Перечитай всё заново, я повторятся не собираюсь — код с селектором уже был.
S>Просто я сейчас изучаю С++ но мне интересно как я могу применить. Или ссылочку на эту конструкцию S>
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Здравствуйте, Serginio1, Вы писали:
S>> Проверка на пустой список.
EP>Она внутри.
S>>Развернем min_element. http://www.cplusplus.com/reference/algorithm/min_element/ S>>Там селектора нет.
EP>Перечитай всё заново, я повторятся не собираюсь — код с селектором уже был.
Ну в итоге то если развернуть твои с селектором то получится то же самое.
Я кстати тебе ссылки даю.
S>>Просто я сейчас изучаю С++ но мне интересно как я могу применить. Или ссылочку на эту конструкцию S>>
S>>[](auto &i){ return i->value; }
S>>
EP>Я же говорил, читай что такое лямбда в C++.
А вот ссылку ну никак не дать. И за слова в 100 раз ну никак не отвечаем?
Но спасибо с лямбдами разобрался. Но min_element с селектором не нашел.
и солнце б утром не вставало, когда бы не было меня
— там два момента. S>>А, ну как и было сказано — иногда больше работы не значит лучше. S>>Специально засёк время — 10 минут на код ушло. Блин, но оформление ответа больше потрачу, наверно S>>Для структур соотношение:
EP>Мы же в данном контексте не производительность перегрузок и т.п. обсуждаем, а разную семантику reference/value, которую нужно обрабатывать отдельным кодом. Я ссылку привёл именно на ветку о семантике.
Еще раз где здесь различие в семантике? На самом деле если уж мы использум Linq то и незачем пренебрегать Where но и без него
можно сократить код.
//if (value == null)
// source=source.Where(x=>x!=null); // Уберем фильтр на Linq из-за тормоза делегатаbool isFirst=true;
bool fl=0;
foreach(var item in source)
{
// Поставим фильтр сюдаif (isNullable && item == null) continue;
var x = selector(item );
if (isFirst)
{
isFirst=false;
fl=-1;
}
else
fl=comparer.Compare(x,value);
if (fl< 0)
{
value = x;
result= item;
}
}
if (isFirst)
{
// по их алгоритму при пустом списке вызвать исключение для Nullableif (isNullable)
throw NoElementsException();
else
return default(TSource); // вернуть default при пустом списке
}
return result;
Ты так и не привел решения с Nullablе типами, пустым списком.
И не привел std::min_element с селектором.
и солнце б утром не вставало, когда бы не было меня
например из соседней темы.
S>А тебе лень развернуть свой ответ и подтвердить свои слова?
Мне лень разворачивать именно тебе, именно в этой теме, ибо приходится постоянно повторяться, ты теряешь контекст, возвращаешься опять с многократно отвеченными вопросами, приписываешь мне слова которые я не говорил и т.д. и т.п. — это всё утомляет
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Здравствуйте, Serginio1, Вы писали:
S>>>>Развернем min_element. http://www.cplusplus.com/reference/algorithm/min_element/ S>>>>Там селектора нет. EP>>>Перечитай всё заново, я повторятся не собираюсь — код с селектором уже был. S>>Все заного? Тебе не смешно? Вон посмотри как Sinix относится к оппонентам https://rsdn.ru/forum/dotnet/6506104.1
например из соседней темы.
Только то, что тебе интересно.
S>>А тебе лень развернуть свой ответ и подтвердить свои слова?
EP>Мне лень разворачивать именно тебе, именно в этой теме, ибо приходится постоянно повторяться, ты теряешь контекст, возвращаешься опять с многократно отвеченными вопросами, приписываешь мне слова которые я не говорил и т.д. и т.п. — это всё утомляет
Так я отвечаю только про то, что ты твердишь постоянно, про то, что на С++ код писать нужно в 100 раз меньше. Ты это говорил.
За то, что ты не говорил про то, что C# медленнее C++ я извинился. И ты постоянно ссылаешься на один пример и по нему делаешь вывод. Когда тебе приводят более сокращенный код и быстрее, ты эти примеры отметаешь и сново ссылаешься на CodeJamp. И твердишь это постоянно.
