Сообщение [Nitra] Принципы построения языка программирования от 22.05.2015 14:40
Изменено 22.05.2015 22:24 VladD2
Терминология
В результате работы интеграции нам нужно получить набор символов
В итоге мы получаем набор аннотированных деревьев AST и набор символов которыми аннотирован AST. Для некоторых языков (типа дотнетных) часть из этих символов составляют иерархию глобальных символов. Для других языков (модульного типа) этот набор символов может быть не структурирован (может не быть иерархии символов).
"Бегая" по аннотированному AST-у можно генерировать исполнимый код, интерпретировать код или реализовать сервисы IDE.
Чтобы создать интеграцию с IDE или компилятор языка нужно решить следующие задачи:
1. Написать грамматику языка. Для большинства существующих языков такие грамматики можно найти в их описании, стандартах или на их сайтах. Обычно это та или иная форма БНФ. Ее не сложно перевести на Nitra.
2. Преобразовать грамматику в парсер. В Nitra это делается путем скармливания .nitra-файлов компилятору Nitra (Nitra.exe).
3. Прогнать парсер по файлам проекта и получить набор деревьев разбора (по одному для каждого файла), а так же некоторую дополнительную информацию: информация для фолдинга (свертывание кода в редакторе), информация о токенах (для подсветки), информацию для атодополения ключевых слов.
4. Описать AST на специальном DSL (внутри .nitra-файла). Отличие AST от дерева разбора (Parse Tree, PT) описаны в терминологии
Пример описания AST:
3. Преобразовать PT в AST. Это так же делается с помощью специализированного DSL.
Пример DSL отображения Parse Tree на AST:
4. С помощью зависимых свойств (о них чуть позже) описать необходимые расчеты на AST.
Пример расчетов на зависимых свойствах:
Зависимые свойства остаются на AST в виде обычных дотнетных свойств которые можно читать из обычного кода.
Суть зависимых свойств в том, что порядок их вычисления определяется их зависимостями (нечто вроде ленивой модели вычислений, но вычисление происходит не тогда когда оно требуется, а тогда когда становятся доступны все исходные данные). Таким образом совершенно все равно в каком порядке они расположены в коде. Вычислены они будут в том порядке в котором их можно вычислить. При этом могут быть зацикливания, но они отслеживаются в рантайме.
Для дотнетного языка есть несколько стадий расчетов:
1. Создание дерева иерархических символов (пространства имен, типы, члены типов, параметры и возвращаемые значения членов).
2. Формирования областей видимости. Они описываются объектами типа Scop, доступными в стандартной библиотеке Nitra.
3. Окончательные вычисления (типизация и т.п.).
Стадии получатся сами собой за счет того, что входные данные для них передаются через отдельные зависимые свойства.
В конце концов в AST появляется информация необходимая для связывания ссылок с символами, и как следствие, сами символы. После этого AST можно использовать для фич IDE, для генерации исполняемого кода или чего-то еще. Причем Nitra будет поддерживать базовые фичи IDE автоматически. Нужно только предоставить необходимые описания на DSL-ях Nitra-ы.
Так как IDE должна работать без задержек даже с огромными проектами, работа с AST и символами ведется не в пакетном режиме, а (как минимум) по файлов, а промежуточные результаты должны кэширвоаться. В будущем мы постараемся уменьшить гранулярность отслеживания изменений до частей AST реализовав инкрементальный парсинг и инкрементальное обновление символов. Кэширование так же будет осуществляться автоматически.
Nitra будет предоставлять автоматическое обновление AST и стратегию инкрементального пересчета символов и связывания. Так что описав в наших DSL-ях свой язык пользователь получит почти автоматическую поддержку в IDE:
1. Подсветку ключевых слов и ссылок (ссылки на разные символы можно будет подсвечивать разными цветами).
2. Фолдинг.
3. Автодополнение при вводе ключевых слов и ссылок на символы.
