Здравствуйте, iZEN, Вы писали:
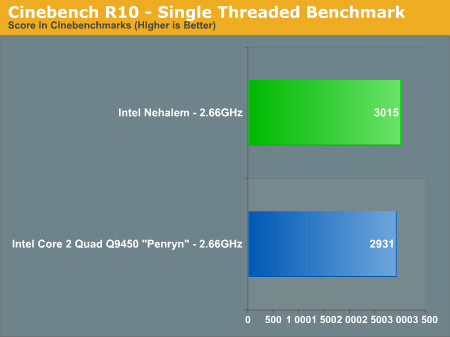
ZEN>Пока никак? Масштабируемость никакая: 40% — это ничто (нормально будет: 100..300% в зависимости от количества ядер).
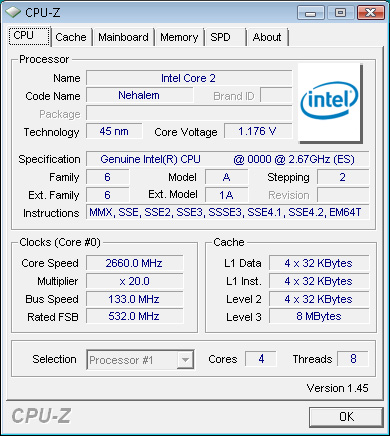
Одна незадача — тот процессор, что тестировался, имел 4 ядра.
... <<RSDN@Home 1.2.0 alpha 4 rev. 1090 on Windows Vista 6.0.6001.65536>>
Здравствуйте, AndrewVK, Вы писали:
AVK>Здравствуйте, iZEN, Вы писали:
ZEN>>Пока никак? Масштабируемость никакая: 40% — это ничто (нормально будет: 100..300% в зависимости от количества ядер).
AVK>Одна незадача — тот процессор, что тестировался, имел 4 ядра.
Видимо, это младшая модель. Они добавили L3 кэш и HT (гипер-тридинг), но ядер по прежнему 4...
Не понятно, за счёт чего прирост производительности — из-за L3 кэша, или HT, или ещё чего-то. Но если за счёт HT, то 40% — это очень и очень хорошо. Предыдущий HT на Pentium4 давал теоретический максимум — +30%, и +30% достигали очень немногие приложения, некоторые получали -5%.
Здравствуйте, remark, Вы писали:
R>Не понятно, за счёт чего прирост производительности — из-за L3 кэша, или HT, или ещё чего-то.
Снижена на 30% латентность доступа к L2 и памяти, добавлена специальная логика, позволяющая значительно снизить проблемы из-за невыровненных по линиям кеша данных (на тестах, это меряющих, производительность растет на 150 и более процентов на одной частоте по сравнению с Penryn). Наконец там не два чипа с медленной шиной между ними, как в yorkfield, а все на одном чипе.
R> Но если за счёт HT, то 40% — это очень и очень хорошо.
Вряд ли.
R> Предыдущий HT на Pentium4 давал теоретический максимум — +30%, и +30% достигали очень немногие приложения, некоторые получали -5%.
HT есть у Atom, и там, судя по тестам, эффект от него весьма приличный.
... <<RSDN@Home 1.2.0 alpha 4 rev. 1090 on Windows Vista 6.0.6001.65536>>
Здравствуйте, iZEN, Вы писали:
R>>16 аппаратных потоков — полёт нормальный.
Улыбнуло
ZEN>Ну и что? ZEN>Sun UltraSPARC T1 работает на частоте 1 или 1,2ГГц, имеет 8 ядер и способен выполнять по 4 потока на каждом ядре. Потребление в пиковом режиме не превышает 80Вт.
Ну и что? Подумаешь, 32. Вторая сановская Ниагара (ultrasparc T1) имеет 64 честных аппаратных потоков — по 8 потоков на ядро. И по FPU на каждом ядре в отличии от первой (у первой было одно FPU на весь кристалл) . И в отличии от изобретения Intel — она не затыкается в пямять, и на реальных серверных приложениях окажется не сильно хуже этого Нехалема. И главное — она уже давно в продаже.
А когда Нехалем выйдет — Сан сделает уже третью Ниагару.
