Здравствуйте, Khimik, Вы писали:
K>Да, GPT алгоритм хорошо работает: то ли потому что не использует вычисления с плавающей точкой, то ли потому что не выделяет дополнительную память для массива, то ли сам алгоритм в принципе лучше — честно говоря я ещё до конца не понял что это за строки Inc(i); Dec(j);. А вы поняли?
Это вызовы стандартных процедур ещё Виртовского Паскаля по инкременту и декременту целых значений.
Реализованы они потому, что в Паскале нет ни compound assignment, ни операторов инкремента/декремента, как в C-подобных языках.
Поэтому приходится писать не i++, а i:= i + 1. Это громоздко и неудобно, если инкрементируемое выражение длинное, и вычисляется с побочными эффектами.
Так что для достижения того же эффекта, что и в C, в Паскаль были добавлены магические процедуры Inc и Dec, а также магические функции Succ и Pred.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Re[5]: Оптимизация через разделение/вынос функционала
Здравствуйте, Sinclair, Вы писали:
K>>Да, GPT алгоритм хорошо работает: то ли потому что не использует вычисления с плавающей точкой, то ли потому что не выделяет дополнительную память для массива, то ли сам алгоритм в принципе лучше — честно говоря я ещё до конца не понял что это за строки Inc(i); Dec(j);. А вы поняли? S>Это вызовы стандартных процедур ещё Виртовского Паскаля по инкременту и декременту целых значений. S>Реализованы они потому, что в Паскале нет ни compound assignment, ни операторов инкремента/декремента, как в C-подобных языках. S>Поэтому приходится писать не i++, а i:= i + 1. Это громоздко и неудобно, если инкрементируемое выражение длинное, и вычисляется с побочными эффектами. S>Так что для достижения того же эффекта, что и в C, в Паскаль были добавлены магические процедуры Inc и Dec, а также магические функции Succ и Pred.
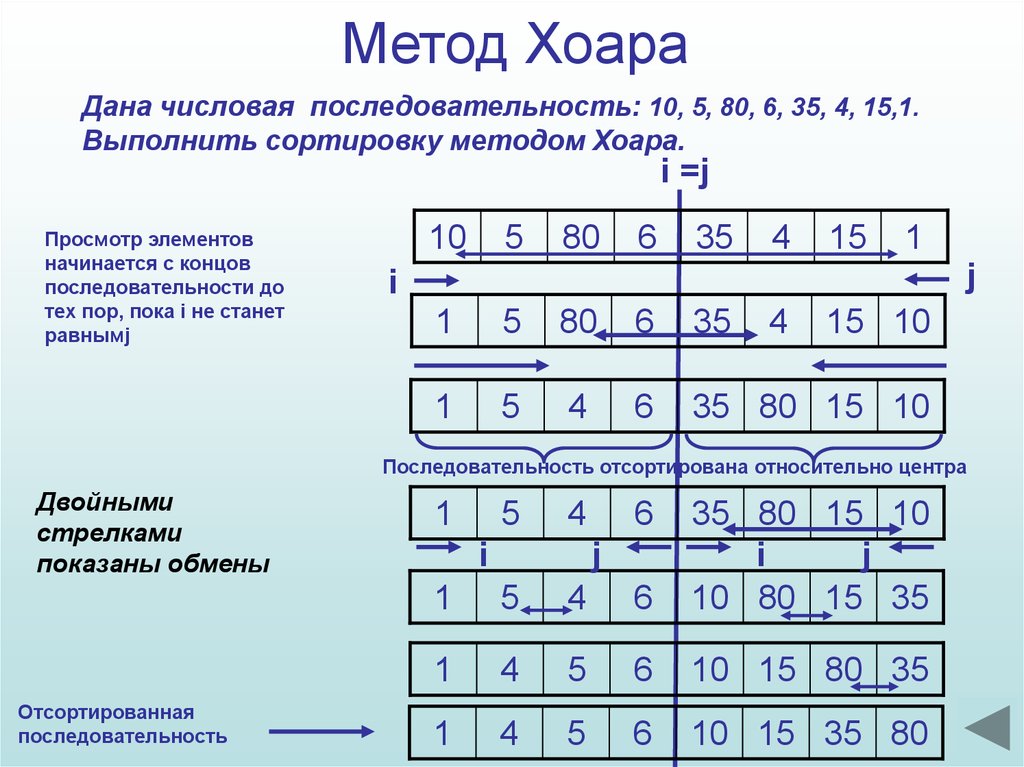
А, ну это я конечно знаю, сорри что не спросил понятно спросил. Мой вопрос был — что делает этот фрагмент процедуры:
repeat
while arr[i] < pivot do
Inc(i);
while arr[j] > pivot do
Dec(j);
if i <= j then
begin
temp := arr[i];
arr[i] := arr[j];
arr[j] := temp;
Inc(i);
Dec(j);
end;
until i > j;
Как бы смутно уже понятно, но хочется чтобы кто-то сказал словами, так не придётся много думать.
