Р>Кто-нибудь понимает суть отказа от зависимостей?
Мой любимый способ разработки. Когда кто-нибудь приходит с очередной гениальной идеей "а давайте впупыжим еще пять микросервисов на критическом пути", я применяю данный паттерн, и говорю "нафиг-нафиг".
Здравствуйте, Разраб, Вы писали:
Р>Кто-нибудь понимает суть отказа от зависимостей? Р>Можете привести пример кода? Р>Или доклад/статью на русском хотя бы
Несколько лет назад я написал книгу «Внедрение зависимостей в .NET», и, так как название этого доклада гласит «От внедрения зависимостей к отказу от зависимостей», возможно, вы ждете, что я отрекусь от всего, что написал в этой книге, но этого не произойдет. Я доволен содержанием книги и думаю, что она предоставляет хорошее руководство по написанию объектно-ориентированных программ.
Отказ от зависимостей — это про способ работы зависимостями в функциональных языках
Несколько лет назад я написал книгу «Внедрение зависимостей в .NET», и, так как название этого доклада гласит «От внедрения зависимостей к отказу от зависимостей», возможно, вы ждете, что я отрекусь от всего, что написал в этой книге, но этого не произойдет. Я доволен содержанием книги и думаю, что она предоставляет хорошее руководство по написанию объектно-ориентированных программ.
Б>Отказ от зависимостей — это про способ работы зависимостями в функциональных языках
Что-то я не понял прикол. Обычный "грязный" код MaitreD в начале, хоть был и грязным, но его можно было хорошо протестировать и бизнес-логика была сосредоточена в одном месте — прочитали список и репозитория, выполнили вычисления, проверили условия, сохранили результат, дали ответ — это всё пишется как слышится по бизнес-требованиям. Соответствующий тест будет тестировать именно бизнес-логику и тест написать легко — запихиваем мок репозитория и ассертим что репозиторий используется ожидаемым образом в разных сценариях.
А "образцово-показательный" код в конце статьи разрывает бизнес-логику посередине — чтение и создание. Выносит чистую функцию (которая настолько проста, что там даже тестировать-то нечего) и код работы с базой в tryAcceptComposition — который тестами уже никак нормально не покрывается, т.к. там connectionString и глобальный DB. И даже теряется тот факт, что чтение и запись данных происходит из того же репозитория.
Ещё "ух! Мы заменили целый класс MaitreD на всего одну функцию tryAccept" — тоже какая-то странная риторика. В реальности MaitreD будет иметь ещё cancelReservation/reschedule/etc и опять же соответствовать вполне реальной бизнес-сущности. Как логически объединять пачку разрозненных функций — тоже неясно.
И если бизнес-логика обрастёт подробностями (например, добавить аудит, посылку емейла о результате, и т.п.) то вообще вся логика раскрошится в пыль и понять что к чему, протетсировать всё как целое — станет совсем сложно.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
·>Что-то я не понял прикол. Обычный "грязный" код MaitreD в начале, хоть был и грязным, но его можно было хорошо протестировать и бизнес-логика была сосредоточена в одном месте — прочитали список и репозитория, выполнили вычисления, проверили условия, сохранили результат, дали ответ — это всё пишется как слышится по бизнес-требованиям ·> Соответствующий тест будет тестировать именно бизнес-логику и тест написать легко — запихиваем мок репозитория и ассертим что репозиторий используется ожидаемым образом в разных сценариях.
Сейчас это называется плохо протестировать — вместо простых и дешовых юнит-тестов вам надо обмазываться моками, и писать хрупкие тесты вида "вызвали функцию репозитория"
То есть, это тесты "как написано", тавтологические
·>А "образцово-показательный" код в конце статьи разрывает бизнес-логику посередине — чтение и создание.
Из бизнес логики здесь только создание. Вот это и тестируем юнит-тестами безо всяких моков. Что там будет в чтении-дело — дело десятое. Отделили мух от котлет.
> Выносит чистую функцию (которая настолько проста, что там даже тестировать-то нечего)
Вот-вот, именно это и есть тренд последних десяти лет, при чем не только в функциональных языках.
> и код работы с базой в tryAcceptComposition — который тестами уже никак нормально не покрывается, т.к. там connectionString и глобальный DB. И даже теряется тот факт, что чтение и запись данных происходит из того же репозитория.
Это интеграционный код, он покрывается интеграционным тестом. не надо мокать базу, что бы убедиться что туда приходит коннекшн стринг. однострочный интеграционный тест даст нам куда более сильную гарантию
·>Ещё "ух! Мы заменили целый класс MaitreD на всего одну функцию tryAccept" — тоже какая-то странная риторика. В реальности MaitreD будет иметь ещё cancelReservation/reschedule/etc и опять же соответствовать вполне реальной бизнес-сущности. Как логически объединять пачку разрозненных функций — тоже неясно. ·>И если бизнес-логика обрастёт подробностями (например, добавить аудит, посылку емейла о результате, и т.п.) то вообще вся логика раскрошится в пыль и понять что к чему, протетсировать всё как целое — станет совсем сложно.
Ничего не крошится. все функции будут сделаны по одной и той же схеме. Аудит, емейл о результате — какую вы здесь проблему видите?
Несколько лет назад я написал книгу «Внедрение зависимостей в .NET», и, так как название этого доклада гласит «От внедрения зависимостей к отказу от зависимостей», возможно, вы ждете, что я отрекусь от всего, что написал в этой книге, но этого не произойдет. Я доволен содержанием книги и думаю, что она предоставляет хорошее руководство по написанию объектно-ориентированных программ.
Б>Отказ от зависимостей — это про способ работы зависимостями в функциональных языках
У автора статьи подмена понятий. Для демонстрации ооп он выбрал дурацкий подход, когда зависимости протаскиваются на всю глубину, а иерархия связывания у него глубокая.
А для хорошести фп он взял другой подход — вместо глубокой взял широкую, и показал как там всё просто.
На самом деле его подход якобы функциональный и есть тот самый, что нужно применять вообще везде, независимо от парадигмы.
Правило большого пальца — длинные, глубокие иерархии, будь то связывание, наследование, определение, заменяем на широкие, когда все дочерние растут из одного рута.
То есть, если привести его ООП код в порядок, используя тот же дизайн, что и во второй части статьи, получим ровно тот же эффект — код станет проще, тестировать его станет легче, протаскивать зависимости будет легче.
Здравствуйте, Pauel, Вы писали:
P>·>Что-то я не понял прикол. Обычный "грязный" код MaitreD в начале, хоть был и грязным, но его можно было хорошо протестировать и бизнес-логика была сосредоточена в одном месте — прочитали список и репозитория, выполнили вычисления, проверили условия, сохранили результат, дали ответ — это всё пишется как слышится по бизнес-требованиям P>·> Соответствующий тест будет тестировать именно бизнес-логику и тест написать легко — запихиваем мок репозитория и ассертим что репозиторий используется ожидаемым образом в разных сценариях. P>Сейчас это называется плохо протестировать — вместо простых и дешовых юнит-тестов вам надо обмазываться моками, и писать хрупкие тесты вида "вызвали функцию репозитория" P>То есть, это тесты "как написано", тавтологические
Технически то же самое. Вместо передачи параметров проверки результатов пюрешки (pure function), прогоняются данные через моки. Тестируется ровно то же, ровно так же. Разница же лишь семантическая — в случае пюрешки у тебя некий абстрактный кусок кода, который как-то преобразует данные которые неясно откуда берутся и куда деваются. В случае моков — готовый к использованию неделимый юнит, один-к-одному отражающий бизнес-требования. В бизнес-требованиях никакого пюре нет, там именно грязная модификация реального мира.
P>·>А "образцово-показательный" код в конце статьи разрывает бизнес-логику посередине — чтение и создание. P>Из бизнес логики здесь только создание. Вот это и тестируем юнит-тестами безо всяких моков. Что там будет в чтении-дело — дело десятое. Отделили мух от котлет.
Создание на основе именно прочитанных данных, а не чего попало. Чтение данных согласуется с созданием.
>> Выносит чистую функцию (которая настолько проста, что там даже тестировать-то нечего) P>Вот-вот, именно это и есть тренд последних десяти лет, при чем не только в функциональных языках.
Тренд в объединении подходов: глобально — грязный ооп (т.е. на уровне больших частей системы) бизнеса, локально — функциональное пюре (на уровне методов) технической реализации.
>> и код работы с базой в tryAcceptComposition — который тестами уже никак нормально не покрывается, т.к. там connectionString и глобальный DB. И даже теряется тот факт, что чтение и запись данных происходит из того же репозитория. P>Это интеграционный код, он покрывается интеграционным тестом. не надо мокать базу, что бы убедиться что туда приходит коннекшн стринг. однострочный интеграционный тест даст нам куда более сильную гарантию
Покажи мне этот однострочный интеграционный тест для tryAcceptComposition. Авторы статьи — "забыли".
Пока итог такой. Был грязный метод tryAccept на 4 строки, который требует только один юнит-тест, хотя с моком.
Они это преобразовали в пюрешный tryAccept на 3 строки, который вроде как легко покрывается юнит-тестом, но без мока. Ура. Но замели сложность в ещё один tryAcceptComposition на 3 строки (притом довольно хитрый! со всякими магическими заклинаниями liftIO, $, return, flip, .), для которого теперь требуется писать ещё и интеграционный тест. Удвоили кол-во кода, усложнили тестирование... а в чём выгода — я ну никак понять не могу.
P>·>Ещё "ух! Мы заменили целый класс MaitreD на всего одну функцию tryAccept" — тоже какая-то странная риторика. В реальности MaitreD будет иметь ещё cancelReservation/reschedule/etc и опять же соответствовать вполне реальной бизнес-сущности. Как логически объединять пачку разрозненных функций — тоже неясно. P>·>И если бизнес-логика обрастёт подробностями (например, добавить аудит, посылку емейла о результате, и т.п.) то вообще вся логика раскрошится в пыль и понять что к чему, протетсировать всё как целое — станет совсем сложно. P>Ничего не крошится. все функции будут сделаны по одной и той же схеме.
Как эти разрозненные функции будут объединяться в единую определяемую бизнесом сущность MaitreD?
P>Аудит, емейл о результате — какую вы здесь проблему видите?
В том, что результатом tryAccept может быть пачка несвязных результатов, которые должны быть распределены соответсвующим образом: результат резервации — клиенту, аудит — сервису аудита, емейл — smtp-серверу и т.п. Если это переделывать в пюре, придётся конструировать какие-то сложные результирующие объекты, которые потом надо будет ещё потом правильно разбирать на части. Или как ты это видишь?
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Любая развитая идея формирует группу антаго(в)нистов, воспринимаю это диалектически. Любой постулат рано или поздно становится объектом критики и так идет по кругу.
Здравствуйте, ·, Вы писали:
P>>Сейчас это называется плохо протестировать — вместо простых и дешовых юнит-тестов вам надо обмазываться моками, и писать хрупкие тесты вида "вызвали функцию репозитория" P>>То есть, это тесты "как написано", тавтологические ·>Технически то же самое.
Тесты "как написано", технически не дают никаких гарантий — вызвал другой метод репозитория, результат тот же, а тесты сломались. Вот вам и "то же самое"
> Вместо передачи параметров проверки результатов пюрешки (pure function), прогоняются данные через моки.
