LVV>>Уровень вопроса или уровень ответа ? C>Главным образом — ответа. C>А это не очевидно?
Нет.
Сам уровень вопроса говорит о квалификции вопрошающего.
По его квалификции и дан ответ: делай так и будет работать.
Писать — мало, ошибок точно нет.
Хочешь быть счастливым — будь им!
Без булдырабыз!!!
Здравствуйте, DiPaolo, Вы писали:
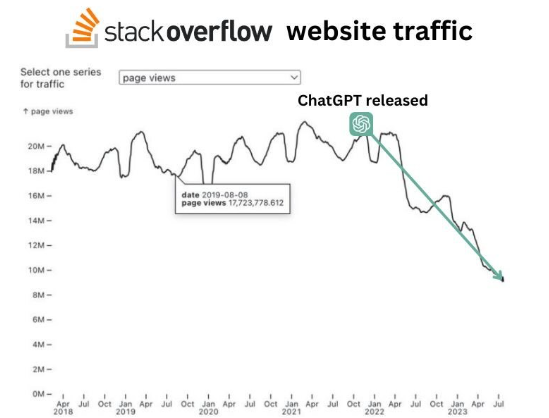
DP>Во-во! Давно уже думаю об этом – многие люди не фильтруют ответы на SO. А то ли еще будет с ChatGPT и ему подобными...
Ну давай проверим, что будет. Задал ему этот вопрос, просто копипастом с SO. Вот его код:
int[] anArray = { 1, 5, 2, 7 };
int maxValue = anArray[0];
int maxIndex = 0;
for (int i = 1; i < anArray.Length; i++)
{
if (anArray[i] > maxValue)
{
maxValue = anArray[i];
maxIndex = i;
}
}
Console.WriteLine($"The highest value is {maxValue} at index {maxIndex}.");
Есть претензии?
А вот его резюме по поводу кода из SO:
While your code works correctly, there are a few points to consider regarding efficiency and resource usage:
Performance:
Multiple Iterations:
Max() iterates over the array once to find the maximum value.
ToList() creates a new list from the array, which is another iteration.
IndexOf() may iterate over the list again to find the index.
Total Iterations: Potentially up to three full iterations over your data.
Memory Usage:
ToList() Allocation: Converting the array to a list creates a new list in memory, which can be significant if the array is large.
Summary:
Your Code Works: For small arrays or non-performance-critical applications, your code is acceptable.
Performance Considerations: If you're working with large arrays or need optimized performance, consider using Array.IndexOf() or a single-pass loop to reduce iterations and memory usage.
Best Practice: Aim for solutions that minimize resource usage while maintaining code readability.
Recommendation:
Given that Array.IndexOf() works directly on arrays and avoids the overhead of list conversion, updating your code as follows would be more efficient:
int maxValue = anArray.Max();
int maxIndex = Array.IndexOf(anArray, maxValue);
This change simplifies your code and improves performance without sacrificing readability.
DP>Некоторые ведь и ему безусловно доверяют.
Если что, ChatGPT уже успешно решает задачи уровня олимпиадных. И уж явно лучше "реальных профи". Так что если будут доверять ему, а не рандомному ответу с SO, по крайней мере в подобных алгоритмических задачах, это будет только лучше.
C> int maxValue = anArray.Max();
C> int maxIndex = anArray.ToList().IndexOf(maxValue);
C>
C>198 плюсов! C>Ох ты ж б*я с*а е*й п*ц.
C>Ну и в качестве вишенки на торте: C>
C>Director/CTO at TensorStack Ltd.
Давай трезво подумаем.
Есть вариант сначала найти максимум — O(N), затем поискать его индекс — снова O(N). Итого O(N).
Есть вариант явным циклом, менее читаемый, и всё равно O(N).
При этом при ответе сказано:
This is not the most glamorous way but works.
Что не так?
Ну да, я бы ещё дописал "а если вы хотите ну совсем экономно, разверните цикл ручками". Собственно это всё, что не совсем хорошо.
PS: А зачем ты вообще пошёл искать ответ на такой вопрос? )
Здравствуйте, netch80, Вы писали:
N>Давай трезво подумаем. N>Есть вариант сначала найти максимум — O(N), затем поискать его индекс — снова O(N). Итого O(N). N>Есть вариант явным циклом, менее читаемый, и всё равно O(N).
Я не очень, правда, понял, зачем там массив в списек разворачивают. Какое-то лишнее телодвижение, IMHO.
Здравствуйте, rFLY, Вы писали:
DP>>Но если ничего не стоит написать быстрее – почему бы не воспользоваться этим FLY>Проблема в том, что этот ответ учит плохому начинающих. Он буквально говорит — смотри как просто, делай так. Причем предлагает как раз "гламурное" решение, хотя автор пишет об обратном. Но ужаснее всего, что это топовый ответ.
