Я работаю программистом баз данных, в основном занимаюсь тем, что пишу процедуры на PL/SQL. Специальность у меня — Информационные технологии, так что к созданию программ на основе процедурного подхода подхожу довольно грамотно — разбиваю сложные алгоритма на части, те еще бью, и так до процедур размером в 20-50 строк. Когда так получается, я считаю, что программа написана правильно. Но иногда встречаются задачи, которые очень трудно разбить, или при разбиении получается слижком громоздкие конструкции. И программа получается довольно сложной. Смотрю я на нее, и впадаю в уныние — потому что упростить не могу
В общем вопрос — как бояться со сложно-алгоритмо-фобией? =)
01.11.08 12:04: Перенесено модератором из 'О жизни' — Хитрик Денис
Здравствуйте, minorlogic, Вы писали:
__>>В общем вопрос — как бояться со сложно-алгоритмо-фобией? =)
M>Пример в студию , может не все так плохо то ?
Действительно, было бы интересно увидеть примеры. Ведь многие классы задач, требующих многоэтажные конструкции if или switch при процедурном подходе,
очень изящно решаются с помощью ООП (Джаву можно подключить через PL/SQL). Кстати, это уже будет не алгоритм в классическом понимании этого слова, а какая-нибудь "бизнес-логика", под которую ООП заточено очень хорошо.
Здравствуйте, __kain, Вы писали:
__>Привет всем!
__>И программа получается довольно сложной. Смотрю я на нее, и впадаю в уныние — потому что упростить не могу
Ну и что? В жизни встречаются сложные вещи.
__>В общем вопрос — как бояться со сложно-алгоритмо-фобией? =)
А не нужно с ней бороться, это полезная фобия. Она удержит вас от того, чтобы всю жизнь искать философский камень и не найти.
__>Я работаю программистом баз данных, в основном занимаюсь тем, что пишу процедуры на PL/SQL. Специальность у меня — Информационные технологии, так что к созданию программ на основе процедурного подхода подхожу довольно грамотно — разбиваю сложные алгоритма на части, те еще бью, и так до процедур размером в 20-50 строк. Когда так получается, я считаю, что программа написана правильно. Но иногда встречаются задачи, которые очень трудно разбить, или при разбиении получается слижком громоздкие конструкции. И программа получается довольно сложной. Смотрю я на нее, и впадаю в уныние — потому что упростить не могу
Конкретно для PL/SQL большое количество строк не так уж страшно, т.к. процедура на много строк может сожержать один-единственный SQL-запрос, код которого может быть даже не на один экран. (причем длинный код запроса получается при аккуратном его форматировании, т.е. когда каждая значащая часть кода вынесена на отдельную строку). И в большинстве случаев правильнее этот запрос так и оставить и поручить его оптимизацию базе, чем пытаться вручную декомпозировать (и, соотвественно, получить вместо одного SQL-запроса несколько).
А бороться с фобией сложных процедур надо традиционными методами — подробным комментированием: что делается, зачем и почему именно так
Сейчас попытаюсь в двух словах описать проблему, которую я решаю, а позже приведу код.
На данный момент, я перерабатываю систему учета посещаемости студентов ВУЗа (пишу заново). Данные для оценки посещений получаются автоматически, за счет проходных турникетов. Можно сказать, что такой подход не точен (мало ли где в универе студент шляется), но практика показала, что если в системе посещаемости студент не ходит, то он и в действительности не ходит.
Старая система работает абсолютно негибко — всякие "неприятности", вроде переноса с одного дня занятий на другой (например, в связи с праздниками), системой никак не обрабатываются, и в результате и без того грубые данные еще сильней портятся.
Наверное, не стоит углубляться в дебри заморочек, именуемых бизнесс-правилами, обрисую общую ситуацию. Есть шаблон расписания, с привязкой к дате начала его действия. У расписания есть временные интервалы — периоды, в течение которых человек должен быть "внутри". Расписания бывают разных приоритетов (1-основное, 2-исключений). Накладывая 2 на 1, получаем "реальное" положение дел.
Для того чтобы оценить, когда кто должен ходить, нужно сгенерировать последовательность интервалов с привязками к конкретной дате и времени, а потом в этой последовательности указывать, кто и как ходил. Так вот самое неприятное — генерировать эту последовательность... Потому как нужно правильно отметить студента, учесть правила, ... В этом моменте наслаиваются правила трех подсистем — "Расписание", "Кадры студентов", "Рабочая нагрузка на преподавателей". И поэтому генерировать не просто В общем все это — приамбула к коду ))))))))
__>Для того чтобы оценить, когда кто должен ходить, нужно сгенерировать последовательность интервалов с привязками к конкретной дате и времени, а потом в этой последовательности указывать, кто и как ходил. Так вот самое неприятное — генерировать эту последовательность... Потому как нужно правильно отметить студента, учесть правила, ... В этом моменте наслаиваются правила трех подсистем — "Расписание", "Кадры студентов", "Рабочая нагрузка на преподавателей".
Если вот это все написать в виде комментариев внутри PL/SQL-процедуры, то код уже покажется не таким страшным, как раньше. Тут общий принцип такой: чем сложнее код и чем менее он очевиден — тем больше в нем надо комментариев
А своим первым постом я хотел сказать, что именно для PL/SQL длиная функция и сложная функция — это совсем не одно и то же. Потому что код на PL/SQL — это симбиоз двух подходов к программированию: алгоритмического (чистый PL/SQL) и декларативного (SQL)
Пусть, например, есть какая-нибудь такая функция:
FUNCTION some_proc() RETURN INTEGER
IS
x INTEGER;
BEGIN
SELECT <что-то> INTO x
FROM <много-много таблиц>
WHERE( <много-много условий> )
AND EXISTS(
SELECT <огромадный вложенный запрос на 100 строк кода...>
...
<и т.д.>
)
RETURN x;
END some_proc;
Сложный ли здесь алгоритм? Алгоритм здесь тривиальный: сделали запрос, вернули его результат.
Сложный ли запрос внутри этого алгоритма? Да, запрос сложный.
Надо ли в этом примере декомпозировать алгоритм? Нет, декомпозировать здесь абсолютно нечего. Главное — к запросу и его частям написать хорошие комментарии.
Кстати, если рассматривать запрос на SQL, то для него некий аналог декомпозиции — это завернуть часть запроса в отдельное представление (view). Но это не для всякого запроса можно сделать.
Здравствуйте, __kain, Вы писали:
__>Сейчас попытаюсь в двух словах описать проблему, которую я решаю, а позже приведу код.
__>На данный момент, я перерабатываю систему учета посещаемости студентов ВУЗа (пишу заново). Данные для оценки посещений получаются автоматически, за счет проходных турникетов. Можно сказать, что такой подход не точен (мало ли где в универе студент шляется), но практика показала, что если в системе посещаемости студент не ходит, то он и в действительности не ходит.
Хм... Вообще-то последнее утверждение тривиально — если, конечно, нельзя пройти помимо турникета.
Если не секрет — какой университет ? Мне просто как преподавателю интересно... Честно говоря, мне бы и в голову не пришло бы, что такое где-нибудь может быть.
Здравствуйте, klopodav, Вы писали:
K>А своим первым постом я хотел сказать, что именно для PL/SQL длиная функция и сложная функция — это совсем не одно и то же. Потому что код на PL/SQL — это симбиоз двух подходов к программированию: алгоритмического (чистый PL/SQL) и декларативного (SQL)
K>Сложный ли здесь алгоритм? Алгоритм здесь тривиальный: сделали запрос, вернули его результат. K>Сложный ли запрос внутри этого алгоритма? Да, запрос сложный. K>Надо ли в этом примере декомпозировать алгоритм? Нет, декомпозировать здесь абсолютно нечего. Главное — к запросу и его частям написать хорошие комментарии.
