В соседнем обсуждении зашла речь о том, что у многих, если не у каждого, скопилось некоторое количество кода, который применяется в большом количестве, если не во всех проектах. В связи с чем родилась идея собрать самое интересное в опенсорсный проект и выложить нугет с библиотечкой, чтобы использовать ее, а не свои велосипеды таскать.
Основные критерии оптимизации — высокая универсальность (т.е. возможность использовать в широком спектре проектов), минимальный объем навязываемых решений (т.е. никаких сквозных подвязок, никаких фреймворков), высокая читаемость и качество кода.
Вопросы:
1) Кто что по этому думает?
2) Что бы хотелось в этой библиотеке увидеть, и что не хотелось бы?
3) Кому интересно в этом поучаствовать?
4) Кому интересно библиотеку в своих проектах использовать?
Здравствуйте, Shmj, Вы писали:
S>Имх, долно начинаться с .Net или N. Сразу видна таргетизация.
Это чисто явовские заморочки. Для дотнета принято соглашение Бренд.ЧтоДелает.
Здравствуйте, Sinix, Вы писали:
S>Чот я не уверен в best ever.
Поверь мне пока на слово К этому имени очень быстро привыкаешь настолько, что все остальные потуги придумать что-либо более удобоваримое выглядят жалкими и смешными.
Хотя я не настаиваю. Давай оставим Format. Остальные предложенные имена подпадают под твои же аргументы.
S>Аргументы против в произвольном порядке:
S>0. Guidelines. Имя метода не совпадает с производимым действием.
Всё так. Но бывают и исключения, которые только подтверждают правила.
С другой стороны к данному методу следует относится не как к действию, а как к параметрам форматной строки. Иначе, если следовать всем буквам guidelines, то форматную строку нужно запретить и заменить её на конкатенацию.
S>1. WTF test fail. S>Возьми произвольного девелопера и спроси: "эй, у нас будет метод-расширение для форматирования строк, как он должен выглядеть?"
Если честно, то я почти никогда не объявляю форматную строку отдельно от string.Format. Поэтому выглядеть это будет так:
return"Hello, {0}".Args(wellKnownNames[0]);
Учитывая подсветку и поддержку решарпера вся конструкция воспринимается не как строка и действие, а как единое целое.
S>2. Совместимость с другими решениями. В куче проектов используется SmartFormat с extensions вида
Это опять лишь твои предпочтения. Если это переназвать в Format, то станет сразу менее WTF? Давай переназовём.
S>3. Too noisy. Подобные узкоприменимые расширения должны быть opt-in.
Это проблема не только этого метода, а любого расширения. Я сам хотел поднять эту тему. Сейчас у нас все расширения находяться в основном пространстве имён, что автоматически добавляет их все. При этом вопрос узкоприменимости представляет собой в чистом виде вкусовщину, поэтому конфликт интересов неизбежен. Дробить всё как ты предлагаешь по пространсту имён на каждый метод, тоже не дело. Но что-то решать надо. Как минимум я бы перенёс все расширения куда-нибудь в CodeJam.Extensions. И заодно перетасовал бы файлы в проекте. Соответсвие папок пространсвам имён тоже вроде пока никто не отменял.
S>Это всё не ради срача, а чтоб сделать код лучше. Если решение принципиально будет "всё равно останется как есть" — можно не спорить, просто так и скажи
Если нам не помогут, то мы тоже никого не пощадим.
AVK>Есть более специфичные штуки — парсер командной строки, парсер CSV, но тут уже я не уверен в уместности такого.
Могу докинуть:
1. Методы NotNullOrEmpty() для строк и для enumerable. Разница такая же как с Any()/All() — одно можно выразить через другое, но читаемость страдает.
2. Ассерты ala Code.NotNull(someValue, "someValue");
3. GetOrAdd() + AddOrUpdate() для словарей.
4. Хелперы для enum-ов — проверка на флаги etc. С нормальной производительностью, а не как у Enum.HasFlag()
5. Factory для Disposable, using(Disposable.Create(()=>OnDispose())) { }
Если кому надо — Range<T>/CompositeRange<T> для операция над диапазонами/наборами диапазонов — объединение, пересечение, дополнение — полный набор.
Здравствуйте, Doc, Вы писали:
Doc>4.5.2 как минимально поддерживаемый это мне кажется разумным. Но вот не ограничит ли это область использования?
Ну можно на 4 откатить, если желающие будут. Не ниже уж точно.
Doc>Плюс зачем игнорить Core? Как по мне, лучше уже что-то исключить из сборки под Core (если что сейчас не поддерживается), чем потом допиливать и тестить все. Отсюда же и для unit test использовать xUnit.
Боюсь я сечас закладываться на кроссплатформенные нюгет-пакеты. Там очередная революция с .platform standard грядёт.
Ну т.е. можно, но нужен доброволец, кто будет оперативно приводить пакеты к актуальному виду.
Здравствуйте, AndrewVK, Вы писали:
AVK>1) Кто что по этому думает?
Моё мнение — не взлетит. Участники не договорятся о деталях.
В процессе споров отвалятся все, кроме двух-четырёх человек, которые и произведут продукт.
И только эти люди да несколько случайных энтузиастов будут этим пользоваться. Да и то недолго, так как поддерживать продукт всем будет лень.
Впрочем, многие люди будут качать исходники и копипастить себе удачные куски кода.
Я через такое проходил один раз сам и пару раз наблюдал со стороны.
Здравствуйте, nigh, Вы писали:
N>Да нет, там все гораздо глубже. Основная мысль в том, что Disposable и try-finally для семантики локов не подходят и создают ложное ощущение безопасности.
Это проблема exception safety guarantees, она существует и без всяких локов или даже потоков. Она даже существует без using'ов, только ещё хуже.
А вот RAII, using'и, try-with-resourcues, with — как раз подходят к семантике локов. А вот ложное ощущение безопасности — это от незнания exception safety
N>
N>WithdrawMoney(AccountB, 100) //throw an exception here, will never unlock unless proper recovery is done - likely a deadlock, but not further data corruption by other threads
N>
Если тебе нравится "likely a deadlock, but not further data corruption by other threads" — то лучше сразу на первом же исключении пристреливать программу и тормозить всю систему, без всяких "likely", чтоб наверняка — так robust'ней
Здравствуйте, Sinix, Вы писали:
S>1. Переименовать в .Format()
Компилятор против
S>2. Спрятать в отдельный namespace.
Спорно.
S>Это всё не ради срача, а чтоб сделать код лучше. Если решение принципиально будет "всё равно останется как есть" — можно не спорить, просто так и скажи
Добавил вообще то IT, а не я.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
Из того что лично у меня часто используется в разных проектах:
1) Инфиксные формы string.Format, IsNull, IsNullOrWS, Join.
2) Упрощение работы с XDocument — доступ к элементам с проверкой на Null или существование, типизированное чтение атрибутов и т.п.
3) Некоторое количество хелперов для рефлекшена — получение текущей сборки, доступ к ресурсу с проверкой наличия, типизированное чтение атрибутов, создание экземпляра объекта по типу со всякими фенечками и проверками.
4) Хелперы для коллекций и линка. Там много разного. Например Concat у которого в параметрах не коллекция, а единичный элемент или метод FirstOrValue.
5) Хелпер для сравнения текстовых дампов — полезно при написании тестов.
6) Словарик с ленивой инициализацией элементов. Что то вроде гибрида Dictionary и Lazy.
7) Хелпер, обеспечивающий использование ReaderWriterLock с оператором using.
8) Хелпер для получения пустых массивов без лишних экземпляров.
Есть более специфичные штуки — парсер командной строки, парсер CSV, но тут уже я не уверен в уместности такого.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
Здравствуйте, AndrewVK, Вы писали:
S>>2. Ассерты ala Code.NotNull(someValue, "someValue"); AVK>Типа шоткатов ддля Debug.Assert или что там внутри?\
Бросание исключения + обязательное прерывание выполнения на сработавшем ассерте (не внутри него), если подключен отладчик.
Отличная штука для доведения до бешенства гарантии, что на ошибку не забьют. Оно работает, проверено
S>>5. Factory для Disposable, using(Disposable.Create(()=>OnDispose())) { } AVK>Это есть в Rx, но ради одной ерунды не всегда его интересно тянуть.
Ну вот поэтому и предлагаю
S>>Если кому надо — Range<T>/CompositeRange<T> AVK>Ой, больной вопрос. У меня есть даже реализация таких структурок, правда не для себя — надо переписывать. Но насколько это часто нужно неясно. У меня в них хранились ренджи символов для лексера.
Значит откладываем, для начала то, что точно нужно людям берём.
Оргпредложения — стандартный набор:
1. Гитхаб + appveyor с публикацией в нюгет.
2. MIT license.
3. Студия 2015, таргетинг на 4.5. Проекты должны открываться и в 2012/2013, т.е. с совместимостью проблем не будет. На кросплатформенность я бы сейчас не замахивался. Хотя я бы переключился на 4.5.2 как минимум.
4. Соглашения по оформлению кода — стандартные дотнетовские, благо поддерживаются автоматом. Если нет — надо делать набор правил StyleCop + рекомендации как настроить какой-нить бесплатный форматтер типа CodeMaid, иначе никто их соблюдать не будет.
5. Threat warnings as errors.
6. XML comments — по-хорошему нужны, надо определиться с языком комментариев.
UPD
7. Нужно с самого начала определиться с тестами. Предлагаю требовать только тесты с сценариями использования, складывать их в отдельную папку (UseCases и назвать), остальное — добровольное, в папку Tests.
Тесты — любые, которые поддерживает appveyor, я бы взял xUnit, хотя бы из-за xBehave или fixie.
Здравствуйте, Doc, Вы писали:
Doc>А это все планируется как единая библиотека (1 пакет NuGet) или же с разделением по темам (ну там lib.Strings , lib.XDoc и т.д.)
Думаю, на первом этапе лучше один пакет. Точнее два — основной функционал и экспериментальный. В дальнейшем можно и порезать на куски, только, конечно, не настолько мелкие.
Doc>Так же для какого .NET это все планируется делать (или для каких). Я как про мин. версию, так и тип.
Да, тут вопрос, на который лично у меня нет ответов. Есть .NET, .NET Core, WinPhone, Xamarin (Silverlight, слава богу, помер). Но в этой области у меня опыта мало.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
Здравствуйте, rameel, Вы писали:
R>2. KeyEqualityComparer с — требуется не так часто, но все же порой сильно не хватает
Это что такое?
R>3. MultiValueDictionary — сейчас есть уже в Corefxlab
И в Microsoft.Experimental.Collections. Fx 4.5+, так что смысла тащить никакого.
R>6. Хелперы для вычисления криптохешей у строк, массива байтов и Stream
Не слишком специфично? Мне вот ни разу такое не требовалось.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
Здравствуйте, v6, Вы писали:
v6>А здесь — возможны непонятки (Not Null) Or Empty VS Not (Null Or Empty) v6>Мне кажется, более однозначно будет NotNullNotEmpty
Тогда уж NotNullNorEmpty или NeitherNullNorEmpty.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
Здравствуйте, Sinix, Вы писали:
S>Можно и там. Как обсуждать отдельные фичи / issue? в самом репо, или на форуме, новым топиком с тегом в теме [CJ]?
По русски если — наверное лучше в форуме. Если по английски, тогда в issues.
S>Как минимум надо завести список планируемых фич, а то они сейчас по топику рассыпаны — потеряются.
Вики-страничку надо сделать
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
Здравствуйте, AndrewVK, Вы писали:
AVK>1) Кто что по этому думает?
Не взлетит. У всех разный набор решений одних и тех же проблем. Универсальной библиотекой просто не будут пользоваться.
AVK>4) Кому интересно библиотеку в своих проектах использовать?
Я лично использую мелкие библиотеки, решающие конкретные проблемы: Polly, CvsHelper, Impromptu, AutoMapper, Oxygenize и так далее. Эти библиотеки не нужны в каждом проекте, они подключаются по мере необходимости.
Здравствуйте, Sinix, Вы писали:
S>>>5. Threat warnings as errors. AVK>>Это уже перебор. S>Вот я сейчас работаю на проекте, на котором это не было сделано с самого начала. С варнингами в итоге никто не борется, потому что они есть даже в автосгенерированном коде. Количество сам можешь представить. S>Поэтому только как errors, подавлять прагмой — её хоть найти можно.
Возможен компромисс. Если мы делаем два проекта, то в главном можно сделать всё по жёстче.
S>По названию — FlockLib пойдёт. Хотя бы не похоже на выхлоп генератора. Хотя CatHerd тоже ничего будет, отражает суть проекта. И реклама готовая есть,
Какие-то невнятные названия.
S>7. Нужно с самого начала определиться с тестами. Предлагаю требовать только тесты с сценариями использования, складывать их в отдельную папку (UseCases и назвать), остальное — добровольное, в папку Tests.
Запутаемся. Думаю одного проекта Tests хватит за глаза.
S>Тесты — любые, которые поддерживает appveyor, я бы взял xUnit, хотя бы из-за xBehave или fixie.
Я бы взял новый NUnit 3. Там всё переработано и сделано очень неплохо, особенно с параметризированными тестами.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, Sinix, Вы писали:
S>Все варианты делают одно и то же, но вариант D самый читабельный, т.к. во-первых не требует скакать взглядом назад, во-вторых, не путается с IsNullOrEmpty() как C.
Скорее всего имеется ввиду, что граммитически Not здесь относится только Null.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, Sinix, Вы писали:
S>Ну, т.е. нужен issue tracker, но, как я понимаю, не гитхаб, т.к. обсуждения планируется на русском.
Не, вот два issue трекера точно заводить не будем, концов не соберешь. Достаточно гитхабовского. Ни или местного, если по каким то причинам гитхаб не устраивает. Просто не надо смешивать обсуждения и трекер, это на гитхабе оно смешано ввиду отсутствия там форума.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
Здравствуйте, AndrewVK, Вы писали:
AVK>Мне, как человеку, испорченному решарпером хватает его подсказок, чтобы держать проект более менее чистым.
В данном случае момент чисто организационный. Ты как человек, испорченный решарпером, станешь гоняться за каждым разработчиком и умолять его убрать ворнинги? А здесь он сам нарвётся на проблему и должен будет её решить. У меня опыт примерно такой же, как и у уважаемого Sinix, стоит немного ослабить и понеслась.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, AndrewVK, Вы писали:
AVK>Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>>+ std::equal_range,
AVK>Это типа .Where(i => i.Equals(value))? Такое где то часто нужно, что к нему шоткат надо делать?
Типа того, но дипазон поиска отсортирован, соответственно, на выходе будет просто поддиапазон, и сложность логарифмическая, а не линейная.
Результат эквивалентен паре результов lower_bound и upper_bound.
Здравствуйте, Sinix, Вы писали:
S>1. Куда заводить тикеты.
github на английском
S>2. Где обсуждать / голосовать фичи
github на английском. Если совсем уж проблемы с английским — можно в форум в надежде что кто то заветет issue на гитхабе. Примерно как сейчас с тем же решарпером — основной трекер англоязычный, а здесь русскоязычный форум.
S>3. Документашка.
Для разработчиков самой библиотеки — пока на русском в местной вике. Для пользователей — md в проекте на английском. Проект/русская версия на русском в местной вике.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
Здравствуйте, Lexey, Вы писали:
AVK>>Это типа .Where(i => i.Equals(value))? Такое где то часто нужно, что к нему шоткат надо делать? L>Типа того, но дипазон поиска отсортирован, соответственно, на выходе будет просто поддиапазон, и сложность логарифмическая, а не линейная. L>Результат эквивалентен паре результов lower_bound и upper_bound.
