Всем привет. Давненько я не появлялся на этом форуме. Если чего, я тот чувак, который 13 лет назад написал VisualGDB, пока VS не умела в Линукс от слова совсем. Ну а потом вырастил из этого огромный мультитул с кучей функционала.
Но сегодня не об этом. Где-то полгода назад я попробовал в работе AI, и сразу понял, что чаты и CLI — жутко неэффективные способы с ним работать. Большую часть контекстного окна занимают мало релевантные вещи, AI часто галлюцинирует фигню, редактирует чего не просили, или в случае с CLI, тормозит и жрет токены, как не в себя.
В общем, я вдохновился этим делом, и написал CodeVROOM. Это написанный с нуля на дотнете кросс-платформенный редактор, который работает на уровне символов. Т.е. если, скажем, ткнуть его носом в недоделанную функцию, он сбросит модели сильно обрезанный вариант файла и обернет это фразой "пока ничего не делай, но скажи, какие символы нужны, чтобы это выполнить". Дальше нужные символы подключаются в контекст, и чат начинается с начала. Все это по одному нажатию, при желании можно настраивать. По ссылке сверху пример, как итеративное добавление контекста вообще без единого слова промпта в 3 шага делает ответ гораздо более разумным. Это работает в разы быстрее, чем если кидать модели целые файлы, и надеяться, что она там что-то найдет.
Тут еще железо от Cerebras подоспело, которое гоняет Ламу с абсолютно космической скоростью, и в итоге получилась гремучая смесь. Т.е. реально кучу рутинного кода больше можно не писать вообще. Даются промпты типа "сделай обертку вокруг этого класса, и добавь туда статус", "вынеси абстрактный класс с X, Y и Z", "добавь еще вариант для foo", и оно через считанные секунды выдает вменяемый код, которым с минимальными доработками можно пользоваться.
Дальше — больше. Раз уж писать редактор с нуля, можно сделать разые крутые вещи, которые не потянет архитектура существующих редакторов. Например, если AI предложил правки в 3 разных класса из 20, можно свернуть классы (и группы методов), не затронутых правками. Т.е. не нужно бегать по всему файлу, и в то же время, железно понятна структура, что правка внутри конструктора вложенного класса, а не черт знает где.
Ну, плюс, сессии редактирования можно шагать вперед/назад, менять модели на ходу, или дать модели одну и ту же задачу 5 раз, потом выбрать лучший вариант, и продолжить с ним.
Или еще фишка — AI techniques. Когда один раз описывается типовая задача, типа как портировать WPF-свойства в Avalonia, и потом можно просто ткнуть в класс и сказать "примени технику @PortProperties к свойствам размеров". И через пару секунд будет результат, на который руками ушли бы минуты.
Впереди еще много всего, типа высокоуровнего дизайна классов на уровне требований, но даже в текущем состоянии редактором можно пользоваться для кучи мелких задач (тут есть примеры).
Сам редактор платный, но не привязан к конкретным моделям, и пока не будет функционала типа сборки и отладки, работает неограниченный триал.
Здравствуйте, bazis1, Вы писали:
B>Комментарии и пожелания приветствуются.
Выглядит очень круто
практический вопрос — как ты строишь промпт (запросы) к моделям, т.е. как именно ты добавляешь "контекст"?
Просто дополняешь текст и посылаешь его снова, или как-то по-другому? Размечаешь ли как-то релевантные фрагменты в этом случае?
Или кладешь в "attachments" (не все модели это поддерживают)
Как ты "разбираешь" ответ, т.е. понимаешь в какие файлы нужно внести какие правки?
В качестве ответа ты получаешь новое содержимое фрагментов, или список операций по редактированию (action list)?
Еще, как ты думаешь, чем твой подход отличается от того, что использует GitHub Copilot (в агентском режиме) или Cursor например?
В смысле, разве они не точно так же собирают контекст перед выполнением операции?
