Здравствуйте, Sinclair, Вы писали:
V>>Данные тебе были даны — более полусекунды лагов при построчном редактировании в простой двухзвенке. S>То есть теперь даны. S>Правда, врушные, но чо уж там.
Факты не подходят под теорию? ))
V>>Формы на FoxPro или на Клиппере имели кое-какую задержку при отображении. S>Я на клиппере писал ещё в 1991. Все "задержки" были исключительно со стороны чтения диска.
От кривых рук они были.
От попыток чтения всего набора возвращаемых данных.
Этого делать не надо было.
Надо было читать только индексы, а сами данные тащить в "ленивой" манере.
Я же говорю, большинство пишущих под БД прикладников того времени НАГЛУХО не соображали в происходящем.
ИМХО, MS Access был как раз подсказкой, типа, эй, болезные, смотрите как надо правильно работать с данными. ))
V>>В асме хотя бы мощнейший макропроцессор, а в Дельфях аж нифига от слова совсем. S>Дельфи — это очень круто, есличо.
Да ХЗ.
Хорошая задумка при плохом языке.
S>Тамошние метаданные и сейчас ещё ого-го. Просто есть разница между теми, кто только компоненты мышой на форму накидывает, и теми, кто может свой компонент написать.
Писал я свои компоненты, ес-но.
Сплошной copy&paste, по-другому в дельфях никак.
S>Мы писали свою ORM систему на Delphi и MS SQL. Ещё до Фаулера с его Энтерпрайз Паттернами и всех основных современных ORM.
Мы еще до MS SQL писали первые модули того самого Паруса, и?
Всё это было и есть г-но на палочке, от которого я потом всю сознательную жизнь старался держаться подальше.
V>>Два диска в параллель и огонь. S>И всё равно это медленнее, чем обращение к памяти.
Это для тех самых ноутов на батарейках разве что.
А так-то уже быстрее.
Вот современный накопитель NVMe SSD. ))
По ссылке картейка, которая втыкается непосредственно в PCIe:
4 SSD в параллель, скорость чтения 3.6 гига.
Кол-во IO в сек (см на NVMe):
Для стандарта PCIe 3.0 пропускная способность в каждом направлении 8 гигабайт/с, т.е. всего 16, что уже покрывает DDR3 1333.
Итого, бери себе такие 4 картейки в параллель и радуйся.
Например, их можно втыкать сюда:
Есть на рынке уже всякие варианты, даже 8 штук (двусторонние):
Потому что уже пошли материнки с PCIe 4.0, с удвоенной пропускной сопособностью, т.е. можно получить 32 гигабайта/с.
V>>Кароч, уже было всё сказано, каким образом использовался MS Access — как GUI платформа, как удобный конструктор и САМЫЙ эффективный (на тот момент) COM-сервер своих объектов. V>>Потому что абсолютно все его контролы были windowsless. S>Ух ты! Только что главным было In-proc, и внезапно мы хотим поговорить об MS Access как GUI-платформе.
Не внезапно, я тебе рассказывал на примере MS Access как надо с ISAM данными работать.
Заодно вспомнил другие его плюшки, почему я надолго на ём остановился в 90-х.
А теперь я их лишь озвучиваю, бо, прямо скажем, твои представления на уровне слухов и обычного для прикладников тех лет непонимания.
Я всю жизнь сталкиваюсь именно с этим.
V>>Для сравнения, в Дельфях windowsless были только лейблы, круги-овалы и всякие рамки вокруг окон. V>>Но эти контролы не "равнозначны" полноценным, а в хосте MS Access любые ActiveX контролы были вполне равнозначный. S>Вполне себе равнозначны. Мы писали windowless компоненты на Delphi в ассортименте.
Не знаю в каком году. В 96-м tabstop работал по таким компонентам коряво — сначала проходился по windowed-контролам и лишь потом, когда доходила очередь до самой формы, она проходилась по windowsless.
А позже я уже не смотрел.
