Здравствуйте, landerhigh, Вы писали:
L>Да нет, проблема возникает как рза, когда все вроде на одной волне. Просто один считает, что требование А — важно, другой считает, что она даже не заслуживает обсуждения, третьи хотят в архитектуру затащить вообще все, что могут представить и так далее. Сама возможность перейти от словесной перепалке к взвешенной метрике позволила бы по крайней мере наложить фильтр на дискуссию.
Метрика не поможет, т.к. она не решает исходную проблему — разные точки зрения на разработку в команде. Самое забавное, что это вообще не проблема. Напротив, это возможность эффективно раскидать задачи, чтобы никто не ушёл обиженным
При поставленном процессе разработке её стремятся не убрать а использовать по максимуму. Например, SkyDance расписывал как это делается в скраме
L>Почему мне это вообще интересно? Есть такая штука, как интуиция. Бывает, начинаешь делать некий сферический в вакууме модуль Х. Нарисовал квадратики, приступил к работе и интуитивно понимаешь, что решение, которое получается, некрасиво, хотя и показать этого не можешь.
А не проще будет разобраться, почему вообще интуиция "выстреливает" только на этапе написания кода?
L>Интуиция все же на чем-то основывается, поэтому, КМК, должна существовать возможность перехода к некой абстрактной модели, в которой некрасивости можно будет банально подсчитать по формуле. Например, слишком большое число состояний модуля, слишком большое количество входов/выходов, наличие непересечающихся областей ответственности и так далее.
Мозг человека насквозь прагматичен, за "красиво-некрасиво" скрывается банальное нежелание делать лишнюю работу — переписывать код, держать в голове лишние детали, вспоминать костыли через полгода спусти и т.п. и т.д.
Если мы отбросим блаватского, ноосферу и прочую торсионщину, то придётся признать что в работе подсознания нет никакой магии, оно исходит ровно из того же, что известно вам лично: из опыта решения похожих проблем, знания матчасти, понимания задачи и способности спрогнозировать дальнейшее развитие событий.
Первые два пункта формализовать не получится никак, следовательно полной формальной модели не будет. Не, если пойти на принцип, всё возможно, но затраты на составление настолько детальной модели будут (как минимум) сопоставимы с написанием кода.
Теперь посмотрим на оставшееся:
С "пониманием" всё непросто — поверхностная оценка недалеко уйдёт от квадратиков на бумаге, детальная — со всеми связями и зависимостями — снова будет практически неотличима от кода.
С прогнозированием всё ещё хуже. Во-первых, вам потребуется модель задачи из предыдущего пункта + возможные будущие требования. Во-вторых, придётся ввести оценочную функцию для каждого из элементов решения — вероятность + стоимость изменения для конкретного требования. В-третьих — попробовать перестроить текущую модель так, чтобы минимизировать стоимость реализации будущих требований. Каждый из пунктов тянет на полноценную докторскую, в особенности третий — это NP-полная задача сопоставимая по сложности с "пчёлы vs задача коммивояжёра".
Поскольку никакой магии в работе подсознания таки нет, то ответы нашей формальной модели ничем не будут отличаться от нашей интуиции — "чую, что дело бесовское, но обосновать не могу"(с). В общем, по соотношению затраты-выхлоп вся затея очень напоминает вот это
Всё, что тут можно сделать — это не пытаться промоделировать сложную проблему, а попробовать свести сложную задачу к чуть менее сложной. Тут всего два варианта и в любом из них формальной моделью всего и близко не пахнет.
Во-первых, можно снизить стоимость "лишней работы" или хотя бы сделать её предсказуемой — вокруг этого пляшут агилисты с TDD, тяжёлый Rup/MSF, и инстурменты разработки — статическая верификация/тесты/анализ кода etc.
Во-вторых, можно сделать так, чтобы подсознание эффективно работало ещё на стадии "квадратики на листе", т.е. найти способ однозначно и полноценно описать модель/требования на естественном языке. Насколько знаю, с этой стороны заходит только в DDD.
На практике, разумеется используются оба подхода, как правило — неосознанно, просто потому, что оно работает.
Здравствуйте, landerhigh, Вы писали: L>В последнее время меня все больше интересуют научные подходы к анализу сложности и стабильности программного решения. Причем, не столько "метрики сложности" вроде цикломатики или связности (или количества строк кода, не к ночи будет помянуто), а больше способы предварительной оценки. L>Накидайте ссылок, пожалуйста.
Я не встречал интересных ссылок по теме и даже особо не интересовался методами анализа решений, но разбирал сам процесс построения решений, думаю, ниже написанное вам пригодится.
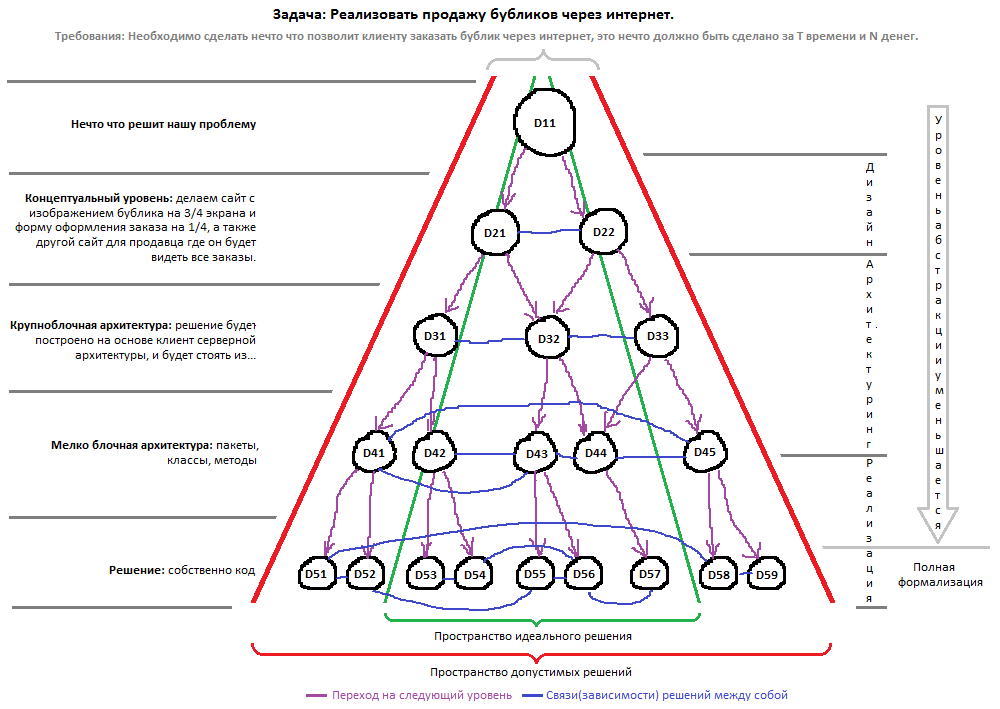
Итак, готовое решение некоторой задачи/проблемы можно представить в виде дерева, состоящего из более мелких(промежуточных) решений, навроде:
Создание решения это собственно построение этого дерева, "решение за решением"(образно можно представить что дерево растёт от корня, и когда все ветки достигают нижнего уровня — решение готово), но это не линейный процесс, некоторые ветки выходят(или могут выйти по мнению разработчиков) за рамки требований, что приводи к их откату и затем перестраиванию, а в худшем случае, и всех связанных с ними веток. Откат может быть небольшим(до предыдущего решения), но может быть и огромным, вплоть до корня.
