описывающих сущности программы (типы, методы, и т.п.), AST-а (описывающего сам код), а так же связать все ссылки (т.е. имена) которые есть в программе с символами на которые они указывают. Все ссылки описываются как свойства содержащие указатель (ссылку в дотнетом понимании) на соответствующий символ. В символах так же хранятся списки ветвей AST-а по которым был создан символ. Их может быть ноль (если символ загружен из внешних модулей или подразумевается, что он существует априори), один — если AST является декларацией символа, или несколько (например, для partial-классов или пространств имен).
В итоге мы получаем набор аннотированных деревьев AST и набор символов которыми аннотирован AST. Для некоторых языков (типа дотнетных) часть из этих символов составляют иерархию глобальных символов. Для других языков (модульного типа) этот набор символов может быть не структурирован (может не быть иерархии символов).
"Бегая" по аннотированному AST-у можно генерировать исполнимый код, интерпретировать код или реализовать сервисы IDE.
Как все это работает?
Чтобы создать интеграцию с IDE или компилятор языка нужно решить следующие задачи:
1. Написать грамматику языка. Для большинства существующих языков такие грамматики можно найти в их описании, стандартах или на их сайтах. Обычно это та или иная форма БНФ. Ее не сложно перевести на Nitra.
2. Преобразовать грамматику в парсер. В Nitra это делается путем скармливания .nitra-файлов компилятору Nitra (Nitra.exe).
3. Прогнать парсер по файлам проекта и получить набор деревьев разбора (по одному для каждого файла), а так же некоторую дополнительную информацию: информация для фолдинга (свертывание кода в редакторе), информация о токенах (для подсветки), информацию для атодополения ключевых слов.
4. Описать AST на специальном DSL (внутри .nitra-файла). Отличие AST от дерева разбора (Parse Tree, PT) описаны в терминологии
Зависимые свойства остаются на AST в виде обычных дотнетных свойств которые можно читать из обычного кода.
Суть зависимых свойств в том, что порядок их вычисления определяется их зависимостями (нечто вроде ленивой модели вычислений, но вычисление происходит не тогда когда оно требуется, а тогда когда становятся доступны все исходные данные). Таким образом совершенно все равно в каком порядке они расположены в коде. Вычислены они будут в том порядке в котором их можно вычислить. При этом могут быть зацикливания, но они отслеживаются в рантайме.
Для дотнетного языка есть несколько стадий расчетов:
1. Создание дерева иерархических символов (пространства имен, типы, члены типов, параметры и возвращаемые значения членов).
2. Формирования областей видимости. Они описываются объектами типа Scop, доступными в стандартной библиотеке Nitra.
3. Окончательные вычисления (типизация и т.п.).
Стадии получатся сами собой за счет того, что входные данные для них передаются через отдельные зависимые свойства.
В конце концов в AST появляется информация необходимая для связывания ссылок с символами, и как следствие, сами символы. После этого AST можно использовать для фич IDE, для генерации исполняемого кода или чего-то еще. Причем Nitra будет поддерживать базовые фичи IDE автоматически. Нужно только предоставить необходимые описания на DSL-ях Nitra-ы.
Под капотом
Так как IDE должна работать без задержек даже с огромными проектами, работа с AST и символами ведется не в пакетном режиме, а (как минимум) по файлов, а промежуточные результаты должны кэширвоаться. В будущем мы постараемся уменьшить гранулярность отслеживания изменений до частей AST реализовав инкрементальный парсинг и инкрементальное обновление символов. Кэширование так же будет осуществляться автоматически.
Nitra будет предоставлять автоматическое обновление AST и стратегию инкрементального пересчета символов и связывания. Так что описав в наших DSL-ях свой язык пользователь получит почти автоматическую поддержку в IDE:
1. Подсветку ключевых слов и ссылок (ссылки на разные символы можно будет подсвечивать разными цветами).
2. Фолдинг.
3. Автодополнение при вводе ключевых слов и ссылок на символы.
4. Навигацию по коду: переход по ссылкам к декларациям символов и просмотр структуры каждого из символов.
5. Рефакторинг переименования.
6. Форматирование кода.
