Здравствуйте, Артём, Вы писали:
Аё>Между работником, который медленно сам изобретает кривой велосипед с багами и работнмком, который склеил решение из ответов на SO в 10 раз быстрее, код хороший, — какого подчинённого ты предпочтёшь? Аё>Гномо###еры ведь тоже не придумывают алгоритм на ходу- а по памяти подбирают и допиливают кем-то давно нацденное решение проблемы.
Какое переобувание. Ты довольно недавно квалификацию программиста и умение кодировать определял через написание на бумажке то ли реверса строки, толи обращение списка.
Здравствуйте, LaptevVV, Вы писали:
LVV>То есть, теперь нужно следить за деятельностью молодых просто под микроскопом!
Так всегда было. Некоторые просто бездумно пишут код. Пример: наняли чувака для GUI, задача — вывести табличку на экран с помощью WPF для данного IList, решение — не долго думая создаёт ObservableCollection, как в книжках и статьях по WPF, примерно так:
observableCollection = new ObservableCollection(customList); //пиздец подкрался незаметно
dataGrid.ItemSource = observableCollection
Всё бы ничего, но за кастомным листом лежала таблица с историей операций, где могло быть и 50 и 200 миллионов строк. Он тупо забил на то, что табличка, которую он на WPF переделывал, была крайне сложной — там виртуальный режим использовался.
То, что он закоммитил кое-ка работало на небольших наборах данных, а потом ко мне прилетела пачка дампов.
Всё сказанное выше — личное мнение, если не указано обратное.
Re[5]: ⅔ зумеров пользуются AI при прохождении собеседования
Здравствуйте, elmal, Вы писали:
E>Какое переобувание. Ты довольно недавно квалификацию программиста и умение кодировать определял через написание на бумажке то ли реверса строки, толи обращение списка.
И сейчас так же считаю. Естественно, при условии, что он не может нагуглить или нагопотить ответ на ходу.
Здравствуйте, Философ, Вы писали:
Ф>как в книжках и статьях по WPF
Ф>- там виртуальный режим использовался.
Просто чел ниасилил виртуальный список- книжки тут ни при чём и молодость ни при чём. Выявлять рукожопов без понимания bigO как раз и позволяют простые задачки на разворот списка.
Здравствуйте, Артём, Вы писали:
Аё>Просто чел ниасилил виртуальный список- книжки тут ни при чём и молодость ни при чём. Выявлять рукожопов без понимания bigO как раз и позволяют простые задачки на разворот списка.
Дело тут не в освоении чего-либо и не в bigO. Проблема в том, что он бездумно применил рецепт из книжки. Притом впоследствии он неоднократно действовал по той же методологии — копировал код из SO.
Проблема тут в том, что он не прочитал (не изучил) код, который был до него, когда его попросили перепилить его на WPF. Проблема тут в том, что он не вник в суть задачи: он делал табличку с историей операций, у него в таске были стриншоты с тем, что было сделано до него — там было достаточно записей, чтобы оценить степень пиздеца.
Если бы ему тогда был доступень ИИ (вайб-кодинг), то его результаты работы были бы точно такими же, но "сделЯлЬ" бы он в десять раз больше.
UPD: да, молодость тут не при чём — он не был молодым, просто стиль работы такой.
Всё сказанное выше — личное мнение, если не указано обратное.
Здравствуйте, Артём, Вы писали:
Аё>Пишущий тим лид.
Понятно. Аё>Нет, я на продукте SaaS B2B. Поддерживаемость и расширяемость кода важна.
Тогда мне не понятно откуда все эти вопросы.
Здравствуйте, Философ, Вы писали:
Ф>Дело тут не в освоении чего-либо и не в bigO. до него — там было достаточно записей, чтобы оценить степень пиздеца.
BigO как раз- это понимание, какой будет производительность на реальных нагрузках. Чувак просто рукожоп, гнать таких надо из профессии.
Здравствуйте, Артём, Вы писали:
Аё>BigO как раз- это понимание, какой будет производительность на реальных нагрузках. Чувак просто рукожоп, гнать таких надо из профессии.
А какое отношение имеет BigO к вытягиванию 100 млн строк в гуй? Какое отношение имеет BigO к бездумному копированию кода из SO и столь же бездумному использованию примеров из книжки?
