


|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 15.10.07 13:25 | ||
| Оценка: |
+2
-1
|
||
N>>Immutable data structures are the way of the future in C#.
Что тут не понятного? ФЯ по Гапертону (и тебе, в общем-то) это запрет на модификацию переменных. А это деградация функциональности и больше ничто. Этот запрет не даст никаких приемущество с точки зрения реализации алгоритмов. Никакие паттерн-матчинги от этого не зависят. Никакие функции высшего порядка тоже. Это просто запрет ради запрета. Он яко бы должен привести к гипотетическому упрощению программирования. Но по жизни, как говорится рулят, ковровые бомбордировки и танковые клинья и еще этот, как его? А, гриб Сарумяна. То есть рулят отладчики, IDE, визуальные дизайнеры и т.п.
...
И вообще, большой вопрос что считать функциональным, а что императивным. Лично я считаю фунциональным стиль программирования в котором программист старается использовть вычисление выражений вместо выполнения инструкций. Гапертон же тут рядом заявил, что если в программе используется модификация переменных, то это уже "императивщина" (таки оскорбление какое-то ).
Так вот можно без проблем писать очень компактный и выразительный код во всю используя модификацию переменных. И программа от этого сложнее не или непонятнее не станет. Так что если определять ФП как это делает Гапертон, то ФП вообще мало чего дает.
...
L> Это новый взгляд на проблему и именно с этой точки зрения я рассматриваю оспариваемый тезис. Собственно мое мнение можно читать как "объектно ориентированный взгляд на проблему имеет оверхед по сравнению с функциональным".
А я считаю это мнение заблуждением. Ну, что же поделаешь?
VD>>А каковы тогда критерии отнесения чего-то к ООП или императивному программированию (ИП)? Ведь ООП код может быть функциональным по сути, а может быть императивным. Как же быть?
L>Что такое функциональный ООП? Это использование ОО и функциональщины в одном флаконе? Если да, то нам не о чем спорить.
Тут г. Гапертон выразил мысль, что главное в ФП это "immutability". А используя ООП я могу сделать класс immutable или mutable. Отличный пример реализация класса строк в std::C++ и в Яве. Пользуясь определением Гапертона, я выбирая реализацию класса делаю выбор между императивным и функциональным дизайном. Так?

|
От: |
minorlogic
|
|
| Дата: | 09.10.07 05:39 | ||
| Оценка: |
+1
-5
|
||
N>Immutable data structures are the way of the future in C#.

|
От: |
kochetkov.vladimir
|
https://kochetkov.github.io |
| Дата: | 10.10.07 08:40 | ||
| Оценка: |
+1

|
||
N>>Immutable data structures are the way of the future in C#.
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 18.10.07 08:51 | ||
| Оценка: | 15 (4) | ||

|
От: |
Sinclair
|
https://github.com/evilguest/ |
| Дата: | 09.10.07 09:55 | ||
| Оценка: | 6 (1) +3 | ||


|
От: |
Константин Л.
|
|
| Дата: | 12.10.07 16:11 | ||
| Оценка: |
+1
|
||

|
От: |
nikov
|
http://www.linkedin.com/in/nikov |
| Дата: | 08.10.07 10:29 | ||
| Оценка: | 34 (2) +1 | ||
Immutable data structures are the way of the future in C#.
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 18.10.07 12:43 | ||
| Оценка: | 23 (3) | ||
|
|
От: |
Sinclair
|
https://github.com/evilguest/ |
| Дата: | 09.10.07 09:04 | ||
| Оценка: | 12 (2) +1 | ||

|
От: |
GlebZ
|
|
| Дата: | 12.10.07 16:57 | ||
| Оценка: | 11 (2) +1 | ||
ОПТИМИЗАЦИЯ И ЭФФЕКТИВНОСТЬ Там же вполне обоснованно описано почему.Резюме
Вера в то,что ключевое слово const помогает компилятору генерировать более качественный код, очень распространена. Да, const действительно хорошая вещь, но основная цель данной задачи — показать, что предназначено это ключевое слово в первую очередь для человека, а не для компиляторов или оптимизаторов..
Когда речь идет о написании безопасного кода, const — отличный инструмент, который позволяет программистам писать более безопасный код с дополнительными проверками компилятором. Но когда речь идет об оптимизации, то const остается в принципе полезным инструментом, поскольку позволяет проектировщикам классов лучше выполнять оптимизацию вручную; но генерировать лучший код компиляторам оно помогает в гораздо меньшей степени.

