Z>>В динамических языках ты не найдешь подстановки констант или удаления анричибл кода. ·>В javascript/groovy я нашел. Или это ненастоящие динамические языки?
Не везде можно поставить флаги, особенно так, чтобы их в runtime можно было переключитить: например версия зависимостей поменялась.
Кроме того, это определеный риск (вдруг ты где то забудешь измененный код в флаг обернуть).
А у QA может просто не быть свободного времени на тестирование корректной работы "переключателя".
Прокомментирую также некоторые другие утверждения: ·>Не понял. Ветка девелопа одна же на все доски. Как и когда организуется резет — вообще неясно в твоей схеме. И что происходит с тасками начатыми до резета — их придётся мучительно ребейзить.
Нет, при ресете develop не придется делать делать rebase для task-веток, т.к. они ответвляются от master (release), а не от develop. И merge из develop в task-ветки не производится.
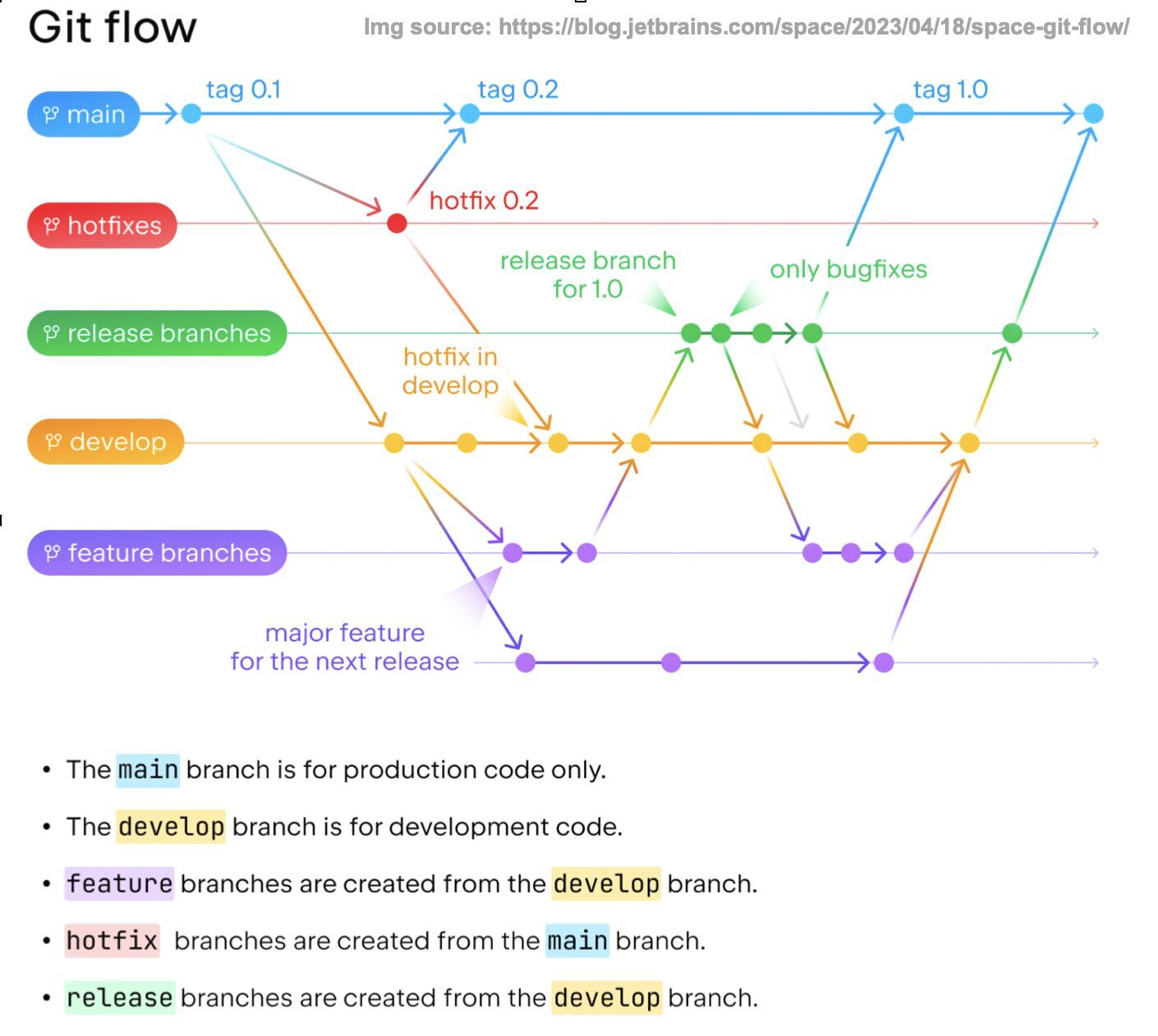
напомню схему:
v QA/fix v done
develop ---------------------------------------
/ /
TASK-01-login-users ----------------------------
/ \
release ---------------------------------------
^ develop/review ^ ready to deploy
·>Вообще, любой воркфлоу в которой происходит резет публичных веток — ущербен и опасен.
В описанной схеме ветка develop это просто ветка, где сливаются фичи. И как отметил Ziaw, ему она нужна, т.к. нет "железных" ресурсов для того, чтобы развернуть тестовое окружение под каждую фиче-(task)-ветку в отдельности.
Т.е. это не что иное, как Throw-away integration branch, описанный в документации по git.
По поводу failure/success path: ·>Твоя схема ориентирована на failure path, когда фичи к QA попадают полусырые, глючные, к релизу не готовые, девелоп-бранч кишит багами, контроля над кодом и функциональностью нет.
приведу пример
У нас на работе тестируют именно фиче-(task)-ветки и только после тестирования и получения отмашки от руководства вливают в upstream ветку, на которой будет ставится релизный тег.
Делается так, потому что:
1) фича может быть совсем экспериментальная без определенной даты релиза вообще. При этом QA тоже участвуют в эксперименте
2) фича может передвинута на следующий релиз т.к.:
2.1) разрабочики/тестировщики не успевают доделать/протестировать или просто перекинуты на более приоритетную задачу
2.3) стейкхолдеры что-то там перетасовали
3) фичи могут изначально разрабатываться под разные релизы — например ближайший и следующий за ним (разница по времени полгода-год)
Сдвиг фичи на другой релиз может произойти в любой момент: до, в ходе или после (успешного) тестирования.
И как я заметил в начале сообщения, feature toggles далеко не всегда применимы.
По поводу конфликтов: .> Ну я не сразу понял, что оно настолько жутко... На 90 таск-ветках конфликты будут гарантированно. Т.е. твоя схема не только требует резет публичных веток, но и постоянный резолв конфликтов
в этой теме уже были комментарии, что если фичи существенно пересекаются по коду, то делается доп. ветка task1+task2 в которой они и разрешаются.
Т.е. при merge в develop (а потом в release) каких-то существенных конфликтов быть не должно.
По поводу diverged history: ·>Чисто теоретически, результаты любых проверок для sha1 X нельзя проецировать на другой sha1 Y. .>И никак не обеспечить, что порядок мержа 90 веток в девелоп будет ровно таким же как в релиз. А значит у тебя есть 90! вариантов как может выглядеть релизная ветка.
Если речь идет о commit id, то он вычисляется на основе многих составляющих в т.ч. commit id родителей.
Я к тому, результаты проверок имеет смысл проецировать на основе идентичности кода, а не commit id.
Сравнение кода позволит выявить потенциальные ситуации, когда конфликты при merge в master(release) разрешены иным образом, чем при merge в develop.
Кроме того для повторного разрешения конфликтов можно использовать git-rerere
Вот пример использования git-rerere в flow, очень похожем на обсуждаемый: A pragmatic guide to the Branch Per Feature git branching strategy
(разница только в том, что там две throw-away интеграционные ветки: одна чисто для разрешения конфликтов, вторая — для QA)
Здравствуйте, Ziaw, Вы писали:
Z> Другими словами, во время регресса приходится принимать решение, катить неготовую фичу, быстр допилить либо срочно ревертить. Вот от этого непростого выбора мы и отказались собственно.
Почему это непростой выбор? Поставьте ограничитель по времени, например: за минуту|час|день не пофиксили — реверт.
Z> feature flag как общий подход выглядит здесь как дорогой костыль, прикрывающий полуготовые фичи.
Костыль не дорогой на самом деле. Хотя требует некую культуру написания кода и тестов.
Зато с лихвой окупается, т.к. бранчей/мержей требуется гораздо меньше, и они короткоживущие.
Ещё и дополнительные возможности даёт типа A/B-тестирования.
Здравствуйте, LaptevVV, Вы писали:
LVV>Народ, поделитесь информацией, есть ли в вашей конторе какая-нить политика-админство гитования. LVV>Или пушат и мержат все кому не лень без всякой политики?
Мне нравится схема, которую показал как-то коллега и она прижилась. Названия не знаю, возможно кто-то подскажет.
Используется две основных ветки: develop/release.
develop развернут на staging, в нем тестируются таски/фичи. release в нем всегда протестированный код (развернут на другом staging, но это по желанию).
В отличии от gitflow, develop в release не вливается никогда.
v QA/fix v done
develop ---------------------------------------
/ /
TASK-01-login-users ----------------------------
/ \
release ---------------------------------------
^ develop/review ^ ready to deploy
Жизненный цикл таски — стартуем ветку от release, вливаем в develop, тестируем, после апрува QA эту же ветку таски вливаем в бранч.
Процесс чуть сложнее gitflow, но гарантирует то, что в release в любой момент лежит только протестированный код и в нем нет ни одной сырой таски. Очень удобно.
Здравствуйте, LaptevVV, Вы писали:
Q>>Есть только общие моменты: Q>>prod/realise — здесь код который уже работает LVV>Одна ветка ?
Одна на выпускаемый продукт
Q>>main/master — здесь код в состоянии "готово", т.е. прошедший полагающиеся этапы проверки Q>>функциональные ветки — здесь код в стадии разработки LVV>Каждый заводит свою под решаемую задачу ?
Да. Q>>dev — здесь происходит слияние резных версий кода, разбор конфликтов. LVV>Интересно: специальная ветка для слияния и разбора конфликтов LVV>Сливаем сюда функциональные ветки, проверяем работу после устранения конфликтов и направляем в ветку prod/realise ?
Да, конфликты лучше разбирать на самой ранней стадии.
Здравствуйте, LaptevVV, Вы писали:
LVV>Народ, поделитесь информацией, есть ли в вашей конторе какая-нить политика-админство гитования. LVV>Или пушат и мержат все кому не лень без всякой политики?
LVV>>А кто нибудь за этим следит? LVV>>Или это записано в каком-то доке?
N>Нет и нет, просто есть культура, которая распространяется сама по себе.
Ну раз Вам всё просто и понятно, то можете прокомментировать ситуацию описанную здесь.
Так ли опасна ситуация, как пишет автор статьи, и почему для решения не достаточно "культуры", а нужен pre-receive hook.
Здравствуйте, LaptevVV, Вы писали:
vsb>>В большинстве проектов есть ветка main, туда все пушат, оно ставится на тестовый сервер. Когда будет решение ставить на рабочий сервер, заводится тег вроде 1.123.0, и этот билд, собственно, ставится. Если нужен хотфикс — делается ветка 1.123.x, туда коммитится что надо и пушится с тегом 1.123.1 и так далее. Если разрабатывается какая-то фича, которую пока ставить не планируется — делается фич-флаг. LVV>А кто такой процесс установил? LVV>И когда ? LVV>Где-то прописано? LVV>Или новичку на словах объясняется ?
Я установил, примерно полтора года назад. Объясняется на словах. Часть правил прописаны в CI. До меня примерно так же было, но без конкретики, я чуток формализовал всё. Где-то расписывал текстом, но сейчас уже не найду.
Много уже хороших политик гитования упомянули тут в чате. Дополню вот какой мыслью.
Важно строить политику гитования отталкиваясь от:
— типа ПО: SaaS, десктоп, мобилки, железячный софт
— релизных политик: раз в день, раз в полгода, катится на прод, отдается заказчикам самая свежая версия на данный момент
— типа софта: аутсорс, проектная работа, продуктовая разработка
— количества людей в команде
В зависимости от этих факторов можно выбрать наиболее оптимальную политику гитования. Не стоит под все вариации применять одну политику.
Например, dev/main ветки хорошо, когда у тебя SaaS и тебе нужно катить в прод один или несколько раз в неделю и/или у тебя есть стейджинг-окружение наряду с продом. Но такая политика не нужна, когда ты делаешь коробочный продукт — там достаточно main.
Еще пример: если на проекте два человека, то для них может быть оптимальным вообще main + 2 персональных ветки.