На этой модели, кстати, можно показать отличия водопадного и итеративного подходов к разработке. Первый предписывает дереву равномерно расти сверху вниз не выходя за рамки требований, второй предписывает в начале как можно быстрей достичь нижнего уровня, даже ценой нарушения некоторых требований, затем расти/уменьшатся в ширь(в цикле перестраиваний), чтобы таки вписаться в рамки требований. L>К примеру, во многих случаях прозрачный и понятный переход от квадратиков на доске к построению мат. модели предлагаемой архитектуры с последующим расчетом неких показателей, идентифициющих "хорошесть" или "ужасность" решения в рамках определенных требований, вероятностей тех или иных событий, нам конкретно помог бы сэкономить тысячи человеко-часов и перевести архитектурные войны в более конструктивное русло дискуссий.
Проблема в том что не возможно однозначно сказать что какое-то из промежуточных решений(например решение D21), принятых при разработке, хорошее/плохое, до тех пор, пока решение задачи не будет _полностью_ готово. Потому что пока задача не решена, для этого не достаточно информации(она ещё не создана, её попросту не существует). Но "хорошесть" или "ужасность" решения можно предположить с некоторой вероятностью, основываясь на информации о текущем состоянии разработки и опыта использования подобного решения в подобных задачах, это пытаются реализовать разработчики аналитических, экспертных систем и прочих ИИ. L>Уже переворошил кучу в том числе научных работ, и такое ощущение, что изыскания по этой теме кончились в середине 80-х (или я не там ищу), да и затрагивали в основном уже написанный код.
ИМХО, они упёрлись в проблему "у нас нету штуковины способной учится и анализировать лучше чем человек" и бросили все силы на её решение.
или
Между тем,что я думаю,тем,что я хочу сказать,тем,что я,как мне кажется,говорю,и тем,что вы хотите услышать,тем,что как вам кажется,вы слышите,тем,что вы понимаете,стоит десять вариантов возникновения непонимания.Но всё-таки давайте попробуем...(Э.Уэллс)
Спасибо за сообщение. В принципе, все это мне известно, но было полезно взглянуть на вопрос в комплексе.
Как раз на прошлой неделе смотрел видео с презентации Гапертона на Software People. Его доклад во многом пересекается с тем что вы написали. В частности о том, что "проектирование это процесс формулирования и проверки гипотез". В этом плане (цитата): "Прототипы, Дизайн-ревью, Код-ревью, Тесты -- вляются не«практиками», а
средствами проверки«гипотез»".
Очень советую посмотреть этот доклад: http://www.youtube.com/watch?v=yzIRO85SO6g Слайды: http://www.slideshare.net/gladerru/gaperton-software-people-2012
Здравствуйте, landerhigh, Вы писали:
L>Бизнес велью к вопросу не имеет никакого отношения. Считайте, что все фичи имеют одинаковое значение.
Тогда содержательного разговора не получится.
Потому что один говорит "давайте втащим абстрактный DAL через ORM для того, чтобы можно было легко заменить СУБД с MS SQL на Oracle".
А другой говорит "требования заменяемости СУБД в ТЗ не было, поэтому давайте прекратим страдать фигнёй и сделаем анемик, в котором максимально легко добавлять новые атрибуты к сущностям".
Первый парирует "требования добавляемости новых атрибутов к сущностям в ТЗ тоже не было, поэтому давайте прекратим страдать фигнёй" и т.п.
Дело не в том, что одно из решений красивее другого. Дело в том, что они покрывают различные требования. Без придания ценности отдельным фичам вы не сможете рассудить такой спор.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
1. АлексКаб нарисовал что-то вроде пирамидки Сагатовского — метод анализа проблем в системном анализе.
2. Можно обмерить увсе, начиная от диграмм use-case до конечного кода (даже код виртуальной машины — этим как раз профайлеры занимаются)
Метрики можно придумать самые разные — не суть. Суть — имеем вектор координат в некотором многомерном пространстве.
3. Далее возникает вопрос, что с этим вектором делать. Вернее — их много векторов — по разным проектам надо такие вектора собрать.
4. Далее можно юзать Теорию принятия решений — при многих критериях.
Или привлечь экспертов для сравнительных оценок по какому-нить методу экспертных оценок.
Например, метод анализа иерархий.
При множестве экспертов потребуется провести процедуру согласования экспертной информации.
5. На основании экспертной информации можно построить функции принадлежности нечетких множеств — понеслись нечеткие оценки. Лингвистические, конечно.
6. Вектор можно подать на вход нейронной сети. Только опять же нечеткой нейронной сети, например, Ванга-Менделя.
На выходе такой сети — значение лингвистической переменной. Что-то вроде " высокая сложность".
В общем, что делать с вектором метрик — это как раз исследовательский проект.
Но можно получить РЕЗУЛЬТАТ...
Если не жаль времени и интересно...
Таким образом, начинать надо с определения набора полезных метрик — это само по-себе — исследование.
Хочешь быть счастливым — будь им!
Без булдырабыз!!!
Здравствуйте, landerhigh, Вы писали:
L>Элементарно. То, что очевидно одному, совсем не очевидно другому. Прийти к общему знаменателю бывает чрезвычайно трудно.
Ну так это выглядит как проблема из "человеческой плоскости" — разрыв в квалификации, провал в коммуникативных навыках — способности конструктивно обсуждать различия во взглядах на проблему и находить этот самый знаменатель. Я сомневаюсь, что это можно решить техническими средствами, применив некую научную наработку из области анализа сложности.
Здравствуйте, landerhigh, Вы писали:
L>Это очень приземленный пример. У меня интуиция прокачана до уровня, что уже на этапе планирования безошибочно определяю вполне рабочие предложения, но с которыми мы огребем серьезных проблем. Проблема в том, что аргументировать это могу далеко не всегда. О чем и сыр-бор, хочется иметь возможность использовать формализованный подход при необходимости.
"Понимаю но не могу объяснить" это близкий родственник "не понимаю". Потому что легко в таком положении поддаться ошибочным позывам.
Попробуй точно сформулировать какие проблемы могут быть в тех или иных решениях. Потом опиши почему они возникнут. На этом этапе можно притянуть формальные метрики, но обычно уже нет необходимости.
Здравствуйте, landerhigh, Вы писали:
L>Накидайте ссылок, пожалуйста.
Сложность и стабильность программного обеспечения относиться к слабо формализуемым понятиям, особенно с учетом возможного изменения требований.
Построения достаточно полной мат. модели и вычисления по ней числового параметра, который характеризует качество того или иного решения — очень сложно.
Могу предложить подойти к проблеме немного с другой стороны.
Есть такая область знаний, которая называется "Теория принятия решений". Принятие решения — это процесс выбора альтернатив, имеющий целью достижение осознаваемого результата.
Для ознакомления можно посмотреть, книгу
Блюмин С.Л., Шуйкова И.А.
Модели и методы принятия решений в условиях неопределенности. — Липецк: ЛЭГИ, 2001. — 138 с.
Математика там несложная, имеются примеры.
Попробую привести простой пример использования данного подхода.
Пусть у нас есть группа архитекторов ПО, готовая к тысячам часов архитектурных войн. Пусть они предложили набор альтернативных архитектур.
Теперь каждый эксперт независимо составляет матрицу предпочтений для альтернатив. Т.е. ставит каждой паре альтернатив число от 0 до 1, которая "меряет" его уверенность в том, что 1-ю архитектуру нужно предпочесть 2-ой.
