Здравствуйте, VladD2, Вы писали:
VD>Здравствуйте, McSeem2, Вы писали:
MS>>Влад, тебе хотя бы знаком смысл слова "убогий"? Посмотри в толковом словаре, если что.
VD>Ты бы сам залез и глянул, чем выпендриваться. Чтобы облегчить тебе жизнь скажу, что одно из значений "жалкий на вид, изувеченный".
MS>> Реализацию итераторов в STL можно назвать какой угодно, но только не убогой. Наоборот, она слишком наворочена.
VD>Хех. К итераторам "итераторы СТЛ" отношения не имеют. А так конечно. Потому и убогий, или если тебе будет угодно, уродливый.
Напрасно ты так категорично. Задача С++ кода времени разработки STL — это задача написания эффективных в run-time решений. Итераторы STL — пока единственное существующее решение, которому удалось имплементировать абстракцию итератора единообразно начиная от голых указателей (итераторы вектороподобных контейнеров) и заканчивая объектами с произвольной сложностью и даже неопределенной структуры (итераторы ввода-вывода). Задача тех итераторов — это адаптирующий механизм, позволяющий использовать готовые и эффективные имплементации алгоритмов на теоретически бесконечном множестве целевых классов объектов.
Мы прекрасно понимаем, что полиморфные итераторы представляют из себя красоту ООП-подхода (опять же — скорее "внутреннюю" красоту, ибо пользоваться готовыми STL-итераторами не сложнее), так же как понимаем, во что обходится динамическое создание объекта и вызов его полиморфных методов в итераторах Java/C#. Платить подобную цену имеет смысл только тогда, когда других путей нет (не ты ли неоднократно советовал использовать for вместо foreach по-возможности )
Для меня "жалким на вид" смотрится замах на рупь а удар на копейку (типа перебрать 5 элементов в контейнере и для этого динамически создать объект-итератор у которого 11 раз вызвать полиморфные методы...).
По крайней мере в STL для меня задача "to be or not to be" не стоит, никакую дополнительную цену за использование итератора мы не платим.
А паттерны — вещь хорошая, разумеется, но им стоило бы быть аккуратнее в именовании тех вещей, в которых не они были первыми. Итератор из GoF они могли бы назвать и подругому, дабы избежать обсуждаемого конфликта одноименных понятий.
Опять же — стоит ли подходить к паттернам GoF так буквально? Часто ли мы применяем паттерны в голом виде? В том же дотнет, берем иерархию и взаимоотношение классов, отвечающих за сервисы WinNT и видим целую гроздь этих паттернов в одном месте, что неудивительно.
Точно так же шаблон "итератор" в GoF (так же как и остальные шаблоны) — это выхолощенное понятие. Задача описания ООП паттерна проктирования — дать самую голую суть ООП-трюка для решения "атомарной" задачи. Для паттерна они поставили задачу "перебрать" элементы коллекции, не зная внутренней структуры самой коллекции. Все! Для описания именно патерна большего и не надо. Но это не значит, что в реальном применении у нас будет стоять именно столь узкая задача. У итераторов STL стояли задачи: доступ, ввод и вывод. И им удалось эти операции сделать весьма единообразными, а значит применимыми в произвольных комбинациях в тех же алгоритмах.
В общем с ярлыками можно было бы и поаккуратнее...
Здравствуйте, VladD2, Вы писали:
К>>А в STL — не восходящая иерархия итераторов (от простейшего input/output до крутейшего random), а деградирующая иерерхия указателей (с постепенным наложением ограничений: дешёвая арифметика, дорогая арифметика, затем запрещение декрементов, и наконец, жёсткий протокол)
VD>Это мягко говоря не итератор. Итератор — это паттерн описанный в GoF. В яве тоже есть IList и т.п. Но к итераторам это отношения не имеет.
Дык я и говорю: терминологическая путаница. Исторически очевидно, что STL iterator-ы — это аксиоматика "указатель на элементы массива". В общем, все вопросы к Степанову.
Ну а пока что — хоть горшком назови. А что? "Горшок произвольного доступа", "горшок ввода" и "горшок вывода".
Горшочек, вари!
Здравствуйте, Трурль, Вы писали:
AG>> Программист дельфи не может ничего сделать такого, чья функциональность выходит за пределы палитры компонентов. Чуть что — бежит в инет в поисках нужного компонента.
Т>Программист C++ не может ничего сделать такого, чья функциональность выходит за пределы STL/ATL/WTL/MFC. Чуть что — бежит в инет в поисках нужной библиотеки.
Ты не прав! Имхо, большинство C++ программистов норовят переписать самостоятельно даже существующие библиотеки. А уж когда готовой сразу под рукой нет, то искать -- это вообще бесполезная трата времени. Нужно незамедлительно писать свою!
... << RSDN@Home 1.1.4 stable rev. 510>>
SObjectizer: <микро>Агентно-ориентированное программирование на C++.
Здравствуйте, VladD2, Вы писали:
VD>Здравствуйте, alexeiz, Вы писали:
A>>Почему-то ты не можешь понять различие в целях дизайна STL и библиотеки коллекций .NET.
VD>Потому что дизайн базовых коллекций сделанный грамотно прекрасно решает и "задачи СТЛ". Весь смысль обобщений заключается в том, чтобы позволить работать с некоторым классом объектов полиморфно.
A>> В STL первоочередной задачей стояло разделение коллекций и алгоритмов. Отсюда и вытекает дизайн STL-ных итераторов, который ты почему-то считаешь убогим. Тем не менее свою задачу STL итераторы выполняют прекрасно. Адгоритмы существуют отдельно, коллекции отдельно, а итераторы позволяют им взаимодействовать через loose coupling.
VD>Слабая связанность и т.п. это уже отдельный вопрос. Здесь же обсуждается совершенно бездарная терминология СТЛ и довольно неудобное использование этих "итераторов".
Что-то я не вижу, где обсуждается неудобное использование. Наоборот, по удобству использованию ничего и рядом не стоит кроме простого указателя. А если ты о сложности создания standard conforming итераторов, то это совсем другой вопрос, который не надо путать с использованием.
Кстати, слабая связанность — это не отдельный вопрос, а основная задача дизайна STL, без понимания которой очень трудно понять суть многих вещей в этой библиотеке.
А вот по терминологии у тебя задвиг, это точно. Внушил себе, что итераторы могут быть только одного типа. Не видишь, что набор задач, в которых могут быть применены итераторы, гораздо шире, чем простое перечисление.
A>>В .NET цели были совершенно другие. Там итераторы (точнее энумераторы) создавались для того, чтобы можно было пробегать по коллекции от начала до конца в одном направлении желательно с применением foreach. Эта цель достигнута. Foreach работает превосходно. К сожалению не для чего другого энумераторы не подходят. Алгоритмы и коллекции жестко связаны.
VD>А, ну, ясно. "Священную корову руками не трогать." Почитай GoF. Думаю тебя удивят некоторые вещи.
Спасибо, "учитель"!
A>> Но этого достаточно для большинства, которые кстати пришли на .NET c Java или с VB, где положение не лучше.
VD>Я вот пришел с С++. И надо признать, и как-то не разделяют твоего мнения. Как впрочем и многие другие пришедшие с плюсов.
C++ допускает программирование на разных уровнях. Можно не понимать концепций STL и все равно писать программы на C++.
A>>На лицо две разные цели и два разных дизайна.
VD>Нет никаких разных целей. Есть желание притянуть что-нить за уши и крайняя предвзятость.
Есть цели. У каждой библиотеки есть design goals. Другое дело, если ты не знаком с целями дизайна STL.
VD>Что до алгоритмов, то зайди на http://www.wintellect.com/powercollections/... погляди.
И что? Вот пример: Algorithms.Fill<T>(IList<T>,int,int,T); Типичный случай алгоритма привязанного к коллекции. Что мне нужен произвольный доступ к элементам коллекции, чтобы запольнить её? Нужна возможность добавлять элементы в любое место, удалять, искать элементы? Нет мне нужен только forward iterator. Додумай на досуге, почему std::fill я могу применить практически к чему угодно (реализовать forward iterator, если такого нет, не стоит никакого труда), а для Algorithms.Fill мне подходит только IList подобная коллекция.
Здравствуйте, McSeem2, Вы писали:
MS>Здравствуйте, Шахтер, Вы писали:
Ш>>Ну почему же. Это просто разные способы применения. Указатель, скажем, позволяет и итерировать, и произвольный доступ. Причем естественным образом.
Ш>>Дело не в стремлении впихнуть все сущности в одно понятие, а в природе вещей. Голый указатель обладает набором определённых свойств -- вот эти свойства и были аксиоматизированы. Получился randon access iterator.
MS>Воот! random access iterator — это pointer и есть. Надо было так и назвать его — pointer, а не итератор.
Ну что поделаешь. Мы живем в эпоху постмодернизма. Афро-американцы, random access iterator ы, список продолжи сам. И никого не смущает, что нет такого континента -- Афро-Америка.
Здравствуйте, VladD2, Вы писали:
VD>Здравствуйте, vdimas, Вы писали:
V>>Да и я не утверждал, что итератор должен обладать качеством прямого доступа.
VD>А именно это и напрягает/путает больше всего.
V>> Кстати, а не трудно тебе сформулировать, что ты называешь прямым доступом применительно к итератору? Может вообще весь этот спор ни о чем...
VD>Ну, вот разные там "it + 2" и т.п.
ясно, тем не менее, вот выдержки из выдержки из "Паттернов" GoF:
дополнительные операции итератора.
Минимальный интерфейс класса
Iterator состоит из операций First, Next, IsDone и Currentltem.1 Но
могут оказаться полезными и некоторые дополнительные операции. Напри-
мер, упорядоченные агрегаты могут предоставлять операцию Previous, по-
зиционирующую итератор на предыдущий элемент. Для отсортированных
или индексированных коллекций интерес представляет операция SkipTo,
которая позиционирует итератор на объект, удовлетворяющий некоторому
критерию;
использование полиморфных итераторов в C++.
С полиморфными итерато-
рами связаны определенные накладные расходы. Необходимо, чтобы объект-
итератор создавался в динамической памяти фабричным методом. Поэтому
использовать их стоит только тогда, когда есть необходимость в полимор-
физме. В противном случае применяйте конкретные итераторы, которые
вполне можно распределять в стеке.
В общем, похоже и по этому вопросу ты остаешься в одиночестве
Мне вообще не понятно, как связана формулировка "абстрагирование перебора" с ограничениями, которые ты пытаешься ввести. Прочитав еще раз внимательно главу об итераторах, я несколько раз наткнулся на формулировкку "минимальный интерфейс итератора". Очевидно, что имелся ввиду интерфейс минимально достаточный для работы описанной концепции.
Никакие обогащения функциональности не дискредитируют сути трюка. Кстати, потоки тоже очень неплохо вписываются в паттерн "итератор". (Тому явный пример омега-C#, где поток int* — это IEnumerable<Int32>). Тем не менее, потоки имеют дополнительную специфику. Например, имеем операцию вывода из потока (один-в-один подходит паттерн Итератор в своем "минимальном" интерфейсе), вполне очевидно сделать "зеркальную" операцию ввода, а там и недалеко до bidirectional. Вот и получили естественную иерархию итераторов в том же С++. И никакого нарушения концепции. Минимальный интерфейс итератора реализуют все члены обсуждаемой иерархии.
Здравствуйте, Кодт, Вы писали:
К>А практика использования двунаправленных итераторов (в первую очередь — указателей на элементы массива) в движении — вот такая: К>
К>*p++; // прочесть/записать и перейти дальше
К>*--p; // отступить и прочесть/записать
К>
К>И это, как несложно заметить, ровно то же самое, что и next(), prev().
Да уж, нагородили... А ноги здесь растут из архитектуры PDP-11, в которой были очень удобные методы адресации — автоинкрементная косвенная и автодекрементная косвенная:
MOV (R0)+,(R1)+
Или
MOV -(R0),-(R1)
То есть, одна инструкция процессора обеспечивала копирование значения и инкрементацию/декрементацию указателей.
И именно отсюда растут ноги Сишных операторов ++ и --. При этом, на PDP-11, наиболее естественными методами итерации были именно *p++ и *--p, то есть, пост-инкремент и пре-декремент. Запись do while(*dst++ = *src++); транслировалась в две инструкции:
L1: MOV (R0)+, (R1)+
BNE L1
А вот пре-инкремент и пост-декремент были несколько неестественными и требовали большего числа команд. А потом всех задавил Intel, в котором нет таких метов адресации и элегантность трансляции ушла в небытие.
А уже потом-потом-потом жависты выдали эту концепию как великое откровение и супер-удобство.
Все что можно было изобрести, уже изобретено... Что-то в этом есть.
McSeem
Я жертва цепи несчастных случайностей. Как и все мы.
IT,
> A>Общественность должна услышать совсем другие слова — design for performance. http://blogs.msdn.com/ricom/archive/2003/12/12/43245.aspx > > Дяденька здесь говорит об элементарных кривых ручках, которыми пытаются дизайнить приложения. Хотя нет, это уже не ручки, это — искривления в ДНК.
Имхо, превращение изначально линейного алгоритма на ровном месте в квадратичный — характерный показатель. Соответственно, имхо, если выбранные абстракции отрицательно влияют на выбор алгоритмов, то абстракции выбраны неверно.
Posted via RSDN NNTP Server 2.0 beta
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
Здравствуйте, c-smile, Вы писали:
CS>Здравствуйте, jazzer, Вы писали:
J>>потому что в STL это делается одним движением мизинца левой ноги: J>>
J>>std::for_each(it1, it2, <всякая фигня>);
J>>
CS>Интересно а что произойдет если it1 и it2 взяты от разных последовательностей?
я думаю, ты и сам знаешь, что произойдет в общем случае. И что с того? Предлагаешь затеять войну на тему "Что безопаснее"?
В STLPort, например, в режиме отладки проверяется выход за границы массива при индексации, так что же тебе ответить на вопрос: "Что произойдет, если индекс массива больше его размера"? В случае STLPort — ничего страшного, тебе укажут на ошибку и ты ее исправишь.
Так вот никто не мешает встроить в итераторы аналогичную защиту. Например, хранить в итераторе указатель (или GUID, предвосхищая плевки в сторону указателей) на контейнер и при сравнении, если сравниваемые итераторы принадлежат разным контейнерам, бросить исключение. Ошибка обнаружится сразу же, при первом обращении к этому коду.
Так что давай на этом закончим обсуждение безопасности и вернемся к содержательной части разговора.
Представь, что у меня есть два предиката P1 и P2 и некий контейнер cont типа MyCont.
И я хочу найти в этом контейнере элемент, удовлетворяющий P1, затем следующий где-то за ним Р2, а затем с выделенной таким образом подпоследовательностью произвести некое действие f.
Все. Это полный код. Если не нашлось элементов, удовлетворяющих Р1 и Р2 — просто ничего не произойдет, так что тут даже никакой дополнительной защиты не нужно.
Согласись, код на STL практически слово в слово повторяет описание на человеческом языке, ничего лишнего писать не пришлось. Причем этот код будет работать, естественно, с разной эффективностью, с любым контейнером, от односвязного списка до массива с произвольным доступом (хотя из-за for_each наименьшая сложность в любом случае будет O(it2-it1) ), более того, этот код можно использовать рекурсивно, например, вместо for_each позвать сам себя, использовав другие предикаты и пришедшие it1 и it2 вместо cont.begin() и cont.end() соответственно.
Опять же, действие над подпоследовательностью может заключаться и не в простом переборе, сразу дающем сложность O(it2-it1), а в каком-либо другом действии, имеющим меньшую сложность и для хорошего контейнера (т.е. контейнера с быстрым поиском) понижающим общую сложность этого кода.
Если .NET или Java может предоставить подобную гибкость, лаконичность и ясность кода, я очень хотел бы это увидеть.
И я очень прошу не поднимать снова тему делегатов и замыканий в том смысле, что на них легче записать предикаты и действие, которое надо произвести, это — тема отдельного разговора. Давайте сконцентрирумеся на итераторах и алгоритмах.
Меня улыбнуло
Твой код удалил не оверквотига ради, а токмо ради сравнения:
VD>
VD>using System;
VD>using System.Collections.Generic;
VD>using System.IO;
VD>class Program
VD>{
VD> static void Main(string[] args)
VD> {
VD> Dictionary<string, int> concordance = new Dictionary<string, int>();
VD> // Перебираем слова...
VD> foreach (string word in GetWord(File.ReadAllText(args[0])))
VD> {
VD> int count;
VD> // Пробуем получить значение. Если оно не задано count будет равен 0.
VD> // что нам и надо.
VD> concordance.TryGetValue(word, out count);
VD> concordance[word] = count + 1;
VD> }
VD> // Копируем список ключей хэш-таблицы в динамический массив и сортируем его.
VD> List<string> keys = new List<string>(concordance.Keys);
VD> keys.Sort();
VD> // Выводим информацию о каждом слове.
VD> foreach (string key in keys)
VD> Console.WriteLine("Слово {0,20} встретилось {1,3} раз[а].",
VD> key, concordance[key]);
VD> }
VD> // Возвращает список слов из мереданного текста.
VD> static IEnumerable<string> GetWord(string text)
VD> {
VD> // Перебираем все символы...
VD> for (int i = 0; i < text.Length; i++)
VD> {
VD> char ch = text[i];
VD> // Если это начало слова...
VD> if (char.IsLetter(ch))
VD> {
VD> int strat = i;
VD> // Ищем его конец.
VD> for (++i; i < text.Length; i++)
VD> {
VD> if (!char.IsLetterOrDigit(ch = text[i]))
VD> {
VD> // Если конец найден, получаем подстроку и вызвращем его в итераторе.
VD> yield return text.Substring(strat, i - strat);
VD> break;
VD> }
VD> }
VD> }
VD> }
VD> }
VD>}
VD>
С++ с голимым концептуально неверным STL-ем:
#include <map>
#include <string>
#include <fstream>
#include <iostream>
using namespace std;
int main(int argc, char * argv[])
{
string str;
map<string, long> concordance;
ifstream input(argv[1]);
if (!input.is_open())
cerr << "Не могу открыть файл" << endl;
while (input >> str)
++concordance[str];
for (map<string, long>::const_iterator i = concordance.begin(); i != concordance.end(); ++i)
cout << "Слово " << i->first << " встретилось " << i->second << " раз[а]" << endl;
return 0;
}
ЗЫ: 6 мин, компилировал 1 раз — первый раз написал while (getline(input, str))
Вывод: нефиг пиписьками меряться, для данной конкретной задачи STL подходит лучше .
А дотнет ... про него ничего тебе не скажу — боюсь . Хотя как таковое творение
микрософтовцев оченна уважаю.
VladD2,
> В дотнетной библиотеке наличие конструктора принимающего энумератор или другую структуру в порядке вещей. А так как почти все коллекции к ним приводятся, то код получается вообще минимальным.
Например, у того же Hashtable конструктора, принимающего IEnumerator или IEnumerable, не обнаружилось. Найден конструктор от IDictionary, что в свете твоего заявления о порядке вещей особенно странно, т.к. энумераторы — общий подход, а создание связей с конкретными интерфейсами ассоциативных контейнеров — частный, не масштабируемый на контейнеры других типов. В частности, как можно сконструировать Hashtable из последовательности пар <key, value>, не прибегая к ручному заполнению в цикле?
Конструкторы ArrayList, Stack и Queue тоже принимают не IEnumerator, и даже не IEnumerable, а ICollection. HybridDictionary, ListDictionary, StringDictionary, NameValueCollection, вообще, не могут быть сконструированы ни из чего подобного
В общем, среди контейнеров конструкторы, принимающие энумератор, не обнаружены... Ессно, это не означает, что такого конструктора не могло быть сделано, просто заставляет задуматься о роли, которую отводили энумераторам при проектировании.
При этом идиология энумераторов .Net от идиологии энумераторов Java очень далека, т.к. в энумераторах Java получение значения совмещено с переходом на следующий/предыдущий элемент, а в .Net эти операции разделены.
Вообще же, энумераторы .Net и итераторы Java, фактически, непригодны для сколько-нибудь сложных алгоритмов, т.к. их даже копировать нельзя.
Posted via RSDN NNTP Server 2.0 beta
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
Здравствуйте, VladD2, Вы писали:
VD>Здравствуйте, vdimas, Вы писали:
VD>Ну, то есть создавать "эффективные в run-time решения" кроме как на С++ с применением СТЛ невозможно?
VD>Надо мужикам рассказать, а то они и не знают.
Разница в быстродействии в 4-5 раз и в требованиях к памяти во столько же раз для меня является показателями сравнительной эффективности, а для мужиков?
Понимаю, что сейчас это уже никого не интересует, но мы ведь STL обсуждали, а ее не вчера написали.
V>>Мы
VD>О как!
V>>прекрасно понимаем, что полиморфные итераторы представляют из себя красоту ООП-подхода (опять же — скорее "внутреннюю" красоту, ибо пользоваться готовыми STL-итераторами не сложнее),
VD>Видимо из-за этого получаются подобные уроды: VD>Читаемость кода
ссылки на foreach для C++ тебе уже давали, а вообще — это дело вкуса. Не факт, что функторы применяются только лишь для подобных примитивных задач. Если функциональность самого функтора занимает приличное число строк, то разумнее использовать именно его, хотя бы из соображений повторного использования (вместо copy&paste который предлагает твой вариант).
V>> так же как понимаем, во что обходится динамическое создание объекта и вызов его полиморфных методов в итераторах Java/C#. Платить подобную цену имеет смысл только тогда, когда других путей нет
VD>Вот еще бы сделать так, чтобы это понимание было хоть на чем-то разумном основано, а не на фобиях...
Дык, были уже замеры, в 4-5 раз разница.
V>>(не ты ли неоднократно советовал использовать for вместо foreach по-возможности )
VD>Нет. Не я. Я как раз советовал использовать foreach. Ты видмо путашь с тем случаем когда я советовал не смешивать ежа с ужем вводя дполнительный индекс к foreach-у. Раз решил работать с индексом, то нефига дурака валять, а работашь с перчисеним — не вводи индксы.
Я не путать видимо, шло обсуждение именно достижения максимального быстродействия в цикле, и это были твои предложения. Жаль, что искать в твоих постах практически нереально из-за их количества.
V>>Для меня "жалким на вид" смотрится замах на рупь а удар на копейку (типа перебрать 5 элементов в контейнере и для этого динамически создать объект-итератор у которого 11 раз вызвать полиморфные методы...).
VD>А для меня жалкими выглядят подобные рассуждения. Сколько стоят те виртуальные вызовы? Неужели дороже основного перебора? А насколько этот перебор повлияет на основной алгоритм?
Пишу сервер приложений на C#, как минимум в половине библиотечных методов над коллекциями 2 доп. виртуальных вызова на итерацию сопоставимы с затратами на тело цикла. Стараюсь использовать по-возможности for(), получаю примерно вдвое выигрыш.
VD>Я согласен, что бывают места где нужна гаранитрованно высокая скорость. В таких местах я и СТЛ на пушочный выстрел не подпущу, так как мне нужен полный контроль, а не зависимость от реализации. Но таких мест доли процента. А 99% кода обычно — это мало влияющий на общую производительность код. За то его 99% и именно его рыхлость и не понятность приводит к тому, что программы становится мучительно тяжкло поддерживать иразвивать.
Скажем так, основная масса действительно сложного и ресурсоемкого кода должна содержаться в background-е, в некоем фреймворке, заточенном под прикладную область. Наверху должна оставаться верхушка айсберга, приятная глазу прикладного программиста. Мне как приходится писать первое. И хотя основная масса кода (зачастую "линейная", т.е. практически без циклов) содержится в прикладной части, эффективность системы в целом определяет все-таки background.
VD>Что же до полиморфизма, то в дотнете можно едеть не полиморфные итераторы. Это как раз не проблема языка. Это проблема дизайна.
Их писать надо под свои коллекции. Перепишем System.Collections? забъем на ICollection и везде будем использовать собсвенную иерархию, вернее даже не иерархию, а сборище итераторов... Обощенные алгоритмы пойдут лесом, похоже, наступит эпоха copy&paste...
V>>По крайней мере в STL для меня задача "to be or not to be" не стоит, никакую дополнительную цену за использование итератора мы не платим.
VD>Мы всегда и за все платим. Просто кто-то это осознает, а кто-то ловит блох по подвалам.
Ну да, работа у меня такая, строить фундаменты с подвалами и, по-возможности, без блох...
V>>А паттерны — вещь хорошая, разумеется, но им стоило бы быть аккуратнее в именовании тех вещей, в которых не они были первыми. Итератор из GoF они могли бы назвать и подругому, дабы избежать обсуждаемого конфликта одноименных понятий.
VD>Нда... Мания величия какая-то. С++ не пуп земли. И уж темболее его библиотечка точно не канает на эталон.
Интересное замечание насчет мании величия. Да и далее совсем не по тексту, почему-то. Речь о банальном конфликте понятий и первенстве в именовании. Насчет "не эталон", я бы не спешил с категоричностью в свете выпуска аналога STL под дотнет. Наверно стоит все-таки определиться: кто яйцо, а кто курица в отношении итераторов и алгоритмов.
VD>GoF ни один паттерн изобретен не был. Они просто написали, о том чем и как пользуются грамотные архитекторы и программисты. Тот же итератор был известен черт знает когда.
Они обощили приемы ООП и взяли на себя смелость дать имена трюкам. Про изобретения никто не говорил.
V>>Опять же — стоит ли подходить к паттернам GoF так буквально?
VD>Ага. Стоит. Иначе получится другие паттерны. Не удоволетворяющие целям описанным в GoF.
V>> Часто ли мы применяем паттерны в голом виде?
VD>Вы? А вы их применяете? По твоим словам в СТЛ же все есть и вам больше не нужно.
По каким моим словам??? А... вы об итераторах... Для меня это далеко не все.
V>>Точно так же шаблон "итератор" в GoF (так же как и остальные шаблоны) — это выхолощенное понятие.
VD>Во оно как? А мужики то и не знали.
Да знают.
V>> Задача описания ООП паттерна проктирования — дать самую голую суть ООП-трюка для решения "атомарной" задачи.
VD>Вообще-то паттерн — это удачный примем для решения часто встречающийся задачи.
Вообще-то коментарий опять мимо текста. Что есть паттерн и задача его описания — это разные вещи.
V>> Для паттерна они поставили задачу "перебрать" элементы коллекции, не зная внутренней структуры самой коллекции. Все!
VD>Согласен.
V>> Для описания именно патерна большего и не надо.
VD>Глупость. Паттерн — это не задача. Это решение часто встречающейся задачи.
Именно глупость, или невнимательное чтение оппонента. Задача описания паттерна — это тоже задача. GoF поставили задачу донести суть повторно применимых приемов до IT-сообщества. Похоже, перестарались с лаконичностью. Кое-кто воспринял слишком буквально. Им стоило разбавить свою книжку примерами и реализациями паттернов с учетом различных специфик, тогда этой ветки могло и не быть.
V>> Но это не значит, что в реальном применении у нас будет стоять именно столь узкая задача.
VD>Именно это и значит. Другие задачи требуют других решений и соотвественно паттернов.
V>> У итераторов STL стояли задачи: доступ, ввод и вывод.
VD>Значит это не итераторы. Задача итератора — абстрагирование перебора элементов коллекции. Все!
Кстати, а с какой целью делается перебор? Наверно, чтобы подсчитать количество элементов?
V>> И им удалось эти операции сделать весьма единообразными, а значит применимыми в произвольных комбинациях в тех же алгоритмах.
VD>"Им", а точнее ему. Не удалось создать стройной и простой концепции.
Опять проблема яйца и курицы. Итераторы в STL не цель, а средство. Собственно, как и везде.
VD>Как минимум получилась куда не годная терминалогия и довольно замусаренный код. Плюс довольно сложная реализация. В общем, нужные задачи решает, но неудобно и не понятно.
Попробуй по-другому.
И придешь к тому же. STL переписывали многократно люди, не глупее тебя. Задачу STL-итераторов я озвучил в предыдущем посте. И именно под эту задачу эти итераторы и разработаны.
Никому не нужны итераторы ради итераторов. По своей сути итератор — посредник, его самого можно описать с помощью пары паттернов. В конкретных условиях к этим посредникам выдвигаются разные требования, соответственно получаем разную специфику.
В этой теме ПК и сотоварищи обсуждали разделение функциональности итераторов для перебора и доступа. (Как в дотнете изменить значения полей value-типа в контейнере?) Не думаю, что ребятам из GoF не была очевидна подобная специфика. Просто она никак не влияет на суть описанного трюка (абтрагирование операций перебора от конкретных коллекций), точно так же как и не ограничивает реализацию (интерфейс и поведение Java и дотнет-итераторов разные, хотя оба реализуют один и тот же паттерн). В общем, зациклился ты на "чистоте" паттерна, хотя этого никто не требовал (и ребята из GoF так же не налагали подобные ограничения).
VladD2,
>>> КЕ>И чем же не устраивает возможность гонять назад и т.п.?
>>> Несоотвествованием сути паттерна. Про бритву Окама слышал?
> ПК>Сути паттерна GoF Iterator (*) не соответствует то, что ты написал ниже:
> А с чего ты взял, что что-то кроме самого итератора должно соотвествовать этому паттерну?
Я ожидаю от собеседника, что начав словами: "Несоотвествованием сути паттерна. <...> Грамотное деление было бы следующим: <...>" — он продолжит о сути паттерна, а не о том, что в Киеве дядька.
> ПК> Соответственно, ставить в один ряд итераторы и коллекции, и говорить о порядке абстракций в этом ряду совершенно бессмысленно. > > Бессмысленно называть указатели или еще чего-то там итераторами. А создать иерархию абстракций повзволяющих оболбщенно работать с разничными списками очень даже осмысленно.
Это и есть иерархия итераторов в STL. А по поводу названия... На тот момент, когда Степанов вводил свою терминологию (1984-1988, 1993), книжки Design Patterns by GoF (1995) еще не было. Соответственно, говорить о правильности терминологии можно весьма условно. Какая из двух терминологий "правильнее" — исключительно вопрос вкуса. О чем, как известно, не спорят.
> ПК> У "списка с произвольным доступом" (что само по себе оксюморон) в случае применения паттерна Iterator будут свои итераторы. > > Да, Пашь, у тебя проблемы с терминологией не хуже чем у Степанова. > Как раз список с прозвольным доступом это более чем нормально. Видимо из-за передозировки С++.
Восстанавливаем контекст:
Грамотное деление было бы следующим:
Итератор — перечисление.
Коллекция — возможность узнанать количество элементов и возможности получения их списка.
Список с произвольным доступом — произвольный доступ к элементам.
Т.е. список вводится сразу именно как список с произвольным доступом, а не вводится список вообще, т.е. с последовательным доступом, а потом уже, как разновидность, "список с произвольным доступом". Вот это выделение первичного назначения списка как контейнера, обеспечивающего произвольный доступ, и есть абсурд, о котором я упомянул.
> Список это абстракция.
Абстракция, или нет — несущественно. Речь о том, что только часть списков обеспечивает произвольный доступ, соответственно, в базовом интерфейсе списка произвольного доступа быть не может, только в одной из разновидностей.
Posted via RSDN NNTP Server 2.0 beta
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
Здравствуйте, VladD2, Вы писали:
VD>Здравствуйте, Костя Ещенко, Вы писали:
КЕ>>И чем же не устраивает возможность гонять назад и т.п.?
VD>Несоотвествованием сути паттерна. Про бритву Окама слышал?
VD>Грамотное деление было бы следующим: VD>Итератор — перечисление. VD>Коллекция — возможность узнанать количество элементов и возможности получения их списка. VD>Список с произвольным доступом — произвольный доступ к элементам.
VD>Причем каждая последующая абстракция должна поддерживать возможности предыдущей.
VD>Именно так и сделно в дотнете (IEnumerable<T>, ICollection<T>, IList<T>). К сожалению тоже не очень грамотно. Так как в интерфейсы коллекции и списка введены методы модификации, а по мне так они должны размещаться в отдельных интерфейсах.
Почему-то ты не можешь понять различие в целях дизайна STL и библиотеки коллекций .NET. В STL первоочередной задачей стояло разделение коллекций и алгоритмов. Отсюда и вытекает дизайн STL-ных итераторов, который ты почему-то считаешь убогим. Тем не менее свою задачу STL итераторы выполняют прекрасно. Адгоритмы существуют отдельно, коллекции отдельно, а итераторы позволяют им взаимодействовать через loose coupling.
В .NET цели были совершенно другие. Там итераторы (точнее энумераторы) создавались для того, чтобы можно было пробегать по коллекции от начала до конца в одном направлении желательно с применением foreach. Эта цель достигнута. Foreach работает превосходно. К сожалению не для чего другого энумераторы не подходят. Алгоритмы и коллекции жестко связаны. Но этого достаточно для большинства, которые кстати пришли на .NET c Java или с VB, где положение не лучше.
Здравствуйте, McSeem2, Вы писали:
MS>Честно сказать, мне концепция итераторов вообще не нравится.
...
Судя по поскипанному тебе не концепция (паттерн) "итератор" не нравится, а его убогая реализация в СТЛ. Вот в Яве как раз они и сделаны по человечески. Их нельзя гонять назад. Нельзя менять и т.п.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
CS> bool found;
CS> foreach( element e; MyCont )
CS> {
CS> if( !found || P1(e) ) found = true; else continue;
CS> if( P2(e) ) break; // open-range case
CS> f(); // your code is here
CS> }
CS>Какой из паттернов естественнее (find_if или foreach) — дело вкуса...
В пользу STL-ного варианта могу сказать, что это явная запись намерений. Он читается с той же скоростью, что и описание задачи на natural language.
В твой вариант все-таки приходится вдумываться — зачем там found и в каких случаях выполнение все-таки дойдет до f().
То есть по изяществу и выразительности тут все-таки рулит STL
VladD2,
> ПК>Классная вышла "оптимизация". Например, в случае LinkedList мы получим совершенно избыточное копирование в массив только для того, чтоб пройтись по нему в обратном порядке.
> Если это станет узким метсом, то не долго написать специализацию и для него: >
Восхитительно! Какой общий подход. Осталось всего лишь добавить в эту функцию каждый из контейнеров, используемых пользователем.
Тем не менее, оставим восторги и вернемся к исходной задаче. Интересно, как будет называться поддиапазон связного списка в данной функции? В самом деле, LinkedList, очевидно, не подойдет... Соответственно, даже с добавлением такого явного "хэка", проблема с эффективностью обращения прохода по подпоследовательности (связного) списка, о чем так давно говорили большевики , при выбранном подходе так и осталась нерешенной.
Posted via RSDN NNTP Server 2.0 beta
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
J>Все. Это полный код. Если не нашлось элементов, удовлетворяющих Р1 и Р2 — просто ничего не произойдет, так что тут даже никакой дополнительной защиты не нужно.
Прекрасный пример.
Итак, давайте представим себе, как будет решена эта задача на С#2.0. Влад уже привел ответ, правда, на другую задачу.
Итак, поехали:
/// Выводит ту часть последовательности input, которая не удовлетворяет критерию limit:public static IEnumerable<T> Limit(IEnumerable<T> input, Predicate<T> limit)
{
foreach(T t in input)
if (limit(t)) return;
else yield return t;
}
/// выводит элементы последовательности input начиная с того, который удовлетворяет start.public static IEnumerable<T> After(IEnumerable<T> input, Predicate<T> start)
{
bool found = false;
foreach(T t in input)
{
found |= start(t);
if(found)
yield return t;
}
}
/// Собственно, код задачи.public static ApplyWithinLimits(IEnumerable input, Action<T> action, Predicate<T> startAt, Predicate<T> stopAt)
{
foreach(T t in Limit(After(input, startAt), stopAt))
action(t);
}
Что мы видим? Да, появилось два "лишних" метода. Они не предусмотрены стандартной библиотекой. Однако, мы восполнили их отсутствие весьма простым и тривиальным способом. Если задачи, которые мы решаем, часто требуют подобных приемов, то эти методы осядут в библиотеке проекта. И объем необходимого кода будет не больше, чем для STL.
... << RSDN@Home 1.1.4 beta 5 rev. 395>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, VladD2, Вы писали:
VD>Что же до гибкости... повторное использование кода — это хорошо. Но это не смоцель. Какая мне радость с того, что я могу повторно использовать алгоритмы если мне приходится писать кучу обязочного кода там где это и нафиг казалось бы не унжно?
К счастью, почти никогда подобный "обвесочный" код не надо писать с 0-ля. К тому же, библиотека и здесь вполне выполняет ф-ию именно библиотеки, т.е. существенно уменьшает наши трудозатраты на решение повседневных задач, ибо трудоемкость разработки этой "обвязки" не видна и под микроскопом, по сравнению с той функциональностью, которую мы получим "задаром".
VD>Коллекция дотнета с его интерфейсами — это не просто эффективно реализованный класс. Это еще и компонет. Его можно использовать в вижуальном дизанере, передавать в другие модули, расширять наследованием и т.п. И это очень дорогого стоит.
Никто не спорил с этим. Вообще, я не удивлюсь, если компиляторы С++ следующего поколения будут выдавать в процессе компилирования не только двоичный код, но и всю метаинформацию к нему (желательно где-нить рядом в какой-нить *.pdb). Достаточно только стандартизировать формат базы данных метаинформации и вуаля... Будут тебе и компоненты и все остальное (ибо при наличии стандарта появятся стандартные ср-ва оперирования метаинформацией. Есть пара аналогичных проектов, но все они непереносимы м/у компиляторами С++).
VD>В общем, по жизи я получаю больше гибкости именно от простых решений, а не от супер-пупер наворотов.
Да не гибкости ты больше получаешь, у упрощение реализации собственного кода, где ты — единственный разработчик. Да и характер развития твоих проектов в общем случае непереносим на коллективы более 2-3-х человек.
В общем случае, при разработке вещей повторного использования (то бишь билиотек) мы балансируем где-то между двумя полярными точками: "библиотекой просто пользоваться, но за счет сложной ее реализации <--> простая реализация билиотеки, но ей сложно пользоваться".
Как было справедливо в этой ветке замечено, эфективность именно билиотек напрямую идет в functional requirements. Так что не всегда от разговоров об эффективности можно отмахнуться как от назойливой мухи, мешающей "красиво жить".В общем, по жизи я получаю больше гибкости именно от простых в использовании повторно-применяемых решений, а не от супер-пупер наворотов.
Здравствуйте, VladD2, Вы писали:
VD>А вот тут позволю себе катигорически не согласиться. Эффективность один из факторов. И довольно часто он ставится намного ниже простоты, понятности или гибкости.
Я уже как пару лет пытаюсь неуклюже донести это дело до общественности. (шёпотом) правильное слово (даже два) — список приоритетов. Первым в этом списке всегда должно стоять functional requirements, вторым — non-functional requirements, третьим — maintenance. Четвёртая космическая, polymorphic behaviour — это всё вторично. Умение правильно расставить приоритеты — это залог успеха.
Если быстродействие системы/модуля/функции является критическим, то такое требование автоматически переходит в разряд non-functional requirements и становится главнее любых требований по соблюдению чистоты кода. В противном случае производительность кода не должна рассматриваться как весомый аргумент.
... << RSDN@Home 1.1.4 beta 5 rev. 395>>
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, Костя Ещенко, Вы писали:
>> Итератор — перечисление.
КЕ>Во-1х имо выделенное неверно. Ты понимаешь под итератором вообще лишь некий минимальный интерфейс итератора. Думаю возникнет меньше терминологических споров, если называть эту сущность энумератором. А итератор — более широкое понятие.
КЕ>Во-2х имо логичнее такая иерархия: итератор потока — forward iterator — bidirectional iterator — random access iterator. При этом надо помнить что работать с файлами через итераторы потока не очень эффективно, да и не всегда удобно.
КЕ>Не знаю, надо ли оно тебе, но на всякий случай расскажу как оно в STL. КЕ>Для итераторов потока определены определены операции ++, ==, != и разыменование, с их помощью нельзя организовать несколько обходов одного и того же потока, они могут использоваться только в однопроходных алгоритмах. КЕ>Forward итератор — то же самое, но возможно несколько проходов, пример контейнера — односвязный список. КЕ>Для bidirectional дополнительнительно определена операция --, пример контейнера — двусвязный список. КЕ>Random access iterator — по сути указатель, дополнительно определены операции +, -, <, >, []. КЕ>Итераторы более высокой категории поддерживают все операции более низких категорий. КЕ>Соответственно алгоритмы деляться на однопроходные и т.д.
В том-то и дело, что вот такая "аксиоматика" STL-итераторов с головой выдаёт в них указатели.
Только строится иерархия не от меньшего к большему, а наоборот:
1) указатель на элементы некоего обобщённого массива — random access tranklukator, над которым определены
— разыменование (очевидно)
— эквивалентность
— адресная арифметика
2) указатель без адресной арифметики — bidirectional tranklukator
— из всей арифметики оставлены только автоинкремент/автодекремент
3) указатель с односторонним инкрементом — forward tranklukator
— оставили только автоинкремент
4) указатель, который совместим с протоколом чтения из последовательного устройства — input tranklukator
— наложили ряд ограничений; использование вне протокола — undefined.
5) указатель, который совместим с протоколом записи — output tranklukator
— наложили другие ограничения
Здравствуйте, VladD2, Вы писали:
VD>Понял. Не уверен. Я как-то с prev не связывался. Но с точки зрения next там именно переход, скажем так, c -1 и далее.
Слушайте, я, кажется, просёк фишку — о чём спор идёт!
Итак, next() и prev() — функции, меняющие состояние. Поэтому сравнивать их с неменяющей функцией (разыменование stl-итератора) — бестолково.
А практика использования двунаправленных итераторов (в первую очередь — указателей на элементы массива) в движении — вот такая:
*p++; // прочесть/записать и перейти дальше
*--p; // отступить и прочесть/записать
И это, как несложно заметить, ровно то же самое, что и next(), prev().
А уж стоит этот итератор "между" элементами или "на" элементе — в данном случае пофиг, как трактовать.
Здравствуйте, VladD2, Вы писали:
VD>Здравствуйте, c-smile, Вы писали:
CS>>Object next() возвращает элемент над которым "пролетает" итератор.
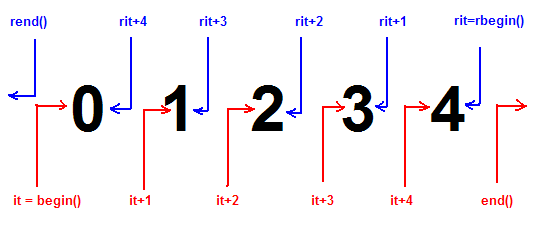
VD>Не выдумывай. next() просто переходит к следующему элементу. При этом в начале итератор находится в состоянии перед первым элементом, а в конце на последнем.
Зуб даешь? (У меня тут уже коллекция "Зубы титанов" намечается)
The next() function returns the item that it jumps over.
The diagram below illustrates the effect of calling next() and previous() on an iterator:
Здравствуйте, VladD2, Вы писали:
VD>Здравствуйте, c-smile, Вы писали:
CS>>Вот меня и инетересует это самое "а что-то другое": що ж це воно такэ, г`а? CS>>Это примерно как приделать seekg с stream. Эх глянуть бы в глаз тому кто это придумал.
VD>Потоки бывают разными. Бывают поледовательными, а бывают с произвольным доступом. Точно так же как списки. Бывают списки на связанных списках, а бывают на массивах.
"Потоки ... бывают с произвольным доступом."
Массивы бывают. Потоки нет. По определению.
"Нельзя войти в одну реку (в один поток) дважды",
(С) Гераклит, 510-512 Anno Domini.
Здравствуйте, c-smile, Вы писали:
CS>Причем здесь индекс и итератор? Весь сыр бор как раз о том CS>что итератор не должен иметь ничего общего с индексом.
Общего не должен, но при реализации индекс там появится с очень большой вероятностью. Мы же ведь не про сфероконей речь ведем?
CS>Загадка: в Java справедливо следующее:
CS>Object a = Enum.next(); CS>Object b = Enum.prev(); CS>assert(a == b); // это true.
CS>Так где находился Enum после next?
Перешел вперед. Вернулся назад. Что же ты еще хотел получить? Хотя по мне так prev совершенно лишний.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Если человек признает свои ошибки, когда он неправ, – значит, он мудр.
Если человек признает свои ошибки, даже когда он прав, – значит, он
женат.
Народная мудрость
Здравствуйте, alexeiz, Вы писали:
A>Так давай-же расставим приоритеты. В данном случае речь идет о библиотеке. Библиотеке, которая состовляет важную часть framework'а. Здесь выбора особенно нет. Быстродействие переходит не только в разряд non-functional, а прямиком в functional requirements.
Абсолютно согласен.
A>И даже в случае applications я несогласен с твоим аргументом. Поставить performance на один уровень с maintenance значит подвергнуть свое приложение реальному риску неудачи.
Дяденька здесь говорит об элементарных кривых ручках, которыми пытаются дизайнить приложения. Хотя нет, это уже не ручки, это — искривления в ДНК.
That means I care deeply about how fast things are, and about keeping them small and tight.
Видишь — "and". Думаешь, к примеру, ввести дополнительный уровень кеширования на всякий случай — it's a way to keep things small and tight? К тому же я нигде у него не увидел упоминания maintenance. Необходимость серьёзно думать о производиельности — увидел, но повсеместно жертвовать простотой кода ради призрачного быстродействия — нет.
... << RSDN@Home 1.1.4 beta 5 rev. 395>>
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, VladD2, Вы писали:
VD>А связь элементарна. Если мне в большинстве случаев нужна простая абстракция перебора элементов, а я вмест нее использую более сложную абстракцию указателия, и если все это в добавок приправленно крайне неудобным, слишком длинным синтаксисом, то я получаю олее сложный, запутанный и плохо читаемый код. Итог всего этого объяснять я думаю не нужено.
Итог получается такой, что начинается обсуждение "абстракция A vs. абстракция B", а тут появляется VladD2 и заявляет: "А мне оно нафиг не нужно и нужно никогда не было и всё это есть путаница на ровном месте!" И вот, спрашивается, какое это имеет отношение к самим абстракциям?
Ладно, звиняй, боле терзать глупыми расспросами не буду.
... << RSDN@Home 1.1.4 beta 3 rev. 185>>
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, VladD2, Вы писали:
VD>Здравствуйте, ArtemGorikov, Вы писали:
VD>ЗЫ
VD>Ты бы создал просто Win32 Console-ый проект и задал бы в нем поддржку ATL. Тогдв жить стало бы проще. А то что-то мучаешся вручную и я вместе с тобой.
Я так и сделал
VD>Да и пример все же лучше повторять без халтуры. А то видимость меньшего объема она и есть видимость. Так, солова у тебя VD>выделяются халтруно и сотрировку результата ты не делашь.
А как ты узнал, что выделяются халтурно? Ты же не смог его собрать. Вот ты требуешь сортировки, при этом против дерева в std::map. Ты бы определился уже, потому что использование дерева как раз даст отсортированный результат, а такого требования первоначально не было.
VD> А все это добавит объема и при твоем методе кодирования ухудшит читаемость. Собственно код уже читается очень плохо в сравнении с эталонным.
Ах ну да, твой код у нас теперь эталон. А я и не знал.
VD> В общем то об этом я и вел речь. Думаю когда ты добъешь свой год и сделашь его полностью аналогичным и работоспособным, то трах и неудобство ты сможешь оценить сам. О них я и говорил.
Мой код полностью работоспособен, я его протестировал в анси и юникод — сборке на студии 2003. То, что ты пользуешься бетой 2005 — не мои проблемы, хотя тут, скорее всего, проблема драйвера клавиатуры. Я код и не задумывал как аналогичный, он лучше. То, что у кого-то руки не от того места растут — иначе как объяснить то, что он не догадался исправить переносы, добавленные в код его чудесным ПО на сервере, написанном на самом лучшем в мире языке — C# .
PS Предлагаю закончить эту дискуссию. Я для себя сделал определенные выводы, больше спорить с тобой не буду. То, что ты не в состоянии (или придуряешься) собрать 1 cpp и обвиняешь в этом меня, не делает тебе чести .
Разрешите и мне чуть-чуть кулаками помахать. MS>Честно сказать, мне концепция итераторов вообще не нравится.
Но тов. Степанову огромное спасибо за то, что он их такими придумал. Есть чего совершенствовать.
Есть такой деятель -- Dietmar Kuehl, член Комитета (не КГБ), бустер, модератор comp.lang.c++.moderated, спортсмен, комсомолец и просто красавец: .
Ему тоже итераторы не нравятся, но у него есть конкретные предложения, и он работает над их реализацией. Основная идея -- разделение обхода структуры данных (курсоры) и доступа к ее элементам (property maps). К сожалению, целиком это нигде не сформулировано, а рассеяно по разным тхредам конференций, типа комп.ланг.с++ и т.д.
Например: http://lists.boost.org/Archives/boost/2002/03/26297.php
Iterators confuse two separate concepts! Separating property access from
object identification clears things up. Of course, everybody is now used
to iterators confusing these two things liberally but this should be
corrected since it causes all kinds of problems. To me the only question
is how the interface is effectively supposed to look like. The question
is not whether iterators and property maps should be separated: That's a
given! For me, at least...
...
here is a list of problems:
— const_iterator vs. iterator:
— can these be compared and/or converted?
— can both be used to specify positions in containers?
— how to get an iterator from a const_iterator?
— value_type
— how to deal with multiple values? map's approach does not scale and
causes eg. problems to key/value organization?
— how to search for key in a sequence of pairs (eg. to implement a
vector based map)?
— how to sort a container with polymorphic object but with a value
like feeling? (the problem is the missing distinction between the
value for the comparison and the holder maintaining the object)
— how to create a proxy container?
— harder to extend:
— creating eg. a filtering iterator requires details on iterator's
member functions
— how to add a derived attribute and use the iterator with find on
the derived attribute?
...
Здравствуйте, McSeem2, Вы писали:
MS>Здравствуйте, c-smile, Вы писали:
CS>>Голый указатель имеет смысл когда используется как указатель на начало CS>>последовательности элементов. Т.е. такое использование итератора CS>>предполагает знание про геометрию контейнера что иделогически (по отношению CS>>к итератору) в корне не верно. Ага?
MS>Честно сказать, мне концепция итераторов вообще не нравится. Просто потому, что ее превратили в какую-то притянутую за уши догму. У итератора по его названию должна быть одна единственная операция — инкремент. На то он и итератор. Если итератор имеет операцию декремент, то это уже не итератор, это нечто другое, скажем, указатель (не обязательно Сишный, просто некий абстрактный). А уж такое понятие, как random access iterator — вообще оксиморон. Примерно как "живой труп". В чистом виде, итератором является только то, что согласуется с полиси InputIterator и не более. И итератор дожен быть принципиально read-only. Иначе это уже не итератор. Указатель в частных случаях имеет право быть итератором, но вообще — он нечто большее, чем итератор.
Итераторы в STL, на мой взгляд, очень удачное решение. Во всяком случае это, пожалуй, лучшее что я видел. Возможно, некоторые алгоритмы записывались бы более компанктно, если бы в них передавались не пара операторов, а один диапазон (поскольку итераторы начала и конца относятся к одному объекту, то и хранить их удобнее вместе). Но это как раз не так важно.
Как я понимаю, вам не нравится название той сущности, которая в STL именуется итератором. Возможно, сущность точнее была бы выражена названием sequence_accessor. Но так уж сложилось, что это назваои итератором. Да, это конфликтует с паттерном Итератор GoF. Но программисты C++ уже давным давно привыкли воспринимать слово итератор как итератор STL.
Я для себя эту проблему решил просто. Я ввел сущность Enumerator. Я выбрал это название, потому что это известная идиома в .NET и большинство разработчиков с ней знакомы. Когда мне нужна сущность, соответствующая паттерну "Итератор" GoF, я использую ее.
Иногда нужно использовать Enumerator в алгоритмах. Для этого нужен лишь небольшой адаптер. При этом алгоритмы STL остаются столь же эффективными с массивами и другими типами последовательностей и реализованы концептуально целостно.
Причем концептуально это более последовательное решение, чем "двунаправленные итераторы".
