Сообщение Re[25]: Опциональные типы от 12.03.2017 6:13
Изменено 12.03.2017 6:24 vdimas
Re[25]: Опциональные типы
Здравствуйте, WolfHound, Вы писали:
V>>У меня лучшее только то, что я делаю на основной своей работе.
WH>Учитывая, что ты тут несёшь я в этом сомневаюсь.
Так и что я "несу"-то?
Покажешь хоть раз или нет?
WH>И это очень быстро. Автор ATNLR на свой парсер потратил 25 лет. И результат хуже.
Автор ATNLR может и меньше чистого времени этим занимался. Он в рабочее время преподаёт, насколько я понял.
И насчет хуже-лучше — это тебе в азы качества ПО надо.
Хуже-лучше определяется только по удовлетворению исходным требованиям.
Если у них не стояла задача разработать ИДЕ, то ты НЕ можешь сравнивать по таким требованиям.
У них стояла задача разработать учебную визуальную модель представления грамматик, по которой (модели) можно визуально отлаживаться в процессе проектирования этих грамматик. В этом плане их результат на порядки лучше твоего, бо у тебя нет таких визуальных ср-в отладки грамматики, как в ANTLR:

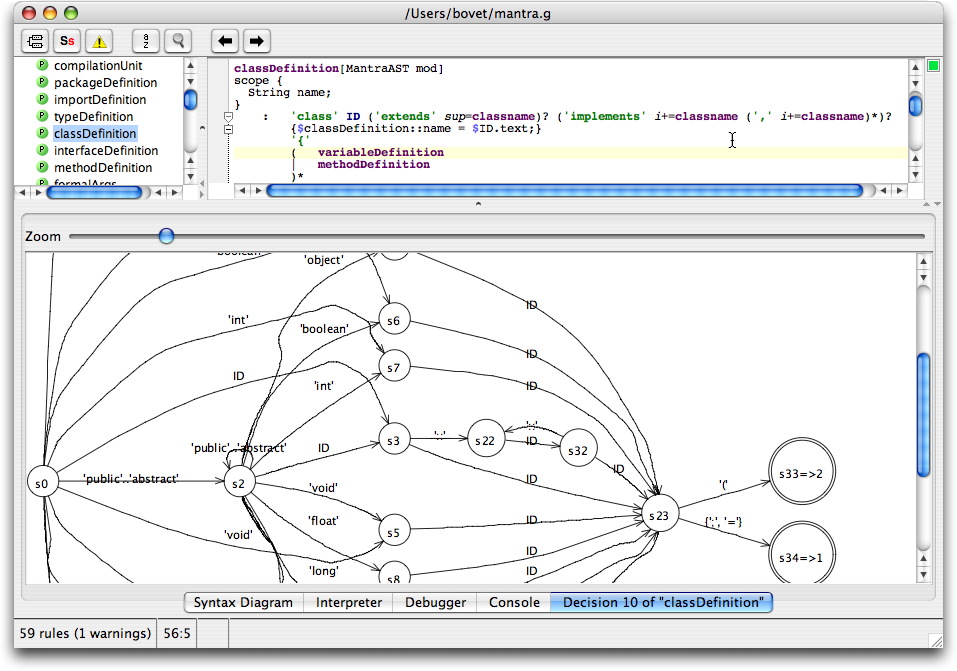
У тебя профайлер грамматики есть?
Каким-либо образом можно узнать в Нитре, на сколько операций парсинга стало больше-меньше на тестовом примере после изменения грамматики?
V>>Потому что в правилах до половины нетерминалов могут быть промежуточными, ни разу не интересными для восстановления до них.
WH>Вот это и есть ручное описание правил восстановления.
WH>В нитре это делать не нужно. Там даже такой возможности нет.
WH>Всё работает в полностью автоматическом режиме.
WH>Прикинь парсер сам понимает, что нужно удалить, что добавить и где начинается нормальный текст.
Ну так не описывай восстановление в Бизоне и тоже всё будет автоматом.
Там вообще своё восстановление написать можно, бо кишки Бизона открыты.
Да и не нужно это восстановление при простой компиляции файла, обычно не стоит задача найти все ошибки в файле во время компиляции.
