Здравствуйте, Klapaucius, Вы писали:
K>>>При этом в C++ нет нормальной реализации практически ни для одной фичи, изобретенной после 68-го года, да и изобретенные до 68-го не все есть. _>>Это в смысле в голом языке или с учётом библиотек? K>С учетом библиотек.
Если с учётом библиотек, то вы очевидно не правы))) Есть множество различных техник, которые добавляются библиотеками. Это же можно целый день перечислять всякие мелочи приятные. Но для примера (просто чтобы не звучало голословно) возьмём например ту же модель акторов.
_>>Нет, вы совсем не то поняли. Речь идёт об одном нюансе, связанном именно с иммутабельностью. Дело в том, что если мы возьмём мутабельный контейнер даже в языке без всяких спец. модификаторов и т.п. на эту тему и будем использовать на нём только не меняющее его подмножество операций, то у нас на самом деле получится полноценная работа с иммутабельными данными. K>1) Это не имеет отношения к обсуждаемому примеру, в котором используются не "не меняющее его подмножество операций", которого вообще у вашего "иммутабельного типа" нет, а мутирующие операции используются таким образом (линейно и уникально), что мутабельность структуры данных семантически не наблюдается.
Это имело отношение к первому примеру на D, когда использовался самый обычный массив, но при этом с модификатором immutable. Как раз с помощью него и ограничивается набор возможных операций (т.е. ~ разрешён, а =~ нет). Так что на мой взгляд тот пример работал с полноценными иммутабельным данными. Только он при этом естественно был очень медленным, т.к. никаких оптимизаций в связи с иммутабельностью не производилось.
K>2) Нет, если вы используете "не меняющее его подмножество операций", то это не является "полноценной работой с иммутабельными данными". Иммутабельность вообще не про это. Иммутабельность — это, например, когда вы можете рассчитывать, что всем остальным держателем ссылки на объект, с которым вы работаете не доступны мутирующие операции над ним и они не могут его "испортить", а значит вам не нужно оборонительно копировать (не поверхностно) обсуждаемый объект.
Да да, immutable в D как раз подобное гарантирует. Если конечно не прибегать к чёрной магии кастов. )))
K>Еще иммутабельность — это дешевое создание версии, этот конкретный аспект обычно называют "персистентность".
Угу, та самая оптимизация. И вот её модификатор immutable в D естественно не предоставляет. Но как я уже показал, мы без проблем можем добавить её сами.
K>Вы же сами такой контроль и преодолели, сделав структуру данных, свободную от какого-то там "контроля". Вообще отслеживание применения запрещенных операций есть в любом типизированном языке. То, что вы называете "проверкой" в Ди — это на самом деле инструмент для "выдавания" структуры, имеющей запрещенные операции за структуру не имеющую их. Т.е. это инструмент для обхода проверки, лупхол.
Просто есть два разных подхода к этому. Можно для каждого нюанса создавать отдельный тип данных (и соответственно заниматься копипастом части кода между ними), а можно создать один универсальный и управлять ситуацией с помощью внешних модификаторов. В C++ у нас есть всего один такой модификатор (const), а в D у нас есть ещё immutable и не только.
Re[124]: Есть ли вещи, которые вы прницпиально не понимаете...
Здравствуйте, alex_public, Вы писали:
_>Нет, дело как раз в Хаскеле. Потому как, раз он не поддерживает связь "симула-стайл", то должен предложить что-то взамен для тех же целей.
Ну вот об этом я и говорю. Ваши представления о хаскеле довольно смутные, так что использовать его для предоставления (контр)примеров в разговоре с вами затруднительно. Связь "симула-стайл" т.е. хранение вместе с данными ссылки на словарь "методов" хаскель поддерживает. С поправкой на различие между "наследованием" и "имплементацией". Поскольку разница между этими отношениями в UML поддерживается, никаких проблем и нет. Но это не важно, потому что не просматривается какой-то несовместимости UML и других способов группировки данных и функций, не симула-стайл, которые используются тоже и не только в хаскеле, но даже и каком-нибудь сишарпе, "протитипных"-ООЯ, языках с развитой системой модулей и т.д.
Потому повторяю вопросы:
1) Откуда следует, что "связь функций и данных" должна быть обязательно симула-стайл, а не какой-то другой?
2) В чем выражается эта заточенность под симула-стайл?
_>Вы в начале опишите с помощью чего на Хаскеле можно спроектировать нормальную иерархическую архитектуру
С помощью классов типов. Как второй вариант — с помощью "ручного управления" словарями "методов", т.е. "прототипного" подхода. Выглядеть на диаграмме это будет точно так же.
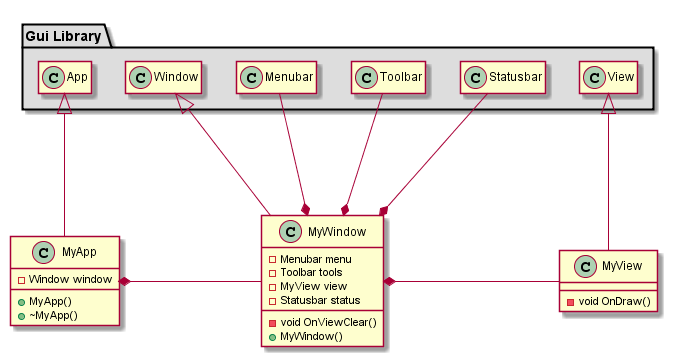
_>Вот например возьмём самую лубочную реализацию обычного ООП GUI приложения:
data MyView = MyView {
drawView :: UI () -- рисуем что-то в окне
}
instance View MyView where onDraw = drawView
-- и т.д.
_>Можно увидеть каноническую реализацию подобного кода на Хаскеле? Т.е. не использование из Хаскеля биндинга к какой-то известной ООП GUI библиотеки (т.к. там всё равно будет сохраняться подобная же структура, хотя и по кривому), а именно если взять GUI библиотеку написанную на Хаскеле с нуля в правильном функциональном стиле.
Ну так
1) С чего вдруг появляться какой-то GUI-библиотеке написанной на хаскеле "с нуля"? Естественно, все библиотеки и будут "биндингами известных библиотек".
2) Что вообще необычного вы ожидаете от изображения виджетов в хаскеле? Все интересное в GUI там в работе с событиями, ну может еще в лайауте виджетов.
_>Вот зачем выдавать какой-то конкретный баг/недоработку в реализации за архитектурную проблему? Это уже демагогия слишком низкого уровня...
Ну перепишите тот конвейер из трех стадий на D, который основную работу делает, и чтоб он оптимизировался. Тогда и посмотрим. А так вы предлагаете верить что все работает, но при этом 1) не демонстрируете рабочий пример. 2) утверждаете, что не пишете код с конвейерами.
_>Хех, ну я бы тоже такое предпочёл. Только вот в реальном мире нет ничего подобного.
Наработки вполне есть. Я же вам в этом споре неоднократно демонстрировал конвейеры, оптимизирующиеся в один цикл, но все это в очередной раз уже из вашей памяти выпало.
_>Например даже C++ со своим автовекторизатором не дотягивает по эффективности до специализированных (и соответственно более низкоуровневых) решений.
Вот только векторизировать цикл вообще-то более сложная задача, чем векторизировать комбинацию комбинаторов. Потому, что во втором случае у компилятора больше информации.
_>Да, но в некоторых языках (типа C++ или D) есть возможности очень сильно изменять язык прямо в коде (метапрограммирование, перегрузка операторов и т.п.). И соответственно в таких языках использование некоторых библиотек очень сильно меняет язык, вплоть до задания полноценных встроенных DSL.
Нет, метапрограммирование в масштабах C++ и уж тем более "перегрузка операторов" на "сильные изменения языка" никак не тянет.
K>>Это то как раз понятно, потому что ваша позиция заключается в том, что ничего сверх того, что есть в C++ (за исключением перламутровых пуговиц добавленных в D) в принципе не нужно. И собственно наличие в c++ и является критерием нужности.
_>Как раз нет. У меня вообще огромный список претензий к C++. В первую очередь это конечно отсутствие статической интроспекции — это просто дико бросается в глаза. Потом переусложнённый и одновременно недостаточно функциональный (в первую очередь нельзя строки передавать как параметры) синтаксис шаблонов (при использование их для метапрограммирования, а не для обобщённого). Далее отсутствие удобной системы модулей и т.д. и т.п.
Я же написал про перламутровые пуговицы.
_>В общем я могу долго продолжать о недостатках C++. Только вот при всём при этом к сожалению ничего лучше по сумме параметров (включающих и наличие библиотек/инструметов и стабильность/оптимизированность) всё равно на рынке не наблюдается.