В общем-то, можно сокрушаться над тем, что термин "итератор" программистами C++ используется не так, как другими, но это свершившийся факт и никто из нас не состоянии это изменить.
MS>В Жаве тоже не лучше. Единственное отличие, как я понимаю, это то, что жавовские итераторы имеют гистерезис, то есть, запаздывание на единицу при смене направления. Что на практике дает больше усложнений, чем кайфов.
Это еще одна сущность с тем же названием Их бессмысленно сравнивать вообще (т.е. без ограничения области применения).
Здравствуйте, c-smile, Вы писали:
CS>Есть два подхода к итераторам: "Java" и "STL" <...>
CS>В принципе дейтвительно Java вариант выглядит логичнее в том смысле что: CS>1) не нужно специального end value (которое кстати не всегда и можно-то натурально определить) CS>2) операции prev / next симметричны.
CS>А вы как думаете?
Прошу прощения за "воскрешение" старой темы, но вот попалась заметка как раз по этому поводу...
The second problem with the Java collection classes is iterator inconvenience. In C++, iterators were simple. If you have a collection with n elements, there are n + 1 iterator positions: At the first, second, . . ., nth element, and past the nth element. You could think of an iterator as a cursor like the old terminals used to have (and Emacs still has). Alternatively, you can think of the iterator as new-fangled caret--a vertical line that is between elements. Then the n + 1 positions are before the first, between the first and second, . . . between the (n-1)st and nth, and past the nth element. Both interpretations are essentially equivalent, but the "cursor" view makes it a bit easier to interpret the element that the iterator currently visits.
What should happen when you add an element at the iterator position? Both C++ and Java do the right thing--which is the same thing your text editor does. The element is inserted before the iterator, and the iterator moves past the inserted element, like this:
a|bc => ax|bc (after inserting x)
How about deleting the iterator position? C++ does what your text editor would do when you press the Delete key (ok, except on the Mac, don't get me going...). The element under the cursor (or to the right of the caret) is deleted, like this:
ax|bc => ax|c (after deleting)
How about Java? Well, you can't tell. It depends if the iterator had just moved to the right, to the left, or not at all. Huh? In the last case, the remove method even throws an exception! If you want to delete two consecutive elements, then you have to move the iterator past the first one, invoke the remove method, and move the iterator over the adjacent element before calling remove again. If my text editor worked like that, it would drive me crazy.
I don't think I am the only one who is aggrieved by Java iterators. Douglas Dunn has a long-winded section in his splendid book "Java Rules", trying to explain the behavior of iterators. (He takes a different tack, taking the remove functionality for granted and then laboriously tries to explain the inconsistency of the add method.)
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
c-smile wrote:
> Есть два подхода к итераторам: "Java" и "STL" > > В Java позиция итератора это позиция *между* элементами последовательности. > > > в stl позиция итератора это позция элемента > > > Вот в статье (здесь) про последнюю QT (v.4.0) утверждается что: >
> The Java-style iterators are new in Qt 4.0 and are the standard ones used in Qt applications. They are more convenient to use than the STL-style iterators, at the price of being slightly less efficient. Their API is modelled on Java's iterator classes.
> > В принципе дейтвительно Java вариант выглядит логичнее в том смысле что: > 1) не нужно специального end value (которое кстати не всегда и можно-то натурально определить) > 2) операции prev / next симметричны. > > А вы как думаете?
Для эффективной реализации (обобщенных) алгоритмов над последовательностями трудно придумать что-то лучшее, чем итераторы STL. У них есть все что надо, но нет ничего лишнего, мы не платим за то, чего не заказывали. В этом видимо и был поинт создателей STL.
Но у конечного юзера алгоритмов и контейнеров могут быть несколько иные требования, чем у реализатора алгоритмов.
Например, стандартартными алгоритмами удобнее пользоваться, если они принимают не итераторы, а диапазоны. И появляются boost::range и прочие подобные решения, где диапазоны реализованы посредством пары STL-итераторов.
А в ситуациях, когда нас меньше волнует эффективность, есть место и для итераторов подобных Джавовским, которые реализуемы посредством STL-итератора + ссылки на контейнер + дополнительных проверок.
Здравствуйте, c-smile, Вы писали:
CS>Голый указатель имеет смысл когда используется как указатель на начало CS>последовательности элементов. Т.е. такое использование итератора CS>предполагает знание про геометрию контейнера что иделогически (по отношению CS>к итератору) в корне не верно. Ага?
Честно сказать, мне концепция итераторов вообще не нравится. Просто потому, что ее превратили в какую-то притянутую за уши догму. У итератора по его названию должна быть одна единственная операция — инкремент. На то он и итератор. Если итератор имеет операцию декремент, то это уже не итератор, это нечто другое, скажем, указатель (не обязательно Сишный, просто некий абстрактный). А уж такое понятие, как random access iterator — вообще оксиморон. Примерно как "живой труп". В чистом виде, итератором является только то, что согласуется с полиси InputIterator и не более. И итератор дожен быть принципиально read-only. Иначе это уже не итератор. Указатель в частных случаях имеет право быть итератором, но вообще — он нечто большее, чем итератор.
В Жаве тоже не лучше. Единственное отличие, как я понимаю, это то, что жавовские итераторы имеют гистерезис, то есть, запаздывание на единицу при смене направления. Что на практике дает больше усложнений, чем кайфов.
McSeem
Я жертва цепи несчастных случайностей. Как и все мы.
VladD2,
> КЕ>И чем же не устраивает возможность гонять назад и т.п.? > > Несоотвествованием сути паттерна. Про бритву Окама слышал?
Сути паттерна GoF Iterator (*) не соответствует то, что ты написал ниже:
> Грамотное деление было бы следующим: > Итератор — перечисление. > Коллекция — возможность узнанать количество элементов и возможности получения их списка. > Список с произвольным доступом — произвольный доступ к элементам. > > Причем каждая последующая абстракция должна поддерживать возможности предыдущей.
Итератор и коллекция — понятия разного порядка: итераторы используются для доступа к коллекции, и вводятся как раз для того, чтоб изолировать доступ к содержимому коллекции от конкретного типа коллекции. Соответственно, ставить в один ряд итераторы и коллекции, и говорить о порядке абстракций в этом ряду совершенно бессмысленно. У "списка с произвольным доступом" (что само по себе оксюморон) в случае применения паттерна Iterator будут свои итераторы.
Пока что к итераторам (особенно к тем, что с произвольным доступом), насколько я вижу, есть одна претензия по существу — название. Возможно, более удачным было бы использование термина Cursor, чтобы не смущать пользователей ассоциациями: "iterator -> перебор". Но, имхо, по отношению к самой концепции название уже вторично.
> Именно так и сделно в дотнете (IEnumerable<T>, ICollection<T>, IList<T>).
IEnumerable != iterator. Итераторам более-менее соответствует IEnumerator, только с той разницей, что в STL итераторы поддерживают большее количество возможностей.
Здравствуйте, Павел Кузнецов, Вы писали:
ПК>У "списка с произвольным доступом" (что само по себе оксюморон) в случае применения паттерна Iterator будут свои итераторы.
Если уж совсем буквоедствовать, то это как раз нормально. Пишем на листочке список продуктов для покупки — он имеет произвольный доступ. В программировании это соответствует массиву. Так что само по себе понятие "список" не указывет, какие методы доступа к нему применимы. Вектор тоже является списком. Другое дело — сложившиеся традиции. Для простоты под понятием "список" подразумевается именно "linked list с последовательным доступом" и ничто другое. С учетом сложившихся традиций, "список с произвольным доступом" действительно является оксюмороном, а вообще — нет. Но это хорошая традиция, достойная уважения. Неуважение к традициям приводит к образованию каких-то совсем уж нелепых сущностей, типа ArrayList. Судя по названию (с учетом традиций) это должен быть связный список массивов, а не массив, в который добавлен IList.
McSeem
Я жертва цепи несчастных случайностей. Как и все мы.
c-smile,
> Вопрос был: Почему авторы QT (и не только они) считают что Java вариант исполнения итератора удобнее?
Может, потому что они используют итераторы только для простых нужд (только последовательный перебор элементов контейнера), а более сложные моменты пишут "ручками", а не используют готовые шаблоны алгоритмов? На это наталкивает множество примеров из статьи об итераторах QT.
while (i.hasNext())
cout << i.next().ascii() << endl;
вместо использования std::copy + boost::bind.
while (i.hasNext()) {
if (i.next() % 2 != 0)
i.remove();
}
вместо использования std::remove_if. Данный случай в "ручном" исполнении уже заметно менее эффективен, например, для вектора.
При последовательном переборе может оказаться чуть более удобным то, что достаточно одного энумератора, а не двух итераторов. В чуть более сложном случае перебора с возвратами, имхо, энумераторы быстро перестают быть удобными из-за того, что приходиться бороться с повтором значений в момент смены направления (next и prev, вызванные последовательно, дают одно и то же значение). A если в язык будет добавлена поддержка лямбда-функций, имхо, итераторы в стиле STL станут более удобными во всех случаях, и в простом, и в сложных. А если еще ввести перегруженные алгоритмы, работающие с диапазонами...
P.S. Можно заметить, что QT мосты не сжигает, и итераторы в стиле STL по-прежнему в наличии.
Posted via RSDN NNTP Server 2.0 beta
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
Здравствуйте, VladD2, Вы писали:
VD>Здравствуйте, vdimas, Вы писали:
V>>Неправда. Суть паттерана итератор — получить доступ к элементам коллекции не зная структуры или интерфейса самой коллекции.
VD>Не получить доступ, а переборать. Как по-твоему итератор переводится iterator?
VD>Иначе указатели и массивы тоже будут итераторами.
ok, перебрать.
И где ограничение на способ или направление перебора?
В описании этого паттерна в GoF такие вещи не уточняются, да и не должны, ибо они не требуются для описания сути паттерна. Однако нигде и не говорится об ограничениях. С чего это тебе захотелось заняться ограничением имплементации паттернов — непонятно.
Ты же не делаешь, например, интерпретатор в том голом виде, как он представлен в паттернах GoF?
Здравствуйте, IT, Вы писали:
V>>Мне как приходится писать первое. И хотя основная масса кода (зачастую "линейная", т.е. практически без циклов) содержится в прикладной части, эффективность системы в целом определяет все-таки background.
IT>Общая эффективность системы определяется общей архитектурой.
Насколько общей?
есть эффективность отдельных подсистем. На стороне GUI эффективность некритична, если же к серваку одновременно подключены тысячи клиентов (часть клиентов у нас — это не юзвери, а программы-агенты-автоматы), одним словом общая картинка получается нескучной, поневоле задумаешься над тем, чему в ВУЗе учили, несмотря на современные мощщща
IT>for или foreach, даже в background, не могут влиять на это кардинально. Если же они всё таки начинают влияют, то нужно поднимать вопрос о смене приоритетов.
Иногда могут влиять кардинально
Если мне итератор не позволяет изменять коллекцию, по которой "бежит", то обычно делают измененную копию этой коллекции. Все это хорошо, пока у нас немного данных и итераторы бегают нечасто. Если же не так, то делаем на for, потому как подобных кешей много, я уверен, что в общем случае они регулярно будут оставаться за бортом второго поколения GC. Для Hashtable и того хуже — сначала отдельно создаем список ключей (для удаления, например), а потом пробегая по этому списку ключей удаляем из hashtable... В общем, некоторая "ломка" из-за отсутствия нечто вроде STL имеется.
Здравствуйте, VladD2, Вы писали:
VD>В общем, по жизи я получаю больше гибкости именно от простых решений, а не от супер-пупер наворотов.
Ну так, ты рассказал, фактически, о том, что "тебе не приходилось...", "ты не сталкивался...", "ты развернулся по течению..." и т.п. Расскажи теперь, плз., какое это отношение имеет к характеристикам рассматриваемых абстракций?
... << RSDN@Home 1.1.4 beta 3 rev. 185>>
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
"IT" <1@users.rsdn.ru> wrote in message news:1161222@news.rsdn.ru > Я уже как пару лет пытаюсь неуклюже донести это дело до > общественности. (шёпотом) правильное слово (даже два) — список > приоритетов. Первым в этом списке всегда должно стоять functional > requirements, вторым — non-functional requirements, третьим - > maintenance. Четвёртая космическая, polymorphic behaviour — это всё > вторично. Умение правильно расставить приоритеты — это залог успеха. > > Если быстродействие системы/модуля/функции является критическим, то > такое требование автоматически переходит в разряд non-functional > requirements и становится главнее любых требований по соблюдению > чистоты кода. В противном случае производительность кода не должна > рассматриваться как весомый аргумент.
Так давай-же расставим приоритеты. В данном случае речь идет о библиотеке. Библиотеке, которая состовляет важную часть framework'а. Здесь выбора особенно нет. Быстродействие переходит не только в разряд non-functional, а прямиком в functional requirements.
И даже в случае applications я несогласен с твоим аргументом. Поставить performance на один уровень с maintenance значит подвергнуть свое приложение реальному риску неудачи. Общественность должна услышать совсем другие слова — design for performance. http://blogs.msdn.com/ricom/archive/2003/12/12/43245.aspx
AG> Программист дельфи не может ничего сделать такого, чья функциональность выходит за пределы палитры компонентов. Чуть что — бежит в инет в поисках нужного компонента.
Программист C++ не может ничего сделать такого, чья функциональность выходит за пределы STL/ATL/WTL/MFC. Чуть что — бежит в инет в поисках нужной библиотеки.
Здравствуйте, VladD2, Вы писали:
VD>Здравствуйте, ArtemGorikov, Вы писали:
VD>Запустил этот тест. Результат получился еще более потрясающим чем предыдущим: VD>
VD> 00427CD0
VD>
Сори, это я файл забыл подставить. Если подставить путь к файлу, то получается более осмысленный вариант:
VladD2,
> ПК> Например, проход по подпоследовательности (связного) списка в обратном порядке не требует ничего копировать в промежуточный массив. > > Ага. Как в прочем и не является последовательным.
А какой же он? Параллельный, или, быть может, случайный?..
> ПК>Нет, я в основном говорю о (связных) списках, которые по определению обладают последовательным доступом. > > Связанные списки вообще особный разговор. Но в данном случае они потребуют полного перебора для прогрутки. И возможность прохода в обратную сторону без копирования будет доступна только при условии, что связанный список двунаправляенный.
Естественно. Это вполне удачно передается концепцией двунаправленных итераторов STL.
> Что еже не хило привязывает к реализацииям списоков или понижает эффективность.
Не к реализациям, а к концепциям. Естественно, обратный проход возможен только при наличии соответствующего итератора. Проблема в том, что энумераторы .Net не позволяют и этого.
> ПК> Классная вышла "оптимизация". Например, в случае LinkedList мы получим совершенно избыточное копирование в массив только для того, чтоб пройтись по нему в обратном порядке. > > Да, но это не так уж и накладно с одной стороны <...>
Ну, ты ж назвал это оптимизацией... Мне только оставалось правильно расставить кавычки
> для прямого однонаправленного итератора в СТЛ прийдется делать тоже самое. Ну, бывает же, что итератор действительно извлекает данные из медленного источника и вообще не хранит структуру?
Конечно. Но это уже другой случай, когда структуры данных не позволяют применить более эффективный алгоритм. Проблема же с предложенными тобой абстракциями, что они сами ограничивают эффективность выбираемых алгоритмов. В случае столь порицаемых тобой итераторов STL этого не происходит. Напротив, они вполне помогают в этом деле...
Posted via RSDN NNTP Server 2.0 beta
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
Просто, имхо, интересно.
> Тут утверждалось что дескать дотнетные коллекции не тем боком проектировались.
Не это утверждалось, а то, что при проектировании итераторов STL и энумераторов .Net преследовались различные цели, соответственно, и результаты различны. В частности, одним из выводов было, что энумераторы .Net мало для чего пригодны, кроме как для последовательного перебора элементов коллекции.
> Как видишь они не помешали создать все что нужно и в довольно приличном виде.
Мы все еще об итераторах/энумераторах? В Power Collections чаще используются сами коллекции, чем их энумераторы. Что как раз и подтверждает то, что энумераторы мало для чего подходят.
> Алгоритмы СТЛ тоже были навеяны функциональными языками. В которых, кстати, они реализуются намного чище и красивее. Просто кто-то был больше знаком с плюсами. Ну, тебе это знакомо.
Уф-ф-ф... Тебе бы все на личности переходить, да авторов концепций как-нибудь "опускать, вместо того чтобы по существу аргументы приводить. Исключительно просвещения для: Степанов сначала реализовал библиотеку алгоритмов и структур данных на Схеме, затем на Аде, и уж потом — на C++.
> Кстати, функциональный подход во втором Шарпе реализуется довольно прозрачно. Что нельзя сказать о плюсах.
Благодаря поддержке лямбда-функций (aka "анонимные делегаты"). Если введут что-нибудь в таком духе в C++, будет и в C++ с этим все хорошо. Так или иначе, чтобы была возможность писать алгоритмы обобщенно, без привязки к контейнеру, нужны некоторые абстракции, аналогичные итераторам STL. Можно их заменить на диапазоны, можно уточнить, разделяя индексацию и доступ к элементу и т.п. — суть от этого не меняется.
Posted via RSDN NNTP Server 2.0 beta
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
Здравствуйте, VladD2, Вы писали:
CS>>Ссылка на источник в первоначальном сообщении.
VD>Для спрвки, чтобы индусам объяснить казалось бы простые и очевидные вещи приходится придумывать вот такую белеберду. Но ты-то вроещ не индус? Тогда должен понимать, что целочисленный индекст не может быть между элементами.
Влад, ты как всегда неподражаем.
Причем здесь индекс и итератор? Весь сыр бор как раз о том
что итератор не должен иметь ничего общего с индексом.
Загадка: в Java справедливо следующее:
Object a = Enum.next();
Object b = Enum.prev();
assert(a == b); // это true.
Sinclair,
>>> ПК>Такой подход либо требует контейнера с произвольным доступом, либо приводит к дополнительному проходу по элементам там, где в случае итераторов он не нужен.
> ПК>В плюсах (точнее, не в плюсах, а если итератор представляет собой позицию)
> Т.е. это контейнер с произвольным доступом
Нет. В случае (связного) списка итератор "внутрях" представляет собой указатель на узел списка. Соответственно, обозначает позицию и обеспечивает прямой доступ к элементу при наличии итератора без необходимости дополнительного прохода по предыдущим элементам.
> ПК> будут только необходимые проходы. Если вместо итераторов вводятся числа, обозначающие порядковый номер элемента, как это было в примере выше, то в общем случае проходов будет больше: первый, чтоб найти элемент, и потом еще по проходу каждый раз, когда данный элемент нужен еще раз, т.к. по индексу без произвольного доступа элемент можно получить только перечислением.
> то есть дополнительный проход.
Этот дополнительный проход — в той схеме, что обозначил ты в сообщени выше (позиции задаются порядковыми номерами). В случае непосредственного указания на элемент, принятого в STL, этого прохода не будет.
> Можно еще раз объяснить, где "такой подход приводит к дополнительному проходу там, где он не нужен"?
Если начальная позиция обозначается порядковым номером, то нужен один проход для определения этого номера, плюс еще один при желании осуществить доступ к элементу/продолжить поиск. В случае, если позиция обозначается итератором, скажем, хранящим указатель на узел в случае списка, второй проход не нужен.
Posted via RSDN NNTP Server 2.0 beta
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
Здравствуйте, c-smile, Вы писали:
CS>Есть два подхода к итераторам: "Java" и "STL"
CS>А вы как думаете?
Смысл твоего сообщения от меня ускользает.
Согласно картинкам, оба варианта изоморфны.
Вообще, не очень понятно, что значит -- указывать между элементами?
Здравствуйте, c-smile, Вы писали:
CS>Есть два подхода к итераторам: "Java" и "STL"
CS>В Java позиция итератора это позиция *между* элементами последовательности. CS>
CS>в stl позиция итератора это позция элемента CS>
CS>А вы как думаете?
в STL она тожа как-бы между, если судить по логике приведения reverse_iterator к iterator при помощи base() — он начинает указывать на другой элемент, на одну позицию правее:
Профессор, мое субъективное восприятие нижеприведенной фразы не позволяет мне объективно
(ака "канкретно") насладиться прелестью оной.
К>Итераторы Java (а также энумераторы COM) — это обобщение идеи сканера файла: доступ к объекту приводит к смене состояния субъекта.
Что в данной сентеции есть "объект", а что "субъект"?
Здравствуйте, Шахтер, Вы писали:
Ш> В stl есть несколько категорий итераторов. Наиболее важная и употребимая -- random access итераторы. Остальные категории получаются удалением некоторых способностей из RanIt.
В том-то и дело, что идеологически, понятие random access iterator является само-противоречивым. Либо random access, либо итератор. По-моему, так. И это не демагогия. Из за стремления впихнуть все сущности в одно понятие, появляются все эти неуклюжие traits & policies, в то время, как сущности просто-напросто принадлежат к разным категориям.
Зачем, скажем сортировке итераторы? Сортировке от контейнера требуется две вещи — аксессор и размер. То есть, operator[] и size(). Все, больше ей ничего не надо.
sort(container);
Если же надо отсортировать в диапазоне, делаем это через простейший-простейший адаптор:
sort(range(container, 10, 20));
При этом у нас автоматически запрещено сортировать списки. А в STL, для того, чтобы запретить сортировку списков, приходится городить дополнительный огород с полиси. Короче говоря, итераторы в STL и тем более в Boost — это пример ненужного усложнения, "типа круто".
Вот что сказал Tony Juricic (один из активных пользователей моего mail-листа):
You won't get argument from me here. While I don't mean to say there are
not many very useful classes in BOOST, the sheer amount of dirt you have
to pull in, just to use it, is making BOOST less and less of a library I
would consider for doing anything.
It is IMO becoming a display of the failure of compilers and language
extensions, on the other extreme but in its practical nonsense
complementary to latest MS additions to 'managed C++'.
McSeem
Я жертва цепи несчастных случайностей. Как и все мы.
VladD2,
> Вдумайся в свои слова "предоставляет концепция итератора stl". Концепция есть концепция. А реализация — реализация. Так что в СТЛ просто неудачная реализация очень правильной концепции.
В STL — именно набор концепций. Просто что-то назвать недостаточно, чтобы это что-то стало концепцией. Нужно это что-то еще и точно специфицировать. Без привязки к конкретном описанию "итератор" концепцией не является, а является просто неоднозначным словом. А вот, скажем, ForwardIterator — одна из таких концепций. Реализации — соответственно, в конкретных реализациях STL.
Posted via RSDN NNTP Server 2.0 beta
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
Здравствуйте, VladD2, Вы писали:
К>>>В том-то и дело, что вот такая "аксиоматика" STL-итераторов с головой выдаёт в них указатели.
КЕ>>Это плохо?
VD>Естественно. Иначе давай называть телефон патефонном с возможностью разговора на растонянии.
Итератор произвольного доступа is a итератор, т.к. поддерживает все операции итератора. А телефон is not a патефон — он не принимает патефонные пластинки
VD>Да и сама концепия довольно непонятна, громоздка и требует кучи лишних действий (неудобна).
Наоборот, концепция очень наглядна для знакомых с указателями. Про кучу действий отчасти верно, но есть способы ее уменьшить.
Здравствуйте, Кодт, Вы писали:
VD>>Кстати, о связанных саписках. Напдо признать, что с точки зрения скорости приложения они почему-то почти всегда проигрывают другим средствам. Не даром до второго фрэймворка МС даже не ввела такой примитив в состав коллекций. Да и с появлением этого дела как-то не тянет его писпользовать.
К>Это ты, наверное, на C# крепко подсел. Конечно, если коллекция указателей, то перетасовать её как нефиг делать. А массивы структур (с глубоким копированием) идут лесом. К>В С++, напомню, это далеко не всегда так.
Да нет, в чем то он прав. Во-первых действительно очень часто все равно приходится делать доступ по индексу (иногда, что самое неприятное, не сразу, а в процессе развития системы). И этот доступ по индексу мигом съедает все преимущества связанных списков. Во-вторых работа со связанными списками с точки зрения современных процессоров не очень удобна из-за существенно более высокой вероятности промаха в кеше данных.
>> In object-oriented programming, an iterator is an object allowing one to sequence through all of the elements or parts contained in some other object, typically a container or list.
> Поскольку в цитате АВК сказано container or list, то ясно что речь идет о списке не как о контейнере. Никакой другой реализации спика-не-контейнера кроме связанного списка я не знаю.
А почему linked list не является контейнером?.. Имхо, фрагмент "a container or list" в цитате выше, вообще, имеет мало смысла: было бы достаточно просто "a container".
Posted via RSDN NNTP Server 2.0 beta
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
Здравствуйте, Павел Кузнецов, Вы писали:
ПК>Есть одно место, где потенциально "сломается" код клиента — вызов шаблона функции с выводом аргумента шаблона по *it. В этом случае все легко "чинится" использованием функции Accessor<>::operator *, принудительно "разыменовывающей" accessor:
ПК>templ_function( **it );
Это плохая идея: получается, что Accessor имеет семантику указателя, а не только ссылки.
Лучше ввести дружественную функцию с "человеческим" именем, или метод
Здравствуйте, jazzer, Вы писали: J>Ну так чего, кто-нибудь приведет код реализации итерации по подпоследовательности средствами итераторов java или .Net?
Вопрос не понял. Что такое "подпоследовательность"? Промежуток промеж двух итераторов? Не имеет смысла, т.к. в Java или .Net не принято использовать енумератор как указатель.
Для них более естественно состряпать адаптер, который переберет весь нужный поддиапазон.
public class MyArrayBasedCollection
{
public IEnumerable SubRange(int start, int end)
{
for(int i = start, i<end; i++)
yield return this[i];
}
}
...
foreach (object o in myabc.SubRange(1, 50))
{
Console.Write(o);
}
...
public static IEnumerable<T> Limit(IEnumerable<T> source, int limit)
{
int i;
foreach(T t in source)
{
if (i++ > limit) return;
yield return t;
}
}
...
int[] a = new int[50];
foreach(object o in Limit(a, 5));
... << RSDN@Home 1.1.4 beta 5 rev. 395>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, jazzer, Вы писали: J>Например. Просто мне каким-то образом известно начало и конец подпоследовательности (в STL это итераторы, в .Net — пусть соответствующие гуру скажут), и я хочу с этой самой подпоследовательностью что-нть сделать. Например, развернуть ее.
Ключевой момент — "каким-то образом". Где ты возьмешь этот "конец подпоследовательности"? J>пример понятен: в C# все будет основываться на индексах в главной последовательности, и, соответственно, для итерации по подпоследовательности нужны эти два индекса и сама эта главная последовательность.
Нет. Я просто привел пример "какого-то образа" получения того самого итератора, спозиционированного хрен знает куда. Итератор "конца последовательности" в .Net не нужен. Какие еще есть полезные способы? Пример с индексами я привел. Приведи другие примеры — и ты убедишься, что есть способ выразить их в терминах .Net.
Не надо пытаться слепо переносить технические приемы из одной среды в другую. В каждом языке — свой способ решить некоторую задачу.
... << RSDN@Home 1.1.4 beta 5 rev. 395>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Serginio1, Вы писали: S> Я имел ввиду правила навигации. Next,Prior,CurrentRecord, GetRecordForKey,SetRange, фильтрация, итд. Причем индексы не всегда и нужны, но с ними оно кошерней.
Угу. А еще полезно в кармане носить подкову. Не всегда нужна, но с ней кошерней.
... << RSDN@Home 1.1.4 beta 5 rev. 395>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Serginio1, Вы писали: S> Ну да, зато при имплементации интефейсов в разных классах полно NotSupported или прикручивание кастрированных итераторов к тому, где нужно деторождение. Для форича может и конулингуса и хватит, а другим хочется и полноценного секса.
Ну, это уж да. Если секс — то непременно полноценный. Давайте на всякий случай доопределим на примитивном односвязном списке суперинтерфейс курсора с тридцатью двумя методами. В шестнадцати насладимся сексом с реализацией Prev с учетом SetRange и фильтрации, а остальные шестнадцать будут возвращать NotSupported. Чтобы и пользователь нашего курсора тоже вкусил полноценного секса. С всенепременным деторождением.
... << RSDN@Home 1.1.4 beta 5 rev. 395>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Serginio1, Вы писали:
S> Ну это уж слишком, камасутра тоже вредна. Суть в том, что для определенного круга задач существующих в нет энумераторов недостаточно. S> И при этом, нарастить функциональность уже существующих классов где такая функциональность нужна, но не реализована и не представляется возможным, но есть огромное желание, а обходить окольными путями не всегда кошерно, а иногда и вредно. Все зависит от задачи. S> Вот и приходится заниматься изобретением велосипеда.
Гм. Божий дар с яичницей... опасная смесь. Что нужно сделать: ввести дополнительные интерфейсы. Отнаследоваться от стандартной коллекции и реализовать эти дополнительные интерфейсы. Совершенно необязательно вручную высверливать трубы для велосипедной рамы из цельной чугунной болванки.
... << RSDN@Home 1.1.4 beta 5 rev. 395>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, vdimas, Вы писали:
V>Пишу сервер приложений на C#, как минимум в половине библиотечных методов над коллекциями 2 доп. виртуальных вызова на итерацию сопоставимы с затратами на тело цикла. Стараюсь использовать по-возможности for(), получаю примерно вдвое выигрыш.
VD>>Я согласен, что бывают места где нужна гаранитрованно высокая скорость. В таких местах я и СТЛ на пушочный выстрел не подпущу, так как мне нужен полный контроль, а не зависимость от реализации. Но таких мест доли процента. А 99% кода обычно — это мало влияющий на общую производительность код. За то его 99% и именно его рыхлость и не понятность приводит к тому, что программы становится мучительно тяжкло поддерживать иразвивать.
V>Скажем так, основная масса действительно сложного и ресурсоемкого кода должна содержаться в background-е, в некоем фреймворке, заточенном под прикладную область. Наверху должна оставаться верхушка айсберга, приятная глазу прикладного программиста.
Точно.
V>Мне как приходится писать первое. И хотя основная масса кода (зачастую "линейная", т.е. практически без циклов) содержится в прикладной части, эффективность системы в целом определяет все-таки background.
Общая эффективность системы определяется общей архитектурой. for или foreach, даже в background, не могут влиять на это кардинально. Если же они всё таки начинают влияют, то нужно поднимать вопрос о смене приоритетов.
... << RSDN@Home 1.1.4 beta 5 rev. 395>>
Если нам не помогут, то мы тоже никого не пощадим.
Здравствуйте, VladD2, Вы писали:
VD>Здравствуйте, jazzer, Вы писали:
VD>>>Ни однин последовательный алгоритм принципиально не может перебирать ничего в обратном порядке без копирования в промежуточный массив.
J>>Ты не прав. В STL из любого двунаправленного (и его потомков) итератора можно получить итератор, дающий обход в обратном порядке.
VD>Без возможности переместиться в конец ты будешь перебирать элементы, что приведет к замедлению работы алгоритма.
Причем тут возможность переместиться в конец???
J>>Причем, опять же, ты можешь абстрагироваться от направления текущего итератора. J>>Т.е. если у тебя на входе итератор, который на самом деле осуществляет обратный обход, ты, обращая его, получаешь прямой, и тебе даже не нужно думать, что же у тебя во что превращается: ты можешь быть уверенным, что в результате ты получишь итератор с противоположным направлением обхода.
VD>Здорово. И получаем не универсальное решение так как однонаправленный итератор или будет крайне не эффективно разворачиваться, или вообще нельзя будет развернуть.
однонаправленный итератор в принципе нельзя эффективно развернуть, независимо от языка и библиотеки.
VD>В итоге мы начинаем зависеть от реализации контейнера, что есть нарушение условий паттерна "итератор".
Ничего подобного.
В STL мы всегда можем узнать у итератора, к какому классу итераторов он принадлежит, и, в зависимости от класса итератора, написать оптимизированные версии алгоритмов. Например, для двунаправленных и производных от них, типа итератора произвольного доступа, мы можем просто разворачивать итераторы, для однонаправленных итераторов — действовать через тот же промежуточный массив.
И контейнер с его реализацией нам тут абсолютно побоку, мы работаем только с итераторами.
Здравствуйте, Павел Кузнецов, Вы писали:
ПК>Конечно. Но это уже другой случай, когда структуры данных не позволяют применить более эффективный алгоритм. Проблема же с предложенными тобой абстракциями, что они сами ограничивают эффективность выбираемых алгоритмов. В случае столь порицаемых тобой итераторов STL этого не происходит. Напротив, они вполне помогают в этом деле...
Да не особо то что-то ограничивается. Ты все о каких-то очень абстрактных вещах рассуждашь, а обычный код он пишется не абстрактно. Они пишится под конкретное проетное решение. А то в свою очередь создается под конкретный фрэймоврк.
Что касается итераторв из СТЛ, то они несомненно гибки. Но притензии то не к этому. Их проблемы в другом. И я это говрил много раз. Они сильно замусоривают код и используют никуда не годную терминологию сбивающую с толку.
Что же до гибкости... повторное использование кода — это хорошо. Но это не смоцель. Какая мне радость с того, что я могу повторно использовать алгоритмы если мне приходится писать кучу обязочного кода там где это и нафиг казалось бы не унжно?
Коллекция дотнета с его интерфейсами — это не просто эффективно реализованный класс. Это еще и компонет. Его можно использовать в вижуальном дизанере, передавать в другие модули, расширять наследованием и т.п. И это очень дорогого стоит.
Понятно что реализации дотнета тоже не идеальна. Я, например, пару раз сталкивался с тем, что хочетелось модифицировать вэшью-типы хранимые в коллекции. А вот развернуть итератор ни разу хотелось (это к слову о теоретике). Однако со временем начал понимать, что нефига пихать в коллекции вэлью-типы. Но не рассчитаны они на них. Они проектировались под хранение ссылочных объектов. И как только перестаешь плыть против течения, то все становится просто и красиво.
Как я уже говорил, тройка IEnumerable<T>, ICollection<T> и IList<T> позволяют решать большинство задачь. Причем решения получаются очень простыми в понимании и достаточно эффективными. Отровенно говоря лично я IList<T> даже и не использовл то никогда. Ненужно как-то. Обычно алгоритмы которые попадаются под руку приходится применять или к массивам (а у них свой набор алгоритмов), или к List<T>. И нет не малейшего желания делать алгоритмы обобщенными. Они ведь решают конкретную задачу.
В общем, по жизи я получаю больше гибкости именно от простых решений, а не от супер-пупер наворотов.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
VladD2 wrote:
> C>Так, небольшая заметка: по правилам русского языка обращение "вы" > C>пишется с большой буквы только в личных письмах (ну или в начале > C>предложения ). > "Вы" пишется с большой буквы когда им заменяется имя или фамилия, т.е. > как раз личное обращение. Именно это имеет место в доанном случае. > "вы" с маленькой буквы — это множественное число.
Да, но только в личных письмах, причем опционально.
VladD2 wrote:
> C>Да, но только в личных письмах, причем опционально. > Не личных писмах, а личном обращении.
"Вы" с большой буквы пишется исключительно в официальных документах:
письмах, меморандумах, обращениях, ультиматумах, поздравительных адресах
и т.п. В остальных случаях местоимение "вы", употребленное в обращении к
одному, говорит само за себя.
Переписал из книжечки "Правила русского языка в таблицах". Так что я про
личные письма тоже немного соврал.
> Если ты говоришь "Вы" в разговоре со мною, то ты как раз обращашся ко > мне лично. В общем, прицип тут простой. Если "Вы" можно заменить на > имя/ник, значит Вы нужно писать с большой буквы.
Такого правила в русском языке нет (хотя есть в немецком и ряде других
языков).
> Или пиши "ты". Иначе это уже смахивает на оскорбление. Это все равно > так писать "*c*yberax".
Нет, имя (в том числе и псевдоним, он же "ник") пишется с болшой буквы
всегда, кроме тех случаев, когда он является корнем притяжательного
подлежащего (cyberax'овский мобильник, владовский стол и т.п.).
Не надо мне ликбез читать. Я имел в виду, что не надо для каждого вызова метода делать AddRef/QI.
AG>> В .NET, думаю, проверки встроены на уровне платформы.
VD>В дотнете нет проверок, так как нет AddRef/Release-ов.
При чем тут опять эти AddRef/Release-ов ?
VD>У всех. Про IConnectionPoint слышал? Стандратно в качестве интерфейсов обратного вызова используется именно IDispatch. Иначе многие среды просто навертываются. ВБ в том числе.
Это если _надо_использовать_connection_point. Если не надо, то в C++ программе вполне сгодится IUnknown.
AG>>Это как же надо постараться, чтобы одну базу открыть 2 экземплярами оутлука.
VD>Легко. Открывали с двух разных машин по очереди. Прописали пути в реестре на сервер... Пару раз открыли сразу с двух машин. Резельтат... данные попортились.
Я понял, что с разных. Это я и называю "целенаправленно портить". Делали ставки, повалится или нет? Нормальный юзер никогда так не сделает.
AG>> Ведь на одной машине они оба не запустятся. А целенаправленно можно и NT-ю повалить, и .NET фреймворк, надо только места знать
VD>Вот представь себе Янус без проблем запускается параллельно с одной БД. Видимо потому что БД не самопал.
Молодцы, умеете прикрутить БД к любой софтине. Предлагаю продолжить эту славную традицию и прикрутить БД к Winamp, winword, excel, mediaplayer, Doom, Quake, HL, и ICQ.
AG>>Вообще-то long и есть int32.
VD>Где как. В С/С++ это вообще не определено. В C# — это 100%-но Inr64.
В VC++ это именно int32.
AG>>Ясен пень, что уникальные. Вот где быстрее будет поиск: на несортированном массиве (хешей) или на сортированном массиве методом половинного деления?
VD>Если значения уникальные? Естественно на хэш-таблице. Ты бы изучил как они работают, тогда и таких вопросов не возникло бы. Хэш-таблица не ищет значение. Она из хэш-значения вычисляет слот в котором лежит значение и получает его. Если коллезий нет или их мало, то скорость поиска константная, т.е. каково бы не было количество элементов все равно скорость поиска будет одинакова. При поиске полвоинном делением скорость деградирует хотя и лагорифимически.
Ок, вычислила из лонга хэш и как дальше ищет слот? Простым перебром слотов или как?
AG>>Не надо целенаправленно вредить, и все будет ок.
VD>Никто специльно себе проблем не создает. Но я как то нарвался на проблему. Уже не помню сути, но выл AV.
VD>>>2. Слишком много траха. Хэширование — трах. Вынуть списко ключей/значений — трах.
AG>>Написать CAtlMap<CAtlString, ...> — трах с хешированием?
VD>1. Не всегда получается написать "просто". VD>2. Кроме объявления переменной ее нужно еще и использвать. А тут почему-то начинается трах. Интуитивностью все это дело не страдает.
Есть typedef в помощь.
VD>Вотс кажи зачем мне разбираться с какими-то POSITION-ами? Или зачем мне разбираться во всех этих KINARGTYPE, KOUTARGTYPE, VINARGTYPE, VOUTARGTYPE.
В самом деле, зачем? Чтобы ковыряться во внутренностях CAtlMap? Для его использования в них разбираться не надо.
VD>А когда я беру Dictionary, то все пишется быстро и легко. Чтобы не быть голословным, я наклепал классический прмер — конкорданс (т.е. программа подсчитывающая слова в файле):
Думаю, на С++ можно было написать также коротко. Единственно что легче — писать foreach.
VD>На написание и отладку ушло около 15 минут (точнее 14). Причем основное время убил на вычленение слов (функцию GetWords). Потребовалось два запуска для того, чтобы пример заработал корректно. И еще один для правильного подбора отступа в строках. Попробуй ради хохмы написать тоже самое на С++ с использованием АТЛ и сравним объем кода, его читаемость и время/количество отладочных запусков.
Ок, завтра.
AG>>Ок, сколько коробочных продуктов выбрало .NET для своего GUI?
VD>Думаю море. Вот только тут не слова нужна, а статистика. А ее у мне нет. Можно поглядеть на количество открытх проектов на сорсфордже.
Из этого моря на моей машине студия и раньше был янус.
VD>Ну, MFC — это на сегодня просто бессмысленный опыт. WinAPI еще лет 5, а то и 10 будет полезен и его можно выучить без С++. Ну, а С++ это, скажем так, неплохая разминка для мозгов. Программировать на нем я бы сейчас не стал, но о том что его знаю лично я не жалею.
Да, мне он давно уже разонравился.
AG>>Респект но пока я еще не подсел на C#, можно пофлеймить
VD>Можно. Но уверяю тебя, что после полугода на Шарпе обратно уже возвращаться противно. Никакие Бустовские фишки не заменяют той простоты и ясности.
Я вот, когда с дельфи пересел на C++, тоже противно стало на нем присать. IMHO дело привычки.
Здравствуйте, Кодт, Вы писали:
К>Моя знать. Однако, std::sort — это быстрая сортировка.
Не совсем. Многие реализации гибридные. А в стандарте вообще алгоритм не указан.
К>Впрочем, возможно, что после некоторой доработки напильником алгоритм быстрой сортировки вполне подойдёт и для списка.
Если только у напильника снять ручку и острием тыкать начать.
К>Тем более, что для списка есть возможность обмена элементов без глубокого копирования. Указатели перебросить, и всё.
1. Не у списка, а у связанного списка.
2. Не пройдет. Или ты скопируешь список в массив и далее применишь исходный алгоритм. Или на жаждом шаке рекурсии тебе прийдется создавать попию подсписка. Вот пример подобной организации на Шарпе:
static IEnumerable<T> Sort2<T>(IEnumerable<T> enumerable)
where T : IComparable<T>
{
// Пытаемся получить медиану для дальнейшего стравнения.
// Так как произвольного доступа к элементам нет, то приходится
// брать первый элемент. Это приведет к плохой производительности
// на отсортированных массивах.
IEnumerator<T> iterator = enumerable.GetEnumerator();
// Если список пуст, то и делать нечего.if (!iterator.MoveNext())
yield break;
T median = iterator.Current; // получили элемент для сравнения
// Фильтруем список отбирая элементы меньшие median-а.
// Для получившегося списка выполняем сортировку (рекурсивно).
// Перебераем получившися (отсортированный) подсписок и возвращаем
// его элементы.foreach (T value in Sort1(Filter(enumerable,
delegate(T item) { return item.CompareTo(median) < 0; })))
yield return value;
// Делам тоже самое но отфильтровываем элеметы большие или равные медиане.foreach (T value in Sort1(Filter(enumerable,
delegate(T item) { return item.CompareTo(median) >= 0; })))
yield return value;
}
// Эта функция создает список в который попадают элементы удовлетворяющие предикату.
// Попросту говоря она отфильтровывает все элементы для которых predicate() вовращает true.static IEnumerable<T> Filter<T>(IEnumerable<T> enumerable, Predicate<T> predicate)
{
foreach (T value in enumerable)
if (predicate(value))
yield return value;
}
Формально это тоже быстрая сортировка (если закрыть глаза на то, что Filter<T> делает два прохода по списку, но это можно устранить). Однако по сравнению с императивной реализацией скорость получится хреновенькая. А то что медиана берется не из середиты еще и ухудшает скоростные характеристики для уже сортированных списков.
Вот, ради любьви к искуству сделал эксперемент сравнивающий скорость классической быстрой сортировки и быстрой сортировки на списках:
//#define USE_ITERATIR_SORTusing System;
using System.Collections.Generic;
class Program
{
const int SecLen = 1000000;
static void Main(string[] args)
{
List<int> result = new List<int>(SecLen);
int start = Environment.TickCount;
#if USE_ITERATIR_SORT
foreach (int i in Sort1(Generator()))
result.Add(i);
#else
result.AddRange(Generator());
result.Sort();
#endif
Console.WriteLine("Time is " + (Environment.TickCount - start));
int sum = 0;
result.ForEach(delegate(int elem) { sum += elem; });
Console.WriteLine(sum);
}
// Генерирует последовательность случайных числе.
// Возвращает итератор который используется для тестов.static IEnumerable<int> Generator()
{
Random random = new Random(123456);
for (int i = 0; i < SecLen; i++)
yield return random.Next();
}
static IEnumerable<T> Sort1<T>(IEnumerable<T> enumerable)
where T : IComparable<T>
{
IEnumerator<T> iterator = enumerable.GetEnumerator();
if (!iterator.MoveNext())
yield break;
T median = iterator.Current;
List<T> left = new List<T>();
List<T> right = new List<T>();
while (iterator.MoveNext())
{
T value = iterator.Current;
if (value.CompareTo(median) < 0)
left.Add(value);
else
right.Add(value);
}
foreach (T value in Sort1(left))
yield return value;
yield return median;
foreach (T value in Sort1(right))
yield return value;
}
static IEnumerable<T> Sort2<T>(IEnumerable<T> enumerable)
where T : IComparable<T>
{
IEnumerator<T> iterator = enumerable.GetEnumerator();
if (!iterator.MoveNext())
yield break;
T median = iterator.Current;
foreach (T value in Sort1(Filter(enumerable,
delegate(T item) { return item.CompareTo(median) < 0; })))
yield return value;
foreach (T value in Sort1(Filter(enumerable,
delegate(T item) { return item.CompareTo(median) >= 0; })))
yield return value;
}
static IEnumerable<T> Filter<T>(IEnumerable<T> enumerable, Predicate<T> predicate)
{
foreach (T value in enumerable)
if (predicate(value))
yield return value;
}
}
В коде два варианта. Один более "быстрый". красивый (совсем функциональный ).
Вот результат "быстрой сортировки на списках" первый вариант:
Time is 4812
-14996129
Тоже самое но второй вариант:
Time is 4907
-14996129
А вот классической:
Time is 187
-14996129
Думаю, все ясно. Хотя надо признать, что для 1 000 000 показатель очень неплохой. Так что для очень многих задач он с успехом пройдет.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
VladD2,
> ПК> В STL — именно набор концепций. Просто что-то назвать недостаточно, чтобы это что-то стало концепцией. Нужно это что-то еще и точно специфицировать. Без привязки к конкретном описанию "итератор" концепцией не является, а является просто неоднозначным словом. А вот, скажем, ForwardIterator — одна из таких концепций. Реализации — соответственно, в конкретных реализациях STL.
> Пашь, McSeem2 павильно сказал. Само название "итератор" подразумевает последовательный доступ (перебор). А итератор произвольного доступа — это глупость.
Это условности. Потоки (stream) тоже предполагают последовательный доступ, да еще и (потенциально) разрушающий. Что не мешает вводить в большинство классов, имеющих в названии слово stream, функции seek. Суть не в названиях, а в обозначаемых ими понятиях, и связи между ними. Естественно, удачное название лучше неудачного, если его удается подобрать.
> Как в прочем глупо использовать какие-то навороченные конструкции для произвольного доступа.
Причем здесь навороченные конструкции? Речь идет о введении абстракции, позволяющей описывать алгоритмы без привязки к контейнерам. Этой абстракцией и являются итераторы STL. Более простой в использовании конструкцией, обладающей более-менее теми же возможностями, вероятно, является (полу-)диапазон. "Более-менее" т.к. итераторы позволяют задать не только диапазон значений, но и позицию.
> Для этого достаточно одного оператора/метода и свойства/метода для того чтобы узнать длинну списка.
Задача определения длины списка в итераторах не нуждается. Речь идет о возможности однократной реализации алгоритмов (например, fill, find, count_if, sort, sort_heap, stable_sort, unique и т.п.). Если нет абстракции, позволяющей абстрагироваться от конкретного контейнера, то для каждого нового представления все эти алгоритмы нужно будет реализовывать заново.
Posted via RSDN NNTP Server 2.0 beta
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
В Java позиция итератора это позиция *между* элементами последовательности.
в stl позиция итератора это позция элемента
Вот в статье (здесь) про последнюю QT (v.4.0) утверждается что:
The Java-style iterators are new in Qt 4.0 and are the standard ones used in Qt applications. They are more convenient to use than the STL-style iterators, at the price of being slightly less efficient. Their API is modelled on Java's iterator classes.
В принципе дейтвительно Java вариант выглядит логичнее в том смысле что:
1) не нужно специального end value (которое кстати не всегда и можно-то натурально определить)
2) операции prev / next симметричны.
Здравствуйте, Павел Кузнецов, Вы писали:
ПК>Кста, в Бусте уже давно маются с разделением двух концепций, совмещенных в стандартных итераторах: обход и доступ к элементу.
Можно ли малой кровью разделить два этих явления — и переключаться между ними в своё удовольствие?
Например, пусть у нас есть Accessor — сущность для доступа, и Generator — сущность для обхода.
some_generator g(some_begin, some_end);
some_accessor a;
...
while(!g.eof())
{
a = g.peek(); // не меняет состояние генератора
a.put(some_value()); // я сознательно не пишу здесь операторы, чтобы не проводить лишних аналогий
a = g.read(); // меняет состояние генератора - тот уезжает вперёд, оставляя за собой Accessor
some_data d = a.get();
...
some_generator h(some_begin, a); // новый генератор: от начала до этого элемента исключительно
...
}
При этом, если генератор определён над потоком (или вычисляемой последовательностью), то возвращаемый аксессор не может быть приведён к какому-либо генератору (кроме генератора одноэлементной последовательности — да и та, скорее всего, будет стремительно инвалидирована).
А если генератор — над хранимой последовательностью, то по его аксессорам можно построить новые генераторы.
(Причём разные!)
Здравствуйте, VladD2, Вы писали:
К>>Э... в двоичном дереве это тоже O(n). Правда, каждый отдельный переход занимает от O(1) до O(log n)... VD>И как же у тебя при переходе с O(log n) получается сумарная O(n)?
Дык просто.
Полный обход любого дерева состоит в том, что по каждому ребру совершается два перехода — вниз и вверх.
Количество рёбер равно количеству узлов — 1.
Итого, полное время обхода — 2n-2 переходов по рёбрам.
Сюда ещё нужно прибавить время на операции NextSibling (следующий ребёнок того же родителя, что и данный узел).
В случае двоичных деревьев — каждая такая операция занимает O(1):
NextSibling(node) = (node->parent->left == node) ? node->parent->right : NULL
В случае, если множество дочерних узлов представлено связным списком, то тоже O(1)
NextSibling(node) = node->next
Если в узле есть массив дочерних узлов размером K, отсортированный каким-то способом, то O(log K) (например, B-деревья).
А если не отсортированный — то O(K).
При этом, для сбалансированного дерева (двоичного или нет — неважно) переход от крайне правого листа левого поддерева к следующему узлу — крайне левому листу правого поддерева — требует подъёма до корня и спуска вниз. Итого, 2*log2(n).
У КЧ- и AVL-деревьев коэффициенты будут отличаться, но это всё равно нечто логарифическое.
Худший случай несбалансированного дерева: путь длиной n-1 рёбер.
Кодт,
> Итак, next() и prev() — функции, меняющие состояние. Поэтому сравнивать их с неменяющей функцией (разыменование stl-итератора) — бестолково. > А практика использования двунаправленных итераторов (в первую очередь — указателей на элементы массива) в движении — вот такая: >
> *p++; // прочесть/записать и перейти дальше
> *--p; // отступить и прочесть/записать
>
> И это, как несложно заметить, ровно то же самое, что и next(), prev().
Но есть нюанс. В результате смешения операций навигации и извлечения значения, естественно, по отдельности их делать нельзя. Это может приводить как к потере производительности, так и к затруднению работы с подобными энумераторами.
Потеря производительности может легко происходить в случае, если, например, происходит итерация по файлу записей, каждая из которых является сериализованным объектом. В этом случае, даже если нам нужен только 128-й объект, все 127 предыдущих объектов придется создать.
Работать с такими энумераторами может оказаться сложнее, например, если упомянутые объекты читаются нетривиально, скажем, с помощью плагинов. Допустим, что если плагина для чтения какого-то объекта нет, то должно генерироваться исключение. В этом случае, если при вызове next() было выброшено исключение, далеко не очевидно, произошел ли фактический инкремент, или же энумератор по-прежнему указывает на запись, которую мы читать не умеем. В последнем случае, как пропустить злополучную запись — неясно.
