Здравствуйте, vsb, Вы писали:
vsb>C отвратительный язык для этого, по крайней мере в текущей инкарнации. К примеру gcc может заменить цикл копирования на memcpy.
Отвратительны не C/C++, как концепции языков и их типовые реализации, а современные тенденции, которые двигают их в сторону формализма. Пока этим еще удается худо-бедно управлять, а как и эта возможность исчезнет, будут просто делать собственные реализации с нужными свойствами, наплевав на стандарты.
vsb>Я теперь знаю, каким флагом отключить у gcc эти выкрутасы с memcpy/memset.
Вы должны были знать это до того, как полезли в потроха. Здесь третьего не дано: либо Вы следуете всем установленным правилам и миритесь с тем, что компилятор ведет себя не так, как Вы ожидали, либо изучаете реализацию и вносите изменения осознанно, а не интуитивно, как Вы начали делать.
vsb>очень весело — прыгать между граблей, заботливо разложенных разработчиками компилятора.
Грабли разложены разработчиками не компилятора, а текущих тенденций, закрепляемых в стандартах. Тенденции таковы, что формальная правильность и абстрактная совместимость поставлены во главу угла, поскольку именно они наиболее важны в разработке массового ПО. А разработчики компиляторов как раз изо всех сил пытаются и обеспечить соблюдение стандартов, и дать программистам возможность уйти от абстракций в реальность. Но нюансов много, их все нужно изучать. Кому лень изучать, тот "берет камень побольше".
vsb>компилятор переписать я не могу
И не надо. В большинстве случаев его достаточно изучить. Тот же VC++ куда менее управляем, чем GCC, однако ж почти всегда позволяет сделать так, как нужно, невзирая на противоречия стандарту.
vsb>Моя позиция простая. Я не хочу бороться с компилятором.
Тогда Вам нужно платить за более мощный МК. Чудес не бывает.
vsb>у меня в прошивке bss на несколько килобайтов и я с этим ничего не могу сделать. Этот bss приезжает из китайской библиотеки
А тут нужно определиться, что выгоднее — сэкономить на разработке, используя библиотеку, или сэкономить на стоимости МК, обойдясь без нее.
vsb>просто смиряюсь с тем, что процессор крутит лишние циклы.
Вы как-то ощущали эти лишние циклы до того, как узнали о них?
Здравствуйте, 777777w, Вы писали:
O>>... обнуляется ядром — потому что в ином случае это была бы утечка данных из какого нить соседнего процесса.
7>А как наш процесс мог этим воспользоваться?
Элементарно же. Чем чаще и дольше получаешь блоки памяти, не очищенные после других процессов, тем выше вероятность, что в этих блоках найдется что-нибудь конфиденциальное.
Здравствуйте, Евгений Музыченко, Вы писали:
V>>Что ты понимаешь под "промышленной" разработкой? ЕМ>Разработку ПО для реальных задач.
Разумеется, реальных.
V>>Если пользуешь Си, то для оперирования объявленными статическими данными (структурами, массивами) необходим CRT. ЕМ>Как именно он необходим для оперирования ими?
Двухфакторная инициализация — статическая и динамическая.
V>>почти всегда микроконтроллеры выполнены по гарвардской ахитектуре, а не по фон-неймановской, с которой ты писал этот пост. ЕМ>Это Вы с чего взяли?
Это потому что микроконтроллеры такие.
Причём, для некоторых — независимо от архитектуры.
Например, ARM и MIPS бывают в обеих архитектурах памяти.
Гарвардская модель удобна для встраиваемых решений, т.к. программы сидят в ПЗУ на кристалле.
ЕМ>Если именно так, как Вы написали, то да. Но я, разумеется, подразумевал не это. Коль Вы знакомы с разными реализациями, то должны знать, как это делается в норме.
С другой реализации, а именно с фон-неймановской, я пишу этот пост, поэтому да, знаю и про это. ))
Да и пишу под неё последние 20+ лет.
