


|
|
От: | HrorH | |
| Дата: | 06.02.12 09:44 | ||
| Оценка: |
+1
-1
|
||

|
От: |
Carc
|
http://www.amlpages.com/home.php |
| Дата: | 06.02.12 09:59 | ||
| Оценка: |
+4
|
||

|
От: | Васильич | |
| Дата: | 06.02.12 10:12 | ||
| Оценка: | 8 (2) +1 | ||

|
От: | BlackEric | http://black-eric.lj.ru |
| Дата: | 06.02.12 10:16 | ||
| Оценка: | +2 | ||

|
От: |
minorlogic
|
|
| Дата: | 06.02.12 10:18 | ||
| Оценка: | |||

|
От: | Artifact | |
| Дата: | 06.02.12 10:21 | ||
| Оценка: | 1 (1) | ||

|
От: |
LaptevVV
|
|
| Дата: | 06.02.12 10:22 | ||
| Оценка: | |||
|
|
От: |
minorlogic
|
|
| Дата: | 06.02.12 10:41 | ||
| Оценка: | |||

|
От: |
vsb
|
|
| Дата: | 06.02.12 11:04 | ||
| Оценка: |
|
||

|
От: |
VsevolodC
|
|
| Дата: | 06.02.12 11:31 | ||
| Оценка: | +3 | ||
|
|
От: | HrorH | |
| Дата: | 06.02.12 12:36 | ||
| Оценка: | |||

|
От: |
Skynin
|
skynin.blogspot.com |
| Дата: | 06.02.12 12:41 | ||
| Оценка: | 9 (1) +1 | ||

|
От: |
Sharov
|
|
| Дата: | 06.02.12 12:47 | ||
| Оценка: | |||

|
От: | _ABC_ | |
| Дата: | 06.02.12 12:58 | ||
| Оценка: | +2 | ||
|
|
От: | Artifact | |
| Дата: | 06.02.12 13:44 | ||
| Оценка: | |||

|
От: |
Геннадий Васильев
|
http://www.livejournal.com/users/gesha_x |
| Дата: | 06.02.12 13:48 | ||
| Оценка: | |||
|
|
От: | HrorH | |
| Дата: | 06.02.12 14:21 | ||
| Оценка: | |||
|
|
От: | HrorH | |
| Дата: | 06.02.12 14:35 | ||
| Оценка: | |||
|
|
От: | HrorH | |
| Дата: | 06.02.12 14:39 | ||
| Оценка: | |||

|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 06.02.12 14:45 | ||
| Оценка: | 4 (1) | ||
for (uint i = items.Length - 1; i >= 0; --i)
{
var item = items[i];
//что-то делаем с item
}foreach (var item in items.Reverse())
{
//что-то делаем с item
}

|
От: |
igna
|
|
| Дата: | 06.02.12 14:50 | ||
| Оценка: | |||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 06.02.12 14:55 | ||
| Оценка: | |||

|
От: |
IT
|
linq2db.com |
| Дата: | 06.02.12 14:56 | ||
| Оценка: | |||
 Если нам не помогут, то мы тоже никого не пощадим.
Если нам не помогут, то мы тоже никого не пощадим.
|
|
От: | HrorH | |
| Дата: | 06.02.12 15:00 | ||
| Оценка: | |||

|
От: |
Константин
|
|
| Дата: | 06.02.12 15:07 | ||
| Оценка: | +2 | ||
|
|
От: |
igna
|
|
| Дата: | 06.02.12 15:09 | ||
| Оценка: | |||
|
|
От: |
IT
|
linq2db.com |
| Дата: | 06.02.12 15:12 | ||
| Оценка: | -1 | ||
Если нам не помогут, то мы тоже никого не пощадим.

|
От: |
velkin
|
https://kisa.biz |
| Дата: | 06.02.12 15:23 | ||
| Оценка: | |||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 06.02.12 15:30 | ||
| Оценка: | 19 (2) | ||
В итоге хотелось бы заметить, что система проверки программного обеспечения компьютеров действительно показывает себя как высококачественная. Судя по всему, там нет места постепенному самообману путем снижения норм, что весьма характерно для систем безопасности твердотопливных ракета-носителей и основных двигателей шаттла. Для вящей убедительности добавлю, что руководство недавно предлагало прекратить такие сложные и дорогие испытания за их ненадобностью в последнее время истории запусков шаттла.
http://scilib.narod.ru/Physics/Feynman/WDYC/ru/feyinman.html#TOC_id2994316За 250 000 секунд работы основные двигатели отказывали, вероятно, раз 16.
Список некоторых проблем (и их состояния):
Трещины лопаток турбины в топливных турбонасосах высокого давления (ТТНВД). (Возможно, решена.)
Трещины лопаток турбины в кислородных турбонасосах высокого давления (КТНВД). (Не решена.)
Пробой линии форсажного искрового воспламенителя (ФИВ). (Возможно, решена.)
Отказ контрольного вентиля для выпуска газов. (Вероятно, решена.)
Эрозия корпуса ФИВ. (Вероятно, решена.)
Растрескивание листового металла корпуса турбины ТТНВД. (Вероятно, решена.)
Повреждение футеровки труб для охлаждения ТТНВД. (Вероятно, решена.)
Отказ выходного коленчатого патрубка основной камеры сгорания. (Вероятно, решена.)
Смещение сварного шва входного коленчатого патрубка основной камеры сгорания. (Вероятно, решена.)
Субсинхронный вихрь КТНВД. (Вероятно, решена.)
Система аварийного отключения ускорения полета (частичный отказ системы с резервированием). (Вероятно, решена.)
Растрескивание подшипников. (Частично решена.)
Вибрация с частотой 4 000 герц, которая приводит некоторые двигатели в нерабочее состояние. (Не решена.)
Многие из этих, на первый взгляд, решенных проблем были видны уже на ранних стадиях использования новой конструкции: 13 из них появились в первые 125 000 секунд эксплуатации двигателя и только 3 – во вторые 125 000 секунд. Естественно, никогда нельзя быть уверенным, что все недостатки устранены; однако, возможно, в отношении некоторых недостатков стремились устранить не ту причину. Вполне разумно предположить, что в следующие 250000 секунд может произойти, по крайней мере, один сюрприз: вероятность равна 1/500 на двигатель на задание.
[..]
Инженеры в Рокетдайне, где производятся двигатели, оценивают полную вероятность как 1/10 000. Инженеры в Маршалле оценивают ее как 1/300, тогда как руководство НАСА, которому эти инженеры отправляют свои отчеты, утверждает, что вероятность равна 1/100 000. Независимый инженер, дающий НАСА консультации, счел разумной оценкой 1 или 2 к 100
[..]
Медленный сдвиг в направлении снижения коэффициента безопасности можно увидеть во множестве примеров.
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 06.02.12 15:45 | ||
| Оценка: | |||
|
|
От: |
igna
|
|
| Дата: | 06.02.12 15:58 | ||
| Оценка: | |||
|
|
От: |
Sharov
|
|
| Дата: | 06.02.12 16:00 | ||
| Оценка: | |||
|
|
От: |
igna
|
|
| Дата: | 06.02.12 16:00 | ||
| Оценка: | |||
|
|
От: | Artifact | |
| Дата: | 06.02.12 16:01 | ||
| Оценка: | |||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 06.02.12 16:01 | ||
| Оценка: | +1 | ||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 06.02.12 16:04 | ||
| Оценка: | +1 | ||