Мы тут с Лешей Чернораенко пообсуждали итераторы, и сошлись на том, что более перспективным является разделение навигации и доступа к элементу не только по разным операциям, но и по разным объектам. В этом случае операция итератора доступа к элементу (operator * в случае итераторов STL) возвращала бы аксессор, прокси-объект, предназначенный для "настоящего" доступа к элементу, на который указывает итератор. Такой подход позволяет избежать создания объекта в случае, если итератор разыменовывается только чтобы ему присвоить новое значение.
*it = create_expensive_object();
Альтернативой, естественно, могут служить именованные операции set/get; или, для C++, введение в язык разных операций разыменования, разделяя случаи использования в качестве l-value и r-value. Но в случае выделения аксессоров в отдельный класс появляется более тонкий контроль над тем, что можно делать клиенту: если ему вернули аксессор, то перемещаться по множеству объектов он уже не может, только получать/менять объект, который он получил. При этом, в отличие от возвращения ссылки, объект изначально существовать не обязан.
Posted via RSDN NNTP Server 2.0 beta
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
Здравствуйте, Кодт, Вы писали:
К>Есть такая методология — стрёмное программирование (XP). К>Надо тебе сделать output iterator поверх какого-то фидера — делаешь тяп-ляп, зато совместимо со всеми прочими алгоритмами.
... К>Потом, когда руки дотянутся — переделаешь так, чтобы не было шансов для misuse. К>Да и, в конце концов, стратегии позволят нарожать таких итераторов сколько хочешь. Только один раз грамотно шаблон сделать...
...
А может панам стоит познакомиться с библиотекой Boost.Iterator или хотя бы с частным случаем Iterator Facade? Право слово, ничуть не хуже чем собственные велосипеды получается.
VladD2,
> ПК> Такой подход либо требует контейнера с произвольным доступом, либо приводит к дополнительному проходу по элементам там, где в случае итераторов он не нужен. > > Это ежу понятно. Вот только с диапазонами обычно и работают когда контейнер обеспечивает (хотя бы внутненне) эффективный индексный доступ.
С диапазонами и в (связных) списках работают, в которых произвольного доступа нет по определению. Например, см. splice — пример функции, часто использующейся с диапазонами.
Также у меня была библиотека для работы с деревьями, интерфейс которой был построен на итераторах. Там работа с диапазонами узлов тоже использовалась очень интенсивно, например, при использовании данного дерева в качестве основы для bounding volumes hierarchy — по мере построения такой иерархии очень удобно иметь возможность эффективно перемещать диапазон узлов в новую вершину, их объединяющую.
Другой пример работы с диапазонами, заданными с помощью forward iterators — std::search.
И т.п.
> "Форвард итераторы" в СТЛ тут ничем не отличаются.
Отличаются принципиально: любой итератор задает позицию, в т.ч. forward iterator (*) позволяет задавать позицию в (связном) списке безо всяких индексов. Возможность скопировать итератор позволяет запомнить эту позицию для нужд алгоритма, и, если надо, вернуться к ней позднее за константное время. С энумераторами такой номер не пройдет: как, имея один энумератор, за константное время создать из него другой, с тем же состоянием?
> yield и делегаты/интерфейсы решают любую проблему.
Если yield основан на все тех же некопирующихся энумераторах, которые не умеют обозначать позицию — вряд ли.
Например, как выразить через yield return и энумераторы с делегатами и интерфейсами ту же std::remove_if, с условием повторного использования аналога std::remove_copy_if?
Еще одна задачка. std::map<>::lower_bound(key) возвращает итератор элемента, равного key, или же следующего, перед которым можно вставить key, так что порядок не нарушится. std::map<>::insert() может принимать в качестве подсказки итератор, с которого начинать поиск позиции для вставки нового элемента. В случаях, когда нужно вставить элемент в std::map только в случае, если такого элемента там нет, это позволяет делать только один поиск, а не два (второй, если не передавать подсказку, будет осуществлен в insert):
Map::iterator pos = m.lower_bound(key); // ищем элементif ( pos == m.end() || pos->first != key )
{
// такого элемента еще нет, добавляем
m.insert(pos, Map::value_type(key, value)); // поиска здесь уже не будет
}
else
{
// OK, такой элемент уже есть, делаем, что нужно для этого случая
// например, изменяем его как-нибудь
modify_existing_value(it->second, key, value);
}
(*) В std::list используются bidirectional iterators, но это несущественно. Если это принципиально можно остановиться и на slist, у которого как раз forward iterators.
Posted via RSDN NNTP Server 2.0 beta
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
jazzer,
> В STLPort, например, в режиме отладки проверяется выход за границы массива при индексации, так что же тебе ответить на вопрос: "Что произойдет, если индекс массива больше его размера"? В случае STLPort — ничего страшного, тебе укажут на ошибку и ты ее исправишь. > > Так вот никто не мешает встроить в итераторы аналогичную защиту.
В STLport она уже встроена, _STLP_DEBUG. Было описано by Cay S. Horstmann в 1995 году (Safe STL).
>
> <...> > Если .NET или Java может предоставить подобную гибкость, лаконичность и ясность кода, я очень хотел бы это увидеть.
+1
> И я очень прошу не поднимать снова тему делегатов и замыканий в том смысле, что на них легче записать предикаты и действие, которое надо произвести, это — тема отдельного разговора. Давайте сконцентрирумеся на итераторах и алгоритмах.
+1
Posted via RSDN NNTP Server 2.0 beta
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
Здравствуйте, VladD2, Вы писали:
VD>Здравствуйте, Павел Кузнецов, Вы писали:
ПК>>С диапазонами и в (связных) списках работают, в которых произвольного доступа нет по определению.
... VD>В связанных списках диапазоном является конкретный узел и количество.
Тогда тебе прийдется хранить в списке его размер и при каждой операции его обновлять. Это хуже по производительности по сравнению с оперированием только итераторами, когда размер списка тебе почти никогда (а если вспомнить, что он в этом случае может вычисляться за линейное время, то вообще никогда) не нужен.
... VD>Ты просто смотришь не стой позиции. Просто логика по запоминанию и т.п. выносится из абстрактного итератора в класс имеющий на то право.
VD>В обющем, концептуально другой подход рассчитанный на упрощение и стандартизацию абстракции. При этом всегда можно выбрать между IEnumerable, ICollection, IList в зависимости от требований предъявляемых к коллекции. Так LinkedList принципиально не будет реализовывать IList и ты не сможешь создать квадратичный алгоритм выбором не верной коллекции.
Возьмем, к примеру, всё тот-же Algorithms.Fill<T>(IList<T>,int,int,T). Что-то его не сильно применишь к LinkedList, который не реализует IList (наверное, из-за опасений создать квадратичный алгоритм ). Градация интерфейсов очень грубая. Либо у тебя есть IEnumerator, который только может ходить вперед, либо IList, который может сразу всё: произвольный доступ и даже изменение коллекции. (ICollection я в расчет не беру. Он для итерирования не подходит.)
VD>В итоге решаются точно такие же задачи, но при этом учитывая скудность стандартных интерфейсов >результат получается более простым в понимании и исключаются ошибки.
(я тут немножко добавил между строк, чтобы показать поспешность твоего заявления).
ПК>>Например, как выразить через yield return и энумераторы с делегатами и интерфейсами ту же std::remove_if, с условием повторного использования аналога std::remove_copy_if?
... VD>Дык, элементарно . Сделать подобные операции методами конкретных контейнеров. Тогда они будут реализованы наиболее оптимально и нельзя будет, к примеру, применить операцию Remove к массиву не поддерживающему подобных операций.
Ты забываешь, что многие алгоритмы могут быть определены над итераторами вполне оптимально. Это дает много приемуществ по сравнению с реализаций этих алгоритмов как часть коллекций. Но, конечно, для этого требуется достаточно мелко градуированная иерархия итераторов. Двух интерфейсов здесь явно недостаточно.
Алгоритм remove, кстати, если определить его соответствующим образом, еще как подходит для массива.
VD>Нельзя забывать о том, что в Шарпе интерфейсы вроде IList, ICollection, IEnumerable применимы так же и к таким встроенным типам как массивы. И семантика того же удаления будет совсем иным. Для массива — это будет создание его копии в котрой будут отсуствовать некоторые ячейки. А для List<T> логично будет удаление по месту.
VD>Так что для List<T> будет добавлен метод вроде: VD>
Несмотря на твои рассуждения, STL'ная комбинация методов remove/erase все равно будет наиболее оптимальной, так как, используя ее, ты не обязан изменять размер коллекции или создавать новый массив, если тебе это не нужно.
VD>Да, я как бы слашал о теории, что это мовитон, но не разделяю ее. По мне так все должно быть просто, удобно и эффективно.
Вот и я про то же. Просто, но не проще. Удобно, но до тех пор, пока удобство не мешает эффективности и не ущемляет мой выбор.
Здравствуйте, uw, Вы писали:
uw>Насколько мне известно итераторы появились несколько раньше итераторов STL. И выглядели они именно как паттерн итератор, описанный GoF. Вообще ребята из GoF не изобретали паттернов, они их только описали. Скорее Степанову следовало бы назвать "итераторы STL" как-нибудь по другому. В STL "итераторы" это скорее constrained pointer abstraction, несколько более общая и интересная концепция чем "паттерн итератор".
Я думаю наиболие подходящие название для STL'ных итераторв это курсоры.
... << RSDN@Home 1.1.4 beta 6a rev. 436>>
Пусть это будет просто:
просто, как только можно,
но не проще.
(C) А. Эйнштейн
VladD2,
> ПК> Вряд ли так получится сделать. По крайней мере, не через IEnumerable/IEnumerator, т.к. он принципиально не способен перебирать в обратном порядке. > > Ни однин последовательный алгоритм принципиально не может перебирать ничего в обратном порядке без копирования в промежуточный массив.
Например, проход по подпоследовательности (связного) списка в обратном порядке не требует ничего копировать в промежуточный массив.
> У тебя опять забавный подход. Ты пыташся сравнивать нечто с прямым доступом и итератор.
Нет, я в основном говорю о (связных) списках, которые по определению обладают последовательным доступом.
> ПК> Соответственно, получив "прямой" энумератор, сделать из него обратный не выйдет. > > Как в прочем и в СТЛ.
В STL это делается легко, если "прямой" итератор является bidirectional.
> Хотя как раз в дотнете можно оптимизировать подобные вещи. Примерно так: >
> static IEnumerable<T> Revers<T>(IEnumerable<T> iter)
> {
> IList<T> list = iter as IList<T>;
> if (list != null)
> <...>
> else
> {
> ICollection<T> collection = iter as ICollection<T>;
> if (collection != null)
> {
> T[] array = new T[collection.Count];
> collection.CopyTo(array, 0);
> for (int i = array.Length; i >= 0; i--)
> yield return array[i];
> }
> else
> {
> Stack<T> stack = new Stack<T>();
> foreach (T value in iter)
> stack.Push(value);
>
> foreach (T value in stack)
> yield return value;
> }
> }
> }
> }
>
Классная вышла "оптимизация". Например, в случае LinkedList мы получим совершенно избыточное копирование в массив только для того, чтоб пройтись по нему в обратном порядке.
> ПК> Впрочем, с удовольствием гляну на код, использующий энумераторы .Net (возможно с привлечением yield return etc.), и делающий описанное (поиск нижней и верхней границы по предикатам с последующим обходом выделенной подпоследовательности в обратном порядке). > > Ну, вот всунь приведенный выше преобразователь и на конечных последовательностях будет работать как часы.
Только очень медленные, и требующие памяти на ровном месте
Posted via RSDN NNTP Server 2.0 beta
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
Здравствуйте, VladD2, Вы писали:
VD>Здравствуйте, vdimas, Вы писали:
V>>Нет, ну это уже несерьезно . Сам-то дочитал хотя бы до середины?
VD>Читал. V>>
V>>l Implementation Issues:
V>>= Who controls the iteration?
V>> — The client => more flexible; called an external iterator
V>> — The iterator itself => called an internal iterator
V>>= Who defines the traversal algorithm?
V>> — The iterator => more common; easier to have variant traversal techniques
V>> — The aggregate => iterator only keeps state of the iteration
V>>= Can the aggregate be modified while a traversal is ongoing? An iterator
V>>that allows insertion and deletions without affecting the traversal and
V>>without making a copy of the aggregate is called a robust iterator.
V>>= Should we enhance the Iterator interface with additional operations, such as
V>>previous()?
V>>Мне больше нечего добавить, считаем тему закрытой.
VD>И что ты тут такого обнаружил? Я где-то заявлял о том, что итераторы должны быть доступны только на чтение? Я гворил, о том, что они должны служить для перебора элементов, и не имеют права предоставлять прямого доступа. Иначе это уже не итераторы.
Да и я не утверждал, что итератор должен обладать качеством прямого доступа. Кстати, а не трудно тебе сформулировать, что ты называешь прямым доступом применительно к итератору? Может вообще весь этот спор ни о чем...
------
может тебе не нравится advance(), дык в итераторах листов она сымплементирована как ++ в цикле, прям "настоящие" тобой любимыые итераторы
вся эта байда с advance() из-за того, что алгоритмы выполнены как внешние сущности по отношению к контейнерам (причины ты сам знаешь), некоторые алгоритмы требуют "бытрого перебора" вперед или назад. Разработчик STL вполне естественно решил инкапсулировать в сам итератор ф-ию приращения на определенное число шагов, будучи уверенным, что во многих случаях это даст существенный выигрыш. Я не верю, что если бы эти алгоритмы разрабатывал ты, то не додумался бы до этого. Сделал бы так же, никуда бы не делся.
Как альтернативный вариант — все алгоритмы инкапсулированы в сами коллекции. Этот вариант даже обсуждать неохота, ибо программист С++ себе нормальную жизнь не представляет без алгоритмов, и "натравливает" он их куда ни попадя.
-------
все-таки нехватает мне в C# лаконичности функторов и просто глобальных ф-ий, одних только компареров уже тонна, а необходимость копировать коллекцию в массив перед сортировкой меня просто умиляет. Как выход — можно пытаться кастить ICollection к массиву или к ArrayList, а потом может еще к чему-либо, и так в каждом месте (а этих мест много) где мне просто требуется отсортировать коллекцию, полученную как результат.
Здравствуйте, VladD2, Вы писали:
VD>>>Глупость. Паттерн — это не задача. Это решение часто встречающейся задачи.
V>>Именно глупость, или невнимательное чтение оппонента. Задача описания паттерна — это тоже задача. GoF поставили задачу донести суть повторно применимых приемов до IT-сообщества. Похоже, перестарались с лаконичностью. Кое-кто воспринял слишком буквально. Им стоило разбавить свою книжку примерами и реализациями паттернов с учетом различных специфик, тогда этой ветки могло и не быть.
VD>Ответь. Ты ее вообще то читал? Там примеров как грязи. Да и не нужно других считать тупее себя. Я с самого начала говорил, о том, что в первую очередь нужно думать головой. Если тебе не подходит перебор, то этот паттерн не для тебя. Ищи другой или придумывай выход сам. Но если подходит, то паттерн определеят четкое решение проблемы. И это его суть. Это строительный блок, а не тема для фантазий.
Угу, и это громкое высказывание на фоне того, что соседней ветке ты сам привел ссылку, где как раз был описан именно минимальный пример, а затем оставлен простор именно для тех самых фантазий, не поленюсь скопирую:
l Implementation Issues:
= Who controls the iteration?
— The client => more flexible; called an external iterator
— The iterator itself => called an internal iterator
= Who defines the traversal algorithm?
— The iterator => more common; easier to have variant traversal techniques
— The aggregate => iterator only keeps state of the iteration
= Can the aggregate be modified while a traversal is ongoing? An iterator
that allows insertion and deletions without affecting the traversal and
without making a copy of the aggregate is called a robust iterator.
= Should we enhance the Iterator interface with additional operations, such as
previous()?
Вопросов оставлено больше, чем дано ответов в примере Так что, к чему столько эмоций?
Здесь предлагается, например:
— перебор в оба направления,
— модифицирование содержимого контейнера.
— далее, кто определяет способ навигации? Предлагается 2 варианта: сам контейнер или итератор. Если навигацией занимается сам контейнер, то вполне в духе инкапсуляции расширить итератор так же ф-ией MoveNextForNSteps(int N);
И т.д. и т.п. Заметь, что суть самого итератора, равно как и способ использования не поменялся — это просто перебор (только ли перебор? ) коллекции не имея представления об ее внешнем интерфейсе.
Я в упор не вижу противоречий ни с паттерном, ни с примерами, которых "как грязи" (т.е. с самыми простейшими обычно), ни тем более с тем, что сами разработчики подсказали первые же очевидные расширения и способы конкретных имплементаций паттерна ("фантазий" (С) Vlad2).
В общем, пока что продолжаю видеть зацикливание на "чистоте".
VD>>>Значит это не итераторы. Задача итератора — абстрагирование перебора элементов коллекции. Все!
Ну все — так все...
Я пока не вижу, чтобы мы вышли за рамки абстрагирования перебора (хотя предлагаются еще и модификации самой коллекции, ну да я не настаиваю). Ты абстрагировался, я абстрагировался, Степанов тоже абстрагировался, в общем все абстрагируются — паттерн работает.
V>>Опять проблема яйца и курицы. Итераторы в STL не цель, а средство. Собственно, как и везде.
VD>Какие яйца? Я СТЛ в глаза не видел, а итератор уже встречал.
Я спрашивал в контексте STL, из текста это понятно было всем. Nадцатый раз повторю, что требования к интерфейсам итераторов STL диктовались потребностями обобщенной работы алгоритмов. Тебе, вроде, должно быть известно, что любая разработка начинается со сбора требований.
V>>Попробуй по-другому.
VD>Зачем мне пробовать? Я делвают.
Да ну? Сделай нечто вроде remove_if на донете на итераторах. А теперь посмотри на то, что сделал (ибо только созданием копии), и преставь, что это кеш на десятки тысяч объектов, таких кешей довольно много, и у них подобная операция вызывается постоянно. (у системы потенциально тысячи одновременных сессий с клиентами, это не "текстовый редактор") Рискнул бы ты, как разработчик сделать, это "красиво" на итераторах?... даже на современной дешевой памяти? Вот и приходится подобную хрень БЕЗ итераторов делать, "в лоб" и "некрасиво".
Я же тебе уже сказал самю суть вопроса, в STL у меня не стоит вопрос: "быть или не быть" — всегда быть и не париться. А в дотнет вопрос постоянно стоит. Там где не требуется оптимизация — пишем "красиво", где требуется — "с умом" (С)Vlad2. В том самом уме надо еще изначально прикидывать, где же она требуется, а где нет...
VD>Я не зацикливаюсь не на чем. Я говрою о простых, казалось бы вещах, о дурной терминологии и мосорности итераторов в СТЛ.
А может просто взять и собрать воедино, перечислить, не торопясь, по пунктам, что там и в каким именно итераторах лишнее, и как именно это лишнее перечеркивает/меняет суть паттерна. А то пока лишь болтовня и бодания...
Здравствуйте, c-smile, Вы писали:
CS>В принципе дейтвительно Java вариант выглядит логичнее в том смысле что: CS>1) не нужно специального end value (которое кстати не всегда и можно-то натурально определить) CS>2) операции prev / next симметричны.
Интересный вопрос. В оправдание STL итераторов — как голый указатель в C/C++ может указывать на нечто между элементами? Это я к тому, что std::vector<>::iterator — это фактически голый указатель и есть. И делать его "межэлементным" не резон по причине производительности. А отсюда пошли и все остальные итераторы. Не знаю, возможно не стоило STL-цам упираться в единость концепции и, например, нагрузить std::set<>::iterator большей функциональностью (в отличие от std::vector).
McSeem
Я жертва цепи несчастных случайностей. Как и все мы.
Здравствуйте, c-smile, Вы писали:
CS>Здравствуйте, Шахтер, Вы писали:
Ш>>Согласно картинкам, оба варианта изоморфны.
CS>Наверное. Но не совсем.
Ш>>Вообще, не очень понятно, что значит -- указывать между элементами?
CS>Object next() возвращает элемент над которым "пролетает" итератор.
CS>В Java не требуется специальное значение end CS>так как тест на bos/eos осущесвляется отдельной функцией (hasNext).
CS>
CS>Еще раз — не знаю — хорошо это или плохо. Поэтому и спросил.
Ага. Понятнее теперь. Мне кажется, ты пытаешься сравнить не совсем сравнимые категории. В stl есть несколько категорий итераторов. Наиболее важная и употребимая -- random access итераторы. Остальные категории получаются удалением некоторых способностей из RanIt. Если я правильно понял, итератор в Java ближе всего к понятию Input Iterator. Вот что касается этой категории итераторов, она действительно выглядит несколько искуственно в stl и подход Java ну по крайней мере не хуже.
ЗХ>Для list — ничего не означает. Я всего лишь привел пример. Пойнт мой был: возможность вызова функции, которая принимает начальный и конечный итераторы, но передать ей не begin и end, а что-то другое; таким образом, обработать лишь часть контейнера.
Это уже не итератор. Это извращение. Итератор должен перечислять то что ему положено. Нужно работать с диапазонами возвращай итераторы диапазонов или работай с массивами.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Шахтер, Вы писали:
Ш>Ну почему же. Это просто разные способы применения. Указатель, скажем, позволяет и итерировать, и произвольный доступ. Причем естественным образом.
Ш>Дело не в стремлении впихнуть все сущности в одно понятие, а в природе вещей. Голый указатель обладает набором определённых свойств -- вот эти свойства и были аксиоматизированы. Получился randon access iterator.
Воот! random access iterator — это pointer и есть. Надо было так и назвать его — pointer, а не итератор. При этом поинтер обладает всеми свойствами итератора, но итератор не обладает некоторыми свойствами поинтера. И всех делов. Сортировка требует именно поинтеров. С итераторами она работать не умеет. При этом вектор имеет поинтеры, а список — итераторы. И никаких полисей.
McSeem
Я жертва цепи несчастных случайностей. Как и все мы.
Здравствуйте, Кодт, Вы писали: К>Однако, мешает. sort нуждается в итераторах произвольного доступа (с дешёвой арифметикой). Конечно, можно определить её через advance — но это будет очень дорого стоить. Вместо O(n*log(n)) получим что-то кубическое.
А это смотря какой сорт. Если обратиться к Кнуту III, то можно найти штук десять всяких сортировок. И в основном они отличаются как раз требованиями к нижележащему интерфейсу. В частности, значительная доля отведена сортировке потоков.
... << RSDN@Home 1.1.4 beta 5 rev. 395>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
McSeem2,
> Воот! random access iterator — это pointer и есть. Надо было так и назвать его — pointer, а не итератор. При этом поинтер обладает всеми свойствами итератора, но итератор не обладает некоторыми свойствами поинтера. И всех делов. Сортировка требует именно поинтеров. С итераторами она работать не умеет.
Как от того, что мы бы переименовали текущие random access iterators в pointers, а текущие forward iterators в iterators изменился бы интерфейс шаблона std::sort(), если не принимать в учет названия параметров шаблона?
На всякий случай напоминаю, что изменить его на такой:
template<class T>
void sort(T* first, T* last);
нельзя из-за того, что в других контейнерах, не в std::vector, итераторы (pardon my French) указателями быть не могут; например, std::deque.
> При этом вектор имеет поинтеры, а список — итераторы.
Пока что я не вижу за этим ничего, кроме смены названий...
> И никаких полисей.
В стандартной std::sort() никакие policies не нужны, т.к., перефразируя, ни с чем, кроме random access iterators она работать не умеет. (Предполагаемое) их наличие в реализации Dinkumware означает, что там в виде расширения решили реализовать std::sort() таким образом, чтоб она умела работать не только с random access iterators, но и с forward iterators.
Posted via RSDN NNTP Server 2.0 beta
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
VladD2,
> A> Но этого достаточно для большинства, которые кстати пришли на .NET c Java или с VB, где положение не лучше. > > Я вот пришел с С++.
Ты не считаешься, т.к. STL не использовал.
> A>На лицо две разные цели и два разных дизайна. > > Нет никаких разных целей. Есть желание притянуть что-нить за уши и крайняя предвзятость.
VladD2,
> CS> Причем здесь индекс и итератор? Весь сыр бор как раз о том что итератор не должен иметь ничего общего с индексом. > > Общего не должен, но при реализации индекс там появится с очень большой вероятностью. Мы же ведь не про сфероконей речь ведем?
А в списке (связном)?
> CS>Загадка: в Java справедливо следующее: > > CS>Object a = Enum.next(); > CS>Object b = Enum.prev(); > CS>assert(a == b); // это true. > > CS>Так где находился Enum после next? > > Перешел вперед. Вернулся назад. Что же ты еще хотел получить? Хотя по мне так prev совершенно лишний.
c-smile в своем ответе выразился в некоторой степени иносказательно. Я спрошу конкретнее: ты уверен, что вопрос понял? Если Enum ходил вперед—назад, то почему значение, которое мы получали, одинаково на шаге 1 и 2? Значение индекса здесь, имхо, совершенно несущественно. Вопрос о том, на какой из элементов указывает энумератор в каждый из моментов времени.
Posted via RSDN NNTP Server 2.0 beta
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
Здравствуйте, Павел Кузнецов, Вы писали:
ПК>Костя,
>>
>>> In object-oriented programming, an iterator is an object allowing one to sequence through all of the elements or parts contained in some other object, typically a container or list.
>> Поскольку в цитате АВК сказано container or list, то ясно что речь идет о списке не как о контейнере. Никакой другой реализации спика-не-контейнера кроме связанного списка я не знаю.
ПК>А почему linked list не является контейнером?..
Linked list может являться просто россыпью отдельных узлов без общего объекта-фасада. Либо под списком-но-не-контейнером это и имелось ввиду, либо непонятно что авторы хотели сказать.
ПК>Имхо, фрагмент "a container or list" в цитате выше, вообще, имеет мало смысла: было бы достаточно просто "a container".
Если бы было просто "a container" я бы ничего и не сказал. Это была мелочная подколка Википедии — типа если термин list не означает linked list, как это выяснилось, то и определение итераторов из Википедии тоже не без греха.
Ну так чего, кто-нибудь приведет код реализации итерации по подпоследовательности средствами итераторов java или .Net?
потому что в STL это делается одним движением мизинца левой ноги:
std::for_each(it1, it2, <всякая фигня>);
А то какая-то бессмысленная священная война о том, как Степанов некорректно применил термин "итератор" из GoF в те времена, когда GoF и в помине не было.
Здравствуйте, Павел Кузнецов, Вы писали:
ПК>Может быть, не знаю. В первоначальном варианте код выглядел так:
ПК>templ_function( get(*it) );
С точностью до имени функции :)
ПК>С другой стороны, использование разыменования подчеркивает дополнительную косвенность, вводимую акцессором.
Тогда акцессор должен иметь семантику указателя.
Я уже напился своих слёз, когда однажды завёл класс с семантикой и указателя, и ссылки :(
ПК>Да и вообще, если исходить из минималистических соображений, то вообще никакие дополнительные operator* или get() не нужны, т.к. можно пользоваться явным преобразованием :-)
ПК>templ_function( static_cast<T&>(*it) );
Это не совсем очевидный способ. Откуда-то возникают явные имена типов... которые ещё и должны быть согласованы с акцессором. Функции автоматического выведения типа — симпатичное решение. Тем более, что можно сделать перегрузку их для любого типа акцессора, в том числе для голого T&.
Здравствуйте, AndrewVK, Вы писали:
AVK>Здравствуйте, jazzer, Вы писали:
J>>Андрей, последний абзац, который ты выкинул при цитировании, как раз был посвящен обсуждению предмета
AVK>Ну и что?
то, что как раз наиболее содержительная часть реплики была проигнорирована и опять начался (продолжился) бессмысленный терминологический спор. А хотелось бы разговора по существу.
Здравствуйте, VladD2, Вы писали:
VD>Здравствуйте, jazzer, Вы писали:
J>>Представь, что у меня есть два предиката P1 и P2 и некий контейнер cont типа MyCont. J>>И я хочу найти в этом контейнере элемент, удовлетворяющий P1, затем следующий где-то за ним Р2, а затем с выделенной таким образом подпоследовательностью произвести некое действие f.
J>>На STL это записывается так: J>>
J>>Все. Это полный код. Если не нашлось элементов, удовлетворяющих Р1 и Р2 — просто ничего не произойдет, так что тут даже никакой дополнительной защиты не нужно.
VD>А если it1 окажется больше чем it2?
Здравствуйте, VladD2, Вы писали:
VD>Здравствуйте, Костя Ещенко, Вы писали:
КЕ>>И чем же не устраивает возможность гонять назад и т.п.?
VD>Несоотвествованием сути паттерна.
Неправда. Суть паттерана итератор — получить доступ к элементам коллекции не зная структуры или интерфейса самой коллекции.
Здравствуйте, vdimas, Вы писали:
V>А паттерны — вещь хорошая, разумеется, но им стоило бы быть аккуратнее в именовании тех вещей, в которых не они были первыми. Итератор из GoF они могли бы назвать и подругому, дабы избежать обсуждаемого конфликта одноименных понятий.
Насколько мне известно итераторы появились несколько раньше итераторов STL. И выглядели они именно как паттерн итератор, описанный GoF. Вообще ребята из GoF не изобретали паттернов, они их только описали. Скорее Степанову следовало бы назвать "итераторы STL" как-нибудь по другому. В STL "итераторы" это скорее constrained pointer abstraction, несколько более общая и интересная концепция чем "паттерн итератор".
Здравствуйте, VladD2, Вы писали:
MS>>Другое дело — сложившиеся традиции. VD>Точнее дурные традиции сложившиеся в некоторых кругах.
Года эдак с 1960-го примерно. И всё дурят старики.
MS>> Для простоты под понятием "список" подразумевается именно "linked list с последовательным доступом" и ничто другое. VD>Почему-то такое предположение больше делают С-шники. Я как-то не слышал, чтобы обычные люди или математики делали подобные предположения.
Nакая трактовка понятия "список" была уже в LISP, а это начало 60-х гг. Языка C, между прочим, тогда ещё и в проекте не было.
... << RSDN@Home 1.1.4 beta 3 rev. 185>>
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Павел Кузнецов, Вы писали:
ПК>Такой подход либо требует контейнера с произвольным доступом, либо приводит к дополнительному проходу по элементам там, где в случае итераторов он не нужен.
Паша, не делай глупое лицо. Я тебе привел пример контейнера, который позволяет получать подпоследовательность с N до M. Что, в плюсах каким-то магическим образом удастся избавиться от лишнего прохода? Нет, не удастся. Ну и о чем тогда спор?
... << RSDN@Home 1.1.4 beta 5 rev. 395>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Sinclair,
> ПК>Такой подход либо требует контейнера с произвольным доступом, либо приводит к дополнительному проходу по элементам там, где в случае итераторов он не нужен.
> <...> Я тебе привел пример контейнера, который позволяет получать подпоследовательность с N до M. Что, в плюсах каким-то магическим образом удастся избавиться от лишнего прохода?
В плюсах (точнее, не в плюсах, а если итератор представляет собой позицию) будут только необходимые проходы. Если вместо итераторов вводятся числа, обозначающие порядковый номер элемента, как это было в примере выше, то в общем случае проходов будет больше: первый, чтоб найти элемент, и потом еще по проходу каждый раз, когда данный элемент нужен еще раз, т.к. по индексу без произвольного доступа элемент можно получить только перечислением.
Posted via RSDN NNTP Server 2.0 beta
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
Здравствуйте, Sinclair, Вы писали:
S>Не надо пытаться слепо переносить технические приемы из одной среды в другую. В каждом языке — свой способ решить некоторую задачу.
Не от среды это зависит, а от задачи. Наример бдшные двухнаправленные курсоры больше подходят, для большинства задач, а применение IList вместо них для отображения и редактирования данных в общем несколько неудачно.
... << RSDN@Home 1.1.4 beta 4 rev. 303>>
и солнце б утром не вставало, когда бы не было меня
J>>Все. Это полный код. Если не нашлось элементов, удовлетворяющих Р1 и Р2 — просто ничего не произойдет, так что тут даже никакой дополнительной защиты не нужно. S>Прекрасный пример. S>Итак, давайте представим себе, как будет решена эта задача на С#2.0. Влад уже привел ответ, правда, на другую задачу.
Во-первых, спасибо за ответ!
К слову, а С#2.0 — это уже в широком использовании, или только планы?
И как бы решение выглядело на первом шарпе?
S>Итак, поехали: S>
S>/// Выводит ту часть последовательности input, которая не удовлетворяет критерию limit:
S>public static IEnumerable<T> Limit(IEnumerable<T> input, Predicate<T> limit)
S>{
S> foreach(T t in input)
S> if (limit(t)) return;
S> else yield return t;
S>}
S>/// выводит элементы последовательности input начиная с того, который удовлетворяет start.
S>public static IEnumerable<T> After(IEnumerable<T> input, Predicate<T> start)
S>{
S> bool found = false;
S> foreach(T t in input)
S> {
S> found |= start(t);
S> if(found)
S> yield return t;
S> }
S>}
S>/// Собственно, код задачи.
S>public static ApplyWithinLimits(IEnumerable input, Action<T> action, Predicate<T> startAt, Predicate<T> stopAt)
S>{
S> foreach(T t in Limit(After(input, startAt), stopAt))
S> action(t);
S>}
S>
Спасибо, в общих чертах понятно. Не могу сказать, правда, что получившийся код обладает высокой читабельностью, и сам по себе, и тем более по сравнению с кодом на STL, который, как кто-то сказал выше, представляет собой явную декларацию намерений Но все более-менее лаконично. Остальные комментарии ниже.
S>Что мы видим? Да, появилось два "лишних" метода. Они не предусмотрены стандартной библиотекой. Однако, мы восполнили их отсутствие весьма простым и тривиальным способом. Если задачи, которые мы решаем, часто требуют подобных приемов, то эти методы осядут в библиотеке проекта. И объем необходимого кода будет не больше, чем для STL.
Так чего ж тогда ругают С++ за то, что у него не все есть в стандартной библиотеке?
Понятно, что можно дописать все, что угодно, положить в библиотеку проекта и легко и просто этим пользоваться, и это, в общем-то, не зависит от языка.
Но это к слову, не флейма ради, тем более я не помню, чтобы конкретно ты такое в адрес СТЛ говорил
Но! STL как раз хорош тем, что у него практически все алгоритмические примитивы уже реализованы.
Вот представь, что у тебя последовательность уже отсортирована по одному из предикатов.
Тогда ты можешь строчку с find_if, соответствую этому предикату, заменить на std::lower_bound, тем самым увеличив производительность, поскольку сложность бинарного поиска меньше сложности последовательного перебора. Причем, заметь, СТЛ пофиг, собираешься ли ты искать во всем контейнере или толкьо в подпоследовательности, выделенной двумя итераторами.
Опять же, если ты потом решил не просто проходить по найденной подпоследовательности, а сделать с ней еще что-нть к с целым, скажем, имеющим логарифмическую сложность, то полная сложность у тебя окажется логарифмической...
Поскольку я уже поблагодарил за ответ, мне теперь просто интересно, как такие изменения условий могут быть отражены на шарпе. Потому что на STL это — тривиальная замена одного алгоритма на другой.
Здравствуйте, Sinclair, Вы писали:
J>>Так чего ж тогда ругают С++ за то, что у него не все есть в стандартной библиотеке? :) S>Ну, я не знаю, кто его ругает. Но вообще это справедливо. Такие велосипеды желательно иметь в стандартной библиотеке, иначе возрастает риск иметь десяток плохо совместимых реализаций.
Так в STL эти примитивы как раз есть. И есть boost, который и делается, чтобы восполнить то, что, как выяснилось, отсутствует в STL. Но и без этого STL уже сейчас имеет все необходимые базовые алгоритмические примитивы, для чего, собственно, она и создавалась.
J>>Вот представь, что у тебя последовательность уже отсортирована по одному из предикатов. S>С учетом того, что предикат — это функция, возвращающая bool, мне довольно сложно представить такую последовательность ;) Ну ладно, предположим, что ты имел в виду последовательность, отсортированную по композитному ключу из атрибутов.
Да, естественно, в данном случае у нас не предикат, а компаратор, из которого предикат получается тривиально :)
И не обязательно это композитный ключ :) Но в общих чертах ты все понял правильно.
J>>Тогда ты можешь строчку с find_if, соответствую этому предикату, заменить на std::lower_bound, тем самым увеличив производительность, поскольку сложность бинарного поиска меньше сложности последовательного перебора. S>А вот тут ты неявно предположил наличие произвольного доступа к контейнеру. Ведь так? Двоичный поиск в односвязном списке будет не намного эффективнее перебора.
Говоря о сложности — да, говоря о замене — нет.
Один и тот же код на STL применим как к итераторам по односвязному списку, так и итераторам с произвольным доступом. Т.е. если мы в один и тот же код засунем итератор по списку — получим линейную сложность, а если итератор по массиву — логарифмическую. Собственно, в этом-то и суть STL — ты полностью отвязываешься от контейнера, а STL сам при инстанцировании выбирает наилучшую версию алгоритма.
J>>Причем, заметь, СТЛ пофиг, собираешься ли ты искать во всем контейнере или толкьо в подпоследовательности, выделенной двумя итераторами. J>>Опять же, если ты потом решил не просто проходить по найденной подпоследовательности, а сделать с ней еще что-нть к с целым, скажем, имеющим логарифмическую сложность, то полная сложность у тебя окажется логарифмической... S>Опять же, никаких гарантий асимптотики у тебя нет.
Если я отдал массив — сложность будет логарифмичской, если список — линейной.
Мой код при этом не меняется.
Твой же нужно будет переписать специально для Array, причем, насколько я понимаю, Limit здесь уже так лихо не сработает.
J>>Поскольку я уже поблагодарил за ответ, мне теперь просто интересно, как такие изменения условий могут быть отражены на шарпе. S>А очень просто. Вот, например, наш контейнер — Array. Для него определено семейство методов Array.BinarySearch(). Существует также ArrayList.BinarySearch.
Вот именно. А у тебя код меняется: тебе нужен сам контейнер и явный вызов его BinarySearch.
Стало быть, твой классный Limit, дающий итератор по подпоследовательности, уже так просто не используешь.
Если это не так, покажи.
J>>Потому что на STL это — тривиальная замена одного алгоритма на другой. S>Тут, увы, все не так просто.
Да нет, в STL как раз все просто :)
Здравствуйте, VladD2, Вы писали:
VD>Здравствуйте, Павел Кузнецов, Вы писали:
ПК>>Вряд ли так получится сделать. По крайней мере, не через IEnumerable/IEnumerator, т.к. он принципиально не способен перебирать в обратном порядке.
VD>Ни однин последовательный алгоритм принципиально не может перебирать ничего в обратном порядке без копирования в промежуточный массив.
Ты не прав. В STL из любого двунаправленного (и его потомков) итератора можно получить итератор, дающий обход в обратном порядке.
Причем, опять же, ты можешь абстрагироваться от направления текущего итератора.
Т.е. если у тебя на входе итератор, который на самом деле осуществляет обратный обход, ты, обращая его, получаешь прямой, и тебе даже не нужно думать, что же у тебя во что превращается: ты можешь быть уверенным, что в результате ты получишь итератор с противоположным направлением обхода.
Здравствуйте, vdimas, Вы писали:
V>Напрасно ты так категорично. Задача С++ кода времени разработки STL — это задача написания эффективных в run-time решений. Итераторы STL — пока единственное существующее решение, которому удалось имплементировать абстракцию итератора единообразно начиная от голых указателей (итераторы вектороподобных контейнеров) и заканчивая объектами с произвольной сложностью и даже неопределенной структуры (итераторы ввода-вывода). Задача тех итераторов — это адаптирующий механизм, позволяющий использовать готовые и эффективные имплементации алгоритмов на теоретически бесконечном множестве целевых классов объектов.
Ну, то есть создавать "эффективные в run-time решения" кроме как на С++ с применением СТЛ невозможно?
Надо мужикам рассказать, а то они и не знают.
V>Мы
О как!
V>прекрасно понимаем, что полиморфные итераторы представляют из себя красоту ООП-подхода (опять же — скорее "внутреннюю" красоту, ибо пользоваться готовыми STL-итераторами не сложнее),
Видимо из-за этого получаются подобные уроды: Читаемость кода
V> так же как понимаем, во что обходится динамическое создание объекта и вызов его полиморфных методов в итераторах Java/C#. Платить подобную цену имеет смысл только тогда, когда других путей нет
Вот еще бы сделать так, чтобы это понимание было хоть на чем-то разумном основано, а не на фобиях...
V>(не ты ли неоднократно советовал использовать for вместо foreach по-возможности )
Нет. Не я. Я как раз советовал использовать foreach. Ты видмо путашь с тем случаем когда я советовал не смешивать ежа с ужем вводя дполнительный индекс к foreach-у. Раз решил работать с индексом, то нефига дурака валять, а работашь с перчисеним — не вводи индксы.
V>Для меня "жалким на вид" смотрится замах на рупь а удар на копейку (типа перебрать 5 элементов в контейнере и для этого динамически создать объект-итератор у которого 11 раз вызвать полиморфные методы...).
А для меня жалкими выглядят подобные рассуждения. Сколько стоят те виртуальные вызовы? Неужели дороже основного перебора? А насколько этот перебор повлияет на основной алгоритм?
Я согласен, что бывают места где нужна гаранитрованно высокая скорость. В таких местах я и СТЛ на пушочный выстрел не подпущу, так как мне нужен полный контроль, а не зависимость от реализации. Но таких мест доли процента. А 99% кода обычно — это мало влияющий на общую производительность код. За то его 99% и именно его рыхлость и не понятность приводит к тому, что программы становится мучительно тяжкло поддерживать иразвивать.
Что же до полиморфизма, то в дотнете можно едеть не полиморфные итераторы. Это как раз не проблема языка. Это проблема дизайна.
V>По крайней мере в STL для меня задача "to be or not to be" не стоит, никакую дополнительную цену за использование итератора мы не платим.
Мы всегда и за все платим. Просто кто-то это осознает, а кто-то ловит блох по подвалам.
V>А паттерны — вещь хорошая, разумеется, но им стоило бы быть аккуратнее в именовании тех вещей, в которых не они были первыми. Итератор из GoF они могли бы назвать и подругому, дабы избежать обсуждаемого конфликта одноименных понятий.
Нда... Мания величия какая-то. С++ не пуп земли. И уж темболее его библиотечка точно не канает на эталон.
GoF ни один паттерн изобретен не был. Они просто написали, о том чем и как пользуются грамотные архитекторы и программисты. Тот же итератор был известен черт знает когда.
V>Опять же — стоит ли подходить к паттернам GoF так буквально?
Ага. Стоит. Иначе получится другие паттерны. Не удоволетворяющие целям описанным в GoF.
V> Часто ли мы применяем паттерны в голом виде?
Вы? А вы их применяете? По твоим словам в СТЛ же все есть и вам больше не нужно.
V>Точно так же шаблон "итератор" в GoF (так же как и остальные шаблоны) — это выхолощенное понятие.
Во оно как? А мужики то и не знали.
V> Задача описания ООП паттерна проктирования — дать самую голую суть ООП-трюка для решения "атомарной" задачи.
Вообще-то паттерн — это удачный примем для решения часто встречающийся задачи.
V> Для паттерна они поставили задачу "перебрать" элементы коллекции, не зная внутренней структуры самой коллекции. Все!
Согласен.
V> Для описания именно патерна большего и не надо.
Глупость. Паттерн — это не задача. Это решение часто встречающейся задачи.
V> Но это не значит, что в реальном применении у нас будет стоять именно столь узкая задача.
Именно это и значит. Другие задачи требуют других решений и соотвественно паттернов.
V> У итераторов STL стояли задачи: доступ, ввод и вывод.
Значит это не итераторы. Задача итератора — абстрагирование перебора элементов коллекции. Все!
V> И им удалось эти операции сделать весьма единообразными, а значит применимыми в произвольных комбинациях в тех же алгоритмах.
"Им", а точнее ему. Не удалось создать стройной и простой концепции. Как минимум получилась куда не годная терминалогия и довольно замусаренный код. Плюс довольно сложная реализация. В общем, нужные задачи решает, но неудобно и не понятно.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Что характерно, в отличие от комбинации двух find_if и for_each, неудачно почти дословно повторяющей условие задачи, сразу видно, что именно хотел выразить этим автор
> Оданко, что характерно ты тоже не угадал, что выдаст данный код. <...>
Это прискорбные последствия "усложнения" последовательности после написания сообщения.
> И это в трех соснах. Что же будет когда кода будет по больше.
Ты искренне считаешь, что дело в коде? Я ориентировался по условию задачи, а не по коду.
Posted via RSDN NNTP Server 2.0 beta
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
Здравствуйте, VladD2, Вы писали:
VD>Я тут недавно... раздобыв вторую бэту сразу же запустил свой проект который сейчас пишу (редактор кода для Януса и R#-па за место Синтилы) под ним. Было забавно, что мои ожидания оказались очень близкими к тому что показал профайлер. Хотя в паре мест я все же ошибся. Так я не обратил внимания на промежуточные динамические массивы создаваемые в узких местах, а оказалось, что они то используются очень нехило. Решение было просто как три копейки. Вместо того, чтобы создавать их каждый раз я просто вынес их в статические переменные или поля класса. Чтобы не было проблем с многопоточностью пометил статические поля атрибутом ThreadStatic: VD>
VD>[ThreadStatic]
VD>private static List<StyledRange> _ranges = new List<StyledRange>(16);
VD>[ThreadStatic]
VD>private static List<int> _ndxs = new List<int>(16);
VD>
VD>И все дела! Если бы я мог вот так же за просто решать проблемы на С++ глядишь я и не стал бы искать лучшей жизни.
__declspec(thread) спасёт отца русской демократии. Реализации TSS есть и в сторонних библиотеках, в том же ACE. Ну только с деструкторами сложности будут. Хотя... с большой вероятностью, на C++ этого просто не понадобится.
... << RSDN@Home 1.1.4 beta 3 rev. 185>>
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, VladD2, Вы писали:
VD>>>В общем, по жизи я получаю больше гибкости именно от простых решений, а не от супер-пупер наворотов. ГВ>>Ну так, ты рассказал, фактически, о том, что "тебе не приходилось...", "ты не сталкивался...", "ты развернулся по течению..." и т.п. Расскажи теперь, плз., какое это отношение имеет к характеристикам рассматриваемых абстракций?
VD>Мне приходилось много чего. Я рассказываю о реалиях жизни.
Э... не люблю заниматься самоцитированием, но вынуждаешь. Итак, повторяю свой вопрос:
...какое это отношение имеет к характеристикам рассматриваемых абстракций?
Начало см. выше.
И?
... << RSDN@Home 1.1.4 beta 3 rev. 185>>
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
> > CX>Если уж сравнивать, то с ним.
> Даже с ним сравнение явно не в его пользу.
+1
Теперь спрашиваем себя: почему? Ясно, что итераторы здесь совсем ни при чем, а дело в отсутствии поддержки лямбда-функций. Т.е. если бы можно было писать, например, так:
Здравствуйте, VladD2, Вы писали:
VD>Я тут недавно... раздобыв вторую бэту сразу же запустил свой проект который сейчас пишу (редактор кода для Януса и R#-па за место Синтилы) под ним. Было забавно, что мои ожидания оказались очень близкими к тому что показал профайлер. Хотя в паре мест я все же ошибся. Так я не обратил внимания на промежуточные динамические массивы создаваемые в узких местах, а оказалось, что они то используются очень нехило. Решение было просто как три копейки. Вместо того, чтобы создавать их каждый раз я просто вынес их в статические переменные или поля класса. Чтобы не было проблем с многопоточностью пометил статические поля атрибутом ThreadStatic: VD>
VD>[ThreadStatic]
VD>private static List<StyledRange> _ranges = new List<StyledRange>(16);
VD>[ThreadStatic]
VD>private static List<int> _ndxs = new List<int>(16);
VD>
VD>И все дела! Если бы я мог вот так же за просто решать проблемы на С++ глядишь я и не стал бы искать лучшей жизни.
На С++ не надо создавать промежуточный да еще и динамический массив. Кстати, твое "интересное" решение действительно быстрее, чем создание промежуточного массива? Когда-то я баловался с TLS — это тоже удовольствие не из самых быстрых.
Здравствуйте, Cyberax, Вы писали:
>> Плиз, или называй на "ты", или "Вы" пиши с большой буквы, а то как-то >> ощущаю себя группой товарищей.
C>Так, небольшая заметка: по правилам русского языка обращение "вы" C>пишется с большой буквы только в личных письмах (ну или в начале C>предложения ).
"Вы" пишется с большой буквы когда им заменяется имя или фамилия, т.е. как раз личное обращение. Именно это имеет место в доанном случае. "вы" с маленькой буквы — это множественное число.
... << RSDN@Home 1.2.0 alpha rev. 606>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, VladD2, Вы писали:
VD>Здравствуйте, ArtemGorikov, Вы писали:
AG>>К примеру, эффективность IDE студии .NET обределяется невооруженным и неопытным взглядом как крайне низкая. Причем, тут коррелирует еще на какой оси стоит — на 2к не тормозит, а на XP/2003 — ж#па.
VD>Купи памяти и научись читать требования к аппаратуре.
Вот и я ж о том, что тормозит. На любой вопрос "почему тормозит" стандартный ответ "докупи памяти и поставь новый камень". Да, это универсальная отмазка, поэтому в каждом новом дистрибутиве винды раз за разом реклама "приложения стали работать еще быстрее и надежнее" (ценой апгрейда). В Vista приложения будут стартовать на 30% быстрее, чем в предыдущих версиях — как думаете, какой ценой?
AG>> Тесты на перебор коллекции COM-интерфейсов и вызове у каждого объекта 1 метода показали разницу в быстродействии м/д С++ и С# в 10 (десять) раз.
VD>Это ты интероп с родным кодом что ли сравнивашь? VD>А ты сравни скорость вызова метода интерфейса/класса в С# и COM-интерфейс в нэйтив-С++. Вот это будет чесно. Думаю результаты тебя удивят.
В таком случае честно будет сравнивать скорость вызова метода класса C# и метода класса С++, который, к тому же, можно сделать инлайновым. В самом деле, надо провести тест — на сколько порядков будет разница — на 1 или 2?
AG>>Когда вы писали COM-объекты на C++ вы знали о существовании контейнеров STL или, может быть, использовали свои поделки или MFC/ATL контейнеры?
VD>А ты поиск по этому сайту сделай. Увидишь. VD>И поверь, что что бы ты не использовал все равно трах создания КОМ-коллекций на С++ и дотнетных коллекций на Шарпе просто не соизмеримы. Все что нужно сделать на шарпе это написать: VD>
VD>далее если захочется реакций разных на добавление там или еще что, то просто перегружашь нужные методы и пишешь код. С помощью IDE — это плевая операция. А вот на плюсах одни IDL-описания запаришся делать. Ну, и результат по производительности не соизмеримый. КОМ-овские коллееции в качестве перечислителя испоьзуют IEnumVARIANT со всеми вытекающими. О статической типизации вообще можно не говорить.
VD>И зачем весь этот трах?
Согласен полностью насчет траха, а нужен он для скорости. Иногда и за 15% прирост стоит потрахаться, а уж за 300% — 700%... Это я о средней разнице в скорости native-кода VC++ и managed-кода VC#. В общем-то, программисту платят и за этот трах в том числе. А если вместо 2 можно посадить кодить одного, да еще и необязательно с высокой квалификацией... Моя мысль в том, что если нужна хорошо написанная, быстрая, нетребовательная к ресурсам программа — плати А если это софтина внутрикорпоративная, поставят ее на ограниченное ч-ло компов (20-200), то дешевле прикупить памяти.
AG>>Обязательно приведите сравнение с Сцинтиллой. Пока только было Ваше высказывание где-то в форуме , что "Янус — проект just for fun
VD>Скачивай и сравнивай.
AG>>и он лучше многих коммерческих проектов на C++". AG>> А с какими такими коммерческими проектами вы его сравнивали?
VD>Это ты сам придумал.
Не спорю, может и привиделось, а может просто кто-то другой написал на форуме это.
