Здравствуйте, AlexGin, Вы писали:
AG>Предполагается, что TCP канал (между сервером и клиентом) всё время установлен. AG>Но мне почему-то кажется, что наличие дополнительного UDP канала обеспечит более быстрое (хотя и менее надежное, нежели TCP) оповещение клиентов.
Это ложное чувство. Разницы в скорости не будет. AG>Если же вводить тайм-аут, как я писал выше, то приимушества от UDP-Notify канала теряются. Как в этом случае быть?
У тебя есть установленное соединение, делай всю работу в нем. Это избавит тебя от сложностей переусложненной архитектуры, проблем маршрутизации и борьбы с межсетевыми экранами и проактивными защитами.
Здравствуйте, AlexGin, Вы писали:
AG>генерируется широковещательная UDP датаграмма, приняв которую, клиенты начинают опрос сервера (серверов). AG>Этот опрос реализован через посылки рабочих TCP запросов к серверу (серверам) приложения.
А если эта датагдама потеряется? С UDB датаграммами это нередко случается, особенно с широковещательными.
AG>И здесь у меня возникает такой вопрос: не "ляжет" ли сервер, если клиентов много?
Здравствуйте, Kernan, Вы писали:
AG>>Сделать pooling — периодически опрос со сервера стороны клиентов? K>Не надо. У тебя же ТСП. Отвалится — узнаешь.
TCP может очень долго не осонавать, что он уже отвалился. Лучше бы в прикладном протоколе предусмотреть периодическое пингование сервера. И быть готовым к тому, что разрыв соединения с последуюшим успешным реконнектом — вполне штатная ситуация, хоть и нечастая.
Здравствуйте, AlexGin, Вы писали:
AG>Если вдруг при расчете что-по пошло не так AG>Напимер, выяснилось, что для данного набора исходних данных применение данной формулы (алгоритма) невозможно!
AG>Как (и главное — когда) ты узнал об этом?
Ну протокол выглядит примерно так:
Клиент: отправил задачу Агенту.
Агент: вернул ОК, соединение разорвали.
Через заданный промежуток времени (5сек, кажется)
Клиент: Агент, что там с задачей?
Агент: Стоит в очереди.
...
...
Клиент: Агент, что там с задачей?
Агент: Начинаю считать.
...
Клиент: Агент, что там с задачей?
Агент: Опаньки, памяти не хватает или лицензии недостаточно, или лицензия у меня протухла...
Тогда Клиент перешлет задачу другому агенту, либо скажет пользователю, мол, "не шмогла".
Т.е. между отправкой и получением информации какое-то время пройдет.
Если передавать какие-то метрики отправляемой задачи, то на ситуации, типа нехватки памяти, можно будет отреагировать сразу, в ответе на сабмит.
AG>Вот для этого я и предлагаю использовать UDP-нотификацию...
Ну про проблемы с пересечением шлюза камрады уже написали. Надо смотреть, в какой среде всё происходит.
Если, к примеру, только в интранете и с предварительной настройкой под руководством специально обученных людей, то это совсем другая кухня.
У нас всё работает, даже если агент стоит на домашней машине, а клиент коннектится из аэропорта на другом конце Шарика по мобильному интернету.
Сетевые задержки пренебрежимо малы на фоне времени вычислений, трафик очень маленький.
_____________________
С уважением,
Stanislav V. Zudin
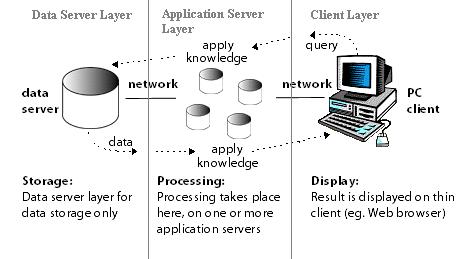
Я разрабатываю приложение с трехуровневой архитектурой:
Действие структуры — классическое:
Каждый новый клиент "прописывается" в этой структуре (используюя TCP запрос к серверу), и с этого момента сервер (сервера) знают о нём и обслуживают его.
