P>>>Ну и что? P>·>Что каждую копию надо покрывать тестом. Ты правда сейчас собираешься копи-пасту продвигать как правильный дизайн? P>Интеграционным, которых ровно столько же, сколько и у вас.
Нет. У меня пирамида тестов. А у тебя — либо цилиндр, либо дырявое решето.
P>>>Затем, что признак хорошего кода это его гибкость, которая проявляется в т.ч. в том, что код можно трансформировать, инлайнить, итд, да хоть вовсе от него избавиться. P>·>Если при этом нужно плодить копипасту, то это явно что-то не то. И неясно причём тут инлайн и гибкость кода. str.length() — это негибкий код?! P>Вы сейчас перевираете.
Неперивираю, ты просто свои слова забыл. Напоминаю: " гибкость, которая проявляется в т.ч. в том, что код можно трансформировать, инлайнить". А дальше чистая логика:
"гибкий код → можно инлайнить" => "инлайнить нельзя → не гибкий код" см. https://en.wikipedia.org/wiki/Contraposition
P>Речь про инлайн вашего nextFriday(). Об ваш супер-крутой подход почему то ИДЕ спотыкается и вы проблемы в этом не видите.
Я спрашиваю "зачем инлайн"? Какую задачу-то решаем этим инлайном?!
P>>>Вы так и не рассказали, как будете решать ту самую задачу с фильтрами. P>·>Рассказал и даже код показал,
насколько понял твою задачу. Если ещё остались вопросы, спрашивай. P>Ваши тесты проверяют только тривиальные кейсы, на которых все зелено. В проде как правило кучка всего подряд.
Ну добавь эту твою кучку в тесты. Вопрос-то в чём?
P>>>И не надо. P>·>Надо, если хотим тестировать поведение, а не детали имплементации. P>Тестируйте базу, я ж не мешаю. Можете еще и операционку и джава рантайм сюда добавить
Я не базу тестирую, а запросы, которые строит мой код. А ты хз чего тестируешь.
P>>>Билдера запросов к базе данных. Вы что думаете, все sql запросы руками пишутся? P>·>Да похрен как они пишутся, хоть левой пяткой. Это всё детали реализации. Главное что они работают ожидаемым способом. P>Работают ожидаемым способом — это вы на примитивных фильтрах, что вы продемонстрировали, не проверите.
Ты так заявляешь, что продемонстированном этим кодом подходе нельзя написать фильтр какой тебе угодно непримитивный. С чего ты взял? Пиши фильтры какие придумаешь.
P>О том, что фильтр может вернуть много записей, вам может сказать или сам запрос, или его результат.
Как запрос может что-то сказать?
P>Второй вариант у вас отпадает, т.к. в тестах у вас не будет хрензнаетсколькилион записей в тестах
Зачем мне столько записей? В простом случае понадобится две записи — та которая я ожидаю, что она должна вернуться и та которая я ожидаю, что не должна вернуться.
P>>> Кое что, для аналитики — возможно. Но это большей частью всё равно перегоняется в орм или билдер. Есть орм — можно проверять построение логики запросов орм. P>·>В смысле ты в своих тестах linq/etc тестируешь? Зачем? У linq свои тесты есть. P>Это вы собираетесь базу тестировать
Опять врёшь. И цитаты, ясен пень, не будет.
P> и топите за поведение. А мне надо всего лишь построение запроса к орм проверить. Если орм не позволяет такого — надо смотреть его sql выхлоп, если и такого нету, значит придется делать так, как вы предлагаете.
"Надо" кому? Мы вроде говорим о тестировании ожиданий бизнеса. Ты правда считаешь, что пользователи ожидают определённый выхлоп sql?!
P>>>Запрос к базе должен соответсвовать бизнес-требованиям. Только проверяем мы это в т.ч. посредством метапрограммирования. P>·>Что за бред? У тебя в FRD прописаны тексты запросов??! Прям где-то у вас есть бизнес-требование "select * from users where id=?" и "in: [fn1]"?! Приходит к вам клиент и говорит "а мне очень нужно чтобы out: [fn2], когда можете сделать?" P>Что вас смущает? Запрос к бд должен возвращать именно те данные, что прописаны в бл или непосредственно следуют из бл, нефункциональных требований итд. Вас почему то тянет всё к абсурду сводить. P>Кроме бизнес требований, у нас куча важных вещей — те самые нефункциональные. Их на порядок больше чем бизнес-требований. P>И всё это нужно покрывать тестами, иначе любой дядел поломает цивилизацию
Ещё раз. У тебя в коде теста, в ожиданиях находится "in: [fn1]" и т.п. Как это соответствует "возвращать именно те данные, что прописаны в бл"? Где в бл вообще будет фигурировать in, fn1 и прочий select?
P>>>·>Цитату в студию или признавайся, что опять соврал. P>·>Цитаты нет. Т.е. соврал. P>Смотрите выше — вы фильтры предлагаете тестировать однострочными вырожденными кейсами. Как вы будете ловить те самые комбинации, не ясно.
Ну я не знаю твой код. Я разрешаю тебе писать кейсы двухстрочные и даже трёхстрочные!
P>>>Вы до сих пор не привели решение кроме "ищем в бд" P>·>Я код
привёл. Что не устраивает-то??! "ищем" — это "find", английский язык знаешь? P>Смотрите сами: assertThat(testSubject.find(new Filter.byEqual("Vasya"))).isPresent(); P>У вас testSubject это или репозиторий, который вы предлагаете с подключеной бд тестировать
Да.
P>Ни то, ни другое проблему с фильтрами не найдут.
Почему?
P>>>·>Куда смотреть? Поломал что? P>>>Вам надо мок подфиксить, что бы время было той системы P>·>Чё? P>Смотрите — первая версия — вызываем бл прямо из контролера. P>Ваши тесты — вы обмокали провайдер времени, передаете туда-сюда, включая тесты контролера P>т.е. тесты контролера зависят от мока
Т.е. в тестах контроллера мы прописали ожидание, что время используется серверное, в соответствии с бизнес-требованиям.
P>Вторая — вызываем бл при чтении из очереди, при этом время должно быть клиенское.
Т.е. это значит, что _изменились_ бизнес-требования и теперь мы должны брать не серверное время, а клиентское. Ясен пень, это фукнциональное изменение и соответствующие тесты надо менять. Если у тебя ни один тест не упадёт, у меня для тебя плохие новости.
P>А контролер занят всего лишь тем, что кладет запрос в очередь. P>А это значит, что ваши тесты контролера идут в топку, как и моки которые вы под это дело прикрутили.
В контроллере надо будет заменить использование systemClock() на eventTimestampClock() и поправить тесты, чтобы зафиксировать функциональное изменение.
P>>>Наша задача гарантировать что запросы соответствуют бизнес-требованиям. Что бы это гарантировать, я выбрал реализацию с метапрограммированием. Вы, очевидно, выбрали другое — гонять горстку данных к базе и обратно, P>·>Покажи пример бизнес-требования. P>зачем?
Чтобы понять какое отношение имеет метапрограммирование к тестированию ожиданий бизнес-требований.
P>>>и у вас кейс с вырожденным фильром до сих пор не покрыт тестом. P>·>Я не видел этого кейса, и не могу нафантазировать какие у тебя возникли проблемы его покрыть. P>А он и не виден, т.к. проблема тупо в количестве вариантов которые могут порождать фильтры. Та самая data complexity.
Ну а в телепанию я не умею.
P>>>Не знаю, что у вас с этим за проблема, тут рукописные логи годами ходят в одном и том же виде, тригерят эвенты, и ничего. А гарантировать сохранность стиля генерируемого кода почему то вам кажется рокетсаенсом. P>·>Да причём тут стиль? Это мелкий чих. Я могу переписать например "SELECT ... X OR Y" на "UNION SELECT ... X ... SELECT ... Y" для оптитмизации. У тебя все тесты посыпятся и любая ошибка — увидишь после деплоя и прогона многочасовых тестов, в лучшем случае (а скорее всего только в проде). А у меня только те тесты грохнутся, если я реально ошибусь и что-то поломаю в поведении, ещё до коммита. P>Очевидно, посыплются не все. Ну нет такой ситуации что бы билдер на каждый запрос лепил UNION. Отвалится скорее всего несколько кейсов, ради которых это все и затевается.
Ну этот кусочек может быть в большой группе запросов, выбирающих разные данные по-разному, но часть логики — общая.
P>>>Потому и стоит менять дизайн что бы это контролировать, а через di протаскивать только технологические зависимости. P>·>Зато этот код очень простой, линейный и на 99% покрывается компилятором. P>Не проверяется. Ваш CalendarLogic может принимать разные экземпляры — с текущим временем, клиентским, серверным, из параметра, итд. Всё что вам компилятор скажет, что типы нужные. P>Ну и что? P>Кто даст гарантию, что в проде вы правильно прописали зависимости для CalendarLogic? Интерфейс то один и то же
Гарантию, конечно, никто не даст, но покрыть тестами с моками тоже можно. Для этого моки и придумали.
>> Остальной 1% покрывается стартом приложения. P>Еще меньшая гарантия.
Опять ты о гарантиях заговорил, опять опозоришься.
P>>>Очень просто — у нас уже есть тесты, одни должны сохраниться без каких либо изменений. P>·>Я спросил как сделать так, чтобы такие тесты были, ты ответил
"Никак.". Т.е. тестов у вас таких просто нет. P>Вы вопрос свой прочитать в состоянии? как именно ты собираешься в "curl" и-тестах ассертить P>Буквально curl тест все что может, это сравнить выхлоп, и всё. Если там время не фигурирует, то никак.
Ну, допустим, фигурирует. И чем это тебе поможет?
P>Если же вы имеете ввиду интеграционные, то будет все ровно как и у вас.
С моками? Ну дык об чём спор-то тогда? Ведь именно моком я могу протащить тестовые значения now в нужные места. Там, где ты предлагаешь Time.Now синглтон, в который ты ничего протащить не сможешь.
P>·>Я о чём и говорю. В каких-то случаях у тебя могут меняться запросы. Ты уже сам говорил о случае с пустым значением, которое ты заявил, что и-тестами тестировать не собираешься. P>·>И это могут быть нефункиональные требования, а какие-то технические детали, оптимизации. Простой пример. Скажем, если идёт выборка по небольшому списку параметров, то строится запрос с "IN (?,?)", иначе создаётся временная табличка и с ней джойнится. P>Бинго! Оптимизация, нефункциональные требования, технические особенности — все это имеет чудовищное влияние, намного больше, чем сама бизнес-логика. P>Если вы потеряете оптимизацию — приплызд. и тест нужен зафиксировать эту особенность что бы сохранить при изменениях.
Это уже будет перф-тест и к обсуждаемой теме не относится. Я пока обсуждаю именно и/ю-тесты. И суть в том, что твоё "интеграционные тесты строятся по функциям, а не по запросам к базе" — несостоятельный подход. Т.е. в бизнес-требованиях будет одна функция "выбрать по списку", следовательно и-тест у тебя тоже один, а то что от размера списка может срабатывать разный код, генеряться разные запросы и т.п. — это ты просто не протестируешь и будешь ловить проблемы на проде.
P>>>А вот запросы к базе вещь слишком сложная и ответственная, потому стоит использовать разные инструменты, а не рассказывать, что вам запретили метапрограммирование P>·>Именно. Поэтому надо их выполнять и проверять результаты, неважно мета там или фета. Никто вам ничего не запрещает, а мой поинт в том, что важно что запросы делают, а не какие инструменты используются. P>См выше — все нефунциональные вещи нужно проверять и фиксировать тестами.
Это не оправдывает твой подход, что функциональные тесты должны тестировать метапрограммирование.
P>>>Видите — не так, как вы привыкли и сразу ужос-ужос-мрак-и-смэрть P>·>Ну вроде это уже вс проходили и забили. Заталкивать тесты в прод-код... зачем??! P>Затем, что это быстрый, дешовый и надежный способ узнавать о проблемах с приложением в целом P>Покажите, как вы все эти кейсы обнаруживать будете.
Возвращаемся к старому спору. Я уже отвечал на это неоднократно: системы мониторинга, health probes и прочие операционные инструменты. Это не тестирование.
P>Полагаю ответ будет "у нас багов на проде нету" ?
Вот таких багов "протух-обновился сертификат" — и не должно быть. Такие вещи именно мониторингом отслеживаются заранее, чтобы пофиксить можно было до возникновения этой ситуации. А у вас серты протухают ВНЕЗАПНО, и обнаруживаются только тестами постфактум, что у вас в проде что-то где-то отвалилось... ну могу только пособолезновать вашим клиентам.
P>>>·>А конкретнее? С примером кода. P>·>Именно. Примера кода я так и не дождусь. P>насколько я понимаю, это я все еще жду вашего примера про фильтры, который решает ту самую data complexity
Какую ту самую? Я никакой "data complexity" не видел и телепатией не обладаю, чтобы выдать какое-то решение для задачи о которой я не слышал.
P>>>Это и есть тесты билдера. Только конкретного, в котором заложено много различных вырожденных кейсов. linq не в курсе, что вы вытаскиваете всю базу, ему по барабану. Мне — нет. P>·>Linq выдаёт список результатов — вот и проверяй, что в этом списке — вся база или не вся. P> Вход на фильтры полным перебором подавать или магией воздействовать?
Да так же, как у тебя. Только ассертить не буквальный текст запроса, а результат его выполнения.
P>>>Ну так найдите эту комбинацию. А их, мягко говоря, немало. Как будете искать? P>·>Анализом требовний, кода, данных, етс. Обычный corner case analysis. А как вы будете искать? P>Вот-вот. Анализом. Только результаты нужно зафиксировать тестами таким образом, что бы следующиее изменение не сломало всё подряд втихую.
Да, верно.
P>>>И вы так прямо и втащите coq в любом проект на джаве? P>·>Нет. А вы таки втащили доказательное программированипе в js? P>Зачем? Доказывать свойства можно и без coq, только результаты нужно выражать в дизайне и подкреплять тестами.
P>>>Еще раз — фильтр не хардкодится, а строится. P>·>Я потерял суть. О чём речь вообще? Пример в студи. КОД! P>Вы когда нибудь видели дашборды где фильтры можно выбирать хрензнаетсколькилионом кнопочек и полей ввода?
Насколько мне доводилось видеть, они обычно через & соединяются. Т.е. список независимых фильтров. Сложность возникает когда фильтры между собой взаимосвязаны, но обычно такое избегают, т.к. юзерам такая compexity тоже не под силу, и использовать нормально всё равно не получается.
P>>>Нет, не называется. Разница между code-first и design-first не формате и расширении файла, как вам кажется, а в очередности деливери. P>·>Верно. В design-first деливерится манифест first. P>Не просто манифест — а любое описание, абы ваши пиры могли его понять и цикл разработки был быстрым.
Что значит за любое описание? Манифест это и есть описание api.
P>>>В том то и дело — ваша задача накидать интерфейсы-модели так, что бы имплементации было 0. Тогда можно деливерить сразу, а вот будет ли деливериться имплементация, и когда — уже дело десятое. P>·>Ну да. Откуда же берутся конфиги/тенанты/http-запросы? P>Появятся после того, как вы заделивирите АПИ, например спустя год, когда у вас уже версия 1.x. И вот здесь вы решите перейти на rust, то в этот момент крайне странно топить за design-first — у нас уже готовое приложение версии 1.x, и нужно сделать так, что бы манифест отрендерился — с учетом тенантов и прочих вещей, включая not implemented. Или вы собираетесь бегать по отделам и рассказывать "а чо вы это делаете — мы же на джаве год назад это решили не делать" ?
У вас уже есть имплементация и мы вот наконец спустя год выкатываем манифест api, но ты всё ещё это называешь design-first?! Нет, это типичный code-first — когда прыгать надо, думать некогда.
P>>>Вы вместо уточнения пытаетесь в телепатию играть. Если у нас готовое приложение, то конечно же генерируется — и странно было бы иначе делать. P>·>Угу. ЧТД. "готовое приложение" == "code-first". P>Я вам говорю откуда возьмется апи в готовом, если вы решите уже готовое переписать на другом языке.
Причём тут design-first?
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>Это я имею ввиду начинку — то, что вы заложите в мок. С параметрами у нас ровно самый минимум — только таблица истинности, и сам код. У вас к этому добавляются еще и моки. ·>И пусть добавляются. Это просто способ передачи значений.
Это дополнительные издержки по сравнению с простыми функциями. Вы это сами показали на тестах календаря.
P>>>>Проверка склейки — такого не будет. А вот поддерживает ли приложение такую функцию — нужно проверять интеграционным тестым. P>>·>Не всегда нужно, в этом и суть. Интеграционный тест проверяет интеграцию, что компоненты работают вместе. А не каждую функцию приложения. P>>То-то и оно. Вот вы снова сами себе и ответили ·>Причём тут тогда "такую функцию"? Интеграция это не "такая функция".
Ощущение что для вас функциональные требования и функция в джаве это одно и то же. Как вы смоделируете, например, функцию удаления пользователя в системе — дело десятое. Это всего одна строчка в функциональных требованиях. А в вашей архитектуре это может быть процесс растянутый на месяц — пишете в очередь, читаете из нее, удаляет порцию, пишете в очередь... и тд и тд.
И у вас вполне вероятно не будет ни одной функции в джаве "удалить пользователя". А будет например "дропнуть док по хешкоду", "дропнуть записи по номеру телефона", "дропнуть сообщения по емейлу", "отозвать сертификат", "пометить спейс юзера к удалению через месяц", "подготовить выгрузку всех данных юзера", "закинуть зип на aws s3 c ttl 1 месяц"
P>>Нисколько. Моки прибивают вас к конкретному дизайну — см пример про инлайн кода. ·>Вас может прибивают, нас — не прибивают.
Вас тоже прибивают, только вы в этом видите пользу какую то.
P>>Этот пример демонстрирует особенность — даже ИДЕ перестает помогать. ·>Помогать в чём? Ещё раз — инлайнинг и т.п. — это средство, а не цель. С какой целью что инлайнить-то?
Рефакторинг, очевидно. Его не раз в год нужно делать, а непрерывно — требования меняются постоянно.
P>>А вот если вы отказываетесь от моков, соотвественно, ИДЕ вам в помощник — вдруг рефакторинг inline начинает работать сам собой ·>Ок, расскажи от каких моков надо избавиться, чтобы рефакторинг inline для str.length() заработал?
Элементарно — замена вызова на константу. Это работает, т.к. str у вас иммутабельная. А вот текущее время такой особенностью не обладает.
Другая проблема — ваша реализация с зависимостью внутри кешированию не поддаётся.
То есть, проблемы с вашей реализацией мы видим, а вот бенефиты какие то мифические, и вы никак не можете их описать.
P>>Дизайн вообще должен меняться постоянно, непрерывно. А вы выбираете такой подход, что изменения раз в год-два. О том я и говорю — вы пилите монолит. ·>Зачем?! Это ты из мира js говоришь, где каждую неделю новый фреймворк выходит и надо всё переписать? А каждые пол года очередной самый правильный дизайн появляется от фаулеров и надо срочно всю архитектуру перекраивать?!
Из вас технологический расизм прёт непрерывно. Извините, но на мой взгляд вместе с телепатией это признак неполной профессиональной компетенции.
Дизайн меняется по простой причине — требования меняются непрерывно. Вот появилось нефункциональное требование "перформанс" и мы видим, что CalendarLogic сидит в hotpath и вызывается сто раз с одним и теми же значениями. Опаньки — меняем дизайн. Как это сделать в вашем случае — не ясно. Разве что прокинуть к вашему CalendarLogic еще и MRU, LRU кеш с конфигом "вот такие значения хранить пять минут". Вот уж простор для моков — теперь можно мокать не одно время, а целых три, а можно MRU, LRU обмокать.
P>>Я ж объяснил — таблица истинности рядом с тестом и кодом, моки-стабы тоньше некуда. Вы рассматриваете систему в отрыве от тестов. Это категрически неверно. Даже конкретный деплоймент не имеет смысла без тестов — чемодан без ручки. Нужно проверить, а все ли путём, без тестов это никак. Более того — поменялись внешние зависимости — снова нужны тесты. ·>Это мы уже обсуждали, в проде мы не тестируем, это дичь какая-то из прошлого века.
Наоборот. В прошлом веке правило было "не трогай прод!!!!!!!1111111ййййкуккуку".
P>>Соответсвенно нужно выбирать такое решение, которое проще мейнтейнить, с учетом тестов. ·>Угу. И моки тут помогают.
Что бы просто так, без контекста — это слишком сильное утверждение. Но в целом оно отражает ваш подход к тестированию
P>>Вот код теста — как только вы его написали, решение о том, как будут протягиваться зависимости, уже принято ·>ТДД диктует необходимость того, чтобы код был тестируемый, а не про то куда как тянуть зависимости. Единственно что он может диктовать, что зависимостями надо управлять явно, чтобы можно было прокидывать тестовые.
Как только вы написали тест, то из него однозначно следует, какой будет АПИ и как будут прокидываться зависимости. Вы поймите — код теста это выражение наших намерений
1 апи
2 зависимости
3 поведение
4 связывание
5 входы-выходы.
По большому счету, идеально свести тест к п5. А вы сюда втаскиваете лошадь размером со слона.
P>> 1,2,3,4,5,6 // и так на каждую строчку в табличке ·>Не понимаю. Ты, похоже, стиль кода путаешь с дизайном. А дизайн с управлением зависимостями. Ну сделай себе таблицу истинности и с моками, и с параметрами:
·>
·> when(dep.getX()).thenReturn(x);
·>
Лишняя строчка
·>Связывание компонент это не то же, что связывание запросов с логикой.
P>> Только еще вводите понятие wiring code. ·>Ок. Возможно я использовал неизвестную тебе терминологию. Это из мира управления зависимостей. "wiring up dependencies", "autowiring", под я под wiring code здесь имел в виду "composition root".
Вот-вот. Статься от 2011го, ссылается на книгу, которую начали писать в 00х на основе опыта накопленного тогда же.
Мы только что выяснили, кто же из нас двоих вещает из нулевых
P>>Часть кода связывания будет вне контролера, и правила вы водите сами, это и есть тот дизайн. Прокидываете через dependency injection — значит внутри контролера этого не будет. ·>Да похрен на дизайн. Это лишь меняет место где "волшебство" происходить будет.
Вам похрен — это и ежу понятно. Отличия в дизайне позволяют применить более эффективные способы, например, тестирования.
P>>Прокидываете now в контролере — эту часть логично исключить из dependency injection. ·>В контроллере now откуда возьмётся?
Вы уже много раз задавали этот вопрос, и я вам много раз на него отвечал. Отмотайте да посмотрите.
P>>Смысл помещения кода связывания в контроллер в том, что бы легче было интеграцию тестировать, делая самое важно явным. ·>Не понял, чем легче?
Самое важное сразу в коде метода, а не раскидано абы где по всеей иерархии dependency injection.
P>>У вас CalendarLogic принимает зависимость к конструкторе. Технически, эта зависимость может быть и null, и предзаписаной, и привязаной к контексту — не принципиально. ·>Это тут причём? Технически передавая через параметр твой now — тоже может быть null и т.п. Всё то же самое.
Нет, не может быть. Это вам нужно делать явно в самом контроллере, который зафейлится сразу же, на первом тесте который его вызовет.
·>В твоём же случае впихивание null будет происходить только при вызове функции приложения. Поэтому вам и требуются тесты всего уже после "успешгого" деплоя в проде.
Я ж вам объяснил — тесты прода нужны для самых разных кейсов.
·>А как ты будешь такой и-тест писать, если у тебя будет Time.Now? Что ассертить-то будешь? Как отличать два разных вызова Time.Now — клиентский от серверного? Впрочем, ты уже ответил "никак". Или я что-то пропустил?
Согласно бл. А вы как собираетесь отличать два разных вызова, клиентский от серверного? Вам для этого придется намастырить кучу кода с инжекцией в конструктор, только всё важное будет "где то там"
P>>Вы похоже сами свой код не читали, т.к. у вас недоумение, откуда может быть null. И ежу понятно — будет передан в конструктор или явно, или неявно. Правильно это или нет — скажут тесты. ·>Так же можно явно или неявно передать now=null в твой nextFriday(now).
Теоретически — можно. Практически — первый интеграционный тест сваливается, когда вызывает этот контроллер.
P>>А щас вы расказываете басню, что компилер как то отличит один провайдер времени от другого времени с таким же интерфейсом ·>Компилятор может отличать имена символов. Это же в коде видно и на ревью всё очень очевидно — где какое поле куда передаётся.
Вот вы сами себе и ответили. Ну или объясните, почему код ревью перестанет работать с параметром в контроллере.
P>>Прямой вызов — ваша функция вызовется прямо сейчас. Отложеный — потом. Например, вы сначала делаете запись, что за функция вызовется, с какими параметрами и тд, а в нужный момент сервис делает собственно сам вызов. ·>Какое это имеет отношение к разговору?
Вы же спрашиваи, что такое отложенный вызов. Если у нас нет зависимости внутри, то отложеный вызов делается как два пальца об асфальт. Это снова про гибкость, которой у вас почему то нет.
P>>Просто разные аргументы. ·>Аргументы чего? Откуда ты знаешь, что значения этих аргументов именно Time.Now и как это проверишь в тесте?
С вашего аккаунта похоже разные люди пишут, да еще и меняются во время написания одного и того же сообщения. Вот некто с вашего аккаунта чуть выше ответил на ваш вопрос:
Компилятор может отличать имена символов. Это же в коде видно и на ревью всё очень очевидно — где какое поле куда передаётся.
P>>·>Что синглтоны — плохо учат ещё в детском садике, ясельной группе. P>>Вы наверное не поняли — никаких синглтонов, только параметры. ·>Откуда возьмутся значения этих параметров во всех местах вызова?
Через параметры функции. Дизайн то плоский, а не глубокий, как у вас.
P>>Мне не надо время тестировать. Мне нужно тестировать логику, в которой один или несколько параметров — время. Вы это время протаскиваете через конструктор косвенно, в виде провайдера. Я протаскиваю через параметр функции, явно. ·>Надо где-то тестировать, что ты протаскиваешь именно Time.Now а не что-то другое.
Вам тоже надо тестировать что вы привязали в проде пров клиенского времени, а не пров серверного или предзаписаного. Похоже, у вас там снова смена автора на вашем аккаунте.
P>>Интеграционным, которых ровно столько же, сколько и у вас. ·>Нет. У меня пирамида тестов. А у тебя — либо цилиндр, либо дырявое решето.
Для пирамиды нужно большое количество дешовых юнит тестов. У вас много полу-интеграционных, на моках, и мало собственно чистых юнитов. У меня — наоброт. Потому именно ваша пирамида видится мне ромбиком.
P>>·>Если при этом нужно плодить копипасту, то это явно что-то не то. И неясно причём тут инлайн и гибкость кода. str.length() — это негибкий код?! P>>Вы сейчас перевираете. ·>Неперивираю, ты просто свои слова забыл. Напоминаю: " гибкость, которая проявляется в т.ч. в том, что код можно трансформировать, инлайнить". А дальше чистая логика: ·>"гибкий код → можно инлайнить" => "инлайнить нельзя → не гибкий код" см. https://en.wikipedia.org/wiki/Contraposition
С str.length всё в порядке — инлайнится с переводом в константу. У вас что то еще?
P>>Речь про инлайн вашего nextFriday(). Об ваш супер-крутой подход почему то ИДЕ спотыкается и вы проблемы в этом не видите. ·>Я спрашиваю "зачем инлайн"? Какую задачу-то решаем этим инлайном?!
Рефакторинг, оптимизации.
P>>Ваши тесты проверяют только тривиальные кейсы, на которых все зелено. В проде как правило кучка всего подряд. ·>Ну добавь эту твою кучку в тесты. Вопрос-то в чём?
Эта кучка называется data complexity. Я, например, билдером могу гарантировать, что данные будут запрашиваться постранично. Или что всегда будет фильтр по времени, где период не более трех месяцев. Соответсвено тестами можно проверить что структура запроса та, что нам надо
P>>О том, что фильтр может вернуть много записей, вам может сказать или сам запрос, или его результат. ·>Как запрос может что-то сказать?
Элементарно — всегда есть шанс, что ваш запрос вернет чего нибудь лишнее. Тестами эта задача не решается, принципиально.
Что бы написать корректный запрос, вам надо
1. гарантировать, что бы на "тех" данных вернется что надо. Это можно решить тестами — накидать данных, обработать, сравнить результат
2. гарантировать, что на других данных, которых у вас нет, тоже вернется ровно то, что надо. И тестами на основе данных это не решается — т.к. данных нет.
Итого — ваши тесты данных не являются решением, т.к. п 2 у нас обязательный. А вот дополнительные методы, например, инварианты, пред, пост условия, контроль построения запроса, код ревью основанное на понимании работы бд — это дает более-менее осязаемые данные.
P>>Второй вариант у вас отпадает, т.к. в тестах у вас не будет хрензнаетсколькилион записей в тестах ·>Зачем мне столько записей? В простом случае понадобится две записи — та которая я ожидаю, что она должна вернуться и та которая я ожидаю, что не должна вернуться.
Я вам выше рассказал. Нужна гарантия, что не вернется вдруг чего нибудь не то. Вариантов "не того" у вас по скромной оценке близко к бесконечности.
P>>>> Кое что, для аналитики — возможно. Но это большей частью всё равно перегоняется в орм или билдер. Есть орм — можно проверять построение логики запросов орм. P>>·>В смысле ты в своих тестах linq/etc тестируешь? Зачем? У linq свои тесты есть. P>>Это вы собираетесь базу тестировать ·>Опять врёшь. И цитаты, ясен пень, не будет.
Вы топите за косвенные проверки запросов, тестируя связку репозиторий+бд. Вот этого оно и есть.
P>> и топите за поведение. А мне надо всего лишь построение запроса к орм проверить. Если орм не позволяет такого — надо смотреть его sql выхлоп, если и такого нету, значит придется делать так, как вы предлагаете. ·>"Надо" кому? Мы вроде говорим о тестировании ожиданий бизнеса. Ты правда считаешь, что пользователи ожидают определённый выхлоп sql?!
Пользователи ожидают, что на их данных, которых в ваших тестах нет, будет нужный результат. Вашими тестами эта задача не решается
P>>И всё это нужно покрывать тестами, иначе любой дядел поломает цивилизацию ·>Ещё раз. У тебя в коде теста, в ожиданиях находится "in: [fn1]" и т.п. Как это соответствует "возвращать именно те данные, что прописаны в бл"? Где в бл вообще будет фигурировать in, fn1 и прочий select?
Не нужно сводить всё к бл напряму. У вас технологического кода в приложении примерно 99%. Он к бл относится крайне опосредовано — через связывание. А тестировать эти 99% тоже нужно.
P>>Смотрите выше — вы фильтры предлагаете тестировать однострочными вырожденными кейсами. Как вы будете ловить те самые комбинации, не ясно. ·>Ну я не знаю твой код. Я разрешаю тебе писать кейсы двухстрочные и даже трёхстрочные!
Вы что, недогоняете, что нет возможности покрыть неизвестные данные и комбинации какими либо тестами?
P>>Ни то, ни другое проблему с фильтрами не найдут. ·>Почему?
Потому, что у вас нет всего множества данных, которые могут приходить от юзеров.
Более того — количество данных дает вам такую особенность, как слишком долгое время выполнения запроса.
Задача с фильтрами у меня выявила такую вещь — если данных слишком много, то запрос с секунд резко уезжает в минуты.
Вот оптимизацию такой вещи закрыть тестами, что бы первый же фикс не сломал всю цивилизацию
P>>т.е. тесты контролера зависят от мока ·>Т.е. в тестах контроллера мы прописали ожидание, что время используется серверное, в соответствии с бизнес-требованиям.
В интеграционном тесте можно сделать то же самое.
P>>Вторая — вызываем бл при чтении из очереди, при этом время должно быть клиенское. ·>Т.е. это значит, что _изменились_ бизнес-требования и теперь мы должны брать не серверное время, а клиентское. Ясен пень, это фукнциональное изменение и соответствующие тесты надо менять. Если у тебя ни один тест не упадёт, у меня для тебя плохие новости.
Это как раз нефункциональное требование. Например, у нас запрос выполнялся слишком долго, и мы процессинг вытолкнули в очередь с отложеным процессингом.
P>>А это значит, что ваши тесты контролера идут в топку, как и моки которые вы под это дело прикрутили. ·>В контроллере надо будет заменить использование systemClock() на eventTimestampClock() и поправить тесты, чтобы зафиксировать функциональное изменение.
Функционых изменений здесь ровно 0. С т.з. пользователя никаких функций не добавляется.
P>>зачем? ·>Чтобы понять какое отношение имеет метапрограммирование к тестированию ожиданий бизнес-требований.
Метапрограммирование дает возможность зафиксировать свойства запроса, которые вы с вашими тестами сделать не сможете, никоим образом.
P>>Очевидно, посыплются не все. Ну нет такой ситуации что бы билдер на каждый запрос лепил UNION. Отвалится скорее всего несколько кейсов, ради которых это все и затевается. ·>Ну этот кусочек может быть в большой группе запросов, выбирающих разные данные по-разному, но часть логики — общая.
Может. Это дополнительные гарантии, сверх тех, что вы можете получить прогоном на тестовых данных. Потому издержки обоснованы.
P>>Кто даст гарантию, что в проде вы правильно прописали зависимости для CalendarLogic? Интерфейс то один и то же ·>Гарантию, конечно, никто не даст, но покрыть тестами с моками тоже можно. Для этого моки и придумали.
Вот вот — прибиваете контроллер к тестам на моках.
P>>Буквально curl тест все что может, это сравнить выхлоп, и всё. Если там время не фигурирует, то никак. ·>Ну, допустим, фигурирует. И чем это тебе поможет?
Тогда можно сравнить выхлоп, тот или не тот.
P>>Если же вы имеете ввиду интеграционные, то будет все ровно как и у вас. ·>С моками? Ну дык об чём спор-то тогда? Ведь именно моком я могу протащить тестовые значения now в нужные места. Там, где ты предлагаешь Time.Now синглтон, в который ты ничего протащить не сможешь.
Этим протаскиванием вы бетонируете весь дизайн. Смена дизайна = переписывание тестов.
P>>Бинго! Оптимизация, нефункциональные требования, технические особенности — все это имеет чудовищное влияние, намного больше, чем сама бизнес-логика. P>>Если вы потеряете оптимизацию — приплызд. и тест нужен зафиксировать эту особенность что бы сохранить при изменениях. ·>Это уже будет перф-тест и к обсуждаемой теме не относится.
Покрыть перформанс тестами все вырожденные кейсы вам время жизни вселенной не позволит. Некоторые детали реализации нужно фиксировать обычыными тестами.
Это нововведение в тестах — кроме функциональности тесты могут фиксировать конкретную особенность.
P>>См выше — все нефунциональные вещи нужно проверять и фиксировать тестами. ·>Это не оправдывает твой подход, что функциональные тесты должны тестировать метапрограммирование.
Метапрограммирование тестируется там, где оно применяется в силу естественных причин. Если у вас запросы тривиальные, вам такое не нужно.
P>>Покажите, как вы все эти кейсы обнаруживать будете. ·>Возвращаемся к старому спору. Я уже отвечал на это неоднократно: системы мониторинга, health probes и прочие операционные инструменты. Это не тестирование.
Неэффективно. Для многих приложений час невалидной работы может стоит любых денег. Дешевле запустить тесты на проде — час-два и у вас информация по всем функциям.
P>>Полагаю ответ будет "у нас багов на проде нету" ? ·>Вот таких багов "протух-обновился сертификат" — и не должно быть. Такие вещи именно мониторингом отслеживаются заранее, чтобы пофиксить можно было до возникновения этой ситуации. А у вас серты протухают ВНЕЗАПНО, и обнаруживаются только тестами постфактум, что у вас в проде что-то где-то отвалилось... ну могу только пособолезновать вашим клиентам.
Вы снова включили телепатию. Сертификат может обновиться не у вашего приложения, а у какого нибудь из внешних сервисов. Мониторинг вам скажет, когда N юзеров напорются на это и у вас начнет расти соответсвующая метрика.
P>>насколько я понимаю, это я все еще жду вашего примера про фильтры, который решает ту самую data complexity ·>Какую ту самую? Я никакой "data complexity" не видел и телепатией не обладаю, чтобы выдать какое-то решение для задачи о которой я не слышал.
У вас есть иллюзия, что ваши тесты гарантируют отсутствие лишнего выхлопа на данных, которые у вас отсутсвуют.
P>> Вход на фильтры полным перебором подавать или магией воздействовать? ·>Да так же, как у тебя. Только ассертить не буквальный текст запроса, а результат его выполнения
P>>Вы когда нибудь видели дашборды где фильтры можно выбирать хрензнаетсколькилионом кнопочек и полей ввода? ·>Насколько мне доводилось видеть, они обычно через & соединяются. Т.е. список независимых фильтров. Сложность возникает когда фильтры между собой взаимосвязаны, но обычно такое избегают, т.к. юзерам такая compexity тоже не под силу, и использовать нормально всё равно не получается.
Ну да, вы сами чего то додумали, и воюеете за это
Я вижу, что в большинстве интернет магазинов в т.ч. крупных фильры работают некорректно.
P>>Не просто манифест — а любое описание, абы ваши пиры могли его понять и цикл разработки был быстрым. ·>Что значит за любое описание? Манифест это и есть описание api.
Любой формат, любое расширение файла У ваших пиров должен быть инструмент для использования такого описания.
Например, вы решили выдать swagger, но описали в ём такое апи, которое ни один генератор кода не понимает. Это значит, что вы АПИ вообще не предоставили — мало кто в своём уме будет вручную имплементать нюансы которые к релизу поменяются 100500 раз
P>>Появятся после того, как вы заделивирите АПИ, например спустя год, когда у вас уже версия 1.x. И вот здесь вы решите перейти на rust, то в этот момент крайне странно топить за design-first — у нас уже готовое приложение версии 1.x, и нужно сделать так, что бы манифест отрендерился — с учетом тенантов и прочих вещей, включая not implemented. Или вы собираетесь бегать по отделам и рассказывать "а чо вы это делаете — мы же на джаве год назад это решили не делать" ? ·>У вас уже есть имплементация и мы вот наконец спустя год выкатываем манифест api, но ты всё ещё это называешь design-first?! Нет, это типичный code-first — когда прыгать надо, думать некогда.
Вы похоже не читаете. Какой смысл вам что либо рассказывать?
1. когда стартуем проект, где центральная часть это АПИ. Идем через design-first, формат файла и расширение — любое, см. выше
2. готовый проект — уже поздно топить за design-first, просто генерим артефакты
3. переписываем проект на rust — снова, нам design-first не нужен, это вариация предыдущего кейса
Вот если у вас переписывание случается каждый день, или даже чаще, да на новый язык, то АПИ нужно держать в каком то универсальном формате.
Правда, в этом случае я более чем уверен, вы дольше всего будете подбирать генераторы кода под это АПИ, или выписывать все загогулины руками с воплями "я уже заимплементал херли вы перенесли параметр из квери в хидеры!!!!!!!11111йййкукуку"
P>>>>Вы вместо уточнения пытаетесь в телепатию играть. Если у нас готовое приложение, то конечно же генерируется — и странно было бы иначе делать. P>>·>Угу. ЧТД. "готовое приложение" == "code-first". P>>Я вам говорю откуда возьмется апи в готовом, если вы решите уже готовое переписать на другом языке. ·>Причём тут design-first?
У вас точно меняется контингент, или в голове, или за компом:
Если вы захотите переписать свой сервис на другой ЯП, ну там с js на rust — что вы будете делать со своими аннотациями?
Переписывание предполагает, что у нас уже есть и АПИ, и реализация этого АПИ. Отсюда ясно, что проще сгенерировать артефакт, чем изначально держаться за конкретный формат и топить за design-first
Здравствуйте, Pauel, Вы писали:
P>>>Это я имею ввиду начинку — то, что вы заложите в мок. С параметрами у нас ровно самый минимум — только таблица истинности, и сам код. У вас к этому добавляются еще и моки. P>·>И пусть добавляются. Это просто способ передачи значений. P>Это дополнительные издержки по сравнению с простыми функциями. Вы это сами показали на тестах календаря.
Ты просто пытаешься ввести в заблуждение. Да, у меня в тестах добавляется одна строчка кода и собственно всё. Зато в твоём решении добавляется N-строчек в _прод_ коде и требуется больше тестов. Иными словами, ты "убираешь" код, но стесняешься говорить _куда_ этот код убирается.
P>>>То-то и оно. Вот вы снова сами себе и ответили P>·>Причём тут тогда "такую функцию"? Интеграция это не "такая функция". P>Ощущение что для вас функциональные требования и функция в джаве это одно и то же. Как вы смоделируете, например, функцию удаления пользователя в системе — дело десятое. Это всего одна строчка в функциональных требованиях. А в вашей архитектуре это может быть процесс растянутый на месяц — пишете в очередь, читаете из нее, удаляет порцию, пишете в очередь... и тд и тд. P>И у вас вполне вероятно не будет ни одной функции в джаве "удалить пользователя". А будет например "дропнуть док по хешкоду", "дропнуть записи по номеру телефона", "дропнуть сообщения по емейлу", "отозвать сертификат", "пометить спейс юзера к удалению через месяц", "подготовить выгрузку всех данных юзера", "закинуть зип на aws s3 c ttl 1 месяц"
Ну будет же где-то какой-то код, который отвечает за бизнес-действие "удалить пользователя", который в итоге сделает всё вот это перечисленное. Почему этот код нельзя собрать в одну языковую сущность и назвать "удалятором пользователей", вызать оттуда эти 7 шагов в нужном порядке с нужными параметрами, покрыть тестами — я не понимаю. В твоём мире ты, наверно, в чатике клиентам пошлёшь инструкцию из этих 7 шагов, да? Поэтому такого кода у тебя не будет, да? Или как?
P>·>Вас может прибивают, нас — не прибивают. P>Вас тоже прибивают, только вы в этом видите пользу какую то.
Нет, не прибивают. Мы используем моки не так, как ты фантазируешь.
P>>>Этот пример демонстрирует особенность — даже ИДЕ перестает помогать. P>·>Помогать в чём? Ещё раз — инлайнинг и т.п. — это средство, а не цель. С какой целью что инлайнить-то? P>Рефакторинг, очевидно. Его не раз в год нужно делать, а непрерывно — требования меняются постоянно.
Опять путаешь цель и средство. Рефакторинг — это средство.
P>>>А вот если вы отказываетесь от моков, соотвественно, ИДЕ вам в помощник — вдруг рефакторинг inline начинает работать сам собой P>·>Ок, расскажи от каких моков надо избавиться, чтобы рефакторинг inline для str.length() заработал? P>Элементарно — замена вызова на константу. Это работает, т.к. str у вас иммутабельная. А вот текущее время такой особенностью не обладает.
На какую константу? Значение length() зависит от того, что лежит в данном конкретном экземляре str:
Давай, покажи свой супер-полезный инлайн рефакоринг!
P>Другая проблема — ваша реализация с зависимостью внутри кешированию не поддаётся. Кешированию чего? Куда прикручивается кеш — надо смотреть на полное решение, а не на данную конкретнную строчку кода. В твоём решении проблема с кешем будет в другом месте, и её решать будет гораздо сложнее. Точнее ты вообще не сможешь кеш прикрутить, т.к. аргумент now — это текущее время, ВНЕЗАПНО. Ты ключoм в кеше будешь делать текущее время??
А у меня всё круто, т.к. реализация nextFriday() знает, что это отностися к следующей пятнице, то может кешировать одно и то же значение в течение недели и обновлять его по таймеру, например.
P>То есть, проблемы с вашей реализацией мы видим, а вот бенефиты какие то мифические, и вы никак не можете их описать.
Ага-ага. Бревно в глазу не замечаешь.
P>>>Дизайн вообще должен меняться постоянно, непрерывно. А вы выбираете такой подход, что изменения раз в год-два. О том я и говорю — вы пилите монолит. P>·>Зачем?! Это ты из мира js говоришь, где каждую неделю новый фреймворк выходит и надо всё переписать? А каждые пол года очередной самый правильный дизайн появляется от фаулеров и надо срочно всю архитектуру перекраивать?! P>Из вас технологический расизм прёт непрерывно. Извините, но на мой взгляд вместе с телепатией это признак неполной профессиональной компетенции. P>Дизайн меняется по простой причине — требования меняются непрерывно. Вот появилось нефункциональное требование "перформанс" и мы видим, что CalendarLogic сидит в hotpath и вызывается сто раз с одним и теми же значениями. Опаньки — меняем дизайн. Не меняем дизайн, а оптимизируем внутреннюю реализацию одного метода, ну того конкретного nextFriday(). Менять дизайн на каждый чих — признак полной профессиональной некомпетенции дизайнера решения. Разуй глаза — в сигнатуре "LocalDate nextFriday()" — совершенно не говорится что откуда должно браться — считаться на лету, из кеша, запрашиваться у пользователя или рандомом генериться от погоды на марсе.
P>Как это сделать в вашем случае — не ясно. Разве что прокинуть к вашему CalendarLogic еще и MRU, LRU кеш с конфигом "вот такие значения хранить пять минут". Вот уж простор для моков — теперь можно мокать не одно время, а целых три, а можно MRU, LRU обмокать.
Толи ты вообще в дизайн не умеешь, толи нарочно какую-то дичь сочиняешь, чтобы мне приписать для strawman fallacy.
P>>>Соответсвенно нужно выбирать такое решение, которое проще мейнтейнить, с учетом тестов. P>·>Угу. И моки тут помогают. P>Что бы просто так, без контекста — это слишком сильное утверждение. Но в целом оно отражает ваш подход к тестированию
Моки — это ещё один дополнительный инструмент в копилку. Больше инструментов — больще возможностей решить задачу более эффективно.
P>>>Вот код теста — как только вы его написали, решение о том, как будут протягиваться зависимости, уже принято P>·>ТДД диктует необходимость того, чтобы код был тестируемый, а не про то куда как тянуть зависимости. Единственно что он может диктовать, что зависимостями надо управлять явно, чтобы можно было прокидывать тестовые. P>Как только вы написали тест, то из него однозначно следует, какой будет АПИ и как будут прокидываться зависимости. Вы поймите — код теста это выражение наших намерений P>1 апи P>2 зависимости P>3 поведение P>4 связывание P>5 входы-выходы. P>По большому счету, идеально свести тест к п5. А вы сюда втаскиваете лошадь размером со слона.
апи диктуется требованиями клиентского кода, а не тестами. А зависимости — это уже как мы обеспечиваем работу этого апи.
P>>> 1,2,3,4,5,6 // и так на каждую строчку в табличке P>·>Не понимаю. Ты, похоже, стиль кода путаешь с дизайном. А дизайн с управлением зависимостями. Ну сделай себе таблицу истинности и с моками, и с параметрами: P>·>
P>·> when(dep.getX()).thenReturn(x);
P>·>
P>Лишняя строчка
Прям ужас-ужас. Но это не главное, главное ты наконец-то таки согласился, что твои "таблицы истинности", не пострадали от моков.
P>>> Только еще вводите понятие wiring code. P>·>Ок. Возможно я использовал неизвестную тебе терминологию. Это из мира управления зависимостей. "wiring up dependencies", "autowiring", под я под wiring code здесь имел в виду "composition root". P>Вот-вот. Статься от 2011го, ссылается на книгу, которую начали писать в 00х на основе опыта накопленного тогда же.
И? Поэтому я и не понимаю как эта терминология мимо тебя прошла.
P>Мы только что выяснили, кто же из нас двоих вещает из нулевых
Вот от твоего любимого фаулера, свежачок: https://martinfowler.com/articles/dependency-composition.html
P>>>Часть кода связывания будет вне контролера, и правила вы водите сами, это и есть тот дизайн. Прокидываете через dependency injection — значит внутри контролера этого не будет. P>·>Да похрен на дизайн. Это лишь меняет место где "волшебство" происходить будет. P>Вам похрен — это и ежу понятно. Отличия в дизайне позволяют применить более эффективные способы, например, тестирования.
Да применяй, я ж не запрещаю. Я ж говорю — похрен какой дизайн.
P>>>Прокидываете now в контролере — эту часть логично исключить из dependency injection. P>·>В контроллере now откуда возьмётся? P>Вы уже много раз задавали этот вопрос, и я вам много раз на него отвечал. Отмотайте да посмотрите.
Я код прошу показать, но ты упорно скрываешь.
P>>>Смысл помещения кода связывания в контроллер в том, что бы легче было интеграцию тестировать, делая самое важно явным. P>·>Не понял, чем легче? P>Самое важное сразу в коде метода, а не раскидано абы где по всеей иерархии dependency injection.
Субъективщина какая-то.
P>>>У вас CalendarLogic принимает зависимость к конструкторе. Технически, эта зависимость может быть и null, и предзаписаной, и привязаной к контексту — не принципиально. P>·>Это тут причём? Технически передавая через параметр твой now — тоже может быть null и т.п. Всё то же самое. P>Нет, не может быть. Это вам нужно делать явно в самом контроллере, который зафейлится сразу же, на первом тесте который его вызовет.
Дык я об этом и талдычу, притом не в абы каком тесте, а конкретно в тесте который тестирует этот конкретную функцию этого конкретного контроллера. А вот в моём случае это придётся делать тоже явно в коде связывания зависимостей и зафейлится если не компилятором, то во время старта, ещё до того как дело дойдёт до запуска каких-либо тестов.
P>·>В твоём же случае впихивание null будет происходить только при вызове функции приложения. Поэтому вам и требуются тесты всего уже после "успешгого" деплоя в проде. P>Я ж вам объяснил — тесты прода нужны для самых разных кейсов.
Они не "нужны". Есть другие подходы, которые покрывают эти же кейсы (по крайней мере, подавляющее большинство), но не требуют прогона тестов.
P>·>А как ты будешь такой и-тест писать, если у тебя будет Time.Now? Что ассертить-то будешь? Как отличать два разных вызова Time.Now — клиентский от серверного? Впрочем, ты уже ответил "никак". Или я что-то пропустил? P>Согласно бл. А вы как собираетесь отличать два разных вызова, клиентский от серверного? Вам для этого придется намастырить кучу кода с инжекцией в конструктор, только всё важное будет "где то там"
Я уже раза три рассказал. Клиентский и серверный будут иметь разный ожидаемый результат.
P>>>Вы похоже сами свой код не читали, т.к. у вас недоумение, откуда может быть null. И ежу понятно — будет передан в конструктор или явно, или неявно. Правильно это или нет — скажут тесты. P>·>Так же можно явно или неявно передать now=null в твой nextFriday(now). P>Теоретически — можно. Практически — первый интеграционный тест сваливается, когда вызывает этот контроллер.
Если этот тест не забудут написать, конечно. Покрытие-то ты анализировать отказываешься...
P>>>А щас вы расказываете басню, что компилер как то отличит один провайдер времени от другого времени с таким же интерфейсом P>·>Компилятор может отличать имена символов. Это же в коде видно и на ревью всё очень очевидно — где какое поле куда передаётся. P>Вот вы сами себе и ответили. Ну или объясните, почему код ревью перестанет работать с параметром в контроллере.
По ревью контроллера не видно какой параметр должен туда передаваться и можно ли или нельзя ли туда загонять null. Вот тут:
load: () => repo1,
load2: () => svc,
Почему один load должен быть такой, а другой сякой? А null туда можно или нет? И т.п. И это всё технические детали внутренней реализации, которые к бизнес-требованиям отношения не имеет. И это всё прод-код, покрытый какими-то тестами, которые неясно как относятся к этому коду и выполняют ли его вообще.
В моём случае:
Тут я уже как ревьювер могу понимать требования бизнеса могу понять, или заглянуть в джиру, чтобы проверить, что dateAAA должно соответствовать системному времени, а не времени события. И это код тестов, который описывает ожидания.
P>>>Прямой вызов — ваша функция вызовется прямо сейчас. Отложеный — потом. Например, вы сначала делаете запись, что за функция вызовется, с какими параметрами и тд, а в нужный момент сервис делает собственно сам вызов. P>·>Какое это имеет отношение к разговору? P>Вы же спрашиваи, что такое отложенный вызов. Если у нас нет зависимости внутри, то отложеный вызов делается как два пальца об асфальт. Это снова про гибкость, которой у вас почему то нет.
Если ты не понимаешь как это делать так спрашивай, а не фантазируй отложенно.
P>>>Просто разные аргументы. P>·>Аргументы чего? Откуда ты знаешь, что значения этих аргументов именно Time.Now и как это проверишь в тесте? P>С вашего аккаунта похоже разные люди пишут, да еще и меняются во время написания одного и того же сообщения. Вот некто с вашего аккаунта чуть выше ответил на ваш вопрос: P>
P>Компилятор может отличать имена символов. Это же в коде видно и на ревью всё очень очевидно — где какое поле куда передаётся.
И как это проверишь в тесте?
И я написал почему в твоём коде это неочевидно на ревью.
P>>>·>Что синглтоны — плохо учат ещё в детском садике, ясельной группе. P>>>Вы наверное не поняли — никаких синглтонов, только параметры. P>·>Откуда возьмутся значения этих параметров во всех местах вызова? P>Через параметры функции. Дизайн то плоский, а не глубокий, как у вас.
Через параметры значения передаются. Откуда они возьмутся-то?
P>>>Мне не надо время тестировать. Мне нужно тестировать логику, в которой один или несколько параметров — время. Вы это время протаскиваете через конструктор косвенно, в виде провайдера. Я протаскиваю через параметр функции, явно. P>·>Надо где-то тестировать, что ты протаскиваешь именно Time.Now а не что-то другое. P>Вам тоже надо тестировать что вы привязали в проде пров клиенского времени, а не пров серверного или предзаписаного. Похоже, у вас там снова смена автора на вашем аккаунте.
Точка привязки будет ровно одна. К символьному имени systemClock будет привязка физического серверного источника времени. А все остальные привязки в бизнес-логике будут покрыты тестами: что ожидаемые значения в результатах связаны с тем же именем assert someResult1.dateAAA == TestData.SystemClock.now(). Если очень хочется, то и привязку физического источника времени можно будет проверить одним _системным_ тестом на всю систему, а не на каждый метод контроллера.
У тебя точек привязки — в каждом месте использования nextFriday и никак не тестируется вообще.
P>>>Интеграционным, которых ровно столько же, сколько и у вас. P>·>Нет. У меня пирамида тестов. А у тебя — либо цилиндр, либо дырявое решето. P>Для пирамиды нужно большое количество дешовых юнит тестов. У вас много полу-интеграционных, на моках, и мало собственно чистых юнитов. У меня — наоброт. Потому именно ваша пирамида видится мне ромбиком.
У меня "дешевые" в том смысле, что они выполняются очень быстро. Так вот даже "полу-интеграционные на моках" — выполняются очень быстро, за минуты всё. А у тебя "дешевые" — выполняются полтора часа, но называешь их "дешевыми" так просто, потому что тебе так их нравится называть, без объективных на то причин.
P>>>·>Если при этом нужно плодить копипасту, то это явно что-то не то. И неясно причём тут инлайн и гибкость кода. str.length() — это негибкий код?! P>>>Вы сейчас перевираете. P>·>Неперивираю, ты просто свои слова забыл. Напоминаю: " гибкость, которая проявляется в т.ч. в том, что код можно трансформировать, инлайнить". А дальше чистая логика: P>·>"гибкий код → можно инлайнить" => "инлайнить нельзя → не гибкий код" см. https://en.wikipedia.org/wiki/Contraposition P>С str.length всё в порядке — инлайнится с переводом в константу. У вас что то еще?
Ну зайнлайнь. Пример кода я тебе выше привёл.
P>>>Речь про инлайн вашего nextFriday(). Об ваш супер-крутой подход почему то ИДЕ спотыкается и вы проблемы в этом не видите. P>·>Я спрашиваю "зачем инлайн"? Какую задачу-то решаем этим инлайном?! P>Рефакторинг, оптимизации.
Рефакторинг это тоже не задача. А инлайнить для оптимизаций только самые ленивые компиляторы в режиме дебага не умеют.
P>>>Ваши тесты проверяют только тривиальные кейсы, на которых все зелено. В проде как правило кучка всего подряд. P>·>Ну добавь эту твою кучку в тесты. Вопрос-то в чём? P>Эта кучка называется data complexity. Я, например, билдером могу гарантировать, что данные будут запрашиваться постранично. Или что всегда будет фильтр по времени, где период не более трех месяцев.
Не очень понял, как гарантировать и что именно? И почему то же самое нельзя гарантировать другими способами? И вообще это всё больше похоже на бизнес-требования, чем на проверки каких-то кейсов в тестах.
P>Соответсвено тестами можно проверить что структура запроса та, что нам надо
Ой. Очень интересно увидеть код как ты проверишь тестами по структуре запроса, что у тебя билдер что-то гарантирует.
P>>>О том, что фильтр может вернуть много записей, вам может сказать или сам запрос, или его результат. P>·>Как запрос может что-то сказать? P>Элементарно — всегда есть шанс, что ваш запрос вернет чего нибудь лишнее. Тестами эта задача не решается, принципиально. P>Что бы написать корректный запрос, вам надо P>1. гарантировать, что бы на "тех" данных вернется что надо. Это можно решить тестами — накидать данных, обработать, сравнить результат P>2. гарантировать, что на других данных, которых у вас нет, тоже вернется ровно то, что надо. И тестами на основе данных это не решается — т.к. данных нет. P>Итого — ваши тесты данных не являются решением, т.к. п 2 у нас обязательный. А вот дополнительные методы, например, инварианты, пред, пост условия, контроль построения запроса, код ревью основанное на понимании работы бд — это дает более-менее осязаемые данные.
Я не знаю на какой вопрос ты ответил, но я напомню что я спрашивал: "Как запрос может что-то сказать?". Контекст выделил жирным выше.
P>>>Второй вариант у вас отпадает, т.к. в тестах у вас не будет хрензнаетсколькилион записей в тестах P>·>Зачем мне столько записей? В простом случае понадобится две записи — та которая я ожидаю, что она должна вернуться и та которая я ожидаю, что не должна вернуться. P>Я вам выше рассказал. Нужна гарантия, что не вернется вдруг чего нибудь не то. Вариантов "не того" у вас по скромной оценке близко к бесконечности.
Как ты это предлагаешь _гарантировать_? И причём тут тесты?
P>>>Это вы собираетесь базу тестировать P>·>Опять врёшь. И цитаты, ясен пень, не будет. P>Вы топите за косвенные проверки запросов, тестируя связку репозиторий+бд. Вот этого оно и есть.
Я топлю за то как надо писать тесты, чтобы от них была хоть какая-то польза и поменьше вреда. А не абстрактные "проверки" которые что-то должны "гарантировать" посредством говорящей рыбы запроса.
P>>> и топите за поведение. А мне надо всего лишь построение запроса к орм проверить. Если орм не позволяет такого — надо смотреть его sql выхлоп, если и такого нету, значит придется делать так, как вы предлагаете. P>·>"Надо" кому? Мы вроде говорим о тестировании ожиданий бизнеса. Ты правда считаешь, что пользователи ожидают определённый выхлоп sql?! P>Пользователи ожидают, что на их данных, которых в ваших тестах нет, будет нужный результат.
Если ожидания есть, то какая проблема их добавить в тесты?
P>Вашими тестами эта задача не решается
Я показал как решение этой задачи можно тестировать моими тестами. Ты так и не рассказал как она решается вашими тестами.
P>>>И всё это нужно покрывать тестами, иначе любой дядел поломает цивилизацию P>·>Ещё раз. У тебя в коде теста, в ожиданиях находится "in: [fn1]" и т.п. Как это соответствует "возвращать именно те данные, что прописаны в бл"? Где в бл вообще будет фигурировать in, fn1 и прочий select? P>Не нужно сводить всё к бл напряму. У вас технологического кода в приложении примерно 99%. Он к бл относится крайне опосредовано — через связывание. А тестировать эти 99% тоже нужно.
Именно. Ты меня обвинил в том, что у меня тесты тестируют детали реализации, а на самом деле ты просто с больной головы на здоровую. Но зато у тебя дизайн самый модный!
P>>>Смотрите выше — вы фильтры предлагаете тестировать однострочными вырожденными кейсами. Как вы будете ловить те самые комбинации, не ясно. P>·>Ну я не знаю твой код. Я разрешаю тебе писать кейсы двухстрочные и даже трёхстрочные! P>Вы что, недогоняете, что нет возможности покрыть неизвестные данные и комбинации какими либо тестами?
Зато есть возможность покрыть известные данные и комбинации тестами. Вы и этого не делаете, а просто имена приватных функций ассертите и буковки сравниваете (тоже, кстати известные). Вот и приходится часами билдить и в проде тесты гонять чтобы хоть что-то как-то обнаружилось.
P>>>Ни то, ни другое проблему с фильтрами не найдут. P>·>Почему? P>Потому, что у вас нет всего множества данных, которые могут приходить от юзеров. P>Более того — количество данных дает вам такую особенность, как слишком долгое время выполнения запроса. P>Задача с фильтрами у меня выявила такую вещь — если данных слишком много, то запрос с секунд резко уезжает в минуты. P>Вот оптимизацию такой вещи закрыть тестами, что бы первый же фикс не сломал всю цивилизацию
Это всё круто. Каким образом твоё "in: [fn1]" обеспечивает тебя всем множеством данных которое может приходить от юзеров?
P>>>т.е. тесты контролера зависят от мока P>·>Т.е. в тестах контроллера мы прописали ожидание, что время используется серверное, в соответствии с бизнес-требованиям. P>В интеграционном тесте можно сделать то же самое.
Как? Код в студию. Вот в куче кода кучи контроллеров где-то у тебя написано Time.Now. Как ты это проверишь в интеграционном тесте что некий результат содержит именно что-то вычисленное от Now, а не что-то другое?
P>>>Вторая — вызываем бл при чтении из очереди, при этом время должно быть клиенское. P>·>Т.е. это значит, что _изменились_ бизнес-требования и теперь мы должны брать не серверное время, а клиентское. Ясен пень, это фукнциональное изменение и соответствующие тесты надо менять. Если у тебя ни один тест не упадёт, у меня для тебя плохие новости. P>Это как раз нефункциональное требование. Например, у нас запрос выполнялся слишком долго, и мы процессинг вытолкнули в очередь с отложеным процессингом.
Не это, а то что вначале мы использовали серверное время, а потом вдруг стали использовать клиентское — это изменение функциональное, т.к. источники времени — принципиально разные и влияют на наблюдаемый результат. Если бы было время клиентское изначально, то никаке функциональные тесты не пострадают.
P>>>А это значит, что ваши тесты контролера идут в топку, как и моки которые вы под это дело прикрутили. P>·>В контроллере надо будет заменить использование systemClock() на eventTimestampClock() и поправить тесты, чтобы зафиксировать функциональное изменение. P>Функционых изменений здесь ровно 0. С т.з. пользователя никаких функций не добавляется. Меняется наблюдаемое поведение и вообще может быть дырой в безопасности. Клиентское время, скажем, можно захакать.
А если в твоём случае systemClock() и eventTimestampClock() — вещи функционально неразличимые, то вообще неясно зачем ты тут с меня трясёшь как я их буду различать.
P>>>зачем? P>·>Чтобы понять какое отношение имеет метапрограммирование к тестированию ожиданий бизнес-требований. P>Метапрограммирование дает возможность зафиксировать свойства запроса, которые вы с вашими тестами сделать не сможете, никоим образом.
А ещё я кофе моими тестами сварить не смогу. Что сказать-то хотел?
Напомню, мы сравниваем тестирование ожиданий бизнес-требований твоими тестами с "in: [fn1]" vs моими тестами c "save/find". Так причём тут метапрограммирование?
P>>>Очевидно, посыплются не все. Ну нет такой ситуации что бы билдер на каждый запрос лепил UNION. Отвалится скорее всего несколько кейсов, ради которых это все и затевается. P>·>Ну этот кусочек может быть в большой группе запросов, выбирающих разные данные по-разному, но часть логики — общая. P>Может. Это дополнительные гарантии, сверх тех, что вы можете получить прогоном на тестовых данных. Потому издержки обоснованы.
Гы. Опять у тебя тесты гарантии дают.
P>>>Кто даст гарантию, что в проде вы правильно прописали зависимости для CalendarLogic? Интерфейс то один и то же P>·>Гарантию, конечно, никто не даст, но покрыть тестами с моками тоже можно. Для этого моки и придумали. P>Вот вот — прибиваете контроллер к тестам на моках.
Ты так говоришь, как будто это что-то плохое.
P>>>Буквально curl тест все что может, это сравнить выхлоп, и всё. Если там время не фигурирует, то никак. P>·>Ну, допустим, фигурирует. И чем это тебе поможет? P>Тогда можно сравнить выхлоп, тот или не тот.
Так я тебя и спрашиваю как ты будешь сравнивать выхлоп зависящий от Time.Now — тот он или не тот?
P>>>Если же вы имеете ввиду интеграционные, то будет все ровно как и у вас. P>·>С моками? Ну дык об чём спор-то тогда? Ведь именно моком я могу протащить тестовые значения now в нужные места. Там, где ты предлагаешь Time.Now синглтон, в который ты ничего протащить не сможешь. P>Этим протаскиванием вы бетонируете весь дизайн. Смена дизайна = переписывание тестов.
Нет.
P>>>Бинго! Оптимизация, нефункциональные требования, технические особенности — все это имеет чудовищное влияние, намного больше, чем сама бизнес-логика. P>>>Если вы потеряете оптимизацию — приплызд. и тест нужен зафиксировать эту особенность что бы сохранить при изменениях. P>·>Это уже будет перф-тест и к обсуждаемой теме не относится. P>Покрыть перформанс тестами все вырожденные кейсы вам время жизни вселенной не позволит. Некоторые детали реализации нужно фиксировать обычыными тестами.
Обычные тесты не могут тестировать перф. А детали реализации лучше не тестировать.
P>>>См выше — все нефунциональные вещи нужно проверять и фиксировать тестами. P>·>Это не оправдывает твой подход, что функциональные тесты должны тестировать метапрограммирование. P>Метапрограммирование тестируется там, где оно применяется в силу естественных причин. Если у вас запросы тривиальные, вам такое не нужно.
Ты не понял. Надо тестировать не метапрограммирование, а ожидания.
P>>>Покажите, как вы все эти кейсы обнаруживать будете. P>·>Возвращаемся к старому спору. Я уже отвечал на это неоднократно: системы мониторинга, health probes и прочие операционные инструменты. Это не тестирование. P>Неэффективно. Для многих приложений час невалидной работы может стоит любых денег. Дешевле запустить тесты на проде — час-два и у вас информация по всем функциям.
Ну никто нам не позволит делать "тестовые" сделки на прод системах. Каждая сделка — это реальные деньги и реальная отчётность перед регуляторами. Так что "информацию по всем функциям" нам приходится выдавать ещё до аппрува релиза.
P>>>Полагаю ответ будет "у нас багов на проде нету" ? P>·>Вот таких багов "протух-обновился сертификат" — и не должно быть. Такие вещи именно мониторингом отслеживаются заранее, чтобы пофиксить можно было до возникновения этой ситуации. А у вас серты протухают ВНЕЗАПНО, и обнаруживаются только тестами постфактум, что у вас в проде что-то где-то отвалилось... ну могу только пособолезновать вашим клиентам. P>Вы снова включили телепатию. Сертификат может обновиться не у вашего приложения, а у какого нибудь из внешних сервисов. Мониторинг вам скажет, когда N юзеров напорются на это и у вас начнет расти соответсвующая метрика.
Нет, мониторинг нам скажет, что сессия с таким-то сервисом сломалась и свистайте всех на верх.
Такое — major incident и соответствующий разбор полётов с пересмотром всех процессов — как такое допустили и определение действий, чтобы такое больше не произошло.
P>>>насколько я понимаю, это я все еще жду вашего примера про фильтры, который решает ту самую data complexity P>·>Какую ту самую? Я никакой "data complexity" не видел и телепатией не обладаю, чтобы выдать какое-то решение для задачи о которой я не слышал. P>У вас есть иллюзия, что ваши тесты гарантируют отсутствие лишнего выхлопа на данных, которые у вас отсутсвуют.
У меня такой иллюзии нет, ты опять насочинял, я такое нигде не писал. О гарантиях в тестах фантазировать любишь только ты.
P>>> Вход на фильтры полным перебором подавать или магией воздействовать? P>·>Да так же, как у тебя. Только ассертить не буквальный текст запроса, а результат его выполнения P>
Угу, вот так вот просто.
P>>>Вы когда нибудь видели дашборды где фильтры можно выбирать хрензнаетсколькилионом кнопочек и полей ввода? P>·>Насколько мне доводилось видеть, они обычно через & соединяются. Т.е. список независимых фильтров. Сложность возникает когда фильтры между собой взаимосвязаны, но обычно такое избегают, т.к. юзерам такая compexity тоже не под силу, и использовать нормально всё равно не получается. P>Ну да, вы сами чего то додумали, и воюеете за это
Потому что ты никогда задачу не обозначил. Задаёшь какие-то наводящие вопросы.
P>>>Не просто манифест — а любое описание, абы ваши пиры могли его понять и цикл разработки был быстрым. P>·>Что значит за любое описание? Манифест это и есть описание api. P>Любой формат, любое расширение файла У ваших пиров должен быть инструмент для использования такого описания. P>Например, вы решили выдать swagger, но описали в ём такое апи, которое ни один генератор кода не понимает. Это значит, что вы АПИ вообще не предоставили — мало кто в своём уме будет вручную имплементать нюансы которые к релизу поменяются 100500 раз
Ну я хотя бы могу начать допиливать этот самый swagger, чтобы генератор таки стал понимать.
А у тебя всё гораздо хуже. Ты пишешь аннотации, конфиги, тенантов, реализацию, веб-сервер, потом у тебя наконец-то http-запрос выдаётся этот же самый swagger по этим аннотациям, который ВНЕЗАПНО ни один генератор кода не понимает. И это реальная ситуация, которую помнится уже обсуждали пару лет назад и твоим решением было "ну пусть клиенты пишут всё ручками", т.к. перепилить свои аннотации и http-запрос ты уже не сможешь, ибо проще пристрелить.
P>>>Появятся после того, как вы заделивирите АПИ, например спустя год, когда у вас уже версия 1.x. И вот здесь вы решите перейти на rust, то в этот момент крайне странно топить за design-first — у нас уже готовое приложение версии 1.x, и нужно сделать так, что бы манифест отрендерился — с учетом тенантов и прочих вещей, включая not implemented. Или вы собираетесь бегать по отделам и рассказывать "а чо вы это делаете — мы же на джаве год назад это решили не делать" ? P>·>У вас уже есть имплементация и мы вот наконец спустя год выкатываем манифест api, но ты всё ещё это называешь design-first?! Нет, это типичный code-first — когда прыгать надо, думать некогда. P>Вы похоже не читаете. Какой смысл вам что либо рассказывать? P>1. когда стартуем проект, где центральная часть это АПИ. Идем через design-first, формат файла и расширение — любое, см. выше P>2. готовый проект — уже поздно топить за design-first, просто генерим артефакты P>3. переписываем проект на rust — снова, нам design-first не нужен, это вариация предыдущего кейса
Не понял, как из 1 получилось 2?
P>Вот если у вас переписывание случается каждый день, или даже чаще, да на новый язык, то АПИ нужно держать в каком то универсальном формате. P>Правда, в этом случае я более чем уверен, вы дольше всего будете подбирать генераторы кода под это АПИ, или выписывать все загогулины руками с воплями "я уже заимплементал херли вы перенесли параметр из квери в хидеры!!!!!!!11111йййкукуку"
Ну я о чём и говорю. У вас "думать некогда, прыгать надо". Пишете аннотации, код, выкатываетет, потом как всегда ВНЕЗАПНО "поздно топить за design-first"
P>>>Я вам говорю откуда возьмется апи в готовом, если вы решите уже готовое переписать на другом языке. P>·>Причём тут design-first? P>У вас точно меняется контингент, или в голове, или за компом: P>
P>Если вы захотите переписать свой сервис на другой ЯП, ну там с js на rust — что вы будете делать со своими аннотациями?
P>Переписывание предполагает, что у нас уже есть и АПИ, и реализация этого АПИ. Отсюда ясно, что проще сгенерировать артефакт, чем изначально держаться за конкретный формат и топить за design-first
Ага, верно, проще прыгать чем думать. Не спорю.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>Это дополнительные издержки по сравнению с простыми функциями. Вы это сами показали на тестах календаря. ·>Ты просто пытаешься ввести в заблуждение. Да, у меня в тестах добавляется одна строчка кода и собственно всё. Зато в твоём решении добавляется N-строчек в _прод_ коде и требуется больше тестов. Иными словами, ты "убираешь" код, но стесняешься говорить _куда_ этот код убирается.
Чего стесняться — я вам прямо говорю. Переносим код связывания из размытого dependency injection в контроллер. Это дает более простые тесты, более гибкий код, проще мейнтейнить — все что надо у вас перед носом.
P>>И у вас вполне вероятно не будет ни одной функции в джаве "удалить пользователя". А будет например "дропнуть док по хешкоду", "дропнуть записи по номеру телефона", "дропнуть сообщения по емейлу", "отозвать сертификат", "пометить спейс юзера к удалению через месяц", "подготовить выгрузку всех данных юзера", "закинуть зип на aws s3 c ttl 1 месяц" ·>Ну будет же где-то какой-то код, который отвечает за бизнес-действие "удалить пользователя", который в итоге сделает всё вот это перечисленное.
Какой то код — будет. Только с т.з. пользователя эта фича уже работает два релиза. А изменения, как пример, нужны по той причине, что удаление ресурсоемко и можно облегчить основной сервер, передав работу вспомогательному инстанцу. С т.з. пользователя изменений в функциональности нет, ни единой. А вот нефункциональные требования изменились.
Это я вам пример привожу, что функциональность приложения и функции в джаве это две большие разницы.
P>>·>Помогать в чём? Ещё раз — инлайнинг и т.п. — это средство, а не цель. С какой целью что инлайнить-то? P>>Рефакторинг, очевидно. Его не раз в год нужно делать, а непрерывно — требования меняются постоянно. ·>Опять путаешь цель и средство. Рефакторинг — это средство.
Именно что средство. Если нам доступно больше средств — гибкости больше. Нет инлайнинга — гибкости, как следствие меньше. Вы то до сих пор не показали где же гибкость вашего подхода.
P>>Элементарно — замена вызова на константу. Это работает, т.к. str у вас иммутабельная. А вот текущее время такой особенностью не обладает. ·>На какую константу? Значение length() зависит от того, что лежит в данном конкретном экземляре str:
Length это интринсик, его сам компилятор заинлайнит, вам не надо заботиться
Инлайнить самому нужно для оптимизации, изменения дизайна, итд
·> Кешированию чего? Куда прикручивается кеш — надо смотреть на полное решение, а не на данную конкретнную строчку кода. В твоём решении проблема с кешем будет в другом месте, и её решать будет гораздо сложнее. Точнее ты вообще не сможешь кеш прикрутить, т.к. аргумент now — это текущее время, ВНЕЗАПНО. Ты ключoм в кеше будешь делать текущее время?? ·>А у меня всё круто, т.к. реализация nextFriday() знает, что это отностися к следующей пятнице, то может кешировать одно и то же значение в течение недели и обновлять его по таймеру, например.
Другими, вы здесь предложили наивную реализацию LRU кеша c контролем ттл по таймеру.
P>>Дизайн меняется по простой причине — требования меняются непрерывно. Вот появилось нефункциональное требование "перформанс" и мы видим, что CalendarLogic сидит в hotpath и вызывается сто раз с одним и теми же значениями. Опаньки — меняем дизайн. ·> Не меняем дизайн, а оптимизируем внутреннюю реализацию одного метода, ну того конкретного nextFriday(). Менять дизайн на каждый чих — признак полной профессиональной некомпетенции дизайнера решения. Разуй глаза — в сигнатуре "LocalDate nextFriday()" — совершенно не говорится что откуда должно браться — считаться на лету, из кеша, запрашиваться у пользователя или рандомом генериться от погоды на марсе.
Запрос из кеша это изменение того самого дизайна. Кеш, как минимум, надо инвалидировать, может и ттл прикрутить, а может и следить, что именно кешировать, а что — нет. Для этого вам нужно будет добавить кеш, настройки к нему, да еще связать правильно и тестами покрыть — что в ваш компонент приходит тот самый кеш а не просто какой то.
P>>Как это сделать в вашем случае — не ясно. Разве что прокинуть к вашему CalendarLogic еще и MRU, LRU кеш с конфигом "вот такие значения хранить пять минут". Вот уж простор для моков — теперь можно мокать не одно время, а целых три, а можно MRU, LRU обмокать. ·>Толи ты вообще в дизайн не умеешь, толи нарочно какую-то дичь сочиняешь, чтобы мне приписать для strawman fallacy.
Смотрите выше — вы сами, безо всякой моей подсказки предложили "может кешировать одно и то же значение в течение недели и обновлять его по таймеру, например" что есть тот самый кеш.
P>>Что бы просто так, без контекста — это слишком сильное утверждение. Но в целом оно отражает ваш подход к тестированию ·>Моки — это ещё один дополнительный инструмент в копилку. Больше инструментов — больще возможностей решить задачу более эффективно.
Моки в большинстве случаев морозят код, т.е. фиксируют код, бетонируют на времена. Вообще всё что вы пишете в тестах, обладает таким свойством
Хотите гибкости — в тесты нужно выносить самый минимум. Как правило это параметры и возвращаемое значение. Вы почему то в этот минимум добавляете все зависимости с их собственным апи.
P>>Как только вы написали тест, то из него однозначно следует, какой будет АПИ и как будут прокидываться зависимости. Вы поймите — код теста это выражение наших намерений P>>1 апи P>>2 зависимости P>>3 поведение P>>4 связывание P>>5 входы-выходы. P>>По большому счету, идеально свести тест к п5. А вы сюда втаскиваете лошадь размером со слона. ·>апи диктуется требованиями клиентского кода, а не тестами. А зависимости — это уже как мы обеспечиваем работу этого апи.
Если вы в юнит-тестах прокидываете мок в конструктор, то вы делаете выбор дизайна — инжекция зависимостей.
Вариантов, как обеспечить работу апи — множество. Но если вы вписали моки, то после этого варианты закончились — дизайн отлит в граните
P>>Лишняя строчка ·>Прям ужас-ужас. Но это не главное, главное ты наконец-то таки согласился, что твои "таблицы истинности", не пострадали от моков.
Вы регулярно приводите примеры лишних строчек, но почему то вам кажется, что у меня кода больше. Код системы это не только функциональная часть, но тестирующая.
P>>Вот-вот. Статься от 2011го, ссылается на книгу, которую начали писать в 00х на основе опыта накопленного тогда же. ·>И? Поэтому я и не понимаю как эта терминология мимо тебя прошла.
Я освоил тот метод именно в нулевых, задолго до той самой статьи. С тех пор много чего эволюционировало. Потому я и пишу вам, что вы продолжаете вещать из нулевых, как будто с тех пор ничего и не было.
P>>Мы только что выяснили, кто же из нас двоих вещает из нулевых ·>Вот от твоего любимого фаулера, свежачок: https://martinfowler.com/articles/dependency-composition.html
Именно что свежачок. Можете заглянуть сразу в Summary
By choosing to fulfill dependency contracts with functions rather than classes, minimizing the code sharing between modules and driving the design through tests, I can create a system composed of highly discrete, evolvable, but still type-safe modules. If you have similar priorities in your next project, consider adopting some aspects of the approach I have outlined.
В 00х Фаулер сотоварищи топили за тот подход, за который вы топите 20 лет спустя.
P>>Вы уже много раз задавали этот вопрос, и я вам много раз на него отвечал. Отмотайте да посмотрите. ·>Я код прошу показать, но ты упорно скрываешь.
Не валяйте дурака — я вам еще на прошлом заходе давал два варианта
1. из реквеста
2. руками вкидываете
С тех пор ничего не изменилось.
Собственно, вам ни один из них не нравится, потому вы здесь и выступаете. А щас вот пишете, что ничего не видели.
P>>Самое важное сразу в коде метода, а не раскидано абы где по всеей иерархии dependency injection. ·>Субъективщина какая-то.
Это никакая не субъективщина. Все что функционально влияет на контроллер, должно связываться прямо в нем. А вот разная хрень пусть проходит через зависимости, ну вот сериализатор тот же.
Т.е. четкое разделение — функциональные вещи и технологические, а у вас в dependency injection всё подряд — "тут я шью, тут я пью, тут селедку заворачиваю"
P>>Нет, не может быть. Это вам нужно делать явно в самом контроллере, который зафейлится сразу же, на первом тесте который его вызовет. ·>Дык я об этом и талдычу, притом не в абы каком тесте, а конкретно в тесте который тестирует этот конкретную функцию этого конкретного контроллера. А вот в моём случае это придётся делать тоже явно в коде связывания зависимостей и зафейлится если не компилятором, то во время старта, ещё до того как дело дойдёт до запуска каких-либо тестов.
У вас там написание кода начинается с деплоя на прод?
Вы узнаете о проблеме во время самого деплоя! А надо во время написания кода которые идут вперемешку с прогном быстрых тестов, и это все за день-неделю-месяц до самого деплоя!
·>Они не "нужны". Есть другие подходы, которые покрывают эти же кейсы (по крайней мере, подавляющее большинство), но не требуют прогона тестов.
Я и вижу — тестируете деплоем на прод.
P>>Согласно бл. А вы как собираетесь отличать два разных вызова, клиентский от серверного? Вам для этого придется намастырить кучу кода с инжекцией в конструктор, только всё важное будет "где то там" ·>Я уже раза три рассказал. Клиентский и серверный будут иметь разный ожидаемый результат.
Ну вот вам и ответ.
P>>Теоретически — можно. Практически — первый интеграционный тест сваливается, когда вызывает этот контроллер. ·>Если этот тест не забудут написать, конечно. Покрытие-то ты анализировать отказываешься...
Вы совсем недавно делали вид, что понимаете как покрытие работает. А сейчас делаете вид, что уже нет. Покрытие говорит что код вызвался во время теста. Но никак не говорит, какие фичи пройдены.
Нам нужны именно фичи, кейсы, сценарии. В строчках кода это не измеряется. Смотрите, как это делают QA.
·>И как это проверишь в тесте? ·>И я написал почему в твоём коде это неочевидно на ревью.
Это вам неочевидно, т.к. вы топите за другой дизайн. Комбинирование функции в общем случае проще композиции классов. Классы никуда не денутся — одно другому помогает.
P>>Через параметры функции. Дизайн то плоский, а не глубокий, как у вас. ·>Через параметры значения передаются. Откуда они возьмутся-то?
А вы не видите? Весь код перед глазами.
·>У тебя точек привязки — в каждом месте использования nextFriday и никак не тестируется вообще.
Еще раз — точки привязки это часть интеграции, которая тестируется интеграционным тестом. Интеграционные тесты не тестируют кусочки "время прокинуто метод класса куда прокинута бд куда прокинут репозиторий".
Вместо этого интеграция проверяет последовательность, которая вытекает из требований:
— зарезервировать столик на трех человек на имя Коля Петров на следующую пятницу 21.00
— столик на трех человек успешно зарезервирован на имя Коля Петров на 26.01.2024 21.00
— на емейл: столик на трех человек зарезервирован на имя Коля Петров на 26.01.2024 21.00
— пуш нотификация: столик на трех человек зарезервирован на имя Коля Петров на 26.01.2024 21.00
— статус через минуту-час-день: столик на трех человек зарезервирован на имя Коля Петров на 26.01.2024 21.00
— список резервирований: 3 человека, Коля Петров, 26.01.2024 21:00, столик номер 2 рядом со сценой
итд
·>У меня "дешевые" в том смысле, что они выполняются очень быстро. Так вот даже "полу-интеграционные на моках" — выполняются очень быстро, за минуты всё. А у тебя "дешевые" — выполняются полтора часа, но называешь их "дешевыми" так просто, потому что тебе так их нравится называть, без объективных на то причин.
Вы, похоже, без телепатии жить не можете. Вы спросили, сколько времени идут тесты. Я вам ответил, еще и добавил, это все тесты, всего-всего, всех видов. Но вам всё равно телепатия ближе.
Юнит тесты — пару минут от силы. Их до 15тыс ориентировочно. Остальных — от 1000 до 5000 и они занимают 99% времени.
P>>Рефакторинг, оптимизации. ·>Рефакторинг это тоже не задача. А инлайнить для оптимизаций только самые ленивые компиляторы в режиме дебага не умеют.
Большинство компиляторов умеют инлайнить только тривиальные вещи. Расчищать hot path это по прежнему ваша забота
P>>Эта кучка называется data complexity. Я, например, билдером могу гарантировать, что данные будут запрашиваться постранично. Или что всегда будет фильтр по времени, где период не более трех месяцев. ·>Не очень понял, как гарантировать и что именно? И почему то же самое нельзя гарантировать другими способами? И вообще это всё больше похоже на бизнес-требования, чем на проверки каких-то кейсов в тестах.
Это и есть тот, другой способ, основаный на метапрограммировании. Главное, что тесты основаные на проверке выборки из бд этот вопрос принципиально не решают, т.к. мы не знаем, что даст ваш запрос на каких других данных, которых у вас нет.
Не нравится метапрограммирование — можете придумать что угодно.
P>>Соответсвено тестами можно проверить что структура запроса та, что нам надо ·>Ой. Очень интересно увидеть код как ты проверишь тестами по структуре запроса, что у тебя билдер что-то гарантирует.
Я ж вам показал идею. Или вы ждёте тьюринг-полного выхлопа, который умеет еще и мысли читать по вашей методике?
P>>Итого — ваши тесты данных не являются решением, т.к. п 2 у нас обязательный. А вот дополнительные методы, например, инварианты, пред, пост условия, контроль построения запроса, код ревью основанное на понимании работы бд — это дает более-менее осязаемые данные. ·>Я не знаю на какой вопрос ты ответил, но я напомню что я спрашивал: "Как запрос может что-то сказать?". Контекст выделил жирным выше.
Вы там ногой читаете? Запрос не человек, сказать не может. А вот ревьюер может сказать "у нас такого индекса нет, тут будет фуллскан по таблице из десятков миллионов записей с выполнением регекспа и время работы на проде надо ждать десятки минут"
P>>Я вам выше рассказал. Нужна гарантия, что не вернется вдруг чего нибудь не то. Вариантов "не того" у вас по скромной оценке близко к бесконечности. ·>Как ты это предлагаешь _гарантировать_? И причём тут тесты?
Это ж вы сунете тесты туда, где они не работают. Как гарантировать — см пример номер 100500 чуть выше
P>>>>Это вы собираетесь базу тестировать P>>·>Опять врёшь. И цитаты, ясен пень, не будет. P>>Вы топите за косвенные проверки запросов, тестируя связку репозиторий+бд. Вот этого оно и есть. ·>Я топлю за то как надо писать тесты, чтобы от них была хоть какая-то польза и поменьше вреда. А не абстрактные "проверки" которые что-то должны "гарантировать" посредством говорящей рыбы запроса.
Ага, за всё хорошее против всего плохого
P>>Пользователи ожидают, что на их данных, которых в ваших тестах нет, будет нужный результат. ·>Если ожидания есть, то какая проблема их добавить в тесты?
У вас данных нет. Или вы щас скажете, что у вас уже есть все данные всех юзеров на будущее тысячелетие?
P>>Вашими тестами эта задача не решается ·>Я показал как решение этой задачи можно тестировать моими тестами. Ты так и не рассказал как она решается вашими тестами.
Я сказал, что тестами эта задача не решается. Вы показали совсем другое — что на ваших данных есть решение. А вот есть ли оно на каких то других — а хрен его знает. Тестами не проверить, т.к. еще не родились юзеры которые создадут эти данные.
Если задача посчитать how many beans make five, то пожалуйста — ваш подход работать будет
А если чтото сложнее — то к тестам не сводится. Именно по этому нужно доказательство корректности алгоритма, запроса, и тд
Собственно, вы раз за разом утверждаете, что с разработкой алгоритмов не знакомы. Мало накидать реализацию и тесты — нужно обосновать и доказать корректность.
P>>Не нужно сводить всё к бл напряму. У вас технологического кода в приложении примерно 99%. Он к бл относится крайне опосредовано — через связывание. А тестировать эти 99% тоже нужно. ·>Именно. Ты меня обвинил в том, что у меня тесты тестируют детали реализации, а на самом деле ты просто с больной головы на здоровую. Но зато у тебя дизайн самый модный!
Наоборот. Это вы пишете что я тестирую те самые детали, которые тестировать, по вашему, не надо.
Похоже, у вас там снова ведущий сменился
·>Зато есть возможность покрыть известные данные и комбинации тестами. Вы и этого не делаете, а просто имена приватных функций ассертите и буковки сравниваете (тоже, кстати известные). Вот и приходится часами билдить и в проде тесты гонять чтобы хоть что-то как-то обнаружилось.
Зачем вам собеседник, если у вас отличный дуэт с вашей телепатией?
P>>Вот оптимизацию такой вещи закрыть тестами, что бы первый же фикс не сломал всю цивилизацию ·>Это всё круто. Каким образом твоё "in: [fn1]" обеспечивает тебя всем множеством данных которое может приходить от юзеров?
Такой тест гарантирует, что всё множество данных будет проходить именно через эту функцию. И если я знаю, что у неё нужные мне свойства(тестами не решается), то результат будет обладать нужными мне свойствами. Например, если функция никогда не возвращает null, то вы можете и не бояться "а вдруг там всё таки null" и сократить hot path
P>>В интеграционном тесте можно сделать то же самое. ·>Как? Код в студию. Вот в куче кода кучи контроллеров где-то у тебя написано Time.Now. Как ты это проверишь в интеграционном тесте что некий результат содержит именно что-то вычисленное от Now, а не что-то другое?
Я вам привел пример про Колю Петрова. Надеюсь, справитесь
·>Не это, а то что вначале мы использовали серверное время, а потом вдруг стали использовать клиентское — это изменение функциональное, т.к. источники времени — принципиально разные и влияют на наблюдаемый результат. Если бы было время клиентское изначально, то никаке функциональные тесты не пострадают.
Нет, это не функциональное изменение. Мы просто перенесли процессинг в очередь. С точки зрения пользователя ничего не изменилось.
Похоже, вы не сильно в курсе разницы между функциональными требованиями и нефукнциональными.
Вот еще один пример:
Функциональное — пользователь должен будет отслеживать прогресс в своем профайле
Нефункциональное — пользователь увидит результат позже, чем раньше
P>>Метапрограммирование дает возможность зафиксировать свойства запроса, которые вы с вашими тестами сделать не сможете, никоим образом. ·>А ещё я кофе моими тестами сварить не смогу. Что сказать-то хотел? ·>Напомню, мы сравниваем тестирование ожиданий бизнес-требований твоими тестами с "in: [fn1]" vs моими тестами c "save/find". Так причём тут метапрограммирование?
Я вам объяснил уже много раз. Вы точно понимаете, что такое метапрограммирование?
P>>Может. Это дополнительные гарантии, сверх тех, что вы можете получить прогоном на тестовых данных. Потому издержки обоснованы. ·>Гы. Опять у тебя тесты гарантии дают.
Тесты дают гарантию, что пайплайн устроен нужным мне образом. А свойства результата, следовательно, будут определяться свойствами пайплайна. Тогда вам нужно сосредоточиться на выявлении этих свойств, а не писать одно и то же третий месяц кряду.
P>>Вот вот — прибиваете контроллер к тестам на моках. ·>Ты так говоришь, как будто это что-то плохое.
Щас у вас ведущий сменится, и вы начнете снова отрицать.
P>>Тогда можно сравнить выхлоп, тот или не тот. ·>Так я тебя и спрашиваю как ты будешь сравнивать выхлоп зависящий от Time.Now — тот он или не тот?
Смотрите пример про Колю Петрова
P>>Этим протаскиванием вы бетонируете весь дизайн. Смена дизайна = переписывание тестов. ·>Нет.
Вы прибили контролер к тестам на моках. А тут надо процессинг вытеснить в очередь. Приплыли.
P>>Покрыть перформанс тестами все вырожденные кейсы вам время жизни вселенной не позволит. Некоторые детали реализации нужно фиксировать обычыными тестами. ·>Обычные тесты не могут тестировать перф. А детали реализации лучше не тестировать.
Детали реализации нужно покрывать тестами, что бы первый залётный дятел не разрушил всю цивилизацию:
— оптимизации
— трудноуловимые баги
— секюрити
— всякие другие -ility
— любой сложный код, где data complexity превышает ваше капасити
P>>Метапрограммирование тестируется там, где оно применяется в силу естественных причин. Если у вас запросы тривиальные, вам такое не нужно. ·>Ты не понял. Надо тестировать не метапрограммирование, а ожидания.
Вы снова решили в слова поиграть.
P>>Неэффективно. Для многих приложений час невалидной работы может стоит любых денег. Дешевле запустить тесты на проде — час-два и у вас информация по всем функциям. ·>Ну никто нам не позволит делать "тестовые" сделки на прод системах. Каждая сделка — это реальные деньги и реальная отчётность перед регуляторами. Так что "информацию по всем функциям" нам приходится выдавать ещё до аппрува релиза.
Вы не просто утверждаете это, а идете дальше — утверждаете, что тесты прода это признак наличия багов, не той квалификации и тд.
Возможно для вашей биржы или что это там еще, тесты на проде слишком рискованы. Это ж не значит, что и везде так же.
P>>Вы снова включили телепатию. Сертификат может обновиться не у вашего приложения, а у какого нибудь из внешних сервисов. Мониторинг вам скажет, когда N юзеров напорются на это и у вас начнет расти соответсвующая метрика. ·>Нет, мониторинг нам скажет, что сессия с таким-то сервисом сломалась и свистайте всех на верх.
А у вас один юзер в день что ли? Пошел трафик, а потом вжик — идут фейлы.
·>Такое — major incident и соответствующий разбор полётов с пересмотром всех процессов — как такое допустили и определение действий, чтобы такое больше не произошло.
Какой процесс вас застрахует от фейла на другой стороне которую вы не контролируте?
P>>У вас есть иллюзия, что ваши тесты гарантируют отсутствие лишнего выхлопа на данных, которые у вас отсутсвуют. ·>У меня такой иллюзии нет, ты опять насочинял, я такое нигде не писал. О гарантиях в тестах фантазировать любишь только ты.
Вы же топите за тесты и утверждаете, что они чего то там решают. Ниже пример этого
P>>·>Да так же, как у тебя. Только ассертить не буквальный текст запроса, а результат его выполнения P>> ·>Угу, вот так вот просто.
Вот этот самый пример — вы здесь утверждаете, что тестами решите проблему с data complexity. Или пишете тесты непонятно для чего, или же не в курсе data complexity
·>Ну я хотя бы могу начать допиливать этот самый swagger, чтобы генератор таки стал понимать. ·>А у тебя всё гораздо хуже. Ты пишешь аннотации, конфиги, тенантов, реализацию, веб-сервер, потом у тебя наконец-то http-запрос выдаётся этот же самый swagger по этим аннотациям, который ВНЕЗАПНО ни один генератор кода не понимает. И это реальная ситуация, которую помнится уже обсуждали пару лет назад и твоим решением было "ну пусть клиенты пишут всё ручками", т.к. перепилить свои аннотации и http-запрос ты уже не сможешь, ибо проще пристрелить.
Вы наверное с кем то меня путаете. Я ни призывал писать всё руками. С аннотациями похоже снова дело в вашей телепатии. Я ж вам сказал — они для конкретных кейсов. Кодогенерация дает медленный цикл разработки. В некоторых кейсах это можно сократить на недели и месяца. Я привел вам примеры но вы как обычно прошли мимо
P>>Вы похоже не читаете. Какой смысл вам что либо рассказывать? P>>1. когда стартуем проект, где центральная часть это АПИ. Идем через design-first, формат файла и расширение — любое, см. выше P>>2. готовый проект — уже поздно топить за design-first, просто генерим артефакты P>>3. переписываем проект на rust — снова, нам design-first не нужен, это вариация предыдущего кейса ·>Не понял, как из 1 получилось 2?
Никак — это разные кейсы.
P>>У вас точно меняется контингент, или в голове, или за компом: P>>
P>>Если вы захотите переписать свой сервис на другой ЯП, ну там с js на rust — что вы будете делать со своими аннотациями?
P>>Переписывание предполагает, что у нас уже есть и АПИ, и реализация этого АПИ. Отсюда ясно, что проще сгенерировать артефакт, чем изначально держаться за конкретный формат и топить за design-first ·>Ага, верно, проще прыгать чем думать. Не спорю.
У нас кейс "переписать апи на rust" был 0 раз за 10 лет. Смена технологий от балды — тоже 0 раз. А у вас иначе, каждый месяц всё с нуля на rust переписываете?
Здравствуйте, Pauel, Вы писали:
P>>>Это дополнительные издержки по сравнению с простыми функциями. Вы это сами показали на тестах календаря. P>·>Ты просто пытаешься ввести в заблуждение. Да, у меня в тестах добавляется одна строчка кода и собственно всё. Зато в твоём решении добавляется N-строчек в _прод_ коде и требуется больше тестов. Иными словами, ты "убираешь" код, но стесняешься говорить _куда_ этот код убирается. P>Чего стесняться — я вам прямо говорю. Переносим код связывания из размытого dependency injection в контроллер
Именно. И по итогу получается, что издержек у тебя больше, строчек кода добавляется огромная куча.
P>Это дает более простые тесты, более гибкий код, проще мейнтейнить — все что надо у вас перед носом.
Это уже вилами писано. Судя по коду который ты показывал, это не соответсвует реальности.
P>>>И у вас вполне вероятно не будет ни одной функции в джаве "удалить пользователя". А будет например "дропнуть док по хешкоду", "дропнуть записи по номеру телефона", "дропнуть сообщения по емейлу", "отозвать сертификат", "пометить спейс юзера к удалению через месяц", "подготовить выгрузку всех данных юзера", "закинуть зип на aws s3 c ttl 1 месяц" P>·>Ну будет же где-то какой-то код, который отвечает за бизнес-действие "удалить пользователя", который в итоге сделает всё вот это перечисленное. P>Какой то код — будет. Только с т.з. пользователя эта фича уже работает два релиза. А изменения, как пример, нужны по той причине, что удаление ресурсоемко и можно облегчить основной сервер, передав работу вспомогательному инстанцу. С т.з. пользователя изменений в функциональности нет, ни единой. А вот нефункциональные требования изменились. P>Это я вам пример привожу, что функциональность приложения и функции в джаве это две большие разницы.
А теперь тебе осталось продемонстировать, что я когда либо утверждал что это одно и то же, или опять софистикой занимаешься? Я лишь говорил, что функциональность можно выражать в виде функций, в т.ч. и ЧПФ. Вот в твоём привёдённом "контрпримере" для "удалить пользователя", что плохого или невозможного в наличии соответствующей функции в яп и покрытии её тестами?
P>>>·>Помогать в чём? Ещё раз — инлайнинг и т.п. — это средство, а не цель. С какой целью что инлайнить-то? P>>>Рефакторинг, очевидно. Его не раз в год нужно делать, а непрерывно — требования меняются постоянно. P>·>Опять путаешь цель и средство. Рефакторинг — это средство. P>Именно что средство.
Дядя Петя... на какой вопрос ты сейчас ответил? Напомню вопрос который я задал: "инлайнинг и т.п. — это средство, а не цель. С какой целью что инлайнить-то?"
P>>>Элементарно — замена вызова на константу. Это работает, т.к. str у вас иммутабельная. А вот текущее время такой особенностью не обладает. P>·>На какую константу? Значение length() зависит от того, что лежит в данном конкретном экземляре str: P>Length это интринсик,
Это где и с какого бодуна?
P>его сам компилятор заинлайнит, вам не надо заботиться P>Инлайнить самому нужно для оптимизации, изменения дизайна, итд
Противоречивые параграфы детектед.
P>·> Кешированию чего? Куда прикручивается кеш — надо смотреть на полное решение, а не на данную конкретнную строчку кода. В твоём решении проблема с кешем будет в другом месте, и её решать будет гораздо сложнее. Точнее ты вообще не сможешь кеш прикрутить, т.к. аргумент now — это текущее время, ВНЕЗАПНО. Ты ключoм в кеше будешь делать текущее время?? P>·>А у меня всё круто, т.к. реализация nextFriday() знает, что это отностися к следующей пятнице, то может кешировать одно и то же значение в течение недели и обновлять его по таймеру, например. P>Другими, вы здесь предложили наивную реализацию LRU кеша c контролем ттл по таймеру.
Угу. С нулевым изменением дизайна.
P>>>Дизайн меняется по простой причине — требования меняются непрерывно. Вот появилось нефункциональное требование "перформанс" и мы видим, что CalendarLogic сидит в hotpath и вызывается сто раз с одним и теми же значениями. Опаньки — меняем дизайн. P>·> Не меняем дизайн, а оптимизируем внутреннюю реализацию одного метода, ну того конкретного nextFriday(). Менять дизайн на каждый чих — признак полной профессиональной некомпетенции дизайнера решения. Разуй глаза — в сигнатуре "LocalDate nextFriday()" — совершенно не говорится что откуда должно браться — считаться на лету, из кеша, запрашиваться у пользователя или рандомом генериться от погоды на марсе. P>Запрос из кеша это изменение того самого дизайна.
Твоего дизайна — да, моего — нет.
P>Кеш, как минимум, надо инвалидировать, может и ттл прикрутить, а может и следить, что именно кешировать, а что — нет. Для этого вам нужно будет добавить кеш, настройки к нему, да еще связать правильно и тестами покрыть — что в ваш компонент приходит тот самый кеш а не просто какой то.
Кеш — это отдельный компонент.
P>>>Как это сделать в вашем случае — не ясно. Разве что прокинуть к вашему CalendarLogic еще и MRU, LRU кеш с конфигом "вот такие значения хранить пять минут". Вот уж простор для моков — теперь можно мокать не одно время, а целых три, а можно MRU, LRU обмокать. P>·>Толи ты вообще в дизайн не умеешь, толи нарочно какую-то дичь сочиняешь, чтобы мне приписать для strawman fallacy. P>Смотрите выше — вы сами, безо всякой моей подсказки предложили "может кешировать одно и то же значение в течение недели и обновлять его по таймеру, например" что есть тот самый кеш.
Именно. А вот ты даже это не смог предложить какого-либо работающего решения, кешировать с ключом по now — это полный бред. И вот тебе придётся для введения кеша в твоём "более гибком коде" перелопатить весь дизайн и тесты, т.к. связывание now и nextFriday у тебя происходит во многих местах и везде надо будет проталкивать этот кеш и его настройки.
P>>>Что бы просто так, без контекста — это слишком сильное утверждение. Но в целом оно отражает ваш подход к тестированию P>·>Моки — это ещё один дополнительный инструмент в копилку. Больше инструментов — больще возможностей решить задачу более эффективно. P>Моки в большинстве случаев морозят код, т.е. фиксируют код, бетонируют на времена. Вообще всё что вы пишете в тестах, обладает таким свойством P>Хотите гибкости — в тесты нужно выносить самый минимум. Как правило это параметры и возвращаемое значение. Вы почему то в этот минимум добавляете все зависимости с их собственным апи.
Я не вижу в этом проблему. Ничего не бетонируется. Всё так же рефакторится. Ещё раз напоминаю, что класс с зависимостями это технически та же функция "параметры и возвращаемое значение", но с ЧПФ. Просто некоторые параметры идут через первое "применение": f(p1, p2) <=> new F(p1).apply(p2).
P>·>апи диктуется требованиями клиентского кода, а не тестами. А зависимости — это уже как мы обеспечиваем работу этого апи. P>Если вы в юнит-тестах прокидываете мок в конструктор, то вы делаете выбор дизайна — инжекция зависимостей.
В каком-то смысле да, я некоторые "параметры" функции делаю более равными, т.к. подразумеваю по дизайну что они изменяются реже. Впрочем, оно рефакторится туда-сюда.
P>Вариантов, как обеспечить работу апи — множество. Но если вы вписали моки, то после этого варианты закончились — дизайн отлит в граните
Не отлит, всегда можно рефакторить.
P>>>Лишняя строчка P>·>Прям ужас-ужас. Но это не главное, главное ты наконец-то таки согласился, что твои "таблицы истинности", не пострадали от моков. P>Вы регулярно приводите примеры лишних строчек, но почему то вам кажется, что у меня кода больше. Код системы это не только функциональная часть, но тестирующая.
Я не привожу лишние строчки. Я привожу полный код, а ты весь код просто не показываешь.
P>>>Вот-вот. Статься от 2011го, ссылается на книгу, которую начали писать в 00х на основе опыта накопленного тогда же. P>·>И? Поэтому я и не понимаю как эта терминология мимо тебя прошла. P>Я освоил тот метод именно в нулевых, задолго до той самой статьи. С тех пор много чего эволюционировало. Потому я и пишу вам, что вы продолжаете вещать из нулевых, как будто с тех пор ничего и не было.
Теперь определись — толи ты сейчас привираешь, что это тебе всё давно знакомо, толи ты просто словоблудил, выразив непонимание что я имею в виду под wiring.
P>>>Мы только что выяснили, кто же из нас двоих вещает из нулевых P>·>Вот от твоего любимого фаулера, свежачок: https://martinfowler.com/articles/dependency-composition.html P>Именно что свежачок. Можете заглянуть сразу в Summary P>
P>By choosing to fulfill dependency contracts with functions rather than classes
За деревьями леса не видишь... ты код-то погляди, то же самое частичное применение функций для эмуляции "классов".
P>В 00х Фаулер сотоварищи топили за тот подход, за который вы топите 20 лет спустя.
Потому что тогда он показывал это на языках 00х, а сейчас ровно то же самое показывает на typescript. Та же ж, вид в профиль. Неужели ты до сих пор не въехал в ЧПФ?!
P>>>Вы уже много раз задавали этот вопрос, и я вам много раз на него отвечал. Отмотайте да посмотрите. P>·>Я код прошу показать, но ты упорно скрываешь. P>Не валяйте дурака — я вам еще на прошлом заходе давал два варианта P>1. из реквеста P>2. руками вкидываете P>С тех пор ничего не изменилось.
Именно. Кода как не было, так и нет. Так как если появится код, так сразу станет очевидно, что лишних строчек у тебя гораздо больше, да ещё и фреймворки какие-то требуются.
P>Собственно, вам ни один из них не нравится, потому вы здесь и выступаете. А щас вот пишете, что ничего не видели.
Именно, кода не видел, т.к. не было.
P>>>Самое важное сразу в коде метода, а не раскидано абы где по всеей иерархии dependency injection. P>·>Субъективщина какая-то. P>Это никакая не субъективщина. Все что функционально влияет на контроллер, должно связываться прямо в нем. А вот разная хрень пусть проходит через зависимости, ну вот сериализатор тот же. P>Т.е. четкое разделение — функциональные вещи и технологические, а у вас в dependency injection всё подряд — "тут я шью, тут я пью, тут селедку заворачиваю"
У тебя проблема даже чётко отделить функциональные вещи от технологических... и не только у тебя. Поэтому более вменяемым и _измеримым_ критерием будет именно разделение по ресурсам — треды/файлы/сеть/etc — отделяем.
P>>>Нет, не может быть. Это вам нужно делать явно в самом контроллере, который зафейлится сразу же, на первом тесте который его вызовет. P>·>Дык я об этом и талдычу, притом не в абы каком тесте, а конкретно в тесте который тестирует этот конкретную функцию этого конкретного контроллера. А вот в моём случае это придётся делать тоже явно в коде связывания зависимостей и зафейлится если не компилятором, то во время старта, ещё до того как дело дойдёт до запуска каких-либо тестов. P>У вас там написание кода начинается с деплоя на прод?
Это где я такое написал? Как вообще такое возможно?!
P>Вы узнаете о проблеме во время самого деплоя!
Во время деплоя вылазят проблемы окружения куда деплоится.
P>А надо во время написания кода которые идут вперемешку с прогном быстрых тестов, и это все за день-неделю-месяц до самого деплоя!
Ну чтобы какой-либо тест прогнать — надо стартовать некий код... не? Вот до выполнения первого попавшегося @Test-метода оно и грохнется, где-нибудь в @SetUp.
P>·>Они не "нужны". Есть другие подходы, которые покрывают эти же кейсы (по крайней мере, подавляющее большинство), но не требуют прогона тестов. P>Я и вижу — тестируете деплоем на прод.
Не знаю где ты это увидел, имеется в виду мы тестируем прод окружение пытаясь деплоить на прод. Вы, кстати, тестируете уже после деплоя на прод.
P>>>Согласно бл. А вы как собираетесь отличать два разных вызова, клиентский от серверного? Вам для этого придется намастырить кучу кода с инжекцией в конструктор, только всё важное будет "где то там" P>·>Я уже раза три рассказал. Клиентский и серверный будут иметь разный ожидаемый результат. P>Ну вот вам и ответ.
Напомню вопрос: А как ты будешь такой и-тест писать, если у тебя будет Time.Now? Что ассертить-то будешь? Как отличать два разных вызова Time.Now — клиентский от серверного?
Вот пришло тебе в ответе в неком поле значение "2024-01-23". как ты в и-тесте отличишь, что это вычислилось от вызова Time.Now на серверной стороне, а не на клиентской?
P>>>Теоретически — можно. Практически — первый интеграционный тест сваливается, когда вызывает этот контроллер. P>·>Если этот тест не забудут написать, конечно. Покрытие-то ты анализировать отказываешься... P>Вы совсем недавно делали вид, что понимаете как покрытие работает. А сейчас делаете вид, что уже нет. Покрытие говорит что код вызвался во время теста. Но никак не говорит, какие фичи пройдены. P>Нам нужны именно фичи, кейсы, сценарии. В строчках кода это не измеряется. Смотрите, как это делают QA.
Как ты убедишься, что некая фича покрыта тестами? Или что все фичи и разные corner cases описаны в бизнес-требованиях? Покрытие хоть и ничего не гарантирует, но часто помогает обнаружить пробелы.
P>·>И как это проверишь в тесте?
Ты в очередной раз проигнорировал неудобный вопрос.
P>·>И я написал почему в твоём коде это неочевидно на ревью. P>Это вам неочевидно, т.к. вы топите за другой дизайн. Комбинирование функции в общем случае проще композиции классов. Классы никуда не денутся — одно другому помогает.
Неочевидно потому что у тебя код так выглядит, а дизайн какой — пофиг.
P>>>Через параметры функции. Дизайн то плоский, а не глубокий, как у вас. P>·>Через параметры значения передаются. Откуда они возьмутся-то? P>А вы не видите? Весь код перед глазами.
Ты показывал код, нет, там этого не видно.
P>·>У тебя точек привязки — в каждом месте использования nextFriday и никак не тестируется вообще. P>Еще раз — точки привязки это часть интеграции, которая тестируется интеграционным тестом. Интеграционные тесты не тестируют кусочки "время прокинуто метод класса куда прокинута бд куда прокинут репозиторий". P>Вместо этого интеграция проверяет последовательность, которая вытекает из требований: P>- зарезервировать столик на трех человек на имя Коля Петров на следующую пятницу 21.00
Этот пример совершенно никак не отностися к обсуждаемому нами методу nextFriday. Или у тебя в твоём дизайне будет семь методов nextMonday...nextSunday?
P>·>У меня "дешевые" в том смысле, что они выполняются очень быстро. Так вот даже "полу-интеграционные на моках" — выполняются очень быстро, за минуты всё. А у тебя "дешевые" — выполняются полтора часа, но называешь их "дешевыми" так просто, потому что тебе так их нравится называть, без объективных на то причин. P>Вы, похоже, без телепатии жить не можете. Вы спросили, сколько времени идут тесты. Я вам ответил, еще и добавил, это все тесты, всего-всего, всех видов. Но вам всё равно телепатия ближе. P>Юнит тесты — пару минут от силы. Их до 15тыс ориентировочно.
С учётом того, что они у вас тестируют имена функций и буквальный текст запросов, то толку от них — не больше нуля.
P>Остальных — от 1000 до 5000 и они занимают 99% времени.
Ну вот и говорю хоупейдж. По acc-тестам (селениум, сеть, многопоток, полный фарш) у нас было на порядок больше, выполнялось за 20 минут, правда на небольшом кластере.
P>>>Рефакторинг, оптимизации. P>·>Рефакторинг это тоже не задача. А инлайнить для оптимизаций только самые ленивые компиляторы в режиме дебага не умеют. P>Большинство компиляторов умеют инлайнить только тривиальные вещи. Расчищать hot path это по прежнему ваша забота Так ведь и большинство IDE умеют инлайнить только тривиальные вещи. И на практике обычно получается так, что компилятор может заинлайнить больше, чем IDE. Если в твоём nextFriday будет много кода, с вспомогательными приватными функциями, несколькими точками return, etc, — то IDE тебе скажет: "упс!".
P>>>Эта кучка называется data complexity. Я, например, билдером могу гарантировать, что данные будут запрашиваться постранично. Или что всегда будет фильтр по времени, где период не более трех месяцев. P>·>Не очень понял, как гарантировать и что именно? И почему то же самое нельзя гарантировать другими способами? И вообще это всё больше похоже на бизнес-требования, чем на проверки каких-то кейсов в тестах. P>Это и есть тот, другой способ, основаный на метапрограммировании. Главное, что тесты основаные на проверке выборки из бд этот вопрос принципиально не решают, т.к. мы не знаем, что даст ваш запрос на каких других данных, которых у вас нет. P>Не нравится метапрограммирование — можете придумать что угодно.
И что? Причём тут тесты-то?
P>>>Соответсвено тестами можно проверить что структура запроса та, что нам надо P>·>Ой. Очень интересно увидеть код как ты проверишь тестами по структуре запроса, что у тебя билдер что-то гарантирует. P>Я ж вам показал идею. Или вы ждёте тьюринг-полного выхлопа, который умеет еще и мысли читать по вашей методике?
Идея вида "мышки станьше ёжиками", "за всё хорошее против всего плохого". А конкретный код _теста_ — осилить не можешь.
P>·>Я не знаю на какой вопрос ты ответил, но я напомню что я спрашивал: "Как запрос может что-то сказать?". Контекст выделил жирным выше. P>Вы там ногой читаете? Запрос не человек, сказать не может. А вот ревьюер может сказать "у нас такого индекса нет, тут будет фуллскан по таблице из десятков миллионов записей с выполнением регекспа и время работы на проде надо ждать десятки минут"
Или у вас неимоверно крутые ревьюверы, помнят наизусть сотни таблиц и тысячи индексов, или у вас хоумпейдж. Не все могут себе такое позволить.
P>>>Я вам выше рассказал. Нужна гарантия, что не вернется вдруг чего нибудь не то. Вариантов "не того" у вас по скромной оценке близко к бесконечности. P>·>Как ты это предлагаешь _гарантировать_? И причём тут тесты? P>Это ж вы сунете тесты туда, где они не работают.
Это ты словоблудием занимаешься. Мы обсуждаем именно тесты, а ты тут в сторону доказательного программирования и мета уходишь.
P>Как гарантировать — см пример номер 100500 чуть выше
Где чуть выше?
P>>>Вы топите за косвенные проверки запросов, тестируя связку репозиторий+бд. Вот этого оно и есть. P>·>Я топлю за то как надо писать тесты, чтобы от них была хоть какая-то польза и поменьше вреда. А не абстрактные "проверки" которые что-то должны "гарантировать" посредством говорящей рыбы запроса. P>Ага, за всё хорошее против всего плохого
Я пальчиком в конкретные места твоего кода тыкнул где плохо и как сделать хорошо. Про "всё" — это твои фантазии опять.
P>>>Пользователи ожидают, что на их данных, которых в ваших тестах нет, будет нужный результат. P>·>Если ожидания есть, то какая проблема их добавить в тесты? P>У вас данных нет. Или вы щас скажете, что у вас уже есть все данные всех юзеров на будущее тысячелетие?
И как тобой предложенное "in: [fn1]" решает эту проблему? Или ты опять в сторону разговор уводишь?
P>>>Вашими тестами эта задача не решается P>·>Я показал как решение этой задачи можно тестировать моими тестами. Ты так и не рассказал как она решается вашими тестами. P>Я сказал, что тестами эта задача не решается.
Напомню контекст. Мы сравниваем ваши тесты с моими. Я показал проблемы в ваших тестах, и показал как эти проблемы решить моими. И ты тут заявил, что моих теста есть проблемы, т.к. они не решают задачи, которые не решаются тестами. Вау!
P>Собственно, вы раз за разом утверждаете, что с разработкой алгоритмов не знакомы. Мало накидать реализацию и тесты — нужно обосновать и доказать корректность.
strawman fallacy это называется, господин словоблуд.
P>>>Не нужно сводить всё к бл напряму. У вас технологического кода в приложении примерно 99%. Он к бл относится крайне опосредовано — через связывание. А тестировать эти 99% тоже нужно. P>·>Именно. Ты меня обвинил в том, что у меня тесты тестируют детали реализации, а на самом деле ты просто с больной головы на здоровую. Но зато у тебя дизайн самый модный! P>Наоборот.
Ваша цитата: Ага, тесты "как написано" Вам придется написать много больше, чем один тест — как минимум, пространство входов более-менее покрыть. Моками вы вспотеете это покрывать.
P>Это вы пишете что я тестирую те самые детали, которые тестировать, по вашему, не надо.
Ну потому что это так, я специально из вас выудил код того самого pattern — там это всё и видно — буквальный текст запроса, имена приватных функций.
P>·>Зато есть возможность покрыть известные данные и комбинации тестами. Вы и этого не делаете, а просто имена приватных функций ассертите и буковки сравниваете (тоже, кстати известные). Вот и приходится часами билдить и в проде тесты гонять чтобы хоть что-то как-то обнаружилось. P>Зачем вам собеседник, если у вас отличный дуэт с вашей телепатией?
В каком месте тут телепатия? Билд занимающий часы — это твои слова. И тесты в проде — тоже.
P>>>Вот оптимизацию такой вещи закрыть тестами, что бы первый же фикс не сломал всю цивилизацию P>·>Это всё круто. Каким образом твоё "in: [fn1]" обеспечивает тебя всем множеством данных которое может приходить от юзеров? P>Такой тест гарантирует, что всё множество данных будет проходить именно через эту функцию.
Не гарантирует. В коде может быть написано "if(thursdayAfterRain())return {...in: [fn42]...}" и тест это не может обнаружить. Ещё раз — тесты ничего не могут гарантировать.
P>И если я знаю, что у неё нужные мне свойства(тестами не решается), то результат будет обладать нужными мне свойствами. Например, если функция никогда не возвращает null, то вы можете и не бояться "а вдруг там всё таки null" и сократить hot path
Наивный юноша.
P>>>В интеграционном тесте можно сделать то же самое. P>·>Как? Код в студию. Вот в куче кода кучи контроллеров где-то у тебя написано Time.Now. Как ты это проверишь в интеграционном тесте что некий результат содержит именно что-то вычисленное от Now, а не что-то другое? P>Я вам привел пример про Колю Петрова. Надеюсь, справитесь
Опять врёшь. Это не код.
P>·>Не это, а то что вначале мы использовали серверное время, а потом вдруг стали использовать клиентское — это изменение функциональное, т.к. источники времени — принципиально разные и влияют на наблюдаемый результат. Если бы было время клиентское изначально, то никаке функциональные тесты не пострадают. P>Нет, это не функциональное изменение. Мы просто перенесли процессинг в очередь. С точки зрения пользователя ничего не изменилось.
Я это и сказал. Если тут всё равно серверное время, то да, не функциональное, и тесты не пострадают. Тесты сломаются и должны сломаться если ты заменишь источник серверного времени на источник клиентского времени.
P>·>А ещё я кофе моими тестами сварить не смогу. Что сказать-то хотел? P>·>Напомню, мы сравниваем тестирование ожиданий бизнес-требований твоими тестами с "in: [fn1]" vs моими тестами c "save/find". Так причём тут метапрограммирование? P>Я вам объяснил уже много раз. Вы точно понимаете, что такое метапрограммирование?
Я не понимаю какое отношение метапрограммирование имеет к бизнес-требованиям и к тому как писать тесты.
P>>>Может. Это дополнительные гарантии, сверх тех, что вы можете получить прогоном на тестовых данных. Потому издержки обоснованы. P>·>Гы. Опять у тебя тесты гарантии дают. P>Тесты дают гарантию, что пайплайн устроен нужным мне образом. А свойства результата, следовательно, будут определяться свойствами пайплайна. Тогда вам нужно сосредоточиться на выявлении этих свойств, а не писать одно и то же третий месяц кряду.
Тесты не могут давать гарантию.
P>>>Тогда можно сравнить выхлоп, тот или не тот. P>·>Так я тебя и спрашиваю как ты будешь сравнивать выхлоп зависящий от Time.Now — тот он или не тот? P>Смотрите пример про Колю Петрова
Не нужен мне пример. Мне нужен код.
P>>>Этим протаскиванием вы бетонируете весь дизайн. Смена дизайна = переписывание тестов. P>·>Нет. P>Вы прибили контролер к тестам на моках. А тут надо процессинг вытеснить в очередь. Приплыли.
Ну выплывайте.
P>>>Покрыть перформанс тестами все вырожденные кейсы вам время жизни вселенной не позволит. Некоторые детали реализации нужно фиксировать обычыными тестами. P>·>Обычные тесты не могут тестировать перф. А детали реализации лучше не тестировать. P>Детали реализации нужно покрывать тестами, что бы первый залётный дятел не разрушил всю цивилизацию: P>- оптимизации
Это перф-тесты.
P>- трудноуловимые баги P>- секюрити P>- всякие другие -ility P>- любой сложный код, где data complexity превышает ваше капасити
Это "за всё хорошее, против всего плохого". А секьюрити — это бизнес-требование и обязано быть покрыто фукнциональными тестами.
P>>>Метапрограммирование тестируется там, где оно применяется в силу естественных причин. Если у вас запросы тривиальные, вам такое не нужно. P>·>Ты не понял. Надо тестировать не метапрограммирование, а ожидания. P>Вы снова решили в слова поиграть.
"Метапрограммирование тестируется" — зачем? Если я какую-то реализацию какого-то метода захочу изменить с/без метапрограммирования — с какго бодуна я должен переписывать тесты? В этом и суть — меняем _реализацию_ логики с/без меты — тесты остаются ровно те же и должны остаться зелёными.
P>>>Неэффективно. Для многих приложений час невалидной работы может стоит любых денег. Дешевле запустить тесты на проде — час-два и у вас информация по всем функциям. P>·>Ну никто нам не позволит делать "тестовые" сделки на прод системах. Каждая сделка — это реальные деньги и реальная отчётность перед регуляторами. Так что "информацию по всем функциям" нам приходится выдавать ещё до аппрува релиза. P>Вы не просто утверждаете это, а идете дальше — утверждаете, что тесты прода это признак наличия багов, не той квалификации и тд.
Признак более позднего обнаружения багов.
P>Возможно для вашей биржы или что это там еще, тесты на проде слишком рискованы. Это ж не значит, что и везде так же.
Ок, для хоумпейджей можно хоть левой пяткой писать, неважно.
P>>>Вы снова включили телепатию. Сертификат может обновиться не у вашего приложения, а у какого нибудь из внешних сервисов. Мониторинг вам скажет, когда N юзеров напорются на это и у вас начнет расти соответсвующая метрика. P>·>Нет, мониторинг нам скажет, что сессия с таким-то сервисом сломалась и свистайте всех на верх. P>А у вас один юзер в день что ли? Пошел трафик, а потом вжик — идут фейлы.
На это и придумали healthchecks (а конкретно liveness probe), проверка, что сервис — operational, явно проверяет себя и свои зависимости, что может отрабатывать трафик без фейлов ещё до того как пошли реальные запросы.
P>·>Такое — major incident и соответствующий разбор полётов с пересмотром всех процессов — как такое допустили и определение действий, чтобы такое больше не произошло. P>Какой процесс вас застрахует от фейла на другой стороне которую вы не контролируте?
Большая тема. Начни отсюда: https://en.wikipedia.org/wiki/High_availability
P>>>У вас есть иллюзия, что ваши тесты гарантируют отсутствие лишнего выхлопа на данных, которые у вас отсутсвуют. P>·>У меня такой иллюзии нет, ты опять насочинял, я такое нигде не писал. О гарантиях в тестах фантазировать любишь только ты. P>Вы же топите за тесты и утверждаете, что они чего то там решают. Ниже пример этого
Решают проблемы в _твоих тестах_.
P>>> P>·>Угу, вот так вот просто. P>Вот этот самый пример — вы здесь утверждаете, что тестами решите проблему с data complexity. Или пишете тесты непонятно для чего, или же не в курсе data complexity
Где здесь? Цитату, или опять соврамши.
P>·>Ну я хотя бы могу начать допиливать этот самый swagger, чтобы генератор таки стал понимать. P>·>А у тебя всё гораздо хуже. Ты пишешь аннотации, конфиги, тенантов, реализацию, веб-сервер, потом у тебя наконец-то http-запрос выдаётся этот же самый swagger по этим аннотациям, который ВНЕЗАПНО ни один генератор кода не понимает. И это реальная ситуация, которую помнится уже обсуждали пару лет назад и твоим решением было "ну пусть клиенты пишут всё ручками", т.к. перепилить свои аннотации и http-запрос ты уже не сможешь, ибо проще пристрелить. P>Вы наверное с кем то меня путаете. Я ни призывал писать всё руками. С аннотациями похоже снова дело в вашей телепатии. Я ж вам сказал — они для конкретных кейсов. Кодогенерация дает медленный цикл разработки. В некоторых кейсах это можно сократить на недели и месяца. Я привел вам примеры но вы как обычно прошли мимо
Кодогенерация сама по себе медленный цикл разаработки не даёт. Любой кодогенератор работает от силы порядка минут.
P>>>Вы похоже не читаете. Какой смысл вам что либо рассказывать? P>>>1. когда стартуем проект, где центральная часть это АПИ. Идем через design-first, формат файла и расширение — любое, см. выше P>>>2. готовый проект — уже поздно топить за design-first, просто генерим артефакты P>>>3. переписываем проект на rust — снова, нам design-first не нужен, это вариация предыдущего кейса P>·>Не понял, как из 1 получилось 2? P>Никак — это разные кейсы.
Ну я за 1 и не люблю 2, а 3 это следствие 2, т.к. "прыгают, а не думают". Об чём спор-то?
P>·>Ага, верно, проще прыгать чем думать. Не спорю. P>У нас кейс "переписать апи на rust" был 0 раз за 10 лет. Смена технологий от балды — тоже 0 раз. А у вас иначе, каждый месяц всё с нуля на rust переписываете?
C++, kotlin, java, groovy, scala (может ещё что забыл)... И таки да, спеки всё-таки есть в виде FIX или хотя бы avro/protobuf. А когда копадаются другие команды/внешине сервисы с подходом "нагенерим из аннотаций" — вечная головная боль интегрироваться с такими.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>Чего стесняться — я вам прямо говорю. Переносим код связывания из размытого dependency injection в контроллер ·>Именно. И по итогу получается, что издержек у тебя больше, строчек кода добавляется огромная куча.
Нету никакой огромной кучи
P>>Это я вам пример привожу, что функциональность приложения и функции в джаве это две большие разницы. ·>А теперь тебе осталось продемонстировать, что я когда либо утверждал что это одно и то же, или опять софистикой занимаешься? Я лишь говорил, что функциональность можно выражать в виде функций, в т.ч. и ЧПФ. Вот в твоём привёдённом "контрпримере" для "удалить пользователя", что плохого или невозможного в наличии соответствующей функции в яп и покрытии её тестами?
А нефункционые требования вы будете в виде нефункций выражать? Вы притягивает юзера к вашим тестам. Юзера можно притянуть только к функциональным тестам. Во всех остальных он не фигурирует.
P>>>>Его не раз в год нужно делать, а непрерывно — требования меняются постоянно
. P>>·>Опять путаешь цель и средство. Рефакторинг — это средство. P>>Именно что средство. ·>Дядя Петя... на какой вопрос ты сейчас ответил? Напомню вопрос который я задал: "инлайнинг и т.п. — это средство, а не цель. С какой целью что инлайнить-то?"
Я вам подсветил, что бы полегче прочесть было
P>>·>На какую константу? Значение length() зависит от того, что лежит в данном конкретном экземляре str: P>>Length это интринсик, ·>Это где и с какого бодуна?
length cводится к
1 получению размера внутреннего массива символов что есть неизменная величина
2 гарантии иммутабельности соответсвующей ссылки. Т.е. никакой modify(str) не сможет легально изменить длину строки str
3 джит компилятор в курсе 1 и 2 и инлайнит метод length минуя все слои абстракции, включая сам массив и его свойство
Если вы запилите свой класс строк, нарушив или 1, или 2, компилятор ничего вам не сможет заинлайнить.
ваш провайдер времени не обладает свойствами навроде 1 или 2, потому не то что компилятор, а ИДЕ, а часто и разработчик не смогут просто так заинлайнить метод
P>>его сам компилятор заинлайнит, вам не надо заботиться P>>Инлайнить самому нужно для оптимизации, изменения дизайна, итд ·>Противоречивые параграфы детектед.
Я вижу здесь другой кейс — вы так торопитесь, что обгоняете сами себя. Инлайнить методы нужно для оптимизации или изменения дизайна. В случае c Length инлайн в целях оптимизации выполнит компилятор.
P>>·>А у меня всё круто, т.к. реализация nextFriday() знает, что это отностися к следующей пятнице, то может кешировать одно и то же значение в течение недели и обновлять его по таймеру, например. P>>Другими, вы здесь предложили наивную реализацию LRU кеша c контролем ттл по таймеру. ·>Угу. С нулевым изменением дизайна.
Ну да — добавить компонент с конфигом и сайд-эффектом это стало вдруг нулевым изменением дизайна
P>>Запрос из кеша это изменение того самого дизайна. ·>Твоего дизайна — да, моего — нет.
Т.е. вы не в курсе, что значение функции закешировать гораздо проще, чем мастырить LRU кеш? Более того — такую кеширующую функцию еще и протестировать проще.
P>>Кеш, как минимум, надо инвалидировать, может и ттл прикрутить, а может и следить, что именно кешировать, а что — нет. Для этого вам нужно будет добавить кеш, настройки к нему, да еще связать правильно и тестами покрыть — что в ваш компонент приходит тот самый кеш а не просто какой то. ·>Кеш — это отдельный компонент.
Вот-вот. Отдельный компонент. В том то и проблема. И вам все это придется мастырить и протаскивать. Только всегда "где то там"
P>>Смотрите выше — вы сами, безо всякой моей подсказки предложили "может кешировать одно и то же значение в течение недели и обновлять его по таймеру, например" что есть тот самый кеш. ·>Именно. А вот ты даже это не смог предложить какого-либо работающего решения, кешировать с ключом по now — это полный бред. И вот тебе придётся для введения кеша в твоём "более гибком коде" перелопатить весь дизайн и тесты, т.к. связывание now и nextFriday у тебя происходит во многих местах и везде надо будет проталкивать этот кеш и его настройки.
Ровно так же как и у вас, только дизайн не надо перелопачивать.
P>>Хотите гибкости — в тесты нужно выносить самый минимум. Как правило это параметры и возвращаемое значение. Вы почему то в этот минимум добавляете все зависимости с их собственным апи. ·>Я не вижу в этом проблему. Ничего не бетонируется. Всё так же рефакторится. Ещё раз напоминаю, что класс с зависимостями это технически та же функция "параметры и возвращаемое значение", но с ЧПФ. Просто некоторые параметры идут через первое "применение": f(p1, p2) <=> new F(p1).apply(p2).
Вы пока что инлайн обеспечить не можете, а замахиваетесь на чтото большее
P>>Вы регулярно приводите примеры лишних строчек, но почему то вам кажется, что у меня кода больше. Код системы это не только функциональная часть, но тестирующая. ·>Я не привожу лишние строчки. Я привожу полный код, а ты весь код просто не показываешь.
И где ваш код nextFriday и всех вариантов инжекции для разных кейсов — клиенское время, серверное, текущие, такое, сякое ?
P>>Я освоил тот метод именно в нулевых, задолго до той самой статьи. С тех пор много чего эволюционировало. Потому я и пишу вам, что вы продолжаете вещать из нулевых, как будто с тех пор ничего и не было. ·>Теперь определись — толи ты сейчас привираешь, что это тебе всё давно знакомо, толи ты просто словоблудил, выразив непонимание что я имею в виду под wiring.
wiring и есть связывание. Код связывания в dependency injection, который вы называете wiring, и код связывания в контроллере — выполняют одно и то же — интеграцию. Разница отражает подходы к дизайну. И то и другое wiring, и то и другое связывание. И задача решается одна и та же. Только свойства решения разные.
P>>
P>>By choosing to fulfill dependency contracts with functions rather than classes
·>За деревьями леса не видишь... ты код-то погляди, то же самое частичное применение функций для эмуляции "классов".
Похоже, что пример для Буравчика вы не поняли
P>>В 00х Фаулер сотоварищи топили за тот подход, за который вы топите 20 лет спустя. ·>Потому что тогда он показывал это на языках 00х, а сейчас ровно то же самое показывает на typescript. Та же ж, вид в профиль. Неужели ты до сих пор не въехал в ЧПФ?!
То же, да не то же. Посмотрите где связывание у него, а где связывание у вас.
P>>С тех пор ничего не изменилось. ·>Именно. Кода как не было, так и нет. Так как если появится код, так сразу станет очевидно, что лишних строчек у тебя гораздо больше, да ещё и фреймворки какие-то требуются.
Фремворки и у вас есть, только из 00х. Вы уже признавались в этом.
P>>У вас там написание кода начинается с деплоя на прод? ·>Это где я такое написал? Как вообще такое возможно?!
Вы же рассказываете, что проблему увидите на старте приложения. Прод у вас получает конфиг прода и другие вещи прода. Вот на старте и узнаете, что у вас не так пошло. А надо зафейлить тест, когда вы только-только накидали первую версию контроллера — в этот момент у вас буквально приложения еще нет
P>>А надо во время написания кода которые идут вперемешку с прогном быстрых тестов, и это все за день-неделю-месяц до самого деплоя! ·>Ну чтобы какой-либо тест прогнать — надо стартовать некий код... не? Вот до выполнения первого попавшегося @Test-метода оно и грохнется, где-нибудь в @SetUp.
Вы тестируете не @Setup а иерархию вызовов dependency injection, которая у вас появляется, появляется... на старте приложения. И фейлы ждете с этого момента. А надо гораздо раньше.
Смотрите тот вариант что у Фаулера — его окончательный дизайн позволяет вам фейлить многие вещи когда ничего другого вообще нет — его связывание в одном месте и покрывается тестами
У вас аналог этого связывания будет а хрен его знает когда
·>Не знаю где ты это увидел, имеется в виду мы тестируем прод окружение пытаясь деплоить на прод. Вы, кстати, тестируете уже после деплоя на прод.
Не после — а задолго до. После деплоя прогон тестов это расширенный мониторинг — проверяется выполнимость сценариев пользователя, а не просто healthcheck который вы предлагаете
Почему может поломаться — потому, что приложение работает с кучей внешних зависимостей, которые мы не контролируем.
P>>Ну вот вам и ответ. ·>Напомню вопрос: А как ты будешь такой и-тест писать, если у тебя будет Time.Now? Что ассертить-то будешь? Как отличать два разных вызова Time.Now — клиентский от серверного? ·>Вот пришло тебе в ответе в неком поле значение "2024-01-23". как ты в и-тесте отличишь, что это вычислилось от вызова Time.Now на серверной стороне, а не на клиентской?
Смотрите пример про Колю Петрова, там ответ на этот вопрос
P>>Нам нужны именно фичи, кейсы, сценарии. В строчках кода это не измеряется. Смотрите, как это делают QA. ·>Как ты убедишься, что некая фича покрыта тестами? Или что все фичи и разные corner cases описаны в бизнес-требованиях? Покрытие хоть и ничего не гарантирует, но часто помогает обнаружить пробелы.
