По подаренной идее ("Поиск с учетом строк и комментариев", спасибо x-code), пишу новый инструмент: FeinFind.
Инсталятор здесь
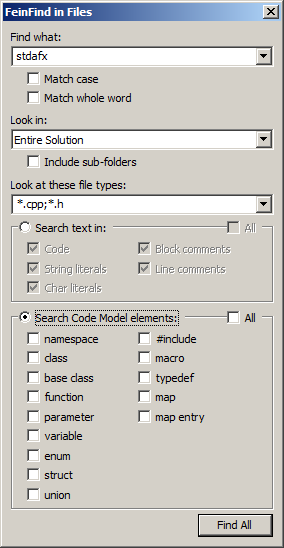
Вот диалог для ввода опций:
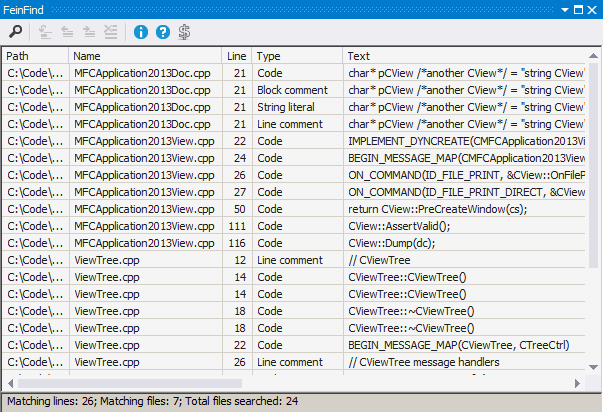
А вот пример вывода:
Обратите внимание:
1. Если текст встречается в строке несколько раз — эта строка повторится столько же раз.
2. В комбо "Look in:", кроме привычных Document, Project и Solution есть ещё Find Results 1 и Find Results 2; эти опции импортируют результаты поиска студии (на всякий случай). Идентификация по коду, литералам или комментарию — в работе.
3. Так же в работе поиск по Code Model. Я полагаю — полезное дополнение.
Пока не работает:
1. Match case
2. Поиск по файловой системе.
3. Сохранение предыдущих параметров поиска.
Критика, замечания, предложения и комплименты приветствуются. (с)
<забыл упомянуть>
Вызвать: Ctrl+Shift+Alt+F.
Легко запомнить: Ctrl+Shift+F — это Find in Files, а у меня — альтернатива
Или Tools -> FeinFind (последняя строка).
Еще недоделано:
4. Поиск по Unicode файлам
5. Match whole word
Здравствуйте, Сергей Мухин
СМ>ВОт поиск строки "abc"
СМ>Image: Снимок.PNG
Спасибо. Я думал объединить результаты, но не стал, т.к. они могут быть разных типов.
Есть универсальное решение — переложить его на клиента
Option: [ ] Combine matches on one line
Здравствуйте, VladFein, Вы писали:
VF><забыл упомянуть> VF>Вызвать: Ctrl+Shift+Alt+F. VF>Легко запомнить: Ctrl+Shift+F — это Find in Files, а у меня — альтернатива VF>Или Tools -> FeinFind (последняя строка). VF>Еще недоделано: VF>4. Поиск по Unicode файлам VF>5. Match whole word
Прекрасно! Я смотрю, вы заложились даже на синтаксический анализ!
(хотя у меня сам поиск не работает, но думаю это вы исправите в окончательной версии).
Одно предложение: если возможно, само окно ввода поиска "FeinFind in Files" тоже сделайте с докингом; я обычно закрепляю его там же где Solution Explorer (у меня слева) и оно там всегда висит и доступно по закладке. Удобно, не закрывает место на редакторе кода.
Хотя я хоткеями в основном не пользуюсь, но Ctrl+Shift+Alt+F это ИМХО перебор, четыре штуки сразу Это нельзя никак в настройки?
Здравствуйте, x-code, Вы писали:
XC>Одно предложение: если возможно, само окно ввода поиска "FeinFind in Files" тоже сделайте с докингом; я обычно закрепляю его там же где Solution Explorer (у меня слева) и оно там всегда висит и доступно по закладке.
Хмм... Вы его сделаете высоким и узким, а кто-то другой — низким и широким. Мне придётся делать гибкий layout. Или.... два фиксированных, на выбор?
XC>Хотя я хоткеями в основном не пользуюсь, но Ctrl+Shift+Alt+F это ИМХО перебор, четыре штуки сразу Это нельзя никак в настройки?
