Там сам по себе алгоритм тяжелый. Еслиб он был на шарп или на джава, работал бы, наверное, час.
Вот если потестировать чтото попроще, аналог
SELECT ... FROM ... GROUP BY ...
по базе, то работает в районе 100-200 тыс запросов/сек по базе в несколько десятков гигабайт.
Здравствуйте, Andrew.W Worobow, Вы писали:
AWW>Здравствуйте, BoobenCom, Вы писали:
AWW>Чем он будет лучше тех что перечисленны в ссылках тут — http://en.wikipedia.org/wiki/Web_crawler
В смысле лучше ?
Краулер это только одна компонента поисковика.
Здравствуйте, Andrew.W Worobow, Вы писали:
AWW>Здравствуйте, BoobenCom, Вы писали:
AWW>Чем он будет лучше тех что перечисленны в ссылках тут — http://en.wikipedia.org/wiki/Web_crawler
Краулер это только одна компонента поисковика (та что занимается выкачиванием контента).
Здравствуйте, BoobenCom, Вы писали:
BC>Здравствуйте, Andrew.W Worobow, Вы писали:
AWW>>Здравствуйте, BoobenCom, Вы писали:
AWW>>Чем он будет лучше тех что перечисленны в ссылках тут — http://en.wikipedia.org/wiki/Web_crawler
BC>Краулер это только одна компонента поисковика (та что занимается выкачиванием контента).
Здравствуйте, BoobenCom, Вы писали:
BC>Добрый День ! BC>Пишу с нуля поисковый движок на Си. На данный момент проиндексировано BC>0,5 ТБ ресурсов. Пока что Вашего сайта нет в индексе, но может скоро появится. BC>Поиск имеет более качественную выдачу, основанную на ассоциативных связях в тексте. BC>http://www.booben.com
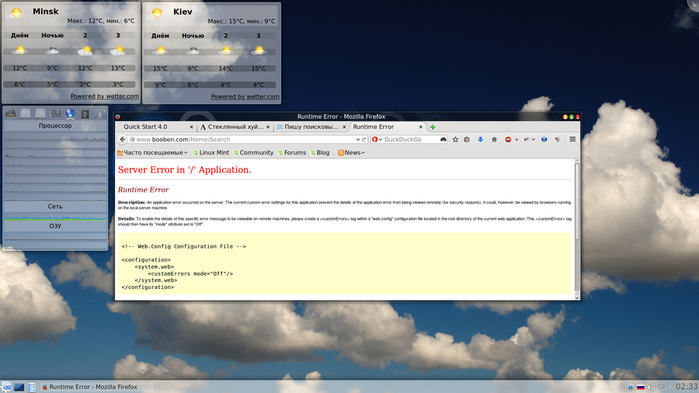
Я такую выдачу не ожидал:
Здравствуйте, Wolverrum, Вы писали:
W>Здравствуйте, BoobenCom, Вы писали:
BC>>Добрый День ! BC>>Пишу с нуля поисковый движок на Си. На данный момент проиндексировано BC>>0,5 ТБ ресурсов. Пока что Вашего сайта нет в индексе, но может скоро появится. BC>>Поиск имеет более качественную выдачу, основанную на ассоциативных связях в тексте. BC>>http://www.booben.com W>Я такую выдачу не ожидал: W>Image: 116902079_large_snimok3.png