Насчёт "нормы" — обсуждаемо.
Для разных сфер разные нормы.
Дык, в гарвардской архитектуре инициализация "внутренней" памяти тоже нифига не автоматическая, требует некоторого кода.
К тому же, в 8-битных микриках банки памяти часто переключаемые, т.е. память требует поддержки на манер указанного по ссылке.
Но это уже относительно поздние нововведения для декларативного абстрагирования от подробностей доступа к неоднородной памяти.
Мы это всё делали ручками, конечно.
ЕМ>А то, может, еще попеняем C/C++ за отсутствие встроенной поддержки переменных, размещенных в файлах и БД?
Допустим, не в БД, а в неоднородном NUMA-окружении, в неких суперкомпах.
Под это есть свои Си-подобные диалекты, позволяющие декларативно описывать неоднородную память, дабы сохранять переносимость программ в исходниках.
(как минимум в целевой части, требуя настройку только в конфигурационной)
V>>на Си под микрики активно пишут примерно с 93/94-х, выкручиваясь уникально для каждого случая. До этого писали сугубо на асмах. ЕМ>Сугубо на асмах писали просто потому, что первые МК имели совсем уж смешные объемы памяти, поэтому впихнуть туда сколько-нибудь сложную программу было физически невозможно
8/16/32 кБ — вполне уже можно было писать и на сях.
И многое писалось.
На асме, однако, приходилось писать критичные вещи, где надо расчитывать код с точностью до такта.
Ну и еще для уменьшения вложенности вызова подпрограмм, т.к. на асме легко сделать в одну подпрограмму несколько точек входа и, грубо, один ret, а на сях такое нельзя и это реальная проблема. А inline добавили в Си только недавно.
Ну и еще там, где требовалось презиционное ручное управление ресурсами (многие переменные могли покрывать адресное пространство друг друга в разные моменты работы программы), а компилятор справляется с этим плохо, т.к. не способен полностью трассировать программу.
ЕМ>а на размерах порядка тысяч команд преимущество C над ассемблерами весьма условно. Как только стало достаточно для реализации преимуществ, так и начали переходить на C.
Вопрос всегда в цене.
Как только на 16/32 КБ встроенного ПЗУ и аналогичной встроенной оперативки пошли адекватные цены на микрики (это уже середина нулевых и совсем неплохо к началу десятых), тогда программировать на ЯВУ стало легче, конечно, выгодней стало экономить на труде программиста.
O>>... обнуляется ядром — потому что в ином случае это была бы утечка данных из какого нить соседнего процесса. 7>Офигеть шпиономания. А как наш процесс мог этим воспользоваться?
Пароль спереть, ваш кэп.
Как много веселых ребят, и все делают велосипед...
vsb>>>Вроде общепринятая точка зрения, что C ближе всего к железу, ну если не считать языков ассемблера. S>>Если ты хочешь это опровергнуть — приведи просто пример языка, который ещё ближе к железу — а вот это всё что ты написал для этого не нужно vsb>Я такого не знаю. Вообще было бы неплохо иметь язык, который уровнем чуть выше ассемблера.
Здравствуйте, vdimas, Вы писали:
V>>>Если пользуешь Си, то для оперирования объявленными статическими данными (структурами, массивами) необходим CRT. ЕМ>>Как именно он необходим для оперирования ими?
V>Двухфакторная инициализация — статическая и динамическая.
CRT не является безусловно необходимым для этого. Он нужен, когда невозможно загрузить инициализированные данные вместе с программой в готовом виде. Если платформа позволяет это делать (с помощью стандартного загрузчика, отображения памяти, или еще как), CRT не требуется.
V>Гарвардская модель удобна для встраиваемых решений, т.к. программы сидят в ПЗУ на кристалле.
Так ПЗУ не является необходимым элементом гарвардской архитектуры. В общем случае эта архитектура никак не мешает загрузке в память заранее подготовленных данных.