Так Ctrl+Shift+F — занят
А в настройках клиент сам может поменять: Tools -> Options -> Keyboard. Удалите что там стоит и поставьте на свой вкус. Откуда я знаю какие hotkey у Вас свободны?
(Это была затравка на практически готовый другой инструмент: FeinCtrl, браузер по всем определённым в студии командам и их keyboard bindings. Планировал выставить здесь на обозрение, но отвлёкся на этот FeinFind.)
Здравствуйте, VladFein, Вы писали:
VF>Хмм... Вы его сделаете высоким и узким, а кто-то другой — низким и широким. Мне придётся делать гибкий layout. Или.... два фиксированных, на выбор?
Стандартный Find and Replace сделан так, что элементы просто ресайзятся по горизонтали, а по вертикали всегда фиксированные. Но в принципе кто-то может действительно разместить его в нижней докинг панели... имеет ли смысл делать два — даже не знаю, вам виднее.
Кстати, забыл спросить — а Replace будет?
VF>Так Ctrl+Shift+F — занят VF>А в настройках клиент сам может поменять: Tools -> Options -> Keyboard. Удалите что там стоит и поставьте на свой вкус. Откуда я знаю какие hotkey у Вас свободны?
А все, спасибо, не знал про это
VF>(Это была затравка на практически готовый другой инструмент: FeinCtrl, браузер по всем определённым в студии командам и их keyboard bindings. Планировал выставить здесь на обозрение, но отвлёкся на этот FeinFind.)
Ну это весьма специфичная фича, напрямую не относящаяся к потребностям юзеров. Я вот даже и не знал про эти вещи, пользовался чем есть. Если вы будете делать коммерческий аддин, советую быть ближе к непосредственным повседневным нуждам программистов
Здравствуйте, x-code, Вы писали:
XC>Кстати, забыл спросить — а Replace будет?
Нет, конечно. По крайней мере — не даром.
VF>>(Это была затравка на практически готовый другой инструмент: FeinCtrl, браузер по всем определённым в студии командам и их keyboard bindings. Планировал выставить здесь на обозрение, но отвлёкся на этот FeinFind.)
XC>Ну это весьма специфичная фича, напрямую не относящаяся к потребностям юзеров. Я вот даже и не знал про эти вещи, пользовался чем есть. Если вы будете делать коммерческий аддин, советую быть ближе к непосредственным повседневным нуждам программистов
А программисты, программирующие для программистов — тоже программисты?
Кстати, Вы будете удивлены количеством комманд. Некоторые из них могут показаться Вам удобными или даже нужными.
У меня нет под руками точных цифр, но в студии зарегистрированы тысячи комманд; сотни из них имеют имя и могут быть Вами вызваны (остальные, вероятно, для внутреннего употребления); паре сотен из них назначены hot keys. Неужели даже не любопытно???
Здравствуйте, VladFein, Вы писали:
VF>Нет, конечно. По крайней мере — не даром.
Я просто напомнил, вдруг вы забыли
VF>А программисты, программирующие для программистов — тоже программисты? VF>Кстати, Вы будете удивлены количеством комманд. Некоторые из них могут показаться Вам удобными или даже нужными. VF>У меня нет под руками точных цифр, но в студии зарегистрированы тысячи комманд; сотни из них имеют имя и могут быть Вами вызваны (остальные, вероятно, для внутреннего употребления); паре сотен из них назначены hot keys. Неужели даже не любопытно???
Любопытно, но думаю что многие из них весьма специфичны. По крайней мере по меню Customize это можно предположить. Кстати, в старых студиях (до 2008 включительно) было гораздо удобнее настраивать тулбары — можно было просто перетаскивать мышью кнопки на нужные места. Теперь все стало очень сложно, даже найти нужный элемент проблема. Интересно, чего в MS сломали удобное и сделали неудобное?
Кстати, если вам интересно — могу еще идейку подкинуть, понавороченнее чем поиск и замена. Я об этом писал давно и здесь, и на хабре вроде бы, но ввиду того что аддины — очень узкая тема, с тех пор так никакой реализации и не появилось, а самому разбираться нет времени (хотя как-то раз даже пытался). Но лучше коллективный разум, так как там все сложнее, подобного никто до сих пор вообще не делал.