Ну вот предположим, я хочу прочитать список чисел из конфигурационного файла, один раз, при старте программы. Найти в списке самое большое число и его позицию в списке. Список чисел заведомо небольшой.
Тогда это — идеальное решение. Простое и в нём не ошибешься.
А с другой стороны, если мне откуда-то сыпятся с невероятной скоростью запросы или события с массивами чисел, и надо искать максимум там, то надо бы взять что-то поприличнее, пусть и посложнее. Но тоже с оговоркой, может мне на каждый такой запрос надо полчаса считать на всех 20-и ядрах, по сути самого запроса, тогда ценой его разбора можно и принебречь.
Так что применимость того или иного решения зависит от контекста. Новички имеют тенденцию писать цикл for (i = 0; i < strlen(s); i ++), не-новички имеют тенденцию использовать крутой алгоритм сортировки, чтобы сортировать массив из трех строк.
Здравствуйте, Osaka, Вы писали:
O>Может, там функция, вызываемая раз в неделю по 1 секунде. O>Ну улучшишь её в 100 раз за цену нескольких синьёро-дней работы, и кто от этого выиграет?
Да вы что, ребята? Речь о простейшем алгоритме, решаемым не менее простейшим способом. О чем вы вообще? Мы на одно и тоже сообщение в SO смотрим? Какие могут быть "За" по предложенному варианту?
Здравствуйте, Osaka, Вы писали:
O>Если написал алгоритм длиннее пары строк, и абсолютно всё в нём предусмотрел, то на реальных данных он всё равно может неожиданно сглючить.
Если нет уверенности в своей способности написать поиск максимума и не облажаться, нужно искать другую работу.
O>Если программист не "немного шарит", а "работает в команде" — процедура исправления даже 1 буквы может затянуться на несколько дней и потребовать участия нескольких человек. O>Со временем возникает привычка по возможности не вы(думывать) и делать простейшим способом.
Здравствуйте, vsb, Вы писали:
vsb>Мой поинт в том, что ChatGPT будет неплохо помогать начинающим, т.к. он действительно пишет хороший код. Может быть не лучший в мире, но уж точно не худший. Конечно если эти начинающие будут включать голову и пытаться разобраться, почему код именно такой. И опять же в этом им ChatGPT поможет, объяснит и разложит всё по полочкам.
Ты что, вложился в акции GPT или за спиной стоит Бэндер?
vsb>Про то, что SO это ресурс не всегда полезный, тут я полностью соглашусь. Хотя гораздо лучше, чем ничего, но всё же там плохого и спорного (с моей точки зрения) много.
На данном примере он не то чтобы "не всегда полезный", он попросту вредный. Посмотри на оценку этого сообщения. Его рейтинг в 4 раза превышает остальные. Множество новичков на это клюнут и будут использовать везде, пока не получат по рукам.
C> int maxValue = anArray.Max();
C> int maxIndex = anArray.ToList().IndexOf(maxValue);
C>
C>198 плюсов! C>Ох ты ж б*я с*а е*й п*ц.
Во-во! Давно уже думаю об этом – многие люди не фильтруют ответы на SO. А то ли еще будет с ChatGPT и ему подобными... Некоторые ведь и ему безусловно доверяют. Тут-то и начнет выясняться квалификация разработчиков. А уж сколько понадобится реальных профи, чтобы исправлять потом ошибки такого начатжыпитишеного
Здравствуйте, DiPaolo, Вы писали:
DP>Но если ничего не стоит написать быстрее – почему бы не воспользоваться этим
Проблема в том, что этот ответ учит плохому начинающих. Он буквально говорит — смотри как просто, делай так. Причем предлагает как раз "гламурное" решение, хотя автор пишет об обратном. Но ужаснее всего, что это топовый ответ.
N>Что не так?
N>Ну да, я бы ещё дописал "а если вы хотите ну совсем экономно, разверните цикл ручками". Собственно это всё, что не совсем хорошо.
Дело не в двойном обходе массива, и какой там к чертям кеш — C# LINQ код такой "оптимальный" что эти понятия не существуют.
Оно создает временный List из массива — при попадании на горячий путь это поставит в неприличное положение всю софтину частыми сборками мусора.
В жизни реального приложения эти сборки приводят к переезду короткоживущих обьектов из других частей программы в старшие поколения и софтина начинает лагать и жрать процессор.