Здравствуйте, Gaperton, Вы писали:
G>Ну и что? Подумаешь, 32. Вторая сановская Ниагара (ultrasparc T1) имеет 64 честных аппаратных потоков — по 8 потоков на ядро. И по FPU на каждом ядре в отличии от первой (у первой было одно FPU на весь кристалл) . И в отличии от изобретения Intel — она не затыкается в пямять, и на реальных серверных приложениях окажется не сильно хуже этого Нехалема. И главное — она уже давно в продаже.
Ниагара весьма неспешная в однопоточной работе. Оно идеально подходит для серверов приложений с кучей потоков, но однопоточная производительность — ниже плинтуса.
И если задача не может нагрузить процессор на таком большом распараллеливании — можно вешаться.
Здравствуйте, Cyberax, Вы писали:
G>>Ну и что? Подумаешь, 32. Вторая сановская Ниагара (ultrasparc T1) имеет 64 честных аппаратных потоков — по 8 потоков на ядро. И по FPU на каждом ядре в отличии от первой (у первой было одно FPU на весь кристалл) . И в отличии от изобретения Intel — она не затыкается в пямять, и на реальных серверных приложениях окажется не сильно хуже этого Нехалема. И главное — она уже давно в продаже. C>Ниагара весьма неспешная в однопоточной работе. Оно идеально подходит для серверов приложений с кучей потоков, но однопоточная производительность — ниже плинтуса.
C>И если задача не может нагрузить процессор на таком большом распараллеливании — можно вешаться.
Никакой идиот не будет тебе совмещать аппаратную многопоточность и суперскаляр (только Intel один раз попробовал в P4 — с тех пор так не делает). Один аппаратный поток Нехалема точно так же single-issue, как и в Ниагаре, так что и будет совершенно та же ситуация, как и с Ниагарой.
Здравствуйте, Gaperton, Вы писали:
C>>И если задача не может нагрузить процессор на таком большом распараллеливании — можно вешаться. G>Никакой идиот не будет тебе совмещать аппаратную многопоточность и суперскаляр (только Intel один раз попробовал в P4 — с тех пор так не делает).
Уже делает — в Nehalem'е. Идея, на самом деле, здравая. Вместо того, чтобы бесцельно тратить время во время cache miss — процессор будет переключаться на другой поток.
G>Один аппаратный поток Нехалема точно так же single-issue, как и в Ниагаре, так что и будет совершенно та же ситуация, как и с Ниагарой.
Разве? Из статьи в Вики видно, что оно будет продолжением Core2.
Здравствуйте, Cyberax, Вы писали:
G>>Один аппаратный поток Нехалема точно так же single-issue, как и в Ниагаре, так что и будет совершенно та же ситуация, как и с Ниагарой. C>Разве? Из статьи в Вики видно, что оно будет продолжением Core2.
Из статьи в вики на самом деле непонятно, сколько инструкций может выдавать одно ядро. На картинках реально присутствует Reorder Buffer, что может говорить о суперскалярном выполнении. И он довольно глубокий. На картинке в вики типа нарисовано 6 каналов арифметики, что _в принципе_ может говорить о пиковой производительности 6 команд за такт, в принципе — потому что не нарисованы байпасы, и поэтому не понятно, сколько он реально может выполнить за такт. Там два потока на ядро, которые конкурируют за один кластер арифметики. А еще — там слишком много ядер, чтобы они были сложными. Они стопудов проще, чем ядра Core2. Короче, информации мало, и про суперскаляр толком ничего не сказано.
Конечно, однопоточная производительность будет выше, чем у Ниагары, но чудес ждать не стоит.
Здравствуйте, Gaperton, Вы писали:
G>Из статьи в вики на самом деле непонятно, сколько инструкций может выдавать одно ядро. На картинках реально присутствует Reorder Buffer, что может говорить о суперскалярном выполнении. И он довольно глубокий.
Ещё и Memory Order Buffer.
G>На картинке в вики типа нарисовано 6 каналов арифметики, что _в принципе_ может говорить о пиковой производительности 6 команд за такт, в принципе — потому что не нарисованы байпасы, и поэтому не понятно, сколько он реально может выполнить за такт. Там два потока на ядро, которые конкурируют за один кластер арифметики. А еще — там слишком много ядер, чтобы они были сложными. Они стопудов проще, чем ядра Core2. Короче, информации мало, и про суперскаляр толком ничего не сказано.