Все, архитектурные войны отменяются, в действие вступает алгоритм, который по набору матриц и правилам нечеткой логики выдает степень предпочтения (число от 0 до 1) для каждой альтернативы.
Осталось только выбрать то решение, которому соответствует максимальное число.
Есть также процедуры выявления факта несогласованности экспертов.
Также рассматриваются варианты, когда эксперты имеют веса, либо между ними задано отношение нечеткого предпочтения.
Безусловно, что такой подход основан на том, что эксперты — это действительно эксперты в своей области.
Здравствуйте, landerhigh, Вы писали:
L>Да нет, проблема возникает как рза, когда все вроде на одной волне. Просто один считает, что требование А — важно, другой считает, что она даже не заслуживает обсуждения, третьи хотят в архитектуру затащить вообще все, что могут представить и так далее. Сама возможность перейти от словесной перепалке к взвешенной метрике позволила бы по крайней мере наложить фильтр на дискуссию.
Ну так это, опять же, не техническая проблема, а проблема несовпадения понимания целей и value участниками процесса. Нужность той или иной фитчи оценивается из понимания целей проект. Если возникает спор, значит понимание разное. Вполне вероятно, что эти цели явно не выявлены и неявно подразумеваются оппонентами.
L>Кроме того, индикатор переусложненности архитектуры также мог бы основываться на каких-либо нормализованных входных данных.
"Переусложенность" архитектуры — это абстракция.
Ты что-то посчитаешь и получишь некое число, что ты потом с ним будешь делать?
(Можно теперь спорить о том, является ли это число слишком большим или нет )
L>Почему мне это вообще интересно? Есть такая штука, как интуиция. Бывает, начинаешь делать некий сферический в вакууме модуль Х. Нарисовал квадратики, приступил к работе и интуитивно понимаешь, что решение, которое получается, некрасиво, хотя и показать этого не можешь. Интуиция все же на чем-то основывается, поэтому, КМК, должна существовать возможность перехода к некой абстрактной модели, в которой некрасивости можно будет банально подсчитать по формуле. Например, слишком большое число состояний модуля, слишком большое количество входов/выходов, наличие непересечающихся областей ответственности и так далее.
Я думаю, что ты решаешь не ту проблему. Я вижу проблему в том, как у вас поставлена работа с требованиями и problem solving.
Трудности с архитектурой — это лишь симптом, а не проблема.
Здравствуйте, landerhigh, Вы писали:
L>Здравствуйте, gandjustas, Вы писали:
G>>Здравствуйте, landerhigh, Вы писали:
L>>>Да нет, проблема возникает как рза, когда все вроде на одной волне. Просто один считает, что требование А — важно, другой считает, что она даже не заслуживает обсуждения, третьи хотят в архитектуру затащить вообще все, что могут представить и так далее. Сама возможность перейти от словесной перепалке к взвешенной метрике позволила бы по крайней мере наложить фильтр на дискуссию. G>>Это уже давно и эффективно решается введением параметра business value, за который обычно отвечают аналитики, составляющие требования. Если требования не приоретизированы адекватно, то вместо хорошего продукта получается бесполезный набор фич.
L>Бизнес велью к вопросу не имеет никакого отношения.
Имеет, всегда, даже если вы этого не хотите или не знаете.
L>Считайте, что все фичи имеют одинаковое значение.
Так не бывает. Всегда можно упорядочить фичи по важности.
Для начала вам всегда требуется выбрать тот набор требований\фич\сценариев, которые необходимо покрыть вашим решением. Когда такой набор сформирован, то стандартные метрики, типа Mantainability Index, помогают оценить качество того что сделано.
Здравствуйте, landerhigh, Вы писали:
L>Все это, конечно, хорошо, но к вопросу не имеет ни малейшего отношения. Задача не в том, как разруливать спор "а давайте сделаем то, а давайте это". Набор фич уже есть, согласован и подлежит реализации. Вопрос состоит в том, как на этапе планирования крупноблочной архитектуры выявлять переусложненные модули, модули со слишком большой областью ответствености, повторение функциональности и так далее.
На этапе планирования крупноблочной архитектуры всё, что вы можете увидеть — это крупные блоки.
Я, если честно, не понимаю, как вы выявите переусложнённость модуля до того, как этот модуль будет описан.
Если я рисую квадратик на доске и говорю: "это — модуль кэширования", и оппонент рисует квадратик и говорит "это — модуль кэширования", то совершенно непонятно, у кого из нас решение переусложнено.
Если у оппонента нет "модуля кэширования", то моё решение переусложнено. При условии, что оно реализует те же фичи.
Если вы получили два одинаковых набора квадратиков, то крупноблочная архитектура выбрана. Начинайте проектировать модули — точно так же, в виде квадратиков. Считаете квадратики — получаете меру сложности.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
В последнее время меня все больше интересуют научные подходы к анализу сложности и стабильности программного решения. Причем, не столько "метрики сложности" вроде цикломатики или связности (или количества строк кода, не к ночи будет помянуто), а больше способы предварительной оценки.
К примеру, во многих случаях прозрачный и понятный переход от квадратиков на доске к построению мат. модели предлагаемой архитектуры с последующим расчетом неких показателей, идентифициющих "хорошесть" или "ужасность" решения в рамках определенных требований, вероятностей тех или иных событий, нам конкретно помог бы сэкономить тысячи человеко-часов и перевести архитектурные войны в более конструктивное русло дискуссий.
Уже переворошил кучу в том числе научных работ, и такое ощущение, что изыскания по этой теме кончились в середине 80-х (или я не там ищу), да и затрагивали в основном уже написанный код.
L>К примеру, во многих случаях прозрачный и понятный переход от квадратиков на доске к построению мат. модели предлагаемой архитектуры с последующим расчетом неких показателей, идентифициющих "хорошесть" или "ужасность" решения в рамках определенных требований, вероятностей тех или иных событий, нам конкретно помог бы сэкономить тысячи человеко-часов и перевести архитектурные войны в более конструктивное русло дискуссий.
А на чем именно терялось время и что есть архитектурные войны в вашем случае. Есть ощущения, что не в том направлении копаешь.
Здравствуйте, 0x7be, Вы писали:
L>>К примеру, во многих случаях прозрачный и понятный переход от квадратиков на доске к построению мат. модели предлагаемой архитектуры с последующим расчетом неких показателей, идентифициющих "хорошесть" или "ужасность" решения в рамках определенных требований, вероятностей тех или иных событий, нам конкретно помог бы сэкономить тысячи человеко-часов и перевести архитектурные войны в более конструктивное русло дискуссий. 0>А на чем именно терялось время и что есть архитектурные войны в вашем случае. Есть ощущения, что не в том направлении копаешь.
Элементарно. То, что очевидно одному, совсем не очевидно другому. Прийти к общему знаменателю бывает чрезвычайно трудно.
Здравствуйте, 0x7be, Вы писали:
0>Здравствуйте, landerhigh, Вы писали:
L>>Элементарно. То, что очевидно одному, совсем не очевидно другому. Прийти к общему знаменателю бывает чрезвычайно трудно. 0>Ну так это выглядит как проблема из "человеческой плоскости" — разрыв в квалификации, провал в коммуникативных навыках — способности конструктивно обсуждать различия во взглядах на проблему и находить этот самый знаменатель. Я сомневаюсь, что это можно решить техническими средствами, применив некую научную наработку из области анализа сложности.