|
От: |
Ромашка
|
|
| Дата: | 06.02.12 16:06 | ||
| Оценка: |
|
||

|
|
От: |
Ромашка
|
|
| Дата: | 06.02.12 16:09 | ||
| Оценка: | |||
|
|
От: |
igna
|
|
| Дата: | 06.02.12 16:10 | ||
| Оценка: | |||
|
|
От: |
IT
|
linq2db.com |
| Дата: | 06.02.12 16:17 | ||
| Оценка: | |||
Если нам не помогут, то мы тоже никого не пощадим.
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 06.02.12 16:27 | ||
| Оценка: | 2 (1) +1 | ||

|
От: |
GlebZ
|
|
| Дата: | 06.02.12 16:46 | ||
| Оценка: |
6 (1)
|
||

|
От: |
Eye of Hell
|
eyeofhell.habr.ru |
| Дата: | 06.02.12 17:01 | ||
| Оценка: | |||
|
|
От: |
Геннадий Васильев
|
http://www.livejournal.com/users/gesha_x |
| Дата: | 06.02.12 17:02 | ||
| Оценка: | +1 | ||

|
От: |
Nuzhny
|
https://github.com/Nuzhny007 |
| Дата: | 06.02.12 17:42 | ||
| Оценка: | |||
|
|
От: |
Skynin
|
skynin.blogspot.com |
| Дата: | 06.02.12 17:44 | ||
| Оценка: | 9 (1) +2 | ||
|
|
От: |
Skynin
|
skynin.blogspot.com |
| Дата: | 06.02.12 18:21 | ||
| Оценка: | |||

|
От: | os24ever |  |
| Дата: | 06.02.12 18:56 | ||
| Оценка: | |||
В качестве средства описания мне до сих пор нравятся старые добрые структурно-информационные временные схемы (СИВС)...
|
|
От: |
Skynin
|
skynin.blogspot.com |
| Дата: | 07.02.12 07:44 | ||
| Оценка: | |||
|
|
От: | HrorH | |
| Дата: | 07.02.12 08:47 | ||
| Оценка: | |||

|
От: |
Undying
|
|
| Дата: | 07.02.12 09:13 | ||
| Оценка: | |||
|
|
От: |
Skynin
|
skynin.blogspot.com |
| Дата: | 07.02.12 09:42 | ||
| Оценка: | +2 | ||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 07.02.12 09:47 | ||
| Оценка: | |||

|
От: | ZOI4 | |
| Дата: | 07.02.12 10:40 | ||
| Оценка: | |||
|
|
От: | HrorH | |
| Дата: | 07.02.12 10:43 | ||
| Оценка: | |||
|
|
От: | HrorH | |
| Дата: | 07.02.12 10:49 | ||
| Оценка: | |||
|
|
От: |
Undying
|
|
| Дата: | 07.02.12 10:52 | ||
| Оценка: | |||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 07.02.12 10:57 | ||
| Оценка: | |||
this.X = new_X1;
this.Update_X_Dependencies();
[..]
this.X = new_X2;
this.Update_X_Dependencies();|
|
От: |
Undying
|
|
| Дата: | 07.02.12 11:00 | ||
| Оценка: | |||
|
|
От: |
Undying
|
|
| Дата: | 07.02.12 11:02 | ||
| Оценка: | +1 | ||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 07.02.12 11:06 | ||
| Оценка: | 2 (2) | ||

|
От: | monax | |
| Дата: | 07.02.12 11:10 | ||
| Оценка: | |||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 07.02.12 11:13 | ||
| Оценка: | |||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 07.02.12 11:16 | ||
| Оценка: | |||
|
|
От: |
Skynin
|
skynin.blogspot.com |
| Дата: | 07.02.12 11:26 | ||
| Оценка: | |||

|
От: | B0FEE664 | |
| Дата: | 07.02.12 12:03 | ||
| Оценка: | |||
|
|
От: |
Геннадий Васильев
|
http://www.livejournal.com/users/gesha_x |
| Дата: | 07.02.12 12:24 | ||
| Оценка: | +1 | ||
|
|
От: | HrorH | |
| Дата: | 07.02.12 12:44 | ||
| Оценка: | |||