4. Навигацию по коду: переход по ссылкам к декларациям символов и просмотр структуры каждого из символов.
5. Рефакторинг переименования.
6. Форматирование кода.
Nitra предоставляет инфраструктуру и набор DSL-ей для создания языка. Большая часть деталей реализации (составляющих основную сложность создания современных тулов для языка) Nitra берет на себя. Разработчику языка нужно предоставить только:
1. Описание грамматики (в виде правил заключенных в синтаксические модули).
2. Описать AST языка (или группы похожих языков).
3. Описать отображение PT на AST.
4. Описать вычисление на AST в виде определения набора зависимых свойств и некоторых вычислений на их основе.
6. Описать файл определения языка (где задается общая информация о языке).
7. Скормить все это компилятору Nitra и получить на выходе готовую интеграцию для своего языка программирования.
8. (если надо) Создать генератор исполнимого кода с использованием других подсистем Nitra.
Автор: VladD2
Дата: 14.03.15
используемая в этом сообщении.Дата: 14.03.15
С высоты птичьего полета
В результате работы интеграции нам нужно получить набор символов
Автор: VladD2
Дата: 14.03.15
описывающих сущности программы (типы, методы, и т.п.), AST-а (описывающего сам код), а так же связать все ссылки (т.е. имена) которые есть в программе с символами на которые они указывают. Все ссылки описываются как свойства содержащие указатель (ссылку в дотнетом понимании) на соответствующий символ. В символах так же хранятся списки ветвей AST-а по которым был создан символ. Их может быть ноль (если символ загружен из внешних модулей или подразумевается, что он существует априори), один — если AST является декларацией символа, или несколько (например, для partial-классов или пространств имен).Дата: 14.03.15
В итоге мы получаем набор аннотированных деревьев AST и набор символов которыми аннотирован AST. Для некоторых языков (типа дотнетных) часть из этих символов составляют иерархию глобальных символов. Для других языков (модульного типа) этот набор символов может быть не структурирован (может не быть иерархии символов).
"Бегая" по аннотированному AST-у можно генерировать исполнимый код, интерпретировать код или реализовать сервисы IDE.
Как все это работает?
Чтобы создать интеграцию с IDE или компилятор языка нужно решить следующие задачи:
1. Написать грамматику языка. Для большинства существующих языков такие грамматики можно найти в их описании, стандартах или на их сайтах. Обычно это та или иная форма БНФ. Ее не сложно перевести на Nitra.
2. Преобразовать грамматику в парсер. В Nitra это делается путем скармливания .nitra-файлов компилятору Nitra (Nitra.exe).
3. Прогнать парсер по файлам проекта и получить набор деревьев разбора (по одному для каждого файла), а так же некоторую дополнительную информацию: информация для фолдинга (свертывание кода в редакторе), информация о токенах (для подсветки), информацию для атодополения ключевых слов.
4. Описать AST на специальном DSL (внутри .nitra-файла). Отличие AST от дерева разбора (Parse Tree, PT) описаны в терминологии
Автор: VladD2
Дата: 14.03.15
. Дата: 14.03.15
Пример описания AST:
asts CompilationUnit
{
| CSharp
{
ExternAlias : ExternAliasDirective*; // "*" - означает "список" (а-ля List<ExternAliasDirective>
UsingDirectives : UsingDirective*;
Members : NamespaceMember*;
}
}3. Преобразовать PT в AST. Это так же делается с помощью специализированного DSL.
Пример DSL отображения Parse Tree на AST:
// Main.CompilationUnit - дерево разбора, CompilationUnit.CSharp - AST
map syntax Main.CompilationUnit -> CompilationUnit.CSharp
{
// указываем какое поле PT преобразовать в какое поле AST
ExternAliasDirectives -> ExternAlias;
UsingDirectives -> UsingDirectives;
NamespaceMemberDeclarations -> Members;
}4. С помощью зависимых свойств (о них чуть позже) описать необходимые расчеты на AST.
