DrDobbs обрадовал небольшой заметкой про использование языка D в таком крупном проекте, как Facebook. 5K LOC — как говорил Семёныч, выходя из пивной: "Маленький шажок человека, но большой шаг для человечества!". Действительно, ну не может же хороший язык быть вечным мальчиком для битья всякими язвительными сипиписниками — "разум когда-нибудь победит" (ц) Смысловые Галлюцинации.
Надеюсь, что уже сам пример использования таким "гигантом", станет хорошим вдохновителем для масс — многие просто боятся использовать что-то малораздутое или новоиспечённые выскочки типа Rust/Go. Ди развивается уже много лет и к счастью — без давления легаси или коммерческой продавабельности (как C#), так что если под Ди встанет хороший фундамент инвестиций, сипипи-убожества навсегда покинут индустрию.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>У каждого языка есть свои цели, свои design guidelines. Язык это не просто набор фич.
Это разве противоречит тому, что С++ просто УСТАРЕЛ? Ну не думал Страуструп, что его клёвые "игры в указатели" всем надоедят! Да и ООП было прикручено сбоку и является наихудшим его воплощением (и это при наличии Смоллтока!).
EP>Как известно, у C++ основным приоритетом является производительность.
В эпоху гигагерцовых смартфонов как-то даже неудобно экономить миллисекунды. Не говоря о том, что Ди — тоже не петрушка, это нативный компилятор — ничто не мешает ему вылизать производительность.
EP>Взять например те же ranges — они проигрывают итераторам по производительности by-design
Если вместо 0.0001 секунды работа будет сделана за 0.0003, никто на такую чепуху даже не обратит внимания. Точечное сравнение каких-то фич бессмысленно, тут надо смотреть ширше — язык Ди уже сам по себе спроектирован для безопасного п-я и очевидно намного больше подходит под язык мэйнстрима 21 века.
Здравствуйте, matumba, Вы писали:
M>DrDobbs обрадовал небольшой заметкой про использование языка D в таком крупном проекте, как Facebook.
Моё видение ситуации такое: Александреску умный мужик и прекрасный инженер с мировым именем. Фэйсбуку прощу потерпеть пять килобайт D-рьма в репозитории, чем расставаться с таким инженером, раз уж у него такой pet language. Будь у него личной игрушкой Malbolge, было бы сейчас в Facebook пять килограмм кода на Malbolge.
Здравствуйте, Константин, Вы писали:
К>Минус за попытку интересную новость превратить в срач.
Никакого срача — это лишь ваше личное восприятие. То, что Ди как язык на голову превосходит С++ — очевидно даже школоло, это я и подчеркнул. Если вам лично обидно за потраченное на С++ время — ССЗБ.
К>P.S. Александреску сам "сипиписник", и много сделал для развития "сипипи-убожества"
БЫЛ, но как только Ди набрал обороты, влился в команду Уолтера — тем самым подчеркнув, что даже для матёрого сипиписника С++ не является идолом и отжил свою эпоху.
Здравствуйте, matumba, Вы писали:
M>Нда... вроде криокамеры ещё не изобрели?
M>
Ну это просто смешно. "D устарел" сам нагуглить сможешь или тоже скриншот показать? Правильный вывод сделать сумеешь?
Вообще отвратительно впечатление производит, когда что-то "рекламируют" таким образом. К счастью о D я узнал гораздо раньше, а то почитав такие "отзывы" только мимо пройти хочется.
Здравствуйте, DarkEld3r, Вы писали:
DE>Вообще отвратительно впечатление производит, когда что-то "рекламируют" таким образом.
Бедного сипипи-кодера обидели фактом, что его язык устарел на 20 лет? Я вообще-то пылесосы не продаю и от тебя лично мне ничего не нужно, особенно если не умеешь читать суть поста. Я написал для потенциальных ди-программистов, что язык стал уже использоваться даже лицокнигой, что даёт ещё больший стимул изучать язык. А перетягивать разных скептиков с сакральными знаниями malloc/free — пусть идут дальше.
Здравствуйте, matumba, Вы писали:
M>DrDobbs обрадовал небольшой заметкой про использование языка D в таком крупном проекте, как Facebook. 5K LOC — как говорил Семёныч, выходя из пивной: "Маленький шажок человека, но большой шаг для человечества!". Действительно, ну не может же хороший язык быть вечным мальчиком для битья всякими язвительными сипиписниками — "разум когда-нибудь победит" (ц) Смысловые Галлюцинации. M>Надеюсь, что уже сам пример использования таким "гигантом", станет хорошим вдохновителем для масс — многие просто боятся использовать что-то малораздутое или новоиспечённые выскочки типа Rust/Go. Ди развивается уже много лет и к счастью — без давления легаси или коммерческой продавабельности (как C#), так что если под Ди встанет хороший фундамент инвестиций, сипипи-убожества навсегда покинут индустрию.
И это при том, что не далее как 3-го октября (т.е. 19 дней назад) Александреску сказал:
Q: Are there plans to use D in Facebook?
A: Not for the time being.
Здравствуйте, matumba, Вы писали:
M>DrDobbs обрадовал небольшой заметкой про использование языка D в таком крупном проекте, как Facebook. 5K LOC — как говорил Семёныч, выходя из пивной: "Маленький шажок человека, но большой шаг для человечества!". Действительно, ну не может же хороший язык быть вечным мальчиком для битья всякими язвительными сипиписниками — "разум когда-нибудь победит" (ц) Смысловые Галлюцинации.
Facebook на три часа оказался недоступен по всему миру
Пользователи Facebook по всему миру жаловались на невозможность опубликовать статус и обновить ленту новостей. При попытке захода в соцсеть отображалось сообщение о закрытии сервиса на временные технические работы
Как сообщили официальные представители Facebook в России, ошибка была вызвана техническим сбоем сети.
"Сегодня утром во время технического обслуживания сети произошла ошибка, не позволявшая некоторым пользователям публиковать статусы и комментировать на Facebook в течение короткого периода времени. Мы быстро решили вопрос и снова работаем на 100%. Приносим извинения за любые неудобства, вызванные сбоем."
В справке Facebook поясняется, что такие проблемы обычно наблюдаются у пользователей, чей аккаунт хранится в базе данных, улучшением которой в данный момент занимается компания.
Не лично ли Александреску занимался этим улучшением?
Здравствуйте, Erop, Вы писали:
E>Ну чё, давай ты покажешь нам GC, линк2скуль, йелд там всякий с делегатами на плюсах
E>Чё за библиотеку посмотреть надо?
, но могу кратко повторить по этим конкретным пунктам:
1. yield.
— для начала он вообще не нужен в C++, т.к. тут применяется совсем другая техника (а именно итераторы), которая намного эффективнее и удобнее чем yield.
— если всё же зачем-то (например если это C# программист, которого заставили поработать на C++) очень хочется использовать именно yield, то он тривиально реализуется в несколько строчек с помощью библиотеки Boost.Coroutine. Могу сразу же заметить, что близкие к этому async/await из C# так же реализуются с помощью Boost.Coroutine в несколько строчек. Подробные примеры уже были на форуме.
2. linq
— для начала он вообще не нужен в C++, т.к. для подобных задач тут есть инструмент (Boost.Range) действующий по другим принципам, но такой же удобный и при этом более эффективный.
— если всё же зачем-то очень хочется использовать именно linq-подобный стиль написания, то соответствующие библиотеки тоже есть на C++. И даже не одна. Например вот http://habrahabr.ru/post/142632/ пример написания подобного. И как я и говорил выше, написано C# программистом, перешедшим к C++ и не пожелавшим сменить стиль.
3. GC
— для начала данная тактика работы с памятью вообще не нужна в C++, т.к. не является оптимальной ни при каких сценариях. Собственно единственный сценарий, при котором GC обходит по эффективности обычную кучу C++, это когда нам требуется выделять и удалять огромное количество мелких объектов с похожим временем жизни. Но для таких целей есть и ещё более эффективное средство, а именно выделение памяти на пуле. Соответственно мы берём аллокатор из Boost.Pool и используем его в любых контейнерах из стандартной библиотеки или просто вручную.
— если всё же зачем-то хочется иметь такую странную вещь в C++, то опять же существует множество различных реализаций. Наверное самая классическая вот http://www.hpl.hp.com/personal/Hans_Boehm/gc/.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>>>А тут разве кто-то вообще говорит что он устарел? M>>Нда... вроде криокамеры ещё не изобрели? EP>Аргументы?
Спорить про мракобесие типа С++ — это подымать больную тему, сводящуюся к тому, что один спец на миллион да, МОЖЕТ написать хорошую, устойчивую программу, которую ВОЗМОЖНО даже смогут сопровождать ещё десяток спецов пониже. В целом же мнение отрасли таково, что С++ ПЛОХО ПРИМЕНИМ в мэйнстриме из-за своей низкоуровневой природы, влекущей море таймбомб (+ ещё сотня причин). Если уж хочется почитать (не верю, что вы этого не читали и почему-то продолжаете настаивать на аргументах), то вот: http://ru.wikipedia.org/wiki/C%2B%2B — наслаждайтесь разделом "Критика" (не забудьте заодно посчитать, сколько страниц там написано на размазывание С++ как котёнка).
И даже если эти аргументы вам (как возможно хорошему спецу на С++) покажутся смешными или устранимыми, это не отменяет факта, что средний спец на С++ всё равно будет говнокодить в разы больше, чем тот же спец на C#/Java/D/etc.
С++ — это катана, принесённая дураками на кухню для нарезки моркови — ей МОЖНО нарезать морковь, но в большинстве случаев это отрезанные пальцы и работа-через-Ж.
EP>Откуда столько злости и ненависти?
Не совсем злости — скорее, этакая досада, что есть море очевидного говнокода на говноязыке, которое по-хорошему давно надо выпилить как зло и заменить намного более удобными/безопасными языками, но т.к. существуют "профессоры" типа вас, адвокатирующие за продолжение сипиписной вакханалии, у руководящих людей создаётся ложное впечатление, что "достаточно взять пару толковых С++ ребят" и все проблемы решены. На деле дуроломство не имеет границ и С++ только подливает масла в огонь, предлагая неокрепшим умам поиграть со своими лезвиями. Цепная реакция даёт ещё больше говнопроектов, которые худо-бедно живут, но при этом не дают развиваться другим языкам, которые, вероятно, могли бы быть в два раза более производительны и надёжны. А время идёт и ждать, пока каждый говнопроект не сдохнет в шаблонно-указательных муках, нет никакого желания. Теперь вы осознаёте, что такое "невинное" существование С++ всё равно гадит в отрасль, не давая ей развиваться с другими, более достойными языками? Даже пример дам — Линукс. Я подобную халтуру не поставлю даже в бортовую радиолу,
M>>Вон, ассемблер — не чета всяким Сям — забыли? EP>Чтобы на ассемблере обогнать результат современных C++ компиляторов, надо очень сильно постараться
Пофиг, человек всё равно умнее — можно найти случай, когда ассемблерный код будет быстрее/короче С++ного. Только чего ради? Посотрясать воздух в споре с очередным умником? Просто сейчас время такое, что ущербность писания на асме уже осознали, но аналогичную ущербность С/С++ ещё только предстоит осознать. Время только жалко...
PS
Не воспринимайте всё так уж лично, просто посмотрите на ситуацию сверху — С++ объективно опасный и бестолковый язык, в мэйнстриме это язык-урод, не отвечающий главным требованиям. Ну а кто хочет на нём писать, пусть пишут — тянуть за рукав не будем.
Здравствуйте, Кодт, Вы писали:
К>>>Не путай свои требования и главные требования. M>>Где они спутаны? Цитату в студию или трепло. К>У тебя в голове спутаны.
Отличный аргумент! Т.е. ты себе придумал, что ты один разбираешься в мэйнстриме и мне на словах вменяешь, будто это я ошибаюсь. Где логика, сэр? Ты уж если хочешь спорить, опирайся хотя бы на цитаты — без них твоё словоблудие ровно ничего не доказывает и только провоцирует конфликты.
К>Задумайся на досуге о том, что промышленность так и не выкинула си. Неспроста, наверное.
На, тоже задумайся:
Если бы Си был действительно подходящим языком, он бы не плёлся десятилетиями как говно на палочке 17%, а вытеснил бы всякую шушеру и был бы "языком №1" с 80% рынка. А используется он исключительно в двух случаях: 1) экстремальные запросы к производительности 2) куча легаси кода, включая какие-нибудь библиотечки "вывода в ком-порт", которые тащат из проекта в проект и для упрощения всё остальное тоже пишут на Сях.
С этими фактами ты спорить не будешь?
По всем остальным аспектам Си — г-но мамонта, безумно затягивающее разработку и до сих пор (напоминаю, 21 век!) подкладывает свинью в виде stack overflow, null pointer, range overwrite и.т.п. — ТАКОМУ в мэйнстриме не место. И если ты посмотришь на C#, то он практически "взлетел" — и это на фоне твоего "мэйнстримного Си" и Жабы — заметь, тоже вроде как претендовавшего на "безопасный Си".
Т.е. если уж кто и претендует сейчас на мэйнстрим, но это, пожалуй, единственный язык — C#. У Ди финансы уровня плинтуса, поэтому увы, он не может проталкивать себя так же активно.
Да, и С++ — тоже обрати внимание на график, он "скатился" практически до уровня Objective-C — языка для нишевой макоси. Почему-то Аппля не стала ставить даже на С++ (хотя подумай, сколько уже написанных библиотек они могли бы поиметь нахаляву!).
M>>...Ди предлагает куда более интересные вещи (CTFE, mixins, ranges, RTTI), под которые надо ЗАНОВО писать код. К>Вот-вот, надо заново писать код. Кто будет платить кодерам?
Те же, кто платили за Сипиписных монстров! Что в этом такого? Новый софт делался и будет делаться, весь вопрос лишь в том, хватит ли ума "боссам" не создавать очередной "быстробегущий труп", чтобы потом годами латать дыры и молиться, чтобы все оба "специалиста по указателям" не махнули из конторы. И в то же время есть громадный выбор C# спецов, знания которых на порядок ценнее, потому что это не знания о костылях языка, а высокоуровневая CS.
К>Народ вовсю фортраном пользуется, чтобы адский матан не переписывать на модные академические языки.
Фортран, Ада — это всё тоже прекрасный пример отстоя, который держат исключительно за "пока ещё работает" и "дорого/незачем переписывать". Ну и сам посуди как руководитель: нужно начинать проект и выбирать язык. Ты что, будешь опираться на древние пылесосы с фортраном, потому что там есть оптимизированый косинус и потом ещё два года искать пердунов, ещё помнящих отступ в 6 пробелов?!! Легаси — оно и есть легаси, подумай насколько высоко прыгнула парадигма от жонглирования указателей в перделках на 1000 строк к облачным вычислениям, паттернам, модульным системам, ООП и прочее — да это небо и земля! Сейчас на "сишной логике" можно писать разве что команду dir — средние и выше системы она уже не потянет.
Здравствуйте, Pzz, Вы писали:
Pzz>Здравствуйте, dalmal, Вы писали:
D>>D не нужен. Потому что его нишу плотно занимают C#/Java с тоннами библиотек на любой вкус. И я не вижу у него никакого преимущества, особенно перед C# в технологическом смысле. D>>Так что D не нужен. И на смену С++ он придет явно не в этом десятилетии.
Pzz>C# работает только на венде, а все практические реализации Явы обладают красотой и грациозностью бегемота, пасущегося на лугах Страны Неограниченных Ресурсов.
Думаю стоит глянуть на Mono и Xamarin, перед тем как толкать такие утверждения. Сейчас спектр систем, где заработает код на C#, примерно такой же, как у java и у обоих гораздо шире, чем у C++.
Pzz>Кросплатформенный язык общего назначения типа "си с классами", не страдающий при этом врожденной склонностью к онкологическим заболеваниям, безусловно, нужен.
Практика показывает что эту нишу занял javascript.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Если кто-то постоянно тем и занимается что итетрирует структуры данных, и ему не хватает текущих возможностей — то пусть отсылает proposal в reflection study group #7, его обязательно рассмотрят.
Вот как раз интроспекции времени компиляции (а не того ненужного недоразумения времени выполнения, как в жабке и шарпе) крайне не хватает в C++. Например для сереализации. Кстати, а RTTI я бы вообще из C++ выкинул — от него вред только один, т.к. не вписывается он до конца в концепцию C++ нулевых накладных расходов.
У нас тут сейчас один тестовый проект на D и некоторыми моментами реально можно наслаждаться именно из-за интроспекции. Т.е. код вида:
struct User{
string name;
int age;
};
Send(Json(User("Alex", 111)));
реально радует (Json естественно ничего не знает про User и вообще не нами написан). Причём т.к. это всё во время компиляции конструируется, оно ещё и очень быстрое.
Правда это всё примеры именно интроспекции, а не метапрограммирования, хотя они и связаны. А в метапрограммирование я могу очень просто объяснить любому специалисту по C++ преимущества D. Для этого я могу предложить им представить себе, чтобы они могли сделать в C++ при двух простейших дополнениях:
1. Если бы в C++ можно было параметризовать шаблоны строками
2. Если бы была функция, которая преобразовывает строку в код, размещаемый (причём с использованием локальных переменных, оптимизации и т.п.) по месту вызова этой функции.
Мне даже страшно себе представить, что бы натворили некоторые маньяки C++ (типа пишущих всякие Boost.Spirit и т.п.), если бы им дали в руки такой инструмент...
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>void sort(RandomAccessRange &x) EP>void sort(BidirectionalRange &x) EP>Это шаблоны функций, перегрузка между которыми происходит автоматом. Требования каждой концепции разбиваются компилятором на атомы, и производится тест вложенности множеств и т.п.
Перегрузка таких шаблонов в D есть, но, насколько я помню, без такого теста вложенности, последовательная, т.к. в условиях может выполняться почти произвольный код, они намного больше всего могут тестировать, поэтому такую проверку "вложенности множеств" провести нереально, она возможна лишь для сильно примитивных условий, которые и обещают в С++.
Вот такой пример на С++ как записывается? http://thedeemon.livejournal.com/53900.html
(проверка переданного шаблона на выполнение аксиом функтора в категории)
EP>Итераторы C++ обеспечивают эффективную композицию. Если у нас есть 4 итератора, то из них можно получить 6 range бесплатно, без runtime penalty — просто выбери нужную пару итераторов.
Здравствуйте, alex_public, Вы писали:
_>2. И read и write можно вызывать в любых потоках. Тогда вообще всё просто и не нужны все эти хитрости типа await/async. Вот корректный асинхронный код: _>
_>thread([]{
_> auto value=read();
_> write(next(value));
_>}).detach();
_>
Потрясающе. Если тебе понадобится обрабатывать сотни подключений у тебя будут сотни потоков. Практический лимит потоков на windows — около 200. Но даже при сотне уже все тормозит. При этом потоки будут ничего не делать.
Кстати код который создает потоки для выполнения называют параллельным, а не асинхронным. Асинхронный это как раз когда потоки без нужды не создаются.
_>А если нам требуется максимальное быстродействие и read и write относятся к разным устройствам, то можно вообще завести 2 независимых потока со своими буферами и синхронизацией (например через обмен сообщений по модели акторов). Но здесь уже понятно что не обойтись без модификации кода.
Ну как-бы проблему множества подключений не решает.
_>В C# всё тоже самое, за исключением того, что обязательно требуется менять указанный код (добавить await). Причём менять надо не только его, но и весь стек вызова (добавить async).
Не тоже самое. Ты просто нихрена в этом не понимаешь
Здравствуйте, minorlogic, Вы писали:
EP>>>>Взять например те же ranges — они проигрывают итераторам по производительности by-design M>>>Этого не понял , ranges же легко делать поверх итераторов , где там производительность потеряется ? EP>>Ranges действительно легко делать поверх итераторов — например Boost.Range. Но в D нет итераторов — там сразу Range. M>М... могу предположить что диапазон из одного элемента вместо указателя использует Range, и в этом накладные расходы ?
Выше уже много примеров было: лишняя работа на каждой итерации в std::find, partition, search. Плохая комбинируемость приводящая к лишним проходам, копиям, созданием новых типов range на ровном месте, пониженная категория результирующих range.
То что где-то будет хранится два итератора, вместо одного само по себе не является серьёзной проблемой. А вот то что нельзя взять вот такие два range, в каждом из которых один элемент, и получить бесплатно range содержащий все элементы между этими двумя — это уже алгоритмическая ивалидность.
Здравствуйте, VladD2, Вы писали:
VD>>На С++ аналог кто нить с бацает? Или времени хватает только на его расхваливание? VD>Я правильно понимаю этот минус как слив темы о невероятной крутизне С++?
А где тут кто-то говорил про невероятную крутизну C++?
Я вот не пойму — откуда у программистов не пишущих на C++ к нему такая злость/зависть/etc?
Здравствуйте, Evgeny.Panasyuk, Вы писали:
M>>Это разве противоречит тому, что С++ просто УСТАРЕЛ?
EP>А тут разве кто-то вообще говорит что он устарел?
Нда... вроде криокамеры ещё не изобрели?
EP>В следующем году будут концепции — большой шаг вперёд.
Большой шаг вперёд из той задницы, откуда шагает С++ — это всё то же сидение в заднице. Хуже того — даже при введении самых суперских фич, в руках остаётся всё тот же тротиловый С++, готовый не то что отстрелить ногу, а вообще всю башку снести! И синтаксис — как гляну, КАК С++ адаптирует всякие новшества, так сразу хочется послать сухарей Страуструпу.
EP> А что тут может предложить D?
эээ... в смысле "какие новые ежемесячные печеньки"? Бог ты мой, да ДАВНО УЖЕ ВСЁ РЕАЛИЗОВАНО!
EP>"Вылизывать" производительность можно в компиляторе, а вот когда сам язык приносит производительность в жертву другим фичам, то тут особо ничего не поделаешь
Да и не надо тут играть похоронный марш! Вон, ассемблер — не чета всяким Сям — забыли? И правильно сделали, ибо некоторые игры свеч не стóят. Если написание программ можно сильно обезопасить, слегка прогнув производительность, это обязательно надо сделать. А некоторые вещи (типа неизменяемости) — вообще дадены забисплатна (почитайте про это у Ди).
EP>Ещё бы, 3x — это уже такая мелочь, да и вообще всё в БАЗУ упирается
Я уверен на 146%, что большинство программ упираются в интеллект прогера, а не возможности CPU. Десктоп софт — тот вообще живёт от клавиши до клавиши, нажатой юзером.
Здравствуйте, Кодт, Вы писали:
К>Не путай свои требования и главные требования.
Где они спутаны? Цитату в студию или трепло.
К>У С++ есть два плюса: мультипарадигменность и поддержка наследия.
Мульти... чо??? Этот ассемблер с классами? Родной, это не "мультипарадигменность", а БАРДАК — так будет точнее.
Наследие? Ну и что с того? Раньше и на PL/1 писали, он что, стал от этого полезнее или правильнее? Его заслуженно забыли, потому что вовремя осознали — не нужен.
К>Сколько стоит перенести гору уже существующего кода с C++ на D?
С чего вы решили, что вообще нужно переносить этот хлам??? Ди — не просто повторение "Си с классами", а практически новая методология! Ну или сильно улучшенная, как нравится. Т.е. переносить старые костыли нет никакого смысла, Ди предлагает куда более интересные вещи (CTFE, mixins, ranges, RTTI), под которые надо ЗАНОВО писать код. Кроме того, "легаси" зачастую грешит полным отсутствием вменяемой архитектуры, шаблонов, да и просто устаревшими приёмами. Пример — GCC, вот уж точно кого следует зазиповать и закопать.
Здравствуйте, matumba, Вы писали:
M>Ты сам-то их читал? А понял о чём речь? Походу, нет.
Читал, понял о чем речь. И вам мой юный друг почитать рекомендую и не разводить демагогию не ознакомившись с материалом.
M>Если кто-то (под воздействием дебильного пузыря "HTML5+JS") стал писать приложения на абсолютно непригодном, тормозном убожестве и при этом получил такие же отстойные приложения, как это соотносится с тем, что 1.5GHz процессор МОЖЕТ И ДОЛЖЕН исполнять всё быстро? Ты вообще в курсе, что первые "окна" работали на 40MHz i386, причём без ускорителя? Это в 37 раз медленнее, чем современный ARM-чип, и это только одно ядро ARM!
Вас что-то понесло в другую сторону.
M>Вот как раз если бы писали под смартфоны на Ди, можно было бы вообще забыть про "тормоза". Вся надежда на D+LLVM.
Вы отчего не поймете простую вещь — на данный момент D c GC это бледная копия C#. D без GC это бледная копия С++. Проблема D на данный момент что никому не нужна бледная копия если можно использовать более эффективный продукт который имеет более высокую производительность, backword compatibility c с ранними версиями, отточенный FCL и прекрасные инструменты.
Здравствуйте, Erop, Вы писали:
E>Ну бывают же не только пары итераторов, но и тройки, скажем, или, наоборот, одинокие итераторы, например итератор элемента std::list'а...
Кстати, по поводу списков — тут дело не только в производительности.
На основе ForwardIterator'ов можно определить LinkedIterator (добавив функцию set_successor) — который позволяет изменять next. На основе таких итераторов можно реализовать разные алгоритмы, типа reverse, merge sort, etc:
template <typename I> // I models Linked Iterator
I reverse_append(I first, I limit, I result)
{
while (first != limit) {
I old_successor = successor(first);
set_successor(first, result);
result = first;
first = old_successor;
}
return result;
}
Но я, например, сходу не вижу как легко можно расширить D Range для поддержки чего-то похожего.
То есть я думаю что концепция "координаты", которая лежит в основе STL итераторов — более фундаментальна для алгоритмов и структур данных, чем Ranges.
Или взять, например, концепцию BifurcateCoordinate из "Elements of Programming"
Здравствуйте, VladD2, Вы писали: VD>Здравствуйте, Evgeny.Panasyuk, Вы писали: EP>>Вспомни консоль: EP>>cat x | grep y | sort VD>Меня от линуксовой консоли всегда мутило.
Да не вопрос:
DOS/WinXP
http://technet.microsoft.com/en-us/library/ee176927.aspx#EDAA
Так что ни у кого, кроме тебя, operator pipe проблем не вызывает. VD>Как-то объектная точка или функциональный оператор |> понятнее.
"объектная точка или функциональный оператор |>" в С++ — не пришей кобыле хвост. VD>А _1 тоже не магия?
Вообще _1 в стандарте С++11 уже, в std::placeholders — см. 20.8.9.1.4 Placeholders. EP>>Каким именно делом? Где тормозить? VD>Бустом. Или что ты там использовал для получения недолямбд с параметрами _1, _2 и т.п.?
В С++11 и без буста все прекрасно реализуется в три строчки (А в С++14 — в одну). Пример с умножением:
struct Mul {
template<class X, class Y>auto operator()(X x, Y y) -> JUST_RETURN(x*y)
};
template<class X, class Y>auto operator*(X x, Y y) -> JUST_RETURN(bind(Mul(), x, y))
полный код с тестом, обрати особое внимание на последние 2 строчки теста
И что тут должно тормозить, по-твоему? Не будет тут тормозов ни при компиляции (потому что код элементарный), ни при исполнении программы. VD>А критикуете вы его совсем не за то.
Мы его не критикуем, вообще-то.
Никто не говорит, что D хуже С++.
Мы говорим, что то, что он может предложить по сравнению с С++11 (и С++14), недостаточно для того, чтоб все бросились переписывать на нем плюсовые программы или нанимать новых/переобучать имеющихся программеров. Овчинка выделки не стоит.
Здравствуйте, gandjustas, Вы писали:
G>Проблема в том что такой код тяжело поддерживать. Сегодня у вас все маршалится в UI поток, завтра в отдельный поток, послезавтра вы используете IOCP, который потом маршлит в UI. G>Библиотечку оформить это примерно х10 затраты по сравнению с просто написать, и х3 с учетом поддержки.
Ооо, этот классический подход в стиле Java/C#, когда мы заранее наворачиваем горы никчемных интерфейсов и классов... Нет, такого нам не надо. )))
G>Ту то есть разбор очереди задач надо руками делать, плачевно... Переключить с UI на пул потоков так просто не выйдет, особенно с точки зрения вызывающего кода.
Применение await/async вне возврата управления в ui поток не имеет вообще никакого смысла. Только лишние накладные расходы и никакой пользы.
G>Чувак, ты слишком плохо разбираешься в .NET чтобы подобные утверждения делать. Посмотри на channel9 как устроен async и таски. Много нового для себя откроешь.
Ну да, конечно. Только вот я выложил уже несколько примеров кода, а от тебя пока не видно ни одного — одна пафосная болтовня. Раз ты считаешь, что я недооцениваю возможности async в .net, то предлагаю тебе показать тут реализацию на C# следующей простейшей задачки:
Предположим, что у нас есть некая сложная библиотечная функция, причём написанная не нами, т.е. переписать её самим вообще не вариант. Изначально она рассчитана только на синхронную работу — читает (многократно) данные из некого блокирующего потока ввода и сама обязательно должна исполняться только в ui потоке. Т.е. синхронный код выглядит так:
ComplexFunction(input_stream);//блокирует исполнение ui потока, пока не обработает все входные данные.
Соответственно задача в том, чтобы сделать этот код асинхронным. На C++ это можно решить тривиально:
Этот код вернёт управление сразу же и при этом ComplexFunction будет периодически (по мере поступления данных) отрабатывать в ui потоке. Функцию ComplexFunction мы естественно вообще не трогали.
А как решить эту задачку на C# с его крутыми "async и тасками"?
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Здравствуйте, gandjustas, Вы писали:
EP>>>std::getline тут стандартная, не модифицированная. Точно также можно протащить yield и через любую другую функцию G>>Да, вот только надо очень хорошо понимать как работает эта функция. К счастью для переписывания синхронного кода в асинхронный в .NET не надо разбираться как он внтури устроен. Можно просто базвоые методы, которые делают IO сделать async, а дальше следуя руганиям компилятора добавить async\await во все методы выше по цепочке вызовов.
EP>В цепочке вызовов находится код исходников которого нет, что теперь?
В .NET очень легко — берешь dll и достаешь исходники.
В С++ — хз что делать, даже твой способ нельзя применять, ибо гарантий никаких.
EP>>>>>Что значит особый случай? Точно также можно завернуть tcp_stream. G>>>>Надо очень хорошо знать как код работает внутри, чтобы делать такую асинхронность. EP>>>Есть любая асинхронная функция которая принимает continuation/.then — мы ей передаём в этот continuation код с yield-ом внутри, что механически превращает остаток нашей функции в продолжение. G>>Пример давай.
EP>Пример.
Понял, но тогда композицию не сделаешь. Вся соль продолжений что их можно комбинировать, цепочку продолжений сделать или fork\join.
Но только как это относится к случаю когда есть код, о котором ты не знаешь вообще ничего? lib или dll с сишным интерфейом (каковых подавляющее большинство).
G>>>>А как комбинировать такие асинхронные вызовы не то что не очевидно, а вообще непонятно как. EP>>>Ты о чём? G>>Напрмиер так: G>>у тебя есть асинхронные функции f1 и f2, внтури они делают какой-то IO. Тебе нужно написать функцию f3, которая вызывает f1 и f2 параллельно, ждет их завершения и вызывает асинхронную операцию. G>>Реальное применение такой функции — сервис поиска авиабилетов. Он обращается параллельно к десяткам перевозчиков, получает данные, выбирает лучшие варианты, отдает клиентам. Естественно это hiload сервис, который не может позволить себе создавать потоки.
EP>То есть ты мой пример
Это сразу же ставит крест на серверных решениях и масштабируемости вообще.
А на клиенте проще отдельный поток запустить для операций, и маршалить вызовы в UI.
EP>>>>>При этом код использующий этот поток не поменяется, а в случае с C# await — нужно будет патчить весь call-stack G>>>>А зачем это делать? Преобразование синхронного кода в асинхронный — механическая операция, легко автоматизируется при желании. Я даже для стримов на roslyn такое переписывание делал. EP>>>С такими же рассуждениями можно прийти к мысли что и yield, и await/async не нужны G>>Практика то показывает что нужны. Причем тут рассуждения?
EP>Ну ты говоришь что преобразование синхронного кода в асинхронный это механическая операция. Так и преобразование кода с await/yield — точно такая же механическая операция
Во-первых это не так из-за message pump.
Во-вторых ты утверждал что надо патчить call-stack. Я выделил твое утверждение.
G>>То что ты считаешь что нужно патчить call-stack — вывод, основанный на неверной посылке. EP>Подробнее.
В .NET нет смысла хранить callstack, потому что нету деструкторов, поэтому очень легко делать продолжения. В C++ тебе нужен callstack для освобождения ресурсов, вот ты и думаешь что он является необходимостью.
Тогда еще не было async\await. В .NET с версии 2.0 есть итераторы, которые явлются частным случаем корутин, которые в свою очередь являются частным случаем продолжений.
Чувак на итераторах изобрел что-то вроде локальных асинхронных корутин, и там совсем не требовались игры с callstack.
Это то, к чему вы с alex_public мееедленно ползете.
(это при том что я сам практически не работаю ни с каким io). G>>Без асинхронного IO это все смысла не имеет. Покажи пример с асинхронным IO.
EP>Слушай, ну если ты не нацелен на конструктив, давай прекратим, ок? По второй ссылке Boost.Asio — самое что ни на есть асинхронное I/O, с тем самым IOCP под капотом
И как это комбинировать? Как запустить два параллельных считывания?
G>>>>Для начала тебе надо будет async io реализовать на IOCP. EP>>>Ты мне предлагаешь реализовать свои обвёртки поверх голого IOCP? Зачем? G>>Без асинхронного IO все что ты пишешь не имеет смысла. Вообще. EP>Подожди, то есть ты думаешь что для C++ нет библиотек асинхронным API
Кроме буст? Увы очень мало и плохо работает.
G>>Ты вообще представляешь как медленно будет работать твой пример с getline на реальном файле? G>>Опубликуешь результаты забегов? При этом масштабирования такой подход не добавил. Ты не сможешь также запустить 100500 чтений файлов и выйграть хоть что-то. EP>getline может читать из любого стрима, например из сокета. В одном потоке будут крутится тысячи потоков с getline внутри, который ничего не знает об корутинах.
И что? Все равно то, что ты показал будет тормозить. Скорее всего аццки тормозить.
EP>>>О том, что для того чтобы сделать yield с самого низа callstack'а на самый вверх, тебе придётся дублировать и модифицировать каждый уровень. Причём эти уровни могут находится в библиотеках к которым нет доступа. G>>В смысле "нет доступа" ? G>>Если библиотеки — "черный ящик", то и твой подход не поможет, потому что требует знать как внутри работа устроена. G>>Если у тебя таки есть доступ к исходникам, то кто мешает сделать ctrl+c-ctrl+v и добавить async\await?
EP>Детский сад — для того чтобы пользоваться библиотекой знать её код не обязательно. В нормальных библиотеках есть чётко определённый интерфес
И что? Как ты гарантируешь что инварианты не поломаются?
Твой пример базируется на том что у тебя функция — прозрачный ящик. В этом случае я просто скопирую код и сделаю его async.
EP>>>У тебя нет кода std::getline (или аналога) — куда ты там собрался дописывать await? G>>Если тебя нет когда getline, то как ты написал свой код? Он же полностью базируется на знании устройства getline, значит код у тебя есть. EP>Это привязка не к устройству, а к интерфейсу
Именно к устройству, потому что иначе гарантий никаких.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Здравствуйте, gandjustas, Вы писали:
G>>>>Кроме того такой вариант гораздо сложнее реализовать. EP>>>Нет. Например при использовании Boost.Asio иметь свой io_service per thread — это нормально, и просто Наоборот, использование одного io_serive на несколько потоков считается более сложным. G>>Ну это только особенности boost. А если смотреть картину в целом, то для маршалинга всех продолжений в один поток надо как-то информацию протаскивать в продолжения.
EP>Да не надо ничего протаскивать — там разные io_service'ы на каждый поток
io_service это очередь и message pump, при вызове функции идет привязка в какой поток маршалить завершение. Думаешь такая привязка бесплатная?
G>>В boot это делается за счет stackfull корутин, что повышает требования к памяти, ибо хранить стек, не тоже само что хранить замыкание с 3-5 значениями. EP>Там такая схема рекомендуется даже без использования корутин, хватит фантазировать.
Там это где? В бусте? Конечно, потому что для нормальной работы C++ нужен стек.
В языках с gc нет такого ограничения, поэтому есть возможность делать более эффетивную асинхронность и агрессивно переписывать код.
Здравствуйте, alex_public, Вы писали:
_> Т.к. все возможности C# можно повторить на C++, а вот часть возможностей C++ на C# повторить невозможно.
Для сферического писькомерства — да, можно сказать "С++ круче", но вам за что деньги платят? За промышленный код, мэйнстрим. И по-моему, вполне очевидно, что нарезка овощей на тёрке (C#) намного быстрее и безопаснее, чем их рубка саблей (С++). Нет никакого "превосходства" С++, если помимо самого алгоритма ты должен держать в голове выкрутасы С++. Про синтаксис вообще молчу — мрак второго уровня (после Перла и Хаскеля).
I>>А вот, скажем, новый компилер шарпа писаный на шарпе рвёт в хлам старый компилер шарпа писаный на плюсах. Странно, да ? _>Это вообще ни о чём не говорит. Современные версии компиляторов C++ тоже делают старые.)))
Это говорит о том, что несмотря на всякие MSIL/JIT'ы, можно безо всяких хаков, на безопасном языке, ваять серьёзные приложения.
_>Как бы это сказать попроще... ) Если бы это было правдой, то у меня на компьютере точно было бы установлено хотя бы несколько модных .net программ
Этот парадокс я сам не пойму, но пара мыслей есть:
1. Хотя дотнету уже 10 лет, свою "идеальную форму" он обрёл далеко не с первой версии — даже WPF появился совсем недавно. Или вот ORM — давно ли вы открывали DataReader'ы? А как появились ORM, стало намного легче дышать.
2. Чтобы писать хорошие приложения на дотнете, сначала надо стать хорошими прогерами на дотнете, а это время, опыт, инертность, отставание от самого дотнета и т.п. Вот сейчас уже есть значимая масса дотнетчиков, готовых заполонить мэйнстрим.
3. Громадное количество "не-дотнет" приложений живы чисто в силу бизнес-соображений: не будет никто переписывать 1С только потому, что это безопасно и перспективно, "работает — и ладно!".
4. У "бывалых сипиписеров" до сих пор костное мышление "раз на С++ можно сделать задачу на 0.0001 секунд быстрее, буду и дальше лабать свои таймбомбы!". Их не волнует, что они не способны гарантировать "безглючность" любой программы длиннее 10KLOC. Равно как не могут гарантировать поддерживаемость своих "хакатонов" средним программистом — все ж спецы, блин!
Так что да, дотнет как-то не очень резво замещает "нативщину", но прелесть ситуации в том, что дотнет объективно удобнее для написания виндоприблуд, чем "старый, добрый С++ + Win32". Думаю, как только планшетно-мобильный маразм поутихнет, все как миленькие вернутся на десктоп и C#.
_>Забавная история. ) Только вот она как раз в точности подтвердила именно мою мысль, что в руках профи и сомнительный инструмент будет эффективнее чем самый мощный в руках неумехи.
История подтверждает то, что С++ нафик не нужен для мэйнстрима — "средний сферический индус" не способен писать на нём нормальные приложения. Это верно даже безотносительно сравнения с C#. Когда же на сцену выходит дотнет с его мощнейшей библиотекой и безопасным C#, тут вообще думать нечего — любой проект на C#, сделаный даже средней руки прогерами, способен развиваться десятилетиями.
Но возвращаясь к Ди, мне он кажется куда более интересным и перспективным, чем кактус сипипей — он не даром Ди, а не "Скала" — Ди поднял планку понятия "современный язык" так, что весь легаси код сипипи кажется унылым наследием времён фортрана. Да, к С++ можно прикрутить много интересных плюшек, но он так и останется С++ — неизлечимым гибридом ассемблера и ООП. скорее бы он уже RIP...
Здравствуйте, alex_public, Вы писали:
I>>В задаче, которую я показал, собственно указаный маппинг это 1% от всей работы. То есть, ни о чем — OR/M это много больше чем вот этот маппинг.
_>Ну так покажи как на .net'e делается хотя бы этот 1% работы... )))
Не хочу, это никак не относится к обсуждаемому вопросу
Неоднократно приходилось читать про использование языка PHP в таком крупном проекте, как Facebook. 100500 LOC — как говорил Семёныч, выходя из пивной: "Маленький шажок человека, но большой шаг для человечества!". Действительно, ну не может же хороший язык быть вечным мальчиком для битья всякими язвительными сипиписниками — "разум когда-нибудь победит" (ц) Смысловые Галлюцинации.
Надеюсь, что уже сам пример использования таким "гигантом", станет хорошим вдохновителем для масс — многие просто боятся использовать что-то малораздутое или новоиспечённые выскочки типа Rust/Go. PHP развивается уже много лет и к счастью — без давления легаси или коммерческой продавабельности (как C#), так что если под PHP встанет хороший фундамент инвестиций, сипипи-убожества навсегда покинут индустрию.
Здравствуйте, alex_public, Вы писали:
_>Не, это gandjustas порадовал нас мыслью, что стандартная библиотека .net мощнее стандартной библиотеки C++ + boost. ))) А я всего лишь предложил показать это на примерах. На которых естественно оказалась обратная ситуация.
Не, это ты начал утверждать что навроде "нож мощнее вилки", т.е. с++ мощнее C# ?
I>>Я, если что, примерно 10 лет занимался софтом, который ближе всего похж на САПР, там этого csv и похожих форматов девать было некуда. Так что если хочешь меня повеселить, валяй.
_>Ну настоящий профи может и на кривом инструменте нормальный код писать. Но как мы видим в основном в мире java и .net процветают совсем другие настроения. Типа "во имя закона Мура". )))
Это миф. Единственно где сливает дотнет и джава, это числодробилки и низкоуровневые операции, в ядро или драйвер не то что GC, даже половину фич С++ не всунешь. Всё.
А вот, скажем, новый компилер шарпа писаный на шарпе рвёт в хлам старый компилер шарпа писаный на плюсах. Странно, да ?
Числодробилок раз два и обчелся. А всё остальное упирается в алгоритмы или ввод вывод.
Вот прямо сейчас товарищ рассказал хохму — крутые индейцы решили заимпрувить алгоритм анализа-оптимизаии дерева и наколбасили визитор с потрохами чуть не в мегабайт кода. Убили месяц времени.
Алгоритм, правда, по перформансу лучше не стал, потому что не могут отловить, отладить кое какие частные случаи и периодически случаются косяки или утечки.
Что характерно, менеджед версию на Скале написал какой то дедушка где то за 6 часов, используя всякие лямбды и паттерн-матчинги. Собтсвенно 80% код это паттерн-матчинг.
Щас у индейцев романтический период — взяли декомпиленый вариант и портируют его на С++ и пытаются угадать, где их обманул декомпилер. Ну и менеджмент памяти пишут специально под этот алгоритм. В скале всё просто — все само освобождается. А в с++ этот вариант не проходит — надо руками-руками-руками, а то выхлоп от скалы если в лоб реализовать, дает кучку циклических ссылок.
Теперь самое интересное — дедушка взял и заимпрувил свою версию, при чем напрочь поменял алгоритм. Потратил еще где то день работы, перформанс вырос вдвое.
Общий расклад такой — на небольших деревьях С++ работает где то в 100 раз быстрее, но вот с реальными данными как то не справляется
Здравствуйте, VladD2, Вы писали:
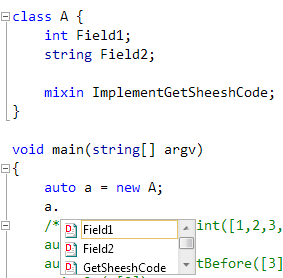
VD>Интереснее было бы на более не тривиальные примеры метапрограммирования посмотреть. VD>Вот как будет выглядеть генерация функции считающей hesh code? И как ее применить?
В простом случае, как у тебя:
mixin template ImplementGetSheeshCode() {
size_t GetSheeshCode() // эта функция станет членом класса
{
alias T = typeof(this);
size_t h = 123;
foreach(m; __traits(allMembers, T)) // проходим по полям; такой foreach будет раскрыт, цикла не останетсяstatic if (m!="Monitor") {
static if (isIntegral!(typeof(__traits(getMember, T, m))))
h ^= __traits(getMember, T, m);
else static if (__traits(hasMember, typeof(__traits(getMember, T, m)), "toHash"))
h ^= __traits(getMember, T, m).toHash;
}
return h;
}
}
class A { // используем МП прямо там же, где только что определилиint Field1;
string Field2;
mixin ImplementGetSheeshCode; // не атрибут, но тоже одна строчка
}
void main(string[] argv)
{
auto a = new A;
writeln(a.GetSheeshCode());
}
Здравствуйте, FR, Вы писали:
FR>При всей моей любви к D он пока непригоден для сколько нибудь серьезных проектов, слишком пока быстро FR>развивается, слишком часто делают ломающие изменения. Разработчикам языка уже давно пора было остановится FR>и сделать стабильную 2.x версию.
Я думаю, последнее время это уже менее актуально. Сейчас они больше багфиксингом заняты. У меня есть несколько проектов, которые успешно пережили несколько версий компилятора, и я как-то не заметил никаких проблем и ломающих изменений. Т.е. формально да, пришлось несколько строчек поменять в коде, чтобы он опять собирался, но это дело минутное.
Здравствуйте, Erop, Вы писали:
E>Ну у меня вот сложилось впечатдение, что диапазоны конкретно хуже, язык лучше, но лучше в основном в тех местах, который в большинстве моих задач не критичны...
Ну у нас аналогично. Собственно критичным (т.е. то что можно на D и нельзя на C++) могут быть только области как-то завязанные на метапрограммирование и т.п. Например как здесь http://vibed.org эти возможности использованы для создания шаблонизатора страниц времени компиляции. Кстати, мы как раз эту штуку используем в тестовом проектике...
А так в большинстве случае конечно D относительно C++ — это в основном масса мелких приятных вкусностей и всё. Ну хотя там ещё многопоточное программирование очень сильно представлено, но это в принципе всё и на C++ реализуется отдельными библиотеками.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>[кэп]А то что ты такую функцию не сможешь использовать и в банальном multi-thread[/кэп]. EP>Те функции которые работают сокетами и т.п. — обычно thread-safe (например хоть urllib2.urlopen(url).read() из примера выше), если же нет — то об этом сказано в документации/интерфейсе
При чем здесь тред-сейф ? В асинхронном коде у тебя внутри ОДНОПОТОЧНОГО приложения будет сотня ниток. Вот эти нитки и будут ломать инварианты в разделяемых ресурсах.
Итого — вроде тредсейф, а инварианты ломаются.
A>>>>Фишка в том, что автор этого "произвольного кода" ничего не знает о том, что в вызывающей стороне делаются хаки и игры со стеком, и в следующей версии функций может поломать инварианты. Не, лучше явный async\await... EP>>>Давай примеры: EP>>>
EP>>>Придумай хотя бы пару примеров поломки инвариантов в функции которая принимает пользовательский stream, и гарантированно работает в многопоточной среде.
A>>Нафига?
EP>Все примеры выше где ломаются инварианты имели не thread-safe код — обсуждать это не интересно.
Вот простой фокус
// Вот код, с которым все шоколадно в синхронном однопоточном коде
value = read()
write(next(value))
// а вот однопоточныый вариант, но асинхронный
нить 1 value = read()
нить 2 value = read()
нить 2 write(next(value))
нить 1 write(next(value)) // нарушение инварианта
// и вот
нить 1 value = read()
нить 2 value = read()
нить 1 write(next(value))
нить 2 write(next(value)) // нарушение инварианта
Теперь делаем тредсейф
lock(_syncroot){
value = read()
write(next(value))
}
Здравствуйте, DarkEld3r, Вы писали:
DE>А можешь книги по Д посоветовать? Просто туториалов/вики как-то мало, хочется более подробного разбора фич. Смущает, что "The D Programming Language" аж в 2010 году издана, по идее, в языке немало изменений было. Или книга всё-таки актуальна?
Вполне актуальна. Т.е. лучше всего изучать по ней, а потом быстро глянуть, что изменилось, там не так много.
Из открытых источников стоит отметить такой: http://ddili.org/ders/d.en/
Еще надавно начали делать tutorial: http://qznc.github.io/d-tut/
Здравствуйте, matumba, Вы писали:
M>В эпоху гигагерцовых смартфонов как-то даже неудобно экономить миллисекунды. Не говоря о том, что Ди — тоже не петрушка, это нативный компилятор — ничто не мешает ему вылизать производительность.
Начнёшь прикручивать распознавание речи и образов, или ещё какую-нибудь числодробилку для домохозяек, в гигагерцовый смартофон — очень быстро вспомнишь про экономию миллисекунд.
Первое, чем захочешь пожертвовать — это сборкой мусора.
Ну а диапазоны вместо итераторов — это, возможно, баловство, а возможно, и не баловство — профайлер покажет.
Здравствуйте, matumba, Вы писали:
К>>Не путай свои требования и главные требования. M>Где они спутаны? Цитату в студию или трепло.
У тебя в голове спутаны. Откуда твоя уверенность, что промышленности позарез нужно именно выкинуть си и взять ди?
Задумайся на досуге о том, что промышленность так и не выкинула си. Неспроста, наверное.
А за "или трепло" сам знаешь, куда тебе пойти.
К>>У С++ есть два плюса: мультипарадигменность и поддержка наследия.
M>Мульти... чо??? Этот ассемблер с классами? Родной, это не "мультипарадигменность", а БАРДАК — так будет точнее. M>Наследие? Ну и что с того? Раньше и на PL/1 писали, он что, стал от этого полезнее или правильнее? Его заслуженно забыли, потому что вовремя осознали — не нужен.
Вот так взяли и вовремя осознали? Да просто DEC не стал портировать PL/1 на PDP, а потом все дождались, когда IBM370 сдохнет.
Найди нишу, в которой D будет доминировать в силу личного предпочтения основателей, и доживи до светлого момента, когда ниша C/C++ закроется.
Только искать и ждать придётся долго: места расхватаны.
К>>Сколько стоит перенести гору уже существующего кода с C++ на D?
M>С чего вы решили, что вообще нужно переносить этот хлам??? Ди — не просто повторение "Си с классами", а практически новая методология! Ну или сильно улучшенная, как нравится. Т.е. переносить старые костыли нет никакого смысла, Ди предлагает куда более интересные вещи (CTFE, mixins, ranges, RTTI), под которые надо ЗАНОВО писать код. Кроме того, "легаси" зачастую грешит полным отсутствием вменяемой архитектуры, шаблонов, да и просто устаревшими приёмами. Пример — GCC, вот уж точно кого следует зазиповать и закопать.
Вот-вот, надо заново писать код. Кто будет платить кодерам?
Народ вовсю фортраном пользуется, чтобы адский матан не переписывать на модные академические языки.
Здравствуйте, matumba, Вы писали:
EP>>У каждого языка есть свои цели, свои design guidelines. Язык это не просто набор фич. M>Это разве противоречит тому, что С++ просто УСТАРЕЛ?
А тут разве кто-то вообще говорит что он устарел?
В следующем году будут концепции — большой шаг вперёд. А что тут может предложить D? duck-typing?
EP>>Как известно, у C++ основным приоритетом является производительность. M>В эпоху гигагерцовых смартфонов как-то даже неудобно экономить миллисекунды.
M>Не говоря о том, что Ди — тоже не петрушка, это нативный компилятор — ничто не мешает ему вылизать производительность.
Ещё раз, язык D может пожертвовать производительностью ради других преимуществ, об этом говорит один из его авторов.
"Вылизывать" производительность можно в компиляторе, а вот когда сам язык приносит производительность в жертву другим фичам, то тут особо ничего не поделаешь
EP>>Взять например те же ranges — они проигрывают итераторам по производительности by-design M>Если вместо 0.0001 секунды работа будет сделана за 0.0003, никто на такую чепуху даже не обратит внимания.
Ещё бы, 3x — это уже такая мелочь, да и вообще всё в БАЗУ упирается
Здравствуйте, matumba, Вы писали:
M>>>Это разве противоречит тому, что С++ просто УСТАРЕЛ? EP>>А тут разве кто-то вообще говорит что он устарел? M>Нда... вроде криокамеры ещё не изобрели?
Аргументы?
EP>>В следующем году будут концепции — большой шаг вперёд.
M>Большой шаг вперёд из той задницы, откуда шагает С++ — это всё то же сидение в заднице.
Откуда столько злости и ненависти?
EP>> А что тут может предложить D? M>эээ... в смысле "какие новые ежемесячные печеньки"? Бог ты мой, да ДАВНО УЖЕ ВСЁ РЕАЛИЗОВАНО!
Реализованы концепции с автоматической перегрузкой?
EP>>"Вылизывать" производительность можно в компиляторе, а вот когда сам язык приносит производительность в жертву другим фичам, то тут особо ничего не поделаешь M>Да и не надо тут играть похоронный марш!
Я лишь говорю то, что слышал в интервью от одного из создателей языка
M>Вон, ассемблер — не чета всяким Сям — забыли?
Чтобы на ассемблере обогнать результат современных C++ компиляторов, надо очень сильно постараться
Здравствуйте, matumba, Вы писали:
M>Здравствуйте, DarkEld3r, Вы писали:
DE>>Вообще отвратительно впечатление производит, когда что-то "рекламируют" таким образом.
M>Бедного сипипи-кодера обидели фактом, что его язык устарел на 20 лет? Я вообще-то пылесосы не продаю и от тебя лично мне ничего не нужно, особенно если не умеешь читать суть поста. Я написал для потенциальных ди-программистов, что язык стал уже использоваться даже лицокнигой, что даёт ещё больший стимул изучать язык. А перетягивать разных скептиков с сакральными знаниями malloc/free — пусть идут дальше.
Вообще-то "бедные сипипи-кодеры" — это (в том числе) и есть потенциальные программисты на Д. Сомневаюсь, что к примеру с шарпа люди прямо так побегут.
Читать умею, тролля сразу заметил. Кстати, очень напоминает разных "лисперов" (в кавычках потому что грамотные специалисты там тоже есть) с лора, примерно такой же уровень артгументации и подачи материала.
Сам-то как думаешь — Александреску с этого дня больше не будет на С++ писать? Или перестанет доклады об этом языке устраивать? Или может ты сам на Д уже несколько проектов начал/завершил и есть чем похвастаться?
Самое забавное, что развитие языка мне интересно и эту "новость" прочёл пару дней назад, даже пару раз искал на рсдн обсуждение, думал может чего интересного напишут. Хотя раст, пожалуй, всё-таки поинтереснее выглядит... Просто надо поменьше фанатизма.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>>А в D спокойно могут пожертвовать производительностью ради других целей (об этом говорил A.A.).
EP><b>например</b>
В монологе с этой позиции Ал-ку говорит совершенно другое. Что они начинают отталкиваться не от угла треугольника эффективность-удобство-безопасность, а от середины, и в некотором смысле опровергают CAP-теорему для такого треугольника, т.е. дотягиваются до _всех_ его углов. И недавно он же писал на реддите:
"D offers the same level of control as C. There is no reason to escape from D into C or C++ for performance.
...
This is just hopeful rationalization of your knowledge and preference for C++ (which is btw entirely understandable). From the viewpoint of one who's fluent in both languages, I can say D's power is way ahead of anything C++14 could hope to achieve."
Здравствуйте, matumba, Вы писали:
M>DrDobbs обрадовал небольшой заметкой про использование языка D в таком крупном проекте, как Facebook. 5K LOC — как говорил Семёныч, выходя из пивной: "Маленький шажок человека, но большой шаг для человечества!". Действительно, ну не может же хороший язык быть вечным мальчиком для битья всякими язвительными сипиписниками — "разум когда-нибудь победит" (ц) Смысловые Галлюцинации.
При всей моей любви к D он пока непригоден для сколько нибудь серьезных проектов, слишком пока быстро
развивается, слишком часто делают ломающие изменения. Разработчикам языка уже давно пора было остановится
и сделать стабильную 2.x версию.
M>Надеюсь, что уже сам пример использования таким "гигантом", станет хорошим вдохновителем для масс — многие просто боятся использовать что-то малораздутое или новоиспечённые выскочки типа Rust/Go. Ди развивается уже много лет и к счастью — без давления легаси или коммерческой продавабельности (как C#), так что если под Ди встанет хороший фундамент инвестиций, сипипи-убожества навсегда покинут индустрию.
А вот за такой троллизм минус.
Основная масса тех кто интересуются D это как раз любители (включая и меня) этого "убожества"
Ты сам-то их читал? А понял о чём речь? Походу, нет.
Если кто-то (под воздействием дебильного пузыря "HTML5+JS") стал писать приложения на абсолютно непригодном, тормозном убожестве и при этом получил такие же отстойные приложения, как это соотносится с тем, что 1.5GHz процессор МОЖЕТ И ДОЛЖЕН исполнять всё быстро? Ты вообще в курсе, что первые "окна" работали на 40MHz i386, причём без ускорителя? Это в 37 раз медленнее, чем современный ARM-чип, и это только одно ядро ARM!
Вот как раз если бы писали под смартфоны на Ди, можно было бы вообще забыть про "тормоза". Вся надежда на D+LLVM.
EP>Такой foreach есть в C++98: boost::fusion::for_each. Не хватает только полиморфной лямбды (нужно вручную делать function object), которую скоро добавят.
Ну реально же страшно по сравнению с D. И не дай бог мелкую ошибку допустить и получим
километровое сообщение, и чуть начни более менее интенсивно такое применять, даже на мелких
проектах будет компиляция несколько минут минимум.
В D же все прозрачно, просто, одинаково что в компил что в ран тайм и без "синтаксического оверхеда"
наконец.
EP>Какой именно static if? В D он может применяться в нескольких разных контекстах.
static if вообще не разделяя на подвиды, и плюс CTFE конечно.
FR>>Ну и плюс такой сахар как Template Constraints позволяет писать в стиле контрактов нового С++, хотя конечно с более примитивным матчингом.
EP>Это же и есть один из вариантов static if, аналог которого есть в C++98 — enable_if.
Это да, я и писал про сахар, но это только одно мелкое применение, ну и опять удобней и проще.
Здравствуйте, matumba, Вы писали:
M>С чего вы решили, что вообще нужно переносить этот хлам??? Ди — не просто повторение "Си с классами", а практически новая методология! Ну или сильно улучшенная, как нравится. Т.е. переносить старые костыли нет никакого смысла, Ди предлагает куда более интересные вещи (CTFE, mixins, ranges, RTTI),
Ну ценность большинства кода состоит не в его технической части, а в содержательной...
M>под которые надо ЗАНОВО писать код.
Вот это-то и печалит...
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, Evgeny.Panasyuk, Вы писали: EP>Да ладно, в чём принципиальная разница EP>
EP>iota(0, 10).map!(x => x *x).filter!(x => x % 2)
EP>// versus
EP>irange(0, 10) | transformed(_1 * _1) | filtered(_1 % 2)
EP>// if use same names:
EP>iota(0, 10) | map(_1 * _1) | filter(_1 % 2)
EP>
?
Так уже лучше, хотя почему для организации цепочки вызовов используется оператор бинарного или все же не ясно.
Но тут встает другой вопрос. На D — это "гражданский" код, а на С++ магия метапограммирования которая в плюсах отнюдь не бесплатна. Проект забитый этим делом будет тормозить и выдавать фееричные сообщения в случае банальных ошибок.
В Ди и пытались сделать как в С++, но без приседаний.
ЗЫ
Ни разу не сторонник Ди, но объективности ради.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Ещё раз: EP>
EP>>Как известно, у C++ основным приоритетом является производительность.
EP>>А в D спокойно могут пожертвовать производительностью ради других целей (об этом говорил A.A.). Взять например те же ranges — они проигрывают итераторам по производительности by-design
Вот и читай свои же слова до просветления. Это не я путаю язык и библиотеку?
EP>Я показываю то, что авторы языка D готовы жертвовать производительностью. Сегодня ranges. А кто знает чем именно они пожертвуют завтра?
Ты показываешь то чего нет. Люди сделали библиотеку, а ты на этом основании делаешь выводы о языке.
Вот возьмем к примеру С. Чем он быстрее нежели Ди? Тем что с ним не идет такая же библиотека?
EP>У C++ zero-overhead (точнее don't pay for what you don't use) это практически главная цель — заменить его сможет только язык с такими же целями.
Про зеро ты сам только что придумал. Оверхед в С++ вполне себе реальный. Страуструп говорил, что мы не платим за то что не используем. Ну, так такой же принцип и тут.
VD>>Что до метапограммирования, то очевидно, что на D мета-код выглядит проще, работает существенно быстрее и выдает внятную диагностику.
EP>Вот тут я как раз и не спорю — на данном этапе у него больше возможностей для метапограммирования.
Данный этап длится около 30 лет.
Я плюсы бросил где-то в начале нулевых. По мне так лучше заплатить небольшим оверхэдом, чем всю жизнь жевать этот кактус.
EP>Что, кстати, немного странно: казалась бы, в языке с лучшей поддержкой compile-time вычислений, compile-time dispatch, метапограммирования — должна быть супер эффективная, гибкая, стандартная библиотека — так ведь нет, STL явно выигрывает
Чтобы что-то утверждать про эффективность нужно написать что-то значимое на том и на этом. А ты уперся в какие-то там итераторы и на их основе делаешь далеко идущие выводы.
Я как человек позанимавшийся метпаропграммированием скажу тебе, что твои рассуждения не о чем. При массовом использовании МП абстракции нижнего уровня вроде итеаторов и т.п. вообще значения не имеют. Мы тупо используем массивы и хардкорный код в стиле С на куда более высокоуровневом языке нежели Ди и С++ вместе взятые. И все потому что код этот мы руками не пишем. Мы его генерируем.
Я в Ди не силен, но думаю, что к нему это применимо точно так же.
Что до библиотек, то обычно 90% кода не критичны к производительности. А там где критично можно и на более низкоуровневый код перейти или создать библиотеки обеспечивающие абстракции с нужными характеристиками. Сам Ди вроде этому не мешает.
Так что по факту продвижению Ди больше мешают привычки и косность мышления нежели какие-то технические сложности.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Ikemefula, Вы писали:
I>>>Покажи реализацию без исключений, особенно return интересует
К>>Фигня-война. Если return void, то делается довольно просто.
I>Для каждого вида АПИ надо писать вот такую пару макросов или переходник, что бы эти макры юзать I>По моему это именно то, чего делать не надо — макросы вот такие.
Ты просил показать реализацию — я показал. Чисто proof of concept.
Другое дело, что это уродливое решение дурацкой проблемы. "А вот захотелось сделать императивный цикл над гетерогенными данными". А вот зачем он такой нужен?
Здравствуйте, jazzer, Вы писали:
J>Никто не говорит, что D хуже С++. J>Мы говорим, что то, что он может предложить по сравнению с С++11 (и С++14), недостаточно для того, чтоб все бросились переписывать на нем плюсовые программы или нанимать новых/переобучать имеющихся программеров. Овчинка выделки не стоит.
Странный аргумент. Программы на коболе, лиспе, фортране, ассемблере и многих других древних языках так же очень редко переписываются чисто ради "язык сменить". То есть, "бросились переписывать" для любого языке вещь крайне редкая.
Поэтому вопрос не в том, будут ли на D переписывать плюсовый код, а в том будет ли в новых проектах использоваться D и, если будет, то для чего.
Здравствуйте, Ikemefula, Вы писали:
I>Здравствуйте, jazzer, Вы писали:
I>>>Поэтому вопрос не в том, будут ли на D переписывать плюсовый код, а в том будет ли в новых проектах использоваться D и, если будет, то для чего.
J>>Для новых проектов на новых языках нужны новые программисты. А такое счастье никому не нужно. Чтоб вложиться в это, выгоды от нового языка должны быть очень большими.
I>Не новые, а уже имеющиеся и для начала этого хватит. В свое время сиплюсники переходили и на джаву, и на дотнет и каких то проблем не вызвало. Вот будут ли выгодны от D — вот это и хочется узнать.
Они туда переходили, потому что была мощнейшая финансовая поддержка со стороны Сана и Мелкософта (кстати, интересно, во сколько им обошелся весь евангелизм и разработка? Кому-нть попадались цифры?). Если Фейсбук вдруг обеспечит такую же мощную поддержку D — может, и взлетит тогда. Но я в этом сомневаюсь — Фейсбуку, в отличие от Мелкософта, никакой выгоды от D нет — Фейсбук не стрижет деньги ни со Студии, ни с Винды, на которой дотнет крутится. Так что вложенные в раскрутку деньги никак не окупятся.
Вот Немерле — замечательный язык — и что? И где он? В 5 с половиной проектах на весь мир? И таких Немерлей — море. У них у всех есть какие-нть преимущества перед имеющимися. Причем реальные преимущества. Но их недостаточно — киллер-фичи нет. А если есть — так скорее мейнстримные языки эту фичу в себя в каком-то виде втянут (что мы все наблюдаем на примере функциональщины и DSL-ей), чем народ все бросит и дружно перейдет на маргинальный язык.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>_1 это библиотечная полиморфная лямбда,
Давай поглядим на ее реализацию. Приведи, плиз.
EP>если считаешь магией — то есть встроенная в язык, но для неё нужно чуть больше закорючек.
Ага. Больше. И существенно. и это через 30 лет эволюции языка. А 29 лет в нем вообще не было бямбд. Хотя лямбды старше С++ еще на 30 лет.
В ди же они встроены и почти не вызывают нареканий.
Мне кажется — это реальный плюс.
EP>Чисто как язык — возможно. Но помимо языка нужна платформа — библиотеки, компиляторы, с которыми, afaik, пока не густо.
Библиотеки дело наживное. Если бы люди вроде тебя вместо того чтобы искать фатальные достатки просто попробовали что-нить написать на Ди, то и библиотеки появились бы.
Что касается ренджей, то они, скорее всего, и так достаточно быстрые и никому не нужно искать им замену. А где нужно битовыжимание можно и специализированные структуры данных использовать.
VD>>За фиг нужен статик иф если есть обычный?
EP>Те ветки кода которые отбраковываются — практически не проверяются компилятором.
я показал аналог D-шного кода на Nemerle. Отличие между ними в том, что в D мета-код — это специальный вид кода, а в Nemerle — это обычный код на Nemerle использующий компилятор как API.
Заметь в Nemerle if самый обыкновенный. static if не нужен, а кодом можно манипулировать как данными.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>>>В С++ пока нет compile-time reflection, VD>>Ага. Это "пока" наблюдается самую малость — на протяжении 30 лет.
EP>В смысле? Study group для reflection появилась недавно.
Кого это трогает? Комитет по С++ существует не менее 20 лет. За это время гора родила мышь.
EP>Или ты думаешь что создатели уже 30 лет думают как бы впихнуть reflection, да всё никак не получается?
Я не думаю. Я знаю об этом. Мы 10 лет назад обсуждали эту тему. А воз и ныне там.
EP>Слушай, я тебе вчера, точнее даже сегодня писал
:... EP>>Вот тут я как раз и не спорю — на данном этапе у него больше возможностей для метапограммирования.
А в какой области то у него что-то лучше?
EP>Или тебе больше не о чём поспорить?
Я и не спорю. Просто тема итераторов смешна. А больше вы ничего предявить не хотите.
Я понимаю, Матумба — это такой матумба. Ему оскорбить окружающий что два пальца об освальт. Но выдвигая, в ответ его наездам, тезис — "С++ лучше", нужно его хоть чем-то обосновать.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Не зачет. Это хрень а не решение. Попробуй всунуть это в имеющуюся программу. Да и говнокод полнейший.
Я подобной хренью с MAP-ами на препроцессоре 10 лет назад маялся. Больше не хочу.
И это еще очень упрощенная задача. Реальные решения сложнее в сотни раз. Там тебе и анализ наследников, и специальные решения для разных типов. И многое другое. А работает это все в разы быстрее чем С++ пережевывает шаблоны и инклюды.
В твоем решении даже нет:
1) проверки для int;
2) формирования метода.
EP>И внезапно, полный код выглядит на порядок чище чем в D и Nemerle
Это потому что ты знаешь ровно один язык. Очень советую изучить тот же D и Nemerle, тогда ты подобные заблуждения высказывать не будешь. Код по ссылке решает исходную задачу, а не подогнанную и упрощенную. И он таки проще, чем твой. Только надо иметь базовые знания для его понимания.
EP>>>Нет. D-style range'и не добавляют ни параллельности, ни иммутабельности. VD>>Они банально удобно для функционального программирования,
EP>Чем они удобней?
Да всем. Ты попробуй реальный код пописать, и сам поймешь.
Ренжи — это аналоги ленивых списков из ФП или IEnumerable из дотнета. Ленивые списки в купе с правильной библиотекой вроде linq-а повышают уровень кода в разы. При этом код компилируется довольно быстро и есть полноценный интелисенс.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>А где тут кто-то говорил про невероятную крутизну C++?
А разве не ты бросился отстаивать его превосходство над тем же D?
EP>Я вот не пойму — откуда у программистов не пишущих на C++ к нему такая злость/зависть/etc?
Лично у меня злобы нет. Может и была лет 10 назад, когда он перестал меня удовлетворять. Но с тех времен я про него уже давно забыл.
Тут скорее есть некоторая злость на таких как вы, защищающих черт знает что не пробовав альтернатив.
У новых языков (D, Scala, F#, Nemerle, Kotlin, Haskel, ...) есть только одна проблема — размеры комьюнити. Куча народа, вроде вас, ходит и что-то там себе доказывает вместо того чтобы взять и начать помогать развивать перспективные языки.
Вот и получается, что в мэйнстриме обитают далеко не лучшие языки, загруженные грузом совместимости и маразма царившего в головах во времена их появления.
Ну, глупо в 21-м веке использовать языки в которых:
1. Не поддерживается модульность, а вместо нее есть препроцессор с инклюдами.
2. 30 лет не могут создать полноценный интелисенс.
3. Скорость компиляции больших проектов чудовищно низкая.
4. Система метапрограммирования основана на побочных эффектах от других средств, а не разработана специально.
5. Нет бинарного ABI.
6. Нет даже соглашений по формированию имен функций в библиотеках.
7. Требуются предварительные декларации.
8. Нет даже опциональной системы автоматического управления памятью.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Да вот здесь (уперся в какую-то незначительную хрень неизвестно зачем): EP>>Как известно, у C++ основным приоритетом является производительность. EP>>А в D спокойно могут пожертвовать производительностью ради других целей (об этом говорил A.A.). EP>2. EP>>Взять например те же ranges — они проигрывают итераторам по производительности by-design EP>[/q]
EP>И ровно в этих рамках я и пытаюсь остаться.
Ага. Приводя говногод на мапах созданных из макросов вместо полноценных решений и называя при этом полноценные решения
EP>Обсуждать метапрограммирование не особо интересно — так как все согласны что оно мощнее у D.
Метапрограммирование способно заменить все твои абстракции и сделать код настолько быстрым насколько это позволяет железо. Я тебе уже говорил об этом. Но ты даже не смог понять моих слов. Начал какие-то ссылки на мат-библиотеки давать.
Пойми, если у тебя выбор между ренжами и итераторами, то у меня выбор между работой с указателями или прямым использованием массивов. Мой выбор априори не имеет оверхэда. И мне плевать, что ты в С++ сочтешь мой подход грязным и неприемлемым, так как я свой код руками писать не буду.
Мои абстракции — это макросы (синтаксические и типизированные) которые скрывают сложность и дерьмвость кода, а так же позволяют изменить реализацию, заменить типы контейнеров (по вашему) и вообще сделать все что угодно, просто заменим реализацию поры генерирующих функций.
Короче, совсем другие подход. Чем-то похоже на метапрограммирование на шаблонах, только без их тормозов, выноса мозга, ограничений и феерических сообщений об ошибках.
EP>Где ты тут видишь "бросился отстаивать его превосходство над тем же D".
Да вот же выше.
EP>>>Я вот не пойму — откуда у программистов не пишущих на C++ к нему такая злость/зависть/etc? VD>>Лично у меня злобы нет.
EP>Да ладно: EP>1. Ты говоришь что я "бросился отстаивать его превосходство над тем же D".
Что вижу, то и говорю. Ты еще довольно адекватен. Некоторые начинают доказывать крутость МП на шаблонах. Это вообще звиздец.
EP>2. Считаешь что программисты которые используют C++ — знают только один язык.
Не программисты, а конкретно ты. Я сам не мало писал на плюсах. Правда тогда они были несколько другими. А один мой коллега писал на плюсах еще 1.5 года назад и весьма в нем приуспел. Сейчас мы вот оба пишем на Nemerle полностью сходимся во мнении по поводу С++ — язык для выжимания битов.
EP>3. Говоришь что кто-то тут выдвигает тезис "С++ лучше"
А что ты тогда делаешь в это теме. Мы кажется выяснили, что твои тезисы не верны. Но ты продолжаешь их отстаивать, подменяя язык библиотекой и оправдываясь тем, что видите ли программистам некогда писать библиотеки.
EP>4. Игнорируешь то, что тут все согласны что в D метапрограммирование лучше, и пытаешься поджечь холивар на эту тему.
ты привел в каких целях? Там еще забавные слова есть:
И внезапно, полный код выглядит на порядок чище чем в D и Nemerle.
хотя решение — банальное мошенничество. Поставленную задачу не решает (и не может, по описанным тобой же причинам).
EP>Если это не от злобы, то от чего?
Поверь. Мне плевать на С++. Да и на D, тоже. Злобы у меня нет ни на гршь. Просто я моя ранимая душа не может спокойно смотреть на бессмысленные и некорреткные обоснования того что обоснования иметь не может, так как не верно.
Правда в том, что единственным реальным преимуществом С++ является его поддержка монстрами индустрии. Ну, и то что родился он в мего-корпорации. Все остальное — следствие.
С++, конечно, не некудышный язык. И он действительно позволяет писать быстродействующий код. Но Ди тут от него ничем не отличается. Да и разрыв между С++ и скажем дотнетом или Явой не так значителен как многие пытаются утверждать. Для большинства применений разница не критична, а стоимость разработки разница на порядки.
EP>Страуструп уже более 30 лет развивает язык, несмотря на его "неидеальность" — улучшает и улучшает.
Честь ему и хвала, претензии ведь не к нему. Он сделал что мог. Ну, возможно, затормоизл равитие языка. Но не это не его одного вина. Там ведь комитет. А комитет — это существо с множеством рук и ног и полным отсутствием головы.
EP>Мог бы он бросить всё и создать "перспективный, динамично развивающийся и т.п."? — да конечно мог бы. Он мог бы делать также как и Вирт — сколько там у него языков было? — вот только где сейчас все эти перспективные и развивающийся?
Не знаю. Мне по фиг. Лучшие языки создали без него. Но серые массыинтеллектуальное большинство вот уже 10 лет ищет оправдание том что мешает им хотя бы попробовать альтернативу. А менеджеры ищут оправдание почему тот или иной язык нельзя применять в разработке. И что характерно, успешно находят.
VD>>Ну, глупо в 21-м веке использовать языки в которых:
EP>Глупо — это ждать того, что программисты внезапно бросят всё и присоединятся к комьюнити малоиспользуемого языка.
Возможно. Я не жду. Моя вера в человеческий разум угасла много лет назад. Я просто пользуюсь тем, что мне удобно и помогаю делать это другим.
EP>Глупо ждать того, что индустрия резко станет оказывать гуманитарную помощь "перспективным языкам".
Глупо говорить о помощи самое себе. Перейдя на более перспективные языки и технологии "индустрия" могла бы повысить свое КПД. Это примерно как называть гуманитарной помощью использование научных достижений в производстве и сельском хозяйстве.
VD>>1. Не поддерживается модульность, а вместо нее есть препроцессор с инклюдами.
EP>Это действительно проблема. Ведётся работа.
Ага. Напомню, ведется 30 лет. Я лично ждал 5 лет и устал.
VD>>2. 30 лет не могут создать полноценный интелисенс.
EP>Ничего критичного.
Критично для производительности.
VD>>3. Скорость компиляции больших проектов чудовищно низкая.
EP>Проблема есть, но не в "чудовищных" масштабах.
Достаточно. Интерактивность разработки падает, а это резко снижает скорость продвижения вперед проекта.
Скажу тебе по серету, что похожая проблема есть в Немерле. Он выводит типы круто, но медленно. Не так медленно, чтобы по 15 минут ждать компиляции проекта, но все же по 2-3 минуты иногда приходится ждать. А это очень замедляет разработку.
По сему мы работаем над тем, чтобы сделать вторую версию лишенную этого недостатка. А вот терпеть — это не для нас. Это без нас как-нибудь.
VD>>4. Система метапрограммирования основана на побочных эффектах от других средств, а не разработа специально.
EP>А кто сказал что нужна какая-то специально разработанная мета-система?
Никто. А надо? Что это меняет?
EP>Метапрограммирование — это практически хак, который приходит на помощь там где недостаточно мощи самого языка.
Вот именно. А недостатков много. Так что Буст чуть менее чем полностью является такими вот костылями.
EP>В большинстве кода нет ничего мета*, только потому, что и без него всё хорошо
В большинстве кода есть мета* из библиотек. В купе с инклюдами это тормоза и невнятна диагностика.
VD>>5. Нет бинарного ABI.
EP>Действительно есть такая проблема, но совсем острая. EP>Если ограничится одной платформой, как делают некоторые языки, например .NET-ом, а-ля C++CLI/CX — то ABI получается что есть
А зачем ограничиваться, если тот же Ди его предоставляет? Может лучше стандартизировать объектно-функциональный ABI и перевести новую версию плюсов на нее? А еще лучше забыть про С++ и сделать новый язык / довести до ума один из имеющихся?
VD>>6. Нет даже соглашений по формированию имен функций в библиотеках.
EP>Мелочь, причём спорная.
Что там спорного? Из-за этого все библиотеки С++ распространяются в исходниках.
VD>>7. Требуются предварительные декларации.
EP>Мелочь.
Все мелочи. Но в купе набегает. И выходит, что язык сильно устарел, а новые не принимают.
VD>>8. Нет даже опциональной системы автоматического управления памятью.
EP>В ISO C++11 есть интерфейс для GC — но он вообще не популярен, что скорее говорит об востребованности
В С++ с его моделью памяти нельзя сделать поддержку точного GC, так что спека тут не поможет. А зачем нужно медленное и кривое решение?
Короче, проблем выше крыши. Они не решаются уже много много лет. И все это время люди упорно игнорируют решения в которых таких проблем нет. Ну разве что МС и Сан смогли протолкнуть языки на базе виртуальных машин. Но ни один нативный язык так в мэйнстрим и не пробился, если не считать дельфи который просто уничтожил МС сманив главного разработчика языка.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, VladD2, Вы писали:
EP>>Там где не хватит скорости Spirit'а или подобного — я спокойно могу взять внешний генератор кода
VD>Spirit — это детство полное. А генераторов динамически расширяемых парсеров пока в природе очень мало. Можно сказать — нет. Мы же не просто очердной Як лепим. У нас задача фикс — сделать фреймворк который позволит создавать языки (любые, от ДСЛ-я, до языка общего назначения) настолько просто, что люди будут тупо решать задачи в терминах предметной области делая на нашем средстве все тулы (от компилятора, до IDE).
Spirit решает совершенно конкретную задачу — рантайм-парсинг. И решает ее на 5. У него нет задачи "сделать фреймворк который позволит создавать языки".
Здравствуйте, alex_public, Вы писали:
_>Теперь посмотри что даёт нам голый D. Удобные массивы со срезами, итерациями, контролем памяти. Плюс ещё ассоциативные массивы. Это покрывает огромное множество задач. Т.е. я думаю что вполне возможно довольно долго работать на D, вообще не заглядывая в те разделы библиотеки.
Да какая разница куда заглядывать — в описание встроенных в язык хэш-таблиц или в описание библиотечных (причём стандартная библиотека это практически часть языка). А заглядывать в любом случае придётся — например чтобы правильно сделать хэширование для своего типа, или хотя бы как правильно удалить.
У нас же нет задачи высадится на остров взяв собой только компилятор, потому что стандартная библиотека в чемодан не помещается
Здравствуйте, alex_public, Вы писали:
DM>>Если мы откуда-то пришли, значит мы там уже были и могли запомнить это место (.save), зачем туда опять пешком идти? _>Дело не в месте, а в направление. Итерация назад в варианте BidirectionalRange возможна только с конца. В то время как у нормального двусвязного списка с любого элемента.
Ну так если мы работаем не с итераторами, а с рэнджами, то к этому любому элементу мы можем прийти только оперируя рэнджем, а значит этот "любой элемент" и будет концом некоторого рэнджа. Неудобно лишь туда-сюда ерзать, но это и не должно быть удобно, такое ерзание — либо редкое извращение (для которого можно и специальный код написать), либо просто плохой алгоритм, для которого есть правильное решение в один проход.
Re[23]: Facebook и язык D - первый шаг к правде ;).
Здравствуйте, alex_public, Вы писали:
_>Если же взять D, то он очевидно нацелен не на новую нишу, а как прямая замена C/C++ в его родных нишах. Ну может быть предлагая небольшое расширение в чужие ниши, за счёт сильного инструмента построения быстрых DSL. Т.е. по сути здесь предполагается, что программисты будут оставаться на своей текущей работе и тратить время на обучение D только ради увеличения удобства. А это у нас крайне консервативный процесс. Достаточно взглянуть на то, что на дико страшном Фортране до сих пор пишут, хотя современный C++ делает его по всем параметрам...
Да даже перевести проект с С++03 на С++11 — та еще история, а тут — целый новый язык
Здравствуйте, D. Mon, Вы писали:
DM>Ну вот Евгений выше очень радел именно за стандартную библиотеку. Говорил, что это часть языка, и ее проблемы становятся проблемами всего языка. Вон сколько сообщений написал про одну единственную функцию поиска..
Во-первых, ты можешь обсудить это с Евгением.
Во-вторых, IMHO, ди в смысле метапрограммирования круче нынешних плюсов, так что то, что можно на них, можно, наверное, как-то и на Ди. Так что можно отдельно сравнивать подходы, отдельно реализации, и отдельно дизайн языков.
Насколько я понял Евгения, он, как впрочем и я, считает дишные интервалы менее удачными, чем сишные, и привёл это в пример того, что авторы зыка готовы идти на неудачные с технической т. з. решения ради своих спорных идей о прекрасном
DM>Если просто save, то скорее всего повторит. Ежели там сложные вычисления, то вместо .save пишешь .array и получаешь все мемоизованное.
Э-э-э, тогда уж лучше итераторы энергично вычислить, чем копию массива делать, не?
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, Erop, Вы писали:
I>>Так это лично твои проблемы
E>не-не-не, у меня нет в продакшине кода на Ди, соответственно и проблем нет... E>Но вот Владу в такой ситуации что-то не нравится
В с++ ты, понятное дело, не используешь ничего из того, чем можно прострелить ногу ? То есть, ни указателей, ни исключений, ни шаблонов, ни виртуальных методов, ни конструкторов, ни деструкторов, ни операторов, ни смартпоинтеров... И вот по этой единственной причине твой проект "выстрелил" ? А то бы выстрелил ты себе в спину и всё, капут
Здравствуйте, alex_public, Вы писали:
_>Да, но применимость этих парадигм в разных языках получается разная. Например лично я при работе на C++ использую STL постоянно, а при работе на D std.range считай что почти не использовал.
Что как бы намекает нам, что из двух удобнее/полезнее и т. д...
При этом С++ не содержит в самом языке никакой поддержки итераторов, вернее раньше не содержал, пока форич не привинтили, в отличии от ди...
_>В итоге, как мы видим по данному вопросу у этих двух языков в разных ситуациях есть свои плюсы и минусы. Но лично мне почему-то чаще встречаются на практике именно те ситуации (пункт 1 и 3), в которых сильнее D.
_>P.S. Основная деятельность у нас как раз на C++. )))
Ну у меня вот сложилось впечатдение, что диапазоны конкретно хуже, язык лучше, но лучше в основном в тех местах, который в большинстве моих задач не критичны...
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, PSV100, Вы писали:
PSV>В принципе, вроде как, он вполне адекватно описывает причины выбора ranges, их плюсы и кривости тоже.
Дык о том и речь же, что D более компромиссный, чем С++, в результате получилось уже не С++, но ещё не C#
То есть, если ты выбираешь из D и C++, и склоняешься с D, то не ясно, почему не к C#?
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, Erop, Вы писали:
E>С некоторой точки зрения мощь вообще вредна, так как требует квалифицированных усилий по управлению собой...
Ну да, согласен, есть такой момент... Собственно именно поэтому я никогда и не говорю чего-то типа "C# не нужен" (а вот как раз его фанаты частенько грешат подобным здесь). В своей родной нише "внутрикорпоративного ПО, созданного низкоквалифицированными программистами, Java и C# безусловно лучшие. Они позволяют неайтишным корпорациям особо не напрягаться по поиску крутых профи в свои IT отделы, которые для них являются лишь вспомогательными. Плюс благодаря единообразию в этих языках получается ещё гарантированная взаимозаменяемость таких сотрудников. Но с точки зрения профи из айтишной компании это всё конечно очень печально выглядит. )))
_>Это не то, это обычная синхронная работа ComplexFunction (блокирующая ui на время ожидания прихода всех данных), только отложенная на потом. В этом никакого особого смысла нет. А нам надо чтобы ComplexFunction отдавал управление, когда во входном потоке нет данных. Как видно на C++ это делается очень просто...
Только я тебя попрошу показать реализацию async_stream(input_stream) и ты опять напишешь 30 и более строк ада с макросами и бустом, а в .NET, с вероятностью 95%, уже есть готовый класс, который решит твою задачу.
G>>Я же говорю, ты слишком плохо .NET знаешь. _>Ага, ага. Только пока что глядя на тебя видно много понтов, а когда доходит до дела, то только пшик.
Какого дела? Ты выососал из пальца какую-то хрень. В реальной програмее ComplexFunction тупо перепишут, потыкав везде await и она станет идеально асинхронной и будет сама маршалить вызовы в UI если надо.
Я же говорю, твое понимание .NET на уровне плинтуса. Ты можешь миллион таких пшиков нагенерить, и все они будут бесконечно далеки от реальной жизни.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Здравствуйте, gandjustas, Вы писали:
G>>Читал, а толку то? Этот подход решает очень узкую задачу — асинхронное чтение буковок. Это можно и с меньшим количеством кода сделать. G>>На обобщенный метод превращения синхронного кода в асинхронный не тянет.
EP>std::getline тут стандартная, не модифицированная. Точно также можно протащить yield и через любую другую функцию
Да, вот только надо очень хорошо понимать как работает эта функция. К счастью для переписывания синхронного кода в асинхронный в .NET не надо разбираться как он внтури устроен. Можно просто базвоые методы, которые делают IO сделать async, а дальше следуя руганиям компилятора добавить async\await во все методы выше по цепочке вызовов.
EP>>>Что значит особый случай? Точно также можно завернуть tcp_stream. G>>Надо очень хорошо знать как код работает внутри, чтобы делать такую асинхронность. EP>Есть любая асинхронная функция которая принимает continuation/.then — мы ей передаём в этот continuation код с yield-ом внутри, что механически превращает остаток нашей функции в продолжение.
Пример давай.
G>>А как комбинировать такие асинхронные вызовы не то что не очевидно, а вообще непонятно как. EP>Ты о чём?
Напрмиер так:
у тебя есть асинхронные функции f1 и f2, внтури они делают какой-то IO. Тебе нужно написать функцию f3, которая вызывает f1 и f2 параллельно, ждет их завершения и вызывает асинхронную операцию.
Реальное применение такой функции — сервис поиска авиабилетов. Он обращается параллельно к десяткам перевозчиков, получает данные, выбирает лучшие варианты, отдает клиентам. Естественно это hiload сервис, который не может позволить себе создавать потоки.
EP>>>При этом код использующий этот поток не поменяется, а в случае с C# await — нужно будет патчить весь call-stack G>>А зачем это делать? Преобразование синхронного кода в асинхронный — механическая операция, легко автоматизируется при желании. Я даже для стримов на roslyn такое переписывание делал.
EP>С такими же рассуждениями можно прийти к мысли что и yield, и await/async не нужны
Практика то показывает что нужны. Причем тут рассуждения?
То что ты считаешь что нужно патчить call-stack — вывод, основанный на неверной посылке.
EP>>>Причём большую часть boilerplate'а необходимого для заворачивания в корутины, легко вынести в библиотеку G>>Почему до сих пор никто не сделал? Видимо не так просто, ибо более чем востребовано в наше время.
EP>Как это никто не сделал? Раз, два, да даже возьми хоть мой пример реализации await
(это при том что я сам практически не работаю ни с каким io).
Без асинхронного IO это все смысла не имеет. Покажи пример с асинхронным IO.
В мире есть два источника асинхронности — люди и IO (на самом деле еще и таймеры, но они не отличаются от людей). Все остальное может и должно выполняться синхронно.
Для действия людей уже есть события. А для IO есть IOCP или аналогичные механизмы в других ОС.
Основная проблема в том, что IOCP и другие механизмы не сохраняют стек, поэтому придется значительно извратиться чтобы на это натянуть stackfull coroutines.
G>>>>Кроме того все это выполняется через глобальную переменную. Запустить два таких считывания уже не выйдет. EP>>>Это минимальный пример показывающий как вызов std::getline может работать с асинхронным потоком. G>>Проблема в том, что они показывает только вызов std::getline. Покажи как сделать тоже самое с вводом-выводом на IOCP. EP>>>Если будет async_tcp_stream — то будет хоть 100k соединений G>>Для начала тебе надо будет async io реализовать на IOCP.
EP>Ты мне предлагаешь реализовать свои обвёртки поверх голого IOCP? Зачем?
Без асинхронного IO все что ты пишешь не имеет смысла. Вообще.
Оно приведет только к деградации производительности.
Ты вообще представляешь как медленно будет работать твой пример с getline на реальном файле?
Опубликуешь результаты забегов? При этом масштабирования такой подход не добавил. Ты не сможешь также запустить 100500 чтений файлов и выйграть хоть что-то.
G>>>>Ты считаешь что такое "решение" способно тягаться с async\await в C#? EP>>>await-like синтаксис легко реализуется поверх корутин
, только получается намного мощнее, так как не ограничен одним уровнем. G>>Каким одним уровнем? ты о чем?
EP>О том, что для того чтобы сделать yield с самого низа callstack'а на самый вверх, тебе придётся дублировать и модифицировать каждый уровень. Причём эти уровни могут находится в библиотеках к которым нет доступа.
В смысле "нет доступа" ?
Если библиотеки — "черный ящик", то и твой подход не поможет, потому что требует знать как внутри работа устроена.
Если у тебя таки есть доступ к исходникам, то кто мешает сделать ctrl+c-ctrl+v и добавить async\await?
Кроме того в .NET код можно вытащить и из скомпилированных бинарников, а отличие от...
G>>>>А вот ты на C# await повторить пример с getline-like никак не сможешь. Разве не очевидно что мощнее G>>А зачем его повторять? Я же говорю что просто дописываешь async\await где можно код становится асинхронным. Даже понимать не надо как код работает.
EP>У тебя нет кода std::getline (или аналога) — куда ты там собрался дописывать await?
Если тебя нет когда getline, то как ты написал свой код? Он же полностью базируется на знании устройства getline, значит код у тебя есть.
Здравствуйте, alex_public, Вы писали:
_>Здравствуйте, gandjustas, Вы писали:
G>>Наверное потому что async\await отлично работает как на клиенте, так и на сервере. А ты сделал менее эффективный пример, который и этом нифига не масштабируется.