AG>> Может быть с MS Outlook / Outlook Express? Он и рядом с ними не стоял. По моему, и не только, мнению, он выглядит и работает как дешевая поделка (just for fun).
VD>Ну, это твое мнение. Можешь оставаться при нем и пользваться NNTP через Outlook Express получая кайф от глюков и убогости.
Вы считаете OE убогим? Не согласен. До него многим софтинам еще расти как в плане интерфейса, так и фич (любители bat, прошу не кидать в меня гнилыми помидорами )
AG>> And nothing more! Я лично пользуюсь web-интерфейсом и он полностью меня устраивает.
VD>Рад за тебя. Он, кстати, тоже на Шарпе написан.
А как это? Т.е., не будь у меня установлена платформа, он бы не работал? А на вид невинный сайт с фреймами и самописным деревом, никаких извратов и выкрутасов на нем мной замечено не было Я его даже на FF загружал — фреймы не таскались, а остальное все шевелилось
AG>>А что такого, что stl::map основан на дереве?
VD>Ничего, просто медленно и требует бессмысленных сравнений на больше/меньше. И вообще, безграмотная структура классов. map == ассоциативный массив. Вот и должне предоставлять добавление, удаление и поиск по ключу. Остальное пусть будет в каком-нибудь TreeMap.
Что медленно? Если std::map<std::string, ...>, то да, а если std::map<size_t,...> то очень даже быстро, теоретически быстрее, чем массив на hash. В случае, если надо ключ в виде строки иметь, то CAtlMap<CAtlString,...> в помощь... — это как раз hash-массив.
AG>> Вот в ATL есть CRBMap, и ничего. А в коллекциях .NET есть аналог мапа?
VD>Есть. Только это уже дерево, а не мап. И необходимость в нем очень редка. VD>Ну, и что касается ATL коллекций... Траха с ними не впример больше чем с дотнетными коллекциями. Да и стандартностью они не отличаются.
Да все понятно, C# для того и задумали, чтобы трах уменьшить. Но при этом сделали его ограниченным — нет множественного наследования, полноценных compile-time шаблонов, заморочки с value-типами и простыми. Память вот еще настоятельно советуют прикупить. Предшественники C# с теми же целями — VB и Delphi. Только они не вытеснили C++ (у них были схожие с C# ограничения), так что подождем его хоронить.
VD>>>Я не зацикливаюсь не на чем. Я говрою о простых, казалось бы вещах, о дурной терминологии и мосорности итераторов в СТЛ.
А мне нравится терминология и идея итераторов STL. IMHO это гениально иметь механизм, позволяющий подсовывать в алгоритмы любые итераторы и при этом не терять вообще ничего в производительности, т.к. компилер все заинлайнит и оптимизирует в лучшем виде. Что вы так к терминологии прицепились? Ну неточная она, но это же не повод не пользоваться итераторами.
AG>>А чем value-типы в массивах .NET лучше в плане чистоты?
VD>Тем что при этом к ним есть прямой (а стало быть эффективный) доступ. Например, такой код: VD>
VD>struct A
VD>{
VD> public int I;
VD>}
VD>class Program
VD>{
VD> static void Main()
VD> {
VD> A[] a = new A[2];
VD> a[1].I++;
VD> }
VD>}
VD>
VD>совершенно законен и эффективен.
Я ж про то, что для <b>"прямой (а стало быть эффективный) доступ"</b> нужно _явно_ указывать, что это value-тип. А в C++ прямой и эффективный доступ просто по умолчанию, и не надо думать, где нужен прямой и эффективный доступ, а где обычный. Т.е. это уже some kind of backdoor, дающий небыстрой реализации так нужный ей "костыль" — это все мое IMHO.
VD>ЗЫ
VD>Плиз, или называй на "ты", или "Вы" пиши с большой буквы, а то как-то ощущаю себя группой товарищей.
Согласен на "ты", но я ведь младше, поэтому и обращаюсь на "вы". И тут ведь публичный треп, а не личная переписка.
E>Ты не прав! Имхо, большинство C++ программистов норовят переписать самостоятельно даже существующие библиотеки. А уж когда готовой сразу под рукой нет, то искать -- это вообще бесполезная трата времени. Нужно незамедлительно писать свою! E>)
Все так бывает даже, что пишет аналог того, что уже написал сосед, просто от того, что считает свое решение более удачным. Бывает, что действительно нужно обойти ограничения/улучшить скорость, а бывает и просто чтобы померяться мужским достоинством
Здравствуйте, VladD2, Вы писали:
AG>>В таком случае честно будет сравнивать скорость вызова метода класса C# и метода класса С++, который, к тому же, можно сделать инлайновым.
VD>Да. И разницы никакой нет.
AG>> В самом деле, надо провести тест — на сколько порядков будет разница — на 1 или 2?
VD>С чего бы ей быть? Ну, если только в одном случае заинлайнится, а в другом нет. Но это и 10% на суровом алгоритме не даст, а в приложении ты это и не заметишь.
Здравствуйте, jedi, Вы писали:
J>Меня улыбнуло J>Твой код удалил не оверквотига ради, а токмо ради сравнения:
J>С++ с голимым концептуально неверным STL-ем:
Слово args встретилось 2 раз[а].
Слово break встретилось 1 раз[а].
Слово ch встретилось 3 раз[а].
Слово char встретилось 3 раз[а].
Слово class встретилось 1 раз[а].
Слово Collections встретилось 1 раз[а].
Слово concordance встретилось 5 раз[а].
Слово Console встретилось 1 раз[а].
Слово count встретилось 4 раз[а].
Слово Dictionary встретилось 2 раз[а].
Слово File встретилось 1 раз[а].
Слово for встретилось 2 раз[а].
Слово foreach встретилось 2 раз[а].
Слово Generic встретилось 1 раз[а].
Слово GetWord встретилось 2 раз[а].
Слово i встретилось 10 раз[а].
Слово IEnumerable встретилось 1 раз[а].
Слово if встретилось 2 раз[а].
Слово in встретилось 2 раз[а].
Слово int встретилось 5 раз[а].
Слово IO встретилось 1 раз[а].
Слово IsLetter встретилось 1 раз[а].
Слово IsLetterOrDigit встретилось 1 раз[а].
Слово key встретилось 3 раз[а].
Слово keys встретилось 3 раз[а].
Слово Keys встретилось 1 раз[а].
Слово Length встретилось 2 раз[а].
Слово List встретилось 2 раз[а].
Слово Main встретилось 1 раз[а].
Слово new встретилось 2 раз[а].
Слово out встретилось 1 раз[а].
Слово Program встретилось 1 раз[а].
Слово ReadAllText встретилось 1 раз[а].
Слово return встретилось 1 раз[а].
Слово Sort встретилось 1 раз[а].
Слово static встретилось 2 раз[а].
Слово strat встретилось 3 раз[а].
Слово string встретилось 9 раз[а].
Слово Substring встретилось 1 раз[а].
Слово System встретилось 3 раз[а].
Слово text встретилось 6 раз[а].
Слово TryGetValue встретилось 1 раз[а].
Слово using встретилось 3 раз[а].
Слово void встретилось 1 раз[а].
Слово word встретилось 3 раз[а].
Слово WriteLine встретилось 1 раз[а].
Слово yield встретилось 1 раз[а].
Тестовый файл, естественно, одинаковый.
Если тяжело понять разницу, то поясню. Разбираются не слова, а черти что. Про кодировку в консоли вообще лучше промолчать.
J>Вывод:...
Если результат не важен, то СТЛ рулит.
ЗЫ
Таки все же интересно глянуть на тоже самое на АТЛ-е.
... << RSDN@Home 1.2.0 alpha rev. 606>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Дай определение слова. В моем понимании это то что разделено пробельными символами — в твоем это видимо идентификаторы и ключевые слова С# (кстати ты не учел "слова" начинающиеся с символа подчеркивания).
ЗЫ про кодировки — это проблема совсем другого плана и в контексте данного алгоритма абсолютно не важна.
...При другом подходе к хешированию таблица рассматривается как массив связанных списков или деревьев ...
Т.е. при получении hash из простого типа (например, long), мы будем иметь в лучшем случае то же дерево, что и stl::map, плюс еще доп. расход памяти — ключи + хэши к ним против только ключи у stl::map. Hash — массивы оправданны только в тех случаях, когда размер типа хэша меньше размера типа ключа.
Здравствуйте, ArtemGorikov, Вы писали:
AG>Здравствуйте, VladD2, Вы писали:
VD>>Почитай http://www.optim.ru/cs/2000/4/bintree_htm/hash.asp
AG>Статья рулит
AG>Вот там написано:
AG>...При другом подходе к хешированию таблица рассматривается как массив связанных списков или деревьев ...
+1
AG>Т.е. при получении hash из простого типа (например, long), мы будем иметь в лучшем случае то же дерево, что и stl::map, плюс еще доп. расход памяти — ключи + хэши к ним против только ключи у stl::map. Hash — массивы оправданны только в тех случаях, когда размер типа хэша меньше размера типа ключа.
А вот это, насколько я понимаю, неверно.
В предыдущей цитате ключевое слово — массив. Хэшированные структуры организуют данные таким образом, что в лучшем случае (при отсутствии коллизий) доступ к элементу с заданным индексом сводится к прямому доступу к ячейке этого самого массива, плюс проверка на то, что мы нашли именно нужный элемент, а не абы что.
Здравствуйте, jedi, Вы писали:
J>Дай определение слова. В моем понимании это то что разделено пробельными символами —
Слово это нечто осмысленное. Уж скобки и т.п. точнро ими являться не должны.
J>в твоем это видимо идентификаторы и ключевые слова С#
Именно. И мне казалось, что это очевидно из приведенного кода.
J>(кстати ты не учел "слова" начинающиеся с символа подчеркивания).
Тут ты прав. Но это мелочь. Нужно всего лишь добавить одну проверку.
J>ЗЫ про кодировки — это проблема совсем другого плана и в контексте данного алгоритма абсолютно не важна.
Нет это тоже проблема и ее решение тоже увеличивает объем кода. А в таком виде это — лажа в которой разобраться то нельзя.
... << RSDN@Home 1.2.0 alpha rev. 606>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
using System;
using System.Collections.Generic;
using System.IO;
static class Program
{
static void Main(string[] args)
{
SortedDictionary<string,int> concordance = new SortedDictionary<string,int>();
foreach (string word in File.ReadAll(args[0]).Split(" \n\r\t!\"#$%&'()*+,-./:;<=>?@[\\]^_`{|}~".ToCharArray()))
if (concordance.ContainsKey(word))
concordance[word] += 1;
else
concordance.Add(word, 1);
foreach (string key in concordance.Keys)
Console.WriteLine("Слово {0,20} встретилось {1,3} раз[а].", key, concordance[key]);
}
}
Вот только разделители будут учитываться все равно не все.
Здравствуйте, VladD2, Вы писали:
VD>Здравствуйте, ArtemGorikov, Вы писали:
VD>>>Ты бы создал просто Win32 Console-ый проект и задал бы в нем поддржку ATL. Тогдв жить стало бы проще. А то что-то мучаешся вручную и я вместе с тобой.
AG>>Я так и сделал
VD>Тогда где строчка: VD>
VD>#include"stdafx.h"
VD>
Могу прислать проект, тока позже — он дома. Там есть и stdafx.h в т.ч.
AG>>А как ты узнал, что выделяются халтурно?
VD>Код прочел. Ты меня за совсем уж полного болвана не считай.
Т.е. скомпилил и отладил в голове? Ну ты прям супер-компьютер А числа большие складывать в уме можешь быстро? Если серьезно, то я в этом сильно сомневаюсь, после того, как тебя поставило в замешательство отсутствие #include "stdafx.h" в начале исходника.
AG>> Ты же не смог его собрать.
VD>Да собрать то я его в конце концов смог. Только на коносли каша. А что там нужно где подкручивать я не помню и желания разбираться нет, так как у меня есть средство разработки вообще не имеющее подобных проблем.
Каша была в первом варианте, которую ты с радостью привел. Я нашел ошибку — ты собрал проект в unicode, и на std::cout << some_unicode_text выводилась не строка, а ее адрес в памяти или еще чего-то. Вообще-то визард консольного проекта по умолчанию настройку ставит на ansi, поэтому я не догадался специально включить unicode и проверить. А вот ты ее включил сам — наверно для того, чтобы сказать "ага! я нашел баг!" — это из той же оперы, когда с ты двух компов завалил базу оутлука и сказал, что он г####.
VD>Что значит не было? Ты оригинальный код читал? Там что сортировка от болды влеплена?
VD>>> А все это добавит объема и при твоем методе кодирования ухудшит читаемость. Собственно код уже читается очень плохо в сравнении с эталонным.
Не знаю зачем влеплена; скорее всего от балды. Надо было подсчитать повторы слов и все.
AG>>Ах ну да, твой код у нас теперь эталон.
VD>Естественно. Он был создан первым. Ты значение слова эталон хорошо понимашь? VD>БСЭ: VD>
Эталон (франц. etalon), образец, мерило, идеальный или установленный тип чего-либо; точно рассчитанная мера чего-либо, принятая в качестве образца.
Ну я это и хотел сказать, что ты свой код назвал "образцовам, идеальным".
VD>>> В общем то об этом я и вел речь. Думаю когда ты добъешь свой код и сделашь его полностью аналогичным и работоспособным, то трах и неудобство ты сможешь оценить сам. О них я и говорил.
Дело привычки.
AG>> То, что ты пользуешься бетой 2005 — не мои проблемы,
VD>Твои, твои. Код должен давать один результат не зависимо от компилятора. Да и не только в абракодабре дело.
Пришлю проект — надеюсь проблем не будет загрузить?
VD>Ты не смог даже воспроизвести примитивный пример, а потнов целая гора. То же что твои примеры не компилируются или выдают абракодабру виноват исключительно ты. И не нужно заставлять других пыжится и исправлять твои ошибки. Например, мой код скомпилируется с первого раза. Нужно только заменить им фал дефолтного консольного проекта.
Да все понятно. Спорить с тобой бессмысленно, твой код просто эталон, а всех кто пытается дискутировать с тобой ты поливаешь грязью. Думаю, настоящий трах — это не писать на С++, а общаться с тобой.
Здравствуйте, McSeem2, Вы писали:
MS>В оправдание STL итераторов — как голый указатель в C/C++....
Голый указатель имеет смысл когда используется как указатель на начало
последовательности элементов. Т.е. такое использование итератора
предполагает знание про геометрию контейнера что иделогически (по отношению
к итератору) в корне не верно. Ага?
Здравствуйте, c-smile, Вы писали:
CS>Есть два подхода к итераторам: "Java" и "STL"
CS>В Java позиция итератора это позиция *между* элементами последовательности. CS>в stl позиция итератора это позция элемента
CS>В принципе дейтвительно Java вариант выглядит логичнее в том смысле что: CS>1) не нужно специального end value (которое кстати не всегда и можно-то натурально определить) CS>2) операции prev / next симметричны.
CS>А вы как думаете?
Когда я после C++ начал программить на Java, возникла простая задача: гуй, 3 кнопки "загрузить", "вперед" и "назад", нужно загрузить из файла список картинок и просматривать.
В C++ я загружал все картинки в некий контейнер и отдавал гую итератор. по "вперед" делаем ++it и показываем, по "назад" --it и показываем.
Попробовал то же самое в Java. По нажатию "вперед" делаю it.next(), получаю картинку, показываю. По нажатию "назад" делаю it.prev() и получаю ту же самую картинку. Тогда плюнул и заюзал Vector и индекс.
Подскажите плз, как сделать это правильно с Java-итераторами?
Здравствуйте, Odi$$ey, Вы писали:
OE>в STL она тожа как-бы между, если судить по логике приведения reverse_iterator к iterator при помощи base() — он начинает указывать на другой элемент, на одну позицию правее:
OE>
Просто для логичекой симметрии пришлось определить
наряду с end еще и rend что имхо выглядит несколько
негармонично.
Здравствуйте, McSeem2, Вы писали:
MS>Честно сказать, мне концепция итераторов вообще не нравится. Просто потому, что ее превратили в какую-то притянутую за уши догму. У итератора по его названию должна быть одна единственная операция — инкремент. На то он и итератор....
Как я понимаю тебя больше бы устроил механизм foreach.
Вот например в D:
// параметризуемый класс (ака template)class Collection(T)
{
int opApply(int delegate(inout T) dg)
{
для всех элементов коллекции вызвать dg...
}
}
Использование:
Collection!(Foo) myFooCollection;
foreach( Foo f; myFooCollection ) // foreach это просто вызов метода opApply
{ // c синтезированным "naked" delegate
f.something() ...
}
Принципиальное отличие (и прэлэсть) состоит в том
коллекция сама управляет перебором — т.е. вопросов
типа "где стоит указатель" просто не возникает.
So far мне в D итераторы не понадобились.
opApply — действительно удобно и идеологически правильно.
Здравствуйте, McSeem2, Вы писали:
CS>>Голый указатель имеет смысл когда используется как указатель на начало CS>>последовательности элементов. Т.е. такое использование итератора CS>>предполагает знание про геометрию контейнера что иделогически (по отношению CS>>к итератору) в корне не верно. Ага?
MS>Честно сказать, мне концепция итераторов вообще не нравится.
[зверьковыгрызено]
Ты знаешь, Макс, в последнее время я тоже стал приходить к этой мысли
Еще полгода назад я лепил их практически везде, где надо перебрать 3 элемента — прилежно реализовывал все 10 операторов.... даже если по юз-кейсу эти итераторы никто никогда не будет сравнивать...
А потом забил. И более того — даже на красоту конструкций it++, *it забил в пользу менее симпатишных, но иногда более очевидных it.get(), it.next()...
И теперь у меня в коде такое... Для каждого контейнеро-образного класса — свой способ перебрать элементы.
Здравствуйте, c-smile, Вы писали:
Ш>>Вообще, не очень понятно, что значит -- указывать между элементами?
CS>Object next() возвращает элемент над которым "пролетает" итератор.
CS>В Java не требуется специальное значение end CS>так как тест на bos/eos осущесвляется отдельной функцией (hasNext).
CS>
Здравствуйте, c-smile, Вы писали:
CS>Есть два подхода к итераторам: "Java" и "STL" CS>А вы как думаете?
Я думаю, что это терминологическая путаница, из-за которой и возникают такие вопросы.
Итераторы STL — это обобщение идеи указателя: они позволяют, не меняя состояние субъекта, многократно (за исключением одебиленных Input/Output Iterator) доступаться к одному объекту.
Итераторы Java (а также энумераторы COM) — это обобщение идеи сканера файла: доступ к объекту приводит к смене состояния субъекта.
Input/Output Iterator — это, на самом деле, синтаксический сахар: чтобы работу со устройствами чтения/записи привести к тому же виду, что и работу с последовательными контейнерами.
В принципе, никто не мешает сделать и наоборот: трактовать указатели контейнеров как сканеры файлов — в тех алгоритмах, где есть однонаправленное чтение/запись.
// вот как выглядят некоторые алогритмыtemplate<class InputScanner, class OutputScanner>
void copy_javalike(InputScanner src, OutputScanner dst)
{
while(!src.finish()) dst.write(src.read());
}
template<class InputScanner, class OutputScanner, class Transform>
void transform_javalike(InputScanner src, OutputScanner dst, Transform tf)
{
while(!src.finish()) dst.write(tf(src.read());
}
template<class InputScanner, class Value, class SumFunc>
Value adjacent_sum_javalike(Value start, InputScanner src, SumFunc sum)
{
while(!src.finish()) start = sum(start,src.read());
return start;
}
// переходники от указателей к сканерамtemplate<class InputIterator>
struct stl_input_scanner
{
InputIterator begin, end; // дань традиции STL: конец диапазона задаётся указателем на "за-конец"
stl_input_scanner(InputIterator b, InputIterator e) : begin(b), end(e) {}
bool finish() const { return begin==end; }
typename std::iterator_traits<InputIterator>::value_type read() { return *begin++; }
};
template<class OutputIterator>
struct stl_output_scanner
{
OutputIterator pos;
stl_output_scanner(OutputIterator p) : pos(p) {}
template<class Value>
void write(Value const& v) { *p++ = v; }
};
Но тут выясняется, что есть алгоритмы, работающие с последовательностями — а есть алгоритмы, работающие с контейнерами. В принципе, для работы с контейнерами очень пригодилась бы модель полуинтервалов (да и на последовательности её можно спроецировать).
Но разнообразие моделей доступа, применительно к одним и тем же объектам (контейнерам или файлам) — это накладно.
Представьте себе модель вектора, у которого есть методы begin(), end(), start_read(), start_write(), full_range().
Мрачновато...
Поэтому STL остановилась на обобщённых указателях (с бонусом в виде синтаксического сахара — совместимости с голыми указателями). И мне кажется, именно этот бонус склонил чашу весов.
А у COM и Java этого сахара не было...
Здравствуйте, Зверёк Харьковский, Вы писали:
ЗХ>Ты знаешь, Макс, в последнее время я тоже стал приходить к этой мысли ЗХ>Еще полгода назад я лепил их практически везде, где надо перебрать 3 элемента — прилежно реализовывал все 10 операторов.... даже если по юз-кейсу эти итераторы никто никогда не будет сравнивать...
ЗХ>А потом забил. И более того — даже на красоту конструкций it++, *it забил в пользу менее симпатишных, но иногда более очевидных it.get(), it.next()... ЗХ>И теперь у меня в коде такое... Для каждого контейнеро-образного класса — свой способ перебрать элементы.
Есть такая методология — стрёмное программирование (XP).
Надо тебе сделать output iterator поверх какого-то фидера — делаешь тяп-ляп, зато совместимо со всеми прочими алгоритмами.
struct my_output_iterator : iterator<input_iterator_tag, Value>
{
my_output_iterator& operator++(int) { return *this; } // тяп-ляп номер раз
my_output_iterator& operator*() { return *this; } // тяп-ляп номер два
my_output_iterator& operator=(Value v) { NowWriteIt(v); }
};
Потом, когда руки дотянутся — переделаешь так, чтобы не было шансов для misuse.
Да и, в конце концов, стратегии позволят нарожать таких итераторов сколько хочешь. Только один раз грамотно шаблон сделать...
// делаем оснастку для SomeInputFilestruct access_to_SomeFile
{
typedef Data value_type;
typedef SomeFile file_type;
static bool eof(file_type& f) { return f.EndOfFile(); }
static Data read(file_type& f) { Data v; f.Read(v); return v; }
};
// строим правильный стопроцентно совместимый и грамотно бьющий по пальцам итератор в духе святого STLtypedef file_input_iterator< access_to_SomeFile > somefile_input_iterator;
CS>А что означает CS>container.begin() + 10 CS>для котейнера типа list?
Для list — ничего не означает. Я всего лишь привел пример. Пойнт мой был: возможность вызова функции, которая принимает начальный и конечный итераторы, но передать ей не begin и end, а что-то другое; таким образом, обработать лишь часть контейнера.
Здравствуйте, Кодт, Вы писали:
К>Здравствуйте, Зверёк Харьковский, Вы писали:
ЗХ>>Ты знаешь, Макс, в последнее время я тоже стал приходить к этой мысли ЗХ>>Еще полгода назад я лепил их практически везде, где надо перебрать 3 элемента — прилежно реализовывал все 10 операторов.... даже если по юз-кейсу эти итераторы никто никогда не будет сравнивать...
ЗХ>>А потом забил. И более того — даже на красоту конструкций it++, *it забил в пользу менее симпатишных, но иногда более очевидных it.get(), it.next()... ЗХ>>И теперь у меня в коде такое... Для каждого контейнеро-образного класса — свой способ перебрать элементы.
К>Есть такая методология — стрёмное программирование (XP).
Прошлым летом поимел опыт экстремального программирования. Ездил в коммандировку. В шахте на глубине 800 метров в каске с фонарём на ноутбуке правил прогу на ассме.
а если серьезно — я обычно именно так и пишу.
но в последнее время стал сталкиваться с тем, что мне от "итератора" надо нааамного меньше, чем предоставляет концепция итератора stl.
последний пример — курсор к БД, который я пытался-пытался сделать итератором, а потом плюнул, сделал вот такое:
class cursor
{
...
bool next();
value_t get();
...
}
и мне от него больше ничего не нада. Причем через .end(), ++, == это выражалось сууущественно хуже.
Здравствуйте, Кодт, я там когда-то обещал статейку по LazyK. Так вот, у меня наконец-то дошли кажется руки этим заняться. Еще актуально или ты уже сам разобрался?
Здравствуйте, Зверёк Харьковский, Вы писали:
ЗХ>а если серьезно — я обычно именно так и пишу. ЗХ>но в последнее время стал сталкиваться с тем, что мне от "итератора" надо нааамного меньше, чем предоставляет концепция итератора stl. ЗХ>последний пример — курсор к БД, который я пытался-пытался сделать итератором, а потом плюнул, сделал вот такое:
ЗХ>и мне от него больше ничего не нада. Причем через .end(), ++, == это выражалось сууущественно хуже.
Так я и говорю: есть разные модели для доступа к элементам. И привести одно к другому — с помощью шаблонов и проксей делается без проблем (как говорится, "день потерять, потом за час долететь").
Другое дело, что если нет потребности в совместимости с каким-то алгоритмом, заточенным под существующую модель — то эту совместимость можно не накладывать.
Кстати, пример адаптации указателя к сканеру — это создание COM-энумератора ко внутреннему STL-контейнеру COM-объекта. Тоже не обходится без этической силы и бениной матери... И тоже решается шаблонами — IEnumOnSTLImpl.
Другое дело, что если нет потребности в совместимости с каким-то алгоритмом, заточенным под существующую модель — то эту совместимость можно не накладывать.
В моем случае (курсора к БД) не-итераторо-совместимый интерфейс — не потому, что итераторо-совместимый было тяжело реализовать, а потому, что существенно лучше соответствует логике юз-кейса. Вотъ.
Здравствуйте, Зверёк Харьковский, Вы писали:
CS>>А что означает CS>>container.begin() + 10 CS>>для котейнера типа list?
ЗХ>Для list — ничего не означает. Я всего лишь привел пример. Пойнт мой был: возможность вызова функции, которая принимает начальный и конечный итераторы, но передать ей не begin и end, а что-то другое; таким образом, обработать лишь часть контейнера.
Вот меня и инетересует это самое "а что-то другое": що ж це воно такэ, г`а?
Это примерно как приделать seekg с stream. Эх глянуть бы в глаз тому кто это придумал.
Здравствуйте, Зверёк Харьковский, Вы писали:
ЗХ>Здравствуйте, Кодт, я там когда-то обещал статейку по LazyK. Так вот, у меня наконец-то дошли кажется руки этим заняться. Еще актуально или ты уже сам разобрался?
Здравствуйте, alexeiz, Вы писали:
A>А может панам стоит познакомиться с библиотекой Boost.Iterator или хотя бы с частным случаем Iterator Facade? Право слово, ничуть не хуже чем собственные велосипеды получается.
CS>>А что означает CS>>container.begin() + 10 CS>>для котейнера типа list?
ЗХ>Для list — ничего не означает. Я всего лишь привел пример. Пойнт мой был: возможность вызова функции, которая принимает начальный и конечный итераторы, но передать ей не begin и end, а что-то другое; таким образом, обработать лишь часть контейнера.
А это ещё одна попытка "впихнуть невпихуемое". Здесь с помощью пары итераторов задаётся сущность "диапазон" (полуинтервал).
В случае последовательных (forward | bidirectional) итераторов — в зависимости от задачи удобно представлять диапазон как пару итераторов "от" и "до", либо как начало и длину.
Написать адаптер итератора с отсчётом — довольно просто... Скажем, это пара из исходного итератора и счётчика. Концевой итератор — у которого счётчик равен 0 (и все концевые итераторы эквивалентны).
Впрочем, никто не мешает сделать
container_type::iterator begin = container.begin(), limit = begin;
advance(limit,10); // по смыслу - limit += 10
sort(begin,limit);
К>container_type::iterator begin = container.begin(), limit = begin;
К>advance(limit,10); // по смыслу - limit += 10
К>sort(begin,limit);
К>
Однако, мешает. sort нуждается в итераторах произвольного доступа (с дешёвой арифметикой). Конечно, можно определить её через advance — но это будет очень дорого стоить. Вместо O(n*log(n)) получим что-то кубическое.
Здравствуйте, alexeiz, Вы писали:
A>А может панам стоит познакомиться с библиотекой Boost.Iterator или хотя бы с частным случаем Iterator Facade? Право слово, ничуть не хуже чем собственные велосипеды получается.
Итераторы в Яве указывают точно так же на элемент. Только в отличии от СТЛ-я они стаоят на вымышленном (несуществующем) элементе не в конце, а в начале. Плюс в них есть понятие HasNext. Вот оно то и дает большее удобство и простоту. И вообще итераторы СТЛ слишком громоздки.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Зверёк Харьковский, Вы писали:
ЗХ>а если серьезно — я обычно именно так и пишу. ЗХ>но в последнее время стал сталкиваться с тем, что мне от "итератора" надо нааамного меньше, чем предоставляет концепция итератора stl.
Вдумайся в свои слова "предоставляет концепция итератора stl". Концепция есть концепция. А реализация — реализация. Так что в СТЛ просто неудачная реализация очень правильной концепции.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, c-smile, Вы писали:
CS>Object next() возвращает элемент над которым "пролетает" итератор.
Не выдумывай. next() просто переходит к следующему элементу. При этом в начале итератор находится в состоянии перед первым элементом, а в конце на последнем. В СТЛ-но в начале он находится на первом, а в конце за последним. Только и всего. А разница в наличии hasNext.
CS>В Java не требуется специальное значение end CS>так как тест на bos/eos осущесвляется отдельной функцией (hasNext).
ЗХ>Другой вопрос — что нужна такая возможность далеко не всегда.
Это недостаток мышеления. Если подобное необходимо, то прост создашь функцию возвращающую частрый итератор и все. А то что ты показал — это использование итераторов не по назначению. Я бы сказал извращение самого понятия итератора, так как эффективная сотрировка требует произвольного доступа, а итератор принципиально предназначен для перебора по элементу.
Например, в дотнете для подобных целей введено понятие коллекции, что отражается в реализации интерфейса ICollectin. У этого интерфейса есть свойство Count и метод CoppyTo с помощью которых содержимое коллекции можно скопировать в массив и произвести над этим массивом опреации тербующие последовательного доступа.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, c-smile, Вы писали:
CS>Вот меня и инетересует это самое "а что-то другое": що ж це воно такэ, г`а? CS>Это примерно как приделать seekg с stream. Эх глянуть бы в глаз тому кто это придумал.
Потоки бывают разными. Бывают поледовательными, а бывают с произвольным доступом. Точно так же как списки. Бывают списки на связанных списках, а бывают на массивах.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, VladD2, Вы писали:
VD>Очень хорошо. но еще лучше:
VD>foreach (SomeType elem in SomeTypeCollentin)
VD> ....
VD>И луче хотя бы потому, что не нужно распознавать паттерн. Вместо этого можно просто оперировать понятием перечесления.
Это декларативное программирование. Я вижу здесь скрытую проблему. Перебор всех элементов в любом контейнере должен иметь сложность O(N). А из подобной записи это совсем не очевидно. Не превратиться ли этот foreach в O(N log N) или того хуже в O(N^2)? Скорее всего не превратится, но это неочевидно и создает дискомфорт. Точно так же, как оптимизатор скорее всего соптимизирует код, но никаких гарантий дать не может.
McSeem
Я жертва цепи несчастных случайностей. Как и все мы.
Здравствуйте, VladD2, Вы писали:
VD>Итераторы в Яве указывают точно так же на элемент. Только в отличии от СТЛ-я они стаоят на вымышленном (несуществующем) элементе не в конце, а в начале. Плюс в них есть понятие HasNext. Вот оно то и дает большее удобство и простоту. И вообще итераторы СТЛ слишком громоздки.
Для справки:
Unlike STL-style iterators, Java-style iterators point between items rather than directly at items. For this reason, they are either pointing to the very beginning of the container (before the first item), at the very end of the container (after the last item), or between two items.
Здравствуйте, VladD2, Вы писали:
MS>>Честно сказать, мне концепция итераторов вообще не нравится. VD>...
VD>Судя по поскипанному тебе не концепция (паттерн) "итератор" не нравится, а его убогая реализация в СТЛ. Вот в Яве как раз они и сделаны по человечески. Их нельзя гонять назад. Нельзя менять и т.п.
А в STL — не восходящая иерархия итераторов (от простейшего input/output до крутейшего random), а деградирующая иерерхия указателей (с постепенным наложением ограничений: дешёвая арифметика, дорогая арифметика, затем запрещение декрементов, и наконец, жёсткий протокол)
Здравствуйте, McSeem2, Вы писали:
MS>Здравствуйте, Шахтер, Вы писали:
Ш>> В stl есть несколько категорий итераторов. Наиболее важная и употребимая -- random access итераторы. Остальные категории получаются удалением некоторых способностей из RanIt.
MS>В том-то и дело, что идеологически, понятие random access iterator является само-противоречивым. Либо random access, либо итератор. По-моему, так.
Ну почему же. Это просто разные способы применения. Указатель, скажем, позволяет и итерировать, и произвольный доступ. Причем естественным образом.
MS>И это не демагогия. Из за стремления впихнуть все сущности в одно понятие, появляются все эти неуклюжие traits & policies, в то время, как сущности просто-напросто принадлежат к разным категориям.
Дело не в стремлении впихнуть все сущности в одно понятие, а в природе вещей. Голый указатель обладает набором определённых свойств -- вот эти свойства и были аксиоматизированы. Получился randon access iterator. Тебе же волновое уравнение не кажется неестественным?
MS>Зачем, скажем сортировке итераторы?
Не итератор, а randon access iterator. А иначе она становится неэффективной.
MS>Сортировке от контейнера требуется две вещи — аксессор и размер.
Сортировке вообще не нужен контейнер -- ей нужен интервал, причем, желательно, с произвольным доступом.
Я отношу фразу "random access iterator" к разряду хохм
типа "старый опытный камикадзе"
Итератор — это итератор. Random access это нечто абсолютно противоположное.
---------------------------
В D есть понятие slice:
char[] range = "Hello world";
foreach(char c; range) { writef("%c", c); }
range = range[0..5]; // slicing
foreach(char c; range) { writef("%c", c); } // та же самая операция но уже над slice
Т.е. с точки зрения D массив и диапазон это одно и то же.
Такие решения возможны по всей видимости только "под GC".
В принципе можно и на C++ что-то на эту тему придумать с подсчетом ссылок но
думаю коряво получится.
Здравствуйте, VladD2, Вы писали:
VD>Судя по поскипанному тебе не концепция (паттерн) "итератор" не нравится, а его убогая реализация в СТЛ.
Влад, тебе хотя бы знаком смысл слова "убогий"? Посмотри в толковом словаре, если что. Реализацию итераторов в STL можно назвать какой угодно, но только не убогой. Наоборот, она слишком наворочена. При этом пользоваться итераторами легко и просто. А вот написать правильный итератор — иногда застрелиться можно, сколько там всего надо учесть.
McSeem
Я жертва цепи несчастных случайностей. Как и все мы.
Здравствуйте, VladD2, Вы писали:
VD>Судя по поскипанному тебе не концепция (паттерн) "итератор" не нравится, а его убогая реализация в СТЛ. Вот в Яве как раз они и сделаны по человечески. Их нельзя гонять назад. Нельзя менять и т.п.
И чем же не устраивает возможность гонять назад и т.п.?
[]
Ш>> В stl есть несколько категорий итераторов. Наиболее важная и употребимая -- random access итераторы. Остальные категории получаются удалением некоторых способностей из RanIt.
MS>В том-то и дело, что идеологически, понятие random access iterator является само-противоречивым. Либо random access, либо итератор. По-моему, так. И это не демагогия. Из за стремления впихнуть все сущности в одно понятие, появляются все эти неуклюжие traits & policies, в то время, как сущности просто-напросто принадлежат к разным категориям. MS>Зачем, скажем сортировке итераторы? Сортировке от контейнера требуется две вещи — аксессор и размер. То есть, operator[] и size(). Все, больше ей ничего не надо. MS>
MS>sort(container);
MS>
MS>Если же надо отсортировать в диапазоне, делаем это через простейший-простейший адаптор: MS>
MS>sort(range(container, 10, 20));
MS>
Использование operator[] для range(range(...)) может не в лучшую сторону сказаться на производительности, в то время как с парой random итераторов такой проблемы нет. Да и forward iterator или его подобие все равно пришлось бы определять.
MS>При этом у нас автоматически запрещено сортировать списки. А в STL, для того, чтобы запретить сортировку списков, приходится городить дополнительный огород с полиси. Короче говоря, итераторы в STL и тем более в Boost — это пример ненужного усложнения, "типа круто".
Для итераторов более низкого уровня чем random просто не определены операторы + и -, так что списки запрещено сортировать и без огорода с полиси.
Здравствуйте, c-smile, Вы писали:
CS>Профессор, мое субъективное восприятие нижеприведенной фразы не позволяет мне объективно CS>(ака "канкретно") насладиться прелестью оной.
К>>Итераторы Java (а также энумераторы COM) — это обобщение идеи сканера файла: доступ к объекту приводит к смене состояния субъекта.
CS>Что в данной сентеции есть "объект", а что "субъект"?
Здравствуйте, Кодт, Вы писали:
К>А в STL — не восходящая иерархия итераторов (от простейшего input/output до крутейшего random), а деградирующая иерерхия указателей (с постепенным наложением ограничений: дешёвая арифметика, дорогая арифметика, затем запрещение декрементов, и наконец, жёсткий протокол)
Это мягко говоря не итератор. Итератор — это паттерн описанный в GoF. В яве тоже есть IList и т.п. Но к итераторам это отношения не имеет.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, McSeem2, Вы писали:
MS>Влад, тебе хотя бы знаком смысл слова "убогий"? Посмотри в толковом словаре, если что.
Ты бы сам залез и глянул, чем выпендриваться. Чтобы облегчить тебе жизнь скажу, что одно из значений "жалкий на вид, изувеченный".
MS> Реализацию итераторов в STL можно назвать какой угодно, но только не убогой. Наоборот, она слишком наворочена.
Хех. К итераторам "итераторы СТЛ" отношения не имеют. А так конечно. Потому и убогий, или если тебе будет угодно, уродливый.
MS>При этом пользоваться итераторами легко и просто. А вот написать правильный итератор — иногда застрелиться можно, сколько там всего надо учесть.
Ненадо. Им и пользоваться не очень удобно. Это довольно невнятное извращение. Явовские итераторы просты и логичны. В Шарпе вообще паттерн введн в язык. Его и реализовывать легко и использовать. Во втором шарпе итераторы вообще как орешки щелкаются (yield-ом).
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Костя Ещенко, Вы писали:
КЕ>И чем же не устраивает возможность гонять назад и т.п.?
Несоотвествованием сути паттерна. Про бритву Окама слышал?
Грамотное деление было бы следующим:
Итератор — перечисление.
Коллекция — возможность узнанать количество элементов и возможности получения их списка.
Список с произвольным доступом — произвольный доступ к элементам.
Причем каждая последующая абстракция должна поддерживать возможности предыдущей.
Именно так и сделно в дотнете (IEnumerable<T>, ICollection<T>, IList<T>). К сожалению тоже не очень грамотно. Так как в интерфейсы коллекции и списка введены методы модификации, а по мне так они должны размещаться в отдельных интерфейсах.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
VD>>foreach (SomeType elem in SomeTypeCollentin)
VD>> ....
MS>
VD>>И луче хотя бы потому, что не нужно распознавать паттерн. Вместо этого можно просто оперировать понятием перечесления.
MS>Это декларативное программирование.
Отнюдь. Это чистый императив. Декларативное это как-то так:
MS> Я вижу здесь скрытую проблему. Перебор всех элементов в любом контейнере должен иметь сложность O(N). А из подобной записи это совсем не очевидно.
1. Никто ничего никому не должен. Например, при переборе элементов дерева O(n) получить сложно (хотя в принципе можно, как например в BTree+).
2. Любой разумный разработчик стремится сделать свою реализацию итератора максимально эффектинвной. Так что в 99% случаев времянные характиристики действительно будут порядка O(n).
MS> Не превратиться ли этот foreach в O(N log N) или того хуже в O(N^2)? Скорее всего не превратится, но это неочевидно и создает дискомфорт. Точно так же, как оптимизатор скорее всего соптимизирует код, но никаких гарантий дать не может.
Этот дискомфорт из догм и привычки жить на уровне битов. Между тем все просто. Если общие характиристики участка код оказались не приемлемыми, то с помощью профайлера или ручных измерений можно очень быстро найти и устранить проблему. А не постоянно заморачиваться скоростью теря при этом (сильно теряя) скорость разработки.
Кстати, мой опыт показывает, что на самом перечислении скорость не теряется. Она теряется тогда когда вместо поиска со скоростными характеристиками типа O(1) или логарифмических использовались переборы. Вот на этом действительно можно любой алгоритм подвесить.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
VladD2 пишет: > VD>>foreach (SomeType elem in SomeTypeCollentin) > > VD>>И луче хотя бы потому, что не нужно распознавать паттерн. Вместо > этого можно просто оперировать понятием перечесления. > > MS>Это декларативное программирование. > > Отнюдь. Это чистый императив. Декларативное это как-то так: > > SomeTypeCollentin.ForEach(delegate(SomeType elem) { ... });
А разница в чем?
--
Andrei N.Sobchuck
JabberID: andreis@jabber.ru. ICQ UIN: 46466235.
Здравствуйте, c-smile, Вы писали:
CS>Для справки:
CS>
CS>Unlike STL-style iterators, Java-style iterators point between items rather than directly at items. For this reason, they are either pointing to the very beginning of the container (before the first item), at the very end of the container (after the last item), or between two items.
CS>Ссылка на источник в первоначальном сообщении.
Для спрвки, чтобы индусам объяснить казалось бы простые и очевидные вещи приходится придумывать вот такую белеберду. Но ты-то вроещ не индус? Тогда должен понимать, что целочисленный индекст не может быть между элементами.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Sinclair, Вы писали:
S>Здравствуйте, Кодт, Вы писали: К>>Однако, мешает. sort нуждается в итераторах произвольного доступа (с дешёвой арифметикой). Конечно, можно определить её через advance — но это будет очень дорого стоить. Вместо O(n*log(n)) получим что-то кубическое. S>А это смотря какой сорт. Если обратиться к Кнуту III, то можно найти штук десять всяких сортировок. И в основном они отличаются как раз требованиями к нижележащему интерфейсу. В частности, значительная доля отведена сортировке потоков.
Моя знать. Однако, std::sort — это быстрая сортировка.
Впрочем, возможно, что после некоторой доработки напильником алгоритм быстрой сортировки вполне подойдёт и для списка.
Тем более, что для списка есть возможность обмена элементов без глубокого копирования. Указатели перебросить, и всё.
VladD2 wrote:
> КЕ>И чем же не устраивает возможность гонять назад и т.п.? > > Несоотвествованием сути паттерна. Про бритву Окама слышал?
Слышал. Также слышал, что с острыми предметами следует обращаться осторожно — можно и порезаться
> Грамотное деление было бы следующим: > Итератор — перечисление. > Коллекция — возможность узнанать количество элементов и возможности получения их списка. > Список с произвольным доступом — произвольный доступ к элементам. > > Причем каждая последующая абстракция должна поддерживать возможности предыдущей.
Во-1х имо выделенное неверно. Ты понимаешь под итератором вообще лишь некий минимальный интерфейс итератора. Думаю возникнет меньше терминологических споров, если называть эту сущность энумератором. А итератор — более широкое понятие.
Во-2х имо логичнее такая иерархия: итератор потока — forward iterator — bidirectional iterator — random access iterator. При этом надо помнить что работать с файлами через итераторы потока не очень эффективно, да и не всегда удобно.
Не знаю, надо ли оно тебе, но на всякий случай расскажу как оно в STL.
Для итераторов потока определены определены операции ++, ==, != и разыменование, с их помощью нельзя организовать несколько обходов одного и того же потока, они могут использоваться только в однопроходных алгоритмах.
Forward итератор — то же самое, но возможно несколько проходов, пример контейнера — односвязный список.
Для bidirectional дополнительнительно определена операция --, пример контейнера — двусвязный список.
Random access iterator — по сути указатель, дополнительно определены операции +, -, <, >, [].
Итераторы более высокой категории поддерживают все операции более низких категорий.
Соответственно алгоритмы деляться на однопроходные и т.д.
Через неконстантые итераторы можно модифицировать элементы, но нельзя добавлять/удалять элементы. Это делается через методы контейнера. Иногда делается так — ссылка на контейнер инкапсулируется в итератор потока, вывод в который добавляет элементы в контейнер.
> Именно так и сделно в дотнете (IEnumerable<T>, ICollection<T>, IList<T>). К сожалению тоже не очень грамотно. Так как в интерфейсы коллекции и списка введены методы модификации, а по мне так они должны размещаться в отдельных интерфейсах.
В этом смысле подход STL грамотнее, но для организации итератора писанины надо немало, это мешает больше всего.
> это использование итераторов не по назначению. Я бы сказал извращение самого понятия итератора, так как эффективная сотрировка требует произвольного доступа, а итератор принципиально предназначен для перебора по элементу.
Неверно. Есть так называемые random access iterators, как следует из названия, поддерживающие произвольный доступ. И, вообще, видов итераторов много, хороших и разных.
> Например, в дотнете для подобных целей введено понятие коллекции, что отражается в реализации интерфейса ICollectin. У этого интерфейса есть свойство Count и метод CoppyTo с помощью которых содержимое коллекции можно скопировать в массив и произвести над этим массивом опреации тербующие последовательного доступа.
Наличие алгоритмов, работающих через итераторы, как раз позволяет избегать этих ненужных операций (копирование в массив и т.п.), если контейнер уже поддерживает произвольный доступ. Типичный пример — std::deque, для которого повторно, отдельно от std::vector, делать sort не нужно. Реализовывать сортировку для "своих" итераторов, поддерживающих произвольный доступ, тоже не надо, т.к. обобщенный алгоритм std::sort работает с любыми random access iterators.
Posted via RSDN NNTP Server 2.0 beta
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
c-smile,
> CS>> А что означает > CS>> container.begin() + 10 > CS>> для котейнера типа list?
> ЗХ> Для list — ничего не означает. Я всего лишь привел пример. Пойнт мой был: возможность вызова функции, которая принимает начальный и конечный итераторы, но передать ей не begin и end, а что-то другое; таким образом, обработать лишь часть контейнера.
> Вот меня и инетересует это самое "а что-то другое": що ж це воно такэ, г`а?
Например, передать в <container>.erase() результат функции std::remove(). Будет работать для std::vector, std::deque etc. Будет даже работать для std::list и slist, хотя для того же std::list, ессно, есть более эффективная std::list::remove().
> Это примерно как приделать seekg с stream. Эх глянуть бы в глаз тому кто это придумал.
Кста, в Бусте уже давно маются с разделением двух концепций, совмещенных в стандартных итераторах: обход и доступ к элементу.
Posted via RSDN NNTP Server 2.0 beta
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
Здравствуйте, c-smile, Вы писали:
CS>В D есть понятие slice:
.... CS>Т.е. с точки зрения D массив и диапазон это одно и то же. CS>Такие решения возможны по всей видимости только "под GC". CS>В принципе можно и на C++ что-то на эту тему придумать с подсчетом ссылок но CS>думаю коряво получится.
К слову сказать, я как раз вчера такое делал для своего контейнерообразного класса. Интересно, что в поисках удачного внешнего интерфейса наткнулся на механизм "срезов" (slice) у std::valarray. Как говаривал Кодт, "все украдено до нас"
Здравствуйте, VladD2, Вы писали:
MS>> Я вижу здесь скрытую проблему. Перебор всех элементов в любом контейнере должен иметь сложность O(N). А из подобной записи это совсем не очевидно.
VD>1. Никто ничего никому не должен. Например, при переборе элементов дерева O(n) получить сложно (хотя в принципе можно, как например в BTree+).
Э... в двоичном дереве это тоже O(n). Правда, каждый отдельный переход занимает от O(1) до O(log n)...
Кодт,
> S>А это смотря какой сорт. Если обратиться к Кнуту III, то можно найти штук десять всяких сортировок. И в основном они отличаются как раз требованиями к нижележащему интерфейсу. В частности, значительная доля отведена сортировке потоков.
> Моя знать. Однако, std::sort — это быстрая сортировка.
Не обязательно.
> Впрочем, возможно, что после некоторой доработки напильником алгоритм быстрой сортировки вполне подойдёт и для списка.
Что интересно, в новой Dinkumware std::sort применима к std::list. Естественно, с другими гарантиями сложности.
> Тем более, что для списка есть возможность обмена элементов без глубокого копирования. Указатели перебросить, и всё.
Для этого есть std::list::sort
Posted via RSDN NNTP Server 2.0 beta
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
Здравствуйте, Кодт, Вы писали:
К>В том-то и дело, что вот такая "аксиоматика" STL-итераторов с головой выдаёт в них указатели.
Это плохо?
К>Только строится иерархия не от меньшего к большему, а наоборот:
К>1) указатель на элементы некоего обобщённого массива — random access tranklukator, над которым определены К>- разыменование (очевидно) К>- эквивалентность К>- адресная арифметика К>2) указатель без адресной арифметики — bidirectional tranklukator К>- из всей арифметики оставлены только автоинкремент/автодекремент К>3) указатель с односторонним инкрементом — forward tranklukator К>- оставили только автоинкремент К>4) указатель, который совместим с протоколом чтения из последовательного устройства — input tranklukator К>- наложили ряд ограничений; использование вне протокола — undefined. К>5) указатель, который совместим с протоколом записи — output tranklukator К>- наложили другие ограничения
Здравствуйте, c-smile, Вы писали:
CS>Здравствуйте, Шахтер, Вы писали:
CS>Я отношу фразу "random access iterator" к разряду хохм CS>типа "старый опытный камикадзе"
CS>Итератор — это итератор. Random access это нечто абсолютно противоположное.
Я думаю, не противоположное, а ортогональное. Именно поэтому голый указатель обладает свойствами и итератора, и random access.
CS>--------------------------- CS>В D есть понятие slice:
CS>
CS>char[] range = "Hello world";
CS>foreach(char c; range) { writef("%c", c); }
CS>range = range[0..5]; // slicing
CS>foreach(char c; range) { writef("%c", c); } // та же самая операция но уже над slice
CS>
CS>Т.е. с точки зрения D массив и диапазон это одно и то же.
Просто в D диапазон удерживает массив, из которого он образовался.
CS>Такие решения возможны по всей видимости только "под GC". CS>В принципе можно и на C++ что-то на эту тему придумать с подсчетом ссылок но CS>думаю коряво получится.
Ну почему, сделать можно. Вопрос только -- нужно ли.
Здравствуйте, Павел Кузнецов, Вы писали:
ПК>Как от того, что мы бы переименовали текущие random access iterators в pointers, а текущие forward iterators в iterators изменился бы интерфейс шаблона std::sort(), если не принимать в учет названия параметров шаблона? ПК>
ПК>нельзя из-за того, что в других контейнерах, не в std::vector, итераторы (pardon my French) указателями быть не могут; например, std::deque.
Ну вообще-то, я имел в виду не T*, а некий std::deque<>::pointer, который отличается от T*. Но с этой точки зрения ты прав — дело лишь в названии. Pointer — тоже не вполне удачно, признаю. Наверное Степанов тоже не мог придумать лучшего названия и оставил так.
Что же касается семантики вызова sort, то она должна быть еще проще:
И у коллекции должно быть два метода — operator[] и size(). Сортировка в диапазоне реализуется с помощью простейшего адаптора, сортировка голого массива — с помощью другого простейшего адаптора.
Но! Здесь я сам поймался на собственном словоблудии
У std::map имеется вышеуказанный интерфейс. Вопрос — что случится, если мы дадим его функции сортировки?
В общем, со всех сторон засада...
ПК>В стандартной std::sort() никакие policies не нужны, т.к., перефразируя, ни с чем, кроме random access iterators она работать не умеет. (Предполагаемое) их наличие в реализации Dinkumware означает, что там в виде расширения решили реализовать std::sort() таким образом, чтоб она умела работать не только с random access iterators, но и с forward iterators.