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
Re[6]: Оптимизация через разделение/вынос функционала
K>А, ну это я конечно знаю, сорри что не спросил понятно спросил. Мой вопрос был — что делает этот фрагмент процедуры:
K>
repeat
K> while arr[i] < pivot do
K> Inc(i);
K> while arr[j] > pivot do
K> Dec(j);
K> if i <= j then
K> begin
K> temp := arr[i];
K> arr[i] := arr[j];
K> arr[j] := temp;
K> Inc(i);
K> Dec(j);
K> end;
K> until i > j;
Очевидно, переставляем элементы внутри подмассива от i до j так, чтобы сначала шли все элементы меньше pivot, а потом — все элементы больше pivot.
Конкретнее:
1. Ищем слева элемент, >= pivot
2. Ищем справа элемент <= pivot
3. Меняем их местами, и сдвигаем границы на следующую пару элементов.
K>Как бы смутно уже понятно, но хочется чтобы кто-то сказал словами, так не придётся много думать.
Это вы зря. Мыслительный мускул нужно тренировать.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Re[7]: Оптимизация через разделение/вынос функционала
Здравствуйте, Sinclair, Вы писали:
S>Очевидно, переставляем элементы внутри подмассива от i до j так, чтобы сначала шли все элементы меньше pivot, а потом — все элементы больше pivot. S>Конкретнее: S>1. Ищем слева элемент, >= pivot S>2. Ищем справа элемент <= pivot S>3. Меняем их местами, и сдвигаем границы на следующую пару элементов.
Ну ок, теперь вроде понятно. Хотя надо ещё проверить, нет ли в gpt-шном алгоритме потенциального бага — в левую или правую часть пойдут эти элементы, если оба они = pivot? Т.е. как вы написали наверно уже неправильно, а это как GPT выдал; надо определиться что элементы, равные pivot, надо поместить например конкретно в левую часть, тогда надо наверно так:
repeat
while arr[i] <= pivot do
Inc(i);
while arr[j] > pivot do
Dec(j);
if i < j then
begin
temp := arr[i];
arr[i] := arr[j];
arr[j] := temp;
Inc(i);
Dec(j);
end;
until i >= j;
И я заменил if i <= j then на if i < j then, это не был баг но чуть некрасиво.
Кроме того, легко сделать ошибки, если например модифицировать этот алгоритм для указания ascending (сортировка по возрастанию или убыванию). Поэтому повторю моё мнение, что оптимальным является мой алгоритм в оп, он только в три раза медленнее gpt-шного, для 99.999% задач это неважно. Ну а если уж очень надо оптимизировать — тогда можно заменить его на gpt-шный.
K>>Как бы смутно уже понятно, но хочется чтобы кто-то сказал словами, так не придётся много думать. S>Это вы зря. Мыслительный мускул нужно тренировать.
Не так. Ресурсы мозга ограничены, если их экономить тут — можно больше потратить на другое.
