Здравствуйте, Danchik, Вы писали:
C>>Естественно, при низких значениях доступных разрешений нужна особая обработка — в опустевшие шарды добавляется "перенаправление" на шарды с ещё оставшимися разрешениями. Там тоже интересный алгоритм, который этим занимается. D>Этот интересный алгоритм в студию, а то опять все простенькое как рокетсайнс выдают. D>Вот как вы обеспечиваете раздачу пряников на шарды?
У шарда есть назначенные "товарищи" (buddies), которые выбираются с помощью gossip-протокола (https://en.wikipedia.org/wiki/Gossip_protocol). Если уровень текущих разрешений больше, чем определённый предел, то шард передаёт часть разрешений своим товарищам.
Так же этим занимается и фоновый reconciler.
C>>Это так по верхам, самые интересные части. D>Как раз наоборот
Ну так эта система, над которой работают сотни очень умных людей. Тонкостей и мелочей там очень много.
Здравствуйте, paucity, Вы писали:
P>В итоге получатся (в свете субжекта этой дискуссии), что, собственно, не NoSQL "победил" сам по себе, а тонна кастомного кода
Угу. NoSQL является таким кирпичиком, просто из-за сложности задачи.
Я думаю, что никто бы не был против, если бы можно было просто воткнуть Oracle/MSSQL и по старинке писать BEGIN/UPDATE/COMMIT. Но это просто не работает.
Здравствуйте, Sharov, Вы писали:
V>>На очередях прекрасно можно реализовать ACID, не лоча при этом единовременно все сущности. S>Типа что-то паттерна saga. V>>Собсно, суть всех lock-free алгоритмов примерно такая же. S>Это глупость. Это все равно что сказать что суть lock-free в однопоточности. Т.е. у нас один поток, поэтому lock-free. Суть lock-free иная.
Такая же точно.
Суть лок-фрии алгоритмов примерно такова:
1. прочитать текущее состояние;
2. сформировать следующее;
3. попытаться атомарно обновить текущее состояние, если не было изменений;
4. если были изменения, goto (1).
В этом цикле может крутиться несколько потоков одновременно.
За один оборот как минимум один поток продвигается.
Здравствуйте, gandjustas, Вы писали:
G>>>Вот ты такой умный собрал систему как описал выше. Система для продажи билетов в кино\театр\еще куданить. G>>>И внезапно одновременно два человека в разных кассах покупают билеты на одни и те же места на один и тот же сеанс. G>>>Оба "клиента" пишут в 100 нод, 90 из которых эту инфу теряют. То есть реальная запись происходит в 10 нодах. На обоих клиентах эти 10 нод разные. G>>>В итоге твоя система с легкостью продает два билета на одно место.
V>>Не продаёт. G>Да-да, только я вживую видел как подобная система делала две подтверждающих транзакции во внешней системы вместо одной. Хорошо что это не списывание денег было, но просто отправка писем.
Такие бока и на MS SQL накрутить можно и скорее всего и было накручено, бо объем данных вокруг кинотеатров, сеансов и мест ничтожен.
V>>Такие операции работают через подтверждение, т.е. максимум что страшного можеть случиться — две операции будут поставлены в очередь на обработку, хотя одну из них можно было в очередь превентивно не ставить. Ну и потом, кто будет второй, тому придёт отлуп "ай нет, сорри, все-таки уже продали билеты". G>Ага, это и называется WAL в ручную поверх NoSQL.
Не важно как это называется.
Важно отсутствие локов в нескольких таблицах одновременно.
Все эти сценарии можно свести к тому, что в каждый момент времени лочится ровно одна запись.
G>А потом еще наступает понимание, что нужны еще и транзакции на несколько строк\документов.
Создай master-документ в состоянии "Initializing" — никто его менять не будет, пока он в этом состоянии.
Неспешно напихай к нему slave-строки и остальные зависимые сущности.
Тоже пихай без одновременной блокировки половины базы, а сугубо построчно.
Как закончишь, попытайся атомарно изменить состояние только лишь master-документа, т.е. одной всего записи.
Если не получилось по каким-то прикладным причинам, то см. п.4. по ссылке.
Далее всё происходит согласно прикладного сценария.
Их два основных:
— дать отлуп всей операции с удалением всех зависимых slave-сущностей и потом самого документа;
— модификация самого master-док-та и, возможно, его строк с учётом изменившейся обстановки с заходом на новый круг.