|
От: | FR | |
| Дата: | 07.02.12 12:49 | ||
| Оценка: | |||
|
|
От: | HrorH | |
| Дата: | 07.02.12 12:54 | ||
| Оценка: | |||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 07.02.12 13:06 | ||
| Оценка: |
|
||
|
|
От: | FR | |
| Дата: | 07.02.12 13:25 | ||
| Оценка: | |||
|
|
От: | HrorH | |
| Дата: | 07.02.12 13:37 | ||
| Оценка: | |||
|
|
От: |
Геннадий Васильев
|
http://www.livejournal.com/users/gesha_x |
| Дата: | 07.02.12 13:41 | ||
| Оценка: | |||
|
|
От: | FR | |
| Дата: | 07.02.12 13:59 | ||
| Оценка: | |||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 07.02.12 14:06 | ||
| Оценка: |
1 (1)
|
||
for (uint i = items.Length - 1; i >= 0; --i)
{
var item = items[i];
//что-то делаем с item
}
foreach (var item in items.Reverse())
{
//что-то делаем с item
}|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 07.02.12 14:13 | ||
| Оценка: | |||
|
|
От: | HrorH | |
| Дата: | 07.02.12 14:26 | ||
| Оценка: | 5 (1) | ||
|
|
От: |
Undying
|
|
| Дата: | 07.02.12 15:08 | ||
| Оценка: | 4 (1) | ||

|
От: | Deprivator | |
| Дата: | 07.02.12 15:11 | ||
| Оценка: | |||
|
|
От: |
Skynin
|
skynin.blogspot.com |
| Дата: | 07.02.12 15:25 | ||
| Оценка: | |||
|
|
От: |
Undying
|
|
| Дата: | 07.02.12 15:29 | ||
| Оценка: | |||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 07.02.12 15:34 | ||
| Оценка: | |||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 07.02.12 15:40 | ||
| Оценка: | |||
|
|
От: |
Undying
|
|
| Дата: | 07.02.12 15:45 | ||
| Оценка: | +1 | ||
|
|
От: |
Undying
|
|
| Дата: | 07.02.12 15:55 | ||
| Оценка: | |||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 07.02.12 16:24 | ||
| Оценка: | |||
void UpdateControl_ForSelectedElement(Control control)
{
control.Font = new Font{Bold=true, Size = default.Font.Size * 1.1};
control.Color = Colors.Green;
}ControlState ControlState_ForSelectedElement()
{
return new ControlState
{
Font = new Font{Bold=true, Size = default.Font.Size * 1.1};
Color = Colors.Green;
};
}ControlState ControlState_ForSelectedElement()
{
return new ControlState
{
Font = new FontState{Bold=true, SizeK = 1.1};
Color = Colors.Green;
};
}|
|
От: |
Undying
|
|
| Дата: | 07.02.12 16:41 | ||
| Оценка: | |||
LazyMaker selectedElementMaker = new LazyMaker(delegate
{
selectedElement.Control.Font = new Font{Bold=true, Size = default.Font.Size * 1.1};
selectedElement.Control.Color = Colors.Green;
},
delegate { return selectedElement; }
);
void OnPaint()
{
selectedElementMaker.Make();
}|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 07.02.12 17:05 | ||
| Оценка: | |||
LazyMaker selectedElementMaker = new LazyMaker(()=>UpdateControl_ForSelectedElement(selectedElement.Control),
delegate { return selectedElement; }
);|
|
От: |
Skynin
|
skynin.blogspot.com |
| Дата: | 07.02.12 17:22 | ||
| Оценка: | 2 (1) | ||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 07.02.12 17:32 | ||
| Оценка: | |||

|
От: | matumba | |
| Дата: | 07.02.12 19:57 | ||
| Оценка: | |||
|
|
От: |
IT
|
linq2db.com |
| Дата: | 07.02.12 22:12 | ||
| Оценка: | |||
Если нам не помогут, то мы тоже никого не пощадим.
|
|
От: |
Ромашка
|
|
| Дата: | 07.02.12 22:43 | ||
| Оценка: | |||
|
|
От: |
IT
|
linq2db.com |
| Дата: | 07.02.12 22:51 | ||
| Оценка: | |||
Если нам не помогут, то мы тоже никого не пощадим.
|
|
От: |
Ромашка
|
|
| Дата: | 08.02.12 00:23 | ||
| Оценка: | |||
|
|
От: |
IT
|
linq2db.com |
| Дата: | 08.02.12 00:55 | ||
| Оценка: | |||
Если нам не помогут, то мы тоже никого не пощадим.
|
|
От: |
Undying
|
|
| Дата: | 08.02.12 03:36 | ||
| Оценка: | |||
DG>LazyMaker selectedElementMaker = new LazyMaker(()=>UpdateControl_ForSelectedElement(selectedElement.Control),
DG> delegate { return selectedElement; }
DG>);
DG>

