Здравствуйте, swame, Вы писали: S>Мой тест показал, что твой алгоритм сопоставим по +/- по скорости со стандартным TList <double>.Sort S>(как раз из за того что внутри использует QSort2GPT) S>и, как и прежде в 2-5 раз медленней quick QSort2GPT. S>При этом расходует в 100 раз и больше памяти. на 5 млн элементов уже переполняет память. S>ты просто замедлил отсебятиной QSort2GPT S>Так что на помойку и хватит бредить.
А вы покажите полностью код для вашего теста. Могу предположить, что ваш вариант медленнее из-за заполнения нулями динамических массивов при инициализации. У меня используется мой класс tdoublearray, представляющий собой кастомный динамический массив:
Скрытый текст
TDoubleArray=class(tsafeobject)
private
public
fcount:integer;
fcapacity:integer;
procedure SetCount(newcount:integer);
procedure SetCapacity(newcapacity:integer);
//procedure SetCapacityQuick(newcapacity:integer);
//Странно, выходит и setcapacity не заполняет нулями. И setcount значит тожеfunction GetItem(index: integer): double;
procedure SetItem(index: integer; Value: double);
public
fitems:pdoublearr;
procedure CopyToSimpleArray(var arr:array of double);
destructor Destroy; override;
property Items[index:integer]:double read GetItem write SetItem; default;
property Count:integer read fcount write setcount;
property Capacity:integer read fcapacity write SetCapacity;
function FirstPointer:pdoublearr;
procedure Grow;
procedure Clear;
function SafeGetItem(ind:integer; errval:double):double;//Если выходит за границы индекса - возвращает errvalfunction TryGetItem(ind:integer; out res:double):boolean;
procedure SetZeroValues(newcount:integer);
procedure SetBlankValues(newcount:integer; newval:double);
procedure Add(value:double);
procedure AddArray(otherarray:tdoublearray);
procedure SwapPoints(pointnum1,pointnum2:integer);
procedure Assign(otherarray:tdoublearray);
procedure SortByGrowing;
function LinInterValue(kx:double):double;//kx-положение в массиве (в вещественных координатах);0 - первая точка, 1 - вторая, 0.5 - посерединеfunction LagrInterpValue(kx:double; polnum:integer):double;//Интерполяция по Лагранжу: polnum - стенень полинома (должно быть четное число). 2 - линейная интерполяцияfunction SumValues:double;
function MaxValue:double;
function HasNonZeroValues:boolean;
procedure QSort(ascending:boolean);
procedure SmoothAdjacentAveraging(numpoints:integer);
procedure GetValuesInterval(minval,maxval:double; out minn,maxn:integer);//определяет интервал точек, попадающих
//в указанные границы (предполагается что точки в массиве расположены по возрастанию)function GetSortedNums(ascending:boolean):tintarray;
//Возвращает список номеров своих элементов, отсортированных по возрастанию (если ascending=true) или убываниюfunction ValuesAreEquiDistant(out beg,step:double):boolean;//Возвращает false если чисел 0 или 1
//Также возвращает false если все значения равныfunction ValuesAreSubsequent(out beg,step:double):boolean;//Возвращает true если идёт непрерывная последовательность эквидистантных значений, постоянно увеличивающихся
//Возвращает false если чисел 0; если 1, возвращает true и step 1procedure AddValues(val:double);
procedure MultValues(val:double);
end;
procedure TDoubleArray.SetCount(newcount: integer);
begin
if newcount>fcapacity then setcapacity(newcount);
fcount := newcount;
end;
procedure TDoubleArray.SetCapacity(newcapacity: integer);
begin
if NewCapacity < fCount then
raise exception.Create('NewCapacity='+inttostr(NewCapacity));
if NewCapacity <> fCapacity then
begin
ReallocMem(fitems, NewCapacity * SizeOf(double));
FCapacity := NewCapacity;
end;
end;
procedure TDoubleArray.Add(value: double);
begin
fcount:=fcount+1;
if fcount>fcapacity then grow;
fitems^[fcount-1]:=value;
end;
Я получил выигрыш в скорости 30% для массивов из 100 000 чисел с равномерно распределенными random-ами.
И если вы даже не можете сразу понять принцип моего алгоритма (и почему он работает быстро), это очередной пример что "профессиональные программеры" с rsdn могут заимствовать чужие идеи, но не генерировать свои. Я в КСВ об этом создал тему.
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
Здравствуйте, Khimik, Вы писали:
K>Здравствуйте, swame, Вы писали:
S>>
S>>Создайте систему, которой сможет пользоваться дурак, и только дурак захочет ею пользоваться.
K>Вот в стандартном алгоритме со схемой Хоара есть фрагмент:
K>
K>if i <= j then
K>begin
K>temp := arr[i];
K>arr[i] := arr[j];
K>arr[j] := temp;
K>Inc(i);
K>Dec(j);
K>end;
K>
K>Как бы немного смущает, что если i=j, то алгоритм впустую произведёт обмен.
1. Давайте попробуем оценить, насколько велики потери от этого бесполезного обмена. Смотрите, на каждой итерации сортировки условие i == j встречается не более одного раза; значит, в худшем случае, алгоритм сделает столько же лишних обменов, сколько будет проходов сортировки. Количество проходов у нас зависит от длины массива: если массив длиной, скажем, 2, то обмен будет ровно 1. Если у нас массив длины N сортируется за X проходов, то массив длины N*2 будет сортироваться за 2X+1 проходов (две сортировки подмассивов по N элементов, плюс ещё один проход перед тем, как вызвать эти две сортировки). Отсюда мы понимаем, что X ~ Log2(N). Логарифмическая асимптотика затрат нас пугать не должна, т.к. она растёт достаточно медленно. Кроме того, мы знаем, что асимптотика quicksort — N * log(N), то есть она в N раз хуже, чем наши дополнительные затраты. K>Я попробовал заменить if i <= j then на if i < j then, ан нет — начались глюки.
2. Если мы хотим исправить алгоритм, нужно внимательно смотреть на то, что он делает. Очевидно, что помимо обмена, под if стоят ещё и инкременты/декременты i и j. Если их не делать, то семантика алгоритма поменяется — отсюда и глюки.
3. С учётом вышесказанного, понятно, что просто поменять условие сравнения нельзя. Придётся сделать две раздельных проверки — одну про необходимость обмена, вторую — про необходимость перемещения счётчиков.
if i <= j then
begin
if(i < j) then begin
temp := arr[i];
arr[i] := arr[j];
arr[j] := temp;
end;
Inc(i);
Dec(j);
end;
Возникает вопрос: а много ли мы экономим? Мы экономим один лишний обмен для i == j, но зато теперь мы на каждой итерации дополнительно сравниваем i и j. Результат может зависеть от точных стоимостей обмена и сравнения. Если в массиве лежат какие-то простые значения, то перестановка — это копирование память-регистр-память и сводится к трём инструкциям CPU. Если там структуры — то копирование может потребовать чего-то более существенного. Проверка — это сравнение регистр-регистр, к тому же она будет неплохо предсказываться процессором, и вряд ли приведёт к потерям больше 1 такта на итерацию.
Но, вспомнив, что в среднем наша "оптимизация" срабатывает 1 раз из N, получаем, что с ростом длины массива даже дорогие обмены будут задоминированы стоимостью дополнительной проверки.
Bottom line: чтобы понять, какой будет реальный эффект в конкретной задаче, нужно точно замерить производительность. Если вас интересует экономия уровня единиц процентов — тогда да, настраиваем окружение, обучаемся корректно тестировать производительность (со сбором статистики, отбрасыванием нерелевантных результатов, и оценкой значимости разницы), тюним всё до мелочей. Если интересует асимптотическая оптимизация — то останавливаемся прямо на шаге №1 выше: наша оптимизация на асимптотику не повлияет, так что лучше не трогать то, что не сломано. K>Такие подводные камни могут всё порушить в программе. Поэтому повторюсь что мой изначальный алгоритм, как мне кажется, во многих отношениях предпочтителен.
Ваш изначальный алгоритм проигрывает коробочному во всех отношениях:
1. Он протестирован заведомо не лучше, чем библиотечная реализация. Просто потому, что у вас нет столько ресурсов, сколько у производителей библиотеки.
2. Он работает медленнее — стало быть, задачу "оптимизации" он не решил.
3. Он гораздо более хрупкий — вы не умеете вносить изменения в алгоритмы так, чтобы не ломать их семантику; и написан он (в отличие от коробочной реализации) без разделения на логику сравнения элементов и логику выбора того, когда и какие элементы сравнивать.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Re: Оптимизация через разделение/вынос функционала
Не очень понятно, что этот пост делает в разделе "Философия программирования", ну да ладно.
Радует, что ты попробовал научиться сделать хоть что-то хорошо, отложив свои гениальные идеи по трансформации мироустройства. Этак, глядишь, лет через двадцать из тебя таки выйдет кодерок, которого можно подпускать к реальным задачам
Re[10]: Оптимизация через разделение/вынос функционала
Здравствуйте, Khimik, Вы писали:
K>У меня есть довольно большой опыт написания и оптимизации разных алгоритмоы, и конкретно в данном случае я мог бы придраться, что если вы например для ascending=false будете менять < на > — вы уверены что надо именно на > а не на >=? Не спутаете?
Вы не поняли мысль. Повторю её помедленнее: сортировать данные нужно стандартным алгоритмом, передавая в неё функцию-компаратор.
Если вам нужно поменять порядок сортировки на обратный, то вы не пишете новую функцию сортировки.
Вы даже не пишете новую функцию-компаратор.
Вы берёте старую функцию компаратор, и оборачиваете её в новую функцию, которая просто вызывает старую, и обращает знак.
K>Этот стандартный алгоритм быстрой сортировки со схемой Хоара очень так сказать хрупкий, надо проверять каждый чих чтобы быть уверенным что он никогда не зависнет
Он совершенно не хрупкий, если вы понимаете, как он устроен. А если нет — берёте библиотечный алгоритм и не создаёте себе проблемы. K>Если же буду вставлять — надо будет делать много тестов, чтобы убедиться что он никогда не зависнет. Ваш самописаный алгоритм скорее всего содержит больше ошибок, чем предложенный chatGPT. Который, в свою очередь, является просто переводом статьи в Википедии с псевдокода на Паскаль.
K>Я конкретно к вам хорошо отношусь, но злит когда "профессиональные программеры" вроде вас учат не думать самому, и находить для всего готовые решения/библиотеки.
Вы просто противоречите сами себе. Вот только что вы отказались думать потому, что у вас нет на это времени. Я вас в этом целиком поддерживаю — нету так нету, берите готовое и не тратьте своё и чужое время на ерунду. K>Слово "велосипед" для них видите ли ругательное. Лично мне довольно часто приходится придумывать относительно сложные алгоритмы.
Если вы считаете себя крутым алгоритмистом — нет проблем. Я же говорю: важно — решить, что именно будет вашим core value. Если вы считаете, что умеете писать алгоритмы сортировки лучше прочих, то сосредоточьтесь на этом.
Но тогда не получится спрятаться за "я не понял, что это за Inc/Dec такие, пусть мне кто-то объяснит, а то самому думать об этом мне некогда".
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Re[2]: Оптимизация через разделение/вынос функционала
K>>tmparray:=tarray.create;
K>>tmparray.count:=count;
K>>for i:=0 to count-1 do tmparray.fitems[i]:=arr[i];
K>>tmparray.superqsort;
K>>for i:=0 to count-1 do arr[i]:=tmparray[i];
K>>tmparray.free;
K>>
M>Чот я не понял — зачем создавать отдельный массив, копировать данные в него, сортировать его и копировать обратно?
Так удобнее, чем писать сортировку внутри какого-то кода где это потребовалось. Мне кажется мой код в данном случае очень простой и понятный.
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
Здравствуйте, Sinclair, Вы писали:
K>>Я часто после end; пишу комментарий вроде //next q, так становится понятнее. S>А можно просто делать отступы
1) Делание отступов тоже занимает время.
2) Я часто помещаю в одну строку несколько операторов.
3) Вместо отступов я размечаю функциональные блоки кода комментариями.
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
Здравствуйте, Khimik, Вы писали:
K>По-моему кто-то давно уже говорил о Delphi, что если вам надо быстрый код — оптимизируйте алгоритм, остальное компилятор сделает сам. K>Для оптимизации кода, как и вообще для написания серьёзного кода, желательно разбить код на фрагменты, "ортогональные" друг к другу, работающие независимо. Чтобы следовать этому принципу, приходится делать на первый взгляд не очень красивые вещи. Например, если мне надо сделать быструю сортировку, я не вставляю её алгоритм в то место где она нужна, а делаю примерно так:
K>Раньше я не понимал принцип быстрой сортировки, а сейчас это кажется очень просто. Вот код, который я написал сходу; специально не тестировал, но уверен что в целом всё правильно:
K>Когда написал, понял что в этом коде есть маленький потенциальный баг, ну да это мелочи. На аналогичном принципе мне удалось ускорить в тысячу раз код, перебирающий атомы в брутто-формуле.
