Здравствуйте, pekabon, Вы писали:
P>А подскажите, плз, как написать правило для парсинга subj?
Никак.
Вот с этим проблема.
followed by the same number of U+0023 (#) characters
В данный момент нет способа сделать зависимый от контекста парсинг.
В принципе это можно сделать. Но нужно перетряхнуть весь парсер.
В качестве временной заплатки можно довольно просто сделать ручной разбор токенов вот с таким интерфейсом:
ParseMyToken(text : string, startPos : int) : int
{
//ручной разбор токена
//возвращаемое значение
//в случае успешного разбора позиция следующего за токеном символа
//в случае не успешного ~(позиция облома)
}
... << RSDN@Home 1.2.0 alpha 5 rev. 62>>
Пусть это будет просто:
просто, как только можно,
но не проще.
(C) А. Эйнштейн
Здравствуйте, WolfHound, Вы писали:
WH>В данный момент нет способа сделать зависимый от контекста парсинг. WH>В принципе это можно сделать. Но нужно перетряхнуть весь парсер.
жаль, выходит плюсы тоже не попарсим.
WH>В качестве временной заплатки можно довольно просто сделать ручной разбор токенов вот с таким интерфейсом:
Было бы здорово, даже не в качестве временной заплатки, а в качестве фолбека. Все равно абсолютно все кейсы вряд ли удастся по крыть.
В antlr такая возможность есть, вроде бы.
Здравствуйте, WolfHound, Вы писали:
WH>В качестве временной заплатки можно довольно просто сделать ручной разбор токенов вот с таким интерфейсом: WH>
WH>ParseMyToken(text : string, startPos : int) : int
WH>{
WH>//ручной разбор токена
WH>//возвращаемое значение
WH>//в случае успешного разбора позиция следующего за токеном символа
WH>//в случае не успешного ~(позиция облома)
WH>}
WH>
И как это будет помогать обрабатывать контекстные данные в условиях откатного парсера с мемоизацией?
Чтобы решить проблему в корне (а за одно и кучу других, например, парсинг отступных грамматик) нужно реализовывать параметризованные правила и сематические предикаты. Это не быстрая песня и по уму ею нужно заниматься WolfHound-у.
Но для практического применения будет достаточно описать 5-10 правил парсящих литералы с заданной длинной последовательностей '#':
syntax RawStringLiteral1 = Open (!Close Any)* Close
{
regex Sharps = "#";
regex Open = "r" Sharps '\"';
regex Close = '\"' Sharps;
}
syntax RawStringLiteral2 = Open (!Close Any)* Close
{
regex Sharps = "##";
regex Open = "r" Sharps '\"';
regex Close = '\"' Sharps;
}
syntax RawStringLiteral3 = Open (!Close Any)* Close
{
regex Sharps = "###";
regex Open = "r" Sharps '\"';
regex Close = '\"' Sharps;
}
// ... размножаем нужное количество раз
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, VladD2, Вы писали:
VD>Но для практического применения будет достаточно описать 5-10 правил парсящих литералы с заданной длинной последовательностей '#':
Здравствуйте, pekabon, Вы писали:
P>жаль, выходит плюсы тоже не попарсим.
Почему?
Я не помню такие правила в плюсах.
P>Было бы здорово, даже не в качестве временной заплатки, а в качестве фолбека. Все равно абсолютно все кейсы вряд ли удастся по крыть.
Может быть.
... << RSDN@Home 1.2.0 alpha 5 rev. 62>>
Пусть это будет просто:
просто, как только можно,
но не проще.
(C) А. Эйнштейн
Здравствуйте, VladD2, Вы писали:
VD>И как это будет помогать обрабатывать контекстные данные в условиях откатного парсера с мемоизацией?
Примерно так же как регексы.
VD>Надо аналог вот этого реализовывать.
Ещё раз. Это всё я придумал за долго до того, как ты показал мне эту статью.
Малой кровью это не сделать. Нужно переписать весь парсер.
... << RSDN@Home 1.2.0 alpha 5 rev. 62>>
Пусть это будет просто:
просто, как только можно,
но не проще.
(C) А. Эйнштейн
Здравствуйте, WolfHound, Вы писали:
WH>Я не помню такие правила в плюсах.
В 11-ом появились.
P>>Было бы здорово, даже не в качестве временной заплатки, а в качестве фолбека. Все равно абсолютно все кейсы вряд ли удастся по крыть. WH>Может быть.
Это надо в откаты и мемоизацию встраивать. А это уже не сильно сложнее нежели нормальные параметризованные правила с семантическими предикатами. Думаю, если ограничиться доступом к литералам это не сложно будет реализовать. За одно сможем отступные грамматики парсить.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, WolfHound, Вы писали:
VD>>И как это будет помогать обрабатывать контекстные данные в условиях откатного парсера с мемоизацией? WH>Примерно так же как регексы.
Не прокатит. Это нужно в syntax-правилах. Там суть в том, что нужно прочесть длину спарсившихся '#' у первого подправила и указать ее в качестве аргумента второму.