Вот это уже плохо. Для списков требуется отдельные методы сортировки, с отдельными названиями. Ну не надо все валить в одну кучу — имеется опасность самовозгорания.
McSeem
Я жертва цепи несчастных случайностей. Как и все мы.
Здравствуйте, McSeem2, Вы писали:
MS>Ну вообще-то, я имел в виду не T*, а некий std::deque<>::pointer, который отличается от T*. Но с этой точки зрения ты прав — дело лишь в названии. Pointer — тоже не вполне удачно, признаю. Наверное Степанов тоже не мог придумать лучшего названия и оставил так.
Ну, а чего тут думать, вон Кодт уже предложил
Answer:
An iterator is a union of two theories. The first theory is a theory of name (handle, cookie, address). A name is something that points to something else. (operator*). We call it Trivial Iterator theory in our site. In addition to the dereferencing, it has equality defined that satisfies the following axiom:
i == j iff &*i == &*j
That is, two iterators are equal if and only if they point to the same object. (Equality, of course, needs to satisfy all the standard axioms.) The second theory is the theory of successor operation (++i) with its refinements: successor — predcessor (++ and --) and addition (++, --, + and -) with the standard axioms. And, of course, pointer is just a model of random access iterator.
... << RSDN@Home 1.1.4 beta 5 rev. 395>> {WinAmp: The Rasmus — In The Shadows}
Здравствуйте, Павел Кузнецов, Вы писали:
ПК>В STL — именно набор концепций. Просто что-то назвать недостаточно, чтобы это что-то стало концепцией. Нужно это что-то еще и точно специфицировать. Без привязки к конкретном описанию "итератор" концепцией не является, а является просто неоднозначным словом. А вот, скажем, ForwardIterator — одна из таких концепций. Реализации — соответственно, в конкретных реализациях STL.
Пашь, McSeem2 павильно сказал. Само название "итератор" подразумевает последовательный доступ (перебор). А итератор произвольного доступа — это глупость.
Как в прочем глупо использовать какие-то навороченные конструкции для произвольного доступа. Для этого достаточно одного оператора/метода и свойства/метода для того чтобы узнать длинну списка.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Костя Ещенко, Вы писали:
КЕ>Во-1х имо выделенное неверно. Ты понимаешь под итератором вообще лишь некий минимальный интерфейс итератора. Думаю возникнет меньше терминологических споров, если называть эту сущность энумератором. А итератор — более широкое понятие.
Итератор — это давно и хорошо известный паттерн проектирования. Называть его можно по разному суть от этого не меняется. А вот в С++ этот термин применен некорректно. Как впрочем и в C# 2.0. Там зачем-то итератором назвали реализацию того что в языке называется энумератором.
КЕ>Во-2х имо логичнее такая иерархия: итератор потока — forward iterator — bidirectional iterator — random access iterator.
Вот это и есть извращение. Ты iteration — это перебор, повторение и т.п. И само понятие перебора не допускает произвольный доступ.
Что да двунаправленных итераторов и т.п. тут не все так просто. Но можно точно сказать, что для самого паттерна и его применения это все не нужно.
КЕ> При этом надо помнить что работать с файлами через итераторы потока не очень эффективно, да и не всегда удобно.
Эффективность тут вообще не причем. И вообще она в основном определяется алгоритмами и их реализацией.
>> Именно так и сделно в дотнете (IEnumerable<T>, ICollection<T>, IList<T>). К сожалению тоже не очень грамотно. Так как в интерфейсы коллекции и списка введены методы модификации, а по мне так они должны размещаться в отдельных интерфейсах.
КЕ>В этом смысле подход STL грамотнее, но для организации итератора писанины надо немало, это мешает больше всего.
По мне так, СТЛ — это просто верх несуразности. По крайней мере с терминологией в этой библиотеке полный абзац.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Костя Ещенко, Вы писали:
КЕ>Здравствуйте, Кодт, Вы писали:
К>>В том-то и дело, что вот такая "аксиоматика" STL-итераторов с головой выдаёт в них указатели.
КЕ>Это плохо?
Естественно. Иначе давай называть телефон патефонном с возможностью разговора на растонянии.
Да и сама концепия довольно непонятна, громоздка и требует кучи лишних действий (неудобна).
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Павел Кузнецов, Вы писали:
ПК>VladD2,
>> КЕ>И чем же не устраивает возможность гонять назад и т.п.? >> >> Несоотвествованием сути паттерна. Про бритву Окама слышал?
ПК>Сути паттерна GoF Iterator (*) не соответствует то, что ты написал ниже:
А с чего ты взял, что что-то кроме самого итератора должно соотвествовать этому паттерну? Речь шла о том, что то что названо в СТЛ итератором нужно было бы разбить на несколько других понятий. Только и всего.
ПК>Итератор и коллекция — понятия разного порядка...
Очередное докапывание к совершенно посторонним словам. Причем тут итератор и коллекция? Кто-то называет коллекцию итератором?
ПК>: итераторы используются для доступа к коллекции,
Да.
ПК> и вводятся как раз для того, чтоб изолировать доступ к содержимому коллекции от конкретного типа коллекции.
Нет. Итератор обобщает процедуру перебора элементов. А вот создатель СТЛ просто не смог подобрать подходящую терминалогию.
ПК> Соответственно, ставить в один ряд итераторы и коллекции, и говорить о порядке абстракций в этом ряду совершенно бессмысленно.
Бессмысленно называть указатели или еще чего-то там итераторами. А создать иерархию абстракций повзволяющих оболбщенно работать с разничными списками очень даже осмысленно.
ПК> У "списка с произвольным доступом" (что само по себе оксюморон) в случае применения паттерна Iterator будут свои итераторы.
Да, Пашь, у тебя проблемы с терминологией не хуже чем у Степанова.
Как раз список с прозвольным доступом это более чем нормально. Видимо из-за передозировки С++.
In computer science, a list is an abstract concept denoting an ordered collection of fixed-length entities. In practice, any list is either an array or a linked list of some sort.
Список это абстракция. Массивы и коллекции предоставляющие эффективный произвольный доступ тоже являются частными случаями (реализациями) списка.
ПК>Пока что к итераторам (особенно к тем, что с произвольным доступом), насколько я вижу, есть одна претензия по существу — название.
Я бы сказал претензия к неверному использованию термина в СТЛ. Хотя конечно есть претензии и к самой сущности. По мне так не удачная идея. И громоздко, и неудобно.
ПК> Возможно, более удачным было бы использование термина Cursor, чтобы не смущать пользователей ассоциациями: "iterator -> перебор". Но, имхо, по отношению к самой концепции название уже вторично.
Курсор тоже не подходит для "итераторов с произвольным доступом". В этом вопросе я согласен с Кодтом. Логичнее всего было назвать это дело указателелем. Но был бы конфликт со встроенными в язык указателями.
>> Именно так и сделно в дотнете (IEnumerable<T>, ICollection<T>, IList<T>).
ПК>IEnumerable != iterator. Итераторам более-менее соответствует IEnumerator, только с той разницей, что в STL итераторы поддерживают большее количество возможностей.
Я так понял ссылка должна подчеркнуть мое незнание в данном вопросе? Ты лучше сам по ним сходи и почитай описание. Вот то что называется Aggregate и представленно интерфейсом IEnumerable в дотнете.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, McSeem2, Вы писали:
MS>Другое дело — сложившиеся традиции.
Точнее дурные традиции сложившиеся в некоторых кругах.
MS> Для простоты под понятием "список" подразумевается именно "linked list с последовательным доступом" и ничто другое.
Почему-то такое предположение больше делают С-шники. Я как-то не слышал, чтобы обычные люди или математики делали подобные предположения.
MS>Но это хорошая традиция, достойная уважения.
Да, точно. Вот в некоторых кругах есть такие хорошие традиции говорить "ложить" вместо "класть", или "шофера" вместо "шоферы". И это хорошо...
MS>Неуважение к традициям приводит к образованию каких-то совсем уж нелепых сущностей, типа ArrayList. Судя по названию (с учетом традиций) это должен быть связный список массивов, а не массив, в который добавлен IList.
Ненадо придумывать. Традиции о которых ты говоришь — это элементарная безграмотность. Формирование имени класса путем склиивания реализации и абстракции примененная в ArrayList тоже не замечательная идея, но в не хотя бы есть логика. По крайней мере по именам ArrayList и LinkedList можно четко понять какими особенностями обладают эти реализации списка. Наверно более верно было бы назвать эти классы как-то вроде ListImplementationOnArray. Но жить с тикими именами как-то не хочется. Во втором фрэймворке орлы из МС решили разывать реализации обобщенных коллекций путем отбрасывания "I" от имени базового интерфейса. Но это тоже не хороший выход, так как название становится мало гворящим. А сочетание List<T> и LinkedList<T> выглядит вообще странно.
Мне кажется логично было бы развать классы просто DinamicArray и LinkedList. А то что они реализуют некие обстракции проистикало бы просто из их сути. Для меня лично очевидно, что массив реализует интерфейс IList. Но видимо орлы из МС решили, что это может запутать новичков.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, alexeiz, Вы писали:
A>Почему-то ты не можешь понять различие в целях дизайна STL и библиотеки коллекций .NET.
Потому что дизайн базовых коллекций сделанный грамотно прекрасно решает и "задачи СТЛ". Весь смысль обобщений заключается в том, чтобы позволить работать с некоторым классом объектов полиморфно.
A> В STL первоочередной задачей стояло разделение коллекций и алгоритмов. Отсюда и вытекает дизайн STL-ных итераторов, который ты почему-то считаешь убогим. Тем не менее свою задачу STL итераторы выполняют прекрасно. Адгоритмы существуют отдельно, коллекции отдельно, а итераторы позволяют им взаимодействовать через loose coupling.
Слабая связанность и т.п. это уже отдельный вопрос. Здесь же обсуждается совершенно бездарная терминология СТЛ и довольно неудобное использование этих "итераторов".
A>В .NET цели были совершенно другие. Там итераторы (точнее энумераторы) создавались для того, чтобы можно было пробегать по коллекции от начала до конца в одном направлении желательно с применением foreach. Эта цель достигнута. Foreach работает превосходно. К сожалению не для чего другого энумераторы не подходят. Алгоритмы и коллекции жестко связаны.
А, ну, ясно. "Священную корову руками не трогать." Почитай GoF. Думаю тебя удивят некоторые вещи.
A> Но этого достаточно для большинства, которые кстати пришли на .NET c Java или с VB, где положение не лучше.
Я вот пришел с С++. И надо признать, и как-то не разделяют твоего мнения. Как впрочем и многие другие пришедшие с плюсов.
A>На лицо две разные цели и два разных дизайна.
Нет никаких разных целей. Есть желание притянуть что-нить за уши и крайняя предвзятость.
Мы отклонились от темы
К>>Моя знать. Однако, std::sort — это быстрая сортировка.
VD>Не совсем. Многие реализации гибридные. А в стандарте вообще алгоритм не указан.
Угу...
К>>Впрочем, возможно, что после некоторой доработки напильником алгоритм быстрой сортировки вполне подойдёт и для списка.
VD>Если только у напильника снять ручку и острием тыкать начать.
К>>Тем более, что для списка есть возможность обмена элементов без глубокого копирования. Указатели перебросить, и всё.
VD>1. Не у списка, а у связанного списка. VD>2. Не пройдет. Или ты скопируешь список в массив и далее применишь исходный алгоритм. Или на жаждом шаке рекурсии тебе прийдется создавать попию подсписка. Вот пример подобной организации на Шарпе:
Почему же? Зачем мне создавать подсписки?
Собственно быстрая сортировка не требует произвольного доступа.
Подсчёт длины интервалов [b,m), [m+1,e) — делается на стадии разбиения и не несёт дополнительных накладных расходов.
Да и известные мне оптимизации — разворот рекурсии, эффективные сортировки коротких массивов, выбор точки разделителя как средней между минимумом и максимумом — не нуждаются в адресной арифметике; вполне можно обойтись ++.
Другое дело, что для двусвязных списков есть более эффективные алгоритмы.
VladD2,
> при переборе элементов дерева O(n) получить сложно (хотя в принципе можно, как например в BTree+).
O(n) при переборе элементов любого дерева (если порядок обхода не важен) получается элементарно, если в качестве представления выбрать классический список смежности.
Posted via RSDN NNTP Server 2.0 beta
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
Здравствуйте, Кодт, Вы писали:
К>Почему же? Зачем мне создавать подсписки? К>Собственно быстрая сортировка не требует произвольного доступа.
Не батенька. Это у тебя очередной пример использования указателей. Да еще и с явными ошибками (хотя бы ++i два раза за проход вызваются). А все эти (m+1) и обновления значений в итераторах...
К тому же ты попробуй ради хохмы отлать это дело и сравни скорость с классической быстрой сортировкой.
К>Да и известные мне оптимизации — разворот рекурсии,
Это не оптимизация. Те времена прошли. Надеюсь на всегда.
К> эффективные сортировки коротких массивов,
Тоже бабка на двое сказала. Я как-то развлекался с этим делом. И основной выигрыш был в оптимизации и инлайнинге алгоритмов сравнения элементов. А все оптимизации для коротких списков ничего не давали. Тот же qsort из МС ЦРТ рапичкан подобными "оптимизациями". И что? Значительно проигрывает лобовой классике не использующей указателей на воид как средство абстрагирования.
К> выбор точки разделителя как средней между минимумом и максимумом — не нуждаются в адресной арифметике; вполне можно обойтись ++.
Да? И как ты себе это представляшь? Легкий перебор списка с целью вычисления его длинны и еще один ненавязчивый для поиска нужного значения? Или наш итератор все же позволяет произвольный доступ и предоставляет информацию о количестве элементов?
К>Другое дело, что для двусвязных списков есть более эффективные алгоритмы.
Ага. Причем самый эффективный копирование в массив. Ну, если конечно объемы позволяют коллекцию в память поднять. Иначе конечно мердж-сортировка является самым правильным выбором.
Кстати, о связанных саписках. Напдо признать, что с точки зрения скорости приложения они почему-то почти всегда проигрывают другим средствам. Не даром до второго фрэймворка МС даже не ввела такой примитив в состав коллекций. Да и с появлением этого дела как-то не тянет его писпользовать.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, VladD2, Вы писали:
К>>Почему же? Зачем мне создавать подсписки? К>>Собственно быстрая сортировка не требует произвольного доступа.
VD>Не батенька. Это у тебя очередной пример использования указателей. Да еще и с явными ошибками (хотя бы ++i два раза за проход вызваются). А все эти (m+1) и обновления значений в итераторах...
Да ладно тебе придираться... Ну если хочешь, iterator m1 = m; ++m1; — так лучше?
Кроме прочего, я просто не стал расписывать фокусы с перестановкой узлов списка (там нужно тщательно последить за граничными условиями).
VD>К тому же ты попробуй ради хохмы отлать это дело и сравни скорость с классической быстрой сортировкой.
И пробовать не буду — слишком много приколов есть в реализации быстрой сортировки. Кстати, "классическая" — это самая тупая, т.е. в каком виде она была изобретена. А дальше начинаются моддинги и тюнинги.
Опять же, я показал контрпример к утверждению "для алгоритма быстрой сортировки нужен произвольный доступ". Не нужен. Точка.
К>> выбор точки разделителя как средней между минимумом и максимумом — не нуждаются в адресной арифметике; вполне можно обойтись ++.
VD>Да? И как ты себе это представляшь? Легкий перебор списка с целью вычисления его длинны и еще один ненавязчивый для поиска нужного значения? Или наш итератор все же позволяет произвольный доступ и предоставляет информацию о количестве элементов?
А какая разница, если мне на стадии выбора медианы или при разбиении всё равно нужно пробежаться по всем элементам. Глубоко фиолетово, произвольный там доступ или последовательный. Заодно и пересчитаю.
Выигрыш может быть (и будет) только за счёт дешевизны последовательного доступа (инкремент индекса/указателя вместо косвенностей).
К>>Другое дело, что для двусвязных списков есть более эффективные алгоритмы.
VD>Ага. Причем самый эффективный копирование в массив. Ну, если конечно объемы позволяют коллекцию в память поднять. Иначе конечно мердж-сортировка является самым правильным выбором.
VD>Кстати, о связанных саписках. Напдо признать, что с точки зрения скорости приложения они почему-то почти всегда проигрывают другим средствам. Не даром до второго фрэймворка МС даже не ввела такой примитив в состав коллекций. Да и с появлением этого дела как-то не тянет его писпользовать.
Это ты, наверное, на C# крепко подсел. Конечно, если коллекция указателей, то перетасовать её как нефиг делать. А массивы структур (с глубоким копированием) идут лесом.
В С++, напомню, это далеко не всегда так.
P.S.
Только не говори мне, что заниматься сортировкой тяжеловесных структур — дурное занятие.
Разумеется, дурное. Нужно вводить индексную коллекцию и сортировать уже её.
Тем не менее, тем не менее...
Здравствуйте, Павел Кузнецов, Вы писали:
>> Я вот пришел с С++.
ПК>Ты не считаешься, т.к. STL не использовал.
Ясно. Не кошерный значичь.
Вообще-то использовал. Но мало. В основном как основу для КОМ-мовских колекций. Но большую часть времени откровенно говоря я особо о ней и не знал. (Видмо к лучшему. Так как это дело сильно портит треминологию и дает друные привычки.) Учил С++ я по Страупотровской книжке 1991-года выпуска. Тогда только-только о шаблонах речь зашла. А уж о бусте и метапрограммировании речь даже и не шала. Самый навороченный компилятор Зортечь и то тянул их очень слабенько. А МС в то время вообще С клепал.
ПК>
Какаяр разница почему что-то появилось? Тут утверждалось что дескать дотнетные коллекции не тем боком проектировались. Как видишь они не помешали создать все что нужно и в довольно приличном виде.
Алгоритмы СТЛ тоже были навеяны функциональными языками. В которых, кстати, они реализуются намного чище и красивее. Просто кто-то был больше знаком с плюсами. Ну, тебе это знакомо.
Кстати, функциональный подход во втором Шарпе реализуется довольно прозрачно. Что нельзя сказать о плюсах. Так что еще бабушка на двое сказала на чем алгоритмы будут выглядеть естественнее и проще. Хотя честно сказать, мне больше нравится идея засовывания алгоритмов в итераторы нежели чисто функциональный подход.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, VladD2, Вы писали:
КЕ>>Во-1х имо выделенное неверно. Ты понимаешь под итератором вообще лишь некий минимальный интерфейс итератора. Думаю возникнет меньше терминологических споров, если называть эту сущность энумератором. А итератор — более широкое понятие.
VD>Итератор — это давно и хорошо известный паттерн проектирования. Называть его можно по разному суть от этого не меняется. А вот в С++ этот термин применен некорректно.
Единственное отличие кроме имен методов — STL-итератор не несет в себе знание о конце последовательности, но может быть сравнен с другим итератором, отмечающим конец. Мне это кажется разумным.
VD>Как впрочем и в C# 2.0. Там зачем-то итератором назвали реализацию того что в языке называется энумератором.
КЕ>>Во-2х имо логичнее такая иерархия: итератор потока — forward iterator — bidirectional iterator — random access iterator.
VD>Вот это и есть извращение. Ты iteration — это перебор, повторение и т.п. И само понятие перебора не допускает произвольный доступ.
Если понимать iteration как перебор в неопределенном порядке, то да, произвольный доступ будет извращением понятия iteration. Но на практике порядок перебора настолько часто имеет значение, что произвольный доступ совсем не кажется извращением iteration.
VD>Что да двунаправленных итераторов и т.п. тут не все так просто. Но можно точно сказать, что для самого паттерна и его применения это все не нужно.
Ничего сложного тут нет. Да и в святых Паттернах двунаправленность указана как возможное расширение.
Здравствуйте, alexeiz, Вы писали:
A>А вот по терминологии у тебя задвиг, это точно. Внушил себе, что итераторы могут быть только одного типа. Не видишь, что набор задач, в которых могут быть применены итераторы, гораздо шире, чем простое перечисление. http://en.wikipedia.org/wiki/Iterator_pattern
In object-oriented programming, an iterator is an object allowing one to sequence through all of the elements or parts contained in some other object, typically a container or list. An iterator is sometimes called a cursor, especially within the context of a database.
P.S.
Демагогия идет лесом. Попробуйте сосредоточиться на обсуждении предмета, а не личности собеседника.
И что тогда "дык"?
>> Тут утверждалось что дескать дотнетные коллекции не тем боком проектировались.
ПК>Не это утверждалось, а то, что при проектировании итераторов STL и энумераторов .Net преследовались различные цели, соответственно, и результаты различны.
А ну, да в дотнете цель была использование в фориче. А в СТЛ виликие дальновидные цели.
ПК>В частности, одним из выводов было, что энумераторы .Net мало для чего пригодны, кроме как для последовательного перебора элементов коллекции.
Вот именно. Выполняют свою роль. Чистая и логичная реализация паттерна итератор. Использовать удобно. Нет гор грязного кода... Ясен пень этого не достаточно.
ПК>Мы все еще об итераторах/энумераторах? В Power Collections чаще используются сами коллекции, чем их энумераторы. Что как раз и подтверждает то, что энумераторы мало для чего подходят.
Ерунду то не лепи. Там IEnumerable<T> — это самое часто используемый интерфейс. А остальные появляются только по мере необходимости, когда решаемая задача требует не итератора, а, например, индесного доступа. Ну, глупо, к примеру, озвращать индекс для IEnumerable<T>.
>> Алгоритмы СТЛ тоже были навеяны функциональными языками. В которых, кстати, они реализуются намного чище и красивее. Просто кто-то был больше знаком с плюсами. Ну, тебе это знакомо.
ПК>Уф-ф-ф... Тебе бы все на личности переходить,
Тебе в очередной раз мерешится.
ПК> да авторов концепций как-нибудь "опускать, вместо того чтобы по существу аргументы приводить. Исключительно просвещения для: Степанов сначала реализовал библиотеку алгоритмов и структур данных на Схеме, затем на Аде, и уж потом — на C++.
Я вообще-то говорил об авторе этих "Power Collections". "кто-то" — это про него. А намек как раз был именно на Степанова, который черпал вдохновение в ФЯ. Так что надо быть менее подозрительным.
>> Кстати, функциональный подход во втором Шарпе реализуется довольно прозрачно. Что нельзя сказать о плюсах.
ПК>Благодаря поддержке лямбда-функций (aka "анонимные делегаты").
Да, им. Но не только. Сами делегаты тоже важны. Да и без параметризации типов все это было бы не очень эффектно. А так получилось очень неплохо. Еще бы нечто вроде кортежей, выода типов, паттерн-матчинга, встроенной работы с диапазонами и было бы совсе клево.
ПК> Если введут что-нибудь в таком духе в C++, будет и в C++ с этим все хорошо.
Согласен. Но следующий стандарт в 2008 вроде? И похоже в него так ничего хорошешо и не введут. А ведь всего то нужно признать ошибки и ввести ссылку на методы и возможность обявлять анонимные методы.
ПК> Так или иначе, чтобы была возможность писать алгоритмы обобщенно, без привязки к контейнеру, нужны некоторые абстракции, аналогичные итераторам STL.
Согласен. Но выглядеть они могли бы и по рпиличнее. Хотя... Мне вот идеи встраивания в язык фич проде конструкторов списков больше нравится. При их наличии многие алгоритмы пишутся на раз самостоятельно.
ПК> Можно их заменить на диапазоны, можно уточнить, разделяя индексацию и доступ к элементу и т.п. — суть от этого не меняется.
Их нужно четко структурировать для начала. И дать нормальные названия. А то "радном эксес итератор" — это уже смешно. Ну, и очень не мешало бы устранить неверотяно длинный код появлящийся при их использовании и упростить их реалализацию. Это любому языку не помешало бы.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
> In object-oriented programming, an iterator is an object allowing one to sequence through all of the elements or parts contained in some other object, typically a container or list. An iterator is sometimes called a cursor, especially within the context of a database.
Это всего лишь википедия. Предлагаю сойтись на том, что СТЛ-итераторы не вполне объектно-ориентированные.
Также в контексте соседнего спора о дотнетных терминах, интересно, что они различают контейнер и список.
Здравствуйте, Павел Кузнецов, Вы писали:
ПК>O(n) при переборе элементов любого дерева (если порядок обхода не важен) получается элементарно, если в качестве представления выбрать классический список смежности.
Я незнаю, что ты имешь в виду под "список смежности". Но в любом случае это дополнительные расширения.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Павел Кузнецов, Вы писали:
ПК>А в списке (связном)?
Нет. Но он не один.
ПК>c-smile в своем ответе выразился в некоторой степени иносказательно. Я спрошу конкретнее: ты уверен, что вопрос понял? Если Enum ходил вперед—назад, то почему значение, которое мы получали, одинаково на шаге 1 и 2? Значение индекса здесь, имхо, совершенно несущественно. Вопрос о том, на какой из элементов указывает энумератор в каждый из моментов времени.
Понял. Не уверен. Я как-то с prev не связывался. Но с точки зрения next там именно переход, скажем так, c -1 и далее.
Я, как ты понимашь, больше с дотнетом вожусь. А в нем вообще нет prev. И все ОК. В остальном подходы схожи.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, VladD2, Вы писали:
VD>Ну, то есть все же O(2 * n — 2). Я собственно об этом речь и вел.
Не понял, о чём ты вёл речь?
Ты сказал "переборе элементов дерева O(n) получить сложно (хотя в принципе можно...)".
Это значило, что "перебор дерева — как правило, больше O(n)" или, "как правило, меньше"? Или что-то совсем иное?
Я не представляю, как это может быть, чтобы перебор n элементов занимал меньше, чем O(n). Значит, больше.
Но это утверждение неверно: для многих реализаций деревьев перебор занимает гарантированно O(n). И алгоритмы там простейшие.
Здравствуйте, VladD2, Вы писали:
ПК>>O(n) при переборе элементов любого дерева (если порядок обхода не важен) получается элементарно, если в качестве представления выбрать классический список смежности.
VD>Я незнаю, что ты имешь в виду под "список смежности". Но в любом случае это дополнительные расширения.
Мы опять начали смешивать абстракции?
Если дерево как иерархическая структура (вложенные списки) — то за линейное время рекурсивно обходим.
Если дерево как граф — то опять линейное время.
Но для этого нам потребуется подходящая реализация этих абстракций.
Придумать заведомо хреновую реализацию — это мы завсегда успеем. А хорошие очевидны.
— для бинарного дерева — в каждом узле есть ссылки
— — вверх,вниз-влево,вниз-вправо (getParent, getLeft, getRight)
— для дерева произвольной арности
— — вверх,вниз,вправо (getParent, getFirstChild, getNextSibling)
Здравствуйте, Кодт, Вы писали:
К>Ты сказал "переборе элементов дерева O(n) получить сложно (хотя в принципе можно...)". К>Это значило, что "перебор дерева — как правило, больше O(n)" или, "как правило, меньше"? Или что-то совсем иное?
Больше естественно. Если нет оптимизаций, то приходится лазить вверх-вниз.
К>Я не представляю, как это может быть, чтобы перебор n элементов занимал меньше, чем O(n). Значит, больше. К>Но это утверждение неверно: для многих реализаций деревьев перебор занимает гарантированно O(n). И алгоритмы там простейшие.
Не для многих, а только для тех в которых где этого специально добивались. Самый быстрый вариант вообще сортированный массив.
И вообще, кроме скоростных характеристик еще есть время доступа. И для деревьев основанных на ссылках оно выше чем для массивов.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, VladD2, Вы писали:
VD>И вообще, кроме скоростных характеристик еще есть время доступа. И для деревьев основанных на ссылках оно выше чем для массивов.
Без вопросов!
Если мы как-либо реализуем дерево поверх массива — то проиграем в том, что деревянный порядок обхода может отличаться от обхода массива (получим соответственные промахи кэша; более сложную, чем инкременты, арифметику; и т.п.)
Останется вопрос, что нам важнее:
— скорость произвольного изменения структуры (сплошной массив проигрывает; либо мы попросту изобретаем аллокатор),
— скорость доступа с сохранением структуры (сплошной массив выигрывает)
— скорость обхода в фиксированном порядке (сплошной массив выигрывает)
— скорость обхода в другом порядке (как карта ляжет)
Здравствуйте, Кодт, Вы писали:
К>Если мы как-либо реализуем дерево поверх массива — то проиграем в том, что деревянный порядок обхода может отличаться от обхода массива (получим соответственные промахи кэша; более сложную, чем инкременты, арифметику; и т.п.)
Если делать все грамотно, то все будет с точностью до наоборот. А проиграм мы в модификации. Эмуляция деревьев на массиве всем хороша кроме того, что модификация приводит к необоходимости двигать память. А это приговор на на больших объемах.
К>Останется вопрос, что нам важнее: К>- скорость произвольного изменения структуры (сплошной массив проигрывает; либо мы попросту изобретаем аллокатор), К>- скорость доступа с сохранением структуры (сплошной массив выигрывает) К>- скорость обхода в фиксированном порядке (сплошной массив выигрывает) К>- скорость обхода в другом порядке (как карта ляжет)
+1
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Кодт, Вы писали:
... К>И это, как несложно заметить, ровно то же самое, что и next(), prev(). К>А уж стоит этот итератор "между" элементами или "на" элементе — в данном случае пофиг, как трактовать.
В общем, да.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, VladD2, Вы писали:
К>>Если мы как-либо реализуем дерево поверх массива — то проиграем в том, что деревянный порядок обхода может отличаться от обхода массива (получим соответственные промахи кэша; более сложную, чем инкременты, арифметику; и т.п.)
VD>Если делать все грамотно, то все будет с точностью до наоборот. А проиграм мы в модификации. Эмуляция деревьев на массиве всем хороша кроме того, что модификация приводит к необоходимости двигать память. А это приговор на на больших объемах.
От грамотности многое зависит Нужно определиться, какой юзкейс будет наиболее востребован, и заточить задачу под него.
Скажем, если нужен поперечный обход дерева — то наиболее удобна одна проекция на массив (соответствующая двоичному поиску — ну или k-ричному). Пример — сортированные деревья.
Если нужен обход в ширину — то удобнее пирамида (дети узла i имеют номера ki+1,ki+1,...ki+k). Пример — очередь с приоритетами.
Если нужна быстрая вставка с упорядочиванием — то массив может выступить в роли типизированной кучи.
В общем, вариантов море, и все они направлены на уменьшение коэффициента при O().
VladD2,
> ПК> O(n) при переборе элементов любого дерева (если порядок обхода не важен) получается элементарно, если в качестве представления выбрать классический список смежности.
> Я незнаю, что ты имешь в виду под "список смежности".
Это не расширения. Это один из нескольких классических вариантов представления графов. Просто замечательно подходит для представления деревьев. И совершенно автоматически дает время обхода всех вершин O(n).
Posted via RSDN NNTP Server 2.0 beta
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
Здравствуйте, VladD2, Вы писали:
КЕ>>Также в контексте соседнего спора о дотнетных терминах, интересно, что они различают контейнер и список.
VD>Это то как раз разумно. Такие контейнеры как ассоциативные массивы списками строго говоря не являются, но при этом они контейнеры.
Наверное было непонятно к чему я это сказал.
> In object-oriented programming, an iterator is an object allowing one to sequence through all of the elements or parts contained in some other object, typically a container or list.
Поскольку в цитате АВК сказано container or list, то ясно что речь идет о списке не как о контейнере. Никакой другой реализации спика-не-контейнера кроме связанного списка я не знаю. Так что в этой цитате из википедии термин list имеет значение linked list. Только и всего.
Hello, McSeem2!
You wrote on Sun, 24 Apr 2005 15:38:16 GMT:
M> Если же надо отсортировать в диапазоне, делаем это через M> простейший-простейший адаптор:
M> sort(range(container, 10, 20));
M>
M> При этом у нас автоматически запрещено сортировать списки. А в STL, для M> того, чтобы запретить сортировку списков, приходится городить M> дополнительный огород с полиси. Короче говоря, итераторы в STL и тем M> более в Boost — это пример ненужного усложнения, "типа круто".
Допустим, есть такая задачка:
в одном контейнере с произвольным доступом (далее — массиве) (А) лежат
строки, в другом массиве (B) — индексы строк, оба массива имеют N элементов.
Надо упорядочить массив A так, чтобы выполнялось B[A[i]] < B[A[j]] для любых
i < j, i > 0, j < N. Массивы большие — копировать их нельзя. С
STL-итераторами и std::sort задача решается , при наличии boost — решается
еще и легко, за счет iterator_facade. А вот с operator[] и size() выходит
закавыка — выясняется, что операции сравнения и модификации элемента —
совершенно разные вещи.
M> Вот что сказал Tony Juricic (один из активных пользователей моего M> mail-листа):
M> You won't get argument from me here. While I don't mean to say there are
M> not many very useful classes in BOOST, the sheer amount of dirt you have
M> to pull in, just to use it, is making BOOST less and less of a library I
M> would consider for doing anything.
M> It is IMO becoming a display of the failure of compilers and language
M> extensions, on the other extreme but in its practical nonsense
M> complementary to latest MS additions to 'managed C++'.
Ну, лишнего в бусте может и много, но вот полезного тоже не мало.
With best regards, Sergey.
Posted via RSDN NNTP Server 1.9
Одним из 33 полных кавалеров ордена "За заслуги перед Отечеством" является Геннадий Хазанов.
Здравствуйте, Павел Кузнецов, Вы писали:
ПК>Альтернативой, естественно, могут служить именованные операции set/get;
Или просто свойство.
ПК>Но в случае выделения аксессоров в отдельный класс появляется более тонкий контроль над тем, что можно делать клиенту: если ему вернули аксессор, то перемещаться по множеству объектов он уже не может, только получать/менять объект, который он получил. При этом, в отличие от возвращения ссылки, объект изначально существовать не обязан.
Но при этом заметно увеличится оверхед и усложнится структура кода.
AndrewVK,
> ПК> Но в случае выделения аксессоров в отдельный класс появляется более тонкий контроль над тем, что можно делать клиенту: если ему вернули аксессор, то перемещаться по множеству объектов он уже не может, только получать/менять объект, который он получил. При этом, в отличие от возвращения ссылки, объект изначально существовать не обязан.
> Но при этом заметно увеличится оверхед и усложнится структура кода.
Это почему? Такие вещи в том же C++ подставляются (inline) "на ура". Структура кода тоже не усложняется. Точнее, в подавляющем большинстве случаев клиентский код будет выглядеть в точности так же, как и в случае возврата прямой ссылки.
Возможный интерфейс аксессора:
template< class T >
class Accessor
{
public:
operator T&();
Accessor<T>& operator =(T const&);
T& operator*();
. . .
};
если все функции-члены Accessor<> inline, то за абстракцию мы (обычно) ничего не платим, если устройство Accessor<> простое, то компилятор в состоянии полностью элиминировать наличие подобного proxy. В случаях же, когда Accessor<> делает что-нибудь более сложное (скажем, продолжая прошлый пример, загрузка объекта из файла), собственно, для чего он и вводится, то на фоне этих операций издержки на создание промежуточного объекта будут ничтожными.
Код клиента остается таким же, как если бы *it возвращал бы ссылку на объект:
T obj = *it; // по-прежнему работает
T& obj = *it; // и это по-прежнему работает
*it = create_obj(); // по-прежнему работает, (потенциально) более эффективно,
// чем ранее, т.к. может избежать создания ненужного объекта
Есть одно место, где потенциально "сломается" код клиента — вызов шаблона функции с выводом аргумента шаблона по *it. В этом случае все легко "чинится" использованием функции Accessor<>::operator *, принудительно "разыменовывающей" accessor:
templ_function( **it );
Posted via RSDN NNTP Server 2.0 beta
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
Здравствуйте, Кодт, Вы писали:
К>Слушайте, я, кажется, просёк фишку — о чём спор идёт! К>Итак, next() и prev() — функции, меняющие состояние. Поэтому сравнивать их с неменяющей функцией (разыменование stl-итератора) — бестолково. К>А практика использования двунаправленных итераторов (в первую очередь — указателей на элементы массива) в движении — вот такая: К>
К>*p++; // прочесть/записать и перейти дальше
К>*--p; // отступить и прочесть/записать
К>
К>И это, как несложно заметить, ровно то же самое, что и next(), prev(). К>А уж стоит этот итератор "между" элементами или "на" элементе — в данном случае пофиг, как трактовать.
Вопрос был: Почему авторы QT (и не только они) считают что Java вариант исполнения итератора удобнее?
Здравствуйте, Sergey, Вы писали:
S>Допустим, есть такая задачка: S>в одном контейнере с произвольным доступом (далее — массиве) (А) лежат S>строки, в другом массиве (B) — индексы строк, оба массива имеют N элементов. S>Надо упорядочить массив A так, чтобы выполнялось B[A[i]] < B[A[j]] для любых S>i < j, i > 0, j < N. Массивы большие — копировать их нельзя. С S>STL-итераторами и std::sort задача решается , при наличии boost — решается S>еще и легко, за счет iterator_facade. А вот с operator[] и size() выходит S>закавыка — выясняется, что операции сравнения и модификации элемента — S>совершенно разные вещи.
Почему закавыка? Заводим фасад массива (ссылающийся на массив данных и массив индексов)...
Заодно, он будет выдавать правильные итераторы и правильные аксессоры.
> Надо упорядочить массив A так, чтобы выполнялось B[A[i]] < B[A[j]] для любых i < j, i > 0, j < N. Массивы большие — копировать их нельзя. С STL-итераторами и std::sort задача решается , при наличии boost — решается еще и легко, за счет iterator_facade. А вот с operator[] и size() выходит закавыка — выясняется, что операции сравнения и модификации элемента — совершенно разные вещи.
Тут не в итераторах дело, а в функции сравнения. Для поддержки данного use case достаточно изменить сигнатуру sort:
sort(A, my_comparer(B));
Posted via RSDN NNTP Server 2.0 beta
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
> Это плохая идея: получается, что Accessor имеет семантику указателя, а не только ссылки. > Лучше ввести дружественную функцию с "человеческим" именем, или метод <...>
Может быть, не знаю. В первоначальном варианте код выглядел так:
templ_function( get(*it) );
С другой стороны, использование разыменования подчеркивает дополнительную косвенность, вводимую акцессором.
Да и вообще, если исходить из минималистических соображений, то вообще никакие дополнительные operator* или get() не нужны, т.к. можно пользоваться явным преобразованием
templ_function( static_cast<T&>(*it) );
> Мне больше нравятся внешние функции
+1
> (Всё вышеперечисленное — это синтаксический сахар, соль и перец по вкусу).
+1
Posted via RSDN NNTP Server 2.0 beta
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
Здорово рассуждаешь! "Короче и яснее"... Просто есть функция (конструктор) рещающая задачу которая иначе решается императивно. Только и всего. Будь функция принимающая обычный итератор, то код был бы еще проше.
В дотнетной библиотеке наличие конструктора принимающего энумератор или другую структуру в порядке вещей. А так как почти все коллекции к ним приводятся, то код получается вообще минимальным.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Павел Кузнецов, Вы писали:
ПК>VladD2,
>> В дотнетной библиотеке наличие конструктора принимающего энумератор или другую структуру в порядке вещей. А так как почти все коллекции к ним приводятся, то код получается вообще минимальным.
ПК>Конструкторы ArrayList, Stack и Queue тоже принимают не IEnumerator, и даже не IEnumerable, а ICollection. HybridDictionary, ListDictionary, StringDictionary, NameValueCollection, вообще, не могут быть сконструированы ни из чего подобного
1. У вас немного не то представление об этих интерфейсов. Как IDictionary так и ICollection наследуется от IEnumerable. То есть, получение Enumeratora возможно.
2. К Владу. Возможность получения энумератора еще совсем не обозначает что это наиболее оптимальный путь. Для быстрого копирования нужно знать длину копируемых данных, что в случае стандартного IEnumerator невозможно. IEnumerator вполне может работать с потоками, за что им и спасибо. В то же время, в ICollection такая информация предоставляется.
ПК>В общем, среди контейнеров конструкторы, принимающие энумератор, не обнаружены... Ессно, это не означает, что такого конструктора не могло быть сделано, просто заставляет задуматься о роли, которую отводили энумераторам при проектировании.
ПК>При этом идиология энумераторов .Net от идиологии энумераторов Java очень далека, т.к. в энумераторах Java получение значения совмещено с переходом на следующий/предыдущий элемент, а в .Net эти операции разделены.
И это есть good.
Что касается получения объекта в энумераторе NET, то в этом случае очень удобно делать ленивое получение объекта. Это есть very good.
ПК>Вообще же, энумераторы .Net и итераторы Java, фактически, непригодны для сколько-нибудь сложных алгоритмов, т.к. их даже копировать нельзя.
Вообще-то, достаточно пригодны. Есть точка входа в виде получения енумератора. В данном случае, как раз и копируются все внутренние данные для егойной работы. И в частности, я по крайней мере практиковал вообще полное копирование коллекции (проблемы изменения коллекции во время работы итератора никто нигде не отменял).
С уважением, Gleb.
PS:Я балдею от STL и считаю их итераторы наиболее удобные для работы в C++. Только не надо из них делать панацею которая удобна во всех случаях. Такого никогда и никто не создавал.
Здравствуйте, GlebZ, Вы писали:
GZ>2. К Владу. Возможность получения энумератора еще совсем не обозначает что это наиболее оптимальный путь. Для быстрого копирования нужно знать длину копируемых данных, что в случае стандартного IEnumerator невозможно. IEnumerator вполне может работать с потоками, за что им и спасибо. В то же время, в ICollection такая информация предоставляется.
На самом деле все еще проще. Конструктор ArrayList с параметром примерно такой.
public ArrayList(ICollection col)
{
_internalBuffer = new object[col.Count];
col.CopyTo(_internalBuffer, 0);
}
Вот ради этого CopyTo туда и передается ICollection. И итераторы для этого не подходят. Любые, сколь угодно навороченные.
GZ>Что касается получения объекта в энумераторе NET, то в этом случае очень удобно делать ленивое получение объекта. Это есть very good.
Здравствуйте, Кодт, Вы писали:
К>А кто мешает сделать прокси-коллекцию? Которая умеет делать CopyTo из энумератора?
Никто. Мало того, я такое делал для копирования из потока в буфер. Но быстрее memmove может быть только Copy из Delphi.
Здравствуйте, Sinclair, Вы писали:
S>Здравствуйте, jazzer, Вы писали: J>>Ну так чего, кто-нибудь приведет код реализации итерации по подпоследовательности средствами итераторов java или .Net? S>Вопрос не понял. Что такое "подпоследовательность"?
Обычная подпоследовательность в математическом смысле. Часть последовательности. S>Промежуток промеж двух итераторов?
Например. Просто мне каким-то образом известно начало и конец подпоследовательности (в STL это итераторы, в .Net — пусть соответствующие гуру скажут), и я хочу с этой самой подпоследовательностью что-нть сделать. Например, развернуть ее. S>Не имеет смысла, т.к. в Java или .Net не принято использовать енумератор как указатель. S>Для них более естественно состряпать адаптер, который переберет весь нужный поддиапазон.
пример понятен: в C# все будет основываться на индексах в главной последовательности, и, соответственно, для итерации по подпоследовательности нужны эти два индекса и сама эта главная последовательность.
Sinclair,
> Для них более естественно состряпать адаптер, который переберет весь нужный поддиапазон. >
> public class MyArrayBasedCollection
> {
> public IEnumerable SubRange(int start, int end)
> {
> for(int i = start, i<end; i++)
> ...
>
> public static IEnumerable<T> Limit(IEnumerable<T> source, int limit)
> {
> int i;
> foreach(T t in source)
> {
> if (i++ > limit) return;
> ...
>
Такой подход либо требует контейнера с произвольным доступом, либо приводит к дополнительному проходу по элементам там, где в случае итераторов он не нужен.
Posted via RSDN NNTP Server 2.0 beta
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
GlebZ,
>>> В дотнетной библиотеке наличие конструктора принимающего энумератор или другую структуру в порядке вещей. А так как почти все коллекции к ним приводятся, то код получается вообще минимальным.
> ПК>Конструкторы ArrayList, Stack и Queue тоже принимают не IEnumerator, и даже не IEnumerable, а ICollection. HybridDictionary, ListDictionary, StringDictionary, NameValueCollection, вообще, не могут быть сконструированы ни из чего подобного
> 1. У вас немного не то представление об этих интерфейсов. Как IDictionary так и ICollection наследуется от IEnumerable. То есть, получение Enumeratora возможно.
Я знаю, что эти интерфейсы наследуются от IEnumerable. Вопрос как раз в том, что именно IEnumerable конструкторы контейнеров не принимают, что говорит о недостаточности возможностей IEnumerable/IEnumerator для этих целей.
> ПК>При этом идиология энумераторов .Net от идиологии энумераторов Java очень далека, т.к. в энумераторах Java получение значения совмещено с переходом на следующий/предыдущий элемент, а в .Net эти операции разделены.
> И это есть good.
Что именно?
> Что касается получения объекта в энумераторе NET, то в этом случае очень удобно делать ленивое получение объекта. Это есть very good.
Да, именно отсутствие такой возможности в итераторах Java мне и не понравилась.
> > ПК>Вообще же, энумераторы .Net и итераторы Java, фактически, непригодны для сколько-нибудь сложных алгоритмов, т.к. их даже копировать нельзя.
> Вообще-то, достаточно пригодны. Есть точка входа в виде получения енумератора. <...>
Для многих алгоритмов, более сложных, чем простой перебор, нужно создавать копии итераторов внутри функции, реализующей алгоритм.
> В данном случае, как раз и копируются все внутренние данные для егойной работы. И в частности, я по крайней мере практиковал вообще полное копирование коллекции (проблемы изменения коллекции во время работы итератора никто нигде не отменял).
Вопрос не о копировании контейнера, а о копировании итераторов/энумераторов.
> PS: Я балдею от STL и считаю их итераторы наиболее удобные для работы в C++. Только не надо из них делать панацею которая удобна во всех случаях.
Естественно. Речь шла о возможностях, которые предоставляют те или иные абстракции. Возможности энумераторов .Net и итераторов Java, на мой взгляд, очень сильно ограничены. Фактически, сводятся к перебору по контейнеру. О чем спор-то? Какие конкретно возможности, помимо последовательного перебора элементов, дают энумераторы .Net или итераторы Java? Какие алгоритмы можно/имеет смысл реализовать с их помощью? Даже для простого копирования элементов, как выяснилось, в контейнерах .Net предпочитают на них не рассчитывать
Posted via RSDN NNTP Server 2.0 beta
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
Здравствуйте, Павел Кузнецов, Вы писали:
ПК>VladD2,
>> В дотнетной библиотеке наличие конструктора принимающего энумератор или другую структуру в порядке вещей. А так как почти все коллекции к ним приводятся, то код получается вообще минимальным.
ПК>Например, у того же Hashtable конструктора, принимающего IEnumerator или IEnumerable, не обнаружилось.
И было бы странно если бы он был. Все же к списку хэш-таблица отношения не имеет.
ПК>Конструкторы ArrayList, Stack и Queue тоже принимают не IEnumerator, и даже не IEnumerable, а ICollection. HybridDictionary, ListDictionary, StringDictionary, NameValueCollection, вообще, не могут быть сконструированы ни из чего подобного
И мне кажется это разумным. Да, ICollection и ICollection<T> несколько более быстры при работе с массивами, но нет проблем написать примерно такой код:
public List(IEnumerable<T> collection)
{
ICollection<T> collection = collection as ICollection<T>;
if (collection != null)
{
int num1 = collection.Count;
_items = new T[num1];
collection1.CopyTo(_items, 0);
_size = num1;
}
else
{
_size = 0;
_items = new T[4];
using (IEnumerator<T> enumerator = collection.GetEnumerator())
while (enumerator.MoveNext())
Add(enumerator.Current);
}
}
Что с успехом и делается в новом фрэймворке. Почему до этого не доперли раньше я не знаю. Видимо ступили.
Для словарей (мапов) этого естественно нет, так как это не размумно (они же не списки).
ПК>При этом идиология энумераторов .Net от идиологии энумераторов Java очень далека, т.к. в энумераторах Java получение значения совмещено с переходом на следующий/предыдущий элемент, а в .Net эти операции разделены.
Для практических нужд это без разницы. Суть итератора от этого не меняется. В Яве нет свойст и дотнетный подход выглядил бы не очень естественно. В дотнете же это очень удобно.
ПК>Вообще же, энумераторы .Net и итераторы Java, фактически, непригодны для сколько-нибудь сложных алгоритмов, т.к. их даже копировать нельзя.
Очень обоснованное и серьезное мнение. Жаль, правда, что ничего с действительностью не имеет.
Что касается копирования, то IEnumerable — это фабрика итераторов. Так что копировать ничего и не нужно. Работа идет обычно именно с этим интерфейсом.
Ну, и не нужно забывать, что итераторы — это хотя и полезная, но не единственная концепция. Как я уже говорил, в дотнете для работы с коллекциями существует иерархия интефейсов и их запрос практически ничего не стоит. Если задачу эффективнее решить с помощью ICollection или IList, а не IEnumerable, то никто не мешает попытаться получить эти интерфейсы и если не получится решить проблему чуть менее эффективно.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Павел Кузнецов, Вы писали:
ПК>Я знаю, что эти интерфейсы наследуются от IEnumerable. Вопрос как раз в том, что именно IEnumerable конструкторы контейнеров не принимают, что говорит о недостаточности возможностей IEnumerable/IEnumerator для этих целей.
Они достаточны, но не оптимальны.
>> И это есть good. ПК>Что именно?
Словоблудие, имелось ввиду то что в следующем предложении. >> Что касается получения объекта в энумераторе NET, то в этом случае очень удобно делать ленивое получение объекта. Это есть very good.
ПК>Для многих алгоритмов, более сложных, чем простой перебор, нужно создавать копии итераторов внутри функции, реализующей алгоритм. ПК>Вопрос не о копировании контейнера, а о копировании итераторов/энумераторов.
Да, с этим нехорошо. Если говорить не о копирования энумераторов (поскольку в действительности их можно получить сколько угодно), а о копирования состояния энумератора в данный момент. Эту полезную функцию придется делать ручками. И она сама сильно зависит от реализации энумератора и его тенденции к ленивости. Поэтому, говорить о каком-то стандартном удовольствии здесь не приходится.
ПК>Естественно. Речь шла о возможностях, которые предоставляют те или иные абстракции. Возможности энумераторов .Net и итераторов Java, на мой взгляд, очень сильно ограничены. Фактически, сводятся к перебору по контейнеру. О чем спор-то? Какие конкретно возможности, помимо последовательного перебора элементов, дают энумераторы .Net или итераторы Java? Какие алгоритмы можно/имеет смысл реализовать с их помощью? Даже для простого копирования элементов, как выяснилось, в контейнерах .Net предпочитают на них не рассчитывать
1. Оптимальность, и еще раз оптимальность. Некоторое время назад, мне приходилось дописывать некоторую левую реализацию STL, чтобы вместо пообъектного копирования с помощью был alloc и memcopy памяти. На элементарных типах это очень даже хорошо прокатывает.
2. Энумераторы живут вместе с контейнером. Это будем говорить вынужденное свойство первой Net, поскольку у них нет шаблонов. Таким образом, получение нескольких разных энумераторов работает только через реализацию интерфейсов(к которому можно уже присобачить делегирование). И как не плюйся, полностью реализации, а ля STL не получится. Хотя если привязать энумератор к IList, то на здоровье. То можно его получать с внешней стороны. Но это не есть good. Так как есть пункт 3.
3. Стандартные энумераторы защищают энумератор от изменений в коллекции. То есть, если было изменение в коллекции, то на следующей итерации, получишь ошибку. Поскольку итераторы в stl внешние, то подобное (мне сходу так кажется) получить сложно. Если IEnumerator знает о коллекции с которой общается, то такая проблема решается на ура.
Так что есть где поработать (и судя по сообщению Влада поработали), и есть плюсы недоступные другим.