V>>При том, что эта технология — это на саммом деле технология маппинга файлов, где для возврата просто целого числа из базы тебе надо воспользоваться 4кB блоком или 8кB в популярных x64. Затратней даже обычного TCP с собственным сервис-провайдером для быстрой картейки какой-нить. S>Конечно. Про "затратней" — это полнейший булшит, естественно. Скорость передачи данных по shared memory не зависит от размера блока — он же на физическом уровне отображён. Просто буфер отправки и приёма одновременно доступен в обоих процессах.
Да вот не просто. Сначала надо освободить ДРУГОЙ буфер со скидыванием его содержимого на диск, если мы нагруженно через эту кухню работаем.
И это непреодолимо, бо даже если ты не задашь свой отображаемый файл, то винды тебе назначат область требуемого размера в system paging file.
Не спорь, кароч. Нормально mmap только в линухах работает.
V>Вся разница с inproc — только во времени переключения контекста процесса.
Пфф... Вопрос в том СКОЛЬКО раз потребуется переключать контекст?
V>>Дешевле WriteProcessMemory/ReadProcessMemory все-равно ничего нет. S>Да? А пацаны говорят, что нет. Что mapped file быстрее, т.к. нет копирований. Кому верить?
Мне.
Про "нет копирований" булшит в обсуждаемом сценарии.
Сервак же не маппированные области базы данных возвращает а формирует в памяти представление твоего рекордсета.
Можно сразу писать результат "туда".
Опять же, глупо возвращать ВСЕ данные сразу, их надо возвращать порциями, чтобы обрабатывать в "оперативной" манере.
V>>Просто ты не в курсе, наверно, что частые ядерные вызовы заметно тормзят систему в целом, даже если сами вызовы ничего сложного не выполняют. S>Я как раз в курсе. Просто, кроме самого факта, нужно немножко себе представлять, сколько этих вызовов происходит, сколько дополнительных вызовов потребуется для IPC в случае out-of-proc, и какова примерно стоимость одного вызова.
Дохрена требуется.
Если на современной технике еще можно пытаться делать вид, что на всё закрыли глаза, то на той технике разница того самого user expierence была просто чудовищная. ))
Я пол-года не выкатывал свою первую систему с использованием SQL-севака, потому что при обычном, принятом по-умолчанию "построчном" редактировании, т.е. с сохранением кажой строки, впечатление было ужасным после варианта с файловой базой. Испробовал много всего и пока не написал свой слой синхронизации локального кеша и SQL-сервака даже не пытался предлагать "это". В принципе, реализовать свои источники данных с интерфейсом OLEDB оказалось не так сложно. Под катом DAO на локальный кеш и очередь изменений для отправки на SQL сервак. При быстром редактировании получалось так, что изменения отправлялись накопленными (после последней транзакции) пачками.
Собсно, сам такой подход оказался универсальным.
Сейчас по основной своей работе я примерно так же работаю с современными быстрыми сетевыми картейками — несколько операций отправки данных (в среднем единицы сотен) заменяются одной операцией записи в сокет.
В упомянутом сценарии кеширования отправки изменений при быстром редактировании за раз отправлялись 2-4 записи, что тоже немного разгружало сам сервак. Длина очереди была порядка одной секунды и периодические "залипания" самого сервака (когда кто-то вызывает тяжеловесные операции) не сказывались на скорости работы десятков людей, активно вводящих данные.
S>Речь не о нём, а о приложении-клиенте. Если локальных CPU мощностей достаточно, чтобы запустить в них ещё и RDBMS, то запустить его локально будет всегда выгоднее, чем на удалённом сервере.
Если речь о трехзвенке, то у нас там получается две пары клиент-сервер. Я всегда топлю за то, чтобы сервер приложений составлял одно целое с сервером данных.
Потому что и трехзвенок тоже писал в достатке.
Правда, не тех, что под ними имеют ввиду сейчас, когда речь о HTTP-фронтенде, а о своих клиентах.
От HTTP-фронтенда тоже стараюсь держаться подальше, бо это просто бррр какое-то уже пару десятков лет.
Люому нормальному инженеру должно быть стыдно.
И да, я помню твои оды самому протоколу и твои восхищения ф-иями кеширования.
Всё вместе рука-лицо как по мне.
Или ты до этого нормально не работал с эффективными кешами никогда.
