Мой доклад успешно прошёл. Запись я обещал не выкладывать до середины ноября, да и не особо там чего смотреть.
Хочу поделиться самой зрелищной частью: сравнение производительности разных способов реализации вычислительно-интенсивного кода.
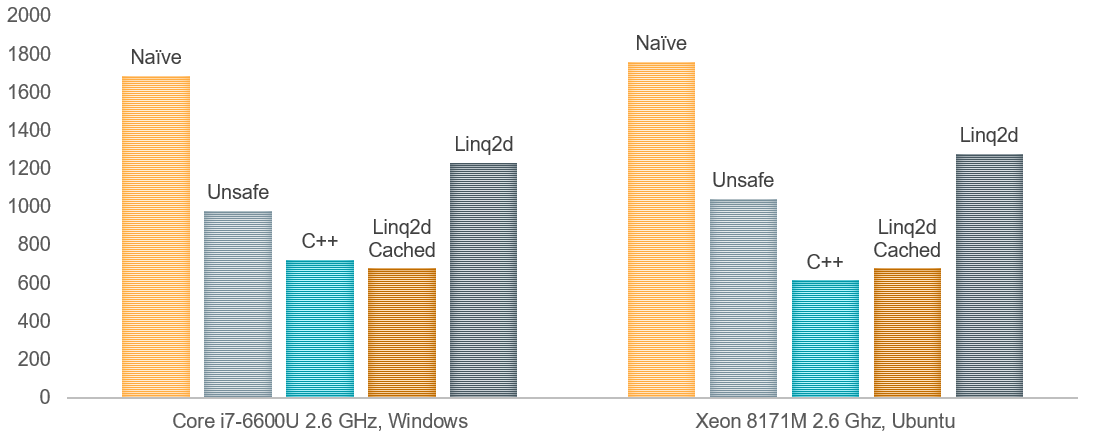
Вот график, который сравнивает разные способы посчитать бинаризацию по Sauvola (2D-Linq и оптимизация цифровых фильтров) для изображения в 33 мегапиксела (время в ms):
Участники:
Naive — простая реализация на C#, на основе двумерных массивов Unsafe — реализация на С# с прямой манипуляцией указателями (fixed) С++ — реализация на С++, внешняя dll, в неё делаем вызов. Стоимостью маршалинга одного указателя на фоне сотен миллисекунд обработки можно пренебречь. Linq — честная реализация на linq2d, которая на каждое вычисление фильтра строит код трансформации с нуля Cached Linq — реализация на linq2d, один раз (за пределами измерений) строит код трансформации и сохраняет его в делегат Func<byte[,], byte[,]>. Замеряется стоимость вычисления фильтра Sauvola при помощи этого сохранённого делегата.
Слева — замеры на моём лаптопе, Windows 10, в качестве С++ выступает MSVC. Справа — замеры на машинке в github, Ubuntu, в качестве С++ выступает gcc. В обоих вариантах сборки указана оптимизация по скорости (-O3).
Итого: гарантированно безопасный код на C# работает быстрее небезопасного кода на C#, и сравнимо с небезопасным кодом на С++.
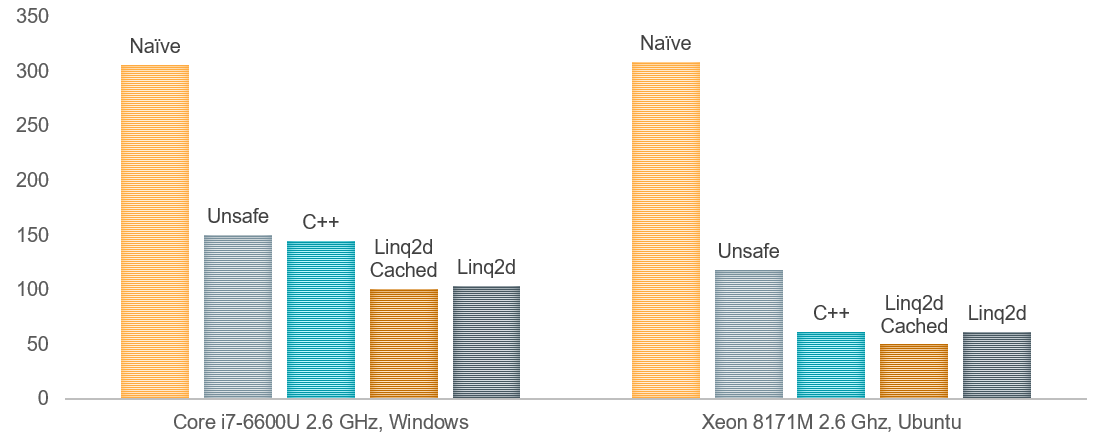
В более простом случае, с фильтром C4, вот такой вот linq2d код объезжает С++ на обеих платформах:
private static Func<byte[,], int[,]> _c4 =
(from d in new byte[0,0]
select (d[-1, 0] + d[1, 0] + d[0, -1] + d[0, 1])/4).Transform;
public static void int[,] C4(byte[,] data) => _c4(data);
Здравствуйте, kaa.python, Вы писали: KP>Вывод тут только один — оптимизатор в Linq2q классный и наивная реализация на C++ проигрывает
На самом деле всё наоборот — оптимизатор в linq2d наивный, написан на коленке. А С++ писали лучшие люди планеты много-много лет.