В процессе функционирования сервер (сервера) приложения выполнияют некоторую работу, связанную с бизнес-логикой продукта.
Если на уровне этих серверов что-либо изменилось (например, получен результат расчётов или выявлено, что дальнейший расчёт навозможен) —
генерируется широковещательная UDP датаграмма, приняв которую, клиенты начинают опрос сервера (серверов).
Этот опрос реализован через посылки рабочих TCP запросов к серверу (серверам) приложения.
И здесь у меня возникает такой вопрос: не "ляжет" ли сервер, если клиентов много?
Может быть, следовало бы настраивать тайм-ауты с разной (для каждого клиента — своё время ожидания) время-выдержкой.
Этот тайм-аут будет отмеряться на каждом из клиентов — от поступления широковещательной UDP датаграммы, до генерации рабочего TCP запроса.
Или же есть какой-либо другой способ, как обойти данную проблему?
В общем — какие у кого соображения на этот счет?
Буду признателен за любые подсказки!
P.S. Картинку приведенную выше, я нашёл в Интернете. У меня клиенты не совсем "тонкие", и работа через Web-browser невозможна.
Но тем не менее, основная суть разрабатывемой мною системы аналогична изображенной на рисунке выше.
Здравствуйте, AlexGin, Вы писали:
AG>Этот опрос реализован через посылки рабочих TCP запросов к серверу (серверам) приложения.
Так TCP коннект состоялся. Что мешает просто оставить соединенеи открытым и пинговать по нему? Ну и броадкаст UDP это самый плохой вариант который только можно придумать из-за наличия фаерволов, НАТ, зарезания UDP на уровне шлюзов. AG>Или же есть какой-либо другой способ, как обойти данную проблему?
Мне кажется так уже никто не делает. AG>Буду признателен за любые подсказки!
Я думаю, тебе надо немного приоткрыть контекст работы системы тогде тебе скажут точнее как лучше сделать.
Здравствуйте, AlexGin, Вы писали:
AG>генерируется широковещательная UDP датаграмма, приняв которую, клиенты начинают опрос сервера (серверов).
Как-то грозно звучит. Может, заменить каким-нибудь модным PubSub решением?
AG>Может быть, следовало бы настраивать тайм-ауты с разной (для каждого клиента — своё время ожидания) время-выдержкой.
Если клиент может подождать, то организуй очередь обработки обращений. Если очередь полна, быстро отвечай клиенту "занято", пусть покурит чуток и снова зайдет.
Здравствуйте, Kernan, Вы писали:
K>Здравствуйте, AlexGin, Вы писали:
K>Я думаю, тебе надо немного приоткрыть контекст работы системы тогде тебе скажут точнее как лучше сделать.
Хорошо, пока я разрабатываю всё просто: один клиент и один сервер. Всё это хозяйство на IP=127.0.0.1 (localhost).
В дальнейшем, я установил отдаельный сервер (на Debian или Ubuntu) и вокруг него расположил клиентов (на Windows или на той же Ubuntu).
Сервер — загружен некоторой работой, предполагается в основном расчетная работа (точнее — моделирование).
Клиенты должны периодически (в любой произвольный момент времени) получать результаты работы.
Предполагается, что TCP канал (между сервером и клиентом) всё время установлен.
Но мне почему-то кажется, что наличие дополнительного UDP канала обеспечит более быстрое (хотя и менее надежное, нежели TCP) оповещение клиентов.
Если же вводить тайм-аут, как я писал выше, то приимушества от UDP-Notify канала теряются. Как в этом случае быть?
Здравствуйте, AlexGin, Вы писали:
AG>Сервер — загружен некоторой работой, предполагается в основном расчетная работа (точнее — моделирование). AG>Клиенты должны периодически (в любой произвольный момент времени) получать результаты работы.
Результаты работы не зависят от запросов клиентов? Клиенты получают всего лишь текущую версию рассчитанного?
AG>Предполагается, что TCP канал (между сервером и клиентом) всё время установлен.
Зачем? Клиент не может обойтись схемой запрос-ответ и отвалился?