Дело в том, что ЛЮБОЕ вменяемое кеширование — оно имеет некую уникальную семантику, наболее полно которой владеет как раз клиент, бо она складывается из ситуации на сервере и на клиенте.
В случае же HTTP этой семантикой владеет только сервер, ы-ы-ы много раз.
S>А если у нас уже и так CPU под завязку (например, мы гоняем сервер приложений), то имеет смысл вынести RDBMS отдельно для того, чтобы можно было параллелить нагрузку добавлением других экземпляров сервера приложений.
Зачем?
Это всё актуально только для stateless "серверов приложений", но это не сервера приложений, а "прокладки"-форматтеры м/у стандартами HTTP и SQL.
Называть их "серверами приложений" — это примазывать не туда и не с той стороны.
Лично мне никогда не нравилось, когда "это" называют "серверами приложений".
Re[50]: В России опять напишут новый объектно-ориентированны
Здравствуйте, vdimas, Вы писали:
V>Факты не подходят под теорию? ))
Факты не подходят под факты.
Мы просто замеряли реальные времена исполнения запросов. По сети MS SQL отдавал данные за ~100мсек. Это в 1997 году, есличо.
Полусекундные паузы из-за out-of-proc на локальной машине — беспардонное враньё.
Ну, то есть в паузы — верю. В то, что они из-за out-of-proc — чушь. Из-за кривых рук они могли быть, исключительно из-за кривых рук.
V>От кривых рук они были. V>От попыток чтения всего набора возвращаемых данных.
На клиппере прочесть "весь набор" — это надо постараться. Я так полагаю, что вы, коллега, Клиппера своими глазами не видели, да?
V>Хорошая задумка при плохом языке.
Отличный язык. Его просто готовить надо уметь.
V>Сплошной copy&paste, по-другому в дельфях никак.
Это больше говорит о ваших способностях, чем о Delphi.
Это как один мой знакомый склонировал полностью исходники TListView, потому что хотел в нём свой потомок TListItem обрабатывать, а AddItem там сразу готовый айтем возвращает.
Не заметил, что можно просто перекрыть CreateListItem. Бывает.
V>>>Два диска в параллель и огонь. S>>И всё равно это медленнее, чем обращение к памяти.
V>Это для тех самых ноутов на батарейках разве что. V>А так-то уже быстрее.
V>Вот современный накопитель NVMe SSD. )) V>По ссылке картейка, которая втыкается непосредственно в PCIe: V>Image: 41WSeu79JHL.jpg V>4 SSD в параллель, скорость чтения 3.6 гига.
Неплохо, неплохо. Даже с учётом того, что реалистичная скорость, намеренная в тестах, около 2х гигов.
V>Есть на рынке уже всякие варианты, даже 8 штук (двусторонние): V>Потому что уже пошли материнки с PCIe 4.0, с удвоенной пропускной сопособностью, т.е. можно получить 32 гигабайта/с.
Ну, во-первых, мы же не порнуху копируем. СУБД редко удаётся свести всё к линейному чтению. Так что с 32гб/с не выйдет.
Во-вторых, а куда мы собираемся заливать эти прочитанные данные? Не в память ли? Какой смысл читать данные с диска втрое быстрее, чем их сможет принять память? V>Кол-во IO в сек (см на NVMe): V>Image: 3lv12.jpg
Вот картинка с IOPS — полезная штука. Видно, что с таким винтом можно делать странички по 4к и он будет их отдавать довольно шустро. Всё равно, конечно, рандомное чтение из памяти будет на порядки быстрее, поэтому пересылка result set через границу процесса будет нам стоить пренебрежимо мало по сравнению со стоимостью исполнения запроса на диск.
V>А теперь я их лишь озвучиваю, бо, прямо скажем, твои представления на уровне слухов и обычного для прикладников тех лет непонимания.
Какие представления?
V>Не знаю в каком году. В 96-м tabstop работал по таким компонентам коряво — сначала проходился по windowed-контролам и лишь потом, когда доходила очередь до самой формы, она проходилась по windowsless.
В 96м — это, наверное, ещё Delphi 1.0? 16-разрядный? Не помню, не застал.