Твои слова
Тут речь не про перегрузки и кодогенерацию, а про то что там разное поведение для reference/value type.
. Но в приведенном тобой примере нет
1. Фильтра на пустой список
2. Нет примера с Nullable типами
3. Нет в std min_element с селектором, а значит его нужно писать отдельно.
То есть даже приводя примеры они далеки от нужной функциональности.
и солнце б утром не вставало, когда бы не было меня
Здравствуйте, Sinix, Вы писали:
S>Для структур соотношение: S>
S> Method | Median | StdDev | Scaled | Min | Lnml(min) | Lnml(max) | Max |
S>-------------- |------------ |----------- |------- |------------ |---------- |---------- |------------ |
S> MinCodeJam | 13.5474 us | 4.2560 us | 1.00 | 9.8527 us | 1.00 | 1.00 | 57.8845 us |
S> MinOk | 17.6527 us | 1.5569 us | 1.30 | 13.9580 us | 1.28 | 1.28 | 25.8633 us |
S> MinOkComparer | 16.4211 us | 1.2513 us | 1.21 | 13.5474 us | 1.18 | 1.18 | 27.0949 us |
S> MinDoneRight | 1.6421 us | 0.5551 us | 0.12 | 1.2316 us | 0.12 | 0.12 | 10.2632 us |
S>
S>сравниваем, если что, с вот этим. 5000 строк неэффективной кодогенерации
Так их кодогенерация в итоге быстрее же чем твой вариант Но это может быть связанно с тем, что у них проверка "hasData" вынесена из цикла.
А вот то что для простейшего алгоритма используется кодогенерация — да, поражает.
S>2. Не менее тяп-ляп код, написанный для конкретного частного случая выполняется на четверть быстрее для ссылочных полей и в 8 раз быстрее — для структур.
MinDoneRight — это же лишь ориентир, в нём же нет селектора. То есть опять таки — это претензия к языку/компилятору/платформе, а не к авторам CodeJam.
S>для строк: S>
S> Method | Median | StdDev | Scaled | Min | Lnml(min) | Lnml(max) | Max |
S>-------------- |-------------- |------------ |------- |-------------- |---------- |---------- |-------------- |
S> MinCodeJam | 331.7068 us | 19.2213 us | 1.00 | 289.4224 us | 1.00 | 1.00 | 419.9704 us |
S> MinOkComparer | 313.6436 us | 38.8401 us | 0.95 | 170.3692 us | 0.94 | 0.94 | 474.9812 us |
S>
S>В чём подвох: S>1. Тяп-ляп универсальный код, написанный без включения мозга оказался немного быстрее "оптимизированного" для ссылочных полей
У них же пропускаются null значения, а у тебя? Плюс смотри — у них Comparer передаётся снаружи, а у тебя он внутри var comparer = Comparer<TValue>.Default; — это может иметь эффект.
S>В общем надо знать матчасть, думать, а затем писать. И мерять. Иначе вот такой вот неудобняк получается.
Кстати, интересно посмотреть на результаты на перетасованном (random shuffle) массиве.
S>Блин, но оформление ответа больше потрачу, наверно
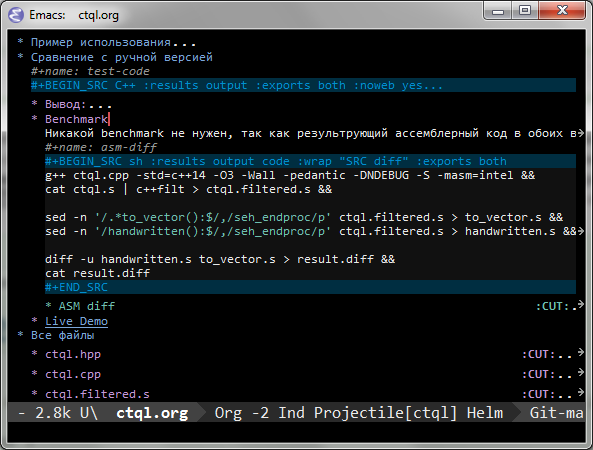
Я для оформления сделал себе экспорт из Org-Mode в формат RSDN. Это outliner, в нём можно вставлять фрагменты кода, выполнять их, результаты вставляются автоматом в документ, перебрасывать результаты между разными кусками кода на разных языках (а-ля Jupyter), также поддерживаются изображения, электронные таблицы, экспорт в различные форматы Markdown, PDF, LaTeX, HTML, ASCII.