Но обычно быстрее, так как большая часть проб проводится однократно.
Здравствуйте, AndrewVK, Вы писали:
AVK>Вопросы: AVK>1) Кто что по этому думает?
http://editorconfig.org/ бы прикрутить, а то у всех настройки редакторов разные, а в проекте должен бьыть один.
Мои личные настроки сильно уж отличаются от того, что в StringExtensions уже есть, посему мне сложно будет добавить.
EP>>>Он может выкинуть исключение откуда угодно? Или только из обозначенных мест?
S>>Откуда угодно.
EP>Очень хрупкая концепция — получается что no-throw кода нет в принципе, что в некоторых случаях сильно затрудняет реализацию транзакционных операций.
EP>Надеюсь оно хоть не выкидывает новое исключение при повтором Thread.Abort в случае когда первое поймано или при выполнении finally/dispose?
(3) carefully implement the bodies of locks that do mutations so that in the event of an exception, the mutated resource is rolled back to a pristine state before the lock is released. (Good, but hard.)
При помощи scope(failure)/scope(success) это намного проще.
Здравствуйте, AndrewVK, Вы писали: AVK>Что то мне результат StrCmpLogical вообще не кажется правдоподобным. Пробелы, к примеру, обрабатываются некорректно.
//NOTTODO: IT: The name is the best ever. Don't change it.public static string Args([NotNull] this string format, params object[] args) => string.Format(format, args);
Чот я не уверен в best ever.
UPD: Я знатно протупил с вариантом .Format(), AndrewVK намекнул ниже Но Args мне всё равно не нравится
Аргументы против в произвольном порядке: 0. Guidelines. Имя метода не совпадает с производимым действием.
1. WTF test fail.
Возьми произвольного девелопера и спроси: "эй, у нас будет метод-расширение для форматирования строк, как он должен выглядеть?"
Сколько напишут
var sayHelloFormat = @"Hello, {0}"!
...
return sayHelloFormat.Args(wellKnownNames[0]); // WTF???
вместо
var sayHelloFormat = @"Hello, {0}"!
...
return sayHelloFormat.Format(wellKnownNames[0]);
?
2. Совместимость с другими решениями. В куче проектов используется SmartFormat с extensions вида
var x = "You have {0} new {0:message|messages}".SmartFromat(emails.Count);
var y = "You have new message(s): {0}".Args(emails.Count); // WTF???
3. Too noisy. Подобные узкоприменимые расширения должны быть opt-in. Иначе после подключения юзинга ради полезной фичи (например, NotNullNorEmpty()) intellisence засоряется куда менее полезными Точнее, абсолютно бесполезными с учётом пары SmartFromat + c# string interpolation. Только чур не спорить "это ж один метод, фигня!".
У меня из-за таких дачобудет в одном из доставшихся в подарок проектов только на object 12 extension-ов вылазят. Нафиг-нафиг.
Ну, т.е.
1. Переименовать в .Format().StringFormat() или что-то типа того.
2. Спрятать в отдельный namespace.
Это всё не ради срача, а чтоб сделать код лучше. Если решение принципиально будет "всё равно останется как есть" — можно не спорить, просто так и скажи
Здравствуйте, Sinix, Вы писали:
AVK>>И? Разве правильно так реагировать на пробелы? S>Тут имхо вопрос не в правильно/неправильно, а в "сохраняем совместимость с StrLogicalCompare/нет".
А это уже зависит от юзкейсов. Поскольку предложил не я, то ХЗ.
По моему опыту 99% применений сортировки это чтобы глазом глядеть какие то списки, для чего точная совместимость вобщем то побоку. Оставшийся 1% это бинарный поиск, но там вообще пофик какая сортировка, лишь бы была стабильной.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
Здравствуйте, Sinix, Вы писали:
AVK>>Большая часть настраивается. И ну ее нафик, такую каноничность как в примере — читать неудобно. S>Ну тут опять-таки вкус фломастеров
Да причем тут вкус? Это в игрушечном примере вроде все видать. А когда строки длинные, что часто бывает, то перемещать глаз в конец строки только чтобы понять что это за конструкция это уже перебор. А оно еще и вложенным может быть.
Если что я по опыту говорю. IT любит в таком виде писать — при чтении кода глаз сломаешь, дико неудобно.
S>Из практики, когда не у всех в команде есть решарпер, поддержать общий стиль форматирования заметно сложнее — получается "или все прогинаемся под R#, или никак".
При чем тут "прогинаемся под R#"? Есть вполне конкретный стиль кодирования, решарпер вполне его реализует. Хочется StyleCop — я не против. Но сам я им не пользуюсь, поэтому и возиться с настройками его не буду.
Да, конкретно StyleCop еще и весьма интрузивный — если его не поставить, проекты с его использованием не открываются, потому что он свой таргет в csproj втыкивает. Вкупе с кучей его безумных правил и вашим предложением treat warnings as errors будет весело. В комплекте с обязательностью тестов и комментов на английском как бы это не стало великим тормозом — даже мелкий метод потребует массу работы.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
AVK>Так а при откусывании зачем префикс/суффикс? Типа сперва нужно проверить на совпадение или это такой извращенный способ передать длину откусываемого?
Да, проверить на совпадение, если совпало-откусить.
Наверное, название не очень удачное (просто я к нему привык, глаз замылился).
Это скорее аналоги TrimStart() и TrimEnd(), которые тримают подстроки, а не отдельные символы.
Хотя, с другой стороны "ababc".CutStart("ab") вернет "abc", а "ababc".TrimStart("ab") по идее должен вернуть только "c".
Здравствуйте, AndrewVK, Вы писали:
AVK>Для константного формата и 6 шарпа уже не надо так делать. Надо так:
Это когда ещё будет. Если помнишь, народ тут просил поддержку 4-го FW, а ты про 6-й решарпер.
IT>>Это проблема не только этого метода, а любого расширения. Я сам хотел поднять эту тему. Сейчас у нас все расширения находяться в основном пространстве имён, что автоматически добавляет их все.
AVK>У меня лично много опыта использования экстеншенов на весьма крупных проектах и большом количестве этих экстеншенов. И на практике оказалось, что никаких проблем нет даже когда все экстеншены находятся в пространстве имен прикладного кода. Тип аргумента обычно достаточно селективен, особенно если не навешивать расширения на object. AVK>Да посмотреть даже на сам Fx. Enumerable цепляется к очень распространенному типу, содержит очень большое количество расширений к нему (в фреймворке, наверное, рекордно большое), находится в том же самом неймспейсе, что и все коллекции, т.е. гарантированно попадает в любой код. Получается worst сценарий. Таки и что? Да ничего, все вполне нормально и удобно.
Т.е. всё-таки не в корневом, а в том к чему оно относится.
AVK>С другой стороны, когда у нас все в одном пространстве имен, это добавляет discoverability, которая при разнесении расширений по куче неймспейсов падает стремительным домкратом до уровня обычных статических методов, за что их не попинал только ленивый любитель С++ и свободных функций. И вот это уже реальная, а не теоретическая проблема.
IT>>Как минимум я бы перенёс все расширения куда-нибудь в CodeJam.Extensions.
AVK>И что это даст? Лишний юсинг в прикладном коде?
У меня лично много опыта использования экстеншенов на весьма крупных проектах и большом количестве этих экстеншенов. И на практике оказалось, что с лишним юзингом нет никаких проблем. Но да фиг с ним. Дело не в нём, а в структуре проекта.
IT>> И заодно перетасовал бы файлы в проекте. Соответсвие папок пространсвам имён тоже вроде пока никто не отменял.
AVK>Очень неудобно.
Очень удобно.
AVK>Если у меня классов много — будут неструктурированные длинные списки, если класс только один — дурацкая ситуация папки с одним файлом. ИМХО ну его нафик, средств навигации даже голой студии вполне достаточно, чтобы не искать классы по структуре папок. Я уж не говорю про решарпер.
Навигация дело десятое, хотя и она для кого-то может оказаться важна.
AVK>Пространства имен предназначены для одного — обеспечения отсутствия конфликта имен. Попытка привязать к ним какую то еще ответственность — отличный способ прострелить себе ногу.
Тогда по твоей логике все классы фреймворка нужно было поместить в System. Конфликтов имён там почти нет, а там где они есть можно всегда создать неймспейс, при этом особо не париться и называть их по порядку A, B, C.
В общем, я даже как-то теряюсь от твоей аргументации. Неймспейсы лично для меня всегда были не средством разруливания конфликтов имён, а преждес всего механизмом организации кода проекта, средством устранения свалки всего в одном месте, как ты здесь предлагаешь. Соотвествие папок неймспейсам — это вообще-то соглашение индустриального уровня и уже давно ни у кого не вызывает вопросов. Сейчас же, уверен, у большинства из тех, кто решит посмотреть на код библиотеки, первым делом возникнет сомнение в профессиональном уровне разработчиков, т.к. возникнет ощущение, что тут собрались не профи, а орлята учатся летать.
Для хелперных классов давно уже существует очень простое правило — их следует помещать в неймспейсы с именем неймспейса того класса, для котого делается хелпер. Так для типов String, Type это может быть корневой неймспейс. Для коллекций Collection, для расширений Linq — соответственно Linq. Не думаю, что таких неймспейсов будет много и что это вызовет какие-то сложности при их использовании. Но зато библиотека станет лучше организована, более логична и предсказуема.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, AndrewVK, Вы писали:
AVK>Основные критерии оптимизации — высокая универсальность (т.е. возможность использовать в широком спектре проектов), минимальный объем навязываемых решений (т.е. никаких сквозных подвязок, никаких фреймворков), высокая читаемость и качество кода.
Два варианта:
1) качество кода + поддержка + универсальность + рецензирование, как следствие высокий порог вхождения нового кода
2) свалка разрозненных компонентов + возможно нестабильное API + быстрая эволюция и т.п. — минимальный порог вхождения
Оба варианта полезны и нужны — первый ради качества, второй ради количества.
В C++ есть первый вариант — Boost. Часто не хватает второго — есть много мелких компонентов раскиданных по сети, которые по качеству не тянут на 1) но тем не менее при этом могли бы приносить бОльшую пользу будь они скомпонованы в одну библиотеку с минимальной структурой, также повысился бы их шанс роста до 1), плюс какая-никакая взаимная синергия.
Отбрасывать второй вариант думаю не стоит, может есть смысл создать два параллельных проекта?
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Два варианта: EP>1) качество кода + поддержка + универсальность + рецензирование, как следствие высокий порог вхождения нового кода EP>2) свалка разрозненных компонентов + возможно нестабильное API + быстрая эволюция и т.п. — минимальный порог вхождения
EP>Оба варианта полезны и нужны — первый ради качества, второй ради количества.
Я думал именно про первый. Ну, по крайней мере мне самому как пользователю первый нужен.
EP>В C++ есть первый вариант — Boost.
Спорно. В бусте много шлака. Ну и с С++ ситуация сильно другая, не надо его практики на дотнет переносить.
EP>Отбрасывать второй вариант думаю не стоит, может есть смысл создать два параллельных проекта?
Два параллельных — перебор. Можно просто две части в рамках одного проекта. Стабильную и экспериментальную.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
Здравствуйте, Sinix, Вы писали:
S>1. Методы NotNullOrEmpty() для строк
Про это вроде написал.
S> и для enumerable. Разница такая же как с Any()/All() — одно можно выразить через другое, но читаемость страдает.
Да это понятно, можешь не объяснять.
S>2. Ассерты ala Code.NotNull(someValue, "someValue");
Типа шоткатов ддля Debug.Assert или что там внутри?
S>3. GetOrAdd() + AddOrUpdate() для словарей.
В ту же кучу GetValueOrDefault — out параметры не позволяют вопхнуть в выражение, а если там еще и анонимный тип, то вообще других вариантов нет.
S>4. Хелперы для enum-ов — проверка на флаги etc. С нормальной производительностью, а не как у Enum.HasFlag()
Угу. И типизированные.
S>5. Factory для Disposable, using(Disposable.Create(()=>OnDispose())) { }
Это есть в Rx, но ради одной ерунды не всегда его интересно тянуть.
S>Если кому надо — Range<T>/CompositeRange<T> для операция над диапазонами/наборами диапазонов — объединение, пересечение, дополнение — полный набор.
Ой, больной вопрос. У меня есть даже реализация таких структурок, правда не для себя — надо переписывать. Но насколько это часто нужно неясно. У меня в них хранились ренджи символов для лексера.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
Здравствуйте, AndrewVK, Вы писали:
EP>>В C++ есть первый вариант — Boost. AVK>Спорно. В бусте много шлака.
Например?
AVK>Ну и с С++ ситуация сильно другая,
И чем она сильно другая?
AVK>не надо его практики на дотнет переносить.
Boost это набор рецензируемых библиотек разрабатываемых сообществом, тематика самая широкая (общеязыковые компоненты типа контейнеров и алгоритмов, прикладные вещи типа Odeint, системные а-ля Asio, C++ специфичные типа Fusion) — чем это отличается от сабжа? Тематика сабжа будет уже?
EP>>Отбрасывать второй вариант думаю не стоит, может есть смысл создать два параллельных проекта? AVK>Два параллельных — перебор. Можно просто две части в рамках одного проекта. Стабильную и экспериментальную.
Да, тоже вариант, только экспериментальная часть должна быть доступна в том числе в виде пакета, должны прогоняться минимальные тесты и т.п. — то есть не просто experimental repo.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>>>В C++ есть первый вариант — Boost. AVK>>Спорно. В бусте много шлака. EP>Например?
Я давно уже туда не заглядывал, поэтому врать не буду.
AVK>>Ну и с С++ ситуация сильно другая, EP>И чем она сильно другая?
Крайне бедная стандартная библиотека, сам язык плохо приспособлен для написания широко используемых библиотек, много извратов с метапрограммированием на шаблонах.
EP> Тематика сабжа будет уже?
Наоборот шире. Но никаких планов по включению туда специализированных вещей типа того же spirit нет. Есть вполне конкретная потребность обобщения вещей, которые используются часто и во многих проектах, т.е. самого универсального кода. А собрать туда все подряд, да еще и с условием отсутствия каких либо сквозных структур — с какой целью? При наличии nuget все что нужно ты можешь собрать из разных библиотек, не?
EP>>>Отбрасывать второй вариант думаю не стоит, может есть смысл создать два параллельных проекта? AVK>>Два параллельных — перебор. Можно просто две части в рамках одного проекта. Стабильную и экспериментальную. EP>Да, тоже вариант, только экспериментальная часть должна быть доступна в том числе в виде пакета, должны прогоняться минимальные тесты и т.п. — то есть не просто experimental repo.
Разумеется.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
CodeJam, CodePieces, CodeShorts (добавил свой вариант: загуглил слово — посмеялся, хотя по смыслу подходит), CodeBlocks/CodeBricks(слишком баззвордово).
Здравствуйте, Sinix, Вы писали:
S>6. XML comments — по-хорошему нужны, надо определиться с языком комментариев.
Нужно все делать с глобальным прицелом. Зачем ограничивать себя?
Англ. не у всех хорош, по этому формируйте мысль попроще и используйте гугле-транслейт. Как минимум чтобы не было орфографических ошибок и смысл можно было уловить. Позже выделить день и сделать найтивную вычитку.
Здравствуйте, AndrewVK, Вы писали:
S>>4. Соглашения по оформлению кода — стандартные дотнетовские AVK>Единственные потенциальные проблемы — 4 пробела в качестве отступа и s_ префикс у статиков.
