 Оценка 286
[+0/-1]
Оценка 286
[+0/-1]

 Оценить
Оценить 






| Оценка 286
[+0/-1]
Оценить
|
Архитектура реляционных баз данных ориентирована на хранение внутри таблиц БД информации о сущностях информационной системы и связях между ними. Каждая из записей таблицы содержит информацию об одном экземпляре. Организация хранения информации о независимых друг от друга экземплярах сущностей (т.е. так называемых «плоских» данных) не вызывает никаких затруднений. Однако, наряду с «плоскими» данными, при построении даже простых информационных систем, приходится хранить в БД и информацию о «вложенных» друг в друга сущностях, т.е иерархические данные. Организация хранения такой информации в реляционных БД проста, но не всегда очевидна для тех, кто впервые сталкивается с подобной задачей. В данной статье я попытаюсь поделиться накопленным опытом.
Примеры, приводимые далее, были созданы и протестированы с помощью Interbase 6.
Чтобы обсудить проблему хранения иерархии в реляционной БД, мы вначале рассмотрим вопрос о том, какие же иерархии данных могут встретиться на практике. В реальной жизни иерархии имеют, как правило, некоторые ограничения. Учитывая эти ограничения, можно построить более эффективные процедуры обработки иерархических данных.
Так, в общем случае, дерево может иметь любое количество уровней иерархии. Но в частных случаях число уровней может, и часто оказывается, конечным. Может быть ограничено количество непосредственных потомков одного элемента иерархии.
Рассмотрим некоторые варианты представления иерархических структур в реляционных БД.
Наиболее общим случаем является дерево с неограниченным уровнем вложенности и неограниченным количеством потомков. Для хранения такого рода иерархии необходимо добавить в описание сущности дополнительное поле – ссылку на первичный ключ предка. Такой способ организации иерархии является самым распространенным и универсальным. Однако ему присущи следующие недостатки:
Необходимость рекурсивных запросов для получения полного пути от произвольного элемента до корня дерева.
Сложность вычисления уровня вложенности произвольного элемента.
Сложность получения всех (в том числе и не прямых) потомков данного узла.
Дальнейшее рассмотрение мы будем вести на примере построения иерархической структуры – тематического каталога библиотеки. Данный каталог применяется для классификации, сортировки и поиска книг по их содержанию. Будем считать, что каждый элемент каталога описывается собственным неуникальным символьным именем. Для обеспечения уникальности записей для каждого элемента каталога необходимо ввести первичный ключ. Для поддержки иерархичности данных введем дополнительное поле-ссылку на предка данного элемента иерархии. Ниже приведено описание полученной структуры на языке SQL:
CREATE TABLE "CATALOG" ( "ID" INTEGER NOT NULL PRIMARY KEY, "NAME" VARCHAR(200) CHARACTER SET WIN1251 NOT NULL, "PARENT_ID" INTEGER ); |
Данная структура является минимально необходимой и достаточной для организации и хранения иерархии. Назовем ее структурой со ссылкой на предка. В данной структуре присутствует как минимум один недостаток – отсутствие контроля правильности ссылки на родителя. Какие же значения поля PARENT_ID являются правильными? Ответ очевиден – весь диапазон значений первичного ключа (поля ID) + одно значение, используемое для обозначения отсутствия родительского элемента. Данное значение необходимо для ввода и хранения корневых элементов иерархии. Чаще всего в качестве значения, обозначающего отсутствие родителя, используется NULL, хотя нет никаких физических ограничений для использования других значений. Так, например, если вы уверены, что значения первичного ключа будут больше 0, в качестве признака корневого элемента можно использовать значение (–1) или другие отрицательные значения в поле PARENT_ID. Я не буду оригинален и в качестве значения PARENT_ID для корневых элементов использую NULL. Тогда для контроля правильности PARENT_ID можно использовать следующее ограничение:
"PARENT_ID" INTEGER CHECK( ("PARENT_ID" IS NULL) OR ( "PARENT_ID" = ANY(SELECT "ID" FROM "CATALOG") ) ) (в принципе, такие ограничения намного проще и эффективнее описывать как внешние ключи. Единственной проблемой при этом является вставка корневой записи, т.к. родительской записи для нее не существует. Обойти такое ограничение можно, добавляя внешний ключ после вставки корневой записи. – прим.ред.) |
Вернемся к отмеченным выше недостаткам данной структуры (сложность формирования полного пути и вычисления уровня элемента). Эти недостатки вытекают из того простого факта, что в данной структуре информация о полном пути и уровне нигде не хранится. Решить проблему быстрого получения уровня вложенности можно введением в структуру таблицы дополнительного поля Level. Описание таблицы тогда будет выглядеть так:
CREATE TABLE "CATALOG" ( "ID" INTEGER NOT NULL PRIMARY KEY, "NAME" VARCHAR(200) CHARACTER SET WIN1251 NOT NULL, "PARENT_ID" INTEGER CHECK( "PARENT_ID" = ANY(SELECT "ID" FROM "CATALOG") or "PARENT_ID" is NULL ), "LEVEL" INTEGER DEFAULT 1 NOT NULL ); |
Структура для хранения иерархии с неограниченным числом уровней вложенности и потомков готова.