Да, имплементации у С++ лучшие на рынке, и вообще богатая инфраструктура в смысле библиотек/инструментов но язык ничего интересного из себя не представляет, крайне убогий и невыразительный.
_>Но вот относительно конкретно сборщика мусора у меня именно идеологическая позиция, что при наличие полноценного RAII он является только вредным элементом.
Это, конечно, вредный элемент в низкоуровневом языке. Но в высокоуровневом зато необходимый.
_>- в принципе ленивость вещь полезная, но не глобально, а в специфических случаях
Тут вообще вопрос не в "глобально", в смысле по-умолчанию или нет. А в поддержке со стороны рантайма, в том числе для SMP и т.д. По-умолчанию ленивость или аннотируется явно, но она должна быстро работать — иначе в ней особого смысла нет. Так вот быстро работающую поддержку ленивости в библиотеке не сделать. по крайней мере, я такой не видел.
_>- все встреченные мною случаи, когда была бы полезна ленивость, покрывались библиотеками из Boost'а.
Учитывая, что с вашей точки зрения (попробую угадать) она полезна примерно никогда — перекрыть пустое множество юзкейсов даже в плюсах не сложно.
_>Всё равно не понял. Ну т.е. если вы говорите о том, что бы заменить код вида "Filter(data);Map(data);Fold(data);" на "data.Filter().Map().Fold();", то это действительно без проблем делается. Только вот какой-либо пользы от подобного нет. А если вы про что-то другое, то тогда поясните подробнее.
Нет, интереснее что-то менее тривиальное. А чтоб мне объяснить подробнее вы сами должны объяснить подробнее, что делаете для этой самой "генерации simd инструкций из спецязыка", и что это за спецязык.
_>Если точно такое же, то тогда никаких противопоставлений. ) Просто вы ни разу не озвучивали тут свои основные инструменты для работы, так что создаётся впечатление, что вы позиционируете Хаскель на эту роль.
Не понятно только, какое это отношение имеет к любой из обсуждаемых нами тем.
'You may call it "nonsense" if you like, but I'VE heard nonsense, compared with which that would be as sensible as a dictionary!' (c) Lewis Carroll
Re[126]: Есть ли вещи, которые вы прницпиально не понимаете...
Здравствуйте, alex_public, Вы писали:
_>Если с учётом библиотек, то вы очевидно не правы))) Есть множество различных техник, которые добавляются библиотеками. Это же можно целый день перечислять всякие мелочи приятные. Но для примера (просто чтобы не звучало голословно) возьмём например ту же модель акторов.
Ну, удивите меня примером. какую-то костыльную модель акторов можно, конечно, в библиотеке сделать. Но это будет такая же недоделанная фича без поддержки языка, как и то, что я перечислял.
_>Это имело отношение к первому примеру на D, когда использовался самый обычный массив, но при этом с модификатором immutable. Как раз с помощью него и ограничивается набор возможных операций (т.е. ~ разрешён, а =~ нет). Так что на мой взгляд тот пример работал с полноценными иммутабельным данными. Только он при этом естественно был очень медленным, т.к. никаких оптимизаций в связи с иммутабельностью не производилось.
И про это вы говорили "получится полноценная работа с иммутабельными данными"? Если это полноценная работа — что же тогда неполноценная?
K>>Еще иммутабельность — это дешевое создание версии, этот конкретный аспект обычно называют "персистентность".
_>Угу, та самая оптимизация.
Это не столько оптимизация, сколько другие структуры данных, лучше подходящие для дешевого создания версий.
_>Но как я уже показал, мы без проблем можем добавить её сами.
Вы этого не показали. Где вы какую-то оптимизацию добавили?
_>Просто есть два разных подхода к этому. Можно для каждого нюанса создавать отдельный тип данных (и соответственно заниматься копипастом части кода между ними), а можно создать один универсальный и управлять ситуацией с помощью внешних модификаторов. В C++ у нас есть всего один такой модификатор (const), а в D у нас есть ещё immutable и не только.
Ну так я и сказал. В языках без какого-нибудь метапрограммирования отличие в ручном написании обертки. там где обертку можно автоматически генерировать — вообще никакой разницы не будет.
'You may call it "nonsense" if you like, but I'VE heard nonsense, compared with which that would be as sensible as a dictionary!' (c) Lewis Carroll
Re[125]: Есть ли вещи, которые вы прницпиально не понимаете...
Здравствуйте, Klapaucius, Вы писали:
K>Ну вот об этом я и говорю. Ваши представления о хаскеле довольно смутные, так что использовать его для предоставления (контр)примеров в разговоре с вами затруднительно. Связь "симула-стайл" т.е. хранение вместе с данными ссылки на словарь "методов" хаскель поддерживает. С поправкой на различие между "наследованием" и "имплементацией". Поскольку разница между этими отношениями в UML поддерживается, никаких проблем и нет. Но это не важно, потому что не просматривается какой-то несовместимости UML и других способов группировки данных и функций, не симула-стайл, которые используются тоже и не только в хаскеле, но даже и каком-нибудь сишарпе, "протитипных"-ООЯ, языках с развитой системой модулей и т.д.
Нет, недостаточное знание Хаскеля может помешать аргументировать что-то его кодом мне, но никак не вам. Не стоит путать возможность читать код и возможность писать классный код на каком-то языке.
K>Потому повторяю вопросы: K>1) Откуда следует, что "связь функций и данных" должна быть обязательно симула-стайл, а не какой-то другой? K>2) В чем выражается эта заточенность под симула-стайл?
Я уже не раз отвечал на это в общем виде, но как обычно у нас с вами это ни к чему продуктивному не привело и разговор пошёл по кругу. Поэтому я и предлагаю перейти к конкретике — на ней демагогия и т.п. не работают. ))) Вот я привёл максимально короткий и банальный пример. Если надо, могу даже диаграммку под него нарисовать, хотя думаю каждый может с ходу представить её в голове. И ожидаю от вас в ответ того же. После этого можем продолжать какую-то конструктивную дискуссию уже на основе этих конкретных данных.
_>>Вы в начале опишите с помощью чего на Хаскеле можно спроектировать нормальную иерархическую архитектуру K>С помощью классов типов. Как второй вариант — с помощью "ручного управления" словарями "методов", т.е. "прототипного" подхода. Выглядеть на диаграмме это будет точно так же.
Это всё общие слова, а интересует конкретика.
_>>Вот например возьмём самую лубочную реализацию обычного ООП GUI приложения:
K>
K>data MyView = MyView {
K> drawView :: UI () -- рисуем что-то в окне
K>}
K>instance View MyView where onDraw = drawView
K>-- и т.д.
K>
И? Где собственно код примера на Хаскеле и его UML диаграмма? Я пока вижу только пример сомнительной реализации аналога виртуальных функций. А где всё остальное? ) У меня же было то всего 3 класса из нескольких строчек — это разве долго показать, если нет никаких проблем?
K>Ну так K>1) С чего вдруг появляться какой-то GUI-библиотеке написанной на хаскеле "с нуля"? Естественно, все библиотеки и будут "биндингами известных библиотек".
Ну если для обычных императивных языков действительно мало смысла повторять уже существующий (хотя и на другом языке) код, то для Хаскеля и ему подобных возможно в этом был бы смысл, т.к. в связи с иной архитектурой это возможно не был бы чистый повтор. Или же вы считаете, что и тут понадобилось бы подделываться под ООП? )
K>2) Что вообще необычного вы ожидаете от изображения виджетов в хаскеле? Все интересное в GUI там в работе с событиями, ну может еще в лайауте виджетов.
Ну для начала композиция... А потом обработка событий была и в моём примере. Выполненная как раз по обычной ООП технике (внутри конструктора Window идёт код вида menuitem1.connect(Window::OnFileNew); и т.п.). Т.е. у вас была возможность кратенько показать, как вы говорите интересное, но что-то вы пропустили эту возможность.
K>Ну перепишите тот конвейер из трех стадий на D, который основную работу делает, и чтоб он оптимизировался. Тогда и посмотрим. А так вы предлагаете верить что все работает, но при этом 1) не демонстрируете рабочий пример. 2) утверждаете, что не пишете код с конвейерами.
Рабочий пример тут уже был. С теми же самыми map'и — там этот принцип работы влиял уже даже не на быстродействия, а на результат кода, так что мы очень чётко это тут отследили. Более того, с until.all тоже пример работал, но наблюдалось падение быстродействия по сравнению с линейным кодом. В чём причина этого падения я не в курсе и разбираться лень, т.к. такой код у меня только на форуме и встречался.