Два аппаратных потока не должны конкурировать — переключение между ними будет происходит, когда процессору нужно ждать из-за промаха по кэшу или какого-то pipeline stall. Это принципиальное различие между Ниагарой и Нехалемом.
G>Конечно, однопоточная производительность будет выше, чем у Ниагары, но чудес ждать не стоит.
Обещают, что будет не хуже Core2.
Здравствуйте, Cyberax, Вы писали:
G>>На картинке в вики типа нарисовано 6 каналов арифметики, что _в принципе_ может говорить о пиковой производительности 6 команд за такт, в принципе — потому что не нарисованы байпасы, и поэтому не понятно, сколько он реально может выполнить за такт. Там два потока на ядро, которые конкурируют за один кластер арифметики. А еще — там слишком много ядер, чтобы они были сложными. Они стопудов проще, чем ядра Core2. Короче, информации мало, и про суперскаляр толком ничего не сказано. C>Два аппаратных потока не должны конкурировать — переключение между ними будет происходит, когда процессору нужно ждать из-за промаха по кэшу или какого-то pipeline stall. Это принципиальное различие между Ниагарой и Нехалемом.
Ты путаешь. Это Ниагара переключается в случае pipline stall по любой причине. Ничего больше она делать не умеет. Нехалем, судя по картинке, работает совершенно не так — он пихает инструкции с обоих потоков в единый буфер переупорядочивания, для того, чтобы лучше нагрузить кластер арифметики — два потока независимы по регистрам, это должно сильно повысить среднюю нагрузку.
Строго говоря, Нехалем вообще не переключается между потоками — он выполняет все подряд инструкции из буфера переупорядочивания, которые готовы к выполнению, независимо от потока. И ему похрен, к какому потоку они относятся — лишь бы были независимы по регистрам. А два разных потока всегда независымы по регистрам.
G>>Конечно, однопоточная производительность будет выше, чем у Ниагары, но чудес ждать не стоит. C>Обещают, что будет не хуже Core2.
Посмотрим. При таком подходе, как я описал выше — вероятно будет не сильно хуже.
Здравствуйте, Gaperton, Вы писали:
G>Ты путаешь. Это Ниагара переключается в случае pipline stall по любой причине.
В Ниагаре "револьверная" система, когда каждый поток получает один слот в "револьвере". Ну и, естественно, на заткнувшийся по cache miss поток оно просто переключать не будет.
G>Ничего больше она делать не умеет. Нехалем, судя по картинке, работает совершенно не так — он пихает инструкции с обоих потоков в единый буфер переупорядочивания, для того, чтобы лучше нагрузить кластер арифметики — два потока независимы по регистрам, это должно сильно повысить среднюю нагрузку.
Во время первого HyperThreading'а оно работало именно как я сказал. Что вполне логично, переключения потока всегда происходит по событиям, при которых всё равно нужно pipeline перестраивать — так что всю систему с декодерами операций можно разделять между потоками, она не будет использоваться конкуррентно. Достаточно только сохранять регистры, по сути. На это намекает и "2x Retirement Register File" — в него скорее всего и кидаются регистры при переключении потоков. В общем, непонятно.
G>Строго говоря, Нехалем вообще не переключается между потоками — он выполняет все подряд инструкции из буфера переупорядочивания, которые готовы к выполнению, независимо от потока. И ему похрен, к какому потоку они относятся — лишь бы были независимы по регистрам. А два разных потока всегда независымы по регистрам. http://en.wikipedia.org/wiki/HyperThreading — похоже, что не так.
C>>Обещают, что будет не хуже Core2. G>Посмотрим. При таком подходе, как я описал выше — вероятно будет не сильно хуже.
Обещают лучше
Здравствуйте, Cyberax, Вы писали:
G>>Конечно, однопоточная производительность будет выше, чем у Ниагары, но чудес ждать не стоит. C>Обещают, что будет не хуже Core2.
