Сообщение Re[6]: Что такое Dependency Rejection от 12.10.2023 11:56
Изменено 12.10.2023 12:04 ·
Re[6]: Что такое Dependency Rejection
Здравствуйте, Pauel, Вы писали:
P>>>Сейчас это называется плохо протестировать — вместо простых и дешовых юнит-тестов вам надо обмазываться моками, и писать хрупкие тесты вида "вызвали функцию репозитория"
P>>>То есть, это тесты "как написано", тавтологические
P>·>Технически то же самое.
P>Тесты "как написано", технически не дают никаких гарантий — вызвал другой метод репозитория, результат тот же, а тесты сломались. Вот вам и "то же самое"
Это уже детали реализации — что именно тестируют тесты. Если я хочу тестировать факт вызова определённого метода, то тест и должен сломаться. Что именно покрывает тест — это должен решать программист. Моки к этому отношения не имеют вообще никакого.
>> Вместо передачи параметров проверки результатов пюрешки (pure function), прогоняются данные через моки.
P>И это проблема, т.к. моки так или иначе искажают действительность. Т.к. всегда есть риск, что с моками работает, а без моков — ни гу-гу. При росте сложности приложения эти риски начинают срабатывать регулярно.
P>Например, научить новичка внятно пользоваться моками да правильно покрывать тесты используя такой подход довольно трудно, на это уходят годы. А потому рано или поздно будете ловить последствия в проде.
Это всё риторика. Любые тесты искажают действительность, просто по определению. Моки — тут вообще не при чём.
>> Тестируется ровно то же, ровно так же. Разница же лишь семантическая
P>Вы сейчас играете в слова. В одном случае вы получаете проблемы из за моков, а в другом случае просто тестируете ключевую функцию юнит-тестами без моков.
Моки это всего лишь механизм передачи данных от одного участка кода другому. Пюрешки могут использовать только передачу параметров и возвращаемое значение. Моки — дополнительно позволяют передавать инфу через вызовы методов. Вот и вся разница.
P>Обмазываетесь моками — значит время на разработку тестов больше, тк тесты хрупкие.
Моки лишь дополнительный инструмент. Можно им всё сломать, а можно сделать красиво.
P>Моки это инструмент решения проблем, а не способ выражения намерений. А раз так, то нужно сперва решить проблему, тогда и отпадет необходимость применять этот инструмент.
Решения каких проблем?
P>·>Создание на основе именно прочитанных данных, а не чего попало. Чтение данных согласуется с созданием.
P>Эти вещи связаны исключительно конкретным пайплайном. А вот логически это разные вещи. Тестировать сам пайплайн удобнее интеграционными тестам — прогнал один, значит пайпалайн работает. А вот отдельные части пайплайна — дешовыми юнит-тестами, их можно настрочить тыщи, хоть генерируй по спеке, время на запуск все равно 0 секунд.
Я о чём и говорю. Шило на мыло меняешь, правда ценой удвоения количества кода.
P>А вот если вы обмазываетесь моками, то пишете тесты "как написано" и другого варианта у вас нет.
Варианта чего? Вынести пюрешку можно банальным extract method refactoring и покрыть отдельно — если это имеет хоть какую-то практическую пользу. Мой поинт в том, что в статье практической пользы делать закат вручную мне не удалось увидеть.
P>·>Тренд в объединении подходов: глобально — грязный ооп (т.е. на уровне больших частей системы) бизнеса, локально — функциональное пюре (на уровне методов) технической реализации.
P>Именно! А вы предлагаете грязный ооп использовать на уровне методов технической реализации. Потому вам и нужны моки. ООП это парадигма для управления сложностью взаимодействия. ФП — для управления сложностью вычислений. Отсюда ясно, что нам надо и то, и другое — склеить взаимодействие с вычислениями. Создание — тупо вычисления, а вы сюда втискиваете зависимость на БД и вещаете что это хорошо.
Я предлагаю использовать ооп. На минутку — что требует бизнес? Реализацию сущности MaitreD. Это такой дядька, который стоит на входе в ресторан и взаимодействует с клиентами обслуживая запросы (притом разные — accept/cancel/reschedule/etc) на резервацию столиков. Т.е. прямое соответствие интерфейсу class MaitreD {int? tryAccept(Reservation r){...}; boolean tryReschdedule(Reservation r, DateTime newTime){...}; ....} — ничего лишнего, как слышится, так и пишется — это и есть описание системы в целом.
В статье на замену предложено вычленить локальное нутро реализации метода, вынести наружу, чтобы получилось вот это: int -> (DateTimeOffset -> Reservation list) -> (Reservation -> int) -> Reservation — это вообще чо??!.
P>·>Покажи мне этот однострочный интеграционный тест для tryAcceptComposition. Авторы статьи — "забыли".
Я не знаю что это такое и к чему относится. Напомню код:
Напиши однострочный интеграционный тест для tryAcceptComposition. Именно этот метод напрямую соответствует рассматриваемому в начале статьи методу "public int? TryAccept(Reservation)" который очень легко тестировать, но с моком.
P>·>Пока итог такой. Был грязный метод tryAccept на 4 строки, который требует только один юнит-тест, хотя с моком.