Из моего опыта с copilot --
Может ли твой редактор искать решение (дополнять контекст) из интернета (GitHub issues/discussions например)
или просто "смотреть" (добавлять в контекст) исходный код или документацию используемых в проекте библиотек, если они доступны в открытом доступе?
Может ли редактор использовать другие инструменты для дополнения контекста, кроме исходных фалов, такие как терминал
(вывод компилятора или других утилит командной строки, логгирование — т.е. самостоятельно добавить логи в нужных местах и потом на них смотреть)
или браузер, т.е. вывод DOM например (в случае HTML)? Понимает ли скриншоты?
Это я просто с Copilot сравниваю. Ну и идеи накидываю
Здравствуйте, bnk, Вы писали:
bnk>Выглядит очень круто
спасибо
bnk>практический вопрос — как ты строишь промпт (запросы) к моделям, т.е. как именно ты добавляешь "контекст"? bnk>Просто дополняешь текст и посылаешь его снова, или как-то по-другому? Размечаешь ли как-то релевантные фрагменты в этом случае? bnk>Как ты "разбираешь" ответ, т.е. понимаешь в какие файлы нужно внести какие правки?
Первый вариант. Основная идея в том, чтобы с точки зрения модели это выглядело, как 2 кожаных программиста, обсуждающих код. И задача моего движка — разбивать рабочие задачи на подобые обсуждния, давать моделям их дополнить, и встраивать обратно.
Технически это реализовано через высокоуровневый merge. Скажем, ты отправил модели класс с кучей всего, и попроил разбить метод X. Модель в ответ выдала отредактированный X, добавленный X_Auxiliary() и новый конструктор. Движок это дело распарсит, заменит оригинальный метод, и добавит рядом вспомогательный + конструктор. Это не работает с переименовыванием, не в большинстве случаев просто в разы быстрее классического пофайлового подхода. Вещи типа прокинуть новую переменную в дерево конструкторов делаются за секунду-две с минимальным промптом.
Кстати, если хочешь поиграться, шаблоны промптов лежат в папке PromptTemplates, а сами промпты и ответы модели со счетчиком токенов есть в AI->Windows->Diagnostics.
bnk>В качестве ответа ты получаешь новое содержимое фрагментов, или список операций по редактированию (action list)?
Пока фрагменты, но руки чешутся сделать прогрессивное редактирование. Когда модель сначала даст высокоуровневый список типа "добавлю переменную X в класс Y", потом отдельные фрагменты кода, потом отредактированные куски. Теоретически, последний этам можно распараллелить, или дать на откуп более простой модели, чем еще выше поднять скорость. Но текущий вариант уже неплохо работает.
bnk>Еще, как ты думаешь, чем твой подход отличается от того, что использует GitHub Copilot (в агентском режиме) или Cursor например? bnk>В смысле, разве они не точно так же собирают контекст перед выполнением операции?
Там, ЕМНИП, используется RAG с векторными базами данных. Т.е. если у тебя код зависит от 20 разных символов, то все соответствущие файлы будут статически подтянуты в контекст. CodeVROOM же работает динамически. Т.е. модель получит неполный кода с вопросом "дай список релевантных, но не указанных символов". Модель выберет, скажем, 5 из них символов. CodeVROOM отактит шаг обратно и повторит все в этими символами.
Плюс, это все можно шагать, как в отладчике. Модель выдала фигню, ты шагаешь обратно, видишь, что в твоем запросе про сортировку она забыла подключить функцио сравнения. Добавляешь ее в контекст одним щелчком, шагаешь вперед и получаешь рабочий код. Или просто повторяешь поиск контекста, и убеждаешься, что модель нашла все нужное. Т.е. вместо черного ящика, который часто не работает, получается достаточно прозрачная система.