WH>>>1)Это куча мутной работы.
V>>Это примерно такая же работа, как в языке расширенных регулярных выражений отличать конечные правила от промежуточных.
WH>Что за бред опять?
Что именно ты тут опять не понял?
Какой из терминов вызывал затруднения?
(и кто-то еще пытается обвинять в непонятливости окружающих :facepalm
WH>>>Если бы нитра текла меня бы тут на смех всем RSDN'ом подняли.
V>>А как бы она у тебя текла на GC?
WH>Да там не важно на ГЦ она или нет. Там всё и без ГЦ переделать можно. И ничего течь не будет.
А с чего ты взял, что Бизон течет?
Там сказано, что после ошибки необходимо выполнить такие-то и такие-то действия.
Откуда Бизон знает — закончил ты извлекать инфу об ошибке или еще нет?
Может, ты вручную восстанавливаешься?
Бизон — это больше конструктор, чем полноценная система.
"Заверни" парсер от Бизона в некую высокоуровневую свою среду, которая будет знать, где она закончила разбираться с ошибками, а где уже работает дальше и ву а ля — пусть вызовет прочистку временных данных в нужный момент времени.
=====================
Кароч, ты всё время не туда и не о том.
Давай в сухом остатке, что ты тут задвигал:
1. Простой пример можно сделать быстро. (С)
Согласен, поэтапная работа должна с чего-то начинаться.
С макета.
Например, первый вариант Эрли, показанный когда-то здесь, был ужасен по эффективности.
На последующих этапах можно смотреть, где и что, как подкрутить и чем вызваны тормоза.
Ты же используешь сейчас Эрли, не смотря на весь его ужас в случае примитивной реализации "в лоб"?
Идём далее. Ты настаиваешь:
2. У меня самый быстрый парсер. (С)
Итого, ЛЮБОЙ самый первый вариант/макет ЛЮБОГО парсера будет подвергнут неадекватной обструкции сходу.
Собсно, весь вот этот топик, всё что ты озвучивал — это фактически твоя клятва на крови, что так и будет.
Молоток, чо!
Идём далее. Даже если через несколько итераций и растраты неимоверных запасов терпения для игнора твоего неадеквата/негатива удаётся довести исходный макет до вмеяемой по скорости работы (в сравнении с твоей вылизанной версией Эрли, хотя бы), то у тебя всё-равно приготовлены пути для отступления:
3. Моя Нитра всё-равно лучше всех восстанавливается, я потратил на это много лет. (С)
Итого — а смысл вообще тратить на что-то время СЕЙЧАС, после потраченный тобой кучи лет на восстановление?
Рука-лицо много раз.
Даже если другой алгоритм разбора будет намного эффективнее Эрли и будет близок к LALR(1) по производительности, это уже не имеет никакого значения. Всё, тю-тю, поезд уже ушёл, а ты проспал.
Тебе надо было смотреть на GLR еще тогда, когда я именно что предлагал посмотреть на этот алгоритм как эффективную альтернативу Эрли.
Потому что иначе получается так, что если на RSDN на блюдечке с голубой каёмочкой кто-то выложил реализацию Эрли, то ты её и асилил.
А если тебе так же под нос не поставили — то уже и нет.
Вот такой у тебя в сухом остатке получается бред.
Ну а я тебе рядом дал ссылки, которые подтверждают мои слова:
http://www.rsdn.org/forum/philosophy/6722767.1
Ты их сам не нашёл? — это минус тебе, а не мне.
Причем, сам алгоритм GLR я тоже когда-то давно "изобрел" независимо (писал тогда же), бо с интернетом в конце 90-х было так себе, т.е. далеко не всё можно было найти в вебе, да и поиск тогда был так себе.
Как и этот фокус с возможностью допиливания исходной идеи параллельного парсинга до эффективной работы на однозначных цепочках (коих до 90% в обычном исходнике). Accent и Elk тогда тоже еще не были опубликованы.
Да и какая разница, опубликован ли Accent или Elk? Мои исходные утверждения были и есть истинными и без этих публикаций.
