Здравствуйте, eustin, Вы писали:
E>Можно ли в 2023 перейти целиком на 64 бита (b2c)? Сейчас для некоторых продуктов тащится 32 Битный exe на всякий случай.
А нафига нужны 64 бита? Имхо, если они в чем-то реально полезны — тогда переходить, а иначе какой смысл?
Здравствуйте, Евгений Музыченко, Вы писали:
S>>Для отладочный версии компилятор может генерировать не самый оптимальный код ЕМ>Запуск под отладчиком не имеет никакого отношения к генерации кода.
Под отладчиком, если без лишний действий, будет запускаться отладочная версия, т.е. не
самая оптимальная.
Здравствуйте, eustin, Вы писали: E>Можно ли в 2023 перейти целиком на 64 бита (b2c)? Сейчас для некоторых продуктов тащится 32 Битный exe на всякий случай.
Я недавно приделал учет активаций, который также рапортует версии системы — 32 бита это где-то 1 из 50 пользователей.
Зато среди пиратов (это видно в моей системе) их хоть жопой жуй, в основном из всяких нищих стран.
Планирую выкинуть 32-битные версии в ближайшее время и вместо них добавить aarch64.
П>А нафига нужны 64 бита? Имхо, если они в чем-то реально полезны — тогда переходить, а иначе какой смысл?
— памяти не хватает тупо
— новые либы все предсобраны под 64, чтобы не собирать их под 32
Здравствуйте, Философ, Вы писали:
Ф> Занимательные результаты, правда!? Конечно же инкремент int64 в x86 медленнее чем int32 — это логично. Но, во-первых код под x64 прям заметно медленнее, а во-вторых даже на x64 инкремент int64 в x86 медленнее чем int32. Притом существенно медленнее!!! Ф> Процессор-то не так прост оказывается..
Этот ваш дотнет — ненастоящий. Вот другие результаты:
Код: (увеличил количество итераций в 10 раз, время в миллисекундах)
program Project1;
uses
SysUtils;
const
Iterations = 100 * 1000 * 1000;
generic procedure TestSpeedIntX<IntX>;
var
a,b,c,d,e,f,g,h : IntX;
SmallArray : array[0..7] of IntX;
VariablesIncrementTime, ArrayItemIncrementTime : Cardinal;
i : NativeInt;
begin
a := 0;
b := 0;
c := 0;
d := 0;
e := 0;
f := 0;
g := 0;
h := 0;
VariablesIncrementTime := GetTickCount;
for i := 1 to Iterations do
begin
Inc(a);
Inc(b);
Inc(c);
Inc(d);
Inc(e);
Inc(f);
Inc(g);
Inc(h);
end;
VariablesIncrementTime := GetTickCount - VariablesIncrementTime;
ArrayItemIncrementTime := GetTickCount;
for i := 1 to Iterations do
begin
Inc(SmallArray[0]);
Inc(SmallArray[1]);
Inc(SmallArray[2]);
Inc(SmallArray[3]);
Inc(SmallArray[4]);
Inc(SmallArray[5]);
Inc(SmallArray[6]);
Inc(SmallArray[7]);
end;
ArrayItemIncrementTime := GetTickCount - ArrayItemIncrementTime;
WriteLn('elapsed for variable = ', VariablesIncrementTime, ' array = ', ArrayItemIncrementTime);
end;
var
i : NativeInt;
begin
WriteLn;
WriteLn({$INCLUDE %FPCTARGETOS%}, ' ', {$INCLUDE %FPCTARGETCPU%}, ' (Free Pascal ', {$INCLUDE %FPCVERSION%}, ')');
WriteLn('test speed for 32');
for i := 1 to 10 do
specialize TestSpeedIntX<Int32>;
WriteLn('test speed for 64');
for i := 1 to 10 do
specialize TestSpeedIntX<Int64>;
end.
Здравствуйте, Евгений Музыченко, Вы писали:
ЕМ> TW>Может паскалевские замарочки?
ЕМ> Скорее всего. В сях при таких тестах тоже надо следить, чтоб шибко умный компилятор не наоптимизировал. Даже древний VC++ конца 90-х много чего умеет.
Я попробовал этот тест собрать паскалем с llvm, так он вообще весь код выкинул за ненадобностью
Здравствуйте, Евгений Музыченко, Вы писали:
A>>У вас такая уверенность в вашей исключительности ЕМ>Определенная исключительность наличествует во многих. Но таки интересно, из чего именно Вы делаете такой вывод?
Потому что вы не умеете входить в ситуации окружающих людей (эгоизм). Например, если вам достаточно 300 Кб для программы, вы делаете вывод что всему миру этого обьема тоже достаточно и начинаете методично разьяснять почему это так и никак иначе для всех и на все времена (контрпродуктивный нигилизм с элементами нарцисизма). Такие дисскуссии даже продолжать не хочеться, потому что они говорят как минимум об элементах незрелости и недальновидности. При этом изначально тема дискуссии была про применимость 64 битных архитектур, но после ваших сообщений происходит мастерский дерейлинг всей ветки. И это не первая и, скорее всего, не последняя тема, в которой всё развивается по одному и тому же патологическому сценарию резонёрства.
Не обижайтесь если я что-то не так написал. Вы спросили — я ответил. Надеюсь это информация для вас будет в конечном итоге полезна, даже если она вызовет разнонаправленные сиюминутные эмоции.
Здравствуйте, Философ, Вы писали:
Ф>Зачем миллионы? Достаточно одного объекта в куче, у которого пара булевых полей, пара интовых, а ещё несколького геттеров, несколько сеттеров и один vtable. Сам посчитай оверхед.
У одного такого объекта оверхед будет десяток-другой байтов, это критично?
Ф>Собственно, чем больше объектов тем меньше оверхед.
Почему меньше? Он постоянный на каждый объект.
Ф>Но даже если их очень много, в этом примере оверхед значительный.
Вот он и становится заметным, только когда таких объектов очень много. Впрочем, на фоне современных браузеров почти любой оверхед уже выглядит незначительным. У них тоже начиналось с "ну ладно, пусть страница занимает на 100 килобайт больше, зато навигация будет быстрее". А теперь — "вроде бы эти 20 мегабайт тут лишние, да и хрен с ними, щас прикрутим еще какую-нибудь свистоперделку".
ЕМ>>все общение с системой идет через трансляцию.
Ф>где об этом можно почитать?
Если про винду, то гуглите по WOW64. Собственно, то же самое происходит и при запуске 16-разрядного кода в 32-разрядной винде.
Ф>Почему при нативных вызовах такого не происходит?
Основной обрабатывающий код реализован в родной разрядности. Дублировать его полностью нецелесообразно, хотя многие мелкие функции полностью отрабатывают в 32-разрядных библиотеках. А когда функция требует обращения к ядру, желательно унифицировать интерфейс, чтобы ядру не приходилось разбираться с разрядностью указателей. Поэтому вся трансляция делается в библиотеках пользовательского режима (DLL в винде), а в ядро уже идут только стандартные, "родные" запросы.
Здравствуйте, Философ, Вы писали:
Ф>Я не плюсовик и настройка проекта для меня не секундное дело
Грешно для такой мелочи создавать проект. Достаточно положить текст в файл .cpp, открыть консоль, вызвать командный файл настройки окружения (например, в VS 2019 это C:\Program Files (x86)\Microsoft Visual Studio\2019\Professional\VC\Auxiliary\Build\vcvarsall.bat) с параметром x86 или x64, и потом дать команду cl file.cpp. Оно само скомпилирует и соберет в EXE.
Здравствуйте, eustin, Вы писали:
E>Можно ли в 2023 перейти целиком на 64 бита (b2c)? Сейчас для некоторых продуктов тащится 32 Битный exe на всякий случай.
Я примерно в 2019 перешёл. Если ты спрашиваешь моего разрешения, то да, можно.
Здравствуйте, JustPassingBy, Вы писали:
П>>А нафига нужны 64 бита? Имхо, если они в чем-то реально полезны — тогда переходить, а иначе какой смысл?
JPB>Эстетика. Может быть плагины какие-то только под 64 бита, или полтитка безопасности в среде, где это устанавливается, позволяет только 64.
Ну, это уже реальные причины, как ни крути. Просто переходить на 64 бита, чтобы было, я лично не вижу смысла
Здравствуйте, eustin, Вы писали:
П>>А нафига нужны 64 бита? Имхо, если они в чем-то реально полезны — тогда переходить, а иначе какой смысл? E>- памяти не хватает тупо E>- новые либы все предсобраны под 64, чтобы не собирать их под 32
Ну, это тоже вполне реальные причины. Хотя я как-то не сталкивался с либами, предсобранными только для x64. Да и проблем с памятью никогда не было
V>- 64-битные указатели требуют больше памяти. Это увеличивает объем занимаемой приложениями оперативной памяти.
А значит меньше программы влезет в кэш процессора
Но эмуляция арифметических 64-бит операций в 32-битной программе будет, конечно, медленней чем нативные 64-бит
Здравствуйте, Евгений Музыченко, Вы писали:
ЕМ>Грешно для такой мелочи создавать проект. Достаточно положить текст в файл .cpp, открыть консоль, вызвать командный файл настройки окружения (например, в VS 2019 это C:\Program Files (x86)\Microsoft Visual Studio\2019\Professional\VC\Auxiliary\Build\vcvarsall.bat) с параметром x86 или x64, и потом дать команду cl file.cpp. Оно само скомпилирует и соберет в EXE.
Фу, сколько телодвижений. У меня для такого cxx03.bat/cxx11.bat/cxx14.bat/cxx17.bat в путях лежат
Здравствуйте, rudzuk, Вы писали:
R>Я попробовал этот тест собрать паскалем с llvm, так он вообще весь код выкинул за ненадобностью
Вот и в сишном приходится добавлять код использования тестовых массивов, а результат передавать куда-нибудь наружу, иначе тоже выкидывает. А если по массиву проходить в цикле, эта гадина еще и инварианты находит и выносит из цикла.
Здравствуйте, Философ, Вы писали:
Ф> Ага, я видел. Только при этом ты на полном серьёзе утверждаешь, что этот наш .net не настоящий. Да-да, медленный слишком.
А ты сам не видишь дичь в результатах своих замеров? 64-битный код с треском сливает 32-битному, работая в родном для себя режиме. И это объясняется тем, что процессор, оказывается, не так прост. фасепальм.
Ф> R>Что есть у нас в паскале я знаю. Код написан именно так, чтобы любой мог его собрать без установки подополнительных пакетов.
Ф> В таких случаях самостоятельно дергают QPC. Некоторые извращенцы при этом даже из .net дёргают RDTSC, например вот здесь Сидиристый поступил именно так.
Как я уже говорил, смысла в этом не много Задачи ловить такты нет. Вот смотри, специально для тебя:
const
Iterations = 10 * 1000 * 1000;
function GetTickCount : Int64;
begin
if not QueryPerformanceCounter(@Result) then
System.Error(reAssertionFailed);
end;
Здравствуйте, eustin, Вы писали:
E>Можно ли в 2023 перейти целиком на 64 бита (b2c)? Сейчас для некоторых продуктов тащится 32 Битный exe на всякий случай.
Да, но зачем? 32 бита жрут меньше памяти, и более портируемые.
64 бита нужны только если 4 гигов мало.
Нет такой подлости и мерзости, на которую бы не пошёл gcc ради бессмысленных 5% скорости в никому не нужном синтетическом тесте
Здравствуйте, eustin, Вы писали:
E>Можно ли в 2023 перейти целиком на 64 бита (b2c)? Сейчас для некоторых продуктов тащится 32 Битный exe на всякий случай.
Я кажется слышал, что Wine для Linux или Mac лучше работает с Win32 версиями. Если кто-то знает конкретнее, прошу написать.
"Ты должен сделать добро из зла, потому что его больше не из чего сделать". АБ Стругацкие.
Здравствуйте, eustin, Вы писали:
E>Можно ли в 2023 перейти целиком на 64 бита (b2c)? Сейчас для некоторых продуктов тащится 32 Битный exe на всякий случай.
У меня процентов 10% качают 32 битные версии, остальные 90% — 64.
Поэтому т.к. сложностей с компиляцией под 32-бит нет, то пока от 32 не отказался.
Здравствуйте, пффф, Вы писали:
E>>Можно ли в 2023 перейти целиком на 64 бита (b2c)? Сейчас для некоторых продуктов тащится 32 Битный exe на всякий случай.
П>А нафига нужны 64 бита? Имхо, если они в чем-то реально полезны — тогда переходить, а иначе какой смысл?
Здравствуйте, пффф, Вы писали:
П>А нафига нужны 64 бита? Имхо, если они в чем-то реально полезны — тогда переходить, а иначе какой смысл?
Когда-то мне понадобилось выделить 80 Мб непрерывной памяти — но на 32 битных системах это часто не срабатывало из-за фрагментации памяти. Вроде как теоретические 4 Гб для 32 бит и доступны, но из них иногда даже относительно скромные 80 Мб одним блоком выделить не получается, потому что в адресном пространстве иногда не бывает достаточно продолжительной свободной "дырки".
Здравствуйте, eustin, Вы писали:
E>Можно ли в 2023 перейти целиком на 64 бита (b2c)? Сейчас для некоторых продуктов тащится 32 Битный exe на всякий случай.
За последнюю неделю 0.6% активных инсталлов — 32-битные. Остальные — 64-битные.
Здравствуйте, wantus, Вы писали:
W>Здравствуйте, eustin, Вы писали:
E>>Можно ли в 2023 перейти целиком на 64 бита (b2c)? Сейчас для некоторых продуктов тащится 32 Битный exe на всякий случай.
W>За последнюю неделю 0.6% активных инсталлов — 32-битные. Остальные — 64-битные.
Спасибо) Очень зачанчиво убрать. А вот трекинга своего пока нет.
M>Я пока не пешёл на x64, так как смысла не вижу. Может лучше пересобрать новые либы на x32 чем терять клиентов ?
Это да.. Но еще размер exe пухнет, а он уже немалый (100 Мб + докачка после установки). Так что вдруг от этого больше народу отвалится)
Здравствуйте, eustin, Вы писали: E>Можно ли в 2023 перейти целиком на 64 бита (b2c)? Сейчас для некоторых продуктов тащится 32 Битный exe на всякий случай.
Чтобы жрать больше памяти? Размер указателя то X2...
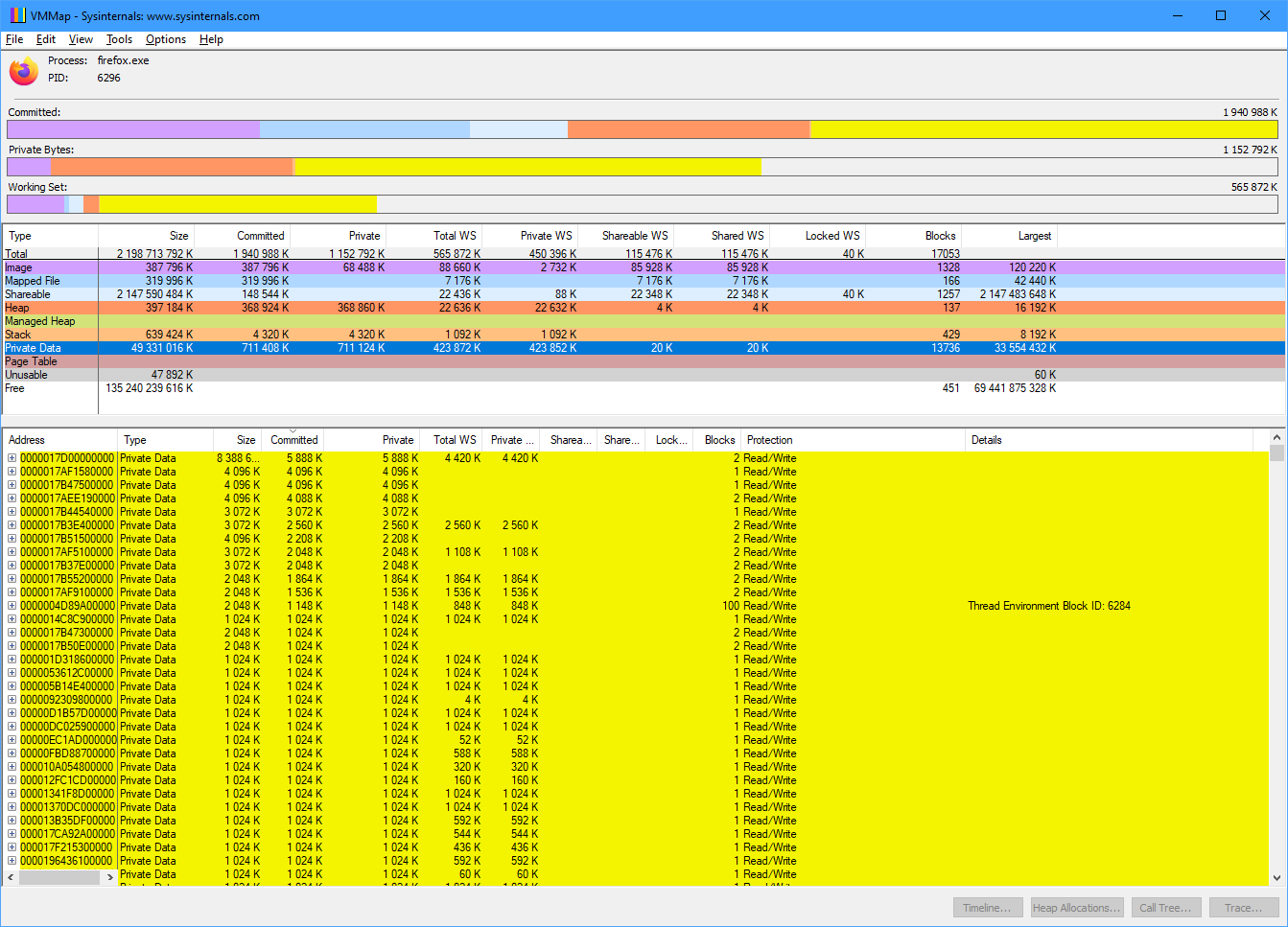
Я сейчас просмотрел список софта на своей машине. Реально в 64-х битах нуждаются только виртуальные машины, студия и некоторые игры. Притом игры, которые хотят 64 бита и больше 4 Гб памяти реально в них не нуждаются: большую часть АП они расходуют на маппинг текстур. Ты можешь сам в этом убедиться, если возьмёшь VMMap из SysinternalsSuite и посмотришь. Притом даже если выделено у них >2 Гб, то размер WS 2 Гб редко превосходит. Хороший пример неадекватного жора — Sims 4:
2,8 Гб Total
580 Mb Heap Size
И вот нафига козе баян!?
Ещё один пример — firefox, возьмём самый жирный процесс:
2.2 Гб Total
1,9 Гб Commited
711 Mb Private data
565 Mb WS
картинка
Притом у FF максимальный закоммиченый блок — около 16 МБ. Т.е. фрагментация памяти для него вообще не проблема.
Всё сказанное выше — личное мнение, если не указано обратное.
Здравствуйте, K13, Вы писали:
Ф>>Я сейчас просмотрел список софта на своей машине. Реально в 64-х битах нуждаются только виртуальные машины, студия и некоторые игры.
K13>Видеомонтаж. Тяжелые алгоритмы обработки фоток. Нейросети. Тут очень часто 32 бита уже не поддерживается.
Тяжёлые алгоритмы обработки фоток Сейчас открыл RAW в Canon Digital Photo Professional, подёргал туда-сюда подавление шумов и автокоррекцию яркости. Судя по скорости работы на моём i9, это тяжёлые алгоритмы. Сожрало в итоге 3.6 Total. Надо полагать, что если бы процесс был 32 бита, то сожрало бы меньше 3-х: 32 бита хватило бы.
Насчёт видео согласен.
Всё сказанное выше — личное мнение, если не указано обратное.
Здравствуйте, Aquilaware, Вы писали:
A>Когда-то мне понадобилось выделить 80 Мб непрерывной памяти — но на 32 битных системах это часто не срабатывало из-за фрагментации памяти.
Какой памяти?
A>иногда даже относительно скромные 80 Мб одним блоком выделить не получается, потому что в адресном пространстве иногда не бывает достаточно продолжительной свободной "дырки".
Чтобы создать такую ситуацию, нужно очень долго и целенаправленно забивать адресное пространство разным мусором. Для типичного приложения такая ситуация нереальна.
Здравствуйте, Философ, Вы писали:
Ф>Чтобы жрать больше памяти? Размер указателя то X2...
"Вот прямо сразу" это ощутимо только на больших (миллионы элементов) списках. Сам по себе рост грамотно организованных кода/данных не настолько значителен.
Основная претензия к 32-разрядному коду в 64-разрядных системах в том, что все общение с системой идет через трансляцию. Приложение загружает 32-разрядные библиотеки-переходники, вызывает оттуда системные функции, те преобразуют параметры, вызывают 64-разрядные библиотеки, затем преобразуют результаты. Когда в запросе участвуют отдельные слова или небольшие структуры, накладные расходы невелики, но при обмене большими массивами данных приходится каждый раз выделять память из кучи, затем освобождать.
Но основной жор, как известно, создают просто неграмотно сделанные приложения. Предел в 2 Гб — единственное, что не дает им возможности жрать больше.
Здравствуйте, eustin, Вы писали:
E>Можно ли в 2023 перейти целиком на 64 бита (b2c)? Сейчас для некоторых продуктов тащится 32 Битный exe на всякий случай.
Как видите, 64-битный режим работы имеет такие плюсы и минусы:
+ 64-битная система может работать со всем объемом оперативной памяти;
+ некоторые операции на 64-битном процессоре выполняются существенно быстрее;
— 64-битные указатели требуют больше памяти. Это увеличивает объем занимаемой приложениями оперативной памяти.
Там ещё идёт сравнение.
Результаты исследования вполне ожидаемы. Из-за использования режима совместимости 64-битная система при работе с обычными 32-битным программами показала чуть меньшую производительность.
Данное сравнение производительности также показало, что реальной пользы от 4 гигабайт оперативной памяти в том наборе приложений нет. Тут важно заметить, что на самом деле в тяжелых приложениях вроде графических редакторов, систем автоматизированного проектирования (CAD) и прочих объем оперативной памяти играет ключевую роль. Там от дополнительных гигабайт оперативной памяти реальная польза действительно есть.
Лично я же думаю так.
1. Смысл в 32-ух битных приложениях для повышенной совместимости включая 32-ух и 64-ёх битную архитектуру процессора и операционной системы.
2. Смысл в 64-ёх битных приложениях для использования 64-ёх битных инструкций и 64-ёх битной адресации при том, что архитектура процессора и операционная система тоже 64-ёх битные.
1. Каждый вариант имеет преимущества и недостатки.
2. Использование сразу двух вариантов имеет только преимущества без недостатков.
Большинство пользователей скорее всего сидят на 64-ёх битных процессорах и операционных системах. Потери 32-ух битных пользователей скорее всего будут небольшими, но они будут. В принципе, конечно, пора уже отказываться от 32-ух битов. Но с другой стороны 32-ух битные приложения более совместимы.
А ещё моду на отбрасывание 32-ух бит задала Apple, но тут нужно понимать, что они вообще всё отбрасывают. Отбрасывают свои же старые интеловские макбуки и переходят на свои процессоры. Отбрасывают стандартные графические библиотеки и пилят своё.
Плюют на крупнейшего производителя игрового движка вроде Unreal Engine от Epic Games. Вообще всех гнобят и старые айфоны уж извините это старые айфоны, покупайте новые или гуляйте без учётной записи.
В общем я тоже разрешаю отказаться от 32-ух битной архитектуры в пользу одной лишь 64-битной. Но если есть время, то можно было бы сделать две версии для каждого семейства операционок.
Cмысла в 32-ух битах лично я не вижу и сам не использую, за исключением того, если только у разработчика есть только такая версия. Хотя для Wine 32-ух битное приложение было бы лучше, но это из-за изначальных настроек и скорости развития самого Wine. Да и здесь больше уже вопрос создания нативных версий для других семейств операционных систем отличных от Windows.
Здравствуйте, Евгений Музыченко, Вы писали:
ЕМ>Здравствуйте, Философ, Вы писали:
Ф>>Чтобы жрать больше памяти? Размер указателя то X2... ЕМ>"Вот прямо сразу" это ощутимо только на больших (миллионы элементов) списках. Сам по себе рост грамотно организованных кода/данных не настолько значителен. ЕМ>.. ЕМ>Но основной жор, как известно, создают просто неграмотно сделанные приложения. Предел в 2 Гб — единственное, что не дает им возможности жрать больше.
Зачем миллионы? Достаточно одного объекта в куче, у которого пара булевых полей, пара интовых, а ещё несколького геттеров, несколько сеттеров и один vtable. Сам посчитай оверхед. Собственно, чем больше объектов тем меньше оверхед. Но даже если их очень много, в этом примере оверхед значительный. Я могу на примере формочки с кнопочкой такое продемонстрировать, с цифирками.
ЕМ>Основная претензия к 32-разрядному коду в 64-разрядных системах в том, что все общение с системой идет через трансляцию.
гм... любопытно. А где об этом можно почитать? Почему при нативных вызовах такого не происходит?
Всё сказанное выше — личное мнение, если не указано обратное.
Здравствуйте, TailWind, Вы писали:
TW>А значит меньше программы влезет в кэш процессора
Думаете, среди нас есть такие, кому лично довелось испытать сколько-нибудь заметное падение быстродействия собственного софта по этой причине, и при этом в софте не было явных косяков?
Здравствуйте, Евгений Музыченко, Вы писали:
ЕМ>Почему меньше? Он постоянный на каждый объект.
А если 0 объектов, а vtable в памяти!?
Ф>>Но даже если их очень много, в этом примере оверхед значительный.
ЕМ>Вот он и становится заметным, только когда таких объектов очень много. Впрочем, на фоне современных браузеров почти любой оверхед уже выглядит незначительным. У них тоже начиналось с "ну ладно, пусть страница занимает на 100 килобайт больше, зато навигация будет быстрее". А теперь — "вроде бы эти 20 мегабайт тут лишние, да и хрен с ними, щас прикрутим еще какую-нибудь свистоперделку".
ЕМ>>>все общение с системой идет через трансляцию. Ф>>где об этом можно почитать? ЕМ>Если про винду, то гуглите по WOW64. Собственно, то же самое происходит и при запуске 16-разрядного кода в 32-разрядной винде.
Ты говорил про большие объёмы данных и выделение памяти в куче для трансляции. Я не могу этого в документации найти, как минимум тут и вот тут нету. Про трансляцию через выделение в куче я ничего не могу найти. Про то, что стековые аргументы расширяются до 64 бит и так ясно. Про то, что ядерные вызовы дорогими получаются тоже понятно, но они без этого как бы не дешёвые.
Всё сказанное выше — личное мнение, если не указано обратное.
ЕМ>Думаете, среди нас есть такие, кому лично довелось испытать сколько-нибудь заметное падение быстродействия собственного софта по этой причине, и при этом в софте не было явных косяков?
Думаю, что вы опять задаёте странные вопросы, когда не согласны с тезисом
Здравствуйте, Евгений Музыченко, Вы писали:
ЕМ>Думаете, среди нас есть такие, кому лично довелось испытать сколько-нибудь заметное падение быстродействия собственного софта по этой причине, и при этом в софте не было явных косяков?
Лично мне просто не приходило в голову собирать под 64 бита то, для чего 32 вполне хватало (это для моих поделок). А на работе всё по большей части упиралось либо в сеть, либо в диск, либо в системные вызовы, либо в SQLite. Ну а потому, когда на работе работаешь обычно не до бенчмарков — данные подбираются так, чтобы их для задачи хватило.
Всё сказанное выше — личное мнение, если не указано обратное.
Здравствуйте, Философ, Вы писали:
Ф>мне просто не приходило в голову собирать под 64 бита то, для чего 32 вполне хватало
Я бы тоже не собирал, но некоторые системные операции (например, установка/удаление драйверов в винде) могут выполняться только из приложений родной разрядности. Ну и многие юзеры искренне полагают, что 32-разрядное приложение в 64-разрядной системе — это что-то кривое, наподобие 16-разрядного в 32-разрядной, и просят "родное". Так что все релизы давно собираются под x86/x86, а сейчас еще и под arm64.
Здравствуйте, Философ, Вы писали:
Ф>А если 0 объектов, а vtable в памяти!?
Мы сейчас реальные, ощутимые затраты оцениваем, или занимаемся мелочным крохоборством?
Ф>Ты говорил про большие объёмы данных и выделение памяти в куче для трансляции.
Я сейчас с ходу не вспомню, где это используется — есть у винды какие-то функции, где могут передаваться/приниматься длинные таблицы, размеры данных в которых зависят от разрядности. А большинство преобразований, конечно же, идет через стек.
Здравствуйте, TailWind, Вы писали:
TW>Минутка психотерапии:
Вы твердо уверены, что из нас двоих психотерапия нужна именно мне?
TW>Сложно сказать: я делал тест производительности с компилятором 32 и 64 бит и на моих задачах не было существенной разницы?
Конечно, делал, и не раз.
Но дискуссия, напомню, не о том, имеют ли смысл 32-разрядные приложения вообще, а о том, стоит ли индивидуальному разработчику (это во многом определяет уровень сложности и применимости задач) полностью переходить на 64-разрядную архитектуру. Раз Вы в рамках этой дискуссии утверждаете "меньше программы влезет в кэш процессора", значит, считаете этот фактор важным и существенным именно в этом аспекте. Вот мне и стало интересно, кому из нас действительно имеет смысл помнить о размере кэша процессора и соотносить его с размером кода/данных, ибо все более важные причины нехватки быстродействия уже устранены.
ЕМ>Вы твердо уверены, что из нас двоих психотерапия нужна именно мне?
Я совершенно по дружески рассказываю вам то что вижу в вашем поведении некую странность
Тут многие пытаются соревносться у кого больше эго, это вообще не про то что я вам говорю
Так что не обижайтесь. Люди вокруг кривые зеркала. Но иногда в них можно увидеть что-то важное для себя
TW>>Сложно сказать: я делал тест производительности с компилятором 32 и 64 бит и на моих задачах не было существенной разницы? ЕМ>Конечно, делал, и не раз.
ЕМ>Раз Вы в рамках этой дискуссии утверждаете "меньше программы влезет в кэш процессора", значит, считаете этот фактор важным и существенным именно в этом аспекте.
Да считаю
Но просто считать мало
Надо делать тесты
Здравствуйте, Евгений Музыченко, Вы писали:
ЕМ>Здравствуйте, icezone, Вы писали:
I>>попробовал собрать AOM AV1 — студия сожрала 50+ GB и вылетела с ошибкой — нехватка памяти
ЕМ>Сама студия, или запущенные ею утилиты (компилятор/линкер и т.п.)?
проверял на 2017 и 2022 Студиях
compiler is out of heap space
сперва пробовал 32-битный компилятор, тот вылетел сразу
потом на ноутбуке с 16Гб оперативки запускал 64-битный компилятор — дошел до 40Гб и выдал ошибку
пересел на десктоп с 32Гб — сожрал примерно 55Гб и тоже упал...
Здравствуйте, TailWind, Вы писали: TW>INT64 + INT64 TW>Или INT64 ++ TW>32-bit compiler разложит на несколько инструкций TW>А 64-bit compiler сделает за одну
Во-первых, AMD64 всё ещё нативно исполняет 32-битный код. Возражение не принято.
Во-вторых, как много у тебя математики на int64? Зачем она нужна? Ну кроме вычисления адреса.
В-третьих, похоже у меня есть повод тебя сильно удивить.
код на шарпе
static void Main(string[] args)
{
Console.WriteLine("test speed for 32");
for (int a = 0; a < 10; a++)
{
TestSpeedInt32();
}
Console.WriteLine("test speed for 64");
for (int a = 0; a < 10; a++)
{
TestSpeedInt64();
}
}
const int iterations = 10 * 1000 * 1000;
private static unsafe void TestSpeedInt32()
{
System.Int32 a, b, c, d, e, f, g, h;
a = b = c = d = e = f = g = h = 0;
var sw = Stopwatch.StartNew();
for (int i = 0; i < iterations; i++)
{
a++;
b++;
c++;
d++;
e++;
f++;
g++;
h++;
}
sw.Stop();
var variablesIncrementTime = sw.ElapsedTicks;
sw.Restart();
var smallArray = stackalloc System.Int32[8];
for (int i = 0; i < iterations; i++)
{
++smallArray[0];
++smallArray[1];
++smallArray[2];
++smallArray[3];
++smallArray[4];
++smallArray[5];
++smallArray[6];
++smallArray[7];
}
sw.Stop();
var arrayItemIncrementTime = sw.ElapsedTicks;
Console.WriteLine("elapsed for variable = {0:D} \tarray = {1:D}", variablesIncrementTime , arrayItemIncrementTime);
}
private static unsafe void TestSpeedInt64()
{
System.Int64 a, b, c, d, e, f, g, h;
a = b = c = d = e = f = g = h = 0;
var sw = Stopwatch.StartNew();
for (int i = 0; i < iterations; i++)
{
a++;
b++;
c++;
d++;
e++;
f++;
g++;
h++;
}
sw.Stop();
var variablesIncrementTime = sw.ElapsedTicks;
sw.Restart();
var smallArray = stackalloc System.Int64[8];
for (int i = 0; i < iterations; i++)
{
++smallArray[0];
++smallArray[1];
++smallArray[2];
++smallArray[3];
++smallArray[4];
++smallArray[5];
++smallArray[6];
++smallArray[7];
}
sw.Stop();
var arrayItemIncrementTime = sw.ElapsedTicks;
Console.WriteLine("elapsed for variable = {0:D} \tarray = {1:D}", variablesIncrementTime , arrayItemIncrementTime);
}
результаты теста на .net 4.8
RELEASE x86
test speed for 32
elapsed for variable = 29938 array = 208879
elapsed for variable = 29850 array = 209862
elapsed for variable = 30037 array = 210031
elapsed for variable = 29861 array = 208852
elapsed for variable = 29823 array = 209040
elapsed for variable = 29852 array = 208794
elapsed for variable = 29806 array = 208832
elapsed for variable = 29969 array = 209887
elapsed for variable = 29888 array = 209699
elapsed for variable = 30235 array = 211679
test speed for 64
elapsed for variable = 46366 array = 358094
elapsed for variable = 33484 array = 357904
elapsed for variable = 35593 array = 357942
elapsed for variable = 36421 array = 358376
elapsed for variable = 34880 array = 358300
elapsed for variable = 36807 array = 357978
elapsed for variable = 36902 array = 357956
elapsed for variable = 33078 array = 357680
elapsed for variable = 34724 array = 358055
elapsed for variable = 33380 array = 357987
RELEASE x64
test speed for 32
elapsed for variable = 74742 array = 238943
elapsed for variable = 74613 array = 238674
elapsed for variable = 74580 array = 239054
elapsed for variable = 74504 array = 238877
elapsed for variable = 74759 array = 238828
elapsed for variable = 74518 array = 238862
elapsed for variable = 74883 array = 239424
elapsed for variable = 74698 array = 244281
elapsed for variable = 74820 array = 238945
elapsed for variable = 74495 array = 238827
test speed for 64
elapsed for variable = 90245 array = 238788
elapsed for variable = 93368 array = 238568
elapsed for variable = 96092 array = 239351
elapsed for variable = 89619 array = 238821
elapsed for variable = 100410 array = 239856
elapsed for variable = 93027 array = 238582
elapsed for variable = 90229 array = 238834
elapsed for variable = 89806 array = 238840
elapsed for variable = 97128 array = 238660
elapsed for variable = 94326 array = 238535
Занимательные результаты, правда!? Конечно же инкремент int64 в x86 медленнее чем int32 — это логично. Но, во-первых код под x64 прям заметно медленнее, а во-вторых даже на x64 инкремент int64 в x86 медленнее чем int32. Притом существенно медленнее!!!
Процессор-то не так прост оказывается..
На дизассемблер пока нет времени — чуть-чуть позже выложу (причёсывать и расписывать его долго). Там ничего не обычного.
Всё сказанное выше — личное мнение, если не указано обратное.
Ф>Занимательные результаты, правда!?
Да
Сделайте кто-нибудь на C++ с оптимизацией, плиз
Я бы сам сделал, но долго разбираться как настроить компилятор на 64-бит
Ф>Во-вторых, как много у тебя математики на int64? Зачем она нужна? Ну кроме вычисления адреса.
У меня лично на каждом шагу. Для вычисления смещений больше 4ГБ
map<INT64, record> часто встречается. А там ещё и операции сравнения вылезают
Кстати хороший тест
Можно сравнить производительность map для ключей ULONG и UINT64, добавляя в него рандомнные значения
Здравствуйте, TailWind, Вы писали:
TW>Интересно, что на 64-бит будет
Не знаю — потом посмотрю. Я не плюсовик и настройка проекта для меня не секундное дело — тратить рабочее время на это не буду.
Тест ИМХО не очень: рэндомайзер убивает повторяемость. Если уж рэндомайзер, то надо надо много проходов, вместе с поиском медианы, минимума и стандартной ошибки.
Всё сказанное выше — личное мнение, если не указано обратное.
Ф>Тест ИМХО не очень: рэндомайзер убивает повторяемость. Если уж рэндомайзер, то надо надо много проходов, вместе с поиском медианы, минимума и стандартной ошибки.
Не убивает
Он обязан выдавать одни и те же значаения при повторном запуске программы
Здравствуйте, TailWind, Вы писали:
Ф>>Тест ИМХО не очень: рэндомайзер убивает повторяемость. Если уж рэндомайзер, то надо надо много проходов, вместе с поиском медианы, минимума и стандартной ошибки. TW>Не убивает TW>Он обязан выдавать одни и те же значаения при повторном запуске программы
Может быть, может быть... А сколько времени работал сам рэндомайзер в этом примере?
Всё сказанное выше — личное мнение, если не указано обратное.
Здравствуйте, Aquilaware, Вы писали:
A>Знаменитые "640 килобайт хватит всем".
У меня, если что, еще ни один бинарник даже за 300 не перевалил, так что в 16-разрядном коде, при той же функциональности, оно бы и на 640 кб работало.
Всем, конечно, не хватит, но подавляющее большинство современного софта превышает реальные потребности в десятки-сотни раз.
Здравствуйте, rudzuk, Вы писали: R>Этот ваш дотнет — ненастоящий. Вот другие результаты: R>Image: KwE4NVU.png R>Код: (увеличил количество итераций в 10 раз, время в миллисекундах) R>
program Project1;
R> VariablesIncrementTime := GetTickCount;
Понятно Наши паскалисты не настоящие.
Не настоящие!
боже, какой позор
[__DynamicallyInvokable]
public long ElapsedTicks
{
[__DynamicallyInvokable] get => this.GetRawElapsedTicks();
}
[__DynamicallyInvokable]
public static long GetTimestamp()
{
if (!Stopwatch.IsHighResolution)
return DateTime.UtcNow.Ticks;
long num = 0;
SafeNativeMethods.QueryPerformanceCounter(out num);
return num;
}
private long GetRawElapsedTicks()
{
long elapsed = this.elapsed;
if (this.isRunning)
{
long num = Stopwatch.GetTimestamp() - this.startTimeStamp;
elapsed += num;
}
return elapsed;
}
[DllImport("kernel32.dll")]
public static extern bool QueryPerformanceCounter(out long value);
Всё сказанное выше — личное мнение, если не указано обратное.
Здравствуйте, Евгений Музыченко, Вы писали:
ЕМ>У меня, если что, еще ни один бинарник даже за 300 не перевалил
Это, кстати, интересная тема. Надо бы замутить опрос по размеру выходных артефактов разрабатываемого ПО. У нас это мегабайты — десятки мегабайт. Меньше не получается, иначе полный функционал продукта невозможно реализовать.
Здравствуйте, Евгений Музыченко, Вы писали:
ЕМ>Вы твердо уверены, что из нас двоих психотерапия нужна именно мне?
Я тоже вижу в вашем поведении такие же странности как и коллега. У вас такая уверенность в вашей исключительности, что вам просто необходимо преобразовать этот напор нарцисизма и эгоизма в деньги, вместо того чтобы воевать с ветрянными мельницами на страницах форума.
Здравствуйте, Aquilaware, Вы писали:
A>У вас такая уверенность в вашей исключительности
Определенная исключительность наличествует во многих. Но таки интересно, из чего именно Вы делаете такой вывод?
A>вам просто необходимо преобразовать этот напор нарцисизма и эгоизма в деньги
Здравствуйте, rudzuk, Вы писали:
R>Здравствуйте, Философ, Вы писали:
Ф>> Понятно Наши паскалисты не настоящие. Ф>> Не настоящие!
R>Не пойму, что ты сказать хотел
Такой код меряют не в милисекундах. Даже во времена Pentium 4 для этого использовался HPET иначе ничего хорошего не намеряешь. Некоторые по привычке использовали RTDSC. А ещё раньше использовали только RDTSC. В крайнем случае люди использовали Multimedia timers.
Позор это потому, что ты что-то намерял, удивился полученным результатам и понёс на форум. Даже не подумал о том, что у тебя результаты прям сильно-сильно другие. Это ошибка десятиклассника, который в физической задаче ошибся на пять порядков, не придал этому значения и записал в ответ.
У вас в паскале есть вот такая обёртка https://wiki.freepascal.org/EpikTimer/ru
Почти во всех языках в стандартных библиотеках такое обычно есть из коробки — профилирование кода слишком распространённая задача.
Здравствуйте, Философ, Вы писали:
Ф> Такой код меряют не в милисекундах. Даже во времена Pentium 4 для этого использовался HPET иначе ничего хорошего не намеряешь. Некоторые по привычке использовали RTDSC. А ещё раньше использовали только RDTSC. В крайнем случае люди использовали Multimedia timers.
Ф> Позор это потому, что ты что-то намерял, удивился полученным результатам и понёс на форум. Даже не подумал о том, что у тебя результаты прям сильно-сильно другие. Это ошибка десятиклассника, который в физической задаче ошибся на пять порядков, не придал этому значения и записал в ответ.
Именно из-за миллисекунд я и увеличил количество итераций. Это первое. Второе. Это не задача профилирования кода, где нужно количество тактов ловить.
Ф> У вас в паскале есть вот такая обёртка https://wiki.freepascal.org/EpikTimer/ru Ф> Почти во всех языках в стандартных библиотеках такое обычно есть из коробки — профилирование кода слишком распространённая задача.
Ф> Там внутри вот это используется.
Что есть у нас в паскале я знаю. Код написан именно так, чтобы любой мог его собрать без установки подополнительных пакетов.
Здравствуйте, rudzuk, Вы писали:
R>Именно из-за миллисекунд я и увеличил количество итераций. Это первое. Второе. Это не задача профилирования кода, где нужно количество тактов ловить.
Ага, я видел. Только при этом ты на полном серьёзе утверждаешь, что этот наш .net не настоящий. Да-да, медленный слишком.
R>Что есть у нас в паскале я знаю. Код написан именно так, чтобы любой мог его собрать без установки подополнительных пакетов.
В таких случаях самостоятельно дергают QPC. Некоторые извращенцы при этом даже из .net дёргают RDTSC, например вот здесь Сидиристый поступил именно так.
Всё сказанное выше — личное мнение, если не указано обратное.
Здравствуйте, rudzuk, Вы писали:
r> А ты сам не видишь дичь в результатах своих замеров? 64-битный код с треском сливает 32-битному, работая в родном для себя режиме. И это объясняется тем, что процессор, оказывается, не так прост. фасепальм.
Здравствуйте, rudzuk, Вы писали:
R>Image: Aqj7Hho.png R>Так что да, ты прав — твой процессор не так прост
Что у тебя за проц? Я всё понять не могу, почему у тебя инкремент Int32 почти в 1.4 раза медленне чем у меня. Тем более, что мой i9 работает на частоте 3.9 — я ему обрезал частоты, чтобы меньше комнату обогревал. И почему такой разброс значений!?
Ты под дебаггером код запускаешь что-ли?
Всё сказанное выше — личное мнение, если не указано обратное.
Здравствуйте, rudzuk, Вы писали: R>А ты сам не видишь дичь в результатах своих замеров? 64-битный код с треском сливает 32-битному, работая в родном для себя режиме. И это объясняется тем, что процессор, оказывается, не так прост. фасепальм.
Во-первых я заглядывал в дизасм, в то, что получилось после джиттера — там не было ничего экстраординарного. Во-вторых, я знаю что команды в современном x86 — это не инструкции. Сегодня x86 имеет RISC ядро, и сами команды декодирует в микрооперации, которые потом исполняте гипер-конвеер. Гипер-конвеерная архитектура появилаесь ещё в Pentium-4, а переупорядочивание команд в конвеере появилось ещё раньше аж в Pentium Pro, читать вот здесь.
Если ты посмотришь на модную штучку времён Core 2Duo ( Wide Dyanamic Execution) то увидишь там более 1 ALU.
В сочетании с переупорядочиванием инструкций (Out of order execution), то должен бы перестать удивлять тому, что частенько 2 команды выполняются дольше чем 5. Я этому удивляться перестал много лет назад, когда экспериментировал с командами процессора: у меня частенько rdtsc мерял 0 тактов на команду. Потом я открыл для себя fence-операции, в частности full-fence (примерно тогда уже узнал зачем нужен барьер памяти).
Понимаешь, нельзя сказать, сколько тактов займёт условный inc qword ptr [r15] и не получится его просто так сравнить с кодом аналогичного назначения для 32-бит. Поэтому и написать вручную оптимизированный ассемблерный код — совсем непростая задача. R>Ну, сильно изменился общий результат?
Для начала расскажи как запускал. Есть серьёзное подозрение, что под дебаггером. На эту мысль наводят довольно большие цифры по сравнению с некоторыми моими. Например increment Int64 под x64 у меня более чем вдвое быстрее. Во-вторых, покажи что там компилятор паскали наоптимизировал.
что произвёл джиттер
как в WinDBG добраться до ассемблера (на примере x64)
Всё это получалось так: после получения резульатов на экране — код должен был отджитится, к процессу цеплялся WinDbg64 или WinDbg32 соответственно. Не студией потому, что студия вностит коррективы в процесс Jitting'а, а меня тут интересовало то, что пойдёт в релиз — что будет на машине условного пользователя.
2) Int64 x64 — тоже ничего необычного, за исключением плясок с бубном вокруг регистра R15. Джиттеру наверное очень нравится адресовать элемент массива с помощью именно этого регистра.
Показывай, что породил FPC для 64-бит, расскажи условия тестирования.
И наконец прекрати постить текст картинками!!!111111 У меня была идея взять твои результаты, посчитать медиану и стандартную ошибку, но с картинки это сделать невозможно.
Всё сказанное выше — личное мнение, если не указано обратное.
Здравствуйте, Aquilaware, Вы писали:
A>вы не умеете входить в ситуации окружающих людей
Я умею, но далеко не всегда хочу это делать. В частности, такого желания не возникает, когда доводы тех людей в итоге сводятся к "мне так тупо проще/удобнее, но вы должны войти в мое положение и пойти мне навстречу". При этом сам он, разумеется, в положение другого входить не намерен, и навстречу пойдет лишь в самом крайнем случае.
A>(эгоизм).
Эгоизм — это то, против чего такая позиция направлена.
A>если вам достаточно 300 Кб для программы, вы делаете вывод что всему миру этого обьема тоже достаточно
Подмена тезиса детектед. Приведите цитаты, в которых я утверждал, чего-то там должно быть достаточно всему миру.
Безусловно, сейчас достаточно задач, требующих большого количества ресурсов. Но это — капля в море всего современного софта, которого неимоверно много. За доказательствами далеко ходить не нужно: откройте Google Play и поищите там какие-нибудь очевидно простые по функциональности приложения. Найдете много приложений на мегабайты и десятки мегабайт, и среди них (но ближе к концу списка) нередко найдете на 100-200 килобайт, функциональность которых может оказаться даже лучше.
И повторю: плохо не то, что такой мусор вообще существует. Плохо то, что он объявлен нормой, на которую ориентируются остальные. И по сути это мало чем отличается от той же Турции, где построенные за последние 10-20 лет здания внешне и внутри выглядели вполне симпатично, разве что разрушительный потенциал меньше.
Здравствуйте, Философ, Вы писали:
Ф> R>Ну, сильно изменился общий результат?
Ф> Для начала расскажи как запускал. Есть серьёзное подозрение, что под дебаггером.
Сборка в релиз (оптимизация O3 + отключение рантайм проверок), запуск из командной строки.
Не изменилась картина, правда? То-то же. Нефиг было гнать на GetTickCount.
Ф> ...покажи что там компилятор паскали наоптимизировал.
Здравствуйте, Философ, Вы писали:
Ф>Есть серьёзное подозрение, что под дебаггером.
Откуда? Отладчик, если он не безнадежно тупой, никак не взаимодействует с отлаживаемым процессом, пока тот не выполнит действие, вызывающее исключение — отладочный вывод, попадание на стоп-точку, ошибка и т.п. Если тестовый код не сыпет отладочными сообщениями сотни раз в секунду, производительность отличаться не будет.
Здравствуйте, Sharowarsheg, Вы писали:
S> R>Я попробовал этот тест собрать паскалем с llvm, так он вообще весь код выкинул за ненадобностью
S> Статья "о ценности синтетических бенчмарков"
Здравствуйте, eustin, Вы писали:
E>Можно ли в 2023 перейти целиком на 64 бита (b2c)? Сейчас для некоторых продуктов тащится 32 Битный exe на всякий случай.
Да, скорее нужно.
SSE2 по умолчанию на всех процессорах
Больше регистров богу регистров
Отсутсвие x86 системной прослойки — влияет на скорость перого запуска после перезагрузки и потребление физической памяти, если x86 софтина единственная.
Можно выделить МНОГО памяти непрерывным куском без извращений с маппингом.
Ф>>Есть серьёзное подозрение, что под дебаггером. ЕМ>Откуда? Отладчик, если он не безнадежно тупой, никак не взаимодействует с отлаживаемым процессом, пока тот не выполнит действие, вызывающее исключение — отладочный вывод, попадание на стоп-точку, ошибка и т.п. Если тестовый код не сыпет отладочными сообщениями сотни раз в секунду, производительность отличаться не будет.
Для отладочный версии компилятор может генерировать не самый оптимальный код в целях улучшения диагностики. По уму, надо релизные версии сравнивать.
Здравствуйте, Sharov, Вы писали:
Ф>>>Есть серьёзное подозрение, что под дебаггером.
S>Для отладочный версии компилятор может генерировать не самый оптимальный код
Запуск под отладчиком не имеет никакого отношения к генерации кода.
Здравствуйте, Евгений Музыченко, Вы писали:
ЕМ>Запуск под отладчиком не имеет никакого отношения к генерации кода.
Не то, чтобы я проверял, но, скажем, в MSVS 2022 есть галка в разделе Options -> Debugging, [ ] Suppress JIT optimization on module load (Managed only). Я не знаю, что она делает, но звучит подозрительно.
Здравствуйте, Sharowarsheg, Вы писали:
S>...[ ] Suppress JIT optimization on module load (Managed only). Я не знаю, что она делает, но звучит подозрительно.
Делает именно то, что написано. А ещё есть переменная среды (с разбегу не нашёл, какая именно), которая позволяет запретить загружать нативные образы из GAC. Тоже помогает при дебаге, особенно таких вещей, как WPF.
Всё сказанное выше — личное мнение, если не указано обратное.
Здравствуйте, Sharowarsheg, Вы писали:
S>скажем, в MSVS 2022 есть галка в разделе Options -> Debugging, [ ] Suppress JIT optimization on module load (Managed only).
Оно и в VS 2005 есть.
S>Я не знаю, что она делает, но звучит подозрительно.
Оно тоже не имеет отношения к "запуску под отладчиком". С тем же успехом тому JIT'у можно как-то иначе передать инструкцию использовать этот режим.
Здравствуйте, Евгений Музыченко, Вы писали:
ЕМ>Оно тоже не имеет отношения к "запуску под отладчиком". С тем же успехом тому JIT'у можно как-то иначе передать инструкцию использовать этот режим.
Здравствуйте, Sharowarsheg, Вы писали:
S>эта штука выключает (какую-то) оптимизацию при запуске под отладчиком, а без отладчика — не выключает. S>Мне представляется, что это имеет отношение к запуску под отладчиком.
Когда процесс запускается из студии, он всегда будет "под отладчиком" (студийным).
А еще есть IsDebuggerPresent.
Ну и уж явно нет никакого смысла кодом, генерируемым хоть каким JIT, измерять время работы команды инкремента, верно?
Здравствуйте, Евгений Музыченко, Вы писали:
ЕМ>Когда процесс запускается из студии, он всегда будет "под отладчиком" (студийным).
В студии есть меню Debug -> Start without debugging.
Будет без отладчика. По крайней мере, без managed отладчика.
ЕМ>Ну и уж явно нет никакого смысла кодом, генерируемым хоть каким JIT, измерять время работы команды инкремента, верно?
Вообще особо нет смысла измерять время работы инкремента, но в целом, почему нет?
Здравствуйте, Евгений Музыченко, Вы писали:
S>>Для отладочный версии компилятор может генерировать не самый оптимальный код ЕМ>Запуск под отладчиком не имеет никакого отношения к генерации кода.
Сборки в dotnet имеют два осн. типа -- debug и release. Для первого типа компилятор не делает слишком много оптимизаций,
чтобы облегчить жизнь отладчику -- не инлайнит ф-ии, переменные, не удаляет недостижимый код и т.п.
Здравствуйте, Sharov, Вы писали:
S>Сборки в dotnet имеют два осн. типа -- debug и release. Для первого типа компилятор не делает слишком много оптимизаций, S>чтобы облегчить жизнь отладчику -- не инлайнит ф-ии, переменные, не удаляет недостижимый код и т.п.
Вероятно речь про jit-компилятор.
Но обсуждение началось с паскаля, компилятор которого генерит нативный код.
Здравствуйте, Sharov, Вы писали:
S>Сборки в dotnet имеют два осн. типа -- debug и release.
Спасибо, кэп. Только при чем здесь dotnet? Они в MS VS такие с незапамятных времен, когда dotnet еще в проекте не было.
S>Для первого типа компилятор не делает слишком много оптимизаций
Верно, только какое это имеет отношение к "запуску под отладчиком"?
Здравствуйте, Sharov, Вы писали:
S>>>Под отладчиком, если без лишний действий, будет запускаться отладочная версия ЕМ>>"Лишних" — это каких?
S>Как минимум перелючение типа сборки из debug в release.
Вставьте в программу операцию, заведомо вызывающую необрабатываемое исключение, переключите в Release, соберите и запустите. Кто обработает исключение?
Здравствуйте, Евгений Музыченко, Вы писали:
ЕМ>Верно, только какое это имеет отношение к "запуску под отладчиком"?
Для .NET есть разница в запуске релиза под отладчиком и без. При запуске релизной сборки (сам .NET "код" в релизе и дебаге одинаковый, для релиза просто соотв. флаг проставляется, так было в старом .NET) под отладчиком JIT генерит нативный код, отличный от того, если запустить сборку без оного. При желании посмотреть сгенерённый код без влияния отладчика использовалась техника запуска сборки (приложения) без отладчика, с дальнейшем аттачем к процессу.
Здравствуйте, pilgrim_, Вы писали:
_>Для .NET есть разница в запуске релиза под отладчиком и без. При запуске релизной сборки (сам .NET "код" в релизе и дебаге одинаковый, для релиза просто соотв. флаг проставляется, так было в старом .NET) под отладчиком JIT генерит нативный код, отличный от того, если запустить сборку без оного.
Значит, и нечего делать с помощью .NET чуждые ему вещи — в частности, измерение времени работы отдельных команд процессора.
S>>Сборки в dotnet имеют два осн. типа -- debug и release. Для первого типа компилятор не делает слишком много оптимизаций, S>>чтобы облегчить жизнь отладчику -- не инлайнит ф-ии, переменные, не удаляет недостижимый код и т.п. _>Вероятно речь про jit-компилятор.
Нет, я имел в виду как раз csc компилятор. Кстати, хороший вопрос, а знает ли jit про debug и release,
или ему это параллельно. Т.е. я знаю, что jit может методы инлайнить, но вот я не уверен, что он
может в тело методов лезть и что-то там делать\оптимизировать, это епархия csc. Но могу ошибаться.
К тому же я говорил, например, про мертвый код( размер сборки), который при release удаляется, а в debug отсается. Это точно
не про jit.
_>Но обсуждение началось с паскаля, компилятор которого генерит нативный код.
Спор зашел про дотнет, вроде Философ начал, а там и про отладочную версию программы.
Здравствуйте, Евгений Музыченко, Вы писали:
S>>Как минимум перелючение типа сборки из debug в release. ЕМ>Вставьте в программу операцию, заведомо вызывающую необрабатываемое исключение, переключите в Release, соберите и запустите. Кто обработает исключение?
Могу ошибаться, но зависит от. Может отладчик подрубиться (ОС предложит запустить), если студия установлена.
В противном случае будет просто окно с ошибкой.
A>Это, кстати, интересная тема. Надо бы замутить опрос по размеру выходных артефактов разрабатываемого ПО. У нас это мегабайты — десятки мегабайт. Меньше не получается, иначе полный функционал продукта невозможно реализовать.
Какой объём исходников ?
Ядро Линукс намного меньше занимает, но исходников там много!
Было бы интересно опрос провести на тему объем исходников и объём кода.