Я ж говорю — смотрите, как это у QA делается.
P>>- зарезервировать столик на трех человек на имя Коля Петров на следующую пятницу 21.00 ·>Этот пример совершенно никак не отностися к обсуждаемому нами методу nextFriday. Или у тебя в твоём дизайне будет семь методов nextMonday...nextSunday?
Примером по Колю Петрова вам показываю, что такое интеграционные тесты. Вы же в них хотите проверять "а должно вот там вызываться!"
P>>Остальных — от 1000 до 5000 и они занимают 99% времени. ·>Ну вот и говорю хоупейдж. По acc-тестам (селениум, сеть, многопоток, полный фарш) у нас было на порядок больше, выполнялось за 20 минут, правда на небольшом кластере.
Подозреваю, вы их просто подробили, "проверим, что время вон то"
P>>Не нравится метапрограммирование — можете придумать что угодно. ·>И что? Причём тут тесты-то?
Тесты где сравнивается выхлоп из базы не решают проблемы data complexity. Отсюда ясно — что нужно добавлять нечто большее.
P>>Вы там ногой читаете? Запрос не человек, сказать не может. А вот ревьюер может сказать "у нас такого индекса нет, тут будет фуллскан по таблице из десятков миллионов записей с выполнением регекспа и время работы на проде надо ждать десятки минут" ·>Или у вас неимоверно крутые ревьюверы, помнят наизусть сотни таблиц и тысячи индексов, или у вас хоумпейдж. Не все могут себе такое позволить.
Зато сразу ясно, где именно хоум пейдж, и почему ваши тесты работают ажно 20 минут.
P>>Это ж вы сунете тесты туда, где они не работают. ·>Это ты словоблудием занимаешься. Мы обсуждаем именно тесты, а ты тут в сторону доказательного программирования и мета уходишь.
Я вам о том, какие гарантии можно получить вашими тестами, а какие — нельзя.
В вашем случае вы ничего не гарантируете на тех данных, что у вас нет.
P>>Как гарантировать — см пример номер 100500 чуть выше ·>Где чуть выше?
Я вам одно и то же пишу второй год.
P>>У вас данных нет. Или вы щас скажете, что у вас уже есть все данные всех юзеров на будущее тысячелетие? ·>И как тобой предложенное "in: [fn1]" решает эту проблему? Или ты опять в сторону разговор уводишь?
Примерно так же, как assert.notnull(parameter) в начале метода или return assert.notEmpty(value) в конце
P>>Наоборот. ·>Ваша цитата: Ага, тесты "как написано" Вам придется написать много больше, чем один тест — как минимум, пространство входов более-менее покрыть. Моками вы вспотеете это покрывать.
Ну ок, значит ничья в этом вопросе
P>>·>Зато есть возможность покрыть известные данные и комбинации тестами. Вы и этого не делаете, а просто имена приватных функций ассертите и буковки сравниваете (тоже, кстати известные). Вот и приходится часами билдить и в проде тесты гонять чтобы хоть что-то как-то обнаружилось. P>>Зачем вам собеседник, если у вас отличный дуэт с вашей телепатией? ·>В каком месте тут телепатия? Билд занимающий часы — это твои слова. И тесты в проде — тоже.
Вы всё знаете — и сложность проекта, и объемы кода, и начинку тестов, и частоту тех или иных тестов. Просто удивительно, как тонкая телепатия.
P>>Такой тест гарантирует, что всё множество данных будет проходить именно через эту функцию. ·>Не гарантирует. В коде может быть написано "if(thursdayAfterRain())return {...in: [fn42]...}" и тест это не может обнаружить. Ещё раз — тесты ничего не могут гарантировать.
А я и говорю в который раз, что основное совсем не в тестах. В них мы всего лишь фиксируем некоторые свойства решения, что бы досталось потомкам в неискаженном виде.
P>>Я вам привел пример про Колю Петрова. Надеюсь, справитесь ·>Опять врёшь. Это не код.
Почему ж не код? Это в кукумбер переводится практически один к одному.
·>Я это и сказал. Если тут всё равно серверное время, то да, не функциональное, и тесты не пострадают. Тесты сломаются и должны сломаться если ты заменишь источник серверного времени на источник клиентского времени.
А вы точно интеграционные пишите? Чтото мне кажется, вы пишете высокоуровневые юнит-тесты.
·>Я не понимаю какое отношение метапрограммирование имеет к бизнес-требованиям и к тому как писать тесты.
Такое же, как ваши классы, методы, dependency injection итд.
P>>Тесты дают гарантию, что пайплайн устроен нужным мне образом. А свойства результата, следовательно, будут определяться свойствами пайплайна. Тогда вам нужно сосредоточиться на выявлении этих свойств, а не писать одно и то же третий месяц кряду. ·>Тесты не могут давать гарантию.
Тесты именно ради гарантий и пишутся. Только чудес от них ждать не надо.
P>>Смотрите пример про Колю Петрова ·>Не нужен мне пример. Мне нужен код.
Бывает и хуже.
P>>Детали реализации нужно покрывать тестами, что бы первый залётный дятел не разрушил всю цивилизацию: P>>- оптимизации ·>Это перф-тесты.
Это слишком долго. Фейлы перформанса в большинстве случаев можно обнаруживать прямо во время юнит-тестирования.
P>>- трудноуловимые баги P>>- секюрити P>>- всякие другие -ility P>>- любой сложный код, где data complexity превышает ваше капасити ·>Это "за всё хорошее, против всего плохого". А секьюрити — это бизнес-требование и обязано быть покрыто фукнциональными тестами.
Важно, что бы явные фейлы обнаруживались гораздо раньше старта после деплоя. Тогда будет время подумать, как получить максимум сведений из самого деплоя.
·>"Метапрограммирование тестируется" — зачем?
Тестировать нужно вообще всё, что вам взбредет в голову спроектировать. Тестируюя только крупные куски вы получаете дырявое покрытие
P>>Вы не просто утверждаете это, а идете дальше — утверждаете, что тесты прода это признак наличия багов, не той квалификации и тд. ·>Признак более позднего обнаружения багов.
Они показывают, выполнимы ли сценарии под нагрузкой(при изменениях сети, топологии, итд) или нет.
·>На это и придумали healthchecks (а конкретно liveness probe), проверка, что сервис — operational, явно проверяет себя и свои зависимости, что может отрабатывать трафик без фейлов ещё до того как пошли реальные запросы.
Каким чудом ваш пробы дают ответ, выполнимы или все ключевые сценарии при максимальной нагрузке? Сценарий — это та часть, про Колю Петрова, которая вам непонятна
P>>Какой процесс вас застрахует от фейла на другой стороне которую вы не контролируте? ·>Большая тема. Начни отсюда: https://en.wikipedia.org/wiki/High_availability
Выполнимость сценариев это consistensy всех функций сервиса, а вовсе не high availability, как вы думаете.
P>>Вы наверное с кем то меня путаете. Я ни призывал писать всё руками. С аннотациями похоже снова дело в вашей телепатии. Я ж вам сказал — они для конкретных кейсов. Кодогенерация дает медленный цикл разработки. В некоторых кейсах это можно сократить на недели и месяца. Я привел вам примеры но вы как обычно прошли мимо ·>Кодогенерация сама по себе медленный цикл разаработки не даёт. Любой кодогенератор работает от силы порядка минут.
Именно что сама по себе. Вам надо таскать тот манифест, сихнронизироваться с ним, следить, что бы все имели ту самую версию, тот самый генератор, итд итд
Во многих случаях этого можно избежать
P>>У нас кейс "переписать апи на rust" был 0 раз за 10 лет. Смена технологий от балды — тоже 0 раз. А у вас иначе, каждый месяц всё с нуля на rust переписываете? ·>C++, kotlin, java, groovy, scala (может ещё что забыл)... И таки да, спеки всё-таки есть в виде FIX или хотя бы avro/protobuf. А когда копадаются другие команды/внешине сервисы с подходом "нагенерим из аннотаций" — вечная головная боль интегрироваться с такими.
И ежу понятно — вам максимум с собой легко интегрироваться
Здравствуйте, Pauel, Вы писали:
P>>>Чего стесняться — я вам прямо говорю. Переносим код связывания из размытого dependency injection в контроллер P>·>Именно. И по итогу получается, что издержек у тебя больше, строчек кода добавляется огромная куча. P>Нету никакой огромной кучи
Потому что ты её скромно скрываешь.
P>>>Это я вам пример привожу, что функциональность приложения и функции в джаве это две большие разницы. P>·>А теперь тебе осталось продемонстировать, что я когда либо утверждал что это одно и то же, или опять софистикой занимаешься? Я лишь говорил, что функциональность можно выражать в виде функций, в т.ч. и ЧПФ. Вот в твоём привёдённом "контрпримере" для "удалить пользователя", что плохого или невозможного в наличии соответствующей функции в яп и покрытии её тестами? P>А нефункционые требования вы будете в виде нефункций выражать?
По логике — двойка.
P>Вы притягивает юзера к вашим тестам. Юзера можно притянуть только к функциональным тестам. Во всех остальных он не фигурирует.
Ну вроде о функциональных тестах тут и говорили, об проверках ожиданий пользователей. Ты опять как уж на сковородке по кочкам прыгаешь. Контекст не теряй, ок?
P>. P>>>·>Опять путаешь цель и средство. Рефакторинг — это средство. P>>>Именно что средство. P>·>Дядя Петя... на какой вопрос ты сейчас ответил? Напомню вопрос который я задал: "инлайнинг и т.п. — это средство, а не цель. С какой целью что инлайнить-то?" P>Я вам подсветил, что бы полегче прочесть было
Ну если для тебя инлайн одной функции — это изменение дизайна приложения, то это твоё очень странное понимание слова "дизайн".
P>>>·>На какую константу? Значение length() зависит от того, что лежит в данном конкретном экземляре str: P>>>Length это интринсик, P>·>Это где и с какого бодуна? P>length cводится к
Ты совершенно неправильно понимаешь интринсики и чем они отличаются от инайлна и уж тем более константности. Мягко говоря, абсолютно разные вещи. Ликбез: https://en.wikipedia.org/wiki/Intrinsic_function
Вот тебе полный список интринзиков jvm, например: https://gist.github.com/apangin/7a9b7062a4bd0cd41fcc
P>1 получению размера внутреннего массива символов что есть неизменная величина P>2 гарантии иммутабельности соответсвующей ссылки. Т.е. никакой modify(str) не сможет легально изменить длину строки str P>3 джит компилятор в курсе 1 и 2 и инлайнит метод length минуя все слои абстракции, включая сам массив и его свойство P>Если вы запилите свой класс строк, нарушив или 1, или 2, компилятор ничего вам не сможет заинлайнить.
Бред, джит великолепно инлайнит length(), например, и у StringBuffer или даже LinkedList, и практически каждый getter/setter. И даже умеет инлайнить виртуальные функции.
P>ваш провайдер времени не обладает свойствами навроде 1 или 2, потому не то что компилятор, а ИДЕ, а часто и разработчик не смогут просто так заинлайнить метод
У тебя опять каша в голове. Напомню конткест: не провайдер времени, а nextFriday() вроде как ты собирался инлайнить.
Но вряд ли это всё заинлайнится, т.к. friday и работа с календарём — довольно сложный код, использующий таймзоны и календари, относительно.
Да, кстати, в качестве ликбеза. Провайдер времени currentTimeMillis() — как раз интринзик, ВНЕЗАПНО!
P>>>его сам компилятор заинлайнит, вам не надо заботиться P>>>Инлайнить самому нужно для оптимизации, изменения дизайна, итд P>·>Противоречивые параграфы детектед. P>Я вижу здесь другой кейс — вы так торопитесь, что обгоняете сами себя. Инлайнить методы нужно для оптимизации или изменения дизайна. В случае c Length инлайн в целях оптимизации выполнит компилятор.
Для оптимизации инлайнят только в в случаях если компилятор слишком тупой (что практически никогда) или случай ужасно нетривиальный (тогда и IDE не справится).
P>·>Угу. С нулевым изменением дизайна. P>Ну да — добавить компонент с конфигом и сайд-эффектом это стало вдруг нулевым изменением дизайна
Ну да. И? Как nextFriday() был, так и остался. Зачем менять дизайн?
P>>>Запрос из кеша это изменение того самого дизайна. P>·>Твоего дизайна — да, моего — нет. P>Т.е. вы не в курсе, что значение функции закешировать гораздо проще, чем мастырить LRU кеш? Более того — такую кеширующую функцию еще и протестировать проще.
Ты издеваешься что-ли? Мы тут конкретный пример рассматриваем. Давай расскажи, как ты nextFriday(now) закешируешь "гораздо проще", где now — это текущее время.
P>>>Кеш, как минимум, надо инвалидировать, может и ттл прикрутить, а может и следить, что именно кешировать, а что — нет. Для этого вам нужно будет добавить кеш, настройки к нему, да еще связать правильно и тестами покрыть — что в ваш компонент приходит тот самый кеш а не просто какой то. P>·>Кеш — это отдельный компонент. P>Вот-вот. Отдельный компонент. В том то и проблема. И вам все это придется мастырить и протаскивать. Только всегда "где то там"
Что всё? _Добавить_ новую логику в CalendarLogic, внутри него использовать этот кеш, и собственно всё. В чём _изменение_ дизайна-то? Можно обойтись одним новым приватным полем.
P>>>Смотрите выше — вы сами, безо всякой моей подсказки предложили "может кешировать одно и то же значение в течение недели и обновлять его по таймеру, например" что есть тот самый кеш. P>·>Именно. А вот ты даже это не смог предложить какого-либо работающего решения, кешировать с ключом по now — это полный бред. И вот тебе придётся для введения кеша в твоём "более гибком коде" перелопатить весь дизайн и тесты, т.к. связывание now и nextFriday у тебя происходит во многих местах и везде надо будет проталкивать этот кеш и его настройки. P>Ровно так же как и у вас, только дизайн не надо перелопачивать.
У меня как-то так. Было
Т.е. меняется внутренняя реализация компонента и, скорее всего, надо будет заинжектить таймер внутрь CalendarLogic — дополнительный парам в конструктор.
Теперь показывай свой код, если потянешь.
P>>>Хотите гибкости — в тесты нужно выносить самый минимум. Как правило это параметры и возвращаемое значение. Вы почему то в этот минимум добавляете все зависимости с их собственным апи. P>·>Я не вижу в этом проблему. Ничего не бетонируется. Всё так же рефакторится. Ещё раз напоминаю, что класс с зависимостями это технически та же функция "параметры и возвращаемое значение", но с ЧПФ. Просто некоторые параметры идут через первое "применение": f(p1, p2) <=> new F(p1).apply(p2). P>Вы пока что инлайн обеспечить не можете, а замахиваетесь на чтото большее
Бла-бла-бла.
P>>>Вы регулярно приводите примеры лишних строчек, но почему то вам кажется, что у меня кода больше. Код системы это не только функциональная часть, но тестирующая. P>·>Я не привожу лишние строчки. Я привожу полный код, а ты весь код просто не показываешь. P>И где ваш код nextFriday и всех вариантов инжекции для разных кейсов — клиенское время, серверное, текущие, такое, сякое ?
А что там показывать? Вроде всё очевидно:
var clientCalendarLogic = new CalendarLogic(timeProviders.clientClock());
var serverCalendarLogic = new CalendarLogic(timeProviders.systemClock());
var eventCalendarLogic = new CalendarLogic(timeProviders.eventTimestampClock());
Всё ещё про ЧПФ не догоняешь?
P>>>Я освоил тот метод именно в нулевых, задолго до той самой статьи. С тех пор много чего эволюционировало. Потому я и пишу вам, что вы продолжаете вещать из нулевых, как будто с тех пор ничего и не было. P>·>Теперь определись — толи ты сейчас привираешь, что это тебе всё давно знакомо, толи ты просто словоблудил, выразив непонимание что я имею в виду под wiring. P>wiring и есть связывание. Код связывания в dependency injection, который вы называете wiring, и код связывания в контроллере — выполняют одно и то же — интеграцию. Разница отражает подходы к дизайну. И то и другое wiring, и то и другое связывание. И задача решается одна и та же. Только свойства решения разные.
Интересная терминология. Покажи хоть одну статью, где код в методах контроллеров называется wiring.
P>·>За деревьями леса не видишь... ты код-то погляди, то же самое частичное применение функций для эмуляции "классов". P>Похоже, что пример для Буравчика вы не поняли
Код я понял. Я не понял зачем такой код и что именно он улучшил, я предполагаю этого никто тут не понял. А про ЧПФ и классы было в обсуждаемой тут в начале топика статье.
P>>>В 00х Фаулер сотоварищи топили за тот подход, за который вы топите 20 лет спустя. P>·>Потому что тогда он показывал это на языках 00х, а сейчас ровно то же самое показывает на typescript. Та же ж, вид в профиль. Неужели ты до сих пор не въехал в ЧПФ?! P>То же, да не то же. Посмотрите где связывание у него, а где связывание у вас.
Мде... Ну ладно, помогу тебе разобраться коли ты сам не осилил.
Связывание у него модуле "the code that assembles my modules": restaurantRatings/index.ts…export const init, вот погляди на "устаревший" composition root. Как у меня. А контроллер у него по сути класс "createTopRatedHandler = (dependencies: Dependencies)" — это конструктор, в который инжектятся депенденси. Как у меня. Экземпляр контроллера там создаётся в строках 45-47, а чуть выше создаются его зависимости, db там, пул какой-то, етс. Практически один-к-одному как и мой пример выше
, у меня правда упрощённо, т.к. не работающий пример, а код набитый на форуме.
В общем та же самая классика 00х. Одно меня не устраивает, что у него в прод-коде грязь в виде "replaceFactoriesForTest". Не очень понял зачем именно так. Впрочем, это скорее всего объясняется тем, что я использую mockito-фреймворк, и он позволеяет весь этот хлам не делать, а у Фаулера просто код, без тестовых фреймоврков
P>>>С тех пор ничего не изменилось. P>·>Именно. Кода как не было, так и нет. Так как если появится код, так сразу станет очевидно, что лишних строчек у тебя гораздо больше, да ещё и фреймворки какие-то требуются. P>Фремворки и у вас есть, только из 00х. Вы уже признавались в этом.
Где именно?
P>>>У вас там написание кода начинается с деплоя на прод? P>·>Это где я такое написал? Как вообще такое возможно?! P>Вы же рассказываете, что проблему увидите на старте приложения. Прод у вас получает конфиг прода и другие вещи прода. Вот на старте и узнаете, что у вас не так пошло. А надо зафейлить тест, когда вы только-только накидали первую версию контроллера — в этот момент у вас буквально приложения еще нет
Чтобы зафейлить тест, код надо стартовать. Не всё приложение, ясен пень, зачем для теста конфиг прода, ты в своём уме?! Конфиг прода девам даже не доступен бывает, т.к. там могут быть секреты.
P>>>А надо во время написания кода которые идут вперемешку с прогном быстрых тестов, и это все за день-неделю-месяц до самого деплоя! P>·>Ну чтобы какой-либо тест прогнать — надо стартовать некий код... не? Вот до выполнения первого попавшегося @Test-метода оно и грохнется, где-нибудь в @SetUp. P>Вы тестируете не @Setup а иерархию вызовов dependency injection, которая у вас появляется, появляется... на старте приложения. И фейлы ждете с этого момента. А надо гораздо раньше.
Это ты что-то не так понял. Я такое никогда не говорил.
P>Смотрите тот вариант что у Фаулера — его окончательный дизайн позволяет вам фейлить многие вещи когда ничего другого вообще нет — его связывание в одном месте и покрывается тестами P>У вас аналог этого связывания будет а хрен его знает когда
Ну так у него там вовсю моки (стабы) используются. С поправкой, что это ts с недоразвитыми мок-либами. У него
var repo = mock(Repo.class);
var vancouverRestaurants = List.of(
new Restaurant("cafegloucesterid", "Cafe Gloucester"),
new Restaurant("baravignonid", "Bar Avignon"),
);
when(repo.getTopRestaurants("vancouverbc")).thenReturn(vancouverRestaurants);
var ratingsHandler new TopRatedHandler(repo);
Теперь чуешь о чём я говорю что кода меньше?
P>·>Не знаю где ты это увидел, имеется в виду мы тестируем прод окружение пытаясь деплоить на прод. Вы, кстати, тестируете уже после деплоя на прод. P>Не после — а задолго до. После деплоя прогон тестов это расширенный мониторинг — проверяется выполнимость сценариев пользователя, а не просто healthcheck который вы предлагаете P>Почему может поломаться — потому, что приложение работает с кучей внешних зависимостей, которые мы не контролируем.
И не можете проверить что зависимости — operational? Пинг послать?
А для проверок consistency — нужно версирование и проверка совместимости версий. Гонять тесты — не _нужно_. Хотя, конечно, в случае хоумпейджей — можно.
P>·>Напомню вопрос: А как ты будешь такой и-тест писать, если у тебя будет Time.Now? Что ассертить-то будешь? Как отличать два разных вызова Time.Now — клиентский от серверного? P>·>Вот пришло тебе в ответе в неком поле значение "2024-01-23". как ты в и-тесте отличишь, что это вычислилось от вызова Time.Now на серверной стороне, а не на клиентской? P>Смотрите пример про Колю Петрова, там ответ на этот вопрос
Смотрю, там нет ответа на этот вопрос. Код покажи.
P>>>Нам нужны именно фичи, кейсы, сценарии. В строчках кода это не измеряется. Смотрите, как это делают QA. P>·>Как ты убедишься, что некая фича покрыта тестами? Или что все фичи и разные corner cases описаны в бизнес-требованиях? Покрытие хоть и ничего не гарантирует, но часто помогает обнаружить пробелы. P>Я ж говорю — смотрите, как это у QA делается.
Может у вас идеальные QA, у нас они бегают к девам, спрашивая что тестировать. А часто вообще QA как отдельной роли нет. Как это делается у ваших QA?
P>>>- зарезервировать столик на трех человек на имя Коля Петров на следующую пятницу 21.00 P>·>Этот пример совершенно никак не отностися к обсуждаемому нами методу nextFriday. Или у тебя в твоём дизайне будет семь методов nextMonday...nextSunday? P>Примером по Колю Петрова вам показываю, что такое интеграционные тесты. Вы же в них хотите проверять "а должно вот там вызываться!"
В том примере неясно как отличить откуда берётся информация. Что тест проходит и работает не означает, что функциональность работает правильно.
P>>>Остальных — от 1000 до 5000 и они занимают 99% времени. P>·>Ну вот и говорю хоупейдж. По acc-тестам (селениум, сеть, многопоток, полный фарш) у нас было на порядок больше, выполнялось за 20 минут, правда на небольшом кластере. P>Подозреваю, вы их просто подробили, "проверим, что время вон то"
Тесты вида: "клиент A через FIX: buy 100@1.23", "клиент B через web ui: sell 20@1.21", "assert: trade done B->A 20@1.22", "assert: dropcopy for trade report", "ждём до конца месяца", "assert: A получил statement по почте и там есть этот trade с ожидаемой датой" и т.п.
P>>>Не нравится метапрограммирование — можете придумать что угодно. P>·>И что? Причём тут тесты-то? P>Тесты где сравнивается выхлоп из базы не решают проблемы data complexity.
А я где-то заявлял обратное? И расскажи заодно какие же _тесты_ _решают_ проблемы data complexity [willy-wonka-meme.gif].
P>Отсюда ясно — что нужно добавлять нечто большее.
Причём тут тесты-то?
P>>>Вы там ногой читаете? Запрос не человек, сказать не может. А вот ревьюер может сказать "у нас такого индекса нет, тут будет фуллскан по таблице из десятков миллионов записей с выполнением регекспа и время работы на проде надо ждать десятки минут" P>·>Или у вас неимоверно крутые ревьюверы, помнят наизусть сотни таблиц и тысячи индексов, или у вас хоумпейдж. Не все могут себе такое позволить. P>Зато сразу ясно, где именно хоум пейдж, и почему ваши тесты работают ажно 20 минут.
И что тебе ясно? Тесты работают столько, потому что надо следить за временем работы тестов и стараться его минимизировать.
P>>>Это ж вы сунете тесты туда, где они не работают. P>·>Это ты словоблудием занимаешься. Мы обсуждаем именно тесты, а ты тут в сторону доказательного программирования и мета уходишь. P>Я вам о том, какие гарантии можно получить вашими тестами, а какие — нельзя. P>В вашем случае вы ничего не гарантируете на тех данных, что у вас нет.
Причём тут _мои_ тесты??! Твои _тесты_ могут гарантировать что-то большее? С какого такого бодуна?
P>>>Как гарантировать — см пример номер 100500 чуть выше P>·>Где чуть выше? P>Я вам одно и то же пишу второй год.
Ну т.е. показать нечего.
P>>>У вас данных нет. Или вы щас скажете, что у вас уже есть все данные всех юзеров на будущее тысячелетие? P>·>И как тобой предложенное "in: [fn1]" решает эту проблему? Или ты опять в сторону разговор уводишь? P>Примерно так же, как assert.notnull(parameter) в начале метода или return assert.notEmpty(value) в конце
Не понял. Откуда у тебя возьмутся все данные всех юзеров на будущее тысячелетие из assert.notnull?
P>>>Наоборот. P>·>Ваша цитата: Ага, тесты "как написано" Вам придется написать много больше, чем один тест — как минимум, пространство входов более-менее покрыть. Моками вы вспотеете это покрывать. P>Ну ок, значит ничья в этом вопросе
Что мои тесты — тесты "как написано" — это твоя личная фантазия, основанная на твоём непонимании что тебе пишут. А вот что твои тесты — тесты "как написано", это видно по куску кода с pattern, который ты привёл.
P>>>Зачем вам собеседник, если у вас отличный дуэт с вашей телепатией? P>·>В каком месте тут телепатия? Билд занимающий часы — это твои слова. И тесты в проде — тоже. P>Вы всё знаете — и сложность проекта, и объемы кода, и начинку тестов, и частоту тех или иных тестов. Просто удивительно, как тонкая телепатия.
Так ты собственно всё рассказал. Перечитай что ты писал.
P>>>Такой тест гарантирует, что всё множество данных будет проходить именно через эту функцию. P>·>Не гарантирует. В коде может быть написано "if(thursdayAfterRain())return {...in: [fn42]...}" и тест это не может обнаружить. Ещё раз — тесты ничего не могут гарантировать. P>А я и говорю в который раз, что основное совсем не в тестах. В них мы всего лишь фиксируем некоторые свойства решения, что бы досталось потомкам в неискаженном виде.
А где у вас основное? И почему _основное_ не покрыто тестами??!
P>>>Я вам привел пример про Колю Петрова. Надеюсь, справитесь P>·>Опять врёшь. Это не код. P>Почему ж не код? Это в кукумбер переводится практически один к одному.
Ну вот давай значит клей показывай.
P>·>Я это и сказал. Если тут всё равно серверное время, то да, не функциональное, и тесты не пострадают. Тесты сломаются и должны сломаться если ты заменишь источник серверного времени на источник клиентского времени. P>А вы точно интеграционные пишите? Чтото мне кажется, вы пишете высокоуровневые юнит-тесты.
Не буду о терминологии спорить. Не так уж важно как какие тесты классифицируются.
P>·>Я не понимаю какое отношение метапрограммирование имеет к бизнес-требованиям и к тому как писать тесты. P>Такое же, как ваши классы, методы, dependency injection итд.
Всё смешалось, люди, кони.
P>>>Тесты дают гарантию, что пайплайн устроен нужным мне образом. А свойства результата, следовательно, будут определяться свойствами пайплайна. Тогда вам нужно сосредоточиться на выявлении этих свойств, а не писать одно и то же третий месяц кряду. P>·>Тесты не могут давать гарантию. P> Тесты именно ради гарантий и пишутся. Только чудес от них ждать не надо.
Гарантий чего? Они могут лишь проверить, что тестируемый сценарий работает. Что как где устроено — никаких гарантий.
P>>>Смотрите пример про Колю Петрова P>·>Не нужен мне пример. Мне нужен код. P>Бывает и хуже.
Как всегда бла-бла-бла, без конкретики.
P>>>Детали реализации нужно покрывать тестами, что бы первый залётный дятел не разрушил всю цивилизацию: P>>>- оптимизации P>·>Это перф-тесты. P>Это слишком долго. Фейлы перформанса в большинстве случаев можно обнаруживать прямо во время юнит-тестирования.
Наивный юноша.
P>>>- трудноуловимые баги P>>>- секюрити P>>>- всякие другие -ility P>>>- любой сложный код, где data complexity превышает ваше капасити P>·>Это "за всё хорошее, против всего плохого". А секьюрити — это бизнес-требование и обязано быть покрыто фукнциональными тестами. P>Важно, что бы явные фейлы обнаруживались гораздо раньше старта после деплоя. Тогда будет время подумать, как получить максимум сведений из самого деплоя.
После деплоя обнаруживаются фейлы в окружении, куда задеплоилось. Неясно как их обнаружить раньше. Это невозможно.
P>·>"Метапрограммирование тестируется" — зачем? P>Тестировать нужно вообще всё, что вам взбредет в голову спроектировать. Тестируюя только крупные куски вы получаете дырявое покрытие
Мде.
P>>>Вы не просто утверждаете это, а идете дальше — утверждаете, что тесты прода это признак наличия багов, не той квалификации и тд. P>·>Признак более позднего обнаружения багов. P>Они показывают, выполнимы ли сценарии под нагрузкой(при изменениях сети, топологии, итд) или нет.
Для этого есть более адекватные подходы.
P>·>На это и придумали healthchecks (а конкретно liveness probe), проверка, что сервис — operational, явно проверяет себя и свои зависимости, что может отрабатывать трафик без фейлов ещё до того как пошли реальные запросы. P>Каким чудом ваш пробы дают ответ, выполнимы или все ключевые сценарии при максимальной нагрузке? Сценарий — это та часть, про Колю Петрова, которая вам непонятна
А ты опять контекст потерял? Напомню: "Сертификат может обновиться не у вашего приложения, а у какого нибудь из внешних сервисов". Причём тут нагрузки? Причём тут Коля? Ты меня утомляешь. В следующий раз прежде чем написать очередную чушь, перечитай конткест. Мне уже порядком надоело твоё словоблудие.
P>>>Какой процесс вас застрахует от фейла на другой стороне которую вы не контролируте? P>·>Большая тема. Начни отсюда: https://en.wikipedia.org/wiki/High_availability P>Выполнимость сценариев это consistensy всех функций сервиса, а вовсе не high availability, как вы думаете.
КОНТЕКСТ!
P>·>Кодогенерация сама по себе медленный цикл разаработки не даёт. Любой кодогенератор работает от силы порядка минут. P>Именно что сама по себе. Вам надо таскать тот манифест, сихнронизироваться с ним, следить, что бы все имели ту самую версию, тот самый генератор, итд итд P>Во многих случаях этого можно избежать
Не осилили, ясно.
P>>>У нас кейс "переписать апи на rust" был 0 раз за 10 лет. Смена технологий от балды — тоже 0 раз. А у вас иначе, каждый месяц всё с нуля на rust переписываете? P>·>C++, kotlin, java, groovy, scala (может ещё что забыл)... И таки да, спеки всё-таки есть в виде FIX или хотя бы avro/protobuf. А когда копадаются другие команды/внешине сервисы с подходом "нагенерим из аннотаций" — вечная головная боль интегрироваться с такими. P>И ежу понятно — вам максимум с собой легко интегрироваться
Ну других по себе не судите, а мне вот сегодня опять приходится ворошить FIX спеку от Bloomberg, 891 страниц в PDF. Не, я работаю не там.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>Вы притягивает юзера к вашим тестам. Юзера можно притянуть только к функциональным тестам. Во всех остальных он не фигурирует. ·>Ну вроде о функциональных тестах тут и говорили, об проверках ожиданий пользователей. Ты опять как уж на сковородке по кочкам прыгаешь. Контекст не теряй, ок?
Вы лучше сами отмотайте, да посмотрите. Я вам про функции приложения, а вы мне про функции в джаве.
P>>Я вам подсветил, что бы полегче прочесть было ·>Ну если для тебя инлайн одной функции — это изменение дизайна приложения, то это твоё очень странное понимание слова "дизайн".
Это самое минимальное изменение дизайна, которое только может быть. Вы чего то заинлайнили — у кода появились новые свойства, например, возможность оптимизации
P>>1 получению размера внутреннего массива символов что есть неизменная величина P>>2 гарантии иммутабельности соответсвующей ссылки. Т.е. никакой modify(str) не сможет легально изменить длину строки str P>>3 джит компилятор в курсе 1 и 2 и инлайнит метод length минуя все слои абстракции, включая сам массив и его свойство
Похоже, тут вы торопились, и прочитать не успели
P>>Если вы запилите свой класс строк, нарушив или 1, или 2, компилятор ничего вам не сможет заинлайнить. ·>Бред, джит великолепно инлайнит length(), например, и у StringBuffer или даже LinkedList, и практически каждый getter/setter. И даже умеет инлайнить виртуальные функции.
Если вы вызовете str.length() сотню раз, джит сделает обращение к памяти ровно единожды — а дальше просто будет использовать значение как константу.
С мутабельной ссылкй или внутренним контейнером переменной длины так поступать нельзя
Похоже, что вы слишком торопитесь чего то настрочить
·>У тебя опять каша в голове. Напомню конткест: не провайдер времени, а nextFriday() вроде как ты собирался инлайнить. ·>Но вряд ли это всё заинлайнится, т.к. friday и работа с календарём — довольно сложный код, использующий таймзоны и календари, относительно.
У меня много чего инлайнится, и это даёт ощутимые бенефиты.
P>>Я вижу здесь другой кейс — вы так торопитесь, что обгоняете сами себя. Инлайнить методы нужно для оптимизации или изменения дизайна. В случае c Length инлайн в целях оптимизации выполнит компилятор. ·>Для оптимизации инлайнят только в в случаях если компилятор слишком тупой (что практически никогда) или случай ужасно нетривиальный (тогда и IDE не справится).
Конечная цель — оптимизация. Её можно достигнуть через изменение дизайна, например — нужные данные расположить рядом, убрать лишнее из hot path итд.
P>>Ну да — добавить компонент с конфигом и сайд-эффектом это стало вдруг нулевым изменением дизайна ·>Ну да. И? Как nextFriday() был, так и остался. Зачем менять дизайн?
Добавление такого компонента и есть изменение дизайна. Например, у вас теперь новый класс ошибок появился, которого раньше не было.
P>>Т.е. вы не в курсе, что значение функции закешировать гораздо проще, чем мастырить LRU кеш? Более того — такую кеширующую функцию еще и протестировать проще. ·>Ты издеваешься что-ли? Мы тут конкретный пример рассматриваем. Давай расскажи, как ты nextFriday(now) закешируешь "гораздо проще", где now — это текущее время.
Вы что, не в курсе мемоизации? Разница только в том, где связывание — или "где то там" или "прямо здесь".
P>>Вот-вот. Отдельный компонент. В том то и проблема. И вам все это придется мастырить и протаскивать. Только всегда "где то там" ·>Что всё? _Добавить_ новую логику в CalendarLogic, внутри него использовать этот кеш, и собственно всё. В чём _изменение_ дизайна-то? Можно обойтись одним новым приватным полем.
Вы описали это изменение дизайна. у вас с вашим кешем как минимум новые свойства у решения появились.
т проталкивать этот кеш и его настройки. P>>Ровно так же как и у вас, только дизайн не надо перелопачивать. ·>У меня как-то так. Было >
·>Т.е. меняется внутренняя реализация компонента и, скорее всего, надо будет заинжектить таймер внутрь CalendarLogic — дополнительный парам в конструктор.
Итого
1 — меняется внутренний дизайн компонента
2 — инжектится таймер
3 — теперь вам надо пройти по всем тестам где это аффектается и всунуть все что надо ради timer.schedule
В моем случае тесты nextFriday остаются неизменными, потому, что нет причины для изменения — кеш будет добавлен снаружи
P>>И где ваш код nextFriday и всех вариантов инжекции для разных кейсов — клиенское время, серверное, текущие, такое, сякое ? ·>А что там показывать? Вроде всё очевидно: ·>
·>var clientCalendarLogic = new CalendarLogic(timeProviders.clientClock());
·>var serverCalendarLogic = new CalendarLogic(timeProviders.systemClock());
·>var eventCalendarLogic = new CalendarLogic(timeProviders.eventTimestampClock());
·>
Вот видите — у вас ровно та же проблема, можно слегка ошибиться и clientClock уйдет в serverLogic.
P>>wiring и есть связывание. Код связывания в dependency injection, который вы называете wiring, и код связывания в контроллере — выполняют одно и то же — интеграцию. Разница отражает подходы к дизайну. И то и другое wiring, и то и другое связывание. И задача решается одна и та же. Только свойства решения разные. ·>Интересная терминология. Покажи хоть одну статью, где код в методах контроллеров называется wiring.
Если вы вызываете какую то функцию, это уже есть интеграция — то самое связывание. В моем случае я помещаю связывания в контроллер, часть — в юз кейс, см у фаулера 'src/restaurantRatings/topRated.ts'
P>>Похоже, что пример для Буравчика вы не поняли ·>Код я понял. Я не понял зачем такой код и что именно он улучшил, я предполагаю этого никто тут не понял. А про ЧПФ и классы было в обсуждаемой тут в начале топика статье.
Вводится изоляция — вместо низкоуровневой зависимости на репозиторий появляется абстракция. Ровно то же делает фаулер, 'src/restaurantRatings/topRated.ts'
P>>Вы же рассказываете, что проблему увидите на старте приложения. Прод у вас получает конфиг прода и другие вещи прода. Вот на старте и узнаете, что у вас не так пошло. А надо зафейлить тест, когда вы только-только накидали первую версию контроллера — в этот момент у вас буквально приложения еще нет ·>Чтобы зафейлить тест, код надо стартовать. Не всё приложение, ясен пень, зачем для теста конфиг прода, ты в своём уме?!
Если зафейлить можно в юнит-тестах, то это всё равно быстрее вашего случая.
·>У меня аналогом будет ·>
·>var repo = mock(Repo.class);
·>var vancouverRestaurants = List.of(
·> new Restaurant("cafegloucesterid", "Cafe Gloucester"),
·> new Restaurant("baravignonid", "Bar Avignon"),
·>);
·>when(repo.getTopRestaurants("vancouverbc")).thenReturn(vancouverRestaurants);
·>var ratingsHandler new TopRatedHandler(repo);
·>
·>Теперь чуешь о чём я говорю что кода меньше?
Я вижу, что вы сравниваете код с фремворков на моках с кодом без такого фремворка. Вот, убрал лишнее, сравнивайте
·>
Похоже, вы не вдупляете ни пример Фаулера, ни мой пример для Буравчика.
·>И не можете проверить что зависимости — operational? Пинг послать? ·>А для проверок consistency — нужно версирование и проверка совместимости версий. Гонять тесты — не _нужно_. Хотя, конечно, в случае хоумпейджей — можно.
Как ваше версионирование расскажет, что под нагрузкой у пользователя оплата не проходит с сообщением "карточка не добавлена" а список карточек вдруг оказывается пуст?
Подробнее, пожалуйста, как такую проблему решит версионирование. Для простоты условимся, что у вас нет внешних зависимостей.
P>>Смотрите пример про Колю Петрова, там ответ на этот вопрос ·>Смотрю, там нет ответа на этот вопрос. Код покажи.
Вы не знаете, что такое кукумбер? Забавно
P>>Я ж говорю — смотрите, как это у QA делается. ·>Может у вас идеальные QA, у нас они бегают к девам, спрашивая что тестировать. А часто вообще QA как отдельной роли нет. Как это делается у ваших QA?
traceability matrix
P>>Примером по Колю Петрова вам показываю, что такое интеграционные тесты. Вы же в них хотите проверять "а должно вот там вызываться!" ·>В том примере неясно как отличить откуда берётся информация. Что тест проходит и работает не означает, что функциональность работает правильно.
Вот-вот.
P>>Тесты где сравнивается выхлоп из базы не решают проблемы data complexity. ·>А я где-то заявлял обратное? И расскажи заодно какие же _тесты_ _решают_ проблемы data complexity [willy-wonka-meme.gif].
Я же вам много раз сказал. Вы утверждаете, что где то показали здесь решение, и несколько раз сослались на свои примитивные тесты. Отсюда следует, что вы настаиваете на тестах.
P>>Отсюда ясно — что нужно добавлять нечто большее. ·>Причём тут тесты-то?
Вы же который раз ссылаетесь на ваши примитивные тесты именно в контексте data complexity
P>>Зато сразу ясно, где именно хоум пейдж, и почему ваши тесты работают ажно 20 минут. ·>И что тебе ясно? Тесты работают столько, потому что надо следить за временем работы тестов и стараться его минимизировать.
А посоны то и не знают... @
P>>В вашем случае вы ничего не гарантируете на тех данных, что у вас нет. ·>Причём тут _мои_ тесты??! Твои _тесты_ могут гарантировать что-то большее? С какого такого бодуна?
У меня два разных набора тестов, каждый из который решает свою часть проблемы. У вас — один.
P>>Примерно так же, как assert.notnull(parameter) в начале метода или return assert.notEmpty(value) в конце ·>Не понял. Откуда у тебя возьмутся все данные всех юзеров на будущее тысячелетие из assert.notnull?
Этот assert сработает для всех вызовов функции, сколько бы вы туда ни пихали, хоть тысячу лет кряду, хоть миллион.
Вы, похоже, не в курсе, как инварианты, пред-, и пост-условия используются.
P>>·>В каком месте тут телепатия? Билд занимающий часы — это твои слова. И тесты в проде — тоже. P>>Вы всё знаете — и сложность проекта, и объемы кода, и начинку тестов, и частоту тех или иных тестов. Просто удивительно, как тонкая телепатия. ·>Так ты собственно всё рассказал. Перечитай что ты писал.
Я писал что много юнит-тестов, но не писал сколько из них чекают запросы к бд. А вы понаделывали выводов без этой информации — телепатия в чистом виде.
P>>А я и говорю в который раз, что основное совсем не в тестах. В них мы всего лишь фиксируем некоторые свойства решения, что бы досталось потомкам в неискаженном виде. ·>А где у вас основное? И почему _основное_ не покрыто тестами??!
Потому, что основная работа по обеспечению качества это совсем не тесты. Тесты это исключительно вспомогательный инструмент — фиксируем некоторые ожидания, свойства решения.
Но само решение нужно иметь до того, как начнете покрывать его тестами
Например — вы можете заложиться на стабильную структуру пайплайна. В этом случае и тестами надо обеспечить именно это — стабильность пайплайна.
А можете на конкретные наборы данных — тогда вам нужно чудовищное количество данных.
А можно взять и то, и другое, добавить код-ревью, ассерты, логирование и получите куда больше, чем одними вашими тестами на провеку выхлопа из базы
P>>Почему ж не код? Это в кукумбер переводит ися практически один к одному. ·>Ну вот давай значит клей показывай.
Какой еще клей?
P>>·>Я это и сказал. Если тут всё равно серверное время, то да, не функциональное, и тесты не пострадают. Тесты сломаются и должны сломаться если ты заменишь источник серверного времени на источник клиентского времени. P>>А вы точно интеграционные пишите? Чтото мне кажется, вы пишете высокоуровневые юнит-тесты. ·>Не буду о терминологии спорить. Не так уж важно как какие тесты классифицируются.
Очень даже важно — если вы в тестах проверяете "вон тот источник не используется" то это к интеграционным имеет крайне слабое отношение
P>>Такое же, как ваши классы, методы, dependency injection итд. ·>Всё смешалось, люди, кони.
Что вам непонятно? Одна техника в программировании и другоя техника в программировании, обеими можно решить задачу.
P>>·>Тесты не могут давать гарантию. P>> Тесты именно ради гарантий и пишутся. Только чудес от них ждать не надо. ·>Гарантий чего? Они могут лишь проверить, что тестируемый сценарий работает. Что как где устроено — никаких гарантий.
Вы сейчас плавно отказываетесь от своих слов "Тесты не могут давать гарантию"
P>>Это слишком долго. Фейлы перформанса в большинстве случаев можно обнаруживать прямо во время юнит-тестирования. ·>Наивный юноша.
Нисколько. Вероятно, вы не догадываетесь, что где то может быть другая область, с другой спецификой.
P>>Важно, что бы явные фейлы обнаруживались гораздо раньше старта после деплоя. Тогда будет время подумать, как получить максимум сведений из самого деплоя. ·>После деплоя обнаруживаются фейлы в окружении, куда задеплоилось. Неясно как их обнаружить раньше. Это невозможно.
Деплой дает вам новое состояние системы, которого раньше не было.
P>>Тестировать нужно вообще всё, что вам взбредет в голову спроектировать. Тестируюя только крупные куски вы получаете дырявое покрытие ·>Мде.
Именно. Вопрос в том, умеете ли вы сделать это дешовым в тестах или нет.
P>>Они показывают, выполнимы ли сценарии под нагрузкой(при изменениях сети, топологии, итд) или нет. ·>Для этого есть более адекватные подходы.
Вы пока ни одного ни привели.
P>>Каким чудом ваш пробы дают ответ, выполнимы или все ключевые сценарии при максимальной нагрузке? Сценарий — это та часть, про Колю Петрова, которая вам непонятна ·>А ты опять контекст потерял? Напомню: "Сертификат может обновиться не у вашего приложения, а у какого нибудь из внешних сервисов". Причём тут нагрузки? Причём тут Коля?
Проблема с сертификатом может повалить выполнение сценариев. Нагрузка может точно так же повалить выполнение сценария. А ценарий один — см Коля Петров.
P>>И ежу понятно — вам максимум с собой легко интегрироваться ·>Ну других по себе не судите, а мне вот сегодня опять приходится ворошить FIX спеку от Bloomberg, 891 страниц в PDF. Не, я работаю не там.
Как думаете, сколько % от общей массы программистов заняты тем же?
Здравствуйте, Pauel, Вы писали:
P>>>Вы притягивает юзера к вашим тестам. Юзера можно притянуть только к функциональным тестам. Во всех остальных он не фигурирует. P>·>Ну вроде о функциональных тестах тут и говорили, об проверках ожиданий пользователей. Ты опять как уж на сковородке по кочкам прыгаешь. Контекст не теряй, ок? P>Вы лучше сами отмотайте, да посмотрите. Я вам про функции приложения, а вы мне про функции в джаве.
У тебя просто как всегда память отшибло, читаем: не будет ни одной функции в джаве "удалить пользователя". Как оказалось, таки скорее всего будет именно функция в джаве для реализации функции приложения "удаление пользователя". И функцию в джаве можно покрыть тестами, чтобы проверять, что функция приложения выполняется ожидаемым способом.
P>>>Я вам подсветил, что бы полегче прочесть было P>·>Ну если для тебя инлайн одной функции — это изменение дизайна приложения, то это твоё очень странное понимание слова "дизайн". P>Это самое минимальное изменение дизайна, которое только может быть. Вы чего то заинлайнили — у кода появились новые свойства, например, возможность оптимизации
Ок. У тебя очень странное понимание слова. Бессмысленно это обсуждать.
P>>>1 получению размера внутреннего массива символов что есть неизменная величина P>>>2 гарантии иммутабельности соответсвующей ссылки. Т.е. никакой modify(str) не сможет легально изменить длину строки str P>>>3 джит компилятор в курсе 1 и 2 и инлайнит метод length минуя все слои абстракции, включая сам массив и его свойство P>Похоже, тут вы торопились, и прочитать не успели
Для инлайна 1 и 2 не нужно. Ещё раз, инлайнт это не про константы, а про стеки вызовов. Вместо call метода , который читает значение приватного поля из памяти, потом делает ret значения через регистры — у тебя по месту вызова будет прямое чтение из участка памяти (часто недоступного напрямую из исходного кода).
P>>>Если вы запилите свой класс строк, нарушив или 1, или 2, компилятор ничего вам не сможет заинлайнить. P>·>Бред, джит великолепно инлайнит length(), например, и у StringBuffer или даже LinkedList, и практически каждый getter/setter. И даже умеет инлайнить виртуальные функции. P>Если вы вызовете str.length() сотню раз, джит сделает обращение к памяти ровно единожды — а дальше просто будет использовать значение как константу.
Константу?! Ты наверное имел в виду загрузку значения в регистр. Ладно хоть про интринзики перестал бред нести...
P>С мутабельной ссылкй или внутренним контейнером переменной длины так поступать нельзя
Можно. если джит видит что внутри func(mutableStr) ничего не меняется, то может и закешировать длину в регистре.
P>Похоже, что вы слишком торопитесь чего то настрочить
Удивляюсь потоку чуши, не знаю с чего начать.
P>·>У тебя опять каша в голове. Напомню конткест: не провайдер времени, а nextFriday() вроде как ты собирался инлайнить. P>·>Но вряд ли это всё заинлайнится, т.к. friday и работа с календарём — довольно сложный код, использующий таймзоны и календари, относительно. P>У меня много чего инлайнится, и это даёт ощутимые бенефиты.
Опять общие слова ни о чём как "опровержение" к конкретному рассматриваемому примеру.
P>>>Я вижу здесь другой кейс — вы так торопитесь, что обгоняете сами себя. Инлайнить методы нужно для оптимизации или изменения дизайна. В случае c Length инлайн в целях оптимизации выполнит компилятор. P>·>Для оптимизации инлайнят только в в случаях если компилятор слишком тупой (что практически никогда) или случай ужасно нетривиальный (тогда и IDE не справится). P>Конечная цель — оптимизация. Её можно достигнуть через изменение дизайна, например — нужные данные расположить рядом, убрать лишнее из hot path итд.
Угу. И инлайн тут как средство оптимизации — на сотом месте, где-то после сдувания пыли с вентилятора cpu.
P>>>Ну да — добавить компонент с конфигом и сайд-эффектом это стало вдруг нулевым изменением дизайна P>·>Ну да. И? Как nextFriday() был, так и остался. Зачем менять дизайн? P>Добавление такого компонента и есть изменение дизайна. Например, у вас теперь новый класс ошибок появился, которого раньше не было.
Ок. Любое изменение кода — изменение дизайна. Не поспоришь.
P>>>Т.е. вы не в курсе, что значение функции закешировать гораздо проще, чем мастырить LRU кеш? Более того — такую кеширующую функцию еще и протестировать проще. P>·>Ты издеваешься что-ли? Мы тут конкретный пример рассматриваем. Давай расскажи, как ты nextFriday(now) закешируешь "гораздо проще", где now — это текущее время. P>Вы что, не в курсе мемоизации? Разница только в том, где связывание — или "где то там" или "прямо здесь".
В курсе. Ты опять вопрос проигнорировал. Давай расскажи, как ты nextFriday(now) закешируешь "гораздо проще", где now — это текущее время. [willi-wonka-meme.gif]
P>>>Вот-вот. Отдельный компонент. В том то и проблема. И вам все это придется мастырить и протаскивать. Только всегда "где то там" P>·>Что всё? _Добавить_ новую логику в CalendarLogic, внутри него использовать этот кеш, и собственно всё. В чём _изменение_ дизайна-то? Можно обойтись одним новым приватным полем. P>Вы описали это изменение дизайна. у вас с вашим кешем как минимум новые свойства у решения появились.
Да у тебя всё изменение дизайна. А что у тебя _не_ изменение дизайна-то?
P>1 — меняется внутренний дизайн компонента
P>2 — инжектится таймер
Жуть.
P>3 — теперь вам надо пройти по всем тестам где это аффектается и всунуть все что надо ради timer.schedule
По каким тестам? Ровно по одному — тот который тестирует ентот самый CalendarLogic. Его, ясен пень, надо будет перепроверить и внести соответствующие правки, добавить новые сценарии что и с этим самым timer всё работает как надо.
Остальные тесты, которые _используют_ CalendarLogic — используют mock(CalendarLogic.class) и туда просто некуда ничего всовывать.
P>В моем случае тесты nextFriday остаются неизменными, потому, что нет причины для изменения — кеш будет добавлен снаружи
Бред. Кода как всегда нет.
P>>>И где ваш код nextFriday и всех вариантов инжекции для разных кейсов — клиенское время, серверное, текущие, такое, сякое ? P>·>А что там показывать? Вроде всё очевидно: P>·>
P>·>var clientCalendarLogic = new CalendarLogic(timeProviders.clientClock());
P>·>var serverCalendarLogic = new CalendarLogic(timeProviders.systemClock());
P>·>var eventCalendarLogic = new CalendarLogic(timeProviders.eventTimestampClock());
P>·>
P>Вот видите — у вас ровно та же проблема, можно слегка ошибиться и clientClock уйдет в serverLogic.
Это тестами покрывается. Я уже рассказывал как. В тех местах где используется "clientCalendarLogic" будут тесты, которые проверяют что результат зависит именно от clientClock который мочится тестовым клиентским временем.
P>>>wiring и есть связывание. Код связывания в dependency injection, который вы называете wiring, и код связывания в контроллере — выполняют одно и то же — интеграцию. Разница отражает подходы к дизайну. И то и другое wiring, и то и другое связывание. И задача решается одна и та же. Только свойства решения разные. P>·>Интересная терминология. Покажи хоть одну статью, где код в методах контроллеров называется wiring. P>Если вы вызываете какую то функцию, это уже есть интеграция — то самое связывание. В моем случае я помещаю связывания в контроллер, часть — в юз кейс, см у фаулера 'src/restaurantRatings/topRated.ts'
У тебя полное непонимание терминологии и отсюда — каша в голове. Так wiring тут причём?! Я тебе не зря про шнурки написал, но ты видимо не понял — shoelaces тоже связывают, но не wiring, а tying. У него в контроллере не wiring а просто бизнес-логика по сути. Там просто дёргаются занижекченные Dependencies в нужном порядке. wiring code находится в restaurantRatings/index.ts.
P>>>Похоже, что пример для Буравчика вы не поняли P>·>Код я понял. Я не понял зачем такой код и что именно он улучшил, я предполагаю этого никто тут не понял. А про ЧПФ и классы было в обсуждаемой тут в начале топика статье. P>Вводится изоляция — вместо низкоуровневой зависимости на репозиторий появляется абстракция. Ровно то же делает фаулер, 'src/restaurantRatings/topRated.ts'
Зачем? И чем это стало лучше?
P>>>Вы же рассказываете, что проблему увидите на старте приложения. Прод у вас получает конфиг прода и другие вещи прода. Вот на старте и узнаете, что у вас не так пошло. А надо зафейлить тест, когда вы только-только накидали первую версию контроллера — в этот момент у вас буквально приложения еще нет P>·>Чтобы зафейлить тест, код надо стартовать. Не всё приложение, ясен пень, зачем для теста конфиг прода, ты в своём уме?! P>Если зафейлить можно в юнит-тестах, то это всё равно быстрее вашего случая.
Что зафейлить? Ты опять контекст потерял? Шла речь о инжекте null вместо зависимости. В ютестах вряд ли кто-то null будет явно писать. Такой null может вылезти, например, если в конфиге парам нужный не определён в каких-то условиях.
P>·>Теперь чуешь о чём я говорю что кода меньше? P>Я вижу, что вы сравниваете код с фремворков на моках с кодом без такого фремворка.
Я об этом ниже написал. Ну без фреймворков тоже можно, но неясно зачем. Если заставят переписать без фреймворов, интерфейс придётся ввести и да, код станет похож.
P>Вот, убрал лишнее, сравнивайте
Ага, вот только типизация куда-то испарилась и вместе с ней много чего полезного. Говорю же, нет вменяемых фреймворков, вот и приходится колбасить.
P>Похоже, вы не вдупляете ни пример Фаулера, ни мой пример для Буравчика.
Что я не вдупляю?
P>Как ваше версионирование расскажет, что под нагрузкой у пользователя оплата не проходит с сообщением "карточка не добавлена" а список карточек вдруг оказывается пуст?
Этим занимается нагрузочное тестирование и происходит задолго до деплоя в прод. Без этого просто не заапрувят в прод деплоить.
P>Подробнее, пожалуйста, как такую проблему решит версионирование. Для простоты условимся, что у вас нет внешних зависимостей.
Я похоже не понял, что ты имел в виду под consistency. Да, версирование тут не при чём.
P>>>Смотрите пример про Колю Петрова, там ответ на этот вопрос P>·>Смотрю, там нет ответа на этот вопрос. Код покажи. P>Вы не знаете, что такое кукумбер? Забавно
Знаю, к сожалению.
P>>>Я ж говорю — смотрите, как это у QA делается. P>·>Может у вас идеальные QA, у нас они бегают к девам, спрашивая что тестировать. А часто вообще QA как отдельной роли нет. Как это делается у ваших QA? P>traceability matrix
По-моему это про то как сопоставить тесты с требованиями. Я спрашивал о том, как узнать, что в списке требований ничего не упущено.
P>>>Примером по Колю Петрова вам показываю, что такое интеграционные тесты. Вы же в них хотите проверять "а должно вот там вызываться!" P>·>В том примере неясно как отличить откуда берётся информация. Что тест проходит и работает не означает, что функциональность работает правильно. P>Вот-вот.
Угу. Поэтому нужно мочить источники информации и сувать туда разные данные, и писать тест так, чтобы он проходил только тогда, когда источник верный. Если ты при запуске своих огуречных сценариев используешь Time.Now — ты не сможешь прописать соотвествующие Then-ожидания.
P>>>Тесты где сравнивается выхлоп из базы не решают проблемы data complexity. P>·>А я где-то заявлял обратное? И расскажи заодно какие же _тесты_ _решают_ проблемы data complexity [willy-wonka-meme.gif]. P>Я же вам много раз сказал.
Цитату или не было.
P>Вы утверждаете, что где то показали здесь решение, и несколько раз сослались на свои примитивные тесты. Отсюда следует, что вы настаиваете на тестах.
Ты врёшь. Я показал решение проблем в твоих _тестах_. А не всех проблем человечества.
P>>>Отсюда ясно — что нужно добавлять нечто большее. P>·>Причём тут тесты-то? P>Вы же который раз ссылаетесь на ваши примитивные тесты именно в контексте data complexity
Речь шла о тестах изначально. Может хватит? Утомляешь. data complexity ты втащил вообще неясно зачем. Ещё какие-то таблицы истинности потерял, правда они потом нашлись, но осадочек остался.
P>>>В вашем случае вы ничего не гарантируете на тех данных, что у вас нет. P>·>Причём тут _мои_ тесты??! Твои _тесты_ могут гарантировать что-то большее? С какого такого бодуна? P>У меня два разных набора тестов, каждый из который решает свою часть проблемы. У вас — один.
Какую ты тут имеешь в виду проблему конкретно? Почему один набор тестов не может решить обе части проблемы? Что это за части?
P>>>Примерно так же, как assert.notnull(parameter) в начале метода или return assert.notEmpty(value) в конце P>·>Не понял. Откуда у тебя возьмутся все данные всех юзеров на будущее тысячелетие из assert.notnull? P>Этот assert сработает для всех вызовов функции, сколько бы вы туда ни пихали, хоть тысячу лет кряду, хоть миллион. P>Вы, похоже, не в курсе, как инварианты, пред-, и пост-условия используются.
Конечно, я совершенно не в курсе какое это имеет отношение к нашей теме. Опять тебя куда-то понесло.
P>>>·>В каком месте тут телепатия? Билд занимающий часы — это твои слова. И тесты в проде — тоже. P>>>Вы всё знаете — и сложность проекта, и объемы кода, и начинку тестов, и частоту тех или иных тестов. Просто удивительно, как тонкая телепатия. P>·>Так ты собственно всё рассказал. Перечитай что ты писал. P>Я писал что много юнит-тестов, но не писал сколько из них чекают запросы к бд. А вы понаделывали выводов без этой информации — телепатия в чистом виде.
И что? У меня были претензии ко времени выполнения билда и тестов, а не к их количеству.
P>>>А я и говорю в который раз, что основное совсем не в тестах. В них мы всего лишь фиксируем некоторые свойства решения, что бы досталось потомкам в неискаженном виде. P>·>А где у вас основное? И почему _основное_ не покрыто тестами??! P>Потому, что основная работа по обеспечению качества это совсем не тесты. Тесты это исключительно вспомогательный инструмент — фиксируем некоторые ожидания, свойства решения.
Именно. Поэтому "Такой тест гарантирует, что " — это в лучшем случае wishful thinking.
P>Но само решение нужно иметь до того, как начнете покрывать его тестами
Это какой-то waterfall. На практике 99% времени у тебя есть уже некое решение и некие тесты и тебе надо что-то поменять.
P>Например — вы можете заложиться на стабильную структуру пайплайна. В этом случае и тестами надо обеспечить именно это — стабильность пайплайна. P>А можете на конкретные наборы данных — тогда вам нужно чудовищное количество данных. P>А можно взять и то, и другое, добавить код-ревью, ассерты, логирование и получите куда больше, чем одними вашими тестами на провеку выхлопа из базы
И? Я пытаюсь вести речь "мои тесты" vs "твои тесты", а ты начинаешь словоблудить: "твои тесты — плохие, т.к. они не делают код-ревью, ассерты, логирование, метапрограммирование, мониторинг". Утомил.
P>>>Почему ж не код? Это в кукумбер переводит ися практически один к одному. P>·>Ну вот давай значит клей показывай. P>Какой еще клей?
Вы не знаете, что такое кукумбер? Забавно. https://www.google.com/search?q=cucumber+glue+code
P>>>А вы точно интеграционные пишите? Чтото мне кажется, вы пишете высокоуровневые юнит-тесты. P>·>Не буду о терминологии спорить. Не так уж важно как какие тесты классифицируются. P>Очень даже важно — если вы в тестах проверяете "вон тот источник не используется" то это к интеграционным имеет крайне слабое отношение
Ты меня заел. Серьёзно. В кавычках надо приводить мою цитату, а не твои фантазии.
P>>>Такое же, как ваши классы, методы, dependency injection итд. P>·>Всё смешалось, люди, кони. P>Что вам непонятно? Одна техника в программировании и другоя техника в программировании, обеими можно решить задачу.
Ок, немного понятнее. Т.е. в зависимости от конкретной техники программирования ты предлагаешь по-разному тестировать бизнес-требования? Почему? Если классы/DI используем, то в тесте пишем бизнес-сценарий, а если метапрограммирование, то в соответсвующем тесте проверяем имя приватных методов. Так что-ли?!
P>>>·>Тесты не могут давать гарантию. P>>> Тесты именно ради гарантий и пишутся. Только чудес от них ждать не надо. P>·>Гарантий чего? Они могут лишь проверить, что тестируемый сценарий работает. Что как где устроено — никаких гарантий. P>Вы сейчас плавно отказываетесь от своих слов "Тесты не могут давать гарантию"
Нет. "Тестовый сценарий работает" — ничего не гарантирует о реальных сценариях.
P>>>Это слишком долго. Фейлы перформанса в большинстве случаев можно обнаруживать прямо во время юнит-тестирования. P>·>Наивный юноша. P>Нисколько. Вероятно, вы не догадываетесь, что где то может быть другая область, с другой спецификой.
Такое только в простых ситуациях работает. Когда о перформансе думать особо не требуется: дождались конца билда — перформанс ок!
Там где перформанс действительно важен, там будут перф-тесты, работающие на отдельном от билдов железе, с профилем нагрузки взятым с прода и т.п. Но в целом согласен. Подавляющему количеству проектов перф-тесты не нужны.
P>>>Важно, что бы явные фейлы обнаруживались гораздо раньше старта после деплоя. Тогда будет время подумать, как получить максимум сведений из самого деплоя. P>·>После деплоя обнаруживаются фейлы в окружении, куда задеплоилось. Неясно как их обнаружить раньше. Это невозможно. P>Деплой дает вам новое состояние системы, которого раньше не было.
Угу. Поэтому это состояние надо уметь валидировать, для этого и есть probes.
P>>>Они показывают, выполнимы ли сценарии под нагрузкой(при изменениях сети, топологии, итд) или нет. P>·>Для этого есть более адекватные подходы. P>Вы пока ни одного ни привели.
Кое что уже приводил. Впрочем, это всё к теме разговора не относится.
P>>>Каким чудом ваш пробы дают ответ, выполнимы или все ключевые сценарии при максимальной нагрузке? Сценарий — это та часть, про Колю Петрова, которая вам непонятна P>·>А ты опять контекст потерял? Напомню: "Сертификат может обновиться не у вашего приложения, а у какого нибудь из внешних сервисов". Причём тут нагрузки? Причём тут Коля? P>Проблема с сертификатом может повалить выполнение сценариев. Нагрузка может точно так же повалить выполнение сценария. А ценарий один — см Коля Петров.
И что? Причём тут нагрузка??! Ты задал конкретную проблему — тухлые серты, я привёл конкретное решение — пробы. Для решения _этой_ проблемы выполнение сценариев не требуется. И пробы решают эту задачу лучше. Т.к. они могут быть настроены в разных местах по-разному. Для каких-то внешних сервисов потеря одного сетевого пакета и tcp retry — критическая ошибка — бежим менять кабель, а где-то можно раз в день пингануть и мыло кинуть что серт протух. Как такую тонкую настройку делать прогоном тестов — вообще неясно.
P>>>И ежу понятно — вам максимум с собой легко интегрироваться P>·>Ну других по себе не судите, а мне вот сегодня опять приходится ворошить FIX спеку от Bloomberg, 891 страниц в PDF. Не, я работаю не там. P>Как думаете, сколько % от общей массы программистов заняты тем же?
Не знаю.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
·>У тебя просто как всегда память отшибло, читаем: не будет ни одной функции в джаве "удалить пользователя". Как оказалось, таки скорее всего будет именно функция в джаве для реализации функции приложения "удаление пользователя". И функцию в джаве можно покрыть тестами, чтобы проверять, что функция приложения выполняется ожидаемым способом.
Это вовсе необязательно. Более того — вопрос в том, как такая функция реализована, если есть
Например —
1 непосредственно удаляет, делает все виды работ
2 всего лишь создает отложеные операции типа "удалить док по хешкоду", "выгрузить данные в s3 с ттл 1 месяц"
С т.з. пользователя это ровно одна и та же функция. Ваши бизнес-требования не менялись.
А вот покрыв моками первую реализауию, вы только добавили себе работ при переходе ко второй.
P>>Если вы вызовете str.length() сотню раз, джит сделает обращение к памяти ровно единожды — а дальше просто будет использовать значение как константу. ·>Константу?! Ты наверное имел в виду загрузку значения в регистр. Ладно хоть про интринзики перестал бред нести...
Вы думаете, что регистров всегда будет хватать по количеству перемненных?
Важно, что str.length() инлайнится гораздо эффективнее аналога для мутабельного контейнера или мутабельной ссылки. Вы слишкмо много придираетесь к каким то ничтожным деталям.
P>>С мутабельной ссылкй или внутренним контейнером переменной длины так поступать нельзя ·>Можно. если джит видит что внутри func(mutableStr) ничего не меняется, то может и закешировать длину в регистре.
Пример как раз про функцию которая ломает ссылочную прозрачность.
P>>Конечная цель — оптимизация. Её можно достигнуть через изменение дизайна, например — нужные данные расположить рядом, убрать лишнее из hot path итд. ·>Угу. И инлайн тут как средство оптимизации — на сотом месте, где-то после сдувания пыли с вентилятора cpu.
Наоборот. При изменении дизайна инлайн и его обратная операция это ключевые рефакторинги. Например, типичный кейс, когда у вас функционал размазан по коду, его можно собрать в один метод, который будет инлайниться где нужно, да еще и будет заоптимизирован по самые нидерланды компилятором и джитом.
Щас вы конечно же скажете, что у вас такого никогда не бывает, и вы дизайн на все кейсы, возможные и невозможные, проектируете на 100 лет вперёд.
P>>Добавление такого компонента и есть изменение дизайна. Например, у вас теперь новый класс ошибок появился, которого раньше не было. ·>Ок. Любое изменение кода — изменение дизайна. Не поспоришь.
Не любое. Изменение конфига сюда не подходит. Форматирование — тоже не подходит. Комментарии — тоже. Изменения внутри одной функии — тоже.
P>>Вы что, не в курсе мемоизации? Разница только в том, где связывание — или "где то там" или "прямо здесь". ·>В курсе. Ты опять вопрос проигнорировал. Давай расскажи, как ты nextFriday(now) закешируешь "гораздо проще", где now — это текущее время. [willi-wonka-meme.gif]
Мемоизацией, естественно. Даже если LRU кеш с конфигом придется протащить — зависимости будут идти чз контроллер, а не абы где.
P>>3 — теперь вам надо пройти по всем тестам где это аффектается и всунуть все что надо ради timer.schedule ·>По каким тестам? Ровно по одному — тот который тестирует ентот самый CalendarLogic. Его, ясен пень, надо будет перепроверить и внести соответствующие правки, добавить новые сценарии что и с этим самым timer всё работает как надо.
Смешно. Вам нужно тестировать компонент без кеширования, и компонент с кешированием, просто потому что вы всунули всё это внутрь.
P>>Вот видите — у вас ровно та же проблема, можно слегка ошибиться и clientClock уйдет в serverLogic. ·>Это тестами покрывается. Я уже рассказывал как. В тех местах где используется "clientCalendarLogic" будут тесты, которые проверяют что результат зависит именно от clientClock который мочится тестовым клиентским временем.
А что мешает это без моков сделать?
P>>Вводится изоляция — вместо низкоуровневой зависимости на репозиторий появляется абстракция. Ровно то же делает фаулер, 'src/restaurantRatings/topRated.ts' ·>Зачем? И чем это стало лучше?
Проще код, больше контроля. Даже те же моки можно прикрутить безо всяких фремворков.
P>>Если зафейлить можно в юнит-тестах, то это всё равно быстрее вашего случая. ·>Что зафейлить? Ты опять контекст потерял? Шла речь о инжекте null вместо зависимости. В ютестах вряд ли кто-то null будет явно писать. Такой null может вылезти, например, если в конфиге парам нужный не определён в каких-то условиях.
У вас куда ни крути — ни одна проблема принципиально невозможна.
P>>Вот, убрал лишнее, сравнивайте ·>Ага, вот только типизация куда-то испарилась и вместе с ней много чего полезного. Говорю же, нет вменяемых фреймворков, вот и приходится колбасить.
Никуда не испарилась. Все один в один, как и у вас.
P>>Похоже, вы не вдупляете ни пример Фаулера, ни мой пример для Буравчика. ·>Что я не вдупляю?
Всё. Вы топите за монолитный оо дизайн, как будто за 20 лет ничего лучшего не придумали. И рассказываете мне тонкости, которые я и без вас использовал где то с середины нулевых.
P>>Как ваше версионирование расскажет, что под нагрузкой у пользователя оплата не проходит с сообщением "карточка не добавлена" а список карточек вдруг оказывается пуст? ·>Этим занимается нагрузочное тестирование и происходит задолго до деплоя в прод. Без этого просто не заапрувят в прод деплоить.
Это сказки вида "у нас проблем на проде не бывает"
P>>Вы не знаете, что такое кукумбер? Забавно ·>Знаю, к сожалению.
Ну так чего вы конкретно просите показать?
P>>·>Может у вас идеальные QA, у нас они бегают к девам, спрашивая что тестировать. А часто вообще QA как отдельной роли нет. Как это делается у ваших QA? P>>traceability matrix ·>По-моему это про то как сопоставить тесты с требованиями. Я спрашивал о том, как узнать, что в списке требований ничего не упущено.
Или код ревью, или некоторая формализация с последующей генерацией тестов, чтото навроде
·>Угу. Поэтому нужно мочить источники информации и сувать туда разные данные, и писать тест так, чтобы он проходил только тогда, когда источник верный. Если ты при запуске своих огуречных сценариев используешь Time.Now — ты не сможешь прописать соотвествующие Then-ожидания.
Потому я и говорю, что лучше брать время прямо из реквеста.
P>>Вы утверждаете, что где то показали здесь решение, и несколько раз сослались на свои примитивные тесты. Отсюда следует, что вы настаиваете на тестах. ·>Ты врёшь. Я показал решение проблем в твоих _тестах_. А не всех проблем человечества.
Каким образом ваши примитивные тесты показывают проблему в моих тестах? Мои то как раз включают ваш набор, и делают много чего еще дополнительно — именно потому, что ваш минимум он довольно хилый.
·>Какую ты тут имеешь в виду проблему конкретно? Почему один набор тестов не может решить обе части проблемы? Что это за части?
Смотря какой этот один. Если тот, что только сравнивает выхлоп из базы — то нет, слабовато.
P>>Вы, похоже, не в курсе, как инварианты, пред-, и пост-условия используются. ·>Конечно, я совершенно не в курсе какое это имеет отношение к нашей теме. Опять тебя куда-то понесло.
Потеряли контекст. Тесты, которые я вам показал, работают примерно таким же образом.
P>>Потому, что основная работа по обеспечению качества это совсем не тесты. Тесты это исключительно вспомогательный инструмент — фиксируем некоторые ожидания, свойства решения. ·>Именно. Поэтому "Такой тест гарантирует, что " — это в лучшем случае wishful thinking.
Вы неверно понимаете тесты. Сначала вы находите свойство — это происходит в вашей голове. Потом находите, что его надо сохранить между версиям. Это тоже в вашей голове. А вот само сохранение это тест + процесс разработки, что там у вас, код ревью, итд.
Если у вас кто угодно может закоментить тест, вставить игнор, или написать обходной путь абы тесты были зелеными — такое надо решать административными методами
Вот у нас было два героя, писали тесты "контроллер существует", "метод существует". Проблемы с такими тестами решились с уволнением этих двух героев.
P>>А можно взять и то, и другое, добавить код-ревью, ассерты, логирование и получите куда больше, чем одними вашими тестами на провеку выхлопа из базы ·>И? Я пытаюсь вести речь "мои тесты" vs "твои тесты", а ты начинаешь словоблудить: "твои тесты — плохие, т.к. они не делают код-ревью, ассерты, логирование, метапрограммирование, мониторинг". Утомил.
Это выяснение свойств — какой подход чего позволяет, или не позволяет, именно так сравнение и делается. А вы именно что сводите к "мое против твоего".
P>>Какой еще клей? ·>Вы не знаете, что такое кукумбер? Забавно. https://www.google.com/search?q=cucumber+glue+code
Здесь будут примитивы вида резервирование, время операции и тд. Что коннкретно вы хотите узнать?
·>Ок, немного понятнее. Т.е. в зависимости от конкретной техники программирования ты предлагаешь по-разному тестировать бизнес-требования? Почему? Если классы/DI используем, то в тесте пишем бизнес-сценарий, а если метапрограммирование, то в соответсвующем тесте проверяем имя приватных методов. Так что-ли?!
Именно. Только не обязательно приватные методы, это просто методы видимость которых ограничена некоторым модулем или пакетом.
P>>Вы сейчас плавно отказываетесь от своих слов "Тесты не могут давать гарантию" ·>Нет. "Тестовый сценарий работает" — ничего не гарантирует о реальных сценариях.
Вы мне про чудеса, а я вам про инженерию. Тесты запускают что бы узнать о наличии проблем, а не об их отсутствии. Пусканули тесты — посыпались ошибки, значит у нас есть данные что не так, где не так, масштаб последствий. Если тесты ничего не показали — это называется "тесты новых проблем не выявили".
Т.е. такие тесты это способ снимать инфу с прода в критические моменты, т.к. в дебаге, стейдже итд у вас точно этой инфы не будет.
Не зеленую галку менеджерам показывать, а обнаруживать те вещи, которые в других условиях не видны
P>>>>И ежу понятно — вам максимум с собой легко интегрироваться P>>·>Ну других по себе не судите, а мне вот сегодня опять приходится ворошить FIX спеку от Bloomberg, 891 страниц в PDF. Не, я работаю не там. P>>Как думаете, сколько % от общей массы программистов заняты тем же? ·>Не знаю.
Здравствуйте, Pauel, Вы писали:
P>>>Вы что, не в курсе мемоизации? Разница только в том, где связывание — или "где то там" или "прямо здесь". P>·>В курсе. Ты опять вопрос проигнорировал. Давай расскажи, как ты nextFriday(now) закешируешь "гораздо проще", где now — это текущее время. [willi-wonka-meme.gif]
P>Мемоизацией, естественно. Даже если LRU кеш с конфигом придется протащить — зависимости будут идти чз контроллер, а не абы где.
Не, вот это как раз плохая идея. Мемоизация работает хорошо для тех случаев, когда pure-функция многократно вызывается с одним и тем же значением аргумента.
А вот наша nextFriday(timestamp) как правило вызывается с новым значением аргумента.
Поэтому вместо мемоизации мы всего лишь изменим её на замыкание:
Теперь при боевом использовании SlowlyCalculatePrevAndNextFridays(dt) будет вызываться не чаще раза в неделю. При этом у нас нет никакого "таймера", который обязательно должен проснуться вовремя. Нет никакого увеличения размера кэша с ростом количества вызовов.
Единсночо — функция nextFriday хоть и осталась чистой, перестала быть потокобезопасной. Но эту проблему можно решить локальными мерами (и они будут зависеть от того, в каком контекесте у нас всё это используется), а весь остальной код как работал, так и работает.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Pauel, Вы писали:
P>·>У тебя просто как всегда память отшибло, читаем: не будет ни одной функции в джаве "удалить пользователя". Как оказалось, таки скорее всего будет именно функция в джаве для реализации функции приложения "удаление пользователя". И функцию в джаве можно покрыть тестами, чтобы проверять, что функция приложения выполняется ожидаемым способом. P>Это вовсе необязательно. Более того — вопрос в том, как такая функция реализована, если есть P>Например - P>1 непосредственно удаляет, делает все виды работ P>2 всего лишь создает отложеные операции типа "удалить док по хешкоду", "выгрузить данные в s3 с ттл 1 месяц" P>С т.з. пользователя это ровно одна и та же функция. Ваши бизнес-требования не менялись.
Не понял, чем отличается 1 от 2? "все виды" это разве не "удалить"+"выгрузить"?
P>А вот покрыв моками первую реализауию, вы только добавили себе работ при переходе ко второй.
Тут все уже поняли, что моками ты пользоваться не умеешь, поэтому не стоит заводить ту же песню.
P>>>Если вы вызовете str.length() сотню раз, джит сделает обращение к памяти ровно единожды — а дальше просто будет использовать значение как константу. P>·>Константу?! Ты наверное имел в виду загрузку значения в регистр. Ладно хоть про интринзики перестал бред нести... P>Вы думаете, что регистров всегда будет хватать по количеству перемненных? P>Важно, что str.length() инлайнится гораздо эффективнее аналога для мутабельного контейнера или мутабельной ссылки. Вы слишкмо много придираетесь к каким то ничтожным деталям.
Не знаю что значит "гораздо эффективнее", но инлайнится она ровно так же. Ещё раз. Инлайн это убирание фрейма стека, ничего общего с мутабельностью. Кандидат на инлайн выбирается по размеру тела функции (в байткодах) и количеству вызовов. https://stackoverflow.com/questions/18737774/hotspot-jit-inlining-strategy-top-down-or-down-top
P>>>С мутабельной ссылкй или внутренним контейнером переменной длины так поступать нельзя P>·>Можно. если джит видит что внутри func(mutableStr) ничего не меняется, то может и закешировать длину в регистре. P>Пример как раз про функцию которая ломает ссылочную прозрачность.
Тогда это пример не про инлайнинг, а про иммутабельность. Для иналайна важен размер тела метода, а потом, после инлайна оно уже может проверять являются ли данные иммутабельными. А уж тем более если вспомнить, что разговор шел про конкретно про инлайн nextFriday — тут вообще неясно что к чему ты тут это выдумываешь.
P>>>Конечная цель — оптимизация. Её можно достигнуть через изменение дизайна, например — нужные данные расположить рядом, убрать лишнее из hot path итд. P>·>Угу. И инлайн тут как средство оптимизации — на сотом месте, где-то после сдувания пыли с вентилятора cpu. P>Наоборот. При изменении дизайна инлайн и его обратная операция это ключевые рефакторинги. Например, типичный кейс, когда у вас функционал размазан по коду, его можно собрать в один метод, который будет инлайниться где нужно, да еще и будет заоптимизирован по самые нидерланды компилятором и джитом. P>Щас вы конечно же скажете, что у вас такого никогда не бывает, и вы дизайн на все кейсы, возможные и невозможные, проектируете на 100 лет вперёд.
Можно, конечно. Но это не происходит непрерывно сто раз на дню как ты тут заявлял выше. Да, возможно раз в месяц надо поискать боттл-нек и как-то порефакторить.
P>>>Добавление такого компонента и есть изменение дизайна. Например, у вас теперь новый класс ошибок появился, которого раньше не было. P>·>Ок. Любое изменение кода — изменение дизайна. Не поспоришь. P>Не любое. Изменение конфига сюда не подходит.
Конфиг это не код. Выделил жирным.
P> Форматирование — тоже не подходит. Комментарии — тоже.
Это тоже не изменение кода, по крайней мере с т.з. компилятора.
P>Изменения внутри одной функии — тоже.
Ну у меня внутри функции изменение и было для добавления кеша.
P>>>Вы что, не в курсе мемоизации? Разница только в том, где связывание — или "где то там" или "прямо здесь". P>·>В курсе. Ты опять вопрос проигнорировал. Давай расскажи, как ты nextFriday(now) закешируешь "гораздо проще", где now — это текущее время. [willi-wonka-meme.gif] P>Мемоизацией, естественно. Даже если LRU кеш с конфигом придется протащить — зависимости будут идти чз контроллер, а не абы где.
Итак, продолжаем разговор. Что будет ключом мемоизации для nextFriday(now)?
P>>>3 — теперь вам надо пройти по всем тестам где это аффектается и всунуть все что надо ради timer.schedule P>·>По каким тестам? Ровно по одному — тот который тестирует ентот самый CalendarLogic. Его, ясен пень, надо будет перепроверить и внести соответствующие правки, добавить новые сценарии что и с этим самым timer всё работает как надо. P>Смешно. Вам нужно тестировать компонент без кеширования, и компонент с кешированием, просто потому что вы всунули всё это внутрь.
Вам тоже нужно.
P>>>Вот видите — у вас ровно та же проблема, можно слегка ошибиться и clientClock уйдет в serverLogic. P>·>Это тестами покрывается. Я уже рассказывал как. В тех местах где используется "clientCalendarLogic" будут тесты, которые проверяют что результат зависит именно от clientClock который мочится тестовым клиентским временем. P>А что мешает это без моков сделать?
Просвети как, с учётом того, что ты предложил использовать Time.now. КОД покажи.
P>>>Вводится изоляция — вместо низкоуровневой зависимости на репозиторий появляется абстракция. Ровно то же делает фаулер, 'src/restaurantRatings/topRated.ts' P>·>Зачем? И чем это стало лучше? P>Проще код, больше контроля. Даже те же моки можно прикрутить безо всяких фремворков.
Почему он проще? Мне показалось ровно наоборот. А моки можно прикручивать без фреймворков в любом случае. Правда количество кода увеличивается.
P>>>Если зафейлить можно в юнит-тестах, то это всё равно быстрее вашего случая. P>·>Что зафейлить? Ты опять контекст потерял? Шла речь о инжекте null вместо зависимости. В ютестах вряд ли кто-то null будет явно писать. Такой null может вылезти, например, если в конфиге парам нужный не определён в каких-то условиях. P>У вас куда ни крути — ни одна проблема принципиально невозможна.
Это твои фантазии.
P>>>Вот, убрал лишнее, сравнивайте P>·>Ага, вот только типизация куда-то испарилась и вместе с ней много чего полезного. Говорю же, нет вменяемых фреймворков, вот и приходится колбасить. P>Никуда не испарилась. Все один в один, как и у вас.
В mock({}).whenCalledWith('getTopRestaurants', 'ляляля').returns(restaurants) оно правда сможет вывести типы?! Что-то не верится...
P>>>Как ваше версионирование расскажет, что под нагрузкой у пользователя оплата не проходит с сообщением "карточка не добавлена" а список карточек вдруг оказывается пуст? P>·>Этим занимается нагрузочное тестирование и происходит задолго до деплоя в прод. Без этого просто не заапрувят в прод деплоить. P>Это сказки вида "у нас проблем на проде не бывает"
Цитаты нет, ты опять врёшь. Опять свои фантазии помещаешь в кавычки и пытаешься выдать за мои слова.
P>>>Вы не знаете, что такое кукумбер? Забавно P>·>Знаю, к сожалению. P>Ну так чего вы конкретно просите показать?
Код на ЯП. Для тебя наверное это новость, но сообщаю: кукумбер — это не яп.
P>>>traceability matrix P>·>По-моему это про то как сопоставить тесты с требованиями. Я спрашивал о том, как узнать, что в списке требований ничего не упущено. P>Или код ревью, или некоторая формализация с последующей генерацией тестов, чтото навроде
Код ревью не укажет на пробелы в требованиях. Формализация — практически анреал, очень редкий зверь.
P>·>Угу. Поэтому нужно мочить источники информации и сувать туда разные данные, и писать тест так, чтобы он проходил только тогда, когда источник верный. Если ты при запуске своих огуречных сценариев используешь Time.Now — ты не сможешь прописать соотвествующие Then-ожидания. P>Потому я и говорю, что лучше брать время прямо из реквеста.
Что значит "лучше"??! Это будет клиентское время, его можно подделывать. Более того, структура запроса диктуется требованиями внешнего api, а не желанием левой пятки, поэтому там его в принципе может не быть.
P>>>Вы утверждаете, что где то показали здесь решение, и несколько раз сослались на свои примитивные тесты. Отсюда следует, что вы настаиваете на тестах. P>·>Ты врёшь. Я показал решение проблем в твоих _тестах_. А не всех проблем человечества. P>Каким образом ваши примитивные тесты показывают проблему в моих тестах? Мои то как раз включают ваш набор, и делают много чего еще дополнительно — именно потому, что ваш минимум он довольно хилый.
Я показал, что твои тесты не делают.
P>·>Какую ты тут имеешь в виду проблему конкретно? Почему один набор тестов не может решить обе части проблемы? Что это за части? P>Смотря какой этот один. Если тот, что только сравнивает выхлоп из базы — то нет, слабовато.
Сильнее, чем у тебя, т.к. хотя бы синтаксис запроса проверяют.
P>>>Вы, похоже, не в курсе, как инварианты, пред-, и пост-условия используются. P>·>Конечно, я совершенно не в курсе какое это имеет отношение к нашей теме. Опять тебя куда-то понесло. P>Потеряли контекст. Тесты, которые я вам показал, работают примерно таким же образом.
Голословно.
P>>>Потому, что основная работа по обеспечению качества это совсем не тесты. Тесты это исключительно вспомогательный инструмент — фиксируем некоторые ожидания, свойства решения. P>·>Именно. Поэтому "Такой тест гарантирует, что " — это в лучшем случае wishful thinking. P>Вы неверно понимаете тесты. Сначала вы находите свойство — это происходит в вашей голове. Потом находите, что его надо сохранить между версиям. Это тоже в вашей голове. А вот само сохранение это тест + процесс разработки, что там у вас, код ревью, итд.
Это "свойство" не эквивалентно работоспособности программы.
P>Если у вас кто угодно может закоментить тест, вставить игнор, или написать обходной путь абы тесты были зелеными — такое надо решать административными методами
Так это было у вас, ты сам рассказывал в прошлой дискуссии.
P>>>А можно взять и то, и другое, добавить код-ревью, ассерты, логирование и получите куда больше, чем одними вашими тестами на провеку выхлопа из базы P>·>И? Я пытаюсь вести речь "мои тесты" vs "твои тесты", а ты начинаешь словоблудить: "твои тесты — плохие, т.к. они не делают код-ревью, ассерты, логирование, метапрограммирование, мониторинг". Утомил. P>Это выяснение свойств — какой подход чего позволяет, или не позволяет, именно так сравнение и делается. А вы именно что сводите к "мое против твоего".
Ну вот и выясняй. Мои тесты позволяют всё вышеперечисленное. И они даже кофе не запрещают варить.
P>>>Какой еще клей? P>·>Вы не знаете, что такое кукумбер? Забавно. https://www.google.com/search?q=cucumber+glue+code P>Здесь будут примитивы вида резервирование, время операции и тд. Что коннкретно вы хотите узнать?
Как выглядит код.
P>·>Ок, немного понятнее. Т.е. в зависимости от конкретной техники программирования ты предлагаешь по-разному тестировать бизнес-требования? Почему? Если классы/DI используем, то в тесте пишем бизнес-сценарий, а если метапрограммирование, то в соответсвующем тесте проверяем имя приватных методов. Так что-ли?! P>Именно. Только не обязательно приватные методы, это просто методы видимость которых ограничена некоторым модулем или пакетом.
Ты сам заявлял, что эти методы видны только с целью использования их в тестах: "fn1 и fn2 должны быть видны в тестах, а не публично". Т.е. твои тесты тестируют никому более невидимые внутренние кишки реализации. Это — отстой.
P>>>Вы сейчас плавно отказываетесь от своих слов "Тесты не могут давать гарантию" P>·>Нет. "Тестовый сценарий работает" — ничего не гарантирует о реальных сценариях. P>Вы мне про чудеса, а я вам про инженерию. Тесты запускают что бы узнать о наличии проблем, а не об их отсутствии. Пусканули тесты — посыпались ошибки, значит у нас есть данные что не так, где не так, масштаб последствий. Если тесты ничего не показали — это называется "тесты новых проблем не выявили". P>Т.е. такие тесты это способ снимать инфу с прода в критические моменты, т.к. в дебаге, стейдже итд у вас точно этой инфы не будет. P>Не зеленую галку менеджерам показывать, а обнаруживать те вещи, которые в других условиях не видны
Верно, но это не единственный способ. И, мягко говоря, не самый лучший.
P>>>Как думаете, сколько % от общей массы программистов заняты тем же? P>·>Не знаю. P>А вы посчитайте.
42.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>1 непосредственно удаляет, делает все виды работ P>>2 всего лишь создает отложеные операции типа "удалить док по хешкоду", "выгрузить данные в s3 с ттл 1 месяц" P>>С т.з. пользователя это ровно одна и та же функция. Ваши бизнес-требования не менялись. ·>Не понял, чем отличается 1 от 2? "все виды" это разве не "удалить"+"выгрузить"?
Разница в слове "отложенные". У вас недавно была проблема с этим словом. Решилась?
P>>Важно, что str.length() инлайнится гораздо эффективнее аналога для мутабельного контейнера или мутабельной ссылки. Вы слишкмо много придираетесь к каким то ничтожным деталям. ·>Не знаю что значит "гораздо эффективнее", но инлайнится она ровно так же. Ещё раз. Инлайн это убирание фрейма стека, ничего общего с мутабельностью.
str.length() можно заменить на str.chars.length и это будет какой то инлайн.
Если вы вызвали str.length() 100 раз у вас есть варианты:
1 везде проставить str.chars.length и это будет работать.
Но это совсем мало.
Компилятор может лучше и делает лучше!
2 можно один раз вызвать str.chars.length и в 99 остальных случаев прописать именно это значение как константу.
Собственно второй вариант возможен исключительно в потому, что str.chars во всех 99 случаях будет одна и та же. В джава строке именно так. Если вы делаете мутабельную строку, ну вот вздумалось вам, то компилятор не сможет вычислить, можно ли применять кейс 2, т.е. более глубокую оптимизацию, т.к. у него нет информации, что там в каждом из 99 случае.
P>>Пример как раз про функцию которая ломает ссылочную прозрачность. ·>Тогда это пример не про инлайнинг, а про иммутабельность.
Джава компилятор на основании иммутабельности умеет вводить кое какие оптимизации. Строки — одна из таких вещей.
P>>Щас вы конечно же скажете, что у вас такого никогда не бывает, и вы дизайн на все кейсы, возможные и невозможные, проектируете на 100 лет вперёд. ·>Можно, конечно. Но это не происходит непрерывно сто раз на дню как ты тут заявлял выше. Да, возможно раз в месяц надо поискать боттл-нек и как-то порефакторить.
"как то" Не как то, а вручную вместо работы компилятором и ИДЕ.
P>>Не любое. Изменение конфига сюда не подходит. ·>Конфиг это не код. Выделил жирным.
А протаскивание такого конфига — тот еще код. Особенно когда это все инжектится
P>>Изменения внутри одной функии — тоже. ·>Ну у меня внутри функции изменение и было для добавления кеша.
А LRU кеш связаный с конфигом, которые надо тащить через dependency injection не считается, да?
P>>Мемоизацией, естественно. Даже если LRU кеш с конфигом придется протащить — зависимости будут идти чз контроллер, а не абы где. ·>Итак, продолжаем разговор. Что будет ключом мемоизации для nextFriday(now)?
Про мемоизацию я трохи погорячился. Вам Синклер рядом ответил.
P>>Смешно. Вам нужно тестировать компонент без кеширования, и компонент с кешированием, просто потому что вы всунули всё это внутрь. ·>Вам тоже нужно.
Нет, не нужно — функция где БЛ никак не изменилась, ни внутри, ни снаружи. Изменилась исключительно интеграция.
В вашем случае вы перепахали внутрянку той самой функции
P>>А что мешает это без моков сделать? ·>Просвети как, с учётом того, что ты предложил использовать Time.now. КОД покажи.
Time.now будет приходить всегда снаружи. В чем вопрос, объясните?
P>>>>Вводится изоляция — вместо низкоуровневой зависимости на репозиторий появляется абстракция. Ровно то же делает фаулер, 'src/restaurantRatings/topRated.ts' P>>·>Зачем? И чем это стало лучше? P>>Проще код, больше контроля. Даже те же моки можно прикрутить безо всяких фремворков. ·>Почему он проще? Мне показалось ровно наоборот. А моки можно прикручивать без фреймворков в любом случае. Правда количество кода увеличивается.
С каких пор низкоуровневые приседания стали проще?
P>>Никуда не испарилась. Все один в один, как и у вас. ·>В mock({}).whenCalledWith('getTopRestaurants', 'ляляля').returns(restaurants) оно правда сможет вывести типы?! Что-то не верится...
У Фаулера код на жээсе. Я вам показал на жээсе. Теперь вы придираетесь, что де на Тайпскрипте будет чтото еще.
Вы все время тратите время на мелкие придирки.
Вот вам типы в TypeScript:
Что теперь, попросите показать как это всё типизуется?
P>>Это сказки вида "у нас проблем на проде не бывает" ·>Цитаты нет, ты опять врёшь. Опять свои фантазии помещаешь в кавычки и пытаешься выдать за мои слова.
Я вам много раз приводил примеры, ради чего нужно запускать такое, но вы упорно видите в этом исключительно доказательство проблем в разработке.
Тесты на проде нынче вариант нормы.
P>>Ну так чего вы конкретно просите показать? ·>Код на ЯП. Для тебя наверное это новость, но сообщаю: кукумбер — это не яп.
Это ЯП, декларативный, высокого уровня
P>>·>По-моему это про то как сопоставить тесты с требованиями. Я спрашивал о том, как узнать, что в списке требований ничего не упущено. P>>Или код ревью, или некоторая формализация с последующей генерацией тестов, чтото навроде ·>Код ревью не укажет на пробелы в требованиях. Формализация — практически анреал, очень редкий зверь.
Смотря что вам надо. Серебряную пулю — такого нет. Составить список требований, сделать ревью, предложить дизайн, сделать ревью, написать тесты, сделать ревью, написать код, сделать ревью, пофиксить баги, сделать ревью — по моему так всё и делается.
P>>Потому я и говорю, что лучше брать время прямо из реквеста. ·>Что значит "лучше"??! Это будет клиентское время, его можно подделывать. Более того, структура запроса диктуется требованиями внешнего api, а не желанием левой пятки, поэтому там его в принципе может не быть.
Структура запроса диктуется много чем кроме внешнего апи — протокол, фремворк, рантайм, операционка, итд. Всегда и везде технологических деталей в десятки раз больше чем бизнеслогики. В случае с хттп там разве что кофе не готовится
P>>Смотря какой этот один. Если тот, что только сравнивает выхлоп из базы — то нет, слабовато. ·>Сильнее, чем у тебя, т.к. хотя бы синтаксис запроса проверяют.
Ну и логика, как набор А, будет сильнее двух наборов А и Б ?
P>>Вы неверно понимаете тесты. Сначала вы находите свойство — это происходит в вашей голове. Потом находите, что его надо сохранить между версиям. Это тоже в вашей голове. А вот само сохранение это тест + процесс разработки, что там у вас, код ревью, итд. ·>Это "свойство" не эквивалентно работоспособности программы.
Нет такого "проверка работоспособности" — это менеджерский сленг. Есть выполнение сценариев А...Z, тесты для всевозможных ...ility, итд итд
То есть, находим конкретные свойства, которые покрываем тестами на том или ином уровне, в зависимости от вашего инструментария
P>>·>Вы не знаете, что такое кукумбер? Забавно. https://www.google.com/search?q=cucumber+glue+code P>>Здесь будут примитивы вида резервирование, время операции и тд. Что коннкретно вы хотите узнать? ·>Как выглядит код.
Зачем?
P>>Именно. Только не обязательно приватные методы, это просто методы видимость которых ограничена некоторым модулем или пакетом. ·>Ты сам заявлял, что эти методы видны только с целью использования их в тестах: "fn1 и fn2 должны быть видны в тестах, а не публично". Т.е. твои тесты тестируют никому более невидимые внутренние кишки реализации. Это — отстой.
Голословно. Любой большой кусок кода нужно в первую очередь тестировать непосредственно. А вы предлагаете всё делать наоборот.
P>>Т.е. такие тесты это способ снимать инфу с прода в критические моменты, т.к. в дебаге, стейдже итд у вас точно этой инфы не будет. P>>Не зеленую галку менеджерам показывать, а обнаруживать те вещи, которые в других условиях не видны ·>Верно, но это не единственный способ. И, мягко говоря, не самый лучший.
Вероятно у вас — не лучший. Зато куча компаний использует именно такой подход. Он сообщает куда больше проблем, чем ваши точечные пробы.
Здравствуйте, Sinclair, Вы писали:
S>Не, вот это как раз плохая идея. Мемоизация работает хорошо для тех случаев, когда pure-функция многократно вызывается с одним и тем же значением аргумента. S>А вот наша nextFriday(timestamp) как правило вызывается с новым значением аргумента. S>Поэтому вместо мемоизации мы всего лишь изменим её на замыкание:
Я думал это тоже мемоизация. Или это принципиальное отличие?
Здравствуйте, Pauel, Вы писали: P>>>1 непосредственно удаляет, делает все виды работ P>>>2 всего лишь создает отложеные операции типа "удалить док по хешкоду", "выгрузить данные в s3 с ттл 1 месяц" P>>>С т.з. пользователя это ровно одна и та же функция. Ваши бизнес-требования не менялись. P>·>Не понял, чем отличается 1 от 2? "все виды" это разве не "удалить"+"выгрузить"? P>Разница в слове "отложенные". У вас недавно была проблема с этим словом. Решилась?
У нас такой проблемы не было. Т.е. разницы нет. ЧТД. P>>>Важно, что str.length() инлайнится гораздо эффективнее аналога для мутабельного контейнера или мутабельной ссылки. Вы слишкмо много придираетесь к каким то ничтожным деталям. P>·>Не знаю что значит "гораздо эффективнее", но инлайнится она ровно так же. Ещё раз. Инлайн это убирание фрейма стека, ничего общего с мутабельностью. P>str.length() можно заменить на str.chars.length и это будет какой то инлайн.
Не "какой-то", а инлайн. P>Если вы вызвали str.length() 100 раз у вас есть варианты: P>1 везде проставить str.chars.length и это будет работать. P>Но это совсем мало. P>Компилятор может лучше и делает лучше!
Возможно, и это уже будут другие техники оптимизации. P>2 можно один раз вызвать str.chars.length и в 99 остальных случаев прописать именно это значение как константу.
Наверно байткод может другой сгенериться для final, может быть. Ну и что?! Причём тут обсуждаемый "инлайн nextFriday"? У тебя там Time.now будет константным, да? P>Собственно второй вариант возможен исключительно в потому, что str.chars во всех 99 случаях будет одна и та же. В джава строке именно так. Если вы делаете мутабельную строку, ну вот вздумалось вам, то компилятор не сможет вычислить, можно ли применять кейс 2, т.е. более глубокую оптимизацию, т.к. у него нет информации, что там в каждом из 99 случае.
Может он сможет и провести compile-time вычисления, но это никакого отношения к инлайн не имеет. P>>>Пример как раз про функцию которая ломает ссылочную прозрачность. P>·>Тогда это пример не про инлайнинг, а про иммутабельность. P>Джава компилятор на основании иммутабельности умеет вводить кое какие оптимизации. Строки — одна из таких вещей.
Допустим, и причём тут инлайн? P>>>Щас вы конечно же скажете, что у вас такого никогда не бывает, и вы дизайн на все кейсы, возможные и невозможные, проектируете на 100 лет вперёд. P>·>Можно, конечно. Но это не происходит непрерывно сто раз на дню как ты тут заявлял выше. Да, возможно раз в месяц надо поискать боттл-нек и как-то порефакторить. P>"как то" Не как то, а вручную вместо работы компилятором и ИДЕ.
Это твои фантазии, или кривая IDE, или неумение ею пользоваться. P>>>Не любое. Изменение конфига сюда не подходит. P>·>Конфиг это не код. Выделил жирным. P>А протаскивание такого конфига — тот еще код. Особенно когда это все инжектится
"изменение конфига" != "протаскивание конфига". P>>>Изменения внутри одной функии — тоже. P>·>Ну у меня внутри функции изменение и было для добавления кеша. P>А LRU кеш связаный с конфигом, которые надо тащить через dependency injection не считается, да?
Считается, конечно. Целую одну строчку посчитать придётся, от силы. P>>>Мемоизацией, естественно. Даже если LRU кеш с конфигом придется протащить — зависимости будут идти чз контроллер, а не абы где. P>·>Итак, продолжаем разговор. Что будет ключом мемоизации для nextFriday(now)? P>Про мемоизацию я трохи погорячился.
Именно, я несколько раз на это "тонко" намекал. Если бы ты подумал как написать такой код, ты бы сразу понял свою ошибку. Поэтому я и пытаюсь из тебя выуживать куски кода — по ним все твои заблуждения видны как на ладони. И ты тут практически по всем вопросам горячишься на самом деле... P>Вам Синклер рядом ответил.
Он _вам_ ответил. Его ответ — другое решение, которое и в моём коде тоже реализуется тривиально. Его решение иногда не подойдёт в том, что у него будет latency spike на cache miss. А моё решение с таймером в твоём коде не реализуется, придётся всё везде перелопачивать. ЧТД — мой код универсальнее, не требует изменения дизайна на каждый чих.
Ещё у него статическая глобальная переменная — за такое в детском саду в угол ставят. Если это переписать нормально, получится как у меня, вариация ЧПФ. P>>>Смешно. Вам нужно тестировать компонент без кеширования, и компонент с кешированием, просто потому что вы всунули всё это внутрь. P>·>Вам тоже нужно. P>Нет, не нужно — функция где БЛ никак не изменилась, ни внутри, ни снаружи. Изменилась исключительно интеграция.
Ага, но у тебя интеграции — на каждый вызов nextFriday из множества методов контроллеров. У меня интеграция wiring — ровно одна строчка. P>В вашем случае вы перепахали внутрянку той самой функции
Ну вы тоже. P>>>А что мешает это без моков сделать? P>·>Просвети как, с учётом того, что ты предложил использовать Time.now. КОД покажи. P>Time.now будет приходить всегда снаружи. В чем вопрос, объясните?
"Снаружи" это откуда? А проблема в том, что множество мест связки nextFriday с Time.now ты протестировать никикак не можешь. Ещё раз повторюсь: ЧПФ. У тебя его нет. P>>>Проще код, больше контроля. Даже те же моки можно прикрутить безо всяких фремворков. P>·>Почему он проще? Мне показалось ровно наоборот. А моки можно прикручивать без фреймворков в любом случае. Правда количество кода увеличивается. P>С каких пор низкоуровневые приседания стали проще?
Я не знаю что называешь низкоуровневыми приседаниями. P>>>Никуда не испарилась. Все один в один, как и у вас. P>·>В mock({}).whenCalledWith('getTopRestaurants', 'ляляля').returns(restaurants) оно правда сможет вывести типы?! Что-то не верится... P>У Фаулера код на жээсе. Я вам показал на жээсе. Теперь вы придираетесь, что де на Тайпскрипте будет чтото еще. P>Вы все время тратите время на мелкие придирки.
Да, в каком-то смысле мелочи, ок, давай тут подытожим. Твой правильный образцово-показательный по Фаулеру код без использования моков будет выгдяеть вот так:
P>Что теперь, попросите показать как это всё типизуется?
Да, серьёзно, Интересно. Ведь в коде теста никакого AnInterface даже и нет, фаулер за типы топит, которые не export. Автодополнятор вставит строчку 'getTopRestaurants' сам? Найдёт|отрефакторит имя функции и определит типы ляляля параметров? P>>>Это сказки вида "у нас проблем на проде не бывает" P>·>Цитаты нет, ты опять врёшь. Опять свои фантазии помещаешь в кавычки и пытаешься выдать за мои слова. P>Я вам много раз приводил примеры, ради чего нужно запускать такое, но вы упорно видите в этом исключительно доказательство проблем в разработке.
Я-то понял. А ты не понял. Мой поинт в том, что ради этого же самого можно делать другое, более подходящее. Пример с тухлыми сертами ты как-то "забыл", перечитай. P>Тесты на проде нынче вариант нормы.
Верю, сегодня вариант нормы такой. Люди пьют и курят — это тоже норма. P>>>Ну так чего вы конкретно просите показать? P>·>Код на ЯП. Для тебя наверное это новость, но сообщаю: кукумбер — это не яп. P>Это ЯП, декларативный, высокого уровня
Сова трещит по швам. P>>>Или код ревью, или некоторая формализация с последующей генерацией тестов, чтото навроде P>·>Код ревью не укажет на пробелы в требованиях. Формализация — практически анреал, очень редкий зверь. P>Смотря что вам надо. Серебряную пулю — такого нет. Составить список требований, сделать ревью, предложить дизайн, сделать ревью, написать тесты, сделать ревью, написать код, сделать ревью, пофиксить баги, сделать ревью — по моему так всё и делается.
Именно. Вот это всё и ещё маленько — оно может давать гарантию. Тесты же гарантию давать не могут, или ты так своё умение варить кашу из топора демонстрируешь? P>>>Потому я и говорю, что лучше брать время прямо из реквеста. P>·>Что значит "лучше"??! Это будет клиентское время, его можно подделывать. Более того, структура запроса диктуется требованиями внешнего api, а не желанием левой пятки, поэтому там его в принципе может не быть. P>Структура запроса диктуется много чем кроме внешнего апи — протокол, фремворк, рантайм, операционка, итд. Всегда и везде технологических деталей в десятки раз больше чем бизнеслогики. В случае с хттп там разве что кофе не готовится
Опять у тебя какая-то особая терминология. Под запросом я имею в виду данные приходящие от клиентов через внешний апи. Вот то что условный curl посылает — это запрос. P>>>Смотря какой этот один. Если тот, что только сравнивает выхлоп из базы — то нет, слабовато. P>·>Сильнее, чем у тебя, т.к. хотя бы синтаксис запроса проверяют. P>Ну и логика, как набор А, будет сильнее двух наборов А и Б ?
Это у тебя странная интерпретация. На самом деле "набор В, будет сильнее двух наборов А и Б". P>>>Вы неверно понимаете тесты. Сначала вы находите свойство — это происходит в вашей голове. Потом находите, что его надо сохранить между версиям. Это тоже в вашей голове. А вот само сохранение это тест + процесс разработки, что там у вас, код ревью, итд. P>·>Это "свойство" не эквивалентно работоспособности программы. P>Нет такого "проверка работоспособности" — это менеджерский сленг. Есть выполнение сценариев А...Z, тесты для всевозможных ...ility, итд итд P>То есть, находим конкретные свойства, которые покрываем тестами на том или ином уровне, в зависимости от вашего инструментария
Реальным клиентам пофиг что у вас за такие сценарии A...Z и когда они у вас гоняются. Им надо их сценарии.
Картинку что-ли забыл? All tests passed!
P>>>·>Вы не знаете, что такое кукумбер? Забавно. https://www.google.com/search?q=cucumber+glue+code P>>>Здесь будут примитивы вида резервирование, время операции и тд. Что коннкретно вы хотите узнать? P>·>Как выглядит код. P>Зачем?
Чтобы можно было пальчиком тыкнуть где конкретно ты заблуждаешься. P>>>Именно. Только не обязательно приватные методы, это просто методы видимость которых ограничена некоторым модулем или пакетом. P>·>Ты сам заявлял, что эти методы видны только с целью использования их в тестах: "fn1 и fn2 должны быть видны в тестах, а не публично". Т.е. твои тесты тестируют никому более невидимые внутренние кишки реализации. Это — отстой. P>Голословно. Любой большой кусок кода нужно в первую очередь тестировать непосредственно.
Зачем? P>А вы предлагаете всё делать наоборот.
Конечно. Т.к. надо тестировать поведение, а не детали реализацию. Это означает, что можно менять реализацию, не боясь сломать поведение, т.к. существующие тесты должны проходить независимо от реализации. P>>>Т.е. такие тесты это способ снимать инфу с прода в критические моменты, т.к. в дебаге, стейдже итд у вас точно этой инфы не будет. P>>>Не зеленую галку менеджерам показывать, а обнаруживать те вещи, которые в других условиях не видны P>·>Верно, но это не единственный способ. И, мягко говоря, не самый лучший. P>Вероятно у вас — не лучший. Зато куча компаний использует именно такой подход. Он сообщает куда больше проблем, чем ваши точечные пробы.
Большинству компаний и проектов не так важно качество и не такое драконовское SLA, это понятно — надо быстрее прыгать, потому что думать некогда. Но выдавать это как "правильный подход" — так себе.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>·>Не понял, чем отличается 1 от 2? "все виды" это разве не "удалить"+"выгрузить"? P>>Разница в слове "отложенные". У вас недавно была проблема с этим словом. Решилась? ·>У нас такой проблемы не было. Т.е. разницы нет. ЧТД.
Забавный аргумент — у вас чего то там не было Мощный заход, внушает!
> Причём тут обсуждаемый "инлайн nextFriday"? У тебя там Time.now будет константным, да?
Вы зачем то полезли в инлайн строк
P>>Джава компилятор на основании иммутабельности умеет вводить кое какие оптимизации. Строки — одна из таких вещей. ·>Допустим, и причём тут инлайн?
Это вы мне объясните, для чего вам понадобилось инлайнить строки. Это ж ваш аргумент был.
Я вам показал, что с str.length() у нас всё близко к идеалу — компилятор и джит без вас умеют инлайнить не абы как, а практически в константу.
P>>·>Можно, конечно. Но это не происходит непрерывно сто раз на дню как ты тут заявлял выше. Да, возможно раз в месяц надо поискать боттл-нек и как-то порефакторить. P>>"как то" Не как то, а вручную вместо работы компилятором и ИДЕ. ·>Это твои фантазии, или кривая IDE, или неумение ею пользоваться.
Вы пока так и не показали, как будете свой nextFriday инлайнить. Ваш последний аргумент — сбежать в сторону "заинлайни str.length()"
P>>>>Не любое. Изменение конфига сюда не подходит. P>>·>Конфиг это не код. Выделил жирным. P>>А протаскивание такого конфига — тот еще код. Особенно когда это все инжектится ·>"изменение конфига" != "протаскивание конфига".
Весело у вас — изменение конфига не является кодом, изменение дерева депенденсов не является кодом, добавление параметра в конструктор не является кодом...
Что еще у вас кодом не является?
Зато интерфейс с аннотациями без реализации у вас почему то "ужос-ужос это код!!!!111111"
·>Он _вам_ ответил. Его ответ — другое решение, которое и в моём коде тоже реализуется тривиально. Его решение иногда не подойдёт в том, что у него будет latency spike на cache miss. А моё решение с таймером в твоём коде не реализуется, придётся всё везде перелопачивать. ЧТД — мой код универсальнее, не требует изменения дизайна на каждый чих.
Не нужно ничего перелопачивать — будет ровно такая же функция как у Синклера, только кеширование будет иначе сделано.
В этом случае мы основную бл тестируем без изменений — эта функция вообще не изменится. Для неё как были тесты по таблице истинности, так и остались.
P>>Нет, не нужно — функция где БЛ никак не изменилась, ни внутри, ни снаружи. Изменилась исключительно интеграция. ·>Ага, но у тебя интеграции — на каждый вызов nextFriday из множества методов контроллеров. У меня интеграция wiring — ровно одна строчка.
Вам нужно в каждый компонент явно вписывать это как зависимость, и не ошибаться — где клиентское, где серверное, где текущее, где предзаписаное время.
P>>В вашем случае вы перепахали внутрянку той самой функции ·>Ну вы тоже.
Нисколько. Сама функция осталась без изменений. Смотрите пример Синклера внимательно — он вызывает основную функцию, а не модифицирует её.
·>"Снаружи" это откуда? А проблема в том, что множество мест связки nextFriday с Time.now ты протестировать никикак не можешь. Ещё раз повторюсь: ЧПФ. У тебя его нет.
Буквально "вызываем метод с параметром x" — такого не будет. И не нужно. А все, что дает конкретные результаты — будет ровно как у вас.
P>>·>Почему он проще? Мне показалось ровно наоборот. А моки можно прикручивать без фреймворков в любом случае. Правда количество кода увеличивается. P>>С каких пор низкоуровневые приседания стали проще? ·>Я не знаю что называешь низкоуровневыми приседаниями.
Посмотрите внимательно — Фаулер для компонента протаскивает не абы что, репозитории-кеши-итд, а интерфейс взаимодействия
·>Да, в каком-то смысле мелочи, ок, давай тут подытожим. Твой правильный образцово-показательный по Фаулеру код без использования моков будет выгдяеть вот так: ·>
P>>Что теперь, попросите показать как это всё типизуется? ·>Да, серьёзно, Интересно. Ведь в коде теста никакого AnInterface даже и нет
Есть, глаза разуйте. Фаулер конструирует этот самый интерфейс. А раз он есть, то можно и тип оформить.
> , фаулер за типы топит, которые не export. Автодополнятор вставит строчку 'getTopRestaurants' сам? Найдёт|отрефакторит имя функции и определит типы ляляля параметров?
Найдет. Отрефакторит. Определит. В тайпскрипте есть внятный вывод типа, и вы можете вывести тип тупла аргументов метода по его имени, тип возвращаемого значения, итд и тд. А раз есть тип, то у нас будет статический контроль и whenCalledWith, и returns, и много чего другого.
P>>Смотря что вам надо. Серебряную пулю — такого нет. Составить список требований, сделать ревью, предложить дизайн, сделать ревью, написать тесты, сделать ревью, написать код, сделать ревью, пофиксить баги, сделать ревью — по моему так всё и делается. ·>Именно. Вот это всё и ещё маленько — оно может давать гарантию. Тесты же гарантию давать не могут, или ты так своё умение варить кашу из топора демонстрируешь?
Без тестов гарантий никаких не будет. Нужно всё вместе:
1 Код ревью не работает в том случае, когда его можно скипнуть
2 Тесты не работают, когда их можно обойти
Что бы добиваться качества, вам нужно решить обе этих проблемы.
·>Опять у тебя какая-то особая терминология. Под запросом я имею в виду данные приходящие от клиентов через внешний апи. Вот то что условный curl посылает — это запрос.
А я вам про принимающую сторону. Серверное и текущее время вы получаете забесплатно. А клиентское и так придет в виде значения, если у вас в апи так прописано.
P>>Нет такого "проверка работоспособности" — это менеджерский сленг. Есть выполнение сценариев А...Z, тесты для всевозможных ...ility, итд итд P>>То есть, находим конкретные свойства, которые покрываем тестами на том или ином уровне, в зависимости от вашего инструментария ·>Реальным клиентам пофиг что у вас за такие сценарии A...Z и когда они у вас гоняются. Им надо их сценарии.
Забавно — это вы всерьёз покрываете тестами левые сценарии? Или это вам видится, что все вокруг вас дураки?
P>>Зачем? ·>Чтобы можно было пальчиком тыкнуть где конкретно ты заблуждаешься.
Я так понимаю, хорошего примера у вас нет.
P>>Голословно. Любой большой кусок кода нужно в первую очередь тестировать непосредственно. ·>Зачем?
1. чем больше кода между замерами, тем хуже детализация ошибок
2. чем больше косвенность, тем вам труднее покрыть основные пути хоть с какой нибудь детализацией
Это особенности тестов вообще. Потому и убирают лишнее из тестового кода, и тут два основных подхода, оба основаны на отделении эффектов и зависимостей:
1. моки — тот подход, который вам кажется единственно верным, т.е. обрезание, подмена зависимостей и эффектов
Пример — обмазали моками и написали тест "таймер вызывается дважды с такими вот аргументами"
2. классический — вытеснение зависимостей и эффектов в код верхнего уровня
Пример "sin(x) = y"
P>>А вы предлагаете всё делать наоборот. ·>Конечно. Т.к. надо тестировать поведение, а не детали реализацию.
Тестируется как раз наблюдаемое поведение вычислителя фильтров. Вычислитель фильтров обычная чистая функция, в ней ничего военного нет — тестируем как любую чистую функцию.
Здравствуйте, Pauel, Вы писали:
P>>>·>Не понял, чем отличается 1 от 2? "все виды" это разве не "удалить"+"выгрузить"? P>>>Разница в слове "отложенные". У вас недавно была проблема с этим словом. Решилась? P>·>У нас такой проблемы не было. Т.е. разницы нет. ЧТД. P>Забавный аргумент — у вас чего то там не было Мощный заход, внушает!
Ты нафантазировал, что у нас есть проблемы с отложенными вычислениями. Какой ты аргумент ожидаешь на такие фантазии?
>> Причём тут обсуждаемый "инлайн nextFriday"? У тебя там Time.now будет константным, да? P>Вы зачем то полезли в инлайн строк
Я пример привёл, что инлайн сам по себе ни о чём не говорит. Ладно, если тебе строки не устраивают, пусть будет list.length() — с инлайном тоже ничего не выйдет.
P>>>Джава компилятор на основании иммутабельности умеет вводить кое какие оптимизации. Строки — одна из таких вещей. P>·>Допустим, и причём тут инлайн? P>Это вы мне объясните, для чего вам понадобилось инлайнить строки. Это ж ваш аргумент был.
Я объяснил, что метод length инлайнить не выйдет, но это вовсе не оозначает, что это какое-то плохой дизайн и код куда-то как-то прибит.
P>Я вам показал, что с str.length() у нас всё близко к идеалу — компилятор и джит без вас умеют инлайнить не абы как, а практически в константу.
Пусть будет list.length(). Дались тебе эти константы, вообще к теме не относится.
P>>>"как то" Не как то, а вручную вместо работы компилятором и ИДЕ. P>·>Это твои фантазии, или кривая IDE, или неумение ею пользоваться. P>Вы пока так и не показали, как будете свой nextFriday инлайнить. Ваш последний аргумент — сбежать в сторону "заинлайни str.length()"
Ты так и не рассказал с какой целью инлайнить.
P>>>А протаскивание такого конфига — тот еще код. Особенно когда это все инжектится P>·>"изменение конфига" != "протаскивание конфига". P>Весело у вас — изменение конфига не является кодом,
Конфиг это какой-нибудь тупой key=value файлик или около того, или файл с сертом например. Это ты правда это считаешь кодом?
P>изменение дерева депенденсов не является кодом, добавление параметра в конструктор не является кодом...
Является, конечно. И ты это называешь изменением дизайна.
P>Что еще у вас кодом не является?
А что у вас не является изменением дизайна?
P>Зато интерфейс с аннотациями без реализации у вас почему то "ужос-ужос это код!!!!111111"
Опять какая-то твоя больная фантазия. Цитаты ведь не будет как всегда.
P>·>Он _вам_ ответил. Его ответ — другое решение, которое и в моём коде тоже реализуется тривиально. Его решение иногда не подойдёт в том, что у него будет latency spike на cache miss. А моё решение с таймером в твоём коде не реализуется, придётся всё везде перелопачивать. ЧТД — мой код универсальнее, не требует изменения дизайна на каждый чих. P>Не нужно ничего перелопачивать — будет ровно такая же функция как у Синклера, только кеширование будет иначе сделано.
А ты вот потрудись код написать, и опять увидишь что погорячился.
P>В этом случае мы основную бл тестируем без изменений — эта функция вообще не изменится. Для неё как были тесты по таблице истинности, так и остались.
Ну да, у меня тоже. В чём у тебя возникли сложности-то?
P>>>Нет, не нужно — функция где БЛ никак не изменилась, ни внутри, ни снаружи. Изменилась исключительно интеграция. P>·>Ага, но у тебя интеграции — на каждый вызов nextFriday из множества методов контроллеров. У меня интеграция wiring — ровно одна строчка. P>Вам нужно в каждый компонент явно вписывать это как зависимость, и не ошибаться — где клиентское, где серверное, где текущее, где предзаписаное время.
И? Это всё покрыто легковесными тестами, с проверками ожиданий правильности источника времени.
P>>>В вашем случае вы перепахали внутрянку той самой функции P>·>Ну вы тоже. P>Нисколько. Сама функция осталась без изменений. Смотрите пример Синклера внимательно — он вызывает основную функцию, а не модифицирует её.
Ты либо его код не понял, либо мой. Основная функция расчётов у него "SlowlyCalculatePrevAndNextFridays", у меня "doSomeComputations".
Да, кстати, у его решения ещё один огромный недостаток. Его реализация неявно подразумевает, что передаваемый "DateTime dt" это DateTime.Now, т.е. плавно изменяющийся параметр, только тогда кеш будет пересчитываться раз в неделю. Кто-то видя сигнатуру nextFriday(DateTime dt) — запросто может позвать её с чем попало, выкашивая кеш в самые неожиданные моменты времени. Отличная такая грабля будущим поколениям, happy debugging. Более того, чтобы даже просто начать такую оптимизацию метода — надо будет исследовать все call sites и удостовериться что туда передаётся именно текущее время, иначе кеш может быть бессмысленным, а в большом проекте эта штука может жить в шаред либе и задача вообще практически неразрешимой становится.
В моём же случае, nextFriday() явно запрещает туда передать что-то не то. Знание об источнике времени тут есть явно. И такие оптимизации делать становится гораздо проще, с более предсказуемым импактом. Иными словами, мы знаем конкретный применённый аргумент ЧПФ и эту информацию фиксируем явно и можем использовать.
P>·>"Снаружи" это откуда? А проблема в том, что множество мест связки nextFriday с Time.now ты протестировать никикак не можешь. Ещё раз повторюсь: ЧПФ. У тебя его нет. P>Буквально "вызываем метод с параметром x" — такого не будет. И не нужно. А все, что дает конкретные результаты — будет ровно как у вас.
Я это и не спрашивал. Я спрашивал "результат зависит от Time.now", а не от чего-то ещё. C Time.now ты не можешь получить "конкретный результат", по определению.
P>>>С каких пор низкоуровневые приседания стали проще? P>·>Я не знаю что называешь низкоуровневыми приседаниями. P>Посмотрите внимательно — Фаулер для компонента протаскивает не абы что, репозитории-кеши-итд, а интерфейс взаимодействия
Просто выражено в терминах явы-шарпов "интерфейс с одним методом". getTopRestaurants — это и есть репозиторий по сути. Для ts оно ок наверное, но в яву-шарп такое лучше не тащить.
P>·>Я правильно понял? P>Чтото навроде, примерно так же и у вас.
Ок. Круто, договорились, наконец-то. Теперь расскажи, как в твоей голове согласуется "код без использования моков" и "mock<AnInterface>"?
P>>>
P>>>Что теперь, попросите показать как это всё типизуется? P>·>Да, серьёзно, Интересно. Ведь в коде теста никакого AnInterface даже и нет P>Есть, глаза разуйте. Фаулер конструирует этот самый интерфейс. А раз он есть, то можно и тип оформить.
Я не вижу, ткни в строчку кода. Откуда ты возьмёшь AnInterface тут?
>> , фаулер за типы топит, которые не export. Автодополнятор вставит строчку 'getTopRestaurants' сам? Найдёт|отрефакторит имя функции и определит типы ляляля параметров? P>Найдет. Отрефакторит. Определит. В тайпскрипте есть внятный вывод типа, и вы можете вывести тип тупла аргументов метода по его имени, тип возвращаемого значения, итд и тд. А раз есть тип, то у нас будет статический контроль и whenCalledWith, и returns, и много чего другого.
Круто, если так. Но ни шарп, ни ява так не умеет. Там такое просто не прокатит.
P>>>Смотря что вам надо. Серебряную пулю — такого нет. Составить список требований, сделать ревью, предложить дизайн, сделать ревью, написать тесты, сделать ревью, написать код, сделать ревью, пофиксить баги, сделать ревью — по моему так всё и делается. P>·>Именно. Вот это всё и ещё маленько — оно может давать гарантию. Тесты же гарантию давать не могут, или ты так своё умение варить кашу из топора демонстрируешь? P>Без тестов гарантий никаких не будет.
Да и в той притче каши без топора таки не было.
P>Нужно всё вместе: P>1 Код ревью не работает в том случае, когда его можно скипнуть P>2 Тесты не работают, когда их можно обойти P>Что бы добиваться качества, вам нужно решить обе этих проблемы.
Угу. И?
P>·>Опять у тебя какая-то особая терминология. Под запросом я имею в виду данные приходящие от клиентов через внешний апи. Вот то что условный curl посылает — это запрос. P>А я вам про принимающую сторону. Серверное и текущее время вы получаете забесплатно.
Допустим. Вопрос-то как проверить, что именно нужный источник времени используется где-то там для расчёта каких-то результатов?
P>А клиентское и так придет в виде значения, если у вас в апи так прописано.
curl генерит клиентское время сам где-то там внутре.
P>·>Реальным клиентам пофиг что у вас за такие сценарии A...Z и когда они у вас гоняются. Им надо их сценарии. P>Забавно — это вы всерьёз покрываете тестами левые сценарии? Или это вам видится, что все вокруг вас дураки?
Тестовые сценарии != реальные сценарии.
P>>>Зачем? P>·>Чтобы можно было пальчиком тыкнуть где конкретно ты заблуждаешься. P>Я так понимаю, хорошего примера у вас нет.
Примера чего?
P>>>Голословно. Любой большой кусок кода нужно в первую очередь тестировать непосредственно. P>·>Зачем? P>1. чем больше кода между замерами, тем хуже детализация ошибок P>2. чем больше косвенность, тем вам труднее покрыть основные пути хоть с какой нибудь детализацией
Для этого и используют разделение на юниты и юнит-тестирование. А моками отрезаются комбинации деталей.
P>Это особенности тестов вообще. Потому и убирают лишнее из тестового кода, и тут два основных подхода, оба основаны на отделении эффектов и зависимостей: P>1. моки — тот подход, который вам кажется единственно верным, т.е. обрезание, подмена зависимостей и эффектов
Не то, что единственно верный, но практически неизбежный в достаточно сложной программе.
P>Пример — обмазали моками и написали тест "таймер вызывается дважды с такими вот аргументами"
Тебе уже двое раз 30 раз повторили — что так делать не надо.
P>2. классический — вытеснение зависимостей и эффектов в код верхнего уровня P>Пример "sin(x) = y"
Это работает только на хоумпейджах. Чуть сложнее и внезапно выяснится что там этих самых верхних уровней штук пять.
А 3. где? В Ложную Дилемму поиграть решил?
P>>>А вы предлагаете всё делать наоборот. P>·>Конечно. Т.к. надо тестировать поведение, а не детали реализацию. P>Тестируется как раз наблюдаемое поведение вычислителя фильтров. Вычислитель фильтров обычная чистая функция, в ней ничего военного нет — тестируем как любую чистую функцию.
Проблема в том, что ты её адекватно протетсировать не можешь. Ассертить имена приватных функций и буквальные тексты запроса — такие тесты — бессмысленные и беспощадные.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали: ·>Да, кстати, у его решения ещё один огромный недостаток. Его реализация неявно подразумевает, что передаваемый "DateTime dt" это DateTime.Now, т.е. плавно изменяющийся параметр, только тогда кеш будет пересчитываться раз в неделю. Кто-то видя сигнатуру nextFriday(DateTime dt) — запросто может позвать её с чем попало, выкашивая кеш в самые неожиданные моменты времени. Отличная такая грабля будущим поколениям, happy debugging. Более того, чтобы даже просто начать такую оптимизацию метода — надо будет исследовать все call sites и удостовериться что туда передаётся именно текущее время, иначе кеш может быть бессмысленным, а в большом проекте эта штука может жить в шаред либе и задача вообще практически неразрешимой становится.
Это работает не совсем так.
Смотрите, любая оптимизация начинается с профилирования и им же заканчивается.
То есть перед тем, как что-то на что-то менять, мы берём и снимаем профиль.
И вот когда мы по профилю видим, что эта функция становится bottleneck, тогда мы и начинаем её оптимизировать.
Когда мы её оптимизируем, мы, конечно же, смотрим на характер нагрузки. Если у нас там приходит небольшое количество одинаковых значений — мы оборачиваем функцию в memoize, проверяем результат, и едем разгребать следующую таску из джиры.
Если у нас вот такой вот монотонно меняющийся параметр — мы оборачиваем функцию вот в такой вот специализированный "memoize", проверяем результат, и едем разгребать следующую таску из джиры.
Если у нас в проде меняется характер нагрузки, то мы
а) определяем это не на глазок, а при помощи мониторинга метрик
б) повторяем профилирование и смотрим, откуда взялся новый боттлнек
в) если оказалось, что сделанные ранее предположения неверны, то мы откатываем оптимизацию и начинаем цикл заново.
Сам подход работает совершенно независимо от выбранной архитектуры — ФП, ПП, или ООП. Но у вас, похоже, возникает иллюзия, что вы можете написать реализацию, которая будет не просто оптимальна, но и устойчива ко всем будущим изменениям характера нагрузки.
Нет, так не получится. Потому, к примеру, что у вас нет гарантий на монотонность применяемого источника времени. Если она есть у вас — то она есть и у вашего оппонента, и оптимизация сработает.
Если есть квазимонотонность — то сработает чуть более сложный алгоритм. Если монотонности нету — то ваш код точно так же встрянет, и будет работать ещё медленнее, чем без кэширования. ·>В моём же случае, nextFriday() явно запрещает туда передать что-то не то.
Это иллюзия. Вот у нас есть "фактическое время" клиента, "фактическое время" сервера. А есть ещё "время по документу клиента". Который в понедельник принёс платёжку за прошлый четверг.
Ну и всё — вы в свой алгоритм nextFriday вынуждены воткнуть зависимость от источника времени, который просто парсит переданный с клиента JSON и возвращает то, что там нашлось.
Отличная такая грабля будущим поколениям, happy debugging.
·>Знание об источнике времени тут есть явно. И такие оптимизации делать становится гораздо проще, с более предсказуемым импактом. Иными словами, мы знаем конкретный применённый аргумент ЧПФ и эту информацию фиксируем явно и можем использовать.
Ну так и мы знаем конкретный применённый аргумент, и явно фиксируем эту информацию. Только она не спрятана внутрь вашего класса с методом nextFriday, а применена по месту использования.
Поэтому в одном месте будет прямой вызов nextFriday, а в другом — вызов функции, полученной при помощи wrapAndCacheMonotonous(nextFriday).
При этом поведение wrapAndCacheMonotonous(nextFriday) мы тестируем тем же набором тестов, что и саму nextFriday (т.к. у них одинаковый контракт). И нам не нужны никакие моки, которые изображают поведение часов.
P>>·>"Снаружи" это откуда? А проблема в том, что множество мест связки nextFriday с Time.now ты протестировать никикак не можешь.
Положа руку на сердце: сколько таких мест вы ожидаете в крупном проекте? Три, пять?
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Sinclair, Вы писали:
S>·>Да, кстати, у его решения ещё один огромный недостаток. Его реализация неявно подразумевает, что передаваемый "DateTime dt" это DateTime.Now, т.е. плавно изменяющийся параметр, только тогда кеш будет пересчитываться раз в неделю. Кто-то видя сигнатуру nextFriday(DateTime dt) — запросто может позвать её с чем попало, выкашивая кеш в самые неожиданные моменты времени. Отличная такая грабля будущим поколениям, happy debugging. Более того, чтобы даже просто начать такую оптимизацию метода — надо будет исследовать все call sites и удостовериться что туда передаётся именно текущее время, иначе кеш может быть бессмысленным, а в большом проекте эта штука может жить в шаред либе и задача вообще практически неразрешимой становится. S>Это работает не совсем так. S>Смотрите, любая оптимизация начинается с профилирования и им же заканчивается. S>То есть перед тем, как что-то на что-то менять, мы берём и снимаем профиль. S>И вот когда мы по профилю видим, что эта функция становится bottleneck, тогда мы и начинаем её оптимизировать. S>Когда мы её оптимизируем, мы, конечно же, смотрим на характер нагрузки. Если у нас там приходит небольшое количество одинаковых значений — мы оборачиваем функцию в memoize, проверяем результат, и едем разгребать следующую таску из джиры.
У меня будет изначально nextFriday() — с которой всё просто, характер "главного" параметра ЧПФ известен. Поэтому такой проблемы не будет в принципе, функция в местах использования одна — вариант использования один, параметров нет.
Конечно, если в моём случае вдруг возникнет необходимость посчитать nextFriday(platezhka.date) — тогда мне придётся ввести новую функцию (новую, т.е. менять ничего не приходится, от чего так страдает Pauel с его постоянными изменениями дизайна) и она будет отдельной и там уже будем посмотреть где что как анализировать и оптимизировать, нужно ли кешировать, если нужно то как.
В твоём случае же решение хоть более универсальное, но за универсальность нужно платить. Ты исходишь из изначально неудачно задизайненного случая. У тебя есть некая универсальная nextFriday(someDay) хотя она везде по факту (вроде бы... надо тщательно проверять по всему коду!), используется только как nextFriday(now), ну значит давайте просто сунем в wrapAndCacheMonotonous, да закроем джиру. Ура. Но знание о том, что этот кеш требует определённый характер значений параметра — нигде в коде не зафиксировано; и когда в следующей джире через год потребуется nextFriday(platezhka.date) — просто так и напишут, проблему обнаружат только потом, когда заметят что кеш теряется в неожиданные моменты времени, придётся искать в мониторинге и метриках корреляцию между внезапными провалами в производительности и запросами, когда клиент приходит со слишком старой платёжкой, что случается только после дождичка в четверг в полнолуние. Happy debugging.
S>Сам подход работает совершенно независимо от выбранной архитектуры — ФП, ПП, или ООП. Но у вас, похоже, возникает иллюзия, что вы можете написать реализацию, которая будет не просто оптимальна, но и устойчива ко всем будущим изменениям характера нагрузки.
Нет, я просто не стараюсь писать универсальные всемогутеры, а ровно то, что требуется для решения конкретной задачи, ну может ещё немного в соответствии с достаточно очевидными прогнозами на будущее. Ясновидец из меня никудышный, поэтому приходится выдавать решение из того что известно сейчас, а не для того, что случиться в будущем, я лучше потом порефакторю.
S>Нет, так не получится. Потому, к примеру, что у вас нет гарантий на монотонность применяемого источника времени. Если она есть у вас — то она есть и у вашего оппонента, и оптимизация сработает.
Я не про монотонность, а про то, что в nextFriday(x) — есть степень свободы что передавать в качестве x — и приходится делать предположения и анализ что может быть этим x во всём коде. В моём случае у меня явное ЧПФ nextFriday = () => nextFriday(timeSource.now()), зафиксированно знание о том, что же может быть этим самым x есть более широкий простор для оптимизаций.