Ну да, поэтому и не настаиваю.
Главное, чтоб было
S>>5. Threat warnings as errors. AVK>Это уже перебор.
Вот я сейчас работаю на проекте, на котором это не было сделано с самого начала. С варнингами в итоге никто не борется, потому что они есть даже в автосгенерированном коде. Количество сам можешь представить.
Поэтому только как errors, подавлять прагмой — её хоть найти можно.
S>>6. XML comments — по-хорошему нужны, надо определиться с языком комментариев. AVK>Английский, разумеется.
Ок
UPD
7. Нужно с самого начала определиться с тестами. Предлагаю требовать только тесты с сценариями использования, складывать их в отдельную папку (UseCases и назвать), остальное — добровольное, в папку Tests.
Тесты — любые, которые поддерживает appveyor, я бы взял xUnit, хотя бы из-за xBehave или fixie.
AVK>Из того что лично у меня часто используется в разных проектах: AVK>1) Инфиксные формы string.Format, IsNull, IsNullOrWS, Join. AVK>2) Упрощение работы с XDocument — доступ к элементам с проверкой на Null или существование, типизированное чтение атрибутов и т.п. AVK>3) Некоторое количество хелперов для рефлекшена — получение текущей сборки, доступ к ресурсу с проверкой наличия, типизированное чтение атрибутов, создание экземпляра объекта по типу со всякими фенечками и проверками. AVK>4) Хелперы для коллекций и линка. Там много разного. Например Concat у которого в параметрах не коллекция, а единичный элемент или метод FirstOrValue. AVK>5) Хелпер для сравнения текстовых дампов — полезно при написании тестов. AVK>6) Словарик с ленивой инициализацией элементов. Что то вроде гибрида Dictionary и Lazy. AVK>7) Хелпер, обеспечивающий использование ReaderWriterLock с оператором using. AVK>8) Хелпер для получения пустых массивов без лишних экземпляров.
А это все планируется как единая библиотека (1 пакет NuGet) или же с разделением по темам (ну там lib.Strings , lib.XDoc и т.д.)
Так же для какого .NET это все планируется делать (или для каких). Я как про мин. версию, так и тип.
Здравствуйте, Sinix, Вы писали:
S>3. Студия 2015, таргетинг на 4.5. Проекты должны открываться и в 2012/2013, т.е. с совместимостью проблем не будет. На кросплатформенность я бы сейчас не замахивался. Хотя я бы переключился на 4.5.2 как минимум.
4.5.2 как минимально поддерживаемый это мне кажется разумным. Но вот не ограничит ли это область использования?
Плюс зачем игнорить Core? Как по мне, лучше уже что-то исключить из сборки под Core (если что сейчас не поддерживается), чем потом допиливать и тестить все. Отсюда же и для unit test использовать xUnit.
Здравствуйте, AndrewVK, Вы писали:
Doc>>Плюс зачем игнорить Core? AVK>Ну, у меня нет опыта совсем с этим делом. Если у тебя есть опыт и желание — можно и не игнорить.
Ну вот подумываю, что можно и присоединиться.
AVK>Связь с xUnit не очень понятна.
Здравствуйте, AndrewVK, Вы писали:
AVK>Кто планирует активно участвовать — кидайте логины на гитхабе, добавлю права чтобы не тратить время на пулреквесты. AVK>И нужен человек, способный без косяков написать readme.md с основной идеологией.
Здравствуйте, AndrewVK, Вы писали:
AVK>Кто планирует активно участвовать — кидайте логины на гитхабе, добавлю права чтобы не тратить время на пулреквесты.
Здравствуйте, Sinix, Вы писали:
S>Здравствуйте, AndrewVK, Вы писали:
AVK>>Есть более специфичные штуки — парсер командной строки, парсер CSV, но тут уже я не уверен в уместности такого. S>Могу докинуть: S>1. Методы NotNullOrEmpty() для строк и для enumerable. Разница такая же как с Any()/All() — одно можно выразить через другое, но читаемость страдает. S>2. Ассерты ala Code.NotNull(someValue, "someValue"); S>3. GetOrAdd() + AddOrUpdate() для словарей. S>4. Хелперы для enum-ов — проверка на флаги etc. С нормальной производительностью, а не как у Enum.HasFlag() S>5. Factory для Disposable, using(Disposable.Create(()=>OnDispose())) { }
S>Если кому надо — Range<T>/CompositeRange<T> для операция над диапазонами/наборами диапазонов — объединение, пересечение, дополнение — полный набор.
S>Может ещё что полезного было, пожже напишу.
"Методы NotNullOrEmpty() для строк" — как это работает?
Название мягко говоря противоречивое
Все варианты делают одно и то же, но вариант D самый читабельный, т.к. во-первых не требует скакать взглядом назад, во-вторых, не путается с IsNullOrEmpty() как C.
В общем я на эти грабли за 10 лет понаступал, больше не тянет.
Перечисленное ранее, плюс что используется у меня:
1. Разный набор методов типа AsArray, AsList, AsHashSet, помогает избежать ненужной конвертации IEnumerable<T>, если на вход подали объект соответствующего типа
2. KeyEqualityComparer с — требуется не так часто, но все же порой сильно не хватает
3. MultiValueDictionary — сейчас есть уже в Corefxlab
4. Хелперы с использованием Expression по типу infoof для получения PropertyInfo, FieldInfo, MethodInfo и ConstructorInfo плюс для свойств и полей имена и полное имя (включая всю цепочку: a => a.User.Name вернет "User.Name")
5. Небольшой набор для Func & Action. Часто требуется, например при сортировке создавать делегат, который возвращает сам себя: o => o
6. Хелперы для вычисления криптохешей у строк, массива байтов и Stream
7. NaturalStringComparer для натурального сравнения строк. Пару раз уже пригодилась, взято отсюда с http://rsdn.ru/forum/src/4246932.1
Здравствуйте, Sinix, Вы писали:
S>Оргпредложения — стандартный набор:
Предлагаю также добавить решарперские аннотации. Для тех, кто решарпер не использует, наличие аннотаций не заметят, а те, кто использует получат свои плюшки
Здравствуйте, vmpire, Вы писали:
AVK>>1) Кто что по этому думает? V>Моё мнение — не взлетит. Участники не договорятся о деталях.
Тут ты преувеличиваешь проблему.
V>В процессе споров отвалятся все, кроме двух-четырёх человек, которые и произведут продукт.
4 человека это существенно больше, чем я ожидаю. И их более чем достаточно.
V>И только эти люди да несколько случайных энтузиастов будут этим пользоваться. Да и то недолго, так как поддерживать продукт всем будет лень.
Мне все равно аналогичную библиотеку приходится для своих проектов поддерживать, так что не вижу разницы.
V>Я через такое проходил один раз сам и пару раз наблюдал со стороны.
Ну мы тоже не совсем новички.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
Здравствуйте, Sinix, Вы писали:
S>Здравствуйте, Doc, Вы писали:
Doc>>4.5.2 как минимально поддерживаемый это мне кажется разумным. Но вот не ограничит ли это область использования? S>Ну можно на 4 откатить, если желающие будут. Не ниже уж точно.
Здравствуйте, AndrewVK, Вы писали:
R>>3. MultiValueDictionary — сейчас есть уже в Corefxlab
AVK>И в Microsoft.Experimental.Collections. Fx 4.5+, так что смысла тащить никакого.
О, и точно
R>>6. Хелперы для вычисления криптохешей у строк, массива байтов и Stream
AVK>Не слишком специфично? Мне вот ни разу такое не требовалось.
Здравствуйте, AndrewVK, Вы писали:
AVK>По поводу студии и языка (не фреймворка!) — ограничиваемся 2013/5.0 или все таки 2015/6.0?
Я за 2015, тем более что она совместима с 2013.
Здравствуйте, AndrewVK, Вы писали:
AVK>Репозиторий — https://github.com/rsdn/CodeJam . Сборка — https://ci.appveyor.com/project/andrewvk/codejam AVK>Кто планирует активно участвовать — кидайте логины на гитхабе, добавлю права чтобы не тратить время на пулреквесты. AVK>И нужен человек, способный без косяков написать readme.md с основной идеологией.
Здравствуйте, rameel, Вы писали:
R>Здравствуйте, AndrewVK, Вы писали:
AVK>>По поводу студии и языка (не фреймворка!) — ограничиваемся 2013/5.0 или все таки 2015/6.0?
R>Я за 2015/6.0
Здравствуйте, Sinix, Вы писали:
AVK>>По поводу студии и языка (не фреймворка!) — ограничиваемся 2013/5.0 или все таки 2015/6.0? S>Я за 2015, тем более что она совместима с 2013.
Она то совместима. Вопрос не столько в ней, сколько в языке.
S>Язык можно ограничить пятым.
Мне хватает решарпера — там в свойствах проекта версия языка задается. Ну и, наверное, где то есть соответствующая настройка в AppVeyor.
Вот, кстати, насколько он удобен? А то у нас http://tc.rsdn.ru есть, если что.
S>Вообще пора в gitter переползать, или issue в самом проекте завести.
Здесь удобнее, ИМХО. По крайней мере пока у проекта не появятся нерусскоговорящие участники.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
Здравствуйте, AndrewVK, Вы писали:
AVK>Ну и, наверное, где то есть соответствующая настройка в AppVeyor. AVK>Вот, кстати, насколько он удобен? А то у нас http://tc.rsdn.ru есть, если что. Я его в режиме закинул-забрал использовал. Не попрёт, можно и на тимсити перетащить.
S>>Вообще пора в gitter переползать, или issue в самом проекте завести. AVK>Здесь удобнее, ИМХО. По крайней мере пока у проекта не появятся нерусскоговорящие участники.
Ок, тогда может отдельный раздел форума завести?
Здравствуйте, Sinix, Вы писали:
S>>>Вообще пора в gitter переползать, или issue в самом проекте завести. AVK>>Здесь удобнее, ИМХО. По крайней мере пока у проекта не появятся нерусскоговорящие участники. S>Ок, тогда может отдельный раздел форума завести?
[Skip]
S>Если кому надо — Range<T>/CompositeRange<T> для операция над диапазонами/наборами диапазонов — объединение, пересечение, дополнение — полный набор.
Интересно посмотреть. Писал такое, хотелось бы сравнить
Здравствуйте, Danchik, Вы писали:
D>Интересно посмотреть. Писал такое, хотелось бы сравнить
Если сами структуры — там вроде все предельно тривиально. Если алгоритмы — они делятся на две части: примитивные, типа объединения, пересечения и т.п., там тоже все тривиально, и хитрые, но они, как правило, уже завязаны на задачу. Ннапример нормализация диапазонов — список диапазонов преобразуется таким образом, чтобы диапазоны внутри него нигде не накладывались друг на друга, при этом дополнительную атрибутику нужно в пересекающихся частях мержить в новый диапазон. В неуниверсальном виде выглядит примерно так:
internal static IEnumerable<RangeDescriptor> NormalizeRanges(IEnumerable<Transition> source)
{
var ranges =
source
.SelectMany(t => t.Ranges.Select(r => new {r.Start, r.End, t.Target}))
.ToArray();
var points =
ranges
.SelectMany(
r =>
new[]
{
new {Pos = (int)r.Start, Targets = new List<State>()},
new {Pos = r.End + 1, Targets = new List<State>()}
})
.OrderBy(p => p.Pos)
.ToArray();
foreach (var range in ranges)
foreach (var point in
points
.SkipWhile(p => p.Pos < range.Start)
.TakeWhile(p => p.Pos <= range.End))
point.Targets.Add(range.Target);
return
points
.Zip(points.Skip(1), (p1, p2) => new {Start = p1, End = p2})
.Where(r => r.Start.Targets.Any() && r.Start.Pos < r.End.Pos)
.Select(
r =>
new RangeDescriptor(
new CharRange(
(ushort) r.Start.Pos,
(ushort) (r.End.Pos - 1)),
r.Start.Targets.ToArray()));
}
Нужно ли такое в универсальной библиотеке? Гложут меня смутные сомнения в том.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
Здравствуйте, Doc, Вы писали:
Doc>А какой будет модель бранчей? Стандартная? master > dev > featues branches Doc>Просто увидел только master, поэтому уточняю.
Да фик его знает. Пока, до выпуска первого релиза, точно смысла в dev бранче нет. Так что, наверное, просто feature, да и то если фича объемная. А всякую мелочевку, имхо, можно сразу в master.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
Здравствуйте, Vladek, Вы писали:
AVK>>1) Кто что по этому думает? V>Не взлетит. У всех разный набор решений одних и тех же проблем.
Это не так.
V> Универсальной библиотекой просто не будут пользоваться.
Ну я вот предпочитаю при наличии готового и более менее качественного использовать его, а не свой велосипед. На тех же кто еще не вышел из стадити любви к велосипедам ориентироваться смысла все равно нет.
V>Авторы полезных решений могут поступать так же — оформлять свои наработки в библиотеки и выкладывать их в общий доступ, а RSDN может просто вести их каталог.
И помнить и подключать 100500 мелких пакетов в каждый проект? Да ну нафик.
V> Вроде оно уже есть: http://rsdn.ru/forum/prj/
Это не совсем то, это какая то выжимка из написания Вольфхаундом бинарного диффа. Ей, кстати, люди даже пользовались, не смотря на полное отсутствие поддержки и какой либо жизни внутри.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
, опоздали
Эх, не успел
S>Есть желание — присоединяйтесь, нет — добавьте в календарик напоминалку на через год, тогда и посмотрим.
Присоединяться пока не буду, но за обсуждением буду наблюдать. Вдруг полезную идею обнаружу, о которой не задумывался.
Могу пока что высказать мнение чего НЕ стоит включать в библиотеку:
— преобразование XML в строку и обратно
— синтаксический сахар, который не уменьшает сильно количество кода.
А вот "парсер командной строки", который AndrewVK включат не хочет, я бы как раз включил. При условии, что он гибко декларативно настраиваемый.
У меня в проекте есть что-то подобное, очень удобно (хоть и не доделано до конца).
Здравствуйте, AndrewVK, Вы писали:
V>>Моё мнение — не взлетит. Участники не договорятся о деталях. AVK>Тут ты преувеличиваешь проблему. V>>В процессе споров отвалятся все, кроме двух-четырёх человек, которые и произведут продукт. AVK>4 человека это существенно больше, чем я ожидаю. И их более чем достаточно.
Ну, если до 4 человек — то, конечно, договорятся.
V>>Я через такое проходил один раз сам и пару раз наблюдал со стороны. AVK>Ну мы тоже не совсем новички.
Да я в курсе, я тут уже несколько лет Правда, больше читаю, чем пишу.
Здравствуйте, vmpire, Вы писали:
V>Могу пока что высказать мнение чего НЕ стоит включать в библиотеку ... V>А вот "парсер командной строки", который AndrewVK включат не хочет, я бы как раз включил. При условии, что он гибко декларативно настраиваемый.
Ну, т.е. нужен issue tracker, но, как я понимаю, не гитхаб, т.к. обсуждения планируется на русском.