Здравствуйте, rFLY, Вы писали:
FLY>Формально так, только O более чем в 3 раза дороже в данном случае. Это же не просто взять значение из соседней ячейки, а сначала получить адрес ноды и уже потом ее значение.
Здравствуйте, rFLY, Вы писали:
Pzz>>И всё равно, это называется O(N) FLY>По этому я и написал "формально".
Ничего не формально, а очень даже содержательно.
Это же асимптотика. Она говорит, на что похожа функция, связывающая нагрузку с потребными ресурсами, а не какой там коэффициент.
С другой стороны, граждане, использующие O-большое на практике, должны учитывать коэффициент тоже. При маленьком объеме входных данных простой квадратичный алгоритм с маленьким коэффициентом может оказаться выгоднее, чем сложный линейный алгоритм с большим коэффициентом. Но при неограниченном росте объема входных даннык квадратичный алгоритм всегда проиграет линейному.
Поэтому надо, конечно, учитывать еще и имеющиеся ограничения объема входных данных (не всегда нам заранее известные, к сожалению).
Здравствуйте, Pzz, Вы писали:
Pzz>Ну вот предположим, я хочу прочитать список чисел из конфигурационного файла, один раз, при старте программы. Найти в списке самое большое число и его позицию в списке. Список чисел заведомо небольшой.
Ну так получи значение в цикле. От дополнительных 5 строк пальцы судорогой не сведет, да и код менее читабельным не станет. Наоборот, когда читаешь такое как в примере ТС, начинаешь задаваться вопросом — почему пошли по такому сложному пути. Что этим хотели сказать, что по-другому это не решается?
Pzz>Тогда это — идеальное решение. Простое и в нём не ошибешься.
Ну конечно. А если массив пустой?
Pzz>А с другой стороны, если мне откуда-то сыпятся с невероятной скоростью запросы или события с массивами чисел, и надо искать максимум там, то надо бы взять что-то поприличнее, пусть и посложнее. Но тоже с оговоркой, может мне на каждый такой запрос надо полчаса считать на всех 20-и ядрах, по сути самого запроса, тогда ценой его разбора можно и принебречь.
Любой глупости можно найти оправдание.
Pzz>Так что применимость того или иного решения зависит от контекста. Новички имеют тенденцию писать цикл for (i = 0; i < strlen(s); i ++), не-новички имеют тенденцию использовать крутой алгоритм сортировки, чтобы сортировать массив из трех строк.
Да тут вроде контекст незамысловатый — получить максимальное значение и его индекс. И не важно сколько раз и с каким промежутком это будет вызываться. Это же не 2 строчки против текста на экран.
Здравствуйте, Pzz, Вы писали:
Pzz>Я не очень, правда, понял, зачем там массив в списек разворачивают. Какое-то лишнее телодвижение, IMHO.
Отвечающий полагал, что ToList() делает каст, а не копирует в список
@millimoose, Casting as IList<int> is the same as ToList(), right? Or does one perform better than the other, I assume ToList() would just return (IList<int>)array;
Pzz>>>Тебе ж сказали, решение не самое гламурное, но работает. И ведь не обманули. Pzz>>>Да еще к тому же сложность O(n), что вообще шикарно. Могла бы быть O(n^2), например. O>>Создать массив пар {value, index} отсортировать его пузырьком по value и взять index из последнего элемента? Pzz>А можно еще лексикографически все перестановки перебрать. Тогда вообще факториал получится.
В принципе если заморочиться, то можно сделать цикл начиная от максимального значения int-а и до нуля, искать каждое значение значение при помощи IndexOf. Метод интересный, но сложность слабенькая — O(N) всего лишь. Хотя N все же мало, тут O(M) скорее.
Как много веселых ребят, и все делают велосипед...
O>>Может, там массив меньше, и на то он и директор, что знает: по итогу в деньгах дешевле так? C>Экономия на спичках ведет к попадалову.
Может, там функция, вызываемая раз в неделю по 1 секунде.
Ну улучшишь её в 100 раз за цену нескольких синьёро-дней работы, и кто от этого выиграет?
Да, всякие физтехи, любящие на пустом месте разводить наукообразие и раздувать простейшую задачу на 100 микросервисов, в которых разберутся только другие физтехи -- если им такое не оплачивать, то попадут на деньги.
LVV>>Сам уровень вопроса говорит о квалификции вопрошающего. LVV>>По его квалификции и дан ответ: делай так и будет работать. LVV>>Писать — мало, ошибок точно нет. C>То есть, если вопрос по твоему недостаточно гламурен, то ты дашь в ответ крайне говенный код, использовать который ни при каких обстоятельствах нельзя.
Почему нельзя?
Отвечающий же написал, что работать будет.
Я вот в дотнете совсем не писал.