_>Клиент или сервер — это не принципиально. Важно количество соединений. И если мы имеем дело с системой под большие нагрузки (множество соединений), то уж точно глупо брать async\await из C# — это мягко говоря не лучший вариант по производительности.
Ты понять показываешь незнание предмета. Какой вариант по твоему лучший?
_>Место async\await из C# как раз в фоновой обработке нажатий на кнопки и т.п. Причём желательно в варианте с запуском потоков.
Пешы исчо....
G>>Если ты начнешь масштабировать свой подход, то он начнет дико тормозить. А если подход нельзя масштабировать, то нафига он такой нужен?
_>Какое масштабировать подход? У нас кнопка на экране для пользователя. По её нажатию в фоне запускается некий процесс, результат которого потом выдаёт на экран. Какое нафиг масштабирование тут? )))
Тут не надо. Тут достаточно потока.
Но видимо тупо везде создавать потоки неэффективно, поэтому и придумали IOCP, пулы потоков, таски и async\await.
_>И кстати как раз для таких вещей системные потоки вполне оптимальны. Более того, как раз если мы попробуем реализовать это без системный потоков, а наш фоновый процесс будер производит какие-то реальные вычисления, то у нас именно из-за отсутствия потоков начнёт подтормаживать интерфейс...
Это зависит от того что за фоновый процесс. Если там IO, то создание потоков — совсем не оптимальный способ. А практика показывает что подобные фоновые процессы в 99% случаев — io.
G>>Решить частную задачу по созданию асинхронности одной функции можно запустив её в отдельном потоке, дописав маршалинг вызовов в UI и получится меньше чем пляски с корутинами\шаблонами\макросами.
_>Ну собственно лично я действительно не вижу особых преимуществ от подобной линеаризации кода, что в .net, что в C++. Но если кому-то нравится, то почему бы и нет. И как мы видим C++ вариант при этом получается мощнее.
Пока не работает с async io говорить не о чем.
_>А так, конечно реальная потребность подобных вещей появляется только при реализации чего-то типа легковесных потоков. Но тут как раз .net вариант заметно слабее, т.к. уже становятся принципиальны накладные расходы.
Ты о чем вообще? Для чего тебе леговесные потоки?
задачку. Ты же обещался: "я напишу такой же на C# в 3 раза короче". Или уже всё, слив? ) G>>Дык я тебе уже написал, примерно с тем же уровнем детализации. _>Это где? Я не видел от тебя ни одного куска кода.
Ок, давай конкретнее, если сам мозгом не работаешь:
Было
void Echo(Stream s)
{
var buf = new byte[256];
while(true)
{
var len = s.Read(buf,0,buf.Lenght);
s.Write(bof,0,len);
}
}
Стало (жирным выделил что изменилось)
async void Echo(Stream s)
{
var buf = new byte[256];
while(true)
{
var len = await s.ReadAsync(buf,0,buf.Lenght);
await s.WriteAsync(bof,0,len);
}
}
А еще парой ловких движений можно и отмену прикрутить.
Но это ты можешь и в документации почитать.
G>>Еще раз повторю — все изменения только в дописывании async\await. _>Дописывание куда? По условиям задачи мы должны использовать существующий библиотечный код. Т.е. его нельзя модифицировать или переписывать.
Кому должны? Какой библиотечный код? Ты же пишешь реализацию оператора >> зная как он используется внтури функции. Это значит что исходники у тебя есть.
Для "черного ящика" ты так не напишешь. Да и в общем случае сделать из синхронного черного ящика асинхронный нельзя, потому что нет гарантии не нарушения инвариантов.
Здравствуйте, alex_public, Вы писали:
_>Здравствуйте, gandjustas, Вы писали:
G>>Думаю стоит глянуть на Mono и Xamarin, перед тем как толкать такие утверждения. Сейчас спектр систем, где заработает код на C#, примерно такой же, как у java и у обоих гораздо шире, чем у C++.
_>С учётом того, на чём написаны сами .net, mono, java, эта фраза звучит особенно пикантно. Видимо здесь присутствует какая-то магия. )))
Это тебе помогает писать код? Какая разница на чем рантайм написан, если ты прикладные вещи пишешь?
Почему-то факт, что райнтайм .NET написан на C++, не помогает произвольному скомпилированному коду на C++ одинаково хорошо работать на iOS, Android и в браузере на клиенте.
Тут же не вопрос яйца или курицы, а вопрос в том сколько надо кода написать, чтобы добиться результата. Увы по этому параметру C++ проигрывает, а в некоторых случаях в принципе не может быть использован.
Здравствуйте, gandjustas, Вы писали:
EP>>std::getline тут стандартная, не модифицированная. Точно также можно протащить yield и через любую другую функцию G>Да, вот только надо очень хорошо понимать как работает эта функция. К счастью для переписывания синхронного кода в асинхронный в .NET не надо разбираться как он внтури устроен. Можно просто базвоые методы, которые делают IO сделать async, а дальше следуя руганиям компилятора добавить async\await во все методы выше по цепочке вызовов.
В цепочке вызовов находится код исходников которого нет, что теперь?
EP>>>>Что значит особый случай? Точно также можно завернуть tcp_stream. G>>>Надо очень хорошо знать как код работает внутри, чтобы делать такую асинхронность. EP>>Есть любая асинхронная функция которая принимает continuation/.then — мы ей передаём в этот continuation код с yield-ом внутри, что механически превращает остаток нашей функции в продолжение. G>Пример давай.
G>>>А как комбинировать такие асинхронные вызовы не то что не очевидно, а вообще непонятно как. EP>>Ты о чём? G>Напрмиер так: G>у тебя есть асинхронные функции f1 и f2, внтури они делают какой-то IO. Тебе нужно написать функцию f3, которая вызывает f1 и f2 параллельно, ждет их завершения и вызывает асинхронную операцию. G>Реальное применение такой функции — сервис поиска авиабилетов. Он обращается параллельно к десяткам перевозчиков, получает данные, выбирает лучшие варианты, отдает клиентам. Естественно это hiload сервис, который не может позволить себе создавать потоки.
int bar(int i)
{
// await is not limited by "one level" as in C#auto result = await async([i]{ return reschedule(), i*100; });
return result + i*10;
}
int foo(int i)
{
cout << i << ":\tbegin" << endl;
// instead of async can be any future with .then
cout << await async([i]{ return reschedule(), i*10; }) << ":\tbody" << endl;
cout << bar(i) << ":\tend" << endl;
return i*1000;
}
void async_user_handler()
{
vector<future<int>> fs;
// instead of `async` at function signature, `asynchronous` should be
// used at the call place:for(auto i=0; i!=5; ++i)
fs.push_back( asynchronous([i]{ return foo(i+1); }) );
for(auto &&f : fs)
cout << await f << ":\tafter end" << endl;
}
EP>>>>При этом код использующий этот поток не поменяется, а в случае с C# await — нужно будет патчить весь call-stack G>>>А зачем это делать? Преобразование синхронного кода в асинхронный — механическая операция, легко автоматизируется при желании. Я даже для стримов на roslyn такое переписывание делал. EP>>С такими же рассуждениями можно прийти к мысли что и yield, и await/async не нужны G>Практика то показывает что нужны. Причем тут рассуждения?
Ну ты говоришь что преобразование синхронного кода в асинхронный это механическая операция. Так и преобразование кода с await/yield — точно такая же механическая операция
G>То что ты считаешь что нужно патчить call-stack — вывод, основанный на неверной посылке.
(это при том что я сам практически не работаю ни с каким io). G>Без асинхронного IO это все смысла не имеет. Покажи пример с асинхронным IO.
Слушай, ну если ты не нацелен на конструктив, давай прекратим, ок? По второй ссылке Boost.Asio — самое что ни на есть асинхронное I/O, с тем самым IOCP под капотом
G>Основная проблема в том, что IOCP и другие механизмы не сохраняют стек, поэтому придется значительно извратиться чтобы на это натянуть stackfull coroutines.
Ты о чём? Корутина вместе со всем стэком ныряет в продолжение, для этого никакого специального "сохранения стэка" от асинхронного API не требуется
G>>>Для начала тебе надо будет async io реализовать на IOCP. EP>>Ты мне предлагаешь реализовать свои обвёртки поверх голого IOCP? Зачем? G>Без асинхронного IO все что ты пишешь не имеет смысла. Вообще.
Подожди, то есть ты думаешь что для C++ нет библиотек асинхронным API
G>Ты вообще представляешь как медленно будет работать твой пример с getline на реальном файле? G>Опубликуешь результаты забегов? При этом масштабирования такой подход не добавил. Ты не сможешь также запустить 100500 чтений файлов и выйграть хоть что-то.
getline может читать из любого стрима, например из сокета. В одном потоке будут крутится тысячи потоков с getline внутри, который ничего не знает об корутинах.
EP>>О том, что для того чтобы сделать yield с самого низа callstack'а на самый вверх, тебе придётся дублировать и модифицировать каждый уровень. Причём эти уровни могут находится в библиотеках к которым нет доступа. G>В смысле "нет доступа" ? G>Если библиотеки — "черный ящик", то и твой подход не поможет, потому что требует знать как внутри работа устроена. G>Если у тебя таки есть доступ к исходникам, то кто мешает сделать ctrl+c-ctrl+v и добавить async\await?
Детский сад — для того чтобы пользоваться библиотекой знать её код не обязательно. В нормальных библиотеках есть чётко определённый интерфес
EP>>У тебя нет кода std::getline (или аналога) — куда ты там собрался дописывать await? G>Если тебя нет когда getline, то как ты написал свой код? Он же полностью базируется на знании устройства getline, значит код у тебя есть.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Ещё раз. Я озвучил факт, который оппонент не знал/не понимал.
Ты сам себе придумал, что ктото чего то не понимает.
>Что с этого? Ну как минимум теперь он знает
Ога.
EP>Вот ты тоже не знал, не верил, отрицал. Зато теперь "И что с того ?" — большой прогресс
Если тебя подводит память, то я напомню — ты утверждал, что асинхронщину не надо всовывать в эвентлуп. И доказал это утверждение кодом в котором всунул асинхронщину в WM_CHAR.
Здравствуйте, alex_public, Вы писали:
_>Здравствуйте, gandjustas, Вы писали:
G>>В отличие от C++ в .NET встроенная библиотека на несколько порядков мощнее, чем C++ даже с бустом. Поэтому нет необходимости привлекать шандарахнутые dll, которые не поддерживают асинхронность.
_>Забавное утверждение. Не подскажешь тогда случаем, как во встроенной библиотеке .Net называется раздел аналогичный например Boost.Spirit? )
Парсеры XML и JSON уже есть. Для более сложных вещей обычно используются нормальные генераторы парсеров.
Spirit это не от хорошей жизни, а от бедности базовой библиотеки.
G>>Чувак, это ты начал такие песи, рассказывая что linq и yield не нужен _>Да, я считаю что не нужны, но при этом я привёл их работающие реализации. Почувствуй разницу ситуаций: _>моя: не нужны (потому что есть способы сделать тоже самое лучше), но без проблем можно реализовать. _>твоя: не нужны (потому что нельзя реализовать) — мне не лень переписывать заново чужие библиотеки.
Ты ничего "лучше" не показал То что ты показал — тормозит, не масштабируется, не решает реальные проблемы, которые существуют в .NET, решает проблемы, которых в .NET никогда не было.
В остальном ты прав
G>>Корутины могут исполняться только в "owning thread" из документации, это значит что тебе надо асинхронные вызовы маршалить в "owning thread". Обычно это делается через очереди и message pump, как в твоем примере. Даже когда ты юзаешь asio у тебя есть очередь дождавшихся завершения IO корутин. _>Callback во всех известных мне C++ библиотеках асинхронного io вызывается именно в том потоке, который я укажу, а не в каком-то там неизвестном.
Да, и это как раз проблема. С таким ограничением work-stealing хрен сделаешь.
G>>Нет. Ты начал говорить о каких-то накладных расходах, вот я и спрашиваю о каких ты говоришь. Ибо async мало что вносит в код, основная работа делается асинхронными методами, которые еще со времен .NET 1.0 существуют.
_>Ну да, о том и речь. Как бы даже если накладные расходы от async небольшие (хотя смотря с чем сравнивать), то всё равно они лишние, т.к. никакой функциональности при этом не приносят.
Еще как приносят, потому async методы переписываются в продолжения. Руками такое сделать в 100 раз сложнее и больше вероятность внести ошибку.
Если бы async ничего не давал, то его бы не использовали. А его используют массово.
G>>Тут ты вообще не в теме. Вопрос не в скорости, а в цене. ngix почти всегда используется как reverse proxy, тупо дешевле, не надо лицензии на венду покупать.
_>Да, да, у топ 1000 по посещению (типа яндекс, вконтаке, фейсбука) не хватает денег на лицензию винды. Исключительно поэтому они используют бесплатный Linux с nginx.
Ты удивишься, но это действительно так. Ты очень далек от реальной экономики.
Здравствуйте, gandjustas, Вы писали:
G>Я сделал версию на C#, которая отрабатывает за 600мс, когда твоя работает около 400мс.
Агааа, а теперь подведём итоги теста. Для написания более менее производительного решения ты не использовал для парсинга ни одной функции из стандартной библиотеки .net! Хотя дискуссия собственно и началась с твоего высказывания о её крутизне. Вместо этого ты написал сотню строк рукопашного нерасширяемого unsafe кода, который при этом оказался всё равно в 2 раза (см ниже) медленнее 5 строк на C++.
G>НО. Чтение 100мб файла с диска без кеша идет 8сек. В этих условиях пидарасить такты вообще бессмысленно.
Ну так и примерчик был максимально простой. Стоит чуть усложнить формат файла и время парсинга станет уже принципиальным.
Это если говорить про не мобильные устройства. А в случае мобильных имеет значение даже и этот пример, потому как получается разница между 0.3 и 3 секундами существенной загрузки процессора. И вот как раз такой "ява подход", что пофиг на оптимальность кода, если всё равно данные ждать надо, и приводит к просадкам батареи...
G>http://files.rsdn.ru/67312/ConsoleApplication5.exe
Кстати, этот exe ещё и не запустился у меня — вот она бинарная переносимость .net'a во всей красе... ))) Пришлось выдрать код и скомпилировать самому. В итоге действительно получилось всего в 2 раза медленнее C++ варианта.
G>Boost:asio? Так она тоже все в один поток маршалит.
Вообще то там всё зависит от выбранной реализации. Для разных платформ там всё разное. Т.е. да, оно подразумевает один поток, но я бы не стал называть какой-нибудь epoll маршалингом. )))
G>Но это неоптимальный сценарий и более сложный для реализации.
Ну т.к. он уже реализован, то как бы проблем нет. Ну и насчёт быстродействия я бы опять же не рекомендовал соревноваться с Boost'ом...
Здравствуйте, gandjustas, Вы писали:
G>Вот в том и проблема C++, то многие библиотеки типа Qt или wxWidgets очень интрузивны. У них свои наборы классов для решения одних и тех же задач, которые причем отличаются от стандартной библиотеки. Чаще всего это касается базовых вещей, типа строк, дат, ввода-вывода итп. Это все ставит крест на преимуществах C++, заставляет писать много plumbing кода.
Да, так и есть, определяют свои. Но в том то всё и дело, что если ставишь такого монстра, то сторонние библиотеки скорее всего не нужны уже будут))) Ну или же обратный вариант — использовать много мелких лёгких библиотек (типа Boost'a, который же не единая библиотека, а просто общий архив разных), которые естественно никаких своих новых строк и т.п. не определяют. Выбор является личным делом каждого.
Кстати, лично я предпочитаю именно второй способ, т.к. там максимально эффективный код выходит. )
_>>Ну и кстати для программиста csv тоже совсем не плохой формат для табличных данных — у него намного меньше накладных расходов в сравнение с остальными перечисленными. G>Ты еще не понял, что мифические "накладные расходы" вообще никого не интересуют?
Даааааа? Хотя действительно, чему я удивляюсь, это же всё просто разные грани одного и того же взгляда на ПО... Ну давай посмотрим наш конкретный случай. Помнишь тот наш тестовый файлик? Расскажи, как бы ты представил эти же самые данные в формате xml? И оценим тогда размер результата в байтах...
G>Более 95% времени программы находятся в ожидании завершения ввода-вывода. Грамотное использование асинхронности делает perceived performance достаточным для большинства приложений.
Асинхронность вообще не имеет никакого отношения к производительности, пока у нас не ставится задача о тысячах параллельных операций.
_>>Кстати, уже и в самой MS сменился вектор с продавливания .net'a на другие технологии. G>Ага, именно поэтому MS парнтерится с Xamarin, который позволяет именно на C# писать приложения для любых устройств. надеются что приложения написанные для iPhone и Android взлетят на WP. G>А вот с Azure ситуация обратная. Чтобы продать как можно больше облаков надо сделать их пригодными для любых приложений. МС в этом преуспел.
Ты хочешь сказать, что совсем совсем не заметил как MS уже наверное второй год постепенно отворачиваются от .net? ))) Или всё же понимаешь о чём я? )))
Что касается существующих приложений на C# для iPhone/Android и WinPhone, то я думаю это очень гармоничное сочетание по месту на рынке. )))
Здравствуйте, alex_public, Вы писали:
_>Здравствуйте, gandjustas, Вы писали:
_>>>Ну и кстати для программиста csv тоже совсем не плохой формат для табличных данных — у него намного меньше накладных расходов в сравнение с остальными перечисленными. G>>Ты еще не понял, что мифические "накладные расходы" вообще никого не интересуют?
_>Даааааа? Хотя действительно, чему я удивляюсь, это же всё просто разные грани одного и того же взгляда на ПО... Ну давай посмотрим наш конкретный случай. Помнишь тот наш тестовый файлик? Расскажи, как бы ты представил эти же самые данные в формате xml? И оценим тогда размер результата в байтах...
Ты лучше скажи какой value от решения задачи, а потом поговрим.
В этом и проблема C++ — он него практической пользы (конвертируемой в деньги) очень мало.
G>>Более 95% времени программы находятся в ожидании завершения ввода-вывода. Грамотное использование асинхронности делает perceived performance достаточным для большинства приложений. _>Асинхронность вообще не имеет никакого отношения к производительности, пока у нас не ставится задача о тысячах параллельных операций.
Ты о какой производительности? Наблюдаемая пользователем производительность (http://en.wikipedia.org/wiki/Perceived_performance) от асинхронности растет ооочень сильно. Хотя при этом общее время выполнение операции может даже падать.
_>>>Кстати, уже и в самой MS сменился вектор с продавливания .net'a на другие технологии. G>>Ага, именно поэтому MS парнтерится с Xamarin, который позволяет именно на C# писать приложения для любых устройств. надеются что приложения написанные для iPhone и Android взлетят на WP. G>>А вот с Azure ситуация обратная. Чтобы продать как можно больше облаков надо сделать их пригодными для любых приложений. МС в этом преуспел.
_>Ты хочешь сказать, что совсем совсем не заметил как MS уже наверное второй год постепенно отворачиваются от .net? ))) Или всё же понимаешь о чём я? )))
Я понимаю о чем ты, и вижу что ты в этом нихрена не понимаешь, как обычно. Смотреть надо не со стороны технологий, а со стороны продаж. Тогда не будет идиотских идей про "поворачивается" и "отворачивается".
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>>>Да мне как-то всё равно — это же ты начал сравнивать количество поддерживаемых СУБД в полноценной ORM vs micro-ORM. I>>Если тебе всё равно, то зачем же ты спрашивал ?
EP>Ты начал мерятся количеством СУБД у решений имеющих разные весовые категории. Я тебе задал наводящие вопросы показывающие что охват возможностей совершенно разный.
Ога. Как то выходит, что там где С++ возможностей меньше, ибо нет поддержки деревьев выражений в языке и через это получается какая то хрень.
I>>Покажи полноценный ORM на с++, посмотрим, шо в ём есть и как это сделано.
EP>http://www.youtube.com/watch?v=B1vgKT-NdRg
Здравствуйте, FR, Вы писали:
E>>Ну бывают же не только пары итераторов, но и тройки, скажем, или, наоборот, одинокие итераторы, например итератор элемента std::list'а... FR>D'шный range не пара итераторов.
Вообще-то как раз про одинокие итераторы jazzer выше приводил ссылку на комментарий A.A.:
Another example of an iterator-based design that's not easy to replicate with ranges is Boost Multi-Index. (Thanks Emil Dotchevski for pointing that out during my talk. (Marshall Clow promised the video will be available Real Real Soon Now(tm).)) In Multi-Index, indexes store iterators; storing ranges would often waste twice the space for little
or no benefit.
А про тройки итераторов — посмотри например на std::partition, возвращая один итератор он даёт нам два новых range'а, причём мы их получаем бесплатно (путём комбинации с имеющимся итераторами).
Или например std::nth_element/partial_sort которые принимают три итератора из одного range
FR>Это весьма абстрактная вещь, минимально и достаточно для (односвязного) списка это: FR>
По факту D Range нормально подходит только для SinglePass.
С Birirectional — проблемы с производительностью, на практических алгоритмах вылезают лишние передёргивания. В RandomAccess используются обычные целочисленные индексы, которые даже менее безопасны чем итераторы.
С Forward тоже ничего хорошего. Например std::find возвращает итератор, который бесплатно определяет два Range — до и после. А вот что советует сделать A.A. чтобы получить первый range:
Another weakness I noticed is visible when translating STL algorithms that return one iterator, such as find, which has this signature:
It find(It b, It e, E value)
where It is a one-pass iterator type and E is the type referenced by the iterator. STL's find returns the first iterator iter between b and (excluding) e that satisfies *iter == value. Once that iterator is returned, you can combine it with b to obtain the range before value, or with e to obtain the range after value.
Ranges lack such capabilities. The range-based find has this signature:
Range find(Range r, E value)
It consumes from r until it finds value and returns what's left of r. This means that you get access to the portion after the found value, but not before.
Fortunately, this problem is easily solved by defining a new range type, Until. Until is a range that takes another range r and a value v, starts at the beginning of r, and ends just before r.front() == v (or at the natural end of r if v is not to be found). Lazy computation for the win!
Причём std::find это один из самых примитивных алгоритмов
Здравствуйте, VladD2, Вы писали:
VD>В С++ с его моделью памяти нельзя сделать поддержку точного GC, так что спека тут не поможет. А зачем нужно медленное и кривое решение?
Справедливости ради, в D с точным GC тоже пока не густо. По умолчанию используется частично консервативный. Есть реализация "почти точного" (используется в VisualD, например), но и там осталась пара мест (вроде замыканий), где осталась консервативность. Т.е. теоретически точный GC сделать можно, но пока его нет. И те, кто в 64 бита компилит, говорят что и не нужно, нынешнего хватает. Другая проблема — скорость нынешнего GC, она печальная.
Здравствуйте, D. Mon, Вы писали:
DM>Если мы откуда-то пришли, значит мы там уже были и могли запомнить это место (.save), зачем туда опять пешком идти?
Дело не в месте, а в направление. Итерация назад в варианте BidirectionalRange возможна только с конца. В то время как у нормального двусвязного списка с любого элемента. Это явно бредово. Но меня не особо напрягает, т.к. я этот DList и вообще BidirectionalRange обхожу стороной. )))
Здравствуйте, alex_public, Вы писали:
_>Вообще то проверка границ у массивов в D встроенная. Правда по умолчанию она выключена (@system). Но легко включается или флагами компилятора на весь проект или спец.атрибутом (@trusted или @safe) прямо в коде.
По умолчанию включена. Выключается ключиком -noboundscheck. Но речь выше не только про массивы шла.
Начал понемногу "D programming language" читать. Местами впечатления неоднозначные. Догадываюсь, что часть вопросов может проясниться со временем, но всё-таки некоторые вещи смущают. Сразу скажу, что плюсы разумеется тоже есть. Просто когда смотришь на "удобную замену С++", то ожидаешь избавления от всех кривостей. И когда находишь там новые, свои собственные неприятные мелочи, то несколько разочаровываешься. Разумеется, часть претензий — это просто от непривычки или "вкусовщина", ещё какая-то часть (наверное) чем-то обьясняется и является разумным компромиссом. Но некоторые вещи понять не могу, возможно, кто-нибудь объяснить.
Не очень понял пример отсюда:
Тот где cast+mutate = UB:
Это не разрешено что ли? Если так, то какой смысл в приведении вообще?
В С++ в этом плане как-то более логично — если кастуешь и модифицируешь "константные" данные, то сам отвечаешь за то реально ли они константные. Или это просто в документации как-то непонятно выразились?
Ну и обьявление указателей мне как-то проще в С++ читать:
// D:
//ptr to const ptr to const intconst(int*)* p;
//const ptr to const ptr to const intconst int** p;
**p = 3; // error
// C:
//ptr to const ptr to const intconst int *const *p;
Приведение типов. Я так понимаю, что на все случаи жизни один каст (cast) предусмотрен? Может в С++ их "многовато", но по моему это удобно. В том смысле, что меньше вероятность случайно что-то не то сделать.
Ещё не очень понял со строками. В С++ долгое время не хватало "raw string literals". В Д они есть, но в виде кучи разных вариантов со своими (местами не очень прозрачными) правилами. Например:
auto a1 = "just a string";
auto a2 = r"raw string\n\r";
auto a3 = `raw string\n\r`;
Плюс строки с задаваемыми разделителями. Правда в качестве "разделителя" может быть только один символ и только из этого списка: "[(<{" (так написано в книге, на самом деле такое тоже работает (q"a123a"), а вот такое уже нет (q"a123a"). Разделители допускают вложение (если честно, то не понял зачем это надо):
Можно задавать разделители из более чем одного символа, но при этом надо разбивать такой литерал на несколько строк (разделители должны быть на разных строках):
auto a1 = q"EOS
Test string
EOS";
Вот так написать нельзя, ну и отступ попал бы в строку:
auto a1 = q"EOS
Test string
EOS";
На мой взгляд, это не очень удoбно. В С++ сделали как-то получше, без необходимости строки разрывать и ломать форматирование:
Здравствуйте, D. Mon, Вы писали:
EP>>В следующем году будут концепции — большой шаг вперёд. А что тут может предложить D? duck-typing? DM>Я не знаю всех подробностей плюсовых концептов, но судя по тому, что Страуструп недавно рассказывал на Going Native, обещая в С++14, это уже очень давно есть в D в намного более удобном и мощном виде. Об этом же говорит Александреску.
Александреску скорей всего говорил о static if — что хоть и пересекается в некоторых простых use-case'а с концепциями, но всё таки является более примитивной feature. Пример использования концепций:
Это шаблоны функций, перегрузка между которыми происходит автоматом. Требования каждой концепции разбиваются компилятором на атомы, и производится тест вложенности множеств и т.п.
DM>Про производительность range'й не очень понял — где именно она хуже? В плюсах принято передавать два итератора, begin и end, в D их объединили в одну структуру, получили range. DM>Смысл тот же, но меньше писанины и меньше ошибок.
Нет — range в D это другое — там совсем убрали итераторы, к ним вообще нет доступа.
Объедение итераторов в структуру это больше про Boost.Range — что действительно сокращает "писанину" и позволяет избежать некоторые ошибки, но из таких Range можно получить доступ к итераторам — они их не прячут.
Итераторы C++ обеспечивают эффективную композицию. Если у нас есть 4 итератора, то из них можно получить 6 range бесплатно, без runtime penalty — просто выбери нужную пару итераторов.
Но, чисто range'ы без итераторов, как в D — теряют свойства композиции, код алгоритмов получается менее эффективным, что неприемлемо для C++. Например тот же partition:
autoresult = r;
for (;;)
{
for (;;)
{
if (r.empty) returnresult;
if (!pred(r.front)) break;
r.popFront();
result.popFront();
}
for (;;)
{
if (pred(r.back)) break;
r.popBack();
if (r.empty) returnresult;
}
swap(r.front, r.back);
r.popFront();
result.popFront();
r.popBack();
}
Чтобы вернуть вменяемый результат, параллельно "рабочему" range'у приходится передёргивать дополнительный range result. В то время как в STL, нет этих лишних телодвижений — возвращается итератор, который практически бесплатно определяет два range'а.
Например код из SGI STL:
while (true)
{
while (true)
if (first == last) return first;
else if (pred(*first)) ++first;
else break;
--last;
while (true)
if (first == last) return first;
else if (!pred(*last)) --last;
else break;
iter_swap(first, last);
++first;
}
Здравствуйте, Erop, Вы писали:
E>Ну, вот, например, надо нам писать драйвера какие-то, или числодробилки. На сколько все эти твои "довольно много" снизят стоимость разработки/поддержки?..
Сложно сказать. Но скажем средства для построения встроенных DSL (чем обычно очень любят заниматься авторы математических библиотек) в D намного сильнее чем в C++. Даже если заговорить о банальной перегрузке операторов... Разделение перегрузки оператора справа и слева уже даёт много вкусного для например матричной алгебры и т.п.
E>А теперь, положим нам надо какое-то формошлёпство с вебом пополам, насколько там Ди окажется ВЫГОДНЕЕ чем шарп?
Ооо, а вот что-то подобное мы как раз сейчас и пытаемся проверить на нашем небольшом проектике. Пока по ощущениям можно будет обойтись хостингом за $10 для той же задачи, что обычно требует хостинга за $500. Но там ещё очень далеко от завершения, так что пока не буду ничего точного говорить. Тем более что это у нас как бы такой стажёрский проектик (правда пока похоже больше обучается руководитель, а не стажёр) и даже не по нашему основному профилю.
Здравствуйте, DarkEld3r, Вы писали:
DE>А можешь книги по Д посоветовать? Просто туториалов/вики как-то мало, хочется более подробного разбора фич. Смущает, что "The D Programming Language" аж в 2010 году издана, по идее, в языке немало изменений было. Или книга всё-таки актуальна?
Здравствуйте, minorlogic, Вы писали:
EP>>Выше уже много примеров было: лишняя работа на каждой итерации в std::find, partition, search. Плохая комбинируемость приводящая к лишним проходам, копиям, созданием новых типов range на ровном месте, пониженная категория результирующих range. M>Это собственно и вытекает из избыточности.
Нет, это не из-за избыточности, а из-за ограниченности. Избыточность это мелкие расходы на хранение — а вот то что аналог std::find, если ему скормить bidirectional range, разбивает его на два range, понижая категорию первого до forward — это как раз ограниченность.
EP>>То что где-то будет хранится два итератора, вместо одного само по себе не является серьёзной проблемой. А вот то что нельзя взять вот такие два range, в каждом из которых один элемент, и получить бесплатно range содержащий все элементы между этими двумя — это уже алгоритмическая ивалидность. M>Тут у меня ступор , почему нельзя бесплатно ? ну или с незначительными расходами (на откуп оптимизатору)
Вообще нельзя, нет такой операции. Например у ForwardRange есть только такие операции:
R r;
if (r.empty) {}
r.popFront();
auto element = r.front;
auto copy = r.save();
Вот тебе два range из одной последовательности:
R r1, r2;
В каждом по одному элементу. То есть после popFront он сразу становится empty.
С такими операциями нельзя получить всё что между ними, by design.
А в случае итераторов всё элементарно, и даже бесплатно:
I i1, i2;
// [i1, i2) - все элементы между, включая первый
Здравствуйте, DarkEld3r, Вы писали:
DE>Пользуясь случаем, спрошу — в студии при использовании вижуал Д никакого интелисенса нет. С этим ничего нельзя поделать?
Какой-то есть:
Стоит зайти в его настройки (через Tools/Options/Text Editor/D), а также из его меню вызвать Build Phobos Browse Info.
Почитал топик. Здешний основной спор вокруг STL-итераторов и D-диапазонов заставил перечитать статью Александреску On Iteration. В принципе, вроде как, он вполне адекватно описывает причины выбора ranges, их плюсы и кривости тоже.
Заодно глянул в потроха итераторов у D-конкурентов — у Rust-строителей. Собственно, даже для стандартного вектора итератор не есть тонкая обвёртка над простым указателем. И похоже, что в стандартной библиотеке особо не рассчитывают хранить итераторы в коллекциях, а также и указатели на хранимые в контейнерах значения, особенно с учётом того, что, как правило, контейнеры блокируются для модификаций на время жизни созданного итератора или ссылки на хранимое значение.
А вообще-то, на сегодня уже хотелось бы обходиться без объектных итераторов и прочих энумераторов, например, по мотивам reducers кложуры.
Здравствуйте, matumba, Вы писали:
M>DrDobbs обрадовал небольшой заметкой про использование языка D в таком крупном проекте, как Facebook. 5K LOC — как говорил Семёныч, выходя из пивной: "Маленький шажок человека, но большой шаг для человечества!".
Здравствуйте, btn1, Вы писали:
B>О, да! По какому тогда критерию в этом списке соседствуют C#, C, C++ и Java? В чём отличие Ruby от JRuby?
Это все весьма популярные вещи, их нельзя не включить.
B> Что important автор нашёл в ATS (я за 20 лет НИ РАЗУ о таком не слышал!),
А вот это напрасно (и больше говорит о вашей неосведомленности), очень рекомендую ознакомиться. Один из самых интересных языков вообще по сочетанию возможностей и скорости. Функциональный язык с зависимыми типами, обгоняющий Си, — другого такого нет и не ожидается.
B>кого там греет Rust, LISP?
Здравствуйте, maloi_alex, Вы писали:
_>ИМХО, языку D не хватает хорошего финансирования на развитие.
В конечном итоге — да, всё упирается в деньги. На самом деле Ди нужно развитие библиотек, т.к. на одних контейнерах Офис не напишешь. GUI, базы, сеть, 3D — на этих китах можно наворотить большую часть десктоп-софта.
Здравствуйте, matumba, Вы писали:
M>Надеюсь, что уже сам пример использования таким "гигантом", станет хорошим вдохновителем для масс — многие просто боятся использовать что-то малораздутое или новоиспечённые выскочки типа Rust/Go.
Про малораздутое не понял. На счет новоиспеченности смешно. Это Ди новоиспеченный. Вернее непропеченный, и всегда таким останется.
На Rust'е Мозила свой браузер начала переписывать. С такой рекламой дело пойдет очень быстро.
И главное там есть новые полезные идеи. При то, что главная идея Ди — спилить некоторые занозы с C++.
Те что совсем уж страшные.
О Go и говорить нечего. На нём уже куча вещей написана.
M>Ди развивается уже много лет и к счастью — без давления легаси или коммерческой продавабельности (как C#),
Читай: на нём ничего до сих пор не написали.
Откуда же его [независимый суд] взять, если в нем такие же как мы? (c) VladD2
Здравствуйте, matumba, Вы писали:
M>Даже пример дам — Линукс. Я подобную халтуру не поставлю даже в бортовую радиолу,
Лол что? Ни с чем не перепутал? Вообще-то Линус категорически не любит С++.
Или ты не разделяешь С и С++? И предлагаешь писать ядро на джава/С#? Кстати, ничего, что винда тоже не на них написана?
Здравствуйте, matumba, Вы писали:
M>Не совсем злости — скорее, этакая досада, что есть море очевидного говнокода на говноязыке, которое по-хорошему давно надо выпилить как зло и заменить намного более удобными/безопасными языками, но т.к. существуют "профессоры" типа вас, адвокатирующие за продолжение сипиписной вакханалии, у руководящих людей создаётся ложное впечатление, что "достаточно взять пару толковых С++ ребят" и все проблемы решены. На деле дуроломство не имеет границ и С++ только подливает масла в огонь, предлагая неокрепшим умам поиграть со своими лезвиями. Цепная реакция даёт ещё больше говнопроектов, которые худо-бедно живут, но при этом не дают развиваться другим языкам, которые, вероятно, могли бы быть в два раза более производительны и надёжны. А время идёт и ждать, пока каждый говнопроект не сдохнет в шаблонно-указательных муках, нет никакого желания. Теперь вы осознаёте, что такое "невинное" существование С++ всё равно гадит в отрасль, не давая ей развиваться с другими, более достойными языками? Даже пример дам — Линукс. Я подобную халтуру не поставлю даже в бортовую радиолу,
Если из-за досады ты линукс в бортовую радиолу не поставишь (сюрприз! в бортовых радиолах линукс уже используется), то это не досада, а злость.
M>Не воспринимайте всё так уж лично, просто посмотрите на ситуацию сверху — С++ объективно опасный и бестолковый язык, в мэйнстриме это язык-урод, не отвечающий главным требованиям. Ну а кто хочет на нём писать, пусть пишут — тянуть за рукав не будем.
Не путай свои требования и главные требования.
У С++ есть два плюса: мультипарадигменность и поддержка наследия. Он и в будущее смотрит, и прошлое не забывает.
Сколько стоит перенести гору уже существующего кода с C++ на D? А без тотального переписывания?
Новые проекты — пожалуйста, начинай хоть на D, хоть на окамле.
Кстати, не на тот язык звереешь. Фортран — вот где ад.
Между прочим, до сих пор используется. Те же промышленные библиотеки линейной алгебры — Intel MKL, AMD ACML — изначально сделаны для фортрана, с переходниками для си.
Здравствуйте, FR, Вы писали:
EP>>В следующем году будут концепции — большой шаг вперёд. А что тут может предложить D? duck-typing? FR>D может предложить намного более полный и мощный контроль в compile-time, тот же static if FR>дополненный foreach как по типам (работающим в compile time) так и по значениям и гораздо
Такой foreach есть в C++98: boost::fusion::for_each. Не хватает только полиморфной лямбды (нужно вручную делать function object), которую скоро добавят.
FR>Да static if с одной стороны конечно вещь гораздо более низкоуровневая чем концепты, но это FR>не только минус но и плюс, мощность у нее гораздо выше.
Какой именно static if? В D он может применяться в нескольких разных контекстах.
FR>Ну и плюс такой сахар как Template Constraints позволяет писать в стиле контрактов нового С++, хотя конечно с более примитивным матчингом.
Это же и есть один из вариантов static if, аналог которого есть в C++98 — enable_if.
Здравствуйте, D. Mon, Вы писали:
DM>Про производительность range'й не очень понял — где именно она хуже? В плюсах принято передавать два итератора, begin и end, в D их объединили в одну структуру, получили range. Смысл тот же, но меньше писанины и меньше ошибок.
Ну бывают же не только пары итераторов, но и тройки, скажем, или, наоборот, одинокие итераторы, например итератор элемента std::list'а...
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
EP>+ если не нравится boost::mpl::vector, то легко сделать for_each который будет принимать сразу variadic pack.
Это уже гораздо лучше, но шума, опять же по моему, гораздо больше необходимого, особенно
если учесть что никаких метабиблиотек мой пример не использовал.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Это называется чуть больше сахара.
Да и прямое следствие из него шаблонный код на D легко читается в отличии от аналога на C++.
EP>Так наоборот хорошо что многое реализуемо в библиотеке. Я, например, предпочёл бы какой-нибудь дополнительный синтаксис для лямбд, вместо range-based-for.
Одно другому не мешает, нужен и сахар в языке и мощные мета возможности для построения библиотек.
По моему для C++ идея что надо стараться максимально возможно реализовывать все в библиотеках плохо
подходит (при всем уважении к Страуструпу) для этого мета возможности C++ совершенно недостаточны.
Здравствуйте, FR, Вы писали:
FR>Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>>По факту D Range нормально подходит только для SinglePass.
FR>Пока остальное отпущу.
FR>Но по этому у нас кажется сильное недопонимание, основной плюсs range это легкая FR>комбинируемость функций с ними работающих и ленивость, все это по моему легко FR>перекрывает недостатки.
FR>
FR>import std.stdio;
FR>import std.range;
FR>import std.algorithm;
FR>void main()
FR>{
FR>iota(0, 10).map!(x => x *x).filter!(x => x % 2).writeln;
FR>}
FR>
Одно другому (в смысле, диапазоны итераторам) не мешают.
Диапазоны хороши, когда надо по ним пройтись один раз и забыть. А итераторы хороши собственно для итерирования, которое может быть каким угодно хитрым. Но после итерирования берешь пару итераторов, заворачиваешь ее в диапазон и вперед — это, что делает boost::range, и твой пример элементарно на нем переписывается:
Здравствуйте, jazzer, Вы писали:
DM>>Тайпклассы, перегрузки, вот они. J>а тут не будет неоднозначности?
Может быть. Сейчас освежил в памяти детали. Короче, сначала констрейнты отсекают неподходящие варианты, а потом специализация выбирает самый подходящий. Если все еще есть неоднозначность, выдается ошибка. Поэтому на практике популярен подход со static if, там в явном виде логика выбора нужного варианта задается.
Здравствуйте, VladD2, Вы писали:
EP>>Ещё раз: EP>>
EP>>>Как известно, у C++ основным приоритетом является производительность.
EP>>>А в D спокойно могут пожертвовать производительностью ради других целей (об этом говорил A.A.). Взять например те же ranges — они проигрывают итераторам по производительности by-design
VD>Вот и читай свои же слова до просветления. Это не я путаю язык и библиотеку?
Это стандартная библиотека языка, которая хоть немного но отражает общую идеологию языка. Эта библиотека которая будет использоваться по-дефолту, и соответственно по-дефолту тормозить.
Я выше давал ссылку на интервью, где один из авторов как раз и сказал, что они не загоняют себя в угол производительности и могут принимать решения, отдавая предпочтения другим качествам.
VD>>>Что до метапограммирования, то очевидно, что на D мета-код выглядит проще, работает существенно быстрее и выдает внятную диагностику. EP>>Вот тут я как раз и не спорю — на данном этапе у него больше возможностей для метапограммирования. VD>Данный этап длится около 30 лет.
По-твоему D 30 лет?
VD>Я плюсы бросил где-то в начале нулевых. По мне так лучше заплатить небольшим оверхэдом, чем всю жизнь жевать этот кактус.
Что конкретно не нравится?
VD>Чтобы что-то утверждать про эффективность нужно написать что-то значимое на том и на этом. А ты уперся в какие-то там итераторы и на их основе делаешь далеко идущие выводы.
На D можно писать столь же эффективно как и в C++ — это следует как минимум из сравнения ключевых фич, тут-то вообще не вижу смысла спорить
Алгоритмы и интервалы из стандартной библиотеки, это то, что используется в 99% программ. И если там тормоза by-design, то это значит что в 99% программах, будет платится за то, что может быть бесплатным
VD>Я как человек позанимавшийся метпаропграммированием скажу тебе, что твои рассуждения не о чем. При массовом использовании МП абстракции нижнего уровня вроде итеаторов и т.п. вообще значения не имеют. Мы тупо используем массивы и хардкорный код в стиле С на куда более высокоуровневом языке нежели Ди и С++ вместе взятые. И все потому что код этот мы руками не пишем. Мы его генерируем.
Surprise, на C++ нечто подобное доступно уже лет 16 — смотри MTL, Blitz++, Eigen
VD>Так что по факту продвижению Ди больше мешают привычки и косность мышления нежели какие-то технические сложности.
Здравствуйте, Кодт, Вы писали:
I>>Покажи реализацию без исключений, особенно return интересует
К>Фигня-война. Если return void, то делается довольно просто.
Для каждого вида АПИ надо писать вот такую пару макросов или переходник, что бы эти макры юзать
По моему это именно то, чего делать не надо — макросы вот такие.
Здравствуйте, D. Mon, Вы писали:
DM>Здравствуйте, jazzer, Вы писали:
I>>>Поэтому вопрос не в том, будут ли на D переписывать плюсовый код, а в том будет ли в новых проектах использоваться D и, если будет, то для чего.
J>>Для новых проектов на новых языках нужны новые программисты. А такое счастье никому не нужно. Чтоб вложиться в это, выгоды от нового языка должны быть очень большими.
DM>Да ладно, откуда например берутся проекты на хаскеле, на руби+рельсах, на go, на clojure? Чаще всего в уже существующих компаниях конкретные программисты настолько вдохновляются каким-то языком, что всячески пытаются его использовать. Когда им разрешают (или не мешают), получаются проекты на этих языках. Иногда новые, иногда переписанные старые. Так что нужен лишь энтузиазм и отстутствие непреодолимых проблем в языке/реализации.
Я и говорю — нужен евангелизм, причем масштабный (т.е. недешевый), если хочется, чтоб случился массовый исход, как в жабу/дотнет. А на голом энтузиазме все таки и будет на уровне стартапов (там хоть на брейнфаке можно писать) и недосмотра (или лапши на ушах) менеджеров — потому что ни один бизнес в здравом уме не подпишется на использование языка, который на 5% (ну хорошо, на 10%) лучше имеющегося, не имея достаточного притока программеров с рынка, достаточной стабильности самого языка (чем D никак не может похвастаться), богатства инфраструктуры, ресурсов в инете, курсов по обучению и повышению квалификации, книжек и прочая и прочая и прочая. То есть того, во что Сан и МС вбухали немалые деньги.
Пример Яху всем известен, правда? Пара маргиналов написали систему на маргинальном языке (лиспе) и свалили. Яху помучилась-помучилась и переписала все на мейнстримовом языке.
Пример Немерле тоже у всех перед глазами — как был маргинальным, так и остается, несмотря на обещания о скором захвате мира.
Здравствуйте, jazzer, Вы писали:
J>Они туда переходили, потому что была мощнейшая финансовая поддержка со стороны Сана и Мелкософта (кстати, интересно, во сколько им обошелся весь евангелизм и разработка? Кому-нть попадались цифры?).
Про джаву ходит фольклор, что в нее Сан миллиард вбухал. Тот же А.А. такую цифру называл.
С другой стороны, в какой-нибудь Руби никто много денег не вкладывал, а свою порцию популярности он получил, и даже гитхаб на рельсах написан был.
DM>>Ты же все приставал с получением двух частей — до найденного элемента и от него дальше. Я показал.
EP>Ну да, показал — неэффективное, негибкое, и более многословное:
Реально же ерундой занимаетесь, сравниваете мягкое с зеленым.
Итераторы C++ и интервалы D слишком различны. Базовое различие все, включая и
меня, совсем упустили, интервалы D в отличии от итераторов не работают по месту,
а выдают новый интервал, по сути ближе к базовым ФВП из функциональщины
работающими со списками. Даже boost::range в основной массе этого не делает
а тоже работает по месту как и его базовые итераторы.
Из этого и вытекает и легкая комбинируемость и сложность написания примитивов
похожие проблемы есть и в реализациях перечислений для других языков, например
в окамловском BatEnum, в случае D еще и углубленная, как не странно, тягой к
максимальной производительности.
Намного проще, тоже кстати, реализация получается если в языке есть yield.
Здравствуйте, FR, Вы писали:
VD>>Я с тобой почти согласен, но вообще-то ты сравнил частный случай для которого у D есть готовое решение. VD>>Интереснее было бы на более не тривиальные примеры метапрограммирования посмотреть. FR>Уже показали, но похоже людям интереснее обсуждение "итераторы от Степанова против интервалов FR>от Александреску",
А что не так? Нормальное обсуждение стандартной алгоритмической библиотеки одного языка — против библиотеки другого.
Такие библиотеки используются в 99% программ, и вполне заслуживают обсуждения в контексте сравнения языков как платформ в целом, а не просто language feature vs feature.
Если ты согласен с тем что STL итераторы удобней, эффективней и мощнее D-style range — то можем прекратить обсуждение. Если есть какие-то аргументы против этого — то мне интересно будет их услышать.
FR>притом что оба реализуются при желании одинаково и на C++ и на D.
С этим-то вроде никто и не спорит
До определённой степени STL можно реализовать, например, на C#-е (разумеется с overhead'ом, но речь не о нём). Но вот как наши C#-коллеги не пытались найти аналог std::deque, дальше попыток продать двусвязный список или дерево под видом деки дело не пошло
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>А что не так? Нормальное обсуждение стандартной алгоритмической библиотеки одного языка — против библиотеки другого. EP>Такие библиотеки используются в 99% программ, и вполне заслуживают обсуждения в контексте сравнения языков как платформ в целом, а не просто language feature vs feature.
Вообще то тут немного другая ситуация. Если мы допустим откажемся использовать STL в C++, то это будет автоматом означать необходимость ручной игры с памятью, что довольно неразумно в большинстве случаев. Более того, если мы используем контейнеры из STL, то знать итераторы крайне рекомендуется (а до появление range for вообще строго обязательно).
В случае же D ситуация совсем другая. Тут у нас в сам язык встроены аналоги (ну с некоторыми хитрыми поправками на не эксклюзивное владение памятью) array, vector и map. И естественно что никакие range (которые являются всего лишь одним из библиотечных модулей) для доступа к ним не требуются. Более того, массивы поддерживают срезы, которые опять же являются частью языка, т.к. по сути являются теми же самыми массивами.
Т.е. в этом смысле range из D и итераторы из C++ имеют очень разную значимость. А основной тон для работы с массивами в D задают скорее срезы. Например вот классический пример двоичного поиска из учебника D:
bool BinarySearch(T)(T[] input, T value)
{
if(input.empty) return false;
auto i=input.length/2;
auto mid=input[i];
if(mid>value) return BinarySearch(input[0..i], value);
if(mid<value) return BinarySearch(input[i+1..$], value);
return true;
}
Здесь хорошо видна цель, которой добивались создатели языка, определяя технику работы с массивами именно таким образом. Думаю можно не уточнять, что никаких лишних выделений памяти при исполнение этого кода нет? )))
EP>До определённой степени STL можно реализовать, например, на C#-е (разумеется с overhead'ом, но речь не о нём). Но вот как наши C#-коллеги не пытались найти аналог std::deque, дальше попыток продать двусвязный список или дерево под видом деки дело не пошло
Хы, а в стандартной библиотеке D с этим вообще всё печально. Я там видел вроде только пару списков, дерево и кучу. Хотя естественно есть все нужные реализации в сторонних источниках (например http://www.dsource.org/projects/dcollections ).
Здравствуйте, D. Mon, Вы писали:
DM>В простом случае, как у тебя: DM>
DM>mixin template ImplementGetSheeshCode() {
DM> size_t GetSheeshCode() // эта функция станет членом класса
DM> {
DM> alias T = typeof(this);
DM> size_t h = 123;
DM> foreach(m; __traits(allMembers, T)) // проходим по полям; такой foreach будет раскрыт, цикла не останется
DM> static if (m!="Monitor") {
DM> static if (isIntegral!(typeof(__traits(getMember, T, m))))
DM> h ^= __traits(getMember, T, m);
DM> else static if (__traits(hasMember, typeof(__traits(getMember, T, m)), "toHash"))
DM> h ^= __traits(getMember, T, m).toHash;
DM> }
DM> return h;
DM> }
DM>}
DM>
DM>И даже никаких строчек и цитат не понадобилось.
Вот аналог на Nemerle:
[MacroUsage(MacroPhase.WithTypedMembers, MacroTargets.Class)]
macro ImplementGetHeshCode(typeBuilder : TypeBuilder)
{
def fields = typeBuilder.GetFields(BindingFlags.Public | BindingFlags.NonPublic | BindingFlags.Instance);
def make(field)
{
if (field.GetMemType().Equals(<[ ttype: int ]>))
<[ result ^= this.$(field.Name : usesite) ]>
else
<[ result ^= this.$(field.Name : usesite).GetHashCode(); ]>
}
typeBuilder.Define(<[ decl:
public override GetHashCode() : int
{
mutable result = 0;
..$(fields.Map(make));
result
}
]>);
}
Здравствуйте, alex_public, Вы писали:
_>Т.е. в этом смысле range из D и итераторы из C++ имеют очень разную значимость. А основной тон для работы с массивами в D задают скорее срезы. Например вот классический пример двоичного поиска из учебника D:
Справидливости ради, мы писали на С++ во времена когда stl еще не стал популярной (на грани этого срока) и прекрасно жили без stl. У нас бил свои (не так хорошо спроектирвоанные) обертки. Еще были разные MFC и другие библиотеки где были обертки. Так что жизнь за пределами stl есть.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Не хватает встроенной в стандарт compile-time reflection — тогда от макроса можно было бы уйти.
FR>Но к сожалению Владовскую задачу не решает, член а класс не добавляет, а без этого на D легко FR>повторить также красиво.
В С++ не принято добавлять члены в класс на каждый чих, наоборот — non-member предпочтительнее.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Не хватает встроенной в стандарт compile-time reflection — тогда от макроса можно было бы уйти.
Угу, притом как Влад уже говорил очень давно не хватает
EP>В С++ не принято добавлять члены в класс на каждый чих, наоборот — non-member предпочтительнее.
Здравствуйте, matumba, Вы писали:
M>Никакого срача — это лишь ваше личное восприятие. То, что Ди как язык на голову превосходит С++ — очевидно даже школоло, это я и подчеркнул. Если вам лично обидно за потраченное на С++ время — ССЗБ.
D не нужен. Потому что его нишу плотно занимают C#/Java с тоннами библиотек на любой вкус. И я не вижу у него никакого преимущества, особенно перед C# в технологическом смысле.
Так что D не нужен. И на смену С++ он придет явно не в этом десятилетии.
Здравствуйте, VladD2, Вы писали:
EP>>>>В С++ пока нет compile-time reflection, VD>>>Ага. Это "пока" наблюдается самую малость — на протяжении 30 лет. EP>>В смысле? Study group для reflection появилась недавно. VD>Кого это трогает? Комитет по С++ существует не менее 20 лет. За это время гора родила мышь.
Это говорит лишь о том, что было не нужно/были вещи по-важнее
EP>>Или ты думаешь что создатели уже 30 лет думают как бы впихнуть reflection, да всё никак не получается? VD>Я не думаю. Я знаю об этом.
То есть ты утверждаешь, что Bjarne тридцать лет назад пытался впихнуть reflection?
VD>Мы 10 лет назад обсуждали эту тему. А воз и ныне там.
Где? На форуме, или в комитете?
EP>>Или тебе больше не о чём поспорить? VD>Я и не спорю.
А вот это к чему было:
VD>Давай или признаем, что в области метапрограммирования С++ существенно уступает D, или вы продемонстрируете аналог генерации функции GetHashCode и мы сравним код.
?
Ты не читаешь ответы на свои сообщения? Я тебе явно сказал, что у D метапрограммирование лучше.
Или если закрыть эту тему — то холивара не получится?
Кто-то считает что в языке который он не использует есть хорошие фичи — внезапно, да?
VD>Просто тема итераторов смешна.
Что смешного?
VD>А больше вы ничего предявить не хотите.
А зачем?
Мне интересна тема Range-only vs Interator+Range, по этому поводу сформировалось некоторое мнение — интересно услышать разные аргументы, точки зрения. В чём проблема? Или тут можно обсуждать только синтаксис? Или так холивара не получится?
VD>Я понимаю, Матумба — это такой матумба. Ему оскорбить окружающий что два пальца об освальт. Но выдвигая, в ответ его наездам, тезис — "С++ лучше", нужно его хоть чем-то обосновать.
Кто и где выдвигал такой тезис? И что значит лучше? Лучше для чего?
Здравствуйте, Erop, Вы писали:
E>Я даже больше имел в виду, у этого нового подинтервала будет, похоже, другой тип. Ну или я чего-то не понял. E>при этом если у нас где-то будет ветвление, ну, например вернуть элементы списка от начала до конца строки, но не больше 100 штук, как написать, я уже вообще не понимаю даже...
auto myfind(Range, T)(Range r, T t)
{
size_t n = 0;
auto left = r.save;
while(!r.empty && r.front != t) {
r.popFront();
n++;
}
return tuple(left.takeExactly(n), r);
}
myfind возвращает два интервала разных типов. У первой части результата — специальный тип который возвращает takeExactly.
Если нужно будет на этих двух range сделать что-то типа: [std::prev(std::find(first, last, x)), last) — видимо придётся вводить ещё два новых типа — один для chain, другой для взятия последнего элемента из первого интервала — вот только как это сделать эффективно? За O(1) — видимо не получится, так как left.takeExactly(n) не знает где середина, а только знает на каком она расстоянии от начала — для bidirectional это будет O(n).
E>То есть, или концепция какая-то совсем кривая, или я не понимаю чего-то самого главного...
Концепция нормально подходит только для single pass, для всего остального как-то не очень.
Здравствуйте, VladD2, Вы писали:
EP>>В смысле? Study group для reflection появилась недавно. VD>Кого это трогает? Комитет по С++ существует не менее 20 лет. За это время гора родила мышь.
Понятное дело, что это плохое оправдание, но наличие (такого?) комитета скорее наоборот замедляет развитие языка: разные люди/организации — разные интересы. Майкрософт, например, забивает на реализацию некоторых вещей.
EP>>Или ты думаешь что создатели уже 30 лет думают как бы впихнуть reflection, да всё никак не получается? VD>Я не думаю. Я знаю об этом. Мы 10 лет назад обсуждали эту тему. А воз и ныне там.
Знаешь, что у них не получается? А какие принципиальные проблемы? Да, потеряли много времени, да иногда делали не то, что хотелось бы, но ведь будет и не так уж долго ждать осталось.
Пример, конечно, удачный и С++ тут сливает — сложно спорить. Но так ведь он не единственный.
VD>Я понимаю, Матумба — это такой матумба. Ему оскорбить окружающий что два пальца об освальт. Но выдвигая, в ответ его наездам, тезис — "С++ лучше", нужно его хоть чем-то обосновать.
Можно подумать, что в теме мало раз озвучивали мысль типа "С++ в среднем хуже, но недостаточно, в немалой степени, из-за сформировавшейся инфраструктуры". Да и развивается, плюс не так быстро как хотелось бы. Хотя сейчас может и прибавят темп.
Тема итераторов и правда поднадоела, но я вот тоже разделяю мнение, что они гибчи и рейнджи поверх добавить проще, чем наоборот. А стиль стандартной библиотеки всё-таки диктует стиль остальных (да хотя бы boost и Qt тоже итераторы поддерживают).
Здравствуйте, VladD2, Вы писали:
VD>Здравствуйте, jazzer, Вы писали:
VD>>>Так уже лучше J>>ничего не изменилось, вообще-то Или ты про переименование?
VD>Ты просто невнимательно читаешь. Вот предыдущий пример: VD>
Здравствуйте, FR, Вы писали:
FR>На самом деле красиво FR>Но к сожалению Владовскую задачу не решает, член а класс не добавляет, а без этого на D легко FR>повторить также красиво.
Там и других "проблем" хватает. Проверки типа поля в коде нет. Она или есть в библиотеке, а значит решение представлено не полностью и оно уже точно не будет "таким красивым", или ее нет вовсе.
Плюс красота очень спорная. Я красивым считаю не количество букв, а соответствие решения намерениям. Если нам нужно добавить код, то хочется и видеть как это происходит, а не загадочные операторы () и прочие хелпер-классы.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, FR, Вы писали:
FR>Здравствуйте, Evgeny.Panasyuk, Вы писали:
DM>>>Ты же все приставал с получением двух частей — до найденного элемента и от него дальше. Я показал.
EP>>Ну да, показал — неэффективное, негибкое, и более многословное:
FR>Реально же ерундой занимаетесь, сравниваете мягкое с зеленым. FR>Итераторы C++ и интервалы D слишком различны. Базовое различие все, включая и FR>меня, совсем упустили, интервалы D в отличии от итераторов не работают по месту, FR>а выдают новый интервал, по сути ближе к базовым ФВП из функциональщины FR>работающими со списками. Даже boost::range в основной массе этого не делает FR>а тоже работает по месту как и его базовые итераторы.
Адаптеры boost::range ленивые все. Пока ты не начнешь реально итерироваться по результату всех тих transformed|filtered|uniqued, ничего вообще не происходит.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>так она вообще в xml хранится, и код из неё нормально генерируется, и не программисты могут с ней работать + всякие xml утилиты, и как-то не комплексуем по поводу "ай-ай-ай, нет reflection, надо менять язык!".
Вот это характерно! Ты программируешь на ХМЛ-е, а не на С++.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>По идее уже в следующем году. Текущий proposal вроде всех устраивает (ну кроме тех кто мечтал об concept map).
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Здравствуйте, VladD2, Вы писали:
EP>>>Более того — у меня в одном из проектов есть большая схема, так она вообще в xml хранится, и код из неё нормально генерируется, и не программисты могут с ней работать + всякие xml утилиты, и как-то не комплексуем по поводу "ай-ай-ай, нет reflection, надо менять язык!". VD>>Вот это характерно! Ты программируешь на ХМЛ-е, а не на С++.
EP>Сейчас вообще обхохочешься: код из схемы генерируется Python'ом
А у меня перлом и седом и xslt из нескольких xml-ей, которыми управляет вообще другая команда
И процесс генерации записан в мейкфайле
Сейчас нам опять расскажут, что мы знаем только один язык
Здравствуйте, alex_public, Вы писали:
_> Но насколько я знаю в C++14 ничего принципиального не ожидается, скорее так, косметика...
На сколько я знаю, в C++14 и не планировали вводить много языковых фич, но тем не менее будут концепции и п.лямбда.
EP>>В C++11 можно (гугли "Using strings in C++ template metaprograms", + должно уже быть в библиотеках) _>Это ты про жуть типа задания отдельными буквами или про что? )
Нет конечно — "отдельными буквами" это доступно и в C++98. Строки с виду вполне обычные: MPLLIBS_STRING("hello")
Там даже как proof-of-concept делали compile-time разбор regexp в дерево Boost.Xpressive.
Здравствуйте, matumba, Вы писали:
К>>Задумайся на досуге о том, что промышленность так и не выкинула си. Неспроста, наверное.
M>На, тоже задумайся:
M>
Этот график наглядно показывает, что с 2000 года, уже 14 лет, старый, добрый, процедурный Си не теряет популярности. И на данный момент самый популярный язык программирования.
Успех ябло-си с 2011 по 2013 год легко объяснить выходом новых телефонов и новизну тренда на разработку мобильных приложений.
Если посмотреть на шарп, то после 2012 года видно, что он немного теряет популярность, а си плюс плюс, после резкого спада еще держится в лидерах.
Смысл моих слов в том, что ынтерпрайз может делать вообще что угодно, вообще на чем угодно, может хоть на хаскеле писать, код от этого лучше не станет.
M>По всем остальным аспектам Си — г-но мамонта, безумно затягивающее разработку и до сих пор (напоминаю, 21 век!) подкладывает свинью в виде stack overflow, null pointer, range overwrite и.т.п. —
Ну это лол, а что в шарпе нет null reference exception, stack overflow и т.д.?
M>Те же, кто платили за Сипиписных монстров! Что в этом такого? Новый софт делался и будет делаться, весь вопрос лишь в том, хватит ли ума "боссам" не создавать очередной "быстробегущий труп", чтобы потом годами латать дыры и молиться, чтобы все оба "специалиста по указателям" не махнули из конторы. И в то же время есть громадный выбор C# спецов, знания которых на порядок ценнее, потому что это не знания о костылях языка, а высокоуровневая CS.
Опять же лол. А что, если я выбрал шарп, как язык для своего проекта, то он автоматически будет хорошо написан?
Нет, конечно, если я захочу просто заформошлепить веб/десктоп/<поставить по вкусу> морду на винде, то брать плюсы, как основной язык, будет глупо.
С другой стороны я бы раз 20 подумал, а стоит ли мне связываться с майкрософтом?
А если не связываться, то лучше графичкского интерфейса чем qt нет.
Java? Полностью, по всем параметрам проигрывает. делфи? Да-да, сейчас...
M>Легаси — оно и есть легаси, подумай насколько высоко прыгнула парадигма от жонглирования указателей в перделках на 1000 строк к облачным вычислениям, паттернам, модульным системам, ООП и прочее — да это небо и земля!
Ога, парадигма прыгнула настолько, что я могу сейчас просто привести любого такого же фанатика хаскеля и он обдристает ваш(наш) си-шарп, си++, java, со всеми паттерными и оопами и точно так же заявит, что все это — говно мамонта и не нужно. А уж как он залечит про алгебраические типы, о том, что потоки не нужны, о том, что хаскель — это язык будущего, а мы все — отстой... Ууу!
В нашем мире много языков программирования и это прекрасно.
а для обычных BidirectionalRange, незнакомых алгоритму — было бы takeExactly, у которого первый range — ForwardRange, и с середины назад уже не пройтись
Здравствуйте, D. Mon, Вы писали:
DM>А, вон меня рядом поправили, можно и in задействовать для своих типов. Вот насчет своих литералов уже не уверен.
Да, эта "претензия" снимается.
DM>Я думаю, при переходе к сторонним библиотекам на С++ почти всегда будет другой интерфейс у контейнеров и придется вообще все переписывать. Насколько просто проходит переход между контейнерами STL, MFC, Qt, WxWidgets? У всех свои, похожие, но тем не менее достаточно разные, чтобы пришлось переписывать код.
Контейнеры Qt как раз поддерживают итераторы, так что комбинировать их с СТЛевскими алгоритмами никаких проблем нет вообще. С WxWidgets не довелось работать, но гугл показывает, что и там есть итераторы, например вот. MFC довольно старая библиотека... там, конечно, никаких итераторов нет.
Ещё буст как пример — отлично комбинируется с СТЛ.
DM>Что до специального синтаксиса, то опыт популярных "высокоуровневых" языков вроде перла/питона/руби/похапе и пр. показал, что они во многом так удобны именно из-за наличия подобных структур данных сразу в языке, без необходимости подключения дополнительных библиотек. Это достаточно базовые вещи, чтобы иметь их в приличном языке сразу.
Тут я немного не понял. Даже вот такая фигня:
int test[] = [1, 2, 3];
test.empty();
без "import std.array;" работать не будет. То есть мы всё равно вынуждены подключать библиотеку.
Насчёт иметь в языке — мне не понятно чем стандартная библиотека хуже. Вот то, что С++ довольно долго не имел хеш таблиц стандартных — это, конечно, не здорово. Но эти времена прошли.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>[q] EP>Only truly useful thing is to decompose your program into clear subroutines, clear units, which you understand. That is the only thing I know which works.
Да, это тоже очень важно. Но что важнее, статически доказанная безошибочность (конечно, только в плане отсутствия исключений, но не в плане соответствия ТЗ) или ясность кода — затрудняюсь сказать. ИМХО, в равной степени важно.
EP>Алан Тьюринг недавно сказал, что у тебя такого компилятора не было и быть не может, и я ему верю
Почему не может-то, уже есть примеры типа ATS или Perfect Developer, правда очень уж многословные и с весьма корявым синтаксисом.
EP>Рост мощи никак не решит halting problem. Разве что можно закрепить на законодательном уровне: "Наговнокодил? 15 суток!"
Ну вы же пишете код, который завершается? И обычно не испытываете затруднений в определении, где есть завершимость, а где нет.
Halting problem вполне можно решить статически в большинстве случаев. А там, где не решается — выкинуть такие случаи. Или написать на С.
Здравствуйте, D. Mon, Вы писали:
DM>Ну так если мы работаем не с итераторами, а с рэнджами, то к этому любому элементу мы можем прийти только оперируя рэнджем, а значит этот "любой элемент" и будет концом некоторого рэнджа. Неудобно лишь туда-сюда ерзать, но это и не должно быть удобно, такое ерзание — либо редкое извращение (для которого можно и специальный код написать), либо просто плохой алгоритм, для которого есть правильное решение в один проход.
Нее, даже на уровне диапазонов BidirectionalRange предоставляет недостаточную функциональность. Правда я даже не представляю как безопасно её можно вставить туда, хотя при этом структуры (типа DList) реализующие BidirectionalRange очень легко могут эту функциональность реализовать.
Например. Есть у нас BidirectionalRange r1. Делаем r2=r1.save. Далее, делаем итерацию r1 вперёд до какого-то элемента. Т.е. r1 у нас теперь задаёт часть r2. А теперь хотим получить BidirectionalRange на разницу между r2 и r1. Логичная же математическая операция, не так ли? ) Но такой у нас нет и в этом вся проблема. Если бы была, то можно было бы делать всё как и с итераторами.
Кстати, если говорить например про DList, то такую функцию довольно просто реализовать — проверить что оба диапазона родные и вернуть новый, с внутренними указателями (DList.Range хранит в себе всего лишь два указателя) из этих двух. Но это конкретно DList, а нам то надо это как функцию работы с произвольным BidirectionalRange...
Здравствуйте, FR, Вы писали:
FR>То что большинство функций работающие с D'шными интервалами выдают новый интервал, а не меняют FR>старый, в отличии от C++ итераторов и Boost.Range. И сравнивать их производительность бессмысленно.
IMHO, тут намного хуже то, что, насколько я понимаю, они не просто выдают новый интервал, но ещё и интервал ДРУГОГО ТИПА, так что комбинировать их без RTTI вообще нельзя. А это уже принципиальный прокол в производительности...
Или таки можно?
Вот смотри, пусть у меня есть односвязанный списко букв в виде интервала, и я хочу написать функцию, которая возвращает подпоследовательность этой последовательности от начала до символа '\n', либо до конца последовательности, если '\n', либо первые 100 символов, если последовательность длиннее, и в первых 100 нет '\n'.
Как такое написать эффективно?
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, Ikemefula, Вы писали:
I>Я на самом деле на D смотрю с большой надеждой. Если он выстрелит нормально в фейсбуке, это будет очень большое событие
Смотря в куда выстрелит... А то из С++ выстрелить в ногу/голову/спину/грудь тоже неплохо можно
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, VladD2, Вы писали:
VD>Библиотеки дело наживное. Если бы люди вроде тебя вместо того чтобы искать фатальные достатки просто попробовали что-нить написать на Ди, то и библиотеки появились бы.
А зачем эти людям писать системные библиотеки для непопулярных языков, нужных, в основном их фанатм и только, когда они могут писать что-то полезное и востребованное?..
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, VladD2, Вы писали:
VD>А они есть. Скорость копиляции, лучший интелисенс, качественное метапрограммирование, более высокоуровневый код. Это довольно много.
Ну, вот, например, надо нам писать драйвера какие-то, или числодробилки. На сколько все эти твои "довольно много" снизят стоимость разработки/поддержки?..
А теперь, положим нам надо какое-то формошлёпство с вебом пополам, насколько там Ди окажется ВЫГОДНЕЕ чем шарп?
Да, "выгоднее" это в баксах, а не в абстрактных понятиях, вроде "высокоуровневый код"...
Ы?
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, VladD2, Вы писали:
VD>У новых языков (D, Scala, F#, Nemerle, Kotlin, Haskel, ...) есть только одна проблема — размеры комьюнити. Куча народа, вроде вас, ходит и что-то там себе доказывает вместо того чтобы взять и начать помогать развивать перспективные языки.
Не, Влад, тебе, как фанату, задают прямой вопрос, "а зачем их развивать/осваивать, например, конеретно мне?"
А ты в ответ банановыми шкуракми кидаешься, программисты видите ли не те языки развивают...
А вообще-то все люди что-то своё делают, намного более востребованное и полезное, чем развивать какие-то н понятно кому и зачем нужные "новые языки"...
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, VladD2, Вы писали:
VD>1. Прямых средств генерации кода, а не с помощью финтов ушами, множественного наследования на ровном месте и прочей фигни. VD>2. Возможности бинарной компиляции метакода, чтобы мета-решения не отличались по скорости от тех что встроены в компилятор. Этого, кстати, и в Ди нет, вроде бы. VD>3. Возможности внятного и удобного расширения и/или реинтерпретации синтаксиса, чтобы мета-решениям можно было придать логичный и удобный вид.
VD>Если добавить эти мелочи, то... получится совсем другой язык.
Вообще-то и в Си и в Паскале и вообще почти везде есть возможность просто взять да и написать генератор кода, если уж задача такая, что без метопрограммирования никуда...
Только такие задачи -- редкость всё-таки...
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, VladD2, Вы писали:
EP>>так она вообще в xml хранится, и код из неё нормально генерируется, и не программисты могут с ней работать + всякие xml утилиты, и как-то не комплексуем по поводу "ай-ай-ай, нет reflection, надо менять язык!".
VD>Вот это характерно! Ты программируешь на ХМЛ-е, а не на С++.
Дык всё так и есть, для задачи, где нужен DSL юзают DSL, средсва поддержки которого написаны на плюсах, например, или ещё на чём-то...
И, скорее всего, тут намного важнее фреймворк для создания DSL'ей, а не язык на котором они создаются...
\
А встраивать один язык в другой вообще путь к запутыванию кода, IMHO, то есть маломасштабируемый и тупиковый.
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, alex_public, Вы писали:
E>>IMHO, тут намного хуже то, что, насколько я понимаю, они не просто выдают новый интервал, но ещё и интервал ДРУГОГО ТИПА, так что комбинировать их без RTTI вообще нельзя. А это уже принципиальный прокол в производительности... E>>Или таки можно? _>А в чём проблема? Это же и в C++ без проблем работает, а уж в D то и подавно. )
Библиотечный findSplit возвращает три range, два из которых результат takeExactly, а третий оригинального типа.
Допустим тебе в функцию передали BidirectionalRange, внутри ты сделал этот findSplit, и тебе нужно вернуть либо первый range либо последний. Как будешь делать?
А вот на итераторах это элементарно разруливается
Re[22]: Facebook и язык D - первый шаг к правде ;).
Здравствуйте, Erop, Вы писали:
E>Ну, в целом это не тока в языках так. Вещи, идущие от практических нужд, обычно намного гармоничнее, чем идущие от идей о "правльном дизайне", например
В отличие от хаскеля и скалы, D как раз пилят практики, можно сказать пролетарии. От этого он получается очень удобным в практическом использовании (и для меня стал language of choice для очень многих задач, сильно потеснив С++ и окамл), но с другой стороны такой подход (от практики) ведет к тому, что у языка нет четкой теоретической базы (в отличие от тех же хаскеля, скалы или окамла), что во многом и служит причиной кучи багов в компиляторе и медленного развития (другая причина — что компилятор написан на С++).
Здравствуйте, D. Mon, Вы писали:
EP>>Это называется type erasure — ты только и подтвердил опасение Erop'а: DM>А VMT относится к RTTI? Тогда да.
Я уверен что он имел ввиду любой runtime полиморфизм. Хоть на виртуальных функциях, хоть на tagged union, хоть на обычных func ptr, хоть на switch'ах по typeid (которое самое что ни на есть RTTI).
Здравствуйте, D. Mon, Вы писали:
DM>Но когда такого ветвления нет, то можно обойтись одной статикой, без виртуальных функций.
а в итераторах можно обойтись статикой для любого поддипазона последовательности всегда и гарантированно...
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Дело в том, что в C++ любой sub-range представляется парой итераторов — и при использовании алгоритмов не появляются новые типы итераторов на ровном месте. EP>А тут если вызвать банальный findSplit — то уже всё, уже приплыли.
Ну, на сколько я понял, новые типы -- это плата за ленивость. В целом в бусте сделали некий разумный компромисс. Хочешь энергично, но всё статически -- юзай итераторы или их пары, хочешь лениво -- юзай линивые конструкции, а в Ди, как я опять же, понял, вынуждают всё писать типа лениво и тем самым удобнее для функциональщины выходит. Но если мне по какому-то поддиапазону надо елозить много раз, то тут ленивость может выйти боком. Ну и вообще ненужная ленивость пости всегда выходит боком, IMHO...
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Re[25]: Facebook и язык D - первый шаг к правде ;).
Здравствуйте, D. Mon, Вы писали:
E>>Что же это они за 10 лет его ни на Ди ни на немерле даже не переписали-то?
DM>Не знаю, все собираются, сам удивляюсь. Говорят, сейчас какой-то конвертер пишут, чтобы компилятор в D сконвертить по частям.
IMHO, это лучший аргумент за то, что пока что не надо спешить переносить свои проекты на ди...
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, Erop, Вы писали:
EP>>Дело в том, что в C++ любой sub-range представляется парой итераторов — и при использовании алгоритмов не появляются новые типы итераторов на ровном месте. EP>>А тут если вызвать банальный findSplit — то уже всё, уже приплыли. E>Ну, на сколько я понял, новые типы -- это плата за ленивость.
А ленивость там от безысходности. Вот есть std::find — возвращает итератор, мы можем легко получить хоть первую половину, хоть вторую.
А в D, когда мы дошагаем до нужного элемента, у нас на руках будут два range:
1. original: [first, last)
2. truncated: [find(first, last, x), last)
Причём это атомы — из них никак не получить [first, find(first, last, x)), вот поэтому и считают, на каком расстоянии находится find(first, last, x) от first, и первая часть там получается вида [first, n), новым "ленивым" типом, причём с ForwardRange категорией (пофиг что исходный range мог быть Bidirectional).
E>Но если мне по какому-то поддиапазону надо елозить много раз, то тут ленивость может выйти боком. Ну и вообще ненужная ленивость пости всегда выходит боком, IMHO...
Что точно выходит боком так это "ленивая" ленивость — когда все ленивые конструкции являются SinglePass, хотя могли бы иметь категорию повыше. Например как тут
Здравствуйте, D. Mon, Вы писали:
DM>А как с ними будут работать стандартные алгоритмы? Или их тоже придется переписать?
Зачем? Это будут тоже итераторы же
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, Erop, Вы писали:
DM>>А кстати как будет выглядеть такой статический итератор, который выдает строчки из файла с таким вот динамическим условием выхода? Скажем, если первая строка "{", то выдает строчки до "}", а если нет — то просто первые 13 строк, если они там есть. И мы хотим этот итератор использовать в стандартных filter и map.
E>Но для таких целей никто не мешает, кстати, наделать анологичных ленивых обёрток над итераторами...
Т.е. городить свои типы на каждый чих? Ну так-то я и в D могу статику гарантировать, это не интересно. Что-то слабовата выходит ваша стандартная библиотека. Наверное, "плохая композиционность" и плохой дизайн.
Здравствуйте, D. Mon, Вы писали:
DM>Т.е. городить свои типы на каждый чих? Ну так-то я и в D могу статику гарантировать, это не интересно. Что-то слабовата выходит ваша стандартная библиотека. Наверное, "плохая композиционность" и плохой дизайн.
при чём тут "наша" или "ваша" стандартная библиотека? Речь же о диапазнах и итераторах, а не о стандартной библиотеке?
STL сам по себе ленивых вычислений не гарантирует, но есть более другие библиотеки...
С другйо стороны, подход прятать ленивость в порождаемые по требованию типы, как бы порождает типы на каждый чих просто по замыслу как бы.
Я так понял, что диапазоны, как они сделаны в Ди, как бы вынуждают нас использовать ленивость, без вариантов, а итераторы, как это сделано сейчас, например, в stl+boost позволяют нам в каждом конкретном месте выбрать лениво считать или энергично...
Кстати, как у Ди с мемоизацией? То есть если я замучу линивый поддиапазон, и потом буду ему save говорить и итерировать сто раз, он сто раз повторит вычисления, или как-то хитрее сделает?
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, alex_public, Вы писали:
_>Вообще то в роли числодробилки C++ однозначно лучший язык. Если сравнивать с Фортраном, то он предлагает намного более высокоуровневые абстракции и при этом даже чуть быстрее в умелых руках. Однако как мы видим во многих местах до сих пор используют Фортран — тут есть и тот самый консерватизм (как при переходе с C++ на D в других местах) и небольшая доля прагматизма, если мы говорим об учёных, а не программистах (C++ очень сложный, по сравнению с Фортраном).
Это главная проблема С++, как числодробилки. Что бы решить сложную вычматематическую задачу нужен не спец в С++, а спец в вычматах. А таким спецм фортран ПОНЯТНЕЕ и УДОБНЕЕ.
В числодробилках хитрые абстракции нужны редко, а вот боевая итерация по каким-то матрицам + возможность компилятора это всё векторизовать на любой платформе более или менее самостоятельно нужна практически всегда.
поэтому-то в руках вычматематика фортран и лучше. Конечно, если ты посадишь кодить числодробилку не математика, а спеца по плюсам там или Ди, он накодит лучше, но не то. Потому что он спец не в том.
_>Если говорить про D в роли числодробилки, то он предлагает ещё более удобные абстракции, менее сложен в обучение (там не обязательно разбираться во всех фичах, чтобы писать приличный код), но при этом немного медленнее и C++ и Фортрана. Так что тут весьма спорный вопрос о его применимости.
IMHO он просто не нужен. Нет никакой выгоды. А накладные расходы больше.
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, D. Mon, Вы писали:
DM>Единственное, что так просто не выйдет, — объединить "плащ" и "палатка" в одно слово с дефисом между ними, ибо когда есть два рэнджа, информация о том, что они к одной строке относятся определенным образом, уже потеряна. Но если такая задача действительно возникнет, то просто вместо диапазонов для слов можно использовать пары индексов или пары позиция-длина. Считай, те же итераторы, только типа int.
1) Это проканает только при произвольном доступе, а в случае интераторов достаточно односвязного списка...
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, D. Mon, Вы писали:
DM>Сейчас память очень медленная по сравнению с вычислениями и число пробежек по данным влияет на скорость намного сильнее,
Ну так примеры выше и показывают, что в D проходов по памяти будет больше, за счёт заниженных категорий. Когда у тебя Bidirectional внезапно становится Forward — тебе придётся снова топать до нужной позиции, или делать лишний раз .array (как раз был в примерах со строкой)
DM>чем лишний инкремент счетчика, о котором беспокоился выше Евгений.
В первую очередь лишний инкремент счётчика это демонстрация неудобства/неправильности концепции. Правильные абстракции зачастую не заставляют делать лишние действия.
Во-вторых — итераторы и range'и шагают далеко не всегда по памяти. Вот даже выше была iota. И в подобных случаях лишний инкремент может быть очень даже заметен
В-третьих — иногда данные могут быть компактными и многократно переиспользоваться, и помещаться целиком в L1.
DM>А попытка перейти на ленивые итераторы есть ничто иное как переход на рэнджи.
Ленивые итераторы есть, например в Boost, и там нет никаких iterator-less range'ей как в D
Если же ты говоришь про iteratorful range'и — так тут и никто не против их использования — они всегда позволяют достать итераторы при необходимости
Здравствуйте, D. Mon, Вы писали:
DM>Да не надо нам много раз бегать туда-сюда. Что за мания у вас такая по данным елозить?
Ну, например, у меня есть список букв, я выдвигаю гипотезы о точках в которых есть границы слов, после чего в каждую границу кладу список итераторов на возможные концы слова начинающегося в этом начале. Получается ациклический граф. Теперь я могу генерить там пути от начала в конец, каждый такой путь -- это гипотеза о том, как строка сегментируется на слова. У меня может быть модель слова, вернее набор моделей, ну там слово из словаря, идентификатор, дата, число, денежная сумма и т. д.
И я каждый такой путь могу оценить, подобрав к каждому слову из пути наилучшую модель и просуммировав качество сопоставления моделей со своими словами. Мало того, у меня могут быть ещё и какие-то модели, оценивающие сочетаемость слов, целые предложения, ещё что-нибудь уровня всего текста/предложения.
Моя цель -- найти лучшую сегментацию текста на слова.
Как написать такой алгоритм на итераторах списка, я понимаю, а вот как на дишных интервалах -- не очень...
Конечно, если ты пишешь некую *стандартную бизнес логику" и тебя устраивают те самые стандартные три-четыре блатные аккорда алгоритма, то всё зашибись, тока шарп с линком наперевес всё равно ещё лучше...
Но мир алгоритмов значительно более другой, вообще-то... Ширее так сказать и сложнее...
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, Erop, Вы писали:
E>Но я верно понял, что ты пришёл к убеждению, что интервалы вообще ненужное УГ, а итераторы, почти такое же УГ, просто чуть лучше и мягче?
Мой вердикт — для многих практических нужд дивных интервалов вполне хватает (подтверждено годом с лишним пракики), а для более заковыристых структур и алгоритмов актуальна прямая работа с этими структурами, тут посредники в виде итераторов и интервалов не так уж и нужны.
Здравствуйте, D. Mon, Вы писали:
E>>Вот тебе пример алгоритма посложнее... DM>В алгоритмах посложнее итераторы все равно малополезны, там структуры данных и перемещение по ним редко сводится к хождению пешком туда-сюда (линейно) по одному элементу. То же дерево возьми, по нему итераторами будешь ходить?
Если по дереву нужно ходить именно как по дереву, то нужна соответствующая концепция. Например, тот же Степанов, в Elements of Programming показывает так называемые BifurcateCoordinate:
+ наборы соответствующих аксиом.
Для этих концепций реализуются соответствующие алгоритмы.
И эти координаты намного ближе к итераторам (которые, по-сути, являются координатами линейных структур), чем к Range.
Вот как сделать нечто подобное на тех принципах, которые используются в D Range?
Здравствуйте, D. Mon, Вы писали:
EP>>Если по дереву нужно ходить именно как по дереву, то нужна соответствующая концепция. DM>Именно!
А разве итераторы обязуются решать все задачи?
Ну там кофе они не умеют варить. Хотя кто его знает что там в кофемашинах используется, возможно даже и STL с итераторами
Здравствуйте, -n1l-, Вы писали:
N>Здравствуйте, alex_public, Вы писали: _>>Хы, так C# уступает по мощи даже C++, не говоря уже о D. )))
N>Мощь в чем? В реализованном и написаном коде? Ну да, только это не мощь а обширность и зрелость языка. N>Шарп более выразительный за счет своих интерфейсов.
А чем шарповские интерфейсы выразительнее с++нутых абстрактных классов?
Здравствуйте, -n1l-, Вы писали:
N>Мощь в чем? В реализованном и написаном коде? Ну да, только это не мощь а обширность и зрелость языка. N>Шарп более выразительный за счет своих интерфейсов.
Не, я про другое. Про быстродействие кода то и обсуждать нечего — это давно известный факт. Но C++ (и тем более D) намного мощнее и при написание кода, за счёт своих средств метапрограммирования. На C# просто не реализуемы подобные вещи. Вообще. И соответственно все модные фичи из C# повторяются на C++ (и тем более D) с помощью этих методов. Единственное преимущество C# в том, что там все эти модности есть уже из коробки, а в C++ их надо искать в сторонних библиотеках... Но на мой взгляд это мелкое преимущество не покрывает указанных недостатков.
Здравствуйте, Sinix, Вы писали:
S>Слишком категорично S>Принципиально — реализуемы, достаточно поглядеть на nemerle. Если нужно ужесейчас — есть постшарп. Ну, или ждём рослин.
Да, nemerle — это как раз приблизительно то, о чём я говорил. Только вот это уже другой язык, а не C#. )))
Здравствуйте, gandjustas, Вы писали:
G>Ты еще не понял, что это или не нужно или элементарно делается с помощью буста G>Теперь все ждут C++14 когда еще больше фишек буста войдет в STL\язык.
Вот уж кому явно не идут шуточки по этой теме, так это тебе. Последний раз, как видел тебя в подобной дискуссии, ты выкинул очаровательный возглас "Давай, детка, сделай это на C++" (http://www.rsdn.ru/forum/philosophy/5208679
), а после того, как тебе показали код, делающий именно требуемое, позорно по тихому слился из дискуссии, даже не признав свою ошибку. Бедный Ikemefula за тебя там отдувался как мог.
Здравствуйте, alex_public, Вы писали:
_>Здравствуйте, gandjustas, Вы писали:
G>>Ты еще не понял, что это или не нужно или элементарно делается с помощью буста G>>Теперь все ждут C++14 когда еще больше фишек буста войдет в STL\язык.
_>Вот уж кому явно не идут шуточки по этой теме, так это тебе. Последний раз, как видел тебя в подобной дискуссии, ты выкинул очаровательный возглас "Давай, детка, сделай это на C++" (http://www.rsdn.ru/forum/philosophy/5208679
), а после того, как тебе показали код, делающий именно требуемое, позорно по тихому слился из дискуссии, даже не признав свою ошибку. Бедный Ikemefula за тебя там отдувался как мог.
Перечитал, но так и не увидел полный код. Не было его тогда, нет и сейчас.
То что там писали про async в бусте, то это не более, чем аналог yield в C#. До полноценного async, как в C# ему очень далеко. Теоретически можно сделать, но начинаются проблемы с детерминированным освобождением памяти.
Ты сам разберись в вопросе, а то будут тебя бустом пугать, а ты и будешь не понимать шутки.
Здравствуйте, alex_public, Вы писали:
_>Здравствуйте, gandjustas, Вы писали:
G>>Тем что на C# это весь код. Он работает когда больше нет ни одной строки. А на C++ нужно еще исполнять танцы с бубном бустом.
_>Агаа... Т.е. чтобы сравнивать C# и C++ надо последнему запретить использовать сторонние библиотеки... Я приблизительно так и думал.
А я разве говорил что надо запретить? Я лишь говорил что требуются дополнительные танцы, даже если в виде макросов (фу!). Как обычно макросы могут очень неоднозначно интерферировать с остальным кодом, а неудачно написанный\вставленный макрос может дать такую ошибку, что её сходу не найдешь. Про типизацию вообще говорить не буду. Не зря макросы считаются не рекомендуемым способом.
G>>async_code это что?
_>Это макрос. Его определение было в моём сообщение (скрытый текст).
Дык функция Post2UI как работает? Там за ней еще десятки строк и несколько макросов?
Гыгы, и снова не то. Здесь тоже самое что и в предыдущем варианте, только блокирующий ComplexFunction запустится после прихода первой порции данных.
G>Только я тебя попрошу показать реализацию async_stream(input_stream) и ты опять напишешь 30 и более строк ада с макросами и бустом, а в .NET, с вероятностью 95%, уже есть готовый класс, который решит твою задачу.
Хы, это же просто асинхронная обёртка под конкретный поток. Т.е. это класс, реализущий интерфейс InputStream и при этом пересылающий все вызовы к имеющейся у него ссылке на реальный поток ввода. Точнее все функции пересылаются напрямую, а одна главная (типа ReadBuf, которую многократно вызывает ComplexFunction) через асинхронный вызов (через await_async как в коде выше) той же функции реального синхронного потока.
G>Какого дела? Ты выососал из пальца какую-то хрень. В реальной програмее ComplexFunction тупо перепишут, потыкав везде await и она станет идеально асинхронной и будет сама маршалить вызовы в UI если надо.
G>Я же говорю, твое понимание .NET на уровне плинтуса. Ты можешь миллион таких пшиков нагенерить, и все они будут бесконечно далеки от реальной жизни.
Воот, до тебя наконец то начала доходить ситуация, хотя признавать это ты конечно же не хочешь. .Net не позволяет нам использовать готовые синхронные функции (которых миллиарды в различных библиотеках) в асинхронном коде, а заставляет нас переписывать их заново. В отличие от C++, где мы можем получить "идеально асинхронную" функцию из синхронной не трогая её код. Но конечно, если ты не видишь в невозможности использовать старые рабочие функции никакого недостатка, то тут уже ситуация безнадёжная...
Здравствуйте, alex_public, Вы писали:
_>Воот, до тебя наконец то начала доходить ситуация, хотя признавать это ты конечно же не хочешь. .Net не позволяет нам использовать готовые синхронные функции (которых миллиарды в различных библиотеках) в асинхронном коде, а заставляет нас переписывать их заново. В отличие от C++, где мы можем получить "идеально асинхронную" функцию из синхронной не трогая её код. Но конечно, если ты не видишь в невозможности использовать старые рабочие функции никакого недостатка, то тут уже ситуация безнадёжная...
Ты как то особенным образом понимаешь асинхронщину. В общем случае переписывать надо не из за дотнета, а из за того, что есть некоторое разделяемое состояние. Вот простой пример
function(){
var value = read();
write(next(value));
}
Вот функция, у ней в синхронном коде простой инвариант, проще не придумаешь. Проблема следующая — когда read или write становится асинхронным, между read и write может произойти нарушение инварианта. Вот из за этого и нужно переписывать код самой функции. Что характерно, в С++ ровно то же самое.
Итого — если ты решительно не согласен — покажи эту секретную технику " можем получить "идеально асинхронную" функцию из синхронной не трогая её код" что бы показаный инвариант сохранился.