Да нет, проблема возникает как рза, когда все вроде на одной волне. Просто один считает, что требование А — важно, другой считает, что она даже не заслуживает обсуждения, третьи хотят в архитектуру затащить вообще все, что могут представить и так далее. Сама возможность перейти от словесной перепалке к взвешенной метрике позволила бы по крайней мере наложить фильтр на дискуссию.
Кроме того, индикатор переусложненности архитектуры также мог бы основываться на каких-либо нормализованных входных данных.
Почему мне это вообще интересно? Есть такая штука, как интуиция. Бывает, начинаешь делать некий сферический в вакууме модуль Х. Нарисовал квадратики, приступил к работе и интуитивно понимаешь, что решение, которое получается, некрасиво, хотя и показать этого не можешь. Интуиция все же на чем-то основывается, поэтому, КМК, должна существовать возможность перехода к некой абстрактной модели, в которой некрасивости можно будет банально подсчитать по формуле. Например, слишком большое число состояний модуля, слишком большое количество входов/выходов, наличие непересечающихся областей ответственности и так далее.
Здравствуйте, landerhigh, Вы писали: L>Почему мне это вообще интересно? Есть такая штука, как интуиция. Бывает, начинаешь делать некий сферический в вакууме модуль Х. Нарисовал квадратики, приступил к работе и интуитивно понимаешь, что решение, которое получается, некрасиво, хотя и показать этого не можешь. Интуиция все же на чем-то основывается, поэтому, КМК, должна существовать возможность перехода к некой абстрактной модели, в которой некрасивости можно будет банально подсчитать по формуле. Например, слишком большое число состояний модуля, слишком большое количество входов/выходов, наличие непересечающихся областей ответственности и так далее.
На индивидуальном опыте.
Между тем,что я думаю,тем,что я хочу сказать,тем,что я,как мне кажется,говорю,и тем,что вы хотите услышать,тем,что как вам кажется,вы слышите,тем,что вы понимаете,стоит десять вариантов возникновения непонимания.Но всё-таки давайте попробуем...(Э.Уэллс)
Здравствуйте, landerhigh, Вы писали:
L>Да нет, проблема возникает как рза, когда все вроде на одной волне. Просто один считает, что требование А — важно, другой считает, что она даже не заслуживает обсуждения, третьи хотят в архитектуру затащить вообще все, что могут представить и так далее. Сама возможность перейти от словесной перепалке к взвешенной метрике позволила бы по крайней мере наложить фильтр на дискуссию.
Это уже давно и эффективно решается введением параметра business value, за который обычно отвечают аналитики, составляющие требования. Если требования не приоретизированы адекватно, то вместо хорошего продукта получается бесполезный набор фич.
L>Почему мне это вообще интересно? Есть такая штука, как интуиция. Бывает, начинаешь делать некий сферический в вакууме модуль Х. Нарисовал квадратики, приступил к работе и интуитивно понимаешь, что решение, которое получается, некрасиво, хотя и показать этого не можешь. Интуиция все же на чем-то основывается, поэтому, КМК, должна существовать возможность перехода к некой абстрактной модели, в которой некрасивости можно будет банально подсчитать по формуле. Например, слишком большое число состояний модуля, слишком большое количество входов/выходов, наличие непересечающихся областей ответственности и так далее.
Оценивать архитектуру безотносительно требований нет смысла. Если есть конкретные требования, то на любой элемент решения можно тыкнуть пальцем и спросить зачем он нужен и насколько он приближает к решению задачи.
Здравствуйте, landerhigh, Вы писали: L>Кроме того, индикатор переусложненности архитектуры также мог бы основываться на каких-либо нормализованных входных данных.
я предлагаю качеством архитектуры называть число, которое можно определить по статистике изменений кода. Посчитайте сколько в среднем мест в коде нужно поменять, если вы хотите поменять только одну вещь. Вот эта чиселка и может сказать о качестве архитетуры и даже позволит сравнивать приложения по качеству кода между собой.
Здравствуйте, landerhigh, Вы писали:
L>Элементарно. То, что очевидно одному, совсем не очевидно другому. Прийти к общему знаменателю бывает чрезвычайно трудно.
Почему бы не решить это разделением ответственности?
Здравствуйте, landerhigh, Вы писали:
L>Почему мне это вообще интересно? Есть такая штука, как интуиция. Бывает, начинаешь делать некий сферический в вакууме модуль Х. Нарисовал квадратики, приступил к работе и интуитивно понимаешь, что решение, которое получается, некрасиво, хотя и показать этого не можешь. Интуиция все же на чем-то основывается, поэтому, КМК, должна существовать возможность перехода к некой абстрактной модели, в которой некрасивости можно будет банально подсчитать по формуле. Например, слишком большое число состояний модуля, слишком большое количество входов/выходов, наличие непересечающихся областей ответственности и так далее.
Это то как раз не интуиция а вполне понятные метрики.
Здравствуйте, gandjustas, Вы писали:
G>Здравствуйте, landerhigh, Вы писали:
L>>Да нет, проблема возникает как рза, когда все вроде на одной волне. Просто один считает, что требование А — важно, другой считает, что она даже не заслуживает обсуждения, третьи хотят в архитектуру затащить вообще все, что могут представить и так далее. Сама возможность перейти от словесной перепалке к взвешенной метрике позволила бы по крайней мере наложить фильтр на дискуссию. G>Это уже давно и эффективно решается введением параметра business value, за который обычно отвечают аналитики, составляющие требования. Если требования не приоретизированы адекватно, то вместо хорошего продукта получается бесполезный набор фич.
Бизнес велью к вопросу не имеет никакого отношения. Считайте, что все фичи имеют одинаковое значение.
Здравствуйте, __kot2, Вы писали:
__>Здравствуйте, landerhigh, Вы писали: L>>Кроме того, индикатор переусложненности архитектуры также мог бы основываться на каких-либо нормализованных входных данных. __>я предлагаю качеством архитектуры называть число, которое можно определить по статистике изменений кода. Посчитайте сколько в среднем мест в коде нужно поменять, если вы хотите поменять только одну вещь. Вот эта чиселка и может сказать о качестве архитетуры и даже позволит сравнивать приложения по качеству кода между собой.
Я что-то подобное давно применяю, называю правило "what if". Для прикидки гибкости решения. Интересно, можно ли подобное формализовать.
Здравствуйте, 0x7be, Вы писали:
0>Здравствуйте, landerhigh, Вы писали:
L>>Да нет, проблема возникает как рза, когда все вроде на одной волне. Просто один считает, что требование А — важно, другой считает, что она даже не заслуживает обсуждения, третьи хотят в архитектуру затащить вообще все, что могут представить и так далее. Сама возможность перейти от словесной перепалке к взвешенной метрике позволила бы по крайней мере наложить фильтр на дискуссию. 0>Ну так это, опять же, не техническая проблема, а проблема несовпадения понимания целей и value участниками процесса. Нужность той или иной фитчи оценивается из понимания целей проект. Если возникает спор, значит понимание разное. Вполне вероятно, что эти цели явно не выявлены и неявно подразумеваются оппонентами.
Вот и я о чем. Я о Фоме, а ты о Ереме.
Еще раз — важность фич не обсуждается. Если угодно, они все одинаково важны.
Обсуждается вопрос планирования и реализации этих фич с как можно более ранним отсевом предложений сделать холодильник и пылесос одним устройством.