Здравствуйте, Sinix, Вы писали:
EP>>В CodeJam в алгоритмах приходится отдельно обрабатывать reference/value типы, это и есть "усложнение инфраструктуры". S>Если честно, там усложнизмы на ровном месте в куче мест емнип. Когда смотрел (ещё в марте), то большая часть кода могла быть переписана без кодогенерации и лишних перегрузок.
Так значит надо переписать. Но только местами там все не так тривиально, как кажется на первый взгляд.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>А вот то что для простейшего алгоритма используется кодогенерация — да, поражает.
Сколько уже можно долбить в одну и ту же точку? Кодогенерация используется не для алгоритма, а для того чтобы использовать для примитивных типов прямые операторы, а не компаратор (тебе это несколько человек уже сказали). Не умеют дотнетные дженерики операторов, вот и весь сказ. Можно было бы заменить на Operators, но они все таки не совсем бесплатны. И, на всякий случай — рассказывать про шаблоны С++ не нужно, все тут в курсе.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
Здравствуйте, AndrewVK, Вы писали:
EP>>А вот то что для простейшего алгоритма используется кодогенерация — да, поражает. AVK>Сколько уже можно долбить в одну и ту же точку?
Я тут вообще другой вопрос поднял, связанный с различием семантики reference/value.
AVK>Кодогенерация используется не для алгоритма
Да понятное дело что без неё будет работать, я как бы и не утверждал обратного. Если бы она была обязательна — то это вообще была бы жесть неимоверная.
Здравствуйте, Serginio1, Вы писали:
S>>>Все заного? Тебе не смешно? Вон посмотри как Sinix относится к оппонентам https://rsdn.ru/forum/dotnet/6506104.1
например из соседней темы. S> Только то, что тебе интересно.
Отрицание действительности? Этот пример мне не был особо интересен, о чём я изначально и говорил. Результат теста вполне ожидаем.
EP>>Мне лень разворачивать именно тебе, именно в этой теме, ибо приходится постоянно повторяться, ты теряешь контекст, возвращаешься опять с многократно отвеченными вопросами, приписываешь мне слова которые я не говорил и т.д. и т.п. — это всё утомляет S> Так я отвечаю только про то, что ты твердишь постоянно, про то, что на С++ код писать нужно в 100 раз меньше. Ты это говорил.
Давай конкретную цитату, пруфлинк.
S>1. Фильтра на пустой список
Он внутри.
S>2. Нет примера с Nullable типами
Это реализуется внешним ортогональным фильтром, незачем тащить его в алгоритм, я тебе уже раз пять это сказал.
S>3. Нет в std min_element с селектором, а значит его нужно писать отдельно.
Я приводил min_element с селектором, в первом же сообщении.
EP>У них же пропускаются null значения, а у тебя? Плюс смотри — у них Comparer передаётся снаружи, а у тебя он внутри var comparer = Comparer<TValue>.Default; — это может иметь эффект.
Там перегрузка методов. Компарер может подаваться как с наружи так и использоваться дефолтный. 1 вызов большой роли не играет по сравнению с 5000 строк
Фильтр на Nullable
if (isNullable && item == null) continue;
тоже большой роли не играет особенно при сравнении строк. Там еще зависит от
Да и при применении Linq где используются делегаты и большая часть времени тратится на их вызов, и тратить силы и время на выискивание увеличения скорости это не проблемы платформы.
Большая часть обычных программистов будут использовать фильтры, знак*Comparer итд.
Ты неправильные делаешь выводы.
Зато я могу легко использовать
1. Рефлексию для использования классов .Net из натива.
2. Использовать Linq как с коллекциями так и с БД
3. Использовать динамическую компиляцию для универсального использования событий .Net как через COM, так и через CallBack, асинхронного программирования например в 1С.