Итого
Nitra предоставляет инфраструктуру и набор DSL-ей для создания языка. Большая часть деталей реализации (составляющих основную сложность создания современных тулов для языка) Nitra берет на себя. Разработчику языка нужно предоставить только:
1. Описание грамматики (в виде правил заключенных в синтаксические модули).
2. Описать AST языка (или группы похожих языков).
3. Описать отображение PT на AST.
4. Описать вычисление на AST в виде определения набора зависимых свойств и некоторых вычислений на их основе.
6. Описать файл определения языка (где задается общая информация о языке).
7. Скормить все это компилятору Nitra и получить на выходе готовую интеграцию для своего языка программирования.
8. (если надо) Создать генератор исполнимого кода с использованием других подсистем Nitra.
PS
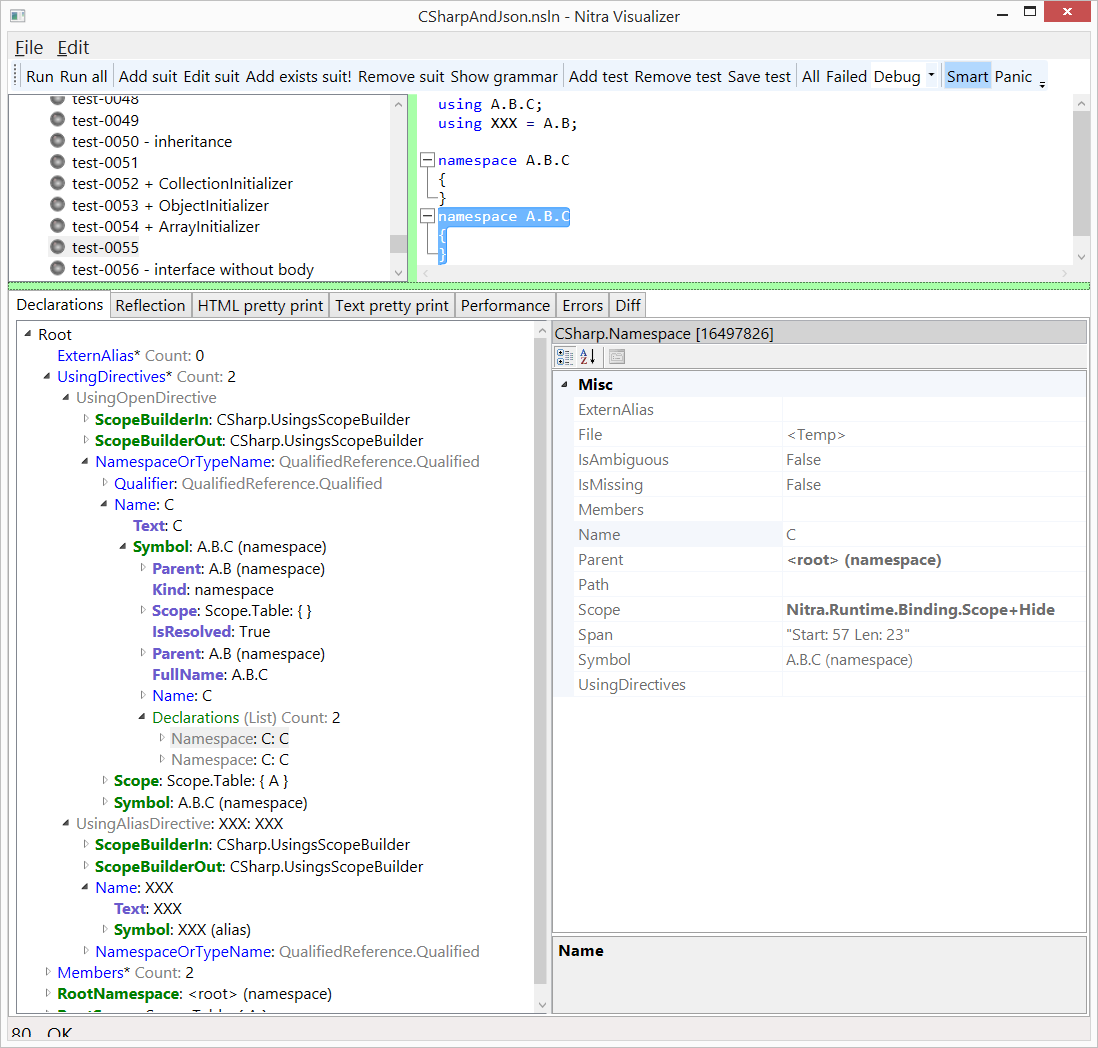
Скришот Nitra.Visualizer.exe в режиме просмотра AST и символов. Nitra.Visualizer — это тестовая утилита в которой можно тестировать грамматики (и т.п.) созданные Nitra.