Здравствуйте, AndrewVK, Вы писали:
AVK>Здравствуйте, Danchik, Вы писали:
D>>Интересно посмотреть. Писал такое, хотелось бы сравнить
AVK>Если сами структуры — там вроде все предельно тривиально. Если алгоритмы — они делятся на две части: примитивные, типа объединения, пересечения и т.п., там тоже все тривиально, и хитрые, но они, как правило, уже завязаны на задачу. Ннапример нормализация диапазонов — список диапазонов преобразуется таким образом, чтобы диапазоны внутри него нигде не накладывались друг на друга, при этом дополнительную атрибутику нужно в пересекающихся частях мержить в новый диапазон. В неуниверсальном виде выглядит примерно так:
Для себя как раз делал "сложные" алгоритмы обьединения диапазонов.
public struct Range<TValue> : IComparable<Range<TValue>>
where TValue : IComparable<TValue>
{
// основные методы
Union
Contains
Intersects
IsAdjastent
}
Основные особенности диапазонов
1. Могут быть бесконечными ..... , S....., ......E
2. Могут включать или не включать грани [S]....., ......[E]
И есть ImmutableRangeList (сортированный)
public class ImmutableRangeList<TValue> : IEnumerable<Range<TValue>>
where TValue : IComparable<TValue>
{
// основные методы
IsEmpty
IsFull
ContainsValue,
Add
Remove
Invert
Intersect
~, +, -, &, |, !
}
С тегами не думал. Пока хватало для своих задач.
Как использовалось. Например когда делал кеш даных по диапазонам (Cached).
Делался вызов — нужен такой то диапазон или набор диапазонов даных (Request).
Request — Cached = То_что_надо_закачать. Потом по этому строился ExpressionTree для IQueryable и накладывалась Where условие. Как результат, на сервер ушел оптимальный запрос, а из кеша взялось то что уже в нем лежит.
Здравствуйте, Doc, Вы писали:
Doc>А это все планируется как единая библиотека (1 пакет NuGet) или же с разделением по темам (ну там lib.Strings , lib.XDoc и т.д.)
Это слишком мелкое дробление. Если что-то выделять в отдельные модули, то, например, связанное с ASP.NET или WCF. Т.е. то, что требует дополнительных зависимостей.
Doc>Так же для какого .NET это все планируется делать (или для каких). Я как про мин. версию, так и тип.
Совершенно не проблема сделать для чего угодно включая сильверлайт и телефон.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, AndrewVK, Вы писали:
AVK>>>Ну и с С++ ситуация сильно другая, EP>>И чем она сильно другая? AVK>Крайне бедная стандартная библиотека,
И как это меняет сабжевую ситуацию?
AVK>сам язык плохо приспособлен для написания широко используемых библиотек,
Почему?
AVK>много извратов с метапрограммированием на шаблонах.
В Boost есть в том числе и мета-библиотеки. Как это меняет сабжевую ситуацию? Метапрограммирование здесь вообще ортогонально
EP>> Тематика сабжа будет уже? AVK>Наоборот шире. Но никаких планов по включению туда специализированных вещей типа того же spirit нет.
Так уже или шире? Если шире — то в каких направлениях?
AVK>Есть вполне конкретная потребность обобщения вещей, которые используются часто и во многих проектах, т.е. самого универсального кода.
То есть только универсальный код? Значит всё таки уже чем Boost? (в котором в том числе есть и не очень часто используемые библиотеки типа Odeint)
EP>>Да, тоже вариант, только экспериментальная часть должна быть доступна в том числе в виде пакета, должны прогоняться минимальные тесты и т.п. — то есть не просто experimental repo. AVK>Разумеется.
Ещё хотелось бы знать какие компоненты и как часто используются. Как бы собрать такую статистику? Может косвенным способом через обращение к страницам документации?
Хочу (к уже ранее написанному):
1) Алгоритмы LowerBound/UpperBound на массивах и list'ах.
2) Коллекцию Disjoint Sets.
3) Хелпер для дампа куска массива байтов в строку (что-то типа .ToHexString(this byte[] array, int offset, int length)) — бывает полезно для отладочных дампов всякого протокольного обмена.
Здравствуйте, Sinix, Вы писали:
S>xBehave — красивая штука для короткой записи тестов. Вместо простыни методов достаточно одного основного. Построен повер xunit
Не понял в чём прикол. Для устранения простыни достаточно параметризированных тестов. В NUnit такого полно.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, IT, Вы писали:
Doc>>А это все планируется как единая библиотека (1 пакет NuGet) или же с разделением по темам (ну там lib.Strings , lib.XDoc и т.д.) IT>Это слишком мелкое дробление. Если что-то выделять в отдельные модули, то, например, связанное с ASP.NET или WCF. Т.е. то, что требует дополнительных зависимостей.
Это для примера. В любом случае, иметь одну сборку, которая будет содержать код "на все случаи жизни" не очень хочется. Ну и по зависимостям в том числе.
Здравствуйте, IT, Вы писали:
AVK>>Ну значит xUnit IT>Да ну его нафиг. Его R# поддерживает?
Билды с Core вроде нет, для обычных — есть расширение R#. Кроме этого какие аргументы против (за были удобство использования и то, что сами MS его используют вместо MS Test).
Здравствуйте, Doc, Вы писали:
Doc>Это для примера. В любом случае, иметь одну сборку, которая будет содержать код "на все случаи жизни" не очень хочется. Ну и по зависимостям в том числе.
Я бы остановился пока на зависимостях.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, Doc, Вы писали:
IT>>Да ну его нафиг. Его R# поддерживает?
Doc>Билды с Core вроде нет, для обычных — есть расширение R#. Кроме этого какие аргументы против (за были удобство использования и то, что сами MS его используют вместо MS Test).
За NUnit
— промышленный стандарт
— развитая, легко кастомизируемая система поддержки параметризированых тестов, для наших задач самое оно
— поддержка R# из коробки
— суперактивная работа над проектом в настоящее время, думаю, что сейчас можно попросить любых ништяков
— поддержка консольного режима запуска, что может быть полезно при автоматических билдах
Против xUnit главным образом R# и по опыту его использования всё у них там как-то из стороны в сторону. Что касается использования самим MS, то создаётся впечатление, что крому MS оно больше особо никому не нужно.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
AVK>>Крайне бедная стандартная библиотека, EP>И как это меняет сабжевую ситуацию?
Другие требования. Подобная библиотека будет содержать в разы больше функционала. Плюс существенно сложнее избавляться от сквозного функционала — одни только разнообразные строки чего стоят.
AVK>>сам язык плохо приспособлен для написания широко используемых библиотек, EP>Почему?
По целому ряду причин. Например, потому что ABI нет. Потому что шаблоны только во время компиляции существуют. Потому что компонентная модель при попытке реализации порождает монстров вроде СОМ. Потому что хидеры за собой надо таскать. И т.д.
EP>>> Тематика сабжа будет уже? AVK>>Наоборот шире. Но никаких планов по включению туда специализированных вещей типа того же spirit нет. EP>Так уже или шире? Если шире — то в каких направлениях?
Во всех. Еще раз — идея в том чтобы собрать максимально неспециализированный код, а не очередной всемогутер типа буста или жабьего спринга.
AVK>>Есть вполне конкретная потребность обобщения вещей, которые используются часто и во многих проектах, т.е. самого универсального кода. EP>То есть только универсальный код?
Да.
AVK>>Разумеется. EP>Ещё хотелось бы знать какие компоненты и как часто используются. Как бы собрать такую статистику? Может косвенным способом через обращение к страницам документации?
Только голосованиями/сурвеями.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
Здравствуйте, vmpire, Вы писали:
V>Могу пока что высказать мнение чего НЕ стоит включать в библиотеку: V>- преобразование XML в строку и обратно
Странная идея. Парсеров xml и так две штуки в фреймворке.
V>- синтаксический сахар, который не уменьшает сильно количество кода.
Почему?
V>А вот "парсер командной строки", который AndrewVK включат не хочет, я бы как раз включил. При условии, что он гибко декларативно настраиваемый.
Здравствуйте, Lexey, Вы писали:
L>Хочу (к уже ранее написанному): L>1) Алгоритмы LowerBound/UpperBound на массивах и list'ах. L>2) Коллекцию Disjoint Sets.
Неплохо бы конкретизировать о чем речь.
L>3) Хелпер для дампа куска массива байтов в строку (что-то типа .ToHexString(this byte[] array, int offset, int length)) — бывает полезно для отладочных дампов всякого протокольного обмена.
Здравствуйте, AndrewVK, Вы писали:
AVK>Не, вот два issue трекера точно заводить не будем, концов не соберешь. Достаточно гитхабовского. Ни или местного, если по каким то причинам гитхаб не устраивает. Просто не надо смешивать обсуждения и трекер, это на гитхабе оно смешано ввиду отсутствия там форума.
Ну в общем нужно волевое решение про:
1. Куда заводить тикеты.
2. Где обсуждать / голосовать фичи
3. Документашка.
Здравствуйте, IT, Вы писали:
AVK>>Мне, как человеку, испорченному решарпером хватает его подсказок, чтобы держать проект более менее чистым. IT>В данном случае момент чисто организационный. Ты как человек, испорченный решарпером, станешь гоняться за каждым разработчиком и умолять его убрать ворнинги?
Я надеюсь на то что основные разработчики достаточно дисциплинированы, чтобы поддерживать проект в resharper clean состоянии. Не люблю драконовских мер без крайней необходимости.
IT> А здесь он сам нарвётся на проблему и должен будет её решить. У меня опыт примерно такой же, как и у уважаемого Sinix, стоит немного ослабить и понеслась.
Предлагаю отложить до появления реальных проблем.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
IT>Против xUnit главным образом R# и по опыту его использования всё у них там как-то из стороны в сторону.
Да есть интеграция. На самом деле оба проекта последние два года активно тянут друг у друга фичи, т.е. выбор, скорее про вкус фломастеров. Лично мне xUnit показался попроще, без хитровымученных сonstraint assertions, но эт опять-таки вопрос вкуса. Любой из вариантов сойдёт.
Здравствуйте, Lexey, Вы писали:
L>Нет, хочется еще иметь возможность форматировать блоками по N (16, например) байт, добавляя впереди смещение. Типа такого:
Понятно. По опыту — нужен тогда заодно и комплиментарный парсер.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
Здравствуйте, Sinix, Вы писали:
IT>>Против xUnit главным образом R# и по опыту его использования всё у них там как-то из стороны в сторону. S>Да есть интеграция.
Не, плагины к решарперу это уже точно перебор. nUnit вполне зрелая и развитая библиотека, вряд ли xUnit принципиально лучше.
S> На самом деле оба проекта последние два года активно тянут друг у друга фичи, т.е. выбор, скорее про вкус фломастеров.
Ну вот о том и речь.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
Здравствуйте, AndrewVK, Вы писали:
AVK>>>Крайне бедная стандартная библиотека, EP>>И как это меняет сабжевую ситуацию? AVK>Другие требования. Подобная библиотека будет содержать в разы больше функционала.
Видимо ты подразумеваешь жирные библиотеки типа POCO, QT и т.п.
AVK>Плюс существенно сложнее избавляться от сквозного функционала — одни только разнообразные строки чего стоят.
Точно — это в QT свои строки, в Boost их нет.
В Boost есть конечно универсальные алгоритмы и библиотеки для работы со строками — String Algo, Spirit, etc — но они не прибиты к конкретным типам строк
EP>>>> Тематика сабжа будет уже? AVK>>>Наоборот шире. Но никаких планов по включению туда специализированных вещей типа того же spirit нет. EP>>Так уже или шире? Если шире — то в каких направлениях? AVK>Во всех. Еще раз — идея в том чтобы собрать максимально неспециализированный код, а не очередной всемогутер типа буста или жабьего спринга.
Раскрой мысль про "максимально неспециализированный код", и почему Boost сюда не подходит?
AVK>>>Есть вполне конкретная потребность обобщения вещей, которые используются часто и во многих проектах, т.е. самого универсального кода. EP>>То есть только универсальный код? AVK>Да.
Значит всё таки уже чем Boost
AVK>>>Разумеется. EP>>Ещё хотелось бы знать какие компоненты и как часто используются. Как бы собрать такую статистику? Может косвенным способом через обращение к страницам документации? AVK>Только голосованиями/сурвеями.
Может прикрутить что-то типа Github'овских звёздочек, но на отдельные компоненты/классы/функции?
Здравствуйте, Evgeny.Panasyuk, Вы писали:
AVK>>Другие требования. Подобная библиотека будет содержать в разы больше функционала. EP>Видимо ты подразумеваешь жирные библиотеки типа POCO, QT и т.п.
Нет, я подразумеваю как раз библиотеки вроде буста, во многом закрывающие убогость библиотеки стандартной. Для дотнета такого просто не нужно.
EP>Точно — это в QT свои строки, в Boost их нет. EP>В Boost есть конечно универсальные алгоритмы и библиотеки для работы со строками — String Algo, Spirit, etc — но они не прибиты к конкретным типам строк
Это просто пример. Та же boost:lambda не в одном месте используется.
AVK>>Во всех. Еще раз — идея в том чтобы собрать максимально неспециализированный код, а не очередной всемогутер типа буста или жабьего спринга. EP>Раскрой мысль про "максимально неспециализированный код",
Код, который не завязан на какую нибудь сравнительно узкую специализацию.
EP> и почему Boost сюда не подходит?
Потому что там много специализированных вещей.
AVK>>Только голосованиями/сурвеями. EP>Может прикрутить что-то типа Github'овских звёздочек, но на отдельные компоненты/классы/функции?
Куда прикрутить?
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
Здравствуйте, xy012111, Вы писали:
X>http://editorconfig.org/ бы прикрутить, а то у всех настройки редакторов разные, а в проекте должен бьыть один.
Ну прикрути. Я правда не очень понял что потом с этим конфигом полезного делать. Какой то питоноскрипт при серверной сборке запускать?
X>Мои личные настроки сильно уж отличаются от того, что в StringExtensions уже есть, посему мне сложно будет добавить.
Здравствуйте, AndrewVK, Вы писали:
X>>http://editorconfig.org/ бы прикрутить, а то у всех настройки редакторов разные, а в проекте должен бьыть один. AVK>Ну прикрути. Я правда не очень понял что потом с этим конфигом полезного делать. Какой то питоноскрипт при серверной сборке запускать?
Смысл в том, что при открытии солюшена расширение изменит настройки форматирования студии в соответствии с этим файлом, если он будет лежать в правильном месте в папке солюшена.
Здравствуйте, AndrewVK, Вы писали:
AVK>>>Другие требования. Подобная библиотека будет содержать в разы больше функционала. EP>>Видимо ты подразумеваешь жирные библиотеки типа POCO, QT и т.п. AVK>Нет, я подразумеваю как раз библиотеки вроде буста, во многом закрывающие убогость библиотеки стандартной. Для дотнета такого просто не нужно.
Пролистай список библиотек Boost, если отбросить то что уже в стандарте, то в .NET из этого есть от силы процентов 20% А вот есть брать что-то типа POCO — там да, очень много пересечения с .NET.
В Boost кстати есть даже многое из того что называли в этом топике:
AVK>Хелпер, обеспечивающий использование ReaderWriterLock с оператором using.
std/boost:: unique_lock, lock_guard
AVK>Есть более специфичные штуки — парсер командной строки
Boost.Program_options
S>Если кому надо — Range<T>/CompositeRange<T> для операция над диапазонами/наборами диапазонов — объединение, пересечение, дополнение — полный набор.
AVK>Это просто пример. Та же boost:lambda не в одном месте используется.
Где? Сделал grep — там только в двух библиотеках добавили расширенную поддержку boost::lambda, никак не заставляя пользователя использовать её, и всё.
AVK>>>Во всех. Еще раз — идея в том чтобы собрать максимально неспециализированный код, а не очередной всемогутер типа буста или жабьего спринга. EP>>Раскрой мысль про "максимально неспециализированный код", AVK>Код, который не завязан на какую нибудь сравнительно узкую специализацию.