Но я б не задавал вопроса, а просто тупо попытался бы написать сам.
А то, что вопрос задан — тоже говорит об уровне вопрошающего.
Наверное, ему поучиться надо? Почитать документацию, книжки, сайты.
Если мне мой студент даже 2 курса задаст такой вопрос, я его просто пошлю книжку прочитать сначала.
Хочешь быть счастливым — будь им!
Без булдырабыз!!!
O>>Может, там функция, вызываемая раз в неделю по 1 секунде. O>>Ну улучшишь её в 100 раз за цену нескольких синьёро-дней работы, и кто от этого выиграет? FLY>Да вы что, ребята? Речь о простейшем алгоритме, решаемым не менее простейшим способом. О чем вы вообще? Мы на одно и тоже сообщение в SO смотрим? Какие могут быть "За" по предложенному варианту?
Такое "за", что написал потратив 2 минуты, а не отлаживал алгоритм от получаса до дней (включая несколько возвратов из тестирования и хождения за подписями ответственных).
Здравствуйте, Osaka, Вы писали:
O>Такое "за", что написал потратив 2 минуты, а не отлаживал алгоритм от получаса до дней (включая несколько возвратов из тестирования и хождения за подписями ответственных).
Дай на вход пустой массив и успехов. Об этом я уже писал. Да и вообще ты о чем? Отладить цикл такая проблема?
Здравствуйте, Codealot, Вы писали:
N>>Давай трезво подумаем. N>>Есть вариант сначала найти максимум — O(N), затем поискать его индекс — снова O(N). Итого O(N). N>>Есть вариант явным циклом, менее читаемый, и всё равно O(N).
C>Твой ответ вгоняет меня в депрессию еще сильнее. В теории почти то же самое, а на практике будет медленнее, возможно, на порядки.
Я уже сказал, что ToList() просто не заметил. Рассмотри с поправкой на это.
А откуда вдруг могут взяться _порядки_?
N>>PS: А зачем ты вообще пошёл искать ответ на такой вопрос? ) C>Проверить — нет ли решения, которое встроено в библиотеку.
Здравствуйте, Codealot, Вы писали:
Pzz>>На практике лично я имею тенденцию переоптимизировать без особой нужды, а потом корю себя за это.
C>Похоже, что теперь ты решил переоптимизировать упрощение кода.
В каком смысле, решил? Это не мой код и не код проекта, которому я имею хоть какое-то отношение. Мы обсуждаем сейчас сообщение из интернета, а не делаем code review. Никакие решения я тут не принимаю, просто делюсь мнением.
Если ты думаешь, что это — худший образец кода из того, что я видел, ты ошибаешься. Этот хоть особых проблем для окружающих не создает.
Здравствуйте, Osaka, Вы писали:
O>Ну улучшишь её в 100 раз за цену нескольких синьёро-дней работы, и кто от этого выиграет?
Гы. При правильной организации процесса производства вся цепочка начальства отчитается о проделанной работе и все от этого выиграют. Особенно, если это займет несколько недель и вовлечет нескольких исполнителей сеньёрского уровня.
Здравствуйте, netch80, Вы писали:
N>При этом, если посмотреть с точки зрения процессора, первый скан погрузит массив в кэш, поэтому второй пройдёт быстрее, и будет, условно, не 2*C*N, а 1.1*C*N.
А точно второй продет быстрее, ToList ничего не "попротит"? Тот же кэш не сбросится, да и сам ToList ничего не стоит?
Здравствуйте, rFLY, Вы писали:
FLY>Здравствуйте, netch80, Вы писали:
N>>При этом, если посмотреть с точки зрения процессора, первый скан погрузит массив в кэш, поэтому второй пройдёт быстрее, и будет, условно, не 2*C*N, а 1.1*C*N. FLY>А точно второй продет быстрее, ToList ничего не "попротит"? Тот же кэш не сбросится, да и сам ToList ничего не стоит?
А, вот это не заметил. Если оно копирует, то тогда часть с кэшом меньше участвует, может оказаться, что нет. Поправлю.
Всё равно остаётся O(N), хоть и криво.
C> int maxIndex = anArray.ToList().IndexOf(maxValue); C>198 плюсов! C>Ох ты ж б*я с*а е*й п*ц. C>Director/CTO at TensorStack Ltd.
Может, там массив меньше, и на то он и директор, что знает: по итогу в деньгах дешевле так?
Здравствуйте, netch80, Вы писали:
N>Всё равно остаётся O(N), хоть и криво.
А почему O(N)? Сначала пройтись по массиву, потом создать список и заново пройтись, но уже по списку.