Измерений не делал, но по виду кода такой алгоритм будет на порядок — два медленнее стандартного дельфового,
так как в нем огромное количество лишнего распределения памяти.
Может использовал бы стандартный — ускорил бы в сто тыщ раз, и некрасивый код с копированием данных не понадобился.
Сделай тест, сравни со стандартным.
И нахрена писать все в строчку.
K>А, ну это я конечно знаю, сорри что не спросил понятно спросил. Мой вопрос был — что делает этот фрагмент процедуры:
K>
repeat
K> while arr[i] < pivot do
K> Inc(i);
K> while arr[j] > pivot do
K> Dec(j);
K> if i <= j then
K> begin
K> temp := arr[i];
K> arr[i] := arr[j];
K> arr[j] := temp;
K> Inc(i);
K> Dec(j);
K> end;
K> until i > j;
Очевидно, переставляем элементы внутри подмассива от i до j так, чтобы сначала шли все элементы меньше pivot, а потом — все элементы больше pivot.
Конкретнее:
1. Ищем слева элемент, >= pivot
2. Ищем справа элемент <= pivot
3. Меняем их местами, и сдвигаем границы на следующую пару элементов.
K>Как бы смутно уже понятно, но хочется чтобы кто-то сказал словами, так не придётся много думать.
Это вы зря. Мыслительный мускул нужно тренировать.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Re[8]: Оптимизация через разделение/вынос функционала
Здравствуйте, Khimik, Вы писали:
K>Здравствуйте, Sinclair, Вы писали:
S>>Очевидно, переставляем элементы внутри подмассива от i до j так, чтобы сначала шли все элементы меньше pivot, а потом — все элементы больше pivot. S>>Конкретнее: S>>1. Ищем слева элемент, >= pivot S>>2. Ищем справа элемент <= pivot S>>3. Меняем их местами, и сдвигаем границы на следующую пару элементов.
K>Ну ок, теперь вроде понятно. Хотя надо ещё проверить, нет ли в gpt-шном алгоритме потенциального бага — в левую или правую часть пойдут эти элементы, если оба они = pivot?
Если они оба == pivot, то алгоритм от chatGPT переставит их местами.
Это в чистом виде схема Хоара.
Т.е. как вы написали наверно уже неправильно, а это как GPT выдал; надо определиться что элементы, равные pivot, надо поместить например конкретно в левую часть
Зачем?
K>Кроме того, легко сделать ошибки, если например модифицировать этот алгоритм для указания ascending (сортировка по возрастанию или убыванию). Поэтому повторю моё мнение, что оптимальным является мой алгоритм в оп, он только в три раза медленнее gpt-шного, для 99.999% задач это неважно.
Простите, но оптимальным совершенно точно является использование коробочного алгоритма, а не выпиливание самодельных велосипедов.
Весь бизнес устроен примерно одинаково:
1. Определяетесь, в чём ваше core value. Это то, что именно вы делаете лучше других.
2. Всё, что относится к Core Value, вы делаете сами, и делаете как можно лучше.
3. Всё, что не относится к Core Value — вы делегируете (берёте готовое, покупаете покупное, етк).
Вот алгоритмы сортировки совершенно точно не являются вашей сильной стороной. Ну так и не надо тратить силы и время на их написание и отладку. Научитесь пользоваться готовыми алгоритмами, и пользуйтесь без стеснения.
K>Не так. Ресурсы мозга ограничены, если их экономить тут — можно больше потратить на другое.
В данном конкретном случае — всё верно. Но вы неверно тратите их на другое. "На другое" — это взять TArray.Sort() и не изобретать в очередной раз quicksort.
Тем более, что в таком подходе нетрудно гарантировать отсутствие ошибок, если например модифицировать этот алгоритм для указания ascending.
Потому что вся замена ascending на descending сводится к обращению знака у функции-компаратора.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Re[9]: Оптимизация через разделение/вынос функционала
Здравствуйте, Sinclair, Вы писали:
S>Тем более, что в таком подходе нетрудно гарантировать отсутствие ошибок, если например модифицировать этот алгоритм для указания ascending. S>Потому что вся замена ascending на descending сводится к обращению знака у функции-компаратора.
У меня есть довольно большой опыт написания и оптимизации разных алгоритмоы, и конкретно в данном случае я мог бы придраться, что если вы например для ascending=false будете менять < на > — вы уверены что надо именно на > а не на >=? Не спутаете? Этот стандартный алгоритм быстрой сортировки со схемой Хоара очень так сказать хрупкий, надо проверять каждый чих чтобы быть уверенным что он никогда не зависнет (и напомню что ChatGPT часто делает ошибки). Я так и не решился вставлять его в свою программу; может сделаю это в будущем если понадобится ещё ускорить быструю сортировку, а так мне хватит того что я написал. Если же буду вставлять — надо будет делать много тестов, чтобы убедиться что он никогда не зависнет.
Я конкретно к вам хорошо отношусь, но злит когда "профессиональные программеры" вроде вас учат не думать самому, и находить для всего готовые решения/библиотеки. Слово "велосипед" для них видите ли ругательное. Лично мне довольно часто приходится придумывать относительно сложные алгоритмы.
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
Re[3]: Оптимизация через разделение/вынос функционала
S>Создайте систему, которой сможет пользоваться дурак, и только дурак захочет ею пользоваться.
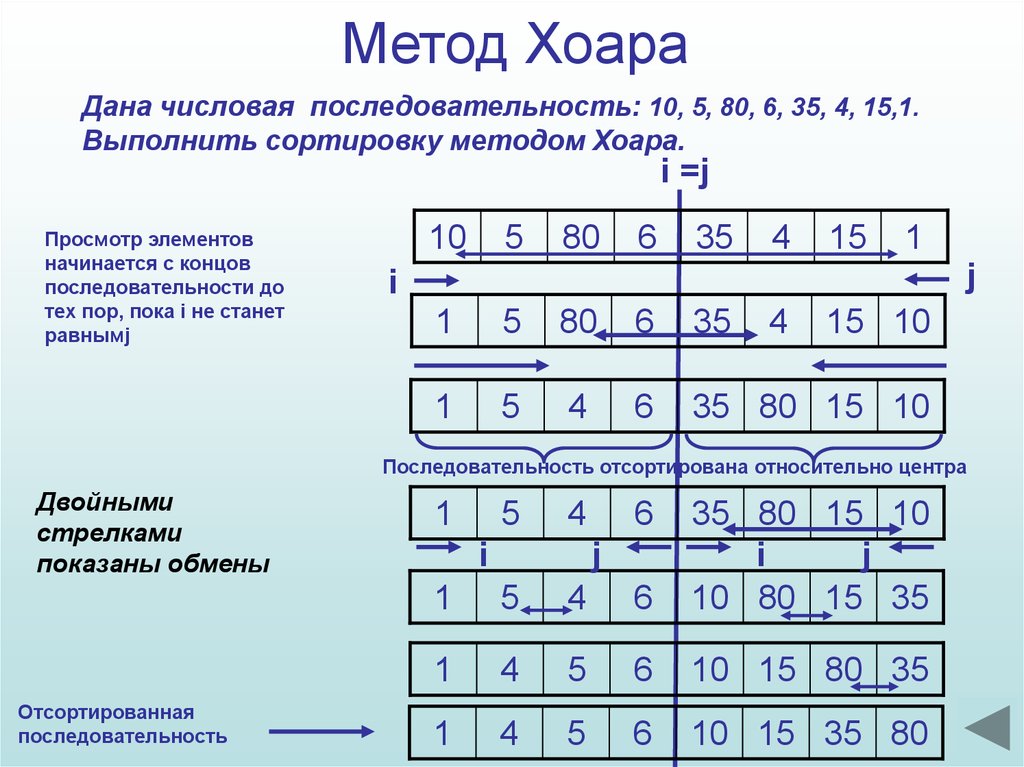
Вот в стандартном алгоритме со схемой Хоара есть фрагмент:
if i <= j then
begin
temp := arr[i];
arr[i] := arr[j];
arr[j] := temp;
Inc(i);
Dec(j);
end;
Как бы немного смущает, что если i=j, то алгоритм впустую произведёт обмен. Я попробовал заменить if i <= j then на if i < j then, ан нет — начались глюки. Такие подводные камни могут всё порушить в программе. Поэтому повторюсь что мой изначальный алгоритм, как мне кажется, во многих отношениях предпочтителен.
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
Re: Оптимизация через разделение/вынос функционала
Азарту ради, я написал код с сортировкой с использованием дополнительной памяти (деление интервала значений на секции):
Скрытый текст
procedure TDoubleArray.QSort10Sections;
const
SectionsCount=100;
var
sectionsize:integer;
Sections:array[0..SectionsCount-1] of tdoublearray;
q,w:integer;
minval,maxval:double;
interval:double;
begin
if fcount<300 then begin
QSort2GPT;
exit;
end;
minval:=MaxSafeFloat;
maxval:=-MaxSafeFloat;
for q:=0 to fcount-1 do begin
if fitems[q]<minval then minval:=fitems[q];
if fitems[q]>maxval then maxval:=fitems[q];
end;//next q
minval:=minval-minsafefloat;
maxval:=maxval+minsafefloat;
interval:=maxval-minval;
sectionsize:=fcount div sectionscount;
for q:=0 to sectionscount-1 do begin
sections[q]:=TDoubleArray.Create;
sections[q].Capacity:=sectionsize*10;
end;
for q:=0 to fcount-1 do begin
sections[floor((sectionscount-1)*(fitems[q]-minval)/interval)].Add(fitems[q]);
end;
count:=0;
for q:=0 to SectionsCount-1 do begin
sections[q].QSort10Sections;
for w:=0 to sections[q].fcount-1 do add(sections[q].fitems[w]);
sections[q].Free;
end;
end;
Прежде чем кликать по спойлеру, ответьте на вопрос — вы бы легко написали этот алгоритм?
Мой алгоритм вышел примерно на 30% быстрее стандартной быстрой сортировки со схемой Хоара. Памяти он расходует не особо много. А вы бы опять искали готовый алгоритм вместо голимого придумывания велосипеда?
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
Re[8]: Оптимизация через разделение/вынос функционала
Здравствуйте, Khimik, Вы писали:
K>Здравствуйте, swame, Вы писали:
S>> tdoublearray = class (TList<double>)
K>Сорри, что такое TList<double> ? Я попробовал это задать, подключил модуль system.classes и там можно сослаться только на просто tlist, т.е. это старый класс из Delphi7, без дженериков. А какой у вас Delphi?
System.Generics.Collections
поддерживается с Delphi 2009
Эти контейнеры развиваются от версии к версии, собранные более поздними версиями могут работать существенно быстрее, возможно в разы.
Есть такой чувак Дмитрий Мозулев, он раньше он был фанатом оптимизации, у него есть библиотека Rapid.Generics,
можно найти на гитхабе, в прежние времена (десятые года)его контейнеры обгоняли стандартные контейнеры Delphi в 2-4 раза,
в отличие от тебя прекрасно знает нутрянку Delphi и действительно в отличие от тебя может написать оптимизированнынй алгоритм.
НО последние годы стандартные контейнеры Delphi были хорошо оптимизированы и видимо догнали его контейнеры, я давно не тестил.
Теперь нет смысла оптимизировать на этом уровне, уже видимо оптимизировано близко к пределу.
K>Вы посмотрите, как в вашем TList обрабатывается SetCapacity — полагаю массив заполняется нулями, а это заведомо тормозит алгоритм.
ну посмотри если интересно, думаю едва ли больше 1% времени работы.
Здравствуйте, swame, Вы писали: S>System.Generics.Collections S>поддерживается с Delphi 2009
Ну да я посмотрел — там идёт заполнение нулями через стандартный setlength:
procedure TList<T>.SetCapacity(Value: Integer);
begin
if Value < Count then
Count := Value;
SetLength(FItems, Value);
end;
Поэтому и дольше. Я вставил ваш код, получилось что мой superqsort очень медленный — в три раза медленнее QuickSort, а QuickSort в полтора раза медленнее QSort10Sections. Мой же класс tdoublearray с процедурой QSort10Sections, код которого я приводил выше, работает ещё на 30% быстрее.