Здравствуйте, GlebZ, Вы писали:
GZ>2. К Владу. Возможность получения энумератора еще совсем не обозначает что это наиболее оптимальный путь. Для быстрого копирования нужно знать длину копируемых данных, что в случае стандартного IEnumerator невозможно. IEnumerator вполне может работать с потоками, за что им и спасибо. В то же время, в ICollection такая информация предоставляется.
Несомненно. Но это безграмотный путь, так как не универсальный. В прочем, я уже все сказал в ответе Паше
.
ПК>>Вообще же, энумераторы .Net и итераторы Java, фактически, непригодны для сколько-нибудь сложных алгоритмов, т.к. их даже копировать нельзя. GZ>Вообще-то, достаточно пригодны.
Ты не понял. Тут задача не установить истину, а обосновать ущербность. Сам факт ущербности как бы даже не обсуждается.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Кодт, Вы писали:
К>А кто мешает сделать прокси-коллекцию? Которая умеет делать CopyTo из энумератора?
Этого не нужно делать. Любой ICollection является наследником IEnumerable. Так что от любого класса реализующего ICollection можно его получить. Причем очень многие классы реализующие IEnumerable реализуют и ICollection. Так что универсальнее было бы просто пытаться привести полученный в качестве параметра IEnumerable к ICollection. В ArrayList этого не сделано (по глупости). Но во втором фрэймворке это сделано по полной программе. Именно о нем я и говорил. Я не знаю, что ПК полез в старье после обсуждения PowerCollections которые по определению на втором фрэймворке.
Здравствуйте, Павел Кузнецов, Вы писали:
ПК>Такой подход либо требует контейнера с произвольным доступом, либо приводит к дополнительному проходу по элементам там, где в случае итераторов он не нужен.
Это ежу понятно. Вот только с диапазонами обычно и работают когда контейнер обеспечивает (хотя бы внутненне) эффективный индексный доступ.
"Форвард итераторы" в СТЛ тут ничем не отличаются. А вместо "рандом эксесс" используюется IList или ICollection.
Вообще подходов море. В общем, yield и делегаты/интерфейсы решают любую проблему. Жаль, что их использование кое что стоит. Была бы оптимизациия этого дела вообще вопросов небыло бы. А пока в особо отвественных местах приходится возиться с массивами.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, VladD2, Вы писали:
>>> В дотнетной библиотеке наличие конструктора принимающего энумератор или другую структуру в порядке вещей. А так как почти все коллекции к ним приводятся, то код получается вообще минимальным.
ПК>>Например, у того же Hashtable конструктора, принимающего IEnumerator или IEnumerable, не обнаружилось. VD>И было бы странно если бы он был. Все же к списку хэш-таблица отношения не имеет.
Очень даже имеет. EntryDictionary никто не отменял. Как и нагрузку по хеширонию перехешированию всей этой гадости.
VD>Что с успехом и делается в новом фрэймворке. Почему до этого не доперли раньше я не знаю. Видимо ступили.
Ну да, а потом объяснять юзверям, что такое боксинг
ПК>>При этом идиология энумераторов .Net от идиологии энумераторов Java очень далека, т.к. в энумераторах Java получение значения совмещено с переходом на следующий/предыдущий элемент, а в .Net эти операции разделены. VD>Для практических нужд это без разницы. Суть итератора от этого не меняется. В Яве нет свойст и дотнетный подход выглядил бы не очень естественно. В дотнете же это очень удобно.
GetCurrentValue(). И вся ленивость готова.
ПК>>Вообще же, энумераторы .Net и итераторы Java, фактически, непригодны для сколько-нибудь сложных алгоритмов, т.к. их даже копировать нельзя. VD>Очень обоснованное и серьезное мнение. Жаль, правда, что ничего с действительностью не имеет. VD>Что касается копирования, то IEnumerable — это фабрика итераторов. Так что копировать ничего и не нужно. Работа идет обычно именно с этим интерфейсом.
Тут ПК прав. Он говорит о копирования состояния итераторов. С yield все становится более печально. Так что голову никто не отменял.
jazzer,
> Так вот никто не мешает встроить в итераторы аналогичную защиту. <...> Так что давай на этом закончим обсуждение безопасности и вернемся к содержательной части разговора.
Добавка. c-smile на самом деле прав в своем замечании. Если бы алгоритмы STL умели бы работать с диапазонами, подобных ошибок было бы меньше, чем при работе с итераторами. Все же контроль подобных ошибок во время компиляции приятнее, чем во время исполнения...
Posted via RSDN NNTP Server 2.0 beta
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
Здравствуйте, Павел Кузнецов, Вы писали:
ПК>С диапазонами и в (связных) списках работают, в которых произвольного доступа нет по определению. Например, см. splice — пример функции, часто использующейся с диапазонами.
В связанных списках диапазоном является конкретный узел и количество.
ПК>Другой пример работы с диапазонами, заданными с помощью forward iterators — std::search.
ПК>Отличаются принципиально: любой итератор задает позицию, в т.ч. forward iterator (*) позволяет задавать позицию в (связном) списке безо всяких индексов. Возможность скопировать итератор позволяет запомнить эту позицию для нужд алгоритма, и, если надо, вернуться к ней позднее за константное время. С энумераторами такой номер не пройдет: как, имея один энумератор, за константное время создать из него другой, с тем же состоянием?
Для юлозенья я предпочел бы индесированный доступ или методы выполняющие работу для тиапазон/возвращающие итератор диапазона. А химия с закладками приведет к сложному и запутанному коду.
>> yield и делегаты/интерфейсы решают любую проблему.
ПК>Если yield основан на все тех же некопирующихся энумераторах, которые не умеют обозначать позицию — вряд ли.
Ты просто смотришь не стой позиции. Просто логика по запоминанию и т.п. выносится из абстрактного итератора в класс имеющий на то право.
В обющем, концептуально другой подход рассчитанный на упрощение и стандартизацию абстракции. При этом всегда можно выбрать между IEnumerable, ICollection, IList в зависимости от требований предъявляемых к коллекции. Так LinkedList принципиально не будет реализовывать IList и ты не сможешь создать квадратичный алгоритм выбором не верной коллекции.
В итоге решаются точно такие же задачи, но при этом результат получается более простым в понимании и исключаются ошибки.
ПК>Например, как выразить через yield return и энумераторы с делегатами и интерфейсами ту же std::remove_if, с условием повторного использования аналога std::remove_copy_if? ПК>
Дык, элементарно . Сделать подобные операции методами конкретных контейнеров. Тогда они будут реализованы наиболее оптимально и нельзя будет, к примеру, применить операцию Remove к массиву не поддерживающему подобных операций.
Нельзя забывать о том, что в Шарпе интерфейсы вроде IList, ICollection, IEnumerable применимы так же и к таким встроенным типам как массивы. И семантика того же удаления будет совсем иным. Для массива — это будет создание его копии в котрой будут отсуствовать некоторые ячейки. А для List<T> логично будет удаление по месту.
Так что для List<T> будет добавлен метод вроде:
public int RemoveAll(Predicate<T> match)
А для обычного массива будет нечто вроде:
public static T[] FindAll<T>(T[] array, Predicate<T> match)
с инвертированным делегатом.
Да, я как бы слашал о теории, что это мовитон, но не разделяю ее. По мне так все должно быть просто, удобно и эффективно.
ПК>Еще одна задачка. std::map<>::lower_bound(key) возвращает итератор элемента, равного key, или же следующего, перед которым можно вставить key, так что порядок не нарушится.
Да уж. Само по себе понятие порядка для не древестного словаря (мапа) у меня вызывает улыбку.
ПК> std::map<>::insert() может принимать в качестве подсказки итератор, с которого начинать поиск позиции для вставки нового элемента. В случаях, когда нужно вставить элемент в std::map только в случае, если такого элемента там нет, это позволяет делать только один поиск, а не два (второй, если не передавать подсказку, будет осуществлен в insert)
Полезная возможность. Но я бы предпочел иметь методы типа TryGetValue и TryAddValue, а не мучиться с итераторами.
ПК>: ПК>
ПК>Map::iterator pos = m.lower_bound(key); // ищем элемент
ПК>if ( pos == m.end() || pos->first != key )
ПК>{
ПК> // такого элемента еще нет, добавляем
ПК> m.insert(pos, Map::value_type(key, value)); // поиска здесь уже не будет
ПК>}
ПК>else
ПК>{
ПК> // OK, такой элемент уже есть, делаем, что нужно для этого случая
ПК> // например, изменяем его как-нибудь
ПК> modify_existing_value(it->second, key, value);
ПК>}
ПК>
ПК> ПК>(*) В std::list используются bidirectional iterators, но это несущественно. Если это принципиально можно остановиться и на slist, у которого как раз forward iterators.
Вот реальный код из редактора кода который я сейчас пишу (вернее не пишу, так как мы тут тепимся ):
public static CombinedStyle Combine(Style style1, Style style2)
{
HashHelper hashHelper = new HashHelper(style1, style2);
CombinedStyle cachedStyle;
if (_styleCache.TryGetValue(hashHelper, out cachedStyle))
return cachedStyle;
CombinedStyle combinedStyle =
new CombinedStyle(hashHelper.HashCode, style1, style2);
_styleCache.Add(hashHelper, combinedStyle);
return combinedStyle;
}
Как видишь все тоже самое, только без лишних телодвижений.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Павел Кузнецов, Вы писали:
ПК>С диапазонами и в (связных) списках работают, в которых произвольного доступа нет по определению.
А в таком разе вариант, предложеный Синклером, оптимален.
ПК>Также у меня была библиотека для работы с деревьями, интерфейс которой был построен на итераторах. Там работа с диапазонами узлов тоже использовалась очень интенсивно, например, при использовании данного дерева в качестве основы для bounding volumes hierarchy — по мере построения такой иерархии очень удобно иметь возможность эффективно перемещать диапазон узлов в новую вершину, их объединяющую.
Да, для работы с деревьями действительно нужен более навороченный итератор (а точнее даже не итератор, а пара — итератор-навигатор). Что собственно в дотнете мы и видим на примере XPathNavigator-XPathNodeIterator. В базовых коллекциях дотнета этого нет, потому что там нет деревьев.
Здравствуйте, Павел Кузнецов, Вы писали:
ПК>Добавка. c-smile на самом деле прав в своем замечании. Если бы алгоритмы STL умели бы работать с диапазонами, подобных ошибок было бы меньше, чем при работе с итераторами. Все же контроль подобных ошибок во время компиляции приятнее, чем во время исполнения...
А как же юнит-тесты?
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, jazzer, Вы писали:
J>Представь, что у меня есть два предиката P1 и P2 и некий контейнер cont типа MyCont. J>И я хочу найти в этом контейнере элемент, удовлетворяющий P1, затем следующий где-то за ним Р2, а затем с выделенной таким образом подпоследовательностью произвести некое действие f.
J>На STL это записывается так: J>
J>Все. Это полный код. Если не нашлось элементов, удовлетворяющих Р1 и Р2 — просто ничего не произойдет, так что тут даже никакой дополнительной защиты не нужно.
VladD2 wrote:
> J>Представь, что у меня есть два предиката P1 и P2 и некий контейнер cont типа MyCont. > J>И я хочу найти в этом контейнере элемент, удовлетворяющий P1, затем следующий где-то за ним Р2, а затем с выделенной таким образом подпоследовательностью произвести некое действие f. > > J>На STL это записывается так: > J>
> J>Все. Это полный код. Если не нашлось элементов, удовлетворяющих Р1 и Р2 — просто ничего не произойдет, так что тут даже никакой дополнительной защиты не нужно. > > А если it1 окажется больше чем it2?
Не окажется
> Ну, да на шарпе это будет выглядить примерно так: >
Этот код делает совсем не то что запрашивал jazzer. Вот подумалась возможная интерпретация задания: модифицировать или вывести все элементы последовательности, находящиеся между первыми открывающим и закрывающим тегами (например < и >). Правда открывающий тег будет входить в диапазон, ну да фиг с этим.
А вообще интересно, в твоем коде будет создан промежуточный контейнер или он будет выполнен лениво?
Здравствуйте, vdimas, Вы писали:
V>Неправда. Суть паттерана итератор — получить доступ к элементам коллекции не зная структуры или интерфейса самой коллекции.
Не получить доступ, а переборать. Как по-твоему итератор переводится iterator?
Иначе указатели и массивы тоже будут итераторами.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Вот вариант на D.
Сканирование последовательности выполняется единожды.
Не требует создания объектов P1, P2 и f —
условия и действо записываются inline.
Можно управлять ситуацией — end condition входит или нет
bool found;
foreach( element e; MyCont )
{
if( !found || P1(e) ) found = true; else continue;
if( P2(e) ) break; // open-range case
f(); // your code is here
}
Какой из паттернов естественнее (find_if или foreach) — дело вкуса.
То же самое можно написать и с помощью стандартного stl::iterator
Как правило в реальной жизни P1, P2 и f нетривиальны.
Поэтому компактность J>MyCont::iterator it1 = std::find_if(cont.begin(), cont.end(), P1); J>MyCont::iterator it2 = std::find_if(it1, cont.end(), P2);
записи пропадает напрочь.
Я лично предпочитаю вариант без find_if. Но это опять же
субъективно.
CS>>Какой из паттернов естественнее (find_if или foreach) — дело вкуса...
ЗХ>В пользу STL-ного варианта могу сказать, что это явная запись намерений. Он читается с той же скоростью, что и описание задачи на natural language. ЗХ>В твой вариант все-таки приходится вдумываться — зачем там found и в каких случаях выполнение все-таки дойдет до f().
ЗХ>То есть по изяществу и выразительности тут все-таки рулит STL
На самом D я бы для своего контейнера написал так:
Здравствуйте, Sinclair, Вы писали:
S>Здравствуйте, jazzer, Вы писали: J>>Например. Просто мне каким-то образом известно начало и конец подпоследовательности (в STL это итераторы, в .Net — пусть соответствующие гуру скажут), и я хочу с этой самой подпоследовательностью что-нть сделать. Например, развернуть ее. S>Ключевой момент — "каким-то образом". Где ты возьмешь этот "конец подпоследовательности"? J>>пример понятен: в C# все будет основываться на индексах в главной последовательности, и, соответственно, для итерации по подпоследовательности нужны эти два индекса и сама эта главная последовательность. S>Нет. Я просто привел пример "какого-то образа" получения того самого итератора, спозиционированного хрен знает куда. Итератор "конца последовательности" в .Net не нужен. Какие еще есть полезные способы? Пример с индексами я привел. Приведи другие примеры — и ты убедишься, что есть способ выразить их в терминах .Net. S>Не надо пытаться слепо переносить технические приемы из одной среды в другую. В каждом языке — свой способ решить некоторую задачу.
Sinclair,
> Итак, давайте представим себе, как будет решена эта задача на С#2.0. <...> >
> /// Выводит ту часть последовательности input, которая не удовлетворяет критерию limit:
> public static IEnumerable<T> Limit(IEnumerable<T> input, Predicate<T> limit)
> {
> foreach(T t in input)
> if (limit(t)) return;
> else yield return t;
> }
>
> /// выводит элементы последовательности input начиная с того, который удовлетворяет start.
> public static IEnumerable<T> After(IEnumerable<T> input, Predicate<T> start)
> {
> bool found = false;
> foreach(T t in input)
> {
> found |= start(t);
> if(found)
> yield return t;
> }
> }
> /// Собственно, код задачи.
> public static ApplyWithinLimits(IEnumerable input, Action<T> action, Predicate<T> startAt, Predicate<T> stopAt)
> {
> foreach(T t in Limit(After(input, startAt), stopAt))
> action(t);
> }
>
Спасибо! Два вопроса.
1) Такая связка Limit и After обеспечивает то, что элементы последовательности, идущие после stopAt, перебираться в итоге вообще не будут?
2) А если нам понадобится в Apply изменить порядок обхода найденной подпоследовательности, скажем, на обратный, какие из функций нужно будет переписать? Подозреваю, что все... В случае STL нужно будет только добавить пару вызовов для создания reverse_iterator, ничего из использованных алгоритмов (find_if, for_each) не переписывая.
Posted via RSDN NNTP Server 2.0 beta
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
Здравствуйте, Павел Кузнецов, Вы писали:
ПК>1) Такая связка Limit и After обеспечивает то, что элементы последовательности, идущие после stopAt, перебираться в итоге вообще не будут?
Нет, не будут. В комменте, ИМХО, ошибка, видимо должно быть как-то так:
>> /// Выводит элементы последовательности input до тех пор, пока соблюдается критерий limit:
>> public static IEnumerable<T> Limit(IEnumerable<T> input, Predicate<T> limit)
ПК>2) А если нам понадобится в Apply изменить порядок обхода найденной подпоследовательности, скажем, на обратный, какие из функций нужно будет переписать? Подозреваю, что все... В случае STL нужно будет только добавить пару вызовов для создания reverse_iterator, ничего из использованных алгоритмов (find_if, for_each) не переписывая.
В ApplyWithinLimits надо передавать уже IEnumerable, обходящий последовательность в обратном порядке. Менять же Limit и After не придётся.
Help will always be given at Hogwarts to those who ask for it.
_FRED_,
> ПК> если нам понадобится в Apply изменить порядок обхода найденной подпоследовательности, скажем, на обратный, какие из функций нужно будет переписать? Подозреваю, что все... В случае STL нужно будет только добавить пару вызовов для создания reverse_iterator, ничего из использованных алгоритмов (find_if, for_each) не переписывая. > > В ApplyWithinLimits надо передавать уже IEnumerable, обходящий последовательность в обратном порядке. Менять же Limit и After не придётся.
Нужно, чтоб начало и конец подпоследовательности искались в порядке прямого обхода, а элементы самой подпоследовательности уже обходились в обратном порядке. В предложенном же варианте и подпоследовательность будет выделяться в порядке обратного обхода.
Posted via RSDN NNTP Server 2.0 beta
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
Здравствуйте, Павел Кузнецов, Вы писали:
>> ПК>Такой подход либо требует контейнера с произвольным доступом, либо приводит к дополнительному проходу по элементам там, где в случае итераторов он не нужен.
ПК>В плюсах (точнее, не в плюсах, а если итератор представляет собой позицию)
Т.е. это контейнер с произвольным доступом ПК>будут только необходимые проходы. Если вместо итераторов вводятся числа, обозначающие порядковый номер элемента, как это было в примере выше, то в общем случае проходов будет больше: первый, чтоб найти элемент, и потом еще по проходу каждый раз, когда данный элемент нужен еще раз, т.к. по индексу без произвольного доступа элемент можно получить только перечислением.
то есть дополнительный проход.
Можно еще раз объяснить, где "такой подход приводит к дополнительному проходу там, где он не нужен"?
... << RSDN@Home 1.1.4 beta 5 rev. 395>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Павел Кузнецов, Вы писали: >> ПК> если нам понадобится в Apply изменить порядок обхода найденной подпоследовательности, скажем, на обратный, какие из функций нужно будет переписать? Подозреваю, что все... В случае STL нужно будет только добавить пару вызовов для создания reverse_iterator, ничего из использованных алгоритмов (find_if, for_each) не переписывая. >> В ApplyWithinLimits надо передавать уже IEnumerable, обходящий последовательность в обратном порядке. Менять же Limit и After не придётся. ПК>Нужно, чтоб начало и конец подпоследовательности искались в порядке прямого обхода, а элементы самой подпоследовательности уже обходились в обратном порядке. В предложенном же варианте и подпоследовательность будет выделяться в порядке обратного обхода.
Да, именно так и будет, я не совсем понял вопрос. Рискну предположить, что без потери "лености" итераторов в обратном порядке результат их работы не обойти
Help will always be given at Hogwarts to those who ask for it.
Здравствуйте, _FRED_, Вы писали:
_FR>Да, именно так и будет, я не совсем понял вопрос. Рискну предположить, что без потери "лености" итераторов в обратном порядке результат их работы не обойти
Рискну предположить, что с помощью делегатов можно управлять также алгоритмом прохода.
И вообще. Тут две задачи. Первая задача — задача поиска. Вторая задача — задача обхода. По одному юзерских делегата(али интерфейса) на каждую задачу, и универсальный алгоритм и энумератор готов.
Здравствуйте, Sinclair, Вы писали:
S>Здравствуйте, Serginio1, Вы писали: S>> Наример бдшные двухнаправленные курсоры больше подходят, для большинства задач, S>Шутку понял. Смешно.
Я имел ввиду правила навигации. Next,Prior,CurrentRecord, GetRecordForKey,SetRange, фильтрация, итд. Причем индексы не всегда и нужны, но с ними оно кошерней.
... << RSDN@Home 1.1.4 beta 4 rev. 303>>
и солнце б утром не вставало, когда бы не было меня
Здравствуйте, Sinclair, Вы писали:
S>Здравствуйте, Serginio1, Вы писали: S>> Я имел ввиду правила навигации. Next,Prior,CurrentRecord, GetRecordForKey,SetRange, фильтрация, итд. Причем индексы не всегда и нужны, но с ними оно кошерней. S>Угу. А еще полезно в кармане носить подкову. Не всегда нужна, но с ней кошерней.
Ну да, зато при имплементации интефейсов в разных классах полно NotSupported или прикручивание кастрированных итераторов к тому, где нужно деторождение. Для форича может и конулингуса и хватит, а другим хочется и полноценного секса.
... << RSDN@Home 1.1.4 beta 4 rev. 303>>
и солнце б утром не вставало, когда бы не было меня
Здравствуйте, Sinclair, Вы писали:
S>Здравствуйте, Serginio1, Вы писали: S>> Ну да, зато при имплементации интефейсов в разных классах полно NotSupported или прикручивание кастрированных итераторов к тому, где нужно деторождение. Для форича может и конулингуса и хватит, а другим хочется и полноценного секса. S>Ну, это уж да. Если секс — то непременно полноценный. Давайте на всякий случай доопределим на примитивном односвязном списке суперинтерфейс курсора с тридцатью двумя методами. В шестнадцати насладимся сексом с реализацией Prev с учетом SetRange и фильтрации, а остальные шестнадцать будут возвращать NotSupported. Чтобы и пользователь нашего курсора тоже вкусил полноценного секса. С всенепременным деторождением.
Ну это уж слишком, камасутра тоже вредна. Суть в том, что для определенного круга задач существующих в нет энумераторов недостаточно.
И при этом, нарастить функциональность уже существующих классов где такая функциональность нужна, но не реализована и не представляется возможным, но есть огромное желание, а обходить окольными путями не всегда кошерно, а иногда и вредно. Все зависит от задачи.
Вот и приходится заниматься изобретением велосипеда.
... << RSDN@Home 1.1.4 beta 4 rev. 303>>
и солнце б утром не вставало, когда бы не было меня
S>> Вот и приходится заниматься изобретением велосипеда. S>Гм. Божий дар с яичницей... опасная смесь. Что нужно сделать: ввести дополнительные интерфейсы. Отнаследоваться от стандартной коллекции и реализовать эти дополнительные интерфейсы. Совершенно необязательно вручную высверливать трубы для велосипедной рамы из цельной чугунной болванки.
Легче его самому написать свою реализацию и при этом затратить меньше труда, чем делать хэлпер (врапер он же посредник) через одно место, а иногда и невозможно из-за невозможности доступа к приватным методам и полям. (Делфевые хэлперы кстати форева)
Нужны разные итераторы при этом стандартизированные и применение их по месту.
... << RSDN@Home 1.1.4 beta 4 rev. 303>>
и солнце б утром не вставало, когда бы не было меня
GlebZ,
> _FR> Да, именно так и будет, я не совсем понял вопрос. Рискну предположить, что без потери "лености" итераторов в обратном порядке результат их работы не обойти
> Рискну предположить, что с помощью делегатов можно управлять также алгоритмом прохода. > И вообще. Тут две задачи. Первая задача — задача поиска. Вторая задача — задача обхода. По одному юзерских делегата(али интерфейса) на каждую задачу, и универсальный алгоритм и энумератор готов.
Вряд ли так получится сделать. По крайней мере, не через IEnumerable/IEnumerator, т.к. он принципиально не способен перебирать в обратном порядке. Соответственно, получив "прямой" энумератор, сделать из него обратный не выйдет. Впрочем, с удовольствием гляну на код, использующий энумераторы .Net (возможно с привлечением yield return etc.), и делающий описанное (поиск нижней и верхней границы по предикатам с последующим обходом выделенной подпоследовательности в обратном порядке).
Posted via RSDN NNTP Server 2.0 beta
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
Здравствуйте, vdimas, Вы писали:
V>ok, перебрать. V>И где ограничение на способ или направление перебора?
В смысле патерна. Полностью его описание звучит так:
Перебрать элементы некоторого списка (контейнера, коллекции) абстрагируясь от его внутренней реализации.
Т.е. за направление, последовательность и т.п. отвечает итератор. В этом и есть суть паттерна. Прямой доступ — это уже точно не итетатор.
V>В описании этого паттерна в GoF такие вещи не уточняются
Плохо читал. Там даже реализация привдена. Причем почти полная копия Шарповских итераторов.
V>, да и не должны, ибо они не требуются для описания сути паттерна. Однако нигде и не говорится об ограничениях. С чего это тебе захотелось заняться ограничением имплементации паттернов — непонятно.
Здравствуйте, Павел Кузнецов, Вы писали:
ПК>Вряд ли так получится сделать. По крайней мере, не через IEnumerable/IEnumerator, т.к. он принципиально не способен перебирать в обратном порядке.
Ни однин последовательный алгоритм принципиально не может перебирать ничего в обратном порядке без копирования в промежуточный массив.
У тебя опять забавный подход. Ты пыташся сравнивать нечто с прямым доступом и итератор.
ПК> Соответственно, получив "прямой" энумератор, сделать из него обратный не выйдет.
Как в прочем и в СТЛ. Хотя как раз в дотнете можно оптимизировать подобные вещи. Примерно так:
using System;
using System.Collections.Generic;
class Program
{
static void Main(string[] args)
{
Print(Revers(new int[] { 1, 2, 4, 5, 7, 12, 26 }));
Print(Revers(Generator(10)));
}
static IEnumerable<int> Generator(int end)
{
for (int i = 0; i <= end; i++)
yield return i;
}
static void Print<T>(IEnumerable<T> iter)
{
foreach (T value in iter)
Console.Write(value + " ");
Console.WriteLine();
}
static IEnumerable<T> Revers<T>(IEnumerable<T> iter)
{
IList<T> list = iter as IList<T>;
if (list != null)
{
for (int i = list.Count - 1; i >= 0; i--)
yield return list[i];
}
else
{
ICollection<T> collection = iter as ICollection<T>;
if (collection != null)
{
T[] array = new T[collection.Count];
collection.CopyTo(array, 0);
for (int i = array.Length; i >= 0; i--)
yield return array[i];
}
else
{
Stack<T> stack = new Stack<T>();
foreach (T value in iter)
stack.Push(value);
foreach (T value in stack)
yield return value;
}
}
}
}
ПК> Впрочем, с удовольствием гляну на код, использующий энумераторы .Net (возможно с привлечением yield return etc.), и делающий описанное (поиск нижней и верхней границы по предикатам с последующим обходом выделенной подпоследовательности в обратном порядке).
Ну, вот всунь приведенный выше преобразователь и на конечных последовательностях будет работать как часы.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, jazzer, Вы писали: J>К слову, а С#2.0 — это уже в широком использовании, или только планы?
В постепенно расширяющемся. J>И как бы решение выглядело на первом шарпе?
Гораздо менее лаконично. J>Спасибо, в общих чертах понятно. Не могу сказать, правда, что получившийся код обладает высокой читабельностью, и сам по себе, и тем более по сравнению с кодом на STL, который, как кто-то сказал выше, представляет собой явную декларацию намерений Но все более-менее лаконично. Остальные комментарии ниже.
J>Так чего ж тогда ругают С++ за то, что у него не все есть в стандартной библиотеке?
Ну, я не знаю, кто его ругает. Но вообще это справедливо. Такие велосипеды желательно иметь в стандартной библиотеке, иначе возрастает риск иметь десяток плохо совместимых реализаций. J>Вот представь, что у тебя последовательность уже отсортирована по одному из предикатов.
С учетом того, что предикат — это функция, возвращающая bool, мне довольно сложно представить такую последовательность Ну ладно, предположим, что ты имел в виду последовательность, отсортированную по композитному ключу из атрибутов. J>Тогда ты можешь строчку с find_if, соответствую этому предикату, заменить на std::lower_bound, тем самым увеличив производительность, поскольку сложность бинарного поиска меньше сложности последовательного перебора.
А вот тут ты неявно предположил наличие произвольного доступа к контейнеру. Ведь так? Двоичный поиск в односвязном списке будет не намного эффективнее перебора. J>Причем, заметь, СТЛ пофиг, собираешься ли ты искать во всем контейнере или толкьо в подпоследовательности, выделенной двумя итераторами. J>Опять же, если ты потом решил не просто проходить по найденной подпоследовательности, а сделать с ней еще что-нть к с целым, скажем, имеющим логарифмическую сложность, то полная сложность у тебя окажется логарифмической...
Опять же, никаких гарантий асимптотики у тебя нет. J>Поскольку я уже поблагодарил за ответ, мне теперь просто интересно, как такие изменения условий могут быть отражены на шарпе.
А очень просто. Вот, например, наш контейнер — Array. Для него определено семейство методов Array.BinarySearch(). Существует также ArrayList.BinarySearch. J>Потому что на STL это — тривиальная замена одного алгоритма на другой.
Тут, увы, все не так просто.
... << RSDN@Home 1.1.4 beta 5 rev. 395>>
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Павел Кузнецов, Вы писали:
ПК>Вряд ли так получится сделать. По крайней мере, не через IEnumerable/IEnumerator, т.к. он принципиально не способен перебирать в обратном порядке. Соответственно, получив "прямой" энумератор, сделать из него обратный не выйдет. Впрочем, с удовольствием гляну на код, использующий энумераторы .Net (возможно с привлечением yield return etc.), и делающий описанное (поиск нижней и верхней границы по предикатам с последующим обходом выделенной подпоследовательности в обратном порядке).
ну чтож. Представляею универсальный enumerator/ Сделаем без всякого синтаксического сахара типа yield return, чтобы даже на 1.1 работало. Возможно где-то ошибки, и можно сильно улучшить, пишу сходу. Использую не объекты, а делегаты (хотя здесь интерфейсы более подошли бы).
class UniversalEnumerator:IEnumerator, IEnumerable
{
public delegate object NextPosition(ref int position, IList collection);
public delegate bool Predicate(object testValue, int position);
private NextPosition _nextPosition;
private Predicate _predicate;
private IList _collection;
private int _position;
private object _current;
public UniversalEnumerator(IList collection, NextPosition nextPosition, Predicate predicate)
{
_nextPosition=nextPosition;
_predicate=predicate;
_collection=collection;
_position=-1;
}
public UniversalEnumerator(UniversalEnumerator source, NextPosition nextPosition, Predicate predicate)
{
_nextPosition=nextPosition;
_predicate=predicate;
_collection=source._collection;
_position=_position;
}
public IEnumerator GetEnumerator()
{
//для того чтобы можно было много раз пользоваться, делаем клоны. Хотя может быть и возвращение this более подошло бы.return this.Clone();
}
public void Reset()
{
_position=-1;
}
public bool MoveNext()
{
while(_current==NextPosition(ref _position, _collection) && (_current!=null) && (!predicate(result, position)));
return (_current!=null);
}
public object Current{get {return _current;}}
}
///определяем то что делаем
//прямой обходpublic object Straight(ref int position, IList collection)
{
position++;
if (position<collection.Count)return collection[position];
position=-1;
return null;
}
//обратный обходpublic object Backward(ref int position, IList collection)
{
position++;
if (position<collection.Count)return collection[position];
position=-1;
return null;
}
//определяем rangepublic bool Range(object testValue, int position)
{
return (position>10 && position<20);
}
//использованиеprivate ArrayList _array;
UniversalEnumerator MyEnum=new UniversalEnumerator(_array, new NextPosition(Straight), new Predicate(Range))
foreach(object x in MyEnum)
{
actions(x);
//а вот тут проходим в обратную сторонуforeach(object y in new UniversalEnumerator(MyEnum, new NextPostition(Backward), new Predicate(Range)))
{
actions(y);
}
};
Возможно тут ввести еще один параметр типа settings чтобы можно было более гибко настраивать делегаты или перевести все на интерфейсы (то бишь классы со своими настройками). В принципе все написано только наметками. Но тут еще важен один момент. В отличие от С++ нет safe поинтеров. Поэтому адрессация в любом случае получается индексной (ссылка на коллекцию + позиция).
Да, еще дополнение. В принципе, можно сделать диапазон используя только делегаты NextPosition, и не используя предикат как таковой (например заглушкой типа {return true;}. Тогда можно было бы вообще убрать как таковые лишние обращения за диапазон. Просто было интересно сделать и показать наиболее универсальный способ.
Что касается отсутсвия yeild то это синтаксический сахар 2.0. Не более того. Если говорить о генериках, то никто не мешает немного подредактировать под них.
Здравствуйте, GlebZ, Вы писали:
ПК>>Вряд ли так получится сделать. По крайней мере, не через IEnumerable/IEnumerator, т.к. он принципиально не способен перебирать в обратном порядке. Соответственно, получив "прямой" энумератор, сделать из него обратный не выйдет. Впрочем, с удовольствием гляну на код, использующий энумераторы .Net (возможно с привлечением yield return etc.), и делающий описанное (поиск нижней и верхней границы по предикатам с последующим обходом выделенной подпоследовательности в обратном порядке).
GZ>ну чтож. Представляею универсальный enumerator/ Сделаем без всякого синтаксического сахара типа yield return, чтобы даже на 1.1 работало. Возможно где-то ошибки, и можно сильно улучшить, пишу сходу. Использую не объекты, а делегаты (хотя здесь интерфейсы более подошли бы).
[skipped]
Это не универсальный енумератор — он базируется на IList. для Hashtable, например, он не подойдёт — Straight(...) и Backward(...) для этого должны, оказываться больше знать о контейнере, нежели просто указатель на IList.
Help will always be given at Hogwarts to those who ask for it.
Здравствуйте, _FRED_, Вы писали:
_FR>Это не универсальный енумератор — он базируется на IList. для Hashtable, например, он не подойдёт — Straight(...) и Backward(...) для этого должны, оказываться больше знать о контейнере, нежели просто указатель на IList.
Порядок в Hashtable при проходе неопределен. Таким образом какие-то специфичные проходы просто бесмысленены. Стандартного хватает за глаза.
С уважением, Gleb.
Хотя если ради принципа, то я первоначально хотел сделать position объектом, но писать было лениво. Что касается делегата направления, то они действительно зависят от типа коллекции(должен быть индексный доступ). Но никто не мешает сделать конкретный под конкретный класс.
Здравствуйте, Павел Кузнецов, Вы писали:
>> ПК> если нам понадобится в Apply изменить порядок обхода найденной подпоследовательности, скажем, на обратный, какие из функций нужно будет переписать? Подозреваю, что все... В случае STL нужно будет только добавить пару вызовов для создания reverse_iterator, ничего из использованных алгоритмов (find_if, for_each) не переписывая. >> >> В ApplyWithinLimits надо передавать уже IEnumerable, обходящий последовательность в обратном порядке. Менять же Limit и After не придётся.
ПК>Нужно, чтоб начало и конец подпоследовательности искались в порядке прямого обхода, а элементы самой подпоследовательности уже обходились в обратном порядке. В предложенном же варианте и подпоследовательность будет выделяться в порядке обратного обхода.
Покажи пожалуйста какой вид приемт вот это: J>На STL это записывается так:
_FRED_,
> ПК>Нужно, чтоб начало и конец подпоследовательности искались в порядке прямого обхода, а элементы самой подпоследовательности уже обходились в обратном порядке. В предложенном же варианте и подпоследовательность будет выделяться в порядке обратного обхода.
> Покажи пожалуйста какой вид приемт вот это: > J>На STL это записывается так: >
GlebZ,
> _FR>Это не универсальный енумератор — он базируется на IList. для Hashtable, например, он не подойдёт — Straight(...) и Backward(...) для этого должны, оказываться больше знать о контейнере, нежели просто указатель на IList.
> Порядок в Hashtable при проходе неопределен <...>
Он и с LinkedList работать не будет, т.к. последний не реализует интерфейс IList...
Posted via RSDN NNTP Server 2.0 beta
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
GlebZ,
> ПК> получив "прямой" энумератор, сделать из него обратный не выйдет. Впрочем, с удовольствием гляну на код, использующий энумераторы .Net (возможно с привлечением yield return etc.), и делающий описанное (поиск нижней и верхней границы по предикатам с последующим обходом выделенной подпоследовательности в обратном порядке).
> универсальный enumerator <...>
Который так и не использует в своей реализации IEnumerator, а использует вместо этого IList, и умеет "поворачивать вспять" только получая объект своего же типа. Соответственно, например, развернуть порядок обхода, получив IEnumerator, скажем, у LinkedList, он нам не поможет.
> В отличие от С++ нет safe поинтеров. Поэтому адрессация в любом случае получается индексной (ссылка на коллекцию + позиция).
Главное, чтоб позиция не была представлена целым числом, т.к. это требует контейнера с произвольным доступом.
Posted via RSDN NNTP Server 2.0 beta
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
Здравствуйте, alexeiz, Вы писали:
A>Тогда тебе прийдется хранить в списке его размер и при каждой операции его обновлять.
Учимся мыслить абстракно. Не в списке, а в итераторе или в диапазоне.
A>Возьмем, к примеру, всё тот-же Algorithms.Fill<T>(IList<T>,int,int,T). Что-то его не сильно применишь к LinkedList, который не реализует IList (наверное, из-за опасений создать квадратичный алгоритм ).
Может это просто неудачная реализация?
VD>>В итоге решаются точно такие же задачи, но при этом A>учитывая скудность стандартных интерфейсов >>результат получается более простым в понимании и исключаются ошибки.
A>(я тут немножко добавил между строк, чтобы показать поспешность твоего заявления).
А ты не добавляй ничего в чужие слова. Это как минимум не прилично.
A>Ты забываешь, что многие алгоритмы могут быть определены над итераторами вполне оптимально.
Не забываю. Но не забываю и о том, что многие могут быть применены крайне не оптимально. А это уже очень плохо. Это требует дополнительного напряжения сил программистов и дополнительных знаний о релазации. Что очень прискорбно.
A>Алгоритм remove, кстати, если определить его соответствующим образом, еще как подходит для массива.
Это если иметь в виду под массивам какой-ниьбудь std::sector. А если встроенный массив языка вроде C# или темболее С++, то вряд ли. К тому же это уход в терминологию с целью уйти от мысли. Суть то ведь в том, что есть реализации не допускающие удаления элементов.
A>Несмотря на твои рассуждения, STL'ная комбинация методов remove/erase все равно будет наиболее оптимальной, так как, используя ее, ты не обязан изменять размер коллекции или создавать новый массив, если тебе это не нужно.
Зашибись. А звучит то как?! "Оптимальное удаление элементов массива размещенного в стэке". "Или отсуствие необходимости знания о количестве элементов при в алгоритме бинарного поиска."
A>Вот и я про то же. Просто, но не проще.
Ага. И почему-то С++-ный код, даже использующий СТЛ (что кстати еще та редкость), почему-то не выглядит просто. А уж как сложно его отлаживать и поддерживать...
A> Удобно, но до тех пор, пока удобство не мешает эффективности и не ущемляет мой выбор.
А вот тут позволю себе катигорически не согласиться. Эффективность один из факторов. И довольно часто он ставится намного ниже простоты, понятности или гибкости. Кстати, я тут вспомнил хороший пример на эту тему. Вот С++-компиляторы крайне не эффективны с точки зрения производительности. И многие из вас закрывают на это глаза ради эфимерной гибкости. А уж про то, что на эту самую эффективность давно забили разные непристойные предметы и разработчики языка и разработчики компиляторов. И все это только ради простоты и удобства. В общем, ущемляют все что попало.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, VladD2, Вы писали:
V>>ok, перебрать. V>>И где ограничение на способ или направление перебора?
VD>В смысле патерна. Полностью его описание звучит так: VD>
Перебрать элементы некоторого списка (контейнера, коллекции) абстрагируясь от его внутренней реализации.
VD>Т.е. за направление, последовательность и т.п. отвечает итератор. В этом и есть суть паттерна. Прямой доступ — это уже точно не итетатор.
V>>В описании этого паттерна в GoF такие вещи не уточняются
VD>Плохо читал. Там даже реализация привдена. Причем почти полная копия Шарповских итераторов.
V>>, да и не должны, ибо они не требуются для описания сути паттерна. Однако нигде и не говорится об ограничениях. С чего это тебе захотелось заняться ограничением имплементации паттернов — непонятно.
VD>Почитай на досуге еще раз. http://www.research.umbc.edu/~tarr/dp/lectures/Iterator.pdf
Нет, ну это уже несерьезно . Сам-то дочитал хотя бы до середины?
l Implementation Issues:
= Who controls the iteration?
— The client => more flexible; called an external iterator
— The iterator itself => called an internal iterator
= Who defines the traversal algorithm?
— The iterator => more common; easier to have variant traversal techniques
— The aggregate => iterator only keeps state of the iteration
= Can the aggregate be modified while a traversal is ongoing? An iterator
that allows insertion and deletions without affecting the traversal and
without making a copy of the aggregate is called a robust iterator.
= Should we enhance the Iterator interface with additional operations, such as
previous()?
Мне больше нечего добавить, считаем тему закрытой.
Здравствуйте, jazzer, Вы писали:
VD>>Ни однин последовательный алгоритм принципиально не может перебирать ничего в обратном порядке без копирования в промежуточный массив.
J>Ты не прав. В STL из любого двунаправленного (и его потомков) итератора можно получить итератор, дающий обход в обратном порядке.
Без возможности переместиться в конец ты будешь перебирать элементы, что приведет к замедлению работы алгоритма.
J>Причем, опять же, ты можешь абстрагироваться от направления текущего итератора. J>Т.е. если у тебя на входе итератор, который на самом деле осуществляет обратный обход, ты, обращая его, получаешь прямой, и тебе даже не нужно думать, что же у тебя во что превращается: ты можешь быть уверенным, что в результате ты получишь итератор с противоположным направлением обхода.
Здорово. И получаем не универсальное решение так как однонаправленный итератор или будет крайне не эффективно разворачиваться, или вообще нельзя будет развернуть.
В итоге мы начинаем зависеть от реализации контейнера, что есть нарушение условий паттерна "итератор".
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, vdimas, Вы писали:
V>Разница в быстродействии в 4-5 раз и в требованиях к памяти во столько же раз для меня является показателями сравнительной эффективности, а для мужиков?
Да мил человек. Со страху еще не такое чудится. Где же ты нашел то разницу в 4-5 раз. У нас тут ассы торможения процессоров более дукратного приемущества не добивались. И то получалось сократить до 30%. А в среднем потерь от выбора не оптимальных решений и неоптытности программистов настолько больше, что об этом говорить не приходится.
Что же до памяти... то тут да. Действительно дотнет прожерлив. Тут разница может дойти до тех самых заветных 4-5 раж. Но в последнее время ее родимой довольно много. И стоит она довольно дешево. Значительно дешевле чем труд программиста.
V>Понимаю, что сейчас это уже никого не интересует, но мы ведь STL обсуждали, а ее не вчера написали.
V>Я именно так и пишу на С++: V>
Во как? И макросы не пугают? А что тогда всем про рандом-эксес-итераторы расказывать?
V>ссылки на foreach для C++ тебе уже давали, а вообще — это дело вкуса. Не факт, что функторы применяются только лишь для подобных примитивных задач. Если функциональность самого функтора занимает приличное число строк, то разумнее использовать именно его, хотя бы из соображений повторного использования (вместо copy&paste который предлагает твой вариант).
Мой? Где? Если мне нужен универсальный алгоритм, то проблем обычно не возникает. На довольно большое приложение/контрол я конечно могу позволить себе 3-4 копипэста, но и то только в целях оптимизации. По крайней мере проблем это не вызывает. А код получается кода чище и поддерживать его проще.
V>Дык, были уже замеры, в 4-5 раз разница.
Ссылки, плиз.
V>Я не путать видимо, шло обсуждение именно достижения максимального быстродействия в цикле, и это были твои предложения. Жаль, что искать в твоих постах практически нереально из-за их количества.
Видимо ты не очень внимательно читал. foreach на массивах разворачивается в for. На некоторых коллекциях он может дать выигрышь, но очень незначительный. И подобные оптимизации нужно применять очень окуратно и только там где оно действительно радо. А то пара обращений к массиву по индексу убьют весь выигрышь.
В общем, все очнь не однозначно. И производительность я ставлю выше простоты только если оно действительно надо. А в 99% случаев этого не требуется. Требуется приемлемая производительность.
V>Пишу сервер приложений на C#, как минимум в половине библиотечных методов над коллекциями 2 доп. виртуальных вызова на итерацию сопоставимы с затратами на тело цикла. Стараюсь использовать по-возможности for(), получаю примерно вдвое выигрыш.
Измерения есть? Или это теоретически?
V>Скажем так, основная масса действительно сложного и ресурсоемкого кода должна содержаться в background-е, в некоем фреймворке, заточенном под прикладную область. Наверху должна оставаться верхушка айсберга, приятная глазу прикладного программиста. Мне как приходится писать первое. И хотя основная масса кода (зачастую "линейная", т.е. практически без циклов) содержится в прикладной части, эффективность системы в целом определяет все-таки background.
Эффективность системы определяется профайлером и опытным зглядом. Ладно. Вряд ли я тебя смогу убедить. Поверь я кое что знаю о производительности. И точно тебе скажу, что разница в 4-5 раз по сранению с нэйтив-кодом — это чушь. Скорее всего это результат кривости дизайна или использование заранее медленного кода (например стороннего).
V>Их писать надо под свои коллекции. Перепишем System.Collections? забъем на ICollection и везде будем использовать собсвенную иерархию, вернее даже не иерархию, а сборище итераторов... Обощенные алгоритмы пойдут лесом, похоже, наступит эпоха copy&paste...
Когда я писал КОМ-объекты на С++ я так и делал. Но там с коллекциями было проблематично. Дотнетные меня лично пока устраивают. Но если не устроят, я их перепишу. Это не та проблема.
V>Ну да, работа у меня такая, строить фундаменты с подвалами и, по-возможности, без блох...
Ага. А у других другая. Я вот ради прикола делал код который действительно требователен к производительности. Тот же R# к примеру. Сейчас вот пишу текстовый редактор для следующей версии Януса. По твоим словам и то, и то должно было бы дико тормозить. А на деле у меня все работает не хуже чем аналогичный код написанный на С++. При этом его примерно на порядок меньше! И я тут не шучу. Доделаю редактор обязательно напишу статейку где приведу сравнение с Синтилой.
V>Интересное замечание насчет мании величия. Да и далее совсем не по тексту, почему-то. Речь о банальном конфликте понятий и первенстве в именовании. Насчет "не эталон", я бы не спешил с категоричностью в свете выпуска аналога STL под дотнет. Наверно стоит все-таки определиться: кто яйцо, а кто курица в отношении итераторов и алгоритмов.
Тут нечему определяться. Итераторы использовались еще на С, а то и раньше. Курсор в области БД был известен с 60-ых годов. А уж значение английского термина вообще не подлежит сомнению.
V>Они обощили приемы ООП и взяли на себя смелость дать имена трюкам. Про изобретения никто не говорил.
Они не придумали ни одного имени. Перечитай еще разок эту книгу. Там есть источники.
V>>> Задача описания ООП паттерна проктирования — дать самую голую суть ООП-трюка для решения "атомарной" задачи.
VD>>Вообще-то паттерн — это удачный примем для решения часто встречающийся задачи.
V>Вообще-то коментарий опять мимо текста. Что есть паттерн и задача его описания — это разные вещи.
Ну, с очевидцами не спорят. Прочти книку еще раз. Там не раз говорится о том, что в ней понимается под паттерном.
V>>> Для описания именно патерна большего и не надо.
VD>>Глупость. Паттерн — это не задача. Это решение часто встречающейся задачи.
V>Именно глупость, или невнимательное чтение оппонента. Задача описания паттерна — это тоже задача. GoF поставили задачу донести суть повторно применимых приемов до IT-сообщества. Похоже, перестарались с лаконичностью. Кое-кто воспринял слишком буквально. Им стоило разбавить свою книжку примерами и реализациями паттернов с учетом различных специфик, тогда этой ветки могло и не быть.
Ответь. Ты ее вообще то читал? Там примеров как грязи. Да и не нужно других считать тупее себя. Я с самого начала говорил, о том, что в первую очередь нужно думать головой. Если тебе не подходит перебор, то этот паттерн не для тебя. Ищи другой или придумывай выход сам. Но если подходит, то паттерн определеят четкое решение проблемы. И это его суть. Это строительный блок, а не тема для фантазий.
VD>>Значит это не итераторы. Задача итератора — абстрагирование перебора элементов коллекции. Все!
V>Кстати, а с какой целью делается перебор? Наверно, чтобы подсчитать количество элементов?
Это не колышет того кто делает итератор и коллекцию. Это проблема программиста. Перебор один из самых часто используемых приемов при работе со списками. Итератор решает эту задачу. Заметь в моем определении есть слово "абстрагирование". Оно там не случайно.
V>Опять проблема яйца и курицы. Итераторы в STL не цель, а средство. Собственно, как и везде.
Какие яйца? Я СТЛ в глаза не видел, а итератор уже встречал.
V>Попробуй по-другому.
Зачем мне пробовать? Я делвают.
V>И придешь к тому же. STL переписывали многократно люди, не глупее тебя.
СТЛ не переписывал никто. О был создан степановым, согласован и стандартизован. С 91 года изменений вроде особо не было. До сих пор в нем есть глупости вроде того, что нет хэш-таблиц, а Map основан на дереве.
V>В этой теме ПК и сотоварищи обсуждали разделение функциональности итераторов для перебора и доступа. (Как в дотнете изменить значения полей value-типа в контейнере?)
Например, с помощью list.ConvertAll(). Хотя я линчо просто стараюсь не хранить вэлью-типы в контейнерах. Для них намного лучше подходят массивы. Вэлью-типы это оптимизация. А раз оптимизируешь, то надо делать это с умом.
V> Не думаю, что ребятам из GoF не была очевидна подобная специфика. Просто она никак не влияет на суть описанного трюка (абтрагирование операций перебора от конкретных коллекций), точно так же как и не ограничивает реализацию (интерфейс и поведение Java и дотнет-итераторов разные, хотя оба реализуют один и тот же паттерн). В общем, зациклился ты на "чистоте" паттерна, хотя этого никто не требовал (и ребята из GoF так же не налагали подобные ограничения).
Я не зацикливаюсь не на чем. Я говрою о простых, казалось бы вещах, о дурной терминологии и мосорности итераторов в СТЛ.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, vdimas, Вы писали:
V>Нет, ну это уже несерьезно . Сам-то дочитал хотя бы до середины?
Читал. V>
V>l Implementation Issues:
V>= Who controls the iteration?
V> — The client => more flexible; called an external iterator
V> — The iterator itself => called an internal iterator
V>= Who defines the traversal algorithm?
V> — The iterator => more common; easier to have variant traversal techniques
V> — The aggregate => iterator only keeps state of the iteration
V>= Can the aggregate be modified while a traversal is ongoing? An iterator
V>that allows insertion and deletions without affecting the traversal and
V>without making a copy of the aggregate is called a robust iterator.
V>= Should we enhance the Iterator interface with additional operations, such as
V>previous()?
V>Мне больше нечего добавить, считаем тему закрытой.
И что ты тут такого обнаружил? Я где-то заявлял о том, что итераторы должны быть доступны только на чтение? Я гворил, о том, что они должны служить для перебора элементов, и не имеют права предоставлять прямого доступа. Иначе это уже не итераторы.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Павел Кузнецов, Вы писали:
ПК>Например, проход по подпоследовательности (связного) списка в обратном порядке не требует ничего копировать в промежуточный массив.
Ага. Как в прочем и не является последовательным.
ПК>Нет, я в основном говорю о (связных) списках, которые по определению обладают последовательным доступом.
Связанные списки вообще особный разговор. Но в данном случае они потребуют полного перебора для прогрутки. И возможность прохода в обратную сторону без копирования будет доступна только при условии, что связанный список двунаправляенный. Что еже не хило привязывает к реализацииям списоков или понижает эффективность.