Таких ты из профессии не выгонишь: они минимум в 4 раза производительнее тебя! Когда ты вот такую таску закрываешь за неделю, в поте жопы, ломоте в пальцах и с помутнением в глазах от кол-ва кода, они не сильно напрягаясь, закрывают такие таски за полтора дня. Со стороны это ты вяглядишь придурком, который за каким-то хреном отчаянно лупит по клавишам — свою нишу они найдут.
Появление ИИ всё ещё более усложнило — теперь можно не искать на SO, а попросить какой-нибудь ГПТ код написать — вайб-кодинг ещё сильнее ускоряет таких комрадов.
Сдаётся мне, что когда ты такое говоришь, ты забываешь о таких вещах как time to market, сроки и дедлайны.
Всё сказанное выше — личное мнение, если не указано обратное.
Здравствуйте, Философ, Вы писали:
Ф>А какое отношение имеет BigO к вытягиванию 100 млн строк в гуй?
Прямое. Виртуальный список- это когда рендерится только видимая пользователю часть элементов. Просчитать смещение (для скролла) видимого элемента без фиксированной высоты каждого элемента- это тебе не жсоны перекладывать.
Здравствуйте, Артём, Вы писали:
Аё>Здравствуйте, Философ, Вы писали:
Ф>>А какое отношение имеет BigO к вытягиванию 100 млн строк в гуй? Аё>Прямое. Виртуальный список- это когда рендерится только видимая пользователю часть элементов. Просчитать смещение (для скролла) видимого элемента без фиксированной высоты каждого элемента- это тебе не жсоны перекладывать.
Там этого не нужно было: фрэймворк определяет видимость элемента, он же скролл рисует — там DataGridView изначально был, он предоставляет всё, что нужно. Да даже если делать такой контрол руками (с ручной отрисовкой), то определить видим он или нет, и где скролл можно без всяких BigO. Точно также никакого труда не составляет определить контрол, который нужно показывать по позиции скролла.
Поверь мне на слово, сделать кастомную релизацию IList над таблицей в БД, так чтобы всё это в сумме не тормозило, значительно сложнее. BigO там может пригодиться, но можно обойтись и обычным здравым смыслом. Попробуй сам такое спроектировать, просто учти, гуй нельзя тормозить вообще — а) твой List должен быть потокобезопасен, б) не нужно на каждый чих в БД лезть, в) в табличку пишут — тебе придётся придумать механизм инвалидации кэша.
Всё сказанное выше — личное мнение, если не указано обратное.
Здравствуйте, Философ, Вы писали:
Ф> определить видим он или нет
Для этого нужно либо прибить высоту элемента гвоздями, либо- в случае если высота не прибита и отличается в зависимости от содержимого, тебя ждёт интересное путешествие по граблям и алгоритмам.
Ф>Поверь мне на слово, сделать кастомную релизацию IList над таблицей в БД,
Хз, я не считаю это чем-то полезным или умным.
Ф> тебе придётся придумать механизм инвалидации кэша.
Я придумывал механизм инвалидации кэша Это не так сложно на самом деле, особенно в сравнении с виртуальным списком.
Здравствуйте, Артём, Вы писали: Ф>> определить видим он или нет Аё>Для этого нужно либо прибить высоту элемента гвоздями, либо- в случае если высота не прибита и отличается в зависимости от содержимого, тебя ждёт интересное путешествие по граблям и алгоритмам.
Для неприбитой высоты гвоздями эта задача не реализуема: чтобы определить видимость элемента по позиции скролла, тебе нужно посчитать размер контрола (самого грида). В случае, когда высота элемента константна, это возможно, но в случае если нет, то список уже должен быть не виртуальным — чтобы определить видимость, тебе нужна позиция скролла, размер грида, размер "окна" и размер каждого элемента. Ф>>Поверь мне на слово, сделать кастомную релизацию IList над таблицей в БД, Аё>Хз, я не считаю это чем-то полезным или умным.