|
От: |
D. Mon
|
http://thedeemon.livejournal.com |
| Дата: | 08.02.12 03:52 | ||
| Оценка: | |||
|
|
От: |
Skynin
|
skynin.blogspot.com |
| Дата: | 08.02.12 06:10 | ||
| Оценка: | +1 | ||
|
|
От: |
Skynin
|
skynin.blogspot.com |
| Дата: | 08.02.12 06:19 | ||
| Оценка: | |||
|
|
От: |
Skynin
|
skynin.blogspot.com |
| Дата: | 08.02.12 06:35 | ||
| Оценка: | +1 | ||
|
|
От: |
D. Mon
|
http://thedeemon.livejournal.com |
| Дата: | 08.02.12 06:57 | ||
| Оценка: | +1 | ||
|
|
От: |
D. Mon
|
http://thedeemon.livejournal.com |
| Дата: | 08.02.12 07:01 | ||
| Оценка: | |||
|
|
От: |
Skynin
|
skynin.blogspot.com |
| Дата: | 08.02.12 07:21 | ||
| Оценка: | |||
|
|
От: |
Skynin
|
skynin.blogspot.com |
| Дата: | 08.02.12 07:32 | ||
| Оценка: | |||
|
|
От: |
D. Mon
|
http://thedeemon.livejournal.com |
| Дата: | 08.02.12 07:33 | ||
| Оценка: | |||
|
|
От: |
D. Mon
|
http://thedeemon.livejournal.com |
| Дата: | 08.02.12 07:36 | ||
| Оценка: | |||
|
|
От: |
D. Mon
|
http://thedeemon.livejournal.com |
| Дата: | 08.02.12 07:51 | ||
| Оценка: | |||
|
|
От: |
D. Mon
|
http://thedeemon.livejournal.com |
| Дата: | 08.02.12 08:01 | ||
| Оценка: | +1 | ||
|
|
От: |
Skynin
|
skynin.blogspot.com |
| Дата: | 08.02.12 08:02 | ||
| Оценка: | +1 | ||
|
|
От: |
Skynin
|
skynin.blogspot.com |
| Дата: | 08.02.12 08:18 | ||
| Оценка: | +1 | ||
|
|
От: |
D. Mon
|
http://thedeemon.livejournal.com |
| Дата: | 08.02.12 08:23 | ||
| Оценка: | |||
|
|
От: |
Skynin
|
skynin.blogspot.com |
| Дата: | 08.02.12 08:31 | ||
| Оценка: | |||
|
|
От: |
D. Mon
|
http://thedeemon.livejournal.com |
| Дата: | 08.02.12 08:39 | ||
| Оценка: | +1 | ||
|
|
От: | HrorH | |
| Дата: | 08.02.12 10:38 | ||
| Оценка: | |||
|
|
От: | matumba | |
| Дата: | 08.02.12 11:05 | ||
| Оценка: | |||
|
|
От: | HrorH | |
| Дата: | 08.02.12 11:52 | ||
| Оценка: | |||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 08.02.12 12:28 | ||
| Оценка: | |||
class Segment
{
public double Left;
public double Right;
public double Top;
public double Bottom;
}|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 08.02.12 13:07 | ||
| Оценка: | |||
|
|
От: |
Геннадий Васильев
|
http://www.livejournal.com/users/gesha_x |
| Дата: | 08.02.12 13:41 | ||
| Оценка: | 1 (1) | ||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 08.02.12 14:56 | ||
| Оценка: | 10 (1) | ||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 08.02.12 15:08 | ||
| Оценка: | |||
DG>>LazyMaker selectedElementMaker = new LazyMaker(()=>UpdateControl_ForSelectedElement(selectedElement.Control),
DG>> delegate { return selectedElement; }
DG>>);
DG>>LazyMaker selectedElementMaker = new LazyMaker(()=>UpdateControl(element.Control, element),
delegate { return element; }
);
//..
void UpdateControl(Control control, Element element)
{
UpdateControl_ForElement(control, element);
if (element.isSelected)
UpdateControl_ForSelectedElement(control, element);
}LazyMaker selectedElementMaker = new LazyMaker(()=>MyCoolBusinessLogic.UpdateControl(element.Control, element),
delegate { return element; }
);LazyMaker selectedElementMaker = new LazyMaker(()=>controller.UpdateControl(element.Control, element),
delegate { return element; }
);//первый способ (Push)
void PartialUpdateControl(Control control, Element element)
{
control.Font = new Font{Bold=true, Size = default.Font.Size * 1.1};
control.Color = Colors.Green;
}
//второй способ (Pull)
ControlState ElementPartialView(Element element)
{
return new ControlState
{
Font = new FontState{Bold=true, SizeK = 1.1};
Color = Colors.Green;
};
}var maker = new LazyMaker(
() => ControlSynchronizer.Synchronize(element_with_control.Control, ElementPartialView(element_with_control.Element)),
() => element_with_control
);|
|
От: |
Ромашка
|
|
| Дата: | 08.02.12 15:45 | ||
| Оценка: | |||
|
|
От: |
IT
|
linq2db.com |
| Дата: | 08.02.12 16:45 | ||
| Оценка: | |||
Если нам не помогут, то мы тоже никого не пощадим.
|
|
От: |
Ромашка
|
|
| Дата: | 08.02.12 20:22 | ||
| Оценка: | |||
|
|
От: |
IT
|
linq2db.com |
| Дата: | 08.02.12 20:44 | ||
| Оценка: | +1 | ||
Если нам не помогут, то мы тоже никого не пощадим.
|
|
От: |
Ромашка
|
|
| Дата: | 08.02.12 21:24 | ||
| Оценка: | |||
|
|
От: |
IT
|
linq2db.com |
| Дата: | 08.02.12 23:42 | ||
| Оценка: | |||
Если нам не помогут, то мы тоже никого не пощадим.
|
|
От: |
Undying
|
|
| Дата: | 09.02.12 04:28 | ||
| Оценка: | |||
|
|
От: | matumba | |
| Дата: | 09.02.12 08:05 | ||
| Оценка: | |||
|
|
От: | FR | |
| Дата: | 09.02.12 09:08 | ||
| Оценка: | |||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 09.02.12 11:20 | ||
| Оценка: |
|
||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 09.02.12 13:00 | ||
| Оценка: | |||
|
|
От: |
IT
|
linq2db.com |
| Дата: | 09.02.12 15:58 | ||
| Оценка: | |||
Если нам не помогут, то мы тоже никого не пощадим.
|
|
От: |
Undying
|
|
| Дата: | 13.02.12 10:49 | ||
| Оценка: | |||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 13.02.12 12:08 | ||
| Оценка: | |||

|
От: |
Real 3L0
|
http://prikhodko.blogspot.com |
| Дата: | 13.02.12 21:14 | ||
| Оценка: | |||
|
|
От: |
Undying
|
|
| Дата: | 14.02.12 16:11 | ||
| Оценка: | |||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 14.02.12 17:34 | ||
| Оценка: | |||

|
От: | konstardiy | |
| Дата: | 14.02.12 21:59 | ||
| Оценка: | |||
|
|
От: |
Undying
|
|
| Дата: | 15.02.12 03:44 | ||
| Оценка: | |||
List<Tab> tabs;
int initialTabCount;
void panel_MouseLeave()
{
initialTabsCount = tabs.Count;
Invalidate();
}
LazyMaker tabMaker = new LazyMaker(
delegate
{
if (tabs.Count == initialTabCount)
{
SyncTab();
}
else
{
SyncTabSpecial();
}
},
delegate { return panel.Size; },
delegate { return tabs.ChangeTick; },
delegate { return initialTabCount; }
);
void ClickTabDelete(Tab tab)
{
tabs.Remove(tab);
Invalidate();
}
void Invalidate()
{
tabMaker.Make();
}