L>>Кроме того, индикатор переусложненности архитектуры также мог бы основываться на каких-либо нормализованных входных данных. 0>"Переусложенность" архитектуры — это абстракция. 0>Ты что-то посчитаешь и получишь некое число, что ты потом с ним будешь делать?
Смотря какой смысл в это число вкладывать. Например, число зон ответственности модуля. Число непересекающихся зон ответственности. Пересечение ответственности между модулями
0>(Можно теперь спорить о том, является ли это число слишком большим или нет )
L>>Почему мне это вообще интересно? Есть такая штука, как интуиция. Бывает, начинаешь делать некий сферический в вакууме модуль Х. Нарисовал квадратики, приступил к работе и интуитивно понимаешь, что решение, которое получается, некрасиво, хотя и показать этого не можешь. Интуиция все же на чем-то основывается, поэтому, КМК, должна существовать возможность перехода к некой абстрактной модели, в которой некрасивости можно будет банально подсчитать по формуле. Например, слишком большое число состояний модуля, слишком большое количество входов/выходов, наличие непересечающихся областей ответственности и так далее. 0>Я думаю, что ты решаешь не ту проблему. Я вижу проблему в том, как у вас поставлена работа с требованиями и problem solving.
Не надо ничего за нас додумывать, окей? Если по теме нечего сказать, то проходи мимо.
Мне интересно выделенное, свою интуицию всем не одолжишь.
0>Трудности с архитектурой — это лишь симптом, а не проблема.
Именно что симптом. Чтобы вылечить проблему, хочется понять, существует ли в принципе возможность формального обоснования архитектурного решения на этапе его планирования, выходящая за рамки разговора у доски
S>Метрика не поможет, т.к. она не решает исходную проблему — разные точки зрения на разработку в команде. Самое забавное, что это вообще не проблема. Напротив, это возможность эффективно раскидать задачи, чтобы никто не ушёл обиженным
Можешь считать, что этой проблемы не существует. Вся команда стоит у доски, чешет репу и хором говорит, что решение вроде хорошее, но что-то не так.
S>При поставленном процессе разработке её стремятся не убрать а использовать по максимуму. Например, SkyDance расписывал как это делается в скраме
Я и сам могу уже трехтомник о скраме написать. А воз и ныне там.
S>
L>>Почему мне это вообще интересно? Есть такая штука, как интуиция. Бывает, начинаешь делать некий сферический в вакууме модуль Х. Нарисовал квадратики, приступил к работе и интуитивно понимаешь, что решение, которое получается, некрасиво, хотя и показать этого не можешь. S>А не проще будет разобраться, почему вообще интуиция "выстреливает" только на этапе написания кода?
Это просто пример. Она выстреливает всегда, просто на этапе кодирования косяки банально выясняются на примере. Когда говорим о более абстрактных вещах, без применения каких-либо формальных метрик обосновывать бывает нечем.
L>>Интуиция все же на чем-то основывается, поэтому, КМК, должна существовать возможность перехода к некой абстрактной модели, в которой некрасивости можно будет банально подсчитать по формуле. Например, слишком большое число состояний модуля, слишком большое количество входов/выходов, наличие непересечающихся областей ответственности и так далее.
S>Если мы отбросим блаватского, ноосферу и прочую торсионщину, то придётся признать что в работе подсознания нет никакой магии, оно исходит ровно из того же, что известно вам лично: из опыта решения похожих проблем, знания матчасти, понимания задачи и способности спрогнозировать дальнейшее развитие событий.
S>Первые два пункта формализовать не получится никак, следовательно полной формальной модели не будет. Не, если пойти на принцип, всё возможно, но затраты на составление настолько детальной модели будут (как минимум) сопоставимы с написанием кода.
S>Теперь посмотрим на оставшееся: S>С "пониманием" всё непросто — поверхностная оценка недалеко уйдёт от квадратиков на бумаге, детальная — со всеми связями и зависимостями — снова будет практически неотличима от кода.
Если поверхностная оценка позволяет принять решение на ее основе, то это уже будет очень и очень хорошо. Рисовать все квадратики заранее оставим апологетам RUP.
S>С прогнозированием всё ещё хуже. Во-первых, вам потребуется модель задачи из предыдущего пункта + возможные будущие требования. Во-вторых, придётся ввести оценочную функцию для каждого из элементов решения — вероятность + стоимость изменения для конкретного требования. В-третьих — попробовать перестроить текущую модель так, чтобы минимизировать стоимость реализации будущих требований. Каждый из пунктов тянет на полноценную докторскую, в особенности третий — это NP-полная задача сопоставимая по сложности с "пчёлы vs задача коммивояжёра".
А вот это уже интересно.
На самом деле некие признаки формальной модели вырисовываются. Но судя по имеющимся материалам, это и правда на несколько докторских тянет.
Здравствуйте, landerhigh, Вы писали:
L>Не надо ничего за нас додумывать, окей? Если по теме нечего сказать, то проходи мимо.
Я считаю, что я говорю по теме.
Впрочем, видимо я и правда пойду.
Здравствуйте, landerhigh, Вы писали:
L>Можешь считать, что этой проблемы не существует. Вся команда стоит у доски, чешет репу и хором говорит, что решение вроде хорошее, но что-то не так.
Согласитесь, в этом случае проблема на 1000% состоит не в отсутствии формальной метрики Я бы поставил на то, что модель на доске не покрывает всех сценариев или недостаточно проста в реализации. Если угадал — никакая формальная метрика тут не поможет: проблема — не в функции оценки, а в анализе входных данных. Соответственно, копать надо в эту сторону.
L>Я и сам могу уже трехтомник о скраме написать. А воз и ныне там.
Так никто и не говорил что скрам идеален. По ссылке — весьма неплохая методика оценки входных требований, которая работает даже если вы не используете скрам в целом. Ну, или не работает, это как повезёт
S>>А не проще будет разобраться, почему вообще интуиция "выстреливает" только на этапе написания кода? L>Это просто пример. Она выстреливает всегда, просто на этапе кодирования косяки банально выясняются на примере. Когда говорим о более абстрактных вещах, без применения каких-либо формальных метрик обосновывать бывает нечем.
С абстрактными вещами проще бороться с помощью анализа требований — стараться не допускать, чтобы на дизайн влияли сиюминутные требования, которые могут легко поменяться в будущем.
С выявлением косяков на этапе кодирования — представлением сценариев использования в виде вызовов методов вашего API. Получим разделение функционала на куски с ограниченной ответственностью. Их написать и поддерживать — гораздо проще, чем монолитный кусок кода.
S>>С "пониманием" всё непросто — поверхностная оценка недалеко уйдёт от квадратиков на бумаге, детальная — со всеми связями и зависимостями — снова будет практически неотличима от кода. L>Если поверхностная оценка позволяет принять решение на ее основе, то это уже будет очень и очень хорошо. Рисовать все квадратики заранее оставим апологетам RUP.
Тогда вам нужно вносить в модель только значимые требования, иначе всякая мелочёвка перетянет одеяло на себя. Если такой способ разделения требований есть — достаточно самих квадратиков, формальная оценка тут не поможет. Если нет — тем более: мусор на входе — мусор на выходе.
S>>Каждый из пунктов тянет на полноценную докторскую, в особенности третий — это NP-полная задача сопоставимая по сложности с "пчёлы vs задача коммивояжёра". L>А вот это уже интересно. L>На самом деле некие признаки формальной модели вырисовываются. Но судя по имеющимся материалам, это и правда на несколько докторских тянет.