4. Удобное асинхронное программирование.
5. Динамики для использования универсальных алгоритмов например парсеров и использования динамических языков.
Да есть потери в скорости. Но все равно это быстрее чем интерпретаторы. А при применении .Net Native то и не сильно и медленнее С++.
При этом мне С++ нравится и я знаю его преймущества, но как общеприменимый язык он сложен. Например я C# в среду 1С ников не могу никак провести не могу. А от С++ они как черт от ладана. При этом они не продавцы а программисты. И говоря об алгоритмической ценности, нужно не забывать прежде всего о том, а кто его использовать будет. И получается, что у С++ есть определенная ниша которую даже и не стоит расширять.
Я верю, что ты сделаешь Linq для БД, но сколько народу будут ей пользоваться? Я так понимаю, что и cppsql не сильно то и применяется в вашей среде?
и солнце б утром не вставало, когда бы не было меня
Здравствуйте, Serginio1, Вы писали:
EP>>У них же пропускаются null значения, а у тебя? Плюс смотри — у них Comparer передаётся снаружи, а у тебя он внутри var comparer = Comparer<TValue>.Default; — это может иметь эффект. S>Там перегрузка методов. Компарер может подаваться как с наружи так и использоваться дефолтный. 1 вызов большой роли не играет по сравнению с 5000 строк
Дело не в вызове, а в том что Comprare находится снаружи, это вполне может влиять на оптимизатор.
S>Фильтр на Nullable S>
S>if (isNullable && item == null) continue;
S>
S> тоже большой роли не играет особенно при сравнении строк.
Строки короткие, а это лишнее сравнение, пусть даже и предсказуемое. Там-то и разница всего 5%~6%
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Здравствуйте, Serginio1, Вы писали:
S>>>>Все заного? Тебе не смешно? Вон посмотри как Sinix относится к оппонентам https://rsdn.ru/forum/dotnet/6506104.1
например из соседней темы. S>> Только то, что тебе интересно.
EP>Отрицание действительности? Этот пример мне не был особо интересен, о чём я изначально и говорил. Результат теста вполне ожидаем.
Кто отрицал? Еще раз тебе говорили, что при работе с БД клиент большей частью простаивает. Например даже интерпретатора 1С хватает.
Кроме того, в .Net запрсы компилируются и кэштруются в рантайме. Да компилятор .Net генерирует чуть медленный код, но все равно значительно быстрее чем 1C. Кроме того в большей степени приходится работать с динамическими запросами.
EP>>>Мне лень разворачивать именно тебе, именно в этой теме, ибо приходится постоянно повторяться, ты теряешь контекст, возвращаешься опять с многократно отвеченными вопросами, приписываешь мне слова которые я не говорил и т.д. и т.п. — это всё утомляет S>> Так я отвечаю только про то, что ты твердишь постоянно, про то, что на С++ код писать нужно в 100 раз меньше. Ты это говорил.
EP>Давай конкретную цитату, пруфлинк. https://rsdn.ru/forum/philosophy/6486253.1
По алгоритмической выразительности среди мэйнстрима C++ сейчас впереди всех.
Для сравнения C#, свежий пример — на C++ десять строк (+ может несколько wrapper'ов, это максимум десятки строк), на C# — несколько сотен строк кода (è1 + è2) причём включая кодогенетратор, который генерирует èнесколько тысяч строк, а алгоритм-то совсем пустяковый.
S>>1. Фильтра на пустой список
EP>Он внутри.
Я его не вижу S>>2. Нет примера с Nullable типами
EP>Это реализуется внешним ортогональным фильтром, незачем тащить его в алгоритм, я тебе уже раз пять это сказал.
В этом алгоритме все в однром. И не нужно писать еще дополнительно ортогональный фильтр.
S>>3. Нет в std min_element с селектором, а значит его нужно писать отдельно.
EP>Я приводил min_element с селектором, в первом же сообщении.
Кому? Так приведи полный код и мы сравним с моим. И ты подтвердишь, что
По алгоритмической выразительности среди мэйнстрима C++ сейчас впереди всех.
Я тебе приводил кучу примеров но ты их игнорируешь и постоянно ссылвешься на CodeJam.