Здравствуйте, rFLY, Вы писали:
N>>Всё равно остаётся O(N), хоть и криво. FLY>А почему O(N)? Сначала пройтись по массиву, потом создать список и заново пройтись, но уже по списку.
Ну так каждая из этих операций имеет ценой длину списка (равной длине массива).
3*O(N) тоже O(N).
Выделение памяти при схеме работы типичного дотнетовского аллокатора, скорее всего, O(1), а остальное у него размазано на другие операции.
Здравствуйте, netch80, Вы писали:
N>Ну так каждая из этих операций имеет ценой длину списка (равной длине массива). N>3*O(N) тоже O(N).
Формально так, только O более чем в 3 раза дороже в данном случае. Это же не просто взять значение из соседней ячейки, а сначала получить адрес ноды и уже потом ее значение.
Ну и тем не менее, лучше уж O(n), чем O(1.1n) и тем более O(2n). Да, нотация нотацией, но практически это плюс-минус в полтора раза быстрее. И да, конечно, этот кусок – песчинка во всей системе. Но если ничего не стоит написать быстрее (более быстрый код) – почему бы не воспользоваться этим
DP>>Но если ничего не стоит написать быстрее – почему бы не воспользоваться этим FLY>Проблема в том, что этот ответ учит плохому начинающих. Он буквально говорит — смотри как просто, делай так. Причем предлагает как раз "гламурное" решение, хотя автор пишет об обратном. Но ужаснее всего, что это топовый ответ.
Это я и сам понимаю. О том же и ответил в соседней ветке Я ж не на стартовое сообщение тут отвечал, а про то, что там есть разница
Ааааа понял где недопонимание вышло – я имел ввиду "написать быстрее" == "написать так, чтобы выполнялось быстрее"
Здравствуйте, Teolog, Вы писали:
N>>Ну да, я бы ещё дописал "а если вы хотите ну совсем экономно, разверните цикл ручками". Собственно это всё, что не совсем хорошо.
T>Дело не в двойном обходе массива, и какой там к чертям кеш — C# LINQ код такой "оптимальный" что эти понятия не существуют.
Во-во. На самом деле для ≈95% кода типичного большого приложения оптимизация не нужна (только не надо утрировать, писать надо прямо, но без явных извратов).
T>Оно создает временный List из массива — при попадании на горячий путь это поставит в неприличное положение всю софтину частыми сборками мусора. T>В жизни реального приложения эти сборки приводят к переезду короткоживущих обьектов из других частей программы в старшие поколения и софтина начинает лагать и жрать процессор.
А вот это уже интересно. Отловить сам по себе hot path и оптимизировать его это достаточно легко, любой профилировщик справится. А вот такой эффект с засорением старших поколений — как его ловить?
N>А вот это уже интересно. Отловить сам по себе hot path и оптимизировать его это достаточно легко, любой профилировщик справится. А вот такой эффект с засорением старших поколений — как его ловить?
Да никак, он врожденный для систем со сборкой мусора.
Можно уменьшить до некритичного уровня, путем унасекомливания любого кто постоянно выделяет память вне пула, с целью сделать сборку нулевого поколения редким явлением.
Любой код вызываемый неприрывно не должен выделять память ни в каком виде, особенно в LOH-куче и все тут.
Любители "чистого и понятного" кода пусть идут в университет и радуют всех простотой и легкостью.
Проще грубо запретить "наивный" стиль кодописания, чем ждать пока оно стрельнет на очередном добавлении функционала.
Кто каждый раз все дерево вызовов проверять будет, на предмет не оставил ли джуниор поганку? Да никто.
Здравствуйте, Teolog, Вы писали:
T>Дело не в двойном обходе массива, и какой там к чертям кеш — C# LINQ код такой "оптимальный" что эти понятия не существуют. T>Оно создает временный List из массива — при попадании на горячий путь это поставит в неприличное положение всю софтину частыми сборками мусора. T>В жизни реального приложения эти сборки приводят к переезду короткоживущих обьектов из других частей программы в старшие поколения и софтина начинает лагать и жрать процессор.
Не все так драматично. В десктоп приложении, где почти всё в старших поколениях, и счет объектов идет на десятки и даже миллионов такое в норме не происходит. По крайней мере так было в 10-12м годах.
Приложение замедляется, но ГЦ здесь далеко не самая частая и важная проблема.
Не совсем понятно, почему при выделении еще одного массива, пусть и конского, система должна чаще собирать мусор.
Здравствуйте, syrompe, Вы писали:
S>У меня на подобное одна мысль: "без работы не останусь"
Общая выгода в том, чтобы работали профессионалы в высоко конкурентной среде. Чтобы продукты были качественнее, работали быстрее, потребляли меньше энергии. И профессиональная среда заставляла всех её участников развиваться.