И это проблема, т.к. моки так или иначе искажают действительность. Т.к. всегда есть риск, что с моками работает, а без моков — ни гу-гу. При росте сложности приложения эти риски начинают срабатывать регулярно.
Например, научить новичка внятно пользоваться моками да правильно покрывать тесты используя такой подход довольно трудно, на это уходят годы. А потому рано или поздно будете ловить последствия в проде.
> Тестируется ровно то же, ровно так же. Разница же лишь семантическая
Вы сейчас играете в слова. В одном случае вы получаете проблемы из за моков, а в другом случае просто тестируете ключевую функцию юнит-тестами без моков.
Обмазываетесь моками — значит время на разработку тестов больше, тк тесты хрупкие.
Моки это инструмент решения проблем, а не способ выражения намерений. А раз так, то нужно сперва решить проблему, тогда и отпадет необходимость применять этот инструмент.
P>>Из бизнес логики здесь только создание. Вот это и тестируем юнит-тестами безо всяких моков. Что там будет в чтении-дело — дело десятое. Отделили мух от котлет. ·>Создание на основе именно прочитанных данных, а не чего попало. Чтение данных согласуется с созданием.
Эти вещи связаны исключительно конкретным пайплайном. А вот логически это разные вещи. Тестировать сам пайплайн удобнее интеграционными тестам — прогнал один, значит пайпалайн работает. А вот отдельные части пайплайна — дешовыми юнит-тестами, их можно настрочить тыщи, хоть генерируй по спеке, время на запуск все равно 0 секунд.
А вот если вы обмазываетесь моками, то пишете тесты "как написано" и другого варианта у вас нет.
P>>Вот-вот, именно это и есть тренд последних десяти лет, при чем не только в функциональных языках. ·>Тренд в объединении подходов: глобально — грязный ооп (т.е. на уровне больших частей системы) бизнеса, локально — функциональное пюре (на уровне методов) технической реализации.
Именно! А вы предлагаете грязный ооп использовать на уровне методов технической реализации. Потому вам и нужны моки. ООП это парадигма для управления сложностью взаимодействия. ФП — для управления сложностью вычислений. Отсюда ясно, что нам надо и то, и другое — склеить взаимодействие с вычислениями. Создание — тупо вычисления, а вы сюда втискиваете зависимость на БД и вещаете что это хорошо.
Опомнитесь — ваш подход из 80х-90х, когда TurboVision в MSDOS встречали на ура.
·>Покажи мне этот однострочный интеграционный тест для tryAcceptComposition. Авторы статьи — "забыли".
·>Пока итог такой. Был грязный метод tryAccept на 4 строки, который требует только один юнит-тест, хотя с моком.
Неверно — была монолитная иерархия вызовов во главе с tryAccept который только сам по себе 4 строки.
И тестировать нужно всю эту иерархию, для чего вам и нужны моки.
·>Они это преобразовали в пюрешный tryAccept на 3 строки, который вроде как легко покрывается юнит-тестом, но без мока. Ура.
Именно!
> Но замели сложность в ещё один tryAcceptComposition на 3 строки (притом довольно хитрый! со всякими магическими заклинаниями liftIO, $, return, flip, .), для которого теперь требуется писать ещё и интеграционный тест. Удвоили кол-во кода, усложнили тестирование... а в чём выгода — я ну никак понять не могу.
Вы по прежнему думаете, что моки избавляют от интеграционных тестов. Ровно наоборот — сверх обычных юнитов вам надо понаписывать моки на все кейсы, и всё равно придется писать интеграционные тесты.
P>>Ничего не крошится. все функции будут сделаны по одной и той же схеме. ·>Как эти разрозненные функции будут объединяться в единую определяемую бизнесом сущность MaitreD?
MaitreD это метафора уровня реализации, никакой бизнес это не определяет. Бизнесу надо что бы работали юз-кейсы вида "зарезервировать столик на 10 мест на 31е декабря между баром и сценой". Используете вы MaitreD или нет, дело десятое.
На основе коротких функций мы можем менять компоновку уже по ходу пьесы подстраиваясь под изменения треботваний, а не бетонировать код на все времена.
P>>Аудит, емейл о результате — какую вы здесь проблему видите? ·>В том, что результатом tryAccept может быть пачка несвязных результатов, которые должны быть распределены соответсвующим образом: результат резервации — клиенту, аудит — сервису аудита, емейл — smtp-серверу и т.п. Если это переделывать в пюре, придётся конструировать какие-то сложные результирующие объекты, которые потом надо будет ещё потом правильно разбирать на части. Или как ты это видишь?
Похоже, вы просто не в курсе, как подобное реализуется в функциональном стиле, а потому порете чушь. Нам нужен аудит не вызова tryAccept, а аудит всей транзации которая изначально будет грязной, принципиально. Т.е. вещи вида "третьего дня разместили заявку xxx(детали) ... статус успешно, детали(...)"
То есть, к известным эффектам мы всего то добавляем еще один. И емейл это ровно такой же эффект. Т.е. нам нужна всего то парочка мидлвар, которые и берут на себя все что надо.
Более того, и запись в очередь это снова такой же эффект
Здравствуйте, Pauel, Вы писали:
P>>>Сейчас это называется плохо протестировать — вместо простых и дешовых юнит-тестов вам надо обмазываться моками, и писать хрупкие тесты вида "вызвали функцию репозитория" P>>>То есть, это тесты "как написано", тавтологические P>·>Технически то же самое. P>Тесты "как написано", технически не дают никаких гарантий — вызвал другой метод репозитория, результат тот же, а тесты сломались. Вот вам и "то же самое"
Это уже детали реализации — что именно тестируют тесты. Если я хочу тестировать факт вызова определённого метода, то тест и должен сломаться. Что именно покрывает тест — это должен решать программист. Моки к этому отношения не имеют вообще никакого. >> Вместо передачи параметров проверки результатов пюрешки (pure function), прогоняются данные через моки. P>И это проблема, т.к. моки так или иначе искажают действительность. Т.к. всегда есть риск, что с моками работает, а без моков — ни гу-гу. При росте сложности приложения эти риски начинают срабатывать регулярно. P>Например, научить новичка внятно пользоваться моками да правильно покрывать тесты используя такой подход довольно трудно, на это уходят годы. А потому рано или поздно будете ловить последствия в проде.
Это всё риторика. Любые тесты искажают действительность, просто по определению. Моки — тут вообще не при чём. >> Тестируется ровно то же, ровно так же. Разница же лишь семантическая P>Вы сейчас играете в слова. В одном случае вы получаете проблемы из за моков, а в другом случае просто тестируете ключевую функцию юнит-тестами без моков.
Моки это всего лишь механизм передачи данных от одного участка кода другому. Пюрешки могут использовать только передачу параметров и возвращаемое значение. Моки — дополнительно позволяют передавать инфу через вызовы методов. Вот и вся разница. P>Обмазываетесь моками — значит время на разработку тестов больше, тк тесты хрупкие.
Моки лишь дополнительный инструмент. Можно им всё сломать, а можно сделать красиво. P>Моки это инструмент решения проблем, а не способ выражения намерений. А раз так, то нужно сперва решить проблему, тогда и отпадет необходимость применять этот инструмент.
Решения каких проблем? P>·>Создание на основе именно прочитанных данных, а не чего попало. Чтение данных согласуется с созданием. P>Эти вещи связаны исключительно конкретным пайплайном. А вот логически это разные вещи. Тестировать сам пайплайн удобнее интеграционными тестам — прогнал один, значит пайпалайн работает. А вот отдельные части пайплайна — дешовыми юнит-тестами, их можно настрочить тыщи, хоть генерируй по спеке, время на запуск все равно 0 секунд.
Я о чём и говорю. Шило на мыло меняешь, правда ценой удвоения количества кода. P>А вот если вы обмазываетесь моками, то пишете тесты "как написано" и другого варианта у вас нет.
Варианта чего? Вынести пюрешку можно банальным extract method refactoring и покрыть отдельно — если это имеет хоть какую-то практическую пользу. Мой поинт в том, что в статье практической пользы делать закат вручную мне не удалось увидеть. P>·>Тренд в объединении подходов: глобально — грязный ооп (т.е. на уровне больших частей системы) бизнеса, локально — функциональное пюре (на уровне методов) технической реализации. P>Именно! А вы предлагаете грязный ооп использовать на уровне методов технической реализации. Потому вам и нужны моки. ООП это парадигма для управления сложностью взаимодействия. ФП — для управления сложностью вычислений. Отсюда ясно, что нам надо и то, и другое — склеить взаимодействие с вычислениями. Создание — тупо вычисления, а вы сюда втискиваете зависимость на БД и вещаете что это хорошо.
Я предлагаю использовать ооп. На минутку — что требует бизнес? Реализацию сущности MaitreD. Это такой дядька, который стоит на входе в ресторан и взаимодействует с клиентами обслуживая запросы (притом разные — accept/cancel/reschedule/etc) на резервацию столиков. Т.е. прямое соответствие интерфейсу class MaitreD {int? tryAccept(Reservation r){...}; boolean tryReschdedule(Reservation r, DateTime newTime){...}; ....} — ничего лишнего, как слышится, так и пишется — это и есть описание системы в целом.
В статье на замену предложено вычленить локальное нутро реализации метода, вынести наружу, чтобы получилось вот это: int -> (DateTimeOffset -> Reservation list) -> (Reservation -> int) -> Reservation — это вообще чо??!. P>·>Покажи мне этот однострочный интеграционный тест для tryAcceptComposition. Авторы статьи — "забыли".
Напиши однострочный интеграционный тест для tryAcceptComposition. Именно этот метод напрямую соответствует рассматриваемому в начале статьи методу "public int? TryAccept(Reservation)" который очень легко тестировать, но с моком. P>·>Пока итог такой. Был грязный метод tryAccept на 4 строки, который требует только один юнит-тест, хотя с моком. P>Неверно — была монолитная иерархия вызовов во главе с tryAccept который только сам по себе 4 строки. P>И тестировать нужно всю эту иерархию, для чего вам и нужны моки.
Не понял ты о чём. Я о "главном герое" статьи, вот этом классе:
P>·>Они это преобразовали в пюрешный tryAccept на 3 строки, который вроде как легко покрывается юнит-тестом, но без мока. Ура. P>Именно!
С моком он так же покрывается на ура. >> Но замели сложность в ещё один tryAcceptComposition на 3 строки (притом довольно хитрый! со всякими магическими заклинаниями liftIO, $, return, flip, .), для которого теперь требуется писать ещё и интеграционный тест. Удвоили кол-во кода, усложнили тестирование... а в чём выгода — я ну никак понять не могу. P> Вы по прежнему думаете, что моки избавляют от интеграционных тестов. Ровно наоборот — сверх обычных юнитов вам надо понаписывать моки на все кейсы, и всё равно придется писать интеграционные тесты.
Зачем писать моки на все кейсы? Моки делаются не для кейсов, а для зависимостей. Тут одна зависимость — репозиторий — значит один мок. Неважно сколько кейсов.
