
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 18.10.07 08:27 | ||
| Оценка: | |||

|
От: |
Cyberax
|
|
| Дата: | 18.10.07 08:36 | ||
| Оценка: | |||
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 18.10.07 08:51 | ||
| Оценка: | 15 (4) | ||
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 18.10.07 09:11 | ||
| Оценка: | |||
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 18.10.07 09:19 | ||
| Оценка: | |||
At the time of its release in December of 2005, a single chip, eight core, 32-thread, 1.2 GHz UltraSPARC T1 server performed similarly to a two-socket, four-core, eight-thread, 1.9 GHz IBM POWER5 server, performed similarly to a four socket, eight-core, sixteen-thread 3.0 GHz Intel Xeon "Paxville MP" server, and exceeded the performance of a four socket, four-core, four-thead 1.6 GHz Intel Itanium server. Arguably, this made the UltraSPARC T1 the world's most powerful general-purpose commercial server processors, when considering multithreaded commercial workloads.

|
От: |
Sinclair
|
https://github.com/evilguest/ |
| Дата: | 18.10.07 09:23 | ||
| Оценка: | |||

|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 18.10.07 12:43 | ||
| Оценка: | 23 (3) | ||
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 18.10.07 13:13 | ||
| Оценка: | |||
|
|
От: |
Cyberax
|
|
| Дата: | 18.10.07 14:19 | ||
| Оценка: | |||
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 18.10.07 14:28 | ||
| Оценка: | |||
|
|
От: |
Cyberax
|
|
| Дата: | 18.10.07 14:31 | ||
| Оценка: | |||
|
|
От: |
Cyberax
|
|
| Дата: | 18.10.07 15:06 | ||
| Оценка: | |||
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 18.10.07 16:45 | ||
| Оценка: | |||
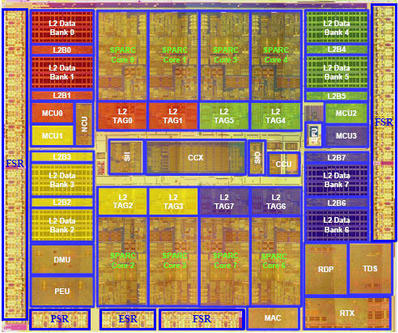

|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 18.10.07 16:49 | ||
| Оценка: | |||
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 18.10.07 17:08 | ||
| Оценка: | +1 | ||
|
|
От: |
Cyberax
|
|
| Дата: | 19.10.07 04:21 | ||
| Оценка: | |||
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 19.10.07 09:54 | ||
| Оценка: | |||

|
От: |
Курилка
|
http://kirya.narod.ru/ |
| Дата: | 19.10.07 10:40 | ||
| Оценка: | |||
|
|
От: | Gaperton | http://gaperton.livejournal.com |
| Дата: | 19.10.07 12:53 | ||
| Оценка: | 1 (1) | ||
|
|
От: |
Cyberax
|
|
| Дата: | 19.10.07 12:56 | ||
| Оценка: | |||