AG>Но мне почему-то кажется, что наличие дополнительного UDP канала обеспечит более быстрое (хотя и менее надежное, нежели TCP) оповещение клиентов. AG>Если же вводить тайм-аут, как я писал выше, то приимушества от UDP-Notify канала теряются. Как в этом случае быть?
Не понятны требования к быстродействию системы в целом. С одной стороны оповещение через широковещательные UDP, с другой и таймауты допустимы.
Здравствуйте, Mihas, Вы писали:
M>Здравствуйте, AlexGin, Вы писали:
AG>>Сервер — загружен некоторой работой, предполагается в основном расчетная работа (точнее — моделирование). AG>>Клиенты должны периодически (в любой произвольный момент времени) получать результаты работы. M>Результаты работы не зависят от запросов клиентов? Клиенты получают всего лишь текущую версию рассчитанного?
Пока планируется именно так. Обший массив данных (пакетов) для всех клиентов.
В будущем может что-то и меняться (например каждому из клиентов — свой массив данных).
AG>>Предполагается, что TCP канал (между сервером и клиентом) всё время установлен. M>Зачем? Клиент не может обойтись схемой запрос-ответ и отвалился?
Кстати да, может. Возможно — это даже правильнее.
Почему я взял вариант с постоянным соединением — из соображений что так быстрее (не тратим время на re-connect).
AG>>Но мне почему-то кажется, что наличие дополнительного UDP канала обеспечит более быстрое (хотя и менее надежное, нежели TCP) оповещение клиентов. AG>>Если же вводить тайм-аут, как я писал выше, то приимушества от UDP-Notify канала теряются. Как в этом случае быть? M>Не понятны требования к быстродействию системы в целом. С одной стороны оповещение через широковещательные UDP, с другой и таймауты допустимы.
Смотря какие тайм-ауты. Три-четыре секунды — допустимы.
Полчаса (или даже 10 минут) НЕДОПУСТИМО.
P.S. А применение схемы запрос-ответ как-то решит проблему нотификации о новых данных на сервере?
Здравствуйте, AlexGin, Вы писали:
AG>Действие структуры — классическое: AG>Каждый новый клиент "прописывается" в этой структуре (используюя TCP запрос к серверу), и с этого момента сервер (сервера) знают о нём и обслуживают его.
AG>В процессе функционирования сервер (сервера) приложения выполнияют некоторую работу, связанную с бизнес-логикой продукта. AG>Если на уровне этих серверов что-либо изменилось (например, получен результат расчётов или выявлено, что дальнейший расчёт навозможен) - AG>генерируется широковещательная UDP датаграмма, приняв которую, клиенты начинают опрос сервера (серверов). AG>Этот опрос реализован через посылки рабочих TCP запросов к серверу (серверам) приложения.
AG>И здесь у меня возникает такой вопрос: не "ляжет" ли сервер, если клиентов много?
Мы числодробительную задачу решали по другому.
"Агент", который выполняет вычисления, пассивен. Сам никому ничего не шлет, открытых соединений не держит. Доступ к нему через REST API.
Клиентская часть рассылает доступным агентам задания, а потом периодически опрашивает состояние и по результатам досылает еще, запрашивает результаты, отменяет вычисления и проч.
Клиентских частей может быть несколько, задания на агенте ставятся в очередь.
Из плюсов — можно засабмитить задачу, выключить лаптоп и поехать домой. Дома подключиться и получить готовый результат.
_____________________
С уважением,
Stanislav V. Zudin
Здравствуйте, AlexGin, Вы писали:
AG>В дальнейшем, я установил отдаельный сервер (на Debian или Ubuntu) и вокруг него расположил клиентов (на Windows или на той же Ubuntu).
Да это не важно. Важно нужна ли согласованность по данным между клиентами или клиенты работают каждый со своими данными. AG>Сервер — загружен некоторой работой, предполагается в основном расчетная работа (точнее — моделирование).
Клиент отдаёт на сервер модель которую надо обсчитать? AG>Клиенты должны периодически (в любой произвольный момент времени) получать результаты работы.
