Здравствуйте, gandjustas, Вы писали:
G>>>Обогнал вашу версию, работает примерно как версия на питоне. Полный код тут: https://github.com/gandjustas/HugeFileSort
_FR>>А что с расходом памяти? Например, если файл в 10 гигов разбиватт на 200 кусков по ~50 метров?
G>Сегодня тестил на 100М строк 14 ГБ, сортировка по дефлоту разбивает на куски по 100к строк, примерно 150мб кусок. Потребление памяти с параллелизмом до 3 гб на моей машине.
Мне всё-таки кажется, что это не совсем правильный подход к решению данной задачи.
Я рассуждаю так: если задача сортировки файла в условиях недлостаточной памяти возникла. значимт при решении задачи нам нужно в первую очередь экономить память, а во-вторую уже ускорять.
Если я правильно понял ваши вводные:
исходный файл на 14Г из 100М строк, каждая строка до 256 символов + строковое представление инта
разбивается на файлы по 100к строк, каждый кусок по 150М
Я как-нибудь попробую. Я себе условия взял пожёсче:
строка до 1024 символов и UInt64 впереди. В файле чуть меньше 20М строк и 10Г (для точности 19,759,397 строк и 10,737,419,483 байт)
разбивается на файлы по 100л строк, выходит по ~54М (54,350,975 байт)
Разбиение занимает 00:01:06, слияние 00:01:10, всё вместе (видимо, добавляется удаление файлов) 00:02:20, при этом памяти в пике потратилось до 500М
| | Картинка Performance Graph |
| | 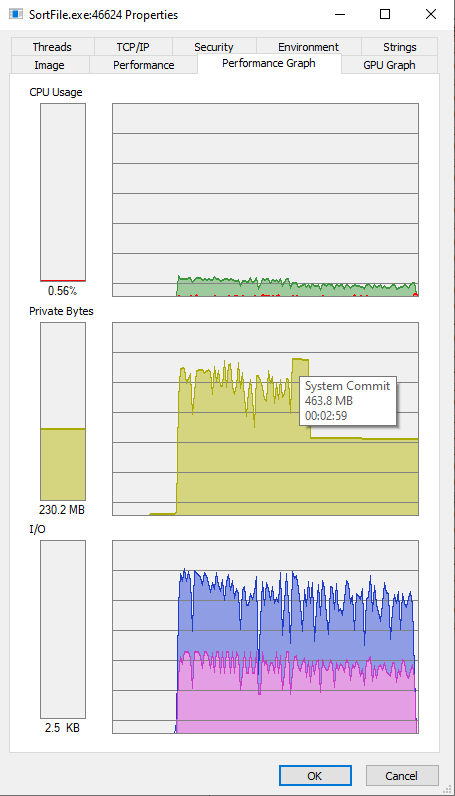 |
| | |
Если при разбиении файла вместо всего двух буферов под данные использовать больше, по числу процессоров, как выше предложили, скорость разбиения улучшается на 20..25 процентов, а память возрастает вдвое, поэтому пока это не так интересно.
Интересно будет ваш и мой код запустить на одном и том же файле на одной и той же машине и сравнить память/время.