_>>Хех, ну я бы тоже такое предпочёл. Только вот в реальном мире нет ничего подобного. K>Наработки вполне есть. Я же вам в этом споре неоднократно демонстрировал конвейеры, оптимизирующиеся в один цикл, но все это в очередной раз уже из вашей памяти выпало.
Вообще то здесь речь шла об автовекторизации. )
K>Вот только векторизировать цикл вообще-то более сложная задача, чем векторизировать комбинацию комбинаторов. Потому, что во втором случае у компилятора больше информации.
Если мы говорим про SIMD, то вряд ли. Там же ещё специфическая векторизация...
K>Нет, метапрограммирование в масштабах C++ и уж тем более "перегрузка операторов" на "сильные изменения языка" никак не тянет.
Это не изменения языка, а инструменты для изменения. В основном путём построения встроенных DSL.
K>Да, имплементации у С++ лучшие на рынке, и вообще богатая инфраструктура в смысле библиотек/инструментов но язык ничего интересного из себя не представляет, крайне убогий и невыразительный.
Я бы такое сказал про C... А вот у C++ имеется целый ряд оригинальных решений. Как насчёт той же move semantic? ) Я уже не говорю про метапрограммирование на шаблонах. )
K>Тут вообще вопрос не в "глобально", в смысле по-умолчанию или нет. А в поддержке со стороны рантайма, в том числе для SMP и т.д. По-умолчанию ленивость или аннотируется явно, но она должна быстро работать — иначе в ней особого смысла нет. Так вот быстро работающую поддержку ленивости в библиотеке не сделать. по крайней мере, я такой не видел.
Хы, вот как раз в обычных реализация C++ ленивость идеально быстрая))) У неё другое ограничение — она скажем так работает только на подмножестве языка.
K>Учитывая, что с вашей точки зрения (попробую угадать) она полезна примерно никогда — перекрыть пустое множество юзкейсов даже в плюсах не сложно.
На самом деле после выхода C++11 практически перестал использовать. Потому как стало проще банально поставить лямбду (такая вот ленивость руками). Конечно это казалось бы лишний шаг, но зато поддерживает любой код и не надо лезть в документацию библиотеки элементов ленивости по каждому чиху. Более того, в итоге код становится понятен всем (лямбды уже все изучили, а вот всякие сложные библиотеки из Boost знают далеко не все).
K>Нет, интереснее что-то менее тривиальное. А чтоб мне объяснить подробнее вы сами должны объяснить подробнее, что делаете для этой самой "генерации simd инструкций из спецязыка", и что это за спецязык.
Эммм, запускаю компилятор этого языка и всё. И потом просто добавляю полученные объектные файлы к построению приложения на C++. А язык собственно такой: https://ispc.github.io/ispc.html#the-ispc-language.
K>Не понятно только, какое это отношение имеет к любой из обсуждаемых нами тем.
Это поясняет общую позицию человека. ) Ну скажем фанатик (готов всё делать на любимом языке из принципа), теоретик (превозносит некий язык из общих соображений, но никогда не делал ничего серьёзного), профи (знает и использует оптимальные инструменты на текущий момент и интересуется остальными для общего развития), неудачливый (вынужден использовать на работе ужасные инструменты и отрывается дома со всяческими игрушками), новичок и т.п.
Re[127]: Есть ли вещи, которые вы прницпиально не понимаете...
Здравствуйте, Klapaucius, Вы писали:
K>Ну, удивите меня примером. какую-то костыльную модель акторов можно, конечно, в библиотеке сделать. Но это будет такая же недоделанная фича без поддержки языка, как и то, что я перечислял.
Т.е. вы считаете, что для реализации модели акторов необходима обязательно поддержка в синтаксисе языка? ) Очень забавная точка зрения. А я тут даже в Прологе видел реализацию потоков в таком стиле... )))
K>И про это вы говорили "получится полноценная работа с иммутабельными данными"? Если это полноценная работа — что же тогда неполноценная?
Полноценная в том смысле, что данные были реально иммутабельные. Хотя при этом мы не использовали никаких отдельных специальных типов. Если добавить ещё и оптимизацию, то вообще всё отлично было бы. )
K>Это не столько оптимизация, сколько другие структуры данных, лучше подходящие для дешевого создания версий.
Я про это и говорю.
K>Вы этого не показали. Где вы какую-то оптимизацию добавили?
Так последний мой пример был как раз с оптимизацией — там была реализована персистентная структура с версиями массива.
K>Ну так я и сказал. В языках без какого-нибудь метапрограммирования отличие в ручном написании обертки. там где обертку можно автоматически генерировать — вообще никакой разницы не будет.
А собственно в каких популярных языках у нас наблюдается эффективное метапрограммирование? )
Re[126]: Есть ли вещи, которые вы прницпиально не понимаете...
Здравствуйте, alex_public, Вы писали:
_>Нет, недостаточное знание Хаскеля может помешать аргументировать что-то его кодом мне, но никак не вам. Не стоит путать возможность читать код и возможность писать классный код на каком-то языке.
Причем тут писать/читать код? Вы приводите, например, такой аргумент
Нет, дело как раз в Хаскеле. Потому как, раз он не поддерживает связь "симула-стайл", то должен предложить что-то взамен для тех же целей.
хотя на самом деле хаскель симула-стайл связь с хранением в "объекте" ссылки на словарь поддерживает с помощью тайпклассов и экзистенциальных типов.
Разница с симула-лайк ООП будет в том, что там, где не нужна дин. диспетчеризация таскать ссылку на словарь не нужно: словарь подставит компилятор. Но на диаграмме это никак не отразится.
Потому я и говорю, что для аргументации вам лучше переключится на язык, который вы знаете, каких-то совершенно диких представлений о хаскеле вы уже достаточно приводили, но аргументацию на фантазиях не построить.
Возможно, можно построить аргументацию за недостаточность средств UML для отображения сложных иерархий классов/инстансов, но то, что средства UML окажутся невостребованными — это полная ерунда.
Потому повторяю вопросы:
1) Откуда следует, что "связь функций и данных" должна быть обязательно симула-стайл, а не какой-то другой?
Вообще, то, что функция задана на множестве объектов какого-то типа — вполне достаточно для того, чтоб были польза и смысл обозначить связь такой функйии и такого тоипа на диаграмме. Техническая же реализация этой связи и ее "виртуальность" (не знаю точно, что вы в этом случае подразумеваете) никакого принципиального архитектурного значения не имеет.
2) В чем выражается эта заточенность под симула-стайл?
Тут, думаю, никаких особых пояснений не требуется, диаграммы используют для совсем не симула-стайл языков. Естественно, для применения UML для очередного языка нужно установить/согласовать некоторые смыслы и интерпретации, отличающиеся от другого языка, но никаких необходимых расширений UML вы так и не показали.
_>Я уже не раз отвечал на это в общем виде, но как обычно у нас с вами это ни к чему продуктивному не привело и разговор пошёл по кругу.
Вы постоянно заявляете, что на что-то ответили. Вот только сослаться на ответ не можете. Вот и сейчас не сошлетесь.
_>Поэтому я и предлагаю перейти к конкретике — на ней демагогия и т.п. не работают.
Конечно не работает, потому-то вы к конкретике и не перейдете.
_>Вот я привёл максимально короткий и банальный пример. Если надо, могу даже диаграммку под него нарисовать, хотя думаю каждый может с ходу представить её в голове. И ожидаю от вас в ответ того же. После этого можем продолжать какую-то конструктивную дискуссию уже на основе этих конкретных данных.
Пример все равно не рабочий, так какой смысл воспроизводить больше, чем нужно для того, чтоб понять как это воспроизвести полностью?
K>>С помощью классов типов. Как второй вариант — с помощью "ручного управления" словарями "методов", т.е. "прототипного" подхода. Выглядеть на диаграмме это будет точно так же.
_>Это всё общие слова, а интересует конкретика.
Чем приведенный мной код не конкретика?
_>И? Где собственно код примера на Хаскеле и его UML диаграмма? Я пока вижу только пример сомнительной реализации аналога виртуальных функций. А где всё остальное? )
А чего вам еще не хватает?
_>У меня же было то всего 3 класса из нескольких строчек — это разве долго показать, если нет никаких проблем?
Это переписывается чисто механически. И что потом?