Юнит-тестов нужно только два — успешная и неуспешная резервация. Интеграционный тест только один — что MaitreD успешно интегрируется со всеми своими зависимостями. P>·>Как эти разрозненные функции будут объединяться в единую определяемую бизнесом сущность MaitreD? P>MaitreD это метафора уровня реализации, никакой бизнес это не определяет. Бизнесу надо что бы работали юз-кейсы вида "зарезервировать столик на 10 мест на 31е декабря между баром и сценой". Используете вы MaitreD или нет, дело десятое. P>На основе коротких функций мы можем менять компоновку уже по ходу пьесы подстраиваясь под изменения треботваний, а не бетонировать код на все времена.
"зарезервировать столик" — это Responsibility выполняемое Actor-ом MaitreD. Это понятно бизнесу. И бизнесу понятно, что клиентов надо направлять именно к MaitreD для резервации, а не к Actor-у Повар. Что резервация должна записываться в Репозитории, а не на стене туалета. И т.п. P>>>Аудит, емейл о результате — какую вы здесь проблему видите? P>·>В том, что результатом tryAccept может быть пачка несвязных результатов, которые должны быть распределены соответсвующим образом: результат резервации — клиенту, аудит — сервису аудита, емейл — smtp-серверу и т.п. Если это переделывать в пюре, придётся конструировать какие-то сложные результирующие объекты, которые потом надо будет ещё потом правильно разбирать на части. Или как ты это видишь? P>Похоже, вы просто не в курсе, как подобное реализуется в функциональном стиле, а потому порете чушь. Нам нужен аудит не вызова tryAccept, а аудит всей транзации которая изначально будет грязной, принципиально. Т.е. вещи вида "третьего дня разместили заявку xxx(детали) ... статус успешно, детали(...)"
Это не аудит, это просто лог для дебага. Аудит это требуемый аудиторами record-keeping процесс определённого формата с определёнными требованиями с целью контролировать business conduct — по тому как происходят различные бизнес-операции с т.з. legal compliance. С т.з. реального мира — тот дядька у входа в ресторан, например, обязан секретно уведомлять полицию если к нему пришёл клиент с признаками наркотического отравления. P>То есть, к известным эффектам мы всего то добавляем еще один. И емейл это ровно такой же эффект. Т.е. нам нужна всего то парочка мидлвар, которые и берут на себя все что надо. P>Более того, и запись в очередь это снова такой же эффект
Ты не отвлекайся. Код в статье рассматривай. Расскажи куда там воткнуть это всё в tryAcceptComposition или куда там получится. Я хочу рассмотреть пример когда у метода будет больше одной зависимости. А ты мне предлагаешь зависимости внедрять неявно через аннотации и глобальные переменные. P>@useAudit(Schema.arrange, Schema.arranged) P>@useEvent(Schema.arranged) P>@validate(Schema.arrange) P>@presenter(Schema.arranged)
Ужас. annotation-driven development. Прям Spring, AOP, ejb, 00-е, application container, framework, middleware. Закопай обратно.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>>>Сейчас это называется плохо протестировать — вместо простых и дешовых юнит-тестов вам надо обмазываться моками, и писать хрупкие тесты вида "вызвали функцию репозитория" P>>>>То есть, это тесты "как написано", тавтологические P>>·>Технически то же самое. P>>Тесты "как написано", технически не дают никаких гарантий — вызвал другой метод репозитория, результат тот же, а тесты сломались. Вот вам и "то же самое" ·>Это уже детали реализации — что именно тестируют тесты. Если я хочу тестировать факт вызова определённого метода, то тест и должен сломаться. Что именно покрывает тест — это должен решать программист. Моки к этому отношения не имеют вообще никакого.
Забавный плюрализм в одной голове — в одном треде вы клеймите позором "тесты как написано", тк "они ничего не тестируют", а здесь это уже "детали реализации"
Как вас понимать, какая версия вашего мнения считается более актуальной?
P>>Например, научить новичка внятно пользоваться моками да правильно покрывать тесты используя такой подход довольно трудно, на это уходят годы. А потому рано или поздно будете ловить последствия в проде. ·>Это всё риторика. Любые тесты искажают действительность, просто по определению. Моки — тут вообще не при чём.
Любые и все по разному, в разной степени. Моки по своей сути сильнее всего этому подвержены. Пол-приложения не работает при зеленых тестах — обычное дело с моками.
P>>Вы сейчас играете в слова. В одном случае вы получаете проблемы из за моков, а в другом случае просто тестируете ключевую функцию юнит-тестами без моков. ·>Моки это всего лишь механизм передачи данных от одного участка кода другому. Пюрешки могут использовать только передачу параметров и возвращаемое значение. Моки — дополнительно позволяют передавать инфу через вызовы методов. Вот и вся разница.
Не вся — моки могут добавлять то чего в природе нет, не водится, или выворачивать наизнанку. Соответствие моков реальному поведению системы всегда остаётся на совести разработчика, а следовательно человеческий фактор в его максимальном проявлении.
P>>Обмазываетесь моками — значит время на разработку тестов больше, тк тесты хрупкие. ·>Моки лишь дополнительный инструмент. Можно им всё сломать, а можно сделать красиво.
У вас моки стали какой то панацеей. Вас послушать так у моков одни преимущества, без каких либо недостатков.
P>>Моки это инструмент решения проблем, а не способ выражения намерений. А раз так, то нужно сперва решить проблему, тогда и отпадет необходимость применять этот инструмент. ·>Решения каких проблем?
Зависимости. Моки отрезают зависимости во время тестирования. Что характерно, моки далеко это не единственный инструмент решения этой поблемы, и далеко не самый эффективный.
А у вас он стал панацеей
P>>Эти вещи связаны исключительно конкретным пайплайном. А вот логически это разные вещи. Тестировать сам пайплайн удобнее интеграционными тестам — прогнал один, значит пайпалайн работает. А вот отдельные части пайплайна — дешовыми юнит-тестами, их можно настрочить тыщи, хоть генерируй по спеке, время на запуск все равно 0 секунд. ·>Я о чём и говорю. Шило на мыло меняешь, правда ценой удвоения количества кода.
Если есть выбор, моком или простым юнит-тестом, то юнит-тест всегда эффективнее. Удвоение количества — это как раз про моки. При одинаковом покрытии кейсов мокам нужно больше кода.
P>>А вот если вы обмазываетесь моками, то пишете тесты "как написано" и другого варианта у вас нет. ·>Варианта чего? Вынести пюрешку можно банальным extract method refactoring и покрыть отдельно — если это имеет хоть какую-то практическую пользу. Мой поинт в том, что в статье практической пользы делать закат вручную мне не удалось увидеть.
Так вы хотели, что бы вам в трех словах все тайны мироздания раскрыли? Все статьи такие, что там можно найти частный случай и заткнуть всё сразу.
P>>Именно! А вы предлагаете грязный ооп использовать на уровне методов технической реализации. Потому вам и нужны моки. ООП это парадигма для управления сложностью взаимодействия. ФП — для управления сложностью вычислений. Отсюда ясно, что нам надо и то, и другое — склеить взаимодействие с вычислениями. Создание — тупо вычисления, а вы сюда втискиваете зависимость на БД и вещаете что это хорошо. ·>Я предлагаю использовать ооп. На минутку — что требует бизнес? Реализацию сущности MaitreD.
Нет, не требует. Бизнесу до ваших сущностей никакого дела нет. А потому разработчик имеет право выбирать, нужна ли ему такая сущность, и как он её будет моделировать — объектами, классами, актерами итд итд итд Хоть набором переменных, абы это имело практическое обоснование
·>В статье на замену предложено вычленить локальное нутро реализации метода, вынести наружу, чтобы получилось вот это: int -> (DateTimeOffset -> Reservation list) -> (Reservation -> int) -> Reservation — это вообще чо??!.
Это описание конкретного пайплайна. В ооп подходе у вас будет примерно такая же штукенция. Покрасивее будет, т.к. именованая. Но принципиально всё сохранится. В том и то и бенефит.
Проблема с самой статье
1. в ооп стоит делать так, как автор показывает для фп варианта — больше контроля, меньше моков, больше юнит-тестов
2. если в фп задаться целью сделать как автор для ооп вариана — можно просто убиться
Это правило для работы с глубокоми иерахиями чего угодно — глубокую запутанную превращаем в плоскую одноуровневую. методы становятся длиннее, но зависимостями управлять легче тк иерархия неглубокая.
>>> Но замели сложность в ещё один tryAcceptComposition на 3 строки (притом довольно хитрый! со всякими магическими заклинаниями liftIO, $, return, flip, .), для которого теперь требуется писать ещё и интеграционный тест. Удвоили кол-во кода, усложнили тестирование... а в чём выгода — я ну никак понять не могу. P>> Вы по прежнему думаете, что моки избавляют от интеграционных тестов. Ровно наоборот — сверх обычных юнитов вам надо понаписывать моки на все кейсы, и всё равно придется писать интеграционные тесты. ·>Зачем писать моки на все кейсы? Моки делаются не для кейсов, а для зависимостей. Тут одна зависимость — репозиторий — значит один мок. Неважно сколько кейсов.
Ваш мок должен поддерживать все эти кейсы, что очевидно. Думаете мок сам догадается, какие кейсы ему поддерживать?
·>Юнит-тестов нужно только два — успешная и неуспешная резервация. Интеграционный тест только один — что MaitreD успешно интегрируется со всеми своими зависимостями.
Юнит-тестов нужно гораздо больше — в зависимости от того, сколько у нас параметров, состояний итд.
P>>На основе коротких функций мы можем менять компоновку уже по ходу пьесы подстраиваясь под изменения треботваний, а не бетонировать код на все времена. ·>"зарезервировать столик" — это Responsibility выполняемое Actor-ом MaitreD. Это понятно бизнесу.
Бизнесу до этого никакого дела нет. MaitreD это абстракция уровня реализации.
·>Это не аудит, это просто лог для дебага. Аудит это требуемый аудиторами record-keeping процесс определённого формата с определёнными требованиями с целью контролировать business conduct — по тому как происходят различные бизнес-операции с т.з. legal compliance. С т.з. реального мира — тот дядька у входа в ресторан, например, обязан секретно уведомлять полицию если к нему пришёл клиент с признаками наркотического отравления.
·>Ты не отвлекайся. Код в статье рассматривай. Расскажи куда там воткнуть это всё в tryAcceptComposition или куда там получится. Я хочу рассмотреть пример когда у метода будет больше одной зависимости. А ты мне предлагаешь зависимости внедрять неявно через аннотации и глобальные переменные.
Это ваши фантазии. Я ничего не предлагаю внедрать неявно, тем более с глобальными переменными. Это вы с голосами в голове спорите.
P>>@useAudit(Schema.arrange, Schema.arranged) P>>@useEvent(Schema.arranged) P>>@validate(Schema.arrange) P>>@presenter(Schema.arranged) ·>Ужас. annotation-driven development. Прям Spring, AOP, ejb, 00-е, application container, framework, middleware. Закопай обратно.
Здравствуйте, Pauel, Вы писали:
P>>>Тесты "как написано", технически не дают никаких гарантий — вызвал другой метод репозитория, результат тот же, а тесты сломались. Вот вам и "то же самое" P>·>Это уже детали реализации — что именно тестируют тесты. Если я хочу тестировать факт вызова определённого метода, то тест и должен сломаться. Что именно покрывает тест — это должен решать программист. Моки к этому отношения не имеют вообще никакого. P>Забавный плюрализм в одной голове — в одном треде вы клеймите позором "тесты как написано", тк "они ничего не тестируют", а здесь это уже "детали реализации"
Это потому что ты сам с собой споришь и с темы спрыгиваешь.