Вот ещё раз полностью мой код:
Скрытый текст
TDoubleArray=class(tsafeobject)
public
fcount:integer;
fcapacity:integer;
fitems:pdoublearr;
procedure SetCount(newcount:integer);
procedure SetCapacity(newcapacity:integer);
procedure Add(value:double);
procedure QSort2GPT;
procedure QSort10Sections;
property Count:integer read fcount write setcount;
property Capacity:integer read fcapacity write SetCapacity;
procedure Grow;
end;
procedure TDoubleArray.SetCount(newcount: integer);
begin
if newcount>fcapacity then setcapacity(newcount);
fcount := newcount;
end;
procedure TDoubleArray.SetCapacity(newcapacity: integer);
begin
if NewCapacity < fCount then
raise exception.Create('NewCapacity='+inttostr(NewCapacity));
if NewCapacity <> fCapacity then
begin
ReallocMem(fitems, NewCapacity * SizeOf(double));
FCapacity := NewCapacity;
end;
end;
procedure TDoubleArray.Add(value: double);
begin
fcount:=fcount+1;
if fcount>fcapacity then grow;
fitems^[fcount-1]:=value;
end;
procedure TDoubleArray.Grow;
begin
if fcapacity<100 then setcapacity(100) else
setcapacity(fcapacity*2);
end;
procedure TDoubleArray.QSort2GPT;
var
arr:array of double;
q:integer;
procedure QSort(low,high:integer);
var
i, j: Integer;
pivot, temp: double;
begin
i := low;
j := high;
pivot := arr[(low + high) div 2];
repeat
while arr[i] < pivot do
Inc(i);
while arr[j] > pivot do
Dec(j);
if i <= j then
begin
temp := arr[i];
arr[i] := arr[j];
arr[j] := temp;
Inc(i);
Dec(j);
end;
until i > j;
if low < j then
QSort(low, j);
if i < high then
QSort(i, high);
end;
begin
if count<=1 then exit;
setlength(arr,count);
for q:=0 to count-1 do arr[q]:=fitems[q];
qsort(0,count-1);
for q:=0 to count-1 do fitems[q]:=arr[q];
setlength(arr,0);
end;
procedure TDoubleArray.QSort10Sections;
const
SectionsCount=100;
var
sectionsize:integer;
Sections:array[0..SectionsCount-1] of tdoublearray;
q,w:integer;
minval,maxval:double;
interval:double;
begin
if fcount<300 then begin
QSort2GPT;
exit;
end;
minval:=MaxSafeFloat;
maxval:=-MaxSafeFloat;
for q:=0 to fcount-1 do begin
if fitems[q]<minval then minval:=fitems[q];
if fitems[q]>maxval then maxval:=fitems[q];
end;//next q
minval:=minval-minsafefloat;
maxval:=maxval+minsafefloat;
interval:=maxval-minval;
sectionsize:=fcount div sectionscount;
for q:=0 to sectionscount-1 do begin
sections[q]:=TDoubleArray.Create;
sections[q].Capacity:=sectionsize*10;
end;
for q:=0 to fcount-1 do begin
sections[floor((sectionscount-1)*(fitems[q]-minval)/interval)].Add(fitems[q]);
end;
count:=0;
for q:=0 to SectionsCount-1 do begin
sections[q].QSort10Sections;
for w:=0 to sections[q].fcount-1 do add(sections[q].fitems[w]);
sections[q].Free;
end;
end;
procedure TMainForm.Button9Click(Sender: TObject);
var
firsttime:longword;
q,w:integer;
curarray:tdoublearray;
begin
RandSeed :=0;
firsttime:=GetTickCount;
for q:=0 to 80 do begin
curarray:=tdoublearray.Create;
curarray.Capacity:=100000;
for w:=0 to 99999 do curarray.Add(random);
curarray.QSort10Sections;
curarray.Free;
end;//next q
caption:=inttostr(GetTickCount-firsttime);
end;
Учите матчасть.
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
Здравствуйте, swame, Вы писали: K>>tdoublearray.QSort2GPT — 1201 ms (это алгоритм от gpt который тут выкладывали, только с инициализацией вспомогательного массива arr в котором выполняется эта сортировка) S>А сколько QSort2GPT без ненужного дополнительного массива?
Это tdoublearray.QSort5GPTNoExtraArr, 1233 мс.
Там с одной стороны экономится время на копирование, но с другой стороны идёт обращение к свойству fitems класса tdoublearray, а это указатель на указатель на массивоуказатель. K>>tdoublearray.QSort5GPTNoExtraArr — 1233 ms (то же самое, только не используется вспомогательный массив, сразу запускается эта стандартная сортировка с Хоаром, обрабатывающая fitems класса tdoublearray) K>>tdoublearray1.superqsort — 8471 ms (tdoublearray1 это то что вы выложили, обертка над tlist<double>, мой алгоритм в оп) K>>tdoublearray1.QuickSortStandHoar — 2918 ms (стандартная сортировка с Хоаром, вызов QuickSort(0,count-1); ) S>непонятно что это, тот что я выкладывал или
Вот она:
Скрытый текст
procedure tdoublearray1.QuickSortStandHoar;
begin
QuickSort(0,count-1);
end;
procedure tdoublearray1.QuickSort(low, high: Integer);
var
i, j: Integer;
pivot, temp: double;
begin
i := low;
j := high;
pivot := Items[(low + high) div 2];
repeat
while Items[i] < pivot do
Inc(i);
while Items[j] > pivot do
Dec(j);
if i <= j then
begin
temp := Items[i];
Items[i] := Items[j];
Items[j] := temp;
Inc(i);
Dec(j);
end;
until i > j;
if low < j then
QuickSort(low, j);
if i < high then
QuickSort(i, high);
end;
Видимо это медленнее потому, что идёт обращение к items, а в моём варианте сначала создаётся массив и к нему обращаться можно быстрее (указатель на массив а не указатель на указатель на массив). S>Сколько QSort2GPT на tdoublearray1? Алгоритм который я выкладывал?
Вроде QuickSortStandHoar или QuickSort(0,count-1) это она и есть. S>Сколько стандартный sort на tdoublearray1? Вызов Sort
В смысле библиотечная функция? Я её не сравнивал, там же надо отдельно функцию-компаратор определить, мне это было лень. S>И кстати тест на 32 или 64 разрядах? Я делал на 32
У меня 64.
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
А что, на делфи не принято делать отступы для логических блоков в коде? Невозможно же читать эту простыню. Страшно даже представить, что у вас будет в реальных проектах.
Здравствуйте, Khimik, Вы писали:
K>Здравствуйте, Sinclair, Вы писали:
S>>Зато эти отступы позволяют быстро видеть границы "вертикальных" блоков, а не выискивать глазами очередной end среди нагромождения ключевых слов:
K>Я часто после end; пишу комментарий вроде //next q, так становится понятнее.
У меня мозг устроен как-то не так как у остальных людей; это проявляется в том, что я пытаюсь войти во все тусовки, немного ознакомиться со всеми точками зрения, и не избегаю когнитивного диссонанса а стремлюсь к нему. Это привело, в частности, к тому, что у меня есть невроз: какая-то часть моей психики находится на стороне паскалистов, и бывало, что я хотел произнести “плюсовики”, а чуть не оговорился сказав “крестобляди”. С этим можно жить, и как мне кажется это помогает мне понимать психологию астисишников-паскалистов.
Я очень развит духовно, и поэтому едва освоил Паскаль в 14 лет, как через считанные месяцы стал одним из самых продвинутых какиров в 9 классе, и даже тогда я понял, что надо ставить отступы.
Нет такой подлости и мерзости, на которую бы не пошёл gcc ради бессмысленных 5% скорости в никому не нужном синтетическом тесте
Здравствуйте, T4r4sB, Вы писали:
П>>Нет никакого желания холиварить с любителями медитировать над исходным кодом.
TB>Я люблю медитировать над полноценными дампами, где сразу вся необходимая инфа про состояние программы в данный момент
Я рад за тебя
TB>>>2. А что, разве генерация отладочной инфы поддерживает только номера строк, но не поддерживает номер символа в строке?
П>>Ты где-то такое видел?
TB>Да. Когда свой компилятор нового языка писал (через генерацию LLVM IR), то добавить туда отладочную инфу с номерами символов, которая ещё и нормально подхватывалась MSVC — оказалось совсем не сложно
Я рад за тебя
П>>Это удобно ещё и тем, что можно по-быстрому закоментить какую-то ветку, вставить альтернативную реализацию, проверить, и потом удалить либо новую версию, либо старую
TB>Закомментить ветку, вставить вывод лога итд — это несколько секунд, сборка занимает намного больше времени (крестопроблемы). Не знаю, как в Жабе, там наверное это действительно заметно.
Здравствуйте, пффф, Вы писали:
П>Да, в догонку. Твой полноценный дамп не расскажет, каким путем программа пришла в это состояние. И он также не расскажет, куда программа двинет дальше.
Да, бывает что приходится добавлять дополнительно отладочные принты. Но вообще код должен быть спроектирован так, чтоб в любой точке дамп позволял понять всё, что нужно.
Нет такой подлости и мерзости, на которую бы не пошёл gcc ради бессмысленных 5% скорости в никому не нужном синтетическом тесте
Здравствуйте, Sinclair, Вы писали:
П>>Вопрос был в том, где, в какой среде, в каком отладчике можно отлаживать плюсовый код по выражениям, а не по строкам? Простите, если краткая форма моего вопроса ввела вас в заблуждение S>Про плюсы, извините, не подскажу. Но всё, как верно заметил коллега T4r4sB, упирается в отладочные символы.
Ну вот когда в плюсы завезут отладочную информацию с позицией в строке, тогда и буду писать пачки выражений в одну строчку
По-моему кто-то давно уже говорил о Delphi, что если вам надо быстрый код — оптимизируйте алгоритм, остальное компилятор сделает сам.
Для оптимизации кода, как и вообще для написания серьёзного кода, желательно разбить код на фрагменты, "ортогональные" друг к другу, работающие независимо. Чтобы следовать этому принципу, приходится делать на первый взгляд не очень красивые вещи. Например, если мне надо сделать быструю сортировку, я не вставляю её алгоритм в то место где она нужна, а делаю примерно так:
tmparray:=tarray.create;
tmparray.count:=count;
for i:=0 to count-1 do tmparray.fitems[i]:=arr[i];
tmparray.superqsort;
for i:=0 to count-1 do arr[i]:=tmparray[i];
tmparray.free;
Раньше я не понимал принцип быстрой сортировки, а сейчас это кажется очень просто. Вот код, который я написал сходу; специально не тестировал, но уверен что в целом всё правильно:
procedure tdoublearray.superqsort;
var
q:integer;
sumval, midval, tmpval: double;
tmparray1, tmparray2: tdoublearray;
begin
if count<=1 then exit;
if count=2 then begin
if fitems[1]<fitems[0] then begin tmp:=fitems[1]; fitems[1]:=fitems[0]; fitems[0]:=tmp; end;
exit;
end;
sumval:=0;
for q:=0 to count do sumval:=sumval+fitems[q];
midval:=sumval/count;
tmparay1:=tdoublearray.create;
tmparray1.capacity:=count;
tmparray2:=tdoublearray.create;
tmparray2.capacity:=count;
for q:=0 to count-1 do if fitems[q]>midval then tmparray2.add(fitems[q]) else tmparray1.add(fitems[q]);
tmparray1.superqsort;
tmparray2.superqsort;
for q:=0 to tmparray1.count-1 do fitems[q]:=tmparray1.fitems[q];
for q:=0 to tmparray2.count-1 do fitems[tmparray1.count+q]:=tmparray2.fitems[q];
tmparray1.free;
tmparray2.free;
end;
Когда написал, понял что в этом коде есть маленький потенциальный баг, ну да это мелочи. На аналогичном принципе мне удалось ускорить в тысячу раз код, перебирающий атомы в брутто-формуле.
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
S>Измерений не делал, но по виду кода такой алгоритм будет на порядок — два медленнее стандартного дельфового, S>так как в нем огромное количество лишнего распределения памяти. S>Может использовал бы стандартный — ускорил бы в сто тыщ раз, и некрасивый код с копированием данных не понадобился. S>Сделай тест, сравни со стандартным. S>И нахрена писать все в строчку.
Понятно что тут лишние такты уходят на выделение памяти, обработку классов и присвоения; полагаю, этот код примерно в 2-5 раз медленнее стандартной быстрой сортировки. Но всё равно для больших массивов он в миллион раз быстрее простой сортировки из двух вложенных циклов. Я же говорю что аналогичным алгоритмом ускорил одну процедуру в своей программе где-то в тысячу раз. Ну а если надо ещё ускорить, наверно первичное — заменить класс на рекорд в Delphi, и ещё наверно держать временные массивы не с числами а с указателями (индексами для исходного массива).
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
Здравствуйте, Khimik, Вы писали:
K>Здравствуйте, swame, Вы писали:
S>>Измерений не делал, но по виду кода такой алгоритм будет на порядок — два медленнее стандартного дельфового, S>>так как в нем огромное количество лишнего распределения памяти. S>>Может использовал бы стандартный — ускорил бы в сто тыщ раз, и некрасивый код с копированием данных не понадобился. S>>Сделай тест, сравни со стандартным. S>>И нахрена писать все в строчку.