Что будет, если свет неожиданно выключат в середине процесса?
Клиенту придёт "потеря связи".
А база затем при старте удаляет док-ты вместе со связанными сущностями, которые (документы) находятся в состоянии "Initializing".
V>>На очередях прекрасно можно реализовать ACID, не лоча при этом единовременно все сущности. V>>Собсно, суть всех lock-free алгоритмов примерно такая же. G>Да-да, и все эти алгоритмы уже реализованы в РСУБД в механизме ЛОГА.
Мне нужны "разрывы" в этих алгоритмах, для обеспечения их легковесности.
Я же обладаю знаниями о том, что происходит в прикладных алгоритмах и какая роль у каждой сущности, верно?
А серваку БД всё это неведомо.
V>>В этом смысле РСУБД обеспечивает столкновение на условных мьютексах, а система с очередями — на условных "неподвижных точках", которые крутятся вокруг некоего прикладного условия. G>Ты сам понял что написал?
Я-то понял, бо последние лет 8 плотно занят именно lock-free алгоритмами.
Они чуть более чем везде в моём коде.
Сходи по ссылке, там приведён "скелет" самого большого класса таких алгоритмов.
Мем "неподвижная точка" — он о сохранении неких значений в процессе преобразования.
В более широком смысле — о сохранении св-в.
Т.е. алгоритм продвинется только если будут соблюдены некоторые гарантии, иначе будет вращаться (в самой популярной своей разновидности) до момента соблюдения этих гарантий.
Единственно какая доработка требуется в этом скелете — это очередь, бо мы имеем дело со СМО.
Поэтому, неудачный цикл отправляется на повтор не сразу, а становится в конец очереди заданий.
В своих аналогичных алгоритмах уровня проца я в этот момент вызываю asm pause — эта команда отдаёт ресурсы проца конкурирующим аппаратным потокам.
Бо если столкновение уже произошло, то лучше дать конкурирующему потоку быстрее отработать, а не продолжать бороться с ним за ресурс.
G>Для пользователя все равно мьютексы так или еще что-то.
Здравствуйте, gandjustas, Вы писали:
V>>"Одноклассники" обрабатывают в пике до миллиона запросов в секунду при объеме даных на сегодня в 50 ТБ. G>Каждый запрос обрабатывает все 50 ТБ ?
Отличный вопрос, кстате.
Стоит начать задаваться такими вопросами и можно быстро выйти на границы применимости РСУБД.
V>>Никакая РСУБД в "чистом виде" это не потянет. G>Миллион запросов в секунду — это каких запросов? Обычная СУБД может и миллион в секунду потянуть, если будет достаточно памяти, дисков и ядре процессора.
На РСУБД такое решение становится резко дорогим.
G>Только если надо миллон раз в секунду обрабатывать 50ТБ, то тут уже никто не справится.
И это хороший вопрос!
Каждый запрос не нуждается в 50 ТБ, но за секунду миллионы их могут потыкать в эти данные довольно-таки размазанно чуть ли не ровным слоем по всевозможным участкам данных.
Распределённые кеши справляются с такой задачей аж бегом.
Собсно, ради этого их разрабатывали.
Здравствуйте, gandjustas, Вы писали:
G>>>Можешь подробнее? V>>По ссылке ходил? G>Да, там про replica set. Какое отношение к кэширванию оно имеет?
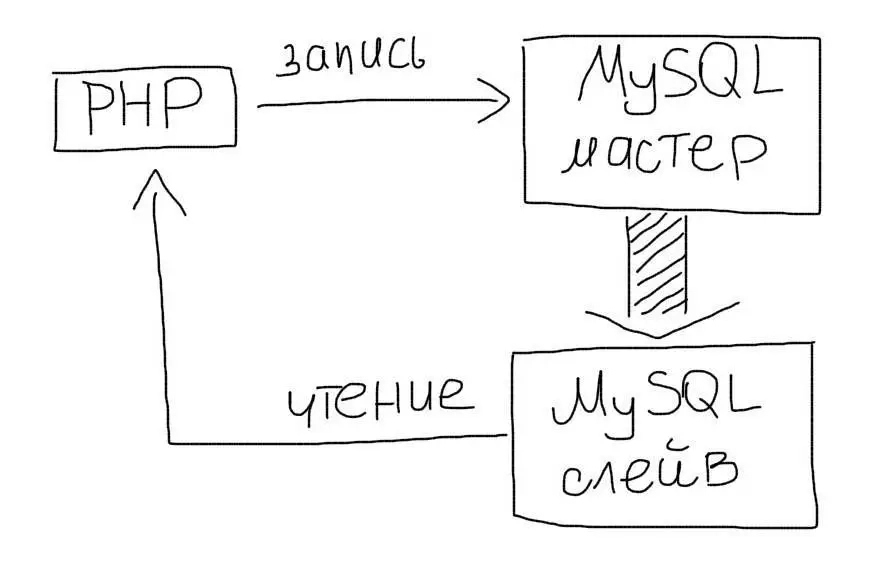
Классика жанра же:
Чаще всего используют схему master-slave:
Master — это основной сервер БД, куда поступают все данные. Все изменения в данных (добавление, обновление, удаление) должны происходить на этом сервере.
