Здравствуйте, Аноним, Вы писали:
А>Собственно ждемс....
Сам парсер уже готов. Сейчас работаем над автоматическим восстановлением после обнаружения ошибок. Исследовательская часть закончена. Сейчас ваяем окончательный код. Как закончим начнем показывать.
Хардкей сейчас вот с инсталлятором борется. Пришлось в Немерле пару багов пофиксить.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, Аноним, Вы писали: А>Собственно ждемс....
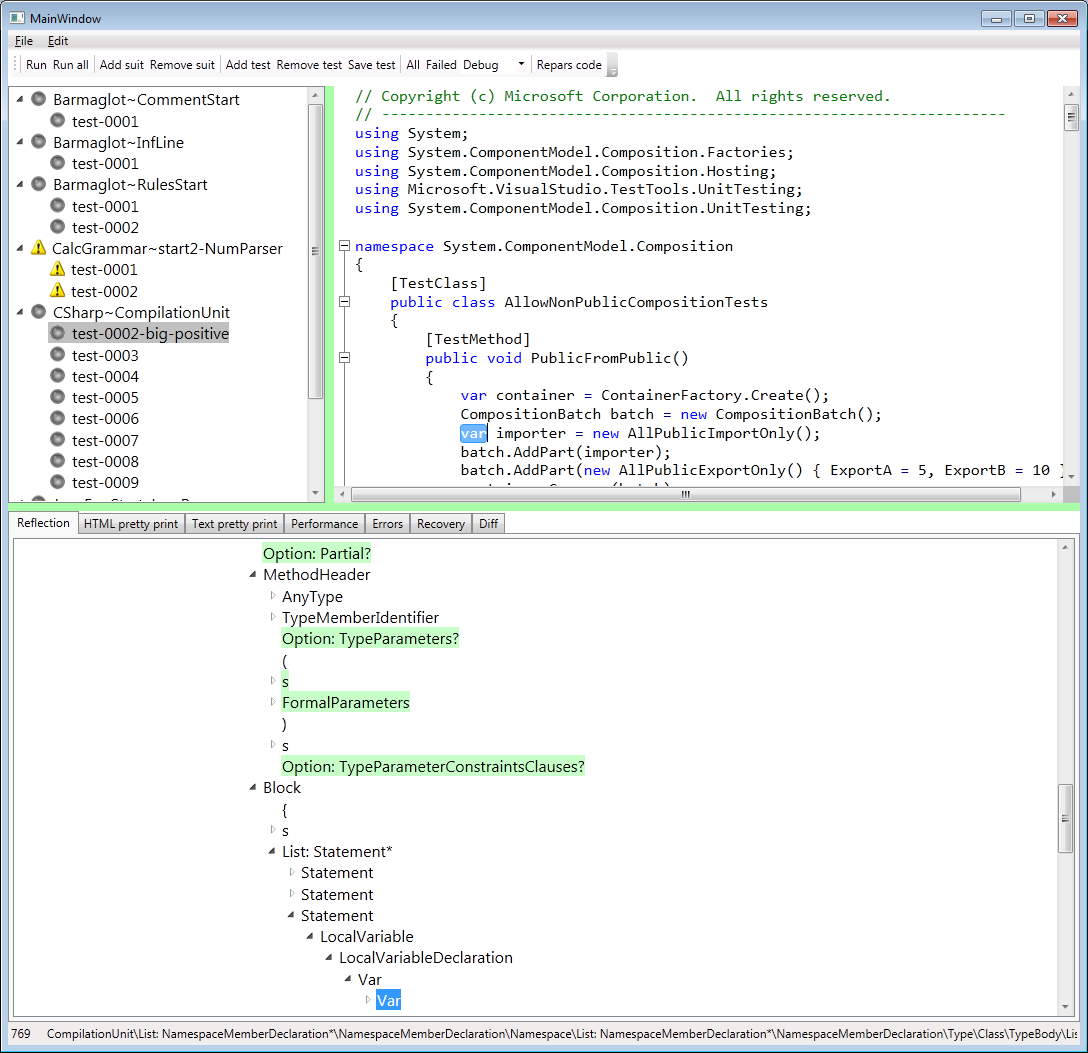
Вот скриншот утилиты предназначенной для отладки и тестирования парсеров. Подсветка и аутлайнинг в ней делаются средствами N2, т.е. код C# честно парсится и уже по выхлопу парсера производится подсветка и аутлайнинг. В результате мы можем правильно подсвечивать контекстные ключевые слова вроде var или get/set. Ниже показано виртуальное АСТ (мы это называем рефлексией).