V>Да вот не просто. Сначала надо освободить ДРУГОЙ буфер со скидыванием его содержимого на диск, если мы нагруженно через эту кухню работаем.
Зачем нам освобождать "другой" буфер? Пишем в буфер 1 — отдаём клиенту — пишем в буфер 2. Получили сигнал "давай ещё" — говорим клиенту "смотри буфер 2", и пишем в буфер 1.
Rinse, Repeat. V>Пфф... Вопрос в том СКОЛЬКО раз потребуется переключать контекст?
Ну всяко меньше раз, чем при чтении файла по кускам.
V>Про "нет копирований" булшит в обсуждаемом сценарии. V>Сервак же не маппированные области базы данных возвращает а формирует в памяти представление твоего рекордсета.
Ну да, всё верно. И in-proc сервер делает то же самое. Рекордсет-то точно такой же.
V>Можно сразу писать результат "туда". V>Опять же, глупо возвращать ВСЕ данные сразу, их надо возвращать порциями, чтобы обрабатывать в "оперативной" манере.
Буфер — наше всё.
V>Если на современной технике еще можно пытаться делать вид, что на всё закрыли глаза, то на той технике разница того самого user expierence была просто чудовищная. ))
Ну-ну.
V>Я пол-года не выкатывал свою первую систему с использованием SQL-севака, потому что при обычном, принятом по-умолчанию "построчном" редактировании, т.е. с сохранением кажой строки, впечатление было ужасным после варианта с файловой базой.
Естественно. Некурящие люди так не делали ни в какие годы. Сохранение делалось "потранзакционно", а строки заказа лежали в памяти.
Теоретически, локальный сервер прекрасно бы работал и при "классическом построчном" изменении — у него даже тулза была, в которой можно было табличку открыть в гриде и работать как в Access-е.
Локально всё бегало на ура, безо всяких пауз и подёргиваний. Просто по тем временам ставить ажно целый SQL Server на десктопную машину было делом маловозможным (типичные объёмы памяти всё ещё измерялись в мегабайтах), а до редакций типа Express оставались десятилетия.
V>Люому нормальному инженеру должно быть стыдно. V>И да, я помню твои оды самому протоколу и твои восхищения ф-иями кеширования. V>Всё вместе рука-лицо как по мне. V>Или ты до этого нормально не работал с эффективными кешами никогда.
Неа, не работал.
V>Зачем?
Для масштабирования.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Re[46]: В России опять напишут новый объектно-ориентированны
Здравствуйте, IB, Вы писали:
_>>Я предлагал обсуждать немного в другом контексте: в данной СУБД есть конкретная интересная (на мой взгляд) функциональность, недоступная в SQL. Это я про исполнение произвольного кода в запросе. IB>Вот внезапно. Что-то эту мысль никто не уловил. Изначально это позиционировалось как отличная замена SQL как по скорости так и по функциональным возможностям.
Кем это так позиционировалось и где? Да и кстати сделать для себя подобные выводы в принципе может только человек очень далёкий от индустрии, т.к. язык запросов Mongo априори не может стать заменой SQL в РСУБД хотя бы потому, что РСУБД не предоставляют ни возможности MapReduce, ни произвольной структуры документа.
_>>И я предлагал обдумать мысль о добавление подобной функциональности в некий гипотетический язык (ну или даже инструмент/протокол — не факт что это должен быть именно язык в стиле SQL, обязательно доступный для написания текстовых запросов бухгалтерами), претендующий на замену SQL. IB>Так linq же. Он и не гипотетический, он вполне практический.
Даже если забыть про обсуждаемые тут минусы Linq (что у нас там например с CTE или рекурсией?), то в любом случае Linq же в данный момент при работе с СУБД работает через посредника в виде SQL, так что это явно не замена, а всего лишь надстройка, полностью ограниченная возможностями SQL.
Re[42]: В России опять напишут новый объектно-ориентированны
Здравствуйте, Sinclair, Вы писали:
_>>Что-то мне кажется или ты не разобрался или я не понимаю твою мысль. Описанные переменные — это всего лишь предопределённые системой частные случаи этого https://docs.mongodb.com/manual/reference/aggregation-variables/. S>Специфика описанных "переменных" — в том, что их нельзя модифицировать. Это константы, поэтому они никак не интересны.