Пример расчетов на зависимых свойствах:
asts CompilationUnit
{
in RootNamespace : NamespaceSymbol;
in RootScope : Scope;
| CSharp
{
Members.Parent = RootNamespace;
ExternAlias.ScopeIn = RootScope;
UsingDirectives.ScopeBuilderIn = UsingsScopeBuilder(ExternAlias.ScopeOut);
Members.Scope = UsingDirectives.ScopeBuilderOut.MakeResultScop();
ExternAlias : ExternAliasDirective*;
UsingDirectives : UsingDirective*;
Members : NamespaceMember*;
}
}Зависимые свойства остаются на AST в виде обычных дотнетных свойств которые можно читать из обычного кода.
Суть зависимых свойств в том, что порядок их вычисления определяется их зависимостями (нечто вроде ленивой модели вычислений, но вычисление происходит не тогда когда оно требуется, а тогда когда становятся доступны все исходные данные). Таким образом совершенно все равно в каком порядке они расположены в коде. Вычислены они будут в том порядке в котором их можно вычислить. При этом могут быть зацикливания, но они отслеживаются в рантайме.
Для дотнетного языка есть несколько стадий расчетов:
1. Создание дерева иерархических символов (пространства имен, типы, члены типов, параметры и возвращаемые значения членов).
2. Формирования областей видимости. Они описываются объектами типа Scop, доступными в стандартной библиотеке Nitra.
3. Окончательные вычисления (типизация и т.п.).
Стадии получатся сами собой за счет того, что входные данные для них передаются через отдельные зависимые свойства.
В конце концов в AST появляется информация необходимая для связывания ссылок с символами, и как следствие, сами символы. После этого AST можно использовать для фич IDE, для генерации исполняемого кода или чего-то еще. Причем Nitra будет поддерживать базовые фичи IDE автоматически. Нужно только предоставить необходимые описания на DSL-ях Nitra-ы.
Под капотом
Так как IDE должна работать без задержек даже с огромными проектами, работа с AST и символами ведется не в пакетном режиме, а (как минимум) по файлов, а промежуточные результаты должны кэширвоаться. В будущем мы постараемся уменьшить гранулярность отслеживания изменений до частей AST реализовав инкрементальный парсинг и инкрементальное обновление символов. Кэширование так же будет осуществляться автоматически.
Nitra будет предоставлять автоматическое обновление AST и стратегию инкрементального пересчета символов и связывания. Так что описав в наших DSL-ях свой язык пользователь получит почти автоматическую поддержку в IDE:
1. Подсветку ключевых слов и ссылок (ссылки на разные символы можно будет подсвечивать разными цветами).
2. Фолдинг.
3. Автодополнение при вводе ключевых слов и ссылок на символы.
4. Навигацию по коду: переход по ссылкам к декларациям символов и просмотр структуры каждого из символов.
5. Рефакторинг переименования.
6. Форматирование кода.
Итого
Nitra предоставляет инфраструктуру и набор DSL-ей для создания языка. Большая часть деталей реализации (составляющих основную сложность создания современных тулов для языка) Nitra берет на себя. Разработчику языка нужно предоставить только:
1. Описание грамматики (в виде правил заключенных в синтаксические модули).
2. Описать AST языка (или группы похожих языков).
3. Описать отображение PT на AST.
4. Описать вычисление на AST в виде определения набора зависимых свойств и некоторых вычислений на их основе.
6. Описать файл определения языка (где задается общая информация о языке).
7. Скормить все это компилятору Nitra и получить на выходе готовую интеграцию для своего языка программирования.
8. (если надо) Создать генератор исполнимого кода с использованием других подсистем Nitra.
[Nitra] Принципы построения языка программирования
Терминология
В результате работы интеграции нам нужно получить набор символов
В итоге мы получаем набор аннотированных деревьев AST и набор символов которыми аннотирован AST. Для некоторых языков (типа дотнетных) часть из этих символов составляют иерархию глобальных символов. Для других языков (модульного типа) этот набор символов может быть не структурирован (может не быть иерархии символов).