Скорее, я поверю в то, что С++ делает консервативные оптимизации, не шибко рассчитывая на наличие, к примеру, avx2.
Наверняка я не прикрутил какие-то флаги, которые зафорсят более агрессивную оптимизацию.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Re[3]: Производительность .Net на вычислительных задачах
Здравствуйте, Sinclair, Вы писали:
S>На самом деле всё наоборот — оптимизатор в linq2d наивный, написан на коленке. А С++ писали лучшие люди планеты много-много лет. S>Скорее, я поверю в то, что С++ делает консервативные оптимизации, не шибко рассчитывая на наличие, к примеру, avx2. S>Наверняка я не прикрутил какие-то флаги, которые зафорсят более агрессивную оптимизацию.
В тезисе доклада указано, что linq2d будет использовать SIMD-инструкции, так что если авторы библиотеки вручную доработали генерацию кода для таких случаев, то результат ожидаемый. Плюсовый код же намекает на большое количество промахов по кэшу, да ассемблерный выхлоп вроде не изобилует векторизацией.
Но в целом посыл доклада верный само собой — если тебе микросекунды не важны, то лучше довериться более высокоуровнему инструменту.
Re[4]: Производительность .Net на вычислительных задачах
Здравствуйте, kaa.python, Вы писали:
KP>В тезисе доклада указано, что linq2d будет использовать SIMD-инструкции, так что если авторы библиотеки вручную доработали генерацию кода для таких случаев, то результат ожидаемый.
Ну да, доработали. KP>Плюсовый код же намекает на большое количество промахов по кэшу, да ассемблерный выхлоп вроде не изобилует векторизацией.
KP>Но в целом посыл доклада верный само собой — если тебе микросекунды не важны, то лучше довериться более высокоуровнему инструменту.
Вот тут я не понял. По результатам вроде бы получается как раз наоборот — если важны микросекунды, то доверять надо высокоуровневому инструменту.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Re[4]: Производительность .Net на вычислительных задачах
Здравствуйте, kaa.python, Вы писали: KP>В тезисе доклада указано, что linq2d будет использовать SIMD-инструкции, так что если авторы библиотеки вручную доработали генерацию кода для таких случаев, то результат ожидаемый. Плюсовый код же намекает на большое количество промахов по кэшу, да ассемблерный выхлоп вроде не изобилует векторизацией.
Кстати, вполне себе изобилует. Смотрите — все эти xmm0/xmm1/xmm2 это же SSE.
Другое дело, что он побоялся (или не смог) использовать Avx2.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Re[5]: Производительность .Net на вычислительных задачах
Здравствуйте, Sinclair, Вы писали:
KP>>Но в целом посыл доклада верный само собой — если тебе микросекунды не важны, то лучше довериться более высокоуровнему инструменту. S>Вот тут я не понял. По результатам вроде бы получается как раз наоборот — если важны микросекунды, то доверять надо высокоуровневому инструменту.
Плюсовый код не годный для продуктового использования, решение в лоб же, не более чем POC. Если его написать с учетом векторизации, он гарантированно будет быстрее того, что было сгенерировано linq2d, но и будет при этом раз в 20-40 объемнее и во столько же раз более геморным в поддержке. А вот тут и возникает вопрос, а нужны ли микросекунды, которые вполне можно выжать?
К вопросу почему гарантированно быстрее. linq2d — это общее решение, которое решает задачу "в общем случае" при этом опирается на тот же ассемблер что и решение на другом языке, в данном случае C++. При этом, если задать как векторизовать вручную, с учетом конкретно этой задачи, решение окажется быстрее, как и любое другое решение для конкретного случая.