Ярком синим отображаются структурные свойства AST-а (получаемые отображением с PT).
Зеленым показываются зависимые свойства, с помощью которых производятся различные вычисления.
Фиолетовым — разные предопределенные свойства.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, VladD2, Вы писали:
VD>Nitra предоставляет инфраструктуру и набор DSL-ей для создания языка. Большая часть деталей реализации (составляющих основную сложность создания современных тулов для языка) Nitra берет на себя. Разработчику языка нужно предоставить только: VD>1. Описание грамматики (в виде правил заключенных в синтаксические модули). VD>2. Описать AST языка (или группы похожих языков). VD>3. Описать отображение PT на AST. VD>4. Описать вычисление на AST в виде определения набора зависимых свойств и некоторых вычислений на их основе. VD>6. Описать файл определения языка (где задается общая информация о языке). VD>7. Скормить все это компилятору Nitra и получить на выходе готовую интеграцию для своего языка программирования. VD>8. (если надо) Создать генератор исполнимого кода с использованием других подсистем Nitra.
Где в этой картине присходят такие вещи, как overload resolution, type inference и типизация лямбд? И в каком виде разработчик должен описывать правила для них?
Можно ли приспособить эту систему к языкам вроде C++?
Re[2]: [Nitra] Принципы построения языка программирования
Здравствуйте, nikov, Вы писали:
N>Где в этой картине присходят такие вещи, как overload resolution, type inference и типизация лямбд? И в каком виде разработчик должен описывать правила для них?
В этой нигде. Для типизации и вывода типов будет отдельная поддержка. Пока что мы только связыванием занимаемся. Зависимые свойства будут использоваться чтобы протащить/расставить места где должны быть типы, а далее в них уже будет нечто вроде переменных-типов по которым будет вывод типов работать. Зависимости будут через отдельный DSL описываться.
Для многих ДСЛ-ей достаточно связывания. Для поддержки MSIL-а, по идее, тоже должно быть достаточно.
N>Можно ли приспособить эту систему к языкам вроде C++?
В теории — да. Парсер у нас генерализованный. Даст две ветки на неоднозначностях. Далее производим связывание и выбираем удачно сросшуюся. Но там еще много всего интересного вроде перегрузки шаблонов (при частичном воплощении) и т.п. Пока не попробуешь, не узнаешь.
Это все в будущем. Сейчас мы даже не определились с окончательным дизайном работы с символами, связыванием и областями видимости. Я как раз сейчас пробую прототип этого дела. Далее, возможно, заДСЛим это дело.
На то что получается можно посмотреть здесь (подкаталоги AST и Symbols).
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Re: [Nitra] Принципы построения языка программирования
Здравствуйте, VladD2, Вы писали:
VD>3. Преобразовать PT в AST. Это так же делается с помощью специализированного DSL.
Не слишком ли просто? Ведь AST будет некой "сжатой" схемой PT (это в самом слабом предположении), тут уже маппинг 1:1 не работает. Плюс (предполагаю), наверняка понадобится обработка подузлов в PT. Например:
В PT:
Класс-(ключ.слово class + Имя + скобочка + члены-(метод1, поле1, метод2,...) ...)
В AST:
Класс-(СписокПолей, СписокМетодов, Атрибуты, ...)
Я правильно понимаю роль и конечный вид AST? Если да, то боюсь одного DSL для отображения будет мало.
Re[3]: [Nitra] Принципы построения языка программирования
Здравствуйте, Kolesiki, Вы писали:
VD>>3. Преобразовать PT в AST. Это так же делается с помощью специализированного DSL.