Ну да, по трудоёмкости это будет тот же код. Только без собственно кода.
Здравствуйте, landerhigh, Вы писали:
L>В последнее время меня все больше интересуют научные подходы к анализу сложности и стабильности программного решения. Причем, не столько "метрики сложности" вроде цикломатики или связности (или количества строк кода, не к ночи будет помянуто), а больше способы предварительной оценки.
L>К примеру, во многих случаях прозрачный и понятный переход от квадратиков на доске к построению мат. модели предлагаемой архитектуры с последующим расчетом неких показателей, идентифициющих "хорошесть" или "ужасность" решения в рамках определенных требований, вероятностей тех или иных событий, нам конкретно помог бы сэкономить тысячи человеко-часов и перевести архитектурные войны в более конструктивное русло дискуссий.
L>Уже переворошил кучу в том числе научных работ, и такое ощущение, что изыскания по этой теме кончились в середине 80-х (или я не там ищу), да и затрагивали в основном уже написанный код.
L>Накидайте ссылок, пожалуйста.
У меня сложилось впечатление, что метрики измерют только сами метрики, а как эти измеренные значения относятся к сложности программы одному богу известно. Ну не поддается воображение программиста сухой статистике, ну и ладно. Хотя можно применить принцип забивания гвоздей, всех заставить писать единообразно. Например, долой все программы с нечетным количеством строк кода !!! Тоже своего рода метрика, можно измерить и подискутировать что лучше листинги с четным и нечетным количеством строчек?
Здравствуйте, Sinix, Вы писали:
S>Здравствуйте, landerhigh, Вы писали:
L>>Можешь считать, что этой проблемы не существует. Вся команда стоит у доски, чешет репу и хором говорит, что решение вроде хорошее, но что-то не так. S>Согласитесь, в этом случае проблема на 1000% состоит не в отсутствии формальной метрики Я бы поставил на то, что модель на доске не покрывает всех сценариев или недостаточно проста в реализации. Если угадал — никакая формальная метрика тут не поможет: проблема — не в функции оценки, а в анализе входных данных. Соответственно, копать надо в эту сторону.
Нет, считаем, что модель на доске покрывает все сценарии. Грабли начинаются несколько позже.
L>>Я и сам могу уже трехтомник о скраме написать. А воз и ныне там. S>Так никто и не говорил что скрам идеален. По ссылке — весьма неплохая методика оценки входных требований, которая работает даже если вы не используете скрам в целом. Ну, или не работает, это как повезёт
В принципе, при правильном подходе скрам позволяет избежать многих проблем. Косяки в архитектуре высшего уровня особенно больно ударяют там, где проект приходится резать на части и реализовывать разными командами. При правильном применении скрама и регулярных scrum of scrum архитектуру можно уточнять итеративно, на основе обратной связи от команд. Это требует определенных затрат на организацию и поддержание процесса.
S>>>А не проще будет разобраться, почему вообще интуиция "выстреливает" только на этапе написания кода? L>>Это просто пример. Она выстреливает всегда, просто на этапе кодирования косяки банально выясняются на примере. Когда говорим о более абстрактных вещах, без применения каких-либо формальных метрик обосновывать бывает нечем.
S>С абстрактными вещами проще бороться с помощью анализа требований — стараться не допускать, чтобы на дизайн влияли сиюминутные требования, которые могут легко поменяться в будущем.
Считаем, что требования не меняются. Речь идет о граблях, когда изначально модули неправильно спланировали, заложили слишком много или мало отвественности и так далее.
S>>>Каждый из пунктов тянет на полноценную докторскую, в особенности третий — это NP-полная задача сопоставимая по сложности с "пчёлы vs задача коммивояжёра". L>>А вот это уже интересно. L>>На самом деле некие признаки формальной модели вырисовываются. Но судя по имеющимся материалам, это и правда на несколько докторских тянет. S>Ну да, по трудоёмкости это будет тот же код. Только без собственно кода.
Не обязательно полностью формализовывать модель. Но во многих случаях иметь возможность базовой формальной проверки выбранной модели до перехода к собственно разработки помогло бы очень сильно.
Здравствуйте, gandjustas, Вы писали:
L>>Бизнес велью к вопросу не имеет никакого отношения. G>Имеет, всегда, даже если вы этого не хотите или не знаете.
Не имеет. Нужно реализовать вообще все фичи. Вопрос в том, как избежать ошибок на этапе планирования крупноблочной архитектуры.
L>>Считайте, что все фичи имеют одинаковое значение. G>Так не бывает. Всегда можно упорядочить фичи по важности.
Здравствуйте, Sinclair, Вы писали:
S>Здравствуйте, landerhigh, Вы писали:
L>>Бизнес велью к вопросу не имеет никакого отношения. Считайте, что все фичи имеют одинаковое значение. S>Тогда содержательного разговора не получится.
Еще раз — все фичи имеют одинаковое значение
S>Потому что один говорит "давайте втащим абстрактный DAL через ORM для того, чтобы можно было легко заменить СУБД с MS SQL на Oracle". S>А другой говорит "требования заменяемости СУБД в ТЗ не было, поэтому давайте прекратим страдать фигнёй и сделаем анемик, в котором максимально легко добавлять новые атрибуты к сущностям". S>Первый парирует "требования добавляемости новых атрибутов к сущностям в ТЗ тоже не было, поэтому давайте прекратим страдать фигнёй" и т.п.
S>Дело не в том, что одно из решений красивее другого. Дело в том, что они покрывают различные требования. Без придания ценности отдельным фичам вы не сможете рассудить такой спор.
Все это, конечно, хорошо, но к вопросу не имеет ни малейшего отношения. Задача не в том, как разруливать спор "а давайте сделаем то, а давайте это". Набор фич уже есть, согласован и подлежит реализации. Вопрос состоит в том, как на этапе планирования крупноблочной архитектуры выявлять переусложненные модули, модули со слишком большой областью ответствености, повторение функциональности и так далее.
AC>Я не встречал интересных ссылок по теме и даже особо не интересовался методами анализа решений, но разбирал сам процесс построения решений, думаю, ниже написанное вам пригодится.
В дополнение к этому я хочу посоветовать прочитать книгу: Буч Г. Объектно-ориентированный анализ и проектирование.
Здравствуйте, landerhigh, Вы писали:
L>Элементарно. То, что очевидно одному, совсем не очевидно другому. Прийти к общему знаменателю бывает чрезвычайно трудно.
Я думаю это не имеет никакого отношения к ИТ. На примере, два кандидат имеют подготовку : структуры данных 1000 И 5000 часов, аргоритмы 1000 и 5000 часов, работали на одной и том же проекте но разное время, но первый имеет опыт асинхронного, многопоточного, UI + попробовал доп язык джаваскрипт, а второй вместо этого занимался архитектурой приложения и управлением командой. У первого опыт 3 года, у второго — 12 лет.
Вопрос — кто из них быстрее поймет функциональное программирование, хаскель тот же, и почему ?
Второй вопрос — кто из них быстрее и качественее напишет какой нибудь актуальный и сложный алгоритм "с нуля" ?
Ни одна методика оценки сложности не даст ответ. Скорее всего хаскель освоит тот, у кого опыт более разнообразный "в ширину". У кого из двух будет ширше — трудно сказать, нужны детали которых в общем случае никогда нет и быть не может.