Ну, предположим ты сделал рукопашный парсинг "регекса". ОК. Но ведь надо из одного такого рукопашного взять информацию о числе спарсившихся '#' и передать во второй. А это нужно делать в рамках syntax-руля.
WH>Малой кровью это не сделать. Нужно переписать весь парсер.
Я не понимаю причин этого. Нам нужно:
1. Передавать в правила параметры (в том числе out).
2. Запоминать значения out-параметров внутри мемоизации.
3. Реализовать предикаты которые будут действовать по raw-AST-у (а не по синтаксису).
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, VladD2, Вы писали:
VD>Не прокатит.
Прокатит. Просто нужно весь литерал отпарсить руками.
WH>>Малой кровью это не сделать. Нужно переписать весь парсер. VD>Я не понимаю причин этого. Нам нужно: VD>1. Передавать в правила параметры (в том числе out). VD>2. Запоминать значения out-параметров внутри мемоизации. VD>3. Реализовать предикаты которые будут действовать по raw-AST-у (а не по синтаксису).
Вот тут вылезает куча деталей реализации плюс куча плясок вокруг восстановления после ошибок.
Это всё только звучит просто. А на практике куча работы.
... << RSDN@Home 1.2.0 alpha 5 rev. 62>>
Пусть это будет просто:
просто, как только можно,
но не проще.
(C) А. Эйнштейн
Здравствуйте, VladD2, Вы писали:
VD>Здравствуйте, pekabon, Вы писали:
P>>Спасибо за совет, пока так и сделаем
VD>Если не секрет, чем занимавшийся? Решил сделать поддержку Rust-а?
Да, решили изучить пару новых для себя технологий на примере поддержки rust
Здравствуйте, VladD2, Вы писали:
P>>Пока нет, будет что открыть — откроем VD>Дык, если сразу открыть, то и вероятность того что что–то получится выше будет. VD>И мы бы помогать смогли бы, и помощники найтись могли бы.
Привет,
У нас кое-что уже нарисовалось.
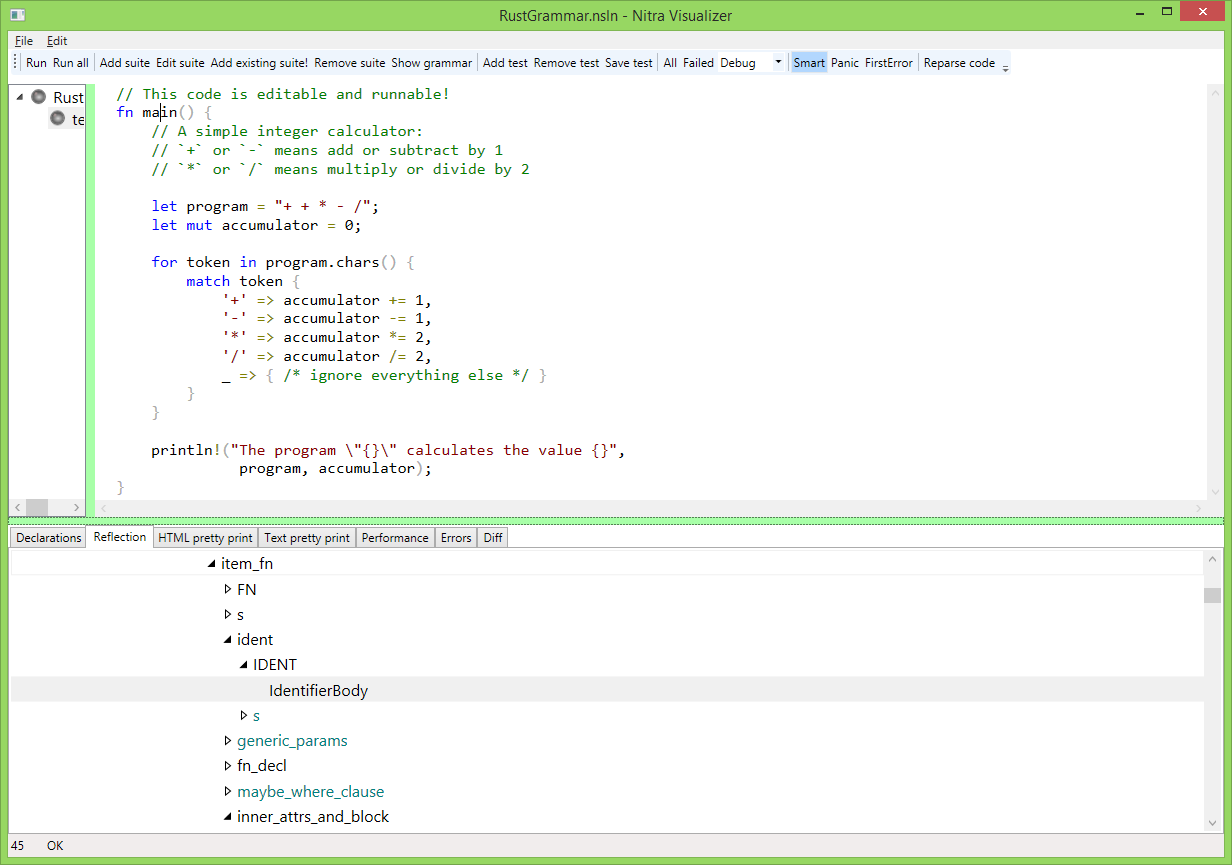
Делаем интеграцию на базе VisualRust, репа здесь.