Мне, может, тогда хотелось лишь обсудить найденные мною трюки, а обсудить на сайте их не с кем. Вот вы с Владом подвернулись тогда, бо тоже носились с парсингом. Но из вас еще те обсуждальщики, угу. У вас же философия — "за пределами МКАДА жизни нет". Т.е., что вы руками сами не трогали, того и не существует... Скучные вы, кароч... )) Не любопытные. И ладно если еще лет 10 назад, когда тебе было 26/27 я еще мог списывать твою неадекватность на подзадержавшееся детство и некую сумбурность в голове, но сейчас такая сумбурность — это очередное ой. ))
V>>У меня лучшее только то, что я делаю на основной своей работе.
WH>Учитывая, что ты тут несёшь я в этом сомневаюсь.
Так и что я "несу"-то?
Покажешь хоть раз или нет?
WH>И это очень быстро. Автор ATNLR на свой парсер потратил 25 лет. И результат хуже.
Автор ATNLR может и меньше чистого времени этим занимался. Он в рабочее время преподаёт, насколько я понял.
И насчет хуже-лучше — это тебе в азы качества ПО надо.
Хуже-лучше определяется только по удовлетворению исходным требованиям.
Если у них не стояла задача разработать ИДЕ, то ты НЕ можешь сравнивать по таким требованиям.
У них стояла задача разработать учебную визуальную модель представления грамматик, по которой (модели) можно визуально отлаживаться в процессе проектирования этих грамматик. В этом плане их результат на порядки лучше твоего, бо у тебя нет таких визуальных ср-в отладки грамматики, как в ANTLR:
У тебя профайлер грамматики есть?
Каким-либо образом можно узнать в Нитре, на сколько операций парсинга стало больше-меньше на тестовом примере после изменения грамматики?
V>>Потому что в правилах до половины нетерминалов могут быть промежуточными, ни разу не интересными для восстановления до них.
WH>Вот это и есть ручное описание правил восстановления.
WH>В нитре это делать не нужно. Там даже такой возможности нет.
WH>Всё работает в полностью автоматическом режиме.
WH>Прикинь парсер сам понимает, что нужно удалить, что добавить и где начинается нормальный текст.
Ну так не описывай восстановление в Бизоне и тоже всё будет автоматом.
Там вообще своё восстановление написать можно, бо кишки Бизона открыты.
Да и не нужно это восстановление при простой компиляции файла, обычно не стоит задача найти все ошибки в файле во время компиляции.
WH>>>1)Это куча мутной работы.
V>>Это примерно такая же работа, как в языке расширенных регулярных выражений отличать конечные правила от промежуточных.
WH>Что за бред опять?
Что именно ты тут опять не понял?
Какой из терминов вызывал затруднения?
(и кто-то еще пытается обвинять в непонятливости окружающих :facepalm
WH>>>Если бы нитра текла меня бы тут на смех всем RSDN'ом подняли.
V>>А как бы она у тебя текла на GC?
WH>Да там не важно на ГЦ она или нет. Там всё и без ГЦ переделать можно. И ничего течь не будет.
А с чего ты взял, что Бизон течет?
Там сказано, что после ошибки необходимо выполнить такие-то и такие-то действия.
Откуда Бизон знает — закончил ты извлекать инфу об ошибке или еще нет?
Может, ты вручную восстанавливаешься?
Бизон — это больше конструктор, чем полноценная система.
"Заверни" парсер от Бизона в некую высокоуровневую свою среду, которая будет знать, где она закончила разбираться с ошибками, а где уже работает дальше и ву а ля — пусть вызовет прочистку временных данных в нужный момент времени.
=====================
Кароч, ты всё время не туда и не о том.
Давай в сухом остатке, что ты тут задвигал:
1. Простой пример можно сделать быстро. (С)
Согласен, поэтапная работа должна с чего-то начинаться.
С макета.
Например, первый вариант Эрли, показанный когда-то здесь, был ужасен по эффективности.
На последующих этапах можно смотреть, где и что, как подкрутить и чем вызваны тормоза.
Ты же используешь сейчас Эрли, не смотря на весь его ужас в случае примитивной реализации "в лоб"?
Идём далее. Ты настаиваешь:
2. У меня самый быстрый парсер. (С)
Итого, ЛЮБОЙ самый первый вариант/макет ЛЮБОГО парсера будет подвергнут неадекватной обструкции сходу.