P>Неверно — была монолитная иерархия вызовов во главе с tryAccept который только сам по себе 4 строки.
P>И тестировать нужно всю эту иерархию, для чего вам и нужны моки.
P>·>Они это преобразовали в пюрешный tryAccept на 3 строки, который вроде как легко покрывается юнит-тестом, но без мока. Ура.
P>Именно!
С моком он так же покрывается на ура.
>> Но замели сложность в ещё один tryAcceptComposition на 3 строки (притом довольно хитрый! со всякими магическими заклинаниями liftIO, $, return, flip, .), для которого теперь требуется писать ещё и интеграционный тест. Удвоили кол-во кода, усложнили тестирование... а в чём выгода — я ну никак понять не могу.
P> Вы по прежнему думаете, что моки избавляют от интеграционных тестов. Ровно наоборот — сверх обычных юнитов вам надо понаписывать моки на все кейсы, и всё равно придется писать интеграционные тесты.
Вы по прежнему думаете, что моки избавляют от интеграционных тестов. Ровно наоборот — сверх обычных юнитов вам надо понаписывать моки на все кейсы, и всё равно придется писать интеграционные тесты.
Зачем писать моки на все кейсы? Моки делаются не для кейсов, а для зависимостей. Тут одна зависимость — репозиторий — значит один мок. Неважно сколько кейсов.
Юнит-тестов нужно только два — успешная и неуспешная резервация. Интеграционный тест только один — что MaitreD успешно интегрируется со всеми своими зависимостями.
P>·>Как эти разрозненные функции будут объединяться в единую определяемую бизнесом сущность MaitreD?
P>MaitreD это метафора уровня реализации, никакой бизнес это не определяет. Бизнесу надо что бы работали юз-кейсы вида "зарезервировать столик на 10 мест на 31е декабря между баром и сценой". Используете вы MaitreD или нет, дело десятое.
P>На основе коротких функций мы можем менять компоновку уже по ходу пьесы подстраиваясь под изменения треботваний, а не бетонировать код на все времена.
"зарезервировать столик" — это Responsibility выполняемое Actor-ом MaitreD. Это понятно бизнесу. И бизнесу понятно, что клиентов надо направлять именно к MaitreD для резервации, а не к Actor-у Повар. Что резервация должна записываться в Репозитории, а не на стене туалета. И т.п.
P>>>Аудит, емейл о результате — какую вы здесь проблему видите?
P>·>В том, что результатом tryAccept может быть пачка несвязных результатов, которые должны быть распределены соответсвующим образом: результат резервации — клиенту, аудит — сервису аудита, емейл — smtp-серверу и т.п. Если это переделывать в пюре, придётся конструировать какие-то сложные результирующие объекты, которые потом надо будет ещё потом правильно разбирать на части. Или как ты это видишь?
P>Похоже, вы просто не в курсе, как подобное реализуется в функциональном стиле, а потому порете чушь. Нам нужен аудит не вызова tryAccept, а аудит всей транзации которая изначально будет грязной, принципиально. Т.е. вещи вида "третьего дня разместили заявку xxx(детали) ... статус успешно, детали(...)"
Это не аудит, это просто лог для дебага. Аудит это требуемый аудиторами record-keeping процесс определённого формата с определёнными требованиями. С т.з. реального мира — тот дядька у входа в ресторан, например, обязан секретно уведомлять полицию если к нему пришёл клиент с признаками наркотического отравления.
P>То есть, к известным эффектам мы всего то добавляем еще один. И емейл это ровно такой же эффект. Т.е. нам нужна всего то парочка мидлвар, которые и берут на себя все что надо.
P>Более того, и запись в очередь это снова такой же эффект
Ты не отвлекайся. Код в статье рассматривай. Расскажи куда там воткнуть это всё в tryAcceptComposition или куда там получится. Я хочу рассмотреть пример когда у метода будет больше одной зависимости. А ты мне предлагаешь зависимости внедрять неявно через аннотации и глобальные переменные.
P>@useAudit(Schema.arrange, Schema.arranged)
P>@useEvent(Schema.arranged)
P>@validate(Schema.arrange)
P>@presenter(Schema.arranged)
Ужас. annotation-driven development. Прям Spring, AOP, ejb, 00-е, application container, framework, middleware. Закопай обратно.
P>>>Сейчас это называется плохо протестировать — вместо простых и дешовых юнит-тестов вам надо обмазываться моками, и писать хрупкие тесты вида "вызвали функцию репозитория"
P>>>То есть, это тесты "как написано", тавтологические
P>·>Технически то же самое.
P>Тесты "как написано", технически не дают никаких гарантий — вызвал другой метод репозитория, результат тот же, а тесты сломались. Вот вам и "то же самое"
Это уже детали реализации — что именно тестируют тесты. Если я хочу тестировать факт вызова определённого метода, то тест и должен сломаться. Что именно покрывает тест — это должен решать программист. Моки к этому отношения не имеют вообще никакого.
>> Вместо передачи параметров проверки результатов пюрешки (pure function), прогоняются данные через моки.