Ну и так далее. Я на личном опыте видел, как в десктоп продукт тащили main+dev только потому, что привыкли так на саасном проекте или прочитали где-то. Хотя там это было во вред. И обратные примеры тоже видел.
LVV>>>Или пушат и мержат все кому не лень без всякой политики? LVV>С правами — это понятно, это все можно настроить т п. LVV>А есть чел, которые за все это отвечает?
Да есть выделенное подразделение (пара человек), которое занимается source control, build`ами и AzureDevops в целом.
Но они не занимаются рутинными слияниями и т.п. В зависимости от направления merge этим занимаются тимлиды лично, либо кто-то из них включается в required reviewers PR, а PR формирует обычный разработчик.
У тимлидов есть повышенные права, либо права им выдаются временно для определенных действий согласно документированному workflow.
LVV>И много ли человек в проекте одновременно работает ?
Над одной feature работает 1-3 команды по 4-8 человек. Feature в разработке обычно несколько и ещё bugfix, поэтому общее число людей, работающих с репозиторием, больше.
По коду пересечений между командами как правило нет, но, т.к. Git в отличие от других VCS не предполагает выборочного merge (если только не использовать cherry pick), то конфликты в "чужом" коде приходится разрешать совместными усилиями
Здравствуйте, Ziaw, Вы писали:
Z> ·>Плохо. Будут мучения с резолвингом конфликтов. Z> ·>Мерж таск-ветки в релиз и в девелоп происходят в разное время. Более менее работоспособно только для маленьких проектов с парой независимых тасков. На большом проекте у тебя будет много таск-веток, некоторые с зависимостями друг от друга, которые вливаются в develop и релиз в разные моменты времени. Z> У нас флоу неплохо работает в проекте побольше, чем ты описал. Таски с зависимостями друг от друга объединяются в фичабранч, который и в тестирование и в релиз идёт одной веткой, а в ревью уходят пиары именно в него.
Просто в общем случае невозможно определить — зависимы ли таски или нет.
Результат мержа в разные ветки — разный, а значит и работать может по-разному.
Z> ·>Это приведёт к конфликтам и они могут разрешаться немного по-разному. В итоге в release окажется код, который немного отличается от того, что было в develop. Z> Такая проблема редка, но есть. Она не является мучением. Ресолвит конфликты тот же человек. Отличия в ресолве редки и незначимы. Время от времени develop ресетится от release и отличия исчезают.
Ужас, ещё и reset. А если что-то в develop было замержено — то потеряется?
Z> >Т.е. тестироваться будет не тот код, который релизится. Опасно. Z> У вас в тестирование задачи идет именно тот код, который будет релизиться? Поделишься опытом цикла релиза?
Да вроде стандартно — в конце спринта делается тег на текущем девелопе и отдаётся в QA. Найденные QA баги правятся на релизной ветке и тут же мержатся назад в девелоп. Когда тестеры счастливы — тег идёт в прод. Если есть хотфиксы в проде, тоже идут в эту же релизную ветку и тут же портятся в девелоп.
[v1.0] — это тег.
Q — это багфиксы обнаруженные во время QA
H — это хотфиксы
* — коммиты.
Заметь, если багов/фиксов в релизном теге не обнаружено (идеальный случай), то релизная ветка собственно не нужна — релизы обозначаются тегами и ничего не ответвляется. Т.е. если вдруг обнаружился баг, то релизную ветку можно создать от тега и туда закоммитить хотфикс.
Здравствуйте, Ziaw, Вы писали:
Z>Отдельно вынесу тред про недостаток гит-флоу, который и мотивировал нас использовать более сложный механизм. Речь идет о тестовом стенде, стейджинге. Либо QA может в два клика развернуть стенд с таской у себя локально или в облаке либо тестировать приходится на едином стейджинге для всех, в этот стейдж раскатывается ветка мастер через CI/CD. Z>В первом случае, каждая таска тестируется в своей песочнице и никакого понимания про то, как они будут работать вместе быть не может, они просто еще не смерджены. Впрочем это не наш случай, разводить по инстансу немаленького веб приложения на каждую таску мы не можем.
Да и не надо. Для этого придумали юнит-тесты — как раз для изолированного тестирования. И сабж тут ортогонален.
Z>Во втором, для релиза нужен какой-то период, за который пройдут тестирование все таски, которые сейчас в мастере (и отдельный стенд на который раскатывается этот релиз). То есть любая таска возвращенная в доработку, требует остановить релиз и дождаться ее завершения, релиз откладывается на неопределенный срок. Это работает только когда вы можете себе такое позволить.
Это не все альтернативы. В релизной ветке можно: не анонсировать фичу, или анонсировать как "preview/PoC" с known issues, если клиенты позволяют.
если поломка мелкая, то просто быстро доработать.
если не получается доработать быстро, то просто закомментировать/отключить сломаную таску (см. feature flags — как общий подход).
Ну совсем всё сломано, даже feature flag глючит — git revert (но тут закономерный вопрос и обсуждение на ретроспективе — а как оно вообще попало в develop в таком виде??!).
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
В большинстве проектов есть ветка main, туда все пушат, оно ставится на тестовый сервер. Когда будет решение ставить на рабочий сервер, заводится тег вроде 1.123.0, и этот билд, собственно, ставится. Если нужен хотфикс — делается ветка 1.123.x, туда коммитится что надо и пушится с тегом 1.123.1 и так далее. Если разрабатывается какая-то фича, которую пока ставить не планируется — делается фич-флаг.
Если проект очень активно разрабатывается — на период активной разработки делается две ветки — dev и main. В dev пишутся новые фичи, main типа стабилизированная ветка.
В целом долгоживущие параллельные ветки считаю неудобным в использовании, слишком много суеты по ребейзам.
Технически запрета на пуш в любую ветку нет, т.к. в гитхабе такого функционала для халявщиков нет. Но желательно нетривиальные изменения через пул-реквест проводить.
У нас программистов мало (<10), а модулей много (несколько десятков). Над одним проектом больше трёх программистов не работает, обычно один. Не знаю, насколько такой процесс скалируется выше, нам пока его хватает.
Здравствуйте, LaptevVV, Вы писали:
LVV>Народ, поделитесь информацией, есть ли в вашей конторе какая-нить политика-админство гитования. LVV>Или пушат и мержат все кому не лень без всякой политики?
develop, master, release/*, hotfix/* — комиты только через mr, с автотестами, в остальных ветках можно делать кто что хочет
LVV>Народ, поделитесь информацией, есть ли в вашей конторе какая-нить политика-админство гитования. LVV>Или пушат и мержат все кому не лень без всякой политики?
В качестве git-сервера используем MS AzureDevops.
Там права (branch permissions) и политики (branch policies) на ветки определяются на базе иерархических имен (Hierarchical branch folders c wildcards).
Через права можно ограничить действия на ветке, например чтение/запись/перезапись истории и пр.
Через политики — настроить gated check-in — через PR c различными предусловиями (сборка build`а, прохождение автотестов, review), а также ограничить способы merge (всего 4 варианта) и пр.
Ветки делим на релизные (прошлые и текущие релизы) и feature (для разработки отдельных feature одной или несколькими командами). На них, как правило, запрещена перезапись истории, настроены политики по PR (автотесты и review на базе путей в репозитории). Иногда могут быть некоторые ограничения по типу merge.
И персональные (личные) ветки — там владелец ветки (разработчик) настраивает всё по своему усмотрению.
Тип ветки, назначение и принадлежность (личных веток) определяется на базе иерхической системы имен.
Есть еще политики на запуск build`ов — какие на каких ветках можно запускать. И др. workflow на разные случаи жизни .
Есть мастер, есть релизы бранчи. Все остальное short-lived branches, включая feature, hotfix, bugfix etc. Создаются и уничтожаются по факту мержа либо в мастер либо в релиз. hotfix/bugfix могут мержится в несколько мест (см. черрипикинг), если проблема в релиз бранче — но самое простое и чистое решение мержить фиксы в релиз и перед отдачей релиза/по мере необходимости мержить весь релиз в мастер (естественно, для этого есть какое то opportunity window, которое со временем закрывается).
Чем больше бранчей, тем больше проблем, количество параллельно поддерживаемых бранчей — главный источник сложности, зачем их плодить? За 10 лет я не видел нужды в develop бранче/где бы это использовалось.
по поводу политик — мне нравится как сделано в GitLab — protected branches, защищенные бранчи — в них нельзя мержить напрямую (или можно, но не всем), обычно это мастер, иногда релизы. Соответственно, для изменения кода необходимо создавать бранч и проходить через процедуру ревью и проверок перед мержем (например запуск тестов и код кавераджа). На практике этого хватает, усложнить, конечно, можно, но зачем?
релиз бранчи формируются и поддерживаются релиз инженером или равноправным лицом, это немного другая работа, нежели непосредственно разработка, но все решается в рамках скрума или для частных случаев митингами.
Здравствуйте, m2user, Вы писали:
m> Z>>В динамических языках ты не найдешь подстановки констант или удаления анричибл кода. m> ·>В javascript/groovy я нашел. Или это ненастоящие динамические языки? m> Не везде можно поставить флаги, особенно так, чтобы их в runtime можно было переключитить: например версия зависимостей поменялась.
Флаги можно делать и compile-time, и build-time.
m> Кроме того, это определеный риск (вдруг ты где то забудешь измененный код в флаг обернуть).
Ну тестировать нужно, конечно.
m> А у QA может просто не быть свободного времени на тестирование корректной работы "переключателя".
Это какая-то вялая отмаза. Если код недостаточно тестируется, то он может быть недостаточно качественным. И тут неважно переключатель тут тестируется или что-то ещё.
m> ·>Не понял. Ветка девелопа одна же на все доски. Как и когда организуется резет — вообще неясно в твоей схеме. И что происходит с тасками начатыми до резета — их придётся мучительно ребейзить. m> Нет, при ресете develop не придется делать делать rebase для task-веток, т.к. они ответвляются от master (release), а не от develop. И merge из develop в task-ветки не производится.
Так ещё терпимо, да. Но всё равно создаёт хаос, т.к. "так а я же вчера уже это выкатил! Тестируйте! Ой, не работает, а мы резет же сделали...". Вместо плавного потока у тебя бурление какое-то туда-сюда.
Т.е. следить за всем этим делом становится сложнее. Ещё как-то синхронизовать резеты нужно глобально между всеми разработчиками и QA.
m> ·>Вообще, любой воркфлоу в которой происходит резет публичных веток — ущербен и опасен. m> В описанной схеме ветка develop это просто ветка, где сливаются фичи. И как отметил Ziaw, ему она нужна, т.к. нет "железных" ресурсов для того, чтобы развернуть тестовое окружение под каждую фиче-(task)-ветку в отдельности. m> Т.е. это не что иное, как Throw-away integration branch, описанный в документации по git.
Ну если почитать этот параграф повнимательнее, и ещё следующий "Branch management for a release", то можно заметить, Throw-away branch больше для демок и экспериментов, чем часть release-пайплайна. Т.е. основная разработка и тестирование всё равно ведётся отдельно в и в релиз уходит таг, т.е. то за что я топлю. По твоей же схеме QA происходит только в Throw-away branch, потом всё перезаливается второй раз (удваивая усилия на мержы-конфликты) в другой бранч и тут же объявляется релизом, без QA. То что результат мержа не тестируется — меня удивляет больше всего. А если перетестируете всё, то это удваивает нагрузку и на QA, а потом совершенно неожиданно: "у QA может просто не быть свободного времени".
m> ·>Твоя схема ориентирована на failure path, когда фичи к QA попадают полусырые, глючные, к релизу не готовые, девелоп-бранч кишит багами, контроля над кодом и функциональностью нет.
m> И как я заметил в начале сообщения, feature toggles далеко не всегда применимы.
Ок, вполне поверю, что такие случаи можно придумать. Но это должно быть редким исключением, чем правилом и основным способом организации пайплайна, и требовать специального подхода и тестирования.
m> .> Ну я не сразу понял, что оно настолько жутко... На 90 таск-ветках конфликты будут гарантированно. Т.е. твоя схема не только требует резет публичных веток, но и постоянный резолв конфликтов m> в этой теме уже были комментарии, что если фичи существенно пересекаются по коду, то делается доп. ветка task1+task2 в которой они и разрешаются.
Это вообще неясно как организовать надёжно.
Как и в каких единицах измерить "существенность пересечения"?
Как детектить неявные пересечения? Даже изменения в разных файлах могут давать логические пересечения — конфликта vcs нет, а код не работает — это самые подлые проблемы.
Что если потом внезапно окажется, что task1 — очень срочно надо, протестировано, требуется релизить, а task2 — "не успевают доделать/протестировать" и вообще "стейкхолдеры что-то там перетасовали"?
m> Т.е. при merge в develop (а потом в release) каких-то существенных конфликтов быть не должно.