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
Здравствуйте, Khimik, Вы писали:
K>Здравствуйте, Sinclair, Вы писали:
S>>Очевидно, переставляем элементы внутри подмассива от i до j так, чтобы сначала шли все элементы меньше pivot, а потом — все элементы больше pivot. S>>Конкретнее: S>>1. Ищем слева элемент, >= pivot S>>2. Ищем справа элемент <= pivot S>>3. Меняем их местами, и сдвигаем границы на следующую пару элементов.
K>Ну ок, теперь вроде понятно. Хотя надо ещё проверить, нет ли в gpt-шном алгоритме потенциального бага — в левую или правую часть пойдут эти элементы, если оба они = pivot?
Если они оба == pivot, то алгоритм от chatGPT переставит их местами.
Это в чистом виде схема Хоара.
Т.е. как вы написали наверно уже неправильно, а это как GPT выдал; надо определиться что элементы, равные pivot, надо поместить например конкретно в левую часть
Зачем?
K>Кроме того, легко сделать ошибки, если например модифицировать этот алгоритм для указания ascending (сортировка по возрастанию или убыванию). Поэтому повторю моё мнение, что оптимальным является мой алгоритм в оп, он только в три раза медленнее gpt-шного, для 99.999% задач это неважно.
Простите, но оптимальным совершенно точно является использование коробочного алгоритма, а не выпиливание самодельных велосипедов.
Весь бизнес устроен примерно одинаково:
1. Определяетесь, в чём ваше core value. Это то, что именно вы делаете лучше других.
2. Всё, что относится к Core Value, вы делаете сами, и делаете как можно лучше.
3. Всё, что не относится к Core Value — вы делегируете (берёте готовое, покупаете покупное, етк).
Вот алгоритмы сортировки совершенно точно не являются вашей сильной стороной. Ну так и не надо тратить силы и время на их написание и отладку. Научитесь пользоваться готовыми алгоритмами, и пользуйтесь без стеснения.
K>Не так. Ресурсы мозга ограничены, если их экономить тут — можно больше потратить на другое.
В данном конкретном случае — всё верно. Но вы неверно тратите их на другое. "На другое" — это взять TArray.Sort() и не изобретать в очередной раз quicksort.
Тем более, что в таком подходе нетрудно гарантировать отсутствие ошибок, если например модифицировать этот алгоритм для указания ascending.
Потому что вся замена ascending на descending сводится к обращению знака у функции-компаратора.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Re[8]: Оптимизация через разделение/вынос функционала
Я обнаружил ошибку в своём исходном алгоритме в оп: он может зависнуть, если в массиве много одинаковых элементов. Вот исправленный вариант:
procedure TDoubleArray.QSort1Old;
var
q:integer;
sumval, midval, tmpval: double;
tmparray1, tmparray2: tdoublearray;
begin
if count<=1 then exit;
if count=2 then begin
if fitems[1]<fitems[0] then begin tmpval:=fitems[1]; fitems[1]:=fitems[0]; fitems[0]:=tmpval; end;
exit;
end;
sumval:=0;
for q:=0 to count-1 do sumval:=sumval+fitems[q];
midval:=sumval/count;
tmparray1:=tdoublearray.create;
tmparray1.capacity:=count;
tmparray2:=tdoublearray.create;
tmparray2.capacity:=count;
for q:=0 to count-1 do if fitems[q]>midval then tmparray2.add(fitems[q]) else tmparray1.add(fitems[q]);
if tmparray1.Count=0 then begin tmparray1.free; tmparray2.free; exit; end;
if tmparray2.Count=0 then begin tmparray1.free; tmparray2.free; exit; end;
tmparray1.QSort1Old;
tmparray2.QSort1Old;
for q:=0 to tmparray1.count-1 do fitems[q]:=tmparray1.fitems[q];
for q:=0 to tmparray2.count-1 do fitems[tmparray1.count+q]:=tmparray2.fitems[q];
tmparray1.free;
tmparray2.free;
end;
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
Re[9]: Оптимизация через разделение/вынос функционала
Здравствуйте, Sinclair, Вы писали:
S>Тем более, что в таком подходе нетрудно гарантировать отсутствие ошибок, если например модифицировать этот алгоритм для указания ascending. S>Потому что вся замена ascending на descending сводится к обращению знака у функции-компаратора.