Посмотрел подробно. 3 канала там всего — два сумматора да один умножитель. Слабее там одно ядро, чем Core 2 — три операции в пике. Пика, впрочем, они должны достигать часто, потому что замешивают в reorder buffer два независимых по регистрам потока. Если, конечно, умножений попадется достаточно. Если, конечно, не будет промахов в кэш .
Короче, не было бы ничего особенного, но каждый из трех каналов — SSE шириной 128 бит. На векторных SSE операциях эта машинка будет реально рвать. Ацкая числодробилка, вот что это такое.
Здравствуйте, Cyberax, Вы писали:
C>На это намекает и "2x Retirement Register File" — в него скорее всего и кидаются регистры при переключении потоков. В общем, непонятно.
Хотел написать "Register Allocation Table", которых тоже два
Здравствуйте, Gaperton, Вы писали:
G>Посмотрел подробно. 3 канала там всего — два сумматора да один умножитель. Слабее там одно ядро, чем Core 2 — три операции в пике. Пика, впрочем, они должны достигать часто, потому что замешивают в reorder buffer два независимых по регистрам потока. Если, конечно, умножений попадется достаточно. Если, конечно, не будет промахов в кэш .
Мне всё же кажется, что не замешивают. А на один поток 3 ALU — самое то, как раз.
G>Короче, не было бы ничего особенного, но каждый из трех каналов — SSE шириной 128 бит. На векторных SSE операциях эта машинка будет реально рвать. Ацкая числодробилка, вот что это такое.
SSE — фигня Скоро будет http://en.wikipedia.org/wiki/Advanced_Vector_Extensions с 256-битным каналом (в будущем до 512 бит).
Здравствуйте, Cyberax, Вы писали:
C>Здравствуйте, Gaperton, Вы писали:
G>>Ты путаешь. Это Ниагара переключается в случае pipline stall по любой причине. C>В Ниагаре "револьверная" система, когда каждый поток получает один слот в "револьвере". Ну и, естественно, на заткнувшийся по cache miss поток оно просто переключать не будет.
По факту это работает именно так — заполняется дырка в конвейре при промахе в кэш или любой другой причине.
G>>Ничего больше она делать не умеет. Нехалем, судя по картинке, работает совершенно не так — он пихает инструкции с обоих потоков в единый буфер переупорядочивания, для того, чтобы лучше нагрузить кластер арифметики — два потока независимы по регистрам, это должно сильно повысить среднюю нагрузку. C>Во время первого HyperThreading'а оно работало именно как я сказал.
гипертрединг — это маркетинговый термин Интела. Аппаратный мультитрединг может быть устроен совершенно по разному, в том числе и у них. Первый гипертрединг у них вообще был ошибкой природы.
C>Что вполне логично, переключения потока всегда происходит по событиям, при которых всё равно нужно pipeline перестраивать — так что всю систему с декодерами операций можно разделять между потоками, она не будет использоваться конкуррентно.
Не всегда. Надо различать промах в кэш команд и в кэш данных. Первое происходит редко, потому что branch prediction в современных процах ацкий, работает с вероятностями более 96-98% и умеет даже косвенные переходы предсказывать. Второе — чаще, но оно лечится суперскаляром и предвыборкой. Как ты думаешь, зачем там reorder buffer глубиной в 128 команд? Грубо — в том числе чтобы выполнять эти команды на фоне ожидания загрузки в регистр при промахе в кэш. Во втором случае у тебя исполнительный конвейер будет с высокой вероятностью разогрет даже при промахе в кэш. Именно поэтому первый гипертрединг и был таким отстоем — толку с него при наличии мощного суперскаляра — почти ноль.
C> Достаточно только сохранять регистры, по сути.
В суперскаляре — не достаточно. У тебя глубоко конвейеризованная арифметика и байпасы. Плюс — состояние станций резервирования, на которых операции ждут операндов. Плюс — состояние исполнительного конвейра. Короче, состояние распылено по самым разным блокам, и его сохранение — реальный challenge, это просто нельзя сделать мгновенно. В Ниагаре таких проблем нет — она single issue, все тупо. И правильно. Так и надо.
C> На это намекает и "2x Retirement Register File" — в него скорее всего и кидаются регистры при переключении потоков. В общем, непонятно.
Непонятно.