Твой ответ — достижение сиюминутной выгоды лишь в твой локальной области и, скорее всего, географической.
Здравствуйте, netch80, Вы писали:
N>А вот это уже интересно. Отловить сам по себе hot path и оптимизировать его это достаточно легко, любой профилировщик справится. А вот такой эффект с засорением старших поколений — как его ловить?
Так и ловить — нормальные профайлеры вам покажут, кто в каком поколении живет. Поколение это ведь кучка хипов, где на каждый хип наложены те или иные правила-ограничения-итд
Т.е. подаете должную нагрузку, и смотрите по профайлеру
— стоимость сборки мусора — частоту, паузы итд
— сколько у вас объектов всего
— в каких они поколениях
— откуда они взялись
Это конечно непростое занятие, счет объектов идет на десятки миллионов, соответственно, от профайлера требуется внятная визуализация всего этого хлама
В 10-12м году профайлеры типа redgate ants и jetbrains dotmemory справлялись с таким. Конечно, если у вас сотни миллионов и выше, будет сложновато. Потому придется поработать руками, что бы воспроизвести те или иные проблемы
Другое дело, если у вас какой жээс — тут профайлеры в зачаточном состоянии, а всяких вспомогательных, скрытых аллокаций столько, что посинеешь профилировать.
нет. в данном конкретном и весьма простом случае — нет.
vsb>Если что, ChatGPT уже успешно решает задачи уровня олимпиадных. И уж явно лучше "реальных профи". Так что если будут доверять ему, а не рандомному ответу с SO, по крайней мере в подобных алгоритмических задачах, это будет только лучше.
да не вопрос. пусть каждый доверяет или не доверяет на свое усмотрение. я лишь о том, что надо думать головой. и если человек не умеет разрабатывать сам и не умеет думать своей головой, то ни СО, ни чатГПТ ему не поможет, а где-то навредит
ну и потом, примеры выше — это ну крайне малые атомарные части всего более сложного кода. их же еще надо как-то вместе "сшить". как это сделает чатГПТ я хз. вот и говорю о том, что в целом код проекта может быть очень забагованным, если бездумно отдать его на откуп чатГПТ
опять же, это мое мнение. не навязываю его, не спорю и менять его пока уж точно не собираюсь
Здравствуйте, DiPaolo, Вы писали:
vsb>>Если что, ChatGPT уже успешно решает задачи уровня олимпиадных. И уж явно лучше "реальных профи". Так что если будут доверять ему, а не рандомному ответу с SO, по крайней мере в подобных алгоритмических задачах, это будет только лучше.
DP>да не вопрос. пусть каждый доверяет или не доверяет на свое усмотрение. я лишь о том, что надо думать головой. и если человек не умеет разрабатывать сам и не умеет думать своей головой, то ни СО, ни чатГПТ ему не поможет, а где-то навредит
DP>ну и потом, примеры выше — это ну крайне малые атомарные части всего более сложного кода. их же еще надо как-то вместе "сшить". как это сделает чатГПТ я хз. вот и говорю о том, что в целом код проекта может быть очень забагованным, если бездумно отдать его на откуп чатГПТ
DP>опять же, это мое мнение. не навязываю его, не спорю и менять его пока уж точно не собираюсь
Мой поинт в том, что ChatGPT будет неплохо помогать начинающим, т.к. он действительно пишет хороший код. Может быть не лучший в мире, но уж точно не худший. Конечно если эти начинающие будут включать голову и пытаться разобраться, почему код именно такой. И опять же в этом им ChatGPT поможет, объяснит и разложит всё по полочкам.
Я уверен, что это как шахматный компьютер, который здорово повысил уровень игроков, т.к. теперь шахматист может играть в шахматы хоть круглые сутки, причём с соперником своего уровня. А не идти два часа в шахматный клуб, ждать там, пока кто-то доиграет, и играть с тем, у кого уровень может быть гораздо выше или ниже, мало чего вынося из подобных игр.
Я по натуре одиночка, во всех компаниях, где я работал, у меня никогда не было коллег моего уровня, я до всего доходил своим умом, или читая статьи в интернете, поэтому для меня ChatGPT это поистине находка, наконец-то "есть с кем поговорить". И, уверен, другим людям, которые хотят развиваться, это тоже сильно поможет. Особенно в нынеших условиях, когда везде удалёнка и возможностей пересечься и поболтать всё меньше.
Про то, что SO это ресурс не всегда полезный, тут я полностью соглашусь. Хотя гораздо лучше, чем ничего, но всё же там плохого и спорного (с моей точки зрения) много.