Парсер командной строки предложенный тобой, парсер CSV, или например предложенное scoped tempdir — это всё довольно узкая специализация
AVK>>>Только голосованиями/сурвеями. EP>>Может прикрутить что-то типа Github'овских звёздочек, но на отдельные компоненты/классы/функции? AVK>Куда прикрутить?
Здравствуйте, AndrewVK, Вы писали:
S>>1. Куда заводить тикеты. AVK>github на английском
+1. Тем более, что они интегрированы с репозиторием.
S>>2. Где обсуждать / голосовать фичи AVK>github на английском. Если совсем уж проблемы с английским — можно в форум в надежде что кто то заветет issue на гитхабе. Примерно как сейчас с тем же решарпером — основной трекер англоязычный, а здесь русскоязычный форум.
Для обсуждений можно у нас форум в проектах завести. На английском сильно не пообсуждаешь, да и голосовалок там нет.
S>>3. Документашка. AVK>Для разработчиков самой библиотеки — пока на русском в местной вике. Для пользователей — md в проекте на английском. Проект/русская версия на русском в местной вике.
На гитхабе есть вика. Можно там.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, rameel, Вы писали:
R>7. NaturalStringComparer для натурального сравнения строк. Пару раз уже пригодилась, взято отсюда с http://rsdn.ru/forum/src/4246932.1
Лучше не с явы, на SO есть почти рабочее решение, очень близкое к нативной StrCmpLogical. В коде опечатка падает при сравнении строк из нулей, как поправить в комментариях есть.
Проверено и тестами и опытной эксплуатацией, работает.
UPD. Подключусь на следующей неделе скорее всего, работа.
Зато вспомнил, за что я не люблю NUnit — Assert.That.This.Asertion.Would.Not.Be.Read.By.Anyone(), 100 способов записать одно и тоже и вечные баги типа такого — подарок тот ещё
Фиг с ним, прорвёмся.
Здравствуйте, AndrewVK, Вы писали:
R>>7. NaturalStringComparer для натурального сравнения строк. Пару раз уже пригодилась, взято отсюда с http://rsdn.ru/forum/src/4246932.1
Здравствуйте, Sinix, Вы писали:
S>Лучше не с явы, на SO есть почти рабочее решение, очень близкое к нативной StrCmpLogical. В коде опечатка падает при сравнении строк из нулей, как поправить в комментариях есть.
Да я вроде жабное портанул уже, вполне рабочее. Так что ХЗ как лучше. Ты как считаешь?
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Это же получается experimental а не main.
Не получается. Разница между experimental и main, во-первых, проявляется в релизе, а не в любом состоянии репа, а во-вторых оно больше относится к собственно публичному API, а не к реализации.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
Здравствуйте, AndrewVK, Вы писали:
AVK>Да я вроде жабное портанул уже, вполне рабочее. Так что ХЗ как лучше. Ты как считаешь?
Проект без кода подобен проекту с кодом, но только без кода
Так что пусть будет то что есть, как будет время / необходимость — можно поменять. Главное, чтоб никто не закладывался на порядок сортировки, а то если будут баги — не исправишь без поломки совместимости.
Здравствуйте, AndrewVK, Вы писали:
AVK>В соседнем обсуждении зашла речь о том, что у многих, если не у каждого, скопилось некоторое количество кода, который применяется в большом количестве, если не во всех проектах. В связи с чем родилась идея собрать самое интересное в опенсорсный проект и выложить нугет с библиотечкой, чтобы использовать ее, а не свои велосипеды таскать. AVK>Основные критерии оптимизации — высокая универсальность (т.е. возможность использовать в широком спектре проектов), минимальный объем навязываемых решений (т.е. никаких сквозных подвязок, никаких фреймворков), высокая читаемость и качество кода. AVK>Вопросы: AVK>1) Кто что по этому думает? AVK>2) Что бы хотелось в этой библиотеке увидеть, и что не хотелось бы? AVK>3) Кому интересно в этом поучаствовать? AVK>4) Кому интересно библиотеку в своих проектах использовать?
Было бы интересно поучаствовать, сейчас посмотрю что там и как, может даже затащу в свой проект.
Ну, если судить по твоей ссылке, то "не рекомендуют" сильно сказано. Кроме того, в случае с RWLock это не борьба с исключением, а просто способ указать в коде scope, в котором лок действует. Примерно как Html.BeginForm в MVC.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
Здравствуйте, AndrewVK, Вы писали:
AVK>Здравствуйте, nigh, Вы писали:
N>>Это, вроде отцы-основатели не рекомендуют делать. Они даже не рекмендуют больше lock использовать https://blogs.msdn.microsoft.com/ericlippert/2009/03/06/locks-and-exceptions-do-not-mix/
AVK>Ну, если судить по твоей ссылке, то "не рекомендуют" сильно сказано. Кроме того, в случае с RWLock это не борьба с исключением, а просто способ указать в коде scope, в котором лок действует. Примерно как Html.BeginForm в MVC.
Да нет, там все гораздо глубже. Основная мысль в том, что Disposable и try-finally для семантики локов не подходят и создают ложное ощущение безопасности.
В случае с rwlock, если в процессе выполнения операции внутри using возникнет исключение, finally-блок радостно разблокирует заблокированный ресурс и вы получите букет с race conditions, unprecitable behavior и т. д. (т.е. unlock произойдет тогда, когда вы его не ожидали, а не должен был произойти в принципе)
Причем, самое ужасное, что такой дизайн кода получается неявно (в случае явного вызова lock / unlock и отсутствия implicit try/finally в глаза сразу бросаются вопросы "а что будет если тут будет exception?")
using(GetRWLock())
{
UpdateJournal(AccountA, AccountB, 100)
AddMoney(AccountA, 100)
WithdrawMoney(AccountB, 100) //throw an exception here, all other threads now receive an account in an incorrect state
}
var lc = GetRWLock();
lc.wlock();
UpdateJournal(AccountA, AccountB, 100)
AddMoney(AccountA, 100)
WithdrawMoney(AccountB, 100) //throw an exception here, will never unlock unless proper recovery is done - likely a deadlock, but no further data corruption by other threads
rwlock.unlock();
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Здравствуйте, nigh, Вы писали:
N>>Да нет, там все гораздо глубже. Основная мысль в том, что Disposable и try-finally для семантики локов не подходят и создают ложное ощущение безопасности.
EP>Это проблема exception safety guarantees, она существует и без всяких локов или даже потоков. Она даже существует без using'ов, только ещё хуже. EP>А вот RAII, Using'и, try-with-resourcues как раз подходят к семантике локов, а ложное ощущение безопасности — это от незнания exception safety.
В C# средствами языка exception safety не достигается. Даже checked exceptions нету (от них больше вреда чем пользы). Мы же тут C# обсуждаем?
Когда вы пишете библиотечный код надо думать о самых глупых пользователях и не подталкивать их писать потенциально проблемный код, давая для этого удобные инструменты.
N>>
N>>WithdrawMoney(AccountB, 100) //throw an exception here, will never unlock unless proper recovery is done - likely a deadlock, but not further data corruption by other threads
N>>
EP>Если тебе нравиться "likely a deadlock, but not further data corruption by other threads" — то лучше сразу на первом же исключении пристреливать программу и тормозить всю систему
Мне оно не особо нравится, просто в ряде задач это лучше, чем data corruption. Более того, правильную обработку exceptionа во втором случае можно где-нибудь ниже по стеку сделать, в отличие от.
Пристреливать всю программу необязательно (хотя можно), есть, скажем таймауты — другие треды будут продолжать нормально работать.
Здравствуйте, xy012111, Вы писали:
X>Мда, я был уверен, что EditorConfig умеет хотя бы скобки расставлять, а там из полезного лишь настройка табуляции
Так про то и речь. Сама студия крайне бедна в этом плане. Розлин немного получше стал, но до решарпера/стайлкопа еще очень далеко. Тащить в проект стайлкоп не хочется, а решарпер платный (через 3 месяца можно попросить для основных девелоперов бесплатную лицензию).
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
Здравствуйте, AndrewVK, Вы писали:
AVK>Так про то и речь. Сама студия крайне бедна в этом плане. Розлин немного получше стал, но до решарпера/стайлкопа еще очень далеко. Тащить в проект стайлкоп не хочется, а решарпер платный (через 3 месяца можно попросить для основных девелоперов бесплатную лицензию).
Чего греха таить -- у всех так или иначе есть либо платная либо бесплатная/самогенереным серийником версия. Что, еще остались люди без решарпера?
Если у кого нету -- реально можно триал а потом выклянчить ключик.
Здравствуйте, AndrewVK, Вы писали:
X>>Мда, я был уверен, что EditorConfig умеет хотя бы скобки расставлять, а там из полезного лишь настройка табуляции
AVK>Так про то и речь. Сама студия крайне бедна в этом плане. Розлин немного получше стал, но до решарпера/стайлкопа еще очень далеко. Тащить в проект стайлкоп не хочется, а решарпер платный (через 3 месяца можно попросить для основных девелоперов бесплатную лицензию).
Может ты просто экспортнёшь свои настройки C# и C# Editor из студии и как отдельный проект в Rsdn опубликуешь? И все кому надо будут его брать и перед работой с rsdn-проектами импортить себе. Туда же рядышком можно положить и файл настроек РеШарпера, для тех, у кого он есть и кто его хочет использовать.
Здравствуйте, xy012111, Вы писали:
X>Может ты просто экспортнёшь свои настройки C# и C# Editor из студии и как отдельный проект в Rsdn опубликуешь?
У меня они дефолтные кроме табуляции, я решарпером пользуюсь.
X>Туда же рядышком можно положить и файл настроек РеШарпера, для тех, у кого он есть и кто его хочет использовать.
Файл настроек решарпера с самого начала лежит в репе рядом с sln.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
Здравствуйте, AndrewVK, Вы писали:
AVK>Здравствуйте, Sinix, Вы писали:
S>>Лучше не с явы, на SO есть почти рабочее решение, очень близкое к нативной StrCmpLogical. В коде опечатка падает при сравнении строк из нулей, как поправить в комментариях есть.
AVK>Да я вроде жабное портанул уже, вполне рабочее. Так что ХЗ как лучше. Ты как считаешь?
А насколько близкое нужно к StrCmpLogicalW? Сейчас ожидаемые результаты лежащие в гите и StrCmpLogical расходятся:
Здравствуйте, _Raz_, Вы писали:
_R_>А насколько близкое нужно к StrCmpLogicalW?
Без понятия. Реквест не мой.
_R_> Сейчас ожидаемые результаты лежащие в гите и StrCmpLogical расходятся: _R_>Получается что компарер со StackOverflow не будет работать с текущими expected.
Что то мне результат StrCmpLogical вообще не кажется правдоподобным. Пробелы, к примеру, обрабатываются некорректно.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
Здравствуйте, AndrewVK, Вы писали:
AVK>Что то мне результат StrCmpLogical вообще не кажется правдоподобным. Пробелы, к примеру, обрабатываются некорректно.
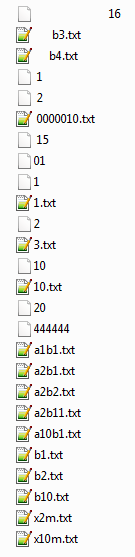
Легко проверить
using System;
using System.Collections.Generic;
using System.Runtime.InteropServices;
namespace ConsoleApplication2
{
class Program
{
public class StrCmpLogicalWComparer : IComparer<string>
{
[DllImport("shlwapi.dll", CharSet = CharSet.Unicode)]
private static extern int StrCmpLogicalW(string psz1, string psz2);
public int Compare(string x, string y)
{
return StrCmpLogicalW(x, y);
}
}
static void Main()
{
var data = new[]
{
" b3.txt",
"10",
"x10m.txt",
"20",
"2",
"444444",
"b10.txt",
"a10b1.txt",
"10.txt",
"3.txt",
"x2m.txt",
"a1b1.txt",
"a2b2.txt",
" ",
"01",
"a2b1.txt",
"a2b11.txt",
" b4.txt ",
"b1.txt",
"1.txt",
"0000010.txt",
"b2.txt",
"1",
"",
" 15",
" 16"
};
var sorted = new List<string>(data);
sorted.Sort(new StrCmpLogicalWComparer());
foreach (var s in sorted)
{
Console.WriteLine("\"{0}\"", s);
}
Console.ReadKey();
}
}
}
Здравствуйте, xy012111, Вы писали:
X>Может ты просто экспортнёшь свои настройки C# и C# Editor из студии и как отдельный проект в Rsdn опубликуешь?
В приличных домах это делается через Rebracer + CodeMaid + StyleCop rule set + CodeAnalysis rule set. Всё настраивается per solution.
Ну и .EditorConfig можно положить чтоббыл, но его редко кто использует.
CodeMaid настраивается на автоформатирование кода при сохранении и любые соглашения по форматированию сводятся к "это правило можно применить автоматически при сохранении файла? нет — до свидания".
Ничего круче (просто открываешь студию, ставишь рекомендованные расширения и просто пишешь код) по удобству не будет.
Не, конечно можно попытать счастья с решарпером, но он во-первых есть не у всех, а во-вторых он использует свои соглашения типа
Здравствуйте, AndrewVK, Вы писали:
S>>1. Переименовать в .Format() AVK>Компилятор против Слона я не заметил
У меня эти штуки сделаны парой UserStringFormat()/ InvariantStringFormat(), забыл про конфликт с static-методом.
Ну и в пару два статик-класса UserString/InvariantString, вызывают методы из System.String, только с соответствующей культурой/comparison.
Может, их тоже добавить?
AVK>Добавил вообще то IT, а не я.
Так ему и отвечал
Здравствуйте, AndrewVK, Вы писали:
S>>Не, конечно можно попытать счастья с решарпером, но он во-первых есть не у всех, AVK>Так и CodeMaid со стайлкопом тоже не у всех.
Зато бесплатные и вызывают гораздо меньше проблем
AVK>Большая часть настраивается. И ну ее нафик, такую каноничность как в примере — читать неудобно.
Ну тут опять-таки вкус фломастеров
Из практики, когда не у всех в команде есть решарпер, поддержать общий стиль форматирования заметно сложнее — получается "или все прогинаемся под R#, или никак".
Здравствуйте, AndrewVK, Вы писали:
AVK>И? Разве правильно так реагировать на пробелы?
Тут имхо вопрос не в правильно/неправильно, а в "сохраняем совместимость с StrLogicalCompare/нет". Если нет, то текущий вариант понятное дело лучше, я за него
Здравствуйте, AndrewVK, Вы писали: AVK>Можно, если поподробнее опишешь.
Ну сценарий простой:
public static class InvariantString
{
public static CultureInfo Culture => CultureInfo.InvariantCulture;
public static string ToInvariantString<T>(this T s) where T : IFormattable => s.ToString(null, Culture);
public static string ToInvariantString<T>(this T s, string format) where T : IFormattable => s.ToString(format, Culture);
// ...public static double ParseDouble(string s) => double.Parse(s, Culture);
}
public class Program
{
static void Main(string[] args)
{
Right();
Wrong();
}
private static void Wrong()
{
Thread.CurrentThread.CurrentCulture = CultureInfo.InvariantCulture;
var x = 12.3.ToString();
// ...
Thread.CurrentThread.CurrentCulture = new CultureInfo("ru-RU");
double y = double.Parse(x); // FAIL
Console.WriteLine(y);
}
private static void Right()
{
Thread.CurrentThread.CurrentCulture = CultureInfo.InvariantCulture;
var x = 12.3.ToInvariantString();
// ...