K>Не слишком ли просто? Ведь AST будет некой "сжатой" схемой PT
В этом весь смысл. Он гораздо компактнее и абстрактнее.
За счет компактности его можно держать в памяти, сериализовать и т.п.
За счет абстрактности на одно AST можно отображать разный синтаксис (например, C# и Nemerle).
Например, в C# поля могут быть объявлены одной декларацией:
public int A, B, C;
а в AST они будут разными элементами.
K>тут уже маппинг 1:1 не работает.
Мапинг и позволят отображать данные не 1 в 1, а с некоторыми преобразованиями. Сейчас Хардкейс заканчивает работу над самым сложным из них — параметризованным отображением. У конструкций map syntax появятся параметры типа AST, так что одно правило можно будет использовать из разных мест и получать ветки AST разных типов. Например, в шарпе декларатор локальных переменных и полей имеют одинаковый синтаксис. За счет параметризованных отображений можно будет использовать единое дерево разбора (не прибегая к копипасте).
K>Плюс (предполагаю), наверняка понадобится обработка подузлов в PT. Например:... K>Я правильно понимаю роль и конечный вид AST? Если да, то боюсь одного DSL для отображения будет мало.
Маппинг и определение AST поддерживают довольно много фич. В том числе есть возможность возвращать списки из одного элемента и "пропускать AST насквозь" избавляясь тем самым от промежуточных полей. В купе с параметризованным отображением и возможностью ручного отображения — это дает довольно большую гибкость. Плюс в AST-е можно применять декомпозицию списков. В следующем реальном примере свойство типа список LanguageProperty разбивается на отдельные подсписки и поля в зависимости от типов подэлементов (при этом исходный список остается доступен):
В приведенном примере элементы из списка Properties раскладываются по полям перечисленным внутри элемента "decompose Properties".
FileExtensions — это список в котором должно быть хотя бы один элемент (или более). Если элементов меньше, будет выдано стандартное сообщение об ошибке.
SpanClassesInlines — список из нуля или более элементов. Если элементов этого типа (т.е. типа LanguageProperty.SpanClassDefinitionInline) нет в Properties, никаких сообщений об ошибках не последует.
StartSyntaxModule — это отдельное поле. Если в Properties нет элементов этого типа или в Properties больше одного элемента этого типа, будет выдано сообщение об ошибке.
RequireLicenseAcceptance — необязательное свойство. Если в Properties нет элементов, в это поле будет помещено значение None(), что означает отсутствие значения (сообщения об ошибке, при этом, выдано не будет). Если в Properties более одного элемента типа LanguageProperty.RequireLicenseAcceptance, будет выдано сообщение об ошибке.
С помощью этой фичи очень удобно создавать типизированные подсписки и делать кое что еще.
В купе с мппингом это позволяет довольно радикально изменить AST, по сравнению с PT.
В итоге AST получается по формату близким к определяемым им символам. Мы надеемся, что в дальнейшем символы будут автоматически порождатся на основании описания деклараций (вид AST-а содержащего имя).
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Re: [Nitra] Принципы построения языка программирования
У меня к тебе (да и к остальным, тоже) вопрос. Насколько понятен код DSL-ей? Насколько интуитивно понятны маппинг, описание АСТ-а, вычисления на зависимых свойствах?
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Re[5]: [Nitra] Принципы построения языка программирования
Здравствуйте, VladD2, Вы писали:
VD>Здравствуйте, nikov, Вы писали:
VD>У меня к тебе (да и к остальным, тоже) вопрос. Насколько понятен код DSL-ей? Насколько интуитивно понятны маппинг, описание АСТ-а, вычисления на зависимых свойствах?
Судя по реакции не понятен....
можно пример использования (калькулятор?)
Re[5]: [Nitra] Принципы построения языка программирования
Здравствуйте, VladD2, Вы писали:
VD>У меня к тебе (да и к остальным, тоже) вопрос. Насколько понятен код DSL-ей? Насколько интуитивно понятны маппинг, описание АСТ-а, вычисления на зависимых свойствах?
Сходу не совсем понятно, но я пока не особо старался разобраться (не сидел и не экспериментировал).