|
От: |
rsn81
|
http://rsn81.wordpress.com |
| Дата: | 08.10.07 11:04 | ||
| Оценка: | 6 (1) +2 | ||
Чего, собственно, хотелось бы и в Java. И что, в принципе, тоже обосновано. Давно уже читал статью, но насколько помню, там та же аргументация: Теория и практика Java: Изменять или не изменять? Неизменяемые объекты могут значительно облегчить вашу жизнь. Уже сейчас в Eclipse чистильщик исходного кода по умолчанию автоматически расставляет атрибут неизменяемости переменной или поля класса (модификатор final) везде, где встречает сущность по факту используемую как неизменяемую; в итоге смотришь, количество immutable-переменных значительно превышает количество mutable. Встает законный вопрос: почему по умолчанию все изменяемо, может сделать наоборот: по умолчанию сущности неизменяемые, а если очень уж нужно, указывай специальным модификатором — как, к примеру, сделано в Nemerle/Scala.ASIDE: Immutable data structures are the way of the future in C#. It is much easier to reason about a data structure if you know that it will never change. Since they cannot be modified, they are automatically threadsafe. Since they cannot be modified, you can maintain a stack of past “snapshots” of the structure, and suddenly undo-redo implementations become trivial. On the down side, they do tend to chew up memory, but hey, that’s what garbage collection was invented for, so don’t sweat it. I’ll be talking more about programming using immutable data structures in this space over the next few months.
|
|
От: |
Sinclair
|
https://github.com/evilguest/ |
| Дата: | 12.10.07 10:37 | ||
| Оценка: |
1 (1)
+1
|
||
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 15.10.07 11:24 | ||
| Оценка: | 5 (2) | ||

|
От: |
Курилка
|
http://kirya.narod.ru/ |
| Дата: | 09.10.07 07:23 | ||
| Оценка: | +2 | ||
N>>Immutable data structures are the way of the future in C#.

|
От: |
deniok
|
|
| Дата: | 09.10.07 08:41 | ||
| Оценка: | +2 | ||
|
|
От: |
Sinclair
|
https://github.com/evilguest/ |
| Дата: | 12.10.07 05:03 | ||
| Оценка: | +2 | ||
|
|
От: |
Sinclair
|
https://github.com/evilguest/ |
| Дата: | 12.10.07 05:03 | ||
| Оценка: | +2 | ||

|
От: |
VladD2
|
www.nemerle.org |
| Дата: | 12.10.07 13:39 | ||
| Оценка: | +2 | ||
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 14.10.07 17:59 | ||
| Оценка: |
-1
|
||
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 19.10.07 14:30 | ||
| Оценка: | 18 (1) | ||

|
От: |
Cyberax
|
|
| Дата: | 18.10.07 01:14 | ||
| Оценка: | 8 (1) | ||
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 19.10.07 12:53 | ||
| Оценка: | 1 (1) | ||

|
От: | CreatorCray | |
| Дата: | 09.10.07 09:25 | ||
| Оценка: | +1 | ||
mutable int m_refCount;|
|
От: |
Курилка
|
http://kirya.narod.ru/ |
| Дата: | 09.10.07 09:27 | ||
| Оценка: |
|
||
CC>mutable int m_refCount;
CC>|
|
От: |
VladD2
|
www.nemerle.org |
| Дата: | 10.10.07 07:23 | ||
| Оценка: |
|
||
N>Immutable data structures are the way of the future in C#.
|
|
От: |
Константин Л.
|
|
| Дата: | 11.10.07 14:31 | ||
| Оценка: | +1 | ||
|
|
От: |
VladD2
|
www.nemerle.org |
| Дата: | 11.10.07 14:35 | ||
| Оценка: |
|
||
|
|
От: |
VladD2
|
www.nemerle.org |
| Дата: | 11.10.07 14:35 | ||
| Оценка: | -1 | ||
|
|
От: | CreatorCray | |
| Дата: | 12.10.07 07:00 | ||
| Оценка: | -1 | ||

|
От: |
Sergey
|
|
| Дата: | 12.10.07 14:15 | ||
| Оценка: | +1 | ||
|
|
От: |
GlebZ
|
|
| Дата: | 12.10.07 14:20 | ||
| Оценка: | +1 | ||