K>Понятно что тут лишние такты уходят на выделение памяти, обработку классов и присвоения; полагаю, этот код примерно в 2-5 раз медленнее стандартной быстрой сортировки. Но всё равно для больших массивов он в миллион раз быстрее простой сортировки из двух вложенных циклов. Я же говорю что аналогичным алгоритмом ускорил одну процедуру в своей программе где-то в тысячу раз. Ну а если надо ещё ускорить, наверно первичное — заменить класс на рекорд в Delphi, и ещё наверно держать временные массивы не с числами а с указателями (индексами для исходного массива).
tdoublearray = class (TList<double>)
Потестировал, взяв tdoublearray = class (TList<double>) и исправив несколько ошибок в коде
твой код сливает стандартной сортировке, которая вызывается в 1 строчку, в 1,5 раза примерно во всем диапазоне. я думал , будет больше.
возможно на твоих классах будет еще медленней, TList<> отлично оптимизирован.
И это еще не считая дополнительного копирования.
Кроме того nвой код рухает, если встречаются одинаковые значения, а на 50 млн уже Out of memory.
Попросил еще ChatGPT сгенерить банальный quicksort он работает в 2,5 — 3 раза быстрей стандарного, и никаких копирований памяти.
В тесте он quick
procedure tdoublearray.QuickSort(low, high: Integer);
var
i, j: Integer;
pivot, temp: double;
begin
i := low;
j := high;
pivot := Items[(low + high) div 2];
repeat
while Items[i] < pivot do
Inc(i);
while Items[j] > pivot do
Dec(j);
if i <= j then
begin
temp := Items[i];
Items[i] := Items[j];
Items[j] := temp;
Inc(i);
Dec(j);
end;
until i > j;
if low < j then
QuickSort(low, j);
if i < high then
QuickSort(i, high);
end;
Здравствуйте, swame, Вы писали:
S>Попросил еще ChatGPT сгенерить банальный quicksort он работает в 2,5 — 3 раза быстрей стандарного, и никаких копирований памяти.
Честно говоря я немного туплю, не до конца понял как работает этот алгоритм. Т.е. понятно что он делает подмассивы прямо в исходном массиве, чтобы сэкономить память, но далее не совсем ясно. Раз уж вы смастерили бенчмарку, оцените насколько быстрый этот код:
procedure TDoubleArray.QSort(Ascending:boolean);
var
arr1,arr2:array of double;
boolarr:array of boolean;
i:integer;
procedure DoQSort(intervalbeg,intervallast:integer);
var
curcount:integer;
sumval:double;
aveval:double;
ii:integer;
curvalscount:integer;
lowvalscount:integer;
tmpval:double;
begin
curcount:=intervallast-intervalbeg+1;
if curcount<=1 then exit;//Всего один элемент, сортировать не надоif curcount=2 then
begin
if (arr1[intervalbeg]<arr1[intervallast])<>ascending then
begin
tmpval:=arr1[intervalbeg];
arr1[intervalbeg]:=arr1[intervallast];
arr1[intervallast]:=tmpval
end;
exit;
end;
//Находим среднее значение в нашем интервале:
sumval:=0;
for ii:=intervalbeg to intervallast do sumval:=sumval+arr1[ii];
aveval:=sumval/curcount;
for ii:=intervalbeg to intervallast do boolarr[ii]:=(arr1[ii]<aveval);
//Помещаем элементы, меньшие aveval, в первую часть arr2:
curvalscount:=0;
for ii:=intervalbeg to intervallast do if boolarr[ii]=ascending then
begin
inc(curvalscount);
arr2[intervalbeg+curvalscount-1]:=arr1[ii];
end;
lowvalscount:=curvalscount;
if (lowvalscount=0) or (lowvalscount=curcount) then
exit;//Все элементы в интервале равны, сортировать нельзя
//Помещаем элементы, большие или равные aveval, в первую часть arr2:for ii:=intervalbeg to intervallast do if boolarr[ii]=not ascending then
begin
inc(curvalscount);
arr2[intervalbeg+curvalscount-1]:=arr1[ii];
end;
//Перемещаем arr2 в arr1:for ii:=intervalbeg to intervallast do arr1[ii]:=arr2[ii];
doqsort(intervalbeg,intervalbeg+lowvalscount-1);
doqsort(intervalbeg+lowvalscount,intervallast);
end;
begin
setlength(arr1,fcount);
setlength(arr2,fcount);
setlength(boolarr,fcount);
for i:=0 to fcount-1 do arr1[i]:=fitems^[i];
doqsort(0,fcount-1);
for i:=0 to fcount-1 do fitems^[i]:=arr1[i];
setlength(arr1,0);
setlength(arr2,0);
setlength(boolarr,0);
end;
Этот код длиннее кода от GPT, но мне кажется понятнее. Не всегда в программировании чем код меньше — тем лучше. Может ещё код от GPT быстрый потому, что ссылается на массив в виде локальной переменной в процедуре, а у меня до этого он ссылался на массив в классе.
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
Здравствуйте, Khimik, Вы писали:
K>По-моему кто-то давно уже говорил о Delphi, что если вам надо быстрый код — оптимизируйте алгоритм, остальное компилятор сделает сам.
delphi так себе оптимизировал код. K>Для оптимизации кода, как и вообще для написания серьёзного кода, желательно разбить код на фрагменты, "ортогональные" друг к другу, работающие независимо.
Тут очень широкая тема. И так просто она не решается. Так как процессоры уже давно спекулятивные, память очень медленная, есть куча ухищрений что бы это нивилировать, множество вычислений могут быть выполнены на gpgpu с десятками тысяч ядер. Поэтому обычно не заморачиваются а используют уже оптимизированный код под определённые типовые задачи.
K>Чтобы следовать этому принципу, приходится делать на первый взгляд не очень красивые вещи.
Оптимизированный код обычно страшный и тяжело поддерживаемый. Поэтому это сваливают на компиляторы
K>Например, если мне надо сделать быструю сортировку, я не вставляю её алгоритм в то место где она нужна, а делаю примерно так:
если вам приходится так делать посмотрите другие языки где так не надо делать, например fortran
Re[5]: Оптимизация через разделение/вынос функционала
Здравствуйте, m2user, Вы писали:
S>>Попросил еще ChatGPT сгенерить банальный quicksort он работает в 2,5 — 3 раза быстрей стандарного, и никаких копирований памяти.
M>Но есть рекурсия.
Рекурсия есть во всех 3 вариантах, не вижу проблемы.
M>Вообще странно, что быстрее стандартного.
Стандартный код написал для дженириков с вызовами Comparer, большой оверхед на универсальность,
вариант GPT чисто для double так что вполне объяснимо.
Кто будет писать код под миллиардные массивы, будет оптимизировать под свой случай.
Re[5]: Оптимизация через разделение/вынос функционала
Здравствуйте, Khimik, Вы писали:
K>Здравствуйте, swame, Вы писали:
S>>Попросил еще ChatGPT сгенерить банальный quicksort он работает в 2,5 — 3 раза быстрей стандарного, и никаких копирований памяти.
K>Честно говоря я немного туплю, не до конца понял как работает этот алгоритм. Т.е. понятно что он делает подмассивы прямо в исходном массиве, чтобы сэкономить память, но далее не совсем ясно.
Не только память но и время.
K>Раз уж вы смастерили бенчмарку, оцените насколько быстрый этот код:
Извини время больше не буду тратить на эти эксперименты уровня первокурсника. Пиши тесты сам.
Просмотрел код принципиально то де что в предыдущем варианте те же лишние выделения памяти, с чего ему быть быстрее.
И по понятности он ужасен.
K>Этот код длиннее кода от GPT, но мне кажется понятнее. Не всегда в программировании чем код меньше — тем лучше.
Код GPT по-моему идеальный. Советую с ним разобраться и научиться писать так.
K>Может ещё код от GPT быстрый потому, что ссылается на массив в виде локальной переменной в процедуре, а у меня до этого он ссылался на массив в классе.
не из за этого. я написал что у тебя тормоза из-за выделений памяти.
Re[2]: Оптимизация через разделение/вынос функционала
Здравствуйте, kov_serg, Вы писали:
_>Здравствуйте, Khimik, Вы писали:
K>>По-моему кто-то давно уже говорил о Delphi, что если вам надо быстрый код — оптимизируйте алгоритм, остальное компилятор сделает сам. _>delphi так себе оптимизировал код.
Я как химик лет 10-20 назад тоже писал свои контейнеры, алгоритмы Delphi, но в отличие от химика они действительно были быстрей чем библиотечные функции того времени, часто в 2-5 раз. НО библиотеки Delphi совершенствуются, от версии к версии, и сейчас догнали мои наработки и превзошли. Так что я теперь постепенно выкидываю свои старые классы, заменяя на стандартные, которые отлично оптимизированы. Но их надо знать конечно "под капотом".
K>>Например, если мне надо сделать быструю сортировку, я не вставляю её алгоритм в то место где она нужна, а делаю примерно так: _>если вам приходится так делать посмотрите другие языки где так не надо делать, например fortran
В Delphi это тоже не надо делать, стандартный quicksort вызывается одной строчкой , химик просто не знает и пишет велосипед.
Ладно, мне захотелось проверить и я написал свою бенчмарку:
Бенчмарка
procedure TMainForm.Button9Click(Sender: TObject);
var
firsttime:longword;
q,w:integer;
curarray:tdoublearray;
begin
firsttime:=GetTickCount;
for q:=0 to 800 do begin
curarray:=tdoublearray.Create;
curarray.Capacity:=10000;
for w:=0 to 9999 do curarray.Add(random);
curarray.QSort1Old;
curarray.Free;
end;//next q
caption:=inttostr(GetTickCount-firsttime);
end;
Мой изначальный код из оп (исправил ошибки)
procedure TDoubleArray.QSort1Old;
var
q:integer;
sumval, midval, tmpval: double;
tmparray1, tmparray2: tdoublearray;
tmp:double;
begin
if count<=1 then exit;
if count=2 then begin
if fitems[1]<fitems[0] then begin tmp:=fitems[1]; fitems[1]:=fitems[0]; fitems[0]:=tmp; end;
exit;
end;
sumval:=0;
for q:=0 to count-1 do sumval:=sumval+fitems[q];
midval:=sumval/count;
tmparray1:=tdoublearray.create;
tmparray1.capacity:=count;
tmparray2:=tdoublearray.create;
tmparray2.capacity:=count;
for q:=0 to count-1 do if fitems[q]>midval then tmparray2.add(fitems[q]) else tmparray1.add(fitems[q]);
tmparray1.QSort1Old;
tmparray2.QSort1Old;
for q:=0 to tmparray1.count-1 do fitems[q]:=tmparray1.fitems[q];
for q:=0 to tmparray2.count-1 do fitems[tmparray1.count+q]:=tmparray2.fitems[q];
tmparray1.free;
tmparray2.free;
end;
2.855 секунды.
Алгоритм GPT
procedure TDoubleArray.QSort2GPT;
var
arr:array of double;
q:integer;
procedure QSort(low,high:integer);
var
i, j: Integer;
pivot, temp: double;
begin
i := low;
j := high;
pivot := arr[(low + high) div 2];
repeat
while arr[i] < pivot do
Inc(i);
while arr[j] > pivot do
Dec(j);
if i <= j then
begin
temp := arr[i];
arr[i] := arr[j];
arr[j] := temp;
Inc(i);
Dec(j);
end;
until i > j;
if low < j then
QSort(low, j);
if i < high then
QSort(i, high);
end;
begin
setlength(arr,count);
for q:=0 to count-1 do arr[q]:=fitems[q];
qsort(0,count-1);
for q:=0 to count-1 do fitems[q]:=arr[q];
setlength(arr,0);
end;
0.983 секунды
Мой чуть улучшенный алгоритм из последнего поста
procedure TDoubleArray.QSort3My;
var
arr1,arr2:array of double;
boolarr:array of boolean;
i:integer;
procedure DoQSort(intervalbeg,intervallast:integer);
var
curcount:integer;
sumval:double;
aveval:double;
ii:integer;
curvalscount:integer;
lowvalscount:integer;
tmpval:double;
begin
curcount:=intervallast-intervalbeg+1;
if curcount<=1 then exit;//Всего один элемент, сортировать не надоif curcount=2 then
begin
if (arr1[intervalbeg]<arr1[intervallast])<>true then
begin
tmpval:=arr1[intervalbeg];
arr1[intervalbeg]:=arr1[intervallast];
arr1[intervallast]:=tmpval
end;
exit;
end;
//Находим среднее значение в нашем интервале:
sumval:=0;
for ii:=intervalbeg to intervallast do sumval:=sumval+arr1[ii];
aveval:=sumval/curcount;
for ii:=intervalbeg to intervallast do boolarr[ii]:=(arr1[ii]<aveval);
//Помещаем элементы, меньшие aveval, в первую часть arr2:
curvalscount:=0;
for ii:=intervalbeg to intervallast do if boolarr[ii]=true then
begin
inc(curvalscount);
arr2[intervalbeg+curvalscount-1]:=arr1[ii];
end;
lowvalscount:=curvalscount;
if (lowvalscount=0) or (lowvalscount=curcount) then
exit;//Все элементы в интервале равны, сортировать нельзя
//Помещаем элементы, большие или равные aveval, в первую часть arr2:for ii:=intervalbeg to intervallast do if boolarr[ii]=not true then
begin
inc(curvalscount);
arr2[intervalbeg+curvalscount-1]:=arr1[ii];
end;
//Перемещаем arr2 в arr1:for ii:=intervalbeg to intervallast do arr1[ii]:=arr2[ii];
doqsort(intervalbeg,intervalbeg+lowvalscount-1);
doqsort(intervalbeg+lowvalscount,intervallast);
end;
begin
setlength(arr1,fcount);
setlength(arr2,fcount);
setlength(boolarr,fcount);
for i:=0 to fcount-1 do arr1[i]:=fitems^[i];
doqsort(0,fcount-1);
for i:=0 to fcount-1 do fitems^[i]:=arr1[i];
setlength(arr1,0);
setlength(arr2,0);
setlength(boolarr,0);
end;
2.371 секунды.
