подводим итоги последних 10 лет — на рынке видеокарт (и доступных для них техпроцессов)
ну чё, пора подвести итоги — за последние 10 лет,
7970 -> 4080 =
28 nm -> 4 nm (TSMC)
x10 плотность (на квадратный миллиметр), x2.5 частота чипа, x2.5 Bandwidth,
x12 TFLOPS (GPGPU), при (TDP 250W vs 320W) и (цена 550$ vs 1200$, без учёта инфляции доллара (за последние 10 лет))
а да, VRAM 3 GB vs 16 GB
правда прирост в трассировке лучей — весьма путёвый, где то в 100-120 раз .. (с перспективой дальнейших оптимизаций до 140-160 раз, за счёт технологии SEC (или как там она называется))
| | как считал |
| | (пересчитал через World of Tanks enCore RT, там разница 7970->1066 где то в 2, может 2.2 раза максимум .. и далее сравнил 1060 -> 2080 Ti (разница в 18-23 раза) и 2080 Ti -> 4080 (разница в 3 раза, условно) в Quake RTX) |
| | |
так что итог, такой — GPGPU терафлопсы растут весьма вяленько, а лучики шустро (или только шустро ранее при старте технологии?),
AI не мерял — у кого есть данные, говорите
P.S.:
шо будет через 10 лет, конечно интересно — но судя по всему дёшево будет вряд ли ..

P.S.2:
Здравствуйте, xma, Вы писали:
xma>7970 -> 4080 =
xma>28 nm -> 4 nm (TSMC)
Там используется
TSMC 4N (который "типа" 5нм):
TSMC 4N process (custom designed for Nvidia) – not to be confused with N4
https://en.wikipedia.org/wiki/GeForce_40_series#Details
Архитектура NVIDIA Ada Lovelace, лежащая в основе каждой видеокарты GeForce RTX 40, обеспечивает огромный скачок в производительности, эффективности и возможностях. Созданная на основе оптимизированного для NVIDIA техпроцесса TSMC 4N
https://www.nvidia.com/ru-ru/geforce/news/rtx-40-series-graphics-cards-announcements/
Если я правильно понял, после т.н. 5 нм у TSMC идёт сразу 3 нм.
Здравствуйте, xma, Вы писали:
xma>x10 плотность (на квадратный миллиметр), x2.5 частота чипа, x2.5 Bandwidth,
xma>x12 TFLOPS (GPGPU), при (TDP 250W vs 320W) и (цена 550$ vs 1200$, без учёта инфляции доллара (за последние 10 лет))