На мой взгляд есть только один подход к общему знаменателю — искать причины непонимания в недостаточной прокачке той или иной области или отсутствии некоторых понятий. Большинство специалистов в ИТ рассуждает приблизительно так(общий знаменатель прочитаного мною на этом форуме):
"Ну почитаешь денек, разберешься и напишешь"
"Я не программист, но понял хаскель за неделю"
"А что тут сложного ? Если кто не понимает монады, то это не ко мне"
Очевидно, для того что бы почитать денек и разобраться нужен уже определенный опыт и знания, при чем степень прокачки достаточная для того, что бы делать рассуждения в уме со скоростью много большей скорости чтения материяла. С хаскелем нужно иметь хорошую математику и достаточно широкий спектр технических приемов.
Выходит так — Нет понятий — нет и рассуждений, а вот скорость рассуждений определяется количеством опыта применения не только конкретного понятия но и взаимосвязаных понятий. Кроме того, еще и глубина памяти, объем воображения и многие другие вещи так же зависят от количества опыта и тд.
То есть решение вырисовывается такое — для каждого баззворда нужно найти некоторый минимальный базис, который необходим что бы освоить баззворд "за две минуты". Тогда станет ясно, почему один понимает, а другой — нет.
P.S. Избитый пример про понятия: "Разные люди работают с полиуретановыми волокнами по разному — продавец трикотажа, покупатель трикотажа, инженер-химик, инженер-технолог, дизайнер одежды и рабочий в цехе по изготовлению одежды. Вопрос — понимают ли эти люди одно и то же когда слышат слово "лайкра" или "спандекс" ?
Здравствуйте, landerhigh, Вы писали:
L>Почему мне это вообще интересно? Есть такая штука, как интуиция. Бывает, начинаешь делать некий сферический в вакууме модуль Х. Нарисовал квадратики, приступил к работе и интуитивно понимаешь, что решение, которое получается, некрасиво, хотя и показать этого не можешь. Интуиция все же на чем-то основывается, поэтому, КМК, должна существовать возможность перехода к некой абстрактной модели, в которой некрасивости можно будет банально подсчитать по формуле. Например, слишком большое число состояний модуля, слишком большое количество входов/выходов, наличие непересечающихся областей ответственности и так далее.
Интуиция это твой переварены опыт. Если ты никогда не делал параметризацию алгоримов или классов, то решение на лямбдах скорее всего покажется крайне некрасивым. А если связыванием , зависимостями и обязанностями никогда не интересовался, то di/ioc покажется глупой затеей которая вводит в заблуждение.
Здравствуйте, __kot2, Вы писали:
__>Здравствуйте, landerhigh, Вы писали: L>>Кроме того, индикатор переусложненности архитектуры также мог бы основываться на каких-либо нормализованных входных данных. __>я предлагаю качеством архитектуры называть число, которое можно определить по статистике изменений кода. Посчитайте сколько в среднем мест в коде нужно поменять, если вы хотите поменять только одну вещь. Вот эта чиселка и может сказать о качестве архитетуры и даже позволит сравнивать приложения по качеству кода между собой.
Во, прямо совпадающее со мной мнение, тока нужно немного подкорректировать. Берем исходную версию программы и 10 фичь(вещь которую можно поменять). Последовательно меняем одну и подсчитываем в сколько мест нужно полезть и поменять. У нас получается всего 10 чисел которые и скажут нам о том насколько исходная версия программы (и только она) приспособлена к внесению изменений для каждой из фичь. Вроде как бы при другой архитектуре должна получиться другая последовательность чисел. То есть другая архитектура более благосклонна к внесению одник фичь и затрудняет внесение других фичь. Очевидно нам нужно из последовательности в 10 чисел получить только одно — символизирующее архитектуру. Значит нам нужно еще и умножать каждое число на степень полезности и востребованности фичи а потом можно и сложить эти числа чтобы получить одно число для каждой архитектуры.
Проблема состоит в том, внесении фичи2 после фичи1 может быть на порядок труднее выполнить чем просто добавление фичи2 без фичи1. То есть сложность внесения изменений кореллируют между собой. Потому исследования сложности для одной единственной версии программы не совсем правильное мероприятие. Нужно измерять не просто внесение фичи2 в исходную версию, но и в версию с уже встроеннной фичей1, а также версией с встроенной фичей 3 и т.д., а также естественно комбиначей. например, с версией где есть фичи 1 3 5, но нет фичь 4, 6 и 8. Потому у нас для 10 фичь получиться вообще говоря не 10 измеренных значений а 2**10 = 1024. Каждое из которых нужно еще умножить на коеффициент полезности фичь.
Я еще не говорил что одна и та же фича в разных версиях программ полезна по разному? Значит полезность фичь нужно задавать относительно версии программы. Хотя конечно есть фичи которые никак не зависят от версии, но такое бывает редко.
Выводы: метрики вообще не то меряют что нужно. Условно говоря метрики измеряют описание программы в некоторый момент времени, а нужно измерять трудоемкость перехода от одного описания к другому. Вся сложность заключена в основном в изменении программы, а не в ее описании в каждый момент времени.
T>Интуиция это твой переварены опыт. Если ты никогда не делал параметризацию алгоримов или классов, то решение на лямбдах скорее всего покажется крайне некрасивым. А если связыванием , зависимостями и обязанностями никогда не интересовался, то di/ioc покажется глупой затеей которая вводит в заблуждение.
Это очень приземленный пример. У меня интуиция прокачана до уровня, что уже на этапе планирования безошибочно определяю вполне рабочие предложения, но с которыми мы огребем серьезных проблем. Проблема в том, что аргументировать это могу далеко не всегда. О чем и сыр-бор, хочется иметь возможность использовать формализованный подход при необходимости.
Здравствуйте, landerhigh, Вы писали:
T>>Интуиция это твой переварены опыт. Если ты никогда не делал параметризацию алгоримов или классов, то решение на лямбдах скорее всего покажется крайне некрасивым. А если связыванием , зависимостями и обязанностями никогда не интересовался, то di/ioc покажется глупой затеей которая вводит в заблуждение.
L>Это очень приземленный пример. У меня интуиция прокачана до уровня, что уже на этапе планирования безошибочно определяю вполне рабочие предложения, но с которыми мы огребем серьезных проблем. Проблема в том, что аргументировать это могу далеко не всегда. О чем и сыр-бор, хочется иметь возможность использовать формализованный подход при необходимости.
Конечно приземленный, я ведь не знаю, чем ты занимаешься по работе Интуитивное понимаение это в некотором приближении характеризует уровень прокачки понятий и саму систему понятий. То есть, не можешь сказать, значит тебе не хватает какого то кусочка опыта или понятия. Формализованый подход здесь уже подсказали со ссылками на Гапертона. В любом случае это просто опробованые эвристики.
Здравствуйте, landerhigh, Вы писали:
L>У меня интуиция прокачана до уровня, что уже на этапе планирования безошибочно определяю вполне рабочие предложения, но с которыми мы огребем серьезных проблем. Проблема в том, что аргументировать это могу далеко не всегда. О чем и сыр-бор, хочется иметь возможность использовать формализованный подход при необходимости.
Не останавливайся на "чувствую, что проблема, но объяснить не могу". Сделай следующий шаг. Попробуй выяснить причину и попробуй ее объяснить.