Да, GPT алгоритм хорошо работает: то ли потому что не использует вычисления с плавающей точкой, то ли потому что не выделяет дополнительную память для массива, то ли сам алгоритм в принципе лучше — честно говоря я ещё до конца не понял что это за строки Inc(i); Dec(j);. А вы поняли?
Надо ещё протестировать. S>В Delphi это тоже не надо делать, стандартный quicksort вызывается одной строчкой , химик просто не знает и пишет велосипед.
Ну и как он вызывается?
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
Re[4]: Оптимизация через разделение/вынос функционала
Здравствуйте, Khimik, Вы писали:
K>2.371 секунды.
K>Да, GPT алгоритм хорошо работает: то ли потому что не использует вычисления с плавающей точкой, то ли потому что не выделяет дополнительную память для массива, то ли сам алгоритм в принципе лучше — честно говоря я ещё до конца не понял что это за строки Inc(i); Dec(j);. А вы поняли? K>Надо ещё протестировать.
Стандартный алгоритм из Delphi использует примерно такой же код. Но он медленней из-за универcальности.
class procedure TArray.QuickSort<T>(var Values: array of T; const Comparer: IComparer<T>;
L, R: Integer);
var
I, J: Integer;
pivot, temp: T;
begin
if L < R then
begin
repeat
if (R - L) = 1 then
begin
if Comparer.Compare(Values[L], Values[R]) > 0 then
begin
temp := Values[L];
Values[L] := Values[R];
Values[R] := temp;
end;
break;
end;
I := L;
J := R;
pivot := Values[L + (R - L) shr 1];
repeat
while Comparer.Compare(Values[I], pivot) < 0 do
Inc(I);
while Comparer.Compare(Values[J], pivot) > 0 do
Dec(J);
if I <= J then
begin
if I <> J then
begin
temp := Values[I];
Values[I] := Values[J];
Values[J] := temp;
end;
Inc(I);
Dec(J);
end;
until I > J;
if (J - L) > (R - I) then
begin
if I < R then
QuickSort<T>(Values, Comparer, I, R);
R := J;
end
else
begin
if L < J then
QuickSort<T>(Values, Comparer, L, J);
L := I;
end;
until L >= R;
end;
end;
Здравствуйте, swame, Вы писали:
S>Стандартный алгоритм из Delphi использует примерно такой же код. Но он медленней из-за универcальности.
Я понял что мой алгоритм был медленнее gpt-шного из-за операций с плавающей точкой (вычисление среднего). Вот ещё его поправил, заменил на среднее по минимальному и максимальному значению:
procedure TDoubleArray.QSort4MyNoFloatSum;
var
arr1,arr2:array of double;
boolarr:array of boolean;
i:integer;
procedure DoQSort(intervalbeg,intervallast:integer; hasminval,hasmaxval:boolean; minval,maxval:double);
const
MaxFloat=1E50;
var
curcount:integer;
aveval:double;
ii:integer;
curvalscount:integer;
lowvalscount:integer;
tmpval:double;
begin
curcount:=intervallast-intervalbeg+1;
if curcount<=1 then exit;//Всего один элемент, сортировать не надоif curcount=2 then
begin
if (arr1[intervalbeg]<arr1[intervallast])<>true then
begin
tmpval:=arr1[intervalbeg];
arr1[intervalbeg]:=arr1[intervallast];
arr1[intervallast]:=tmpval
end;
exit;
end;
if not hasminval then
begin
minval:=MaxFloat;
for ii:=intervalbeg to intervallast do if arr1[ii]<minval then minval:=arr1[ii];
end;
if not hasminval then
begin
maxval:=-MaxFloat;
for ii:=intervalbeg to intervallast do if arr1[ii]>maxval then maxval:=arr1[ii];
end;
aveval:=(minval+maxval)*0.5;
for ii:=intervalbeg to intervallast do boolarr[ii]:=(arr1[ii]<aveval);
//Помещаем элементы, меньшие aveval, в первую часть arr2:
curvalscount:=0;
for ii:=intervalbeg to intervallast do if boolarr[ii]=true then
begin
inc(curvalscount);
arr2[intervalbeg+curvalscount-1]:=arr1[ii];
end;
lowvalscount:=curvalscount;
if (lowvalscount=0) or (lowvalscount=curcount) then
exit;//Все элементы в интервале равны, сортировать нельзя
//Помещаем элементы, большие или равные aveval, в первую часть arr2:for ii:=intervalbeg to intervallast do if boolarr[ii]=not true then
begin
inc(curvalscount);
arr2[intervalbeg+curvalscount-1]:=arr1[ii];
end;
//Перемещаем arr2 в arr1:for ii:=intervalbeg to intervallast do arr1[ii]:=arr2[ii];
doqsort(intervalbeg,intervalbeg+lowvalscount-1,true,false,minval,0);
doqsort(intervalbeg+lowvalscount,intervallast,false,true,0,maxval);
end;
begin
setlength(arr1,fcount);
setlength(arr2,fcount);
setlength(boolarr,fcount);
for i:=0 to fcount-1 do arr1[i]:=fitems^[i];
doqsort(0,fcount-1,false,false,0,0);
for i:=0 to fcount-1 do fitems^[i]:=arr1[i];
setlength(arr1,0);
setlength(arr2,0);
setlength(boolarr,0);
end;
С этим кодом получилось 0.484 секунды, т.е. в два раза быстрее GPT-шного. С другой стороны мой алгоритм использует больше памяти. Если честно, я туплю и не понял до сих пор что там выполняется в GPT-шном или стандартном алгоритме, можете словами сформулировать? Я конечно могу и сам понять, только лень скрипеть мозгами.
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
Re[6]: Оптимизация через разделение/вынос функционала
Здравствуйте, Khimik, Вы писали:
K>Здравствуйте, swame, Вы писали:
S>>Стандартный алгоритм из Delphi использует примерно такой же код. Но он медленней из-за универcальности.
K>С этим кодом получилось 0.484 секунды, т.е. в два раза быстрее GPT-шного. С другой стороны мой алгоритм использует больше памяти. Если честно, я туплю и не понял до сих пор что там выполняется в GPT-шном или стандартном алгоритме, можете словами сформулировать? Я конечно могу и сам понять, только лень скрипеть мозгами.
А ты проверил свой алгоритм?
ОН cортирует правильно? Результат совпадает со стандартным? отрабатывает совпадающие значения?
Когда проверишь посмотрю, хотя что он быстрей верится слабо.
Re[6]: Оптимизация через разделение/вынос функционала
K> Если честно, я туплю и не понял до сих пор что там выполняется в GPT-шном или стандартном алгоритме, можете словами сформулировать? Я конечно могу и сам понять, только лень скрипеть мозгами
В википедии есть статья QuickSort. Там и анимация и объяснение.
Нет такой подлости и мерзости, на которую бы не пошёл gcc ради бессмысленных 5% скорости в никому не нужном синтетическом тесте
Re[7]: Оптимизация через разделение/вынос функционала
Здравствуйте, swame, Вы писали:
S>А ты проверил свой алгоритм? S>ОН cортирует правильно? Результат совпадает со стандартным? отрабатывает совпадающие значения? S>Когда проверишь посмотрю, хотя что он быстрей верится слабо.
Проверил. Ох, да, сорри, в моём коде с процедурой QSort4MyNoFloatSum ошибка (второй if not hasminval then надо заменить на if not hasmaxval then). Сейчас он делает правильно, но длится это 2.558 секунд, т.е. даже чуть медленнее моего кода с подсчётом среднего. Буду разбираться дальше.
Вы можете сейчас сказать, почему стандартная/gpt сортировка выполняется быстрее моей? Понимаете её суть? Как я уже сказал, мне пока чуть лень скрипеть мозгами.
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
K>> Если честно, я туплю и не понял до сих пор что там выполняется в GPT-шном или стандартном алгоритме, можете словами сформулировать? Я конечно могу и сам понять, только лень скрипеть мозгами
TB>В википедии есть статья QuickSort. Там и анимация и объяснение.
Начал читать, тоже немного лень вникать. У меня сейчас такой вопрос: вот этот код в GPT-алгоритме — это разбиение Ломуто или схема Хоара или что-то другое?
repeat
while arr[i] < pivot do
Inc(i);
while arr[j] > pivot do
Dec(j);
if i <= j then
begin
temp := arr[i];
arr[i] := arr[j];
arr[j] := temp;
Inc(i);
Dec(j);
end;
until i > j;
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
Re[8]: Оптимизация через разделение/вынос функционала
Посмотрел другие варианты размера сортируемого массива: вроде соотношение времени работы алгоритмов не зависит, или почти не зависит, от размера массива. Всегда мой алгоритм с подсчётом среднего (QSort3My) работает примерно в 1.3 раза медленнее GPT-шного. Предлагаю проанализировать, почему так.
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
Re[4]: Оптимизация через разделение/вынос функционала
Здравствуйте, Khimik, Вы писали:
K>Да, GPT алгоритм хорошо работает: то ли потому что не использует вычисления с плавающей точкой, то ли потому что не выделяет дополнительную память для массива, то ли сам алгоритм в принципе лучше — честно говоря я ещё до конца не понял что это за строки Inc(i); Dec(j);. А вы поняли?
Это вызовы стандартных процедур ещё Виртовского Паскаля по инкременту и декременту целых значений.
Реализованы они потому, что в Паскале нет ни compound assignment, ни операторов инкремента/декремента, как в C-подобных языках.
Поэтому приходится писать не i++, а i:= i + 1. Это громоздко и неудобно, если инкрементируемое выражение длинное, и вычисляется с побочными эффектами.
Так что для достижения того же эффекта, что и в C, в Паскаль были добавлены магические процедуры Inc и Dec, а также магические функции Succ и Pred.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Re[5]: Оптимизация через разделение/вынос функционала
Здравствуйте, Sinclair, Вы писали:
K>>Да, GPT алгоритм хорошо работает: то ли потому что не использует вычисления с плавающей точкой, то ли потому что не выделяет дополнительную память для массива, то ли сам алгоритм в принципе лучше — честно говоря я ещё до конца не понял что это за строки Inc(i); Dec(j);. А вы поняли? S>Это вызовы стандартных процедур ещё Виртовского Паскаля по инкременту и декременту целых значений. S>Реализованы они потому, что в Паскале нет ни compound assignment, ни операторов инкремента/декремента, как в C-подобных языках. S>Поэтому приходится писать не i++, а i:= i + 1. Это громоздко и неудобно, если инкрементируемое выражение длинное, и вычисляется с побочными эффектами. S>Так что для достижения того же эффекта, что и в C, в Паскаль были добавлены магические процедуры Inc и Dec, а также магические функции Succ и Pred.
А, ну это я конечно знаю, сорри что не спросил понятно спросил. Мой вопрос был — что делает этот фрагмент процедуры:
repeat
while arr[i] < pivot do
Inc(i);
while arr[j] > pivot do
Dec(j);
if i <= j then
begin
temp := arr[i];
arr[i] := arr[j];
arr[j] := temp;
Inc(i);
Dec(j);
end;
until i > j;
Как бы смутно уже понятно, но хочется чтобы кто-то сказал словами, так не придётся много думать.