Следующей по степени универсальности является иерархия с неограниченным числом уровней вложенности и конечным числом потомков элемента иерархии. Ограничение количества потомков позволяет хранить данные в следующем виде.
Ссылка на предка содержит в себе ссылку на запись, хранящую информацию о предыдущем уровне иерархии и смещение (номер столбца) с описанием родителя.
В нашем примере мы ограничим количество предков числом 5, тогда SQL-описание таблицы будет выглядеть следующим образом:
CREATE TABLE "CATALOG2" ( "LEVEL" INTEGER NOT NULL, "OFFSET" SMALLINT NOT NULL CHECK("OFFSET" > 0 and "OFFSET" < 6), "NAME_1" VARCHAR(200) CHARACTER SET WIN1251, "NAME_2" VARCHAR(200) CHARACTER SET WIN1251, "NAME_3" VARCHAR(200) CHARACTER SET WIN1251, "NAME_4" VARCHAR(200) CHARACTER SET WIN1251, "NAME_5" VARCHAR(200) CHARACTER SET WIN1251, "PARENT_LEVEL" INTEGER, "PARENT_OFFSET" SMALLINT CHECK(("PARENT_OFFSET" > 0 and "PARENT_OFFSET" < 6) or ("PARENT_OFFSET" is NULL)), CONSTRAINT "PK_CATALOG2" PRIMARY KEY("LEVEL","OFFSET") ); |
Больших преимуществ использования такой структуры я не вижу, недостаток же налицо – при изменении максимального количества потомков одного узла придется добавлять еще один столбец таблицы, что крайне неудобно. По этой причине подробно рассматривать эту структуру мы не станем, а перейдем к следующему случаю – иерархии с конечным числом уровней вложенности и бесконечным числом потомков узла.
Одним из вариантов хранения таких иерархий является поуровневое хранение в различных таблицах. Например, таблица CATALOG_LEVEL_1 хранит все элементы первого уровня вложенности, таблица CATALOG_LEVEL_2 – второго, и т.д. Ниже приведено описание такой структуры для случая трехуровневой иерархии.