bnk>Из моего опыта с copilot -- bnk>Может ли твой редактор искать решение (дополнять контекст) из интернета (GitHub issues/discussions например) bnk>или просто "смотреть" (добавлять в контекст) исходный код или документацию используемых в проекте библиотек, если они доступны в открытом доступе? bnk>Может ли редактор использовать другие инструменты для дополнения контекста, кроме исходных фалов, такие как терминал bnk>(вывод компилятора или других утилит командной строки, логгирование — т.е. самостоятельно добавить логи в нужных местах и потом на них смотреть) bnk>или браузер, т.е. вывод DOM например (в случае HTML)? Понимает ли скриншоты? bnk>Это я просто с Copilot сравниваю. Ну и идеи накидываю
Терминала пока нет, но будет очень скоро. Поиск и скриншоты пока не планируется, т.к. это сложно сделать лучшего того же Codex или Claude CLI. Здесь ниша — сверхбыстрая реализация мелких и муторных задач. Когда в голове есть четкое представление, что и куда надо добавить, но руками это займет несколько минут, но объяснять в чате обычной модели и потом перероверять, не сильно меньше. А с промптом из 2-3 слов и несколькими итерациями получается реально быстрее, и сильно меньше отвлекает.
Кстати, с поиском, мне всегда интересно, насколько это работает на практике? Из моего опыта работы с LLM, они часто принимают неверное "решение" на уровне одного токена, и потом весь последующий ответ пытаются это решение воплотить. Когда ищешь руками, половина задачи — это интуиция понять, фигню ты сейчас нагуглил, или не фигню. У LLM с этим, по-моему, принципальная проблема. Если у тебя есть примеры, когда поиск из копилота делал что-то полезное, будет интересно почитать.
С логированием это будет отдельный высокоуровневый инструмент вместе с отладчиком. Можно будет давать задание типа "разберись, почему после X происходит Y", одобрять/отклонять идеи по инструментации кода, и шагать все это вперед-назад. Но это ближе к концу года, после интеграции с VisualGDB.
bnk>Я только скачал, обязательно посмотрю
Здравствуйте, bazis1, Вы писали:
bnk>>практический вопрос — как ты строишь промпт (запросы) к моделям, т.е. как именно ты добавляешь "контекст"? bnk>>Просто дополняешь текст и посылаешь его снова, или как-то по-другому? Размечаешь ли как-то релевантные фрагменты в этом случае? bnk>>Как ты "разбираешь" ответ, т.е. понимаешь в какие файлы нужно внести какие правки? B>Первый вариант. Основная идея в том, чтобы с точки зрения модели это выглядело, как 2 кожаных программиста, обсуждающих код. И задача моего движка — разбивать рабочие задачи на подобые обсуждния, давать моделям их дополнить, и встраивать обратно. B>Технически это реализовано через высокоуровневый merge. Скажем, ты отправил модели класс с кучей всего, и попроил разбить метод X. Модель в ответ выдала отредактированный X, добавленный X_Auxiliary() и новый конструктор. Движок это дело распарсит, заменит оригинальный метод, и добавит рядом вспомогательный + конструктор. Это не работает с переименовыванием, не в большинстве случаев просто в разы быстрее классического пофайлового подхода. Вещи типа прокинуть новую переменную в дерево конструкторов делаются за секунду-две с минимальным промптом.
B>Кстати, если хочешь поиграться, шаблоны промптов лежат в папке PromptTemplates, а сами промпты и ответы модели со счетчиком токенов есть в AI->Windows->Diagnostics.
Да, большое спасибо, очень полезно!
bnk>>В качестве ответа ты получаешь новое содержимое фрагментов, или список операций по редактированию (action list)? B>Пока фрагменты, но руки чешутся сделать прогрессивное редактирование. Когда модель сначала даст высокоуровневый список типа "добавлю переменную X в класс Y", потом отдельные фрагменты кода, потом отредактированные куски. Теоретически, последний этам можно распараллелить, или дать на откуп более простой модели, чем еще выше поднять скорость. Но текущий вариант уже неплохо работает.