Здравствуйте, dalmal, Вы писали:
D>D не нужен. Потому что его нишу плотно занимают C#/Java с тоннами библиотек на любой вкус. И я не вижу у него никакого преимущества, особенно перед C# в технологическом смысле. D>Так что D не нужен. И на смену С++ он придет явно не в этом десятилетии.
C# работает только на венде, а все практические реализации Явы обладают красотой и грациозностью бегемота, пасущегося на лугах Страны Неограниченных Ресурсов.
Кросплатформенный язык общего назначения типа "си с классами", не страдающий при этом врожденной склонностью к онкологическим заболеваниям, безусловно, нужен.
Здравствуйте, alex_public, Вы писали:
_>Здравствуйте, gandjustas, Вы писали:
G>>Потрясающе. Если тебе понадобится обрабатывать сотни подключений у тебя будут сотни потоков. Практический лимит потоков на windows — около 200. Но даже при сотне уже все тормозит. При этом потоки будут ничего не делать.
_>Если нам потребуются легковесные потоки, то Boost.Coroutine прямо их и реализует. Т.е. уже без моих хитрых макросов для реализации await/async. Причём делает это несравнимо эффективнее других, обсуждаемых тут, реализаций.
А ты действительно не врубаешься. Копать в сторону IOCP...
И вообще, задача сделать существующий синхронный код асинхронным (с кооперативной многозадачностью и переключениями в момент обращения к стримам), не побоюсь этого слова, на практике редко встречается. Ибо вот так вот одним махом взять и сделать произвольный код асинхронным (при этом не смотря в него) — это нужно быть очень "смелым" и отчаяным — получившиеся "потоки" могут иметь разделяемые изменяемые данные со всеми вытекающими.
Основная проблема, которая, на мой субъективный взгляд, решается через async\await такая: плодить дофига потоков, которые 99% времени только и делают, что ждут IO — непозволительн расточительность ресурсов. Прикол в том, что на уровне ОС IO уже является асинхронным. Но ОС выставляет API синхронный (т.е. это "привычный" IO API, знакомый всем и каждому). А при чтении\записи система блокирует поток до тех пор, пока операция не завершится. Чтобы эти синхронные чтения\записи сделать обратно асинхронными разработчикам приходится плодить потоки. Даже пул потоков не спасает — все его потоки быстро "съедаются" ничегонеделающими операциями ожидания и приходится добавлять в пул все новые и новые потоки. И тут на помощь приходит IOCP! Благодаря ему можно обойтись одним потоком на все операции IO в приложении. Для IO-операции регистрируется callback, который будет вызван в потоке, предназначенным для разгребания очереди IOCP, в момент, когда ОС оповестит о завершении этой операции. Причем в этом callback-е делается не собственно обработка результата операции, а добавление задания (обработчика результата) в дотнетный пул потоков. Т.е. нагрузка на этот поток минимальна, благодаря чему в .Net можно обойтись одним таким IOCP потоком на весь процесс.
Так вот, задача такая: есть множество изначально асинхронных операций (т.е. они не являются результатом "об-асинхронивания" синхронных операций), сделанных в Continuation Passing Style; нужно сделать так, чтобы последовательность их "вызова" выглядела как простой линейный код (плюс, конечно, еще нужны всякие SynchronizationContext, возможность переключения на поток в пуле, назад в вызывающий поток и прочие плюшки). Async\await все это обеспечивает.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Здравствуйте, gandjustas, Вы писали:
_>>>Теперь показывай решение этой примитивной тестовой задачки на C#. G>>Компилируемый код дай.
EP>Вот полный код
Которая работает в том же потоке что и UI. client_stream считывает буковки по WM_CHAR. std::getline — это стандартная функция, которая ничего не знает о корутинах.
Ты как-то забыл написать что основная асинхронность создается тут:
Здравствуйте, alex_public, Вы писали:
_>Здравствуйте, gandjustas, Вы писали:
G>>Как помогут легковесные потоки если IO блокирующий, как в твоем примере?
_>А причём тут легковесные потоки и мой пример? У меня там, как ты видел, обычное десктопное приложение (окошко с кнопкой), а не сервер с тысячами подключений. Зачем мне там такие потоки?
Наверное потому что async\await отлично работает как на клиенте, так и на сервере. А ты сделал менее эффективный пример, который и этом нифига не масштабируется.
G>>Неблокирование путем создания другого потока — хреновая идея. В твоем примере так. _>Ну покажи в чём хреновость. )
Если ты начнешь масштабировать свой подход, то он начнет дико тормозить. А если подход нельзя масштабировать, то нафига он такой нужен? Решить частную задачу по созданию асинхронности одной функции можно запустив её в отдельном потоке, дописав маршалинг вызовов в UI и получится меньше чем пляски с корутинами\шаблонами\макросами.
G>>А чем копирование файла отличается от считывания потока данных из сети и записи на диск?
_>Не важно что и куда, а важно сколько операций параллельно. Реализация через пару системных потоков будет максимально эффективной и для сети (собственно там вообще идеально, т.к. устройства точно разные). Однако если нам понадобится много таких параллельных скачиваний, то эффективность будет ухудшаться с их увеличением. Так что начиная с какого-то момента уже выгоднее использовать другую модель (легковесные потоки например).
А можно не выдумывать хрень и использовать IOCP, эффективнее на винде ниче пока не придумали.
Вот только код будет не такой, как у тебя.
_>>>Конечно не тоже самое. C# реализация заметно более слабая. ))) Или быть может ты уже готов показать решение той тривиальной тестовой задачки? G>>Легко.
_>Это была речь про эту http://www.rsdn.ru/forum/philosophy/5357968
Здравствуйте, gandjustas, Вы писали:
G>Думаю стоит глянуть на Mono и Xamarin, перед тем как толкать такие утверждения. Сейчас спектр систем, где заработает код на C#, примерно такой же, как у java и у обоих гораздо шире, чем у C++.
С учётом того, на чём написаны сами .net, mono, java, эта фраза звучит особенно пикантно. Видимо здесь присутствует какая-то магия. )))
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Плохой пример чего? Ты о чём? matumba считал что Linux это C++
Плохой пример чего бы то ни было, кроме писания монолитных ядер юникс-подобных ОС. Ядро линуха очень похоже на другие подобные ядра, и очень мало похоже на какие-либо другие программы.
Здравствуйте, gandjustas, Вы писали:
G>Ты понять показываешь незнание предмета. Какой вариант по твоему лучший?
IOCP использовался задолго до появления async\await. Это как раз и есть лучший вариант для систем со множеством параллельных операций и дополнительные накладные расходу от async\await ему совершенно ни к чему.
G>Тут не надо. Тут достаточно потока.
Ага. И я пока что вижу твою неспособность повторить на C# даже такой простейший вариант.
G>Но видимо тупо везде создавать потоки неэффективно, поэтому и придумали IOCP, пулы потоков, таски и async\await.
Только все эти вещи не завязаны друг на друга, а существую параллельно. Каждая для своих целей.
G>Это зависит от того что за фоновый процесс. Если там IO, то создание потоков — совсем не оптимальный способ. А практика показывает что подобные фоновые процессы в 99% случаев — io.
С чего бы это? Накладные расходы на переключение контекстов при таком раскладе вообще не принципиальны.
G>Ты о чем вообще? Для чего тебе леговесные потоки?
Я о сравнение накладных расходов у async/await из C# и аналогичных реализаций (например Boost.Coroutine)...
G>Ок, давай конкретнее, если сам мозгом не работаешь:
Что-то ты утомил своими кривыми отмазками. Каждому же в темке видно как ты пытаешься увильнуть от своих слов. Надоело это. Всё, есть всего два возможных варианта:
1. Ты признаешь, что реализация async/await C# слабее чем простейший вариант в десяток строк на C++.
2. Ты показываешь полный аналог этого http://www.rsdn.ru/forum/philosophy/5357968
поправкой (вариант без ненавистных тебе потоков). И мы все признаём, что реализация на C# не слабее.
Если в последующих твоих сообщениях не будет одного из этих двух вариантов, то это будет автоматом означать, что ты просто обычный форумный болтун, на которого нет никакого смысла тратить время.
Здравствуйте, alex_public, Вы писали:
_>Здравствуйте, gandjustas, Вы писали:
G>>А какой тогда смысл в асинхронности вообще? Запусти в отдельном потоке и радуйся.
_>Да, это как раз самое лучшее решение (для работы с блокирующим кодом). Но оно далеко не всегда возможно. Проблема в том (на нашем примере), что ComplexFunction нельзя выполнять в отдельном потоке, а можно только в ui.
Ну сделай маршалинг UI вызовов, это все равно будет эффективнее создания кучи потоков.
G>>Без асинхронного IO бесполезная тема. А тебя единственный способ превращения синхронного в асинхронный — создание потока. Я и предлагаю не мучать жопу с корутинами, а сразу на потоках построить. _>Да, можно. Опять же переписав сложную библиотечную функцию...
У тебя же есть исходники, иначе как ты узнаешь какие методы надо переопределять?
G>>Но Async\await умеет и в рамках нескольких потоков работать и с async io, а Boost.Coroutine — увы G>>Так что несимметричная. _>Как раз Boost.Coroutine только в рамках одного потока и работает. Это я её раскидал на несколько с помощью своего кода.
А ты попробуй написать так, чтобы вообще без доп потоков. Иначе смысл твоего переписывания теряется.
G>> G>>Она только тебе интересно, потому что другие случаи ты сделать не сможешь.
_>Не могу? )))
Конечно не можешь. Потому что надо научиться комбинировать асинхронные вызовы и масштабировать это все.
Да_> это же ещё проще чем вариант с потоками. Ну смотри, будет тебе вторая задачка... И так берём этот http://www.rsdn.ru/forum/philosophy/5357968
Поздравляю, ты осилил асинхронный IO. Теперь попробуй научиться комбинировать асинхронные вызовы.
Например у тебя идет подряд два чтения — одно из файла, другое из сети, нет смысла дожидаться завершения первого, чтобы запустить второе. Можно запустить их параллельно, а потом вернуться как оба закончатся.
Осилишь такое с корутинами?
Вот пример на C#
Было
var len1 = network.Read(buf1,0, buf1.Length);
var len2 = file.Read(buf2,0, buf2.Length);
someF(buf1,len1, buf2, len2)
Стало
var result = await Task.WhenAll(network.ReadAsync(buf1,0, buf1.Length),file.ReadAsync(buf2,0, buf2.Length));
someF(buf1,result[0], buf2, result[1])
Ограничений никаких нет.
G>>На практике как раз самое интересное — асинхронный IO и масштабирование. G>>Если у тебя IO должен быть синхронный (странно почему, Windows поддерживает IOCP с тех пор когда буста еще не было), то просто делаешь потоки. Но у тебя наступает вполне резонная жопа с масштабируемостью.
_>Ещё раз, описываемые тобой проблемы с многопоточным вариантом актуальны только для специфической области типа написания высоконагруженных серверов.
Наверное поэтому весь IO в WinRT сделали асинхронным
_>И если уж мы говорим о ней и нам критично быстродействие, то C# await/async тоже не стоит применять.
С чего ты это взял?
Здравствуйте, Evgeny.Panasyuk, Вы писали:
I>>Вот такие фокусы и в джаве, и в дотнете, и в питоне.
EP>Откуда именно тут coroutine, покажи полный код на C#.
Здравствуйте, alex_public, Вы писали: _>Здравствуйте, gandjustas, Вы писали: G>>Ну сделай маршалинг UI вызовов, это все равно будет эффективнее создания кучи потоков. _>У тебя какая-то паранойя с потоками. В не северных ситуаций они очень даже эффективны. Тем более, если учесть текущие тенденции в развитие процессоров...
Для клиента я пишу на JS, там однопоточная асинхронность. На сервере — async\await самое то.
Это как раз к тому, что потоки, особенно созданные вручную, почти не нужны, если у тебя есть нормальный асинронный IO. G>>У тебя же есть исходники, иначе как ты узнаешь какие методы надо переопределять? _>У меня заголовочные файлы и скомпилированные lib/dll файлы. Многие библиотеки распространяются именно так. Но даже если бы и были исходники. Я не собираюсь переписывать кучи чужих библиотек, если этого можно не делать. И это возможно, в C++, но не в .net.
Да и в C++ в общем случае невозможно. Инварианты посыпятся в любом нетривиальном коде. А тривиальный можно и переписать.
Кстати в .NET тоже вполне возможно:
Вот функция:
static void ComplexFunc(Stream src, Stream dst)
{
var buf = new byte[256];
while(src.Position < src.Length)
{
var len = src.Read(buf,0,buf.Length);
dst.Write(buf, 0, len);
}
}
Примитивное копирование потока.
Вот эвентхендлер:
private void button1_Click(object sender, EventArgs e)
{
for (int i = 0; i < 100; i++)
{
using (var src = File.OpenRead("TextFile1.txt"))
using (var dst = File.Create("TextFile2.txt"))
ComplexFunc(src, dst);
Console.WriteLine("Iteration " + i);
}
}
Вот он-же в криво-асинхронном варианте:
private void button1_Click(object sender, EventArgs e)
{
scheduler.CreateFiber((s, yield) => {
for (int i = 0; i < 100; i++)
{
using (var src = new AsyncStream(File.OpenRead("TextFile1.txt"), yield))
using (var dst = new AsyncStream(File.Create("TextFile2.txt"), yield))
ComplexFunc(src, dst);
Console.WriteLine("Iteration " + i);
}
});
}
Реализация AsyncStream (значимые части):
class AsyncStream:Stream
{
Stream baseStream;
Action<bool> yield;
public AsyncStream(Stream baseStream, Action<bool> yield)
{
this.baseStream = baseStream;
this.yield = yield;
}
public override int Read(byte[] buffer, int offset, int count)
{
var task = baseStream.ReadAsync(buffer, offset, count);
task.GetAwaiter().OnCompleted(() => yield(true));
yield(false);
return task.Result;
}
public override void Write(byte[] buffer, int offset, int count)
{
var task = baseStream.WriteAsync(buffer, offset, count);
task.GetAwaiter().OnCompleted(() => yield(true));
yield(false);
return;
}
}
Заметь, никаких потоков, await просто руками написал. IO делается асинхронно за счет IOCP.
Код шедулера:
Скрытый текст
public class FiberScheduler
{
private ConcurrentQueue<Fiber> queue = new ConcurrentQueue<Fiber>();
public uint PrimaryId { get; private set; }
public FiberScheduler()
{
this.PrimaryId = UnmanagedFiberAPI.ConvertThreadToFiber(0);
if (this.PrimaryId == 0)
{
throw new Win32Exception();
}
}
public Fiber CreateFiber(Action<FiberScheduler, Action<bool>> action)
{
var fiber = new Fiber(action, this);
queue.Enqueue(fiber);
return fiber;
}
public void Delete(Fiber fiber)
{
fiber.Delete();
UnmanagedFiberAPI.DeleteFiber(fiber.Id);
}
internal void Switch(Fiber fib, bool enqueue)
{
if (enqueue)
{
queue.Enqueue(fib);
}
UnmanagedFiberAPI.SwitchToFiber(this.PrimaryId);
}
public void Next()
{
Fiber fib;
if (queue.TryDequeue(out fib))
{
switch (fib.Status)
{
case FiberStatus.Error:
case FiberStatus.Started:
case FiberStatus.Done:
UnmanagedFiberAPI.SwitchToFiber(fib.Id);
break;
default:
break;
}
}
}
}
Вспомогательные классы:
Скрытый текст
public enum FiberStatus
{
Error,
Started,
Done,
Deleted
}
public class Fiber
{
private Action<FiberScheduler, Action<bool>> action;
public uint Id { get; private set; }
public FiberScheduler Scheduler { get; private set; }
public FiberStatus Status { get; internal set; }
internal Fiber(Action<FiberScheduler, Action<bool>> action, FiberScheduler scheduler)
{
this.action = action;
Scheduler = scheduler;
Status = FiberStatus.Started;
UnmanagedFiberAPI.LPFIBER_START_ROUTINE lpFiber = new UnmanagedFiberAPI.LPFIBER_START_ROUTINE(FiberRunnerProc);
Id = UnmanagedFiberAPI.CreateFiber(0, lpFiber, 0);
if(Id == 0)
{
throw new Win32Exception();
}
}
private uint FiberRunnerProc(uint lpParam)
{
uint status = 0;
try
{
action(this.Scheduler, Yield);
Status = FiberStatus.Done;
}
catch (Exception)
{
status = 1;
Status = FiberStatus.Error;
throw;
}
finally
{
Yield(false);
UnmanagedFiberAPI.DeleteFiber((uint)Id);
Status = FiberStatus.Deleted;
}
return status;
}
private void Yield(bool enqueue)
{
this.Scheduler.Switch(this, enqueue);
}
internal void Delete()
{
this.Status = FiberStatus.Deleted;
}
}
internal static class UnmanagedFiberAPI
{
public delegate uint LPFIBER_START_ROUTINE(uint param);
[DllImport("Kernel32.dll")]
public static extern uint ConvertThreadToFiber(uint lpParameter);
[DllImport("Kernel32.dll")]
public static extern void SwitchToFiber(uint lpFiber);
[DllImport("Kernel32.dll")]
public static extern void DeleteFiber(uint lpFiber);
[DllImport("Kernel32.dll")]
public static extern uint CreateFiber(uint dwStackSize, LPFIBER_START_ROUTINE lpStartAddress, uint lpParameter);
}
Но со сложным кодом в complexdunc такое сделать не выйдет, .NET начнет бить тревогу.
Аналогично любой сложный библиотечный код поломается если ему вместо синхронной реализации подсунуть хрен-пойми-какую.
Гораздо проще в .NET вытащить async api. В C++ покачто с async api проблемы, может в C++14 починят. G>>Поздравляю, ты осилил асинхронный IO. Теперь попробуй научиться комбинировать асинхронные вызовы. G>>Например у тебя идет подряд два чтения — одно из файла, другое из сети, нет смысла дожидаться завершения первого, чтобы запустить второе. Можно запустить их параллельно, а потом вернуться как оба закончатся. G>>Осилишь такое с корутинами? _>А в чём проблема то в этой простейшей задачке? ) Синхронный код: _>
Это так сказать внутренности. Как ты понимаешь, это всё без проблем упаковывается в симпатичный макрос, который делает всё автоматически и даже будет красивее твоего вариант. Но я это не стал делать, т.к. ты бы тогда наверняка тут же придрался и потребовал показать внутренности макроса.
Поздравляю, ты изобрел асинхронные корутины. Их для .NET Рихтер изобрел в 2007 году
Но у тебя как обычно несколько проблемы:
1) нужен message pump для корутин, обязательно однопоточный.
2) Нужен message pump для асинхронного IO, тут уже зависит от реализации.
3) Все это дико тормозит без возможности улучшения (потому что 1 и 2). _>>>И если уж мы говорим о ней и нам критично быстродействие, то C# await/async тоже не стоит применять. G>>С чего ты это взял? _>Потому что этот синтаксический сахар не является бесплатным по накладным ресурсам.
Здравствуйте, gandjustas, Вы писали:
G>Для клиента я пишу на JS, там однопоточная асинхронность. На сервере — async\await самое то. G>Это как раз к тому, что потоки, особенно созданные вручную, почти не нужны, если у тебя есть нормальный асинронный IO.
У тебя сервер утилизирует только одно ядро процессора? )
G>Кстати в .NET тоже вполне возможно:
Ооо, наконец то код. Ну что же, я его весь посмотрел и вот мои выводы:
1. Он принимается. В том смысле что он действительно делает тоже самое что и мой. Правда переписать в 3 раза короче у тебя не вышло, а получилось скорее наоборот... Ну да ладно, я не буду цепляться к мелочам.
2. Как следствие пункта 1 делаем вывод, что с тобой всё же возможно конструктивное общение, хотя и долго пришлось добиваться этого.
3. Твоё решение задачки является чётким доказательством моего тезиса, что реализация await/async в C# заметно слабее простейшей реализации того же на C++ с помощью Boost.Coroutine. Т.к. тебе пришлось использовать системные сопроцедуры, предоставляемые виндой (которые являются полным аналогом Boost.Coroutine, только платформозависимым и независящим от языка), а не использовать механизм await/async (который тоже представляет собой сопроцедуры, но гораздо более слабые).
G>Поздравляю, ты изобрел асинхронные корутины. Их для .NET Рихтер изобрел в 2007 году G>Но у тебя как обычно несколько проблемы: G>1) нужен message pump для корутин, обязательно однопоточный. G>2) Нужен message pump для асинхронного IO, тут уже зависит от реализации. G>3) Все это дико тормозит без возможности улучшения (потому что 1 и 2).
А где ты увидел в этом моём коде использование очереди сообщений? )
И кстати как раз .net вариант использует очередь сообщений, в то время как это совсем не обязательно для неблокирующего IO.
_>>Потому что этот синтаксический сахар не является бесплатным по накладным ресурсам. G>
Ну посмотри на реализацию реально нагруженных серверов. Тот же nginx глянь. А потом покажи мне нечто сравнимое на C# await/async.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
I>>А почему инварианты должны ломаться именно в этой функции ?
EP>Тогда покажи пример где они ломаются не в этой функции.
А ты не читатель ?
I>>Ты хочешь решить локальную проблему, глобальным механизмом. Соответсвенно инварианты будут ломаться так же глобально. I>>Ты не можешь заранее сказать, что будет выполняться в тот момент, когда одна из нитей вызывает getline. Что будет если вторая нить вызовет тот же getline, скажем по какому нибудь эвенту и тд ?
EP>Ты не болтай, а примеры приведи
Я уже показал. В обычном приложении я имею право вызывать getline где мне вздумается, хоть в обрабочике события какого. А вот с твоей модной асинхронщиной это уже не пройдет.
EP>Вот есть thread safe функция, пусть тот же самый getline. Когда есть несколько потоков — её могут прервать в любой момент. EP>Что может может поломаться если ей передать stream который делает yield внутри.
Ты проверь на деле, у тебя ведь есть нужный код ? Добавь всего ничего — там где пополнение буфера эвент. А в хандлере вызови еще один getline.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
I>>>>Вот такие фокусы и в джаве, и в дотнете, и в питоне. EP>>>Откуда именно тут coroutine, покажи полный код на C#. I>>Из либы. Зачем тебе код ?
EP>Полный код примера.
Что ты хочешь сделать с этим кодом ? Там, естественно, нет полноценных stackfull, их должен gc поддерживать.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>>>Ещё раз. Я озвучил факт, который оппонент не знал/не понимал. I>>Ты сам себе придумал, что ктото чего то не понимает.
EP>Например gandjustas начинает петь ту же самую песню про message pump, которую ты пел летом
I>>Ну значит UI Loop из моего примера вызовется чудом, например сканированием адресного пространства на предмет наличия ::GetMessage и ::TranslateMessage или, как вариант, короутина догадается WinMain вызвать.
Правильно. Ты ведь говорил, что твоим короутинам не надо ничего знать про эвентлуп ? А оказалось не только надо, но и больше — надо всё приложение делать так, что бы поддерживать эту асинхронщину.
EP>>>Вот ты тоже не знал, не верил, отрицал. Зато теперь "И что с того ?" — большой прогресс I>>Если тебя подводит память, то я напомню — ты утверждал, что асинхронщину не надо всовывать в эвентлуп. И доказал это утверждение кодом в котором всунул асинхронщину в WM_CHAR.
EP>Опять двадцать пять
EP>// было:
мусор выбросил
case WM_SIZE:
switch(w_param)
{
case SIZE_MAXIMIZED:
task();
break;
case SIZE_MINIMIZED:
if(on_minization) on_minization();
break;
}
EP>}
EP>
Трансформация полностью локальная
И в итоге вся твоя асинхронщина прибита гвоздями к эвентлупу. Глаза раскрой — эвентлуп используется у тебя как примитивный диспетчер.
В другом твоем примере ты сделал точно так же — привязался к WM_CHAR.
То есть, в кратце, короутин как минимум недостаточно для асинхронщины, нужен диспетчер прибитый гвоздями к эвентлупу.
Здравствуйте, gandjustas, Вы писали:
G>Ну давай покажи какие realworld проблемы решает spirit. На проверку окажется что 90% уже решены в современных платформах, а еще 10% закрываются специальными средствами. G>Это кстати не только spirit касается, но и других "универсальных всемогутеров".
Вообще то spirit хорош не столько возможностью легко задавать прямо в коде сложные грамматики, сколько своим быстродействием.
Можем провести простейший тест. Допустим есть обычный текстовый файл. Он состоит из 100 строк. Каждая строка состоит из 100 000 (вполне нормальная ситуация для обработки экспериментальных данных) int'ов, разделённых запятыми. Задачка: прочитать файл, посчитать среднее по каждой строке и допустим вывести в отсортированном виде в консоль (это чтобы проконтролировать результат работы — тогда можно exe обменяться, а не напрягаться с построением чужих библиотек). С помощью Boost'a я напишу решение всей задачки ровно в 5 строк. И при этом оно будет думаю где-то раз в 10 быстрее твоего, сделанного с помощью стандартной библиотеки .Net.
G>Ты опять повторяешь заблуждение что решение на C++ лучше. Оно не лучше потому что: G>1) тормозит G>2) не масштабируется
Тебе осталось доказать эти два тезиса. Потому как ты их тут уже не раз повторяешь, но пока не привёл ни единого аргумента в из защиту. Показывай давай конкретно что там тормозит и где. )))
G>С чего ты взял? perceived performance от async IO растет, а распараллеливание IO без блокировки потоков делает софт быстрее\улучшает масштабируемость.
Ага. Только await/async для этого не требуется. )))
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Здравствуйте, gandjustas, Вы писали:
EP>>>Почему все в одном? Запускай несколько потоков, каждый со своими корутинами. G>>Это априори более медленный вариант, чем пул потков с продолжениями.
EP>Если у тебя .then выполняется в другом потоке то смысла в await мало. Например для UI продолжения должны запускаться в UI Thread
Те продолжения, которые должны в UI запускаться там и будут запускаться, но если ты например делаешь копирование из одного потока в другой в асинхронном цикле, то какой смысл маршалить в UI продолжения?
Как раз более половины продолжений в прикладной программе не нуждаются в выполнении в UI. А в библиотеке все 100%.
G>>Кроме того такой вариант гораздо сложнее реализовать. EP>Нет. Например при использовании Boost.Asio иметь свой io_service per thread — это нормально, и просто Наоборот, использование одного io_serive на несколько потоков считается более сложным.
Ну это только особенности boost. А если смотреть картину в целом, то для маршалинга всех продолжений в один поток надо как-то информацию протаскивать в продолжения. В boot это делается за счет stackfull корутин, что повышает требования к памяти, ибо хранить стек, не тоже само что хранить замыкание с 3-5 значениями.
Здравствуйте, koodeer, Вы писали:
K>Чтобы дойти до Boost.Asio, корутин и прочего — нужен многолетний опыт.
Никогда не занимался профессиональной разработкой client/server — не было таких задач. Изучал/игрался только ради интереса.
В Boost.Asio корутины уже встроены, причём и stackless и stackful.
Более того, что-то производное от Asio должно войти в стандартную библиотеку. Плюс по корутинам сейчас есть два proposal'а, то есть вероятно они войдут в C++17.
K>Серьёзнейший недостаток C++ в том, что новые возможности и библиотеки рекламируются очень и очень мало. Более того, сами же матёрые плюсисты, в ответ на вопрос начинающих, с чего начать учиться, чаще всего предлагают старую замшелую литературу 90-х годов. Не, так-то те книги хорошие.
1. По C++ есть много плохих книг, которые учат стилю который не свойственен языку. Новичку выбрать правильную книгу без постороннего совета действительно трудно.
2. То что было в 90-х, мало применимо сегодня. Учить C++ нужно по современным книгам. Например книга Страуструпа — Programming -- Principles and Practice Using C++ — (Причём она нацелена не просто на новичков в C++, а на новичков в программирование вообще. Надеюсь он её обновит до C++11/14).
K>Вот только начав с них, до корутин/буста/etc новоиспечённый плюсист дойдёт ой как не скоро.
По библиотекам Boost есть различные overview, слайды, видео-презентации, и т.п. Также Boost упоминается во многих книгах, например у Страуструпа, Александреску, Саттера, Майерса.
Но в целом согласен, какой-то общепринятой книги, которая делает high-level обзор распространённых библиотек (Boost, Poco, QT, Cinder, openFrameworks, etc) — я не встречал. И да — заблудится новичку без посторонней помощи очень легко, поэтому нужно постоянно задавать вопросы (например тут, или на stackoverflow).
Здравствуйте, koodeer, Вы писали:
K>Просто я снова наткнулся на одном форуме на свежее обсуждение многопоточного сервера на C++. И снова там матёрые плюсисты (сужу банально по количеству их сообщений на форуме) предлагают на каждое соединение создавать по потоку. То есть 50 соединений с клиентами — 50 потоков. Имхо, ни один дотнетчик-миддл не мог бы сморозить такую глупость...
Нуу при определённых условиях (на количество одновременных подключений) это тоже может быть самым оптимальным решением... )))
K>Я обеими руками за нативный код. Однако в очередной раз вынужден сказать: всё, что в этой теме приводят в пример alex_public, Evgeny.Panasyuk и прочие, — это удел гуру C++. Чтобы дойти до Boost.Asio, корутин и прочего — нужен многолетний опыт. K>Между тем, в дотнете уже джуниоры вовсю юзают TPL и async/await.
Согласен, но с одной поправкой. Всё же Boost уже явно стал стандартом де факто, про который знает (но не значит что использует) наверное каждый C++'ник.
K>Моя мысля: достоинство дотнета в том, что он активно рекламируется и продвигается, выпускается масса новой литературы, где освещены новейшие фичи. Поэтому даже новички вовсю пишут асинхронный код.
Да, у .net'a и java есть своя ниша, в которой они однозначно лучшие.
K>Серьёзнейший недостаток C++ в том, что новые возможности и библиотеки рекламируются очень и очень мало. Более того, сами же матёрые плюсисты, в ответ на вопрос начинающих, с чего начать учиться, чаще всего предлагают старую замшелую литературу 90-х годов. Не, так-то те книги хорошие. Вот только начав с них, до корутин/буста/etc новоиспечённый плюсист дойдёт ой как не скоро.
В этом смысле D как получше будет для новичков. )))
Здравствуйте, Ikemefula, Вы писали:
I>У меня за все время ни разу не случались исключительно последовательне запросы в асинхронщине Пудозреваю, это именно та причина, из за которой я сомневаюсь в возможностях С++
Так твой пример же как раз чётко последовательный. В начале read, а потом write. Его нельзя переделать в параллельный даже если очень захочется. )))
I>Да очень прость — между стартом и концом асинхронного write появляется еще один асинхронный запрос которй затрагивает инвариант. всё, приехали.
Откуда он появляется то? Или ты снова про кривой асинхронный внешний код? Ты имеешь привычку запускать параллельные асинхронные операции модифицирующие одни и те же данные? )
Здравствуйте, alex_public, Вы писали:
_>Здравствуйте, gandjustas, Вы писали:
G>>Я сделал версию на C#, которая отрабатывает за 600мс, когда твоя работает около 400мс.
_>Агааа, а теперь подведём итоги теста. Для написания более менее производительного решения ты не использовал для парсинга ни одной функции из стандартной библиотеки .net! Хотя дискуссия собственно и началась с твоего высказывания о её крутизне. Вместо этого ты написал сотню строк рукопашного нерасширяемого unsafe кода, который при этом оказался всё равно в 2 раза (см ниже) медленнее 5 строк на C++.
Это чтобы семантика соответствовала.
Какой смысл мерить время работы функции int.Parse, которая учитывает локальные настройки с рукопашным парсером?
Это ведь не реальная задача, а .net на реальные ориентирован.
G>>НО. Чтение 100мб файла с диска без кеша идет 8сек. В этих условиях пидарасить такты вообще бессмысленно. _>Ну так и примерчик был максимально простой. Стоит чуть усложнить формат файла и время парсинга станет уже принципиальным.
Но тогда и сложность решения будет другая. Ты ведь как обычно придумал пример, который не является даже близко похожим на реальную задачу.
Лучше покажи парсеры json и xml.
_>Это если говорить про не мобильные устройства. А в случае мобильных имеет значение даже и этот пример, потому как получается разница между 0.3 и 3 секундами существенной загрузки процессора. И вот как раз такой "ява подход", что пофиг на оптимальность кода, если всё равно данные ждать надо, и приводит к просадкам батареи...
да-да. парсить 100мб чисел на мобильном устройстве — очень актуально.
Можешь привести хоть одну реальную задачу? А то C++ получается силен только в искусственных примерах.
G>>Boost:asio? Так она тоже все в один поток маршалит.
_>Вообще то там всё зависит от выбранной реализации. Для разных платформ там всё разное. Т.е. да, оно подразумевает один поток, но я бы не стал называть какой-нибудь epoll маршалингом. )))
Нет, в документации черным по английскому написано что в один поток.
G>>Но это неоптимальный сценарий и более сложный для реализации. _>Ну т.к. он уже реализован, то как бы проблем нет.
Что реализовано? Грамотное распределение корутин по потокам? Я такого не увидел.
_>Ну и насчёт быстродействия я бы опять же не рекомендовал соревноваться с Boost'ом...
Учитывая что все в один поток маршалит — тормозить будет при масштабировании.
Здравствуйте, gandjustas, Вы писали:
G>Такое есть, а парсинга json и xml нет. Либы для веб-запросов нет. Работы с БД нет.
G>Ты ща приведешь 100500 примеров таких либ на просторах интернета, но они нифига не совместимы с современным стандартом C++ и между собой. Это значит что придется писать (и поддерживать) тонны plumbing кода в приложении чтобы с ними работать. А если эти либы еще и C-style интерфейс имеют, то становится совсем грустно.
Вообще то есть фреймворки, которые так же как и .net пытаются вместить в себя сразу всё. Я бы не сказал что согласен с этим подходом. Множество отдельных специализированных и при этом крайне эффективных библиотек выглядят явно лучше. Но если очень хочется всё сразу в одном пакете, то надо просто взять Qt или wxWidgets. Там и gui и xml и web-запросы и базы данных и ещё дофига всего, интегрированного в единый комплекс.
G>Но ты ведь понимаешь, что имея нормальный язык с нормальной библиотекой программист почти никогда напрямую с xml не сталкивается.
А причём тут программисты то? ) Я писал про обычных пользователей, которые по любому с csv работают. Ну и кстати для программиста csv тоже совсем не плохой формат для табличных данных — у него намного меньше накладных расходов в сравнение с остальными перечисленными.
G>И тут снова никого не интересует относительная величина. G>Если твоя программа парсит один раз в час 1мб за 3мс вместо 0.3мс, то пользователь это никогда в жизни не заметит. G>Если же ты делаешь эту операцию раз в секунду, то гораздо больше батарейки потратится на получение этого 1мб, тем на его парсинг.
Так я то писал не про конкретный парсер, а про этот java/c# стиль вообще. Если люди так пишут, то они напишут в этом стиле не только парсер, а вообще всё. И хотя пользователь при этом по прежнему может не замечать разницу в отклике, но расход энергии будет намного больше, т.к. везде будет отъедаться понемногу. Хотя для стационарных компов это никогда не было проблемой, а как раз для них java и .net и создавались. Это сейчас пошёл максимальный уклон в мобильность. И думаю он будет только нарастать с приходом носимых устройств. Кстати, уже и в самой MS сменился вектор с продавливания .net'a на другие технологии. Правда приход мобильных устройств далеко не единственная причина этого (есть и более интересные), но думаю это тоже внесло небольшой вклад. )))
Здравствуйте, exalicygane, Вы писали:
E>Для сферического писькомерства — да, можно сказать "С++ круче", но вам за что деньги платят? За промышленный код, мэйнстрим. И по-моему, вполне очевидно, что нарезка овощей на тёрке (C#) намного быстрее и безопаснее, чем их рубка саблей (С++). Нет никакого "превосходства" С++, если помимо самого алгоритма ты должен держать в голове выкрутасы С++. Про синтаксис вообще молчу — мрак второго уровня (после Перла и Хаскеля).
Ну конкретно в нашем случае, у нас не просто область, где может "и C# и C++", а как раз где может только C++. ))) Однако я считаю, что C++ надо использовать не только в таких случаях, но и там где C++ и C# могут работать оба. При условии что мы говорим об IT компаниях (см. в конец сообщения).
>Этот парадокс я сам не пойму, но пара мыслей есть: >...
Комментарии см. опять же в конце сообщения.
E>Так что да, дотнет как-то не очень резво замещает "нативщину", но прелесть ситуации в том, что дотнет объективно удобнее для написания виндоприблуд, чем "старый, добрый С++ + Win32". Думаю, как только планшетно-мобильный маразм поутихнет, все как миленькие вернутся на десктоп и C#.
1. "С++ + Win32" — это действительно довольно жёстко. А вот как насчёт C++ + Qt или wxWidget? )
2. Переход к мобильности будет только усиливаться — впереди носимые устройства. )))
E>История подтверждает то, что С++ нафик не нужен для мэйнстрима — "средний сферический индус" не способен писать на нём нормальные приложения. Это верно даже безотносительно сравнения с C#. Когда же на сцену выходит дотнет с его мощнейшей библиотекой и безопасным C#, тут вообще думать нечего — любой проект на C#, сделаный даже средней руки прогерами, способен развиваться десятилетиями.
Тут какое-то очень странное понимание мэйнстрима. За ним чётко угадывается так называемый Enterprise, т.е. ПО пишущееся в IT отделах не IT компаний. Там действительно очень востребована возможность использования низкоквалифицированных и хорошо взаимозаменяемых программистов, т.к. это совсем не основное направление компании, а всего лишь один из внутренних сервисов. И как раз в этой области Java и C# наголову сильнее любых других решений. Я кстати с этим никогда не спорил...
Но я бы точно не стал называть Enterprise мэйнстримом. Разве что по количеству строк кода. А так, весь основной софт, окружающий нас, написан в профессиональных IT компаниях, для которых создание ПО главное предназначение. И которые соответственно могут себе позволить держать лучших профессионалов и использовать самые сложные (и при этом соответственно эффективные) инструменты.
E>Но возвращаясь к Ди, мне он кажется куда более интересным и перспективным, чем кактус сипипей — он не даром Ди, а не "Скала" — Ди поднял планку понятия "современный язык" так, что весь легаси код сипипи кажется унылым наследием времён фортрана. Да, к С++ можно прикрутить много интересных плюшек, но он так и останется С++ — неизлечимым гибридом ассемблера и ООП. скорее бы он уже RIP...
Безусловно. У D основная проблема в отсутствие большого сообщества (написавшего бы необходимые библиотеки/инструменты) или же крупной корпорации, толкающей его. При нынешнем развитие его использование ограничено узкими областями, для которых уже написана необходима инфраструктура. И то при этом есть неудобства в следствие отсутствия удобного редактора (с полноценным дополнением и т.п.).
Здравствуйте, alex_public, Вы писали:
_>Здравствуйте, gandjustas, Вы писали:
G>>Такое есть, а парсинга json и xml нет. Либы для веб-запросов нет. Работы с БД нет.
G>>Ты ща приведешь 100500 примеров таких либ на просторах интернета, но они нифига не совместимы с современным стандартом C++ и между собой. Это значит что придется писать (и поддерживать) тонны plumbing кода в приложении чтобы с ними работать. А если эти либы еще и C-style интерфейс имеют, то становится совсем грустно.
_>Вообще то есть фреймворки, которые так же как и .net пытаются вместить в себя сразу всё. Я бы не сказал что согласен с этим подходом. Множество отдельных специализированных и при этом крайне эффективных библиотек выглядят явно лучше.
Разве одно другому мешает? Вот в .net часть активно развивающихся компонент вынесли в отдельные либы, доставаемые через NuGet. От этого они не перестали быть частью .NET.
_>Но если очень хочется всё сразу в одном пакете, то надо просто взять Qt или wxWidgets. Там и gui и xml и web-запросы и базы данных и ещё дофига всего, интегрированного в единый комплекс.
Вот в том и проблема C++, то многие библиотеки типа Qt или wxWidgets очень интрузивны. У них свои наборы классов для решения одних и тех же задач, которые причем отличаются от стандартной библиотеки. Чаще всего это касается базовых вещей, типа строк, дат, ввода-вывода итп. Это все ставит крест на преимуществах C++, заставляет писать много plumbing кода.
G>>Но ты ведь понимаешь, что имея нормальный язык с нормальной библиотекой программист почти никогда напрямую с xml не сталкивается.
_>А причём тут программисты то? ) Я писал про обычных пользователей, которые по любому с csv работают.
Обычные пользователи не работают с csv. Вообще.
_>Ну и кстати для программиста csv тоже совсем не плохой формат для табличных данных — у него намного меньше накладных расходов в сравнение с остальными перечисленными.
Ты еще не понял, что мифические "накладные расходы" вообще никого не интересуют?
G>>И тут снова никого не интересует относительная величина. G>>Если твоя программа парсит один раз в час 1мб за 3мс вместо 0.3мс, то пользователь это никогда в жизни не заметит. G>>Если же ты делаешь эту операцию раз в секунду, то гораздо больше батарейки потратится на получение этого 1мб, тем на его парсинг.
_>Так я то писал не про конкретный парсер, а про этот java/c# стиль вообще. Если люди так пишут, то они напишут в этом стиле не только парсер, а вообще всё. И хотя пользователь при этом по прежнему может не замечать разницу в отклике, но расход энергии будет намного больше, т.к. везде будет отъедаться понемногу.
Более 95% времени программы находятся в ожидании завершения ввода-вывода. Грамотное использование асинхронности делает perceived performance достаточным для большинства приложений.
_>Хотя для стационарных компов это никогда не было проблемой, а как раз для них java и .net и создавались. Это сейчас пошёл максимальный уклон в мобильность. И думаю он будет только нарастать с приходом носимых устройств. _>Большая часть заряда батареи мобильных устройств расходуется на сеть и экран, а не на работу процессора.
Это только в случае игрушек может быть актуально то, что ты пишешь.
Но по странному стечению обстоятельств немало игрушек делается на Unity (Mono) из-за кросс-платформенности
_>Кстати, уже и в самой MS сменился вектор с продавливания .net'a на другие технологии.
Ага, именно поэтому MS парнтерится с Xamarin, который позволяет именно на C# писать приложения для любых устройств. надеются что приложения написанные для iPhone и Android взлетят на WP.
А вот с Azure ситуация обратная. Чтобы продать как можно больше облаков надо сделать их пригодными для любых приложений. МС в этом преуспел.
Здравствуйте, alex_public, Вы писали:
I>>1 вариант сама функция запускает кучу параллельных цепочек
_>И на C++ и на C# это не сделать без переписывания нашей библиотечной функции. Ну а с переписыванием понятно что проблем уже нет нигде... )))
Итого — 1й вариант надо переписывать.
I>>2 вариант — функция запускается в нескольких паралельных цепочках
_>На C# это опять же записывается только с переписыванием функции. На C++ это получается автоматически, без переписывания. Но и в том и в другом случае, такой код не является корректным, если в асинхронном хранилище данных не предусмотрена какая-то своя синхронизация.
В асинхронном хранилище такое как раз и не предусматривается. Там будут функции навроде read(value, callback)
Итого — 2 вариант требует переписывать. В сумме остаётся следующее — не важно, какой язык, для корректной асинхронщины код надо переписать. В C# это будет async/await, в с++ — приседания с каким нибудь фремворком.
То есть, в кратце, способ который вы с EP предлагаете, имеет смысл в частных случаях, когда во всех возможных цепочках нет разделяемых ресурсов. Как только они появляются, весь код надо переписывать.
В C# ты сразу видишь async/await и надо проанализировать только сам конкретный метод. Все остальное сделает компилер.
В С++ ты не можешь сказать ничего, глядя только в конкретный метод. А ну как хрен знает на какой глубине вызовов сработает короутина ?
то есть,
Begin();
Processing();
End();
Вот такой код потенциально некорректный, если хрен знает гду унутре Processing сработает короутина.
И для того, что бы не гадать над возможными путями выполнения программы придумали async/await.
То есть, асинхронщина это слишком большая деталь, что бы её игнорировать.
>Ну или же ещё будет нормальное если она вообще не требуется (например мы запускаем параллельное скачивание 10 файлов) по условию задачи.
Если только скачать, ничего с ними не делать и даже результат скачивания не важен, то да, всё сильно
Здравствуйте, Ikemefula, Вы писали:
I>Это каменный век. Нужна поддержка компилятором всех типов. Т.е. переименовал колонку и прога не скомпилилась.
Эээ что? ) Ты хочешь переименовать колонку в базе данных, ничего не трогать в программе и чтобы всё работало по прежнему? Или что?
I>У дотнета для десктопа ровно два недостатка — долгое время запуска и отсутствие кроссплатформенности. Все питоновские, джавовские приложения кроссплатформенные, но имеют кучу своих проблем. По перформансу они все сливают дотнету.
Ты что-то всё напутал. Сравнение вообще не такое.
1. У нас есть C++. Это максимальная производительность и нормальное удобство написание кода. Требует серьёзного умения.
2. У нас есть языки типа Питона. Это во много раз худшая производительность и проблематичное написание сложных проектов. Однако взамен намного более быстрое написание кода.
3. У нас есть Java/C#. Это несколько меньшая производительность чем пункт 1 и заметно большая чем 2. И такое же удобство написание кода как в пункте 1. Или даже местами хуже, если уместно метапрограммирование. Но порог вхождения заметно ниже пункта 1.
Из этой схемки очевидно следуют оптимальные ниши для данных технологий. Для варианта 2 явно оптимальны различные скрипты (как внешние, так и внутренние) и небольшие проекты не требующие серьёзной производительности. Вариант 3 подходит для случая потребности использовать в команде орду индусов. Ну и соответственно вариант 1 для всех остальных случаев. Что полностью подтверждается раскладом по софту на компе среднестатистического юзера.
I>Продукты, но не для открытой продажи.
Почему-то я так и думал... )))
I>Битторент написан на пейтоне
Вообще то нет. ) Но даже если бы и так, то всё равно же не .net. )))
Здравствуйте, Ikemefula, Вы писали:
I>>>Само это значит небольшой кусок кода автоматизирует всю ручную работу. С маппингами все так и есть — тебе не надо мотаться по коду и искать, где какая колонка может использоваться. NB>>не вижу принципиальных ограничений генерировать то же самое на плюсах. I>Принципиальные ограничения в работе с такими маппингами. Для этого нужны деревья выражений и их поддержка в языке.
Если работа с фиксированными типами, поля которых известны в compile-time — то нужно только от-рефлектить поля а-ля Boost.Serialization/Fusion, или ODB:
odb::sqlite::database db ("people.db");
person john ("john@doe.org", "John Doe", 31);
person jane ("jane@doe.org", "Jane Doe", 29);
odb::transaction t (db.begin ());
db.persist (john);
db.persist (jane);
typedef odb::query<person> person_query;
for (person& p: db.query<person> (person_query::age < 30));
cerr << p << endl;
jane.age (jane.age () + 1);
db.update (jane);
t.commit ();
Деревья выражений в C++ уже лет 18 реализуются, причём их можно обходить и оптимизировать в compile-time
Если имя поля никак не связанно с типом, то можно использовать:
db.query<person>( ID("age") < 30 )
но — твоё дерево выражения в C# задаётся в compile-time, значит имя всё-таки известно, тогда всё что нужно это:
DEFINE_ID(age)
// ...
db.query<person>( age < 30 )
Здравствуйте, night beast, Вы писали:
NB>ну эт ты начал рассказывать про какие-то непонятные трудности
Сложность реализации мягко говоря разная.
I>>А еще интереснее вот так — order.Where(Filter).Select(x => x.Total), где фильтр это почти обычная фукнция.
NB>интереснее здесь то, где фильтруются полученные данные.
Неужели в компайлтайм ?
I>>Где он генерируется, не важно. Важно, что это делается не руками.
NB>а кто заставляет генерировать руками в плюсах?
Здравствуйте, D. Mon, Вы писали:
B>>О, да! По какому тогда критерию в этом списке соседствуют C#, C, C++ и Java? В чём отличие Ruby от JRuby?
DM>Это все весьма популярные вещи, их нельзя не включить.
По-любому как дышло ни выворачивай, Ди там НУЖЕН — либо по тем, либо по другим причинам, по которым выбраны анахронизмы типа АСТ или ЛИСП.
B>> Что important автор нашёл в ATS (я за 20 лет НИ РАЗУ о таком не слышал!),
DM>А вот это напрасно (и больше говорит о вашей неосведомленности)
Ерунда. Это говорит только о том, что владелец сайта выбирает языки от балды — нашёл какую-то маргинальщину, о которой не упоминают даже старпёры, а ты мне тут втыкаешь про осведомлённость! Даже про богом забытый Оккамл — и то говорят больше (правда, в свете F#), чем об этом АТС. Не надо путать понятия "где-то в институте прочесть страничку об АТС" и "знать и постоянно встречать интересный язык АТС" — судя по его "никакой" популярности, нужен он не больше, чем брэйнфак или рефал. ОСОБЕННО на ресурсе, предназначенном для новичков и (вроде бы) помогающем выбрать инструмент.
DM> Функциональный язык...
Сразу в реактор — мэйнстриму это фуфло не нужно. Хотя не, как раз для бенчей самое оно.
B>>кого там греет Rust, LISP? DM>Их многочисленных поклонников, очевидно.
Вот именно. Чем провинился Ди (будучи развиваемым и перспективным языком), да ещё когда он уже был в списке — непонятно. Лучше бы он свой АСТ выпилил.
Здравствуйте, D. Mon, Вы писали:
DM>Говорят, у clang'a все равно длиннее быстрее.
Ди создаётся как надёжный инструмент, скорость которого — вопрос лишь времени, принципиальных проблем нет. Кроме того, измерение "быстрее-медленнее" имеет смысл только для RSDN, в реальном проекте это превращается в "достаточно быстро/нужно доработать".
21.10.2013 19:17, matumba пишет: > так что если под Ди встанет > хороший фундамент инвестиций, сипипи-убожества навсегда покинут индустрию.
Убожества не в языке, а в прослойке.
Здравствуйте, matumba, Вы писали:
M>так что если под Ди встанет хороший фундамент инвестиций, сипипи-убожества навсегда покинут индустрию.
У каждого языка есть свои цели, свои design guidelines. Язык это не просто набор фич.
Как известно, у C++ основным приоритетом является производительность.
А в D спокойно могут пожертвовать производительностью ради других целей (об этом говорил A.A.). Взять например те же ranges — они проигрывают итераторам по производительности by-design
Хорошо известный D-разработчик Андрей Александреску внёс в репозиторий Facebook первые 5112 строк кода на языке D, так что теперь гигант социальных сетей может сказать, что "использует язык D в серийном производстве". Язык был разработан Уолтером Брайтом, главным разработчиком компилятора C++ — "Zortech C++".
Александреску подтвердил, что проект, что называется, в "ежедневном, тяжёлом использовании" центром Facebook и в сравнении с оригинальной С++ версией, команда отметила множество выйгрышей во всех аспектах, включая размер исходников, скорость компилляции и скорость исполнения.
"D однозначно больше не может затмеваться С++, потому что превосходит не только слабые, но и сильные стороны С++. Касательно языка Go, вряд ли он будет преемником Си, т.к. не охватывает всего того, что Си умеет и что востребовано в некоторых системах — произвольный доступ к памяти, ручное управление памятью, да к тому же плохо взаимодействует с Си", — сказал Александреску.
*здесь пропущены характеристики Ди — всё и даже больше, чем всё есть на оффсайте*
Уолтер Брайт прокомментировал новость как "начало первого сражения, предвещающего конец Средиземья и наступление Эры D" (видимо, отнесение к Толкиену и его Кольцам, прим. пер.)
Другие D-разработчики, такие как J. M. Davis, выразились более прозаично: "Это не означает, что D типа захватил мир программирования, но это хорошо показывает, что язык D взрослеет и реальные компании хотят его реально использовать".
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>В следующем году будут концепции — большой шаг вперёд. А что тут может предложить D? duck-typing?
Я не знаю всех подробностей плюсовых концептов, но судя по тому, что Страуструп недавно рассказывал на Going Native, обещая в С++14, это уже очень давно есть в D в намного более удобном и мощном виде. Об этом же говорит Александреску.
Про производительность range'й не очень понял — где именно она хуже? В плюсах принято передавать два итератора, begin и end, в D их объединили в одну структуру, получили range. Смысл тот же, но меньше писанины и меньше ошибок.
Про конкретный пример с фейсбуком, его слова:
"I wrote the core of the C++ implementation. Then many engineers contributed on top of it. The translation to D has been near-verbatim, i.e. as close to the C++ code as possible. Even git detected the new files as modified copies of the existing ones (!).
As I mentioned elsewhere: the D version compiles 5 times faster, runs 1.67 times faster on real workloads, and has 17% less code."
Здравствуйте, ins-omnia, Вы писали:
IO>На Rust'е Мозила свой браузер начала переписывать. С такой рекламой дело пойдет очень быстро. IO>И главное там есть новые полезные идеи. При то, что главная идея Ди — спилить некоторые занозы с C++.
Что за идеи? Встроенные смартпоинтеры или что-то еще?
Здравствуйте, include2h, Вы писали:
IO>>И главное там есть новые полезные идеи. При то, что главная идея Ди — спилить некоторые занозы с C++.
I>Что за идеи? Встроенные смартпоинтеры или что-то еще?
Там вроде нет встроенных смартпоинтеров.
Зато есть вменяемая модель многопоточности. И модель памяти, которая с этой многопоточностью работает.
И всё это безопасно — на уровне "управляемых платформ", но без их оверхеда.
Плюс некоторые функциональные фичи. Это конечно трудно назвать новой идеей, но если
уж мы серьёзно рассматриваем C++ и D...
Откуда же его [независимый суд] взять, если в нем такие же как мы? (c) VladD2
Здравствуйте, matumba, Вы писали:
EP>>>>А тут разве кто-то вообще говорит что он устарел? M>>>Нда... вроде криокамеры ещё не изобрели? EP>>Аргументы? M>Спорить про мракобесие типа С++ — это подымать больную тему, сводящуюся к тому, что один спец на миллион да, МОЖЕТ написать хорошую, устойчивую программу, которую ВОЗМОЖНО даже смогут сопровождать ещё десяток спецов пониже. В целом же мнение отрасли таково, что С++ ПЛОХО ПРИМЕНИМ в мэйнстриме из-за своей низкоуровневой природы, влекущей море таймбомб (+ ещё сотня причин).
Угадай какому языку учат дизайнеров "Parsons The New School for Design"? Which language would you recommend for creative graphics written by non-CS majors?
M>И даже если эти аргументы вам (как возможно хорошему спецу на С++) покажутся смешными или устранимыми, это не отменяет факта, что средний спец на С++ всё равно будет говнокодить в разы больше, чем тот же спец на C#/Java/D/etc. M>С++ — это катана, принесённая дураками на кухню для нарезки моркови — ей МОЖНО нарезать морковь, но в большинстве случаев это отрезанные пальцы и работа-через-Ж.
Я не увидел аргументов в пользу того что C++ устарел. Вот выше Java упомянут, в котором даже лямбд нету
EP>>Откуда столько злости и ненависти? M>[...] А время идёт и ждать, пока каждый говнопроект не сдохнет в шаблонно-указательных муках, нет никакого желания. Теперь вы осознаёте, что такое "невинное" существование С++ всё равно гадит в отрасль, не давая ей развиваться с другими, более достойными языками? Даже пример дам — Линукс. Я подобную халтуру не поставлю даже в бортовую радиолу,
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Как известно, у C++ основным приоритетом является производительность. EP>А в D спокойно могут пожертвовать производительностью ради других целей (об этом говорил A.A.). Взять например те же ranges — они проигрывают итераторам по производительности by-design
Это мнение только одного из авторов. Основной автор как раз подчеркивает что высокая производительность
одна из основных целей:
D is a general purpose systems and applications programming language. It is a high level language, but retains the ability to write high performance code and interface directly with the operating system API's and with hardware.
Притом это начало обзора языка.
Ну и встроенный ассемблер, интрисики в стандартной библиотеке и практически включенный
как подмножество язык си это уже вполне серьезно.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>В следующем году будут концепции — большой шаг вперёд. А что тут может предложить D? duck-typing?
D может предложить намного более полный и мощный контроль в compile-time, тот же static if
дополненный foreach как по типам (работающим в compile time) так и по значениям и гораздо
более мощнные чем constexpr CTFE.
Да static if с одной стороны конечно вещь гораздо более низкоуровневая чем концепты, но это
не только минус но и плюс, мощность у нее гораздо выше.
Ну и плюс такой сахар как Template Constraints позволяет писать в стиле контрактов нового
С++, хотя конечно с более примитивным матчингом.
Или вот в ту же тему в последней версии вводят новый сахар new eponymous template syntax
EP>Итераторы C++ обеспечивают эффективную композицию. Если у нас есть 4 итератора, то из них можно получить 6 range бесплатно, без runtime penalty — просто выбери нужную пару итераторов.
Да все так, но плата за эффективность внутри как раз практически невозможность композиции на итераторах снаружи,
цепочку из функций работающих с парами независимых итераторов делать практически невозможно. Понятно что тот же
boost::range все исправляет, но похоже что лучше иметь в стандартной библиотеке (как в C++ так и в D) и итераторы
и range.
Ну и кстати написать для D итераторы ничего не мешает, и эффективность у них будет такой же как и в C++, так что
к недостаткам языка их отсутствие никак нельзя отнести.
EP>Чтобы вернуть вменяемый результат, параллельно "рабочему" range'у приходится передёргивать дополнительный range result. В то время как в STL, нет этих лишних телодвижений — возвращается итератор, который практически бесплатно определяет два range'а.
Тут кстати еще в профайлер надо смотреть, эти лишние телодвижения по сути в машинном коде добавят пару
лишних инкрементов, это будет заметно только в очень вырожденных случаях.
Здравствуйте, D. Mon, Вы писали:
EP>>Итераторы C++ обеспечивают эффективную композицию. Если у нас есть 4 итератора, то из них можно получить 6 range бесплатно, без runtime penalty — просто выбери нужную пару итераторов.
DM>Хороший пример, спасибо.
Так это все обсуждалось 100 лет назад, когда Александреску только выступил со своим iterators must go
Вот, например: http://www.rsdn.ru/forum/cpp/3491669
Здравствуйте, ins-omnia, Вы писали:
IO>Зато есть вменяемая модель многопоточности. И модель памяти, которая с этой многопоточностью работает. IO>И всё это безопасно — на уровне "управляемых платформ", но без их оверхеда.
А можешь книги по Д посоветовать? Просто туториалов/вики как-то мало, хочется более подробного разбора фич. Смущает, что "The D Programming Language" аж в 2010 году издана, по идее, в языке немало изменений было. Или книга всё-таки актуальна?
Здравствуйте, D. Mon, Вы писали:
EP>>>А в D спокойно могут пожертвовать производительностью ради других целей (об этом говорил A.A.). EP>><b>например</b> DM>В монологе с этой позиции Ал-ку говорит совершенно другое. Что они начинают отталкиваться не от угла треугольника эффективность-удобство-безопасность, а от середины,
Он сказал, что начинают с середины и пытаются завоевать столько территории сколько возможно.
DM>и в некотором смысле опровергают CAP-теорему для такого треугольника, т.е. дотягиваются до _всех_ его углов.
Он не говорил что получилось дотянуться до всех углов
Здравствуйте, D. Mon, Вы писали:
EP>>void sort(RandomAccessRange &x) EP>>void sort(BidirectionalRange &x) EP>>Это шаблоны функций, перегрузка между которыми происходит автоматом. Требования каждой концепции разбиваются компилятором на атомы, и производится тест вложенности множеств и т.п.
DM>Перегрузка таких шаблонов в D есть,
По примитивному static if? Такой уровень есть и в C++98, через enable_if.
DM>но, насколько я помню, без такого теста вложенности, последовательная,
Что значит последовательная? В порядке объявления?
DM>т.к. в условиях может выполняться почти произвольный код, они намного больше всего могут тестировать,
enable_if тоже много чего может тестировать.
DM>поэтому такую проверку "вложенности множеств" провести нереально, она возможна лишь для сильно примитивных условий, которые и обещают в С++.
Не-примитивные условия а-ля static if/enable_if есть уже давно. Дело как раз в удобстве автоматической перегрузки.
DM>Вот такой пример на С++ как записывается? DM>http://thedeemon.livejournal.com/53900.html
Эти has_member доступны начиная с C++98, через SFINAE.
А вот что доступно C++14:
template<typename T>
concept bool Equality_comparable()
{
return requires(T a, T b)
{
bool = {a == b};
bool = {a != b};
};
}
Причём проверки такого вида были доступны и в C++11, через decltype, только в более нагромождённой форме.
DM>(проверка переданного шаблона на выполнение аксиом функтора в категории)
Я не увидел там никаких аксиом, только синтаксические проверки. Вообще "проверка выполнения аксиом" — звучит крайне дико
EP>>Итераторы C++ обеспечивают эффективную композицию. Если у нас есть 4 итератора, то из них можно получить 6 range бесплатно, без runtime penalty — просто выбери нужную пару итераторов. DM>Хороший пример, спасибо.
Есть ещё другой момент — безопасность реализации алгоритмов работающих с random access.
Итератор это и индекс и "accessor". В то время как D Range используют просто целые индексы которые не знают откуда они пришли, и по факту являются "обрезанными" итераторами.
Здравствуйте, FR, Вы писали:
EP>>Итераторы C++ обеспечивают эффективную композицию. Если у нас есть 4 итератора, то из них можно получить 6 range бесплатно, без runtime penalty — просто выбери нужную пару итераторов. FR>Да все так, но плата за эффективность внутри как раз практически невозможность композиции на итераторах снаружи, FR>цепочку из функций работающих с парами независимых итераторов делать практически невозможно. Понятно что тот же FR>boost::range все исправляет, но похоже что лучше иметь в стандартной библиотеке (как в C++ так и в D) и итераторы FR>и range.
В C++ добавят range'ы (которые пара итераторов) — afaik для этого есть целая study group.
FR>Ну и кстати написать для D итераторы ничего не мешает, и эффективность у них будет такой же как и в C++, так что FR>к недостаткам языка их отсутствие никак нельзя отнести.
Во-первых что-то для range'ей уже встроено непосредственно в язык, тот же foreach или slice'ы.
Во-вторых я показал range'ы как пример того, что авторы жертвуют производительностью ради других преимуществ.
В-третьих я сомневаюсь что итераторы теперь встроят в стандартную библиотеку D, без поддержки которой они вряд ли будут распространёнными.
EP>>Чтобы вернуть вменяемый результат, параллельно "рабочему" range'у приходится передёргивать дополнительный range result. В то время как в STL, нет этих лишних телодвижений — возвращается итератор, который практически бесплатно определяет два range'а. FR>Тут кстати еще в профайлер надо смотреть, эти лишние телодвижения по сути в машинном коде добавят пару FR>лишних инкрементов, это будет заметно только в очень вырожденных случаях.
Пара лишних инкремнтов будут на простейших range'ах, а если там что-то более сложное?
Мой поинт в том, что если абстракция порождает не-эффективный код by-design — то это изначально плохая абстракция.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
DM>>Вот такой пример на С++ как записывается? DM>>http://thedeemon.livejournal.com/53900.html
EP>Эти has_member доступны начиная с C++98, через SFINAE.
Речь не о них. Читай дальше, внимательнее, не спеши с ответом.
EP>А вот что доступно C++14: EP>
EP>template<typename T>
EP>concept bool Equality_comparable()
EP>{
EP> return requires(T a, T b)
EP> {
EP> bool = {a == b};
EP> bool = {a != b};
EP> };
EP>}
EP>
EP>Причём проверки такого вида были доступны и в C++11, через decltype, только в более нагромождённой форме.
В С++ это только обещают, в D это давно есть. Но не только это, а выполнение почти произвольного кода. Прочитать файл, отсортировать, распарсить, посчитать... Проверить компилируемость выражения, опять же, и в зависимости от результата делать осмысленные вещи.
DM>>(проверка переданного шаблона на выполнение аксиом функтора в категории)
EP>Я не увидел там никаких аксиом, только синтаксические проверки.
Внимательнее посмотри. Там описываются шаблонные функции и вызываются, результат вычислений используется в static if'e. Вычисления могут быть весьма нетривиальными.
EP> Вообще "проверка выполнения аксиом" — звучит крайне дико
Если тебе нужно реализовать, например, класс кольца или группы, то в тестах нужно проверить, что выполнены аксиомы кольца/группы. Это просто математика. Не нравится такое слово, можно говорить о "законах", каковое слово и было в посте.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Он не говорил что получилось дотянуться до всех углов
Если насчет угла отвечающего за производительность, то ничего кроме плохого оптимизатора
в оригинальной версии dmd не мешает. На D вполне можно писать в стиле си или си с шаблонами
полностью отказавшись от GC.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>В C++ добавят range'ы (которые пара итераторов) — afaik для этого есть целая study group.
Уже в 14 ?
FR>>Ну и кстати написать для D итераторы ничего не мешает, и эффективность у них будет такой же как и в C++, так что FR>>к недостаткам языка их отсутствие никак нельзя отнести.
EP>Во-первых что-то для range'ей уже встроено непосредственно в язык, тот же foreach или slice'ы.
EP>Во-вторых я показал range'ы как пример того, что авторы жертвуют производительностью ради других преимуществ.
С этим согласен, но согласись жертва невелика и никто ни мешает сделать свои итераторы.
EP>В-третьих я сомневаюсь что итераторы теперь встроят в стандартную библиотеку D, без поддержки которой они вряд ли будут распространёнными.
Это да, зря Александреску свою знаменитую статью писал
EP>Пара лишних инкремнтов будут на простейших range'ах, а если там что-то более сложное?
А что может быть еще сложнее? Что-то функций с десятком итераторов я не видел.
И опять таки скажем даже тот же std::transform (первое что пришло в голову с кучей итераторов)
переведется на range без всякой потери производительности.
В результате как я и говорил все сведется к достаточно узким случаям.
EP>Мой поинт в том, что если абстракция порождает не-эффективный код by-design — то это изначально плохая абстракция.
Здравствуйте, D. Mon, Вы писали:
EP>>Причём проверки такого вида были доступны и в C++11, через decltype, только в более нагромождённой форме. DM>В С++ это только обещают, в D это давно есть.
Проверки с таким синтаксисом уже есть через decltype.
DM>Но не только это, а выполнение почти произвольного кода. Прочитать файл, отсортировать, распарсить, посчитать...
Это действительно круто(так же круто как и mixins), но эта фича слабо связанна с концепциям
DM>Проверить компилируемость выражения, опять же, и в зависимости от результата делать осмысленные вещи.
В каком виде? В смысле только SFINAE-like или, допустим, можно поймать static_assert где-то в глубине call-stack'а?
EP>> Вообще "проверка выполнения аксиом" — звучит крайне дико DM>Если тебе нужно реализовать, например, класс кольца или группы, то в тестах нужно проверить, что выполнены аксиомы кольца/группы. Это просто математика. Не нравится такое слово, можно говорить о "законах", каковое слово и было в посте.
1. Перегружаться на основе таких тестов крайне опасно: практически никогда нельзя проверить все возможные значения — на тестовых оно пройдёт, а на других сфейлится заодно поломав инварианты.
2. С другой стороны, сам пользователь может знать, что на некоторых значениях эти свойства не выполняются, и не использует эти значения в runtime — а в такой проверке как раз будет это значение.
3. Даже если есть набор правильных тестовых значений, не всегда есть возможность протестировать все свойства. Вот например, есть такой алгоритм std::find, одним из его постусловий является то, что в range [first, result_of_find) нет искомого значения. В случае single pass range нет никакой возможности проверить это постусловие через black-box test.
4. Какой тест позволит различить InputIterator и ForwardIterator?
5. Пользователь может сознательно "расслабить семантику типа". Например он может специально "наделить" сложение floating-point чисел ассоциативностью, которой у них нет, чтобы сделать parallel reduction.
В общем "проверка аксиом" крайне сомнительная затея
Здравствуйте, FR, Вы писали:
EP>>Такой foreach есть в C++98: boost::fusion::for_each. Не хватает только полиморфной лямбды (нужно вручную делать function object), которую скоро добавят. FR>Ну реально же страшно по сравнению с D.
Имхо, ничего страшного
FR>И не дай бог мелкую ошибку допустить и получим километровое сообщение,
Против километровых ошибок помогут концепции.
FR>и чуть начни более менее интенсивно такое применять, даже на мелких проектах будет компиляция несколько минут минимум.
В таком самодельном полиморфном for_each нет ничего, что принципиально будет сильно тормозить компиляцию.
FR>В D же все прозрачно, просто, одинаково что в компил что в ран тайм и без "синтаксического оверхеда"
FR>>>Ну и плюс такой сахар как Template Constraints позволяет писать в стиле контрактов нового С++, хотя конечно с более примитивным матчингом. EP>>Это же и есть один из вариантов static if, аналог которого есть в C++98 — enable_if. FR>Это да, я и писал про сахар, но это только одно мелкое применение, ну и опять удобней и проще.
Это не удобней, не проще и не наглядней чем концепции:
Здравствуйте, FR, Вы писали:
EP>>В C++ добавят range'ы (которые пара итераторов) — afaik для этого есть целая study group. FR>Уже в 14 ?
Вряд ли, скорее в C++17. Но range не к спеху, так как есть Boost.Range.
FR>>>Ну и кстати написать для D итераторы ничего не мешает, и эффективность у них будет такой же как и в C++, так что FR>>>к недостаткам языка их отсутствие никак нельзя отнести. EP>>Во-первых что-то для range'ей уже встроено непосредственно в язык, тот же foreach или slice'ы. FR>Нет для foreach range не нужны http://dlang.org/statement.html#ForeachStatement достаточно перезагрузки FR>операторов: [...]. Для slice аналогично.
Для стандартных массивов перегрузки в библиотеке или в языке?
EP>>Пара лишних инкремнтов будут на простейших range'ах, а если там что-то более сложное? FR>А что может быть еще сложнее?
Сам range может быть чем угодно — например может управлять файловой системой. Где-то передёргивание будет незаметным (а где-то может быть убрано компилятором), но не во всех range'ах это простейшие операции.
FR>Что-то функций с десятком итераторов я не видел.
В смысле?
FR>И опять таки скажем даже тот же std::transform (первое что пришло в голову с кучей итераторов) переведется на range без всякой потери производительности.
std::transform это простейший случай. Но даже в нём проявляется неудобство.
У него результат итератор — я могу спокойно соединить этот итератор с теми, что у меня были ранее (или с теми, что получу потом), образуя новые range'ы бесплатно.
FR>В результате как я и говорил все сведется к достаточно узким случаям. EP>>Мой поинт в том, что если абстракция порождает не-эффективный код by-design — то это изначально плохая абстракция. FR>Зависит от ситуации.
Я показал конкретную ситуацию в стандартной библиотеке D и сравнил её side-by-side с STL.
Здравствуйте, matumba, Вы писали:
M>Надеюсь, что уже сам пример использования таким "гигантом", станет хорошим вдохновителем для масс — многие просто боятся использовать что-то малораздутое или новоиспечённые выскочки типа Rust/Go. Ди развивается уже много лет и к счастью — без давления легаси или коммерческой продавабельности (как C#), так что если под Ди встанет хороший фундамент инвестиций, сипипи-убожества навсегда покинут индустрию.
В целом я с вами согласен, С++ рано или поздно должен уступить место лучшим языкам (D вполне подходит), но выражаетесь вы весьма экстравагантно.
Здравствуйте, Erop, Вы писали:
E>Ну бывают же не только пары итераторов, но и тройки, скажем, или, наоборот, одинокие итераторы, например итератор элемента std::list'а...
Ну так и в D range это не обязательно пара. Для списка он будет как плюсовый. Range — это нечто (обычно структура, но необязательно) с определенным интерфейсом. Что внутри — уже детали реализации.
Изобрази пожалуйста самый примитивный пример: функция печатающая названия типов своих
аргументов, только законченный компилируемый пример, на D это будет так:
import std.stdio;
void print_type(A...)(A a)
{
foreach(T; A)
writeln(typeid(T));
}
void main()
{
print_type(1, 2.0, "3");
}
Здравствуйте, FR, Вы писали:
FR>Да спасибо, для меня вполне демонстрирует что С++11 с D по выразительности шаблонов состязаться не может.
void print_type(A...)(A a)
{
foreach(T; A)
writeln(typeid(T));
}
// versustemplate<typename ...Ts> void foo(Ts...)
{
for_each<Ts...>([](auto x)
{
writeln(type_name(decltype(x)));
});
}
Это называется чуть больше сахара.
FR>Это уже гораздо лучше, но шума, опять же по моему, гораздо больше необходимого, особенно FR>если учесть что никаких метабиблиотек мой пример не использовал.
Так наоборот хорошо что многое реализуемо в библиотеке. Я, например, предпочёл бы какой-нибудь дополнительный синтаксис для лямбд, вместо range-based-for.
EP>Для стандартных массивов перегрузки в библиотеке или в языке?
В языке.
EP>Сам range может быть чем угодно — например может управлять файловой системой. Где-то передёргивание будет незаметным (а где-то может быть убрано компилятором), но не во всех range'ах это простейшие операции.
Согласен, но в таких случаях часто ленивость спасает.
FR>>Что-то функций с десятком итераторов я не видел.
EP>В смысле?
В прямом
Итераторов мало обычно.
EP>std::transform это простейший случай. Но даже в нём проявляется неудобство. EP>У него результат итератор — я могу спокойно соединить этот итератор с теми, что у меня были ранее (или с теми, что получу потом), образуя новые range'ы бесплатно.
По моему у тебя идея фикс "новые range бесплатно" , по моему гораздо чаще нужны цепочки обрабатывающие range.
EP>Я показал конкретную ситуацию в стандартной библиотеке D и сравнил её side-by-side с STL.
Здравствуйте, FR, Вы писали:
EP>>Для стандартных массивов перегрузки в библиотеке или в языке? FR>В языке.
О чём и речь — что-то для range'ей уже встроено непосредственно в язык.
EP>>Сам range может быть чем угодно — например может управлять файловой системой. Где-то передёргивание будет незаметным (а где-то может быть убрано компилятором), но не во всех range'ах это простейшие операции. FR>Согласен, но в таких случаях часто ленивость спасает.
У нас чистый permutation алгоритм — std::partition. В Phobos'е лишний раз дёргаются ручки у range'а, как тут поможет ленивость?
EP>>std::transform это простейший случай. Но даже в нём проявляется неудобство. EP>>У него результат итератор — я могу спокойно соединить этот итератор с теми, что у меня были ранее (или с теми, что получу потом), образуя новые range'ы бесплатно. FR>По моему у тебя идея фикс "новые range бесплатно" ,
Не только у меня — смотри выше что пишет A.A. про std::find — чтобы получить первую часть, нужно делать реализовывать новый тип range — Until, в то время как в STL он действительно получается бесплатно: [first, find(first, last, x))
FR>по моему гораздо чаще нужны цепочки обрабатывающие range.
Здравствуйте, FR, Вы писали:
EP>>Это называется чуть больше сахара. FR>Да и прямое следствие из него шаблонный код на D легко читается в отличии от аналога на C++.
Это скорей всего так и есть, но отнюдь никак не следует из сравнения этих кусочков в 7 строк.
FR>По моему для C++ идея что надо стараться максимально возможно реализовывать все в библиотеках плохо FR>подходит (при всем уважении к Страуструпу) для этого мета возможности C++ совершенно недостаточны.
И meta-возможности у C++ постепенно расширяются, есть study group для reflection. Конечно не так быстро как в языке у которого целых полтора компилятора
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>По факту D Range нормально подходит только для SinglePass.
Пока остальное отпущу.
Но по этому у нас кажется сильное недопонимание, основной плюсs range это легкая
комбинируемость функций с ними работающих и ленивость, все это по моему легко
перекрывает недостатки.
import std.stdio;
import std.range;
import std.algorithm;
void main()
{
iota(0, 10).map!(x => x *x).filter!(x => x % 2).writeln;
}
Здравствуйте, FR, Вы писали:
FR>Но по этому у нас кажется сильное недопонимание, основной плюсs range это легкая FR>комбинируемость функций с ними работающих и ленивость, все это по моему легко FR>перекрывает недостатки.
Есть три сущности:
1. итераторы, как в STL
2. Range обвёртки над итераторами, как в Boost.Range или в Adobe ASL
3. D Range — в них нет никаких итераторов, есть только ranges
Комбинируемость есть и в 3 и в 2. А вот недостатки которые я выше перечислял — относятся только к 3.
FR>
FR>void main()
FR>{
FR>iota(0, 10).map!(x => x *x).filter!(x => x % 2).writeln;
FR>}
FR>
Пример комбинируемости range обвёрток над итераторами:
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>>>Для стандартных массивов перегрузки в библиотеке или в языке? FR>>В языке.
EP>О чём и речь — что-то для range'ей уже встроено непосредственно в язык.
Нет там ничего для range обычная перегрузка операторов.
Массивы были в самой первой версии языка, в то время когда у Алекандреску с его rangeманией
была совсем другая любимая игрушка
FR>>Согласен, но в таких случаях часто ленивость спасает.
EP>У нас чистый permutation алгоритм — std::partition. В Phobos'е лишний раз дёргаются ручки у range'а, как тут поможет ленивость?
Тут возможно и нет.
FR>>По моему у тебя идея фикс "новые range бесплатно" ,
EP>Не только у меня — смотри выше что пишет A.A. про std::find — чтобы получить первую часть, нужно делать реализовывать новый тип range — Until, в то время как в STL он действительно получается бесплатно: [first, find(first, last, x))
Думаю, пока как выкрутится
Пока как идея реализовать кроме range еще и zipper думаю поиск и многое другое он вполне закроет.
Здравствуйте, FR, Вы писали:
EP>>>>Для стандартных массивов перегрузки в библиотеке или в языке? FR>>>В языке. EP>>О чём и речь — что-то для range'ей уже встроено непосредственно в язык. FR>Нет там ничего для range обычная перегрузка операторов. FR>Массивы были в самой первой версии языка,
То что они были это понятно, речь о том что их адаптировали к range.
FR>в то время когда у Алекандреску с его rangeманией была совсем другая любимая игрушка
Какая?
FR>>>По моему у тебя идея фикс "новые range бесплатно" , EP>>Не только у меня — смотри выше что пишет A.A. про std::find — чтобы получить первую часть, нужно делать реализовывать новый тип range — Until, в то время как в STL он действительно получается бесплатно: [first, find(first, last, x)) FR>Думаю, пока как выкрутится
Пока думаешь, можешь любоваться на:
template<typename I, typename T>
I find(I first, I last, const T& x)
{
while(first != last && *first != x)
++first;
return first;
}
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>>>Не только у меня — смотри выше что пишет A.A. про std::find — чтобы получить первую часть, нужно делать реализовывать новый тип range — Until, в то время как в STL он действительно получается бесплатно: [first, find(first, last, x)) FR>>Думаю, пока как выкрутится
EP>Пока думаешь, можешь любоваться на
EP>
EP>template<typename I, typename T>
EP>I find(I first, I last, const T& x)
EP>{
EP> while(first != last && *first != x)
EP> ++first;
EP> return first;
EP>}
EP>
Свой тип не нужен, нужные типы генерятся сами при использовании комбинаторов из стандартной библиотеки.
auto firstPart(R,T)(R xs, T x)
{
auto n = xs.save.countUntil(x);
if (n < 0) return xs;
return xs.takeExactly(n);
}
Те же три строчки, та же сложность, меньше мест для ошибки.
(и нет, тут нет двухкратного прохода)
Здравствуйте, Evgeny.Panasyuk, Вы писали:
DM>>Но не только это, а выполнение почти произвольного кода. Прочитать файл, отсортировать, распарсить, посчитать... EP>Это действительно круто(так же круто как и mixins), но эта фича слабо связанна с концепциям
Потому что концепции — слабое решение более общей проблемы — компайл-тайм проверки входных параметров на нужные свойства и выбор действий в зависимости от этого. Так вот, подобные проверки в D всегда будут мощнее плюсовых за счет встроенного интерпретатора.
DM>>Проверить компилируемость выражения, опять же, и в зависимости от результата делать осмысленные вещи. EP>В каком виде? В смысле только SFINAE-like или, допустим, можно поймать static_assert где-то в глубине call-stack'а?
Можно в любом месте кода написать что-нибудь подобное:
static if (__traits(compiles, x + 1))
writeln("number");
else
writeln("owl");
Где вместо "х + 1" может быть любое выражение.
EP>4. Какой тест позволит различить InputIterator и ForwardIterator?
В стандартной либе есть предикаты вроде isForwardRange, внутри там обычный hasMember, т.к. подобные штуки имеют разные наборы функций.
Здравствуйте, D. Mon, Вы писали:
DM>Здравствуйте, Evgeny.Panasyuk, Вы писали:
DM>>>Но не только это, а выполнение почти произвольного кода. Прочитать файл, отсортировать, распарсить, посчитать... EP>>Это действительно круто(так же круто как и mixins), но эта фича слабо связанна с концепциям
DM>Потому что концепции — слабое решение более общей проблемы — компайл-тайм проверки входных параметров на нужные свойства и выбор действий в зависимости от этого. Так вот, подобные проверки в D всегда будут мощнее плюсовых за счет встроенного интерпретатора.
Концепции — это не только проверки, это еще и type classes из Haskell. Плюс соответствующие перегрузки/специализации. Ты не офигеешь все это явно кодить на D-шном интерпретаторе?
DM>>>Проверить компилируемость выражения, опять же, и в зависимости от результата делать осмысленные вещи. EP>>В каком виде? В смысле только SFINAE-like или, допустим, можно поймать static_assert где-то в глубине call-stack'а?
DM>Можно в любом месте кода написать что-нибудь подобное: DM>
DM>static if (__traits(compiles, x + 1))
DM> writeln("number");
DM>else
DM> writeln("owl");
DM>
DM>Где вместо "х + 1" может быть любое выражение.
в С++11 есть SFINAE for expressions — практически то же самое, что __traits(compiles).
Здравствуйте, Evgeny.Panasyuk, Вы писали:
FR>>Массивы были в самой первой версии языка,
EP>То что они были это понятно, речь о том что их адаптировали к range.
В языке не адаптировали, в языке только массивы и срезы, вся адаптация для range в
std::array похоже я тебя просто недопонял и говорил именно про операцию индексации и
среза. Вот пример:
import std.stdio;
import std.array;
int count(Range)(Range r)
{
int result = 0;
for(; !r.empty; r.popFront())
++result;
return result;
}
void main()
{
writeln(count([1, 2, 3]));
}
если закомментировать import std.array; то будет такая ошибка компиляции:
count000.d(7): Error: no property 'empty' for type 'int[]'
count000.d(7): Error: no property 'popFront' for type 'int[]'
count000.d(14): Error: template instance count000.count!(int[]) error instantiating
FR>>в то время когда у Алекандреску с его rangeманией была совсем другая любимая игрушка
EP>Какая?
Ну "вот и выросло поколение" С++ конечно, как раз наверно писал свое "Современное проектирование на C++".
FR>>Думаю, пока как выкрутится
EP>Пока думаешь, можешь любоваться на: EP>
EP>template<typename I, typename T>
EP>I find(I first, I last, const T& x)
EP>{
EP> while(first != last && *first != x)
EP> ++first;
EP> return first;
EP>}
EP>
Если не нужна голова с рангами также:
Range find(Range, T)(Range r, T t)
{
while(!r.empty && r.front != t)
r.popFront();
return r;
}
А вообще я уже хотел идти искать белый флаг и приготовился начать писать
итераторы на D, но что-то нашептывало что где-то ошибка в рассуждениях.
В общем все просто мы тут пытаемся скопом сравнивать любые итераторы и так как-будто
для любых из них все плюсы имеют место.
А надо все-таки смотреть на их типы.
Берем простейший input iterator и соответственно input range. Для них описываемый
тобой плюс в виде легкого бесплатного одновременного получения головы и хвоста не
верен, голову мы получить не можем, поток всегда проходится только раз.
Идем дальше forward iterator и forward range. Тут мы всегда можем комбинировать
пару итераторов и легко получить и голову и хвост. Но это же означает что мы всегда
можем дешево сохранять состояние forward range, и действительно в D это обязательное
требование (и такой интервал должен иметь член save), следовательно все возражения о дорогих
копиях интервалов и их дорогих прокрутках отметаются, все очень дешево.
Для bidirectional справедливо все тоже что и для forward.
Для random_access все вообще полностью бесплатно, доступны длина и индекс.
В сухом остатке получается что единственно некоторые алгоритмы запишутся с интервалами
менее красиво чем с итераторами, но тут рулит то что интервалы очень легко комбинируются в
отличии от итераторов и на примере того же find выше
Здравствуйте, jazzer, Вы писали:
J>Концепции — это не только проверки, это еще и type classes из Haskell. Плюс соответствующие перегрузки/специализации. Ты не офигеешь все это явно кодить на D-шном интерпретаторе?
А чего там кодить?
void test(R)(R xs) if (isRandomAccessRange!R)
{...}
void test(R)(R xs) if (isForwardRange!R)
{...}
Тайпклассы, перегрузки, вот они.
J>в С++11 есть SFINAE for expressions — практически то же самое, что __traits(compiles).
Но только снаружи функции? Посреди метода я могу сделать несколько таких вложенных проверок?
Здравствуйте, matumba, Вы писали:
M>Вся надежда на D+LLVM.
И тебя не смущает, что LLVM на С++ написана? Как же можно на "говнокод на говноязыке" полагаться? Нее, надо срочно переписывать на D, а до этого ни за какие проекты браться ни в коем случае нельзя.
Здравствуйте, D. Mon, Вы писали:
DM>Здравствуйте, jazzer, Вы писали:
J>>Концепции — это не только проверки, это еще и type classes из Haskell. Плюс соответствующие перегрузки/специализации. Ты не офигеешь все это явно кодить на D-шном интерпретаторе?
DM>А чего там кодить? DM>
DM>void test(R)(R xs) if (isRandomAccessRange!R)
DM>{...}
DM>void test(R)(R xs) if (isForwardRange!R)
DM>{...}
DM>
DM>Тайпклассы, перегрузки, вот они.
а тут не будет неоднозначности?
Ну и тайпклассы еще осуществляют маппинг типов на концепции. Типа если у тебя концепция требует, чтоб у класса был size(), а у него вместо этого length(), то тайпклассы и концепции позволяют указать, что для этого класса надо звать length().
J>>в С++11 есть SFINAE for expressions — практически то же самое, что __traits(compiles).
DM>Но только снаружи функции? Посреди метода я могу сделать несколько таких вложенных проверок?
Здравствуйте, D. Mon, Вы писали:
EP>>Пока думаешь, можешь любоваться на EP>>
EP>>template<typename I, typename T>
EP>>I find(I first, I last, const T& x)
EP>>{
EP>> while(first != last && *first != x)
EP>> ++first;
EP>> return first;
EP>>}
EP>>
DM>Свой тип не нужен, нужные типы генерятся сами при использовании комбинаторов из стандартной библиотеки. DM>
DM>auto firstPart(R,T)(R xs, T x)
DM>{
DM> auto n = xs.save.countUntil(x);
DM> if (n < 0) return xs;
DM> return xs.takeExactly(n);
DM>}
DM>
DM>Те же три строчки, та же сложность, меньше мест для ошибки. DM>(и нет, тут нет двухкратного прохода)
1. Если звать стандартную библиотеку на помощь, то почему бы не взять сразу Until Речь то идёт об реализации. Код find выше — полностью self-contained.
2. find работает и для single pass range, а твой .save есть только начиная с forward — так?
3. Во время поиска у тебя передёргиваются и popFront и n, в find только итератор — оверхед по вычислениям
4. У тебя в результате будет и range и n, а в find только один итератор — то есть получается оверхед по памяти.
5. Это n, по сути является разжалованным итератором. Точно также, как я показывал выше, в Phobos'е, для алгоритмов по RandomAccess используются обычные целые, которые не знают откуда они пришли, и по сути те же итераторы, только менее удобные и безопасные.
6. В STL есть так называемые Counted Range — они определяются итератором и количеством элементов. Ты как раз попытался изобразить этот CountedRange, только менее эффективно.
7. find даёт два range'а, бесплатно, а у тебя только один. Например:
auto it = find(first, last, x);
process_first_half(first, it);
process_second_half(it, last);
8. У тебя возвращается либо один тип range (исходный), либо другой (то что вернёт takeExactly) — какой в итоге тип у твоего firstPart?
Здравствуйте, FR, Вы писали:
FR>если закомментировать import std.array; то будет такая ошибка компиляции: FR>
FR>count000.d(7): Error: no property 'empty' for type 'int[]'
FR>count000.d(7): Error: no property 'popFront' for type 'int[]'
FR>count000.d(14): Error: template instance count000.count!(int[]) error instantiating
FR>
ок, спасибо за информацию.
FR>>>в то время когда у Алекандреску с его rangeманией была совсем другая любимая игрушка EP>>Какая? FR>Ну "вот и выросло поколение" С++ конечно, как раз наверно писал свое "Современное проектирование на C++".
Я думал ты про D А эту книжку он лет за 8 перед range'ами написал.
FR>Если не нужна голова с рангами также: FR>
Как не нужна — конечно нужна, A.A. ведь как раз про голову и говорил.
FR>А вообще я уже хотел идти искать белый флаг и приготовился начать писать итераторы на D,
Хорошая идея
FR>но что-то нашептывало что где-то ошибка в рассуждениях.
Гони эти мысли, нет тут ошибки
FR>В общем все просто мы тут пытаемся скопом сравнивать любые итераторы и так как-будто FR>для любых из них все плюсы имеют место. FR>А надо все-таки смотреть на их типы.
FR>Берем простейший input iterator и соответственно input range. Для них описываемый FR>тобой плюс в виде легкого бесплатного одновременного получения головы и хвоста не FR>верен, голову мы получить не можем, поток всегда проходится только раз.
Я как раз выше и говорил, что D ranges для single pass ещё ничего:
EP>По факту D Range нормально подходит только для SinglePass.
FR>Идем дальше forward iterator и forward range. Тут мы всегда можем комбинировать FR>пару итераторов и легко получить и голову и хвост. Но это же означает что мы всегда FR>можем дешево сохранять состояние forward range, и действительно в D это обязательное FR>требование (и такой интервал должен иметь член save), следовательно все возражения о дорогих FR>копиях интервалов и их дорогих прокрутках отметаются, все очень дешево. FR>Для bidirectional справедливо все тоже что и для forward. FR>Для random_access все вообще полностью бесплатно, доступны длина и индекс.
Какие копии? Напиши find, который работает для всего начиная с single pass, а для forward и выше позволяет бесплатно получить первую часть в придачу ко второй
Лишние прокрутки были и есть в bidirectional partition, цена этих лишних прокруток зависит от используемой реализации range. Где-то передёргивание может быть дорогим, где-то дешёвым. В версии с итераторами, этих прокруток нет, by design
FR>В сухом остатке получается что единственно некоторые алгоритмы запишутся с интервалами FR>менее красиво чем с итераторами, но тут рулит то что интервалы очень легко комбинируются в FR>отличии от итераторов
Я же не против range'ей в стиле Boost.Range — они действительно легко комбинируются:
Но — из таких range всегда можно достать итераторы, и работать с ними, а вот из D-style range — нет.
То есть гибридное решение — итераторы + сахар в виде range вокруг них, вполне жизнеспособное.