P>Как вас понимать, какая версия вашего мнения считается более актуальной?
Разжевываю:
"тесты как написано", тк "они ничего не тестируют" — позор. Не важно с моками они или нет.
Использование моков или нет — "детали реализации".
P>>>Например, научить новичка внятно пользоваться моками да правильно покрывать тесты используя такой подход довольно трудно, на это уходят годы. А потому рано или поздно будете ловить последствия в проде. P>·>Это всё риторика. Любые тесты искажают действительность, просто по определению. Моки — тут вообще не при чём. P>Любые и все по разному, в разной степени. Моки по своей сути сильнее всего этому подвержены. Пол-приложения не работает при зеленых тестах — обычное дело с моками.
Ещё раз повторюсь. Моки — инструмент. Если ты молотком пользоваться не умеешь и постоянно попадаешь по пальцам, то правильным решением будет научиться пользоваться молотком, а не продолжать закручивать гвозди отвёрткой.
P>·>Моки это всего лишь механизм передачи данных от одного участка кода другому. Пюрешки могут использовать только передачу параметров и возвращаемое значение. Моки — дополнительно позволяют передавать инфу через вызовы методов. Вот и вся разница. P>Не вся — моки могут добавлять то чего в природе нет, не водится, или выворачивать наизнанку. Соответствие моков реальному поведению системы всегда остаётся на совести разработчика, а следовательно человеческий фактор в его максимальном проявлении.
В параметры тоже можно передавать то чего в природе нет. И что?
P>>>Обмазываетесь моками — значит время на разработку тестов больше, тк тесты хрупкие. P>·>Моки лишь дополнительный инструмент. Можно им всё сломать, а можно сделать красиво. P>У вас моки стали какой то панацеей. Вас послушать так у моков одни преимущества, без каких либо недостатков.
Это твои фантазии.
P>>>Моки это инструмент решения проблем, а не способ выражения намерений. А раз так, то нужно сперва решить проблему, тогда и отпадет необходимость применять этот инструмент. P>·>Решения каких проблем? P>Зависимости. Моки отрезают зависимости во время тестирования. Что характерно, моки далеко это не единственный инструмент решения этой поблемы, и далеко не самый эффективный.
Ты так и не показал как ты предлагаешь решать эту проблему, только заявил, что решается одной строчкой, но не показал как. Проигнорировал вопрос дважды: Напиши однострочный интеграционный тест для tryAcceptComposition.
P>А у вас он стал панацеей
Не панацеей, а конкретным решением твоей конкретной проблемы.
P>>>Эти вещи связаны исключительно конкретным пайплайном. А вот логически это разные вещи. Тестировать сам пайплайн удобнее интеграционными тестам — прогнал один, значит пайпалайн работает. А вот отдельные части пайплайна — дешовыми юнит-тестами, их можно настрочить тыщи, хоть генерируй по спеке, время на запуск все равно 0 секунд. P>·>Я о чём и говорю. Шило на мыло меняешь, правда ценой удвоения количества кода. P>Если есть выбор, моком или простым юнит-тестом, то юнит-тест всегда эффективнее.
Классика же — у каждой проблемы есть простое, ясное, эффективное, но неправильное решение.
P>Удвоение количества — это как раз про моки. При одинаковом покрытии кейсов мокам нужно больше кода.
Я говорю конкретно о статье. Там кол-во кода удвоилось. Тестовое покрытие упало в несколько раз, зато Без Моков™.
P>·>Варианта чего? Вынести пюрешку можно банальным extract method refactoring и покрыть отдельно — если это имеет хоть какую-то практическую пользу. Мой поинт в том, что в статье практической пользы делать закат вручную мне не удалось увидеть. P>Так вы хотели, что бы вам в трех словах все тайны мироздания раскрыли? Все статьи такие, что там можно найти частный случай и заткнуть всё сразу.
Я хотел, чтобы мне разъяснили нераскрытый вопрос в статье.
P>·>Я предлагаю использовать ооп. На минутку — что требует бизнес? Реализацию сущности MaitreD. P>Нет, не требует. Бизнесу до ваших сущностей никакого дела нет. А потому разработчик имеет право выбирать, нужна ли ему такая сущность, и как он её будет моделировать — объектами, классами, актерами итд итд итд Хоть набором переменных, абы это имело практическое обоснование
Ясен пень, можно хоть на brainfuck писать, без этого вашего ООП. Но чем модель ближе — тем лучше. ООП как раз направлено на моделирование бизнес-требований как можно более похожим образом — именованная сущность там — именованная сущность здесь. Набор переменных это круто, конечно, но обычно только как практическое обоснование для жоп-секьюрити.
P>·>В статье на замену предложено вычленить локальное нутро реализации метода, вынести наружу, чтобы получилось вот это: int -> (DateTimeOffset -> Reservation list) -> (Reservation -> int) -> Reservation — это вообще чо??!. P>Это описание конкретного пайплайна. В ооп подходе у вас будет примерно такая же штукенция. Покрасивее будет, т.к. именованая. Но принципиально всё сохранится. В том и то и бенефит.
Какова цель этой штуки? Зачем нам описывать конкретный пайплайн? Что можно полезного делать с этим описанием? Как проверить, что писание верное? Откуда взялось, что "принципиально всё сохранится"?
P>Проблема с самой статье P>1. в ооп стоит делать так, как автор показывает для фп варианта — больше контроля, меньше моков, больше юнит-тестов
И кода стало больше, и бОльшая часть нетривиального кода не протестирована.
P>2. если в фп задаться целью сделать как автор для ооп вариана — можно просто убиться
А какой целью надо задаваться-то?
P>Это правило для работы с глубокоми иерахиями чего угодно — глубокую запутанную превращаем в плоскую одноуровневую. методы становятся длиннее, но зависимостями управлять легче тк иерархия неглубокая.
Ну так внедрение зависимостей DI+CI это и есть плоская иерархия. В конструкторе все зависимости, методы — целевая бизнес-логика. В статье это и было показано, что такой подход эквивалентен частичному применению функций — код под капотом идентичный получается.
P>>> Вы по прежнему думаете, что моки избавляют от интеграционных тестов. Ровно наоборот — сверх обычных юнитов вам надо понаписывать моки на все кейсы, и всё равно придется писать интеграционные тесты. P>·>Зачем писать моки на все кейсы? Моки делаются не для кейсов, а для зависимостей. Тут одна зависимость — репозиторий — значит один мок. Неважно сколько кейсов. P>Ваш мок должен поддерживать все эти кейсы, что очевидно. Думаете мок сам догадается, какие кейсы ему поддерживать?
Ещё раз повторюсь — мок это лишь способ передачи данных внуть метода. В твоём случае ровно то же придётся делать, но передавать через параметры, а не через мок, вот и вся разница.
P>·>Юнит-тестов нужно только два — успешная и неуспешная резервация. Интеграционный тест только один — что MaitreD успешно интегрируется со всеми своими зависимостями. P>Юнит-тестов нужно гораздо больше — в зависимости от того, сколько у нас параметров, состояний итд.
Сосредоточься на обсуждаемой теме. Я говорю конкретно о коде в статье. Там видно сколько конкретно параметров, состояний и т.д.
P>>>На основе коротких функций мы можем менять компоновку уже по ходу пьесы подстраиваясь под изменения треботваний, а не бетонировать код на все времена. P>·>"зарезервировать столик" — это Responsibility выполняемое Actor-ом MaitreD. Это понятно бизнесу. P>Бизнесу до этого никакого дела нет. MaitreD это абстракция уровня реализации.
Слова Responsibility и Actor — это из словаря FRD. Т.е. именно эта терминология используется бизнесом для общения с девами.
P>·>Ты не отвлекайся. Код в статье рассматривай. Расскажи куда там воткнуть это всё в tryAcceptComposition или куда там получится. Я хочу рассмотреть пример когда у метода будет больше одной зависимости. А ты мне предлагаешь зависимости внедрять неявно через аннотации и глобальные переменные. P>Это ваши фантазии. Я ничего не предлагаю внедрать неявно, тем более с глобальными переменными. Это вы с голосами в голове спорите.
Аннотации именно так и работают.
P>·>Ужас. annotation-driven development. Прям Spring, AOP, ejb, 00-е, application container, framework, middleware. Закопай обратно. P>Это то куда идут по большому счету все платформы.
Когда отдают на аутсорс в индию, да. Именно такое рассуждение я как-то слышал "у нас требование покрытия тестами >90%. Аннотации в покрытии не участвуют. Давайте программировать на аннотациях".
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
·>Что-то я не понял прикол. Обычный "грязный" код MaitreD в начале, хоть был и грязным, но его можно было хорошо протестировать и бизнес-логика была сосредоточена в одном месте...
Да, ты не понял. Чувак — специались, он написал мильён блог постов. Твои проблемы ему не интересны.
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, IT, Вы писали:
IT>·>Что-то я не понял прикол. Обычный "грязный" код MaitreD в начале, хоть был и грязным, но его можно было хорошо протестировать и бизнес-логика была сосредоточена в одном месте... IT>Да, ты не понял. Чувак — специались, он написал мильён блог постов. Твои проблемы ему не интересны.
К чему эта апелляция к авторитетам? По делу есть что сказать?
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>Как вас понимать, какая версия вашего мнения считается более актуальной? ·>Разжевываю: ·>"тесты как написано", тк "они ничего не тестируют" — позор. Не важно с моками они или нет. ·>Использование моков или нет — "детали реализации".
"деталь реализации" означает что разница в свойствах несущественна и инструменты взаимозаменяемы, т.к. эквивалентны
Моки и сравнения вовзращаемого значения не эквивалентны. Это следует хотя бы из того факта, что их приходится использовать совместно.
То есть, это инструменты которые решают разные классы задач — вместо "assert x = y" тестируем "унутре вызвали вон тот метод с такими параметрами"
Собственно, уже 20 лет как известно, что особенностью тестов на моках является их хрупкость, т.к. привязываемся буквально к "как написано"
P>>·>Это всё риторика. Любые тесты искажают действительность, просто по определению. Моки — тут вообще не при чём. P>>Любые и все по разному, в разной степени. Моки по своей сути сильнее всего этому подвержены. Пол-приложения не работает при зеленых тестах — обычное дело с моками. ·>Ещё раз повторюсь. Моки — инструмент. Если ты молотком пользоваться не умеешь и постоянно попадаешь по пальцам, то правильным решением будет научиться пользоваться молотком, а не продолжать закручивать гвозди отвёрткой.
Есть два подхода к покрытию — на моках, и классический. У каждого есть и достоинства, и недостатки.
А вы вместо обсуждения конкретных свойств каждого подхода пытаетесь переходить на личности и обсуждать мою квалификацию.
P>>Не вся — моки могут добавлять то чего в природе нет, не водится, или выворачивать наизнанку. Соответствие моков реальному поведению системы всегда остаётся на совести разработчика, а следовательно человеческий фактор в его максимальном проявлении. ·>В параметры тоже можно передавать то чего в природе нет. И что?
Именно. Для классических тестов вы просто берете и покрываете входы по таблице истинности, покрывая именно ожидания пользователя.