|
От: | Tanker | |
| Дата: | 15.02.12 08:42 | ||
| Оценка: | |||

|
|
От: | Tanker | |
| Дата: | 15.02.12 08:46 | ||
| Оценка: | |||
|
|
От: | Tanker | |
| Дата: | 15.02.12 08:49 | ||
| Оценка: | |||
|
|
От: | Tanker | |
| Дата: | 15.02.12 08:58 | ||
| Оценка: | |||
|
|
От: |
Ромашка
|
|
| Дата: | 15.02.12 09:49 | ||
| Оценка: | |||
|
|
От: |
Ромашка
|
|
| Дата: | 15.02.12 09:56 | ||
| Оценка: | |||

|
От: | Klapaucius | |
| Дата: | 15.02.12 10:17 | ||
| Оценка: | 3 (1) | ||
|
|
От: | Tanker | |
| Дата: | 15.02.12 10:46 | ||
| Оценка: | |||
|
|
От: | Tanker | |
| Дата: | 15.02.12 10:47 | ||
| Оценка: | |||
|
|
От: |
Ромашка
|
|
| Дата: | 15.02.12 10:58 | ||
| Оценка: | |||
|
|
От: |
Ромашка
|
|
| Дата: | 15.02.12 11:00 | ||
| Оценка: | |||
|
|
От: | Tanker | |
| Дата: | 15.02.12 11:05 | ||
| Оценка: | |||
|
|
От: | Tanker | |
| Дата: | 15.02.12 11:07 | ||
| Оценка: | |||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 15.02.12 11:27 | ||
| Оценка: | |||
|
|
От: | Tanker | |
| Дата: | 15.02.12 11:44 | ||
| Оценка: | |||
|
|
От: | Tanker | |
| Дата: | 15.02.12 11:53 | ||
| Оценка: | |||
|
|
От: |
Carc
|
http://www.amlpages.com/home.php |
| Дата: | 15.02.12 12:05 | ||
| Оценка: | +2 | ||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 15.02.12 12:39 | ||
| Оценка: | |||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 15.02.12 12:42 | ||
| Оценка: | |||
|
|
От: | Tanker | |
| Дата: | 15.02.12 12:59 | ||
| Оценка: | |||
|
|
От: | Tanker | |
| Дата: | 15.02.12 13:24 | ||
| Оценка: | |||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 15.02.12 13:48 | ||
| Оценка: | |||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 15.02.12 13:50 | ||
| Оценка: | |||
|
|
От: |
IT
|
linq2db.com |
| Дата: | 15.02.12 14:06 | ||
| Оценка: | |||
Если нам не помогут, то мы тоже никого не пощадим.
|
|
От: | Tanker | |
| Дата: | 15.02.12 14:13 | ||
| Оценка: | |||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 15.02.12 14:42 | ||
| Оценка: | |||
|
|
От: | Tanker | |
| Дата: | 15.02.12 14:58 | ||
| Оценка: | |||
|
|
От: |
igna
|
|
| Дата: | 15.02.12 17:55 | ||
| Оценка: | |||
|
|
От: |
Undying
|
|
| Дата: | 16.02.12 03:45 | ||
| Оценка: | |||
List<Tab> tabs;
int initialTabCount;
DateTime animateTime;
Timer animateTimer;
animateTimer.Tick += delegate
{
if (DateTime.UtcNow - animateTimer > animateDuration)
{
initialTabCount = tabs.Count;
animateTimer.Stop();
return;
}
Invalidate();
};
void panel_MouseLeave()
{
animateTime = DateTime.UtcNow;
animateTimer.Start();
Invalidate();
}
LazyMaker tabMaker = new LazyMaker(
delegate
{
if (tabs.Count == initialTabCount)
{
SyncTab();
}
else if (DateTime.UtcNow - animateTime < animateDuration)
{
SyncTabWithAnimate(DateTime.UtcNow - animateTime);
}
else
{
SyncTabSpecial();
}
},
delegate { return panel.Size; },
delegate { return tabs.ChangeTick; },
delegate { return initialTabCount; }
);
void ClickTabDelete(Tab tab)
{
tabs.Remove(tab);
Invalidate();
}
void Invalidate()
{
tabMaker.Make();
}