И даже в тех случаях, когда такой возможности нет, именно CRT не требуется. Для одномодульной программы компилятор может складывать код инициализации в заранее известную функцию, которую нужно будет явно вызвать до использования статических переменных. Для многомодульных программ это делается складыванием кода в секции, для обработки которых также могла бы генерироваться служебная функция, вызываемая явно. По сути, это часть CRT, но поднятая чуть выше, вроде явной инициализации вместо умолчания.
Здравствуйте, vdimas, Вы писали:
V>в гарвардской архитектуре инициализация "внутренней" памяти тоже нифига не автоматическая, требует некоторого кода.
Но не обязательно в CRT. Это может быть тот же загрузчик — хоть примитивный в МК, хоть навороченный в ОС.
V>Допустим, не в БД, а в неоднородном NUMA-окружении, в неких суперкомпах. V>Под это есть свои Си-подобные диалекты, позволяющие декларативно описывать неоднородную память, дабы сохранять переносимость программ в исходниках.
Такое надо делать на плюсах, заворачивая в классы.
V>На асме, однако, приходилось писать критичные вещи, где надо расчитывать код с точностью до такта. V>Ну и еще для уменьшения вложенности вызова подпрограмм, т.к. на асме легко сделать в одну подпрограмму несколько точек входа
Все это успешно делается на "расширенных сях" с псевдопеременными, intrinsic-функциями, ассемблерными вставками и т.п., которые успешно делались под разные архитектуры. Если под архитектуру есть только "канонический" C, то вряд ли она сильно популярна.
V>многие переменные могли покрывать адресное пространство друг друга в разные моменты работы программы), а компилятор справляется с этим плохо, т.к. не способен полностью трассировать программу.
Не понял, для чего здесь "трассировка". Эта задача решается сочетанием struct/union.
Здравствуйте, night beast, Вы писали:
M>>ЗЫ Ты бы разобрался сначала, кто за что отвечает и кто что гарантирует и тд и тп, а потом бы уже с шашкой махаться выходил
NB>а может ты сам того, этого?
NB>https://en.wikipedia.org/wiki/Data_segment NB>и дальше по ссылкам
The BSS segment contains uninitialized static data, both variables and constants, i.e. global variables and local static variables that are initialized to zero or do not have explicit initialization in source code. Examples in C include:
static int i;
static char a[12];
BSS in C
In C, statically allocated objects without an explicit initializer are initialized to zero (for arithmetic types) or a null pointer (for pointer types). Implementations of C typically represent zero values and null pointer values using a bit pattern consisting solely of zero-valued bits (despite filling bss with zero is not required by the C standard, all variables in .bss are required to be individually initialized to some sort of zeroes according to Section 6.7.8 of C ISO Standard 9899:1999 or section 6.7.9 for newer standards).
Здравствуйте, vdimas, Вы писали:
M>>Ну, или у тебя тулчейн какой-то странный и кривой
V>Или на микроконтроллере мало памяти, что всё лишнее выметается, т.е. даже подменяется CRT.
Не очень понятно, в чем смысл подмены CRT? Я вот как-то и не припомню, что из CRT я использовал. Разве что mem* функции
Здравствуйте, Marty, Вы писали:
M>в чем смысл подмены CRT?
В реализациях для мелких МК CRT/startup обычно весьма грамотные, минималистичные, возиться с ними приходится редко. А в реализациях для массовых ОС "минимально необходимый набор" легко может занять сотню килобайт. Просто потому, что зависимости не продуманы, одно тянет за собой другое, потом третье, понеслось.
M>как-то и не припомню, что из CRT я использовал. Разве что mem* функции
Они могут быть оптимизированы под разные модели одной серии, и тянуть вместе разные версии кода, плюс код, выясняющий, на какой модели работаем. В отладочных версиях CRT там могут быть проверки на валидность указателей, вызывающие функции сообщения об ошибке, и т.п.
Здравствуйте, Евгений Музыченко, Вы писали:
M>>в чем смысл подмены CRT?