У меня есть довольно большой опыт написания и оптимизации разных алгоритмоы, и конкретно в данном случае я мог бы придраться, что если вы например для ascending=false будете менять < на > — вы уверены что надо именно на > а не на >=? Не спутаете? Этот стандартный алгоритм быстрой сортировки со схемой Хоара очень так сказать хрупкий, надо проверять каждый чих чтобы быть уверенным что он никогда не зависнет (и напомню что ChatGPT часто делает ошибки). Я так и не решился вставлять его в свою программу; может сделаю это в будущем если понадобится ещё ускорить быструю сортировку, а так мне хватит того что я написал. Если же буду вставлять — надо будет делать много тестов, чтобы убедиться что он никогда не зависнет.
Я конкретно к вам хорошо отношусь, но злит когда "профессиональные программеры" вроде вас учат не думать самому, и находить для всего готовые решения/библиотеки. Слово "велосипед" для них видите ли ругательное. Лично мне довольно часто приходится придумывать относительно сложные алгоритмы.
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
Re[10]: Оптимизация через разделение/вынос функционала
Здравствуйте, Khimik, Вы писали:
K>У меня есть довольно большой опыт написания и оптимизации разных алгоритмоы, и конкретно в данном случае я мог бы придраться, что если вы например для ascending=false будете менять < на > — вы уверены что надо именно на > а не на >=? Не спутаете?
Вы не поняли мысль. Повторю её помедленнее: сортировать данные нужно стандартным алгоритмом, передавая в неё функцию-компаратор.
Если вам нужно поменять порядок сортировки на обратный, то вы не пишете новую функцию сортировки.
Вы даже не пишете новую функцию-компаратор.
Вы берёте старую функцию компаратор, и оборачиваете её в новую функцию, которая просто вызывает старую, и обращает знак.
K>Этот стандартный алгоритм быстрой сортировки со схемой Хоара очень так сказать хрупкий, надо проверять каждый чих чтобы быть уверенным что он никогда не зависнет
Он совершенно не хрупкий, если вы понимаете, как он устроен. А если нет — берёте библиотечный алгоритм и не создаёте себе проблемы. K>Если же буду вставлять — надо будет делать много тестов, чтобы убедиться что он никогда не зависнет. Ваш самописаный алгоритм скорее всего содержит больше ошибок, чем предложенный chatGPT. Который, в свою очередь, является просто переводом статьи в Википедии с псевдокода на Паскаль.
K>Я конкретно к вам хорошо отношусь, но злит когда "профессиональные программеры" вроде вас учат не думать самому, и находить для всего готовые решения/библиотеки.
Вы просто противоречите сами себе. Вот только что вы отказались думать потому, что у вас нет на это времени. Я вас в этом целиком поддерживаю — нету так нету, берите готовое и не тратьте своё и чужое время на ерунду. K>Слово "велосипед" для них видите ли ругательное. Лично мне довольно часто приходится придумывать относительно сложные алгоритмы.
Если вы считаете себя крутым алгоритмистом — нет проблем. Я же говорю: важно — решить, что именно будет вашим core value. Если вы считаете, что умеете писать алгоритмы сортировки лучше прочих, то сосредоточьтесь на этом.
Но тогда не получится спрятаться за "я не понял, что это за Inc/Dec такие, пусть мне кто-то объяснит, а то самому думать об этом мне некогда".
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Re[6]: Оптимизация через разделение/вынос функционала
K>Как бы смутно уже понятно, но хочется чтобы кто-то сказал словами, так не придётся много думать.
Это прекрасно. Человек, который не любит думать, считает себя интеллектуалом и постоянно выдвигает теории космического масштаба о том, как нам надо жить
Re[8]: Оптимизация через разделение/вынос функционала
Здравствуйте, Khimik, Вы писали:
K>Кроме того, легко сделать ошибки, если например модифицировать этот алгоритм для указания ascending (сортировка по возрастанию или убыванию).