P>И это проблема, т.к. моки так или иначе искажают действительность. Т.к. всегда есть риск, что с моками работает, а без моков — ни гу-гу. При росте сложности приложения эти риски начинают срабатывать регулярно.
P>Например, научить новичка внятно пользоваться моками да правильно покрывать тесты используя такой подход довольно трудно, на это уходят годы. А потому рано или поздно будете ловить последствия в проде.
Это всё риторика. Любые тесты искажают действительность, просто по определению. Моки — тут вообще не при чём.
>> Тестируется ровно то же, ровно так же. Разница же лишь семантическая
P>Вы сейчас играете в слова. В одном случае вы получаете проблемы из за моков, а в другом случае просто тестируете ключевую функцию юнит-тестами без моков.
Моки это всего лишь механизм передачи данных от одного участка кода другому. Пюрешки могут использовать только передачу параметров и возвращаемое значение. Моки — дополнительно позволяют передавать инфу через вызовы методов. Вот и вся разница.
P>Обмазываетесь моками — значит время на разработку тестов больше, тк тесты хрупкие.
Моки лишь дополнительный инструмент. Можно им всё сломать, а можно сделать красиво.
P>Моки это инструмент решения проблем, а не способ выражения намерений. А раз так, то нужно сперва решить проблему, тогда и отпадет необходимость применять этот инструмент.
Решения каких проблем?
P>·>Создание на основе именно прочитанных данных, а не чего попало. Чтение данных согласуется с созданием.
P>Эти вещи связаны исключительно конкретным пайплайном. А вот логически это разные вещи. Тестировать сам пайплайн удобнее интеграционными тестам — прогнал один, значит пайпалайн работает. А вот отдельные части пайплайна — дешовыми юнит-тестами, их можно настрочить тыщи, хоть генерируй по спеке, время на запуск все равно 0 секунд.
Я о чём и говорю. Шило на мыло меняешь, правда ценой удвоения количества кода.
P>А вот если вы обмазываетесь моками, то пишете тесты "как написано" и другого варианта у вас нет.
Варианта чего? Вынести пюрешку можно банальным extract method refactoring и покрыть отдельно — если это имеет хоть какую-то практическую пользу. Мой поинт в том, что в статье практической пользы делать закат вручную мне не удалось увидеть.
P>·>Тренд в объединении подходов: глобально — грязный ооп (т.е. на уровне больших частей системы) бизнеса, локально — функциональное пюре (на уровне методов) технической реализации.
P>Именно! А вы предлагаете грязный ооп использовать на уровне методов технической реализации. Потому вам и нужны моки. ООП это парадигма для управления сложностью взаимодействия. ФП — для управления сложностью вычислений. Отсюда ясно, что нам надо и то, и другое — склеить взаимодействие с вычислениями. Создание — тупо вычисления, а вы сюда втискиваете зависимость на БД и вещаете что это хорошо.
Я предлагаю использовать ооп. На минутку — что требует бизнес? Реализацию сущности MaitreD. Это такой дядька, который стоит на входе в ресторан и взаимодействует с клиентами обслуживая запросы (притом разные — accept/cancel/reschedule/etc) на резервацию столиков. Т.е. прямое соответствие интерфейсу class MaitreD {int? tryAccept(Reservation r){...}; boolean tryReschdedule(Reservation r, DateTime newTime){...}; ....} — ничего лишнего, как слышится, так и пишется — это и есть описание системы в целом.
В статье на замену предложено вычленить локальное нутро реализации метода, вынести наружу, чтобы получилось вот это: int -> (DateTimeOffset -> Reservation list) -> (Reservation -> int) -> Reservation — это вообще чо??!.
P>·>Покажи мне этот однострочный интеграционный тест для tryAcceptComposition. Авторы статьи — "забыли".
P>expect(service.arrange({sits: goodValue})).to.match({succeed: {id: notEmpty(string())}});Я не знаю что это такое и к чему относится. Напомню код:
tryAcceptComposition :: Reservation -> IO (Maybe Int)
tryAcceptComposition reservation = runMaybeT $
liftIO (DB.readReservations connectionString $ date reservation)
>>= MaybeT . return . flip (tryAccept 10) reservation
>>= liftIO . DB.createReservation connectionStringНапиши однострочный интеграционный тест для tryAcceptComposition. Именно этот метод напрямую соответствует рассматриваемому в начале статьи методу "public int? TryAccept(Reservation)" который очень легко тестировать, но с моком.
P>·>Пока итог такой. Был грязный метод tryAccept на 4 строки, который требует только один юнит-тест, хотя с моком.
P>Неверно — была монолитная иерархия вызовов во главе с tryAccept который только сам по себе 4 строки.