|
От: |
jhfrek
|
|
| Дата: | 16.02.12 04:08 | ||
| Оценка: | |||
|
|
От: |
Real 3L0
|
http://prikhodko.blogspot.com |
| Дата: | 16.02.12 05:14 | ||
| Оценка: | |||
|
|
От: |
jhfrek
|
|
| Дата: | 16.02.12 07:00 | ||
| Оценка: |
1 (1)
+1
|
||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 16.02.12 11:00 | ||
| Оценка: | |||
|
|
От: |
Undying
|
|
| Дата: | 16.02.12 11:12 | ||
| Оценка: | |||
|
|
От: |
jhfrek
|
|
| Дата: | 16.02.12 11:13 | ||
| Оценка: | +1 | ||
|
|
От: |
jhfrek
|
|
| Дата: | 16.02.12 11:16 | ||
| Оценка: | |||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 16.02.12 11:18 | ||
| Оценка: | |||
|
|
От: | Klapaucius | |
| Дата: | 16.02.12 11:43 | ||
| Оценка: | 12 (1) | ||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 16.02.12 11:44 | ||
| Оценка: | |||
|
|
От: | Klapaucius | |
| Дата: | 16.02.12 11:46 | ||
| Оценка: | |||
|
|
От: |
Undying
|
|
| Дата: | 16.02.12 11:53 | ||
| Оценка: | |||
|
|
От: |
Undying
|
|
| Дата: | 16.02.12 11:56 | ||
| Оценка: | |||
void ClickTabDelete(Tab tab)
{
tabs.Remove(tab);
animateTime = DateTime.UtcNow;
Invalidate();
}|
|
От: |
jhfrek
|
|
| Дата: | 16.02.12 12:11 | ||
| Оценка: | |||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 16.02.12 12:18 | ||
| Оценка: | |||
|
|
От: | Klapaucius | |
| Дата: | 16.02.12 12:41 | ||
| Оценка: | |||
|
|
От: |
jhfrek
|
|
| Дата: | 16.02.12 12:57 | ||
| Оценка: | +1 | ||
|
|
От: | Klapaucius | |
| Дата: | 16.02.12 13:12 | ||
| Оценка: | |||
|
|
От: |
jhfrek
|
|
| Дата: | 16.02.12 13:23 | ||
| Оценка: | |||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 16.02.12 13:52 | ||
| Оценка: | |||
animateTimer.Tick += delegate
{
..
Invalidate();
}; SyncTab();
SyncTabSpecial();
SyncTabWithAnimate(DateTime.UtcNow - animateTime);LazyMaker tabMaker = new LazyMaker(
delegate {..}
delegate { return panel.Size; },
delegate { return tabs.ChangeTick; },
delegate { return initialTabCount; }
);|
|
От: |
Undying
|
|
| Дата: | 17.02.12 03:47 | ||
| Оценка: | |||
|
|
От: |
Undying
|
|
| Дата: | 17.02.12 03:53 | ||
| Оценка: | |||
|
|
От: | Klapaucius | |
| Дата: | 17.02.12 10:10 | ||
| Оценка: | |||

|
От: |
Sinclair
|
https://github.com/evilguest/ |
| Дата: | 22.02.12 08:35 | ||
| Оценка: | |||

|
|
От: |
Sinclair
|
https://github.com/evilguest/ |
| Дата: | 22.02.12 08:41 | ||
| Оценка: | 1 (1) +1 | ||
|
|
От: |
Sinclair
|
https://github.com/evilguest/ |
| Дата: | 22.02.12 08:56 | ||
| Оценка: | +1 | ||
|
|
От: | B0FEE664 | |
| Дата: | 22.02.12 12:44 | ||
| Оценка: | +1 | ||
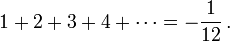
|
|
От: | Klapaucius | |
| Дата: | 24.02.12 12:10 | ||
| Оценка: | |||

|
От: | Sharowarsheg | |
| Дата: | 24.02.12 12:33 | ||
| Оценка: | |||
|
|
От: | Sharowarsheg | |
| Дата: | 24.02.12 12:37 | ||
| Оценка: | |||
|
|
От: | Sharowarsheg | |
| Дата: | 24.02.12 12:43 | ||
| Оценка: | -1 | ||
|
|
От: |
Sinclair
|
https://github.com/evilguest/ |
| Дата: | 24.02.12 16:23 | ||
| Оценка: | |||
|
|
От: | Sharowarsheg | |
| Дата: | 24.02.12 17:21 | ||
| Оценка: | |||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 25.02.12 15:17 | ||
| Оценка: | |||
|
|
От: |
Sinclair
|
https://github.com/evilguest/ |
| Дата: | 26.02.12 12:41 | ||
| Оценка: | |||
|
|
От: | Sharowarsheg | |
| Дата: | 26.02.12 14:03 | ||
| Оценка: | |||
1) Не формулируется математическая модель предметной области, не доказываются необходимые теоремы. Возможно не везде это требуется, но в нетривиальных случаях без этого не обойтись.
2) Не учитываются свойства системы, о которых надо помнить при проектировании каждой операции (например, это могут быть такие свойства, как безопасность, одновременный доступ к ресурсам, блокировки, какие-то инварианты предметной области)
3) Не осуществляется полный анализ всех возможных вариантов. Такой анализ вообще возможен только в случае, когда у нас есть нечто хотя бы напоминающее абстрактную* математическую модель.
|
|
От: | Sharowarsheg | |
| Дата: | 26.02.12 14:19 | ||
| Оценка: | +1 | ||
|
|
От: |
Sinclair
|
https://github.com/evilguest/ |
| Дата: | 26.02.12 15:48 | ||
| Оценка: | +1 | ||

|
От: | m e | |
| Дата: | 27.02.12 01:43 | ||
| Оценка: | |||
|
|
От: | Sharowarsheg | |
| Дата: | 27.02.12 05:01 | ||
| Оценка: | -1 | ||
|
|
От: | m e | |
| Дата: | 27.02.12 22:39 | ||
| Оценка: | |||

|
От: |
Pzz
|
https://github.com/alexpevzner |
| Дата: | 27.02.12 23:15 | ||
| Оценка: | |||
|
|
От: |
Pzz
|
https://github.com/alexpevzner |
| Дата: | 27.02.12 23:16 | ||
| Оценка: | |||
|
|
От: |
Undying
|
|
| Дата: | 28.02.12 03:35 | ||
| Оценка: | +1 | ||
|
|
От: | Sharowarsheg | |
| Дата: | 28.02.12 08:17 | ||
| Оценка: | |||
|
|
От: | HrorH | |
| Дата: | 28.02.12 14:23 | ||
| Оценка: | |||

|
От: |
Ziaw
|
|
| Дата: | 01.03.12 12:13 | ||
| Оценка: | |||
|
|
От: |
jhfrek
|
|
| Дата: | 01.03.12 12:50 | ||
| Оценка: | |||
|
|
От: | Klapaucius | |
| Дата: | 01.03.12 12:57 | ||
| Оценка: | |||
|
|
От: |
Ziaw
|
|
| Дата: | 01.03.12 13:36 | ||
| Оценка: | |||