|
От: | WolfHound | |
| Дата: | 12.10.07 16:52 | ||
| Оценка: | +1 | ||
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 14.10.07 11:30 | ||
| Оценка: | -1 | ||
|
|
От: |
Cyberax
|
|
| Дата: | 15.10.07 02:56 | ||
| Оценка: | +1 | ||
|
|
От: |
Cyberax
|
|
| Дата: | 15.10.07 02:57 | ||
| Оценка: | +1 | ||
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 15.10.07 12:18 | ||
| Оценка: | -1 | ||
По существу вопроса возражения есть?2) От хотя бы однобитного счетчика ссылок вряд-ли кто откажется в данной ситуации — уж очень он здорово поправляет здоровье отца русской демократии — сильно разгружается GC.
|
|
От: |
Cyberax
|
|
| Дата: | 15.10.07 22:09 | ||
| Оценка: | +1 | ||
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 17.10.07 15:45 | ||
| Оценка: |
|
||
|
|
От: |
Cyberax
|
|
| Дата: | 17.10.07 16:06 | ||
| Оценка: | +1 | ||
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 18.10.07 17:08 | ||
| Оценка: | +1 | ||
|
|
От: |
Константин Л.
|
|
| Дата: | 08.10.07 20:06 | ||
| Оценка: | |||
|
|
От: | CreatorCray | |
| Дата: | 09.10.07 07:11 | ||
| Оценка: | |||
N>Immutable data structures are the way of the future in C#.
|
|
От: | CreatorCray | |
| Дата: | 09.10.07 08:12 | ||
| Оценка: | |||
|
|
От: |
Курилка
|
http://kirya.narod.ru/ |
| Дата: | 09.10.07 08:23 | ||
| Оценка: | |||
|
|
От: |
Курилка
|
http://kirya.narod.ru/ |
| Дата: | 09.10.07 08:24 | ||
| Оценка: | |||
|
|
От: | CreatorCray | |
| Дата: | 09.10.07 09:02 | ||
| Оценка: | |||
|
|
От: | WolfHound | |
| Дата: | 09.10.07 14:46 | ||
| Оценка: | |||

|
От: | _d_m_ | |
| Дата: | 10.10.07 09:17 | ||
| Оценка: | |||
N>>Immutable data structures are the way of the future in C#.
Если гений не понят и не признан, значит, он ещё жив
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 11.10.07 14:09 | ||
| Оценка: | |||
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 11.10.07 14:24 | ||
| Оценка: | |||
|
|
От: |
VladD2
|
www.nemerle.org |
| Дата: | 11.10.07 14:35 | ||
| Оценка: | |||
|
|
От: |
kochetkov.vladimir
|
https://kochetkov.github.io |
| Дата: | 11.10.07 14:58 | ||
| Оценка: | |||
|
|
От: |
Константин Л.
|
|
| Дата: | 12.10.07 10:05 | ||
| Оценка: | |||

|
От: |
igna
|
|
| Дата: | 12.10.07 10:21 | ||
| Оценка: | |||
|
|
От: |
VladD2
|
www.nemerle.org |
| Дата: | 12.10.07 13:39 | ||
| Оценка: | |||

|
От: |
_FRED_
|
@ViIvanov |
| Дата: | 12.10.07 13:42 | ||
| Оценка: | |||
|
|
От: |
minorlogic
|
|
| Дата: | 14.10.07 09:30 | ||
| Оценка: | |||
|
|
От: |
Курилка
|
http://kirya.narod.ru/ |
| Дата: | 14.10.07 10:32 | ||
| Оценка: | |||
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 14.10.07 11:10 | ||
| Оценка: | |||
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 14.10.07 11:25 | ||
| Оценка: | |||
|
|
От: |
deniok
|
|
| Дата: | 14.10.07 12:01 | ||
| Оценка: | |||
|
|
От: |
GlebZ
|
|
| Дата: | 14.10.07 12:22 | ||
| Оценка: | |||
|
|
От: |
Константин Л.
|
|
| Дата: | 14.10.07 19:16 | ||
| Оценка: | |||
|
|
От: |
Константин Л.
|
|
| Дата: | 14.10.07 20:17 | ||
| Оценка: | |||
|
|
От: |
Sinclair
|
https://github.com/evilguest/ |
| Дата: | 15.10.07 02:41 | ||
| Оценка: | |||
|
|
От: |
Sinclair
|
https://github.com/evilguest/ |
| Дата: | 15.10.07 02:59 | ||
| Оценка: | |||

|
От: |
inko
|
|
| Дата: | 15.10.07 10:49 | ||
| Оценка: | |||
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 15.10.07 11:49 | ||
| Оценка: | |||
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 15.10.07 12:34 | ||
| Оценка: | |||