"Бегая" по аннотированному AST-у можно генерировать исполнимый код, интерпретировать код или реализовать сервисы IDE.
Чтобы создать интеграцию с IDE или компилятор языка нужно решить следующие задачи:
1. Написать грамматику языка. Для большинства существующих языков такие грамматики можно найти в их описании, стандартах или на их сайтах. Обычно это та или иная форма БНФ. Ее не сложно перевести на Nitra.
2. Преобразовать грамматику в парсер. В Nitra это делается путем скармливания .nitra-файлов компилятору Nitra (Nitra.exe).
3. Прогнать парсер по файлам проекта и получить набор деревьев разбора (по одному для каждого файла), а так же некоторую дополнительную информацию: информация для фолдинга (свертывание кода в редакторе), информация о токенах (для подсветки), информацию для атодополения ключевых слов.
4. Описать AST на специальном DSL (внутри .nitra-файла). Отличие AST от дерева разбора (Parse Tree, PT) описаны в терминологии
Пример описания AST:
3. Преобразовать PT в AST. Это так же делается с помощью специализированного DSL.
Пример DSL отображения Parse Tree на AST:
4. С помощью зависимых свойств (о них чуть позже) описать необходимые расчеты на AST.
Пример расчетов на зависимых свойствах:
Зависимые свойства остаются на AST в виде обычных дотнетных свойств которые можно читать из обычного кода.
Суть зависимых свойств в том, что порядок их вычисления определяется их зависимостями (нечто вроде ленивой модели вычислений, но вычисление происходит не тогда когда оно требуется, а тогда когда становятся доступны все исходные данные). Таким образом совершенно все равно в каком порядке они расположены в коде. Вычислены они будут в том порядке в котором их можно вычислить. При этом могут быть зацикливания, но они отслеживаются в рантайме.
Для дотнетного языка есть несколько стадий расчетов:
1. Создание дерева иерархических символов (пространства имен, типы, члены типов, параметры и возвращаемые значения членов).
2. Формирования областей видимости. Они описываются объектами типа Scop, доступными в стандартной библиотеке Nitra.
3. Окончательные вычисления (типизация и т.п.).
Стадии получатся сами собой за счет того, что входные данные для них передаются через отдельные зависимые свойства.
В конце концов в AST появляется информация необходимая для связывания ссылок с символами, и как следствие, сами символы. После этого AST можно использовать для фич IDE, для генерации исполняемого кода или чего-то еще. Причем Nitra будет поддерживать базовые фичи IDE автоматически. Нужно только предоставить необходимые описания на DSL-ях Nitra-ы.
Так как IDE должна работать без задержек даже с огромными проектами, работа с AST и символами ведется не в пакетном режиме, а (как минимум) по файлов, а промежуточные результаты должны кэширвоаться. В будущем мы постараемся уменьшить гранулярность отслеживания изменений до частей AST реализовав инкрементальный парсинг и инкрементальное обновление символов. Кэширование так же будет осуществляться автоматически.
Nitra будет предоставлять автоматическое обновление AST и стратегию инкрементального пересчета символов и связывания. Так что описав в наших DSL-ях свой язык пользователь получит почти автоматическую поддержку в IDE:
1. Подсветку ключевых слов и ссылок (ссылки на разные символы можно будет подсвечивать разными цветами).
2. Фолдинг.
3. Автодополнение при вводе ключевых слов и ссылок на символы.
4. Навигацию по коду: переход по ссылкам к декларациям символов и просмотр структуры каждого из символов.
5. Рефакторинг переименования.
6. Форматирование кода.
Nitra предоставляет инфраструктуру и набор DSL-ей для создания языка. Большая часть деталей реализации (составляющих основную сложность создания современных тулов для языка) Nitra берет на себя. Разработчику языка нужно предоставить только:
1. Описание грамматики (в виде правил заключенных в синтаксические модули).