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, VladD2, Вы писали:
VD>ключевые слова вроде var или get/set. Ниже показано виртуальное АСТ (мы это называем рефлексией).
А в чём его виртуальность? И почему рефлексией.
Здравствуйте, fddima, Вы писали:
VD>>ключевые слова вроде var или get/set. Ниже показано виртуальное АСТ (мы это называем рефлексией). F> А в чём его виртуальность? И почему рефлексией.
Судя по скрину AST сгенерировано автоматически, на основании парсера. Видимо поэтому и виртуальное
Здравствуйте, fddima, Вы писали:
F> А в чём его виртуальность? И почему рефлексией.
Потому что как-такового АСТ нет. Есть два массива типа int. Один хранит лог парсера (записанная в int-ах информация о спаривавшихся правилах). Второй хранит ссылку на список мемоизации хранящийся в первом массиве.
Первый массив хранит не только конечные ветки, но и те что обломались пропарсив несколько символов, и те альтернативы спарсили текст одинаковой длинны. Наш алгоритм позволяет парсить неоднозначные грамматики. В случае, если альтернативы разбирают текст разной длинны, побеждает длиннейшая. В случае если одинаковой, получается неоднозначность. Неоднозначности можно потом разруливать. Это позволяет парсить С++ без использования таблицы символов во время парсинга.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, VladD2, Вы писали:
F>> А в чём его виртуальность? И почему рефлексией. VD>Потому что как-такового АСТ нет. Есть два массива типа int. Один хранит лог парсера (записанная в int-ах информация о спаривавшихся правилах). Второй хранит ссылку на список мемоизации хранящийся в первом массиве.
Спасибо. Звучит круто. Это же ради оптимизации, так?
VD>Первый массив хранит не только конечные ветки, но и те что обломались пропарсив несколько символов, и те альтернативы спарсили текст одинаковой длинны. Наш алгоритм позволяет парсить неоднозначные грамматики. В случае, если альтернативы разбирают текст разной длинны, побеждает длиннейшая. В случае если одинаковой, получается неоднозначность. Неоднозначности можно потом разруливать. Это позволяет парсить С++ без использования таблицы символов во время парсинга.
А для чего сохраняются неудачные ветки — где это применяется? Т.е. почему не остаются только удачные и неоднозначные?
Здравствуйте, fddima, Вы писали:
F> А для чего сохраняются неудачные ветки — где это применяется? Т.е. почему не остаются только удачные и неоднозначные?
Коротко — они используются при парсинге для восстановления после синтаксических ошибок.
Здравствуйте, hardcase, Вы писали:
F>> А для чего сохраняются неудачные ветки — где это применяется? Т.е. почему не остаются только удачные и неоднозначные? H>Коротко — они используются при парсинге для восстановления после синтаксических ошибок.
Да длинно и не надо — всё равно до конца не пойму.
Т.е. эти массивы интов — они являются прямым выводом парсера — и "чистить" эти ветки наверное не очень и целесообразно?
Здравствуйте, fddima, Вы писали:
F> Спасибо. Звучит круто. Это же ради оптимизации, так? F> А для чего сохраняются неудачные ветки — где это применяется? Т.е. почему не остаются только удачные и неоднозначные?
Для разных целей. И для восстановления, и просто потому-что мы не знаем обломается ветка или нет, а GC в массивах нет, да и дорого время тратить на очистку. По сути это лог компиляции, двоичный АСТ и многое другое в одном флаконе. Потом этот подход очень легко переносится на низкоуровневые языки вроде С или ассемблера. Так что в последстивии можно будет легко поднять производительность генерируя код парсера на C, llvm или просто в маш-кодах.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
VD>Потому что как-такового АСТ нет. Есть два массива типа int. Один хранит лог парсера (записанная в int-ах информация о спаривавшихся правилах). Второй хранит ссылку на список мемоизации хранящийся в первом массиве.