Здравствуйте, x-code, Вы писали:
XC>Кстати, если вам интересно — могу еще идейку подкинуть, понавороченнее чем поиск и замена. Я об этом писал давно и здесь, и на хабре вроде бы, но ввиду того что аддины — очень узкая тема, с тех пор так никакой реализации и не появилось, а самому разбираться нет времени (хотя как-то раз даже пытался). Но лучше коллективный разум, так как там все сложнее, подобного никто до сих пор вообще не делал.
Конечно интересно!
Можно здесь, или у меня на форуме или на facebook, ну или просто в личную почту.
Забыл упомянуть необходимость очень важной фичи, и тоже крайне простой в реализации: ignore spaces
Простейший пример. Допустим, мы ищем
x=y
Но в коде могут встречаться варианты
x = y
x= y
x =y
x = /* some comment */ y
и т.д.
( и даже более сложные — посмотрите в реальном коде, как это бывает... к сожалению...)
В общем идея — при поиске проводить базовый лексический анализ и игнорировать определенные элементы, которые не оказывают влияния на код с точки зрения компилятора — пробелы/табуляции, переносы строк, комментарии. В основном актуально конечно разное количество пробелов вокруг операторов.
Этот набор опций из той же группы что и классические ignore case и match whole words only.
Здравствуйте, x-code, Вы писали:
XC>Забыл упомянуть необходимость очень важной фичи, и тоже крайне простой в реализации:
XC>В общем идея — при поиске проводить базовый лексический анализ и игнорировать определенные элементы, которые не оказывают влияния на код с точки зрения компилятора — пробелы/табуляции, переносы строк, комментарии. В основном актуально конечно разное количество пробелов вокруг операторов. XC>Этот набор опций из той же группы что и классические ignore case и match whole words only.
А можно push back?
Мой поиск по файлам пока был в режиме read only.
Ваше предложение требует пре-процес исходные файлы, вырезая из них whitespace и, заодно, комментарии.
Я представляю себе как это делать, но не уверен в отдаче.
Простая опция ignore case замедляет поиск в 2-3 раза; не уверен, во что выльется это художественное вырезание...
Здравствуйте, VladFein, Вы писали:
VF>А можно push back? VF>Мой поиск по файлам пока был в режиме read only. VF>Ваше предложение требует пре-процес исходные файлы, вырезая из них whitespace и, заодно, комментарии. VF>Я представляю себе как это делать, но не уверен в отдаче. VF>Простая опция ignore case замедляет поиск в 2-3 раза; не уверен, во что выльется это художественное вырезание...
Нет, не нужно никакого препроцессинга. Достаточно написать элементарную функцию сравнения двух строк, пропускающую символы из определенного множества (в частности пробелы/табы). Игнирирование комментариев чуть сложнее, но тоже элементарное — перед сравнением двух очередных символов нужно проверить для каждой строки, а не начало ли это комментария, и если начало — дойти в этой строке до конца комментария.
Кстати, пропускать нужно в обоих строках — и в паттерне, и в тексте файла.
Здравствуйте, x-code, Вы писали:
XC>Нет, не нужно никакого препроцессинга. Достаточно написать элементарную функцию сравнения двух строк...
каких строк?
Первая строка — это паттерн, а вторая — весь файл...
Элементарная функция поиска строки в текстовом файле — strstr().
Строку поиска (паттерн) я могу сколько угодно "массажировать", но сам файл предпочитаю не трогать.
Здравствуйте, VladFein, Вы писали:
VF>каких строк? VF>Первая строка — это паттерн, а вторая — весь файл... VF>Элементарная функция поиска строки в текстовом файле — strstr(). VF>Строку поиска (паттерн) я могу сколько угодно "массажировать", но сам файл предпочитаю не трогать.
Ну вы же файл загружаете в какой-то буфер перед тем как искать?
Вот простейший "псеводкод", могут быть нюансы, но думаю что даже скомпилируется и заработает:
bool compare_without_spaces(const char *text, const char *pattern)
{
// пока текстовый буфер или паттерн не закончатсяwhile(*text && *pattern)
{
// пропускаем все пробелы до первого непробельного символа в текстовом буфереwhile(isspace(*text))
text++;
// пропускаем все пробелы до первого непробельного символа в паттернеwhile(isspace(*pattern))
pattern++;
// непробельные символы разные - в данной точке текст не равен паттернуif(*text!= *pattern)
return false;
text++;
pattern++;
}
// если паттерн закончился - здесь совпадениеif(*pattern == 0)
return true;
// иначе закончился текстовый буферreturn false;
}
и использование — для каждого символа текстового буфера вызывать эту функцию.
while(*text)
{
if(compare_without_spaces(text, pattern))
{
// совпало: здесь запоминаем номер строки и смещение в строке для списка найденных элементов...