CREATE TABLE "CATALOG3_LEVEL1" ( "ID" INTEGER NOT NULL PRIMARY KEY, "NAME" VARCHAR(200) CHARACTER SET WIN1251 NOT NULL ); CREATE TABLE "CATALOG3_LEVEL2" ( "ID" INTEGER NOT NULL UNIQUE, "NAME" VARCHAR(200) CHARACTER SET WIN1251 NOT NULL, "PARENT_ID" INTEGER NOT NULL REFERENCES "CATALOG3_LEVEL1"("ID"), PRIMARY KEY("ID","PARENT_ID") ); CREATE TABLE "CATALOG3_LEVEL3" ( "ID" INTEGER NOT NULL UNIQUE, "NAME" VARCHAR(200) CHARACTER SET WIN1251 NOT NULL, "PARENT_ID" INTEGER NOT NULL REFERENCES "CATALOG3_LEVEL1"("ID"), "PARENT_ID2" INTEGER NOT NULL REFERENCES "CATALOG3_LEVEL2"("ID"), PRIMARY KEY ("ID", "PARENT_ID", "PARENT_ID2") ); |
При большем количестве уровней необходимо определить дополнительные таблицы для каждого уровня, по структуре аналогичные таблице CATALOG3_LEVEL2. В данной структуре получение уровня элемента не представляет никакой сложности, т.к однозначно определяется таблицей, в которой он хранится. Полный путь от любого элемента до корня также определяется составным первичным ключом таблицы. Этот вид структуры назовем структурой с потабличным хранением уровней
Последний из видов иерархии – иерархия с ограниченной вложенностью и ограниченным числом потомков. Многие из реальных задач, встречавшихся мне, в той или иной степени можно было свести к этому виду иерархии. Так, например, наша задача с каталогом библиотеки, хотя в строгом виде и является иерархией с неограниченным числом потомков узла и вложенностью, может быть сведена к рассматриваемому типу иерархии. Вполне можно ограничить количество элементов на одном уровне значением 9 (или другим достаточно большим числом) и 5 уровнями вложенности. Зачем? Затем, что в данном типе иерархии при определенной организации первичного ключа можно существенно упростить работу с иерархией. Для хранения данного вида иерархии можно использовать ранее описанные структуры иерархий с неограниченной вложенностью и количеством потомков и иерархий с ограниченным количеством уровней и неограниченным числом потомков. Однако есть две модификации структур специфичных для данного типа иерархии.
Первый тип приведен ниже:
CREATE TABLE "CATALOG4" ( "ID" DECIMAL(5) NOT NULL PRIMARY KEY, "NAME" VARCHAR(200) CHARACTER SET WIN1251 NOT NULL ); |
Весь фокус в принципе формирования первичного ключа ID. Позиция последнего ненулевого десятичного разряда ключа – это уровень элемента, а цифра в этой позиции – номер элемента на данном уровне. Например, первый элемент первого уровня будет иметь ID = 00001, второй – 00002. На втором уровне третий элемент, имеющий предком первый элемент первого уровня, будет иметь ID = 00031, и т.д. Данная структура хороша при равномерном распределении элементов по уровням. Ее мы назовем структурой с поразрядным ключом. В зависимости от того, справа или слева находится разряд, кодирующий первый уровень, можно выделить структуру с поразрядным правым ключом и структуру с поразрядным левым ключом. В нашем случае я описал правый ключ. Если же максимальное число элементов конечно, но различно для различных ветвей дерева, и хотя бы приблизительно может быть оценено для каждой ветви, можно воспользоваться следующей структурой:
CREATE TABLE "CATALOG5" ( "ID" INTEGER NOT NULL PRIMARY KEY, "NAME" VARCHAR(200) CHARACTER SET WIN1251 NOT NULL, "PARENT_ID" INTEGER CHECK( "PARENT_ID" = ANY(SELECT "ID" FROM "CATALOG") or "PARENT_ID" is NULL ), "LOW" INTEGER NOT NULL, "HIGH" INTEGER NOT NULL ); |
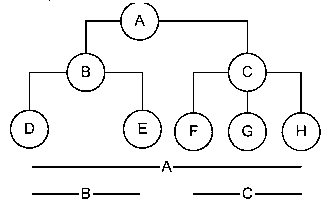
Данная структура является модификацией структуры для хранения иерархии с неограниченным уровнем вложенности и количеством потомков. В структуру добавлены поля LOW и HIGH для хранения начала и конца диапазона первичных ключей всех потомков данного элемента. Такая иерархия может быть представлена набором отрезков (см. рисунок). Это позволяет быстро и легко выбрать всех потомков данного элемента. Данную структуру назовем структурой с хранением границ ветви.