|
От: | vshemm | |
| Дата: | 04.03.12 01:13 | ||
| Оценка: | |||

|
От: |
Mamut
|
http://dmitriid.com |
| Дата: | 07.03.12 09:06 | ||
| Оценка: | 17 (2) | ||
После того как я прочел книгу академика Алексея Николаевича Крылова “Мои воспоминания” жаркие споры на профессиональных формах о том, что программисты недостаточно используют математику, что когда космические корабли бороздят программы будут записываться как доказательства теорем и т.д., я невольно вспоминаю большую главу из этой книги под названием “Служба в Военно-морской академии и в Академии наук” (и ее раздел “Значение математики для кораблестроения”). Процитирую оттуда один фрагмент для демонстрации:
Знаменитый английский натуралист лет 70 тому назад сказал: «Математика подобно жернову перемалывает лишь то, что под него засыплют». Вы видели, что в строгой эвклидовой математике эта засыпка состоит из таких аксиом и постулатов, в справедливости которых инженер усомниться не может, а так как лишь эти аксиомы и постулаты «перемалываются» без добавления новых (а если что добавляется, то должно быть точно и ясно указано), то инженер и придает такую веру математическому доказательству. Но здесь необходимо постоянно иметь в виду следующее обстоятельство: когда конкретный вопрос приводится к вопросу математическому, то всегда приходится делать ряд допущений, ибо математика вместе с механикой оперируют над объектами идеальными, лишь более или менее близкими к объектам реальным, к которым инженер будет прилагать полученные математические выводы. Ясно, что сколько бы ни было точно математическое решение, оно не может быть точнее тех приближенных предпосылок, на коих оно основано. Об этом часто забывают, делают вначале какое-нибудь грубое приближенное предположение или допущение, часто даже не оговорив таковое, а затем придают полученной формуле гораздо большее доверие, нежели она заслуживает, и это потому, что ее вывод сложный.
Напомню, что это сказал не программист, а человек, занимавшийся кораблестроением – отраслью много более наукоемкой, чем программирование. И стоимость ошибки в которой много выше, чем в среднем по софтостроению.
|
|
От: |
jhfrek
|
|
| Дата: | 07.03.12 09:16 | ||
| Оценка: | |||
...
Хозяева Hyatt Regency – нового отеля в Канзас Сити, мечтали, чтобы всё у них было со всякими сопелками и свистелками. Архитектурная фирма, ответственная за дизайн здания, выступила с предложением сделать несколько галерей, которые крепились бы к потолку. Задумка была очень изящной. Вот только её воплощение привело к гибели более ста человек.
Недостаток проекта был прост до смешного:
Один длинный стержень был заменен на два коротких.
...
|
|
От: |
Carc
|
http://www.amlpages.com/home.php |
| Дата: | 07.03.12 09:46 | ||
| Оценка: | |||
Супер!M>После того как я прочел книгу академика Алексея Николаевича Крылова “Мои воспоминания” жаркие споры на профессиональных формах о том, что программисты недостаточно используют математику, что когда космические корабли бороздят программы будут записываться как доказательства теорем и т.д., я невольно вспоминаю большую главу из этой книги под названием “Служба в Военно-морской академии и в Академии наук” (и ее раздел “Значение математики для кораблестроения”). Процитирую оттуда один фрагмент для демонстрации:
M>
Знаменитый английский натуралист лет 70 тому назад сказал: «Математика подобно жернову перемалывает лишь то, что под него засыплют». Вы видели, что в строгой эвклидовой математике эта засыпка состоит из таких аксиом и постулатов, в справедливости которых инженер усомниться не может, а так как лишь эти аксиомы и постулаты «перемалываются» без добавления новых (а если что добавляется, то должно быть точно и ясно указано), то инженер и придает такую веру математическому доказательству. Но здесь необходимо постоянно иметь в виду следующее обстоятельство: когда конкретный вопрос приводится к вопросу математическому, то всегда приходится делать ряд допущений, ибо математика вместе с механикой оперируют над объектами идеальными, лишь более или менее близкими к объектам реальным, к которым инженер будет прилагать полученные математические выводы. Ясно, что сколько бы ни было точно математическое решение, оно не может быть точнее тех приближенных предпосылок, на коих оно основано. Об этом часто забывают, делают вначале какое-нибудь грубое приближенное предположение или допущение, часто даже не оговорив таковое, а затем придают полученной формуле гораздо большее доверие, нежели она заслуживает, и это потому, что ее вывод сложный.
M>
M>Напомню, что это сказал не программист, а человек, занимавшийся кораблестроением – отраслью много более наукоемкой, чем программирование. И стоимость ошибки в которой много выше, чем в среднем по софтостроению.
|
|
От: | HrorH | |
| Дата: | 07.03.12 11:17 | ||
| Оценка: | |||
|
|
От: |
Mamut
|
http://dmitriid.com |
| Дата: | 07.03.12 13:00 | ||
| Оценка: | |||
когда конкретный вопрос приводится к вопросу математическому, то всегда приходится делать ряд допущений, ибо математика вместе с механикой оперируют над объектами идеальными, лишь более или менее близкими к объектам реальным, к которым инженер будет прилагать полученные математические выводы.
|
|
От: | HrorH | |
| Дата: | 07.03.12 13:47 | ||
| Оценка: | |||
|
|
От: | Sharowarsheg | |
| Дата: | 07.03.12 14:00 | ||
| Оценка: | +1 | ||
|
|
От: |
Mamut
|
http://dmitriid.com |
| Дата: | 07.03.12 14:02 | ||
| Оценка: | 1 (1) +2 | ||
А что если предположить, что баг не должно быть вообще? Почему человек не может думать без ошибок? В чем причина ошибок?
Мне кажется, основная причина в том...
|
|
От: |
Mamut
|
http://dmitriid.com |
| Дата: | 07.03.12 14:03 | ||
| Оценка: | |||
|
|
От: | HrorH | |
| Дата: | 07.03.12 14:28 | ||
| Оценка: | +1 | ||
|
|
От: |
Mamut
|
http://dmitriid.com |
| Дата: | 07.03.12 14:33 | ||
| Оценка: | |||
|
|
От: | HrorH | |
| Дата: | 07.03.12 14:41 | ||
| Оценка: |