FR>и на примере того же find выше
Здравствуйте, D. Mon, Вы писали:
DM>>>Но не только это, а выполнение почти произвольного кода. Прочитать файл, отсортировать, распарсить, посчитать... EP>>Это действительно круто(так же круто как и mixins), но эта фича слабо связанна с концепциям DM>Потому что концепции — слабое решение более общей проблемы — компайл-тайм проверки входных параметров на нужные свойства и выбор действий в зависимости от этого. Так вот, подобные проверки в D всегда будут мощнее плюсовых за счет встроенного интерпретатора.
Более мощные проверки — это всё понятно, и действительно мощно. Но это всё не то, и скорее относятся к compile-time вычислениям в общем, чем к концепциям.
Концепции выберут нужную перегрузку, а static if из твоего примера:
void test(R)(R xs) if (isRandomAccessRange!R)
{...}
void test(R)(R xs) if (isForwardRange!R)
{...}
сфейлится
DM>>>Проверить компилируемость выражения, опять же, и в зависимости от результата делать осмысленные вещи. EP>>В каком виде? В смысле только SFINAE-like или, допустим, можно поймать static_assert где-то в глубине call-stack'а? DM>Можно в любом месте кода написать что-нибудь подобное: DM>
DM>static if (__traits(compiles, x + 1))
DM> writeln("number");
DM>else
DM> writeln("owl");
DM>
DM>Где вместо "х + 1" может быть любое выражение.
Это как раз SFINAE-like.
А мне интересно, можно ли поймать такое:
static if (__traits(compiles, some_function_with_static_assert_inside() ))
// ..
EP>>4. Какой тест позволит различить InputIterator и ForwardIterator? DM>В стандартной либе есть предикаты вроде isForwardRange, внутри там обычный hasMember, т.к. подобные штуки имеют разные наборы функций.
В STL их тоже можно различить, но речь не об этом, а о том, что далеко не все свойства можно протестировать.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>1. Если звать стандартную библиотеку на помощь, то почему бы не взять сразу Until Речь то идёт об реализации. Код find выше — полностью self-contained.
В библиотеке уже есть findSplit, findSplitAfter и findSplitBefore, первый как раз дает два рэнджа, два других — левую и правую часть. Но они ищут не один элемент, а сразу "подстроку", поэтому их приводить я не стал.
EP>2. find работает и для single pass range, а твой .save есть только начиная с forward — так?
Так. Возврат левой части (от начала до найденного элемента) для не forward рэнджа смысла не имеет, элементы уже однажды прочитаны. D такую попытку здесь пресекает. А плюсы? Спокойно вернут итератор на протухшие данные?
EP>3. Во время поиска у тебя передёргиваются и popFront и n, в find только итератор — оверхед по вычислениям
Ага, на один инкремент целого. Что на порядок быстрее, чем чтение байта из ближайшего кэша даже. Т.е. реально не оверхэд абсолютно, спасибо instruction level parallelism.
EP>4. У тебя в результате будет и range и n, а в find только один итератор — то есть получается оверхед по памяти.
Да, опять же на целое одно число. Мы собираемся зачем-то хранить мильоны итераторов/рэнджей? На практике их обычно в один момент до нескольких штук используется, и те на стеке.
EP>5. Это n, по сути является разжалованным итератором. Точно также, как я показывал выше, в Phobos'е, для алгоритмов по RandomAccess используются обычные целые, которые не знают откуда они пришли, и по сути те же итераторы, только менее удобные и безопасные.
А какая есть безопасная альтернатива для Random access?
EP>6. В STL есть так называемые Counted Range — они определяются итератором и количеством элементов. Ты как раз попытался изобразить этот CountedRange, только менее эффективно.
Почему менее?
EP>7. find даёт два range'а, бесплатно, а у тебя только один.
Мне только он и нужен был. Вернуть вместо xs tuple(xs, ys) (где ys — сохраненный двумя строчками выше xs.save) много ума не нужно.
EP>8. У тебя возвращается либо один тип range (исходный), либо другой (то что вернёт takeExactly) — какой в итоге тип у твоего firstPart?
Хороший вопрос. Почему-то компилятор в нем разобрался без моей помощи.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
DM>>static if (__traits(compiles, x + 1)) DM>>Где вместо "х + 1" может быть любое выражение.
EP>Это как раз SFINAE-like.
Я не вижу сходства. Выше уже сказали, что SFINAE нельзя использовать внутри функций, в отличие от static if.
EP>А мне интересно, можно ли поймать такое: EP>
EP>static if (__traits(compiles, some_function_with_static_assert_inside() ))
EP>// ..
EP>
Да, может. Хоть static assert, хоть динамическая проверка.
Такой пример только что запустил:
EP>>1. Если звать стандартную библиотеку на помощь, то почему бы не взять сразу Until Речь то идёт об реализации. Код find выше — полностью self-contained.
DM>В библиотеке уже есть findSplit, findSplitAfter и findSplitBefore, первый как раз дает два рэнджа, два других — левую и правую часть.
findSplit вообще возвращает три range, а нужны [first, find(first, last)) и [find(first, last), last), или например тоже самое с partition.
EP>>2. find работает и для single pass range, а твой .save есть только начиная с forward — так? DM>Так. Возврат левой части (от начала до найденного элемента) для не forward рэнджа смысла не имеет, элементы уже однажды прочитаны. D такую попытку здесь пресекает. А плюсы? Спокойно вернут итератор на протухшие данные?
Покажи реализацию аналога std::find.
EP>>3. Во время поиска у тебя передёргиваются и popFront и n, в find только итератор — оверхед по вычислениям DM>Ага, на один инкремент целого. Что на порядок быстрее, чем чтение байта из ближайшего кэша даже. Т.е. реально не оверхэд абсолютно, спасибо instruction level parallelism.
Не один инкремент, а на каждой итерации. И не instruction level parallelism, а overhead by design, чего тут спорить
EP>>4. У тебя в результате будет и range и n, а в find только один итератор — то есть получается оверхед по памяти. DM>Да, опять же на целое одно число. Мы собираемся зачем-то хранить мильоны итераторов/рэнджей? На практике их обычно в один момент до нескольких штук используется, и те на стеке.
Тут согласен — в большинстве случаев будет не заметно. Я лишь показываю насколько абстракция неудобная, даже для простых случаев
EP>>5. Это n, по сути является разжалованным итератором. Точно также, как я показывал выше, в Phobos'е, для алгоритмов по RandomAccess используются обычные целые, которые не знают откуда они пришли, и по сути те же итераторы, только менее удобные и безопасные. DM>А какая есть безопасная альтернатива для Random access?
В смысле? Вот ты реализуешь некий алгоритм который использует несколько random access range'ей — дёргаешь индексы туда-сюда, при использовании D Range нужно ещё не перепутать из какого range какой индекс, в том время как из самого итератора можно и читать/писать.
EP>>6. В STL есть так называемые Counted Range — они определяются итератором и количеством элементов. Ты как раз попытался изобразить этот CountedRange, только менее эффективно. DM>Почему менее?
Лишние операции, лишняя память.
EP>>7. find даёт два range'а, бесплатно, а у тебя только один. DM>Мне только он и нужен был. Вернуть вместо xs tuple(xs, ys) (где ys — сохраненный двумя строчками выше xs.save) много ума не нужно.
Ну так покажи полную реализацию аналога find, если всё так просто
EP>>8. У тебя возвращается либо один тип range (исходный), либо другой (то что вернёт takeExactly) — какой в итоге тип у твоего firstPart? DM>Хороший вопрос. Почему-то компилятор в нем разобрался без моей помощи.
Здравствуйте, D. Mon, Вы писали:
DM>>>static if (__traits(compiles, x + 1)) DM>>>Где вместо "х + 1" может быть любое выражение. EP>>Это как раз SFINAE-like. DM>Я не вижу сходства. Выше уже сказали, что SFINAE нельзя использовать внутри функций, в отличие от static if.
Сходство в том, что можно узнать поддержку синтаксиса в comiple time, и сделать по результату compile time выбор.
Встроенного в функции static if нет, и скорей всего не будет (см. статью "static if considered"), но при желании внутри функции можно сделать и эту проверку, и compile time dispatch + добавить сахара.
А при наличии концепций, можно не запихивать всё в одну функцию с лапшой static if'ов, а сделать нормальные перегрузки
EP>>А мне интересно, можно ли поймать такое: EP>>
EP>>static if (__traits(compiles, some_function_with_static_assert_inside() ))
EP>>// ..
EP>>
DM>Да, может. Хоть static assert, хоть динамическая проверка.
FR>>>И не дай бог мелкую ошибку допустить и получим километровое сообщение, EP>>Против километровых ошибок помогут концепции. I>Концепции уже для того, нужны что бы просто из функции выйти.
И желательно, что бы эта хрень _не_ бросала исключения, иначе дебаг превращается в бедствие.
FR>>>>И не дай бог мелкую ошибку допустить и получим километровое сообщение, EP>>>Против километровых ошибок помогут концепции. I>>Концепции уже для того, нужны что бы просто из функции выйти.
EP>Подробнее.
Да всё ты понимаешь, не надо шлангом прикидываться.
Здравствуйте, Ikemefula, Вы писали:
I>И желательно, что бы эта хрень _не_ бросала исключения, иначе дебаг превращается в бедствие.
В смысле вообще не бросала? Так зачем ограничивать?
Или ты про реализацию CONTINUE/etc? Так там нет исключений
FR>>>>>И не дай бог мелкую ошибку допустить и получим километровое сообщение, EP>>>>Против километровых ошибок помогут концепции. I>>>Концепции уже для того, нужны что бы просто из функции выйти. EP>>Подробнее. I>Да всё ты понимаешь
Здравствуйте, Evgeny.Panasyuk, Вы писали:
I>>И желательно, что бы эта хрень _не_ бросала исключения, иначе дебаг превращается в бедствие.
EP>В смысле вообще не бросала? Так зачем ограничивать? EP>Или ты про реализацию CONTINUE/etc? Так там нет исключений
Покажи реализацию без исключений, особенно return интересует
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>findSplit вообще возвращает три range, а нужны [first, find(first, last)) и [find(first, last), last), или например тоже самое с partition.
Если позарез нужны именно такие, то берем chain() и соединяем второй с третьим в один. Делов-то.
EP>>>2. find работает и для single pass range, а твой .save есть только начиная с forward — так? DM>>Так. Возврат левой части (от начала до найденного элемента) для не forward рэнджа смысла не имеет, элементы уже однажды прочитаны. D такую попытку здесь пресекает. А плюсы? Спокойно вернут итератор на протухшие данные?
EP>Покажи реализацию аналога std::find.
В каком смысле аналога? Если он будет с range'ами, он по-любому не будет полным аналогом. Если с разбиением на два рэнджа, то например так:
auto myfind(Range, T)(Range r, T t)
{
size_t n = 0;
auto left = r.save;
while(!r.empty && r.front != t) {
r.popFront();
n++;
}
return tuple(left.takeExactly(n), r);
}
А теперь ты покажи аналог, не требующий forward итератор.
EP>Тут согласен — в большинстве случаев будет не заметно. Я лишь показываю насколько абстракция неудобная, даже для простых случаев
Неудобная — это таскание и передача пар итераторов повсюду с постоянным риском их перепутать и разведением писанины. А дивные рэнджи и алгоритмы на практике крайне удобны в использовании.
EP>>>5. Это n, по сути является разжалованным итератором. Точно также, как я показывал выше, в Phobos'е, для алгоритмов по RandomAccess используются обычные целые, которые не знают откуда они пришли, и по сути те же итераторы, только менее удобные и безопасные. DM>>А какая есть безопасная альтернатива для Random access?
EP>В смысле? Вот ты реализуешь некий алгоритм который использует несколько random access range'ей — дёргаешь индексы туда-сюда, при использовании D Range нужно ещё не перепутать из какого range какой индекс, в том время как из самого итератора можно и читать/писать.
A такой итератор дает random access? Если нет, то причем тут индексы, а если да, то как он это делает без "опасных" индексов?
EP>>>8. У тебя возвращается либо один тип range (исходный), либо другой (то что вернёт takeExactly) — какой в итоге тип у твоего firstPart? DM>>Хороший вопрос. Почему-то компилятор в нем разобрался без моей помощи. EP>Как именно? Какой typeof у результата?
Оказалось, я его проверял на массивах, а для них в обоих ветках массивы получаются. С более другим контейнером вылезла ожидаемая ошибка.
Здравствуйте, D. Mon, Вы писали:
EP>>findSplit вообще возвращает три range, а нужны [first, find(first, last)) и [find(first, last), last), или например тоже самое с partition. DM>Если позарез нужны именно такие, то берем chain() и соединяем второй с третьим в один. Делов-то.
chain в общем случае возвращает range нового типа, с добавленным оверхедом, и увеличенным размером?
Не, когда range'и из одного контейнера, да ещё и смежные — такое не интересно
EP>>Покажи реализацию аналога std::find. DM>В каком смысле аналога? Если он будет с range'ами, он по-любому не будет полным аналогом. Если с разбиением на два рэнджа, то например так: DM>
DM>auto myfind(Range, T)(Range r, T t)
DM>{
DM> size_t n = 0;
DM> auto left = r.save;
DM> while(!r.empty && r.front != t) {
DM> r.popFront();
DM> n++;
DM> }
DM> return tuple(left.takeExactly(n), r);
DM>}
DM>
DM>А теперь ты покажи аналог, не требующий forward итератор.
Ну так вот же он:
template<typename I, typename T>
I find(I first, I last, const T& x)
{
while(first != last && *first != x)
++first;
return first;
}
Если input range — то возвращается только вторая часть, но во всех остальных — обе.
У тебя же .save, который как я понял — даст compile error на single pass.
Далее, что будешь делать, например, чтобы получить: [std::prev(find(first, last, x)), last) — опять chain overhead?
Простота реализации, мощность и эффективность — налицо
EP>>Тут согласен — в большинстве случаев будет не заметно. Я лишь показываю насколько абстракция неудобная, даже для простых случаев DM>Неудобная — это таскание и передача пар итераторов повсюду с постоянным риском их перепутать и разведением писанины. А дивные рэнджи и алгоритмы на практике крайне удобны в использовании.
Когда есть действительно пара итераторов — их не нужно таскать по отдельности. И есть соответствующие обвёртки над алгоритмами(Boost.Range, Adobe ASL):
Плюс это будет в будущих стандартах (хотя легко доступно в виде библиотек).
EP>>В смысле? Вот ты реализуешь некий алгоритм который использует несколько random access range'ей — дёргаешь индексы туда-сюда, при использовании D Range нужно ещё не перепутать из какого range какой индекс, в том время как из самого итератора можно и читать/писать. DM>A такой итератор дает random access? Если нет, то причем тут индексы, а если да, то как он это делает без "опасных" индексов?
В смысле?
Там где в STL будут два итератора:
*x++ = *y++;
В D-like range будет два range, и два индекса:
w[x++] = z[y++];
(move может быть намного сложнее ++).
EP>>Как именно? Какой typeof у результата? DM>Оказалось, я его проверял на массивах, а для них в обоих ветках массивы получаются. С более другим контейнером вылезла ожидаемая ошибка.
Ок, а то я, как один из вариантов, предположил что там автоматический type-erasure а-ля boost::any_range, со всем runtime overhead'ом.
Здравствуйте, Кодт, Вы писали:
I>>Покажи реализацию без исключений, особенно return интересует К>Фигня-война. Если return void, то делается довольно просто. К>С возвратом чего-то типизированного будет сложнее и грязнее. Но тоже ничего невозможного нет.
Это первый вариант. А второй в возвращении не просто has/no optional, а с enum {returned, breaked, continued, normal_exit}. Тогда break превращается в return breaked, и т.п.
Здравствуйте, include2h, Вы писали:
IO>>Зато есть вменяемая модель многопоточности. И модель памяти, которая с этой многопоточностью работает. IO>>И всё это безопасно — на уровне "управляемых платформ", но без их оверхеда.
I>Можете рассказать подробнее?
Параллельность реализована тасками, которые не имеют разделяемого состояния. Т.е. одновременный доступ к одной структуре данных невозможен.
Структуры данных можно передавать в/из тасков как сообщения (без копирования). Код, передающий сообщение при этом теряет доступ к объекту, который он передаёт
в другую таску. Это обеспечивается статической проверкой. Кстати это не требует сборки мусора — время жизни вычисляется статически.
На самом деле там модель более сложная, чем в С. Есть несколько типов указателей. Основные — это owned, которые могут, грубо говоря, существовать
только в одном месте в каждый момент, и managed, которые отслеживаются сборщиком мусора. Передавать между тасками можно только первые.
При этом всё сделано умно — т.е. не тип указателя не обязательно всегда и везде указывать точно. В одну и ту же функцию можно передавать указатели разных типов.
Откуда же его [независимый суд] взять, если в нем такие же как мы? (c) VladD2
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Но — из таких range всегда можно достать итераторы, и работать с ними, а вот из D-style range — нет. EP>То есть гибридное решение — итераторы + сахар в виде range вокруг них, вполне жизнеспособное.
Ты на логику свою посмотри. Ты выставляешь против языка некий паттерн и его библиотечную поддержку в стандартной библиотеке языка.
Язык то тут причем? Нравятся тебе итераторы? Напиши либу на их основе и радуйся жизни. В С++ они тоже не сразу появились.
Что до метапограммирования, то очевидно, что на D мета-код выглядит проще, работает существенно быстрее и выдает внятную диагностику. Единственная его проблема — есть решения куда более гибкие и мощные. А вы тут о чем-то спорите.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
VD>Ага. Только выглядит как деромокод и понять могут толко посвященные. Код на D я понял на раз.
Да ладно, в чём принципиальная разница
iota(0, 10).map!(x => x *x).filter!(x => x % 2)
// versus
irange(0, 10) | transformed(_1 * _1) | filtered(_1 % 2)
// if use same names:
iota(0, 10) | map(_1 * _1) | filter(_1 % 2)
?
C++ версию запостили одновременно двое, причём если не считать whitespace, код диапазона идентичен — и это уж точно никак не тянет на какие-то сакральные знания доступные "посвящённым"
Здравствуйте, VladD2, Вы писали:
EP>>Но — из таких range всегда можно достать итераторы, и работать с ними, а вот из D-style range — нет. EP>>То есть гибридное решение — итераторы + сахар в виде range вокруг них, вполне жизнеспособное. VD>Ты на логику свою посмотри. Ты выставляешь против языка некий паттерн и его библиотечную поддержку в стандартной библиотеке языка.
Ещё раз:
EP>Как известно, у C++ основным приоритетом является производительность.
EP>А в D спокойно могут пожертвовать производительностью ради других целей (об этом говорил A.A.). Взять например те же ranges — они проигрывают итераторам по производительности by-design
VD>Язык то тут причем? Нравятся тебе итераторы? Напиши либу на их основе и радуйся жизни. В С++ они тоже не сразу появились.
Я показываю то, что авторы языка D готовы жертвовать производительностью. Сегодня ranges. А кто знает чем именно они пожертвуют завтра?
У C++ zero-overhead (точнее don't pay for what you don't use) это практически главная цель — заменить его сможет только язык с такими же целями.
VD>Что до метапограммирования, то очевидно, что на D мета-код выглядит проще, работает существенно быстрее и выдает внятную диагностику.
Вот тут я как раз и не спорю — на данном этапе у него больше возможностей для метапограммирования.
Что, кстати, немного странно: казалась бы, в языке с лучшей поддержкой compile-time вычислений, compile-time dispatch, метапограммирования — должна быть супер эффективная, гибкая, стандартная библиотека — так ведь нет, STL явно выигрывает
Здравствуйте, VladD2, Вы писали:
VD>Так уже лучше, хотя почему для организации цепочки вызовов используется оператор бинарного или все же не ясно.
Вспомни консоль:
cat x | grep y | sort
VD>Но тут встает другой вопрос. На D — это "гражданский" код, а на С++ магия метапограммирования которая в плюсах отнюдь не бесплатна.
Да никакой тут магии нет — в "|" столько же магии, сколько и в "<<", а это уже
std::cout << "Hello, World!" << std::endl;
VD>Проект забитый этим делом будет тормозить и выдавать фееричные сообщения в случае банальных ошибок.
Каким именно делом? Где тормозить?
VD>Ни разу не сторонник Ди, но объективности ради.
D — хорошая попытка, мне даже нравится.
Но, во-первых — он пытается усидеть сразу на многих стульях. А во-вторых, такое впечатление что фичи добавляются направо и налево, и это наверное даже правильно пока мало пользователей, но реальная проверка на прочность начнётся когда появится большая пользовательская база и хотя бы несколько солидных компиляторов.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Вспомни консоль: EP>cat x | grep y | sort
Меня от линуксовй консоли всегда мутило. Как-то объектная точка или функциональный оператор |> понятнее.
EP>Да никакой тут магии нет — в "|" столько же магии, сколько и в "<<", а это уже
А _1 тоже не магия?
EP>Каким именно делом? Где тормозить?
Бустом. Или что ты там использовал для получения недолямбд с параметрами _1, _2 и т.п.?
EP>D — хорошая попытка, мне даже нравится. EP>Но, во-первых — он пытается усидеть сразу на многих стульях. А во-вторых, такое впечатление что фичи добавляются направо и налево, и это наверное даже правильно пока мало пользователей, но реальная проверка на прочность начнётся когда появится большая пользовательская база и хотя бы несколько солидных компиляторов.
Ну, то что авторов несет периодически — это да. Но как замена для плюсов в задачах где нужно битовижимательство вполне потянет.
А критикуете вы его совсем не за то. Я бы вот скорее обратил внимание на то что МП в Ди тоже хиленький. Правильный МП должен позволять писать метапрограммы на том же языке что и обычные. В Ди с этим по лучше чем в С++ (где МП надо делать на побочных эффектах от материализации шаблонов), но все же не фирст-класс. За фиг нужен статик иф если есть обычный?
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, VladD2, Вы писали:
EP>>Да никакой тут магии нет — в "|" столько же магии, сколько и в "<<", а это уже VD>А _1 тоже не магия?
_1 это библиотечная полиморфная лямбда, если считаешь магией — то есть встроенная в язык, но для неё нужно чуть больше закорючек.
VD>Но как замена для плюсов в задачах где нужно битовижимательство вполне потянет.
Чисто как язык — возможно. Но помимо языка нужна платформа — библиотеки, компиляторы, с которыми, afaik, пока не густо.
VD>За фиг нужен статик иф если есть обычный?
Те ветки кода которые отбраковываются — практически не проверяются компилятором.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
DM>>А теперь ты покажи аналог, не требующий forward итератор. EP>Ну так вот же он: EP>Если input range — то возвращается только вторая часть, но во всех остальных — обе. EP>У тебя же .save, который как я понял — даст compile error на single pass.
Именно, D на этапе компиляции уже не даст сделать глупость. В твоем же случае компилятор даже не заикнется, если ты применишь свою функцию на одноразовом итераторе и будешь из результата строить "первую часть", которая уже съедена.
DM>>A такой итератор дает random access? Если нет, то причем тут индексы, а если да, то как он это делает без "опасных" индексов? EP>В смысле? EP>Там где в STL будут два итератора: EP>*x++ = *y++; EP>(move может быть намного сложнее ++).
Вот именно этот момент и интересен для random access. Какой у move аргумент? То же самое целое число? Тогда я не вижу особой разницы.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
VD>>Так что по факту продвижению Ди больше мешают привычки и косность мышления нежели какие-то технические сложности. EP>afaik, как минимум нет быстрого компилятора
Быстрого именно компилятора как раз нет у С++. D компилируется на порядок быстрее. Если же речь о получаемом коде, то есть же GDC и LDC, где codegen'ы из GCC и LLVM соответственно.
Здравствуйте, VladD2, Вы писали:
VD>А критикуете вы его совсем не за то. Я бы вот скорее обратил внимание на то что МП в Ди тоже хиленький. Правильный МП должен позволять писать метапрограммы на том же языке что и обычные. В Ди с этим по лучше чем в С++ (где МП надо делать на побочных эффектах от материализации шаблонов), но все же не фирст-класс. За фиг нужен статик иф если есть обычный?
В D как раз вполне себе можно использовать тот же язык как в обычном коде, так и в МП (в компайл-тайме).
auto getNums(int k) // описываем обычную функцию
{
return iota(0,k).filter!(x => x*x % 10 == 1).array;
}
void main(string[] argv)
{
auto runTimeValue = getNums(argv[1].to!int); //вызываем ее в рантайме
writeln(runTimeValue);
enum compileTimeValue = getNums(100); //вызываем ее же в компайл-тайме
writeln(compileTimeValue);
}
Причем обычный код и МП можно писать прямо рядом и вперемежку, нет разделения на стадии, как в более примитивных подходах.
И чтобы можно было при такой записи вперемежку выбирать между рантаймом и компайлтаймом, есть static.
Здравствуйте, D. Mon, Вы писали:
DM>В D как раз вполне себе можно использовать тот же язык как в обычном коде, так и в МП (в компайл-тайме). DM>Причем обычный код и МП можно писать прямо рядом и вперемежку, нет разделения на стадии, как в более примитивных подходах. DM>И чтобы можно было при такой записи вперемежку выбирать между рантаймом и компайлтаймом, есть static.
Твой пример примерно соответствует constexpr-функциям из C++11.
Здравствуйте, jazzer, Вы писали:
J>Твой пример примерно соответствует constexpr-функциям из C++11.
Только там такие функции нужно перелопатить, расставив везде constexpr, и они сильно ограничены по тому, что в них можно делать. А тут берешь готовый код из стандартной или других библиотек и используешь. Ограничения тоже есть, конечно, но их меньше.
Здравствуйте, D. Mon, Вы писали:
DM>Здравствуйте, jazzer, Вы писали:
J>>Твой пример примерно соответствует constexpr-функциям из C++11.
DM>Только там такие функции нужно перелопатить, расставив везде constexpr, и они сильно ограничены по тому, что в них можно делать. А тут берешь готовый код из стандартной или других библиотек и используешь. Ограничения тоже есть, конечно, но их меньше.
Ну так я поэтому и говорю — примерно. Но если у тебя есть функция constexpr — ты ее можешь звать откуда угодно — и во время компиляции, и во время исполнения.
Плюс раз уж мы говорим о "готовом коде из стандартной или других библиотек" — так в С++ сейчас все (в бусте, по крайней мере) стараются по возможности делать свои функции constexpr, так что для юзера то же самое получится — он просто заюзает соответствующую функцию из либы.
Здравствуйте, Ikemefula, Вы писали:
I>Здравствуйте, jazzer, Вы писали:
J>>Никто не говорит, что D хуже С++. J>>Мы говорим, что то, что он может предложить по сравнению с С++11 (и С++14), недостаточно для того, чтоб все бросились переписывать на нем плюсовые программы или нанимать новых/переобучать имеющихся программеров. Овчинка выделки не стоит.
I>Странный аргумент. Программы на коболе, лиспе, фортране, ассемблере и многих других древних языках так же очень редко переписываются чисто ради "язык сменить". То есть, "бросились переписывать" для любого языке вещь крайне редкая.
I>Поэтому вопрос не в том, будут ли на D переписывать плюсовый код, а в том будет ли в новых проектах использоваться D и, если будет, то для чего.
Для новых проектов на новых языках нужны новые программисты. А такое счастье никому не нужно. Чтоб вложиться в это, выгоды от нового языка должны быть очень большими.
Здравствуйте, jazzer, Вы писали:
I>>Поэтому вопрос не в том, будут ли на D переписывать плюсовый код, а в том будет ли в новых проектах использоваться D и, если будет, то для чего.
J>Для новых проектов на новых языках нужны новые программисты. А такое счастье никому не нужно. Чтоб вложиться в это, выгоды от нового языка должны быть очень большими.
Да ладно, откуда например берутся проекты на хаскеле, на руби+рельсах, на go, на clojure? Чаще всего в уже существующих компаниях конкретные программисты настолько вдохновляются каким-то языком, что всячески пытаются его использовать. Когда им разрешают (или не мешают), получаются проекты на этих языках. Иногда новые, иногда переписанные старые. Так что нужен лишь энтузиазм и отстутствие непреодолимых проблем в языке/реализации.
Здравствуйте, jazzer, Вы писали:
I>>Поэтому вопрос не в том, будут ли на D переписывать плюсовый код, а в том будет ли в новых проектах использоваться D и, если будет, то для чего.
J>Для новых проектов на новых языках нужны новые программисты. А такое счастье никому не нужно. Чтоб вложиться в это, выгоды от нового языка должны быть очень большими.
Не новые, а уже имеющиеся и для начала этого хватит. В свое время сиплюсники переходили и на джаву, и на дотнет и каких то проблем не вызвало. Вот будут ли выгодны от D — вот это и хочется узнать.
Здравствуйте, D. Mon, Вы писали:
DM>>>А теперь ты покажи аналог, не требующий forward итератор. EP>>Ну так вот же он: EP>>Если input range — то возвращается только вторая часть, но во всех остальных — обе. EP>>У тебя же .save, который как я понял — даст compile error на single pass. DM>Именно, D на этапе компиляции уже не даст сделать глупость.
Какую? Найти позицию элемента в single pass range это глупость? Интересный подход.
DM>В твоем же случае компилятор даже не заикнется, если ты применишь свою функцию на одноразовом итераторе и будешь из результата строить "первую часть", которая уже съедена.
Да нет в этом ничего страшного. Когда ты одеваешь смирительную рубашку — она часто запрещает тебе делать и опасные и полезные действия.
"Отрицательные числа позволяют делать очень плохие вещи когда у нас есть квадратный корень. Давайте решим проблему с квадратным корнем, тем что запретим отрицательные числа" (68:23)
Плохих же программистов никакие рубашки не остановят — они очень находчивые.
Ограничить себя в чём-то всегда можно успеть, безопасность это всё лирика, а вот ты всё-таки попробуй сделать полноценный аналог.
DM>Вот именно этот момент и интересен для random access. Какой у move аргумент? То же самое целое число? Тогда я не вижу особой разницы.
Если будет число, то оно появится и в случае с range.
// 5 entities:
w += n;
z += n/2;
x[w] = y[z];
// versus 3 entities:
x += n;
y += n/2;
*x = *y;
Здравствуйте, D. Mon, Вы писали:
DM>Если же речь о получаемом коде, то есть же GDC и LDC, где codegen'ы из GCC и LLVM соответственно.
Если они стабильно работают, поддерживают последнюю версию языка, и при этом генерируют код не хуже C++ компиляторов — то это действительно было бы круто.
Здравствуйте, jazzer, Вы писали:
EP>>>Вспомни консоль: EP>>>cat x | grep y | sort VD>>Меня от линуксовой консоли всегда мутило. J>Да не вопрос: J>DOS/WinXP
И про консоль, и про имена — это всё придирки к мелочам.
J>В С++11 и без буста все прекрасно реализуется в три строчки (А в С++14 — в одну).
Причём в C++14 добавилось несколько способов — transparent operator functors и само-собой п.лямбды.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
DM>>Если же речь о получаемом коде, то есть же GDC и LDC, где codegen'ы из GCC и LLVM соответственно.
EP>Если они стабильно работают, поддерживают последнюю версию языка, и при этом генерируют код не хуже C++ компиляторов — то это действительно было бы круто.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
DM>>>>А теперь ты покажи аналог, не требующий forward итератор. EP>>>Ну так вот же он: EP>>>Если input range — то возвращается только вторая часть, но во всех остальных — обе. EP>>>У тебя же .save, который как я понял — даст compile error на single pass. DM>>Именно, D на этапе компиляции уже не даст сделать глупость.
EP>Какую? Найти позицию элемента в single pass range это глупость? Интересный подход.
Ты же все приставал с получением двух частей — до найденного элемента и от него дальше. Я показал. Ты попросил завел речь про forward iterator. Я и говорю, что для него получение первой части смысла не имеет, это ошибка, и D ее ловит системой типов.
Здравствуйте, D. Mon, Вы писали:
EP>>>>У тебя же .save, который как я понял — даст compile error на single pass. DM>>>Именно, D на этапе компиляции уже не даст сделать глупость. EP>>Какую? Найти позицию элемента в single pass range это глупость? Интересный подход. DM>Ты же все приставал с получением двух частей — до найденного элемента и от него дальше. Я показал.
Ну да, показал — неэффективное, негибкое, и более многословное:
auto myfind(Range, T)(Range r, T t)
{
size_t n = 0;
auto left = r.save;
while(!r.empty && r.front != t) {
r.popFront();
n++;
}
return tuple(left.takeExactly(n), r);
}
// versustemplate<typename I, typename T>
I find(I first, I last, const T& x)
{
while(first != last && *first != x)
++first;
return first;
}
И это всего лишь примитивный линейный поиск А вот что будет, например, с бинарным а-ля std::partition_point?
DM>Ты попросил завел речь про forward iterator. Я и говорю, что для него получение первой части смысла не имеет
Для forward как раз имеет смысл.
DM>это ошибка, и D ее ловит системой типов.
Для single pass range он запрещает и получение первой части и второй — вторая часть вполне легальна
Здравствуйте, FR, Вы писали:
FR>D'шный range не пара итераторов. FR>Это весьма абстрактная вещь, минимально и достаточно для (односвязного) списка это: FR>
хорошо, и как, например, написать функцию, которая вернёт поддиапазон этого диапазона, от начала и до чего-нибудь, ну там элемента с таким-то значением, или, например, "первые пять"?..
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, Erop, Вы писали:
E>хорошо, и как, например, написать функцию, которая вернёт поддиапазон этого диапазона, от начала и до чего-нибудь, ну там элемента с таким-то значением, или, например, "первые пять"?..
Так же как вернуть такой же диапазон для C++ input iterator, то есть никак и бессмысленно.
вообще смотри сюда
VD>Я с тобой почти согласен, но вообще-то ты сравнил частный случай для которого у D есть готовое решение.
VD>Интереснее было бы на более не тривиальные примеры метапрограммирования посмотреть.
Уже показали, но похоже людям интереснее обсуждение "итераторы от Степанова против интервалов
от Александреску", притом что оба реализуются при желании одинаково и на C++ и на D.
Здравствуйте, FR, Вы писали:
DM>>>Ты же все приставал с получением двух частей — до найденного элемента и от него дальше. Я показал. EP>>Ну да, показал — неэффективное, негибкое, и более многословное: FR>Реально же ерундой занимаетесь, сравниваете мягкое с зеленым. FR>Итераторы C++ и интервалы D слишком различны.
Boost.Range даёт многие преимущества D-style range, не внося их недостатки
FR>Базовое различие все, включая и FR>меня, совсем упустили, интервалы D в отличии от итераторов не работают по месту, FR>а выдают новый интервал,
Что значит не по месту? В смысле ленивость? Так эта ленивости доступна и Boost.Range, да и вообще в самих итераторах (а-ля transformed iterator)
FR>по сути ближе к базовым ФВП из функциональщины FR>работающими со списками.
Подробнее.
FR>Даже boost::range в основной массе этого не делает FR>а тоже работает по месту как и его базовые итераторы.
Что значит работает по месту?
FR>Намного проще, тоже кстати, реализация получается если в языке есть yield.
yield действительно помогает генерировать ленивые последовательности. Но у него огромный минус — такие последовательности являются примитивным single pass'ом, который приводит к излишним копиям.
Да и вообще, как я говорил ранее:
EP>По факту D Range нормально подходит только для SinglePass.
Здравствуйте, Ikemefula, Вы писали:
I>Поэтому вопрос не в том, будут ли на D переписывать плюсовый код, а в том будет ли в новых проектах использоваться D и, если будет, то для чего.
Я скорее уже сильно скептически отношусь к тому что D хоть как-то приблизится к мейнстриму.
Правда я пока, в отличии от хорошо известного тебе, Евгения полностью в нем не разочаровался, все-таки язык хороший.
EP>Boost.Range даёт многие преимущества D-style range, не внося их недостатки
Boost.Range да отличная вещь, избавляет от этих страшных .begin() .end(), но это только
обертка в основном, а если перестает быть оберткой вылезают те же проблемы.
FR>>Базовое различие все, включая и FR>>меня, совсем упустили, интервалы D в отличии от итераторов не работают по месту, FR>>а выдают новый интервал,
EP>Что значит не по месту? В смысле ленивость? Так эта ленивости доступна и Boost.Range, да и вообще в самих итераторах (а-ля transformed iterator)
То что большинство функций работающие с D'шными интервалами выдают новый интервал, а не меняют
старый, в отличии от C++ итераторов и Boost.Range. И сравнивать их производительность бессмысленно.
В Boost.Range да это тоже возможно, но реализация будет очень близка к реализации в D.
FR>>по сути ближе к базовым ФВП из функциональщины FR>>работающими со списками.
EP>Подробнее.
Близка неизменяемостью источника. Тот же BatEnum можешь посмотреть.
FR>>Даже boost::range в основной массе этого не делает FR>>а тоже работает по месту как и его базовые итераторы.
EP>Что значит работает по месту?
Меняет например контейнер из которого получен интервал а не выдает новый (или ленивый новый).
FR>>Намного проще, тоже кстати, реализация получается если в языке есть yield.
EP>yield действительно помогает генерировать ленивые последовательности. Но у него огромный минус — такие последовательности являются примитивным single pass'ом, который приводит к излишним копиям.
Угу и огромный плюс вытекающий из этого минуса легкая комбинируемость.
EP>Да и вообще, как я говорил ранее: EP>
EP>>По факту D Range нормально подходит только для SinglePass.
EP>для всего остального и неудобно и неэффективно.
Не согласен, но согласен с тем что реализация примитивов сильно усложняется.
Здравствуйте, FR, Вы писали:
FR>Так же как вернуть такой же диапазон для C++ input iterator, то есть никак и бессмысленно.
Почему это, для односвязного списка, например, о котором была речь, это бессмысленно?
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, FR, Вы писали:
EP>>Boost.Range даёт многие преимущества D-style range, не внося их недостатки FR>Boost.Range да отличная вещь, избавляет от этих страшных .begin() .end(), но это только FR>обертка в основном, а если перестает быть оберткой вылезают те же проблемы.
Так наоборот здорово. Когда нужно делать различные манипуляторы с итераторами — всегда есть такая возможность. Зачем себя в этом ограничивать?
FR>>>Базовое различие все, включая и FR>>>меня, совсем упустили, интервалы D в отличии от итераторов не работают по месту, FR>>>а выдают новый интервал, EP>>Что значит не по месту? В смысле ленивость? Так эта ленивости доступна и Boost.Range, да и вообще в самих итераторах (а-ля transformed iterator) FR>То что большинство функций работающие с D'шными интервалами выдают новый интервал, а не меняют FR>старый, в отличии от C++ итераторов и Boost.Range. И сравнивать их производительность бессмысленно. FR>В Boost.Range да это тоже возможно, но реализация будет очень близка к реализации в D.
Так Boost.Range не заставляет менять исходный интервал. Контейнер вообще может быть константным — и быть пропущенным через | transformed(...) | filtered(...) и т.п — всё также лениво
FR>>>Даже boost::range в основной массе этого не делает FR>>>а тоже работает по месту как и его базовые итераторы EP>>Что значит работает по месту? FR>Меняет например контейнер из которого получен интервал а не выдает новый (или ленивый новый).
transformed iterator не меняет контейнер из которого получен интервал
FR>>>Намного проще, тоже кстати, реализация получается если в языке есть yield.
EP>>yield действительно помогает генерировать ленивые последовательности. Но у него огромный минус — такие последовательности являются примитивным single pass'ом, который приводит к излишним копиям. FR>Угу и огромный плюс вытекающий из этого минуса легкая комбинируемость.
Вот выше показывали map/transformed — ты бы как его реализовал? Как range или через yield?
EP>>Да и вообще, как я говорил ранее: EP>>
EP>>>По факту D Range нормально подходит только для SinglePass.
EP>>для всего остального и неудобно и неэффективно. FR>Не согласен,
Выше были примеры — std::partition, std::find. Если мало — попробуй сделать аналог std::partition_point.
FR>но согласен с тем что реализация примитивов сильно усложняется.
Интересно получается — лёгкость реализации примитивов рекламировалась как одна из особенностей D-style range
Здравствуйте, Erop, Вы писали:
FR>>Так же как вернуть такой же диапазон для C++ input iterator, то есть никак и бессмысленно. E>Почему это, для односвязного списка, например, о котором была речь, это бессмысленно?
У односвязного списка — forward iterator. Я думаю ты его имел ввиду:
E>хорошо, и как, например, написать функцию, которая вернёт поддиапазон этого диапазона, от начала и до чего-нибудь, ну там элемента с таким-то значением, или, например, "первые пять"?..
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>А что не так? Нормальное обсуждение стандартной алгоритмической библиотеки одного языка — против библиотеки другого.
В зациклености на этом.
Это конечно намного проще чем скажем попытатся реализовать на C++ задачку от Влада
например.
EP>Такие библиотеки используются в 99% программ, и вполне заслуживают обсуждения в контексте сравнения языков как платформ в целом, а не просто language feature vs feature.
В этом контексте надо учитывать и то что D скажем старается хорошо поддерживать иммутабельность и
параллельность и именно это может быть одной из причин выбора менее эффективных чем итераторы
интервалов.
EP>Если ты согласен с тем что STL итераторы удобней, эффективней и мощнее D-style range — то можем прекратить обсуждение. Если есть какие-то аргументы против этого — то мне интересно будет их услышать.
STL итераторы жутко неудобны: нужно использовать пары везде,
даже там где бессмысленны одиночные, практически не комбинируются.
Опасны в использовании могут легко протухнуть, можно перепутать от разных контейнеров,
запросто уйти за пределы итерирования.
(Просвещать меня про отладочный режим, внимательное кодирование и boost.range не надо).
Да очень эффективны, так как работают по месту и часто являются тончайшей оберткой над указателем.
Что имеешь в виду под "мощнее" я не понял.
Где?
FR>но похоже людям интереснее обсуждение "итераторы от Степанова против интервалов FR>от Александреску", притом что оба реализуются при желании одинаково и на C++ и на D.
+1
Сам уровень обсуждаемых проблем просто "радует". Изученные языки явно влияют на людей.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, FR, Вы писали:
EP>>А что не так? Нормальное обсуждение стандартной алгоритмической библиотеки одного языка — против библиотеки другого. FR>В зациклености на этом.
Да это не зацикленность — это просто отдельная ветка.
FR>Это конечно намного проще чем скажем попытатся реализовать на C++ задачку от Влада
В С++ пока нет compile-time reflection, без этого пробежка по членам в той или иной степени потребует дублирования (которое можно спрятать макросами), или перехода от структур к чему-то более абстрактному типа boost::fusion::map.
Например с помощью чего-то типа BOOST_FUSION_DEFINE_STRUCT + boost::fusion::fold:
Никто не спорит с тем, что хорошо бы было иметь compile-time reflection
EP>>Такие библиотеки используются в 99% программ, и вполне заслуживают обсуждения в контексте сравнения языков как платформ в целом, а не просто language feature vs feature. FR>В этом контексте надо учитывать и то что D скажем старается хорошо поддерживать иммутабельность и FR>параллельность и именно это может быть одной из причин выбора менее эффективных чем итераторы FR>интервалов.
Нет. D-style range'и не добавляют ни параллельности, ни иммутабельности.
EP>>Если ты согласен с тем что STL итераторы удобней, эффективней и мощнее D-style range — то можем прекратить обсуждение. Если есть какие-то аргументы против этого — то мне интересно будет их услышать. FR>STL итераторы жутко неудобны: нужно использовать пары везде, FR>даже там где бессмысленны одиночные, практически не комбинируются. FR>Опасны в использовании могут легко протухнуть, можно перепутать от разных контейнеров, FR>запросто уйти за пределы итерирования. FR>(Просвещать меня про отладочный режим, внимательное кодирование и boost.range не надо).
Почему не надо? Итераторы не запрещают удобных обёрток, Boost.Range тому пример (+ такие range будут в будущем стандарте).
А вот из D-style range — итераторов уже не вытащить
FR>Да очень эффективны, так как работают по месту и часто являются тончайшей оберткой над указателем.
Дело не только в этом — range также может быть обвёрткой над двумя указателями. Но смотри к чему это привело в partition.
FR>Что имеешь в виду под "мощнее" я не понял.
Выше был пример find — даже реализация базовых возможностей не была продемонстрирована на D, не говоря уж об [prev(find(first, last)), last)
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>В С++ пока нет compile-time reflection,
Ага. Это "пока" наблюдается самую малость — на протяжении 30 лет.
EP>без этого пробежка по членам в той или иной степени потребует дублирования (которое можно спрятать макросами), или перехода от структур к чему-то более абстрактному типа boost::fusion::map. EP>Например с помощью чего-то типа BOOST_FUSION_DEFINE_STRUCT + boost::fusion::fold:
"Например" не катит. Давай или признаем, что в области метапрограммирования С++ существенно уступает D, или вы продемонстрируете аналог генерации функции GetHashCode и мы сравним код.
EP>Нет. D-style range'и не добавляют ни параллельности, ни иммутабельности.
Они банально удобно для функционального программирования, которое в D, так же поддерживается значительно лучше чем в С++ (без костылей в библиотеках).
Что там у вас с интелисенсом при использовании приведенного тобой примера с "пайпами"?
И вообще, как на счет интелисенса? Почему за 30 лет не создано ни одного вменяемого тула?
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
например.
EP>В С++ пока нет compile-time reflection, без этого пробежка по членам в той или иной степени потребует дублирования (которое можно спрятать макросами), или перехода от структур к чему-то более абстрактному типа boost::fusion::map. EP>Например с помощью чего-то типа BOOST_FUSION_DEFINE_STRUCT + boost::fusion::fold: EP>
Никто не спорит с тем, что хорошо бы было иметь compile-time reflection
Угу "красота" просто
compile-time reflection да хорошо, но мало, без миксинов и static if тоже будет сложно, близко по
выразительности не повторить.
EP>Нет. D-style range'и не добавляют ни параллельности, ни иммутабельности.
Потенциально добавляют, плюс возможность работать в compile time.
EP>Почему не надо? Итераторы не запрещают удобных обёрток, Boost.Range тому пример (+ такие range будут в будущем стандарте). EP>А вот из D-style range — итераторов уже не вытащить
Потому что зациклимся.
FR>>Что имеешь в виду под "мощнее" я не понял.
EP>Выше был пример find — даже реализация базовых возможностей не была продемонстрирована на D, не говоря уж об [prev(find(first, last)), last)
Это не мощнее, это значит только то что примитивы реализовать легче. Но это проблемы разработчика библиотеки
(Александреску кстати очень любит проблемы ), для прикладного программиста это не имеет никакого значения
для него важнее легкость использования и возможность комбинирования, а в этом интервалы гораздо "мощнее".
Здравствуйте, alex_public, Вы писали:
_> Более того, если мы используем контейнеры из STL, то знать итераторы крайне рекомендуется (а до появление range for вообще строго обязательно).
В большинстве случаев контейнеры можно использовать без итераторов.
_>В случае же D ситуация совсем другая. Тут у нас в сам язык встроены аналоги (ну с некоторыми хитрыми поправками на не эксклюзивное владение памятью) array, vector и map. И естественно что никакие range (которые являются всего лишь одним из библиотечных модулей) для доступа к ним не требуются. Более того, массивы поддерживают срезы, которые опять же являются частью языка, т.к. по сути являются теми же самыми массивами.
Вообще-то при работе из STL используются не только контейнеры, но и алгоритмы, причём алгоритмы намного разнообразней.
И в том же std.algorithm в D — там всё на range'ах, так что от них никуда не уйти.
_>А основной тон для работы с массивами в D задают скорее срезы. Например вот классический пример двоичного поиска из учебника D: _>[...]
Это не интересно — практически идентично переносится на C++:
BinarySearch(input[0..i], value);
// versus
BinarySearch(input | sliced(0,i), value);
А вот попробуй сделать аналог std::partition_point
EP>>До определённой степени STL можно реализовать, например, на C#-е (разумеется с overhead'ом, но речь не о нём). Но вот как наши C#-коллеги не пытались найти аналог std::deque, дальше попыток продать двусвязный список или дерево под видом деки дело не пошло _>Хы, а в стандартной библиотеке D с этим вообще всё печально. Я там видел вроде только пару списков, дерево и кучу. Хотя естественно есть все нужные реализации в сторонних источниках (например http://www.dsource.org/projects/dcollections ).
Так в том то и дело, что они не то что стандартную — они вообще никакую деку не нашли.
Здравствуйте, VladD2, Вы писали:
EP>>В С++ пока нет compile-time reflection, VD>Ага. Это "пока" наблюдается самую малость — на протяжении 30 лет.
В смысле? Study group для reflection появилась недавно.
Или ты думаешь что создатели уже 30 лет думают как бы впихнуть reflection, да всё никак не получается?
VD>"Например" не катит. Давай или признаем, что в области метапрограммирования С++ существенно уступает D,
VD>>Что до метапограммирования, то очевидно, что на D мета-код выглядит проще, работает существенно быстрее и выдает внятную диагностику.
EP>Вот тут я как раз и не спорю — на данном этапе у него больше возможностей для метапограммирования.
EP>Что, кстати, немного странно: казалась бы, в языке с лучшей поддержкой compile-time вычислений, compile-time dispatch, метапограммирования — должна быть супер эффективная, гибкая, стандартная библиотека — так ведь нет, STL явно выигрывает
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Вообще-то при работе из STL используются не только контейнеры, но и алгоритмы, причём алгоритмы намного разнообразней. EP>И в том же std.algorithm в D — там всё на range'ах, так что от них никуда не уйти.
Массивы эти алгоритмы (кроме редких исключений) сохраняют масcивами:
Здравствуйте, FR, Вы писали:
FR>Я скорее уже сильно скептически отношусь к тому что D хоть как-то приблизится к мейнстриму. FR>Правда я пока, в отличии от хорошо известного тебе, Евгения полностью в нем не разочаровался, все-таки язык хороший.
Я на самом деле на D смотрю с большой надеждой. Если он выстрелит нормально в фейсбуке, это будет очень большое событие
Здравствуйте, FR, Вы писали:
EP>>Вообще-то при работе из STL используются не только контейнеры, но и алгоритмы, причём алгоритмы намного разнообразней. EP>>И в том же std.algorithm в D — там всё на range'ах, так что от них никуда не уйти. FR>Массивы эти алгоритмы (кроме редких исключений) сохраняют масcивами:
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>>>Вообще-то при работе из STL используются не только контейнеры, но и алгоритмы, причём алгоритмы намного разнообразней. EP>>>И в том же std.algorithm в D — там всё на range'ах, так что от них никуда не уйти. FR>>Массивы эти алгоритмы (кроме редких исключений) сохраняют масcивами:
EP>Ты используешь только алгоритмы для массивов?
Так ты же и завел речь про алгоритмы
Я показал что их без проблем и оверхеда можно использовать с массивами.
Здравствуйте, FR, Вы писали:
EP>>>>Вообще-то при работе из STL используются не только контейнеры, но и алгоритмы, причём алгоритмы намного разнообразней. EP>>>>И в том же std.algorithm в D — там всё на range'ах, так что от них никуда не уйти. FR>>>Массивы эти алгоритмы (кроме редких исключений) сохраняют масcивами: EP>>Ты используешь только алгоритмы для массивов? FR>Так ты же и завел речь про алгоритмы
Где я ограничивал разговор алгоритмами для массивов?
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Где я ограничивал разговор алгоритмами для массивов?
alex_public выразил мысль что в D можно прекрасно обойтись без интервалов, заменив их массивами
и срезами, ты сказал что нельзя так как будет невозможно пользоваться std.algorithm я показал
что это не так, можно вполне свободно использовать и не использовать при этом интервалы.
Тем более range в D (как и итераторы в C++) чистая абстракция все что удовлетворяет сигнатуре
можно использовать как range.
Здравствуйте, FR, Вы писали:
FR>Угу "красота" просто FR>compile-time reflection да хорошо, но мало, без миксинов и static if тоже будет сложно, близко по FR>выразительности не повторить.
static if-ы — баловство. Мета-код не должен отличаться от обычного.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, FR, Вы писали:
EP>>Где я ограничивал разговор алгоритмами для массивов? FR>alex_public выразил мысль что в D можно прекрасно обойтись без интервалов, заменив их массивами FR>и срезами, ты сказал что нельзя так как будет невозможно пользоваться std.algorithm я показал FR>что это не так, можно вполне свободно использовать и не использовать при этом интервалы.
alex_public сказал, что для работы с контейнерами STL крайне рекомендуется знать итераторы — а в D можно обойтись без интервалов, на что я ответил:
EP>Вообще-то при работе из STL используются не только контейнеры, но и алгоритмы, причём алгоритмы намного разнообразней.
EP>И в том же std.algorithm в D — там всё на range'ах, так что от них никуда не уйти.
Здравствуйте, VladD2, Вы писали:
VD>static if-ы — баловство. Мета-код не должен отличаться от обычного.
Так это и не отличие а точка перехода из обычного в статический
Конечно перегрузкой шаблонов местами и красивей и декларативней выходит
(особенно с будущими концептами), но писать со static if гораздо проще.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>alex_public сказал, что для работы с контейнерами STL крайне рекомендуется знать итераторы — а в D можно обойтись без интервалов, на что я ответил: EP>
EP>>Вообще-то при работе из STL используются не только контейнеры, но и алгоритмы, причём алгоритмы намного разнообразней.
EP>>И в том же std.algorithm в D — там всё на range'ах, так что от них никуда не уйти.
Так я и показал что можно использовать std.algorithm и даже не подозревать что там есть какие-то range.
Здравствуйте, jazzer, Вы писали:
J>Для новых проектов на новых языках нужны новые программисты.
То есть ты не осилишь D?
J>А такое счастье никому не нужно. Чтоб вложиться в это, выгоды от нового языка должны быть очень большими.
А они есть. Скорость копиляции, лучший интелисенс, качественное метапрограммирование, более высокоуровневый код. Это довольно много. Хотя у D тут есть не мало конкурентов. Но D, в отличии от них, старается предоставлять близкие к С++ показатели в области быстродействия получаемого кода.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
VD>А 29 лет в нем вообще не было бямбд. Хотя лямбды старше С++ еще на 30 лет.
Ты считаешь что в язык нужно тащить каждую фичу?
EP>>Чисто как язык — возможно. Но помимо языка нужна платформа — библиотеки, компиляторы, с которыми, afaik, пока не густо. VD>Библиотеки дело наживное.
Естественно. Можно прям сегодня придумать супер-пупер язык, и сказать что библиотеки, компиляторы, и т.п. — всё наживное, и возмущаться — почему же никто не переходит на этот супер-пупер язык
VD>Если бы люди вроде тебя вместо того чтобы искать фатальные достатки просто попробовали что-нить написать на Ди, то и библиотеки появились бы.
А, ну то есть программисты во всём виноваты — не пишут библиотеки для языка который непонятно взлетит или нет, непонятно с каким runtime overhead'ом (см. выше интервью с автором). Да как они посмели!
VD>Что касается ренджей, то они, скорее всего, и так достаточно быстрые и никому не нужно искать им замену.
Помимо скорости, они ещё и менее удобные, и менее мощные.
VD>Заметь в Nemerle if самый обыкновенный. static if не нужен, а кодом можно манипулировать как данными.
В D можно манипулировать кодом как строкой — см. mixin.
Здравствуйте, FR, Вы писали:
FR>Так я и показал что можно использовать std.algorithm и даже не подозревать что там есть какие-то range.
1. Массивы это не единственные используемые структуры данных. Если бы всё ограничивалось обычными массивами то не зачем было бы возится с STL, D Rane, etc.
2. Помимо непосредственно использования готовых алгоритмов, часто пишут свои.
Здравствуйте, FR, Вы писали:
FR>Так это и не отличие а точка перехода из обычного в статический FR>Конечно перегрузкой шаблонов местами и красивей и декларативней выходит FR>(особенно с будущими концептами), но писать со static if гораздо проще.
А зачем вообще смешивать мета-код с обычным? Чтобы крыша ехала надежнее?
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, D. Mon, Вы писали:
DM>В D как раз вполне себе можно использовать тот же язык как в обычном коде, так и в МП (в компайл-тайме).
Если бы это было так, то static if был бы не нужен.
DM>
DM> auto runTimeValue = getNums(argv[1].to!int); //вызываем ее в рантайме
DM> enum compileTimeValue = getNums(100); //вызываем ее же в компайл-тайме
DM>}
DM>
это частный случай.
DM>Причем обычный код и МП можно писать прямо рядом и вперемежку, нет разделения на стадии, как в более примитивных подходах.
Смешивание метакода и обычного кода — это недостаток. В "более примитивных" подходах МП используется чуть менее чем везде, в отличии от ...
DM>И чтобы можно было при такой записи вперемежку выбирать между рантаймом и компайлтаймом, есть ...
костыли.
Про невозможность менять синтаксис я уже молчу.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, FR, Вы писали:
EP>>Не хватает встроенной в стандарт compile-time reflection — тогда от макроса можно было бы уйти. FR>Угу, притом как Влад уже говорил очень давно не хватает
Если кто-то постоянно тем и занимается что итетрирует структуры данных, и ему не хватает текущих возможностей — то пусть отсылает proposal в reflection study group #7, его обязательно рассмотрят.
EP>>В С++ не принято добавлять члены в класс на каждый чих, наоборот — non-member предпочтительнее. FR>Конечно, но задача не решена.
В разных языках разные подходы. Non-member функция hash_value — это стандартный протокол в C++. И я не вижу никакого смысла использовать функцию член, когда допустим хэш-таблица ожидает non-member, только ради какой-то синтетической задачи.
[MacroUsage(MacroPhase.WithTypedMembers, MacroTargets.Class)]
macro ImplementGetHeshCode(typeBuilder : TypeBuilder)
{
def fields = typeBuilder.GetFields(BindingFlags.Public | BindingFlags.NonPublic | BindingFlags.Instance);
def make(field)
{
if (field.GetMemType().Equals(<[ ttype: int ]>))
<[ result ^= this.$(field.Name : usesite) ]>
else
<[ result ^= this.$(field.Name : usesite).GetHashCode(); ]>
}
typeBuilder.Define(<[ decl:
public override GetHashCode() : int
{
mutable result = 0;
..$(fields.Map(make));
result
}
]>);
}
versus
mixin template ImplementGetSheeshCode() {
size_t GetSheeshCode()
{
alias T = typeof(this);
size_t h = 123;
foreach(m; __traits(allMembers, T))
static if (m!="Monitor") {
static if (isIntegral!(typeof(__traits(getMember, T, m))))
h ^= __traits(getMember, T, m);
else static if (__traits(hasMember, typeof(__traits(getMember, T, m)), "toHash"))
h ^= __traits(getMember, T, m).toHash;
}
return h;
}
}
Разве не очевидно какой код второй по счёту пахнет резче остальных?
VD>В твоем решении даже нет: VD>1) проверки для int;
Вообще-то boost::hash_combine вызывает нужную hash_value
VD>2) формирования метода.
Так а зачем мне метод, если спокойно реализуется внешней функцией, и более того — является стандартным интерфейсом.
EP>>И внезапно, полный код выглядит на порядок чище чем в D и Nemerle
Твоя телепатия не работает.
VD>Очень советую изучить тот же D и Nemerle, тогда ты подобные заблуждения высказывать не будешь.
D — возможно, Nemerle — нет уж, спасибо
VD>Код по ссылке решает исходную задачу, а не подогнанную и упрощенную. И он таки проще, чем твой. Только надо иметь базовые знания для его понимания.
ога, "код становится простым, после изучения малоиспользуемого языка"
EP>>>>Нет. D-style range'и не добавляют ни параллельности, ни иммутабельности. VD>>>Они банально удобно для функционального программирования, EP>>Чем они удобней? VD>Да всем. Ты попробуй реальный код пописать, и сам поймешь.
Практически все преимущества range-only решения, доступны для решения итераторы+обвёртки.
VD>Ренжи — это аналоги ленивых списков из ФА или IEnumerable из дотнета.
Это ты сильно льстишь IEnumerable — D-Range намного мощнее
VD>Ленивые списки в купе с правильной библиотекой вроде linq-а повышают уровень кода в разы.
Эта ленивость доступна и для STL итераторов, причём без бешеной abstraction penalty
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>У односвязного списка — forward iterator. Я думаю ты его имел ввиду:
Я даже больше имел в виду, у этого нового подинтервала будет, похоже, другой тип. Ну или я чего-то не понял.
при этом если у нас где-то будет ветвление, ну, например вернуть элементы списка от начала до конца строки, но не больше 100 штук, как написать, я уже вообще не понимаю даже...
То есть, или концепция какая-то совсем кривая, или я не понимаю чего-то самого главного...
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, FR, Вы писали:
EP>>Нет. D-style range'и не добавляют ни параллельности, ни иммутабельности. FR>Потенциально добавляют,
Что именно они добавляют, чего нет в решении типа обёрток над парой итераторов?
FR>плюс возможность работать в compile time.
Я думаю это ортогонально нашей дискуссии. И по-идее итераторы точно также можно использовать в compile time.
FR>>>Что имеешь в виду под "мощнее" я не понял. EP>>Выше был пример find — даже реализация базовых возможностей не была продемонстрирована на D, не говоря уж об [prev(find(first, last)), last) FR>Это не мощнее, это значит только то что примитивы реализовать легче. Но это проблемы разработчика библиотеки FR>(Александреску кстати очень любит проблемы ),
Если программист не делает что-то совсем примитивное типа переливания из одного места в другое (для чего, кстати, часто подходят вообще динамические языки) — то ему рано или поздно понадобятся свои алгоритмы.
FR>для прикладного программиста это не имеет никакого значения FR>для него важнее легкость использования и возможность комбинирования, а в этом интервалы гораздо "мощнее".
Эта лёгкость комбинирования доступна и решению с итераторами, а не только в range-only.
Мне же интересно сравнение iterator+range vs range-only.
Здравствуйте, VladD2, Вы писали:
EP>>А где тут кто-то говорил про невероятную крутизну C++? VD>А разве не ты бросился отстаивать его превосходство над тем же D?
1.
EP>У каждого языка есть свои цели, свои design guidelines. Язык это не просто набор фич.
EP>Как известно, у C++ основным приоритетом является производительность.
EP>А в D спокойно могут пожертвовать производительностью ради других целей (об этом говорил A.A.).
2.
EP>Взять например те же ranges — они проигрывают итераторам по производительности by-design
И ровно в этих рамках я и пытаюсь остаться. Обсуждать метапрограммирование не особо интересно — так как все согласны что оно мощнее у D.
Где ты тут видишь "бросился отстаивать его превосходство над тем же D".
EP>>Я вот не пойму — откуда у программистов не пишущих на C++ к нему такая злость/зависть/etc? VD>Лично у меня злобы нет.
Да ладно:
1. Ты говоришь что я "бросился отстаивать его превосходство над тем же D".
2. Считаешь что программисты которые используют C++ — знают только один язык.
3. Говоришь что кто-то тут выдвигает тезис "С++ лучше"
4. Игнорируешь то, что тут все согласны что в D метапрограммирование лучше, и пытаешься поджечь холивар на эту тему.
и т.п.
Если это не от злобы, то от чего?
VD>Тут скорее есть некоторая злость на таких как вы, защищающих черт знает что не пробовав альтернатив. VD>У новых языков (D, Scala, F#, Nemerle, Kotlin, Haskel, ...) есть только одна проблема — размеры комьюнити. Куча народа, вроде вас, ходит и что-то там себе доказывает вместо того чтобы взять и начать помогать развивать перспективные языки.
Страуструп уже более 30 лет развивает язык, несмотря на его "неидеальность" — улучшает и улучшает.
Мог бы он бросить всё и создать "перспективный, динамично развивающийся и т.п."? — да конечно мог бы. Он мог бы делать также как и Вирт — сколько там у него языков было? — вот только где сейчас все эти перспективные и развивающийся?
VD>Ну, глупо в 21-м веке использовать языки в которых:
Глупо — это ждать того, что программисты внезапно бросят всё и присоединятся к комьюнити малоиспользуемого языка.
Глупо ждать того, что индустрия резко станет оказывать гуманитарную помощь "перспективным языкам".
VD>1. Не поддерживается модульность, а вместо нее есть препроцессор с инклюдами.
Это действительно проблема. Ведётся работа.
VD>2. 30 лет не могут создать полноценный интелисенс.
Ничего критичного.
VD>3. Скорость компиляции больших проектов чудовищно низкая.
Проблема есть, но не в "чудовищных" масштабах.
VD>4. Система метапрограммирования основана на побочных эффектах от других средств, а не разработа специально.
А кто сказал что нужна какая-то специально разработанная мета-система? Метапрограммирование — это практически хак, который приходит на помощь там где недостаточно мощи самого языка.
В большинстве кода нет ничего мета*, только потому, что и без него всё хорошо
VD>5. Нет бинарного ABI.
Действительно есть такая проблема, но совсем острая.
Если ограничится одной платформой, как делают некоторые языки, например .NET-ом, а-ля C++CLI/CX — то ABI получается что есть
VD>6. Нет даже соглашений по формированию имен функций в библиотеках.
Мелочь, причём спорная.
VD>7. Требуются предварительные декларации.
Мелочь.
VD>8. Нет даже опциональной системы автоматического управления памятью.
В ISO C++11 есть интерфейс для GC — но он вообще не популярен, что скорее говорит об востребованности
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Вообще-то при работе из STL используются не только контейнеры, но и алгоритмы, причём алгоритмы намного разнообразней. EP>И в том же std.algorithm в D — там всё на range'ах, так что от них никуда не уйти.
Не, алгоритмы в D едят и просто массивы. И выдают их же при этом. Кстати, надо будет посмотреть как там в этом смысле с другими коллекциями, которые не встроенные — вдруг их тоже едят напрямую, без Range.
EP>Это не интересно — практически идентично переносится на C++: EP>
EP>BinarySearch(input[0..i], value);
EP>// versus
EP>BinarySearch(input | sliced(0,i), value);
EP>
Не, это не то. Ты же при этом заменил входные параметры функции с массивов на range. Вот если бы у range можно было вызывать функции массива (хотя в данном конкретном примере это и не пригодилось)...
EP>А вот попробуй сделать аналог std::partition_point
А что там такого? Ну будет например функция с прототипом вида Tuple!(T[], T[]) partition_point(T[], ...)
EP>Так в том то и дело, что они не то что стандартную — они вообще никакую деку не нашли.
Кстати, мне кто-то писал фразу что типа C# — это типа самый продвинутый язык из мейнстримовых. Я в ответ спросил как у нас с метапрограммированием в самом продвинутом языке. Мне в ответ гордо назвали T4 и Reflection.Emit, на что я предложил написать например Boost.Spirit на этом... А сейчас я представил себе как этот народ отреагировал бы на примеры, которые способен решать D.
Здравствуйте, alex_public, Вы писали:
EP>>Вообще-то при работе из STL используются не только контейнеры, но и алгоритмы, причём алгоритмы намного разнообразней. EP>>И в том же std.algorithm в D — там всё на range'ах, так что от них никуда не уйти. _>Не, алгоритмы в D едят и просто массивы. И выдают их же при этом.
Ну так не одни же массивы используются.
EP>>Это не интересно — практически идентично переносится на C++: EP>>
EP>>BinarySearch(input[0..i], value);
EP>>// versus
EP>>BinarySearch(input | sliced(0,i), value);
EP>>
_>Не, это не то. Ты же при этом заменил входные параметры функции с массивов на range.
Всё то — в C++ вот такой массив int x[11] — тоже range.
_>Вот если бы у range можно было вызывать функции массива (хотя в данном конкретном примере это и не пригодилось)...
Какие?
EP>>А вот попробуй сделать аналог std::partition_point _>А что там такого? Ну будет например функция с прототипом вида Tuple!(T[], T[]) partition_point(T[], ...)
Только массивы вообще не интересны. std::partition_point работает даже с Forward итераторами. Попробуй сделать интерфейс, и хотя бы набросай реализацию (мелкие баги не имеют значения).
EP>>Так в том то и дело, что они не то что стандартную — они вообще никакую деку не нашли. _>Кстати, мне кто-то писал фразу что типа C# — это типа самый продвинутый язык из мейнстримовых. Я в ответ спросил как у нас с метапрограммированием в самом продвинутом языке. Мне в ответ гордо назвали T4 и Reflection.Emit, на что я предложил написать например Boost.Spirit на этом... А сейчас я представил себе как этот народ отреагировал бы на примеры, которые способен решать D.
Я предполагаю что Spirit-like там возможен двумя путями: через разбор встроенных в язык Expression Trees, либо через перегрузку операторов. Но видимо и там и там будет runtime overhead.
Здравствуйте, alex_public, Вы писали:
EP>>Если кто-то постоянно тем и занимается что итетрирует структуры данных, и ему не хватает текущих возможностей — то пусть отсылает proposal в reflection study group #7, его обязательно рассмотрят. _>Вот как раз интроспекции времени компиляции (а не того ненужного недоразумения времени выполнения, как в жабке и шарпе) крайне не хватает в C++. Например для сереализации.
Не хватает, но это не так критично как тут пытаются представить "omg нет reflection! все на D, Nemerle и т.п."
_>Кстати, а RTTI я бы вообще из C++ выкинул — от него вред только один, т.к. не вписывается он до конца в концепцию C++ нулевых накладных расходов.
А какие накладные расходы он по-твоему добавляет?
_>У нас тут сейчас один тестовый проект на D и некоторыми моментами реально можно наслаждаться именно из-за интроспекции. Т.е. код вида: _>[...] _>реально радует (Json естественно ничего не знает про User и вообще не нами написан). Причём т.к. это всё во время компиляции конструируется, оно ещё и очень быстрое.
Это всё понятно, и действительно круто. Но сейчас — отчасти решается макросами, либо с небольшим дублированием в виде описания схемы в одном из форматов(Boost.Fusion, или например Boost.Serialization).
Более того — у меня в одном из проектов есть большая схема, так она вообще в xml хранится, и код из неё нормально генерируется, и не программисты могут с ней работать + всякие xml утилиты, и как-то не комплексуем по поводу "ай-ай-ай, нет reflection, надо менять язык!".
_>А в метапрограммирование я могу очень просто объяснить любому специалисту по C++ преимущества D.
Да многие тут знают эти преимущества.
_>Для этого я могу предложить им представить себе, чтобы они могли сделать в C++ при двух простейших дополнениях: _>1. Если бы в C++ можно было параметризовать шаблоны строками
В C++11 можно (гугли "Using strings in C++ template metaprograms", + должно уже быть в библиотеках)
_>2. Если бы была функция, которая преобразовывает строку в код, размещаемый (причём с использованием локальных переменных, оптимизации и т.п.) по месту вызова этой функции.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>>>_1 это библиотечная полиморфная лямбда, VD>>Давай поглядим на ее реализацию. Приведи, плиз.
EP>уже было выше
Дык там нигде реализации не приводилось. А она явно весьма объемная.
VD>>А 29 лет в нем вообще не было бямбд. Хотя лямбды старше С++ еще на 30 лет.
EP>Ты считаешь что в язык нужно тащить каждую фичу?
В хороший язык тащат только базовые вещи вроде полноценной поддержки метапрограммирования и средств расширения синтаксиса. Но С++ к этому классу языков отношения не имеет. По тому я последние 7 лет с удовольствием использую Nemerle вместо C++. С огромным удовольствием, надо заметить!
VD>>Библиотеки дело наживное.
EP>Естественно. Можно прям сегодня придумать супер-пупер язык, и сказать что библиотеки, компиляторы, и т.п. — всё наживное, и возмущаться — почему же никто не переходит на этот супер-пупер язык
Это демагогия. Компилятор, как ползователь, ты сделать не можешь. А библиотеки — без проблем. Тот же STL написал рядовой пользователь С++ работавший в HP.
VD>>Если бы люди вроде тебя вместо того чтобы искать фатальные достатки просто попробовали что-нить написать на Ди, то и библиотеки появились бы.
EP>А, ну то есть программисты во всём виноваты
Нет, часовинку это до вас — в 17 веке (с)
А так кто еще кроме нас виноват в том, что у нас чего-то нет? Если ждать дядю, то так и будешь чем попало пользоваться.
EP> — не пишут библиотеки для языка который непонятно взлетит или нет,
D появился в 1999 году, то есть ему лет немногим менее чем тебе, а ты все сомневаешься взлетит он или нет. Если он не взлетел, то у него комитов в репозитории не было бы.
EP> непонятно с каким runtime overhead'ом (см. выше интервью с автором). Да как они посмели!
И не поймешь, пока не попробуешь. Вот те кто пробовал говорят, что сравнимо с С. А остальные сомневаются и сомневаются.
Я вот использую язык рантаймом для которого является дотнет. Не самый производительный рантайм, да? Сборка мусора с сопутствующими мемори-барьерами и прочими велелостями. Но вот код в нашем современном проекте работат очень даже шутсро. Знаешь почему? Да потому что почти любой рантайм может быть вполне быстрым, если не пользоваться тем что вызывает тормоза.
Мы сейчас делаем генератор парсеров. Он вместо объектоного АСТ создает массив int-ов (точнее парочку). А код выглядит как-то так:
Ты на С++ такой писать не будешь, так как это жутко грязный низкоуровневый код.
А мы вот себе это позволить можем, хотя в отличии от вас у нас есть и GC, и полноценные замыкания (изменяемые и живущие любое время), и даже алгебраические типы с паттернматчингом. И можем мы это себе позволить потому что генерация кода в нашем языке — это шатная фича которая не ломает мозг и не нагибает компилятор.
VD>>Что касается ренджей, то они, скорее всего, и так достаточно быстрые и никому не нужно искать им замену.
EP>Помимо скорости, они ещё и менее удобные, и менее мощные.
Это в тебе Блаб говрит. Ты просто не умеешь их готовить. Точнее ты настолько уткнулся в детали реализации, что не можешь оторваться от них и посмотреть на то что они дают. Вот к примеру, что можно сделать на прототипе ренджей (энумераблах шарпа).
Вот этот код грузит объекты по описанию хмл-конфиге:
var root = XElement.Load(gonfigPath);
var libs = root.Elements("Lib").ToList();
var result =
libs.Select(lib => Utils.LoadAssembly(Path.GetFullPath(Path.Combine(rootPath, lib.Attribute("Path").Value)))
.Join(lib.Elements("SyntaxModule"),
m => m.FullName,
m => m.Attribute("Name").Value,
(m, info) => new { Module = m, StartRule = GetStratRule(info.Attribute("StartRule"), m) }));
А этот:
var libs = syntaxModules.GroupBy(m => MakeRelativePath(from:root, isFromDir:true, to:m.GetType().Assembly.Location, isToDir:false))
.Select(asm =>
new XElement("Lib",
new XAttribute("Path", asm.Key),
asm.Select(mod =>
new XElement("SyntaxModule",
new XAttribute("Name", mod.FullName),
mod.Rules.Contains(startRule) ? new XAttribute("StartRule", startRule.Name) : null))
));
return new XElement("Config", libs);
сериализует объекты обратно в конфиг.
Медленно ли работает этот код? В ГУЕ, где он применяется, времени его работы не видно в микроскоп. А вот времени он сэкномил массу.
И не надо мне рассказывать, что подобную лабуду ты сможешь написать и на С++. По целому ряду причин ФП неудобен в С++. Потому так пишут редко. Те же проблемы с интелисенсом не дают быстро написать такой "запрос".
VD>>Заметь в Nemerle if самый обыкновенный. static if не нужен, а кодом можно манипулировать как данными.
EP>В D можно манипулировать кодом как строкой — см. mixin.
Надеюсь человеку знакомому с прероцессором С не надо объяснять чем чреваты манипуляции строками? Да и выглядит это убого. В этом отношении у Ди серьезные проблемы.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
VD>Дык там нигде реализации не приводилось. А она явно весьма объемная.
Смотри внимательней, там под cut'ом.
VD>>>А 29 лет в нем вообще не было бямбд. Хотя лямбды старше С++ еще на 30 лет. EP>>Ты считаешь что в язык нужно тащить каждую фичу? VD>В хороший язык тащат только базовые вещи вроде полноценной поддержки метапрограммирования и средств расширения синтаксиса.
Хороший для чего?
VD>Но С++ к этому классу языков отношения не имеет. По тому я последние 7 лет с удовольствием использую Nemerle вместо C++. С огромным удовольствием, надо заметить!
Да я вижу — и тихо ненавидишь всех кто его не расширяет/не использует. Нет уж, спасибо.
VD>А библиотеки — без проблем. Тот же STL написал рядовой пользователь С++ работавший в HP.
Тут как раз уж и не рядовой. Он эти идеи вынашивал много лет, и до этого делал реализации на разных языках (Scheme, Ada, etc)
VD>Если он не взлетел, то у него комитов в репозитории не было бы.
Да уж — вот это взлёт.
VD>Мы сейчас делаем генератор парсеров. Он вместо объектоного АСТ создает массив int-ов (точнее парочку). А код выглядит как-то так: VD>
VD>
VD>Ты на С++ такой писать не будешь, так как это жутко грязный низкоуровневый код.
Там где не хватит скорости Spirit'а или подобного — я спокойно могу взять внешний генератор кода
Если приспичит, внешний генератор даже может подключатся к expression tree из кода — прям брать неопределённый символ с закодированной грамматикой из obj, и генерировать нужный код — но это только если делать нечего.
VD>А мы вот себе это позволить можем, хотя в отличии от вас у нас есть и GC, и полноценные замыкания (изменяемые и живущие любое время)
Что значит живущие любое время? А если там ресурс?
VD>>>Что касается ренджей, то они, скорее всего, и так достаточно быстрые и никому не нужно искать им замену. EP>>Помимо скорости, они ещё и менее удобные, и менее мощные. VD>Это в тебе Блаб говрит.
VD>Ты просто не умеешь их готовить. Точнее ты настолько уткнулся в детали реализации, что не можешь оторваться от них и посмотреть на то что они дают. Вот к примеру, что можно сделать на прототипе ренджей (энумераблах шарпа).
Да не надо сравнивать "энумераблы шарпа" с D-Range — они им и в подмётки не годятся
"энумерабл" это single pass — а в D далеко не одна категория Range, также как в STL
VD>>>Заметь в Nemerle if самый обыкновенный. static if не нужен, а кодом можно манипулировать как данными. EP>>В D можно манипулировать кодом как строкой — см. mixin. VD>Надеюсь человеку знакомому с прероцессором С не надо объяснять чем чреваты манипуляции строками? Да и выглядит это убого. В этом отношении у Ди серьезные проблемы.
Ну вроде бы всё ясно. "D хорош, но у него серьёзные проблемы — нужен Nemerle"
А вообще — если ты пытался разрекламировать Nemerle — то получилось всё как раз наоборот.
EP> if (field.GetMemType().Equals(<[ ttype: int ]>))
EP> <[ result ^= this.$(field.Name : usesite) ]>
EP> else
EP> <[ result ^= this.$(field.Name : usesite).GetHashCode(); ]>
он генерирует разный код для разных типов полей. Где хотя бы это в твоем решении?
А где возможность добавить к произвольному классу атрибут (или что-то похожее) чтобы получить в нем метод?
Я не просил реализовывать операторы () и внешние функции.
EP>Разве не очевидно какой код второй по счёту пахнет резче остальных?
Очевидно, что ты решил другую, намного более простую, для тебя задачу. Очевидно, что это мошенничество. А оно меня не интересует.
Если бы в плюсах были средства подобные тем что есть в D и Nemerle, то я бы вряд ли бросил плюсы.
VD>>В твоем решении даже нет: VD>>1) проверки для int;
EP>Вообще-то boost::hash_combine вызывает нужную hash_value
Я наверно очень отстал от прогресса в С++. Покажи мне как это приводит к генерации разного кода для int-а, и других объектов.
Если что-то реализовано еще где-то, то надо было это привести. А то я тебе тоже могу библиотечный макрос привести и сказать, что у меня тут все очень кратко.
Интересные же возможности языка, а не библиотека которую уже кто-то написал.
VD>>2) формирования метода.
EP>Так а зачем мне метод, если спокойно реализуется внешней функцией, и более того — является стандартным интерфейсом.
Затем, что в задаче было такое условие.
EP>>>И внезапно, полный код выглядит на порядок чище чем в D и Nemerle
VD>>Это потому что ты знаешь ровно один язык.
EP>Твоя телепатия не работает.
Тут не нужно телепатии. Танцы с бубном ты называешь "порядок чище", а прямое создание нужного кода — чем-то грязным, очевидно.
VD>>Очень советую изучить тот же D и Nemerle, тогда ты подобные заблуждения высказывать не будешь.
EP>D — возможно, Nemerle — нет уж, спасибо
Ну, в принципе — да. Начинать надо с более легких задач. Потом может и до Немерла дорастешь. А то паттерн-матчинг и прочие алгебраические типы данных частенько плохо принимаются без должной подготовки.
VD>>Код по ссылке решает исходную задачу, а не подогнанную и упрощенную. И он таки проще, чем твой. Только надо иметь базовые знания для его понимания.
EP>ога, "код становится простым, после изучения малоиспользуемого языка"
Чтобы понимать код нужно знать идиомы использованные в нем. Лично мне твой код менее понятен, так как большая его часть просто скрыта от глаз в библиотеке. Код на Ди мне понятен, но я не знаю его АПИ (этих трейтсов). Код на немерле прост как три копейки, но я знаю все идиомы в нем использованные и знаю его АПИ. По сему мне проще читать код на Немерле. Дальше идет Ди, и только потом С++. И это при том что я на С++ писал лет 5 (если не считать времени когда писал на С).
Думаю, что если тебе дать пару пояснений, то и ты поймешь, что он очень прост.
EP>Практически все преимущества range-only решения, доступны для решения итераторы+обвёртки.
Ну, да. С помощью адаптеров из неудобных, но гибких итераторов можно сделать удобные ренжи или их аналоги. Бесспорно.
Возможно для Ди так и нужно было бы сделать. Ну, так это никогда не поздно сделать. Если конечно, обертка не будет давать оверхэд.
VD>>Ренжи — это аналоги ленивых списков из ФА или IEnumerable из дотнета.
EP>Это ты сильно льстишь IEnumerable — D-Range намного мощнее
Я говорю, что есть. Мощнее / слабее — без разницы. Ленивого списка достаточно для получения плюшек ФП. Да и не ленивый сойдет в 90% случаев.
VD>>Ленивые списки в купе с правильной библиотекой вроде linq-а повышают уровень кода в разы.
EP>Эта ленивость доступна и для STL итераторов, причём без бешеной abstraction penalty
Да понятно, что доступно. Просто авторы Ди, видимо, решили, что не нужды в создании прогладок и создали удобный механизм который и используют в свое удовольствие.
В С вот нет ни ренжей, ни итераторов, а не нем по прежнему большая часть Виндов и Линукса написаны. Стало быть не в абстракциях счастье. Функция тоже не плохая абстракция, в конце концов.
Все что я тебе пытался сказать, что ты прицепился к мелочи, которая, к тому же, легко исправляется. А вот обсуждать реальные преимущества и недостатки ты уже не хочешь. Все у тебя "незначительно" и "не важно".
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, VladD2, Вы писали:
VD>Да вот здесь (уперся в какую-то незначительную хрень неизвестно зачем):
Ты сначала разберись о чём речь — и тогда не будет странных сравнений D-Range с примитивным IEnumerable
VD>Ага. Приводя говногод на мапах созданных из макросов вместо полноценных решений и называя при этом полноценные решения
Чего?
EP>>Обсуждать метапрограммирование не особо интересно — так как все согласны что оно мощнее у D. VD>Метапрограммирование способно заменить все твои абстракции и сделать код настолько быстрым насколько это позволяет железо. Я тебе уже говорил об этом. Но ты даже не смог понять моих слов. Начал какие-то ссылки на мат-библиотеки давать.
Библиотеки это пример того, что полноценная генерация произвольного кода нужна далеко не всегда — там нет ручных итераций, и при это всё оптимизируется на стадии компиляции
VD>Пойми, если у тебя выбор между ренжами и итераторами, то у меня выбор между работой с указателями или прямым использованием массивов. Мой выбор априори не имеет оверхэда.
Во многих случаях итераторы добавляют 0 оверхеда
VD>И мне плевать, что ты в С++ сочтешь мой подход грязным и неприемлемым, так как я свой код руками писать не буду.
Да ты наверно код генерирующий генератор генератора генератора кода пишешь
VD>Мои абстракции — это макросы (синтаксические и типизированные) которые скрывают сложность и дерьмвость кода, а так же позволяют изменить реализацию, заменить типы контейнеров (по вашему) и вообще сделать все что угодно, просто заменим реализацию поры генерирующих функций.
Я тебя поздравляю. Зачем ты мне об этом пишешь? Тем более если нормально не хочешь вести беседу?
EP>>2. Считаешь что программисты которые используют C++ — знают только один язык. VD>Не программисты, а конкретно ты.
Как ты пришёл к такому умозаключению?
VD>Я сам не мало писал на плюсах. Правда тогда они были несколько другими. А один мой коллега писал на плюсах еще 1.5 года назад и весьма в нем приуспел. Сейчас мы вот оба пишем на Nemerle полностью сходимся во мнении по поводу С++ — язык для выжимания битов.
Мне эти самые биты и нужно выжимать
EP>>3. Говоришь что кто-то тут выдвигает тезис "С++ лучше" VD>А что ты тогда делаешь в это теме.
VD>Мы кажется выяснили, что твои тезисы не верны.
Где? Кто вы?
VD>Но ты продолжаешь их отстаивать, подменяя язык библиотекой и оправдываясь тем, что видите ли программистам некогда писать библиотеки.
Да где я подменяю язык библиотекой?
VD>Поставленную задачу не решает (и не может, по описанным тобой же причинам).
А что из поставленной задачи он не решает?
То что аттрибута нет — так его и не будет, по очевидным причинам. Эта задача что-ли такая — за-использовать атрибут? Не — не интересно.
Добавить метод в класс? Тоже не серьёзно. Я бы этот метод не добавил в класс даже если бы код вручную писал, зачем он там?
То что вместо
?
Не — это всё несерьёзные придирки. Ты лучше в следующий раз что-нибудь посложнее придумай.
VD>>>4. Система метапрограммирования основана на побочных эффектах от других средств, а не разработа специально. EP>>А кто сказал что нужна какая-то специально разработанная мета-система? VD>Никто. А надо? Что это меняет?
Так ты же и говоришь, что "не разработана специальна -> является недостатком". Или нет?
EP>>Метапрограммирование — это практически хак, который приходит на помощь там где недостаточно мощи самого языка. VD>Вот именно. А недостатков много.
Выделенное относится не только к C++
VD>все библиотеки С++ распространяются в исходниках.
Ложь.
VD>>>7. Требуются предварительные декларации. EP>>Мелочь. VD>Все мелочи. Но в купе набегает. И выходит, что язык сильно устарел, а новые не принимают.
Куда не принимают? Это же свободный рынок.
Если твой язык позволяет решать задачи в 10x быстрее, генерировать в 10x более быстрый код, лёгок в изучении, поддержке и т.п. — то и компания которая его выберет будет в большом профите, всё элементарно
VD>>>8. Нет даже опциональной системы автоматического управления памятью. EP>>В ISO C++11 есть интерфейс для GC — но он вообще не популярен, что скорее говорит об востребованности VD>В С++ с его моделью памяти нельзя сделать поддержку точного GC, так что спека тут не поможет.
http://www.stroustrup.com/C++11FAQ.html#gc-abi
VD>Короче, проблем выше крыши. Они не решаются уже много много лет. И все это время люди упорно игнорируют решения в которых таких проблем нет. Ну разве что МС и Сан смогли протолкнуть языки на базе виртуальных машин. Но ни один нативный язык так в мэйнстрим и не пробился, если не считать дельфи который просто уничтожил МС сманив главного разработчика языка.
В Delphi как в языке нет ничего интересного/оригинального. Не спасла бы его Эмбаркадеро — был бы уже в истории
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Не хватает встроенной в стандарт compile-time reflection — тогда от макроса можно было бы уйти.
Еще не хватает:
1. Прямых средств генерации кода, а не с помощью финтов ушами, множественного наследования на ровном месте и прочей фигни.
2. Возможности бинарной компиляции метакода, чтобы мета-решения не отличались по скорости от тех что встроены в компилятор. Этого, кстати, и в Ди нет, вроде бы.
3. Возможности внятного и удобного расширения и/или реинтерпретации синтаксиса, чтобы мета-решениям можно было придать логичный и удобный вид.
Если добавить эти мелочи, то... получится совсем другой язык.
EP>В С++ не принято добавлять члены в класс на каждый чих, наоборот — non-member предпочтительнее.
Это все оправдания. А по факту в С++ не принято решать проблемы просто и качественно. Все больше через зад, да автогеном.
Добавление метода может быть нужно просто для того, чтобы переопределить виртуальный метод. Не все проблемы, знаете ли, решаются в компайлтайме. Есть еще динамический полиморфизм.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, alex_public, Вы писали:
_>Мне даже страшно себе представить, что бы натворили некоторые маньяки C++ (типа пишущих всякие Boost.Spirit и т.п.), если бы им дали в руки такой инструмент...
Что там представлять? Они и натварили. Сначала PegGrammar
, а потом и Nitra. В Nitra так и происходит. Берем строку... из файла на диске... читаем из нее грамматику и генерируем на выхде динамически расширяемый эффективный парсер.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Если кто-то постоянно тем и занимается что итетрирует структуры данных, и ему не хватает текущих возможностей — то пусть отсылает proposal в reflection study group #7, его обязательно рассмотрят.
Лет 10 как отправили. Нам сказали, что RTTI должно быть достаточно для любых задач .
EP>В разных языках разные подходы. Non-member функция hash_value — это стандартный протокол в C++. И я не вижу никакого смысла использовать функцию член, когда допустим хэш-таблица ожидает non-member, только ради какой-то синтетической задачи.
Да вопрос то не в хэше. Вопрос в возможности решить конкретную задачу. Представь, что ты делаешь некий компонентный фреймворк или плагин и тебе нужна динамика. Вот у нас, например, парсеры динамически грузятся и кобмбинируются в составные. Берем грамматику, расширяем на лету другой и получаем С++ с поддержкой алгебраических типов данных и паттерн-матчинга .
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, VladD2, Вы писали:
VD>он генерирует разный код для разных типов полей. Где хотя бы это в твоем решении? VD>[...] VD>Я наверно очень отстал от прогресса в С++. Покажи мне как это приводит к генерации разного кода для int-а, и других объектов.
Разный код разгуливается перегрузкой hash_value.
VD>Если что-то реализовано еще где-то, то надо было это привести. А то я тебе тоже могу библиотечный макрос привести и сказать, что у меня тут все очень кратко.
Да какая разница если библиотека даёт всё необходимое для решения задачи. Причём библиотека не сферическая, а реальная, уже готовая. И код примера — также реальный, с демо в online компиляторе — в отличии от D и Nemerle вариантов.
VD>Интересные же возможности языка, а не библиотека которую уже кто-то написал.
Почему? Это демо того, какую библиотеку можно написать на языке.
У тебя в задачи не было условия не-использования библиотек — так что не надо дописывать новые условия. А то без библиотек пришлось бы и класс строки писать
EP>>>>И внезапно, полный код выглядит на порядок чище чем в D и Nemerle
VD>>>Это потому что ты знаешь ровно один язык. EP>>Твоя телепатия не работает. VD>Тут не нужно телепатии. Танцы с бубном ты называешь "порядок чище", а прямое создание нужного кода — чем-то грязным, очевидно.
Да ты сам посмотри на код — это готовое решение, с онлайн-demo-run, причём более чистое.
И ты при этом называешь его "говнокодом", приводя только какие-то уродливые обрезки с мясокомбината
VD>Думаю, что если тебе дать пару пояснений, то и ты поймешь, что он очень прост.