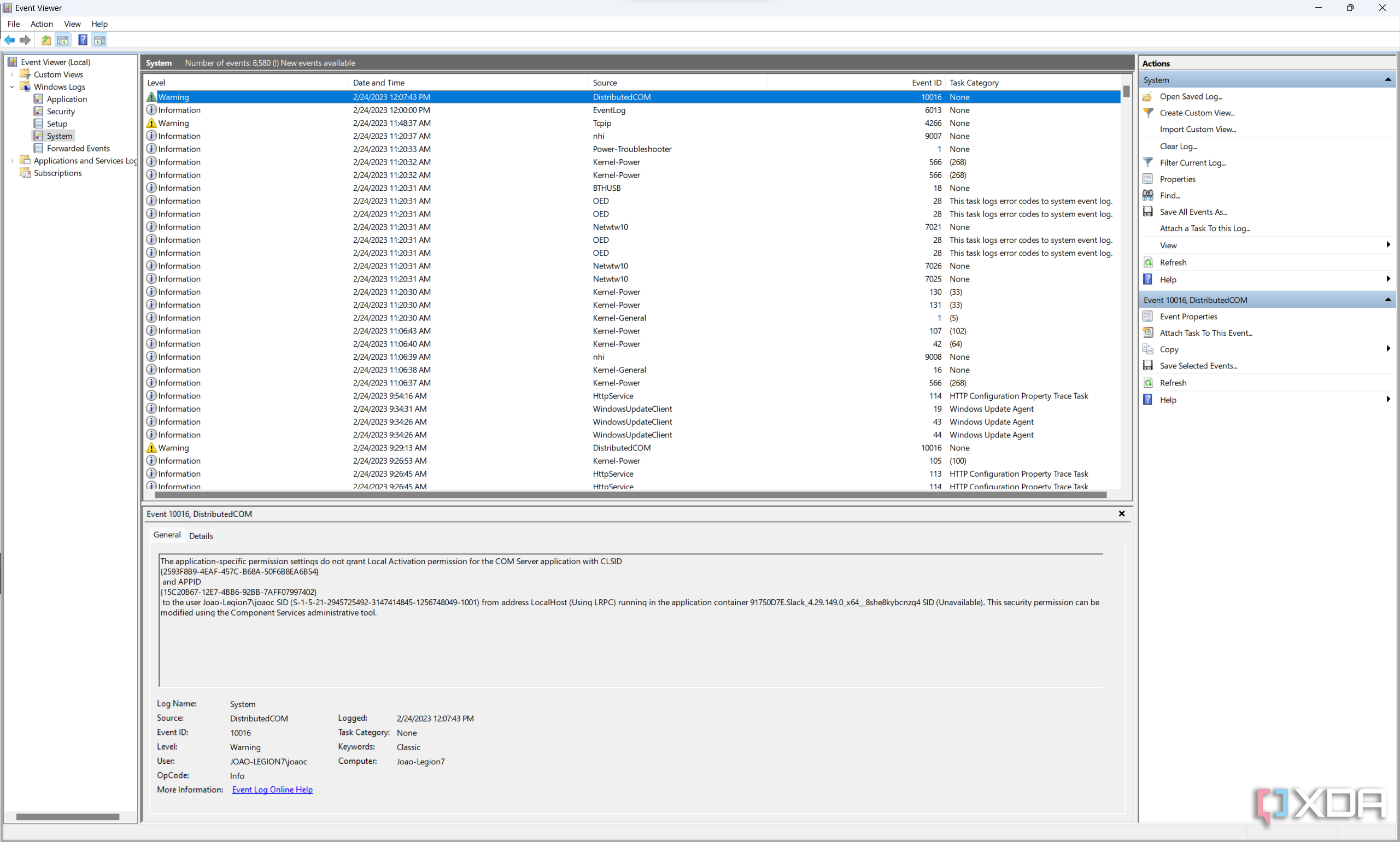
Просто ты не сталкивался с такими задачами. Чтобы осознать нужность такого механизма, тебе нужно попробовать придумать (спроектировать) GUI (с нормальным UX), который бы мог одинаково хорошо отображать и 20, и 200, и и 100 миллионов элементов — самома область такая: отображение истории операций в хронологическом порядке. Примерно представить зачем это нужно, ты можешь, открыв виндовый Event Viewer. Но они там решили эту задачу на троечку.