Thread.CurrentThread.CurrentCulture = new CultureInfo("ru-RU");
double y = InvariantString.ParseDouble(x); // OK
Console.WriteLine(y);
}
}
В реальности разумеется CurrentCulture может поменять что угодно — от перекидывания в другой поток и до чтения на другой машине.
В InvariantString дублируем основные методы из String, вызываем c InvariantCulture. Смысл в том, чтоб не путаться с текущей культурой.
Кто с ходу назовёт хотя бы пару методов, в которых используется culture-insensitive?
Здравствуйте, AndrewVK, Вы писали:
AVK>ToInvariantString добавил, перебитые методы string тогда сам добавь. И за тобой еще как минимум ассерты.
В курсе Со следующей недели постараюсь.
Здравствуйте, Sinix, Вы писали:
S>Чот я не уверен в best ever.
Исключительно как потенциальный пользователь библиотеки, выскажусь в пользу варианта Args. У нас в проекте как раз хелпер с именно таким названием, проблем не припомню.
S> //NOTTODO: IT: The name is the best ever. Don't change it.
S> public static string Args([NotNull] this string format, params object[] args) => string.Format(format, args);
S>Чот я не уверен в best ever.
S>UPD: Я знатно протупил с вариантом .Format(), AndrewVK намекнул ниже Но Args мне всё равно не нравится
+1. Я делаю FormatWith:
text.FormatWith("a", 2); // Invariant by default
text.FormatWith(CultureInfo.CurrentCulture, "a", 2);
"Invariant by default" академически кажется спорным, ибо и WTF и неожиданно, зато покрывает мои без малого 100% случаев :о)
Можнос делать InvariantFormatWith.
Было бы не плохо давать ссылки редактированием стартового сообщения. И продублировать в "Проектах".
А вообще я бы в стартовом сообщении указал ссылку на репо а, ссылку на нугет писал в readme.md. А тут написать новым сообщением, что в ридми добавлена/изменена такая-то ссылка.
Здравствуйте, AndrewVK, Вы писали:
S>>[/code]Если нет реальных сценариев использования, то лучше выбросить. AVK>Подождем что автор предложения ответит.
(там в самом начале) о методах, возвращающих интерфейсы, аналогах Enumerable.Asenumerable.
Лично мне такие методы под конкретные типы не были нужны ни разу, а интерфейсные вот напротив.
Здравствуйте, fatkh, Вы писали:
F>Исключительно как потенциальный пользователь библиотеки, выскажусь в пользу варианта Args. У нас в проекте как раз хелпер с именно таким названием, проблем не припомню.
Здравствуйте, _Raz_, Вы писали:
AVK>>Фид с серверными сборками пакетов — https://ci.appveyor.com/nuget/codejam _R_>Было бы не плохо давать ссылки редактированием стартового сообщения. И продублировать в "Проектах".
В проектах все есть. Здесь я просто продублировал на всякий случай.
_R_>А вообще я бы в стартовом сообщении указал ссылку на репо а, ссылку на нугет писал в readme.md. А тут написать новым сообщением, что в ридми добавлена/изменена такая-то ссылка.
Здравствуйте, IT, Вы писали:
R>>Нельзя, не скомпилируется
IT>Почему это? IsNullOrEmpty компилируется а Format нет. У меня это кругом в linq2db, заменил на Format всё отлично компилируется.
Будет ошибка, если первый параметр строка. Компилятор в этом случае предпочитает смотреть на string.Format(string, params object[])
Здравствуйте, AndrewVK, Вы писали:
AVK>Чего то ничего не придумывается. Есть идеи?
KrymNash.NET
ну а если серьезно, в принципе, это интересно, но боюсь у каждого свои привычки и свои велосипеды.
мне вот нравятся string extension strTill и strAfter, которые возвращают подстроку до указанного паттерна или после.
еще генерация нормально распреденных случайных чисел.
public static void xmlSerialize<T>(T obj, string fileName)
public static void xmlDeserialize<T>(string fileName, out T obj)
то же для binary.
сериализируемый в XML dictionary
static public T getAssemblyAttribute<T>() where T : Attribute
averageOrZero, которая нуль на пустой последовательности возвращает а не исключениями кидается
standard deviation
в юниксное и из юниксного времени (в 4.6 вроде штатное сделали?)
всякие время в EST и американские Bank Holidays полагаю только мне нужны?
.isWeekend для даты вполне полезен всем, проверка на субботу или воскресенье
Здравствуйте, DreamMaker, Вы писали:
DM>ну а если серьезно, в принципе, это интересно, но боюсь у каждого свои привычки и свои велосипеды.
Ничего страшного. Нормальный программист свои привычки меняет, особенно если особого рационала в них нет. А упертые все равно свои велосипеды будут изобретать для несложных вещей.
DM>мне вот нравятся string extension strTill и strAfter, которые возвращают подстроку до указанного паттерна или после.
Полезная вещь. Родной Substring поддерживает только два сценария нормально — произвольный кусок из середины и произвольный кусок с начала. Когда нужно с конца код превращается в кракозябу. А руки написал хелпер как обычно не доходят, ибо мелкий и проще забить.
DM>еще генерация нормально распреденных случайных чисел.
Нормально в матсмысле, т.е. по Гауссу, или просто равномерное с хорошим качеством?
DM> public static void xmlSerialize<T>(T obj, string fileName) DM> public static void xmlDeserialize<T>(string fileName, out T obj) DM>то же для binary.
А тут какой смысл?
DM>сериализируемый в XML dictionary
Сериализуемость в XML понятие растяжимое. XmlDataSerializer, к примеру, словари сериализует искаропки.
DM> static public T getAssemblyAttribute<T>() where T : Attribute
Это в роадмапе уже есть.
DM>averageOrZero, которая нуль на пустой последовательности возвращает а не исключениями кидается
Это вроде уже реализовано даже.
DM>всякие время в EST и американские Bank Holidays полагаю только мне нужны?
Время в EST несложно и так посчитать, а праздники в код хардкодить — сомнительная практика. Я понимаю что не РФ, где каждый год выпускаюьт указ, но все таки изменения могут быть.
DM>.isWeekend для даты вполне полезен всем, проверка на субботу или воскресенье
Викэнд зависит от культуры, так что корректная реализация такого дело очень нетривиальное. МС, к сожалению, не озаботилась добавлением соответствующего функционала в календари.
DM>ну это на вскидку.
Ну вскидывай дальше.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
Здравствуйте, IT, Вы писали:
IT>Если честно, то я почти никогда не объявляю форматную строку отдельно от string.Format. Поэтому выглядеть это будет так:
IT>
Для константного формата и 6 шарпа уже не надо так делать. Надо так:
return $"Hello, {wellKnownNames[0]}";
А вот если не константа ...
IT>Это проблема не только этого метода, а любого расширения. Я сам хотел поднять эту тему. Сейчас у нас все расширения находяться в основном пространстве имён, что автоматически добавляет их все.
У меня лично много опыта использования экстеншенов на весьма крупных проектах и большом количестве этих экстеншенов. И на практике оказалось, что никаких проблем нет даже когда все экстеншены находятся в пространстве имен прикладного кода. Тип аргумента обычно достаточно селективен, особенно если не навешивать расширения на object.
Да посмотреть даже на сам Fx. Enumerable цепляется к очень распространенному типу, содержит очень большое количество расширений к нему (в фреймворке, наверное, рекордно большое), находится в том же самом неймспейсе, что и все коллекции, т.е. гарантированно попадает в любой код. Получается worst сценарий. Таки и что? Да ничего, все вполне нормально и удобно.
С другой стороны, когда у нас все в одном пространстве имен, это добавляет discoverability, которая при разнесении расширений по куче неймспейсов падает стремительным домкратом до уровня обычных статических методов, за что их не попинал только ленивый любитель С++ и свободных функций. И вот это уже реальная, а не теоретическая проблема.
IT>Как минимум я бы перенёс все расширения куда-нибудь в CodeJam.Extensions.
И что это даст? Лишний юсинг в прикладном коде?
IT> И заодно перетасовал бы файлы в проекте. Соответсвие папок пространсвам имён тоже вроде пока никто не отменял.
Очень неудобно. Если у меня классов много — будут неструктурированные длинные списки, если класс только один — дурацкая ситуация папки с одним файлом. ИМХО ну его нафик, средств навигации даже голой студии вполне достаточно, чтобы не искать классы по структуре папок. Я уж не говорю про решарпер.
Пространства имен предназначены для одного — обеспечения отсутствия конфликта имен. Попытка привязать к ним какую то еще ответственность — отличный способ прострелить себе ногу.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
И по-поводу сборки в nuget-пакет есть вот какие соображения.
При наличии specific framework (WinForms/WPF, WCF, ASP.NET MVC, System.XML и т.п.)-ориентированного кода будут тянуться лишние зависимости, которые понятное дело не всем нужны.
Мы так пробовали и в итоге отказались от одного большого пакета с хелперами.
Сейчас пользуемся идеей, описанной в https://github.com/phatboyg/Internals.
Т.е. подключаем репозиторий как сабмодуль, в солюшене делаем собственную сборку MyCompany.MyProject.Internals,
накидываем туда нужные файлы через "Add as link", подключаем нужные либы. Так в каждый проект попадают только реально нужные хелперы.
Одно другого не отменяет, но, возможно, есть смысл упомянуть и о таком подходе где-нибудь в документации.
И что они должны делать?
RD>И по-поводу сборки в nuget-пакет есть вот какие соображения. RD>При наличии specific framework (WinForms/WPF, WCF, ASP.NET MVC, System.XML и т.п.)-ориентированного кода будут тянуться лишние зависимости, которые понятное дело не всем нужны.
С самого начала было сказано — на пакеты делить по зависимостям. Но на текущем этапе разработка ведется только для полностью универсального кода, зависящего только от ядра фреймворка. Никаких WPF и ASP.NET. Чем, правда, System.Xml не угодил я не понял.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
AVK>И что они должны делать?
Откусывать от начала/конца строки заданную подстроку (если она там есть). Удобно при разборе строк использовать e.g.
var str = @"SOMEDOMAIN\UserName@somedomain.com";
var userName = str.CutStart(@"SOMEDOMAIN\").CutEnd("@somedomain.com");
// Вместо if (str.StartsWith(@"SOMEDOMAIN\")) str = str.Substring(@"SOMEDOMAIN\".Length);
if (str.EndsWith("@somedomain.com") str = str.Substring(0, str.Length-"@somedomain.com".Length);
// P.S. str.Replace(@"SOMEDOMAIN\", "").Replace("@somedomain.com", "") в общем случае не подойдет, т.к. заменит по всей строке
AVK> Чем, правда, System.Xml не угодил я не понял.
К слову пришлось. Я решарперовским "Remove unused library references" часто пользуюсь — не люблю, чтобы в солюшене были ссылки на неиспользуемые либы.
Здравствуйте, RushDevion, Вы писали:
AVK>>И что они должны делать? RD>Откусывать от начала/конца строки заданную подстроку (если она там есть). Удобно при разборе строк использовать e.g.
Так а при откусывании зачем префикс/суффикс? Типа сперва нужно проверить на совпадение или это такой извращенный способ передать длину откусываемого?
AVK>> Чем, правда, System.Xml не угодил я не понял. RD>К слову пришлось. Я решарперовским "Remove unused library references" часто пользуюсь — не люблю, чтобы в солюшене были ссылки на неиспользуемые либы.
Не особо осмысленное занятие. Неиспользуемые сборки все равно не грузятся, даже если на них ссылка есть.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
Здравствуйте, IT, Вы писали:
AVK>>Да посмотреть даже на сам Fx. Enumerable цепляется к очень распространенному типу, содержит очень большое количество расширений к нему (в фреймворке, наверное, рекордно большое), находится в том же самом неймспейсе, что и все коллекции, т.е. гарантированно попадает в любой код. Получается worst сценарий. Таки и что? Да ничего, все вполне нормально и удобно.
IT>Т.е. всё-таки не в корневом, а в том к чему оно относится.
Оно прежде всего в томже неймспейсе, что и this аругмент, а не в System.Collections.Generic.Extensions. Я вообще не припомню в фреймворке случая чтобы экстеншены были в отдельном неймспейсе.
IT>У меня лично много опыта использования экстеншенов на весьма крупных проектах и большом количестве этих экстеншенов. И на практике оказалось, что с лишним юзингом нет никаких проблем.
Это лишнее действие, лишняя строка кода.
AVK>>Если у меня классов много — будут неструктурированные длинные списки, если класс только один — дурацкая ситуация папки с одним файлом. ИМХО ну его нафик, средств навигации даже голой студии вполне достаточно, чтобы не искать классы по структуре папок. Я уж не говорю про решарпер. IT>Навигация дело десятое, хотя и она для кого-то может оказаться важна.
Тогда зачем вообще соответствие неймспейсов и папок?
AVK>>Пространства имен предназначены для одного — обеспечения отсутствия конфликта имен. Попытка привязать к ним какую то еще ответственность — отличный способ прострелить себе ногу. IT>Тогда по твоей логике все классы фреймворка нужно было поместить в System.
Нет.
IT> Конфликтов имён там почти нет
Там — нет. А вот в прикладном коде, если бы весь фреймворк был в одном неймспейсе, было бы много просто в силу объема фреймворка. У нас же таких объемов не будет никогда.
При этом, если есть каой то крупный и обособленный кусок — абсолютно согласен ч тем чтобы вытащить его в отдельный неймспейс. См. тот же парсер командной строки — там куча специфичных классов. Поэтому я его и вынес в CodeJam.CmdLine.
А вот выносить в отдельный неймспейс 2-3 функции, или объединять совершенно разнородные методы просто потому что они extension — это какой то процесс ради процесса. К примеру, есть у нас класс Disposable и класс DisposableExtensions. Их надо по разным неймспейсам разнести или как?
Резюмируя — предлагаю вводить новый неймспейс тогда, когда есть хотя бы с десяток классов, тесно и однозначно чем то объединенных. А когда там 2-3 класса на всю тематику, то нефик и сиськи мять, пусть все лежит в корневом.
IT>В общем, я даже как-то теряюсь от твоей аргументации. Неймспейсы лично для меня всегда были не средством разруливания конфликтов имён, а преждес всего механизмом организации кода проекта, средством устранения свалки всего в одном месте, как ты здесь предлагаешь.
А чем тебя в этом качестве не устраивают банальные папки?
IT> Соотвествие папок неймспейсам — это вообще-то соглашение индустриального уровня и уже давно ни у кого не вызывает вопросов.
Регулярно вижу обратное.
IT> Сейчас же, уверен, у большинства из тех, кто решит посмотреть на код библиотеки, первым делом возникнет сомнение в профессиональном уровне разработчиков, т.к. возникнет ощущение, что тут собрались не профи, а орлята учатся летать.
Ага, вот тут еще орлята-ламеры, к примеру, собрались — https://github.com/dotnet/roslyn/tree/master/src/Compilers/Server/PortableServer
Всегда знал что с розлином что то не так.
Ребята из решапрера, кстати, поначалу тоже так как ты считали, но быстро от иллюзий избавились. И сейчас в решарпере связь эта настраиваемая, а не жесткая, а относительно свежие версии еще и научились смотреть на соседние файлики, а не тупо на структуру каталогов.
IT>Для хелперных классов давно уже существует очень простое правило — их следует помещать в неймспейсы с именем неймспейса того класса, для котого делается хелпер.