Проблема в том, что мерж веток A,B,C может работать очень по-другому, с разными конфликтами чем B,C,A — и это нетривиально понимать как всё работает.
m> ·>Чисто теоретически, результаты любых проверок для sha1 X нельзя проецировать на другой sha1 Y. m> .>И никак не обеспечить, что порядок мержа 90 веток в девелоп будет ровно таким же как в релиз. А значит у тебя есть 90! вариантов как может выглядеть релизная ветка.
m> Если речь идет о commit id, то он вычисляется на основе многих составляющих в т.ч. commit id родителей. m> Я к тому, результаты проверок имеет смысл проецировать на основе идентичности кода, а не commit id. m> Сравнение кода позволит выявить потенциальные ситуации, когда конфликты при merge в master(release) разрешены иным образом, чем при merge в develop.
Каким образом ты будешь сравнивать код? С учётом того, что как ты выразился выше, не всё может быть замержено. Дифы могут быть практически любого размера и сложности. Т.е. весь этот процесс нетривиальный, запутанный, легко пропустить ошибки. В отличие от того, чтобы тупо сравнить два commitId — это работает железно.
m> Кроме того для повторного разрешения конфликтов можно использовать git-rerere m> Вот пример использования git-rerere в flow, очень похожем на обсуждаемый: A pragmatic guide to the Branch Per Feature git branching strategy m> (разница только в том, что там две throw-away интеграционные ветки: одна чисто для разрешения конфликтов, вторая — для QA)
Это 2013 год, для "project first switched from Subversion to Git" — наверное сгодится.
Чуваки наученные к траходному с vcs пока сидели на svn — считают нормой писать магические ruby-скрипты и централизованно постоянно что-то ребейзить.
Народ, поделитесь информацией, есть ли в вашей конторе какая-нить политика-админство гитования.
Или пушат и мержат все кому не лень без всякой политики?
Хочешь быть счастливым — будь им!
Без булдырабыз!!!
LVV>>Народ, поделитесь информацией, есть ли в вашей конторе какая-нить политика-админство гитования. LVV>>Или пушат и мержат все кому не лень без всякой политики?
С правами — это понятно, это все можно настроить т п.
А есть чел, которые за все это отвечает?
И много ли человек в проекте одновременно работает ?
Хочешь быть счастливым — будь им!
Без булдырабыз!!!
Здравствуйте, m2user, Вы писали:
M>Ну раз Вам всё просто и понятно, то можете прокомментировать ситуацию описанную здесь. M>Так ли опасна ситуация, как пишет автор статьи, и почему для решения не достаточно "культуры", а нужен pre-receive hook.
Зависит от конкретной команды. У нас можно в течение 5-10 минут собраться и устно всё порешать. А ещё более менее известно, кто и за какой кусок кода отвечает.
Здравствуйте, LaptevVV, Вы писали:
LVV>С правами — это понятно, это все можно настроить т п. LVV>А есть чел, которые за все это отвечает? LVV>И много ли человек в проекте одновременно работает ?
Мы тоже используем Azure. В разных репозиториях разные настройки. Наиболее строгие в корневых С++ библиотеках и продуктах, отвечает за них тех.лид. Человек 20 туда коммитит.
Здравствуйте, Ziaw, Вы писали:
Z> Жизненный цикл таски — стартуем ветку от release, вливаем в develop, тестируем, после апрува QA эту же ветку таски вливаем в бранч.
Плохо. Будут мучения с резолвингом конфликтов.
Мерж таск-ветки в релиз и в девелоп происходят в разное время. Более менее работоспособно только для маленьких проектов с парой независимых тасков. На большом проекте у тебя будет много таск-веток, некоторые с зависимостями друг от друга, которые вливаются в develop и релиз в разные моменты времени.
Это приведёт к конфликтам и они могут разрешаться немного по-разному. В итоге в release окажется код, который немного отличается от того, что было в develop. Т.е. тестироваться будет не тот код, который релизится. Опасно.
Z>> Жизненный цикл таски — стартуем ветку от release, вливаем в develop, тестируем, после апрува QA эту же ветку таски вливаем в бранч. ·>Плохо. Будут мучения с резолвингом конфликтов. ·>Мерж таск-ветки в релиз и в девелоп происходят в разное время. Более менее работоспособно только для маленьких проектов с парой независимых тасков. На большом проекте у тебя будет много таск-веток, некоторые с зависимостями друг от друга, которые вливаются в develop и релиз в разные моменты времени.
Полагаю, что раз выбран такой подход, то таски у них не пересекаются по коду (такое может быть и на больших проектах). А если так случится, что пересекаются, то сделают промежуточную ветку task01+task02.
·>Т.е. тестироваться будет не тот код, который релизится. Опасно.
А это и так будет, потому что фичи могли в develop тестироваться вместе, а в release попасть в разное время. Или вообще фичу могут по результатам тестирования отложить до лучших времен.
Очевидно, что все это будет надежно, только если фичи независимы.
Здравствуйте, m2user, Вы писали:
m> Z>> Жизненный цикл таски — стартуем ветку от release, вливаем в develop, тестируем, после апрува QA эту же ветку таски вливаем в бранч. m> ·>Плохо. Будут мучения с резолвингом конфликтов. m> ·>Мерж таск-ветки в релиз и в девелоп происходят в разное время. Более менее работоспособно только для маленьких проектов с парой независимых тасков. На большом проекте у тебя будет много таск-веток, некоторые с зависимостями друг от друга, которые вливаются в develop и релиз в разные моменты времени. m> Полагаю, что раз выбран такой подход, то таски у них не пересекаются по коду (такое может быть и на больших проектах).
Вполне верю. Просто он это описал как альтернативу стандартного flow. Нет уж, стандартный flow вполне универсален, а предложенное выше работает только в определённых тепличных условиях.
m>А если так случится, что пересекаются, то сделают промежуточную ветку task01+task02.
Угу, много чего интересного может случиться (где например хотфиксы в его схеме?), и появятся новые магические ветки. И в итоге у них получится кривоватое подмножество flow.
m> ·>Т.е. тестироваться будет не тот код, который релизится. Опасно. m> А это и так будет, потому что фичи могли в develop тестироваться вместе, а в release попасть в разное время. Или вообще фичу могут по результатам тестирования отложить до лучших времен. m> Очевидно, что все это будет надежно, только если фичи независимы.
Угу. Притом независимость — нетривиальное свойство, т.е. без серьёзного доказательства и исследования определить независимость фич невозможно.
Здравствуйте, LaptevVV, Вы писали:
LVV>Народ, поделитесь информацией, есть ли в вашей конторе какая-нить политика-админство гитования. LVV>Или пушат и мержат все кому не лень без всякой политики?
Только мастер, релизы из мастера, фича ветки мерджатся в мастер в течение 1-2 дней после создания. Плюсы: разработчики не тратят время на мерджи. Минусы: нужно правильно выбирать задачи на реализацию и почти никогда не косячить.
Здравствуйте, ·, Вы писали:
·>Плохо. Будут мучения с резолвингом конфликтов. ·>Мерж таск-ветки в релиз и в девелоп происходят в разное время. Более менее работоспособно только для маленьких проектов с парой независимых тасков. На большом проекте у тебя будет много таск-веток, некоторые с зависимостями друг от друга, которые вливаются в develop и релиз в разные моменты времени.
У нас флоу неплохо работает в проекте побольше, чем ты описал. Таски с зависимостями друг от друга объединяются в фичабранч, который и в тестирование и в релиз идёт одной веткой, а в ревью уходят пиары именно в него.
·>Это приведёт к конфликтам и они могут разрешаться немного по-разному. В итоге в release окажется код, который немного отличается от того, что было в develop.
Такая проблема редка, но есть. Она не является мучением. Ресолвит конфликты тот же человек. Отличия в ресолве редки и незначимы. Время от времени develop ресетится от release и отличия исчезают.
>Т.е. тестироваться будет не тот код, который релизится. Опасно.
У вас в тестирование задачи идет именно тот код, который будет релизиться? Поделишься опытом цикла релиза?
Здравствуйте, ·, Вы писали:
·>Просто в общем случае невозможно определить — зависимы ли таски или нет.
На практике я таких случаев не встречал. Если тебя блочит код другой таски ты знаешь про это и вы можете объеденить их в один фича-бранч, который лучше тестировать совметстно.
·>Результат мержа в разные ветки — разный, а значит и работать может по-разному.
Может и что? Чем это качественно отличается от того, что он может работать в релизе по разному и в твоем флоу?
·>Ужас, ещё и reset. А если что-то в develop было замержено — то потеряется?
Туда замерджены только таски в тестировании, они все на доске. Процедура ресета редкая, это не проблема для нас.
·>Да вроде стандартно — в конце спринта делается тег на текущем девелопе и отдаётся в QA. Найденные QA баги правятся на релизной ветке и тут же мержатся назад в девелоп. Когда тестеры счастливы — тег идёт в прод. Если есть хотфиксы в проде, тоже идут в эту же релизную ветку и тут же портятся в девелоп.
Ты про релиз и регресс сейчас написал, при чем тут он? Я в своем флоу вообще не касался этого процесса, хотя он становится заметно легче (не описание процесса, а само прохождение). Я спросил, как ты тестируешь таски именно в том коде который пойдет в релиз?
У тебя есть флоу тестирования конкретной таски, а не регресс релиза? Кстати, у тебя мобилка/десктоп/веб?
Здравствуйте, ·, Вы писали:
·>Угу, много чего интересного может случиться (где например хотфиксы в его схеме?), и появятся новые магические ветки. И в итоге у них получится кривоватое подмножество flow.
Проблема ветвления зависимых задач стоит в любом флоу и универсального решения на данный момент не имеет. Как ты в своем флоу ее решаешь?
Есть два вида зависимости:
— задача А требует функционал Б, как зависимость.
— А и Б работают по отдельности, но вместе не работает хотя бы кто-то из них.
Первая решается ровно такими же бранчами на несколько задач, как и в git-flow. Вторая решается только регрессом, зачастую это вопрос везения.
Здравствуйте, ·, Вы писали:
·>Да вроде стандартно — в конце спринта делается тег на текущем девелопе и отдаётся в QA. Найденные QA баги правятся на релизной ветке и тут же мержатся назад в девелоп. Когда тестеры счастливы — тег идёт в прод. Если есть хотфиксы в проде, тоже идут в эту же релизную ветку и тут же портятся в девелоп. ·>
Отдельно вынесу тред про недостаток гит-флоу, который и мотивировал нас использовать более сложный механизм. Речь идет о тестовом стенде, стейджинге. Либо QA может в два клика развернуть стенд с таской у себя локально или в облаке либо тестировать приходится на едином стейджинге для всех, в этот стейдж раскатывается ветка мастер через CI/CD.
В первом случае, каждая таска тестируется в своей песочнице и никакого понимания про то, как они будут работать вместе быть не может, они просто еще не смерджены. Впрочем это не наш случай, разводить по инстансу немаленького веб приложения на каждую таску мы не можем.
Во втором, для релиза нужен какой-то период, за который пройдут тестирование все таски, которые сейчас в мастере (и отдельный стенд на который раскатывается этот релиз). То есть любая таска возвращенная в доработку, требует остановить релиз и дождаться ее завершения, релиз откладывается на неопределенный срок. Это работает только когда вы можете себе такое позволить.
Здравствуйте, Ziaw, Вы писали:
Z>·>Просто в общем случае невозможно определить — зависимы ли таски или нет. Z>На практике я таких случаев не встречал. Если тебя блочит код другой таски ты знаешь про это и вы можете объеденить их в один фича-бранч, который лучше тестировать совметстно.
Странно. Часто бывает, когда меняются разные аспекты. Например, один таск — добавить поле ко всем сообщениям, а другой таск — добавить новый тип сообщения. В итоге может оказаться так, что в зависимости в каком порядке делать, в новом сообщении как может оказаться новое поле, так и может не оказаться.
Z>·>Результат мержа в разные ветки — разный, а значит и работать может по-разному. Z>Может и что? Чем это качественно отличается от того, что он может работать в релизе по разному и в твоем флоу?
В том, что в твоей схеме тестируется ревизия X, в прод уходит Y и X≠Y. В моей схеме X=Y.
Z>·>Ужас, ещё и reset. А если что-то в develop было замержено — то потеряется? Z>Туда замерджены только таски в тестировании, они все на доске. Процедура ресета редкая, это не проблема для нас.
Одна доска, это от силы десяток человек. Бывает гораздо больше.
Z>·>Да вроде стандартно — в конце спринта делается тег на текущем девелопе и отдаётся в QA. Найденные QA баги правятся на релизной ветке и тут же мержатся назад в девелоп. Когда тестеры счастливы — тег идёт в прод. Если есть хотфиксы в проде, тоже идут в эту же релизную ветку и тут же портятся в девелоп. Z>Ты про релиз и регресс сейчас написал, при чем тут он? Я в своем флоу вообще не касался этого процесса, хотя он становится заметно легче (не описание процесса, а само прохождение). Я спросил, как ты тестируешь таски именно в том коде который пойдет в релиз?