|
От: |
vdimas
|
|
| Дата: | 16.10.07 08:29 | ||
| Оценка: | |||
N>Immutable data structures are the way of the future in C#.
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 16.10.07 09:46 | ||
| Оценка: | |||
Xbox 360 Performance
The performance of synchronization instructions and functions on Xbox 360 will vary depending on what other code is running. Acquiring locks will take much longer if another thread currently owns the lock. InterlockedIncrement and critical section operations will take much longer if other threads are writing to the same cache line. The contents of the store queues can also affect performance. Therefore, all of these numbers are just approximations, generated from very simple tests:
lwsync was measured as taking 33-48 cycles.
InterlockedIncrement was measured as taking 225-260 cycles. (казалось бы, медленно, но дело в том, что в PowerPC на это уходит три инструкции, и в этот момент проц не простаивает, а моментально переключается на другой аппаратный тред, так что на практике все хорошо)
Acquiring or releasing a critical section was measured as taking about 345 cycles.
Acquiring or releasing a mutex was measured as taking about 2350 cycles.
Windows Performance
The performance of synchronization instructions and functions on Windows vary widely depending on the processor type and configuration, and on what other code is running. Multi-core and multi-socket systems often take longer to execute synchronizing instructions. Acquiring locks take much longer if another thread currently owns the lock. However, even some measurements generated from very simple tests are helpful:
MemoryBarrier was measured as taking 20-90 cycles.
InterlockedIncrement was measured as taking 36-90 cycles. (Wintel рулит! Реально быстрый интерлокед инеремент, на который наложатся следующие инструкции, так как Core Duo — суперскалярный проц)
Acquiring or releasing a critical section was measured as taking 40-100 cycles.
Acquiring or releasing a mutex was measured as taking about 750-2500 cycles.
|
|
От: |
Cyberax
|
|
| Дата: | 16.10.07 19:20 | ||
| Оценка: | |||
|
|
От: |
Sergey
|
|
| Дата: | 17.10.07 08:33 | ||
| Оценка: | |||
|
|
От: |
Sinclair
|
https://github.com/evilguest/ |
| Дата: | 17.10.07 11:40 | ||
| Оценка: | |||
|
|
От: |
VladD2
|
www.nemerle.org |
| Дата: | 17.10.07 12:47 | ||
| Оценка: | |||
|
|
От: |
Sergey
|
|
| Дата: | 17.10.07 12:56 | ||
| Оценка: | |||
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 17.10.07 15:00 | ||
| Оценка: | |||
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 17.10.07 15:21 | ||
| Оценка: | |||
UltraSPARC T1 has two varieties of instructions for synchronization: memory
barriers and flush. The following memory barrier instructions ensure that any load,
store, or atomic memory operation issued after it take effect after all memory
operations issued before it:
■ MEMBAR with mmask{1} = 1 (MEMBAR #StoreLoad)
■ MEMBAR with cmask{1} = 1 (MEMBAR #MemIssue)
■ MEMBAR with cmask{2} = 1 MEMBAR #Sync)
All other types of membar instructions are treated as NOPs, since they are implied
by the TSO memory ordering protocol followed by UltraSPARC T1.
Multithreading
In UltraSPARC T1, execution is switched in round-robin fashion every cycle among
the strands that are ready to issue another instruction. Context switching is built into
the UltraSPARC T1 pipeline and takes place during the SWITCH stage, thus contexts
are switched each cycle with no pipeline stall penalty.
The following instructions change a strand from a ready-to-issue state to a not-
ready-to-issue state, until hardware determines that their input/execution
requirements can be satisfied:
■ All branches (including CALL, JMPL, etc.)
■ All VIS instructions
■ All floating point (FPops)
■ All WRPR, WR, WRHPR
■ All RDPR, RD, RDHPR
■ SAVE(D), RESTORE(D), RETURN, FLUSHW (all register management)
■ All MUL and DIV
■ MULSCC
■ MEMBAR #Sync, MEMBAR #StoreLoad, MEMBAR #MemIssue
■ FLUSH
■ All loads
■ All floating-point memory operations
■ All memory operations to alternate space
■ All atomics load-store operations
■ Prefetch
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 17.10.07 15:23 | ||
| Оценка: | |||
|
|
От: |
Cyberax
|
|
| Дата: | 17.10.07 16:00 | ||
| Оценка: | |||
|
|
От: |
Курилка
|
http://kirya.narod.ru/ |
| Дата: | 17.10.07 17:58 | ||
| Оценка: | |||
|
|
От: |
Sinclair
|
https://github.com/evilguest/ |
| Дата: | 18.10.07 02:34 | ||
| Оценка: | |||
|
|
От: |
Cyberax
|
|
| Дата: | 18.10.07 05:36 | ||
| Оценка: | |||
|
|
От: |
Sinclair
|
https://github.com/evilguest/ |
| Дата: | 18.10.07 05:59 | ||
| Оценка: | |||
|
|
От: |
Cyberax
|
|
| Дата: | 18.10.07 06:06 | ||
| Оценка: | |||
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 18.10.07 08:27 | ||
| Оценка: | |||
|
|
От: |
Cyberax
|
|
| Дата: | 18.10.07 08:36 | ||
| Оценка: | |||
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 18.10.07 09:11 | ||
| Оценка: | |||
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 18.10.07 09:19 | ||
| Оценка: | |||
At the time of its release in December of 2005, a single chip, eight core, 32-thread, 1.2 GHz UltraSPARC T1 server performed similarly to a two-socket, four-core, eight-thread, 1.9 GHz IBM POWER5 server, performed similarly to a four socket, eight-core, sixteen-thread 3.0 GHz Intel Xeon "Paxville MP" server, and exceeded the performance of a four socket, four-core, four-thead 1.6 GHz Intel Itanium server. Arguably, this made the UltraSPARC T1 the world's most powerful general-purpose commercial server processors, when considering multithreaded commercial workloads.
|
|
От: |
Sinclair
|
https://github.com/evilguest/ |
| Дата: | 18.10.07 09:23 | ||
| Оценка: | |||
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 18.10.07 13:13 | ||
| Оценка: | |||
|
|
От: |
Cyberax
|
|
| Дата: | 18.10.07 14:19 | ||
| Оценка: | |||
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 18.10.07 14:28 | ||
| Оценка: | |||
|
|
От: |
Cyberax
|
|
| Дата: | 18.10.07 14:31 | ||
| Оценка: | |||
|
|
От: |
Cyberax
|
|
| Дата: | 18.10.07 15:06 | ||
| Оценка: | |||
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 18.10.07 16:45 | ||
| Оценка: | |||
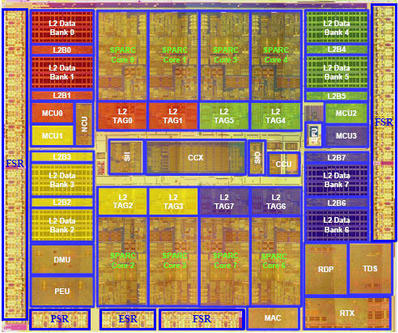