В моках у вас такого ориентира, как ожидания пользователя, нет и быть не может.
Отсюда понятно, почему так трудно научить людей правильно пользоваться моками.
P>>·>Моки лишь дополнительный инструмент. Можно им всё сломать, а можно сделать красиво. P>>У вас моки стали какой то панацеей. Вас послушать так у моков одни преимущества, без каких либо недостатков. ·>Это твои фантазии.
Почитайте что сами пишете
P>>Зависимости. Моки отрезают зависимости во время тестирования. Что характерно, моки далеко это не единственный инструмент решения этой поблемы, и далеко не самый эффективный. ·>Ты так и не показал как ты предлагаешь решать эту проблему, только заявил, что решается одной строчкой, но не показал как. Проигнорировал вопрос дважды: Напиши однострочный интеграционный тест для tryAcceptComposition.
Однострочный интеграционный код для tryAcceptCompositio это просто вызов самого контроллера верхнего уровня.
P>>А у вас он стал панацеей ·>Не панацеей, а конкретным решением твоей конкретной проблемы.
Уже который раз мы с вами обсуждаем тестирование, и вы всё время тащите моки в задачи которые легко решаются обычными тестами.
P>>Удвоение количества — это как раз про моки. При одинаковом покрытии кейсов мокам нужно больше кода. ·>Я говорю конкретно о статье. Там кол-во кода удвоилось. Тестовое покрытие упало в несколько раз, зато Без Моков™.
Потому что статья такая.
P>>Так вы хотели, что бы вам в трех словах все тайны мироздания раскрыли? Все статьи такие, что там можно найти частный случай и заткнуть всё сразу. ·>Я хотел, чтобы мне разъяснили нераскрытый вопрос в статье.
Так уже. Это ж вы почемуто считаете что моки делают иерархию плоской, и аргументов не приводите.
P>>·>Я предлагаю использовать ооп. На минутку — что требует бизнес? Реализацию сущности MaitreD. P>>Нет, не требует. Бизнесу до ваших сущностей никакого дела нет. А потому разработчик имеет право выбирать, нужна ли ему такая сущность, и как он её будет моделировать — объектами, классами, актерами итд итд итд Хоть набором переменных, абы это имело практическое обоснование ·>Ясен пень, можно хоть на brainfuck писать, без этого вашего ООП. Но чем модель ближе — тем лучше. ООП как раз направлено на моделирование бизнес-требований как можно более похожим образом — именованная сущность там — именованная сущность здесь. Набор переменных это круто, конечно, но обычно только как практическое обоснование для жоп-секьюрити.
Это принцип direct mapping, к ооп он имеет опосредованное отношение. Как вы будете сами сущности моделировать — дело десятое. Городить классы сущностей — нужно обоснование
P>>Это описание конкретного пайплайна. В ооп подходе у вас будет примерно такая же штукенция. Покрасивее будет, т.к. именованая. Но принципиально всё сохранится. В том и то и бенефит. ·>Какова цель этой штуки? Зачем нам описывать конкретный пайплайн? Что можно полезного делать с этим описанием? Как проверить, что писание верное? Откуда взялось, что "принципиально всё сохранится"?
P>>Проблема с самой статье P>>1. в ооп стоит делать так, как автор показывает для фп варианта — больше контроля, меньше моков, больше юнит-тестов ·>И кода стало больше, и бОльшая часть нетривиального кода не протестирована.
Какой именно код не протестирован?
P>>Это правило для работы с глубокоми иерахиями чего угодно — глубокую запутанную превращаем в плоскую одноуровневую. методы становятся длиннее, но зависимостями управлять легче тк иерархия неглубокая. ·>Ну так внедрение зависимостей DI+CI это и есть плоская иерархия. В конструкторе все зависимости, методы — целевая бизнес-логика. В статье это и было показано, что такой подход эквивалентен частичному применению функций — код под капотом идентичный получается.
Вам для моков нужно реализовывать в т.ч. неявные зависимости. Если вы делаете моками плоску структуру, получаются тесты "проверим что вызвали вон тот метод" т.е. "как написано"
А если мокаете клиент БД или саму бд, то вам надо под тест сконструировать пол-приложения.
·>Ещё раз повторюсь — мок это лишь способ передачи данных внуть метода. В твоём случае ровно то же придётся делать, но передавать через параметры, а не через мок, вот и вся разница.
Мок это тесты конкретного протокола взаимодействия, посредством контроля вызова методов. Отсюда ясно, что внятного оринтира нет — только то, как написано
С обычными тестами вы закладываетесь на ожидания пользователя, и это достаточно осязаемый результат
P>>>>На основе коротких функций мы можем менять компоновку уже по ходу пьесы подстраиваясь под изменения треботваний, а не бетонировать код на все времена. P>>·>"зарезервировать столик" — это Responsibility выполняемое Actor-ом MaitreD. Это понятно бизнесу. P>>Бизнесу до этого никакого дела нет. MaitreD это абстракция уровня реализации. ·>Слова Responsibility и Actor — это из словаря FRD. Т.е. именно эта терминология используется бизнесом для общения с девами.
Успокойтесь. Добавлять классы на основании разговора на митинге — дело так себе. Актор может вообще оказаться целой подсистемой, а может и наколеночным воркером, или даже лямда-функцией
P>>·>Ты не отвлекайся. Код в статье рассматривай. Расскажи куда там воткнуть это всё в tryAcceptComposition или куда там получится. Я хочу рассмотреть пример когда у метода будет больше одной зависимости. А ты мне предлагаешь зависимости внедрять неявно через аннотации и глобальные переменные. P>>Это ваши фантазии. Я ничего не предлагаю внедрать неявно, тем более с глобальными переменными. Это вы с голосами в голове спорите. ·>Аннотации именно так и работают.
Вероятно, это вы их так пишете. У меня с аннотациями никаких глобальных переменных нет, и неявного внедрения зависимостей тоже нет.
У вас видение из 90х или 00х, когда аннотациями лепили абы что.
P>>·>Ужас. annotation-driven development. Прям Spring, AOP, ejb, 00-е, application container, framework, middleware. Закопай обратно. P>>Это то куда идут по большому счету все платформы. ·>Когда отдают на аутсорс в индию, да. Именно такое рассуждение я как-то слышал "у нас требование покрытия тестами >90%. Аннотации в покрытии не участвуют. Давайте программировать на аннотациях".
Я ж говорю — у вас 90е в голове бумкают.
Ровно наоборот — аннотации в покрытии учавствуют, просто обязаны. Прикрутили метаданные — есть тест на это. Используются ли эти метаданные — тоже есть тест.
т.е. аннотация определяет
1. тип
2. схему
3. связывание
4. параметры
Толькое не посредством инжекции и глобальных переменных, как вы думаете, и как это было популярно в 90х и 00х, а цивилизоваными методами.
Здравствуйте, Pauel, Вы писали:
P>·>Разжевываю: P>·>"тесты как написано", тк "они ничего не тестируют" — позор. Не важно с моками они или нет. P>·>Использование моков или нет — "детали реализации". P>"деталь реализации" означает что разница в свойствах несущественна и инструменты взаимозаменяемы, т.к. эквивалентны
Да. Верно. Вместо "дёрнуть метод" — "вернуть данные, которые будут переданы методу".
P>Моки и сравнения вовзращаемого значения не эквивалентны. Это следует хотя бы из того факта, что их приходится использовать совместно. P>То есть, это инструменты которые решают разные классы задач — вместо "assert x = y" тестируем "унутре вызвали вон тот метод с такими параметрами"
"verify(mock).x(y)"
P>Собственно, уже 20 лет как известно, что особенностью тестов на моках является их хрупкость, т.к. привязываемся буквально к "как написано"
Это твои заморочки.
P>·>Ещё раз повторюсь. Моки — инструмент. Если ты молотком пользоваться не умеешь и постоянно попадаешь по пальцам, то правильным решением будет научиться пользоваться молотком, а не продолжать закручивать гвозди отвёрткой. P>Есть два подхода к покрытию — на моках, и классический. У каждого есть и достоинства, и недостатки. P>А вы вместо обсуждения конкретных свойств каждого подхода пытаетесь переходить на личности и обсуждать мою квалификацию.
Я не понимаю какие проблемы у тебя с моками. А ты хранишь это в секрете. Только общие слова-отмазы "всем давно известно".
P>>>Не вся — моки могут добавлять то чего в природе нет, не водится, или выворачивать наизнанку. Соответствие моков реальному поведению системы всегда остаётся на совести разработчика, а следовательно человеческий фактор в его максимальном проявлении. P>·>В параметры тоже можно передавать то чего в природе нет. И что? P>Именно. Для классических тестов вы просто берете и покрываете входы по таблице истинности, покрывая именно ожидания пользователя. P>В моках у вас такого ориентира, как ожидания пользователя, нет и быть не может. P>Отсюда понятно, почему так трудно научить людей правильно пользоваться моками.
Единственное что не так с моками, это то, что это по сути подразумевается дизайн с side effects и non-pure функции. Это может быть плохо с т.з. теории и прочей чистой функциональщины, но на практике подавляющее количество кода всё равно с side effects. Может у тебя другой опыт и у тебя большинство проектов на хаскелле с монадами... но я почему-то сомневаюсь.
И ты тут телегу впереди лошади поставил. Ну да, у нас есть дизайн с side effects — что ж, либо давайте всё переписывать на хаскель, либо просто заюзаем моки для тестирования. У тебя есть третий вариант?
P>>>Зависимости. Моки отрезают зависимости во время тестирования. Что характерно, моки далеко это не единственный инструмент решения этой поблемы, и далеко не самый эффективный. P>·>Ты так и не показал как ты предлагаешь решать эту проблему, только заявил, что решается одной строчкой, но не показал как. Проигнорировал вопрос дважды: Напиши однострочный интеграционный тест для tryAcceptComposition. P>Однострочный интеграционный код для tryAcceptCompositio это просто вызов самого контроллера верхнего уровня.
Проигнорировал вопрос трижды: Напиши однострочный интеграционный тест для tryAcceptComposition. Код в студию!
P>>>Удвоение количества — это как раз про моки. При одинаковом покрытии кейсов мокам нужно больше кода. P>·>Я говорю конкретно о статье. Там кол-во кода удвоилось. Тестовое покрытие упало в несколько раз, зато Без Моков™. P>Потому что статья такая.
У тебя есть что-то лучше?
P>>>Так вы хотели, что бы вам в трех словах все тайны мироздания раскрыли? Все статьи такие, что там можно найти частный случай и заткнуть всё сразу. P>·>Я хотел, чтобы мне разъяснили нераскрытый вопрос в статье. P>Так уже. Это ж вы почемуто считаете что моки делают иерархию плоской, и аргументов не приводите.
Где я так считаю? Моки ничего сами не делают. Это инструмент тестирования.
P>·>Ясен пень, можно хоть на brainfuck писать, без этого вашего ООП. Но чем модель ближе — тем лучше. ООП как раз направлено на моделирование бизнес-требований как можно более похожим образом — именованная сущность там — именованная сущность здесь. Набор переменных это круто, конечно, но обычно только как практическое обоснование для жоп-секьюрити. P>Это принцип direct mapping, к ооп он имеет опосредованное отношение. Как вы будете сами сущности моделировать — дело десятое. Городить классы сущностей — нужно обоснование
Ок. Могу согласится, что это дело вкуса. Не так важно класс это или лямбда. Суть моего вопроса по статье — как же писать тесты, чтобы не оставалось непокрытого кода.