Тестируется результат мержа тасков в девелоп, одна из ревизий которого помечается релизным тегом.
Z>У тебя есть флоу тестирования конкретной таски, а не регресс релиза?
QA тестирует не код конкретной таски. Зачем? Для этого есть юнит-тесты, которые сами всё делают. Тестируется замерженный в девелоп код, который потенциально уйдёт в прод.
Z>Кстати, у тебя мобилка/десктоп/веб?
Эээ.. Ну ближе к вебу, скорее.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, Ziaw, Вы писали:
Z>·>Угу, много чего интересного может случиться (где например хотфиксы в его схеме?), и появятся новые магические ветки. И в итоге у них получится кривоватое подмножество flow. Z>Проблема ветвления зависимых задач стоит в любом флоу и универсального решения на данный момент не имеет. Как ты в своем флоу ее решаешь?
Опытным путём. Проверяется смерженный код. А не делаются предположения о том какой будет результат мержа на основании тестирования частей.
Z>Есть два вида зависимости: Z>- задача А требует функционал Б, как зависимость.
В твоей схеме А может уехать в прод до Б и ничего даже не пискнет.
Z>- А и Б работают по отдельности, но вместе не работает хотя бы кто-то из них.
Поэтому и надо тестировать их вместе перед отправкой в прод.
Z>Первая решается ровно такими же бранчами на несколько задач, как и в git-flow. Вторая решается только регрессом, зачастую это вопрос везения.
Ещё проблема в том, что нет никакого простого критерия, чтобы достоверно предварительно определить, что задача А хоть как-то зависит от задачи Б или нет. Теорема Райса и всё такое.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
·>Странно. Часто бывает, когда меняются разные аспекты. Например, один таск — добавить поле ко всем сообщениям, а другой таск — добавить новый тип сообщения. В итоге может оказаться так, что в зависимости в каком порядке делать, в новом сообщении как может оказаться новое поле, так и может не оказаться.
Такое должны тесты выявлять. Описаная проблема случается независимо от флоу.
·>В том, что в твоей схеме тестируется ревизия X, в прод уходит Y и X≠Y. В моей схеме X=Y.
В твоей схеме вообще не показано, как тестируется таска. Только регресс при релизе. Этот процесс можно делать в обоих флоу, он за рамками того, о чем я писал.
·>Одна доска, это от силы десяток человек. Бывает гораздо больше.
Это актуально для каждой доски.
·>Тестируется результат мержа тасков в девелоп, одна из ревизий которого помечается релизным тегом. ·>QA тестирует не код конкретной таски. Зачем? Для этого есть юнит-тесты, которые сами всё делают. Тестируется замерженный в девелоп код, который потенциально уйдёт в прод.
У вас тестируется весь результат спринта команды гораздо больше 10 человек? То есть к тестированию приступаете, только когда все таски влиты?
Здравствуйте, ·, Вы писали:
·>Да и не надо. Для этого придумали юнит-тесты — как раз для изолированного тестирования. И сабж тут ортогонален.
Если у вас задачи катятся в мастер до регресса без тестирования, тогда конечно git-flow сильно лучше. Хотя бы тем, что заметно проще.
·>Это не все альтернативы. В релизной ветке можно: ·> ·> не анонсировать фичу, или анонсировать как "preview/PoC" с known issues, если клиенты позволяют. ·> если поломка мелкая, то просто быстро доработать. ·> если не получается доработать быстро, то просто закомментировать/отключить сломаную таску (см. feature flags — как общий подход). ·> Ну совсем всё сломано, даже feature flag глючит — git revert (но тут закономерный вопрос и обсуждение на ретроспективе — а как оно вообще попало в develop в таком виде??!). ·>
Другими словами, во время регресса приходится принимать решение, катить неготовую фичу, быстр допилить либо срочно ревертить. Вот от этого непростого выбора мы и отказались собственно.
feature flag как общий подход выглядит здесь как дорогой костыль, прикрывающий полуготовые фичи.
Здравствуйте, ·, Вы писали:
·>Опытным путём. Проверяется смерженный код. А не делаются предположения о том какой будет результат мержа на основании тестирования частей.
Это красивые слова. В итоге проверяется код, от которого начался процесс тестирования и потом фрагментарно допроверятся результат фиксов, откатов, доливок, отключений фича флагов и всего подобного.
Z>>- задача А требует функционал Б, как зависимость. ·>В твоей схеме А может уехать в прод до Б и ничего даже не пискнет.
Она не сможет, она именно требует этот функционал. То, что она сделана и работает означает, что требуемый функционал в ней появился.
Z>>- А и Б работают по отдельности, но вместе не работает хотя бы кто-то из них. ·>Поэтому и надо тестировать их вместе перед отправкой в прод.
Ты снова говоришь про общий регресс перед релизом, который вообще за скобками описываемой схемы ветвления.
Здравствуйте, Ziaw, Вы писали:
Z>·>Странно. Часто бывает, когда меняются разные аспекты. Например, один таск — добавить поле ко всем сообщениям, а другой таск — добавить новый тип сообщения. В итоге может оказаться так, что в зависимости в каком порядке делать, в новом сообщении как может оказаться новое поле, так и может не оказаться. Z>Такое должны тесты выявлять. Описаная проблема случается независимо от флоу.
Которые? Юнит-тесты тестируют юниты. А QA это для результата полной интеграции. По твоей схеме тестируется результат интеграции в девелопе, а в прод идёт результат другой интеграции в совершенно другой ветке, без какого либо QA, судя по твоей картинке.
Z>·>В том, что в твоей схеме тестируется ревизия X, в прод уходит Y и X≠Y. В моей схеме X=Y. Z>В твоей схеме вообще не показано, как тестируется таска. Только регресс при релизе. Этот процесс можно делать в обоих флоу, он за рамками того, о чем я писал.
Она тестируется в составе ветки девелопа. Принципиальная разница в том, какая ревизия (commit sha1) проверяется QA и какая уходит в прод. В моей схеме, как правило, ревизия ровно та же, эквивалент с точностью до бита. В твоей — что попало.
Z>·>Одна доска, это от силы десяток человек. Бывает гораздо больше. Z>Это актуально для каждой доски.
Не понял. Ветка девелопа одна же на все доски. Как и когда организуется резет — вообще неясно в твоей схеме. И что происходит с тасками начатыми до резета — их придётся мучительно ребейзить.
Вообще, любой воркфлоу в которой происходит резет публичных веток — ущербен и опасен.
Z>·>Тестируется результат мержа тасков в девелоп, одна из ревизий которого помечается релизным тегом. Z>·>QA тестирует не код конкретной таски. Зачем? Для этого есть юнит-тесты, которые сами всё делают. Тестируется замерженный в девелоп код, который потенциально уйдёт в прод. Z>У вас тестируется весь результат спринта команды гораздо больше 10 человек? То есть к тестированию приступаете, только когда все таски влиты?
Тестирование идёт постоянно, в течение спринта. Накладывание релизного тега — это "freeze" изменений в конце спринта с целью прогона всех самых возможных QA проверок для sign-off релиза.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, Ziaw, Вы писали:
Z>·>Опытным путём. Проверяется смерженный код. А не делаются предположения о том какой будет результат мержа на основании тестирования частей. Z>Это красивые слова. В итоге проверяется код, от которого начался процесс тестирования и потом фрагментарно допроверятся результат фиксов, откатов, доливок, отключений фича флагов и всего подобного.
Frozen код с точечными правками проверять проще (при этом другие девы не блокируются и продолжают гадить в девелоп как обычно).
Z>>>- задача А требует функционал Б, как зависимость. Z>·>В твоей схеме А может уехать в прод до Б и ничего даже не пискнет. Z>Она не сможет, она именно требует этот функционал. То, что она сделана и работает означает, что требуемый функционал в ней появился.
Ну так она сделана и протестирована в девелопе, где Б уже влит. При этом кто-то решил, что А уже готова и влил в релиз, а Б ещё требует небольших правок и в релиз ещё не влит.
Z>>>- А и Б работают по отдельности, но вместе не работает хотя бы кто-то из них. Z>·>Поэтому и надо тестировать их вместе перед отправкой в прод. Z>Ты снова говоришь про общий регресс перед релизом, который вообще за скобками описываемой схемы ветвления.
Т.е. у вас ещё один полный раунд QA и для релизной ветки?
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
·>Ну так она сделана и протестирована в девелопе, где Б уже влит. При этом кто-то решил, что А уже готова и влил в релиз, а Б ещё требует небольших правок и в релиз ещё не влит.
Код Б в ветку А не может попасть случайно, автор А знает, что задачи связаны и отразил это в Jira. Если задачи связаны зависимостью, то выкатка А будет ждать полной готовности Б. Либо (скорее всего) они пойдут одним фичабранчем.
А как ты решаешь эту проблему в git-flow? А и Б в мастере, в Б оказались критические проблемы и ты выбрал один из предложенных тобой путей. Отключил ее фича флагом или сделал ей git revert. Как твои QA узнали, что функционал А тоже надо перетестировать?
·>Т.е. у вас ещё один полный раунд QA и для релизной ветки?
Не всегда. Чаще всего в этом нет необходимости, мы считаем, что код релиза всегда готов к раскатке.
Здравствуйте, Ziaw, Вы писали:
Z>·>Ну так она сделана и протестирована в девелопе, где Б уже влит. При этом кто-то решил, что А уже готова и влил в релиз, а Б ещё требует небольших правок и в релиз ещё не влит. Z>Код Б в ветку А не может попасть случайно, автор А знает, что задачи связаны и отразил это в Jira. Если задачи связаны зависимостью, то выкатка А будет ждать полной готовности Б. Либо (скорее всего) они пойдут одним фичабранчем.
Откуда он это знает-то? Потестил таску немного сам — работает, влил в девелоп, немного порезолвил конфликты, вроде работает. QA начали тестировать — работает. Замержил в релиз — а оно сломалось, т.к. отсутствуют некоторые изменения от Б, которые ещё тестируются и чуточку дорабатываются. Или, хуже того, порешил конфликты немножко по-другому.
Z>А как ты решаешь эту проблему в git-flow? А и Б в мастере, в Б оказались критические проблемы и ты выбрал один из предложенных тобой путей. Отключил ее фича флагом или сделал ей git revert. Как твои QA узнали, что функционал А тоже надо перетестировать?
Тут надо по тому списку из 4 пунктов действовать. Тяжесть последствий возрастает от первого пункта к последнему. Поэтому если в проекте часто что-то уходит дальше первого-второго пункта, то надо делать разбор полётов и что-то менять в консерватории. В общем случае, правки в релизе требуют перетестировать все фичи данного релиза, если нет полной уверенности, что правка действительно точечная и ничего другого сломать не может. Скажем, на втором пункте обычно правится какая-то мелочь, отследить влияние которой обычно тривиально и понять влияние на все фичи релиза. Третий пункт подразумевает, что QA должны протестировать что feature flag действительно сработал и старое поведение функционирует.
Z>·>Т.е. у вас ещё один полный раунд QA и для релизной ветки? Z>Не всегда. Чаще всего в этом нет необходимости, мы считаем, что код релиза всегда готов к раскатке.
Неясно на основании чего так считаете. Ведь этот данный код с данным sha1, судя по твоей схеме ни разу не тестировался.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
·>Откуда он это знает-то? Потестил таску немного сам — работает, влил в девелоп, немного порезолвил конфликты, вроде работает. QA начали тестировать — работает. Замержил в релиз — а оно сломалось, т.к. отсутствуют некоторые изменения от Б, которые ещё тестируются и чуточку дорабатываются. Или, хуже того, порешил конфликты немножко по-другому.
Откуда в его ветке появился код Б с которым он это немного потестил?
·>Тут надо по тому списку из 4 пунктов действовать. Тяжесть последствий возрастает от первого пункта к последнему. Поэтому если в проекте часто что-то уходит дальше первого-второго пункта, то надо делать разбор полётов и что-то менять в консерватории. В общем случае, правки в релизе требуют перетестировать все фичи данного релиза, если нет полной уверенности, что правка действительно точечная и ничего другого сломать не может. Скажем, на втором пункте обычно правится какая-то мелочь, отследить влияние которой обычно тривиально и понять влияние на все фичи релиза. Третий пункт подразумевает, что QA должны протестировать что feature flag действительно сработал и старое поведение функционирует.
Не могу понять как у тебя все устроено. Команда из сильно больше (?) десятка программистов клепает фичи целый спринт и только потом начинается тестирование всего, что они накодили. В процессе тестирования в релиз докидываются хотфиксы найденных багов и из него выпиливаются или отключаются те фичи, правка которых не делается парой строк и может затянуться. Я ничего не перепутал?
