Сообщение Re[11]: Несколько соображений по дизайну C# от 15.07.2016 17:53
Изменено 15.07.2016 17:57 Evgeny.Panasyuk
Здравствуйте, Sinix, Вы писали:
S>Для структур соотношение:
S>
S>сравниваем, если что, с вот этим. 5000 строк неэффективной кодогенерации
Так их кодогенерация в итоге быстрее же чем твой вариант Но этом может быть связанно с тем, что у них проверка "hasData" вынесена из цикла.
Но этом может быть связанно с тем, что у них проверка "hasData" вынесена из цикла.
А вот то что для простейшего алгоритма используется кодогенерация — да, поражает.
S>2. Не менее тяп-ляп код, написанный для конкретного частного случая выполняется на четверть быстрее для ссылочных полей и в 8 раз быстрее — для структур.
MinDoneRight — это же лишь ориентир, в нём же нет селектора. То есть опять таки — это претензия к языку/компилятору/платформе, а не к авторам CodeJam.
S>для строк:
S>
S>В чём подвох:
S>1. Тяп-ляп универсальный код, написанный без включения мозга оказался немного быстрее "оптимизированного" для ссылочных полей
У них же пропускаются null значения, а у тебя? Плюс смотри — у них Comparer передаётся снаружи, а у тебя он внутри var comparer = Comparer<TValue>.Default; — это может иметь эффект.
S>В общем надо знать матчасть, думать, а затем писать. И мерять. Иначе вот такой вот неудобняк получается.
Кстати, интересно посмотреть на результаты на перетасованном (random shuffle) массиве.
S>Блин, но оформление ответа больше потрачу, наверно
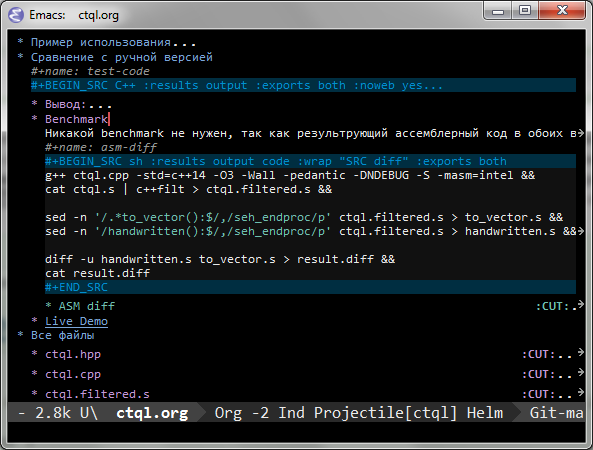
Я для оформления сделал себе экспорт из Org-Mode в формат RSDN. Это outliner, в нём можно вставлять фрагменты кода, выполнять их, результаты вставляются автоматом в документ, перебрасывать результаты между разными кусками кода на разных языках (а-ля Jupyter), также поддерживаются изображения, электронные таблицы, экспорт в различные форматы Markdown, PDF, LaTeX, HTML, ASCII.
S>Для структур соотношение:
S>
S> Method | Median | StdDev | Scaled | Min | Lnml(min) | Lnml(max) | Max |
S>-------------- |------------ |----------- |------- |------------ |---------- |---------- |------------ |
S> MinCodeJam | 13.5474 us | 4.2560 us | 1.00 | 9.8527 us | 1.00 | 1.00 | 57.8845 us |
S> MinOk | 17.6527 us | 1.5569 us | 1.30 | 13.9580 us | 1.28 | 1.28 | 25.8633 us |
S> MinOkComparer | 16.4211 us | 1.2513 us | 1.21 | 13.5474 us | 1.18 | 1.18 | 27.0949 us |
S> MinDoneRight | 1.6421 us | 0.5551 us | 0.12 | 1.2316 us | 0.12 | 0.12 | 10.2632 us |
S>S>сравниваем, если что, с вот этим. 5000 строк неэффективной кодогенерации
Так их кодогенерация в итоге быстрее же чем твой вариант
А вот то что для простейшего алгоритма используется кодогенерация — да, поражает.
S>2. Не менее тяп-ляп код, написанный для конкретного частного случая выполняется на четверть быстрее для ссылочных полей и в 8 раз быстрее — для структур.
MinDoneRight — это же лишь ориентир, в нём же нет селектора. То есть опять таки — это претензия к языку/компилятору/платформе, а не к авторам CodeJam.
S>для строк:
S>
S> Method | Median | StdDev | Scaled | Min | Lnml(min) | Lnml(max) | Max |
S>-------------- |-------------- |------------ |------- |-------------- |---------- |---------- |-------------- |
S> MinCodeJam | 331.7068 us | 19.2213 us | 1.00 | 289.4224 us | 1.00 | 1.00 | 419.9704 us |
S> MinOkComparer | 313.6436 us | 38.8401 us | 0.95 | 170.3692 us | 0.94 | 0.94 | 474.9812 us |
S>S>В чём подвох:
S>1. Тяп-ляп универсальный код, написанный без включения мозга оказался немного быстрее "оптимизированного" для ссылочных полей
У них же пропускаются null значения, а у тебя? Плюс смотри — у них Comparer передаётся снаружи, а у тебя он внутри var comparer = Comparer<TValue>.Default; — это может иметь эффект.
S>В общем надо знать матчасть, думать, а затем писать. И мерять. Иначе вот такой вот неудобняк получается.