Я и так понимаю что он делает. Но генерировать код — не проще и не элегантней чем просто взять готовый fold, который пробежится по всем полям
EP>>Практически все преимущества range-only решения, доступны для решения итераторы+обвёртки. VD>Ну, да. С помощью адаптеров из неудобных, но гибких итераторов можно сделать удобные ренжи или их аналоги. Бесспорно. VD>Возможно для Ди так и нужно было бы сделать. Ну, так это никогда не поздно сделать. Если конечно, обертка не будет давать оверхэд.
В некоторых редких случаях, такая обвёртка даст небольшой оверхед. Но преимущества range-only исчезающе малы.
VD>Функция тоже не плохая абстракция, в конце концов.
Не плохая, согласен
VD>Все что я тебе пытался сказать, что ты прицепился к мелочи, которая, к тому же, легко исправляется.
Это не мелочь.
VD>А вот обсуждать реальные преимущества и недостатки ты уже не хочешь. Все у тебя "незначительно" и "не важно".
Я знаю какие у него есть преимущества, и обсуждать мне их не интересно. Что тут обсуждать? Ну есть и есть
Здравствуйте, VladD2, Вы писали:
EP>>Не хватает встроенной в стандарт compile-time reflection — тогда от макроса можно было бы уйти. VD>Еще не хватает: VD>1. Прямых средств генерации кода, а не с помощью финтов ушами, множественного наследования на ровном месте и прочей фигни.
Это не критично.
VD>2. Возможности бинарной компиляции метакода, чтобы мета-решения не отличались по скорости от тех что встроены в компилятор. Этого, кстати, и в Ди нет, вроде бы.
Что ты имеешь ввиду? В D можно генерировать строку кода, которая будет компилироваться в нужном месте.
VD>3. Возможности внятного и удобного расширения и/или реинтерпретации синтаксиса, чтобы мета-решениям можно было придать логичный и удобный вид.
Согласен, не хватает. Но требуется редко.
VD>Добавление метода может быть нужно просто для того, чтобы переопределить виртуальный метод. Не все проблемы, знаете ли, решаются в компайлтайме. Есть еще динамический полиморфизм.
Читай исходную задачу, которую сам и поставил. Где там переопределение виртуального метода?
Здравствуйте, VladD2, Вы писали:
EP>>Если кто-то постоянно тем и занимается что итетрирует структуры данных, и ему не хватает текущих возможностей — то пусть отсылает proposal в reflection study group #7, его обязательно рассмотрят. VD>Лет 10 как отправили. Нам сказали, что RTTI должно быть достаточно для любых задач .
Какой Proposal?
Почему RTTI — вы предлагали runtime reflection?
Здравствуйте, VladD2, Вы писали:
EP>>Более того — у меня в одном из проектов есть большая схема, так она вообще в xml хранится, и код из неё нормально генерируется, и не программисты могут с ней работать + всякие xml утилиты, и как-то не комплексуем по поводу "ай-ай-ай, нет reflection, надо менять язык!". VD>Вот это характерно! Ты программируешь на ХМЛ-е, а не на С++.
Сейчас вообще обхохочешься: код из схемы генерируется Python'ом
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Смотри внимательней, там под cut'ом.
Дык, под катом тоже не все. Там два инклюда. Я же не могу сказать, сколько мегатонн кода нужно загрузить из них, чтобы получить все что нужно. Когда-то давно я пытался разобраться с бустовской реализацией и малость прифигел.
VD>>В хороший язык тащат только базовые вещи вроде полноценной поддержки метапрограммирования и средств расширения синтаксиса.
EP>Хороший для чего?
Для программирования. Особенно для решения сложных задач малым числом людей.
EP>Да я вижу — и тихо ненавидишь всех кто его не расширяет/не использует. Нет уж, спасибо.
Да пойми ты, нет тут никакой ненависти. Мне скорее вас жалко. Убедить я вас все равно не могу. Но хоть пожалеть тех кто с костылями то ходит можно?
VD>>А библиотеки — без проблем. Тот же STL написал рядовой пользователь С++ работавший в HP.
EP>Тут как раз уж и не рядовой. Он эти идеи вынашивал много лет, и до этого делал реализации на разных языках (Scheme, Ada, etc)
Ту главное, что он не был автором языка и не работал в фирме где велась его разработка. Он просто написал библиотеку для чужого языка. До него STL не было. И писать на С++ было еще неудобнее.
Сейчас же эти концепции известны любому школьнику. Так что в чем проблема их реализовать в библиотеке? Можно даже тупо списать.
EP>Да уж — вот это взлёт.
А что не так? Живет 10 лет. Помирать не собирается. Главная претензия того же FR — слишком бурно развивается.
EP>Там где не хватит скорости Spirit'а или подобного — я спокойно могу взять внешний генератор кода
Spirit — это детство полное. А генераторов динамически расширяемых парсеров пока в природе очень мало. Можно сказать — нет. Мы же не просто очердной Як лепим. У нас задача фикс — сделать фреймворк который позволит создавать языки (любые, от ДСЛ-я, до языка общего назначения) настолько просто, что люди будут тупо решать задачи в терминах предметной области делая на нашем средстве все тулы (от компилятора, до IDE).
EP>Если приспичит, внешний генератор даже может подключатся к expression tree из кода — прям брать неопределённый символ с закодированной грамматикой из obj, и генерировать нужный код — но это только если делать нечего.
У нас AST автоматом создается. А для пользователя его вообще не видно. В грамматике можно просто методы объявлять которые видят правила как объекты с полями в виде подправил. Даже имена полей автоматом выводятся.
Но парсинг — это только пол дела (да даже не пол, а четверть). Еще нужен связывание символов, описание областей видимости, импорты разные, внешние метаданные, вывод типов, кодогенерация... Короче то чего как раз не хватало в С++.
Но речь то не о том. Речь о том, что метакод он и есть главная абстракция. Ты и сам ХМЛ используешь, так как проще сгенерировать код по нему, чем пытаться выписать его на шаблонах.
EP>Что значит живущие любое время? А если там ресурс?
В плюсах они рейдонли. И это не с проста. Ведь чтобы ничего не долбануло замыкание (созданное лямбдой) должна жить столько сколько ее используют. А в С++ у нас ручное управление памятью. Просто создать замыкание и забыть про него нельзя. Хорошо если это просто алгоритм и его можно заинлайнить. А если замыкание нужно где-то хранить, то это пипец как сложно в условиях отсутствия автоматического управления памятью.
EP>http://files.rsdn.ru/64603/nemerle2.jpg[/img]
Жалкая подделка. Правильный слон должен быть розовым!
VD>>Ты просто не умеешь их готовить. Точнее ты настолько уткнулся в детали реализации, что не можешь оторваться от них и посмотреть на то что они дают. Вот к примеру, что можно сделать на прототипе ренджей (энумераблах шарпа).
EP>Да не надо сравнивать "энумераблы шарпа" с D-Range — они им и в подмётки не годятся EP>"энумерабл" это single pass — а в D далеко не одна категория Range, также как в STL
Ты пример то посмотрел? Знаток подметок, блин. Я тебе говорю, что энумерабла достаточно. Так что уж рэнджи точно прокатят. Главную фичу они повторяют — предоставляют абстракцию линивого списка. Остальное дают правильный набор функций и переупорядочение и откладывание вычислений которое с ними происходит.
EP>Ну вроде бы всё ясно. "D хорош, но у него серьёзные проблемы — нужен Nemerle"
Ди хорошо как замена С++, на что он и был рассчитан. А в области МП он с немерлом тягаться не может. Хотя в последнее время он явно подтянулся. Они ведь на Немерл тоже смотрели.
EP>А вообще — если ты пытался разрекламировать Nemerle — то получилось всё как раз наоборот.
Я с такими как ты уже 10 лет общаюсь. Я знаю какие вы упертые. Так что я не надеюсь, что кто-то из вас меня послушает. Это религия. Ее аргументами не пробьешь.
Да и немерл не мой. Я, просто не мирюсь с неудобствами и проблемами, а устраняю их чтобы самому было чем пользоваться. Ну, и это чертовски интересно! Куда интереснее чем мечтать о светлом будущем в котором у С++ появятся средства интроспекции и т.п.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Причём в C++14 добавилось несколько способов — transparent operator functors и само-собой п.лямбды.
Вот тоже самое, помню, говорили в 2002-ом про концепты. Хорошая идея была, эти концепты...
В прочем, шутка про то что цифра (в номере стандарта) является шестнадцатеричной не отменяется! Так что можно надеяться, что в 0x14 (т.е. в 2020-ом) году чудо случится и долгожданное чудо придет!
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, DarkEld3r, Вы писали:
DE>И тебя не смущает, что LLVM на С++ написана? Как же можно на "говнокод на говноязыке" полагаться? Нее, надо срочно переписывать на D, а до этого ни за какие проекты браться ни в коем случае нельзя.
Меня смущает. Это главный его недостаток. Нужны обертки для использования не из С++. Если бы у него был сишный АПИ было бы в сто раз лучше. Но это не совсем о "написан на". Это о том, что имеет интерфейс С++.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, VladD2, Вы писали:
EP>>Смотри внимательней, там под cut'ом. VD>Дык, под катом тоже не все. Там два инклюда. Я же не могу сказать, сколько мегатонн кода нужно загрузить из них, чтобы получить все что нужно. Когда-то давно я пытался разобраться с бустовской реализацией и малость прифигел.
В том то и фишка, что std::bind сам строит expression tree.
VD>>>В хороший язык тащат только базовые вещи вроде полноценной поддержки метапрограммирования и средств расширения синтаксиса. EP>>Хороший для чего? VD>Для программирования. Особенно для решения сложных задач малым числом людей.
За всё хорошее и против всего плохого! Ты конкретней говори.
EP>>Да я вижу — и тихо ненавидишь всех кто его не расширяет/не использует. Нет уж, спасибо. VD>Да пойми ты, нет тут никакой ненависти. Мне скорее вас жалко. Убедить я вас все равно не могу. Но хоть пожалеть тех кто с костылями то ходит можно?
В чём убедить? В том что в не-мейнстримовых языках есть какие-то особенные и полезные, а порой экспериментальные фичи? Да тут вроде никто и не спорит
EP>>Там где не хватит скорости Spirit'а или подобного — я спокойно могу взять внешний генератор кода VD>Spirit — это детство полное. А генераторов динамически расширяемых парсеров пока в природе очень мало. Можно сказать — нет. Мы же не просто очердной Як лепим. У нас задача фикс — сделать фреймворк который позволит создавать языки (любые, от ДСЛ-я, до языка общего назначения) настолько просто, что люди будут тупо решать задачи в терминах предметной области делая на нашем средстве все тулы (от компилятора, до IDE).
Ну, удачи
EP>>Что значит живущие любое время? А если там ресурс? VD>В плюсах они рейдонли. И это не с проста.
Это дефолт — там при необходимости легко добавить "mutable".
VD>Ведь чтобы ничего не долбануло замыкание (созданное лямбдой) должна жить столько сколько ее используют. А в С++ у нас ручное управление памятью. Просто создать замыкание и забыть про него нельзя. Хорошо если это просто алгоритм и его можно заинлайнить. А если замыкание нужно где-то хранить, то это пипец как сложно в условиях отсутствия автоматического управления памятью.
Да нет ничего сложного. Ты лучше на выделенный вопрос ответь. А то вот Ikemefula мне тоже лапшу на уши вешал что лямбду в C# можно передавать как угодно, и куда угодно
EP>>http://files.rsdn.ru/64603/nemerle2.jpg
VD>Жалкая подделка. Правильный слон должен быть розовым!
Правильный слон должен быть незаметным:
VD>Ты пример то посмотрел? Знаток подметок, блин. Я тебе говорю, что энумерабла достаточно. Так что уж рэнджи точно прокатят. Главную фичу они повторяют — предоставляют абстракцию линивого списка. Остальное дают правильный набор функций и переупорядочение и откладывание вычислений которое с ними происходит.
И что из этого тебе недоступно в C++?
EP>>А вообще — если ты пытался разрекламировать Nemerle — то получилось всё как раз наоборот. VD>Я с такими как ты уже 10 лет общаюсь. Я знаю какие вы упертые. Так что я не надеюсь, что кто-то из вас меня послушает. Это религия. Ее аргументами не пробьешь.
Здравствуйте, VladD2, Вы писали:
VD>Вот тоже самое, помню, говорили в 2002-ом про концепты. Хорошая идея была, эти концепты...
Те концепции были тяжёлыми (одна спецификация страниц сто), эти намного легче.
Практически всё необходимое уже есть в самом языке, нужен только небольшой сахар, для удобства.
VD>В прочем, шутка про то что цифра (в номере стандарта) является шестнадцатеричной не отменяется! Так что можно надеяться, что в 0x14 (т.е. в 2020-ом) году чудо случится и долгожданное чудо придет!
По идее уже в следующем году. Текущий proposal вроде всех устраивает (ну кроме тех кто мечтал об concept map).
Здравствуйте, VladD2, Вы писали:
VD>Меня смущает. Это главный его недостаток. Нужны обертки для использования не из С++. Если бы у него был сишный АПИ было бы в сто раз лучше. Но это не совсем о "написан на". Это о том, что имеет интерфейс С++.
Вроде, есть? http://llvm.org/docs/doxygen/html/group__LLVMC.html
Или сишный апи неполный/недостаточно быстро обновляется?
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Всё то — в C++ вот такой массив int x[11] — тоже range.
Хы, ну да, забавно. ))) Но всё же массивы D это скорее аналог std.vector, а не массивов C++. Хотя последнее в D тоже по сути есть, как свойство ptr массива. )))
_>>Вот если бы у range можно было вызывать функции массива (хотя в данном конкретном примере это и не пригодилось)... EP>Какие?
Ну например размер узнать или поменять. Или получить прямой указатель на данные...
EP>Только массивы вообще не интересны. std::partition_point работает даже с Forward итераторами. Попробуй сделать интерфейс, и хотя бы набросай реализацию (мелкие баги не имеют значения).
Для не массивов уже диапазоны надо использовать... А я как раз старался без них обойтись. ))) Да, но вообще для partition_point по идее и обычного InputRange будет достаточно. Собственно тут уже приводили подобный код с диапазоном. Просто возвращаем кортеж из двух диапазонов...
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Не хватает, но это не так критично как тут пытаются представить "omg нет reflection! все на D, Nemerle и т.п."
Нуу естественно, что одной интроспекции недостаточно для перехода с C++ на D, но по сумме удобных фич D всё же настолько лучше, что это того стоит. И кстати со скоростью там говорят всё отлично, если взять gdc (я то только их родной тестировал. т.к. gdc кривоват под виндой).
Но это если мы говорим именно про сам язык и может компилятор/стандартную библиотеку. Если же брать остальную инфраструктуру, т.е. сторонние библиотеки, инструменты (IDE и т.п.), то как бы
получается что в итоге разработка на D может даже дороже обойтись.
В общем никакого однозначного решения "переходит или нет" на мой взгляд сейчас не существует. И там и там свои плюсы и минусы, причём очень разные. Мы тут пока просто пробуем на одном можно сказать стажёрском проекте. Правда при этом похоже больше обучается не стажёр, а как раз главный разработчик.
EP>А какие накладные расходы он по-твоему добавляет?
Ну как минимум ненужные строки в исполняемый файл. Правда я смотрю в последнее время компиляторы (во всяком случае gcc) умнее стали и запихивают это дело только по надобности. Но раньше помнится всё подряд валили. Что кстати весьма неприятно, если в коде имеются какие-то сильно секретные нюансы. Вообще на мой взгляд с rtti единственная проблема в том, что оно по умолчанию включено, а выключается опцией. Если бы наоборот было, то никаких проблем.
EP>Это всё понятно, и действительно круто. Но сейчас — отчасти решается макросами, либо с небольшим дублированием в виде описания схемы в одном из форматов(Boost.Fusion, или например Boost.Serialization). EP>Более того — у меня в одном из проектов есть большая схема, так она вообще в xml хранится, и код из неё нормально генерируется, и не программисты могут с ней работать + всякие xml утилиты, и как-то не комплексуем по поводу "ай-ай-ай, нет reflection, надо менять язык!".
Вообще если бы C++11 не вышел, то мне кажется что D очень резко пошёл бы вперёд. Т.к. C++03 был уж очень отсталым и набор фич в D просто потрясал. C++11 можно сказать серьёзно подпортил жизнь D, т.к. смысл переходить заметно уменьшился. Хотя всё равно ещё есть на мой взгляд. Если в C++14 взяли бы ещё несколько модных вещей из D, то может уже вообще вопрос не стоял бы. Но насколько я знаю в C++14 ничего принципиального не ожидается, скорее так, косметика...
EP>В C++11 можно (гугли "Using strings in C++ template metaprograms", + должно уже быть в библиотеках)
Это ты про жуть типа задания отдельными буквами или про что? )
, а потом и Nitra. В Nitra так и происходит. Берем строку... из файла на диске... читаем из нее грамматику и генерируем на выхде динамически расширяемый эффективный парсер.
Интересно. )
А мы тут на D используем что-то из подобной же области, правда написанное не нами. Там значит при сборке исполняемого файла читаются текстовые файлы с диска, написанные на спец. языке шаблонизатора с определённой грамматикой. Кстати туда входят в том числе и вставки кусков кода на D. Это всё собирается в бинарник, который запускается и с безумной скоростью выдаёт по запросам генерируемые странички.
Здравствуйте, DarkEld3r, Вы писали:
DE>Здравствуйте, VladD2, Вы писали:
VD>>Меня смущает. Это главный его недостаток. Нужны обертки для использования не из С++. Если бы у него был сишный АПИ было бы в сто раз лучше. Но это не совсем о "написан на". Это о том, что имеет интерфейс С++. DE>Вроде, есть?
Есть. Но обертки есть обертки. Нет никакой гарантии, что через них доступны все функции и что нет никаких проблем.
По факту зачастую совместимость обеспечивается за счет генерации кода на их языке. То есть язык становится средством совместимости.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, D. Mon, Вы писали:
DM>Справедливости ради, в D с точным GC тоже пока не густо. По умолчанию используется частично консервативный. Есть реализация "почти точного" (используется в VisualD, например), но и там осталась пара мест (вроде замыканий), где осталась консервативность. Т.е. теоретически точный GC сделать можно, но пока его нет. И те, кто в 64 бита компилит, говорят что и не нужно, нынешнего хватает.
Дык это плохо. В С++ же даже возможности такой нет. Память на классы не делится. 30 лет назад об этом не думали.
DM>Другая проблема — скорость нынешнего GC, она печальная.
Естественно. Хорошую скорость может обеспечить только точный ЖЦ с нехилой поддержкой компилятора. Задача не из легкий.
Но это опять же следствие малости комьюнити и не заинтересованности мега-корпораций. Иначе давно написали бы. Для Явы ЖЦ выше крыши. У дотнета с ним тоже все ОК.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, alex_public, Вы писали:
EP>>Всё то — в C++ вот такой массив int x[11] — тоже range. _>Хы, ну да, забавно. ))) Но всё же массивы D это скорее аналог std.vector, а не массивов C++. Хотя последнее в D тоже по сути есть, как свойство ptr массива. )))
std::vector — тоже range.
_>>>Вот если бы у range можно было вызывать функции массива (хотя в данном конкретном примере это и не пригодилось)... EP>>Какие? _>Ну например размер узнать или поменять. Или получить прямой указатель на данные...
А что произойдёт, если допустим slice'у от массива попытаться увеличить размер?
EP>>Только массивы вообще не интересны. std::partition_point работает даже с Forward итераторами. Попробуй сделать интерфейс, и хотя бы набросай реализацию (мелкие баги не имеют значения). _>Для не массивов уже диапазоны надо использовать... А я как раз старался без них обойтись. ))) Да, но вообще для partition_point по идее и обычного InputRange будет достаточно.
partition_point делает бинарный поиск — поэтому ему нужен ForwardRange как минимум.
_>Собственно тут уже приводили подобный код с диапазоном. Просто возвращаем кортеж из двух диапазонов...
Даже в том коде были разнообразные проблемы, как с гибкостью, так и с производительностью.
А в случае partition_point ещё и реализация будет неудобная. AFAIK в D есть бинарный поиск только для RandomAccess, в то время как в STL он спокойно работает и для ForwardIterator.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>std::vector — тоже range.
Он гораздо большее)
EP>А что произойдёт, если допустим slice'у от массива попытаться увеличить размер?
Оно заживёт самостоятельной жизнью (данные скопируются в новую область).
EP>partition_point делает бинарный поиск — поэтому ему нужен ForwardRange как минимум.
Тьфу, я в этих названия у них путаюсь. Собственно я ещё ни разу не использовал range в D, хотя уже много чего делали...
EP>Даже в том коде были разнообразные проблемы, как с гибкостью, так и с производительностью. EP>А в случае partition_point ещё и реализация будет неудобная. AFAIK в D есть бинарный поиск только для RandomAccess, в то время как в STL он спокойно работает и для ForwardIterator.
А что там неудобного? Насколько я помню нормальный код.
Здравствуйте, alex_public, Вы писали:
EP>>А что произойдёт, если допустим slice'у от массива попытаться увеличить размер? _>Оно заживёт самостоятельной жизнью (данные скопируются в новую область).
А какие типы будут у: массива, массива после slice, массива после slice и resize?
Если одинаковые, то получается оверхед на хранение own_flag, и его постоянную проверку.
EP>>partition_point делает бинарный поиск — поэтому ему нужен ForwardRange как минимум. _>Тьфу, я в этих названия у них путаюсь.
Ну пусть будет std::lower_bound — практически тоже самое.
EP>>Даже в том коде были разнообразные проблемы, как с гибкостью, так и с производительностью. EP>>А в случае partition_point ещё и реализация будет неудобная. AFAIK в D есть бинарный поиск только для RandomAccess, в то время как в STL он спокойно работает и для ForwardIterator. _>А что там неудобного? Насколько я помню нормальный код.
В STL как раз нормальный. А в D, хоть и делали с оглядкой на STL — бинарный поиск, afaik, только для RandomAccess.
Ну или другой пример — есть строка UTF-8, по ней нужно бегать туда-сюда. На BidirectionalIterator — это делается влёт.
А на D BidirectionalRange — нет, так как такие range только уменьшаются, но не растут обратно.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>А какие типы будут у: массива, массива после slice, массива после slice и resize? EP>Если одинаковые, то получается оверхед на хранение own_flag, и его постоянную проверку.
Одинаковые. Добавление данных к слайсу действительно имеет некоторый оверхед. Если нужно много данных добавлять подряд, есть быстрый std.array.Appender.
Здравствуйте, D. Mon, Вы писали:
EP>>А какие типы будут у: массива, массива после slice, массива после slice и resize? EP>>Если одинаковые, то получается оверхед на хранение own_flag, и его постоянную проверку. DM>Одинаковые. Добавление данных к слайсу действительно имеет некоторый оверхед.
Хотя я думаю в случае с resize, при использовании GC, можно обойтись без overhead'а: у slice'а автоматом capacity устанавливается равной .size() — тогда дополнительные проверки не нужны.
Но как, например, разгуливается ситуация с popBack? Если у нас "оригинальный" массив — то нужно позвать деструктор (либо сообщить GC — занулить указатель), а если slice — то нужно только сдвинуть указатель/уменьшить size.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Но как, например, разгуливается ситуация с popBack? Если у нас "оригинальный" массив — то нужно позвать деструктор (либо сообщить GC — занулить указатель), а если slice — то нужно только сдвинуть указатель/уменьшить size.
Просто уменьшается длина слайса. Данные не освобождаются и не обнуляются сразу, это отдается на откуп GC. Пока хоть один слайс ссылается на исходный массив, все его данные будут в памяти. (тут как со строками в джаве до 1.7) Можно, конечно, вручную подчистить, если уверен, что на них точно нет других ссылок, но это считается небезопасным и неидиоматичным, однако вполне доступно.
Здравствуйте, D. Mon, Вы писали:
EP>>Но как, например, разгуливается ситуация с popBack? Если у нас "оригинальный" массив — то нужно позвать деструктор (либо сообщить GC — занулить указатель), а если slice — то нужно только сдвинуть указатель/уменьшить size. DM>Просто уменьшается длина слайса. Данные не освобождаются и не обнуляются сразу, это отдается на откуп GC.
Это понятно, а что происходит когда оригинальный массив без всяких slice'ов делает popBack? Он тоже не зануляет/не деструктит?
То есть что происходит в такой ситуации:
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Это понятно, а что происходит когда оригинальный массив без всяких slice'ов делает popBack? Он тоже не зануляет/не деструктит?
Да. У него и нет никакого pop_back, а есть изменяемая length. Если ее уменьшить на 1, это эквивалентно взятию слайса
v = v[0..$-1];
Если нужно детерминированное освобождение ресурсов при этом, то простой массив не годится, нужна обертка над ним с соответствующей логикой.
Здравствуйте, D. Mon, Вы писали:
EP>>Это понятно, а что происходит когда оригинальный массив без всяких slice'ов делает popBack? Он тоже не зануляет/не деструктит? DM>Если нужно детерминированное освобождение ресурсов при этом, то простой массив не годится, нужна обертка над ним с соответствующей логикой.
Здравствуйте, minorlogic, Вы писали:
EP>>Взять например те же ranges — они проигрывают итераторам по производительности by-design M>Этого не понял , ranges же легко делать поверх итераторов , где там производительность потеряется ?
Ranges действительно легко делать поверх итераторов — например Boost.Range. Но в D нет итераторов — там сразу Range.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>А какие типы будут у: массива, массива после slice, массива после slice и resize? EP>Если одинаковые, то получается оверхед на хранение own_flag, и его постоянную проверку.
Ну я же говорил, что оно хотя и похоже на std::vector, но со специфическими свойствами владения. Т.е. кроме того, что не освобождает память в деструкторе, оно ещё и в операторе присваивания копирует только указатель. Соответственно раз у нас даже просто копии массива являются по своей сути ссылками на чужие данные, то понятно что уж срезы то точно именно через это и реализуют.
Т.е. изменение элементов как просто копий массива, так и срезов, затрагивает изначальные данные. А вот операция добавления элемента в массив порождает новую область памяти, в которую копируется старая и новый элемент. Ну и естественно у каждого массива есть метод dup, порождающий новую реальную копию данных.
Вообще говоря при изучение этого я бы не сказал что оно вот так прямо интуитивно реализовано. Однако на практике пользоваться довольно удобно.
EP>В STL как раз нормальный. А в D, хоть и делали с оглядкой на STL — бинарный поиск, afaik, только для RandomAccess.
EP>Ну или другой пример — есть строка UTF-8, по ней нужно бегать туда-сюда. На BidirectionalIterator — это делается влёт. EP>А на D BidirectionalRange — нет, так как такие range только уменьшаются, но не растут обратно.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Нашёл — нужен std.container.Array
Ага. А ещё массив из D фиксированного размера имеет поведение уже не как странный std::vector, а как std::array, т.е. по сути как массив C++. Т.е. выделение на стеке и соответственно гарантированное освобождение.
Здравствуйте, alex_public, Вы писали:
_>Ага. А ещё массив из D фиксированного размера имеет поведение уже не как странный std::vector, а как std::array, т.е. по сути как массив C++.
Что значит "странный std::vector"?
EP>>Ну или другой пример — есть строка UTF-8, по ней нужно бегать туда-сюда. На BidirectionalIterator — это делается влёт. EP>>А на D BidirectionalRange — нет, так как такие range только уменьшаются, но не растут обратно. _>Так там же save есть у большинства диапазонов.
BidirectionalRange это по сути два Forward итератора бегущих друг на встречу другу, а для нормальной обработки UTF-8 нужен Bidirectional Iterator. И .save() тут никак не поможет (точнее может, но это будут дополнительные расходы в виде временных буферов).
Например простейший случай: найти заданный символ в строке, и вывести N предыдущих в обратном порядке.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Что значит "странный std::vector"?
Да это я всё про то, что массивы D — это std::vector, но извращённый. )))
EP>BidirectionalRange это по сути два Forward итератора бегущих друг на встречу другу, а для нормальной обработки UTF-8 нужен Bidirectional Iterator. И .save() тут никак не поможет (точнее может, но это будут дополнительные расходы в виде временных буферов). EP>Например простейший случай: найти заданный символ в строке, и вывести N предыдущих в обратном порядке.
Аааа теперь понял про что ты. Ну да, собственно BidirectionalRange — это вообще странная конструкция. ))) А DList из стандартной библиотеки (заточенный под эту хрень) соответственно не умеет такую очевидную вещь, как "получить предыдущий элемент" — ужас. )))
Но это именно BidirectionalRange, а вот если у нас RandomAccessRange (кстати, строки то как раз почти всегда или такие или InputRange), то наоборот всё становится очень и очень удобно.
Здравствуйте, alex_public, Вы писали:
_>Но это именно BidirectionalRange, а вот если у нас RandomAccessRange (кстати, строки то как раз почти всегда или такие или InputRange), то наоборот всё становится очень и очень удобно.
Для UTF-8 строк нет random access без дополнительного расхода памяти, а вот bidirectional — есть (например boost::u8_to_u32_iterator).
RandomAccessRange по сравнению с итераторами как-то тоже не айс:
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Для UTF-8 строк нет random access без дополнительного расхода памяти, а вот bidirectional — есть (например boost::u8_to_u32_iterator).
Ну так это ты про итерацию уже по символам, а на нижнем уровне то массив байт обычно.
Кстати, если говорить конкретно про utf(8, 16, 32), то в D это всё встроено прямо в язык. Т.е. можно написать так:
string str="Привет";//str - массив байт со строкой utf-8foreach(c; str) writeln(c);//выведет хреньforeach(dchar c; str) writeln(c);//выведет корректно по буквам
Здравствуйте, alex_public, Вы писали:
_>Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>>Нашёл — нужен std.container.Array
_>Ага. А ещё массив из D фиксированного размера имеет поведение уже не как странный std::vector
Здравствуйте, DarkEld3r, Вы писали: DE>Лол что? Ни с чем не перепутал? Вообще-то Линус категорически не любит С++.
Линус кроме ядра линукса и гита ничем не занимается, в принципе.
А вот всякие гномы и кеды и остальные из мира опенсорса сделаны на инкрементированных сях.
Здравствуйте, -n1l-, Вы писали:
N>Здравствуйте, DarkEld3r, Вы писали: DE>>Лол что? Ни с чем не перепутал? Вообще-то Линус категорически не любит С++. N>Линус кроме ядра линукса и гита ничем не занимается, в принципе. N>А вот всякие гномы и кеды и остальные из мира опенсорса сделаны на инкрементированных сях.
Я как бы в курсе. Но речь шла про "бортовую радиолу", вот и предположил, что речь, в первую очередь, именно о ядре. Ну и разработчики гнома продвигают Vala, вроде.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Наверное только в одну сторону? То есть вот такое не получится: найти заданный символ в строке, и вывести N предыдущих в обратном порядке.
Пользуясь случаем хочу спросить.
На чем в linux'e больше программируют(чистых сях или инкрементированных) и что(встраиваемые системы, десктопчики, мобилки, веб)?
Кстати, у retro есть проверка на isRandomAccessRange — в этом случае также возвращается RandomAccessRange, а вот isSomeString уже нет.
То есть, по идее, вот такой код не скомпилируется:
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>а для обычных BidirectionalRange, незнакомых алгоритму — было бы takeExactly, у которого первый range — ForwardRange, и с середины назад уже не пройтись
Эммм, так я же это и сказал чуть выше. Что для строк D (которые являются char[], т.е. RandomAccess) всё шоколадно. А вот BidirectionalRange — это действительно какая-то сомнительная хрень, которая похоже была введена для обобщения на двусвязные списки, но при этом в итоге испортила их же функциональность.
Ну точнее строки char[] и wchar[] (но не dchar[]) возвращают false на isRandomAccessRange, как раз из-за переменного размера символа... Но при этом по сути это всё равно сущности с произвольным доступом, просто не через диапазоны, а через срезы (т.е. побайтово). И у нас есть замечательная функция toUTFindex, т.е. написав например str[0..str.toUTFindex(10)], мы получим снова сущность с произвольным доступом из первых 10 символов. Это как бы на низком уровне и тут у строк в D никаких проблем. А на высоком уровне (когда играем с диапазонами) они действительно формально как BidirectionalRange проходят, но при этом произвольный доступ по байтам то остаётся и соответственно просто во всех функция библиотеки должна быть предусмотрена специальная обработка строк, раз уж это поддерживается на низком уровне.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Кстати, у retro есть проверка на isRandomAccessRange — в этом случае также возвращается RandomAccessRange, а вот isSomeString уже нет. EP>То есть, по идее, вот такой код не скомпилируется: EP>
выдаёт правильный результат. Но это естественно не правильное решение, а костыль для демонстрации реального проблемного места в библиотеке.
Вообще там в библиотеке ещё много чего недоделанного и данный момент это вообще ерунда на фоне например того же странного DList и ещё кучи подобных мест.
Но хочу заметить один нюанс из практики. Лично я уже пробуя кое-что делать с D так ни разу и не залез в раздел Range. Массивы (фиксированные, динамические, ассоциативные) встроенные в язык с их срезами и тот факт, что функции из библиотеки работают с ними сохраняя их семантику, покрывают большинство потребностей. А всякие сложные структуры (типа списков, деревьев и т.п.) я всё равно привык обычно сам делать, уже не в виде контейнера. Т.е. могу ещё раз повторить свою начальную мысль тут: диапазоны в D — это совсем не так важно как итераторы в C++. В D скорее рулят срезы. )))
Здравствуйте, alex_public, Вы писали:
_> А на высоком уровне (когда играем с диапазонами) они действительно формально как BidirectionalRange проходят, но при этом произвольный доступ по байтам то остаётся и соответственно просто во всех функция библиотеки должна быть предусмотрена специальная обработка строк, раз уж это поддерживается на низком уровне.
1. В примере выше произвольный доступ используется для обхода надуманных ограничений Range. Там нет никакого RandomAccess, индексы используются для взятия слайсов по границам до которых мы уже дотопали, в случае итераторов была бы просто комбинация [first, search(...)). То же std::search спокойно работает для всего начиная от ForwardIterator, без всякого дополнительного специального кода внутри.
2. Специальная обработка строк в алгоритмах библиотеки — это самый что ни на есть костыль, обходящий проблемы Range, да и то не везде подставленный.
3. Сама по себе такая категория range была бы интересна только при наличии возможности быстрого вычисления индекса. Если же индекс считается линейно, как в toUTFindex, то это ничем не лучше BidirectionalIterator, так как str.toUTFindex(10) — даёт тоже самое что и std::next(first, 10), только в менее удобном виде.
И реализация у toUTFindex такая же как и у std::next, со специальной обработкой random access.
Как раз по этой причине: первый retro возвращает BidirectionalRange, который уже не isSomeString, поэтому первый range в результате findSplit — это то, что выдал takeExactly, который возвращает ForwardRange. Вот из этого Forward как раз и не получается взять retro — поэтому ты и скопировал его в array перед .retro().
_> Т.е. могу ещё раз повторить свою начальную мысль тут: диапазоны в D — это совсем не так важно как итераторы в C++. В D скорее рулят срезы. )))
Это уже другой вопрос — во многих языках (стандартных библиотеках) кроме SinglePass и Arrays, вообще ничего не предлагается. И многие функции высшего порядка возвращают только SinglePass, что приводит к излишним копиям. Но как-то же получается обходится.
Здравствуйте, alex_public, Вы писали:
_>Массивы (фиксированные, динамические, ассоциативные) встроенные в язык с их срезами...
Кстати, правильно ли я понимаю, что свой аналог хеш-таблицы (ассоциативного массива) с таким же синтаксисом, как встроенные (ValueType [KeyType]), сделать нельзя?
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>1. В примере выше произвольный доступ используется для обхода надуманных ограничений Range. Там нет никакого RandomAccess, индексы используются для взятия слайсов по границам до которых мы уже дотопали, в случае итераторов была бы просто комбинация [first, search(...)). То же std::search спокойно работает для всего начиная от ForwardIterator, без всякого дополнительного специального кода внутри.
Ну так для Forward и в D всё отлично. Кривым выглядит именно Bidirectional.
EP>2. Специальная обработка строк в алгоритмах библиотеки — это самый что ни на есть костыль, обходящий проблемы Range, да и то не везде подставленный.
Строки то не простые, а utf8/utf16. Скажем если будем сравнивать с C++, то там в стандартной библиотеке нет вообще никакой поддержки подобного.
Далее, в большинстве случаев эти костыли сводятся не к написанию новой ветки алгоритма, а к добавлению строк в static if для ветки RandomAccess. Ну и т.к. это всё во время компиляции, то никакого оверхеда не приносит. Т.е. вне зависимости от того хорошие Range или плохие, идея делать алгоритмы в несколько веток (и соответственно каждая ветка более оптимизированная) под разные тип данных прослеживается много где в D и не кажется мне плохой. Кстати, благодаря перегрузке по типу шаблонного параметра, это ещё и частенько реализуется в виде отдельных функций. Т.е. наглядно и расширяемо.
EP>3. Сама по себе такая категория range была бы интересна только при наличии возможности быстрого вычисления индекса. Если же индекс считается линейно, как в toUTFindex, то это ничем не лучше BidirectionalIterator, так как str.toUTFindex(10) — даёт тоже самое что и std::next(first, 10), только в менее удобном виде. EP>И реализация у toUTFindex такая же как и у std::next, со специальной обработкой random access.
Ну естественно, чудес то не бывает. Если мы хотим посимвольную итерацию по utf8/utf16 строкам, то по любому где-то необходим этот код.
Да, кстати, а вот лично я предпочитаю (что в C++, что в D) работать внутри программы с широкими строками, у которых нет всех этих проблем. А utf8 использовать исключительно для хранения данных где-то снаружи программы.
Здравствуйте, DarkEld3r, Вы писали:
DE>Кстати, правильно ли я понимаю, что свой аналог хеш-таблицы (ассоциативного массива) с таким же синтаксисом, как встроенные (ValueType [KeyType]), сделать нельзя?
По идее, ничто не мешает — описываешь структуру/класс с оператором обращения по индексу и вперед.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Как раз по этой причине: первый retro возвращает BidirectionalRange, который уже не isSomeString, поэтому первый range в результате findSplit — это то, что выдал takeExactly, который возвращает ForwardRange. Вот из этого Forward как раз и не получается взять retro — поэтому ты и скопировал его в array перед .retro().
Ну да. Я неправильно понял ту твою фразу)
А вообще, как я уже писал в предыдущем сообщение, в реальности у меня скорее был бы код вида
который позволяет полностью забыть о BidirectionalRange, как о кошмарном сне. )))
И кстати в C++ я тоже предпочитаю подобное, хотя под виндой с этим у C++ есть нюансы.
EP>Это уже другой вопрос — во многих языках (стандартных библиотеках) кроме SinglePass и Arrays, вообще ничего не предлагается. И многие функции высшего порядка возвращают только SinglePass, что приводит к излишним копиям. Но как-то же получается обходится.
Я всё немного про другое.
Вот смотри, что нам даёт голый C++ (без STL и т.п.) в этом смысле? По сути голые указатели, плюс сахар в виде обращения к ним через оператор индекса. И в общем то всё. Очевидно, что этого абсолютно недостаточно для нормального написания софта. Т.е. если бы STL и аналогов не было, то всё равно каждая команда писала бы себе в начале свой маленький вариант STL и работала только через него.
Теперь посмотри что даёт нам голый D. Удобные массивы со срезами, итерациями, контролем памяти. Плюс ещё ассоциативные массивы. Это покрывает огромное множество задач. Т.е. я думаю что вполне возможно довольно долго работать на D, вообще не заглядывая в те разделы библиотеки.
Здравствуйте, DarkEld3r, Вы писали:
DE>Кстати, правильно ли я понимаю, что свой аналог хеш-таблицы (ассоциативного массива) с таким же синтаксисом, как встроенные (ValueType [KeyType]), сделать нельзя?
С чего это нельзя? Собственно я уже даже видел подобные реализации, потому как встроенная реализация не сохраняет порядок элементов, а там для задачи он был нужен.
который позволяет полностью забыть о BidirectionalRange, как о кошмарном сне. )))
А вот если у тебя такая задача, каким бы был идиоматичный код на D?
Есть массив целых чисел, нужно найти искомое число, потом отсчитать вниз 2 четных числа, а потом наверх 5 нечетных.
Т.е. для массива 1,2,3,4,5,6,7,8,9,10,11,12 мы находим 5, потом отсчитываем 2 четных числа вниз (4,2), потом 5 нечетных вверх (3,5,7,9,11) — ответ 11.
Мне вот не приходит в голову, как такую задачу решать на диапазонах. А на итераторах все естественно.
Здравствуйте, alex_public, Вы писали:
EP>>То же std::search спокойно работает для всего начиная от ForwardIterator, без всякого дополнительного специального кода внутри. _>Ну так для Forward и в D всё отлично. Кривым выглядит именно Bidirectional.
Я о том, что код у std::search может содержать реализацию только для ForwardIterator, и для всего остального будет работать без дополнительных движений. Без всяких isSomeString и isRandomAccessRange, и при этом даже будет быстрее, так как не имеет лишних операций.
EP>>2. Специальная обработка строк в алгоритмах библиотеки — это самый что ни на есть костыль, обходящий проблемы Range, да и то не везде подставленный. _>Строки то не простые, а utf8/utf16. Скажем если будем сравнивать с C++, то там в стандартной библиотеке нет вообще никакой поддержки подобного.
Есть литералы UTF-8/16/32, итераторов в стандартной библиотеке пока нет, но есть во внешних.
_>Далее, в большинстве случаев эти костыли сводятся не к написанию новой ветки алгоритма, а к добавлению строк в static if для ветки RandomAccess. Ну и т.к. это всё во время компиляции, то никакого оверхеда не приносит. Т.е. вне зависимости от того хорошие Range или плохие, идея делать алгоритмы в несколько веток (и соответственно каждая ветка более оптимизированная) под разные тип данных прослеживается много где в D и не кажется мне плохой. Кстати, благодаря перегрузке по типу шаблонного параметра, это ещё и частенько реализуется в виде отдельных функций. Т.е. наглядно и расширяемо.
Эта идея естественно хорошая, и применяется в стандартном C++ начиная с первой его версии — C++98. Как раз концепции помогут делать перегрузки ещё проще и элегантней.
Другое дело когда эти ветки приходится писать не для оптимизации, а для получения хоть чего-то полезного.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Здравствуйте, minorlogic, Вы писали:
EP>>>Взять например те же ranges — они проигрывают итераторам по производительности by-design M>>Этого не понял , ranges же легко делать поверх итераторов , где там производительность потеряется ?
EP>Ranges действительно легко делать поверх итераторов — например Boost.Range. Но в D нет итераторов — там сразу Range.
М... могу предположить что диапазон из одного элемента вместо указателя использует Range, и в этом накладные расходы ?
Здравствуйте, jazzer, Вы писали:
J>А вот если у тебя такая задача, каким бы был идиоматичный код на D?
Эм, я не знаю какой был бы идиоматичный код на D. Я в нём пока что совсем не спец., а так присматриваюсь понемногу. )))
J>Есть массив целых чисел, нужно найти искомое число, потом отсчитать вниз 2 четных числа, а потом наверх 5 нечетных. J>Т.е. для массива 1,2,3,4,5,6,7,8,9,10,11,12 мы находим 5, потом отсчитываем 2 четных числа вниз (4,2), потом 5 нечетных вверх (3,5,7,9,11) — ответ 11.
J>Мне вот не приходит в голову, как такую задачу решать на диапазонах. А на итераторах все естественно.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Я о том, что код у std::search может содержать реализацию только для ForwardIterator, и для всего остального будет работать без дополнительных движений. Без всяких isSomeString и isRandomAccessRange, и при этом даже будет быстрее, так как не имеет лишних операций.
Ну быстрее то вряд ли, т.к. там все эти ветвления в основном времени компиляции.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Да какая разница куда заглядывать — в описание встроенных в язык хэш-таблиц или в описание библиотечных (причём стандартная библиотека это практически часть языка). А заглядывать в любом случае придётся — например чтобы правильно сделать хэширование для своего типа, или хотя бы как правильно удалить. EP>У нас же нет задачи высадится на остров взяв собой только компилятор, потому что стандартная библиотека в чемодан не помещается
Например я заглянул в std.container только в следствие нашей дискуссии тут. Хотя при этом у нас есть некий небольшой проектик на D.
Здравствуйте, alex_public, Вы писали:
EP>>Я о том, что код у std::search может содержать реализацию только для ForwardIterator, и для всего остального будет работать без дополнительных движений. Без всяких isSomeString и isRandomAccessRange, и при этом даже будет быстрее, так как не имеет лишних операций. _>Ну быстрее то вряд ли, т.к. там все эти ветвления в основном времени компиляции.
Я не про static if'ы, а например про это. В версии с итераторами этого не будет вообще, by-design.
EP>Выше уже много примеров было: лишняя работа на каждой итерации в std::find, partition, search. Плохая комбинируемость приводящая к лишним проходам, копиям, созданием новых типов range на ровном месте, пониженная категория результирующих range.
Это собственно и вытекает из избыточности.
EP>То что где-то будет хранится два итератора, вместо одного само по себе не является серьёзной проблемой. А вот то что нельзя взять вот такие два range, в каждом из которых один элемент, и получить бесплатно range содержащий все элементы между этими двумя — это уже алгоритмическая ивалидность.
Тут у меня ступор , почему нельзя бесплатно ? ну или с незначительными расходами (на откуп оптимизатору)
Здравствуйте, D. Mon, Вы писали:
DM>Здравствуйте, DarkEld3r, Вы писали:
DE>>Кстати, правильно ли я понимаю, что свой аналог хеш-таблицы (ассоциативного массива) с таким же синтаксисом, как встроенные (ValueType [KeyType]), сделать нельзя?
DM>По идее, ничто не мешает — описываешь структуру/класс с оператором обращения по индексу и вперед.
А всякие вещи типа "in"?
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>То что где-то будет хранится два итератора, вместо одного само по себе не является серьёзной проблемой. А вот то что нельзя взять вот такие два range, в каждом из которых один элемент, и получить бесплатно range содержащий все элементы между этими двумя — это уже алгоритмическая ивалидность.
Я бы сказал это здравый смысл и обеспечение корректности. Твои слова звучат как "А вот то что нельзя взять произвольное число, превратить в указатель и получить бесплатно итератор — это уже алгоритмическая ивалидность". Возможность лепить range из произвольных не связанных друг с другом итераторов — слишком опасная граната, слишком много ног можно ей оторвать. Так что это просто такой design choice в пользу корректности.
Только что на эту тему неплохие слова услышал: http://youtu.be/TS1lpKBMkgg?t=16m28s
Здравствуйте, DarkEld3r, Вы писали:
DE>>>Кстати, правильно ли я понимаю, что свой аналог хеш-таблицы (ассоциативного массива) с таким же синтаксисом, как встроенные (ValueType [KeyType]), сделать нельзя? DM>>По идее, ничто не мешает — описываешь структуру/класс с оператором обращения по индексу и вперед. DE>А всякие вещи типа "in"?
Это уже синтаксис, он так просто не меняется. Делай функцию. Будет вместо "x in a" "x.isIn(a)" или "a.has(x)".
Здравствуйте, -n1l-, Вы писали:
N>Пользуясь случаем хочу спросить. N>На чем в linux'e больше программируют(чистых сях или инкрементированных) и что(встраиваемые системы, десктопчики, мобилки, веб)?
Кто на чем может, на том и программирует. C++ присутствует всерьез: (кроссплатформенная) библиотека Qt — едва ли не лучшее, что есть в хозяйстве. Я тоже побаиваюсь, что выбор языка еще даст о себе знать, но пока полет нормальный. В смысле, Qt-приложения заметно выигрывают на фоне своих альтернатив на других фреймворках, в среднем по больнице. Сложно все, одним словом. С другой стороны, если пользоваться биндингами для Питона (PyQt, PySide), можно не заметить, что там внутри .
Здравствуйте, D. Mon, Вы писали:
DM>Здравствуйте, DarkEld3r, Вы писали:
DE>>>>Кстати, правильно ли я понимаю, что свой аналог хеш-таблицы (ассоциативного массива) с таким же синтаксисом, как встроенные (ValueType [KeyType]), сделать нельзя? DM>>>По идее, ничто не мешает — описываешь структуру/класс с оператором обращения по индексу и вперед. DE>>А всякие вещи типа "in"?
DM>Это уже синтаксис, он так просто не меняется. Делай функцию. Будет вместо "x in a" "x.isIn(a)" или "a.has(x)".
Ну я про синтаксис и спрашивал.
Возможно, это глупая придирка, просто не уверен, что мне нравится идея добавлять "настолько высокоуровневые" вещи "прямо в язык" со специальным отдельным синтаксисом. В этом плане стл больше нравится — контейнеры/алгоритмы там ведь на правах обычных классов/функций. Соответственно при переходе от стандартных вещей к сторонним библиотекам (или своим велосипедам) особо ничего и не поменяется (при желании сохранить "интерфейс").
Выигрыш в краткости ведь небольшой, но уже добавляются дополнительные ключевые слова. "in expression" ведь только для ассоциативных массивов используется?
Здравствуйте, DarkEld3r, Вы писали:
DM>>Это уже синтаксис, он так просто не меняется. Делай функцию. Будет вместо "x in a" "x.isIn(a)" или "a.has(x)". DE>Ну я про синтаксис и спрашивал.
А, вон меня рядом поправили, можно и in задействовать для своих типов. Вот насчет своих литералов уже не уверен.
DE>Возможно, это глупая придирка, просто не уверен, что мне нравится идея добавлять "настолько высокоуровневые" вещи "прямо в язык" со специальным отдельным синтаксисом. В этом плане стл больше нравится — контейнеры/алгоритмы там ведь на правах обычных классов/функций. Соответственно при переходе от стандартных вещей к сторонним библиотекам (или своим велосипедам) особо ничего и не поменяется (при желании сохранить "интерфейс").
Я думаю, при переходе к сторонним библиотекам на С++ почти всегда будет другой интерфейс у контейнеров и придется вообще все переписывать. Насколько просто проходит переход между контейнерами STL, MFC, Qt, WxWidgets? У всех свои, похожие, но тем не менее достаточно разные, чтобы пришлось переписывать код. Что до специального синтаксиса, то опыт популярных "высокоуровневых" языков вроде перла/питона/руби/похапе и пр. показал, что они во многом так удобны именно из-за наличия подобных структур данных сразу в языке, без необходимости подключения дополнительных библиотек. Это достаточно базовые вещи, чтобы иметь их в приличном языке сразу.
Здравствуйте, D. Mon, Вы писали:
EP>>То что где-то будет хранится два итератора, вместо одного само по себе не является серьёзной проблемой. А вот то что нельзя взять вот такие два range, в каждом из которых один элемент, и получить бесплатно range содержащий все элементы между этими двумя — это уже алгоритмическая ивалидность. DM>Я бы сказал это здравый смысл и обеспечение корректности. Твои слова звучат как "А вот то что нельзя взять произвольное число, превратить в указатель и получить бесплатно итератор — это уже алгоритмическая ивалидность".
в стандартной библиотеке, по которому видно к чему эта ограниченность приводит — к абсолютно ненужному коду в алгоритмах, обслуживающему только узкие специальные случаи, хотя при нормальном дизайне достаточно было бы кода для одного общего случая.
Или, например то, что по двусвязному списку нельзя пройтись в обратном направлении тому откуда мы пришли — это тоже вполне конкретная алгоритмическая инвалидность.
Это не какие-то сферические касты целых чисел в итераторы, а вполне реальные алгоритмические ограничения
DM>Возможность лепить range из произвольных не связанных друг с другом итераторов — слишком опасная граната, слишком много ног можно ей оторвать. Так что это просто такой design choice в пользу корректности.
Да нет тут ничего опасного — в большинстве кода пусть используются структура с парой итераторов, большинство даже не будет знать что там внутри, но в тех местах где есть соответствующая потребность — пусть будет возможность достать эти итераторы, а не подставлять костыли (которые ни разу не безопасны).
С тем же успехом можно вообще запретить все range/view — так как они могут протухать — и ни какой GC тут не спасёт.
DM>Только что на эту тему неплохие слова услышал: DM>http://youtu.be/TS1lpKBMkgg?t=16m28s
You have to write correct code. If you want to prove it correct — wonderful. You cannot make it correct by bizarre syntactic limitations. It's just cannot be done.
In some sense, Turing machine is fundamentaly unsafe — it could loop forever. As long as you give me while statement — I could write an unsafe program.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Или, например то, что по двусвязному списку нельзя пройтись в обратном направлении тому откуда мы пришли — это тоже вполне конкретная алгоритмическая инвалидность.
Если мы откуда-то пришли, значит мы там уже были и могли запомнить это место (.save), зачем туда опять пешком идти?
DM>>Возможность лепить range из произвольных не связанных друг с другом итераторов — слишком опасная граната, слишком много ног можно ей оторвать. Так что это просто такой design choice в пользу корректности.
EP>Да нет тут ничего опасного — в большинстве кода пусть используются структура с парой итераторов, большинство даже не будет знать что там внутри, но в тех местах где есть соответствующая потребность — пусть будет возможность достать эти итераторы, а не подставлять костыли
Достать итераторы — да, дело хорошее. Но я же про другое — про возможность слепить range из несвязанных итераторов. Это обратная операция, и она примерно настолько же ошибкоемкая как прямая работа с указателями: да, если соблюдать осторожность? написать корректный код можно, но шанс наступить на мину очень велик.
EP>С тем же успехом можно вообще запретить все range/view — так как они могут протухать — и ни какой GC тут не спасёт.
В иных языках так и сделали — зафорсили иммутабельность. Корректность еще возрасла. Однако если в каком-то одном месте мы допустили возможность ошибок, это еще не повод плодить такие места дальше. Вопрос того, насколько язык помогает или мешает писать корректный код, он не черно-белый, не 1 или 0, тут есть градации. D тут ближе к корректности, чем С++, некоторые другие языки еще ближе.
EP>Вот правильные слова (~4 минуты, [16m00s, 19m42s) ):
Да, очень правильные — при его дизайне с итераторами действительно нет возможности проверить, что два итератора относятся к одному списку. А подход с range эту задачу успешно решает. И в этом их большое преимущество. Что до следующих его слов, то языки вроде Rust и ATS отлично показывают, что подобные проверки корректности (pointer aliasing) вполне можно проводить в компайл-тайме, просто нужна хорошая система типов и несколько другой язык, не С++. Что до МТ и while, то можно и без полноты по Тьюрингу прекрасно программы писать, которые делают все что нужно и гарантированно не виснут. См. тот же ATS, а также Idris, Agda.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>You have to write correct code. If you want to prove it correct — wonderful. You cannot make it correct by bizarre syntactic limitations. It's just cannot be done. EP>In some sense, Turing machine is fundamentaly unsafe — it could loop forever. As long as you give me while statement — I could write an unsafe program. EP>[/q]
Раз нельзя сделать тотально корректным — значит ничего делать не нужно? Отличная точка зрения.
А вечные циклы теоретически можно и запретить. И так неизбежно и будет, с ростом мощи компиляторов. (Ну, останется 0,001% программ, где будет присутствовать циклы, доказать завершимость которых не удастся, такие программы напишут на Ц )
Здравствуйте, D. Mon, Вы писали:
EP>>Или, например то, что по двусвязному списку нельзя пройтись в обратном направлении тому откуда мы пришли — это тоже вполне конкретная алгоритмическая инвалидность. DM>Если мы откуда-то пришли, значит мы там уже были и могли запомнить это место (.save), зачем туда опять пешком идти?
Запоминать каждое состояние range которое мы посетили? Машина Тьюринга как-то умеет обходится без этого:
DM>Достать итераторы — да, дело хорошее. Но я же про другое — про возможность слепить range из несвязанных итераторов. Это обратная операция, и она примерно настолько же ошибкоемкая как прямая работа с указателями: да, если соблюдать осторожность? написать корректный код можно, но шанс наступить на мину очень велик.
Она ошибкоёмкая только в плохом коде, в котором и так вообще всё ошибкоёмкое.
Например тут:
class Foo
{
// only internals:typedef std::list<Bar> List;
List something
vector<List::iterator> chunks;
public:
// ...
};
вообще никак нельзя смешать итераторы из разных range'ей — опасность сильно преувеличенна.
Единственное зачем нужно следить — это добавлять итераторы в вектор в возрастающем порядке, но инварианты-то везде есть.
EP>>С тем же успехом можно вообще запретить все range/view — так как они могут протухать — и ни какой GC тут не спасёт. DM>В иных языках так и сделали — зафорсили иммутабельность. Корректность еще возрасла. Однако если в каком-то одном месте мы допустили возможность ошибок, это еще не повод плодить такие места дальше. Вопрос того, насколько язык помогает или мешает писать корректный код, он не черно-белый, не 1 или 0, тут есть градации. D тут ближе к корректности, чем С++, некоторые другие языки еще ближе.
auto myfind(Range, T)(Range r, T t)
{
size_t n = 0;
auto left = r.save;
while(!r.empty && r.front != t) {
r.popFront();
n++;
}
return tuple(left.takeExactly(n), r);
}
// versustemplate<typename I, typename T>
I find(I first, I last, const T& x)
{
while(first != last && *first != x)
++first;
return first;
}
В первом варианте даже не весь код показан — нет реализации takeExactly, нет костыля для строк и массивов, а во втором случае — это полный код. И корректность какого из вариантов легче достигается? По-моему очевидно
Да, при использовании только диапазонов нельзя смешать что-то совсем несвязанное — но толку от этого, если код алгоритмов распухает в разы?
Код в котором нет каких-то ошибок свойственных только итераторам, но не выполняющий основную свою основную функцию — не достигает постусловия (которые намного труднее достичь когда этого кода в разы больше) — никому не нужен.
EP>>Вот правильные слова (~4 минуты, [16m00s, 19m42s) ): DM>Да, очень правильные — при его дизайне с итераторами действительно нет возможности проверить, что два итератора относятся к одному списку. А подход с range эту задачу успешно решает. И в этом их большое преимущество.
На RandomAccessRange вылезают те же проблемы, только даже ещё хуже.
Как ты проверишь что индекс принадлежит правильному диапазону? В случае итераторов ещё можно включать проверки в debug — а с индексами что делать?
DM>Что до МТ и while, то можно и без полноты по Тьюрингу прекрасно программы писать, которые делают все что нужно и гарантированно не виснут. См. тот же ATS, а также Idris, Agda.
Согласен — специальные языки действительно полезны.
DE>без "import std.array;" работать не будет. То есть мы всё равно вынуждены подключать библиотеку. DE>Насчёт иметь в языке — мне не понятно чем стандартная библиотека хуже. Вот то, что С++ довольно долго не имел хеш таблиц стандартных — это, конечно, не здорово. Но эти времена прошли.
std.array — это как раз обёртка вокруг стандартных массив, для поддержки диапазонов (std.range), которые являются именно библиотечной конструкцией. К самим массивам это отношения не имеет. У массивов всегда есть просто test.length.
Мелкие замечания: круглые скобки после empty не нужны, а квадратные принято ставить после типа, а не переменной (хотя тут вообще auto хватило бы).
Здравствуйте, DarkEld3r, Вы писали:
DM>>Что до специального синтаксиса, то опыт популярных "высокоуровневых" языков вроде перла/питона/руби/похапе и пр. показал, что они во многом так удобны именно из-за наличия подобных структур данных сразу в языке, без необходимости подключения дополнительных библиотек. Это достаточно базовые вещи, чтобы иметь их в приличном языке сразу.
DE>Тут я немного не понял. Даже вот такая фигня:
test.empty(); DE>без "import std.array;" работать не будет.
Будет работать "test.length==0". empty — уже второстепенная функция, ей можно и в библиотеке побыть.
DE>Насчёт иметь в языке — мне не понятно чем стандартная библиотека хуже. Вот то, что С++ довольно долго не имел хеш таблиц стандартных — это, конечно, не здорово. Но эти времена прошли.
Теоретически — если нечто реализуется чисто библиотечно, то вся его логика должна быть в библиотеке, а когда это нечто встроено в язык, то о нем знает компилятор и может применять свою особую компиляторную магию для большей эффективности. Тот же foreach делать без лишних лямбд.
Only truly useful thing is to decompose your program into clear subroutines, clear units, which you understand. That is the only thing I know which works.
ARK>А вечные циклы теоретически можно и запретить. И так неизбежно и будет, с ростом мощи компиляторов. ARK>(Ну, останется 0,001% программ, где будет присутствовать циклы, доказать завершимость которых не удастся, такие программы напишут на Ц )
Алан Тьюринг недавно сказал, что у тебя такого компилятора не было и быть не может, и я ему верю
Рост мощи никак не решит halting problem. Разве что можно закрепить на законодательном уровне: "Наговнокодил? 15 суток!"
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>>>Или, например то, что по двусвязному списку нельзя пройтись в обратном направлении тому откуда мы пришли — это тоже вполне конкретная алгоритмическая инвалидность. DM>>Если мы откуда-то пришли, значит мы там уже были и могли запомнить это место (.save), зачем туда опять пешком идти? EP>Запоминать каждое состояние range которое мы посетили?
Зачем каждое? Какую задачу мы решаем?
Рэнджи и итераторы применяются для работы с контейнерами и ленивыми потоками данных. 99,5325371% реального кода с ними сводятся к iterate/filter/map/reduce/find, которые все работают в один проход. Желание ерзать итератором взад-вперед и итерировать UTF-8 строки задом-наперед — это что-то очень странное. Да, для таких странностей стандартная библиотека D может быть не очень годится, их можно делать руками, если очень хочется.
EP>Корректность достигается правильной декомпозицией: EP>auto myfind(Range, T)(Range r, T t) EP>// versus EP>template<typename I, typename T> EP>I find(I first, I last, const T& x) EP>[/ccode] В первом варианте даже не весь код показан — нет реализации takeExactly, нет костыля для строк и массивов, а во втором случае — это полный код. И корректность какого из вариантов легче достигается? По-моему очевидно
Ты уже несколько раз этот код цитировал. И пытался из результата своего find строить "первую часть" диапазона для однопроходного итератора. Т.е. действительно очевидно, что твой вариант больше подвержен ошибкам. Мы это уже обсудили, зачем повторять?
EP>Да, при использовании только диапазонов нельзя смешать что-то совсем несвязанное — но толку от этого, если код алгоритмов распухает в разы?
Если содержимое стандартной библиотеки распухает — мне не страшно. Зато пользовательский код, ее использующий, получается коротким и корректным. А вот с STL'ными итераторами он практически всегда пухлый и уродливый.
DM>>Да, очень правильные — при его дизайне с итераторами действительно нет возможности проверить, что два итератора относятся к одному списку. А подход с range эту задачу успешно решает. И в этом их большое преимущество.
EP>На RandomAccessRange вылезают те же проблемы, только даже ещё хуже. EP>Как ты проверишь что индекс принадлежит правильному диапазону? В случае итераторов ещё можно включать проверки в debug — а с индексами что делать?
Опять повторяемся. Еще раз спрошу: как обращение по произвольному индексу в случае итераторов может быть безопаснее, чем в случае ренджей?
И какую конкретно проблему ты имел в виду по той ссылке?
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Кстати, насчёт "опасных" итераторов — в общем случае takeExactly не делает проверок на empty: EP>void popFront() { _input.popFront(); --_n; } EP> Спокойно можно выйти за границы.
Если делать несколько раз popFront, не проверяя на empty? Ну так в пользовательском коде такой низкоуровневой работы не будет, а будет либо foreach, либо передача в другую функцию, потребляющую range. А в библиотечном коде это был бы баг, да, но маловероятный.
Здравствуйте, AlexRK, Вы писали:
EP>>[q] EP>>Only truly useful thing is to decompose your program into clear subroutines, clear units, which you understand. That is the only thing I know which works. ARK>Да, это тоже очень важно. Но что важнее, статически доказанная безошибочность (конечно, только в плане отсутствия исключений, но не в плане соответствия ТЗ) или ясность кода — затрудняюсь сказать. ИМХО, в равной степени важно.
Там где система типов может отловить целый класс ошибок, и не мешает при этом разработке — то естественно, почему бы не использовать.
Но если она ловит одни ошибки(да и то в редких случаях, причём которые без неё ловятся assert'ами), но тем самым заставляет писать на порядок больше кода — то это сомнительная выгода
EP>>Алан Тьюринг недавно сказал, что у тебя такого компилятора не было и быть не может, и я ему верю ARK>Почему не может-то, уже есть примеры типа ATS или Perfect Developer, правда очень уж многословные и с весьма корявым синтаксисом.
Пока нам доступна вся мощь МТ — в общем случае определить зациклится программа на входных данных или нет, не получится.
Если от этой мощи отказываемся — то вполне возможно.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Как ты проверишь что индекс принадлежит правильному диапазону? В случае итераторов ещё можно включать проверки в debug — а с индексами что делать?
Вообще то проверка границ у массивов в D встроенная. Правда по умолчанию она выключена (@system). Но легко включается или флагами компилятора на весь проект или спец.атрибутом (@trusted или @safe) прямо в коде.
Здравствуйте, alex_public, Вы писали:
_>std.array — это как раз обёртка вокруг стандартных массив, для поддержки диапазонов (std.range), которые являются именно библиотечной конструкцией. К самим массивам это отношения не имеет. У массивов всегда есть просто test.length.
Ок, теперь понятно.
_>Мелкие замечания: круглые скобки после empty не нужны, а квадратные принято ставить после типа, а не переменной (хотя тут вообще auto хватило бы).
auto как раз попробовал использовать, но тупо заменил им тип не убрав скобки после переменной и получил ошибку.
Здравствуйте, D. Mon, Вы писали:
DM>Будет работать "test.length==0". empty — уже второстепенная функция, ей можно и в библиотеке побыть.
Ну вот именно это разделение мне и не кажется логичным...
DM>Теоретически — если нечто реализуется чисто библиотечно, то вся его логика должна быть в библиотеке, а когда это нечто встроено в язык, то о нем знает компилятор и может применять свою особую компиляторную магию для большей эффективности. Тот же foreach делать без лишних лямбд.
Согласен, просто не уверен, что хеш таблицам надо именно в языке быть. Впрочем, это совсем не важный недостаток, если недостаток вообше.
Пользуясь случаем, спрошу — в студии при использовании вижуал Д никакого интелисенса нет. С этим ничего нельзя поделать?
Здравствуйте, alex_public, Вы писали:
_>Здравствуйте, jazzer, Вы писали:
J>>А вот если у тебя такая задача, каким бы был идиоматичный код на D?
_>Эм, я не знаю какой был бы идиоматичный код на D. Я в нём пока что совсем не спец., а так присматриваюсь понемногу. )))
J>>Есть массив целых чисел, нужно найти искомое число, потом отсчитать вниз 2 четных числа, а потом наверх 5 нечетных. J>>Т.е. для массива 1,2,3,4,5,6,7,8,9,10,11,12 мы находим 5, потом отсчитываем 2 четных числа вниз (4,2), потом 5 нечетных вверх (3,5,7,9,11) — ответ 11.
J>>Мне вот не приходит в голову, как такую задачу решать на диапазонах. А на итераторах все естественно.
_>
Не, ну это неинтересно, я надеялся код на диапазонах увидеть, а массив и индексы...
_>А на C++ ты бы какой код взял? )
Ну что-нть вроде такого (пишу в браузере)
template<class It, class Val>
It f25(It begin, It end, Val val)
{
auto found = find( begin, end, val );
auto even2 = prev(make_filter_iterator( is_even, found ), 2);
auto odd5 = next(make_filter_iterator( is_odd, even2.base() ), 4);
return odd5.base();
}
код будет работать с любыми двунаправленными итераторами — хоть массив, хоть двусвязный список...
Можно и честно через обратный итератор, если смущает "-2":
template<class It, class Val>
It f25(It begin, It end, Val val)
{
auto found = find( begin, end, val );
auto back_even2 = next(make_filter_iterator( is_even, make_reverse_iterator(found) ), 1);
auto odd5 = next(make_filter_iterator( is_odd, back_even.base().base() ), 4);
return odd5.base();
}
(1 и 4 — потому что началом считается первый, удовлетворяющий условию)
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Там где система типов может отловить целый класс ошибок, и не мешает при этом разработке — то естественно, почему бы не использовать. EP>Но если она ловит одни ошибки(да и то в редких случаях, причём которые без неё ловятся assert'ами), но тем самым заставляет писать на порядок больше кода — то это сомнительная выгода
Пока что все, кто переписывал что-то с С++ на D, сообщают об уменьшении размеров кода.
EP>Пока нам доступна вся мощь МТ — в общем случае определить зациклится программа на входных данных или нет, не получится. EP>Если от этой мощи отказываемся — то вполне возможно.
Это не "мощь", это просто свойство, отказавшись от которого, мы ничуть не теряем в "мощи" (кроме как "мощи" совершать глупости). Осмысленные алгоритмы вполне себе записываются на тотальных языках с проверкой завершимости.
Здравствуйте, D. Mon, Вы писали:
DM>Да, для таких странностей стандартная библиотека D может быть не очень годится, их можно делать руками, если очень хочется.
Так о том и речь, что для этого не годится. Странности это или нет другой вопрос. Вообще — всё для чего они не годятся можно назвать странностями
DM>Ты уже несколько раз этот код цитировал. И пытался из результата своего find строить "первую часть" диапазона для однопроходного итератора.
Я не пытался, это бессмысленно. Для однопроходного я пытался получить вторую часть — а у тебя там был .save(), который есть только у forward.
DM>Т.е. действительно очевидно, что твой вариант больше подвержен ошибкам. Мы это уже обсудили, зачем повторять?
В полном варианте find для range будет реализация takeExactly и костылей для RandomAccess и isSomeString — в итоге займёт строк сто, а в моём варианте их 7. Разве не очевидно что более подвержено ошибкам?
EP>>Да, при использовании только диапазонов нельзя смешать что-то совсем несвязанное — но толку от этого, если код алгоритмов распухает в разы? DM>Если содержимое стандартной библиотеки распухает — мне не страшно. Зато пользовательский код, ее использующий, получается коротким и корректным. А вот с STL'ными итераторами он практически всегда пухлый и уродливый.
Опять 25 Итераторы элементарно апргейдятся до range'ей, и код получается корректным, и доступ к мощи остаётся
DM>Опять повторяемся. Еще раз спрошу: как обращение по произвольному индексу в случае итераторов может быть безопаснее, чем в случае ренджей?
Я уже показывал примеры — как минимум в случае итераторов будет меньше переменных, и это безопаснее.
DM>И какую конкретно проблему ты имел в виду по той ссылке?
Здравствуйте, alex_public, Вы писали:
EP>>Как ты проверишь что индекс принадлежит правильному диапазону? В случае итераторов ещё можно включать проверки в debug — а с индексами что делать? _>Вообще то проверка границ у массивов в D встроенная.
А что, например, делать с пользовательскими диапазонами?
_>Правда по умолчанию она выключена (@system). Но легко включается или флагами компилятора на весь проект или спец.атрибутом (@trusted или @safe) прямо в коде.
В реализациях STL она тоже встроена, и также есть ручки для включения/выключения. Если полагаться на эти проверки — то вообще не вижу смысла в обсуждении "опасности" итераторов.
Здравствуйте, jazzer, Вы писали:
J>Не, ну это неинтересно, я надеялся код на диапазонах увидеть, а массив и индексы...
Так я про это Евгению и пишу))) Нафиг не сдались мне эти диапазоны в D. )))
J>Ну что-нть вроде такого (пишу в браузере) J>
J>template<class It, class Val>
J>It f25(It begin, It end, Val val)
J>{
J> auto found = find( begin, end, val );
J> auto even2 = prev(make_filter_iterator( is_even, found ), 2);
J> auto odd5 = next(make_filter_iterator( is_odd, even2.base() ), 4);
J> return odd5.base();
J>}
J>
J>код будет работать с любыми двунаправленными итераторами — хоть массив, хоть двусвязный список... J>Можно и честно через обратный итератор, если смущает "-2":
Угу, симпатично и так функциональненько. Хотя по длине так же как и мой вариант в лоб. ))) Ну если убрать объявление функции конечно же.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
DM>>Ты уже несколько раз этот код цитировал. И пытался из результата своего find строить "первую часть" диапазона для однопроходного итератора. EP>Я не пытался, это бессмысленно. Для однопроходного я пытался получить вторую часть — а у тебя там был .save(), который есть только у forward.
Так ты же изначально просил функцию, возвращающую _обе_ части. Я ее и показал. Для однопроходного она смысла не имеет, поэтому использование .save абсолютно оправдано. Если нужна только вторая часть, есть уже готовые варианты find в библиотеке, и довольно короткие.
EP>В полном варианте find для range будет реализация takeExactly и костылей для RandomAccess и isSomeString — в итоге займёт строк сто, а в моём варианте их 7. Разве не очевидно что более подвержено ошибкам?
Твой вариант тоже не содержит всего кода для решения изначальной задачи (получения двух частей).
DM>>Опять повторяемся. Еще раз спрошу: как обращение по произвольному индексу в случае итераторов может быть безопаснее, чем в случае ренджей? EP>Я уже показывал примеры — как минимум в случае итераторов будет меньше переменных, и это безопаснее.
Не будет. Там, где в плюсах инкремент итератора, в D popFront. Там где в плюсах обращение по индексу, в D обращение по индексу.
DM>>И какую конкретно проблему ты имел в виду по той ссылке? EP>Использование и простых индексов и range'ей.
Здравствуйте, D. Mon, Вы писали:
EP>>В полном варианте find для range будет реализация takeExactly и костылей для RandomAccess и isSomeString — в итоге займёт строк сто, а в моём варианте их 7. Разве не очевидно что более подвержено ошибкам? DM>Твой вариант тоже не содержит всего кода для решения изначальной задачи (получения двух частей).
Если не устраивает комбинация на пользовательской стороне, то пусть будет пара range'ей — максимум станет больше на одну строчку
DM>>>Опять повторяемся. Еще раз спрошу: как обращение по произвольному индексу в случае итераторов может быть безопаснее, чем в случае ренджей? EP>>Я уже показывал примеры — как минимум в случае итераторов будет меньше переменных, и это безопаснее. DM>Не будет. Там, где в плюсах инкремент итератора, в D popFront. Там где в плюсах обращение по индексу, в D обращение по индексу.
Если бы RandomAccessRange продолжил бы изначальную линию срезания концов диапазона — и оставил бы только popFrontN/popBackN, без обычного доступа по индексу — то так бы и было, но это ещё бы снизило их применимость, тут-то хоть одумались.
А с индексами получается:
// 5 entities:
w += n;
z += n/2;
x[w] = y[z];
// versus 3 entities:
x += n;
y += n/2;
*x = *y;
Семантика кода одинаковая, но переменных в случае итераторов — меньше
DM>>>И какую конкретно проблему ты имел в виду по той ссылке? EP>>Использование и простых индексов и range'ей. DM>И почему это проблема?
Большинство проблем присущих итераторам — например, нелегальное смешивание индексов из разных диапазонов, выход за границы.
Плюс дополнительные проблемы, которых нет у итераторов — "разыменовывавшие" индекса на неправильном диапазоне, что нельзя сделать на итераторах, by-design.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>// versus 3 entities: EP>x += n; EP>y += n/2; EP>*x = *y; EP>[/ccode] Семантика кода одинаковая, но переменных в случае итераторов — меньше
Если ты так сделаешь — то опять вылезают проблемы с ростом "назад" и склейкой.
Или например помнишь лишние передёргивания в partition? Так вот, в partition который используется в quickSortImpl — этих передёргиваний нет, потому что индексы используются в качестве итераторов.
Если бы были те popFrontN которые ты показываешь — то передёргивания опять бы появились, и было бы ещё неудобней. Если думаешь что это не так — просто попробуй использовать popFrontN/popBackN в этом кусочке
Здравствуйте, VladD2, Вы писали:
VD>Ага. Это "пока" наблюдается самую малость — на протяжении 30 лет.
Ну за 30 лет в С++ многео поменялось. Но миксинов всё равно нет. зато есть POD'ы, кстати.
VD>"Например" не катит. Давай или признаем, что в области метапрограммирования С++ существенно уступает D, или вы продемонстрируете аналог генерации функции GetHashCode и мы сравним код.
Ну ты сам, что ли, не знаешь, как оно в С++ будет?
Будет что-то вроде:
Хуже то, что участвующие поля прийдётся указатьявно, лучше то, что можно выбрать какие из полей участвуют в хэше...
VD>Они банально удобно для функционального программирования, которое в D, так же поддерживается значительно лучше чем в С++ (без костылей в библиотеках).
Ну кто тебе мешает так же работать на итераторах-то? Они же все с семантикой значения.
ну напиши себе template<typename TIterator> TIterator succ( const TIterator& ); и template<typename TIterator> TIterator pred( const TIterator& ); и радуйся
Лучше поясни что делать с тем, что дишные диапазоны всё время приходится делать разного типа?
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, FR, Вы писали:
FR>compile-time reflection да хорошо, но мало, без миксинов и static if тоже будет сложно, близко по FR>выразительности не повторить.
Вместо миксинов можно CRTP заюзать, например...
Будет чуть хуже, но не принципиально.
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, Erop, Вы писали:
E>IMHO, тут намного хуже то, что, насколько я понимаю, они не просто выдают новый интервал, но ещё и интервал ДРУГОГО ТИПА, так что комбинировать их без RTTI вообще нельзя. А это уже принципиальный прокол в производительности... E>Или таки можно? E>Вот смотри, пусть у меня есть односвязанный списко букв в виде интервала, и я хочу написать функцию, которая возвращает подпоследовательность этой последовательности от начала до символа '\n', либо до конца последовательности, если '\n', либо первые 100 символов, если последовательность длиннее, и в первых 100 нет '\n'. E>Как такое написать эффективно?
— там два return'а, которые возвращают разные типы (ниже по ветке разбор). Пока был массив — там видимо работала специализация, но для общего случае оно не заведётся
Re[19]: Facebook и язык D - первый шаг к правде ;).
Здравствуйте, VladD2, Вы писали:
VD>Кого это трогает? Комитет по С++ существует не менее 20 лет. За это время гора родила мышь.
О да! С++ комитет -- это что-то с чем-то.
но мы можем посмотреть на то, каких успехов смогли добиться те, кто развивают какой-нибудь иной язык без боьших вливаний в продвижение, ну там на Ди, Хаскель, Эн2, наконец...
Ланцетник-то хотя бы родил кто-нибудь из этих людей?
В реале все мы знаем и любим плюсы, пэхэрэ, ну там пёрл, прости Господи, с питоном... Это из тех, кого мегабаксами не толкали в каждый дом.
Так что, чисто по опыту языки, которые "пробились сами" делятся на две группы
1) Очень плохие.
2) Мало кому нужные.
Плюсы -- они из первой группы, а Ди -- из второй
Главный недостаток Ди лежит не в том, что там диапазоны или ещё что-то не то, а в том, что его в продакшин пускать страшно, так как стабильных версий нет, программистов нет, библиотек нет и всё такое.
И самая адекватная реклама ди приключится, когда Александерску из фейсбука уйдёт, а ди нет...
Тошльк ты веришь, что так и будет?
А то пока что всё выглядет так, что Ди, конечно хороший язык, но что бы ставить его в продакшин надо иметь в штате человека уровня Александреску...
VD>А в какой области то у него что-то лучше?
В области числа инсталляций написанного на нём кода, в области числа LOC на нём эксплуатируемых в продакшине, в области числа программистов, которые умеют и знают и т. д... Ты и сам всё знаешь.
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, Erop, Вы писали:
E>IMHO, тут намного хуже то, что, насколько я понимаю, они не просто выдают новый интервал, но ещё и интервал ДРУГОГО ТИПА, так что комбинировать их без RTTI вообще нельзя. А это уже принципиальный прокол в производительности...
RTTI там не используется как раз. Типы выводятся и определяются статически.
E>Вот смотри, пусть у меня есть односвязанный списко букв в виде интервала, и я хочу написать функцию, которая возвращает подпоследовательность этой последовательности от начала до символа '\n', либо до конца последовательности, если '\n', либо первые 100 символов, если последовательность длиннее, и в первых 100 нет '\n'.
E>Как такое написать эффективно?
auto firstLineOr100(R)(R xs)
{
return xs.take(100).until('\n');
}
Всего и делов.
take тут берет до 100 элементов и делает это лениво, поэтому если встретится '\n', то дальше итерация не пойдет.
Re[20]: Facebook и язык D - первый шаг к правде ;).
Здравствуйте, Erop, Вы писали:
E>Главный недостаток Ди лежит не в том, что там диапазоны или ещё что-то не то, а в том, что его в продакшин пускать страшно, так как стабильных версий нет, программистов нет, библиотек нет и всё такое.
Этот замкнутый круг для всех малоизвестных языков актуален.
E>И самая адекватная реклама ди приключится, когда Александерску из фейсбука уйдёт, а ди нет... E>Тошльк ты веришь, что так и будет?
В фейсбуке точно есть и другие люди, заинтересованные в D, еще в мае на конференции человек оттуда спрашивал Ал-ку когда же наконец им можно будет официально его использовать. Кстати, у него был довольно интересный доклад там.
E>А то пока что всё выглядет так, что Ди, конечно хороший язык, но что бы ставить его в продакшин надо иметь в штате человека уровня Александреску...
На той же майской DConf были люди из компании с сотней программистов (и без Ал-ку), где вообще весь код на D. Еще Remedy Games тоже его используют, так что прецеденты уже имеются.
Здравствуйте, Erop, Вы писали:
E>IMHO, тут намного хуже то, что, насколько я понимаю, они не просто выдают новый интервал, но ещё и интервал ДРУГОГО ТИПА, так что комбинировать их без RTTI вообще нельзя. А это уже принципиальный прокол в производительности...
E>Или таки можно?
А в чём проблема? Это же и в C++ без проблем работает, а уж в D то и подавно. )
E>Вот смотри, пусть у меня есть односвязанный списко букв в виде интервала, и я хочу написать функцию, которая возвращает подпоследовательность этой последовательности от начала до символа '\n', либо до конца последовательности, если '\n', либо первые 100 символов, если последовательность длиннее, и в первых 100 нет '\n'.
E>Как такое написать эффективно?
— там два return'а, которые возвращают разные типы (ниже по ветке разбор). Пока был массив — там видимо работала специализация, но для общего случае оно не заведётся
Ну это один из вопросов, который я в Ди не просёк. Хотел бы посмотреть, что скажут по этому поводу профи в вопросе...
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, D. Mon, Вы писали:
DM>RTTI там не используется как раз. Типы выводятся и определяются статически.
В смысле? Как статически выбрать тип "первые Н" или "отсюда до обеда", если оно от данных зависит?
DM>take тут берет до 100 элементов и делает это лениво, поэтому если встретится '\n', то дальше итерация не пойдет.
Это уход от вопроса, на самом деле. Вопрос был про то, что делать, если НУЖНО ВЕТВЛЕНИЕ.
Ну, например, если в последовательности ГДЕ_ТО есть конец строки, то вернуть до него, а если нет, то первые 100 и т. д...
Или ты хочешь сказать, что обычно всегда всё можно как-то хитро лениво закодировать так, что никогда не надо ветвиться?
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Re[21]: Facebook и язык D - первый шаг к правде ;).
Здравствуйте, D. Mon, Вы писали:
DM>Этот замкнутый круг для всех малоизвестных языков актуален.
Ну да. То есть, реально, выживают не те языки, которые чем-то там абстрактным хороши, а те, которые выживают
В частности, если есть какая-то конкретная ниша, для которой язык сильно хорошо подходит/разработан, это сильный повод ему взлететь...
Ну, в целом это не тока в языках так. Вещи, идущие от практических нужд, обычно намного гармоничнее, чем идущие от идей о "правльном дизайне", например
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, alex_public, Вы писали:
_>А в чём проблема? Это же и в C++ без проблем работает, а уж в D то и подавно. )
Какая разница в данном случае Си или Ди? Вопрос в том, как использоваь такую концепцию интервалов, а не то, в каком языке её реализовывать.
В каком-то смысле этот вопрос вообще ортоганален языку. Главное что бы концепция в язык укладывалась
E>>Как такое написать эффективно?
_>
Это не эффективно, так как мы, что бы вывести 6 букв просмотрели 7...
тут можно, конечно, схимичить и взять первые 6, а потом поискать, но вдруг оба предиката будут такие, что "бесплатно" их не прокрутишь?
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, Erop, Вы писали:
E>Здравствуйте, Ikemefula, Вы писали:
I>>Я на самом деле на D смотрю с большой надеждой. Если он выстрелит нормально в фейсбуке, это будет очень большое событие
E>Смотря в куда выстрелит... А то из С++ выстрелить в ногу/голову/спину/грудь тоже неплохо можно
Здравствуйте, VladD2, Вы писали:
VD>Да вопрос то не в хэше. Вопрос в возможности решить конкретную задачу. Представь, что ты делаешь некий компонентный фреймворк или плагин и тебе нужна динамика. Вот у нас, например, парсеры динамически грузятся и кобмбинируются в составные. Берем грамматику, расширяем на лету другой и получаем С++ с поддержкой алгебраических типов данных и паттерн-матчинга .
А теперь попытаемся скрестить две библиотеки, разработанные на разных расширениях и получаем вообще малопонятнокак разрешимую клизьму...
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, Erop, Вы писали:
DM>>RTTI там не используется как раз. Типы выводятся и определяются статически. E>В смысле? Как статически выбрать тип "первые Н" или "отсюда до обеда", если оно от данных зависит? E>Вопрос был про то, что делать, если НУЖНО ВЕТВЛЕНИЕ.
Если ветвление и в разных ветках разные типы получаются, то получается, что на выходе нечто с известным интерфейсом (функциями вроде empty и popFront), но как именно они работают (какая из реализаций выбрана) определяется в рантайме. Ничто не напоминает? Правильно, таблица виртуальных функций. Для этого есть функция inputRangeObject, которая принимает input range некоторого типа (известного статически) и делает из него объект типа InputRangeObject, он будет одинаковый для всех веток.
Но когда такого ветвления нет, то можно обойтись одной статикой, без виртуальных функций.
Здравствуйте, D. Mon, Вы писали:
DM>Если ветвление и в разных ветках разные типы получаются, то получается, что на выходе нечто с известным интерфейсом (функциями вроде empty и popFront), но как именно они работают (какая из реализаций выбрана) определяется в рантайме. Ничто не напоминает? Правильно, таблица виртуальных функций. Для этого есть функция inputRangeObject, которая принимает input range некоторого типа (известного статически) и делает из него объект типа InputRangeObject, он будет одинаковый для всех веток.
Это называется type erasure — ты только и подтвердил опасение Erop'а:
E>IMHO, тут намного хуже то, что, насколько я понимаю, они не просто выдают новый интервал, но ещё и интервал ДРУГОГО ТИПА, так что комбинировать их без RTTI вообще нельзя. А это уже принципиальный прокол в производительности...
Дело в том, что в C++ любой sub-range представляется парой итераторов — и при использовании алгоритмов не появляются новые типы итераторов на ровном месте.
А тут если вызвать банальный findSplit — то уже всё, уже приплыли.
Здравствуйте, alex_public, Вы писали:
_>Сложно сказать. Но скажем средства для построения встроенных DSL (чем обычно очень любят заниматься авторы математических библиотек) в D намного сильнее чем в C++. Даже если заговорить о банальной перегрузке операторов... Разделение перегрузки оператора справа и слева уже даёт много вкусного для например матричной алгебры и т.п.
IMHO, если мы таки за рассчёты-рассчёты, то ничего лучше фортрана либо матлаба (в зависимости от того, что за рассчёты) не придумали. Это я тебе как вычматик говорю...
И библиотеки там ЛУЧШИЕ, хотя совсем перегрузками операторов не балуются при этом...
Тут IMHO, С++ будет очень сильно оверкилл. И Ди, насколько я понимаю, тоже...
ну и потом, библиотеки -- особенно их интерфейс -- это микроскопическая часть кода, вообще-то.
_>Ооо, а вот что-то подобное мы как раз сейчас и пытаемся проверить на нашем небольшом проектике. Пока по ощущениям можно будет обойтись хостингом за $10 для той же задачи, что обычно требует хостинга за $500. Но там ещё очень далеко от завершения, так что пока не буду ничего точного говорить. Тем более что это у нас как бы такой стажёрский проектик (правда пока похоже больше обучается руководитель, а не стажёр) и даже не по нашему основному профилю.
Ж
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, Ikemefula, Вы писали:
I>Подразумевается, что на D одни дураки пишут ?
Ну про С++ же подразумевается?..
Вот, например, работа с кодом, как со строкой меня в этом языке пугает, скажем...
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, alex_public, Вы писали:
_>С чего бы это? И until и take — это ленивые функции.
А если ленивость вредна?
Скажем я по этому диапазону буду потом 100500 раз елозить и не хотел бы все 100500 раз вычислять предикаты?..
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Re[23]: Facebook и язык D - первый шаг к правде ;).
Здравствуйте, D. Mon, Вы писали:
DM>(другая причина — что компилятор написан на С++).
Что же это они за 10 лет его ни на Ди ни на немерле даже не переписали-то?
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, D. Mon, Вы писали:
DM>А VMT относится к RTTI? Тогда да.
Я имел в виду, что не статика. Ну, типа нельзя подставить всё инлайн, например...
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, Erop, Вы писали:
DM>>Но когда такого ветвления нет, то можно обойтись одной статикой, без виртуальных функций. E>а в итераторах можно обойтись статикой для любого поддипазона последовательности всегда и гарантированно...
А кстати как будет выглядеть такой статический итератор, который выдает строчки из файла с таким вот динамическим условием выхода? Скажем, если первая строка "{", то выдает строчки до "}", а если нет — то просто первые 13 строк, если они там есть. И мы хотим этот итератор использовать в стандартных filter и map.
Re[24]: Facebook и язык D - первый шаг к правде ;).
Здравствуйте, D. Mon, Вы писали:
DM>А кстати как будет выглядеть такой статический итератор, который выдает строчки из файла с таким вот динамическим условием выхода? Скажем, если первая строка "{", то выдает строчки до "}", а если нет — то просто первые 13 строк, если они там есть. И мы хотим этот итератор использовать в стандартных filter и map.
Файл -- это именно то, что умеет диапазон. Типа читаем один раз и в зад ужо вернуться не могём.
А даже односвязный список может больше, не говоря уже об итераторых других типов...
Но для таких целей никто не мешает, кстати, наделать анологичных ленивых обёрток над итераторами...
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, Erop, Вы писали:
E>Файл -- это именно то, что умеет диапазон. Типа читаем один раз и в зад ужо вернуться не могём. E>Но для таких целей никто не мешает, кстати, наделать анологичных ленивых обёрток над итераторами...
А как с ними будут работать стандартные алгоритмы? Или их тоже придется переписать?
Здравствуйте, D. Mon, Вы писали:
DM>И да, как на итераторах будет выглядеть хотя бы xs.take(100).until('\n') без пробега по лишним символам?
В смысле? Если ты хочешь линивых вычислений, затолканных в тип итератора, то ничего не мешает так и сделать, тем более, что оно уже всё написано по пять раз, правда тут будет одно хитрое отличие. Мона будет в конце сказать что-то вроде .base() и получить неленивый исходный итератор...
А можно просто циулом прокрутить, если надо энергично...
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, Erop, Вы писали:
DM>>И да, как на итераторах будет выглядеть хотя бы xs.take(100).until('\n') без пробега по лишним символам?