·>Неясно на основании чего так считаете. Ведь этот данный код с данным sha1, судя по твоей схеме ни разу не тестировался.
А ты узнай сколько времени тестировался код sha1 которого ушел в твой последний релиз. Может оказаться, что тоже не так много.
Здравствуйте, Ziaw, Вы писали:
Z>·>Откуда он это знает-то? Потестил таску немного сам — работает, влил в девелоп, немного порезолвил конфликты, вроде работает. QA начали тестировать — работает. Замержил в релиз — а оно сломалось, т.к. отсутствуют некоторые изменения от Б, которые ещё тестируются и чуточку дорабатываются. Или, хуже того, порешил конфликты немножко по-другому. Z>Откуда в его ветке появился код Б с которым он это немного потестил?
Вот тут "стартуем ветку от release, вливаем в develop" — прежде чем влить в девелоп, надо с ним замержиться и отрезолвить конфликты, ведь там уже болтаются коммиты Б. Следовательно в А случайно попадут некоторые коммиты из Б, которым ещё не дали добро QA. При вливании QA-заапрувленного А в релизную ветку — мы туда случайно зафигачим часть коммитов Б без аппрува QA.
И даже после аппрува QA обоих А и Б — нет никакого способа определить порядок их вливания в релиз. Начинается бардак и конфликты с ручным разрешением.
Да, ещё веселуха начинается, когда таск T завершен, залит в девелоп, а QA сейчас заняты и начинают тестировать неделю спустя. Вроде всё ок, аппрув дали — мол, вливайте в релиз, happy days! А чувак который пилил T на больничный ушел и вообще за неделю уже всё забыл после пьянки. При вливании обнаруживаются конфликты и никто толком не знает как их правильно разрешать... В итоге простой случай должен быть самым простым и частым — головная боль.
В моей схеме такого просто нет. Все мерж-конфликты разрешаются тут же. Я даже пайплайн настраивал — при сборке хотфикса в релизной ветке — вначале происходит автомерж в девелоп, потом только сборка проекта.
Z>·>Тут надо по тому списку из 4 пунктов действовать. Тяжесть последствий возрастает от первого пункта к последнему. Поэтому если в проекте часто что-то уходит дальше первого-второго пункта, то надо делать разбор полётов и что-то менять в консерватории. В общем случае, правки в релизе требуют перетестировать все фичи данного релиза, если нет полной уверенности, что правка действительно точечная и ничего другого сломать не может. Скажем, на втором пункте обычно правится какая-то мелочь, отследить влияние которой обычно тривиально и понять влияние на все фичи релиза. Третий пункт подразумевает, что QA должны протестировать что feature flag действительно сработал и старое поведение функционирует. Z>Не могу понять как у тебя все устроено. Команда из сильно больше (?) десятка программистов клепает фичи целый спринт и только потом начинается тестирование всего, что они накодили. В процессе тестирования в релиз докидываются хотфиксы найденных багов и из него выпиливаются или отключаются те фичи, правка которых не делается парой строк и может затянуться. Я ничего не перепутал?
Почти. Только "потом начинается тестирование всего" — это QA полной интерации всего и вся, а не конкретной таски.
Это ещё зависит от разных проектов. В одном из проектов QA команда тестирует релиз предыдущего спринта.
В другом проекте как таковой команды QA не было. В конце спринта делается таг и деплоится для теста как "релиз-кандидат" в staging. Потом каждый проверяет свои завершенные таски, кликая кнопки в нужном порядке, проверяя логи, что без ошибок, и т.п. — но тут не надо тестировать все возможные сценарии, которые уже покрыты юнит-тестами, а только общую интеграцию.
В ещё другом проекте на теге гонялись самые тяжелые авто-тесты.
Z>·>Неясно на основании чего так считаете. Ведь этот данный код с данным sha1, судя по твоей схеме ни разу не тестировался. Z>А ты узнай сколько времени тестировался код sha1 которого ушел в твой последний релиз. Может оказаться, что тоже не так много.
Больше, чем любой другой sha1. Просто по определению.
Чисто теоретически, результаты любых проверок для sha1 X нельзя проецировать на другой sha1 Y.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
·>Почему это непростой выбор? Поставьте ограничитель по времени, например: за минуту|час|день не пофиксили — реверт.
Это подойдет в тех компаниях, где стейкхолдерам пофиг, когда выйдет фича и под ее выход ничего не планируется. В других компаниях за такие шутки можно пойти писать авто-тесты на UI, чтобы качество принятия решений пришло в соответствие с должностными обязанностями.
·>Костыль не дорогой на самом деле. Хотя требует некую культуру написания кода и тестов. ·>Зато с лихвой окупается, т.к. бранчей/мержей требуется гораздо меньше, и они короткоживущие. ·>Ещё и дополнительные возможности даёт типа A/B-тестирования.
Фича флаг как общий подход безумно дорог в поддержке. Сложность между O(n^2) — O(n!). Сам по себе он конечно хорошо и зачастую незаменим, но как костыль для оперативного отключения нерабочей фичи в релизе — такое себе.
Здравствуйте, Ziaw, Вы писали:
Z>·>Почему это непростой выбор? Поставьте ограничитель по времени, например: за минуту|час|день не пофиксили — реверт. Z>Это подойдет в тех компаниях, где стейкхолдерам пофиг, когда выйдет фича и под ее выход ничего не планируется. В других компаниях за такие шутки можно пойти писать авто-тесты на UI, чтобы качество принятия решений пришло в соответствие с должностными обязанностями.
Это ты словоблудием занялся. Вопрос был "что делать, если релиз уже сегодня, а QA не хочет аппрувить одну фичу и отключить флагом её нельзя?". Предлагаешь объявлять компании банкротство или что? Твоя схема гитования ничем не поможет. И я уже писал, что это крайний случай, который требует разбора полётов.
Z>·>Костыль не дорогой на самом деле. Хотя требует некую культуру написания кода и тестов. Z>·>Зато с лихвой окупается, т.к. бранчей/мержей требуется гораздо меньше, и они короткоживущие. Z>·>Ещё и дополнительные возможности даёт типа A/B-тестирования. Z>Фича флаг как общий подход безумно дорог в поддержке. Сложность между O(n^2) — O(n!). Сам по себе он конечно хорошо и зачастую незаменим, но как костыль для оперативного отключения нерабочей фичи в релизе — такое себе.
Это если фича-флаги не удалять. Такое будет при отсутствии культуры написания кода. Мол, выкатили фичу, в пабе обмыли и дальше пилим нетленку. А самый важный шаг — удаление флага — забывают. Количество фичафлагов в каждый момент времени должна быть 2-3 (недопиленные в течение спринта фичи). Меньше десятка уж точно. Но таки да, я видал ситуации, когда в проекте сотни флагов, созданных в течение десятка лет — это ужас.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
·>Вот тут "стартуем ветку от release, вливаем в develop" — прежде чем влить в девелоп, надо с ним замержиться
Не надо так делать. Вливать мастер в релиз у нас нельзя, соответственно и в ветки его никто не вливает. Если делать как ты предлагаешь, весь смысл схемы теряется сразу.
·>Да, ещё веселуха начинается, когда таск T завершен, залит в девелоп, а QA сейчас заняты и начинают тестировать неделю спустя. Вроде всё ок, аппрув дали — мол, вливайте в релиз, happy days! А чувак который пилил T на больничный ушел и вообще за неделю уже всё забыл после пьянки. При вливании обнаруживаются конфликты и никто толком не знает как их правильно разрешать... В итоге простой случай должен быть самым простым и частым — головная боль.
Что за проект такой, что конфликты вливания дело настолько частое и нетривиальное? В таком проекте я крайне не рекомендую флоу с двойным вливанием.
·>В моей схеме такого просто нет. Все мерж-конфликты разрешаются тут же. Я даже пайплайн настраивал — при сборке хотфикса в релизной ветке — вначале происходит автомерж в девелоп, потом только сборка проекта.
Ну да, в гитфлоу мердж один. Ты как будто только что обнаружил, что в моей схеме два мерджа на одну таску, хотя об этом сразу было сказано.
·>Почти. Только "потом начинается тестирование всего" — это QA полной интерации всего и вся, а не конкретной таски.
Ты уклоняешься от описания процесса тестирования тасок и заявляешь о том, что это должны делать юниттесты. Описываемая схема именно для тестирования тасок.
·>Это ещё зависит от разных проектов. В одном из проектов QA команда тестирует релиз предыдущего спринта. ·>В другом проекте как таковой команды QA не было. В конце спринта делается таг и деплоится для теста как "релиз-кандидат" в staging. Потом каждый проверяет свои завершенные таски, кликая кнопки в нужном порядке, проверяя логи, что без ошибок, и т.п. — но тут не надо тестировать все возможные сценарии, которые уже покрыты юнит-тестами, а только общую интеграцию. ·>В ещё другом проекте на теге гонялись самые тяжелые авто-тесты.
Без QA на тасках смысл предлагаемой схемы теряется полностью. Мне казалось это очевидно, таски вливаются на стейдж именно для гранулярного тестирования.
·>Больше, чем любой другой sha1. Просто по определению.
Верится с трудом, но чем черт не шутит. Напиши примерный процесс со сроками типа:
— день 1. hash1 пошел в релиз, там 90 непротестированнных задач.
— день 2. QA протестировали функционал 25 из 90 задач, нашли 3 крита и 1 замечание. Они будут взяты в работу 4 программистами.
— день 3. у нас в релизе 4 новых мерджа, последний комит называется hash2
— ....
Вот тут мне хочется понять, как работает дальше твоя команда из десятков программистов и десятков QA. Через сколько времени появляется последний hash и по какому определению он тестируется дольше первого.
·>Чисто теоретически, результаты любых проверок для sha1 X нельзя проецировать на другой sha1 Y.
Главное не забудь про это, когда будешь описывать процесс выше.
Здравствуйте, ·, Вы писали:
·>Это ты словоблудием занялся. Вопрос был "что делать, если релиз уже сегодня, а QA не хочет аппрувить одну фичу и отключить флагом её нельзя?". Предлагаешь объявлять компании банкротство или что? Твоя схема гитования ничем не поможет. И я уже писал, что это крайний случай, который требует разбора полётов.
Моя схема поможет релизнуть эту фичу тогда, когда она будет готова. А твое решение — ставим таймер и если не успели починить вырезаем, это действительно какое-то словоблудие.
·>Это если фича-флаги не удалять. Такое будет при отсутствии культуры написания кода. Мол, выкатили фичу, в пабе обмыли и дальше пилим нетленку. А самый важный шаг — удаление флага — забывают. Количество фичафлагов в каждый момент времени должна быть 2-3 (недопиленные в течение спринта фичи). Меньше десятка уж точно. Но таки да, я видал ситуации, когда в проекте сотни флагов, созданных в течение десятка лет — это ужас.
У тебя команда из десятков программистов пилит 2-3 фичи в спринт? Как построен процесс выпиливания флагов?
Здравствуйте, Ziaw, Вы писали:
Z>·>Вот тут "стартуем ветку от release, вливаем в develop" — прежде чем влить в девелоп, надо с ним замержиться Z>Не надо так делать. Вливать мастер в релиз у нас нельзя, соответственно и в ветки его никто не вливает. Если делать как ты предлагаешь, весь смысл схемы теряется сразу.
Делаешь ты push из task в develop, а он говорит, что diverged и конфликты. Тебе надо вначале вытянуть из develop в task, разрешить конфликты, потом push. Т.е. в task оказываются рандомные коммиты из develop.
Z>весь смысл схемы теряется сразу.
Было бы что терять.
Z>·>Да, ещё веселуха начинается, когда таск T завершен, залит в девелоп, а QA сейчас заняты и начинают тестировать неделю спустя. Вроде всё ок, аппрув дали — мол, вливайте в релиз, happy days! А чувак который пилил T на больничный ушел и вообще за неделю уже всё забыл после пьянки. При вливании обнаруживаются конфликты и никто толком не знает как их правильно разрешать... В итоге простой случай должен быть самым простым и частым — головная боль. Z>Что за проект такой, что конфликты вливания дело настолько частое и нетривиальное? В таком проекте я крайне не рекомендую флоу с двойным вливанием.
Тривиально когда ты вливаешь сейчас. А через неделю уже может быть нетривиально.
Z>·>В моей схеме такого просто нет. Все мерж-конфликты разрешаются тут же. Я даже пайплайн настраивал — при сборке хотфикса в релизной ветке — вначале происходит автомерж в девелоп, потом только сборка проекта. Z>Ну да, в гитфлоу мердж один. Ты как будто только что обнаружил, что в моей схеме два мерджа на одну таску, хотя об этом сразу было сказано.