Абсолютно с Вами согласен!
K>Кстати, если рассматривать запрос на SQL, то для него некий аналог декомпозиции — это завернуть часть запроса в отдельное представление (view).
Да, в принципе я так и делаю. Однообразные соединения отправляю во вью, а потом их использую. В общем, подождите пару дней, не буду голословным и приведу пример!
2 Pavel Dvorkin
ВУЗ Ростовский, называется РГУПС (Ростовский Государственный Университет Путей Сообщения).
Задумка получения "халявных" данных о посещаемости хорошая, осталось ее до ума довести А вообще эта система — любимая погремушка деканатов и проректоров
Здравствуйте, __kain, Вы писали:
__>Привет всем!
__>Я работаю программистом баз данных, в основном занимаюсь тем, что пишу процедуры на PL/SQL. Специальность у меня — Информационные технологии, так что к созданию программ на основе процедурного подхода подхожу довольно грамотно — разбиваю сложные алгоритма на части, те еще бью, и так до процедур размером в 20-50 строк. Когда так получается, я считаю, что программа написана правильно. Но иногда встречаются задачи, которые очень трудно разбить, или при разбиении получается слижком громоздкие конструкции. И программа получается довольно сложной. Смотрю я на нее, и впадаю в уныние — потому что упростить не могу
__>В общем вопрос — как бояться со сложно-алгоритмо-фобией? =)
Сложно посоветовать что-то конкретное, поэтому ограничусь
общими советами.
1. Сначала надо разобраться с логической структурой базы данных,
упростить в случае необходимости. Сложность алгоритмов зависит
от того, насколько хорошо спроектирована база данных. В твоем случае
структура базы довольно сложная, тем более что используются темпоральные
данные, так что этому надо уделить особое внимание.
2. Процедурный код упрощается путем разбиения на части, как ты и делаешь.
Код со сложной логикой (признак такого кода — много сложных вложенных операторов
if, в которых трудно разобраться) можно упростить, например, если сначала
описать решение при помощи таблицы решений, а потом уже на ее основе
писать код.
3. Сложные SQL-запросы можно упростить несколькими способами:
— Использовать представления для выделения отдельных частей
запроса, как уже было сказано выше.
— Использовать WITH для улучшения читабельности запроса
(описано, например, в блоге Кевина Мида).
— Писать свои функции для упрощения сложных выражений в запросах
— Использовать табличные функции.
Уже обсуждалось и тут тоже... CTE (Common Table Expressions) называется... Очень удобно использовать для рекурсий, построения деревьев, например, в MS SQL... в оракле для этого давно CONNECT BY есть, при этом в Оракле CTE и CONNECT BY можно смешивать ...
Вот в MS SQL есть табличные функции с параметрами, а в Оракле ничего подобного нет, но в Оракле есть Пакеты, а подобного нет в MS SQL... они словно сговорились... =((
2 Flying Dutchman > В твоем случае структура базы довольно сложная, тем более что используются темпоральные данные, так что этому надо уделить особое внимание.
Структуру я весь диплом проектировал, и потом еще месяц =) Она получилась универсальной и вроде более-менее простой, но, действительно, наличие темпоральных данных только усложняет дело. Причем все эти данные могут потом еще и перегенерироваться (полностью и частично)... Я тут подумал, нужно наверное в структуру еще что-то добавить, чтобы в коде нужно было проводить меньше вычислений.
> Код со сложной логикой (признак такого кода — много сложных вложенных операторов if, в которых трудно разобраться)
В моем случае, это большая вложенность и большая осмысленность каждого курсора выборки данных...
> 3. Сложные SQL-запросы можно упростить несколькими способами:
Спасибо
В общем я понял, нет неразрешаемых проблем, просто мне нехватает теоретической базы Буду изучать предложенную матчасть
Наконец принес код. Прошу не вчитываться в него, это только пробный вариант, да и непонятен он будет. Просто взгляните на картинку
DECLARE
PROCEDURE BuildIntervalSeq(p_att_User IN
p_date_from IN TIMESTAMP := NULL,
p_date_to IN TIMESTAMP := NULL) IS
v_priority_idz isa_att.TimeTableType.idz%TYPE;
v_time_table_idz isa_att.TimeTable.idz%TYPE;
v_index BINARY_INTEGER;
v_date_offset TIMESTAMP;
v_interval_offset TIMESTAMP;
v_time_step INTERVAL DAY TO SECOND := p_att_common.GetSingleAdjustment('STUD_RASP_DUR');
TYPE IntervalArray IS TABLE OF isa_att.TimeInterval%ROWTYPE;
v_intervalArray IntervalArray;
-- Выбрать типы расписаний по приоритетам.CURSOR cTimeTablePriority IS
SELECT idz
FROM isa_att.TimeTableType
ORDER BY priority ASC;
-- Выбираем расписания, принадлежащие
-- иерархическим группам студентов.CURSOR cTimeTableCur IS
SELECT TimeTable_view.*
FROM isa_att.TimeTable_view,
isa_att.HierarchyGroup
WHERE HierarchyGroup.s_HierarchyType = p_att_common.GetSingleAdjustment('STUD_HIERARCHY')
AND TimeTable_view.s_Timetabletype = v_priority_idz
AND TimeTable_view.s_HierarchyGroup = HierarchyGroup.Idz
AND SYSTIMESTAMP BETWEEN TimeTable_view.Validfrom
AND NVL(TimeTable_view.ValidTo, SYSTIMESTAMP);
CURSOR cTimeIntervals IS
SELECT *
FROM isa_att.TimeInterval
WHERE s_TimeTable = v_time_table_idz
ORDER BY fl_nad_chertoy DESC, TimeOffset;
-- Выбираем расписание и валидных
-- юзеров для этого времениCURSOR cTimeTableValidView IS
SELECT *
FROM isa_att.TimetableValid_View
WHERE s_TimeTable = v_time_table_idz
AND s_attUser = (SELECT idz FROM isa_att.AttUser where s_teksost = 40351);
BEGIN
v_intervalArray := IntervalArray();
FOR curPriority IN cTimeTablePriority LOOP
v_priority_idz := curPriority.Idz;
FOR curTimeTable IN cTimeTableCur LOOP
v_time_table_idz := curTimeTable.Idz;
-- Выбираем в массив для многократного использованияOPEN cTimeIntervals;
FETCH cTimeIntervals BULK COLLECT INTO v_intervalArray;
CLOSE cTimeIntervals;
FOR curUserValidView IN cTimeTableValidView LOOP
-- Получили временную метку начала расписания: отступаем "назад" до понедельника,
-- т.к. занятия начинаются не обязательно в понедельник, а отсчет
-- временных интервалов начинается с понедельника.