E>В смысле? Если ты хочешь линивых вычислений, затолканных в тип итератора, то ничего не мешает так и сделать, тем более, что оно уже всё написано по пять раз
Здравствуйте, D. Mon, Вы писали:
DM>>>И да, как на итераторах будет выглядеть хотя бы xs.take(100).until('\n') без пробега по лишним символам?
E>>В смысле? Если ты хочешь линивых вычислений, затолканных в тип итератора, то ничего не мешает так и сделать, тем более, что оно уже всё написано по пять раз
DM>Пример кода можно? Конкретно для данного случая.
Если очень хочется, можешь вообще написать так, что будет просто один в один:
Скажем на плюсах будет как-то так:
auto i_begin = lazy::untill(lazy::take( xs_begin, 100 ), '\n' );
auto i_end = i.end( xz_end );
// тут что-то на стандартных алгоритмах на ленивых итераторахauto res = xxx( i_begin, i_end );
// потом можешь вернуться к исходному итератору, до которого удалось доползти, скажем так:return lazy::base( res );
Ы?
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, Erop, Вы писали:
E>Ну, например, если в последовательности ГДЕ_ТО есть конец строки, то вернуть до него, а если нет, то первые 100 и т. д...
E>Или ты хочешь сказать, что обычно всегда всё можно как-то хитро лениво закодировать так, что никогда не надо ветвиться?
Вообще говоря можно в большинстве случаев, т.к. все эти алгоритмы работы с диапазонами в D параметризуются функциями. И until в том числе. Просто я в этом примере использовал дефолтное значение ("a==b"), поэтому этого нюанса не было видно. Кстати, формально говоря в этом примере можно было и не использовать take вообще, а затащить всю нужную тебе логику в until, передав соответствующую сложную функцию. Но это было бы заметно менее красиво. )))
Re[22]: Facebook и язык D - первый шаг к правде ;).
Здравствуйте, Erop, Вы писали:
E>Ну да. То есть, реально, выживают не те языки, которые чем-то там абстрактным хороши, а те, которые выживают E>В частности, если есть какая-то конкретная ниша, для которой язык сильно хорошо подходит/разработан, это сильный повод ему взлететь...
E>Ну, в целом это не тока в языках так. Вещи, идущие от практических нужд, обычно намного гармоничнее, чем идущие от идей о "правльном дизайне", например
Нет, оно не так устроено. Хорошо взлетают новые языки, ориентированные на какую-то новую нишу. И взлёт происходит в основном за счёт развития самой ниши (при этом в неё приходят люди, которые по любому будут обучаться работать по другому), а не за счёт перераспределения доли между языками.
Если же взять D, то он очевидно нацелен не на новую нишу, а как прямая замена C/C++ в его родных нишах. Ну может быть предлагая небольшое расширение в чужие ниши, за счёт сильного инструмента построения быстрых DSL. Т.е. по сути здесь предполагается, что программисты будут оставаться на своей текущей работе и тратить время на обучение D только ради увеличения удобства. А это у нас крайне консервативный процесс. Достаточно взглянуть на то, что на дико страшном Фортране до сих пор пишут, хотя современный C++ делает его по всем параметрам...
Здравствуйте, Erop, Вы писали:
E>А встраивать один язык в другой вообще путь к запутыванию кода, IMHO, то есть маломасштабируемый и тупиковый.
Сильно зависит. Тот же парсер я с большим удовольствием, скоростью и удобством напишу на Spirit прямо внутри программы (и где он будет естественно с ней взаимодействовать, используя из контекста типы, переменные и прочая), чем буду дергать стороннюю тулзу и размазывать код по ее конфигурационным файлам.
Здравствуйте, Erop, Вы писали:
E>Скажем на плюсах будет как-то так: [c] E>auto i_begin = lazy::untill(lazy::take( xs_begin, 100 ), '\n' ); E> Ы?
Годится. А теперь давай с ветвлением логики завершения в рантайме (аналог твоего вопроса выше), и чтобы "а в итераторах можно обойтись статикой для любого поддипазона последовательности всегда и гарантированно...".
Здравствуйте, Erop, Вы писали:
E>при чём тут "наша" или "ваша" стандартная библиотека? Речь же о диапазнах и итераторах, а не о стандартной библиотеке?
Ну вот Евгений выше очень радел именно за стандартную библиотеку. Говорил, что это часть языка, и ее проблемы становятся проблемами всего языка. Вон сколько сообщений написал про одну единственную функцию поиска..
E>Кстати, как у Ди с мемоизацией? То есть если я замучу линивый поддиапазон, и потом буду ему save говорить и итерировать сто раз, он сто раз повторит вычисления, или как-то хитрее сделает?
Если просто save, то скорее всего повторит. Ежели там сложные вычисления, то вместо .save пишешь .array и получаешь все мемоизованное.
Здравствуйте, Erop, Вы писали:
E>Если очень хочется, можешь вообще написать так, что будет просто один в один: E>Скажем на плюсах будет как-то так: [c] E>auto i_begin = lazy::untill(lazy::take( xs_begin, 100 ), '\n' ); E>auto i_end = i.end( xz_end ); E>// тут что-то на стандартных алгоритмах на ленивых итераторах E>auto res = xxx( i_begin, i_end );
Не, погоди. По идее, результаты until и take начало-то одно имеют, а влияют именно на конец итерирования. Стандартный алгоритм будет же итератор с переданным end сравнивать, с чем именно он будет сравнивать и как? Или логика окончания заложена в операцию сравнения для такого итератора? Тогда это уже range, и никакой end ему не нужен по-хорошему..
E>// потом можешь вернуться к исходному итератору, до которого удалось доползти, скажем так: E>return lazy::base( res );
Если у нас в xxx был filter или map, это не имеет никакого смысла.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Библиотечный findSplit возвращает три range, два из которых результат takeExactly, а третий оригинального типа. EP>Допустим тебе в функцию передали BidirectionalRange, внутри ты сделал этот findSplit, и тебе нужно вернуть либо первый range либо последний. Как будешь делать?
Ну да, есть такое. Только ты забыл уточнить пару нюансов:
1. Описанное тобой поведение относится только к не RandomAccess диапазонам, так что удобные встроенные типы (массивы, строки) опять же сюда не попадают. А проблемы есть только у всяких SList, DList и т.п.
2. Указанная проблема является следствием ленивости, но её можно в любой момент устранить сделав .array (например).
EP>А вот на итераторах это элементарно разруливается
На итераторах можно элементарно написать код, который одновременно и ленивый и с ветвлением? )
Здравствуйте, Erop, Вы писали:
E>IMHO, если мы таки за рассчёты-рассчёты, то ничего лучше фортрана либо матлаба (в зависимости от того, что за рассчёты) не придумали. Это я тебе как вычматик говорю...
E>И библиотеки там ЛУЧШИЕ, хотя совсем перегрузками операторов не балуются при этом...
E>Тут IMHO, С++ будет очень сильно оверкилл. И Ди, насколько я понимаю, тоже...
Вообще то в роли числодробилки C++ однозначно лучший язык. Если сравнивать с Фортраном, то он предлагает намного более высокоуровневые абстракции и при этом даже чуть быстрее в умелых руках. Однако как мы видим во многих местах до сих пор используют Фортран — тут есть и тот самый консерватизм (как при переходе с C++ на D в других местах) и небольшая доля прагматизма, если мы говорим об учёных, а не программистах (C++ очень сложный, по сравнению с Фортраном).
Если говорить про D в роли числодробилки, то он предлагает ещё более удобные абстракции, менее сложен в обучение (там не обязательно разбираться во всех фичах, чтобы писать приличный код), но при этом немного медленнее и C++ и Фортрана. Так что тут весьма спорный вопрос о его применимости.
Здравствуйте, alex_public, Вы писали:
_>Вообще говоря можно в большинстве случаев, т.к. все эти алгоритмы работы с диапазонами в D параметризуются функциями. И until в том числе. Просто я в этом примере использовал дефолтное значение ("a==b"), поэтому этого нюанса не было видно. Кстати, формально говоря в этом примере можно было и не использовать take вообще, а затащить всю нужную тебе логику в until, передав соответствующую сложную функцию. Но это было бы заметно менее красиво. )))
Ну, во-первых, то же самое можно же сделать и с итераторами.
Во-вторых, ничто не мешает написать тогда и цикл, вообще-то...
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Re[23]: Facebook и язык D - первый шаг к правде ;).
Здравствуйте, alex_public, Вы писали:
E>>Ну, в целом это не тока в языках так. Вещи, идущие от практических нужд, обычно намного гармоничнее, чем идущие от идей о "правльном дизайне", например
_>Нет, оно не так устроено. Хорошо взлетают новые языки, ориентированные на какую-то новую нишу. И взлёт происходит в основном за счёт развития самой ниши (при этом в неё приходят люди, которые по любому будут обучаться работать по другому), а не за счёт перераспределения доли между языками.
Так это же тоже самое. Типа если есть ниша, где из практических соображений нужен новый язык, то на ней он взлетает. А так, из теоретических соображений и ниши всё время плодятся и языки, но не выходит всё каменный цветок жеж...
Если тебе удобнее говорить на языке "ниш", то можно попробовать обсудить что за ниша даст старт Ди?..
_>Достаточно взглянуть на то, что на дико страшном Фортране до сих пор пишут, хотя современный C++ делает его по всем параметрам...
В том-то и фигня, что не делает...
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, jazzer, Вы писали:
J>Сильно зависит. Тот же парсер я с большим удовольствием, скоростью и удобством напишу на Spirit прямо внутри программы (и где он будет естественно с ней взаимодействовать, используя из контекста типы, переменные и прочая), чем буду дергать стороннюю тулзу и размазывать код по ее конфигурационным файлам.
Но, всё-таки, ты при этом синтаксис плюсов-то не поменяешь...
А вот прикинь, что будет какой-то Фреймворк, который меняет синтаксис входного языка компилятора для того, что бы круто-круто описывать GUI декларативно, и будет другой, который мат-формулы позволит шпарить, например. И в какой-то момент тебе понадобится скрестить в одном исходнике оба...
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, D. Mon, Вы писали:
E>>Скажем на плюсах будет как-то так: [c] E>>auto i_begin = lazy::untill(lazy::take( xs_begin, 100 ), '\n' ); E>> Ы?
DM>Годится. А теперь давай с ветвлением логики завершения в рантайме (аналог твоего вопроса выше), и чтобы "а в итераторах можно обойтись статикой для любого поддипазона последовательности всегда и гарантированно...".
"динамика" в этом подходе -- плата за ленивость же. Если ленивость не нужна, то просто энергично ВЫЧИСЛЯЕШЬ нужные позиции итераторов, как угодно и возвращаешь нужную пару...
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, Erop, Вы писали:
E>Здравствуйте, jazzer, Вы писали:
J>>Сильно зависит. Тот же парсер я с большим удовольствием, скоростью и удобством напишу на Spirit прямо внутри программы (и где он будет естественно с ней взаимодействовать, используя из контекста типы, переменные и прочая), чем буду дергать стороннюю тулзу и размазывать код по ее конфигурационным файлам.
E>Но, всё-таки, ты при этом синтаксис плюсов-то не поменяешь...
Т.е. против встроенных ДСЛ типа Спирита ты ничего не имеешь и не агитируешь их выносить наружу, правильно?
E>А вот прикинь, что будет какой-то Фреймворк, который меняет синтаксис входного языка компилятора для того, что бы круто-круто описывать GUI декларативно, и будет другой, который мат-формулы позволит шпарить, например. И в какой-то момент тебе понадобится скрестить в одном исходнике оба...
Ну, в принципе, если один дсл глобальный (гуй), то есть задающий общую структуру, внутри которой выражения на хост-языке, а другой локальный на уровне этих самых выражений (формулы) — то я не вижу, почему бы им и не сочетаться...
Здравствуйте, D. Mon, Вы писали:
DM>Тогда это уже range, и никакой end ему не нужен по-хорошему..
Почему это не нужен? Просто он умеет переходить в состояние, которое считается равным его аналогу полученному из любой позиции базового итератора.
А так все те же поддиапазоны останутся...
DM>Если у нас в xxx был filter или map, это не имеет никакого смысла.
Ну тут надо выбрать -- ленивость или статика...
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, Erop, Вы писали:
DM>>Годится. А теперь давай с ветвлением логики завершения в рантайме (аналог твоего вопроса выше), и чтобы "а в итераторах можно обойтись статикой для любого поддипазона последовательности всегда и гарантированно...".
E>"динамика" в этом подходе -- плата за ленивость же. Если ленивость не нужна, то просто энергично ВЫЧИСЛЯЕШЬ нужные позиции итераторов, как угодно и возвращаешь нужную пару...
И получаешь два прохода (при поиске конца и при использовании) вместо одного. Вместо "всегда и гарантировано" получили "в некоторых случаях". Ладно, понятно.
Здравствуйте, Erop, Вы писали:
DM>>Если просто save, то скорее всего повторит. Ежели там сложные вычисления, то вместо .save пишешь .array и получаешь все мемоизованное.
E>Э-э-э, тогда уж лучше итераторы энергично вычислить, чем копию массива делать, не?
В смысле? Есть у нас, скажем, xs.map!someComputation.filter!someCondition. Как тут итераторы помогают с мемоизацией, где их тут энергично вычислять?
Здравствуйте, D. Mon, Вы писали:
E>>при чём тут "наша" или "ваша" стандартная библиотека? Речь же о диапазнах и итераторах, а не о стандартной библиотеке? DM>Ну вот Евгений выше очень радел именно за стандартную библиотеку. Говорил, что это часть языка, и ее проблемы становятся проблемами всего языка.
То о чём ты говоришь реализуется на итераторах — и until и takeExactly, и даже ленивое ветвление по {/}.
В топике шла речь про принципиальную ограниченность Range — нормальный find для bidirectional нельзя сделать, вообще никак
Здравствуйте, D. Mon, Вы писали:
DM>В смысле? Есть у нас, скажем, xs.map!someComputation.filter!someCondition. Как тут итераторы помогают с мемоизацией, где их тут энергично вычислять?
Ну, например, если нам надо в конце концов получить какой-то поддиапазон какого-то итератора, то можно его энергично вычислить и перейти к диапазону заданному не черз хитрые, обеспечивающие ленивость типы, а через тупую и простую пару итераторов.
В этом смысле и С++ с мемоизацией в рантайме всё плохо, надо как-то обесепечиить самому.
Я Ди не особо глубоко смотрел, так что просто не знаю, вдруг там есть какая-то поддержка мемоизации, в языке или в библиотеке или в сочетани того и другого...
Если всё так же, как и в плюсах, то воможность перейти от ленивого интервала к энергичному ценна, если же есть надежда на то, что, например, оптимизатор, обеспечит мемоизацию, то, это не так критично было бы...
Вот смотри, пусть у нас есть итератор/интервал букв в тексте, и мы хотим превратить его в итератор слов, в каждом из которых есть итератор букв.
В случае с итераторами всё решается прямо, типа мапом получаем итератор границ слов, потом последовательные границы берём, из каждой добываем оригинальный итератор букв и получаем диапазоны, соответствующие словам. Потом, например, можем поанализировать каждое слово так или этак и выделить границы предложений или там именных групп, например, и опять можем слова в группе итерировать, а можем буквы, а можем ещё что-то...
А как это будет на Ди-образных интервалах?..
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, D. Mon, Вы писали:
DM>И получаешь два прохода (при поиске конца и при использовании) вместо одного. Вместо "всегда и гарантировано" получили "в некоторых случаях". Ладно, понятно.
А что мешает получить нужные позиции в исходном итераторе за один проход ленивого?..
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, jazzer, Вы писали:
J>Т.е. против встроенных ДСЛ типа Спирита ты ничего не имеешь и не агитируешь их выносить наружу, правильно?
Я против фич и методов, которые дают всего лишь синтаксический сахар, но не гарантируют при этом непротиворечивости себя в большой программе...
E>>А вот прикинь, что будет какой-то Фреймворк, который меняет синтаксис входного языка компилятора для того, что бы круто-круто описывать GUI декларативно, и будет другой, который мат-формулы позволит шпарить, например. И в какой-то момент тебе понадобится скрестить в одном исходнике оба...
J>Ну, в принципе, если один дсл глобальный (гуй), то есть задающий общую структуру, внутри которой выражения на хост-языке, а другой локальный на уровне этих самых выражений (формулы) — то я не вижу, почему бы им и не сочетаться...
Ну, ты хочешь сказать, что можно для языка построенного таким образом, что можно произвольно патчить его парсер прямо из кода, можно выработать какие-то методы программирования, такие, что они гарантируют отсутсвие противоречий в синтаксисе входного языка? -- Ну, скорее всего можно. Но, если мы не навяжем эту стратегию ВСЕМ разработчикам всех фреймворков для всех целей, то рискуем нарваться на то, что сочетать два фреймворка в одной программе нам будет очень трудно...
Скажем подход, что типа мы делаем генераторы кода для DSL'ий, и каждый из генераторов запускаем непротиворечивым образом, например на файлы с другим расширением, или, там, внутри явно вызванных макросов, будет работать, скорее всего.
но, насколько я понял Влада с его концепцией языков 21-го века, он призывает проектировать язык так, что мы можем написать такой хедер или модуль или что-то ещё, что позволит писать часть кода на Си, например, или на паскале.
Потом кто-то напишет библу, которая вносит нам во входной язык Си, а кто-то такую, кто вносит паскаль. В паскале текст в {} -- это комментарий, а в Cи -- блок кода. А что получится в нашем входном языке, когда мы попробуем подключить обе библиотеки? Как там будет рулится, текст в скобках -- это бок или комментарий?
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, Erop, Вы писали:
E>но, насколько я понял Влада с его концепцией языков 21-го века, он призывает проектировать язык так, что мы можем написать такой хедер или модуль или что-то ещё, что позволит писать часть кода на Си, например, или на паскале. E>Потом кто-то напишет библу, которая вносит нам во входной язык Си, а кто-то такую, кто вносит паскаль. В паскале текст в {} -- это комментарий, а в Cи -- блок кода. А что получится в нашем входном языке, когда мы попробуем подключить обе библиотеки? Как там будет рулится, текст в скобках -- это бок или комментарий?
Но ты же где-то будешь явно указывать, что вот сейчас у нас пошел Си, а сейчас — Паскаль, правильно?
Т.е. одна макра будет с синтаксисом c_code[int main(){}], а другая — с синтаксисом paskal_code[procedure Main {comment} begin ... end]
Ну и пусть себе живут рядом в одном коде
Здравствуйте, alex_public, Вы писали:
_>На итераторах можно элементарно написать код, который одновременно и ленивый и с ветвлением? )
Конечно можно, как и на интервалах, но тогда будет динамика где-то...
Но её в любой момент можно энергично "прокачать" и снова вернуться к статике, если надо. А вот в интервалах, как они сделаны в Ди так не получится, насколько я понял...
Вот смотри, простая задача. У меня есть итератор букв в тексте, я сначала разбиваю текст на слова, потомнекоторые слова, вроде слова "плащ-палатка", например, клею обратно, и хочу в конце увидеть однородный итератор слов. Как сделать на ди-образных интервалах?
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, jazzer, Вы писали:
J>Но ты же где-то будешь явно указывать, что вот сейчас у нас пошел Си, а сейчас — Паскаль, правильно?
Ха, так можно прямо сейчас на плюсах сделать. Речь, как я понял, именно о бесшовной интеграции...
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, Erop, Вы писали:
E>Здравствуйте, jazzer, Вы писали:
J>>Но ты же где-то будешь явно указывать, что вот сейчас у нас пошел Си, а сейчас — Паскаль, правильно? E>Ха, так можно прямо сейчас на плюсах сделать. Речь, как я понял, именно о бесшовной интеграции...
Ну так а что ты понимаешь под бесшовной интеграцией?
имхо, это как раз интеграция в стиле
//C#int dbl(int x){ return x+x; }
c_code[
int triple(int x){ returndbl(x); } // use dbl
]
// back to C#var r = triple(5); // use triple
assert(r == 10);
Здравствуйте, Erop, Вы писали:
DM>>Годится. А теперь давай с ветвлением логики завершения в рантайме (аналог твоего вопроса выше), и чтобы "а в итераторах можно обойтись статикой для любого поддипазона последовательности всегда и гарантированно...".
E>"динамика" в этом подходе -- плата за ленивость же. Если ленивость не нужна, то просто энергично ВЫЧИСЛЯЕШЬ нужные позиции итераторов, как угодно и возвращаешь нужную пару...
DM>>И получаешь два прохода (при поиске конца и при использовании) вместо одного. Вместо "всегда и гарантировано" получили "в некоторых случаях". Ладно, понятно.
E>А что мешает получить нужные позиции в исходном итераторе за один проход ленивого?..
Твои же слова выше мешают — сам предложил энергично искать. Если сначала ищем, а потом используем (во время использования идет проход по итератору), получается два прохода по данным.
Здравствуйте, Erop, Вы писали:
DM>>В смысле? Есть у нас, скажем, xs.map!someComputation.filter!someCondition. Как тут итераторы помогают с мемоизацией, где их тут энергично вычислять?
E>Ну, например, если нам надо в конце концов получить какой-то поддиапазон какого-то итератора, то можно его энергично вычислить и перейти к диапазону заданному не черз хитрые, обеспечивающие ленивость типы, а через тупую и простую пару итераторов.
Так нет же, в большинстве случаев (как в предложенном примере) на выходе не будет поддиапазона входа, а будут совсем другие данные. Кстати, в некоторых случаях к исходному диапазону можно получить доступ через свойство .source у рэнджа.
E>Если всё так же, как и в плюсах, то воможность перейти от ленивого интервала к энергичному ценна, если же есть надежда на то, что, например, оптимизатор, обеспечит мемоизацию, то, это не так критично было бы...
Не, оптимизатор не настолько умен. Для таких высокоуровневых вещей нужен хаскель, в грязных языках без referential transparency компилятор никогда не будет достаточно смелым и умным для подобных оптимизаций.
E>Вот смотри, пусть у нас есть итератор/интервал букв в тексте, и мы хотим превратить его в итератор слов, в каждом из которых есть итератор букв. E>В случае с итераторами всё решается прямо, типа мапом получаем итератор границ слов, потом последовательные границы берём, из каждой добываем оригинальный итератор букв и получаем диапазоны, соответствующие словам.
В D все то же самое. Получим рэндж рэнджей.
Единственное, что так просто не выйдет, — объединить "плащ" и "палатка" в одно слово с дефисом между ними, ибо когда есть два рэнджа, информация о том, что они к одной строке относятся определенным образом, уже потеряна. Но если такая задача действительно возникнет, то просто вместо диапазонов для слов можно использовать пары индексов или пары позиция-длина. Считай, те же итераторы, только типа int.
Здравствуйте, Erop, Вы писали:
E>Конечно можно, как и на интервалах, но тогда будет динамика где-то... E>Но её в любой момент можно энергично "прокачать" и снова вернуться к статике, если надо. А вот в интервалах, как они сделаны в Ди так не получится, насколько я понял...
E>Вот смотри, простая задача. У меня есть итератор букв в тексте, я сначала разбиваю текст на слова, потомнекоторые слова, вроде слова "плащ-палатка", например, клею обратно, и хочу в конце увидеть однородный итератор слов. Как сделать на ди-образных интервалах?
Вообще не понял ни задачу, ни подразумеваемую ею проблему. Но может такой код
Здравствуйте, D. Mon, Вы писали:
DM>Твои же слова выше мешают — сам предложил энергично искать. Если сначала ищем, а потом используем (во время использования идет проход по итератору), получается два прохода по данным.
В смысле? Если есть алгоритм, где надо МНОГО раз по интервалу бегать, то сначала ищем, потом используем.
Если так уж критично сделать -1, то можно сделать итератор с мемоизацией, но я не верю, что он может быть нужен.
Что будем делать с интервалами?..
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, Ikemefula, Вы писали:
I>Так это лично твои проблемы
не-не-не, у меня нет в продакшине кода на Ди, соответственно и проблем нет...
Но вот Владу в такой ситуации что-то не нравится
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, Erop, Вы писали:
E>В смысле? Если есть алгоритм, где надо МНОГО раз по интервалу бегать, то сначала ищем, потом используем. E>Если так уж критично сделать -1, то можно сделать итератор с мемоизацией, но я не верю, что он может быть нужен.
E>Что будем делать с интервалами?..
Да не надо нам много раз бегать туда-сюда. Что за мания у вас такая по данным елозить? Я уже выше говорил: большая часть реальной работы с контейнерами и потоками сводится к iterate/filter/map/reduce/find, все они работают за один проход, и их комбинации тоже. И дивные интервалы/диапазоны/рэнджи позволяют работать так, чтобы почти всегда по данным был ровно один проход. Сейчас память очень медленная по сравнению с вычислениями, и число пробежек по данным влияет на скорость намного сильнее, чем лишний инкремент счетчика, о котором беспокоился выше Евгений. Так вот, решение с энергичными итераторами ведет к неэффективности — многократному проходу по данным. А попытка перейти на ленивые итераторы есть ничто иное как переход на рэнджи.
Здравствуйте, Erop, Вы писали:
E>Ну, например, у меня есть список букв,
Не, не верю. Ты действительно решаешь такую задачу, храня строки в *двухсвязном списке букв*? Если по ним нужно много бегать туда-сюда, то никакой итератор не сделает это быстрее, чем записать их в массив (вот и random access, все ваши проблемы с bidirectional улетучились) и работать с ним.
Здравствуйте, D. Mon, Вы писали:
DM>Не, не верю.
Почему? "буквы"-то могут быть довольно сложными структурами данных. Например результатами распознавания куска ПРОЧИТАННОГО ВСЛУХ текста, или версиями обратного криптования исходника, или ещё чем-то хитрым.
Пока обсуждение итераторы vs регионы сводится к тому, что ПРОСТЫЕ алгоритмы можно легко закодировать и на том и на том, но даже для простых нужны читы в библиотеке...
Вот тебе пример алгоритма посложнее...
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, Erop, Вы писали:
DM>>Не, не верю. E>Почему? "буквы"-то могут быть довольно сложными структурами данных.
Ну и положи в массив на них указатели.
Я к тому, что основные сложности с рэнджами возникают на довольно экзотическом случае — когда есть bidirectional, но нет random access. Это экзотика совершенно необязательная.
E>Вот тебе пример алгоритма посложнее...
В алгоритмах посложнее итераторы все равно малополезны, там структуры данных и перемещение по ним редко сводится к хождению пешком туда-сюда (линейно) по одному элементу. То же дерево возьми, по нему итераторами будешь ходить?
Здравствуйте, D. Mon, Вы писали:
DM>Ну и положи в массив на них указатели.
Ну вот и выходит, что итераторы дают больше возможностей, чем дишные интервалы, так как итераторам ничего не надо дополнительного, а интервалам нужен массив указателей...
Отдельным вопросом может быть то, нужно ли это. Ну то есть, ты тцт всё время намекаешь, что мощь итераторов избыточна, и типа скорее идёт во вред, чем в пользу. Мне, например, это не очевидно. Тем более, чот если мы говорим не о конкретных библиотеках, а о паттернах и приёмах, то итератор списка, ака указатель на ноду списка намного лучше, проще и понятнее, чем интервал списка...
То есть я бы сказал так, что если для массивов итераторы -- несколько противоестественны, то для всяких списочных структур вполне адекватны. А дишные интервалы, выходит, естественны только для вещей вроде потоков ввода, а для массивов им всё равно надо явно знать, что это массив и всё время в исходный массив лазить, или делать массивы ссылок на элементы исходного...
То есть получается, что абстракция ещё более кривая, чем итераторы...
DM>Я к тому, что основные сложности с рэнджами возникают на довольно экзотическом случае — когда есть bidirectional, но нет random access. Это экзотика совершенно необязательная.
Э-э-э, двусвязанный список/ прошитое дерево / рассованный по сегментам массив / массив пар {элемент, число повторов} / большинство графов -- это всё, по твоему экзотика?
DM>В алгоритмах посложнее итераторы все равно малополезны, там структуры данных и перемещение по ним редко сводится к хождению пешком туда-сюда (линейно) по одному элементу. То же дерево возьми, по нему итераторами будешь ходить?
Э-э-э, месье с std::map знаком?..
Вообще-то, если у меня есть какая-то состоящая из как-то свзяанных между собой, содержащих данные узлов и нам надо перебрать все узлы, то у нас есть всего два варианта.
1) Написать код, который умеет выдавать нам узлы один за другим
2) Написать код, который вызовет наш колбэк на каждом узле
(1) можно завернуть и в итераторы и в интервалы. В интервалы, как мы выше видели, выйдет хуже...
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, Erop, Вы писали:
DM>>Я к тому, что основные сложности с рэнджами возникают на довольно экзотическом случае — когда есть bidirectional, но нет random access. Это экзотика совершенно необязательная.
E>Э-э-э, двусвязанный список/ прошитое дерево / рассованный по сегментам массив / массив пар {элемент, число повторов} / большинство графов -- это всё, по твоему экзотика?
Это обычно требует более специфического обращения, чем то, что дают итераторы.
DM>>В алгоритмах посложнее итераторы все равно малополезны, там структуры данных и перемещение по ним редко сводится к хождению пешком туда-сюда (линейно) по одному элементу. То же дерево возьми, по нему итераторами будешь ходить?
E>Э-э-э, месье с std::map знаком?..
А что хорошего делают там итераторы? Указатель на конкретный элемент и пробежаться по всей коллекции — это не то, что я называю хождением по дереву, это и рэнджи все умеют. Я имел в виду более осмысленное перемещение по дереву, когда нет четко предопределенного понятия prev/next. Т.е. не вперед-назад, а вверх-влево-вправо хотя бы, ну и другие нелинейные обходы по другим структурам.
E>Вообще-то, если у меня есть какая-то состоящая из как-то свзяанных между собой, содержащих данные узлов и нам надо перебрать все узлы, то у нас есть всего два варианта.
На операции "перебрать все узлы" разница между итераторами и рэнджами незаметна. А более сложные операции требуют и более сложного обращения, итераторов там недостаточно все равно.
Здравствуйте, D. Mon, Вы писали:
DM>А что хорошего делают там итераторы?
Возможность перебрать все элементы или какое-то их подмножество, часто в определённом порядке.
Например, итератор красно-чёрного дерева, который обычно сидит в std:map::iterator позволяет передать как поддиапазон любое поддерево...
DM>На операции "перебрать все узлы" разница между итераторами и рэнджами незаметна. А более сложные операции требуют и более сложного обращения, итераторов там недостаточно все равно.
Это от операций зависит...
Но я верно понял, что ты пришёл к убеждению, что интервалы вообще ненужное УГ, а итераторы, почти такое же УГ, просто чуть лучше и мягче?
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, Erop, Вы писали:
E>Вообще-то, если у меня есть какая-то состоящая из как-то свзяанных между собой, содержащих данные узлов и нам надо перебрать все узлы, то у нас есть всего два варианта.
E>1) Написать код, который умеет выдавать нам узлы один за другим E>2) Написать код, который вызовет наш колбэк на каждом узле
E>(1) можно завернуть и в итераторы и в интервалы. В интервалы, как мы выше видели, выйдет хуже...
Ага, а вот как раз 2-ой вариант имеет прямую поддержку в D.
Нам достаточно переопределить у нашего типа Х операцию opApply (или opApplyReverse) и после этого мы сможем везде писать
foreach(х; Х){
...//тут любой код на D
}
Причём что самое главное, тут нигде нет никаких интервалов вообще. Т.е. для обычных случаев мы используем встроенные типы (массивы и словари), а для сложных случаев используем свои типы. И никаких range.
Единственная ситуация, в которой я сейчас их вспоминаю, это если вдруг очень захочется применить функции из std.algorithm к сущности не имеющей произвольного доступа к элементам (с RandomAccess сущностями функции из std.algorithm работают через срезы, а не через интервалы).
Здравствуйте, alex_public, Вы писали:
_>Причём что самое главное, тут нигде нет никаких интервалов вообще. Т.е. для обычных случаев мы используем встроенные типы (массивы и словари), а для сложных случаев используем свои типы. И никаких range.
Во-первых, в С++ точно так же.
Во-вторых, мы вроде как обсуждаем парадигмы, а не языки, в этой подветке.
но, главное, тут иное. Для foreach-то интервалы годятся, а вот для более сложных алгоритмов уже не особо...
_>Единственная ситуация, в которой я сейчас их вспоминаю, это если вдруг очень захочется применить функции из std.algorithm к сущности не имеющей произвольного доступа к элементам (с RandomAccess сущностями функции из std.algorithm работают через срезы, а не через интервалы).
Конечно же, через интервалы невозможно потому что, в силу обсуждаемой тут их убогости
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, Erop, Вы писали:
E>Во-первых, в С++ точно так же.
Не, в C++ не так совсем. Смотри ниже.
E>Во-вторых, мы вроде как обсуждаем парадигмы, а не языки, в этой подветке.
Да, но применимость этих парадигм в разных языках получается разная. Например лично я при работе на C++ использую STL постоянно, а при работе на D std.range считай что почти не использовал.
Вообще если проводить полное сравнение, то ситуация получается такая:
1. Массивы всяких разновидностей.
— В самом C++ есть кое-что встроенное, но крайне убогое. Все предпочитают использовать STL, которая в этом смысле довольно хороша.
— В D встроенные средства намного удобнее чем даже все возможности STL. Про Range при этом даже не вспоминаем.
2. Всяческие стандартные источники данных с не произвольным доступом (те же самые связные списки и т.п.).
— В самом C++ почти ничего нет, только поддержка циклов по итераторам (сущности из STL). А в STL великолепная реализация, как раз заточенная под такое.
— В самом D аналогично почти ничего нет, только поддержка циклов по диапазонам (сущности из библиотеки). В библиотеке D есть реализация через диапазоны, которая по возможностям хуже чем в STL.
3. Сложные пользовательские источники данных.
— В C++ есть минимальная поддержка через перегрузку операторов [] и *. Плюс есть возможность навесить на свой тип интерфейс контейнера STL, что даст нам возможность использовать циклы языка и алгоритмы из STL.
— В D есть гораздо большая поддержка из-за возможности перегрузки всех операторов, включая операторы среза, цикла, проверки наличия в словаре, доступа к члену (например можно реализовать контейнер Json, доступ к элементам которого будет в виде json.field) и т.п. Плюс есть возможность навесить на свой тип интерфейс диапазонов, что позволит нам использовать алгоритмы из std.algorithm (обычно нафиг не нужно для сложных типов).
В итоге, как мы видим по данному вопросу у этих двух языков в разных ситуациях есть свои плюсы и минусы. Но лично мне почему-то чаще встречаются на практике именно те ситуации (пункт 1 и 3), в которых сильнее D.
P.S. Основная деятельность у нас как раз на C++. )))
Здравствуйте, alex_public, Вы писали:
_>Нам достаточно переопределить у нашего типа Х операцию opApply (или opApplyReverse) и после этого мы сможем везде писать _>
_>foreach(х; Х){
_> ...//тут любой код на D
_>}
_>
_>Причём что самое главное, тут нигде нет никаких интервалов вообще.
Вот именно что нет — это просто передаётся continuation, со всеми вытекающими. В C++ для этого легко получить такой синтаксис:
FOREACH(x, X)
{
// ...
};
Но zip (одновременный обход двух контейнеров) на таком opApply уже не сделать.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Вот именно что нет — это просто передаётся continuation, со всеми вытекающими. В C++ для этого легко получить такой синтаксис: EP>
EP>FOREACH(x, X)
EP>{
EP> // ...
EP>};
EP>
Дааа? ) А как насчёт break и continue внутри такого кода на C++? )
Здравствуйте, alex_public, Вы писали:
EP>>Вот именно что нет — это просто передаётся continuation, со всеми вытекающими. В C++ для этого легко получить такой синтаксис: EP>>
EP>>FOREACH(x, X)
EP>>{
EP>> // ...
EP>>};
EP>>
_>Дааа? ) А как насчёт break и continue внутри такого кода на C++? )
При желании можно и break, и continue, и даже return получить (выше уже было), который кстати в D не работает
Самое простое это делать return BREAK; — точно также как делается в D, только с сахаром:
The body of the apply function iterates over the elements it aggregates, passing them each to the dg function. If the dg returns 0, then apply goes on to the next element. If the dg returns a nonzero value, apply must cease iterating and return that value. Otherwise, after done iterating across all the elements, apply will return 0.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>При желании можно и break, и continue,
Ну родные то не получится. ) Максимум макрос BREAK ввести (который внутри будет return 1 или что-то подобное и плюс ещё код анализирующий это), а это уже не то.
EP> и даже return получить (выше уже было), который кстати в D не работает
Эмм, в D return из кода в foreach (не важно по чему) как и положено вызовет выход из функции в которой расположен цикл, а не из этого куска кода. Кстати, ещё один пример того, что не будет работать на C++. Причём если попытаться и здесь макрос устроить, то всё будет намного сложнее, т.к. надо будет ещё как-то протаскивать через всю цепочку возвращаемое значение.
EP>Самое простое это делать return BREAK; — точно также как делается в D, только с сахаром:
Ну так собственно если не учитывать метапрограммирование, то D — это и есть сахар над C++. Только ведь сахар — это же тоже достаточно важно для эффективной работы. )
EP>То есть там return только целыми ограничен
Это вообще о другом. ))) Это речь про делегат, который генерирует компилятор из того куска кода и своих дополнений...
Здравствуйте, alex_public, Вы писали:
EP>>При желании можно и break, и continue, _>Ну родные то не получится. ) Максимум макрос BREAK ввести (который внутри будет return 1 или что-то подобное и плюс ещё код анализирующий это), а это уже не то.
Выше есть решение с родными break, continue и return.
EP>> и даже return получить (выше уже было), который кстати в D не работает _>Эмм, в D return из кода в foreach (не важно по чему) как и положено вызовет выход из функции в которой расположен цикл, а не из этого куска кода.
Точно? Попробуй вернуть объект какого-нибудь произвольно типа, а не int.
Здравствуйте, alex_public, Вы писали:
EP>>Выше есть решение с родными break, continue и return. _>Эээ что за решение? )
Кодт показывал код. Где-то в первой половине сообщений.
EP>>Точно? Попробуй вернуть объект какого-нибудь произвольно типа, а не int.
_>Такой код _>выводит _>
_>1
_>2
_>[5, 6]
_>
А как именно оно внутри работает? Какой путь проделывает объект от return'а?
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Если по дереву нужно ходить именно как по дереву, то нужна соответствующая концепция.
Именно!
EP>И эти координаты намного ближе к итераторам (которые, по-сути, являются координатами линейных структур), чем к Range. EP>Вот как сделать нечто подобное на тех принципах, которые используются в D Range?
По-моему, этот вопрос не имеет смысла.
Итератор — воплощение идеи координаты, прокачанный указатель, он имеет какой-то смысл в контексте дерева.
Range — воплощение идеи последовательности, для нелинейных структур смысла не имеет (за исключением перечисления элементов, но это операция вырожденная).
Здравствуйте, D. Mon, Вы писали:
EP>>И эти координаты намного ближе к итераторам (которые, по-сути, являются координатами линейных структур), чем к Range. EP>>Вот как сделать нечто подобное на тех принципах, которые используются в D Range? DM>По-моему, этот вопрос не имеет смысла. DM>Итератор — воплощение идеи координаты, прокачанный указатель, он имеет какой-то смысл в контексте дерева. DM>Range — воплощение идеи последовательности, для нелинейных структур смысла не имеет (за исключением перечисления элементов, но это операция вырожденная).
Надо шире смотреть: range — воплощение идеи работы со структурой, и её подмножествами.
BifurcateRange ещё можно придумать — отрезаем либо левую часть, либо правую, вместе с головой — прямая аналогия popFront из ForwardRange.
А вот с аналогом BidirectionalBifurcateCoordinate — опять начинаются те же проблемы, что и с BidirectionalRange.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Кодт показывал код. Где-то в первой половине сообщений.
О, я это как-то пропустил всё. А оказывается прямо тоже самое уже обсуждали. )))
Ну да, в общем то решение как у Кодта я себе и представлял. Правда до идеи дополнительной функции и цикла для отлова нативных не успел дойти.
EP>А как именно оно внутри работает? Какой путь проделывает объект от return'а?
Без понятия, но для компилятора то так протащить точно не проблема.
Здравствуйте, alex_public, Вы писали: _>Хы, так C# уступает по мощи даже C++, не говоря уже о D. )))
Мощь в чем? В реализованном и написаном коде? Ну да, только это не мощь а обширность и зрелость языка.
Шарп более выразительный за счет своих интерфейсов.
Здравствуйте, alex_public, Вы писали:
_>Хы, так C# уступает по мощи даже C++, не говоря уже о D. )))
Что значит "уступает в мощи"? Вот, например, где в С++ есть линк?..
С некоторой точки зрения мощь вообще вредна, так как требует квалифицированных усилий по управлению собой...
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, Erop, Вы писали:
E>Здравствуйте, alex_public, Вы писали:
_>>Хы, так C# уступает по мощи даже C++, не говоря уже о D. )))
E>Что значит "уступает в мощи"? Вот, например, где в С++ есть линк?..
Вроде появился с 11ым стандартом.
Здравствуйте, alex_public, Вы писали:
E>>То есть, если ты выбираешь из D и C++, и склоняешься с D, то не ясно, почему не к C#?
_>Хы, так C# уступает по мощи даже C++, не говоря уже о D. )))
Здравствуйте, -n1l-, Вы писали:
N>Здравствуйте, Erop, Вы писали:
E>>Здравствуйте, alex_public, Вы писали:
_>>>Хы, так C# уступает по мощи даже C++, не говоря уже о D. )))
E>>Что значит "уступает в мощи"? Вот, например, где в С++ есть линк?.. N>Вроде появился с 11ым стандартом.
MS так затаскал слово LINQ, что сейчас фиг поймешь что оно означает.
Что ты имеешь в виду? Сразу могу сказать, линк2sql в плюсах нет.
Здравствуйте, alex_public, Вы писали:
_>Не, я про другое. Про быстродействие кода то и обсуждать нечего — это давно известный факт. Но C++ (и тем более D) намного мощнее и при написание кода, за счёт своих средств метапрограммирования. На C# просто не реализуемы подобные вещи. Вообще.
Слишком категорично
Принципиально — реализуемы, достаточно поглядеть на nemerle. Если нужно ужесейчас — есть постшарп. Ну, или ждём рослин.
Здравствуйте, alex_public, Вы писали:
_>На C# просто не реализуемы подобные вещи. Вообще. И соответственно все модные фичи из C# повторяются на C++ (и тем более D) с помощью этих методов. Единственное преимущество C# в том, что там все эти модности есть уже из коробки, а в C++ их надо искать в сторонних библиотеках... Но на мой взгляд это мелкое преимущество не покрывает указанных недостатков.
Ну чё, давай ты покажешь нам GC, линк2скуль, йелд там всякий с делегатами на плюсах
Чё за библиотеку посмотреть надо?
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, alex_public, Вы писали:
E>>Ну чё, давай ты покажешь нам GC, линк2скуль, йелд там всякий с делегатами на плюсах
_>2. linq
Я просил таки 2sql, а не просто интервалы... и с делегатами там что у нас?..
_>- для начала он вообще не нужен в C++, т.к. тут применяется совсем другая техника (а именно итераторы), которая намного эффективнее и удобнее чем yield.
_>- для начала он вообще не нужен в C++, т.к. для подобных задач тут есть инструмент (Boost.Range) действующий по другим принципам, но такой же удобный и при этом более эффективный.
_>3. GC
_>- для начала данная тактика работы с памятью вообще не нужна в C++, т.к. не является оптимальной ни при каких сценариях. Собственно единственный сценарий, при котором GC обходит по эффективности обычную кучу C++, это когда нам требуется выделять и удалять огромное количество мелких объектов с похожим временем жизни. Но для таких целей есть и ещё более эффективное средство, а именно выделение памяти на пуле. Соответственно мы берём аллокатор из Boost.Pool и используем его в любых контейнерах из стандартной библиотеки или просто вручную.
Ну, если ты думаешь, что сказал что-то новое, то нет. Анекдот про то, что сегодня потребности в колбасе нет, придумали ещё при Ильиче...
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, Erop, Вы писали:
E>Здравствуйте, alex_public, Вы писали:
_>>На C# просто не реализуемы подобные вещи. Вообще. И соответственно все модные фичи из C# повторяются на C++ (и тем более D) с помощью этих методов. Единственное преимущество C# в том, что там все эти модности есть уже из коробки, а в C++ их надо искать в сторонних библиотеках... Но на мой взгляд это мелкое преимущество не покрывает указанных недостатков.
E>Ну чё, давай ты покажешь нам GC, линк2скуль, йелд там всякий с делегатами на плюсах
E>Чё за библиотеку посмотреть надо?
Ты еще не понял, что это или не нужно или элементарно делается с помощью буста
Теперь все ждут C++14 когда еще больше фишек буста войдет в STL\язык.
А спрашивать надо на самом деле не про языковые фишки, а про прикладные вещи:
1) Как сделать веб-приложение на C++, которое работает на обычном IIS?
2) Как сделать базоморду на C++ (разместить грид на форме).
3) Как написать одно приложение на С++ сразу для трех мобильных платформ (по аналогии http://xamarin.com/)
Я вот изучаю современный C++, он совсем не похож на тот С++, который я изучал 10 лет назад.
Это мощный функциональный (!) язык, с выводом типов, с офигенными шаблонам, автоматическим управлением памятью (!) и высокой эффективностью. Но вот все примеры, которые я на нем вижу — консольные приложения.
Где веб и мобилки? Где работа с данным и веб-сервисы? Где асинхронный IO, который не требует слишком интрузивного буста или ацккого кода?
А когда я нахожу примеры, которые взаимодействуют с внешним миром, то это или буст, или голый С. Вся красота и мощЪ языка куда-то улетучивается.
Здравствуйте, Erop, Вы писали:
E>Я просил таки 2sql, а не просто интервалы... и с делегатами там что у нас?..
А что не так с делегатами? ) Они были в языке давным давно. А с появлением лямбд в C++11 вообще стало всё удобно. Разве что синтаксис несколько сомнительный у них... Но по удобству никаких минусов не вижу.
E>Ну, если ты думаешь, что сказал что-то новое, то нет. Анекдот про то, что сегодня потребности в колбасе нет, придумали ещё при Ильиче...
Эммм, какой-то странный вывод. Разве то, что я сказал что эти вещи не нужны, отменяет тот факт (который я тоже показал), что они без проблем реализованы в разных библиотеках и т.п? Ведь спор то был что в C++ эти фичи C# нереализуемы — я показал что делается без проблем. А то, что при этом в C++ есть механизмы лучше и поэтому нет смысла использовать данные реализации, никак не отменяет факта их существования.
Кстати, раз уж у нас пошло подобное сравнение и я подробно ответил на вопрос со своей стороны... Может теперь продемонстрируешь например аналог Boost.Spirit на C#? )
Здравствуйте, alex_public, Вы писали:
_>Здравствуйте, gandjustas, Вы писали:
G>>Ты еще не понял, что это или не нужно или элементарно делается с помощью буста G>>Теперь все ждут C++14 когда еще больше фишек буста войдет в STL\язык.
_>Вот уж кому явно не идут шуточки по этой теме, так это тебе. Последний раз, как видел тебя в подобной дискуссии, ты выкинул очаровательный возглас "Давай, детка, сделай это на C++" (http://www.rsdn.ru/forum/philosophy/5208679
), а после того, как тебе показали код, делающий именно требуемое, позорно по тихому слился из дискуссии, даже не признав свою ошибку. Бедный Ikemefula за тебя там отдувался как мог.
Сорри, чувак. Это ты всех пытаешься бустом запугать.
Так вот я тебе скажу — буст в плане async и IO умеет максимум 30% от того, что умеет C#.
Лично я вижу небольшие отличия, но как раз в пользу C++ варианта:
1. Не требуется заводить специальный асинхронный аналог для каждой библиотечной функции — достаточно наличия синхронного.
2. Можно написать например такой код:
который запустит параллельное выполнение CheckServer для каждого элемента в списке и соберёт все результаты в переменной result.
G>То что там писали про async в бусте, то это не более, чем аналог yield в C#. До полноценного async, как в C# ему очень далеко. Теоретически можно сделать, но начинаются проблемы с детерминированным освобождением памяти.
Для начала в Boost'e нет никаких async. Там есть только Coroutine, причём с реализацией намного более сильной, чем в .net. А уже на базе этого любой async и т.п. делается за пару минут. Причём эта реализация за пару минут оказывается ещё и с большими возможностями (см. пункт2 выше), чем async/await из .net.
На всякий случай приведу ещё раз один из примеров реализации await/async под код выше:
Скрытый текст
using __Coro=boost::coroutines::coroutine<void()>;
void Post2UI(const void* coro);
template<typename L> auto __await_async(const __Coro* coro, __Coro::caller_type& yield, L lambda)->decltype(lambda())
{
auto f=async(launch::async, [=](){
auto r=lambda();
Post2UI(coro);
return r;
});
yield();
return f.get();
}
void CallFromUI(void* c)
{
__Coro* coro=static_cast<__Coro*>(c);
(*coro)();
if(!*coro) delete coro;
}
#define async_code(block) { __Coro* __coro=new __Coro; *__coro=__Coro([=](__Coro::caller_type& __yield){block});}
#define await_async(l) __await_async(__coro, __yield, l)
P.S. Самое забавное, что эта темка форума вроде как про язык D, который в этом смысле заметно сильнее и C++, не говоря уже о C#...
Здравствуйте, alex_public, Вы писали:
_>Здравствуйте, gandjustas, Вы писали:
G>>Перечитал, но так и не увидел полный код. Не было его тогда, нет и сейчас.
_>Ооо, замечательно. Ну тогда покажи чем этот код (твой) _>
_>private async void handler(object sender, TaskArgs args)
_>{
_> var client = new HttpClient();
_> var response = await client.GetAsync(args.Url, args.Cancellation);
_> response.EnsureSuccessStatusCode();
_> textBox.Text += await response.Content.ReadAsStringAsync();
_>}
_>
Тем что на C# это весь код. Он работает когда больше нет ни одной строки. А на C++ нужно еще исполнять танцы с бубном бустом.
_>Лично я вижу небольшие отличия, но как раз в пользу C++ варианта: _>1. Не требуется заводить специальный асинхронный аналог для каждой библиотечной функции — достаточно наличия синхронного. _>2. Можно написать например такой код: _>
Здравствуйте, gandjustas, Вы писали:
G>Тем что на C# это весь код. Он работает когда больше нет ни одной строки. А на C++ нужно еще исполнять танцы с бубном бустом.
Агаа... Т.е. чтобы сравнивать C# и C++ надо последнему запретить использовать сторонние библиотеки... Я приблизительно так и думал.
G>async_code это что?
Это макрос. Его определение было в моём сообщение (скрытый текст).
Здравствуйте, gandjustas, Вы писали:
G>А я разве говорил что надо запретить? Я лишь говорил что требуются дополнительные танцы, даже если в виде макросов (фу!).
И в чём проблема, если это пишется один раз? Можно даже в библиотечку (из одного заголовочного файла) оформить, хотя это смешно при таких размерах.
G>Как обычно макросы могут очень неоднозначно интерферировать с остальным кодом, а неудачно написанный\вставленный макрос может дать такую ошибку, что её сходу не найдешь.
Не путай с шаблонами. У макросов как раз вполне краткие и однозначные сообщения об ошибках.
G>Про типизацию вообще говорить не буду. Не зря макросы считаются не рекомендуемым способом.
И снова путаешь. Макросы не рекомендуются там, где их использование является альтернативой какой-то конструкции языка. Например определение различных констант макросами довольно распространено и как раз это плохой стиль, т.к. есть enum'ы. А здесь макрос применяется только для своей изначальной цели — метапрограммирования, которое по другому никак не записывается. Т.е. все типизации здесь стандартные, а макрос используется для манипуляций блоками кода. Тут никаких странных ошибок не будет и никаких антирекомендаций нет.
G>Дык функция Post2UI как работает? Там за ней еще десятки строк и несколько макросов?
Не, это обычная функция в одну строчку. Просто она зависит от используемой приложением схемы управления сообщениями и поэтому должна определяться конкретным приложением. Например, если мы говорим об обычном win32 приложение с очередью сообщений, то реализация может выглядеть так:
Однако может быть и совсем другая реализация, например в приложение вообще без очереди сообщений или с вызовами продолжений внутри кусков нашего кода. И кстати это ещё одно заметное преимущество над реализацией .net'а, в которой одна схема зашита намертво.
Здравствуйте, alex_public, Вы писали:
_>Здравствуйте, gandjustas, Вы писали:
G>>А я разве говорил что надо запретить? Я лишь говорил что требуются дополнительные танцы, даже если в виде макросов (фу!).
_>И в чём проблема, если это пишется один раз? Можно даже в библиотечку (из одного заголовочного файла) оформить, хотя это смешно при таких размерах.
Проблема в том что такой код тяжело поддерживать. Сегодня у вас все маршалится в UI поток, завтра в отдельный поток, послезавтра вы используете IOCP, который потом маршлит в UI.
Библиотечку оформить это примерно х10 затраты по сравнению с просто написать, и х3 с учетом поддержки.
G>>Как обычно макросы могут очень неоднозначно интерферировать с остальным кодом, а неудачно написанный\вставленный макрос может дать такую ошибку, что её сходу не найдешь. _>Не путай с шаблонами. У макросов как раз вполне краткие и однозначные сообщения об ошибках.
Видел эти "однозначные сообщения", спасибо, хватило.
G>>Дык функция Post2UI как работает? Там за ней еще десятки строк и несколько макросов?
_>Не, это обычная функция в одну строчку. Просто она зависит от используемой приложением схемы управления сообщениями и поэтому должна определяться конкретным приложением. Например, если мы говорим об обычном win32 приложение с очередью сообщений, то реализация может выглядеть так: _>
Ту то есть разбор очереди задач надо руками делать, плачевно... Переключить с UI на пул потоков так просто не выйдет, особенно с точки зрения вызывающего кода.
_>Однако может быть и совсем другая реализация, например в приложение вообще без очереди сообщений или с вызовами продолжений внутри кусков нашего кода. И кстати это ещё одно заметное преимущество над реализацией .net'а, в которой одна схема зашита намертво.
Чувак, ты слишком плохо разбираешься в .NET чтобы подобные утверждения делать. Посмотри на channel9 как устроен async и таски. Много нового для себя откроешь.
Здравствуйте, alex_public, Вы писали:
_>Здравствуйте, gandjustas, Вы писали:
G>>Проблема в том что такой код тяжело поддерживать. Сегодня у вас все маршалится в UI поток, завтра в отдельный поток, послезавтра вы используете IOCP, который потом маршлит в UI. G>>Библиотечку оформить это примерно х10 затраты по сравнению с просто написать, и х3 с учетом поддержки.
_>Ооо, этот классический подход в стиле Java/C#, когда мы заранее наворачиваем горы никчемных интерфейсов и классов... Нет, такого нам не надо. )))
В .NET это уже все есть, а Java скорее всего тоже, а в C++ надо таки писать.
G>>Ту то есть разбор очереди задач надо руками делать, плачевно... Переключить с UI на пул потоков так просто не выйдет, особенно с точки зрения вызывающего кода. _>Применение await/async вне возврата управления в ui поток не имеет вообще никакого смысла. Только лишние накладные расходы и никакой пользы.
В С++ наверное не имеет смысла, а в .NET:
а) накладных расходов на async\await для синхронных вызовов нет
б) повсеместно используется асинхронный IO, который еще и масштабируемость улучшает.
G>>Чувак, ты слишком плохо разбираешься в .NET чтобы подобные утверждения делать. Посмотри на channel9 как устроен async и таски. Много нового для себя откроешь.
_>Ну да, конечно. Только вот я выложил уже несколько примеров кода, а от тебя пока не видно ни одного — одна пафосная болтовня. Раз ты считаешь, что я недооцениваю возможности async в .net, то предлагаю тебе показать тут реализацию на C# следующей простейшей задачки:
_>Предположим, что у нас есть некая сложная библиотечная функция, причём написанная не нами, т.е. переписать её самим вообще не вариант. Изначально она рассчитана только на синхронную работу — читает (многократно) данные из некого блокирующего потока ввода и сама обязательно должна исполняться только в ui потоке. Т.е. синхронный код выглядит так: _>
_>ComplexFunction(input_stream);//блокирует исполнение ui потока, пока не обработает все входные данные.
_>
_>Соответственно задача в том, чтобы сделать этот код асинхронным. На C++ это можно решить тривиально: _>
_>Этот код вернёт управление сразу же и при этом ComplexFunction будет периодически (по мере поступления данных) отрабатывать в ui потоке. Функцию ComplexFunction мы естественно вообще не трогали.
_>А как решить эту задачку на C# с его крутыми "async и тасками"?
Я же говорю, ты слишком плохо .NET знаешь.
Но это слишком примитивный способ использования async\await. Ты вот лучше расскажи как из из одного async метода вызвать другой, чтобы они корректно построились в цепочку асинхронных вызовов.
ЗЫ. Обычно "знатоки", которые пытаются доказать что .NET что-то не умеет нихрена в нем не понимают
Это не то, это обычная синхронная работа ComplexFunction (блокирующая ui на время ожидания прихода всех данных), только отложенная на потом. В этом никакого особого смысла нет. А нам надо чтобы ComplexFunction отдавал управление, когда во входном потоке нет данных. Как видно на C++ это делается очень просто...
G>Я же говорю, ты слишком плохо .NET знаешь.
Ага, ага. Только пока что глядя на тебя видно много понтов, а когда доходит до дела, то только пшик.
Здравствуйте, alex_public, Вы писали:
_>Здравствуйте, gandjustas, Вы писали:
G>>Ту то есть разбор очереди задач надо руками делать, плачевно... Переключить с UI на пул потоков так просто не выйдет, особенно с точки зрения вызывающего кода. _>Применение await/async вне возврата управления в ui поток не имеет вообще никакого смысла. Только лишние накладные расходы и никакой пользы.
Хотелось бы увидеть обоснование этому утверждению.
_>Гыгы, и снова не то. Здесь тоже самое что и в предыдущем варианте, только блокирующий ComplexFunction запустится после прихода первой порции данных.
Покажи как внтури работает твой ComplexFunction, async_code и async_stream. Желательно компилируемый пример, я напишу такой же на C# в 3 раза короче.
G>>Только я тебя попрошу показать реализацию async_stream(input_stream) и ты опять напишешь 30 и более строк ада с макросами и бустом, а в .NET, с вероятностью 95%, уже есть готовый класс, который решит твою задачу.
_>Хы, это же просто асинхронная обёртка под конкретный поток. Т.е. это класс, реализущий интерфейс InputStream и при этом пересылающий все вызовы к имеющейся у него ссылке на реальный поток ввода. Точнее все функции пересылаются напрямую, а одна главная (типа ReadBuf, которую многократно вызывает ComplexFunction) через асинхронный вызов (через await_async как в коде выше) той же функции реального синхронного потока.
Код покажи.
G>>Какого дела? Ты выососал из пальца какую-то хрень. В реальной програмее ComplexFunction тупо перепишут, потыкав везде await и она станет идеально асинхронной и будет сама маршалить вызовы в UI если надо.
G>>Я же говорю, твое понимание .NET на уровне плинтуса. Ты можешь миллион таких пшиков нагенерить, и все они будут бесконечно далеки от реальной жизни.
_>Воот, до тебя наконец то начала доходить ситуация, хотя признавать это ты конечно же не хочешь. .Net не позволяет нам использовать готовые синхронные функции (которых миллиарды в различных библиотеках) в асинхронном коде, а заставляет нас переписывать их заново. В отличие от C++, где мы можем получить "идеально асинхронную" функцию из синхронной не трогая её код. Но конечно, если ты не видишь в невозможности использовать старые рабочие функции никакого недостатка, то тут уже ситуация безнадёжная...
ОК, покажи компилируемый пример. Я чето не верю что ты его сможешь написать.
Здравствуйте, alex_public, Вы писали:
_>Применение await/async вне возврата управления в ui поток не имеет вообще никакого смысла. Только лишние накладные расходы и никакой пользы.
Чудеса да и только. UI поток это частный случай потока с эвенлупом. Сейчас чуть более чем все приложения сложнее helloworld используют эти эвентлупы.
Асинхронщина сама по себе не нужна. Она нужна там, где работа с внешней системой где другое время. Без малого, весь сихронный ввод-вывод делается одинаково — шлется запрос и потом ожидание до окончания.
Здравствуйте, gandjustas, Вы писали: G>Покажи как внтури работает твой ComplexFunction, async_code и async_stream. Желательно компилируемый пример, я напишу такой же на C# в 3 раза короче.
O, отлично. Только теперь смотри, не забудь в это раз о своём обещание. Я то тебя за язык не тянул...
Кстати, мне нравится какое развитие получила наша дискуссия. Последние несколько сообщений ты пытаешься (естественно безуспешно) доказать, что реализация async/await в C# не хуже чем один из вариантов (мой) реализации async/await на C++. Это выглядит весьма забавно с учётом того, что сама дискуссия началась с твоего выкрика "попробуйте сделать подобное на C++". )))
Ну да ладно, перейдём к коду:
1. Синхронный библиотечный код.
Скрытый текст
class OutputStream;//Реализация не важна. Выводит данные+отладочную информацию в некое окно (т.е. только для ui потока)class InputStream{//Тестовый блокирующий поток ввода. Можно вызывать из любого потока.public:
virtual InputStream& operator>>(vector<int>& buf)
{
this_thread::sleep_for(chrono::seconds(1));
static int d=0;
for(auto& b: buf) b=d++;
return *this;
}
};
void ComplexFunction(InputStream& input, OutputStream& output)//Тестовая синхронная функция. Только для ui потока.
{
vector<int> buf(16);
do{
input>>buf;
output<<buf<<nl;
}while(buf.back()<100);
}
2. Его обычное использование.
Такой код (часть класса приложения):
Скрытый текст
void OnTest()
{
output<<L"Вход в OnTest"<<nl;
auto input=InputStream();
ComplexFunction(input, output);
output<<L"Выход из OnTest"<<nl;
}
void OnTimer()
{
output<<L"Таймер!"<<nl;
}
Теперь у нас ставится задача: сделать этот код асинхронным, но при этом продолжая использовать готовые библиотечные функции. Т.е. код из пункта 1 менять или переписывать нельзя.
Здравствуйте, Ikemefula, Вы писали:
I>Чудеса да и только. UI поток это частный случай потока с эвенлупом. Сейчас чуть более чем все приложения сложнее helloworld используют эти эвентлупы.
I>Асинхронщина сама по себе не нужна. Она нужна там, где работа с внешней системой где другое время. Без малого, весь сихронный ввод-вывод делается одинаково — шлется запрос и потом ожидание до окончания.
Ну я собственно это и имел в виду. Т.е. не принципиально ui это поток или нет (я просто называю так для краткости), главное что продолжение исполняется в том же потоке, который и инициировал асинхронный вызов. Вот в таком использование смысл имеется. А вот вариант, когда мы продолжим исполнение в каком-то произвольном пуле потоков (про что и писал gandjustas), уже на мой взгляд не приносит никакой пользы.
Здравствуйте, Ikemefula, Вы писали:
I>Ты как то особенным образом понимаешь асинхронщину. В общем случае переписывать надо не из за дотнета, а из за того, что есть некоторое разделяемое состояние.
Не, переписывать надо исключительно из-за особенностей реализации await/async в .net.
I>Вот простой пример
I>function(){
I> var value = read();
I> write(next(value));
I> }
I>
I>Вот функция, у ней в синхронном коде простой инвариант, проще не придумаешь. Проблема следующая — когда read или write становится асинхронным, между read и write может произойти нарушение инварианта. Вот из за этого и нужно переписывать код самой функции. Что характерно, в С++ ровно то же самое.
I>Итого — если ты решительно не согласен — покажи эту секретную технику " можем получить "идеально асинхронную" функцию из синхронной не трогая её код" что бы показаный инвариант сохранился.
Ты что-то всё путаешь. Всё зависит от того, как реализованы read и write. А точнее в каких потоках их можно вызывать. Есть варианты:
1. И read и write можно вызывать только в изначальном потоке. Тогда вообще ничего сделать нельзя и функция обречена быть синхронной.
2. И read и write можно вызывать в любых потоках. Тогда вообще всё просто и не нужны все эти хитрости типа await/async. Вот корректный асинхронный код:
thread([]{
auto value=read();
write(next(value));
}).detach();
А если нам требуется максимальное быстродействие и read и write относятся к разным устройствам, то можно вообще завести 2 независимых потока со своими буферами и синхронизацией (например через обмен сообщений по модели акторов). Но здесь уже понятно что не обойтись без модификации кода.
3. Смешанный вариант. Допустим read можно в любых потоках, а write только в изначальном. И только вот тут нам становятся нужны обсуждаемые хитрости. В C++ варианте я просто подменю функцию read на свою, содержащую вызов await_async([]{return read();}), и тогда напишу просто:
async_code(
auto value=read();
write(next(value));
)
В C# всё тоже самое, за исключением того, что обязательно требуется менять указанный код (добавить await). Причём менять надо не только его, но и весь стек вызова (добавить async).
Здравствуйте, gandjustas, Вы писали:
G>Компилируемый код дай.
Это он и есть. ) Точнее его часть, отвечающая за обсуждаемый вопрос. Остальной код касается исключительно вывода на экран окошка с кнопкой, причём реализованного через жирную GUI библиотеку, так что ты его всё равно у себя не соберёшь. Или же не поленишься поставить себе эту GUI библиотеку ради форумного спора? )))
Здравствуйте, alex_public, Вы писали:
_>Здравствуйте, gandjustas, Вы писали:
G>>Компилируемый код дай.
_>Это он и есть. ) Точнее его часть, отвечающая за обсуждаемый вопрос. Остальной код касается исключительно вывода на экран окошка с кнопкой, причём реализованного через жирную GUI библиотеку, так что ты его всё равно у себя не соберёшь. Или же не поленишься поставить себе эту GUI библиотеку ради форумного спора? )))
Ты все зависимости в исходники включи и залей архив сюда. Желательно чтобы в VS собиралось.
Здравствуйте, gandjustas, Вы писали:
G>Потрясающе. Если тебе понадобится обрабатывать сотни подключений у тебя будут сотни потоков. Практический лимит потоков на windows — около 200. Но даже при сотне уже все тормозит. При этом потоки будут ничего не делать.
Если нам потребуются легковесные потоки, то Boost.Coroutine прямо их и реализует. Т.е. уже без моих хитрых макросов для реализации await/async. Причём делает это несравнимо эффективнее других, обсуждаемых тут, реализаций.
Однако в разговоре с Ikemefula, в который ты вклинился, речь шла совсем не о легковесных потоках. Так что непонятно к чему ты это всё написал.
G>Кстати код который создает потоки для выполнения называют параллельным, а не асинхронным. Асинхронный это как раз когда потоки без нужды не создаются.
Асинхронность никак не связана с наличие или отсутствием системных потоков. Это всего лишь означает, что мы не блокируем поток исполнения в ожидание результата вычислений, а ставим некую функцию обратного вызова, которую вызовут после готовности данных. А уж как реализована проверка готовности, через опрос некого состояния, ожидание завершения потока или появление сообщения в очереди — это дело десятое.
G>Ну как-бы проблему множества подключений не решает.
А оно и не должно было. Это было описание оптимальной функции копирования файла, а не http-демона. Снова ты не по теме говоришь.
G>Не тоже самое. Ты просто нихрена в этом не понимаешь
Конечно не тоже самое. C# реализация заметно более слабая. ))) Или быть может ты уже готов показать решение той тривиальной тестовой задачки?
Здравствуйте, gandjustas, Вы писали:
G>Ты все зависимости в исходники включи и залей архив сюда. Желательно чтобы в VS собиралось.
Ты похоже совсем не в теме. ))) Папка Boost'a занимает у меня 560 МБ, а wxWidgets 400МБ. Это с lib файлами собранными под gcc. А так и мой примерчик и эти две библиотеки собираются под любым C++11 компилятором и под виндой и под линухом/маком и ещё много где.
Которая работает в том же потоке что и UI. client_stream считывает буковки по WM_CHAR. std::getline — это стандартная функция, которая ничего не знает о корутинах.
Здравствуйте, alex_public, Вы писали:
_>Здравствуйте, gandjustas, Вы писали:
G>>Потрясающе. Если тебе понадобится обрабатывать сотни подключений у тебя будут сотни потоков. Практический лимит потоков на windows — около 200. Но даже при сотне уже все тормозит. При этом потоки будут ничего не делать.
_>Если нам потребуются легковесные потоки, то Boost.Coroutine прямо их и реализует. Т.е. уже без моих хитрых макросов для реализации await/async. Причём делает это несравнимо эффективнее других, обсуждаемых тут, реализаций.
Как помогут легковесные потоки если IO блокирующий, как в твоем примере?
_>Асинхронность никак не связана с наличие или отсутствием системных потоков. Это всего лишь означает, что мы не блокируем поток исполнения в ожидание результата вычислений, а ставим некую функцию обратного вызова, которую вызовут после готовности данных. А уж как реализована проверка готовности, через опрос некого состояния, ожидание завершения потока или появление сообщения в очереди — это дело десятое.
Неблокирование путем создания другого потока — хреновая идея. В твоем примере так.
G>>Ну как-бы проблему множества подключений не решает. _>А оно и не должно было. Это было описание оптимальной функции копирования файла, а не http-демона. Снова ты не по теме говоришь.
А чем копирование файла отличается от считывания потока данных из сети и записи на диск?
G>>Не тоже самое. Ты просто нихрена в этом не понимаешь _>Конечно не тоже самое. C# реализация заметно более слабая. ))) Или быть может ты уже готов показать решение той тривиальной тестовой задачки?
Легко.
Было:
void func()
{
var x = read();
write(x);
}
стало:
async Task func()
{
var x = async read();
async write(x);
}
И оно не порождает дополнительные потоки, в отличие от твоего примера.
Здравствуйте, gandjustas, Вы писали:
EP>>Которая работает в том же потоке что и UI. client_stream считывает буковки по WM_CHAR. std::getline — это стандартная функция, которая ничего не знает о корутинах. G>Ты как-то забыл написать что основная асинхронность создается тут: G>
А выделенное ты не читал?
G>То есть это очень частный случай. Сколько у тебя таких частных случаев в программе будет? 100? Задолбаешься поддерживать.
Что значит особый случай? Точно также можно завернуть tcp_stream. При этом код использующий этот поток не поменяется, а в случае с C# await — нужно будет патчить весь call-stack
Причём большую часть boilerplate'а необходимого для заворачивания в корутины, легко вынести в библиотеку
G>Кроме того все это выполняется через глобальную переменную. Запустить два таких считывания уже не выйдет.
Это минимальный пример показывающий как вызов std::getline может работать с асинхронным потоком. Если будет async_tcp_stream — то будет хоть 100k соединений
G>Ты считаешь что такое "решение" способно тягаться с async\await в C#?
, только получается намного мощнее, так как не ограничен одним уровнем. А вот ты на C# await повторить пример с getline-like никак не сможешь. Разве не очевидно что мощнее
Здравствуйте, artelk, Вы писали:
A>И вообще, задача сделать существующий синхронный код асинхронным (с кооперативной многозадачностью и переключениями в момент обращения к стримам), не побоюсь этого слова, на практике редко встречается.
The example above used gevent.socket for socket operations. If the standard socket module was used it would took it 3 times longer to complete because the DNS requests would be sequential. Using the standard socket module inside greenlets makes gevent rather pointless, so what about module and packages that are built on top of socket?
That’s what monkey patching for. The functions in gevent.monkey carefully replace functions and classes in the standard socket module with their cooperative counterparts. That way even the modules that are unaware of gevent can benefit from running in multi-greenlet environment.
#!/usr/bin/python
# Copyright (c) 2009 Denis Bilenko. See LICENSE for details.
"""Spawn multiple workers and wait for them to complete"""
urls = ['http://www.google.com', 'http://www.yandex.ru', 'http://www.python.org']
import gevent
from gevent import monkey
# patches stdlib (including socket and ssl modules) to cooperate with other greenlets
monkey.patch_all()
import urllib2
def print_head(url):
print'Starting %s' % url
data = urllib2.urlopen(url).read()
print'%s: %s bytes: %r' % (url, len(data), data[:50])
jobs = [gevent.spawn(print_head, url) for url in urls]
gevent.joinall(jobs)
A>Так вот, задача такая: есть множество изначально асинхронных операций (т.е. они не являются результатом "об-асинхронивания" синхронных операций), сделанных в Continuation Passing Style; нужно сделать так, чтобы последовательность их "вызова" выглядела как простой линейный код (плюс, конечно, еще нужны всякие SynchronizationContext, возможность переключения на поток в пуле, назад в вызывающий поток и прочие плюшки). Async\await все это обеспечивает.
Обеспечивает — и довольно неплохо. Но, тут два основных момента:
1. await-like реализуется поверх stackful coroutine, с точно таким же синтаксисом
int bar(int i)
{
// await is not limited by "one level" as in C#auto result = await async([i]{ return reschedule(), i*100; });
// attaches rest of method as continuation into .then of returned futurereturn result + i*10;
}
2. С помощью корутин решаются такие задачи, которые не под силу C# await. И не надо разводить демагогию на тему "это не нужно/это редко встречается".
Здравствуйте, gandjustas, Вы писали:
G> Сейчас спектр систем, где заработает код на C#, примерно такой же, как у java и у обоих гораздо шире, чем у C++.
C++ работает и на десктопах, и на планшетах, и на телефонах (разве что кроме первых версий windows phone), и на 8-битных контролерах, и даже внутри javascript
Здравствуйте, artelk, Вы писали:
A>И вообще, задача сделать существующий синхронный код асинхронным (с кооперативной многозадачностью и переключениями в момент обращения к стримам), не побоюсь этого слова, на практике редко встречается. Ибо вот так вот одним махом взять и сделать произвольный код асинхронным (при этом не смотря в него) — это нужно быть очень "смелым" и отчаяным — получившиеся "потоки" могут иметь разделяемые изменяемые данные со всеми вытекающими.
Задача использовать существующие библиотеки в современном коде, а не переписывать их самим — это редко встречаемая? ) Нуну)))
A>Основная проблема, которая, на мой субъективный взгляд, решается через async\await такая: плодить дофига потоков, которые 99% времени только и делают, что ждут IO — непозволительн расточительность ресурсов.
Что-то я не понял где вообще может встретиться подобная задачка, даже если бы это и не было роскошью. "Дофига потоков" нам может понадобиться в серверных решениях со множеством клиентов (например http-демон). Но даже если мы и предположим сделаем такую неразумную вещь, как реализацию высоконагруженного сервера через системные потоки, то они при этом явно не будут долго сидеть в ожидание — будут отрабатывать запрос и завершаться. Если же мы говорим о каких-то десктопных приложениях, то там действительно бывают ничегонеделающие потоки, но откуда там потребность в тысячах таких? Так что получается что вся эта твоя речь — это спор с голосами в твоей же голове. )))
A>Прикол в том, что на уровне ОС IO уже является асинхронным. Но ОС выставляет API синхронный (т.е. это "привычный" IO API, знакомый всем и каждому).
Вообще то выставляются оба варианта.
A>А при чтении\записи система блокирует поток до тех пор, пока операция не завершится. Чтобы эти синхронные чтения\записи сделать обратно асинхронными разработчикам приходится плодить потоки. Даже пул потоков не спасает — все его потоки быстро "съедаются" ничегонеделающими операциями ожидания и приходится добавлять в пул все новые и новые потоки.
Так что же это за софт такой, который плодит тысячи ничегонеделающих потоков? Можно пример? )
A>И тут на помощь приходит IOCP! Благодаря ему можно обойтись одним потоком на все операции IO в приложении. Для IO-операции регистрируется callback, который будет вызван в потоке, предназначенным для разгребания очереди IOCP, в момент, когда ОС оповестит о завершении этой операции. Причем в этом callback-е делается не собственно обработка результата операции, а добавление задания (обработчика результата) в дотнетный пул потоков. Т.е. нагрузка на этот поток минимальна, благодаря чему в .Net можно обойтись одним таким IOCP потоком на весь процесс.
А причём тут дотнет то? Это всё есть в обычном win32 апи с древних времён. Да и в posix есть свой аналог.
A>Так вот, задача такая: есть множество изначально асинхронных операций (т.е. они не являются результатом "об-асинхронивания" синхронных операций), сделанных в Continuation Passing Style; нужно сделать так, чтобы последовательность их "вызова" выглядела как простой линейный код (плюс, конечно, еще нужны всякие SynchronizationContext, возможность переключения на поток в пуле, назад в вызывающий поток и прочие плюшки). Async\await все это обеспечивает.
Классно. ))) Правда это уже всё работает не одно десятилетие без всякого .net'а... Ну разве что кроме линеаризации такого кода. И вот обсуждаемые тут Boost.Coroutine как раз и реализуют эту самую линеаризацию для C++ кода. Причём более эффективно (и по возможностям и по быстродействию) чем .net вариант.
Здравствуйте, gandjustas, Вы писали:
G>Как помогут легковесные потоки если IO блокирующий, как в твоем примере?
А причём тут легковесные потоки и мой пример? У меня там, как ты видел, обычное десктопное приложение (окошко с кнопкой), а не сервер с тысячами подключений. Зачем мне там такие потоки?
G>Неблокирование путем создания другого потока — хреновая идея. В твоем примере так.
Ну покажи в чём хреновость. )
G>А чем копирование файла отличается от считывания потока данных из сети и записи на диск?
Не важно что и куда, а важно сколько операций параллельно. Реализация через пару системных потоков будет максимально эффективной и для сети (собственно там вообще идеально, т.к. устройства точно разные). Однако если нам понадобится много таких параллельных скачиваний, то эффективность будет ухудшаться с их увеличением. Так что начиная с какого-то момента уже выгоднее использовать другую модель (легковесные потоки например).
_>>Конечно не тоже самое. C# реализация заметно более слабая. ))) Или быть может ты уже готов показать решение той тривиальной тестовой задачки? G>Легко.
В этом случае если внутри "stream >> x" произойдёт yield, то инварианты могут быть поломаны. Но, если есть такой код — то ты его и на обычных потоках не сможешь запустить, корутины тут не причём
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Здравствуйте, gandjustas, Вы писали:
EP>>>Которая работает в том же потоке что и UI. client_stream считывает буковки по WM_CHAR. std::getline — это стандартная функция, которая ничего не знает о корутинах. G>>Ты как-то забыл написать что основная асинхронность создается тут: G>>
EP>А выделенное ты не читал?
Читал, а толку то? Этот подход решает очень узкую задачу — асинхронное чтение буковок. Это можно и с меньшим количеством кода сделать.
На обобщенный метод превращения синхронного кода в асинхронный не тянет.
G>>То есть это очень частный случай. Сколько у тебя таких частных случаев в программе будет? 100? Задолбаешься поддерживать.
EP>Что значит особый случай? Точно также можно завернуть tcp_stream.
Надо очень хорошо знать как код работает внутри, чтобы делать такую асинхронность. А как комбинировать такие асинхронные вызовы не то что не очевидно, а вообще непонятно как.
EP>При этом код использующий этот поток не поменяется, а в случае с C# await — нужно будет патчить весь call-stack
А зачем это делать? Преобразование синхронного кода в асинхронный — механическая операция, легко автоматизируется при желании. Я даже для стримов на roslyn такое переписывание делал.
EP>Причём большую часть boilerplate'а необходимого для заворачивания в корутины, легко вынести в библиотеку
Почему до сих пор никто не сделал? Видимо не так просто, ибо более чем востребовано в наше время.
G>>Кроме того все это выполняется через глобальную переменную. Запустить два таких считывания уже не выйдет.
EP>Это минимальный пример показывающий как вызов std::getline может работать с асинхронным потоком.
Проблема в том, что они показывает только вызов std::getline. Покажи как сделать тоже самое с вводом-выводом на IOCP.
EP>Если будет async_tcp_stream — то будет хоть 100k соединений
Для начала тебе надо будет async io реализовать на IOCP.
G>>Ты считаешь что такое "решение" способно тягаться с async\await в C#?
EP>await-like синтаксис легко реализуется поверх корутин
, только получается намного мощнее, так как не ограничен одним уровнем.
Каким одним уровнем? ты о чем?
G>>А вот ты на C# await повторить пример с getline-like никак не сможешь. Разве не очевидно что мощнее
А зачем его повторять? Я же говорю что просто дописываешь async\await где можно код становится асинхронным. Даже понимать не надо как код работает.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Здравствуйте, gandjustas, Вы писали:
G>> Сейчас спектр систем, где заработает код на C#, примерно такой же, как у java и у обоих гораздо шире, чем у C++.
EP>C++ работает и на десктопах, и на планшетах, и на телефонах (разве что кроме первых версий windows phone), и на 8-битных контролерах, и даже внутри javascript
Здравствуйте, gandjustas, Вы писали:
G>Читал, а толку то? Этот подход решает очень узкую задачу — асинхронное чтение буковок. Это можно и с меньшим количеством кода сделать. G>На обобщенный метод превращения синхронного кода в асинхронный не тянет.
std::getline тут стандартная, не модифицированная. Точно также можно протащить yield и через любую другую функцию
EP>>Что значит особый случай? Точно также можно завернуть tcp_stream. G>Надо очень хорошо знать как код работает внутри, чтобы делать такую асинхронность.
Есть любая асинхронная функция которая принимает continuation/.then — мы ей передаём в этот continuation код с yield-ом внутри, что механически превращает остаток нашей функции в продолжение.
G>А как комбинировать такие асинхронные вызовы не то что не очевидно, а вообще непонятно как.
Ты о чём?
EP>>При этом код использующий этот поток не поменяется, а в случае с C# await — нужно будет патчить весь call-stack G>А зачем это делать? Преобразование синхронного кода в асинхронный — механическая операция, легко автоматизируется при желании. Я даже для стримов на roslyn такое переписывание делал.
С такими же рассуждениями можно прийти к мысли что и yield, и await/async не нужны
Зачем переделывать весь код если можно просто передать ему объект другого типа?
Или как в том же gevent это:
monkey.patch_all()
всё — ничего переписывать не надо
EP>>Причём большую часть boilerplate'а необходимого для заворачивания в корутины, легко вынести в библиотеку G>Почему до сих пор никто не сделал? Видимо не так просто, ибо более чем востребовано в наше время.
(это при том что я сам практически не работаю ни с каким io).
G>>>Кроме того все это выполняется через глобальную переменную. Запустить два таких считывания уже не выйдет. EP>>Это минимальный пример показывающий как вызов std::getline может работать с асинхронным потоком. G>Проблема в том, что они показывает только вызов std::getline. Покажи как сделать тоже самое с вводом-выводом на IOCP. EP>>Если будет async_tcp_stream — то будет хоть 100k соединений G>Для начала тебе надо будет async io реализовать на IOCP.
Ты мне предлагаешь реализовать свои обвёртки поверх голого IOCP? Зачем?
G>>>Ты считаешь что такое "решение" способно тягаться с async\await в C#? EP>>await-like синтаксис легко реализуется поверх корутин
, только получается намного мощнее, так как не ограничен одним уровнем. G>Каким одним уровнем? ты о чем?
О том, что для того чтобы сделать yield с самого низа callstack'а на самый вверх, тебе придётся дублировать и модифицировать каждый уровень. Причём эти уровни могут находится в библиотеках к которым нет доступа.
G>>>А вот ты на C# await повторить пример с getline-like никак не сможешь. Разве не очевидно что мощнее G>А зачем его повторять? Я же говорю что просто дописываешь async\await где можно код становится асинхронным. Даже понимать не надо как код работает.
У тебя нет кода std::getline (или аналога) — куда ты там собрался дописывать await?
Да даже если взять что-то совершенно не связанное с вводом/выводом, например есть любая функция которая принимает другую функцию как параметр. Ты передаёшь лямбду внутри которой надо yield'нуть/await'нуть — где ты тут что будешь дописывать?
Здравствуйте, gandjustas, Вы писали:
G>>> Сейчас спектр систем, где заработает код на C#, примерно такой же, как у java и у обоих гораздо шире, чем у C++. EP>>C++ работает и на десктопах, и на планшетах, и на телефонах (разве что кроме первых версий windows phone), и на 8-битных контролерах, и даже <b><u>внутри javascript</u></b> G>А в браузере на клиенте?
Да, в браузере, на клиенте — открой ссылку выше.
Даже QT работает.
Здравствуйте, gandjustas, Вы писали:
G>В выделенном коде у тебя порождается новый поток. Это бредовая асинхронность...
А ты никакую другую и не сделаешь, если у тебя по условию задачи входной поток данных блокирующий. Ну и в любом случае, даже если предположим она бредовая, то повтори хоть такую. Ты же обещался что без проблем... Или же признаёшь, что реализация в C# слабее?
G>Дальше можно не продолжать.
Я правильно понимаю, что это означает слив? )
G>твоем примеру бесконечно далеко до async\await.
Что-то ты вообще куда-то не туда полез. Async\await в C# без проблем умеет работать и в рамках одного потока и с несколькими (await Task.Run()). Аналогично Boost.Coroutine без проблем умеет работать и в рамках одного потока (собственно только это в ней и есть) и с несколькими (с несколькими строками дополнения, типа моих выше). Так что ситуация абсолютно симметричная.
Я показал пример, использующий работу именно с несколькими потоками, т.к. она наиболее интересна на практике. Однако точно так же можно было бы придумать и вариант со сменой источника данных на внутреннее асинхронный, которому уже не понадобились бы потоки.
Здравствуйте, gandjustas, Вы писали:
G>Наверное потому что async\await отлично работает как на клиенте, так и на сервере. А ты сделал менее эффективный пример, который и этом нифига не масштабируется.
Клиент или сервер — это не принципиально. Важно количество соединений. И если мы имеем дело с системой под большие нагрузки (множество соединений), то уж точно глупо брать async\await из C# — это мягко говоря не лучший вариант по производительности. Место async\await из C# как раз в фоновой обработке нажатий на кнопки и т.п. Причём желательно в варианте с запуском потоков.
G>Если ты начнешь масштабировать свой подход, то он начнет дико тормозить. А если подход нельзя масштабировать, то нафига он такой нужен?
Какое масштабировать подход? У нас кнопка на экране для пользователя. По её нажатию в фоне запускается некий процесс, результат которого потом выдаёт на экран. Какое нафиг масштабирование тут? ))) И кстати как раз для таких вещей системные потоки вполне оптимальны. Более того, как раз если мы попробуем реализовать это без системный потоков, а наш фоновый процесс будер производит какие-то реальные вычисления, то у нас именно из-за отсутствия потоков начнёт подтормаживать интерфейс...
G>Решить частную задачу по созданию асинхронности одной функции можно запустив её в отдельном потоке, дописав маршалинг вызовов в UI и получится меньше чем пляски с корутинами\шаблонами\макросами.
Ну собственно лично я действительно не вижу особых преимуществ от подобной линеаризации кода, что в .net, что в C++. Но если кому-то нравится, то почему бы и нет. И как мы видим C++ вариант при этом получается мощнее.
А так, конечно реальная потребность подобных вещей появляется только при реализации чего-то типа легковесных потоков. Но тут как раз .net вариант заметно слабее, т.к. уже становятся принципиальны накладные расходы.
G>А можно не выдумывать хрень и использовать IOCP, эффективнее на винде ниче пока не придумали. G>Вот только код будет не такой, как у тебя.
О, кстати... А можно потестировать и главное при этом более менее вернуться к темке (языку D). Я тут видел в учебнике по D забавную реализацию в несколько строчек как раз функции копирования на базе потоков взаимодействующих по модели акторов.
_>>Это была речь про эту http://www.rsdn.ru/forum/philosophy/5357968
задачку. Ты же обещался: "я напишу такой же на C# в 3 раза короче". Или уже всё, слив? )
G>Дык я тебе уже написал, примерно с тем же уровнем детализации.
Это где? Я не видел от тебя ни одного куска кода.
G>Еще раз повторю — все изменения только в дописывании async\await.
Дописывание куда? По условиям задачи мы должны использовать существующий библиотечный код. Т.е. его нельзя модифицировать или переписывать.
G>Или давай компилируемый код, я тот же результат на C#, будет МИНИМУМ в 3 раза короче, даже если считать только значимый код.
Ты покажи хоть какой-нибудь код для начала. А то пока после всего своего пафоса на словах и полного отсутствие результата в делах ты выглядишь сам понимаешь как...
Здравствуйте, alex_public, Вы писали:
I>>Ты как то особенным образом понимаешь асинхронщину. В общем случае переписывать надо не из за дотнета, а из за того, что есть некоторое разделяемое состояние.
_>Не, переписывать надо исключительно из-за особенностей реализации await/async в .net.
Судя по примером ниже, это утверждение ты не смог обосновать.
I>>Вот простой пример _>
I>>function(){
I>> var value = read();
I>> write(next(value));
I>> }
I>>
_>Ты что-то всё путаешь. Всё зависит от того, как реализованы read и write. А точнее в каких потоках их можно вызывать.
Опаньки ! "переписывать надо исключительно из-за особенностей реализации await/async в .net"
И одновременно, оказывается, дотнет ни при чем, а всё зависит от особенностей реализации. Браво !
_>1. И read и write можно вызывать только в изначальном потоке. Тогда вообще ничего сделать нельзя и функция обречена быть синхронной.
Это неверно. Сделать можно и в С++ и в C# — переписывая функцию. Ты забыл, что мы про асинхронщину ?
_>2. И read и write можно вызывать в любых потоках. Тогда вообще всё просто и не нужны все эти хитрости типа await/async. Вот корректный асинхронный код: _>
_>thread([]{
_> auto value=read();
_> write(next(value));
_>}).detach();
_>
Ровно такой способ доступен в .Net Или ты хотел сказать, что в .Net нельзя фукнции запусать в отдельных потоках ?
_>А если нам требуется максимальное быстродействие и read и write относятся к разным устройствам, то можно вообще завести 2 независимых потока со своими буферами и синхронизацией (например через обмен сообщений по модели акторов). Но здесь уже понятно что не обойтись без модификации кода.
Опаньки — снова переписывать надо и там и там.
_>3. Смешанный вариант. Допустим read можно в любых потоках, а write только в изначальном. И только вот тут нам становятся нужны обсуждаемые хитрости. В C++ варианте я просто подменю функцию read на свою, содержащую вызов await_async([]{return read();}), и тогда напишу просто: _>
_>async_code(
_> auto value=read();
_> write(next(value));
_>)
_>
И получаешь нарушение инварианта.
_>В C# всё тоже самое, за исключением того, что обязательно требуется менять указанный код (добавить await). Причём менять надо не только его, но и весь стек вызова (добавить async).
Я шота смотрю, ты показал совсем не то, что декларировал
Здравствуйте, alex_public, Вы писали:
_>Ну я собственно это и имел в виду. Т.е. не принципиально ui это поток или нет (я просто называю так для краткости), главное что продолжение исполняется в том же потоке, который и инициировал асинхронный вызов. Вот в таком использование смысл имеется. А вот вариант, когда мы продолжим исполнение в каком-то произвольном пуле потоков (про что и писал gandjustas), уже на мой взгляд не приносит никакой пользы.
Наоборот. Когда исполнение уходит в другой поток, совершенно незачем придумывать для этго какие то особенные формы вызова функций, наводе thread( ля ля ля)
То есть, независимо от диспетчеризации, код выглядит одинаково. В С++ это не получится
2. С помощью корутин решаются такие задачи, которые не под силу C# await. И не надо разводить демагогию на тему "это не нужно/это редко встречается".