Итак, мы рассмотрели несколько различных типов структур для хранения иерархий. Далее мы рассмотрим решение задач, связанных с использованием этих структур:
Получение потомков элемента является основной задачей при построении и отображении дерева. Далее мы рассмотрим получение потомков для:
К этому виду структур относится и модификация с поддержкой информации об уровне элемента, а также структура с хранением границ ветви. Очевидно, что в такой структуре потомками элемента будут все элементы, ссылающиеся на данный (PARENT_ID потомков равен ID родителя). Запрос на выборку потомков (имена таблицы и полей взяты из приведенных выше описаний) выглядит так:
SELECT “ID” FROM CATALOG WHERE “PARENT_ID” = <значение id родителя> |
В данной структуре для определения потомков необходимо знать уровень вложенности предка. Зная уровень вложенности, можно определить имя таблицы, в которой хранится информация о потомках. Запрос на выборку потомков:
SELECT “ID” FROM <имя таблицы с потомками> where <сложная ссылка на предка> = <сложный первичный ключ предка> |
Например, для определения потомков узла второго уровня с ID = 10 и PARENT_ID = 5 запрос будет:
SELECT “ID” FROM CATALOG3_LEVEL3 WHERE “PARENT_ID”=5 AND “PARENT_ID2” = 10 |
При структуре с поразрядным правым ключом непосредственные потомки имеют первичные ключи c ненулевым следующим разрядом и таким же, как первичный ключ предка числом в младших разрядах. В ранее рассмотренном нами случае потомки первого корневого элемента (ID = 1) будут иметь ID 11,21,31,41, …91. Запрос на выборку:
SELECT “ID” FROM “CATALOG4” WHERE “ID” IN (11,21,31,41,51,61,71,81,91)
Структура с левым ключом для первого корневого элемента (ID = 10000) потомки 11000, 12000,13000…19000.
Довольно часто возникает задача получения всех, в том числе и не прямых потомков данного элемента. Рассмотрим решение этой задачи для приведенных структур.
Простого способа, к сожалению, нет. Приходится организовывать рекурсию запросов.
Потомки данного элемента содержатся в “нижележащих” таблицах и имеют как часть составной ссылки на предка в одном из полей значение ID предка. Общий список потомков можно получить объединением (UNION) запросов.
select "ID",'1' as "LEVEL" from CATALOG3_LEVEL2 where PARENT_ID = 1 union select "ID",'2' as "LEVEL" from CATALOG3_LEVEL3 where PARENT_ID = 1 |
Ввод дополнительного поля LEVEL в запрос обусловлен тем, что потомки элемента в разных таблицах могут иметь одинаковые ID и при объединении запросов вместо нескольких строк в результате будет получена одна. Еще одна проблема, приводящая к необходимости ввода дополнительного поля в запрос, т.к. надо знать, из какой таблицы выбран данный ID.
В данной структуре содержится информация о полном пути к элементу. Это облегчает выборку всех потомков.
Для первого корневого элемента диапазон ID потомков будет 10001… 19999, для второго 20001…29999 и т.д.
Ну, здесь тоже все просто. Первый элемент иерархии ID = 1, на втором уровне его первый предок 11 и т.д. Таким образом, потомки будут иметь в конце ID цифры, совпадающие с ID предка.
Элементы структуры LOW и HIGH хранят границы диапазона первичных ключей всех потомков.
Часто уровень вложенности элемента иерархии привязан к какому-либо классификационному признаку предметной области. Отсюда возникает задача определения уровня вложенности произвольного элемента.
Построение полного пути к корню дерева и определение числа предков. Довольно неудобно, но другого способа нет.
Недаром мы ввели поле для хранения уровня вложенности. Оно-то и содержит нужную нам информацию.
Уровень вложенности определяется таблицей, в которой хранится запись об элементе.
Уровень вложенности определяется положением последнего ненулевого разряда в ключе.