P>>>Проблема с самой статье P>>>1. в ооп стоит делать так, как автор показывает для фп варианта — больше контроля, меньше моков, больше юнит-тестов P>·>И кода стало больше, и бОльшая часть нетривиального кода не протестирована. P>Какой именно код не протестирован?
функция tryAcceptComposition. Ты обещал привести однострочный тест, но до сих пор не смог.
P>>>Это правило для работы с глубокоми иерахиями чего угодно — глубокую запутанную превращаем в плоскую одноуровневую. методы становятся длиннее, но зависимостями управлять легче тк иерархия неглубокая. P>·>Ну так внедрение зависимостей DI+CI это и есть плоская иерархия. В конструкторе все зависимости, методы — целевая бизнес-логика. В статье это и было показано, что такой подход эквивалентен частичному применению функций — код под капотом идентичный получается. P>Вам для моков нужно реализовывать в т.ч. неявные зависимости. Если вы делаете моками плоску структуру, получаются тесты "проверим что вызвали вон тот метод" т.е. "как написано"
Это называется whitebox тестирование. Причём тут моки?
P>А если мокаете клиент БД или саму бд, то вам надо под тест сконструировать пол-приложения.
Не очень понял что именно ты имеешь в виду. Вот мы тут вроде статью обсуждаем, там есть код, вот покажи на том коде что не так и как сделать так.
P>·>Ещё раз повторюсь — мок это лишь способ передачи данных внуть метода. В твоём случае ровно то же придётся делать, но передавать через параметры, а не через мок, вот и вся разница. P>Мок это тесты конкретного протокола взаимодействия, посредством контроля вызова методов. Отсюда ясно, что внятного оринтира нет — только то, как написано P>С обычными тестами вы закладываетесь на ожидания пользователя, и это достаточно осязаемый результат
А конкретно? С примерами кода. Как эти ожидания выражаются? Почему "вернуть X" — ты называешь "ожидание пользователя", а "вызвать x()" — "протокол взаимодействия"? И что всё эти термины значат? В чём принципиальная разница?
P>·>Слова Responsibility и Actor — это из словаря FRD. Т.е. именно эта терминология используется бизнесом для общения с девами. P>Успокойтесь. Добавлять классы на основании разговора на митинге — дело так себе. Актор может вообще оказаться целой подсистемой, а может и наколеночным воркером, или даже лямда-функцией
Ок. Каким образом ты делаешь соответствие термина в FRD с куском кода?
P>·>Аннотации именно так и работают. P>Вероятно, это вы их так пишете. У меня с аннотациями никаких глобальных переменных нет, и неявного внедрения зависимостей тоже нет. P>У вас видение из 90х или 00х, когда аннотациями лепили абы что.
А что сейчас? Сделай show&tell, или хотя бы ссылку на.
P>>>·>Ужас. annotation-driven development. Прям Spring, AOP, ejb, 00-е, application container, framework, middleware. Закопай обратно. P>>>Это то куда идут по большому счету все платформы. P>·>Когда отдают на аутсорс в индию, да. Именно такое рассуждение я как-то слышал "у нас требование покрытия тестами >90%. Аннотации в покрытии не участвуют. Давайте программировать на аннотациях". P>Я ж говорю — у вас 90е в голове бумкают. P>Ровно наоборот — аннотации в покрытии учавствуют, просто обязаны.
Покажи мне coverage report, где непокрытые аннотации красненьким подсвечены.
P>Прикрутили метаданные — есть тест на это. Используются ли эти метаданные — тоже есть тест.
Покажи как выглядит тест на то, что аннотация повешена корректно.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>"деталь реализации" означает что разница в свойствах несущественна и инструменты взаимозаменяемы, т.к. эквивалентны ·>Да. Верно. Вместо "дёрнуть метод" — "вернуть данные, которые будут переданы методу"
Это и есть проблема. В новой версии кода например некому будет возвращать, и некому передавать, при полном соответствии с требованиям.
А вот тесты стали красными. Гы-гы.
И если код меняется часто, в силу изменения требований, вам надо каждый раз строчить все тесты с нуля.
Вот пример — у нас есть требование вернуть hash токен что бы по контенту можно было находить метадату итд
Мокист-джедай на полном серьезе мокает
1 импорт — убеждается что импортируется именно тот самый класс из той самой либы
2 класс — что бы мокнуть метод и проверяет, что переданы те самые параметры
3 метод hash — что бы мокнуть другой метод, убеждается, что в него приходят те самые значения
4 метод digest, что бы получить значение
и проверяет, что полученное значение и есть то, что было выдано digest
кода получается вагон и маленькая тележка
А теперь фиаско — в либе есть уязвимость и проблема с перформансом, и её надо заменить, гы-гы все тесты на моках ушли на помойкку
А если делать иначе, то юнит тестом покрываем вычисления токена — передаём контент и для него получаем тот самый токен.
Теперь можно либу менять хоть по сто раз на дню, тесты это никак не меняет
и кода у нас ровно один короткий тест, который вызывается с двумя-тремя десятками разных вариантов параметров, из которых большая часть это обработка ошибок, граничных случаев итд итд
P>>То есть, это инструменты которые решают разные классы задач — вместо "assert x = y" тестируем "унутре вызвали вон тот метод с такими параметрами" ·>"verify(mock).x(y)"
Вместо просто assert x = y вам надо засетапить мок и надеяться, что новые требования не сломают дизайн вашего решения.
P>>Собственно, уже 20 лет как известно, что особенностью тестов на моках является их хрупкость, т.к. привязываемся буквально к "как написано" ·>Это твои заморочки.
Вы чуть ниже сами об этом же пишете. Тесты на моках это те самые вайт бокс тесты, принципиально. И у них известный набор проблем, среди которых основной это хрупкость.
P>>Есть два подхода к покрытию — на моках, и классический. У каждого есть и достоинства, и недостатки. P>>А вы вместо обсуждения конкретных свойств каждого подхода пытаетесь переходить на личности и обсуждать мою квалификацию. ·>Я не понимаю какие проблемы у тебя с моками. А ты хранишь это в секрете. Только общие слова-отмазы "всем давно известно".
Проблема простая — из тех проектов, что попадают ко мне, хоть опенсорс, хоть нет, в большинстве случаев тесты на моках или бесполезны, и толку нет, или дырявые, и надо фиксить, или вносят путаницу из за объема кода, и это тоже надо фиксить, или требования меняются радикально, а значит смена дизайна, и это снова надо фиксать
А вот если в проекте пошли по пути классического юнит-тестирования, то как правило тесты особого внимания не требуют — все работает само.
·>И ты тут телегу впереди лошади поставил. Ну да, у нас есть дизайн с side effects — что ж, либо давайте всё переписывать на хаскель, либо просто заюзаем моки для тестирования. У тебя есть третий вариант?
При чем здесь сайд эффекты?
P>>·>Ты так и не показал как ты предлагаешь решать эту проблему, только заявил, что решается одной строчкой, но не показал как. Проигнорировал вопрос дважды: Напиши однострочный интеграционный тест для tryAcceptComposition. P>>Однострочный интеграционный код для tryAcceptCompositio это просто вызов самого контроллера верхнего уровня. ·>Проигнорировал вопрос трижды: Напиши однострочный интеграционный тест для tryAcceptComposition. Код в студию!
P>>Так уже. Это ж вы почемуто считаете что моки делают иерархию плоской, и аргументов не приводите. ·>Где я так считаю? Моки ничего сами не делают. Это инструмент тестирования.
Вот некто с вашего акканута пишет
Ну так внедрение зависимостей DI+CI это и есть плоская иерархия.
P>>Это принцип direct mapping, к ооп он имеет опосредованное отношение. Как вы будете сами сущности моделировать — дело десятое. Городить классы сущностей — нужно обоснование ·>Ок. Могу согласится, что это дело вкуса. Не так важно класс это или лямбда. Суть моего вопроса по статье — как же писать тесты, чтобы не оставалось непокрытого кода.
Нету такой задачи покрывать код. Тестируются ожидания пользователя, соответствие требованиями, выявление особенностей поведения и тд.
P>>Какой именно код не протестирован? ·>функция tryAcceptComposition. Ты обещал привести однострочный тест, но до сих пор не смог.
Мне непонято что в моем объяснении вам не ясно
P>>·>Ну так внедрение зависимостей DI+CI это и есть плоская иерархия. В конструкторе все зависимости, методы — целевая бизнес-логика. В статье это и было показано, что такой подход эквивалентен частичному применению функций — код под капотом идентичный получается. P>>Вам для моков нужно реализовывать в т.ч. неявные зависимости. Если вы делаете моками плоску структуру, получаются тесты "проверим что вызвали вон тот метод" т.е. "как написано" ·>Это называется whitebox тестирование. Причём тут моки?
Браво — вы вспомнили про вайтбокс. Моки это в чистом виде вайтбокс, я это вам в прошлый раз говорил раз десять
А следовательно, у моков есть все недостатки, характерные для вайтбокс
Первая ссылка в гугле:
Expensive
If the code base is changing quickly, automated test cases are useless
Incomplete cases
Time consuming
More errors
А вот если вы идете методом блакбокс тестирования, то никакие моки вам применить не удастся, и это дает более устойчивый код решения и более устойчивые тесты
P>>А если мокаете клиент БД или саму бд, то вам надо под тест сконструировать пол-приложения. ·>Не очень понял что именно ты имеешь в виду. Вот мы тут вроде статью обсуждаем, там есть код, вот покажи на том коде что не так и как сделать так.
Уже объяснил. Что именно вам непонятно?
·>А конкретно? С примерами кода. Как эти ожидания выражаются? Почему "вернуть X" — ты называешь "ожидание пользователя", а "вызвать x()" — "протокол взаимодействия"? И что всё эти термины значат? В чём принципиальная разница?
Например, сделали другой дизайн решения, например, отказались от сущности MaitreD, и всё ваше на моках сломано.
А вот простые тесты на вычисления резервирования остаются, потому как ни на какой MaitreD не завязаны. Что будет вместо MaitreD — вообще дело десятое.
P>>·>Слова Responsibility и Actor — это из словаря FRD. Т.е. именно эта терминология используется бизнесом для общения с девами. P>>Успокойтесь. Добавлять классы на основании разговора на митинге — дело так себе. Актор может вообще оказаться целой подсистемой, а может и наколеночным воркером, или даже лямда-функцией ·>Ок. Каким образом ты делаешь соответствие термина в FRD с куском кода?
Выбираю абстракцию наименьшего размера, которая покрывает кейс, и которую я могу протестировать
P>>У вас видение из 90х или 00х, когда аннотациями лепили абы что. ·>А что сейчас? Сделай show&tell, или хотя бы ссылку на.
Я уже показывал что в прошлый раз, что в этот — отлистайте да посмотрите. Это ваша проблема что вы умеете только свойства инжектать да конструкторы лепить
Вы в очередной раз просто обесцениваете, а потом просите что бы я показал вам тож самое еще раз
P>>Ровно наоборот — аннотации в покрытии учавствуют, просто обязаны. ·>Покажи мне coverage report, где непокрытые аннотации красненьким подсвечены.