Собсно, весь вот этот топик, всё что ты озвучивал — это фактически твоя клятва на крови, что так и будет.
Молоток, чо!
Идём далее. Даже если через несколько итераций и растраты неимоверных запасов терпения для игнора твоего неадеквата/негатива удаётся довести исходный макет до вмеяемой по скорости работы (в сравнении с твоей вылизанной версией Эрли, хотя бы), то у тебя всё-равно приготовлены пути для отступления:
3. Моя Нитра всё-равно лучше всех восстанавливается, я потратил на это много лет. (С)
Итого — а смысл вообще тратить на что-то время СЕЙЧАС, после потраченный тобой кучи лет на восстановление?
Рука-лицо много раз.
Даже если другой алгоритм разбора будет намного эффективнее Эрли и будет близок к LALR(1) по производительности, это уже не имеет никакого значения. Всё, тю-тю, поезд уже ушёл, а ты проспал.
Тебе надо было смотреть на GLR еще тогда, когда я именно что предлагал посмотреть на этот алгоритм как эффективную альтернативу Эрли.
Потому что иначе получается так, что если на RSDN на блюдечке с голубой каёмочкой кто-то выложил реализацию Эрли, то ты её и асилил.
А если тебе так же под нос не поставили — то уже и нет.
Вот такой у тебя в сухом остатке получается бред.
Ну а я тебе рядом дал ссылки, которые подтверждают мои слова:
http://www.rsdn.org/forum/philosophy/6722767.1
Ты их сам не нашёл? — это минус тебе, а не мне.
Причем, сам алгоритм GLR я тоже когда-то давно "изобрел" независимо (писал тогда же), бо с интернетом в конце 90-х было так себе, т.е. далеко не всё можно было найти в вебе, да и поиск тогда был так себе.
Как и этот фокус с возможностью допиливания исходной идеи параллельного парсинга до эффективной работы на однозначных цепочках (коих до 90% в обычном исходнике). Accent и Elk тогда тоже еще не были опубликованы.
Да и какая разница, опубликован ли Accent или Elk? Мои исходные утверждения были и есть истинными и без этих публикаций.
Мне, может, тогда хотелось лишь обсудить найденные мною трюки, а обсудить на сайте их не с кем. Вот вы с Владом подвернулись тогда, бо тоже носились с парсингом. Но из вас еще те обсуждальщики, угу. У вас же философия — "за пределами МКАДА жизни нет". Т.е., что вы руками сами не трогали, того и не существует... Скучные вы, кароч... )) Не любопытные. И ладно если еще лет 10 назад, когда тебе было 26/27 я еще мог списывать твою неадекватность на подзадержавшееся детство и некую сумбурность в голове, но сейчас такая сумбурность — это очередное ой. ))
Re[25]: Опциональные типы
Здравствуйте, WolfHound, Вы писали:
V>>У меня лучшее только то, что я делаю на основной своей работе.
WH>Учитывая, что ты тут несёшь я в этом сомневаюсь.
Так и что я "несу"-то?
Покажешь хоть раз или нет?
WH>И это очень быстро. Автор ATNLR на свой парсер потратил 25 лет. И результат хуже.
Автор ATNLR может и меньше чистого времени этим занимался. Он в рабочее время преподаёт, насколько я понял.
И насчет хуже-лучше — это тебе в азы качества ПО надо.
Хуже-лучше определяется только по удовлетворению исходным требованиям.
Если у них не стояла задача разработать ИДЕ для целевых языков программирования, то ты НЕ можешь сравнивать по таким требованиям.
У них вообще не было таких ограничений — разработка пасеров только под ЯП.
Они и над бинарными данными чудесно парсинг делают.
У них стояла задача разработать учебную визуальную модель представления грамматик, по которой (модели) можно визуально отлаживаться в процессе проектирования этих грамматик. В этом плане их результаты лучше твоего, бо у тебя нет таких визуальных ср-в отладки грамматики, как в ANTLR:
А профайлер грамматики у тебя есть?
Каким-либо образом можно узнать в Нитре, на сколько операций парсинга стало больше-меньше на тестовом примере после изменения грамматики?
V>>Потому что в правилах до половины нетерминалов могут быть промежуточными, ни разу не интересными для восстановления до них.