v_date_offset := curTimeTable.ValidFrom - TO_NUMBER(TO_CHAR(curTimeTable.Validfrom, 'D')) + 1;
-- <Перебираем даты>
LOOP
EXIT WHEN v_date_offset > curTimeTable.ValidTo;
-- <Перебираем интервалы>
v_index := v_intervalArray.FIRST;
LOOP
EXIT WHEN v_index IS NULL;
v_interval_offset := v_intervalArray(v_index).TimeOffset + v_date_offset;
IF v_intervalArray(v_index).fl_nad_chertoy = 0 THEN
v_interval_offset := v_interval_offset + 7;
END IF;
IF v_interval_offset >= curTimeTable.ValidFrom THEN--dbms_output.put_line(TO_CHAR(v_interval_offset, 'DD.MM.YYYY HH24:MI'));
DoLogic (v_interval_offset,
v_intervalArray(v_index).Duration,
curUserValidView.s_AttUser,
curUserValidView.Validfrom,
curUserValidView.Validto,
curTimeTable.s_Hierarchygroup,
curTimeTable.Idz,
v_intervalArray(v_index).idz);
END IF;
v_index := v_intervalArray.NEXT(v_index);
END LOOP; -- </Перебираем интервалы>
v_date_offset := v_date_offset + v_time_step;
END LOOP; -- </Перебираем даты>END LOOP; -- </Перебираем пользователей>END LOOP;
END LOOP;
END;
BEGIN
BuildIntervalSeq;
END;
Здравствуйте, Pavel Dvorkin, Вы писали:
PD>Здравствуйте, __kain, Вы писали:
__>>Сейчас попытаюсь в двух словах описать проблему, которую я решаю, а позже приведу код.
__>>На данный момент, я перерабатываю систему учета посещаемости студентов ВУЗа (пишу заново). Данные для оценки посещений получаются автоматически, за счет проходных турникетов. Можно сказать, что такой подход не точен (мало ли где в универе студент шляется), но практика показала, что если в системе посещаемости студент не ходит, то он и в действительности не ходит.
PD>Хм... Вообще-то последнее утверждение тривиально — если, конечно, нельзя пройти помимо турникета.
PD>Если не секрет — какой университет ? Мне просто как преподавателю интересно... Честно говоря, мне бы и в голову не пришло бы, что такое где-нибудь может быть.
Такое даже в некоторых школах (в Москве) есть.
У учеников есть персональные магнитные карты, которые они прикладывают к турникету. В этот момент на экране монитора у охранника высвечивается фотография ученика и какие-то данные (наверное опаздывает ли учник в соответствии с расписанием). Если опаздывает, могут поругать =))
А также записывается в базу данных время входа и выхода из школы. В конце каждого месяца данные распечатываются и передаются классному руководителю.
Здравствуйте, maggot, Вы писали:
M>Такое даже в некоторых школах (в Москве) есть. M>У учеников есть персональные магнитные карты, которые они прикладывают к турникету. В этот момент на экране монитора у охранника высвечивается фотография ученика и какие-то данные (наверное опаздывает ли учник в соответствии с расписанием). Если опаздывает, могут поругать =)) M>А также записывается в базу данных время входа и выхода из школы. В конце каждого месяца данные распечатываются и передаются классному руководителю.
У мну подсистема связана с кадрами, рабочей нагрузкой и учебным расписанием. Отчет выдается в виде соответствия расписания и посещения его человеком, т.е. автоматизация полная. Если сделать тупо, то да, за месяц можно. А если сделать нормально — с учетом плавающих, периодических и других графиков посещений, то тут прийдется извилины напрягать!
Здравствуйте, __kain, Вы писали:
__>Наконец принес код. Прошу не вчитываться в него, это только пробный вариант, да и непонятен он будет. Просто взгляните на картинку
Итого, что я вижу — несколько запросов, все под курсоры и далее пошла их ручная обработка в циклах...
Можно я выступлю с радикальным предложением?
А тебе точно надо все это писать на Pl/SQL? Может вынести обработку данных из базы в отдельное приложение, написанное на Java или .NET?
Меня вообще немного коробит, когда в SQL-коде появляются курсоры и циклы, а тут в относительно небольшой процедуре 4 вложенных цикла да еще и условное ветвление в теле, а все запросы — только для курсоров...
Нафига, а?
Императивная обработка данных гораздо лучше делается в императивных языках. А ООП для данной задачи позволит лучше ее декомпозировать, построить более красивое и удобное решение. Из базы тянуть естественно не все, а только то что надо, отдельными запросами (либо более "чистыми" хранимками, либо вообще через view)
SQL хорош для описания декларативных запросов, которые потом база эффективно оптимизирует и выбирает нужные данных. Оптимизировать циклы и прочую императивщину база умеет очень плохо. Фактически, вынеся императивную обработку из процедуры на верхний уровень можно получить даже заметное увеличение производительности (зависит от объемов данных и сложности вычислений над ними).
И уж точно будет удобнее программировать (именно в императивном стиле), чем может предложить PL/SQL...
За Java или .NET меня по голове не полгадят, но сделать по-другому мало мальский читаемый и понимаемый с первого взгляда код, видимо по-другому не выйдет.
Кстати, а что вы думаете на счет объектных возможностей Oracle? Может с помощью них получится нормально сделать?
Здравствуйте, __kain, Вы писали:
__>Здравствуйте, fmiracle! __>За Java или .NET меня по голове не полгадят, но сделать по-другому мало мальский читаемый и понимаемый с первого взгляда код, видимо по-другому не выйдет.
Это аспирантская работа? Расскажи, что это новое и перспективное направление
Серьезно же — я просто не вижу резона, почему это должно строиться чисто на PL SQL. Интерфейс приложения на чем делается? Или тоже возможностми самого Оракла?
__>Кстати, а что вы думаете на счет объектных возможностей Oracle? Может с помощью них получится нормально сделать?
К сожалению, ничего не могу сказать, не работал.
Но можно, например, писать в Оракле хранимки на Java. Непосредственно это я тоже не пробовал, но пробовал аналогичные хранимки на .net в MS SQL — для сложной императивной обработки вполне приятно.
__>Наконец принес код. Прошу не вчитываться в него, это только пробный вариант, да и непонятен он будет. Просто взгляните на картинку
Код написана с использованием курсоров, что сильно усложняет
программу (в принципе, в 95% всех задач курсоры не нужны).
Если переписать все в декларативном виде без курсоров,
программа получится значительно проще.
Здравствуйте, fmiracle, Вы писали:
F>Это аспирантская работа? Расскажи, что это новое и перспективное направление
Нет, это подсистема промышленного сервера
F>Серьезно же — я просто не вижу резона, почему это должно строиться чисто на PL SQL. Интерфейс приложения на чем делается? Или тоже возможностми самого Оракла?
Если все лежит на сервере, то во-первых, клиенту ставить ничего не нужно (учитывая слабость клиентских машин-это существенный довод). И потом, если будет где-то ошибка, в базе данных ее легче поправить будет.
2 Flying Dutchman F>Код написана с использованием курсоров, что сильно усложняет F>программу (в принципе, в 95% всех задач курсоры не нужны). F>Если переписать все в декларативном виде без курсоров, F>программа получится значительно проще.
Не понял, что вы имеете в виду? По-моему так наоборо проще, селектов в коде нету
Здравствуйте, __kain, Вы писали:
__>2 Flying Dutchman F>>Код написана с использованием курсоров, что сильно усложняет F>>программу (в принципе, в 95% всех задач курсоры не нужны). F>>Если переписать все в декларативном виде без курсоров, F>>программа получится значительно проще. __>Не понял, что вы имеете в виду? По-моему так наоборо проще, селектов в коде нету
Ну так с селектами оно проще будет, чем с курсорами. Проблема в том, что (судя по
твоему коду) ты думаешь и пишешь в процедурном стиле, тогда как для
эффективной работы на SQL нужно думать по-другому.
Как хорошо кто-то сказал (кажется, Джо Селко):
Before SQL programmers could begin working with OLTP (On-Line Transaction
Processing) systems, they had to unlearn procedural, record-oriented
programming before moving on to SQLs declarative, set-oriented programming
И этот переход к декларативному программированию сложен для
тех, кто занимался только процедурным программированием.
Для сравнения, мой текущий проект во многом похож на твой.