структура со ссылкой на предка и ее модификация с поддержкой информации об уровне элемента, структура с хранением границ ветви
Опять же, для вычисления полного пути нужно получать предков с помощью последовательных запросов. Одним простым запросом здесь не обойтись. Ниже приведен текст хранимой процедуры получения полного пути от произвольного элемента:
CREATE PROCEDURE GET_PARENTS (ID INTEGER) RETURNS (E_ID INTEGER, NAME CHAR(200)) AS declare variable P_ID integer; BEGIN select PARENT_ID from CATALOG where ID = :ID into :ID; WHILE (ID > 0) DO BEGIN SELECT C.ID, C.PARENT_ID, C.NAME FROM CATALOG C WHERE ID = :ID INTO :E_ID, :P_ID,:NAME; ID=P_ID; SUSPEND; END END ^ |
структура с потабличным хранением уровней, структура с поразрядным ключом
Полный путь содержится в первичном ключе элемента.
Добавление нового элемента:
insert into “CATALOG”(“name”,”parent_id”) values( _win1251 ‘Новый элемент’, <значение первичного ключа предка>); |
Удаление элемента: Кроме непосредственно самого элемента необходимо удалить и его потомков. Проблема решается введением триггера:
CREATE TRIGGER "CATALOG_AFTER_DEL" FOR "CATALOG" ACTIVE AFTER DELETE POSITION 0 AS BEGIN delete from "CATALOG" where "PARENT_ID" = OLD."ID"; END ^ |
Перемещение элемента: надо просто поменять ссылку на родителя.
UPDATE “CATALOG” SET “PARENT_ID” = <Значение первичного ключа нового родителя> WHERE “ID” = <Значение первичного ключа элемента> |
Можно использовать запросы, аналогичные случаю с базовой структурой. Для проверки корректности поля Level можно ввести дополнительные триггеры:
CREATE EXCEPTION "WRONG_LEVEL" 'Неверный уровень вложенности элемента'; /* Триггер перед вставкой записи в таблицу - проверяет корректность поля Level и формиррует ID записи */ CREATE TRIGGER "CATALOG_BEFORE_INS" FOR "CATALOG" ACTIVE BEFORE INSERT POSITION 0 AS declare variable parent_level integer; BEGIN if (NEW."ID" is null) then NEW."ID" =GEN_ID(CATALOG_GEN,1); /*Корневые элементы имеют уровень 1*/ if ((NEW."PARENT_ID" is NULL) and (NEW."LEVEL" <> 1)) then exception WRONG_LEVEL; /*Значение поля Level для некорневых элементов должно быть на 1 больше, чем у их родителя*/ if (NEW."PARENT_ID" is NOT NULL) THEN begin select "LEVEL" from "CATALOG" WHERE "ID" = NEW."PARENT_ID" into :parent_level; if (NEW."LEVEL" <> :parent_level+1) then exception WRONG_LEVEL; end END ^ /* Триггер перед обновлением - контролирует правильность поля Level */ CREATE TRIGGER "CATALOG_BEFORE_UPD" FOR "CATALOG" ACTIVE BEFORE UPDATE POSITION 0 AS declare variable parent_level integer; declare variable child_id integer; BEGIN if ((NEW."PARENT_ID" is NULL) and (NEW."LEVEL" <> 1)) then exception WRONG_LEVEL; select "LEVEL" from "CATALOG" WHERE "ID" = NEW."PARENT_ID" into :parent_level; if (NEW."LEVEL" <> :parent_level+1) then exception WRONG_LEVEL; END ^ /* Триггер после обновления - контролирует правильность поля Level */ CREATE TRIGGER "CATALOG_AFTER_UPD" FOR "CATALOG" ACTIVE AFTER UPDATE POSITION 0 AS BEGIN update "CATALOG" set "LEVEL" = NEW."LEVEL"+1 where "PARENT_ID" = NEW."ID"; END ^ |
Запросы на вставку и перемещения тривиальны, и потому не приводятся. При удалении элемента можно ввести дополнительный триггер для удаления потомков, аналогично триггеру для структуры со ссылкой на предка.
Вставка и удаление аналогичны случаю структуры со ссылкой на предка. Перемещение элемента в общем случае невозможно без перегенерации первичных ключей элементов, поэтому применяется редко.
Ну вот, пожалуй, и все. Надеюсь, что данная статья будет вам полезна. Если у вас появились замечания, предложения или Вы обнаружили какие-либо ошибки, пишите мне mgoblin@mail.ru
| Оценка 286
[+0/-1]
Оценить
|