У меня сложилось впечателение что клиенты работают над одними и теми же данными и результаты обработки этих данных надо синхрониировать между всеми клиентами. Это так? AG>Предполагается, что TCP канал (между сервером и клиентом) всё время установлен.
Тогда ЮДП не нужен. AG>Но мне почему-то кажется, что наличие дополнительного UDP канала обеспечит более быстрое (хотя и менее надежное, нежели TCP) оповещение клиентов.
Нет, он создат дополнительный геморрой на сервене. У тебя нет никаких причин не послать команду на опрос через этот коннекшн. Можно делать с некоторым гэпом по времени для разных клиентов. AG>Если же вводить тайм-аут, как я писал выше, то приимушества от UDP-Notify канала теряются. Как в этом случае быть?
Не парится. Мне кажется тут вообще вёбсокет какой-нибудь можно создать и всё средствами http делать в браузере.
Здравствуйте, Kernan, Вы писали:
AG>>Сервер — загружен некоторой работой, предполагается в основном расчетная работа (точнее — моделирование). K>Клиент отдаёт на сервер модель которую надо обсчитать?
Нет, это заранее известные константные данные.
Они считываются сервером из БД.
AG>>Клиенты должны периодически (в любой произвольный момент времени) получать результаты работы. K>У меня сложилось впечателение что клиенты нарботают над одними и теми же данными и результаты обработки этих данных надо синхрониировать между всеми клиентами. Это так?
Да, над одними и теми же данными. Результаты следует синхронизировать — именно так.
AG>>Предполагается, что TCP канал (между сервером и клиентом) всё время установлен. K>Тогда ЮДП не нужен.
Сделать pooling — периодически опрос со сервера стороны клиентов?
Или же просто в TCP-сокете (объект типа QTcpSocket) вызывать write(...) при готовности данных?
AG>>Но мне почему-то кажется, что наличие дополнительного UDP канала обеспечит более быстрое (хотя и менее надежное, нежели TCP) оповещение клиентов. K>Нет, он создат дополнительный геморрой на сервене. У тебя нет никаких причин не послать команду на опрос через этот коннекшн. Можно делать с некоторым гэпом по времени для разных клиентов.
Возможно, что будет дополнительный геморрой за счёт UDP. Может даже придется выбросить этот самый UDP канал...
AG>>Если же вводить тайм-аут, как я писал выше, то приимушества от UDP-Notify канала теряются. Как в этом случае быть? K>Не парится. Мне кажется тут вообще вёбсокет какой-нибудь можно создать и всё средствами http делать в браузере.
Ну броузер здесь вроде как совсем не в тему. Но вот вариант — сделать HTTP и раздавать JSON-строки — возможно даже и неплохой.
Здравствуйте, AlexGin, Вы писали:
AG>P.S. А применение схемы запрос-ответ как-то решит проблему нотификации о новых данных на сервере?
Нет. Только, если долбить постоянно запросами.
Мне кажется, ты пытаешься изобрести систему мгновенных сообщений. Рассмотри готовые решения.
Для схемы сервер оповещает клиента, самое простое — websocket.
Для схемы клиент оповещает другого клиента через сервер мы использовали протокол MQTT. Из китов его использует Амазон в своем сервисе IoT. Так что, вполне себе вариант.
Также я экспериментировал с Redis — тоже умеет.
Здравствуйте, Stanislav V. Zudin, Вы писали:
SVZ>Мы числодробительную задачу решали по другому. SVZ>"Агент", который выполняет вычисления, пассивен. Сам никому ничего не шлет, открытых соединений не держит. Доступ к нему через REST API.
Сделать HTTP пассивный сервер, который по определенному запросу отсылает JSON-строки?
SVZ>Клиентская часть рассылает доступным агентам задания, а потом периодически опрашивает состояние и по результатам досылает еще, запрашивает результаты, отменяет вычисления и проч. SVZ>Клиентских частей может быть несколько, задания на агенте ставятся в очередь.
Рассылает как?
Через HTTP запрос PUT/POST?