Компаратор на входе задаётся и всё. Хз как это в ваших делфях
K>Поэтому повторю моё мнение, что оптимальным является мой алгоритм в оп, он только в три раза медленнее gpt-шного, для 99.999% задач это неважно.
Нда... Такого же качества и твои идеи по переустройству мира
K>Не так. Ресурсы мозга ограничены, если их экономить тут — можно больше потратить на другое.
Какой-то хиленький у вас мыслительный мускул, раз написание сортировки вызывает его перерасход. Зарядку, видимо, по той же причине не делаете, чтобы не расходовать зря мускульный ресурс, а то потом ведь надо затылок чесать, придумывая теории мироустройства, а сил на это уже не будет
Re: Оптимизация через разделение/вынос функционала
Мой нелепый алгоритм в оп можно легко объяснить в словах:
1) Находим среднее значение в массиве;
2) Создаём два вспомогательных массива;
3) Значения в исходном массиве, которые меньше среднего, помещаем в первый вспомогательный массив, а которые больше — во второй;
4) Рекурсивно сортируем оба вспомогательных массива;
5) Переливаем в исходный массив сначала первый вспомогательный, потом второй;
6) Удаляем вспомогательные массивы.
А вы могли бы так же просто изложить стандартный алгоритм быстрой сортировки со схемой Хоара?
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
Re[2]: Оптимизация через разделение/вынос функционала
Здравствуйте, Khimik, Вы писали:
K>Мой нелепый алгоритм в оп можно легко объяснить в словах: K>1) Находим среднее значение в массиве; K>2) Создаём два вспомогательных массива; K>3) Значения в исходном массиве, которые меньше среднего, помещаем в первый вспомогательный массив, а которые больше — во второй; K>4) Рекурсивно сортируем оба вспомогательных массива; K>5) Переливаем в исходный массив сначала первый вспомогательный, потом второй; K>6) Удаляем вспомогательные массивы.
S>Создайте систему, которой сможет пользоваться дурак, и только дурак захочет ею пользоваться.
Вот в стандартном алгоритме со схемой Хоара есть фрагмент:
if i <= j then
begin
temp := arr[i];
arr[i] := arr[j];
arr[j] := temp;
Inc(i);
Dec(j);
end;
Как бы немного смущает, что если i=j, то алгоритм впустую произведёт обмен. Я попробовал заменить if i <= j then на if i < j then, ан нет — начались глюки. Такие подводные камни могут всё порушить в программе. Поэтому повторюсь что мой изначальный алгоритм, как мне кажется, во многих отношениях предпочтителен.
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
Re[4]: Оптимизация через разделение/вынос функционала
Здравствуйте, Khimik, Вы писали:
K>Здравствуйте, swame, Вы писали:
S>>
S>>Создайте систему, которой сможет пользоваться дурак, и только дурак захочет ею пользоваться.
K>Вот в стандартном алгоритме со схемой Хоара есть фрагмент:
K>
K>if i <= j then
K>begin
K>temp := arr[i];
K>arr[i] := arr[j];
K>arr[j] := temp;
K>Inc(i);
K>Dec(j);
K>end;
K>
K>Как бы немного смущает, что если i=j, то алгоритм впустую произведёт обмен.
1. Давайте попробуем оценить, насколько велики потери от этого бесполезного обмена. Смотрите, на каждой итерации сортировки условие i == j встречается не более одного раза; значит, в худшем случае, алгоритм сделает столько же лишних обменов, сколько будет проходов сортировки. Количество проходов у нас зависит от длины массива: если массив длиной, скажем, 2, то обмен будет ровно 1. Если у нас массив длины N сортируется за X проходов, то массив длины N*2 будет сортироваться за 2X+1 проходов (две сортировки подмассивов по N элементов, плюс ещё один проход перед тем, как вызвать эти две сортировки). Отсюда мы понимаем, что X ~ Log2(N). Логарифмическая асимптотика затрат нас пугать не должна, т.к. она растёт достаточно медленно. Кроме того, мы знаем, что асимптотика quicksort — N * log(N), то есть она в N раз хуже, чем наши дополнительные затраты. K>Я попробовал заменить if i <= j then на if i < j then, ан нет — начались глюки.