ЕМ>В реализациях для мелких МК CRT/startup обычно весьма грамотные, минималистичные, возиться с ними приходится редко. А в реализациях для массовых ОС "минимально необходимый набор" легко может занять сотню килобайт. Просто потому, что зависимости не продуманы, одно тянет за собой другое, потом третье, понеслось.
Ну мы же про CRT для MK, нет?
M>>как-то и не припомню, что из CRT я использовал. Разве что mem* функции
ЕМ>Они могут быть оптимизированы под разные модели одной серии, и тянуть вместе разные версии кода, плюс код, выясняющий, на какой модели работаем. В отладочных версиях CRT там могут быть проверки на валидность указателей, вызывающие функции сообщения об ошибке, и т.п.
Ок, ошибся, неинициализированные данные забиваются нулями.
К слову, я никогда на это не полагался, потому и упустил этот момент. Если не инициализировано, то я принимаю, что там изначально лежит любой мусор. Не важно, глобальная переменная или локальная
Здравствуйте, Евгений Музыченко, Вы писали: M>>Ну мы же про CRT для MK, нет? ЕМ>А Вы смотрели объемы CRT, подключаемые автоматически для разных моделей МК?
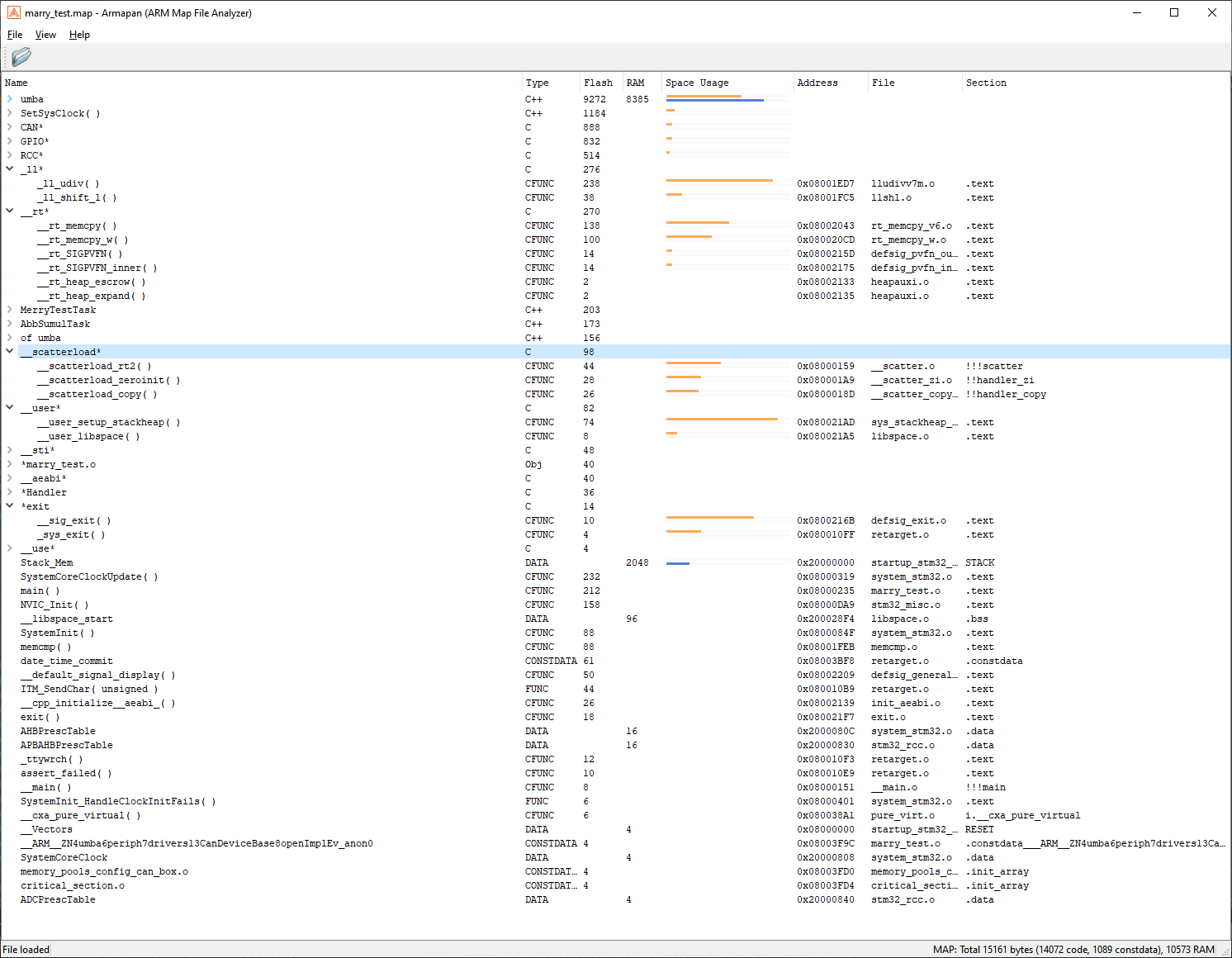
Я не только смотрел объемы не только CRT, но и вообще всего кода, а когда в одном проекте прошивка перестала влезать во флешку, а возможности сменить чип не было, я написал анализатор .map файлов, который показывал, кто сколько места кушает, благодаря которому удалось хорошо обезжирить свои библиотеки, и в дальнейшем он помогал неоднократно
Вот тут видно, что фактически никакого CRT считай что и нет:
Скрытый текст
M>>Кто в здравом уме будет для МК такое делать? ЕМ>Если б мне приходилось регулярно что-то писать для МК, я первым делом сделал бы такие средства отладки.
Нафуа? Еще и с автодетектом типа камешка? И как оно помогало бы отладке?
Здравствуйте, Marty, Вы писали:
M>Вот тут видно, что фактически никакого CRT считай что и нет:
Судя по размерам memcpy и memcmp, первая таки сильно оптимизирована по скорости (но не по размеру), а еще их там две.
M>Нафуа? Еще и с автодетектом типа камешка? И как оно помогало бы отладке?
Я в первую очередь про отладочные версии со встроенными проверками.
Здравствуйте, Евгений Музыченко, Вы писали:
M>>Вот тут видно, что фактически никакого CRT считай что и нет:
ЕМ>Судя по размерам memcpy и memcmp, первая таки сильно оптимизирована по скорости (но не по размеру), а еще их там две.
Что-то я в глаза видимо долблюсь, не вижу никакой memcpy, только memcmp. И про какие ещё две речь?
M>>Нафуа? Еще и с автодетектом типа камешка? И как оно помогало бы отладке?
ЕМ>Я в первую очередь про отладочные версии со встроенными проверками.
Проверками чего?
Исходно я спрашивал про это:
ЕМ>Они могут быть оптимизированы под разные модели одной серии, и тянуть вместе разные версии кода, плюс код, выясняющий, на какой модели работаем. В отладочных версиях CRT там могут быть проверки на валидность указателей, вызывающие функции сообщения об ошибке, и т.п.
Кто в здравом уме будет для МК такое делать?
Ты сказал, что
Если б мне приходилось регулярно что-то писать для МК, я первым делом сделал бы такие средства отладки.
Вот я и пытаюсь понять, что бы ты такое сделал. Мой вопрос был скорее по первому предложению. А ты, как я понимаю, развил мысль по второму, а про первое забыл, хотя сам и предложил
Ассерты у нас обычно и так везде были пораспиханы (не в CRT, в своём коде), только они ничего не сообщали, а просто хальтили систему, а вот про какие сообщения об ошибках в контексте МК ты пишешь — не очень понятно.
А CRT — она в общем-то и не нужна, и у нас не использовалась практически. Кроме mem* функций, ничего в голову не приходит, что бы могло понадобиться из CRT на микроконтроллере