WH>Вот это и есть ручное описание правил восстановления.
WH>В нитре это делать не нужно. Там даже такой возможности нет.
WH>Всё работает в полностью автоматическом режиме.
WH>Прикинь парсер сам понимает, что нужно удалить, что добавить и где начинается нормальный текст.
Ну так не описывай восстановление в Бизоне и тоже всё будет автоматом.
Там вообще своё восстановление написать можно, бо кишки Бизона открыты.
Да и не нужно это восстановление при простой компиляции файла, обычно не стоит задача найти все ошибки в файле во время компиляции.
WH>>>1)Это куча мутной работы.
V>>Это примерно такая же работа, как в языке расширенных регулярных выражений отличать конечные правила от промежуточных.
WH>Что за бред опять?
Что именно ты тут опять не понял?
Какой из терминов вызывал затруднения?
(и кто-то еще пытается обвинять в непонятливости окружающих )
WH>>>Если бы нитра текла меня бы тут на смех всем RSDN'ом подняли.
V>>А как бы она у тебя текла на GC?
WH>Да там не важно на ГЦ она или нет. Там всё и без ГЦ переделать можно. И ничего течь не будет.
А с чего ты взял, что Бизон течет?
Там сказано, что после ошибки необходимо выполнить такие-то и такие-то действия.
Откуда Бизон знает — закончил ты извлекать инфу об ошибке или еще нет?
Может, ты вручную восстанавливаешься?
Бизон — это больше конструктор, чем полноценная система.
"Заверни" парсер от Бизона в некую высокоуровневую свою среду, которая будет знать, где она закончила разбираться с ошибками, а где уже работает дальше и ву а ля — пусть вызовет прочистку временных данных в нужный момент времени.
=====================
Кароч, ты всё время не туда и не о том.
Давай в сухом остатке, что ты тут задвигал:
1. Простой пример можно сделать быстро. (С)
Согласен, поэтапная работа должна с чего-то начинаться.
С макета.
Например, первый вариант Эрли, показанный когда-то здесь, был ужасен по эффективности.
На последующих этапах можно смотреть, где и что, как подкрутить и чем вызваны тормоза.
Ты же используешь сейчас Эрли, не смотря на весь его ужас в случае примитивной реализации "в лоб"?
Идём далее. Ты настаиваешь:
2. У меня самый быстрый парсер. (С)
Итого, ЛЮБОЙ самый первый вариант/макет ЛЮБОГО парсера будет подвергнут неадекватной обструкции сходу.
Собсно, весь вот этот топик, всё что ты озвучивал — это фактически твоя клятва на крови, что так и будет.
Молоток, чо!
Идём далее. Даже если через несколько итераций и растраты неимоверных запасов терпения для игнора твоего неадеквата/негатива удаётся довести исходный макет до вмеяемой по скорости работы (в сравнении с твоей вылизанной версией Эрли, хотя бы), то у тебя всё-равно приготовлены пути для отступления:
3. Моя Нитра всё-равно лучше всех восстанавливается, я потратил на это много лет. (С)
Итого — а смысл вообще тратить на что-то время СЕЙЧАС, после потраченный тобой кучи лет на восстановление?
Рука-лицо много раз.
Даже если другой алгоритм разбора будет намного эффективнее Эрли и будет близок к LALR(1) по производительности, это уже не имеет никакого значения. Всё, тю-тю, поезд уже ушёл, а ты проспал.
Тебе надо было смотреть на GLR еще тогда, когда я именно что предлагал посмотреть на этот алгоритм как эффективную альтернативу Эрли.
Потому что иначе получается так, что если на RSDN на блюдечке с голубой каёмочкой кто-то выложил реализацию Эрли, то ты её и асилил.
А если тебе так же под нос не поставили — то уже и нет.
Вот такой у тебя в сухом остатке получается бред. Даже не бред, а просто позор какой-то — разрабатывать парсеры и не обладать при этом достаточной эрудицией в своей основной предметной области. Хотя да, само такое положение вещей бредовое, ес-но.
Хотя да, само такое положение вещей бредовое, ес-но.