P>И тестировать нужно всю эту иерархию, для чего вам и нужны моки.
| Не понял ты о чём. Я о "главном герое" статьи, вот этом классе: | |
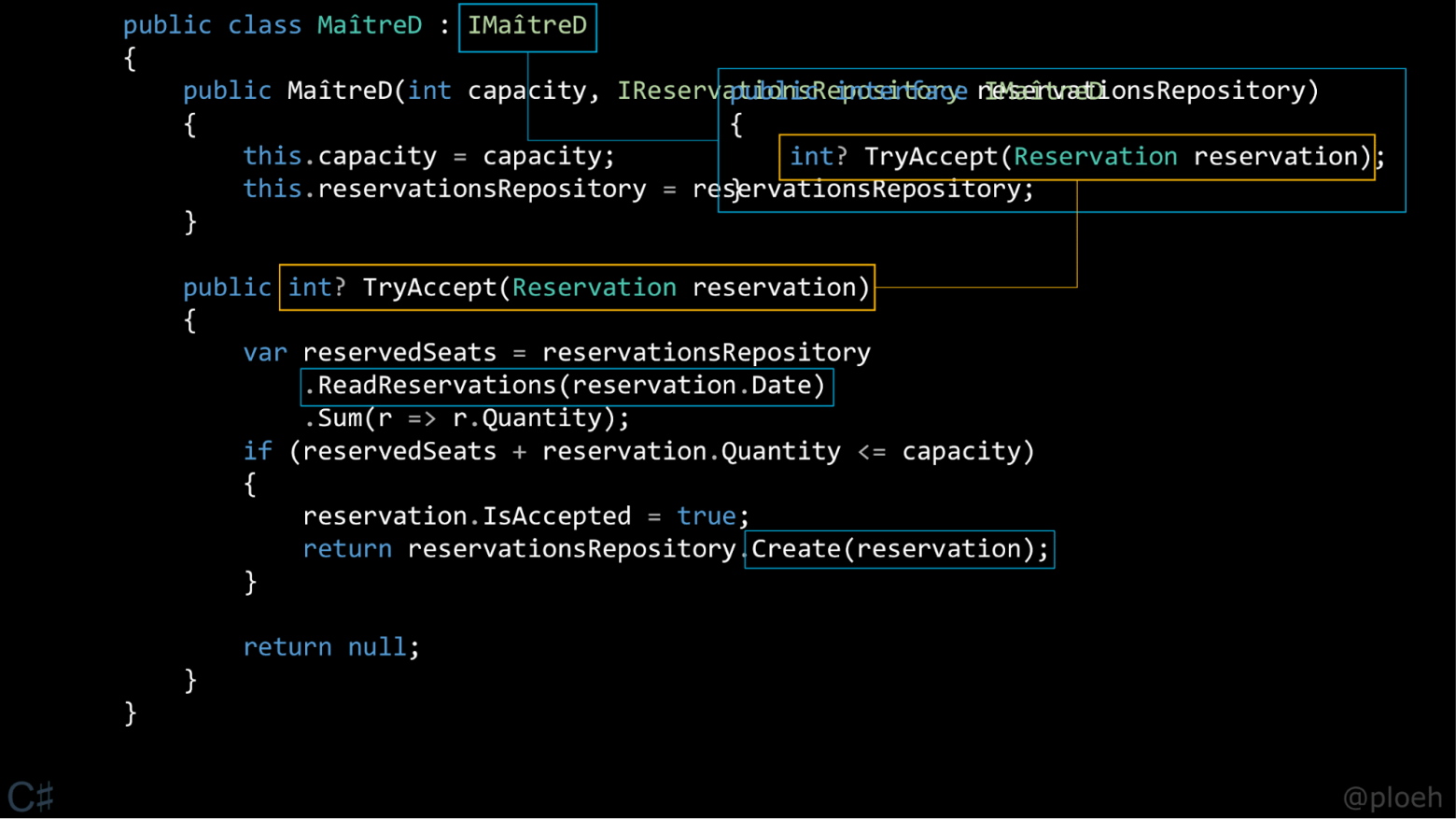 | |
P>·>Они это преобразовали в пюрешный tryAccept на 3 строки, который вроде как легко покрывается юнит-тестом, но без мока. Ура.
P>Именно!
С моком он так же покрывается на ура.
>> Но замели сложность в ещё один tryAcceptComposition на 3 строки (притом довольно хитрый! со всякими магическими заклинаниями liftIO, $, return, flip, .), для которого теперь требуется писать ещё и интеграционный тест. Удвоили кол-во кода, усложнили тестирование... а в чём выгода — я ну никак понять не могу.
P>
Зачем писать моки на все кейсы? Моки делаются не для кейсов, а для зависимостей. Тут одна зависимость — репозиторий — значит один мок. Неважно сколько кейсов.
Юнит-тестов нужно только два — успешная и неуспешная резервация. Интеграционный тест только один — что MaitreD успешно интегрируется со всеми своими зависимостями.
P>·>Как эти разрозненные функции будут объединяться в единую определяемую бизнесом сущность MaitreD?
P>MaitreD это метафора уровня реализации, никакой бизнес это не определяет. Бизнесу надо что бы работали юз-кейсы вида "зарезервировать столик на 10 мест на 31е декабря между баром и сценой". Используете вы MaitreD или нет, дело десятое.
P>На основе коротких функций мы можем менять компоновку уже по ходу пьесы подстраиваясь под изменения треботваний, а не бетонировать код на все времена.
"зарезервировать столик" — это Responsibility выполняемое Actor-ом MaitreD. Это понятно бизнесу. И бизнесу понятно, что клиентов надо направлять именно к MaitreD для резервации, а не к Actor-у Повар. Что резервация должна записываться в Репозитории, а не на стене туалета. И т.п.