2. Описать AST языка (или группы похожих языков).
3. Описать отображение PT на AST.
4. Описать вычисление на AST в виде определения набора зависимых свойств и некоторых вычислений на их основе.
6. Описать файл определения языка (где задается общая информация о языке).
7. Скормить все это компилятору Nitra и получить на выходе готовую интеграцию для своего языка программирования.
8. (если надо) Создать генератор исполнимого кода с использованием других подсистем Nitra.
PS
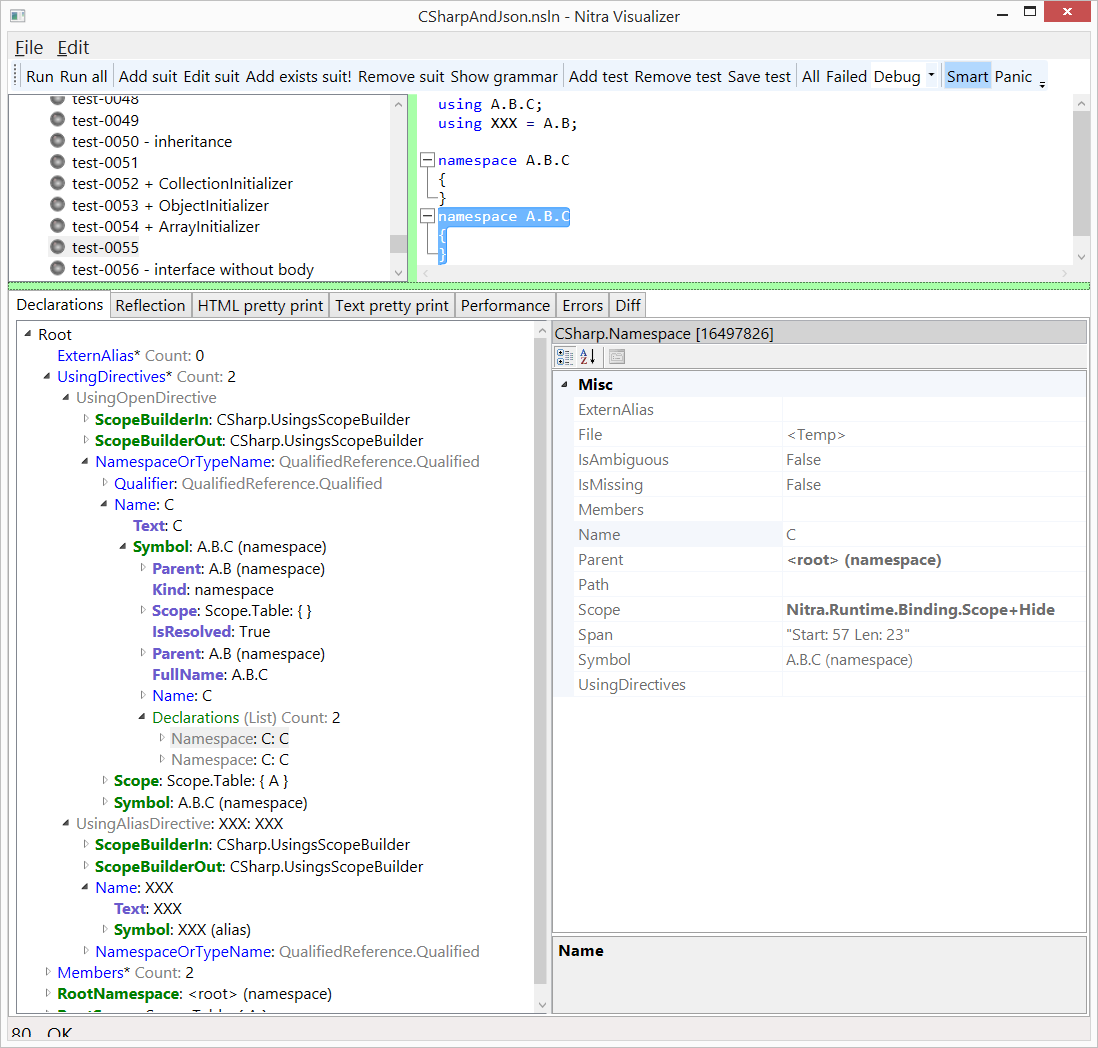
Скришот Nitra.Visualizer.exe в режиме просмотра AST и символов. Nitra.Visualizer — это тестовая утилита в которой можно тестировать грамматики (и т.п.) созданные Nitra.