Хотелось бы увидеть tutorials со сравнительно простыми примерами (то не насколько тривиальными, как калькулятор).
Можно взять синтаксически простые языки: LISP, Prolog, базовый SQL, JavaScript (хороший пример языка с DSL — регулярными выражениями). Типизацию было бы хорошо посмотреть на примере упрощённого Haskell (без user-defined типов данных, без классов типов).
Из сложных примеров мне было бы интересно увидеть грамматику и типизацию для Котлина.
Интересно посмотреть, как обрабатываются языки, где язык разметки смешан с языком вычислений (ASP.NET, или XML-литералы в VB.NET).
Re[6]: [Nitra] Принципы построения языка программирования
Здравствуйте, nikov, Вы писали:
N>Хотелось бы увидеть tutorials со сравнительно простыми примерами (то не насколько тривиальными, как калькулятор).
В калькуляторе нечего вызывать.
N>Можно взять синтаксически простые языки: LISP, Prolog, базовый SQL, JavaScript (хороший пример языка с DSL — регулярными выражениями). Типизацию было бы хорошо посмотреть на примере упрощённого Haskell (без user-defined типов данных, без классов типов).
Как я уже говорил, типизации пока что нет. Пока что есть прототип подсистемы связывания. На нем можно реализовать языки без вывода типов или тот же Шарп до уровня тел методов. В принципе на Шарпе мы и экспериментируем.
Проблема заключается в том, что многие игрушечные (и старые) языки используют очень примитивное связывание. Интересным примером является разве что тот же C#. Там много интересных случаев, но результат, вроде бы, выглядит довольно просто.
Может стоит описать вопросы связывания на примере шарпа? Тем более, что язык всем известный.
N>Из сложных примеров мне было бы интересно увидеть грамматику и типизацию для Котлина.
Для начала надо эту грамматику написать. Это довольно не малый объем работы. А, я в нем не шарю. Даже не знаю где взять его БНФ и есть ли он.
Собственно, можно поступить так. Я в ближайшее врем постараюсь описать вопросы связывания и отображения для шарпа, а ты можешь попрбовать на основе этого сделать тоже самое для Котлина (до уровня тел методов, так как там можно обойтись без вывода типов). Я с удовольствием помогу по скайпу.
N>Интересно посмотреть, как обрабатываются языки, где язык разметки смешан с языком вычислений (ASP.NET, или XML-литералы в VB.NET).
Такие языки делятся на две группы. Те что можно представить как вложенные языки (например, XML-литералы, VB.NET и Разор) и те, что требуют двойного парсинга (например, регулярные выражения встроенные в строку C#-а). Первые можно реализовать искаропки (ц), за счет расширения грамматик. Вторые требуют двухпроходной схемы, что требует специальной поддержки, которой пока нет и которой в ближайшее время мы заниматься не будем, так как полно других дел.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Re[7]: [Nitra] Принципы построения языка программирования
Здравствуйте, VladD2, Вы писали:
N>>Из сложных примеров мне было бы интересно увидеть грамматику и типизацию для Котлина.
VD>Для начала надо эту грамматику написать. Это довольно не малый объем работы. А, я в нем не шарю. Даже не знаю где взять его БНФ и есть ли он.
Kotlin (Ко́тлин) — статически типизированный язык программирования, работающий поверх JVM, и разрабатываемый компанией JetBrains. Компилируется также в JavaScript.
Re[8]: [Nitra] Принципы построения языка программирования
Здравствуйте, s22, Вы писали:
s22>Kotlin (Ко́тлин) — статически типизированный язык программирования, работающий поверх JVM, и разрабатываемый компанией JetBrains. Компилируется также в JavaScript.
Это ровным счетом ничего не значит. Команда котлина отдельная команад. Ников к ней имеет отношения, я — нет. Котлиновцы седят в Питере и общаться мы сними можем только через скапй. Что ставит нас с тобой, например, в одинаковое положение.
Поднять Котлин на Найтре было бы прикольно и полезно, но у нас в команде всего 3 человека, а фронт работ зашкаливающий. Если Ников, или кто-то еще, возьмется помочь, мы будем премного благодарны.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.