P>>>Аудит, емейл о результате — какую вы здесь проблему видите?
P>·>В том, что результатом tryAccept может быть пачка несвязных результатов, которые должны быть распределены соответсвующим образом: результат резервации — клиенту, аудит — сервису аудита, емейл — smtp-серверу и т.п. Если это переделывать в пюре, придётся конструировать какие-то сложные результирующие объекты, которые потом надо будет ещё потом правильно разбирать на части. Или как ты это видишь?
P>Похоже, вы просто не в курсе, как подобное реализуется в функциональном стиле, а потому порете чушь. Нам нужен аудит не вызова tryAccept, а аудит всей транзации которая изначально будет грязной, принципиально. Т.е. вещи вида "третьего дня разместили заявку xxx(детали) ... статус успешно, детали(...)"
Это не аудит, это просто лог для дебага. Аудит это требуемый аудиторами record-keeping процесс определённого формата с определёнными требованиями. С т.з. реального мира — тот дядька у входа в ресторан, например, обязан секретно уведомлять полицию если к нему пришёл клиент с признаками наркотического отравления.
P>То есть, к известным эффектам мы всего то добавляем еще один. И емейл это ровно такой же эффект. Т.е. нам нужна всего то парочка мидлвар, которые и берут на себя все что надо.
P>Более того, и запись в очередь это снова такой же эффект
Ты не отвлекайся. Код в статье рассматривай. Расскажи куда там воткнуть это всё в tryAcceptComposition или куда там получится. Я хочу рассмотреть пример когда у метода будет больше одной зависимости. А ты мне предлагаешь зависимости внедрять неявно через аннотации и глобальные переменные.
P>@useAudit(Schema.arrange, Schema.arranged)
P>@useEvent(Schema.arranged)
P>@validate(Schema.arrange)
P>@presenter(Schema.arranged)
Ужас. annotation-driven development. Прям Spring, AOP, ejb, 00-е, application container, framework, middleware. Закопай обратно.
Re[6]: Что такое Dependency Rejection
Здравствуйте, Pauel, Вы писали:
P>>>Сейчас это называется плохо протестировать — вместо простых и дешовых юнит-тестов вам надо обмазываться моками, и писать хрупкие тесты вида "вызвали функцию репозитория"
P>>>То есть, это тесты "как написано", тавтологические
P>·>Технически то же самое.
P>Тесты "как написано", технически не дают никаких гарантий — вызвал другой метод репозитория, результат тот же, а тесты сломались. Вот вам и "то же самое"
Это уже детали реализации — что именно тестируют тесты. Если я хочу тестировать факт вызова определённого метода, то тест и должен сломаться. Что именно покрывает тест — это должен решать программист. Моки к этому отношения не имеют вообще никакого.
>> Вместо передачи параметров проверки результатов пюрешки (pure function), прогоняются данные через моки.
P>И это проблема, т.к. моки так или иначе искажают действительность. Т.к. всегда есть риск, что с моками работает, а без моков — ни гу-гу. При росте сложности приложения эти риски начинают срабатывать регулярно.
P>Например, научить новичка внятно пользоваться моками да правильно покрывать тесты используя такой подход довольно трудно, на это уходят годы. А потому рано или поздно будете ловить последствия в проде.
Это всё риторика. Любые тесты искажают действительность, просто по определению. Моки — тут вообще не при чём.
>> Тестируется ровно то же, ровно так же. Разница же лишь семантическая
P>Вы сейчас играете в слова. В одном случае вы получаете проблемы из за моков, а в другом случае просто тестируете ключевую функцию юнит-тестами без моков.
Моки это всего лишь механизм передачи данных от одного участка кода другому. Пюрешки могут использовать только передачу параметров и возвращаемое значение. Моки — дополнительно позволяют передавать инфу через вызовы методов. Вот и вся разница.
P>Обмазываетесь моками — значит время на разработку тестов больше, тк тесты хрупкие.
Моки лишь дополнительный инструмент. Можно им всё сломать, а можно сделать красиво.
P>Моки это инструмент решения проблем, а не способ выражения намерений. А раз так, то нужно сперва решить проблему, тогда и отпадет необходимость применять этот инструмент.
Решения каких проблем?
P>·>Создание на основе именно прочитанных данных, а не чего попало. Чтение данных согласуется с созданием.
P>Эти вещи связаны исключительно конкретным пайплайном. А вот логически это разные вещи. Тестировать сам пайплайн удобнее интеграционными тестам — прогнал один, значит пайпалайн работает. А вот отдельные части пайплайна — дешовыми юнит-тестами, их можно настрочить тыщи, хоть генерируй по спеке, время на запуск все равно 0 секунд.
Я о чём и говорю. Шило на мыло меняешь, правда ценой удвоения количества кода.
P>А вот если вы обмазываетесь моками, то пишете тесты "как написано" и другого варианта у вас нет.
Варианта чего? Вынести пюрешку можно банальным extract method refactoring и покрыть отдельно — если это имеет хоть какую-то практическую пользу. Мой поинт в том, что в статье практической пользы делать закат вручную мне не удалось увидеть.