S>·>В моём же случае, nextFriday() явно запрещает туда передать что-то не то. S>Это иллюзия. Вот у нас есть "фактическое время" клиента, "фактическое время" сервера. А есть ещё "время по документу клиента". Который в понедельник принёс платёжку за прошлый четверг. S>Ну и всё — вы в свой алгоритм nextFriday вынуждены воткнуть зависимость от источника времени, который просто парсит переданный с клиента JSON и возвращает то, что там нашлось. S>Отличная такая грабля будущим поколениям, happy debugging.
Вот когда появится бизнес-требование обработки старых платёжек, тогда можно будет отрефакторить, добавив новую функцию nextFriday(someDay) или даже вообще сразу ЧПФ nextFriday(platezhka).
S>·>Знание об источнике времени тут есть явно. И такие оптимизации делать становится гораздо проще, с более предсказуемым импактом. Иными словами, мы знаем конкретный применённый аргумент ЧПФ и эту информацию фиксируем явно и можем использовать. S>Ну так и мы знаем конкретный применённый аргумент, и явно фиксируем эту информацию. Только она не спрятана внутрь вашего класса с методом nextFriday, а применена по месту использования. S>Поэтому в одном месте будет прямой вызов nextFriday, а в другом — вызов функции, полученной при помощи wrapAndCacheMonotonous(nextFriday). S>При этом поведение wrapAndCacheMonotonous(nextFriday) мы тестируем тем же набором тестов, что и саму nextFriday (т.к. у них одинаковый контракт). И нам не нужны никакие моки, которые изображают поведение часов.
Ну как выяснили, немного меняется синтаксис в коде теста, больше разницы никакой. Т.е. первый параметр ЧПФ идёт "особым" образом, остальное всё то же самое.
P>>>·>"Снаружи" это откуда? А проблема в том, что множество мест связки nextFriday с Time.now ты протестировать никикак не можешь. S>Положа руку на сердце: сколько таких мест вы ожидаете в крупном проекте? Три, пять?
Не очень понял что ты именно спрашиваешь, ясен пень, что nextFriday я вообще считаю такого не будет нигде. Аналогом могу придумать например бизнес-понятие tradeDate() — текущий торговый день биржи. Который обычно переключается раз в сутки, зависит от системный часов, таймзоны биржи, официального времени работы с учётом праздников, т.е. вычисление не очень тривиально, но значение используется очень часто и из разных мест, в т.ч. и latency sensitive.
Иметь синглтон static-кеш как у тебя — просто недопустимо, т.к. торговая система может работать с толпой разных бирж.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
·>У меня будет изначально nextFriday() — с которой всё просто, характер "главного" параметра ЧПФ известен. Поэтому такой проблемы не будет в принципе, функция в местах использования одна — вариант использования один, параметров нет.
Ну как же. У вас с самого начала нельзя внутри nextFriday вызывать now() — потому что тогда вы не сможете её даже протестировать.
Вам сходу придётся реализовывать концепт тайм-провайдера, и как-то привязывать его к вашей nextFriday().
Дальше проблемы начинают собираться в снежный ком — потому, что при малейшем изменении требований вам придётся изобретать очередной изящный способ подсунуть в nextFriday() правильный провайдер времени.
На первый взгляд кажется, что это как раз даёт вам нужную гибкость — типа сама по себе nextFriday() у вас одна и та же, и вы там каким-нибудь DI-конфигом подсовываете ей то обычный DateTime.now(), то Request.ArriveTime, то Request.SubmitTime, то ещё какой-нибудь Request.Document.SignOffTime.
Но на практике это превращается в we wish you a happy debugging, потому что конфиги теперь становятся частью решения, а для них нет ни средств рефакторинга, ни измерения тестового покрытия.
В итоге рано или поздно замена одного провайдера времени на другого, отлаженная на стейджинге, не доезжает до прода, и упс.
Либо вы выкидываете к хренам конфиги, и возвращаетесь к инициализации зависимостей в коде — прямо в контроллере.
То есть вместо того, чтобы полагаться на NextFridayProvider, которого вам дали снаружи, и на то, что в него засунули нужный вам TimeSource, вы просто пишете
var nfp = new NextFridayProvider(new TimeSources.RequestSendTimeSource(this.request));
nfp.NextFriday();
И в итоге вы получаете ровно ту же топологию решения, как и в ФП, вид сбоку. Преимуществ от вашего подхода уже никаких не осталось; остались только недостатки — усложнение тестирования.
В частности, у вас дизайн кэширования может нечаянно положиться на монотонность timeSource, которая в терминах ООП-контрактов невыразима, и вы это никак не обнаружите.
Потому что мок timeSource, с которым вы тестируете, совершенно случайно будет монотонным.
·>Конечно, если в моём случае вдруг возникнет необходимость посчитать nextFriday(platezhka.date) — тогда мне придётся ввести новую функцию (новую, т.е. менять ничего не приходится, от чего так страдает Pauel с его постоянными изменениями дизайна) и она будет отдельной и там уже будем посмотреть где что как анализировать и оптимизировать, нужно ли кешировать, если нужно то как.
Тут вы попадаете в ловушку. Как раз у Pauel никакого изменения дизайна не случится, потому что у него nextFriday с самого начала имела нужную ему сигнатуру.
А вы теперь будете вынуждены продублировать код nextFriday — ну, либо всё же перенести его в новую nextFriday, а старую переделать на вызов новой. Что влечёт за собой не только тестирование новой функции, но и перетестирование и старой.
Оба варианта выглядят так себе, если честно. И это — только одна крошечная функция. В более сложных случаях вы будете тонуть в моках, при этом никак не улучшая качество тестирования.
Да, кстати, забыл спросить — вы же там к своему кэшу собирались таймер приделать, если я не ошибаюсь? А это вы как собираетесь тестировать — будете сидеть каждый раз в ожидании пятницы?
Или там будет ещё один mock?
·>В твоём случае же решение хоть более универсальное, но за универсальность нужно платить. Ты исходишь из изначально неудачно задизайненного случая. У тебя есть некая универсальная nextFriday(someDay) хотя она везде по факту (вроде бы... надо тщательно проверять по всему коду!), используется только как nextFriday(now), ну значит давайте просто сунем в wrapAndCacheMonotonous, да закроем джиру.
Нет, это работает не так. Я же вроде вам написал простую пошаговую инструкцию. Повторю на всякий случай: мы НЕ пишем универсальную политику кэширования.
Начинается всё не с того, что у нас там "везде по факту". А с того, что у нас есть конкретный запрос, который выходит за рамки нормативов. Мы профилируем его, и если видим, что боттлнек — именно в вызове nextFriday, мы в этом конкретном месте пишем
nextFriday = wrapAndCacheMonotonous(nextFriday);
Всё. У нас нет множества хрупких связей, где потянув за одну мы разрушаем всё здание. У нас всё плоское и простое. Нет регрессии остального кода, его не нужно перетестировать. Корректность wrapAndCacheMonotonous проверяется набором юнит-тестов, которые никак не зависят от текущего таймстемпа, и вообще отрабатывают за миллисекунды.
·>Ура. Но знание о том, что этот кеш требует определённый характер значений параметра — нигде в коде не зафиксировано; и когда в следующей джире через год потребуется nextFriday(platezhka.date) — просто так и напишут, проблему обнаружат только потом, когда заметят что кеш теряется в неожиданные моменты времени, придётся искать в мониторинге и метриках корреляцию между внезапными провалами в производительности и запросами, когда клиент приходит со слишком старой платёжкой, что случается только после дождичка в четверг в полнолуние. Happy debugging.
Вот видите, сколько неверных выводов вы сделали из неверных предпосылок.
·>Нет, я просто не стараюсь писать универсальные всемогутеры, а ровно то, что требуется для решения конкретной задачи, ну может ещё немного в соответствии с достаточно очевидными прогнозами на будущее. Ясновидец из меня никудышный, поэтому приходится выдавать решение из того что известно сейчас, а не для того, что случиться в будущем, я лучше потом порефакторю.
Это всё верно, вот только смысла при этом увлекаться stateful-дизайном нет никакого. А stateless и в тестировании проще, и в последующем рефакторинге. В частности, у вас кэширование приходится тащить внутрь nextFriday, а в ФП оно прекрасно сидит снаружи.
·>Я не про монотонность, а про то, что в nextFriday(x) — есть степень свободы что передавать в качестве x — и приходится делать предположения и анализ что может быть этим x во всём коде. В моём случае у меня явное ЧПФ nextFriday = () => nextFriday(timeSource.now()), зафиксированно знание о том, что же может быть этим самым x есть более широкий простор для оптимизаций.
Ну нет конечно. Вы же не зафиксировали, что такое у вас timeSource. Единственный способ гарантировать, что у вас там именно now() со всеми его свойствами (кстати, монотонность к их числу не относится ) — это выкинуть timeSource и написать прямо DateTime.Now. Но так нельзя — будут проблемы с тестированием; поэтому придумываем timeSource. Но вы никак степень свободы не изменили — вы просто отложили проблему на один уровень дальше по стеку. Достаточно написать новую реализацию ITimeSource, которая ведёт себя не так, как ваш мок, как ваш код запросто сломается. Причём самое клёвое — так это то, что вы эту сломанность никакими тестами не обнаружите Только по жалобам клиентов в продакшне.
·>Вот когда появится бизнес-требование обработки старых платёжек, тогда можно будет отрефакторить, добавив новую функцию nextFriday(someDay) или даже вообще сразу ЧПФ nextFriday(platezhka).
Вы предлагаете всё более и более плохие решения. В частности, nextFriday(platezhka), где алгоритмы вычисления границ недели (неизменные примерно с 14 века) смешиваются с подробностями реализации конкретного бизнес-документа. Это — прямо канонический пример того, как делать не надо. Вы минимизируете повторную используемость кода, увеличивая coupling и снижая cohesion.
S>>Положа руку на сердце: сколько таких мест вы ожидаете в крупном проекте? Три, пять? ·>Не очень понял что ты именно спрашиваешь, ясен пень, что nextFriday я вообще считаю такого не будет нигде. Аналогом могу придумать например бизнес-понятие tradeDate() — текущий торговый день биржи. Который обычно переключается раз в сутки, зависит от системный часов, таймзоны биржи, официального времени работы с учётом праздников, т.е. вычисление не очень тривиально, но значение используется очень часто и из разных мест, в т.ч. и latency sensitive.
Прекрасный пример. ·>Иметь синглтон static-кеш как у тебя — просто недопустимо, т.к. торговая система может работать с толпой разных бирж.
Ну так нам и кэш будет не нужен.
Просто во всех местах, где нам нужен tradeDate, мы включаем его в сигнатуру функций, и скармливаем снаружи. И код, который процессит ордер, так и написан processExchangeOrder(order, exchange.tradeDate).
Что, в частности, позволяет нам лёгким движением руки выполнить replay пятничной сессии в понедельник, если в коде биржи обнаружилась ошибка и мы вынуждены аннулировать результаты торгов.
Вообще, практически 100% бизнес-кода, в котором есть прямые вызовы DateTime.Now() — это просто ошибка, которая ждёт своего момента. Но это так, уже беллетристика.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Sinclair, Вы писали:
S>·>У меня будет изначально nextFriday() — с которой всё просто, характер "главного" параметра ЧПФ известен. Поэтому такой проблемы не будет в принципе, функция в местах использования одна — вариант использования один, параметров нет. S>Ну как же. У вас с самого начала нельзя внутри nextFriday вызывать now() — потому что тогда вы не сможете её даже протестировать. S>Вам сходу придётся реализовывать концепт тайм-провайдера, и как-то привязывать его к вашей nextFriday().
Не знаю о чём ты тут говоришь. Выше по топику у меня был код тестов.
S>Дальше проблемы начинают собираться в снежный ком — потому, что при малейшем изменении требований вам придётся изобретать очередной изящный способ подсунуть в nextFriday() правильный провайдер времени.
Ну перечитай топик что-ли.
S>На первый взгляд кажется, что это как раз даёт вам нужную гибкость — типа сама по себе nextFriday() у вас одна и та же, и вы там каким-нибудь DI-конфигом подсовываете ей то обычный DateTime.now(), то Request.ArriveTime, то Request.SubmitTime, то ещё какой-нибудь Request.Document.SignOffTime.
Разговор об этом не шел. Был именно "серверное время". Вот _если_ у меня появится требование с Request.Document.SignOffTime, вот тогда я и введу nextFriday(someDay), я же это уже написал ~час назад. Это вопрос автоматического рефакторинга "extract method" и нескольких минут от силы. Зато вся эта ботва с кешами и оптимизациями — будет видна как на ладони.
S>Но на практике это превращается в we wish you a happy debugging, потому что конфиги теперь становятся частью решения, а для них нет ни средств рефакторинга, ни измерения тестового покрытия.
Какие конфиги?
S>В итоге рано или поздно замена одного провайдера времени на другого, отлаженная на стейджинге, не доезжает до прода, и упс. S>Либо вы выкидываете к хренам конфиги, и возвращаетесь к инициализации зависимостей в коде — прямо в контроллере.
Зависимости собираются в Composition Root. Тоже уже обсуждалось.
S>То есть вместо того, чтобы полагаться на NextFridayProvider, которого вам дали снаружи, и на то, что в него засунули нужный вам TimeSource, вы просто пишете S>
S>var nfp = new NextFridayProvider(new TimeSources.RequestSendTimeSource(this.request));
S>nfp.NextFriday();
S>
S>И в итоге вы получаете ровно ту же топологию решения, как и в ФП, вид сбоку. Преимуществ от вашего подхода уже никаких не осталось; остались только недостатки — усложнение тестирования.
Ты почему-то решил, что добавить параметр в NextFriday является какой-то проблемой. Совсем наоборот — добавить просто, т.к. это новое требование и новый код. Убрать или зафиксировать — сложнее, т.к. надо исследовать все варианты и места использования во всём существующем коде.
Да даже с таким кодом — я не понял где тут усложнение тестирования. В худшем случае пара лишних new, которые наверняка вырежутся оптимизатором.
S>В частности, у вас дизайн кэширования может нечаянно положиться на монотонность timeSource, которая в терминах ООП-контрактов невыразима, и вы это никак не обнаружите.
Она выразима в сигнатуре метода nextFriday() — в call sites не надо заботиться от timeSource. Об этом уже позаботились за меня, заинжектили всё готовенькое. Inversion Of Control.
Если ты имеешь в виду как выражать свойства самого timeSource — в терминах ООП будет другой тип MonotonicTimeSource. И конструктор|фабрика NextFridayProvider может для разых подтипов TimeSource выбирать разные подходы к кешированию.
S>Потому что мок timeSource, с которым вы тестируете, совершенно случайно будет монотонным.
Что значит случайно? Это тестами покрывается.
S>·>Конечно, если в моём случае вдруг возникнет необходимость посчитать nextFriday(platezhka.date) — тогда мне придётся ввести новую функцию (новую, т.е. менять ничего не приходится, от чего так страдает Pauel с его постоянными изменениями дизайна) и она будет отдельной и там уже будем посмотреть где что как анализировать и оптимизировать, нужно ли кешировать, если нужно то как. S>Тут вы попадаете в ловушку. Как раз у Pauel никакого изменения дизайна не случится, потому что у него nextFriday с самого начала имела нужную ему сигнатуру. S>А вы теперь будете вынуждены продублировать код nextFriday — ну, либо всё же перенести его в новую nextFriday, а старую переделать на вызов новой.
Аж два рефакторинга "extract method", "move method". Всё. 2 минуты времени.
S>Что влечёт за собой не только тестирование новой функции, но и перетестирование и старой.
Тесты как проходили, так и будут проходить. Впрочем, наверное после этого стоит тесты перенести тоже, для красоты.
S>Оба варианта выглядят так себе, если честно. И это — только одна крошечная функция. В более сложных случаях вы будете тонуть в моках, при этом никак не улучшая качество тестирования. S>Да, кстати, забыл спросить — вы же там к своему кэшу собирались таймер приделать, если я не ошибаюсь? А это вы как собираетесь тестировать — будете сидеть каждый раз в ожидании пятницы? S>Или там будет ещё один mock?
Да. Таймеры мочить надо в любом случае. Иначе как _вы_ это будете тестировать? Деплоить всё на сервера и ждать пятницы? Или системные часы в операционке перематывать?
Я, конечно, имею в виду, что мы оба сравниваем одинаковые подходы с обновлением кеша по таймеру. Твой подход с обновлением кеша в момент первого вызова я тоже могу реализовать, без использования таймеров естественно. Но это не универсальный всемогутер, операционные недостатки такого подхода я уже упомянул.
S>·>В твоём случае же решение хоть более универсальное, но за универсальность нужно платить. Ты исходишь из изначально неудачно задизайненного случая. У тебя есть некая универсальная nextFriday(someDay) хотя она везде по факту (вроде бы... надо тщательно проверять по всему коду!), используется только как nextFriday(now), ну значит давайте просто сунем в wrapAndCacheMonotonous, да закроем джиру. S>Нет, это работает не так. Я же вроде вам написал простую пошаговую инструкцию. Повторю на всякий случай: мы НЕ пишем универсальную политику кэширования. S>Начинается всё не с того, что у нас там "везде по факту". А с того, что у нас есть конкретный запрос, который выходит за рамки нормативов. Мы профилируем его, и если видим, что боттлнек — именно в вызове nextFriday, мы в этом конкретном месте пишем S>
S>Всё. У нас нет множества хрупких связей, где потянув за одну мы разрушаем всё здание. У нас всё плоское и простое. Нет регрессии остального кода, его не нужно перетестировать. Корректность wrapAndCacheMonotonous проверяется набором юнит-тестов, которые никак не зависят от текущего таймстемпа, и вообще отрабатывают за миллисекунды.
Я же показал где хрупкость связи. До строчки nextFriday = wrapAndCacheMonotonous(nextFriday); писать nextFriday(platezhka.date) можно, а после только nextFriday(Time.Now) и больше никак. И факт этот никак в коде не выражен.
S>Вот видите, сколько неверных выводов вы сделали из неверных предпосылок.
Может ты не понял что я имею в виду.
S>·>Нет, я просто не стараюсь писать универсальные всемогутеры, а ровно то, что требуется для решения конкретной задачи, ну может ещё немного в соответствии с достаточно очевидными прогнозами на будущее. Ясновидец из меня никудышный, поэтому приходится выдавать решение из того что известно сейчас, а не для того, что случиться в будущем, я лучше потом порефакторю. S>Это всё верно, вот только смысла при этом увлекаться stateful-дизайном нет никакого. А stateless и в тестировании проще, и в последующем рефакторинге. В частности, у вас кэширование приходится тащить внутрь nextFriday, а в ФП оно прекрасно сидит снаружи. Открой для себя паттерн Декоратор.
Насчёт stateless я не спорю, тут полностью согласен. Но не всегда есть такая роскошь.
S>·>Я не про монотонность, а про то, что в nextFriday(x) — есть степень свободы что передавать в качестве x — и приходится делать предположения и анализ что может быть этим x во всём коде. В моём случае у меня явное ЧПФ nextFriday = () => nextFriday(timeSource.now()), зафиксированно знание о том, что же может быть этим самым x есть более широкий простор для оптимизаций. S>Ну нет конечно. Вы же не зафиксировали, что такое у вас timeSource. Единственный способ гарантировать, что у вас там именно now() со всеми его свойствами (кстати, монотонность к их числу не относится ) — это выкинуть timeSource и написать прямо DateTime.Now. Но так нельзя — будут проблемы с тестированием; поэтому придумываем timeSource. Но вы никак степень свободы не изменили — вы просто отложили проблему на один уровень дальше по стеку. Достаточно написать новую реализацию ITimeSource, которая ведёт себя не так, как ваш мок, как ваш код запросто сломается. Причём самое клёвое — так это то, что вы эту сломанность никакими тестами не обнаружите Только по жалобам клиентов в продакшне.
S>·>Вот когда появится бизнес-требование обработки старых платёжек, тогда можно будет отрефакторить, добавив новую функцию nextFriday(someDay) или даже вообще сразу ЧПФ nextFriday(platezhka). S>Вы предлагаете всё более и более плохие решения. В частности, nextFriday(platezhka), где алгоритмы вычисления границ недели (неизменные примерно с 14 века) смешиваются с подробностями реализации конкретного бизнес-документа. Это — прямо канонический пример того, как делать не надо. Вы минимизируете повторную используемость кода, увеличивая coupling и снижая cohesion.
Это называется code reuse. Если у меня в 100 местах нужно посчитать nextFriday для платёжки, то я заведу именно такой метод nextFriday(platezhka), а не буду в 100 местах копипастить nextFriday(platezhka.date). Потому что в моей системе в первую очередь важны бизнес-документы, а не алгоритмы 14го века.
S>>>Положа руку на сердце: сколько таких мест вы ожидаете в крупном проекте? Три, пять? S>·>Не очень понял что ты именно спрашиваешь, ясен пень, что nextFriday я вообще считаю такого не будет нигде. Аналогом могу придумать например бизнес-понятие tradeDate() — текущий торговый день биржи. Который обычно переключается раз в сутки, зависит от системный часов, таймзоны биржи, официального времени работы с учётом праздников, т.е. вычисление не очень тривиально, но значение используется очень часто и из разных мест, в т.ч. и latency sensitive. S>Прекрасный пример. S>·>Иметь синглтон static-кеш как у тебя — просто недопустимо, т.к. торговая система может работать с толпой разных бирж. S>Ну так нам и кэш будет не нужен. S>Просто во всех местах, где нам нужен tradeDate, мы включаем его в сигнатуру функций, и скармливаем снаружи. И код, который процессит ордер, так и написан processExchangeOrder(order, exchange.tradeDate).
Нет. Метод, который процессит ордер будет выглядеть примерно так processMessage(ByteBuffer order) и зваться напрямую из сетевого стека. Откуда в сетевом стеке возьмётся вся эта инфа о биржах — я не знаю. Сетевой стек тупой — пришёл пакет из сокета X, дёргаем метод у привязанного к этому сокету messageHandler.
S>Что, в частности, позволяет нам лёгким движением руки выполнить replay пятничной сессии в понедельник, если в коде биржи обнаружилась ошибка и мы вынуждены аннулировать результаты торгов.
Для этого просто подменяется timeSource. Во время replay он будет не system clock, а timestamp из event log.
S>Вообще, практически 100% бизнес-кода, в котором есть прямые вызовы DateTime.Now() — это просто ошибка, которая ждёт своего момента. Но это так, уже беллетристика.
Естественно, т.к. это типичный глобальный синглтон. Поэтому и изобрели InstantSource. И если я правильно понимаю Pauel (код он как всегда скрывает), он предлагает писать DateTime.Now() в каждом методе контроллера, т.к. именно там у него интеграция всего со всем.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>>>Разница в слове "отложенные". У вас недавно была проблема с этим словом. Решилась? P>>·>У нас такой проблемы не было. Т.е. разницы нет. ЧТД. P>>Забавный аргумент — у вас чего то там не было Мощный заход, внушает! ·>Ты нафантазировал, что у нас есть проблемы с отложенными вычислениями. Какой ты аргумент ожидаешь на такие фантазии?
Я вам сказал, что при переходе от одного дизайна к другому моки отваливаются. Если вы мокнули репозиторий в одном варианте, а в другом варианте репозиторий вызывается не там, не так, не тогда — всё, приплыли.
·>Я пример привёл, что инлайн сам по себе ни о чём не говорит. Ладно, если тебе строки не устраивают, пусть будет list.length() — с инлайном тоже ничего не выйдет.
Мы говорим не про сам по себе, а про вполне конкретный кейс — когда лично вы протащили внутрь функции зависимость. Вот именно эта зависимость и мешает инлайну. Без неё все становится хорошо.
P>>Это вы мне объясните, для чего вам понадобилось инлайнить строки. Это ж ваш аргумент был. ·>Я объяснил, что метод length инлайнить не выйдет, но это вовсе не оозначает, что это какое-то плохой дизайн и код куда-то как-то прибит.
Вам не нужно инлайнить чтото вручную именно потому, что компилятор справляется с такой работой идеальнее некуда — инлайнит сразу в константу.
P>>Я вам показал, что с str.length() у нас всё близко к идеалу — компилятор и джит без вас умеют инлайнить не абы как, а практически в константу. ·>Пусть будет list.length(). Дались тебе эти константы, вообще к теме не относится.
Если это hot path в числодробилке, то вполне может понадобиться убрать лишние обращения к памяти, в тех случаях, когда вы точно знаете, что длина не меняется.
P>>Вы пока так и не показали, как будете свой nextFriday инлайнить. Ваш последний аргумент — сбежать в сторону "заинлайни str.length()" ·>Ты так и не рассказал с какой целью инлайнить.
Инлайн и его противоположность это два базовых рефакторинга, к которым сводятся почти все остальные. Простой кейс -собрать клочки функциональности там и сям, а потом заинлайнить их в отдельный метод который уже можно будет отптимизировать как вам хочется.
Или наоборот — нарезать метод на функции, и заинлайнить каждую куда нужно, вместо вызова основного метода, что бы там заоптимизировать.
P>>изменение дерева депенденсов не является кодом, добавление параметра в конструктор не является кодом... ·>Является, конечно. И ты это называешь изменением дизайна.
Именно.
P>>Что еще у вас кодом не является? ·>А что у вас не является изменением дизайна?
Изолированое изменение кода внутри функции, не меняя ни результат, ни параметры, ни какие либо зависимости.
P>>Не нужно ничего перелопачивать — будет ровно такая же функция как у Синклера, только кеширование будет иначе сделано. ·>А ты вот потрудись код написать, и опять увидишь что погорячился.
Не знаю, что вы там себе думаете, кеширование куда угодно притягивается через композицию. Что бы встраивать это внутрь, нужно иметь внятные основания. Вы эти самые основания привести не хотите, вместо этого повторяете "покажи код"
P>>В этом случае мы основную бл тестируем без изменений — эта функция вообще не изменится. Для неё как были тесты по таблице истинности, так и остались. ·>Ну да, у меня тоже. В чём у тебя возникли сложности-то?
Вы перерендерили функцию, полностью:
class CalendarLogic {
...
LocalDate nextFriday() {
return doSomeComputations(instantSource.now());
}
}
class CalendarLogic {
private volatile LocalDate currentFriday;//вот наш кеш
constructor... {
var updater = () => currentFriday = doSomeComputations(instantSource.now());
timer.schedule(updater, ... weekly);
updater.run();
}
...
LocalDate nextFriday() {
return currentFriday; // вот эта функция перестала тригерить какие либо вызовы, а значит моки сдохли
}
А вот ваш тест
var clock = mock(InstantSource.class);
var testSubject = new CalendarLogic(clock); // создаёте один раз на тест - сами на этом настаивали!
when(clock.instant()).thenReturn(Instant.of("2023-12-28T12:27:00Z")); // этот мок больше не тригерится
assertThat(testSubject.nextFriday()).equalTo(LocalDate.of("2023-12-29")); // фейл
when(clock.instant()).thenReturn(Instant.of("2023-12-29T23:59:59Z")); // итд
assertThat(testSubject.nextFriday()).equalTo(LocalDate.of("2023-12-29")); // фейл
when(clock.instant()).thenReturn(Instant.of("2023-12-30T00:00:00Z")); // итд
assertThat(testSubject.nextFriday()).equalTo(LocalDate.of("2024-01-05")); // фейл
Для того, что бы все работало без затей, надо
1 nextFriday вытестить в "пюрешечку", те самые детали реализации
2 покрыть обычными тестами безо всяких моков
А потом эту "пюрешечку" вы можете комбинировать с чем угодно, и так и сяк.
В вашем же случае получаете умножение работ с тестами, что отдаляет более менее внятное покрытие до второго пришествия Христа
P>>Нисколько. Сама функция осталась без изменений. Смотрите пример Синклера внимательно — он вызывает основную функцию, а не модифицирует её. ·>Ты либо его код не понял, либо мой. Основная функция расчётов у него "SlowlyCalculatePrevAndNextFridays", у меня "doSomeComputations".
doSomeComputations это те самые "детали" которые вы не собираетесь тестировать, по вашему утверждению
И выше иллюстрация — что и как ломается в ваших же примерах
P>>Посмотрите внимательно — Фаулер для компонента протаскивает не абы что, репозитории-кеши-итд, а интерфейс взаимодействия ·>Просто выражено в терминах явы-шарпов "интерфейс с одним методом". getTopRestaurants — это и есть репозиторий по сути. Для ts оно ок наверное, но в яву-шарп такое лучше не тащить.
Это не репозиторий! getTopRestaurants реализуется чз репозиторий, но сам им не является — это вызов репозитория с конкретным фильтром, примерно так.
P>>Чтото навроде, примерно так же и у вас. ·>Ок. Круто, договорились, наконец-то. Теперь расскажи, как в твоей голове согласуется "код без использования моков" и "mock<AnInterface>"?
Я вам пример привел, как моки у Фаулера привести к вашему виду.
P>>Найдет. Отрефакторит. Определит. В тайпскрипте есть внятный вывод типа, и вы можете вывести тип тупла аргументов метода по его имени, тип возвращаемого значения, итд и тд. А раз есть тип, то у нас будет статический контроль и whenCalledWith, и returns, и много чего другого. ·>Круто, если так. Но ни шарп, ни ява так не умеет. Там такое просто не прокатит.
Помните, вы у меня пример спрашивали, что такого в ТС, что не умеет джава? Вот это он
P>>Нужно всё вместе: P>>1 Код ревью не работает в том случае, когда его можно скипнуть P>>2 Тесты не работают, когда их можно обойти P>>Что бы добиваться качества, вам нужно решить обе этих проблемы. ·>Угу. И?
У нас разговор, что же нужно добавить к тестам, что бы от них польза была. Я вам и рассказываю
P>>А я вам про принимающую сторону. Серверное и текущее время вы получаете забесплатно. ·>Допустим. Вопрос-то как проверить, что именно нужный источник времени используется где-то там для расчёта каких-то результатов?
Я же вроде рассказал — через результат вычислений всего пайплайна. Это интеграционный тест — мы проверяем весь путь следования нашего значения от входного реквеста, до бд, всех участников, и до выхлопа.
Даже если вы обмокаете все приложение, то интеграционный тест всё равно нужен, т.к. суть моков в нарезке пайпалайна как колбасы.
P>>Забавно — это вы всерьёз покрываете тестами левые сценарии? Или это вам видится, что все вокруг вас дураки? ·>Тестовые сценарии != реальные сценарии.
Реальные сценарии это приемочные тесты. Их больше пары десятков вы сильно вряд ли написать сможете, ну сотню осилите.
Запустили тесты с конфигом X, это значит что пол-приложения у вас ни при каких условиях не активируется. Приплыли.
P>>·>Зачем? P>>1. чем больше кода между замерами, тем хуже детализация ошибок P>>2. чем больше косвенность, тем вам труднее покрыть основные пути хоть с какой нибудь детализацией ·>Для этого и используют разделение на юниты и юнит-тестирование. А моками отрезаются комбинации деталей.
Моки это не единственный вариант.
P>>1. моки — тот подход, который вам кажется единственно верным, т.е. обрезание, подмена зависимостей и эффектов ·>Не то, что единственно верный, но практически неизбежный в достаточно сложной программе.
Это смотря какие идеи закладывались в дизайн. Если тестопригодность — то совсем не факт.
·>Это работает только на хоумпейджах. Чуть сложнее и внезапно выяснится что там этих самых верхних уровней штук пять.
Вы собираетесь любоваться этими уровнями? Вместо уровней можно трансформировать код в линейный и раз в десять глубину стека сократить.
·>А 3. где? В Ложную Дилемму поиграть решил?
Всегда можно сказать "у нас смоук тесты"
·>Проблема в том, что ты её адекватно протетсировать не можешь. Ассертить имена приватных функций и буквальные тексты запроса — такие тесты — бессмысленные и беспощадные.
Её как раз можно оттестировать. Имена буквально никакие не приватные, они ограниченно видимые. Текст запроса — это проблема, для sql. А если orm, там бывает и маппер, с ним куда проще. Но даже если sql — не такая уж и большая, эта проблема.
Здравствуйте, Pauel, Вы писали:
P>>>Забавный аргумент — у вас чего то там не было Мощный заход, внушает! P>·>Ты нафантазировал, что у нас есть проблемы с отложенными вычислениями. Какой ты аргумент ожидаешь на такие фантазии? P>Я вам сказал, что при переходе от одного дизайна к другому моки отваливаются. Если вы мокнули репозиторий в одном варианте, а в другом варианте репозиторий вызывается не там, не так, не тогда — всё, приплыли.
Голословно заявил, да.
P>·>Я пример привёл, что инлайн сам по себе ни о чём не говорит. Ладно, если тебе строки не устраивают, пусть будет list.length() — с инлайном тоже ничего не выйдет. P>Мы говорим не про сам по себе, а про вполне конкретный кейс — когда лично вы протащили внутрь функции зависимость. Вот именно эта зависимость и мешает инлайну. Без неё все становится хорошо.
Инлайну много что мешает. И я привёл пример с list.lenght(). А тебе придётся протаскивать зависимость снаружи функции, везде.
P>>>Это вы мне объясните, для чего вам понадобилось инлайнить строки. Это ж ваш аргумент был. P>·>Я объяснил, что метод length инлайнить не выйдет, но это вовсе не оозначает, что это какое-то плохой дизайн и код куда-то как-то прибит. P>Вам не нужно инлайнить чтото вручную именно потому, что компилятор справляется с такой работой идеальнее некуда — инлайнит сразу в константу.
Именно, я это неделю тебе уже втолковываю. А в константу-неконстанту — совершенно неважно.
P>>>Я вам показал, что с str.length() у нас всё близко к идеалу — компилятор и джит без вас умеют инлайнить не абы как, а практически в константу. P>·>Пусть будет list.length(). Дались тебе эти константы, вообще к теме не относится. P>Если это hot path в числодробилке, то вполне может понадобиться убрать лишние обращения к памяти, в тех случаях, когда вы точно знаете, что длина не меняется.
Инлайнить-то как?
P>>>Вы пока так и не показали, как будете свой nextFriday инлайнить. Ваш последний аргумент — сбежать в сторону "заинлайни str.length()" P>·>Ты так и не рассказал с какой целью инлайнить. P>Инлайн и его противоположность это два базовых рефакторинга, к которым сводятся почти все остальные. Простой кейс -собрать клочки функциональности там и сям, а потом заинлайнить их в отдельный метод который уже можно будет отптимизировать как вам хочется. P>Или наоборот — нарезать метод на функции, и заинлайнить каждую куда нужно, вместо вызова основного метода, что бы там заоптимизировать.
Ну да. Я об этом давно написал, см. ниже цитату.
P>>>Что еще у вас кодом не является? P>·>А что у вас не является изменением дизайна? P>Изолированое изменение кода внутри функции, не меняя ни результат, ни параметры, ни какие либо зависимости.
Например, для чего?
P>>>Не нужно ничего перелопачивать — будет ровно такая же функция как у Синклера, только кеширование будет иначе сделано. P>·>А ты вот потрудись код написать, и опять увидишь что погорячился. P>Не знаю, что вы там себе думаете, кеширование куда угодно притягивается через композицию. Что бы встраивать это внутрь, нужно иметь внятные основания. Вы эти самые основания привести не хотите, вместо этого повторяете "покажи код"
Я тебе приводил основания уже, в ответах Sinclair есть подробнее.
P>>>В этом случае мы основную бл тестируем без изменений — эта функция вообще не изменится. Для неё как были тесты по таблице истинности, так и остались. P>·>Ну да, у меня тоже. В чём у тебя возникли сложности-то? P>Вы перерендерили функцию, полностью:
Ну требования поменялись, меняется и реализация.
P>А вот ваш тест
Конечно надо исправить, чтобы учитывало изменение в логике что когда возвращается по каким таймерам. Но это исправляется один тест конкретной функции в соответствии с изменением требований. И тут, кстати, скорее всего выплывут вот эти все тонкости с монотонностью таймера и т.п.
P>Для того, что бы все работало без затей, надо P>1 nextFriday вытестить в "пюрешечку", те самые детали реализации P>2 покрыть обычными тестами безо всяких моков
Круто, конечно, но я об этом писал месяц назад:
Я вполне допускаю, что внутри CalendarLogic отрефакторить nextFriday() так, чтобы оно звало какой-нибудь static nextFriday(now) который можно потестирвать как пюрешку, но зачем? Если у нас конечная цель иметь именно nextFriday(), то рисовать ещё один слой, увеличивать количество прод-кода ради "единственно верного дизайна" — только энтропию увеличивать.
P>А потом эту "пюрешечку" вы можете комбинировать с чем угодно, и так и сяк.
Ты так и не понял мысль что я пытаюсь до тебя донести: ты путаешь надо и можно.
P>В вашем же случае получаете умножение работ с тестами, что отдаляет более менее внятное покрытие до второго пришествия Христа
Это опять твоя больная фантазия.
P>>>Нисколько. Сама функция осталась без изменений. Смотрите пример Синклера внимательно — он вызывает основную функцию, а не модифицирует её. P>·>Ты либо его код не понял, либо мой. Основная функция расчётов у него "SlowlyCalculatePrevAndNextFridays", у меня "doSomeComputations". P>doSomeComputations это те самые "детали" которые вы не собираетесь тестировать, по вашему утверждению
Собираюсь если надо, и не собираюсь если не надо.
P>>>Посмотрите внимательно — Фаулер для компонента протаскивает не абы что, репозитории-кеши-итд, а интерфейс взаимодействия P>·>Просто выражено в терминах явы-шарпов "интерфейс с одним методом". getTopRestaurants — это и есть репозиторий по сути. Для ts оно ок наверное, но в яву-шарп такое лучше не тащить. P>Это не репозиторий! getTopRestaurants реализуется чз репозиторий, но сам им не является — это вызов репозитория с конкретным фильтром, примерно так.
Ок, не важно, пусть не репозиторий, а бл, который дёргает репо. Всё в стиле 00х, только на новомодном js, для фронтендеров.
P>>>Чтото навроде, примерно так же и у вас. P>·>Ок. Круто, договорились, наконец-то. Теперь расскажи, как в твоей голове согласуется "код без использования моков" и "mock<AnInterface>"? P> Я вам пример привел, как моки у Фаулера привести к вашему виду.
Какая разница какой вид. У Фаулера в коде были моки, против которых ты топишь, при этом ссылаясь на него.
P>>>Найдет. Отрефакторит. Определит. В тайпскрипте есть внятный вывод типа, и вы можете вывести тип тупла аргументов метода по его имени, тип возвращаемого значения, итд и тд. А раз есть тип, то у нас будет статический контроль и whenCalledWith, и returns, и много чего другого. P>·>Круто, если так. Но ни шарп, ни ява так не умеет. Там такое просто не прокатит. P>Помните, вы у меня пример спрашивали, что такого в ТС, что не умеет джава? Вот это он
Это такой пример, скорее всего доказывающий противоположное, уж лучше бы не умел. mock<AnInterface>().whenCalledWith('getTopRestaurants', 'vancouverbc').returns(restaurants);
Выглядит хуже, чем when(repo.getTopRestaurants("vancouverbc")).thenReturn(vancouverRestaurants);
Зачем имя метода брать в кавычки — неясно, только путаница.
P>>>Нужно всё вместе: P>>>1 Код ревью не работает в том случае, когда его можно скипнуть P>>>2 Тесты не работают, когда их можно обойти P>>>Что бы добиваться качества, вам нужно решить обе этих проблемы. P>·>Угу. И? P>У нас разговор, что же нужно добавить к тестам, что бы от них польза была. Я вам и рассказываю
Нет, у нас разговор не про пользу, а про твоё утверждение, что тесты дают гарантию.
P>>>А я вам про принимающую сторону. Серверное и текущее время вы получаете забесплатно. P>·>Допустим. Вопрос-то как проверить, что именно нужный источник времени используется где-то там для расчёта каких-то результатов? P>Я же вроде рассказал — через результат вычислений всего пайплайна. Это интеграционный тест — мы проверяем весь путь следования нашего значения от входного реквеста, до бд, всех участников, и до выхлопа. P>Даже если вы обмокаете все приложение, то интеграционный тест всё равно нужен, т.к. суть моков в нарезке пайпалайна как колбасы.
Нет, суть моков в протаскивании тестовых значений в нужные места. Интеграционный тест может быть на весь пайплайн, в котором моками закрыты системные зависимости, которыми сложно управлять. Нарезка кода а части — это разбиение на юниты.
P>>>1. чем больше кода между замерами, тем хуже детализация ошибок P>>>2. чем больше косвенность, тем вам труднее покрыть основные пути хоть с какой нибудь детализацией P>·>Для этого и используют разделение на юниты и юнит-тестирование. А моками отрезаются комбинации деталей. P>Моки это не единственный вариант.
Верно, это один из инструментов, об этом я тоже ~месяц назад писал.
P>>>1. моки — тот подход, который вам кажется единственно верным, т.е. обрезание, подмена зависимостей и эффектов P>·>Не то, что единственно верный, но практически неизбежный в достаточно сложной программе. P>Это смотря какие идеи закладывались в дизайн. Если тестопригодность — то совсем не факт.
Ну Фаулер заложил все идеи которые ты любишь, а тесты — с моками. Как так?
P>·>Это работает только на хоумпейджах. Чуть сложнее и внезапно выяснится что там этих самых верхних уровней штук пять. P>Вы собираетесь любоваться этими уровнями? Вместо уровней можно трансформировать код в линейный и раз в десять глубину стека сократить.
Ты это "чудо" показал — количество кода сократилось раз в 0.5.
P>·>А 3. где? В Ложную Дилемму поиграть решил? P>Всегда можно сказать "у нас смоук тесты"
Чё?
P>·>Проблема в том, что ты её адекватно протетсировать не можешь. Ассертить имена приватных функций и буквальные тексты запроса — такие тесты — бессмысленные и беспощадные. P>Её как раз можно оттестировать. Имена буквально никакие не приватные, они ограниченно видимые. Текст запроса — это проблема, для sql. А если orm, там бывает и маппер, с ним куда проще. Но даже если sql — не такая уж и большая, эта проблема.
Словоблудишь. Их видимость ограничена тестами. Это значит что они сделаны видимыми исключительно для тестов. Для всего остального — приватные.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали: S>>Вам сходу придётся реализовывать концепт тайм-провайдера, и как-то привязывать его к вашей nextFriday(). ·>Не знаю о чём ты тут говоришь. Выше по топику у меня был код тестов.
Простите, не нашёл. Вижу вот такой код:
Это был прекрасный код, который не устраивал только одним — невозможно проверить, что он работает корректно. Поэтому пришлось заменять статик метод зависимостью; потом мокать зависимость; потом — молиться, что мок адекватно отражает поведение LocalDateTime.
·>Ну перечитай топик что-ли.
Да я его читаю с самого начала. И коллега Pauel, хоть и ошибается в мелочах, в целом совершенно прав.
·>Разговор об этом не шел. Был именно "серверное время". Вот _если_ у меня появится требование с Request.Document.SignOffTime, вот тогда я и введу nextFriday(someDay), я же это уже написал ~час назад. Это вопрос автоматического рефакторинга "extract method" и нескольких минут от силы. Зато вся эта ботва с кешами и оптимизациями — будет видна как на ладони.
И я вам больше часа назад объяснил, в чём проблема этого рефакторинга. А ваши рассуждения продиктованы как раз тем, что вы не понимаете, что такое "серверное время" и "клиентское время".
Вопрос не в том, что есть различные "источники времени", которые производят новые инстанты императивным способом. А просто в том, что "время" — это величина, которая копируется из разных мест, но предсказуемым образом.
И если, скажем, у нас в коде стоит задача "сделать выписку за период от прошлого понедельника до следующей пятницы", то нам категорически противопоказано в коде этого отчёта вызывать lastMonday() и nextFriday(), реализованные в вашем стиле. Просто потому, что между этими вызовами код workflow может быть вытеснен на произвольное время — в том числе и такое, за которое результат nextFriday() изменится. \
Именно поэтому мы не делаем класс TransactionReport — наследник класса Report, оборудованный зависимостями от ScheduleCalculator, зависящего от InstantSource.
Мы делаем набор простых чистых функций:
(Start, End) GetReportDateRange(DateTime) // вычисляет начало и конец диапазона отчёта для заданной даты. Не задумывается, откуда берётся дата - зато внутри этой функции начало и конец диапазона всегда согласованы
DataQuery GetReportDataQuery( // строит запрос для выборки данных по заданным параметрам. Пространство комбинаций велико, но счётно.
UserID id, // Каждый из тестов выполняется мгновенно, так что мы можем себе позволить выполнять весь набор на каждый коммит
Account[] accounts, // а если у нас возникнет комбинаторный взрыв, то мы порежем эту функцию на куски
DateTime start, // превратив объём тестирования из произведения в сумму
DateTime end)
Transaction[] GetReportData( // эту функцию вообще не надо тестировать, т.к. её реализовали другие люди, которые уже провели за нас подробнейшее тестирование.
DataQuery query // Найти СУБД, которая даёт некорректные результаты по корректному SQL, практически невозможно (даже в MySQL осталось всего несколько известных глюков)
)
XXX GetReportMarkup(Transaction[] ) // Это тоже чистая функция, которая прекрасно тестируется на различных примерах - пустой список, непустой список, етк.byte[] RenderMarkupToPDF(ХХХ) // опять чистая функция; протестировать её тяжело - но этим опять занимаются другие люди, которые могут себе это позволить
// потому что одна и та же функция используется в тыщах мест - и мы переносим усилия по тестированию каждого отдельного отчёта в тесты рендерилки PDF.
Всё. У нас юнит-тестами покрыто 100% нашего кода; а код вне зоны нашей ответственности даже не исполняется во время наших тестов.
Теперь остаётся всё это склеить. Риск при склейке минимален — просто потому, что в ней очень мало кода:
Я не отказываю этому коду в шансе содержать ошибку — действительно, мы могли напороть примерно везде. Например, неверно поняли требования, и в маркапе есть косяк (скажем, числа в таблице выровнены влево, а не по десятичной точке). Или, скажем, мы использовали как раз не то время — между подачей запроса на отчёт и началом работы обработчика как раз минула полночь на первое, и вместо отчёта за январь 2024 пользователь получает отчёт за февраль, в котором 0 строк (ведь февраль еле успел начаться).
Такие вещи ловятся интеграционным тестированием, которое один хрен нужно проводить. Но к моменту, когда у нас дошла очередь интеграционного тестирования, где (медленно!) тащатся реальные данные из реальной базы, выполняется (медленный!) UI workflow с навигацией от логина до этого отчёта, и т.п., у нас уже есть очень-очень хорошая уверенность в том, что как минимум логика вычисления дат, логика построения запроса, и логика порождения разметки верна. Нам не нужно ждать развёртывания боевой системы, или даже заполнения in-memory database для того, чтобы поймать какой-нибудь "<" вместо ">" или ошибку склеивания двух предикатов в SQL.
На то это и unit тесты, что они тестируют поведение отдельных юнитов, у которых у самих нет состояния, и на состояние других они тоже не полагаются никак.
S>>Но на практике это превращается в we wish you a happy debugging, потому что конфиги теперь становятся частью решения, а для них нет ни средств рефакторинга, ни измерения тестового покрытия. ·>Какие конфиги?
Не знаю. А откуда у вас в CalendarLogic берётся instantSource?
·>Зависимости собираются в Composition Root. Тоже уже обсуждалось.
Ага, то есть у нас где-то есть тот самый код, который выполняет вот это вот
var cl = new CalendarLogic(new LocalDateTimeSource());
var nf = cl.nextFriday();
И вы почему-то думаете, что это как-то сильно понятнее, очевиднее, и лучше, чем
var nf = CalendarUtils.nextFriday(LocalDateTime.now());
·>Ты почему-то решил, что добавить параметр в NextFriday является какой-то проблемой. Совсем наоборот — добавить просто, т.к. это новое требование и новый код. Убрать или зафиксировать — сложнее, т.к. надо исследовать все варианты и места использования во всём существующем коде.
Ну так задачи убрать или зафиксировать — нету. И простота с добавлением — кажущаяся.
·>Да даже с таким кодом — я не понял где тут усложнение тестирования. В худшем случае пара лишних new, которые наверняка вырежутся оптимизатором.
Вы для начала покажите, как вы протестируете код, апдейтящий ваш кэш.
·>Если ты имеешь в виду как выражать свойства самого timeSource — в терминах ООП будет другой тип MonotonicTimeSource. И конструктор|фабрика NextFridayProvider может для разых подтипов TimeSource выбирать разные подходы к кешированию.
Да не будет у вас никакого другого типа. Вы уже навелосипедили код так, как навелосипедили — потому что не знали о требованиях монотонности.
Вот когда вы видите функцию nextFriday(DateTime) — вы почему-то сразу задумываетесь о том, как она будет работать, если в неё подаются произвольные значения аргумента.
А пока вы мыслили в категориях "как бы мне замокать now()", вы навелосипедили вот это:
И это у вас прекрасно грохнется в продакшне, как только на машине сменят таймзону аккурат около полуночи пятницы. Обратите внимание — в моём коде вы усмотрели проблему перформанса; ваш код некорректен функционально.
Понимаете? Автор исходной CalendarLogic считает, что всё ок — он же всего лишь заменил now() на instantSource для удобства тестирования.
Автор тестов CalendarLogic считает, что всё ок — ну как же, у него code coverage == 100%, все бранчи протестированы, сломаться нечему.
Автор изменения CalendarLogic считает, что всё ок — он же прогнал все тесты; регрессии нету. Он даже (наверное) как-то протестировал, что updater реально исполняется так, как он ожидает.
·>Что значит случайно? Это тестами покрывается.
Ну, так вы напишете такой тест, в котором instantSource возвращает немонотонные значения? А такой, который ломает ваш CalendarLogic, процитированный выше?
S>>Тут вы попадаете в ловушку. Как раз у Pauel никакого изменения дизайна не случится, потому что у него nextFriday с самого начала имела нужную ему сигнатуру. S>>А вы теперь будете вынуждены продублировать код nextFriday — ну, либо всё же перенести его в новую nextFriday, а старую переделать на вызов новой. ·>Аж два рефакторинга "extract method", "move method". Всё. 2 минуты времени. Отож. И плюс новый набор тестов. При этом старые тесты тоже нужно гонять, удваивая время исполнения. Прикольно, чо. Поднимаем себестоимость на ровном месте.
·>Тесты как проходили, так и будут проходить. Впрочем, наверное после этого стоит тесты перенести тоже, для красоты.
Что значит "перенести"? А новый код старой функции у вас что, будет непокрытым?
А как тогда вы защититесь от будущего джуна, который там что-нибудь отвинтит?
·>Да. Таймеры мочить надо в любом случае. Иначе как _вы_ это будете тестировать? Деплоить всё на сервера и ждать пятницы? Или системные часы в операционке перематывать?
Я это никак не буду тестировать. Потому, что мне даже не придёт в голову такая хрупкая архитектура. Делать обновление кэша по таймеру — одна из худших идей, которые только можно придумать. ·>Я, конечно, имею в виду, что мы оба сравниваем одинаковые подходы с обновлением кеша по таймеру.
Не, я не хочу сравнивать одинаковые подходы. Вы просто наглядно показываете, что ваш способ мышления примерно такой:
1. Сначала вы выбираете неудачный подход
2. Когда вам говорят про его недостатки, вы заявляете, что недостатков там нет
3. Когда вам недостатки указывают, вы придумываете решения, которые делают код хуже
4. Повторяем с п.2.
Твой подход с обновлением кеша в момент первого вызова я тоже могу реализовать, без использования таймеров естественно. Но это не универсальный всемогутер, операционные недостатки такого подхода я уже упомянул.
С моей точки зрения, там операционные недостатки в 10-1000 раз меньше, чем один внедрённый в задачу таймер. Во-первых, там код работает корректно, в отличие от кода с таймером.
Во-вторых, он легко обобщается на случай "незначительной" немонотонности (например, иногда подают дату с прошлой недели, хотя в основном — с этой).
В-третьих, там этот "спайк задержки" работает на 1 запрос. Практически невозможно придумать SLA, на которое это повлияет.
Например, если у нас требования "99% запросов укладываются в X", при этом поток запросов велик — спайк попадёт в 1% и на процентиль не повлияет.
Если у нас поток запросов низкий, то, собственно, выигрыш за счёт кэширования вряд ли будет значительным. Нам полезнее будет покрутить реализацию "SlowNextFriday", чтобы она стала менее slow.
Ну, и в самом крайнем случае, мы тоже можем привинтить к FP-коду таймер, если это окажется единственным выходом.
·>Я же показал где хрупкость связи. До строчки nextFriday = wrapAndCacheMonotonous(nextFriday); писать nextFriday(platezhka.date) можно, а после только nextFriday(Time.Now) и больше никак.
Почему никак? Вполне можно. Код продолжит корректно работать. Просто иногда он будет чуть медленнее исполняться. Если это создаст проблему — то мы это обнаружим.
А, главное, все эти связи — ровно в одном месте, у нас перед глазами. Нет никаких неявных зависимостей и сложных соотношений. platezhka.date написано примерно там же, где и wrapAndCacheMonotonous. Поэтому шансы на то, что я там напорю, минимальны. Но главное не в этом — а том, что в вашем подходе нет никаких преимуществ. Ну нету у вас способа гарантировать монотонность источника времени. Недостаточно выразительная система типов, увы.
И рассказы о том, что вы будете делать рефакторинг вашего CalendarLogic, я воспринимаю скептически. Вы — может быть и будете, вы автор этого кода, вам с ним комфортно.
А кто-то другой, например джун, которому поручили починить проблему, пойдёт по пути наименьшего сопротивления: ага, видим, что гуру . уже спроектировал CalendarLogic так, чтобы он умел брать дату из внешнего источника.
Ну прекрасно — мы просто скормим ему вместо SystemLocalDateSource экземпляр нового класса PlatezhkaSource(platezhka), у которого now() перегружен соответствующим образом.
Это ж краеугольный камень ООП — все проблемы решаем при помощи агрегации и полиморфизма.
·> Открой для себя паттерн Декоратор.
Да я в курсе про паттерн Декоратор. Я, если чо, несколько лет преподавал объектно-ориентированный анализ и дизайн в университете
Но вот в вашем коде, обратите внимание, нет никакого декоратора. Это опять означает, что вас надо бить лопатой для того, чтобы вы сделали код, хотя бы приблизительно дотягивающий до кода, который ФП-программист пишет инстинктивно, т.к. в ФП такая идиоматика. ·>Насчёт stateless я не спорю, тут полностью согласен. Но не всегда есть такая роскошь.
Тут главное — знать, к чему стремиться. Пока что выглядит так, что вы на ровном месте пишете stateful не потому, что иное невозможно, а так — на всякий случай. Аргументируя в стиле "зато когда потом, в будущем, мне понадобится стейт — вот он, у меня уже есть!". А заодно вы любите протаскивать зависимости от стейтфул-объектов.
А надо — наоборот: зависимостей — избегать, стейта — избегать.
Понадобится стейт — всегда можно добавить его по необходимости.
S>>·>Я не про монотонность, а про то, что в nextFriday(x) — есть степень свободы что передавать в качестве x — и приходится делать предположения и анализ что может быть этим x во всём коде. В моём случае у меня явное ЧПФ nextFriday = () => nextFriday(timeSource.now()), зафиксированно знание о том, что же может быть этим самым x есть более широкий простор для оптимизаций.
Нет у вас никакого широкого простора для оптимизаций. Есть иллюзии того, что timeSource.now() ведёт себя как-то иначе, чем аргумент (x). И, естественно, оптимизации, построенные на этих иллюзиях, будут приводить к фейлам.
·>Это называется code reuse. Если у меня в 100 местах нужно посчитать nextFriday для платёжки, то я заведу именно такой метод nextFriday(platezhka), а не буду в 100 местах копипастить nextFriday(platezhka.date). Потому что в моей системе в первую очередь важны бизнес-документы, а не алгоритмы 14го века.
Ну так это если. А вы всё время пытаетесь решить проблему, которая ещё не возникла, как правило, привнося проблему, которой не было.
·>Нет. Метод, который процессит ордер будет выглядеть примерно так processMessage(ByteBuffer order) и зваться напрямую из сетевого стека. Откуда в сетевом стеке возьмётся вся эта инфа о биржах — я не знаю. Сетевой стек тупой — пришёл пакет из сокета X, дёргаем метод у привязанного к этому сокету messageHandler.
Это вы играете словами. Всё равно внутри processMessage(ByteBuffer buffer) будет декодирование этого buffer, и диспетчеризация по его содержимому.
То, что вы хотите это делать при помощи хрупкого набора ссылающихся друг на друга стейтфул-сущностей — ваше право. Я даже могу себе представить ситуацию, где это будет оправдано.
Но в большинстве случаев даже для такой задачи т.н. anemic model окажется сильно более пригодной, чем любая иерархия толстых сущностей в описываемом вами стиле.
S>>Что, в частности, позволяет нам лёгким движением руки выполнить replay пятничной сессии в понедельник, если в коде биржи обнаружилась ошибка и мы вынуждены аннулировать результаты торгов. ·>Для этого просто подменяется timeSource. Во время replay он будет не system clock, а timestamp из event log. Ну прекрасно — ваш CalendarLogic, завязанный на таймер, опять выдал неверный результат. Несмотря на успешные юнит-тесты
Даштоштакое-то!
·>Естественно, т.к. это типичный глобальный синглтон. Поэтому и изобрели InstantSource. И если я правильно понимаю Pauel (код он как всегда скрывает), он предлагает писать DateTime.Now() в каждом методе контроллера, т.к. именно там у него интеграция всего со всем.
Совершенно верно — это самый нормальный способ писать контроллер.
Вместо того, чтобы костылить себе путь при помощи повышения уровня косвенности.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Sinclair, Вы писали:
S>>>Вам сходу придётся реализовывать концепт тайм-провайдера, и как-то привязывать его к вашей nextFriday(). S>·>Не знаю о чём ты тут говоришь. Выше по топику у меня был код тестов. S>Простите, не нашёл. Вижу вот такой код: S>Вот тут у вас уже есть некий instantSource. Откуда он появился?
Заинжектился в конструктор. Тут код тестов
.
S>Это был прекрасный код, который не устраивал только одним — невозможно проверить, что он работает корректно.
Это то что рассказывает Pauel у него происходит:
·>Так как именно ты собираешься в "curl" и-тестах ассертить, что туда передаётся именно текущее время?
Никак.
S>Поэтому пришлось заменять статик метод зависимостью; потом мокать зависимость; потом — молиться, что мок адекватно отражает поведение LocalDateTime.
Ну это то что Pauel предлагает, засовывая Time.now в контроллеры, ставит мне в пику, что я это мокаю: " Во вторых, чуть далее, тоже недавно, вы рассказывали, как моками отрезали Time.now".
S>·>Ну перечитай топик что-ли. S>Да я его читаю с самого начала. И коллега Pauel, хоть и ошибается в мелочах, в целом совершенно прав.
У меня другое впечатление.
S>·>Разговор об этом не шел. Был именно "серверное время". Вот _если_ у меня появится требование с Request.Document.SignOffTime, вот тогда я и введу nextFriday(someDay), я же это уже написал ~час назад. Это вопрос автоматического рефакторинга "extract method" и нескольких минут от силы. Зато вся эта ботва с кешами и оптимизациями — будет видна как на ладони. S>И я вам больше часа назад объяснил, в чём проблема этого рефакторинга. А ваши рассуждения продиктованы как раз тем, что вы не понимаете, что такое "серверное время" и "клиентское время". S>Вопрос не в том, что есть различные "источники времени", которые производят новые инстанты императивным способом. А просто в том, что "время" — это величина, которая копируется из разных мест, но предсказуемым образом. S>И если, скажем, у нас в коде стоит задача "сделать выписку за период от прошлого понедельника до следующей пятницы", то нам категорически противопоказано в коде этого отчёта вызывать lastMonday() и nextFriday(), реализованные в вашем стиле. а в вашем стиле lastMonday(LocalDateTime.now()) и nextFriday(LocalDateTime.now()) можно вызывать, да?!
S>Просто потому, что между этими вызовами код workflow может быть вытеснен на произвольное время — в том числе и такое, за которое результат nextFriday() изменится. \
Ну ясен пень. Это слишком простой вопрос, не стоящий обсуждения. Ну да, мы должны получить некий момент и от него плясать по бизнес-логике. Скажем, тот же TradeDate нужно взять только один раз для данного ордера, в момент его прихода в handler, запомнить его и плясать от него далее, вычисляя всякие там settlement date, days to maturity и т.п.
А вопрос об источниках времени — это интересный вопрос, именно его я и обсуждаю. И что один и тот же код, как в недавнем примере, может работать с системным источником RTC в боевой системе, а потом с источником времени из event log во время replay, а ещё и с тестовым источником времени (мок!) во время прогона тестов, чтобы можно было тестировать сценарии "подождём до конца финансового года".
Вот это интересное обсуждение.
Я в первую очередь говорю о главном применении моков — отрезать входы-выходы системы (тот самый Time.Now, а ещё сеть, фс, бд, етс), которые в реальности завязываются на что-то тяжело контролируемое или очень медленное.
Вы же с Pauel рассуждаете о скучных нутрах бизнес-логики. Там всё тривиально.
S>Такие вещи ловятся интеграционным тестированием, которое один хрен нужно проводить. Но к моменту, когда у нас дошла очередь интеграционного тестирования, где (медленно!) тащатся реальные данные из реальной базы, выполняется (медленный!) UI workflow с навигацией от логина до этого отчёта, и т.п., у нас уже есть очень-очень хорошая уверенность в том, что как минимум логика вычисления дат, логика построения запроса, и логика порождения разметки верна. Нам не нужно ждать развёртывания боевой системы, или даже заполнения in-memory database для того, чтобы поймать какой-нибудь "<" вместо ">" или ошибку склеивания двух предикатов в SQL.
Вот это я не понял. У него в примере тест буквально сравнивал текст sql "select * ...". Как такое поймает это?
Суть в том, что программист пишет код+тест. В тесте вручную прописывает ожидание =="sellect * ...". Потом тест, ясен пень проходит, потом ревью, который тоже наверняка пройдёт, не каждый ревьювер способен заметить лишнюю букву. И только потом, когда некий тест пройдёт от логина до отчёта, то оно грохнется, может быть, если этот тест таки использует именно эту ветку кода для тестовых параметров отчёта. Ведь итесты в принципе не могут покрыть все комбинации, их может быть просто экспоненциально дохрена.
S>На то это и unit тесты, что они тестируют поведение отдельных юнитов, у которых у самих нет состояния, и на состояние других они тоже не полагаются никак.
С этим осторожнее. Вот этот твой кеш оказался — с состоянием, внезапно, да ещё и static global.
S>>>Но на практике это превращается в we wish you a happy debugging, потому что конфиги теперь становятся частью решения, а для них нет ни средств рефакторинга, ни измерения тестового покрытия. S>·>Какие конфиги? S>Не знаю. А откуда у вас в CalendarLogic берётся instantSource?
Через DI/CI.
S>·>Зависимости собираются в Composition Root. Тоже уже обсуждалось. S>Ага, то есть у нас где-то есть тот самый код, который выполняет вот это вот
Не так. Вот так:
SINGLE line composition root:
S>var cl = new CalendarLogic(new LocalDateTimeSource());
logic in many-many places, hundreds lines:
S>var nf = cl.nextFriday();
CompositionRoot — один на всё приложение, меняется относительно редко, обычно тупой линейный код, и составляет доли процента от объёма всего приложения. Его можно ежедневно глазками каждую строчку просматривать всей командой.
Даже больше. Composition Root можно делить на модули. Будет модуль типа:
class ApplicationModule
{
public ApplicationModule(TimeSource timeSource)
{
var cl = new CalendarLogic(timeSource);
var reportLogic = new ReportLogic(timeSource);
var blahThing = new BlahThing(cl, reportLogic, 42);
var businessLogic = new BusinessLogic(blahThing, timeSource);
var restHandler = new RestHandler(businessLogic, "qwt");
}
}
И вот такой модуль можно тестировать простыми тестами, подсовывая туда моковый timeSource и ровно этот же модуль будет зваться из "main" метода реального приложения, куда будет запихан SystemClock в качестве timeSource.
S>И вы почему-то думаете, что это как-то сильно понятнее, очевиднее, и лучше, чем S>
S>
И это по всему коду — везде в тысячах мест. Да? И как это тестировать? Как делать replay?
S>·>Ты почему-то решил, что добавить параметр в NextFriday является какой-то проблемой. Совсем наоборот — добавить просто, т.к. это новое требование и новый код. Убрать или зафиксировать — сложнее, т.к. надо исследовать все варианты и места использования во всём существующем коде. S>Ну так задачи убрать или зафиксировать — нету. И простота с добавлением — кажущаяся.
Почему? У нас появляется требование считать nextFriday для платёжки — добавляем новый код для этого, другой код вообще можно не трогать.
S>·>Да даже с таким кодом — я не понял где тут усложнение тестирования. В худшем случае пара лишних new, которые наверняка вырежутся оптимизатором. S>Вы для начала покажите, как вы протестируете код, апдейтящий ваш кэш.
Я обычно использую специальный тестовый шедулер, который запускает установленные таймеры при изменении тестового источника времени. У есть метод типа tickClock(7, DAYS). Код писать лень, но идея, надеюсь, очевидна...
S>·>Если ты имеешь в виду как выражать свойства самого timeSource — в терминах ООП будет другой тип MonotonicTimeSource. И конструктор|фабрика NextFridayProvider может для разых подтипов TimeSource выбирать разные подходы к кешированию. S>Да не будет у вас никакого другого типа. Вы уже навелосипедили код так, как навелосипедили — потому что не знали о требованиях монотонности. S>Вот когда вы видите функцию nextFriday(DateTime) — вы почему-то сразу задумываетесь о том, как она будет работать, если в неё подаются произвольные значения аргумента.
Именно. Универсальность — не даёт делать более эффективую реализацию.
S>И это у вас прекрасно грохнется в продакшне, как только на машине сменят таймзону аккурат около полуночи пятницы.
Нет, конечно. Таймеры ставят на instant, т.е. абсолютный момент времени, независящий от зоны.
S>Обратите внимание — в моём коде вы усмотрели проблему перформанса; ваш код некорректен функционально.
Ну я код в браузере набирал, мог и ошибиться. В реальности буду запускать тесты, ясен пень.
S>·>Что значит случайно? Это тестами покрывается. S>Ну, так вы напишете такой тест, в котором instantSource возвращает немонотонные значения?
Через моки же — возвращай что хошь в каком хошь порядке.
S>А такой, который ломает ваш CalendarLogic, процитированный выше?
В сымсле ботва с таймзонами? Ну это у меня уже привычка — писать тесты для дат около всяких dst переходов и с экзотическими таймзонами.
S>>>Тут вы попадаете в ловушку. Как раз у Pauel никакого изменения дизайна не случится, потому что у него nextFriday с самого начала имела нужную ему сигнатуру. S>>>А вы теперь будете вынуждены продублировать код nextFriday — ну, либо всё же перенести его в новую nextFriday, а старую переделать на вызов новой. S>·>Аж два рефакторинга "extract method", "move method". Всё. 2 минуты времени. S> Отож. И плюс новый набор тестов. При этом старые тесты тоже нужно гонять, удваивая время исполнения. Прикольно, чо. Поднимаем себестоимость на ровном месте.
Такие тесты работают порядка миллисекунд. Их можно гонять миллионами и не заметить.
S>·>Тесты как проходили, так и будут проходить. Впрочем, наверное после этого стоит тесты перенести тоже, для красоты. S>Что значит "перенести"? А новый код старой функции у вас что, будет непокрытым?
Ну смысле если мы из одного юнита А перенесли код в другой юнит Б, то тесты А всё ещё должны проходить. Но они будут идти через А в Б. Это некрасиво. После того как убедились, что А всё ещё работает. Тесты желательно перенести чтобы тестить Б напрямую.
S>А как тогда вы защититесь от будущего джуна, который там что-нибудь отвинтит?
Не понял, что "что-нибудь"?
S>·>Да. Таймеры мочить надо в любом случае. Иначе как _вы_ это будете тестировать? Деплоить всё на сервера и ждать пятницы? Или системные часы в операционке перематывать? S>Я это никак не буду тестировать. Потому, что мне даже не придёт в голову такая хрупкая архитектура. Делать обновление кэша по таймеру — одна из худших идей, которые только можно придумать.
Ну не нравится, не ешь. Об чём спор? Для чего нужен таймер — я тебе написал, для low latency. Без таймера твой вариант у меня тоже элементарно реализуется, правда мне совесть не позволит убить ещё одного котёнка делая static глобальную переменную. Можно даже гибридное решение наворотить, обновляя кеш по таймеру из другого треда, но если вдруг момент timeSource.now() промазывает по кешу, то идти по медленному пути.
S>·>Я, конечно, имею в виду, что мы оба сравниваем одинаковые подходы с обновлением кеша по таймеру. S>Не, я не хочу сравнивать одинаковые подходы. Вы просто наглядно показываете, что ваш способ мышления примерно такой: S>1. Сначала вы выбираете неудачный подход
Он удачный в определённых условиях. То что твой подход "удачный" и универсальный всемогутер — твоё большое заблуждние.
S>2. Когда вам говорят про его недостатки, вы заявляете, что недостатков там нет S>3. Когда вам недостатки указывают, вы придумываете решения, которые делают код хуже S>4. Повторяем с п.2.
S>·>Твой подход с обновлением кеша в момент первого вызова я тоже могу реализовать, без использования таймеров естественно. Но это не универсальный всемогутер, операционные недостатки такого подхода я уже упомянул. S>С моей точки зрения, там операционные недостатки в 10-1000 раз меньше, чем один внедрённый в задачу таймер. Во-первых, там код работает корректно, в отличие от кода с таймером.
Это как? Если у нас в SLA написано, что max response time 10ms, а SlowlyCalculatePrevAndNextFridays работает 11ms, то выбора тупо нет, и похрен всем твоя точка зрения.
S>В-третьих, там этот "спайк задержки" работает на 1 запрос. Практически невозможно придумать SLA, на которое это повлияет.
Открой для себя мир low latency.
S>·>Я же показал где хрупкость связи. До строчки nextFriday = wrapAndCacheMonotonous(nextFriday); писать nextFriday(platezhka.date) можно, а после только nextFriday(Time.Now) и больше никак. S>Почему никак? Вполне можно. Код продолжит корректно работать. Просто иногда он будет чуть медленнее исполняться. Если это создаст проблему — то мы это обнаружим.
У нас это было серьёзный production incident. Каждый запрос, обработка которого была >10ms — тикет и расследование. Больше таких двух в день — и клиент нам звонит для разборок.
S>А, главное, все эти связи — ровно в одном месте, у нас перед глазами. Нет никаких неявных зависимостей и сложных соотношений. platezhka.date написано примерно там же, где и wrapAndCacheMonotonous. Поэтому шансы на то, что я там напорю, минимальны. Но главное не в этом — а том, что в вашем подходе нет никаких преимуществ. Ну нету у вас способа гарантировать монотонность источника времени. Недостаточно выразительная система типов, увы. S>И рассказы о том, что вы будете делать рефакторинг вашего CalendarLogic, я воспринимаю скептически. Вы — может быть и будете, вы автор этого кода, вам с ним комфортно. S>А кто-то другой, например джун, которому поручили починить проблему, пойдёт по пути наименьшего сопротивления: ага, видим, что гуру . уже спроектировал CalendarLogic так, чтобы он умел брать дату из внешнего источника. S>Ну прекрасно — мы просто скормим ему вместо SystemLocalDateSource экземпляр нового класса PlatezhkaSource(platezhka), у которого now() перегружен соответствующим образом. S>Это ж краеугольный камень ООП — все проблемы решаем при помощи агрегации и полиморфизма.
Это повлияет только на новый код с платёжкой. Подменить "случайно" по всему приложению так не выйдет. А вот твоя глобальная переменная — happy debugging.
S>·> Открой для себя паттерн Декоратор. S>Да я в курсе про паттерн Декоратор. Я, если чо, несколько лет преподавал объектно-ориентированный анализ и дизайн в университете S>Но вот в вашем коде, обратите внимание, нет никакого декоратора. Это опять означает, что вас надо бить лопатой для того, чтобы вы сделали код, хотя бы приблизительно дотягивающий до кода,
У меня была цель продемонстрировать не основы объектно-ориентированного анализа, а факт, что можно максимально оптимизировать реализацию nextFriday(), т.к. у нас известно многое внутри самого метода. Навешивая это всё снаружи, приходится делать всё более пессимистично, т.к. инфы тупо меньше.
S>который ФП-программист пишет инстинктивно, т.к. в ФП такая идиоматика.
Ага, смешно у Pauel инстинкт с memoize сработал.
S>·>Насчёт stateless я не спорю, тут полностью согласен. Но не всегда есть такая роскошь. S>Тут главное — знать, к чему стремиться. Пока что выглядит так, что вы на ровном месте пишете stateful не потому, что иное невозможно, а так — на всякий случай. Аргументируя в стиле "зато когда потом, в будущем, мне понадобится стейт — вот он, у меня уже есть!". А заодно вы любите протаскивать зависимости от стейтфул-объектов. S>А надо — наоборот: зависимостей — избегать, стейта — избегать.
Ага, и ты тут такой: static (DateTime prevFriday, DateTime nextFriday)? _cache А потом хрясь и в догонку nextFriday(LocalDateTime.now())!
S>Понадобится стейт — всегда можно добавить его по необходимости.
А вот попробуй избавиться от этого static и у тебя полезет колбасня.
S>>>·>Я не про монотонность, а про то, что в nextFriday(x) — есть степень свободы что передавать в качестве x — и приходится делать предположения и анализ что может быть этим x во всём коде. В моём случае у меня явное ЧПФ nextFriday = () => nextFriday(timeSource.now()), зафиксированно знание о том, что же может быть этим самым x есть более широкий простор для оптимизаций. S>Нет у вас никакого широкого простора для оптимизаций. Есть иллюзии того, что timeSource.now() ведёт себя как-то иначе, чем аргумент (x). И, естественно, оптимизации, построенные на этих иллюзиях, будут приводить к фейлам.
ЧПФ же. У нас зафиксирован timeSource же.
S>·>Это называется code reuse. Если у меня в 100 местах нужно посчитать nextFriday для платёжки, то я заведу именно такой метод nextFriday(platezhka), а не буду в 100 местах копипастить nextFriday(platezhka.date). Потому что в моей системе в первую очередь важны бизнес-документы, а не алгоритмы 14го века. S>Ну так это если. А вы всё время пытаетесь решить проблему, которая ещё не возникла, как правило, привнося проблему, которой не было.
Так на практике так и бывает. Т.к. в бизнес-логике бизнес-документы, а не алгоритмы 14го века.
S>·>Нет. Метод, который процессит ордер будет выглядеть примерно так processMessage(ByteBuffer order) и зваться напрямую из сетевого стека. Откуда в сетевом стеке возьмётся вся эта инфа о биржах — я не знаю. Сетевой стек тупой — пришёл пакет из сокета X, дёргаем метод у привязанного к этому сокету messageHandler. S>Это вы играете словами. Всё равно внутри processMessage(ByteBuffer buffer) будет декодирование этого buffer, и диспетчеризация по его содержимому.
Сокет ещё утром был подключён к конкретной бирже. Диспечерезацией уже занимается сетевая карта.
S>>>Что, в частности, позволяет нам лёгким движением руки выполнить replay пятничной сессии в понедельник, если в коде биржи обнаружилась ошибка и мы вынуждены аннулировать результаты торгов. S>·>Для этого просто подменяется timeSource. Во время replay он будет не system clock, а timestamp из event log. S> Ну прекрасно — ваш CalendarLogic, завязанный на таймер, опять выдал неверный результат. Несмотря на успешные юнит-тесты S>Даштоштакое-то!
Почему неверный? Таймеры тоже срабатывают по timeSource. Проигрывание лога воспроизводит всё поведение системы, но уже без привязки к физическим часам. Ровно это же используется в тестах, когда мы выполняем шаги: "Делаем трейд. Ждём до конца месяца. Получаем стейтмент".
S>·>Естественно, т.к. это типичный глобальный синглтон. Поэтому и изобрели InstantSource. И если я правильно понимаю Pauel (код он как всегда скрывает), он предлагает писать DateTime.Now() в каждом методе контроллера, т.к. именно там у него интеграция всего со всем. S>Совершенно верно — это самый нормальный способ писать контроллер.
Т.е. делать его нетестируемым. Спасибо, не надо.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>Мы говорим не про сам по себе, а про вполне конкретный кейс — когда лично вы протащили внутрь функции зависимость. Вот именно эта зависимость и мешает инлайну. Без неё все становится хорошо. ·>Инлайну много что мешает. И я привёл пример с list.lenght(). А тебе придётся протаскивать зависимость снаружи функции, везде.
Ради того всё и делается! За счет этого мы расширяем набор инструментов для управления сложностью. Например, тестирование становится проще в большинстве случаев — ключевой код легче покрывать дешовыми юнит-тестами. Связывание переносится наверх — заходя в контроллер вы видите сразу какой масштаб последствий. Например — вам не надо рыскать по конструкторам и мапить реализации на интерфейсы что бы выяснять подробности.
P>>Вам не нужно инлайнить чтото вручную именно потому, что компилятор справляется с такой работой идеальнее некуда — инлайнит сразу в константу. ·>Именно, я это неделю тебе уже втолковываю. А в константу-неконстанту — совершенно неважно.
Важно для изменения дизайна. Там где вы вызываете list.length() никакого изменения дизайна не предполагается. А вот с вашим тайм провайдеров всё ровно наоборот.
P>>Если это hot path в числодробилке, то вполне может понадобиться убрать лишние обращения к памяти, в тех случаях, когда вы точно знаете, что длина не меняется. ·>Инлайнить-то как?
Если это джава — то заводят прозрачный контейнер и раскладывают байты руками. В дотнете у вас есть некоторые низкоуровневые механизмы, которых нет в джаве, например, контроль Layout, внятные value types на стеке, ref- и out- параметры.
P>>>>Что еще у вас кодом не является? P>>·>А что у вас не является изменением дизайна? P>>Изолированое изменение кода внутри функции, не меняя ни результат, ни параметры, ни какие либо зависимости. ·>Например, для чего?
Что угодно — багфикс, изменение требований, оптимизация.
P>>·>Ну да, у меня тоже. В чём у тебя возникли сложности-то? P>>Вы перерендерили функцию, полностью: ·>Ну требования поменялись, меняется и реализация.
Условно, вы просто провели очередные замеры и выяснили, что в старые требования не вмещаетесь, и теперь надо найти где сэкономить.
·>
Я вполне допускаю, что внутри CalendarLogic отрефакторить nextFriday() так, чтобы оно звало какой-нибудь static nextFriday(now) который можно потестирвать как пюрешку, но зачем? Если у нас конечная цель иметь именно nextFriday(), то рисовать ещё один слой, увеличивать количество прод-кода ради "единственно верного дизайна" — только энтропию увеличивать.
Не ради дизайна, а ради тестопригодности. Дизайн всегда вторичен — это инструмент достижения целений. Тестопригодность, гибкость, оптимизации — это некоторые из целей.
P>>Это не репозиторий! getTopRestaurants реализуется чз репозиторий, но сам им не является — это вызов репозитория с конкретным фильтром, примерно так. ·>Ок, не важно, пусть не репозиторий, а бл, который дёргает репо. Всё в стиле 00х, только на новомодном js, для фронтендеров.
Почти. Фаулер показывает как это можно делать функциями. Только можно идти дальше. Жээсность здесь ни при чем.
P>> Я вам пример привел, как моки у Фаулера привести к вашему виду. ·>Какая разница какой вид. У Фаулера в коде были моки, против которых ты топишь, при этом ссылаясь на него.
Я топлю за композицию функций, а не моки Это еще один инструмент управления сложностью в дополнение к ОО-механизмам.
P>>Помните, вы у меня пример спрашивали, что такого в ТС, что не умеет джава? Вот это он ·>Это такой пример, скорее всего доказывающий противоположное, уж лучше бы не умел. ·>mock<AnInterface>().whenCalledWith('getTopRestaurants', 'vancouverbc').returns(restaurants); ·>Выглядит хуже, чем ·>when(repo.getTopRestaurants("vancouverbc")).thenReturn(vancouverRestaurants); ·>Зачем имя метода брать в кавычки — неясно, только путаница.
Можно и так сделать, чз т.н. Proxy, и тоже будет типизация, не хуже чем в джаве. Тайпскрипт он весь про типизацию даже одиозного кода на жээсе, потому в ём много чего есть.
P>>У нас разговор, что же нужно добавить к тестам, что бы от них польза была. Я вам и рассказываю ·>Нет, у нас разговор не про пользу, а про твоё утверждение, что тесты дают гарантию.
А что вы подразумеваете под гарантиями? Гарантии, что багов нет, тесты дать не могут. Тесты дают гарантию, что ваше решение соответсвует конкретным ожиданиями. Буквально. Ничего сверх этого тесты дать не могут.
P>>Даже если вы обмокаете все приложение, то интеграционный тест всё равно нужен, т.к. суть моков в нарезке пайпалайна как колбасы. ·>Нет, суть моков в протаскивании тестовых значений в нужные места.
Это и есть та самая нарезка — вы протаскиваете не абы как, а подменяя зависимости на стаб и мок. Т.е. вместо всего пайплайна у вас тоненький кусочек колбасы, слева стаб, вбрасывает значение, справа мок — ловит результат.
P>>Это смотря какие идеи закладывались в дизайн. Если тестопригодность — то совсем не факт. ·>Ну Фаулер заложил все идеи которые ты любишь, а тесты — с моками. Как так?
Комбинация функций и моки это вещи ортогональные, как говорит Синклер. Меня интересует первое, а вас — второе.
P>>Вы собираетесь любоваться этими уровнями? Вместо уровней можно трансформировать код в линейный и раз в десять глубину стека сократить. ·>Ты это "чудо" показал — количество кода сократилось раз в 0.5.
Зато вы самолично показали как сломать все тесты простым кешированием
P>>Всегда можно сказать "у нас смоук тесты" ·>Чё?
Что именно вам здесь непонятно? Смоук тесты — это стратегия, которую можно применять хоть в ручных, хоть в автоматических тестах. Подход известный где то с 00х
P>>Её как раз можно оттестировать. Имена буквально никакие не приватные, они ограниченно видимые. Текст запроса — это проблема, для sql. А если orm, там бывает и маппер, с ним куда проще. Но даже если sql — не такая уж и большая, эта проблема. ·>Словоблудишь. Их видимость ограничена тестами. Это значит что они сделаны видимыми исключительно для тестов. Для всего остального — приватные.
Тестопригодность и означает, что вы делаете дополнительные инвестиции ради возможности плотнее покрыть тестами. Возврат инвестиций начинается прямо со следующего захода вас или другого разработчика в этот файл. Если у вас такое редко бывает — тестопригодность вам не нужна. Но как правило, это не так.
.
Ну, то есть мои примеры верно отражают степень падения в пропасть. ·>Это то что рассказывает Pauel у него происходит: ·>Ну это то что Pauel предлагает, засовывая Time.now в контроллеры, ставит мне в пику, что я это мокаю: " Во вторых, чуть далее, тоже недавно, вы рассказывали, как моками отрезали Time.now".
Всё правильно он пишет. Вы заменили прямолинейный понятный код, в котором негде сделать ошибку, на код с распределённой ответственностью. Теперь у вас Time.now() расположен максимально далеко от места его использования.
·>У меня другое впечатление.
S>>Вопрос не в том, что есть различные "источники времени", которые производят новые инстанты императивным способом. А просто в том, что "время" — это величина, которая копируется из разных мест, но предсказуемым образом. S>>И если, скажем, у нас в коде стоит задача "сделать выписку за период от прошлого понедельника до следующей пятницы", то нам категорически противопоказано в коде этого отчёта вызывать lastMonday() и nextFriday(), реализованные в вашем стиле. ·> а в вашем стиле lastMonday(LocalDateTime.now()) и nextFriday(LocalDateTime.now()) можно вызывать, да?!
Можно, но так никто не делает. Потому, что то место, где они нужны — это тоже функция. И в неё по умолчанию не передаётся ссылка на instantSource, а передаются готовые аргументы start и end. Не её дело принимать решения о том, где начало интервала, а где — конец.
Поэтому мы в неё передаём значения. А значения — тоже вычисляются чистой функцией. Чистота означает, что мы не делаем из неё грязных вызовов — поэтому никаких lastMonday(LocalDateTime.now()) и nextFriday(LocalDateTime.now()), а исключительно lastMonday(currentTime) и nextFriday(currentTime)/
·>Ну ясен пень. Это слишком простой вопрос, не стоящий обсуждения. Ну да, мы должны получить некий момент и от него плясать по бизнес-логике. Скажем, тот же TradeDate нужно взять только один раз для данного ордера, в момент его прихода в handler, запомнить его и плясать от него далее, вычисляя всякие там settlement date, days to maturity и т.п.
Ну вы же так не делаете. У вас nextFriday пляшет не от "некоего момента", а от instantSource.now() И вы настаиваете на том, что это — правильный дизайн. А чтобы вы всё-таки написали более-менее рабочую версию с приемлемым дизайном вас нужно долго и нудно загонять в угол. По-моему — всё очевидно.
·>А вопрос об источниках времени — это интересный вопрос, именно его я и обсуждаю. И что один и тот же код, как в недавнем примере, может работать с системным источником RTC в боевой системе, а потом с источником времени из event log во время replay, а ещё и с тестовым источником времени (мок!) во время прогона тестов, чтобы можно было тестировать сценарии "подождём до конца финансового года". ·>Вот это интересное обсуждение.
Ну, пока что ваш код не удовлетворяет предлагаемым вами же требованиям Напомню, что ваш кэш знать не знает ни про какой event log. И возвращает всегда локальное поле, а чтобы его обновить, нужно срабатывание таймера. Таймер ваш никак с instantSource не связан, это прямая дорога к рассогласованию.
·>Я в первую очередь говорю о главном применении моков — отрезать входы-выходы системы (тот самый Time.Now, а ещё сеть, фс, бд, етс), которые в реальности завязываются на что-то тяжело контролируемое или очень медленное.
Ок, давайте откажемся от обсуждения времени — в конце концов, сделать lastFriday достаточно медленной, чтобы наше обсуждение имело смысл, скорее всего не получится.
Правильный способ отрезания входов-выходов — ровно такой, как настаивает коллега Pauel. Потому что в вашем способе вы их никуда не отрезаете — вы их заменяете плохими аналогами. Ващ подход мы, как и все на рынке, применяли в бою. И неоднократно обожглись о то, что мок не мокает настоящее решение; он мокает ожидания разработчика об этом решении.
·>Вот это я не понял. У него в примере тест буквально сравнивал текст sql "select * ...". Как такое поймает это?
Это он просто переводит с рабочего на понятный. Он же пытался вам объяснить, что проверяет структурную эквивалентность. Тут важно понимать, какие компоненты у нас в пайплайне.
Если вы строите текст SQL руками — ну да, тогда будет именно сравнение текстов. Но в наше время так делать неэффективно. Обычно мы порождаем не текст SQL, а его AST. Генерацией текста по AST занимается отдельный компонент (чистая функция), и он покрыт своими тестами — нам их писать не надо.
·>Суть в том, что программист пишет код+тест. В тесте вручную прописывает ожидание =="sellect * ...". Потом тест, ясен пень проходит, потом ревью, который тоже наверняка пройдёт, не каждый ревьювер способен заметить лишнюю букву.
Ну, во-первых, программист же пишет код не в воздухе. Как правило, сначала нужный SQL пишется руками и проверяется интерактивно с тестовой базой, пока не начнёт работать так, как ожидается. Лично я работаю с SQL примерно 30 лет, из них 10 проработал очень плотно. Но и то — сходу не всегда могу написать корректный SQL. Поэтому мы сначала пишем несколько характерных вариантов запроса и прогоняем их на базе (в том числе — используем ровно тот движок, с которым работает прод. Никаких замен боевого постгре на тестовый SQLite или ещё каких-нибудь моков.)
Потом вставляем готовые команды в тест. Потом пишем код.
·>И только потом, когда некий тест пройдёт от логина до отчёта, то оно грохнется, может быть, если этот тест таки использует именно эту ветку кода для тестовых параметров отчёта. Ведь итесты в принципе не могут покрыть все комбинации, их может быть просто экспоненциально дохрена.
У вас — та же проблема, просто вы её предпочитаете не замечать. Вы там запустили тест, а вместо опечатки sellect у вас там вызов функции, которая в inmemory DB работает, а в боевой — нет. SQL вообще состоит из диалектных различий чуть менее, чем полностью.
·>С этим осторожнее. Вот этот твой кеш оказался — с состоянием, внезапно, да ещё и static global.
Да, такие вещи нужно делать аккуратно, вы правы.
S>>Не знаю. А откуда у вас в CalendarLogic берётся instantSource? ·>Через DI/CI.
Ну вот он у вас в тестах — один, в продакшне — другой. Упс.
S>>Ага, то есть у нас где-то есть тот самый код, который выполняет вот это вот ·>Не так. Вот так:
·>CompositionRoot — один на всё приложение, меняется относительно редко, обычно тупой линейный код, и составляет доли процента от объёма всего приложения. Его можно ежедневно глазками каждую строчку просматривать всей командой.
Ну, так это ровно тот же аргумент "против", который вы мне только что рассказывали. Вот вы взяли и заменили ваш код глобально, не разбираясь, где там можно применять кэширование, а где — нельзя.
Потому что ваш кэширующий CalendarLogic полагается на то, что в нём timeSource согласован с timer, а в коде это никак не выражено. Вот вы написали replay, который полагается на возможность замены глобального timeSource на чтение из eventLog, и погоняли его. И так получилось, что данные, на которых вы его гоняли, границу пятницы не пересекали. Откуда вы знаете, что нужно пересечь границу пятницы? Да ниоткуда, у вас в проекте таких "особых моментов" — тыщи и тыщи. Код коверадж вам красит весь ваш CalendarLogic зелёненьким, причин сомневаться в работоспособности нету.
·>И вот такой модуль можно тестировать простыми тестами, подсовывая туда моковый timeSource и ровно этот же модуль будет зваться из "main" метода реального приложения, куда будет запихан SystemClock в качестве timeSource.
Проблема опять только в двух вещах:
1. Слишком много кода в стеке при выполнении тестов
2. Слишком много доверия к тому, что моки адекватно изображают реальные компоненты.
·>И это по всему коду — везде в тысячах мест. Да? И как это тестировать? Как делать replay?
Смотря как мы сохраняем историю для этого replay. Но в целом — код, в котором зашит Time.now(), replay не поддаётся. Это одна из его проблем.
Поэтому у нас там будут вызовы не Time.now(), а какого-нибудь request.ArrivalTime. С самого начала, естественно. Обратите внимание — в каждом вызове время будет своё, и мне достаточно поднять реквест из лога и скормить его ровно тому же методу обработки.
Вам придётся лепить костыли и шаманить, чтобы прикрутить магический instantSource, способный доставать время не из глобального RTC-источника, а из "текущего обрабатываемого запроса".
·>Почему? У нас появляется требование считать nextFriday для платёжки — добавляем новый код для этого, другой код вообще можно не трогать.
Вы же только что поняли, что "другой код" всё же придётся трогать
·>Я обычно использую специальный тестовый шедулер, который запускает установленные таймеры при изменении тестового источника времени. У есть метод типа tickClock(7, DAYS). Код писать лень, но идея, надеюсь, очевидна...
Не, нифига не очевидна. В том-то и дело, что ваш тестовый "источник времени" — это мок, который только и умеет что отдавать заданную вами константу в ответ на now(). Написать его так, чтобы он умел корректно триггерить таймеры можно, но не факт, что вы про это вспомните вовремя
·>Именно. Универсальность — не даёт делать более эффективую реализацию.
Даёт, даёт
S>>И это у вас прекрасно грохнется в продакшне, как только на машине сменят таймзону аккурат около полуночи пятницы. ·>Нет, конечно. Таймеры ставят на instant, т.е. абсолютный момент времени, независящий от зоны.
Вот именно об этом я и говорю. Инстант не наступил, а nextFriday уже должна возвращать новое значение. Упс.
·>Ну я код в браузере набирал, мог и ошибиться. В реальности буду запускать тесты, ясен пень.
Так у вас и тесты ничего не покажут.
·>Через моки же — возвращай что хошь в каком хошь порядке.
Ну так для начала надо захотеть. Вы — не захотели.
·>В сымсле ботва с таймзонами? Ну это у меня уже привычка — писать тесты для дат около всяких dst переходов и с экзотическими таймзонами.
Ботва с таймзонами очень простая: у вас один и тот же instantSource() сначала возвращает "01:00 пятницы", а потом — "17:00 четверга". Просто пользователь перелетел через Атлантику, делов-то.
А у вас уже всё — таймер сработал, nextFriday теперь возвращает следующую неделю.
S>> Отож. И плюс новый набор тестов. При этом старые тесты тоже нужно гонять, удваивая время исполнения. Прикольно, чо. Поднимаем себестоимость на ровном месте. ·>Такие тесты работают порядка миллисекунд. Их можно гонять миллионами и не заметить.
Ну, ок, пусть будут миллионами.
·>Ну смысле если мы из одного юнита А перенесли код в другой юнит Б, то тесты А всё ещё должны проходить. Но они будут идти через А в Б. Это некрасиво. После того как убедились, что А всё ещё работает. Тесты желательно перенести чтобы тестить Б напрямую.
Не перенести, а скопировать. А для полноты ощущений наверное нужно в тестах А заменить Б на мок Б — чтобы это был именно юнит тест, а то уже какая-то интеграция получается.
S>>А как тогда вы защититесь от будущего джуна, который там что-нибудь отвинтит? ·>Не понял, что "что-нибудь"?
Значит возьмёт и поменяет вызов вашего компонента Б на какую-нибудь ерунду.
·>Ну не нравится, не ешь. Об чём спор? Для чего нужен таймер — я тебе написал, для low latency. Без таймера твой вариант у меня тоже элементарно реализуется, правда мне совесть не позволит убить ещё одного котёнка делая static глобальную переменную. Можно даже гибридное решение наворотить, обновляя кеш по таймеру из другого треда, но если вдруг момент timeSource.now() промазывает по кешу, то идти по медленному пути.
Это решение, очевидно, хуже обоих обсуждаемых вариантов. Оно одновременно оборудовано таймером (усложнение зависимостей, хрупкость) и всё ещё иногда идёт по медленному пути.
Так-то и в ФП ваш вариант элементарно реализуется, потому что способ закинуть замыкание в таймер есть более-менее везде.
·>Он удачный в определённых условиях. То что твой подход "удачный" и универсальный всемогутер — твоё большое заблуждние.
Он у вас неудачный в исходных условиях.
·>Это как? Если у нас в SLA написано, что max response time 10ms, а SlowlyCalculatePrevAndNextFridays работает 11ms, то выбора тупо нет, и похрен всем твоя точка зрения.
Ну, ок, я таких SLA не встречал. Это примерно как 100% availability — обеспечить невозможно. Если у вас такой SLA — ну, ок, согласен, это может влиять на дизайн.
S>>В-третьих, там этот "спайк задержки" работает на 1 запрос. Практически невозможно придумать SLA, на которое это повлияет. ·>Открой для себя мир low latency.
С удовольствием. Пришлите ссылку на публичную SLA, в которой есть такие требования, я почитаю.
·>У нас это было серьёзный production incident. Каждый запрос, обработка которого была >10ms — тикет и расследование. Больше таких двух в день — и клиент нам звонит для разборок.
Ну, тогда у нас есть тесты не только функциональные, но и с бенчмарками, и никто не выкатывает в прод код, надеясь, что он быстрый. И ошибки вроде промахов кэша обнаруживаются регулярным способом, а не мамойклянус.
·>Это повлияет только на новый код с платёжкой. Подменить "случайно" по всему приложению так не выйдет. А вот твоя глобальная переменная — happy debugging.
У нас тоже подменить случайно по всему приложению не выйдет — потому что "всё приложение" пользуется функцией nextFriday(x). А кэширование к этой функции приделано только там, где это потребовалось.
·>У меня была цель продемонстрировать не основы объектно-ориентированного анализа, а факт, что можно максимально оптимизировать реализацию nextFriday(), т.к. у нас известно многое внутри самого метода. Навешивая это всё снаружи, приходится делать всё более пессимистично, т.к. инфы тупо меньше.
Нет такого факта, я вам в который раз повторяю. В вашем instantSource нет никакой гарантии, что следующий вызов now() не вернёт момент времени раньше, чем предыдущий.
И по коду, который вы пишете, примерно понятно, как вы будете это делать в продакшн — в частности, вы даже не задумались о том, что CalendarLogic у вас будет декоратором или наследником старого CalendarLogic. Просто взяли и заменили код, на который завязан весь проект. Ну заменили вы "статик глобал" на "глобал синглтон" — что улучшилось-то?
S>>который ФП-программист пишет инстинктивно, т.к. в ФП такая идиоматика. ·>Ага, смешно у Pauel инстинкт с memoize сработал.
Бывает, чо. В реале он бы привинтил к nextFriday memoize, убедился, что тот не помогает, и сел бы разбираться в причинах и искать способ сделать это корректно. Но у него понятная архитектура.
S>>А надо — наоборот: зависимостей — избегать, стейта — избегать. ·>Ага, и ты тут такой: static (DateTime prevFriday, DateTime nextFriday)? _cache А потом хрясь и в догонку nextFriday(LocalDateTime.now())!
Всё правильно — весь стейт торчит на самом верху, и его мало. А глубокие вызовы все pure, и позволяют тестироваться по табличкам безо всяких моков.
S>>Понадобится стейт — всегда можно добавить его по необходимости. ·>А вот попробуй избавиться от этого static и у тебя полезет колбасня.
Не полезет у меня никакой колбасни
Просто будет локальная переменная в замыкании.
S>>Нет у вас никакого широкого простора для оптимизаций. Есть иллюзии того, что timeSource.now() ведёт себя как-то иначе, чем аргумент (x). И, естественно, оптимизации, построенные на этих иллюзиях, будут приводить к фейлам. ·>ЧПФ же. У нас зафиксирован timeSource же.
Ну и что, что ЧПФ? Вы вообще ближе к началу этого поста признались, что вам как таковой instantSource() вовсе не нужен, а нужен ровно один instant, от которого пляшет вся бизнес-логика.
Так и какой смысл подменять параметр типа instant на параметр типа instantSource, который вы хотите позвать ровно один раз в рамках экземпляра бизнес-логики? С какой целью вы это делаете?
·>Так на практике так и бывает. Т.к. в бизнес-логике бизнес-документы, а не алгоритмы 14го века.
·>Сокет ещё утром был подключён к конкретной бирже. Диспечерезацией уже занимается сетевая карта.
Ну и прекрасно — тогда у нас есть глобальная информация о том, с какой биржей мы работаем, внутри messageHandler.
·>Почему неверный? Таймеры тоже срабатывают по timeSource. Проигрывание лога воспроизводит всё поведение системы, но уже без привязки к физическим часам. Ровно это же используется в тестах, когда мы выполняем шаги: "Делаем трейд. Ждём до конца месяца. Получаем стейтмент".
Где у вас это выражено в коде? Как у вас срабатывают таймеры, когда время идёт "назад"?
·>Т.е. делать его нетестируемым. Спасибо, не надо.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Sinclair, Вы писали:
S>Всё правильно он пишет. Вы заменили прямолинейный понятный код, в котором негде сделать ошибку, на код с распределённой ответственностью. Теперь у вас Time.now() расположен максимально далеко от места его использования.
Где можно сделать ошибки — я описывал. Проблемы с Time.now я тоже описывал. Несколько раз. Вы на это просто закрываете глаза.
S>·> а в вашем стиле lastMonday(LocalDateTime.now()) и nextFriday(LocalDateTime.now()) можно вызывать, да?! S>Можно, но так никто не делает. Потому, что то место, где они нужны — это тоже функция. И в неё по умолчанию не передаётся ссылка на instantSource, а передаются готовые аргументы start и end. Не её дело принимать решения о том, где начало интервала, а где — конец. S>Поэтому мы в неё передаём значения. А значения — тоже вычисляются чистой функцией. Чистота означает, что мы не делаем из неё грязных вызовов — поэтому никаких lastMonday(LocalDateTime.now()) и nextFriday(LocalDateTime.now()), а исключительно lastMonday(currentTime) и nextFriday(currentTime)/
Это очевидный детский сад. Я говорю о коде, где будет стоять LocalDateTime.now(). И как это место протестировать?
S>·>Ну ясен пень. Это слишком простой вопрос, не стоящий обсуждения. Ну да, мы должны получить некий момент и от него плясать по бизнес-логике. Скажем, тот же TradeDate нужно взять только один раз для данного ордера, в момент его прихода в handler, запомнить его и плясать от него далее, вычисляя всякие там settlement date, days to maturity и т.п. S>Ну вы же так не делаете.
Делаю конечно, не фантазируй. Я говорю об "острых краях" приложения, а ты о скучной рутине внутри. Как именно покрывать максимальное количество кода легковесными быстрыми тестами, чтобы подавляющее большинство ошибок ловить ещё до коммита, а не после "успешного" деплоя на прод.
S>Ну, пока что ваш код не удовлетворяет предлагаемым вами же требованиям Напомню, что ваш кэш знать не знает ни про какой event log. И возвращает всегда локальное поле, а чтобы его обновить, нужно срабатывание таймера. Таймер ваш никак с instantSource не связан, это прямая дорога к рассогласованию.
Связан, конечно.
S>·>Я в первую очередь говорю о главном применении моков — отрезать входы-выходы системы (тот самый Time.Now, а ещё сеть, фс, бд, етс), которые в реальности завязываются на что-то тяжело контролируемое или очень медленное. S>Ок, давайте откажемся от обсуждения времени — в конце концов, сделать lastFriday достаточно медленной, чтобы наше обсуждение имело смысл, скорее всего не получится.
Ну lastFriday это довольно условный пример. И медленность там может много откуда взяться. Да даже тупо проверка всех таблиц таймзон, dst-переходов, а ещё можно придумать логику хождения в бд для проверки праздников и т.п. — внезапно и не такой уж скучный пример.
S>Правильный способ отрезания входов-выходов — ровно такой, как настаивает коллега Pauel. Потому что в вашем способе вы их никуда не отрезаете — вы их заменяете плохими аналогами. Ващ подход мы, как и все на рынке, применяли в бою. И неоднократно обожглись о то, что мок не мокает настоящее решение; он мокает ожидания разработчика об этом решении.
Ожидания разработчика берутся не из пустого места, а из фиксации поведения боевой системы. Ну по крайней мере если использовать моки правильно, а не так как Pauel думает их используют.
S>·>Вот это я не понял. У него в примере тест буквально сравнивал текст sql "select * ...". Как такое поймает это? S>Это он просто переводит с рабочего на понятный. Он же пытался вам объяснить, что проверяет структурную эквивалентность. Тут важно понимать, какие компоненты у нас в пайплайне.
При этом он меня обвинил в том, что мои тесты проверяют как написано, а не ожидания пользователей. А бревно в глазу не замечаете — пользователям-то похрен какая-то там эквивалентность у вас, структурная или не очень.
S>Если вы строите текст SQL руками — ну да, тогда будет именно сравнение текстов. Но в наше время так делать неэффективно. Обычно мы порождаем не текст SQL, а его AST. Генерацией текста по AST занимается отдельный компонент (чистая функция), и он покрыт своими тестами — нам их писать не надо.
И накой сдалась эта ваша AST вашим пользователям? А что если завтра понадобится заменить вашу AST на очередной TLA, то придётся переписывать все тесты, рискуя всё сломать.
S>·>Суть в том, что программист пишет код+тест. В тесте вручную прописывает ожидание =="sellect * ...". Потом тест, ясен пень проходит, потом ревью, который тоже наверняка пройдёт, не каждый ревьювер способен заметить лишнюю букву. S>Ну, во-первых, программист же пишет код не в воздухе. Как правило, сначала нужный SQL пишется руками и проверяется интерактивно с тестовой базой, пока не начнёт работать так, как ожидается. Лично я работаю с SQL примерно 30 лет, из них 10 проработал очень плотно. Но и то — сходу не всегда могу написать корректный SQL. Поэтому мы сначала пишем несколько характерных вариантов запроса и прогоняем их на базе (в том числе — используем ровно тот движок, с которым работает прод. Никаких замен боевого постгре на тестовый SQLite или ещё каких-нибудь моков.) S>Потом вставляем готовые команды в тест. Потом пишем код.
Именно! Против этих всех ручных пассов я и возражаю. Верю, что писать запросики в консоли и копипастить в код было ещё ок 30 лет назад... но пора сказать стоп! Ровно так же можно подключаться из тестов к какому хошь движку и напрямую _автоматически_ выполнять запросы и _автоматически_ ассертить результаты чем вручную копипастить туда-сюда из консоли в код и проверять глазками, похож ли результат ли на правду. А если sqlite (есть кстати ещё h2 которая неплохо умеет притворяться популярными субд) чем-то не устраивает, то запустить с точностью до бита идентичный проду постре что локально, что в CI-пайплайне для прогона тестов — дело минут в современном мире докеров.
S>·>И только потом, когда некий тест пройдёт от логина до отчёта, то оно грохнется, может быть, если этот тест таки использует именно эту ветку кода для тестовых параметров отчёта. Ведь итесты в принципе не могут покрыть все комбинации, их может быть просто экспоненциально дохрена. S>У вас — та же проблема, просто вы её предпочитаете не замечать. Вы там запустили тест, а вместо опечатки sellect у вас там вызов функции, которая в inmemory DB работает, а в боевой — нет. SQL вообще состоит из диалектных различий чуть менее, чем полностью.
Эта проблема надумана.
S>·>С этим осторожнее. Вот этот твой кеш оказался — с состоянием, внезапно, да ещё и static global. S>Да, такие вещи нужно делать аккуратно, вы правы.
Тут у вас вся ваша функциональщина и вылазит боком, т.к. кеш — это состояние, даже хуже того — шаред, по определению. И вся пюрешность улетучивается. Приходится нехило прыгать по монадам и прочим страшным словам. А в шарпах-ts где нет нормальной чистоты, только и остаётся отстреливать себе ноги.
S>>>Не знаю. А откуда у вас в CalendarLogic берётся instantSource? S>·>Через DI/CI. S>Ну вот он у вас в тестах — один, в продакшне — другой. Упс.
Суть в том, что тест от прода отличается ровно одной строчкой кода, в этом и цель всего этого. И строчка эта если и меняется, то раз в никогда. И если требует изменения — это становится явным и очевидным, требует более аккуратной валидации релиза. У вас же эта вся грязь будет в каждом методе каждого контроллера.
S>·>CompositionRoot — один на всё приложение, меняется относительно редко, обычно тупой линейный код, и составляет доли процента от объёма всего приложения. Его можно ежедневно глазками каждую строчку просматривать всей командой. S>Ну, так это ровно тот же аргумент "против", который вы мне только что рассказывали. Вот вы взяли и заменили ваш код глобально, не разбираясь, где там можно применять кэширование, а где — нельзя.
Именно. Т.к. nextFriday() — всё сразу видно, всё на ладони — нужно заглянуть ровно в одно место чтобы понять можно ли применять кеширование и если можно то какое, и, во время релиза, не надо проверять каждый метод контроллера, а достаточно один сценарий, на то что хоть где-то этот кеш заработал ожидаемым способом, т.к. во всех остальных местах всё работает так же, т.к. код идентичный.
S>Потому что ваш кэширующий CalendarLogic полагается на то, что в нём timeSource согласован с timer, а в коде это никак не выражено. Вот вы написали replay, который полагается на возможность замены глобального timeSource на чтение из eventLog, и погоняли его. И так получилось, что данные, на которых вы его гоняли, границу пятницы не пересекали. Откуда вы знаете, что нужно пересечь границу пятницы? Да ниоткуда, у вас в проекте таких "особых моментов" — тыщи и тыщи. Код коверадж вам красит весь ваш CalendarLogic зелёненьким, причин сомневаться в работоспособности нету.
Именно, что это ровно один компонент CalendarLogic на всё приложение, вся грязь и грабли рядышком. В этом и суть, что всё в одном месте, а не размазано по всему коду.
S>·>И вот такой модуль можно тестировать простыми тестами, подсовывая туда моковый timeSource и ровно этот же модуль будет зваться из "main" метода реального приложения, куда будет запихан SystemClock в качестве timeSource. S>Проблема опять только в двух вещах: S>1. Слишком много кода в стеке при выполнении тестов
Тесты, которые тестируют такой модуль, конечно, тяжелее чем типичные юнит-тесты, но они всё равно достаточно быстрые, т.к. никакого IO нет, всё внутри языка.
S>2. Слишком много доверия к тому, что моки адекватно изображают реальные компоненты.
Это ортогональная проблема. В тестировании пюрешек ровно эта же проблема тоже есть, для параметров. Тебе приходится верить, что твои тестовые параметры изображают реальные значения. Ещё раз, моки отличаются от параметров лишь способом доставки значений. Реальность данных относится именно к самим значениям, а не способу их передачи.
S>·>И это по всему коду — везде в тысячах мест. Да? И как это тестировать? Как делать replay? S>Смотря как мы сохраняем историю для этого replay. Но в целом — код, в котором зашит Time.now(), replay не поддаётся. Это одна из его проблем.
Ясен пень, типичный синглтон же.
S>Поэтому у нас там будут вызовы не Time.now(), а какого-нибудь request.ArrivalTime. С самого начала, естественно. Обратите внимание — в каждом вызове время будет своё, и мне достаточно поднять реквест из лога и скормить его ровно тому же методу обработки.
А откуда в request появится ArrivalTime? И как все эти места протестировать? Учти, у нас 100500 различных видов request.
S>Вам придётся лепить костыли и шаманить, чтобы прикрутить магический instantSource, способный доставать время не из глобального RTC-источника, а из "текущего обрабатываемого запроса".
event sourcing.
S>·>Почему? У нас появляется требование считать nextFriday для платёжки — добавляем новый код для этого, другой код вообще можно не трогать. S>Вы же только что поняли, что "другой код" всё же придётся трогать
Ы?
S>·>Я обычно использую специальный тестовый шедулер, который запускает установленные таймеры при изменении тестового источника времени. У есть метод типа tickClock(7, DAYS). Код писать лень, но идея, надеюсь, очевидна... S>Не, нифига не очевидна. В том-то и дело, что ваш тестовый "источник времени" — это мок, который только и умеет что отдавать заданную вами константу в ответ на now(). Написать его так, чтобы он умел корректно триггерить таймеры можно, но не факт, что вы про это вспомните вовремя
Самое позднее когда я вспомню — это после упавшего локально теста, ещё до коммита.
S>·>Именно. Универсальность — не даёт делать более эффективую реализацию. S>Даёт, даёт
А ты попробуй. Над мемоизацией посмеялись, над статической глобальной переменной _cache поплакали. Ещё идеи остались?
S>>>И это у вас прекрасно грохнется в продакшне, как только на машине сменят таймзону аккурат около полуночи пятницы. S>·>Нет, конечно. Таймеры ставят на instant, т.е. абсолютный момент времени, независящий от зоны. S>Вот именно об этом я и говорю. Инстант не наступил, а nextFriday уже должна возвращать новое значение. Упс.
Шозабред? Этот инстант логически эквивалентен твоему _cache.nextFriday. В любом случае, это всё элементарно покрывается юнит-тестами (ага, с моками), даже если я и налажал код в браузере правильно написать.
S>·>Ну я код в браузере набирал, мог и ошибиться. В реальности буду запускать тесты, ясен пень. S>Так у вас и тесты ничего не покажут.
Шозабред.
S>·>Через моки же — возвращай что хошь в каком хошь порядке. S>Ну так для начала надо захотеть. Вы — не захотели.
Для моей реализации это и не надо.
S>·>В сымсле ботва с таймзонами? Ну это у меня уже привычка — писать тесты для дат около всяких dst переходов и с экзотическими таймзонами. S>Ботва с таймзонами очень простая: у вас один и тот же instantSource() сначала возвращает "01:00 пятницы", а потом — "17:00 четверга". Просто пользователь перелетел через Атлантику, делов-то.
Это ты наверное имеешь в виду, если wall clock поменяет таймзону. Только это невозможно в моём случае по дизайну. Или ты не понимаешь что такое instant. Это конретная точка на линии физического времени, а не показания на циферблате часов типа "01:00 пятница" для человеков.
Хотя да, это наверное может поломаться, если эффекты СТО учитывать...
S>·>Ну смысле если мы из одного юнита А перенесли код в другой юнит Б, то тесты А всё ещё должны проходить. Но они будут идти через А в Б. Это некрасиво. После того как убедились, что А всё ещё работает. Тесты желательно перенести чтобы тестить Б напрямую. S>Не перенести, а скопировать. А для полноты ощущений наверное нужно в тестах А заменить Б на мок Б — чтобы это был именно юнит тест, а то уже какая-то интеграция получается.
Можно и скопировать. Потом удалить лишнее, если мешается.
S>>>А как тогда вы защититесь от будущего джуна, который там что-нибудь отвинтит? S>·>Не понял, что "что-нибудь"? S>Значит возьмёт и поменяет вызов вашего компонента Б на какую-нибудь ерунду.
А если в твоей функции джун поменяет вызов на какую-нибудь ерунду?
S>·>Ну не нравится, не ешь. Об чём спор? Для чего нужен таймер — я тебе написал, для low latency. Без таймера твой вариант у меня тоже элементарно реализуется, правда мне совесть не позволит убить ещё одного котёнка делая static глобальную переменную. Можно даже гибридное решение наворотить, обновляя кеш по таймеру из другого треда, но если вдруг момент timeSource.now() промазывает по кешу, то идти по медленному пути. S>Это решение, очевидно, хуже обоих обсуждаемых вариантов. Оно одновременно оборудовано таймером (усложнение зависимостей, хрупкость) и всё ещё иногда идёт по медленному пути.
Это же я фантазирую. Наверно да, такое вряд ли понадобится.
S>Так-то и в ФП ваш вариант элементарно реализуется, потому что способ закинуть замыкание в таймер есть более-менее везде.
Как?
S>·>Это как? Если у нас в SLA написано, что max response time 10ms, а SlowlyCalculatePrevAndNextFridays работает 11ms, то выбора тупо нет, и похрен всем твоя точка зрения. S>Ну, ок, я таких SLA не встречал. Это примерно как 100% availability — обеспечить невозможно. Если у вас такой SLA — ну, ок, согласен, это может влиять на дизайн.
Ну... было всего 99.99% афаир.
S>>>В-третьих, там этот "спайк задержки" работает на 1 запрос. Практически невозможно придумать SLA, на которое это повлияет. S>·>Открой для себя мир low latency. S>С удовольствием. Пришлите ссылку на публичную SLA, в которой есть такие требования, я почитаю.
Было дело в lmax. Насчёт публичных доков — не знаю.
S>·>У нас это было серьёзный production incident. Каждый запрос, обработка которого была >10ms — тикет и расследование. Больше таких двух в день — и клиент нам звонит для разборок. S>Ну, тогда у нас есть тесты не только функциональные, но и с бенчмарками, и никто не выкатывает в прод код, надеясь, что он быстрый. И ошибки вроде промахов кэша обнаруживаются регулярным способом, а не мамойклянус.
Ясен пень. Но это ещё и означает, что такие фривольности с глобальными кешами просто недопустимы. Т.к. промахи могут быть недетерминированными и все эти бенчмарки их ловят негарантированно. Как в примере со _слишком_ старой платёжкой. Обычно платёжки не очень старые и даже прогон месячной прод-нагрузки может ничего не выявить, а случайный залётный дятел попадается редко, но метко.
S>·>Это повлияет только на новый код с платёжкой. Подменить "случайно" по всему приложению так не выйдет. А вот твоя глобальная переменная — happy debugging. S>У нас тоже подменить случайно по всему приложению не выйдет — потому что "всё приложение" пользуется функцией nextFriday(x). А кэширование к этой функции приделано только там, где это потребовалось.
Требоваться может везде (или почти везде), в этом и проблема. Суть примера была в том, что "всё приложение" использует не общий "nextFriday(x)", а конкретный "nextFriday(Time.Now)" во многих местах (см. моё начальное "Если у нас конечная цель иметь именно nextFriday()"). Поэтому этот общий код у меня и вынесен в одно место, которое безопасно кешировать, т.к. известен этот самый x. У тебя — неизвестно, в этом и беда. Напомню: ЧПФ.
S>·>У меня была цель продемонстрировать не основы объектно-ориентированного анализа, а факт, что можно максимально оптимизировать реализацию nextFriday(), т.к. у нас известно многое внутри самого метода. Навешивая это всё снаружи, приходится делать всё более пессимистично, т.к. инфы тупо меньше. S>Нет такого факта, я вам в который раз повторяю. В вашем instantSource нет никакой гарантии, что следующий вызов now() не вернёт момент времени раньше, чем предыдущий.
Это не так. В худшем случае, я могу тупо найти все те одно-два места использования _конструктора_ CalendarLogic удостовериться что там может быть и какими свойствами обладает. Ещё раз. ЧПФ.
S>И по коду, который вы пишете, примерно понятно, как вы будете это делать в продакшн — в частности, вы даже не задумались о том, что CalendarLogic у вас будет декоратором или наследником старого CalendarLogic. Просто взяли и заменили код, на который завязан весь проект. Ну заменили вы "статик глобал" на "глобал синглтон" — что улучшилось-то?
Нет никакого глобал. Есть composition root.
S>>>который ФП-программист пишет инстинктивно, т.к. в ФП такая идиоматика. S>·>Ага, смешно у Pauel инстинкт с memoize сработал. S>Бывает, чо. В реале он бы привинтил к nextFriday memoize, убедился, что тот не помогает, и сел бы разбираться в причинах и искать способ сделать это корректно. Но у него понятная архитектура.
Совершенно верно! Любая, даже самая сложная проблема обязательно имеет простое, легкое для понимания, неправильное решение.
S>>>А надо — наоборот: зависимостей — избегать, стейта — избегать. S>·>Ага, и ты тут такой: static (DateTime prevFriday, DateTime nextFriday)? _cache А потом хрясь и в догонку nextFriday(LocalDateTime.now())! S>Всё правильно — весь стейт торчит на самом верху, и его мало. А глубокие вызовы все pure, и позволяют тестироваться по табличкам безо всяких моков.
Может я не понял, что ты называешь самым верхом, но это у вас — метод контроллера, коих в типичном приложении сотни. У же меня этим верхом является один на всех composition root.
S>>>Понадобится стейт — всегда можно добавить его по необходимости. S>·>А вот попробуй избавиться от этого static и у тебя полезет колбасня. S>Не полезет у меня никакой колбасни S>Просто будет локальная переменная в замыкании.
Как эта локальная переменная будет шариться между контроллерами?
S>>>Нет у вас никакого широкого простора для оптимизаций. Есть иллюзии того, что timeSource.now() ведёт себя как-то иначе, чем аргумент (x). И, естественно, оптимизации, построенные на этих иллюзиях, будут приводить к фейлам. S>·>ЧПФ же. У нас зафиксирован timeSource же. S>Ну и что, что ЧПФ? Вы вообще ближе к началу этого поста признались, что вам как таковой instantSource() вовсе не нужен, а нужен ровно один instant, от которого пляшет вся бизнес-логика. S>Так и какой смысл подменять параметр типа instant на параметр типа instantSource, который вы хотите позвать ровно один раз в рамках экземпляра бизнес-логики? С какой целью вы это делаете?
В случае trade date, instant — это физическая точка во времени, для железки. А для ордера нужны календарные показания, для трейдеров. CalendarLogic эту логику и обеспечивает.
S>·>Сокет ещё утром был подключён к конкретной бирже. Диспечерезацией уже занимается сетевая карта. S>Ну и прекрасно — тогда у нас есть глобальная информация о том, с какой биржей мы работаем, внутри messageHandler.
Что значит глобальная? Приложение может подключаться не нескольким биржам одновременно, разными сокетами.
S>·>Почему неверный? Таймеры тоже срабатывают по timeSource. Проигрывание лога воспроизводит всё поведение системы, но уже без привязки к физическим часам. Ровно это же используется в тестах, когда мы выполняем шаги: "Делаем трейд. Ждём до конца месяца. Получаем стейтмент". S>Где у вас это выражено в коде? Как у вас срабатывают таймеры, когда время идёт "назад"? Время не ходит назад. Это физически невозможно. Проблема возникла конкретно у тебя, т.к. у тебя общий всемогутер nextFriday(x), где в качестве x может быть как и текущее время, так и старые платёжки.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
·>Это очевидный детский сад. Я говорю о коде, где будет стоять LocalDateTime.now(). И как это место протестировать?
Примерно так же, как тестируется ваш "compositionRoot" .
S>>Ну вы же так не делаете. ·>Делаю конечно, не фантазируй. Я говорю об "острых краях" приложения, а ты о скучной рутине внутри. Как именно покрывать максимальное количество кода легковесными быстрыми тестами, чтобы подавляющее большинство ошибок ловить ещё до коммита, а не после "успешного" деплоя на прод.
Понимаете, тут вот в чём сложность: превратить код в "нашем" с Pauel стиле в код в вашем стиле — дело простое и очевидное. Просто берём хорошо и дёшево оттестированный stateless код и запихиваем в него state (в виде обращений к instantSource, который в терминах FP — обычный future) или грязь (в виде обращения к time.now()).
Таким образом, можно комбинировать преимущества обоих подходов там, где это нужно.
А вот сделать из грязного недетерминистического кода чистый детерминистический — дудки.
·>Связан, конечно.
В коде это никак не отражено (c).
·>Ну lastFriday это довольно условный пример. И медленность там может много откуда взяться. Да даже тупо проверка всех таблиц таймзон, dst-переходов, а ещё можно придумать логику хождения в бд для проверки праздников и т.п. — внезапно и не такой уж скучный пример.
Ну, это ещё более хороший пример — потому, что чем дальше вы навешиваете на эту lastFriday стейтфул-сложность, тем дороже и хуже будет обходиться его тестирование.
Теперь он у вас зависит от "источника инфы про таймзоны", "бд со списком праздников", етк. Чтобы протестировать собственно логику всего этого contrivance вам придётся скормить ему чёртову гору моков, и шансы на то, что вы всё это верно замокаете, падают по экспоненте.
·>Ожидания разработчика берутся не из пустого места, а из фиксации поведения боевой системы. Ну по крайней мере если использовать моки правильно, а не так как Pauel думает их используют.
Это какие-то абстрактные рассуждения, простите. Получается, для написания мока вам надо сначала провести все нужные тесты с боевой системой, а уже потом что-то там мокать.
Не у всех есть эта роскошь — боевая система может быть недоступна (вам дали спецификацию от сервиса, который будет выпущен в марте 2024), или медленно работать (и вы будете дожидаться тестового покрытия неделями и месяцами). И некоторые аспекты поведения вы можете на боевой системе просто не увидеть — в силу банальных причин. Из самого простого — может так оказаться, что в вашей боевой системе случайно ни разу не встетился пользователь с именем, в котором есть не-Latin1 символы. Нет никакого поведения, которое вы могли бы "зафиксировать" — только слова разработчиков "боевой системы" о том, как это должно работать.
А потом такой пользователь заводится — и всё, оказывается, что где-то там внутри разработчик ограничил длину байтами, а не code point-ами. Упс.
·>При этом он меня обвинил в том, что мои тесты проверяют как написано, а не ожидания пользователей. А бревно в глазу не замечаете — пользователям-то похрен какая-то там эквивалентность у вас, структурная или не очень.
Совершенно верно. Но тут речь идёт несколько о другом аспекте. Если мы "мокаем репозиторий", то тестируем "как написано" — неважно, то ли мы следим за тем, что наш код в каком порядке вызывает, то ли запрашиваем из него список "операций", которые будем вызывать мы. Но вот что касается сложных запросов — тут разница не в стоимости поддержания тестов, а в стоимости их исполнения.
·>И накой сдалась эта ваша AST вашим пользователям? А что если завтра понадобится заменить вашу AST на очередной TLA, то придётся переписывать все тесты, рискуя всё сломать.
Это вы сейчас аргументируете в пользу отказа от юнит-тестирования, я правильно понял?
Потому что разница, собственно, примерно такая: вот у нас есть цепочка зависимостей A->B->C->D, где A — это у нас БЛ, B — это query-часть ORM, С — это генератор SQL-запросов, а D — это БД с тестовыми данными.
И вы типа говорите "мы хотим тестировать всю цепочку, чтобы сэкономить на поддержании тестов в случае замены компонентов B/C".
Это разумная идея, которая будет хорошо работать в тех случаях, когда компоненты B/C подлежат частой замене; при этом у вас легко поддерживать как D, так и тесты результатов к ней. Например, запросы у вас сводятся к GetObjectById(), который вы вчера делали при помощи метода "репозитория" в стиле Фаулера тридцатилетней давности с зашитым внутри "select * from Objects where id = ?", а сегодня вы переехали на JOOQ или Hibernate, но всё остальное осталось неизменным.
Но вот когда начинаются широко разветвлённые пути исполнения в вашем построении запросов, этот подход утонет из-за размера таблиц истинности. Просто возможность указать поле, по которому сортировать, из списка в десяток, потребует от вас довольно-таки длинного набора записей в тестовую таблицу — иначе ваш тест будет некорректным. Нельзя просто добавить пару записей, которые отличаются одним полем, попросить отсортировать по нему, и убедиться, что вторая идёт после первой. Очень может оказаться, что в запросе — косяк, просто он не проявляется на этих данных. Вам нужен такой набор записей, который для каждого из заданных 10 полей будет идти в своём, определённом порядке.
Как только начинается вариативность в критериях отбора, всё становится ещё веселее. Вылезает та самая экспонента, о которой вам твердит Pauel.
И не надо думать, что это касается только data warehouse, проблемы которых можно закрыть, просто передав их в другой отдел — "мы вообще не будем писать никакие отчёты на Java, пусть там аналитики самостоятельно пердолятся в своём Tableau".
Запросто может оказаться, что во вполне себе OLTP-коде навёрнута развесистая логика вроде "если запрошенная лицензия ещё не проэкспайрилась, то находим SKU для её renewal и order date будет датой экспирации; если проэкспайрилась меньше месяца назад — берём SKU для renewal, но дата будет сегодняшим днём; иначе берём SKU для новой покупки, дата ордера будет сегодняшняя, но дата следующего обновления округляется до целого месяца вверх", и поверх этого всякие "если продукт снят с продажи — поискать продукт следуюшей версии в таблице преемственности; если нет новой версии — поискать продукт в списке преемственности; если лицензия учитывает платформу — поискать продукт с такой же платформой; если не нашёлся или лицензия была anyplatform — поискать продукт anyplatform", и такой ботвы — шесть страниц со сносками, примечаниями, и исключениями.
Вот эта вот вся штука — одна функция типа "найди мне код продукта для продления лицензии", один входной параметр, один выходной параметр.
Если вы захотите покрыть всё это при помощи заботливо приготовленной тестовой таблицы (точнее, пяти таблиц) и некоторого набора запросов — удачи.
Есть только два способа с этим справиться:
1. Молиться, мониторить фидбек пользователей, ежемесячно править баги после выхода каждого нового прайс-листа
2. Пилить эту развесистую функцию, зависящую от внешней БД, на набор простых чистых функций, и тестировать каждую из них в отдельности.
Обратите внимание — тут как раз юмор в том, что "ожидания пользователя" — это как раз то, что "если вот такой поиск не удался, то будем использовать вот такой". А не так, что "да похрен, как там SQL написан — главное, чтобы она возвращала что должна". Нет никакой возможности даже сформулировать "что должна" в терминах конечных данных. Например, потому, что прайслиста за июнь 2024 ещё не существует в природе, и какие там будут данные — а хрен его знает. Какие-то продукты будут закрыты вовсе, какие-то смигрированы на другие платформы и так далее.
И вот такого как правило в реальных системах — дохрена и больше. Иногда разработчики просто делают вид, что этого ужаса не существует — ну, такое отрицание реальности. Дескать, "да что там может пойти не так — я же прогоняю тесты с настоящим постгре, и даже запихиваю туда тестовые данные". А потом выясняется, что QA-шники в тестовых данных позабивали всяких очевидных "острых случаев" вроде пользователей с именем AAAAAAAAAAAAAAA, а потом кто-то в реальной системе пытается продлить подписку, за которую оформлен возврат, и получается непредвиденный результат.
·>Именно! Против этих всех ручных пассов я и возражаю. Верю, что писать запросики в консоли и копипастить в код было ещё ок 30 лет назад... но пора сказать стоп! Ровно так же можно подключаться из тестов к какому хошь движку и напрямую _автоматически_ выполнять запросы и _автоматически_ ассертить результаты чем вручную копипастить туда-сюда из консоли в код и проверять глазками, похож ли результат ли на правду.
В мало-мальски реалистичном случае вы вспотеете автоматически ассертить результаты запроса к данным.
·>А если sqlite (есть кстати ещё h2 которая неплохо умеет притворяться популярными субд) чем-то не устраивает, то запустить с точностью до бита идентичный проду постре что локально, что в CI-пайплайне для прогона тестов — дело минут в современном мире докеров.
Минут????? Ну круто — вы только что предложили перейти от тестов, которые исполняются миллисекунды, к тестам длиной в минуты.
И у нас ещё будет большой вопрос про согласованность тестов и данных.
Потому что есть два подхода:
1. Берём контейнер с СУБД, маунтим образ тестовой БД, прогоняем тесты и ассерты
2. Берём контейнер с СУБД, создаём пустую БД, накатываем в неё тестовые данные, прогоняем тесты и ассерты.
Первый вариант — быстрее, но рискованнее: наши ассерты должны соответствовать содержимому тестовой БД. Можно запросто сломать пачку тестов, просто добавив пару записей. И вернуться к тому, с чего начинали — глазками просматривать различия между ожиданиями и реальностью, и править расхождения.
Второй вариант — надёжнее, т.к. параметры и ожидания лежат рядом друг с другом, и скорее соответствуют друг другу.
Но он и заметно медленнее — потому, что нам нужен какой-никакой размер тестовых данных, а коммит в СУБД работает сильно медленнее, чем восстановление файла из образа.
Ну, и есть трудности с параллельным исполнением. Не, я понимаю, что никто нам не мешает поднять одновременно полсотни контейнеров, в кажлом из которых постгре обрабатывает свой изолированный тест.
Но и ресурсов на это нужно примерно в бесконечность раз больше, чем для прогона unit-тестов, проверяющих факты вроде "если у лицензии не задана платформа, то её не будем учитывать, а если задана — то будем".
·>Эта проблема надумана.
Выстрадана кровью и потом.
·>Тут у вас вся ваша функциональщина и вылазит боком, т.к. кеш — это состояние, даже хуже того — шаред, по определению. И вся пюрешность улетучивается.
Никуда она не улетучивается. У нас — 90% пюрешного кода обмазаны 10% императивной грязи; а у вас — все 100% кода состоят из грязи, и даже для тестирования банальных вещей вроде арифметики приходится туда и сюда просовывать моки.
·>Приходится нехило прыгать по монадам и прочим страшным словам. А в шарпах-ts где нет нормальной чистоты, только и остаётся отстреливать себе ноги.
Признаюсь честно — сам я на практике (в пет-проджектах) тяготею к написанию тестов именно в вашем стиле; по ряду причин. Основная из которых — непреодолимая привлекательность: сходу понятно, что именно писать. Куда проще проверить, что запрос вида "2*2+2" вернёт 6, чем сидеть и формализовывать "умножение матриц у нас должно конвертироваться вот в такой вот набор скалярных умножений, а сложение — вот в такой".
Но и ловится такими тестами далеко не всё. Недавно у меня случился баг как раз такого типа — вроде и возвращалось всё правильно; а поменял размеры тестовых массивов — и упс! оказалось, в одном месте при переходе от скаляров к векторам менялся знак.
·>Суть в том, что тест от прода отличается ровно одной строчкой кода, в этом и цель всего этого. И строчка эта если и меняется, то раз в никогда. И если требует изменения — это становится явным и очевидным, требует более аккуратной валидации релиза. У вас же эта вся грязь будет в каждом методе каждого контроллера.
Если захотим — да. А если мы увидим в этом проблему, то "вся грязь" будет выписана в виде грязной ФВП и применена единообразно. Вы же не думаете, что агрегация — это прерогатива рич-ООП?
Нет ровно никакой проблемы взять и добавить к чистой функции nextFriday(timestamp) грязную функцию nextFriday()=>nextFriday(Time.now()), и заменить вызовы повсеместно.
Но это будет осознанным шагом, а не следствием случайного дизайна под давлением "ну мы хотели просто повызывать Console.WriteLine и DateTime.Now, но тим лид велел сделать юнит-тесты через моки".
·>Именно. Т.к. nextFriday() — всё сразу видно, всё на ладони — нужно заглянуть ровно в одно место чтобы понять можно ли применять кеширование и если можно то какое
Да нельзя, нельзя заглянуть. Вот вы только что написали код с багом, мы уже пять постов это обсуждаем, а вы, похоже, даже не поняли, что там баг.
·>Тесты, которые тестируют такой модуль, конечно, тяжелее чем типичные юнит-тесты, но они всё равно достаточно быстрые, т.к. никакого IO нет, всё внутри языка.
И тем не менее — тут умножили в 2 раза, там в 2 раза — так и набегает "тесты исполняются несколько часов".
·>Это ортогональная проблема. В тестировании пюрешек ровно эта же проблема тоже есть, для параметров. Тебе приходится верить, что твои тестовые параметры изображают реальные значения. Ещё раз, моки отличаются от параметров лишь способом доставки значений. Реальность данных относится именно к самим значениям, а не способу их передачи.
Ну, в некоторых изолированных случаях — да.
Можно писать код в стиле
GetItems(int a, List<int> list)
{
list.Add(a);
list.Add(a*2);
}
и тестировать его при помощи стейтфул-"мока":
var l = new List<int>();
GetItems(2, l);
Assert.SequenceEquals(l, new[]{2, 4});
(ну или задом-наперёд, написать моку каких вызовов ожидать).
Можно переписать это в виде чистой функции — и тестировать ровно то же самое:
IEnumerable<int> GetItems(int a, List<int> list)
{
yield return a;
yield return a*2;
}
...
var l = GetItems(2);
Assert.SequenceEquals(l, new[]{2, 4});
В более интересных случаях, когда "мокировать" приходится более сложный набор взаимосвязей, чем 1 вход и 1 выход, распиливание на pure-куски позволяет нам упростить тестирование.
·>Ясен пень, типичный синглтон же.
Не, типичный хардкод.
·>А откуда в request появится ArrivalTime? И как все эти места протестировать? Учти, у нас 100500 различных видов request.
Как откуда? Из общей инфраструктуры. У нас система типов построена так, что в любом request есть ArrivalTime, а его генерация делается примерно в одном месте, которое обеспечивает приём запроса ещё до его роутинга.
·>Ы?
Там, где вы "старый" код, который обращался к instantSource, заменили на вызов "новой" nextFriday(instantSource.now()).
·>Самое позднее когда я вспомню — это после упавшего локально теста, ещё до коммита.
Это если он упадёт
·>А ты попробуй. Над мемоизацией посмеялись, над статической глобальной переменной _cache поплакали. Ещё идеи остались?
Вы серьёзно? Давайте вы для начала напишете корректный код кэширования, пусть даже и не самый быстрый в общем случае.
S>>Вот именно об этом я и говорю. Инстант не наступил, а nextFriday уже должна возвращать новое значение. Упс. ·>Шозабред? Этот инстант логически эквивалентен твоему _cache.nextFriday. В любом случае, это всё элементарно покрывается юнит-тестами (ага, с моками), даже если я и налажал код в браузере правильно написать.
Ну, всё верно. Именно поэтому у меня там не одна пятница, а две, и код возвращает закешированное значение только в том случае, если instant попадает в их диапазон
S>>Так у вас и тесты ничего не покажут. ·>Шозабред.