_>Ну если для обычных императивных языков действительно мало смысла повторять уже существующий (хотя и на другом языке) код, то для Хаскеля и ему подобных возможно в этом был бы смысл, т.к. в связи с иной архитектурой это возможно не был бы чистый повтор. Или же вы считаете, что и тут понадобилось бы подделываться под ООП? )
Даже если что-то, допустим, имеет смысл — это вовсе не означает, что это сделают. Думаю, что человекогоды, вложенные в любой из популярных GUI-тулкитов, вроде QT превышают человекогоды вложенные во всю инфраструктуру хаскеля, причем в разы. Т.е. при самых оптимистичных оценках увеличения производительности программиста на хаскеле, по сравнению с программистом на языке, на котором эта самая GUI библиотека реализована — воспроизведение полноценной гуи-библиотеки на хаскеле — совершенно нереальный проект для комьюнити.
_>Ну для начала композиция... А потом обработка событий была и в моём примере. Выполненная как раз по обычной ООП технике (внутри конструктора Window идёт код вида menuitem1.connect(Window::OnFileNew); и т.п.). Т.е. у вас была возможность кратенько показать, как вы говорите интересное, но что-то вы пропустили эту возможность.
И то и другое более высокоуровневые конструкции, низкоуровневое представление тут особого значения не имеет. FRP для обработки событий, например, применяется в сочетании с биндингами для популярных гуи-тулкитов. И я вам это уже показывал в примере с игрой "астероиды" выше в этой ветке (уже, наверное, больше полугода назад).
_>Рабочий пример тут уже был. С теми же самыми map'и — там этот принцип работы влиял уже даже не на быстродействия, а на результат кода, так что мы очень чётко это тут отследили. Более того, с until.all тоже пример работал, но наблюдалось падение быстродействия по сравнению с линейным кодом.
Рабочий не в том смысле, что что-то считает. А рабочий пример оптимизации. Код, который считает что нужно и для которого оптимизация работает.
_>В чём причина этого падения я не в курсе и разбираться лень, т.к. такой код у меня только на форуме и встречался.
Ну тут видимо дело в специфической субкультуре программирования, потому что убогость чего-то, обычно, превращает это в фичу "только для форумов", но вот только в какой-нибудь linq to objects используется не только на форумах, хотя судя по всему, он работает даже хуже дишных рейнджей.
K>>Наработки вполне есть. Я же вам в этом споре неоднократно демонстрировал конвейеры, оптимизирующиеся в один цикл, но все это в очередной раз уже из вашей памяти выпало. _>Вообще то здесь речь шла об автовекторизации. )
По автовекторизации тоже работы есть.
K>>Вот только векторизировать цикл вообще-то более сложная задача, чем векторизировать комбинацию комбинаторов. Потому, что во втором случае у компилятора больше информации.
_>Если мы говорим про SIMD, то вряд ли. Там же ещё специфическая векторизация...
Так какая разница? В комбинации комбинаторов более явно обозначен замысел программиста, легче интерпретировать что этот код делает.
K>>Нет, метапрограммирование в масштабах C++ и уж тем более "перегрузка операторов" на "сильные изменения языка" никак не тянет. _>Это не изменения языка, а инструменты для изменения. В основном путём построения встроенных DSL.
ОК, это инструменты, которыми "сильные изменения языка" не осуществить.
Втроенный DSL — это не изменение языка. Это "использование библиотеки". Вообще, весь смысл "встроенности" DSL в том и заключается, что язык остается тем же самым.
_>Я бы такое сказал про C... А вот у C++ имеется целый ряд оригинальных решений. Как насчёт той же move semantic? )
В C++ есть интересные решения, но к высокоуровневости и выразительности они никакого отношения не имеют.
_>Я уже не говорю про метапрограммирование на шаблонах. )
Практически все, что называют "метапрограммированием" в других языках, лучше, чем "метапрограммирование на шаблонах".
_>Хы, вот как раз в обычных реализация C++ ленивость идеально быстрая)))
Правда что-ли? А подтверждения для этого заявления какие-нибудь есть?
_>У неё другое ограничение — она скажем так работает только на подмножестве языка.
Не понятно, что это значит.
_>На самом деле после выхода C++11 практически перестал использовать. Потому как стало проще банально поставить лямбду (такая вот ленивость руками).
Это вообще не ленивость, даже если считать, что лямбда настоящая, а не плюсовая, которая лямбдой не является.
Причем "не ленивость" в данном случае означает не "испорченная" ленивость, как в случае "лямбдой не является". В данном случае это как в "ворон не конторка".
_>Эммм, запускаю компилятор этого языка и всё. И потом просто добавляю полученные объектные файлы к построению приложения на C++. А язык собственно такой: https://ispc.github.io/ispc.html#the-ispc-language.
Понятно, что вы запускаете компилятор этого языка. Вопрос был о том EDSL, который вы в этот язык транслируете.
K>>Не понятно только, какое это отношение имеет к любой из обсуждаемых нами тем. _>Это поясняет общую позицию человека. ) Ну скажем фанатик (готов всё делать на любимом языке из принципа), теоретик (превозносит некий язык из общих соображений, но никогда не делал ничего серьёзного), профи (знает и использует оптимальные инструменты на текущий момент и интересуется остальными для общего развития), неудачливый (вынужден использовать на работе ужасные инструменты и отрывается дома со всяческими игрушками), новичок и т.п.
Ну вот мы обсуждаем поддержку иммутабельности в D. Т.е. для начала мы проясняем не мою позицию. Далее, поддержка иммутабельности в D никак не зависит от того, к какому из перечисленных типажей мы с вами относимся. Такая классификация пригодится только в том случае, если кто-то захочет навешать лапши на уши, представить оппонента неадекватным, свести разговор с рельс. Вот тут подход понадобится разный для каждого типажа. Но для предметного разговора это все не нужно, нужно вам реализовать пример, который демонстрирует эту самую заявленную поддержку. Все.
Собственно, я это сделал, так что понятно, что я подразумеваю под поддержкой иммутабельности.
Что подразумеваете вы — я тоже понял: инструментарий для легковесного оборачивания мутабельных данных в "иммутабельные" интерфейсы, с возможностью извлечения из "обертки" без копирования, т.е. инвалидируя все ссылки на эту структуру данных, как на "иммутабельную". Какая-то польза в этом может и есть, но, в основном, она в том будет заключатся, что программистам жизнь медом не покажется (хотя, она наверняка уже им медом не кажется, еще до столкновения с такими чумовыми фичами).
'You may call it "nonsense" if you like, but I'VE heard nonsense, compared with which that would be as sensible as a dictionary!' (c) Lewis Carroll
Re[128]: Есть ли вещи, которые вы прницпиально не понимаете...
Здравствуйте, alex_public, Вы писали:
_>Т.е. вы считаете, что для реализации модели акторов необходима обязательно поддержка в синтаксисе языка? ) Очень забавная точка зрения.
В первую очередь, конечно, поддержка рантайма, вроде сегментированного стеков в куче и т.д. Но примером вы меня, как я понял, решили не удивлять.
_>А я тут даже в Прологе видел реализацию потоков в таком стиле... )))
В Прологе, это, конечно, нормально. Там все примерно одинаково недоделанное.
_>Полноценная в том смысле, что данные были реально иммутабельные.
На самом деле — нет.
K>>Это не столько оптимизация, сколько другие структуры данных, лучше подходящие для дешевого создания версий. _>Я про это и говорю.
Вы говорили "оптимизации".
_>Так последний мой пример был как раз с оптимизацией — там была реализована персистентная структура с версиями массива.
Не понимаю, на что вы рассчитываете, когда снова повторяете эту ерунду. Очень просто показать, что никакой персистентной структуры вы не реализовали, что я и сделал тут: http://rsdn.ru/forum/philosophy/5714706.1
Никакой оптимизации там тем более нет.
K>>Ну так я и сказал. В языках без какого-нибудь метапрограммирования отличие в ручном написании обертки. там где обертку можно автоматически генерировать — вообще никакой разницы не будет. _>А собственно в каких популярных языках у нас наблюдается эффективное метапрограммирование? )
А в каких популярных языках у нас наблюдается "поддержка иммутабельности" а-ля D?
Но это вообще не такая важная деталь. Вручную обертку написать можно в любом языке (хотя польза от этого всего вообще сомнительная). А вот реально полезную поддержку для иммутабельности, вроде более-менее хорошего GC, так просто в любой язык не добавишь.
'You may call it "nonsense" if you like, but I'VE heard nonsense, compared with which that would be as sensible as a dictionary!' (c) Lewis Carroll
Re[122]: Есть ли вещи, которые вы прницпиально не понимаете...
Здравствуйте, alex_public, Вы писали:
I>>И давно nginx на erlang переписали ?
_>Nginx там только для оценочного сравнения, т.к. вообще не относится к группе исследуемых фреймворков (они же все для динамики). Т.е. фреймворка на C/C++ в данном тесте вообще не было. А первое место занял именно ерланговский фреймворк, что абсолютно не удивительно с учётом пристрастий автора теста.