Некоторое время назад я стал просить коллег заставлять меня объяснять почему мне не нравится какое-либо решение. Времени, конечно, тратиться на это много так как ты себе не всегда можешь объяснить почему тебе что-то нравится или нет. Но польза несомненна. Ты начинаешь лучше понимать проблему, коллеги узнают что-то новое. И, главное, они могу аргументированно возразить тебе. Последнее особенно ценно. Избавиться от "суеверий" всегда полезно.
Поначалу это сложно, но чем больше ты пробуешь докопаться до причины, тем проще. Вообще, причин не так уж и много (скажем типов причин), поэтому следующие объяснения могут опираться на предыдущие.
Проверено на людях (на мне и моей команде)
СУВ, Aikin
И, опять же, ссылка на доклад Гапертона.
Правила проверки решений
• «Это неправильно» «Как ваше решение будет работать вот в такой ситуации?»
• Давление на авторитеты Ссылки на конкретный опыт с примерами
• Убеждения В инженерии все можно обосновать логически
• Это будет так! «В закон Ома верю. Все остальное надо проверять»
Здравствуйте, Aikin, Вы писали:
L>>У меня интуиция прокачана до уровня, что уже на этапе планирования безошибочно определяю вполне рабочие предложения, но с которыми мы огребем серьезных проблем. Проблема в том, что аргументировать это могу далеко не всегда. О чем и сыр-бор, хочется иметь возможность использовать формализованный подход при необходимости. A>Не останавливайся на "чувствую, что проблема, но объяснить не могу". Сделай следующий шаг. Попробуй выяснить причину и попробуй ее объяснить.
Здравствуйте, gandjustas, Вы писали:
G>Здравствуйте, landerhigh, Вы писали:
L>>Это очень приземленный пример. У меня интуиция прокачана до уровня, что уже на этапе планирования безошибочно определяю вполне рабочие предложения, но с которыми мы огребем серьезных проблем. Проблема в том, что аргументировать это могу далеко не всегда. О чем и сыр-бор, хочется иметь возможность использовать формализованный подход при необходимости.
G>"Понимаю но не могу объяснить" это близкий родственник "не понимаю". Потому что легко в таком положении поддаться ошибочным позывам.
Видимо, неправильно выразился. В данном случае "не могу" — это скорее "не хочу", ибо многие вещи считаю очевидными. Когда команда устоялась, это не является проблемой — люди сработались, понимают друг друга с полуслова и знают сильные или слабые стороны друг друга и не принимают критику как личное оскорбление, но при этом не позволяют авторитету превалировать над логикой.
В новых командах или в межкомандном взаимодействии все совсем иначе.
G>Попробуй точно сформулировать какие проблемы могут быть в тех или иных решениях. Потом опиши почему они возникнут. На этом этапе можно притянуть формальные метрики, но обычно уже нет необходимости.
Дело в том, что подобный подход понятен не всем. Некоторые его вообще никогда не осилят. Но при этом могут переспорить (и перетроллить) половину этого форума.
Формальный подход как раз нужен для борьбы с ними.
Здравствуйте, landerhigh, Вы писали:
G>>Попробуй точно сформулировать какие проблемы могут быть в тех или иных решениях. Потом опиши почему они возникнут. На этом этапе можно притянуть формальные метрики, но обычно уже нет необходимости.
L>Дело в том, что подобный подход понятен не всем. Некоторые его вообще никогда не осилят. Но при этом могут переспорить (и перетроллить) половину этого форума. L>Формальный подход как раз нужен для борьбы с ними.
Формальный подход не поможет, слишком много неочевидных факторов и железные аргументы, вроде "мы всегда так делали". Тут скорее нужно умение объяснять и доказывать.
Здравствуйте, gandjustas, Вы писали:
L>>Дело в том, что подобный подход понятен не всем. Некоторые его вообще никогда не осилят. Но при этом могут переспорить (и перетроллить) половину этого форума. L>>Формальный подход как раз нужен для борьбы с ними.
G>Формальный подход не поможет, слишком много неочевидных факторов и железные аргументы, вроде "мы всегда так делали". Тут скорее нужно умение объяснять и доказывать.
Вот как раз для борьбы с "мы всегда так делали" все средства хороши. Товарищи с подобным подходом сами кому угодно что угодно докажут, еще и тебя виноватым сделают, ибо "никогда не спорь с дураками". К сожалению, с ними иногда приходится работать.
Возможность применить научно обоснованную формальную метрику до начала разработки в подобных случаях помогло бы перевести разговор в более конструктивное русло (или принять административное решение).
Здравствуйте, landerhigh, Вы писали:
L>Возможность применить научно обоснованную формальную метрику до начала разработки в подобных случаях помогло бы перевести разговор в более конструктивное русло (или принять административное решение).
Метрики — не закон Ома. Метрики не говорят о том, как они влияют на процессы.
Например никто не скажет что уменьшение mantainability index в два раза уменьшит количество ошибок в два раза. Я даже сомневаюсь что в значительной мере влияет.
Поэтому даже если найти метрику, то она не поможет доказать правильность. Тут нужно именно уметь объяснять и доказывать.
Здравствуйте, Sinclair, Вы писали:
S>На этапе планирования крупноблочной архитектуры всё, что вы можете увидеть — это крупные блоки.
Очень, очень много факапов происходят именно на этапе планирования крупноблочной архитектуры
S>Я, если честно, не понимаю, как вы выявите переусложнённость модуля до того, как этот модуль будет описан.
На самом деле, довольно просто — какой-то модуль удостоился больше внимания, нежели он того заслуживает, а какой-то очень важный модуль оказался обделен вниманием
S>Если я рисую квадратик на доске и говорю: "это — модуль кэширования", и оппонент рисует квадратик и говорит "это — модуль кэширования", то совершенно непонятно, у кого из нас решение переусложнено.
Это, кстати, хороший пример. Модуль должен заслужить свое место на доске с крупноблочной архитектурой. "Модуль кеширования" чего? Как он интегрируется с остальными модулями? Очень часто оказывается, что этот модуль кеширует нечто, что сидит глубоко внутри другого модуля и никому снаружи не видно, посему и модуль кеширования не должен существовать в виде отдельного крупного блока. Вместо этого он должен оказаться частью одного из крупных блоков на доске.
Игнорирование подобных вещей приводит к неоправданно дикому усложнению архитектуры, когда в диаграмму высокого уровня вытаскиваются вещи, которым в ней нет места. Обратное тоже часто случается — пропускаются критические для данного уровня архитектуры вещи. Все это приводит к неизбежной макаронизации уже на архитектурном уровне.
Далеко не все примеры так очевидны — "модуль кеширования" слишком конкретный. Чаще всего происходит ситуация, когда обсуждение идет по плану "у нас будет фича X, сделаем модуль, ответственный за эту фичу" или "фича Y реализовывается модулем Z, поэтому выделять ее отдельно ". Все молча кивают и потом огребают по полной, когда выясняется, что фича X на самом деле реализуется модулем M и более нигде не используется, а "простая" фича Y, про которую все думали, что она элементарно реализовывается модулем Z, на самом деле используется повсеместно и имеет кучу архитектурных зависимостей и приходится ставить кучу костылей, чтобы вытащить ее наружу.
Вот формальный подход помог бы в подобных случаях — любой квадратик, сколь много или сколь мало о нем на данный момент известно, должен заслужить свое место на диаграмме крупноблочной архитектуры. Если про какой-то квадратик пока известно очень мало конкретики, значит, будем использовать формальный подход, чтобы эту самую конкретику вытащить на свет.