Вот, я рядом дал ссылки, которые подтверждают мои слова:
http://www.rsdn.org/forum/philosophy/6722767.1
Ты их сам не нашёл? — это минус тебе, а не мне.
Причем, сам алгоритм GLR я тоже когда-то давно "изобрел" независимо (писал тогда же), бо с интернетом в конце 90-х/начале 2000-х было так себе, т.е. далеко не всё можно было найти в вебе, да и поиск тогда был не особо.
Как и этот фокус с возможностью допиливания исходной идеи параллельного парсинга до эффективной работы на однозначных цепочках (коих до 90% в обычном исходнике). Accent и Elk тогда тоже еще не были опубликованы.
Да и какая разница, опубликован ли Accent или Elk? И какая разница, насколько активны эти проекты прямо сейчас (вон ты рядом пинал даже на это — опять рука лицо).
Мои исходные утверждения были и есть истинными и без этих публикаций.
Да мне вообще тогда хотелось лишь обсудить найденные мною трюки, а обсудить на сайте их не с кем.
Вот вы с Владом подвернулись тогда, бо тоже носились с парсингом. Но из вас еще те обсуждальщики, угу. У вас же философия — "за пределами МКАДА жизни нет". Т.е., что вы руками сами не трогали, того и не существует... Скучные вы, кароч... )) Не любопытные. И ладно если еще лет 10 назад, когда тебе было 26/27 я мог списывать твою неадекватность на подзадержавшееся детство и некую сумбурность в голове, то сейчас такая сумбурность/непоследовательность — это уже ой. ))
V>>У меня лучшее только то, что я делаю на основной своей работе.
WH>Учитывая, что ты тут несёшь я в этом сомневаюсь.
Так и что я "несу"-то?
Покажешь хоть раз или нет?
WH>И это очень быстро. Автор ATNLR на свой парсер потратил 25 лет. И результат хуже.
Автор ATNLR может и меньше чистого времени этим занимался. Он в рабочее время преподаёт, насколько я понял.
И насчет хуже-лучше — это тебе в азы качества ПО надо.
Хуже-лучше определяется только по удовлетворению исходным требованиям.
Если у них не стояла задача разработать ИДЕ для целевых языков программирования, то ты НЕ можешь сравнивать по таким требованиям.
У них вообще не было таких ограничений — разработка пасеров только под ЯП.
Они и над бинарными данными чудесно парсинг делают.
У них стояла задача разработать учебную визуальную модель представления грамматик, по которой (модели) можно визуально отлаживаться в процессе проектирования этих грамматик. В этом плане их результаты лучше твоего, бо у тебя нет таких визуальных ср-в отладки грамматики, как в ANTLR:
А профайлер грамматики у тебя есть?
Каким-либо образом можно узнать в Нитре, на сколько операций парсинга стало больше-меньше на тестовом примере после изменения грамматики?
V>>Потому что в правилах до половины нетерминалов могут быть промежуточными, ни разу не интересными для восстановления до них.
WH>Вот это и есть ручное описание правил восстановления.
WH>В нитре это делать не нужно. Там даже такой возможности нет.
WH>Всё работает в полностью автоматическом режиме.
WH>Прикинь парсер сам понимает, что нужно удалить, что добавить и где начинается нормальный текст.
Ну так не описывай восстановление в Бизоне и тоже всё будет автоматом.
Там вообще своё восстановление написать можно, бо кишки Бизона открыты.
Да и не нужно это восстановление при простой компиляции файла, обычно не стоит задача найти все ошибки в файле во время компиляции.
WH>>>1)Это куча мутной работы.
V>>Это примерно такая же работа, как в языке расширенных регулярных выражений отличать конечные правила от промежуточных.
WH>Что за бред опять?
Что именно ты тут опять не понял?
Какой из терминов вызывал затруднения?
(и кто-то еще пытается обвинять в непонятливости окружающих
WH>>>Если бы нитра текла меня бы тут на смех всем RSDN'ом подняли.
V>>А как бы она у тебя текла на GC?
WH>Да там не важно на ГЦ она или нет. Там всё и без ГЦ переделать можно. И ничего течь не будет.
А с чего ты взял, что Бизон течет?
Там сказано, что после ошибки необходимо выполнить такие-то и такие-то действия.