Еще раз я тоже могу написать на C++ кучу кода, и что из этого
Мало того я как и ты могу вынести
min_element с селектором и получится тот же самый алгоритм. Проблема не в языке, а в головах. В том числе и твей.
и солнце б утром не вставало, когда бы не было меня
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Здравствуйте, Serginio1, Вы писали:
EP>>>У них же пропускаются null значения, а у тебя? Плюс смотри — у них Comparer передаётся снаружи, а у тебя он внутри var comparer = Comparer<TValue>.Default; — это может иметь эффект. S>>Там перегрузка методов. Компарер может подаваться как с наружи так и использоваться дефолтный. 1 вызов большой роли не играет по сравнению с 5000 строк
EP>Дело не в вызове, а в том что Comprare находится снаружи, это вполне может влиять на оптимизатор.
При вызовое 5000 строк?
public static TSource MinItem<TSource, TValue>(
[NotNull, InstantHandle] this IEnumerable<TSource> source,
[NotNull, InstantHandle] Func<TSource, TValue> selector) => MinItem(source, selector, Comparer<TValue>.Default);
Там вызов одного селектора и компарера значительно дороже.
S>>Фильтр на Nullable S>>
S>>if (isNullable && item == null) continue;
S>>
S>> тоже большой роли не играет особенно при сравнении строк.
EP>Строки короткие, а это лишнее сравнение, пусть даже и предсказуемое. Там-то и разница всего 5%~6%
Ну и смысл воротить кучу кода ради небольшого выигрыша? Все равно большую часть съедают селектор и компарер.
Раз ты использушь Linq то и стремится к уменьшению затрат не стоит, а стоит писать простой и понятный код, пусть и менее оптимальный по скорости.
и солнце б утром не вставало, когда бы не было меня
EP>Мы же в данном контексте не производительность перегрузок и т.п. обсуждаем, а разную семантику reference/value, которую нужно обрабатывать отдельным кодом. Я ссылку привёл именно на ветку о семантике.
Там вся "семантика" заключается в обработке if (!hasData), для ref-типов null возвращается. И нужно оно только для совместимости с фреймворком.
EP>Да, но я говорю о том что в большинстве случае ничего подобного не происходит.
Пруфов не приведу, ибо дело давнее, но во всех статьях / обсуждениях, где это дело обсуждалось с участием сотрудников MS утверждалось прямо обратное. Проверили, без кардинального изменения объектной модели разработки слабый. Читал где-то в 2008/2009, гугл ничего не находит, т.к. не могу вспомнить точные ключевые слова
В общем, пока .net native не доведут до ума, inline содержимого полей объекта — штука малополезная и в тех редких случаях, когда оно действительно надо, делается вручную. А вот аллокация на стеке (в том числе и типов с ссылочными полями) — это таки да, имеет смысл обсуждать.
AVK>Так значит надо переписать. Но только местами там все не так тривиально, как кажется на первый взгляд.
Да это больше ворчание, чем полезная критика. Чтоб что полезного предложить — надо время, с чем у меня откровенный ой.
На самом деле некритично, т.к. прочие реализации немногим лучше, да и проект все забросили, только я перфтесты добиваю.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
S>>сравниваем, если что, с вот этим. 5000 строк неэффективной кодогенерации
EP>Так их кодогенерация в итоге быстрее же чем твой вариант
Так речь не про скорость, а про эффективность, это комплексная штука. В любом реальном проекте это кусок был бы выпилен немедленно. Разница в 20% не окупает 5 килострок лишнего кода. Тем более, что когда перфоманс _действительно_ важен, узкие места просто переписываются врукопашную с сменой алгоритма. Как вариант, достаточно один раз отсортировать список и загонять дальше данные бинарным поиском. В вставке теряем, зато выборка — O(1) для оптимистов и O(log(n)) для произвольных значений.
EP>А вот то что для простейшего алгоритма используется кодогенерация — да, поражает.
Она там не требуется, если честно. У кода нет ни одного теста, который наглядно оправдывает потерю нескольких человекочасов на такую мелочь. Но в проекте для души можно и не так упороться (в хорошем смысле ).