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
Re[7]: Оптимизация через разделение/вынос функционала
Здравствуйте, Sinclair, Вы писали:
S>Очевидно, переставляем элементы внутри подмассива от i до j так, чтобы сначала шли все элементы меньше pivot, а потом — все элементы больше pivot. S>Конкретнее: S>1. Ищем слева элемент, >= pivot S>2. Ищем справа элемент <= pivot S>3. Меняем их местами, и сдвигаем границы на следующую пару элементов.
Ну ок, теперь вроде понятно. Хотя надо ещё проверить, нет ли в gpt-шном алгоритме потенциального бага — в левую или правую часть пойдут эти элементы, если оба они = pivot? Т.е. как вы написали наверно уже неправильно, а это как GPT выдал; надо определиться что элементы, равные pivot, надо поместить например конкретно в левую часть, тогда надо наверно так:
repeat
while arr[i] <= pivot do
Inc(i);
while arr[j] > pivot do
Dec(j);
if i < j then
begin
temp := arr[i];
arr[i] := arr[j];
arr[j] := temp;
Inc(i);
Dec(j);
end;
until i >= j;
И я заменил if i <= j then на if i < j then, это не был баг но чуть некрасиво.
Кроме того, легко сделать ошибки, если например модифицировать этот алгоритм для указания ascending (сортировка по возрастанию или убыванию). Поэтому повторю моё мнение, что оптимальным является мой алгоритм в оп, он только в три раза медленнее gpt-шного, для 99.999% задач это неважно. Ну а если уж очень надо оптимизировать — тогда можно заменить его на gpt-шный.
K>>Как бы смутно уже понятно, но хочется чтобы кто-то сказал словами, так не придётся много думать. S>Это вы зря. Мыслительный мускул нужно тренировать.
Не так. Ресурсы мозга ограничены, если их экономить тут — можно больше потратить на другое.
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
Я обнаружил ошибку в своём исходном алгоритме в оп: он может зависнуть, если в массиве много одинаковых элементов. Вот исправленный вариант:
procedure TDoubleArray.QSort1Old;
var
q:integer;
sumval, midval, tmpval: double;
tmparray1, tmparray2: tdoublearray;
begin
if count<=1 then exit;
if count=2 then begin
if fitems[1]<fitems[0] then begin tmpval:=fitems[1]; fitems[1]:=fitems[0]; fitems[0]:=tmpval; end;
exit;
end;
sumval:=0;
for q:=0 to count-1 do sumval:=sumval+fitems[q];
midval:=sumval/count;
tmparray1:=tdoublearray.create;
tmparray1.capacity:=count;
tmparray2:=tdoublearray.create;
tmparray2.capacity:=count;
for q:=0 to count-1 do if fitems[q]>midval then tmparray2.add(fitems[q]) else tmparray1.add(fitems[q]);
if tmparray1.Count=0 then begin tmparray1.free; tmparray2.free; exit; end;
if tmparray2.Count=0 then begin tmparray1.free; tmparray2.free; exit; end;
tmparray1.QSort1Old;
tmparray2.QSort1Old;
for q:=0 to tmparray1.count-1 do fitems[q]:=tmparray1.fitems[q];
for q:=0 to tmparray2.count-1 do fitems[tmparray1.count+q]:=tmparray2.fitems[q];
tmparray1.free;
tmparray2.free;
end;
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
Re[6]: Оптимизация через разделение/вынос функционала
K>Как бы смутно уже понятно, но хочется чтобы кто-то сказал словами, так не придётся много думать.
Это прекрасно. Человек, который не любит думать, считает себя интеллектуалом и постоянно выдвигает теории космического масштаба о том, как нам надо жить
Re[8]: Оптимизация через разделение/вынос функционала
Здравствуйте, Khimik, Вы писали:
K>Кроме того, легко сделать ошибки, если например модифицировать этот алгоритм для указания ascending (сортировка по возрастанию или убыванию).
Компаратор на входе задаётся и всё. Хз как это в ваших делфях
K>Поэтому повторю моё мнение, что оптимальным является мой алгоритм в оп, он только в три раза медленнее gpt-шного, для 99.999% задач это неважно.
Нда... Такого же качества и твои идеи по переустройству мира
K>Не так. Ресурсы мозга ограничены, если их экономить тут — можно больше потратить на другое.
Какой-то хиленький у вас мыслительный мускул, раз написание сортировки вызывает его перерасход. Зарядку, видимо, по той же причине не делаете, чтобы не расходовать зря мускульный ресурс, а то потом ведь надо затылок чесать, придумывая теории мироустройства, а сил на это уже не будет
Re: Оптимизация через разделение/вынос функционала
Мой нелепый алгоритм в оп можно легко объяснить в словах:
1) Находим среднее значение в массиве;
2) Создаём два вспомогательных массива;
3) Значения в исходном массиве, которые меньше среднего, помещаем в первый вспомогательный массив, а которые больше — во второй;
4) Рекурсивно сортируем оба вспомогательных массива;
5) Переливаем в исходный массив сначала первый вспомогательный, потом второй;
6) Удаляем вспомогательные массивы.
А вы могли бы так же просто изложить стандартный алгоритм быстрой сортировки со схемой Хоара?
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
Re[2]: Оптимизация через разделение/вынос функционала
Здравствуйте, Khimik, Вы писали:
K>Мой нелепый алгоритм в оп можно легко объяснить в словах: K>1) Находим среднее значение в массиве; K>2) Создаём два вспомогательных массива; K>3) Значения в исходном массиве, которые меньше среднего, помещаем в первый вспомогательный массив, а которые больше — во второй; K>4) Рекурсивно сортируем оба вспомогательных массива; K>5) Переливаем в исходный массив сначала первый вспомогательный, потом второй; K>6) Удаляем вспомогательные массивы.
Здравствуйте, Khimik, Вы писали:
K> Мой алгоритм вышел примерно на 30% быстрее стандартной быстрой сортировки со схемой Хоара. Памяти он расходует не особо много. А вы бы опять искали готовый алгоритм вместо голимого придумывания велосипеда?
Ну вот смотри реализацию сортировки в jdk. Полагаю, что в этот код вложено несколько человеколет и защищено несколько кандидатских.
Ты правда надеешься придумать что-то лучшее самостоятельно?
Здравствуйте, Khimik, Вы писали:
K>Азарту ради, я написал код с сортировкой с использованием дополнительной памяти (деление интервала значений на секции):
K>end; K>[/pascal] K>[/cut]
K>Прежде чем кликать по спойлеру, ответьте на вопрос — вы бы легко написали этот алгоритм?
Абы какую сортировку написал бы легко. Чтобы он реально обогнал алгоритмы рекордсмены — вряд ли.
K>Мой алгоритм вышел примерно на 30% быстрее стандартной быстрой сортировки со схемой Хоара. Памяти он расходует не особо много. А вы бы опять искали готовый алгоритм вместо голимого придумывания велосипеда?
Учитывая предыдущий опыт думаю что ты опять морочишь голову. Либо не работает, либо некорректный тест.
Тут содержится некий QSort2GPT. Это что ?
30% по сравнению с QSort2GPT или TList <double>.Sort?
Здравствуйте, swame, Вы писали:
S>Учитывая предыдущий опыт думаю что ты опять морочишь голову. Либо не работает, либо некорректный тест.
Я проверил, работает правильно.
S>Тут содержится некий QSort2GPT. Это что ?
Это сортировка от ChatGPT (с Хоаром) которую выложили в этой теме выше. Т.е. строго говоря я не заменил быструю сортировку с Хоаром своим алгоритмом, с совместил свой алгоритм с ней. А вам даже непонятно о чём речь? Алгоритм мой можете распарсить?
S>30% по сравнению с QSort2GPT или TList <double>.Sort?
По сравнению с QSort2GPT.
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
Re[4]: Оптимизация через разделение/вынос функционала
Здравствуйте, Khimik, Вы писали:
K>Здравствуйте, swame, Вы писали:
S>>Учитывая предыдущий опыт думаю что ты опять морочишь голову. Либо не работает, либо некорректный тест.
K>Я проверил, работает правильно.
Исправил ошибки опять
S>>Тут содержится некий QSort2GPT. Это что ?
K>Это сортировка от ChatGPT (с Хоаром) которую выложили в этой теме выше. Т.е. строго говоря я не заменил быструю сортировку с Хоаром своим алгоритмом, с совместил свой алгоритм с ней. А вам даже непонятно о чём речь? Алгоритм мой можете распарсить?
S>>30% по сравнению с QSort2GPT или TList <double>.Sort?
K>По сравнению с QSort2GPT.
Мой тест показал, что твой алгоритм сопоставим по +/- по скорости со стандартным TList <double>.Sort
(как раз из за того что внутри использует QSort2GPT)
и, как и прежде в 2-5 раз медленней quick QSort2GPT.
При этом расходует в 100 раз и больше памяти. на 5 млн элементов уже переполняет память.
ты просто замедлил отсебятиной QSort2GPT
Так что на помойку и хватит бредить.