Покажи ошибку в его подходе
_>В большинстве таких фреймворков сервер интегрирован во фреймворк, а не живёт где-то отдельно. )
Общие слова, ни о чем.
Re[156]: Есть ли вещи, которые вы прницпиально не понимаете...
Здравствуйте, alex_public, Вы писали:
I>>Ты можешь внятно ответить на вопрос — каким чудом один и тот же файл можно отдавать через свой сервер, но так, что бы запрос не доходил до сервера ?
_>Я тебе уже несколько раз говорил, но до тебя похоже даже прямой текст перестал доходить. Сервер отработает один раз (отдавая в CDN).
То есть, ты предлагаешь захардкодить кучу темплейтов для того, что бы отдать ровно один респонс ? Чтото я не пойму такую концепцию
_>Хотя если у нас вообще только статика на сервере, то естественно никакие фреймворки типа vibe.d вообще не нужны, т.к. привносят только ненужную сложность. Но дело именно в сложности и неудобности (в сравнение со статическим сервером), а не в меньшем быстродействие, которое мы тут обсуждали.
Не только ненужную сложность, но и потерю производительности. Пока твой код получит управление, внятный вебсервер уже успеет отдать статику.
Единственная вещь, где у тебя будет профит, это меньшие затраты дискового пространства.
Re[126]: Есть ли вещи, которые вы прницпиально не понимаете...
Здравствуйте, alex_public, Вы писали:
_>Если с учётом библиотек, то вы очевидно не правы))) Есть множество различных техник, которые добавляются библиотеками. Это же можно целый день перечислять всякие мелочи приятные. Но для примера (просто чтобы не звучало голословно) возьмём например ту же модель акторов.
Поделись, как на этих самых библиотеках получить внятную изоляцию, что бы не дай бог не проткнуть каким нибудь левым указателем. Или бесконечную рекурсию сорганизовать. Вобщем, назови эту чудо-библиотеку, шоб без изменения языка да все фичи для акторов были реализованы.
Re[127]: Есть ли вещи, которые вы прницпиально не понимаете...
Здравствуйте, Klapaucius, Вы писали:
K>Причем тут писать/читать код? Вы приводите, например, такой аргумент
Нет, дело как раз в Хаскеле. Потому как, раз он не поддерживает связь "симула-стайл", то должен предложить что-то взамен для тех же целей.
хотя на самом деле хаскель симула-стайл связь с хранением в "объекте" ссылки на словарь поддерживает с помощью тайпклассов и экзистенциальных типов.
Ну так тогда в чём проблема это продемонстрировать? )
K>Потому я и говорю, что для аргументации вам лучше переключится на язык, который вы знаете, каких-то совершенно диких представлений о хаскеле вы уже достаточно приводили, но аргументацию на фантазиях не построить.
Ещё раз повторяю: мне аргументировать на Хаскеле ничего и не надо. И соответственно я этого и не делаю. Это вам требуется продемонстрировать код на нём (плюс UML диаграммка), чтобы подтвердить свою точку зрения. А уж с прочтением его я как-нибудь постараюсь справиться. )))
K>Возможно, можно построить аргументацию за недостаточность средств UML для отображения сложных иерархий классов/инстансов, но то, что средства UML окажутся невостребованными — это полная ерунда.
Вы похоже вообще из какой-то другой реальности или просто никогда не проектировали серьёзные вещи. Да не принципиальны все эти отображения (инструментами типа автогенерации кода мало кто пользуется). Принципиальной является возможность для лёгкого построения сложной иерархической архитектуры. В первую очередь в исходниках — для этого служит грубо говоря ООП (как один из вариантов). И как вспомогательный инструмент — визуализация с помощью UML, который частично (как минимум диаграммы классов/объектов) заточен под ООП. Соответственно в случае Хаскеля (и других языков без ООП) возникает вопрос об аналогичных инструментах. Причём если говорить про код, то там ещё могут быть варианты, а вот с их визуализаций похоже всё совсем печально. И ровно 0 примеров от вас только укрепляют такое впечатление.
K>Вообще, то, что функция задана на множестве объектов какого-то типа — вполне достаточно для того, чтоб были польза и смысл обозначить связь такой функйии и такого тоипа на диаграмме. Техническая же реализация этой связи и ее "виртуальность" (не знаю точно, что вы в этом случае подразумеваете) никакого принципиального архитектурного значения не имеет.
Подразумевается рисовать типы данных значками классов и отображать в них все функции, которые принимают в качестве параметра этот тип? ) Ну даже если забыть про ситуацию с функциями многих параметров, то в обычно в ООП функции принадлежащие классу и не принадлежащие классу, видят его очень по разному... И именно в этом заключается основной смысл, а не просто в принятие скрытого параметра определённого типа.
Кстати, а для отображения связи типа вышеописанной в UML есть отдельный вид стрелочек... ) Правда они связывают не функцию (т.к. тут их не бывает по отдельности) с типами её параметров, а класс, содержащий эту функцию.
K>Тут, думаю, никаких особых пояснений не требуется, диаграммы используют для совсем не симула-стайл языков. Естественно, для применения UML для очередного языка нужно установить/согласовать некоторые смыслы и интерпретации, отличающиеся от другого языка, но никаких необходимых расширений UML вы так и не показали.
В начале надо определиться о каких конкретно диаграммах UML идёт речь. Там их большой набор и подходят они разным языкам по разному. Но здесь мы кажется говорили о диаграмме классов (как о главной структурной, позволяющей подробно задавать архитектуру приложения). Так вот, если говорить об этой диаграмме, то её применение для не ООП языков очень сомнительно. Eсли конечно не считать случая, когда мы реально задаём "ручное" ООП в программе (как иногда делают на C), но тогда это скорее означает, что мы не верно выбрали себе язык под задачу.
_>>Поэтому я и предлагаю перейти к конкретике — на ней демагогия и т.п. не работают. K>Конечно не работает, потому-то вы к конкретике и не перейдете.
Я что-то не понял, кто из нас прислал пример кода и спрашивает его аналог на Хаскеле, а получает в ответ пространные рассуждения? )
Ну на всякий случай пришлю ещё диаграммку для того примера:
По такой картинке сразу становится очевидна вся архитектура приложения.
И я по прежнему жду аналог того моего кода на Хаскеле и UML диаграмму к нему.
K>Пример все равно не рабочий, так какой смысл воспроизводить больше, чем нужно для того, чтоб понять как это воспроизвести полностью?
Что бы можно было сравнить с аналогом на C++. Пока что сравнивать нечего.
K>Чем приведенный мной код не конкретика?
Потому как он не соответствует моему коду, т.е. является каким то абстрактным примером неизвестно чего.
K>А чего вам еще не хватает?
Кода на хаскеле и диаграммы.
K>Это переписывается чисто механически. И что потом?
Потом у вас появится хоть какой-то аргумент в подтверждение ваших тезисов. Если сможете продемонстрировать требуемое. А если нет, то это будет аргументом к моим тезисам. )
K>Даже если что-то, допустим, имеет смысл — это вовсе не означает, что это сделают. Думаю, что человекогоды, вложенные в любой из популярных GUI-тулкитов, вроде QT превышают человекогоды вложенные во всю инфраструктуру хаскеля, причем в разы. Т.е. при самых оптимистичных оценках увеличения производительности программиста на хаскеле, по сравнению с программистом на языке, на котором эта самая GUI библиотека реализована — воспроизведение полноценной гуи-библиотеки на хаскеле — совершенно нереальный проект для комьюнити.
А зачем обязательно сразу Qt повторять? ) Это же собственно не просто GUI библиотека, а жирный фреймворк. Нормальные GUI библиотеки на порядки легче и пишутся очень быстро.
K>Ну тут видимо дело в специфической субкультуре программирования, потому что убогость чего-то, обычно, превращает это в фичу "только для форумов", но вот только в какой-нибудь linq to objects используется не только на форумах, хотя судя по всему, он работает даже хуже дишных рейнджей.
Да, встречается такое. Но если говорить про диапазоны D (и алгоритмы на них), то на мой взгляд это всё же не форумная игрушка, а весьма полезная вещь. Просто лично мне эта конкретная проблема так и не попалась в наших задачах на D (собственно у нас и не особо большая практика по нему), поэтому указать её решение с ходу я не могу, ну и идти ковыряться ради форумного спора тоже не собираюсь. )))
K>По автовекторизации тоже работы есть.