Никакого бреда. Вы же не догадались, что ваш instantSource может возвращать время в обратном порядке — значит и тесты у вас будут только прямой порядок тестировать
·>Для моей реализации это и не надо.
S>>Ботва с таймзонами очень простая: у вас один и тот же instantSource() сначала возвращает "01:00 пятницы", а потом — "17:00 четверга". Просто пользователь перелетел через Атлантику, делов-то. ·>Это ты наверное имеешь в виду, если wall clock поменяет таймзону. Только это невозможно в моём случае по дизайну. Или ты не понимаешь что такое instant. Это конретная точка на линии физического времени, а не показания на циферблате часов типа "01:00 пятница" для человеков.
Тогда вы, наверное, неверно решили задачу. Потому что человека интересовала следующая пятница по wall time, а не абстрактная точка на линии "физического времени". Если бы речь щла о физическом времени, то вся эта ботва со следующей пятницей сводилась бы к паре делений и умножений.
S>>Значит возьмёт и поменяет вызов вашего компонента Б на какую-нибудь ерунду. ·>А если в твоей функции джун поменяет вызов на какую-нибудь ерунду?
В какой именно? У меня нет двух разных calendarLogic,
S>>Так-то и в ФП ваш вариант элементарно реализуется, потому что способ закинуть замыкание в таймер есть более-менее везде. ·>Как?
В смысле "как"?
Так и пишем:
public static Func<int, int> Cache(Func<int, int> func)
{
int? c = null;
return (i) =>
(c is int r && r >= i) ? r : (c = func(i)).Value ;
}
Здесь у нас на каждый вызов Cache() возвращается новая функция со своим кэшем, независимым от результатов других вызовов. АФАИК, в джаве это работает так же.
S>>С удовольствием. Пришлите ссылку на публичную SLA, в которой есть такие требования, я почитаю. ·>Было дело в lmax. Насчёт публичных доков — не знаю.
Ну, LMAX — парни известные. Но если почитать их Terms of Business, то слово latency там упомянуто всего лишь трижды, и ни в одном из случаев там не фигурируют никакие цифры. https://www.lmax.com/documents/LMAXGlobal-eu-Terms-of-Business.pdf
Наверняка вы с лёгкостью найдёте каких-то других парней (да хоть вашего работодателя), где есть SLA c параметрами латентности, да ещё и не процентилях, а в виде ограничения сверху.
Я в такое не очень верю — компания, которая такое рисует, будет либо в качестве штрафов писать что-нибудь типа скидки на следующую оплату услуг, либо очень быстро вылетит из бизнеса.
·>Ясен пень. Но это ещё и означает, что такие фривольности с глобальными кешами просто недопустимы. Т.к. промахи могут быть недетерминированными и все эти бенчмарки их ловят негарантированно.
Вопрос к автору бенчмарков
·>Как в примере со _слишком_ старой платёжкой. Обычно платёжки не очень старые и даже прогон месячной прод-нагрузки может ничего не выявить, а случайный залётный дятел попадается редко, но метко.
Расскажите, как в вашем подходе решается эта проблема. Как вы собираетесь поймать "клиента со слишком старой платёжкой"?
·>Требоваться может везде (или почти везде), в этом и проблема. Суть примера была в том, что "всё приложение" использует не общий "nextFriday(x)", а конкретный "nextFriday(Time.Now)" во многих местах (см. моё начальное "Если у нас конечная цель иметь именно nextFriday()"). Поэтому этот общий код у меня и вынесен в одно место, которое безопасно кешировать, т.к. известен этот самый x. У тебя — неизвестно, в этом и беда. Напомню: ЧПФ.
На это уже ответил выше — ЧПФ придумали не в ООП
S>>Нет такого факта, я вам в который раз повторяю. В вашем instantSource нет никакой гарантии, что следующий вызов now() не вернёт момент времени раньше, чем предыдущий. ·>Это не так. В худшем случае, я могу тупо найти все те одно-два места использования _конструктора_ CalendarLogic удостовериться что там может быть и какими свойствами обладает. Ещё раз. ЧПФ.
Вы повторяете это как мантру. ЧПФ вам тут никак не поможет — нет такой системы типов, которая бы позволила вам записать монотонность стейтфул-функции.
·>Нет никакого глобал. Есть composition root.
Ну, ок.
S>>Всё правильно — весь стейт торчит на самом верху, и его мало. А глубокие вызовы все pure, и позволяют тестироваться по табличкам безо всяких моков. ·>Может я не понял, что ты называешь самым верхом, но это у вас — метод контроллера, коих в типичном приложении сотни. У же меня этим верхом является один на всех composition root.
Если нас не устраивает высота "метода контроллера", то мы запихиваем то, что вы называете "composition root" туда, откуда эти контроллеры вызываются.
S>>Просто будет локальная переменная в замыкании. ·>Как эта локальная переменная будет шариться между контроллерами?
Как захотим — так и будет. Через указатель на функцию
S>>Так и какой смысл подменять параметр типа instant на параметр типа instantSource, который вы хотите позвать ровно один раз в рамках экземпляра бизнес-логики? С какой целью вы это делаете? ·>В случае trade date, instant — это физическая точка во времени, для железки. А для ордера нужны календарные показания, для трейдеров. CalendarLogic эту логику и обеспечивает.
Ну так этой логике нужен ровно один instant, который физическая точка во времени. А не возможность получить неограниченное количество этих инстантов, продолжая вызывать недетерминистическую timeSource.now().
S>>Ну и прекрасно — тогда у нас есть глобальная информация о том, с какой биржей мы работаем, внутри messageHandler. ·>Что значит глобальная? Приложение может подключаться не нескольким биржам одновременно, разными сокетами.
Ну так наверное у них и хэндлеры будут разными. Вы же как-то должны понимать, с какой из бирж работаете.
S>>Где у вас это выражено в коде? Как у вас срабатывают таймеры, когда время идёт "назад"? ·> Время не ходит назад. Это физически невозможно.
При replay — ещё как идёт. Вот только что был понедельник, и тут поехал replay четверга. И ещё есть много случаев.
Вы пытаетесь искать ключи под фонарём: "а вот у меня instant source — он другой, я про него всё знаю". Нет, нихрена вы не знаете, потому что у вас instantSource — это интерфейс.
Императивные инварианты — это вообще такая штука, которую крайне сложно выразить в терминах системы типов. Банальнейшие вещи вроде "делать socket.Read() нельзя до socket.Open() и после socket.Close()" в терминах ООП невыразимы. А в реальных системах встречаются ещё и чудесные вещи типа "после того, как сделал var u = service.CreateUser(...), нужно выждать не менее 5 минут перед service.UpdateUser(u, ...)", с которыми совсем всё плохо.
Правильный способ с такими вещами работать требует очень сильно другой матаппарат, чем реализован в той же джаве.
Поэтому беспокоиться нужно не о том, что джун заменит request.ArrivalTime на Time.now() (в конце концов, это можно отловить через styleCop и прочие радости жизни) — беспокоиться надо о том, как покрыть все ожидания адекватными тестами. В том числе и все вот эти вот ожидания по поводу валидных трансформаций состояния.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Sinclair, Вы писали:
S>·>Это ортогональная проблема. В тестировании пюрешек ровно эта же проблема тоже есть, для параметров. Тебе приходится верить, что твои тестовые параметры изображают реальные значения. Ещё раз, моки отличаются от параметров лишь способом доставки значений. Реальность данных относится именно к самим значениям, а не способу их передачи.
S>Ну, в некоторых изолированных случаях — да.
Я так и не понял, как протестировать код, завязанный на внешние системы. Ответ от Pauel если и был, то размазался где-то среди кучи сообщений.
Алгоритмы (доменная логика) уже вынесена в чистые функции, и это действительно банально.
Но осталось связать эту логику с данными из внешних систем. Ведь где-то при обработке запроса это должно происходить. Кстати, где?
Полагаю, что работа с внешними зависимостями будут закрыты функциями, которые будут переданы в функцию do_logic. Аналогично для моков зависимости будут закрыты интерфейсом (группа функций), и он будет передан в do_logic. Т.е. с точки зрения тестирования разницы нет — в обоих случаях подменяется поведение внешней системы — передается функция возвращающая нужное для теста значение.
Здравствуйте, Буравчик, Вы писали: Б>Я так и не понял, как протестировать код, завязанный на внешние системы. Ответ от Pauel если и был, то размазался где-то среди кучи сообщений. Б>Полагаю, что работа с внешними зависимостями будут закрыты функциями, которые будут переданы в функцию do_logic. Аналогично для моков зависимости будут закрыты интерфейсом (группа функций), и он будет передан в do_logic. Т.е. с точки зрения тестирования разницы нет — в обоих случаях подменяется поведение внешней системы — передается функция возвращающая нужное для теста значение.
Для внешних систем у нас вариантов немного — либо моки, либо интеграционное тестирование.
При этом я предпочитаю интеграцию — потому, что она даёт нам гораздо больше уверенности в результатах.
Даже "эмулятор" продакшн системы на стороне партнёра часто даёт неверные результаты.
У интеграции есть ровно один недостаток — она дорогая. Но обычно это приемлемая стоимость, с учётом того, что интеграционных тестов гораздо меньше. В моей практике обычно основная сложность (в которой можно напороть) спрятана именно в бизнес логике на нашей стороне; а взаимодействие со внешними системами — это ограниченное количество сценариев. И нам собственно нужно оттестировать как раз не саму логику, а расхождения между нашими ожиданиями от внешней системы и её реализацией.
Вот, кстати, когда мы работали с CREST API от Microsoft, нами был напилен набор интеграционных тестов, которые гонялись в каждом acceptance. И мы чаще всего ловили там не глюки нашего софта (которые были отловлены юнит-тестами), а регрессию со стороны Microsoft .
Было всего несколько случаев, когда поведение API было не таким, как мы ожидали, и это не было признано багом.
Но я могу себе представить ситуацию, когда 100% интеграционное тестирование недоступно или настолько дорого, чтобы оправдать написание моков. Тут вы совершенно правы — принцип остаётся ровно тем же самым: мы будем передавать в do_logic какие-то функции, эмулирующие поведение внешней системы.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Буравчик, Вы писали: Б>Я так и не понял, как протестировать код, завязанный на внешние системы. Ответ от Pauel если и был, то размазался где-то среди кучи сообщений. Б>Полагаю, что работа с внешними зависимостями будут закрыты функциями, которые будут переданы в функцию do_logic. Аналогично для моков зависимости будут закрыты интерфейсом (группа функций), и он будет передан в do_logic. Т.е. с точки зрения тестирования разницы нет — в обоих случаях подменяется поведение внешней системы — передается функция возвращающая нужное для теста значение.
Для внешних систем у нас вариантов немного — либо моки, либо интеграционное тестирование.
При этом я предпочитаю интеграцию — потому, что она даёт нам гораздо больше уверенности в результатах.
Даже "эмулятор" продакшн системы на стороне партнёра часто даёт неверные результаты.
У интеграции есть ровно один недостаток — она дорогая. Но обычно это приемлемая стоимость, с учётом того, что интеграционных тестов гораздо меньше. В моей практике обычно основная сложность (в которой можно напороть) спрятана именно в бизнес логике на нашей стороне; а взаимодействие со внешними системами — это ограниченное количество сценариев. И нам собственно нужно оттестировать как раз не саму логику, а расхождения между нашими ожиданиями от внешней системы и её реализацией.
Вот, кстати, когда мы работали с CREST API от Microsoft, нами был напилен набор интеграционных тестов, которые гонялись в каждом acceptance. И мы чаще всего ловили там не глюки нашего софта (которые были отловлены юнит-тестами), а регрессию со стороны Microsoft .
Было всего несколько случаев, когда поведение API было не таким, как мы ожидали, и это не было признано багом.
Но я могу себе представить ситуацию, когда 100% интеграционное тестирование недоступно или настолько дорого, чтобы оправдать написание моков. Тут вы совершенно правы — принцип остаётся ровно тем же самым: мы будем передавать в do_logic какие-то функции, эмулирующие поведение внешней системы.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Sinclair, Вы писали:
S>·>Это очевидный детский сад. Я говорю о коде, где будет стоять LocalDateTime.now(). И как это место протестировать? S>Примерно так же, как тестируется ваш "compositionRoot" .
composition root — это технический, "подвальный" код. Конкретно инжекция системного источника времени — одна строчка кода, которая за жизнь проекта трогается практически ни разу. И тестируется относительно просто — приложение скомпилировалось, стартовало, даёт зелёный healthcheck — значит работает.
У тебя же now() лежит в коде бизнес-логики (как я понял из объяснений Pauel). Будет стоять в каждом втором методе контроллеров, т.е. в сотнях мест и код этот постоянно меняется.
S>·>Делаю конечно, не фантазируй. Я говорю об "острых краях" приложения, а ты о скучной рутине внутри. Как именно покрывать максимальное количество кода легковесными быстрыми тестами, чтобы подавляющее большинство ошибок ловить ещё до коммита, а не после "успешного" деплоя на прод. S>Понимаете, тут вот в чём сложность: превратить код в "нашем" с Pauel стиле в код в вашем стиле — дело простое и очевидное. Просто берём хорошо и дёшево оттестированный stateless код и запихиваем в него state (в виде обращений к instantSource, который в терминах FP — обычный future) или грязь (в виде обращения к time.now()). S>Таким образом, можно комбинировать преимущества обоих подходов там, где это нужно. S>А вот сделать из грязного недетерминистического кода чистый детерминистический — дудки.
Если бы такое писать на хаскеле... А так это всё лирика. На практике же — понадобился кеш и полезло static по ногам стрелять...
S>·>Связан, конечно. S>В коде это никак не отражено (c).
В сигнатуре nextFriday() это собсвенно негде даже отражать, в этом и суть. А в CalendarLogic — отразить можно. Опять же — это одно место на всё приложение.
S>·>Ну lastFriday это довольно условный пример. И медленность там может много откуда взяться. Да даже тупо проверка всех таблиц таймзон, dst-переходов, а ещё можно придумать логику хождения в бд для проверки праздников и т.п. — внезапно и не такой уж скучный пример. S>Ну, это ещё более хороший пример — потому, что чем дальше вы навешиваете на эту lastFriday стейтфул-сложность, тем дороже и хуже будет обходиться его тестирование.
Логично, чем больше логики, тем больше тестов. Стейт тут не при чём.
S>Теперь он у вас зависит от "источника инфы про таймзоны", "бд со списком праздников", етк. Чтобы протестировать собственно логику всего этого contrivance вам придётся скормить ему чёртову гору моков, и шансы на то, что вы всё это верно замокаете, падают по экспоненте.
Если сложность конкретно CalendarLogic будет выходить за рамки разумного, то начнём резать части логики в отдельные компоненты.
S>·>Ожидания разработчика берутся не из пустого места, а из фиксации поведения боевой системы. Ну по крайней мере если использовать моки правильно, а не так как Pauel думает их используют. S>Это какие-то абстрактные рассуждения, простите. Получается, для написания мока вам надо сначала провести все нужные тесты с боевой системой, а уже потом что-то там мокать.
Не для написания мока, а для написания теста. Как и у тебя. Ешё раз — мок средство доставки тестовых данных, а не сами данные. Именно данные нужно проводить в соответствие с реальностью. Даже вообще я не очень понимаю, что за процесс такой "написание мока".
S>Не у всех есть эта роскошь — боевая система может быть недоступна (вам дали спецификацию от сервиса, который будет выпущен в марте 2024), или медленно работать (и вы будете дожидаться тестового покрытия неделями и месяцами). И некоторые аспекты поведения вы можете на боевой системе просто не увидеть — в силу банальных причин. Из самого простого — может так оказаться, что в вашей боевой системе случайно ни разу не встетился пользователь с именем, в котором есть не-Latin1 символы. Нет никакого поведения, которое вы могли бы "зафиксировать" — только слова разработчиков "боевой системы" о том, как это должно работать. S>А потом такой пользователь заводится — и всё, оказывается, что где-то там внутри разработчик ограничил длину байтами, а не code point-ами. Упс.
И? Ты тоже рассуждаешь об абстрактных проблемах программирования вместо того чтобы сравнивать "моки vs немоки".
S>·>При этом он меня обвинил в том, что мои тесты проверяют как написано, а не ожидания пользователей. А бревно в глазу не замечаете — пользователям-то похрен какая-то там эквивалентность у вас, структурная или не очень. S>Совершенно верно. Но тут речь идёт несколько о другом аспекте. Если мы "мокаем репозиторий", то тестируем "как написано" — неважно, то ли мы следим за тем, что наш код в каком порядке вызывает, то ли запрашиваем из него список "операций", которые будем вызывать мы. Но вот что касается сложных запросов — тут разница не в стоимости поддержания тестов, а в стоимости их исполнения.
Мокаем это значит определяем контракт. И ожидаем, что он выполняется реальным репо. А реальный репо тестируется и-тестом с субд, на то, что он этот же контракт выполняет. Цель всего это действа — отпилить быстрые легковесные тесты логики от тяжелых тестов интеграции яп с субд.
S>·>И накой сдалась эта ваша AST вашим пользователям? А что если завтра понадобится заменить вашу AST на очередной TLA, то придётся переписывать все тесты, рискуя всё сломать. S>Это вы сейчас аргументируете в пользу отказа от юнит-тестирования, я правильно понял? S>Потому что разница, собственно, примерно такая: вот у нас есть цепочка зависимостей A->B->C->D, где A — это у нас БЛ, B — это query-часть ORM, С — это генератор SQL-запросов, а D — это БД с тестовыми данными. S>И вы типа говорите "мы хотим тестировать всю цепочку, чтобы сэкономить на поддержании тестов в случае замены компонентов B/C".
Не очень понял чем B от C отличается. Но суть моего тезиса в том, что просто сгенерированный SQL особо не нужен. В тесте его нужно сгенерировать (не важно как), загнать туда параметры, выполнить, ассертить результаты. См. мой примерчик выше с "save/find". И это делать с бизнес-сущностями, а не абстрактными sql-текстами и именами функций маппинга. А потом, ещё отдельные тесты для бизнес-логики, которые используют контракт репо.
S>Это разумная идея, которая будет хорошо работать в тех случаях, когда компоненты B/C подлежат частой замене; при этом у вас легко поддерживать как D, так и тесты результатов к ней. Например, запросы у вас сводятся к GetObjectById(), который вы вчера делали при помощи метода "репозитория" в стиле Фаулера тридцатилетней давности с зашитым внутри "select * from Objects where id = ?", а сегодня вы переехали на JOOQ или Hibernate, но всё остальное осталось неизменным. S>Но вот когда начинаются широко разветвлённые пути исполнения в вашем построении запросов, этот подход утонет из-за размера таблиц истинности. Просто возможность указать поле, по которому сортировать, из списка в десяток, потребует от вас довольно-таки длинного набора записей в тестовую таблицу — иначе ваш тест будет некорректным. Нельзя просто добавить пару записей, которые отличаются одним полем, попросить отсортировать по нему, и убедиться, что вторая идёт после первой. Очень может оказаться, что в запросе — косяк, просто он не проявляется на этих данных. Вам нужен такой набор записей, который для каждого из заданных 10 полей будет идти в своём, определённом порядке.
Если ты это уже знаешь, то в чём проблема это загнать через save в тестовые данные? Никто ж не запрещает использовать больше 2 записей. Тут просто желательно делать поменьше записей, чтобы человекам было проще разобраться в сценарии.
S>Как только начинается вариативность в критериях отбора, всё становится ещё веселее. Вылезает та самая экспонента, о которой вам твердит Pauel. S>И не надо думать, что это касается только data warehouse, проблемы которых можно закрыть, просто передав их в другой отдел — "мы вообще не будем писать никакие отчёты на Java, пусть там аналитики самостоятельно пердолятся в своём Tableau". S>Запросто может оказаться, что во вполне себе OLTP-коде навёрнута развесистая логика вроде "если запрошенная лицензия ещё не проэкспайрилась, то находим SKU для её renewal и order date будет датой экспирации; если проэкспайрилась меньше месяца назад — берём SKU для renewal, но дата будет сегодняшим днём; иначе берём SKU для новой покупки, дата ордера будет сегодняшняя, но дата следующего обновления округляется до целого месяца вверх", и поверх этого всякие "если продукт снят с продажи — поискать продукт следуюшей версии в таблице преемственности; если нет новой версии — поискать продукт в списке преемственности; если лицензия учитывает платформу — поискать продукт с такой же платформой; если не нашёлся или лицензия была anyplatform — поискать продукт anyplatform", и такой ботвы — шесть страниц со сносками, примечаниями, и исключениями. S>Вот эта вот вся штука — одна функция типа "найди мне код продукта для продления лицензии", один входной параметр, один выходной параметр.
Ну как видишь эта самая фунция бизнес-логики состоит из меньших шагов бизнес логики с кучей "если-то". И это всё бизнес-логика. Вот и бей на части.
И где же тут эта ваша структурная эквивалентность? Где метапрограммирование? Где буквальный текст sql? И имя функции fn1?
S>Если вы захотите покрыть всё это при помощи заботливо приготовленной тестовой таблицы (точнее, пяти таблиц) и некоторого набора запросов — удачи.
Ну так еште слона по частям. В одной части "находим SKU для её renewal и order date", "поискать продукт в списке преемственности", "поискать продукт с такой же платформой" и т.п. Это всё бизнес-кейсы для тестов разных методов репы.
А потом из этого собирается цельный бизнес-метод дёргающий в нужном порядке моки предыдущих.
S>Обратите внимание — тут как раз юмор в том, что "ожидания пользователя" — это как раз то, что "если вот такой поиск не удался, то будем использовать вот такой". А не так, что "да похрен, как там SQL написан — главное, чтобы она возвращала что должна". Нет никакой возможности даже сформулировать "что должна" в терминах конечных данных. Например, потому, что прайслиста за июнь 2024 ещё не существует в природе, и какие там будут данные — а хрен его знает. Какие-то продукты будут закрыты вовсе, какие-то смигрированы на другие платформы и так далее. S>И вот такого как правило в реальных системах — дохрена и больше. Иногда разработчики просто делают вид, что этого ужаса не существует — ну, такое отрицание реальности. Дескать, "да что там может пойти не так — я же прогоняю тесты с настоящим постгре, и даже запихиваю туда тестовые данные". А потом выясняется, что QA-шники в тестовых данных позабивали всяких очевидных "острых случаев" вроде пользователей с именем AAAAAAAAAAAAAAA, а потом кто-то в реальной системе пытается продлить подписку, за которую оформлен возврат, и получается непредвиденный результат.
А что предлагается-то взамен, я не понял.
S>·>Именно! Против этих всех ручных пассов я и возражаю. Верю, что писать запросики в консоли и копипастить в код было ещё ок 30 лет назад... но пора сказать стоп! Ровно так же можно подключаться из тестов к какому хошь движку и напрямую _автоматически_ выполнять запросы и _автоматически_ ассертить результаты чем вручную копипастить туда-сюда из консоли в код и проверять глазками, похож ли результат ли на правду. S>В мало-мальски реалистичном случае вы вспотеете автоматически ассертить результаты запроса к данным.
Если вспотею делать это автоматически, то если такое придется делать вручную, то просто сдохну. Да ещё перед каждым релизом, как минимум!
S>·>А если sqlite (есть кстати ещё h2 которая неплохо умеет притворяться популярными субд) чем-то не устраивает, то запустить с точностью до бита идентичный проду постре что локально, что в CI-пайплайне для прогона тестов — дело минут в современном мире докеров. S>Минут????? Ну круто — вы только что предложили перейти от тестов, которые исполняются миллисекунды, к тестам длиной в минуты.
Минуты на разворачивание тестового окружения. Тесты потом пачками гоняются быстро.
S>И у нас ещё будет большой вопрос про согласованность тестов и данных. S>Потому что есть два подхода: S>1. Берём контейнер с СУБД, маунтим образ тестовой БД, прогоняем тесты и ассерты S>2. Берём контейнер с СУБД, создаём пустую БД, накатываем в неё тестовые данные, прогоняем тесты и ассерты. S>Первый вариант — быстрее, но рискованнее: наши ассерты должны соответствовать содержимому тестовой БД. Можно запросто сломать пачку тестов, просто добавив пару записей. И вернуться к тому, с чего начинали — глазками просматривать различия между ожиданиями и реальностью, и править расхождения. S>Второй вариант — надёжнее, т.к. параметры и ожидания лежат рядом друг с другом, и скорее соответствуют друг другу. S>Но он и заметно медленнее — потому, что нам нужен какой-никакой размер тестовых данных, а коммит в СУБД работает сильно медленнее, чем восстановление файла из образа. S>Ну, и есть трудности с параллельным исполнением. Не, я понимаю, что никто нам не мешает поднять одновременно полсотни контейнеров, в кажлом из которых постгре обрабатывает свой изолированный тест. S>Но и ресурсов на это нужно примерно в бесконечность раз больше, чем для прогона unit-тестов, проверяющих факты вроде "если у лицензии не задана платформа, то её не будем учитывать, а если задана — то будем".
Мы делали примерно так: "открываем транзакцию, суём данные, проверяем результаты запросов, откатываем транзакцию". Подавляющее число тестов можно уложить в такое.
S>·>Тут у вас вся ваша функциональщина и вылазит боком, т.к. кеш — это состояние, даже хуже того — шаред, по определению. И вся пюрешность улетучивается. S>Никуда она не улетучивается. У нас — 90% пюрешного кода обмазаны 10% императивной грязи; а у вас — все 100% кода состоят из грязи, и даже для тестирования банальных вещей вроде арифметики приходится туда и сюда просовывать моки.
Повторюсь: "Если у нас конечная цель иметь именно nextFriday()". Про арифметику ты загнул. Я не отрицаю полезность пюре, но злоупотреблять тоже не стоит.
S>·>Приходится нехило прыгать по монадам и прочим страшным словам. А в шарпах-ts где нет нормальной чистоты, только и остаётся отстреливать себе ноги. S> S>Признаюсь честно — сам я на практике (в пет-проджектах) тяготею к написанию тестов именно в вашем стиле; по ряду причин. Основная из которых — непреодолимая привлекательность: сходу понятно, что именно писать. Куда проще проверить, что запрос вида "2*2+2" вернёт 6, чем сидеть и формализовывать "умножение матриц у нас должно конвертироваться вот в такой вот набор скалярных умножений, а сложение — вот в такой". S>Но и ловится такими тестами далеко не всё. Недавно у меня случился баг как раз такого типа — вроде и возвращалось всё правильно; а поменял размеры тестовых массивов — и упс! оказалось, в одном месте при переходе от скаляров к векторам менялся знак.
Именно что "тестовых массивов". Причём тут моки и пюре? Догадался бы заранее протестировать правильные массивы, поймал бы сразу. Вне зависимости от моков.
S>·>Суть в том, что тест от прода отличается ровно одной строчкой кода, в этом и цель всего этого. И строчка эта если и меняется, то раз в никогда. И если требует изменения — это становится явным и очевидным, требует более аккуратной валидации релиза. У вас же эта вся грязь будет в каждом методе каждого контроллера. S>Если захотим — да. А если мы увидим в этом проблему, то "вся грязь" будет выписана в виде грязной ФВП и применена единообразно. Вы же не думаете, что агрегация — это прерогатива рич-ООП? S>Нет ровно никакой проблемы взять и добавить к чистой функции nextFriday(timestamp) грязную функцию nextFriday()=>nextFriday(Time.now()), и заменить вызовы повсеместно.
Так и обратное — на столько же верно.
S>Но это будет осознанным шагом, а не следствием случайного дизайна под давлением "ну мы хотели просто повызывать Console.WriteLine и DateTime.Now, но тим лид велел сделать юнит-тесты через моки".
Это ортогональная проблема. Console и DateTime.Now — глобальные переменные, синглтоны. И с этим борятся через DI.
S>Да нельзя, нельзя заглянуть. Вот вы только что написали код с багом, мы уже пять постов это обсуждаем, а вы, похоже, даже не поняли, что там баг.
Нету никакого бага. А вот что у тебя, что у Pauel — баги были.
S>·>Тесты, которые тестируют такой модуль, конечно, тяжелее чем типичные юнит-тесты, но они всё равно достаточно быстрые, т.к. никакого IO нет, всё внутри языка. S>И тем не менее — тут умножили в 2 раза, там в 2 раза — так и набегает "тесты исполняются несколько часов".
Как я понял подобные тесты у Pauel будут требовать поднятия всего сразу. Т.е. там не в 2 раза, а в 2к раза, как минимум.
S>·>Это ортогональная проблема. В тестировании пюрешек ровно эта же проблема тоже есть, для параметров. Тебе приходится верить, что твои тестовые параметры изображают реальные значения. Ещё раз, моки отличаются от параметров лишь способом доставки значений. Реальность данных относится именно к самим значениям, а не способу их передачи. S>Ну, в некоторых изолированных случаях — да. S>В более интересных случаях, когда "мокировать" приходится более сложный набор взаимосвязей, чем 1 вход и 1 выход, распиливание на pure-куски позволяет нам упростить тестирование.
Я не понял как этот пример относится к моей цитате выше о "Реальность данных относится именно к самим значениям". Ну распилил ты, ну пюре, круто чё... и чё?.. как тестировал для значения "2", так и тестируешь. А надо было ещё протестировать и для внезапного курса зимбабвийских долларов 2_000_000_000. Упс.
S>·>А откуда в request появится ArrivalTime? И как все эти места протестировать? Учти, у нас 100500 различных видов request. S>Как откуда? Из общей инфраструктуры. У нас система типов построена так, что в любом request есть ArrivalTime, а его генерация делается примерно в одном месте, которое обеспечивает приём запроса ещё до его роутинга.
Даже если для половины из них никакой ArrivalTime не нужен, вы всё равно его вычисляете, проставляете и протаскиваете через весь стек? Да ещё и инфраструктур может быть несколько, где-то через rest, где-то через FIX где-то через mq, в разных форматах.
И далее лавай заглядывать, откуда в этих инфрах берётся ArrivalTime и как оно тестируется?
Ну это ладно, что timestamp какой-то, а бывает и более интересные данные, которые не настолько общие чтобы стоило запихать везде.
S>·>Ы? S>Там, где вы "старый" код, который обращался к instantSource, заменили на вызов "новой" nextFriday(instantSource.now()).
Может заменили (точнее авмтоматически отрефакторили), а может и оставили как есть. Для платёжки может логика и чуть отличаться, по-другому таймзоны или ещё чего работать.
S>·>А ты попробуй. Над мемоизацией посмеялись, над статической глобальной переменной _cache поплакали. Ещё идеи остались? S>Вы серьёзно? Давайте вы для начала напишете корректный код кэширования, пусть даже и не самый быстрый в общем случае.
У меня он был вполне корректным, но, соглашусь, не универсальным, а подразумевающим определённое поведение зависимостей.
S>>>Вот именно об этом я и говорю. Инстант не наступил, а nextFriday уже должна возвращать новое значение. Упс. S>·>Шозабред? Этот инстант логически эквивалентен твоему _cache.nextFriday. В любом случае, это всё элементарно покрывается юнит-тестами (ага, с моками), даже если я и налажал код в браузере правильно написать. S>Ну, всё верно. Именно поэтому у меня там не одна пятница, а две, и код возвращает закешированное значение только в том случае, если instant попадает в их диапазон
А первая пятница у меня лежала в волатильной переменной как текущее значение для возврата до момента наступления следующей пятницы.
S>>>Так у вас и тесты ничего не покажут. S>·>Шозабред. S>Никакого бреда. Вы же не догадались, что ваш instantSource может возвращать время в обратном порядке — значит и тесты у вас будут только прямой порядок тестировать
Ну мой instantSource не может время в обратном порядке возвращать. Я это знаю, в реале он привязывается к системным часам, про которые я знаю, что они монотонны.
S>·>Это ты наверное имеешь в виду, если wall clock поменяет таймзону. Только это невозможно в моём случае по дизайну. Или ты не понимаешь что такое instant. Это конретная точка на линии физического времени, а не показания на циферблате часов типа "01:00 пятница" для человеков. S>Тогда вы, наверное, неверно решили задачу. Потому что человека интересовала следующая пятница по wall time, а не абстрактная точка на линии "физического времени". Если бы речь щла о физическом времени, то вся эта ботва со следующей пятницей сводилась бы к паре делений и умножений.
Соглашусь, я явно не озвучивал этот момент. Имхо очевидно было... Конечно, пятница — это человеческая конструкция, требует правил календаря, таймзоны и т.п. А instant — это физическая штука. Да, CalendarLogic должен содержать как-то инфу о календарях, не особо важно как, таймзону инжектить в конструктор, например. Или просто использовать Clock класс, который по сути InstantSource+tz.
Более того, система типов (по крайней мере в java.time) не позволит поставить таймер на "01:00 пятницы", ибо бессмысленно. Код с такой ошибкой тупо не скомпилится.
S>>>Значит возьмёт и поменяет вызов вашего компонента Б на какую-нибудь ерунду. S>·>А если в твоей функции джун поменяет вызов на какую-нибудь ерунду? S>В какой именно? У меня нет двух разных calendarLogic,
Тогда я вопрос не понял "поменяет вызов вашего компонента Б на какую-нибудь ерунду". Что на что поменяет и с какого бодуна?
S>>>Так-то и в ФП ваш вариант элементарно реализуется, потому что способ закинуть замыкание в таймер есть более-менее везде. S>·>Как? S>В смысле "как"?
А таймер где? У тебя при cache miss будет latency spike.
S>Так и пишем: S>Здесь у нас на каждый вызов Cache() возвращается новая функция со своим кэшем, независимым от результатов других вызовов. АФАИК, в джаве это работает так же.
Т.е. по сути класс с приватным полем и конструктором, та же ж, вид сбоку. Вот только вместо осмысленных имён типов некий Func.
Более того, ты как-то забыл, что теперь тебе придётся пройтись по всему коду, где используется nextFriday(x), понять в каждом конкретном случае что значение этого x идёт именно из instant source (а ведь это вовсе не означает, что стоит ровно nextFriday(instantSource.now()), а может протаскиваться через несколько слоёв. Потом тебе надо будет заменить все эти вызовы на обёрку Cache, ещё как-то позаботиться, что эти общие места должны шарить один инстанс Cache, иначе игра и не стоит свеч.
В моём же случае эта информация уже известна из сигнатуры nextFriday и самого CalendarLogic — всё в одном месте.
S>>>С удовольствием. Пришлите ссылку на публичную SLA, в которой есть такие требования, я почитаю. S>·>Было дело в lmax. Насчёт публичных доков — не знаю. S>Ну, LMAX — парни известные. Но если почитать их Terms of Business, то слово latency там упомянуто всего лишь трижды, и ни в одном из случаев там не фигурируют никакие цифры. https://www.lmax.com/documents/LMAXGlobal-eu-Terms-of-Business.pdf
Ну это их selling point. В рекламе обещают 300us mean time и 4ms для 99.99. Или что-то в этом духе.
S>Наверняка вы с лёгкостью найдёте каких-то других парней (да хоть вашего работодателя), где есть SLA c параметрами латентности, да ещё и не процентилях, а в виде ограничения сверху. S>Я в такое не очень верю — компания, которая такое рисует, будет либо в качестве штрафов писать что-нибудь типа скидки на следующую оплату услуг, либо очень быстро вылетит из бизнеса.
Тут прямая конкуренция за latency. Чем она лучше, тем market maker может делать меньше спред. Чем меньше спред, тем привлекательнее цена. Чем привлекательнее цена, тем выше шанс, что сделка состоится именно на этой бирже. Каждая сделка — копеечка в прибыль биржи.
Если market maker видит скачки latency, это означает, что он расширит спред, и сделки будут идти на других биржах.
S>·>Ясен пень. Но это ещё и означает, что такие фривольности с глобальными кешами просто недопустимы. Т.к. промахи могут быть недетерминированными и все эти бенчмарки их ловят негарантированно. S>Вопрос к автору бенчмарков
Бенчмарки — не панацея.
S>·>Как в примере со _слишком_ старой платёжкой. Обычно платёжки не очень старые и даже прогон месячной прод-нагрузки может ничего не выявить, а случайный залётный дятел попадается редко, но метко. S>Расскажите, как в вашем подходе решается эта проблема. Как вы собираетесь поймать "клиента со слишком старой платёжкой"?
Не надо его ловить. Надо контролировать какие процессы происходят в latency sensitive пути на уровне дизайна.
S>·>Требоваться может везде (или почти везде), в этом и проблема. Суть примера была в том, что "всё приложение" использует не общий "nextFriday(x)", а конкретный "nextFriday(Time.Now)" во многих местах (см. моё начальное "Если у нас конечная цель иметь именно nextFriday()"). Поэтому этот общий код у меня и вынесен в одно место, которое безопасно кешировать, т.к. известен этот самый x. У тебя — неизвестно, в этом и беда. Напомню: ЧПФ. S>На это уже ответил выше — ЧПФ придумали не в ООП
Да я знаю. Просто перевожу на другой язык. Обсуждаемая в начале топика статья — там как раз было про это — DI/CI это ЧПФ. Просто пытаюсь донести мысль — что если мы заменяем класс на лямбду — меняем лишь как код выражен на ЯП, но это не делает никакой волшебной магии.
S>>>Нет такого факта, я вам в который раз повторяю. В вашем instantSource нет никакой гарантии, что следующий вызов now() не вернёт момент времени раньше, чем предыдущий. S>·>Это не так. В худшем случае, я могу тупо найти все те одно-два места использования _конструктора_ CalendarLogic удостовериться что там может быть и какими свойствами обладает. Ещё раз. ЧПФ. S>Вы повторяете это как мантру. ЧПФ вам тут никак не поможет — нет такой системы типов, которая бы позволила вам записать монотонность стейтфул-функции.
Это ты куда-то не в ту степь рванул. Надо уж начинать с того, что нет такой системы типов, для записи, что nextFriday возвращает хотя бы пятницу.
ЧПФ мне помогает тем, что я имею один кусок кода в котором происходит композиция Ф и одного из её парамов.
S>>>Всё правильно — весь стейт торчит на самом верху, и его мало. А глубокие вызовы все pure, и позволяют тестироваться по табличкам безо всяких моков. S>·>Может я не понял, что ты называешь самым верхом, но это у вас — метод контроллера, коих в типичном приложении сотни. У же меня этим верхом является один на всех composition root. S>Если нас не устраивает высота "метода контроллера", то мы запихиваем то, что вы называете "composition root" туда, откуда эти контроллеры вызываются.
Ну тогда об чём спор. У вас всё то же самое, как и в 00х, как я и говорил, просто переложенное на синтаксис js. Да моки в примере у Фаулера мы тоже нашли.
S>>>Просто будет локальная переменная в замыкании. S>·>Как эта локальная переменная будет шариться между контроллерами? S>Как захотим — так и будет. Через указатель на функцию
Ок, теплее. А как теперь с тестами дела обстоят? В тестах этим указатель будет на мок, верно?
S>>>Так и какой смысл подменять параметр типа instant на параметр типа instantSource, который вы хотите позвать ровно один раз в рамках экземпляра бизнес-логики? С какой целью вы это делаете? S>·>В случае trade date, instant — это физическая точка во времени, для железки. А для ордера нужны календарные показания, для трейдеров. CalendarLogic эту логику и обеспечивает. S>Ну так этой логике нужен ровно один instant, который физическая точка во времени. А не возможность получить неограниченное количество этих инстантов, продолжая вызывать недетерминистическую timeSource.now().
Можно, но в бизнес как правило логике нигде не нужен по факту физический инстант сам по себе, нужен календарный.
S>>>Ну и прекрасно — тогда у нас есть глобальная информация о том, с какой биржей мы работаем, внутри messageHandler. S>·>Что значит глобальная? Приложение может подключаться не нескольким биржам одновременно, разными сокетами. S>Ну так наверное у них и хэндлеры будут разными. Вы же как-то должны понимать, с какой из бирж работаете.
Да, разными. В т.ч. по разным аспектам разными. Разные протоколы, таймзоны и т.п. Но все они используют один и тот же класс CalendarLogic.
S>>>Где у вас это выражено в коде? Как у вас срабатывают таймеры, когда время идёт "назад"? S>·> Время не ходит назад. Это физически невозможно. S>При replay — ещё как идёт. Вот только что был понедельник, и тут поехал replay четверга. И ещё есть много случаев.
Не понял как. replay нужен для воспроизведения происходившего в проде. В проде время назад не ходит.
S>Вы пытаетесь искать ключи под фонарём: "а вот у меня instant source — он другой, я про него всё знаю". Нет, нихрена вы не знаете, потому что у вас instantSource — это интерфейс.
Ясен пень. А твой код будет правильно работать, если nextFriday вдруг четверг возвратит? Есть же контракт...
S>Императивные инварианты — это вообще такая штука, которую крайне сложно выразить в терминах системы типов. Банальнейшие вещи вроде "делать socket.Read() нельзя до socket.Open() и после socket.Close()" в терминах ООП невыразимы.
А в какой они выразимы? В rust для такого нужен borrow checker.
S>А в реальных системах встречаются ещё и чудесные вещи типа "после того, как сделал var u = service.CreateUser(...), нужно выждать не менее 5 минут перед service.UpdateUser(u, ...)", с которыми совсем всё плохо.
Тут и borrw checker не поможет.
S>Правильный способ с такими вещами работать требует очень сильно другой матаппарат, чем реализован в той же джаве. S>Поэтому беспокоиться нужно не о том, что джун заменит request.ArrivalTime на Time.now() (в конце концов, это можно отловить через styleCop и прочие радости жизни) — беспокоиться надо о том, как покрыть все ожидания адекватными тестами. В том числе и все вот эти вот ожидания по поводу валидных трансформаций состояния.
Именно. И моки тут — в помощь.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, Sinclair, Вы писали:
Б>>Я так и не понял, как протестировать код, завязанный на внешние системы. Ответ от Pauel если и был, то размазался где-то среди кучи сообщений. Б>>Полагаю, что работа с внешними зависимостями будут закрыты функциями, которые будут переданы в функцию do_logic. Аналогично для моков зависимости будут закрыты интерфейсом (группа функций), и он будет передан в do_logic. Т.е. с точки зрения тестирования разницы нет — в обоих случаях подменяется поведение внешней системы — передается функция возвращающая нужное для теста значение. S>Для внешних систем у нас вариантов немного — либо моки, либо интеграционное тестирование.
+1
S>При этом я предпочитаю интеграцию — потому, что она даёт нам гораздо больше уверенности в результатах.
В каком-то смысле согласен... но это очень быстро выходит из под контроля. Начали с системы, где 5 сценариев и запустить целиком, прогнать 5 тестов — заняло минуту. Потом ВНЕЗАПНО через пару лет оказывается что сценариев уже 5000 и тестов ждать приходится часами, да ещё они как-то через раз падают, т.к. все лазят в одно и то же тестовое окружение и иногда друг-другу мешают... Но менять это уже поздно, ведь можно что-то сломать.
S>Даже "эмулятор" продакшн системы на стороне партнёра часто даёт неверные результаты. S>У интеграции есть ровно один недостаток — она дорогая. Но обычно это приемлемая стоимость, с учётом того, что интеграционных тестов гораздо меньше. В моей практике обычно основная сложность (в которой можно напороть) спрятана именно в бизнес логике на нашей стороне; а взаимодействие со внешними системами — это ограниченное количество сценариев. И нам собственно нужно оттестировать как раз не саму логику, а расхождения между нашими ожиданиями от внешней системы и её реализацией.
Ну вот самый тупой кейс — system clock — это и есть взаимодействие с внешней системой. И никакими вменяемыми интеграционными тестами не покрывается.
S>Вот, кстати, когда мы работали с CREST API от Microsoft, нами был напилен набор интеграционных тестов, которые гонялись в каждом acceptance. И мы чаще всего ловили там не глюки нашего софта (которые были отловлены юнит-тестами), а регрессию со стороны Microsoft . S>Было всего несколько случаев, когда поведение API было не таким, как мы ожидали, и это не было признано багом.
Это называется conformance tests. У нас был специальный набор тестов, который тестировал внешние системы на соответствие нашим ожиданиям. Иными словами, в наших моках "мы думаем" что система работает так. И вот это самое "мы думаем" — покрывается conformance тестами.
S>Но я могу себе представить ситуацию, когда 100% интеграционное тестирование недоступно или настолько дорого, чтобы оправдать написание моков. Тут вы совершенно правы — принцип остаётся ровно тем же самым: мы будем передавать в do_logic какие-то функции, эмулирующие поведение внешней системы.
Ваша ситуация когда мы тестируем наш продукт подключаясь к внешней системе — работает тоже только в простейшем случае, когда у вас мало таких внешних систем.
И это означает, что если таких систем много, что мы можем пройти acceptance для нашего проекта только в момент когда _все_ внешние тестовые системы работают.
Если хоть что-то из внешних систем сейчас лежит, вы не можете ничего зарелизить. При росте количества систем вероятность что все они будут работать одновременно быстро стремится к нулю.
Поэтому, мочим всё внешнее и делаем релиз независимым. Делаем conformance tests и убеждаемся что наши моки всё ещё адекватны. Conformance tests можно гонять независимо от наших релизов.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
·>composition root — это технический, "подвальный" код. Конкретно инжекция системного источника времени — одна строчка кода, которая за жизнь проекта трогается практически ни разу. И тестируется относительно просто — приложение скомпилировалось, стартовало, даёт зелёный healthcheck — значит работает.
В ФП можно аналогично. ·>У тебя же now() лежит в коде бизнес-логики (как я понял из объяснений Pauel). Будет стоять в каждом втором методе контроллеров, т.е. в сотнях мест и код этот постоянно меняется.
По умолчанию — да. YAGNI в полный рост. По мере необходимости — оборудуем функции контекстом, в который запихиваем всю повторно используемую грязь.
·>Если бы такое писать на хаскеле... А так это всё лирика. На практике же — понадобился кеш и полезло static по ногам стрелять...
Никакой лирики, никакой стрельбы.
·>В сигнатуре nextFriday() это собсвенно негде даже отражать, в этом и суть. А в CalendarLogic — отразить можно. Опять же — это одно место на всё приложение.
В теории — да. А на практике вы об этом даже не задумались. Потому что это неявные связи
S>>Ну, это ещё более хороший пример — потому, что чем дальше вы навешиваете на эту lastFriday стейтфул-сложность, тем дороже и хуже будет обходиться его тестирование. ·>Логично, чем больше логики, тем больше тестов. Стейт тут не при чём.
Вполне себе при чём. Вся сложность — именно в том, что у вас там добавляется дюжина stateful-компонентов. И результат зависит не от параметров функции, а от состояния этих компонентов. Которое ещё и меняться может во время исполнения вашего кода логики.
·>Если сложность конкретно CalendarLogic будет выходить за рамки разумного, то начнём резать части логики в отдельные компоненты.
И они по-прежнему останутся stateful.
·>Не для написания мока, а для написания теста. Как и у тебя. Ешё раз — мок средство доставки тестовых данных, а не сами данные. Именно данные нужно проводить в соответствие с реальностью. Даже вообще я не очень понимаю, что за процесс такой "написание мока".
Во времена оные мок был просто альтернативной реализацией того же интерфейса, что и "настоящий" объект. И писался, естественно, вручную.
То, что у вас сейчас есть возможность описывать мок декларативно — это деталь реализации.
·>И? Ты тоже рассуждаешь об абстрактных проблемах программирования вместо того чтобы сравнивать "моки vs немоки".
Это не абстрактные проблемы программирования. Это то, на что мы налетали, когда переходили от тестирования с "моками" и "стабами" к интеграционному тестированию.
·>Мокаем это значит определяем контракт. И ожидаем, что он выполняется реальным репо. А реальный репо тестируется и-тестом с субд, на то, что он этот же контракт выполняет. Цель всего это действа — отпилить быстрые легковесные тесты логики от тяжелых тестов интеграции яп с субд.
Большого смысла и-тестировать отдельно репо я не вижу. В хорошей системе слишком много движущихся частей, чтобы попарные тестирования дали адекватную картину.
S>>Потому что разница, собственно, примерно такая: вот у нас есть цепочка зависимостей A->B->C->D, где A — это у нас БЛ, B — это query-часть ORM, С — это генератор SQL-запросов, а D — это БД с тестовыми данными. S>>И вы типа говорите "мы хотим тестировать всю цепочку, чтобы сэкономить на поддержании тестов в случае замены компонентов B/C". ·>Не очень понял чем B от C отличается.
B — это та часть, которая отвечает за построение запроса. В Hibernate это Criteria API; в Linq — это собственно IQueryable и его методы. C нам нужен тогда, когда запрос полностью сформирован и можно отправлять его в СУБД на исполнение. ·>Но суть моего тезиса в том, что просто сгенерированный SQL особо не нужен. В тесте его нужно сгенерировать (не важно как), загнать туда параметры, выполнить, ассертить результаты.
Это вам кажется, что SQL не особо нужен. Так-то и now() не особо нужен — нужна реализация пользовательского сценария. Но получить полное покрытие всех путей исполнения в таком обобщающем подходе невозможно, поэтому мы делим решение на части и каждую тестируем отдельно.
Вы, получается, тестируете не только свою БЛ, но и заодно тестируете репо, а также саму СУБД. То, о чём говорит Pauel — это доведение идеи "давайте проверим, что мы вызываем правильные методы repo в правильном порядке" до логического завершения: если у нас в роли репо выступает сама СУБД, то мы проверяем ровно то, что наша логика вызывает правильные запросы в правильном порядке.
Если в роли репо выступает нормальный ОРМ, то мы проверяем корректность построения ОРМ-запроса.
·>Если ты это уже знаешь, то в чём проблема это загнать через save в тестовые данные?
Проблема в экспоненциальности. Вот вы сходу можете сказать, сколько должно быть записей в тестовом наборе, который позволит протестировать корректность сортировки по каждому из 10 критериев? ·>Никто ж не запрещает использовать больше 2 записей. Тут просто желательно делать поменьше записей, чтобы человекам было проще разобраться в сценарии.
Отож.
·>Ну как видишь эта самая фунция бизнес-логики состоит из меньших шагов бизнес логики с кучей "если-то". И это всё бизнес-логика. Вот и бей на части.
Вот мы и будем бить на части. ·>И где же тут эта ваша структурная эквивалентность?
А ровно там, где мы будем проверять, что в IQueryable был добавлен нужный критерий.
·>Где метапрограммирование? Где буквальный текст sql? И имя функции fn1?
Буквальный текст SQL остался там, где мы напрямую лезем в базу из бизнес-логики.
·>Ну так еште слона по частям. В одной части "находим SKU для её renewal и order date", "поискать продукт в списке преемственности", "поискать продукт с такой же платформой" и т.п. Это всё бизнес-кейсы для тестов разных методов репы.
Ну, всё верно. Просто вы это себе видите методами репы, а мы — структурой запроса. У вас получается, что отделение репы от БЛ — фикция, т.к. при любом изменении требований нужно менять обе части решения. Это — канонический критерий того, что разбиение на компоненты выполнено неправильно.
·>А потом из этого собирается цельный бизнес-метод дёргающий в нужном порядке моки предыдущих.
·>А что предлагается-то взамен, я не понял.
Взамен предлагается проверять запросы проверкой запросов, а не их результатов. А согласованность всех частей — проверять интеграционными тестами.
S>>В мало-мальски реалистичном случае вы вспотеете автоматически ассертить результаты запроса к данным. ·>Если вспотею делать это автоматически, то если такое придется делать вручную, то просто сдохну. Да ещё перед каждым релизом, как минимум!
Ну отчего же. Если всё правильно сделано, то перед релизом достаточно убедиться, что ничего не отломано. Примерно как у вас в начале поста — если завелось и лампочки зелёные, то скорее всего и всё остальное тоже сработает.
·>Минуты на разворачивание тестового окружения. Тесты потом пачками гоняются быстро.
Опять-таки с чем сравнивать. Проверки структуры запросов — это микросекунды. Тесты против СУБД — секунды.
·>Мы делали примерно так: "открываем транзакцию, суём данные, проверяем результаты запросов, откатываем транзакцию". Подавляющее число тестов можно уложить в такое.
Можно, но это медленно. Возвращаюсь к вопросу о том, сколько записей нужно для проверки сортировки. Предположим, вам не нужно проверять сложные случаи вроде того, что после "А.Иванов" идёт "А. Иванов", а не "А.Петров".
·>Повторюсь: "Если у нас конечная цель иметь именно nextFriday()". Про арифметику ты загнул. Я не отрицаю полезность пюре, но злоупотреблять тоже не стоит.
Ну почему же загнул. Собственно, nextFriday — это арифметика чистой воды.
·>Именно что "тестовых массивов". Причём тут моки и пюре? Догадался бы заранее протестировать правильные массивы, поймал бы сразу. Вне зависимости от моков.
При том, что если бы я тестировал не конечный результат, а построение SIMD-кода по скалярному, то поймал бы это сразу. Ещё до того, как придуман первый тестовый массив.
S>>Нет ровно никакой проблемы взять и добавить к чистой функции nextFriday(timestamp) грязную функцию nextFriday()=>nextFriday(Time.now()), и заменить вызовы повсеместно. ·>Так и обратное — на столько же верно.
Ну, так зачем же вы сопротивляетесь?
·>Это ортогональная проблема. Console и DateTime.Now — глобальные переменные, синглтоны. И с этим борятся через DI.
Math.Sqrt() — тоже синглтон. Будете бороться через DI?
·>Нету никакого бага. А вот что у тебя, что у Pauel — баги были.
Есть. nextFriday должна вычисляться по wall time, и она так и делала, пока ей в аргументы отдавали now(). А вы то ли заменили её на вычисление следующей пятницы по "физическому времени" (кстати, а в какой тайм зоне?), то ли оставили как есть, но с багом при смене тайм зоны пользователя.
А баги, что у меня, что у Pauel — это нефункциональные параметры. Вы попытались задним числом изменить условия забега, чтобы выиграть, но так не получится. Да, бывают ситуации, в которых нефункциональные требования тоже повышаются до обязательных; но не бывает ситуаций, когда ради перформанса можно пожертвовать функциональностью.
·>Как я понял подобные тесты у Pauel будут требовать поднятия всего сразу. Т.е. там не в 2 раза, а в 2к раза, как минимум.
Да, но их будет мало.
·>Я не понял как этот пример относится к моей цитате выше о "Реальность данных относится именно к самим значениям". Ну распилил ты, ну пюре, круто чё... и чё?
И то, что я таким образом сокращаю объём данных, необходимых для тестирования.
·>Даже если для половины из них никакой ArrivalTime не нужен, вы всё равно его вычисляете, проставляете и протаскиваете через весь стек?
Конечно. Вычисление нам всё равно понадобится — мы же в логи его пишем.
А "протаскивание" стоит примерно 0, потому что речь идёт просто об ещё одном поле в структуре, указатель на которую лежит в RAX.
·>Да ещё и инфраструктур может быть несколько, где-то через rest, где-то через FIX где-то через mq, в разных форматах.
И в каждой это будет вычисляться по своему. Делов-то. ·>И далее лавай заглядывать, откуда в этих инфрах берётся ArrivalTime и как оно тестируется?
Откуда-то берётся. Тестируется — известно как: каждый вид канала обслуживается своим кусочком; естественно он обложен тестами по самое не балуйся.
В рамках разработки БЛ об этом думать нет никакой необходимости. Точно так же, как нет нужды проверять способность Oracle исполнять SQL, или способность ASP.NET корректно достать запрос из http.sys и дороутить его до кода контроллера. ·>Ну это ладно, что timestamp какой-то, а бывает и более интересные данные, которые не настолько общие чтобы стоило запихать везде.
Предлагайте варианты — посмотрим что можно сделать.
·>Может заменили (точнее авмтоматически отрефакторили), а может и оставили как есть. Для платёжки может логика и чуть отличаться, по-другому таймзоны или ещё чего работать.
То, что вы рассказываете — верный путь к деградации качества.
·>У меня он был вполне корректным, но, соглашусь, не универсальным, а подразумевающим определённое поведение зависимостей.
S>>Ну, всё верно. Именно поэтому у меня там не одна пятница, а две, и код возвращает закешированное значение только в том случае, если instant попадает в их диапазон ·>А первая пятница у меня лежала в волатильной переменной как текущее значение для возврата до момента наступления следующей пятницы.
Ну, всё верно. Поэтому она непригодна для обработки ситуации, когда now() выдаёт значение раньше, чем "нынешняя пятница".
·>Ну мой instantSource не может время в обратном порядке возвращать. Я это знаю, в реале он привязывается к системным часам, про которые я знаю, что они монотонны.
А исходная now(), которую вы решили заменить на instantSource, могла.
·>Соглашусь, я явно не озвучивал этот момент. Имхо очевидно было... Конечно, пятница — это человеческая конструкция, требует правил календаря, таймзоны и т.п. А instant — это физическая штука. Да, CalendarLogic должен содержать как-то инфу о календарях, не особо важно как, таймзону инжектить в конструктор, например. Или просто использовать Clock класс, который по сути InstantSource+tz.
Ну, то есть вы провели некорректную замену в рамках DI. ·>Более того, система типов (по крайней мере в java.time) не позволит поставить таймер на "01:00 пятницы", ибо бессмысленно. Код с такой ошибкой тупо не скомпилится.
Ну, то есть пока что у нас нет рабочего кода, который бы делал то, что ожидает пользователь.
·>Тогда я вопрос не понял "поменяет вызов вашего компонента Б на какую-нибудь ерунду". Что на что поменяет и с какого бодуна?
Ну, вот вы только что рассказали, что хотите по-разному вычислять nextFriday "для платёжек" и для "всего остального", в том числе — по разному работать с временными зонами.
Это как раз подход типичного джуна — ему дали багу про таймзоны в платёжке, он починил в одном месте, но не починил в другом. В итоге имеем тонкое расхождение в логике, которое будет заметно далеко не сразу.
S>>В смысле "как"? ·>А таймер где? У тебя при cache miss будет latency spike.
А, это я протупил. Ну точно так же:
public static Func<int, int> Cache(Func<int, int> func)
{
int c = 42;
var timer = new Timer(()=>{c = new Random().Next()}, null, TimeSpan.FromDays(7), TimeSpan.FromDays(7));
return (i) => (c >= i) ? c : (c = func(i));
}
·>Т.е. по сути класс с приватным полем и конструктором, та же ж, вид сбоку. Вот только вместо осмысленных имён типов некий Func. "Осмысленные имена типов" часто переоценивают.
·>Более того, ты как-то забыл, что теперь тебе придётся пройтись по всему коду, где используется nextFriday(x), понять в каждом конкретном случае что значение этого x идёт именно из instant source (а ведь это вовсе не означает, что стоит ровно nextFriday(instantSource.now()), а может протаскиваться через несколько слоёв.
Ничего подобного мне не потребуется.
Напомню, что performance optimization всегда начинается не с гениальной идеи, а с бенчмарка.
У нас есть N мест, которые не устраивают по производительности. Идти мы будем по этим местам, а не по "местам применения функции".
·>Ну это их selling point. В рекламе обещают 300us mean time и 4ms для 99.99. Или что-то в этом духе.
Хотелось бы посмотреть на эту рекламу — хоть она-то публично доступна?
А 99.99 означает, что мы запросто можем себе позволить 1 т.н. spike каждые 10000 запросов. С чем вы спорите-то?
·>Если market maker видит скачки latency, это означает, что он расширит спред, и сделки будут идти на других биржах.
У market maker — точно такой же измеритель на его конце. И он не "скачки latency" анализирует, а те самые 99%, 99.9%, 99.99%. Если он смотрит усреднённую latency, то это вообще ни о чём — mean там сгладит примерно всё.
·>Бенчмарки — не панацея.
Простите, но я не знаю другого способа контролировать performance. Ну, точнее, знаю один — это Ada. Но на ней почему-то практически никто не пишет. То есть либо спроса нет, либо в использовании запредельно сложно.
S>>·>Как в примере со _слишком_ старой платёжкой. Обычно платёжки не очень старые и даже прогон месячной прод-нагрузки может ничего не выявить, а случайный залётный дятел попадается редко, но метко. S>>Расскажите, как в вашем подходе решается эта проблема. Как вы собираетесь поймать "клиента со слишком старой платёжкой"? ·>Не надо его ловить. Надо контролировать какие процессы происходят в latency sensitive пути на уровне дизайна.
Простите, не понимаю. Как вы на уровне дизайна запретите клиенту приходить со старой платёжкой?
·>Да я знаю. Просто перевожу на другой язык. Обсуждаемая в начале топика статья — там как раз было про это — DI/CI это ЧПФ. Просто пытаюсь донести мысль — что если мы заменяем класс на лямбду — меняем лишь как код выражен на ЯП, но это не делает никакой волшебной магии.
Волшебной магии вообще нигде нет. Но есть некоторые улучшения дизайна, которые мы можем получить, разделяя чистый и грязный код.
·>Это ты куда-то не в ту степь рванул. Надо уж начинать с того, что нет такой системы типов, для записи, что nextFriday возвращает хотя бы пятницу. ·>ЧПФ мне помогает тем, что я имею один кусок кода в котором происходит композиция Ф и одного из её парамов.
Это прекрасно. И ничто не мешает вам перейти от "чистой, но неэффективной" nextFridayFrom(x) к "грязной, но эффективной" nextFridayFromNow(). При этом вы воспользуетесь как преимуществом того, что чистая nextFridayFrom(x)у вас уже оттестирована и ведёт себя гарантированно корректно, так и возможностью полагаться на поведение вашего источника времени.
·>Ну тогда об чём спор. У вас всё то же самое, как и в 00х, как я и говорил, просто переложенное на синтаксис js. Да моки в примере у Фаулера мы тоже нашли.
·>Ок, теплее. А как теперь с тестами дела обстоят? В тестах этим указатель будет на мок, верно?
Может быть и мок придётся сделать
S>>Ну так этой логике нужен ровно один instant, который физическая точка во времени. А не возможность получить неограниченное количество этих инстантов, продолжая вызывать недетерминистическую timeSource.now(). ·>Можно, но в бизнес как правило логике нигде не нужен по факту физический инстант сам по себе, нужен календарный.
Да, это мы уже обсудили — вы сломали функциональность, перейдя от календарного инстанта к физическому. Но речь-то не об этом — а ровно о том, что бизнес-логике нужен не источник инстантов, а сам инстант. Календарный.
S>>Ну так наверное у них и хэндлеры будут разными. Вы же как-то должны понимать, с какой из бирж работаете. ·>Да, разными. В т.ч. по разным аспектам разными. Разные протоколы, таймзоны и т.п. Но все они используют один и тот же класс CalendarLogic.
А экземпляр у этого класса один или разные?
S>>При replay — ещё как идёт. Вот только что был понедельник, и тут поехал replay четверга. И ещё есть много случаев. ·>Не понял как. replay нужен для воспроизведения происходившего в проде. В проде время назад не ходит.
Вот именно так и ходит — вот у нас понедельник, мы запускаем replay четверга.
·>Ясен пень. А твой код будет правильно работать, если nextFriday вдруг четверг возвратит? Есть же контракт...
Ну, какой день возвращает nextFriday, проверить можно. Если задуриться, можно даже это статически доказать
Ещё Хоар придумал способ убедиться, что некая функция f (пусть даже и императивно определённая) возвращает то, что обещано контрактом.
А вот способ убедиться, что результаты последовательных вызовов методов, тем более разных, связаны какими-то соотношениями, мне неизвестен.
·>А в какой они выразимы? В rust для такого нужен borrow checker.
Rust, афаик, позволяет выражать очень ограниченное подмножество контрактов. Каким способом он предлагает решить описанную задачу? Подозреваю, что будет что-то изоморфное ФП.
Вообще, большинство доказательств строилось как раз для ФП. Как раз переход к чистым функциям позволяет нам усилить контракты так, чтобы иметь предсказуемость поведения.
S>>А в реальных системах встречаются ещё и чудесные вещи типа "после того, как сделал var u = service.CreateUser(...), нужно выждать не менее 5 минут перед service.UpdateUser(u, ...)", с которыми совсем всё плохо. ·>Тут и borrw checker не поможет.
Ну вот и я о чём.
S>>Поэтому беспокоиться нужно не о том, что джун заменит request.ArrivalTime на Time.now() (в конце концов, это можно отловить через styleCop и прочие радости жизни) — беспокоиться надо о том, как покрыть все ожидания адекватными тестами. В том числе и все вот эти вот ожидания по поводу валидных трансформаций состояния. ·>Именно. И моки тут — в помощь.
Главное, чтобы они не превращались в самоцель .
Там, где можно обойтись без моков, лучше обойтись без моков. Ну, если уж припёрло, тогда можно и моки впилить. Но не раньше
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Sinclair, Вы писали:
S>·>composition root — это технический, "подвальный" код. Конкретно инжекция системного источника времени — одна строчка кода, которая за жизнь проекта трогается практически ни разу. И тестируется относительно просто — приложение скомпилировалось, стартовало, даёт зелёный healthcheck — значит работает. S>В ФП можно аналогично.
Можно, конечно. Но тогда будет тестирование с моками.
S>·>У тебя же now() лежит в коде бизнес-логики (как я понял из объяснений Pauel). Будет стоять в каждом втором методе контроллеров, т.е. в сотнях мест и код этот постоянно меняется. S>По умолчанию — да. YAGNI в полный рост. По мере необходимости — оборудуем функции контекстом, в который запихиваем всю повторно используемую грязь.
Угу, и для тестирования ВНЕЗАПНО начинают требоваться моки.
S>·>Если бы такое писать на хаскеле... А так это всё лирика. На практике же — понадобился кеш и полезло static по ногам стрелять... S>Никакой лирики, никакой стрельбы.
Ну вы оба себе и стрельнули.
S>·>В сигнатуре nextFriday() это собсвенно негде даже отражать, в этом и суть. А в CalendarLogic — отразить можно. Опять же — это одно место на всё приложение. S>В теории — да. А на практике вы об этом даже не задумались. Потому что это неявные связи
Мысли мои читаешь — о чём я думаю, о чём не думаю. Что Pauel телепат, что ты.
S>·>Логично, чем больше логики, тем больше тестов. Стейт тут не при чём. S>Вполне себе при чём. Вся сложность — именно в том, что у вас там добавляется дюжина stateful-компонентов. И результат зависит не от параметров функции, а от состояния этих компонентов. Которое ещё и меняться может во время исполнения вашего кода логики.
Welcome to real life.
S>·>Если сложность конкретно CalendarLogic будет выходить за рамки разумного, то начнём резать части логики в отдельные компоненты. S>И они по-прежнему останутся stateful.
На это ещё я два месяца назад ответил: "внутри CalendarLogic отрефакторить nextFriday() так, чтобы оно звало какой-нибудь static nextFriday(now) который можно потестирвать как пюрешку". Это всё мелкие тривиальности, скукота детсадовская.
S>·>Не для написания мока, а для написания теста. Как и у тебя. Ешё раз — мок средство доставки тестовых данных, а не сами данные. Именно данные нужно проводить в соответствие с реальностью. Даже вообще я не очень понимаю, что за процесс такой "написание мока". S>Во времена оные мок был просто альтернативной реализацией того же интерфейса, что и "настоящий" объект. И писался, естественно, вручную. S>То, что у вас сейчас есть возможность описывать мок декларативно — это деталь реализации.
В "оные" времена это какие? Мы тут статью 2023 года читали, оно и есть: альтернативная реализациия того же интерфейса. Появилсь что-то новее?
S>·>И? Ты тоже рассуждаешь об абстрактных проблемах программирования вместо того чтобы сравнивать "моки vs немоки". S>Это не абстрактные проблемы программирования. Это то, на что мы налетали, когда переходили от тестирования с "моками" и "стабами" к интеграционному тестированию.
Халва-халва. "У нас не моки, у нас альтернативная реализация".
S>·>Мокаем это значит определяем контракт. И ожидаем, что он выполняется реальным репо. А реальный репо тестируется и-тестом с субд, на то, что он этот же контракт выполняет. Цель всего это действа — отпилить быстрые легковесные тесты логики от тяжелых тестов интеграции яп с субд. S>Большого смысла и-тестировать отдельно репо я не вижу. В хорошей системе слишком много движущихся частей, чтобы попарные тестирования дали адекватную картину.
Смысл в отпиливании медленного от быстрого.
S>>>И вы типа говорите "мы хотим тестировать всю цепочку, чтобы сэкономить на поддержании тестов в случае замены компонентов B/C". S>·>Не очень понял чем B от C отличается. S>B — это та часть, которая отвечает за построение запроса. В Hibernate это Criteria API; в Linq — это собственно IQueryable и его методы. C нам нужен тогда, когда запрос полностью сформирован и можно отправлять его в СУБД на исполнение.
Т.е. если нам придётя немного переделать какие-то методы с linq/criteria/etc на чего-то другое — всё посыпется, и тестов нет, т.к. ютесты все завязаны на конкретную реализацию и бесполезны. А ваших интеграционных тестов значительно меньше, следовательно все эти разные вариации не — тупо не покрыты.
S>·>Но суть моего тезиса в том, что просто сгенерированный SQL особо не нужен. В тесте его нужно сгенерировать (не важно как), загнать туда параметры, выполнить, ассертить результаты. S>Это вам кажется, что SQL не особо нужен. Так-то и now() не особо нужен — нужна реализация пользовательского сценария. Но получить полное покрытие всех путей исполнения в таком обобщающем подходе невозможно, поэтому мы делим решение на части и каждую тестируем отдельно.
now() отражает момент времени. Он и в описании бизнес-сценариев напрямую фигурирует "в момент когда пришел запрос, проверяем trade date". SQL-запросов я никогда в бизнес-требованиях не видел. Так что твоя аналогия в топку.
S>Вы, получается, тестируете не только свою БЛ, но и заодно тестируете репо, а также саму СУБД. То, о чём говорит Pauel — это доведение идеи "давайте проверим, что мы вызываем правильные методы repo в правильном порядке" до логического завершения: если у нас в роли репо выступает сама СУБД, то мы проверяем ровно то, что наша логика вызывает правильные запросы в правильном порядке. S>Если в роли репо выступает нормальный ОРМ, то мы проверяем корректность построения ОРМ-запроса.
Неверно. Я тестрирую какие данные мой репо возвращает в сооветствующих бизнес-сценариях. Что там внутре как-то собирается запрос, параметризуется, где-то как-то выполняется, парсится резалтсет — это всё неинтересные с тз теста детали.
S>·>Если ты это уже знаешь, то в чём проблема это загнать через save в тестовые данные? S>Проблема в экспоненциальности. Вот вы сходу можете сказать, сколько должно быть записей в тестовом наборе, который позволит протестировать корректность сортировки по каждому из 10 критериев?
Проблема в том, что ты словоблудишь. Ровно та же экспоненциальность будет и в твоём процессе с прогонкой вручную написанных запросов на неких (каких?) данных тестовой базы. Вот только программно можно обрабатыать больше деталей, чем ты способен анализировать вручную глазками.
S>·>И где же тут эта ваша структурная эквивалентность? S>А ровно там, где мы будем проверять, что в IQueryable был добавлен нужный критерий.
А как ты будешь убеждаться, что он нужный? А то что он всё ещё нужный спустя код после пачки исправлений соседнего кода? Каждый раз вручную?
S>·>Где метапрограммирование? Где буквальный текст sql? И имя функции fn1? S>Буквальный текст SQL остался там, где мы напрямую лезем в базу из бизнес-логики.
И в коде тестов.
S>·>Ну так еште слона по частям. В одной части "находим SKU для её renewal и order date", "поискать продукт в списке преемственности", "поискать продукт с такой же платформой" и т.п. Это всё бизнес-кейсы для тестов разных методов репы. S>Ну, всё верно. Просто вы это себе видите методами репы, а мы — структурой запроса. У вас получается, что отделение репы от БЛ — фикция, т.к. при любом изменении требований нужно менять обе части решения. Это — канонический критерий того, что разбиение на компоненты выполнено неправильно.
Не понял зачем обе. Если меняется логика как именно надо "искать продукт в списке преемственности", то меняется только код репы.
S>·>А потом из этого собирается цельный бизнес-метод дёргающий в нужном порядке моки предыдущих. S>
Ровно по описанному тобой бизнес-требованию. Раз так требуется, так и проверяем. Ты же будешь проверять, что имя у функции fn1, а не fn2 в каком порядке идут запятые в sql-тексте.
S>·>А что предлагается-то взамен, я не понял. S>Взамен предлагается проверять запросы проверкой запросов, а не их результатов.
Чё? Проверять "как в коде написано"?
S>А согласованность всех частей — проверять интеграционными тестами.
Не сможешь. Т.к. комбинаторно рванут варианты согласования частей.
S>>>В мало-мальски реалистичном случае вы вспотеете автоматически ассертить результаты запроса к данным. S>·>Если вспотею делать это автоматически, то если такое придется делать вручную, то просто сдохну. Да ещё перед каждым релизом, как минимум! S>Ну отчего же. Если всё правильно сделано, то перед релизом достаточно убедиться, что ничего не отломано. Примерно как у вас в начале поста — если завелось и лампочки зелёные, то скорее всего и всё остальное тоже сработает.
Как убедитья?
S>·>Минуты на разворачивание тестового окружения. Тесты потом пачками гоняются быстро. S>Опять-таки с чем сравнивать. Проверки структуры запросов — это микросекунды. Тесты против СУБД — секунды.
А толку? С таким же успехом можно проверять, что все запросы начинаются со слова "select" — жутко полезно, ага, ну чтобы sellect не пролез.
S>·>Мы делали примерно так: "открываем транзакцию, суём данные, проверяем результаты запросов, откатываем транзакцию". Подавляющее число тестов можно уложить в такое. S>Можно, но это медленно. Возвращаюсь к вопросу о том, сколько записей нужно для проверки сортировки. Предположим, вам не нужно проверять сложные случаи вроде того, что после "А.Иванов" идёт "А. Иванов", а не "А.Петров".
Не больше (скорее всего на порядки меньше), чем в твоей базе по которой ты ручками свои запросы проверяешь.
S>·>Повторюсь: "Если у нас конечная цель иметь именно nextFriday()". Про арифметику ты загнул. Я не отрицаю полезность пюре, но злоупотреблять тоже не стоит. S>Ну почему же загнул. Собственно, nextFriday — это арифметика чистой воды.
Я не отрицаю полезность пюре.
S>·>Именно что "тестовых массивов". Причём тут моки и пюре? Догадался бы заранее протестировать правильные массивы, поймал бы сразу. Вне зависимости от моков. S>При том, что если бы я тестировал не конечный результат, а построение SIMD-кода по скалярному, то поймал бы это сразу. Ещё до того, как придуман первый тестовый массив.
Не знаю, я не понял суть проблемы.
S>>>Нет ровно никакой проблемы взять и добавить к чистой функции nextFriday(timestamp) грязную функцию nextFriday()=>nextFriday(Time.now()), и заменить вызовы повсеместно. S>·>Так и обратное — на столько же верно. S>Ну, так зачем же вы сопротивляетесь?
Я рассказываю когда это работает плохо.
S>·>Это ортогональная проблема. Console и DateTime.Now — глобальные переменные, синглтоны. И с этим борятся через DI. S>Math.Sqrt() — тоже синглтон. Будете бороться через DI? Ты юродствуешь или правда не догоняешь? Загляни внутрь реализаций и поищи глобальные переменны там и там. И вспомни что такое синглтон, перечитай лекции которые ты типа читал, у тебя в памяти провал.
S>·>Нету никакого бага. А вот что у тебя, что у Pauel — баги были. S>Есть. nextFriday должна вычисляться по wall time, и она так и делала, пока ей в аргументы отдавали now(). А вы то ли заменили её на вычисление следующей пятницы по "физическому времени" (кстати, а в какой тайм зоне?), то ли оставили как есть, но с багом при смене тайм зоны пользователя.
Бред какой-то.
S>А баги, что у меня, что у Pauel — это нефункциональные параметры.
Оппа! А кеш это именно что нефункциональный параметр и есть. Внезапно! Читаем Pauel: Вот появилось нефункциональное требование "перформанс" и мы видим.
S>Вы попытались задним числом изменить условия забега, чтобы выиграть, но так не получится.
Ну я ж не знал, что побегу в одном забеге с нефункциональными соперниками...
S>Да, бывают ситуации, в которых нефункциональные требования тоже повышаются до обязательных; но не бывает ситуаций, когда ради перформанса можно пожертвовать функциональностью.
Ну кешами мериться Pauel первым надумал...
И видишь какая интересная история вышла.
Трагикомедия "Функциональная Клоунада".
Акт первый. Действующее лицо Pauel: Прикручивает мемоизацию за минуту, выкатил в прод, тесты все зелёные, ну что-то вроде пока улучшения перформанса не очень заметно... надо ещё подождать для сбора статистики... хм.. гхм... Ой! Оно по OOM навернулось чего-то!!! ААА!! Синлкер, помоги!!
Акт второй. Вбегает Синклер: Ну вот же: Static cache! Ой... а перформанс всё ещё сосет.
Акт третий. Заходит заказчик с мешком патефонных иголок.
Акт четвёртый. Синклер и Pauel перелопачивают все свои контроллеры и учатся писать моки.
The End.
S>·>Как я понял подобные тесты у Pauel будут требовать поднятия всего сразу. Т.е. там не в 2 раза, а в 2к раза, как минимум. S>Да, но их будет мало.
Т.е. не будет покрывать все эти ваши комбинации 10и типов сортировки.
S>·>Я не понял как этот пример относится к моей цитате выше о "Реальность данных относится именно к самим значениям". Ну распилил ты, ну пюре, круто чё... и чё? S>И то, что я таким образом сокращаю объём данных, необходимых для тестирования.
Не понял как. Как было одно единственное данное "2", так и осталось. Ты в один раз сократил? Хвалю.
S>·>Даже если для половины из них никакой ArrivalTime не нужен, вы всё равно его вычисляете, проставляете и протаскиваете через весь стек? S>Конечно. Вычисление нам всё равно понадобится — мы же в логи его пишем. S>А "протаскивание" стоит примерно 0, потому что речь идёт просто об ещё одном поле в структуре, указатель на которую лежит в RAX.
Угу. Именно, что "примерно".
S>·>Да ещё и инфраструктур может быть несколько, где-то через rest, где-то через FIX где-то через mq, в разных форматах. S>И в каждой это будет вычисляться по своему. Делов-то.
И тестироваться, внезапно, моками.
S>·>Может заменили (точнее авмтоматически отрефакторили), а может и оставили как есть. Для платёжки может логика и чуть отличаться, по-другому таймзоны или ещё чего работать. S>То, что вы рассказываете — верный путь к деградации качества.
Баланс всегда — риск vs выигриш.
S>·>У меня он был вполне корректным, но, соглашусь, не универсальным, а подразумевающим определённое поведение зависимостей. S>
Определённое поведение зависимостей вполне общеизвестно, я думал очевидно, ошибся.
S>>>Ну, всё верно. Именно поэтому у меня там не одна пятница, а две, и код возвращает закешированное значение только в том случае, если instant попадает в их диапазон S>·>А первая пятница у меня лежала в волатильной переменной как текущее значение для возврата до момента наступления следующей пятницы. S>Ну, всё верно. Поэтому она непригодна для обработки ситуации, когда now() выдаёт значение раньше, чем "нынешняя пятница".
Оно не может так себя вести, по крайней мере в проде.
S>·>Ну мой instantSource не может время в обратном порядке возвращать. Я это знаю, в реале он привязывается к системным часам, про которые я знаю, что они монотонны. S>А исходная now(), которую вы решили заменить на instantSource, могла.
Ну это проблема вашего DateTime.Now(), а не конкретно моего кода. В моём коде такой проблемы нет.
S>·>Соглашусь, я явно не озвучивал этот момент. Имхо очевидно было... Конечно, пятница — это человеческая конструкция, требует правил календаря, таймзоны и т.п. А instant — это физическая штука. Да, CalendarLogic должен содержать как-то инфу о календарях, не особо важно как, таймзону инжектить в конструктор, например. Или просто использовать Clock класс, который по сути InstantSource+tz. S>Ну, то есть вы провели некорректную замену в рамках DI.
Замену чего на что?
S>·>Более того, система типов (по крайней мере в java.time) не позволит поставить таймер на "01:00 пятницы", ибо бессмысленно. Код с такой ошибкой тупо не скомпилится. S>Ну, то есть пока что у нас нет рабочего кода, который бы делал то, что ожидает пользователь.
Я его в браузере набирал, конечно, он не работает. Думаю там даже полно синтаксических ошибок. . Я лишь идею пытался продемонстрировать, что нужное значение обновляется по таймеру, а не вычисляется из переданных аргументов. В случае с event sourcing подходом — было бы просто событие, генерируемое таймером в поток сообщений "наступила пятница", которое в процессорах обновит это поле в CalendarLogic.
S>·>Тогда я вопрос не понял "поменяет вызов вашего компонента Б на какую-нибудь ерунду". Что на что поменяет и с какого бодуна? S>Ну, вот вы только что рассказали, что хотите по-разному вычислять nextFriday "для платёжек" и для "всего остального", в том числе — по разному работать с временными зонами.
Ясен пень. Платёжка должна обрабатваться по правилам когда она была создана. Если платёжка прошлогодняя, у неё могли бы быть другие правила расчёта таймзон, вон недавно в России меняли правила dst.
S>Это как раз подход типичного джуна — ему дали багу про таймзоны в платёжке, он починил в одном месте, но не починил в другом. В итоге имеем тонкое расхождение в логике, которое будет заметно далеко не сразу.
Вот у тебя как раз подход джуна, который совершенно не понимает все тонкости календарей.
S>>>В смысле "как"? S>·>А таймер где? У тебя при cache miss будет latency spike. S>А, это я протупил. Ну точно так же: S> var timer = new Timer(()=>{c = new Random().Next()}, null, TimeSpan.FromDays(7), TimeSpan.FromDays(7));
Уже лучше. И как ты это будешь тестировать? Тест будет делать Sleep(7, Days)?
S>·>Более того, ты как-то забыл, что теперь тебе придётся пройтись по всему коду, где используется nextFriday(x), понять в каждом конкретном случае что значение этого x идёт именно из instant source (а ведь это вовсе не означает, что стоит ровно nextFriday(instantSource.now()), а может протаскиваться через несколько слоёв. S>Ничего подобного мне не потребуется. S>Напомню, что performance optimization всегда начинается не с гениальной идеи, а с бенчмарка. S>У нас есть N мест, которые не устраивают по производительности. Идти мы будем по этим местам, а не по "местам применения функции".
Напоминаю, что "Если у нас конечная цель иметь именно nextFriday()".
S>·>Ну это их selling point. В рекламе обещают 300us mean time и 4ms для 99.99. Или что-то в этом духе. S>Хотелось бы посмотреть на эту рекламу — хоть она-то публично доступна?
Не знаю, я там давно не работаю. Вот презентация какая-то, там цифири какие-то есть. https://www.infoq.com/presentations/lmax-trading-architecture/
S>А 99.99 означает, что мы запросто можем себе позволить 1 т.н. spike каждые 10000 запросов. С чем вы спорите-то?
Ни о чём не спорю. Рассказываю, что на спайки более 10ms создавали тикеты и расследовали.
Скажем, обращение к ZoneInfo в jdk может порождать чтение ресурсов с информацией о таймзонах, т.е. чтение файла, т.е. сискол, блокировку и т.п.
Сравни это с intrinsic Math.sqrt, который превращается в одну асм-инструкцию или около того, который ты с какого-то бодуна решил инжектить. Вот такая, гы, арифметика.
S>·>Если market maker видит скачки latency, это означает, что он расширит спред, и сделки будут идти на других биржах. S>У market maker — точно такой же измеритель на его конце. И он не "скачки latency" анализирует, а те самые 99%, 99.9%, 99.99%. Если он смотрит усреднённую latency, то это вообще ни о чём — mean там сгладит примерно всё.
market maker не интерсуется mean. Его интересуют именно спайки. Спайк означает, что его опубликованная цена засевшая дольше чем надо могла прыгнуть в нетуда и совершится невыгодная сделка.
S>·>Бенчмарки — не панацея. S>Простите, но я не знаю другого способа контролировать performance. Ну, точнее, знаю один — это Ada. Но на ней почему-то практически никто не пишет. То есть либо спроса нет, либо в использовании запредельно сложно.
Бенчмарки это тесты... они не тестируют неизвестное, а для регрессии по сути.
S>·>Не надо его ловить. Надо контролировать какие процессы происходят в latency sensitive пути на уровне дизайна. S>Простите, не понимаю. Как вы на уровне дизайна запретите клиенту приходить со старой платёжкой?
По дизайну со старыми платёжками ходят в другое место. У тебя проблема была в том, что твой static cache оказывает влияние на всё приложение.
S>·>Да я знаю. Просто перевожу на другой язык. Обсуждаемая в начале топика статья — там как раз было про это — DI/CI это ЧПФ. Просто пытаюсь донести мысль — что если мы заменяем класс на лямбду — меняем лишь как код выражен на ЯП, но это не делает никакой волшебной магии. S>Волшебной магии вообще нигде нет. Но есть некоторые улучшения дизайна, которые мы можем получить, разделяя чистый и грязный код.
Угу. Но это не избавляет от необходимости моков, т.к. от грязного кода практически невозможно избавиться.
S>·>Это ты куда-то не в ту степь рванул. Надо уж начинать с того, что нет такой системы типов, для записи, что nextFriday возвращает хотя бы пятницу. S>·>ЧПФ мне помогает тем, что я имею один кусок кода в котором происходит композиция Ф и одного из её парамов. S>Это прекрасно. И ничто не мешает вам перейти от "чистой, но неэффективной" nextFridayFrom(x) к "грязной, но эффективной" nextFridayFromNow(). При этом вы воспользуетесь как преимуществом того, что чистая nextFridayFrom(x)у вас уже оттестирована и ведёт себя гарантированно корректно, так и возможностью полагаться на поведение вашего источника времени.
Ну я и не спорил об этом. Вопрос был в целесообразности. В nextFriday(x) будет пол строчки кода. Больше места займёт обвязка сигнатуры самой функции. Насколько целесообразно вводить это всё при условии что цель всё равно иметь везде конкренто nextFridayFromNow и покрывать тестами надо и её тоже.
S>·>Ок, теплее. А как теперь с тестами дела обстоят? В тестах этим указатель будет на мок, верно? S>Может быть и мок придётся сделать
ЧТД. Эту я мысль я и пытался донести. Можно сворачивать обсуждение.
S>Да, это мы уже обсудили — вы сломали функциональность, перейдя от календарного инстанта к физическому.
Я ничего не ломал. Возможно я не рассказал очевидные для меня детали: инстант это Instant. Что такое "календарный инстант" — мне неведомо. А "пятница" — это из календаря уже, ясен пень.
Полагаю путаница пошла из того, что в c# нет вменяемого time api и там всё намешано без разбору.
S>Но речь-то не об этом — а ровно о том, что бизнес-логике нужен не источник инстантов, а сам инстант. Календарный.
Для этого я и делаю логику преобразования инстантов в календарные данные в классе CalendarLogic, который зависит от источкика инстантов.
S>>>Ну так наверное у них и хэндлеры будут разными. Вы же как-то должны понимать, с какой из бирж работаете. S>·>Да, разными. В т.ч. по разным аспектам разными. Разные протоколы, таймзоны и т.п. Но все они используют один и тот же класс CalendarLogic. S>А экземпляр у этого класса один или разные?
Ну в общем случае разные, скроее всего.
S>>>При replay — ещё как идёт. Вот только что был понедельник, и тут поехал replay четверга. И ещё есть много случаев. S>·>Не понял как. replay нужен для воспроизведения происходившего в проде. В проде время назад не ходит. S>Вот именно так и ходит — вот у нас понедельник, мы запускаем replay четверга.
event sourcing так не работает.
S>·>Ясен пень. А твой код будет правильно работать, если nextFriday вдруг четверг возвратит? Есть же контракт... S>Ну, какой день возвращает nextFriday, проверить можно. Если задуриться, можно даже это статически доказать
Круто, конечно, но ни ява, ни шарп, ни ts такое, скорее всего не понятнут. А если и потянут, то это будет в лучшем случае академический этюд, чем используемый практически код.
S>·>А в какой они выразимы? В rust для такого нужен borrow checker. S>Rust, афаик, позволяет выражать очень ограниченное подмножество контрактов. Каким способом он предлагает решить описанную задачу? Подозреваю, что будет что-то изоморфное ФП.
Не знаю, лень думать, да и оффтоп.
S>Вообще, большинство доказательств строилось как раз для ФП. Как раз переход к чистым функциям позволяет нам усилить контракты так, чтобы иметь предсказуемость поведения.
Неясно как это относится к обсуждаемомому тут источнику системного времени.
S>Ну вот и я о чём.
Неясно к чему эти все возражения, что видите ли после пятницы теоретически может наступать четверг. Нет, не может на практике, по тому что мы так договорились в нашем коде (т.к. это нахрен не надо с т.з. бизнеса), а не потому что система типов это нам доказала.
S>Там, где можно обойтись без моков, лучше обойтись без моков. Ну, если уж припёрло, тогда можно и моки впилить. Но не раньше
Ну просто под этим флагом вы почему-то проносите какие-то сомнительные практики как ручное написанипе и проверка запросов и т.п.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали: S>>В ФП можно аналогично. ·>Можно, конечно. Но тогда будет тестирование с моками.
Необязательно. "Просмотр 1 строчки глазами" != "тестирование с моками".
·>Угу, и для тестирования ВНЕЗАПНО начинают требоваться моки.
Или мы обходимся integration tests.
·>Ну вы оба себе и стрельнули.
Пока что нет. Вы усердно пытаетесь изобрести окружение, в котором наш код бы что-то сломал, но пока успехи сомнительны.
·>Мысли мои читаешь — о чём я думаю, о чём не думаю. Что Pauel телепат, что ты.
Зачем мысли? Я читаю код. В нём всё написано. Когда собеседник предлагает вариант кода с ошибкой — это уже что-то говорит.
А когда он эту ошибку отказывается чинить даже тогда, когда на неё восемь раз укажут — тут уже никакая телепатия не нужна
S>>Вполне себе при чём. Вся сложность — именно в том, что у вас там добавляется дюжина stateful-компонентов. И результат зависит не от параметров функции, а от состояния этих компонентов. Которое ещё и меняться может во время исполнения вашего кода логики. ·>Welcome to real life.
Ну, где-то это real life, а где-то — трудности, искусственно созданные самому себе.
·>На это ещё я два месяца назад ответил: "внутри CalendarLogic отрефакторить nextFriday() так, чтобы оно звало какой-нибудь static nextFriday(now) который можно потестирвать как пюрешку". Это всё мелкие тривиальности, скукота детсадовская.
·>В "оные" времена это какие?
Лет двадцать назад — как раз когда в моду вошло плотное покрытие тестированием, а основным методом декомпозиции кода было всё вот это вот ООП, и DDD с рич-моделью, где каждая ерунда реализовывалась как stateful object.
·>Халва-халва. "У нас не моки, у нас альтернативная реализация".
·>Смысл в отпиливании медленного от быстрого.
Этого недостаточно для хорошего дизайна
·>Т.е. если нам придётя немного переделать какие-то методы с linq/criteria/etc на чего-то другое — всё посыпется, и тестов нет, т.к. ютесты все завязаны на конкретную реализацию и бесполезны.
Это не "немного переделать". Это смена дизайна, сопоставимая с переездом из SQL в NoSQL. Понятно, что вашей реальности смена ORM — это частое явление, а изменения BL — редкое. Но у меня (и у Pauel, и у примерно всех проектов, с которыми я имел дело с 1999 года) всё строго наоборот.
·>А ваших интеграционных тестов значительно меньше, следовательно все эти разные вариации не — тупо не покрыты.
Ну да, есть такой момент — когда мы режем компоненты определённым образом, то при смене архитектуры одного из них придётся переделывать тесты смежных с ним систем.
·>now() отражает момент времени. Он и в описании бизнес-сценариев напрямую фигурирует "в момент когда пришел запрос, проверяем trade date". SQL-запросов я никогда в бизнес-требованиях не видел. Так что твоя аналогия в топку.
Это вы уже задним числом требования меняете. Начиналось всё с nextFriday, который никак не может быть привязан к физическому времени, т.к. в физическом времени никаких пятниц нет, а есть только продолжительности.
·>Неверно. Я тестрирую какие данные мой репо возвращает в сооветствующих бизнес-сценариях. Что там внутре как-то собирается запрос, параметризуется, где-то как-то выполняется, парсится резалтсет — это всё неинтересные с тз теста детали. ·>Проблема в том, что ты словоблудишь. Ровно та же экспоненциальность будет и в твоём процессе с прогонкой вручную написанных запросов на неких (каких?) данных тестовой базы.
Нет такой проблемы. В моём процессе никакой экспоненциальности не будет — будет проверено, что если в параметрах функции сказано "сортировать по фамилии", то в запрос уедет "order by LastName". Всё. Нет никакой "тестовой базы". СУБД совершенно точно умеет делать order by LastName, поэтому проверять, что она там не вернёт данные в неверном порядке (какие бы они ни были), нам не надо.
А вы уже оценили количество строк, которые вам потребуется вставлять в тестовую таблицу, чтобы получить аналогичную гарантию?
·>А как ты будешь убеждаться, что он нужный? А то что он всё ещё нужный спустя код после пачки исправлений соседнего кода? Каждый раз вручную?
По-моему, кто-то начал словоблудить.
·>И в коде тестов.
Повторюсь: если мы лезем в базу напрямую из бизнес-логики, в стиле 1994, то да, код тестов может содержать прямой SQL.
Если мы пишем на чём-то новее 2005, то SQL проверять необходимости нет — какой-нибудь linq2db его генерирует заведомо корректно.
S>>Ну, всё верно. Просто вы это себе видите методами репы, а мы — структурой запроса. У вас получается, что отделение репы от БЛ — фикция, т.к. при любом изменении требований нужно менять обе части решения. Это — канонический критерий того, что разбиение на компоненты выполнено неправильно. ·>Не понял зачем обе. Если меняется логика как именно надо "искать продукт в списке преемственности", то меняется только код репы.
Ну нет конечно. У вас "репа" — это интерфейс с пачкой специализированных методов, которые отражают ровно обсуждённые этапы исполнения бизнес-логики. И вот эта бизнес-логика будет меняться чаще всего — в стиле "раньше у нас была разница между сетевыми лицензиями и индивидуальными, но с 2021 её уже нет". Поэтому список пунктов "в каком порядке что искать" будет меняться — а с ним и набор методов репы.
Или я неверно понял вашу идею? Как выглядят сигнатуры методов репы которые достают из БД нужные мне данные?
S>>·>А потом из этого собирается цельный бизнес-метод дёргающий в нужном порядке моки предыдущих.
Ну, то есть всё-таки три метода на три этапа бизнес-сценария. Сценарий поменялся — будет не три, а четыре метода, с другими аргументами.
Переписали репо, переписали тесты репы, переписали тесты бизнес-логики, которые вызывают замоканную репу. Где экономим? S>> ·>Ровно по описанному тобой бизнес-требованию. Раз так требуется, так и проверяем. Ты же будешь проверять, что имя у функции fn1, а не fn2 в каком порядке идут запятые в sql-тексте.
Нет, зачем. Проверю, что для соответствующих веток логики в запрос добавляются соответствующие критерии.
Запятые в тексте расставляет конвертер AST запроса в SQL. Заодно у нас есть гарантия отсутствия опечаток в ключевых словах и идентификаторах.
S>>Взамен предлагается проверять запросы проверкой запросов, а не их результатов. ·>Чё? Проверять "как в коде написано"?
Почти, но не совсем.
S>>А согласованность всех частей — проверять интеграционными тестами. ·>Не сможешь. Т.к. комбинаторно рванут варианты согласования частей.
Ну так интеграционным тестам не нужно покрывать 100% сценариев.
Грубо говоря, если у меня вдруг разъехалось определение entity в коде с именем колонки в базе, то никакой юнит-тест это не поймает.
Зато первый же запрос в базу, где задействована эта entity, упадёт. Мне не нужно гонять все сотни разных вариантов запросов с десятками тысяч строк в базе, чтобы это обнаружить.
S>>Ну отчего же. Если всё правильно сделано, то перед релизом достаточно убедиться, что ничего не отломано. Примерно как у вас в начале поста — если завелось и лампочки зелёные, то скорее всего и всё остальное тоже сработает. ·>Как убедитья?
интеграционными тестами S>>Опять-таки с чем сравнивать. Проверки структуры запросов — это микросекунды. Тесты против СУБД — секунды. ·>А толку? С таким же успехом можно проверять, что все запросы начинаются со слова "select" — жутко полезно, ага, ну чтобы sellect не пролез.
Какой конкретно тип бага вы боитесь упустить?
·>Не больше (скорее всего на порядки меньше), чем в твоей базе по которой ты ручками свои запросы проверяешь.
·>Я не отрицаю полезность пюре.
·>Не знаю, я не понял суть проблемы.
Суть проблемы очень простая — мы по скалярному коду вида a=x*b+y порождаем оптимизированный SIMD код.
Задача изоморфна компилятору. То есть на входе — текст на каком-то языке высокого уровня, на выходе — программа на другом языке.
Ваш подход (который у меня и применён) — "давайте проверим, что функция вычисления квадратного корня после компиляции компилятором реально вычисляет квадратный корень". Берём исходник, компилируем его, и начинаем серию запусков, проверяя, что для 4 функция вернёт 2, а для 9 — 3.
Проблема этого подхода — в том, что без заглядывания в целевой код невозможно понять, сколько и каких тестов для вот этой программы запустить.
Более конструктивный способ проверять компилятор — убеждаться, что для функции вычисления квадратного корня порождается код с FSQRT. Тестировать, что FSQRT корректно вычисляет квадратный корень, нам не нужно.
Этот тест сломается, если мы захотим оборудовать компилятор оптимизатором, который вставляет табличку для часто встречающихся аргументов — но оно как раз хорошо: после оптимизации нам надо будет переписать тест; зато теперь у нас будет уверенность, что оптимизация случайно не отпадёт после какого-нибудь рефакторинга или доработки. А вот тест, который проверяет результаты на 4 и 9, ничего не обнаружит.
Вот примерно так же устроена и бизнес-логика поверх RDBMS. Мне важно не то, что там вернёт select person.name from person order by person.name — мне важно, чтобы в моём запросе корректно был выбран критерий сортировки.
·>Я рассказываю когда это работает плохо.
Верно, рассказываете. Но пока выходит не очень убедительно — наверное, потому что вы под NDA и реальный код обсуждать не получится.
S>>Math.Sqrt() — тоже синглтон. Будете бороться через DI? ·> Ты юродствуешь или правда не догоняешь? Загляни внутрь реализаций и поищи глобальные переменны там и там. Посмотрел. Нет глобальных переменных ни там, ни там.
Дальше что? ·>И вспомни что такое синглтон, перечитай лекции которые ты типа читал, у тебя в памяти провал.
Ближе к делу, меньше лирики.
·>Бред какой-то.
Понятно.
·>Оппа! А кеш это именно что нефункциональный параметр и есть. Внезапно! Читаем Pauel: Вот появилось нефункциональное требование "перформанс" и мы видим.
Ну так я про него и говорю. Самые тяжёлые последствия от кривой реализация кэша — потеря нефункциональных требований.
·>Ну я ж не знал, что побегу в одном забеге с нефункциональными соперниками...
S>>Да, но их будет мало. ·>Т.е. не будет покрывать все эти ваши комбинации 10и типов сортировки.
А этого и не надо. Зачем? Хватит одной "комбинации". Остальные заведомо работают корректно — проверено дешёвыми юнит-тестами.
Это примерно как проверять URL партнёрского API — если парочка вызовов обработана корректно, то и остальные заработают. А если мы накосячили в конфигурации, то упадёт первый же вызов.
S>>И то, что я таким образом сокращаю объём данных, необходимых для тестирования. ·>Не понял как. Как было одно единственное данное "2", так и осталось. Ты в один раз сократил? Хвалю.
А чего тут не понимать? У меня было x=y*z+w. Если каждый из трёх параметров принимает N значений, то мне нужно проверить N^3 сочетаний.
Если я распилю формулу на сложение и умножение, то я смогу протестировать сложение отдельно (N^2 значений), умножение отдельно (N^2 значений).
И ещё 1 (один) тест, который проверяет, что функция AddMul является корректной комбинацией сложения и умножения. Это если я не доверяю своей способности увидеть это глазами.
·>Угу. Именно, что "примерно". ·>И тестироваться, внезапно, моками.
Или нет. Потому что у меня, возможно, не будет грязной функции process(..., time: Future<DateTime>), которая внутри будет вызывать грязную time.Value.
У меня будет pure функция process(request), в которую я буду запихивать request-ы с различным ArrivalTime безо всяких моков.
·>Баланс всегда — риск vs выигриш.
Отож.
·>Оно не может так себя вести, по крайней мере в проде.
·>Ну это проблема вашего DateTime.Now(), а не конкретно моего кода. В моём коде такой проблемы нет. Вы лёгким манием руки поменяли одну проблему на другую.
·>Замену чего на что?
now() на instantSource.instant().
>>Это как раз подход типичного джуна — ему дали багу про таймзоны в платёжке, он починил в одном месте, но не починил в другом. В итоге имеем тонкое расхождение в логике, которое будет заметно далеко не сразу. ·>Вот у тебя как раз подход джуна, который совершенно не понимает все тонкости календарей.
·>Уже лучше. И как ты это будешь тестировать? Тест будет делать Sleep(7, Days)?
Поскольку этот код заведомо некорректен, не очень важно чем его тестировать.
·>Напоминаю, что "Если у нас конечная цель иметь именно nextFriday()".
Я не могу себе представить ситуацию, в которой у нас возникает такая цель. Непонятно, какую проблему она решает, и как эта проблема вообще возникла.
·>Не знаю, я там давно не работаю. Вот презентация какая-то, там цифири какие-то есть. https://www.infoq.com/presentations/lmax-trading-architecture/
Ну, ок. Есть, значит. 4ms max, в 8 раз больше 99.99%, в 25 раз больше 99%. Сколько стоит промах мимо кэша nextFriday?
·>Ни о чём не спорю. Рассказываю, что на спайки более 10ms создавали тикеты и расследовали.
Ну, значит нужно строить процесс разработки так, чтобы таких спайков не было. То есть — всё профилировать, бенчмаркать, и вставлять это в приёмочные тесты.
·>Сравни это с intrinsic Math.sqrt, который превращается в одну асм-инструкцию или около того, который ты с какого-то бодуна решил инжектить. Вот такая, гы, арифметика.
Вот это уже ближе к делу. Не в сигнлтоне дело, выходит.
Кстати, инжектить может иметь смысл — потому, что математика математике рознь. И где-то может вместо FSQRT мы будем использовать табличную аппроксимацию .
·>market maker не интерсуется mean. Его интересуют именно спайки. Спайк означает, что его опубликованная цена засевшая дольше чем надо могла прыгнуть в нетуда и совершится невыгодная сделка.
Ну, хорошо, коли так.
·>Бенчмарки это тесты... они не тестируют неизвестное, а для регрессии по сути.
И как вы предлагаете тестировать неизвестное?
·>По дизайну со старыми платёжками ходят в другое место. У тебя проблема была в том, что твой static cache оказывает влияние на всё приложение.
Нет, это у вас такая проблема, потому что единый composition root.
А у нас такая проблема появится только если мы руками её создадим.
·>Угу. Но это не избавляет от необходимости моков, т.к. от грязного кода практически невозможно избавиться.
Моки перестают быть необходимостью. Их с одной стороны подпирают дешёвые юнит-тесты пюрешки, а с другой — полноценные интеграционные тесты взаимодействий.
В итоге, ниша для моков сжимается до околонулевой. Потому что они недостаточно дешёвые по сравнению с юнитами, и недостаточно релевантные по сравнению с интеграцией.
·>Ну я и не спорил об этом. Вопрос был в целесообразности. В nextFriday(x) будет пол строчки кода.
Наоборот — это в nextFriday() будет полстрочки кода, с вызовом nextFriday(now()).
А в nextFriday вся вот эта тяжёлая артиллерия — с загрузкой timeZoneInfo и прочим.
·>Больше места займёт обвязка сигнатуры самой функции. Насколько целесообразно вводить это всё при условии что цель всё равно иметь везде конкренто nextFridayFromNow и покрывать тестами надо и её тоже.
Нет такой цели. Вы её выдумали для оправдания stateful дизайна.
Если посмотреть ту самую презентацию LMAX, там чёрным по белому напиcано "time sourced from events". Слайд 34, "System must be deterministic".
Господь вас упаси использовать какие-то там instantSource. Добро пожаловать в мир низкой латентности
·>ЧТД. Эту я мысль я и пытался донести. Можно сворачивать обсуждение.
Можно.
·>Я ничего не ломал. Возможно я не рассказал очевидные для меня детали: инстант это Instant. Что такое "календарный инстант" — мне неведомо. А "пятница" — это из календаря уже, ясен пень.
Дело же не в устройстве АПИ. А в том, что у меня сейчас "следующая пятница" — это через неделю; а если я поменяю таймзону — следующая пятница станет наступать через час. Да, это календарь, а не инстант, но задача формулировалась в терминах календаря. Инстант придумали именно вы, причём в рамках решения своих архитектурных задач, на которые пользователям наплевать. Пользователя очень удивит такая штука, что "следующая пятница" вдруг вместо полуночи по его локальным часам показывает 22 часа следующего четверга.
·>Для этого я и делаю логику преобразования инстантов в календарные данные в классе CalendarLogic, который зависит от источкика инстантов.
При этом кэш у вас об этом ничего не знает. Не-кэшированное вычисление nextFriday берёт текущую тайм-зону; кэш возвращает значение, рассчитанное по тайм-зоне в момент популяции кэша
И вы продолжаете утверждать, что у вас нет баги.
·>event sourcing так не работает.
·>Круто, конечно, но ни ява, ни шарп, ни ts такое, скорее всего не понятнут. А если и потянут, то это будет в лучшем случае академический этюд, чем используемый практически код.
Шарп — потянет. Но с оговорками. Про TS ничего не могу сказать, не знаю, что у них там с верификацией.
·>Неясно как это относится к обсуждаемомому тут источнику системного времени.
Это относится к контрактам, на которые вы собираетесь положиться.
·>Неясно к чему эти все возражения, что видите ли после пятницы теоретически может наступать четверг. Нет, не может на практике, по тому что мы так договорились в нашем коде (т.к. это нахрен не надо с т.з. бизнеса), а не потому что система типов это нам доказала.
Ваши договорённости не выражены в коде, и не стоят примерно ничего.
·>Ну просто под этим флагом вы почему-то проносите какие-то сомнительные практики как ручное написанипе и проверка запросов и т.п.
Это были простые примеры на пальцах, призванные помочь вам понять принцип.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Sinclair, Вы писали:
S>>>В ФП можно аналогично. S>·>Можно, конечно. Но тогда будет тестирование с моками. S>Необязательно. "Просмотр 1 строчки глазами" != "тестирование с моками".
Одной строчки в каждом методе контроллеров?
S>·>Угу, и для тестирования ВНЕЗАПНО начинают требоваться моки. S>Или мы обходимся integration tests.
Вы не можете через integration tests протестировать системные часы.
S>·>Ну вы оба себе и стрельнули. S>Пока что нет. Вы усердно пытаетесь изобрести окружение, в котором наш код бы что-то сломал, но пока успехи сомнительны.
Pauel поставил задачу сделать кеш. И вы оба не справились.
S>·>Мысли мои читаешь — о чём я думаю, о чём не думаю. Что Pauel телепат, что ты. S>Зачем мысли? Я читаю код. В нём всё написано. Когда собеседник предлагает вариант кода с ошибкой — это уже что-то говорит.
Это говорит о том, что ты не понял код. Ошибки там нет. Следующая пятница календаря — соответствует определённой точке физического времени. Вот в эту точку и ставится таймер для обновления значения в кеше. Поставить таймер на некую "пятница 11:00" теоретически невозможно.
S>А когда он эту ошибку отказывается чинить даже тогда, когда на неё восемь раз укажут — тут уже никакая телепатия не нужна
Нечего чинить.
S>·>В "оные" времена это какие? S>Лет двадцать назад — как раз когда в моду вошло плотное покрытие тестированием, а основным методом декомпозиции кода было всё вот это вот ООП, и DDD с рич-моделью, где каждая ерунда реализовывалась как stateful object.
Похрен что было 20 лет назад. Я послал ссылку на ровно такой же код от 2023 года. Ты скромно сделал вид что этого не было.
S>·>Смысл в отпиливании медленного от быстрого. S>Этого недостаточно для хорошего дизайна
А дальше идёт вкусовщина, субъективщина и веяния моды. Хорошеметр дизайна ещё не изобрели. А медленное от быстрого можно отличить по секундомеру.
S>·>Т.е. если нам придётя немного переделать какие-то методы с linq/criteria/etc на чего-то другое — всё посыпется, и тестов нет, т.к. ютесты все завязаны на конкретную реализацию и бесполезны. S>Это не "немного переделать". Это смена дизайна, сопоставимая с переездом из SQL в NoSQL. Понятно, что вашей реальности смена ORM — это частое явление, а изменения BL — редкое. Но у меня (и у Pauel, и у примерно всех проектов, с которыми я имел дело с 1999 года) всё строго наоборот.
Потому что проблемы бывают именно когда надо менять код по серьёзному, и тут правильно написанные тесты и приносят реальную пользу. А у вас тесты похоже "шоб було, красиво жеж".
S>·>А ваших интеграционных тестов значительно меньше, следовательно все эти разные вариации не — тупо не покрыты. S>Ну да, есть такой момент — когда мы режем компоненты определённым образом, то при смене архитектуры одного из них придётся переделывать тесты смежных с ним систем.
Это означает, что вы переделываете без тестов вообще. Старые тесты ломаются полностью и новый код пишется с нуля, без проверки всё ещё работает.
S>·>now() отражает момент времени. Он и в описании бизнес-сценариев напрямую фигурирует "в момент когда пришел запрос, проверяем trade date". SQL-запросов я никогда в бизнес-требованиях не видел. Так что твоя аналогия в топку. S>Это вы уже задним числом требования меняете. Начиналось всё с nextFriday, который никак не может быть привязан к физическому времени, т.к. в физическом времени никаких пятниц нет, а есть только продолжительности. Физическое время + календарные правила => пятница.
S>·>Проблема в том, что ты словоблудишь. Ровно та же экспоненциальность будет и в твоём процессе с прогонкой вручную написанных запросов на неких (каких?) данных тестовой базы. S>Нет такой проблемы. В моём процессе никакой экспоненциальности не будет — будет проверено, что если в параметрах функции сказано "сортировать по фамилии", то в запрос уедет "order by LastName". Всё.
А если будет "сортировать по убыванию", то уедет ошибка копипасты "order by LastName asc" и бага обнаружится только в проде по звоку от клиентов.
И это самый простейший очевидный случай. Если будет код чуть посложнее, то перепутать < и >, + или - очень даже запросто. Не знаю о других, но я путаю if-else раз в неделю, не реже.
S>Нет никакой "тестовой базы". СУБД совершенно точно умеет делать order by LastName, поэтому проверять, что она там не вернёт данные в неверном порядке (какие бы они ни были), нам не надо.
Надо проверять не то, что order by выполняется базой верно, а то что в бизнес сценарии "вывести клиентов по фамилии" генерит верный список.
S>А вы уже оценили количество строк, которые вам потребуется вставлять в тестовую таблицу, чтобы получить аналогичную гарантию?
Оценка от балды — десяток строк.
S>·>А как ты будешь убеждаться, что он нужный? А то что он всё ещё нужный спустя код после пачки исправлений соседнего кода? Каждый раз вручную? S>По-моему, кто-то начал словоблудить.
Нет, я задаю конкретный вопрос.
S>·>И в коде тестов. S>Повторюсь: если мы лезем в базу напрямую из бизнес-логики, в стиле 1994, то да, код тестов может содержать прямой SQL. S>Если мы пишем на чём-то новее 2005, то SQL проверять необходимости нет — какой-нибудь linq2db его генерирует заведомо корректно.
Я ссылаюсь на кусок кода с "pattern" который мне показал Pauel. Вопросы к нему какого года этот код.
S>·>Не понял зачем обе. Если меняется логика как именно надо "искать продукт в списке преемственности", то меняется только код репы. S>Ну нет конечно. У вас "репа" — это интерфейс с пачкой специализированных методов, которые отражают ровно обсуждённые этапы исполнения бизнес-логики. И вот эта бизнес-логика будет меняться чаще всего — в стиле "раньше у нас была разница между сетевыми лицензиями и индивидуальными, но с 2021 её уже нет". Поэтому список пунктов "в каком порядке что искать" будет меняться — а с ним и набор методов репы.
Т.е. при изменении бизнес-логики надо будет менять и тесты. Всё ок. Что не так?
S>Или я неверно понял вашу идею? Как выглядят сигнатуры методов репы которые достают из БД нужные мне данные?
Ну как слышится, так и пишется "находим SKU для её renewal" => "Sku find(License lic)". Честно говоря я не очень в теме этой предментой области и не очень понимаю что такое sku, renewal и т.п.
S>>>·>А потом из этого собирается цельный бизнес-метод дёргающий в нужном порядке моки предыдущих. S>Ну, то есть всё-таки три метода на три этапа бизнес-сценария. Сценарий поменялся — будет не три, а четыре метода, с другими аргументами. S>Переписали репо, переписали тесты репы, переписали тесты бизнес-логики, которые вызывают замоканную репу. Где экономим?
В тестировании бизнес-логики. Вот этот весь твой шестистраничный процесс с пачкой "если-то" будет покрыт десятками тестов, которые быстро пролетают за микросекунды.
S>>> S>·>Ровно по описанному тобой бизнес-требованию. Раз так требуется, так и проверяем. Ты же будешь проверять, что имя у функции fn1, а не fn2 в каком порядке идут запятые в sql-тексте. S>Нет, зачем. Проверю, что для соответствующих веток логики в запрос добавляются соответствующие критерии.
А как ты убедишься, что добавленные критерии написаны правильно? Условие "лицензия ещё не проэкспайрилась" у тебя преобразуется в код "licence.date > todayDate" — это правильное условие? Может должно быть "<"? Или вообще "<="? Или "licence.expiryDate"? Всё компилится, но результаты — неверные.
А покрывается это условие одной строчкой в бд и тремя ассертами, что-то вроде:
Такой код можно хоть заказчиу в чатике написать и спросить — верно ли.
S>Запятые в тексте расставляет конвертер AST запроса в SQL. Заодно у нас есть гарантия отсутствия опечаток в ключевых словах и идентификаторах.
Вау, круто. А толку...
S>>>Взамен предлагается проверять запросы проверкой запросов, а не их результатов. S>·>Чё? Проверять "как в коде написано"? S>Почти, но не совсем.
Совсем.
S>>>А согласованность всех частей — проверять интеграционными тестами. S>·>Не сможешь. Т.к. комбинаторно рванут варианты согласования частей. S>Ну так интеграционным тестам не нужно покрывать 100% сценариев.
Вам — нужно. Просто вы не можете, т.к. дизайн слишком хороший.
S>Грубо говоря, если у меня вдруг разъехалось определение entity в коде с именем колонки в базе, то никакой юнит-тест это не поймает. S>Зато первый же запрос в базу, где задействована эта entity, упадёт. Мне не нужно гонять все сотни разных вариантов запросов с десятками тысяч строк в базе, чтобы это обнаружить.
Или не упадёт, т.к. копипаста и данное берётся не из той колонки.
S>>>Опять-таки с чем сравнивать. Проверки структуры запросов — это микросекунды. Тесты против СУБД — секунды. S>·>А толку? С таким же успехом можно проверять, что все запросы начинаются со слова "select" — жутко полезно, ага, ну чтобы sellect не пролез. S>Какой конкретно тип бага вы боитесь упустить?
Написанный код не соответствует ожиданиям пользователя.
S>·>Не знаю, я не понял суть проблемы. S>Суть проблемы очень простая — мы по скалярному коду вида a=x*b+y порождаем оптимизированный SIMD код. S>Задача изоморфна компилятору. То есть на входе — текст на каком-то языке высокого уровня, на выходе — программа на другом языке.
Т.е. ваша бизнес-домен — это компилятор. Результат компилятора — код. Тогда логично, тестировать что код порождается верный. Тут возражений нет.
S>Ваш подход (который у меня и применён) — "давайте проверим, что функция вычисления квадратного корня после компиляции компилятором реально вычисляет квадратный корень". Берём исходник, компилируем его, и начинаем серию запусков, проверяя, что для 4 функция вернёт 2, а для 9 — 3.
Логично. Т.к. наша бизнес-задача — это компилятор, а не квадратный корень.
S>Вот примерно так же устроена и бизнес-логика поверх RDBMS. Мне важно не то, что там вернёт select person.name from person order by person.name — мне важно, чтобы в моём запросе корректно был выбран критерий сортировки.
Ок, если вы пишете библиотеку orm или подобное, то согласен полностью, всё верно делаете.
S>>>Math.Sqrt() — тоже синглтон. Будете бороться через DI? S>·> Ты юродствуешь или правда не догоняешь? Загляни внутрь реализаций и поищи глобальные переменны там и там. S>Посмотрел. Нет глобальных переменных ни там, ни там. S>Дальше что?
Ты троллишь что-ли?
S>Ближе к делу, меньше лирики.
rdtsc
S>·>Оппа! А кеш это именно что нефункциональный параметр и есть. Внезапно! Читаем Pauel: Вот появилось нефункциональное требование "перформанс" и мы видим. S>Ну так я про него и говорю. Самые тяжёлые последствия от кривой реализация кэша — потеря нефункциональных требований.
В смысле? Задача была поставлена "нужно нефункциональное требование!". И как решение "не шмогли нефункциональные требования, ну и чё, зато вроде работает"? Троллите что-ли?!
S>>>Да, но их будет мало. S>·>Т.е. не будет покрывать все эти ваши комбинации 10и типов сортировки. S>А этого и не надо. Зачем? Хватит одной "комбинации". Остальные заведомо работают корректно — проверено дешёвыми юнит-тестами.
Нихрена не проверено. Проверено, что "works as coded".
S>Это примерно как проверять URL партнёрского API — если парочка вызовов обработана корректно, то и остальные заработают. А если мы накосячили в конфигурации, то упадёт первый же вызов.
Зависит от кода. Если у вас каждый вызов к базовому урлу аппендит разные строчки с именами разных ресурсов, то их надо валидировать как-то, обязательно. Либо по их swagger-like схеме с валидированной версией, либо conformance tests, если схемы нет.
S>>>И то, что я таким образом сокращаю объём данных, необходимых для тестирования. S>·>Не понял как. Как было одно единственное данное "2", так и осталось. Ты в один раз сократил? Хвалю. S>А чего тут не понимать? У меня было x=y*z+w. Если каждый из трёх параметров принимает N значений, то мне нужно проверить N^3 сочетаний. S>Если я распилю формулу на сложение и умножение, то я смогу протестировать сложение отдельно (N^2 значений), умножение отдельно (N^2 значений). S>И ещё 1 (один) тест, который проверяет, что функция AddMul является корректной комбинацией сложения и умножения. Это если я не доверяю своей способности увидеть это глазами.
Я не знаю о чём ты тут говоришь. Тут речь шла о твоём конкретном коде с GetItems и тестом со значением данного "2". Ты видимо лажанулся, сейчас ужом извиваешься подменяя тему.
S>·>И тестироваться, внезапно, моками. S>Или нет. Потому что у меня, возможно, не будет грязной функции process(..., time: Future<DateTime>), которая внутри будет вызывать грязную time.Value. S>У меня будет pure функция process(request), в которую я буду запихивать request-ы с различным ArrivalTime безо всяких моков.
S>·>Оно не может так себя вести, по крайней мере в проде. S>
Да. Бизнес требует наличия PTP на прод серверах и монотонный rtc источник.
S>·>Ну это проблема вашего DateTime.Now(), а не конкретно моего кода. В моём коде такой проблемы нет. S> Вы лёгким манием руки поменяли одну проблему на другую. S>·>Замену чего на что? S>now() на instantSource.instant().
Ты видимо дальше носа не видишь. Загляни внутро now(). Там несколько синглтонов — локаль, календарь, таймзона, источник времени.
В этом и был мой поинт — нельзя использовать Now в коде логики, который синглтон синглтонами погоняющий. А надо явно испоьзовать DI и инжектить источник времени в composition root.
S>·>Уже лучше. И как ты это будешь тестировать? Тест будет делать Sleep(7, Days)? S>Поскольку этот код заведомо некорректен, не очень важно чем его тестировать.
Т.е. ты корректный код написать не в состоянии?..
S>·>Напоминаю, что "Если у нас конечная цель иметь именно nextFriday()". S>Я не могу себе представить ситуацию, в которой у нас возникает такая цель. Непонятно, какую проблему она решает, и как эта проблема вообще возникла.
Как игрушечный пример для обсуждения на форуме.
S>·>Не знаю, я там давно не работаю. Вот презентация какая-то, там цифири какие-то есть. https://www.infoq.com/presentations/lmax-trading-architecture/ S>Ну, ок. Есть, значит. 4ms max, в 8 раз больше 99.99%, в 25 раз больше 99%. Сколько стоит промах мимо кэша nextFriday?
Я уже говорил — сискол и чтение из файла. В low latency path такое недопустимо. Чтение волатильной переменной отличается от обращения к файлу на 3-4 порядка афаир.
S>·>Ни о чём не спорю. Рассказываю, что на спайки более 10ms создавали тикеты и расследовали. S>Ну, значит нужно строить процесс разработки так, чтобы таких спайков не было. То есть — всё профилировать, бенчмаркать, и вставлять это в приёмочные тесты.
Ну так и было. Но это не даёт гарантию. Нужно ещё и правильно дизайнить всё.
S>·>Сравни это с intrinsic Math.sqrt, который превращается в одну асм-инструкцию или около того, который ты с какого-то бодуна решил инжектить. Вот такая, гы, арифметика. S>Вот это уже ближе к делу. Не в сигнлтоне дело, выходит.
Синглтонность — это про тестируемость, а не про перформанс.
S>Кстати, инжектить может иметь смысл — потому, что математика математике рознь. И где-то может вместо FSQRT мы будем использовать табличную аппроксимацию .
Ну это экзотика какая-то... чтобы требовалось на ходу менять алгоритм sqrt. Но теоретически да, можно и инжектить.
S>·>Бенчмарки это тесты... они не тестируют неизвестное, а для регрессии по сути. S>И как вы предлагаете тестировать неизвестное?
Я такого не предлагаю.
S>·>По дизайну со старыми платёжками ходят в другое место. У тебя проблема была в том, что твой static cache оказывает влияние на всё приложение. S>Нет, это у вас такая проблема, потому что единый composition root.
У нас такой проблемы не было.
S>А у нас такая проблема появится только если мы руками её создадим.
У тебя такую проблему ты сам показал в своём коде со "static _cache". У меня бы спазм пальцев возник при наборе такого кода, а ты с ходу выдал "решение", функциональщик блин. Кстати, и мемоизация — это тоже фактически глобальный кеш и отжор памяти, который надо как-то контролировать.
S>·>Угу. Но это не избавляет от необходимости моков, т.к. от грязного кода практически невозможно избавиться. S>Моки перестают быть необходимостью. Их с одной стороны подпирают дешёвые юнит-тесты пюрешки, а с другой — полноценные интеграционные тесты взаимодействий. S>В итоге, ниша для моков сжимается до околонулевой. Потому что они недостаточно дешёвые по сравнению с юнитами, и недостаточно релевантные по сравнению с интеграцией.
Ок. Для проекта класса сложности "хоумпейдж" — верю.
S>·>Ну я и не спорил об этом. Вопрос был в целесообразности. В nextFriday(x) будет пол строчки кода. S>Наоборот — это в nextFriday() будет полстрочки кода, с вызовом nextFriday(now()). S>А в nextFriday вся вот эта тяжёлая артиллерия — с загрузкой timeZoneInfo и прочим.
Да пофиг, совершенно неважно. Это будет всё неинтересные внутренности.
S>·>Больше места займёт обвязка сигнатуры самой функции. Насколько целесообразно вводить это всё при условии что цель всё равно иметь везде конкренто nextFridayFromNow и покрывать тестами надо и её тоже. S>Нет такой цели. Вы её выдумали для оправдания stateful дизайна. S>Если посмотреть ту самую презентацию LMAX, там чёрным по белому напиcано "time sourced from events". Слайд 34, "System must be deterministic". S>Господь вас упаси использовать какие-то там instantSource. Добро пожаловать в мир низкой латентности
Был интерфейс TimeSource или типа того. Использовался кастомный, т.к. нужны были long-наносекунды, т.к. милисекундной точности не хватает.
И да, в зависимости от каждого конкретного участка кода, либо инжект TimeSource, либо передача через параметры методов, либо внутри каких-то request-like объектов. Нигде никакого Time.Now(), ясен пень.
S>·>Я ничего не ломал. Возможно я не рассказал очевидные для меня детали: инстант это Instant. Что такое "календарный инстант" — мне неведомо. А "пятница" — это из календаря уже, ясен пень. S>Дело же не в устройстве АПИ. А в том, что у меня сейчас "следующая пятница" — это через неделю; а если я поменяю таймзону — следующая пятница станет наступать через час. Да, это календарь, а не инстант, но задача формулировалась в терминах календаря.
Следующая пятница это "nextFriday()", а вся кухня с таймзонами и календарями это CalendarLogic, объяснял же уже. Например, в решении с таймером, если будет логика динамически менять таймзону, то будет соответсвующая логика переставить таймер на другой момент времени.
S>Инстант придумали именно вы, причём в рамках решения своих архитектурных задач, на которые пользователям наплевать. Пользователя очень удивит такая штука, что "следующая пятница" вдруг вместо полуночи по его локальным часам показывает 22 часа следующего четверга.
Просто ты, видимо, не понимаешь, что происходит внутри типичного Time.now(). Я ошибся, подумав, что это всем очевидно.
S>·>Для этого я и делаю логику преобразования инстантов в календарные данные в классе CalendarLogic, который зависит от источкика инстантов. S>При этом кэш у вас об этом ничего не знает. Не-кэшированное вычисление nextFriday берёт текущую тайм-зону; кэш возвращает значение, рассчитанное по тайм-зоне в момент популяции кэша S>И вы продолжаете утверждать, что у вас нет баги.
Верно, нет бага.
S>·>Неясно как это относится к обсуждаемомому тут источнику системного времени. S>Это относится к контрактам, на которые вы собираетесь положиться.
Если контракты не проверяются системой типов ЯП, это ещё не значит, что они не выполняются и на них нельзя полагаться.
S>·>Неясно к чему эти все возражения, что видите ли после пятницы теоретически может наступать четверг. Нет, не может на практике, по тому что мы так договорились в нашем коде (т.к. это нахрен не надо с т.з. бизнеса), а не потому что система типов это нам доказала. S>Ваши договорённости не выражены в коде, и не стоят примерно ничего.
Они выражены в бизнес-требованиях.
S>·>Ну просто под этим флагом вы почему-то проносите какие-то сомнительные практики как ручное написанипе и проверка запросов и т.п. S>Это были простые примеры на пальцах, призванные помочь вам понять принцип.
Плохой принцип. Я считаю, что лучше иметь автоматические тесты с моками, или даже неспешные тесты с субд, чем полагаться на ручную проверку запросов.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
·>Одной строчки в каждом методе контроллеров?
Или в методе, который готовит входы для "методов контроллеров".
·>Вы не можете через integration tests протестировать системные часы.
Могу, но с ограничениями.
·>Pauel поставил задачу сделать кеш. И вы оба не справились.
·>Это говорит о том, что ты не понял код. Ошибки там нет. Следующая пятница календаря — соответствует определённой точке физического времени. Вот в эту точку и ставится таймер для обновления значения в кеше. Поставить таймер на некую "пятница 11:00" теоретически невозможно.
Это значит, что таймер непригоден для решения поставленной задачи. Потому, что пользователю нужна именно "пятница", а не то, куда вам там удобно ставить таймер. ·>Нечего чинить.
·>А дальше идёт вкусовщина, субъективщина и веяния моды. Хорошеметр дизайна ещё не изобрели. А медленное от быстрого можно отличить по секундомеру.
·>Потому что проблемы бывают именно когда надо менять код по серьёзному, и тут правильно написанные тесты и приносят реальную пользу. А у вас тесты похоже "шоб було, красиво жеж".
·>Это означает, что вы переделываете без тестов вообще. Старые тесты ломаются полностью и новый код пишется с нуля, без проверки всё ещё работает.
S>>Это вы уже задним числом требования меняете. Начиналось всё с nextFriday, который никак не может быть привязан к физическому времени, т.к. в физическом времени никаких пятниц нет, а есть только продолжительности. ·> Физическое время + календарные правила => пятница.
Ну, всё верно. Только таймер обновляет вот это вот "Физическое время + календарные правила" невовремя.
·>А если будет "сортировать по убыванию", то уедет ошибка копипасты "order by LastName asc" и бага обнаружится только в проде по звоку от клиентов. ·>И это самый простейший очевидный случай. Если будет код чуть посложнее, то перепутать < и >, + или - очень даже запросто. Не знаю о других, но я путаю if-else раз в неделю, не реже.
S>>Нет никакой "тестовой базы". СУБД совершенно точно умеет делать order by LastName, поэтому проверять, что она там не вернёт данные в неверном порядке (какие бы они ни были), нам не надо. ·>Надо проверять не то, что order by выполняется базой верно, а то что в бизнес сценарии "вывести клиентов по фамилии" генерит верный список.
S>>А вы уже оценили количество строк, которые вам потребуется вставлять в тестовую таблицу, чтобы получить аналогичную гарантию? ·>Оценка от балды — десяток строк.
Да, с сортировками вы правы, это с фильтрацией там экспонента.
·>Нет, я задаю конкретный вопрос.
Исправление соседнего кода, очевидно, не затронет мой код. ·>Я ссылаюсь на кусок кода с "pattern" который мне показал Pauel. Вопросы к нему какого года этот код.
Ну, пусть ответит.
·>Т.е. при изменении бизнес-логики надо будет менять и тесты. Всё ок. Что не так?
Двойной комплект тестов.
·>Ну как слышится, так и пишется "находим SKU для её renewal" => "Sku find(License lic)". Честно говоря я не очень в теме этой предментой области и не очень понимаю что такое sku, renewal и т.п.
Не. Sku find(License lic) — это и есть метод бизнес-логики. Внутри там код с множеством ветвлений, потому что способов найти замену одной лицензии на другую — много, правила запутанные и частично противоречивые.
·>В тестировании бизнес-логики. Вот этот весь твой шестистраничный процесс с пачкой "если-то" будет покрыт десятками тестов, которые быстро пролетают за микросекунды.
Микросекунд не будет — там "на дне" вызов SQL-запросов. То есть — поднимаем докерный образ, инициалзируем данные, и т.п.
За микросекунды пролетит тот самый код юнит-тестов, проверяющих чистые функции.
·>А как ты убедишься, что добавленные критерии написаны правильно? Условие "лицензия ещё не проэкспайрилась" у тебя преобразуется в код "licence.date > todayDate" — это правильное условие? Может должно быть "<"? Или вообще "<="? Или "licence.expiryDate"? Всё компилится, но результаты — неверные.
Мы всегда можем вычислить полученный предикат на экземпляре DTO — это же чистая функция
Если мы не доверяем собственной способности корректно написать семантический тест.
·>А покрывается это условие одной строчкой в бд и тремя ассертами, что-то вроде: ·>
Всё точно так же, только save() не нужен. isExpired — это Expression Tree. ·>Такой код можно хоть заказчиу в чатике написать и спросить — верно ли.
Ну, а SQL — это практически 1:1 английский. Его точно так же можно написать заказчику в чатике и спросить — верно ли.
·>Вау, круто. А толку...
·>Совсем.
·>Вам — нужно. Просто вы не можете, т.к. дизайн слишком хороший.
·>Или не упадёт, т.к. копипаста и данное берётся не из той колонки.
Ну, с тем же успехом у вас копипаста будет и в тесте.
S>>Какой конкретно тип бага вы боитесь упустить? ·>Написанный код не соответствует ожиданиям пользователя.
Это общие слова.
·>Т.е. ваша бизнес-домен — это компилятор. Результат компилятора — код. Тогда логично, тестировать что код порождается верный. Тут возражений нет.
Пользователь не видит кода. Пользователь видит результат вычисления функции, которую он предоставил. ·>Логично. Т.к. наша бизнес-задача — это компилятор, а не квадратный корень.
S>>Вот примерно так же устроена и бизнес-логика поверх RDBMS. Мне важно не то, что там вернёт select person.name from person order by person.name — мне важно, чтобы в моём запросе корректно был выбран критерий сортировки. ·>Ок, если вы пишете библиотеку orm или подобное, то согласен полностью, всё верно делаете.
S>>Посмотрел. Нет глобальных переменных ни там, ни там. S>>Дальше что? ·>Ты троллишь что-ли?
Нет. Я даже дал ссылку на исходник. Посмотрите — там нет никаких глобальных переменных. S>>Ближе к делу, меньше лирики. ·>rdtsc
Что rdtsc? Нет в now() никаких rdtsc.
·>В смысле? Задача была поставлена "нужно нефункциональное требование!". И как решение "не шмогли нефункциональные требования, ну и чё, зато вроде работает"? Троллите что-ли?!
Почему же "не шмогли"? Покажите бенчмарк.
S>>А этого и не надо. Зачем? Хватит одной "комбинации". Остальные заведомо работают корректно — проверено дешёвыми юнит-тестами. ·>Нихрена не проверено. Проверено, что "works as coded".
·>Зависит от кода. Если у вас каждый вызов к базовому урлу аппендит разные строчки с именами разных ресурсов, то их надо валидировать как-то, обязательно. Либо по их swagger-like схеме с валидированной версией, либо conformance tests, если схемы нет.
Ну вот "по схеме" — это и есть дешёвые юнит-тесты, которые проверяют соответствие строчки спеке.
S>>А чего тут не понимать? У меня было x=y*z+w. Если каждый из трёх параметров принимает N значений, то мне нужно проверить N^3 сочетаний. S>>Если я распилю формулу на сложение и умножение, то я смогу протестировать сложение отдельно (N^2 значений), умножение отдельно (N^2 значений). S>>И ещё 1 (один) тест, который проверяет, что функция AddMul является корректной комбинацией сложения и умножения. Это если я не доверяю своей способности увидеть это глазами. ·>Я не знаю о чём ты тут говоришь. Тут речь шла о твоём конкретном коде с GetItems и тестом со значением данного "2". Ты видимо лажанулся, сейчас ужом извиваешься подменяя тему.
Для GetItems — да, всё упирается в тестовые данные. Как я и говорил — в отдельных изолированных случаях поведение грязных функций с моками эквивалентно поведению чистых функций с таблицами истинности.
В более сложных я могу декомпозировать задачу, а с ней и тесты.
·>Да. Бизнес требует наличия PTP на прод серверах и монотонный rtc источник.
Хм. А в презентации — event time sourcing.
·>Ты видимо дальше носа не видишь. Загляни внутро now(). Там несколько синглтонов — локаль, календарь, таймзона, источник времени.
Я заглянул, даже ссылку дал ·>В этом и был мой поинт — нельзя использовать Now в коде логики, который синглтон синглтонами погоняющий. А надо явно испоьзовать DI и инжектить источник времени в composition root.
Первая часть у вас корректна. Вторая — нет. Зачем нам "источник времени", который ещё и не даёт информации о локали, календаре, и тайм-зоне?
Нам нужно отдавать в БЛ момент времени, относительно которого она будет рассчитываться.
·>Т.е. ты корректный код написать не в состоянии?..
Я — в состоянии, но сейчас ваша очередь
·>Как игрушечный пример для обсуждения на форуме.
Ну, тогда и игрушечные ответы подходят.
·>Я уже говорил — сискол и чтение из файла.
Из какого файла?
S>>Ну, значит нужно строить процесс разработки так, чтобы таких спайков не было. То есть — всё профилировать, бенчмаркать, и вставлять это в приёмочные тесты. ·>Ну так и было. Но это не даёт гарантию. Нужно ещё и правильно дизайнить всё.