Re: Производительность .Net на вычислительных задачах
S>Naive — простая реализация на C#, на основе двумерных массивов S>Unsafe — реализация на С# с прямой манипуляцией указателями (fixed) S>С++ — реализация на С++, внешняя dll, в неё делаем вызов. Стоимостью маршалинга одного указателя на фоне сотен миллисекунд обработки можно пренебречь. S>Linq — честная реализация на linq2d, которая на каждое вычисление фильтра строит код трансформации с нуля S>Cached Linq — реализация на linq2d, один раз (за пределами измерений) строит код трансформации и сохраняет его в делегат Func<byte[,], byte[,]>. Замеряется стоимость вычисления фильтра Sauvola при помощи этого сохранённого делегата. S>S>Слева — замеры на моём лаптопе, Windows 10, в качестве С++ выступает MSVC. Справа — замеры на машинке в github, Ubuntu, в качестве С++ выступает gcc. В обоих вариантах сборки указана оптимизация по скорости (-O3).
Вопрос: почему в С++ dll?
Загрузка ее когда происходит?
Хочешь быть счастливым — будь им!
Без булдырабыз!!!
Re[2]: Производительность .Net на вычислительных задачах
Здравствуйте, LaptevVV, Вы писали: LVV>Вопрос: почему в С++ dll?
Ну, на винде — dll, на убунте — .so.
А какие альтернативы? Применить c++/cli? Будет заведомо медленнее. Делать прямо отдельный C++ executable? Тогда заколебёшься делать нормальный аналог benchmarkdotnet. LVV>Загрузка ее когда происходит?
Хз, если честно. Не позже, чем первый вызов к соответствующему методу, не раньше, чем JIT основной assembly приложения.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Re[3]: Производительность .Net на вычислительных задачах
LVV>>Вопрос: почему в С++ dll? S>Ну, на винде — dll, на убунте — .so. S>А какие альтернативы? Применить c++/cli? Будет заведомо медленнее. Делать прямо отдельный C++ executable? Тогда заколебёшься делать нормальный аналог benchmarkdotnet.
Не. CLI — это кошмар, который забыть и не использовать.
Почему не консольное? Бенчмарком гугла время мерить. LVV>>Загрузка ее когда происходит? S>Хз, если честно. Не позже, чем первый вызов к соответствующему методу, не раньше, чем JIT основной assembly приложения.
Вот. Дык вся медленность С++ мож поэтому и происходит?
Хочешь быть счастливым — будь им!
Без булдырабыз!!!
Re[6]: Производительность .Net на вычислительных задачах
Здравствуйте, kaa.python, Вы писали:
KP>Плюсовый код не годный для продуктового использования, решение в лоб же, не более чем POC. Если его написать с учетом векторизации, он гарантированно будет быстрее того, что было сгенерировано linq2d, но и будет при этом раз в 20-40 объемнее и во столько же раз более геморным в поддержке. А вот тут и возникает вопрос, а нужны ли микросекунды, которые вполне можно выжать?
А, в этом смысле. Ну да, ну да. Я бы был благодарен, если бы кто-то показал рукопашный код, пусть даже в 20-40 раз объёмнее, который бы сильно выиграл у результата linq2d.
Тогда можно было бы попытаться понять, что он делает по-другому, и прикрутить это к linq2d
Ладно, я вроде бы нашёл, что добавление -march=skylake форсит более современную векторизацию. Сейчас посмотрим, что получится.
KP>К вопросу почему гарантированно быстрее. linq2d — это общее решение, которое решает задачу "в общем случае" при этом опирается на тот же ассемблер что и решение на другом языке, в данном случае C++. При этом, если задать как векторизовать вручную, с учетом конкретно этой задачи, решение окажется быстрее, как и любое другое решение для конкретного случая.
В этом смысле — да, согласен.
Но тут получается, что решение на C++ — это какой-то неудачный компромисс. То есть оно недостаточно низкоуровневое, чтобы быть быстрым (надо лезть ещё на уровень глубже), и недостаточно высокоуровневое, чтобы быть безопасным.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Re[5]: Производительность .Net на вычислительных задачах
S>Другое дело, что он побоялся (или не смог) использовать Avx2.
В Студии надо режим генерации в настройках проекта ручками ставить.
В gcc — не знаю как.
Хочешь быть счастливым — будь им!
Без булдырабыз!!!
Re[4]: Производительность .Net на вычислительных задачах
Здравствуйте, LaptevVV, Вы писали: LVV>Почему не консольное? Бенчмарком гугла время мерить.
Непонятно, будет ли сопоставим результат бенчмарков. S>>Хз, если честно. Не позже, чем первый вызов к соответствующему методу, не раньше, чем JIT основной assembly приложения. LVV>Вот. Дык вся медленность С++ мож поэтому и происходит?