ПК>В STL это делается легко, если "прямой" итератор является bidirectional.
Тогда он уже не очень прямоу.
ПК>Классная вышла "оптимизация". Например, в случае LinkedList мы получим совершенно избыточное копирование в массив только для того, чтоб пройтись по нему в обратном порядке.
Да, но это не так уж и накладно с одной стороны, а с другой для прямого однонаправленного итератора в СТЛ прийдется делать тоже самое. Ну, бывает же, что итератор действительно извлекает данные из медленного источника и вообще не хранит структуру?
ПК>Только очень медленные, и требующие памяти на ровном месте
"Очень медленно" понятие очень относительное. Думаю, на последовательностях порядка десятков мег будет воркать в мгновение ока. А там можно будет взять в руки профайлер и покорпеть над узкими местами какое-то время. Один фиг выйдет быстрее.
ЗЫ
Я тут недавно... раздобыв вторую бэту сразу же запустил свой проект который сейчас пишу (редактор кода для Януса и R#-па за место Синтилы) под ним. Было забавно, что мои ожидания оказались очень близкими к тому что показал профайлер. Хотя в паре мест я все же ошибся. Так я не обратил внимания на промежуточные динамические массивы создаваемые в узких местах, а оказалось, что они то используются очень нехило. Решение было просто как три копейки. Вместо того, чтобы создавать их каждый раз я просто вынес их в статические переменные или поля класса. Чтобы не было проблем с многопоточностью пометил статические поля атрибутом ThreadStatic:
[ThreadStatic]
private static List<StyledRange> _ranges = new List<StyledRange>(16);
[ThreadStatic]
private static List<int> _ndxs = new List<int>(16);
И все дела! Если бы я мог вот так же за просто решать проблемы на С++ глядишь я и не стал бы искать лучшей жизни.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Павел Кузнецов, Вы писали:
ПК>Классная вышла "оптимизация". Например, в случае LinkedList мы получим совершенно избыточное копирование в массив только для того, чтоб пройтись по нему в обратном порядке.
Если это станет узким метсом, то не долго написать специализацию и для него:
static IEnumerable<T> Revers<T>(IEnumerable<T> iter)
{
IList<T> list = iter as IList<T>;
if (list != null)
{
for (int i = list.Count - 1; i >= 0; i--)
yield return list[i];
}
else
{
ICollection<T> collection = iter as ICollection<T>;
if (collection != null)
{
T[] array = new T[collection.Count];
collection.CopyTo(array, 0);
for (int i = array.Length; i >= 0; i--)
yield return array[i];
}
else
{
LinkedList<T> ll = iter as LinkedList<T>;
if (ll != null)
{
LinkedListNode<T> node = ll.Last;
while (node != null)
{
yield return node.Value;
node = node.Previous;
}
yield break;
}
Stack<T> stack = new Stack<T>();
foreach (T value in iter)
stack.Push(value);
foreach (T value in stack)
yield return value;
}
}
}
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Оданко, что характерно ты тоже не угадал, что выдаст данный код. Я взял на себя смелость его скопилировать и запустить... результат оказался следующим:
7 6 8 5 0 1
1 0 5 8 6 7
И это в трех соснах. Что же будет когда кода будет по больше.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Sinclair, Вы писали:
S>Ну, это уж да. Если секс — то непременно полноценный. Давайте на всякий случай доопределим на примитивном односвязном списке суперинтерфейс курсора с тридцатью двумя методами. В шестнадцати насладимся сексом с реализацией Prev с учетом SetRange и фильтрации, а остальные шестнадцать будут возвращать NotSupported. Чтобы и пользователь нашего курсора тоже вкусил полноценного секса. С всенепременным деторождением.
Я плякаль... И почему нельзя ставить много смайликов сразу?
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Ну, как я есть автор приведенного поста, позволю себе высказаться.
Код — в чистом виде учебный, негоже его использовать как аргумент.
Если почитаешь ту ветку, найдешь такое решение (практическое), выполняющее ту же задачу:
Здравствуйте, VladD2, Вы писали:
VD>Здорово. И получаем не универсальное решение так как однонаправленный итератор или будет крайне не эффективно разворачиваться, или вообще нельзя будет развернуть.
VD>В итоге мы начинаем зависеть от реализации контейнера, что есть нарушение условий паттерна "итератор".
Никакого нарушения паттерна в данном случае нет, поскольку:
1) Об эффективности перебора речи в описании паттерна не идёт;
2) Нельзя "разворачивать" однонаправленный итератор, т.е., в данном случае алгоритм манипуляции итератором зависит от самого итератора, а не контейнера.
Ну а в остальном присоединяюсь к jazzer.
... << RSDN@Home 1.1.4 beta 3 rev. 185>>
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, vdimas, Вы писали:
V>Да и я не утверждал, что итератор должен обладать качеством прямого доступа.
А именно это и напрягает/путает больше всего.
V> Кстати, а не трудно тебе сформулировать, что ты называешь прямым доступом применительно к итератору? Может вообще весь этот спор ни о чем...
Ну, вот разные там "it + 2" и т.п.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Павел Кузнецов, Вы писали:
ПК>Восхитительно! Какой общий подход. Осталось всего лишь добавить в эту функцию каждый из контейнеров, используемых пользователем.
Нет нужды. Все контейнеры уже учтены. Скажу боьше. LinkedList вообще нафиг не уперся. Я его прилепил уже в пылу теоритического спора.
ПК>Тем не менее, оставим восторги и вернемся к исходной задаче. Интересно, как будет называться поддиапазон связного списка в данной функции? В самом деле, LinkedList, очевидно, не подойдет... Соответственно, даже с добавлением такого явного "хэка", проблема с эффективностью обращения прохода по подпоследовательности (связного) списка, о чем так давно говорили большевики , при выбранном подходе так и осталась нерешенной.
Паш, проблем в том, что LinkedList в 99% задач вообще не нужен. Ну, не эффективен он. Особненно в дотнете где присвоение указателей стоит дороже чем в С++.
С диапазонами по энумераторам задача решается введением некого класса хранящего итератор и количество элементов. Однако опять же как-то не нужно оно на повреку. LinkedList по жизни не удачный выборк. А у IList нет проблемы пользоваться индексами. Возможно это не так гибко как если б ввести еще штук 5 промежуточных интерфейсов, но это просто и эффективно.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Павел Кузнецов, Вы писали:
ПК>Что характерно, в отличие от комбинации двух find_if и for_each, неудачно почти дословно повторяющей условие задачи, сразу видно, что именно хотел выразить этим автор
Что характерно, задачи такие в природе не часто встречаются. А подобные крейне не эффективные решения еще реже. И по жизни как раз на С++ получается намного большее награмождение кода.
>> Оданко, что характерно ты тоже не угадал, что выдаст данный код. <...>
ПК>Это прискорбные последствия "усложнения" последовательности после написания сообщения.
Не, это замечательный пример того насколько понятный код был создан. Ну, и надуманности задачи.
>> И это в трех соснах. Что же будет когда кода будет по больше.
ПК>Ты искренне считаешь, что дело в коде? Я ориентировался по условию задачи, а не по коду.
Паш, тут две строчки кода. Я понял, что ты ошибся, но понять что вернет этот код без его запуска тоже не смог. Итого получается, что два не очень глупых человека прочтя эти две строчки кода не смогли правильно понять как он работает. Я не говорю, что это проблемы итераторов СТЛ. Но я искренее считаю, что — это пример плохого решения задачи, или ее надуманности.
Подобная задача требует отдельного абстрагирования. Тут разумно было бы создать понятие диапазана и условия вхождения в этот диапазон. Тогда бы конечный код стал действительно простым и никто бы не запутался.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, IT, Вы писали:
IT>Если быстродействие системы/модуля/функции является критическим, то такое требование автоматически переходит в разряд non-functional requirements и становится главнее любых требований по соблюдению чистоты кода. В противном случае производительность кода не должна рассматриваться как весомый аргумент.
Полностью согласен.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Геннадий Васильев, Вы писали:
VD>>В общем, по жизи я получаю больше гибкости именно от простых решений, а не от супер-пупер наворотов. ГВ>Ну так, ты рассказал, фактически, о том, что "тебе не приходилось...", "ты не сталкивался...", "ты развернулся по течению..." и т.п. Расскажи теперь, плз., какое это отношение имеет к характеристикам рассматриваемых абстракций?
Мне приходилось много чего. Я рассказываю о реалиях жизни.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Павел Кузнецов, Вы писали:
ПК>Теперь спрашиваем себя: почему? Ясно, что итераторы здесь совсем ни при чем, а дело в отсутствии поддержки лямбда-функций.
От части. Но не только. Все же слишком много "шума" у СТЛ-овских итераторов. И два конца совершенно не нужных для простого перебора. И определение внутри типа контейнера.
Кстати, _1 — это тоже изврат какой-то.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
VD>От части. Но не только. Все же слишком много "шума" у СТЛ-овских итераторов. И два конца совершенно не нужных для простого перебора. И определение внутри типа контейнера.
Проблема с концами разрешима, например в boost::range. Вместо такого кода:
Здравствуйте, VladD2, Вы писали:
ГВ>>Э... не люблю заниматься самоцитированием, но вынуждаешь. Итак, повторяю свой вопрос: ГВ>>
ГВ>>...какое это отношение имеет к характеристикам рассматриваемых абстракций?
VD>
В общем, по жизи я получаю больше гибкости именно от простых решений, а не от супер-пупер наворотов.
Ну а какова связь-то между свойствами абстракций и твоей жизнью?
... << RSDN@Home 1.1.4 beta 3 rev. 185>>
Я знаю только две бесконечные вещи — Вселенную и человеческую глупость, и я не совсем уверен насчёт Вселенной. (c) А. Эйнштейн
P.S.: Винодельческие провинции — это есть рулез!
Здравствуйте, Геннадий Васильев, Вы писали:
ГВ>Ну а какова связь-то между свойствами абстракций и твоей жизнью?
А связь элементарна. Если мне в большинстве случаев нужна простая абстракция перебора элементов, а я вмест нее использую более сложную абстракцию указателия, и если все это в добавок приправленно крайне неудобным, слишком длинным синтаксисом, то я получаю олее сложный, запутанный и плохо читаемый код. Итог всего этого объяснять я думаю не нужено.
... << RSDN@Home 1.1.4 beta 4 rev. 351>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
So what is the STL? It has now been part of Standard C++ for almost a decade, so you really should know, but if you are new to modern C++ here is a brief explanation with a bias towards ideals and language usage.
Consider the problem of storing objects in containers and writing algorithms to manipulate such objects. Consider this problem in the light of the ideals of direct, independent, and composable representation of concepts listed in §2. Naturally, we want to be able to store objects of a variety of types (e.g. ints, Points, pointers to Shapes) in a variety of containers (e.g. lists, vectors, maps) and to apply a variety of algorithms (e.g. sort, find, accumulate) to the objects in the containers. Furthermore, we want the use of these objects, containers, and algorithms to be statically type safe, as fast as possible, as compact as possible, not verbose, and readable. Achieving all of this simultaneously isn’t easy. In fact, I spent about 10 years unsuccessfully looking for a solution to this puzzle.
The STL solution is based on parameterizing containers with their element types and on completely separating the algorithms from the containers. Each type of container provides an iterator type and all access to the elements of the container can be done using only those iterators. That way, an algorithm can be written to use iterators without having to know about the container that supplied them. Each type of iterator is completely independent of all others except for supplying the same semantics to required operations, such as * and ++. We can illustrate this graphically:
Let’s consider a fairly well-known example based on finding elements of various types in various containers. First, here are a couple of containers
vector<int> vi; // vector of ints
list<double> vd; // list of doubles
These are the standard library versions of the notions of vector and list implemented as templates (§D&E15.3). Assume that they have been suitably initialized with values of their respective element types. It then makes sense to try to find the first element with the value 7 in vi and the first element with the value 3.14 in vd:
vector<int>::iterator p = find(vi.begin(),vi.end(),7);
list<double>::iterator q = find(vd.begin(),vd.end(),3.14);
The basic idea is that you can consider the elements of any container as a sequence of elements. A container “knows” where its first element is and where its last element is. We call an object that points to an element “an iterator”. We can then represent the elements of a container by a pair of iterators, begin() and end(), where begin() points to the first element and end() to one-beyond-the-last element:
The end() iterator points to one-past-the-last element rather than to the last element to allow the empty sequence not to be a special case:
What can you do with an iterator? You can get the value of the element pointed to (using * just like for a pointer), make the iterator point to the next element (using ++ just like for a pointer) and compare two iterators to see if they point to the same element (using == or != of course). Surprisingly, this is sufficient for implementing find():
template<class Iter, class T> Iter find(Iter first, Iter last, const T& val)
{
while (first!=last && *first!=val) ++first;
return first;
}
This is a simple – very simple really – template function as described in §D&E15.6. People familiar with C and C++ pointers should find the code easy the read: first!=last checks whether we have reached the end and *first!=val checks whether we have found the value val that we were looking for. If not, we increment the iterator first to make it point to the next element and try again. Thus, when find() returns its value will point to either the first element with the value val or one-past-the-last element (end()). So we can write:
vector<int>::iterator p = find(vi.begin(),vi.end(),7);
if (p != vi.end()) { // we found 7
// …
}
else { // no 7 in vi
// …
}
This is very, very simple. It is simple like the first couple of pages in a Math book and simple enough to be really fast. However, I know that I’m not the only person to take significant time figuring out what really is going on here and longer to figure out why this is actually a good idea. Like simple Math, the first STL rules and principles generalize beyond belief.
Consider first the implementation: In the call find(vi.begin(),vi.end(),7), the iterators vi.begin() and vi.end() that become first and last, respectively, inside find() are something that points to an int. The obvious implementation of vector<int>::iterator is therefore a pointer to int, an int*. With that implementation, * becomes pointer dereference ++ becomes pointer increment, and != becomes pointer comparison. That is, the implementation of find() is obvious and optimal. In particular, we do not use function calls to access the operations (such as * and !=) that are effectively arguments to the algorithm because they depend on a template argument. In this, templates differ radically from most mechanisms for “generics”, relying on indirect function calls (like virtual functions), in current programming languages. Given a good optimizer, vector<int>::iterator can without overhead be a class with * and ++ provided as inline functions. Such optimizers are now not uncommon and using a class improves type checking by catching unwarranted assumption, such as
int* p = find(vi.begin(),vi.end(),7); // oops: the iterator type need not be int*
So why didn’t we just dispense with all that “iterator stuff” and use pointers? One reason is that vector<int>::iterator could have been a class providing range checked access. For a less subtle explanation, have a look at the other call of find():
list<double>::iterator q= find(vd.begin(),vd.end(),3.14);
if (q != vd.end()) { // we found 3.14
// …
}
else { // no 3.14 in vi
// …
}
Here, list<double>::iterator isn’t going to be a double*. In fact, assuming the most common implementation of a linked list, list<double>::iterator is going to be a Link* where Link is a link node type, such as:
template<class T> struct Link {
T value;
Link* suc;
Link* pre;
};
That means that * means p->value (“return the value field”), ++ means p->suc (“return a pointer to the next link”), and != pointer comparison (comparing Link*s). Again the implementation is obvious and optimal. However, it is completely different from what we saw for vector<int>::iterator.
We have used a combination of templates and overload resolution to pick radically different, yet optimal, code for a single source code definition find() and for the uses of find(). Note that there is no run-time dispatch, no virtual function calls. In fact, there are only calls of trivially inlined functions and fundamental operations such as * and ++ for a pointer. In terms of speed and code size, we have hit rock bottom!
Why not use “sequence” or “container” as the fundamental notion rather than “pair of iterators”? Part of the reason is that “pair of iterators” is simply a more general concept than “container”. For example, given iterators, we can sort the first half of a container only: sort(vi.begin(), vi.begin()+vi.size()/2). Another reason is that the STL follows the C++ design rules that we must provide transition paths and support-built in and user-defined types uniformly. What if someone kept data in an ordinary array? We can still use the STL algorithms. For example:
char buf[ max ];
// … fill buf …int* p = find(buf,buf+max,7);
if (p != buf+max) { // we found 7
// …
}
else { // no 7 in buf
// …
}
Here, the *, ++, and != in find() really are pointer operations! Like C++ itself, the STL is compatible with older notions such as C arrays. As always, we provide a transition path (§D&E4.2). This also serves the ideal of providing uniform treatment to user-defined types (such as vector) and built-in types (in this case, array) (§D&E4.4).
The STL, as adopted as the containers and algorithms framework of the ISO C++ standard library, consists of a dozen containers (such as vector, list, and map) and data structures (such as arrays) that can be used as sequences. In addition, there are about 60 algorithms (such as find, sort, accumulate, and merge). It would not be reasonable to present all of those here. For details, see [Austern, 1998], [Stroustrup, 2000].
The key to both the elegance and the performance of the STL is that it – like C++ itself (§D&E2.5.2, §D&E2.9.3, §D&E3.5.1, §D&E12.4) – is based directly on the hardware model of memory and computation. The STL notion of a sequence is basically that of the hardware’s view of memory as a set of sequences of objects. The basic semantics of the STL maps directly into hardware instructions allowing algorithms to be implemented optimally. The compile-time resolution of templates and the perfect inlining they support is then key to the efficient mapping of high level expression of the STL to the hardware level.
... << RSDN@Home 1.1.4 beta 6a rev. 436>>
SObjectizer: <микро>Агентно-ориентированное программирование на C++.
Здравствуйте, Павел Кузнецов, Вы писали:
ПК>Здравствуйте, c-smile, Вы писали:
Чего-то я ничего не понял а какие-то проблемы?
Говоря о редакторах...
Мой Блокнот например имеет четко Java iterator с "фичами" которые мне самому очень
нравятся.
Например каретка расположена так:
раз|три.
В случае Word (C++ iterator) как впечатать в позицию слово "два" чтобы оно было
или bold или italic — по выбору?
В случае Блокнота все просто — если каретка пришла со слова "раз" то будет bold
если со слова "три" то будет italic. Очень удобно.
По поводу удаления в вообще все просто — есть два удаления delete (справа от каретки) и backspace — слева.
Так с итераторами должно быть в Java RemoveLeft/Right и всех делов.
c-smile,
> ПК>Здравствуйте, c-smile, Вы писали: > > Чего-то я ничего не понял а какие-то проблемы?
С удалением. То, что будет удалено, зависит от того, какие операции были выполнены до того.
> <... рассуждения об использовании редакторов пропущены, т.к. выводы об итераторах на их основании делать некорректно ...>
> По поводу удаления в вообще все просто — есть два удаления delete (справа от каретки) и backspace — слева. > Так с итераторами должно быть в Java RemoveLeft/Right и всех делов.
Проблема как раз в том, что в Java это не так А с предложенной тобой схемой появятся проблемы с обобщенными алгоритмами: если передать в аналог std::remove_if подобный итератор, не вполне ясно, как он будет себя вести: будет удалять "слева" или "справа". Почему-то мне кажется, что выбор какого-либо одного из двух вариантов приводит к тем же проблемам, что и с итераторами Java (см. ниже). А если все алгоритмы типа remove_if дублировать...
В случае с итераторами Java то, как будет себя вести remove_if, зависит от того, какие операции с итератором делались перед вызовом. Если next не сделали, и remove_if сначала удаляет, а потом делает next — будет исключение. Если remove_if сначала делает next, а потом удаляет, то проблема будет в случае, если нужно удалять начиная с некоторого найденного элемента: чтобы его найти, нужно было сделать next, и теперь remove_if его уже не удалит, т.к. сам сделает next.
С итераторами в духе STL таких проблем нет
Posted via RSDN NNTP Server 1.9
Легче одурачить людей, чем убедить их в том, что они одурачены. — Марк Твен
VD>Эффективность системы определяется профайлером и опытным зглядом. Ладно. Вряд ли я тебя смогу убедить. Поверь я кое что знаю о производительности. И точно тебе скажу, что разница в 4-5 раз по сранению с нэйтив-кодом — это чушь. Скорее всего это результат кривости дизайна или использование заранее медленного кода (например стороннего).
К примеру, эффективность IDE студии .NET обределяется невооруженным и неопытным взглядом как крайне низкая. Причем, тут коррелирует еще на какой оси стоит — на 2к не тормозит, а на XP/2003 — ж#па. Тесты на перебор коллекции COM-интерфейсов и вызове у каждого объекта 1 метода показали разницу в быстродействии м/д С++ и С# в 10 (десять) раз.
VD>Когда я писал КОМ-объекты на С++ я так и делал. Но там с коллекциями было проблематично. Дотнетные меня лично пока устраивают. Но если не устроят, я их перепишу. Это не та проблема.
Когда вы писали COM-объекты на C++ вы знали о существовании контейнеров STL или, может быть, использовали свои поделки или MFC/ATL контейнеры?
VD>Ага. А у других другая. Я вот ради прикола делал код который действительно требователен к производительности. Тот же R# к примеру. Сейчас вот пишу текстовый редактор для следующей версии Януса. По твоим словам и то, и то должно было бы дико тормозить. А на деле у меня все работает не хуже чем аналогичный код написанный на С++. При этом его примерно на порядок меньше! И я тут не шучу. Доделаю редактор обязательно напишу статейку где приведу сравнение с Синтилой.
Обязательно приведите сравнение с Сцинтиллой. Пока только было Ваше высказывание где-то в форуме , что "Янус — проект just for fun и он лучше многих коммерческих проектов на C++". А с какими такими коммерческими проектами вы его сравнивали? Может быть с MS Outlook / Outlook Express? Он и рядом с ними не стоял. По моему, и не только, мнению, он выглядит и работает как дешевая поделка (just for fun). And nothing more! Я лично пользуюсь web-интерфейсом и он полностью меня устраивает.
VD>СТЛ не переписывал никто. О был создан степановым, согласован и стандартизован. С 91 года изменений вроде особо не было. До сих пор в нем есть глупости вроде того, что нет хэш-таблиц, а Map основан на дереве.
А что такого, что stl::map основан на дереве? Вот в ATL есть CRBMap, и ничего. А в коллекциях .NET есть аналог мапа?
VD>Например, с помощью list.ConvertAll(). Хотя я линчо просто стараюсь не хранить вэлью-типы в контейнерах. Для них намного лучше подходят массивы. Вэлью-типы это оптимизация. А раз оптимизируешь, то надо делать это с умом.
Все надо делать с умом, особенно оптимизировать, когда наступаешь на новые грабли новой и модной платформы.
VD>Я не зацикливаюсь не на чем. Я говрою о простых, казалось бы вещах, о дурной терминологии и мосорности итераторов в СТЛ.
А чем value-типы в массивах .NET лучше в плане чистоты?
Здравствуйте, ArtemGorikov, Вы писали:
AG>К примеру, эффективность IDE студии .NET обределяется невооруженным и неопытным взглядом как крайне низкая. Причем, тут коррелирует еще на какой оси стоит — на 2к не тормозит, а на XP/2003 — ж#па.
Купи памяти и научись читать требования к аппаратуре.
AG> Тесты на перебор коллекции COM-интерфейсов и вызове у каждого объекта 1 метода показали разницу в быстродействии м/д С++ и С# в 10 (десять) раз.
Это ты интероп с родным кодом что ли сравнивашь?
А ты сравни скорость вызова метода интерфейса/класса в С# и COM-интерфейс в нэйтив-С++. Вот это будет чесно. Думаю результаты тебя удивят.
AG>Когда вы писали COM-объекты на C++ вы знали о существовании контейнеров STL или, может быть, использовали свои поделки или MFC/ATL контейнеры?
А ты поиск по этому сайту сделай. Увидишь.
И поверь, что что бы ты не использовал все равно трах создания КОМ-коллекций на С++ и дотнетных коллекций на Шарпе просто не соизмеримы. Все что нужно сделать на шарпе это написать:
class SomeTypeCollection : Collection<SomeType>
{
}
далее если захочется реакций разных на добавление там или еще что, то просто перегружашь нужные методы и пишешь код. С помощью IDE — это плевая операция. А вот на плюсах одни IDL-описания запаришся делать. Ну, и результат по производительности не соизмеримый. КОМ-овские коллееции в качестве перечислителя испоьзуют IEnumVARIANT со всеми вытекающими. О статической типизации вообще можно не говорить.
И зачем весь этот трах?
AG>Обязательно приведите сравнение с Сцинтиллой. Пока только было Ваше высказывание где-то в форуме , что "Янус — проект just for fun
Скачивай и сравнивай.
AG>и он лучше многих коммерческих проектов на C++". AG> А с какими такими коммерческими проектами вы его сравнивали?
Это ты сам придумал.
AG> Может быть с MS Outlook / Outlook Express? Он и рядом с ними не стоял. По моему, и не только, мнению, он выглядит и работает как дешевая поделка (just for fun).
Ну, это твое мнение. Можешь оставаться при нем и пользваться NNTP через Outlook Express получая кайф от глюков и убогости.
AG> And nothing more! Я лично пользуюсь web-интерфейсом и он полностью меня устраивает.
Рад за тебя. Он, кстати, тоже на Шарпе написан.
VD>>СТЛ не переписывал никто. О был создан степановым, согласован и стандартизован. С 91 года изменений вроде особо не было. До сих пор в нем есть глупости вроде того, что нет хэш-таблиц, а Map основан на дереве.
AG>А что такого, что stl::map основан на дереве?
Ничего, просто медленно и требует бессмысленных сравнений на больше/меньше. И вообще, безграмотная структура классов. map == ассоциативный массив. Вот и должне предоставлять добавление, удаление и поиск по ключу. Остальное пусть будет в каком-нибудь TreeMap.
AG> Вот в ATL есть CRBMap, и ничего. А в коллекциях .NET есть аналог мапа?
Есть. Только это уже дерево, а не мап. И необходимость в нем очень редка.
Ну, и что касается ATL коллекций... Траха с ними не впример больше чем с дотнетными коллекциями. Да и стандартностью они не отличаются.
AG>Все надо делать с умом, особенно оптимизировать, когда наступаешь на новые грабли новой и модной платформы.
VD>>Я не зацикливаюсь не на чем. Я говрою о простых, казалось бы вещах, о дурной терминологии и мосорности итераторов в СТЛ.
AG>А чем value-типы в массивах .NET лучше в плане чистоты?
Тем что при этом к ним есть прямой (а стало быть эффективный) доступ. Например, такой код:
struct A
{
public int I;
}
class Program
{
static void Main()
{
A[] a = new A[2];
a[1].I++;
}
}
совершенно законен и эффективен.
ЗЫ
Плиз, или называй на "ты", или "Вы" пиши с большой буквы, а то как-то ощущаю себя группой товарищей.
... << RSDN@Home 1.2.0 alpha rev. 606>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, ArtemGorikov, Вы писали:
AG>Вот и я ж о том, что тормозит. На любой вопрос "почему тормозит" стандартный ответ "докупи памяти и поставь новый камень".
Новый комень не нужно. ОС на скорость приложений не влияют если памяти достаточно. Переключение контекстов в ХРюще или 2003 медленнее не стало.
AG>Да, это универсальная отмазка, поэтому в каждом новом дистрибутиве винды раз за разом реклама "приложения стали работать еще быстрее и надежнее"
Это правда. Как и правад рекомендуемые ресурсы. Не нравится? Используй старые ОС. Вынь 95 на 8 метрах работает.
AG> (ценой апгрейда). В Vista приложения будут стартовать на 30% быстрее, чем в предыдущих версиях — как думаете, какой ценой?
Не уверен, что это будет так, но если будет, то видимо за счет опримизации запуска дров. Между нами девочками ХРюша действитнльно намного быстрее грузится чем Вынь 2000. Я вообще использую резим сна и машины включаются со скоростью нагрева мониторов.
AG>В таком случае честно будет сравнивать скорость вызова метода класса C# и метода класса С++, который, к тому же, можно сделать инлайновым.
Да. И разницы никакой нет.
AG> В самом деле, надо провести тест — на сколько порядков будет разница — на 1 или 2?
С чего бы ей быть? Ну, если только в одном случае заинлайнится, а в другом нет. Но это и 10% на суровом алгоритме не даст, а в приложении ты это и не заметишь.
В общем, пробема в твоем восприятии дотнета. Ты почему-то не можешь поверить в то, что это такой же компилятор как и С++. У дотнета есть свои проблемы, но они не там где ты их хочешь найти. Оптимизатор у послених компиляторов С++ действительно круче дотнетного, но разами тут и не пхнет. Если тормоза где-то и есть, то они в более частом использвании виртуальных вызовов (так как многие пробелм решаются не шаблонами, а через ООП), ну, и ЖЦ вносит некоторые накладные расходы. Так в нем есть барьер-записи который замедляет любую модификацию указателей. Змедляет где-то в три раза. Но к счастью модификация указателей значительно более радкое явление, чем их чтение. Так что на робщем фоне разница не вилека. В худшем случае получается двухкратное замеделение по сравнению с оптимальным кодом созданным на С++. В среднем же проигрыш измеряется в процентах от 5 до 20.
AG>Согласен полностью насчет траха, а нужен он для скорости.
Скорости? Не смешите мои тапочки (с).
IEnumVARIANT и это тормоз еще тот. Да и КОМ в общем, не подарок. Это не голвй С++-ный код.
AG> Иногда и за 15% прирост стоит потрахаться, а уж за 300% — 700%... Это я о средней разнице в скорости native-кода VC++ и managed-кода VC#.
Ну, так доказательства этих поэтических строк таки поседуют?
VD>>Это ты сам придумал. AG>Не спорю, может и привиделось, а может просто кто-то другой написал на форуме это.
Я такого не помню. Речь все время идет о том, что бы поглядеть на аналог Януса созданный на плюсах.
AG>Вы считаете OE убогим?
Да, и с большим удовольствием им не пользуюсь уже несколько лет. А года пользовался, то постоянно матерился.
AG>А как это? Т.е., не будь у меня установлена платформа, он бы не работал?
На сервере, естественно. Так что работать будет везде. Просто сервер это те самые ненависные C# + .Net + IIS + MSSQL.
AG> А на вид невинный сайт с фреймами и самописным деревом, никаких извратов и выкрутасов на нем мной замечено не было
А кто это дерево рендерит то?
AG> Я его даже на FF загружал — фреймы не таскались, а остальное все шевелилось
У меня таскаются. Только не голубенькие.
AG>Что медленно?
Алгоритм. Хэширование в болшинстве случае это O(1), а дерево логарифмическую характеристику имеет.
AG> Если std::map<std::string, ...>, то да, а если std::map<size_t,...> то очень даже быстро, теоретически быстрее, чем массив на hash.
Опиши данноую теорию. Только при хорошем распределении хэш-значений, плиз.
AG> В случае, если надо ключ в виде строки иметь, то CAtlMap<CAtlString,...> в помощь... — это как раз hash-массив.
Мы говорили о СТЛ.
AG>Да все понятно, C# для того и задумали, чтобы трах уменьшить.
Ну, это то понятно. Меня вот знашь что удивляет? Зачем задумывается трах в С++-ных библиотеках? Ну, не ужели это неотемлемый компонет?
AG> Но при этом сделали его ограниченным — нет множественного наследования, полноценных compile-time шаблонов, заморочки с value-типами и простыми. Память вот еще настоятельно советуют прикупить.
Что ты там против value-типов имешь я не знаю, но поверь, что остальным действительно стоит пожертвовать. Для статической типизации в большинстве случае достаточно дженериков. А генерацией кода можно заняться и явно. Наследование... да тоже как-то не мешает если сразу проектируешь все без рассчета на него. Я бы может прикрутил некие миксины, но пока и без них прожить можно.
AG> Предшественники C# с теми же целями — VB и Delphi. Только они не вытеснили C++ (у них были схожие с C# ограничения), так что подождем его хоронить.
Я бы назвал главным предшественником все же Яву. А она С++ с корпоративного рынка вытеснила очень успешно. Да и Дельфи с ВБ вытесняли его не плохо. Дотнет же вытесняет его и из более системных областей. Сейчас я смотрю на тех то клепает Активыксы как на ненормальных. Ведь контролы в ВинФормс просто совершенство по сравнению с Активыксами.
AG>А мне нравится терминология и идея итераторов STL. IMHO это гениально иметь механизм, позволяющий подсовывать в алгоритмы любые итераторы и при этом не терять вообще ничего в производительности, т.к. компилер все заинлайнит и оптимизирует в лучшем виде.
И зачем "это" называть итератором?
AG> Что вы так к терминологии прицепились?
Потому что она никакая. Потмоу что это и есть проявление кривизны С++-стиля — все через зад.
AG> Ну неточная она, но это же не повод не пользоваться итераторами.
Проблема в том, что это не единственная проблема.
Мне тяжело это объяснить, но нет в этой всей фигне интуитивности и простоты. А создание программ — это выражение своих мыслей. И я хотел бы иметь возможность вражать их наиболее понятно и просто.
AG>Я ж про то, что для <b>"прямой (а стало быть эффективный) доступ"</b> нужно _явно_ указывать, что это value-тип. А в C++ прямой и эффективный доступ просто по умолчанию, и не надо думать, где нужен прямой и эффективный доступ, а где обычный. Т.е. это уже some kind of backdoor, дающий небыстрой реализации так нужный ей "костыль" — это все мое IMHO.
Указывать ничего не нужно. Вернее все что нужно ты указвашь при орпделении типа. Что до прямоты С++ в этом аспете, то достаточно вспомнить, что все это сновано на указателях и проблемах с ними связанными. Ведь же нельзя сказать, что вот это:
void F(int * p)
{
int a = 1;
p = &a;
}
нормально?
Или ручное управление памятью?
AG>Согласен на "ты",
ОК
AG>но я ведь младше, поэтому и обращаюсь на "вы".
Откада ты знашь, что младше? Может я грудной младенец.
AG>И тут ведь публичный треп, а не личная переписка.
Ну, раз обращаешся лично, то все же от части и лична переписка.
... << RSDN@Home 1.2.0 alpha rev. 606>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
AG>>В таком случае честно будет сравнивать скорость вызова метода класса C# и метода класса С++, который, к тому же, можно сделать инлайновым.
VD>Да. И разницы никакой нет.
VD>IEnumVARIANT и это тормоз еще тот. Да и КОМ в общем, не подарок. Это не голвй С++-ный код.
Да вроде COM — это голые виртуальные вызовы, чем он здесь медленнее, чем виртуальные вызовы C++ или C#? Никто же не заставляет пользоваться дисп-интерфейсами в C++ программах?
AG>> Иногда и за 15% прирост стоит потрахаться, а уж за 300% — 700%... Это я о средней разнице в скорости native-кода VC++ и managed-кода VC#.
VD>Ну, так доказательства этих поэтических строк таки поседуют?
К моему сожалению, я не пишу на C# и поэтому могу лишь высказать мнение других людей, писавших на C++ и C# и описывающих разницу в различных форумах. В т.ч. на rsdn.ru и privet.com. Я вижу тормоза нашей внутрикорпоративной утилки, когда она показывает простенькую диаложку с 2 кнопками и 5 edit-ми. Бывают моменты, что как в замедленной съемке видно, как один за одним отрисовываются ее контролы на старте. При повторном вызове она уже выстреливает мгновенно.
VD>>>Это ты сам придумал. AG>>Не спорю, может и привиделось, а может просто кто-то другой написал на форуме это.
VD>Я такого не помню. Речь все время идет о том, что бы поглядеть на аналог Януса созданный на плюсах.
Я так понимаю, Янус — аналог Outlook — по крайней мере, его GUI пытается повторить GUI аутлука.
AG>>Вы считаете OE убогим? VD>Да, и с большим удовольствием им не пользуюсь уже несколько лет. А года пользовался, то постоянно матерился.
Странно... А что не так? Нормально он работает. Есть косяки, конечно, главный — что он базу свою прячет где-то глубоко в Documents And Settings, но путь ведь можно настроить?
AG>>А как это? Т.е., не будь у меня установлена платформа, он бы не работал? VD>На сервере, естественно. Так что работать будет везде. Просто сервер это те самые ненависные C# + .Net + IIS + MSSQL.
Это некорректное сравнение. В таком случае, сайт писан на C++ через такую цепочку: HTML->Asp, C#, IIS, MSSQL->VC++
AG>> Я его даже на FF загружал — фреймы не таскались, а остальное все шевелилось VD>У меня таскаются. Только не голубенькие.
Ну да ладно, какой броузер юзать — дело вкуса. Мне нравится IE.
AG>>Что медленно?
VD>Алгоритм. Хэширование в болшинстве случае это O(1), а дерево логарифмическую характеристику имеет.
Все правильно, а вот как по-вашему получить хэш от ключа, скажем, long? ATL эту проблему с CAtlMap (хэш-массив) решает очень просто: хэш-функция от long возвращает этот самый long _без изменений_. В итоге, по базовым типам, дерево _быстрее_ хэш-массива, т.е. чем больше элементов, тем больше разница в скорости. Вот тебе и логарифм
AG>> Если std::map<std::string, ...>, то да, а если std::map<size_t,...> то очень даже быстро, теоретически быстрее, чем массив на hash. VD>Опиши данноую теорию. Только при хорошем распределении хэш-значений, плиз.
Up. При любом распределении хэш-значений. С std::string действительно прокололись в реализации, так же как и с отсутствием hash_map в стандарте. Идиотизм сравнивать строки в мапе, тут уж нечего прибавить — не надо такой связкой пользоваться вообще.
AG>> В случае, если надо ключ в виде строки иметь, то CAtlMap<CAtlString,...> в помощь... — это как раз hash-массив. VD>Мы говорили о СТЛ.
В каждодневной работе я использую наиболее оптимальные, с моей точки зрения, решения. Я сравниваю C++ с библиотеками с C# с библиотеками, мне важна не "чистота языка", а практический результат.
AG>>Да все понятно, C# для того и задумали, чтобы трах уменьшить. VD>Ну, это то понятно. Меня вот знашь что удивляет? Зачем задумывается трах в С++-ных библиотеках? Ну, не ужели это неотемлемый компонет?
Ну не нравится что-то в какой-то либе C++ — не используй. Всегда можно прикрутить другой велосипед, написать свой, смешать разные концепции, тут никаких ограничений нет. В C# надо пользоваться навязанной концепцией, нравится это или нет. Или я не прав?
AG>> Но при этом сделали его ограниченным — нет множественного наследования, полноценных compile-time шаблонов, заморочки с value-типами и простыми. Память вот еще настоятельно советуют прикупить.
VD>Что ты там против value-типов имешь я не знаю, но поверь, что остальным действительно стоит пожертвовать. Для статической типизации в большинстве случае достаточно дженериков. А генерацией кода можно заняться и явно. Наследование... да тоже как-то не мешает если сразу проектируешь все без рассчета на него. Я бы может прикрутил некие миксины, но пока и без них прожить можно.
Против value-типов — то, что они есть. Это похоже на Delphi, там тоже были встроенные массивы для базовых типов и объекты, которые на самом деле были ссылками, при этом тяжело понять, откуда ноги растут. А отсутствие множественного наследования — в ATL очень удачно его использовали, тут сравнение MFC vs ATL явно не в пользу первого, он как раз множ. наследования не использовал.
AG>> Предшественники C# с теми же целями — VB и Delphi. Только они не вытеснили C++ (у них были схожие с C# ограничения), так что подождем его хоронить.
VD>Я бы назвал главным предшественником все же Яву. А она С++ с корпоративного рынка вытеснила очень успешно. Да и Дельфи с ВБ вытесняли его не плохо. Дотнет же вытесняет его и из более системных областей. Сейчас я смотрю на тех то клепает Активыксы как на ненормальных. Ведь контролы в ВинФормс просто совершенство по сравнению с Активыксами.
Вообще это изврат клепать на MFC формочное приложение. .NET вытеснил как раз VB и Delphi из их ниш, Java он не вытеснит никогда, пока он привязан к Windows. Только не надо мне указывать на Mono — всерьез его никто не воспринимает, это только попытка показать, что "оно работает даже на линухе", при этом нет полноценного .NET-фреймворка.
Я для себя сейчас не вижу больших преимуществ от WinForms в коробочных продуктах перед ATL/WTL/MFC. Что такого есть в WinForms, чего нет в указанных либах?
AG>> Что вы так к терминологии прицепились? VD>Потому что она никакая. Потмоу что это и есть проявление кривизны С++-стиля — все через зад.
Ну, это твое личное мнение. Поверь, на C++ можно писать очень даже вменяемый и красивый код, тут дело вкуса, какие либы пользовать.
AG>> Ну неточная она, но это же не повод не пользоваться итераторами.
VD>Проблема в том, что это не единственная проблема. VD>Мне тяжело это объяснить, но нет в этой всей фигне интуитивности и простоты. А создание программ — это выражение своих мыслей. И я хотел бы иметь возможность вражать их наиболее понятно и просто.
В STL нет простоты? Что может быть проще, чем написать std::vector<int>? Не надо boost тут приводить, я же говорю, использовать либу или нет — дело вкуса. Многое из C# есть/можно сделать на VC 7.1. Атрибуты, чтобы не писать IDL-ки, делегаты, коллекции, да что угодно. Я пользуюсь своими рукописными делегатами, и это пример того, как действительно полезные вещи легко и быстро появляются в инструментарии VC++ — программиста. Когда выйдет Avalon — думаю, через 2-3 м-ца появится бесплатная либа на WTL, которая будет работать _везде_ начиная от 9х и NT4, и при этом особо не выпендриваться насчет оси и количества памяти < 512 на борту.
VD>Указывать ничего не нужно. Вернее все что нужно ты указвашь при орпделении типа. Что до прямоты С++ в этом аспете, то достаточно вспомнить, что все это сновано на указателях и проблемах с ними связанными. Ведь же нельзя сказать, что вот это: VD>
VD>void F(int * p)
VD>{
VD> int a = 1;
VD> p = &a;
VD>}
VD>
VD>нормально?
Кстати в этом коде ничего не упадет. Пользы, правда, тоже никакой
А что такого в использовании указателей? Это так тяжело? Если не понимаешь указателей, зачем идти в программеры?
VD>Или ручное управление памятью?
Да, ручное управление памятью есть хорошо. Хорошо, когда ты знаешь, что вот сейчас ты эту память освободил, этот ресурс отпустил и т.д. Для некоторых вещей действительно становится трудно отследить "висяки". Но в таком случае это проблема кривой архитектуры, или тут можно применить GC. Хотя лучше до этого вообще не доводить, а проектировать правильно.
Здравствуйте, Cyberax, Вы писали:
C>Да, но только в личных письмах, причем опционально.
Не личных писмах, а личном обращении. Если ты говоришь "Вы" в разговоре со мною, то ты как раз обращашся ко мне лично. В общем, прицип тут простой. Если "Вы" можно заменить на имя/ник, значит Вы нужно писать с большой буквы. Или пиши "ты". Иначе это уже смахивает на оскорбление. Это все равно так писать "cyberax".
... << RSDN@Home 1.2.0 alpha rev. 606>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Что-то я не понял... Ответ вроде мне, а сообщение у меня прилеплено не к моему.
AG>Да вроде COM — это голые виртуальные вызовы, чем он здесь медленнее, чем виртуальные вызовы C++ или C#? Никто же не заставляет пользоваться дисп-интерфейсами в C++ программах?
Гы. А ничего что еще есть:
1. Подсчет ссылок.
2. QI.
3. Проверка HRESULT? Или ты пишешь код без проверок? Ну, тогда подумай о надежности оного.
Более того COM — это всегда виртуальные вызовы. А дотнете ты без проблем можешь использовать прямые. Нужно рассказывать насколько прямые вызовы быстрее виртуальных?
А как насчет дисп-интерфейсов? Ведь все события идут через них.
AG>Я так понимаю, Янус — аналог Outlook — по крайней мере, его GUI пытается повторить GUI аутлука.
Ничего никто повторить не пытался. Скорее использованы идиомы из VS (приклеивающиеся и скрываемые окна). Расположение и количество окон взято с сайта. Ну, а то что оно похоже на половину читалок почты — это уже вопрос дизайна оных.
AG>Странно... А что не так?
Проще ответить что так. Я такого не помню. Outlook 2003 меня более менее встраивает, хотя тоже с удовольствием кое-что подрихтавал бы.
AG> Нормально он работает. Есть косяки, конечно, главный — что он базу свою прячет где-то глубоко в Documents And Settings, но путь ведь можно настроить?
Не нормально он работает. А если БД ничайно параллельно открыть, так еще и данные грохает. Да и БД у него нет. Самопальщина какая-то.
AG>>>А как это? Т.е., не будь у меня установлена платформа, он бы не работал? VD>>На сервере, естественно. Так что работать будет везде. Просто сервер это те самые ненависные C# + .Net + IIS + MSSQL.
AG>Это некорректное сравнение.
Тю! Чем же это?
AG> В таком случае, сайт писан на C++ через такую цепочку: HTML->Asp, C#, IIS, MSSQL->VC++
Что за трава?
AG>Ну да ладно, какой броузер юзать — дело вкуса. Мне нравится IE.
Мне тоже.
AG>Все правильно, а вот как по-вашему получить хэш от ключа, скажем, long?
Усечь значение до int32 и все.
AG> ATL эту проблему с CAtlMap (хэш-массив) решает очень просто: хэш-функция от long возвращает этот самый long _без изменений_. В итоге, по базовым типам, дерево _быстрее_ хэш-массива, т.е. чем больше элементов, тем больше разница в скорости. Вот тебе и логарифм
Не вижу связи. Если в этом long уникльные значения, то все будет ОК.
AG>>> Если std::map<std::string, ...>, то да, а если std::map<size_t,...> то очень даже быстро, теоретически быстрее, чем массив на hash. VD>>Опиши данноую теорию. Только при хорошем распределении хэш-значений, плиз.
AG>Up. При любом распределении хэш-значений. С std::string действительно прокололись в реализации, так же как и с отсутствием hash_map в стандарте. Идиотизм сравнивать строки в мапе, тут уж нечего прибавить — не надо такой связкой пользоваться вообще.
+1
AG>>> В случае, если надо ключ в виде строки иметь, то CAtlMap<CAtlString,...> в помощь... — это как раз hash-массив. VD>>Мы говорили о СТЛ. AG>В каждодневной работе я использую наиболее оптимальные, с моей точки зрения, решения. Я сравниваю C++ с библиотеками с C# с библиотеками, мне важна не "чистота языка", а практический результат.
Дык для Шарпа есть тоже сторонние классы. Мы говорили об СТЛ. Ты спросил, что мне в ней не нравится. К АТЛ у меня только две притензии:
1. Слишком легко создать не типобезопасный код.
2. Слишком много траха. Хэширование — трах. Вынуть списко ключей/значений — трах.
В итоге создание и чтение код использующего дотнтеные хэш-таблицы оказывается намного более простым.
AG>Ну не нравится что-то в какой-то либе C++ — не используй.
А что использовать? Я бибилиотек без траха вообще на плюсах почти не видел.
AG> Всегда можно прикрутить другой велосипед, написать свой, смешать разные концепции, тут никаких ограничений нет. В C# надо пользоваться навязанной концепцией, нравится это или нет. Или я не прав?
В C#, как не странно, тоже можно свой код писать. Вот только в большинстве случаев просто не хочется этого делать. Стандартные реализации удовлетворяют.
И я почти уверен, что дело тут не в C#. Дело тут в подходе к проектированию библиотек и рантайма.
AG>Против value-типов — то, что они есть. Это похоже на Delphi, там тоже были встроенные массивы для базовых типов и объекты, которые на самом деле были ссылками, при этом тяжело понять, откуда ноги растут.
Ты на результат смотри. А результат очень приличный. Разделение на вэлью-типы и ссылочные типы позволило привнести очень эффетивные (в некоторых случаях) корстркуции в язык с автоматическим управлением памятью. Сравни, например, скорость кода созданного на VB.Net и на VB6. Вдь до десятков раз разница доходит.
AG>А отсутствие множественного наследования — в ATL очень удачно его использовали, тут сравнение MFC vs ATL явно не в пользу первого, он как раз множ. наследования не использовал.
Да, согласен, в ATL множественное наследование (МН) действительно использовано очень элегантно. Однако нужно посмотреть зачем вообще нужнен АТЛ?! Это же библиотека затычек. Если исключить из нее контейнеры (которые есть и в СТЛ и которые все же уступают по удобству дотнетным), то в библиотеке остаются только довольно поверхносные обертки и затычки цель которых упростить разработку КОМ-приложений на С++. Но, черт побери, на C# без единой затычки разрабатывать приложения, в том числе и COM-приложения, несравнимо проще! Все что мне унжно чтобы создать COM-объект — это написать:
Все что нужно задать (что задается в АТЛ-проектах задается в IDL) я могу задать атрибутами.
AG>Вообще это изврат клепать на MFC формочное приложение.
Согласен, но и документо-ориентированное тоже на компонентных средствах разрабокти созадавать проще.
AG> .NET вытеснил как раз VB и Delphi из их ниш, Java он не вытеснит никогда, пока он привязан к Windows.
Ну, Ява уже потеснилась. Народ выбирает дотнет для создания ГУИ и Веб-приложений. А это не мало. Мой прогноз — Ява и дотнет (или его потомок) поделят рынок, а С++ останутся более системные ниши, которых со временем будет все меньше.
AG> Только не надо мне указывать на Mono — всерьез его никто не воспринимает,
А зря. Очень серьезный проект.
AG> это только попытка показать, что "оно работает даже на линухе", при этом нет полноценного .NET-фреймворка.
Ну, почему же? Тет только полноценного ВыньФормс. Остальное все очень прилично.
AG>Я для себя сейчас не вижу больших преимуществ от WinForms в коробочных продуктах перед ATL/WTL/MFC.
Гы. Для меня это звучит даже не смешно. Это такой изащьренный сарказм.
AG> Что такого есть в WinForms, чего нет в указанных либах?
Да так... мелочь... Возможеность быстро созоавать качественные компоненты и приложения. Отсуствие моря багов и посчетов допущенных в идеологии ActiveX. Ну, и такие мелочи как рефакторин, работоспособный интелисенс (комплит ворд, подсказки. ХМЛ-документация на классы иметоды), наличие полноценного дизайнера форм и компонетов, отсуствие необходимости контролировать память вручную... В общем, казалось бы ничего особенного. Вот только разработка становится простым и приятным делом, а не трахом как это в ATL/WTL/MFC. Даже такая мелочь как интуитивная понятность уже повод чтобы отказаться от ATL/WTL/MFC. Никак не забуду как хлопая глазами я пытался понять как вызывается обработчких стандатрых кнопок тулбара в МФЦ. Разве это можно сравнить с выбором события у контрола тулбара?
В общем, ATL/WTL/MFC и ВыньФормс это разные подходы к построению библиотек. ATL/WTL/MFC — это попытка упростить разработку ГУИ и компонетов на С++. Вырождается это в наклпывание оберток вокруг существующих технологий вроде КОМ-а или ВыньАПИ. ВыньФормс (да и вообще библиотеки фрэймворка) — это бибилиотеки специально спроектированные с целью сделать разработку максимально простой и интуитивно понятной.
В общем, дело в отсуствии компромисов и в присуствии проектирования. В ATL/WTL/MFC все обертки пытаются скрыть проблемы КОМ-а и ВыньАПИ, а в ВыньФормс под заранее спроектированный интерфейс пишется код который реализует функциональность. Если функцинальность достижима за счет использгвания ВыньАПИ, то используется оно, а если нет, то код пишется за нова.
AG>>> Что вы так к терминологии прицепились? VD>>Потому что она никакая. Потмоу что это и есть проявление кривизны С++-стиля — все через зад. AG>Ну, это твое личное мнение.
Естественно! Но оно появилось не на пустом месте. Я как бы программировал на С++ 10 лет. И с ATL/WTL потрахался не мало. С MFC тоже повозился, хотя не так плотно как с ATL/WTL. Погляди мои старые статьи и тебе все станет ясно.
AG> Поверь, на C++ можно писать очень даже вменяемый и красивый код, тут дело вкуса, какие либы пользовать.
Да, верю, верю. Только вот почему-то результат чаще бывает не очнь красивым.
AG>В STL нет простоты? Что может быть проще, чем написать std::vector<int>?