Эмм, что? ) https://docs.mongodb.com/manual/reference/operator/aggregation/let/
_>>Ну это зависит от конкретной реализации. Например в том же C++ я могу просто добавить одну коротенькую строчку перед циклом (директиву openmp) и получу нужный результат. S>Судя по примерам из MSDN, одной коротенькой строчкой вы не обойдётесь. Потребуется хотя бы две.
Ну собственно для распараллеливания понадобится ровно одна. А вот если в цикле будут какие-то нетривиальные вычисления (типа той же агрегации, а не просто отображения), то тогда возможно понадобится ещё одна директива.
_>>И в разных СУБД аналогично, всё зависит от конкретной реализации. Например для Mongo ключевым будет вопрос в том действуем ли мы внутри одного документа или между разными — автоматический массовый параллелизм в этой СУБД имеет вполне конкретную природу. И да, как я уже говорил, я не считаю Mongo идеалом, но некоторые весьма интересные решения (которые можно было бы позаимствовать при попытке создания идеального решения) в ней явно есть. S>Вот сомнения меня мучают. Тот же OpenMP при всей его могучести — ну не верю я в то, что он сможет разбить агрегацию на локальные фрагменты, чтобы воспользоваться коммутативностью. S>Всё, что он сделает — это атомизирует обращения к разделяемой переменной. А это — сразу смерть, с точки зрения производительности.
Эээ что? ) OpenMP просто запускает N (по умолчанию по числу ядер процессора) потоков и выполняет в каждом свою часть цикла (обычно разбивая по переменной итерации), вставляя в конце барьер (ожидание завершение работы всех потоков). В случае потребности в агрегации, так же будет проведена соответствующая операция над вычисленными в каждом потоке промежуточными результатами. Это всё делается автоматически компилятором, причём уже очень много лет...
S>В отношении user-defined aggregate я в прошлый раз погорячился: прозрачным образом получить из "произвольного императивного кода" кастомный агрегат не получится.
Это не суть, т.к. всё равно данный подход не тянет на звание универсального решения. Даже если бы такое работало...
Re[44]: В России опять напишут новый объектно-ориентированны
Здравствуйте, Sinclair, Вы писали:
_>>Естественно, так же как и в ассемблере х86. Однако при этом они есть и в C++ (на уровне библиотек или спец. версий компиляторов) и в C# (на уровне компилятора), и именно с их помощью работает твой код с yield. S>Но JIT оптимизирует не "код с yield", а значительно более банальную штуку. "Код с yield" порождает структурный тип. Инлайн вызова GetEnumerator() делает это видимым, после этого обращения к Current и MoveNext() теряют виртуальность и тоже могут быть заинлайнены. Все эти переменные __state и прочий стуфф, сгенерированный для енумератора, остаются в локальном скоупе и подлежат всем тем же оптимизациям, что и обычные локальные переменные.
Так а где там область видимости этого самого "структурного типа"? В случае await оно вообще в куче создаётся и потом вызывается из цикла обработки сообщений или вообще другого потока. В случае yield я сам не проверял — у тебя есть точные данные, что оно размещается на стеке и при этом в области видимости вызывающего цикла? )
_>>Ну есть обычное произвольное неотсортированное дерево и требуется найти количество узлов на кратчайшем пути между двумя заданными узлами. S>По-прежнему непонятно. Как устроено дерево? У каждого элемента есть указатель на parent?
S>linq как таковой тут ни при чём. Мы решаем задачу "найти common tail у двух связных списков", а точнее — "найти различные головы двух связных списков". S>Есть N способов записать решение этой задачи; С# тут будет удобен невыразимой лёгкостью превращения ноды дерева в коллекцию её предков, что позволит нам использовать обобщённую версию поиска совпадений в коллекциях.
Да, Linq тут оказывается действительно ни при чём, хотя это как раз классическая работа с одним из базовых видов коллекций...