Здравствуйте, m2l, Вы писали:
m2l>Здравствуйте, AlexGin, Вы писали:
AG>>Предполагается, что TCP канал (между сервером и клиентом) всё время установлен. AG>>Но мне почему-то кажется, что наличие дополнительного UDP канала обеспечит более быстрое (хотя и менее надежное, нежели TCP) оповещение клиентов. m2l>Это ложное чувство. Разницы в скорости не будет. AG>>Если же вводить тайм-аут, как я писал выше, то приимушества от UDP-Notify канала теряются. Как в этом случае быть? m2l>У тебя есть установленное соединение, делай всю работу в нем. Это избавит тебя от сложностей переусложненной архитектуры, проблем маршрутизации и борьбы с межсетевыми экранами и проактивными защитами.
Интересная мысль...
То есть — обойтись ТОЛЬКО TCP соединением?
Здравствуйте, AlexGin, Вы писали:
SVZ>>Мы числодробительную задачу решали по другому. SVZ>>"Агент", который выполняет вычисления, пассивен. Сам никому ничего не шлет, открытых соединений не держит. Доступ к нему через REST API. AG>Сделать HTTP пассивный сервер, который по определенному запросу отсылает JSON-строки?
Ага. Я использовал Poco для сетевой части.
Сейчас сомневаюсь, может и зря. Для работы с http в Poco есть всё, но работает в блокирующем режиме.
Умеет ли Poco работать с http в неблокирующем режиме или придется вручную всё делать — пока не разбирался.
SVZ>>Клиентская часть рассылает доступным агентам задания, а потом периодически опрашивает состояние и по результатам досылает еще, запрашивает результаты, отменяет вычисления и проч. SVZ>>Клиентских частей может быть несколько, задания на агенте ставятся в очередь. AG>Рассылает как? AG>Через HTTP запрос PUT/POST?
Именно так.
_____________________
С уважением,
Stanislav V. Zudin
Здравствуйте, Stanislav V. Zudin, Вы писали:
AG>>Через HTTP запрос PUT/POST?
SVZ>Именно так.
Если вдруг при расчете что-по пошло не так
Напимер, выяснилось, что для данного набора исходних данных применение данной формулы (алгоритма) невозможно!
Как (и главное — когда) ты узнал об этом?
Вот для этого я и предлагаю использовать UDP-нотификацию...
Здравствуйте, AlexGin, Вы писали:
AG>Да, над одними и теми же данными. Результаты следует синхронизировать — именно так.
Тогда коннект надо деражть +- открытым. AG>Сделать pooling — периодически опрос со сервера стороны клиентов?
Не надо. У тебя же ТСП. Отвалится — узнаешь. AG>Или же просто в TCP-сокете (объект типа QTcpSocket) вызывать write(...) при готовности данных?
Сервер легко может уведомлять клиента о наличии данных и даже их сразу же отдавать. Вопрос в том, готов ли клиент их принять поэтому пинг-понг + ГЕТ модель неплоха. AG>Возможно, что будет дополнительный геморрой за счёт UDP. Может даже придется выбросить этот самый UDP канал...
Тебе не нужен ЮДП, он внесёт только проблемы. AG>Ну броузер здесь вроде как совсем не в тему. Но вот вариант — сделать HTTP и раздавать JSON-строки — возможно даже и неплохой.
На схеме браузер был. Я думал клиенты это приложения в браузере.
Здравствуйте, Kernan, Вы писали:
K>Здравствуйте, AlexGin, Вы писали:
AG>>Да, над одними и теми же данными. Результаты следует синхронизировать — именно так. K>Тогда коннект надо деражть +- открытым. AG>>Сделать pooling — периодически опрос со сервера стороны клиентов? K>Не надо. У тебя же ТСП. Отвалится — узнаешь. AG>>Или же просто в TCP-сокете (объект типа QTcpSocket) вызывать write(...) при готовности данных? K>Сервер легко может уведомлять клиента о наличии данных и даже их сразу же отдавать. Вопрос в том, готов ли клиент их принять поэтому пинг-понг + ГЕТ модель неплоха.