Expectation failed: ControllerX tryAccept to have metadata {...}
P>>Прикрутили метаданные — есть тест на это. Используются ли эти метаданные — тоже есть тест. ·>Покажи как выглядит тест на то, что аннотация повешена корректно.
Здравствуйте, Pauel, Вы писали:
P>>>"деталь реализации" означает что разница в свойствах несущественна и инструменты взаимозаменяемы, т.к. эквивалентны P>·>Да. Верно. Вместо "дёрнуть метод" — "вернуть данные, которые будут переданы методу" P>Это и есть проблема. В новой версии кода например некому будет возвращать, и некому передавать, при полном соответствии с требованиям. P>А вот тесты стали красными. Гы-гы. P>И если код меняется часто, в силу изменения требований, вам надо каждый раз строчить все тесты с нуля. P>Вот пример — у нас есть требование вернуть hash токен что бы по контенту можно было находить метадату итд P>кода получается вагон и маленькая тележка
Лучше код покажи. Так что-то не очень ясно.
P>А теперь фиаско — в либе есть уязвимость и проблема с перформансом, и её надо заменить, гы-гы все тесты на моках ушли на помойкку
Круто же — все тесты кода, который используют уязвимую тормозную либу — стали красными. По-моему, успех.
P>А если делать иначе, то юнит тестом покрываем вычисления токена — передаём контент и для него получаем тот самый токен. P>Теперь можно либу менять хоть по сто раз на дню, тесты это никак не меняет
Иными словами ты просто предлагаешь заворачивать стороннюю либу в свою обёртку. Это хорошо, иногда. Вот только моки-то тут причём?
P>и кода у нас ровно один короткий тест, который вызывается с двумя-тремя десятками разных вариантов параметров, из которых большая часть это обработка ошибок, граничных случаев итд итд
Ага. Вот только эта твоя обёртка как будет попадать в использующий код? Через зависимости. И будешь мокать эту обёртку.
P>>>То есть, это инструменты которые решают разные классы задач — вместо "assert x = y" тестируем "унутре вызвали вон тот метод с такими параметрами" P>·>"verify(mock).x(y)" P>Вместо просто assert x = y вам надо засетапить мок и надеяться, что новые требования не сломают дизайн вашего решения.
А чего там сетапить-то? var mock = Mockito.mock(Thing.class). А что там может ломаться и зачем?
P>>>Собственно, уже 20 лет как известно, что особенностью тестов на моках является их хрупкость, т.к. привязываемся буквально к "как написано" P>·>Это твои заморочки. P>Вы чуть ниже сами об этом же пишете. Тесты на моках это те самые вайт бокс тесты, принципиально. И у них известный набор проблем, среди которых основной это хрупкость.
Моки и вайтбокс — это ортогональные понятия.
P>·>Я не понимаю какие проблемы у тебя с моками. А ты хранишь это в секрете. Только общие слова-отмазы "всем давно известно". P>Проблема простая — из тех проектов, что попадают ко мне, хоть опенсорс, хоть нет, в большинстве случаев тесты на моках или бесполезны, и толку нет, или дырявые, и надо фиксить, или вносят путаницу из за объема кода, и это тоже надо фиксить, или требования меняются радикально, а значит смена дизайна, и это снова надо фиксать P>А вот если в проекте пошли по пути классического юнит-тестирования, то как правило тесты особого внимания не требуют — все работает само.
Можно ссылочки?
P>·>И ты тут телегу впереди лошади поставил. Ну да, у нас есть дизайн с side effects — что ж, либо давайте всё переписывать на хаскель, либо просто заюзаем моки для тестирования. У тебя есть третий вариант? P>При чем здесь сайд эффекты?
Условно говоря... Моки используются чтобы чего-то передать или проверить чего нет в сигнатуре метода. Т.е. метод с сайд-эффектами — его поведение зависит не только от его параметров и|или его результат влияет не только на возвращаемое значение.
P>>>·>Ты так и не показал как ты предлагаешь решать эту проблему, только заявил, что решается одной строчкой, но не показал как. Проигнорировал вопрос дважды: Напиши однострочный интеграционный тест для tryAcceptComposition. P>>>Однострочный интеграционный код для tryAcceptCompositio это просто вызов самого контроллера верхнего уровня. P>·>Проигнорировал вопрос трижды: Напиши однострочный интеграционный тест для tryAcceptComposition. Код в студию! P>
P>>>Так уже. Это ж вы почемуто считаете что моки делают иерархию плоской, и аргументов не приводите. P>·>Где я так считаю? Моки ничего сами не делают. Это инструмент тестирования. P>Вот некто с вашего акканута пишет P>
P>Ну так внедрение зависимостей DI+CI это и есть плоская иерархия.
Выделил твою цитату выше. И где ты у меня тут слово "мок" нашел?
P>>>Это принцип direct mapping, к ооп он имеет опосредованное отношение. Как вы будете сами сущности моделировать — дело десятое. Городить классы сущностей — нужно обоснование P>·>Ок. Могу согласится, что это дело вкуса. Не так важно класс это или лямбда. Суть моего вопроса по статье — как же писать тесты, чтобы не оставалось непокрытого кода. P>Нету такой задачи покрывать код. Тестируются ожидания пользователя, соответствие требованиями, выявление особенностей поведения и тд.
Покрытие позволяет найти непротестированный код. Если мы его нашли — мы видим пропущенные требования и начинаем выяснять ожидание пользователя в пропущенном сценарии. И вот после этого тестируем ожидание.
P>>>Какой именно код не протестирован? P>·>функция tryAcceptComposition. Ты обещал привести однострочный тест, но до сих пор не смог. P>Мне непонято что в моем объяснении вам не ясно
Как выглядит код, который тестирует tryAcceptComposition.
P>>>·>Ну так внедрение зависимостей DI+CI это и есть плоская иерархия. В конструкторе все зависимости, методы — целевая бизнес-логика. В статье это и было показано, что такой подход эквивалентен частичному применению функций — код под капотом идентичный получается. P>>>Вам для моков нужно реализовывать в т.ч. неявные зависимости. Если вы делаете моками плоску структуру, получаются тесты "проверим что вызвали вон тот метод" т.е. "как написано" P>·>Это называется whitebox тестирование. Причём тут моки? P>Браво — вы вспомнили про вайтбокс. Моки это в чистом виде вайтбокс, я это вам в прошлый раз говорил раз десять P>А вот если вы идете методом блакбокс тестирования, то никакие моки вам применить не удастся, и это дает более устойчивый код решения и более устойчивые тесты
Вайтбокс знает имплементацию. Каким образом ты будешь блакбоксить такое? int square(int x) {return x == 47919 ? 1254 : x * x;}. Заметь, никаки моков, тривиальная пюрешка.
P>>>А если мокаете клиент БД или саму бд, то вам надо под тест сконструировать пол-приложения. P>·>Не очень понял что именно ты имеешь в виду. Вот мы тут вроде статью обсуждаем, там есть код, вот покажи на том коде что не так и как сделать так. P>Уже объяснил. Что именно вам непонятно?
А я просил что-то объяснять? Я просил показать код.
P>·>А конкретно? С примерами кода. Как эти ожидания выражаются? Почему "вернуть X" — ты называешь "ожидание пользователя", а "вызвать x()" — "протокол взаимодействия"? И что всё эти термины значат? В чём принципиальная разница? P>Например, сделали другой дизайн решения, например, отказались от сущности MaitreD, и всё ваше на моках сломано. P>А вот простые тесты на вычисления резервирования остаются, потому как ни на какой MaitreD не завязаны. Что будет вместо MaitreD — вообще дело десятое.
А конкретно? Простые тесты чего именно в терминах ЯП? Какой языковой конструкции? И почему эта конкретная языковая конструкция отлита в граните и никак никогда поменяться не может?
P>>>Успокойтесь. Добавлять классы на основании разговора на митинге — дело так себе. Актор может вообще оказаться целой подсистемой, а может и наколеночным воркером, или даже лямда-функцией P>·>Ок. Каким образом ты делаешь соответствие термина в FRD с куском кода? P>Выбираю абстракцию наименьшего размера, которая покрывает кейс, и которую я могу протестировать
А если её потом надо будет переделать на другой размер?
P>>>У вас видение из 90х или 00х, когда аннотациями лепили абы что. P>·>А что сейчас? Сделай show&tell, или хотя бы ссылку на. P>Я уже показывал что в прошлый раз, что в этот — отлистайте да посмотрите. Это ваша проблема что вы умеете только свойства инжектать да конструкторы лепить
Ты просто всё ещё не понял: я умею не лепить аннотации.
P>>>Ровно наоборот — аннотации в покрытии учавствуют, просто обязаны. P>·>Покажи мне coverage report, где непокрытые аннотации красненьким подсвечены. P>
P>Expectation failed: ControllerX tryAccept to have metadata {...}
P>
Это не coverage report, это test report.
P>>>Прикрутили метаданные — есть тест на это. Используются ли эти метаданные — тоже есть тест. P>·>Покажи как выглядит тест на то, что аннотация повешена корректно. P>
Самое что ни на есть вайтбокс тестирование. Что конкретный метод содержит конкретную аннотацию. В случае моков это можно изоморфно написать как-то так:
вот только у тебя не будет приколачивания к конкретному методу и никакой рефлекии не надо.
Особенно приключения начнутся, если действия, совершаемые аннотацией потребуют какой-то логики. Например, "а вот в этом методе не делать аудит для внутреннего аккаунта, если цена меньше 100".
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
P>>И если код меняется часто, в силу изменения требований, вам надо каждый раз строчить все тесты с нуля. P>>Вот пример — у нас есть требование вернуть hash токен что бы по контенту можно было находить метадату итд P>>кода получается вагон и маленькая тележка ·>Лучше код покажи. Так что-то не очень ясно.
P>>А теперь фиаско — в либе есть уязвимость и проблема с перформансом, и её надо заменить, гы-гы все тесты на моках ушли на помойкку ·>Круто же — все тесты кода, который используют уязвимую тормозную либу — стали красными. По-моему, успех.
Ну да — проблемы нет а тесты стали красными. И так каждый раз.
P>>А если делать иначе, то юнит тестом покрываем вычисления токена — передаём контент и для него получаем тот самый токен. P>>Теперь можно либу менять хоть по сто раз на дню, тесты это никак не меняет ·>Иными словами ты просто предлагаешь заворачивать стороннюю либу в свою обёртку. Это хорошо, иногда. Вот только моки-то тут причём?
Иными словами я предлагаю использовать value тест где только можно, т.к. таких можно настрочить сколько угодно.
P>>и кода у нас ровно один короткий тест, который вызывается с двумя-тремя десятками разных вариантов параметров, из которых большая часть это обработка ошибок, граничных случаев итд итд ·>Ага. Вот только эта твоя обёртка как будет попадать в использующий код? Через зависимости. И будешь мокать эту обёртку.
Вот я и говорю, что вы без моков жить не можете. Если мы проверили, что функция валидная, зачем нам её мокать? Проблема то какая?