P>·>Тренд в объединении подходов: глобально — грязный ооп (т.е. на уровне больших частей системы) бизнеса, локально — функциональное пюре (на уровне методов) технической реализации.
P>Именно! А вы предлагаете грязный ооп использовать на уровне методов технической реализации. Потому вам и нужны моки. ООП это парадигма для управления сложностью взаимодействия. ФП — для управления сложностью вычислений. Отсюда ясно, что нам надо и то, и другое — склеить взаимодействие с вычислениями. Создание — тупо вычисления, а вы сюда втискиваете зависимость на БД и вещаете что это хорошо.
Я предлагаю использовать ооп. На минутку — что требует бизнес? Реализацию сущности MaitreD. Это такой дядька, который стоит на входе в ресторан и взаимодействует с клиентами обслуживая запросы (притом разные — accept/cancel/reschedule/etc) на резервацию столиков. Т.е. прямое соответствие интерфейсу class MaitreD {int? tryAccept(Reservation r){...}; boolean tryReschdedule(Reservation r, DateTime newTime){...}; ....} — ничего лишнего, как слышится, так и пишется — это и есть описание системы в целом.
В статье на замену предложено вычленить локальное нутро реализации метода, вынести наружу, чтобы получилось вот это: int -> (DateTimeOffset -> Reservation list) -> (Reservation -> int) -> Reservation — это вообще чо??!.
P>·>Покажи мне этот однострочный интеграционный тест для tryAcceptComposition. Авторы статьи — "забыли".
Я не знаю что это такое и к чему относится. Напомню код:
Напиши однострочный интеграционный тест для tryAcceptComposition. Именно этот метод напрямую соответствует рассматриваемому в начале статьи методу "public int? TryAccept(Reservation)" который очень легко тестировать, но с моком.
P>·>Пока итог такой. Был грязный метод tryAccept на 4 строки, который требует только один юнит-тест, хотя с моком.
P>Неверно — была монолитная иерархия вызовов во главе с tryAccept который только сам по себе 4 строки.
P>И тестировать нужно всю эту иерархию, для чего вам и нужны моки.
P>·>Они это преобразовали в пюрешный tryAccept на 3 строки, который вроде как легко покрывается юнит-тестом, но без мока. Ура.
P>Именно!
С моком он так же покрывается на ура.
>> Но замели сложность в ещё один tryAcceptComposition на 3 строки (притом довольно хитрый! со всякими магическими заклинаниями liftIO, $, return, flip, .), для которого теперь требуется писать ещё и интеграционный тест. Удвоили кол-во кода, усложнили тестирование... а в чём выгода — я ну никак понять не могу.
P> Вы по прежнему думаете, что моки избавляют от интеграционных тестов. Ровно наоборот — сверх обычных юнитов вам надо понаписывать моки на все кейсы, и всё равно придется писать интеграционные тесты.
Зачем писать моки на все кейсы? Моки делаются не для кейсов, а для зависимостей. Тут одна зависимость — репозиторий — значит один мок. Неважно сколько кейсов.
Юнит-тестов нужно только два — успешная и неуспешная резервация. Интеграционный тест только один — что MaitreD успешно интегрируется со всеми своими зависимостями.
P>·>Как эти разрозненные функции будут объединяться в единую определяемую бизнесом сущность MaitreD?
P>MaitreD это метафора уровня реализации, никакой бизнес это не определяет. Бизнесу надо что бы работали юз-кейсы вида "зарезервировать столик на 10 мест на 31е декабря между баром и сценой". Используете вы MaitreD или нет, дело десятое.
P>На основе коротких функций мы можем менять компоновку уже по ходу пьесы подстраиваясь под изменения треботваний, а не бетонировать код на все времена.
"зарезервировать столик" — это Responsibility выполняемое Actor-ом MaitreD. Это понятно бизнесу. И бизнесу понятно, что клиентов надо направлять именно к MaitreD для резервации, а не к Actor-у Повар. Что резервация должна записываться в Репозитории, а не на стене туалета. И т.п.
P>>>Аудит, емейл о результате — какую вы здесь проблему видите?
P>·>В том, что результатом tryAccept может быть пачка несвязных результатов, которые должны быть распределены соответсвующим образом: результат резервации — клиенту, аудит — сервису аудита, емейл — smtp-серверу и т.п. Если это переделывать в пюре, придётся конструировать какие-то сложные результирующие объекты, которые потом надо будет ещё потом правильно разбирать на части. Или как ты это видишь?
P>Похоже, вы просто не в курсе, как подобное реализуется в функциональном стиле, а потому порете чушь. Нам нужен аудит не вызова tryAccept, а аудит всей транзации которая изначально будет грязной, принципиально. Т.е. вещи вида "третьего дня разместили заявку xxx(детали) ... статус успешно, детали(...)"
Это не аудит, это просто лог для дебага. Аудит это требуемый аудиторами record-keeping процесс определённого формата с определёнными требованиями с целью контролировать business conduct — по тому как происходят различные бизнес-операции с т.з. legal compliance. С т.з. реального мира — тот дядька у входа в ресторан, например, обязан секретно уведомлять полицию если к нему пришёл клиент с признаками наркотического отравления.