|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 18.10.07 16:49 | ||
| Оценка: | |||
|
|
От: |
Cyberax
|
|
| Дата: | 19.10.07 04:21 | ||
| Оценка: | |||
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 19.10.07 09:54 | ||
| Оценка: | |||
|
|
От: |
Курилка
|
http://kirya.narod.ru/ |
| Дата: | 19.10.07 10:40 | ||
| Оценка: | |||
|
|
От: |
Cyberax
|
|
| Дата: | 19.10.07 12:56 | ||
| Оценка: | |||
|
|
От: |
Курилка
|
http://kirya.narod.ru/ |
| Дата: | 19.10.07 12:58 | ||
| Оценка: | |||

|
От: | BulatZiganshin | |
| Дата: | 25.10.07 20:51 | ||
| Оценка: | |||
|
|
От: | BulatZiganshin | |
| Дата: | 25.10.07 20:58 | ||
| Оценка: | |||
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 29.10.07 10:57 | ||
| Оценка: | |||
|
|
От: | CreatorCray | |
| Дата: | 29.10.07 11:34 | ||
| Оценка: | |||
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 29.10.07 12:36 | ||
| Оценка: | |||
|
|
От: | BulatZiganshin | |
| Дата: | 29.10.07 12:48 | ||
| Оценка: | |||
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 29.10.07 13:21 | ||
| Оценка: | |||
|
|
От: | BulatZiganshin | |
| Дата: | 29.10.07 15:12 | ||
| Оценка: | |||
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 29.10.07 16:39 | ||
| Оценка: | |||
|
|
От: |
igna
|
|
| Дата: | 02.11.07 16:15 | ||
| Оценка: | |||