Это никакая не демагогия. Абстрактные рассуждения о мощности языка без рассмотрения реальных сценариев никому не интересны, это просто "разговоры о прекрасном"
С помощью ассемблера например решаются такие задачи, которые даже в С++ не под силу. Однако ассемблер это почему то шаг назад
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>В этом случае если внутри "stream >> x" произойдёт yield, то инварианты могут быть поломаны. Но, если есть такой код — то ты его и на обычных потоках не сможешь запустить, корутины тут не причём
И этот сценарий встречается практически везде, когда имеешь дело с асинхронным кодом.
Здравствуйте, Ikemefula, Вы писали:
EP>>2. С помощью корутин решаются такие задачи, которые не под силу C# await. И не надо разводить демагогию на тему "это не нужно/это редко встречается". I>Это никакая не демагогия. Абстрактные рассуждения о мощности языка без рассмотрения реальных сценариев никому не интересны, это просто "разговоры о прекрасном"
Stackful coroutine мощнее — и это факт. А реальные примеры я уже показал
Здравствуйте, Ikemefula, Вы писали:
EP>>В этом случае если внутри "stream >> x" произойдёт yield, то инварианты могут быть поломаны. Но, если есть такой код — то ты его и на обычных потоках не сможешь запустить, корутины тут не причём I>И этот сценарий встречается практически везде, когда имеешь дело с асинхронным кодом.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>>>В этом случае если внутри "stream >> x" произойдёт yield, то инварианты могут быть поломаны. Но, если есть такой код — то ты его и на обычных потоках не сможешь запустить, корутины тут не причём I>>И этот сценарий встречается практически везде, когда имеешь дело с асинхронным кодом.
EP>Выше
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>>>2. С помощью корутин решаются такие задачи, которые не под силу C# await. И не надо разводить демагогию на тему "это не нужно/это редко встречается". I>>Это никакая не демагогия. Абстрактные рассуждения о мощности языка без рассмотрения реальных сценариев никому не интересны, это просто "разговоры о прекрасном"
EP>Stackful coroutine мощнее — и это факт. А реальные примеры я уже показал
Здравствуйте, Ikemefula, Вы писали:
I>Опаньки ! "переписывать надо исключительно из-за особенностей реализации await/async в .net" I>И одновременно, оказывается, дотнет ни при чем, а всё зависит от особенностей реализации. Браво !
Не, не так. Есть функции которые можно преобразовать в асинхронные без переписывания, а есть такие, которые нельзя. А вот .net заставляет нас переписывать любые, т.к. требует раскидывания async по всему стеку вызова.
I>Это неверно. Сделать можно и в С++ и в C# — переписывая функцию. Ты забыл, что мы про асинхронщину ?
Переписывая, естественно что угодно можно сделать. )
I>Ровно такой способ доступен в .Net Или ты хотел сказать, что в .Net нельзя фукнции запусать в отдельных потоках ?
Я хотел сказать, что и в .net и в C++ модель await/async в общем то не так уж и нужна. ))) По сути это сахар на достаточно специфическую ситуацию. Собственно мы это уже обсуждали в той старой темке.
I>И получаешь нарушение инварианта.
С чего бы это? Там выполнение будет строго последовательным, просто разделённым на два потока.
был пример gevent, где этого не было. Это по твоему какой-то редкий случай? I>Да, это редкий случай. Патчить можно и в джаве, и в дотнете, при чем без особых затруднений.
Здравствуйте, Ikemefula, Вы писали:
I>Наоборот. Когда исполнение уходит в другой поток, совершенно незачем придумывать для этго какие то особенные формы вызова функций, наводе thread( ля ля ля) I>То есть, независимо от диспетчеризации, код выглядит одинаково. В С++ это не получится
Ага, только это у нас и так шло выполнение в фоновом потоке. Соответственно непонятно зачем вообще плодить новый поток. Разве что потому что системке так удобнее (у неё нет диспечеризации в старый не ui поток)...
Здравствуйте, Ikemefula, Вы писали:
EP>>Stackful coroutine мощнее — и это факт. А реальные примеры я уже показал I>А ассемблер еще мощнее. И что с того ?
Вот это:
2. С помощью корутин решаются такие задачи, которые не под силу C# await. И не надо разводить демагогию на тему "это не нужно/это редко встречается".
Я писал не тебе. artelk, как впрочем и gandjustas , по всей видимости не знали/не понимали что корутины мощнее. (впрочем и до тебя это страниц сорок доходило)
Здравствуйте, gandjustas, Вы писали:
Pzz>>C# работает только на венде, а все практические реализации Явы обладают красотой и грациозностью бегемота, пасущегося на лугах Страны Неограниченных Ресурсов. G>Думаю стоит глянуть на Mono и Xamarin, перед тем как толкать такие утверждения. Сейчас спектр систем, где заработает код на C#, примерно такой же, как у java и у обоих гораздо шире, чем у C++.
Моно — это пионерская поделка, годящаясь только на то, чтобы изготавливать пионерские поделки. Существенной проблемой при этом является то, что пионеры не в состоянии понять, что кроссплатформенные пионерские поделки надо тестировать на всех платформах, а не только на любимом компьютере разработчила. Поэтому даже для изготовления кроссплатформенных пионерских поделок моно не годится. А пионерские поделки под венду проще все же делать, используя родные для венды средства.
В этой связи приходится признать, что единственное применение моно заключается в том, что пионеры могут с умным видом заявлять в форумах, что C# подходит для кроссплатформенной разработки.
Pzz>>Кросплатформенный язык общего назначения типа "си с классами", не страдающий при этом врожденной склонностью к онкологическим заболеваниям, безусловно, нужен. G>Практика показывает что эту нишу занял javascript.
Яваскрипт занял нишу "хотим писать скрипты-плагины, но не на питоне". Кроме того, в силу политических, а не технических причин, явяскрипт имеет весьма специфические отношения с некоторыми платформами, такими, как веб-программирование (в основном на стороне клиента), и т.п.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Здравствуйте, gandjustas, Вы писали:
G>>>> Сейчас спектр систем, где заработает код на C#, примерно такой же, как у java и у обоих гораздо шире, чем у C++. EP>>>C++ работает и на десктопах, и на планшетах, и на телефонах (разве что кроме первых версий windows phone), и на 8-битных контролерах, и даже <b><u>внутри javascript</u></b> G>>А в браузере на клиенте?
EP>Да, в браузере, на клиенте — открой ссылку выше.
Не взлетело...
Хотя внутри там JS увидел.
EP>Даже QT работает.
Canvas+javascript
Можно было и покрасивше нарисовать.
Здравствуйте, alex_public, Вы писали:
_>Здравствуйте, gandjustas, Вы писали:
G>>В выделенном коде у тебя порождается новый поток. Это бредовая асинхронность...
_>А ты никакую другую и не сделаешь, если у тебя по условию задачи входной поток данных блокирующий.
А какой тогда смысл в асинхронности вообще? Запусти в отдельном потоке и радуйся.
Без асинхронного IO бесполезная тема. А тебя единственный способ превращения синхронного в асинхронный — создание потока. Я и предлагаю не мучать жопу с корутинами, а сразу на потоках построить.
G>>Дальше можно не продолжать. _>Я правильно понимаю, что это означает слив? )
Слив чего? Где исходник?
Яж говорю — сделаю тот же алгоритм в 3 раза короче.
G>>твоем примеру бесконечно далеко до async\await. _>Что-то ты вообще куда-то не туда полез. Async\await в C# без проблем умеет работать и в рамках одного потока и с несколькими (await Task.Run()). Аналогично Boost.Coroutine без проблем умеет работать и в рамках одного потока (собственно только это в ней и есть) и с несколькими (с несколькими строками дополнения, типа моих выше). Так что ситуация абсолютно симметричная.
Но Async\await умеет и в рамках нескольких потоков работать и с async io, а Boost.Coroutine — увы
Так что несимметричная.
_>Я показал пример, использующий работу именно с несколькими потоками, т.к. она наиболее интересна на практике. Однако точно так же можно было бы придумать и вариант со сменой источника данных на внутреннее асинхронный, которому уже не понадобились бы потоки.
Она только тебе интересно, потому что другие случаи ты сделать не сможешь.
На практике как раз самое интересное — асинхронный IO и масштабирование.
Если у тебя IO должен быть синхронный (странно почему, Windows поддерживает IOCP с тех пор когда буста еще не было), то просто делаешь потоки. Но у тебя наступает вполне резонная жопа с масштабируемостью.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>На чём по-твоему написано ядро Linux?
Ядро линуха — это плохой пример. Ядро линуха содержит очень небольшое количество реально сложного кода, и огромное количество довольно простого кода, но при этом имеющего дело с такими низкоуровневыми вещами, как физическая память, регистры аппаратуры и бинарные структуры фиксорованного, и при этом довольно простого, формата, описывающие данные, ходящие по сети или между хостом и какой-нибудь железкой.
Чистый си очень неплохо подходит для решения подобных задач. Но подобных программ в индустрии пишется подавляющее меньшинство.
Здравствуйте, -n1l-, Вы писали:
N>А вот всякие гномы и кеды и остальные из мира опенсорса сделаны на инкрементированных сях.
В основном гном написан на чистом си. Читать его код, не матерясь, невозможно. Проблема там, впрочем, заключается не в языке, а в том, что разработчики — пионеры. Достаточно посмотреть, как они работают с д-басом, чтобы все про них стало ясно.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>>>Stackful coroutine мощнее — и это факт. А реальные примеры я уже показал I>>А ассемблер еще мощнее. И что с того ?
EP>Вот это: EP>
EP>2. С помощью корутин решаются такие задачи, которые не под силу C# await. И не надо разводить демагогию на тему "это не нужно/это редко встречается".
J>Пример Яху всем известен, правда? Пара маргиналов написали систему на маргинальном языке (лиспе) и свалили. Яху помучилась-помучилась и переписала все на мейнстримовом языке.
Пример яху как раз шикарен. Пара маргиналов на маргинальном языке внезапно! в ошмётки порвала многочисленных конкурентов на мэйнстримовых языках, за что и были были куплены яху. Тут бы уже задаться вопросом, а с чего бы им это удалось?! Но ты акцентируешь внимание на том что в яху не смогла ни самих маргиналов удержать, ни проект ими поднятый, выдаёшь это за некое преимущество мэйнстримовых языков
А мне кажется, то что менеджмент яху, в отличии от раннего гугла, не умел строить бизнес силами маргиналов, как раз и есть причина их быстрого слива по всем направлениям
Здравствуйте, alex_public, Вы писали:
I>>Наоборот. Когда исполнение уходит в другой поток, совершенно незачем придумывать для этго какие то особенные формы вызова функций, наводе thread( ля ля ля) I>>То есть, независимо от диспетчеризации, код выглядит одинаково. В С++ это не получится
_>Ага, только это у нас и так шло выполнение в фоновом потоке. Соответственно непонятно зачем вообще плодить новый поток. Разве что потому что системке так удобнее (у неё нет диспечеризации в старый не ui поток)...
Всё в один поток не всунешь. Нужен инструмент, который дает единообразный код независимо от диспетчеризации. Если винда не умеет чего то диспетчеризовать в какой то поток, это ничего не меняет. Пишешь диспетчер и все дела — сам код каким был, таким и остался.
Здравствуйте, Кодт, Вы писали:
К>У С++ есть два плюса: мультипарадигменность и поддержка наследия. Он и в будущее смотрит, и прошлое не забывает. К>Сколько стоит перенести гору уже существующего кода с C++ на D? А без тотального переписывания?
Индустрия, наконец, осознала ту мысль, что реальный коммерческий проект может быть написан на смеси языков. Это, как бы, решает проблему, что делать с бабушкиным наследством.
К>Кстати, не на тот язык звереешь. Фортран — вот где ад.
Современный фортран — это очень хороший язык, для своей целевой ниши. Товарищи ученые способны писать на нем програмки, решающие их задачи. Просто не надо относиться к этому языку, как к языку общего назначения (и не надо путать Фортран с Фортраном IV).
был пример gevent, где этого не было. Это по твоему какой-то редкий случай? I>>Да, это редкий случай. Патчить можно и в джаве, и в дотнете, при чем без особых затруднений.
EP>Как ты пропатчишь что-нибудь типа std::getline?
Его не надо патчить, всё остаётся как было. Все что нужно — подсунуть ему стрим, который унутре будет yield вызывать. Вот yield и делается через патч.
Вот такие фокусы и в джаве, и в дотнете, и в питоне. Толко вот странно, мало кто этим занимается.
Более того — файберы в линуксе или винде использует примерно такое же количество людей, если не меньше.
Здравствуйте, gandjustas, Вы писали:
G>А какой тогда смысл в асинхронности вообще? Запусти в отдельном потоке и радуйся.
Да, это как раз самое лучшее решение (для работы с блокирующим кодом). Но оно далеко не всегда возможно. Проблема в том (на нашем примере), что ComplexFunction нельзя выполнять в отдельном потоке, а можно только в ui.
G>Без асинхронного IO бесполезная тема. А тебя единственный способ превращения синхронного в асинхронный — создание потока. Я и предлагаю не мучать жопу с корутинами, а сразу на потоках построить.
Да, можно. Опять же переписав сложную библиотечную функцию...
G>Слив чего? Где исходник? G>Яж говорю — сделаю тот же алгоритм в 3 раза короче.
, а от тебя пока не было ни одной строчки, а только отмазки. Приведи подобные выкладки (те же самые 4 пункта) на C#, а без этого ты сам понимаешь кем выглядишь...
G>Но Async\await умеет и в рамках нескольких потоков работать и с async io, а Boost.Coroutine — увы G>Так что несимметричная.
Как раз Boost.Coroutine только в рамках одного потока и работает. Это я её раскидал на несколько с помощью своего кода.
G> G>Она только тебе интересно, потому что другие случаи ты сделать не сможешь.
#define AsyncInputStream() __AsyncInputStream(__yield, __coro)
class __AsyncInputStream: public InputStream{
__Coro::caller_type& __yield;
__Coro* __coro;
public:
__AsyncInputStream(__Coro::caller_type& y, __Coro* c): __yield(y), __coro(c){}
InputStream& operator>>(vector<int>& buf) override
{
StartAsyncRead(buf, []{CallFromUI(__coro);});
__yield();
}
};
Соответственно StartAsyncRead — это функция из асинхронного IO API (типа libevent), которая вызывает callback (второй параметр) из ui потока после завершения работы. Ну вот тебе полноценный вариант без единого дополнительного потока. Давай, повторяй на C# в 3 раза короче. Хотя меня удивит если вообще сможешь хоть как-то повторить.
G>На практике как раз самое интересное — асинхронный IO и масштабирование. G>Если у тебя IO должен быть синхронный (странно почему, Windows поддерживает IOCP с тех пор когда буста еще не было), то просто делаешь потоки. Но у тебя наступает вполне резонная жопа с масштабируемостью.
Ещё раз, описываемые тобой проблемы с многопоточным вариантом актуальны только для специфической области типа написания высоконагруженных серверов. И если уж мы говорим о ней и нам критично быстродействие, то C# await/async тоже не стоит применять.
Здравствуйте, gandjustas, Вы писали:
G>>>>> Сейчас спектр систем, где заработает код на C#, примерно такой же, как у java и у обоих гораздо шире, чем у C++. EP>>>>C++ работает и на десктопах, и на планшетах, и на телефонах (разве что кроме первых версий windows phone), и на 8-битных контролерах, и даже <b><u>внутри javascript</u></b> G>>>А в браузере на клиенте? EP>>Да, в браузере, на клиенте — открой ссылку выше. G>Не взлетело...
Можешь тут потыкать — там много примеров.
EP>>Даже QT работает. G>Canvas+javascript G>Ты о чем вообще?
Здравствуйте, Pzz, Вы писали:
M>>>[...] А время идёт и ждать, пока каждый говнопроект не сдохнет в шаблонно-указательных муках, нет никакого желания. Теперь вы осознаёте, что такое "невинное" существование С++ всё равно гадит в отрасль, не давая ей развиваться с другими, более достойными языками? Даже пример дам — Линукс. Я подобную халтуру не поставлю даже в бортовую радиолу, EP>>На чём по-твоему написано ядро Linux? Pzz>Ядро линуха — это плохой пример.
Плохой пример чего? Ты о чём? matumba считал что Linux это C++
Здравствуйте, Pzz, Вы писали:
Pzz>Здравствуйте, gandjustas, Вы писали:
Pzz>>>C# работает только на венде, а все практические реализации Явы обладают красотой и грациозностью бегемота, пасущегося на лугах Страны Неограниченных Ресурсов. G>>Думаю стоит глянуть на Mono и Xamarin, перед тем как толкать такие утверждения. Сейчас спектр систем, где заработает код на C#, примерно такой же, как у java и у обоих гораздо шире, чем у C++.
Pzz>Моно — это пионерская поделка, годящаясь только на то, чтобы изготавливать пионерские поделки. Существенной проблемой при этом является то, что пионеры не в состоянии понять, что кроссплатформенные пионерские поделки надо тестировать на всех платформах, а не только на любимом компьютере разработчила. Поэтому даже для изготовления кроссплатформенных пионерских поделок моно не годится. А пионерские поделки под венду проще все же делать, используя родные для венды средства.
А что мешает протестировать моно на разных компьютерах?
Кстати я собирал в студии проект который взлете на mono. Я наверное что-то не так сделал.
Pzz>В этой связи приходится признать, что единственное применение моно заключается в том, что пионеры могут с умным видом заявлять в форумах, что C# подходит для кроссплатформенной разработки.
Расскажи это тут: http://unity3d.com/
Pzz>>>Кросплатформенный язык общего назначения типа "си с классами", не страдающий при этом врожденной склонностью к онкологическим заболеваниям, безусловно, нужен. G>>Практика показывает что эту нишу занял javascript.
Pzz>Яваскрипт занял нишу "хотим писать скрипты-плагины, но не на питоне". Кроме того, в силу политических, а не технических причин, явяскрипт имеет весьма специфические отношения с некоторыми платформами, такими, как веб-программирование (в основном на стороне клиента), и т.п.
Ну да, все происки ZOG.
Здравствуйте, Ikemefula, Вы писали:
EP>>>>Stackful coroutine мощнее — и это факт. А реальные примеры я уже показал I>>>А ассемблер еще мощнее. И что с того ? EP>>Вот это: EP>>
EP>>2. С помощью корутин решаются такие задачи, которые не под силу C# await. И не надо разводить демагогию на тему "это не нужно/это редко встречается".
EP>>Я писал не тебе. I>Это не важно. Ты на вопрос ответь.
На какой? На этот:
I>>>А ассемблер еще мощнее. И что с того ?
?
Ещё раз. Я озвучил факт, который оппонент не знал/не понимал. Что с этого? Ну как минимум теперь он знает
Вот ты тоже не знал, не верил, отрицал. Зато теперь "И что с того ?" — большой прогресс
Здравствуйте, Ikemefula, Вы писали:
I>Всё в один поток не всунешь. Нужен инструмент, который дает единообразный код независимо от диспетчеризации. Если винда не умеет чего то диспетчеризовать в какой то поток, это ничего не меняет. Пишешь диспетчер и все дела — сам код каким был, таким и остался.
Причём тут в один поток? Здесь речь не о запуске нового потока, а об исполнение продолжения в новом. Хотя инициации запуска была уже не в ui потоке (который мы там как-то ещё уже запустили). Смысла у этого особо не видно.
был пример gevent, где этого не было. Это по твоему какой-то редкий случай? I>>>Да, это редкий случай. Патчить можно и в джаве, и в дотнете, при чем без особых затруднений. EP>>Как ты пропатчишь что-нибудь типа std::getline? I> Его не надо патчить, всё остаётся как было. Все что нужно — подсунуть ему стрим, который унутре будет yield вызывать. Вот yield и делается через патч. I>То есть, I>
Здравствуйте, gandjustas, Вы писали:
Pzz>>Моно — это пионерская поделка, годящаясь только на то, чтобы изготавливать пионерские поделки. Существенной проблемой при этом является то, что пионеры не в состоянии понять, что кроссплатформенные пионерские поделки надо тестировать на всех платформах, а не только на любимом компьютере разработчила. Поэтому даже для изготовления кроссплатформенных пионерских поделок моно не годится. А пионерские поделки под венду проще все же делать, используя родные для венды средства.
G>А что мешает протестировать моно на разных компьютерах?
Ничего не мешает, но пионеры этого не делают. Вероятно, им в голову не приходит то, что это необходимо делать, и что на разных компьютерах программа может вести себя по-разному.
G>Кстати я собирал в студии проект который взлете на mono. Я наверное что-то не так сделал.
Здравствуйте, gandjustas, Вы писали:
G>Да и в общем случае сделать из синхронного черного ящика асинхронный нельзя, потому что нет гарантии не нарушения инвариантов.
Придумай хотя бы пару примеров поломки инвариантов в функции которая принимает пользовательский stream, и гарантированно работает в многопоточной среде.
Здравствуйте, gandjustas, Вы писали:
_>>С учётом того, на чём написаны сами .net, mono, java, эта фраза звучит особенно пикантно. Видимо здесь присутствует какая-то магия. ))) G>Это тебе помогает писать код? Какая разница на чем рантайм написан, если ты прикладные вещи пишешь?
Ууу снова отмазки пошли. В твоём сообщение то была фраза: "Сейчас спектр систем, где заработает код на C#, примерно такой же, как у java и у обоих гораздо шире, чем у C++". Т.е. подразумевается, что есть ОС где C# или java код запустится, а C/C++ нет.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Здравствуйте, artelk, Вы писали:
A>>Не будет ли проблемы?
EP>Нет — эти сопроцедуры работают в одном потоке.
def download_and_update_statistics(url):
x = statistics
y = download_and_calculate_statistics(url)
statistics = x + y
Не будет ли проблемы?
EP>Проблемы с внешнем кодом могут быть если внутри есть что-то типа: EP>
В этом случае если внутри "stream >> x" произойдёт yield, то инварианты могут быть поломаны. Но, если есть такой код — то ты его и на обычных потоках не сможешь запустить, корутины тут не причём
Т.е. вот так взять и сделать произвольный синхронный код асинхронным,при этом не смотря в него, нельзя.
Фишка в том, что автор этого "произвольного кода" ничего не знает о том, что в вызывающей стороне делаются хаки и игры со стеком, и в следующей версии функций может поломать инварианты. Не, лучше явный async\await...
Здравствуйте, gandjustas, Вы писали:
G>Ну сделай маршалинг UI вызовов, это все равно будет эффективнее создания кучи потоков.
У тебя какая-то паранойя с потоками. В не северных ситуаций они очень даже эффективны. Тем более, если учесть текущие тенденции в развитие процессоров...
G>У тебя же есть исходники, иначе как ты узнаешь какие методы надо переопределять?
У меня заголовочные файлы и скомпилированные lib/dll файлы. Многие библиотеки распространяются именно так. Но даже если бы и были исходники. Я не собираюсь переписывать кучи чужих библиотек, если этого можно не делать. И это возможно, в C++, но не в .net.
G>Поздравляю, ты осилил асинхронный IO. Теперь попробуй научиться комбинировать асинхронные вызовы. G>Например у тебя идет подряд два чтения — одно из файла, другое из сети, нет смысла дожидаться завершения первого, чтобы запустить второе. Можно запустить их параллельно, а потом вернуться как оба закончатся. G>Осилишь такое с корутинами?
G>Вот пример на C#
G>Было G>
Это так сказать внутренности. Как ты понимаешь, это всё без проблем упаковывается в симпатичный макрос, который делает всё автоматически и даже будет красивее твоего вариант. Но я это не стал делать, т.к. ты бы тогда наверняка тут же придрался и потребовал показать внутренности макроса.
_>>И если уж мы говорим о ней и нам критично быстродействие, то C# await/async тоже не стоит применять. G>С чего ты это взял?
Потому что этот синтаксический сахар не является бесплатным по накладным ресурсам.
P.S. Пока ещё жду твоего ответа на моё предыдущее сообщение...
Здравствуйте, alex_public, Вы писали:
_>Здравствуйте, Ikemefula, Вы писали:
I>>Всё в один поток не всунешь. Нужен инструмент, который дает единообразный код независимо от диспетчеризации. Если винда не умеет чего то диспетчеризовать в какой то поток, это ничего не меняет. Пишешь диспетчер и все дела — сам код каким был, таким и остался.
_>Причём тут в один поток? Здесь речь не о запуске нового потока, а об исполнение продолжения в новом. Хотя инициации запуска была уже не в ui потоке (который мы там как-то ещё уже запустили). Смысла у этого особо не видно.
Смысл простой — есть результаты, которые нужны сразу, и на них требование например время отклика ограничено. А остальные могут и подождать. Эта задача, к слову, встречается не только в UI.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
G>>Да и в общем случае сделать из синхронного черного ящика асинхронный нельзя, потому что нет гарантии не нарушения инвариантов.
EP>Придумай хотя бы пару примеров поломки инвариантов в функции которая принимает пользовательский stream, и гарантированно работает в многопоточной среде.
А почему инварианты должны ломаться именно в этой функции ? Ты хочешь решить локальную проблему, глобальным механизмом. Соответсвенно инварианты будут ломаться так же глобально.
Ты не можешь заранее сказать, что будет выполняться в тот момент, когда одна из нитей вызывает getline. Что будет если вторая нить вызовет тот же getline, скажем по какому нибудь эвенту и тд ?
В синхронном коде это не составит проблемы — понадобился ввод, пиши getline и все дела. А с твоими короутинами надо отслеживать руками, что же может выполняться в нити и у тебя нет никакого ограничивающего контекста.
Здравствуйте, alex_public, Вы писали:
I>>Опаньки ! "переписывать надо исключительно из-за особенностей реализации await/async в .net" I>>И одновременно, оказывается, дотнет ни при чем, а всё зависит от особенностей реализации. Браво !
_>Не, не так. Есть функции которые можно преобразовать в асинхронные без переписывания, а есть такие, которые нельзя. А вот .net заставляет нас переписывать любые, т.к. требует раскидывания async по всему стеку вызова.
И это правильно ! Ты не думал, почему аналогичные структуры хотят ввести в стандарт С++ ?
_>Я хотел сказать, что и в .net и в C++ модель await/async в общем то не так уж и нужна. ))) По сути это сахар на достаточно специфическую ситуацию. Собственно мы это уже обсуждали в той старой темке.
Наоборот — именно этот механизм и нужен для асинхронщины. Просто по той простой причине, что асинхронная многозадачность на порядок сложнее обычной скажем многопоточной многозадачности. В ней нет никакого ограничивающего контекста. Соответственно любая локальная задача превращается в глобальную проблему.
Потому и нужен механизм, который позволит решать такие проблемы локально, а не неявно модифицировать поведение непойми каких функций.
I>>И получаешь нарушение инварианта.
_>С чего бы это? Там выполнение будет строго последовательным, просто разделённым на два потока.
Cам подумай:
// Вот код, с которым все шоколадно в синхронном однопоточном коде
value = read()
write(next(value))
// а вот однопоточныый вариант, но асинхронный
нить 1 value = read()
нить 2 value = read()
нить 2 write(next(value))
нить 1 write(next(value)) // нарушение инварианта
// и вот
нить 1 value = read()
нить 2 value = read()
нить 1 write(next(value))
нить 2 write(next(value)) // нарушение инварианта
Здравствуйте, artelk, Вы писали:
A>>>Не будет ли проблемы? EP>>Нет — эти сопроцедуры работают в одном потоке. A>
A>def download_and_update_statistics(url):
A> x = statistics
A> y = download_and_calculate_statistics(url)
A> statistics = x + y
A>
A>Не будет ли проблемы?
Тут проблема будет даже и с обычными потоками — download_and_update_statistics не thread safe
EP>>Проблемы с внешнем кодом могут быть если внутри есть что-то типа: EP>>
В этом случае если внутри "stream >> x" произойдёт yield, то инварианты могут быть поломаны. Но, если есть такой код — то ты его и на обычных потоках не сможешь запустить, корутины тут не причём A>Т.е. вот так взять и сделать произвольный синхронный код асинхронным,при этом не смотря в него, нельзя. A>Фишка в том, что автор этого "произвольного кода" ничего не знает о том, что в вызывающей стороне делаются хаки и игры со стеком, и в следующей версии функций может поломать инварианты. Не, лучше явный async\await...
Давай примеры:
Придумай хотя бы пару примеров поломки инвариантов в функции которая принимает пользовательский stream, и гарантированно работает в многопоточной среде.
EP>>>>std::getline тут стандартная, не модифицированная. Точно также можно протащить yield и через любую другую функцию G>>>Да, вот только надо очень хорошо понимать как работает эта функция. К счастью для переписывания синхронного кода в асинхронный в .NET не надо разбираться как он внтури устроен. Можно просто базвоые методы, которые делают IO сделать async, а дальше следуя руганиям компилятора добавить async\await во все методы выше по цепочке вызовов. EP>>В цепочке вызовов находится код исходников которого нет, что теперь? G>В .NET очень легко — берешь dll и достаешь исходники.
Отличный способ
G>В С++ — хз что делать, даже твой способ нельзя применять, ибо гарантий никаких.
.
EP>>>>>>Что значит особый случай? Точно также можно завернуть tcp_stream. G>>>>>Надо очень хорошо знать как код работает внутри, чтобы делать такую асинхронность. EP>>>>Есть любая асинхронная функция которая принимает continuation/.then — мы ей передаём в этот continuation код с yield-ом внутри, что механически превращает остаток нашей функции в продолжение. G>>>Пример давай. EP>>Пример.
// Custom scheduling is not required - can be integrated
// to other systems transparently
main_tasks.push([]
{
asynchronous([]
{
return async_user_handler(),
finished = true;
});
});
Task task;
while(!finished)
{
main_tasks.pop(task);
task();
}
G>Это сразу же ставит крест на серверных решениях и масштабируемости вообще.
Почему? Такой подход спокойно работает с Boost.Asio — хватит уже чушь нести.
EP>>Ну ты говоришь что преобразование синхронного кода в асинхронный это механическая операция. Так и преобразование кода с await/yield — точно такая же механическая операция G>Во-первых это не так из-за message pump.
G>Во-вторых ты утверждал что надо патчить call-stack. Я выделил твое утверждение.
Ну так ты же и говоришь, что тебе нужно доставать исходники:
G>В .NET очень легко — берешь dll и достаешь исходники.
чтобы проставить await'ы
G>>>То что ты считаешь что нужно патчить call-stack — вывод, основанный на неверной посылке. EP>>Подробнее. G>В .NET нет смысла хранить callstack, потому что нету деструкторов, поэтому очень легко делать продолжения. В C++ тебе нужен callstack для освобождения ресурсов, вот ты и думаешь что он является необходимостью.
G>Аналог твоего кода на github для .NET еще в 2008 году писал Richter: G>http://msdn.microsoft.com/ru-ru/magazine/cc546608.aspx
И где там аналог? Там те же самые примитивные одноуровневые stackless coroutine что и у await
EP>>>>Как это никто не сделал? Раз, два, да даже возьми хоть мой пример реализации await
(это при том что я сам практически не работаю ни с каким io). G>>>Без асинхронного IO это все смысла не имеет. Покажи пример с асинхронным IO. EP>>Слушай, ну если ты не нацелен на конструктив, давай прекратим, ок? По второй ссылке Boost.Asio — самое что ни на есть асинхронное I/O, с тем самым IOCP под капотом G>И как это комбинировать? Как запустить два параллельных считывания?
Через boost::asio::spawn
G>>>Ты вообще представляешь как медленно будет работать твой пример с getline на реальном файле? G>>>Опубликуешь результаты забегов? При этом масштабирования такой подход не добавил. Ты не сможешь также запустить 100500 чтений файлов и выйграть хоть что-то. EP>>getline может читать из любого стрима, например из сокета. В одном потоке будут крутится тысячи потоков с getline внутри, который ничего не знает об корутинах. G>И что? Все равно то, что ты показал будет тормозить. Скорее всего аццки тормозить.
Здравствуйте, hi_octane, Вы писали:
J>>Пример Яху всем известен, правда? Пара маргиналов написали систему на маргинальном языке (лиспе) и свалили. Яху помучилась-помучилась и переписала все на мейнстримовом языке.
_>Пример яху как раз шикарен. Пара маргиналов на маргинальном языке внезапно! в ошмётки порвала многочисленных конкурентов на мэйнстримовых языках, за что и были были куплены яху. Тут бы уже задаться вопросом, а с чего бы им это удалось?! Но ты акцентируешь внимание на том что в яху не смогла ни самих маргиналов удержать, ни проект ими поднятый, выдаёшь это за некое преимущество мэйнстримовых языков
Перечитай мое сообщение еще раз, что ли Я даже не знаю, что тут еще сказать.
_>А мне кажется, то что менеджмент яху, в отличии от раннего гугла, не умел строить бизнес силами маргиналов, как раз и есть причина их быстрого слива по всем направлениям
О чем я и говорил в том сообщении, на которое ты отвечаешь
Здравствуйте, Ikemefula, Вы писали:
EP>>Ещё раз. Я озвучил факт, который оппонент не знал/не понимал. I>Ты сам себе придумал, что ктото чего то не понимает.
Например gandjustas начинает петь ту же самую песню про message pump, которую ты пел летом
I>Ну значит UI Loop из моего примера вызовется чудом, например сканированием адресного пространства на предмет наличия ::GetMessage и ::TranslateMessage или, как вариант, короутина догадается WinMain вызвать.
Репертуар "Осень 2013":
EP>>Ну ты говоришь что преобразование синхронного кода в асинхронный это механическая операция. Так и преобразование кода с await/yield — точно такая же механическая операция
G>Во-первых это не так из-за message pump.
EP>>Вот ты тоже не знал, не верил, отрицал. Зато теперь "И что с того ?" — большой прогресс I>Если тебя подводит память, то я напомню — ты утверждал, что асинхронщину не надо всовывать в эвентлуп. И доказал это утверждение кодом в котором всунул асинхронщину в WM_CHAR.
Здравствуйте, Ikemefula, Вы писали:
I>>>Вот такие фокусы и в джаве, и в дотнете, и в питоне. EP>>Откуда именно тут coroutine, покажи полный код на C#. I>Из либы. Зачем тебе код ?
Здравствуйте, Erop, Вы писали:
E>Здравствуйте, alex_public, Вы писали:
_>>Вообще то в роли числодробилки C++ однозначно лучший язык. Если сравнивать с Фортраном, то он предлагает намного более высокоуровневые абстракции и при этом даже чуть быстрее в умелых руках. Однако как мы видим во многих местах до сих пор используют Фортран — тут есть и тот самый консерватизм (как при переходе с C++ на D в других местах) и небольшая доля прагматизма, если мы говорим об учёных, а не программистах (C++ очень сложный, по сравнению с Фортраном).
E>Это главная проблема С++, как числодробилки. Что бы решить сложную вычматематическую задачу нужен не спец в С++, а спец в вычматах. А таким спецм фортран ПОНЯТНЕЕ и УДОБНЕЕ. E>В числодробилках хитрые абстракции нужны редко, а вот боевая итерация по каким-то матрицам + возможность компилятора это всё векторизовать на любой платформе более или менее самостоятельно нужна практически всегда.
Ну ты сильно преувеличиваешь возможности встроенной автоматической оптимизации всего и вся компилятором.
Те же cache locality, false sharing и прочие милые эффекты никто не отменял, и человек, который знает только абстрактные вычматы в вакууме (в которых скорость доступа к любому элементу любой матрицы одинаково мгновенная и считается только количество сложений/умножений) и полагающийся исключительно на возможности компилятора, максимально быстрый код не выдаст.
Здравствуйте, Ikemefula, Вы писали:
G>>>Да и в общем случае сделать из синхронного черного ящика асинхронный нельзя, потому что нет гарантии не нарушения инвариантов. EP>>Придумай хотя бы пару примеров поломки инвариантов в функции которая принимает пользовательский stream, и гарантированно работает в многопоточной среде. I>А почему инварианты должны ломаться именно в этой функции ?
Тогда покажи пример где они ломаются не в этой функции.
I>Ты хочешь решить локальную проблему, глобальным механизмом. Соответсвенно инварианты будут ломаться так же глобально. I>Ты не можешь заранее сказать, что будет выполняться в тот момент, когда одна из нитей вызывает getline. Что будет если вторая нить вызовет тот же getline, скажем по какому нибудь эвенту и тд ?
Ты не болтай, а примеры приведи
Вот есть thread safe функция, пусть тот же самый getline. Когда есть несколько потоков — её могут прервать в любой момент.
Что может может поломаться если ей передать stream который делает yield внутри.
Другими словами, чем std::this_thread::yield безопасней this_coroutine::yield?
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Здравствуйте, artelk, Вы писали:
EP>Тут проблема будет даже и с обычными потоками — download_and_update_statistics не thread safe Не thread safe, и что? Автор download_and_update_statistics и не задумывал его потокобезопасным. Метод работал корректно в однопоточном варианте. А после monkey.patch_all() перестал.
A>>Фишка в том, что автор этого "произвольного кода" ничего не знает о том, что в вызывающей стороне делаются хаки и игры со стеком, и в следующей версии функций может поломать инварианты. Не, лучше явный async\await... EP>Давай примеры: EP>
EP>Придумай хотя бы пару примеров поломки инвариантов в функции которая принимает пользовательский stream, и гарантированно работает в многопоточной среде.
Здравствуйте, artelk, Вы писали:
EP>>Тут проблема будет даже и с обычными потоками — download_and_update_statistics не thread safe A> Не thread safe, и что? Автор download_and_update_statistics и не задумывал его потокобезопасным. Метод работал корректно в однопоточном варианте. А после monkey.patch_all() перестал.
[кэп]А то что ты такую функцию не сможешь использовать и в банальном multi-thread[/кэп].
Те функции которые работают сокетами и т.п. — обычно thread-safe (например хоть urllib2.urlopen(url).read() из примера выше), если же нет — то об этом сказано в документации/интерфейсе
A>>>Фишка в том, что автор этого "произвольного кода" ничего не знает о том, что в вызывающей стороне делаются хаки и игры со стеком, и в следующей версии функций может поломать инварианты. Не, лучше явный async\await... EP>>Давай примеры: EP>>
EP>>Придумай хотя бы пару примеров поломки инвариантов в функции которая принимает пользовательский stream, и гарантированно работает в многопоточной среде.
A>Нафига?
Все примеры выше где ломаются инварианты имели не thread-safe код — обсуждать это не интересно.
J>Те же cache locality, false sharing и прочие милые эффекты никто не отменял, и человек, который знает только абстрактные вычматы в вакууме (в которых скорость доступа к любому элементу любой матрицы одинаково мгновенная и считается только количество сложений/умножений) и полагающийся исключительно на возможности компилятора, максимально быстрый код не выдаст.
Сейчас, конечно, полегче стало, так как х86 победил всех. Я ещё помню времена, когда типовой сценарий был такой, что отлаживал ты код на персоналке, а боевой прогон делал на суперкомпе, время которого — дефицит, как бы.
Сейчас, конечно, отлаживаешь на персоналке, а прогон на кластере, но тоже компы в кластере и на столе могут сильно отличаться таки...
и тут фортран именно потому и лучше, что НУЖНЫЕ ДЛЯ ВЫЧМАТОВ оптимизации там вылизанны до блеска, а не так, как в си...
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, jazzer, Вы писали:
J>который знает только абстрактные вычматы в вакууме (в которых скорость доступа к любому элементу любой матрицы одинаково мгновенная и считается только количество сложений/умножений) и полагающийся исключительно на возможности компилятора, максимально быстрый код не выдаст.
Уточню свой прошлый пост. Тут, безусловно, ты прав в том смысле, что твой алгоритм должен пролазить во все целевые архитектуры. Ну там блочные операции должны быть такими, что бы блоки помещались в память/кэш, если возможно, то использовалось зацепление и векторизация, вектора помещались в векторные регистры, если они на целевой платформе бывают и т. д.
А не прав в том, что вычматематики этого всего не знают. Абстрактные вычматы читают в ВУЗах на непрофильных специализациях, а спецы всё давно занют, понимают и использывают на боевых прогонах. Думаешь какой-нибудь крэй было так уж просто загрузить хотя бы процентов на 70% пиковой производительности?
И тем, не менее, все всё делали. Только это и так сложные довольно задачи, и тратить ещё силы и внимание на всякую ерунду, вроде той или иной векторизации там, или той или иной стратегии предсказания ветвлений, аппаратную поддержку циклов и прочие штуки не хочется, и во многих случаях фортран тут безусловно помогает.
Все эмоциональные формулировки не соотвествуют действительному положению вещей и приведены мной исключительно "ради красного словца". За корректными формулировками и неискажённым изложением идей, следует обращаться к их автором или воспользоваться поиском
Здравствуйте, alex_public, Вы писали:
_>Здравствуйте, gandjustas, Вы писали:
G>>Для клиента я пишу на JS, там однопоточная асинхронность. На сервере — async\await самое то. G>>Это как раз к тому, что потоки, особенно созданные вручную, почти не нужны, если у тебя есть нормальный асинронный IO.
_>У тебя сервер утилизирует только одно ядро процессора? )
Нет, там пул потоков оптимизированный под работу сервера. Создание дополнительных потоков на каждый чих ухудшает работу.
G>>Кстати в .NET тоже вполне возможно:
_>Ооо, наконец то код. Ну что же, я его весь посмотрел и вот мои выводы:
_>1. Он принимается. В том смысле что он действительно делает тоже самое что и мой. Правда переписать в 3 раза короче у тебя не вышло, а получилось скорее наоборот... Ну да ладно, я не буду цепляться к мелочам.
С учетом реализации boost coroutine мой код порядка на два короче
У меня кода, относящегося к задаче, меньше чем у тебя примерно в половину. Нет макросов и дополнительных функций для маршалинга в UI.
_>2. Как следствие пункта 1 делаем вывод, что с тобой всё же возможно конструктивное общение, хотя и долго пришлось добиваться этого.
_>3. Твоё решение задачки является чётким доказательством моего тезиса, что реализация await/async в C# заметно слабее простейшей реализации того же на C++ с помощью Boost.Coroutine. Т.к. тебе пришлось использовать системные сопроцедуры, предоставляемые виндой (которые являются полным аналогом Boost.Coroutine, только платформозависимым и независящим от языка), а не использовать механизм await/async (который тоже представляет собой сопроцедуры, но гораздо более слабые).
Прости, но ты походу не понимаешь о чем пишешь. В том коде что я показал нет async\await, там можно было и без тасков сделать, вышло бы на 3 строчки длиннее.
Вот тебе решение той же задачи с async\await:
private async void button1_Click(object sender, EventArgs e)
{
for (int i = 0; i < 100; i++)
{
using (var src = File.OpenRead("TextFile1.txt"))
using (var dst = File.Create("TextFile2.txt"))
await ComplexFuncAsync(src, dst);
Console.WriteLine("Iteration " + i);
}
}
static async Task ComplexFuncAsync(Stream src, Stream dst)
{
var buf = new byte[256];
while(src.Position < src.Length)
{
var len = await src.ReadAsync(buf,0,buf.Length);
await dst.WriteAsync(buf, 0, len);
}
}
Это весь код, больше ни одной строчки не надо. И так пишут нормальные люди на C#.
А ты пытаешься доказать что на C# нельзя написать как на C++. Так оно и не нужно, есть более эффективные способы. Более того, на C++ гораздо хуже работает твой вариант, чем код выше.
G>>Поздравляю, ты изобрел асинхронные корутины. Их для .NET Рихтер изобрел в 2007 году G>>Но у тебя как обычно несколько проблемы: G>>1) нужен message pump для корутин, обязательно однопоточный. G>>2) Нужен message pump для асинхронного IO, тут уже зависит от реализации. G>>3) Все это дико тормозит без возможности улучшения (потому что 1 и 2).
_>А где ты увидел в этом моём коде использование очереди сообщений? )
Оно там есть. Как у тебя продолжения маршалятся в UI поток? Ты же из IOCP треда не дергаешь корутину?
_>И кстати как раз .net вариант использует очередь сообщений, в то время как это совсем не обязательно для неблокирующего IO.
Ты о чем? IOCP и есть очередь сообщений, ты про какую очередь?
Или ты про то, что по дефолту таски выполняют продолжение в текущем контексте синхронизации? Так это сделано для комфорта разработчика и решается вызовом ConfigureAwait(false).
_>>>Потому что этот синтаксический сахар не является бесплатным по накладным ресурсам. G>>
_>Ну посмотри на реализацию реально нагруженных серверов. Тот же nginx глянь. А потом покажи мне нечто сравнимое на C# await/async.
Ты реально гонишь...
В C++ все сильно завязано на стек, поэтому там нельзя автоматом переписывать хвост метода в продолжение, как это делает компилятор C#. Когда изобретут capture-by-move для лямбд, тогда это станет возможно, покачто нет.
А компилятор C еще более примитивный, он слишком низкоуровневый, чтобы таким заниматься.
Поэтому в программах на C никогда не будет аналога async\await, а на C++ ближайшее время не будет, может быть жалкое подобие.
Здравствуйте, Ikemefula, Вы писали:
I>То есть, в кратце, короутин как минимум недостаточно для асинхронщины, нужен диспетчер прибитый гвоздями к эвентлупу.
Хватит уже передёргивать, у нас уже была асинхронная функция:
Здравствуйте, Ikemefula, Вы писали:
I>И это правильно ! Ты не думал, почему аналогичные структуры хотят ввести в стандарт С++ ?
Это ты про что? ) Я краем глаза посматриваю на C++14, но что-то не помню там такого. )
I>Наоборот — именно этот механизм и нужен для асинхронщины. Просто по той простой причине, что асинхронная многозадачность на порядок сложнее обычной скажем многопоточной многозадачности. В ней нет никакого ограничивающего контекста. Соответственно любая локальная задача превращается в глобальную проблему.
I>Потому и нужен механизм, который позволит решать такие проблемы локально, а не неявно модифицировать поведение непойми каких функций.
Запуск нового потока с использованием блокирующих функций в нём — это тоже со стороны получается асинхронным вызовом. Причём он прост и удобен для программирования. К сожалению он не подходит для 100% задач, но для очень многих всё же подходит...
I>Cам подумай: I>
I>// Вот код, с которым все шоколадно в синхронном однопоточном коде
I>value = read()
I>write(next(value))
I>// а вот однопоточныый вариант, но асинхронный
I>нить 1 value = read()
I>нить 2 value = read()
I>нить 2 write(next(value))
I>нить 1 write(next(value)) // нарушение инварианта
I>// и вот
I>нить 1 value = read()
I>нить 2 value = read()
I>нить 1 write(next(value))
I>нить 2 write(next(value)) // нарушение инварианта
I>
Не знаю откуда ты взял это, но оно явно не имеет никакого отношения к моей реализации. Т.к. в ней наша функция теряет управление сразу же после инициации асинхронного вызова read. И соответственно пока эта операция не будет завершена (плюс ещё пока поток занятый чем-то другим не освободится), никаких новых вызовов read или write не будет. Причём этот расклад никак не связан с внутренним устройством нашей функции.
_>Не знаю откуда ты взял это, но оно явно не имеет никакого отношения к моей реализации.
Я показываю, что твое решение не имеет никакого отношения к задаче.
> Т.к. в ней наша функция теряет управление сразу же после инициации асинхронного вызова read. И соответственно пока эта операция не будет завершена (плюс ещё пока поток занятый чем-то другим не освободится), никаких новых вызовов read или write не будет. Причём этот расклад никак не связан с внутренним устройством нашей функции.
А кто гарантирует, что новых вызовов не будет ? Представь, в однопоточном коде сто штук таких вот вызово. Когда синхронно, все шоколадно — отработали последовательно, каждая следующая модифицирует результат предыдущей.
Когда появляется асинхронщина, каждая следующая перезатирает результат предыдущей.
Здравствуйте, Ikemefula, Вы писали:
EP>>Наконец-то долгожданный пример I>Я этот вариант упоминал раз сто когда ты летом сказки рассказывал про короутины.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Здравствуйте, artelk, Вы писали:
EP>>>Тут проблема будет даже и с обычными потоками — download_and_update_statistics не thread safe A>> Не thread safe, и что? Автор download_and_update_statistics и не задумывал его потокобезопасным. Метод работал корректно в однопоточном варианте. А после monkey.patch_all() перестал.
EP>[кэп]А то что ты такую функцию не сможешь использовать и в банальном multi-thread[/кэп]. EP>Те функции которые работают сокетами и т.п. — обычно thread-safe (например хоть urllib2.urlopen(url).read() из примера выше), если же нет — то об этом сказано в документации/интерфейсе
Обычно != всегда, да и "обычность" неочевидна.
И, наверно, напрасно в gevent свои примитивы синхронизации добавлены, ведь существующие системные напрочь не игнорируются. Если метод thread safe, то он тоочно будеть работать правильно, когда мы его пересадим на наши короутины.
EP>Все примеры выше где ломаются инварианты имели не thread-safe код — обсуждать это не интересно.
Ну заверни ты тело download_and_update_statistics в mutex Enter\Exit.
Чуть более жизненный пример (раз уж просил):
lock(sync)
{
if(list != null)
return list;
list = new List();
using(var stream = createStream())
{
string s;
while ((s=stream.ReadLine())!=null)
list.Add(s);
}
}
Здравствуйте, Evgeny.Panasyuk, Вы писали:
I>>То есть, в кратце, короутин как минимум недостаточно для асинхронщины, нужен диспетчер прибитый гвоздями к эвентлупу.
EP>Хватит уже передёргивать, у нас уже была асинхронная функция: EP>
Здравствуйте, artelk, Вы писали:
A>Чуть более жизненный пример (раз уж просил): A>
A>lock(sync)
A>{
A> if(list != null)
A> return list;
A> list = new List();
A> using(var stream = createStream())
A> {
A> string s;
A> while ((s=stream.ReadLine())!=null)
A> list.Add(s);
A> }
A>}
Здравствуйте, Ikemefula, Вы писали:
I>>>То есть, в кратце, короутин как минимум недостаточно для асинхронщины, нужен диспетчер прибитый гвоздями к эвентлупу. EP>>Хватит уже передёргивать, у нас уже была асинхронная функция: EP>>
Здравствуйте, gandjustas, Вы писали:
G>Нет, там пул потоков оптимизированный под работу сервера. Создание дополнительных потоков на каждый чих ухудшает работу.
Ну вот видишь, а говорил можно без потоков... )))
G>С учетом реализации boost coroutine мой код порядка на два короче
Ну ты всё же уникальный, такое иногда придумаешь, чтобы только не признать чужую правоту, что просто шедевр. А может тогда за одно учтём ещё и размер реализации виндовыx fiber?
G>Нет макросов и дополнительных функций для маршалинга в UI.
Да, да, в C# нет макросов и поэтому у тебя код получился не только длиннее, но и заметно страшнее, с ручным протаскиванием yield, в котором легко ошибиться.
И кстати в варианте с асинхронным io у меня тоже нет никаких дополнительных функций.
G>Вот тебе решение той же задачи с async\await:
Это не решение той же задачи, т.к. ты тут модифицировал функцию ComplexFunc. Т.е. ты ещё раз доказал, что на async\await решить эту задачку не можешь. А вот на виндовых fiber'ax можешь. Всё логично.
Т.е. ты сам сейчас подтвердил мой основной тезис, что реализация async\await в C# слабее, т.к. заставляет нас переписывать существующий синхронный библиотечный код, в то время как его можно было бы спокойно использовать в асинхронном коде. И даже на .net'e.
G>А ты пытаешься доказать что на C# нельзя написать как на C++. Так оно и не нужно, есть более эффективные способы. Более того, на C++ гораздо хуже работает твой вариант, чем код выше.
Ооо, ну да, началась классическая песня "а оно нам и не нужно". Сразу почему-то вспоминаются фанаты продукции Apple...
G>Оно там есть. Как у тебя продолжения маршалятся в UI поток? Ты же из IOCP треда не дергаешь корутину?
Зачем, если это уже делает библиотека асинхронного io? ) Это было нужно именно в варианте с потоками и блокирующим io. Я потому и сказал, что он интереснее, т.к. там всё чуть сложнее. А с асинхронным io всё вообще просто.
G>Ты о чем? IOCP и есть очередь сообщений, ты про какую очередь?
Нет, очередь сообщений, это всего лишь один из вариантов работы с асинхронным io. Есть и другие, поинтереснее. В том числе и в винде. А например в линухе асинхронный io вообще только через сигналы — никаких очередей.
G>Ты реально гонишь... G>В C++ все сильно завязано на стек, поэтому там нельзя автоматом переписывать хвост метода в продолжение, как это делает компилятор C#. Когда изобретут capture-by-move для лямбд, тогда это станет возможно, покачто нет. G>А компилятор C еще более примитивный, он слишком низкоуровневый, чтобы таким заниматься.
Ты не понял смысл моей фразы. Речь о том, что когда у нас критична производительность, то нам уже не до красивостей в коде — главное результат. Поэтому надо брать максимально быстрое решение, как бы оно там не выглядело.
G>Кстати nginx не быстрее IIS
Здравствуйте, Ikemefula, Вы писали:
I>А кто гарантирует, что новых вызовов не будет ? Представь, в однопоточном коде сто штук таких вот вызово. Когда синхронно, все шоколадно — отработали последовательно, каждая следующая модифицирует результат предыдущей. I>Когда появляется асинхронщина, каждая следующая перезатирает результат предыдущей.
Как это кто гарантирует? Мы конечно же! Ведь это всё происходит уже в нашем асинхронном коде приложения, а не в неизвестном библиотечном.
Вот смотри. Допустим есть такая (как у тебя) библиотечная функция:
void f(R read, W write)
{
auto v=read();
write(next(v));
}
и синхронный код:
for(;;) f(read, write);
Мы конечно же можем написать такой асинхронный код:
for(;;) async_code(
f(async_read, write);
)
и получим как раз описанную тобой проблему. Но это будет следствием исключительно кривизны нашего асинхронного кода, а не особенностью реализации библиотечной функции (про которую мы типа ничего не знаем). Стоит нам написать так:
async_code(
for(;;) f(async_read, write);
)
и проблема исчезнет — код станет полностью корректным.
Т.е. если мы пишем корректный асинхронный код, то использование синхронных библиотечных функций нам ничуть не мешает.
Здравствуйте, alex_public, Вы писали:
_>Т.е. если мы пишем корректный асинхронный код, то использование синхронных библиотечных функций нам ничуть не мешает.
То есть, с++ с короутинами ничем не поможет, т.к. корректных синхронный код и полученый из него асинхронный это две большие разницы
Здравствуйте, alex_public, Вы писали:
_>Здравствуйте, gandjustas, Вы писали:
G>>Нет, там пул потоков оптимизированный под работу сервера. Создание дополнительных потоков на каждый чих ухудшает работу. _>Ну вот видишь, а говорил можно без потоков... )))
Я говорил что не нужно их создавать, это сильно разные утверждения.
G>>С учетом реализации boost coroutine мой код порядка на два короче _>Ну ты всё же уникальный, такое иногда придумаешь, чтобы только не признать чужую правоту, что просто шедевр. А может тогда за одно учтём ещё и размер реализации виндовыx fiber?
Тогда давай сразу всего виндовса, чего уж там
G>>Нет макросов и дополнительных функций для маршалинга в UI. _>Да, да, в C# нет макросов и поэтому у тебя код получился не только длиннее, но и заметно страшнее, с ручным протаскиванием yield, в котором легко ошибиться.
Чувак, да успокойся, такой бред в здравом уме никто писать не будет. И ошибаться не будет соответственно.
_>И кстати в варианте с асинхронным io у меня тоже нет никаких дополнительных функций.
G>>Вот тебе решение той же задачи с async\await:
_>Это не решение той же задачи, т.к. ты тут модифицировал функцию ComplexFunc. Т.е. ты ещё раз доказал, что на async\await решить эту задачку не можешь. А вот на виндовых fiber'ax можешь. Всё логично.
Чувак, таже же задача — это одинаковый output при одинаковых input. Ограничения ты всегда сам себе придумываешь.
В реальной жизни неподходящую библиотеку просто перепишут.
В отличие от C++ в .NET встроенная библиотека на несколько порядков мощнее, чем C++ даже с бустом. Поэтому нет необходимости привлекать шандарахнутые dll, которые не поддерживают асинхронность.
Описанная тобой проблема только в С++ и существует. В .NET её нет и, соответственно, решать её никто не собирается.
_>Т.е. ты сам сейчас подтвердил мой основной тезис, что реализация async\await в C# слабее, т.к. заставляет нас переписывать существующий синхронный библиотечный код, в то время как его можно было бы спокойно использовать в асинхронном коде. И даже на .net'e.
Ты думаешь от повторения ты правее станешь? Или ты таки покажешь как масштабировать корутины? Чтобы не надо было эвентлуп крутить, ибо в серверном варианте это жопа.
G>>А ты пытаешься доказать что на C# нельзя написать как на C++. Так оно и не нужно, есть более эффективные способы. Более того, на C++ гораздо хуже работает твой вариант, чем код выше. _>Ооо, ну да, началась классическая песня "а оно нам и не нужно". Сразу почему-то вспоминаются фанаты продукции Apple...
Чувак, это ты начал такие песи, рассказывая что linq и yield не нужен
А по поводу твоей проблемы — таки не нужно, мне за 5 лет один раз понадобилось работать с библиотекой, которая не поддерживала асинхронность. И я её переписал на таски, банально открыв в Reflector и выдрав нужный мне код.
G>>Оно там есть. Как у тебя продолжения маршалятся в UI поток? Ты же из IOCP треда не дергаешь корутину?
_>Зачем, если это уже делает библиотека асинхронного io? ) Это было нужно именно в варианте с потоками и блокирующим io. Я потому и сказал, что он интереснее, т.к. там всё чуть сложнее. А с асинхронным io всё вообще просто.
Что делает? В UI маршалит?
Корутины могут исполняться только в "owning thread" из документации, это значит что тебе надо асинхронные вызовы маршалить в "owning thread". Обычно это делается через очереди и message pump, как в твоем примере. Даже когда ты юзаешь asio у тебя есть очередь дождавшихся завершения IO корутин.
То есть ты можешь увеличить плотность потоков, на одном системном запускать несколько корутин, но эффективно использовать ресурсы компьютера (читай использовать work-stealing) не получится. Плюс ты имеешь накладные расходы на маршалинг и message pump.
В .NET из-за отсутствия привязки к "owning thread" можно использовать пулы потоков, не делать message pump, параллелить работу.
G>>Ты о чем? IOCP и есть очередь сообщений, ты про какую очередь?
_>Нет, очередь сообщений, это всего лишь один из вариантов работы с асинхронным io. Есть и другие, поинтереснее. В том числе и в винде. А например в линухе асинхронный io вообще только через сигналы — никаких очередей.
И что?
G>>Ты реально гонишь... G>>В C++ все сильно завязано на стек, поэтому там нельзя автоматом переписывать хвост метода в продолжение, как это делает компилятор C#. Когда изобретут capture-by-move для лямбд, тогда это станет возможно, покачто нет. G>>А компилятор C еще более примитивный, он слишком низкоуровневый, чтобы таким заниматься.
_>Ты не понял смысл моей фразы. Речь о том, что когда у нас критична производительность, то нам уже не до красивостей в коде — главное результат. Поэтому надо брать максимально быстрое решение, как бы оно там не выглядело.
Нет. Ты начал говорить о каких-то накладных расходах, вот я и спрашиваю о каких ты говоришь. Ибо async мало что вносит в код, основная работа делается асинхронными методами, которые еще со времен .NET 1.0 существуют.
G>>Кстати nginx не быстрее IIS _>Ага, ага. И как раз поэтому популярность apache и iis падает при переходе к более нагруженным серверам, а у nginx наоборот http://w3techs.com/technologies/cross/web_server/ranking.
Тут ты вообще не в теме. Вопрос не в скорости, а в цене. ngix почти всегда используется как reverse proxy, тупо дешевле, не надо лицензии на венду покупать.
Особенно важно когда надо апач экранировать с php, ибо он умирает от 40 одновременных запросов на сервак.
Здравствуйте, Ikemefula, Вы писали:
I>То есть, с++ с короутинами ничем не поможет, т.к. корректных синхронный код и полученый из него асинхронный это две большие разницы
Так это само собой. Фокус в том, что мы при этом можем спокойно использовать в асинхронном стеке вызова синхронные библиотечные функции. А в C# не можем — их надо переписывать заново.
Здравствуйте, alex_public, Вы писали:
I>>То есть, с++ с короутинами ничем не поможет, т.к. корректных синхронный код и полученый из него асинхронный это две большие разницы
_>Так это само собой. Фокус в том, что мы при этом можем спокойно использовать в асинхронном стеке вызова синхронные библиотечные функции.
И получишь показное мною нарушение инварианта.
>А в C# не можем — их надо переписывать заново.
Здравствуйте, alex_public, Вы писали:
_>Здравствуйте, Ikemefula, Вы писали:
I>>А кто гарантирует, что новых вызовов не будет ? Представь, в однопоточном коде сто штук таких вот вызово. Когда синхронно, все шоколадно — отработали последовательно, каждая следующая модифицирует результат предыдущей. I>>Когда появляется асинхронщина, каждая следующая перезатирает результат предыдущей.
_>Как это кто гарантирует? Мы конечно же! Ведь это всё происходит уже в нашем асинхронном коде приложения, а не в неизвестном библиотечном.
Но тогда ты должен знать как работает этот библиотечный код. Вдруг создает тред и дергает твою функцию, все, твоя хитрая система рассыпается.
_>Т.е. если мы пишем корректный асинхронный код, то использование синхронных библиотечных функций нам ничуть не мешает.
Это в теории, а на практике ограничений будет выше крыши.
Судя по гуглу такими извращениями только пара человек на rsdn и занимается, а все остальные предпочитают писать нормальный код.
Да и вообще непонятно зачем нужна такая асинхронность, которая:
1) тормозит
2) не машстабируется
_>>А мне кажется, то что менеджмент яху, в отличии от раннего гугла, не умел строить бизнес силами маргиналов, как раз и есть причина их быстрого слива по всем направлениям
J>О чем я и говорил в том сообщении, на которое ты отвечаешь
Таки из твоего сообщения получается что язык годен для бизнеса тогда и только тогда когда всё готово, есть программисты, книжки, библиотеки и т.п., т.е. когда это уже мэйнстрим. Но для получения конкурентного преимущества необходимо использовать инженерные решения на шаг впереди мэйнстрима. А это как раз ниша маргинальных языков. Гугл взлетал одновременно с падением яхи, и вполне себе спокойно использовал маргинальный и незрелый тогда питон (значительная доля популярности которого выросла на хайпе вокруг гугла). У яху такого менеджмента просто не было, вот они не смогли удержать то что купили.
Здравствуйте, gandjustas, Вы писали:
G>В отличие от C++ в .NET встроенная библиотека на несколько порядков мощнее, чем C++ даже с бустом. Поэтому нет необходимости привлекать шандарахнутые dll, которые не поддерживают асинхронность.
Забавное утверждение. Не подскажешь тогда случаем, как во встроенной библиотеке .Net называется раздел аналогичный например Boost.Spirit? )
G>Чувак, это ты начал такие песи, рассказывая что linq и yield не нужен
Да, я считаю что не нужны, но при этом я привёл их работающие реализации. Почувствуй разницу ситуаций:
моя: не нужны (потому что есть способы сделать тоже самое лучше), но без проблем можно реализовать.
твоя: не нужны (потому что нельзя реализовать) — мне не лень переписывать заново чужие библиотеки.
G>А по поводу твоей проблемы — таки не нужно, мне за 5 лет один раз понадобилось работать с библиотекой, которая не поддерживала асинхронность. И я её переписал на таски, банально открыв в Reflector и выдрав нужный мне код.
Ага, ага.
G>Корутины могут исполняться только в "owning thread" из документации, это значит что тебе надо асинхронные вызовы маршалить в "owning thread". Обычно это делается через очереди и message pump, как в твоем примере. Даже когда ты юзаешь asio у тебя есть очередь дождавшихся завершения IO корутин.
Callback во всех известных мне C++ библиотеках асинхронного io вызывается именно в том потоке, который я укажу, а не в каком-то там неизвестном.
G>Нет. Ты начал говорить о каких-то накладных расходах, вот я и спрашиваю о каких ты говоришь. Ибо async мало что вносит в код, основная работа делается асинхронными методами, которые еще со времен .NET 1.0 существуют.
Ну да, о том и речь. Как бы даже если накладные расходы от async небольшие (хотя смотря с чем сравнивать), то всё равно они лишние, т.к. никакой функциональности при этом не приносят.
G>Тут ты вообще не в теме. Вопрос не в скорости, а в цене. ngix почти всегда используется как reverse proxy, тупо дешевле, не надо лицензии на венду покупать.
Да, да, у топ 1000 по посещению (типа яндекс, вконтаке, фейсбука) не хватает денег на лицензию винды. Исключительно поэтому они используют бесплатный Linux с nginx.
Здравствуйте, Ikemefula, Вы писали:
I>И получишь показное мною нарушение инварианта.
Я же показал тебе, что не получу, если напиши корректный асинхронный код (не меняя синхронную библиотечную функцию). Или же ты хочешь сказать, что если я напишу на C# так:
async void f(read, write)//вот она твоя переписанная функция по всем правилам
{
var v=await read();
write(next(v));
}
f(async_read, write);
f(async_read, write);
то получится корректный код? ) А это полный аналог того, что ты предлагаешь мне как приводящий к ошибкам код на C++...
Здравствуйте, hi_octane, Вы писали:
_>>>А мне кажется, то что менеджмент яху, в отличии от раннего гугла, не умел строить бизнес силами маргиналов, как раз и есть причина их быстрого слива по всем направлениям
J>>О чем я и говорил в том сообщении, на которое ты отвечаешь
_>Таки из твоего сообщения получается что язык годен для бизнеса тогда и только тогда когда всё готово, есть программисты, книжки, библиотеки и т.п., т.е. когда это уже мэйнстрим. Но для получения конкурентного преимущества необходимо использовать инженерные решения на шаг впереди мэйнстрима. А это как раз ниша маргинальных языков. Гугл взлетал одновременно с падением яхи, и вполне себе спокойно использовал маргинальный и незрелый тогда питон (значительная доля популярности которого выросла на хайпе вокруг гугла). У яху такого менеджмента просто не было, вот они не смогли удержать то что купили.
Именно так, я и говорил, что маргинальные языки — удел стартапов, а в больших компаниях от них больше вреда, чем пользы.
ЗЫ ну и я не думаю, что Питон — это технологический фундамент гугла
Здравствуйте, gandjustas, Вы писали:
_>>Забавное утверждение. Не подскажешь тогда случаем, как во встроенной библиотеке .Net называется раздел аналогичный например Boost.Spirit? ) G>Парсеры XML и JSON уже есть. Для более сложных вещей обычно используются нормальные генераторы парсеров. G>Spirit это не от хорошей жизни, а от бедности базовой библиотеки.
Хыхы, ты всё же великолепен. Думаю достоин звания "лучший мастер отмазок rsdn'a".
G>>>Чувак, это ты начал такие песи, рассказывая что linq и yield не нужен _>>Да, я считаю что не нужны, но при этом я привёл их работающие реализации. Почувствуй разницу ситуаций: _>>моя: не нужны (потому что есть способы сделать тоже самое лучше), но без проблем можно реализовать. _>>твоя: не нужны (потому что нельзя реализовать) — мне не лень переписывать заново чужие библиотеки. G>Ты ничего "лучше" не показал То что ты показал — тормозит, не масштабируется, не решает реальные проблемы, которые существуют в .NET, решает проблемы, которых в .NET никогда не было. G>В остальном ты прав
Вообще то это был речь о другом. О linq (boost.range), yield (итераторы) и т.п. Что же касается обсуждаемого тут решения await/async в C++, то на мой взгляд это опять же из категории "можно без проблем реализовать на C++, хотя и не особо нужно". То, что оно при этом получилось ещё и лучше оригинала — это так, просто забавный нюанс.
G>Еще как приносят, потому async методы переписываются в продолжения. Руками такое сделать в 100 раз сложнее и больше вероятность внести ошибку.
Ещё раз, это польза для программиста, а не для быстродействия продукта. Точнее оно его даже уменьшает.
G>Если бы async ничего не давал, то его бы не использовали. А его используют массово.
Да, потому что высоконагруженные серверы массово не пишут. )))
_>>Да, да, у топ 1000 по посещению (типа яндекс, вконтаке, фейсбука) не хватает денег на лицензию винды. Исключительно поэтому они используют бесплатный Linux с nginx. G>Ты удивишься, но это действительно так. Ты очень далек от реальной экономики.
О сколько нам открытий чудных готовит обычный программистский форум. )
Здравствуйте, alex_public, Вы писали:
_>Здравствуйте, gandjustas, Вы писали:
_>>>Забавное утверждение. Не подскажешь тогда случаем, как во встроенной библиотеке .Net называется раздел аналогичный например Boost.Spirit? ) G>>Парсеры XML и JSON уже есть. Для более сложных вещей обычно используются нормальные генераторы парсеров. G>>Spirit это не от хорошей жизни, а от бедности базовой библиотеки.
_>Хыхы, ты всё же великолепен. Думаю достоин звания "лучший мастер отмазок rsdn'a".
Конечно, когда аргументы кончаются начинают искать причины в оппоненте.
Ну давай покажи какие realworld проблемы решает spirit. На проверку окажется что 90% уже решены в современных платформах, а еще 10% закрываются специальными средствами.
Это кстати не только spirit касается, но и других "универсальных всемогутеров".
G>>>>Чувак, это ты начал такие песи, рассказывая что linq и yield не нужен _>>>Да, я считаю что не нужны, но при этом я привёл их работающие реализации. Почувствуй разницу ситуаций: _>>>моя: не нужны (потому что есть способы сделать тоже самое лучше), но без проблем можно реализовать. _>>>твоя: не нужны (потому что нельзя реализовать) — мне не лень переписывать заново чужие библиотеки. G>>Ты ничего "лучше" не показал То что ты показал — тормозит, не масштабируется, не решает реальные проблемы, которые существуют в .NET, решает проблемы, которых в .NET никогда не было. G>>В остальном ты прав
_>Вообще то это был речь о другом. О linq (boost.range), yield (итераторы) и т.п. Что же касается обсуждаемого тут решения await/async в C++, то на мой взгляд это опять же из категории "можно без проблем реализовать на C++, хотя и не особо нужно". То, что оно при этом получилось ещё и лучше оригинала — это так, просто забавный нюанс.
Ты опять повторяешь заблуждение что решение на C++ лучше. Оно не лучше потому что:
1) тормозит
2) не масштабируется
Живое решение может иметь максимум один недостаток, а вот у "решения" на C++ оба.
В отличие от "решения" на C++, конструкции async\await и TPL не тормозят и масштабируются. Более того, придуманный 5 лет назад AsyncEnumerator на итераторах, работающий почти также, как твой пример на C++, масштабировался.
G>>Еще как приносят, потому async методы переписываются в продолжения. Руками такое сделать в 100 раз сложнее и больше вероятность внести ошибку. _>Ещё раз, это польза для программиста, а не для быстродействия продукта. Точнее оно его даже уменьшает.
С чего ты взял? perceived performance от async IO растет, а распараллеливание IO без блокировки потоков делает софт быстрее\улучшает масштабируемость.
Но в твоем случае надо еще руками реализовывать параллельность IO.
G>>Если бы async ничего не давал, то его бы не использовали. А его используют массово. _>Да, потому что высоконагруженные серверы массово не пишут. )))
Очень много пишут. Уж побольше чем корутины
Здравствуйте, alex_public, Вы писали:
_>Я же показал тебе, что не получу, если напиши корректный асинхронный код (не меняя синхронную библиотечную функцию). Или же ты хочешь сказать, что если я напишу на C# так: _>
_>async void f(read, write)//вот она твоя переписанная функция по всем правилам
_>{
_> var v=await read();
_> write(next(v));
_>}
_>f(async_read, write);
_>f(async_read, write);
_>
_>то получится корректный код? ) А это полный аналог того, что ты предлагаешь мне как приводящий к ошибкам код на C++...
Если по f ты подразумеваешь асинхронный мутекс, то это будет правильный код.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Здравствуйте, Ikemefula, Вы писали:
I>>То есть, в кратце, короутин как минимум недостаточно для асинхронщины, нужен диспетчер прибитый гвоздями к эвентлупу.
EP>Хватит уже передёргивать, у нас уже была асинхронная функция: EP>
и весь код ничего не знал про корутины. Они добавляются сюда локальной трансформацией кода
Объяснил бы мне кто-нибудь вот что:
Асинхронные операции могут выполняться (и\или завершаться) в другом потоке (потоке IOCP, потоке тред пула или явно создаваемом потоке при старте асинхронной операции).
При кооперативной многозадачности со stackfull coroutines работа выполняется в одном системном потоке, т.е. этот поток должен существовать постоянно и как-то уметь "ждать" окончания асинхронных операций из первого пункта.
Вопрос: как реализовано это "ожидание"? Гоняем холостой цикл с проверками "а не завершился ли кто"? Ждем на каком-нибудь системном объекте синхронизации (системном событии, например)? Как-то еще?
Здравствуйте, artelk, Вы писали:
A>Объяснил бы мне кто-нибудь вот что: A> A> Асинхронные операции могут выполняться (и\или завершаться) в другом потоке (потоке IOCP, потоке тред пула или явно создаваемом потоке при старте асинхронной операции). A> При кооперативной многозадачности со stackfull coroutines работа выполняется в одном системном потоке, т.е. этот поток должен существовать постоянно и как-то уметь "ждать" окончания асинхронных операций из первого пункта. A>A>Вопрос: как реализовано это "ожидание"? Гоняем холостой цикл с проверками "а не завершился ли кто"? Ждем на каком-нибудь системном объекте синхронизации (системном событии, например)? Как-то еще?
А тут факт наличия stackful coroutine ортогонален, так как трансформация кода полностью локальная.
"цикл с проверками" если и присутствует, то он был и до добавления корутин, например это может быть UI Loop, а-ля:
Здравствуйте, Ikemefula, Вы писали:
I>Если по f ты подразумеваешь асинхронный мутекс, то это будет правильный код.
Ага, как и в C++.
Ну в общем ты сам видишь, что если мы пишем кривой асинхронный код, то он будет одинаково глючить и в C++ и в C# — никакого волшебства нет. А если писать асинхронную часть корректно, то опять же никаких проблем не будет ни там, ни там. Единственная разница в том, что при реализации асинхронности через async/await в C# (а это кстати не единственный способ даже для .net'a), нам строго обязательно переписывать заново все библиотечные функции, использующиеся в стеке вызова. А в C++ можно спокойно использовать старые функции без такого переписывания.
Здравствуйте, alex_public, Вы писали:
_>Здравствуйте, Ikemefula, Вы писали:
I>>Если по f ты подразумеваешь асинхронный мутекс, то это будет правильный код.
_>Ага, как и в C++.
_>Ну в общем ты сам видишь, что если мы пишем кривой асинхронный код, то он будет одинаково глючить и в C++ и в C# — никакого волшебства нет.
_>А в C++ можно спокойно использовать старые функции без такого переписывания.
Два высказывания сильно противоречат. Вроде как убедились, что корректный синхронный код != корректный асинхронный.
То есть, если ты захочешь поменять поведение на асинхронное, то в большинстве случаев этот код превращется в некорректный асинхронный.
В кратце это так:
Begin()
Processing()
End()
Корректный синхронный ? Корректный. Переделываем в асинхронный твоей секретной техникой и получаем некорректный асинхронный.
Вопрос — кто будет переколбашивать код вот в такой
Здравствуйте, artelk, Вы писали:
A>Объяснил бы мне кто-нибудь вот что:
A> A> Асинхронные операции могут выполняться (и\или завершаться) в другом потоке (потоке IOCP, потоке тред пула или явно создаваемом потоке при старте асинхронной операции). A> При кооперативной многозадачности со stackfull coroutines работа выполняется в одном системном потоке, т.е. этот поток должен существовать постоянно и как-то уметь "ждать" окончания асинхронных операций из первого пункта. A>
A>Вопрос: как реализовано это "ожидание"? Гоняем холостой цикл с проверками "а не завершился ли кто"? Ждем на каком-нибудь системном объекте синхронизации (системном событии, например)? Как-то еще?
Как хочешь так и реализуй — полная свобода. Конкретно в моей реализации (20 строк простейшего кода, которые уже были в этой темке) было две функции:
Соответственно для многопоточной асинхронности в обычном GUI приложение реализуем что-то вроде:
Post2UI(void* coro) {PostMessage(coro);}
...
OnAsync(event_data* coro) {CallFromUI(coro);}//обработчик в классе приложения
А для консольного приложения без системных очередей можем сделать например так:
queue<void*> coro_queue;//предположим что это lock-free
Post2UI(void* coro) {coro_queue.push(coro);}
...
while(!coro_queue.empty) {CallFromUI(coro_queue.front()); coro_queue.pop();}//строчка где-то в глубине основного цикла вычислений
Ну а для серверного приложения работающего через асинхронный io вообще просто — там Post2UI в принципе не нужен, т.к. C++ библиотеки асинхронного UI уже сами делают всё что нужно (вызывают callback'и из нужных потоков):
StartAsyncOp(..., [=]{CallFromUI(__coro);});//последний параметр - callback, который будет вызван из нужного потока
Ничего более не требуется. Причём никто не мешает совместить это например с каким-то из вариантов выше.
И это только в рамках простейшей реализации, возникшей в результате форумного спора. А если серьёзно заняться этим вопросом, то там ещё столько всего модного можно наделать при таком уровне свободы...
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Здравствуйте, artelk, Вы писали:
A>>Вопрос: как реализовано это "ожидание"? Гоняем холостой цикл с проверками "а не завершился ли кто"? Ждем на каком-нибудь системном объекте синхронизации (системном событии, например)? Как-то еще?
EP>А тут факт наличия stackful coroutine ортогонален, так как трансформация кода полностью локальная. EP>"цикл с проверками" если и присутствует, то он был и до добавления корутин, например это может быть UI Loop, а-ля: EP>
Т.е. из другого потока "шлется" "message", чтобы разбудить UI-поток и заставить его выполнить продолжение? Или продолжение будет выполнено не сразу, а только после того, как "хоть какой-то" message придет?
А что если UI Loop-а нет?
EP>[/ccode] Либо как в моем примере блокирующая очередь с active messages:
<...>
На сколько удалось разобрать (давно с++ не трогал), в качестве "оповещения о завершении" из других потоков у тебя делается добавление задания в main_tasks, которое будет выполняться в main потоке. "Задание" заключается в том, чтобы "перескочить" в место, откуда делался await, так? EP>
Так я нигде и не говорю о каком-то волшебном автоматическом превращение старого синхронного приложения в асинхронное. Речь именно о библиотеках. Т.е. мы пишем новое асинхронное приложение с нуля, но при этом можем спокойно использовать в нём синхронные библиотечные функции. Я думаю не нужно уточнять какое соотношение между написанными за всё время классическими библиотеками и переписанными под await/async? )
Здравствуйте, artelk, Вы писали:
EP>>А тут факт наличия stackful coroutine ортогонален, так как трансформация кода полностью локальная. EP>>"цикл с проверками" если и присутствует, то он был и до добавления корутин, например это может быть UI Loop, а-ля: EP>>
A>Т.е. из другого потока "шлется" "message", чтобы разбудить UI-поток и заставить его выполнить продолжение? Или продолжение будет выполнено не сразу, а только после того, как "хоть какой-то" message придет? A>А что если UI Loop-а нет?
Вот у нас есть async_something — функция, которая принимает callback. Когда async_something выполнит свою работу (например считает данные из сокета), она вызовет наш callback:
async_something([]
{
// Will be called on completion.
});
Как произойдёт вызов callback'а? Есть разные варианты: например код который получит событие, сразу вызовет наш callback, или другой вариант — он пошлёт сообщение в очередь (например через PostMessage), а тот кто делает pop из очереди запустит callback.
Заметь, callback нужно вызывать независимо от того есть ли у нас корутины или нет.
EP>>[/ccode] Либо как в моем примере блокирующая очередь с active messages: A><...> A>На сколько удалось разобрать (давно с++ не трогал), в качестве "оповещения о завершении" из других потоков у тебя делается добавление задания в main_tasks, которое будет выполняться в main потоке. "Задание" заключается в том, чтобы "перескочить" в место, откуда делался await, так?
Да, абсолютно верно. В данном примере await помогает заменить код вида:
async([] // запустить в thread pool
{
int result = do_job_in_pool();
return result;
}).then([](int res)
{
main_tasks.push([]
{
cout << "Job completed, result is: " << res << end;
});
});
на:
int res = await async([] // запустить в thread pool
{
int result = do_job_in_pool();
return result;
});
cout << "Job completed, result is: " << res << end;
Причём это простейший пример, если добавляются циклы, условия — без await/yield/coroutine/etc, код становится запутанным и утомительным.
A>
A> void pop(T &result)
A> {
A> unique_lock<mutex> u(m);
A> c.wait(u, [&]{return !q.empty();} );
A> result = move_if_noexcept(q.front());
A> q.pop();
A> }
A>
A>В "pop" делается блокировка. Т.е. это случай "ждем на каком-нибудь системном объекте синхронизации", так?
Да, всё правильно — объект синхронизации здесь это mutex + condition_variable. Грубо говоря поток засыпает пока данные не придут в очередь.
Здравствуйте, alex_public, Вы писали:
_>Здравствуйте, gandjustas, Вы писали:
G>>Ну давай покажи какие realworld проблемы решает spirit. На проверку окажется что 90% уже решены в современных платформах, а еще 10% закрываются специальными средствами. G>>Это кстати не только spirit касается, но и других "универсальных всемогутеров".
_>Вообще то spirit хорош не столько возможностью легко задавать прямо в коде сложные грамматики, сколько своим быстродействием.
_>Можем провести простейший тест. Допустим есть обычный текстовый файл. Он состоит из 100 строк. Каждая строка состоит из 100 000 (вполне нормальная ситуация для обработки экспериментальных данных) int'ов, разделённых запятыми. Задачка: прочитать файл, посчитать среднее по каждой строке и допустим вывести в отсортированном виде в консоль (это чтобы проконтролировать результат работы — тогда можно exe обменяться, а не напрягаться с построением чужих библиотек). С помощью Boost'a я напишу решение всей задачки ровно в 5 строк. И при этом оно будет думаю где-то раз в 10 быстрее твоего, сделанного с помощью стандартной библиотеки .Net.
Но что-то мне кажется что на такой задаче ввод-вывод будет занимать большую часть времени.
Кстати это верно для любого простого парсинга. А для сложного, Spitit неочень подойдет.
Присылай exe, проверим.
G>>Ты опять повторяешь заблуждение что решение на C++ лучше. Оно не лучше потому что: G>>1) тормозит G>>2) не масштабируется
_>Тебе осталось доказать эти два тезиса. Потому как ты их тут уже не раз повторяешь, но пока не привёл ни единого аргумента в из защиту. Показывай давай конкретно что там тормозит и где. )))
Конкретно тормозит маршалинг каждого вызова через UI. Это для простых фоновых операций подойдет, а для сложных — будет тормозить.
Да и банально запусти синхронный и "асинхронный" вариант и сравни.
В C# достаточно написать ConfigureAwait(false) и продолжение будет запускаться по месту, а не в контексте синхронизации. А в C++ у тебя корутины привязаны к потоку, в котором создаются.
Что касается масштабирования, то все просто — все корутины работают в одном потоке, по факту получится очередь с одним читателем, даже если у тебя в системе десятки ядер.
G>>С чего ты взял? perceived performance от async IO растет, а распараллеливание IO без блокировки потоков делает софт быстрее\улучшает масштабируемость.
_>Ага. Только await/async для этого не требуется. )))
Конечно не требуется await/async "всего лишь" способ удобно записать асинхронные вызовы, которые в .NET существуют 10 лет.
Но именно при появлении await/async
Здравствуйте, gandjustas, Вы писали:
G>Что касается масштабирования, то все просто — все корутины работают в одном потоке, по факту получится очередь с одним читателем, даже если у тебя в системе десятки ядер.
Почему все в одном? Запускай несколько потоков, каждый со своими корутинами.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Здравствуйте, gandjustas, Вы писали:
G>>Что касается масштабирования, то все просто — все корутины работают в одном потоке, по факту получится очередь с одним читателем, даже если у тебя в системе десятки ядер.
EP>Почему все в одном? Запускай несколько потоков, каждый со своими корутинами.
Это априори более медленный вариант, чем пул потков с продолжениями.
Кроме того такой вариант гораздо сложнее реализовать.
Здравствуйте, gandjustas, Вы писали:
EP>>Почему все в одном? Запускай несколько потоков, каждый со своими корутинами. G>Это априори более медленный вариант, чем пул потков с продолжениями.
Если у тебя .then выполняется в другом потоке то смысла в await мало. Например для UI продолжения должны запускаться в UI Thread
G>Кроме того такой вариант гораздо сложнее реализовать.
Нет. Например при использовании Boost.Asio иметь свой io_service per thread — это нормально, и просто Наоборот, использование одного io_serive на несколько потоков считается более сложным.
Здравствуйте, gandjustas, Вы писали:
G>>>Кроме того такой вариант гораздо сложнее реализовать. EP>>Нет. Например при использовании Boost.Asio иметь свой io_service per thread — это нормально, и просто Наоборот, использование одного io_serive на несколько потоков считается более сложным. G>Ну это только особенности boost. А если смотреть картину в целом, то для маршалинга всех продолжений в один поток надо как-то информацию протаскивать в продолжения.
Да не надо ничего протаскивать — там разные io_service'ы на каждый поток
G>В boot это делается за счет stackfull корутин, что повышает требования к памяти, ибо хранить стек, не тоже само что хранить замыкание с 3-5 значениями.
Там такая схема рекомендуется даже без использования корутин, хватит фантазировать.
Здравствуйте, alex_public, Вы писали:
_>Здравствуйте, Ikemefula, Вы писали:
_>Так я нигде и не говорю о каком-то волшебном автоматическом превращение старого синхронного приложения в асинхронное. Речь именно о библиотеках. Т.е. мы пишем новое асинхронное приложение с нуля, но при этом можем спокойно использовать в нём синхронные библиотечные функции. Я думаю не нужно уточнять какое соотношение между написанными за всё время классическими библиотеками и переписанными под await/async? )
Что бы давать гарантию, код в такой библиотеке придется писать через continuation и прочие приседения, и только в таких вот местах ты получишь профит от бустовых короутин.
Т.е. в C# нужно будет переделать код на await/async, а в c++ переколбасить на чтото вроде f(begin, processing, end)
Ты не правильно прочитал условие задачки. Я поправлю в рамках моего знания C# (если что не так, то скажи — поправим и протестируем заново):
foreach(var a in File.ReadAllLines("Numbers.txt")
.Select(l => l.Split(',').Select(int.Parse).Average(v => v))
.OrderBy(i => i))
Console.WriteLine(a);
G>Но что-то мне кажется что на такой задаче ввод-вывод будет занимать большую часть времени.
Ну так тогда значит и время исполнения будет не сильно отличаться...
G>Кстати это верно для любого простого парсинга. А для сложного, Spitit неочень подойдет.
Пока что я вижу что это не верно даже для такого. )))
G>Присылай exe, проверим.
И так результаты:
C#: TotalMilliseconds : 3888,1258
C++: TotalMilliseconds : 280,8465
О, я даже немного ошибся в своём прогнозе... Не в 10 раз тормознее .net код, а в 14!
G>Конкретно тормозит маршалинг каждого вызова через UI. Это для простых фоновых операций подойдет, а для сложных — будет тормозить.
Кто такие "сложные" фоновые операции? Если ты снова про серверный вариант, то там никто и не собирается использовать цикл сообщений — там рулит библиотека IO.
G>Что касается масштабирования, то все просто — все корутины работают в одном потоке, по факту получится очередь с одним читателем, даже если у тебя в системе десятки ядер.
Ну так и запускаем много потоков и в каждом свой набор сопроцедур. Собственно Boost.Asio именно на такой сценарий и заточен (в смысле без сопроцедур, а просто с коллбэками)
G>Конечно не требуется await/async "всего лишь" способ удобно записать асинхронные вызовы, которые в .NET существуют 10 лет. G>Но именно при появлении await/async
О чём я и говорю. Пользы для быстродействия они не приносят (только некий сахар для программиста), а накладные расходы добавляют. Пусть и не особо страшные.
Здравствуйте, Ikemefula, Вы писали:
I>Что бы давать гарантию, код в такой библиотеке придется писать через continuation и прочие приседения, и только в таких вот местах ты получишь профит от бустовых короутин.
I>Т.е. в C# нужно будет переделать код на await/async, а в c++ переколбасить на чтото вроде f(begin, processing, end)
I>Итого — кде профит ?
Не, не так. Достаточно чтобы функции библиотеки использовали блокирующий код передающийся (как функция или класс) откуда-то снаружи, а не зашитый внутри самой функции. Т.е. например если функция получает в качестве параметра не имя файла, а ссылку на поток ввода. В таком случае можем легко использовать в асинхронном коде без всякого переписывания.
Здравствуйте, alex_public, Вы писали:
_>Не, не так. Достаточно чтобы функции библиотеки использовали блокирующий код передающийся (как функция или класс) откуда-то снаружи, а не зашитый внутри самой функции. Т.е. например если функция получает в качестве параметра не имя файла, а ссылку на поток ввода. В таком случае можем легко использовать в асинхронном коде без всякого переписывания.
function operation(stream)
{
var value = read(stream);
write(next(value), stream)
}
Поясни, чем тебе помог этот параметр ? Когда код станет асинхронным, цепочки будут работать как попало
I>function operation(stream)
I>{
I> var value = read(stream);
I> write(next(value), stream)
I>}
I>
I>Поясни, чем тебе помог этот параметр ? Когда код станет асинхронным, цепочки будут работать как попало
Тем, что тогда можно написать так:
async_code(
operation(async_stream);
)
А что за цепочки то, ты вообще про что? Поясню на всякий случай как работает этот код:
1. вход в блок асинхронного кода
2. вызов operation
3. вызов read
4. вызов read члена async_stream, который инициализирует начало асинхронного чтения (через соответствующие функции или в другом потоке) и сразу после этого инициирует выход из сопроцедуры
5. управление передаётся на код следующий за блоком асинхронного кода
...
5. данные прочитались, а наш поток освободился и инициировал вход в сопроцедуру
6. функция read возвращает прочитанное значение
7. продолжение нормального синхронного исполнения функции operation в изначальном потоке, с прочитанными асинхронно данными.
...
И теперь шедулер должен знать, как с каким ресурсом работать, что вроде как очевидно. Для простейших случаев всё в порядке. Для сложных — пилить и пилить.
Получается так — async/await это подсказки шедулеру, что в каком порядке вызывать. Как видно, в С++ нужны ровно те же подсказки.
Итого — ты изобрел аналог async/await, но работающий только для простейших случаев.
Здравствуйте, Ikemefula, Вы писали:
I>Теперь вопрос — что если разделяемое состояние не связано со стримом или кроме стрима есть еще какое то разделяемое состояние ?
I>Это значит, что надо вводить еще одну конструкцию
I>
I>И теперь шедулер должен знать, как с каким ресурсом работать, что вроде как очевидно. Для простейших случаев всё в порядке. Для сложных — пилить и пилить.
Не, даже если мы захотим переделать несколько синхронных операций на асинхронные внутри одной функции, то всё равно они все будут реализованы через одну сопроцедуру (которая задаётся скобками async_code) и соответственно друг относительно друга будут выполняться последовательно. Так что никаких проблем.
Вот если бы мы захотели именно параллельное исполнение нескольких асинхронных операций (запускаемых изнутри operation), то это уже да, действительно потребует переписывания нашей функции...