Ярком синим отображаются структурные свойства AST-а (получаемые отображением с PT).
Зеленым показываются зависимые свойства, с помощью которых производятся различные вычисления.
Фиолетовым — разные предопределенные свойства.
Автор: VladD2
Дата: 14.03.15
используемая в этом сообщении.Дата: 14.03.15
С высоты птичьего полета
В результате работы интеграции нам нужно получить набор символов
Автор: VladD2
Дата: 14.03.15
описывающих сущности программы (типы, методы, и т.п.), AST-а (описывающего сам код), а так же связать все ссылки (т.е. имена) которые есть в программе с символами на которые они указывают. Все ссылки описываются как свойства содержащие указатель (ссылку в дотнетом понимании) на соответствующий символ. В символах так же хранятся списки ветвей AST-а по которым был создан символ. Их может быть ноль (если символ загружен из внешних модулей или подразумевается, что он существует априори), один — если AST является декларацией символа, или несколько (например, для partial-классов или пространств имен).Дата: 14.03.15
В итоге мы получаем набор аннотированных деревьев AST и набор символов которыми аннотирован AST. Для некоторых языков (типа дотнетных) часть из этих символов составляют иерархию глобальных символов. Для других языков (модульного типа) этот набор символов может быть не структурирован (может не быть иерархии символов).
"Бегая" по аннотированному AST-у можно генерировать исполнимый код, интерпретировать код или реализовать сервисы IDE.
Как все это работает?
Чтобы создать интеграцию с IDE или компилятор языка нужно решить следующие задачи:
1. Написать грамматику языка. Для большинства существующих языков такие грамматики можно найти в их описании, стандартах или на их сайтах. Обычно это та или иная форма БНФ. Ее не сложно перевести на Nitra.
2. Преобразовать грамматику в парсер. В Nitra это делается путем скармливания .nitra-файлов компилятору Nitra (Nitra.exe).
3. Прогнать парсер по файлам проекта и получить набор деревьев разбора (по одному для каждого файла), а так же некоторую дополнительную информацию: информация для фолдинга (свертывание кода в редакторе), информация о токенах (для подсветки), информацию для атодополения ключевых слов.
4. Описать AST на специальном DSL (внутри .nitra-файла). Отличие AST от дерева разбора (Parse Tree, PT) описаны в терминологии
Автор: VladD2
Дата: 14.03.15
. Дата: 14.03.15
Пример описания AST:
asts CompilationUnit
{
| CSharp
{
ExternAlias : ExternAliasDirective*; // "*" - означает "список" (а-ля List<ExternAliasDirective>
UsingDirectives : UsingDirective*;
Members : NamespaceMember*;
}
}3. Преобразовать PT в AST. Это так же делается с помощью специализированного DSL.
Пример DSL отображения Parse Tree на AST:
// Main.CompilationUnit - дерево разбора, CompilationUnit.CSharp - AST
map syntax Main.CompilationUnit -> CompilationUnit.CSharp
{
// указываем какое поле PT преобразовать в какое поле AST
ExternAliasDirectives -> ExternAlias;
UsingDirectives -> UsingDirectives;
NamespaceMemberDeclarations -> Members;
}4. С помощью зависимых свойств (о них чуть позже) описать необходимые расчеты на AST.