_>>Кстати, сейчас подумалось ещё... А что там вообще у нас у linq с работой по отсортированным массивам? Вот есть у нас обычный вектор неких структурок и мы знаем, что этот вектор отсортирован по некоторому полю. Можем ли мы сказать об этом linq, чтобы фильтр where по этому полю стал логарфимическим? ) В императивном коде, как ты понимаешь, никаких проблем с этим нет. S>Конечно можем, почему нет. Мы это сделаем при помощи реализации класса SortedList(), параметризованного селектором ключа сортировки, и метода Where в нём, который умеет принимать Expression<...> и разбирать его точно таким же образом, как это делает i4o.
Ээээ что? Какое ещё SortedList? Зачем нам этот жирный тормоз? Смотри, вот буквально детская задачка из самых основ работы с коллекциями: имеем простейший int[], заполненный отсортированными значениями. Надо получить его подмассив, находящийся в пределах значений от 0 и до 1000. Я могу это сделать на linq за логарифмическое, а не линейное время?
Re[51]: В России опять напишут новый объектно-ориентированны
Здравствуйте, Sinclair, Вы писали:
S>Мы просто замеряли реальные времена исполнения запросов. По сети MS SQL отдавал данные за ~100мсек. Это в 1997 году, есличо.
Ага, если один чел-клиент на ём работает.
Фтопку такие замеры.
У меня реальное боевое применение в течени нескольких лет было, если чо.
Два десятка девочек строчат накладные, менеджер их проверяет/проводит/откатывает, ком.директор продажи итогами просматривает — не жило оно "в лоб" от слова ни-фи-га.
S>Полусекундные паузы из-за out-of-proc на локальной машине — беспардонное враньё.
Смотря какая очередь запросов накопилась.
Задержки по передаче каждого запроса из очереди сказываются на суммарном времени задержки по каждому из них.
Кароч, чего тут говорить. Когда на Дельфях вовсю еше выполняли все операции прямо в потоке GUI, мы вовсю выносили IO в отдельный поток и получали настоящую асинхронность. Если даже на современной технике и с современной сеткой переход на асинхронность считается хорошим тоном, то про те времена и говорить было бесполезно — это вообще было условие существования более-менее отзывчивой системы на том железе.
Во фрилансерстве в 2000-е применял эти же подходы уже и на C#, задолго до всяких async — делали систему POS+учёт для торговых точек в США.
S>Ну, то есть в паузы — верю. В то, что они из-за out-of-proc — чушь. Из-за кривых рук они могли быть, исключительно из-за кривых рук.
Т.е. у всей индустрии кривые руки? ))
Заметная разница есть у всех.
Просто ты не занимался такими вещами вплотную.
V>>От попыток чтения всего набора возвращаемых данных. S>На клиппере прочесть "весь набор" — это надо постараться. Я так полагаю, что вы, коллега, Клиппера своими глазами не видели, да?
Ошибочно полагаешь.
V>>Сплошной copy&paste, по-другому в дельфях никак. S>Это больше говорит о ваших способностях, чем о Delphi.
Тут желателен был бы пример типизированной коллекции, чтобы без copy&paste, или слил.
S>Это как один мой знакомый склонировал полностью исходники TListView, потому что хотел в нём свой потомок TListItem обрабатывать, а AddItem там сразу готовый айтем возвращает. S>Не заметил, что можно просто перекрыть CreateListItem. Бывает.
При чём тут твой знакомый?
V>>4 SSD в параллель, скорость чтения 3.6 гига. S>Неплохо, неплохо. Даже с учётом того, что реалистичная скорость, намеренная в тестах, около 2х гигов.
Врать не надоело?
Полно обозоров на ютубе, народ показывает скриншоты — получают те самые 3.6 гига/с.
V>>Потому что уже пошли материнки с PCIe 4.0, с удвоенной пропускной сопособностью, т.е. можно получить 32 гигабайта/с. S>Ну, во-первых, мы же не порнуху копируем. СУБД редко удаётся свести всё к линейному чтению. Так что с 32гб/с не выйдет.
Выйдёт.
Скорость же удельная величина.
Просто где-то надо не 32 гига за секунду, а 32 метра за 1ms.
S>Во-вторых, а куда мы собираемся заливать эти прочитанные данные? Не в память ли? Какой смысл читать данные с диска втрое быстрее, чем их сможет принять память?