Почему? benchmark.net достаточно умный, чтобы исключать прогрев из замеров. Замеряется исключительно собственно вызов — там из накладных расходов только маршаллинг.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Re[6]: Производительность .Net на вычислительных задачах
Здравствуйте, LaptevVV, Вы писали:
S>>Другое дело, что он побоялся (или не смог) использовать Avx2. LVV>В Студии надо режим генерации в настройках проекта ручками ставить.
Где именно? LVV>В gcc — не знаю как.
Ну вот для GCC я ручку нашёл, теперь надо сделать так, чтобы она применилась из vcxproj. Пока что не выходит
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Re[7]: Производительность .Net на вычислительных задачах
Здравствуйте, Sinclair, Вы писали:
S>А, в этом смысле. Ну да, ну да. Я бы был благодарен, если бы кто-то показал рукопашный код, пусть даже в 20-40 раз объёмнее, который бы сильно выиграл у результата linq2d.
У меня главная притензия к C++ коду в том, что он постоянно будет сбрасывать кэши т.к. прыгает по большой куче адресов. Тоесть проблема может даже не на уровне векторизации, а на уровне самого предложенного алгоритма. Кстати, вполне может быть что именно эта проблема в linq2d решена.
S>Но тут получается, что решение на C++ — это какой-то неудачный компромисс. То есть оно недостаточно низкоуровневое, чтобы быть быстрым (надо лезть ещё на уровень глубже), и недостаточно высокоуровневое, чтобы быть безопасным.
Ну, так и есть. Сейчас не так уж и много мест где использование плюсов реально оправданно, что уж тут
Re[7]: Производительность .Net на вычислительных задачах
S>>>Другое дело, что он побоялся (или не смог) использовать Avx2. LVV>>В Студии надо режим генерации в настройках проекта ручками ставить. S>Где именно?
Проект — Свойства проекта — С++ — Создание кода — Включить расширенный набор инструкций.
И еще Релиз х86-64 надо ставить.
Хочешь быть счастливым — будь им!
Без булдырабыз!!!
Re[5]: Производительность .Net на вычислительных задачах
LVV>>Почему не консольное? Бенчмарком гугла время мерить. S>Непонятно, будет ли сопоставим результат бенчмарков.
Это да. Тут только пробовать и анализировать — другого пути нет. S>>>Хз, если честно. Не позже, чем первый вызов к соответствующему методу, не раньше, чем JIT основной assembly приложения. LVV>>Вот. Дык вся медленность С++ мож поэтому и происходит? S>Почему? benchmark.net достаточно умный, чтобы исключать прогрев из замеров. Замеряется исключительно собственно вызов — там из накладных расходов только маршаллинг.
Все же у меня вызывает сомнения такое БОЛЬШОЕ преимущество додиеза.
Хотя выше уже возникла гипотеза о "качании" кэша.
Хочешь быть счастливым — будь им!
Без булдырабыз!!!
S>>А, в этом смысле. Ну да, ну да. Я бы был благодарен, если бы кто-то показал рукопашный код, пусть даже в 20-40 раз объёмнее, который бы сильно выиграл у результата linq2d. KP>У меня главная притензия к C++ коду в том, что он постоянно будет сбрасывать кэши т.к. прыгает по большой куче адресов. Тоесть проблема может даже не на уровне векторизации, а на уровне самого предложенного алгоритма. Кстати, вполне может быть что именно эта проблема в linq2d решена.
Это да, может быть.
Я сам сталкивался, когда обработка матрицы по вертикали была в 4 раза медленнее обработки по горизонтали.
Я тупо переписывал столбец в строку и вместо 4-хкратного замедления получал 1.25 KP>Ну, так и есть. Сейчас не так уж и много мест где использование плюсов реально оправданно, что уж тут
Ну, у меня была задача моделирования перколяционного процесса, когда надо было заполнять матрицу (примерно 25000*25000 или больше) специальным образом.
И заполнение это надо было гонять не менее 1000 раз для усреднения.
Чистый Монте-Карло.
Хочешь быть счастливым — будь им!
Без булдырабыз!!!
Re[6]: Производительность .Net на вычислительных задачах
Здравствуйте, LaptevVV, Вы писали: LVV>Все же у меня вызывает сомнения такое БОЛЬШОЕ преимущество додиеза. LVV>Хотя выше уже возникла гипотеза о "качании" кэша.
Не, скорее всего именно разница в instruction set.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Re[4]: Производительность .Net на вычислительных задачах
Здравствуйте, LaptevVV, Вы писали:
LVV>Не. CLI — это кошмар, который забыть и не использовать.
Ох, CLI прекрасен, это офигенное преимущество dotnet'а перед всеми остальными платформами. Нет и не может быть ничего лучше для взаимодействия между управляемой и неуправляемой платформой. Жаль, что только под винду