Slave — это вспомогательный сервер БД, который копирует все данные с мастера. С этого сервера следует читать данные. Таких серверов может быть несколько.
Репликация позволяет использовать два или больше одинаковых серверов вместо одного. Операций чтения (SELECT) данных часто намного больше, чем операций изменения данных (INSERT/UPDATE). Поэтому, репликация позволяет разгрузить основной сервер за счет переноса операций чтения на слейв.
Собсно, именно про этот сценарий моя ссылка двумя сообщениями выше.
Здравствуйте, Cyberax, Вы писали: C>TPC-C — это вообще смех на палочке. Я уже привёл примеры масштаба — у Амазона хранилище выдерживает миллионы запросов в секунду. Это почти на три порядка больше, чем лучший результат TPC-C.
Вы какие порядки имеете в виду?
Лучший результат TPC-C — 30M tpmс, или полмиллиона транзакций в секунду.
Вы точно уверены, что Амазон держит полмиллиарда запросов в секунду?
По-поему, вы переоценили соотношение производительностей раз примерно в сто.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, gandjustas, Вы писали:
G>И что? Ты или пишешь в те ноды, из которых потом читаешь, или продаешь два билета на место. Про это как раз написано сразу после процитированного тобой блока.
Вот не понял как ты такой вывод сделал, БД запускает раунд какого-нибудь mulit-paxos-а, точно также как при записи, только данные не меняются.
Ты когда свой MSSQL реплицируешь, то тоже самое может быть, если ты читаешь данные из реплики, КМК.
CK>>И BTW, у тебя данные будут храниться не на всех нодах а на %replication-factor% нодах (на пяти например), поэтому кворум ты будешь гонять не между всеми нодами а только между пятью. G>Тут конечно можно играться кворумом, но надо понимать, что при отвале кворума все стопорится. И нет смысла в твоих 100 нодах если при падении двух из них ты не можешь продавать билеты.
Когда у тебя единственный мастер твоего MSSQL кластера отвалится ничего не застопроится, надо понимать?
Вот давай на примере HBase (чтобы быть конкретным). Ты пишешь в регион (ака шард) который хранится на трех data node-ах HDFS, одна из которых отвалилась. На самом деле запись пройдет, т.к. данные пишутся в WAL (который тоже хранится в HDFS). HDFS перераспределит данные между оставшимися нодами рано или поздно. Если отвалится data node, на которой крутится region server, то запись не пройдет пока регион, в который ты пишешь, не переместится на другой region server (что вполне логично).
Если вернуться к примеру с билетами, я бы выбрал такую схему для hbase — каждый концерт, это отдельный ряд в hbase. Каждому месту соответствует отдельная колонка. Каждаый ряд в зале — отдельный column family (т.к. люди редко покупают билеты сразу в несколько рядов). Запись по одному ключу в hbase — атомарна, т.е. я могу сколько угодно билетов купить без нарушения целостности. Все что можно прочитать в HBase записано на диск (т.е. в HDFS с репликацией). Можно записывать транзакционно с помощью checkAndMutate, этого достаточно для того, чтобы проверить перед записью, что билет не куплен. Т.е. по сути, ни одна из проблем, описанных тобою выше, не имеет место и решение тривиально.
Здравствуйте, gandjustas, Вы писали:
G>Выяснили уже что это не движок делает, а middleware. Middleware с такими функциями можно построить поверх любой субд.