Я участвую в разработке большой системы для компании — поставщика
временного персонала. Программа предназначена для планирования работников,
расстановки их по сменам и т.д. Также используется несколько типов
расписаний с разнами приоритетами (точнее, это данные о доступности работника
для работы в зависимости от дня недели, например). Для получения
данных о доступности в определенный день нужно накладывать разные
типы расписаний друг на друга, а также генерировать интервалы, как у тебя.
Так вот, если я хочу с учетом всех расписаний и т.д. получить информацию
о доступности работников во времени, у меня это все делается одним запросом,
который состоит из 6 довольно простых select'ов, соединенных при помощи union.
Твой код можно сильно упростить, если переписать его чисто декларативно.
(если и не весь, то большую часть).
Если интересуют подробности, сообщи следующую информацию:
— Структуру используемых таблиц
— Точное описание того, что нужно сделать.
Здравствуйте, __kain, Вы писали:
F>>Серьезно же — я просто не вижу резона, почему это должно строиться чисто на PL SQL. Интерфейс приложения на чем делается? Или тоже возможностми самого Оракла? __>Если все лежит на сервере, то во-первых, клиенту ставить ничего не нужно (учитывая слабость клиентских машин-это существенный довод). И потом, если будет где-то ошибка, в базе данных ее легче поправить будет.
Понятно, но вообще это ничего не значит Та же проблема решается трехзвенкой — application server к которому уже коннектятся пользователи. Простейший пример — веб-приложения (appServer — iis+asp.net, клиент — браузер).
И к клиентам требования минимальны и изменения производятся только на одной машине.
F>>Если переписать все в декларативном виде без курсоров, F>>программа получится значительно проще. __>Не понял, что вы имеете в виду? По-моему так наоборо проще, селектов в коде нету
SQL — декларативный язык, и базы данных ориентированы именно на него. В том числе и по производительности.
Императивные конструкции в хранимках (расширения PlSql) — это костыли, как с точки зрения дизайна, так и эффективности.
Если хочешь программировать чисто в Оракле — изучай глубже SQL и максимально описывай все в запросах, а не пытайся сэмулировать С в Оракле. То есть хранимка остается, но в ней должны быть не итерации по курсорам, а набор запросов (или вообще 1 запрос). Императивные конструкции — в минимальнейшем количестве и наиболее простые (например, условным оператором проверив параметры, или результат запроса, выполнить далее тот или иной запрос). А лучше — вообще без них.
FD>Before SQL programmers could begin working with OLTP (On-Line Transaction
FD>Processing) systems, they had to unlearn procedural, record-oriented
FD>programming before moving on to SQLs declarative, set-oriented programming
Ценная мысль, однако
FD>Твой код можно сильно упростить, если переписать его чисто декларативно. FD>(если и не весь, то большую часть).
FD>Если интересуют подробности, сообщи следующую информацию: FD>- Структуру используемых таблиц FD>- Точное описание того, что нужно сделать.
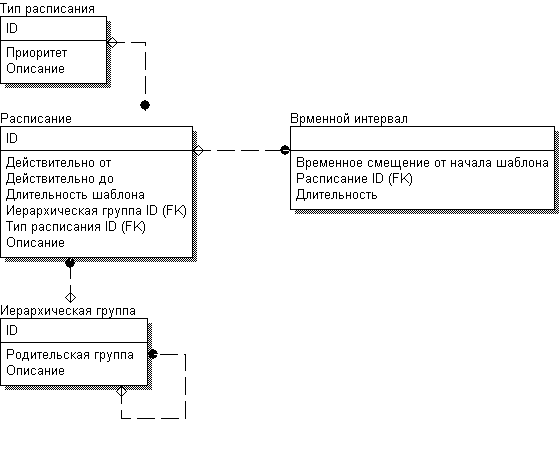
Для начала приведу упрощенную схему (~6 кб):
Опишу словами. Пользователи объедены в группы, группы выстроены в иерархию. Изменения в верхней точке иерархии спускаются вниз. Если временные интервалы расписания пересекаются, то верхний интервал разбивает нижний. Поясню: пусть нижний интервал начинается в 9:00 и заканчивается в 12:00, то после наложения "верхнего" интервала 10:00-11:00 должно получиться так: 9:00-10:00; 10:00-11:00; 11:00-12:00.
Расписание я организовал так: есть временной шаблон, который повторяется с периодичностью в "Длительность шаблона". Шаблон начинаем применять с "Действительно от". У временного интервала указано смещение во времени относительно начала действия шаблона, указана длительность. В итоге получился гибкий шаблон, под который можно засунуть луюбой график, имеющий период
Итак задача такая: сгенерировать последовательность интервалов с привязкой к конкретной дате, а также учесть иерархию, и приоритет расписания. Если вы очитали до сюда, у Вас крепкие нервы
На мой взгляд, накладывать расписание вниз по иерархии чисто декларативно невозможно.
Здравствуйте, fmiracle, Вы писали:
F>Понятно, но вообще это ничего не значит Та же проблема решается трехзвенкой — application server к которому уже коннектятся пользователи. Простейший пример — веб-приложения (appServer — iis+asp.net, клиент — браузер). F>И к клиентам требования минимальны и изменения производятся только на одной машине.
У нас для трехзвенки Java используется. Но я согласен с Flying Dutchman, в том, что можно сделать проще и на SQL
F>SQL — декларативный язык, и базы данных ориентированы именно на него. В том числе и по производительности. F>Императивные конструкции в хранимках (расширения PlSql) — это костыли, как с точки зрения дизайна, так и эффективности.
F>Если хочешь программировать чисто в Оракле — изучай глубже SQL и максимально описывай все в запросах, а не пытайся сэмулировать С в Оракле. То есть хранимка остается, но в ней должны быть не итерации по курсорам, а набор запросов (или вообще 1 запрос). Императивные конструкции — в минимальнейшем количестве и наиболее простые (например, условным оператором проверив параметры, или результат запроса, выполнить далее тот или иной запрос). А лучше — вообще без них.
F>Сперва непривычно, но оно того стоит.
Интересный и правильный ход мыслей. Я запомню
__>Опишу словами. Пользователи объедены в группы, группы выстроены в иерархию. Изменения в верхней точке иерархии спускаются вниз. Если временные интервалы расписания пересекаются, то верхний интервал разбивает нижний. Поясню: пусть нижний интервал начинается в 9:00 и заканчивается в 12:00, то после наложения "верхнего" интервала 10:00-11:00 должно получиться так: 9:00-10:00; 10:00-11:00; 11:00-12:00.
Я правильно понял, что:
1. "Верхний" интервал — это интервал с большим приоритетом или
2. Стоящий выше в иерархии ?
__>Расписание я организовал так: есть временной шаблон, который повторяется с периодичностью в "Длительность шаблона".
В каких единицах выражается "Длительность шаблона" ?
__>Шаблон начинаем применять с "Действительно от". У временного интервала указано смещение во времени относительно начала действия шаблона, указана длительность.
"Шаблон" — это набор интервалов ?
__>В итоге получился гибкий шаблон, под который можно засунуть луюбой график, имеющий период
Я не совсем в этом разобрался. Не мог бы ты прислать немного данных из таблиц
для примера ? Желательно скрипт в виде набора команд CREATE TABLE для создания
таблиц + INSERT для их заполнения.
__>На мой взгляд, накладывать расписание вниз по иерархии чисто декларативно невозможно.
Здравствуйте, Flying Dutchman, Вы писали:
FD>Я правильно понял, что: FD>1. "Верхний" интервал — это интервал с большим приоритетом или FD>2. Стоящий выше в иерархии ?