Event Viewer
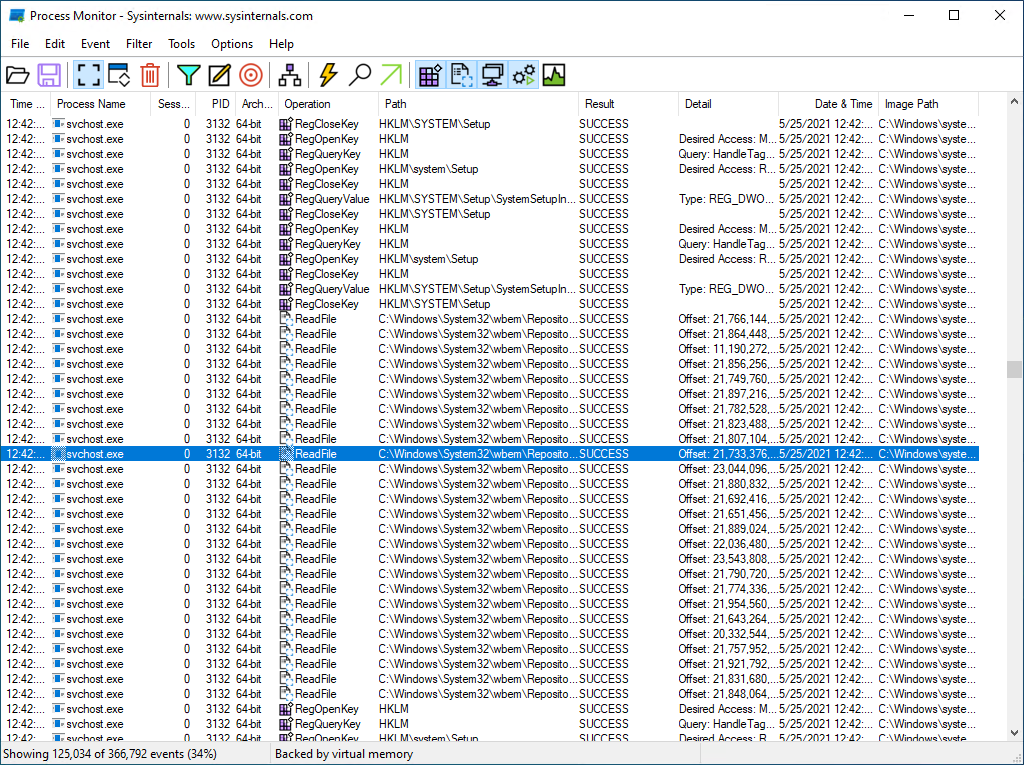
у Sysinternals вышло немножко лучше
Раз ты считаешь, что это не нужно, то выкати свой рецепт: как бы ты отобразил (показал пользователю) историю операций? Напиши User Story — интересно.
Всё сказанное выше — личное мнение, если не указано обратное.
Здравствуйте, Философ, Вы писали: Ф>Для неприбитой высоты гвоздями эта задача не реализуема: чтобы определить видимость элемента по позиции скролла, тебе нужно посчитать размер контрола (самого грида). В случае, когда высота элемента константна, это возможно, но в случае если нет, то список уже должен быть не виртуальным — чтобы определить видимость, тебе нужна позиция скролла, размер грида, размер "окна" и размер каждого элемента.
Мы не ищем простых путей Ф>>>Поверь мне на слово, сделать кастомную релизацию IList над таблицей в БД, Аё>>Хз, я не считаю это чем-то полезным или умным. Ф>Просто ты не сталкивался с такими задачами. Чтобы осознать нужность такого механизма, тебе нужно попробовать придумать (спроектировать) GUI (с нормальным UX), который бы мог одинаково хорошо отображать и 20, и 200, и и 100 миллионов элементов — самома область такая: отображение истории операций в хронологическом порядке. Примерно представить зачем это нужно, ты можешь, открыв виндовый Event Viewer. Но они там решили эту задачу на троечку. Ф>
Высота прибита гвоздями. Что там сложного? Выглядит страшненько кстати. Ф>Раз ты считаешь, что это не нужно, то выкати свой рецепт: как бы ты отобразил (показал пользователю) историю операций? Напиши User Story — интересно.
История заказов на мобильном устройстве — кастомный грид на основе виртуального списока, с неизвестной заранее высотой элемента и с до-запросами на следующие N записей при скролле в конец
Re: ⅔ зумеров пользуются AI при прохождении собеседования
Здравствуйте, r0nd, Вы писали:
R>[q]Около ⅔ зумеров используют искусственный интеллект во время прохождения технических собеседований для оперативного поиска ответов на вопросы. По данным независимого исследования на 2025 год, молодые кандидаты активно применяют различные AI-инструменты — от чат-ботов до расширений для среды разработки — чтобы в реальном времени находить объяснения, фрагменты кода и точные формулировки.
R>Сами соискатели воспринимают это как современный способ повысить свои шансы в условиях цифровой конкуренции. В свою очередь, как отмечают опрошенные работодатели, подобная практика рассматривается как нарушение правил и попытка обмана, из-за чего такие кандидаты часто отсеиваются уже на ранних этапах.