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Здравствуйте, artelk, Вы писали:
A>>На сколько удалось разобрать (давно с++ не трогал), в качестве "оповещения о завершении" из других потоков у тебя делается добавление задания в main_tasks, которое будет выполняться в main потоке. "Задание" заключается в том, чтобы "перескочить" в место, откуда делался await, так?
EP>Да, абсолютно верно. В данном примере await помогает заменить код вида:
<...> EP>Причём это простейший пример, если добавляются циклы, условия — без await/yield/coroutine/etc, код становится запутанным и утомительным.
Хорошо. А что если захочется продолжиться в тред пуле, как быть?
Представь, нам нужно:
1. Скачать что-то по сети
2. Провести над содержимым некие вычисления
3. Записать что-то в файл
4. Вернуть что-то
Здравствуйте, alex_public, Вы писали:
_>Не, даже если мы захотим переделать несколько синхронных операций на асинхронные внутри одной функции, то всё равно они все будут реализованы через одну сопроцедуру (которая задаётся скобками async_code) и соответственно друг относительно друга будут выполняться последовательно. Так что никаких проблем.
Смотри внимательно — у тебя все хорошо работает, если read асинхронный. А теперь фокус — асинхронным становится еще и write.
Как шедулер узнает, что ему надо подождать с переключением очередной короутины ?
Здравствуйте, alex_public, Вы писали:
_>Здравствуйте, gandjustas, Вы писали:
G>>Кстати это верно для любого простого парсинга. А для сложного, Spitit неочень подойдет. _>Пока что я вижу что это не верно даже для такого. )))
G>>Присылай exe, проверим.
_>http://files.rsdn.ru/98162/rsdn.zip — прошу. )
_>И так результаты: _>C#: TotalMilliseconds : 3888,1258 _>C++: TotalMilliseconds : 280,8465
_>О, я даже немного ошибся в своём прогнозе... Не в 10 раз тормознее .net код, а в 14!
Я сделал версию на C#, которая отрабатывает за 600мс, когда твоя работает около 400мс.
НО. Чтение 100мб файла с диска без кеша идет 8сек. В этих условиях пидарасить такты вообще бессмысленно.
http://files.rsdn.ru/67312/ConsoleApplication5.exe
G>>Конкретно тормозит маршалинг каждого вызова через UI. Это для простых фоновых операций подойдет, а для сложных — будет тормозить. _>Кто такие "сложные" фоновые операции? Если ты снова про серверный вариант, то там никто и не собирается использовать цикл сообщений — там рулит библиотека IO.
Boost:asio? Так она тоже все в один поток маршалит.
G>>Что касается масштабирования, то все просто — все корутины работают в одном потоке, по факту получится очередь с одним читателем, даже если у тебя в системе десятки ядер. _>Ну так и запускаем много потоков и в каждом свой набор сопроцедур. Собственно Boost.Asio именно на такой сценарий и заточен (в смысле без сопроцедур, а просто с коллбэками)
Но это неоптимальный сценарий и более сложный для реализации.
Простите великодушно, что снова влезаю в спор столь учёных мужей.
Просто я снова наткнулся на одном форуме на свежее обсуждение многопоточного сервера на C++. И снова там матёрые плюсисты (сужу банально по количеству их сообщений на форуме) предлагают на каждое соединение создавать по потоку. То есть 50 соединений с клиентами — 50 потоков. Имхо, ни один дотнетчик-миддл не мог бы сморозить такую глупость...
Я обеими руками за нативный код. Однако в очередной раз вынужден сказать: всё, что в этой теме приводят в пример alex_public, Evgeny.Panasyuk и прочие, — это удел гуру C++. Чтобы дойти до Boost.Asio, корутин и прочего — нужен многолетний опыт.
Между тем, в дотнете уже джуниоры вовсю юзают TPL и async/await.
Моя мысля: достоинство дотнета в том, что он активно рекламируется и продвигается, выпускается масса новой литературы, где освещены новейшие фичи. Поэтому даже новички вовсю пишут асинхронный код.
Серьёзнейший недостаток C++ в том, что новые возможности и библиотеки рекламируются очень и очень мало. Более того, сами же матёрые плюсисты, в ответ на вопрос начинающих, с чего начать учиться, чаще всего предлагают старую замшелую литературу 90-х годов. Не, так-то те книги хорошие. Вот только начав с них, до корутин/буста/etc новоиспечённый плюсист дойдёт ой как не скоро.
P.S. продолжайте в том же духе: почерпнул очень много полезного по крутым фичам цпп.
Здравствуйте, Ikemefula, Вы писали:
I>Смотри внимательно — у тебя все хорошо работает, если read асинхронный. А теперь фокус — асинхронным становится еще и write.
Ну и никаких проблем. Исполнение функции то прекращается внутри async_read и возвращается только после прочтения данных. Так что async_write будет запущен только после этого, и там дальше по той же схеме. В общем если мы говорим о последовательных асинхронных запусках, то их можно делать сколько угодно и без всякого переписывания нашей функции.
I>Как шедулер узнает, что ему надо подождать с переключением очередной короутины ?
Здравствуйте, alex_public, Вы писали:
_>Здравствуйте, Ikemefula, Вы писали:
I>>Смотри внимательно — у тебя все хорошо работает, если read асинхронный. А теперь фокус — асинхронным становится еще и write.
_>Ну и никаких проблем. Исполнение функции то прекращается внутри async_read и возвращается только после прочтения данных. Так что async_write будет запущен только после этого, и там дальше по той же схеме. В общем если мы говорим о последовательных асинхронных запусках, то их можно делать сколько угодно и без всякого переписывания нашей функции.
У меня за все время ни разу не случались исключительно последовательне запросы в асинхронщине Пудозреваю, это именно та причина, из за которой я сомневаюсь в возможностях С++
I>>Как шедулер узнает, что ему надо подождать с переключением очередной короутины ?
_>Эээ кому ждать, где, зачем?
Да очень прость — между стартом и концом асинхронного write появляется еще один асинхронный запрос которй затрагивает инвариант. всё, приехали.
Здравствуйте, gandjustas, Вы писали:
G>Это чтобы семантика соответствовала.
Ну т.е. в самой библиотеки .net нет ничего с нужной семантикой... )
G>Какой смысл мерить время работы функции int.Parse, которая учитывает локальные настройки с рукопашным парсером?
Потому что тут мы сравниваем библиотеки, а не языки.
G>Но тогда и сложность решения будет другая. Ты ведь как обычно придумал пример, который не является даже близко похожим на реальную задачу. G>Лучше покажи парсеры json и xml.
Ха, вообще говоря то, чем мы сейчас тут с тобой развлекались — это было по сути написание парсера csv формата (собственно если ограничиться числами, то это в точности он и был). А csv — это один из самых популярных форматов для данных. Экспорт/импорт в него есть и в Офисе и во всех база данных (и там как раз бывают не только мегабайтные, но и гигабайтные файлы) и ещё много где. Так что может это ты у нас не в курсе реальных задач? )))
Кстати, масштаб потребности можно легко увидеть введя в гугле например "csv .net" — т.к. в самой стандартной библиотеке решения нет, то инет переполнен вариантами. Ну а с помощью Boost'a полноценный csv парсер пишется в 3 строки, причём он ещё будет намного быстрее всех этих сторонних .net библиотек.
G>да-да. парсить 100мб чисел на мобильном устройстве — очень актуально.
Да какая разница какой объём. Даже если 100Кб, он всё равно будет тратить в 10 раз больше процессорного времени. Соответственно при постоянном пользование таким кривым софтом, время жизни от аккумулятора заметно уменьшается. Представляю сколько бы жили смартфоны, если например все браузерные движки были написаны в стиле java/.net...
G>Нет, в документации черным по английскому написано что в один поток.
Ну так я и говорю что в одном потоке, но я бы не стал называть epoll маршалингом. )))
G>Что реализовано? Грамотное распределение корутин по потокам? Я такого не увидел.
Boost.Asio вообще не заточен под сопроцедуры. Там основной интерфейс на функциях обратного вызова. Что правда отлично подходит для записи через сопроцедуры типа бустовских.
Здравствуйте, alex_public, Вы писали:
I>>У меня за все время ни разу не случались исключительно последовательне запросы в асинхронщине Пудозреваю, это именно та причина, из за которой я сомневаюсь в возможностях С++
_>Так твой пример же как раз чётко последовательный. В начале read, а потом write. Его нельзя переделать в параллельный даже если очень захочется. )))
Я могу запустить сколько угодно таких операций. Собственно так большей частью и происходит.
I>>Да очень прость — между стартом и концом асинхронного write появляется еще один асинхронный запрос которй затрагивает инвариант. всё, приехали.
_>Откуда он появляется то? Или ты снова про кривой асинхронный внешний код? Ты имеешь привычку запускать параллельные асинхронные операции модифицирующие одни и те же данные? )
Пока что не придумали хорошего способа поместить всю базу данных в локальную переменную со всеми таблицами, колонками и строчками.
Здравствуйте, gandjustas, Вы писали:
_>>О, я даже немного ошибся в своём прогнозе... Не в 10 раз тормознее .net код, а в 14! G>Я сделал версию на C#, которая отрабатывает за 600мс, когда твоя работает около 400мс. G>НО. Чтение 100мб файла с диска без кеша идет 8сек. В этих условиях пидарасить такты вообще бессмысленно.
Здравствуйте, alex_public, Вы писали:
_>И так результаты: _>C#: TotalMilliseconds : 3888,1258 _>C++: TotalMilliseconds : 280,8465
_>О, я даже немного ошибся в своём прогнозе... Не в 10 раз тормознее .net код, а в 14!
Ты сравнил хрен с пальцем — ленивый процессинг с энергичным. Не надо долго думать, что бы выяснить, что разница на порядок будет на любом языке. Т.е. ленивый С++ в 10 реаз медленнее энергичного С++, если в лоб, как то сделано в linq.
Здравствуйте, alex_public, Вы писали:
G>>Это чтобы семантика соответствовала.
_>Ну т.е. в самой библиотеки .net нет ничего с нужной семантикой... )
В самой библиотеке есть парсер csv, он, что естественно, не заточен под такие вырожденые сценарии. Реальные csv вполне сносно парсит.
_>Потому что тут мы сравниваем библиотеки, а не языки.
Ога, библиотеки ориентированые на принципиально разные области.
_>Кстати, масштаб потребности можно легко увидеть введя в гугле например "csv .net" — т.к. в самой стандартной библиотеке решения нет, то инет переполнен вариантами. Ну а с помощью Boost'a полноценный csv парсер пишется в 3 строки, причём он ещё будет намного быстрее всех этих сторонних .net библиотек.
Да ладно, не гони. Раки и олени не могут заглянуть в соседний неймспейс.
_>Да какая разница какой объём. Даже если 100Кб, он всё равно будет тратить в 10 раз больше процессорного времени. Соответственно при постоянном пользование таким кривым софтом, время жизни от аккумулятора заметно уменьшается. Представляю сколько бы жили смартфоны, если например все браузерные движки были написаны в стиле java/.net...
В реальных приложениях процессинг минимум раз в 100 дольше, чем загрузка файла и его парсинг.
Здравствуйте, Ikemefula, Вы писали:
_>>Так твой пример же как раз чётко последовательный. В начале read, а потом write. Его нельзя переделать в параллельный даже если очень захочется. ))) I>Я могу запустить сколько угодно таких операций. Собственно так большей частью и происходит.
Да, можешь. И в C++ и в C#. И в обеих реализациях получишь некорректный код. Если конечно не вставишь какую-то синхронизацию в async_read. Но это уже другая история и опять же доступно в обеих реализациях.
I>Пока что не придумали хорошего способа поместить всю базу данных в локальную переменную со всеми таблицами, колонками и строчками.
Агааа. И ещё интересно зачем это в базах данных придумали такую странную вещь, как транзакции... )
Здравствуйте, Ikemefula, Вы писали:
I>Ты сравнил хрен с пальцем — ленивый процессинг с энергичным. Не надо долго думать, что бы выяснить, что разница на порядок будет на любом языке. Т.е. ленивый С++ в 10 реаз медленнее энергичного С++, если в лоб, как то сделано в linq.
С чего бы это? При нормальной статической реализации не должно быть никакой разницы в скорости.
Это если говорить вообще про ленивость. А если говорить про конкретный случай, то как раз Boost.Spirit весь построен на ленивости (через библиотеку Boost.Phoenix)! Там же все действия по обработке данных задаются прямо в грамматике, т.е. через ленивый код.
А вот как раз реализация gandjustas'а и является классической энергичной реализацией в лоб. И она уступила по скорости ленивой из spirit'a в 2 раза.
Здравствуйте, Ikemefula, Вы писали:
I>В самой библиотеке есть парсер csv, он, что естественно, не заточен под такие вырожденые сценарии. Реальные csv вполне сносно парсит.
Ну я естественно не претендую на подробное знание библиотеки .net. Так, глянул что куча людей ищет сторонние решения... Раз есть, то кинешь ссылку на него в msdn?
I>Ога, библиотеки ориентированые на принципиально разные области.
Согласен. Но если ты следил за темкой, то знаешь, что идею посравнивать эти библиотеки предложил совсем не я... )
I>В реальных приложениях процессинг минимум раз в 100 дольше, чем загрузка файла и его парсинг.
Ага, но товарищи пишущие в стиле .net/java и процессинг ведь так же напишут. ))) Ведь за тактами гнаться смысла нет... (c)
Здравствуйте, alex_public, Вы писали:
_>>>Так твой пример же как раз чётко последовательный. В начале read, а потом write. Его нельзя переделать в параллельный даже если очень захочется. ))) I>>Я могу запустить сколько угодно таких операций. Собственно так большей частью и происходит.
_>Да, можешь. И в C++ и в C#. И в обеих реализациях получишь некорректный код. Если конечно не вставишь какую-то синхронизацию в async_read. Но это уже другая история и опять же доступно в обеих реализациях.
Это вся та же история.
I>>Пока что не придумали хорошего способа поместить всю базу данных в локальную переменную со всеми таблицами, колонками и строчками.
_>Агааа. И ещё интересно зачем это в базах данных придумали такую странную вещь, как транзакции... )
покажи кодом:
var value = readAsyncFromDatabase();
writeAsyncToDatabase(next(value));
Здравствуйте, alex_public, Вы писали:
_>Здравствуйте, gandjustas, Вы писали:
G>>Это чтобы семантика соответствовала.
_>Ну т.е. в самой библиотеки .net нет ничего с нужной семантикой... )
Конечно, парсить 1000 мб чисел предельно тупым методом — далекая от реальности задача.
Парсить хотябы одну строку с учетом локали — предельно практическая. Еще во времена писания на делфях я сталкивался с такой проблемой и там адекватного решения не было.
G>>Какой смысл мерить время работы функции int.Parse, которая учитывает локальные настройки с рукопашным парсером? _>Потому что тут мы сравниваем библиотеки, а не языки.
Дык библиотеки проектируются под задачи.
Я понимают что задача спирита генерировать сверхбыстрые примитивные парсеры. Задача .net — облегчать практическую разработку.
G>>Но тогда и сложность решения будет другая. Ты ведь как обычно придумал пример, который не является даже близко похожим на реальную задачу. G>>Лучше покажи парсеры json и xml.
_>Ха, вообще говоря то, чем мы сейчас тут с тобой развлекались — это было по сути написание парсера csv формата (собственно если ограничиться числами, то это в точности он и был). А csv — это один из самых популярных форматов для данных. Экспорт/импорт в него есть и в Офисе и во всех база данных (и там как раз бывают не только мегабайтные, но и гигабайтные файлы) и ещё много где. Так что может это ты у нас не в курсе реальных задач? )))
Что-то я на практике csv видел только когда на стороне источника данных не было толковой сериализации в xml\json.
Я тебя расстрою, но же лет 10 или больше CSV для практических задач применяется мало. В нем нет ни структуры, ни информации о типах и расширяемость хромает. Поэтому в 99,99% случаев взаимодействие делается на xml\json.
Если же появится ситуация, где будет много CSV данных, то я просто загружу их в СУБД и буду отчеты по ней Excel_ем строить. Вообще ни строчки не напишу.
Так что далека твоя задача от практики очень далека.
_>Кстати, масштаб потребности можно легко увидеть введя в гугле например "csv .net" — т.к. в самой стандартной библиотеке решения нет, то инет переполнен вариантами. Ну а с помощью Boost'a полноценный csv парсер пишется в 3 строки, причём он ещё будет намного быстрее всех этих сторонних .net библиотек.
Linq2csv придумали ооооочень давно. Но даже его совершенно тупо используют чтобы заливать файлы в базу. Это можно вообще без кода делать.
Кстати глянь по нему доку: http://www.codeproject.com/Articles/25133/LINQ-to-CSV-library
Как долго такое на spirit будешь делать?
G>>да-да. парсить 100мб чисел на мобильном устройстве — очень актуально.
_>Да какая разница какой объём.
Огромная.
_>Даже если 100Кб, он всё равно будет тратить в 10 раз больше процессорного времени.
Относительное быстродействие не интересует. Не бывает "медленных" программ, бывают "недостаточно быстрые".
.NET код в 3 строки на 100кб отработает за 2,5 мс. Это достаточно быстро.
Кстати ты забыл что в отличие от компа в устройстве не будет такого кеша диска и тебе придется уже не парсинг оптимизировать, а чтение.
_>Соответственно при постоянном пользование таким кривым софтом, время жизни от аккумулятора заметно уменьшается. Представляю сколько бы жили смартфоны, если например все браузерные движки были написаны в стиле java/.net...
Как связаны браузерные движки и парсинг 100мб чисел?
Здравствуйте, alex_public, Вы писали:
I>>В самой библиотеке есть парсер csv, он, что естественно, не заточен под такие вырожденые сценарии. Реальные csv вполне сносно парсит.
_>Ну я естественно не претендую на подробное знание библиотеки .net. Так, глянул что куча людей ищет сторонние решения... Раз есть, то кинешь ссылку на него в msdn?
А вроде как ты.
I>>В реальных приложениях процессинг минимум раз в 100 дольше, чем загрузка файла и его парсинг.
_>Ага, но товарищи пишущие в стиле .net/java и процессинг ведь так же напишут. ))) Ведь за тактами гнаться смысла нет... (c)
Ну да, а база данных чудом узнает, что к ней обращаются из С++ и начнет работать в 10 раз быстрее.
Я, если что, примерно 10 лет занимался софтом, который ближе всего похж на САПР, там этого csv и похожих форматов девать было некуда. Так что если хочешь меня повеселить, валяй.
Что-то я смотрю мы уже на второй круг пошли в дискуссии, а повторять одно и тоже утомляет... Вроде бы же выяснили уже, что при корректном внешнем (относительно наших библиотечных функций) асинхронном коде всё работает одинаково нормально и в C++ и в C# (только тут надо ещё и переписать библиотечные функции, расставив await и async). А при некорректном внешнем коде будет опять же одинаково глючить как в C++, так и в C#. Рассмотрели это всё, в том числе и на примерах, и пошли дальше. А сейчас ты снова это же самое начинаешь по второму кругу? )))
Здравствуйте, gandjustas, Вы писали:
G>Конечно, парсить 1000 мб чисел предельно тупым методом — далекая от реальности задача. G>Парсить хотябы одну строку с учетом локали — предельно практическая. Еще во времена писания на делфях я сталкивался с такой проблемой и там адекватного решения не было.
Ну так а в библиотеке C++ есть и такое решение. Т.е. имеем и то и то. В отличие от...
G>Что-то я на практике csv видел только когда на стороне источника данных не было толковой сериализации в xml\json. G>Я тебя расстрою, но же лет 10 или больше CSV для практических задач применяется мало. В нем нет ни структуры, ни информации о типах и расширяемость хромает. Поэтому в 99,99% случаев взаимодействие делается на xml\json.
Ага, ага. ) Расскажи это финансистам, инженерам, учёным и т.п. ))) Им будет любопытно узнать новые для них слова. )))
G>Если же появится ситуация, где будет много CSV данных, то я просто загружу их в СУБД и буду отчеты по ней Excel_ем строить. Вообще ни строчки не напишу. G>Так что далека твоя задача от практики очень далека.
Ну правильно, идея о том что может самим понадобится написать эту самую СУБД, программисту .net видимо не может прийти в голову... )))
G>Кстати глянь по нему доку: http://www.codeproject.com/Articles/25133/LINQ-to-CSV-library G>Как долго такое на spirit будешь делать?
Ага... Я смотрю великолепной библиотеки .net уже не хватает, приходится лезть в сторонние...
G>Относительное быстродействие не интересует. Не бывает "медленных" программ, бывают "недостаточно быстрые". G>.NET код в 3 строки на 100кб отработает за 2,5 мс. Это достаточно быстро. G>Кстати ты забыл что в отличие от компа в устройстве не будет такого кеша диска и тебе придется уже не парсинг оптимизировать, а чтение.
Ужас какая ересь. ) Если одна и та же задача выполняется при полной загрузке процессора одним кодом за время N, а другим за 10*N, то это значит что второй дико неэффективно расходует аккумулятор. И совершенно не важно что разница в реакции софта будет незаметна для пользователя — энергия при этом тратится несравнимая.
О, VB... ))) Понятно почему у некоторых проблемы с его нахождением)))
I>А вроде как ты.
Не, это gandjustas порадовал нас мыслью, что стандартная библиотека .net мощнее стандартной библиотеки C++ + boost. ))) А я всего лишь предложил показать это на примерах. На которых естественно оказалась обратная ситуация.
I>Я, если что, примерно 10 лет занимался софтом, который ближе всего похж на САПР, там этого csv и похожих форматов девать было некуда. Так что если хочешь меня повеселить, валяй.
Ну настоящий профи может и на кривом инструменте нормальный код писать. Но как мы видим в основном в мире java и .net процветают совсем другие настроения. Типа "во имя закона Мура". )))
Здравствуйте, alex_public, Вы писали:
_>Что-то я смотрю мы уже на второй круг пошли в дискуссии, а повторять одно и тоже утомляет... Вроде бы же выяснили уже, что при корректном внешнем (относительно наших библиотечных функций) асинхронном коде всё работает одинаково нормально и в C++ и в C# (только тут надо ещё и переписать библиотечные функции, расставив await и async). А при некорректном внешнем коде будет опять же одинаково глючить как в C++, так и в C#. Рассмотрели это всё, в том числе и на примерах, и пошли дальше. А сейчас ты снова это же самое начинаешь по второму кругу? )))
У тебя пока не видно решения для случая когда цепочки работают параллельно.
1 вариант сама функция запускает кучу параллельных цепочек
2 вариант — функция запускается в нескольких паралельных цепочках
Здравствуйте, Ikemefula, Вы писали:
I>У тебя пока не видно решения для случая когда цепочки работают параллельно.
I>1 вариант сама функция запускает кучу параллельных цепочек
И на C++ и на C# это не сделать без переписывания нашей библиотечной функции. Ну а с переписыванием понятно что проблем уже нет нигде... )))
I>2 вариант — функция запускается в нескольких паралельных цепочках
На C# это опять же записывается только с переписыванием функции. На C++ это получается автоматически, без переписывания. Но и в том и в другом случае, такой код не является корректным, если в асинхронном хранилище данных не предусмотрена какая-то своя синхронизация. Ну или же ещё будет нормальное если она вообще не требуется (например мы запускаем параллельное скачивание 10 файлов) по условию задачи.
Здравствуйте, Ikemefula, Вы писали:
I>Не, это ты начал утверждать что навроде "нож мощнее вилки", т.е. с++ мощнее C# ?
Это да, я утверждал такое... И собственно это очевидно так и есть. Т.к. все возможности C# можно повторить на C++, а вот часть возможностей C++ (в основном реализуемых через метапрограммирование или же наоборот на самом низком уровне) на C# повторить невозможно.
Собственно по тому же критерию язык D очевидно мощнее чем C++ (а с C# вообще уже смешно сравнивать было бы)... Правда тут у него только в сторону высокоуровневых вещей развитие, а по низкому уровню у них с C++ одинаковых доступ.
Но это речь была только про сам язык, а не про библиотеки... Встроенные там или сторонние. Если смотреть на библиотеки, то тут тому же D очень не хватает своего Boost'a, не говоря уже о GUI фреймворках и т.п. В общем с библиотеками ситуация совсем другая, чем с языками. И я собственно не собирался их обсуждать, если бы не забавное замечание gandjustas.
I>Это миф. Единственно где сливает дотнет и джава, это числодробилки и низкоуровневые операции, в ядро или драйвер не то что GC, даже половину фич С++ не всунешь. Всё.
Вообще то C++ сейчас уже даже на микроконтроллёры пролез (естественно как следствие роста возможностей МК в мире). ))) И он там заметно удобнее обычного C. Но это так, просто мелкое замечание, а не по поводу главного.
I>А вот, скажем, новый компилер шарпа писаный на шарпе рвёт в хлам старый компилер шарпа писаный на плюсах. Странно, да ?
Это вообще ни о чём не говорит. Современные версии компиляторов C++ тоже делают старые.)))
I>Числодробилок раз два и обчелся. А всё остальное упирается в алгоритмы или ввод вывод.
Как бы это сказать попроще... ) Если бы это было правдой, то у меня на компьютере точно было бы установлено хотя бы несколько модных .net программ (уж за более чем десятилетие должны же были появиться такие). Но из более чем 250 папок в Program Files насколько я помню ни одна не работает через .net. Раньше правда была одна такая мощная папка (Visual Studio), но уже несколько лет как ушёл и с неё. И то это не особо аргумент, т.к. для MS это был скорее их обычный пиар технологии. Так что похоже мифом у нас являются как раз перспективы .net. )))
I>Вот прямо сейчас товарищ рассказал хохму — крутые индейцы решили заимпрувить алгоритм анализа-оптимизаии дерева и наколбасили визитор с потрохами чуть не в мегабайт кода. Убили месяц времени. I>Алгоритм, правда, по перформансу лучше не стал, потому что не могут отловить, отладить кое какие частные случаи и периодически случаются косяки или утечки.
I>Что характерно, менеджед версию на Скале написал какой то дедушка где то за 6 часов, используя всякие лямбды и паттерн-матчинги. Собтсвенно 80% код это паттерн-матчинг. I>Щас у индейцев романтический период — взяли декомпиленый вариант и портируют его на С++ и пытаются угадать, где их обманул декомпилер. Ну и менеджмент памяти пишут специально под этот алгоритм. В скале всё просто — все само освобождается. А в с++ этот вариант не проходит — надо руками-руками-руками, а то выхлоп от скалы если в лоб реализовать, дает кучку циклических ссылок.
I>Теперь самое интересное — дедушка взял и заимпрувил свою версию, при чем напрочь поменял алгоритм. Потратил еще где то день работы, перформанс вырос вдвое. I>Общий расклад такой — на небольших деревьях С++ работает где то в 100 раз быстрее, но вот с реальными данными как то не справляется
Забавная история. ) Только вот она как раз в точности подтвердила именно мою мысль, что в руках профи и сомнительный инструмент будет эффективнее чем самый мощный в руках неумехи.
Здравствуйте, alex_public, Вы писали:
_>Здравствуйте, gandjustas, Вы писали:
G>>Конечно, парсить 1000 мб чисел предельно тупым методом — далекая от реальности задача. G>>Парсить хотябы одну строку с учетом локали — предельно практическая. Еще во времена писания на делфях я сталкивался с такой проблемой и там адекватного решения не было.
_>Ну так а в библиотеке C++ есть и такое решение. Т.е. имеем и то и то. В отличие от...
Такое есть, а парсинга json и xml нет. Либы для веб-запросов нет. Работы с БД нет.
Ты ща приведешь 100500 примеров таких либ на просторах интернета, но они нифига не совместимы с современным стандартом C++ и между собой. Это значит что придется писать (и поддерживать) тонны plumbing кода в приложении чтобы с ними работать. А если эти либы еще и C-style интерфейс имеют, то становится совсем грустно.
G>>Что-то я на практике csv видел только когда на стороне источника данных не было толковой сериализации в xml\json. G>>Я тебя расстрою, но же лет 10 или больше CSV для практических задач применяется мало. В нем нет ни структуры, ни информации о типах и расширяемость хромает. Поэтому в 99,99% случаев взаимодействие делается на xml\json.
_>Ага, ага. ) Расскажи это финансистам, инженерам, учёным и т.п. ))) Им будет любопытно узнать новые для них слова. )))
Рассказываю:
0) Самый любимый инструмент финансистов — Excel, к нему через OLDB можно напрямую подключиться. Иногда приходится парсить\генерить xslx файлы, которые внезапно (!) xml.
1) на стороне 1с очень удобно работать с XML
2) Axapta — веб-сервисы
3) SAP — вот тут действительно выставить веб-сервис и обратиться к нему проблема, поэтому появляются csv, но чаще xml.
Но ты ведь понимаешь, что имея нормальный язык с нормальной библиотекой программист почти никогда напрямую с xml не сталкивается.
G>>Если же появится ситуация, где будет много CSV данных, то я просто загружу их в СУБД и буду отчеты по ней Excel_ем строить. Вообще ни строчки не напишу. G>>Так что далека твоя задача от практики очень далека. _>Ну правильно, идея о том что может самим понадобится написать эту самую СУБД, программисту .net видимо не может прийти в голову... )))
СУБД и так написано немало, зачем еще? Лучше научиться правильно использовать существующие средства, чем писать свои велосипеды.
G>>Кстати глянь по нему доку: http://www.codeproject.com/Articles/25133/LINQ-to-CSV-library G>>Как долго такое на spirit будешь делать? _>Ага... Я смотрю великолепной библиотеки .net уже не хватает, приходится лезть в сторонние...
Ты от ответа уходишь.
Когда задача редкая — действительно приходится лезть. Нет смысла требовать от одной либы решения всех проблем. Надо чтобы она решала часто возникающие проблемы.
G>>Относительное быстродействие не интересует. Не бывает "медленных" программ, бывают "недостаточно быстрые". G>>.NET код в 3 строки на 100кб отработает за 2,5 мс. Это достаточно быстро. G>>Кстати ты забыл что в отличие от компа в устройстве не будет такого кеша диска и тебе придется уже не парсинг оптимизировать, а чтение.
_>Ужас какая ересь. ) Если одна и та же задача выполняется при полной загрузке процессора одним кодом за время N, а другим за 10*N, то это значит что второй дико неэффективно расходует аккумулятор. И совершенно не важно что разница в реакции софта будет незаметна для пользователя — энергия при этом тратится несравнимая.
И тут снова никого не интересует относительная величина.
Если твоя программа парсит один раз в час 1мб за 3мс вместо 0.3мс, то пользователь это никогда в жизни не заметит.
Если же ты делаешь эту операцию раз в секунду, то гораздо больше батарейки потратится на получение этого 1мб, тем на его парсинг.
Пойми наконец, пока программа работает достаточно быстро и потребляет достаточно мало ресурсов никого не будет интересовать, что можно сделать её в 10 раз быстрее и 10 раз легче.
Здравствуйте, alex_public, Вы писали:
_>Ну правильно, идея о том что может самим понадобится написать эту самую СУБД, программисту .net видимо не может прийти в голову... )))
Кстати вот одному пришло такое в голову, посмотри чем он занимается:
Здравствуйте, exalicygane, Вы писали:
E>Нет никакого "превосходства" С++, если помимо самого алгоритма ты должен держать в голове выкрутасы С++. Про синтаксис вообще молчу — мрак второго уровня (после Перла и Хаскеля).
Я бы не стал их на один уровень ставить...
Тем более, что в шарпе фичи тоже постоянно добавляются. То есть "выкрутасы" тоже добавляются. В итоге напрягать голову тоже придётся.
E>2. Чтобы писать хорошие приложения на дотнете, сначала надо стать хорошими прогерами на дотнете, а это время, опыт, инертность, отставание от самого дотнета и т.п. Вот сейчас уже есть значимая масса дотнетчиков, готовых заполонить мэйнстрим.
Так можно просто писать безопасный код или всё-таки нужно "стать хорошим прогером", получить опыт и т.д.? То есть без знания "выкрутасов" и в дотнете никуда?
E>4. Их не волнует, что они не способны гарантировать "безглючность" любой программы длиннее 10KLOC.
А ты можешь?
Сомневаюсь, что это вообще на любом языке возможно.
E>Но возвращаясь к Ди, мне он кажется куда более интересным и перспективным, чем кактус сипипей — он не даром Ди, а не "Скала" — Ди поднял планку понятия "современный язык" так, что весь легаси код сипипи кажется унылым наследием времён фортрана.
Мне вот даже интересно зачем тебе D, если есть такой замечательный С#/дотнет. Они ведь лучше, правда?
E>скорее бы он уже RIP...
Боюсь, что до этого мы не доживём.
G>Ты о какой производительности? Наблюдаемая пользователем производительность (http://en.wikipedia.org/wiki/Perceived_performance) от асинхронности растет ооочень сильно. Хотя при этом общее время выполнение операции может даже падать.
Мне эта мантра про await/perceived performance напомнила:
Because it's got electrolytes perceived performance!
Здравствуйте, alex_public, Вы писали:
_>Это да, я утверждал такое... И собственно это очевидно так и есть. Т.к. все возможности C# можно повторить на C++, а вот часть возможностей C++ (в основном реализуемых через метапрограммирование или же наоборот на самом низком уровне) на C# повторить невозможно.
Ну повтори query comprehension и Expressions.
I>>А вот, скажем, новый компилер шарпа писаный на шарпе рвёт в хлам старый компилер шарпа писаный на плюсах. Странно, да ?
_>Это вообще ни о чём не говорит. Современные версии компиляторов C++ тоже делают старые.)))
Старый он условно старый — C# 5.0 все еще на с++, и рослин рвет его в хлам.
I>>Числодробилок раз два и обчелся. А всё остальное упирается в алгоритмы или ввод вывод.
_>Как бы это сказать попроще... ) Если бы это было правдой, то у меня на компьютере точно было бы установлено хотя бы несколько модных .net программ (уж за более чем десятилетие должны же были появиться такие).
Вероятно ты пользуешься одним и тем же набором программ
>Но из более чем 250 папок в Program Files насколько я помню ни одна не работает через .net. Раньше правда была одна такая мощная папка (Visual Studio), но уже несколько лет как ушёл и с неё. И то это не особо аргумент, т.к. для MS это был скорее их обычный пиар технологии. Так что похоже мифом у нас являются как раз перспективы .net. )))
Большие продукты в общем случае не переписываются. Так что это не аргумент.
_>Забавная история. ) Только вот она как раз в точности подтвердила именно мою мысль, что в руках профи и сомнительный инструмент будет эффективнее чем самый мощный в руках неумехи.
Стало быть у тебя есть хороший аналог паттерн-матчинга на с++. Самое главное — что бы алгоритм можно было менять на раз, а не тратить месяцы времени.
Здравствуйте, Ikemefula, Вы писали:
I>Ну повтори query comprehension и Expressions.
Ты не решение из C# назови, а задачку. ))) Ведь никто же не будет повторять кривые реализации, если есть более удобные...
I>Вероятно ты пользуешься одним и тем же набором программ
Не, частенько новый софт ставлю. Вот недавно добавил Double Commander вместо сочетания Проводник/Far, а перед этим BitTorrent Sync, а ещё раньше Zim. А ещё самолётики (world of warplanes) весной ставил. Это то, что прямо с ходу вспомнилось. ))) Да и вообще цифра в 250 папок должна была навести на мысли... И нигде никаких намёков на .net.
Но ты лучше приведи свои примеры, какой .net софт стоит у тебя на компе. Ну кроме VisualStudio, которая особый случай...
I>Стало быть у тебя есть хороший аналог паттерн-матчинга на с++. Самое главное — что бы алгоритм можно было менять на раз, а не тратить месяцы времени.
Реально мощный паттерн-матчинг я знаю только в одном языке — в Прологе. Во всех остальных это обычно просто продвинутые версии switch'a... ))) В C++ такое чаще всего реализуется прямо в коде через перегрузку. Но можно и написать библиотечку на эту тему, например такую: https://parasol.tamu.edu/~yuriys/pm/.
Да, всё так. Кроме одного нюанса... Правда этот нюанс меняет всю картину. )))
Ты так пишешь, как будто бы сценарий запуска нескольких параллельных асинхронных операций на одних и тех же данных является основным. В то время как на мой взгляд основной сценарий как раз с последовательным запуском (с которым никаких проблем нет), а для твоего сценария я вот даже так с ходу и не могу подобрать задачку... Т.е. теоретически то я такое допускаю, но ни разу ничего подобного не припомню.
Вот приведи хоть один реальный практический пример такого...
Здравствуйте, alex_public, Вы писали:
I>>Ну повтори query comprehension и Expressions.
_>Ты не решение из C# назови, а задачку. ))) Ведь никто же не будет повторять кривые реализации, если есть более удобные...
Задачка простая — есть несколько вариантов хранилища, обеспечить единый интерфейс для них, что бы всё было типизировано и смена провайдера не требовала бы переписывание приложения.
_>Не, частенько новый софт ставлю. Вот недавно добавил Double Commander вместо сочетания Проводник/Far, а перед этим BitTorrent Sync, а ещё раньше Zim. А ещё самолётики (world of warplanes) весной ставил. Это то, что прямо с ходу вспомнилось. ))) Да и вообще цифра в 250 папок должна была навести на мысли... И нигде никаких намёков на .net.
wowp частично на питоне написан, кстати говоря, который еще более тормозной чем .net, странно да ?
_>Но ты лучше приведи свои примеры, какой .net софт стоит у тебя на компе. Ну кроме VisualStudio, которая особый случай...
У меня по большому счету только вижла, офис и фиддлер, они требуют .net не ниже 2.0
Проги которые приходится иногда ставить, требуют периодически .Net, но я как то уже не слежу, что на чем написано.
I>>Стало быть у тебя есть хороший аналог паттерн-матчинга на с++. Самое главное — что бы алгоритм можно было менять на раз, а не тратить месяцы времени.
_>Реально мощный паттерн-матчинг я знаю только в одном языке — в Прологе. Во всех остальных это обычно просто продвинутые версии switch'a... ))) В C++ такое чаще всего реализуется прямо в коде через перегрузку. Но можно и написать библиотечку на эту тему, например такую: https://parasol.tamu.edu/~yuriys/pm/.
Эта библиотечка ничем не лучше визитров — объем выхлопа почти такой же и проблемы ровно такие же — она расширяется как и визиторы, через одно место. У ПМ основное достоинство это компактный прозрачный код и тривиальная расширяемость.
Здравствуйте, alex_public, Вы писали:
_>Ты так пишешь, как будто бы сценарий запуска нескольких параллельных асинхронных операций на одних и тех же данных является основным.
Да, как правило всегда есть несколько паралельных цепочек. Например сихронизация локальной базы с сервером .
>В то время как на мой взгляд основной сценарий как раз с последовательным запуском (с которым никаких проблем нет), а для твоего сценария я вот даже так с ходу и не могу подобрать задачку... Т.е. теоретически то я такое допускаю, но ни разу ничего подобного не припомню.
Потому, что сложно использовать такие вещи как асинхронные притимивы синхронизации.
Сколько можно флеймить абсолютно посторонними технологиями? Что бы ни сделали в C# или примотали изолентой к Си++, это их сугубо личные дела. Главное — что Ди как-то продирается сквозь 30-летнюю скорлупу сознания и уже выходит в обсуждаемые языки. Если каждый уделит время для изучения хотя бы возможностей языка, сообщество профи перестанет быть таким плюсово-однобоким: Ди уже показал, что главный его курс — мэйнстрим, а количество исправленных С++-недоразумений зашкаливает, так что Ди — вполне осязаемая надежда писать нативные приложения и при этом не быть на крючке мелкософта.
Здравствуйте, Ikemefula, Вы писали:
I>Задачка простая — есть несколько вариантов хранилища, обеспечить единый интерфейс для них, что бы всё было типизировано и смена провайдера не требовала бы переписывание приложения.
Мммм, так это же простейшая вещь, если я правильно тебя понял. Например для доступа в многочисленные sql базы обычно делают единый интерфейс. И на C++ таких решений естественно тоже полно. В чём проблема то? Или ты про что-то другое?
I>wowp частично на питоне написан, кстати говоря, который еще более тормозной чем .net, странно да ?
Почему странно? ) Я сам его использую частенько, в том числе и в паре с C++.
I>У меня по большому счету только вижла, офис и фиддлер, они требуют .net не ниже 2.0
Офис написан на .net? ) Это с какой версии интересно? ))) Я конечно самые последние не ставил, но моя явно не на .net и что-то сомневаюсь, что они решили его переписать именно сейчас...
I>Проги которые приходится иногда ставить, требуют периодически .Net, но я как то уже не слежу, что на чем написано.
В общем, как я понимаю, ты тоже не можешь назвать у себя на компе ни одного продукта написанного на .net? ))) Да, а посмотреть то это довольно просто — изучаешь есть ли библиотека .net'a в списке зависимостей exe...
Кстати, обрати внимание, что часть поставленных мною продуктов в последнее время — это совсем молодые проекты. Так что отмазка типа "просто старый софт нет смысла переписывать" совсем не работает...
I>Эта библиотечка ничем не лучше визитров — объем выхлопа почти такой же и проблемы ровно такие же — она расширяется как и визиторы, через одно место. У ПМ основное достоинство это компактный прозрачный код и тривиальная расширяемость.
Ты не внимательно посмотрел. ) Кстати, я там заметил ещё один забавный момент связанный именно со сравнением языков не по скорости (чем в основном заняты авторы), а по коду... Если ты скачаешь архив с библиотекой, то увидишь там в корне 3 файла: cmp_cpp.cxx, cmp_haskell.hs, cmp_ocaml.ml. Они там естественно для сравнения производительности... Но меня повеселило другое. В варианте haskell и ocaml мы имеем здоровенные таблицы типов... А в C++ варианте нет ничего подобного — всё решено через циклы! ))) Это не плохой пример для тех, кто недооценивает возможности метапрограммирования... )
Это уже было в этой темке, чуть выше. И что-то никто так и не отреагировал...
E>Сколько можно флеймить абсолютно посторонними технологиями? Что бы ни сделали в C# или примотали изолентой к Си++, это их сугубо личные дела. Главное — что Ди как-то продирается сквозь 30-летнюю скорлупу сознания и уже выходит в обсуждаемые языки. Если каждый уделит время для изучения хотя бы возможностей языка, сообщество профи перестанет быть таким плюсово-однобоким: Ди уже показал, что главный его курс — мэйнстрим, а количество исправленных С++-недоразумений зашкаливает, так что Ди — вполне осязаемая надежда писать нативные приложения и при этом не быть на крючке мелкософта.
Согласен со всем, кроме последней фразы — она явно не про нашу реальность (в которой живут gcc, clang, или вообще Intel). )))
Здравствуйте, alex_public, Вы писали:
_>Мммм, так это же простейшая вещь, если я правильно тебя понял. Например для доступа в многочисленные sql базы обычно делают единый интерфейс. И на C++ таких решений естественно тоже полно. В чём проблема то? Или ты про что-то другое?
Давай проверим. Ты пишешь код для оракла, даёшь его мне. Я запускаю его против моей базы и все должно работать без перекомпиляции, меняем только строчку конфигурации.
I>>wowp частично на питоне написан, кстати говоря, который еще более тормозной чем .net, странно да ?
_>Почему странно? ) Я сам его использую частенько, в том числе и в паре с C++.
Тогда почему у тебя возникает удивление на счет дотнете ? Очевидно — куча задач не требует битовыжимания.
I>>У меня по большому счету только вижла, офис и фиддлер, они требуют .net не ниже 2.0
_>Офис написан на .net? ) Это с какой версии интересно? ))) Я конечно самые последние не ставил, но моя явно не на .net и что-то сомневаюсь, что они решили его переписать именно сейчас...
Процитируй, пожалуйста, где я написал что офис написан на дотнете.
_>В общем, как я понимаю, ты тоже не можешь назвать у себя на компе ни одного продукта написанного на .net? ))) Да, а посмотреть то это довольно просто — изучаешь есть ли библиотека .net'a в списке зависимостей exe...
Ты наверное хочешь сказать чтото вроде "раз никто не переписал офис на дотнете, значит дотнета в природе нет".
Я вот 10 лет проработал в конторе, которая новые продукты сделала на дотнете/Джаве. Эти продукты включают в себя сапр и вещи навроде того. Их можно считать или нет ? Старые версии были все плюсовые.
_>Кстати, обрати внимание, что часть поставленных мною продуктов в последнее время — это совсем молодые проекты. Так что отмазка типа "просто старый софт нет смысла переписывать" совсем не работает...
Здравствуйте, Ikemefula, Вы писали:
I>Давай проверим. Ты пишешь код для оракла, даёшь его мне. Я запускаю его против моей базы и все должно работать без перекомпиляции, меняем только строчку конфигурации.
Да без проблем. ) Только вот я думаю, что мы обойдёмся в данном случае без придумывания и тестирования своих примеров, а ты просто глянешь сюда http://soci.sourceforge.net.
I>Тогда почему у тебя возникает удивление на счет дотнете ? Очевидно — куча задач не требует битовыжимания.
Как бы Питон привносит минусы (ухудшение скорости, типобезопасности) относительно C++, но взамен даёт гору своих плюсов. Соответственно во многих ситуациях этот компромисс становится выгоден. А C#, при известных нам минусах, не привносит считай вообще никаких плюсов. Ну разве что только возможность использовать индусов в проекте, что для нас совсем не актуально.
I>Я вот 10 лет проработал в конторе, которая новые продукты сделала на дотнете/Джаве. Эти продукты включают в себя сапр и вещи навроде того. Их можно считать или нет ? Старые версии были все плюсовые.
Это продукты для открытой продажи или внутрикорпоративные/для заказчика?
_>>Кстати, обрати внимание, что часть поставленных мною продуктов в последнее время — это совсем молодые проекты. Так что отмазка типа "просто старый софт нет смысла переписывать" совсем не работает... I>Системнозависимый командер ?
Хы, вообще то он как раз работает под кучей разных ОС: http://doublecmd.sourceforge.net, но в данном случая я имел в виду не его, т.к. он всё же не совсем новый продукт. А вот если взять BitTorrent Sync например...
Здравствуйте, alex_public, Вы писали: _>Да без проблем. ) Только вот я думаю, что мы обойдёмся в данном случае без придумывания и тестирования своих примеров, а ты просто глянешь сюда http://soci.sourceforge.net.
А как там разруливать ситации, когда в случае MS SQL нужен TOP, а MySQL — LIMIT ?
Здравствуйте, alex_public, Вы писали:
I>>Давай проверим. Ты пишешь код для оракла, даёшь его мне. Я запускаю его против моей базы и все должно работать без перекомпиляции, меняем только строчку конфигурации.
_>Да без проблем. ) Только вот я думаю, что мы обойдёмся в данном случае без придумывания и тестирования своих примеров, а ты просто глянешь сюда http://soci.sourceforge.net.
Это каменный век. Нужна поддержка компилятором всех типов. Т.е. переименовал колонку и прога не скомпилилась.
I>>Тогда почему у тебя возникает удивление на счет дотнете ? Очевидно — куча задач не требует битовыжимания.
_>Как бы Питон привносит минусы (ухудшение скорости, типобезопасности) относительно C++, но взамен даёт гору своих плюсов. Соответственно во многих ситуациях этот компромисс становится выгоден. А C#, при известных нам минусах, не привносит считай вообще никаких плюсов. Ну разве что только возможность использовать индусов в проекте, что для нас совсем не актуально.
У дотнета для десктопа ровно два недостатка — долгое время запуска и отсутствие кроссплатформенности. Все питоновские, джавовские приложения кроссплатформенные, но имеют кучу своих проблем. По перформансу они все сливают дотнету.
I>>Я вот 10 лет проработал в конторе, которая новые продукты сделала на дотнете/Джаве. Эти продукты включают в себя сапр и вещи навроде того. Их можно считать или нет ? Старые версии были все плюсовые.
_>Это продукты для открытой продажи или внутрикорпоративные/для заказчика?
Продукты, но не для открытой продажи.
_>>>Кстати, обрати внимание, что часть поставленных мною продуктов в последнее время — это совсем молодые проекты. Так что отмазка типа "просто старый софт нет смысла переписывать" совсем не работает... I>>Системнозависимый командер ?
_>Хы, вообще то он как раз работает под кучей разных ОС: http://doublecmd.sourceforge.net, но в данном случая я имел в виду не его, т.к. он всё же не совсем новый продукт. А вот если взять BitTorrent Sync например...
Это не важно, под какими ОС он работает. Он юзает напрямую АПИ которое в менеджед большей частью напрямую недоступно. Кроме того, кроссплатформенностью дотнет не отличается.
Здравствуйте, alex_public, Вы писали:
_>Эээ что? ) Ты хочешь переименовать колонку в базе данных, ничего не трогать в программе и чтобы всё работало по прежнему? Или что?
Я хочу что бы компилятор подсказал _все_ ошибки.
_>Ты что-то всё напутал. Сравнение вообще не такое.
_>1. У нас есть C++. Это максимальная производительность и нормальное удобство написание кода. Требует серьёзного умения.
Я не сильно в курсе, как проверить "нормальное удобство". Предложишь хороший тест ?
_>3. У нас есть Java/C#. Это несколько меньшая производительность чем пункт 1 и заметно большая чем 2. И такое же удобство написание кода как в пункте 1. Или даже местами хуже, если уместно метапрограммирование. Но порог вхождения заметно ниже пункта 1.
И с удобством ровно тоже что и выше — не ясно как померить.
_>Из этой схемки очевидно следуют оптимальные ниши для данных технологий. Для варианта 2 явно оптимальны различные скрипты (как внешние, так и внутренние) и небольшие проекты не требующие серьёзной производительности. Вариант 3 подходит для случая потребности использовать в команде орду индусов. Ну и соответственно вариант 1 для всех остальных случаев. Что полностью подтверждается раскладом по софту на компе среднестатистического юзера.
Питон давно уже перерос стадию скриптов и небольших проектов. Для орды индусов дотнет и джава слишком сложные.
I>>Продукты, но не для открытой продажи.
_>Почему-то я так и думал... )))
У конкурентов ровно тоже вне зависимости от ЯП
I>>Битторент написан на пейтоне
_>Вообще то нет. ) Но даже если бы и так, то всё равно же не .net. )))
Вообще то на питоне. Причины я уже указал. Как видишь, эти самые причины кроются совсем не в производительности.
Здравствуйте, Ikemefula, Вы писали:
I>Я хочу что бы компилятор подсказал _все_ ошибки.
Это компилятор должен в процессе работы к базе обращаться? ) Иначе как ты отследишь все ошибки, если при работе с базой данных они возникают в основном в самой базе в динамике и зависят от структуры таблиц?
I>Я не сильно в курсе, как проверить "нормальное удобство". Предложишь хороший тест ?
Не нужен тест. Мы просто фиксируем какой-то определённый уровень, относительно которого и будем дальше рассуждать. Т.е. нет абсолютной шкалы, но сравнить два конкретных языка и сказать какой из них удобнее в какой-то области вполне можно.
I>И с удобством ровно тоже что и выше — не ясно как померить.
А что не ясного? Если не учитывать области, где полезно применение метапрограммирования или же каких-то совсем низкоуровневых возможностей, то в остальном решения ня C++, C# и Java будут иметь довольно похожую структуру (в отличие от скажем решений на динамических языках). И соответственно удобство разработки будет довольно близким.
I>Питон давно уже перерос стадию скриптов и небольших проектов. Для орды индусов дотнет и джава слишком сложные.
Сложный проект без статической типизации? Да ну нафиг такой мазохизм...
I>Вообще то на питоне. Причины я уже указал. Как видишь, эти самые причины кроются совсем не в производительности.
Здравствуйте, alex_public, Вы писали:
_>Это компилятор должен в процессе работы к базе обращаться? ) Иначе как ты отследишь все ошибки, если при работе с базой данных они возникают в основном в самой базе в динамике и зависят от структуры таблиц?
Что тебя смущает ? Ты же говорил, что метапрограммирование адски круто в С++, вот и продемонстрируй. Положим, для простоты, что структура базы в динамике не меняется.
Не нужно кода, общие вещи расскажи, как будут делаться. Скажем, в дотнете есть Expressions. Пишешь вот так
u = (from o in db.Orders select o.Total).Sum();
И все становится шоколадно. Переименовал колонку в базе — код компилироваться не должен. Переименовал свойство в коде — изменения можно применить и к базе, но, более того, все запросы которые дергают эту колонку должны или перестать компилироваться или должны пофикситься автоматически.
I>>Я не сильно в курсе, как проверить "нормальное удобство". Предложишь хороший тест ?
_>Не нужен тест. Мы просто фиксируем какой-то определённый уровень, относительно которого и будем дальше рассуждать. Т.е. нет абсолютной шкалы, но сравнить два конкретных языка и сказать какой из них удобнее в какой-то области вполне можно.
Так ты расскажи, что это за определенный уровень, шоб я мог его проверить и убедиться, что мне на нем так же удобно как и тебе.
_>А что не ясного? Если не учитывать области, где полезно применение метапрограммирования или же каких-то совсем низкоуровневых возможностей, то в остальном решения ня C++, C# и Java будут иметь довольно похожую структуру (в отличие от скажем решений на динамических языках). И соответственно удобство разработки будет довольно близким.
Это разве что в самых примитивных конструкциях — циклах на массиве каком. Управление ресурсами делается иначе, ОО-модель совершенно другая. Системный код пишется совершенно иначе, и тд и тд и тд.
I>>Питон давно уже перерос стадию скриптов и небольших проектов. Для орды индусов дотнет и джава слишком сложные.
_>Сложный проект без статической типизации? Да ну нафиг такой мазохизм...
"А посоны то и не знают " @
I>>Вообще то на питоне. Причины я уже указал. Как видишь, эти самые причины кроются совсем не в производительности.
_>Ну давай пруфлинк тогда. )
Здравствуйте, Ikemefula, Вы писали:
_>>Это компилятор должен в процессе работы к базе обращаться? ) Иначе как ты отследишь все ошибки, если при работе с базой данных они возникают в основном в самой базе в динамике и зависят от структуры таблиц?
I>Что тебя смущает ? Ты же говорил, что метапрограммирование адски круто в С++, вот и продемонстрируй. Положим, для простоты, что структура базы в динамике не меняется. I>Не нужно кода, общие вещи расскажи, как будут делаться. Скажем, в дотнете есть Expressions. Пишешь вот так
I>
I>u = (from o in db.Orders select o.Total).Sum();
I>
I>И все становится шоколадно. Переименовал колонку в базе — код компилироваться не должен. Переименовал свойство в коде — изменения можно применить и к базе, но, более того, все запросы которые дергают эту колонку должны или перестать компилироваться или должны пофикситься автоматически.
Linq2Sql? почему у меня при переименовании код все равно компилируется?
Здравствуйте, night beast, Вы писали:
I>>И все становится шоколадно. Переименовал колонку в базе — код компилироваться не должен. Переименовал свойство в коде — изменения можно применить и к базе, но, более того, все запросы которые дергают эту колонку должны или перестать компилироваться или должны пофикситься автоматически.
NB>Linq2Sql? почему у меня при переименовании код все равно компилируется?
Здравствуйте, Ikemefula, Вы писали:
I>>>И все становится шоколадно. Переименовал колонку в базе — код компилироваться не должен. Переименовал свойство в коде — изменения можно применить и к базе, но, более того, все запросы которые дергают эту колонку должны или перестать компилироваться или должны пофикситься автоматически.
NB>>Linq2Sql? почему у меня при переименовании код все равно компилируется?
I>Потому, что надо и маппинг обновлять.
дык как я тебя понял, "оно само" должно обновляться. а тут оказывается, что не само. ты уж определись.
а если учесть что коннекшн вообще из конфига может браться, вообще интересно получается.
Здравствуйте, exalicygane, Вы писали:
E>Для сферического писькомерства — да, можно сказать "С++ круче", но вам за что деньги платят? За промышленный код, мэйнстрим. И по-моему, вполне очевидно, что нарезка овощей на тёрке (C#) намного быстрее и безопаснее, чем их рубка саблей (С++). Нет никакого "превосходства" С++, если помимо самого алгоритма ты должен держать в голове выкрутасы С++. Про синтаксис вообще молчу — мрак второго уровня (после Перла и Хаскеля).
Перл ещё ладно, а хаскель-то чем провинился?
Пользовательскими операторами, что ли? Так они ничем не хуже фортрановско-сишных сокращений вида cblas_cgbmv или дотнетовско-явовских theKingdonOfNounsMethodNamig.
Если уж катить бочку на синтаксис, это надо APL/J/K вспомнить (как конкурент перлу) и окамл (конкурент плюсам по разнообразию фич).
Здравствуйте, Ikemefula, Вы писали:
I>Что тебя смущает ? Ты же говорил, что метапрограммирование адски круто в С++, вот и продемонстрируй. Положим, для простоты, что структура базы в динамике не меняется.
Так ты не ответил, компилятор должен лазить в базу данных или нет? ) Если да, то тогда действительно на C++ такое не реально (кстати, а вот на D вполне реализуемо). Если же нет, и ты всё же задаёшь соответствие названий колонок каким-то сущностям в коде где-то в другом месте кода, то это буквально есть в том же COCI.
I>Не нужно кода, общие вещи расскажи, как будут делаться. Скажем, в дотнете есть Expressions. Пишешь вот так I>
I>u = (from o in db.Orders select o.Total).Sum();
I>
Что-то мне не очень нравится такая запись. От неё складывается визуальное ощущение, что мы запрашиваем у базы не сумму по полю Total, а запрашиваем список значений Total и потом у себя суммируем.
I>Так ты расскажи, что это за определенный уровень, шоб я мог его проверить и убедиться, что мне на нем так же удобно как и тебе.
Так не важно что это за уровень. ))) Назовём его "уровень удобства C++" и будем рассуждать про другие языки, в каких он выше, а в каких ниже или равен. Понятна мысль? )
I>Это разве что в самых примитивных конструкциях — циклах на массиве каком. Управление ресурсами делается иначе, ОО-модель совершенно другая. Системный код пишется совершенно иначе, и тд и тд и тд.
Это внутри оно другое, а код похожий выходит (если конечно не использовать в C++ самые мощные и сложные возможности).
I>у него реп на соурсфордже
Ах вот ты про что...
Ну для начала надо читать внимательнее — у меня стоит не BitTorrent (который во-первых старый проект, а во-вторых вообще мне не нужен), а BitTorrent Sync (который вышел только в этом году и является весьма полезной штучкой).
Ну и потом даже сам BitTorrent написан на C++, а версия на Питоне — это самый первый прототип 10-и летней давности, который уже давно переписали. И кстати в отличие от прототипа это всё не Open source... )
Здравствуйте, alex_public, Вы писали:
I>>Что тебя смущает ? Ты же говорил, что метапрограммирование адски круто в С++, вот и продемонстрируй. Положим, для простоты, что структура базы в динамике не меняется.
_>Так ты не ответил, компилятор должен лазить в базу данных или нет? ) Если да, то тогда действительно на C++ такое не реально (кстати, а вот на D вполне реализуемо). Если же нет, и ты всё же задаёшь соответствие названий колонок каким-то сущностям в коде где-то в другом месте кода, то это буквально есть в том же COCI.
Задавай как угодно, главное что бы запросы были все до одного типизироваными.
I>>Не нужно кода, общие вещи расскажи, как будут делаться. Скажем, в дотнете есть Expressions. Пишешь вот так I>>
I>>u = (from o in db.Orders select o.Total).Sum();
I>>
_>Что-то мне не очень нравится такая запись. От неё складывается визуальное ощущение, что мы запрашиваем у базы не сумму по полю Total, а запрашиваем список значений Total и потом у себя суммируем.
Это неправильное ощущение.
I>>Так ты расскажи, что это за определенный уровень, шоб я мог его проверить и убедиться, что мне на нем так же удобно как и тебе.
_>Так не важно что это за уровень. ))) Назовём его "уровень удобства C++" и будем рассуждать про другие языки, в каких он выше, а в каких ниже или равен. Понятна мысль? )
В таком случае мне этот уровень удобства крайне неудобен.
I>>Это разве что в самых примитивных конструкциях — циклах на массиве каком. Управление ресурсами делается иначе, ОО-модель совершенно другая. Системный код пишется совершенно иначе, и тд и тд и тд.
_>Это внутри оно другое, а код похожий выходит (если конечно не использовать в C++ самые мощные и сложные возможности).
Это заблуждение. Сиплюсники бывает годами не могут перестроиться под дотнет.
_>Ну и потом даже сам BitTorrent написан на C++, а версия на Питоне — это самый первый прототип 10-и летней давности, который уже давно переписали. И кстати в отличие от прототипа это всё не Open source... )
Здравствуйте, Ikemefula, Вы писали:
I>Задавай как угодно, главное что бы запросы были все до одного типизироваными.
В общем, если мы всё равно задаём имена колонок руками где-то в коде, то я не вижу никакой разницы.
I>>> u = (from o in db.Orders select o.Total).Sum();
_>>Что-то мне не очень нравится такая запись. От неё складывается визуальное ощущение, что мы запрашиваем у базы не сумму по полю Total, а запрашиваем список значений Total и потом у себя суммируем.
I>Это неправильное ощущение.
Я в курсе. ))) Но внешне оно выглядит именно так. ))) Так что на мой взгляд гораздо очевиднее выглядит строка вида:
db<<"select sum(Total) from Orders", into(u);
I>В таком случае мне этот уровень удобства крайне неудобен.
Это не имеет значения, пока ты не сравниваешь с другими языками. Я к примеру тоже не в особом восторге от синтаксиса C++, но как бы лучше то всё равно нет из мейнстримовых. Вот только надежда что D всё же взлетит...
I>И он такой же кроссплатформенный ?
Здравствуйте, night beast, Вы писали:
I>>Потому, что надо и маппинг обновлять.
NB>дык как я тебя понял, "оно само" должно обновляться. а тут оказывается, что не само. ты уж определись.
Само это значит небольшой кусок кода автоматизирует всю ручную работу. С маппингами все так и есть — тебе не надо мотаться по коду и искать, где какая колонка может использоваться.
NB>а если учесть что коннекшн вообще из конфига может браться, вообще интересно получается.
Коннекшн всегда из конфига берётся и никаких проблем с этим не бывает.
Здравствуйте, Ikemefula, Вы писали:
I>>>Потому, что надо и маппинг обновлять.
NB>>дык как я тебя понял, "оно само" должно обновляться. а тут оказывается, что не само. ты уж определись.
I>Само это значит небольшой кусок кода автоматизирует всю ручную работу. С маппингами все так и есть — тебе не надо мотаться по коду и искать, где какая колонка может использоваться.
не вижу принципиальных ограничений генерировать то же самое на плюсах.
NB>>а если учесть что коннекшн вообще из конфига может браться, вообще интересно получается.
I>Коннекшн всегда из конфига берётся и никаких проблем с этим не бывает.
Здравствуйте, night beast, Вы писали:
I>>Само это значит небольшой кусок кода автоматизирует всю ручную работу. С маппингами все так и есть — тебе не надо мотаться по коду и искать, где какая колонка может использоваться.
NB>не вижу принципиальных ограничений генерировать то же самое на плюсах.
Принципиальные ограничения в работе с такими маппингами. Для этого нужны деревья выражений и их поддержка в языке.
NB>>>а если учесть что коннекшн вообще из конфига может браться, вообще интересно получается. I>>Коннекшн всегда из конфига берётся и никаких проблем с этим не бывает. NB>из конфига в смысле в рантайме.
Здравствуйте, Ikemefula, Вы писали:
I>>>Само это значит небольшой кусок кода автоматизирует всю ручную работу. С маппингами все так и есть — тебе не надо мотаться по коду и искать, где какая колонка может использоваться.
NB>>не вижу принципиальных ограничений генерировать то же самое на плюсах.
I>Принципиальные ограничения в работе с такими маппингами. Для этого нужны деревья выражений и их поддержка в языке.
принципиальные ограничения мы выдумываем себе сами.
сформировать запрос по автоматически сгенерированным типам -- задача вполне реальная.
NB>>>>а если учесть что коннекшн вообще из конфига может браться, вообще интересно получается. I>>>Коннекшн всегда из конфига берётся и никаких проблем с этим не бывает. NB>>из конфига в смысле в рантайме.
I>Именно так.
Здравствуйте, night beast, Вы писали:
NB>принципиальные ограничения мы выдумываем себе сами. NB>сформировать запрос по автоматически сгенерированным типам -- задача вполне реальная.
А что, где ты было сказано что это нереальная задача ?
Покажи пример, хотя бы вот такой пример order.Select(x => x.Total)
Такие вещи почти не встречаются. Обычно чтото сложнее, например так — order.Where(x => x.State == State.Closed).Select(x => x.Total)
А еще интереснее вот так — order.Where(Filter).Select(x => x.Total), где фильтр это почти обычная фукнция.
NB>>>из конфига в смысле в рантайме.
I>>Именно так.
NB>в рантайме маппинг генерируешь? ну-ну.
Где он генерируется, не важно. Важно, что это делается не руками.
Здравствуйте, Ikemefula, Вы писали:
I>Правильно понимаю, ты собираешься пропатчить компилятор, что бы он умел деревья выражений ?
I>Забудем пока про query comprehension.
I>Покажи, как ты собираешься вот такое реализовывать
I>Select(x => x.Total)
I>Здесь нечто, похожее на лямбду, на самом деле не лямбда, а языковая фича которая в С++ не поддерживается — Expression TreeПокаж.
I>Покажи аналог на С++
Ты снова описываешь решение, а не задачу. Давай задачку и там посмотрим как её оптимально решить. Пока что ты просил универсальный доступ к базам данных. Я тебе показал красивый и удобный универсальный вариант. Давай, покажи что теперь ещё хочешь...)))
Здравствуйте, alex_public, Вы писали:
_>универсальный доступ к базам данных. Я тебе показал красивый и удобный универсальный вариант. Давай, покажи что теперь ещё хочешь...)))
А все-таки, что с моим вопросом: http://rsdn.ru/forum/philosophy/5366518.1
Здравствуйте, Ikemefula, Вы писали:
EP>>Деревья выражений в C++ уже лет 18 реализуются, причём их можно обходить и оптимизировать в compile-time I>Реализуются, при этом сложность реализации либы на порядок выше, чем в дотнете.
Для compile-time обработки выражений есть Boost.Proto — он берёт большую часть работы на себя.
Но, деревья выражений можно строить и в runtime — там вообще нет ничего сложного
Здравствуйте, alex_public, Вы писали: _>Давай задачку и там посмотрим как её оптимально решить.
Вот мы пишем
using (var db = new DataContext())
{
var products = db
.Products
.Take(5)
.ToArray();
}
Для этого кода безразлично, какая СУБД используется — Oracle, MySQL, MS SQL и т.д.
То есть при запуске, если в ConnectionString:
a) прописана база MS SQL, то сгенерируется соответствующий SQL вида SELECT TOP 5 * FROM Products
б) прописан MySQL, то сгенерируется SQL вида SELECT * FROM Products LIMIT 5
в) ...
Таким образом, задача вообще не писать SQL руками, а простой сменой 1 строчки в конфиг файле перейти на другую СУБД.
Здравствуйте, alex_public, Вы писали:
>>Покажи аналог на С++
_>Ты снова описываешь решение, а не задачу. Давай задачку и там посмотрим как её оптимально решить. Пока что ты просил универсальный доступ к базам данных. Я тебе показал красивый и удобный универсальный вариант. Давай, покажи что теперь ещё хочешь...)))
Внятный OR/Mapper. Годится ? Только ты уже расслабься, EP уже всё показал.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Для compile-time обработки выражений есть Boost.Proto — он берёт большую часть работы на себя. EP>Но, деревья выражений можно строить и в runtime — там вообще нет ничего сложного
Ога. Ты лучше покажи либу, которая умеет столько же бд, как и всякие дотнетовские аналоги. Ну, возьмем опенсорс — linq2db
Здравствуйте, Ikemefula, Вы писали:
NB>>принципиальные ограничения мы выдумываем себе сами. NB>>сформировать запрос по автоматически сгенерированным типам -- задача вполне реальная.
I>А что, где ты было сказано что это нереальная задача ?
ну эт ты начал рассказывать про какие-то непонятные трудности
I>Покажи пример, хотя бы вот такой пример order.Select(x => x.Total)
order x;
auto r = db::select( x.Total ).eval( );
I>Такие вещи почти не встречаются. Обычно чтото сложнее, например так — order.Where(x => x.State == State.Closed).Select(x => x.Total)
order x;
auto r = db::select( x.Total ).where( x.State == State.Closed ).eval( );
I>А еще интереснее вот так — order.Where(Filter).Select(x => x.Total), где фильтр это почти обычная фукнция.
интереснее здесь то, где фильтруются полученные данные.
NB>>>>из конфига в смысле в рантайме.
I>>>Именно так.
NB>>в рантайме маппинг генерируешь? ну-ну.
I>Где он генерируется, не важно. Важно, что это делается не руками.
Здравствуйте, Ikemefula, Вы писали:
I>Ога. Ты лучше покажи либу, которая умеет столько же бд, как и всякие дотнетовские аналоги. Ну, возьмем опенсорс — linq2db
ODB поддерживает mainstream (хотя может это и не mainstream уже, я с DB не работаю — нет таких задач):
MySQL, SQLite, PostgreSQL, Oracle, MSSQL.
О, сорри, не заметил. Если говорим про библиотечку SOCI, то это она всё сама делает внутри. Собственно там две основных схемы для этого:
1. Возвращается итератор. Тут соответственно размер вообще не надо указывать, т.к. тут получается по запросу к базе на каждую строку. Это весьма удобно, но не всегда оптимально по быстродействию.
2. Выгружаем данные сразу в некий массив (вектор нужного типа) одним запросом. Тогда запрашивается как раз сколько надо автоматом.
Здравствуйте, Ikemefula, Вы писали:
I>Внятный OR/Mapper. Годится ? Только ты уже расслабься, EP уже всё показал.
Так пример этого же был в две строки буквально на заглавной странице той простенькой библиотечки, что я тебе показывал. Ну могу показать чуть подробнее:
struct Person{
int id;
string name;
double total;
};
for(auto& p: rowset<Person>(session(sqlite3, "test.db").prepare<<"select * from Persons"))
wcout<<p.id<<' '<<p.name<<' '<<p.total<<endl;
Ну а Евгений показал уже что-то совсем мощное, с автогенерацией кода и т.п...
Здравствуйте, QrystaL, Вы писали:
QL>Вот мы пишем
QL>
QL>using (var db = new DataContext())
QL>{
QL> var products = db
QL> .Products
QL> .Take(5)
QL> .ToArray();
QL>}
QL>
QL>Для этого кода безразлично, какая СУБД используется — Oracle, MySQL, MS SQL и т.д. QL>То есть при запуске, если в ConnectionString: QL>a) прописана база MS SQL, то сгенерируется соответствующий SQL вида SELECT TOP 5 * FROM Products QL>б) прописан MySQL, то сгенерируется SQL вида SELECT * FROM Products LIMIT 5 QL>в) ...
Ну на это я уже ответил — см. два мои сообщения выше в темке. )
QL>Таким образом, задача вообще не писать SQL руками, а простой сменой 1 строчки в конфиг файле перейти на другую СУБД.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
I>>Ога. Ты лучше покажи либу, которая умеет столько же бд, как и всякие дотнетовские аналоги. Ну, возьмем опенсорс — linq2db
EP>ODB поддерживает mainstream (хотя может это и не mainstream уже, я с DB не работаю — нет таких задач): EP>MySQL, SQLite, PostgreSQL, Oracle, MSSQL.
То есть, ни о чем Вот чудо — есть мега пулька, но шота люди ей не пользуются
Здравствуйте, alex_public, Вы писали:
_>Так пример этого же был в две строки буквально на заглавной странице той простенькой библиотечки, что я тебе показывал. Ну могу показать чуть подробнее: _>
Здравствуйте, Ikemefula, Вы писали:
I>>>А еще интереснее вот так — order.Where(Filter).Select(x => x.Total), где фильтр это почти обычная фукнция.
NB>>интереснее здесь то, где фильтруются полученные данные.
I>Неужели в компайлтайм ?
ключевое слово, "где". ну да не важно. ответ я услышал.
Здравствуйте, alex_public, Вы писали:
I>>Ты показал чтото непонятное — Persons так же должно быть типизированым, а у тебя это в строчке.
_>Ээээ что? ) Имя таблицы в базе данных типизированное? )))
Здравствуйте, Ikemefula, Вы писали:
I>А имя переменной типизировано или нет ?
I>Типа ты не понял, ага
Если ты про то, чтобы жёстко связать имя таблицы и класс, как было в примерах к ODB, то на мой взгляд это не удобная схема. Мы же можем использовать один и тот же класс с разными таблицами... Но если вдруг всё же захочется такого, то тоже без проблем делается. И даже без всякой внешней кодогенерации. С учётом того, что soci делает всю основную работу (поддерживает все виды баз данных с единым удобным интерфейсом и пользовательскими типами), то реализовать подобное можно уже в десяток строк. Например для класса
struct Person{
int id;
string name;
double total;
int runtime=time(nullptr);//не сохраняем в базу
};
Причём функции CreateTable, Insert, Select и т.п. ничего не знают о Person, т.е. они общие для всех. И больше никакого дополнительного кода, кроме показанного выше объявления, писать не требуется. Причём все будет происходить жёстко типизированно... )
Так что, как видишь, все эти маппинги и т.п. — это всё ерунда, реализуемая в несколько строк. А самое сложное, это написать кучу кода реализующего работу сразу со всеми библиотеками. Что и сделано например в библиотечка soci и многих других.
Здравствуйте, alex_public, Вы писали:
_>Так что, как видишь, все эти маппинги и т.п. — это всё ерунда, реализуемая в несколько строк. А самое сложное, это написать кучу кода реализующего работу сразу со всеми библиотеками. Что и сделано например в библиотечка soci и многих других.
soci это вообще никакой типизации, все строчками, неинтересно. odb уже интереснее, но шота при одинаковом размере кода с linq2db имеет вдвое меньше провайдеров. Да и по возможностям как то не впечатляет
Здравствуйте, Ikemefula, Вы писали:
I> Да и по возможностям как то не впечатляет
Есть ли в linq2db генерация схемы (вообще, есть ли какая-нибудь схема), автоматическая миграция между разными версиями схемы?
Есть ли нормальная поддержка типов/mapping'ов, а не только POCO? Наследование, абстрактные классы?
Здравствуйте, Ikemefula, Вы писали:
I>soci это вообще никакой типизации, все строчками, неинтересно.
Не, там запросы строчками, а данные все типизированы. А я тебе показал как тривиально ещё и запросы сделать типизированными. ))) Другой вопрос в том а надо ли оно...
I>odb уже интереснее, но шота при одинаковом размере кода с linq2db имеет вдвое меньше провайдеров. Да и по возможностям как то не впечатляет
Нуу расскажи как делается в .net маппинг в таблицу некого нашего класса. Который естественно там уже от кого-то библиотечного пронаследован и соответственно имеет набор полей, которые не надо сохранять в базу.
Здравствуйте, alex_public, Вы писали:
I>>soci это вообще никакой типизации, все строчками, неинтересно.
_>Не, там запросы строчками, а данные все типизированы. А я тебе показал как тривиально ещё и запросы сделать типизированными. ))) Другой вопрос в том а надо ли оно...
Нужно что бы запросы были типизироваными.
I>>odb уже интереснее, но шота при одинаковом размере кода с linq2db имеет вдвое меньше провайдеров. Да и по возможностям как то не впечатляет
_>Нуу расскажи как делается в .net маппинг в таблицу некого нашего класса. Который естественно там уже от кого-то библиотечного пронаследован и соответственно имеет набор полей, которые не надо сохранять в базу.
POCO и в большинстве этого достаточно. Если чтото больше надо, то обычно атрибутами.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
I>> Да и по возможностям как то не впечатляет
EP>Есть ли в linq2db генерация схемы (вообще, есть ли какая-нибудь схема), автоматическая миграция между разными версиями схемы? EP>Есть ли нормальная поддержка типов/mapping'ов, а не только POCO? Наследование, абстрактные классы?
Тут есть целый форум, можешь там спросить автора этого фремворка.
Здравствуйте, Ikemefula, Вы писали:
I>>> Да и по возможностям как то не впечатляет EP>>Есть ли в linq2db генерация схемы (вообще, есть ли какая-нибудь схема), автоматическая миграция между разными версиями схемы? EP>>Есть ли нормальная поддержка типов/mapping'ов, а не только POCO? Наследование, абстрактные классы? I>Тут есть целый форум, можешь там спросить автора этого фремворка.
Да мне как-то всё равно — это же ты начал сравнивать количество поддерживаемых СУБД в полноценной ORM vs micro-ORM.
Здравствуйте, Evgeny.Panasyuk, Вы писали:
EP>Да мне как-то всё равно — это же ты начал сравнивать количество поддерживаемых СУБД в полноценной ORM vs micro-ORM.
Если тебе всё равно, то зачем же ты спрашивал ? Покажи полноценный ORM на с++, посмотрим, шо в ём есть и как это сделано.
Здравствуйте, Ikemefula, Вы писали:
EP>>Да мне как-то всё равно — это же ты начал сравнивать количество поддерживаемых СУБД в полноценной ORM vs micro-ORM. I>Если тебе всё равно, то зачем же ты спрашивал ?
Ты начал мерятся количеством СУБД у решений имеющих разные весовые категории. Я тебе задал наводящие вопросы показывающие что охват возможностей совершенно разный.
I>Покажи полноценный ORM на с++, посмотрим, шо в ём есть и как это сделано.
Здравствуйте, Ikemefula, Вы писали:
I>Нужно что бы запросы были типизироваными.
И как ты это сделаешь не фиксируя связь таблицы и класса? А это совсем не всегда удобно — часто одни и те же данные хранятся в нескольких таблицах.
_>>Нуу расскажи как делается в .net маппинг в таблицу некого нашего класса. Который естественно там уже от кого-то библиотечного пронаследован и соответственно имеет набор полей, которые не надо сохранять в базу. I>POCO и в большинстве этого достаточно. Если чтото больше надо, то обычно атрибутами.
Здравствуйте, alex_public, Вы писали:
I>>Нужно что бы запросы были типизироваными.
_>И как ты это сделаешь не фиксируя связь таблицы и класса? А это совсем не всегда удобно — часто одни и те же данные хранятся в нескольких таблицах.
А я говорил что это всегда нужно ? Ты просил конкретную задачу — я дал. Если у тебя непойми что в базе, то ORM вообще не нужен.
_>>>Нуу расскажи как делается в .net маппинг в таблицу некого нашего класса. Который естественно там уже от кого-то библиотечного пронаследован и соответственно имеет набор полей, которые не надо сохранять в базу. I>>POCO и в большинстве этого достаточно. Если чтото больше надо, то обычно атрибутами.
_>Ну покажи пример то под моё описание...
Какое отношение маппинг имеет к С++ и деревьям выражений ?
Здравствуйте, Ikemefula, Вы писали:
I>А я говорил что это всегда нужно ? Ты просил конкретную задачу — я дал. Если у тебя непойми что в базе, то ORM вообще не нужен.
Ты говоришь что надо чтобы все запросы всегда были типизированы. Кстати, ещё интересно как реализуются типизированные с использованием своих функций (введённых в предыдущих sql запросах)...
I>Какое отношение маппинг имеет к С++ и деревьям выражений ?
Здравствуйте, alex_public, Вы писали:
_>Ты говоришь что надо чтобы все запросы всегда были типизированы. Кстати, ещё интересно как реализуются типизированные с использованием своих функций (введённых в предыдущих sql запросах)...
I>>Какое отношение маппинг имеет к С++ и деревьям выражений ?
_>Не знаю) Это ты мне скажи http://www.rsdn.ru/forum/philosophy/5367843
Здравствуйте, Ikemefula, Вы писали:
I>Ты говорил вот что — "маппинг в таблицу некого нашего класса"
I>В задаче, которую я показал, собственно указаный маппинг это 1% от всей работы. То есть, ни о чем — OR/M это много больше чем вот этот маппинг.
Ну так покажи как на .net'e делается хотя бы этот 1% работы... )))
M>>Вон, ассемблер — не чета всяким Сям — забыли?
Кто тебе сказал что его забыли? Реверс-инженерия тоже не в моде?
EP>Чтобы на ассемблере обогнать результат современных C++ компиляторов, надо очень сильно постараться
Дело даже не в скорости, иногда на С/C++ (D-подавно) нельзя сделать то что можно сделать на ASM.
Прелесть С/C++ его легкость интеграции с ASM, на D такое возможно?
Здравствуйте, nen777w, Вы писали:
EP>>Чтобы на ассемблере обогнать результат современных C++ компиляторов, надо очень сильно постараться N>Дело даже не в скорости, иногда на С/C++ (D-подавно) нельзя сделать то что можно сделать на ASM.
Само собой — в abstract machine model нет прямого аналога для каждой ASM фичи.
N>Прелесть С/C++ его легкость интеграции с ASM, на D такое возможно?
Здравствуйте, IID, Вы писали:
G>>> Сейчас спектр систем, где заработает код на C#, примерно такой же, как у java и у обоих гораздо шире, чем у C++. EP>>C++ работает и на десктопах, и на планшетах, и на телефонах (разве что кроме первых версий windows phone), и на 8-битных контролерах, и даже внутри javascript IID>чойта ? Там ОС это WinCE6.0R3, которая целиком C/C++. Прикладному нейтиву вход закрыли, да. Но это искусственное ограничение, и на язык не завязанное.
Речь была именно про прикладной код. То есть что использовать для создания кросс-платформенных приложений.
Заинтесовал меня один вопрос. А почему D никак не представлено в языковой пиписькомерке The Computer Language Benchmarks Game? Казалось бы, важная составляющая в продвижении любого языка программирвоания – доказать что вот с его-то помощью код можно писать компактнее, а скорость получить не хуже чем у оппонента, а тут, такой облом-с
Здравствуйте, kaa.python, Вы писали:
KP> А почему D никак не представлено в языковой пиписькомерке
Потому что те, кто в этом напрямую заинтересован, заняты пилением компилятора. (как вариант) Фактически, "мир Ди" — это Дижиталмарс (Уолтер + Александреску) и "все остальные". Последние занимаются Ди в виде хобби, что подразумевает занятие проектами, которые нравятся лично, а не которые являются "важной составляющей продвижения".
KP> ... а тут, такой облом-с
Ну а что удивительного? Ди — язык МОЩНЫЙ и при видимой простоте, требует неслабых мозговых возможностей для правильного использования фич (как ЛИСП, например). Поэтому из тех энтузазистов, которые тратят свободное время на Ди, мало кто может заявить "я знаю Ди досконально" — соотв. никто не берётся выступать за всех на публичных ресурсах.
Вот я тоже знаю про traits, mixins, ranges, templates, но не чувствую, что могу показать код, который бы явно доказывал преимущество Ди (хотя уверен, Ди на голову превосходит существующие языки) — это надо делать Уолтеру — хотя бы на уровне одностраничных примеров.
Здравствуйте, btn1, Вы писали:
B>Ну а что удивительного? Ди — язык МОЩНЫЙ и при видимой простоте, требует неслабых мозговых возможностей для правильного использования фич (как ЛИСП, например). Поэтому из тех энтузазистов, которые тратят свободное время на Ди, мало кто может заявить "я знаю Ди досконально" — соотв. никто не берётся выступать за всех на публичных ресурсах.
Erlang знают, Clojure знаютб Haskell знают, а D нет? Мне кажется, такое предположение выглядит не очень правдоподобным и причина в чем-то другом.
Здравствуйте, kaa.python, Вы писали:
KP>Erlang знают, Clojure знаютб Haskell знают, а D нет? Мне кажется, такое предположение выглядит не очень правдоподобным и причина в чем-то другом.
Здравствуйте, btn1, Вы писали:
B>Вы не пробовали читать ВЕСЬ комментарий?
Конечно пробовал. Краткий пересказ: D офигенно мощный и сложный язык для энтузиастов и двух перцев – авторов. Он на столько мощный, что его никто не знает и не решается запилить решения для пиписькомерки.
Ну как бы такая теория не внушает доверия хотя бы потому, что он явно не более сложный, комплексный, мощный и тыды и тыпы чем Lisp (Clojure не Лисп, но один из диалектов, как никак) или Хаскель. Оба из них редки, кроме энтузиастов мало кому вперлись, но в индексе участвуют.
Здравствуйте, kaa.python, Вы писали:
KP>Конечно пробовал. Краткий пересказ
Это всё тот же вырваный кусок, который вы отважно оспариваете. Ключ был чуть выше:
...и "все остальные". Последние занимаются Ди в виде хобби, что подразумевает занятие проектами, которые нравятся лично, а не которые являются "важной составляющей продвижения".
Подумайте, кому интересно переписывать скучные бенчмарки, когда можно заняться созданием грандиозных библиотек! Кстати, пару-тройку бенчей я всё же написал, потому что существующие показывали странные, слишком медленные результаты. Почему-то сейчас их нет (или это был другой ресурс?...). Не исключено, что Ди просто выкинули, потому что некому было делать рутину.
Здравствуйте, kaa.python, Вы писали:
KP>Erlang знают, Clojure знаютб Haskell знают, а D нет? Мне кажется, такое предположение выглядит не очень правдоподобным и причина в чем-то другом.
Кстати говоря, в случае D можно банально взять готовый код тестов на C и он практически без изменений заработает в виде D кода. И не лишь немного медленнее (а собственно это и измеряют там в основном) за счёт чуть худшего оптимизатора. Ну а потом уже можно посидеть над кодом, занимаясь приведением его к красивому виду. Но лично мне таким заниматься точно нет времени, да и вообще лень. Подозреваю что не только мне. )))
Здравствуйте, kaa.python, Вы писали:
KP>Заинтесовал меня один вопрос. А почему D никак не представлено в языковой пиписькомерке The Computer Language Benchmarks Game?
Он там был раньше, и на хороших позициях. А потом организаторы писькомерки его убрали.
The thing about that shootout is D used to be on there, until the maintainer of
the site removed it. He refuses to include D on the benchmarks.
...
It mostly boils down to reducing the amount of effort to keep the site up and
running.
The author has decided to keep only languages sufficiently important (as in
used) or sufficiently different from the other languages. D is not used enough
and it's too much similar to other languages (for speed reasons D entries were
very similar to C/C++ ones).
Здравствуйте, alex_public, Вы писали:
_>Кстати говоря, в случае D можно банально взять готовый код тестов на C и он практически без изменений заработает в виде D кода. И не лишь немного медленнее (а собственно это и измеряют там в основном) за счёт чуть худшего оптимизатора.
Если взять не DMD, a GDC или LDC, то разницы с Си не должно быть.
Здравствуйте, D. Mon, Вы писали:
DM>The author has decided to keep only languages sufficiently important (as in DM>used) or sufficiently different from the other languages.
О, да! По какому тогда критерию в этом списке соседствуют C#, C, C++ и Java? В чём отличие Ruby от JRuby? Что important автор нашёл в ATS (я за 20 лет НИ РАЗУ о таком не слышал!), кого там греет Rust, LISP?
Короче, это обычный чмошник, то ли проплаченный (см. наличие Go), то ли технически ущербный — не понимать отличия D от C#/C++ это вообще не понимать Ди.
В успокоение могу только сказать, что сайт очень удачно назван "писькомеркой", ибо никакого практического смысла не имеет — ну "порвал" интеловский фортран какие-нибудь Ruby — что, кто-то бросил RoR? Вот так же и Ди — даже в чём-то проигрывая "ассемюлеру с объектами", всё равно по-сути — перспективный язык и вытеснит шушару с рынка. Хороший язык просто не может не вызывать интерес, особенно видя стагнирующий, коммерческий C#.
Здравствуйте, kaa.python, Вы писали:
DM>>Он там был раньше, и на хороших позициях. А потом организаторы писькомерки его убрали.
KP>Интересно как. Дико странное решение
По-моему, там вообще последнее время сильно меньше языков и реализаций стало, чем было раньше.
Здравствуйте, btn1, Вы писали:
B>>> Что important автор нашёл в ATS (я за 20 лет НИ РАЗУ о таком не слышал!), DM>>А вот это напрасно (и больше говорит о вашей неосведомленности) B>Ерунда. Это говорит только о том, что владелец сайта выбирает языки от балды — нашёл какую-то маргинальщину, о которой не упоминают даже старпёры, а ты мне тут втыкаешь про осведомлённость! Даже про богом забытый Оккамл — и то говорят больше (правда, в свете F#), чем об этом АТС.
Какая разница, о чем больше говорят? Я говорю, что сам язык весьма интересный, и автор шутаута тоже так думает.
DM>> Функциональный язык... B>Сразу в реактор — мэйнстриму это фуфло не нужно. Хотя не, как раз для бенчей самое оно.
Он и императивный тоже, не беспокойтесь. И я вас огорчу: функциональщина уже давно сливается с мейнстримом, отворачиваться от нее — это уходить от мэйнстрима в отшельники-старперы. Все современные языки либо сразу функциональные, либо приобрели функциональные фишки за последние годы. Даже С++ вон лямбд нахватался.
Здравствуйте, D. Mon, Вы писали: DM>Какая разница, о чем больше говорят?
Большая. Если ты тратишь время на язык, который пусть даже скудно, но используют в мэйнстриме, это куда полезнее "интересного языка", про который не знают даже сами программисты. Можешь даже сделать опрос, сколько людей знают об АСТ и могут по памяти набросать на нём хотя бы пару строк (т.е. минимальный критерий, когда о языке можно говорить как о живом).
DM>И я вас огорчу: функциональщина уже давно сливается с мейнстримом
Если к запорожцу приделать закрылки, он не станет от этого самолётом. Парадигма либо нормальная и она сразу полностью адаптируется мэйнстримом (ООП), либо она шизанутая и от неё только откусываются отдельные полезные идеи (ФП, ЛП).
За всё время пузыря "ФП — это круто" я так и не увидел массового исхода на какой-нибудь F# (казалось бы, идеальное сочетание мощи .НЕТа и так расхваливаемого ФП). Мыслить функциями можно, но это слишком напряжная работа для мозга.
Здравствуйте, btn1, Вы писали:
DM>>Какая разница, о чем больше говорят?
B>Большая. Если ты тратишь время на язык, который пусть даже скудно, но используют в мэйнстриме, это куда полезнее "интересного языка", про который не знают даже сами программисты.
Вот только это не имеет отношения к принципам выбора языков для шутаута. Ну и само утверждение спорное, т.к. понятие "полезнее" можно по-разному определять. В изучении очередного кобола вряд ли много пользы.
Здравствуйте, D. Mon, Вы писали:
DM>Вот только это не имеет отношения к принципам выбора языков для шутаута.
Вот потому я и говорю, что "шутаут" что по набору языков, что по тестам — бесполезная писькомерка, просто буду надеяться, что Ди прорвётся самостоятельно.
DM> Ну и само утверждение спорное, т.к. понятие "полезнее" можно по-разному определять. В изучении очередного кобола вряд ли много пользы.
Вот поэтому и удивляет, что Ди (как очевидно намного лучшая замена сям/сипипям) был выкинут по безалаберной причине "автор устал". Выкинул бы маргинальщину — стало бы на порядок проще.
Здравствуйте, matumba, Вы писали:
M>DrDobbs обрадовал небольшой заметкой про использование языка D в таком крупном проекте, как Facebook.
D — не нужен.
Вот и Facebook вместо D написали Hack — статически типизированный PHP.
















 Перекуём баги на фичи!
Перекуём баги на фичи!