А возможность собирать свой АСТ будет? Я имею в виду, удобно ли будет использовать этот парсер вне контекста IDE и разбора языков программирования? Какой-нибудь самопальный формат конфигов распарсить, к примеру?
Здравствуйте, STDray, Вы писали:
STD>А возможность собирать свой АСТ будет? Я имею в виду, удобно ли будет использовать этот парсер вне контекста IDE и разбора языков программирования? Какой-нибудь самопальный формат конфигов распарсить, к примеру?
Создать объектный AST можно и сейчас. Это делается с помощью специального обходчика. Можно будет сделать и свой обходчик который сгенерирует AST нужной "формы".
В будущем мы планируем работу без объектного AST-а. У нас уже есть механизм эдаких методов на AST-е. Это DSL позволяющий манипулировать непосредственно ветками AST как значениями. Сейчас он работает по объектному AST. Мы планируем сделать так, чтобы он работал, непосредственно, по массивам интов. Тогда нужда в наличии объектного AST-а отпадет полностью.
Вот пример калькулятора вычисления в котором производятся с помощью этих методов:
syntax module Calc
{
using PrettyPrint;
using Outline;
using TokenNames;
using StandardSpanClasses;
using Whitespaces;
using Identifiers;
using CStyleComments;
[StartRule, ExplicitSpaces]
syntax Start = s Expression !Any
{
Value() : double = Expression.Value();
}
extend syntax IgnoreToken
{
| [SpanClass(Comment)] SingleLineComment = SingleLineComment;
| [SpanClass(Comment)] MultiLineComment;
}
token Number = ['0'..'9']+ ('.' ['0'..'9']*)?;
syntax Expression
{
Value() : double;
missing Value = double.NaN;
| Number
{
override Value = double.Parse(GetText(this.Number));
}
| Add = Expression sm '+' sm Expression precedence 10
{
override Value = Expression1.Value() + Expression2.Value();
}
| Sub = Expression sm '-' sm Expression precedence 10
{
override Value = Expression1.Value() - Expression2.Value();
}
| Mul = Expression sm '*' sm Expression precedence 20
{
override Value = Expression1.Value() * Expression2.Value();
}
| Div = Expression sm '/' sm Expression precedence 20
{
override Value = Expression1.Value() / Expression2.Value();
}
| Pow = Expression sm '^' sm Expression precedence 30 right-associative
{
override Value = System.Math.Pow(Expression1.Value(), Expression2.Value());
}
| Neg = '-' Expression precedence 100
{
override Value = -Expression.Value();
}
| Plus = '+' Expression precedence 100
{
override Value = Expression.Value();
}
| Rounds = '(' Expression ')'
{
override Value = Expression.Value();
}
}
}
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, VladD2, Вы писали:
VD>Сам парсер уже готов. Сейчас работаем над автоматическим восстановлением после обнаружения ошибок. Исследовательская часть закончена. Сейчас ваяем окончательный код. Как закончим начнем показывать.
VD>Хардкей сейчас вот с инсталлятором борется. Пришлось в Немерле пару багов пофиксить.
А можно выкатить сейчас парсер без восстановления после ошибок, он заменил бы Nemerle.Peg, в котором тоже нет особого восстановления, заодно сообщество бы потестило парсер и высказало бы впечатления и предложения о дизайне языка парсера?
Здравствуйте, VladD2, Вы писали:
VD>В будущем мы планируем работу без объектного AST-а. У нас уже есть механизм эдаких методов на AST-е. Это DSL позволяющий манипулировать непосредственно ветками AST как значениями. Сейчас он работает по объектному AST. Мы планируем сделать так, чтобы он работал, непосредственно, по массивам интов. Тогда нужда в наличии объектного AST-а отпадет полностью.
VD>Вот пример калькулятора вычисления в котором производятся с помощью этих методов:
А для чего нужны AST методы без объектного дерева, я так полагаю они как в Nemerle.Peg позволяют создать ветку объектного дерева, но отдельные методы без дерева имеют ли применения кроме калькулятора? Я не могу представить где это будет нужно.