2. Если мы хотим исправить алгоритм, нужно внимательно смотреть на то, что он делает. Очевидно, что помимо обмена, под if стоят ещё и инкременты/декременты i и j. Если их не делать, то семантика алгоритма поменяется — отсюда и глюки.
3. С учётом вышесказанного, понятно, что просто поменять условие сравнения нельзя. Придётся сделать две раздельных проверки — одну про необходимость обмена, вторую — про необходимость перемещения счётчиков.
if i <= j then
begin
if(i < j) then begin
temp := arr[i];
arr[i] := arr[j];
arr[j] := temp;
end;
Inc(i);
Dec(j);
end;
Возникает вопрос: а много ли мы экономим? Мы экономим один лишний обмен для i == j, но зато теперь мы на каждой итерации дополнительно сравниваем i и j. Результат может зависеть от точных стоимостей обмена и сравнения. Если в массиве лежат какие-то простые значения, то перестановка — это копирование память-регистр-память и сводится к трём инструкциям CPU. Если там структуры — то копирование может потребовать чего-то более существенного. Проверка — это сравнение регистр-регистр, к тому же она будет неплохо предсказываться процессором, и вряд ли приведёт к потерям больше 1 такта на итерацию.
Но, вспомнив, что в среднем наша "оптимизация" срабатывает 1 раз из N, получаем, что с ростом длины массива даже дорогие обмены будут задоминированы стоимостью дополнительной проверки.
Bottom line: чтобы понять, какой будет реальный эффект в конкретной задаче, нужно точно замерить производительность. Если вас интересует экономия уровня единиц процентов — тогда да, настраиваем окружение, обучаемся корректно тестировать производительность (со сбором статистики, отбрасыванием нерелевантных результатов, и оценкой значимости разницы), тюним всё до мелочей. Если интересует асимптотическая оптимизация — то останавливаемся прямо на шаге №1 выше: наша оптимизация на асимптотику не повлияет, так что лучше не трогать то, что не сломано. K>Такие подводные камни могут всё порушить в программе. Поэтому повторюсь что мой изначальный алгоритм, как мне кажется, во многих отношениях предпочтителен.
Ваш изначальный алгоритм проигрывает коробочному во всех отношениях:
1. Он протестирован заведомо не лучше, чем библиотечная реализация. Просто потому, что у вас нет столько ресурсов, сколько у производителей библиотеки.
2. Он работает медленнее — стало быть, задачу "оптимизации" он не решил.
3. Он гораздо более хрупкий — вы не умеете вносить изменения в алгоритмы так, чтобы не ломать их семантику; и написан он (в отличие от коробочной реализации) без разделения на логику сравнения элементов и логику выбора того, когда и какие элементы сравнивать.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Re: Оптимизация через разделение/вынос функционала
Азарту ради, я написал код с сортировкой с использованием дополнительной памяти (деление интервала значений на секции):
Скрытый текст
procedure TDoubleArray.QSort10Sections;
const
SectionsCount=100;
var
sectionsize:integer;
Sections:array[0..SectionsCount-1] of tdoublearray;
q,w:integer;
minval,maxval:double;
interval:double;
begin
if fcount<300 then begin
QSort2GPT;
exit;
end;
minval:=MaxSafeFloat;
maxval:=-MaxSafeFloat;
for q:=0 to fcount-1 do begin
if fitems[q]<minval then minval:=fitems[q];
if fitems[q]>maxval then maxval:=fitems[q];
end;//next q
minval:=minval-minsafefloat;
maxval:=maxval+minsafefloat;
interval:=maxval-minval;
sectionsize:=fcount div sectionscount;
for q:=0 to sectionscount-1 do begin
sections[q]:=TDoubleArray.Create;
sections[q].Capacity:=sectionsize*10;
end;
for q:=0 to fcount-1 do begin
sections[floor((sectionscount-1)*(fitems[q]-minval)/interval)].Add(fitems[q]);
end;
count:=0;
for q:=0 to SectionsCount-1 do begin
sections[q].QSort10Sections;
for w:=0 to sections[q].fcount-1 do add(sections[q].fitems[w]);
sections[q].Free;
end;
end;
Прежде чем кликать по спойлеру, ответьте на вопрос — вы бы легко написали этот алгоритм?