Понял. Я переключился в моем случае на structured outputs (но это не про редактор, немного другой случай, намного проще)
Проблема с текстом была в том что несмотря на инструкции, модель им (иногда) не следовала. structured output фиксирует схему генерируемого моделью json, и гораздо практичнее для использования кодом, ничего не нужно парсить.
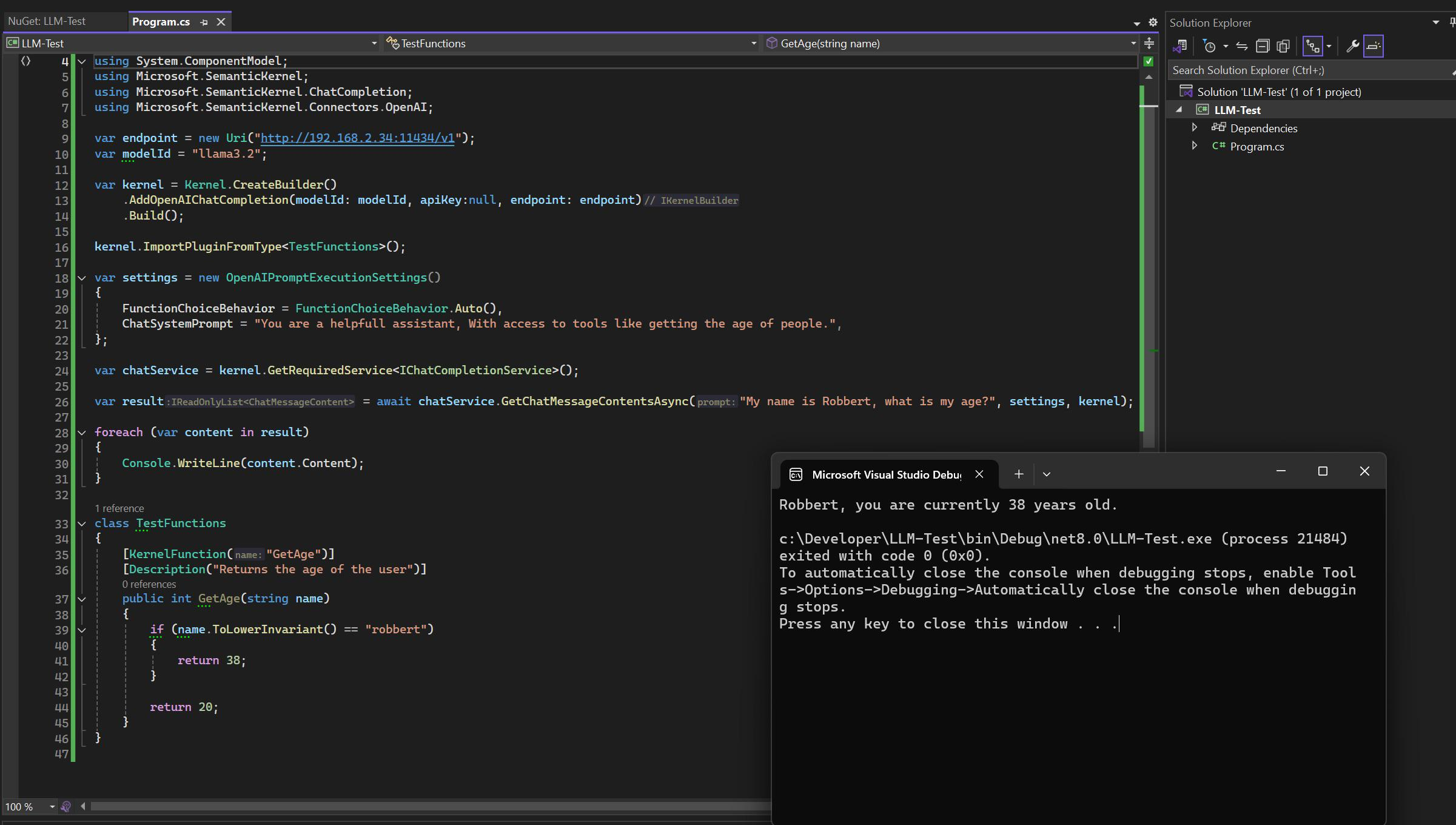
Как-то это все в общем кустарно выглядит у меня все равно, думаю посмотреть на semantic kernel (пока так и не собрался правда), там можно контекст прямо функциями фигачить, "тулами"
Здравствуйте, bnk, Вы писали:
bnk>Понял. Я переключился в моем случае на structured outputs (но это не про редактор, немного другой случай, намного проще) bnk>Проблема с текстом была в том что несмотря на инструкции, модель им (иногда) не следовала. structured output фиксирует схему генерируемого моделью json, и гораздо практичнее для использования кодом, ничего не нужно парсить.