Здравствуйте, CodingUnit, Вы писали:
CU>А можно выкатить сейчас парсер без восстановления после ошибок, он заменил бы Nemerle.Peg, в котором тоже нет особого восстановления, заодно сообщество бы потестило парсер и высказало бы впечатления и предложения о дизайне языка парсера?
Полагаю, почти всё, связанное с N2 будет платным. Не за идею же ребята работают. Не для того JB оплачивает работу, чтобы отдавать задаром. Это не Nemerle, это N2...
Хотя для тестирования, да, могли бы выложить. Им же выгодней.
Здравствуйте, koodeer, Вы писали:
K>Полагаю, почти всё, связанное с N2 будет платным. Не за идею же ребята работают. Не для того JB оплачивает работу, чтобы отдавать задаром. Это не Nemerle, это N2... K>Хотя для тестирования, да, могли бы выложить. Им же выгодней.
Про парсер уже говорили что будет бесплатным, код не будет открываться но сами бинарники будут.
Здравствуйте, CodingUnit, Вы писали:
CU>А для чего нужны AST методы без объектного дерева, я так полагаю они как в Nemerle.Peg позволяют создать ветку объектного дерева, но отдельные методы без дерева имеют ли применения кроме калькулятора? Я не могу представить где это будет нужно.
Методы в Nemerle.Peg не позволяют задать порядок обхода нужный для решения задач вроде типизации. Кроме того они вызваются в момент завершения разбора правила, а это может происходить многократно (учитывая откаты). Методы в N2 могут принимать любой список параметров и вызвать любые другие методы. Кроме того их вызов осуществляется после окончания разбора, так что они вызваниваются одинаковое количество раз и не зависят от откатов.
Методы эквивалентны атрибутным грамматикам Кнута. Они поддерживают декларативную мемоизацию. Мепоизированный метод порождает свойство на АСТ-е.
В N2 с помощью этих методов сделана вся типизация (самого себя).
В общем, методы в N2 не имеют ничего общего с методами в Nemerle.Peg.
Ну, а реализация без объектного АСТ-а позволит производить вычисления не создавая горы объектов описывающих АСТ. Это будет более экономично и быстро.
Есть логика намерений и логика обстоятельств, последняя всегда сильнее.
Здравствуйте, VladD2, Вы писали:
VD>Методы в Nemerle.Peg не позволяют задать порядок обхода нужный для решения задач вроде типизации. Кроме того они вызваются в момент завершения разбора правила, а это может происходить многократно (учитывая откаты). Методы в N2 могут принимать любой список параметров и вызвать любые другие методы. Кроме того их вызов осуществляется после окончания разбора, так что они вызваниваются одинаковое количество раз и не зависят от откатов.
Ну порядок обхода можно задавать самому когда будет готовое дерево, с помощью обходчиков, в любом порядке, preorder, postorder, breadth first , в этом сложностей не должно быть с объектным деревом. По поводу откатов да, лучше бы чтобы метод вызывался один раз в конце разбора правила
VD>Методы эквивалентны атрибутным грамматикам Кнута. Они поддерживают декларативную мемоизацию. Мепоизированный метод порождает свойство на АСТ-е.
мемоизированное свойство это интересно, может пригодится
VD>В N2 с помощью этих методов сделана вся типизация (самого себя).
методы типизации в самом парсере? я думал парсер нужен для порождения АСТ но не для типизации, закладывать такую зависимость разных шагов компилятора в один парсер кажется неверным. Типизацию же можно делать с уже готовым деревом на следующих шагах по своему алгоритму и методу обхода, может порождая новое специализированное дерево
VD>В общем, методы в N2 не имеют ничего общего с методами в Nemerle.Peg.
VD>Ну, а реализация без объектного АСТ-а позволит производить вычисления не создавая горы объектов описывающих АСТ. Это будет более экономично и быстро.
непонятно как это будет связано с грамматикой, хотелось иметь все же независимый компонент абстрагированный от остального, в объекте АСТ нет ничего навороченного, он представляет модель дерева, с ним можно просто работать как с данными. Как бы эта быстрота и экономичность не сказались на дизайне приложения которое будет использовать парсер, каждый раз править грамматику для того чтобы что то сделать с деревом не очень удобная вещь, как кажется. Хорошо бы было посмотреть на все это может мои опасения не имеют основания и все выглядит стройно и гармонично.