Написать:
List<int>
AG> Не надо boost тут приводить, я же говорю, использовать либу или нет — дело вкуса. Многое из C# есть/можно сделать на VC 7.1. Атрибуты, чтобы не писать IDL-ки, делегаты, коллекции, да что угодно.
Языком множно. А на практике получается не так просто и стройно.
AG> Я пользуюсь своими рукописными делегатами, и это пример того, как действительно полезные вещи легко и быстро появляются в инструментарии VC++ — программиста.
Делегаты ты сделал (хотя не верен, что полностью, и уверен, что в КОМ ты их использовать не сможешь). Ладно. Но анонимные методы ты как повторишь?
AG> Когда выйдет Avalon — думаю, через 2-3 м-ца появится бесплатная либа на WTL, которая будет работать _везде_ начиная от 9х и NT4, и при этом особо не выпендриваться насчет оси и количества памяти < 512 на борту.
Блажен кто верует. Авалон — это несколько мег кода.
VD>>Указывать ничего не нужно. Вернее все что нужно ты указвашь при орпделении типа. Что до прямоты С++ в этом аспете, то достаточно вспомнить, что все это сновано на указателях и проблемах с ними связанными. Ведь же нельзя сказать, что вот это: VD>>
VD>>void F(int * p)
VD>>{
VD>> int a = 1;
VD>> p = &a;
VD>>}
VD>>
VD>>нормально?
AG>Кстати в этом коде ничего не упадет.
Еще как упадет. Далее в коде вызываем последовательно этот метод и какой-нить другой которому передаем указатель. В этом другом указатель будет указывать на внутреннюю переменную модификация которой уничтожит хранящиеся в "a" данные.
AG> Пользы, правда, тоже никакой
Что значит пользы никакой? Я вернул значение. Ну, типа оно мого быть большим и я передал его по ссылке. Это конечно пример утрированный, но я видел как довольно серьезный программист сделал подобную ошибку как раз используя АТЛ. Шаблоны завуалировали суть и он вернул адрес стековой переменной.
AG>А что такого в использовании указателей? Это так тяжело? Если не понимаешь указателей, зачем идти в программеры?
Похоже указателей не понимашь ты. Мало понимать адресную арифметику, нужно еще понимать, что они создают трудности в проектировании. Если ты заметил, то буквально все высокоскильные С++-ники на этом сайте пытаются оборачивать голые указатели в смарт-поинтеры и т.п. Кстати, одна из основых задач АТЛ как раз обертывание КОМ-овских указателей.
Другими словами указетели — это потенциальные баги. Для прикладного программирования они по сути не нужны. А так как никаких средств контроля за ними нет, то они прврещаются в головную боль программиста. Ведь за ними приходится постоянно следить, а это чревато ошибками.
VD>>Или ручное управление памятью?
AG>Да, ручное управление памятью есть хорошо. Хорошо, когда ты знаешь, что вот сейчас ты эту память освободил, этот ресурс отпустил и т.д.
А причем тут ресурс и память? Если мне нужно котролировать ресурс, то я знаю как это сделать. Памяти в приложении неимоврено больше чем ресурсов. К тому же некоторые ресурсы не очень важны, так как есть механизм фоновой подчистки. Например, если не уничтожить шрифт или картинку, то ровным счетом ничего не убдет. Они уничтожатся при первой сборке мусора нулевого поколения. А это делается очень часто.
По жизни контролировать приходится несколько ресурсов в приложении. Зачастую их не наберется и десятка. Проследить за 10 объектами вручную уже не так сложно. А учитывая, что есть паттрен dispose и оператор using, то задача становится просто примитивной (хотя и требует некоторого напряжения от программиста). Я бы был рад если бы и это было автоматизировано. Но все равно это не сравнить с ручным управлением памятью.
AG> Для некоторых вещей действительно становится трудно отследить "висяки". Но в таком случае это проблема кривой архитектуры,
Ну, ну. Попробуй ради хохмы создать пару-тройку COM-овских синглтонов на АТЛ и разобраться со ссылками.
AG>или тут можно применить GC. Хотя лучше до этого вообще не доводить, а проектировать правильно.
Применить? Не, батенька его можно только иметь в рамках рантайма. GC прикрученный сбоку к плюсам создаст больше проблем чем решит. Это все балоство.
Главное, что нужно понимать — GC снимает с программиста необходимость следить за памятью. А это очень не мло и при проектировании, и ири реализации.
В итоге код с GC становится меньше и проще. А это как раз то, что требовалось.
... << RSDN@Home 1.2.0 alpha rev. 606>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, VladD2, Вы писали:
AG>>Да вроде COM — это голые виртуальные вызовы, чем он здесь медленнее, чем виртуальные вызовы C++ или C#? Никто же не заставляет пользоваться дисп-интерфейсами в C++ программах?
VD>Гы. А ничего что еще есть: VD>1. Подсчет ссылок. VD>2. QI. VD>3. Проверка HRESULT? Или ты пишешь код без проверок? Ну, тогда подумай о надежности оного.
Зачем мне для каждого вызова метода делать AddRef/Release? Зачем делать QI? В .NET, думаю, проверки встроены на уровне платформы.
VD>Более того COM — это всегда виртуальные вызовы. А дотнете ты без проблем можешь использовать прямые. Нужно рассказывать насколько прямые вызовы быстрее виртуальных?
Ну я сравнил виртуальные с виртуальными.
VD>А как насчет дисп-интерфейсов? Ведь все события идут через них.
У кого идут? У VB?
AG>>Странно... А что не так?
VD>Проще ответить что так. Я такого не помню. Outlook 2003 меня более менее встраивает, хотя тоже с удовольствием кое-что подрихтавал бы.
AG>> Нормально он работает. Есть косяки, конечно, главный — что он базу свою прячет где-то глубоко в Documents And Settings, но путь ведь можно настроить?
VD>Не нормально он работает. А если БД ничайно параллельно открыть, так еще и данные грохает. Да и БД у него нет. Самопальщина какая-то.
Это как же надо постараться, чтобы одну базу открыть 2 экземплярами оутлука. Ведь на одной машине они оба не запустятся. А целенаправленно можно и NT-ю повалить, и .NET фреймворк, надо только места знать
AG>>Все правильно, а вот как по-вашему получить хэш от ключа, скажем, long?
VD>Усечь значение до int32 и все.
Вообще-то long и есть int32.
AG>> ATL эту проблему с CAtlMap (хэш-массив) решает очень просто: хэш-функция от long возвращает этот самый long _без изменений_. В итоге, по базовым типам, дерево _быстрее_ хэш-массива, т.е. чем больше элементов, тем больше разница в скорости. Вот тебе и логарифм
VD>Не вижу связи. Если в этом long уникльные значения, то все будет ОК.
Ясен пень, что уникальные. Вот где быстрее будет поиск: на несортированном массиве (хешей) или на сортированном массиве методом половинного деления?
VD>Дык для Шарпа есть тоже сторонние классы. Мы говорили об СТЛ. Ты спросил, что мне в ней не нравится. К АТЛ у меня только две притензии: VD>1. Слишком легко создать не типобезопасный код.
Не надо целенаправленно вредить, и все будет ок.
VD>2. Слишком много траха. Хэширование — трах. Вынуть списко ключей/значений — трах.
Написать CAtlMap<CAtlString, ...> — трах с хешированием?
VD>Ну, Ява уже потеснилась. Народ выбирает дотнет для создания ГУИ и Веб-приложений. А это не мало. Мой прогноз — Ява и дотнет (или его потомок) поделят рынок, а С++ останутся более системные ниши, которых со временем будет все меньше.
Ок, сколько коробочных продуктов выбрало .NET для своего GUI?
AG>> Только не надо мне указывать на Mono — всерьез его никто не воспринимает,
VD>А зря. Очень серьезный проект.
Примеры коммерческого использования Mono — в студию
AG>> это только попытка показать, что "оно работает даже на линухе", при этом нет полноценного .NET-фреймворка.
VD>Ну, почему же? Тет только полноценного ВыньФормс. Остальное все очень прилично.
А что тогда на нем делать? веб-приложения?
AG>>Я для себя сейчас не вижу больших преимуществ от WinForms в коробочных продуктах перед ATL/WTL/MFC.
VD>Гы. Для меня это звучит даже не смешно. Это такой изащьренный сарказм.
VD>В общем, ATL/WTL/MFC и ВыньФормс это разные подходы к построению библиотек. ATL/WTL/MFC — это попытка упростить разработку ГУИ и компонетов на С++. Вырождается это в наклпывание оберток вокруг существующих технологий вроде КОМ-а или ВыньАПИ. ВыньФормс (да и вообще библиотеки фрэймворка) — это бибилиотеки специально спроектированные с целью сделать разработку максимально простой и интуитивно понятной.
Вот именно. Это была цель Delphi с ее VCL. Результаты мы все уже видели. Программист дельфи не может ничего сделать такого, чья функциональность выходит за пределы палитры компонентов. Чуть что — бежит в инет в поисках нужного компонента. Как следствие, квалификация распространяется тока на БД и "мышевозительство".
Такая простота окажет медвежью услугу тем, кто пришел сразу на C# и не имеет опыта C++/WinAPI/MFC.
VD>Естественно! Но оно появилось не на пустом месте. Я как бы программировал на С++ 10 лет. И с ATL/WTL потрахался не мало. С MFC тоже повозился, хотя не так плотно как с ATL/WTL. Погляди мои старые статьи и тебе все станет ясно.
Респект но пока я еще не подсел на C#, можно пофлеймить
AG>> Поверь, на C++ можно писать очень даже вменяемый и красивый код, тут дело вкуса, какие либы пользовать.
VD>Да, верю, верю. Только вот почему-то результат чаще бывает не очнь красивым.
А что результат на C# всегда красивый? Или все-таки это больше от человека зависит?
AG>>В STL нет простоты? Что может быть проще, чем написать std::vector<int>?
VD>Написать: VD>
VD>List<int>
VD>
VD>
И в чем проще? что в слове List на 1 букву меньше?
AG>> Не надо boost тут приводить, я же говорю, использовать либу или нет — дело вкуса. Многое из C# есть/можно сделать на VC 7.1. Атрибуты, чтобы не писать IDL-ки, делегаты, коллекции, да что угодно.
VD>Языком множно. А на практике получается не так просто и стройно.
Все действительно просто и стройно. И атрибуты, и делегаты.
AG>> Я пользуюсь своими рукописными делегатами, и это пример того, как действительно полезные вещи легко и быстро появляются в инструментарии VC++ — программиста.
VD>Делегаты ты сделал (хотя не верен, что полностью, и уверен, что в КОМ ты их использовать не сможешь). Ладно. Но анонимные методы ты как повторишь?
А в чем проблема использовать в COM? Более того, у делегата можно взять совершенно обычный C-указатель на функцию и дать его куда-нибудь в сишный колбэк, например, в WinAPI. С анонимными методами действительно никак Пусть это будет ограничением C++. Но ведь у C# ограничений заметно больше UP, и никто из пишуших на нем от этого не страдает
AG>> Когда выйдет Avalon — думаю, через 2-3 м-ца появится бесплатная либа на WTL, которая будет работать _везде_ начиная от 9х и NT4, и при этом особо не выпендриваться насчет оси и количества памяти < 512 на борту.
VD>Блажен кто верует. Авалон — это несколько мег кода.
Не обязательно реализовывать его весь. Главное — идея, а взята она была у HTML и VRML. Думаю, много усилий затрачено в нем именно на прикручивание его к концепции .NET и оптимизацию.
VD>>>Указывать ничего не нужно. Вернее все что нужно ты указвашь при орпделении типа. Что до прямоты С++ в этом аспете, то достаточно вспомнить, что все это сновано на указателях и проблемах с ними связанными. Ведь же нельзя сказать, что вот это: VD>>>
VD>>>void F(int * p)
VD>>>{
VD>>> int a = 1;
VD>>> p = &a;
VD>>>}
VD>>>
VD>>>нормально?
AG>>Кстати в этом коде ничего не упадет.
VD>Еще как упадет. Далее в коде вызываем последовательно этот метод и какой-нить другой которому передаем указатель. В этом другом указатель будет указывать на внутреннюю переменную модификация которой уничтожит хранящиеся в "a" данные.
В функцию передали указатель по значению, затем значение указателя, т.е. адрес в памяти, модифицировали. При этом после выхода из функции все осталось как прежде. Надо было написать так: int*& p , тогда бы получили желаемую порчу стека.
VD> Похоже указателей не понимашь ты. Мало понимать адресную арифметику, нужно еще понимать, что они создают трудности в проектировании. Если ты заметил, то буквально все высокоскильные С++-ники на этом сайте пытаются оборачивать голые указатели в смарт-поинтеры и т.п. Кстати, одна из основых задач АТЛ как раз обертывание КОМ-овских указателей.
Ну в примере был как раз голый указатель. А в обертку его заворачивают обычно для хранения и последующего разрушения в деструкторе при выходе обертки из области видимости. Ну да, COM — теперь стало злом, хотя винда, MS и не только софтины, тот же .NET фреймворк по-прежнему его используют. То, что в .NET не нужен COM, еще не значит, что он сам COM не использует для своей работы.
VD>Другими словами указетели — это потенциальные баги. Для прикладного программирования они по сути не нужны. А так как никаких средств контроля за ними нет, то они прврещаются в головную боль программиста. Ведь за ними приходится постоянно следить, а это чревато ошибками.
Да все программирование — потенциальные баги.
VD>По жизни контролировать приходится несколько ресурсов в приложении. Зачастую их не наберется и десятка. Проследить за 10 объектами вручную уже не так сложно. А учитывая, что есть паттрен dispose и оператор using, то задача становится просто примитивной (хотя и требует некоторого напряжения от программиста). Я бы был рад если бы и это было автоматизировано. Но все равно это не сравнить с ручным управлением памятью.
Т.е. где-то сложности убавилось, а где-то прибавилось.
AG>> Для некоторых вещей действительно становится трудно отследить "висяки". Но в таком случае это проблема кривой архитектуры,
VD>Ну, ну. Попробуй ради хохмы создать пару-тройку COM-овских синглтонов на АТЛ и разобраться со ссылками.
COM-синглтон вообще кладет на подсчет ссылок и не разрушается сам. Подразумевается, что винда сама освободит память и ресурсы программы при ее завершении. Так что этот пример не из той оперы.
VD>Главное, что нужно понимать — GC снимает с программиста необходимость следить за памятью. А это очень не мло и при проектировании, и ири реализации.
И добавляет pinned-poinеrs для обхода этого блага.
VD>В итоге код с GC становится меньше и проще. А это как раз то, что требовалось.
При этом время разрушения утраченного объекта недетерминировано, и уже нельзя ничего освобождать в деструкторе, плюс, прилага подвисает в самый неподходящий момент — пример — студия 2003. Если запущено несколько студий, и одна из них собирает проект, то другая или обе начинают подвисать при попытке сохранить исходник или просто что-то набрать в редакторе. После подвисания у этой студии мигает каретка, а заголовок окна неактивный — вот и хваленый WinForms. У нее вообще часто каретка живет своей жизнью, а окно — своей.
Т>Программист C++ не может ничего сделать такого, чья функциональность выходит за пределы STL/ATL/WTL/MFC. Чуть что — бежит в инет в поисках нужной библиотеки.
Вы знаете, может. Пример тому — www.codeproject.comwww.rsdn.ruwww.boost.org. Обычно пишется что-то такое, что расширяет уже существующую функциональность или добавляет новую, а потом выкладывается для публичного пользования. Дельфист обычно знает, как пользоваться канвасом и THandle, присвоить свойству другое значение, и непосредственное обращение к winapi для него — уже высший пилотаж.
Здравствуйте, ArtemGorikov, Вы писали:
AG>Зачем мне для каждого вызова метода делать AddRef/Release?
При передаче ссылок.
AG>Зачем делать QI?
При приведении типов.
AG> В .NET, думаю, проверки встроены на уровне платформы.
В дотнете нет проверок, так как нет AddRef/Release-ов.
AG>Ну я сравнил виртуальные с виртуальными.
Дык дело в том, что в КОМ методы виртуальны без особой необходимости. В дотонете на это можно забить, и как следствие получить серьезный выигрыш в скорости.
VD>>А как насчет дисп-интерфейсов? Ведь все события идут через них. AG>У кого идут? У VB?
У всех. Про IConnectionPoint слышал? Стандратно в качестве интерфейсов обратного вызова используется именно IDispatch. Иначе многие среды просто навертываются. ВБ в том числе.
AG>Это как же надо постараться, чтобы одну базу открыть 2 экземплярами оутлука.
Легко. Открывали с двух разных машин по очереди. Прописали пути в реестре на сервер... Пару раз открыли сразу с двух машин. Резельтат... данные попортились.
AG> Ведь на одной машине они оба не запустятся. А целенаправленно можно и NT-ю повалить, и .NET фреймворк, надо только места знать
Вот представь себе Янус без проблем запускается параллельно с одной БД. Видимо потому что БД не самопал.
AG>Вообще-то long и есть int32.
Где как. В С/С++ это вообще не определено. В C# — это 100%-но Inr64.
AG>Ясен пень, что уникальные. Вот где быстрее будет поиск: на несортированном массиве (хешей) или на сортированном массиве методом половинного деления?
Если значения уникальные? Естественно на хэш-таблице. Ты бы изучил как они работают, тогда и таких вопросов не возникло бы. Хэш-таблица не ищет значение. Она из хэш-значения вычисляет слот в котором лежит значение и получает его. Если коллезий нет или их мало, то скорость поиска константная, т.е. каково бы не было количество элементов все равно скорость поиска будет одинакова. При поиске полвоинном делением скорость деградирует хотя и лагорифимически.
AG>Не надо целенаправленно вредить, и все будет ок.
Никто специльно себе проблем не создает. Но я как то нарвался на проблему. Уже не помню сути, но выл AV.
VD>>2. Слишком много траха. Хэширование — трах. Вынуть списко ключей/значений — трах.
AG>Написать CAtlMap<CAtlString, ...> — трах с хешированием?
1. Не всегда получается написать "просто".
2. Кроме объявления переменной ее нужно еще и использвать. А тут почему-то начинается трах. Интуитивностью все это дело не страдает.
Вотс кажи зачем мне разбираться с какими-то POSITION-ами? Или зачем мне разбираться во всех этих KINARGTYPE, KOUTARGTYPE, VINARGTYPE, VOUTARGTYPE.
А когда я беру Dictionary, то все пишется быстро и легко. Чтобы не быть голословным, я наклепал классический прмер — конкорданс (т.е. программа подсчитывающая слова в файле):
using System;
using System.Collections.Generic;
using System.IO;
class Program
{
static void Main(string[] args)
{
Dictionary<string, int> concordance = new Dictionary<string, int>();
// Перебираем слова...foreach (string word in GetWord(File.ReadAllText(args[0])))
{
int count;
// Пробуем получить значение. Если оно не задано count будет равен 0.
// что нам и надо.
concordance.TryGetValue(word, out count);
concordance[word] = count + 1;
}
// Копируем список ключей хэш-таблицы в динамический массив и сортируем его.
List<string> keys = new List<string>(concordance.Keys);
keys.Sort();
// Выводим информацию о каждом слове.foreach (string key in keys)
Console.WriteLine("Слово {0,20} встретилось {1,3} раз[а].",
key, concordance[key]);
}
// Возвращает список слов из мереданного текста.static IEnumerable<string> GetWord(string text)
{
// Перебираем все символы...for (int i = 0; i < text.Length; i++)
{
char ch = text[i];
// Если это начало слова...if (char.IsLetter(ch))
{
int strat = i;
// Ищем его конец.for (++i; i < text.Length; i++)
{
if (!char.IsLetterOrDigit(ch = text[i]))
{
// Если конец найден, получаем подстроку и вызвращем его в итераторе.yield return text.Substring(strat, i - strat);
break;
}
}
}
}
}
}
На написание и отладку ушло около 15 минут (точнее 14). Причем основное время убил на вычленение слов (функцию GetWords). Потребовалось два запуска для того, чтобы пример заработал корректно. И еще один для правильного подбора отступа в строках. Попробуй ради хохмы написать тоже самое на С++ с использованием АТЛ и сравним объем кода, его читаемость и время/количество отладочных запусков.
Вот результат этого примера если его натравить на свой же исходный код:
Слово args встретилось 2 раз[а].
Слово break встретилось 1 раз[а].
Слово ch встретилось 3 раз[а].
Слово char встретилось 3 раз[а].
Слово class встретилось 1 раз[а].
Слово Collections встретилось 1 раз[а].
Слово concordance встретилось 5 раз[а].
Слово Console встретилось 1 раз[а].
Слово count встретилось 4 раз[а].
Слово Dictionary встретилось 2 раз[а].
Слово File встретилось 1 раз[а].
Слово for встретилось 2 раз[а].
Слово foreach встретилось 2 раз[а].
Слово Generic встретилось 1 раз[а].
Слово GetWord встретилось 2 раз[а].
Слово i встретилось 10 раз[а].
Слово IEnumerable встретилось 1 раз[а].
Слово if встретилось 2 раз[а].
Слово in встретилось 2 раз[а].
Слово int встретилось 5 раз[а].
Слово IO встретилось 1 раз[а].
Слово IsLetter встретилось 1 раз[а].
Слово IsLetterOrDigit встретилось 1 раз[а].
Слово key встретилось 3 раз[а].
Слово keys встретилось 3 раз[а].
Слово Keys встретилось 1 раз[а].
Слово Length встретилось 2 раз[а].
Слово List встретилось 2 раз[а].
Слово Main встретилось 1 раз[а].
Слово new встретилось 2 раз[а].
Слово out встретилось 1 раз[а].
Слово Program встретилось 1 раз[а].
Слово ReadAllText встретилось 1 раз[а].
Слово return встретилось 1 раз[а].
Слово Sort встретилось 1 раз[а].
Слово static встретилось 2 раз[а].
Слово strat встретилось 3 раз[а].
Слово string встретилось 9 раз[а].
Слово Substring встретилось 1 раз[а].
Слово System встретилось 3 раз[а].
Слово text встретилось 6 раз[а].
Слово TryGetValue встретилось 1 раз[а].
Слово using встретилось 3 раз[а].
Слово void встретилось 1 раз[а].
Слово word встретилось 3 раз[а].
Слово WriteLine встретилось 1 раз[а].
Слово yield встретилось 1 раз[а].
AG>Ок, сколько коробочных продуктов выбрало .NET для своего GUI?
Думаю море. Вот только тут не слова нужна, а статистика. А ее у мне нет. Можно поглядеть на количество открытх проектов на сорсфордже.
AG>Примеры коммерческого использования Mono — в студию
Ты гуглем не умешь пользоваться? Сейчас море хостеров на Линуксах предлагают Моно в качестве одной из попций.
AG>А что тогда на нем делать? веб-приложения?
Ага. Для этого, как я понимаю, он в основном и разрабатывался.
Хотя разные консольные приблуды и демоны тоже можно.
AG>Вот именно. Это была цель Delphi с ее VCL. Результаты мы все уже видели.
А что плохие результаты? 80 бывшего СССР на ней работало.
AG> Программист дельфи не может ничего сделать такого, чья функциональность выходит за пределы палитры компонентов.
Это в тебе говорит снобизм. Есть разные Дельфи-программисты. Как в прочем и С++-программисты тоже, как не странно, разными бывают. Зайди в форм по С++ и увидишь, сколько там ламерских вопросов. Тот же Синклер из нешей команды тоже Дельфи-программист вроде, но это не мешает ему быть в топе.
AG> Чуть что — бежит в инет в поисках нужного компонента.
А средний С++-ник кидается все написать сам. Это крайности. Разумный человек думает. Не нужно вешать ярлыков.
AG> Как следствие, квалификация распространяется тока на БД и "мышевозительство". AG>Такая простота окажет медвежью услугу тем, кто пришел сразу на C# и не имеет опыта C++/WinAPI/MFC.
Ну, MFC — это на сегодня просто бессмысленный опыт. WinAPI еще лет 5, а то и 10 будет полезен и его можно выучить без С++. Ну, а С++ это, скажем так, неплохая разминка для мозгов. Программировать на нем я бы сейчас не стал, но о том что его знаю лично я не жалею.
Если выключить снобизм, то довольно быстро становится понятным, что во все времена есть люди которые стремятся к саморазвитию. Такие люди никогда не утопнут в RAD-остях и GUI-ёвостях. Они будут неплохо программировать и не имея опыта С++ за спиной. Вместо этого они будут изучать паттерны, технологии, новые более перспективные языки и т.п. И будут те кому и так достаточно. Вот они будут похоже на тех кого ты ассоциируешь с дельфистами.
AG>Респект но пока я еще не подсел на C#, можно пофлеймить
Можно. Но уверяю тебя, что после полугода на Шарпе обратно уже возвращаться противно. Никакие Бустовские фишки не заменяют той простоты и ясности.
AG>А что результат на C# всегда красивый? Или все-таки это больше от человека зависит?
Не. Не всегда. Но тем не менее намного чаще чем на плюсах. На то работает буквально все. И более простые библиотеки. И более ясные паттерны. И заточенность Шарпа на более простые решения. И IDE с ее рефакторингом и интелисенсом. И даже быстрый цикл компиляция/отладка. Все это позволяет сделать код.
AG>>>В STL нет простоты? Что может быть проще, чем написать std::vector<int>?
VD>>Написать: VD>>
VD>>List<int>
VD>>
VD>>
AG>И в чем проще? что в слове List на 1 букву меньше?
Ну, все же проще.
Смотреть конечно унжно на более рельном коде. Ну, да я тебе его уже выше привел. Повтори его на МФЦ, АТЛ и СТЛ. Сравним что получилось.
AG>А в чем проблема использовать в COM?
А ты попробуй. Твои делегаты сущность времени компиляции. А КОМ понимает только интерфейсы.
AG> Более того, у делегата можно взять совершенно обычный C-указатель на функцию и дать его куда-нибудь в сишный колбэк, например, в WinAPI.
А КОМ-у твои указатели неизвесны.
AG> С анонимными методами действительно никак
Ну, те так чтобы уж совсем. Какие-то извраты в Бусте вроде есть. Но это извраты еще те.
AG> Пусть это будет ограничением C++. Но ведь у C# ограничений заметно больше UP, и никто из пишуших на нем от этого не страдает
Дык его ограничения — это как бы культура программирования. Он ограничивает тебя рамками ООП/КОП, но в этих рамках дает поистене отличные инструменты.
AG>Не обязательно реализовывать его весь.
Ну, тогда да.
AG>В функцию передали указатель по значению, затем значение указателя, т.е. адрес в памяти, модифицировали. При этом после выхода из функции все осталось как прежде. Надо было написать так: int*& p , тогда бы получили желаемую порчу стека.
А, да конечно... торможу. Нужно было двойой указатель делать. Но сути дела это не меняет.
AG>Т.е. где-то сложности убавилось, а где-то прибавилось.
Она в основном убавилась.
AG>COM-синглтон вообще кладет на подсчет ссылок и не разрушается сам.
Это АТЛ-ьный. А ты зацепи за него пару других объектов и посмейся когда будешь забираться с политикой владения.
AG> Подразумевается, что винда сама освободит память и ресурсы программы при ее завершении. Так что этот пример не из той оперы.
А если это компонет в сервере приложений? Ну, бизнес объект...
VD>>Главное, что нужно понимать — GC снимает с программиста необходимость следить за памятью. А это очень не мло и при проектировании, и ири реализации. AG>И добавляет pinned-poinеrs для обхода этого блага.
Не в коем случае! Если ты не лезишь в интероп, то никакие поинтеры. Теболее пиннед тебе не нужны вовсе.
VD>>В итоге код с GC становится меньше и проще. А это как раз то, что требовалось. AG>При этом время разрушения утраченного объекта недетерминировано,
Неверно. Его просто нет. Объект мертв если не доступен. И не нужно на него вообще обращать внимание.
AG> и уже нельзя ничего освобождать в деструкторе,
А нечего освобождать. Он если и держит, то тоже память. Или у него есть Dispose с финалайзером.
AG> плюс, прилага подвисает в самый неподходящий момент — пример — студия 2003.
Это тут причем? Студия вообще онменеджед продукт.
AG> Если запущено несколько студий, и одна из них собирает проект, то другая или обе начинают подвисать при попытке сохранить исходник или просто что-то набрать в редакторе.
У меня такого нет. Но даже если бы было, это никак не доказывает каких-то пробелм ЖЦ.
AG> После подвисания у этой студии мигает каретка, а заголовок окна неактивный — вот и хваленый WinForms. У нее вообще часто каретка живет своей жизнью, а окно — своей.
Редактор нэйтивный. Работа с файлами идет через КОМ. Так что о чем ты я не знаю. В моих программах проблем с ресурсами нет. И я вообще о них почти не забочусь. Попробуй и поймешь что это очень удобно.
... << RSDN@Home 1.2.0 alpha rev. 606>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
CS>>Интересно а что произойдет если it1 и it2 взяты от разных последовательностей? J>я думаю, ты и сам знаешь, что произойдет в общем случае. И что с того? Предлагаешь затеять войну на тему "Что безопаснее"?
И откуда вы вообще такие ошибки берёте?
Вроде STL пользую, а такого ляпа не делал. И даже как-то в голову не приходило, что там ляп может быть...
Здравствуйте, ArtemGorikov, Вы писали:
AG>Ок, вычислила из лонга хэш и как дальше ищет слот? Простым перебром слотов или как?
Почитай http://www.optim.ru/cs/2000/4/bintree_htm/hash.asp
VD>>1. Не всегда получается написать "просто". VD>>2. Кроме объявления переменной ее нужно еще и использвать. А тут почему-то начинается трах. Интуитивностью все это дело не страдает.
AG>Есть typedef в помощь.
Ну, вот воспроизведи пример и сравним.
AG>В самом деле, зачем? Чтобы ковыряться во внутренностях CAtlMap? Для его использования в них разбираться не надо.
А зачем они есть и документированы? Почему Dictionary<K, V> без всего успешно обходится?
AG>Думаю, на С++ можно было написать также коротко. Единственно что легче — писать foreach.
Я почти уверен. Но почему-то не пишут. Вот и интересно почему?
VD>>На написание и отладку ушло около 15 минут (точнее 14). Причем основное время убил на вычленение слов (функцию GetWords). Потребовалось два запуска для того, чтобы пример заработал корректно. И еще один для правильного подбора отступа в строках. Попробуй ради хохмы написать тоже самое на С++ с использованием АТЛ и сравним объем кода, его читаемость и время/количество отладочных запусков.
AG>Ок, завтра.
Ну, как?
AG>Из этого моря на моей машине студия и раньше был янус.
У тебя на машине еще маковских приложений нет. Но это же не значит что их нет вообще. Ты же не бухгалтер или продавец?
AG>Я вот, когда с дельфи пересел на C++, тоже противно стало на нем присать. IMHO дело привычки.
Может быть. Только противно почему-то переходиь к плюсам. А обратно без проблем.
... << RSDN@Home 1.2.0 alpha rev. 606>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, ArtemGorikov, Вы писали:
AG>Т.е. при получении hash из простого типа (например, long), мы будем иметь в лучшем случае то же дерево, что и stl::map, плюс еще доп. расход памяти — ключи + хэши к ним против только ключи у stl::map. Hash — массивы оправданны только в тех случаях, когда размер типа хэша меньше размера типа ключа.
Где смеяться? Что не так? Хэш таблица ускоряет доступ к элементам за счет памяти не зависимо от того, что хэшируется.
Здравствуйте, ArtemGorikov, Вы писали:
AG>Статья рулит
AG>Вот там написано:
AG>...При другом подходе к хешированию таблица рассматривается как массив связанных списков или деревьев ...
AG>Т.е. при получении hash из простого типа (например, long), мы будем иметь в лучшем случае то же дерево, что и stl::map, плюс еще доп. расход памяти — ключи + хэши к ним против только ключи у stl::map. Hash — массивы оправданны только в тех случаях, когда размер типа хэша меньше размера типа ключа.
Это из серии "гляжу в книгу — вижу фигу". Прочти еще раз зачем там нужен список или дерево. Могу дать наводящее слово "коллизии".
... << RSDN@Home 1.2.0 alpha rev. 606>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, ArtemGorikov, Вы писали:
AG>Здравствуйте, VladD2, Вы писали:
VD>>Таки все же интересно глянуть на тоже самое на АТЛ-е.
AG>ATL — в студию
...
Ну, вот совсем другое дело! Истенный С++-стиль! Чтобы разобраться нужно потрахаться. Код "улучшен" отсуствием декомпозиции. В общем, отличный наглядный пример того как написать шифрогрмму.
... << RSDN@Home 1.2.0 alpha rev. 606>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, VladD2, Вы писали:
VD>Здравствуйте, VladD2, Вы писали:
VD>Сори, это я файл забыл подставить. Если подставить путь к файлу, то получается более осмысленный вариант:
VD>
На какой файл натравили? Че за бред вообще вывело? У меня на текстовом файле прекрасно работает. Количество траха такое же, как в Вашем варианте, если отбросить "синтаксический оверхед".
Здравствуйте, ArtemGorikov, Вы писали:
AG>Здравствуйте, VladD2, Вы писали:
VD>>Здравствуйте, VladD2, Вы писали:
VD>>Сори, это я файл забыл подставить. Если подставить путь к файлу, то получается более осмысленный вариант:
VD>>
AG>На какой файл натравили? Че за бред вообще вывело? У меня на текстовом файле прекрасно работает. Количество траха такое же, как в Вашем варианте, если отбросить "синтаксический оверхед".
Скопиковал код из своего же поста в новый проект, собрал — работает.
Собирал и с managed extensions и без, все равно работает. Натравил на exe-шник — все равно все работает, вывела кучу "слов" на консоль. Как Вы ее собирали, ума не приложу. Поделитесь опытом
Нашел, где была проблема. К сожалению, std::cout не принял unicode, а я раньше тестил в ansi/mbcs сборке. Надо было везде на консоль выводить ansi text. Вот правильный код:
// StringTest.cpp : Defines the entry point for the console application.
//#include <iostream>
#include <tchar.h>
#define _ATL_CSTRING_EXPLICIT_CONSTRUCTORS // some CString constructors will be explicit#include <atlbase.h>
#include <atlfile.h>
#include <atlstr.h>
#include <atlcoll.h>
int _tmain(int argc, _TCHAR* argv[])
{
typedef char XCHAR; // define which format do we work with: ansi/mbcs or unicodetypedef ChTraitsCRT<XCHAR> ChTraitsX; // define char traits for strings (will use it also seperately)typedef CStringT< XCHAR, StrTraitATL<XCHAR, ChTraitsX> > CStringX; // our strings;typedef CAtlMap<CStringX, size_t> str_map; // string map ( uses hash capability of atl strings )
CAtlFile file; // atl wrapper for files
CAtlFileMapping<XCHAR> mapping; // atl wrapper for memory-mapped files. Allows access to files up to 2 GB length as
memory area.
if(argc < 2
|| FAILED(file.Create(argv[1], GENERIC_READ, FILE_SHARE_READ, OPEN_EXISTING))
|| FAILED(mapping.MapFile(file))
)
{
std::cout << "error opening file";
return 0;
}
static CStringX space_mask(" \t\r\n,./?;:\"'!()-+*=\\|{}<>[]"); // mask with seperator symbols
str_map words; // map objectfor(const XCHAR *it = mapping, *it_end = (const XCHAR*)mapping + mapping.GetMappingSize();
it < it_end;
it = ChTraitsX::CharNext(it)) // function needed to operate with mbcs symbols correctly
{
const XCHAR* it_prev = it;
while(it_prev != it_end && 0 <= space_mask.Find(*it_prev)) // skip seperator symbols at the beginning
it_prev = ChTraitsX::CharNext(it_prev);
it = it_prev;
while(it != it_end && space_mask.Find(*it) < 0) // find seperator
it = ChTraitsX::CharNext(it);
if(it != it_prev)
{
CStringX word(it_prev, it - it_prev); // extract the word
str_map::CPair* pPair = words.Lookup(word); // lookup if the word is allready in the mapif(pPair)
++pPair->m_value; // if yes, increase counterelse
words[word] = 1; // if no, reset counter to 1
}
}
std::cout << "======Begin dump=======\r\n";
for(POSITION pos = words.GetStartPosition(); pos; ) // enumerate pairs in the map and dump them to cout
{
str_map::CPair* pPair = words.GetNext(pos);
std::cout << "word \"" << CStringA(pPair->m_key) << "\" accured " << pPair->m_value << "times\r\n";
}
std::cout << "======End dump=======\r\n";
return 0;
}
Здравствуйте, ArtemGorikov, Вы писали:
AG>На какой файл натравили?
На тот же самый на который и два других примера, т.е. на исхоный шарповский.
AG> Че за бред вообще вывело?
Это тебя нужно спросить. Ты бы хоать перед тем как браво посотить этот бред проверил бы что он выдает. Идиально конечно вообще добиться аналогичного результата.
AG> У меня на текстовом файле прекрасно работает. Количество траха такое же, как в Вашем варианте, если отбросить "синтаксический оверхед".
Я не знаю что у тебя работает. Но читать твой код очень не просто. А результат вообще проверить невозможно.
... << RSDN@Home 1.2.0 alpha rev. 606>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, ArtemGorikov, Вы писали:
AG>Скопиковал код из своего же поста в новый проект, собрал — работает. AG>Собирал и с managed extensions и без, все равно работает. Натравил на exe-шник — все равно все работает, вывела кучу "слов" на консоль. Как Вы ее собирали, ума не приложу. Поделитесь опытом
Ну, незнаю. Может это из-за того что я на 2005 студии собираю. Чесно говоря сейчас копаться в отладчике влом. Один хрен выделение слов похоже не врено, так как нужно не разделители использовать, а алгоритм.
... << RSDN@Home 1.2.0 alpha rev. 606>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
------ Build started: Project: ConcordanceAtl, Configuration: Debug Win32 ------
Compiling...
ConcordanceAtl.cpp
c:\myprojects\tests\concordanceatl\concordanceatl\concordanceatl.cpp(28) : error C2065: 'memory' : undeclared identifier
c:\myprojects\tests\concordanceatl\concordanceatl\concordanceatl.cpp(28) : error C2146: syntax error : missing ';' before identifier 'area'
c:\myprojects\tests\concordanceatl\concordanceatl\concordanceatl.cpp(28) : error C2065: 'area' : undeclared identifier
c:\myprojects\tests\concordanceatl\concordanceatl\concordanceatl.cpp(29) : error C2059: syntax error : 'if'
c:\myprojects\tests\concordanceatl\concordanceatl\concordanceatl.cpp(33) : error C2143: syntax error : missing ';' before '{'
c:\myprojects\tests\concordanceatl\concordanceatl\concordanceatl.cpp(34) : error C2228: left of '.cout' must have class/struct/union
c:\myprojects\tests\concordanceatl\concordanceatl\concordanceatl.cpp(34) : error C2228: left of '.<<' must have class/struct/union
type is ''unknown-type''
c:\myprojects\tests\concordanceatl\concordanceatl\concordanceatl.cpp(38) : error C2146: syntax error : missing ';' before identifier 'space_mask'
c:\myprojects\tests\concordanceatl\concordanceatl\concordanceatl.cpp(38) : error C4430: missing type specifier - int assumed. Note: C++ does not support default-int
c:\myprojects\tests\concordanceatl\concordanceatl\concordanceatl.cpp(38) : error C2377: 'CStringX' : redefinition; typedef cannot be overloaded with any other symbol
c:\myprojects\tests\concordanceatl\concordanceatl\concordanceatl.cpp(22) : see declaration of 'CStringX'
c:\myprojects\tests\concordanceatl\concordanceatl\concordanceatl.cpp(40) : error C2146: syntax error : missing ';' before identifier 'words'
c:\myprojects\tests\concordanceatl\concordanceatl\concordanceatl.cpp(42) : error C4430: missing type specifier - int assumed. Note: C++ does not support default-int
c:\myprojects\tests\concordanceatl\concordanceatl\concordanceatl.cpp(42) : error C2143: syntax error : missing ',' before '*'
c:\myprojects\tests\concordanceatl\concordanceatl\concordanceatl.cpp(42) : error C4430: missing type specifier - int assumed. Note: C++ does not support default-int
c:\myprojects\tests\concordanceatl\concordanceatl\concordanceatl.cpp(42) : error C2146: syntax error : missing ')' before identifier 'XCHAR'
c:\myprojects\tests\concordanceatl\concordanceatl\concordanceatl.cpp(42) : error C2059: syntax error : ')'
c:\myprojects\tests\concordanceatl\concordanceatl\concordanceatl.cpp(44) : error C2228: left of '.CharNextW' must have class/struct/union
c:\myprojects\tests\concordanceatl\concordanceatl\concordanceatl.cpp(44) : error C2059: syntax error : ')'
c:\myprojects\tests\concordanceatl\concordanceatl\concordanceatl.cpp(45) : error C2143: syntax error : missing ';' before '{'
c:\myprojects\tests\concordanceatl\concordanceatl\concordanceatl.cpp(46) : error C4430: missing type specifier - int assumed. Note: C++ does not support default-int
c:\myprojects\tests\concordanceatl\concordanceatl\concordanceatl.cpp(46) : error C2143: syntax error : missing ';' before '*'
c:\myprojects\tests\concordanceatl\concordanceatl\concordanceatl.cpp(46) : error C2086: 'const int XCHAR' : redefinition
c:\myprojects\tests\concordanceatl\concordanceatl\concordanceatl.cpp(42) : see declaration of 'XCHAR'
c:\myprojects\tests\concordanceatl\concordanceatl\concordanceatl.cpp(47) : error C2228: left of '.Find' must have class/struct/union
type is ''unknown-type''
c:\myprojects\tests\concordanceatl\concordanceatl\concordanceatl.cpp(47) : fatal error C1903: unable to recover from previous error(s); stopping compilation
Build log was saved at "file://c:\MyProjects\Tests\ConcordanceAtl\ConcordanceAtl\Debug\BuildLog.htm"
ConcordanceAtl - 24 error(s), 0 warning(s)
========== Build: 0 succeeded, 1 failed, 0 up-to-date, 0 skipped ==========
ЗЫ
Ты бы создал просто Win32 Console-ый проект и задал бы в нем поддржку ATL. Тогдв жить стало бы проще. А то что-то мучаешся вручную и я вместе с тобой. Да и пример все же лучше повторять без халтуры. А то видимость меньшего объема она и есть видимость. Так, солова у тебя выделяются халтруно и сотрировку результата ты не делашь. А все это добавит объема и при твоем методе кодирования ухудшит читаемость. Собственно код уже читается очень плохо в сравнении с эталонным. В общем то об этом я и вел речь. Думаю когда ты добъешь свой год и сделашь его полностью аналогичным и работоспособным, то трах и неудобство ты сможешь оценить сам. О них я и говорил.
... << RSDN@Home 1.2.0 alpha rev. 606>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, ArtemGorikov, Вы писали:
VD>>Ты бы создал просто Win32 Console-ый проект и задал бы в нем поддржку ATL. Тогдв жить стало бы проще. А то что-то мучаешся вручную и я вместе с тобой.
AG>Я так и сделал
Тогда где строчка:
#include"stdafx.h"
AG>А как ты узнал, что выделяются халтурно?
Код прочел. Ты меня за совсем уж полного болвана не считай.
AG> Ты же не смог его собрать.
Да собрать то я его в конце концов смог. Только на коносли каша. А что там нужно где подкручивать я не помню и желания разбираться нет, так как у меня есть средство разработки вообще не имеющее подобных проблем.
AG> Вот ты требуешь сортировки, при этом против дерева в std::map.
Я не против дерева "вообще". В данном случае оно конечно позволяет уменьшить код на две строки. Но эффективность будет ведь ниже.
Ну, и главное, пример ведь не аналогичен. Хотя бы взял для приличия тогда каой-нить CRBMap.
AG> Ты бы определился уже, потому что использование дерева как раз даст отсортированный результат, а такого требования первоначально не было.
Что значит не было? Ты оригинальный код читал? Там что сортировка от болды влеплена?
VD>> А все это добавит объема и при твоем методе кодирования ухудшит читаемость. Собственно код уже читается очень плохо в сравнении с эталонным.
AG>Ах ну да, твой код у нас теперь эталон.
Естественно. Он был создан первым. Ты значение слова эталон хорошо понимашь?
БСЭ:
Эталон (франц. etalon), образец, мерило, идеальный или установленный тип чего-либо; точно рассчитанная мера чего-либо, принятая в качестве образца.
VD>> В общем то об этом я и вел речь. Думаю когда ты добъешь свой код и сделашь его полностью аналогичным и работоспособным, то трах и неудобство ты сможешь оценить сам. О них я и говорил.
AG>Мой код полностью работоспособен,
Я бы сказал, что он просто некондиционен. Он и не аналогичен, и выдает абракодабру.
AG> я его протестировал в анси и юникод — сборке на студии 2003.
И что он выдает результаты аналогичные исходному примеру?
AG> То, что ты пользуешься бетой 2005 — не мои проблемы,
Твои, твои. Код должен давать один результат не зависимо от компилятора. Да и не только в абракодабре дело.
AG> хотя тут, скорее всего, проблема драйвера клавиатуры.
Чего?
AG> Я код и не задумывал как аналогичный, он лучше.
AG> То, что у кого-то руки не от того места растут — иначе как объяснить то, что он не догадался исправить переносы, добавленные в код его чудесным ПО на сервере, написанном на самом лучшем в мире языке — C# .
Про руки чья бы корова мычала.
AG>PS Предлагаю закончить эту дискуссию.
Да, пожалй. На конструктив ты не настроен.
AG> Я для себя сделал определенные выводы, больше спорить с тобой не буду. То, что ты не в состоянии (или придуряешься) собрать 1 cpp и обвиняешь в этом меня, не делает тебе чести .
Это из серии "- Нет, дотктор. Это у вас картиночки такие.".
Ты не смог даже воспроизвести примитивный пример, а потнов целая гора. То же что твои примеры не компилируются или выдают абракодабру виноват исключительно ты. И не нужно заставлять других пыжится и исправлять твои ошибки. Например, мой код скомпилируется с первого раза. Нужно только заменить им фал дефолтного консольного проекта.
... << RSDN@Home 1.2.0 alpha rev. 606>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, VladD2, Вы писали:
VD>От части. Но не только. Все же слишком много "шума" у СТЛ-овских итераторов. И два конца совершенно не нужных для простого перебора. И определение внутри типа контейнера.
Просто они более низкоуровневые. Соответственно возможностей больше, за счет этого "шума".
От этих двух подробностей (два конца, тип контейнера) можно избавиться, написав обертку поверх stl-итераторов.
Вот, набросал тут
Здравствуйте, ArtemGorikov, Вы писали:
AG>Т.е. скомпилил и отладил в голове? Ну ты прям супер-компьютер А числа большие складывать в уме можешь быстро? Если серьезно, то я в этом сильно сомневаюсь, после того, как тебя поставило в замешательство отсутствие #include "stdafx.h" в начале исходника.
А ты не сомневайся. В тебе же никто не сомневается? Вот и ты уважай других.
Что касается "stdafx.h", то тебе как бы прозрачно намекали, что код нужно постить работоспособный. Чтобы другие не мучались. Пойми, что твой код просто никто не будет смотреть если он не скомпилируется с первого раза.
AG>Каша была в первом варианте, которую ты с радостью привел. Я нашел ошибку — ты собрал проект в unicode,
Так учись писать код так чтобы он не зависил от таких мелочей. Я собрал просто дефолтный проект ничего не переключая.
AG> и на std::cout << some_unicode_text выводилась не строка, а ее адрес в памяти или еще чего-то. Вообще-то визард консольного проекта по умолчанию настройку ставит на ansi,
Не нужно быть таким уверенным в себе. В VS 2005 визард по-умолчанию как раз создает юникодный проект. Что, кстати, логично. Ну, а то что std::cout не может нормально работать с юникодом — это опять же проблема этой библиотеки приводящая в конце коцов к тому самому траху о котором я говорю. Налепленные же тобой макросы _T() усугибили эту проблему.
AG> поэтому я не догадался специально включить unicode и проверить.
Писать нужно так чтобы догадываться не приходилось. Но тут я согласен, что основная вина лежит на реализации STL.
AG> А вот ты ее включил сам — наверно для того, чтобы сказать "ага! я нашел баг!" — это из той же оперы, когда с ты двух компов завалил базу оутлука и сказал, что он г####.
Мне не очень наравится твой тон и отношение. Дай договоримся, что ты все же будешь более уважительно относиться к собеседнику. ОК? По крайней мере все свои предположения на счет честности или подлости собеседника держи при себе. А если что просто переспроси.
VD>>Что значит не было? Ты оригинальный код читал? Там что сортировка от болды влеплена?
VD>>>> А все это добавит объема и при твоем методе кодирования ухудшит читаемость. Собственно код уже читается очень плохо в сравнении с эталонным.
AG>Не знаю зачем влеплена; скорее всего от балды. Надо было подсчитать повторы слов и все.
Что то ты изворачиваешся. Ну, да говорю тебе открытым текстом — сортировка была введена как раз чтобы можно было сравнить результаты теста. Результат твоего кода не только не отсортирован, но еще и отличается по количеству слов (еще бы ведь разбор слов попросту не сделан).
Короче, тесты не идентичены и сравнивать их нельзя. Но уже видно, что код получился очень грязным и плохо читаемым. Уверен, что будучи доведенным до полной аналогичности он будет еще хуже. Так что в качестве демонстрации он подходит уже сейчас.
AG>Ну я это и хотел сказать, что ты свой код назвал "образцовам, идеальным".
"Образец" не равно "образец для подрожания". Задача была создать аналогичный по функциональности код и сравнить время затраченное на его созадание, объем и читабельность получившегося кода.
VD>>>> В общем то об этом я и вел речь. Думаю когда ты добъешь свой код и сделашь его полностью аналогичным и работоспособным, то трах и неудобство ты сможешь оценить сам. О них я и говорил.
AG>Дело привычки.
Привыкнуть можно ко многму. Когда-то люди привыкали писать на ассемблере. Сейчас же, думаю, большинство сойдется во мнении, что это мазахистская привычка.
AG>Пришлю проект — надеюсь проблем не будет загрузить?
Ты лучше код допиши и приводи его в таком виде, чтобы его можно было просто копипэстом в пустой файл дефолтного консольного проекта засовывать.
AG>Да все понятно. Спорить с тобой бессмысленно, твой код просто эталон, а всех кто пытается дискутировать с тобой ты поливаешь грязью. Думаю, настоящий трах — это не писать на С++, а общаться с тобой.
Ну, ты на правильном пути. Воспринимай замечания как оскорбления и никогда не делай, что от тебя требуется. При этом во всем вени окружающих. Тогда всегда будешь прав.
ЗЫ
Грязь на тебя никто не выливал. Тебя просто попросили воспроисзвести тест. Ты же это не сделал и ищишь отмазки. Какова цель? Думаю, это вопрос риторический.
... << RSDN@Home 1.2.0 alpha rev. 606>>
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, VladD2, Вы писали:
VD>Здравствуйте, ArtemGorikov, Вы писали:
AG>>Т.е. скомпилил и отладил в голове? Ну ты прям супер-компьютер А числа большие складывать в уме можешь быстро? Если серьезно, то я в этом сильно сомневаюсь, после того, как тебя поставило в замешательство отсутствие #include "stdafx.h" в начале исходника.
VD>А ты не сомневайся. В тебе же никто не сомневается? Вот и ты уважай других. VD>Что касается "stdafx.h", то тебе как бы прозрачно намекали, что код нужно постить работоспособный. Чтобы другие не мучались. Пойми, что твой код просто никто не будет смотреть если он не скомпилируется с первого раза.
AG>>Каша была в первом варианте, которую ты с радостью привел. Я нашел ошибку — ты собрал проект в unicode,
VD>Так учись писать код так чтобы он не зависил от таких мелочей. Я собрал просто дефолтный проект ничего не переключая.
А если используется командная строка, то stdafx.h нафиг не нужен.




 Перекуём баги на фичи!
Перекуём баги на фичи!













 Если нам не помогут, то мы тоже никого не пощадим.
Если нам не помогут, то мы тоже никого не пощадим.