Любопытно) Ну т.е. автовекторизация циклов есть уже во многих компиляторах, но до настоящей (ручной) ей всегда очень далеко... Если бы кто-то сделал что-то сравнимое и при этом автоматическое, то это конечно же был бы прорыв. )
K>Практически все, что называют "метапрограммированием" в других языках, лучше, чем "метапрограммирование на шаблонах".
В соседнем сообщение это уже всплывало... Действительно существует множество языков с гораздо более мощным метапрограммированием, чем в C++. Только вот все они где-то в области маргинальных. А если мы хотим что-то из мейнстрима и при этом с МП, то... )
_>>Хы, вот как раз в обычных реализация C++ ленивость идеально быстрая))) K>Правда что-ли? А подтверждения для этого заявления какие-нибудь есть?
Так оно там такое "by design" — реализовано через МП на шаблонах и соответственно отрабатывает во время компиляции.
_>>У неё другое ограничение — она скажем так работает только на подмножестве языка. K>Не понятно, что это значит.
Это значит, что не любой код можно сделать ленивым. В смысле без доработки библиотеки под себя, а пользуясь только готовым набором из неё.
K>Это вообще не ленивость, даже если считать, что лямбда настоящая, а не плюсовая, которая лямбдой не является. K>Причем "не ленивость" в данном случае означает не "испорченная" ленивость, как в случае "лямбдой не является". В данном случае это как в "ворон не конторка".
Формально это конечно не ленивость... Но на практике, в большинстве случаев, где раньше использовалась ленивость, получилось заменить её обёртыванием нужных кусков кода в лямбды. Кода при этом чуть больше, но при этом он намного прозрачнее.
Что касается лямбд в C++... http://coliru.stacked-crooked.com/a/ce0de866fa9e05bc — с нынешними темпами развития, боюсь что это Хаскелю скоро придётся догонять. )))
K>Понятно, что вы запускаете компилятор этого языка. Вопрос был о том EDSL, который вы в этот язык транслируете.
Никаких dsl нет — просто пишется код на этом языке. И собственно зачем dsl, если этот язык приблизительнo такого же уровня как C++? )
Если уж транслировать некий edsl, то в sse интрисинки (вот они уже совсем низкоуровневые) с помощью МП. И такие решения тоже есть. Но это уже речь о совсем другой архитектуре.
K>Ну вот мы обсуждаем поддержку иммутабельности в D. Т.е. для начала мы проясняем не мою позицию. Далее, поддержка иммутабельности в D никак не зависит от того, к какому из перечисленных типажей мы с вами относимся. Такая классификация пригодится только в том случае, если кто-то захочет навешать лапши на уши, представить оппонента неадекватным, свести разговор с рельс. Вот тут подход понадобится разный для каждого типажа. Но для предметного разговора это все не нужно, нужно вам реализовать пример, который демонстрирует эту самую заявленную поддержку. Все.
Безусловно это всё не имеет отношения к нашей дискуссии, т.к. факт истинности утверждения не зависит от личности того, кто его высказывает. Однако это не мешает делать мне наблюдения за собеседниками... )
K>Собственно, я это сделал, так что понятно, что я подразумеваю под поддержкой иммутабельности. K>Что подразумеваете вы — я тоже понял: инструментарий для легковесного оборачивания мутабельных данных в "иммутабельные" интерфейсы, с возможностью извлечения из "обертки" без копирования, т.е. инвалидируя все ссылки на эту структуру данных, как на "иммутабельную". Какая-то польза в этом может и есть, но, в основном, она в том будет заключатся, что программистам жизнь медом не покажется (хотя, она наверняка уже им медом не кажется, еще до столкновения с такими чумовыми фичами).
Почти правильно. Я бы сказал, что речь идёт о самой возможности построения "иммутабельных интерфейсов", причём с гарантиями компилятора. Если язык предоставляет подобное, то всё остальное дорабатывается библиотеками очень легко. Причём можно делать как вышеописанный вариант реализации, так и множество совсем других.
Re[129]: Есть ли вещи, которые вы прницпиально не понимаете...
Здравствуйте, Klapaucius, Вы писали:
K>В первую очередь, конечно, поддержка рантайма, вроде сегментированного стеков в куче и т.д. Но примером вы меня, как я понял, решили не удивлять.
Пример в смысле библиотеки? ) Ну например вот http://www.theron-library.com есть симпатичная. Но вообще говоря для реализации модели акторов в C++ даже спец. библиотек не требуется. У нас уже есть прямо в языке std::thread, соответственно добавив к ним шаблонные функции типа send и receive и договорившись не использовать другие способы обмена данными (типа общей памяти) между потоками, мы уже получим полноценный вариант модели акторов.
K>Не понимаю, на что вы рассчитываете, когда снова повторяете эту ерунду. Очень просто показать, что никакой персистентной структуры вы не реализовали, что я и сделал тут: http://rsdn.ru/forum/philosophy/5714706.1
Дорисовать пару строчек в класс, чтобы было полноценное универсальное решение, а не для форума? ) Или вы сами в силах себе их представить? )
K>А в каких популярных языках у нас наблюдается "поддержка иммутабельности" а-ля D? K>Но это вообще не такая важная деталь. Вручную обертку написать можно в любом языке (хотя польза от этого всего вообще сомнительная). А вот реально полезную поддержку для иммутабельности, вроде более-менее хорошего GC, так просто в любой язык не добавишь.
Сомнительный аргумент. Если язык позволяет работать только с GC, то весьма вероятно у него он уже не плохой. А если не только с GC (как в D например), то можно использовать более эффективные способы (типа стека, пула и т.п.) в том числе и с иммутабельными данными.
Re[124]: Есть ли вещи, которые вы прницпиально не понимаете...
Здравствуйте, alex_public, Вы писали: _>Нет, вы совсем не то поняли. Речь идёт об одном нюансе, связанном именно с иммутабельностью. Дело в том, что если мы возьмём мутабельный контейнер даже в языке без всяких спец. модификаторов и т.п. на эту тему и будем использовать на нём только не меняющее его подмножество операций, то у нас на самом деле получится полноценная работа с иммутабельными данными.
Простите, но это — феерическая чушь.
Давайте проиллюстрируем это воображаемым языком, в котором вообще нет понятия типа данных. Все выражения в нём имеют один "тип" — это четыре байта.
Семантика этих четырёх байт зависит от операции, в которой они используются: если это +, то речь идёт о целочисленном сложении с дополнением до двух. Если это унарный *, то речь идёт об снятии ссылки с указателя. Если это log, то речь идёт о логарифмировании IEEE-шных single. Если toupper, то речь идёт о конкатенации zero-terminated строк. Если concat, то перед телом строки должны быть записаны их длины (в специальной кодировке: если старший бит значения по смещению -4 установлен в 1, то длина строки вычисляется как (*(str-4))&0x7FFFFFFF + (*(str-8)<<32, и так далее).
Это только типы, описанные в спецификации нашего языка. Разработчики библиотек, понятное дело, вольны использовать данные как угодно: для операции addkeyvalue() первый аргумент запросто может указывать на начало (или середину) структуры данных некоего словаря.
Важный момент вот какой: компилятор о типах не знает вообще ничего. У него очень простые правила синтакического разбора и кодогенерации.
И вот теперь я делаю утверждение, что этот язык полноценно поддерживает работу с ограниченными диапазонами целых чисел (типа 0..100).
Ведь если не выполнять над данными операций, выводящих их за пределы диапазона, то у нас на самом деле получится полноценная работа с ограниченными целыми!
Правда, все обязанности по контролю за тем, чтобы не передать в функцию число за пределами этого диапазона лежат на программисте. После каждой арифметической операции надо проверять результат вручную. Компилятор никак не намекнёт программисту, что a = a * 2 потенциально выводит число за диапазон. Более того, компилятор прекрасно позволит передать в функцию, ожидающую целое от 0 до 100, хоть флоат, хоть строку.
Лично мне такая "поддержка" не представляется "полноценной".
Точно так же и ваша "поддержка иммутабельности", построенная исключительно на самодисциплине, никак полноценной являться не может.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Re[125]: Есть ли вещи, которые вы прницпиально не понимаете...
Здравствуйте, Sinclair, Вы писали:
S>Простите, но это — феерическая чушь. S>Давайте проиллюстрируем это воображаемым языком, в котором вообще нет понятия типа данных. Все выражения в нём имеют один "тип" — это четыре байта. S>Семантика этих четырёх байт зависит от операции, в которой они используются: если это +, то речь идёт о целочисленном сложении с дополнением до двух. Если это унарный *, то речь идёт об снятии ссылки с указателя. Если это log, то речь идёт о логарифмировании IEEE-шных single. Если toupper, то речь идёт о конкатенации zero-terminated строк. Если concat, то перед телом строки должны быть записаны их длины (в специальной кодировке: если старший бит значения по смещению -4 установлен в 1, то длина строки вычисляется как (*(str-4))&0x7FFFFFFF + (*(str-8)<<32, и так далее). S>Это только типы, описанные в спецификации нашего языка. Разработчики библиотек, понятное дело, вольны использовать данные как угодно: для операции addkeyvalue() первый аргумент запросто может указывать на начало (или середину) структуры данных некоего словаря.