Pzz>Тебе ж сказали, решение не самое гламурное, но работает. И ведь не обманули. Pzz>Да еще к тому же сложность O(n), что вообще шикарно. Могла бы быть O(n^2), например.
Создать массив пар {value, index} отсортировать его пузырьком по value и взять index из последнего элемента?
Как много веселых ребят, и все делают велосипед...
vsb>Мой поинт в том, что ChatGPT будет неплохо помогать начинающим, т.к. он действительно пишет хороший код. Может быть не лучший в мире, но уж точно не худший. Конечно если эти начинающие будут включать голову и пытаться разобраться, почему код именно такой. И опять же в этом им ChatGPT поможет, объяснит и разложит всё по полочкам.
может быть и так. хорошая мысль
но меня настораживает пара моментов:
— не получится ли так, что теперь это будет один единственный вариант решения каждой конкретной задачи? а мы знаем, что вариантов решения каждой конкретной локальной задачи целое множество, и каждый разработчик может написать свое
— а как же подискутировать/похоливарить? из этого тоже рождаются новые полезные мысли же
в целом, лично меня такой глубокий уход в ЧатГПТ немного и пугает, и вызывает грусть
Здравствуйте, ononim, Вы писали:
Pzz>>Тебе ж сказали, решение не самое гламурное, но работает. И ведь не обманули. Pzz>>Да еще к тому же сложность O(n), что вообще шикарно. Могла бы быть O(n^2), например. O>Создать массив пар {value, index} отсортировать его пузырьком по value и взять index из последнего элемента?
А можно еще лексикографически все перестановки перебрать. Тогда вообще факториал получится.
Здравствуйте, Pzz, Вы писали:
Pzz>Это же асимптотика. Она говорит, на что похожа функция, связывающая нагрузку с потребными ресурсами, а не какой там коэффициент.
Если я вижу блок, отвечающий за поиск максимального значения и его индекса в массиве, то я ожидаю N раз прохода по списку и операцию сравнения и возможное обращение к переменным. А тут вообще черт знает что.
Здравствуйте, netch80, Вы писали:
N>Давай трезво подумаем. N>Есть вариант сначала найти максимум — O(N), затем поискать его индекс — снова O(N). Итого O(N). N>Есть вариант явным циклом, менее читаемый, и всё равно O(N).
Твой ответ вгоняет меня в депрессию еще сильнее. В теории почти то же самое, а на практике будет медленнее, возможно, на порядки.
N>PS: А зачем ты вообще пошёл искать ответ на такой вопрос? )
Проверить — нет ли решения, которое встроено в библиотеку.
Здравствуйте, LaptevVV, Вы писали:
LVV>Сам уровень вопроса говорит о квалификции вопрошающего. LVV>По его квалификции и дан ответ: делай так и будет работать. LVV>Писать — мало, ошибок точно нет.
То есть, если вопрос по твоему недостаточно гламурен, то ты дашь в ответ крайне говенный код, использовать который ни при каких обстоятельствах нельзя.
Здравствуйте, netch80, Вы писали:
N>Давай трезво подумаем. N>Есть вариант сначала найти максимум — O(N), затем поискать его индекс — снова O(N). Итого O(N). N>Есть вариант явным циклом, менее читаемый, и всё равно O(N).
"Но есть нюанс".
Здравствуйте, Codealot, Вы писали:
C>Твой ответ вгоняет меня в депрессию еще сильнее. В теории почти то же самое, а на практике будет медленнее, возможно, на порядки.
Если ты о двоичных порядках, то на 1 порядок.
Здравствуйте, Osaka, Вы писали:
O>Может, там массив меньше, и на то он и директор, что знает: по итогу в деньгах дешевле так?
Директора не только про это знают. Они иногда знают, что пропофол дешевле трёхкомпонентного наркоза. Анастезиолог же не знает про закупки — ему на подпись не приносят. Они ещё мноооого чего знают! Такого, от которого потом анастезиологи-реаниматологи меньше своих пациентов в среднем на 20 лет живут.
Мне только вот что интересно: а это только в России так или в остальном мире тоже самое?
Всё сказанное выше — личное мнение, если не указано обратное.
O>>Ну улучшишь её в 100 раз за цену нескольких синьёро-дней работы, и кто от этого выиграет? C>Ты там под наркотой, что ли? Решить эту задачу — 10 минут для любого программиста, который хоть немного шарит.
Если написал алгоритм длиннее пары строк, и абсолютно всё в нём предусмотрел, то на реальных данных он всё равно может неожиданно сглючить.