Пока сделали автоматическую конвертацию бизоновской грамматики в найтровскую, работаем над инкрементальным обновлением.
Здравствуйте, pekabon, Вы писали:
P>Делаем интеграцию на базе VisualRust, репа здесь.
P>Пока сделали автоматическую конвертацию бизоновской грамматики в найтровскую, работаем над инкрементальным обновлением.
Поздравляю! Но парсер это пол дела. Надо еще, как минимум, типизацию сделать.
Не стесняйтесь обращаться. Поможем чем сможем.
ЗЫ
Я, тем временем, работаю над новой, клиент-серверной, версией движка IDE. Он будет пахать в другом процессе, а клиент будет очень простым и его можно будет подключить к любым IDE (в том числе на Линукс и Макоси). В перспективе можно будет, на его основе, и Веб-морду сделать. Визуалайзер будет тоже через него работать, так что везде будет использоваться единый интерфейс. Сами интеграции станут очень тонкими обертками содержащими исключительно презентационную логику.
Думаю, в течении пары недель восстановить функциональность визуалайзера на новом движке. Далее сделаем безрешарперный плагин на основе клиент-серверной версии.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, VladD2, Вы писали:
VD>Может лучше для этого конвертера создать отдельный репозиторий? Он может многим пригладиться.
А сделаем.
P>>работаем над инкрементальным обновлением. VD>Обновлением чего?
Обновлением грамматики. С одной стороны исходник на бизоне будет обновляться, с другой — мы будем вносить в грамматику всякие nl, outline и т.д. А поскольку объем большой, руками это сливать не хочется.
Плюс нам еще сам конвертер предстоит покрутить, чтобы причесать результат. Например, избавиться от фейковых правил, которыми в бизоне принято опциональность делать.
VD>Я, тем временем, работаю над новой, клиент-серверной, версией движка IDE. Он будет пахать в другом процессе, а клиент будет очень простым и его можно будет подключить к любым IDE (в том числе на Линукс и Макоси). В перспективе можно будет, на его основе, и Веб-морду сделать. Визуалайзер будет тоже через него работать, так что везде будет использоваться единый интерфейс. Сами интеграции станут очень тонкими обертками содержащими исключительно презентационную логику.
Здравствуйте, pekabon, Вы писали:
P>Обновлением грамматики. С одной стороны исходник на бизоне будет обновляться, с другой — мы будем вносить в грамматику всякие nl, outline и т.д. А поскольку объем большой, руками это сливать не хочется.
А их грамматика часто сильно меняется?
P>Плюс нам еще сам конвертер предстоит покрутить, чтобы причесать результат. Например, избавиться от фейковых правил, которыми в бизоне принято опциональность делать.
Круто, конечно. Я бы, наверно, один раз конвертнул и дальше уже руками правил. Не думаю, что там будут значительные изменения. Ну, а на крайняк сгенерировать новую версию и дифнуть/мержнуть.
В прочем, если у вас получится и мерджилка, то вообще снимаю шляпу!
ЗЫ
А что у вас с типизацией? В списке фич есть переход к определению и комплишен. Но судя по подсветке вы наши символы не используете.
Намерены использовать или какие-то сложности?
Только используя типизацию на АСТ-е с нашими символами можно получить от Найтры максимум.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, VladD2, Вы писали:
VD>Здравствуйте, pekabon, Вы писали:
P>>Обновлением грамматики. С одной стороны исходник на бизоне будет обновляться, с другой — мы будем вносить в грамматику всякие nl, outline и т.д. А поскольку объем большой, руками это сливать не хочется.
VD>А их грамматика часто сильно меняется?
За 2015 год менялась более 10 раз
P>>Плюс нам еще сам конвертер предстоит покрутить, чтобы причесать результат. Например, избавиться от фейковых правил, которыми в бизоне принято опциональность делать.
VD>Круто, конечно. Я бы, наверно, один раз конвертнул и дальше уже руками правил. Не думаю, что там будут значительные изменения. Ну, а на крайняк сгенерировать новую версию и дифнуть/мержнуть. VD>В прочем, если у вас получится и мерджилка, то вообще снимаю шляпу!
VD>ЗЫ
VD>А что у вас с типизацией? В списке фич есть переход к определению и комплишен. Но судя по подсветке вы наши символы не используете.
VD>Намерены использовать или какие-то сложности?