// ...
// смещаемся в буфере на длину паттерна
text += strlen(pattern);
}
else
{
// не совпало: смещаемся в буфере на одну позицию
text++;
}
}
Здравствуйте, x-code, Вы писали:
XC>Достаточно написать элементарную функцию сравнения двух строк, пропускающую символы из определенного множества (в частности пробелы/табы).
Чем больше я думаю — тем меньше мне нравится эта идея.
Вы предлагаете найти "int e" в "double interest;"?
Здравствуйте, VladFein, Вы писали:
VF>Я Computer Science давно проходил, здесь какая big-O сложность получится?
Такая же как и при обычном поиске вхождений.
Очевидно, что пропуск пробелов не добавляет сложности: каждая итерация во вложенном цикле while(isspace(*p)) уменьшает количество итераций во внешнем цикле. Фактически, это все и можно было бы запихать во внешний цикл, но так нагляднее и не нужно городить машину состояний.
Если длина буфера N, а длину паттерна считаем константой, то сложность в худшем случае O(N). Если учитываем длину паттерна тоже то O(N*N), но реально в этом смысла нет, так как разумная длина паттерна редко больше 20 символов (имя переменной, функции, класса, короткое выражение...)
Ну а в среднем случае все еще лучше: если первый символ буфера не совпал с первым символом паттерна, сразу переходим на второй символ буфера. Не знаю как тут оценить сложность, может кто из форумчан подскажет... логарифмическая?
Здравствуйте, VladFein, Вы писали:
VF>Чем больше я думаю — тем меньше мне нравится эта идея. VF>Вы предлагаете найти "int e" в "double interest;"?
Я вас понял; да, простейшая функция, которую я написал, будет находить здесь совпадение. Ну что-же, лексическая машина состояний неизбежна. Пробелы нужно не учитывать только после операторных символов; в остальных случаях нужно сводить все пробелы к одному пробелу. И даже в этом случае такие конструкции как "x & &y" и "x && y" будут совпадать, хотя с точки зрения синтаксиса С/С++ такое встречается крайне редко.
Общая идея вырисовывается такая — машина состояний анализирует поток и включает/отключает внутренний флаг ignore space mode в зависимости от символов потока. Я писал лексические анализаторы, в данном случае достаточно завести таблицу операторов и разместить в ней сначала трехсимвольные, затем двух и затем односимвольные — тогда, анализируя поток и понимая что перед нами реальный оператор (а не просто сплошная последовательность операторных символов), всегда можно получить, через сколько символов включать ignore space mode. Но вообще надо подумать и рассмотреть все возможные состояния, по крайней мере для C++ и C#.
Сложность этой штуки в любом случае будет такая же как у обычного поиска.
Здравствуйте, x-code, Вы писали:
XC>Ну а в среднем случае все еще лучше: если первый символ буфера не совпал с первым символом паттерна, сразу переходим на второй символ буфера. Не знаю как тут оценить сложность, может кто из форумчан подскажет... логарифмическая?
Я снимаю свои аргументы а сложности (и скорости).
Если народ хочет сравнивать с "ignore white space" — я бы так сравнивал. Но хочет ли он?
Если я правильно понимаю Ваше требование — Вы хотите "ignore white space difference", т.е. считать любую последовательность white space символов за один, скажем, пробел.
Это не решит проблему с "x=y" и "x = y".
А может ну его?
Здравствуйте, VladFein, Вы писали:
VF>Если я правильно понимаю Ваше требование — Вы хотите "ignore white space difference", т.е. считать любую последовательность white space символов за один, скажем, пробел. VF>Это не решит проблему с "x=y" и "x = y". VF>А может ну его?
Не совсем. Нужно игнорировать пробелы в некоторых местах (но не во всех). Иногда обязательный пробел все-же оставляем (на первый взгляд — между одним алфавитно-цифровым и другим алфавитно-цифровым символом, чтобы идентификаторы не сливались).
Ну и с операторами хитрость... но это как раз можно забить, в С++ исчезающе мало таких конструкций. Разве что начало многострочного комментария совпадает с делением на разыменование указателя.
Сейчас уже поздно, попробую завтра написать такую функцию.