Оба раза вы правы Пусть есть иерархическая группа: Университет -> Факультет -> Кафедра -> Группа. Тогда, если у Университета есть расписание, то интервалы университета будут более приоритетным ко всем другим интервалам подчиненных узлов.
FD>В каких единицах выражается "Длительность шаблона" ?
INTERVAL DAY TO SECOND
FD>"Шаблон" — это набор интервалов ?
"Шаблон" — набор интервалов и указание их длительности.
FD>Я не совсем в этом разобрался. Не мог бы ты прислать немного данных из таблиц FD>для примера ? Желательно скрипт в виде набора команд CREATE TABLE для создания FD>таблиц + INSERT для их заполнения.
Понять действительно сразу не получится — я своему дипломному руководителю вживую полчаса рассказывал, а он программер со стажем...
Ну, держитесь, скрипт для создания схемы и данных:
-- Создание таблицы "Тип расписания"CREATE TABLE TimeTableType (
Descript VARCHAR2(128),
Priority NUMBER(1),
id NUMBER(1),
PRIMARY KEY (id)
)
-- Создать таблицу иерархических группCREATE TABLE HierarchyGroup (
id NUMBER,
Descript VARCHAR2(128),
s_parent NUMBER,
PRIMARY KEY (id),
FOREIGN KEY (s_parent) REFERENCES HierarchyGroup (id)
)
-- Создать таблицу расписаниеCREATE TABLE TimeTable (
id NUMBER,
ValidFrom TIMESTAMP,
ValidTo TIMESTAMP,
Duration INTERVAL DAY TO SECOND,
s_HierarchyGroup NUMBER,
s_TimeTableType NUMBER(1),
Descript VARCHAR2(128),
PRIMARY KEY(id),
FOREIGN KEY (s_HierarchyGroup) REFERENCES HierarchyGroup (Id)
)
-- Таблица временных интерваловCREATE TABLE TimeInterval (
id NUMBER,
TimeOffset INTERVAL DAY TO SECOND,
Duration INTERVAL DAY TO SECOND,
s_TimeTable NUMBER,
FOREIGN KEY (s_TimeTable) REFERENCES TimeTable (id),
PRIMARY KEY (id)
)
-- Вставляем данныеBEGIN
INSERT INTO TimeTableType (Id, Priority, Descript) VALUES (1, 1, 'Основное расписание');
INSERT INTO TimeTableType (Id, Priority, Descript) VALUES (2, 2, 'Расписание исключений');
INSERT INTO HierarchyGroup (Id, Descript, s_Parent) VALUES (1, 'Университет (самый верхний узел)', NULL);
INSERT INTO HierarchyGroup (Id, Descript, s_Parent) VALUES (2, 'Факультет АТС (родитель-Университет)', 1);
INSERT INTO HierarchyGroup (Id, Descript, s_Parent) VALUES (3, 'Факультет ДСМ (родитель-Университет)', 1);
INSERT INTO HierarchyGroup (Id, Descript, s_Parent) VALUES (4, 'Кафедра ВТ и АСУ (родитель-факультет АТС)', 2);
INSERT INTO HierarchyGroup (Id, Descript, s_Parent) VALUES (5, 'Кафедра АМС (родитель-факультет АТС)', 2);
INSERT INTO HierarchyGroup (Id, Descript, s_parent) VALUES (6, 'Группа АИ-5-010 (родитель-кафедра ВТ и АСУ)', 4);
INSERT INTO TimeTable (Id, Validfrom, Validto, Duration, s_Hierarchygroup, Descript, s_TimeTableType)
VALUES (1,
TO_TIMESTAMP('01.09.2008', 'DD.MM.YYYY'),
TO_TIMESTAMP('31.12.2008', 'DD.MM.YYYY'),
'+14 00:00:00.0',
6,
'Стандартное расписание',
1);
FOR l_ned IN 1..5 LOOP
INSERT INTO TimeInterval (id, TimeOffset, Duration, s_TimeTable)
VALUES ((l_ned-1) * 5 + 1, '+' || TO_CHAR(l_ned-1) || ' 8:20:00.0', '+00 1:30:00.0', 1);
INSERT INTO TimeInterval (id, TimeOffset, Duration, s_TimeTable)
VALUES ((l_ned-1) * 5 + 2, '+' || TO_CHAR(l_ned-1) || ' 10:05:00.0', '+00 1:30:00.0', 1);
INSERT INTO TimeInterval (id, TimeOffset, Duration, s_TimeTable)
VALUES ((l_ned-1) * 5 + 3, '+' || TO_CHAR(l_ned-1) || ' 12:05:00.0', '+00 1:30:00.0', 1);
INSERT INTO TimeInterval (id, TimeOffset, Duration, s_TimeTable)
VALUES ((l_ned-1) * 5 + 4, '+' || TO_CHAR(l_ned-1) || ' 13:50:00.0', '+00 1:30:00.0', 1);
END LOOP;
INSERT INTO TimeTable (Id, Validfrom, Validto, Duration, s_Hierarchygroup, Descript, s_TimeTableType)
VALUES (2,
TO_TIMESTAMP('03.09.2008', 'DD.MM.YYYY'),
TO_TIMESTAMP('03.09.2008', 'DD.MM.YYYY'),
'+1 00:00:00.0',
1,
'3-го отключили свет, универ закрыли',
2);
INSERT INTO TimeInterval (id, TimeOffset, Duration, s_TimeTable)
VALUES (25, '+0 0:0:0.0', '+1 0:0:0.0', 2);
COMMIT;
END;
--Посмотреть дерево иерархии:SELECT DECODE(level, 1, '', LPAD(' ', level * 5, ' ')) || h.descript AS descript
FROM HierarchyGroup h
START WITH s_parent IS NULL
CONNECT BY s_parent = PRIOR id
Был занят по работе, поэтому сразу не ответил.
__>Оба раза вы правы Пусть есть иерархическая группа: Университет -> Факультет -> Кафедра -> Группа. Тогда, если у Университета есть расписание, то интервалы университета будут более приоритетным ко всем другим интервалам подчиненных узлов.
Каким образом
Допустим, у нас есть расписание Университета:
9:00 — 11:00
14:00 — 16:00
и расписание кафедры
10:00 — 12:00
13:00 — 13:30
15:00 — 17:00
Каким будет результирующее расписание ?
Будут ли интервалы просто складываться или интервал Университета
отменяет интервал кафедры ?
Что касается интервалов для одной и той же иерархической группы,
но с разными приоритетами. Из приведенного ниже примера создается
впечатление, что интервал с приоритетом 2 отменяет все интервалы
с приоритетом 1. То есть для 03.09.2008 в результате не существует
ни одного интервала. Так ли это ?
__>[sql] __>-- Создание таблицы "Тип расписания" __>CREATE TABLE TimeTableType ( __> Descript VARCHAR2(128), __> Priority NUMBER(1), __> id NUMBER(1), __> PRIMARY KEY (id) __>)
__>-- Создать таблицу иерархических групп __>CREATE TABLE HierarchyGroup ( __> id NUMBER, __> Descript VARCHAR2(128), __> s_parent NUMBER, __> PRIMARY KEY (id), __> FOREIGN KEY (s_parent) REFERENCES HierarchyGroup (id) __>)
__>-- Создать таблицу расписание __>CREATE TABLE TimeTable ( __> id NUMBER, __> ValidFrom TIMESTAMP, __> ValidTo TIMESTAMP, __> Duration INTERVAL DAY TO SECOND, __> s_HierarchyGroup NUMBER, __> s_TimeTableType NUMBER(1), __> Descript VARCHAR2(128), __> PRIMARY KEY(id), __> FOREIGN KEY (s_HierarchyGroup) REFERENCES HierarchyGroup (Id) __>)
Насколько я понимаю,
ValidFrom — дата начала действия расписания
ValidTo — дата окончания действия расписания
Duration — период действия расписания
То есть в приведенном ниже примере создается расписание на 2 недели,
которое циклически повторяется, начиная с ValidFrom.