EP>У них же пропускаются null значения, а у тебя? Плюс смотри — у них Comparer передаётся снаружи, а у тебя он внутри var comparer = Comparer<TValue>.Default; — это может иметь эффект.
EP>Кстати, интересно посмотреть на результаты на перетасованном (random shuffle) массиве.
Не вопрос, завтра проверю.
S>>Блин, но оформление ответа больше потрачу, наверно EP>Я для оформления сделал себе экспорт из Org-Mode в формат RSDN.
Так проблема не в таблички нарисовать, они перфтестами генерятся. Время уходит на подумать, текст, вычитку, проверку на грубые ляпы и тыды. Автоматизируй это(с)
IT>>>т.е. требует минимальной поддержки.
EP>>Генерируемый код через склейку текста требует большей поддержки нежели аналогичный обычный код выраженный средствами языка — его труднее писать, труднее отлаживать, труднее править и т.д. и т.п.
IT>Генерируемый код вообще не требует никакой поддержки. Поддержки требует код генератора. В данном случае код генератора прост как угол дома. Вообще-то, precompile time генерация кода самый простой и на сегодняшний день доступный вид метапрограммирования. Так что твои жалобы на сложность поддержки такого решения я не разделяю.
EP>>Так их кодогенерация в итоге быстрее же чем твой вариант S>Так речь не про скорость, а про эффективность, это комплексная штука.
Да, но мы вот видим вполне конкретное решение реализованное на практике.
S>Тем более, что когда перфоманс _действительно_ важен, узкие места просто переписываются врукопашную с сменой алгоритма. Как вариант, достаточно один раз отсортировать список и загонять дальше данные бинарным поиском.
Это уже лирика, естественно правильный выбор алгоритма решает. При этом поиск минимального элемента — вполне практичный алгоритм, и имеет вполне реальные применения.
EP>>А вот то что для простейшего алгоритма используется кодогенерация — да, поражает. S>Она там не требуется, если честно. У кода нет ни одного теста, который наглядно оправдывает потерю нескольких человекочасов на такую мелочь. Но в проекте для души можно и не так упороться (в хорошем смысле ).
Вот обычно со стороны евангелистов C# в КСВ темах звучат тезисы мол ну и что что медленно, зато мы вас переархитектурим/переалгоритмим и т.п. Да пока вы будете "с памятью возится" мы получим 2000% ускорения и т.п. Да и вообще всё в базу упирается.
При всём при этом был сильно удивлён увидеть вот такую текстовую кодогенерацию, считай на ровном месте, даже в "проекте для души".
S>>>Блин, но оформление ответа больше потрачу, наверно EP>>Я для оформления сделал себе экспорт из Org-Mode в формат RSDN. S>Так проблема не в таблички нарисовать, они перфтестами генерятся.
Это само собой.
Конечно можно генерировать и напрямую, но фишка в том что из одного исходника (.org файла) есть экспорт помимо RSDN ещё и в форматы типа PDF, HTML, LaTeX, ODT, etc — и везде свои таблицы.
Помимо этого таблицу-результат из одного фрагмента кода, можно передать на входу другому. Например сгенерировать таблицу кодом C++, передать в Python, и тот в свою очередь нарисует по ней SVG, который вставится в итоговое сообщение например как data uri base64.
S>Время уходит на подумать, текст, вычитку, проверку на грубые ляпы и тыды. Автоматизируй это(с)
Так в том-то и дело, что во время составления, вычитки и т.п. постоянно приходят идеи что-то подправить в коде и т.п.
Откладывать вставку кода/результатов на последний момент далеко не всегда получается. Например вставил код/результат, проверяешь, и захотелось что-то исправить, дополнить и т.п.
При этом изменения в коде могут влиять на результат и т.п. — хочется чтобы всё было актуальное.
Особенно это всё проявляется на больших сообщениях, где несколько разных примеров, тестов и т.п.
Здравствуйте, Sinix, Вы писали:
S>На самом деле некритично, т.к. прочие реализации немногим лучше, да и проект все забросили, только я перфтесты добиваю.
Проект не забросили, просто основное что планировали уже добавили.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>