Пример расчетов на зависимых свойствах:
asts CompilationUnit
{
in RootNamespace : NamespaceSymbol;
in RootScope : Scope;
| CSharp
{
Members.Parent = RootNamespace;
ExternAlias.ScopeIn = RootScope;
UsingDirectives.ScopeBuilderIn = UsingsScopeBuilder(ExternAlias.ScopeOut);
Members.Scope = UsingDirectives.ScopeBuilderOut.MakeResultScop();
ExternAlias : ExternAliasDirective*;
UsingDirectives : UsingDirective*;
Members : NamespaceMember*;
}
}Зависимые свойства остаются на AST в виде обычных дотнетных свойств которые можно читать из обычного кода.
Суть зависимых свойств в том, что порядок их вычисления определяется их зависимостями (нечто вроде ленивой модели вычислений, но вычисление происходит не тогда когда оно требуется, а тогда когда становятся доступны все исходные данные). Таким образом совершенно все равно в каком порядке они расположены в коде. Вычислены они будут в том порядке в котором их можно вычислить. При этом могут быть зацикливания, но они отслеживаются в рантайме.
Для дотнетного языка есть несколько стадий расчетов:
1. Создание дерева иерархических символов (пространства имен, типы, члены типов, параметры и возвращаемые значения членов).
2. Формирования областей видимости. Они описываются объектами типа Scop, доступными в стандартной библиотеке Nitra.
3. Окончательные вычисления (типизация и т.п.).
Стадии получатся сами собой за счет того, что входные данные для них передаются через отдельные зависимые свойства.
В конце концов в AST появляется информация необходимая для связывания ссылок с символами, и как следствие, сами символы. После этого AST можно использовать для фич IDE, для генерации исполняемого кода или чего-то еще. Причем Nitra будет поддерживать базовые фичи IDE автоматически. Нужно только предоставить необходимые описания на DSL-ях Nitra-ы.
Под капотом
Так как IDE должна работать без задержек даже с огромными проектами, работа с AST и символами ведется не в пакетном режиме, а (как минимум) по файлов, а промежуточные результаты должны кэширвоаться. В будущем мы постараемся уменьшить гранулярность отслеживания изменений до частей AST реализовав инкрементальный парсинг и инкрементальное обновление символов. Кэширование так же будет осуществляться автоматически.
Nitra будет предоставлять автоматическое обновление AST и стратегию инкрементального пересчета символов и связывания. Так что описав в наших DSL-ях свой язык пользователь получит почти автоматическую поддержку в IDE:
1. Подсветку ключевых слов и ссылок (ссылки на разные символы можно будет подсвечивать разными цветами).
2. Фолдинг.
3. Автодополнение при вводе ключевых слов и ссылок на символы.
4. Навигацию по коду: переход по ссылкам к декларациям символов и просмотр структуры каждого из символов.
5. Рефакторинг переименования.
6. Форматирование кода.
Итого
Nitra предоставляет инфраструктуру и набор DSL-ей для создания языка. Большая часть деталей реализации (составляющих основную сложность создания современных тулов для языка) Nitra берет на себя. Разработчику языка нужно предоставить только:
1. Описание грамматики (в виде правил заключенных в синтаксические модули).
2. Описать AST языка (или группы похожих языков).
3. Описать отображение PT на AST.
4. Описать вычисление на AST в виде определения набора зависимых свойств и некоторых вычислений на их основе.
6. Описать файл определения языка (где задается общая информация о языке).
7. Скормить все это компилятору Nitra и получить на выходе готовую интеграцию для своего языка программирования.
8. (если надо) Создать генератор исполнимого кода с использованием других подсистем Nitra.
PS
Скришот Nitra.Visualizer.exe в режиме просмотра AST и символов. Nitra.Visualizer — это тестовая утилита в которой можно тестировать грамматики (и т.п.) созданные Nitra.
Ярком синим отображаются структурные свойства AST-а (получаемые отображением с PT).
Зеленым показываются зависимые свойства, с помощью которых производятся различные вычисления.
Фиолетовым — разные предопределенные свойства.