Ха! Если бы все было так просто. Проблема в том, что у LLM нет интуиции. Если повесить на нее структурные ограничения с API или схемой, то, по сути, за каждый токен будут драться две подсети: одна, пытающаяся вписаться в формат, и другая, пытающася выдать смысловой результат.
В итоге, на выходе часто получается структурно корректное сообщение, абсолютно бесполезное для пользователя. Как в анекдоте про программиста и воздушный шар.
Свежий пример: код, который собирается, но вместо текущего значения даты, пишет для всех строк самое первое, потому что импульс "вынести переменную за цикл" переборол импульс "не менять поведение кода".
Это решается переключением на более мощные модели, но рефакторинг по цене чашки кофе, которого ждать надо, как эту самую чашку — дело довольно бесполезное.
А если дать модели больше свободы, и структуру парсить отдельно, таких косяков получается заметное меньше. Теоретически, можно взять разные модели для генерации идеи, и воплощения в конкретные правки, но мой подход с парсингом работает практически мгновенно, в отличие от дополнительной модели.
Здравствуйте, bazis1, Вы писали: B>Здравствуйте, bnk, Вы писали: bnk>>Понял. Я переключился в моем случае на structured outputs (но это не про редактор, немного другой случай, намного проще) bnk>>Проблема с текстом была в том что несмотря на инструкции, модель им (иногда) не следовала. structured output фиксирует схему генерируемого моделью json, и гораздо практичнее для использования кодом, ничего не нужно парсить. B>Ха! Если бы все было так просто. Проблема в том, что у LLM нет интуиции. Если повесить на нее структурные ограничения с API или схемой, то, по сути, за каждый токен будут драться две подсети: одна, пытающаяся вписаться в формат, и другая, пытающася выдать смысловой результат. B>В итоге, на выходе часто получается структурно корректное сообщение, абсолютно бесполезное для пользователя. Как в анекдоте про программиста и воздушный шар.
Я имел в виду построение (собирание) промпта. Вручную это делать как-то по кустарному, как мне кажется. Вот пример ниже, чтобы проиллюстрировать что я имел в виду
А, ну это reflection-обертка для вызова функций. MCP это дело еще дальше доводит, когда можно свою функциою вклинить в тот же Claude CLI, унаследовав остальной его функционал.
Это полезно, если есть много функций с разными наборами параметров, и модель сама решает, что и когда вызывать.
В моем же случае, это будет дикий оверинженеринг. Просить модель дать JSON, который через reflection вызоват функцию, которая примет массив строк и прикрепит его к снапшоту состояния. И тянуть ради этого фреймворк, с async-функциями, которые нетривиально отлаживать. Проще попросить модель выдать CSV, и распарсить его в лоб.
Здравствуйте, bazis1, Вы писали:
B>Всем привет. Давненько я не появлялся на этом форуме. Если чего, я тот чувак, который 13 лет назад написал VisualGDB
Оффтоп. VisualGDB из РФ никак сейчас не приобрести?