С удовольствием послушал бы ответ ИИ на вопрос "расскажите про свои прошлые проекты, что было интересного, какие решения вы бы сейчас написали иначе". А если на собеседованиях гоняют по справочным знаниям, то сами себе злые буратины.
Здравствуйте, Философ, Вы писали:
Ф>Просто ты не сталкивался с такими задачами. Чтобы осознать нужность такого механизма, тебе нужно попробовать придумать (спроектировать) GUI (с нормальным UX), который бы мог одинаково хорошо отображать и 20, и 200, и и 100 миллионов элементов — самома область такая: отображение истории операций в хронологическом порядке.
Я тоже не сильно понимаю масштабы проблемы. Ладно, с миллионами записей не помню, но для десятков тысяч также делал на WinAPI с custom draw через GDI. Скрины уже не приведу, т.к. это было 20 лет назад, но принципиальных проблем не вижу.
Но там всё равно надо немного понимать в алгоритмы, чтобы делать сортировку, поиск, фильтрацию значений.
Здравствуйте, Nuzhny, Вы писали:
Ф>>Просто ты не сталкивался с такими задачами.... Ф>>отображать и 20, и 200, и и 100 миллионов элементов — ...отображение истории операций в хронологическом порядке.
N>Я тоже не сильно понимаю масштабы проблемы. Ладно, с миллионами записей не помню, но для десятков тысяч также делал на WinAPI с custom draw через GDI. Скрины уже не приведу, т.к. это было 20 лет назад, но принципиальных проблем не вижу.
Мы о разном говорим: его комментарий был критикой идеи реализации поставщика данных, в виде имплементации IList. Он про это говорил "я не считаю это чем-то полезным или умным".
Дело тут не только в самом объёме данных, но и в том, что доступ к данным не мгновенный — легко повесить UI. К тому же для использовании Virtual Mode нужно учитывать особенности запроса данных у поставщика — в любом случае сначала потребуется общее кол-во строк, потом будут вытягиваться строки, вошедшие в окно отображения.
Я тоже принципиальных проблем реализации именно контрола не вижу.
Кстати, вопрос — работало? Вопрос потому, что для GDI 32к пикселей — максимальный размер контрола по одной оси. Тестировали на эдж-кейсах?
Всё сказанное выше — личное мнение, если не указано обратное.
Здравствуйте, Философ, Вы писали:
Ф>Кстати, вопрос — работало? Вопрос потому, что для GDI 32к пикселей — максимальный размер контрола по одной оси. Тестировали на эдж-кейсах?
Работало, но там не было столько пикселей — сравнимо с разрешением монитора. Зачем что-то сильно больше?
Здравствуйте, Nuzhny, Вы писали:
Ф>>Кстати, вопрос — работало? Вопрос потому, что для GDI 32к пикселей — максимальный размер контрола по одной оси. Тестировали на эдж-кейсах? N>Работало, но там не было столько пикселей — сравнимо с разрешением монитора. Зачем что-то сильно больше?
Я спросил, потому что наивная реализация — создать окно, или битмап под кол-во элементов, а потом (при скролле) либо двигать окно, в соответствии с окном отображения (вью-портом), либо с помощью BitBlt копировать нарисованное во вью-порт — так часто делают, притом даже если не отрисовывают все элементы сразу (только вью-порт).
Если правда работало на эдж-кейсах, то размер твоего "канваса" для рисования был виртуальным. Вопрос также возник потому, что я видел как некоторые тестируют — некоторые считают, что 200 — 500 элементов вполне достаточно. Однако потом оказывается, что у настоящих пользователей несколько больше.
Ну вот, собственно: в ProcMon'е высота элемента — примерно 16 пикселей, т.е. чтобы сожрать доступный лимит, достаточно чуть больше чем 2к таких элементов.
Всё сказанное выше — личное мнение, если не указано обратное.
Здравствуйте, Философ, Вы писали:
Ф>Мы о разном говорим: его комментарий был критикой идеи реализации поставщика данных, в виде имплементации IList. Он про это говорил "я не считаю это чем-то полезным или умным".
Извини, если обидел. Я хотел сказать другое- что логика на фронте бывает не только формошлёпная и в таком случае, она не уступает бэку по сложности и алгоритмам.
Ф> в любом случае сначала потребуется общее кол-во строк,
А вот эту оптимищацию недавно прикрутили- дозапрашивать больше. Ибо по какой-то прмчине в монго подсчитать число элементов посое филттров стоит дорого по времени и памяти. Но я в монго не понимаю.