S>Важный момент вот какой: компилятор о типах не знает вообще ничего. У него очень простые правила синтакического разбора и кодогенерации.
Нет, он не не знает о них (как в динамических языках, в которых типы всё же есть), а при таком раскладе типов просто не существует. Ни в статике, ни в динамике. Т.е. это у нас тут по сути описан некий вариант ассемблера.
S>И вот теперь я делаю утверждение, что этот язык полноценно поддерживает работу с ограниченными диапазонами целых чисел (типа 0..100). S>Ведь если не выполнять над данными операций, выводящих их за пределы диапазона, то у нас на самом деле получится полноценная работа с ограниченными целыми!
Да, получится полноценная работа с ограниченными целыми. Правда это будет без всякой поддержки компилятора. Собственно это всё очевидно и можно даже легко увидеть пример такого кода, взяв пример на C++ (там будет и полноценная работа с таким типом и полный контроль компилятора корректностью) и скомпилировать его в ассемблер.
S>Правда, все обязанности по контролю за тем, чтобы не передать в функцию число за пределами этого диапазона лежат на программисте. После каждой арифметической операции надо проверять результат вручную. Компилятор никак не намекнёт программисту, что a = a * 2 потенциально выводит число за диапазон. Более того, компилятор прекрасно позволит передать в функцию, ожидающую целое от 0 до 100, хоть флоат, хоть строку.
Ну для начала никаких проверок после каждой операции не требуется. А требуется чёткое (и да, в данном случае ручное) отслеживание соответствия применяемой операции и передаваемых параметров (тип которых существует только в голове программиста). Но т.к. в данном языке подобный расклад идёт для всего, а не только для нашего специфического типа, то это как бы является нормой (для тех, кто выбирает подобные языки).
S>Лично мне такая "поддержка" не представляется "полноценной".
Поддержки тут собственно нет никакой — всё руками. Но при этом работа с этим специфическим типом является вполне полноценной. Это классический расклад для ассемблера.
Ну и лично я тоже не любитель такого программирования. Хотя изредка всё же приходится обращаться и к нему.
S>Точно так же и ваша "поддержка иммутабельности", построенная исключительно на самодисциплине, никак полноценной являться не может.
Вообще то если говорить о моих примерах поддержки иммутабельности в данной темке, то они все были реализованы на языке D, в котором как раз есть поддержка полного контроля компилятором. И соответственно никакой самодисциплины там не требуется.
Re[150]: Есть ли вещи, которые вы прницпиально не понимаете...
Здравствуйте, alex_public, Вы писали:
_>Ну как бы она не решается через массив, а по сути ставится через массив.
Так бывает очень редко. Если ставить задачу "через массив", то получится, как правило, фигня.
Вот, например, если хочется сделать фильтрацию сигнала по какой-то частоте, то естественным решением кажется
1) Взять массив значений нужной нам величины в разные моменты времени
2) Преобразовать его через дискретное преобразование Фурье в массив фаз/интенсивностей по частотам
3) Свернуть этот массив с массивом 111111....10......000000, где "ненужная" нам часть спектра занулена
4) Преобразовать массив обратно через дискретное преобразование Фурье в значения-во-времени.
Если массив у нас длиной N, то этот наивный подход даст нам O(N^2). Ну, потому, что школьная формула для DFT это X[k] = sum[n=0..N-1](x[n]*exp(-2*Pi*I*n*k/N)). _>Т.е. это изначально из самой задачи (физики, математики) идёт. Соответственно, если ты захочешь применять что-то другое (я кстати пока так и не понял что), то это будет уже не естественный способ, а какая-то эмуляция.
Конечно же, никто в здравом уме не применяет "естественный способ" для вычисления ДФТ. Применяют "эмуляцию" — Fast Fourier Transform, пользуясь некоторыми свойствами комплексной экспоненты.
Таким образом, нам удастся снизить асимптоту стоимости до NlogN.
Но ведь и это — вовсе не идеальный способ. Правильное решение поставленной задачи работает за O(N). Вот только сможете ли вы его найти, если вам поставить задачу "через массив"?
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Re[128]: Есть ли вещи, которые вы прницпиально не понимаете...
Здравствуйте, alex_public, Вы писали:
_>Ну так тогда в чём проблема это продемонстрировать? )
Так я и продемонстрировал.
_>чтобы подтвердить свою точку зрения. А уж с прочтением его я как-нибудь постараюсь справиться. )))
Я вам задаю вопросы, вы не них не отвечаете, но требуете от меня код подтверждающий мою точку зрения.
Но у меня ее по этому вопросу нет. Вы утверждаете, что для использования с ФЯ в UML 1) Нужно что-то добавить, но что — не говорите. 2) Много такого, что в ФЯ не востребовано. Тут во-первых, не понятно, что в этом является проблемой. Во-вторых, это очень сомнительное утверждение, которое вы пытались подтвердить примерами, что в хаскеле якобы нет привязки словаря методов, хотя на самом деле она есть.
Моя позиция тут заключается в том, что я не вижу, в чем проблема использовать UML с ФЯ, с учетом того, что UML используется с другими языками, в которых тот ООП, который вы классическим считаете, расширен. Собственно, других ООП языков — не расширенных — и нет. Каким образом я должен "подтверждать" свой скепсис тут?
K>>Возможно, можно построить аргументацию за недостаточность средств UML для отображения сложных иерархий классов/инстансов, но то, что средства UML окажутся невостребованными — это полная ерунда.
_>Вы похоже вообще из какой-то другой реальности или просто никогда не проектировали серьёзные вещи. Да не принципиальны все эти отображения (инструментами типа автогенерации кода мало кто пользуется).
Ни про какую автогенерацию в абзаце на который вы отвечаете нет. Откуда вы ее вдруг вытащили?
_>Принципиальной является возможность для лёгкого построения сложной иерархической архитектуры. В первую очередь в исходниках — для этого служит грубо говоря ООП (как один из вариантов). И как вспомогательный инструмент — визуализация с помощью UML, который частично (как минимум диаграммы классов/объектов) заточен под ООП.
Легким является скорее только построение легкой иерархической архитектуры. Утверждения о том, что ООП и UML подходят для описания/визуализации сложной иерархической архитектуры мне кажутся сомнительными.
Про заточенность диаграммы классов под ООП вы тоже все повторяете и повторяете, но вот только никак не можете сформулировать, в чем же эта заточенность проявляется?
_>Соответственно в случае Хаскеля (и других языков без ООП) возникает вопрос об аналогичных инструментах. Причём если говорить про код, то там ещё могут быть варианты, а вот с их визуализаций похоже всё совсем печально. И ровно 0 примеров от вас только укрепляют такое впечатление.
Про 0 примеров — это явная неправда, я в самом начале дал ссылку на UML-диаграмму для кода на хаскеле http://hackage.haskell.org/package/lens , в которой как раз симула-лайк инструментарий не используется, а то, что используется, в ООЯ отсутствует.
_>Подразумевается рисовать типы данных значками классов и отображать в них все функции, которые принимают в качестве параметра этот тип? )
В тех случаях, когда это "архитектурно" оправдано. Включение функции в "прямоугольник" типа показывает роль, которая ей архитектором отводится, а не механизм ее связи с данными.
_>Ну даже если забыть про ситуацию с функциями многих параметров
Про функции многих параметров можно смело забыть, потому что в большинстве ФЯ их нет — только функции одного параметра.
_>то в обычно в ООП функции принадлежащие классу и не принадлежащие классу, видят его очень по разному... И именно в этом заключается основной смысл, а не просто в принятие скрытого параметра определённого типа.
Да, включение функции в прямоугольник так же показывает доступ к приватным полям. Но как я уже не один раз говорил, доступ в разных языках регулируется разными способами.
_>В начале надо определиться о каких конкретно диаграммах UML идёт речь. Там их большой набор и подходят они разным языкам по разному.
Речь у нас всю дорогу шла в основном про диаграмму классов, потому как в остальных диаграммах тем более никакой языковой специфики нет.
_>Но здесь мы кажется говорили о диаграмме классов (как о главной структурной, позволяющей подробно задавать архитектуру приложения). Так вот, если говорить об этой диаграмме, то её применение для не ООП языков очень сомнительно.