P>>>>То есть, это инструменты которые решают разные классы задач — вместо "assert x = y" тестируем "унутре вызвали вон тот метод с такими параметрами" P>>·>"verify(mock).x(y)" P>>Вместо просто assert x = y вам надо засетапить мок и надеяться, что новые требования не сломают дизайн вашего решения. ·>А чего там сетапить-то? var mock = Mockito.mock(Thing.class). А что там может ломаться и зачем?
Я не понимаю, что здесь происходит.
P>>Вы чуть ниже сами об этом же пишете. Тесты на моках это те самые вайт бокс тесты, принципиально. И у них известный набор проблем, среди которых основной это хрупкость. ·>Моки и вайтбокс — это ортогональные понятия.
Вы там в своём уме? Чтобы замокать чего нибудь ради теста, вам нужно знание о реализации, следовательно, тесткейс автоматически становится вайтбоксом.
P>>А вот если в проекте пошли по пути классического юнит-тестирования, то как правило тесты особого внимания не требуют — все работает само. ·>Можно ссылочки?
Зачем?
·>Условно говоря... Моки используются чтобы чего-то передать или проверить чего нет в сигнатуре метода. Т.е. метод с сайд-эффектами — его поведение зависит не только от его параметров и|или его результат влияет не только на возвращаемое значение.
В том то и проблема, что вы строите такой дизайн, что бы его потом моками тестировать. Потому и топите везде за моки.
P>>·>Проигнорировал вопрос трижды: Напиши однострочный интеграционный тест для tryAcceptComposition. Код в студию! P>>
·>Заходим на четвёртый круг. Я не знаю что это такое и к чему относится. Напомню код:
Я не в курсе того фп языка, и ничего на нем не выдам. Для интеграционного тестам нам надо вызвать контроллер верхнего уровня, и убедиться, что результат тот самый.
В том и бенефит — раз вся логика покрыта юнит-тестами, то tryAcceptComposition нужно покрыть интеграционным тестом, ради чего никаких моков лепить не нужно
Вы идете наоброт — выпихиваете всё в контроллер, тогда дешевыми юнит-тестами покрывать нечего, зато теперь надо контроллер обкладывать моками, чтобы хоть как то протестировать.
P>>Вот некто с вашего акканута пишет P>>
P>>Ну так внедрение зависимостей DI+CI это и есть плоская иерархия.
·>Выделил твою цитату выше. И где ты у меня тут слово "мок" нашел?
Если это не про моки, то вопросов еще больше. Каким образом иерархия контроллер <- сервис-бл <- репозиторий <- клиент-бд стала у вас вдруг плоской?
Я думал вы собираетесь замокать все зависимости контроллера, но вы похоже бьете все рекорды
P>>Нету такой задачи покрывать код. Тестируются ожидания пользователя, соответствие требованиями, выявление особенностей поведения и тд. ·>Покрытие позволяет найти непротестированный код. Если мы его нашли — мы видим пропущенные требования и начинаем выяснять ожидание пользователя в пропущенном сценарии. И вот после этого тестируем ожидание.
Совсем необязательно. Тесты это далеко не единственный инструмент в обеспечении качества. Потому покрывать код идея изначально утопичная. Покрывать нужно требования, ожидания вызывающей стороны, а не код.
Для самого кода у нас много разных инструментов — от генерации по мат-модели, всяких инвариантов-пред-пост-условий и до код-ревью.
P>>Мне непонято что в моем объяснении вам не ясно ·>Как выглядит код, который тестирует tryAcceptComposition.
Да хоть вот так, утрирую конечно
curl -X POST -H "Content-Type: application/json" -d '{<резервирование>}' http://localhost:3000/api/v3/reservation
P>>Браво — вы вспомнили про вайтбокс. Моки это в чистом виде вайтбокс, я это вам в прошлый раз говорил раз десять P>>А вот если вы идете методом блакбокс тестирования, то никакие моки вам применить не удастся, и это дает более устойчивый код решения и более устойчивые тесты ·>Вайтбокс знает имплементацию. Каким образом ты будешь блакбоксить такое? int square(int x) {return x == 47919 ? 1254 : x * x;}. Заметь, никаки моков, тривиальная пюрешка.
Постусловия к вам еще не завезли? Это блакбокс, только это совсем не тест.
P>>Уже объяснил. Что именно вам непонятно? ·>А я просил что-то объяснять? Я просил показать код.
curl -X POST -H "Content-Type: application/json" -d '{<резервирование>}' http://localhost:3000/api/v3/reservation
P>>А вот простые тесты на вычисления резервирования остаются, потому как ни на какой MaitreD не завязаны. Что будет вместо MaitreD — вообще дело десятое. ·>А конкретно? Простые тесты чего именно в терминах ЯП? Какой языковой конструкции? И почему эта конкретная языковая конструкция отлита в граните и никак никогда поменяться не может?
Вы же моками обрезаете зависимости. Забыли? Каждая зависимость = причины для изменений.
Простая функция типа "пюрешечки" — у неё зависимостей около нуля. Меньше зависимостей — меньше причин для изменения.
В идеале меняем только если поменяется бизнес-логика. Например, решим сделать все большие столы общими, что бы усадить больше гостей. Тогда нам нужно будет переделать функцию резервирования и много чего еще И это единственное основание для изменения, кроме найденных багов.
Вот с maitred все не просто — любое изменение дизайна затрагивает такой класс, тк у него куча зависимостей, каждая из которых может меняться по разными причнам.
И вам каждый раз надо будет подфикшивать тесты.
P>>Выбираю абстракцию наименьшего размера, которая покрывает кейс, и которую я могу протестировать ·>А если её потом надо будет переделать на другой размер?
Мне нужно, что бы изменения были из за изменения бизнес-логики, а не из за изменения дизайна смежных компонентов.
P>>>>Ровно наоборот — аннотации в покрытии учавствуют, просто обязаны. P>>·>Покажи мне coverage report, где непокрытые аннотации красненьким подсвечены. P>>
P>>Expectation failed: ControllerX tryAccept to have metadata {...}
P>>
·>Это не coverage report, это test report.
Тогда не совсем понятен ваш вопрос.
P>>>>Прикрутили метаданные — есть тест на это. Используются ли эти метаданные — тоже есть тест. P>>·>Покажи как выглядит тест на то, что аннотация повешена корректно. P>>
·>Самое что ни на есть вайтбокс тестирование. Что конкретный метод содержит конкретную аннотацию.
Мы тестируем, что есть те или иные метаданные. А вот чем вы их установите — вообще дело десятое.
А вот метаданные это совсем не вайтбокс, это нефункциональные требования.
·>
·>вот только у тебя не будет приколачивания к конкретному методу
Ну то есть tryAccept что в вашем тесте это никакой не конкретный метод?
> и никакой рефлекии не надо.
В вашем случае придется пол-приложения перемокать, что бы сделать вызов tryAccept, и так повторить для каждого публичного метода.
·>Особенно приключения начнутся, если действия, совершаемые аннотацией потребуют какой-то логики. Например, "а вот в этом методе не делать аудит для внутреннего аккаунта, если цена меньше 100".
В вашем случае придется писать намного больше кода из за моков — перемокать всё подряд что бы выдать "вот этот метод не вызвался тут, там" и так по всем 100500 кейсам
Мне нужно будет добавить функцию которая будет возвращать экземпляр аудитора по метаданным и покрыть её простыми дешовыми тестами. А раз весь аудит проходить будет через неё, то достаточно сверху накинуть интеграционный тест, 1шт









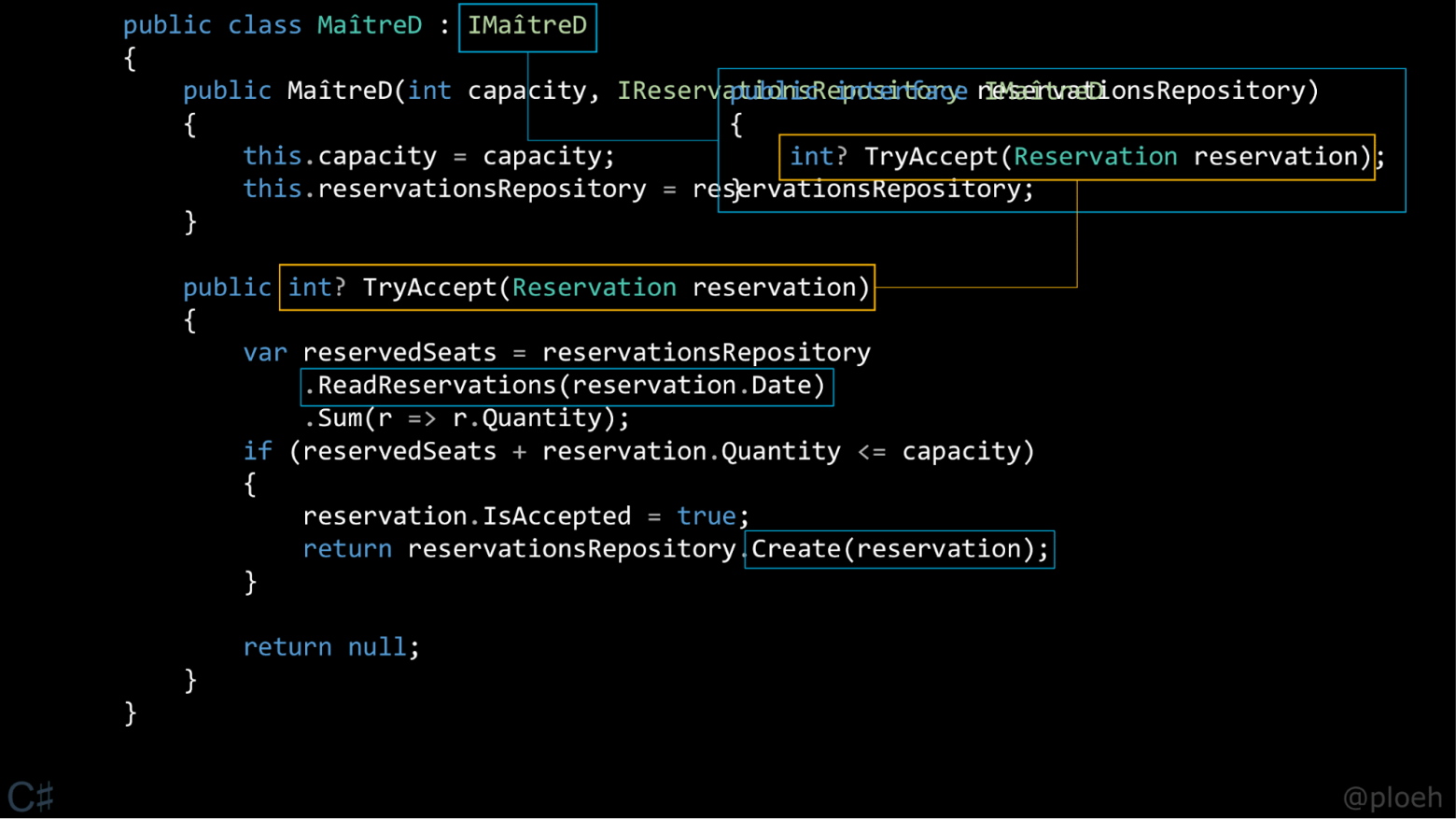

 Если нам не помогут, то мы тоже никого не пощадим.
Если нам не помогут, то мы тоже никого не пощадим.