AG>>Возможно, что будет дополнительный геморрой за счёт UDP. Может даже придется выбросить этот самый UDP канал... K>Тебе не нужен ЮДП, он внесёт только проблемы.
Ясно, похоже что это именно так.
AG>>Ну броузер здесь вроде как совсем не в тему. Но вот вариант — сделать HTTP и раздавать JSON-строки — возможно даже и неплохой. K>На схеме браузер был. Я думал клиенты это приложения в браузере.
Я взял картинку из Интернета — но у меня броузерного клиента пока не предвидится.
Здравствуйте, AlexGin, Вы писали:
AG>Интересная мысль... AG>То есть — обойтись ТОЛЬКО TCP соединением?
Да. А если ты собираешься раздавать своего клиента широкому кругу пользователей, то лучше вообще использовать HTTP (или websock поверх HTTP). Бывают такие места, откуда местные фаирволы по абы какому TCP не пускают.
Здравствуйте, Pzz, Вы писали:
Pzz>Да. А если ты собираешься раздавать своего клиента широкому кругу пользователей, то лучше вообще использовать HTTP (или websock поверх HTTP). Бывают такие места, откуда местные фаирволы по абы какому TCP не пускают.
Нет, круг пользователей скорее узкий и специфичный.
В общем — пока я убрал UDP и оставил только один TCP.
Вроде все нормально работает
Здравствуйте, Pzz, Вы писали:
Pzz>А если эта датагдама потеряется? С UDB датаграммами это нередко случается, особенно с широковещательными.
+100500
Отказался я от UDP и датаграмм. Оставил только TCP (всё при этом нормально функционирует).
По крайней мере, я понял, что в UDP нет необходимости в контексте данной задачи.
Pzz>А "много" — это сколько?
Пока — сколько точно будет клентов — сам не знаю.
Может пару десятков, а может пару сотен.
Для Заказчика нужно подготовить масштабируемое решение.
Вполне допускаю, что придется делать балансировку нагрузки на серверах — в общем жизнь покажет.
Здравствуйте, AlexGin, Вы писали:
AG>Для Заказчика нужно подготовить масштабируемое решение. AG>Вполне допускаю, что придется делать балансировку нагрузки на серверах — в общем жизнь покажет.
Ну вообще-то, на этапе постановки задачи неплохо бы понимать, насколько оно будет массштабируемое. Ну или быть готовым к тому, что сейчас вы делаете прототип, а потом все перепишете нафиг. Потому что степень массштабируемости оказывает существенное влияние на общую архитектуру, да и в прикладном протоколе, возможно, придется потом это учитывать. Не каждая конструкция хорошо массштабируется, если просто добавить серверов.
Здравствуйте, Pzz, Вы писали:
Pzz>Ну вообще-то, на этапе постановки задачи неплохо бы понимать, насколько оно будет массштабируемое. Ну или быть готовым к тому, что сейчас вы делаете прототип, а потом все перепишете нафиг.
+100500
Это в принцыпе вполне возможный вариант.
Тем более, что переписывать придется не всё: алгоритмы и формулы всё-таки будут отработаны, GUI — также частично проработан.
Сетевой уровень, сервисные службы — да похоже, что кардинально изменятся, но прсматриваться к проблеме, ИМХО, нужно и важно уже теперь (на дальних подступах).
Pzz>Потому что степень массштабируемости оказывает существенное влияние на общую архитектуру, да и в прикладном протоколе, возможно, придется потом это учитывать. Не каждая конструкция хорошо массштабируется, если просто добавить серверов.
+100500
Здесь еще имеет место тот факт, что архитектура завязана на контект задач Заказчика, и пока его _не_понимеешь_/_не_видишь_, проще заниматься "кирпичиками", из которых в дальнейшем бедем строить дом.
И вполне возможно, что какие-нибудь "кирпичики" придётся выбросить и заменить на другие. Как-то так
Важно:
Оснастить наши "кирпичики" такими интерфейсами, чтобы замена/апгрейд одного, не оказывали (кардинального?) влияния на все остальные.