Вопрос: Это расписание всегда начинается с понедельника или может
начинаться с другого дня недели ?
__>-- Таблица временных интервалов __>CREATE TABLE TimeInterval ( __> id NUMBER, __> TimeOffset INTERVAL DAY TO SECOND, __> Duration INTERVAL DAY TO SECOND, __> s_TimeTable NUMBER, __> FOREIGN KEY (s_TimeTable) REFERENCES TimeTable (id), __> PRIMARY KEY (id) __>)
Могут ли интервалы из этой таблицы перекрываться ?
Как происходит генерация расписания для определенного узла
иерархии ? В моем представлении так (для приведенного примера):
1. Выбираем узел иерархии
2. Составляем основное расписание на основе расписаний этого
узла и всех родительских узлов
3. Составляем расписание-исключение на основе расписаний этого
узла и всех родительских узлов
4. Начинаем с 01.09.2008, используем интервалы из таблицы
TimeInterval. Для нахождения начала интервала прибавляем
TimeOffset к 01.09.2008 00:00. Для нахождения конца интервала
прибавляем Duration к началу интервала.
При этом применяем расписание-исключение к дате 03.09.2008,
в результате чего на эту дату нет интервалов.
5. Потом переходим к 14.09.2008 и повторяем пункт 3.
6. Повторяем до конца года.
Здравствуйте, Flying Dutchman, Вы писали:
FD>Каким образом FD>Допустим, у нас есть расписание Университета:
FD> 9:00 — 11:00 FD> 14:00 — 16:00
FD>и расписание кафедры
FD> 10:00 — 12:00 FD> 13:00 — 13:30 FD> 15:00 — 17:00
FD>Каким будет результирующее расписание ?
1 интервал: 9:00 — 11:00. Интервал принадлежит университету.
2 интервал: 11:00 — 12:99. Интервал принадлежит кафедре.
3 интервал: 14:00 — 16:00. Интервал принадлежит университету.
4 интервал 16:00 — 17:00. Интервал принадлежит кафедре.
FD>Будут ли интервалы просто складываться или интервал Университета FD>отменяет интервал кафедры ?
|==]---------[====| (результрующий интервал).
FD>Что касается интервалов для одной и той же иерархической группы, FD>но с разными приоритетами. Из приведенного ниже примера создается FD>впечатление, что интервал с приоритетом 2 отменяет все интервалы FD>с приоритетом 1. То есть для 03.09.2008 в результате не существует FD>ни одного интервала. Так ли это ?
Нет. Интервалы в одном расписании никак между собой не пересекаются. Приоритет интервала прямо зависит от его связи с иерархической группой. Чем "выше" группа, тем приоритетней ее интервал.
FD>То есть в приведенном ниже примере создается расписание на 2 недели, FD>которое циклически повторяется, начиная с ValidFrom.
Все верно
FD>Вопрос: Это расписание всегда начинается с понедельника или может FD>начинаться с другого дня недели ?
Расписание начинает быть действительным точно во время ValidFrom.
FD>Могут ли интервалы из этой таблицы перекрываться ?
Нет, в пределах расписания интервалы не пересекаются.
FD>Как происходит генерация расписания для определенного узла FD>иерархии ? В моем представлении так (для приведенного примера):
Алгоритм построения последовательности у меня такой:
1) Начинаем с иерархической группы. Для этой группы строим иерархию "вверх" — то есть, выбираем все вышестоящие группы.
2) Сверху вниз, начинаем генерировать интервалы. Если запись на период действия интервала уже есть, мы ее либо разбиваем, либо удаляем (если наша запись полностью перекрывает уже существующую).
Здравствуйте, __kain, Вы писали:
FD>>Что касается интервалов для одной и той же иерархической группы, FD>>но с разными приоритетами. Из приведенного ниже примера создается FD>>впечатление, что интервал с приоритетом 2 отменяет все интервалы FD>>с приоритетом 1. То есть для 03.09.2008 в результате не существует FD>>ни одного интервала. Так ли это ?
__>Нет. Интервалы в одном расписании никак между собой не пересекаются. Приоритет интервала прямо зависит от его связи с иерархической группой. Чем "выше" группа, тем приоритетней ее интервал.
Непонятно, как происходит наложение расписания исключений на основное расписание.
Еще раз, в приведенном примере расписание исключений содержит интервал для всего дня
на 03.09.2008, то есть по логике вещей все интервалы из основного
расписания, попадающие в это промежуток, отменяются (то есть все
занятия отменяются, потому что в Университете в этот день отключили свет).
Так ли это ?
FD>>Вопрос: Это расписание всегда начинается с понедельника или может FD>>начинаться с другого дня недели ?
__>Расписание начинает быть действительным точно во время ValidFrom.
Если расписание повторяется циклически
(то есть если Duration < (ValidTo — ValidFrom)),
то значение в колонке Duration таблицы TimeTable должно
быть равно 1 дню или быть кратно 7 дням. Так ли это ?
В противном случае его невозможно будет повторить.
Допустим, например, что Duration = 3. Начиная применять его с понедельника,
получим, что расписания повторяются таким образом:
Пн Вт Ср
Чт Пт Сб
Вс Пн Вт
Что, наверное, является неправильным. Или правильным ?
Не говоря уже о таком Duration, как 2.5 дня и т.д.
__>P.S. __>Сложновато получается, а? =)
Здравствуйте, Flying Dutchman, Вы писали:
FD>Здравствуйте, __kain, Вы писали:
FD>>>Что касается интервалов для одной и той же иерархической группы, FD>>>но с разными приоритетами. Из приведенного ниже примера создается FD>>>впечатление, что интервал с приоритетом 2 отменяет все интервалы FD>>>с приоритетом 1. То есть для 03.09.2008 в результате не существует FD>>>ни одного интервала. Так ли это ?
Интервалы дробятся. Представьте, сидит сторож 12 часов, и на последней минуте его дежурства отключают свет. Мы же не будем отменять весь интервал, только уменьшим для этой даты его продолжительность
FD>Если расписание повторяется циклически FD>(то есть если Duration < (ValidTo — ValidFrom)), FD>то значение в колонке Duration таблицы TimeTable должно FD>быть равно 1 дню или быть кратно 7 дням. Так ли это ?
Расписание начинается с ValidFrom, циклически повторяется с продолжительностью в Duration, и генерация интервалов заканчивается по достижение ValidTo.
Расписание исключений генерирует интервалы точно также. Просто сначала мы проходим снизу вверх с учетом основного расписания, потом мы опять проходим сверху вниз, но с учетом только расписаний исключения.
Я в принципе код набросал, осталось потестить. В декларативном виде без "своих" групповых функций здесь точно не получится...
Расписание исключений генерирует интервалы точно также. Просто сначала мы проходим снизу вверх с учетом основного расписания, потом мы опять проходим снизу вверх, но с учетом только расписаний исключения.
Реализовано для Oracle 10g и выше. Я реализовал только обработку
основных расписаний, но обработка расписаний исключений также может быть
добавлена.
Я произвел следующие изменения в структуре БД (в основном привел к
соответствию к моему собственному стилю — мне так удобнее):
1. Имена таблиц и колонок созданы с использованием '_' в качестве
разделителя слов.