S>>·>Сравни это с intrinsic Math.sqrt, который превращается в одну асм-инструкцию или около того, который ты с какого-то бодуна решил инжектить. Вот такая, гы, арифметика. S>>Вот это уже ближе к делу. Не в сигнлтоне дело, выходит. ·>Синглтонность — это про тестируемость, а не про перформанс.
S>>Кстати, инжектить может иметь смысл — потому, что математика математике рознь. И где-то может вместо FSQRT мы будем использовать табличную аппроксимацию . ·>Ну это экзотика какая-то... чтобы требовалось на ходу менять алгоритм sqrt. Но теоретически да, можно и инжектить.
Ну, вы же не собираетесь на ходу менять алгоритм instantSource, который там у вас rdtsc вызывает. Значит — и его можно не инжектить
·>Я такого не предлагаю.
Тогда и говорить не о чем.
·>У нас такой проблемы не было.
S>>А у нас такая проблема появится только если мы руками её создадим. ·>У тебя такую проблему ты сам показал в своём коде со "static _cache". У меня бы спазм пальцев возник при наборе такого кода, а ты с ходу выдал "решение", функциональщик блин. Кстати, и мемоизация — это тоже фактически глобальный кеш и отжор памяти, который надо как-то контролировать.
В разных платформах — по-разному. Где-то это глобальный кэш, где-то — локальный. Можно и контролировать — обычно помимо примитивной memoize есть более подробные версии, с рукоятками по макс. размеру кэша и политике инвалидации. ·>Ок. Для проекта класса сложности "хоумпейдж" — верю.
Хорошо, остановимся на проектах класса сложности "хоумпейдж"
·>Да пофиг, совершенно неважно. Это будет всё неинтересные внутренности.
Ну, ок.
S>>Если посмотреть ту самую презентацию LMAX, там чёрным по белому напиcано "time sourced from events". Слайд 34, "System must be deterministic". S>>Господь вас упаси использовать какие-то там instantSource. Добро пожаловать в мир низкой латентности ·>Был интерфейс TimeSource или типа того. Использовался кастомный, т.к. нужны были long-наносекунды, т.к. милисекундной точности не хватает. ·>И да, в зависимости от каждого конкретного участка кода, либо инжект TimeSource, либо передача через параметры методов, либо внутри каких-то request-like объектов. Нигде никакого Time.Now(), ясен пень.
Непонятно, зачем вам инжект TimeSource в коде, который обязан брать время из event. Вместе со всеми настройками календаря и прочим — если event был по летнему времени, то и преобразование его в календарную дату тоже будет по летнему времени, даже если в момент его обработки время сменилось на зимнее.
·>Следующая пятница это "nextFriday()", а вся кухня с таймзонами и календарями это CalendarLogic, объяснял же уже. Например, в решении с таймером, если будет логика динамически менять таймзону, то будет соответсвующая логика переставить таймер на другой момент времени.
Логика смены таймзоны уже реализована за вас, на уровне ОС. Вам остаётся только к ней адаптироваться.
·>Просто ты, видимо, не понимаешь, что происходит внутри типичного Time.now(). Я ошибся, подумав, что это всем очевидно.
Наверное, не понимаю. В моём воображении Time.now() берёт Utc-шное время из операционной системы (https://learn.microsoft.com/en-us/windows/win32/api/sysinfoapi/nf-sysinfoapi-getsystemtimeasfiletime), а потом прибавляет к нему текущее смещение текущей таймзоны. Как вы собрались заменить это на instant — интересная загадка.
Как вы собираетесь "переставлять таймер" — тоже загадка. Я вот сходу не вспомнил надёжного способа задетектить изменение тайм зоны даже для винды; тем более — кроссплатформенным способом.
·>Верно, нет бага. Угу. Только nextFriday иногда возвращает 23:00 следующего четверга, а так — бага нету. Удачи, чо.
·>Если контракты не проверяются системой типов ЯП, это ещё не значит, что они не выполняются и на них нельзя полагаться.
Хм. В целом я согласен. Но тогда у нас должен быть какой-то другой способ проверить выполнение контрактов, не так ли?
·>Они выражены в бизнес-требованиях.
Ну, да. Выражены. Я вот в бизнес-требованиях не вижу никаких упоминаний того, что пятница обязательно идёт после четверга, и никогда не бывает наоборот. А мой жизненный опыт показывает, что это не то что бы сплошь и рядом происходит, но встречается достаточно часто для того, чтобы считать это штатной ситуацией.
А если у нас будут такие бизнес-требования, то это будет не то, на что мы будем полагаться, а то, что мы должны обеспечить. А если обеспечиваем не мы — то убедиться, что всё сделано так, как требуется.
·>Плохой принцип. Я считаю, что лучше иметь автоматические тесты с моками, или даже неспешные тесты с субд, чем полагаться на ручную проверку запросов.
Ну, ок.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Sinclair, Вы писали:
S>·>Одной строчки в каждом методе контроллеров? S>Или в методе, который готовит входы для "методов контроллеров".
Наверное сойдёт для простых случаев, когда такой метод только один и не надо париться о перформансе.
S>·>Вы не можете через integration tests протестировать системные часы. S>Могу, но с ограничениями.
Как? Невозможно будет отличить время взятое сервером из своего источника от времени пришедшее в запросе от клиента.
S>·> Физическое время + календарные правила => пятница. S>Ну, всё верно. Только таймер обновляет вот это вот "Физическое время + календарные правила" невовремя.
Бред.
S>>>А вы уже оценили количество строк, которые вам потребуется вставлять в тестовую таблицу, чтобы получить аналогичную гарантию? S>·>Оценка от балды — десяток строк. S>Да, с сортировками вы правы, это с фильтрацией там экспонента.
Имхо, то же самое. Просто одни и те же данные можно запрашивать разными фильтрами. Я уже примерный код показывал где-то выше.
S>·>Нет, я задаю конкретный вопрос. S>Исправление соседнего кода, очевидно, не затронет мой код.
Поля могли немного переместиться, переделаться, они стали работать несколько иначе. Что может повлиять на логику фильтров.
S>·>Т.е. при изменении бизнес-логики надо будет менять и тесты. Всё ок. Что не так? S>Двойной комплект тестов.
Разные тесты тестируют разные вещи. Первый комплект — бизнес-логика, второй комплект — загрузка/выгрузка данных в бд.
S>·>Ну как слышится, так и пишется "находим SKU для её renewal" => "Sku find(License lic)". Честно говоря я не очень в теме этой предментой области и не очень понимаю что такое sku, renewal и т.п. S>Не. Sku find(License lic) — это и есть метод бизнес-логики. Внутри там код с множеством ветвлений, потому что способов найти замену одной лицензии на другую — много, правила запутанные и частично противоречивые.
Т.е. у тебя бизнес-логика не отделима от персистенса? Ну хз, может это какой-то особенный проект.
S>·>В тестировании бизнес-логики. Вот этот весь твой шестистраничный процесс с пачкой "если-то" будет покрыт десятками тестов, которые быстро пролетают за микросекунды. S>Микросекунд не будет — там "на дне" вызов SQL-запросов. То есть — поднимаем докерный образ, инициалзируем данные, и т.п. S>За микросекунды пролетит тот самый код юнит-тестов, проверяющих чистые функции.
За микросекунды летают десятки тестов для ветвистой бизнес-логики. А докер-образ это для тестирования персистенса данных в субд.
S>·>А как ты убедишься, что добавленные критерии написаны правильно? Условие "лицензия ещё не проэкспайрилась" у тебя преобразуется в код "licence.date > todayDate" — это правильное условие? Может должно быть "<"? Или вообще "<="? Или "licence.expiryDate"? Всё компилится, но результаты — неверные. S>Мы всегда можем вычислить полученный предикат на экземпляре DTO — это же чистая функция
Ну это и есть фактически тестирование на "in-memory" бд. Если это делаете, то спору нет.
S>Если мы не доверяем собственной способности корректно написать семантический тест.
Неужели никогда + и — или подобное не путаете?
S>Всё точно так же, только save() не нужен. isExpired — это Expression Tree.
save нужен для того, чтобы убедиться создаваемая лицензия при записи даты экспирации кладёт всё в нужную колонку бд, в ту же самую, которая потом при чтении в isExpired матчится.
Если вы это не тестируете, то .
S>·>Такой код можно хоть заказчиу в чатике написать и спросить — верно ли. S>Ну, а SQL — это практически 1:1 английский. Его точно так же можно написать заказчику в чатике и спросить — верно ли.
Только что был expression tree, теперь sql. Если sql генерится из ET, то он может быть довольно хитрым и навороченным, с кучей лишних деталей. Код теста же затачивается под один бизнес-аспект, технические детали реализации запрятаны.
S>·>Или не упадёт, т.к. копипаста и данное берётся не из той колонки. S>Ну, с тем же успехом у вас копипаста будет и в тесте.
Её там гораздо проще заметить.
S>>>Какой конкретно тип бага вы боитесь упустить? S>·>Написанный код не соответствует ожиданиям пользователя. S>Это общие слова.
Лично я не умею выполнять в уме sql запросы. Увидеть ошибку в тексте запроса или даже ET — мне гораздо сложнее, чем на конкретном тестовом примере, показывающем, например, что такой-то конкретный фильтр выбирает эту запись, но не ту. Может это только мои заморочки, конечно...
S>·>Т.е. ваша бизнес-домен — это компилятор. Результат компилятора — код. Тогда логично, тестировать что код порождается верный. Тут возражений нет. S>Пользователь не видит кода. Пользователь видит результат вычисления функции, которую он предоставил.
Компилятор порождает код для машины, а не для пользователя.
S>>>Посмотрел. Нет глобальных переменных ни там, ни там. S>>>Дальше что? S>·>Ты троллишь что-ли? S>Нет. Я даже дал ссылку на исходник. Посмотрите — там нет никаких глобальных переменных. В строке 1083 идёт чтение из глобальной переменной TSC или аналога.
S>·>rdtsc S>Что rdtsc? Нет в now() никаких rdtsc.
S>·>В смысле? Задача была поставлена "нужно нефункциональное требование!". И как решение "не шмогли нефункциональные требования, ну и чё, зато вроде работает"? Троллите что-ли?! S>Почему же "не шмогли"? Покажите бенчмарк.
Я рассказал. Бенчмарком заморачиваться не буду.
S>·>Зависит от кода. Если у вас каждый вызов к базовому урлу аппендит разные строчки с именами разных ресурсов, то их надо валидировать как-то, обязательно. Либо по их swagger-like схеме с валидированной версией, либо conformance tests, если схемы нет. S>Ну вот "по схеме" — это и есть дешёвые юнит-тесты, которые проверяют соответствие строчки спеке.
Угу. Если спека есть. И есть возможность верифицировать, что базовый урл работает с той же спекой.
S>·>Я не знаю о чём ты тут говоришь. Тут речь шла о твоём конкретном коде с GetItems и тестом со значением данного "2". Ты видимо лажанулся, сейчас ужом извиваешься подменяя тему. S>Для GetItems — да, всё упирается в тестовые данные. Как я и говорил — в отдельных изолированных случаях поведение грязных функций с моками эквивалентно поведению чистых функций с таблицами истинности.
Я знаю, я об этом говорил ещё ~2 месяца назад, когда Pauel свои таблицы истинности потерял.
S>В более сложных я могу декомпозировать задачу, а с ней и тесты.
И моки тут непричём.
S>·>Да. Бизнес требует наличия PTP на прод серверах и монотонный rtc источник. S>Хм. А в презентации — event time sourcing.
А думаешь откуда в events берётся time? От святого духа?
S>·>Ты видимо дальше носа не видишь. Загляни внутро now(). Там несколько синглтонов — локаль, календарь, таймзона, источник времени. S>Я заглянул, даже ссылку дал
Смотришь в книгу, видишь...
S>·>В этом и был мой поинт — нельзя использовать Now в коде логики, который синглтон синглтонами погоняющий. А надо явно испоьзовать DI и инжектить источник времени в composition root. S>Первая часть у вас корректна. Вторая — нет. Зачем нам "источник времени", который ещё и не даёт информации о локали, календаре, и тайм-зоне? S>Нам нужно отдавать в БЛ момент времени, относительно которого она будет рассчитываться.
У момента времени нет локали, календаря и тайм-зоны. Это просто число. Обычно unix epoch.
S>·>Т.е. ты корректный код написать не в состоянии?.. S>Я — в состоянии, но сейчас ваша очередь
Я уже давно написал, тебе осталось разобраться.
S>·>Как игрушечный пример для обсуждения на форуме. S>Ну, тогда и игрушечные ответы подходят.
Ок, но сломанные игрушки — no fun.
S>·>Я уже говорил — сискол и чтение из файла. S>Из какого файла?
"Скажем, обращение к ZoneInfo в jdk может порождать чтение ресурсов с информацией о таймзонах, т.е. чтение файла, т.е. сискол, блокировку и т.п."
S>>>Кстати, инжектить может иметь смысл — потому, что математика математике рознь. И где-то может вместо FSQRT мы будем использовать табличную аппроксимацию . S>·>Ну это экзотика какая-то... чтобы требовалось на ходу менять алгоритм sqrt. Но теоретически да, можно и инжектить. S>Ну, вы же не собираетесь на ходу менять алгоритм instantSource, который там у вас rdtsc вызывает. Значит — и его можно не инжектить
Для replay и для тестов — надо. Менять алгоритм извлечения квадратного корня мне не приходилось.
S>>>А у нас такая проблема появится только если мы руками её создадим. S>·>У тебя такую проблему ты сам показал в своём коде со "static _cache". У меня бы спазм пальцев возник при наборе такого кода, а ты с ходу выдал "решение", функциональщик блин. Кстати, и мемоизация — это тоже фактически глобальный кеш и отжор памяти, который надо как-то контролировать. S>В разных платформах — по-разному. Где-то это глобальный кэш, где-то — локальный. Можно и контролировать — обычно помимо примитивной memoize есть более подробные версии, с рукоятками по макс. размеру кэша и политике инвалидации.
Вот только это уже не будет так всё просто как обещано — "пишем всю интеграцию в контроллерах".
S>·>Ок. Для проекта класса сложности "хоумпейдж" — верю. S>Хорошо, остановимся на проектах класса сложности "хоумпейдж"
Ну там всё работает, хоть левой пяткой пиши, всё равно.
S>·>Был интерфейс TimeSource или типа того. Использовался кастомный, т.к. нужны были long-наносекунды, т.к. милисекундной точности не хватает. S>·>И да, в зависимости от каждого конкретного участка кода, либо инжект TimeSource, либо передача через параметры методов, либо внутри каких-то request-like объектов. Нигде никакого Time.Now(), ясен пень. S>Непонятно, зачем вам инжект TimeSource в коде, который обязан брать время из event.
Потому что если это не хоумпейдж, то кода много, большого и разного. Поток ордеров да, он евент, притом генерится из центрального ll сервиса. К этому всему нужны ещё несколько десятков сервисов со своей логикой, со своими реквестами и очередями.
S>Вместе со всеми настройками календаря и прочим — если event был по летнему времени, то и преобразование его в календарную дату тоже будет по летнему времени, даже если в момент его обработки время сменилось на зимнее.
Бред.
S>·>Следующая пятница это "nextFriday()", а вся кухня с таймзонами и календарями это CalendarLogic, объяснял же уже. Например, в решении с таймером, если будет логика динамически менять таймзону, то будет соответсвующая логика переставить таймер на другой момент времени. S>Логика смены таймзоны уже реализована за вас, на уровне ОС. Вам остаётся только к ней адаптироваться.
ОС — это для десктопных приложений. Серверное приложение имеет свои таймзоны, в зависимости куда ходит. Я же рассказывал, например, что разные коннекшны к разным бирзам имеют разные зоны.
А в процессе разработки адаптироваться к ОС это вообще грабля. Код работающий у девелопера в Лондоне, падает у девелопера в Сиднее.
S>·>Просто ты, видимо, не понимаешь, что происходит внутри типичного Time.now(). Я ошибся, подумав, что это всем очевидно. S>Наверное, не понимаю. В моём воображении Time.now() берёт Utc-шное время из операционной системы (https://learn.microsoft.com/en-us/windows/win32/api/sysinfoapi/nf-sysinfoapi-getsystemtimeasfiletime), а потом прибавляет к нему текущее смещение текущей таймзоны. Как вы собрались заменить это на instant — интересная загадка.
Я же написал, не использовать Time.now() с его синглтонами, а напрямую использовать источники времени и таймзоны.
S>Как вы собираетесь "переставлять таймер" — тоже загадка. Я вот сходу не вспомнил надёжного способа задетектить изменение тайм зоны даже для винды; тем более — кроссплатформенным способом.
Что значит "задедектить"? В админке меняем таймзону в настройках биржи и сообщение отправляется соответсвующему сервису, который отменяет таймер и ставит новый.
S>·>Верно, нет бага. S> Угу. Только nextFriday иногда возвращает 23:00 следующего четверга, а так — бага нету. Удачи, чо. nextFriday возващает LocalDate, в котором никакого времени нет и быть не должно. Это ты с колокольни корявейшего time api из дотнета и винды говоришь, видимо.
S>·>Если контракты не проверяются системой типов ЯП, это ещё не значит, что они не выполняются и на них нельзя полагаться. S>Хм. В целом я согласен. Но тогда у нас должен быть какой-то другой способ проверить выполнение контрактов, не так ли?
Ну да.
S>·>Они выражены в бизнес-требованиях. S>Ну, да. Выражены. Я вот в бизнес-требованиях не вижу никаких упоминаний того, что пятница обязательно идёт после четверга, и никогда не бывает наоборот. S>А мой жизненный опыт показывает, что это не то что бы сплошь и рядом происходит, но встречается достаточно часто для того, чтобы считать это штатной ситуацией.
Потому что ты календарное время путаешь и физическое.
S>А если у нас будут такие бизнес-требования, то это будет не то, на что мы будем полагаться, а то, что мы должны обеспечить. А если обеспечиваем не мы — то убедиться, что всё сделано так, как требуется.
Обеспечиваем соответствующим железом и настройкой PTP.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
S>>Правильный способ отрезания входов-выходов — ровно такой, как настаивает коллега Pauel. Потому что в вашем способе вы их никуда не отрезаете — вы их заменяете плохими аналогами. Ващ подход мы, как и все на рынке, применяли в бою. И неоднократно обожглись о то, что мок не мокает настоящее решение; он мокает ожидания разработчика об этом решении. ·>Ожидания разработчика берутся не из пустого места, а из фиксации поведения боевой системы. Ну по крайней мере если использовать моки правильно, а не так как Pauel думает их используют.
Вы сейчас в чистом виде топите за человеческий фактор. Вроде бы все пишут с оглядкой на эту боевую систему, но вот почему то результат слишком сильно коррелирует с квалификацией. И это большая проблема.
Задача инженера как раз исключать человеческий фактор, а не вводить его
Б>Алгоритмы (доменная логика) уже вынесена в чистые функции, и это действительно банально. Б>Но осталось связать эту логику с данными из внешних систем. Ведь где-то при обработке запроса это должно происходить. Кстати, где?
Б>Полагаю, что работа с внешними зависимостями будут закрыты функциями, которые будут переданы в функцию do_logic. Аналогично для моков зависимости будут закрыты интерфейсом (группа функций), и он будет передан в do_logic. Т.е. с точки зрения тестирования разницы нет — в обоих случаях подменяется поведение внешней системы — передается функция возвращающая нужное для теста значение.
Разница в том, что именно будете мокать. Или низкоуровневые репозитории, или высокоуровневые абстракции.
В вашем случае нужны и интеграционные, и моки. Если беретесь за моки, нужно сделать их максимально надежными и наименее дешевыми. И для этого стоит уйти от моков низкоуровневых зависимостей типа "репозиторий"
Здравствуйте, ·, Вы писали:
S>>·>Вот это я не понял. У него в примере тест буквально сравнивал текст sql "select * ...". Как такое поймает это? S>>Это он просто переводит с рабочего на понятный. Он же пытался вам объяснить, что проверяет структурную эквивалентность. Тут важно понимать, какие компоненты у нас в пайплайне. ·>При этом он меня обвинил в том, что мои тесты проверяют как написано, а не ожидания пользователей.
Я вам привожу общеизвестный факт — моки всех сортов обладают таким вот свойством. И вы показали почему то именно такие тесты, смотрите сами, что пишете.
> А бревно в глазу не замечаете — пользователям-то похрен какая-то там эквивалентность у вас, структурная или не очень.
И точно так же похрен на ваши классы и интерфейсы. Но вы их не стесняетесь использовать, а структурная эквивалентность это ужос-ужос.
S>>Если вы строите текст SQL руками — ну да, тогда будет именно сравнение текстов. Но в наше время так делать неэффективно. Обычно мы порождаем не текст SQL, а его AST. Генерацией текста по AST занимается отдельный компонент (чистая функция), и он покрыт своими тестами — нам их писать не надо. ·>И накой сдалась эта ваша AST вашим пользователям? А что если завтра понадобится заменить вашу AST на очередной TLA, то придётся переписывать все тесты, рискуя всё сломать.
А ифы, циклы, классы, экземпляры зачем вашим пользователям? А что если понадобится поменять один класс-интерфейс на другой?
Впрочем, вы уже сами согласились, что изменения дизайна сначала ломают моки.
Я взял пример для иллюстрации подхода. В другом месте вместо sql будет json-like структура, которая отлично сравнивается и визуализируется — например, при запросах по http или orm.
Вот сегодня сделал тож самое для запросов к http rpc сервису — параметры, retry, api-key, итд. Теперь в тестах сразу видно, что именно уходит на сервис.
Здравствуйте, ·, Вы писали:
·>composition root — это технический, "подвальный" код. Конкретно инжекция системного источника времени — одна строчка кода, которая за жизнь проекта трогается практически ни разу. И тестируется относительно просто — приложение скомпилировалось, стартовало, даёт зелёный healthcheck — значит работает. ·>У тебя же now() лежит в коде бизнес-логики (как я понял из объяснений Pauel). Будет стоять в каждом втором методе контроллеров, т.е. в сотнях мест и код этот постоянно меняется.
У вас будет как минимум несколько этих composition root, т.к. юзкейсы разные. А следовательно будут ошибки вида "посмотрел не туда"
·>Ну как видишь эта самая фунция бизнес-логики состоит из меньших шагов бизнес логики с кучей "если-то". И это всё бизнес-логика. Вот и бей на части. ·>И где же тут эта ваша структурная эквивалентность? Где метапрограммирование? Где буквальный текст sql? И имя функции fn1?
Вы почему в моем примере видите только сравнение текста sql, и дальше этого смотреть не хотите. SQL потому, что фильтры сделаны именно так. Соответственно, можно подкинуть дешовых тестов используя структурную эквивалентность.
Соответсвенно, фиксируем тестами свои ожидания, что бы будущие изменения в коде не сломали всё подряд
Здравствуйте, Pauel, Вы писали:
P>Разница в том, что именно будете мокать. Или низкоуровневые репозитории, или высокоуровневые абстракции.
Какая-то вода. Почему ты называешь репозитории низкоуровневыми? Они вполне себе работают с объектами бизнес-логики, и достаточно высокоуровневые.
Разъясни, что ты называешь высокоуровневыми абстракциями.
P>В вашем случае нужны и интеграционные, и моки. Если беретесь за моки, нужно сделать их максимально надежными и наименее дешевыми. И для этого стоит уйти от моков низкоуровневых зависимостей типа "репозиторий"
Да, интеграционные нужны — чтобы протестировать внешние системы и репозитории, а также проверить интеграцию (и только интеграцию) компонент между собой. Остальной код покрывается юнит-тестами (как с моками, так и без).
При этом подход с моками не исключает разбивку по функциям. Можно код переразбивать как хочешь и рефакторить, в том числе выделяя бизнес-логику в чистые функции, — тесты от этого не меняются. В отличие от искусственного разбинения на маленькие вспомогательнные функции и их отдельного тестирования.
Здравствуйте, Pauel, Вы писали:
P>·>При этом он меня обвинил в том, что мои тесты проверяют как написано, а не ожидания пользователей. P>Я вам привожу общеизвестный факт — моки всех сортов обладают таким вот свойством. И вы показали почему то именно такие тесты, смотрите сами, что пишете.
Давай определимся. В том образцовом коде у Фаулера — моки есть?
>> А бревно в глазу не замечаете — пользователям-то похрен какая-то там эквивалентность у вас, структурная или не очень. P>И точно так же похрен на ваши классы и интерфейсы. Но вы их не стесняетесь использовать, а структурная эквивалентность это ужос-ужос.
Так я это и говорю, похрен на эквивалентность, и на классы, интерфейсы тоже похрен. Важно чтобы код выражал ожидания пользователя, а не что =="select *". Пользователь может ожидать, что "для такого фильтра вернуть такой-то список штуковин". А у тебя "для такого фильтра верунть такой sql-код и использовать такие-то приватные методы".
P>·>И накой сдалась эта ваша AST вашим пользователям? А что если завтра понадобится заменить вашу AST на очередной TLA, то придётся переписывать все тесты, рискуя всё сломать. P>А ифы, циклы, классы, экземпляры зачем вашим пользователям? А что если понадобится поменять один класс-интерфейс на другой?
Ровно та же проблема, если понадобится поменять твою структуру на другую.
P>Впрочем, вы уже сами согласились, что изменения дизайна сначала ломают моки.
Это ты опять что-то перефантазировал.
P>Я взял пример для иллюстрации подхода. В другом месте вместо sql будет json-like структура, которая отлично сравнивается и визуализируется — например, при запросах по http или orm. P>Вот сегодня сделал тож самое для запросов к http rpc сервису — параметры, retry, api-key, итд. Теперь в тестах сразу видно, что именно уходит на сервис.
А толку? Ну уходит, а с чего ты решил, что сервис будет с этим ушедшим работать? Будешь тесты в проде гонять?
P>·>У тебя же now() лежит в коде бизнес-логики (как я понял из объяснений Pauel). Будет стоять в каждом втором методе контроллеров, т.е. в сотнях мест и код этот постоянно меняется. P>У вас будет как минимум несколько этих composition root, т.к. юзкейсы разные. А следовательно будут ошибки вида "посмотрел не туда"
Эти же кусочки composition root будут использоваться и в тестах этих юзкейсов. От тестов моками отделяются "плохие" зависимости. Т.е. выделение "плохих" зависимостей — чисто техническое — медленное (сеть-диск-етс), неконтролируемое (системные штуки типа clock) и т.п. А юзкейсы — это логика, этот же код что в проде, что в тестах — один и тот же.
P>·>Ну как видишь эта самая фунция бизнес-логики состоит из меньших шагов бизнес логики с кучей "если-то". И это всё бизнес-логика. Вот и бей на части. P>·>И где же тут эта ваша структурная эквивалентность? Где метапрограммирование? Где буквальный текст sql? И имя функции fn1? P>Вы почему в моем примере видите только сравнение текста sql, и дальше этого смотреть не хотите.
Я вижу ровно то, что ты мне показал. Фантазии и телепатия — не моя стезя.
P>SQL потому, что фильтры сделаны именно так.
Именно — и это отстой. Тестируете детали как сделано, что works as coded.
P>Соответственно, можно подкинуть дешовых тестов используя структурную эквивалентность. Соответсвенно, фиксируем тестами свои ожидания, что бы будущие изменения в коде не сломали всё подряд
Это плохой критерий для выбора тестов.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>Я вам привожу общеизвестный факт — моки всех сортов обладают таким вот свойством. И вы показали почему то именно такие тесты, смотрите сами, что пишете. ·>Давай определимся. В том образцовом коде у Фаулера — моки есть?
Тот образцовый код демонстрирует совсем другое — композицию функциями, это основное, ради чего его стоит смотреть.
>>> А бревно в глазу не замечаете — пользователям-то похрен какая-то там эквивалентность у вас, структурная или не очень. P>>И точно так же похрен на ваши классы и интерфейсы. Но вы их не стесняетесь использовать, а структурная эквивалентность это ужос-ужос. ·>Так я это и говорю, похрен на эквивалентность, и на классы, интерфейсы тоже похрен. Важно чтобы код выражал ожидания пользователя, а не что =="select *". Пользователь может ожидать, что "для такого фильтра вернуть такой-то список штуковин". А у тебя "для такого фильтра верунть такой sql-код и использовать такие-то приватные методы".
Похоже, объяснения Синклера и мои про data complexity вам не помогли. Нету у вас варианта покрыть фильтры тестами на данных. Ради каждого теста, условно, вам надо не 2-3 элемента забрасывать в БД, а кучу данных во все таблицы которые учавствуют прямо или косвенно.
Отсюда ясно, что мелкие тесты фильтров вы будете гонять на бд близкой к боевой. Ну или игнорировать такую проблему делая вид что "и так сойдет"
P>>А ифы, циклы, классы, экземпляры зачем вашим пользователям? А что если понадобится поменять один класс-интерфейс на другой? ·>Ровно та же проблема, если понадобится поменять твою структуру на другую.
Вы снова игнорируете аргументы — глубина и частота правок зависят от количества зависимостей, которое у вас получается конским. У меня же простой маппер. Его править придется только в том случае, если поменяется БЛ. У вас — любое изменение дизайна, например, ради оптимизации.
P>>Впрочем, вы уже сами согласились, что изменения дизайна сначала ломают моки. ·>Это ты опять что-то перефантазировал.
Смотрите сами:
P>Я вам сказал, что при переходе от одного дизайна к другому моки отваливаются. Если вы мокнули репозиторий в одном варианте, а в другом варианте репозиторий вызывается не там, не так, не тогда — всё, приплыли.
Голословно заявил, да.
P>>Я взял пример для иллюстрации подхода. В другом месте вместо sql будет json-like структура, которая отлично сравнивается и визуализируется — например, при запросах по http или orm. P>>Вот сегодня сделал тож самое для запросов к http rpc сервису — параметры, retry, api-key, итд. Теперь в тестах сразу видно, что именно уходит на сервис. ·>А толку? Ну уходит, а с чего ты решил, что сервис будет с этим ушедшим работать? Будешь тесты в проде гонять?
1 Задача "работает ли сервис с тем и этим" решается интеграционными тестами.
2 Задача "создаём только такие запросы, которых понятны тому сервису. Это решается простыми дешовыми юнит-тестами.
Это две разные задачи. Вторую можно игнорировать, переложить на интеграционные, если у вас один единственный вариант запроса. А если у вас сложное вычисление — то интеграционными вы вспотеете всё это тестировать. И моки вам точно так же не помогут.
P>>SQL потому, что фильтры сделаны именно так. ·>Именно — и это отстой. Тестируете детали как сделано, что works as coded.
Тестируется вычисление фильтров, которое довольно сложное.
P>>Соответственно, можно подкинуть дешовых тестов используя структурную эквивалентность. Соответсвенно, фиксируем тестами свои ожидания, что бы будущие изменения в коде не сломали всё подряд ·>Это плохой критерий для выбора тестов.
Вы так и не дали никакого адекватного решения для фильтров. Те примеры, что вы приводили именно для тестирования фильтров не годятся.
Здравствуйте, Буравчик, Вы писали:
P>>Разница в том, что именно будете мокать. Или низкоуровневые репозитории, или высокоуровневые абстракции.
Б>Какая-то вода. Почему ты называешь репозитории низкоуровневыми? Они вполне себе работают с объектами бизнес-логики, и достаточно высокоуровневые. Б>Разъясни, что ты называешь высокоуровневыми абстракциями.
Я вам уже приводил пример — вы его обсуждать не хотите, делаете вид, что сложно раскрывать подветки
Здравствуйте, Pauel, Вы писали:
P>>>Я вам привожу общеизвестный факт — моки всех сортов обладают таким вот свойством. И вы показали почему то именно такие тесты, смотрите сами, что пишете. P>·>Давай определимся. В том образцовом коде у Фаулера — моки есть? P>Тот образцовый код демонстрирует совсем другое
Школьное сочинение на тему "что хотел сказать автор".
P> — композицию функциями, это основное, ради чего его стоит смотреть.
Я не знаю на какой вопрос ты отвечал. Напомню вопрос: "моки есть?". Варианты ответа: "Да", "Нет".
P>>>И точно так же похрен на ваши классы и интерфейсы. Но вы их не стесняетесь использовать, а структурная эквивалентность это ужос-ужос. P>·>Так я это и говорю, похрен на эквивалентность, и на классы, интерфейсы тоже похрен. Важно чтобы код выражал ожидания пользователя, а не что =="select *". Пользователь может ожидать, что "для такого фильтра вернуть такой-то список штуковин". А у тебя "для такого фильтра верунть такой sql-код и использовать такие-то приватные методы". P>Похоже, объяснения Синклера и мои про data complexity вам не помогли. Нету у вас варианта покрыть фильтры тестами на данных. Ради каждого теста, условно, вам надо не 2-3 элемента забрасывать в БД, а кучу данных во все таблицы которые учавствуют прямо или косвенно. P>Отсюда ясно, что мелкие тесты фильтров вы будете гонять на бд близкой к боевой. Ну или игнорировать такую проблему делая вид что "и так сойдет"
Совершенно верно, именно эта альтернатива и имеет место быть. Я использую подход "гонять на бд близкой к боевой" (только не по количеству записей, а по качеству), а у вас подход "и так сойдет" + куча хрупких бесполезных тестов.
P>>>А ифы, циклы, классы, экземпляры зачем вашим пользователям? А что если понадобится поменять один класс-интерфейс на другой? P>·>Ровно та же проблема, если понадобится поменять твою структуру на другую. P>Вы снова игнорируете аргументы — глубина и частота правок зависят от количества зависимостей, которое у вас получается конским. У меня же простой маппер. Его править придется только в том случае, если поменяется БЛ. У вас — любое изменение дизайна, например, ради оптимизации.
Количество зависимостей зависит от сложности задачи, моки тут не при чём. Если у тебя простой маппер, то и у меня будет простой репо.
P>>>Впрочем, вы уже сами согласились, что изменения дизайна сначала ломают моки. P>·>Это ты опять что-то перефантазировал. P>Смотрите сами: P>
P>>Я вам сказал, что при переходе от одного дизайна к другому моки отваливаются. Если вы мокнули репозиторий в одном варианте, а в другом варианте репозиторий вызывается не там, не так, не тогда — всё, приплыли.
P>Голословно заявил, да.
Я согласился с тем, что ты это заявил, а не то, что я с этим заявлением согласился.
P>>>Я взял пример для иллюстрации подхода. В другом месте вместо sql будет json-like структура, которая отлично сравнивается и визуализируется — например, при запросах по http или orm. P>>>Вот сегодня сделал тож самое для запросов к http rpc сервису — параметры, retry, api-key, итд. Теперь в тестах сразу видно, что именно уходит на сервис. P>·>А толку? Ну уходит, а с чего ты решил, что сервис будет с этим ушедшим работать? Будешь тесты в проде гонять? P>1 Задача "работает ли сервис с тем и этим" решается интеграционными тестами.
В тривиальных случаях только. В реальных случаях нужны конформационные тесты.
P>2 Задача "создаём только такие запросы, которых понятны тому сервису. Это решается простыми дешовыми юнит-тестами.
Не решается, совершенно. Это может быть решено, только если есть некая формальная спека сервиса, совместимость с которой можно тестировать.
P>Это две разные задачи. Вторую можно игнорировать, переложить на интеграционные, если у вас один единственный вариант запроса. А если у вас сложное вычисление — то интеграционными вы вспотеете всё это тестировать. И моки вам точно так же не помогут.
Помогут совместно с конформационными тестами.
P>>>SQL потому, что фильтры сделаны именно так. P>·>Именно — и это отстой. Тестируете детали как сделано, что works as coded. P>Тестируется вычисление фильтров, которое довольно сложное.
Без тестирования того факта, что вычисленный фильтр, тот самый твой "pattern" — правильный — это бесполезно.
P>>>Соответственно, можно подкинуть дешовых тестов используя структурную эквивалентность. Соответсвенно, фиксируем тестами свои ожидания, что бы будущие изменения в коде не сломали всё подряд P>·>Это плохой критерий для выбора тестов. P>Вы так и не дали никакого адекватного решения для фильтров. Те примеры, что вы приводили именно для тестирования фильтров не годятся.
Я не понял в чём негодность.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>> — композицию функциями, это основное, ради чего его стоит смотреть. ·>Я не знаю на какой вопрос ты отвечал. Напомню вопрос: "моки есть?". Варианты ответа: "Да", "Нет".
Вы продолжаете играть в какие то игры, и задаёте много раз вопрос на который ответ даден несколько раз.
Есть у фаулера моки или нет — в данном примере он демонстрирует совсем другое!
P>>Отсюда ясно, что мелкие тесты фильтров вы будете гонять на бд близкоагй к боевой. Ну или игнорировать такую проблему делая вид что "и так сойдет" ·>Совершенно верно, именно эта альтернатива и имеет место быть. Я испоо льзую подход "гонять на бд близкой к боевой" (только не по количеству записей, а по качеству), а у вас подход "и так сойдет" + куча хрупких бесполезных тестов.
То есть, вы снова предлагаете бороться с data complexity посредством большого количества тестов на реальной бд.
Вы раз за разом повторяете свое предложение, но почему то возмущаетесь, когда я вам про это напоминаю.
P>>Вы снова игнорируете аргументы — глубина и частота правок зависят от количества зависимостей, которое у вас получается конским. У меня же простой маппер. Его править придется только в том случае, если поменяется БЛ. У вас — любое изменение дизайна, например, ради оптимизации. ·>Количество зависимостей зависит от сложности задачи, моки тут не при чём. Если у тебя простой маппер, то и у меня будет простой репо.
Маппер тестируется простыми юнит-тестами. А ваш репозиторий, с ваших слов, надо "гонять на бд близкой к боевой"
И теперь остаётся надеяться на квалификацию того, кто бдет запорлнять эту бд — человечески фактор.
P>>
P>>>Я вам сказал, что при переходе от одного дизайна к другому моки отваливаются. Если вы мокнули репозиторий в одном варианте, а в другом варианте репозиторий вызывается не там, не так, не тогда — всё, приплыли.
P>>Голословно заявил, да.
·>Я согласился с тем, что ты это заявил, а не то, что я с этим заявлением согласился
Итого — вы тестируете контролер, который вызывает репозиторий. Мок нужен? Нужен.
Второй вариант, после оптимизации, вам приходится сначала писать в очередь, а сам репозиторий будет вызван другим процессом/сервисом при чтении из очереди.
Функциональных изменений нет.
Теперь заглядываем в ваши тесты контроллера, и видим:
Самое забавное, вы продолжаете с этим несоглашаться
P>>1 Задача "работает ли сервис с тем и этим" решается интеграционными тестами. ·>В тривиальных случаях только. В реальных случаях нужны конформационные тесты.
Это разновидность интеграционных. Вы снова играете в слова.
P>>2 Задача "создаём только такие запросы, которых понятны тому сервису. Это решается простыми дешовыми юнит-тестами. ·>Не решается, совершенно. Это может быть решено, только если есть некая формальная спека сервиса, совместимость с которой можно тестировать.
Вы ухитряетесь противоречить себе же в одном абзаце. Репозиторий вы гоняете на боевой бд. А вызов другого сервиса будете тестировать на боевом сервисе?
У вас здесь ровно та же data complexity.
Например, мы можем проверить, что делаем правильный энкодинг, правильную склейку, правильный маппинг, правильный эскейпинг, итд и тд.
P>>Это две разные задачи. Вторую можно игнорировать, переложить на интеграционные, если у вас один единственный вариант запроса. А если у вас сложное вычисление — то интеграционными вы вспотеете всё это тестировать. И моки вам точно так же не помогут. ·>Помогут совместно с конформационными тестами.
Подробнее — как вам моки помогут гарантировать, что всё многообразие символов вы энкодите согласно протоколу?
P>>Тестируется вычисление фильтров, которое довольно сложное. ·>Без тестирования того факта, что вычисленный фильтр, тот самый твой "pattern" — правильный — это бесполезно.
С этим никто и не спорит!!! Вы хоть читаете?
1) Рабочий паттерн или нет — это проверяется на бд, в идеале, той, что содержит реальные данные. А они могут появиться только после релиза в следующем году?
Вы что, пойдете к менеджеру и скажете "нет боевой базы" я запрос через год напишу?
2) При этом для реализации фильтра вам нужно понимать, что возможные параметры будут давать рабочие паттерны.
Тестов только для 1) недостаточно, т.к. например ваш маппер рендерит 'test1 test2' вместо 'test1','test2'. Такое вы проверите только на тех наборах данных, где есть пробел.
А если вдруг нужно энкодить всё многообразие спецсимволов, юникод строк
А потом может оказаться так, что некоторые параметры надо энкодить так, другие — эдак, один и тот же параметр в зависимости от места применения должен кодироваться то так, то эдак.
И всё это вы собираетесь "гонять на бд близкой к боевой"
P>>Вы так и не дали никакого адекватного решения для фильтров. Те примеры, что вы приводили именно для тестирования фильтров не годятся. ·>Я не понял в чём негодность.
В том, что в фильтр приходит конское количество данных самых разных типов, а на выходе должны быть только рабочие паттерны
Здравствуйте, Pauel, Вы писали:
P>>> — композицию функциями, это основное, ради чего его стоит смотреть. P>·>Я не знаю на какой вопрос ты отвечал. Напомню вопрос: "моки есть?". Варианты ответа: "Да", "Нет". P>Вы продолжаете играть в какие то игры, и задаёте много раз вопрос на который ответ даден несколько раз.
Так "да" или "нет"?
P>Есть у фаулера моки или нет — в данном примере он демонстрирует совсем другое!
Это твои личные заморочки что конкретно _ты_ увидел в этой демонстрации. Суть в том, что даже в таком тривиальном примере мок есть и это факт, а факт вещь упрямая. Если ты считаешь, что можно по-другому — весь код у тебя есть, форкни, сделай всё как считаешь должным.
P>·>Совершенно верно, именно эта альтернатива и имеет место быть. Я испоо льзую подход "гонять на бд близкой к боевой" (только не по количеству записей, а по качеству), а у вас подход "и так сойдет" + куча хрупких бесполезных тестов. P>То есть, вы снова предлагаете бороться с data complexity посредством большого количества тестов на реальной бд.
Нет, такое я не предгалаю.
P>Вы раз за разом повторяете свое предложение, но почему то возмущаетесь, когда я вам про это напоминаю.
Это твои фантазии.
P>·>Количество зависимостей зависит от сложности задачи, моки тут не при чём. Если у тебя простой маппер, то и у меня будет простой репо. P>Маппер тестируется простыми юнит-тестами. А ваш репозиторий, с ваших слов, надо "гонять на бд близкой к боевой" P>И теперь остаётся надеяться на квалификацию того, кто бдет запорлнять эту бд — человечески фактор.
Я на это уже отвечал.
P>·>Я согласился с тем, что ты это заявил, а не то, что я с этим заявлением согласился P>Итого — вы тестируете контролер, который вызывает репозиторий. Мок нужен? Нужен.
Он нужен не потому, что я тестирую контроллер, а потому что я отрезаю медленный и неуклюжий, но простой переситсенс от быстрой, но сложной бизнес-логики.
P>Второй вариант, после оптимизации, вам приходится сначала писать в очередь, а сам репозиторий будет вызван другим процессом/сервисом при чтении из очереди. P>Функциональных изменений нет.
Есть, конечно. Например, изменяется транзакционность, согласованность, &c. Ты это даже не понимаешь, что это именно функциональность. Отсюда у тебя потом ВНЕЗАПНО возникают чудесные вещи типа "после того, как сделал var u = service.CreateUser(...), нужно выждать не менее 5 минут перед service.UpdateUser(u, ...)".
get-return это запрос-ответ. Неясно как это можно переписать на очередь без значительного изменения функциональности.
P>>>1 Задача "работает ли сервис с тем и этим" решается интеграционными тестами. P>·>В тривиальных случаях только. В реальных случаях нужны конформационные тесты. P>Это разновидность интеграционных. Вы снова играете в слова.
Да у тебя всё разновидность интеграционных. Конформационные тесты подразумевают, что внешний сервис тестируется отдельно от проекта. И проект отдельно тестируется с моками внешнего сервиса. Что с чем тут интегриуется — я не могу представить, моя фантазия не настолько безграничная.
P>·>Не решается, совершенно. Это может быть решено, только если есть некая формальная спека сервиса, совместимость с которой можно тестировать. P>Вы ухитряетесь противоречить себе же в одном абзаце. Репозиторий вы гоняете на боевой бд.
Это ты опять врёшь, надеюсь, что хоть чуточку краснея.
P> А вызов другого сервиса будете тестировать на боевом сервисе?
Нет. Я же написал как. Несколько раз.
P>У вас здесь ровно та же data complexity. P>Например, мы можем проверить, что делаем правильный энкодинг, правильную склейку, правильный маппинг, правильный эскейпинг, итд и тд.
Не можете. Такими тестами вы можете проверить, что текст запроса равен select *...., но не можете проверить, что он правильный. Правильность текста запроса будут проверять только ваши юзеры в проде, т.к. и интеграционными тестами не можете покрыть каждый запрос, ибо data complexity для тестов проекта в сборе выше, чем в тестах реп.
P>>>Это две разные задачи. Вторую можно игнорировать, переложить на интеграционные, если у вас один единственный вариант запроса. А если у вас сложное вычисление — то интеграционными вы вспотеете всё это тестировать. И моки вам точно так же не помогут. P>·>Помогут совместно с конформационными тестами. P>Подробнее — как вам моки помогут гарантировать, что всё многообразие символов вы энкодите согласно протоколу?
"согласно протоколу" — это и есть конформационные тесты, по определению. Моки же позволяют не маяться дурью гарантирования энкодинга в тестах вашей бизнес-логики.
P>·>Без тестирования того факта, что вычисленный фильтр, тот самый твой "pattern" — правильный — это бесполезно. P>С этим никто и не спорит!!! Вы хоть читаете? P>1) Рабочий паттерн или нет — это проверяется на бд, в идеале, той, что содержит реальные данные. А они могут появиться только после релиза в следующем году? P>Вы что, пойдете к менеджеру и скажете "нет боевой базы" я запрос через год напишу?
Т.е. ты не можешь написать тест т.к. для проверки паттерна у тебя ещё нет реальных данных? Совершенно верно. И это плохо. Не надо так делать.
P>2) При этом для реализации фильтра вам нужно понимать, что возможные параметры будут давать рабочие паттерны. P>Тестов только для 1) недостаточно, т.к. например ваш маппер рендерит 'test1 test2' вместо 'test1','test2'. Такое вы проверите только на тех наборах данных, где есть пробел. P>А если вдруг нужно энкодить всё многообразие спецсимволов, юникод строк P>А потом может оказаться так, что некоторые параметры надо энкодить так, другие — эдак, один и тот же параметр в зависимости от места применения должен кодироваться то так, то эдак. P>И всё это вы собираетесь "гонять на бд близкой к боевой"
И? Предлагаешь это не тестировать вообще? По факту ты просто загоняешь свои assumptions что надо "так, а не эдак" в свой pattern и оставляешь это вообще не покрытым вообще никак. Поэтому и необходимы конф-тесты вида, что repo.save(...."многообразие спецсимволов"); assertThat(repo.load(....)).isGood() на системе близкой к боевой, а не просто так как тебе кажется должно быть. Имея такие тесты можно уже спокойно тестировать свою бизнес-логику моками вида verify(repo).save(...."simple value") зная, что энкодинг спецсиволов уже проверен конф-тестами.
P>·>Я не понял в чём негодность. P>В том, что в фильтр приходит конское количество данных самых разных типов, а на выходе должны быть только рабочие паттерны
Ты всё ещё скрываешь как же ты ассертишь рабочесть паттернов. Кода я, конечно, не увижу, т.к. это делаешь на честном слове, вручную, если не забыл.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>Есть у фаулера моки или нет — в данном примере он демонстрирует совсем другое! ·>Это твои личные заморочки что конкретно _ты_ увидел в этой демонстрации.
Даем слово Фаулеру, again
By choosing to fulfill dependency contracts with functions rather than classes, minimizing the code sharing between modules and driving the design through tests, I can create a system composed of highly discrete, evolvable, but still type-safe modules
Фаулер пишет, что он взял функции вместо классов. Это и есть его цель. А вы думаете, что он показывал, будто без моков нельзя
> Суть в том, что даже в таком тривиальном примере мок есть и это факт, а факт вещь упрямая.
Что раз Фаулер так делает, то иначе ну никак нельзя? Моки можно всунуть куда угодно, хоть для теста синусов и косинусов, — это ничего не говорит.
P>>·>Совершенно верно, именно эта альтернатива и имеет место быть. Я испоо льзую подход "гонять на бд близкой к боевой" (только не по количеству записей, а по качеству), а у вас подход "и так сойдет" + куча хрупких бесполезных тестов. P>>То есть, вы снова предлагаете бороться с data complexity посредством большого количества тестов на реальной бд. ·>Нет, такое я не предгалаю.
Именно это вы и говорите. Ну, как вариант, не читаете.
Речь именно про фильтры. Смотрите сами:
Отсюда ясно, что мелкие тесты фильтров вы будете гонять на бд близкоагй к боевой. Ну или игнорировать такую проблему делая вид что "и так сойдет"
·>Совершенно верно, именно эта альтернатива и имеет место быть. Я испоо льзую подход "гонять на бд близкой к боевой"
И вы предлагаете вместо этих тестов гонять всё через бд. Откуда ясно, что 1 время прогона увеличивается на порядки, 2 боевых данных у вас нет — пойдете к менедеджеру "Вася, я тесты в следуюем году подкину"
P>>Итого — вы тестируете контролер, который вызывает репозиторий. Мок нужен? Нужен. ·>Он нужен не потому, что я тестирую контроллер, а потому что я отрезаю медленный и неуклюжий, но простой переситсенс от быстрой, но сложной бизнес-логики.
Сейчас важно, что он нужен.
P>>Второй вариант, после оптимизации, вам приходится сначала писать в очередь, а сам репозиторий будет вызван другим процессом/сервисом при чтении из очереди. P>>Функциональных изменений нет. ·>Есть, конечно. Например, изменяется транзакционность, согласованность, &c. Ты это даже не понимаешь, что это именно функциональность.
Согласованность, транзакционность, задержка — это всё НЕФУНКЦИОНАЛЬНЫЕ.
Т.е., условно, вы выяснили, что не успеваете, опаньки! И надо выталкивать процессинг в очередь. Упс — написали тесты, покрыли моками, выбросили моки, переписали тесты, но уже на других моках, ой...
·>
·>get-return это запрос-ответ. Неясно как это можно переписать на очередь без значительного изменения функциональности.
Вам сюда: https://en.wikipedia.org/wiki/Non-functional_requirement
P>>Это разновидность интеграционных. Вы снова играете в слова. ·>Да у тебя всё разновидность интеграционных. Конформационные тесты подразумевают, что внешний сервис тестируется отдельно от проекта. И проект отдельно тестируется с моками внешнего сервиса. Что с чем тут интегриуется — я не могу представить, моя фантазия не настолько безграничная.
Интеграция начинается с момента, когда одна ваша функция вызывает другую вашу функцию. Конформационный тест требует запуска приложения или подсистемы, что автоматически означает интеграционный уровень.
Правильно понимаю, вы собираетесь тестировать эскейпинг каких кавычек, собирая приложение и запуская его против мока внешнего сервиса?
Весело у вас там.
P>>Вы ухитряетесь противоречить себе же в одном абзаце. Репозиторий вы гоняете на боевой бд. ·>Это ты опять врёшь, надеюсь, что хоть чуточку краснея.
Вот ваши слова про репозиторий "гонять на бд близкой к боевой"
Так и вижу — тесты на эскейпинг символов прогонять на клоне прода. Собственно, это и есть ваша идея применения конформационных тестов.
P>>Например, мы можем проверить, что делаем правильный энкодинг, правильную склейку, правильный маппинг, правильный эскейпинг, итд и тд. ·>Не можете. Такими тестами вы можете проверить, что текст запроса равен select *...., но не можете проверить, что он правильный. Правильность текста запроса будут проверять только ваши юзеры в проде, т.к. и интеграционными тестами не можете покрыть каждый запрос, ибо data complexity для тестов проекта в сборе выше, чем в тестах реп.
В который раз объясняю. Нам нужны 2 условия(ДВА!)
1. рабочий паттерн запроса — это проверяется сначала руками, а потом тестом против бд минимально заполненой под задачу
2. рабочая схема построения такого паттерна
1 — необходимое условие
1 + 2 необходимое и достаточное
Почему недостаточно п1
— сервис или бд или сторадж требует эспейпить, энкодить, инлайнить, склеивать, подставлять итд и тд
— маппер параметр->значение это целая куча кейсов, много больше, чем вы можете себе позволить методом "гонять на бд близкой к боевой"
P>>Подробнее — как вам моки помогут гарантировать, что всё многообразие символов вы энкодите согласно протоколу? ·>"согласно протоколу" — это и есть конформационные тесты, по определению. Моки же позволяют не маяться дурью гарантирования энкодинга в тестах вашей бизнес-логики.
Вы реализацию хоть какого клиентского протокола видели когда нибудь? Там сотни и тысячи тестов покрывают кейсы вида '$var- заменяем на значение var с удалением всех пробельных символов после нее'
Фильтр который вы пишете, это ровно такой же специализированый клиент. И тут, о чудо, можно обходиться без всех таких кейсов
P>>Вы что, пойдете к менеджеру и скажете "нет боевой базы" я запрос через год напишу? ·>Т.е. ты не можешь написать тест т.к. для проверки паттерна у тебя ещё нет реальных данных? Совершенно верно. И это плохо. Не надо так делать.
Где взять боевые данные за февраль 2025го? Вы в курсе, что сейчас 2024й год ?
P>>А потом может оказаться так, что некоторые параметры надо энкодить так, другие — эдак, один и тот же параметр в зависимости от места применения должен кодироваться то так, то эдак. P>>И всё это вы собираетесь "гонять на бд близкой к боевой" ·>И? Предлагаешь это не тестировать вообще?
Я уже третий месяц рассказываю как именно это нужно тестировать.
>По факту ты просто загоняешь свои assumptions что надо "так, а не эдак" в свой pattern и оставляешь это вообще не покрытым вообще никак.
Работает ли паттерн корретно, и строится ли он корректно — это два множества вариантов которые всего лишь пересекаются.
> зная, что энкодинг спецсиволов уже проверен конф-тестами.
Я так и думал — вы будете собирать пол-приложения что бы погонять против внешнего сервиса на предмет "заэскейпили кавычку"
P>>В том, что в фильтр приходит конское количество данных самых разных типов, а на выходе должны быть только рабочие паттерны ·>Ты всё ещё скрываешь как же ты ассертишь рабочесть паттернов. Кода я, конечно, не увижу, т.к. это делаешь на честном слове, вручную, если не забыл.
Я ж вам сказал — рабочий паттерн или нет, это проверяем до того, как начнем код коммитить, руками на бд. Интеграционные тесты проверяют его еще раз, на бд.
А дальше нужно покрыть тестами всю мелочевку — построение запроса таким образом, что бы получался рабочий паттерн
P>·>Так "да" или "нет"?
Т.е. прямой вопрос ты опять игнорируешь и продолжаешь лить воду.
P>Фаулер пишет, что он взял функции вместо классов. Это и есть его цель. А вы думаете, что он показывал, будто без моков нельзя
Ещё бы, ведь в js тупо нет классов. Да и похрен, к обсуждаемой теме это не относится. К обсуждению отностится твои заявления о том, что функции и вообще весь такой современный правильный дизайн без классов как-то избавляет от моков. Мой поинт в том, что моки это не про то как пишется код, функциями, классами или чёртом лысым, а про внешние зависимости. И никакой правильный дизайн от них не избавляет, т.к. зависимости диктуются требованиями, а не дизайном. Если у тебя есть субд, будут моки, как ни дизайни. Ну или если у тебя хоумпейдж, а там что угодно делай, не важно.
>> Суть в том, что даже в таком тривиальном примере мок есть и это факт, а факт вещь упрямая. P>Что раз Фаулер так делает, то иначе ну никак нельзя?
Нельзя. И ты ещё не показал, что можно. Код у тебя весь есть, сделай форк и вперёд, а я [willy-wonka-meme.gif].
P>Моки можно всунуть куда угодно, хоть для теста синусов и косинусов, — это ничего не говорит.
Ты говорил, что моки и это всё — это старьё из 00х. Как оказалось — и тут ты налажал, т.к. статья 2023 года имеет те же самые "устаревшие" моки.
P>>>То есть, вы снова предлагаете бороться с data complexity посредством большого количества тестов на реальной бд. P>·>Нет, такое я не предгалаю. P>Именно это вы и говорите. Ну, как вариант, не читаете.
Ты нафантазировал "на реальной бд", а я писал "на бд близкой к боевой (только не по количеству записей, а по качеству)". Разницу не видишь, да?
P>И вы предлагаете вместо этих тестов гонять всё через бд. Откуда ясно, что 1 время прогона увеличивается на порядки, 2 боевых данных у вас нет — пойдете к менедеджеру "Вася, я тесты в следуюем году подкину"
Это опять твои фантазии из неумения читать, что тебе пишут.
P>>>Итого — вы тестируете контролер, который вызывает репозиторий. Мок нужен? Нужен. P>·>Он нужен не потому, что я тестирую контроллер, а потому что я отрезаю медленный и неуклюжий, но простой переситсенс от быстрой, но сложной бизнес-логики. P>Сейчас важно, что он нужен.
Потому что он необходим.
P>·>Есть, конечно. Например, изменяется транзакционность, согласованность, &c. Ты это даже не понимаешь, что это именно функциональность. P> Согласованность, транзакционность, задержка — это всё НЕФУНКЦИОНАЛЬНЫЕ.
Как это? Возможность поизменять пользователя после его создания — это функциональное требование.
P>Т.е., условно, вы выяснили, что не успеваете, опаньки! И надо выталкивать процессинг в очередь. Упс — написали тесты, покрыли моками, выбросили моки, переписали тесты, но уже на других моках, ой...
Это требует согласования с бизнесом, а не просто так, чтобы не было тех чудес как у тебя бывает.
P>·>Да у тебя всё разновидность интеграционных. Конформационные тесты подразумевают, что внешний сервис тестируется отдельно от проекта. И проект отдельно тестируется с моками внешнего сервиса. Что с чем тут интегриуется — я не могу представить, моя фантазия не настолько безграничная. P>Интеграция начинается с момента, когда одна ваша функция вызывает другую вашу функцию. Конформационный тест требует запуска приложения или подсистемы, что автоматически означает интеграционный уровень.
Нет, конформационный тест не требует запуска приложения или системы. Читай мою переписку с Sinclair.
P>Правильно понимаю, вы собираетесь тестировать эскейпинг каких кавычек, собирая приложение и запуская его против мока внешнего сервиса?
Нет, не правильно понимаешь.
P>>>Вы ухитряетесь противоречить себе же в одном абзаце. Репозиторий вы гоняете на боевой бд. P>·>Это ты опять врёшь, надеюсь, что хоть чуточку краснея. P>Вот ваши слова про репозиторий "гонять на бд близкой к боевой" P>Так и вижу — тесты на эскейпинг символов прогонять на клоне прода. Собственно, это и есть ваша идея применения конформационных тестов.
Бредишь.
P>>>Например, мы можем проверить, что делаем правильный энкодинг, правильную склейку, правильный маппинг, правильный эскейпинг, итд и тд. P>·>Не можете. Такими тестами вы можете проверить, что текст запроса равен select *...., но не можете проверить, что он правильный. Правильность текста запроса будут проверять только ваши юзеры в проде, т.к. и интеграционными тестами не можете покрыть каждый запрос, ибо data complexity для тестов проекта в сборе выше, чем в тестах реп. P>В который раз объясняю. Нам нужны 2 условия(ДВА!) P>1. рабочий паттерн запроса — это проверяется сначала руками, а потом тестом против бд минимально заполненой под задачу P>2. рабочая схема построения такого паттерна P>1 — необходимое условие P>1 + 2 необходимое и достаточное
Я не знаю что ты в этом месте понимаешь под "паттерн", но я всегда имел в виду твой конкретный "const pattern =" вот тут
. Такой паттерн вручную прповерять — большая беда, надо тестировать с бд автоматически.
P>Почему недостаточно п1 P>- сервис или бд или сторадж требует эспейпить, энкодить, инлайнить, склеивать, подставлять итд и тд
Так это сервис требует, а не твоя бизнес-логика, это и будет конф-тест тестировать.
P>- маппер параметр->значение это целая куча кейсов, много больше, чем вы можете себе позволить методом "гонять на бд близкой к боевой"
Но эти кейсы плотно связаны с тем как выглядит реальный recordset. Например, о том как субд превращает null в default value я тебе уже рассказал. И в твоём подходе это остаётся непокрытым.
P>>>Подробнее — как вам моки помогут гарантировать, что всё многообразие символов вы энкодите согласно протоколу? P>·>"согласно протоколу" — это и есть конформационные тесты, по определению. Моки же позволяют не маяться дурью гарантирования энкодинга в тестах вашей бизнес-логики. P>Вы реализацию хоть какого клиентского протокола видели когда нибудь? Там сотни и тысячи тестов покрывают кейсы вида '$var- заменяем на значение var с удалением всех пробельных символов после нее' P>Фильтр который вы пишете, это ровно такой же специализированый клиент. И тут, о чудо, можно обходиться без всех таких кейсов
Это будет код и тесты клиента для протокола, а не код бизнес-логики твеого приложения, которое этого клиента использует.
P>>>Вы что, пойдете к менеджеру и скажете "нет боевой базы" я запрос через год напишу? P>·>Т.е. ты не можешь написать тест т.к. для проверки паттерна у тебя ещё нет реальных данных? Совершенно верно. И это плохо. Не надо так делать. P>Где взять боевые данные за февраль 2025го? Вы в курсе, что сейчас 2024й год ?
Не знаю, ты рассказывай, ведь тебе требуется "Рабочий паттерн или нет — это проверяется на бд, в идеале, той, что содержит реальные данные". Рассказывай где-ты берёшь реальные данные за 2025 год для проверки работосбособности твоих паттернов.
P>·>И? Предлагаешь это не тестировать вообще? P>Я уже третий месяц рассказываю как именно это нужно тестировать.
Меня ответы "никак", "руками", "используя реальные данные за 2025 год" не устраивают. А с другими ответами ты не соглашаешься.
>>По факту ты просто загоняешь свои assumptions что надо "так, а не эдак" в свой pattern и оставляешь это вообще не покрытым вообще никак. P>Работает ли паттерн корретно, и строится ли он корректно — это два множества вариантов которые всего лишь пересекаются.
Почему пересекаются? Каким образом некорректно построенный паттерн может работать корректно? Раз работает, значит построен.
Разница значительна: "Работает ли" — важно и нужно тестировать, инвариант диктуемый бизнесом, "строится ли" — это мелкие детали имплементации, которые меняются постоянно.
>> зная, что энкодинг спецсиволов уже проверен конф-тестами. P>Я так и думал — вы будете собирать пол-приложения что бы погонять против внешнего сервиса на предмет "заэскейпили кавычку"
Я знаю что ты так думал, осталось тебе перестать так думать.
P>>>В том, что в фильтр приходит конское количество данных самых разных типов, а на выходе должны быть только рабочие паттерны P>·>Ты всё ещё скрываешь как же ты ассертишь рабочесть паттернов. Кода я, конечно, не увижу, т.к. это делаешь на честном слове, вручную, если не забыл. P>Я ж вам сказал — рабочий паттерн или нет, это проверяем до того, как начнем код коммитить, руками на бд.
P>Интеграционные тесты проверяют его еще раз, на бд.
В на прод-бд с данными за 2025 год. Я правильно понял?
P>А дальше нужно покрыть тестами всю мелочевку — построение запроса таким образом, что бы получался рабочий паттерн
Отстой.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>·>Так "да" или "нет"? ·>Т.е. прямой вопрос ты опять игнорируешь и продолжаешь лить воду.
Зачем? Прямой ответ уже был даден. Раз вы продолжаете вопрошать, значит вам точно надо чтото другое. Играйте в свои игры без меня.
P>>Фаулер пишет, что он взял функции вместо классов. Это и есть его цель. А вы думаете, что он показывал, будто без моков нельзя ·>Ещё бы, ведь в js тупо нет классов.
Одно из двух — вы пользуетесь Internet Explorer или у вас апдейты Лялиха поломались еще в нулевых.
>Мой поинт в том, что моки это не про то как пишется код, функциями, классами или чёртом лысым, а про внешние зависимости. И никакой правильный дизайн от них не избавляет, т.к. зависимости диктуются требованиями, а не дизайном. Если у тебя есть субд, будут моки, как ни дизайни. Ну или если у тебя хоумпейдж, а там что угодно делай, не важно.
Зависимости — требованиями, а способ их протаскивания — дизайном. Соответственно, моки это обрезание тех зависимостей, которые вы же сами затолкали куда поглубже, да еще неглядя.
P>>Что раз Фаулер так делает, то иначе ну никак нельзя? ·>Нельзя. И ты ещё не показал, что можно.
Серьёзная логика. А еще Фаулер показал олдскульный жээс и вдвое большее количество кода, чем нужно, даже с его подходом.
Полагаю, вы щас начнете удваивать количество кода и возвращаться на 8ю джаву?
P>>Моки можно всунуть куда угодно, хоть для теста синусов и косинусов, — это ничего не говорит. ·>Ты говорил, что моки и это всё — это старьё из 00х. Как оказалось — и тут ты налажал, т.к. статья 2023 года имеет те же самые "устаревшие" моки.
Статья совсем про другое, о чем сам же Фаулер и пишет — про композицию функций. А вы там только моки видите.
P>>Именно это вы и говорите. Ну, как вариант, не читаете. ·>Ты нафантазировал "на реальной бд", а я писал "на бд близкой к боевой (только не по количеству записей, а по качеству)". Разницу не видишь, да?
Небольшая разница — Data complexity говорит о том, что вам не покрыть и ничтожной части вариантов вашими тестами.
P>>·>Есть, конечно. Например, изменяется транзакционность, согласованность, &c. Ты это даже не понимаешь, что это именно функциональность. P>> Согласованность, транзакционность, задержка — это всё НЕФУНКЦИОНАЛЬНЫЕ. ·>Как это? Возможность поизменять пользователя после его создания — это функциональное требование.
А так — в контроллере останется ровно то, что требуется для функциональных требований. А вот всё остальное вам придется распихивать, например, в ту же очередь. И вот такие изменения ломают и ваши моки, и тесты на них.
P>>Т.е., условно, вы выяснили, что не успеваете, опаньки! И надо выталкивать процессинг в очередь. Упс — написали тесты, покрыли моками, выбросили моки, переписали тесты, но уже на других моках, ой... ·>Это требует согласования с бизнесом, а не просто так, чтобы не было тех чудес как у тебя бывает.
Я так вижу, бизнес вам имена классов и названия методов диктует, да еще 100500 готовых тестов подкидывает.
P>>Интеграция начинается с момента, когда одна ваша функция вызывает другую вашу функцию. Конформационный тест требует запуска приложения или подсистемы, что автоматически означает интеграционный уровень. ·>Нет, конформационный тест не требует запуска приложения или системы. Читай мою переписку с Sinclair.
Вы наверное подумали, но забыли написать. Поиск по треду никаких пояснений, как вы используете конформационные тесты, не дал.
Могу рассказать, как это делается при реализации клиента под протокол — у вас есть 100500 эталонов на все случаи жизни, которые должен проглотить ваш клиент.
Ровно так же поступают и с компилятором — запускают и прогоняют 100500 примеров кода по спецификации.
Если вы сами пишете фильтры — а именно такую задачу я вам предложил, то это ваша ответсвенность учесть все возможные кейсы того, как хранятся и кодируются данные в бд — имена колонок, таблиц, строк, подстрок, кусков json, итд итд.
Фактически, вы пишете ни больше, ни меньше, а небольшой компилятор из json в sql. Только у вас нет этих самых эталонов — под вашу бд и придумки их никто не заготовил.
P>>В который раз объясняю. Нам нужны 2 условия(ДВА!) P>>1. рабочий паттерн запроса — это проверяется сначала руками, а потом тестом против бд минимально заполненой под задачу P>>2. рабочая схема построения такого паттерна P>>1 — необходимое условие P>>1 + 2 необходимое и достаточное ·>Я не знаю что ты в этом месте понимаешь под "паттерн", но я всегда имел в виду твой конкретный "const pattern =" вот тут
. Такой паттерн вручную прповерять — большая беда, надо тестировать с бд автоматически.
Похоже, вы что Фаулера, что меня, понимаете както слишком буквально. Я вам показал перевод из рабочего в минимально понятный здесь, вне контекста.
1. получили рабочий паттерн
2. строим маппер вокруг этого паттерна
п1 — паттерн тестируется на бд, далее — интеграционными тестами
п2 — построение запроса тестируется как все мапперы, без исключения
Без п2 вы спокойно напоретесь на кейс с уязвимостью, или поломкой на энкодинге данных, или с (не)подтягиванием данных из (не)тех таблиц
P>>- сервис или бд или сторадж требует эспейпить, энкодить, инлайнить, склеивать, подставлять итд и тд ·>Так это сервис требует, а не твоя бизнес-логика, это и будет конф-тест тестировать.
Подробнее — кто и где выдаст вам конф-тест, что запросы смогут внятн что работать с такими вещами — email в таблице users это сам емейл строкой, а email в таблице reply будет mailto:<email>, а в customer он будет в колонке типа json с названием поля 'details' который есть список имя-значение.
P>>Фильтр который вы пишете, это ровно такой же специализированый клиент. И тут, о чудо, можно обходиться без всех таких кейсов ·>Это будет код и тесты клиента для протокола, а не код бизнес-логики твеого приложения, которое этого клиента использует.
А разница то какая? Вы одну часть тестов назвали другим именем, от этого сложность поменялась?
P>>Где взять боевые данные за февраль 2025го? Вы в курсе, что сейчас 2024й год ? ·>Не знаю, ты рассказывай, ведь тебе требуется "Рабочий паттерн или нет — это проверяется на бд, в идеале, той, что содержит реальные данные". Рассказывай где-ты берёшь реальные данные за 2025 год для проверки работосбособности твоих паттернов.
Мне нужно всего лишь паттерн проверить, а не конечный запрос, как у вас. Потому мне в будущее заглядывать не надо, цитирую себя "тестом бд минимально заполненой под задачу"
P>>Я уже третий месяц рассказываю как именно это нужно тестировать. ·>Меня ответы "никак", "руками", "используя реальные данные за 2025 год" не устраивают. А с другими ответами ты не соглашаешься.
Смотрите внимательно — объяснение ниже я вам приводил уже около десятка раз
В который раз объясняю. Нам нужны 2 условия(ДВА!)
1. рабочий паттерн запроса — это проверяется сначала руками, а потом тестом против бд минимально заполненой под задачу
2. рабочая схема построения такого паттерна
1 — необходимое условие
1 + 2 необходимое и достаточное
P>>Работает ли паттерн корретно, и строится ли он корректно — это два множества вариантов которые всего лишь пересекаются. ·>Почему пересекаются? Каким образом некорректно построенный паттерн может работать корректно? Раз работает, значит построен.
Вот-вот. Вы здесь снова пишете, что не в курсе data complexity и объяснения Sinclair прошли мимо, и понимать это не хотите
·>Разница значительна: "Работает ли" — важно и нужно тестировать, инвариант диктуемый бизнесом, "строится ли" — это мелкие детали имплементации, которые меняются постоянно.
Вы что, не помните как в школе на математике или физике подгоняли решение под ответ? Правильный паттерн, некорректно построен, ответ верный — "Молодец, садись, два балла!".
Почему некорретно построеный паттерн дает корректный результат:
1. у вас нет данных на год вперёд, и половина базы вообще пустая.
2. у вас в бд только 1% частных случаев
3. вы думаете, что бд у вас заполнена верно, но реально это не так.
4. у вас в базе много данных, которые похожи друг на друга
Т.е. это те самые ошибки которые вы на тестах бд не увидите. Но они видны при построении запроса.
P>>А дальше нужно покрыть тестами всю мелочевку — построение запроса таким образом, что бы получался рабочий паттерн ·>Отстой.
Ну да, Фаулер пока не написал такую статью. Ждите еще 20 лет
Здравствуйте, Pauel, Вы писали:
P>·>Т.е. прямой вопрос ты опять игнорируешь и продолжаешь лить воду. P>Зачем? Прямой ответ уже был даден. Раз вы продолжаете вопрошать, значит вам точно надо чтото другое. Играйте в свои игры без меня.
Где?
>>Мой поинт в том, что моки это не про то как пишется код, функциями, классами или чёртом лысым, а про внешние зависимости. И никакой правильный дизайн от них не избавляет, т.к. зависимости диктуются требованиями, а не дизайном. Если у тебя есть субд, будут моки, как ни дизайни. Ну или если у тебя хоумпейдж, а там что угодно делай, не важно. P>Зависимости — требованиями, а способ их протаскивания — дизайном. Соответственно, моки это обрезание тех зависимостей, которые вы же сами затолкали куда поглубже, да еще неглядя.
Пофиг. Зависимости надо мокать. Точка. В этом твоём потоке речи единственный факт: "моки это обрезание зависимостей". А остальное — бессмысленные фантазии.
P>>>Что раз Фаулер так делает, то иначе ну никак нельзя? P>·>Нельзя. И ты ещё не показал, что можно. P>Серьёзная логика. А еще Фаулер показал олдскульный жээс и вдвое большее количество кода, чем нужно, даже с его подходом.
Серьёзная, да. Ни показать своё решение, ни улучшить чужое ты не можешь.
P>>>Моки можно всунуть куда угодно, хоть для теста синусов и косинусов, — это ничего не говорит. P>·>Ты говорил, что моки и это всё — это старьё из 00х. Как оказалось — и тут ты налажал, т.к. статья 2023 года имеет те же самые "устаревшие" моки. P>Статья совсем про другое, о чем сам же Фаулер и пишет — про композицию функций. А вы там только моки видите.
Ну покажи код без моков.
P>>>Именно это вы и говорите. Ну, как вариант, не читаете. P>·>Ты нафантазировал "на реальной бд", а я писал "на бд близкой к боевой (только не по количеству записей, а по качеству)". Разницу не видишь, да? P>Небольшая разница — Data complexity говорит о том, что вам не покрыть и ничтожной части вариантов вашими тестами.
Покажи пример кода.
P>>> Согласованность, транзакционность, задержка — это всё НЕФУНКЦИОНАЛЬНЫЕ. P>·>Как это? Возможность поизменять пользователя после его создания — это функциональное требование. P>А так — в контроллере останется ровно то, что требуется для функциональных требований. А вот всё остальное вам придется распихивать, например, в ту же очередь. И вот такие изменения ломают и ваши моки, и тесты на них.
Изменения ломают моки только если они изменяют функциональность.
P>>>Т.е., условно, вы выяснили, что не успеваете, опаньки! И надо выталкивать процессинг в очередь. Упс — написали тесты, покрыли моками, выбросили моки, переписали тесты, но уже на других моках, ой... P>·>Это требует согласования с бизнесом, а не просто так, чтобы не было тех чудес как у тебя бывает. P>Я так вижу, бизнес вам имена классов и названия методов диктует, да еще 100500 готовых тестов подкидывает.
Раньше после нажатия на кнопочку "создать" появлялась кнопочка "поменять" и она работала, но ты сделал очень такое "нефункциональное" изменение, и теперь эту кнопочку можно нажимать только через пять минут, а до этого какие-то невнятные ошибки. Молодец, чё, а юзерам всегда можно сказать "have you tried to turning it on and off again?". Зато тесты не сломались!
P>>>Интеграция начинается с момента, когда одна ваша функция вызывает другую вашу функцию. Конформационный тест требует запуска приложения или подсистемы, что автоматически означает интеграционный уровень. P>·>Нет, конформационный тест не требует запуска приложения или системы. Читай мою переписку с Sinclair. P>Вы наверное подумали, но забыли написать. Поиск по треду никаких пояснений, как вы используете конформационные тесты, не дал. Тут
.
P>Могу рассказать, как это делается при реализации клиента под протокол — у вас есть 100500 эталонов на все случаи жизни, которые должен проглотить ваш клиент. P>Ровно так же поступают и с компилятором — запускают и прогоняют 100500 примеров кода по спецификации.
Аналогом твоего решения будет тестировать, что функция createUser компилируется в конкретный ассемблерный код.
P>Если вы сами пишете фильтры — а именно такую задачу я вам предложил, то это ваша ответсвенность учесть все возможные кейсы того, как хранятся и кодируются данные в бд — имена колонок, таблиц, строк, подстрок, кусков json, итд итд. P>Фактически, вы пишете ни больше, ни меньше, а небольшой компилятор из json в sql. Только у вас нет этих самых эталонов — под вашу бд и придумки их никто не заготовил.
Вот я и не понимаю каким образом ты собираешься проверять, что этот самый sql выдаёт хоть какие-то правильные данные, а не > кто-то перепутал с < на какой-то комбинации входных данных. И не один раз "проверить" (а на самом деле скопипастить из реализации в тест) в процессе набора кода, но и для регрессии.
P>·>Я не знаю что ты в этом месте понимаешь под "паттерн", но я всегда имел в виду твой конкретный "const pattern =" вот тут
. Такой паттерн вручную прповерять — большая беда, надо тестировать с бд автоматически. P>Похоже, вы что Фаулера, что меня, понимаете както слишком буквально. Я вам показал перевод из рабочего в минимально понятный здесь, вне контекста.
Конечно, я ни телепатией, ни безграничной фантазией не обладаю. Что написано, то и читаю.
P>1. получили рабочий паттерн P>2. строим маппер вокруг этого паттерна
Что за маппер вокруг паттерна? У тебя маппер был частью паттерна как transformations: out:[fn1]
P>п1 — паттерн тестируется на бд, далее — интеграционными тестами
Тут два варианта:
Этих паттернов будут на каждый сценарий/юнит-тест. Т.е. кол-во ручного тестирования и и-тестов получается такое же. Следовательно смысла от таких тестов ноль.
Этих паттерны не будут покрываться интеграцией, а значит опечатки в тексте sql скопипасченные из реализации в тест и регрессии будут обнаруживаться только на проде юзерами.
P>п2 — построение запроса тестируется как все мапперы, без исключения P>Без п2 вы спокойно напоретесь на кейс с уязвимостью, или поломкой на энкодинге данных, или с (не)подтягиванием данных из (не)тех таблиц
У тебя что-то очень не то с дизайном, что у тебя какие-то технические детали с энкодингом данных намешаны с бизнес-логикой реализации сценариев.
P>>>- сервис или бд или сторадж требует эспейпить, энкодить, инлайнить, склеивать, подставлять итд и тд P>·>Так это сервис требует, а не твоя бизнес-логика, это и будет конф-тест тестировать. P>Подробнее — кто и где выдаст вам конф-тест, что запросы смогут внятн что работать с такими вещами — email в таблице users это сам емейл строкой, а email в таблице reply будет mailto:<email>, а в customer он будет в колонке типа json с названием поля 'details' который есть список имя-значение.
Я не понял что ты тут спрашиваешь. Какой ещё емейл?
P>>>Фильтр который вы пишете, это ровно такой же специализированый клиент. И тут, о чудо, можно обходиться без всех таких кейсов P>·>Это будет код и тесты клиента для протокола, а не код бизнес-логики твеого приложения, которое этого клиента использует. P>А разница то какая? Вы одну часть тестов назвали другим именем, от этого сложность поменялась?
Поменялась, т.к. отделили мух от котлет. И вместо умножения комбинаций, мы тестируем их сумму.
Т.е. правила енкодинга определяются для типов данных, например, в строках надо non-ascii енкодить. А бизнес-логика работает со значениниями. И все значения firstname/lastname/&c это строки, енкодинг которых уже покрыт. И не надо отдельно проверять что каждое поле правильно енкодится.
P>>>Где взять боевые данные за февраль 2025го? Вы в курсе, что сейчас 2024й год ? P>·>Не знаю, ты рассказывай, ведь тебе требуется "Рабочий паттерн или нет — это проверяется на бд, в идеале, той, что содержит реальные данные". Рассказывай где-ты берёшь реальные данные за 2025 год для проверки работосбособности твоих паттернов. P>Мне нужно всего лишь паттерн проверить,
А как ты его проверишь-то?
P>а не конечный запрос, как у вас. Потому мне в будущее заглядывать не надо, цитирую себя "тестом бд минимально заполненой под задачу"
Ты уже запамятовал? Ты показывал код, где у тебя в паттерне был конечный запрос.
P>>>Я уже третий месяц рассказываю как именно это нужно тестировать. P>·>Меня ответы "никак", "руками", "используя реальные данные за 2025 год" не устраивают. А с другими ответами ты не соглашаешься.
P>Смотрите внимательно — объяснение ниже я вам приводил уже около десятка раз
Это всё вода. Ты показал конкретный код, я указал в этом конкретном коде конкретную проблему. Ты теперь заявляешь что что-то мне объяснял. Без кода объяснения идут в топку. Я никогда не просил ничего объяснять, я просил показать код.
P>·>Разница значительна: "Работает ли" — важно и нужно тестировать, инвариант диктуемый бизнесом, "строится ли" — это мелкие детали имплементации, которые меняются постоянно. P>Вы что, не помните как в школе на математике или физике подгоняли решение под ответ? Правильный паттерн, некорректно построен, ответ верный — "Молодец, садись, два балла!".
Мы говорим о тестах. В коде теста есть паттерн который туда кто-то как-то напечатал, хз как. Ты так и не рассказал как убедиться что этот самый код корректный. "погонять запрос вручную в sql-консоли" — это был твой лучший ответ. И этот ответ сильно хуже моего ответа "погонять запрос автоматически". Так что ты опять занялся софизмами.
P>Т.е. это те самые ошибки которые вы на тестах бд не увидите. Но они видны при построении запроса.
Как они видны-то? Где что красненьким подчеркнётся?
P>>>А дальше нужно покрыть тестами всю мелочевку — построение запроса таким образом, что бы получался рабочий паттерн P>·>Отстой. P>Ну да, Фаулер пока не написал такую статью. Ждите еще 20 лет
А вы тестируйте в проде.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
>>>Мой поинт в том, что моки это не про то как пишется код, функциями, классами или чёртом лысым, а про внешние зависимости. И никакой правильный дизайн от них не избавляет, т.к. зависимости диктуются требованиями, а не дизайном. Если у тебя есть субд, будут моки, как ни дизайни. Ну или если у тебя хоумпейдж, а там что угодно делай, не важно. P>>Зависимости — требованиями, а способ их протаскивания — дизайном. Соответственно, моки это обрезание тех зависимостей, которые вы же сами затолкали куда поглубже, да еще неглядя. ·>Пофиг. Зависимости надо мокать. Точка. В этом твоём потоке речи единственный факт: "моки это обрезание зависимостей". А остальное — бессмысленные фантазии.
Вы раз за разом повторяете что верите в моки. Зачем? Это ж не аргумент, зато выглядит смешно.
Зависимости нужно учитывать в тестах
1. классический — убираем их целиком, что есть особенность дизайна
2. моки — собственно, пишем моки, код можно писать как попало
В первом случае у нас приложение будет похоже вот на такой слоеный пирог, где 0 это точка отсчета
3 - контроллер - линейный код
2 - use case - именно здесь вызывается DB, этот код делаем максимально линейным
1 - BL - чистая
0 - модель - чистая
Второй вариант, ваш любимый
3 - контроллер
1 - BL грязная, DTO и есть наша модель, вызывает DB или напрямую DAL, или через ваши репозитории, итд, что требует инжекции
0 - DB
P>>Серьёзная логика. А еще Фаулер показал олдскульный жээс и вдвое большее количество кода, чем нужно, даже с его подходом. ·>Серьёзная, да. Ни показать своё решение, ни улучшить чужое ты не можешь.
Я вам уже много раз предлагал посмотреть clean architecture, глянуть, как там работают с бд. Вы хотите что бы я все это пересказал вам здесь?
P>>А так — в контроллере останется ровно то, что требуется для функциональных требований. А вот всё остальное вам придется распихивать, например, в ту же очередь. И вот такие изменения ломают и ваши моки, и тесты на них. ·>Изменения ломают моки только если они изменяют функциональность.
У вас функциональность это весьма расплывчатое понятие. Туда разве что каменты не входят. Или входят?
·>Раньше после нажатия на кнопочку "создать" появлялась кнопочка "поменять" и она работала, но ты сделал очень такое "нефункциональное" изменение, и теперь эту кнопочку можно нажимать только через пять минут, а до этого какие-то невнятные ошибки. Молодец, чё, а юзерам всегда можно сказать "have you tried to turning it on and off again?". Зато тесты не сломались!
Кто вам такое сказал? Вам нужно редактировать не все отношения юзера, а только user-facing. Все остальное вы вас не заботит.
P>>Вы наверное подумали, но забыли написать. Поиск по треду никаких пояснений, как вы используете конформационные тесты, не дал. ·>Тут
нами был напилен набор интеграционных тестов, которые гонялись в каждом acceptance. И мы чаще всего ловили там не глюки нашего софта (которые были отловлены юнит-тестами), а регрессию со стороны Microsoft .
S>Было всего несколько случаев, когда поведение API было не таким, как мы ожидали, и это не было признано багом.
Это называется conformance tests.
То есть, здесь вы назвали интеграционные тесты conformance.
Если вы все еще не согласны — объясните внятно
1 кто пишет эти conformance tests
2 какой код должен выполниться, что бы пройти эти тесты
Ощущение, что вы путаете вид тестов и уровень. Уровень — сколько строк, компонентов, ид задействуется при тесте — юниты, и интеграционные, куда относятся компоненты, функциональные, приложение, система.
Вид — контрактные, конформанс, пенетрейшн, перформанс, e2e, на моках, без моков, приемочные, итд
Конформанс — интеграционные. По определению.
P>>Ровно так же поступают и с компилятором — запускают и прогоняют 100500 примеров кода по спецификации. ·>Аналогом твоего решения будет тестировать, что функция createUser компилируется в конкретный ассемблерный код.
Незачем — у нас трансляция json -> sql.
P>>Фактически, вы пишете ни больше, ни меньше, а небольшой компилятор из json в sql. Только у вас нет этих самых эталонов — под вашу бд и придумки их никто не заготовил. ·>Вот я и не понимаю каким образом ты собираешься проверять, что этот самый sql выдаёт хоть какие-то правильные данные, а не > кто-то перепутал с < на какой-то комбинации входных данных. И не один раз "проверить" (а на самом деле скопипастить из реализации в тест) в процессе набора кода, но и для регрессии.
Я ж вам объяснил раз пять
1. находим паттерн и проверяем его
2. пишем маппер вокруг паттерна и проверяем маппер
Нам нужны и 1 и 2.
Если 1 без 2, то всё в порядке — запрос работает на тестовых данных, но в проде вгружает всю БД в память, потому что подстановки параметров работают только для тестов
Если 2 без 1, то хер его знает, что там делается вообще
А если и 1, и 2, то
1. благодаря правильному паттерну у нас рабочая схема
2. благодаря 2 у нас правильные подстановки в этот паттерн
P>>1. получили рабочий паттерн P>>2. строим маппер вокруг этого паттерна ·>Что за маппер вокруг паттерна? У тебя маппер был частью паттерна как transformations: out:[fn1]
А название таблицы само выросло, да? Подстановка параметров, условий, названий колонок, таблиц, подстановка fn1 и fn2 тоже само? Это именно работа маппера — по json получить рабочий запрос, который будет соответствовать нашим ожиданиям
Это нужно на тот случай, если некто решит сделать "быстрый маленький фикс" после того, как вы уволитесь и контролировать код перестанете
·>Этих паттернов будут на каждый сценарий/юнит-тест. Т.е. кол-во ручного тестирования и и-тестов получается такое же. Следовательно смысла от таких тестов ноль.
В вашей схеме ровно так же. Только вы построение запроса никак не контролируете.
·>Этих паттерны не будут покрываться интеграцией, а значит опечатки в тексте sql скопипасченные из реализации в тест и регрессии будут обнаруживаться только на проде юзерами.
Вы в адеквате? Я ж сказал — интеграционные тесты никуда не деваются. А вы читаете чтото своё.
P>>п2 — построение запроса тестируется как все мапперы, без исключения P>>Без п2 вы спокойно напоретесь на кейс с уязвимостью, или поломкой на энкодинге данных, или с (не)подтягиванием данных из (не)тех таблиц ·>У тебя что-то очень не то с дизайном, что у тебя какие-то технические детали с энкодингом данных намешаны с бизнес-логикой реализации сценариев.
Причин сломать построение запроса при валидном паттерне — огромной количество — например, пупутать названия таблиц, колонок, приоритет операторов итд и тди итд.
P>>Подробнее — кто и где выдаст вам конф-тест, что запросы смогут внятн что работать с такими вещами — email в таблице users это сам емейл строкой, а email в таблице reply будет mailto:<email>, а в customer он будет в колонке типа json с названием поля 'details' который есть список имя-значение. ·>Я не понял что ты тут спрашиваешь. Какой ещё емейл?
Я вам пример привел, что построение запроса по json должно учитывать схему бд. Вот это и проверяем. В каких то случаях невалидный запрос может выдавать данные очень похожие на правильные, и это вполне себе реальная проблема.
·>Т.е. правила енкодинга определяются для типов данных, например, в строках надо non-ascii енкодить. А бизнес-логика работает со значениниями. И все значения firstname/lastname/&c это строки, енкодинг которых уже покрыт. И не надо отдельно проверять что каждое поле правильно енкодится.
Кто будет проверять, что email может энкодиться десятком способов в вашей бд? Подробнее. Ну вот досталось вам от предшественника такое. Ваши действия?
·>А как ты его проверишь-то?
Примерно так же, как и вы. Только проверка паттерна мало что гарантирует. См выше про загрузку всей бд в память. Паттерн корректный, ошибочка при рендеринге некоторых комбинаций фильтров.
P>>а не конечный запрос, как у вас. Потому мне в будущее заглядывать не надо, цитирую себя "тестом бд минимально заполненой под задачу" ·>Ты уже запамятовал? Ты показывал код, где у тебя в паттерне был конечный запрос.
Это выхлоп билдера запросов. не рукописный sql, а результат билдера. Соответсвенно, мы можем проверить работу сложного маппера json -> sql, при чем гораздо плотнее, чем вашими косвенными тестами.
Например, я могу просто заложиться на юнит-тест, и потребовать двойную фильтрацию — первая по периоду, вторая — по параметрам, или вставить limit x, итд итд
И у меня точно не будет кейса "вгружаем всю бд в память".
Даже если в интеграционных тестах у меня не будет 100_000_000_000 записей, ничего страшного — запрос всё равно будет с безопасной структурой.
P>>Смотрите внимательно — объяснение ниже я вам приводил уже около десятка раз ·>Это всё вода. Ты показал конкретный код, я указал в этом конкретном коде конкретную проблему. Ты теперь заявляешь что что-то мне объяснял. Без кода объяснения идут в топку. Я никогда не просил ничего объяснять, я просил показать код.
Правильнее сказать, что вам непонятно, почему ваш подход не будет работать, а мой — будет.
Ваш никак не учитывает data complexity. Мой — именно на этом и строится, см пример выше про 100_000_000_000 записей.
Т.е. мне нужно
1. быть в курсе про возможную проблему с загрузкой конской таблицы из за ошибок в построении фильтров
2. найти решение
3. зафиксировать теми тестами, которые вам кажутся лишними
А вот вы так и не показали тест "никогда не будем загружать всю бд в память". Вы показали другой совсем другой тест — загрузим 1, если только что записали 1.
·>Мы говорим о тестах. В коде теста есть паттерн который туда кто-то как-то напечатал, хз как. Ты так и не рассказал как убедиться что этот самый код корректный. "погонять запрос вручную в sql-консоли" — это был твой лучший ответ.
Читаем вместе:
п1 — паттерн тестируется на бд, далее — интеграционными тестами
Сколько бы я ни писал про интеграционные тесты, вам мерещится "погонять вручную"
Это какая то особенность вашего восприятия
·>Как они видны-то? Где что красненьким подчеркнётся?
См выше, "никогда не будем загружать всю бд в память" — для этого кейса у вас ни одного теста, а у меня хоть какие то.
Здравствуйте, Pauel, Вы писали:
>>>>Мой поинт в том, что моки это не про то как пишется код, функциями, классами или чёртом лысым, а про внешние зависимости. И никакой правильный дизайн от них не избавляет, т.к. зависимости диктуются требованиями, а не дизайном. Если у тебя есть субд, будут моки, как ни дизайни. Ну или если у тебя хоумпейдж, а там что угодно делай, не важно. P>>>Зависимости — требованиями, а способ их протаскивания — дизайном. Соответственно, моки это обрезание тех зависимостей, которые вы же сами затолкали куда поглубже, да еще неглядя. P>·>Пофиг. Зависимости надо мокать. Точка. В этом твоём потоке речи единственный факт: "моки это обрезание зависимостей". А остальное — бессмысленные фантазии. P>Вы раз за разом повторяете что верите в моки. Зачем? Это ж не аргумент, зато выглядит смешно.
Без моков внешних зависимостей ты не можешь тестировать свой код если эта самая зависимость по разным причинам недоступна.
P>>>Серьёзная логика. А еще Фаулер показал олдскульный жээс и вдвое большее количество кода, чем нужно, даже с его подходом. P>·>Серьёзная, да. Ни показать своё решение, ни улучшить чужое ты не можешь. P>Я вам уже много раз предлагал посмотреть clean architecture, глянуть, как там работают с бд. Вы хотите что бы я все это пересказал вам здесь?
Нет, я хочу чтобы ты код показал.
P>·>Раньше после нажатия на кнопочку "создать" появлялась кнопочка "поменять" и она работала, но ты сделал очень такое "нефункциональное" изменение, и теперь эту кнопочку можно нажимать только через пять минут, а до этого какие-то невнятные ошибки. Молодец, чё, а юзерам всегда можно сказать "have you tried to turning it on and off again?". Зато тесты не сломались! P>Кто вам такое сказал? Вам нужно редактировать не все отношения юзера, а только user-facing. Все остальное вы вас не заботит.
Не распарсил.
P>То есть, здесь вы назвали интеграционные тесты conformance.
Наверное я плохо выразился, я не назвал, я возразил, что такие вещи надо не интеграционными тестами тестировать а конформационными, иначе будет беда с процессом релиза когда внешние система(ы) недоступны. Цитирую: "мы можем пройти acceptance для нашего проекта только в момент когда _все_ внешние тестовые системы работают".
У Sinclair был тривиальнейший случай "когда мы работали с CREST API от Microsoft". Т.е. внешняя зависимость одна и от более-менее надёжного вендора, у которого обычно всё работает. В более-менее больших сложных проектах такой халявы не бывает.
P>Если вы все еще не согласны — объясните внятно P>1 кто пишет эти conformance tests
Мы.
P>2 какой код должен выполниться, что бы пройти эти тесты
Код этих тестов. Поднимать само приложение для этого не нужно. Никакой интеграции. Цитирую: "Conformance tests можно гонять независимо от наших релизов".
P>>>Ровно так же поступают и с компилятором — запускают и прогоняют 100500 примеров кода по спецификации. P>·>Аналогом твоего решения будет тестировать, что функция createUser компилируется в конкретный ассемблерный код. P>Незачем — у нас трансляция json -> sql.
Опять у тебя мешанина. Тогда это будет метод translateJsonToSql , а не бизнес-специфичный createUser. Тесты createUser должны тестировать создание юзера, а не трансляцию json.
P>>>Фактически, вы пишете ни больше, ни меньше, а небольшой компилятор из json в sql. Только у вас нет этих самых эталонов — под вашу бд и придумки их никто не заготовил. P>·>Вот я и не понимаю каким образом ты собираешься проверять, что этот самый sql выдаёт хоть какие-то правильные данные, а не > кто-то перепутал с < на какой-то комбинации входных данных. И не один раз "проверить" (а на самом деле скопипастить из реализации в тест) в процессе набора кода, но и для регрессии. P>Я ж вам объяснил раз пять P>1. находим паттерн и проверяем его
Где находим? Как проверяем? Когда проверяем?
P>1. благодаря правильному паттерну у нас рабочая схема P>2. благодаря 2 у нас правильные подстановки в этот паттерн
Я не понял детали. Код покажи.
P>·>Что за маппер вокруг паттерна? У тебя маппер был частью паттерна как transformations: out:[fn1] P>А название таблицы само выросло, да? Подстановка параметров, условий, названий колонок, таблиц, подстановка fn1 и fn2 тоже само? Это именно работа маппера — по json получить рабочий запрос, который будет соответствовать нашим ожиданиям P>Это нужно на тот случай, если некто решит сделать "быстрый маленький фикс" после того, как вы уволитесь и контролировать код перестанете
Да ты меня запутал. Была и трансляция, и трансформация, и маппер, и паттерн, и ещё чего. Я уже перестал понимать кто на ком стоял.
P>·>Этих паттернов будут на каждый сценарий/юнит-тест. Т.е. кол-во ручного тестирования и и-тестов получается такое же. Следовательно смысла от таких тестов ноль. P>В вашей схеме ровно так же. Только вы построение запроса никак не контролируете.
Не правда, что ровно так же. Ручное тестирование исключается, т.к. есть тесты репо+бд. А построение не контролирую, потому что считаю что запрос не важно как строится, т.к. это детали реализации, важно что запрос работает в соответствии с бизнес-ожиданиями. Конкретный пример когда это не сработает я так и не увидел.
P>·>Этих паттерны не будут покрываться интеграцией, а значит опечатки в тексте sql скопипасченные из реализации в тест и регрессии будут обнаруживаться только на проде юзерами. P>Вы в адеквате? Я ж сказал — интеграционные тесты никуда не деваются. А вы читаете чтото своё.
Не деваются, но такие тесты которые ты имеешь в виду (проверяющие интеграцию в контроллере всего со всем) не могут покрыть все возможные комбинации.
В моей схеме будут тесты репо+бд, которые тестируют только часть системы, относящуюся к персистенсу.
P>>>п2 — построение запроса тестируется как все мапперы, без исключения P>>>Без п2 вы спокойно напоретесь на кейс с уязвимостью, или поломкой на энкодинге данных, или с (не)подтягиванием данных из (не)тех таблиц P>·>У тебя что-то очень не то с дизайном, что у тебя какие-то технические детали с энкодингом данных намешаны с бизнес-логикой реализации сценариев. P>Причин сломать построение запроса при валидном паттерне — огромной количество — например, пупутать названия таблиц, колонок, приоритет операторов итд и тди итд.
Именно, для этого и нужны тесты репо+бд. А при наличии таких тестов писать тесты ещё и на построение запросов — неясно зачем.
P>·>Я не понял что ты тут спрашиваешь. Какой ещё емейл? P>Я вам пример привел, что построение запроса по json должно учитывать схему бд. Вот это и проверяем. В каких то случаях невалидный запрос может выдавать данные очень похожие на правильные, и это вполне себе реальная проблема.
Ты так и не рассказал как _тестировать_ валидность запроса. Сравнение с твоим pattern ничего о валидности не говорит.
P>·>Т.е. правила енкодинга определяются для типов данных, например, в строках надо non-ascii енкодить. А бизнес-логика работает со значениниями. И все значения firstname/lastname/&c это строки, енкодинг которых уже покрыт. И не надо отдельно проверять что каждое поле правильно енкодится. P>Кто будет проверять, что email может энкодиться десятком способов в вашей бд? Подробнее. Ну вот досталось вам от предшественника такое. Ваши действия?
В смысле "действия"? Тестами покрывать что есть — разбираться какие способы существуют в легаси и воспроизводить в тестах. И потом потихоньку мигрировать легаси, например.
P>·>А как ты его проверишь-то? P>Примерно так же, как и вы. Только проверка паттерна мало что гарантирует. См выше про загрузку всей бд в память. Паттерн корректный, ошибочка при рендеринге некоторых комбинаций фильтров.
Я до сих пор не понимаю почему у тебя есть проблема с загрузкой всей бд в память, решается же элементарно.
P>>>а не конечный запрос, как у вас. Потому мне в будущее заглядывать не надо, цитирую себя "тестом бд минимально заполненой под задачу" P>·>Ты уже запамятовал? Ты показывал код, где у тебя в паттерне был конечный запрос. P>Это выхлоп билдера запросов. не рукописный sql, а результат билдера. Соответсвенно, мы можем проверить работу сложного маппера json -> sql, при чем гораздо плотнее, чем вашими косвенными тестами. P>Например, я могу просто заложиться на юнит-тест, и потребовать двойную фильтрацию — первая по периоду, вторая — по параметрам, или вставить limit x, итд итд P>И у меня точно не будет кейса "вгружаем всю бд в память". P>Даже если в интеграционных тестах у меня не будет 100_000_000_000 записей, ничего страшного — запрос всё равно будет с безопасной структурой.
Как ты отличишь в тесте запрос с безопасной структурой от запроса с небезопасной?
P>>>Смотрите внимательно — объяснение ниже я вам приводил уже около десятка раз P>·>Это всё вода. Ты показал конкретный код, я указал в этом конкретном коде конкретную проблему. Ты теперь заявляешь что что-то мне объяснял. Без кода объяснения идут в топку. Я никогда не просил ничего объяснять, я просил показать код. P>Правильнее сказать, что вам непонятно, почему ваш подход не будет работать, а мой — будет.
Ага, это я давно пытаюсь из тебя выудить. И в виде кода, а не вилами по воде.
P>Ваш никак не учитывает data complexity. Мой — именно на этом и строится, см пример выше про 100_000_000_000 записей.
Бла-бла-бла.
P>Т.е. мне нужно P>1. быть в курсе про возможную проблему с загрузкой конской таблицы из за ошибок в построении фильтров P>2. найти решение P>3. зафиксировать теми тестами, которые вам кажутся лишними
Если у тебя не получается это зафиксировать это нормальными тестами, то создай новый топик, поможем, не бином ньютона.
P>А вот вы так и не показали тест "никогда не будем загружать всю бд в память".
Ты тоже такой тест не показал.
P> Вы показали другой совсем другой тест — загрузим 1, если только что записали 1.
Я такой тест не показывал.
P>·>Мы говорим о тестах. В коде теста есть паттерн который туда кто-то как-то напечатал, хз как. Ты так и не рассказал как убедиться что этот самый код корректный. "погонять запрос вручную в sql-консоли" — это был твой лучший ответ. P>Читаем вместе: P>
P>п1 — паттерн тестируется на бд, далее — интеграционными тестами
Где? Как? Напомню, у тебя было: deep.eq(pattern). В каком тут месте "тестируется на бд"?
P>Сколько бы я ни писал про интеграционные тесты, вам мерещится "погонять вручную"
У тебя интеграционные тесты тестируют каждый паттерн?
P>Это какая то особенность вашего восприятия
Я воспринимаю то что написано, а не фантазирую.
P>·>Как они видны-то? Где что красненьким подчеркнётся? P>См выше, "никогда не будем загружать всю бд в память" — для этого кейса у вас ни одного теста, а у меня хоть какие то.
Ну потому что ты "1. был в курсе" и написал хоть какой-то тест. Т.е. они были не видны, как ты обещал, а у вас видимо на проде у вас что-то навернулось и ты это "увидел".
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, Sinclair, Вы писали:
S>Теперь остаётся всё это склеить. Риск при склейке минимален — просто потому, что в ней очень мало кода:
S>DateTime.now()
S> .GetReportDateRange()
...
S>Я не отказываю этому коду в шансе содержать ошибку — действительно, мы могли напороть примерно везде.
По-моему я не донёс эту мысль. Да, совершенно верно: "Риск при склейке минимален — просто потому, что в ней очень мало кода". Настоящая проблема в том, что тут у нас как правило не одна "плохая зависимость" как DateTime.now(); и этот код склейки будет в каждой мелкой бизнес-операции приложения. Т.е. в каждом контроллере мало кода, да, но в реальной большой системе зависимостей будет больше, контроллеров сотни-тысячи, этот "минимальный риск" надо возводить в тысячную степень и ВНЕЗАПНО риск получается серьёзным, и тестами прикрыть себе пятую точку не выйдет, т.к. "DateTime.now()" не тестируемо.
Суть всех этих модулей, слоёв, composition root, &c — минимизировать общее количество такого кода склейки. И максимизировать покрытие тестами в том числе и кода склейки.
S>Такие вещи ловятся интеграционным тестированием, которое один хрен нужно проводить.
А что ты в таком тесте, зависящем от DateTime.now() (и ещё пачки внешних зависимостей в неизвестном тесту состоянии) будешь ассертить? Ведь каждый раз у тебя будут выдаваться потенциально совершенно разные результаты. Ну выдался отчёт с 0 строк — тест пройден или как?
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>Вы раз за разом повторяете что верите в моки. Зачем? Это ж не аргумент, зато выглядит смешно. ·>Без моков внешних зависимостей ты не можешь тестировать свой код если эта самая зависимость по разным причинам недоступна.
Слишком категорично. Правильно так — часть тестов прогнать не получится. Соответсвенно в моки можно выносить не вообще всё, а только такие кейсы, без которых ну никак нельзя.
P>>Я вам уже много раз предлагал посмотреть clean architecture, глянуть, как там работают с бд. Вы хотите что бы я все это пересказал вам здесь? ·>Нет, я хочу чтобы ты код показал.
Это и есть пересказ всего, что изложено в clean architecture. Я уже приводил пример, вы прицепились к проверке sql и до сих пор успокоиться не можете.
Какой смысл приводить еще один пример, если вы еще на предыдущий продолжаете наскакивать?
P>>Кто вам такое сказал? Вам нужно редактировать не все отношения юзера, а только user-facing. Все остальное вы вас не заботит. ·>Не распарсил.
Очень просто — редактироавние после записи нужно для конкретных целей, например — что бы администратор мог подправить свойства только что созданного юзера, а не ждать пять минут.
Соответсвенно, в самом запросе мы обеспечиваем ровно этот минимум, а вообще всё, включая паблик кей спейса юзера
Если ваш бизнес аналиитк затребовал вообще всё такое — то вы приплыли.
P>>То есть,в т здесь вы назвали интеграционные тесты conformance. ·>Наверное я плохо выразился, я не назвал, я возразил, что такие вещи надо не интеграционными тестами тестировать а конформационными, иначе будет беда с процессом релиза когда внешние система(ы) недоступны. Цитирую: "мы можем пройти acceptance для нашего проекта только в момент когда _все_ внешние тестовые системы работают".
А как понять из ваших конформационных тестов, что ваши фильтры не будут вгружать вообще всё из вашей же местной бд?
P>>Если вы все еще не согласны — объясните внятно P>>1 кто пишет эти conformance tests ·>Мы.
P>>2 какой код должен выполниться, что бы пройти эти тесты ·>Код этих тестов. Поднимать само приложение для этого не нужно. Никакой интеграции. Цитирую: "Conformance tests можно гонять независимо от наших релизов".
Непонятно. Это вы тестируете внешние зависимости что ли? Непонятно. Как это к задаче с фильтрами относится?
P>>Незачем — у нас трансляция json -> sql. ·>Опять у тебя мешанина. Тогда это будет метод translateJsonToSql , а не бизнес-специфичный createUser. Тесты createUser должны тестировать создание юзера, а не трансляцию json.
Совсем необязательно. Частный случай маппера проще написать, проще протестировать. обобщенный translateJsonToSql это забег на месяцы или даже годы. Соответсвенно, наш маппер будет просто выдавать запрос createUser, в том виде, как требуется под именно эту задачу
1. все маппинги, с учетом всех дикостей схемы и бд
2. параметры
3. выражение, приоритеты
4. и энкодинг, без этого никуда
В вашем случае вы 1, 2, 3 и 4 будете проверять косвенными тестами, которые заведомо дырявые.
P>>Я ж вам объяснил раз пять P>>1. находим паттерн и проверяем его ·>Где находим? Как проверяем? Когда проверяем?
Извините, но вам стоит читать внимательнее. Я последее время слишком часто цитирую самого себя. Не можете удерживать контекст — чего вам неймется, "в интернете ктото неправ"?
P>>1. благодаря правильному паттерну у нас рабочая схема P>>2. благодаря 2 у нас правильные подстановки в этот паттерн ·>Я не понял детали. Код покажи.
Все код был даден, отмотайте и посмотрите, это всё та же структурная эквивалентность запроса к бд.
P>>Это нужно на тот случай, если некто решит сделать "быстрый маленький фикс" после того, как вы уволитесь и контролировать код перестанете ·>Да ты меня запутал. Была и трансляция, и трансформация, и маппер, и паттерн, и ещё чего. Я уже перестал понимать кто на ком стоял.
маппер — по json строит конкретный запрос, createUser
паттерн — основа этого запроса
трансформация — часть маппера, трансформируем json в нужный нам вид, на выходе — делаем обратное преобразование.
P>>В вашей схеме ровно так же. Только вы построение запроса никак не контролируете. ·>Не правда, что ровно так же. Ручное тестирование исключается, т.к. есть тесты репо+бд. А построение не контролирую, потому что считаю что запрос не важно как строится, т.к. это детали реализации, важно что запрос работает в соответствии с бизнес-ожиданиями. Конкретный пример когда это не сработает я так и не увидел.
Я вам продолжаю приводить тот же самый пример — фильтры, когда из за ошибки в построении запроса вгружается вся бд. Вы его усиленно игнорируете.
P>>Вы в адеквате? Я ж сказал — интеграционные тесты никуда не деваются. А вы читаете чтото своё. ·>Не деваются, но такие тесты которые ты имеешь в виду (проверяющие интеграцию в контроллере всего со всем) не могут покрыть все возможные комбинации.
Зато sql в этих тестах как раз так выполняется, и проходит тот самый чек, что и у вас.
А раз покрыть все комбинации не получится, то незачем и пытаться — нужно переложить критические кейсы на другие методы.
·>В моей схеме будут тесты репо+бд, которые тестируют только часть системы, относящуюся к персистенсу.
И как вы протестируете, что у вас невозможна ситуация, что прод вгружает вообще всё?
P>>Причин сломать построение запроса при валидном паттерне — огромной количество — например, пупутать названия таблиц, колонок, приоритет операторов итд и тди итд. ·>Именно, для этого и нужны тесты репо+бд. А при наличии таких тестов писать тесты ещё и на построение запросов — неясно зачем.
Я ж вам говорил — некорректный запрос в тестах может выдавать корректный результат. И примеры привел.
·>Ты так и не рассказал как _тестировать_ валидность запроса. Сравнение с твоим pattern ничего о валидности не говорит.
Валидность вообще всех запросов проверить не выйдет — та самая data complexity. Зато можно проверить известные проблемы для тех случаев, когда точная комбинация входа неизвестна.
P>>Кто будет проверять, что email может энкодиться десятком способов в вашей бд? Подробнее. Ну вот досталось вам от предшественника такое. Ваши действия? ·>В смысле "действия"? Тестами покрывать что есть — разбираться какие способы существуют в легаси и воспроизводить в тестах. И потом потихоньку мигрировать легаси, например.
Это значит, что вам нужно каждый такой кейс или через базу гонять, или же написать маппер, который можно дополнительно покрыть тестами, где учтем все возможные кейсы что есть в бд прода, или нам известно, что такие будут.
P>>Примерно так же, как и вы. Только проверка паттерна мало что гарантирует. См выше про загрузку всей бд в память. Паттерн корректный, ошибочка при рендеринге некоторых комбинаций фильтров. ·>Я до сих пор не понимаю почему у тебя есть проблема с загрузкой всей бд в память, решается же элементарно.
Вы до сих пор не показали решения. Комбинация параметров вам неизвестна. Действуйте.
P>>Даже если в интеграционных тестах у меня не будет 100_000_000_000 записей, ничего страшного — запрос всё равно будет с безопасной структурой. ·>Как ты отличишь в тесте запрос с безопасной структурой от запроса с небезопасной?
В зависимости от задачи. Например — двойная фильтрация. Часть фильтров в самом запросе, ограничивают выборку, не параметризуются, часть — параметры для фильтрации оставшегося.
Теперь что бы вы не подкидывали в фильтр, у вас никогда не будет кейса "вгрузить всё"
P>>А вот вы так и не показали тест "никогда не будем загружать всю бд в память". ·>Ты тоже такой тест не показал.
Тест — показал, только вы его понять не можете.
P>> Вы показали другой совсем другой тест — загрузим 1, если только что записали 1. ·>Я такой тест не показывал.
Это именно ваш подход — записать три значения в бд и надеяться что этого хватит. А как протестировать "запрос не тащит откуда не надо" вы не показали.
P>>Читаем вместе: P>>
P>>п1 — паттерн тестируется на бд, далее — интеграционными тестами
·>Где? Как? Напомню, у тебя было: deep.eq(pattern). В каком тут месте "тестируется на бд"?
Вы дурака валяете? deep.eq.pattern это тест для п2. Тесты для п1 — обычные интеграционные.
P>>Сколько бы я ни писал про интеграционные тесты, вам мерещится "погонять вручную" ·>У тебя интеграционные тесты тестируют каждый паттерн?
По числу юз кейсов. Все юз кейсы должны быть покрыты интеграционными тестами.
P>>См выше, "никогда не будем загружать всю бд в память" — для этого кейса у вас ни одного теста, а у меня хоть какие то. ·>Ну потому что ты "1. был в курсе" и написал хоть какой-то тест. Т.е. они были не видны, как ты обещал, а у вас видимо на проде у вас что-то навернулось и ты это "увидел".
Покрыть все возможные комбинации фильтров тестом с бд — нереально. Вы можете покрыть ну 5, ну 10, ну 50, но если у вас фильтров на страницу — вы ошалеете. Здесь забег на тысячи комбинаций.
На каждую комбинацию накидать минимальную бд — уже мало реально.
Особенно что нужно проверять и кейсы "не тащим откуда не надо"
Т.е. каждая комбинация это тесты вида "тащим откуда надо" + тесты вида "не тащим откуда не надо" коих много больше.
Здравствуйте, Pauel, Вы писали:
P>>>Вы раз за разом повторяете что верите в моки. Зачем? Это ж не аргумент, зато выглядит смешно. P>·>Без моков внешних зависимостей ты не можешь тестировать свой код если эта самая зависимость по разным причинам недоступна. P>Слишком категорично. Правильно так — часть тестов прогнать не получится. Соответсвенно в моки можно выносить не вообще всё, а только такие кейсы, без которых ну никак нельзя.
Всё верно, в этом и мой поинт. Про то, что в моки нужно выносить всё — это ты сам придумал.
P>>>Я вам уже много раз предлагал посмотреть clean architecture, глянуть, как там работают с бд. Вы хотите что бы я все это пересказал вам здесь? P>·>Нет, я хочу чтобы ты код показал. P>Это и есть пересказ всего, что изложено в clean architecture. Я уже приводил пример, вы прицепились к проверке sql и до сих пор успокоиться не можете. P>Какой смысл приводить еще один пример, если вы еще на предыдущий продолжаете наскакивать?
Действительно. Какой смысл искать верное решение задачи, если в предыдущем были ошибки. Отличная логика!
P>>>Кто вам такое сказал? Вам нужно редактировать не все отношения юзера, а только user-facing. Все остальное вы вас не заботит. P>·>Не распарсил. P>Очень просто — редактироавние после записи нужно для конкретных целей, например — что бы администратор мог подправить свойства только что созданного юзера, а не ждать пять минут.
Это вроде очевидное требование. Необходимость пользователям ждать по пять минут перед тем как нажать кнопочку — должно быть серьёзно обоснованно и обговорено с заказчиком. Как ты это вообще представляешь? Кнопочка как обычно рисуется на экране, но пользователям надо в инструкции написать, что "не нажимайте кнопочку быстрее чем через 5 минут". Бред же. Если такое "нефункциональное" изменение вдруг понадобится, то оно потребует заметную переработку UI и т.п. Тесты просто обязаны грохнуться!
P>Соответсвенно, в самом запросе мы обеспечиваем ровно этот минимум, а вообще всё, включая паблик кей спейса юзера P>Если ваш бизнес аналиитк затребовал вообще всё такое — то вы приплыли.
Я не в курсе что такое "паблик кей спейса юзера".
P>>>2 какой код должен выполниться, что бы пройти эти тесты P>·>Код этих тестов. Поднимать само приложение для этого не нужно. Никакой интеграции. Цитирую: "Conformance tests можно гонять независимо от наших релизов". P>Непонятно. Это вы тестируете внешние зависимости что ли? Непонятно. Как это к задаче с фильтрами относится?
Про конформанс я говорил в контексте "CREST API". Фильтры это репо+бд тесты.
P>В вашем случае вы 1, 2, 3 и 4 будете проверять косвенными тестами, которые заведомо дырявые.
Не перекладывай с больной головы. Косвенные тесты как раз у вас, т.к. тестируют не поведение системы, а внутреннюю имплементацию; и с дырами в которые я тебе пальчиком тыкал несколько раз; да ещё и хрупкие.
P>>>Я ж вам объяснил раз пять P>>>1. находим паттерн и проверяем его P>·>Где находим? Как проверяем? Когда проверяем? P>Извините, но вам стоит читать внимательнее. Я последее время слишком часто цитирую самого себя. Не можете удерживать контекст — чего вам неймется, "в интернете ктото неправ"?
Ты ни разу не ответил прямо на этот вопрос.
P>·>Я не понял детали. Код покажи. P>Все код был даден, отмотайте и посмотрите, это всё та же структурная эквивалентность запроса к бд.
Мы рассмотрели этот пример, ты вроде даже признал, что там лажа.
P>>>Это нужно на тот случай, если некто решит сделать "быстрый маленький фикс" после того, как вы уволитесь и контролировать код перестанете P>·>Да ты меня запутал. Была и трансляция, и трансформация, и маппер, и паттерн, и ещё чего. Я уже перестал понимать кто на ком стоял. P>маппер — по json строит конкретный запрос, createUser P>паттерн — основа этого запроса
что за основа? Запроса какого? sql?
P>трансформация — часть маппера, трансформируем json в нужный нам вид, на выходе — делаем обратное преобразование.
Трансформация? Обратная? А что такое transformations? out:...? Это было частью pattern в твоём сниппете. Тут ты говоришь, что это часть маппера.
Ты можешь внятный код написать? Ты уже в своей терминологии сам запутался.
P>·>Не правда, что ровно так же. Ручное тестирование исключается, т.к. есть тесты репо+бд. А построение не контролирую, потому что считаю что запрос не важно как строится, т.к. это детали реализации, важно что запрос работает в соответствии с бизнес-ожиданиями. Конкретный пример когда это не сработает я так и не увидел. P>Я вам продолжаю приводить тот же самый пример — фильтры, когда из за ошибки в построении запроса вгружается вся бд. Вы его усиленно игнорируете.
Я не игнорирую, я уже где-то месяц назад написал как его покрыть нормальным тестом. Это ты игнорируешь мои ответы.
P>>>Вы в адеквате? Я ж сказал — интеграционные тесты никуда не деваются. А вы читаете чтото своё. P>·>Не деваются, но такие тесты которые ты имеешь в виду (проверяющие интеграцию в контроллере всего со всем) не могут покрыть все возможные комбинации. P>Зато sql в этих тестах как раз так выполняется, и проходит тот самый чек, что и у вас.
Он выполняется косвенно, через кучу слоёв: "когда у нас дошла очередь интеграционного тестирования, где (медленно!) тащатся реальные данные из реальной базы, выполняется (медленный!) UI workflow с навигацией от логина до этого отчёта, и т.п.".
Т.е. либо у тебя такие тесты будут гонятся неделями, либо ты сможешь покрыть только ничтожную долю комбинаций этих конкретных запросов.
В моём случае тесты выполняют только связку репо+бд и там можно гонять на порядки больше комбинаций.
P>А раз покрыть все комбинации не получится, то незачем и пытаться — нужно переложить критические кейсы на другие методы.
Вот и неясно зачем вы пытаетесь это перекладывать на эти ваши странные бесполезные тесты, т.к. нужно другие методы использовать.
P>·>В моей схеме будут тесты репо+бд, которые тестируют только часть системы, относящуюся к персистенсу. P>И как вы протестируете, что у вас невозможна ситуация, что прод вгружает вообще всё?
Вы тоже не можете это _протестировать_. Просто ещё этого не поняли.
P>>>Причин сломать построение запроса при валидном паттерне — огромной количество — например, пупутать названия таблиц, колонок, приоритет операторов итд и тди итд. P>·>Именно, для этого и нужны тесты репо+бд. А при наличии таких тестов писать тесты ещё и на построение запросов — неясно зачем. P>Я ж вам говорил — некорректный запрос в тестах может выдавать корректный результат. И примеры привел.
Я примеров не видел. Я видел "объяснения".
P>·>Ты так и не рассказал как _тестировать_ валидность запроса. Сравнение с твоим pattern ничего о валидности не говорит. P>Валидность вообще всех запросов проверить не выйдет — та самая data complexity. Зато можно проверить известные проблемы для тех случаев, когда точная комбинация входа неизвестна.
Как? Ты это Проблему Останова решил тестами?
P>·>В смысле "действия"? Тестами покрывать что есть — разбираться какие способы существуют в легаси и воспроизводить в тестах. И потом потихоньку мигрировать легаси, например. P>Это значит, что вам нужно каждый такой кейс или через базу гонять, или же написать маппер, который можно дополнительно покрыть тестами, где учтем все возможные кейсы что есть в бд прода, или нам известно, что такие будут.
Ложная альтернатива. Ты "забыл" вариант: гонять через базу все возможные кейсы что есть в бд прода, или нам известно, что такие будут.
P>>>Примерно так же, как и вы. Только проверка паттерна мало что гарантирует. См выше про загрузку всей бд в память. Паттерн корректный, ошибочка при рендеринге некоторых комбинаций фильтров. P>·>Я до сих пор не понимаю почему у тебя есть проблема с загрузкой всей бд в память, решается же элементарно. P>Вы до сих пор не показали решения. Комбинация параметров вам неизвестна. Действуйте.
Только после вас.
P>>>Даже если в интеграционных тестах у меня не будет 100_000_000_000 записей, ничего страшного — запрос всё равно будет с безопасной структурой. P>·>Как ты отличишь в тесте запрос с безопасной структурой от запроса с небезопасной? P>В зависимости от задачи. Например — двойная фильтрация. Часть фильтров в самом запросе, ограничивают выборку, не параметризуются, часть — параметры для фильтрации оставшегося. P>Теперь что бы вы не подкидывали в фильтр, у вас никогда не будет кейса "вгрузить всё"
И что ты будешь ассертить в твоём тесте? sql.contains("LIMIT 1000")?
P>>>А вот вы так и не показали тест "никогда не будем загружать всю бд в память". P>·>Ты тоже такой тест не показал. P>Тест — показал, только вы его понять не можете.
Это который? "select * from users"?
P>>> Вы показали другой совсем другой тест — загрузим 1, если только что записали 1. P>·>Я такой тест не показывал. P>Это именно ваш подход — записать три значения в бд и надеяться что этого хватит. А как протестировать "запрос не тащит откуда не надо" вы не показали.
Показал. Запрос должен из условных трёх записей выбирать только условно две.
P>>>
P>>>п1 — паттерн тестируется на бд, далее — интеграционными тестами
P>·>Где? Как? Напомню, у тебя было: deep.eq(pattern). В каком тут месте "тестируется на бд"? P>Вы дурака валяете? deep.eq.pattern это тест для п2. Тесты для п1 — обычные интеграционные.
Я читаю что написано. В цитате выше написано "тестируется" (само как-то?), потом стоит запятая и слово "далее" и про интеграционные тесты. Если эта твоя цитата не говорит что ты хочешь сказать, переформулируй, у меня очень плохо с телепатией.
P>>>Сколько бы я ни писал про интеграционные тесты, вам мерещится "погонять вручную" P>·>У тебя интеграционные тесты тестируют каждый паттерн? P>По числу юз кейсов. Все юз кейсы должны быть покрыты интеграционными тестами.
Давай цифири приведу. В типичном проекте какие мне доводилось наблюдать таких юзкекйсов порядка 100k при более-менее хорошо организованном тестировании. Каждый интеграционный тест вида "...UI workflow с навигацией от логина..." это порядка нескольких секунд, даже без учёта разворачивания и подготовки инфры. Прикинь сколько будет занимать прогон всех таких тестов. В реальности интеграцией можно покрыть от силы 1% кейсов. Если это, конечно, не хоумпейдж.
P>>>См выше, "никогда не будем загружать всю бд в память" — для этого кейса у вас ни одного теста, а у меня хоть какие то. P>·>Ну потому что ты "1. был в курсе" и написал хоть какой-то тест. Т.е. они были не видны, как ты обещал, а у вас видимо на проде у вас что-то навернулось и ты это "увидел". P>Покрыть все возможные комбинации фильтров тестом с бд — нереально. Вы можете покрыть ну 5, ну 10, ну 50, но если у вас фильтров на страницу — вы ошалеете. Здесь забег на тысячи комбинаций. P>На каждую комбинацию накидать минимальную бд — уже мало реально.
Я тебе уже объяснял. Не надо накидывать бд на каждую комбинацию. Какие-то жалкие 30 (тридцать!) записей можно фильтровать миллиардом (230) уникальных способов, без учёта сортироваки.
P>Т.е. каждая комбинация это тесты вида "тащим откуда надо" + тесты вида "не тащим откуда не надо" коих много больше.
Не так, а так: для комбинации X выбираем эти 7 записей из 30.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали: S>>Такие вещи ловятся интеграционным тестированием, которое один хрен нужно проводить. ·>А что ты в таком тесте, зависящем от DateTime.now() (и ещё пачки внешних зависимостей в неизвестном тесту состоянии) будешь ассертить? Ведь каждый раз у тебя будут выдаваться потенциально совершенно разные результаты. Ну выдался отчёт с 0 строк — тест пройден или как?
Смотря чего мы ожидали.
Например, мы точно знаем, как должен выглядеть отчёт за 2023 год — ведь прошлое не меняется. Запускаем, сверяем.
Ничего "потенциально разного" тут не будет, т.к. речь идёт об интеграции с боевой системой, и там мусора не бывает.
Либо мы сверяем интеграцию с Test-In-Production — боевой системой, на которой можно экспериментировать бесплатно.
Тогда интеграционный тест — это прогонка полного цикла типа "создать клиента — зарегистрировать пользователей — выполнить ряд заказов — проверить результаты"
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, ·, Вы писали:
P>>Это и есть пересказ всего, что изложено в clean architecture. Я уже приводил пример, вы прицепились к проверке sql и до сих пор успокоиться не можете. P>>Какой смысл приводить еще один пример, если вы еще на предыдущий продолжаете наскакивать? ·>Действительно. Какой смысл искать верное решение задачи, если в предыдущем были ошибки. Отличная логика!
Вы пока ошибок не показали. Основная ваша придирка в том, что структурная эквивалентность не нужна, хрупкая, итд — при этом альтернативы такому решению у вас нет.
P>>Очень просто — редактироавние после записи нужно для конкретных целей, например — что бы администратор мог подправить свойства только что созданного юзера, а не ждать пять минут. ·>Это вроде очевидное требование. Необходимость пользователям ждать по пять минут перед тем как нажать кнопочку — должно быть серьёзно обоснованно и обговорено с заказчиком. Как ты это вообще представляешь?
Вы снова с колокольни? Ничего ждать не надо — в том то и особенность. И всё работает. Потому как данные по пользователю делятся на две большие части — те, что нужны сейчас, и те, что просто нужны.
Вот например — под нового сотрудника аккаунт создаётся заранее. Здесь заботиться о том, что бы всё-всё-всё(и все гуиды редактировали руками, ага) было доступно к редактированию через 50мс — требование неадекватное.
А вот изменение имени пользователя спустя секунду после создания — очень даже адекватно.
P>>Если ваш бизнес аналиитк затребовал вообще всё такое — то вы приплыли. ·>Я не в курсе что такое "паблик кей спейса юзера".
public ssl key — ничего военного. Пересоздавать этот кей спустя секунду после создания занятие абсолютно бессмысленное. А вас послушать, так окажется что любые данные ассоциированые с пользователем могут меняться сразу же, включая гуиды ссылок на любую глубину связности.
P>>·>Где находим? Как проверяем? Когда проверяем? P>>Извините, но вам стоит читать внимательнее. Я последее время слишком часто цитирую самого себя. Не можете удерживать контекст — чего вам неймется, "в интернете ктото неправ"? ·>Ты ни разу не ответил прямо на этот вопрос.
Цитирую себя N+1й и N+2q разы
п1 — паттерн тестируется на бд, далее — интеграционными тестами
...
1. рабочий паттерн запроса — это проверяется сначала руками, а потом тестом против бд минимально заполненой под задачу
Я вот почему то уверен, что несмотря на эти цитаты вы еще месяц или два будете мне доказывать, что я тестирую только юнит-тестами.
P>>Все код был даден, отмотайте и посмотрите, это всё та же структурная эквивалентность запроса к бд. ·>Мы рассмотрели этот пример, ты вроде даже признал, что там лажа.
Пример недостаточно информативный. А вот сам подход — проверять построение запроса — очень даже хороший.
P>>маппер — по json строит конкретный запрос, createUser P>>паттерн — основа этого запроса ·>что за основа? Запроса какого? sql?
Какого угодно. Если вам для запроса данных нужна цепочка джойнов или вложеный запрос — то это и есть паттерн. А дальше наш билдер должен гарантировать, что для любых возможных параметров, а не только тех, что вы косвенно подкинули в тестах, запрос будет соответствовать заданному паттерно — цепочка джойнов, вложеный запрос, итд итд итд.
А так же надо учесть вещи вида "не делает то чего делать не должен".
P>>трансформация — часть маппера, трансформируем json в нужный нам вид, на выходе — делаем обратное преобразование., ·>Трансформация? Обратная? А что такое transformations? out:...? Это было частью pattern в твоём сниппете. Тут ты говоришь, что это часть маппера.
Путаница из за того, что есть паттерн запроса и паттерн в тесте это похожее, но разное
Вот смотрите
Все что передается в eq — паттерн для теста. А ' наш конкретный запрос' тут проверяем паттерн запроса к бд. Синклер говорит, что эффективнее AST. Это конечно же так. Только пилить АСТ под частный случай я не вижу смысла, во первых. А во вторых, по похожей схеме мы можем проверять запросы любого вида http, rest, rpc, graphql, odata итд.
Например, для эластика у вас будет обычный http запрос.
Можно точно так же проверять запросы к ORM. Это решает проблемы с джигитам "я быстренько, там всё просто"
P>>Я вам продолжаю приводить тот же самый пример — фильтры, когда из за ошибки в построении запроса вгружается вся бд. Вы его усиленно игнорируете. ·>Я не игнорирую, я уже где-то месяц назад написал как его покрыть нормальным тестом. Это ты игнорируешь мои ответы.
Вы показали примитивные тесты вида "положили в таблицу, проверили, что нашли положенное". А как протестировать "не нашли неположенного" или "не начали вгружать вообще всё" — вы такого не показали.
И то, и другое вашими примитивными тестами не решается.
Частично можно решить на боевой бд или приравненой к ней, но только для тех данных что есть сейчас. Как это сделать для тех данных, что у нас будут через год — загадка.
·>Он выполняется косвенно, через кучу слоёв: "когда у нас дошла очередь интеграционного тестирования, где (медленно!) тащатся реальные данные из реальной базы, выполняется (медленный!) UI workflow с навигацией от логина до этого отчёта, и т.п.". ·>Т.е. либо у тебя такие тесты будут гонятся неделями, либо ты сможешь покрыть только ничтожную долю комбинаций этих конкретных запросов. ·>В моём случае тесты выполняют только связку репо+бд и там можно гонять на порядки больше комбинаций.
Связка репо+бд называется интеграционный тест. Вы такими тестами собираетесь покрывать все комбинации
И щас же будете рассказывать, что вы имели в виду чтото другое.
Сколько бы вы комбинаций не всунули в репо+бд тесты — Data Complexity вам такими тестами не сбороть, ну никак.
Но вы продолжаете это пытаться.
Интеграционные нужны для проверки, что репо умеет работать с бд, а вовсе не для проверок комбинаций. Для проверок комбинаций есть другие методы, гораздо более эффективные.
P>>А раз покрыть все комбинации не получится, то незачем и пытаться — нужно переложить критические кейсы на другие методы. ·>Вот и неясно зачем вы пытаетесь это перекладывать на эти ваши странные бесполезные тесты, т.к. нужно другие методы использовать.
Вы только что "показали" — для проверок комбинций использовать интеграционный тест репо+бд
P>>И как вы протестируете, что у вас невозможна ситуация, что прод вгружает вообще всё? ·>Вы тоже не можете это _протестировать_. Просто ещё этого не поняли.
Могу. Например, для тестов которые тянут больше одной строки могу просто затребовать `LIMIT 10`.
P>>·>Именно, для этого и нужны тесты репо+бд. А при наличии таких тестов писать тесты ещё и на построение запросов — неясно зачем. P>>Я ж вам говорил — некорректный запрос в тестах может выдавать корректный результат. И примеры привел. ·>Я примеров не видел. Я видел "объяснения".
Мы уже проходили — код всегда частный случай, на что у вас железный аргумент "у нас такой проблемы быть не может принципиально"
P>>Валидность вообще всех запросов проверить не выйдет — та самая data complexity. Зато можно проверить известные проблемы для тех случаев, когда точная комбинация входа неизвестна. ·>Как? Ты это Проблему Останова решил тестами?
Не я, а вы. Это у вас комбинации покрываются repo+db тестами. А мне достаточно гарантировать наличие свойства запроса. см пример с LIMIT 10 выше. И это свойство сохранится на все времена, а потому проблема останова для меня здесь неактуальна.
·>Ложная альтернатива. Ты "забыл" вариант: гонять через базу все возможные кейсы что есть в бд прода, или нам известно, что такие будут.
Скажите честно, сколько уникальных тестов у вас всего в проекте, всех уровней, видов, итд? И сколько у вас таблиц и связей в бд?
Моя оценка — уникальных тестов у вас самое большее 1000 помножить на число девелоперов. А тестов "комбинаций" из этого будет от силы 1%.
Итого — сколько тестов , таблиц, связей?р
P>>·>Я до сих пор не понимаю почему у тебя есть проблема с загрузкой всей бд в память, решается же элементарно. P>>Вы до сих пор не показали решения. Комбинация параметров вам неизвестна. Действуйте. ·>Только после вас.
Я уже привел кучу примеров. А вы всё никак.
P>>В зависимости от задачи. Например — двойная фильтрация. Часть фильтров в самом запросе, ограничивают выборку, не параметризуются, часть — параметры для фильтрации оставшегося. P>>Теперь что бы вы не подкидывали в фильтр, у вас никогда не будет кейса "вгрузить всё" ·>И что ты будешь ассертить в твоём тесте? sql.contains("LIMIT 1000")?
Зачем contains ? Проверяться будет весь паттерн запроса, а не его фрагмент.
P>>Это именно ваш подход — записать три значения в бд и надеяться что этого хватит. А как протестировать "запрос не тащит откуда не надо" вы не показали. ·>Показал. Запрос должен из условных трёх записей выбирать только условно две.
Не работает. Фильтры могут тащить из херовой тучи таблиц, связей итд. Вам надо самое меньшее — заполнение всех возможных данных, таблиц, связей и тд. И так на каждый тест.
У вас здесь сложность растет экспоненциально.
P>>Вы дурака валяете? deep.eq.pattern это тест для п2. Тесты для п1 — обычные интеграционные. ·>Я читаю что написано.
Ну сейчас то понятно, что интеграционные никто не отменял, или еще месяц-два будете это игнорировать?