Я обнаружил, и начал разговор с объяснений, что два мержа — это кака, мучительно, ненадёжно и никаких преимуществ.
Z>·>Почти. Только "потом начинается тестирование всего" — это QA полной интерации всего и вся, а не конкретной таски. Z>Ты уклоняешься от описания процесса тестирования тасок и заявляешь о том, что это должны делать юниттесты. Описываемая схема именно для тестирования тасок.
Видов тестирования несколько. Поэтому задавай вопрос точнее. Таски QA тестирует в девелоп бранче. И именно от девелоп бранча создаются релизные таги — релизится ровно та же sha1 ревизия, что была протестирована.
Z>·>Это ещё зависит от разных проектов. В одном из проектов QA команда тестирует релиз предыдущего спринта. Z>·>В другом проекте как таковой команды QA не было. В конце спринта делается таг и деплоится для теста как "релиз-кандидат" в staging. Потом каждый проверяет свои завершенные таски, кликая кнопки в нужном порядке, проверяя логи, что без ошибок, и т.п. — но тут не надо тестировать все возможные сценарии, которые уже покрыты юнит-тестами, а только общую интеграцию. Z>·>В ещё другом проекте на теге гонялись самые тяжелые авто-тесты. Z>Без QA на тасках смысл предлагаемой схемы теряется полностью. Мне казалось это очевидно, таски вливаются на стейдж именно для гранулярного тестирования.
Таски тестируются уже слитыми в один бранч во время аппрува релиза. Потому что релиз релизит либо всё, либо ничего (если происходит роллбак). Неясно в чём преимущество тестирования по отдельности, если в проде будет целое.
Z>·>Больше, чем любой другой sha1. Просто по определению. Z>Верится с трудом, но чем черт не шутит. Напиши примерный процесс со сроками типа: Z>- день 1. hash1 пошел в релиз, там 90 непротестированнных задач.
Т.е., несколько сотен коммитов!
Z>- день 2. QA протестировали функционал 25 из 90 задач, нашли 3 крита и 1 замечание. Они будут взяты в работу 4 программистами. Z>- день 3. у нас в релизе 4 новых мерджа, последний комит называется hash2
Четыре коммита! Их можно аккуратно проверить вручную и исследовать ипакт, дав указания QA какой функционал нужно перетестировать.
Z>- .... Z>Вот тут мне хочется понять, как работает дальше твоя команда из десятков программистов и десятков QA. Через сколько времени появляется последний hash и по какому определению он тестируется дольше первого.
При таком кол-ве задач их можно тестировать в процессе спринта. Большинство критов будет пофикшено в девелопе в течение спринта. В конце спринта создаётся таг и прогоняются тесты ещё раз на теге.
Z>·>Чисто теоретически, результаты любых проверок для sha1 X нельзя проецировать на другой sha1 Y. Z>Главное не забудь про это, когда будешь описывать процесс выше.
Самое большое я видел около десятка коммитов в релиз-ветке, при этом не особо больших. Обычно меньше 3.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, Ziaw, Вы писали:
Z> ·>Это ты словоблудием занялся. Вопрос был "что делать, если релиз уже сегодня, а QA не хочет аппрувить одну фичу и отключить флагом её нельзя?". Предлагаешь объявлять компании банкротство или что? Твоя схема гитования ничем не поможет. И я уже писал, что это крайний случай, который требует разбора полётов. Z> Моя схема поможет релизнуть эту фичу тогда, когда она будет готова.
Как она поможет релизнуть в условиях "где стейкхолдерам НЕ пофиг, когда выйдет фича"? Z> А твое решение — ставим таймер и если не успели починить вырезаем, это действительно какое-то словоблудие.
Вырезаем из текущего релиза и откладываем до следующего если ВНЕЗАПНО обнаружилось, что не готово. А в твоей схеме — пытаемся не мержить в релиз, пока не готово.
Т.е. отличие в общем настроении.
Твоя схема ориентирована на failure path, когда фичи к QA попадают полусырые, глючные, к релизу не готовые, девелоп-бранч кишит багами, контроля над кодом и функциональностью нет. Начинается футбол тестеров с девами с критами и замечаниями, допиливая и на ходу и пытаясь запрыгнуть в отправляющийся поезд релиза.
Моя схема ориентирована на success path — большинство фич пилятся в более менее готовом виде, мелочи закрываются точечными правками, девелоп бранч поддерживается в releaseable виде.
Z> ·>Это если фича-флаги не удалять. Такое будет при отсутствии культуры написания кода. Мол, выкатили фичу, в пабе обмыли и дальше пилим нетленку. А самый важный шаг — удаление флага — забывают. Количество фичафлагов в каждый момент времени должна быть 2-3 (недопиленные в течение спринта фичи). Меньше десятка уж точно. Но таки да, я видал ситуации, когда в проекте сотни флагов, созданных в течение десятка лет — это ужас. Z> У тебя команда из десятков программистов пилит 2-3 фичи в спринт?
Большие фичи, которые меняют поведение, да. Далеко не каждая фича требует флага.
Z> Как построен процесс выпиливания флагов?
После того как фича выкачена в прод, всё работает, клиенты счастливы, флаг и все соответствующие if-ветки удаляются. Clean-up таск для следующего спринта обычно.
Здравствуйте, ·, Вы писали:
·>Делаешь ты push из task в develop, а он говорит, что diverged и конфликты. Тебе надо вначале вытянуть из develop в task, разрешить конфликты, потом push. Т.е. в task оказываются рандомные коммиты из develop.
Не понимаю почему ты решил учить меня гиту. Для разрешения конфликтов вливание мастера не требуется, это факт.
·>Было бы что терять.
Ну да? Ты поэтому уже который пост придумываешь ситуации, в которых схема не сработает )))
·>Тривиально когда ты вливаешь сейчас. А через неделю уже может быть нетривиально.
На практике заметной разницы чаще всего нет.
·>Я обнаружил, и начал разговор с объяснений, что два мержа — это кака, мучительно, ненадёжно и никаких преимуществ.
Я не понимаю, зачем ты это объясняешь тому, кто уже несколько лет применяет это на практике? Откуда эта уверенность, что твои фантазии объективнее моего опыта? Откуда уверенность, что твой опыт регулярного болезненного разрешения конфликтов универсален?
·>Видов тестирования несколько. Поэтому задавай вопрос точнее. Таски QA тестирует в девелоп бранче. И именно от девелоп бранча создаются релизные таги — релизится ровно та же sha1 ревизия, что была протестирована.
Если таски QA тестируют в девелоп бранче, то проблема того, что следующая задача может повлиять на тестируемую никуда не девается. То, что ты называешь надежным, становится гораздо менее надежным моей схемы, когда ты сильно правишь или откатываешь таски из релиза.
·>Таски тестируются уже слитыми в один бранч во время аппрува релиза. Потому что релиз релизит либо всё, либо ничего (если происходит роллбак). Неясно в чём преимущество тестирования по отдельности, если в проде будет целое.
Ты же писал, что есть практика отката одной задачи? Куда она делась?
·>Четыре коммита! Их можно аккуратно проверить вручную и исследовать ипакт, дав указания QA какой функционал нужно перетестировать.
Серьезно? Вы смотрите в код каждого фикса и сообщаете QA, что именно стоит перетестировать в регрессе релиза?
·>При таком кол-ве задач их можно тестировать в процессе спринта. Большинство критов будет пофикшено в девелопе в течение спринта. В конце спринта создаётся таг и прогоняются тесты ещё раз на теге.
Ты определись, вы тестируете задачи в процессе спринта или это делают юниттесты, а QA нужны для регресса перед релизом?
·>Самое большое я видел около десятка коммитов в релиз-ветке, при этом не особо больших. Обычно меньше 3.
Теперь расскажи, как получается, что именно последний тестируется больше всего?
Здравствуйте, Ziaw, Вы писали:
Z>·>Делаешь ты push из task в develop, а он говорит, что diverged и конфликты. Тебе надо вначале вытянуть из develop в task, разрешить конфликты, потом push. Т.е. в task оказываются рандомные коммиты из develop. Z>Не понимаю почему ты решил учить меня гиту. Для разрешения конфликтов вливание мастера не требуется, это факт.
Ох, т.е. в таск-ветке девелопа нет? И при вливании в релиз все эти конфликты придётся снова разрешать второй раз? Мда уж.
Z>·>Было бы что терять. Z>Ну да? Ты поэтому уже который пост придумываешь ситуации, в которых схема не сработает )))
Что значит не сработает? Эта схема привычна для старинных СВК типа cvs/svn и т.п., которые в мержи и в граф истории не умеют. Однако ими пользовались многие годы. Выбора не было. А сегодня не пользоваться современными средствами организации истории, просто неэффективно.
Z>·>Тривиально когда ты вливаешь сейчас. А через неделю уже может быть нетривиально. Z>На практике заметной разницы чаще всего нет.
Через неделю я обычно забываю что я делал, и конфликты разрешать сложнее. Плюс сливаться приходится с бОльшим кол-вом изменений. Чем дольше растут ветки, тем больше они diverged. Это факт.
Z>·>Я обнаружил, и начал разговор с объяснений, что два мержа — это кака, мучительно, ненадёжно и никаких преимуществ. Z>Я не понимаю, зачем ты это объясняешь тому, кто уже несколько лет применяет это на практике? Откуда эта уверенность, что твои фантазии объективнее моего опыта?
Приходилось видеть и участвовать в исправлении таких вот многолетних практик.
Z>Откуда уверенность, что твой опыт регулярного болезненного разрешения конфликтов универсален?
У меня болезненный опыт организации нормального процесса управлениями ветками.
Z>·>Видов тестирования несколько. Поэтому задавай вопрос точнее. Таски QA тестирует в девелоп бранче. И именно от девелоп бранча создаются релизные таги — релизится ровно та же sha1 ревизия, что была протестирована. Z>Если таски QA тестируют в девелоп бранче, то проблема того, что следующая задача может повлиять на тестируемую никуда не девается. То, что ты называешь надежным, становится гораздо менее надежным моей схемы,
Судя по твоей схеме QA тоже тестируют в девелоп бранче. Внезапно.
В моей схеме потом делается фриз с помощью тега и делается QA sign-off. В таком случае никаких 3 критов в подавляющем случае тупо не будет.
Z>когда ты сильно правишь или откатываешь таски из релиза.
Это редкая редкость, это означает серьёзный факап. Может раз в год такое в худшем случае.
Ещё я забыл пунктик, что в такой ситуации можно просто отложить релиз, а особо необходимые таски замержить в виде хотфиков на прод.
Z>·>Таски тестируются уже слитыми в один бранч во время аппрува релиза. Потому что релиз релизит либо всё, либо ничего (если происходит роллбак). Неясно в чём преимущество тестирования по отдельности, если в проде будет целое. Z>Ты же писал, что есть практика отката одной задачи? Куда она делась?
Это не повседневное практика, а разгребание последствий серьёзного факапа.
Z>·>Четыре коммита! Их можно аккуратно проверить вручную и исследовать ипакт, дав указания QA какой функционал нужно перетестировать. Z>Серьезно? Вы смотрите в код каждого фикса и сообщаете QA, что именно стоит перетестировать в регрессе релиза?
Для коммита в три строчки — почему бы и нет?
Z>·>При таком кол-ве задач их можно тестировать в процессе спринта. Большинство критов будет пофикшено в девелопе в течение спринта. В конце спринта создаётся таг и прогоняются тесты ещё раз на теге. Z>Ты определись, вы тестируете задачи в процессе спринта или это делают юниттесты, а QA нужны для регресса перед релизом?
Да.
Z>·>Самое большое я видел около десятка коммитов в релиз-ветке, при этом не особо больших. Обычно меньше 3. Z>Теперь расскажи, как получается, что именно последний тестируется больше всего?
Потому что на нём прогоняются все авто-тесты, которые гоняются на девелопе, плюс всякие медленные тесты, плюс на нём гоняются ручные тесты обнаруженных критических мест и т.п. И отличается от девелопа всего на < ~3 коммитов, которые видны как на ладони.
В твоей схеме на релизной ревизии тестов гоняется очевидно меньше, чем на дев-ветке. И разница в коде в принципе неизвестна, тупо выяснить разницу между тем что тестировали в девелопе и что сейчас в релизе — очень сложно, т.к. история у них серьёзно diverged.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
·>Как она поможет релизнуть в условиях "где стейкхолдерам НЕ пофиг, когда выйдет фича"?
Ей достаточно быть лучше предлагаемой тобой схемы — ждите наш следующий регресс.
·>Вырезаем из текущего релиза и откладываем до следующего если ВНЕЗАПНО обнаружилось, что не готово. А в твоей схеме — пытаемся не мержить в релиз, пока не готово.