2. Имена колонок — первичных ключей изменены с ID на
<Имя таблицы>_ID. Соответственно изменены имена колонок, используемых
во внешних ключах. Это дает возможность использовать
синтаксис Inner join ... using (...) в запросах.
3. Тип колонок ValidFrom и ValidTo изменен на более логичный тип DATE
4. Тестовые данные — только на английском (мой сервер что-то русские
буквы не воспринимает, а разбираться нет времени).
create_db.sql Создание БД
load_test_data.sql Загрузка тестовых данных
create_views.sql Создание представлений
Начинаем с представления V_Hierarchy
-- Get the list of all nodes with all parent nodescreate or replace view V_Hierarchy
as
with hierarchy as (
select Hierarchy_Group_Id,
sys_connect_by_path(Hierarchy_Group_Id, '/') || '/' as full_path,
level as Priority
from Hierarchy_Group
start with Parent_Group_Id is null
connect by Parent_Group_Id = prior Hierarchy_Group_id
)
select hier1.Hierarchy_Group_Id as Hierarchy_Group_Id,
hier2.Hierarchy_Group_id as Participating_Hier_Group_Id,
hier1.full_path,
hier2.Priority
from hierarchy hier1 cross join hierarchy hier2
where instr(hier1.full_path, '/' || to_char(hier2.Hierarchy_Group_id) || '/') > 0;
Назначение колонок результата:
Hierarchy_Group_Id — идентификатор узла иерархии.
Participating_Hier_Group_Id — идентификатор узла иерархии, начиная от
текущего и до самого верхнего родителя.
Priority — приоритет узла Participating_Hier_Group_Id (1 — самый
высокий).
Следующее представление генерирует все интервалы для всех расписаний,
разворачивая все цикличиские расписания.
create or replace view V_Unrolled_Interval
as
with numbers as (
select level num
from dual
connect by level <= 100),
all_interval as (
select Time_Table_Id,
Time_Table.Hierarchy_Group_Id,
Time_Table.Valid_From,
Time_Table.Valid_To,
Time_Table.Valid_From +
Time_Table.Duration * (numbers.num - 1) +
Time_Interval.Time_Offset as Start_Date_Time,
Time_Table.Valid_From +
Time_Table.Duration * (numbers.num - 1) +
Time_Interval.Time_Offset +
Time_Interval.Duration as End_Date_Time,
Time_Interval.duration as Duration
from Time_Table cross join numbers
inner join Time_Interval using(Time_table_Id)
)
select Hierarchy_Group_Id,
Time_Table_Id,
Start_Date_Time,
End_Date_Time,
Duration
from all_interval
where trunc(Start_Date_Time) <= Valid_To;
Следующее представление добавляет к интервалам каждого узла
иерархии интервалы для родительских узлов.
create or replace view V_All_Unrolled_Interval
as
select V_Hierarchy.Hierarchy_Group_Id,
V_Hierarchy.Priority,
V_Unrolled_Interval.Time_Table_Id,
V_Unrolled_Interval.Start_Date_Time,
V_Unrolled_Interval.End_Date_Time,
V_Unrolled_Interval.Duration
from V_Hierarchy inner join V_Unrolled_Interval
on V_Hierarchy.Participating_Hier_Group_Id = V_Unrolled_Interval.Hierarchy_Group_Id;
Наконец, самое сложное — комбинирование интервалов с разными
приоритетами.
create or replace view v_combined_interval
as
with-- Select all DISTINCT start/end points of all intervals
all_point as (
select Hierarchy_Group_Id,
start_date_time as date_time
from V_All_Unrolled_Interval
union
select Hierarchy_Group_Id,
end_date_time as date_time
from V_All_Unrolled_Interval),
-- Generate sequence of all intervals between consecutive points
all_interval0 as (
select Hierarchy_Group_Id,
date_time as start_date_time,
lead(date_time) over (partition by Hierarchy_Group_Id order by date_time) as end_date_time
from all_point
),
-- Remove the last interval with end_date_time is null
all_interval as (
select Hierarchy_Group_Id,
start_date_time,
end_date_Time
from all_interval0
where end_Date_time is not null
),
-- Split all intervals
split_interval as (
select V_All_Unrolled_Interval.Hierarchy_Group_Id,
V_All_Unrolled_Interval.priority,
all_interval.start_date_time,
all_interval.end_date_time
from V_All_Unrolled_Interval cross join all_interval
where V_All_Unrolled_Interval.Hierarchy_Group_Id = All_Interval.Hierarchy_Group_Id
and All_Interval.start_date_Time >= V_All_Unrolled_Interval.start_date_Time
and All_Interval.start_date_Time < V_All_Unrolled_Interval.end_date_Time
)
-- Select only intervals with highest priority (= lowest priority value).select Hierarchy_Group_Id,
min(priority) as priority,
start_date_Time,
end_date_Time
from split_interval
group by Hierarchy_Group_Id, start_date_Time, end_date_time;
Немного пояснений.
Результат представления V_All_Unrolled_Interval
(для одного дня и для Hierarchy_Group_Id = 3)
Результат промежуточного запроса SPLIT_INTERVAL — все исходные интервалы,
разбитые на меньшие интервалы, определяемые точками из результата
запроса ALL_POINT:
Мне кажется, что существует болле простое и элегантное решение,
но я пока не смог его найти.
Как видишь, все сделано декларативно и без курсоров, ни одной строки
процедурного кода.
Описание краткое и несколько сумбурное. Если будут вопросы — пиши.
На этом уже можно было бы остановиться, но приведеное решение
имеет один недостаток — существующие интервалы с приоритетом 1
оказались разбитыми на несколько интервалов.
FD>Мне кажется, что существует болле простое и элегантное решение, FD>но я пока не смог его найти.
FD>Как видишь, все сделано декларативно и без курсоров, ни одной строки FD>процедурного кода.
FD>Описание краткое и несколько сумбурное. Если будут вопросы — пиши.
FD>На этом уже можно было бы остановиться, но приведеное решение FD>имеет один недостаток — существующие интервалы с приоритетом 1 FD>оказались разбитыми на несколько интервалов.
FD>Я исправлю это через некоторое время.
Что тут скажешь? Снимаю шляпу, маэстро! Буду разбираться, как у вас это работает Удивительно, как килограммы кода превратились в пару вью... Я немного в прострации сейчас
FD>Мне кажется, что существует болле простое и элегантное решение, FD>но я пока не смог его найти.
Реализована только обработка основных расписаний, без
расписаний-исключений.
Сделаны следующие изменения по сравнению с первоначальным решением:
— Новое представление V_Max_Repetition_Number.
— Изменено представление V_Unrolled_Interval.
— Добавлены констрейнты для таблицы Time_Table.
— Добавлены комментарии.
— Изменена структура тестовых данных.
— Добавлены для учебных целей: тестовое представление v_test_interval,
Файл simplified_combined_interval_query.sql, Файл simplified_interval_query.sql
— Добавлено представление V_Interval
convert_test_data_to_1day.sql
convert_test_data_to_2day.sql
create_db.sql — Создание БД
create_views.sql — Создание представлений
load_test_data_1day.sql — Загрузка тестовых данных
simplified_combined_interval_query.sql — Упрощенный вариант запроса
для представления V_Combined_Interval
simplified_interval_query.sql — Упрощенный вариант запроса
для представления V_Interval
v_test_interval.sql Тестовые данные для запроса из файла
simplified_interval_query.sql
Начинаем с представления V_Hierarchy
-- Get the list of all nodes with all parent nodescreate or replace view V_Hierarchy
as
with hierarchy as (
select Hierarchy_Group_Id,
sys_connect_by_path(Hierarchy_Group_Id, '/') || '/' as full_path,
level as Priority
from Hierarchy_Group
start with Parent_Group_Id is null
connect by Parent_Group_Id = prior Hierarchy_Group_id
)
select hier1.Hierarchy_Group_Id as Hierarchy_Group_Id,
hier2.Hierarchy_Group_id as Participating_Hier_Group_Id,
hier1.full_path,
hier2.Priority
from hierarchy hier1 cross join hierarchy hier2
where instr(hier1.full_path, '/' || to_char(hier2.Hierarchy_Group_id) || '/') > 0;
Назначение колонок результата:
Hierarchy_Group_Id — идентификатор узла иерархии.