P>>По числу юз кейсов. Все юз кейсы должны быть покрыты интеграционными тестами. ·>Давай цифири приведу. В типичном проекте какие мне доводилось наблюдать таких юзкекйсов порядка 100k при более-менее хорошо организованном тестировании. Каждый интеграционный тест вида "...UI workflow с навигацией от логина..." это порядка нескольких секунд, даже без учёта разворачивания и подготовки инфры. Прикинь сколько будет занимать прогон всех таких тестов. В реальности интеграцией можно покрыть от силы 1% кейсов. Если это, конечно, не хоумпейдж.
100к юзкейсов протестировать сложно, а написать легко? Чтото тут не сходится. Вы вероятно юзкейсом называете просто разные варианты параметров для одного и того же вызова контроллера.
P>>На каждую комбинацию накидать минимальную бд — уже мало реально. ·>Я тебе уже объяснял. Не надо накидывать бд на каждую комбинацию. Какие-то жалкие 30 (тридцать!) записей можно фильтровать миллиардом (230) уникальных способов, без учёта сортироваки.
Похоже, вы точно не понимаете data complexity.
Эти 30 комбинаций разложить по таблицам и колонкам и окажется в среднем около нуля на большинстве комбинаций фильров.
P>>Т.е. каждая комбинация это тесты вида "тащим откуда надо" + тесты вида "не тащим откуда не надо" коих много больше. ·>Не так, а так: для комбинации X выбираем эти 7 записей из 30.
См выше — вы разложили 30 записей по таблицами и колонкам и в большинстве случаев у вас выходит 0 значений. А потому 7 из 30 это ни о чем.
Соответственно, пускаете фильтр на проде, и приложение вгружает базу целиком.
Здравствуйте, Sinclair, Вы писали:
S>>>Такие вещи ловятся интеграционным тестированием, которое один хрен нужно проводить. S>·>А что ты в таком тесте, зависящем от DateTime.now() (и ещё пачки внешних зависимостей в неизвестном тесту состоянии) будешь ассертить? Ведь каждый раз у тебя будут выдаваться потенциально совершенно разные результаты. Ну выдался отчёт с 0 строк — тест пройден или как? S>Смотря чего мы ожидали. S>Например, мы точно знаем, как должен выглядеть отчёт за 2023 год — ведь прошлое не меняется. Запускаем, сверяем. S>Ничего "потенциально разного" тут не будет, т.к. речь идёт об интеграции с боевой системой, и там мусора не бывает. S>Либо мы сверяем интеграцию с Test-In-Production — боевой системой, на которой можно экспериментировать бесплатно. S>Тогда интеграционный тест — это прогонка полного цикла типа "создать клиента — зарегистрировать пользователей — выполнить ряд заказов — проверить результаты"
В общем да, при удачном стечении обстоятельств такой подход может и сработает. Но тут столько вещей может пойти не так, притом совершенно ВНЕЗАПНО, что на хоть сколько-то надёжный и универсальный подход никак не тянет.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, Pauel, Вы писали:
P>·>Действительно. Какой смысл искать верное решение задачи, если в предыдущем были ошибки. Отличная логика! P>Вы пока ошибок не показали. Основная ваша придирка в том, что структурная эквивалентность не нужна, хрупкая, итд — при этом альтернативы такому решению у вас нет.
Это и есть ошибка. Плюс показал потенциальные ошибки например с дефолтным значением vs null. Альтернативу тоже показал. Просто ты проигнорировал.
P>>>Очень просто — редактироавние после записи нужно для конкретных целей, например — что бы администратор мог подправить свойства только что созданного юзера, а не ждать пять минут. P>·>Это вроде очевидное требование. Необходимость пользователям ждать по пять минут перед тем как нажать кнопочку — должно быть серьёзно обоснованно и обговорено с заказчиком. Как ты это вообще представляешь? P>Вы снова с колокольни? Ничего ждать не надо — в том то и особенность. И всё работает. Потому как данные по пользователю делятся на две большие части — те, что нужны сейчас, и те, что просто нужны. P>Вот например — под нового сотрудника аккаунт создаётся заранее. Здесь заботиться о том, что бы всё-всё-всё(и все гуиды редактировали руками, ага) было доступно к редактированию через 50мс — требование неадекватное. P>А вот изменение имени пользователя спустя секунду после создания — очень даже адекватно.
Ты путаешься в показаниях. Ты сам-то адекватен? Откуда взялось "50мс"??! Ты тут сказал, что синхронное сохранение внезапно заменил на асинхронное и у тебя возникли проблемы с тем, что теперь другой метод можно позвать только через 5 минут. Хуже того, асинхронное вообще не обещает, что оно таки когда-либо произойдёт, а не выпадет какая-нибудь ошибка, которую теперь надо как-то отображать.
P>>>Если ваш бизнес аналиитк затребовал вообще всё такое — то вы приплыли. P>·>Я не в курсе что такое "паблик кей спейса юзера". P>public ssl key — ничего военного. Пересоздавать этот кей спустя секунду после создания занятие абсолютно бессмысленное. А вас послушать, так окажется что любые данные ассоциированые с пользователем могут меняться сразу же, включая гуиды ссылок на любую глубину связности.
Я не знаю что это и какое это всё имеет отношение к обсуждаемому.
P>·>Ты ни разу не ответил прямо на этот вопрос. P>Цитирую себя N+1й и N+2q разы P>
P>п1 — паттерн тестируется на бд, далее — интеграционными тестами
P>...
P>1. рабочий паттерн запроса — это проверяется сначала руками, а потом тестом против бд минимально заполненой под задачу
P>Я вот почему то уверен, что несмотря на эти цитаты вы еще месяц или два будете мне доказывать, что я тестирую только юнит-тестами.
Ты пишешь бред. Я задаю вопрос, ты игнорируешь и снова повторяешь то же самое. Попробуем ещё раз:
Я читаю что написано. В цитате выше написано "тестируется" (само как-то?), потом стоит запятая и слово "далее" и про интеграционные тесты. Если эта твоя цитата не говорит что ты хочешь сказать, переформулируй, у меня очень плохо с телепатией.
P>>>Все код был даден, отмотайте и посмотрите, это всё та же структурная эквивалентность запроса к бд. P>·>Мы рассмотрели этот пример, ты вроде даже признал, что там лажа. P>Пример недостаточно информативный. А вот сам подход — проверять построение запроса — очень даже хороший.
Т.е. код не был даден. ЧТД. Куда отматывать-то?
P>·>что за основа? Запроса какого? sql? P>Какого угодно. Если вам для запроса данных нужна цепочка джойнов или вложеный запрос — то это и есть паттерн.
Это ты цель со средством путаешь. Мне надо чтобы запрос выдавал результат который нужен по спеке. А что там — цепочка джойнов или чёрт лысый — абсолютно пофиг. Более того, если сегодня написали запрос с джойнами, а завтра, после разговора с dba его переписали на вложенный — то ни один тест упасть не должен.
P>А дальше наш билдер должен гарантировать, что для любых возможных параметров, а не только тех, что вы косвенно подкинули в тестах, запрос будет соответствовать заданному паттерно — цепочка джойнов, вложеный запрос, итд итд итд. P>А так же надо учесть вещи вида "не делает то чего делать не должен".
Мы говорим о тестах. Как тебе тесты помогут что-то гарантировать? Причём тут тесты??!
P>>>трансформация — часть маппера, трансформируем json в нужный нам вид, на выходе — делаем обратное преобразование., P>·>Трансформация? Обратная? А что такое transformations? out:...? Это было частью pattern в твоём сниппете. Тут ты говоришь, что это часть маппера.
P>Путаница из за того, что есть паттерн запроса и паттерн в тесте это похожее, но разное P>Вот смотрите P>
P>Все что передается в eq — паттерн для теста. А ' наш конкретный запрос' тут проверяем паттерн запроса к бд.
Здесь в коде это просто строка полного sql-запроса, которая сравнивается по equals. Я не понимаю почему ты это называешь паттерном, что в тут паттернится-то?
P>Синклер говорит, что эффективнее AST. Это конечно же так. Только пилить АСТ под частный случай я не вижу смысла, во первых. А во вторых, по похожей схеме мы можем проверять запросы любого вида http, rest, rpc, graphql, odata итд. P>Например, для эластика у вас будет обычный http запрос. P>Можно точно так же проверять запросы к ORM. Это решает проблемы с джигитам "я быстренько, там всё просто"
Ясно. Так я код с такими "паттернами" пишу как раз когда надо "я быстренько, там всё просто". В серьёзных ситуациях за такое надо бить по рукам.
P>>>Я вам продолжаю приводить тот же самый пример — фильтры, когда из за ошибки в построении запроса вгружается вся бд. Вы его усиленно игнорируете. P>·>Я не игнорирую, я уже где-то месяц назад написал как его покрыть нормальным тестом. Это ты игнорируешь мои ответы. P>Вы показали примитивные тесты вида "положили в таблицу, проверили, что нашли положенное". А как протестировать "не нашли неположенного" или "не начали вгружать вообще всё" — вы такого не показали.
Показал. Ещё раз разжую. Минимальный пример: Если мы в таблицу кладём "Vasya", то при поиске, например по шаблону по startsWith("Vas") — должны найти одну запись, а по startsWith("Vaz") — ноль. Второй тест как раз и ассертит, что твой этот фильтр не вгружает всё, а только то, что должно было заматчиться. Ещё раз. Одна запись в БД — это 21 вариантов результата, которые можно различить.
P>И то, и другое вашими примитивными тестами не решается.
Решается.
P>Частично можно решить на боевой бд или приравненой к ней, но только для тех данных что есть сейчас. Как это сделать для тех данных, что у нас будут через год — загадка.
Ты же уже сам привёл ответ на эту загадку: "все возможные кейсы что есть в бд прода, или нам известно, что такие будут".
P>·>Он выполняется косвенно, через кучу слоёв: "когда у нас дошла очередь интеграционного тестирования, где (медленно!) тащатся реальные данные из реальной базы, выполняется (медленный!) UI workflow с навигацией от логина до этого отчёта, и т.п.". P>·>Т.е. либо у тебя такие тесты будут гонятся неделями, либо ты сможешь покрыть только ничтожную долю комбинаций этих конкретных запросов. P>·>В моём случае тесты выполняют только связку репо+бд и там можно гонять на порядки больше комбинаций. P>Связка репо+бд называется интеграционный тест. Вы такими тестами собираетесь покрывать все комбинации
Совершенно похрен как оно называется. Я говорю конкретно что с чем тестируется и как.
P>И щас же будете рассказывать, что вы имели в виду чтото другое.
Я имел в виду ровно то, что написал. Если что-то неясно, перечитай.
P>Сколько бы вы комбинаций не всунули в репо+бд тесты — Data Complexity вам такими тестами не сбороть, ну никак. P>Но вы продолжаете это пытаться.
P>Интеграционные нужны для проверки, что репо умеет работать с бд, а вовсе не для проверок комбинаций. Для проверок комбинаций есть другие методы, гораздо более эффективные.
Что значит "умеет работать"?
P>>>А раз покрыть все комбинации не получится, то незачем и пытаться — нужно переложить критические кейсы на другие методы. P>·>Вот и неясно зачем вы пытаетесь это перекладывать на эти ваши странные бесполезные тесты, т.к. нужно другие методы использовать. P>Вы только что "показали" — для проверок комбинций использовать интеграционный тест репо+бд
Почему нет-то?
P>>>И как вы протестируете, что у вас невозможна ситуация, что прод вгружает вообще всё? P>·>Вы тоже не можете это _протестировать_. Просто ещё этого не поняли. P>Могу. Например, для тестов которые тянут больше одной строки могу просто затребовать `LIMIT 10`.
Как?
P>>>·>Именно, для этого и нужны тесты репо+бд. А при наличии таких тестов писать тесты ещё и на построение запросов — неясно зачем. P>>>Я ж вам говорил — некорректный запрос в тестах может выдавать корректный результат. И примеры привел. P>·>Я примеров не видел. Я видел "объяснения". P>Мы уже проходили — код всегда частный случай, на что у вас железный аргумент "у нас такой проблемы быть не может принципиально"
Код — это формальный язык. По нему сразу видно все ошибки. То что ты стесняешься написать формально — означает, что у тебя из аргументов только словоблудие, на ходу меняешь смысл терминов.
P>>>Валидность вообще всех запросов проверить не выйдет — та самая data complexity. Зато можно проверить известные проблемы для тех случаев, когда точная комбинация входа неизвестна. P>·>Как? Ты это Проблему Останова решил тестами? P>Не я, а вы. Это у вас комбинации покрываются repo+db тестами. А мне достаточно гарантировать наличие свойства запроса. см пример с LIMIT 10 выше. И это свойство сохранится на все времена, а потому проблема останова для меня здесь неактуальна.
Гарантировать наличие любого нетривиального свойства у кода (а запрос — это код) — алгоритмически неразрешимая задача (т. Райса), значит тесты тут никоим образом не помогут.
P>·>Ложная альтернатива. Ты "забыл" вариант: гонять через базу все возможные кейсы что есть в бд прода, или нам известно, что такие будут. P>Скажите честно, сколько уникальных тестов у вас всего в проекте, всех уровней, видов, итд? И сколько у вас таблиц и связей в бд? P>Моя оценка — уникальных тестов у вас самое большее 1000 помножить на число девелоперов. А тестов "комбинаций" из этого будет от силы 1%. P>Итого — сколько тестов , таблиц, связей?р
Цифры я ниже привёл. Базы мелкие, да, ну может порядка сотни таблиц.
P>>>·>Я до сих пор не понимаю почему у тебя есть проблема с загрузкой всей бд в память, решается же элементарно. P>>>Вы до сих пор не показали решения. Комбинация параметров вам неизвестна. Действуйте. P>·>Только после вас. P>Я уже привел кучу примеров. А вы всё никак.
Нигде не было неизвестных комбинаций параметров, не ври.
P>·>И что ты будешь ассертить в твоём тесте? sql.contains("LIMIT 1000")? P>Зачем contains ? Проверяться будет весь паттерн запроса, а не его фрагмент.
Как именно?
P>>>Это именно ваш подход — записать три значения в бд и надеяться что этого хватит. А как протестировать "запрос не тащит откуда не надо" вы не показали. P>·>Показал. Запрос должен из условных трёх записей выбирать только условно две. P>Не работает. Фильтры могут тащить из херовой тучи таблиц, связей итд. Вам надо самое меньшее — заполнение всех возможных данных, таблиц, связей и тд. И так на каждый тест.
Работает. И не на каждый тест, а на прогон практически всех тестов.
P>У вас здесь сложность растет экспоненциально.
Не растёт.
P>>>Вы дурака валяете? deep.eq.pattern это тест для п2. Тесты для п1 — обычные интеграционные. P>·>Я читаю что написано. P>Ну сейчас то понятно, что интеграционные никто не отменял, или еще месяц-два будете это игнорировать?
Я задал вопрос. Ты его удалил не ответив.
P>·>Давай цифири приведу. В типичном проекте какие мне доводилось наблюдать таких юзкекйсов порядка 100k при более-менее хорошо организованном тестировании. Каждый интеграционный тест вида "...UI workflow с навигацией от логина..." это порядка нескольких секунд, даже без учёта разворачивания и подготовки инфры. Прикинь сколько будет занимать прогон всех таких тестов. В реальности интеграцией можно покрыть от силы 1% кейсов. Если это, конечно, не хоумпейдж. P>100к юзкейсов протестировать сложно, а написать легко? Чтото тут не сходится.
Ты откуда нателепатировал "сложно/легко"? Я написал про скорость прогона тестов.
P> Вы вероятно юзкейсом называете просто разные варианты параметров для одного и того же вызова контроллера.
Юзкейс — это в первом приближении кусочек спеки из бизнес-требования, одна хотелка заказчика.
P>>>На каждую комбинацию накидать минимальную бд — уже мало реально. P>·>Я тебе уже объяснял. Не надо накидывать бд на каждую комбинацию. Какие-то жалкие 30 (тридцать!) записей можно фильтровать миллиардом (230) уникальных способов, без учёта сортироваки. P>Похоже, вы точно не понимаете data complexity. P>Эти 30 комбинаций разложить по таблицам и колонкам и окажется в среднем около нуля на большинстве комбинаций фильров.
Почему так окажется? "все возможные кейсы что есть в бд прода, или нам известно, что такие будут.", т.е. раскладываются различные с т.з. бизнеса сущности, а не просто "Account 1", "Account 2".
P>>>Т.е. каждая комбинация это тесты вида "тащим откуда надо" + тесты вида "не тащим откуда не надо" коих много больше. P>·>Не так, а так: для комбинации X выбираем эти 7 записей из 30. P>См выше — вы разложили 30 записей по таблицами и колонкам и в большинстве случаев у вас выходит 0 значений. А потому 7 из 30 это ни о чем. P>Соответственно, пускаете фильтр на проде, и приложение вгружает базу целиком.
Бред.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Вспомнил ваше утверждение про покрытие интеграционными тестами. Смотрите, что вы пишете в очередной раз: > В реальности интеграцией можно покрыть от силы 1% кейсов.
Помните? Вот здесь вы написали обоснование тем самым тестам на проде. Оставшиеся 99% ваши моки не заткнут, как бы вы не старались. Хоть обпишитесь. И даже если вы обмажетесь всеми возможными юнит-тестами, моками, какими угодно — покрытие интеграционными тестами в 1% говорит о том, что за продом нужно наблюдать более серьезными методами, нежели ваши health check.
Для этого подходят e2e тесты — один такой тест может затронуть чуть не половину всех юзкейсов в приложении.
Если же вы хотите заткнуть 99% непокрытых юзкейсов мониторингом на основе с healthcheck — чтото здесь не сходится.
P>>·>Действительно. Какой смысл искать верное решение задачи, если в предыдущем были ошибки. Отличная логика! P>>Вы пока ошибок не показали. Основная ваша придирка в том, что структурная эквивалентность не нужна, хрупкая, итд — при этом альтернативы такому решению у вас нет. ·>Это и есть ошибка. Плюс показал потенциальные ошибки например с дефолтным значением vs null. Альтернативу тоже показал. Происто ты проигнорировал.
Вы показали теоретически возможные ошибки при построении запроса "а вдруг не учтем дефолтное значение". Ну так это и у вас будет — если чего то не учтете.
Ваша альтернатива не работает — упираемся в конское количество колонок, связей и разнообразия свойств внутри джсона — так вот всё хранится.
И ваш подход к тестированию фильтров не палит.
P>>А вот изменение имени пользователя спустя секунду после создания — очень даже адекватно. ·>Ты путаешься в показаниях. Ты сам-то адекватен? Откуда взялось "50мс"??! Ты тут сказал, что синхронное сохранение внезапно заменил на асинхронное и у тебя возникли проблемы с тем, что теперь другой метод можно позвать только через 5 минут.
Я такого не говорил — это вы начали фантазировать, что придется ждать 5 минут и никак иначе не выйдет. Обоснования у вас никакого нет.
P>>public ssl key — ничего военного. Пересоздавать этот кей спустя секунду после создания занятие абсолютно бессмысленное. А вас послушать, так окажется что любые данные ассоциированые с пользователем могут меняться сразу же, включая гуиды ссылок на любую глубину связности. ·>Я не знаю что это и какое это всё имеет отношение к обсуждаемому.
Я вам привел пример, что данные разделяются на те, что нужны сейчас, и те, что нужны потом, когда нибудь. Так не бывает, что всё всегда нужно сразу на любую глубину вложенности.
Если у вас хватает капасити обработать всё за один реквест — отлично. Самый простой вариант, без какого либо усложения архитектуры.
Как только вашего капасити перестает хватать — см требованиия, там написано, что из данных юзера нужно сразу, а что нет.
P>>Я вот почему то уверен, что несмотря на эти цитаты вы еще месяц или два будете мне доказывать, что я тестирую только юнит-тестами. ·>Ты пишешь бред. Я задаю вопрос, ты игнорируешь и снова повторяешь то же самое. Попробуем ещё раз: ·>Я читаю что написано. В цитате выше написано "тестируется" (само как-то?), потом стоит запятая и слово "далее" и про интеграционные тесты. Если эта твоя цитата не говорит что ты хочешь сказать, переформулируй, у меня очень плохо с телепатией.
Цитирую себя N+3й и N+4й разы — выделил
п1 — паттерн тестируется на бд, далее — интеграционными тестами
...
1. рабочий паттерн запроса — это проверяется сначала руками, а потом тестом против бд минимально заполненой под задачу
P>>Пример недостаточно информативный. А вот сам подход — проверять построение запроса — очень даже хороший. ·>Т.е. код не был даден. ЧТД. Куда отматывать-то?
Структурная эквивалентность запроса — все что надо, было показано. Вам десяток страниц кода билдера фильтров показать или что?
P>>Какого угодно. Если вам для запроса данных нужна цепочка джойнов или вложеный запрос — то это и есть паттерн. ·>Это ты цель со средством путаешь. Мне надо чтобы запрос выдавал результат который нужен по спеке. А что там — цепочка джойнов или чёрт лысый — абсолютно пофиг. Более того, если сегодня написали запрос с джойнами, а завтра, после разговора с dba его переписали на вложенный — то ни один тест упасть не должен.
Я ж вам сразу сказал — такой тест более хрупкий. Его нужно применять ради решения конкретных проблем, а не лепить вообще везде. Одна из проблема — те самые фильтры.
P>>А так же надо учесть вещи вида "не делает то чего делать не должен". ·>Мы говорим о тестах. Как тебе тесты помогут что-то гарантировать? Причём тут тесты??!
Тесты пишутся именно ради гарантий:
1 делает что надо
2 не делает того, чего не надо
P>>Все что передается в eq — паттерн для теста. А ' наш конкретный запрос' тут проверяем паттерн запроса к бд. ·>Здесь в коде это просто строка полного sql-запроса, которая сравнивается по equals. Я не понимаю почему ты это называешь паттерном, что в тут паттернится-то?
Паттерн — потому, что название даётся по назначению. Назначение этого подхода — проверять построеный запрос на соответствие паттерну.
Если у вас есть более эффективный вариант, например, json-like или AST на алгебраических типах данных, будет еще лучше
P>>Например, для эластика у вас будет обычный http запрос. P>>Можно точно так же проверять запросы к ORM. Это решает проблемы с джигитам "я быстренько, там всё просто" ·>Ясно. Так я код с такими "паттернами" пишу как раз когда надо "я быстренько, там всё просто". В серьёзных ситуациях за такое надо бить по рукам.
Проблема с фильтрами вполне себе серьезная. А вы никак адекватного решения не предложите.
P>>Вы показали примитивные тесты вида "положили в таблицу, проверили, что нашли положенное". А как протестировать "не нашли неположенного" или "не начали вгружать вообще всё" — вы такого не показали. ·>Показал. Ещё раз разжую. Минимальный пример: Если мы в таблицу кладём "Vasya", то при поиске, например по шаблону по startsWith("Vas") — должны найти одну запись, а по startsWith("Vaz") — ноль. Второй тест как раз и ассертит, что твой этот фильтр не вгружает всё, а только то, что должно было заматчиться. Ещё раз. Одна запись в БД — это 21 вариантов результата, которые можно различить.
Очень смешно. Как ваш пример экстраполировать на полторы сотни свойств разного рода — колонки, свойства внутри джсон колонокк, таблиц которые могут джойнами подтягиваться?
Вы ранее говорили — 30 значений положить в бд. Это значит, что 120 свойств будут незаполнеными, и мы не узнаем или ваш запрос фильтрует, или же хавает пустые значения которые в проде окажутся непустыми.
P>>И то, и другое вашими примитивными тестами не решается. ·>Решается.
Нисколько. Если вы положили в таблицу Vasya, то к нему нужно подкинуть полторы сотни так или иначе связанных с ним свойств. Не 30, как вам кажется, а минимум 150. И желательно, что бы таких васей было больше одного.
Фильтр будет не startwith, а
1. конское количество условий — приоритеты, скобки
2. паттерны строк что само по себе хороший цирк
3. джойны в зависимости от условий итд
4. приседания с джсон разной структуры
5. группировки, агрегирование, итд
Например — найти всех вась которые между июнем и июлем делали повторные возвраты товаров из перечня которые были куплены между январем и мартом оформлены менеджерами которые были наняты не позже декабря прошлого года и получив % от сделок уволились с августа по сентябрь
Еще интереснее — найти все товары, которые двигались во всей этой кунсткамере.
P>>Интеграционные нужны для проверки, что репо умеет работать с бд, а вовсе не для проверок комбинаций. Для проверок комбинаций есть другие методы, гораздо более эффективные. ·>Что значит "умеет работать"?
Например, репозиторий Users метод create — параметры — данные юзера, возвращаемое значение — созданный юзер + ассоциированные данные. Нас интересует
1. разложит данные юзера в соответствии со схемой, подкинет гуид где надо
2. построит запрос один или несколько, сколько надо для той бд-сервиса-итд, что в конфигурации
3. отшлет вбд и вернет данные с запрошеными ассоциациями, иды, гуиды — будут соответсвовать схеме, входным данным итд
4. подклеит метадату
5. повторый запрос с тем же гуид должен зафейлиться с конкретной ошибкой
6. такой же запрос с другим гуид должен выполнится хорошо
7. корректно пробрасывать ошибки вида "дисконнект бд из за рестарта"
8. сумеет в опции — ничего не тащить из бд если был флаг write-only
Вот такие вещи показывают интеграцию. Это если вы сами пишете репозиторий, а не берете его готовым в ОРМ фремворке.
Тесты на фильтры здесь минимальные — есть, нету, т.к. нам надо что репозиторий их строит и отдаёт в бд.
А вот всё множество комбинаций в фильтрах нужно покрывать совсем другими тестами.
P>>Вы только что "показали" — для проверок комбинций использовать интеграционный тест репо+бд ·>Почему нет-то?
Потому, что
1 это медленно
2 вы подкидываете небольшое количество значений. Смотрите пример фильтра с васями, только не ваш, а мой
P>>Могу. Например, для тестов которые тянут больше одной строки могу просто затребовать `LIMIT 10`. ·>Как?
Вот так:
`конский запрос LIMIT 10`
И добавить подобное в тесты всех критических запросов.
Т.е. это просто пост условие, и давать будет ровно те же гарантии.
P>>Мы уже проходили — код всегда частный случай, на что у вас железный аргумент "у нас такой проблемы быть не может принципиально" ·>Код — это формальный язык. По нему сразу видно все ошибки. То что ты стесняешься написать формально — означает, что у тебя из аргументов только словоблудие, на ходу меняешь смысл терминов.
С этим есть сложность — ваш код с тестами фильров, те самые васи, говорит о том, что мы с вами совершенно иначе понимаем data complexity
P>>Не я, а вы. Это у вас комбинации покрываются repo+db тестами. А мне достаточно гарантировать наличие свойства запроса. см пример с LIMIT 10 выше. И это свойство сохранится на все времена, а потому проблема останова для меня здесь неактуальна. ·>Гарантировать наличие любого нетривиального свойства у кода (а запрос — это код) — алгоритмически неразрешимая задача (т. Райса), значит тесты тут никоим образом не помогут.
Теорема Райса про алгоритмы и свойства функций, а не про код.
Забавно, что вы только что сами себе рассказали, почему любые ваши тесты без толку. Только такого рода гарантий тестами вообще никто никогда не ставит.
P>>Я уже привел кучу примеров. А вы всё никак. ·>Нигде не было неизвестных комбинаций параметров, не ври.
Это очевидно — никто не даст вам списка "вот только с этими комбинациями не всё в порядке". Вы будете узнавать о той или иной комбинации после креша на проде.
Поэтому вполне логично добавить пост-условие.
P>>Зачем contains ? Проверяться будет весь паттерн запроса, а не его фрагмент. ·>Как именно?
Вы то помните, то не помните. В данной задаче — просто сравнением sql. Назначение теста — зафиксировать паттерн.
P>>Не работает. Фильтры могут тащить из херовой тучи таблиц, связей итд. Вам надо самое меньшее — заполнение всех возможных данных, таблиц, связей и тд. И так на каждый тест. ·>Работает. И не на каждый тест, а на прогон практически всех тестов.
Т.е. вы уже меняете подход к тестам — изначально у вас было "записать три значения в бд и проверить, что они находятся фильтром"
P>>У вас здесь сложность растет экспоненциально. ·>Не растёт.
Растет. Докинули поле — нужно докинуть данных на все случаи, где это будет играть, включая паттерны строк, джойны, итд итд.
P>>Ну сейчас то понятно, что интеграционные никто не отменял, или еще месяц-два будете это игнорировать? ·>Я задал вопрос. Ты его удалил не ответив.
Цитирую себя N+5й и N+6й разы — выделил
п1 — паттерн тестируется на бд, далее — интеграционными тестами
...
1. рабочий паттерн запроса — это проверяется сначала руками, а потом тестом против бд минимально заполненой под задачу
P>>100к юзкейсов протестировать сложно, а написать легко? Чтото тут не сходится. ·>Ты откуда нателепатировал "сложно/легко"? Я написал про скорость прогона тестов.
Вот видите — это у вас времени на тесты не хватает, т.к. логику да комбинации вы чекаете на реальной бд
P>> Вы вероятно юзкейсом называете просто разные варианты параметров для одного и того же вызова контроллера. ·>Юзкейс — это в первом приближении кусочек спеки из бизнес-требования, одна хотелка заказчика.
Вам надо определиться — не то есть тесты, не то нету.Код написан — должны быть тесты. А на комбинации времени не хватает, т.к. через бд гоняете.
P>>Эти 30 комбинаций разложить по таблицам и колонкам и окажется в среднем около нуля на большинстве комбинаций фильров. ·>Почему так окажется? "все возможные кейсы что есть в бд прода, или нам известно, что такие будут.", т.е. раскладываются различные с т.з. бизнеса сущности, а не просто "Account 1", "Account 2".
Здравствуйте, Pauel, Вы писали:
>> В реальности интеграцией можно покрыть от силы 1% кейсов. P>Помните? Вот здесь вы написали обоснование тем самым тестам на проде.
Я здесь писал про интеграционные тесты вида "когда у нас дошла очередь интеграционного тестирования, где (медленно!) тащатся реальные данные из реальной базы, выполняется (медленный!) UI workflow с навигацией от логина до этого отчёта, и т.п.". И 1% тут получается не потому что нам лень покрывать всё на 100%, а потому что эти тесты медленные, т.е. 100% будет требовать в 100 раз больше времени, чем 1%. А с учётом праздников и выходных это означает, что вместо получаса это выльется в неделю.
P>Оставшиеся 99% ваши моки не заткнут, как бы вы не старались. Хоть обпишитесь.
Именно это и есть основное предназначение моков — ускорять процесс тестирования.
P>И даже если вы обмажетесь всеми возможными юнит-тестами, моками, какими угодно — покрытие интеграционными тестами в 1% говорит о том, что за продом нужно наблюдать более серьезными методами, нежели ваши health check. P>Для этого подходят e2e тесты — один такой тест может затронуть чуть не половину всех юзкейсов в приложении.
В хоумпейдж приложении — запросто. В реальном приложениии — всё грустно. Вот взять какой-нибудь FX Options. Есть несколько видов Options: Vanilla, Barrier, Binary, KnockIn/Out, Accumulator, Swap, Buttefly, &c. У каждого вида ещё нескольо вариаций Call/Put, Buy/Sell, Hi/Lo, &c. Потом разница algo/manual прайсинг, потом дюжина вариантов booking. И эти все комбинации — валидные сценарии. Одних таких тестов для разных комбинаций будут сотни. В e2e это будет часами тестироваться. Поэтому и приходится бить на части, мокать зависимости и тестировать по частям. Поэтому e2e тест будет один или около того, только одна конкретная комбинация. "Vanilla Buy Call, Auto Price, Execute, B2B Book -> assert trade reports, assert UI". Все остальные комбинации — должны быть покрыты быстрыми тестами.
P>Если же вы хотите заткнуть 99% непокрытых юзкейсов мониторингом на основе с healthcheck — чтото здесь не сходится.
Ты не понял что делает healthcheck.
P>>>Вы пока ошибок не показали. Основная ваша придирка в том, что структурная эквивалентность не нужна, хрупкая, итд — при этом альтернативы такому решению у вас нет. P>·>Это и есть ошибка. Плюс показал потенциальные ошибки например с дефолтным значением vs null. Альтернативу тоже показал. Происто ты проигнорировал. P>Вы показали теоретически возможные ошибки при построении запроса "а вдруг не учтем дефолтное значение". Ну так это и у вас будет — если чего то не учтете.
Если чего-то не учтёте — та же проблема и у вас. Я говорю о другом. Ты вроде учёл "а что если поле null" — и подставил nullзначение в своём pattern-тесте и прописал ожидания, тест зелёный. Но ты не учёл, что реальная субд null заменяет null на дефолтное значение и ведёт не так как ты предположил в своём тесте. А прогонять полные тесты "где (медленно!) тащатся реальные данные" для каждого поля где потенциально может быть null — ты не дождёшься окончания.
P>Ваша альтернатива не работает — упираемся в конское количество колонок, связей и разнообразия свойств внутри джсона — так вот всё хранится. P>И ваш подход к тестированию фильтров не палит.
Режь слона на части, тогда всё запалит.
P>>>А вот изменение имени пользователя спустя секунду после создания — очень даже адекватно. P>·>Ты путаешься в показаниях. Ты сам-то адекватен? Откуда взялось "50мс"??! Ты тут сказал, что синхронное сохранение внезапно заменил на асинхронное и у тебя возникли проблемы с тем, что теперь другой метод можно позвать только через 5 минут. P>Я такого не говорил — это вы начали фантазировать, что придется ждать 5 минут и никак иначе не выйдет. Обоснования у вас никакого нет.
Про 5 минут я не фантазировал, это твоя цитата.
P>>>public ssl key — ничего военного. Пересоздавать этот кей спустя секунду после создания занятие абсолютно бессмысленное. А вас послушать, так окажется что любые данные ассоциированые с пользователем могут меняться сразу же, включая гуиды ссылок на любую глубину связности. P>·>Я не знаю что это и какое это всё имеет отношение к обсуждаемому. P>Я вам привел пример, что данные разделяются на те, что нужны сейчас, и те, что нужны потом, когда нибудь. Так не бывает, что всё всегда нужно сразу на любую глубину вложенности. P>Если у вас хватает капасити обработать всё за один реквест — отлично. Самый простой вариант, без какого либо усложения архитектуры. P>Как только вашего капасити перестает хватать — см требованиия, там написано, что из данных юзера нужно сразу, а что нет.
Да похрен на архитектуру, главное — это означает, что какие-то операции временно перестанут работать как раньше, меняется happens-before гарантии. Появляется необходимость синхронизации, т.е. функциональное изменение, модификация API, документации и т.п. Тесты ну просто обязаны грохнуться!
P>·>Ты пишешь бред. Я задаю вопрос, ты игнорируешь и снова повторяешь то же самое. Попробуем ещё раз: P>·>Я читаю что написано. В цитате выше написано "тестируется" (само как-то?), потом стоит запятая и слово "далее" и про интеграционные тесты. Если эта твоя цитата не говорит что ты хочешь сказать, переформулируй, у меня очень плохо с телепатией. P>Цитирую себя N+3й и N+4й разы — выделил P>
P>п1 — паттерн тестируется на бд, далее — интеграционными тестами
P>...
P>1. рабочий паттерн запроса — это проверяется сначала руками, а потом тестом против бд минимально заполненой под задачу
Я тебе в N+5й раз повторяю. Твоя формулировка неоднозначна. Напиши чётко.
P>>>Пример недостаточно информативный. А вот сам подход — проверять построение запроса — очень даже хороший. P>·>Т.е. код не был даден. ЧТД. Куда отматывать-то? P>Структурная эквивалентность запроса — все что надо, было показано. Вам десяток страниц кода билдера фильтров показать или что?
Было показано deep.eq(..."some string"...), т.е. буквальное, посимвольное сравнение текста sql-запроса. Неясно где какой тут паттерн который ты "объясняешь", но код не показываешь.
P>>>Какого угодно. Если вам для запроса данных нужна цепочка джойнов или вложеный запрос — то это и есть паттерн. P>·>Это ты цель со средством путаешь. Мне надо чтобы запрос выдавал результат который нужен по спеке. А что там — цепочка джойнов или чёрт лысый — абсолютно пофиг. Более того, если сегодня написали запрос с джойнами, а завтра, после разговора с dba его переписали на вложенный — то ни один тест упасть не должен. P>Я ж вам сразу сказал — такой тест более хрупкий.
Не, ты это не говорил. Но не важно...
P>Его нужно применять ради решения конкретных проблем, а не лепить вообще везде. Одна из проблема — те самые фильтры.
...главное — неясно зачем писать такой хрупкий тест, когда можно банально гонять его же на бд, ровно с теми же сценариями и ассертами (ок, может чуть медленнее).
P>>>А так же надо учесть вещи вида "не делает то чего делать не должен". P>·>Мы говорим о тестах. Как тебе тесты помогут что-то гарантировать? Причём тут тесты??! P>Тесты пишутся именно ради гарантий: P>1 делает что надо P>2 не делает того, чего не надо
Так и я показал как учитывать такие вещи в тестах репо+бд.
P>>>Все что передается в eq — паттерн для теста. А ' наш конкретный запрос' тут проверяем паттерн запроса к бд. P>·>Здесь в коде это просто строка полного sql-запроса, которая сравнивается по equals. Я не понимаю почему ты это называешь паттерном, что в тут паттернится-то? P>Паттерн — потому, что название даётся по назначению. Назначение этого подхода — проверять построеный запрос на соответствие паттерну.
Словоблудие.
P>Если у вас есть более эффективный вариант, например, json-like или AST на алгебраических типах данных, будет еще лучше
Как это будет выглядеть в коде?
P>>>Вы показали примитивные тесты вида "положили в таблицу, проверили, что нашли положенное". А как протестировать "не нашли неположенного" или "не начали вгружать вообще всё" — вы такого не показали. P>·>Показал. Ещё раз разжую. Минимальный пример: Если мы в таблицу кладём "Vasya", то при поиске, например по шаблону по startsWith("Vas") — должны найти одну запись, а по startsWith("Vaz") — ноль. Второй тест как раз и ассертит, что твой этот фильтр не вгружает всё, а только то, что должно было заматчиться. Ещё раз. Одна запись в БД — это 21 вариантов результата, которые можно различить. P>Очень смешно. Как ваш пример экстраполировать на полторы сотни свойств разного рода — колонки, свойства внутри джсон колонокк, таблиц которые могут джойнами подтягиваться? P>Вы ранее говорили — 30 значений положить в бд. Это значит, что 120 свойств будут незаполнеными, и мы не узнаем или ваш запрос фильтрует, или же хавает пустые значения которые в проде окажутся непустыми.
Я имею в виду положить 30 записей. Фильтрами потом выбираем из этих 30 и проверяем, что выбраны только те записи, которые должны попадать под данный фильтр. У каждой записи может быть сколь угодно свойств.
P>>>И то, и другое вашими примитивными тестами не решается. P>·>Решается. P> P>Нисколько. Если вы положили в таблицу Vasya, то к нему нужно подкинуть полторы сотни так или иначе связанных с ним свойств. Не 30, как вам кажется, а минимум 150. И желательно, что бы таких васей было больше одного.
Ну да. И? Можешь сформировать как тестовый объект vasya и для него вызвать тот же repo.save(vasya). Т.е. вставляешь 30 вась в базу и фильтруешь их в хвост и гриву.
P>Фильтр будет не startwith, а P>1. конское количество условий — приоритеты, скобки P>2. паттерны строк что само по себе хороший цирк P>3. джойны в зависимости от условий итд P>4. приседания с джсон разной структуры P>5. группировки, агрегирование, итд
Ну это всё ты вроде сказал уже и так будет в твоих паттерн-тестах. Суть в том, что вместо тупого побуквенного сравнения sql-текста, они этот самый sql-текст выполнят на базе из 30и записей и заасертят выданный список.
P>Например — найти всех вась которые между июнем и июлем делали повторные возвраты товаров из перечня которые были куплены между январем и мартом оформлены менеджерами которые были наняты не позже декабря прошлого года и получив % от сделок уволились с августа по сентябрь P>Еще интереснее — найти все товары, которые двигались во всей этой кунсткамере.
И? А ты что предлагаешь? Запустить эту колбасу вручную на прод-базе и глазками проверить выдачу, что вроде похоже на правду?
P>>>Интеграционные нужны для проверки, что репо умеет работать с бд, а вовсе не для проверок комбинаций. Для проверок комбинаций есть другие методы, гораздо более эффективные. P>·>Что значит "умеет работать"? P>Например, репозиторий Users метод create — параметры — данные юзера, возвращаемое значение — созданный юзер + ассоциированные данные. Нас интересует P>1. разложит данные юзера в соответствии со схемой, подкинет гуид где надо P>2. построит запрос один или несколько, сколько надо для той бд-сервиса-итд, что в конфигурации P>3. отшлет вбд и вернет данные с запрошеными ассоциациями, иды, гуиды — будут соответсвовать схеме, входным данным итд P>4. подклеит метадату P>5. повторый запрос с тем же гуид должен зафейлиться с конкретной ошибкой P>6. такой же запрос с другим гуид должен выполнится хорошо P>7. корректно пробрасывать ошибки вида "дисконнект бд из за рестарта" P>8. сумеет в опции — ничего не тащить из бд если был флаг write-only
Давай теперь по каждому из этих пунктов, как это валидируется в твоих интеграционных тестах.
А то вообще, внезапно может случиться так, что в тесте результат подсосался из кеша и до репы вообще дело не долшо?
P>А вот всё множество комбинаций в фильтрах нужно покрывать совсем другими тестами.
Т.е. если одна из комбинаций фильтров нарушит, скажем пункт 8, то ты об этом узнаешь только в проде от счастливых юзеров.
P>>>Вы только что "показали" — для проверок комбинций использовать интеграционный тест репо+бд P>·>Почему нет-то? P>Потому, что P>1 это медленно
Согласен, медленнее, т.к. лезет в бд. Но бд может выполнять тысячи запросов в секунду.
P>2 вы подкидываете небольшое количество значений. Смотрите пример фильтра с васями, только не ваш, а мой
Подкидывай большое число значений. Разрешаю.
P>>>Могу. Например, для тестов которые тянут больше одной строки могу просто затребовать `LIMIT 10`. P>·>Как? P>Вот так: P>`конский запрос LIMIT 10`
Согласен, иногда такое может сработать, не помню как оно себя поведёт с какими-нибудь union... Да ещё и в разных базах этот самый LIMIT может выглядеть по-разному. А как ты будешь отличать "тянут больше одной строки"?
P>И добавить подобное в тесты всех критических запросов. P>Т.е. это просто пост условие, и давать будет ровно те же гарантии.
Неясно как это согласуется с бизнес-требованиями.
P>>>Не я, а вы. Это у вас комбинации покрываются repo+db тестами. А мне достаточно гарантировать наличие свойства запроса. см пример с LIMIT 10 выше. И это свойство сохранится на все времена, а потому проблема останова для меня здесь неактуальна. P>·>Гарантировать наличие любого нетривиального свойства у кода (а запрос — это код) — алгоритмически неразрешимая задача (т. Райса), значит тесты тут никоим образом не помогут. P>Теорема Райса про алгоритмы и свойства функций, а не про код. — код это один из видов формальной записи алгоритмов. А функции (ты наверно имеешь в виду чрф) эквивалентны алгоритмам по тезису Тьюринга-Чёрча. Ок... С натяжкой можно сказать, что sql не является тьюринг-полным (обычно), поэтому по его коду можно иногда определить его некоторые свойства.
P>Забавно, что вы только что сами себе рассказали, почему любые ваши тесты без толку. Только такого рода гарантий тестами вообще никто никогда не ставит.
Поправил, чтобы верно стало. Я это давно тебе пытаюсь объяснить. Наконец-то ты начал чего-то подозревать.
P>>>Я уже привел кучу примеров. А вы всё никак. P>·>Нигде не было неизвестных комбинаций параметров, не ври. P>Это очевидно — никто не даст вам списка "вот только с этими комбинациями не всё в порядке". Вы будете узнавать о той или иной комбинации после креша на проде. P>Поэтому вполне логично добавить пост-условие.
Ну добавь. Тесты тут не причём. Сразу замечу, что тестировать наличие постусловий — это уже лютейший бред.
P>>>Зачем contains ? Проверяться будет весь паттерн запроса, а не его фрагмент. P>·>Как именно? P>Вы то помните, то не помните. В данной задаче — просто сравнением sql. Назначение теста — зафиксировать паттерн.
Назначение теста — это твои фантазии. Суть теста — это то что он делает по факту. А по факту он сравнивает побуквенно sql, а паттерны запроса и прочие страшные слова — это пустое словоблудие.
P>>>Не работает. Фильтры могут тащить из херовой тучи таблиц, связей итд. Вам надо самое меньшее — заполнение всех возможных данных, таблиц, связей и тд. И так на каждый тест. P>·>Работает. И не на каждый тест, а на прогон практически всех тестов. P>Т.е. вы уже меняете подход к тестам — изначально у вас было "записать три значения в бд и проверить, что они находятся фильтром"
Ты опять врёшь. Вот моя настоящая цитата: "Достаточно иметь одно значение и слать разные фильтры.". Открой мой код и прочитай его ещё раз. Внимательно.
P>>>У вас здесь сложность растет экспоненциально. P>·>Не растёт. P>Растет. Докинули поле — нужно докинуть данных на все случаи, где это будет играть, включая паттерны строк, джойны, итд итд.
Ок, переформулирую. Сложность у нас растёт ровно так же, как и у вас.
P>>>Ну сейчас то понятно, что интеграционные никто не отменял, или еще месяц-два будете это игнорировать? P>·>Я задал вопрос. Ты его удалил не ответив. P>Цитирую себя N+5й и N+6й разы — выделил
Ты написал: "паттерн тестируется на бд, далее — интеграционными тестами". Я спрашиваю: как паттерн тестируется на бд _перед_ интеграционными тестами?
P>1. рабочий паттерн запроса — это проверяется сначала руками, а потом тестом против бд минимально заполненой под задачу
Каким именно тестом? Как этот тест выглядит и какой код этот тест покрывает?
P>>>100к юзкейсов протестировать сложно, а написать легко? Чтото тут не сходится. P>·>Ты откуда нателепатировал "сложно/легко"? Я написал про скорость прогона тестов. P>Вот видите — это у вас времени на тесты не хватает, т.к. логику да комбинации вы чекаете на реальной бд
На реальной бд мы чекаем только связку бд+репо, т.е. код персистенса, а не логику и комбинации.
P>>>Эти 30 комбинаций разложить по таблицам и колонкам и окажется в среднем около нуля на большинстве комбинаций фильров. P>·>Почему так окажется? "все возможные кейсы что есть в бд прода, или нам известно, что такие будут.", т.е. раскладываются различные с т.з. бизнеса сущности, а не просто "Account 1", "Account 2". P>У вас комбинаций меньше чем условий в фильтре.
30 это было число записей, которые могут обеспечить 230 комбинаций. Тебе столько не хватает?
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
>>> В реальности интеграцией можно покрыть от силы 1% кейсов. P>>Помните? Вот здесь вы написали обоснование тем самым тестам на проде. ·>Я здесь писал про интеграционные тесты вида "когда у нас дошла очередь интеграционного тестирования, где (медленно!) тащатся реальные данные из реальной базы, выполняется (медленный!) UI workflow с навигацией от логина до этого отчёта, и т.п.". И 1% тут получается не потому что нам лень покрывать всё на 100%, а потому что эти тесты медленные, т.е. 100% будет требовать в 100 раз больше времени, чем 1%. А с учётом праздников и выходных это означает, что вместо получаса это выльется в неделю.
Будут. Но их всё равно нужно делать, т.к. никакие другие виды тестов их не заменяют, только кое где могут скомпенсировать.
Например — если логика сложная, а воркфлоу простой, то можно забить на e2e и заложиться на юнит-тесты.
Если у вас сложный воркфлоу, то его нечем протестировать, кроме вот этих e2e
P>>Оставшиеся 99% ваши моки не заткнут, как бы вы не старались. Хоть обпишитесь. ·>Именно это и есть основное предназначение моков — ускорять процесс тестирования.
Вы сейчас снова утверждаете, что моки могут заменять интеграционные.
Не могут — моки по своей сути подменяют интеграцию отсебятиной.
И вы проверяете, что ваш код справляется с этой отсебятиной.
Как он будет справляться с интеграцией — остаётся неизвестным, вообще.
Ответ даёт исключительно прямая проверка этой интеграции
P>>Для этого подходят e2e тесты — один такой тест может затронуть чуть не половину всех юзкейсов в приложении. ·>В хоумпейдж приложении — запросто. В реальном приложениии — всё грустно. Вот взять какой-нибудь FX Options. Есть несколько видов Options: Vanilla, Barrier, Binary, KnockIn/Out, Accumulator, Swap, Buttefly, &c. У каждого вида ещё нескольо вариаций Call/Put, Buy/Sell, Hi/Lo, &c. Потом разница algo/manual прайсинг, потом дюжина вариантов booking. И эти все комбинации — валидные сценарии. Одних таких тестов для разных комбинаций будут сотни. В e2e это будет часами тестироваться. Поэтому и приходится бить на части, мокать зависимости и тестировать по частям.
Итого, с ваших слов "задача сложная, нахер e2e, будем моки писать и сделаем вид, что это равноценная замена"
e2e у вас должен покрывать все ключевые опции, т.к. это разные сценарии.
Еще раз — все.
Если вам непонятно — все означает все.
На случай если вы и здесь игнорите — все.
Вопрос только в том, как вы будете временем распоряжяться.
1 Аксиома — количество юнит-тестов и полуинтеграционных на моках никак не влияет на количество e2e. Никак, нисколько!
юниты и ваши полуинтеграционные пишите сколько надо, что бы быстро детектить мелочевку во время разработки
2 e2e можно сделать так —
— при билде — три самых частых
— при деплое — три десятка самых частых
— после деплоя — всё вместе, рандомно, то одно, то другое, с таким расчетом, что бы за день вы получили сведения что где может отвалиться
Итого — ваши 99% кейсов вы будете тестировать после деплоя. Боитесь делать это на проде — делайте на стейдже, деве и тд.
Как решить:
1. деплоймент, например, стейдж, отдаёт манифест — версия-тег, урл репозитория с тестами конкретной этой версии.
2. e2e тесты умеют запуск рандомного сценария
3. каждые N минут запускаете `curl <stage>/manifest.test | run-test --random --url <stage>`
4. результаты запусков кладете не абы куда, а в репозиторий
5. в каждый момент времени вы можете обновить этот репозиторий и посмотреть состояние всего, что у вас происходит
6. сыплются ошибки — заводятся баги
P>>Если же вы хотите заткнуть 99% непокрытых юзкейсов мониторингом на основе с healthcheck — чтото здесь не сходится. ·>Ты не понял что делает healthcheck.
Это ж не я пытаюсь заменить 99% e2e тестов моками.
P>>Вы показали теоретически возможные ошибки при построении запроса "а вдруг не учтем дефолтное значение". Ну так это и у вас будет — если чего то не учтете. ·>Если чего-то не учтёте — та же проблема и у вас. Я говорю о другом. Ты вроде учёл "а что если поле null" — и подставил nullзначение в своём pattern-тесте и прописал ожидания, тест зелёный. Но ты не учёл, что реальная субд null заменяет null на дефолтное значение и ведёт не так как ты предположил в своём тесте. А прогонять полные тесты "где (медленно!) тащатся реальные данные" для каждого поля где потенциально может быть null — ты не дождёшься окончания.
Это полные тесты, где всё тащится медленно и реально — они нужны и вам, и мне. Если вы не учли этот кейс с нулём, то будет проблема. Ровно так же и у меня.
P>>Ваша альтернатива не работает — упираемся в конское количество колонок, связей и разнообразия свойств внутри джсона — так вот всё хранится. P>>И ваш подход к тестированию фильтров не палит. ·>Режь слона на части, тогда всё запалит.
Не запалит. По частям мы выясним, что каждая часть по отдельности работает. А вот как поведут себя комбинации частей — остаётся неизвестным.
И задача с фильтрами это про комбинации
P>>Я такого не говорил — это вы начали фантазировать, что придется ждать 5 минут и никак иначе не выйдет. Обоснования у вас никакого нет. ·>Про 5 минут я не фантазировал, это твоя цитата.
Я нигде не говорил, что юзер должен ждать 5 минут. Даже если профиль создаётся неделю, редактировать данные можно сразу.
Вам нужно спросить у BA, какие данные надо сейчас, а какие — вообще.
P>>Если у вас хватает капасити обработать всё за один реквест — отлично. Самый простой вариант, без какого либо усложения архитектуры. P>>Как только вашего капасити перестает хватать — см требованиия, там написано, что из данных юзера нужно сразу, а что нет. ·>Да похрен на архитектуру, главное — это означает, что какие-то операции временно перестанут работать как раньше, меняется happens-before гарантии. Появляется необходимость синхронизации, т.е. функциональное изменение, модификация API, документации и т.п. Тесты ну просто обязаны грохнуться!
Вы похоже так и не поняли, что такое функциональные требования, а что такое нефункциональные.
Пример:
Функциональные — админ может создать спейс для юзера, админ может отредактировать профиль юзера.
Нефункциональные — профиль юзера можно редактировать сразу после создания. Профиль юзера создаётся за 100 мсек. админ не должен ждать чего то там.
Вы сами себе придумали какой то вариант, где сделано заведомо кривое решение, и теперь рассказываете будто это самый типичный случай.
На самом деле нет — см функциональные и нефункциональные требования.
Зачем вам менять апишку для этого кейса?
P>>·>Я читаю что написано. В цитате выше написано "тестируется" (само как-то?), потом стоит запятая и слово "далее" и про интеграционные тесты. Если эта твоя цитата не говорит что ты хочешь сказать, переформулируй, у меня очень плохо с телепатией. P>>Цитирую себя N+3й и N+4й разы — выделил P>>
P>>п1 — паттерн тестируется на бд, далее — интеграционными тестами
P>>...
P>>1. рабочий паттерн запроса — это проверяется сначала руками, а потом тестом против бд минимально заполненой под задачу
·>Я тебе в N+5й раз повторяю. Твоя формулировка неоднозначна. Напиши чётко.
Я не в курсе, что именно вам непонятно
Какой вопрос вы не озвочили — мне неизвестно.
На мой взгляд что надо в моем ответе есть
1. кто тестирует
2. на чем тестирует
3. какими тестами
4. какая бд и чем заполнена
Что вам в этом ответе непонятно? Что конкретно? Вы вопрос внятно сформулировать можете или мне за вас это делать четвертый месяц?
P>>Структурная эквивалентность запроса — все что надо, было показано. Вам десяток страниц кода билдера фильтров показать или что? ·>Было показано deep.eq(..."some string"...), т.е. буквальное, посимвольное сравнение текста sql-запроса. Неясно где какой тут паттерн который ты "объясняешь", но код не показываешь.
проверка паттерна посимвольным сравнением
1. что делаем — сравниваем посимвольно, т.к. другого варианта нет — на одну задачу пилить ast на алгебраических типах данных это овердохрена
2. для чего делаем — что бы зафиксировать паттерн
P>>Его нужно применять ради решения конкретных проблем, а не лепить вообще везде. Одна из проблема — те самые фильтры. ·>...главное — неясно зачем писать такой хрупкий тест, когда можно банально гонять его же на бд, ровно с теми же сценариями и ассертами (ок, может чуть медленнее).
Я ж вас попросил — покажите тест, который на неизвестной комбинации фильтров будет гарантировано вгружать в память не более 10 строк.
Вы до сих пор такой тест не показали
P>>Тесты пишутся именно ради гарантий: P>>1 делает что надо P>>2 не делает того, чего не надо ·>Так и я показал как учитывать такие вещи в тестах репо+бд.
Я ж вас попросил — покажите тест, который на неизвестной комбинации фильтров будет гарантировано вгружать в память не более 10 строк.
Вы до сих пор такой тест не показали
P>>Паттерн — потому, что название даётся по назначению. Назначение этого подхода — проверять построеный запрос на соответствие паттерну. ·>Словоблудие.
Вы в который раз просите объяснений, и тут же всё это обесцениваете.
Зачем вы вообще сюда пишете, показать, что у вас адекватных, релевантных аргументов нет, или что "в интернете ктото неправ" ?
P>>Если у вас есть более эффективный вариант, например, json-like или AST на алгебраических типах данных, будет еще лучше ·>Как это будет выглядеть в коде?
В результате этот request вы сможете сравнить с другим, как целиком, так и частично.
Например, у нас здесь простой паттерн — выбрать десять последних с простым фильтром.
Например, для такого паттерна я могу написать тест, который будет ограничивать filterExpression простыми выражениями
Можно ограничить таблицы, из которых может или не может делаться джойн итд
P>>Очень смешно. Как ваш пример экстраполировать на полторы сотни свойств разного рода — колонки, свойства внутри джсон колонокк, таблиц которые могут джойнами подтягиваться? P>>Вы ранее говорили — 30 значений положить в бд. Это значит, что 120 свойств будут незаполнеными, и мы не узнаем или ваш запрос фильтрует, или же хавает пустые значения которые в проде окажутся непустыми. ·>Я имею в виду положить 30 записей. Фильтрами потом выбираем из этих 30 и проверяем, что выбраны только те записи, которые должны попадать под данный фильтр. У каждой записи может быть сколь угодно свойств.
Кто вам скажет, что в ваших этих 30 записях есть все потенциально опасные или невалидные комбинации?
P>>Например — найти всех вась которые между июнем и июлем делали повторные возвраты товаров из перечня которые были куплены между январем и мартом оформлены менеджерами которые были наняты не позже декабря прошлого года и получив % от сделок уволились с августа по сентябрь P>>Еще интереснее — найти все товары, которые двигались во всей этой кунсткамере. ·>И? А ты что предлагаешь? Запустить эту колбасу вручную на прод-базе и глазками проверить выдачу, что вроде похоже на правду?
Вручную всё равно придется проверять, это обязательный этап — с этого всё начинается.
P>>Например, репозиторий Users метод create — параметры — данные юзера, возвращаемое значение — созданный юзер + ассоциированные данные. Нас интересует P>>1. разложит данные юзера в соответствии со схемой, подкинет гуид где надо P>>2. построит запрос один или несколько, сколько надо для той бд-сервиса-итд, что в конфигурации P>>3. отшлет вбд и вернет данные с запрошеными ассоциациями, иды, гуиды — будут соответсвовать схеме, входным данным итд P>>4. подклеит метадату P>>5. повторый запрос с тем же гуид должен зафейлиться с конкретной ошибкой P>>6. такой же запрос с другим гуид должен выполнится хорошо P>>7. корректно пробрасывать ошибки вида "дисконнект бд из за рестарта" P>>8. сумеет в опции — ничего не тащить из бд если был флаг write-only ·>Давай теперь по каждому из этих пунктов, как это валидируется в твоих интеграционных тестах.
Эта часть же как и у вас. Это именно интеграционный тест репозитория.
Только сверх этого вы собираетесь и комбинации фильтров гонять здесь же. И на мой взгляд это совсем не то, чем нужно заниматься в этом виде тестов.
P>>А вот всё множество комбинаций в фильтрах нужно покрывать совсем другими тестами. ·>Т.е. если одна из комбинаций фильтров нарушит, скажем пункт 8, то ты об этом узнаешь только в проде от счастливых юзеров.
А у вас как будет? Сколько процентов комбинаций вам известно и сколько из них вы покрыли интеграционным тестом?
Вы только недавно жаловались, что у вас покрывается внятно только 1% кейсов
Поскольку комбинаций фильтров может быть на порядки больше, чем вы можете позволить себе покрыть тестами, то:
1 подкинули флаг и выхлоп пустой — интеграционный тест, по одному на самые частые паттерны запросов
1. update — возвращаем пусто если write-only, или новое состояние
2. get — кидаем исключение, если write-only
3. итд
2 пост-условие — выхлоп пустой — это не тест, а именно пост-условие. Та часть которая вам непонятна последние 4 месяца
3 логирование — выхлоп игнорируется, если есть, с записью в лог, далее — всплывет в мониторинге при первом же случае.
4 дизайн — пре-, и пост-процессинг определяется маппером, а не набором if. Маппер тестируем юнит тестами.
P>>2 вы подкидываете небольшое количество значений. Смотрите пример фильтра с васями, только не ваш, а мой ·>Подкидывай большое число значений. Разрешаю.
Проблемные комбинации вам неизвестны.
Что будете в тест писать ?
P>>`конский запрос LIMIT 10` ·>Согласен, иногда такое может сработать, не помню как оно себя поведёт с какими-нибудь union... Да ещё и в разных базах этот самый LIMIT может выглядеть по-разному. А как ты будешь отличать "тянут больше одной строки"?
Это же в операции известно, какие данные она возвращает. Если users.byId() то очевидно здесь один. А если users.where — вот тут а хрен его знает
P>>Т.е. это просто пост условие, и давать будет ровно те же гарантии. ·>Неясно как это согласуется с бизнес-требованиями.
У вас что, в требованиях позволено сдыхать при процессинге?
1 Нужно обработать весь объем данных
2 дизайн под обработку частями
3 запросы в соответствии с дизайном
4 тесты запросов на соответствие с дизайном, решает вопрос с "я быстренько, там всё просто"
5 код ревью "не выключил ли кто тесты а б и цэ"
ут. P>>Теорема Райса про алгоритмы и свойства функций, а не про код. ·> — код это один из видов формальной записи алгоритмов.
Если пользоваться вашим пониманием т. Райса, то например тесты это тот алгоритм, которому нужно выяснить наличие свойств у функции system-under-test
И тут мы узнаем... что тестами ничо не сделаешь. Гы-гы.
Как только вам это стало понятно, нужно вспомнить, что тестами вы выражаете свои собственные ожидания. Даже если вы их взяли из спеке — интерпретация все равно ваша собственная, и вы в тестах фиксируете свои ожидания от того, как в каких случаях работет система
Соотвественно, гарантии у вас будут не с т.з. т.Райса, а с т.з. вероятностей
— функция которая проходит тесты по таблице истинности подходит лучше, чем та, которая эти тесты не проходит
P>>Забавно, что вы только что сами себе рассказали, почему любые ваши тесты без толку. Только такого рода гарантий тестами вообще никто никогда не ставит. ·>Поправил, чтобы верно стало. Я это давно тебе пытаюсь объяснить. Наконец-то ты начал чего-то подозревать.
Вам стоило бы почитать Гленфорда Майерса — он объясняет подробно, что к чему, откуда какие гарантии берутся
P>>Поэтому вполне логично добавить пост-условие. ·>Ну добавь. Тесты тут не причём. Сразу замечу, что тестировать наличие постусловий — это уже лютейший бред.
У вас всё бред, чего вы не понимаете
P>>Вы то помните, то не помните. В данной задаче — просто сравнением sql. Назначение теста — зафиксировать паттерн. ·>Назначение теста — это твои фантазии. Суть теста — это то что он делает по факту. А по факту он сравнивает побуквенно sql, а паттерны запроса и прочие страшные слова — это пустое словоблудие.
Давайте проверим. Покажите мне пример, как изменение паттерна, структуры запроса будет зеленым в таком тесте.
P>>Т.е. вы уже меняете подход к тестам — изначально у вас было "записать три значения в бд и проверить, что они находятся фильтром" ·>Ты опять врёшь. Вот моя настоящая цитата: "Достаточно иметь одно значение и слать разные фильтры.". Открой мой код и прочитай его ещё раз. Внимательно.
Это еще слабее тест. С одним значением мы не в курсе, а не вгружает ли ваш фильтр секретные данные каким либо джойном
P>>Растет. Докинули поле — нужно докинуть данных на все случаи, где это будет играть, включая паттерны строк, джойны, итд итд. ·>Ок, переформулирую. Сложность у нас растёт ровно так же, как и у вас.
В том то и дело, что растет экспоненциально.
·>Ты написал: "паттерн тестируется на бд, далее — интеграционными тестами". Я спрашиваю: как паттерн тестируется на бд _перед_ интеграционными тестами?
Первые запуски — руками. Потом автоматизируете и получаете интеграционный тест.
P>>Вот видите — это у вас времени на тесты не хватает, т.к. логику да комбинации вы чекаете на реальной бд ·>На реальной бд мы чекаем только связку бд+репо, т.е. код персистенса, а не логику и комбинации.
Вы совсем недавно собирались все комбинации тестировать, разве нет?
Если нет, то ваши же слова
"если одна из комбинаций фильтров нарушит, скажем пункт 8, то ты об этом узнаешь только в проде от счастливых юзеров."
P>>У вас комбинаций меньше чем условий в фильтре. ·>30 это было число записей, которые могут обеспечить 230 комбинаций. Тебе столько не хватает?
Фильтры дают на десяток порядков больше комбинаций. В этом и проблем
Здравствуйте, Pauel, Вы писали:
P>·>Я здесь писал про интеграционные тесты вида "когда у нас дошла очередь интеграционного тестирования, где (медленно!) тащатся реальные данные из реальной базы, выполняется (медленный!) UI workflow с навигацией от логина до этого отчёта, и т.п.". И 1% тут получается не потому что нам лень покрывать всё на 100%, а потому что эти тесты медленные, т.е. 100% будет требовать в 100 раз больше времени, чем 1%. А с учётом праздников и выходных это означает, что вместо получаса это выльется в неделю. P>Будут. Но их всё равно нужно делать, т.к. никакие другие виды тестов их не заменяют, только кое где могут скомпенсировать.
Нужно, но как-то всё равно придётся покрывать остальные 99%. Вот тут и приходят на помощь моки и конф-тесты.
P>Например — если логика сложная, а воркфлоу простой, то можно забить на e2e и заложиться на юнит-тесты. P>Если у вас сложный воркфлоу, то его нечем протестировать, кроме вот этих e2e
Я тебе уже рассказал чем: моки и конф-тесты.
P>>>Оставшиеся 99% ваши моки не заткнут, как бы вы не старались. Хоть обпишитесь. P>·>Именно это и есть основное предназначение моков — ускорять процесс тестирования. P>Вы сейчас снова утверждаете, что моки могут заменять интеграционные. P>Не могут — моки по своей сути подменяют интеграцию отсебятиной.
Не только моки, но конф-тесты. Плюс соответствующий дизайн и процесс разработки.
P>И вы проверяете, что ваш код справляется с этой отсебятиной. P>Как он будет справляться с интеграцией — остаётся неизвестным, вообще.
Я тебе уже объяснил как это сделать известным.
P>Ответ даёт исключительно прямая проверка этой интеграции
Нет, не исключительно.
P>>>Для этого подходят e2e тесты — один такой тест может затронуть чуть не половину всех юзкейсов в приложении. P>·>В хоумпейдж приложении — запросто. В реальном приложениии — всё грустно. Вот взять какой-нибудь FX Options. Есть несколько видов Options: Vanilla, Barrier, Binary, KnockIn/Out, Accumulator, Swap, Buttefly, &c. У каждого вида ещё нескольо вариаций Call/Put, Buy/Sell, Hi/Lo, &c. Потом разница algo/manual прайсинг, потом дюжина вариантов booking. И эти все комбинации — валидные сценарии. Одних таких тестов для разных комбинаций будут сотни. В e2e это будет часами тестироваться. Поэтому и приходится бить на части, мокать зависимости и тестировать по частям. P>Итого, с ваших слов "задача сложная, нахер e2e, будем моки писать и сделаем вид, что это равноценная замена"
Не "нахер e2e", а "хрень получается с e2e".
P>e2e у вас должен покрывать все ключевые опции, т.к. это разные сценарии. P>Еще раз — все. P>Если вам непонятно — все означает все. P>На случай если вы и здесь игнорите — все. P>Вопрос только в том, как вы будете временем распоряжяться. P>1 Аксиома — количество юнит-тестов и полуинтеграционных на моках никак не влияет на количество e2e. Никак, нисколько!
Тавтология. Я говорю о другом: количество e2e ограничивается доступными ресурсами. Чем меньше доступных e2e, тем больше приходится вкладываться в юнит и "полуинтеграционные".
P> юниты и ваши полуинтеграционные пишите сколько надо, что бы быстро детектить мелочевку во время разработки P>2 e2e можно сделать так - P>- при билде — три самых частых P>- при деплое — три десятка самых частых P>- после деплоя — всё вместе, рандомно, то одно, то другое, с таким расчетом, что бы за день вы получили сведения что где может отвалиться
Не годится. Мы не можем релизиться только с тремя десятками сценариев. Надо проверять 100%.
P>Итого — ваши 99% кейсов вы будете тестировать после деплоя. Боитесь делать это на проде — делайте на стейдже, деве и тд.
Не можем мы деплоить продукт оттестированный на 1%.
P>Как решить: P>1. деплоймент, например, стейдж, отдаёт манифест — версия-тег, урл репозитория с тестами конкретной этой версии. P>2. e2e тесты умеют запуск рандомного сценария P>3. каждые N минут запускаете `curl <stage>/manifest.test | run-test --random --url <stage>` Т.е. качество продукта проверяем случайно. Это только для хоумпейджей годится.
P>4. результаты запусков кладете не абы куда, а в репозиторий P>5. в каждый момент времени вы можете обновить этот репозиторий и посмотреть состояние всего, что у вас происходит P>6. сыплются ошибки — заводятся баги
P>>>Если же вы хотите заткнуть 99% непокрытых юзкейсов мониторингом на основе с healthcheck — чтото здесь не сходится. P>·>Ты не понял что делает healthcheck. P>Это ж не я пытаюсь заменить 99% e2e тестов моками.
Тебе повезло, что вам позволительно сыпаться ошибками в проде.
P>>>Вы показали теоретически возможные ошибки при построении запроса "а вдруг не учтем дефолтное значение". Ну так это и у вас будет — если чего то не учтете. P>·>Если чего-то не учтёте — та же проблема и у вас. Я говорю о другом. Ты вроде учёл "а что если поле null" — и подставил nullзначение в своём pattern-тесте и прописал ожидания, тест зелёный. Но ты не учёл, что реальная субд null заменяет null на дефолтное значение и ведёт не так как ты предположил в своём тесте. А прогонять полные тесты "где (медленно!) тащатся реальные данные" для каждого поля где потенциально может быть null — ты не дождёшься окончания. P>Это полные тесты, где всё тащится медленно и реально — они нужны и вам, и мне. Если вы не учли этот кейс с нулём, то будет проблема. Ровно так же и у меня.
Ясен пень. Ты вообще читаешь что я пишу? Суть в том, что даже если вы учли кейс с нулём, то у вас всё равно будет проблема, а нас проблемы не будет.
P>·>Режь слона на части, тогда всё запалит. P>Не запалит. По частям мы выясним, что каждая часть по отдельности работает. А вот как поведут себя комбинации частей — остаётся неизвестным.
Угу, вот поэтому и придётся выдумывать правильную архитектуру и подходы контроля качества, чтобы риск неизвестного минимизировать.
P>И задача с фильтрами это про комбинации
Может я не понял твою задачу правильно, но в моём понимании, фильтры это задача которая сводится к одному компоненту, который может быть протестирован отдельно, а не комбинации различных компонент, которые надо интегрировать и тестировать целиком. Для тестирования фильтров не нужно "выполняется (медленный!) UI workflow с навигацией от логина до этого отчёта", не нужен логин и UI для тестирования комбинации фильтров.
P>>>Я такого не говорил — это вы начали фантазировать, что придется ждать 5 минут и никак иначе не выйдет. Обоснования у вас никакого нет. P>·>Про 5 минут я не фантазировал, это твоя цитата. P>Я нигде не говорил, что юзер должен ждать 5 минут. Даже если профиль создаётся неделю, редактировать данные можно сразу.
Говорил, цитирую: чудесные вещи типа "после того, как сделал var u = service.CreateUser(...), нужно выждать не менее 5 минут перед service.UpdateUser(u, ...)".
P>Вам нужно спросить у BA, какие данные надо сейчас, а какие — вообще.
Именно — вопросы за которые отвечает BA — это функциональные требования по сути.
P>·>Да похрен на архитектуру, главное — это означает, что какие-то операции временно перестанут работать как раньше, меняется happens-before гарантии. Появляется необходимость синхронизации, т.е. функциональное изменение, модификация API, документации и т.п. Тесты ну просто обязаны грохнуться! P>Вы похоже так и не поняли, что такое функциональные требования, а что такое нефункциональные. P>Пример: P>Функциональные — админ может создать спейс для юзера, админ может отредактировать профиль юзера. P>Нефункциональные — профиль юзера можно редактировать сразу после создания. Профиль юзера создаётся за 100 мсек. админ не должен ждать чего то там.
У тебя есть бизнес-функция "создать юзера". Результат который возвращается из этой функции — это тоже функциональный элемент. Результат говорит о том, что что-то произошло. Если ты вместо того, чтобы сделать саму операцию кладёшь что-то в очередь, то и результат функции меняется — вместо "что-то произошло", будет "что-то произойдёт".
P>Вы сами себе придумали какой то вариант, где сделано заведомо кривое решение, и теперь рассказываете будто это самый типичный случай.
Это не я придумал, это ты придумал.
P>На самом деле нет — см функциональные и нефункциональные требования. P>Зачем вам менять апишку для этого кейса?
Затем, что функция API "выполнить действие X" != "положить в очередь чтобы действие X когда-нибудь выполнилось (может быть)". Апишка просто обязана быть разной, чтобы не было таких "чудесных вещей", которые ты так любишь.
P>>>
P>>>п1 — паттерн тестируется на бд, далее — интеграционными тестами
P>>>...
P>>>1. рабочий паттерн запроса — это проверяется сначала руками, а потом тестом против бд минимально заполненой под задачу
P>·>Я тебе в N+5й раз повторяю. Твоя формулировка неоднозначна. Напиши чётко. P>Я не в курсе, что именно вам непонятно P>Какой вопрос вы не озвочили — мне неизвестно. P>На мой взгляд что надо в моем ответе есть P>1. кто тестирует
Из слов "паттерн тестируется" неясно кем.
P>3. какими тестами
Из слов "паттерн тестируется" неясно какими тестами.
P>>>Структурная эквивалентность запроса — все что надо, было показано. Вам десяток страниц кода билдера фильтров показать или что? P>·>Было показано deep.eq(..."some string"...), т.е. буквальное, посимвольное сравнение текста sql-запроса. Неясно где какой тут паттерн который ты "объясняешь", но код не показываешь. P>проверка паттерна посимвольным сравнением P>1. что делаем — сравниваем посимвольно, т.к. другого варианта нет — на одну задачу пилить ast на алгебраических типах данных это овердохрена
Другой вариант я рассказал — выполнить запрос на базе и заасертить результат.
P>2. для чего делаем — что бы зафиксировать паттерн
Зачем?
P>>>Его нужно применять ради решения конкретных проблем, а не лепить вообще везде. Одна из проблема — те самые фильтры. P>·>...главное — неясно зачем писать такой хрупкий тест, когда можно банально гонять его же на бд, ровно с теми же сценариями и ассертами (ок, может чуть медленнее). P>Я ж вас попросил — покажите тест, который на неизвестной комбинации фильтров будет гарантировано вгружать в память не более 10 строк. P>Вы до сих пор такой тест не показали
Это не покрывается тестами принципиально.
Только если у тебя какой-то очень частый случай и ты завязываешься на какую-то конкретную реализацию — а это значит, что у тебя тесты не будут тестировать даже регрессию.
P>>>Паттерн — потому, что название даётся по назначению. Назначение этого подхода — проверять построеный запрос на соответствие паттерну. P>·>Словоблудие. P>Вы в который раз просите объяснений, и тут же всё это обесцениваете.
Я никогда не просил объяснений, я просил код. Ибо по коду видны факты, а не твои фантазии. Так что не удивляйся, что твои объяснения являются словоблудием. Просто объявить "этот код будет проверять построеный запрос на соответствие паттерну" — этого мало. Надо чтобы написанный код действтительно это делал. У тебя же код тупо проверяет sql-текст запроса и имена приватных методов. Никаих паттернов нет, как бы тебе этого ни хотелось.
P>Зачем вы вообще сюда пишете, показать, что у вас адекватных, релевантных аргументов нет, или что "в интернете ктото неправ" ?
Чтобы обсуждать факты, а не фантазии.
P>>>Если у вас есть более эффективный вариант, например, json-like или AST на алгебраических типах данных, будет еще лучше P>·>Как это будет выглядеть в коде? P>Примерно так: P>
P>В результате этот request вы сможете сравнить с другим, как целиком, так и частично. P>Например, у нас здесь простой паттерн — выбрать десять последних с простым фильтром. P>Например, для такого паттерна я могу написать тест, который будет ограничивать filterExpression простыми выражениями P>Можно ограничить таблицы, из которых может или не может делаться джойн итд
Т.е. в тесте ты единственное что можешь зафиксировать, что в коде у тебя действительно стоит .top(10). И что? Зачем? Наличие .top(10) и так видно, оно уже и так явно прописано в коде.
Чем тест поможет? В лучшем случе — тем, что если кто-то случайно удалит .top(10) в коде, но забудет в тесте?
Но если тебе лично так хочется для личного спокойствия, то такое и с моками можно заасертить "в коде есть такая деталь реализации".
P>>>Очень смешно. Как ваш пример экстраполировать на полторы сотни свойств разного рода — колонки, свойства внутри джсон колонокк, таблиц которые могут джойнами подтягиваться? P>>>Вы ранее говорили — 30 значений положить в бд. Это значит, что 120 свойств будут незаполнеными, и мы не узнаем или ваш запрос фильтрует, или же хавает пустые значения которые в проде окажутся непустыми. P>·>Я имею в виду положить 30 записей. Фильтрами потом выбираем из этих 30 и проверяем, что выбраны только те записи, которые должны попадать под данный фильтр. У каждой записи может быть сколь угодно свойств. P>Кто вам скажет, что в ваших этих 30 записях есть все потенциально опасные или невалидные комбинации?
Это не решается тестами, никакими.
P>·>И? А ты что предлагаешь? Запустить эту колбасу вручную на прод-базе и глазками проверить выдачу, что вроде похоже на правду? P>Вручную всё равно придется проверять, это обязательный этап — с этого всё начинается.
Почему обязательный?
P>·>Давай теперь по каждому из этих пунктов, как это валидируется в твоих интеграционных тестах. P>Эта часть же как и у вас. Это именно интеграционный тест репозитория.
Т.е. тест репо+бд? У вас есть и такие тесты?
P>Только сверх этого вы собираетесь и комбинации фильтров гонять здесь же. И на мой взгляд это совсем не то, чем нужно заниматься в этом виде тестов.
Потому что юнит-тесты побуквенного сравнения sql-текста практически бесполезны и даже вредны.
P>>>А вот всё множество комбинаций в фильтрах нужно покрывать совсем другими тестами. P>·>Т.е. если одна из комбинаций фильтров нарушит, скажем пункт 8, то ты об этом узнаешь только в проде от счастливых юзеров. P>А у вас как будет? Сколько процентов комбинаций вам известно и сколько из них вы покрыли интеграционным тестом? P>Вы только недавно жаловались, что у вас покрывается внятно только 1% кейсов
Быстрые интеграционные тесты с замоканными внешними зависимостями, которые покрывают как можно ближе к 100% интеграции между компонентами, но не все комбинации логики отдельных компонент. Это обязанность других тестов, ещё более быстрых.
P>Поскольку комбинаций фильтров может быть на порядки больше, чем вы можете позволить себе покрыть тестами, то:
... то похрен, т.к. разговор идёт о тестах, оффтоп.
P>>>2 вы подкидываете небольшое количество значений. Смотрите пример фильтра с васями, только не ваш, а мой P>·>Подкидывай большое число значений. Разрешаю. P>Проблемные комбинации вам неизвестны. P>Что будете в тест писать ?
В тесте по определению тестируется известное. Если ты считаешь твои тесты тестируют неизвестное — ты заблуждаешься.
P>>>`конский запрос LIMIT 10` P>·>Согласен, иногда такое может сработать, не помню как оно себя поведёт с какими-нибудь union... Да ещё и в разных базах этот самый LIMIT может выглядеть по-разному. А как ты будешь отличать "тянут больше одной строки"? P>Это же в операции известно, какие данные она возвращает. Если users.byId() то очевидно здесь один. А если users.where — вот тут а хрен его знает
Угу, именно, что "очевидно", но кто-то накосячил с фильтром в byId и у тебя внезапно не один... Т.е. если это и как-то проверяется, но не тестами.
P>>>Т.е. это просто пост условие, и давать будет ровно те же гарантии. P>·>Неясно как это согласуется с бизнес-требованиями. P>У вас что, в требованиях позволено сдыхать при процессинге?
http 4xx или 5xx. Везде тупо возвращать только первые 10 записей и делать вид что так и надо — это какая-то студенческя поделка.
P>>>Теорема Райса про алгоритмы и свойства функций, а не про код. P>·> — код это один из видов формальной записи алгоритмов. P>Если пользоваться вашим пониманием т. Райса, то например тесты это тот алгоритм, которому нужно выяснить наличие свойств у функции system-under-test P>И тут мы узнаем... что тестами ничо не сделаешь. Гы-гы.
Тесты могут проверять только тривиальные свойства. В данном случае "код для входных данных X выдал результат Y и уложился во время T". Ты же утверждаешь, что твои тесты проверяют нетривиальные свойства вида "на неизвестных проблемных комбинациях не падает по OOM". Ты заблуждаешься, это теоретически невозможно.
P>Как только вам это стало понятно, нужно вспомнить, что тестами вы выражаете свои собственные ожидания. Даже если вы их взяли из спеке — интерпретация все равно ваша собственная, и вы в тестах фиксируете свои ожидания от того, как в каких случаях работет система P>Соотвественно, гарантии у вас будут не с т.з. т.Райса, а с т.з. вероятностей P>- функция которая проходит тесты по таблице истинности подходит лучше, чем та, которая эти тесты не проходит
Мде... Ещё и вероятности пришли.
P>>>Поэтому вполне логично добавить пост-условие. P>·>Ну добавь. Тесты тут не причём. Сразу замечу, что тестировать наличие постусловий — это уже лютейший бред. P>У вас всё бред, чего вы не понимаете
Я понимаю на шаг вперёд.
P>>>Вы то помните, то не помните. В данной задаче — просто сравнением sql. Назначение теста — зафиксировать паттерн. P>·>Назначение теста — это твои фантазии. Суть теста — это то что он делает по факту. А по факту он сравнивает побуквенно sql, а паттерны запроса и прочие страшные слова — это пустое словоблудие. P>Давайте проверим. Покажите мне пример, как изменение паттерна, структуры запроса будет зеленым в таком тесте.
Не понял к чему такой вопрос. Я наоборт утверждаю, что любое мелкое изменение реализации сломает тест, даже если это небольшой рефакторинг или тупо стиль. В этом и проблема такого твоего теста, он хрупкий. Часто падает когда не надо и иногда не падает когда надо, т.к. тестирует внутренние детали реализации, а не ожидания.
P>>>Т.е. вы уже меняете подход к тестам — изначально у вас было "записать три значения в бд и проверить, что они находятся фильтром" P>·>Ты опять врёшь. Вот моя настоящая цитата: "Достаточно иметь одно значение и слать разные фильтры.". Открой мой код и прочитай его ещё раз. Внимательно. P>Это еще слабее тест. С одним значением мы не в курсе, а не вгружает ли ваш фильтр секретные данные каким либо джойном
А контекст той цитаты ты тоже не прочитал. Открой блин и прочитай наконец-то что тебе пишут.
P>>>Растет. Докинули поле — нужно докинуть данных на все случаи, где это будет играть, включая паттерны строк, джойны, итд итд. P>·>Ок, переформулирую. Сложность у нас растёт ровно так же, как и у вас. P>В том то и дело, что растет экспоненциально.
И что ты этим хочешь сказать?
P>·>Ты написал: "паттерн тестируется на бд, далее — интеграционными тестами". Я спрашиваю: как паттерн тестируется на бд _перед_ интеграционными тестами? P>Первые запуски — руками. Потом автоматизируете и получаете интеграционный тест.
Зачем руками-то? В чём такая необходимость? И почему только первые запуски?
P>>>Вот видите — это у вас времени на тесты не хватает, т.к. логику да комбинации вы чекаете на реальной бд P>·>На реальной бд мы чекаем только связку бд+репо, т.е. код персистенса, а не логику и комбинации. P>Вы совсем недавно собирались все комбинации тестировать, разве нет?
Не все e2e комбинации, а комбинации конкретно данного куска кода, sut.
P>Если нет, то ваши же слова P>"если одна из комбинаций фильтров нарушит, скажем пункт 8, то ты об этом узнаешь только в проде от счастливых юзеров."
Потому что это уже другая подсистема, не та которая конкретно отвечает за комбинации фильтров. Слон — по кусочкам.. помнишь?
P>>>У вас комбинаций меньше чем условий в фильтре. P>·>30 это было число записей, которые могут обеспечить 230 комбинаций. Тебе столько не хватает? P>Фильтры дают на десяток порядков больше комбинаций. В этом и проблем
Ну сделай 60 записей, будет как раз на десяток порядков больше комбинаций. В чём проблема-то?
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
P>>>>Я такого не говорил — это вы начали фантазировать, что придется ждать 5 минут и никак иначе не выйдет. Обоснования у вас никакого нет. P>>·>Про 5 минут я не фантазировал, это твоя цитата. P>>Я нигде не говорил, что юзер должен ждать 5 минут. Даже если профиль создаётся неделю, редактировать данные можно сразу. ·>Говорил, цитирую: чудесные вещи типа "после того, как сделал var u = service.CreateUser(...), нужно выждать не менее 5 минут перед service.UpdateUser(u, ...)".
Это я говорил. Это — реальный случай: парни, которые реализовывали API, завели его в ActiveDirectory с round-robin.
Объект "пользователь" в ихнем волшебном API создавался с "автосгенерённым паролем", коий предлагалось как-то заперсистить и донести до конечного пользователя.
С нашей стороны, конечно же, сразу была сделана обвязка этого API, которая принимала пароль от пользователя вместе со всеми остальными параметрами, и создавала объект в два вызова — CreateUser и UpdatePassword.
С моками всё работало прекрасно. И в первом же e2e тесте упало, потому что неумолимый round-robin роутил UpdatePassword на другой AD-контроллер, на котором свежесозданного user ещё нет, и нам прилетел 404.
А вот если подождать 5 минут, то скорее всего UpdatePassword сработает, потому что пройдёт репликация AD, и все контроллеры этого пользователя увидят.
Как вы такие вещи будете ловить при помощи моков — я так и не понял.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Sinclair, Вы писали:
S>·>Говорил, цитирую: чудесные вещи типа "после того, как сделал var u = service.CreateUser(...), нужно выждать не менее 5 минут перед service.UpdateUser(u, ...)". S>Это я говорил.
Ой, прошу прощения, я перепутал.
S>Это — реальный случай: парни, которые реализовывали API, завели его в ActiveDirectory с round-robin.
Перепутал наверное потому, что эти парни с той же логикой что и у Pauel — подменили синхронный код асинхронным с eventual consistency — и делают вид что всё в порядке, так и должно работать, назвали это как "нефункциональное требование" в API, и никакие тесты у них наверняка не упали.
S>А вот если подождать 5 минут, то скорее всего UpdatePassword сработает, потому что пройдёт репликация AD, и все контроллеры этого пользователя увидят.
Да, именно что "скорее всего". В общем явная лажа в дизайне, даже неясно как consistency обеспечить хотя бы eventual.
S>Как вы такие вещи будете ловить при помощи моков — я так и не понял.
Я же рассказал — такое ловится конформационными тестами — небольшие быстрые тесты, которые дёргают "ихнее API" и ассертят результаты, проверяют на адекватность assumptions, сделанные в моках. Ловить такое в e2e вида "выполняется (медленный!) UI workflow с навигацией от логина" — можно только в простых случаях.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>Будут. Но их всё равно нужно делать, т.к. никакие другие виды тестов их не заменяют, только кое где могут скомпенсировать. ·>Нужно, но как-то всё равно придётся покрывать остальные 99%. Вот тут и приходят на помощь моки и конф-тесты.
И вам всё еще непонятно, почему люди на проде тестируют? моки и конформационные тесты это не решение, а компенсация.
Вы отказываетесь идти дальше, и делать внятное покрытие e2e, и посмеиваетесь с тех, кто всё таки покрывает эти 99% как следует.
P>>Если у вас сложный воркфлоу, то его нечем протестировать, кроме вот этих e2e ·>Я тебе уже рассказал чем: моки и конф-тесты.
Пример у вас есть внятный? Мне непонятно, каким чудом моки репозитория помогут понять, что же с интеграцией не так.
Какой компоент системы вы собираетесь конф тестами покрывать?
P>>Не могут — моки по своей сути подменяют интеграцию отсебятиной. ·>Не только моки, но конф-тесты. Плюс соответствующий дизайн и процесс разработки.
Расскажите внятно, как мок репозитория поможет вам с интеграцией уровня приложения?
P>>Как он будет справляться с интеграцией — остаётся неизвестным, вообще. ·>Я тебе уже объяснил как это сделать известным.
Невнятно, если честно. Общие слова "конф-тесты помогут"
P>>Итого, с ваших слов "задача сложная, нахер e2e, будем моки писать и сделаем вид, что это равноценная замена" ·>Не "нахер e2e", а "хрень получается с e2e".
Наоборот, e2e показывает те ошибки, которые проходят мимо ваших моков. Они показывают, что приложение склеено как положено.
P>>1 Аксиома — количество юнит-тестов и полуинтеграционных на моках никак не влияет на количество e2e. Никак, нисколько! ·>Тавтология. Я говорю о другом: количество e2e ограничивается доступными ресурсами. Чем меньше доступных e2e, тем больше приходится вкладываться в юнит и "полуинтеграционные".
Ну да — вы забили на интеграционные тесты.
P>> юниты и ваши полуинтеграционные пишите сколько надо, что бы быстро детектить мелочевку во время разработки P>>2 e2e можно сделать так - P>>- при билде — три самых частых P>>- при деплое — три десятка самых частых P>>- после деплоя — всё вместе, рандомно, то одно, то другое, с таким расчетом, что бы за день вы получили сведения что где может отвалиться ·>Не годится. Мы не можем релизиться только с тремя десятками сценариев. Надо проверять 100%.
Я ж вам не предлагаю выбросить — я вам предлагаю добавить, и показываю, как именно.
Вы уже релизитесь без 99%. Если к вашим тестами добавите e2e, то покрытие станет плотнее.
Если не хватает времени — e2e можно гонять и после деплоймента, хоть круглые сутки, они хлеба не просят.
P>>Итого — ваши 99% кейсов вы будете тестировать после деплоя. Боитесь делать это на проде — делайте на стейдже, деве и тд. ·>Не можем мы деплоить продукт оттестированный на 1%.
Вы уже это делаете. e2e всего то сделают видимыми проблемы в тех 99% которые ходили мимо ваших моков.
P>>3. каждые N минут запускаете `curl <stage>/manifest.test | run-test --random --url <stage>` ·> Т.е. качество продукта проверяем случайно. Это только для хоумпейджей годится.
Это способ выполнять те тесты, которые у вас вообще отсутствуют.
P>>Это полные тесты, где всё тащится медленно и реально — они нужны и вам, и мне. Если вы не учли этот кейс с нулём, то будет проблема. Ровно так же и у меня. ·>Ясен пень. Ты вообще читаешь что я пишу? Суть в том, что даже если вы учли кейс с нулём, то у вас всё равно будет проблема, а нас проблемы не будет.
Непонятно — как X может быть больше чем X + Y если и X и Y больше нуля?
Вы тестируете минимально, репозиторий + бд. Эта часть есть и у меня.
Только вы здесь останавливаетесь, а я, дополнительно, покрываю другим видом тестом несколько критичных кейсов.
И по вашему у меня покрытие будет хуже
Извините, но вы или не читаете, или вас чтото не то с логикой.
P>>И задача с фильтрами это про комбинации ·>Может я не понял твою задачу правильно, но в моём понимании, фильтры это задача которая сводится к одному компоненту, который может быть протестирован отдельно, а не комбинации различных компонент
Комбинации различных условий в фильтре, что дает нам ту самую data complexity, и проблемные комбинации вы будете узнавать только на проде, одну за другой
Собственно из за того, что никто вам заранее не выдал список проблемных комбинаций, нужно "придётся выдумывать правильную архитектуру и подходы контроля качества, чтобы риск неизвестного минимизировать"
P>>>>Я такого не говорил — это вы начали фантазировать, что придется ждать 5 минут и никак иначе не выйдет. Обоснования у вас никакого нет. P>>·>Про 5 минут я не фантазировал, это твоя цитата. P>>Я нигде не говорил, что юзер должен ждать 5 минут. Даже если профиль создаётся неделю, редактировать данные можно сразу. ·>Говорил, цитирую: чудесные вещи типа "после того, как сделал var u = service.CreateUser(...), нужно выждать не менее 5 минут перед service.UpdateUser(u, ...)".
Вы или поиском пользоваться не умеете, или запомнить трудно.
Синклер привел пример "А в реальных системах встречаются ещё и чудесные вещи типа "после того, как сделал var u = service.CreateUser(...), нужно выждать не менее 5 минут перед service.UpdateUser(u, ...)", с которыми совсем всё плохо." И пример был про то, откуда берется время "задним числом"
Можно ли нажимать конопку, нельзя — у Синклера пример про то откуда будет браться время отличное от текущего.
P>>Вам нужно спросить у BA, какие данные надо сейчас, а какие — вообще. ·>Именно — вопросы за которые отвечает BA — это функциональные требования по сути.
Вот-вот. И если BA даёт добро — всё хорошо.
·>У тебя есть бизнес-функция "создать юзера". Результат который возвращается из этой функции — это тоже функциональный элемент. Результат говорит о том, что что-то произошло. Если ты вместо того, чтобы сделать саму операцию кладёшь что-то в очередь, то и результат функции меняется — вместо "что-то произошло", будет "что-то произойдёт".
Не вместо, а вместе. Все что нужно для редактирования — возвращаем сразу, BA так сказал. Всё, что для редактирования не нужно — вообще не возвращаем. А раз так, то можем поступать как проще — можно сразу, можно потом.
Уже в который раз уточняю, но вы всё равно видите чтото свое
P>>Вы сами себе придумали какой то вариант, где сделано заведомо кривое решение, и теперь рассказываете будто это самый типичный случай. ·>Это не я придумал, это ты придумал.
Уже выяснили — это вы притянули пример Синклера который был совсем про другое.
P>>Зачем вам менять апишку для этого кейса? ·>Затем, что функция API "выполнить действие X" != "положить в очередь чтобы действие X когда-нибудь выполнилось (может быть)". Апишка просто обязана быть разной, чтобы не было таких "чудесных вещей", которые ты так любишь.
Вы путаете интерфейс и реализацию. API — create user, данные вернуть сразу — id, имя, фамилию. Всё не id-имя-фамилия, вы может создавать когда угодно, хоть с очередью, хоть без. Можете создать сразу — отлично. Не получается — ну и хрен с ним, абы id-имя-фамилия были дадены сразу
P>>>>
P>>>>п1 — паттерн тестируется на бд, далее —
интеграционными тестами
P>>>>...
P>>>>1. рабочий паттерн запроса — это проверяется
сначала руками, а потом тестом против бд минимально заполненой под задачу
P>>·>Я тебе в N+5й раз повторяю. Твоя формулировка неоднозначна. Напиши чётко. P>>Я не в курсе, что именно вам непонятно P>>Какой вопрос вы не озвочили — мне неизвестно. P>>На мой взгляд что надо в моем ответе есть P>>1. кто тестирует ·>Из слов "паттерн тестируется" неясно кем.
Если руками, что следует из выделеного, то какие варианты?
P>>3. какими тестами ·>Из слов "паттерн тестируется" неясно какими тестами
Я вам выделил, что бы виднее было.
P>>1. что делаем — сравниваем посимвольно, т.к. другого варианта нет — на одну задачу пилить ast на алгебраических типах данных это овердохрена ·>Другой вариант я рассказал — выполнить запрос на базе и заасертить результат.
Не работает — вы не знаете проблемной комбинации для фильтров. Знаете только что они есть и их хрензнаетсколькилион
P>>2. для чего делаем — что бы зафиксировать паттерн ·>Зачем?
Что бы исключить ту самую проблему в явном виде — потенциальная загрузка всего содержимого таблицы.
P>>Вы до сих пор такой тест не показали ·>Это не покрывается тестами принципиально.
Покрывается. Я ж вам показал. Только решение и покрытие это разные вещи. В данном случае решение — постусловие. А тестами фиксируем, что бы не убежало
·>Только если у тебя какой-то очень частый случай и ты завязываешься на какую-то конкретную реализацию — а это значит, что у тебя тесты не будут тестировать даже регрессию.
Покажите пример регрессии, которая не будет обнаружена этим тестом.
·>Я никогда не просил объяснений, я просил код. Ибо по коду видны факты, а не твои фантазии. Так что не удивляйся, что твои объяснения являются словоблудием.
С кодом у вас два варианта
1. не будет работать
2. словоблудие
На примере — вам был даден код про структурную эквивалентность — вам надо знать, кто тестирует, какими тестами. Пять сообщений подряд и выделение болдом не помогло. Надеюсь, выделение H1 сделало это заметным
P>>Можно ограничить таблицы, из которых может или не может делаться джойн итд ·>Т.е. в тесте ты единственное что можешь зафиксировать, что в коде у тебя действительно стоит .top(10). И что? Зачем? Наличие .top(10) и так видно, оно уже и так явно прописано в коде.
Необязательно. Если я руками пишу весь запрос — то будет в коде явно. но запрос может и билдер создать.
Некоторые детали нужно фиксировать в тестах, что бы случайно залетевший дятел не разрушил цивилизацию.
P>>Кто вам скажет, что в ваших этих 30 записях есть все потенциально опасные или невалидные комбинации? ·>Это не решается тестами, никакими.
Решение — пост-условие. А вот тест который я показал, он всего то гарантирует сохранность этого пост-условия.
P>>Вручную всё равно придется проверять, это обязательный этап — с этого всё начинается. ·>Почему обязательный?
Если вы не можете сделать этого руками, то ваши попытки выразить это в коде и генерации данных будут иметь ту же особенность.
P>>Эта часть же как и у вас. Это именно интеграционный тест репозитория. ·>Т.е. тест репо+бд? У вас есть и такие тесты?
Я вам уже который месяц говорю, что предлагаю добавить, а не выбросить.
Есть и такие — их проще писать сразу, проще отдладить по горячим следам.
Но с ростом сложности приходится вводить дополнительные инструменты.
P>>Только сверх этого вы собираетесь и комбинации фильтров гонять здесь же. И на мой взгляд это совсем не то, чем нужно заниматься в этом виде тестов. ·>Потому что юнит-тесты побуквенного сравнения sql-текста практически бесполезны и даже вредны.
А разве я говорю, что это надо повсеместно?
P>>Проблемные комбинации вам неизвестны. P>>Что будете в тест писать ? ·>В тесте по определению тестируется известное. Если ты считаешь твои тесты тестируют неизвестное — ты заблуждаешься.
Пост-условия похоже для вас пустой звук, вам это всё равно кажется тестом. Тест всего лишь гарантирует сохранность пост-условия
А вот пост условие отработаетт для всего выхлопа, сколько бы раз вы ни вызывали его
P>>Это же в операции известно, какие данные она возвращает. Если users.byId() то очевидно здесь один. А если users.where — вот тут а хрен его знает ·>Угу, именно, что "очевидно", но кто-то накосячил с фильтром в byId и у тебя внезапно не один... Т.е. если это и как-то проверяется, но не тестами.
Эта проблема и у вас будет. Например, вы тестируете на бд, где id это праймари кей, а в проде каким то чудом окажется другая схема, где id может иметь дубликаты
И решения и у меня, и у вас, для подобных кейсов будут одни и те же.
P>>У вас что, в требованиях позволено сдыхать при процессинге? ·>http 4xx или 5xx. Везде тупо возвращать только первые 10 записей и делать вид что так и надо — это какая-то студенческя поделка.
Вы снова чего то фантазируете.
P>>И тут мы узнаем... что тестами ничо не сделаешь. Гы-гы. ·>Тесты могут проверять только тривиальные свойства.
Нет, не могут. Так, как это утверждает т. Райса — вы true от false отличить не сможете. Можете потренироваться — тестами обнаружить функцию, которая всегда возвращает true. Валяйте.
Как напишете ваш тест — кидайте сюда, а я покажу, какая фукнция проходит ваш тест и не удовлетворяет условию
Для простоты, функция будет такой — () -> true, т.к. никаких параметров и тд и тд и тд
Как наиграетесь, приходите
P>>Соотвественно, гарантии у вас будут не с т.з. т.Райса, а с т.з. вероятностей P>>- функция которая проходит тесты по таблице истинности подходит лучше, чем та, которая эти тесты не проходит ·>Мде... Ещё и вероятности пришли.
Они всегда были. см выше про т. Райса
P>>>>Поэтому вполне логично добавить пост-условие. P>>·>Ну добавь. Тесты тут не причём. Сразу замечу, что тестировать наличие постусловий — это уже лютейший бред. P>>У вас всё бред, чего вы не понимаете ·>Я понимаю на шаг вперёд.
Смотрите выше, текст выделен H1, как раз эту вашу способность и "демонстрирует"
P>>·>Назначение теста — это твои фантазии. Суть теста — это то что он делает по факту. А по факту он сравнивает побуквенно sql, а паттерны запроса и прочие страшные слова — это пустое словоблудие. P>>Давайте проверим. Покажите мне пример, как изменение паттерна, структуры запроса будет зеленым в таком тесте. ·>Не понял к чему такой вопрос. Я наоборт утверждаю, что любое мелкое изменение реализации сломает тест, даже если это небольшой рефакторинг или тупо стиль. В этом и проблема такого твоего теста, он хрупкий. Часто падает когда не надо и иногда не падает когда надо, т.к. тестирует внутренние детали реализации, а не ожидания.
Хрупкий — это я вам сразу сказал. Так я ж и не предлагаю посимвольное сравнение на все случаи жизни.
P>>·>Ок, переформулирую. Сложность у нас растёт ровно так же, как и у вас. P>>В том то и дело, что растет экспоненциально. ·>И что ты этим хочешь сказать?
Да то, что искать тестами проблемные комбинации вы вспотеете. Нужно искать решение вне тестов.
P>>Первые запуски — руками. Потом автоматизируете и получаете интеграционный тест. ·>Зачем руками-то? В чём такая необходимость? И почему только первые запуски?
Ну можете не руками, а попросить того, кто знает схему бд и язык запросов к ней. Ну или чат-гпт спросите.
Почему первые запуски — потому, что после них как раз будет известен паттерн, по которому нужно будет строить запросы. дальше в ручных проверках смысла не много.
P>>Вы совсем недавно собирались все комбинации тестировать, разве нет? ·>Не все e2e комбинации, а комбинации конкретно данного куска кода, sut.
С фильтрами комбинаций столько, что солнце погаснет раньше ваших тестов.
P>>"если одна из комбинаций фильтров нарушит, скажем пункт 8, то ты об этом узнаешь только в проде от счастливых юзеров." ·>Потому что это уже другая подсистема, не та которая конкретно отвечает за комбинации фильтров. Слон — по кусочкам.. помнишь?
Я то помню, а вы — нет. Смотрите, кто погаснет раньше,солнце, или перебор комбинаций на фильтрах.
P>>·>30 это было число записей, которые могут обеспечить 230 комбинаций. Тебе столько не хватает? P>>Фильтры дают на десяток порядков больше комбинаций. В этом и проблем ·>Ну сделай 60 записей, будет как раз на десяток порядков больше комбинаций. В чём проблема-то?
Проблема в том, что бы генерить данные, нужно знать комбинации которые будут проблемными.
Здравствуйте, ·, Вы писали:
·>Перепутал наверное потому, что эти парни с той же логикой что и у Pauel — подменили синхронный код асинхронным с eventual consistency — и делают вид что всё в порядке, так и должно работать, назвали это как "нефункциональное требование" в API, и никакие тесты у них наверняка не упали.
Мы "этих парней" регулярно ловили с фатальными багами в проде. Причём за время моей работы на проекте на той стороне сменилось четыре поколения одного и того же API, и, судя по всему, писали каждый раз новой командой.
Я, помнится, даже предлагал им наши автотесты бесплатно, чтобы они так не позорились. Не взяли :xz:/
·>Да, именно что "скорее всего". В общем явная лажа в дизайне, даже неясно как consistency обеспечить хотя бы eventual.
Да почему — конечно ясно. Добавляется хидер "affinity key", и всё начинает работать. Как, в общем-то, они и сделали после того, как мы слегка побили их палкой за такие вещи.
·>Я же рассказал — такое ловится конформационными тестами — небольшие быстрые тесты, которые дёргают "ихнее API" и ассертят результаты, проверяют на адекватность assumptions, сделанные в моках.
Простите, но это — набор слов. Дёргать "ихнее API" мы дёргаем — просто шансы на то, что мы будем дёргать именно так, чтобы поймать на вот таких вещах, примерно нуль.
Тесты на "создание пользователя" проходят прекрасно.
Тесты на получение списка пользователей проходят прекрасно.
Тесты на модификацию пользователя, и отдельно на сброс пароля тоже прекрасно проходят (ну, мы так думаем — ведь для настоящей проверки нужно этим пользователем с этим паролем куда-то залогиниться, а у нас к этому куда-то доступа на тот момент нету).
Тесты на удаление пользователя проходят.
Более того — у "тех парней" естественно есть полный набор вот таких вот "небольших быстрых тестов".
Проблема — как раз в том, что нам важна не работоспособность методов по отдельности, а e2e-workflow.
И именно его-то мы и проверяем нашими авто-тестами. Которые как раз вполне себе "небольшие и быстрые", так что о том, что свежевыкаченная на прод версия сломана, мы узнавали примерно через полчаса. ·>Ловить такое в e2e вида "выполняется (медленный!) UI workflow с навигацией от логина" — можно только в простых случаях.
UI Workflow не намного медленнее чисто-бэкендного набора вызовов. В реальности мы делали e2e не через UI (это у нас тестировалось отдельно, селениумом), а через наш собственный API, торчаший наружу.
Но разница небольшая — потому что наш UI был просто обёрткой над нашим же API, так что если API не работает, то в UI можно даже не смотреть.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Sinclair, Вы писали:
S>·>Да, именно что "скорее всего". В общем явная лажа в дизайне, даже неясно как consistency обеспечить хотя бы eventual. S>Да почему — конечно ясно. Добавляется хидер "affinity key", и всё начинает работать. Как, в общем-то, они и сделали после того, как мы слегка побили их палкой за такие вещи.
Ну как исправить-то ясно, конечно. Я имел в виду, что без исправления, с таким дизайном api надёжно пользоваться невозможно.
Суть в том, что как Pauel утверждает, мол, что если заменили прямой вызов действия на асинхронную очередь — тесты не должны падать. Это ущербная логика.
S>·>Я же рассказал — такое ловится конформационными тестами — небольшие быстрые тесты, которые дёргают "ихнее API" и ассертят результаты, проверяют на адекватность assumptions, сделанные в моках. S>Простите, но это — набор слов. Дёргать "ихнее API" мы дёргаем — просто шансы на то, что мы будем дёргать именно так, чтобы поймать на вот таких вещах, примерно нуль.
Конф-тесты дёргают "ихнее API" в ожидаемом вами порядке.
S>Проблема — как раз в том, что нам важна не работоспособность методов по отдельности, а e2e-workflow.
e2e — означает полный фарш всей логики всей системы, кучей разных "ихних API". Конф-тесты же отдельно проверяют конкретно этот участок вашей системы — взаимодействие с одним конкретным "ихним API".
Но в простом случае если таких api один-два, то получается вырожденный случай, и разделение не требуется.
S>И именно его-то мы и проверяем нашими авто-тестами. Которые как раз вполне себе "небольшие и быстрые", так что о том, что свежевыкаченная на прод версия сломана, мы узнавали примерно через полчаса.
Ну примерно для этого конф-тесты и нужны.
S>·>Ловить такое в e2e вида "выполняется (медленный!) UI workflow с навигацией от логина" — можно только в простых случаях. S>UI Workflow не намного медленнее чисто-бэкендного набора вызовов. В реальности мы делали e2e не через UI (это у нас тестировалось отдельно, селениумом), а через наш собственный API, торчаший наружу. S>Но разница небольшая — потому что наш UI был просто обёрткой над нашим же API, так что если API не работает, то в UI можно даже не смотреть.
Ну как бы внезапно получилось, что не совсем e2e оказывается.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, Pauel, Вы писали:
P>>>Будут. Но их всё равно нужно делать, т.к. никакие другие виды тестов их не заменяют, только кое где могут скомпенсировать. P>·>Нужно, но как-то всё равно придётся покрывать остальные 99%. Вот тут и приходят на помощь моки и конф-тесты. P>И вам всё еще непонятно, почему люди на проде тестируют?
Потому что могут (с)
P>моки и конформационные тесты это не решение, а компенсация.
Способ экономии ресурсов.
P>Вы отказываетесь идти дальше, и делать внятное покрытие e2e, и посмеиваетесь с тех, кто всё таки покрывает эти 99% как следует.
Скорее завидую простоте системы, что её реально покрыть e2e на 99%.
P>>>Если у вас сложный воркфлоу, то его нечем протестировать, кроме вот этих e2e P>·>Я тебе уже рассказал чем: моки и конф-тесты. P>Пример у вас есть внятный? Мне непонятно, каким чудом моки репозитория помогут понять, что же с интеграцией не так.
Они не для этого.
P>Какой компоент системы вы собираетесь конф тестами покрывать?
Конф-тесты тестируют чужое api. Система (по крайней мере её прод-часть) не принимает участие в конф-тестах.
P>>>Не могут — моки по своей сути подменяют интеграцию отсебятиной. P>·>Не только моки, но конф-тесты. Плюс соответствующий дизайн и процесс разработки. P>Расскажите внятно, как мок репозитория поможет вам с интеграцией уровня приложения?
Никак. Мок поможет тестировать часть приложения с меньшим количеством ресурсов, следовательно позволит иметь больше покрытых сценариев.
P>>>Итого, с ваших слов "задача сложная, нахер e2e, будем моки писать и сделаем вид, что это равноценная замена" P>·>Не "нахер e2e", а "хрень получается с e2e". P>Наоборот, e2e показывает те ошибки, которые проходят мимо ваших моков.
Если оно это показывает случайно, через несколько часов — то это называется хрень, а не показания.
P> Они показывают, что приложение склеено как положено.
Это и проблема твоего подхода — у тебя в приложении на строчку кода ведро клея, который никак и не тестируется, кроме как тонной e2e.
P>>>1 Аксиома — количество юнит-тестов и полуинтеграционных на моках никак не влияет на количество e2e. Никак, нисколько! P>·>Тавтология. Я говорю о другом: количество e2e ограничивается доступными ресурсами. Чем меньше доступных e2e, тем больше приходится вкладываться в юнит и "полуинтеграционные". P>Ну да — вы забили на интеграционные тесты.
Ну так в моём подходе этой интеграции кот наплакал, поэтому "приложение не упало при старте" уже практически означает, что 100% тех ошибок, "которые проходят мимо ваших моков" показано.
P>>> юниты и ваши полуинтеграционные пишите сколько надо, что бы быстро детектить мелочевку во время разработки P>>>2 e2e можно сделать так - P>>>- при билде — три самых частых P>>>- при деплое — три десятка самых частых P>>>- после деплоя — всё вместе, рандомно, то одно, то другое, с таким расчетом, что бы за день вы получили сведения что где может отвалиться P>·>Не годится. Мы не можем релизиться только с тремя десятками сценариев. Надо проверять 100%. P>Я ж вам не предлагаю выбросить — я вам предлагаю добавить, и показываю, как именно.
Добавлять тест, который запускается рандомно через раз — это какое-то извращение. Если некий тест запускать не обязательно для релиза, клиенты переживут и так — накой его вообще запускать?
P>Вы уже релизитесь без 99%. Если к вашим тестами добавите e2e, то покрытие станет плотнее.
Не станет.
P>Если не хватает времени — e2e можно гонять и после деплоймента, хоть круглые сутки, они хлеба не просят.
Зачем? Если они что-то обнаружат, это значит что у клиентов проблемы прямо сейчас, prod incident. Поздно борожоми пить.
P>>>Итого — ваши 99% кейсов вы будете тестировать после деплоя. Боитесь делать это на проде — делайте на стейдже, деве и тд. P>·>Не можем мы деплоить продукт оттестированный на 1%. P>Вы уже это делаете. e2e всего то сделают видимыми проблемы в тех 99% которые ходили мимо ваших моков.
Ещё раз. Если ты догадался нечто описать в виде теста, пусть e2e — это значит какой-то вполне определённый известный сценарий. Всегда есть возможность покрыть этот сценарий покрыть более дешёвыми тестами и выполнять до релиза, всегда, а не по броску монеты.
P>>>3. каждые N минут запускаете `curl <stage>/manifest.test | run-test --random --url <stage>` P>·> Т.е. качество продукта проверяем случайно. Это только для хоумпейджей годится. P>Это способ выполнять те тесты, которые у вас вообще отсутствуют.
Потому что нахрен не нужны.
P>>>Это полные тесты, где всё тащится медленно и реально — они нужны и вам, и мне. Если вы не учли этот кейс с нулём, то будет проблема. Ровно так же и у меня. P>·>Ясен пень. Ты вообще читаешь что я пишу? Суть в том, что даже если вы учли кейс с нулём, то у вас всё равно будет проблема, а нас проблемы не будет. P>Непонятно — как X может быть больше чем X + Y если и X и Y больше нуля? P>Вы тестируете минимально, репозиторий + бд. Эта часть есть и у меня.
Где конкретно эта часть есть у тебя? Ты заявлял, что в твоих pattern-тестах ты репозиторий + бд не тестируешь; а в e2e ты каждую переменную на null тестирвать не будешь, да и не сможешь.
P>Извините, но вы или не читаете, или вас чтото не то с логикой.
Я читаю что ты мне пишешь.
P>>>И задача с фильтрами это про комбинации P>·>Может я не понял твою задачу правильно, но в моём понимании, фильтры это задача которая сводится к одному компоненту, который может быть протестирован отдельно, а не комбинации различных компонент P>Комбинации различных условий в фильтре, что дает нам ту самую data complexity, и проблемные комбинации вы будете узнавать только на проде, одну за другой
Ты тоже.
P>Собственно из за того, что никто вам заранее не выдал список проблемных комбинаций, нужно "придётся выдумывать правильную архитектуру и подходы контроля качества, чтобы риск неизвестного минимизировать"
Ну да. А что делать? Не всем так везёт, как в твоём хоумпейдже: тебе сразу выдали список проблемных комбинаций, так что в твоём случае всё равно, хоть левой пяткой тестируй, а клиентам пофиг на сломаный код в проде — все подходы работают.
P>>>>>Я такого не говорил — это вы начали фантазировать, что придется ждать 5 минут и никак иначе не выйдет. Обоснования у вас никакого нет. P>>>·>Про 5 минут я не фантазировал, это твоя цитата. P>>>Я нигде не говорил, что юзер должен ждать 5 минут. Даже если профиль создаётся неделю, редактировать данные можно сразу. P>·>Говорил, цитирую: чудесные вещи типа "после того, как сделал var u = service.CreateUser(...), нужно выждать не менее 5 минут перед service.UpdateUser(u, ...)". P>Вы или поиском пользоваться не умеете, или запомнить трудно.
Да, ошибся, см. ответы с Синклером сегодня.
P>Синклер привел пример "А в реальных системах встречаются ещё и чудесные вещи типа "после того, как сделал var u = service.CreateUser(...), нужно выждать не менее 5 минут перед service.UpdateUser(u, ...)", с которыми совсем всё плохо." И пример был про то, откуда берется время "задним числом"
Перечитай. Проблема была не со временем, а с синхронизацией действий.
P>Можно ли нажимать конопку, нельзя — у Синклера пример про то откуда будет браться время отличное от текущего.
Причём тут текущее время? Проблема как раз была в том, что ты называешь "нефункциональные требования": "ну юзер же создался, а что ещё не совсем до конца создался, ничего страшного..".
P>>>Вам нужно спросить у BA, какие данные надо сейчас, а какие — вообще. P>·>Именно — вопросы за которые отвечает BA — это функциональные требования по сути. P>Вот-вот. И если BA даёт добро — всё хорошо.
Ну вот это "добро" тебе и надо будет выразить в тестах.
P>·>У тебя есть бизнес-функция "создать юзера". Результат который возвращается из этой функции — это тоже функциональный элемент. Результат говорит о том, что что-то произошло. Если ты вместо того, чтобы сделать саму операцию кладёшь что-то в очередь, то и результат функции меняется — вместо "что-то произошло", будет "что-то произойдёт". P>Не вместо, а вместе. Все что нужно для редактирования — возвращаем сразу, BA так сказал. Всё, что для редактирования не нужно — вообще не возвращаем. А раз так, то можем поступать как проще — можно сразу, можно потом. P>Уже в который раз уточняю, но вы всё равно видите чтото свое
В прыжке переобуваешься. Это совершенно не то, что ты изначально утверждал "БЛ начала вызываться через очередь, с задержкой от часов до дней". Написал "БЛ", а на самом деле телепатировал, есть части логики нужные сейчас, а есть части не сейчас. Если ты не понимаешь как это выражается с моками, задавай вопросы, а не фантазируй проблемы.
P>>>Вы сами себе придумали какой то вариант, где сделано заведомо кривое решение, и теперь рассказываете будто это самый типичный случай. P>·>Это не я придумал, это ты придумал. P>Уже выяснили — это вы притянули пример Синклера который был совсем про другое.
Да, я перепутал. У Синклера было про 5 минут, а у тебя было часы-дни.
P>>>Зачем вам менять апишку для этого кейса? P>·>Затем, что функция API "выполнить действие X" != "положить в очередь чтобы действие X когда-нибудь выполнилось (может быть)". Апишка просто обязана быть разной, чтобы не было таких "чудесных вещей", которые ты так любишь. P>Вы путаете интерфейс и реализацию. API — create user, данные вернуть сразу — id, имя, фамилию. Всё не id-имя-фамилия, вы может создавать когда угодно, хоть с очередью, хоть без. Можете создать сразу — отлично. Не получается — ну и хрен с ним, абы id-имя-фамилия были дадены сразу
Это вы путаетесь в показаниях.
P>·>Из слов "паттерн тестируется" неясно кем. P>Если руками, что следует из выделеного, то какие варианты?
Мде, отстой.
P>>>3. какими тестами P>·>Из слов "паттерн тестируется" неясно какими тестами P>Я вам выделил, что бы виднее было.
Что за тест "против бд минимально заполненой под задачу"? Какие части системы он тестирует? e2e? или связка репо+бд? Или ещё что?
P>>>1. что делаем — сравниваем посимвольно, т.к. другого варианта нет — на одну задачу пилить ast на алгебраических типах данных это овердохрена P>·>Другой вариант я рассказал — выполнить запрос на базе и заасертить результат. P>Не работает — вы не знаете проблемной комбинации для фильтров. Знаете только что они есть и их хрензнаетсколькилион
Комбинация ровно та же — что и в твоём тесте. Тест почти такой же — только вместо деталей реализации ассертится поведение.
P>>>2. для чего делаем — что бы зафиксировать паттерн P>·>Зачем? P>Что бы исключить ту самую проблему в явном виде — потенциальная загрузка всего содержимого таблицы.
Эта проблема не исключается тестом, как бы тебе это ни хотелось.
P>>>Вы до сих пор такой тест не показали P>·>Это не покрывается тестами принципиально. P>Покрывается. Я ж вам показал. Только решение и покрытие это разные вещи. В данном случае решение — постусловие. А тестами фиксируем, что бы не убежало
Что значит "не убежало"?
P>·>Только если у тебя какой-то очень частый случай и ты завязываешься на какую-то конкретную реализацию — а это значит, что у тебя тесты не будут тестировать даже регрессию. P>Покажите пример регрессии, которая не будет обнаружена этим тестом.
Ну загрузится пол таблицы. Или банально твой .top(10) не появится для какой-то конкретной комбинации фильтров, т.к. для этой комбинации решили немного переписать кусочек кода и забыли засунуть .top(10).
P>·>Я никогда не просил объяснений, я просил код. Ибо по коду видны факты, а не твои фантазии. Так что не удивляйся, что твои объяснения являются словоблудием. P>С кодом у вас два варианта P>1. не будет работать
Так я объясняю почему не будет работать и как надо сделать чтобы работало.
P>>>Можно ограничить таблицы, из которых может или не может делаться джойн итд P>·>Т.е. в тесте ты единственное что можешь зафиксировать, что в коде у тебя действительно стоит .top(10). И что? Зачем? Наличие .top(10) и так видно, оно уже и так явно прописано в коде. P>Необязательно. Если я руками пишу весь запрос — то будет в коде явно. но запрос может и билдер создать.
Магически что-ли? Билдер рандомно top(10) не вставит, будет некий кусок кода который его ставит.
P>Некоторые детали нужно фиксировать в тестах, что бы случайно залетевший дятел не разрушил цивилизацию.
Дятлы тесты тоже умеют редактировать. А с учётом того, что у тебя в тестах полный текст sql — то это будет простой copy-paste и вечнозелёный тест. А на ревью определить корректность sql на вид могут не только лишь все.
P>>>Кто вам скажет, что в ваших этих 30 записях есть все потенциально опасные или невалидные комбинации? P>·>Это не решается тестами, никакими. P>Решение — пост-условие. А вот тест который я показал, он всего то гарантирует сохранность этого пост-условия.
Не гарантирует.
P>>>Вручную всё равно придется проверять, это обязательный этап — с этого всё начинается. P>·>Почему обязательный? P>Если вы не можете сделать этого руками, то ваши попытки выразить это в коде и генерации данных будут иметь ту же особенность.
Ты не понял. Я могу сделать это не руками, а кодом.
P>>>Эта часть же как и у вас. Это именно интеграционный тест репозитория. P>·>Т.е. тест репо+бд? У вас есть и такие тесты? P>Я вам уже который месяц говорю, что предлагаю добавить, а не выбросить. P>Есть и такие — их проще писать сразу, проще отдладить по горячим следам. P>Но с ростом сложности приходится вводить дополнительные инструменты.
Это где ты говорил такое месяц назад? Цитату.
P>>>Только сверх этого вы собираетесь и комбинации фильтров гонять здесь же. И на мой взгляд это совсем не то, чем нужно заниматься в этом виде тестов. P>·>Потому что юнит-тесты побуквенного сравнения sql-текста практически бесполезны и даже вредны. P>А разве я говорю, что это надо повсеместно?
Да нигде не надо.
P>>>Что будете в тест писать ? P>·>В тесте по определению тестируется известное. Если ты считаешь твои тесты тестируют неизвестное — ты заблуждаешься. P>Пост-условия похоже для вас пустой звук, вам это всё равно кажется тестом. Тест всего лишь гарантирует сохранность пост-условия
Не гарантирует.
P>>>Это же в операции известно, какие данные она возвращает. Если users.byId() то очевидно здесь один. А если users.where — вот тут а хрен его знает P>·>Угу, именно, что "очевидно", но кто-то накосячил с фильтром в byId и у тебя внезапно не один... Т.е. если это и как-то проверяется, но не тестами. P>Эта проблема и у вас будет. Например, вы тестируете на бд, где id это праймари кей, а в проде каким то чудом окажется другая схема, где id может иметь дубликаты P>И решения и у меня, и у вас, для подобных кейсов будут одни и те же.
Ну может быть колонок id несколько разных и иногда они совпадают... но не всегда.
P>>>У вас что, в требованиях позволено сдыхать при процессинге? P>·>http 4xx или 5xx. Везде тупо возвращать только первые 10 записей и делать вид что так и надо — это какая-то студенческя поделка. P>Вы снова чего то фантазируете.
Что фантазирую? Это вроде ты предлагаешь в код вставлять top(10) и тестом "фиксировать".
P>>>И тут мы узнаем... что тестами ничо не сделаешь. Гы-гы. P>·>Тесты могут проверять только тривиальные свойства. P>Нет, не могут. Так, как это утверждает т. Райса — вы true от false отличить не сможете. Можете потренироваться — тестами обнаружить функцию, которая всегда возвращает true. Валяйте.
"всегда" — это уже нетривиальное свойство. Проверка тривиального свойства это по сути "выполнить код и поглядеть на результат", т.е. тест практически.
P>Как напишете ваш тест — кидайте сюда, а я покажу, какая фукнция проходит ваш тест и не удовлетворяет условию P>Для простоты, функция будет такой — () -> true, т.к. никаких параметров и тд и тд и тд P>Как наиграетесь, приходите
Не понял. Да, эта функция возвращает true. Тестом будет "f=() -> true; assertTrue(f())".
P>>>Соотвественно, гарантии у вас будут не с т.з. т.Райса, а с т.з. вероятностей P>>>- функция которая проходит тесты по таблице истинности подходит лучше, чем та, которая эти тесты не проходит P>·>Мде... Ещё и вероятности пришли. P>Они всегда были. см выше про т. Райса
P>>>·>Ну добавь. Тесты тут не причём. Сразу замечу, что тестировать наличие постусловий — это уже лютейший бред. P>>>У вас всё бред, чего вы не понимаете P>·>Я понимаю на шаг вперёд. P>Смотрите выше, текст выделен H1, как раз эту вашу способность и "демонстрирует"
Так ещё до того как ты это написал уже говорил, что _необходимость_ ручного тестирования — проблема. Не надо так делать и рассказал как избежать эту необходимость.
P>·>Не понял к чему такой вопрос. Я наоборт утверждаю, что любое мелкое изменение реализации сломает тест, даже если это небольшой рефакторинг или тупо стиль. В этом и проблема такого твоего теста, он хрупкий. Часто падает когда не надо и иногда не падает когда надо, т.к. тестирует внутренние детали реализации, а не ожидания. P>Хрупкий — это я вам сразу сказал. Так я ж и не предлагаю посимвольное сравнение на все случаи жизни.
deep.eq по-другому тупо не умеет.
P>·>И что ты этим хочешь сказать? P>Да то, что искать тестами проблемные комбинации вы вспотеете. Нужно искать решение вне тестов.
Ясен пень, тестами комбинации не ищутся, а тестируются. Анализируешь код, coverage report, логи, спеки и т.п., потом пишешь тест подозрительной комбинации и смотришь как себя система ведёт.
P>>>Первые запуски — руками. Потом автоматизируете и получаете интеграционный тест. P>·>Зачем руками-то? В чём такая необходимость? И почему только первые запуски? P>Ну можете не руками, а попросить того, кто знает схему бд и язык запросов к ней.
А этот кто-то как будет, ногами что-ли?
Ок, допустим ногами. А какие в базе будут данные на которой этот чаи-гпт будет проверять свои запросы вножную? За 2025 год, правильно?
P>Ну или чат-гпт спросите.
P>Почему первые запуски — потому, что после них как раз будет известен паттерн, по которому нужно будет строить запросы. дальше в ручных проверках смысла не много.
Потом система меняется и паттерн перестаёт функционировать проверенным вручную способом, а тестам — пофиг, они вечнозелёные.
P>>>Вы совсем недавно собирались все комбинации тестировать, разве нет? P>·>Не все e2e комбинации, а комбинации конкретно данного куска кода, sut. P>С фильтрами комбинаций столько, что солнце погаснет раньше ваших тестов.
Даже если и так, то до e2e-комбинаций и жизни Вселенной не хватит уж точно.
P>>>·>30 это было число записей, которые могут обеспечить 230 комбинаций. Тебе столько не хватает? P>>>Фильтры дают на десяток порядков больше комбинаций. В этом и проблем P>·>Ну сделай 60 записей, будет как раз на десяток порядков больше комбинаций. В чём проблема-то? P>Проблема в том, что бы генерить данные, нужно знать комбинации которые будут проблемными.
Это же требуется и для того чтобы чтобы руками проверять запросы.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали: P>>·>Только если у тебя какой-то очень частый случай и ты завязываешься на какую-то конкретную реализацию — а это значит, что у тебя тесты не будут тестировать даже регрессию. P>>Покажите пример регрессии, которая не будет обнаружена этим тестом. ·>Ну загрузится пол таблицы. Или банально твой .top(10) не появится для какой-то конкретной комбинации фильтров, т.к. для этой комбинации решили немного переписать кусочек кода и забыли засунуть .top(10).
Нет. Эта проблема возникает только в том случае, если тестируется весь кусок про генерацию запроса целиком.
Вы предлагаете тестировать этот момент косвенно, через подсчёт реального количества записей, которые вернёт ваш репозиторий, подключенный к моку базы.
Альтернатива — не в том, чтобы сгенерировать 2N комбинаций условий фильтрации, а в том, чтобы распилить функцию построения запроса на две части:
1. Сгенерировать предикатную часть запроса
2. Добавить к любому запросу .top(10).
Тестируем эти две штуки по частям, и всё:
IQueryable<User> buildQuery(UserFilter criteria, int pageSize)
=> buildWhere(criteria).addLimit(pageSize);
Вот этот addLimit мы тестируем отдельным набором тестов, чтобы посмотреть, что он будет делать для отрицательных, нулевых, и положительных значений аргумента. Трёх бесконечно дешёвых юнит-тестов нам хватит для того, чтобы убедиться в его корректной работе с произвольным запросом. Так мы убираем множитель 3 из формулы 3*2N.
Шанс "забыть засунуть .top(10)" у нас ровно в одном месте — конкретно вот в этой glue-функции, которая клеит два куска запроса.
Для того, чтобы этот шанс окончательно устранить, нам достаточно 1 (одного) теста для функции buildQuery — благодаря линейности кода, этот тест покроет нужный нам путь.
А 2^N комбинаций фильтров уезжают в функцию buildWhere, которая тестируется отдельно.
При её тестировании мы точно так же заменяем 2N тестов на 2+2N-1 — режем на части примерно таким образом:
IQueryable<User> buildWhere(UserFilter criteria)
{
var q = db.Users;
if (criteria.Name != null)
q = q.Where(u=>u.Name.Contains(criteria.Name));
...
return q;
}
теперь нам достаточно двух тестов — в одном criteria.Name == null, в другом — не-null. Test Coverage нам покажет, что все строчки покрыты, а сам тест убедится, что у нас там — ровно нужный предикат — Сontains, BeginsWith, EndsWith или что там у нас требовалось по ТЗ.
Со следующим критерием всё будет точно так же — мы расщепляем код на линейно независимые куски, каждый из которых тестируется по отдельности. Если есть боязнь того, что нубас напишет некорректную комбинацию if-ов, вроде такой:
var q = db.Users;
if (criteria.Name != null)
q = q.Where(u => u.Name.Contains(criteria.Name))
else
if (criteria.MinLastLoginTimestamp.HasValue)
q = q.Where(u => u.LastLoginTimeStamp >= criteria.MinLastLoginTimestamp.Value);
...
Эта функция — строго линейна, она проверяется ровно одним тестом, который убеждается, что мы не забыли собрать все компоненты предиката.
А каждая из запчастей проверяется двумя или четырьмя тестами для всех нужных нам комбинаций её значений.
Всё, мы вместо 144 тестов (3*24*3) получили 3+2+4+2+2+3+1 = 17 тестов. При этом нам не нужны ни моки БД, ни тестовая БД в памяти, в которую запихано большое количество записей с разными комбинациями параметров.
То есть мы имеем 17 мгновенных тестов вместо 144 медленных, и гарантию полного покрытия.
По мере роста количества возможных критериев, разница между O(N) и O(2N) будет ещё больше.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, ·, Вы писали:
P>>моки и конформационные тесты это не решение, а компенсация. ·>Способ экономии ресурсов.
Имено — за счет покрытия.
P>>Вы отказываетесь идти дальше, и делать внятное покрытие e2e, и посмеиваетесь с тех, кто всё таки покрывает эти 99% как следует. ·>Скорее завидую простоте системы, что её реально покрыть e2e на 99%.
Вы сами себя ограбили когда строили вашу пирамиду тестов в виде трапеции — полуинтеграционные на моках + конформанс, которые к вашей системе имеют слабое отношение.
P>>Пример у вас есть внятный? Мне непонятно, каким чудом моки репозитория помогут понять, что же с интеграцией не так. ·>Они не для этого.
В том то и дело — вы оставили себе только полуинтеграционные тесты на моках.
Юнит-тесты вы не пишете, т.к. "это детали реализации, их не надо писать"
e2e "слишком долго"
P>>Какой компоент системы вы собираетесь конф тестами покрывать? ·>Конф-тесты тестируют чужое api. Система (по крайней мере её прод-часть) не принимает участие в конф-тестах.
Про то и речь — про интеграцию ваших компонентов с другими вашими же компонентами они ничего не говорят.
P>>Расскажите внятно, как мок репозитория поможет вам с интеграцией уровня приложения? ·>Никак. Мок поможет тестировать часть приложения с меньшим количеством ресурсов, следовательно позволит иметь больше покрытых сценариев.
В сценариях нас интересует интеграция прежде всего.
Например — юзер регистрируется, уточняет сведения, подтверждает регистрацию, делает N действий, смотрит в аудит, все ли хорошо, и делает логаут.
Итого:
Данные от входного запроса POST /users будут передаваться как положено во все части системы, и обратно, и это будет отражено везде — в профайле юзера, во всех частях админке
А далее, апдейт того же юзера снова даст ожидаемый результат и в профайле, и во всех частях админки
И так со всеми действиями согласно сценарию до самого последнего.
Если вы моками нарезали весь этот путь на части, вы знаете, что внутри каждой из частей всё хорошо
А вот склейку всех частей тестируют тесты системного уровня, например, те самые e2e
P>>Наоборот, e2e показывает те ошибки, которые проходят мимо ваших моков. ·>Если оно это показывает случайно, через несколько часов — то это называется хрень, а не показания.
Это намного лучше, чем их отсутствие.
P>> Они показывают, что приложение склеено как положено. ·>Это и проблема твоего подхода — у тебя в приложении на строчку кода ведро клея, который никак и не тестируется, кроме как тонной e2e.
Обратите внимание — сколько бы я вам ни говорил про юнит-тесты и интеграционные, вы всё равно видите своё.
Я даже цифры привел
Еще раз
e2e — меньше всего, десятки
интеграционные, функциональные — x10..x100 раз больше чем e2e
юнит-тесты, компонентные — x10..x100 раз больше, чем интеграционных
Вы выбросили:
верхний уровень — долго,
нижний — это "детали реализации"
Сверх этого кастрировали средний уровень и получили полуинтеграционные на моках
Итого — от вашей пирамиды остался поясок стыдливости
P>>Ну да — вы забили на интеграционные тесты. ·>Ну так в моём подходе этой интеграции кот наплакал, поэтому "приложение не упало при старте" уже практически означает, что 100% тех ошибок, "которые проходят мимо ваших моков" показано.
Это иллюзия. В сложном приложении интеграция не может быть простой, по определению.
Если у вас есть несколько источников данных для времени, то нужно гарантировать, что все они прописаны корректно для соответствующих юз кейсов
Как это проверяется стартом приложения — не ясно.
P>>·>Не годится. Мы не можем релизиться только с тремя десятками сценариев. Надо проверять 100%. P>>Я ж вам не предлагаю выбросить — я вам предлагаю добавить, и показываю, как именно. ·>Добавлять тест, который запускается рандомно через раз — это какое-то извращение. Если некий тест запускать не обязательно для релиза, клиенты переживут и так — накой его вообще запускать?
Вы и запускаете его для релиза — только результаты собираете не разово, а в течение первых часов после деплоя.
Здесь важно обнаружить проблемы раньше юзеров на проде.
Очевидно, что если собирать сведения не раз. а несколько часов, то сведений будет больше, и диагностика будет точнее
P>>Вы уже релизитесь без 99%. Если к вашим тестами добавите e2e, то покрытие станет плотнее. ·>Не станет.
e2e регулярно находят проблемы которые другими тестам даже обнаружить сложно.
P>>Если не хватает времени — e2e можно гонять и после деплоймента, хоть круглые сутки, они хлеба не просят. ·>Зачем? Если они что-то обнаружат, это значит что у клиентов проблемы прямо сейчас, prod incident. Поздно борожоми пить.