Т.е. помещаем DisposableExtensions в System?
IT> Так для типов String, Type это может быть корневой неймспейс. Для коллекций Collection, для расширений Linq — соответственно Linq.
Но у IEnumerable неймспейс не Linq, а System.Collections.Generic. У коллекций же их вообще несколько. Как то все очень расплывчато получается.
IT> Не думаю, что таких неймспейсов будет много и что это вызовет какие-то сложности при их использовании.
Это прежде всего лишние сущности, лишние юзинги и снижение discoverability, хз как это по русски.
IT> Но зато библиотека станет лучше организована,
Лучше ли?
IT> более логична и предсказуема.
Обоснуй.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
Здравствуйте, AndrewVK, Вы писали:
IT>>Т.е. всё-таки не в корневом, а в том к чему оно относится.
AVK>Оно прежде всего в томже неймспейсе, что и this аругмент, а не в System.Collections.Generic.Extensions. Я вообще не припомню в фреймворке случая чтобы экстеншены были в отдельном неймспейсе.
Extensions имеет смысл, если их туда собрать все. А так следует всё помещать в соответствующие неймспейсы.
IT>>У меня лично много опыта использования экстеншенов на весьма крупных проектах и большом количестве этих экстеншенов. И на практике оказалось, что с лишним юзингом нет никаких проблем. AVK>Это лишнее действие, лишняя строка кода.
Почему лишняя? Очень полезная строка. Позволяет быстро прикинуть, что используется в коде.
AVK>Тогда зачем вообще соответствие неймспейсов и папок?
Затем, что это предсказуемо.
AVK>Там — нет. А вот в прикладном коде, если бы весь фреймворк был в одном неймспейсе, было бы много просто в силу объема фреймворка.
Давай сразу определимся. Мы тут пишем не прикладной код, а библиотеку общего назначение и требования к ней должны быть соответствующие.
AVK>А вот выносить в отдельный неймспейс 2-3 функции, или объединять совершенно разнородные методы просто потому что они extension — это какой то процесс ради процесса. К примеру, есть у нас класс Disposable и класс DisposableExtensions. Их надо по разным неймспейсам разнести или как?
Какая разница сколько там функций? Да хоть одна. Не вижу никаких проблем. Зато искать будет легко и просто.
AVK>Резюмируя — предлагаю вводить новый неймспейс тогда, когда есть хотя бы с десяток классов, тесно и однозначно чем то объединенных. А когда там 2-3 класса на всю тематику, то нефик и сиськи мять, пусть все лежит в корневом.
А если потом к твоим 2-3-м классам добавиться ещё 7-8, то ты их перенесёшь в отдельный неймспейс? Мы тут делаем библиотеку общего назначения, не забыл? С таким подходом у неё нет будущего.
AVK>А чем тебя в этом качестве не устраивают банальные папки?
Навигация в решарпере — это хорошо. Но тот, кто поставит нугет и будет пользоваться этой библиотекой вряд ли будет качать её исходники и включать её в свой проект ради решарпера. Когда мне нужно посмотреть код в какой-то открытой библиотеке и она находится на гитхабе, то я иду туда и ищу нужный класс ориентируясь прежде всего по неймспейсам. Ты эту возможность народу сразу закрываешь, при этом вся твоя аргументация базируется исключительно на вкусовщине.
IT>> Соотвествие папок неймспейсам — это вообще-то соглашение индустриального уровня и уже давно ни у кого не вызывает вопросов. AVK>Регулярно вижу обратное.
Мне тоже доводилось такое видеть. Как правило в таких прокетах чёрт ногу сломит. Давай с самого начала и здесь устроим подобный бардак?
IT>> Сейчас же, уверен, у большинства из тех, кто решит посмотреть на код библиотеки, первым делом возникнет сомнение в профессиональном уровне разработчиков, т.к. возникнет ощущение, что тут собрались не профи, а орлята учатся летать.
AVK>Ага, вот тут еще орлята-ламеры, к примеру, собрались — https://github.com/dotnet/roslyn/tree/master/src/Compilers/Server/PortableServer AVK>Всегда знал что с розлином что то не так.
И что там не так?
AVK>Ребята из решапрера, кстати, поначалу тоже так как ты считали, но быстро от иллюзий избавились. И сейчас в решарпере связь эта настраиваемая, а не жесткая, а относительно свежие версии еще и научились смотреть на соседние файлики, а не тупо на структуру каталогов.
Ещё раз.
1. Мы делаем не конечный продукт на который никогда не появлится не одного референса, а библиотеку общего назначения. Т.е. требования к ней принципиально другие, чем к тому же Решарперу или мелкой утилитке из Рослина.
2. Из каждого правила есть исключения лишь подтверждающие правила. Если есть нормальное логическое обоснование, а не просто личные предпочтения, то всегда можно сделать по-другому. Но не надо это сразу превращать в правило.
IT>>Для хелперных классов давно уже существует очень простое правило — их следует помещать в неймспейсы с именем неймспейса того класса, для котого делается хелпер. AVK>Т.е. помещаем DisposableExtensions в System?
В CodeJam.
Всё касающееся коллекций в CodeJam.Collections.
Linq в CodeJam.Linq.
И так далее по аналогии. Т.е. вместо System ставим CodeJam. Ещё я бы не стал всё, касающееся коллекций запихивать в соостветствующие неймспейсы. Collections вполне достаточно.
IT>> Так для типов String, Type это может быть корневой неймспейс. Для коллекций Collection, для расширений Linq — соответственно Linq.
AVK>Но у IEnumerable неймспейс не Linq, а System.Collections.Generic. У коллекций же их вообще несколько. Как то все очень расплывчато получается.
Это как раз то самое исключение.
IT>> Не думаю, что таких неймспейсов будет много и что это вызовет какие-то сложности при их использовании. AVK>Это прежде всего лишние сущности, лишние юзинги и снижение discoverability, хз как это по русски.
Ты же решарпером пользуещься, там это без проблем.
IT>> более логична и предсказуема. AVK>Обоснуй.
Размещая расширения в произвольных папках ты только путаешь тех, кто будет изучать код библиотеки. Открыв проект и увидев папку String первое, что мне придёт в голову, что есть такой namespace CodeJam.String. Или наоборот, если я захочу посмотреть на гитхабе код StringExtensions.Substring, то искать я его буду в корне и очень сильно удивлюсь не найдя его там. И придётся мне с матом бродить по всем папкам. Что касается строк, то проявив смекалку я может быть быстро дойду до папки String, но вот с тем же CharExtensions.IsDigit уже могут быть проблемы.
Далее. Как я уже говорил, критерий выноса кода в отдельный неймспейс по количеству файлов приведёт либо к бардаку, либо к ломке совместимости в будущем, т.е. ни к чему хорошему.
Наличие открытых неймспейсов в коде — это не лишная, а очень даже полезная информация, которая лично мне сразу даёт представление с чем в данном файле придётся столкнуться. Поэтому увидев в коде using CodeJam.Collections; мне уже будет примерно понятно с чем я тут буду иметь дело.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, IT, Вы писали:
AVK>>Оно прежде всего в томже неймспейсе, что и this аругмент, а не в System.Collections.Generic.Extensions. Я вообще не припомню в AVK>>Это лишнее действие, лишняя строка кода. IT>Почему лишняя? Очень полезная строка. Позволяет быстро прикинуть, что используется в коде.
Сомнительное достоинство.
AVK>>Тогда зачем вообще соответствие неймспейсов и папок? IT>Затем, что это предсказуемо.
Но неудобно.
AVK>>Там — нет. А вот в прикладном коде, если бы весь фреймворк был в одном неймспейсе, было бы много просто в силу объема фреймворка. IT>Давай сразу определимся. Мы тут пишем не прикладной код, а библиотеку общего назначение и требования к ней должны быть соответствующие.
Еще раз. В фреймворке очень много типов, поэтому один неймспейс обладал бы очень высокой вероятностью порождения конфликтов. У нас типов вряд ли будет сильно больше чем в каком нибудь System.Windows.Forms, так что и подобной проблемы тоже нет.
IT>Какая разница сколько там функций?
Большая. Неймспейс становится бесполезным в качестве средства организации и порождает ненужные развесистые деревья каталогов. Мне в свое время хватило жабы с ее жесткой привязкой каталогов к неймспейсам. Независимая структура намного удобнее — МС вполне правильно и осознанно ввели директиву namespace с самого начала.
IT> Да хоть одна. Не вижу никаких проблем. Зато искать будет легко и просто.
Искать и так легко и просто, вызвав Find Symbol.
IT>А если потом к твоим 2-3-м классам добавиться ещё 7-8, то ты их перенесёшь в отдельный неймспейс?
Вероятность такого близка к 0. У нас все таки не большие и сложные вещи предполагаются, которые могут неузнаваемо эволюционировать со временем.
AVK>>А чем тебя в этом качестве не устраивают банальные папки? IT>Навигация в решарпере — это хорошо. Но тот, кто поставит нугет и будет пользоваться этой библиотекой вряд ли будет качать её исходники и включать её в свой проект ради решарпера.
Тот кто ее поставит — ему вообще будет покласть на структуру папок.
IT> Когда мне нужно посмотреть код в какой-то открытой библиотеке и она находится на гитхабе, то я иду туда и ищу нужный класс ориентируясь прежде всего по неймспейсам.
А я пользуюсь поиском, так быстрее. А если просто глазком взглянуть — просто смотрю декомпилят решарпера.
AVK>>Регулярно вижу обратное. IT>Мне тоже доводилось такое видеть. Как правило в таких прокетах чёрт ногу сломит. Давай с самого начала и здесь устроим подобный бардак?
Я не считаю это бардаком. Я писал код в том числе и в крупных проектах, и никаких проблем по поводу несоответствия каталогов не испытывал. А вот когда лет 10-15 назад пытались форсить их соответствие, вот тогда это мне сильно мешало.
IT>И что там не так?
Нет точного соответствия папок неймспейсам. Если логическая группировка файлов по фолдерам, но никакой аналогичной группировки по неймспейсам. Так что там с твоими сомнениями в профессиональном уровне разработчиков розлина?
IT>1. Мы делаем не конечный продукт на который никогда не появлится не одного референса, а библиотеку общего назначения.
Еще раз — пользователям библиотеки насрать на организацию файлов по каталогам. Твой пример с ручным поиском по каталогу исходников сильно натянут. Если тебе так уж сильно хочется — можно вообще в автогенеренном хелпе вставить прямую ссылку на исходник. Или поднять source server или воспользоваться готовым, тогда вообще можно будет в студии одним кликом смотреть, да еще и отлаживаться при необходимости.
IT>2. Из каждого правила есть исключения лишь подтверждающие правила.
С этим ты к Владу сходи, он объяснит.
IT> Если есть нормальное логическое обоснование, а не просто личные предпочтения, то всегда можно сделать по-другому. Но не надо это сразу превращать в правило.
Можно теперь попонятнее объяснить, что ты этой фразой хотел сказать? Я вроде понятно объяснил — мне не нравятся лишние ограничения на структуру каталогов, они мне мешают делать эту структуру такой, какой мне хочется. А ты мне какие то асбтракции про исключения и правила втираешь.
IT>>>Для хелперных классов давно уже существует очень простое правило — их следует помещать в неймспейсы с именем неймспейса того класса, для котого делается хелпер. AVK>>Т.е. помещаем DisposableExtensions в System?
IT>В CodeJam.
Почему именно туда?
IT>Всё касающееся коллекций в CodeJam.Collections.
А почему не в CodeJam.Collections.Generic? Или часть, касающуюся массивов в CodeJam, часть в CodeJam.Enumerable, а часть в CodeJam.Collection?
Я тут еще одну прекрасную вещь про много неймспейсов вспомнил. Ты же помнишь, что называть класс так же, как и часть неймспейса мягко говоря не рекомендуется?
IT>Linq в CodeJam.Linq.
А что такое Linq формально? Вот Concat который у нас — это LINQ? А DisposeAll это LINQ?
IT>И так далее по аналогии.
Я по прежнему не вижу здесь формальной системы.
IT>Т.е. вместо System ставим CodeJam.
Тогда почему не CodeJam.Collections.Generic? И откуда взялся Linq, если в виде неймспейса он только в Xml.Linq?
IT> Ещё я бы не стал всё, касающееся коллекций запихивать в соостветствующие неймспейсы. Collections вполне достаточно.
Вот вот. Все к тому и сводится, что не надо себя ограничивать формализмами там, где в них нет крайней необходимости.
AVK>>Но у IEnumerable неймспейс не Linq, а System.Collections.Generic. У коллекций же их вообще несколько. Как то все очень расплывчато получается. IT>Это как раз то самое исключение.
Ну то есть теория не работает, давай заткнем дырку красивой пословицей? Или все таки признаем, что не надо себя в ненужные рамки загонять?
IT>>> Не думаю, что таких неймспейсов будет много и что это вызовет какие-то сложности при их использовании. AVK>>Это прежде всего лишние сущности, лишние юзинги и снижение discoverability, хз как это по русски. IT>Ты же решарпером пользуещься, там это без проблем.
Что там без проблем? Вот сейчас я пишу using CodeJam и при нажатии на точку вижу все расширения. А если раскидать все по неймспейсам, так мне придется вспоминать что в какой неймспейсе находится, либо смотреть список вообще без разграничений по неймспейсам. А вот так чтобы попросить его контекстно показать мне список мемберов в неймспейсе CodeJam.*, такого он пока не умеет, только список типов.
IT>>> более логична и предсказуема. AVK>>Обоснуй. IT>Размещая расширения в произвольных папках
Они не произвольные, не надо гипертрофировать. Они просто связаны с неймспейсами нежестко. Я даже согласен на правило, что в одной папке не может быть разных неймспейсов, это вполне нормально и логично. Но вот чтобы я не мог создать подпапки для группировки части файлов, не создавая лишних неймспейсов — тут я не согласен.
Пример розлина я уже приводил. Посмотри теперь в проекте experimental — там есть папка CmdLine.Model.Checking, причем типы там публичные. Ну вот удобно мне так при разработке — поместить этот кусочек модели в отдельную подпапку. А вот нафига при этом еще и в CodeJam.CmdLine.Model.Checking типы засовывать, а потом плодить стадо юзингов и внутри кода библиотеки, и внутри прикладного кода — это мне непонятно.
Лично у меня эвристика папочная простая. Если нужно несколько неймспейсов в одном проекте (потребность в неймспейсе при этом первична и не имеет никакого отношения к папкам) — завожу для каждого отдельную папку. В 95% случаев создавать неймспейсы 3 уровня не требуется. Далее, внутри папок или корня проекта с одним неймспейсом, если вдруг образуется больше двух тесно связанных между собой файлов (не обязательно исходников! ресурсы, картинки и т.п. тоже считаются) — завожу для них отдельную папочку без образования неймспейса. И уж точно боже упаси для группировки пихать несколько типов в один файл.
IT> ты только путаешь тех, кто будет изучать код библиотеки. Открыв проект и увидев папку String первое, что мне придёт в голову, что есть такой namespace CodeJam.String. Или наоборот, если я захочу посмотреть на гитхабе код StringExtensions.Substring, то искать я его буду в корне и очень сильно удивлюсь не найдя его там. И придётся мне с матом бродить по всем папкам. Что касается строк, то проявив смекалку я может быть быстро дойду до папки String, но вот с тем же CharExtensions.IsDigit уже могут быть проблемы.