Если программист не "немного шарит", а "работает в команде" — процедура исправления даже 1 буквы может затянуться на несколько дней и потребовать участия нескольких человек.
Со временем возникает привычка по возможности не вы(думывать) и делать простейшим способом.
Здравствуйте, Teolog, Вы писали:
T>Любой код вызываемый неприрывно не должен выделять память ни в каком виде, особенно в LOH-куче и все тут.
В языках типа C# как в контексте тут это возможно только при очень специальном программировании, но, главное, обычно это просто не нужно.
Ну разве что у вас hard realtime и нужно обеспечить стабильность в пределах микросекунд, но тогда непонятно, при чём тут C#.
T>Любители "чистого и понятного" кода пусть идут в университет и радуют всех простотой и легкостью. T>Проще грубо запретить "наивный" стиль кодописания, чем ждать пока оно стрельнет на очередном добавлении функционала.
А потом окажется, что всё это было нафиг не нужно за пределами 1% кода hot path.
T>Кто каждый раз все дерево вызовов проверять будет, на предмет не оставил ли джуниор поганку? Да никто.
Именно что при постановке задачи оптимизации конкретного вида нагрузки — будут, и активно.
Здравствуйте, Codealot, Вы писали:
Pzz>>Да еще к тому же сложность O(n), что вообще шикарно. Могла бы быть O(n^2), например.
C>Тэорэтики. C>На практике, этот код может быть медленнее на порядки.
На практике лично я имею тенденцию переоптимизировать без особой нужды, а потом корю себя за это.
Здравствуйте, Pzz, Вы писали:
Pzz>Никакие решения я тут не принимаю, просто делюсь мнением.
Про твое мнение я и написал.
Pzz>Если ты думаешь, что это — худший образец кода из того, что я видел, ты ошибаешься. Этот хоть особых проблем для окружающих не создает.
Видел и похуже, но вот с таким всеобщим одобрением — вроде нет.
Здравствуйте, Pzz, Вы писали:
Pzz>Гы. При правильной организации процесса производства вся цепочка начальства отчитается о проделанной работе и все от этого выиграют. Особенно, если это займет несколько недель и вовлечет нескольких исполнителей сеньёрского уровня.
N>Ну разве что у вас hard realtime и нужно обеспечить стабильность в пределах микросекунд, но тогда непонятно, при чём тут C#.
Микросекунды — это к любителям bare-metal и hard-realtime
Миллисекунды-натив код и редкие выплески с лагами от переключения потоков.
Тут речь идет о величинах 5мс и выше — вплоть до секунд в пиковых случаях. Длительность нелинейно растет с объемами и иерархичностью данных.
Пропустил как-то боксинг из-за сравнения Enum в Generic методе — GC занял 97% процессорного времени.
LVV>>Но я б не задавал вопроса, а просто тупо попытался бы написать сам. C>Именно, что тупо. Сначала проверь, нет ли встроенного в библиотеку решения. Не велосипедь.
Ну дык я это и имел ввиду.
Что ж я буду писать свой код, когда во фреймворке уже все есть...
Хочешь быть счастливым — будь им!
Без булдырабыз!!!
Здравствуйте, Codealot, Вы писали:
C>Здравствуйте, vsb, Вы писали:
vsb>>Ну давай проверим, что будет. Задал ему этот вопрос, просто копипастом с SO. Вот его код:
C>Мда. Тот случай когда ИИ победил, потому что люди окончательно отупели.
O>>Ну улучшишь её в 100 раз за цену нескольких синьёро-дней работы, и кто от этого выиграет? Pzz>Гы. При правильной организации процесса производства вся цепочка начальства отчитается о проделанной работе и все от этого выиграют.
Кроме директора, за счёт которого жрёт вся эта толпа дармоедов. Я пытался проиллюстрировать, как рассуждает владелец бизнеса.
Ф>Директора не только про это знают. Они иногда знают, что пропофол дешевле трёхкомпонентного наркоза. Анастезиолог же не знает про закупки — ему на подпись не приносят. Они ещё мноооого чего знают! Такого, от которого потом анастезиологи-реаниматологи меньше своих пациентов в среднем на 20 лет живут.
Это уже наличие/отсутствие в психике поциента запрета на людоедство. Данная характеристика может иметь самые неожиданные значения независимо от образования и этнической/классовой принадлежности. Ф>Мне только вот что интересно: а это только в России так или в остальном мире тоже самое?
Там, где остался свободный рынок и естественный отбор по эффективности трудозатрат.
Здравствуйте, Osaka, Вы писали:
O>Кроме директора, за счёт которого жрёт вся эта толпа дармоедов. Я пытался проиллюстрировать, как рассуждает владелец бизнеса.