Мой алгоритм вышел примерно на 30% быстрее стандартной быстрой сортировки со схемой Хоара. Памяти он расходует не особо много. А вы бы опять искали готовый алгоритм вместо голимого придумывания велосипеда?
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
Re[2]: Оптимизация через разделение/вынос функционала
Здравствуйте, Khimik, Вы писали:
K> Мой алгоритм вышел примерно на 30% быстрее стандартной быстрой сортировки со схемой Хоара. Памяти он расходует не особо много. А вы бы опять искали готовый алгоритм вместо голимого придумывания велосипеда?
Ну вот смотри реализацию сортировки в jdk. Полагаю, что в этот код вложено несколько человеколет и защищено несколько кандидатских.
Ты правда надеешься придумать что-то лучшее самостоятельно?
Здравствуйте, Khimik, Вы писали:
K>Азарту ради, я написал код с сортировкой с использованием дополнительной памяти (деление интервала значений на секции):
K>end; K>[/pascal] K>[/cut]
K>Прежде чем кликать по спойлеру, ответьте на вопрос — вы бы легко написали этот алгоритм?
Абы какую сортировку написал бы легко. Чтобы он реально обогнал алгоритмы рекордсмены — вряд ли.
K>Мой алгоритм вышел примерно на 30% быстрее стандартной быстрой сортировки со схемой Хоара. Памяти он расходует не особо много. А вы бы опять искали готовый алгоритм вместо голимого придумывания велосипеда?
Учитывая предыдущий опыт думаю что ты опять морочишь голову. Либо не работает, либо некорректный тест.
Тут содержится некий QSort2GPT. Это что ?
30% по сравнению с QSort2GPT или TList <double>.Sort?
Здравствуйте, swame, Вы писали:
S>Учитывая предыдущий опыт думаю что ты опять морочишь голову. Либо не работает, либо некорректный тест.
Я проверил, работает правильно.
S>Тут содержится некий QSort2GPT. Это что ?
Это сортировка от ChatGPT (с Хоаром) которую выложили в этой теме выше. Т.е. строго говоря я не заменил быструю сортировку с Хоаром своим алгоритмом, с совместил свой алгоритм с ней. А вам даже непонятно о чём речь? Алгоритм мой можете распарсить?
S>30% по сравнению с QSort2GPT или TList <double>.Sort?
По сравнению с QSort2GPT.
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
Re[4]: Оптимизация через разделение/вынос функционала
Здравствуйте, Khimik, Вы писали:
K>Здравствуйте, swame, Вы писали:
S>>Учитывая предыдущий опыт думаю что ты опять морочишь голову. Либо не работает, либо некорректный тест.
K>Я проверил, работает правильно.
Исправил ошибки опять
S>>Тут содержится некий QSort2GPT. Это что ?
K>Это сортировка от ChatGPT (с Хоаром) которую выложили в этой теме выше. Т.е. строго говоря я не заменил быструю сортировку с Хоаром своим алгоритмом, с совместил свой алгоритм с ней. А вам даже непонятно о чём речь? Алгоритм мой можете распарсить?
S>>30% по сравнению с QSort2GPT или TList <double>.Sort?
K>По сравнению с QSort2GPT.
Мой тест показал, что твой алгоритм сопоставим по +/- по скорости со стандартным TList <double>.Sort
(как раз из за того что внутри использует QSort2GPT)
и, как и прежде в 2-5 раз медленней quick QSort2GPT.
При этом расходует в 100 раз и больше памяти. на 5 млн элементов уже переполняет память.
ты просто замедлил отсебятиной QSort2GPT
Так что на помойку и хватит бредить.