А как надо? Если использовать то, что ты предлагаешь, то надо и StringExtensions, и CharExtensions кидать в корень, рядом с Disposable, DisposableExtensions, парочкой файлов Fn. Туда же до кучи намешать из коллекций те методы, у которых в параметрах массивчик. Полученная каша правда удобнее? Или это очередное исключение?
IT>Далее. Как я уже говорил, критерий выноса кода в отдельный неймспейс по количеству файлов приведёт либо к бардаку, либо к ломке совместимости в будущем, т.е. ни к чему хорошему.
Ломка совместимости это как раз когда упираться рогом и пытаться на каждый фолдер заводить неймспейс. А бардака никакого не будет, если каталоги не от балды заводить, а с умом.
IT>Наличие открытых неймспейсов в коде — это не лишная, а очень даже полезная информация, которая лично мне сразу даёт представление с чем в данном файле придётся столкнуться.
Ну а лично я туда никогда не заглядываю. Как то информация об использовании чего то в файле не очень интересна — файл почти не фигурирует как значимая сущность при анализе кода.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
Здравствуйте, AndrewVK, Вы писали:
IT>>Почему лишняя? Очень полезная строка. Позволяет быстро прикинуть, что используется в коде. AVK>Сомнительное достоинство.
Офигительное достоинство, если много работаешь с чужим кодом, а не только со своим.
AVK>>>Тогда зачем вообще соответствие неймспейсов и папок? IT>>Затем, что это предсказуемо. AVK>Но неудобно.
Тебе может и не удобно. Или ты этот проект затеял исключительно для себя?
AVK>Еще раз. В фреймворке очень много типов, поэтому один неймспейс обладал бы очень высокой вероятностью порождения конфликтов. У нас типов вряд ли будет сильно больше чем в каком нибудь System.Windows.Forms, так что и подобной проблемы тоже нет.
Т.е. у нас будет всего немного. Ага. Ставим сюда закладку.
IT>>Какая разница сколько там функций?
AVK>Большая. Неймспейс становится бесполезным в качестве средства организации и порождает ненужные развесистые деревья каталогов. Мне в свое время хватило жабы с ее жесткой привязкой каталогов к неймспейсам. Независимая структура намного удобнее — МС вполне правильно и осознанно ввели директиву namespace с самого начала.
Тем не менее MS не часто отходит от правила "один неймспейс — один фолдер".
IT>> Да хоть одна. Не вижу никаких проблем. Зато искать будет легко и просто. AVK>Искать и так легко и просто, вызвав Find Symbol.
Ещё раз. Это если у тебя есть Find Symbol, а если у тебя есть только браузер, то не легко и не просто.
IT>>А если потом к твоим 2-3-м классам добавиться ещё 7-8, то ты их перенесёшь в отдельный неймспейс? AVK>Вероятность такого близка к 0. У нас все таки не большие и сложные вещи предполагаются, которые могут неузнаваемо эволюционировать со временем.
Ой я тебя умоляю. Если есть вероятность чего-то плохого, то это обязательно произойдёт. Ты как будто не программист.
AVK>Я не считаю это бардаком. Я писал код в том числе и в крупных проектах, и никаких проблем по поводу несоответствия каталогов не испытывал. А вот когда лет 10-15 назад пытались форсить их соответствие, вот тогда это мне сильно мешало.
А я считаю это самым натуральным бардаком. В библиотеке 3 класса, а найти что-нибудь в ней может только тот, кто их писал. Афигенный порядок.
IT>>И что там не так? AVK>Нет точного соответствия папок неймспейсам.
Да там всего три файла в одном неймспейсе, какие папки?
IT>>1. Мы делаем не конечный продукт на который никогда не появлится не одного референса, а библиотеку общего назначения. AVK>Еще раз — пользователям библиотеки насрать на организацию файлов по каталогам.
Пока, глядя не нелогичность структуры проекта можно сделать вывод, что это разработчикам библиотеке насрать на их потенциальных пользователей.
IT>>2. Из каждого правила есть исключения лишь подтверждающие правила. AVK>С этим ты к Владу сходи, он объяснит.
О, да. Как раз у нас Влад большой любитель прогибать логику под свои предпочтения.
IT>> Если есть нормальное логическое обоснование, а не просто личные предпочтения, то всегда можно сделать по-другому. Но не надо это сразу превращать в правило. AVK>Можно теперь попонятнее объяснить, что ты этой фразой хотел сказать? Я вроде понятно объяснил — мне не нравятся лишние ограничения на структуру каталогов, они мне мешают делать эту структуру такой, какой мне хочется. А ты мне какие то асбтракции про исключения и правила втираешь.
Объясняю. Ограничения существуют, чтобы им следовали, не обязательно жёстко, но следовали. А для тебя похоже они существуют исключительно, чтобы их сразу нарушать.
IT>>>>Для хелперных классов давно уже существует очень простое правило — их следует помещать в неймспейсы с именем неймспейса того класса, для котого делается хелпер. AVK>>>Т.е. помещаем DisposableExtensions в System?
IT>>В CodeJam. AVK>Почему именно туда?
А что здесь непонятног?
IT>>Всё касающееся коллекций в CodeJam.Collections. AVK>А почему не в CodeJam.Collections.Generic?
Можно и туда, но думаю, CodeJam.Collections достаточно.
AVK>Я тут еще одну прекрасную вещь про много неймспейсов вспомнил. Ты же помнишь, что называть класс так же, как и часть неймспейса мягко говоря не рекомендуется?
Не помню.
IT>>Linq в CodeJam.Linq. AVK>А что такое Linq формально? Вот Concat который у нас — это LINQ? А DisposeAll это LINQ?
Чего эти классы хелперы?
AVK>Тогда почему не CodeJam.Collections.Generic? И откуда взялся Linq, если в виде неймспейса он только в Xml.Linq?
Откуда?
IT>> Ещё я бы не стал всё, касающееся коллекций запихивать в соостветствующие неймспейсы. Collections вполне достаточно. AVK>Вот вот. Все к тому и сводится, что не надо себя ограничивать формализмами там, где в них нет крайней необходимости.
Судя по твоим рассуждениям у тебя вообще нет ниобходимости ни в каких правилах. Это как раз то, что я называл нелогичностью и непредсказуемостью. И это делается с самого начала, а что будет дальше?
AVK>Ну то есть теория не работает, давай заткнем дырку красивой пословицей? Или все таки признаем, что не надо себя в ненужные рамки загонять?
Ну не надо рамок, так нк надо. Один местный проект без рамок у нас уже есть.
AVK>Пример розлина я уже приводил.
В том примере три класса по 20 строчек и один неймспейс.
AVK>Посмотри теперь в проекте experimental — там есть папка CmdLine.Model.Checking, причем типы там публичные. Ну вот удобно мне так при разработке — поместить этот кусочек модели в отдельную подпапку. А вот нафига при этом еще и в CodeJam.CmdLine.Model.Checking типы засовывать, а потом плодить стадо юзингов и внутри кода библиотеки, и внутри прикладного кода — это мне непонятно.
Посмотрел. Похоже в CmdLine неслабый монстрик зарождается. Там делов максимум на 200 строк кода, а у нас уже 3 папки и 25 классов. Даже не знаю что тут и посоветовать.
Кстати, от подобной практики, когда модель убирается в отдельную папку я уже давно отказался даже в WPF. На практике крайне не удобно бегать из папки в папку, работая по сути над одной и той же вещью.
AVK>А как надо? Если использовать то, что ты предлагаешь, то надо и StringExtensions, и CharExtensions кидать в корень, рядом с Disposable, DisposableExtensions, парочкой файлов Fn. Туда же до кучи намешать из коллекций те методы, у которых в параметрах массивчик. Полученная каша правда удобнее? Или это очередное исключение?
Я вообще не вижу смысла разбивать расширения со строками и символами на пять файлов. Всё можно поместить в один, а группы методов разделаить регионами и, опаньки, проблема с папкой исчезает сама собой.
AVK>Ломка совместимости это как раз когда упираться рогом и пытаться на каждый фолдер заводить неймспейс. А бардака никакого не будет, если каталоги не от балды заводить, а с умом.
Да бардак уже есть. При этом базируется он на твоих рассуждениях. в которых я никак не уловлю логики. С одной стороны ты говоришь, что у нас в проекте классов будет немного, поэтому неймспейсы не нужны. С другой, у нас много файлов, поэтому нужны папки.
Короче. Обсуждать это я больше не намерен, т.к. похоже, что стороны пришли к взаимному несогласию и дальшее обсуждени лишено всякого смысла. Делай как считаешь нужным.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, IT, Вы писали:
AVK>>Но неудобно. IT>Тебе может и не удобно. Или ты этот проект затеял исключительно для себя?
А ты готов утверждать, что твой вариант удобнее для большего количества людей, нежели мой?
IT>Тем не менее MS не часто отходит от правила "один неймспейс — один фолдер".
Ты преувеличиваешь.
IT>>>1. Мы делаем не конечный продукт на который никогда не появлится не одного референса, а библиотеку общего назначения. AVK>>Еще раз — пользователям библиотеки насрать на организацию файлов по каталогам. IT>Пока, глядя не нелогичность структуры проекта
Структура логична, просто там не та логика, которую ты привык видеть.
IT>Объясняю. Ограничения существуют, чтобы им следовали, не обязательно жёстко, но следовали.
Зашибись. Нет уж, ограничения нужны чтобы получать от них какую то пользу, а не просто им следовать. Иначе получается "если вы такие умные, то почему строем не ходите".
IT> А для тебя похоже они существуют исключительно, чтобы их сразу нарушать.
Нет. Уж ты то должен бы помнить, что я вообще большой любитель порядка в коде. Я даже написал небольшой документик, там 6 ограничений уже указано, из них 4 строгих. А вот конкретно идея со знаком равенства между каталогом и немспейсом мне категорически не нравится. Не потому что я вообще против, а потому что попробовал сие на практике и сделал выводы.
IT>>>В CodeJam. AVK>>Почему именно туда? IT>А что здесь непонятног?
Ну, правило твое как ты его сформулировал ничего про этот не говорит.
IT>>>Всё касающееся коллекций в CodeJam.Collections. AVK>>А почему не в CodeJam.Collections.Generic? IT>Можно и туда, но думаю, CodeJam.Collections достаточно.
Думаешь? А можно ход твоих дум? Ну чтобы я тоже мог правильным образом думать, а не только у тебя консультации спрашивать.
AVK>>Я тут еще одну прекрасную вещь про много неймспейсов вспомнил. Ты же помнишь, что называть класс так же, как и часть неймспейса мягко говоря не рекомендуется? IT>Не помню.
Ну вот теперь помнишь. В результате, когда у тебя некая сучность имеет одно устоявшееся название, и этой сучности соответствует какой нибудь класс, то придумывание неймспейса для нее превращается в увлекательнейший аттракцион "догадайся что я имел в виду".
AVK>>А что такое Linq формально? Вот Concat который у нас — это LINQ? А DisposeAll это LINQ? IT>Чего эти классы хелперы?
А вот интересный вопрос. У Concat еще ладно — можно формально отнести к IEnumerable. А вот у второго — IEnumerable<IDisposable>. Куда его, в collections или в корень?
AVK>>Пример розлина я уже приводил. IT>В том примере три класса по 20 строчек и один неймспейс.
Так это вообще то типичная ситуация. Бывает даже что класс один, а файлов несколько потому что класс на несколько кусков разрезан ввиду его размеров. Если кусков штук 5 — логично все такие куски засунуть в подкаталог, нет?
IT>Посмотрел. Похоже в CmdLine неслабый монстрик зарождается. Там делов максимум на 200 строк кода
Исходя из требования декларативного описания схемы — в 200 строк кода ты ну никак не впихнешь. Да и функционал там пока что сильно зачаточный, многого не хватает.
IT>Кстати, от подобной практики, когда модель убирается в отдельную папку я уже давно отказался даже в WPF. На практике крайне не удобно бегать из папки в папку, работая по сути над одной и той же вещью.
Это осталось от R.SAT где оно вообще в разных проектах было. А сейчас это просто группировка, чтобы было понятно что к чему относится. Как раз борьба с тем самым бардаком, который тебе так активно не нравится.
IT>Я вообще не вижу смысла разбивать расширения со строками и символами на пять файлов.
Смысл в несоздании монстрофайлов — с большими файлами неудобно работать.
IT> Всё можно поместить в один, а группы методов разделаить регионами и, опаньки, проблема с папкой исчезает сама собой.
Зато появится пачка других — тормозящий решарпер/розлин, увеличенная вероятность конфликтов, усложнение одновременной работы с двумя частями внутри одного файла и т.п.
IT>Да бардак уже есть.
Нету.
IT> При этом базируется он на твоих рассуждениях. в которых я никак не уловлю логики. С одной стороны ты говоришь, что у нас в проекте классов будет немного, поэтому неймспейсы не нужны.
Я не говорю что неймспейсы нам не нужны. Я говорю о том, что:
1) Заводить отдельный неймспейс для всех расширений как ты предлагал — точно хрень
2) Заводить много неймспейсов — неудобно в использовании, так как порождает тучу ненужных юсингов и сильно ухудшает discoverability библиотеки. А для нас это очень важно, так как библиотека не на одном аспекте сфокусирована, а наоборот, предполагает очень широкий спектр функционала.
3) Заводить неймспейс только потому что мне захотелось сгруппировать несколько файлов в один каталог — бессмысленная имитация бурной деятельности, еще к тому же, как ты правильно заметил, ломающая совместимость в перспективе.
При этом я совершенно не против разумного добавления неймспейсов. К примеру, CodeJam.CmdLine, CodeJam.TableParsers, CodeJam.Threading точно выглядят разумно. А вот создание неймспейса CodeJam.TableParser.Csv.Escaped или пихание всех парсеров в один каталог мне разумным не кажется.
IT>Короче. Обсуждать это я больше не намерен, т.к. похоже, что стороны пришли к взаимному несогласию и дальшее обсуждени лишено всякого смысла. Делай как считаешь нужным.
Ну, как минимум тебе стоит описать ход своих мыслей достаточно подробно. Вариант "я так думаю" плохо воспроизводим.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
Здравствуйте, AndrewVK, Вы писали:
EP>>+ boost::optional<T> AVK>Просто праздный интерес — для тебя настолько важно, что это есть в бусте, что ты не поленился написать отдельное сообщение?
Ты ведь изначально сказал:
EP>>В C++ есть первый вариант — Boost.
AVK>Спорно. В бусте много шлака. Ну и с С++ ситуация сильно другая, не надо его практики на дотнет переносить.
В итоге шлак так и не показал, совершил какие-то невнятные наезды на строки и Lambda, а в итоге именно Boost'овские практики и переносятся
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>В итоге шлак так и не показал, совершил какие-то невнятные наезды на строки и Lambda, а в итоге именно Boost'овские практики и переносятся
А, опять флейм на тему С++ лучше дотнета? Ну, как то так я и думал.
P.S. Я не говорил, что в бусте нет полезного вообще.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
Здравствуйте, AndrewVK, Вы писали:
AVK>А, опять флейм на тему С++ лучше дотнета? Ну, как то так я и думал.
Нет, флеймить на эту тему не хочу, и он не лучше — они разные, для разных задач. Мне просто непонятна эта аллергическая реакция на изначальное упоминание Boost
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Нет, флеймить на эту тему не хочу, и он не лучше — они разные, для разных задач. Мне просто непонятна эта аллергическая реакция на изначальное упоминание Boost
Тебе показалось. Не было никакой аллергической реакции.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>


 Если нам не помогут, то мы тоже никого не пощадим.
Если нам не помогут, то мы тоже никого не пощадим.