Здравствуйте, Khimik, Вы писали: K>Здравствуйте, swame, Вы писали: S>>Мой тест показал, что твой алгоритм сопоставим по +/- по скорости со стандартным TList <double>.Sort S>>(как раз из за того что внутри использует QSort2GPT) S>>и, как и прежде в 2-5 раз медленней quick QSort2GPT. S>>При этом расходует в 100 раз и больше памяти. на 5 млн элементов уже переполняет память. S>>ты просто замедлил отсебятиной QSort2GPT S>>Так что на помойку и хватит бредить. K>А вы покажите полностью код для вашего теста. Могу предположить, что ваш вариант медленнее из-за заполнения нулями динамических массивов при инициализации. У меня используется мой класс tdoublearray, представляющий собой кастомный динамический массив:
Скрытый текст
tdoublearray = class (TList<double>)
boolarr:array of boolean;
arr2:array of double;
procedure superqsort;
procedure Log (FN: string; bCnt: boolean=true);
procedure QuickSort(low, high: Integer);
procedure QSort4;
procedure QSort10Sections;
procedure DoQSort(intervalbeg,intervallast:integer; hasminval,hasmaxval:boolean; minval,maxval:double);
end;
procedure tdoublearray.Log (FN: string; bCnt: boolean=true);
var
S, SCNT: string;
i: integer;
SA: TStringArray;
begin
SetLength (SA, count);
for i := 0 to count-1 do begin
SA [i] := Items[i].ToString;
end;
S := JoinStr (SA, ' ');
if bCnt then
SCNT := count.ToString
else
SCNT := '';
LOgger.AppendS (FN+'_'+SCNT + '.txt', S);
end;
procedure tdoublearray.superqsort;
var
q:integer;
sumval, midval, tmpval: double;
tmparray1, tmparray2: tdoublearray;
tmp: double;
begin//Log;if count<=1 then exit;
if count=2 then begin
if items[1]<items[0] then begin
tmp:=items[1];
items[1]:=items[0];
items[0]:=tmp;
end;
exit;
end;
sumval:=0;
for q:=0 to count-1 do
sumval:=sumval+items[q];
midval:=sumval/count;
tmparray1:=tdoublearray.create;
tmparray1.capacity:=count;
tmparray2:=tdoublearray.create;
tmparray2.capacity:=count;
for q:=0 to count-1 do begin
if items[q]>midval then
tmparray2.add(items[q])
else
tmparray1.add(items[q]);
end;
tmparray1.superqsort;
tmparray2.superqsort;
for q:=0 to tmparray1.count-1 do
items[q]:=tmparray1.items[q];
for q:=0 to tmparray2.count-1 do
items[tmparray1.count+q]:=tmparray2.items[q];
tmparray1.free;
tmparray2.free;
end;
procedure tdoublearray.QSort4;
begin
setlength(arr2,count);
setlength(boolarr,count);
DoQSort(0, count-1,false,false,0,0);
setlength(arr2,0);
setlength(boolarr,0);
end;
procedure tdoublearray.DoQSort(intervalbeg,intervallast:integer; hasminval,hasmaxval:boolean; minval,maxval:double);
const
MaxFloat=1E50;
var
curcount:integer;
aveval:double;
ii:integer;
curvalscount:integer;
lowvalscount:integer;
tmpval:double;
begin
curcount:=intervallast-intervalbeg+1;
if curcount<=1 then exit;//Всего один элемент, сортировать не надоif curcount=2 then
begin
if (Items[intervalbeg]<Items[intervallast])<>true then
begin
tmpval:=Items[intervalbeg];
Items[intervalbeg]:=Items[intervallast];
Items[intervallast]:=tmpval
end;
exit;
end;
if not hasminval then
begin
minval:=MaxFloat;
for ii:=intervalbeg to intervallast do if Items[ii]<minval then minval:=Items[ii];
end;
if not hasminval then
begin
maxval:=-MaxFloat;
for ii:=intervalbeg to intervallast do if Items[ii]>maxval then maxval:=Items[ii];
end;
aveval:=(minval+maxval)*0.5;
for ii:=intervalbeg to intervallast do boolarr[ii]:=(Items[ii]<aveval);
//Помещаем элементы, меньшие aveval, в первую часть arr2:
curvalscount:=0;
for ii:=intervalbeg to intervallast do if boolarr[ii]=true then
begin
inc(curvalscount);
arr2[intervalbeg+curvalscount-1]:=Items[ii];
end;
lowvalscount:=curvalscount;
if (lowvalscount=0) or (lowvalscount=curcount) then
exit;//Все элементы в интервале равны, сортировать нельзя
//Помещаем элементы, большие или равные aveval, в первую часть arr2:for ii:=intervalbeg to intervallast do if boolarr[ii]=not true then
begin
inc(curvalscount);
arr2[intervalbeg+curvalscount-1]:=Items[ii];
end;
//Перемещаем arr2 в arr1:for ii:=intervalbeg to intervallast do Items[ii]:=arr2[ii];
doqsort(intervalbeg,intervalbeg+lowvalscount-1,true,false,minval,0);
doqsort(intervalbeg+lowvalscount,intervallast,false,true,0,maxval);
end;
procedure TDoubleArray.QSort10Sections;
const
SectionsCount=100;
MaxSafeFloat= 1E9;
minsafefloat= 1E-9;
var
sectionsize:integer;
Sections:array[0..SectionsCount] of tdoublearray;
q,w:integer;
minval,maxval:double;
interval:double;
begin
if count<300 then begin//Log ('C:\tems3\q10_', false);
QuickSort (0, Count-1);
exit;
end;
minval:=MaxSafeFloat;
maxval:=-MaxSafeFloat;
for q:=0 to count-1 do begin
if items[q]<minval then minval:=items[q];
if items[q]>maxval then maxval:=items[q];
end;//next q
minval:=minval-minsafefloat;
maxval:=maxval+minsafefloat;
interval:=maxval-minval;
sectionsize:=count div sectionscount;
for q:=0 to sectionscount-1 do begin
sections[q]:=TDoubleArray.Create;
sections[q].Capacity:=sectionsize*10;
end;
for q:=0 to count-1 do begin
sections[floor((sectionscount-1)*(items[q]-minval)/interval)].Add(items[q]);
end;
count:=0;
for q:=0 to SectionsCount-1 do begin
if q < SectionsCount-1 then begin
sections[q].QSort10Sections;
for w:=0 to sections[q].count-1 do
add(sections[q].items[w]);
end;
sections[q].Free;
end;
end;
*procedure tdoublearray.QuickSort(low, high: Integer);
var
i, j: Integer;
pivot, temp: double;
begin
i := low;
j := high;
pivot := Items[(low + high) div 2];
repeat
while Items[i] < pivot do
Inc(i);
while Items[j] > pivot do
Dec(j);
if i <= j then
begin
temp := Items[i];
Items[i] := Items[j];
Items[j] := temp;
Inc(i);
Dec(j);
end;
until i > j;
if low < j then
QuickSort(low, j);
if i < high then
QuickSort(i, high);
end;
procedure TestDoubleArray (L: integer; Cicles: integer);
var
A, A1: tdoublearray;
i, j: integer;
S: string;
begin
A:= tdoublearray.Create;
A1 := tdoublearray.Create;
A.Count := L;
for i :=0 to L-1 do
A [i] := Random (1000) + Random (1000) / 1000 + i / 100000000;
S := 'standard' + ' ' + L.ToString + ' ' + Cicles.ToString;
A1.Clear;
A1.AddRange (A);
TB (S);
for i := 1 to Cicles do begin
if i > 1 then begin
A1.Clear;
A1.AddRange (A);
end;
A1.Sort;
end;
TE (S);
if L <= 10000000 then begin
S := 'super' + ' ' + L.ToString + ' ' + Cicles.ToString;
A1.Clear;
A1.AddRange (A);
TB (S);
for i := 1 to Cicles do begin
if i > 1 then begin
A1.Clear;
A1.AddRange (A);
end;
A1.superqsort;
end;
TE (S);
S := 'q4' + ' ' + L.ToString + ' ' + Cicles.ToString;
A1.Clear;
A1.AddRange (A);
TB (S);
for i := 1 to Cicles do begin
if i > 1 then begin
A1.Clear;
A1.AddRange (A);
end;
A1.QSort4;
if (i = 1) and (L <= 100000) then
A1.Log ('C:\tems3\q4');
end;
TE (S);
S := 'q10' + ' ' + L.ToString + ' ' + Cicles.ToString;
A1.Clear;
A1.AddRange (A);
TB (S);
for i := 1 to Cicles do begin
if i > 1 then begin
A1.Clear;
A1.AddRange (A);
end;
A1.QSort10Sections;
if (i = 1) and (L <= 100000) then
A1.Log ('C:\tems3\q10');
end;
TE (S);
end;
S := 'quick' + ' ' + L.ToString + ' ' + Cicles.ToString;
A1.Clear;
A1.AddRange (A);
TB (S);
for i := 1 to Cicles do begin
if i > 1 then begin
A1.Clear;
A1.AddRange (A);
end;
A1.QuickSort (0, A1.Count-1);
if (i = 1) and (L <= 100000) then
A1.Log ('C:\tems3\quick');
end;
TE (S);
A.Free;
A1.Free;
end;
initialization
Initializer.RegisterProc (ipLast,
procedure
var
i: integer;
begin
TestDoubleArray (1000, 1000);
TestDoubleArray (1000000, 1);
TestDoubleArray (2000000, 1);
// TestDoubleArray (10000000, 1);
//TestDoubleArray (50000000, 1);end);
K>Я получил выигрыш в скорости 30% для массивов из 100 000 чисел с равномерно распределенными random-ами. K>И если вы даже не можете сразу понять принцип моего алгоритма (и почему он работает быстро), это очередной пример что "профессиональные программеры" с rsdn могут заимствовать чужие идеи, но не генерировать свои. Я в КСВ об этом создал тему.
Re[7]: Оптимизация через разделение/вынос функционала
Здравствуйте, swame, Вы писали:
S> tdoublearray = class (TList<double>)
Сорри, что такое TList<double> ? Я попробовал это задать, подключил модуль system.classes и там можно сослаться только на просто tlist, т.е. это старый класс из Delphi7, без дженериков. А какой у вас Delphi?
Вы посмотрите, как в вашем TList обрабатывается SetCapacity — полагаю массив заполняется нулями, а это заведомо тормозит алгоритм.
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
Re: Оптимизация через разделение/вынос функционала
K>tmparray:=tarray.create;
K>tmparray.count:=count;
K>for i:=0 to count-1 do tmparray.fitems[i]:=arr[i];
K>tmparray.superqsort;
K>for i:=0 to count-1 do arr[i]:=tmparray[i];
K>tmparray.free;
K>
Чот я не понял — зачем создавать отдельный массив, копировать данные в него, сортировать его и копировать обратно?
Re[10]: Оптимизация через разделение/вынос функционала
K>Поэтому и дольше. Я вставил ваш код, получилось что мой superqsort очень медленный — в три раза медленнее QuickSort, а QuickSort в полтора раза медленнее QSort10Sections. Мой же класс tdoublearray с процедурой QSort10Sections, код которого я приводил выше, работает ещё на 30% быстрее.
Не вижу замеры
Re[11]: Оптимизация через разделение/вынос функционала
K>>Поэтому и дольше. Я вставил ваш код, получилось что мой superqsort очень медленный — в три раза медленнее QuickSort, а QuickSort в полтора раза медленнее QSort10Sections. Мой же класс tdoublearray с процедурой QSort10Sections, код которого я приводил выше, работает ещё на 30% быстрее.
S>Не вижу замеры
procedure TMainForm.Button9Click(Sender: TObject);
var
firsttime:longword;
q,w:integer;
curarray:tdoublearray;
begin
RandSeed :=0;
firsttime:=GetTickCount;
for q:=0 to 80 do begin
curarray:=tdoublearray.Create;
curarray.Capacity:=100000;
for w:=0 to 99999 do curarray.Add(random);
curarray.QSort10Sections;
curarray.Free;
end;//next q
caption:=inttostr(GetTickCount-firsttime);
end;
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
Re[3]: Оптимизация через разделение/вынос функционала
Здравствуйте, Khimik, Вы писали:
K>Здравствуйте, swame, Вы писали:
K>>>Поэтому и дольше. Я вставил ваш код, получилось что мой superqsort очень медленный — в три раза медленнее QuickSort, а QuickSort в полтора раза медленнее QSort10Sections. Мой же класс tdoublearray с процедурой QSort10Sections, код которого я приводил выше, работает ещё на 30% быстрее.
S>>Не вижу замеры
Не вижу замеры
Цифры сравнения разных алгоритмов с твоими и стандартными дженериковыми листами.
Re[13]: Оптимизация через разделение/вынос функционала
Здравствуйте, swame, Вы писали:
S>Не вижу замеры S>Цифры сравнения разных алгоритмов с твоими и стандартными дженериковыми листами.
Ну хорошо, вот ещё раз замерил:
tdoublearray.QSort10Sections — 858 ms (это мой tdoublearray без заполнения нулями)
tdoublearray.QSort1Old(true) — 3245 ms (это мой алгоритм в оп)
tdoublearray.QSort2GPT — 1201 ms (это алгоритм от gpt который тут выкладывали, только с инициализацией вспомогательного массива arr в котором выполняется эта сортировка)
tdoublearray.QSort5GPTNoExtraArr — 1233 ms (то же самое, только не используется вспомогательный массив, сразу запускается эта стандартная сортировка с Хоаром, обрабатывающая fitems класса tdoublearray)
tdoublearray1.superqsort — 8471 ms (tdoublearray1 это то что вы выложили, обертка над tlist<double>, мой алгоритм в оп)
tdoublearray1.QuickSortStandHoar — 2918 ms (стандартная сортировка с Хоаром, вызов QuickSort(0,count-1); )
tdoublearray1.QSort10Sections — 1154 ms (моя сортировка с секциями, то же что в tdoublearray.QSort10Sections).
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
Re[14]: Оптимизация через разделение/вынос функционала
Здравствуйте, Khimik, Вы писали:
K>Здравствуйте, swame, Вы писали:
S>>Не вижу замеры S>>Цифры сравнения разных алгоритмов с твоими и стандартными дженериковыми листами.
K>Ну хорошо, вот ещё раз замерил:
K>tdoublearray.QSort10Sections — 858 ms (это мой tdoublearray без заполнения нулями)
K>tdoublearray.QSort1Old(true) — 3245 ms (это мой алгоритм в оп)
K>tdoublearray.QSort2GPT — 1201 ms (это алгоритм от gpt который тут выкладывали, только с инициализацией вспомогательного массива arr в котором выполняется эта сортировка)
А сколько QSort2GPT без ненужного дополнительного массива?
K>tdoublearray.QSort5GPTNoExtraArr — 1233 ms (то же самое, только не используется вспомогательный массив, сразу запускается эта стандартная сортировка с Хоаром, обрабатывающая fitems класса tdoublearray)
K>tdoublearray1.superqsort — 8471 ms (tdoublearray1 это то что вы выложили, обертка над tlist<double>, мой алгоритм в оп)
K>tdoublearray1.QuickSortStandHoar — 2918 ms (стандартная сортировка с Хоаром, вызов QuickSort(0,count-1); )
непонятно что это, тот что я выкладывал или K>tdoublearray1.QSort10Sections — 1154 ms (моя сортировка с секциями, то же что в tdoublearray.QSort10Sections).
Сколько QSort2GPT на tdoublearray1? Алгоритм который я выкладывал?
Сколько стандартный sort на tdoublearray1? Вызов Sort
И кстати тест на 32 или 64 разрядах? Я делал на 32
Здравствуйте, SaZ, Вы писали:
K>>...
SaZ>А что, на делфи не принято делать отступы для логических блоков в коде? Невозможно же читать эту простыню. Страшно даже представить, что у вас будет в реальных проектах.
Мне кажется, что как у меня — удобнее. Может это какая-то моя специфика. Конечно если устроюсь в контору — придётся переучиваться.
Часто бывает удобно, например, поместить блок begin end с несколькими операторами в одну строку, потому что смысл блока понятен и часто эти блоки повторяются (в моём коде выше это есть).
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
Здравствуйте, Khimik, Вы писали:
K>Здравствуйте, SaZ, Вы писали:
K>>>...
SaZ>>А что, на делфи не принято делать отступы для логических блоков в коде? Невозможно же читать эту простыню. Страшно даже представить, что у вас будет в реальных проектах.