P>То есть, к известным эффектам мы всего то добавляем еще один. И емейл это ровно такой же эффект. Т.е. нам нужна всего то парочка мидлвар, которые и берут на себя все что надо.
P>Более того, и запись в очередь это снова такой же эффект
Ты не отвлекайся. Код в статье рассматривай. Расскажи куда там воткнуть это всё в tryAcceptComposition или куда там получится. Я хочу рассмотреть пример когда у метода будет больше одной зависимости. А ты мне предлагаешь зависимости внедрять неявно через аннотации и глобальные переменные.
P>@useAudit(Schema.arrange, Schema.arranged)
P>@useEvent(Schema.arranged)
P>@validate(Schema.arrange)
P>@presenter(Schema.arranged)
Ужас. annotation-driven development. Прям Spring, AOP, ejb, 00-е, application container, framework, middleware. Закопай обратно.
P>>>Сейчас это называется плохо протестировать — вместо простых и дешовых юнит-тестов вам надо обмазываться моками, и писать хрупкие тесты вида "вызвали функцию репозитория"
P>>>То есть, это тесты "как написано", тавтологические
P>·>Технически то же самое.
P>Тесты "как написано", технически не дают никаких гарантий — вызвал другой метод репозитория, результат тот же, а тесты сломались. Вот вам и "то же самое"
Это уже детали реализации — что именно тестируют тесты. Если я хочу тестировать факт вызова определённого метода, то тест и должен сломаться. Что именно покрывает тест — это должен решать программист. Моки к этому отношения не имеют вообще никакого.
>> Вместо передачи параметров проверки результатов пюрешки (pure function), прогоняются данные через моки.
P>И это проблема, т.к. моки так или иначе искажают действительность. Т.к. всегда есть риск, что с моками работает, а без моков — ни гу-гу. При росте сложности приложения эти риски начинают срабатывать регулярно.
P>Например, научить новичка внятно пользоваться моками да правильно покрывать тесты используя такой подход довольно трудно, на это уходят годы. А потому рано или поздно будете ловить последствия в проде.
Это всё риторика. Любые тесты искажают действительность, просто по определению. Моки — тут вообще не при чём.
>> Тестируется ровно то же, ровно так же. Разница же лишь семантическая
P>Вы сейчас играете в слова. В одном случае вы получаете проблемы из за моков, а в другом случае просто тестируете ключевую функцию юнит-тестами без моков.
Моки это всего лишь механизм передачи данных от одного участка кода другому. Пюрешки могут использовать только передачу параметров и возвращаемое значение. Моки — дополнительно позволяют передавать инфу через вызовы методов. Вот и вся разница.
P>Обмазываетесь моками — значит время на разработку тестов больше, тк тесты хрупкие.
Моки лишь дополнительный инструмент. Можно им всё сломать, а можно сделать красиво.
P>Моки это инструмент решения проблем, а не способ выражения намерений. А раз так, то нужно сперва решить проблему, тогда и отпадет необходимость применять этот инструмент.
Решения каких проблем?
P>·>Создание на основе именно прочитанных данных, а не чего попало. Чтение данных согласуется с созданием.
P>Эти вещи связаны исключительно конкретным пайплайном. А вот логически это разные вещи. Тестировать сам пайплайн удобнее интеграционными тестам — прогнал один, значит пайпалайн работает. А вот отдельные части пайплайна — дешовыми юнит-тестами, их можно настрочить тыщи, хоть генерируй по спеке, время на запуск все равно 0 секунд.
Я о чём и говорю. Шило на мыло меняешь, правда ценой удвоения количества кода.
P>А вот если вы обмазываетесь моками, то пишете тесты "как написано" и другого варианта у вас нет.
Варианта чего? Вынести пюрешку можно банальным extract method refactoring и покрыть отдельно — если это имеет хоть какую-то практическую пользу. Мой поинт в том, что в статье практической пользы делать закат вручную мне не удалось увидеть.
P>·>Тренд в объединении подходов: глобально — грязный ооп (т.е. на уровне больших частей системы) бизнеса, локально — функциональное пюре (на уровне методов) технической реализации.
P>Именно! А вы предлагаете грязный ооп использовать на уровне методов технической реализации. Потому вам и нужны моки. ООП это парадигма для управления сложностью взаимодействия. ФП — для управления сложностью вычислений. Отсюда ясно, что нам надо и то, и другое — склеить взаимодействие с вычислениями. Создание — тупо вычисления, а вы сюда втискиваете зависимость на БД и вещаете что это хорошо.
Я предлагаю использовать ооп. На минутку — что требует бизнес? Реализацию сущности MaitreD. Это такой дядька, который стоит на входе в ресторан и взаимодействует с клиентами обслуживая запросы (притом разные — accept/cancel/reschedule/etc) на резервацию столиков. Т.е. прямое соответствие интерфейсу class MaitreD {int? tryAccept(Reservation r){...}; boolean tryReschdedule(Reservation r, DateTime newTime){...}; ....} — ничего лишнего, как слышится, так и пишется — это и есть описание системы в целом.