Затем, что бы
1 обнаружить на самых ранних этапах
2 сразу собрать максимальное количество сведений. По этим тестам у вас больше всего сведений, как и что воспроизвестир
3 e2e репортает все найденные проблемы
Юзеры
1 репортают проблемы не сразу, а с большой задержкой
2 репортают не все сведения, а часто еще и лишних подкидывают
3 большинство вообще ничего не репортает, по разным причинам — к вам попадает ничтожная часть
Итого — разница 3:0 в пользу e2e
P>>Вы уже это делаете. e2e всего то сделают видимыми проблемы в тех 99% которые ходили мимо ваших моков. ·>Ещё раз. Если ты догадался нечто описать в виде теста, пусть e2e — это значит какой-то вполне определённый известный сценарий. Всегда есть возможность покрыть этот сценарий покрыть более дешёвыми тестами и выполнять до релиза, всегда, а не по броску монеты.
Сценарии и так покрыты дешовыми тестами. Эти дешовые тесты, особенно на моках, не покрывают всю интеграцию, что очевидно.
См пример сценария выше.
P>>Это способ выполнять те тесты, которые у вас вообще отсутствуют. ·>Потому что нахрен не нужны.
Вот это ваш самый частый аргумент вместе с "словоблудие" итд
P>>Вы тестируете минимально, репозиторий + бд. Эта часть есть и у меня. ·>Где конкретно эта часть есть у тебя? Ты заявлял, что в твоих pattern-тестах ты репозиторий + бд не тестируешь; а в e2e ты каждую переменную на null тестирвать не будешь, да и не сможешь.
Там же где и у вас — это часть интеграционных тестов.
P>>Комбинации различных условий в фильтре, что дает нам ту самую data complexity, и проблемные комбинации вы будете узнавать только на проде, одну за другой ·>Ты тоже.
Именно. И я этим знанием пользуюсь, а вы — нет. например, я точно знаю, как выглядит проблема с фильтрами — вгружается вообще всё. Соответсвенно вариантов решения у меня несколько
Даже если я не знаю комбинации, то могу подстараховаться пост-условием
А что бы пост-условие не потерялось, подкидываю тест
·>Причём тут текущее время? Проблема как раз была в том, что ты называешь "нефункциональные требования": "ну юзер же создался, а что ещё не совсем до конца создался, ничего страшного..".
Именно это нефункциональные требования и описывают — когда именно произойдет событие "юзер создался до конца". Вот здесь как правило запас по времени существенный.
Чем вы и пользуетесь для изменения дизайна.
P>>Вот-вот. И если BA даёт добро — всё хорошо. ·>Ну вот это "добро" тебе и надо будет выразить в тестах.
Разумеется.
P>>Уже в который раз уточняю, но вы всё равно видите чтото свое ·>В прыжке переобуваешься. Это совершенно не то, что ты изначально утверждал "БЛ начала вызываться через очередь, с задержкой от часов до дней". Написал "БЛ", а на самом деле телепатировал, есть части логики нужные сейчас, а есть части не сейчас. Если ты не понимаешь как это выражается с моками, задавай вопросы, а не фантазируй проблемы.
Что вас смущает? БЛ вызывается из разных мест приложения. Ключевое — консистентность тех или иных сведений.
P>>·>Из слов "паттерн тестируется" неясно кем. P>>Если руками, что следует из выделеного, то какие варианты? ·>Мде, отстой.
Расскажите, как лучше. Желательно на тех самых фильтрах — откуда возьмете первый вариант запроса к бд, орм, нужное-вписать, и как будете его тестировать
P>>Я вам выделил, что бы виднее было. ·>Что за тест "против бд минимально заполненой под задачу"? Какие части системы он тестирует? e2e? или связка репо+бд? Или ещё что?
В зависимости от конкретного дизайна:
репозиторий + бд — если все запросы генерируются самим репозиторием
юз-кейс + репозиторий + бд — если у нас генерация выражений находится вне репозитория
P>>Не работает — вы не знаете проблемной комбинации для фильтров. Знаете только что они есть и их хрензнаетсколькилион ·>Комбинация ровно та же — что и в твоём тесте. Тест почти такой же — только вместо деталей реализации ассертится поведение.
Что вы будете ассертить в поведении?
P>>Что бы исключить ту самую проблему в явном виде — потенциальная загрузка всего содержимого таблицы. ·>Эта проблема не исключается тестом, как бы тебе это ни хотелось.
И давно у вас пост-условие стало тестом ?
P>>Покрывается. Я ж вам показал. Только решение и покрытие это разные вещи. В данном случае решение — постусловие. А тестами фиксируем, что бы не убежало ·>Что значит "не убежало"?
Пришел некто резкий и дерзкий и фиксанул "тут всё просто, я быстро". На его тестовой бд записей 60 штук, мелочовочка. А на проде это десятки миллионов.
P>>Покажите пример регрессии, которая не будет обнаружена этим тестом. ·>Ну загрузится пол таблицы.
Полтаблицы это 20 записей? Не понял, что за кейс такой.
> Или банально твой .top(10) не появится для какой-то конкретной комбинации фильтров, т.к. для этой комбинации решили немного переписать кусочек кода и забыли засунуть .top(10).
Что значит не появится? Если это пост-условие,оно будет применено для всего выхлопа, а не для разных подветок в вычислениях.
P>>Необязательно. Если я руками пишу весь запрос — то будет в коде явно. но запрос может и билдер создать. ·>Магически что-ли? Билдер рандомно top(10) не вставит, будет некий кусок кода который его ставит.
Поскольку билдер сложный, то можно сказать, что да, магически — прямой связи входа и выхода вы на глазок не обнаружите. Потому и надо подстраховываться в тестах.
P>>Некоторые детали нужно фиксировать в тестах, что бы случайно залетевший дятел не разрушил цивилизацию. ·>Дятлы тесты тоже умеют редактировать.
Умеют — здесь только код-ревью может помочь. О чем я вам и говорю в который раз.
> А с учётом того, что у тебя в тестах полный текст sql — то это будет простой copy-paste и вечнозелёный тест. А на ревью определить корректность sql на вид могут не только лишь все.
В данном случае и не нужно, что бы все могли определять корректность — код заведомо нетривиальный.
P>>Решение — пост-условие. А вот тест который я показал, он всего то гарантирует сохранность этого пост-условия. ·>Не гарантирует.
Видите — снова без аргументов, голословно
P>>Если вы не можете сделать этого руками, то ваши попытки выразить это в коде и генерации данных будут иметь ту же особенность. ·>Ты не понял. Я могу сделать это не руками, а кодом.
Для простых фильров это работает. Для сложных — проще найти решение напрямую, в бд, что бы представлять, куда всё двигать
P>>Есть и такие — их проще писать сразу, проще отдладить по горячим следам. P>>Но с ростом сложности приходится вводить дополнительные инструменты. ·>Это где ты говорил такое месяц назад? Цитату.
Вам не только я, но и Синклер это же сказал.
P>>Пост-условия похоже для вас пустой звук, вам это всё равно кажется тестом. Тест всего лишь гарантирует сохранность пост-условия ·>Не гарантирует.
У вас похоже тесты вообще ничего не гарантируют. Зачем же вы их пишете?
P>>И решения и у меня, и у вас, для подобных кейсов будут одни и те же. ·>Ну может быть колонок id несколько разных и иногда они совпадают... но не всегда.
каким образом в одной таблице users может быть несколько колонок id ? byId — это запрос к праймари кей. Ломается только если схема поломана.
P>>Вы снова чего то фантазируете. ·>Что фантазирую? Это вроде ты предлагаешь в код вставлять top(10) и тестом "фиксировать".
Это же пост-условие.
P>>Нет, не могут. Так, как это утверждает т. Райса — вы true от false отличить не сможете. Можете потренироваться — тестами обнаружить функцию, которая всегда возвращает true. Валяйте. ·>"всегда" — это уже нетривиальное свойство. Проверка тривиального свойства это по сути "выполнить код и поглядеть на результат", т.е. тест практически.
Ловко вы опровергли теорему Райса!
В т.Райса нетривиальное свойство означает, что есть функции, которые им обладают, а есть те, которые не обладают.
То есть, искать разницу между двумя функциями вы будете до скончания времён
P>>Как наиграетесь, приходите ·>Не понял. Да, эта функция возвращает true. Тестом будет "f=() -> true; assertTrue(f())".
Вот-вот. Опровержение теоремы Райса! Ну Нобелевка же!
P>>Смотрите выше, текст выделен H1, как раз эту вашу способность и "демонстрирует" ·>Так ещё до того как ты это написал уже говорил, что _необходимость_ ручного тестирования — проблема. Не надо так делать и рассказал как избежать эту необходимость.
Ручное тестирование плохо не само по себе, а когда оно увеличивает время разработки
В данном случае мы ищем решение — потому и тестируем руками, т.к. запрос ни разу не тривиальный и нужно быстро перебрать десяток другой вариантов.
Это намного быстрее чем делать то же самое кодом к orm или билдером запросов.
В тривиальный случаях, типа "user.byId()" ровно наоборот — быстрее именно кодом
P>>Хрупкий — это я вам сразу сказал.
Так я ж и не предлагаю посимвольное сравнение на все случаи жизни.
·>deep.eq по-другому тупо не умеет.
Я снова выделил, что бы вам виднее было. Посимвольно это потому, что у меня в конкретном случае нет ни json, ни orm, ни еще какого ast.
deep.eq дает нам вполне годную структурную эквивалентность.
Если вы ей не умеете пользоваться — значит это не ваш вариант
P>>Да то, что искать тестами проблемные комбинации вы вспотеете. Нужно искать решение вне тестов. ·>Ясен пень, тестами комбинации не ищутся, а тестируются. Анализируешь код, coverage report, логи, спеки и т.п., потом пишешь тест подозрительной комбинации и смотришь как себя система ведёт.
И так будете для каждой комбинации, да? Дадите шанс юзеру убиться об ваш билдер фильтров?
P>>Ну можете не руками, а попросить того, кто знает схему бд и язык запросов к ней. ·>А этот кто-то как будет, ногами что-ли? ·>Ок, допустим ногами. А какие в базе будут данные на которой этот чаи-гпт будет проверять свои запросы вножную? За 2025 год, правильно?
Жалко, что нет шрифта больше чем h1
сначала руками, а потом тестом против бд минимально заполненой под задачу
P>>Почему первые запуски — потому, что после них как раз будет известен паттерн, по которому нужно будет строить запросы. дальше в ручных проверках смысла не много. ·>Потом система меняется и паттерн перестаёт функционировать проверенным вручную способом, а тестам — пофиг, они вечнозелёные.
А интеграционные тесты вы забыли, да?
Мне что, каждую строчку теперь H1 выделять, что бы вам виднее было?
P>>С фильтрами комбинаций столько, что солнце погаснет раньше ваших тестов. ·>Даже если и так, то до e2e-комбинаций и жизни Вселенной не хватит уж точно.
В том то и дело — количество e2e никак не зависит от количества комбинаций в фильтрах.
P>>Проблема в том, что бы генерить данные, нужно знать комбинации которые будут проблемными. ·>Это же требуется и для того чтобы чтобы руками проверять запросы.
Похоже, пост-условия для вас пустой звук. Для моего варианта нужно проверить,
1 работает ли пост-условие
2 находится ли оно на своем месте
3 все ли ветки ифов получат его
Вот это — решение. А тестами фиксируем сохранность этого условия. Т.е. тесты это второстепенная роль в данном случае.
Здравствуйте, Sinclair, Вы писали:
P>>>·>Только если у тебя какой-то очень частый случай и ты завязываешься на какую-то конкретную реализацию — а это значит, что у тебя тесты не будут тестировать даже регрессию. P>>>Покажите пример регрессии, которая не будет обнаружена этим тестом. S>·>Ну загрузится пол таблицы. Или банально твой .top(10) не появится для какой-то конкретной комбинации фильтров, т.к. для этой комбинации решили немного переписать кусочек кода и забыли засунуть .top(10). S>Нет. Эта проблема возникает только в том случае, если тестируется весь кусок про генерацию запроса целиком.
Мой поинт, что такой тест запроса целиком должен быть в любом случае. Что делает ценность этих ваших тестов <=0.
S>Вы предлагаете тестировать этот момент косвенно, через подсчёт реального количества записей, которые вернёт ваш репозиторий, подключенный к моку базы.
Я предлагаю тестировать не моменты, а бизнес-требования. Не бывает в реальности таких требований как "построить кусочек запроса".
S>Альтернатива — не в том, чтобы сгенерировать 2N комбинаций условий фильтрации, а в том, чтобы распилить функцию построения запроса на две части: S>1. Сгенерировать предикатную часть запроса
Это всё скучные тривиальные детали реализации.
S>2. Добавить к любому запросу .top(10).
Вот только невозможно проверить в _тесте_, что .top(10) действительно добавляется к _любому_ запросу.
S>Вот этот addLimit мы тестируем отдельным набором тестов, чтобы посмотреть, что он будет делать для отрицательных, нулевых, и положительных значений аргумента.
Это уже лажа. addLimit это метод некоего QueryBuilder, некий библиотечный метод, который уже имеет свои тесты, включая эти твои отрицательные аргументы. Мы полагаемся, что он работает в соотвествии с контрактом когда им пользуемся. А здесь мы говорим о тестировании некего условного UserRepository, которому какие-либо QueryBuilders совершенно побоку. В контексте разговора UserRepositoryTest предлагать тесты работоспособности addLimit — это как минимум паранойя.
S>Шанс "забыть засунуть .top(10)" у нас ровно в одном месте — конкретно вот в этой glue-функции, которая клеит два куска запроса. S>Для того, чтобы этот шанс окончательно устранить, нам достаточно 1 (одного) теста для функции buildQuery — благодаря линейности кода, этот тест покроет нужный нам путь.
А зачем этот тест нужен-то? Убедиться, что в двух строчках кода одна из них действительно addLimit? Это и так напрямую явно видно в коде и каждый заметит наличие-отсутствие этого вызова и в PR диффе.
Ты по сути предлагаешь написать строчку кода, а потом продублировать в тесте, что эта строчка действительно написана. Ценность околонулевая. Твои тесты тестируют "works as coded".
Завтра придёт "специалист" и немного допишет:
И твои супер-тесты это не обнаружат. Т.е. твой тест даст false negative. Или тебе известна методология тестирования кода на простоту и линейность?
Мой поинт в том, что ценным тестом будет проверка что addLimit строчка действительно работает в соответствии с бизнес-требованиями — запустить на 11 записях и заассертить, что вернулось только 10 как прописано в FRD — это цель этой строчки, а сама по себе строчка — это средство. И заметь, такой 11/10 тест достаточно сделать для ровно той же комбинации фильтров что и в твоём тесте на наличие addLimit в коде, никакой экспоненциальности которой ты грозишься. Твой тест теоретически не может гарантировать, что некая функция buildQuery возвращает IQueryable с addLimit всегда, для любых входных параметров, такое можно лишь гарантировать через ревью текста самого кода.
Цель моего теста: если мы завтра перепишем addLimit на голый sql c "where rownum <= 10" или наоборот — то у нас будет регрессия, т.е. тесты которые так же продолжают работать и ожидаются, что должны быть зелёными без каких-либо изменений после рефакторинга. Такие тесты нужны в любом случае. А твой тест даст false positive и будет просто выкинут. Напишут взамен другой тест, в который закопипастят .contains("rownum < 10") перепутав что rownum zero- или one- based. Отличить на ревью корректность <= от < гораздо сложнее, чем условно save(...11 records...); assert find(10).size() == 10; assert find(5).size() == 5;.
S>Эта функция — строго линейна, она проверяется ровно одним тестом, который убеждается, что мы не забыли собрать все компоненты предиката.
Это какой-то тривиальный случай. Это значит не то, что мы магически сделали функцию линейной, а что никаких зависимостей между фильтрами нет в требованиях и никаких 2^N комбинаций просто не нужно, где тут эта ваша грозная data complexity — совершенно неясно.
В реальности у тебя могут быть хитрые зависимости между параметрами фильтра и вот тут и полезут неявные комбинации экспоненциально всё взрывающие и код несводимый к линейной функции, а будет хитрая if-else-switch лесенка.
S>А каждая из запчастей проверяется двумя или четырьмя тестами для всех нужных нам комбинаций её значений. S>Всё, мы вместо 144 тестов (3*24*3) получили 3+2+4+2+2+3+1 = 17 тестов. При этом нам не нужны ни моки БД, ни тестовая БД в памяти, в которую запихано большое количество записей с разными комбинациями параметров. S>То есть мы имеем 17 мгновенных тестов вместо 144 медленных, и гарантию полного покрытия.
Гарантию того, что у тебя works as coded. Зато отличить u => u.LastLoginTimeStamp >= criteria.MinLastLoginTimestamp.Value) от u => u.LastLoginTimeStamp <= criteria.MinLastLoginTimestamp.Value) такие тесты не смогут, т.к. пишутся как правило копипастом. На ревью очепятку очень вряд ли кто-то заметит.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
S>>Вы предлагаете тестировать этот момент косвенно, через подсчёт реального количества записей, которые вернёт ваш репозиторий, подключенный к моку базы. ·>Я предлагаю тестировать не моменты, а бизнес-требования. Не бывает в реальности таких требований как "построить кусочек запроса".
Это игра словами.
·>Это всё скучные тривиальные детали реализации.
Ну так дьявол-то как раз в деталях.
·>Вот только невозможно проверить в _тесте_, что .top(10) действительно добавляется к _любому_ запросу.
Я же показал, как именно проверить. Какое место осталось непонятным?
·>Это уже лажа. addLimit это метод некоего QueryBuilder, некий библиотечный метод, который уже имеет свои тесты, включая эти твои отрицательные аргументы. Мы полагаемся, что он работает в соотвествии с контрактом когда им пользуемся. Если AddLimit — библиотечный, то всё прекрасно, и вы правы — тестировать его не надо вовсе.
·>А зачем этот тест нужен-то? Убедиться, что в двух строчках кода одна из них действительно addLimit? Это и так напрямую явно видно в коде и каждый заметит наличие-отсутствие этого вызова и в PR диффе.
Ну вы же почему-то не верите в то, что в двух строчках кода в контроллере берётся именно request.ClientTime и требуете, чтобы это было покрыто тестами
·>
·>И твои супер-тесты это не обнаружат.
У меня не супер-тесты, а самые примитивные юнит-тесты. ·>Т.е. твой тест даст false negative. Или тебе известна методология тестирования кода на простоту и линейность?
Основная методология — такая же, как вы привели выше. Каждый заметит наличие-отсутствие этого вызова и в PR диффе, поэтому такой код не пройдёт ревью. От автора потребуют переместить свой buildOptimizedQuery внутрь buildWhere. Если у нас нет под рукой theorem prover, то надёжных автоматических альтернатив нет.
Впрочем, в вашем подходе всё будет ровно так же — вы же ведь не собираетесь перебирать все мыслимые сочетания значений аргументов в тесте, который проверяет количество записей?
·>Мой поинт в том, что ценным тестом будет проверка что addLimit строчка действительно работает в соответствии с бизнес-требованиями — запустить на 11 записях и заассертить, что вернулось только 10 как прописано в FRD — это цель этой строчки, а сама по себе строчка — это средство. И заметь, такой 11/10 тест достаточно сделать для ровно той же комбинации фильтров что и в твоём тесте на наличие addLimit в коде, никакой экспоненциальности которой ты грозишься.
Ну это же просто обман. Смотрите за руками: если комбинация фильтров, которая использовалась в тесте на addLimit, попадает под условия someMagicalCondition, то тест сразу сфейлится.
А если не попадает — то ващ тест точно так же вернёт 10 записей, и всё.
·>Твой тест теоретически не может гарантировать, что некая функция buildQuery возвращает IQueryable с addLimit всегда, для любых входных параметров, такое можно лишь гарантировать через ревью текста самого кода. ·>Цель моего теста: если мы завтра перепишем addLimit на голый sql c "where rownum <= 10" или наоборот — то у нас будет регрессия,
Всё правильно. Вредителей, которые заменяют рабочий код на голый SQL, нужно бить по рукам. ·>т.е. тесты которые так же продолжают работать и ожидаются, что должны быть зелёными без каких-либо изменений после рефакторинга. Такие тесты нужны в любом случае. А твой тест даст false positive и будет просто выкинут. ·>Напишут взамен другой тест, в который закопипастят .contains("rownum < 10") перепутав что rownum zero- или one- based. Отличить на ревью корректность <= от < гораздо сложнее, чем условно save(...11 records...); assert find(10).size() == 10; assert find(5).size() == 5;.
Если в проекте завёлся вредитель, то никакими тестами вы его не поймаете. Он просто возьмёт и сломает всё, что угодно. Сейчас вы мне рассказываете, что ловите баги при помощи review кода.
Ну, вот и в нашем случае делается review кода, только код — простой, а за наращивание сложности на ровном месте можно бить человека палкой.
·>Это какой-то тривиальный случай. Это значит не то, что мы магически сделали функцию линейной, а что никаких зависимостей между фильтрами нет в требованиях и никаких 2^N комбинаций просто не нужно, где тут эта ваша грозная data complexity — совершенно неясно.
Ну так этой complexity нету как раз потому, что мы её факторизовали. И сделали это благодаря тому, что распилили сложную функцию на набор простых частей.
А вы предлагаете тестировать весь монолит — в рамках него вы не можете полагаться ни на какую независимость. Ну, вот так устроена pull-модель — вам надо построить полный фильтр и выполнить запрос, и никакого способа проверить первую половину запроса отдельно от второй половины запроса не существует.
·>В реальности у тебя могут быть хитрые зависимости между параметрами фильтра и вот тут и полезут неявные комбинации экспоненциально всё взрывающие и код несводимый к линейной функции, а будет хитрая if-else-switch лесенка.
Нет, по-прежнему будет простая линейная цепочка, только кусочки её будут чуть более длинными.
·>Гарантию того, что у тебя works as coded. Зато отличить u => u.LastLoginTimeStamp >= criteria.MinLastLoginTimestamp.Value) от u => u.LastLoginTimeStamp <= criteria.MinLastLoginTimestamp.Value) такие тесты не смогут, т.к. пишутся как правило копипастом. На ревью очепятку очень вряд ли кто-то заметит.
Если пишут разные люди, то заметят. Ну и, опять же, у нас код каждой функции — очень короткий. Там всего-то пара операций.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Pauel, Вы писали:
P>·>Способ экономии ресурсов. P>Имено — за счет покрытия.
За счёт разделения слона на части.
P>>>Вы отказываетесь идти дальше, и делать внятное покрытие e2e, и посмеиваетесь с тех, кто всё таки покрывает эти 99% как следует. P>·>Скорее завидую простоте системы, что её реально покрыть e2e на 99%. P>Вы сами себя ограбили когда строили вашу пирамиду тестов в виде трапеции — полуинтеграционные на моках + конформанс, которые к вашей системе имеют слабое отношение.
В чём ограбили? На прогон тестов и релиз мы тратим как лохи всего пол часа и уныло идём домой, скучаем на прод-саппорте, когда за углом тесты гоняют неделями и нон-стоп вечеринка в проде с юзерами?
P>>>Пример у вас есть внятный? Мне непонятно, каким чудом моки репозитория помогут понять, что же с интеграцией не так. P>·>Они не для этого. P>В том то и дело — вы оставили себе только полуинтеграционные тесты на моках. P>Юнит-тесты вы не пишете, т.к. "это детали реализации, их не надо писать"
Юнит-тесты с моками — это тоже юнит-тесты. Ты до сих пор не въехал что такое моки и как ими надо пользоаться.
P>e2e "слишком долго"
Потому что очень много компонент в системе. Разворачивается на кластере в пол сотни машин. Гонять там проверки каждого поля на null просто невозможно.
P>·>Конф-тесты тестируют чужое api. Система (по крайней мере её прод-часть) не принимает участие в конф-тестах. P>Про то и речь — про интеграцию ваших компонентов с другими вашими же компонентами они ничего не говорят.
Есть тесты репо + бд — они тестируют интеграцию нашей системы с бд и адеквтатность репо-моков. Есть тесты бл + репо-моки — которые не требуют субд/сокетов/етс и работают быстро.
Можно тесты репо+бд назвать неким подвидом конф-тестов, т.к. субд — это внешняя зависимость по сути.
P> И так со всеми действиями согласно сценарию до самого последнего.
Всё красиво, но медленно. Такой один сценарий отрабатывает e2e секунды, может даже минуты. Пока браузер откроется, пока поля введутся, кнопочки всякие кликаются, установятся сессии по разным каналам, подпишутся очереди и т.п. Сложно иметь много таких тестов.
P>Если вы моками нарезали весь этот путь на части, вы знаете, что внутри каждой из частей всё хорошо P>А вот склейку всех частей тестируют тесты системного уровня, например, те самые e2e
Угу. Но они не могут тестировать все сценарии, времени не хватит как минимум.
А ещё всякие завязанные на реальное время тесты. Как ты e2e будешь тестировать, что через 30 минут неактивностии юзера происходит логаут? Будешь ждать по пол часа каждый раз?
P>>>Наоборот, e2e показывает те ошибки, которые проходят мимо ваших моков. P>·>Если оно это показывает случайно, через несколько часов — то это называется хрень, а не показания. P>Это намного лучше, чем их отсутствие.
Если это действительно намного лучше, это значит что у вас внизу пирамиды дыры зияют.
P>>> Они показывают, что приложение склеено как положено. P>·>Это и проблема твоего подхода — у тебя в приложении на строчку кода ведро клея, который никак и не тестируется, кроме как тонной e2e. P>Обратите внимание — сколько бы я вам ни говорил про юнит-тесты и интеграционные, вы всё равно видите своё.
Потому что ты жонглируешь терминологией в соседних предожениях.
P>Вы выбросили:
Ты сочиняешь. Не выбросили. Пирамида такая и есть по форме.
Моки этому всему ортогональны. Они могут быть на любом уровне. Ещё раз, это тупо способ протаскивать данные, альтернатива параметрам.
P>Итого — от вашей пирамиды остался поясок стыдливости
Бредишь.
P>>>Ну да — вы забили на интеграционные тесты. P>·>Ну так в моём подходе этой интеграции кот наплакал, поэтому "приложение не упало при старте" уже практически означает, что 100% тех ошибок, "которые проходят мимо ваших моков" показано. P>Это иллюзия. В сложном приложении интеграция не может быть простой, по определению.
Не знаю что ты тут подразумеваешь. Обычно вся интеграция происходит в composition root wiring коде, который составляет доли процента от кодовой базы.
У тебя да — кода интеграции дохрена, вот и проблемы с тестированием.
P>Если у вас есть несколько источников данных для времени, то нужно гарантировать, что все они прописаны корректно для соответствующих юз кейсов
Рассказывал же уже. Коррекность проверяется с помощью моков, подсовываем разное время в разные источники чтобы их можно было различать в тестах.
P>Как это проверяется стартом приложения — не ясно.
Я вроде всё расписал с примерами кода. Перечитай если всё ещё неясно, вопросы задавай чего неясно.
P>>>·>Не годится. Мы не можем релизиться только с тремя десятками сценариев. Надо проверять 100%. P>>>Я ж вам не предлагаю выбросить — я вам предлагаю добавить, и показываю, как именно. P>·>Добавлять тест, который запускается рандомно через раз — это какое-то извращение. Если некий тест запускать не обязательно для релиза, клиенты переживут и так — накой его вообще запускать? P>Вы и запускаете его для релиза — только результаты собираете не разово, а в течение первых часов после деплоя. P>Здесь важно обнаружить проблемы раньше юзеров на проде.
Через несколько секунд после релиза юзеры на проде уже могут иметь проблемы. Ещё раз. Мы не можем себе повзолить трогать чего-либо в проде до прогона всех тестов.
P>Очевидно, что если собирать сведения не раз. а несколько часов, то сведений будет больше, и диагностика будет точнее
И эти несколько часов у юзеров будут проблемы на проде.
P>>>Вы уже релизитесь без 99%. Если к вашим тестами добавите e2e, то покрытие станет плотнее. P>·>Не станет. P>e2e регулярно находят проблемы которые другими тестам даже обнаружить сложно.
Это потому что у вас беда с другими тестами. У нас в точности наоборот, вся та небольшая кучка e2e в подавляющем большинстве случаев просто работает на стейдже. А тот практически единственный TiL тест в худшем случае обнаруживет железные проблемы в инфре.
P>>>Если не хватает времени — e2e можно гонять и после деплоймента, хоть круглые сутки, они хлеба не просят. P>·>Зачем? Если они что-то обнаружат, это значит что у клиентов проблемы прямо сейчас, prod incident. Поздно борожоми пить. P>Затем, что бы P>1 обнаружить на самых ранних этапах
"после деплоймента" — это для нас очень поздний этап. Сразу после деплоя мы идём домой, какой к хрену круглые сутки?
P>2 сразу собрать максимальное количество сведений. По этим тестам у вас больше всего сведений, как и что воспроизвестир
Мы собираем сведения ещё до планирования деплоя.
P>1 репортают проблемы
Это уже полный провал. Будут разборки.
P>·>Ещё раз. Если ты догадался нечто описать в виде теста, пусть e2e — это значит какой-то вполне определённый известный сценарий. Всегда есть возможность покрыть этот сценарий покрыть более дешёвыми тестами и выполнять до релиза, всегда, а не по броску монеты. P>Сценарии и так покрыты дешовыми тестами. Эти дешовые тесты, особенно на моках, не покрывают всю интеграцию, что очевидно.
Все условно полторы строчки интеграции? Какой ужас!
P>>>Это способ выполнять те тесты, которые у вас вообще отсутствуют. P>·>Потому что нахрен не нужны. P>Вот это ваш самый частый аргумент вместе с "словоблудие" итд
Конечно, ибо есть более надёжные и адектватные подходы. Надеяться что юзеры репортают проблемы — это уже дно какое-то.
P>>>Вы тестируете минимально, репозиторий + бд. Эта часть есть и у меня. P>·>Где конкретно эта часть есть у тебя? Ты заявлял, что в твоих pattern-тестах ты репозиторий + бд не тестируешь; а в e2e ты каждую переменную на null тестирвать не будешь, да и не сможешь. P>Там же где и у вас — это часть интеграционных тестов.
Т.е. у тебя есть ровно те же "репозиторий + бд" тесты?
P>>>Комбинации различных условий в фильтре, что дает нам ту самую data complexity, и проблемные комбинации вы будете узнавать только на проде, одну за другой P>·>Ты тоже. P>Именно. И я этим знанием пользуюсь, а вы — нет. например, я точно знаю, как выглядит проблема с фильтрами — вгружается вообще всё.
А я не знаю такой проблемы... не было у нас такой. ЧЯДНТ?
P>Соответсвенно вариантов решения у меня несколько P>Даже если я не знаю комбинации, то могу подстараховаться пост-условием P>А что бы пост-условие не потерялось, подкидываю тест
Ещё молитву скажи и свечку поставь, тоже, говорят, помогает.
P>·>Причём тут текущее время? Проблема как раз была в том, что ты называешь "нефункциональные требования": "ну юзер же создался, а что ещё не совсем до конца создался, ничего страшного..". P>Именно это нефункциональные требования и описывают — когда именно произойдет событие "юзер создался до конца". Вот здесь как правило запас по времени существенный. P>Чем вы и пользуетесь для изменения дизайна
"Событие" — это функциональная сущность. Возврат результата из метода — это событие. Вначале у тебя событие означало "юзер создался до конца", а после того как ты переложил обработку в очередь, то смысл события поменялся на "создался, но не очеь". Это функциональное изменение.
P>>>Вот-вот. И если BA даёт добро — всё хорошо. P>·>Ну вот это "добро" тебе и надо будет выразить в тестах. P>Разумеется.
Т.е. без добра существующие тесты должны падать. ЧТД.
P>>>·>Из слов "паттерн тестируется" неясно кем. P>>>Если руками, что следует из выделеного, то какие варианты? P>·>Мде, отстой. P>Расскажите, как лучше. Желательно на тех самых фильтрах — откуда возьмете первый вариант запроса к бд, орм, нужное-вписать, и как будете его тестировать
Напишу. Тестировать — тестами.
P>>>Я вам выделил, что бы виднее было. P>·>Что за тест "против бд минимально заполненой под задачу"? Какие части системы он тестирует? e2e? или связка репо+бд? Или ещё что? P>В зависимости от конкретного дизайна: P>репозиторий + бд — если все запросы генерируются самим репозиторием P>юз-кейс + репозиторий + бд — если у нас генерация выражений находится вне репозитория
Что именно ты не сможешь покрыть такими тестами, что тебе требуется побуквенно sql сравнивать?
P>>>Не работает — вы не знаете проблемной комбинации для фильтров. Знаете только что они есть и их хрензнаетсколькилион P>·>Комбинация ровно та же — что и в твоём тесте. Тест почти такой же — только вместо деталей реализации ассертится поведение. P>Что вы будете ассертить в поведении?
Что возвращается ровно столько записей сколько требуется.
P>>>Что бы исключить ту самую проблему в явном виде — потенциальная загрузка всего содержимого таблицы. P>·>Эта проблема не исключается тестом, как бы тебе это ни хотелось. P>И давно у вас пост-условие стало тестом ?
С тех пор как ты так написал. Ты тут предложил проблему "потенциальная загрузка всего содержимого таблицы" исключать тестом с паттерном. Какое ещё постусловие? Ты контекст потерял. Напоминаю:
·>Было показано deep.eq(..."some string"...), т.е. буквальное, посимвольное сравнение текста sql-запроса. Неясно где какой тут паттерн который ты "объясняешь", но код не показываешь.
проверка паттерна посимвольным сравнением
1. что делаем — сравниваем посимвольно, т.к. другого варианта нет — на одну задачу пилить ast на алгебраических типах данных это овердохрена
2. для чего делаем — что бы зафиксировать паттерн
P>>>Покрывается. Я ж вам показал. Только решение и покрытие это разные вещи. В данном случае решение — постусловие. А тестами фиксируем, что бы не убежало P>·>Что значит "не убежало"? P>Пришел некто резкий и дерзкий и фиксанул "тут всё просто, я быстро". На его тестовой бд записей 60 штук, мелочовочка. А на проде это десятки миллионов.
Твои тесты с паттернами дерзкого не остановят. Свечка и молитва — гораздо надёжнее твоих тестов! Рекомендую.
P>>>Покажите пример регрессии, которая не будет обнаружена этим тестом. P>·>Ну загрузится пол таблицы. P>Полтаблицы это 20 записей? Не понял, что за кейс такой.
У тебя же таблица это "это десятки миллионов".
>> Или банально твой .top(10) не появится для какой-то конкретной комбинации фильтров, т.к. для этой комбинации решили немного переписать кусочек кода и забыли засунуть .top(10). P>Что значит не появится? Если это пост-условие,оно будет применено для всего выхлопа, а не для разных подветок в вычислениях.
Если это постусловие, то и такой тест и не нужен — он не может дать ничего полезного.
P>>>Необязательно. Если я руками пишу весь запрос — то будет в коде явно. но запрос может и билдер создать. P>·>Магически что-ли? Билдер рандомно top(10) не вставит, будет некий кусок кода который его ставит. P>Поскольку билдер сложный, то можно сказать, что да, магически — прямой связи входа и выхода вы на глазок не обнаружите. Потому и надо подстраховываться в тестах.
Это значит, что и тесты могут пропустить некий вход, для которого твой билдер пропустит твой top(10) на выходе.
P>>>Некоторые детали нужно фиксировать в тестах, что бы случайно залетевший дятел не разрушил цивилизацию. P>·>Дятлы тесты тоже умеют редактировать. P>Умеют — здесь только код-ревью может помочь. О чем я вам и говорю в который раз.
Так я об этом и говорю, что тесты в твоём виде бесполезны и даже вредны, т.к. код-ревью усложняют. Давай приведи пример целиком — код + твой тест с паттерном и я тебе тыкну пальчиком что на ревью может пойти не так. Это происходит потому, что код в тесте будет практически копипаст главного кода, значит ревьюверу вообще смысла на код теста смотреть нет, т.к. там тупо то же самое.
>> А с учётом того, что у тебя в тестах полный текст sql — то это будет простой copy-paste и вечнозелёный тест. А на ревью определить корректность sql на вид могут не только лишь все. P>В данном случае и не нужно, что бы все могли определять корректность — код заведомо нетривиальный. Не то что "не нужно", а просто невозможно. Тесты никакой ценности не дают, просто шоб-було, культ карго. Всё делаетя только под пристальным вниманием Верховного Программиста.
P>>>Решение — пост-условие. А вот тест который я показал, он всего то гарантирует сохранность этого пост-условия. P>·>Не гарантирует. P>Видите — снова без аргументов, голословно
Я рассказал о false positive/negative таких тестов в ответе Sinclair. Да и ты сам написал только что — нужен кто-то очень умный для проведения PR для гарантии сохранности пост-условия, а всё потому, что твои тесты ничего не дают.
P>>>Если вы не можете сделать этого руками, то ваши попытки выразить это в коде и генерации данных будут иметь ту же особенность. P>·>Ты не понял. Я могу сделать это не руками, а кодом. P>Для простых фильров это работает. Для сложных — проще найти решение напрямую, в бд, что бы представлять, куда всё двигать
Потому что у тебя беда с тестами и тестовым окружением. Я понимаю, все там были, мне тоже в юности было комфортнее лезть напрямую в прод и там тестить.
P>·>Это где ты говорил такое месяц назад? Цитату. P>Вам не только я, но и Синклер это же сказал.
Цитату месячной давности в студию. Или не было.
P>>>Пост-условия похоже для вас пустой звук, вам это всё равно кажется тестом. Тест всего лишь гарантирует сохранность пост-условия P>·>Не гарантирует. P>У вас похоже тесты вообще ничего не гарантируют. Зачем же вы их пишете?
Как инструмент упрощения и ускорения процесса разработки и контроля качества. Чтобы вручную не возиться, чтобы в прод не лазить за каждым чихом, чтобы за минуты проводить acceptance, а не ждать часами после релиза репортов от юзеров.
P>>>И решения и у меня, и у вас, для подобных кейсов будут одни и те же. P>·>Ну может быть колонок id несколько разных и иногда они совпадают... но не всегда. P>каким образом в одной таблице users может быть несколько колонок id ? byId — это запрос к праймари кей. Ломается только если схема поломана.
externalId, internalId, globalId, replicationId и хз что. byId — ну может быть и праймари, очень частный скучный случай. А более весёлым будет если у тебя появится byId(List<int> ids) и будешь возвращать всю базу для пустого входного списка, для которого забудешь e2e тест написать.
P>>>Вы снова чего то фантазируете. P>·>Что фантазирую? Это вроде ты предлагаешь в код вставлять top(10) и тестом "фиксировать". P>Это же пост-условие.
Я имел в виду, что если реквест потенциально выдаёт слишком много записей, то тупо брать только первые 10 — это очень странное решение. По уму надо либо делать пейджинг, либо просто слать отказ в виде 4xx/5xx кода, но нужно дать понять клиенту, что в его запросе неожиданно много записей, а не просто 10. Так что такое постусловие это какой-то очень частный случай который, честно говоря, я нигде не видел, чтобы это считалось нормой молча обрезать данные.
P>>>Нет, не могут. Так, как это утверждает т. Райса — вы true от false отличить не сможете. Можете потренироваться — тестами обнаружить функцию, которая всегда возвращает true. Валяйте. P>·>"всегда" — это уже нетривиальное свойство. Проверка тривиального свойства это по сути "выполнить код и поглядеть на результат", т.е. тест практически. P>Ловко вы опровергли теорему Райса! P>В т.Райса нетривиальное свойство означает, что есть функции, которые им обладают, а есть те, которые не обладают.
Не совсем. Тривиальным условием например будет "код анализируемой программы содержит инструкцию X".
P>·>Не понял. Да, эта функция возвращает true. Тестом будет "f=() -> true; assertTrue(f())". P>Вот-вот. Опровержение теоремы Райса!
Нет. Опровержением будет, если я напишу алшгоритм который будет для любого данного f утверждать, что этот самый f всегда возвращает true (что по твоим заверениям твои тесты тестируют "мой тест гарантирует, что top(10) будет стоять для всех комбинаций фильтров"). А для () -> true — данный конкретный случай, код известен полностью заранее и для него существует известный полный комплект входов/выходов.
P>>>Смотрите выше, текст выделен H1, как раз эту вашу способность и "демонстрирует" P>·>Так ещё до того как ты это написал уже говорил, что _необходимость_ ручного тестирования — проблема. Не надо так делать и рассказал как избежать эту необходимость. P>Ручное тестирование плохо не само по себе, а когда оно увеличивает время разработки P>А когда сокращает — очень даже хорошо
Это сигнал, что автоматическое тестирование организовано плохо.
P>>>Хрупкий — это я вам сразу сказал. P>
Так я ж и не предлагаю посимвольное сравнение на все случаи жизни.
P>·>deep.eq по-другому тупо не умеет. P>Я снова выделил, что бы вам виднее было. Посимвольно это потому, что у меня в конкретном случае нет ни json, ни orm, ни еще какого ast.
Какие другие случаи бывают и как будет выглядеть код?
P>deep.eq дает нам вполне годную структурную эквивалентность. P>Если вы ей не умеете пользоваться — значит это не ваш вариант
Мы умеем ей не пользоваться.
P>>>Да то, что искать тестами проблемные комбинации вы вспотеете. Нужно искать решение вне тестов. P>·>Ясен пень, тестами комбинации не ищутся, а тестируются. Анализируешь код, coverage report, логи, спеки и т.п., потом пишешь тест подозрительной комбинации и смотришь как себя система ведёт. P>И так будете для каждой комбинации, да? Дадите шанс юзеру убиться об ваш билдер фильтров?
Зачем для каждой? Классифицируем, моделируем, алгоритмизируем, етс. Вон как у Sinclair оказалось, что функция-то линейная и никаких экспоненциальых переборов комбинаций и не требуется, покрывается полностью от силы десятком тестов.
P>·>А этот кто-то как будет, ногами что-ли? P>·>Ок, допустим ногами. А какие в базе будут данные на которой этот чаи-гпт будет проверять свои запросы вножную? За 2025 год, правильно? P>Жалко, что нет шрифта больше чем h1
Ты не ответил на вопрос "А какие в базе будут данные в момент ручной проверки"?
P>·>Потом система меняется и паттерн перестаёт функционировать проверенным вручную способом, а тестам — пофиг, они вечнозелёные. P>А интеграционные тесты вы забыли, да?
Ты заявлял, что интеграционными тестами ты не проверяешь всё.
P>Мне что, каждую строчку теперь H1 выделять, что бы вам виднее было?
Нет, достаточно внятно излагать свои мысли и отвечать на вопросы которые я задаю.
P>>>С фильтрами комбинаций столько, что солнце погаснет раньше ваших тестов. P>·>Даже если и так, то до e2e-комбинаций и жизни Вселенной не хватит уж точно. P>В том то и дело — количество e2e никак не зависит от количества комбинаций в фильтрах.
Почему?
P>>>Проблема в том, что бы генерить данные, нужно знать комбинации которые будут проблемными. P>·>Это же требуется и для того чтобы чтобы руками проверять запросы. P>Похоже, пост-условия для вас пустой звук. Для моего варианта нужно проверить, P>1 работает ли пост-условие P>2 находится ли оно на своем месте P>3 все ли ветки ифов получат его
Именно. И для этого нужно знать комбинации которые будут проблемными.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>·>Способ экономии ресурсов. P>>Имено — за счет покрытия. ·>За счёт разделения слона на части.
А как убедиться, что все части собраные вместе дают нужный результат?
P>>Вы сами себя ограбили когда строили вашу пирамиду тестов в виде трапеции — полуинтеграционные на моках + конформанс, которые к вашей системе имеют слабое отношение. ·>В чём ограбили? На прогон тестов и релиз мы тратим как лохи всего пол часа и уныло идём домой, скучаем на прод-саппорте, когда за углом тесты гоняют неделями и нон-стоп вечеринка в проде с юзерами?
Причин может быть много. Качество не сводится к тестам. Более того — тесты в обеспечении качества это минорная часть.
P>>Юнит-тесты вы не пишете, т.к. "это детали реализации, их не надо писать" ·>Юнит-тесты с моками — это тоже юнит-тесты. Ты до сих пор не въехал что такое моки и как ими надо пользоаться.
Юнит-тесты тестируют те самые детали реализации, которые, по вашему, тестировать не нужно.
P>>e2e "слишком долго" ·>Потому что очень много компонент в системе. Разворачивается на кластере в пол сотни машин. Гонять там проверки каждого поля на null просто невозможно.
Какая связь e2e и "гонять проверки каждого поля на null" ? e2e это про сценарий, а не прогон по всем комбинациям полей/значений.
·>Всё красиво, но медленно. Такой один сценарий отрабатывает e2e секунды, может даже минуты. Пока браузер откроется, пока поля введутся, кнопочки всякие кликаются, установятся сессии по разным каналам, подпишутся очереди и т.п. Сложно иметь много таких тестов.
e2e много и не нужно.
·>Угу. Но они не могут тестировать все сценарии, времени не хватит как минимум. ·>А ещё всякие завязанные на реальное время тесты. Как ты e2e будешь тестировать, что через 30 минут неактивностии юзера происходит логаут? Будешь ждать по пол часа каждый раз?
Как без таких тестов сможете убедиться, что на реальной системе у вас действительно эти 30 минут а не месяцы и годы?
Если этот шаг неважный, его в e2e выносить не нужно. А если это важно, то это проверять надо регулярно:
1 юзера не выбрасывает раньше
2 юзера выбрасывает спустя 30 минут
Для этого не нужны разные e2e — это отдельный долгоиграющий сценарий, где юзер делает чтото время от времени. Такие сценарии включать в билд смысла нет. Зато его можно запускать регулярно на работающей системе.
P>>Это намного лучше, чем их отсутствие. ·>Если это действительно намного лучше, это значит что у вас внизу пирамиды дыры зияют.
Вы так и не объяснили, как добавление e2e добавит дыр внизу пирамиды. У вас что, лимит на количество тестов, добавили e2e — теперь надо сотню юнит-тестов удалить? Не пойму ваш кейс.
P>>Это иллюзия. В сложном приложении интеграция не может быть простой, по определению. ·>Не знаю что ты тут подразумеваешь. Обычно вся интеграция происходит в composition root wiring коде, который составляет доли процента от кодовой базы. ·>У тебя да — кода интеграции дохрена, вот и проблемы с тестированием.
Интеграция начинается с того момента, когда вы из одной своей функции вызвали другую. А вы под интеграционным кодом подразумеваете только composition root. Такого кода действительно мало — процент от силы. То есть основной интеграционный код находится как раз вне composition root.
В типичном приложении технологического кода раз в 10-100 и более больше чем кода БЛ. Например, те самые лайки — здесь, условно, всей БЛ просто подсчет юзеров — десяток утверждений покрывает всё это.
Зато система лайков, которая поглощает трафик от ютуба, будет сложнее 90% процентов всех серверных приложений на рынке.
P>>Как это проверяется стартом приложения — не ясно. ·>Я вроде всё расписал с примерами кода. Перечитай если всё ещё неясно, вопросы задавай чего неясно.
Вы, похоже, под интеграционным кодом называете только тот, что в composition root. Контроллер, роутер, юз-кейс — это всё интеграционный код в чистом виде, эти вещи ничего сами не делают. Задача контроллера — связать конкретный вызов от роутера с юзкейсом, валидацией и де/серилизацией. Роутера — конкретный запрос с контроллером. юз-кейс — связать воедино пайплайн для работы БЛ для конкретного запроса.
P>>Вы и запускаете его для релиза — только результаты собираете не разово, а в течение первых часов после деплоя. P>>Здесь важно обнаружить проблемы раньше юзеров на проде. ·>Через несколько секунд после релиза юзеры на проде уже могут иметь проблемы. Ещё раз. Мы не можем себе повзолить трогать чего-либо в проде до прогона всех тестов.
Непонятно — вы добавили ровно один тест, и юзеры получили проблему. Такое может быть только в следующих случаях, если
1. тест сам создаёт проблему
2. тест делает проблему видимой
Что у вас за система, когда вам нельзя ни п1 ни п2 ?
P>>Очевидно, что если собирать сведения не раз. а несколько часов, то сведений будет больше, и диагностика будет точнее ·>И эти несколько часов у юзеров будут проблемы на проде.
Откуда возьмутся проблемы у юзеров на проде? Ваши имеющиеся тесты отработали — за счет чего регрессия произойдет?
Новый тест повалит всё? Или сделает проблему видимой?
P>>Затем, что бы P>>1 обнаружить на самых ранних этапах ·>"после деплоймента" — это для нас очень поздний этап. Сразу после деплоя мы идём домой, какой к хрену круглые сутки?
Ну и идите. У вас варианты
1 о новых проблемах узнать наутро
2 через неделю от суппорта.
Вам какой вариант ближе? Дайте угадаю "у нас до прода баги недоходят"
P>>2 сразу собрать максимальное количество сведений. По этим тестам у вас больше всего сведений, как и что воспроизвестир ·>Мы собираем сведения ещё до планирования деплоя.
Это все так делают. И никто, кроме лично вас не утверждает "на проде багов быть не может"
Могут.
P>>1 репортают проблемы ·>Это уже полный провал. Будут разборки.
Т.е. проблема стала видимой, и у вас разборки?
По вашему, лучше проблему юзер через суппорт сообщит, да?
P>>Сценарии и так покрыты дешовыми тестами. Эти дешовые тесты, особенно на моках, не покрывают всю интеграцию, что очевидно. ·>Все условно полторы строчки интеграции? Какой ужас!
Вы из своих функций вызываете другие свои функции? Вот вам и интеграционный код. Посмотрите, сколько у вас такого.
Ориентировочно — 99%, если у вас чтото большее hello world
P>>Вот это ваш самый частый аргумент вместе с "словоблудие" итд ·>Конечно, ибо есть более надёжные и адектватные подходы. Надеяться что юзеры репортают проблемы — это уже дно какое-то.
Надеяться, что на проде багов нет — вот это дно. Все адекватные вендоры оговаривают обеспечение гарантий, например,
— баги с прода фиксим в течение x недель, иначе платим пенальти
По такой схеме, работают, например, вендоры ПО для американского медицинского страхования.
P>>·>Где конкретно эта часть есть у тебя? Ты заявлял, что в твоих pattern-тестах ты репозиторий + бд не тестируешь; а в e2e ты каждую переменную на null тестирвать не будешь, да и не сможешь. P>>Там же где и у вас — это часть интеграционных тестов. ·>Т.е. у тебя есть ровно те же "репозиторий + бд" тесты?
Есть конечно же. Только таких тестов немного — они дают слабые гарантии в силу своей косвенности.
P>>·>Ты тоже. P>>Именно. И я этим знанием пользуюсь, а вы — нет. например, я точно знаю, как выглядит проблема с фильтрами — вгружается вообще всё. ·>А я не знаю такой проблемы... не было у нас такой. ЧЯДНТ?
Вероятно, у вас не было такой задачи. Вы видите билдер запросов как часть репозитория или орм который даден вам в готовом виде.
А я вам привел пример задачи, которая требует написание такого билдера.
P>>Именно это нефункциональные требования и описывают — когда именно произойдет событие "юзер создался до конца". Вот здесь как правило запас по времени существенный. P>>Чем вы и пользуетесь для изменения дизайна ·>"Событие" — это функциональная сущность. Возврат результата из метода — это событие. Вначале у тебя событие означало "юзер создался до конца", а после того как ты переложил обработку в очередь, то смысл события поменялся на "создался, но не очеь". Это функциональное изменение.
Функциональное — это действия юзера согласно требованиям от BA. Всё остальное — нефункциональное.
P>>·>Ну вот это "добро" тебе и надо будет выразить в тестах. P>>Разумеется. ·>Т.е. без добра существующие тесты должны падатьн. ЧТД.
Все функциональные требования удовлетворены. Непонятно, почему тесты должны падать. У вас, похоже, в функциональных требованиях и имена классов, методов, и даже переменных прописаны.
P>>Расскажите, как лучше. Желательно на тех самых фильтрах — откуда возьмете первый вариант запроса к бд, орм, нужное-вписать, и как будете его тестировать ·>Напишу. Тестировать — тестами.
Для простого запроса это сработает. А если запрос к бд потянет на страницу кода — проще и быстрее проверить это напрямую в бд. За полчаса можно перебрать десяток другой вариантов, и выбрать тот, что проще всего.
P>>репозиторий + бд — если все запросы генерируются самим репозиторием P>>юз-кейс + репозиторий + бд — если у нас генерация выражений находится вне репозитория ·>Что именно ты не сможешь покрыть такими тестами, что тебе требуется побуквенно sql сравнивать?
Те самые фильтры. Вы не знаете комбинаций которые приводят к загрузке слишком большого объема данных в память приложения.
P>>Что вы будете ассертить в поведении? ·>Что возвращается ровно столько записей сколько требуется.
Проблемных комбинаций вам никто не сказал. Вы о них узнаете после деплоя на прод.
А до того что вы ассертить будете, что бы исключить такую проблему на проде?
P>>И давно у вас пост-условие стало тестом ? ·>С тех пор как ты так написал. Ты тут предложил проблему "потенциальная загрузка всего содержимого таблицы" исключать тестом с паттерном. Какое ещё постусловие?
Например, .top(10) дает нам пост-условие 'не более 10 записей'
А дальше нам нужно
1. зафиксировать паттерн — проверяем посимвольно за отсутствием других инструментов
2. покрыть это тестом
P>>Пришел некто резкий и дерзкий и фиксанул "тут всё просто, я быстро". На его тестовой бд записей 60 штук, мелочовочка. А на проде это десятки миллионов. ·>Твои тесты с паттернами дерзкого не остановят. Свечка и молитва — гораздо надёжнее твоих тестов! Рекомендую.
Я ж вам говорю — тесты в задаче с построением запроса это вещь второстепенная, в порядке убывания важности
1. дизайн который адресно решает проблему, например, пост-условия — часть этого дизайна.
2. паттерн который соответствует дизайну
3. код ревью
4. тесты, которые фиксируют сохранность 1 и 2
Вы из 1..4 видите только тесты, а всё остальное для вас пустое место.
P>>Полтаблицы это 20 записей? Не понял, что за кейс такой. ·>У тебя же таблица это "это десятки миллионов".
Каким образом .top(10) пропустит десятки миллионов записей? подробнее.
P>>Что значит не появится? Если это пост-условие,оно будет применено для всего выхлопа, а не для разных подветок в вычислениях. ·>Если это постусловие, то и такой тест и не нужен — он не может дать ничего полезного.
Наоборот. Потерять пост-условие в коде всегда легче легкого.
Для того и нужны код ревью и тесты, что бы сохранить свойства кода
P>>Поскольку билдер сложный, то можно сказать, что да, магически — прямой связи входа и выхода вы на глазок не обнаружите. Потому и надо подстраховываться в тестах. ·>Это значит, что и тесты могут пропустить некий вход, для которого твой билдер пропустит твой top(10) на выходе.
Цитирую себя
Я ж вам говорю — тесты в задаче с построением запроса это вещь второстепенная, в порядке убывания важности
1. дизайн который адресно решает проблему, например, пост-условия — часть этого дизайна.
2. паттерн который соответствует дизайну
3. код ревью
4. тесты, которые фиксируют сохранность 1 и 2
Вы из 1..4 видите только тесты, а всё остальное для вас пустое место.
P>>Умеют — здесь только код-ревью может помочь. О чем я вам и говорю в который раз. ·>Так я об этом и говорю, что тесты в твоём виде бесполезны и даже вредны, т.к. код-ревью усложняют.
Облегчают. Вместо погружения во все детали реализации во время код-ревью, вы смотрите какие тесты были исключены.
·>Я рассказал о false positive/negative таких тестов в ответе Sinclair. Да и ты сам написал только что — нужен кто-то очень умный для проведения PR для гарантии сохранности пост-условия, а всё потому, что твои тесты ничего не дают.
Вы пока и такого не выдали — за отсутствием нужных комбинаций ваше решение вываливает проблему на юзера на проде.
·>Как инструмент упрощения и ускорения процесса разработки и контроля качества. Чтобы вручную не возиться, чтобы в прод не лазить за каждым чихом, чтобы за минуты проводить acceptance, а не ждать часами после релиза репортов от юзеров.
acceptance в минутах считается только для hello world.
P>>каким образом в одной таблице users может быть несколько колонок id ? byId — это запрос к праймари кей. Ломается только если схема поломана. ·>externalId, internalId, globalId, replicationId и хз что. byId — ну может быть и праймари, очень частный скучный случай. А более весёлым будет если у тебя появится byId(List<int> ids) и будешь возвращать всю базу для пустого входного списка, для которого забудешь e2e тест написать.
Непонятно, что за кунсткамера — запрос byId а на пустой список аргументов вгружается вся база?
·>Я имел в виду, что если реквест потенциально выдаёт слишком много записей, то тупо брать только первые 10 — это очень странное решение. По уму надо либо делать пейджинг
Вот вы сами себе ответили. Только проверять пейджинг нужно не только косвенно, как вы это делаете, а напрямую — контролируя запрос.
P>>Ловко вы опровергли теорему Райса! P>>В т.Райса нетривиальное свойство означает, что есть функции, которые им обладают, а есть те, которые не обладают. ·>Не совсем. Тривиальным условием например будет "код анализируемой программы содержит инструкцию X".
Теорема Райса не про код, а про семантику. Содержит инструкцию X — такое успешно решает любой компилятор.
А вот "выполнится ли инструкция X" — вот такое сводится к проблеме останова.
Современная разработка это проверка свойств программы через свойства код — та самая статическая типизация, контракты — инварианты, пред-, пост- условия, структурная эквивалентность и тд и тд
Вы же своими косвенными тестами воюете именно с теоремой Райса. Забавно, да?
·>Нет. Опровержением будет, если я напишу алшгоритм который будет для любого данного f утверждать, что этот самый f всегда возвращает true (что по твоим заверениям твои тесты тестируют "мой тест гарантирует, что top(10) будет стоять для всех комбинаций фильтров"). А для () -> true — данный конкретный случай, код известен полностью заранее и для него существует известный полный комплект входов/выходов.
Вот-вот. Вы путаете синтаксис и семантику. Любой компилятор справляется и с синтаксисом, и со структурой, но не с семантикой.
P>>Ручное тестирование плохо не само по себе, а когда оно увеличивает время разработки P>>А когда сокращает — очень даже хорошо ·>Это сигнал, что автоматическое тестирование организовано плохо.
Расскажите, как вы будете искать новые, неизвестные ранее проблемы, используя ваши автоматическими тесты
Например — те самые фильтры. Вы так и не показали ни одного автоматического теста, который находит проблему.
У вас в очередной раз какая то детская идеализация инструмента. Любой инструмент, если он реален, имеет недостатки.
А раз так — то имеет границы применимости.
Там, где у автоматических тестов начинаются недостатки, у других методов будут преимущества.
P>>Я снова выделил, что бы вам виднее было. Посимвольно это потому, что у меня в конкретном случае нет ни json, ни orm, ни еще какого ast. ·>Какие другие случаи бывают и как будет выглядеть код?
Развитией этой идеи вам Синклер показал. Но похоже, вы учитесь только на своих ошибках
P>>И так будете для каждой комбинации, да? Дадите шанс юзеру убиться об ваш билдер фильтров? ·>Зачем для каждой? Классифицируем, моделируем, алгоритмизируем, етс. Вон как у Sinclair оказалось, что функция-то линейная и никаких экспоненциальых переборов комбинаций и не требуется, покрывается полностью от силы десятком тестов.
Ну так вы от его подхода отказались. А раз так — то вам нужны тесты на тех самых комбинациях которых у вас нет
P>>·>Ок, допустим ногами. А какие в базе будут данные на которой этот чаи-гпт будет проверять свои запросы вножную? За 2025 год, правильно? P>>Жалко, что нет шрифта больше чем h1 ·>Ты не ответил на вопрос "А какие в базе будут данные в момент ручной проверки"?
Ищите по огромным синим буквам.
P>>·>Потом система меняется и паттерн перестаёт функционировать проверенным вручную способом, а тестам — пофиг, они вечнозелёные. P>>А интеграционные тесты вы забыли, да? ·>Ты заявлял, что интеграционными тестами ты не проверяешь всё.
Комбинации — нет, не проверяю. Т.к. интеграционные тесты здесь ничего не добавляют. Сколько бы вы комбинаций не проверили интеграционными тестами, это всё равно проверка интеграции. А вот юнитами можно оформить куда лучше.
P>>В том то и дело — количество e2e никак не зависит от количества комбинаций в фильтрах. ·>Почему?
Потому, что e2e это про интеграцию верхнего уровня.
Задача проверки "фильтры работают согласно спеке" дробится на части, и проверяется на всех уровнях
1 e2e — "юзер может отфильтровать"
2 интеграционные, функциональные — "фильтры умеют ... список фич прилагается"
4 юнит-тесты, компонентные — "выражение фильтра генерируется согласно дизайну для каждого паттерна в приложении, например (запрос, предикат, лимит) (запрос, предикат, вложеный запрос, предикат, лимит ) итд итд"
P>>2 находится ли оно на своем месте P>>3 все ли ветки ифов получат его ·>Именно. И для этого нужно знать комбинации которые будут проблемными.
Вам не нужен перечень всех четных или нечетнных чисел, что бы написать фунции isOdd и isEven.
Вам нужно знание о том, как устроены четные и нечетные — у одних младший бит 1, у других — младший бит 0
В переводе на фильтры — у запроса всегда есть лимит.
Здравствуйте, Pauel, Вы писали:
P>>>Имено — за счет покрытия. P>·>За счёт разделения слона на части. P>А как убедиться, что все части собраные вместе дают нужный результат?
smoke tests — как вишенка на торт, но в остальном — проверять две вещи: части работают, части собираются между собой нужным образом.
P>>>Вы сами себя ограбили когда строили вашу пирамиду тестов в виде трапеции — полуинтеграционные на моках + конформанс, которые к вашей системе имеют слабое отношение. P>·>В чём ограбили? На прогон тестов и релиз мы тратим как лохи всего пол часа и уныло идём домой, скучаем на прод-саппорте, когда за углом тесты гоняют неделями и нон-стоп вечеринка в проде с юзерами? P>Причин может быть много. Качество не сводится к тестам. Более того — тесты в обеспечении качества это минорная часть.
Минорная?! Без тестов обеспечить качество практически невозможно.
P>>>Юнит-тесты вы не пишете, т.к. "это детали реализации, их не надо писать" P>·>Юнит-тесты с моками — это тоже юнит-тесты. Ты до сих пор не въехал что такое моки и как ими надо пользоаться. P>Юнит-тесты тестируют те самые детали реализации, которые, по вашему, тестировать не нужно.
Это ты опять нафантазировал. Те детали реализации которые _ты_ предлагаешь тестировать — верно, не нужно.
P>>>e2e "слишком долго" P>·>Потому что очень много компонент в системе. Разворачивается на кластере в пол сотни машин. Гонять там проверки каждого поля на null просто невозможно. P>Какая связь e2e и "гонять проверки каждого поля на null" ? e2e это про сценарий, а не прогон по всем комбинациям полей/значений.
Связь в том, что ты в своих юнит-тестах предлагаешь проверять поля на null, но интеграцию этого же кода с реальной субд — провеять уже через e2e.
P>·>Всё красиво, но медленно. Такой один сценарий отрабатывает e2e секунды, может даже минуты. Пока браузер откроется, пока поля введутся, кнопочки всякие кликаются, установятся сессии по разным каналам, подпишутся очереди и т.п. Сложно иметь много таких тестов. P>e2e много и не нужно.
Где ты предлагаешь проверять поля на null тогда?
P>·>Угу. Но они не могут тестировать все сценарии, времени не хватит как минимум. P>·>А ещё всякие завязанные на реальное время тесты. Как ты e2e будешь тестировать, что через 30 минут неактивностии юзера происходит логаут? Будешь ждать по пол часа каждый раз? P>Как без таких тестов сможете убедиться, что на реальной системе у вас действительно эти 30 минут а не месяцы и годы?
Ты и со своими тестами не сможешь убедиться. Ещё раз, это достигается другим способом. Строишь модель физического времени, например как int64 unix-epoch nanoseconds. А дальше в тестах тупо прибавляешь разное количество наносекунд к моку источника времени и смотришь, что логаут не|произошел. Тогда и конкретное количество времени неважно, хоть 30 минут, хоть 30 лет — тест будет выполяться мгновенно в любом случае. И нет никаких проблем прогонять этот тест каждый раз перед каждым релизом.
P>Если этот шаг неважный, его в e2e выносить не нужно. А если это важно, то это проверять надо регулярно:
Ок... ну может логаут неважный. Но вот например "отослать statement в конце каждого месяца" — шаг ооочень важный. Тоже e2e тест сделаешь со sleep(1 month)?
P> Зато его можно запускать регулярно на работающей системе.
P>>>Это намного лучше, чем их отсутствие. P>·>Если это действительно намного лучше, это значит что у вас внизу пирамиды дыры зияют. P>Вы так и не объяснили, как добавление e2e добавит дыр внизу пирамиды.
А зачем я буду объяснять бред который ты нафантазировал?
P> У вас что, лимит на количество тестов, добавили e2e — теперь надо сотню юнит-тестов удалить? Не пойму ваш кейс.
Падение e2e-теста означает дыру в нижележащих тестах. Если ваши e2e-тесты падают, чаще чем рак на горе свистит, значит у вас внизу пирамиды дырявые тесты.
P>·>Не знаю что ты тут подразумеваешь. Обычно вся интеграция происходит в composition root wiring коде, который составляет доли процента от кодовой базы. P>·>У тебя да — кода интеграции дохрена, вот и проблемы с тестированием. P>Интеграция начинается с того момента, когда вы из одной своей функции вызвали другую. А вы под интеграционным кодом подразумеваете только composition root. Такого кода действительно мало — процент от силы. То есть основной интеграционный код находится как раз вне composition root.
Я под интеграционным кодом подразумеваю который вызывает "те ошибки, которые проходят мимо ваших моков". Так вот мимо моков проходят ошибки в доле процента кода, который выполняется только при реальном старте приложения, код в том самом composition root.
P>В типичном приложении технологического кода раз в 10-100 и более больше чем кода БЛ. Например, те самые лайки — здесь, условно, всей БЛ просто подсчет юзеров — десяток утверждений покрывает всё это. P>Зато система лайков, которая поглощает трафик от ютуба, будет сложнее 90% процентов всех серверных приложений на рынке.
У технологического кода другой бизнес-домен. Технологический код, который, скажем, реплицирует базу записей в несколько датацентров — оперирует не бизнес-сущностью лайка, а "запись данных", "датацентр" и т.п. А дальше уже идёт интеграция, когда мы в качестве записи берём лайк и получаем надёжное реплицированное хранилище лайков. У тебя же твой билдер билдит конкретный запрос сущности из бизнес-домена, но вместо ассертов бизнес-сущностей ты тестируешь технические детали.
P>>>Как это проверяется стартом приложения — не ясно. P>·>Я вроде всё расписал с примерами кода. Перечитай если всё ещё неясно, вопросы задавай чего неясно. P>Вы, похоже, под интеграционным кодом называете только тот, что в composition root. Контроллер, роутер, юз-кейс — это всё интеграционный код в чистом виде, эти вещи ничего сами не делают. Задача контроллера — связать конкретный вызов от роутера с юзкейсом, валидацией и де/серилизацией. Роутера — конкретный запрос с контроллером. юз-кейс — связать воедино пайплайн для работы БЛ для конкретного запроса.
Только тот код, что в composition root сложно покрывается тестами, т.к. там создаются и инжектятся реальные объекты и требует дорогого e2e тестирования. Остальное — неинтересно, ибо быстро, тривиально и надёжно тестируется с помощью моков.
Если вы не в сосотянии протестировать контроллер, роутер, юзекйс валидацию и сериализацию без e2e — у вас проблемы.
P>>>Вы и запускаете его для релиза — только результаты собираете не разово, а в течение первых часов после деплоя. P>>>Здесь важно обнаружить проблемы раньше юзеров на проде. P>·>Через несколько секунд после релиза юзеры на проде уже могут иметь проблемы. Ещё раз. Мы не можем себе повзолить трогать чего-либо в проде до прогона всех тестов. P>Непонятно — вы добавили ровно один тест, и юзеры получили проблему. Такое может быть только в следующих случаях, если
Ты предложил прогонять не все тесты перед выкаткой в прод. Т.е. вы добавили тест, но он не отработал, т.к. random не выпал. Отработает "в течение первых часов после деплоя". А у юзеров проблемы уже прямо сейчас.
P>1. тест сам создаёт проблему P>2. тест делает проблему видимой P>Что у вас за система, когда вам нельзя ни п1 ни п2 ?
Бред какой-то. Откуда ты это вообще взял?
P>>>Очевидно, что если собирать сведения не раз. а несколько часов, то сведений будет больше, и диагностика будет точнее P>·>И эти несколько часов у юзеров будут проблемы на проде. P>Откуда возьмутся проблемы у юзеров на проде?
Не все тесты выполнены.
P>Ваши имеющиеся тесты отработали — за счет чего регрессия произойдет?
Наши да, ваши — не все.
P>>>Затем, что бы P>>>1 обнаружить на самых ранних этапах P>·>"после деплоймента" — это для нас очень поздний этап. Сразу после деплоя мы идём домой, какой к хрену круглые сутки? P>Ну и идите. У вас варианты P>1 о новых проблемах узнать наутро P>2 через неделю от суппорта. P>Вам какой вариант ближе? Дайте угадаю "у нас до прода баги недоходят"
Те, для которых написаны тесты — ясен пень не доходят. Если какой-либо тест красный для данной версии системы — в прод она не попадёт.
P>>>2 сразу собрать максимальное количество сведений. По этим тестам у вас больше всего сведений, как и что воспроизвестир P>·>Мы собираем сведения ещё до планирования деплоя. P>Это все так делают.
Откуда тогда у тебя берутся красные тесты после деплоя в прод?
P>И никто, кроме лично вас не утверждает "на проде багов быть не может"
Ты меня заебал. Не пиши свои бредовые фантазии как мои цитаты. Я такого никогда нигде не утверждал.
P>>>1 репортают проблемы P>·>Это уже полный провал. Будут разборки. P>Т.е. проблема стала видимой, и у вас разборки? P>По вашему, лучше проблему юзер через суппорт сообщит, да?
Ты опять контектст потерял? Твоё высказывание было "[Юзеры] репортают проблемы". У нас это значит разборки. Если у вас не так, могу только посочувствовать вашим юзерам.
P>>>Сценарии и так покрыты дешовыми тестами. Эти дешовые тесты, особенно на моках, не покрывают всю интеграцию, что очевидно. P>·>Все условно полторы строчки интеграции? Какой ужас! P>Вы из своих функций вызываете другие свои функции? Вот вам и интеграционный код. Посмотрите, сколько у вас такого.
Непокрытого лёгкими тестами? Полторы строчки, всё верно.
P>Ориентировочно — 99%, если у вас чтото большее hello world
Ну если у вас 99%, сочувствую.
P>>>Вот это ваш самый частый аргумент вместе с "словоблудие" итд P>·>Конечно, ибо есть более надёжные и адектватные подходы. Надеяться что юзеры репортают проблемы — это уже дно какое-то. P>Надеяться, что на проде багов нет — вот это дно. Все адекватные вендоры оговаривают обеспечение гарантий, например,
Ну так бросай ружьё, да всплывай!
P>>>Там же где и у вас — это часть интеграционных тестов. P>·>Т.е. у тебя есть ровно те же "репозиторий + бд" тесты? P>Есть конечно же. Только таких тестов немного — они дают слабые гарантии в силу своей косвенности.
Слабые относительно чего?
P>>>Именно. И я этим знанием пользуюсь, а вы — нет. например, я точно знаю, как выглядит проблема с фильтрами — вгружается вообще всё. P>·>А я не знаю такой проблемы... не было у нас такой. ЧЯДНТ? P>Вероятно, у вас не было такой задачи. Вы видите билдер запросов как часть репозитория или орм который даден вам в готовом виде. P>А я вам привел пример задачи, которая требует написание такого билдера.
Возможно. Непонятно почему этот билдер специфичный под этот конкретный метод, а не универсальный типа linq со своими тестами.
P>·>"Событие" — это функциональная сущность. Возврат результата из метода — это событие. Вначале у тебя событие означало "юзер создался до конца", а после того как ты переложил обработку в очередь, то смысл события поменялся на "создался, но не очеь". Это функциональное изменение. P>Функциональное — это действия юзера согласно требованиям от BA. Всё остальное — нефункциональное.
Если юзер не может выполнить функцию, то это отказ системы, нарушение требований, то что отказ временный — не так важно.
P>·>Т.е. без добра существующие тесты должны падатьн. ЧТД. P>Все функциональные требования удовлетворены. Непонятно, почему тесты должны падать.
Потому что попытка юзера выполнить функцию проваливается из-за ошибок в синхронизации.
P>>>Расскажите, как лучше. Желательно на тех самых фильтрах — откуда возьмете первый вариант запроса к бд, орм, нужное-вписать, и как будете его тестировать P>·>Напишу. Тестировать — тестами. P>Для простого запроса это сработает. А если запрос к бд потянет на страницу кода —
Это значит у вас примитивная модель тестов, не вытягивает страницу кода.
P>проще и быстрее проверить это напрямую в бд. За полчаса можно перебрать десяток другой вариантов, и выбрать тот, что проще всего.
Понимаю, все там были в студенчестве.
P>>>Что вы будете ассертить в поведении? P>·>Что возвращается ровно столько записей сколько требуется. P>Проблемных комбинаций вам никто не сказал.
Ну если вам сказали, поздравляю, но не всем так везёт...
P>А до того что вы ассертить будете, что бы исключить такую проблему на проде?
Ещё раз, эта проблема ассертами в тестах не решается.
P>>>И давно у вас пост-условие стало тестом ? P>·>С тех пор как ты так написал. Ты тут предложил проблему "потенциальная загрузка всего содержимого таблицы" исключать тестом с паттерном. Какое ещё постусловие? P>Например, .top(10) дает нам пост-условие 'не более 10 записей' P>А дальше нам нужно P>1. зафиксировать паттерн — проверяем посимвольно за отсутствием других инструментов P>2. покрыть это тестом
Верно. Но ты не догоняешь, что во 2м пункте можно просто ассертить число записей, с тем же успехом, но лучшим результатом.
P>Я ж вам говорю — тесты в задаче с построением запроса это вещь второстепенная, в порядке убывания важности P>1. дизайн который адресно решает проблему, например, пост-условия — часть этого дизайна. P>2. паттерн который соответствует дизайну P>3. код ревью P>4. тесты, которые фиксируют сохранность 1 и 2 P>Вы из 1..4 видите только тесты, а всё остальное для вас пустое место.
Не потому что пустое место, а потому что мы тут обсуждаем тесты и разные подходы к тестированию, а 1..3 — оффтопик. Но ты всё не успокоишься и продолжаешь словоблудить.
P>>>Полтаблицы это 20 записей? Не понял, что за кейс такой. P>·>У тебя же таблица это "это десятки миллионов". P>Каким образом .top(10) пропустит десятки миллионов записей? подробнее.
Поставлен не туда или поставлен условно.
P>>>Что значит не появится? Если это пост-условие,оно будет применено для всего выхлопа, а не для разных подветок в вычислениях. P>·>Если это постусловие, то и такой тест и не нужен — он не может дать ничего полезного. P>Наоборот. Потерять пост-условие в коде всегда легче легкого. P>Для того и нужны код ревью и тесты, что бы сохранить свойства кода
_такой_ тест не нужен. Нужен другой тест.
P>>>Поскольку билдер сложный, то можно сказать, что да, магически — прямой связи входа и выхода вы на глазок не обнаружите. Потому и надо подстраховываться в тестах. P>·>Это значит, что и тесты могут пропустить некий вход, для которого твой билдер пропустит твой top(10) на выходе. P>Цитирую себя P>Вы из 1..4 видите только тесты, а всё остальное для вас пустое место.
Т.е. твои тесты — проверяют меньше, чем мои. Мои, помимо того, что кол-во записей ограничивается 10ю так же протестирует и валидность запросов, подстановку парамов и т.п.
P>>>Умеют — здесь только код-ревью может помочь. О чем я вам и говорю в который раз. P>·>Так я об этом и говорю, что тесты в твоём виде бесполезны и даже вредны, т.к. код-ревью усложняют. P>Облегчают. Вместо погружения во все детали реализации во время код-ревью, вы смотрите какие тесты были исключены.
Ты о чём? Что за исключённые тесты?
P>·>Я рассказал о false positive/negative таких тестов в ответе Sinclair. Да и ты сам написал только что — нужен кто-то очень умный для проведения PR для гарантии сохранности пост-условия, а всё потому, что твои тесты ничего не дают. P>Вы пока и такого не выдали — за отсутствием нужных комбинаций ваше решение вываливает проблему на юзера на проде.
Ваше вываливает больше проблем на проде.
P>·>Как инструмент упрощения и ускорения процесса разработки и контроля качества. Чтобы вручную не возиться, чтобы в прод не лазить за каждым чихом, чтобы за минуты проводить acceptance, а не ждать часами после релиза репортов от юзеров. P>acceptance в минутах считается только для hello world.
Завидуешь, да? Ну вообще говоря acceptance гоняется на кластере, вот и укладывается в пол часа.
P>>>каким образом в одной таблице users может быть несколько колонок id ? byId — это запрос к праймари кей. Ломается только если схема поломана. P>·>externalId, internalId, globalId, replicationId и хз что. byId — ну может быть и праймари, очень частный скучный случай. А более весёлым будет если у тебя появится byId(List<int> ids) и будешь возвращать всю базу для пустого входного списка, для которого забудешь e2e тест написать. P>Непонятно, что за кунсткамера — запрос byId а на пустой список аргументов вгружается вся база?
Ну можно придумать что, например, для пустого списка cгенерится пустой фильтр.
P>·>Я имел в виду, что если реквест потенциально выдаёт слишком много записей, то тупо брать только первые 10 — это очень странное решение. По уму надо либо делать пейджинг P>Вот вы сами себе ответили. Только проверять пейджинг нужно не только косвенно, как вы это делаете, а напрямую — контролируя запрос.
Не нужно.
P>>>Ловко вы опровергли теорему Райса! P>>>В т.Райса нетривиальное свойство означает, что есть функции, которые им обладают, а есть те, которые не обладают. P>·>Не совсем. Тривиальным условием например будет "код анализируемой программы содержит инструкцию X". P>Теорема Райса не про код, а про семантику. Содержит инструкцию X — такое успешно решает любой компилятор. P>А вот "выполнится ли инструкция X" — вот такое сводится к проблеме останова.
В тесте же конкретный сценарий — запускаем код, дождались завершения, проверяем, выполнилась ли инструкция X. Никакой проблемы останова.
P>·>Нет. Опровержением будет, если я напишу алшгоритм который будет для любого данного f утверждать, что этот самый f всегда возвращает true (что по твоим заверениям твои тесты тестируют "мой тест гарантирует, что top(10) будет стоять для всех комбинаций фильтров"). А для () -> true — данный конкретный случай, код известен полностью заранее и для него существует известный полный комплект входов/выходов. P>Вот-вот. Вы путаете синтаксис и семантику. Любой компилятор справляется и с синтаксисом, и со структурой, но не с семантикой.
Так ты зачем-то синтаксис и проверяешь "есть ли в коде .top(10)".
P>·>Это сигнал, что автоматическое тестирование организовано плохо. P>Расскажите, как вы будете искать новые, неизвестные ранее проблемы, используя ваши автоматическими тесты
Если есть зрелая система автоматических тестов, это значит, что можно делая exploratory testing (это видимо что ты тут имеешь в виду) описывать новые сценарии, пользуясь уже готовым test harness. Тут же запускать их, смотреть на поведение системы и, может быть, даже закоммитить результат как новый автотест.
P>Например — те самые фильтры. Вы так и не показали ни одного автоматического теста, который находит проблему.
Если я правильно понял проблему, то она не находится никакими тестами, хоть ручными, хоть ножными. Если только случайно.
P>У вас в очередной раз какая то детская идеализация инструмента. Любой инструмент, если он реален, имеет недостатки. P>А раз так — то имеет границы применимости. P>Там, где у автоматических тестов начинаются недостатки, у других методов будут преимущества.
Если ты под другими методами имеешь в виду ручные тесты, то у меня для тебя плохие новости.
P>>>Я снова выделил, что бы вам виднее было. Посимвольно это потому, что у меня в конкретном случае нет ни json, ни orm, ни еще какого ast. P>·>Какие другие случаи бывают и как будет выглядеть код? P>Я вам уже приводил пример
[код скипнут]
Главное пока умалчиваешь: тест как выглядит для этого кода? Ну где там deep.eq, pattern или что?
P>Развитией этой идеи вам Синклер показал. Но похоже, вы учитесь только на своих ошибках
Это вряд ли. Но вы даже на своих не учитесь.
P>·>Зачем для каждой? Классифицируем, моделируем, алгоритмизируем, етс. Вон как у Sinclair оказалось, что функция-то линейная и никаких экспоненциальых переборов комбинаций и не требуется, покрывается полностью от силы десятком тестов. P>Ну так вы от его подхода отказались. А раз так — то вам нужны тесты на тех самых комбинациях которых у вас нет
Это твои бредни.
P>>>Жалко, что нет шрифта больше чем h1 P>·>Ты не ответил на вопрос "А какие в базе будут данные в момент ручной проверки"? P>Ищите по огромным синим буквам.
Там нет ответа на этот вопрос. Там сказано "далее ...бд минимально заполненой", а что было с бд до "далее" — ты надёжно скрываешь.
P>>>А интеграционные тесты вы забыли, да? P>·>Ты заявлял, что интеграционными тестами ты не проверяешь всё. P>Комбинации — нет, не проверяю. Т.к. интеграционные тесты здесь ничего не добавляют. Сколько бы вы комбинаций не проверили интеграционными тестами, это всё равно проверка интеграции. А вот юнитами можно оформить куда лучше.
Какие поля когда могут быть null — это дохрена комбинаций в типичном приложении. Т.е. получается, что ты интеграцию null-полей проверяешь только на юзерах.
P>>>В том то и дело — количество e2e никак не зависит от количества комбинаций в фильтрах. P>·>Почему? P>Потому, что e2e это про интеграцию верхнего уровня. P>Задача проверки "фильтры работают согласно спеке" дробится на части, и проверяется на всех уровнях P>1 e2e — "юзер может отфильтровать" P>2 интеграционные, функциональные — "фильтры умеют ... список фич прилагается" P>4 юнит-тесты, компонентные — "выражение фильтра генерируется согласно дизайну для каждого паттерна в приложении, например (запрос, предикат, лимит) (запрос, предикат, вложеный запрос, предикат, лимит ) итд итд"
Где у тебя null-поля с базой тестируются?
P>·>Именно. И для этого нужно знать комбинации которые будут проблемными. P>Вам не нужен перечень всех четных или нечетнных чисел, что бы написать фунции isOdd и isEven. P>Вам нужно знание о том, как устроены четные и нечетные — у одних младший бит 1, у других — младший бит 0
Отлично. Вот ты и выявил какие комбинации будут проблемными. Придумать входные парамы и ожидания с вариациями младшего бита. Т.е. и тестировать надо именно на комбинациях младшего бита.
P>В переводе на фильтры — у запроса всегда есть лимит.
"у запроса всегда есть лимит" в переводе в твоём случае будет "функция isOdd всегда использует битовую операцию взятия младшего бита".
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>А как убедиться, что все части собраные вместе дают нужный результат? ·>smoke tests — как вишенка на торт, но в остальном — проверять две вещи: части работают, части собираются между собой нужным образом.
Что это за тесты, кто их выполняет?
P>>>>Вы сами себя ограбили когда строили вашу пирамиду тестов в виде трапеции — полуинтеграционные на моках + конформанс, которые к вашей системе имеют слабое отношение.
P>>Причин может быть много. Качество не сводится к тестам. Более того — тесты в обеспечении качества это минорная часть. ·>Минорная?! Без тестов обеспечить качество практически невозможно.
Минорная — это значит, что есть вещи более важные
1. методология
2. требования
3. дизайн согласно методологии
4. реализация согласно дизайна
5. квалификация людей в команде
Если у вас нет хотя бы одного 1..4 никакие тесты вам не помогут, хоть обмажтесь.
А вот если есть всё выше, то можете подключать
6. контроль качества
При этом, тесты это всего лишь часть контроля качества
P>>Какая связь e2e и "гонять проверки каждого поля на null" ? e2e это про сценарий, а не прогон по всем комбинациям полей/значений. ·>Связь в том, что ты в своих юнит-тестах предлагаешь проверять поля на null, но интеграцию этого же кода с реальной субд — провеять уже через e2e.
Похоже, ваш капасити переполнен три месяца назад. Вы здесь, извините, порете отсебятину.
P>>e2e много и не нужно. ·>Где ты предлагаешь проверять поля на null тогда?
Какие именно поля на null ? ui, dto, bl, конфиг, бд?
P>>·>А ещё всякие завязанные на реальное время тесты. Как ты e2e будешь тестировать, что через 30 минут неактивностии юзера происходит логаут? Будешь ждать по пол часа каждый раз? P>>Как без таких тестов сможете убедиться, что на реальной системе у вас действительно эти 30 минут а не месяцы и годы? ·>Ты и со своими тестами не сможешь убедиться. Ещё раз, это достигается другим способом. Строишь модель физического времени, например как int64 unix-epoch nanoseconds. А дальше в тестах тупо прибавляешь разное количество наносекунд к моку источника времени и смотришь, что логаут не|произошел. Тогда и конкретное количество времени неважно, хоть 30 минут, хоть 30 лет — тест будет выполяться мгновенно в любом случае. И нет никаких проблем прогонять этот тест каждый раз перед каждым релизом.
Смотрите внимательно — щас будут примеры и вы наверняка скажете, что у вас такого быть не может, невозможно, никогда, у вас багов вообще не бывает итд.
Итого:
Написали вы такой тест на моках, а на проде выяснилось, что юзер всё равно не логаутится. Например, пототому, что в UI приложении есть фоновый процессинг, который мимоходом и обновляет токен продляя сессию.
Пофиксили, и выяснили, юзер всё равно не логаутится, т.е. время жизни сессии берется из конфига, который неправильно смержился.
Пофиксили, и выяснили, что всё равно не логаутится — ваш фикс фонового процессинга сломал один из долгоиграющих кейсов, разработчик Вася подкинул рядом с вашим кодом свой, и фоновый процессинг всё равно обновляет сессию.
Пофиксили и это, и выяснили, что логаут стартует когда подходит ttl сессии, но ничего не делает — потому что очередь шедулинга с этим связаный забита под завязку другими вещами. Пофиксили и это — обнаружили, что строчка тестового кода пролезла на прод в одном из больших пул реквестов и логаут вызывается только для тестовых юзеров.
Проблему нужно решать не моками, а дизайном. Например — отделить фоновый процессинг от интерактивного, что бы у него даже не было никакой возможности получить токен для обновления.
Если у вас мержатся конфиги — в панели диагностики у вас должны быть реальные данные, из того же источника что и все конфиги в приложении, а критические вещи закрыты тестом, что бы явно обозначить проблему
Что бы разработчик Вася не подломил, и не воскресил проблему, нужен e2e тест и процесс код-ревью, что бы вы оба знали вот такую вещь
А если время сессии это критическая вещь, то e2e ну просится — архитектура аутентификации всегда сложная, там много чего может пойти странными путями.
P>>Если этот шаг неважный, его в e2e выносить не нужно. А если это важно, то это проверять надо регулярно: ·>Ок... ну может логаут неважный. Но вот например "отослать statement в конце каждого месяца" — шаг ооочень важный. Тоже e2e тест сделаешь со sleep(1 month)?
В данном случае здесь решение что через мониторинг, что через e2e будет приблизительно одинаковым. Разница будет только в том, где именно и как запускается скрипт для проверки что statement действительно создался. e2e можно запускать регулярно, впрочем, я уже это говорил.
P>> У вас что, лимит на количество тестов, добавили e2e — теперь надо сотню юнит-тестов удалить? Не пойму ваш кейс. ·>Падение e2e-теста означает дыру в нижележащих тестах. Если ваши e2e-тесты падают, чаще чем рак на горе свистит, значит у вас внизу пирамиды дырявые тесты.
Нету способа гарантировать отсутствие дыр, багов, уязвимостей итд. e2e это способ задешево выявить большинство проблемав в интеграции верхнего уровня, которая как раз тестами на нижних уровнях не покрывается.
P>>Интеграция начинается с того момента, когда вы из одной своей функции вызвали другую. А вы под интеграционным кодом подразумеваете только composition root. Такого кода действительно мало — процент от силы. То есть основной интеграционный код находится как раз вне composition root. ·>Я под интеграционным кодом подразумеваю который вызывает "те ошибки, которые проходят мимо ваших моков". Так вот мимо моков проходят ошибки в доле процента кода, который выполняется только при реальном старте приложения, код в том самом composition root.
Ну да, вы выдумали какое то своё определение интеграционного кода. А ошибки с построением запроса фильтров, они как, по вашему, где ходят?
·>У технологического кода другой бизнес-домен. Технологический код, который, скажем, реплицирует базу записей в несколько датацентров — оперирует не бизнес-сущностью лайка, а "запись данных", "датацентр" и т.п. А дальше уже идёт интеграция, когда мы в качестве записи берём лайк и получаем надёжное реплицированное хранилище лайков. У тебя же твой билдер билдит конкретный запрос сущности из бизнес-домена, но вместо ассертов бизнес-сущностей ты тестируешь технические детали.
Потому, что покрывать тестами нужно все критические свойства, а не ограничиваться только теми, что в спеке написаны.
P>>Вы, похоже, под интеграционным кодом называете только тот, что в composition root. Контроллер, роутер, юз-кейс — это всё интеграционный код в чистом виде, эти вещи ничего сами не делают. Задача контроллера — связать конкретный вызов от роутера с юзкейсом, валидацией и де/серилизацией. Роутера — конкретный запрос с контроллером. юз-кейс — связать воедино пайплайн для работы БЛ для конкретного запроса. ·>Только тот код, что в composition root сложно покрывается тестами, т.к. там создаются и инжектятся реальные объекты и требует дорогого e2e тестирования. Остальное — неинтересно, ибо быстро, тривиально и надёжно тестируется с помощью моков. ·>Если вы не в сосотянии протестировать контроллер, роутер, юзекйс валидацию и сериализацию без e2e — у вас проблемы.
Успокойтесь, e2e это не для теста контролера. Наверное вы забыли, что я вам предлагал тестировать валидацию юнит-тестами?
P>>Непонятно — вы добавили ровно один тест, и юзеры получили проблему. Такое может быть только в следующих случаях, если ·>Ты предложил прогонять не все тесты перед выкаткой в прод.
Я вам даже рассказал как именно — все ваши тесты вместе взятые пускаете как сейчас. Допустим их 1000 штук. Вот эту 1000 оставьте и не трогайте.
А вот далее вы добавляете новый вид тестов, которые будут запускаться регулярно после деплоя. Их штук 10, новых.
Итого — 1000 пускаете как раньше, + 10 новых регулярно.
P>>Откуда возьмутся проблемы у юзеров на проде? ·>Не все тесты выполнены.
Похоже, X + 1 у вас может быть меньше X. Забавно!
P>>Ваши имеющиеся тесты отработали — за счет чего регрессия произойдет? ·>Наши да, ваши — не все.
Непонятно — регрессии откуда взяться? Вы добавили новый вид тестов — старые не трогали. Новые предназначены для регулярного запуска после деплоя.
Откуда возьмется регрессия?
P>>Ну и идите. У вас варианты P>>1 о новых проблемах узнать наутро P>>2 через неделю от суппорта. P>>Вам какой вариант ближе? Дайте угадаю "у нас до прода баги недоходят" ·>Те, для которых написаны тесты — ясен пень не доходят. Если какой-либо тест красный для данной версии системы — в прод она не попадёт.
Вот и отлично — значит наличие красных тестов наутро сообщит вам о проблеме еще на стейдже.
P>>Это все так делают. ·>Откуда тогда у тебя берутся красные тесты после деплоя в прод?
1 нагрузка
2 количество и качество юзеров итд
3 новое состояние, которого на тестовом окружении никогда не было
4 инфраструктура
5 внешние системы
6 ошибки, которые были не видны на тестовом окружении, но стали видны на проде, например, эффект накопления
7 редкие ошибки — прод тупо работает на порядки дольше тестового окружения
P>>И никто, кроме лично вас не утверждает "на проде багов быть не может" ·>Ты меня заебал. Не пиши свои бредовые фантазии как мои цитаты. Я такого никогда нигде не утверждал.
Смотрите, вот ваши цитата выше:
"Те, для которых написаны тесты — ясен пень не доходят(до прода)" — в скобках это контекст обозначил
Есть бага. Ну написали вы тест, два, десять, сто. И пофиксили багу. Зеленые тесты.
Но бага это не про фикс, а про поведение. А теперь см п 1..7 выше, каждый из этих пунктов спокойно может воскресить вашу багу.
А вы утверждаете, что раз есть тест, то такой баги на проде точно нет
P>>Вы из своих функций вызываете другие свои функции? Вот вам и интеграционный код. Посмотрите, сколько у вас такого. ·>Непокрытого лёгкими тестами? Полторы строчки, всё верно.
Сюда нужно вписать data complexity. Хороший пример — те самые фильтры.
P>>·>Т.е. у тебя есть ровно те же "репозиторий + бд" тесты? P>>Есть конечно же. Только таких тестов немного — они дают слабые гарантии в силу своей косвенности. ·>Слабые относительно чего?
Относительно других методов. Ваши косвенные тесты упираются в теорему Райса.
А вот синтаксические свойства можно обеспечивать той же статической типизацией. Надеюсь, вам теорема Райса здесь не мешает?
Кроме синтаксических есть структурные — те самые пред-, пост-, условия, инварианты.
Проектирование — формальные методы, например, доказательства тех или иных свойств.
P>>Вероятно, у вас не было такой задачи. Вы видите билдер запросов как часть репозитория или орм который даден вам в готовом виде. P>>А я вам привел пример задачи, которая требует написание такого билдера. ·>Возможно. Непонятно почему этот билдер специфичный под этот конкретный метод, а не универсальный типа linq со своими тестами.
Как это будет с linq вам Синклер рядом показал. Сама задача в том, что фильтровать нужно по выражению от юзера, который а хрен знает что может понавыбирать.
P>>Все функциональные требования удовлетворены. Непонятно, почему тесты должны падать. ·>Потому что попытка юзера выполнить функцию проваливается из-за ошибок в синхронизации.
Необязательно, перестаньте фантазировать.
P>>А до того что вы ассертить будете, что бы исключить такую проблему на проде? ·>Ещё раз, эта проблема ассертами в тестах не решается.
В том то и дело. А что у вас есть кроме тестов?
P>>А дальше нам нужно P>>1. зафиксировать паттерн — проверяем посимвольно за отсутствием других инструментов P>>2. покрыть это тестом ·>Верно. Но ты не догоняешь, что во 2м пункте можно просто ассертить число записей, с тем же успехом, но лучшим результатом.
Что бы ассертить число записей нужно знать комбинацию которой у вас точно нет. Можно реализовать ленивую подгрузку. Это вобщем тот же вариант, вид сбоку — юнит-тестом вы можете зафиксировать именно такую особенность структуры.
P>>1. дизайн который адресно решает проблему, например, пост-условия — часть этого дизайна. P>>2. паттерн который соответствует дизайну P>>3. код ревью P>>4. тесты, которые фиксируют сохранность 1 и 2 P>>Вы из 1..4 видите только тесты, а всё остальное для вас пустое место. ·>Не потому что пустое место, а потому что мы тут обсуждаем тесты и разные подходы к тестированию, а 1..3 — оффтопик. Но ты всё не успокоишься и продолжаешь словоблудить.
Никакой это не оффтопик. пп 1 2 и 3 говорят о том, что можно изменить дизайн, и ваши моки будут больше не нужны.
P>>Каким образом .top(10) пропустит десятки миллионов записей? подробнее. ·>Поставлен не туда или поставлен условно.
Вот вам и стало понятно, что покрываем тестами — поставлен именно туда, куда надо. Только сначала дизайн решения. См сообщение Синклера
P>>Наоборот. Потерять пост-условие в коде всегда легче легкого. P>>Для того и нужны код ревью и тесты, что бы сохранить свойства кода ·>_такой_ тест не нужен. Нужен другой тест.
Другой, которого вы так и не показали?
P>>·>Это значит, что и тесты могут пропустить некий вход, для которого твой билдер пропустит твой top(10) на выходе. P>>Цитирую себя P>>Вы из 1..4 видите только тесты, а всё остальное для вас пустое место. ·>Т.е. твои тесты — проверяют меньше, чем мои. Мои, помимо того, что кол-во записей ограничивается 10ю так же протестирует и валидность запросов, подстановку парамов и т.п.
Мои тесты фиксируют структуру решения. Ваши без конкретного перечня комбинаций ничего не гарантируют.
P>>Облегчают. Вместо погружения во все детали реализации во время код-ревью, вы смотрите какие тесты были исключены. ·>Ты о чём? Что за исключённые тесты?
Закоментили, удалили, исправили ожидания. Если вы видите, что тест на .top убрали, надо пойти и дать по шее.
P>>acceptance в минутах считается только для hello world. ·>Завидуешь, да? Ну вообще говоря acceptance гоняется на кластере, вот и укладывается в пол часа.
Полчаса это десятки минут. e2e это вобщем тот же acceptance. Если у вас есть такое, чего же вы здесь выступаете?
P>>Непонятно, что за кунсткамера — запрос byId а на пустой список аргументов вгружается вся база? ·>Ну можно придумать что, например, для пустого списка cгенерится пустой фильтр.
P>>Теорема Райса не про код, а про семантику. Содержит инструкцию X — такое успешно решает любой компилятор. P>>А вот "выполнится ли инструкция X" — вот такое сводится к проблеме останова. ·>В тесте же конкретный сценарий — запускаем код, дождались завершения, проверяем, выполнилась ли инструкция X. Никакой проблемы останова.
Вы успешно опровергли теорему Райса
P>>Вот-вот. Вы путаете синтаксис и семантику. Любой компилятор справляется и с синтаксисом, и со структурой, но не с семантикой. ·>Так ты зачем-то синтаксис и проверяешь "есть ли в коде .top(10)".
В том то и дело — я проверяю структуру, а вы пытаетесь тестами семантику проверять. Отсюда ясно, что вашими тестами вы в теорему Райса упретесь гораздо раньше
P>>Расскажите, как вы будете искать новые, неизвестные ранее проблемы, используя ваши автоматическими тесты ·>Если есть зрелая система автоматических тестов, это значит, что можно делая exploratory testing (это видимо что ты тут имеешь в виду) описывать новые сценарии, пользуясь уже готовым test harness. Тут же запускать их, смотреть на поведение системы и, может быть, даже закоммитить результат как новый автотест.
exploratory testing это
1. построение нового кейса-сценария-итд — это человек в уме делает, здесь он ограничен только воображением
2. запись шагов используя готовый набор инструментов
п1 вы можете переложить разве что на AI. До недавних дней это делал исключительно человек.
·>Если я правильно понял проблему, то она не находится никакими тестами, хоть ручными, хоть ножными. Если только случайно.
Её можно исключить методами родственными знакомой вам статической типизации. Те самые предусловия и соответствующий дизайн.
P>>Там, где у автоматических тестов начинаются недостатки, у других методов будут преимущества. ·>Если ты под другими методами имеешь в виду ручные тесты, то у меня для тебя плохие новости.
Ручные методы это в т.ч. exploratory, и вообще исследование.
·>Главное пока умалчиваешь: тест как выглядит для этого кода? Ну где там deep.eq, pattern или что?
Вам примера Синклера недостаточно, вы хотите у меня тож самое спросить?
вот так мы можем проверить, добавляет ли билдер top или нет. Билдер будет примерно как у Синклера.
P>>Ищите по огромным синим буквам. ·>Там нет ответа на этот вопрос. Там сказано "далее ...бд минимально заполненой", а что было с бд до "далее" — ты надёжно скрываешь.
Забавно, вы вырезали часть цитаты, и не знаете, что было в той части, что вы же и выбросили? Ищите — я для вас синим подсветил
·>Какие поля когда могут быть null — это дохрена комбинаций в типичном приложении. Т.е. получается, что ты интеграцию null-полей проверяешь только на юзерах.
Пример у вас есть?
P>>Вам нужно знание о том, как устроены четные и нечетные — у одних младший бит 1, у других — младший бит 0 ·>Отлично. Вот ты и выявил какие комбинации будут проблемными. Придумать входные парамы и ожидания с вариациями младшего бита. Т.е. и тестировать надо именно на комбинациях младшего бита.
Комбинации как раз не выявлены. Только свойство построения чисел
P>>В переводе на фильтры — у запроса всегда есть лимит. ·>"у запроса всегда есть лимит" в переводе в твоём случае будет "функция isOdd всегда использует битовую операцию взятия младшего бита".
Вы уже почти научились. В случае с битами все просто — половина целых четные, половина — нечетные. Это значит, что тестовый набор вы сможете намастырить самостоятельно.
А вот где взять запрос, у которого будет нарушено свойство длины — загадка
Здравствуйте, Pauel, Вы писали:
P>>>А как убедиться, что все части собраные вместе дают нужный результат? P>·>smoke tests — как вишенка на торт, но в остальном — проверять две вещи: части работают, части собираются между собой нужным образом. P>Что это за тесты, кто их выполняет?
CI/CD
P>>>>>Вы сами себя ограбили когда строили вашу пирамиду тестов в виде трапеции — полуинтеграционные на моках + конформанс, которые к вашей системе имеют слабое отношение. P>>>Причин может быть много. Качество не сводится к тестам. Более того — тесты в обеспечении качества это минорная часть. P>·>Минорная?! Без тестов обеспечить качество практически невозможно. P>Минорная — это значит, что есть вещи более важные P>Если у вас нет хотя бы одного 1..4 никакие тесты вам не помогут, хоть обмажтесь.
А без тестов 1-6 уйдут лесом. Единственное, что может не сразу, но уйдут точно.
P>>>Какая связь e2e и "гонять проверки каждого поля на null" ? e2e это про сценарий, а не прогон по всем комбинациям полей/значений. P>·>Связь в том, что ты в своих юнит-тестах предлагаешь проверять поля на null, но интеграцию этого же кода с реальной субд — провеять уже через e2e. P>Похоже, ваш капасити переполнен три месяца назад. Вы здесь, извините, порете отсебятину.
У тебя память как у рыбки. Цитирую:
·>потенциально может быть null — ты не дождёшься окончания.
Это полные тесты, где всё тащится медленно и реально
P>>>e2e много и не нужно. P>·>Где ты предлагаешь проверять поля на null тогда? P>Какие именно поля на null ? ui, dto, bl, конфиг, бд?
Перечитай топик, всё написано. Твоя цитата:
...в составе юнит-тестов, где нас интересуют подробности
— а что если в колонке пусто
P>>>Как без таких тестов сможете убедиться, что на реальной системе у вас действительно эти 30 минут а не месяцы и годы? P>·>Ты и со своими тестами не сможешь убедиться. Ещё раз, это достигается другим способом. Строишь модель физического времени, например как int64 unix-epoch nanoseconds. А дальше в тестах тупо прибавляешь разное количество наносекунд к моку источника времени и смотришь, что логаут не|произошел. Тогда и конкретное количество времени неважно, хоть 30 минут, хоть 30 лет — тест будет выполяться мгновенно в любом случае. И нет никаких проблем прогонять этот тест каждый раз перед каждым релизом. P>Смотрите внимательно — щас будут примеры и вы наверняка скажете, что у вас такого быть не может, невозможно, никогда, у вас багов вообще не бывает итд.
Таких примитивных тривиальных багов как у вас — не бывает. Ибо это всё лечится элементарно.
Подавляющее большинство багов — неверно поняли спеку и реализовали поведение не такое, какое хотел юзер. Но такие баги в большинстве ловятся на этапе демо.
P>Итого: P>Написали вы такой тест на моках, а на проде выяснилось, что юзер всё равно не логаутится. Например, пототому, что в UI приложении есть фоновый процессинг, который мимоходом и обновляет токен продляя сессию.
Так фоновой процессинг не с божьего попущения работает, а с того же мочёного источника времени. Т.е. тест будет выполнять и все шедулеры-фоновые процессы при перемотке времени. В этом и цель этих моков — полный контроль внешних зависимостей. С этим будут проблемы только у тебя, т.к. у тебя по всему коду глобальные переменные в виде DateTime.Now() и никак не контролируются.
P>Пофиксили, и выяснили, юзер всё равно не логаутится, т.е. время жизни сессии берется из конфига, который неправильно смержился.
Не понял. По ошибке указали в прод конфиге не 30 минут, а 300?
На это дело есть специальный процесс, который показывает diff конфига между продом и тестом. Каждая разница должна быть проревьювена и заапрувлена.
P>Пофиксили, и выяснили, что всё равно не логаутится — ваш фикс фонового процессинга сломал один из долгоиграющих кейсов, разработчик Вася подкинул рядом с вашим кодом свой, и фоновый процессинг всё равно обновляет сессию.
Детский сад. Не используйте глобальные переменные.
P>Пофиксили и это, и выяснили, что логаут стартует когда подходит ttl сессии, но ничего не делает — потому что очередь шедулинга с этим связаный забита под завязку другими вещами.
Забитость очереди — это красный сигнал в мониторинге.
P>Пофиксили и это — обнаружили, что строчка тестового кода пролезла на прод в одном из больших пул реквестов и логаут вызывается только для тестовых юзеров.
"строчка тестового кода" это как?! Тестовый код физически лежит в другом каталоге от прода.
P>Проблему нужно решать не моками, а дизайном.
Ага, т.е. опять оффтоп. Мы же тут обсуждаем тесты, а не дизайн.
P>Например — отделить фоновый процессинг от интерактивного, что бы у него даже не было никакой возможности получить токен для обновления.
Мде. Тупо — не используйте глобальные переменные.
P>А если время сессии это критическая вещь, то e2e ну просится — архитектура аутентификации всегда сложная, там много чего может пойти странными путями.
Это легко лечится: Любая вещь, сложная или не сложная — первый вопрос на который должен быть дан ответ прежде чем приступать к обсуждению дизайна и уж тем более реализации — как мы это можем покрыть быстрыми автотестами?
P>>>Если этот шаг неважный, его в e2e выносить не нужно. А если это важно, то это проверять надо регулярно: P>·>Ок... ну может логаут неважный. Но вот например "отослать statement в конце каждого месяца" — шаг ооочень важный. Тоже e2e тест сделаешь со sleep(1 month)? P>В данном случае здесь решение что через мониторинг, что через e2e будет приблизительно одинаковым.
Мониторинг обнаруживает проблемы мгновенно, в отличие от.
P>Разница будет только в том, где именно и как запускается скрипт для проверки что statement действительно создался. e2e можно запускать регулярно, впрочем, я уже это говорил.
e2e чего? e2e — это сценарий, когда какой-то тестовый юзер чего-то сделал и проверяем, что система совершила ожидаемые действия. А statement создаётся для реальных юзеров для действий которые они совершили.
P>>> У вас что, лимит на количество тестов, добавили e2e — теперь надо сотню юнит-тестов удалить? Не пойму ваш кейс. P>·>Падение e2e-теста означает дыру в нижележащих тестах. Если ваши e2e-тесты падают, чаще чем рак на горе свистит, значит у вас внизу пирамиды дырявые тесты. P>Нету способа гарантировать отсутствие дыр, багов, уязвимостей итд. e2e это способ задешево выявить большинство проблемав в интеграции верхнего уровня, которая как раз тестами на нижних уровнях не покрывается.
Тут речь идёт о том, что _все_ тесты должны быть запущены и успешно пройдены до того, как код увидят юзеры. А у вас это настолько "задешево", что вы не можете себе этого позволить и выполняеете acceptance частично.
P>·>Я под интеграционным кодом подразумеваю который вызывает "те ошибки, которые проходят мимо ваших моков". Так вот мимо моков проходят ошибки в доле процента кода, который выполняется только при реальном старте приложения, код в том самом composition root. P>Ну да, вы выдумали какое то своё определение интеграционного кода.
Да мне похрен на определения. Я написал суть. Но на суть тебе плевать, придираешься к терминологии.
P>А ошибки с построением запроса фильтров, они как, по вашему, где ходят?
Не знаю где они у вас ходят. Судя по тому что ты рассказал — на проде.
P>·>У технологического кода другой бизнес-домен. Технологический код, который, скажем, реплицирует базу записей в несколько датацентров — оперирует не бизнес-сущностью лайка, а "запись данных", "датацентр" и т.п. А дальше уже идёт интеграция, когда мы в качестве записи берём лайк и получаем надёжное реплицированное хранилище лайков. У тебя же твой билдер билдит конкретный запрос сущности из бизнес-домена, но вместо ассертов бизнес-сущностей ты тестируешь технические детали. P>Потому, что покрывать тестами нужно все критические свойства, а не ограничиваться только теми, что в спеке написаны.
Так ты не те свойства покрываешь и не так.
P>·>Только тот код, что в composition root сложно покрывается тестами, т.к. там создаются и инжектятся реальные объекты и требует дорогого e2e тестирования. Остальное — неинтересно, ибо быстро, тривиально и надёжно тестируется с помощью моков. P>·>Если вы не в сосотянии протестировать контроллер, роутер, юзекйс валидацию и сериализацию без e2e — у вас проблемы. P>Успокойтесь, e2e это не для теста контролера. Наверное вы забыли, что я вам предлагал тестировать валидацию юнит-тестами?
А чем тестируется контроллер-то?
P>>>Непонятно — вы добавили ровно один тест, и юзеры получили проблему. Такое может быть только в следующих случаях, если P>·>Ты предложил прогонять не все тесты перед выкаткой в прод. P>Я вам даже рассказал как именно — все ваши тесты вместе взятые пускаете как сейчас. Допустим их 1000 штук. Вот эту 1000 оставьте и не трогайте. P>А вот далее вы добавляете новый вид тестов, которые будут запускаться регулярно после деплоя. Их штук 10, новых. P>Итого — 1000 пускаете как раньше, + 10 новых регулярно.
Зачем, чтобы что? Гораздо выгоднее вместо этой хрени пойти в паб отметить — эффект гораздо лучше.
P>>>Откуда возьмутся проблемы у юзеров на проде? P>·>Не все тесты выполнены. P>Похоже, X + 1 у вас может быть меньше X. Забавно!
Потому что твоё "добавление" имеет отрицательный эффект. Тратит ресурсы с нулевой пользой. Зачем это +1 запускать после релиза, если мы можем себе это позволить запустить до? У вас беда в том, что из-за детских проблем в проекте вы не можете эти "10 новых регулярно" запускать ещё за день перед релизом. Я тыкаю пальчиком в проблемы и пытаюсь объяснить что вам надо исправить, чтобы вы тоже смогли, но ты продолжаешь надувать щёки со своей data complexity.
P>>>Ваши имеющиеся тесты отработали — за счет чего регрессия произойдет? P>·>Наши да, ваши — не все. P>Непонятно — регрессии откуда взяться? Вы добавили новый вид тестов — старые не трогали. Новые предназначены для регулярного запуска после деплоя. P>Откуда возьмется регрессия?
Если эти ваши "новые" тесты могут упасть в принципе, то значит у вас регрессия не найденная тестами до деплоя.
Если они не могут упасть принципиально, то зачем их запускать-то?
P>·>Те, для которых написаны тесты — ясен пень не доходят. Если какой-либо тест красный для данной версии системы — в прод она не попадёт. P>Вот и отлично — значит наличие красных тестов наутро сообщит вам о проблеме еще на стейдже.
Зачем наутро? Через 20 минут же, спасибо мокам.
P>... P>7 редкие ошибки — прод тупо работает на порядки дольше тестового окружения
Это всё задачи мониторинга и операционного контроля, а не тестов. Тестами в принципе такие задачи надёжно не решаются.
Мониторинг и контроль — другие задачи, другие системы со своим набором тестов, тоже выполняемых до деплоя. Что у вас операционные процессы в плачевном состоянии я ещё больше года назад писал.
P>>>И никто, кроме лично вас не утверждает "на проде багов быть не может" P>·>Ты меня заебал. Не пиши свои бредовые фантазии как мои цитаты. Я такого никогда нигде не утверждал. P>Смотрите, вот ваши цитата выше: P>"Те, для которых написаны тесты — ясен пень не доходят(до прода)" — в скобках это контекст обозначил
И? В логику не умеешь? Помогу: это значит, что могут доходить только те баги, для которых не существует тестов. Из чего ты высосал "багов быть не может" — это мне даже неинтересно.
P>А вы утверждаете, что раз есть тест, то такой баги на проде точно нет
Ты в логику не умеешь совершенно. Это значит, что этот тест будет зелёным и на проде тоже. Либо он может быть красным синхронно с какой-нибудь лампочкой в системе мониторинга. Что делает запуск теста — бесполезным, никакой новой информации он дать не может.
P>>>Вы из своих функций вызываете другие свои функции? Вот вам и интеграционный код. Посмотрите, сколько у вас такого. P>·>Непокрытого лёгкими тестами? Полторы строчки, всё верно. P>Сюда нужно вписать data complexity. Хороший пример — те самые фильтры.
Какое это имеет отношение к интеграционному коду?
P>>>·>Т.е. у тебя есть ровно те же "репозиторий + бд" тесты? P>>>Есть конечно же. Только таких тестов немного — они дают слабые гарантии в силу своей косвенности. P>·>Слабые относительно чего? P>Относительно других методов. Ваши косвенные тесты упираются в теорему Райса.
Ага-ага, а ваши "прямые" тесты не упираются. Да вы круты неимоверно.
P>А вот синтаксические свойства можно обеспечивать той же статической типизацией. Надеюсь, вам теорема Райса здесь не мешает? P>Кроме синтаксических есть структурные — те самые пред-, пост-, условия, инварианты. P>Проектирование — формальные методы, например, доказательства тех или иных свойств.
Оффтоп, т.к. мы обсуждаем методы тестирования.
P>·>Возможно. Непонятно почему этот билдер специфичный под этот конкретный метод, а не универсальный типа linq со своими тестами. P>Как это будет с linq вам Синклер рядом показал. Сама задача в том, что фильтровать нужно по выражению от юзера, который а хрен знает что может понавыбирать.
Я указал на недостатки и дыры в таком подходе в ответе ему.
P>>>Все функциональные требования удовлетворены. Непонятно, почему тесты должны падать. P>·>Потому что попытка юзера выполнить функцию проваливается из-за ошибок в синхронизации. P>Необязательно, перестаньте фантазировать.
Ну так и моки падают необязательно, перестаньте фантазировать.
P>·>Ещё раз, эта проблема ассертами в тестах не решается. P>В том то и дело. А что у вас есть кроме тестов?
Всё что надо, не волнуйся, но это оффтоп. Если интересно, заводи новую тему.
P>·>Верно. Но ты не догоняешь, что во 2м пункте можно просто ассертить число записей, с тем же успехом, но лучшим результатом. P>Что бы ассертить число записей нужно знать комбинацию которой у вас точно нет.
Нужно знать ровно то же, что и у вас.
P>>>Вы из 1..4 видите только тесты, а всё остальное для вас пустое место. P>·>Не потому что пустое место, а потому что мы тут обсуждаем тесты и разные подходы к тестированию, а 1..3 — оффтопик. Но ты всё не успокоишься и продолжаешь словоблудить. P>Никакой это не оффтопик. пп 1 2 и 3 говорят о том, что можно изменить дизайн, и ваши моки будут больше не нужны.
Может быть, но тебе не удалось. Ни для примере Буравчика, ни в примере Фаулера.
P>>>Каким образом .top(10) пропустит десятки миллионов записей? подробнее. P>·>Поставлен не туда или поставлен условно. P>Вот вам и стало понятно, что покрываем тестами — поставлен именно туда, куда надо. Только сначала дизайн решения. См сообщение Синклера
Похрен на дизайн. Ты простую мысль так и не понял. Проверять кол-во записей и проверять наличие top — даёт те же гарантии. Но проверка кол-ва записей проверяет больше.
P>·>_такой_ тест не нужен. Нужен другой тест. P>Другой, которого вы так и не показали?
Показал.
P>·>Т.е. твои тесты — проверяют меньше, чем мои. Мои, помимо того, что кол-во записей ограничивается 10ю так же протестирует и валидность запросов, подстановку парамов и т.п. P>Мои тесты фиксируют структуру решения. Ваши без конкретного перечня комбинаций ничего не гарантируют.
Гарантируют то же что и твои.
P>>>Облегчают. Вместо погружения во все детали реализации во время код-ревью, вы смотрите какие тесты были исключены. P>·>Ты о чём? Что за исключённые тесты? P>Закоментили, удалили, исправили ожидания. Если вы видите, что тест на .top убрали, надо пойти и дать по шее.
Детский сад какой-то.
P>>>acceptance в минутах считается только для hello world. P>·>Завидуешь, да? Ну вообще говоря acceptance гоняется на кластере, вот и укладывается в пол часа. P>Полчаса это десятки минут. e2e это вобщем тот же acceptance. Если у вас есть такое, чего же вы здесь выступаете?
Выступаю о том, что это всё выполняется ещё до деплоя. Не нужно выполнять ничего после деплоя (ок, один smoke test), и уж тем более частично по random.
P>·>В тесте же конкретный сценарий — запускаем код, дождались завершения, проверяем, выполнилась ли инструкция X. Никакой проблемы останова. P>Вы успешно опровергли теорему Райса
P>>>Вот-вот. Вы путаете синтаксис и семантику. Любой компилятор справляется и с синтаксисом, и со структурой, но не с семантикой. P>·>Так ты зачем-то синтаксис и проверяешь "есть ли в коде .top(10)". P>В том то и дело — я проверяю структуру, а вы пытаетесь тестами семантику проверять. Отсюда ясно, что вашими тестами вы в теорему Райса упретесь гораздо раньше
Ты не проверяешь структуру, ты копипастишь её из прод-кода в тест-код. Т.е. для надёжности для надёжности пишешь пишешь дважды ровно то же самое то же самое. А то вдруг чего. А то вдруг чего.
P>·>Если я правильно понял проблему, то она не находится никакими тестами, хоть ручными, хоть ножными. Если только случайно. P>Её можно исключить методами родственными знакомой вам статической типизации. Те самые предусловия и соответствующий дизайн.
Похрен. Идёт речь про тесты. Ты заявляешь "Вы так и не показали ни одного автоматического теста". И что, и не обязан был. Ты не показал вообще никакого теста. И не сможешь, ясен пень.
P>>>Там, где у автоматических тестов начинаются недостатки, у других методов будут преимущества. P>·>Если ты под другими методами имеешь в виду ручные тесты, то у меня для тебя плохие новости. P>Ручные методы это в т.ч. exploratory, и вообще исследование.
И? Из ручного тут лишь само создание автоматических тестов. Да, если ты не знал — код тестов пишут вручную. Если вы их герените автоматом, то не делайте так больше.
P>·>Главное пока умалчиваешь: тест как выглядит для этого кода? Ну где там deep.eq, pattern или что? P>Вам примера Синклера недостаточно, вы хотите у меня тож самое спросить? P>
P>вот так мы можем проверить, добавляет ли билдер top или нет. Билдер будет примерно как у Синклера.
Не понял. Где тут прод-код, где тут тест-код? Напиши однозначно — код под тестом и сам тест.
P>>>Ищите по огромным синим буквам. P>·>Там нет ответа на этот вопрос. Там сказано "далее ...бд минимально заполненой", а что было с бд до "далее" — ты надёжно скрываешь. P>Забавно, вы вырезали часть цитаты, и не знаете, что было в той части, что вы же и выбросили? Ищите — я для вас синим подсветил
Нашел. Там нет ответа на мой вопрос.
P>·>Какие поля когда могут быть null — это дохрена комбинаций в типичном приложении. Т.е. получается, что ты интеграцию null-полей проверяешь только на юзерах. P>Пример у вас есть?
Всё тот же, не теряй контекст.
P>>>Вам нужно знание о том, как устроены четные и нечетные — у одних младший бит 1, у других — младший бит 0 P>·>Отлично. Вот ты и выявил какие комбинации будут проблемными. Придумать входные парамы и ожидания с вариациями младшего бита. Т.е. и тестировать надо именно на комбинациях младшего бита. P>Комбинации как раз не выявлены. Только свойство построения чисел
Вариации младшего бита и есть проблемные комбинации.
P>>>В переводе на фильтры — у запроса всегда есть лимит. P>·>"у запроса всегда есть лимит" в переводе в твоём случае будет "функция isOdd всегда использует битовую операцию взятия младшего бита". P>Вы уже почти научились. В случае с битами все просто — половина целых четные, половина — нечетные. Это значит, что тестовый набор вы сможете намастырить самостоятельно.
Половина бесконечности, если что — тоже бесконечность.
P>А вот где взять запрос, у которого будет нарушено свойство длины — загадка
Что за свойство длины?
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, Sinclair, Вы писали:
S>>>Вы предлагаете тестировать этот момент косвенно, через подсчёт реального количества записей, которые вернёт ваш репозиторий, подключенный к моку базы. S>·>Я предлагаю тестировать не моменты, а бизнес-требования. Не бывает в реальности таких требований как "построить кусочек запроса". S>Это игра словами.
Это разница между хрупкими тестами, которые тестируют детали реализации и полезными тестами, которые тестируют аспекты поведения.
S>·>Вот только невозможно проверить в _тесте_, что .top(10) действительно добавляется к _любому_ запросу. S>Я же показал, как именно проверить. Какое место осталось непонятным?
Как проверить что к _любому_ запросу. В твоём _тесте_ проверяется только для одного конкртетного запроса с одним из заданных в тесте criteria.
S>·>Это уже лажа. addLimit это метод некоего QueryBuilder, некий библиотечный метод, который уже имеет свои тесты, включая эти твои отрицательные аргументы. Мы полагаемся, что он работает в соотвествии с контрактом когда им пользуемся. S>Если AddLimit — библиотечный, то всё прекрасно, и вы правы — тестировать его не надо вовсе.
Из привёдённых снипппетов кода я вижу что именно библотечный и по-другому вряд ли может быть, т.к. код получится совсем другим.
S>·>А зачем этот тест нужен-то? Убедиться, что в двух строчках кода одна из них действительно addLimit? Это и так напрямую явно видно в коде и каждый заметит наличие-отсутствие этого вызова и в PR диффе. S>Ну вы же почему-то не верите в то, что в двух строчках кода в контроллере берётся именно request.ClientTime и требуете, чтобы это было покрыто тестами
S>·>
S>·>И твои супер-тесты это не обнаружат. S>У меня не супер-тесты, а самые примитивные юнит-тесты. S>·>Т.е. твой тест даст false negative. Или тебе известна методология тестирования кода на простоту и линейность? S>Основная методология — такая же, как вы привели выше. Каждый заметит наличие-отсутствие этого вызова и в PR диффе, поэтому такой код не пройдёт ревью. От автора потребуют переместить свой buildOptimizedQuery внутрь buildWhere. Если у нас нет под рукой theorem prover, то надёжных автоматических альтернатив нет.
Да банально скобочки забыты вокруг ?: — ошиблись в приоритете операций, должно было быть (someMagicalCondition(criteria) ? buildOptimizedQuery(criteria) : buildWhere(criteria)).addLimit(pageSize). Ведь проблема в том, что мы не описали в виде теста ожидаемое поведение. А тестирование синтаксиса никакой _новой_ информации не даёт, синтаксис и так виден явно в диффе.
S>Впрочем, в вашем подходе всё будет ровно так же — вы же ведь не собираетесь перебирать все мыслимые сочетания значений аргументов в тесте, который проверяет количество записей?
В этом и суть что с т.з. _кода теста_ — проверять наличие addLimit или size()==10 — даёт ровно те же гарантии корректности лимитирования числа записей. Но у меня дополнительно к этому ещё некоторые вещи проверяются и нет завязки на конкретную реализацию, что делает тест менее хрупким.
Ах да. Вы ведь делаете свои тесты красными? Адекватность теста проверить легко — комментируешь "addLimit" и прогоняешь тесты. Если ничего не покраснело, значит надо чинить тесты.
S>·>Мой поинт в том, что ценным тестом будет проверка что addLimit строчка действительно работает в соответствии с бизнес-требованиями — запустить на 11 записях и заассертить, что вернулось только 10 как прописано в FRD — это цель этой строчки, а сама по себе строчка — это средство. И заметь, такой 11/10 тест достаточно сделать для ровно той же комбинации фильтров что и в твоём тесте на наличие addLimit в коде, никакой экспоненциальности которой ты грозишься. S>Ну это же просто обман. Смотрите за руками: если комбинация фильтров, которая использовалась в тесте на addLimit, попадает под условия someMagicalCondition, то тест сразу сфейлится.
И мой, и твой.
S>А если не попадает — то ващ тест точно так же вернёт 10 записей, и всё.
Верно. Т.е. оба подхода при прочих равных этот аспект проверяют ровно так же. Но твой тест покрывает меньше аспектов.
S>·>т.е. тесты которые так же продолжают работать и ожидаются, что должны быть зелёными без каких-либо изменений после рефакторинга. Такие тесты нужны в любом случае. А твой тест даст false positive и будет просто выкинут. ·>Напишут взамен другой тест, в который закопипастят .contains("rownum < 10") перепутав что rownum zero- или one- based. Отличить на ревью корректность <= от < гораздо сложнее, чем условно save(...11 records...); assert find(10).size() == 10; assert find(5).size() == 5;. S>Если в проекте завёлся вредитель, то никакими тестами вы его не поймаете. Он просто возьмёт и сломает всё, что угодно. Сейчас вы мне рассказываете, что ловите баги при помощи review кода.
Причём тут вредители? Я очень часто путаю == и != или < и > в коде. Поэтому ещё один способ выразить намерение кода в виде тестового примера с конкретным значением помогает поймать такие опечатки ещё до коммита. Может ты способен в сотне строк обнаружить неверный оператор или забытые строки приоритета, но я на такое не тяну. Поэтому мне надо это дело запустить и просмотреть на результат для конкретного примера.
S>Ну, вот и в нашем случае делается review кода, только код — простой, а за наращивание сложности на ровном месте можно бить человека палкой.
Так ведь ревью делается и для тестов, и для кода. Мне по коду теста сразу видно, что find(10).size() == 10 — правильно. А вот уверено решить что должно быть "rownum > 10", "rownum <= 10" или "rownum < 10" — лично я не смогу, тем более как ревьювер большого PR. Если ты и все члены твоей команды так умеют, то могу только позавидовать.
S>·>Это какой-то тривиальный случай. Это значит не то, что мы магически сделали функцию линейной, а что никаких зависимостей между фильтрами нет в требованиях и никаких 2^N комбинаций просто не нужно, где тут эта ваша грозная data complexity — совершенно неясно. S>Ну так этой complexity нету как раз потому, что мы её факторизовали. И сделали это благодаря тому, что распилили сложную функцию на набор простых частей.
Какую сложную функцию? Вы просто переписали кривой код на прямой. Тесты тут причём?
S>А вы предлагаете тестировать весь монолит — в рамках него вы не можете полагаться ни на какую независимость. Ну, вот так устроена pull-модель — вам надо построить полный фильтр и выполнить запрос, и никакого способа проверить первую половину запроса отдельно от второй половины запроса не существует.
Я такого не предлагаю.
S>·>В реальности у тебя могут быть хитрые зависимости между параметрами фильтра и вот тут и полезут неявные комбинации экспоненциально всё взрывающие и код несводимый к линейной функции, а будет хитрая if-else-switch лесенка. S>Нет, по-прежнему будет простая линейная цепочка, только кусочки её будут чуть более длинными.
Да пожалуйста, если получится.
S>·>Гарантию того, что у тебя works as coded. Зато отличить u => u.LastLoginTimeStamp >= criteria.MinLastLoginTimestamp.Value) от u => u.LastLoginTimeStamp <= criteria.MinLastLoginTimestamp.Value) такие тесты не смогут, т.к. пишутся как правило копипастом. На ревью очепятку очень вряд ли кто-то заметит. S>Если пишут разные люди, то заметят.
Код и тесты обычно пишет один человек. Или вы парное программирование используете?
S>Ну и, опять же, у нас код каждой функции — очень короткий. Там всего-то пара операций.
Если код функции котороткий, то значит у тебя такхи функций овердофига. И в каждой из паре операций можно сделать очепятку.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>·>smoke tests — как вишенка на торт, но в остальном — проверять две вещи: части работают, части собираются между собой нужным образом. P>>Что это за тесты, кто их выполняет? ·>CI/CD
Чем ваши acceptance и smoke отличаются от e2e ?
P>>Минорная — это значит, что есть вещи более важные P>>Если у вас нет хотя бы одного 1..4 никакие тесты вам не помогут, хоть обмажтесь. ·>А без тестов 1-6 уйдут лесом. Единственное, что может не сразу, но уйдут точно.
Тесты напрямую не влияют на качество — это просто индикаторы симптомов.
Более того, если тесты зеленые, это говорит всего лишь "не обнаружили", а что там на самом деле с софтиной — а хрен его знает, если у вас нет 1-4
Хотите повышать качество — нужно проектировать, кодить больше, лучше, помогать другим, документировать, итд, итд.
P>>Похоже, ваш капасити переполнен три месяца назад. Вы здесь, извините, порете отсебятину. ·>У тебя память как у рыбки. Цитирую: ·>
·>·>потенциально может быть null — ты не дождёшься окончания.
Я шота не понял ваш аргумент.
P>>Какие именно поля на null ? ui, dto, bl, конфиг, бд? ·>Перечитай топик, всё написано. Твоя цитата: ·>
·>...в составе юнит-тестов, где нас интересуют подробности
·>— а что если в колонке пусто
Непонятный аргумент. Подробнее никак?
P>>Смотрите внимательно — щас будут примеры и вы наверняка скажете, что у вас такого быть не может, невозможно, никогда, у вас багов вообще не бывает итд. ·>Таких примитивных тривиальных багов как у вас — не бывает. Ибо это всё лечится элементарно.
Видите — я угадал.
·>Подавляющее большинство багов — неверно поняли спеку и реализовали поведение не такое, какое хотел юзер. Но такие баги в большинстве ловятся на этапе демо.
Это значит, что у вас простой кейс — для всего дадена спека. Что делать будете, кода результат вашей работы это и спека, и софт по ней?
·>Так фоновой процессинг н е с божьего попущения работает, а с того же мочёного источника времени.
Вы зачем то снова пустились в фантазирование. Юзер у вас что, на бакенде сидит? Нет ведь. Он в каком то клиентском приложении. Вот там и ищите фоновый процессинг.
Я вам просто пример привел, откуда может прийти проблема, которая в ваших моках никак не отражена.
P>>Пофиксили, и выяснили, юзер всё равно не логаутится, т.е. время жизни сессии берется из конфига, который неправильно смержился. ·>Не понял. По ошибке указали в прод конфиге не 30 минут, а 300?
В проде указали 30 минут, а из за мержа конфигов у вас стало 300, например, потому что это дефолтное значение. Это снова пример проблемы которая идет мимо ваших моков.
·>На это дело есть специальный процесс, который показывает diff конфига между продом и тестом. Каждая разница должна быть проревьювена и заапрувлена.
Вот вам дифф ничего и не показал — всё кошерно. А на проде дефолтное значение перетерло значение из конфига. Упс.
P>>Пофиксили, и выяснили, что всё равно не логаутится — ваш фикс фонового процессинга сломал один из долгоиграющих кейсов, разработчик Вася подкинул рядом с вашим кодом свой, и фоновый процессинг всё равно обновляет сессию. ·>Детский сад. Не используйте глобальные переменные.
Забавная телепатия. Где вы увидели глобальные переменные?
P>>Пофиксили и это, и выяснили, что логаут стартует когда подходит ttl сессии, но ничего не делает — потому что очередь шедулинга с этим связаный забита под завязку другими вещами. ·>Забитость очереди — это красный сигнал в мониторинге.
Именно что в мониторинге, а не в ваших тестах на моках. И только под нагрузкой.
P>>Пофиксили и это — обнаружили, что строчка тестового кода пролезла на прод в одном из больших пул реквестов и логаут вызывается только для тестовых юзеров. ·>"строчка тестового кода" это как?! Тестовый код физически лежит в другом каталоге от прода.
Очень просто. Код для тестов и тесты для кода это две большие разницы, как говорят в Одессе.
Например, разработчик кое что подтюнил в коде, что бы легче было воспроизвести другую багу. И забыл это убрать.
P>>Проблему нужно решать не моками, а дизайном. ·>Ага, т.е. опять оффтоп. Мы же тут обсуждаем тесты, а не дизайн.
Вы до сих пор название топика не вкурили? dependency rejection это целиком про дизайн.
А тесты это всего лишь результат того, как вы дизайн построили.
Построили дизайн под моки — естественно, кроме моков ничего и не будет.
P>>Например — отделить фоновый процессинг от интерактивного, что бы у него даже не было никакой возможности получить токен для обновления. ·>Мде. Тупо — не используйте глобальные переменные.
Это всё мимо. Экземпляр UI приложения это штука глобальная, вне зависимости от того, где вы держите переменную app — глобально или в стеке функции main или хоть вообще нигде. Это ж не сервер, где на запрос можно поднимать хоть целый процесс.
Вопрос в том, как у вас сделано разделение фонового и интерактивного приложений.
P>>А если время сессии это критическая вещь, то e2e ну просится — архитектура аутентификации всегда сложная, там много чего может пойти странными путями. ·>Это легко лечится: Любая вещь, сложная или не сложная — первый вопрос на который должен быть дан ответ прежде чем приступать к обсуждению дизайна и уж тем более реализации — как мы это можем покрыть быстрыми автотестами?
Вот-вот — фоновый процессинг совместили с интерактивным именно потому, что так быстрее было тестировать.
Отсюда и баги из за этого совмещения — вечноактивный юзер.
P>>В данном случае здесь решение что через мониторинг, что через e2e будет приблизительно одинаковым. ·>Мониторинг обнаруживает проблемы мгновенно, в отличие от.
Да, вы эту сказку много раз повторяли — у вас мониторинг любую даже гипотетически возможную проблему обнаруживает сразу.
·>e2e чего? e2e — это сценарий, когда какой-то тестовый юзер чего-то сделал и проверяем, что система совершила ожидаемые действия. А statement создаётся для реальных юзеров для действий которые они совершили.
Вы что, повсюду в бизнес-логике пишете "if user.isTest() " ? Очень вряд ли. Интеграция для тестового юзера и реального будет та же самая. Соответственно, обнаруженные проблемы практически наверняка будут играть и для тестовых юзеров.
·>Тут речь идёт о том, что _все_ тесты должны быть запущены и успешно пройдены до того, как код увидят юзеры. А у вас это настолько "задешево", что вы не можете себе этого позволить и выполняеете acceptance частично.
Мы уже выясняли — вы держите только ту часть acceptance, которую можно выполнить за полчаса. А другие на идут дальше этого 1%
P>>Ну да, вы выдумали какое то своё определение интеграционного кода. ·>Да мне похрен на определения. Я написал суть. Но на суть тебе плевать, придираешься к терминологии.
Через ваши доморощенные определения крайне трудно продираться.
P>>·>Если вы не в сосотянии протестировать контроллер, роутер, юзекйс валидацию и сериализацию без e2e — у вас проблемы. P>>Успокойтесь, e2e это не для теста контролера. Наверное вы забыли, что я вам предлагал тестировать валидацию юнит-тестами? ·>А чем тестируется контроллер-то?
Интеграционными — средний уровень в пирамиде. Я ж вам объяснял уже.
P>>Итого — 1000 пускаете как раньше, + 10 новых регулярно. ·>Зачем, чтобы что? Гораздо выгоднее вместо этой хрени пойти в паб отметить — эффект гораздо лучше.