Почему пытаемся? Не мерджим, доводим до нужного качества в песочнице.
·>Т.е. отличие в общем настроении. ·>Твоя схема ориентирована на failure path, когда фичи к QA попадают полусырые, глючные, к релизу не готовые, девелоп-бранч кишит багами, контроля над кодом и функциональностью нет. Начинается футбол тестеров с девами с критами и замечаниями, допиливая и на ходу и пытаясь запрыгнуть в отправляющийся поезд релиза.
Нет, это не так.
·>Моя схема ориентирована на success path — большинство фич пилятся в более менее готовом виде, мелочи закрываются точечными правками, девелоп бранч поддерживается в releaseable виде.
Да, это так. Твоя схема нормально работает только в success path.
·>Большие фичи, которые меняют поведение, да. Далеко не каждая фича требует флага.
Вот именно.
·>После того как фича выкачена в прод, всё работает, клиенты счастливы, флаг и все соответствующие if-ветки удаляются. Clean-up таск для следующего спринта обычно.
Как-то не вяжется это с процессом команды в десятки разработчиков. Ты уж извини.
Здравствуйте, ·, Вы писали:
·>Ох, т.е. в таск-ветке девелопа нет? И при вливании в релиз все эти конфликты придётся снова разрешать второй раз? Мда уж.
Да, второй. Понимаю, что чукча не читатель, но ты пошел по кругу уже как писатель даже.
·>Что значит не сработает? Эта схема привычна для старинных СВК типа cvs/svn и т.п., которые в мержи и в граф истории не умеют. Однако ими пользовались многие годы. Выбора не было. А сегодня не пользоваться современными средствами организации истории, просто неэффективно.
Это не так. Эта схема вообще не подходит для VCS без нормальных веток. Прекращай уже высасывать из пальца.
·>Через неделю я обычно забываю что я делал, и конфликты разрешать сложнее. Плюс сливаться приходится с бОльшим кол-вом изменений. Чем дольше растут ветки, тем больше они diverged. Это факт.
Изменения одни и те же, конфликты практически идентичны. Нет, я понимаю, что задел твою какую-то больную тему с кривыми ресолвами, но в нашей практике эта проблема от разработчиков не звучит совсем.
·>У меня болезненный опыт организации нормального процесса управлениями ветками.
Почти готов тебе поверить, но то как ты меняешь показания на лету, больше походит на то, что ты этот опыт сейчас придумываешь на ходу.
·>Судя по твоей схеме QA тоже тестируют в девелоп бранче. Внезапно.
Вот именно. И я не вижу в этом проблемы.
·>В моей схеме потом делается фриз с помощью тега и делается QA sign-off. В таком случае никаких 3 критов в подавляющем случае тупо не будет.
Что за заклинание, которое заставляет десятки программистов не допустить ни одного крита за спринт?
·>Для коммита в три строчки — почему бы и нет?
Не испытываю доверия к практикам в которых программист диктует QA, что нужно тестировать, а что нет.
Z>>Ты определись, вы тестируете задачи в процессе спринта или это делают юниттесты, а QA нужны для регресса перед релизом? ·>Да.
Вот уж определился так определился.
·>Потому что на нём прогоняются все авто-тесты, которые гоняются на девелопе, плюс всякие медленные тесты, плюс на нём гоняются ручные тесты обнаруженных критических мест и т.п. И отличается от девелопа всего на < ~3 коммитов, которые видны как на ладони.
Это должно быть сильно меньше чем нормальный регресс по результатам которого найдены причины для трех комитов. Ну и автотесты всякие вы же гоняете не просто так, они что-то изредка ловят? Это надо чинить?
Ты правильно описал, твоя схема работает когда все хорошо и к моменту конца спринта ветка девелоп практически готова к релизу. Судя по описанию, ее тестирование у вас практически формальность.
·>В твоей схеме на релизной ревизии тестов гоняется очевидно меньше, чем на дев-ветке. И разница в коде в принципе неизвестна, тупо выяснить разницу между тем что тестировали в девелопе и что сейчас в релизе — очень сложно, т.к. история у них серьёзно diverged.
Здравствуйте, Ziaw, Вы писали:
Z> ·>Ох, т.е. в таск-ветке девелопа нет? И при вливании в релиз все эти конфликты придётся снова разрешать второй раз? Мда уж. Z> Да, второй. Понимаю, что чукча не читатель, но ты пошел по кругу уже как писатель даже.
Ну я не сразу понял, что оно настолько жутко... На 90 таск-ветках конфликты будут гарантированно. Т.е. твоя схема не только требует резет публичных веток, но и постоянный резолв конфликтов.
Z> ·>Что значит не сработает? Эта схема привычна для старинных СВК типа cvs/svn и т.п., которые в мержи и в граф истории не умеют. Однако ими пользовались многие годы. Выбора не было. А сегодня не пользоваться современными средствами организации истории, просто неэффективно. Z> Это не так. Эта схема вообще не подходит для VCS без нормальных веток. Прекращай уже высасывать из пальца.
Почему не подходит? Нормальные мержи ничего интересного не в твоей схеме не дают. Коммиты можно просто копировать на другую базу как в каком-нибудь svn. Именно потому во всяких svn-ах твоя модель и была распространена. Сейчас просто мержат, получая красивый DAG.
Z> ·>Через неделю я обычно забываю что я делал, и конфликты разрешать сложнее. Плюс сливаться приходится с бОльшим кол-вом изменений. Чем дольше растут ветки, тем больше они diverged. Это факт. Z> Изменения одни и те же, конфликты практически идентичны.
Нет, совсем нет. Т.к. у тебя таска мержится разное кол-во раз в девелоп и в релиз.
И никак не обеспечить, что порядок мержа 90 веток в девелоп будет ровно таким же как в релиз. А значит у тебя есть 90! вариантов как может выглядеть релизная ветка.
Z> Нет, я понимаю, что задел твою какую-то больную тему с кривыми ресолвами, но в нашей практике эта проблема от разработчиков не звучит совсем.
Потому что считают это нормой. В норме резолв конфликта это редкость. А уж резолв одного и того же — это уже исправление какой-то лажи.
Z> ·>У меня болезненный опыт организации нормального процесса управлениями ветками. Z> Почти готов тебе поверить, но то как ты меняешь показания на лету, больше походит на то, что ты этот опыт сейчас придумываешь на ходу.
Какие показания меняю? Я просто участвовал в очень разных проектах. Даже участвовал в ужасе переезда с clearcase (в котором использовалась твоя схема) на git.
Z> ·>Судя по твоей схеме QA тоже тестируют в девелоп бранче. Внезапно. Z> Вот именно. И я не вижу в этом проблемы.
Именно. А раз там всё протестировано, то можно и зарелизить. Зачем что-то перемерживать-то?!
Z> ·>В моей схеме потом делается фриз с помощью тега и делается QA sign-off. В таком случае никаких 3 критов в подавляющем случае тупо не будет. Z> Что за заклинание, которое заставляет десятки программистов не допустить ни одного крита за спринт?
Крита в релиз-кандидате же. А спринт идёт на девелопе, там криты — не больно совершенно.
Z> ·>Для коммита в три строчки — почему бы и нет? Z> Не испытываю доверия к практикам в которых программист диктует QA, что нужно тестировать, а что нет.
Почему диктует-то? Просто сообщается известная инфа — в чём был root cause найденного крита и каким способом пофикшен. А решение о том что и как тестировать — принимает QA.
Z> Z>>Ты определись, вы тестируете задачи в процессе спринта или это делают юниттесты, а QA нужны для регресса перед релизом? Z> ·>Да. Z> Вот уж определился так определился.
Непонятно почему ты в меня ложными альтернативами кидаешь. Мы и тестируем, и юнит-тесты пишем, и QA проверяет, и регресс, и прогресс.
Z> ·>Потому что на нём прогоняются все авто-тесты, которые гоняются на девелопе, плюс всякие медленные тесты, плюс на нём гоняются ручные тесты обнаруженных критических мест и т.п. И отличается от девелопа всего на < ~3 коммитов, которые видны как на ладони. Z> Это должно быть сильно меньше чем нормальный регресс по результатам которого найдены причины для трех комитов.
Ну да. Принять решение об упрощённом QA после трёх точечных коммитов — легко.
Z>Ну и автотесты всякие вы же гоняете не просто так, они что-то изредка ловят? Это надо чинить?
Не понял почему это вообще проблема. Автотесты гоняются на девелопе. Следовательно когда ставишь тег [1.0] — автотесты заведомо зелёные. Потенциальный багфикс для [1.1] — это один PR, который тоже вроде как зелёный должен быть для аппрува — сломаться там нечему, т.к. это просто fast-forward, тот же sha1 что и у PR.
Z> Ты правильно описал, твоя схема работает когда все хорошо и к моменту конца спринта ветка девелоп практически готова к релизу.
А почему должно быть не так? Иначе в чём смысл спринта?
Z>Судя по описанию, ее тестирование у вас практически формальность.
Не формальность, нужно тестирование интеграции всего со всем, того, что пойдёт в прод.
Z> ·>В твоей схеме на релизной ревизии тестов гоняется очевидно меньше, чем на дев-ветке. И разница в коде в принципе неизвестна, тупо выяснить разницу между тем что тестировали в девелопе и что сейчас в релизе — очень сложно, т.к. история у них серьёзно diverged. Z> Не серьезно.
В твоём релизе как минимум 90 лишних мерж-коммитов каждой таски, каждый из которых с каким-то неизвестным conflict resolution. Я считаю, что 90 коммитов серьёзно отличается от трёх.
Здравствуйте, Ziaw, Вы писали:
Z> ·>Моя схема ориентирована на success path — большинство фич пилятся в более менее готовом виде, мелочи закрываются точечными правками, девелоп бранч поддерживается в releaseable виде. Z> Да, это так. Твоя схема нормально работает только в success path.
Это то к чему должно стремиться состояние проекта. Чтобы запиливаемые фичи работали. А не проходили через круги отладки и доработки напильником, и всё стоит колом блокируя релиз.
Z> ·>Большие фичи, которые меняют поведение, да. Далеко не каждая фича требует флага. Z> Вот именно.
Ну и? Это означает, что залитая фича в "песочницу" ничего не ломает и релизить её можно без проблем. Неясно зачем перемерживать её ещё раз, рискуя налажать на неизбежных конфликтах.
Z> ·>После того как фича выкачена в прод, всё работает, клиенты счастливы, флаг и все соответствующие if-ветки удаляются. Clean-up таск для следующего спринта обычно. Z> Как-то не вяжется это с процессом команды в десятки разработчиков. Ты уж извини.
Почему не вяжется-то? Это стандартная и давно известная техника.
vsb>В большинстве проектов есть ветка main, туда все пушат, оно ставится на тестовый сервер. Когда будет решение ставить на рабочий сервер, заводится тег вроде 1.123.0, и этот билд, собственно, ставится. Если нужен хотфикс — делается ветка 1.123.x, туда коммитится что надо и пушится с тегом 1.123.1 и так далее. Если разрабатывается какая-то фича, которую пока ставить не планируется — делается фич-флаг.
А кто такой процесс установил?
И когда ?
Где-то прописано?
Или новичку на словах объясняется ?
Хочешь быть счастливым — будь им!
Без булдырабыз!!!
Здравствуйте, LaptevVV, Вы писали:
vsb>>В большинстве проектов есть ветка main, туда все пушат, оно ставится на тестовый сервер. Когда будет решение ставить на рабочий сервер, заводится тег вроде 1.123.0, и этот билд, собственно, ставится. Если нужен хотфикс — делается ветка 1.123.x, туда коммитится что надо и пушится с тегом 1.123.1 и так далее. Если разрабатывается какая-то фича, которую пока ставить не планируется — делается фич-флаг. LVV>А кто такой процесс установил? LVV>И когда ? LVV>Где-то прописано? LVV>Или новичку на словах объясняется ?
Логика то в чем: у нас есть в один момент времени несколько версий кода находящихся на разных этапах конвейера разработки. Веток может быть много, под каждый такой этап. Есть только общие моменты:
prod/realise — здесь код который уже работает
main/master — здесь код в состоянии "готово", т.е. прошедший полагающиеся этапы проверки
функциональные ветки — здесь код в стадии разработки
dev — здесь происходит слияние резных версий кода, разбор конфликтов.
А все остальное вы можете под себя добавить или убрать лишнее.
Q>Есть только общие моменты: Q>prod/realise — здесь код который уже работает
Одна ветка ? Q>main/master — здесь код в состоянии "готово", т.е. прошедший полагающиеся этапы проверки Q>функциональные ветки — здесь код в стадии разработки
Каждый заводит свою под решаемую задачу ? Q>dev — здесь происходит слияние резных версий кода, разбор конфликтов.