|
||
|
|
От: | HrorH | |
| Дата: | 07.03.12 15:04 | ||
| Оценка: | |||
|
|
От: |
Mamut
|
http://dmitriid.com |
| Дата: | 07.03.12 15:11 | ||
| Оценка: | -1 | ||
|
|
От: | HrorH | |
| Дата: | 07.03.12 15:16 | ||
| Оценка: | |||
|
|
От: |
Mamut
|
http://dmitriid.com |
| Дата: | 07.03.12 15:17 | ||
| Оценка: | |||
|
|
От: |
Mamut
|
http://dmitriid.com |
| Дата: | 07.03.12 15:20 | ||
| Оценка: | |||
|
|
От: |
jhfrek
|
|
| Дата: | 07.03.12 15:27 | ||
| Оценка: |
15 (1)
+1
|
||
|
|
От: | FR | |
| Дата: | 07.03.12 16:52 | ||
| Оценка: | |||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 07.03.12 19:07 | ||
| Оценка: | |||
|
|
От: |
minorlogic
|
|
| Дата: | 08.03.12 16:10 | ||
| Оценка: | |||
|
|
От: | HrorH | |
| Дата: | 09.03.12 13:12 | ||
| Оценка: | |||
|
|
От: | HrorH | |
| Дата: | 09.03.12 13:48 | ||
| Оценка: | |||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 09.03.12 14:07 | ||
| Оценка: | |||
|
|
От: | FR | |
| Дата: | 09.03.12 14:19 | ||
| Оценка: | |||
Из неприводимости числа Ω следует, что всеобъемлющей математической теории существовать не может. Бесконечное множество битов Ω составляет бесконечное множество математических фактов (является ли каждый выбранный бит единицей или нулем), которые не могут быть выведены из каких бы то ни было принципов, более простых, чем сама последовательность битов. Значит, сложность математики бесконечна, тогда как любая отдельная теория «всего на свете» характеризуется конечной сложностью и, следовательно, не может охватить все богатство мира математических истин
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 09.03.12 14:19 | ||
| Оценка: | |||
|
|
От: | FR | |
| Дата: | 09.03.12 14:22 | ||
| Оценка: | +1 | ||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 09.03.12 14:32 | ||
| Оценка: | |||
|
|
От: | FR | |
| Дата: | 09.03.12 14:55 | ||
| Оценка: | |||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 09.03.12 16:00 | ||
| Оценка: | |||

|
От: |
Vain
|
google.ru |
| Дата: | 09.03.12 16:05 | ||
| Оценка: | |||
|
|
От: | FR | |
| Дата: | 09.03.12 16:46 | ||
| Оценка: | |||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 09.03.12 17:02 | ||
| Оценка: | |||
|
|
От: | FR | |
| Дата: | 09.03.12 17:12 | ||
| Оценка: | |||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 09.03.12 17:21 | ||
| Оценка: | |||
|
|
От: | FR | |
| Дата: | 09.03.12 17:30 | ||
| Оценка: | |||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 09.03.12 17:49 | ||
| Оценка: | |||
|
|
От: | FR | |
| Дата: | 09.03.12 17:56 | ||
| Оценка: | |||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 09.03.12 18:01 | ||
| Оценка: |
|
||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 09.03.12 18:50 | ||
| Оценка: | |||
|
|
От: | FR | |
| Дата: | 10.03.12 02:45 | ||
| Оценка: | |||
|
|
От: |
jhfrek
|
|
| Дата: | 10.03.12 06:15 | ||
| Оценка: | |||
|
|
От: | HrorH | |
| Дата: | 11.03.12 09:46 | ||
| Оценка: | |||
|
|
От: | HrorH | |
| Дата: | 11.03.12 10:05 | ||
| Оценка: | |||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 11.03.12 12:13 | ||
| Оценка: | |||
|
|
От: | HrorH | |
| Дата: | 11.03.12 12:42 | ||
| Оценка: | |||
FR>Из неприводимости числа Ω следует, что всеобъемлющей математической теории существовать не может. Бесконечное множество битов Ω составляет бесконечное множество математических фактов (является ли каждый выбранный бит единицей или нулем), которые не могут быть выведены из каких бы то ни было принципов, более простых, чем сама последовательность битов. Значит, сложность математики бесконечна, тогда как любая отдельная теория «всего на свете» характеризуется конечной сложностью и, следовательно, не может охватить все богатство мира математических истин
|
|
От: | HrorH | |
| Дата: | 11.03.12 13:28 | ||
| Оценка: | |||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 11.03.12 14:39 | ||
| Оценка: | +1 | ||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 11.03.12 14:57 | ||
| Оценка: | |||
|
|
От: | HrorH | |
| Дата: | 11.03.12 15:12 | ||
| Оценка: | |||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 11.03.12 15:19 | ||
| Оценка: | |||
|
|
От: | HrorH | |
| Дата: | 11.03.12 15:20 | ||
| Оценка: | |||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 11.03.12 15:41 | ||
| Оценка: | |||
|
|
От: |
jhfrek
|
|
| Дата: | 11.03.12 15:53 | ||
| Оценка: | +1 | ||
|
|
От: |
DarkGray
|
http://blog.metatech.ru/post/ogni-razrabotki.aspx |
| Дата: | 11.03.12 16:07 | ||
| Оценка: | +2 | ||
|
|
От: | FR | |
| Дата: | 12.03.12 04:23 | ||
| Оценка: | |||
|
|
От: | HrorH | |
| Дата: | 12.03.12 08:38 | ||
| Оценка: | |||
|
|
От: | HrorH | |
| Дата: | 12.03.12 08:48 | ||
| Оценка: | |||
|
|
От: | FR | |
| Дата: | 12.03.12 09:02 | ||
| Оценка: | |||
|
|
От: |
jhfrek
|
|
| Дата: | 12.03.12 09:13 | ||
| Оценка: | |||
|
|
От: | HrorH | |
| Дата: | 12.03.12 12:30 | ||
| Оценка: | |||