В статье на замену предложено вычленить локальное нутро реализации метода, вынести наружу, чтобы получилось вот это: int -> (DateTimeOffset -> Reservation list) -> (Reservation -> int) -> Reservation — это вообще чо??!.
P>·>Покажи мне этот однострочный интеграционный тест для tryAcceptComposition. Авторы статьи — "забыли".
P>expect(service.arrange({sits: goodValue})).to.match({succeed: {id: notEmpty(string())}});Я не знаю что это такое и к чему относится. Напомню код:
tryAcceptComposition :: Reservation -> IO (Maybe Int)
tryAcceptComposition reservation = runMaybeT $
liftIO (DB.readReservations connectionString $ date reservation)
>>= MaybeT . return . flip (tryAccept 10) reservation
>>= liftIO . DB.createReservation connectionStringНапиши однострочный интеграционный тест для tryAcceptComposition. Именно этот метод напрямую соответствует рассматриваемому в начале статьи методу "public int? TryAccept(Reservation)" который очень легко тестировать, но с моком.
P>·>Пока итог такой. Был грязный метод tryAccept на 4 строки, который требует только один юнит-тест, хотя с моком.
P>Неверно — была монолитная иерархия вызовов во главе с tryAccept который только сам по себе 4 строки.
P>И тестировать нужно всю эту иерархию, для чего вам и нужны моки.
| Не понял ты о чём. Я о "главном герое" статьи, вот этом классе: | |
| |
P>·>Они это преобразовали в пюрешный tryAccept на 3 строки, который вроде как легко покрывается юнит-тестом, но без мока. Ура.
P>Именно!
С моком он так же покрывается на ура.
>> Но замели сложность в ещё один tryAcceptComposition на 3 строки (притом довольно хитрый! со всякими магическими заклинаниями liftIO, $, return, flip, .), для которого теперь требуется писать ещё и интеграционный тест. Удвоили кол-во кода, усложнили тестирование... а в чём выгода — я ну никак понять не могу.
P>
Зачем писать моки на все кейсы? Моки делаются не для кейсов, а для зависимостей. Тут одна зависимость — репозиторий — значит один мок. Неважно сколько кейсов.
Юнит-тестов нужно только два — успешная и неуспешная резервация. Интеграционный тест только один — что MaitreD успешно интегрируется со всеми своими зависимостями.
P>·>Как эти разрозненные функции будут объединяться в единую определяемую бизнесом сущность MaitreD?
P>MaitreD это метафора уровня реализации, никакой бизнес это не определяет. Бизнесу надо что бы работали юз-кейсы вида "зарезервировать столик на 10 мест на 31е декабря между баром и сценой". Используете вы MaitreD или нет, дело десятое.
P>На основе коротких функций мы можем менять компоновку уже по ходу пьесы подстраиваясь под изменения треботваний, а не бетонировать код на все времена.
"зарезервировать столик" — это Responsibility выполняемое Actor-ом MaitreD. Это понятно бизнесу. И бизнесу понятно, что клиентов надо направлять именно к MaitreD для резервации, а не к Actor-у Повар. Что резервация должна записываться в Репозитории, а не на стене туалета. И т.п.
P>>>Аудит, емейл о результате — какую вы здесь проблему видите?
P>·>В том, что результатом tryAccept может быть пачка несвязных результатов, которые должны быть распределены соответсвующим образом: результат резервации — клиенту, аудит — сервису аудита, емейл — smtp-серверу и т.п. Если это переделывать в пюре, придётся конструировать какие-то сложные результирующие объекты, которые потом надо будет ещё потом правильно разбирать на части. Или как ты это видишь?
P>Похоже, вы просто не в курсе, как подобное реализуется в функциональном стиле, а потому порете чушь. Нам нужен аудит не вызова tryAccept, а аудит всей транзации которая изначально будет грязной, принципиально. Т.е. вещи вида "третьего дня разместили заявку xxx(детали) ... статус успешно, детали(...)"
Это не аудит, это просто лог для дебага. Аудит это требуемый аудиторами record-keeping процесс определённого формата с определёнными требованиями с целью контролировать business conduct — по тому как происходят различные бизнес-операции с т.з. legal compliance. С т.з. реального мира — тот дядька у входа в ресторан, например, обязан секретно уведомлять полицию если к нему пришёл клиент с признаками наркотического отравления.
P>То есть, к известным эффектам мы всего то добавляем еще один. И емейл это ровно такой же эффект. Т.е. нам нужна всего то парочка мидлвар, которые и берут на себя все что надо.
P>Более того, и запись в очередь это снова такой же эффект
Ты не отвлекайся. Код в статье рассматривай. Расскажи куда там воткнуть это всё в tryAcceptComposition или куда там получится. Я хочу рассмотреть пример когда у метода будет больше одной зависимости. А ты мне предлагаешь зависимости внедрять неявно через аннотации и глобальные переменные.
P>@useAudit(Schema.arrange, Schema.arranged)
P>@useEvent(Schema.arranged)
P>@validate(Schema.arrange)
P>@presenter(Schema.arranged)
Ужас. annotation-driven development. Прям Spring, AOP, ejb, 00-е, application container, framework, middleware. Закопай обратно.