Откуда Бизон знает — закончил ты извлекать инфу об ошибке или еще нет?
Может, ты вручную восстанавливаешься?
Бизон — это больше конструктор, чем полноценная система.
"Заверни" парсер от Бизона в некую высокоуровневую свою среду, которая будет знать, где она закончила разбираться с ошибками, а где уже работает дальше и ву а ля — пусть вызовет прочистку временных данных в нужный момент времени.
=====================
Кароч, ты всё время не туда и не о том.
Давай в сухом остатке, что ты тут задвигал:
1. Простой пример можно сделать быстро. (С)
Согласен, поэтапная работа должна с чего-то начинаться.
С макета.
Например, первый вариант Эрли, показанный когда-то здесь, был ужасен по эффективности.
На последующих этапах можно смотреть, где и что, как подкрутить и чем вызваны тормоза.
Ты же используешь сейчас Эрли, не смотря на весь его ужас в случае примитивной реализации "в лоб"?
Идём далее. Ты настаиваешь:
2. У меня самый быстрый парсер. (С)
Итого, ЛЮБОЙ самый первый вариант/макет ЛЮБОГО парсера будет подвергнут неадекватной обструкции сходу.
Собсно, весь вот этот топик, всё что ты озвучивал — это фактически твоя клятва на крови, что так и будет.
Молоток, чо!
Идём далее. Даже если через несколько итераций и растраты неимоверных запасов терпения для игнора твоего неадеквата/негатива удаётся довести исходный макет до вмеяемой по скорости работы (в сравнении с твоей вылизанной версией Эрли, хотя бы), то у тебя всё-равно приготовлены пути для отступления:
3. Моя Нитра всё-равно лучше всех восстанавливается, я потратил на это много лет. (С)
Итого — а смысл вообще тратить на что-то время СЕЙЧАС, после потраченный тобой кучи лет на восстановление?
Рука-лицо много раз.
Даже если другой алгоритм разбора будет намного эффективнее Эрли и будет близок к LALR(1) по производительности, это уже не имеет никакого значения. Всё, тю-тю, поезд уже ушёл, а ты проспал.
Тебе надо было смотреть на GLR еще тогда, когда я именно что предлагал посмотреть на этот алгоритм как эффективную альтернативу Эрли.
Потому что иначе получается так, что если на RSDN на блюдечке с голубой каёмочкой кто-то выложил реализацию Эрли, то ты её и асилил.
А если тебе так же под нос не поставили — то уже и нет.
Вот такой у тебя в сухом остатке получается бред. Даже не бред, а просто позор какой-то — разрабатывать парсеры и не обладать при этом достаточной эрудицией в своей основной предметной области.
Вот, я рядом дал ссылки, которые подтверждают мои слова:
http://www.rsdn.org/forum/philosophy/6722767.1
Ты их сам не нашёл? — это минус тебе, а не мне.
Причем, сам алгоритм GLR я тоже когда-то давно "изобрел" независимо (писал тогда же), бо с интернетом в конце 90-х/начале 2000-х было так себе, т.е. далеко не всё можно было найти в вебе, да и поиск тогда был не особо.
Как и этот фокус с возможностью допиливания исходной идеи параллельного парсинга до эффективной работы на однозначных цепочках (коих до 90% в обычном исходнике). Accent и Elk тогда тоже еще не были опубликованы.
Да и какая разница, опубликован ли Accent или Elk? И какая разница, насколько активны эти проекты прямо сейчас (вон ты рядом пинал даже на это — опять рука лицо).
Мои исходные утверждения были и есть истинными и без этих публикаций.
Да мне вообще тогда хотелось лишь обсудить найденные мною трюки, а обсудить на сайте их не с кем.
Вот вы с Владом подвернулись тогда, бо тоже носились с парсингом. Но из вас еще те обсуждальщики, угу. У вас же философия — "за пределами МКАДА жизни нет". Т.е., что вы руками сами не трогали, того и не существует... Скучные вы, кароч... )) Не любопытные. И ладно если еще лет 10 назад, когда тебе было 26/27 я мог списывать твою неадекватность на подзадержавшееся детство и некую сумбурность в голове, то сейчас такая сумбурность/непоследовательность — это уже ой. ))