зависит от БД, обычно все же этим БД занимается, т.к. движок БД должен знать где какой шард хранится, чтобы иметь возможность писать/читать
G>SQL Azure умеет не хуже. Даже лучше во многих местах.
SQL Azure КМК не совсем СУБД, там скорее всего либо ограничения на транзакции/консистентность (как PNUTS, где транзакции работают только внутри таблиц), либо там не очень с масштабированием. Я правда никогда на эту БД не смотрел.
G>И что это дает? G>Внезапно за земле cattle имеет слишком большой оверхэд.
это дает современные девопс практики, автоматизация операций, запустили скрипт, изменили размер кластера, упала нода, просто убили ее и запустили новую и тд
что значит "на земле"?
G>Потому что с гарантией записи все преимущества nosql баз теряются, она начинают работать не быстрее взрослых субд.
безосновательное утверждение, давай на примерах чтоли? вот hbase например, гарантии записи есть, работает быстро даже на очень больших данных
G>И? Ты теперь считаешь этот пример показательным? Вот ты на сайте RSDN. Нагрузка немаленькая, железо не космическое и таблицы нормализованные.
У РСДН смешная аудитория, сайт, который я имел ввиду, это классифайд (один из крупнейших в РФ), по которому пользователи (порядка миллиона уников) непрерывно ищут товары со всякими хитровывернутыми фильтрами. При этом скорость выборки очень критична (пользователи теряют интерес к шопингу очень быстро, если сайт тупит над запросами по пол секунды).
Здравствуйте, Sinclair, Вы писали:
C>>TPC-C — это вообще смех на палочке. Я уже привёл примеры масштаба — у Амазона хранилище выдерживает миллионы запросов в секунду. Это почти на три порядка больше, чем лучший результат TPC-C. S>Вы какие порядки имеете в виду? S>Лучший результат TPC-C — 30M tpmс, или полмиллиона транзакций в секунду. S>Вы точно уверены, что Амазон держит полмиллиарда запросов в секунду?
Да. В этом году примерно столько и было.
Стоит понимать, что один просмотр страницы выливается в несколько запросов к хранилищу.
S>По-поему, вы переоценили соотношение производительностей раз примерно в сто.
Нет.
Здравствуйте, gandjustas, Вы писали:
S>>Будет новый раунд консенсуса, не более. Стопориться ничего не будет. G>Количество раундов заранее сверху ограничено?
Здравствуйте, Cyberax, Вы писали:
S>>И? Рано или поздно консенсус же должен отработать. Где проблема-то? C>Проблема в том, что для consistent-транзакций консенсус надо запускать при чтении данных, а не записи.
C>Т.е. в природе нет consistent write, есть только consistent read.
Логично. Но вернемся к дороговизне (см. дискуссию выше). Как ее избежать?
Здравствуйте, vdimas, Вы писали:
V>>>Собсно, суть всех lock-free алгоритмов примерно такая же. S>>Это глупость. Это все равно что сказать что суть lock-free в однопоточности. Т.е. у нас один поток, поэтому lock-free. Суть lock-free иная.
V>Такая же точно. V>Суть лок-фрии алгоритмов примерно такова: V>1. прочитать текущее состояние; V>2. сформировать следующее; V>3. попытаться атомарно обновить текущее состояние, если не было изменений; V>4. если были изменения, goto (1).
V>В этом цикле может крутиться несколько потоков одновременно. V>За один оборот как минимум один поток продвигается.
С этим я не спорю (про lock-free). Я не очень понимаю аналогию с очередями и ACID? Если у нас [b]одна/b] очередь и много микросервисов(бд), то это равносильно одному потоку, который по очереди с ними что-то делает,
и если всё успешно, то ок, иначе повтор.
Здравствуйте, Cyberax, Вы писали:
C>Здравствуйте, gandjustas, Вы писали:
G>>>>Давай с этого места поподробнее. Как обеспечивается транзакционность счетчиков? C>>>В другом сообщении описал. G>>И ответь всетаки чем из CAP жертвуется? Я так понимаю что availability. C>Consistency. Она обеспечивается частично — есть гарантия того, что нельзя продать больше товаров, чем есть на складе. Но нет гарантии, что клиент может купить товар, если товар ещё доступен.
Ты все уходишь от вопроса каким образом это достигается.
Если у тебя атомарные счетчика в разных шардах, то каким образом обеспечивается атомарное изменение обоих?