Participating_Hier_Group_Id — идентификатор узла иерархии, начиная от
текущего и до самого верхнего родителя.
Priority — приоритет узла Participating_Hier_Group_Id (1 — самый
высокий).
Следующее представление используется для получения максимального числа
повторений для повторяющихся расписаний:
--------------------------------------------------------------------------
-- Get the maximal repetition number for the cyclic timetables.
-- The value is not exact< but it's guaranteed to be no less that
-- the real value.
--------------------------------------------------------------------------create or replace view V_Max_Repetition_Number
as
with period_sec as (
select (trunc(Valid_To) - trunc(Valid_From) + 1) * 60 * 60 * 24 as Valid_Period_Sec,
(to_number(extract(second from Duration)) +
to_number(extract(minute from Duration)) * 60 +
to_number(extract(hour from Duration)) * 60 * 60 +
to_number(extract(day from Duration)) * 60 * 60* 24) as Duration_Sec
from Time_Table
)
select max(Valid_Period_Sec / Duration_Sec + 1) as Max_Repetition_Number
from period_Sec;
Следующее представление генерирует все интервалы для всех расписаний,
разворачивая все циклические расписания.
create or replace view V_Unrolled_Interval
as
with numbers as (
select level num
from dual
connect by level <= (select Max_Repetition_Number from V_Max_Repetition_Number)),
all_interval as (
select Time_Table_Id,
Time_Table.Hierarchy_Group_Id,
Time_Table.Valid_From,
Time_Table.Valid_To,
Time_Table.Valid_From +
Time_Table.Duration * (numbers.num - 1) +
Time_Interval.Time_Offset as Start_Date_Time,
Time_Table.Valid_From +
Time_Table.Duration * (numbers.num - 1) +
Time_Interval.Time_Offset +
Time_Interval.Duration as End_Date_Time,
Time_Interval.duration as Duration
from Time_Table cross join numbers
inner join Time_Interval using(Time_table_Id)
)
select Hierarchy_Group_Id,
Time_Table_Id,
Start_Date_Time,
End_Date_Time,
Duration
from all_interval
where trunc(Start_Date_Time) <= Valid_To;
Следующее представление добавляет к интервалам каждого узла
иерархии интервалы для родительских узлов.
create or replace view V_All_Unrolled_Interval
as
select V_Hierarchy.Hierarchy_Group_Id,
V_Hierarchy.Priority,
V_Unrolled_Interval.Time_Table_Id,
V_Unrolled_Interval.Start_Date_Time,
V_Unrolled_Interval.End_Date_Time,
V_Unrolled_Interval.Duration
from V_Hierarchy inner join V_Unrolled_Interval
on V_Hierarchy.Participating_Hier_Group_Id = V_Unrolled_Interval.Hierarchy_Group_Id;
Наконец, самое сложное — комбинирование интервалов с разными
приоритетами.
create or replace view v_combined_interval
as
with-- Select all DISTINCT start/end points of all intervals
all_point as (
select Hierarchy_Group_Id,
start_date_time as date_time
from V_All_Unrolled_Interval
union
select Hierarchy_Group_Id,
end_date_time as date_time
from V_All_Unrolled_Interval),
-- Generate sequence of all intervals between consecutive points
all_interval0 as (
select Hierarchy_Group_Id,
date_time as start_date_time,
lead(date_time) over (partition by Hierarchy_Group_Id order by date_time) as end_date_time
from all_point
),
-- Remove the last interval with end_date_time is null
all_interval as (
select Hierarchy_Group_Id,
start_date_time,
end_date_Time
from all_interval0
where end_Date_time is not null
),
-- Split all intervals
split_interval as (
select V_All_Unrolled_Interval.Hierarchy_Group_Id,
V_All_Unrolled_Interval.priority,
all_interval.start_date_time,
all_interval.end_date_time
from V_All_Unrolled_Interval cross join all_interval
where V_All_Unrolled_Interval.Hierarchy_Group_Id = All_Interval.Hierarchy_Group_Id
and All_Interval.start_date_Time >= V_All_Unrolled_Interval.start_date_Time
and All_Interval.start_date_Time < V_All_Unrolled_Interval.end_date_Time
)
-- Select only intervals with highest priority (= lowest priority value).select Hierarchy_Group_Id,
min(priority) as priority,
start_date_Time,
end_date_Time
from split_interval
group by Hierarchy_Group_Id, start_date_Time, end_date_time;
Немного пояснений.
Результат представления V_All_Unrolled_Interval
(для одного дня и для Hierarchy_Group_Id = 3)
Результат промежуточного запроса Split_Interval — все исходные интервалы,
разбитые на меньшие интервалы, определяемые точками из результата
запроса ALL_POINT:
Наконец, интервалы, примыкающие друг к другу, "cклеиваются" при помощи
представления V_Interval:
create or replace view V_Interval
as
with time_int2 as (
select Hierarchy_Group_Id,
Priority,
Start_Date_Time,
End_Date_Time,
case when lag(End_Date_Time) Over(Partition by Hierarchy_Group_Id, Priority order by Start_Date_Time) = Start_Date_Time then 0
else 1
end as flag
from V_Combined_Interval
),
time_int3 as (
select Hierarchy_Group_Id,
Priority,
Start_Date_Time,
End_Date_Time,
sum(flag) over(Partition by Hierarchy_Group_Id, Priority order by Start_Date_Time) as Interval_Group
from time_int2
)
select Hierarchy_Group_Id,
Priority,
interval_group,
min(Start_Date_Time) as Start_Date_Time,
max(End_Date_Time) as End_Date_Time
from time_Int3
group by Hierarchy_Group_Id, Priority, Interval_Group;
Здравствуйте, __kain, Вы писали:
__>Здравствуйте, Flying Dutchman, Вы писали:
FD>>Скрипты находятся здесь.
__>Ссылка не работает. Вы не могли бы еще раз выложить?..
__>P.S. __>Читаю ваши скрипты и просвещаюсь
Здравствуйте, __kain, Вы писали:
__>2 Flying Dutchman >> В твоем случае структура базы довольно сложная, тем более что используются темпоральные данные, так что этому надо уделить особое внимание. __>Структуру я весь диплом проектировал, и потом еще месяц =) Она получилась универсальной и вроде более-менее простой, но, действительно, наличие темпоральных данных только усложняет дело. Причем все эти данные могут потом еще и перегенерироваться (полностью и частично)... Я тут подумал, нужно наверное в структуру еще что-то добавить, чтобы в коде нужно было проводить меньше вычислений.
Для темпоральных данных иногда подходят materialized view.
__>Кстати, а что вы думаете на счет объектных возможностей Oracle? Может с помощью них получится нормально сделать?
Объектами назвать это сложно, но коллекции этих самых объектов вполне удобны для переноса больших объемов данных между процедурами. Значительно улучшается повторное использование и структура кода.
Минус — оптимизации тут как бы не при делах, поэтому злоупотреблять не стоит.