G>>Строго говоря, Нехалем вообще не переключается между потоками — он выполняет все подряд инструкции из буфера переупорядочивания, которые готовы к выполнению, независимо от потока. И ему похрен, к какому потоку они относятся — лишь бы были независимы по регистрам. А два разных потока всегда независымы по регистрам. C>http://en.wikipedia.org/wiki/HyperThreading — похоже, что не так.
Напрасно на это смотришь. У них это в разных процах сделано по разному стопудов.
C>>>Обещают, что будет не хуже Core2. G>>Посмотрим. При таком подходе, как я описал выше — вероятно будет не сильно хуже. C>Обещают лучше
Увидим.
Здравствуйте, AndrewVK, Вы писали:
G>>Слабее там одно ядро, чем Core 2
Чудес не бывает. Nehalem выдает всего три арифметических инструкции за такт в пике, но зато каждая из них — SSE, в отличии от Core 2. А этот тест скорее всего с SSE инструкциями. Больно название у него подозрительное.
AVK>
Здравствуйте, AndrewVK, Вы писали:
R>> Но если за счёт HT, то 40% — это очень и очень хорошо.
AVK>Вряд ли.
R>> Предыдущий HT на Pentium4 давал теоретический максимум — +30%, и +30% достигали очень немногие приложения, некоторые получали -5%.
AVK>HT есть у Atom, и там, судя по тестам, эффект от него весьма приличный.
А сколько тогда процентов будет очень и очень хорошо (для процессора типа Интела — всеядного зверя, которому приходится рассчитывать на все типы нагрузок, в т.ч. и на однопоточные приложения)? 100?
Моё понимание такое, что HT — это не основной конёк Интел, это просто способ выжать дополнительные Х% производительности за дополнительные 10% пространства. Они и делают всего 2 аппаратных потока на ядро, а не 8 как Sun.
В таком контексте, мне кажется, дополнительные 30-40% это вполне хорошо. Это как 8 лет назад 1.4ГГц, а не 1.0ГГц.
Здравствуйте, Gaperton, Вы писали:
C>>Во время первого HyperThreading'а оно работало именно как я сказал. G>гипертрединг — это маркетинговый термин Интела. Аппаратный мультитрединг может быть устроен совершенно по разному, в том числе и у них. Первый гипертрединг у них вообще был ошибкой природы.
Первый гипертрединг был вполне неплохой вещью, а вот P4 в целом — ошибкой природы.
То что аппаратный мультитрединг по-разному можно сделать — так я про это и говорю.
G>Не всегда. Надо различать промах в кэш команд и в кэш данных. Первое происходит редко, потому что branch prediction в современных процах ацкий, работает с вероятностями более 96-98% и умеет даже косвенные переходы предсказывать. Второе — чаще, но оно лечится суперскаляром и предвыборкой.
Однако, по меркам общей системы оно происходит очень часто. И это как раз прекрасный повод перключиться на другой поток.
G>Как ты думаешь, зачем там reorder buffer глубиной в 128 команд? Грубо — в том числе чтобы выполнять эти команды на фоне ожидания загрузки в регистр при промахе в кэш. Во втором случае у тебя исполнительный конвейер будет с высокой вероятностью разогрет даже при промахе в кэш.
Это понятно. Но что делать с зависимыми данными? А их ведь в реальности очень много.
G>Именно поэтому первый гипертрединг и был таким отстоем — толку с него при наличии мощного суперскаляра — почти ноль.
На P4 слишком глубокий pipeline был, он всё портил.
C>> Достаточно только сохранять регистры, по сути. G>В суперскаляре — не достаточно. У тебя глубоко конвейеризованная арифметика и байпасы. Плюс — состояние станций резервирования, на которых операции ждут операндов. Плюс — состояние исполнительного конвейра. Короче, состояние распылено по самым разным блокам, и его сохранение — реальный challenge, это просто нельзя сделать мгновенно.
Я предполагаю, что как раз переключение потоков как раз происходит при событиях, когда вся конвееризированая система летит к чёрту. Т.е. когда нечего терять от повторного построения конвейера команд для другого потока, так как это и так придётся сделать.
C>>http://en.wikipedia.org/wiki/HyperThreading — похоже, что не так. G>Напрасно на это смотришь. У них это в разных процах сделано по разному стопудов.
Почему?