Здравствуйте, Cyberax, Вы писали:
S>>Вы точно уверены, что Амазон держит полмиллиарда запросов в секунду? C>Да. В этом году примерно столько и было.
C>Стоит понимать, что один просмотр страницы выливается в несколько запросов к хранилищу.
Стоит наверное уточнить, что полмиллиарда распределены по всем датацентрам Амазона, а их вообще-то 18 штук, ну и так далее.
Здравствуйте, Anton Batenev, Вы писали:
g>> AB>Цитата: "Поисковые логи и индексы, пользовательские данные, картографическая информация, промежуточные данные и результаты алгоритмов машинного обучения — все это может занимать сотни петабайт дискового пространства." (это про YT, но для обсуждаемого вопроса не принципиально). g>> Ключевое выделил.
AB>Ты же понимаешь, что это всего лишь фигура речи и оно там реально столько занимает? Если хочешь конкретных цифр, например вот для ClickHouse речь идет про 17 ПБ "сырых" данных без дублирования и репликации (и это было 4 года назад, и только для одной из подсистем, если верить написанному).
Я того, чтобы просто хранить огромные объемы данных не нужны ни базы данных, ни hadoop. Нужно просто много дисков. Даже не много серверов, а просто дисков.
Ну ок, сложили 20 триллионов строк на диски. Какие запросы к ним делаются? Хоть один запрос трогает хотя бы 10% этих данных? Что-то сомневаюсь. Я так понимаю, что scope большинства запросов ограничен одним сайтом, то есть где-то 0.01% от данных.
То есть можно считать что 374 сервера и 2 ПБ сжатых данных, это около 5 тб на сервер. У меня кейс с большим объемом на сервер был и РСУБД (не олап система, а именно РСУБД) нормально пережевывала этот объем.
А если бы надо было несколько за раз ПБ обработать, то появилось бы несколько серверов, они бы прожевали каждый свой кусок данных, а потом в каком-нить middleware промежуточные результаты были бы объединены. Я думаю и в яндексе происходит то же самое.
Здравствуйте, vdimas, Вы писали:
V>Здравствуйте, gandjustas, Вы писали:
V>>>"Одноклассники" обрабатывают в пике до миллиона запросов в секунду при объеме даных на сегодня в 50 ТБ. G>>Каждый запрос обрабатывает все 50 ТБ ?
V>Отличный вопрос, кстате. V>Стоит начать задаваться такими вопросами и можно быстро выйти на границы применимости РСУБД.
За границы прмиернимости любой базы так можно выйти.
V>>>Никакая РСУБД в "чистом виде" это не потянет. G>>Миллион запросов в секунду — это каких запросов? Обычная СУБД может и миллион в секунду потянуть, если будет достаточно памяти, дисков и ядре процессора. V>На РСУБД такое решение становится резко дорогим.
Это зависит от РСУБД. Например на MS SQL scale-up обходится дешевле, чем scale-out в монге. Потому что диски и память дешевы, а процессоры с материнками — нет. Получается что поставить 10 серверов монги дороже, чем в 10 раз увеличить память и диски в сервере ms sql и увеличить количество ядер для удержания нагрузки. С оркалом может быть другая картина.
Для нищебродов всегда есть postgres.
G>>Только если надо миллон раз в секунду обрабатывать 50ТБ, то тут уже никто не справится. V>И это хороший вопрос! V>Каждый запрос не нуждается в 50 ТБ, но за секунду миллионы их могут потыкать в эти данные довольно-таки размазанно чуть ли не ровным слоем по всевозможным участкам данных. V>Распределённые кеши справляются с такой задачей аж бегом. V>Собсно, ради этого их разрабатывали.
Только распределенные кэши не умеют оперировать данными, которые имеют объем более размера оперативной памяти. А 50ТБ оперативки это прям много.
Здравствуйте, vdimas, Вы писали:
V>Здравствуйте, gandjustas, Вы писали:
G>>>>Можешь подробнее? V>>>По ссылке ходил? G>>Да, там про replica set. Какое отношение к кэширванию оно имеет?
V>Классика жанра же: V>Image: smngoz6r70gecjbhs.bbbb4a9b.jpg
А при чем тут кэш? Ты просто все известные слова решал написать?
Я тебе напомню исходный вопрос:
Что ты имеешь ввиду под "нормально кешировать данные" и какая РСУБД этого не умеет?
И тут второй вопрос родился. Как репликация связана с кэшем?