xma>а да, VRAM 3 GB vs 16 GB
Все б хорошо. Но вот чет мне ща 4090 покупать как то не очень есть желание. Ибо вроде и шустрая, но жрет столько, что контакты плавятся

. Хотя 4080 собираюсь в ближайшее время купить, в то 2080 в некоторых вещах устраивает слайдшоу.
Здравствуйте, xma, Вы писали:
xma>P.S.2:
xma>[cut=доп информация]
xma>Image: post.cgi
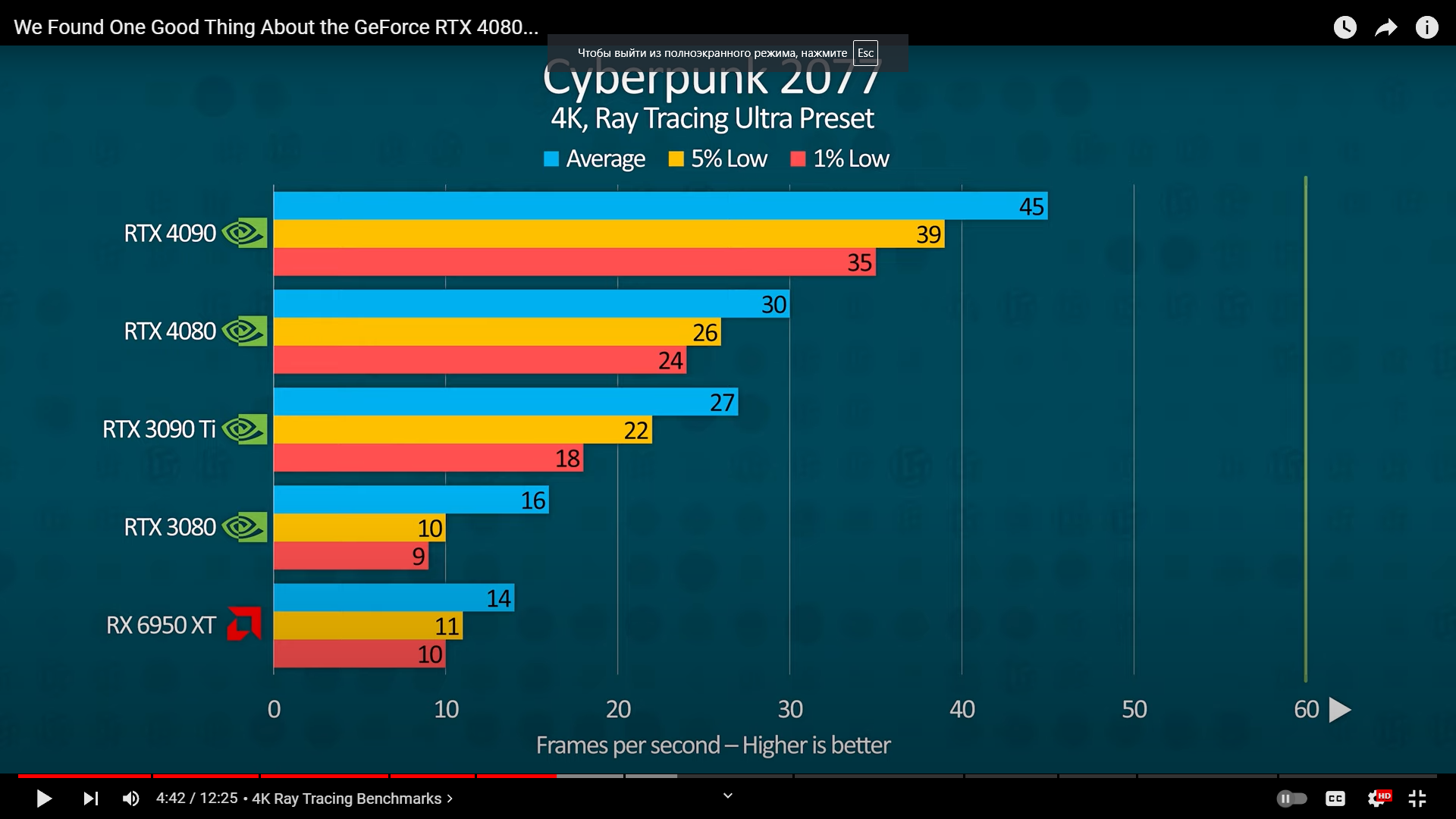
То есть, для 4K-игр с включенными лучами только RTX 4090 обеспечивает относительно приличный FPS (не менее 30), хотя все еще маловатый для тех, кто считает, что играть надо с fps не менее 60.
Здравствуйте, xma, Вы писали:
xma>AI не мерял — у кого есть данные, говорите
Данных нет прямо сейчас, но тут два направления развития видеокарт:
1. Обучение нейросетей
2. Инференс (грубо говоря, работа в продакшене обученной нейросети.
Для обучения важно в первую очередь, чтобы у видеокарты было много памяти. Поэтому лучше использовать не видеокарты, а Tesla типа A100. Большой batch size, большие модели, сама NVidia выпускает
суперкомпьютер DGX.
Тут прогресс в числах можно посчитать, но сложно. По факту, обучение многих современных моделей на старых видеокартах тупо невозможно из-за нехватки памяти.
Инференс ускорился в тысячи раз за счёт ряда факторов:
1. Увеличилось число мультипроцессоров в одной видеокарте.
2. Увеличился объём видеопамяти, можно одновременно обрабатывать не одну картинку, а несколько.
3. В видеокартах, начиная с поколения 20хх появились тензорные ядра, ускоряющие процесс.
4. Аппаратная поддержка float16 позволяет ускорить многие архитектуры в 2 раза по сравнению с float32.
5. Аппаратная поддержка int8 вкупе с развитием подходов к вантизации нейросетей позволяет ускорить в 4 раза по сравнению с float32.
Поэтому сейчас говорят не о FLOPS, а о TOPS (тензорные операции, имея ввиду int8). Даже в новых edge устройствах jetson, следующее поколение Orin быстрее предыдущего в 80 раз (!!!). Производительность увеличилась на порядки.