Что вам непонятно было в прошлый раз? Вы продолжаете задавать один и тот же вопрос, получаете один и тот же ответ. Чего вы ждете?
P>>Похоже, X + 1 у вас может быть меньше X. Забавно! ·>Потому что твоё "добавление" имеет отрицательный эффект. Тратит ресурсы с нулевой пользой. Зачем это +1 запускать после релиза, если мы можем себе это позволить запустить до?
Вы же сами сказали — у вас ажно 1% покрыт. Вот на остальные 99% и нужно придумать чтото получше чем есть у вас.
P>>Откуда возьмется регрессия? ·>Если эти ваши "новые" тесты могут упасть в принципе, то значит у вас регрессия не найденная тестами до деплоя.
Теорема Райса с вами не согласна. Нету у вас 100% надежного способа гарантировать даже true из boolean.
Баги имеют свойство воспроизводиться повторно, например, потому что
1 часто у бага больше одной причины — далеко не все они дружно сами себя документируют в тестовом прогоне
2 разница прода и стейджа (нагрузка, время, объемы данных, итд)
3 итд
P>>Вот и отлично — значит наличие красных тестов наутро сообщит вам о проблеме еще на стейдже. ·>Зачем наутро? Через 20 минут же, спасибо мокам.
Вашу интеграцию тестируют acceptance и smoke. я вот не удивлюсь, если окажется что ваши acсeptance это ровно то же, что и e2e
P>>"Те, для которых написаны тесты — ясен пень не доходят(до прода)" — в скобках это контекст обозначил ·>И? В логику не умеешь? Помогу: это значит, что могут доходить только те баги, для которых не существует тестов. Из чего ты высосал "багов быть не может" — это мне даже неинтересно.
А также те, для которых тесты существуют, но причин более одной, разница прода и стейджа итд.
·>Ты в логику не умеешь совершенно. Это значит, что этот тест будет зелёным и на проде тоже.
Теорема Райса с вами не согласна. Нету у вас 100% надежного способа гарантировать даже true из boolean.
> Либо он может быть красным синхронно с какой-нибудь лампочкой в системе мониторинга. Что делает запуск теста — бесполезным, никакой новой информации он дать не может.
А еще он поможет подсветиться лампочке в мониторинга до того, как юзер напорется на проблему, а не после
Вы разницу до и после надеюсь понимаете?
P>>>>Вы из своих функций вызываете другие свои функции? Вот вам и интеграционный код. Посмотрите, сколько у вас такого. P>>·>Непокрытого лёгкими тестами? Полторы строчки, всё верно. P>>Сюда нужно вписать data complexity. Хороший пример — те самые фильтры. ·>Какое это имеет отношение к интеграционному коду?
Вы же их тестировать предложили в связке с бд. Так? Это и есть интеграционный код.
Комбинаций у вас нет. Так?
Вот вам и ответ.
P>>Относительно других методов. Ваши косвенные тесты упираются в теорему Райса. ·>Ага-ага, а ваши "прямые" тесты не упираются. Да вы круты неимоверно.
Вы одной ногой понимаете, а другой — уже нет.
Мой подход того же поля что и статическая типизация — проверяет структуру, синтаксис.
Структурная эквивалентность, синтаксис теореме Райса не подчиняются.
А вот ваши тесты это чистой воды семантические свойства которые полностью подчиняются теореме Райса
P>>Проектирование — формальные методы, например, доказательства тех или иных свойств. ·>Оффтоп, т.к. мы обсуждаем методы тестирования.
Это вы так хотите. Я все время говорю про подход к дизайну. Dependency Rejection — это принцип дизайна прежде всего
P>>Как это будет с linq вам Синклер рядом показал. Сама задача в том, что фильтровать нужно по выражению от юзера, который а хрен знает что может понавыбирать. ·>Я указал на недостатки и дыры в таком подходе в ответе ему.
Ваши тесты еще хуже. По уму, нужно и то и другое. Но вы почему то выбираете худшее из двух.
Ваши тесты ничего не дают без знания конкретных комбинаций на которых можно отработать тест
P>>В том то и дело. А что у вас есть кроме тестов? ·>Всё что надо, не волнуйся, но это оффтоп. Если интересно, заводи новую тему.
Я вам уже третий месяц предлагаю показать это "всё что надо" и вы приводите только тесты, которые требуют комбинаций которых у вас нет
·>Может быть, но тебе не удалось. Ни для примере Буравчика, ни в примере Фаулера.
У Буравчика как раз тот случай, где нужны моки. Я же сразу это сказал, а вы третий месяц срываете покровы.
·>Похрен на дизайн. Ты простую мысль так и не понял. Проверять кол-во записей и проверять наличие top — даёт те же гарантии. Но проверка кол-ва записей проверяет больше.
В том то и дело, что не даёт. У вас нет комбинаций, а потому проверяние количества записей смысла не имеет — в тестовой базе просто нет тех самых данных.
P>>Полчаса это десятки минут. e2e это вобщем тот же acceptance. Если у вас есть такое, чего же вы здесь выступаете? ·>Выступаю о том, что это всё выполняется ещё до деплоя. Не нужно выполнять ничего после деплоя (ок, один smoke test), и уж тем более частично по random.
Вы еще и кластер по acceptance разворачиваете. Или у вас там тоже моки?
P>>В том то и дело — я проверяю структуру, а вы пытаетесь тестами семантику проверять. Отсюда ясно, что вашими тестами вы в теорему Райса упретесь гораздо раньше ·>Ты не проверяешь структуру, ты копипастишь её из прод-кода в тест-код. Т.е. для надёжности для надёжности пишешь пишешь дважды ровно то же самое то же самое. А то вдруг чего. А то вдруг чего.
В прод коде только билдер. Откуда копипаста взялась?
·>Похрен. Идёт речь про тесты. Ты заявляешь "Вы так и не показали ни одного автоматического теста". И что, и не обязан был. Ты не показал вообще никакого теста. И не сможешь, ясен пень.
В данном случае я вам все показал, кроме реального запроса, который будет построен билдером. Там естественно, будет не limit, и не набор AND OR итд.
P>>Ручные методы это в т.ч. exploratory, и вообще исследование. ·>И? Из ручного тут лишь само создание автоматических тестов. Да, если ты не знал — код тестов пишут вручную. Если вы их герените автоматом, то не делайте так больше.
Автоматизируется только рутина. Результат exploratory это не автоматический тест, а обозначение проблемы и перечня новых тест кейсов. Будут ли они автоматизироваться, или нет, дело десятое
P>>·>Главное пока умалчиваешь: тест как выглядит для этого кода? Ну где там deep.eq, pattern или что? P>>Вам примера Синклера недостаточно, вы хотите у меня тож самое спросить? P>>
P>>вот так мы можем проверить, добавляет ли билдер top или нет. Билдер будет примерно как у Синклера. ·>Не понял. Где тут прод-код, где тут тест-код? Напиши однозначно — код под тестом и сам тест.
Это весь тест. прод код — функция builder. Параметры я опустил, для наглядности, как и filterExpression
Это всё из другого проекта, я им больше не занимаюсь
P>>Забавно, вы вырезали часть цитаты, и не знаете, что было в той части, что вы же и выбросили? Ищите — я для вас синим подсветил ·>Нашел. Там нет ответа на мой вопрос.
Попробуйте заново сформулировать вопрос. А на ваши огрызки цитат ответы ищите в синих буквах.
P>>·>"у запроса всегда есть лимит" в переводе в твоём случае будет "функция isOdd всегда использует битовую операцию взятия младшего бита". P>>Вы уже почти научились. В случае с битами все просто — половина целых четные, половина — нечетные. Это значит, что тестовый набор вы сможете намастырить самостоятельно. ·>Половина бесконечности, если что — тоже бесконечность.
Вот вы важное ограничение вашего подхода и нашли — бесконечность.
А вот у пост-условия такого ограничения нет в принципе.
Идея понятна?
P>>А вот где взять запрос, у которого будет нарушено свойство длины — загадка ·>Что за свойство длины?
Здравствуйте, Pauel, Вы писали:
P>>>Что это за тесты, кто их выполняет? P>·>CI/CD P>Чем ваши acceptance и smoke отличаются от e2e ?
acceptance и smoke — подвиды e2e. Первые запускаются до деплоя, вторые запускаются сразу после. Если smoke-тест падает — делается откат к предыдущей версии.
P>>>Минорная — это значит, что есть вещи более важные P>>>Если у вас нет хотя бы одного 1..4 никакие тесты вам не помогут, хоть обмажтесь. P>·>А без тестов 1-6 уйдут лесом. Единственное, что может не сразу, но уйдут точно. P>Тесты напрямую не влияют на качество — это просто индикаторы симптомов. P>Более того, если тесты зеленые, это говорит всего лишь "не обнаружили", а что там на самом деле с софтиной — а хрен его знает, если у вас нет 1-4 P>Хотите повышать качество — нужно проектировать, кодить больше, лучше, помогать другим, документировать, итд, итд.
Угу. Вот только все эти усилия помножатся на ноль без авто-тестов.
P>·>У тебя память как у рыбки. Цитирую: P>·>
P>·>·>потенциально может быть null — ты не дождёшься окончания.
P>·>
P>Я шота не понял ваш аргумент.
В смысле ты не понял что ты хотел сказать своей цитатой? Ничем помочь не могу.
P>>>Какие именно поля на null ? ui, dto, bl, конфиг, бд? P>·>Перечитай топик, всё написано. Твоя цитата: P>·>
P>·>...в составе юнит-тестов, где нас интересуют подробности
P>·>— а что если в колонке пусто
P>·>
P>Непонятный аргумент. Подробнее никак?
Аргумент чего? Это твоя цитата. Что она значит — разбирайся сам.
P>·>Подавляющее большинство багов — неверно поняли спеку и реализовали поведение не такое, какое хотел юзер. Но такие баги в большинстве ловятся на этапе демо. P>Это значит, что у вас простой кейс — для всего дадена спека. Что делать будете, кода результат вашей работы это и спека, и софт по ней?
Ещё проще.
P>·>Так фоновой процессинг н е с божьего попущения работает, а с того же мочёного источника времени. P>Вы зачем то снова пустились в фантазирование. Юзер у вас что, на бакенде сидит? Нет ведь. Он в каком то клиентском приложении. Вот там и ищите фоновый процессинг.
В смысле фоновой процессинг в 3rd party внешней системе? Ну тогда это их проблема, поведение нашего api задокументировано.
P>Я вам просто пример привел, откуда может прийти проблема, которая в ваших моках никак не отражена.
Поведение нашей системы ограничивается нашей системой. Если другие делают ошибки, то в лучшем случае мы им поможем их найти.
P>>>Пофиксили, и выяснили, юзер всё равно не логаутится, т.е. время жизни сессии берется из конфига, который неправильно смержился. P>·>Не понял. По ошибке указали в прод конфиге не 30 минут, а 300? P>В проде указали 30 минут, а из за мержа конфигов у вас стало 300, например, потому что это дефолтное значение. Это снова пример проблемы которая идет мимо ваших моков.
Дифф конфигов прода и теста покажет отстутствие параметра.
P>·>На это дело есть специальный процесс, который показывает diff конфига между продом и тестом. Каждая разница должна быть проревьювена и заапрувлена. P>Вот вам дифф ничего и не показал — всё кошерно. А на проде дефолтное значение перетерло значение из конфига. Упс.
Если диффа нет, это значит что значение одинаково.
P>>>Пофиксили, и выяснили, что всё равно не логаутится — ваш фикс фонового процессинга сломал один из долгоиграющих кейсов, разработчик Вася подкинул рядом с вашим кодом свой, и фоновый процессинг всё равно обновляет сессию. P>·>Детский сад. Не используйте глобальные переменные. P>Забавная телепатия. Где вы увидели глобальные переменные?
В DateTime.Now().
P>>>Пофиксили и это, и выяснили, что логаут стартует когда подходит ttl сессии, но ничего не делает — потому что очередь шедулинга с этим связаный забита под завязку другими вещами. P>·>Забитость очереди — это красный сигнал в мониторинге. P>Именно что в мониторинге, а не в ваших тестах на моках. И только под нагрузкой.
Угу, и?
P>>>Пофиксили и это — обнаружили, что строчка тестового кода пролезла на прод в одном из больших пул реквестов и логаут вызывается только для тестовых юзеров. P>·>"строчка тестового кода" это как?! Тестовый код физически лежит в другом каталоге от прода. P>Очень просто. Код для тестов и тесты для кода это две большие разницы, как говорят в Одессе. P>Например, разработчик кое что подтюнил в коде, что бы легче было воспроизвести другую багу. И забыл это убрать.
Треш какой-то у вас творится.
P>>>Проблему нужно решать не моками, а дизайном. P>·>Ага, т.е. опять оффтоп. Мы же тут обсуждаем тесты, а не дизайн. P>Вы до сих пор название топика не вкурили? dependency rejection это целиком про дизайн.
Это вроде давно обсудили. Ты потом переключился на моки.
P>А тесты это всего лишь результат того, как вы дизайн построили. P>Построили дизайн под моки — естественно, кроме моков ничего и не будет.
Нет никакого дизайна под моки. Есть внешние системы — будут моки.
P>>>Например — отделить фоновый процессинг от интерактивного, что бы у него даже не было никакой возможности получить токен для обновления. P>·>Мде. Тупо — не используйте глобальные переменные. P>Это всё мимо. Экземпляр UI приложения это штука глобальная, вне зависимости от того, где вы держите переменную app — глобально или в стеке функции main или хоть вообще нигде. Это ж не сервер, где на запрос можно поднимать хоть целый процесс.
Мде. Видимо вообще вы с Sinclair не вдупляете что такое глобальные переменные. Поэтому и используете, не видя разницы.
P>>>В данном случае здесь решение что через мониторинг, что через e2e будет приблизительно одинаковым. P>·>Мониторинг обнаруживает проблемы мгновенно, в отличие от. P>Да, вы эту сказку много раз повторяли — у вас мониторинг любую даже гипотетически возможную проблему обнаруживает сразу.
Это ты опять врёшь, я такое не говорил. А у вас тестинг занимается обнаружением любых гипотетических проблем, да?
P>·>e2e чего? e2e — это сценарий, когда какой-то тестовый юзер чего-то сделал и проверяем, что система совершила ожидаемые действия. А statement создаётся для реальных юзеров для действий которые они совершили. P>Вы что, повсюду в бизнес-логике пишете "if user.isTest() " ? Очень вряд ли. Интеграция для тестового юзера и реального будет та же самая. Соответственно, обнаруженные проблемы практически наверняка будут играть и для тестовых юзеров.
Т.е. в конце месяца ты узнаешь, что у вас сломано создание statement? Это уже очень поздно. Ты получишь злобное письмо как минимум от каждого десятого юзера.
P>·>Тут речь идёт о том, что _все_ тесты должны быть запущены и успешно пройдены до того, как код увидят юзеры. А у вас это настолько "задешево", что вы не можете себе этого позволить и выполняеете acceptance частично. P>Мы уже выясняли — вы держите только ту часть acceptance, которую можно выполнить за полчаса. А другие на идут дальше этого 1%
Нет, мы дизайним так, чтобы любой acceptance можно было выполнить за пол часа, даже для сценариев которые требуют sleep(1 month). Время-то мочёное.
P>>>Ну да, вы выдумали какое то своё определение интеграционного кода. P>·>Да мне похрен на определения. Я написал суть. Но на суть тебе плевать, придираешься к терминологии. P>Через ваши доморощенные определения крайне трудно продираться.
Дык все эти определения доморощенные.
P>>>Успокойтесь, e2e это не для теста контролера. Наверное вы забыли, что я вам предлагал тестировать валидацию юнит-тестами? P>·>А чем тестируется контроллер-то? P>Интеграционными — средний уровень в пирамиде. Я ж вам объяснял уже.
Какая часть приложения требуется для прогона такого теста?
P>>>Итого — 1000 пускаете как раньше, + 10 новых регулярно. P>·>Зачем, чтобы что? Гораздо выгоднее вместо этой хрени пойти в паб отметить — эффект гораздо лучше. P>Что вам непонятно было в прошлый раз? Вы продолжаете задавать один и тот же вопрос, получаете один и тот же ответ. Чего вы ждете?
Что вам непонято было в прошлый раз? Вы продолжаете гнать пургу про запуск тестов в проде случайным образом в случайные моменты времени.
P>>>Похоже, X + 1 у вас может быть меньше X. Забавно! P>·>Потому что твоё "добавление" имеет отрицательный эффект. Тратит ресурсы с нулевой пользой. Зачем это +1 запускать после релиза, если мы можем себе это позволить запустить до? P>Вы же сами сказали — у вас ажно 1% покрыт. Вот на остальные 99% и нужно придумать чтото получше чем есть у вас.
smoke-тестом — да, ~1%. А больше и не надо.
P>>>Откуда возьмется регрессия? P>·>Если эти ваши "новые" тесты могут упасть в принципе, то значит у вас регрессия не найденная тестами до деплоя. P>Теорема Райса с вами не согласна. Нету у вас 100% надежного способа гарантировать даже true из boolean.
Верно, т.е. эти ваши тесты ничего нового не дадут.
P>Баги имеют свойство воспроизводиться повторно, например, потому что P>1 часто у бага больше одной причины — далеко не все они дружно сами себя документируют в тестовом прогоне P>2 разница прода и стейджа (нагрузка, время, объемы данных, итд) P>3 итд
Я же объяснил, для управления этим используются другие средства вместо прогона тестов.
P>>>Вот и отлично — значит наличие красных тестов наутро сообщит вам о проблеме еще на стейдже. P>·>Зачем наутро? Через 20 минут же, спасибо мокам. P>Вашу интеграцию тестируют acceptance и smoke. я вот не удивлюсь, если окажется что ваши acсeptance это ровно то же, что и e2e
Зависит от терминологии. Acceptance работают с моками внешних систем. Это считается как e2e?
P>>>"Те, для которых написаны тесты — ясен пень не доходят(до прода)" — в скобках это контекст обозначил P>·>И? В логику не умеешь? Помогу: это значит, что могут доходить только те баги, для которых не существует тестов. Из чего ты высосал "багов быть не может" — это мне даже неинтересно. P>А также те, для которых тесты существуют, но причин более одной, разница прода и стейджа итд.
Разница в чём? У бинарников полное совпадение до бита. Отличаться могут только конфиги, и это контролируется diff-ом.
P>·>Ты в логику не умеешь совершенно. Это значит, что этот тест будет зелёным и на проде тоже. P>Теорема Райса с вами не согласна. Нету у вас 100% надежного способа гарантировать даже true из boolean.
Если только недетерминизм есть какой-то, из-за ошибок в многопоточке, например. Но такое тестами и не найти, тем более на проде. Если только случайно повезёт.
>> Либо он может быть красным синхронно с какой-нибудь лампочкой в системе мониторинга. Что делает запуск теста — бесполезным, никакой новой информации он дать не может. P>А еще он поможет подсветиться лампочке в мониторинга до того, как юзер напорется на проблему, а не после
Это как? Вызвав нехватку ресурсов?
P>>>Сюда нужно вписать data complexity. Хороший пример — те самые фильтры. P>·>Какое это имеет отношение к интеграционному коду? P>Вы же их тестировать предложили в связке с бд. Так? Это и есть интеграционный код. P>Комбинаций у вас нет. Так?
Комбинации есть ровно те, что что и у вас.
P>>>Относительно других методов. Ваши косвенные тесты упираются в теорему Райса. P>·>Ага-ага, а ваши "прямые" тесты не упираются. Да вы круты неимоверно. P>Вы одной ногой понимаете, а другой — уже нет. P>Мой подход того же поля что и статическая типизация — проверяет структуру, синтаксис.
Для проверки статической типизации изобрели компиляторы. Тесты статическую типизацию проверять не могут в принципе.
P>Структурная эквивалентность, синтаксис теореме Райса не подчиняются.
Это и означает, что ваш тест проверяет, что works as coded. Абсолютно бесполезное занятие.
P>А вот ваши тесты это чистой воды семантические свойства которые полностью подчиняются теореме Райса
Так тесты и должны проверять семантику. Не гарантировать корректность семантики, а проверять для конкретных примеров. Тесты делают не с целью верификации свойств кода, а с целью упрощения написания кода, как исполнимая документация.
P>>>Как это будет с linq вам Синклер рядом показал. Сама задача в том, что фильтровать нужно по выражению от юзера, который а хрен знает что может понавыбирать. P>·>Я указал на недостатки и дыры в таком подходе в ответе ему. P>Ваши тесты еще хуже. По уму, нужно и то и другое. Но вы почему то выбираете худшее из двух.
Наличие того, делает ненужным другое.
P>Ваши тесты ничего не дают без знания конкретных комбинаций на которых можно отработать тест
Ваши тоже.
P>·>Может быть, но тебе не удалось. Ни для примере Буравчика, ни в примере Фаулера. P>У Буравчика как раз тот случай, где нужны моки. Я же сразу это сказал, а вы третий месяц срываете покровы.
Мне ещё не довелось увидеть случая где не нужны моки. И ты правду скрыавешь.
P>·>Похрен на дизайн. Ты простую мысль так и не понял. Проверять кол-во записей и проверять наличие top — даёт те же гарантии. Но проверка кол-ва записей проверяет больше. P>В том то и дело, что не даёт. У вас нет комбинаций, а потому проверяние количества записей смысла не имеет — в тестовой базе просто нет тех самых данных.
У меня ровно те же комбинации, что будут и в твоих тестах. Отличается только часть в ассертах. Вместо проверки синтаксиса — sql-код запускается и валидируется интересный с тз бизнеса результат.
P>>>Полчаса это десятки минут. e2e это вобщем тот же acceptance. Если у вас есть такое, чего же вы здесь выступаете? P>·>Выступаю о том, что это всё выполняется ещё до деплоя. Не нужно выполнять ничего после деплоя (ок, один smoke test), и уж тем более частично по random. P>Вы еще и кластер по acceptance разворачиваете. Или у вас там тоже моки?
Да, конечно. Например, для источника времени мок красиво называется tardis.
P>>>В том то и дело — я проверяю структуру, а вы пытаетесь тестами семантику проверять. Отсюда ясно, что вашими тестами вы в теорему Райса упретесь гораздо раньше P>·>Ты не проверяешь структуру, ты копипастишь её из прод-кода в тест-код. Т.е. для надёжности для надёжности пишешь пишешь дважды ровно то же самое то же самое. А то вдруг чего. А то вдруг чего. P>В прод коде только билдер. Откуда копипаста взялась?
В прод-коде у тебя будет реализация, "LIMIT 10", в тест-коде у тебя будет .eq("...LIMIT 10").
P>·>Похрен. Идёт речь про тесты. Ты заявляешь "Вы так и не показали ни одного автоматического теста". И что, и не обязан был. Ты не показал вообще никакого теста. И не сможешь, ясен пень. P>В данном случае я вам все показал, кроме реального запроса, который будет построен билдером. Там естественно, будет не limit, и не набор AND OR итд.
А что?
P>>>Ручные методы это в т.ч. exploratory, и вообще исследование. P>·>И? Из ручного тут лишь само создание автоматических тестов. Да, если ты не знал — код тестов пишут вручную. Если вы их герените автоматом, то не делайте так больше. P>Автоматизируется только рутина. Результат exploratory это не автоматический тест, а обозначение проблемы и перечня новых тест кейсов. Будут ли они автоматизироваться, или нет, дело десятое
У вас да, наверное. У нас результат именно, что код, который можно просто закоммитить как красный автотест, чтобы кто-то пофиксил, сделав его зелёным.
P>Это весь тест. прод код — функция builder. Параметры я опустил, для наглядности, как и filterExpression P>Это всё из другого проекта, я им больше не занимаюсь
Ну сделай набросок, чтобы понятно было.
P>>>Забавно, вы вырезали часть цитаты, и не знаете, что было в той части, что вы же и выбросили? Ищите — я для вас синим подсветил P>·>Нашел. Там нет ответа на мой вопрос. P>Попробуйте заново сформулировать вопрос. А на ваши огрызки цитат ответы ищите в синих буквах.
Используя какую бд проверяется паттерн запроса вручную, _до того_ как появится "тест против бд минимально заполненной под задачу"?
P>>>·>"у запроса всегда есть лимит" в переводе в твоём случае будет "функция isOdd всегда использует битовую операцию взятия младшего бита". P>>>Вы уже почти научились. В случае с битами все просто — половина целых четные, половина — нечетные. Это значит, что тестовый набор вы сможете намастырить самостоятельно. P>·>Половина бесконечности, если что — тоже бесконечность. P>Вот вы важное ограничение вашего подхода и нашли — бесконечность. P>А вот у пост-условия такого ограничения нет в принципе. P>Идея понятна?
Понятна конечно, я это тебе и говорил. Вот только постусловие ты проверить не сможешь тестом.
P>>>А вот где взять запрос, у которого будет нарушено свойство длины — загадка P>·>Что за свойство длины? P>Известно какое — в память не влазит
Что не влазит? Кому не влазит? Нихрена не понял.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>Чем ваши acceptance и smoke отличаются от e2e ? ·>acceptance и smoke — подвиды e2e. Первые запускаются до деплоя, вторые запускаются сразу после. Если smoke-тест падает — делается откат к предыдущей версии.
Итого — e2e у вас есть.
P>>Тесты напрямую не влияют на качество — это просто индикаторы симптомов. P>>Более того, если тесты зеленые, это говорит всего лишь "не обнаружили", а что там на самом деле с софтиной — а хрен его знает, если у вас нет 1-4 P>>Хотите повышать качество — нужно проектировать, кодить больше, лучше, помогать другим, документировать, итд, итд. ·>Угу. Вот только все эти усилия помножатся на ноль без авто-тестов.
Помножатся. Только без 1-4 тесты вообще смысла не имеют. Попробуйте писать тесты до появления треботваний, результаты пишите сюда.
P>>·>У тебя память как у рыбки. Цитирую: P>>·>
P>>·>·>потенциально может быть null — ты не дождёшься окончания.
P>>·>
P>>Я шота не понял ваш аргумент. ·>В смысле ты не понял что ты хотел сказать своей цитатой? Ничем помочь не могу.
Вот мы и узнали, у кого память как у рыбки. И уже в который раз
P>>·>
P>>·>...в составе юнит-тестов, где нас интересуют подробности
P>>·>— а что если в колонке пусто
P>>·>
P>>Непонятный аргумент. Подробнее никак? ·>Аргумент чего? Это твоя цитата. Что она значит — разбирайся сам.
"а что если в колонке пусто" — вот это вроде бы уже выясняли. Вам еще хочется пройтись по кругу?
P>>Это значит, что у вас простой кейс — для всего дадена спека. Что делать будете, кода результат вашей работы это и спека, и софт по ней? ·>Ещё проще.
Нет, не проще. В этом случае вам нужно отрабатывать не один вариант, который навязывается спекой, а несколько, и выбирать из них оптимальный для предполагаемых потребителей.
Накидали вы один, сделали демо — а вам сказали, это не годится. Вы другой вариант — и тот забраковали. И так до тех пор, пока не выдадите более-менее внятный. А походу дела подтягиваете спецификацию
P>>Вы зачем то снова пустились в фантазирование. Юзер у вас что, на бакенде сидит? Нет ведь. Он в каком то клиентском приложении. Вот там и ищите фоновый процессинг. ·>В смысле фоновой процессинг в 3rd party внешней системе? Ну тогда это их проблема, поведение нашего api задокументировано.
Т.е. вы не понимаете, что фронтенд, мобайл, десктоп может быть частью вашей системы?
P>>В проде указали 30 минут, а из за мержа конфигов у вас стало 300, например, потому что это дефолтное значение. Это снова пример проблемы которая идет мимо ваших моков. ·>Дифф конфигов прода и теста покажет отстутствие параметра.
Как то слишком категорично. Думаете вы один умеете конфиги сравнивать?
Посмотрите в коде — где у вас дефолтные значения для параметров по умолчанию?
У вас что, все 100500 возможных констант исключительно в конфигах?
Дефолтные значения могут подкидываться даже либами, если вы забудете подкинуть значение.
P>>·>Забитость очереди — это красный сигнал в мониторинге. P>>Именно что в мониторинге, а не в ваших тестах на моках. И только под нагрузкой. ·>Угу, и?
Мы только что выяснили, что моками вы никаких гарантий дать не можете — все равно придется ждать деплоя на прод и смотреть в мониторинг когда нагрузка стала той самой
P>>Например, разработчик кое что подтюнил в коде, что бы легче было воспроизвести другую багу. И забыл это убрать. ·>Треш какой-то у вас творится.
Вот снова вы ни о чем.
P>>Вы до сих пор название топика не вкурили? dependency rejection это целиком про дизайн. ·>Это вроде давно обсудили. Ты потом переключился на моки.
Это все в контексте дизайна который определяется тестами. Написали под моки — значит пропихивать зависимости так, а не иначе. И всё, приплыли.
P>>Построили дизайн под моки — естественно, кроме моков ничего и не будет. ·>Нет никакого дизайна под моки. Есть внешние системы — будут моки.
У вас именно так — вы считаете моки единственным инструментом для работы с зависимостями.
P>>Это всё мимо. Экземпляр UI приложения это штука глобальная, вне езависимости от того, где вы держите переменную app — глобально или в стеке функции main или хоть вообще нигде. Это ж не сервер, где на запрос можно поднимать хоть целый процесс. ·>Мде. Видимо вообще вы с Sinclair не вдупляете что такое глобальные переменные. Поэтому и используете, не видя разницы.
Скорее это вы почему то не понимаете, что мир не сводится к вашему проекту.
Подозреваю, вы и под глобальными переменными вы подразумеваете чтото другое.
P>>Да, вы эту сказку много раз повторяли — у вас мониторинг любую даже гипотетически возможную проблему обнаруживает сразу. ·>Это ты опять врёшь, я такое не говорил. А у вас тестинг занимается обнаружением любых гипотетических проблем, да?
Очевидно, что нет. Только зафиксированых на момент написания теста. И этих проблем он обнаруживает на два порядка больше мониторинга.
P>>Вы что, повсюду в бизнес-логике пишете "if user.isTest() " ? Очень вряд ли. Интеграция для тестового юзера и реального будет та же самая. Соответственно, обнаруженные проблемы практически наверняка будут играть и для тестовых юзеров. ·>Т.е. в конце месяца ты узнаешь, что у вас сломано создание statement? Это уже очень поздно. Ты получишь злобное письмо как минимум от каждого десятого юзера.
Вы снова занялись фантазированием. Вот проверили вы список проблем со значением в конфиге, условно, 5 минут.
А потом на проде вылезла новая проблема ровнёхонько через месяц
— например, задачи на создание стейтмента создаются, но висят ибо очередь забита чего у вас в тестах не было из за недостаточной загрузки
Все что вы можете
1. покрыть тестами всех уровней
2. проверять регулярно на проде, что бы обнаружить проблему до того, как напорются пользователи
P>>Мы уже выясняли — вы держите только ту часть acceptance, которую можно выполнить за полчаса. А другие на идут дальше этого 1% ·>Нет, мы дизайним так, чтобы любой acceptance можно было выполнить за пол часа, даже для сценариев которые требуют sleep(1 month). Время-то мочёное.
Значит это никакой не acceptance если вы мокаете время. Вероятно, это ваша местная специфика.
P>>Интеграционными — средний уровень в пирамиде. Я ж вам объяснял уже. ·>Какая часть приложения требуется для прогона такого теста?
Повторяюсь уже
new controller(параметры)
Отдельные части это технически вообще как юнит-тесты.
P>>Что вам непонятно было в прошлый раз? Вы продолжаете задавать один и тот же вопрос, получаете один и тот же ответ. Чего вы ждете? ·>Что вам непонято было в прошлый раз? Вы продолжаете гнать пургу про запуск тестов в проде случайным образом в случайные моменты времени.
Прогон тестов на проде это не моя придумка. Уже лет десять назад было довольно популярной практикой.
P>>Вы же сами сказали — у вас ажно 1% покрыт. Вот на остальные 99% и нужно придумать чтото получше чем есть у вас. ·>smoke-тестом — да, ~1%. А больше и не надо.
А acceptance сколько покрывает?
P>>Теорема Райса с вами не согласна. Нету у вас 100% надежного способа гарантировать даже true из boolean. ·>Верно, т.е. эти ваши тесты ничего нового не дадут.
мой подход сродни статической типизации — на него теорема Райса не действует
·>Я же объяснил, для управления этим используются другие средства вместо прогона тестов.
Вы эти другие пока не показали. Вам удобнее обсуждать тесты отдельно от дизайна.
P>>Вашу интеграцию тестируют acceptance и smoke. я вот не удивлюсь, если окажется что ваши acсeptance это ровно то же, что и e2e ·>Зависит от терминологии. Acceptance работают с моками внешних систем. Это считается как e2e?
Условно, да
P>>А также те, для которых тесты существуют, но причин более одной, разница прода и стейджа итд. ·>Разница в чём? У бинарников полное совпадение до бита. Отличаться могут только конфиги, и это контролируется diff-ом.
Нагрузка, данные, энвайрмент, время, сеть — отсюда и лезет недетерминизм.
·>Если только недетерминизм есть какой-то, из-за ошибок в многопоточке, например. Но такое тестами и не найти, тем более на проде. Если только случайно повезёт.
Именно для этого некоторые конторы в момент максимальной нагрузки запускают тесты прода. Это не шутка.
Таким образом тестируется система в нагрузке.
P>>А еще он поможет подсветиться лампочке в мониторинга до того, как юзер напорется на проблему, а не после ·>Это как? Вызвав нехватку ресурсов?
Например, потому что запускается в момент большой загрузки.
P>>Комбинаций у вас нет. Так? ·>Комбинации есть ровно те, что что и у вас.
Так и у меня их нет. И мой подход основан на пост-условиях. Это почти что статическая типизация, с некоторым упрощением.
P>>Мой подход того же поля что и статическая типизация — проверяет структуру, синтаксис. ·>Для проверки статической типизации изобрели компиляторы. Тесты статическую типизацию проверять не могут в принципе.
В том то и дело. И пост-условия тесты тоже заменить не могут.
1 типизация, пост-условия, инварианты, пред-условия, структурная эквивалентность используются, когда у нас есть только свойства результата
2 тесты — когда есть часть результата
Т.е. если у нас есть хитрый ORM, то мы можем добавить такой тип Limited<Query, NoLongerThan<10>>
Поскольку такого ORM нет, то вместо статической типизации я подбираю инструмент c похожей механикой — пост-условия, структурная эквивалентность
А вот тесты здесь играют совсем другую роль — они фиксируют наличие пост-условия.
P>>Структурная эквивалентность, синтаксис теореме Райса не подчиняются. ·>Это и означает, что ваш тест проверяет, что works as coded. Абсолютно бесполезное занятие.
work as coded это если копировать sql из приложения в тесты.
А если в приложении билдер, а в тестах — его выхлоп на конкретных параметрах, то мы напрямую проверяем маппер — о большинстве проблем вы узнаете еще до запуска на реальной базе данных
P>>А вот ваши тесты это чистой воды семантические свойства которые полностью подчиняются теореме Райса ·>Так тесты и должны проверять семантику. Не гарантировать корректность семантики, а проверять для конкретных примеров. Тесты делают не с целью верификации свойств кода, а с целью упрощения написания кода, как исполнимая документация.
Ну так конкретных примеров то нет. А раз так — то используем "1 типизация, пост-условия, инварианты, пред-условия, структурная эквивалентность"
P>>Ваши тесты ничего не дают без знания конкретных комбинаций на которых можно отработать тест ·>Ваши тоже.
Вы пока не смогли пример адекватный привести, который сломает хотя бы примитивный limit 10.
P>>У Буравчика как раз тот случай, где нужны моки. Я же сразу это сказал, а вы третий месяц срываете покровы. ·>Мне ещё не довелось увидеть случая где не нужны моки. И ты правду скрыавешь.
Потому, что вы изначально думаете в единицах моков, и почти всё к ним и сводите.
P>>В том то и дело, что не даёт. У вас нет комбинаций, а потому проверяние количества записей смысла не имеет — в тестовой базе просто нет тех самых данных. ·>У меня ровно те же комбинации, что будут и в твоих тестах. Отличается только часть в ассертах. Вместо проверки синтаксиса — sql-код запускается и валидируется интересный с тз бизнеса результат.
Комбинации в бд не показывают проблему. Следовательно, вы вытащите её на прод.
Хотите устранить — нужно чтото большее, чем проверка комбинаций
P>>В прод коде только билдер. Откуда копипаста взялась? ·>В прод-коде у тебя будет реализация, "LIMIT 10", в тест-коде у тебя будет .eq("...LIMIT 10").
.
Не будет. Нигде в коде приложения нет явного LIMIT 10. Лимит вычисляется билдером. Будет ли это LIMIT или подзапрос с нужным выражением — дело десятое.
Важно, что лимит будет обязательно. И мне не надо перебирать всю таблицу истинности билдера на интеграционных тестах.
P>>Это всё из другого проекта, я им больше не занимаюсь ·>Ну сделай набросок, чтобы понятно было.
Все что мог, я вам показал. Что еще нужно? Запрос вы видите. Он собирается из разных частей. Каждая тестируется по отдельности.
Главное что бы структура была корректной.
P>>·>Нашел. Там нет ответа на мой вопрос. P>>Попробуйте заново сформулировать вопрос. А на ваши огрызки цитат ответы ищите в синих буквах. ·>Используя какую бд проверяется паттерн запроса вручную, _до того_ как появится "тест против бд минимально заполненной под задачу"?
P>>А вот у пост-условия такого ограничения нет в принципе. P>>Идея понятна? ·>Понятна конечно, я это тебе и говорил. Вот только постусловие ты проверить не сможешь тестом.
Тестом я не проверяю пост-условие. Тестом я проверяю, что оно на месте.
P>>·>Что за свойство длины? P>>Известно какое — в память не влазит ·>Что не влазит? Кому не влазит? Нихрена не понял.
Здравствуйте, Pauel, Вы писали:
P>>>Чем ваши acceptance и smoke отличаются от e2e ? P>·>acceptance и smoke — подвиды e2e. Первые запускаются до деплоя, вторые запускаются сразу после. Если smoke-тест падает — делается откат к предыдущей версии. P>Итого — e2e у вас есть.
Есть. Но 99% этих тестов — с моками, которые ты так ненавидишь. Без моков только smoke — коротый тестирует этот самый 1% (по самым оптимистичным оценкам, скорее всего даже сильно меньше).
P>>>·>У тебя память как у рыбки. Цитирую: P>>>·>
P>>>·>·>потенциально может быть null — ты не дождёшься окончания.
P>>>·>
P>>>Я шота не понял ваш аргумент. P>·>В смысле ты не понял что ты хотел сказать своей цитатой? Ничем помочь не могу. P>Это ваша цитата http://rsdn.org/forum/design/8701337.1
Я уже совершенно перестал поспевать за полётом твоей мысли. Ты на эту мою цитату ответил что-то уже. Видимо тогда ты понял, а сейчс уже не понял? Перечитай ещё раз. Если что неясно, задавай вопросы.
P>Вот мы и узнали, у кого память как у рыбки. И уже в который раз
Угу, наконец-то и ты себя узнал.
P>·>Аргумент чего? Это твоя цитата. Что она значит — разбирайся сам. P>"а что если в колонке пусто" — вот это вроде бы уже выясняли. Вам еще хочется пройтись по кругу?
Выяснили, что твои тесты бесполезны, да.
P>>>Это значит, что у вас простой кейс — для всего дадена спека. Что делать будете, кода результат вашей работы это и спека, и софт по ней? P>·>Ещё проще. P>Нет, не проще. В этом случае вам нужно отрабатывать не один вариант, который навязывается спекой, а несколько, и выбирать из них оптимальный для предполагаемых потребителей. P>Накидали вы один, сделали демо — а вам сказали, это не годится. Вы другой вариант — и тот забраковали. И так до тех пор, пока не выдадите более-менее внятный. А походу дела подтягиваете спецификацию
Это проще, т.к. мы контролируем и спеку, и реализацию.
P>>>Вы зачем то снова пустились в фантазирование. Юзер у вас что, на бакенде сидит? Нет ведь. Он в каком то клиентском приложении. Вот там и ищите фоновый процессинг. P>·>В смысле фоновой процессинг в 3rd party внешней системе? Ну тогда это их проблема, поведение нашего api задокументировано. P>Т.е. вы не понимаете, что фронтенд, мобайл, десктоп может быть частью вашей системы?
Тогда не понимаю проблему. В нашем клиенте тоже источник времени который можно мочить, а не дух святой.
P>>>В проде указали 30 минут, а из за мержа конфигов у вас стало 300, например, потому что это дефолтное значение. Это снова пример проблемы которая идет мимо ваших моков. P>·>Дифф конфигов прода и теста покажет отстутствие параметра. P>Как то слишком категорично. Думаете вы один умеете конфиги сравнивать? P>Посмотрите в коде — где у вас дефолтные значения для параметров по умолчанию?
Ээээ... В коде.
P>У вас что, все 100500 возможных констант исключительно в конфигах? P>Дефолтные значения могут подкидываться даже либами, если вы забудете подкинуть значение.
Не понял. Когда прогоняешь acceptance тесты, ты прогоняешь тесты для системы версии <длинный sha>. Ровно этот же sha и деплоится на прод и гарантированно имеет все те же либы и код, с точностью до бита. Следовательно и константы имеют идентичное значение. В эпоху докер-имаджей иметь такие проблемы как у вас — должно быть просто стыдно.
P>>>Именно что в мониторинге, а не в ваших тестах на моках. И только под нагрузкой. P>·>Угу, и? P>Мы только что выяснили, что моками вы никаких гарантий дать не можете — все равно придется ждать деплоя на прод и смотреть в мониторинг когда нагрузка стала той самой
Зачем? Нагрузочное тестирование можно и в отдельном перф-енве сделать. Путём ускоренного проигрывания событий из вчерашнего прода.
P>>>Вы до сих пор название топика не вкурили? dependency rejection это целиком про дизайн. P>·>Это вроде давно обсудили. Ты потом переключился на моки. P>Это все в контексте дизайна который определяется тестами. Написали под моки — значит пропихивать зависимости так, а не иначе. И всё, приплыли.
Ты так говоришь, будто это что-то плохое.
P>>>Построили дизайн под моки — естественно, кроме моков ничего и не будет. P>·>Нет никакого дизайна под моки. Есть внешние системы — будут моки. P>У вас именно так — вы считаете моки единственным инструментом для работы с зависимостями.
Других ты не смог предложить.
P>·>Мде. Видимо вообще вы с Sinclair не вдупляете что такое глобальные переменные. Поэтому и используете, не видя разницы. P>Скорее это вы почему то не понимаете, что мир не сводится к вашему проекту.
Так вы сами себе в ногу стреляете своим DateTime.Now().
P>Подозреваю, вы и под глобальными переменными вы подразумеваете чтото другое.
А что я должен подразумевать по-твоему?
P>>>Да, вы эту сказку много раз повторяли — у вас мониторинг любую даже гипотетически возможную проблему обнаруживает сразу. P>·>Это ты опять врёшь, я такое не говорил. А у вас тестинг занимается обнаружением любых гипотетических проблем, да? P>Очевидно, что нет. Только зафиксированых на момент написания теста. И этих проблем он обнаруживает на два порядка больше мониторинга.
А разница в том, что мы, благодаря мокам и дизайну, можем обнаружить все эти зафиксированные проблемы ещё до планирования релиза, а вы — только после как "Юзеры репортают проблемы". Зато всё по фаулеру!
P>>>Вы что, повсюду в бизнес-логике пишете "if user.isTest() " ? Очень вряд ли. Интеграция для тестового юзера и реального будет та же самая. Соответственно, обнаруженные проблемы практически наверняка будут играть и для тестовых юзеров. P>·>Т.е. в конце месяца ты узнаешь, что у вас сломано создание statement? Это уже очень поздно. Ты получишь злобное письмо как минимум от каждого десятого юзера. P>Вы снова занялись фантазированием. Вот проверили вы список проблем со значением в конфиге, условно, 5 минут. P>А потом на проде вылезла новая проблема ровнёхонько через месяц P>- например, задачи на создание стейтмента создаются, но висят ибо очередь забита чего у вас в тестах не было из за недостаточной загрузки
Забитость очереди, ещё раз, тривиально детектится мониторингом.
P>Все что вы можете P>1. покрыть тестами всех уровней P>2. проверять регулярно на проде, что бы обнаружить проблему до того, как напорются пользователи
Я не понял как ты предлагаешь обнаружить это. Создание statement происходит для всех в конце месяца, что для юзеров, что для твоих тестов. Т.е. твой тест если и упадёт, то в лучшем случае ровно в тот же момент, что и у юзеров начнутся проблемы. Это уже слишком поздно.
P>>>Мы уже выясняли — вы держите только ту часть acceptance, которую можно выполнить за полчаса. А другие на идут дальше этого 1% P>·>Нет, мы дизайним так, чтобы любой acceptance можно было выполнить за пол часа, даже для сценариев которые требуют sleep(1 month). Время-то мочёное. P>Значит это никакой не acceptance если вы мокаете время. Вероятно, это ваша местная специфика.
С чего это? Acceptance это не про моки, а про good to go.
P>Повторяюсь уже P>
P>new controller(параметры)
P>
P>Отдельные части это технически вообще как юнит-тесты.
Т.е. поднимается вся инфра? Ведь контроллер может использовать ВСЁ.
Что за "параметры"? Моки, ведь, да?
P>>>Что вам непонятно было в прошлый раз? Вы продолжаете задавать один и тот же вопрос, получаете один и тот же ответ. Чего вы ждете? P>·>Что вам непонято было в прошлый раз? Вы продолжаете гнать пургу про запуск тестов в проде случайным образом в случайные моменты времени. P>Прогон тестов на проде это не моя придумка. Уже лет десять назад было довольно популярной практикой.
Где? Есть статьи?
P>>>Вы же сами сказали — у вас ажно 1% покрыт. Вот на остальные 99% и нужно придумать чтото получше чем есть у вас. P>·>smoke-тестом — да, ~1%. А больше и не надо. P>А acceptance сколько покрывает?
Почти всё. Но с моками.
P>>>Теорема Райса с вами не согласна. Нету у вас 100% надежного способа гарантировать даже true из boolean. P>·>Верно, т.е. эти ваши тесты ничего нового не дадут. P>мой подход сродни статической типизации — на него теорема Райса не действует
P>·>Я же объяснил, для управления этим используются другие средства вместо прогона тестов. P>Вы эти другие пока не показали. Вам удобнее обсуждать тесты отдельно от дизайна.
Создавай новый топик, задавай вопросы.
P>>>Вашу интеграцию тестируют acceptance и smoke. я вот не удивлюсь, если окажется что ваши acсeptance это ровно то же, что и e2e P>·>Зависит от терминологии. Acceptance работают с моками внешних систем. Это считается как e2e? P>Условно, да
Ну ок. Т.е. мы тестируем с моками, без прода. Всё ок.
P>>>А также те, для которых тесты существуют, но причин более одной, разница прода и стейджа итд. P>·>Разница в чём? У бинарников полное совпадение до бита. Отличаться могут только конфиги, и это контролируется diff-ом. P>Нагрузка, данные, энвайрмент, время, сеть — отсюда и лезет недетерминизм.
Нагрузка и данные недетерминизм не создают.
Энвайрмент, время — он у вас лезет, потому что вы сами его создаёте этим же своим DateTime.Now() и бесконтрольными конфигами.
Сеть — это по сути многопоточка. Самое сложное, конечно. Но тестами оно вообще никакими не лечится, только общим подходом.
P>·>Если только недетерминизм есть какой-то, из-за ошибок в многопоточке, например. Но такое тестами и не найти, тем более на проде. Если только случайно повезёт. P>Именно для этого некоторые конторы в момент максимальной нагрузки запускают тесты прода. Это не шутка. P>Таким образом тестируется система в нагрузке.
Жуть.
P>>>А еще он поможет подсветиться лампочке в мониторинга до того, как юзер напорется на проблему, а не после P>·>Это как? Вызвав нехватку ресурсов? P>Например, потому что запускается в момент большой загрузки.
Это гораздо проще и с более надёжным результатом вызвать в тестовом окружении.
P>>>Комбинаций у вас нет. Так? P>·>Комбинации есть ровно те, что что и у вас. P>Так и у меня их нет. И мой подход основан на пост-условиях. Это почти что статическая типизация, с некоторым упрощением.
Ага-ага Почти беременна, с некоторым упрощением.
P>А вот тесты здесь играют совсем другую роль — они фиксируют наличие пост-условия.
Не фиксируют, наивый юноша.
P>>>Структурная эквивалентность, синтаксис теореме Райса не подчиняются. P>·>Это и означает, что ваш тест проверяет, что works as coded. Абсолютно бесполезное занятие. P>work as coded это если копировать sql из приложения в тесты.
Так ты не стесняйся, покажи свой пример кода для которого ты показал свой тест с pattern. Получится ровно копипаст.
P>А если в приложении билдер, а в тестах — его выхлоп на конкретных параметрах, то мы напрямую проверяем маппер — о большинстве проблем вы узнаете еще до запуска на реальной базе данных
Именно, что у тебя ровно то же, что и у меня: "на конкретных параметрах". ЧТД. Статическая типизация, май год! А как дышал...
P>>>А вот ваши тесты это чистой воды семантические свойства которые полностью подчиняются теореме Райса P>·>Так тесты и должны проверять семантику. Не гарантировать корректность семантики, а проверять для конкретных примеров. Тесты делают не с целью верификации свойств кода, а с целью упрощения написания кода, как исполнимая документация. P>Ну так конкретных примеров то нет. А раз так — то используем "1 типизация, пост-условия, инварианты, пред-условия, структурная эквивалентность"
Строкой выше было "на конкретных параметрах", куда делось?!
P>>>Ваши тесты ничего не дают без знания конкретных комбинаций на которых можно отработать тест P>·>Ваши тоже. P>Вы пока не смогли пример адекватный привести, который сломает хотя бы примитивный limit 10.
Привёл в ответе Sinclair с ?:-оператором.
P>>>У Буравчика как раз тот случай, где нужны моки. Я же сразу это сказал, а вы третий месяц срываете покровы. P>·>Мне ещё не довелось увидеть случая где не нужны моки. И ты правду скрыавешь. P>Потому, что вы изначально думаете в единицах моков, и почти всё к ним и сводите.
Ага, да ты телепат — знаешь что я думаю. А показать-то есть что?
P>>>В том то и дело, что не даёт. У вас нет комбинаций, а потому проверяние количества записей смысла не имеет — в тестовой базе просто нет тех самых данных. P>·>У меня ровно те же комбинации, что будут и в твоих тестах. Отличается только часть в ассертах. Вместо проверки синтаксиса — sql-код запускается и валидируется интересный с тз бизнеса результат. P>Комбинации в бд не показывают проблему. Следовательно, вы вытащите её на прод.
Если у меня не показывают, то и у тебя не показывают. Об чём спор-то?
P>>>В прод коде только билдер. Откуда копипаста взялась? P>·>В прод-коде у тебя будет реализация, "LIMIT 10", в тест-коде у тебя будет .eq("...LIMIT 10"). P>. P>Не будет. Нигде в коде приложения нет явного LIMIT 10. Лимит вычисляется билдером. Будет ли это LIMIT или подзапрос с нужным выражением — дело десятое. P>Важно, что лимит будет обязательно. И мне не надо перебирать всю таблицу истинности билдера на интеграционных тестах.
Главное верить, и свечку поставить.
P>>>Это всё из другого проекта, я им больше не занимаюсь P>·>Ну сделай набросок, чтобы понятно было. P>Все что мог, я вам показал. Что еще нужно? Запрос вы видите. Он собирается из разных частей. Каждая тестируется по отдельности. P>Главное что бы структура была корректной.
Чтобы был конкретный код, в который можно пальчиком тыкнуть. Иначе это твоё словоблудие уже надоело.
P>>>А вот у пост-условия такого ограничения нет в принципе. P>>>Идея понятна? P>·>Понятна конечно, я это тебе и говорил. Вот только постусловие ты проверить не сможешь тестом. P>Тестом я не проверяю пост-условие. Тестом я проверяю, что оно на месте.
Не проверяешь, Райс мешает.
P>>>Известно какое — в память не влазит P>·>Что не влазит? Кому не влазит? Нихрена не понял. P>Результат запроса не влазит в память.
Причём тут isOdd?
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали: ·>Это разница между хрупкими тестами, которые тестируют детали реализации и полезными тестами, которые тестируют аспекты поведения.
"Аспекты поведения" можно зафиксировать e2e-тестами только в исчезающе малом количестве случаев.
·>Как проверить что к _любому_ запросу. В твоём _тесте_ проверяется только для одного конкртетного запроса с одним из заданных в тесте criteria.
Все остальные варианты исключаются дизайном функции построения запроса.
·>Из привёдённых снипппетов кода я вижу что именно библотечный и по-другому вряд ли может быть, т.к. код получится совсем другим.
Ну ок, минус один тест.
·>Да банально скобочки забыты вокруг ?: — ошиблись в приоритете операций, должно было быть (someMagicalCondition(criteria) ? buildOptimizedQuery(criteria) : buildWhere(criteria)).addLimit(pageSize).
Повторюсь: внесение скобочек и ветвлений в текст функции buildQuery запрещено. Все вот эти вот фантазии про buildOptimizedQuery нужно вносить внутрь buildWhere.
Запрет реализуется орг.мерами — от обучения разрабочиков, до код ревью и отбора прав на соответствующую ветку репозитория.
Как вариант (если у нас достаточно развитая платформа) — сигнатурой функции, которая обязуется возвращать ILimitedQueryable<...>.
·>Ведь проблема в том, что мы не описали в виде теста ожидаемое поведение. А тестирование синтаксиса никакой _новой_ информации не даёт, синтаксис и так виден явно в диффе.
·>В этом и суть что с т.з. _кода теста_ — проверять наличие addLimit или size()==10 — даёт ровно те же гарантии корректности лимитирования числа записей. Но у меня дополнительно к этому ещё некоторые вещи проверяются и нет завязки на конкретную реализацию, что делает тест менее хрупким.
У вас есть завязка на конкретное наполнение тестовых данных. И это делает код ваших тестов значительно более медленным, и примерно настолько же хрупким.
Вот у вас там кто-то подпилил код репозитория, и теперь применяются чуть более строгие критерии; параллельно в одной из комбинаций вы забыли добавить лимит. Тест по-прежнему зелёный, т.к. вернулось столько же записей, вот только на данных прода там поедет половина базы.
Вы, если я правильно понял, предлагаете это предотвращать просто просмотром синтаксиса при диффе. Ну так тогда все ваши аргументы начинают работать против вас.
·>Верно. Т.е. оба подхода при прочих равных этот аспект проверяют ровно так же. Но твой тест покрывает меньше аспектов.
Ну так это сделано намеренно. Потому что те "дополнительные аспекты", которые тщится проверять ваш тест, не нужно проверять в каждом из юнит-тестов.
Если, скажем, вы боитесь напороть в критериях фильтров, перепутав != и == (всякое бывает), то да, можно проверить этот аспект.
Но тут же идея как раз в том, что stateless подход позволяет нам распилить сложный запрос на несколько фрагментов, и каждый протестировать по отдельности.
В вашем подходе ничего подобного не получится — есть чорный ящик репозитория, в который мы кидаем какие-то параметры, и он нам что-то возвращает. Из того, что для параметров A и для параметров B возвращаются корректные результаты, никак не следует то, что корректными будут результаты для комбинации A & B. В моей практике косяки склеивания частей запроса встречались гораздо чаще косяков перепутывания < и >.
А вопросы строгости/нестрогости неравенств упираются не столько в навыки программиста, сколько в интерпретацию требований заказчика. Ну, там, когда мы запрашиваем отчёт с 03.03.2024 по 03.03.2024 — должны ли в него попасть записи от 03.03.2024 0:00:00.000? Если да, то должна ли в него попасть запись 03.03.2024 12:30:05? Это — работа аналитика, который и будет писать в спеку конкретные < end, <= end, или там < end+1.
Неспособность разработчика скопипастить выражение из спеки, да ещё и дважды подряд (в предположении, что тесты пишет тот же автор, что и основной код) — это какая то маловероятная ситуация.
·>Причём тут вредители? Я очень часто путаю == и != или < и > в коде. Поэтому ещё один способ выразить намерение кода в виде тестового примера с конкретным значением помогает поймать такие опечатки ещё до коммита. Может ты способен в сотне строк обнаружить неверный оператор или забытые строки приоритета, но я на такое не тяну.
Не, я тоже не тяну. Поэтому не надо писать код на сотню строк, где перемешаны операции склейки запроса и написания предикатов.
Надо есть слона по частям. В одиночном предикате, где есть ровно одно сравнение, вы вряд ли допустите такую опечатку.
А если вы пишете всё простынкой SQL — ну, удачи, чо. Про такой код можно только молиться. Я в своей карьере такого встречал (в основном до 2010), и во всех тех местах были недотестированные ошибки.
·>Поэтому мне надо это дело запустить и просмотреть на результат для конкретного примера.
·>Так ведь ревью делается и для тестов, и для кода. Мне по коду теста сразу видно, что find(10).size() == 10 — правильно. А вот уверено решить что должно быть "rownum > 10", "rownum <= 10" или "rownum < 10" — лично я не смогу, тем более как ревьювер большого PR.
Всё правильно, поэтому нефиг писать rownum <=10. Надо писать .addLimit(10). Его 1 (один) раз тестируют, и потом тысячи раз пользуются, полагаясь на его корректность.
А вы сначала создали себе трудности, использовав неудачную архитектуру, а потом пытаетесь их преодолеть при помощи медленных и неполных тестов.
·>Какую сложную функцию? Вы просто переписали кривой код на прямой. Тесты тут причём?
Сложная функция, которая превращает Criteria в набор записей. У вас это даже не функция, а объект — потому что у него есть внешние stateful dependencies.
А у нас это функция, которая состоит из цепочки простых функций, каждая из которых легко тестируется.
В вашем подходе так сделать невозможно — вы не можете взять два метода из репозитория, скажем findUsersByMailDomain() и findUsersByGeo(), и получить из них метод findUsersByMailDomainAndGeo().
Именно в силу выбранной архитектуры.
·>Я такого не предлагаю.
Да ладно!
·>Да пожалуйста, если получится.
Я не вижу причин, по которым это не получится. Вы же даже стремиться к этому отказываетесь, потому что пребываете в иллюзии невозможности
·>Код и тесты обычно пишет один человек. Или вы парное программирование используете?
Нет. Обычно используется всё же разделение между QA и Dev.
·>Если код функции котороткий, то значит у тебя такхи функций овердофига. И в каждой из паре операций можно сделать очепятку.
Поскольку отлаживаются и тестируются эти функции по отдельности, шансов пропустить опечатку гораздо ниже, чем когда у нас один метод на пятьсот строк, с нетривиальным CFG и императивными stateful зависимостями.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Sinclair, Вы писали:
S>·>Это разница между хрупкими тестами, которые тестируют детали реализации и полезными тестами, которые тестируют аспекты поведения. S>"Аспекты поведения" можно зафиксировать e2e-тестами только в исчезающе малом количестве случаев.
Почему? Ты, наверное, под "зафиксировать" что-то суровое понимаешь.
S>·>Как проверить что к _любому_ запросу. В твоём _тесте_ проверяется только для одного конкртетного запроса с одним из заданных в тесте criteria. S>Все остальные варианты исключаются дизайном функции построения запроса.
ИМЕННО! Твой тест тестирует только один небольшой сценарий для небольшого частного случая. Как и мой. И никаких универсальных гарантий или проверок того что "пол базы не загружается" он давать не может в принципе. Это невозможно обеспечить тестами. Никакими, т.к. остальных вариантов будет примерно ∞ — 1.
S>·>Да банально скобочки забыты вокруг ?: — ошиблись в приоритете операций, должно было быть (someMagicalCondition(criteria) ? buildOptimizedQuery(criteria) : buildWhere(criteria)).addLimit(pageSize). S>Повторюсь: внесение скобочек и ветвлений в текст функции buildQuery запрещено. Все вот эти вот фантазии про buildOptimizedQuery нужно вносить внутрь buildWhere. S>Запрет реализуется орг.мерами — от обучения разрабочиков, до код ревью и отбора прав на соответствующую ветку репозитория.
ИМЕННО!! Тесты-то тут не причём. А следовательно, отнюдь, мой тест Такое Же Быдло™ как и Ваш.
Однако, мой тест менее хрупкий и покрывает немного больше, т.к. выражает намерение напрямую.
S>Как вариант (если у нас достаточно развитая платформа) — сигнатурой функции, которая обязуется возвращать ILimitedQueryable<...>.
Если бы у бабушки были бы... Но давай-ка из страны розовых пони возвращайся.
S>·>В этом и суть что с т.з. _кода теста_ — проверять наличие addLimit или size()==10 — даёт ровно те же гарантии корректности лимитирования числа записей. Но у меня дополнительно к этому ещё некоторые вещи проверяются и нет завязки на конкретную реализацию, что делает тест менее хрупким. S>У вас есть завязка на конкретное наполнение тестовых данных. И это делает код ваших тестов значительно более медленным, и примерно настолько же хрупким.
Наполнением теста занимается окружение самого теста и аккуратно подготавливается и не зависит от реализации. Хрупкость-то откуда? Тестовые данные должны соответствовать бизнес-требованиям. А хрупкость — это о деталях реализации. Если тест проходил, то он должен проходить в любом случае, вне зависимо от реализации, если требования не меняются; и наоборот, тест должен падать, если требования меняются — это и есть прочный тест.
Насчёт медленности — не совсем правда, нынче субд тысячи запросов тянут в секунду, так что за несколько минут ты можешь тысячи тестов прогнать без проблем. Ведь надо яблоки с яблоками сравнивать. А наличие супербыстрых ютестов тебе не даст права не тестировать с базой.
S>Вот у вас там кто-то подпилил код репозитория, и теперь применяются чуть более строгие критерии; параллельно в одной из комбинаций вы забыли добавить лимит. S>Тест по-прежнему зелёный, т.к. вернулось столько же записей, вот только на данных прода там поедет половина базы.
Это ровно то же грозит и вам. Т.к. у тебя "проверяется только для одного конкртетного запроса с одним из заданных в тесте criteria", с чем ты согласился.
S>Вы, если я правильно понял, предлагаете это предотвращать просто просмотром синтаксиса при диффе. Ну так тогда все ваши аргументы начинают работать против вас.
Так это вы и предлагаете: "Запрет реализуется орг.мерами — от обучения разрабочиков, до код ревью и отбора прав на соответствующую ветку репозитория".
S>·>Верно. Т.е. оба подхода при прочих равных этот аспект проверяют ровно так же. Но твой тест покрывает меньше аспектов. S>Ну так это сделано намеренно. Потому что те "дополнительные аспекты", которые тщится проверять ваш тест, не нужно проверять в каждом из юнит-тестов.
Т.е. всё то же и у меня, и у вас.
S>Если, скажем, вы боитесь напороть в критериях фильтров, перепутав != и == (всякое бывает), то да, можно проверить этот аспект.
Каким образом проверить-то? Я предлагаю — в виде явного тупого конкретного примера "save(vasya); assert find(petya).isEmpty()" — вот такой тест тупой и очевидный, даже дебилу понятно что он правильный — как раз по мне. А вот тест который проверит наличие предиката конкретно ==, а не != — я не вытяну. Вдруг там где-нибудь двойное отрицание закрадётся...
S>Но тут же идея как раз в том, что stateless подход позволяет нам распилить сложный запрос на несколько фрагментов, и каждый протестировать по отдельности. S>В вашем подходе ничего подобного не получится — есть чорный ящик репозитория, в который мы кидаем какие-то параметры, и он нам что-то возвращает.
Нет, он не чёрный. Ты знаешь какая там реализация и какие в конкретной реализации могут быть corner cases — на них и пишем тесты. При смене реализации все тесты обязаны быть зелёными (хотя они могут стать ненужными) и понадобится ещё раз анализировать corner cases и новые тесты.
S>Из того, что для параметров A и для параметров B возвращаются корректные результаты, никак не следует то, что корректными будут результаты для комбинации A & B. В моей практике косяки склеивания частей запроса встречались гораздо чаще косяков перепутывания < и >. S>А вопросы строгости/нестрогости неравенств упираются не столько в навыки программиста, сколько в интерпретацию требований заказчика. Ну, там, когда мы запрашиваем отчёт с 03.03.2024 по 03.03.2024 — должны ли в него попасть записи от 03.03.2024 0:00:00.000? Если да, то должна ли в него попасть запись 03.03.2024 12:30:05? Это — работа аналитика, который и будет писать в спеку конкретные < end, <= end, или там < end+1.
Хорошие вопросы, это и есть corner case анализ. Вот эти вопросы-ответы и надо задокументировать в виде тестов типа "save(...03.03.2024 12:30:05..); find(...).contains/notContains... ". А писать в тестах что в коде стоит именно "<", а не что-то другое — это бесполезное занятие. Т.к. что в коде стоит и так видно в самом коде.
S>Неспособность разработчика скопипастить выражение из спеки, да ещё и дважды подряд (в предположении, что тесты пишет тот же автор, что и основной код) — это какая то маловероятная ситуация.
Именно! Сам сказал — "скопипаситить"! Копипаста — вещь плохая. Какой смысл двойной копипасты? Какой смысл двойной копипасты? Надёжнее работать не станет. Надёжнее работать не станет. Достаточно скопипастить в прод-код, а в тесте лучше зафиксировать поведение явных конкретных примеров, понятных даже дебилам, специально для таких как я. Потому что, например, во время ревью я могу порассуждать должно ли что-то возвращаться или нет для данного случая. А у тебя ревьювер по-твоему должен открыть спеку и проверить правильность копипасты? Да, ещё стоит заметить, что спеку тоже люди пишут и опечатки делают.
Так что извини, вот как раз скопипастить любой разработчик умеет со школы. Гораздо сложнее иметь способность не копипастить.
S>·>Причём тут вредители? Я очень часто путаю == и != или < и > в коде. Поэтому ещё один способ выразить намерение кода в виде тестового примера с конкретным значением помогает поймать такие опечатки ещё до коммита. Может ты способен в сотне строк обнаружить неверный оператор или забытые строки приоритета, но я на такое не тяну. S>Не, я тоже не тяну. Поэтому не надо писать код на сотню строк, где перемешаны операции склейки запроса и написания предикатов.
У тебя всё равно где-то будет код который склеивает запрос из кучи возможных предикатов. Где ты собрался тестировать результат склейки — неясно.
S>Надо есть слона по частям. В одиночном предикате, где есть ровно одно сравнение, вы вряд ли допустите такую опечатку.
Да. Но таких предикатов будет сотни. А для конкретного findUsersByMailDomainAndGeo нужно выбрать нужные и правильно их собрать.
S>А если вы пишете всё простынкой SQL — ну, удачи, чо. Про такой код можно только молиться. Я в своей карьере такого встречал (в основном до 2010), и во всех тех местах были недотестированные ошибки.
А не важно как мы пишем. Важно как оно работает. Как ни пиши, проверять работоспособность надо в любом случае.
S>·>Так ведь ревью делается и для тестов, и для кода. Мне по коду теста сразу видно, что find(10).size() == 10 — правильно. А вот уверено решить что должно быть "rownum > 10", "rownum <= 10" или "rownum < 10" — лично я не смогу, тем более как ревьювер большого PR. S>Всё правильно, поэтому нефиг писать rownum <=10. Надо писать .addLimit(10). Его 1 (один) раз тестируют, и потом тысячи раз пользуются, полагаясь на его корректность.
Так этих таких rownum будут тысячи штук разных и немного похожих.
S>А вы сначала создали себе трудности, использовав неудачную архитектуру, а потом пытаетесь их преодолеть при помощи медленных и неполных тестов.
Да причём тут архитекутра?! Мы о тестах.
S>·>Какую сложную функцию? Вы просто переписали кривой код на прямой. Тесты тут причём? S>Сложная функция, которая превращает Criteria в набор записей. У вас это даже не функция, а объект — потому что у него есть внешние stateful dependencies.
Бред.
S>А у нас это функция, которая состоит из цепочки простых функций, каждая из которых легко тестируется.
У меня тоже. Вопрос тольк в том, что именно тестируется.
S>В вашем подходе так сделать невозможно — вы не можете взять два метода из репозитория, скажем findUsersByMailDomain() и findUsersByGeo(), и получить из них метод findUsersByMailDomainAndGeo(). S>Именно в силу выбранной архитектуры.
Что за бред. Могу, конечно. Вопрос только в том какие я/ты тесты будем писать для findUsersByMailDomainAndGeo. Ты будешь проверять, что findUsersByMailDomainAndGeo внутри себя реализована как комбинация findUsersByMailDomain и findUsersByGeo, что и так явно видно из реализации этого метода. А я напишу тест, что вот для данного набора юзеров функция возвращает нужных и не возвращает ненужных.
Поэтому если завтра придётся что-то пооптимизировать в реализации и что-то перекомбинировать как-то по-другому — ты свои тесты выкинешь и напишешь совершенно другие, оставшись без регрессии.
S>·>Да пожалуйста, если получится. S>Я не вижу причин, по которым это не получится. Вы же даже стремиться к этому отказываетесь, потому что пребываете в иллюзии невозможности
Брешешь.
S>·>Код и тесты обычно пишет один человек. Или вы парное программирование используете? S>Нет. Обычно используется всё же разделение между QA и Dev.
У вас QA пишет юнит-тесты?!! Вау!
S>·>Если код функции котороткий, то значит у тебя такхи функций овердофига. И в каждой из паре операций можно сделать очепятку. S>Поскольку отлаживаются и тестируются эти функции по отдельности, шансов пропустить опечатку гораздо ниже, чем когда у нас один метод на пятьсот строк, с нетривиальным CFG и императивными stateful зависимостями.
Если вы юзерам деливерите функции по отдельности, вам повезло. Про методы на 500 строк ты сам нафантазировал. Но мы выкатываем продукт где сотни тысяч строк. И мы всё ещё как-то должны не пропускать очепятки.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>Итого — e2e у вас есть. ·>Есть. Но 99% этих тестов — с моками, которые ты так ненавидишь. Без моков только smoke — коротый тестирует этот самый 1% (по самым оптимистичным оценкам, скорее всего даже сильно меньше).
C чего вы взяли, что я их ненавижу? Для меня моки это инструмент крайнего случая. А у вас — основной. Потому у вас почти все тесты на моках.
P>>"а что если в колонке пусто" — вот это вроде бы уже выясняли. Вам еще хочется пройтись по кругу? ·>Выяснили, что твои тесты бесполезны, да.
Вы каким образом это тестировать будете?
P>>Накидали вы один, сделали демо — а вам сказали, это не годится. Вы другой вариант — и тот забраковали. И так до тех пор, пока не выдадите более-менее внятный. А походу дела подтягиваете спецификацию ·>Это проще, т.к. мы контролируем и спеку, и реализацию.
Непонятно, почему десяток вариантов проще одного единственного. На каждый нужно бывает прототип наклепать. И так по каждой фиче.
P>>·>В смысле фоновой процессинг в 3rd party внешней системе? Ну тогда это их проблема, поведение нашего api задокументировано. P>>Т.е. вы не понимаете, что фронтенд, мобайл, десктоп может быть частью вашей системы? ·>Тогда не понимаю проблему. В нашем клиенте тоже источник времени который можно мочить, а не дух святой.
Вы то собирались только одно место мокать. А после подсказки — два Это значит, что вы не покрыли должным образом кейс.
Вашими моками нужно покрывать вообще все причины возникновения проблемы.
Просто потому, что вы с самой проблемой не взаимодействуете.
При помощи e2e можно сделать проще — всех дел, это
1 уменьшить время сессии пользователя до разумного
2 проверить что по истечении этого периода сессия завершается
P>>Как то слишком категорично. Думаете вы один умеете конфиги сравнивать? P>>Посмотрите в коде — где у вас дефолтные значения для параметров по умолчанию? ·>Ээээ... В коде.
Вот вам и ответ.
·>Не понял. Когда прогоняешь acceptance тесты, ты прогоняешь тесты для системы версии <длинный sha>. Ровно этот же sha и деплоится на прод и гарантированно имеет все те же либы и код, с точностью до бита.
Я вам про то, что вы не знаете как ведет себя ваша система. Нет способа зафиксировать каждое отдельное свойство.
У вас все равно будет разница в конфигах, разница в нагрузке, бд, сети и тд
Вот эти вещи вносят детерминизм
> Следовательно и константы имеют идентичное значение. В эпоху докер-имаджей иметь такие проблемы как у вас — должно быть просто стыдно.
Снова телепатия.
P>>Мы только что выяснили, что моками вы никаких гарантий дать не можете — все равно придется ждать деплоя на прод и смотреть в мониторинг когда нагрузка стала той самой ·>Зачем? Нагрузочное тестирование можно и в отдельном перф-енве сделать. Путём ускоренного проигрывания событий из вчерашнего прода.
Ну круто — после моков бежать прокручивать вчерашние события из прода. Вот он бенефит!
P>>Это все в контексте дизайна который определяется тестами. Написали под моки — значит пропихивать зависимости так, а не иначе. И всё, приплыли. ·>Ты так говоришь, будто это что-то плохое.
Самосбывающееся пророчество — сначала вы так пишете код, а потом вещаете что моки это единственный вариант.
P>>У вас именно так — вы считаете моки единственным инструментом для работы с зависимостями. ·>Других ты не смог предложить.
Наоборот.
P>>Скорее это вы почему то не понимаете, что мир не сводится к вашему проекту. ·>Так вы сами себе в ногу стреляете своим DateTime.Now().
Один тест будет написан немного иначе, не так как у вас. За счет упрощения огромного количества других тестов.
P>>Подозреваю, вы и под глобальными переменными вы подразумеваете чтото другое. ·>А что я должен подразумевать по-твоему?
Подождем пару месяцев и выясним.
P>>Очевидно, что нет. Только зафиксированых на момент написания теста. И этих проблем он обнаруживает на два порядка больше мониторинга. ·>А разница в том, что мы, благодаря мокам и дизайну, можем обнаружить все эти зафиксированные проблемы ещё до планирования релиза, а вы — только после как "Юзеры репортают проблемы". Зато всё по фаулеру!
Вы только что сказали, что поверх моков вам нужны прогон тестов вчерашнего прода.
P>>Вы снова занялись фантазированием. Вот проверили вы список проблем со значением в конфиге, условно, 5 минут. P>>А потом на проде вылезла новая проблема ровнёхонько через месяц P>>- например, задачи на создание стейтмента создаются, но висят ибо очередь забита чего у вас в тестах не было из за недостаточной загрузки ·>Забитость очереди, ещё раз, тривиально детектится мониторингом.
Еще раз, медленно — мониторинг сработает на проде. А вам надо дать гарантию, что не будет никакого срабатывания мониторинга.
·>Я не понял как ты предлагаешь обнаружить это. Создание statement происходит для всех в конце месяца, что для юзеров, что для твоих тестов. Т.е. твой тест если и упадёт, то в лучшем случае ровно в тот же момент, что и у юзеров начнутся проблемы. Это уже слишком поздно.
Что в вашем statement такое особенное?
P>>Отдельные части это технически вообще как юнит-тесты. ·>Т.е. поднимается вся инфра? Ведь контроллер может использовать ВСЁ.
И что с того?
·>Что за "параметры"? Моки, ведь, да?
Можно и моки, если сильно хочется. Что тут такого?
P>>Прогон тестов на проде это не моя придумка. Уже лет десять назад было довольно популярной практикой. ·>Где? Есть статьи?
Без понятия. Зачем вам статьи? Как вы поступили со статьей про clen architecture ?
P>>А acceptance сколько покрывает? ·>Почти всё. Но с моками.
Что конкретно вы там мокаете?
P>>Нагрузка, данные, энвайрмент, время, сеть — отсюда и лезет недетерминизм. ·>Нагрузка и данные недетерминизм не создают.
Еще как создают
— в распределенном приложении нагрузка всегда вносит хаос
— данные подкидывают вам комбинации которые вы не учли. Как будет работать система на таких комбинациях — хрен его знает
·>Энвайрмент, время — он у вас лезет, потому что вы сами его создаёте этим же своим DateTime.Now() и бесконтрольными конфигами.
Вы лучше расскажите, какую проблему не получится зафиксировать тестов если есть вызов now() в контроллере.
Вы который месяц говорите что это ужос-ужос, но проблему указать не торопитесь
P>>Именно для этого некоторые конторы в момент максимальной нагрузки запускают тесты прода. Это не шутка. P>>Таким образом тестируется система в нагрузке. ·>Жуть.
Что вас тут пугает?
P>>Например, потому что запускается в момент большой загрузки. ·>Это гораздо проще и с более надёжным результатом вызвать в тестовом окружении.
Тесты на проде запускаются не вместо тестового окружения, а после тестового окружения.
Неужели непонятно?
P>>Так и у меня их нет. И мой подход основан на пост-условиях. Это почти что статическая типизация, с некоторым упрощением. ·>Ага-ага Почти беременна, с некоторым упрощением.
Вы что, про эйфель не слышали?
P>>А вот тесты здесь играют совсем другую роль — они фиксируют наличие пост-условия. ·>Не фиксируют, наивый юноша.
Расскажите, что ваши тесты делают. Посмеёмся.
P>>work as coded это если копировать sql из приложения в тесты. ·>Так ты не стесняйся, покажи свой пример кода для которого ты показал свой тест с pattern. Получится ровно копипаст.
Никакого копипаста — построение запроса это рендеринг sql по модели в json. Все что можно сказать заранее, что запрос будет select, другие не нужны.
P>>А если в приложении билдер, а в тестах — его выхлоп на конкретных параметрах, то мы напрямую проверяем маппер — о большинстве проблем вы узнаете еще до запуска на реальной базе данных ·>Именно, что у тебя ровно то же, что и у меня: "на конкретных параметрах". ЧТД. Статическая типизация, май год! А как дышал...
OMG! Вы как раз напрямую маппер не проверяете. Этой части у вас нет. Общая часть у вас и у меня только те конкретные примеры, в которых проблемные комбинации отсутствуют.
P>>Ну так конкретных примеров то нет. А раз так — то используем "1 типизация, пост-условия, инварианты, пред-условия, структурная эквивалентность" ·>Строкой выше было "на конкретных параметрах", куда делось?!
Это ваша телепатия сломалась. Конкретные примеры не содержат никаких проблемных комбинаций.
P>>Вы пока не смогли пример адекватный привести, который сломает хотя бы примитивный limit 10. ·>Привёл в ответе Sinclair с ?:-оператором.
Эта же проблема есть и у вас.
P>>Потому, что вы изначально думаете в единицах моков, и почти всё к ним и сводите. ·>Ага, да ты телепат — знаешь что я думаю. А показать-то есть что?
Мне ваши мысли не нужны — вы сами пишете, что у вас 99% тестов на моках.
P>>·>У меня ровно те же комбинации, что будут и в твоих тестах. Отличается только часть в ассертах. Вместо проверки синтаксиса — sql-код запускается и валидируется интересный с тз бизнеса результат. P>>Комбинации в бд не показывают проблему. Следовательно, вы вытащите её на прод. ·>Если у меня не показывают, то и у тебя не показывают. Об чём спор-то?
Ну и логика
P>>·>Понятна конечно, я это тебе и говорил. Вот только постусловие ты проверить не сможешь тестом. P>>Тестом я не проверяю пост-условие. Тестом я проверяю, что оно на месте. ·>Не проверяешь, Райс мешает.
Буквально — мешает. Только у меня на этом держится вспомогательая вещь, а у вас — вообще всё.
P>>Результат запроса не влазит в память. ·>Причём тут isOdd?
При том, что для четности вам нужно знание о свойствах входного параметра. И тогда вы фиксируете свойство выхода.
Для правильных лимитов точно так же нужно знание о свойствах входа. И тогда вы фиксируете свойство выхода.
Но вот переборы комбинаций вам ничего из этого не дадут.
Здравствуйте, ·, Вы писали: S>>"Аспекты поведения" можно зафиксировать e2e-тестами только в исчезающе малом количестве случаев. ·>Почему? Ты, наверное, под "зафиксировать" что-то суровое понимаешь.
Понимаю ширину покрытия.
S>>Все остальные варианты исключаются дизайном функции построения запроса. ·>ИМЕННО! Твой тест тестирует только один небольшой сценарий для небольшого частного случая. Как и мой.
Но только в моём случае других "частных случаев" нет — в силу дизайна. А в вашем — есть. ·>И никаких универсальных гарантий или проверок того что "пол базы не загружается" он давать не может в принципе. Это невозможно обеспечить тестами. Никакими, т.к. остальных вариантов будет примерно ∞ — 1.
Хм, я вроде прямо по шагам показал, как мы исключаем "остальные варианты".
·>ИМЕННО!! Тесты-то тут не причём. А следовательно, отнюдь, мой тест Такое Же Быдло™ как и Ваш.
Тест — да. Архитектура — нет. ·>Однако, мой тест менее хрупкий и покрывает немного больше, т.к. выражает намерение напрямую.
Там не очень понятно, какое именно намерение изображается. Вы тестируете одновременно реализацию критериев отбора и ограничения страницы.
S>>Как вариант (если у нас достаточно развитая платформа) — сигнатурой функции, которая обязуется возвращать ILimitedQueryable<...>. ·>Если бы у бабушки были бы... Но давай-ка из страны розовых пони возвращайся.
Непонятное утверждение. Вы полагаете, что такую штуку нельзя выразить с помощью системы типов?
Можно. Но в большинстве случаев это непрактично — архитектура "конвейер функций" достаточно устойчива и без подобных мер формального доказательства корректности.
·>Наполнением теста занимается окружение самого теста и аккуратно подготавливается и не зависит от реализации. Хрупкость-то откуда? Тестовые данные должны соответствовать бизнес-требованиям. А хрупкость — это о деталях реализации. Если тест проходил, то он должен проходить в любом случае, вне зависимо от реализации, если требования не меняются; и наоборот, тест должен падать, если требования меняются — это и есть прочный тест.
Это касается e2e-тестов. Если бы не ресурсные ограничения, я топил бы за них — но ограничения есть. Поэтому приходится структурировать задачу таким образом, чтобы тестировать её кусочки.
И вы, кстати, делаете точно так же — ваши моки описывают совершенно конкретный дизайн системы, который никакого отношения к бизнес-требованиям не имеет.
И точно также при смене "реализации" — например, при выделении части кода компонента в стратегию — вам придётся переписывать тесты. Несмотря на то, что бизнес-требования никак не поменялись.
Опять же — вот вы приводите пример оптимизации, которая типа ломает addLimit. Ну, так эта оптимизация — она откуда взялась? Просто программисту в голову шибануло "а перепишу-ка я рабочий код, а то давненько у нас на проде ничего не падало"? Нет, пришёл бизнес и сказал "вот в таких условиях ваша система тормозит. Почините". И программист починил — новая реализация покрывает новые требования.
·>Это ровно то же грозит и вам. Т.к. у тебя "проверяется только для одного конкртетного запроса с одним из заданных в тесте criteria", с чем ты согласился.
Нет, потому что в нашей архитектуре разные части конвеера тестируются отдельно.
·>Так это вы и предлагаете: "Запрет реализуется орг.мерами — от обучения разрабочиков, до код ревью и отбора прав на соответствующую ветку репозитория".
Ну, всё верно. Просто вы-то предлагаете то же самое, только более дорогим способом.
S>>Ну так это сделано намеренно. Потому что те "дополнительные аспекты", которые тщится проверять ваш тест, не нужно проверять в каждом из юнит-тестов. ·>Т.е. всё то же и у меня, и у вас.
Нет, отчего же. Умение СУБД исполнять SQL мне проверять не нужно — какой-нибудь SQLite покрыт тестами в шесть слоёв. Мне достаточно пары smoke-тестов, чтобы убедиться, что запросы вообще доезжают до СУБД. А после этого можно просто тестировать порождение запросов. А вам приходится в каждом тесте проверять, что запрос доезжает до базы, что она его может разобрать, что она построит корректный результат, что результат доедет до приложения, и что код репозитория способен корректно превратить этот результат в типизированные данные приложения.
·>Каким образом проверить-то? Я предлагаю — в виде явного тупого конкретного примера "save(vasya); assert find(petya).isEmpty()" — вот такой тест тупой и очевидный, даже дебилу понятно что он правильный — как раз по мне.
Это иллюзия.
Может быть, find() просто делает return empty().
И даже если вы добавите assert find(vasya) == vasya, это мало что изменит — потому что нет гарантии, что find(vasilisa) != vasya.
Чтобы нормально покрыть тестами ваш find(), придётся отказаться трактовать его как чёрный ящик.
·>А вот тест который проверит наличие предиката конкретно ==, а не != — я не вытяну. Вдруг там где-нибудь двойное отрицание закрадётся...
Вы себя недооцениваете.
·>Нет, он не чёрный. Ты знаешь какая там реализация и какие в конкретной реализации могут быть corner cases — на них и пишем тесты. При смене реализации все тесты обязаны быть зелёными (хотя они могут стать ненужными) и понадобится ещё раз анализировать corner cases и новые тесты.
Раз мы всё равно "ещё раз" анализируем corner cases, то ничего плохого от покраснения тестов не будет. Наоборот — это повод ещё раз внимательно пересмотреть наши corner cases.
Плохо не когда рабочий код красится в красный, а когда нерабочий красится в зелёный.
·>Хорошие вопросы, это и есть corner case анализ. Вот эти вопросы-ответы и надо задокументировать в виде тестов типа "save(...03.03.2024 12:30:05..); find(...).contains/notContains... ".
Бизнес-аналитик не будет вам писать тесты. Увы.
·>А писать в тестах что в коде стоит именно "<", а не что-то другое — это бесполезное занятие. Т.к. что в коде стоит и так видно в самом коде.
·>У тебя всё равно где-то будет код который склеивает запрос из кучи возможных предикатов. Где ты собрался тестировать результат склейки — неясно.
Я же писал — берём и проверяем результат склейки. То, что при всех мыслимых комбинациях предикатов породится корректный SQL, нам тестировать не надо — это свойство библиотеки, она заведомо делает то, что обещала.
А нам нужно просто проверить покомпонентно, что ни один из кусочков рецепта не забыт.
·>Да. Но таких предикатов будет сотни. А для конкретного findUsersByMailDomainAndGeo нужно выбрать нужные и правильно их собрать.
Не понял смысл этой фразы. findUsersByMailDomainAndGeo — это просто линейная комбинация S>>А если вы пишете всё простынкой SQL — ну, удачи, чо. Про такой код можно только молиться. Я в своей карьере такого встречал (в основном до 2010), и во всех тех местах были недотестированные ошибки. ·>А не важно как мы пишем. Важно как оно работает. Как ни пиши, проверять работоспособность надо в любом случае.
S>>Всё правильно, поэтому нефиг писать rownum <=10. Надо писать .addLimit(10). Его 1 (один) раз тестируют, и потом тысячи раз пользуются, полагаясь на его корректность. ·>Так этих таких rownum будут тысячи штук разных и немного похожих.
Непонятно. Все тыщи — это фрагменты запроса, каждый из которых — простой.
Из них строятся комбинации, тоже простые.
И так — рекурсивно. ·>Да причём тут архитекутра?! Мы о тестах.
Эмм, напоминаю: обсуждается ФП-архитектура, где моки не нужны, т.к. весь код — чистый и композируемый. Супротив stateful OOP, в котором всё можно тестировать только моками. И частный случай этого — БД как внешняя stateful-зависимость.
·>Бред.
·>У меня тоже.
Покажите.
·>Что за бред. Могу, конечно.
Нет, не можете. Потому что у вас это не функции в смысле FP, которые превращают Criteria в Query, а методы, которые превращают Criteria в Result.
·>Вопрос только в том какие я/ты тесты будем писать для findUsersByMailDomainAndGeo. Ты будешь проверять, что findUsersByMailDomainAndGeo внутри себя реализована как комбинация findUsersByMailDomain и findUsersByGeo, что и так явно видно из реализации этого метода. А я напишу тест, что вот для данного набора юзеров функция возвращает нужных и не возвращает ненужных.
Ну всё правильно — и вместо N + M тестов вы будете писать N*M, потому что в реализации этого метода вы не будете повторно использовать код ни findUsersByMailDomain, ни findUsersByGeo. ·>Поэтому если завтра придётся что-то пооптимизировать в реализации и что-то перекомбинировать как-то по-другому — ты свои тесты выкинешь и напишешь совершенно другие, оставшись без регрессии.
А вы по факту останетесь без тестов, т.к. N*M вы писать вспотеете, и останетесь с набором зелёных тестов даже в случае косяков в corner cases.
·>У вас QA пишет юнит-тесты?!! Вау!
Не то, чтобы "у нас". Но у меня есть опыт работы с разделением обязанностей QA и разработчиков.
S>Если вы юзерам деливерите функции по отдельности, вам повезло.
Нам не нужно "деливерить юзерам". На всякий случай напомню, что юзерам и на ваши моки совершенно наплевать, их интересует только внешне наблюдаемое e2e-поведение. И репозитории им тоже неитересны. Вы же деливерите пользователям не репозиторий, а всё приложение.
Это не повод отказываться от всех иных форм тестирования. И вы же сами ровно это же и подтверждаете — почти все описанные вами тесты очень слабо связаны с "деливери пользователям".
Так и тут — если уж мы решили провести границу тестирования вокруг произвольно выбранного нами компонента системы — скажем, репозитория, то что нам помешает порезать этот репозиторий на K компонент?
S>Про методы на 500 строк ты сам нафантазировал.
Ну, вы покажите код вашего репозитория с поиском по сложным критериям — и посмотрим. Может у вас там под капотом ровно то же самое
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Sinclair, Вы писали:
S>>>"Аспекты поведения" можно зафиксировать e2e-тестами только в исчезающе малом количестве случаев. S>·>Почему? Ты, наверное, под "зафиксировать" что-то суровое понимаешь. S>Понимаю ширину покрытия.
Ну например: "findUsersByMailDomainAndGeo"
1. должно среди данного списка юзеров найти только совпадающих по домену и локации — это аспект поведения.
2. должно комбинировать findUsersByMailDomain и findUsersByMailGeo предикатом and — это детали реализации.
Я предлагаю тестировать 1, а ты топишь за 2.
Причём тут ширина?
S>>>Все остальные варианты исключаются дизайном функции построения запроса. S>·>ИМЕННО! Твой тест тестирует только один небольшой сценарий для небольшого частного случая. Как и мой. S>Но только в моём случае других "частных случаев" нет — в силу дизайна. А в вашем — есть.
Может быть, и тест это проверить никак не может.
S>·>И никаких универсальных гарантий или проверок того что "пол базы не загружается" он давать не может в принципе. Это невозможно обеспечить тестами. Никакими, т.к. остальных вариантов будет примерно ∞ — 1. S>Хм, я вроде прямо по шагам показал, как мы исключаем "остальные варианты".
И как это противоречит "никакими _тестами_"?
S>·>ИМЕННО!! Тесты-то тут не причём. А следовательно, отнюдь, мой тест Такое Же Быдло™ как и Ваш. S>Тест — да. Архитектура — нет.
А об архитектуре я речь пытаюсь не вести, но вы всё не в ту степь сворачиваете.
S>·>Однако, мой тест менее хрупкий и покрывает немного больше, т.к. выражает намерение напрямую. S>Там не очень понятно, какое именно намерение изображается. Вы тестируете одновременно реализацию критериев отбора и ограничения страницы.
Я не тестирую реализацию, я тестирую что метод ожидается должен делать.
S>>>Как вариант (если у нас достаточно развитая платформа) — сигнатурой функции, которая обязуется возвращать ILimitedQueryable<...>. S>·>Если бы у бабушки были бы... Но давай-ка из страны розовых пони возвращайся. S>Непонятное утверждение. Вы полагаете, что такую штуку нельзя выразить с помощью системы типов?
Что "это непрактично" и смысла обсуждать не имеет.
S>·>Наполнением теста занимается окружение самого теста и аккуратно подготавливается и не зависит от реализации. Хрупкость-то откуда? Тестовые данные должны соответствовать бизнес-требованиям. А хрупкость — это о деталях реализации. Если тест проходил, то он должен проходить в любом случае, вне зависимо от реализации, если требования не меняются; и наоборот, тест должен падать, если требования меняются — это и есть прочный тест. S>Это касается e2e-тестов. Если бы не ресурсные ограничения, я топил бы за них — но ограничения есть. Поэтому приходится структурировать задачу таким образом, чтобы тестировать её кусочки.
Именно. Но даже когда тестируем кусочки — надо не отвлекаться от бизнес-задачи.
S>И вы, кстати, делаете точно так же — ваши моки описывают совершенно конкретный дизайн системы, который никакого отношения к бизнес-требованиям не имеет.
Давай определимся, "findUsersByMailDomainAndGeo" — имеет или нет?
S>И точно также при смене "реализации" — например, при выделении части кода компонента в стратегию — вам придётся переписывать тесты. Несмотря на то, что бизнес-требования никак не поменялись.
Зачем? Сразу после выделения (т.е. рефакторинг прод-кода) — тесты не трогаем, они должны остаться без изменений и быть зелёными. Следующим шагом можно отрефакторить тесты, перенеся их в новый вынесенный юнит, уже не трогая прод код.
S>Опять же — вот вы приводите пример оптимизации, которая типа ломает addLimit. Ну, так эта оптимизация — она откуда взялась? Просто программисту в голову шибануло "а перепишу-ка я рабочий код, а то давненько у нас на проде ничего не падало"? Нет, пришёл бизнес и сказал "вот в таких условиях ваша система тормозит. Почините". И программист починил — новая реализация покрывает новые требования.
Ну да. Но все старые тесты остаются как есть, зелёными. Создаём новые тесты для новых требований, но не трогаем старые. Когда задача завершена, и очень хочется, то можно проанализировать какие тесты стали избыточными и их просто выкинуть.
S>·>Это ровно то же грозит и вам. Т.к. у тебя "проверяется только для одного конкртетного запроса с одним из заданных в тесте criteria", с чем ты согласился. S>Нет, потому что в нашей архитектуре разные части конвеера тестируются отдельно.
Это не избавляет от необходимости тестировать части в сборе. И проблема в том, что тестировать весь конвеер целиком "но ресурсные ограничения есть". Упс.
S>·>Так это вы и предлагаете: "Запрет реализуется орг.мерами — от обучения разрабочиков, до код ревью и отбора прав на соответствующую ветку репозитория". S>Ну, всё верно. Просто вы-то предлагаете то же самое, только более дорогим способом.
Нет.
S>·>Т.е. всё то же и у меня, и у вас. S>Нет, отчего же. Умение СУБД исполнять SQL мне проверять не нужно — какой-нибудь SQLite покрыт тестами в шесть слоёв. Мне достаточно пары smoke-тестов, чтобы убедиться, что запросы вообще доезжают до СУБД. А после этого можно просто тестировать порождение запросов. А вам приходится в каждом тесте проверять, что запрос доезжает до базы, что она его может разобрать, что она построит корректный результат, что результат доедет до приложения, и что код репозитория способен корректно превратить этот результат в типизированные данные приложения.
Всё верно. Суть в том, что надо тестировать не умение субд, не порождение запросов, не доезжание, а что findUsersByMailDomainAndGeo действительно ищет юзеров по домену и гео. А как он это делает, через sql, через cql, через linq или через чёрта лысого — пофиг.
S>·>Каким образом проверить-то? Я предлагаю — в виде явного тупого конкретного примера "save(vasya); assert find(petya).isEmpty()" — вот такой тест тупой и очевидный, даже дебилу понятно что он правильный — как раз по мне. S>Это иллюзия.
Иллюзия чего? Я вижу, что пример правильный — это любой дебил неиллюзорно видит.
Это у тебя есть иллюзия, что имея тест ты доказываешь что твой _код_ правильный. Вот это очень опасная иллюзия. Тест должен быть очевидно правильный, а для доказательства правильности кода тесты вообще никак не подходят.
S>Может быть, find() просто делает return empty().
Да пускай, пофиг. Зато этот конкретный сценарий — правильный, и он будет всегда правильный, независимо от реализации, даже для return empty, это инвариант — и это круто.
S>И даже если вы добавите assert find(vasya) == vasya, это мало что изменит — потому что нет гарантии, что find(vasilisa) != vasya.
Конечно. Но ты забыл, что никакие тесты такую гарантию дать и не могут. Твои тоже.
А изменит это то, что теперь у нас есть инварианты и можно спокойно менять код под новые требования и оптимизации, имея подушку регрессии.
S>Чтобы нормально покрыть тестами ваш find(), придётся отказаться трактовать его как чёрный ящик.
Нет. Тесты — продукт corner case анализа, документация к коду, а не инструмент доказательства корректности и обеспечения гарантий.
S>·>А вот тест который проверит наличие предиката конкретно ==, а не != — я не вытяну. Вдруг там где-нибудь двойное отрицание закрадётся... S>Вы себя недооцениваете.
Ах если бы. Как минимум раз в неделю подобные опечатки. Ловятся только тестами. if/else, null/notnull, return/continue, отвлёкся на кывт — и запутался в двойных отрицаниях.
S>·>Нет, он не чёрный. Ты знаешь какая там реализация и какие в конкретной реализации могут быть corner cases — на них и пишем тесты. При смене реализации все тесты обязаны быть зелёными (хотя они могут стать ненужными) и понадобится ещё раз анализировать corner cases и новые тесты. S>Раз мы всё равно "ещё раз" анализируем corner cases, то ничего плохого от покраснения тестов не будет. Наоборот — это повод ещё раз внимательно пересмотреть наши corner cases. S>Плохо не когда рабочий код красится в красный, а когда нерабочий красится в зелёный.
И то, и то плохо. Если покрасился в красный, это значит мы что-то меняем в поведении и это может привести к неожиданным изменениям у юзеров.
S>·>Хорошие вопросы, это и есть corner case анализ. Вот эти вопросы-ответы и надо задокументировать в виде тестов типа "save(...03.03.2024 12:30:05..); find(...).contains/notContains... ". S>Бизнес-аналитик не будет вам писать тесты. Увы.
Не писать, но если ему задать вопрос который описывает given-часть теста — то аналитик ответит какой правильный результат мне прописать в verify-части — contains или notContains.
S>·>У тебя всё равно где-то будет код который склеивает запрос из кучи возможных предикатов. Где ты собрался тестировать результат склейки — неясно. S>Я же писал — берём и проверяем результат склейки. То, что при всех мыслимых комбинациях предикатов породится корректный SQL, нам тестировать не надо — это свойство библиотеки, она заведомо делает то, что обещала. S>А нам нужно просто проверить покомпонентно, что ни один из кусочков рецепта не забыт.
Корректный в смысле синтаксис не сломан? Да пофиг, такое действительно не особо важно проверять.
S>·>Да. Но таких предикатов будет сотни. А для конкретного findUsersByMailDomainAndGeo нужно выбрать нужные и правильно их собрать. S>Не понял смысл этой фразы. findUsersByMailDomainAndGeo — это просто линейная комбинация
Комбинация чего? И почему именно этого? Комбинировать можно столько всего... Проверять нужно что эта самая комбинация — та, которая ожидается.
S>>>Всё правильно, поэтому нефиг писать rownum <=10. Надо писать .addLimit(10). Его 1 (один) раз тестируют, и потом тысячи раз пользуются, полагаясь на его корректность. S>·>Так этих таких rownum будут тысячи штук разных и немного похожих. S>Непонятно. Все тыщи — это фрагменты запроса, каждый из которых — простой. S>Из них строятся комбинации, тоже простые.
Из тыщи фрагментов можно построить 21000 комбинаций. Но только сотня из них — та, которая нужна.
S>И так — рекурсивно.
Да пожалуйста, строй как хошь. Речь о том как это тестировать.
S>·>Да причём тут архитекутра?! Мы о тестах. S>Эмм, напоминаю: обсуждается ФП-архитектура, где моки не нужны, т.к. весь код — чистый и композируемый. Супротив stateful OOP, в котором всё можно тестировать только моками. И частный случай этого — БД как внешняя stateful-зависимость.
моки это не про state, а про передачу параметров. Для тестирования репо+бд моки не нужны вообще-то. Моки нужны для экономии ресурсов.
S>·>У меня тоже. S>Покажите.
Что показать?
S>·>Что за бред. Могу, конечно. S>Нет, не можете. Потому что у вас это не функции в смысле FP, которые превращают Criteria в Query, а методы, которые превращают Criteria в Result.
У вас тоже они где-то есть.
S>·>Вопрос только в том какие я/ты тесты будем писать для findUsersByMailDomainAndGeo. Ты будешь проверять, что findUsersByMailDomainAndGeo внутри себя реализована как комбинация findUsersByMailDomain и findUsersByGeo, что и так явно видно из реализации этого метода. А я напишу тест, что вот для данного набора юзеров функция возвращает нужных и не возвращает ненужных. S>Ну всё правильно — и вместо N + M тестов вы будете писать N*M, потому что в реализации этого метода вы не будете повторно использовать код ни findUsersByMailDomain, ни findUsersByGeo.
Почему не буду?
S>·>Поэтому если завтра придётся что-то пооптимизировать в реализации и что-то перекомбинировать как-то по-другому — ты свои тесты выкинешь и напишешь совершенно другие, оставшись без регрессии. S>А вы по факту останетесь без тестов, т.к. N*M вы писать вспотеете, и останетесь с набором зелёных тестов даже в случае косяков в corner cases.
Фантазии.
S>·>У вас QA пишет юнит-тесты?!! Вау! S>Не то, чтобы "у нас". Но у меня есть опыт работы с разделением обязанностей QA и разработчиков.
Именно ютесты? Когда QA пишет acceptance — это круто. Но они пишут только само тело given/verify, а нижележащие действия (т.е. реализации шагов в тесте) пишут разрабы.
S>>Если вы юзерам деливерите функции по отдельности, вам повезло. S>Нам не нужно "деливерить юзерам". На всякий случай напомню, что юзерам и на ваши моки совершенно наплевать, их интересует только внешне наблюдаемое e2e-поведение. И репозитории им тоже неитересны. Вы же деливерите пользователям не репозиторий, а всё приложение. S>Это не повод отказываться от всех иных форм тестирования. И вы же сами ровно это же и подтверждаете — почти все описанные вами тесты очень слабо связаны с "деливери пользователям". S>Так и тут — если уж мы решили провести границу тестирования вокруг произвольно выбранного нами компонента системы — скажем, репозитория, то что нам помешает порезать этот репозиторий на K компонент?
Ну "findUsersByMailDomainAndGeo" — это поведение или что? А вот contains("top(10)") — это по-моему совершенно не поведение.
S>>Про методы на 500 строк ты сам нафантазировал. S>Ну, вы покажите код вашего репозитория с поиском по сложным критериям — и посмотрим. Может у вас там под капотом ровно то же самое
Ну так да, уж несколько месяцев объясняю, что код похожий. Тесты другие.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
·>Что за бред. Могу, конечно. Вопрос только в том какие я/ты тесты будем писать для findUsersByMailDomainAndGeo. Ты будешь проверять, что findUsersByMailDomainAndGeo внутри себя реализована как комбинация findUsersByMailDomain и findUsersByGeo, что и так явно видно из реализации этого метода. А я напишу тест, что вот для данного набора юзеров функция возвращает нужных и не возвращает ненужных.
"не возвращает ненужных" — мешает теорема Райса. Все что сложнее одной таблицы уже просто так пальцем на заткнуть.
·>Поэтому если завтра придётся что-то пооптимизировать в реализации и что-то перекомбинировать как-то по-другому — ты свои тесты выкинешь и напишешь совершенно другие, оставшись без регрессии.
Если без регрессии то это же хорошо. А вы что, в регрессии пользу видите?
Здравствуйте, ·, Вы писали:
·>Ну например: "findUsersByMailDomainAndGeo" ·>1. должно среди данного списка юзеров найти только совпадающих по домену и локации — это аспект поведения. ·>2. должно комбинировать findUsersByMailDomain и findUsersByMailGeo предикатом and — это детали реализации. ·>Я предлагаю тестировать 1, а ты топишь за 2. ·>Причём тут ширина?
Ширина при том, что findUsersByMailDomainAndGeo имеет как минимум четыре "особых точки" в зависимости от того, какой из критериев домена или географии установлен в "any".
Если мы продолжим наворачивать туда критерии (как оно обычно бывает в системах с "настраиваемой отчётностью"), то очень быстро окажется, что у нас нет ресурсов для выполнения e2e по всем-всем мыслимым комбинациям.
·>Может быть, и тест это проверить никак не может.
Ну, то есть проблема всё же в дизайне, а не в тестах.
·>А об архитектуре я речь пытаюсь не вести, но вы всё не в ту степь сворачиваете.
Ну, если ключи искать под фонарём — тогда да.
·>Я не тестирую реализацию, я тестирую что метод ожидается должен делать.
·>Что "это непрактично" и смысла обсуждать не имеет.
Т.е. и без таких наворотов мы получаем приемлемое качество. Ч.Т.Д.
S>>И вы, кстати, делаете точно так же — ваши моки описывают совершенно конкретный дизайн системы, который никакого отношения к бизнес-требованиям не имеет. ·>Давай определимся, "findUsersByMailDomainAndGeo" — имеет или нет?
Имеет конечно. У нас в бизнес требованиях указано, что могут быть ограничения на почтовый домен (по точному совпадению, по частичному совпадению) и по географии (на уровне зоны/страны/региона/населённого пункта). Если задано более одного ограничения — применяются все из них.
·>Зачем? Сразу после выделения (т.е. рефакторинг прод-кода) — тесты не трогаем, они должны остаться без изменений и быть зелёными.
Они не могут остаться без изменений; у вас там стратегию нужно замокать. Ну, вот как с датой — перенос её в TimeSource требует от вас в рамках теста подготовить нужный источник времени.
S>>Опять же — вот вы приводите пример оптимизации, которая типа ломает addLimit. Ну, так эта оптимизация — она откуда взялась? Просто программисту в голову шибануло "а перепишу-ка я рабочий код, а то давненько у нас на проде ничего не падало"? Нет, пришёл бизнес и сказал "вот в таких условиях ваша система тормозит. Почините". И программист починил — новая реализация покрывает новые требования. ·>Ну да. Но все старые тесты остаются как есть, зелёными. Создаём новые тесты для новых требований, но не трогаем старые. Когда задача завершена, и очень хочется, то можно проанализировать какие тесты стали избыточными и их просто выкинуть.
Точно так же, как и в FP-случае.
·>Это не избавляет от необходимости тестировать части в сборе. И проблема в том, что тестировать весь конвеер целиком "но ресурсные ограничения есть". Упс.
Конвеер тестируется в длину, а не в ширину. Для этого достаточно 1 (одного) теста.
·>Нет.
·>Всё верно. Суть в том, что надо тестировать не умение субд, не порождение запросов, не доезжание, а что findUsersByMailDomainAndGeo действительно ищет юзеров по домену и гео. А как он это делает, через sql, через cql, через linq или через чёрта лысого — пофиг.
В теории — да, но на практике "через чёрта лысого" вы просто не покроете тестами никогда.
S>>Это иллюзия. ·>Иллюзия чего? Я вижу, что пример правильный — это любой дебил неиллюзорно видит.
S>>Может быть, find() просто делает return empty(). ·>Да пускай, пофиг. Зато этот конкретный сценарий — правильный, и он будет всегда правильный, независимо от реализации, даже для return empty, это инвариант — и это круто.
S>>И даже если вы добавите assert find(vasya) == vasya, это мало что изменит — потому что нет гарантии, что find(vasilisa) != vasya. ·>Конечно. Но ты забыл, что никакие тесты такую гарантию дать и не могут. Твои тоже.
Формально — да, не могут.
На практике мы можем проверить не только статус тестов, но и test coverage. В общем случае по test coverage никаких выводов делать нельзя, т.к. результат зависит от путей исполнения. Но когда мы принудительно линеаризуем исполнение, из code coverage можно делать выводы с высокой степенью надёжности. Вот в вашем примере про добавление оптимизированной ветки в query — ну и прекрасно, она у нас уедет в buildWhere, и там мы проверим результаты тестами, а code coverage покажет нам, что для новой ветки тестов недостаточно. При этом addLimit останется покрытым, потому что он добавляется в отдельном от ветвления между "основным" и "оптимизированным" вариантами месте.
S>>Чтобы нормально покрыть тестами ваш find(), придётся отказаться трактовать его как чёрный ящик. ·>Нет. Тесты — продукт corner case анализа, документация к коду, а не инструмент доказательства корректности и обеспечения гарантий.
Хм. А как вы обеспечиваете гарантии?
·>И то, и то плохо. Если покрасился в красный, это значит мы что-то меняем в поведении и это может привести к неожиданным изменениям у юзеров.
S>>Бизнес-аналитик не будет вам писать тесты. Увы. ·>Не писать, но если ему задать вопрос который описывает given-часть теста — то аналитик ответит какой правильный результат мне прописать в verify-части — contains или notContains.
А если ему задать вопрос про то, почему должен быть такой результат — он скажет, каким должен быть оператор
·>Корректный в смысле синтаксис не сломан? Да пофиг, такое действительно не особо важно проверять.
Синтаксис и семантика.
·>Комбинация чего? И почему именно этого?
комбинация предикатов по домену и по географии. И потому, что это задано бизнес-требованиями.
·>Комбинировать можно столько всего... Проверять нужно что эта самая комбинация — та, которая ожидается.
S>>Из них строятся комбинации, тоже простые. ·>Из тыщи фрагментов можно построить 21000 комбинаций. Но только сотня из них — та, которая нужна.
Ну вот нам достаточно один раз описать способ построения этой комбинации, и в дальнейшем проверять именно его.
·>Да пожалуйста, строй как хошь. Речь о том как это тестировать.
Вроде всё написал.
·>моки это не про state, а про передачу параметров. Для тестирования репо+бд моки не нужны вообще-то. Моки нужны для экономии ресурсов.
Эмм, ваша "модельная БД" — это тоже мок. Нет никакой разницы с т.з. архитектуры тестирования, то ли вы пишете мок вручную и хардкодите в него ответы на find(vasya), то ли вы его описываете декларативно с помощью мок-фреймворка, то ли берёте "квазинастоящую БД" и напихиваете данными перед тестом.
Это всё — про одно и то же "у меня есть stateful dependency, и я моделирую этот state перед каждым тестом". ·>Что показать?
Код.
·>У вас тоже они где-то есть.
Они — на самом верху, в конце конвеера, и их достаточно проверить при помощи немногих e2e тестов.
S>>Ну всё правильно — и вместо N + M тестов вы будете писать N*M, потому что в реализации этого метода вы не будете повторно использовать код ни findUsersByMailDomain, ни findUsersByGeo. ·>Почему не буду?
Потому что в stateful OOP реализации невозможно повторно использовать код этих методов. Они возвращают некомбинируемые результаты.
Ну, то есть формально-то они комбинируемые — можно взять два набора Result, и выполнить их пересечение за O(N logM), но на практике это приведёт к неприемлемой производительности.
S>>А вы по факту останетесь без тестов, т.к. N*M вы писать вспотеете, и останетесь с набором зелёных тестов даже в случае косяков в corner cases. ·>Фантазии. Жизненный опыт.
S>>Так и тут — если уж мы решили провести границу тестирования вокруг произвольно выбранного нами компонента системы — скажем, репозитория, то что нам помешает порезать этот репозиторий на K компонент? ·>Ну "findUsersByMailDomainAndGeo" — это поведение или что? А вот contains("top(10)") — это по-моему совершенно не поведение.
Поведение.
·>Ну так да, уж несколько месяцев объясняю, что код похожий. Тесты другие.
Ну, штош.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Sinclair, Вы писали:
S>·>Причём тут ширина? S>Ширина при том, что findUsersByMailDomainAndGeo имеет как минимум четыре "особых точки" в зависимости от того, какой из критериев домена или географии установлен в "any".
Ты ж вроде сам расписал как это линеаризуется.
S>Если мы продолжим наворачивать туда критерии (как оно обычно бывает в системах с "настраиваемой отчётностью"), то очень быстро окажется, что у нас нет ресурсов для выполнения e2e по всем-всем мыслимым комбинациям.
Ну не наворачивай.
S>·>Может быть, и тест это проверить никак не может. S>Ну, то есть проблема всё же в дизайне, а не в тестах.
Именно. У ваших тестов совершенно другая проблема.
S>·>Что "это непрактично" и смысла обсуждать не имеет. S>Т.е. и без таких наворотов мы получаем приемлемое качество. Ч.Т.Д.
Угу, не знаю к чему ты завёл речь о системе типов. Это тоже оффтоп.
S>·>Давай определимся, "findUsersByMailDomainAndGeo" — имеет или нет? S>Имеет конечно. У нас в бизнес требованиях указано, что могут быть ограничения на почтовый домен (по точному совпадению, по частичному совпадению) и по географии (на уровне зоны/страны/региона/населённого пункта). Если задано более одного ограничения — применяются все из них.
Ну вот, это и надо тестировать. А факт того, что "применяются все из них" — говорит о том, что никакого взрыва комбинаций тестировать не надо, т.к. код линейный. Достаточно протестировать каждый критерий отдельно.
S>·>Зачем? Сразу после выделения (т.е. рефакторинг прод-кода) — тесты не трогаем, они должны остаться без изменений и быть зелёными. S>Они не могут остаться без изменений; у вас там стратегию нужно замокать. Ну, вот как с датой — перенос её в TimeSource требует от вас в рамках теста подготовить нужный источник времени.
Если существующий тест как-то умудрялся работать без подготовленного источника, то он должен работать ровно так же и с подготовленным.
S>>>Опять же — вот вы приводите пример оптимизации, которая типа ломает addLimit. Ну, так эта оптимизация — она откуда взялась? Просто программисту в голову шибануло "а перепишу-ка я рабочий код, а то давненько у нас на проде ничего не падало"? Нет, пришёл бизнес и сказал "вот в таких условиях ваша система тормозит. Почините". И программист починил — новая реализация покрывает новые требования. S>·>Ну да. Но все старые тесты остаются как есть, зелёными. Создаём новые тесты для новых требований, но не трогаем старые. Когда задача завершена, и очень хочется, то можно проанализировать какие тесты стали избыточными и их просто выкинуть. S>Точно так же, как и в FP-случае.
Именно. ЧТД, дизайн тут непричём.
S>·>Это не избавляет от необходимости тестировать части в сборе. И проблема в том, что тестировать весь конвеер целиком "но ресурсные ограничения есть". Упс. S>Конвеер тестируется в длину, а не в ширину. Для этого достаточно 1 (одного) теста.
Судя по тому что писал Pauel этот самый конвеер есть в каждом методе каждого контроллера. Т.е. таких конвееров туча у вас.
S>·>Всё верно. Суть в том, что надо тестировать не умение субд, не порождение запросов, не доезжание, а что findUsersByMailDomainAndGeo действительно ищет юзеров по домену и гео. А как он это делает, через sql, через cql, через linq или через чёрта лысого — пофиг. S>В теории — да, но на практике "через чёрта лысого" вы просто не покроете тестами никогда.
Возможно, зависит от конкретноого чёрта, вот только моки тут непричём.
S>>>Может быть, find() просто делает return empty(). S>·>Да пускай, пофиг. Зато этот конкретный сценарий — правильный, и он будет всегда правильный, независимо от реализации, даже для return empty, это инвариант — и это круто.
S>>>И даже если вы добавите assert find(vasya) == vasya, это мало что изменит — потому что нет гарантии, что find(vasilisa) != vasya. S>·>Конечно. Но ты забыл, что никакие тесты такую гарантию дать и не могут. Твои тоже. S>Формально — да, не могут. S>На практике мы можем проверить не только статус тестов, но и test coverage. В общем случае по test coverage никаких выводов делать нельзя, т.к. результат зависит от путей исполнения. Но когда мы принудительно линеаризуем исполнение, из code coverage можно делать выводы с высокой степенью надёжности.
Угу. Вот только это зависит от дизайна, стиля, ревью и т.п., а не от наличия моков или подходу к тестированию.
S>Вот в вашем примере про добавление оптимизированной ветки в query — ну и прекрасно, она у нас уедет в buildWhere, и там мы проверим результаты тестами, а code coverage покажет нам, что для новой ветки тестов недостаточно. При этом addLimit останется покрытым, потому что он добавляется в отдельном от ветвления между "основным" и "оптимизированным" вариантами месте.
Именно, ведь наличие addLimit в правильном месте обеспечивается не тестами, а совершенно другими средствами.
S>>>Чтобы нормально покрыть тестами ваш find(), придётся отказаться трактовать его как чёрный ящик. S>·>Нет. Тесты — продукт corner case анализа, документация к коду, а не инструмент доказательства корректности и обеспечения гарантий. S>Хм. А как вы обеспечиваете гарантии?
Ты же сам рассказывал: "от обучения разрабочиков, до код ревью и отбора прав" и т.п.
S>>>Бизнес-аналитик не будет вам писать тесты. Увы. S>·>Не писать, но если ему задать вопрос который описывает given-часть теста — то аналитик ответит какой правильный результат мне прописать в verify-части — contains или notContains. S>А если ему задать вопрос про то, почему должен быть такой результат — он скажет, каким должен быть оператор
Не скажет в общем случае, т.к. оператор это детали реализации и специфично для яп. Про sql "between" он может и не знать и его совершенно может не волновать inlcusive он или exclusive. zero-based, one-based индексация и т.п. в итоге приводит к off-by-one ошибкам.
S>·>Корректный в смысле синтаксис не сломан? Да пофиг, такое действительно не особо важно проверять. S>Синтаксис и семантика. Корректность семантики проверить тестами невозможно.
S>·>Из тыщи фрагментов можно построить 21000 комбинаций. Но только сотня из них — та, которая нужна. S>Ну вот нам достаточно один раз описать способ построения этой комбинации, и в дальнейшем проверять именно его.
Так проблема в том, как, например, проверять опечатки в этом самом описании. Учти, эти опечатки могут быть даже в требованиях. Бизнес-аналист написал "исползуем оператор <" но перепутал левую часть с правой. Ты просто скопипастишь < в прод-код и тест-код — и всё зелёное, ибо works as coded. А вот по внезапно красному тесту "saveDocument(2024); findDocumentsNewerThan(2025) == empty" который очевидно верный — ты сразу увидишь ошибку.
Может для < это ещё просто, но в каких-то более хитрых сценариях, когда разные знаки например, payer/payee, buy/sell, call/put, bid/ask — очень легко заблудиться.
S>·>моки это не про state, а про передачу параметров. Для тестирования репо+бд моки не нужны вообще-то. Моки нужны для экономии ресурсов. S>Эмм, ваша "модельная БД" — это тоже мок. Нет никакой разницы с т.з. архитектуры тестирования, то ли вы пишете мок вручную и хардкодите в него ответы на find(vasya), то ли вы его описываете декларативно с помощью мок-фреймворка, то ли берёте "квазинастоящую БД" и напихиваете данными перед тестом. S>Это всё — про одно и то же "у меня есть stateful dependency, и я моделирую этот state перед каждым тестом".
Так это один-в-одит переводится в ФП без state: val records = [vasya]; find(records, criteria) == vasya. Тут дело не в state, а что именно проверяется тестами.
Ещё раз — моки это лишь механизм передачи данных. Цель тестов с субд не в том, чтобы иметь состояние, а в том, чтобы проверять взаимодействие нашего кода с субд, что все компоненты (запрос, bind-парамы, схема, поля в select, result-set процессоры, етс...) согласованы. Проверять эту согласованность через e2e — очень накладно. Но где-то придётся, в любом случае.
S>·>Что показать? S>Код.
Да такой же как ты показал. Разница только в том, что делается в тестах для тестирования этого кода.
S>·>У вас тоже они где-то есть. S>Они — на самом верху, в конце конвеера, и их достаточно проверить при помощи немногих e2e тестов.
В конце каждого из конвееров.
S>·>Почему не буду? S>Потому что в stateful OOP реализации невозможно повторно использовать код этих методов. Они возвращают некомбинируемые результаты. S>Ну, то есть формально-то они комбинируемые — можно взять два набора Result, и выполнить их пересечение за O(N logM), но на практике это приведёт к неприемлемой производительности.
Причём тут вообще state?
S>>>Так и тут — если уж мы решили провести границу тестирования вокруг произвольно выбранного нами компонента системы — скажем, репозитория, то что нам помешает порезать этот репозиторий на K компонент? S>·>Ну "findUsersByMailDomainAndGeo" — это поведение или что? А вот contains("top(10)") — это по-моему совершенно не поведение. S>Поведение.
А если вместо top(10) реализуешь то же самое через between какой-нибдуь?
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, Pauel, Вы писали:
P>·>Что за бред. Могу, конечно. Вопрос только в том какие я/ты тесты будем писать для findUsersByMailDomainAndGeo. Ты будешь проверять, что findUsersByMailDomainAndGeo внутри себя реализована как комбинация findUsersByMailDomain и findUsersByGeo, что и так явно видно из реализации этого метода. А я напишу тест, что вот для данного набора юзеров функция возвращает нужных и не возвращает ненужных. P>"не возвращает ненужных" — мешает теорема Райса. Все что сложнее одной таблицы уже просто так пальцем на заткнуть.
_Для данного набора_ ведь.
P>·>Поэтому если завтра придётся что-то пооптимизировать в реализации и что-то перекомбинировать как-то по-другому — ты свои тесты выкинешь и напишешь совершенно другие, оставшись без регрессии. P>Если без регрессии то это же хорошо. А вы что, в регрессии пользу видите?
Ну вот я и тут ошибся в двойном отрицании. Очевидно, я тут имел в виду "без регрессионного тестирования".
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>"не возвращает ненужных" — мешает теорема Райса. Все что сложнее одной таблицы уже просто так пальцем на заткнуть. ·>_Для данного набора_ ведь.
Из этого утверждения следует, что ваши тесты для конкретного набора не дают основания считать что будет корректная работа на другом наборе данных.
То есть, ваши тесты никакой свойство функции зафиксировать не могут.
А вот статическая типизация как раз таки фиксирует свойство функции. Ровно как и пред-, пост-условия, инварианты. Технически, пост-условие можно выразить синтаксисом. Практически, таких языков не так много в природе.
Здравствуйте, ·, Вы писали:
S>>·>Корректный в смысле синтаксис не сломан? Да пофиг, такое действительно не особо важно проверять. S>>Синтаксис и семантика. ·>Корректность семантики проверить тестами невозможно.
Именно так. Потому ваши утверждения про тесты можно повычеркивать.
Здравствуйте, Pauel, Вы писали:
P>>>"не возвращает ненужных" — мешает теорема Райса. Все что сложнее одной таблицы уже просто так пальцем на заткнуть. P>·>_Для данного набора_ ведь. P>Цитирую одного из тех, кто пишет с вашего аккауна P>
А я не корректность семантики проверяю, а исполнимость конкретного сценария. Возвращает ли данный метод конкретный список записей для конкретных параметров за конкретное время билда или нет — Райсу никак не противоречит.
P>Из этого утверждения следует, что ваши тесты для конкретного набора не дают основания считать что будет корректная работа на другом наборе данных.
И ваши тесты тоже.
P>То есть, ваши тесты никакой свойство функции зафиксировать не могут.
И ваши тесты тоже.
P>А вот статическая типизация как раз таки фиксирует свойство функции. Ровно как и пред-, пост-условия, инварианты. Технически, пост-условие можно выразить синтаксисом. Практически, таких языков не так много в природе.
Похрен. Разговор идёт про тесты.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, Pauel, Вы писали:
S>>>Синтаксис и семантика.
Забыл добавить: а синтакстис и так проверяет компилятор, неясно зачем это проверять ещё и тестами.
P>·>Корректность семантики проверить тестами невозможно. P>Именно так. Потому ваши утверждения про тесты можно повычеркивать.
Какие же именно _мои утверждения_? Цитаты, ты конечно, не сможешь привести.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
·>А я не корректность семантики проверяю, а исполнимость конкретного сценария. Возвращает ли данный метод конкретный список записей для конкретных параметров за конкретное время билда или нет — Райсу никак не противоречит.
Исполнимость конкретного сценария это и есть семантика. Противоречит, еще как.
P>>Из этого утверждения следует, что ваши тесты для конкретного набора не дают основания считать что будет корректная работа на другом наборе данных. ·>И ваши тесты тоже.
Ну так у меня основная работа вне тестов сделана — соответствующий дизайн и вполне осязаемое постусловие
P>>А вот статическая типизация как раз таки фиксирует свойство функции. Ровно как и пред-, пост-условия, инварианты. Технически, пост-условие можно выразить синтаксисом. Практически, таких языков не так много в природе. ·>Похрен. Разговор идёт про тесты.
Здравствуйте, ·, Вы писали:
P>>·>Корректность семантики проверить тестами невозможно. P>>Именно так. Потому ваши утверждения про тесты можно повычеркивать. ·>Какие же именно _мои утверждения_? Цитаты, ты конечно, не сможешь привести.
Смотрите что сами пишете — выполнимость конкретного сценария.
Здравствуйте, Pauel, Вы писали:
P>·>А я не корректность семантики проверяю, а исполнимость конкретного сценария. Возвращает ли данный метод конкретный список записей для конкретных параметров за конкретное время билда или нет — Райсу никак не противоречит. P>Исполнимость конкретного сценария это и есть семантика. Противоречит, еще как.
Нет.
P>>>Из этого утверждения следует, что ваши тесты для конкретного набора не дают основания считать что будет корректная работа на другом наборе данных. P>·>И ваши тесты тоже. P>Ну так у меня основная работа вне тестов сделана — соответствующий дизайн и вполне осязаемое постусловие
И у меня так. Но у меня ещё и тесты неговно.
P>>>А вот статическая типизация как раз таки фиксирует свойство функции. Ровно как и пред-, пост-условия, инварианты. Технически, пост-условие можно выразить синтаксисом. Практически, таких языков не так много в природе. P>·>Похрен. Разговор идёт про тесты. P>Это вы хотите говорить только про тесты.
Потому что ты наезжаешь именно на мои тесты. Цитирую: "что ваши тесты для конкретного набора...".
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, Pauel, Вы писали:
P>>>Именно так. Потому ваши утверждения про тесты можно повычеркивать. P>·>Какие же именно _мои утверждения_? Цитаты, ты конечно, не сможешь привести. P>Смотрите что сами пишете — выполнимость конкретного сценария.
Угу, тебе осталось понять написнное.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>>>Именно так. Потому ваши утверждения про тесты можно повычеркивать. P>>·>Какие же именно _мои утверждения_? Цитаты, ты конечно, не сможешь привести. P>>Смотрите что сами пишете — выполнимость конкретного сценария. ·>Угу, тебе осталось понять написнное.
Вот вы пишите: "Возвращает ли данный метод конкретный список записей для конкретных параметров за конкретное время билда или нет"
Видите — здесь вы утверждаете вроде бы верное утверждение — конкретные параметры, конкретный билд и тд. В этом случае противоречия с т. Райса нет.
Если бы вы изначально это повторяли, к вам бы и вопросов не было — тесты показывают исключительно здесь и сейчас. Это их сила и слабость.
А вы идете дальше, и утверждаете, что
1 ваши распрекрасные тесты крутые
2 следовательно, после деплоймента их повторять смысла нет
Собственно, здесь вы сами себе противоречите. Крутость тестов ничего не говорит про их возможное состояние в другой момент запуска, в других условиях.
Потому как семантику они не проверяют, не могут — с этим вы вроде бы согласились.
А раз не могут, то семантика которая делает их красными вполне себе вероятна — сама по себе она никуда не денется.
Вот вам снова обоснование тестам после деплоймента. Причины — тот самый недетерминизм, который гарантированно есть:
другое время,
другая сеть,
другой энвайрмент,
другие данные,
другая нагрузка
итд
хоть бит-перфект соответствие энвайрментов — всё равно есть недерминизм.
Здравствуйте, Pauel, Вы писали:
P>Вот вам снова обоснование тестам после деплоймента. Причины — тот самый недетерминизм, который гарантированно есть:
По недетерминизму я тоже тебе всё объяснял. Его нужно менеджить. Выявлять и бороться.
P>другое время,
Рассказал как до мелочей, с примерами кода. Но ты сам себе стреляешь в ногу отстаивая право засирать весь код DateTime.Now глобальными переменными.
P>другая сеть,
Многопоточка, по сути. В проде её выцепить гораздо сложнее, чем в тестовом енве.
P>другой энвайрмент,
Конфиги? Менеджатся, расказал как.
P>другие данные,
У тестов данные по определению ровно такие же.
P>другая нагрузка
Мониторится.
P>итд P>хоть бит-перфект соответствие энвайрментов — всё равно есть недерминизм.
Исследуем, находим, воюем с недетерминизмом. Тесты для этого — далеко не лучший инструмент.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>другая сеть, ·>Многопоточка, по сути. В проде её выцепить гораздо сложнее, чем в тестовом енве.
Неадекватное упрощение. Сеть принципиально ненадежна, и никогда надежной не бывает. Все что вы можете в тестовом энвайрменте — это смоделировать конкретные условия.
А вот что бы смоделировать любые условия вместе взятые — на такое у вас ресурсов не хватит.
P>>другой энвайрмент, ·>Конфиги? Менеджатся, расказал как.
Энвайрмент это весь ваш клауд со всеми потрохами, кроме внешних зависимостей
P>>другие данные, ·>У тестов данные по определению ровно такие же.
У вас что, стейдж работает на базе прода?
P>>другая нагрузка ·>Мониторится.
Ага, приборы двести.
P>>итд P>>хоть бит-перфект соответствие энвайрментов — всё равно есть недерминизм. ·>Исследуем, находим, воюем с недетерминизмом. Тесты для этого — далеко не лучший инструмент.
Здравствуйте, Pauel, Вы писали:
P>·>Многопоточка, по сути. В проде её выцепить гораздо сложнее, чем в тестовом енве. P>Неадекватное упрощение. Сеть принципиально ненадежна, и никогда надежной не бывает.
И? По итогу — байты приходящие/не приходящие в разном порядке. Сводится к таймингам (который вы не можете контролировать) и приходу сетевых пакетов.
P>>>другой энвайрмент, P>·>Конфиги? Менеджатся, расказал как. P>Энвайрмент это весь ваш клауд со всеми потрохами, кроме внешних зависимостей
Ну да.
P>>>другие данные, P>·>У тестов данные по определению ровно такие же. P>У вас что, стейдж работает на базе прода?
Твои тесты по твоим же рассказам используют тестовые аккаунунты и т.п. Т.е. реальные данные в базе прода на них влиять не могут. А если могут, то они будут перманентно давать false positive.
P>>>хоть бит-перфект соответствие энвайрментов — всё равно есть недерминизм. P>·>Исследуем, находим, воюем с недетерминизмом. Тесты для этого — далеко не лучший инструмент. P>У вас что, недетерминизм как то тесты обходит?
Конечно обходит, притом недетерминированно.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>Неадекватное упрощение. Сеть принципиально ненадежна, и никогда надежной не бывает. ·>И? По итогу — байты приходящие/не приходящие в разном порядке. Сводится к таймингам (который вы не можете контролировать) и приходу сетевых пакетов.
Не сводится. Как вы собираетесь моделировать тайминги и пакеты в распределенном приложении?
> Т.е. реальные данные в базе прода на них влиять не могут. А если могут, то они будут перманентно давать false positive.
Откуда такая уверенность, что будут только false positive да еще перманентно?
P>>У вас что, недетерминизм как то тесты обходит? ·>Конечно обходит, притом недетерминированно.
какойто у вас детерминированый недетерминизм, умеет мимо тестов ходить.
Здравствуйте, Разраб, Вы писали:
Р>Кто-нибудь понимает суть отказа от зависимостей? Р>Можете привести пример кода? Р>Или доклад/статью на русском хотя бы
Когда вместо использования конкретной функции ты предполагаешь наличие некой абстрактной
функции с определёнными свойствами, которую тебе дают в качестве параметра, например.
Вместо функции может выступать класс с заранее определённым интерфейсом.









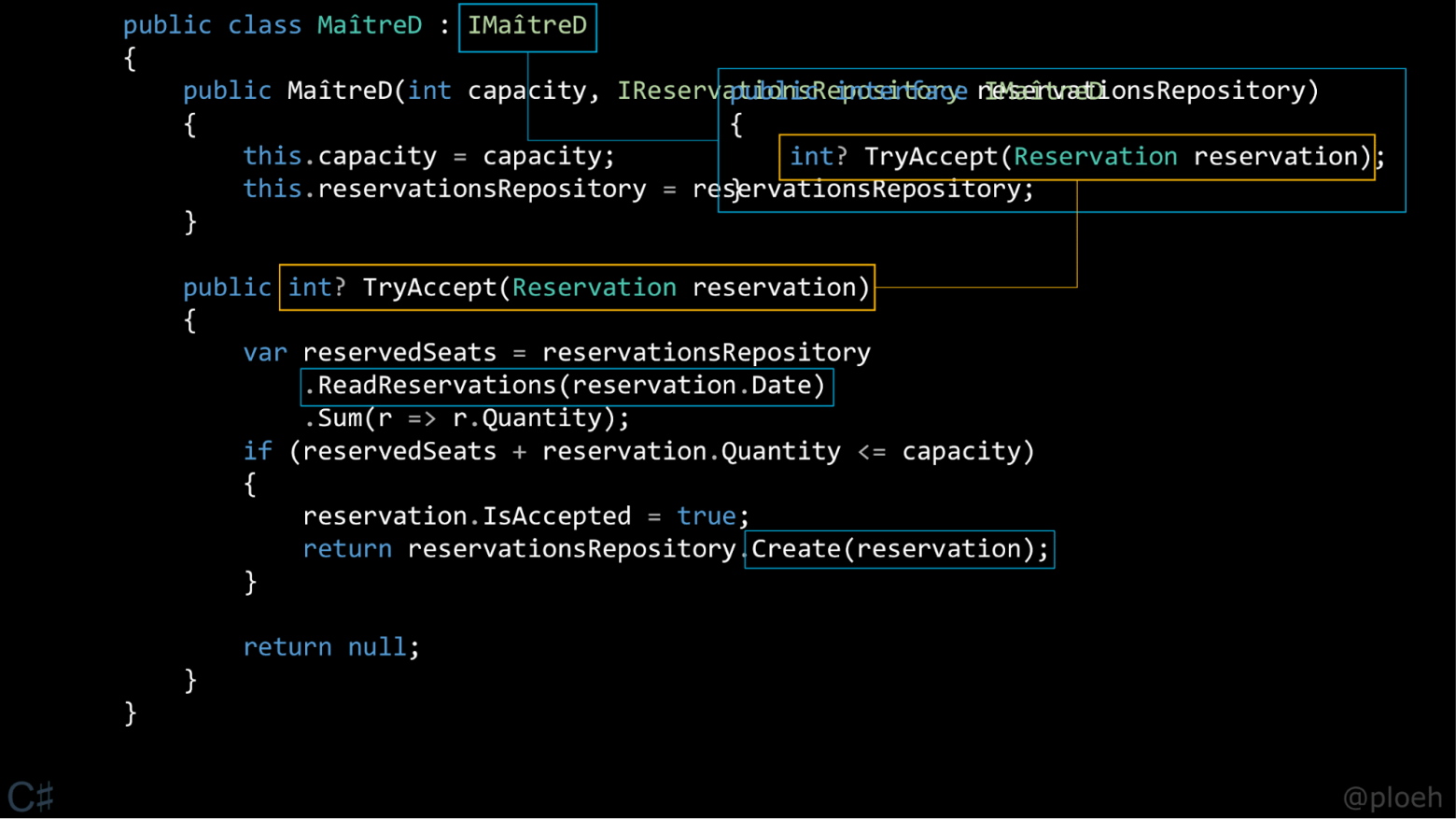

 Если нам не помогут, то мы тоже никого не пощадим.
Если нам не помогут, то мы тоже никого не пощадим.