Почему вы так считаете?
_>Я что-то не понял, кто из нас прислал пример кода и спрашивает его аналог на Хаскеле, а получает в ответ пространные рассуждения? )
Я вам задал конкретные вопросы, вы прислали "пример кода", причем не в качестве ответа, а вместо него. Теперь я должен переписывать его на язык, который вы все равно не читаете, а вопросы мои, видимо, так и останутся без ответа.
Меня это не устраивает, жду ответа на мои вопросы.
_>И я по прежнему жду аналог того моего кода на Хаскеле и UML диаграмму к нему.
K>>Пример все равно не рабочий, так какой смысл воспроизводить больше, чем нужно для того, чтоб понять как это воспроизвести полностью? _>Что бы можно было сравнить с аналогом на C++. Пока что сравнивать нечего.
Как нечего? Пример трансляции приведен. Если вы не можете объяснить чего вам не хватает на таком примере, то от увеличения его вам легче точно не станет.
K>>Чем приведенный мной код не конкретика? _>Потому как он не соответствует моему коду, т.е. является каким то абстрактным примером неизвестно чего.
В чем тут отличие от вашего примера?
K>>А чего вам еще не хватает? _>Кода на хаскеле и диаграммы.
Я показал, на примере одного класса трансляцию на хаскель. Чего вам не хватает помимо этого?
_>Потом у вас появится хоть какой-то аргумент в подтверждение ваших тезисов. Если сможете продемонстрировать требуемое. А если нет, то это будет аргументом к моим тезисам. )
Мои "тезисы" — это просто просьбы не обосновать даже, а хотя-бы конкретизировать ваш тезис о том, что UML для ФЯ нужно как-то дополнять. Т.е. хотя-бы показать чем дополнять и чего не хватает.
_>А зачем обязательно сразу Qt повторять? ) Это же собственно не просто GUI библиотека, а жирный фреймворк. Нормальные GUI библиотеки на порядки легче и пишутся очень быстро.
Ну да, наверное какие-нибудь GTK и WPF-ы на "порядки легче". Но на самом деле нет.
_>Да, встречается такое. Но если говорить про диапазоны D (и алгоритмы на них), то на мой взгляд это всё же не форумная игрушка, а весьма полезная вещь. Просто лично мне эта конкретная проблема так и не попалась в наших задачах на D (собственно у нас и не особо большая практика по нему), поэтому указать её решение с ходу я не могу, ну и идти ковыряться ради форумного спора тоже не собираюсь. )))
Но если вы не имеете времени что-то обосновывать, то наверное, логичным было бы и не утверждать это что-то и предлагать верить в это без всякого обоснования.
K>>По автовекторизации тоже работы есть. _>Любопытно) Ну т.е. автовекторизация циклов есть уже во многих компиляторах, но до настоящей (ручной) ей всегда очень далеко... Если бы кто-то сделал что-то сравнимое и при этом автоматическое, то это конечно же был бы прорыв. )
Речь разумеется не идет о решении всех проблем с векторизацией, а об облегчении той части, которая связана с анализом векторизуемого кода.
_>Действительно существует множество языков с гораздо более мощным метапрограммированием, чем в C++. Только вот все они где-то в области маргинальных. А если мы хотим что-то из мейнстрима и при этом с МП, то... )
Это никак не делает C++ не убогим. Это только говори о том, что в мейнстриме убогость — норма. В числе прочего — и метапрограммирование.
_>Так оно там такое "by design" — реализовано через МП на шаблонах и соответственно отрабатывает во время компиляции.
Ленивость — это оптимизация времени выполнения для нонстрикт-семантики. В компайл-тайм она, конечно, работать не может. В компайл-тайм можно только отключить ее там, где она точно не нужна (не везде, консервативно).
_>Это значит, что не любой код можно сделать ленивым. В смысле без доработки библиотеки под себя, а пользуясь только готовым набором из неё.
Код вообще нельзя "делать ленивым".
_>Формально это конечно не ленивость... Но на практике, в большинстве случаев, где раньше использовалась ленивость, получилось заменить её обёртыванием нужных кусков кода в лямбды. Кода при этом чуть больше, но при этом он намного прозрачнее.
Очевидно, что там, где ленивость можно заменить лямбдами — она не использовалась. Потому, что ленивость — это замена функции вычислителя на ее результат после первого вычисления для предотвращения повторных вычислений.
Ленивость — это такая одноразовая мутабельность, для эффективной работы с иммутабельными структурами данных и эффективной реализации нон-стрикт. Лямбды тут никак не помогут, это наивная реализация нон-стрикт.
_>Что касается лямбд в C++... http://coliru.stacked-crooked.com/a/ce0de866fa9e05bc — с нынешними темпами развития, боюсь что это Хаскелю скоро придётся догонять. )))
Ни какой язык без ГЦ по части лямбд никогда догонять не придется.
_>Никаких dsl нет — просто пишется код на этом языке. И собственно зачем dsl, если этот язык приблизительнo такого же уровня как C++? )
Затем, чтоб писать код на языке более высокого уровня, очевидно же.
_>Безусловно это всё не имеет отношения к нашей дискуссии, т.к. факт истинности утверждения не зависит от личности того, кто его высказывает. Однако это не мешает делать мне наблюдения за собеседниками... )
Наблюдения за собеседниками вы делать, конечно, можете, но на сотрудничество с моей стороны в ущерб основной теме разговора вы можете не рассчитывать.
_>Почти правильно. Я бы сказал, что речь идёт о самой возможности построения "иммутабельных интерфейсов", причём с гарантиями компилятора. Если язык предоставляет подобное, то всё остальное дорабатывается библиотеками очень легко. Причём можно делать как вышеописанный вариант реализации, так и множество совсем других.
Поскольку существует каст — никакой реальной гарантии компилятора тут нет, но лучше чем ничего, да.
'You may call it "nonsense" if you like, but I'VE heard nonsense, compared with which that would be as sensible as a dictionary!' (c) Lewis Carroll
Re[130]: Есть ли вещи, которые вы прницпиально не понимаете...
Здравствуйте, alex_public, Вы писали:
_>Пример в смысле библиотеки?
Пример в смысле работающего кода, на котором можно производительность оценить.
_>У нас уже есть прямо в языке std::thread, соответственно добавив к ним шаблонные функции типа send и receive и договорившись не использовать другие способы обмена данными (типа общей памяти) между потоками, мы уже получим полноценный вариант модели акторов.
Спасибо, подозрения о уровне полноценности подтвердились.
_>Дорисовать пару строчек в класс, чтобы было полноценное универсальное решение, а не для форума? ) Или вы сами в силах себе их представить? )
Вы, видимо, имеете в виду копирование массива при создании версии. Ну так какое это отношение имеет к персистентным структурам данных?
_>Сомнительный аргумент. Если язык позволяет работать только с GC, то весьма вероятно у него он уже не плохой. А если не только с GC (как в D например), то можно использовать более эффективные способы (типа стека, пула и т.п.) в том числе и с иммутабельными данными.
Опять двадцать пять. 1) Для хоть сколько-нибудь нетривиальных иммутабельных структур данных вы стеком не обойдетесь. 2) С какой стати пул эффективнее ГЦ на сценариях использования иммутабельных объектов?
Вы не сможете освободить большинство пулов, в каждом останется 5% живых объектов. Эффективность, конечно, лучше некуда.
'You may call it "nonsense" if you like, but I'VE heard nonsense, compared with which that would be as sensible as a dictionary!' (c) Lewis Carroll
Re[2]: Есть ли вещи, которые вы прницпиально не понимаете...
Здравствуйте, Dair, Вы писали:
D>Для меня загадка — современные алгоритмы шифрования (криптографии). Мат.аппарата не хватает
К уже сказанному выше: есть замечательная тулза Cryptool, в числе фич которой — визуализация работы тех или иных алгоритмов криптографии или криптоанализа в динамике:
Очень помогает разобраться с тем или иным алгоритмом
P.S: Если кому интересно, могу рассказать об атаках на алгоритмы криптографии и/или их реализации/способы использования
Здравствуйте, Sinclair, Вы писали:
S>Здравствуйте, alex_public, Вы писали:
_>>Ну по моей ссылке только лицензия на винду стоит 25 евро/месяц. Так что будет интересно взглянуть на vps с виндой за 8 евро. ) S>За 8 долларов пойдёт? http://www.hyper-v-mart.com/hyper-v-hosting-specials-express.aspx
Так а лицензия на винду то входит в эту цену или нет? )
P.S. Цена по ссылке 10 баксов, хотя это и не принципиально тут. )))