Именно с этой целью я при разработке стараюсь уменьшать связность между компонентами наших проектов.
Как показала практика — это очень верный выбор (даже если данный шаг вызовет некоторую избыточность, он оправдывает себя).
А почему не используются IGMP и мультикасты? У меня стойкое ощущение, что будет самое то.
AG>Каждый новый клиент "прописывается" в этой структуре (используюя TCP запрос к серверу), и с этого момента сервер (сервера) знают о нём и обслуживают его.
Т.е. клиент посылает join-запрос в группу
AG>Если на уровне этих серверов что-либо изменилось (например, получен результат расчётов или выявлено, что дальнейший расчёт навозможен) - AG>генерируется широковещательная UDP датаграмма...
Мультикаст как он есть. Только, в отличие от широковещалки, оно
* доставляется только заинтересованным сторонам
* умеет проходить через маршрутизаторы (если там явно не запрещено)
* будет работать на IPv6
AG> ...приняв которую, клиенты начинают опрос сервера (серверов). AG>Этот опрос реализован через посылки рабочих TCP запросов к серверу (серверам) приложения.
Ну, тут уже на свой вкус — как по мне, вплоне себе рабочее решение.
AG>И здесь у меня возникает такой вопрос: не "ляжет" ли сервер, если клиентов много? AG>Может быть, следовало бы настраивать тайм-ауты с разной (для каждого клиента — своё время ожидания) время-выдержкой. AG>Этот тайм-аут будет отмеряться на каждом из клиентов — от поступления широковещательной UDP датаграммы, до генерации рабочего TCP запроса.
Можно решать по-разному:
* клиент бросает кубик и выбирает себе рандомную задержку перед началом запроса к серверу, равно как и сервер может ответить "сейчас не могу, повтори запрос через N времени" и закрыть сокет
* сервер не один, а прячется целая ферма за Load balancer (которую тот же nGinx разруливает, например)
* или serverless-подход в облаке, тогда нет проблем с автоскейлингом, были б деньги
Здравствуйте, Kernan, Вы писали:
K>Не надо. У тебя же ТСП. Отвалится — узнаешь.
А вот не факт. Достаточно одного дурного маршрутизатора, который не отпустил у себя туннель, и всё — готова чёрная дыра. Поэтому для гарантий "отавлится узнаешь" — только heartbit на уровне прикладного протокола. Двойной интервал истёк — дропаем у себя коннект не взирая на.
AG>>Или же просто в TCP-сокете (объект типа QTcpSocket) вызывать write(...) при готовности данных? K>Сервер легко может уведомлять клиента о наличии данных и даже их сразу же отдавать. Вопрос в том, готов ли клиент их принять поэтому пинг-понг + ГЕТ модель неплоха. AG>>Возможно, что будет дополнительный геморрой за счёт UDP. Может даже придется выбросить этот самый UDP канал... K>Тебе не нужен ЮДП, он внесёт только проблемы. AG>>Ну броузер здесь вроде как совсем не в тему. Но вот вариант — сделать HTTP и раздавать JSON-строки — возможно даже и неплохой. K>На схеме браузер был. Я думал клиенты это приложения в браузере.
Я не увидел возможности применения данной технологии в нашем продукте:
-видеопотока у нас нет. Сам по себе объем данных, у нас меньше, чем при видеопотоке;
-все данные, курсирующие по сети, достаточно критичны (в т.ч. и к потере пакетов), посему — реализовал идею полного отказа от UDP канала (полностью всё на TCP);
-сама по себе разбивка юзеров на группы неочевидна. Также, (пока?) нет очевидности в необходимости наличия самих пользовательских групп.
MD>Можно решать по-разному: MD>* клиент бросает кубик и выбирает себе рандомную задержку перед началом запроса к серверу, равно как и сервер может ответить "сейчас не могу, повтори запрос через N времени" и закрыть сокет
Идея интересная, но закрытие сокета не предусмотрено. У меня постоянный канал между сервером и клиентом.
MD>* сервер не один, а прячется целая ферма за Load balancer (которую тот же nGinx разруливает, например)