Кстати, интересно посмотреть на результаты на перетасованном (random shuffle) массиве.
S>Блин, но оформление ответа больше потрачу, наверно
Я для оформления сделал себе экспорт из Org-Mode в формат RSDN. Это outliner, в нём можно вставлять фрагменты кода, выполнять их, результаты вставляются автоматом в документ, перебрасывать результаты между разными кусками кода на разных языках (а-ля Jupyter), также поддерживаются изображения, электронные таблицы, экспорт в различные форматы Markdown, PDF, LaTeX, HTML, ASCII.
Re[11]: Несколько соображений по дизайну C#
Здравствуйте, Sinix, Вы писали:
S>Для структур соотношение:
S>
S>сравниваем, если что, с вот этим. 5000 строк неэффективной кодогенерации
Так их кодогенерация в итоге быстрее же чем твой вариант Но это может быть связанно с тем, что у них проверка "hasData" вынесена из цикла.
А вот то что для простейшего алгоритма используется кодогенерация — да, поражает.
S>2. Не менее тяп-ляп код, написанный для конкретного частного случая выполняется на четверть быстрее для ссылочных полей и в 8 раз быстрее — для структур.
MinDoneRight — это же лишь ориентир, в нём же нет селектора. То есть опять таки — это претензия к языку/компилятору/платформе, а не к авторам CodeJam.
S>для строк:
S>
S>В чём подвох:
S>1. Тяп-ляп универсальный код, написанный без включения мозга оказался немного быстрее "оптимизированного" для ссылочных полей
У них же пропускаются null значения, а у тебя? Плюс смотри — у них Comparer передаётся снаружи, а у тебя он внутри var comparer = Comparer<TValue>.Default; — это может иметь эффект.
S>В общем надо знать матчасть, думать, а затем писать. И мерять. Иначе вот такой вот неудобняк получается.
Кстати, интересно посмотреть на результаты на перетасованном (random shuffle) массиве.
S>Блин, но оформление ответа больше потрачу, наверно
Я для оформления сделал себе экспорт из Org-Mode в формат RSDN. Это outliner, в нём можно вставлять фрагменты кода, выполнять их, результаты вставляются автоматом в документ, перебрасывать результаты между разными кусками кода на разных языках (а-ля Jupyter), также поддерживаются изображения, электронные таблицы, экспорт в различные форматы Markdown, PDF, LaTeX, HTML, ASCII.
S>Для структур соотношение:
S>
S> Method | Median | StdDev | Scaled | Min | Lnml(min) | Lnml(max) | Max |
S>-------------- |------------ |----------- |------- |------------ |---------- |---------- |------------ |
S> MinCodeJam | 13.5474 us | 4.2560 us | 1.00 | 9.8527 us | 1.00 | 1.00 | 57.8845 us |
S> MinOk | 17.6527 us | 1.5569 us | 1.30 | 13.9580 us | 1.28 | 1.28 | 25.8633 us |
S> MinOkComparer | 16.4211 us | 1.2513 us | 1.21 | 13.5474 us | 1.18 | 1.18 | 27.0949 us |
S> MinDoneRight | 1.6421 us | 0.5551 us | 0.12 | 1.2316 us | 0.12 | 0.12 | 10.2632 us |
S>S>сравниваем, если что, с вот этим. 5000 строк неэффективной кодогенерации
Так их кодогенерация в итоге быстрее же чем твой вариант
А вот то что для простейшего алгоритма используется кодогенерация — да, поражает.
S>2. Не менее тяп-ляп код, написанный для конкретного частного случая выполняется на четверть быстрее для ссылочных полей и в 8 раз быстрее — для структур.
MinDoneRight — это же лишь ориентир, в нём же нет селектора. То есть опять таки — это претензия к языку/компилятору/платформе, а не к авторам CodeJam.
S>для строк:
S>
S> Method | Median | StdDev | Scaled | Min | Lnml(min) | Lnml(max) | Max |
S>-------------- |-------------- |------------ |------- |-------------- |---------- |---------- |-------------- |
S> MinCodeJam | 331.7068 us | 19.2213 us | 1.00 | 289.4224 us | 1.00 | 1.00 | 419.9704 us |
S> MinOkComparer | 313.6436 us | 38.8401 us | 0.95 | 170.3692 us | 0.94 | 0.94 | 474.9812 us |
S>S>В чём подвох:
S>1. Тяп-ляп универсальный код, написанный без включения мозга оказался немного быстрее "оптимизированного" для ссылочных полей
У них же пропускаются null значения, а у тебя? Плюс смотри — у них Comparer передаётся снаружи, а у тебя он внутри var comparer = Comparer<TValue>.Default; — это может иметь эффект.
S>В общем надо знать матчасть, думать, а затем писать. И мерять. Иначе вот такой вот неудобняк получается.
Кстати, интересно посмотреть на результаты на перетасованном (random shuffle) массиве.
S>Блин, но оформление ответа больше потрачу, наверно
Я для оформления сделал себе экспорт из Org-Mode в формат RSDN. Это outliner, в нём можно вставлять фрагменты кода, выполнять их, результаты вставляются автоматом в документ, перебрасывать результаты между разными кусками кода на разных языках (а-ля Jupyter), также поддерживаются изображения, электронные таблицы, экспорт в различные форматы Markdown, PDF, LaTeX, HTML, ASCII.