K>Мне кажется, что как у меня — удобнее. Может это какая-то моя специфика. Конечно если устроюсь в контору — придётся переучиваться. K>Часто бывает удобно, например, поместить блок begin end с несколькими операторами в одну строку, потому что смысл блока понятен и часто эти блоки повторяются (в моём коде выше это есть).
Это никак не противоречит нормальным отступам.
Зато эти отступы позволяют быстро видеть границы "вертикальных" блоков, а не выискивать глазами очередной end среди нагромождения ключевых слов:
procedure tdoublearray.superqsort;
var
q:integer;
sumval, midval, tmpval: double;
tmparray1, tmparray2: tdoublearray;
begin
if count <= 1 then exit;
if count = 2 then begin
if fitems[1] < fitems[0] then begin tmp := fitems[1]; fitems[1] := fitems[0]; fitems[0 ]:= tmp; end;
exit;
end; // вот этот end - он от какого begin? Отступы позволяют сразу это увидеть, не тратя мозг на поиск незакрытых begin вверх по тексту
sumval := 0;
for q := 0 to count do sumval := sumval + fitems[q];
midval := sumval / count;
tmparay1 := tdoublearray.create;
tmparray1.capacity := сount; // почему нельзя сразу передать capacity в конструктор?
tmparray2 := tdoublearray.create;
tmparray2.capacity := count;
for q := 0 to count-1 do if fitems[q] > midval then tmparray2.add(fitems[q]) else tmparray1.add(fitems[q]);
tmparray1.superqsort;
tmparray2.superqsort;
for q := 0 to tmparray1.count - 1 do fitems[q]:=tmparray1.fitems[q];
for q := 0 to tmparray2.count - 1 do fitems[tmparray1.count + q] := tmparray2.fitems[q];
tmparray1.free;
tmparray2.free;
end;
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Я ещё чуть соптимизировал свой алгоритм, уменьшив изначальный размер массивов в секциях:
[cut]
procedure TDoubleArray.QSort10Sections;
const
SectionsCount=100;
var
sectionsize:integer;
Sections:array[0..SectionsCount-1] of tdoublearray;
q,w:integer;
minval,maxval:double;
interval:double;
begin
if fcount<300 then begin
QSort2GPT;
exit;
end;
minval:=MaxSafeFloat;
maxval:=-MaxSafeFloat;
for q:=0 to fcount-1 do begin
if fitems[q]<minval then minval:=fitems[q];
if fitems[q]>maxval then maxval:=fitems[q];
end;//next q
minval:=minval-minsafefloat;
maxval:=maxval+minsafefloat;
interval:=maxval-minval;
sectionsize:=fcount div sectionscount;
for q:=0 to sectionscount-1 do begin
sections[q]:=TDoubleArray.Create;
sections[q].Capacity:=sectionsize*2;
end;
for q:=0 to fcount-1 do begin
sections[floor((sectionscount-1)*(fitems[q]-minval)/interval)].Add(fitems[q]);
end;
count:=0;
for q:=0 to SectionsCount-1 do begin
sections[q].QSort10Sections;
for w:=0 to sections[q].fcount-1 do add(sections[q].fitems[w]);
sections[q].Free;
end;
[/cut]
end;
Я тут заменил
sections[q].Capacity:=sectionsize*10;
на
sections[q].Capacity:=sectionsize*2;
Мне вообще удивительно, почему так вышло. Я думал, чем больше этот размер, тем лучше (если хватает на всё памяти). Если его сделать маленьким — лишнее время будет уходить на пересоздавание массивов и перефрагментирование, когда в capacity не влезает count. Но почему с большим размером тоже скорость чуть помедленнее — для меня странно. Вроде ReallocMem в Delphi не заполняет массив нулями? Значит лишние такты уходят на какое-то перефрагментирование?
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
Здравствуйте, Sinclair, Вы писали:
S>Зато эти отступы позволяют быстро видеть границы "вертикальных" блоков, а не выискивать глазами очередной end среди нагромождения ключевых слов:
Я часто после end; пишу комментарий вроде //next q, так становится понятнее.
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
Здравствуйте, пффф, Вы писали:
П>Попробуй пройтись отладчиком
1. Что такое отладчик и зачем он нужен?
2. А что, разве генерация отладочной инфы поддерживает только номера строк, но не поддерживает номер символа в строке?
3. Тернарник делает то же самое, пишется в 1 строчку, но никто не жужжит
Нет такой подлости и мерзости, на которую бы не пошёл gcc ради бессмысленных 5% скорости в никому не нужном синтетическом тесте
Здравствуйте, T4r4sB, Вы писали:
TB>1. Что такое отладчик и зачем он нужен?
Нет никакого желания холиварить с любителями медитировать над исходным кодом.
TB>2. А что, разве генерация отладочной инфы поддерживает только номера строк, но не поддерживает номер символа в строке?
Ты где-то такое видел?
TB>3. Тернарник делает то же самое, пишется в 1 строчку, но никто не жужжит
Я пишу в четыре строчки, если там есть какие-то вызовы:
auto var = getCondition()
? makeSomething()
: makeSomethingElse()
;
Это удобно ещё и тем, что можно по-быстрому закоментить какую-то ветку, вставить альтернативную реализацию, проверить, и потом удалить либо новую версию, либо старую
Здравствуйте, пффф, Вы писали:
П>Нет никакого желания холиварить с любителями медитировать над исходным кодом.
Я люблю медитировать над полноценными дампами, где сразу вся необходимая инфа про состояние программы в данный момент
TB>>2. А что, разве генерация отладочной инфы поддерживает только номера строк, но не поддерживает номер символа в строке?
П>Ты где-то такое видел?
Да. Когда свой компилятор нового языка писал (через генерацию LLVM IR), то добавить туда отладочную инфу с номерами символов, которая ещё и нормально подхватывалась MSVC — оказалось совсем не сложно
П>Это удобно ещё и тем, что можно по-быстрому закоментить какую-то ветку, вставить альтернативную реализацию, проверить, и потом удалить либо новую версию, либо старую
Закомментить ветку, вставить вывод лога итд — это несколько секунд, сборка занимает намного больше времени (крестопроблемы). Не знаю, как в Жабе, там наверное это действительно заметно.
Нет такой подлости и мерзости, на которую бы не пошёл gcc ради бессмысленных 5% скорости в никому не нужном синтетическом тесте
Здравствуйте, пффф, Вы писали:
П>Попробуй пройтись отладчиком
В принципе это то же, что и a(b(c), d(e)). Тут тоже в одной строчке три действия и те же вопросы про отладчик возникают, но вроде никто не призывает это разносить на 3 строки.
Некоторые отладчики (например идея) при установке брякпоинта умеют спросить, на какое именно выражение программист его хочет поставить. И по шагам умеют работать в пределах строки. Не знаю, что там в дельфи.
Здравствуйте, vsb, Вы писали:
П>>Попробуй пройтись отладчиком
vsb>В принципе это то же, что и a(b(c), d(e)). Тут тоже в одной строчке три действия и те же вопросы про отладчик возникают, но вроде никто не призывает это разносить на 3 строки.
Не призывает, но это тоже неудобно
vsb>Некоторые отладчики (например идея) при установке брякпоинта умеют спросить, на какое именно выражение программист его хочет поставить. И по шагам умеют работать в пределах строки. Не знаю, что там в дельфи.
Я тоже не в курсе, что там в дельфи.
Но MSVC и VSCode так не умеют.
VSCode вообще не умеет в интелисенс для параметров шаблонов, только от безнадеги на нем сижу
Здравствуйте, пффф, Вы писали:
п> Это удобно ещё и тем, что можно по-быстрому закоментить какую-то ветку, вставить альтернативную реализацию, проверить, и потом удалить либо новую версию, либо старую
VCS, не?
Здравствуйте, T4r4sB, Вы писали:
TB>Я люблю медитировать над полноценными дампами, где сразу вся необходимая инфа про состояние программы в данный момент
Да, в догонку. Твой полноценный дамп не расскажет, каким путем программа пришла в это состояние. И он также не расскажет, куда программа двинет дальше.
Здравствуйте, T4r4sB, Вы писали:
П>>Да, в догонку. Твой полноценный дамп не расскажет, каким путем программа пришла в это состояние. И он также не расскажет, куда программа двинет дальше.
TB>Да, бывает что приходится добавлять дополнительно отладочные принты. Но вообще код должен быть спроектирован так, чтоб в любой точке дамп позволял понять всё, что нужно.
А, ты хочешь поговорить о поведении сферических коней в вакууме, когда ты сидишь на проекте 20+ лет?
Я чаще меняю работу. И пройтись под отладчиком по коду, задав свои входные условия, и посмотреть, как проходит execution flow, для изучения очередного дерьмового фрейворка — это бесценно.
А методы медитации над херотой очень любят в дерьмоконторах типа яндекса или вк, я там это всё понюхал и свалил, сейчас промышленность поднимаю, а не развожу хомячков рекламой.
Re[2]: Оптимизация через разделение/вынос функционала
Здравствуйте, Khimik, Вы писали:
K>Азарту ради, я написал код с сортировкой с использованием дополнительной памяти (деление интервала значений на секции):
K>Прежде чем кликать по спойлеру, ответьте на вопрос — вы бы легко написали этот алгоритм?
По спойлеру не кликал, там какая-то студенческая практическая работа первокура, скорее всего.
Если бы ты знал, что приходится делать разработчикам в реальной жизни...
Но ты лучше экономь моск, а то кто без тебя Россию обустроит
K>Мой алгоритм вышел примерно на 30% быстрее стандартной быстрой сортировки со схемой Хоара. Памяти он расходует не особо много. А вы бы опять искали готовый алгоритм вместо голимого придумывания велосипеда?
Скорее всего ты обосрался с тестами, или намухлевал
Здравствуйте, Khimik, Вы писали:
K>1) Делание отступов тоже занимает время.\
Не занимает — их делает IDE. K>2) Я часто помещаю в одну строку несколько операторов.
Я вам показал пример оформления вашего же кода с несколькими операторами в одной строке. Какие вопросы у вас остались? K>3) Вместо отступов я размечаю функциональные блоки кода комментариями.
По факту — нет, не размечаете.
На написание комментариев уходит больше времени, чем на автоматические отступы.
При этом при чтении кода, на поиск функциональных блоков по комментариям уходит гораздо больше времени. А типичный код читается примерно вдесятеро чаще, чем пишется.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Sinclair, Вы писали:
П>>Ты где-то такое видел? S>"такое" — это какое? S>C#, Java, Javascript прекрасно отлаживаются "внутри" строки по F11.
Ну, мы ещё про плюсы, или вообще? Вопрос был в том, где, в какой среде, в каком отладчике можно отлаживать плюсовый код по выражениям, а не по строкам? Простите, если краткая форма моего вопроса ввела вас в заблуждение
Здравствуйте, Sinclair, Вы писали:
П>>Но MSVC и VSCode так не умеют. S>Для каких языков? Typescript в VSCode прекрасно ставит бряки внутрь строки: S>Image: 2024_06_04_22_53_56_image.png
Ну, обсуждали изначально Дельфи, я приводил примеры про плюсы, ну окей, это было не очевидно. Хотя MSVC — это MS Visual C(++), а не MSVS — MS Visual Studio. Для других языков студия наверное умеет, не знаю. Про VSCode — ну тут да, он изначально под зоопарк сделан, тут неочевидно.
Но в целом, T4r4sB — вроде как плюсовик, я тоже только про плюсы пишу, думал, понятно будет
Здравствуйте, пффф, Вы писали:
П>Ну, мы ещё про плюсы, или вообще?
Топик — про дельфи. П>Вопрос был в том, где, в какой среде, в каком отладчике можно отлаживать плюсовый код по выражениям, а не по строкам? Простите, если краткая форма моего вопроса ввела вас в заблуждение
Про плюсы, извините, не подскажу. Но всё, как верно заметил коллега T4r4sB, упирается в отладочные символы.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Re[15]: Оптимизация через разделение/вынос функционала
На rsdn уже высказывали мысль, что человек отождествляет себя со своими воззрениями, и воспринимает перемену взглядов, признание своей неправоты как смерть личности. По-моему молчание swame в теме — хороший пример. Вам так сложно сделать тест, чтобы убедиться что моя сортировка быстрее стандартной? Или может снова всё дело в моих политических взглядах?
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
Re[9]: Оптимизация через разделение/вынос функционала
Здравствуйте, swame, Вы писали:
K>>Сорри, что такое TList<double> ? Я попробовал это задать, подключил модуль system.classes и там можно сослаться только на просто tlist, т.е. это старый класс из Delphi7, без дженериков. А какой у вас Delphi?
S>System.Generics.Collections S>поддерживается с Delphi 2009
swame, вы кажется знаете Delphi, загляните пожалуйста в эту тему: