Вопрос Sinix: я верно понимаю, что проверки на то, что такое значение енума есть в списке значений, и соответствующего метода в Code после всех обсуждений так и не появилось?
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
Здравствуйте, AndrewVK, Вы писали:
AVK>Вопрос Sinix: я верно понимаю, что проверки на то, что такое значение енума есть в списке значений, и соответствующего метода в Code после всех обсуждений так и не появилось?
Неа.
Я слегка застрял с перфтестами. Сам код готов, всё работает, косяк
с вот этим — на appveyor не получается получить более-менее стабильные результаты. Проблема не в самих перфтестах, а в том, что замеры для кода под VM получаются с шикарным разбросом в +-20% (что самое обидное, на свежих ноутбуках то же самое). В итоге нужно каждый метод в перфтесте запускать сотню раз минимум, чтобы получить боль-менее точную статистику. Чуть позже закину вопрос в алгоритмы, как сам у себя в голове всё более-менее утрясу.
Если важно / срочно — могу переключиться на EnumHelper.
Здравствуйте, Sinix, Вы писали:
S>Я слегка застрял с перфтестами. Сам код готов, всё работает, косяк с вот этим — на appveyor не получается получить более-менее стабильные результаты. Проблема не в самих перфтестах, а в том, что замеры для кода под VM получаются с шикарным разбросом в +-20%
Ну значит надо чуть посильнее закопаться в статистику, она как раз для такого придумана. Мое имхо с поправкой на то, что я последний раз ее изучал 18 лет назад.
0) appveyor гоняет тесты на виртуальной машине, так что про стабильность скоростных параметров на коротких интервалах можно забыть.
1) Про количество самплов меньше 30 даже на выделенном CI-сервере можно сразу забывать. Если 30 прогонов слишком долго — значит надо уменьшать сами прогоны, но увеличивать количество замеров времени. Для нестабильных сред вроде av 30 слишком мало тоже. Подбирать надо эмпирически, но, думаю, стабильность начнется в интервале 100-1000 самплов.
2) Тем не менее, если посмотреть на твои графики, то отчетливо видно, что правильная информация глазом таки неплохо видна, так что опускать руки не стоит.
3) Теперь давай подумаем о природе сильных сбоев. Она очень проста — в какой то момент процессор сильно занят и кванты просто не выделаются. Происходит это случайно, и, судя по графикам, далеко не всегда, потому что главная последовательность имеет место быть.
4) Поэтому первое что нужно сделать — отбросить те семплы, которые явно некорректны. Мы, думаю, можем предположить, что, в идеале, сэмплы должны быть абсолютно одинаковыми. Поэтому можно смело отрезать выбросы больше
3 сигм, а может даже и поуже отрезать.
5) Что характерно — чем больше сэмплов, и чем короче сами сэмплы, тем меньше сэмплов будут бракованными из-за нестабильной среды. Но при уменьшении размера сэмпла растут накладные расходы, так что тут нужна золотая середина.
6) После этого можно уже посчитать медианное значение.
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>
Здравствуйте, AndrewVK, Вы писали:
AVK>Ну значит надо чуть посильнее закопаться в статистику, она как раз для такого придумана.
Ну да. я тут потихоньку копаюсь (копаюсь — т.к. временами утыкаюсь в "страдаю фигнёй вместо того, чтоб посмотреть, что на самом деле происходит").
Пока получается, что спрашивать на форуме нечего, т.к. к моменту, когда я формулирую вопрос, до меня доходит, что спрашиваю я полную фигню, не учёл какой-то момент и надо посмотреть на проблему по-другому.
В итоге я наконец понял, что я снова и снова наступал на те же грабли: если результаты мне казались "неправильными" я в первую очередь пытался поправить код бенчмарка, а не разобраться, что происходит на самом деле. Парадокс блин, когда работа по профилю, я обычно ровно наоборот делаю

В общем самый главный мой косяк в трёх вещах был.
1. Я собирал недостаточно семплов.
2. Я за каким-то фигом заложился на нормальное распределение для результатов замеров.
3. Я отчаянно протупил и не сообразил, что семплы нет смысла визуально сравнивать в том порядке, в котором они получены — оно полезно только чтоб быстро проверить выборку на предмет временных корелляций. А нас интересует распределение значений. Почему — см ниже.
В общем на сейчас получается так:
1. Простейшие тесты меряются абсолютно корректно. Ну, т.е. если оно пишет, что 95й перцентиль метода 10xSlower по факту занимает 8.48x..11.67x — оно на самом деле так, косяк в том, что распределения величин не совпадают. Т.е. в одном запуске "хвост" длиннее у первого метода, в другом — у другого. Т.е. не замеры фигня, а метрика, которая используется для сравнения бенчмарков.
2. В сложных случаях надо смотреть на распределения значений, по одним метрикам (медиана, дисперсия и тыды) ничего понять низзя.
Самый сложный и самый противный тест — CallCostPerfTests. Во-первых, он меряет буквально копейки — стоимость вызовов, т.е. это по сути предел того, что может быть нормально померяно.
Во-вторых, в тест впихнут 21 метод. Угу, снова запредельные требования по аккуратности измерений: выброс по времени для любого метода — приплыли, тест упал. Приходится делать лимиты по времени с запасом.
Да, в реальности я сразу сделал бы правильно — разбил бы тест на 4-5 разных по группам (обычные вызовы, виртуальные, интерфейсы, лямбды) — результаты были бы точнее.
Но поскольку цель — добиться нормальных результатов для самых извращённых случаев, лёгких путей мы не ищем

Ну и в итоге получается, что результаты я получил правильные — в смысле, все тайминги собраны точно, косяков нет. Проблема с интерпретацией результатов.
Я выше писал про "семплы нет смысла визуально сравнивать в том порядке, в котором они получены" — и вот эта ошибка меня остановила на пару вечеров, пока я медитировал на вот такую психоделику:
| | психоделика |
| | 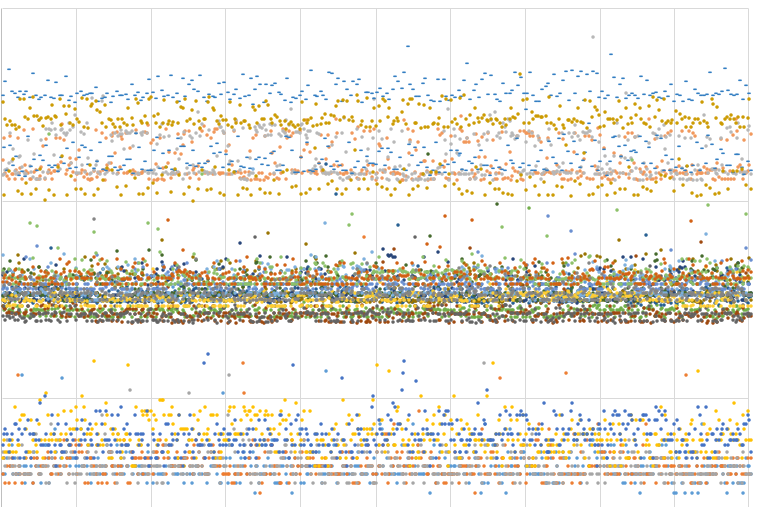 |
| | |
после того, как семплы отсортированы по длительности, получаем страшную и ужасную правду
| | страшная и ужасная правда |
| | 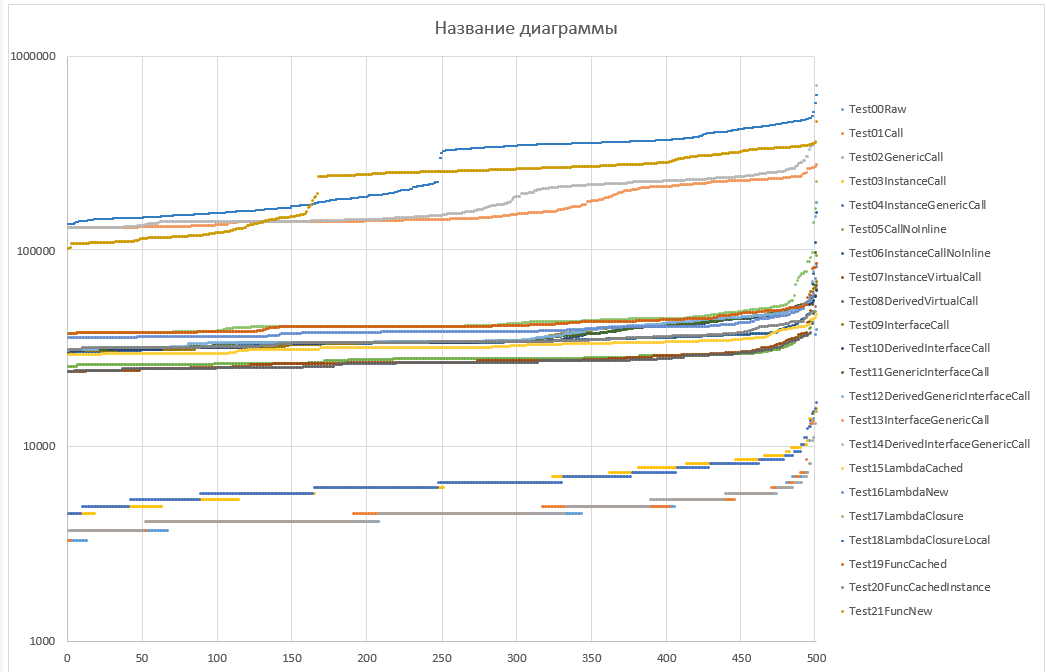
(y — время в наносекундах, шкала логарифмическая!!!) |
| | |
что мы с этого имеем:
1. Видна чёткая дискретность распределений для "простых" вызовов, точность таймеров — примерно 400 ns (что мягко говоря отстой). Т.е. если мы хотим, чтобы погрешность из-за таймеров была не такой пипец кошмарной, то нужно отойти от персентилей, т.к. они берут или конкретное значение, либо аппроксимацию между двумя соседними значениями. Доверительный интервал подойдёт, думаю.
Ну, или можно увеличить время для самого простого семпла с 4 микросекунд до чего-то типа 400 микросекунд. На самом деле это не вариант, т.к. время на весь тест вырастет соответственно.
2. Почти всегда значения распределены более-менее равномерно за исключением хвоста (последних 10%). Разница только в ширине распределения (наклоне линий)
3. Смотрим на распределения для верхней группы — это вызовы генерик-интерфейсов и создание лямбд. Угу, там есть явный "перегиб", т.е. моды для этих методов будут явно не совпадать с остальными. Отсюда простой вывод: среднее, медиана, среднеквадратичное отклонение и тыды и тыпы нам не скажут ничего, т.к. мы пытаемся сравнивать случайные величины с разными законами распределения.
4. Ну и итог всё тот же самый — намерено всё ок, но для оценки используется неправильная метрика. Нужно отдельно сравнивать нижний и верхний концы доверительного диапазона. CI 90 думаю подойдёт.
В общем фронт работ понятен, пошёл проверять идею.