Интересно: специальная ветка для слияния и разбора конфликтов
Сливаем сюда функциональные ветки, проверяем работу после устранения конфликтов и направляем в ветку prod/realise ?
Хочешь быть счастливым — будь им!
Без булдырабыз!!!
Q>>>dev — здесь происходит слияние резных версий кода, разбор конфликтов. LVV>>Интересно: специальная ветка для слияния и разбора конфликтов LVV>>Сливаем сюда функциональные ветки, проверяем работу после устранения конфликтов и направляем в ветку prod/realise ? Q>Да, конфликты лучше разбирать на самой ранней стадии.
Супер!
Спасибо за интересное решение.
Хочешь быть счастливым — будь им!
Без булдырабыз!!!
Здравствуйте, ·, Вы писали:
·>Это то к чему должно стремиться состояние проекта. Чтобы запиливаемые фичи работали. А не проходили через круги отладки и доработки напильником, и всё стоит колом блокируя релиз.
А еще нужно стремиться писать код без ошибок. Тем не менее тестировать надо и ты так и не определился, фича у тебя тестируется в ветке девелоп внутри спринта или уже в релизном теге перед релизом.
·>Ну и?
Далеко не каждая фича требует флага.
если не получается доработать быстро, то просто закомментировать/отключить сломаную таску (см. feature flags — как общий подход).
То общий, то не каждый.
·>Почему не вяжется-то? Это стандартная и давно известная техника.
На таких объемам протестировать релиз спринта, выкатить его в прод, убедиться, что все работает и клиенты счастливы и пойти удалять фича-тоглы на следующий спринт — нереально. Разве что десятки разрабов пилят настолько простые фичи, что их включение и выключение тривиальны.
Здравствуйте, ·, Вы писали:
·>Какие показания меняю? Я просто участвовал в очень разных проектах. Даже участвовал в ужасе переезда с clearcase (в котором использовалась твоя схема) на git.
Я не знаю, в чем ты там участвовал, но здесь на форуме ты явно проецируешь какие-то свои внутренние ужасы.
Наши разрабы этих ужасов не видят и эту схему крайне ценят и ни грамма критики я не вижу. Лично я изначально относился к ней скептически, но сейчас, при всех ее недостатках, ни за что не поменяю ее на гитфлоу, у которой куда больше неприятных моментов, но это отдельная тема.
Здравствуйте, Ziaw, Вы писали:
Z>·>Это то к чему должно стремиться состояние проекта. Чтобы запиливаемые фичи работали. А не проходили через круги отладки и доработки напильником, и всё стоит колом блокируя релиз. Z>А еще нужно стремиться писать код без ошибок. Тем не менее тестировать надо и ты так и не определился, фича у тебя тестируется в ветке девелоп внутри спринта или уже в релизном теге перед релизом.
Релизный тег ставится на коммит девелопа, в конце спринта.
Z>·>Ну и? Z>
Z> Далеко не каждая фича требует флага.
Z>
Z>если не получается доработать быстро, то просто закомментировать/отключить сломаную таску (см. feature flags — как общий подход).
Z>То общий, то не каждый.
Общий в том смысле как методика реализации отключаемой фичи. Это вовсе не означает, что все фичи обязаны быть отключаемыми.
Z>·>Почему не вяжется-то? Это стандартная и давно известная техника. Z>На таких объемам протестировать релиз спринта, выкатить его в прод, убедиться, что все работает и клиенты счастливы и пойти удалять фича-тоглы на следующий спринт — нереально. Разве что десятки разрабов пилят настолько простые фичи, что их включение и выключение тривиальны.
Ты не понял. Пилят рискованные фичи так, чтобы их включение и выключение было тривиальным.
Удаление фича-флага это два рефакторинга: подстановка константы (т.е. featureFlag==true) и удаление unreachable code (т.е. if(true){newStuff()}else{oldStuff()} — ветка else просто удаляется).
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, Ziaw, Вы писали:
Z>·>Какие показания меняю? Я просто участвовал в очень разных проектах. Даже участвовал в ужасе переезда с clearcase (в котором использовалась твоя схема) на git. Z>Я не знаю, в чем ты там участвовал, но здесь на форуме ты явно проецируешь какие-то свои внутренние ужасы. Z>Наши разрабы этих ужасов не видят и эту схему крайне ценят и ни грамма критики я не вижу. Лично я изначально относился к ней скептически, но сейчас, при всех ее недостатках, ни за что не поменяю ее на гитфлоу, у которой куда больше неприятных моментов, но это отдельная тема.
Интересно послушать об этих моментах.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
·>Релизный тег ставится на коммит девелопа, в конце спринта.
Те задачи, которые тестировали в спринте, тестируете заново в этом комите?
·>Общий в том смысле как методика реализации отключаемой фичи.
Может быть по другому что ли?
·>Ты не понял. Пилят рискованные фичи так, чтобы их включение и выключение было тривиальным. ·>Удаление фича-флага это два рефакторинга: подстановка константы (т.е. featureFlag==true) и удаление unreachable code (т.е. if(true){newStuff()}else{oldStuff()} — ветка else просто удаляется).
Это ты не понял. Так можно выключать только простейшие фичи и только в определенных стеках. Например фича — новая система уведомлений пользователя так просто не переключится. В динамических языках ты не найдешь подстановки констант или удаления анричибл кода.
Здравствуйте, Ziaw, Вы писали:
Z>·>Релизный тег ставится на коммит девелопа, в конце спринта. Z>Те задачи, которые тестировали в спринте, тестируете заново в этом комите?
Зависит от. Решение принимает QA. Особо сложные/рискованные фичи — да.
Подумай, что криты, которые могут в этом коммите появиться для уже протестированных тасков — это те криты, которые возникнут при мерже следующих изменений. Т.е. то, что вы, по вашей схеме, не тестируете вообще.
Z>·>Общий в том смысле как методика реализации отключаемой фичи. Z>Может быть по другому что ли?
Не понял вопрос.
Z>·>Ты не понял. Пилят рискованные фичи так, чтобы их включение и выключение было тривиальным. Z>·>Удаление фича-флага это два рефакторинга: подстановка константы (т.е. featureFlag==true) и удаление unreachable code (т.е. if(true){newStuff()}else{oldStuff()} — ветка else просто удаляется). Z>Это ты не понял. Так можно выключать только простейшие фичи и только в определенных стеках. Например фича — новая система уведомлений пользователя так просто не переключится.
Сама нет, конечно. Просто напиши код так, чтобы новую систему уведомлений пользователя можно было переключить просто.
Z>В динамических языках ты не найдешь подстановки констант или удаления анричибл кода.
В javascript/groovy я нашел. Или это ненастоящие динамические языки?
Здравствуйте, m2user, Вы писали:
M>Если речь идет о commit id, то он вычисляется на основе многих составляющих в т.ч. commit id родителей. M>Я к тому, результаты проверок имеет смысл проецировать на основе идентичности кода, а не commit id.
Подумалось тут... Иметь идентичный tree id, но сознательно отказываться от идентичности commit id — это уже шизофрения какая-то.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
·>Флаги можно делать и compile-time, и build-time.
Это усложняет поддержку кода. При разработке новых фичей придется учитывать присутствие в коде этой отложенной (на неопределенный срок) фичи.
m>> А у QA может просто не быть свободного времени на тестирование корректной работы "переключателя". ·>Это какая-то вялая отмаза. Если код недостаточно тестируется, то он может быть недостаточно качественным. И тут неважно переключатель тут тестируется или что-то ещё.
Это работает, если более-менее понятно, что спрятанная за переключателем фича точно попадет в релиз и в какие сроки попадет.
Т.е. QA могут просчитать, что они потратят время на тестирование фичи сейчас, но сэкономят позднее.
Для экспериментальных фичей с неопределенным будущим это не годится.
m>> Т.е. это не что иное, как Throw-away integration branch, описанный в документации по git. ·>Ну если почитать этот параграф повнимательнее, и ещё следующий "Branch management for a release", то можно заметить, Throw-away branch больше для демок и экспериментов, чем часть release-пайплайна. Т.е. основная разработка и тестирование всё равно ведётся отдельно в и в релиз уходит таг, т.е. то за что я топлю. По твоей же схеме QA происходит только в Throw-away branch, потом всё перезаливается второй раз (удваивая усилия на мержы-конфликты) в другой бранч и тут же объявляется релизом, без QA. То что результат мержа не тестируется — меня удивляет больше всего. А если перетестируете всё, то это удваивает нагрузку и на QA, а потом совершенно неожиданно: "у QA может просто не быть свободного времени".
QA пишут интеграционные автотесты. Они прогоняются на каждом build`е, в т.ч. после merge. Вручную результат merge не проверяется.
·>Это вообще неясно как организовать надёжно. ·>Как и в каких единицах измерить "существенность пересечения"? ·>Как детектить неявные пересечения? Даже изменения в разных файлах могут давать логические пересечения — конфликта vcs нет, а код не работает — это самые подлые проблемы. ·>Что если потом внезапно окажется, что task1 — очень срочно надо, протестировано, требуется релизить, а task2 — "не успевают доделать/протестировать" и вообще "стейкхолдеры что-то там перетасовали"?
Такие решения принимаются заблаговременно (я привел ниже ориентиры по нашим срокам релизов для наглядности).
Были конечно ситуации, когда фичу с пересечениями передвинули на след. релиз, и были применены feature toggles. Но так получилось из-за "экономии" на ветках (source control был не на Git).
m>> Т.е. при merge в develop (а потом в release) каких-то существенных конфликтов быть не должно. ·>Проблема в том, что мерж веток A,B,C может работать очень по-другому, с разными конфликтами чем B,C,A — и это нетривиально понимать как всё работает. m>> .>И никак не обеспечить, что порядок мержа 90 веток в девелоп будет ровно таким же как в релиз. А значит у тебя есть 90! вариантов как может выглядеть релизная ветка.
Конкретизирую: у нас обычно на релизный цикл (4-8 месяцев) порядка 10-15 бизнес-фичей. В конфликтах по коду (файлам) участвуют максимум 2-3 фичи (на конфликт), логическое пересечения где-то в таком же объеме.
Есть ещё bugfix и support, он обычно попадает к QA на тестирование уже в release ветке (практически как в твоем workflow).
А также не-бизнес-фичи (всякий тех. долг, аудит кода и т.п.) без первоначальной привязки к релизу.
Кстати bugfix (на который ещё нет автотестов) вполне может проверяться вручную для каждой релизной ветки отдельно. И это в общем-то неизбежно.
m>> Сравнение кода позволит выявить потенциальные ситуации, когда конфликты при merge в master(release) разрешены иным образом, чем при merge в develop. ·>Каким образом ты будешь сравнивать код? С учётом того, что как ты выразился выше, не всё может быть замержено. Дифы могут быть практически любого размера и сложности. Т.е. весь этот процесс нетривиальный, запутанный, легко пропустить ошибки. В отличие от того, чтобы тупо сравнить два commitId — это работает железно.
через git diff по подкаталогам.
Конкретизирую: у нас monorepo (плюс пара субмодулей под бинарники и т.д) продукта, который поставляется конечному пользователю в одном инсталляторе, но внутри содержить много независимых по пользовательскому функционалу решений, которые пересекаются только по некоторым общим библиотекам. Поэтому сравнивать весь репо бессмысленно.
Если какая-то фича была "выкинута", то разрешить конфликты вручную заново. Проблему потенциальных "логических" пересечений закрыть через автотесты.
m>> Вот пример использования git-rerere в flow, очень похожем на обсуждаемый: [url=https://drupalsun.com/katherinebailey/2013/03/05/pragmatic-guide-branch-feature-git-branching-strategy]A pragmatic guide to the Branch Per ·>Это 2013 год, для "project first switched from Subversion to Git" — наверное сгодится.
Ну они пишут, что попробовали сначала git-flow, но в итоге отказались о него
M>>Ну раз Вам всё просто и понятно, то можете прокомментировать ситуацию описанную здесь. M>>Так ли опасна ситуация, как пишет автор статьи, и почему для решения не достаточно "культуры", а нужен pre-receive hook.
N>Зависит от конкретной команды. У нас можно в течение 5-10 минут собраться и устно всё порешать.
Сомневаюсь насчет возможности порешать за 5-10 минут. Разве что всем всё равно.
N>А ещё более менее известно, кто и за какой кусок кода отвечает.
Но если репо один, то история общая как и проблемы с ней.
На реддите эта статья обсуждалась несколько лет назад и, как обычно бывает в случае git, мнения разделились. Ссылка (запасная ссылка на web.archive).
Здравствуйте, LaptevVV, Вы писали:
LVV>А кто нибудь за этим следит?
Используется Azure DevOps и там прописаны права кто куда пушить может, ну и code-review прямо на web странице делается, что удобно.
Я особо в эту кухню не вникал.