Память уже давно многоканальная, особенно на серваках.
Да и на ноутах минимум двухканальная уже стандарт де-факто.
V>>Кол-во IO в сек (см на NVMe): V>>Image: 3lv12.jpg S>Вот картинка с IOPS — полезная штука. Видно, что с таким винтом можно делать странички по 4к и он будет их отдавать довольно шустро. Всё равно, конечно, рандомное чтение из памяти будет на порядки быстрее
Это если брать полный цикл чтения одного блока, но это никогда не требуется.
Классический сервак баз данных создаёт очереди обработки, как раз через эти очереди насыщается пиковая пропускная способность.
Обрати внимание на графике на размер очереди запросов IO самого накопителя.
А так-то есть накопители и с большим размером очереди.
S>поэтому пересылка result set через границу процесса будет нам стоить пренебрежимо мало по сравнению со стоимостью исполнения запроса на диск.
Ай, какое нубство...
Драйвер может помещать в очередь за раз кучу запросов к диску и за одно прерывание тоже выгребается куча же ответов.
А в твоём варианте мы имеем от сервака приложений сотни/тысячи коннекшенов к SQL-серваку одновременно, где в каждый коннекшен серваку надо отдать данные индивидуально. Из-за этого не получается "размазать" затраты на одну операцию ввода/вывода на сотни логических прикладных операций.
Судя по всему, ты не понимаешь примеры группировки операций, которые я постоянно привожу.
V>>А теперь я их лишь озвучиваю, бо, прямо скажем, твои представления на уровне слухов и обычного для прикладников тех лет непонимания. S>Какие представления?
Да хотя бы почему приложение на дельфях медленнее работает с базами данных при отображении в таблицах.
Сейчас-то это трудно заметить, а в 96-м году это было более чем очевидно, особенно при листании выборок в таблицах.
Насчёт FoxPro аналогично — такая же точно ошибка в архитектуре и пой же самой причине тормоза, GUI морозилось, пока все данные для отображаемых строк не прочитает. ))
Учитывая, что мы уже выяснили, что ты не понимал, что такое ISAM, приходится объяснять, какой от него вообще толк, т.е. как именно с этим подходом можно эффективно работать.
V>>Не знаю в каком году. В 96-м tabstop работал по таким компонентам коряво — сначала проходился по windowed-контролам и лишь потом, когда доходила очередь до самой формы, она проходилась по windowsless. S>В 96м — это, наверное, ещё Delphi 1.0? 16-разрядный? Не помню, не застал.
И в институте не программировал ни разу?
V>>Да вот не просто. Сначала надо освободить ДРУГОЙ буфер со скидыванием его содержимого на диск, если мы нагруженно через эту кухню работаем. S>Зачем нам освобождать "другой" буфер? Пишем в буфер 1 — отдаём клиенту — пишем в буфер 2. Получили сигнал "давай ещё" — говорим клиенту "смотри буфер 2", и пишем в буфер 1.
Опять какой-то детсад, сорри.
Ключевое выделил.
Пока у клиента "живой" рекордсет на руках, выделенная под него shared-память будет только расти.
Избежать этого можно только при открытии рекодрсета в режиме forward only, но такой рекордсет нельзя было напрямую прибиндить к форме в Дельфи, Фокспро или MS Access.
Т.е., с единственным "лекарством" от этой болезни можно было работать лишь обслуживая низкоуровневую механику ручками. К чему я и пришел в итоге, после серии экспериментов с локальным кешированием записей. Потому что выбора у меня всё-равно не было, ведь после выхода 7-го MS SQL альтернативы ему для "обычного" железа, считай, отсутствовали. А его ни in-proc не подключить, ни написать свой драйвер передачи данных для сервака, есть лишь выбор из предоставляемого. Вот и выкручивайся.
V>>Пфф... Вопрос в том СКОЛЬКО раз потребуется переключать контекст? S>Ну всяко меньше раз, чем при чтении файла по кускам.
Файл читается большими страницами. Почти всегда за раз скидывается или читается большое кол-во страниц. Т.е. затраты одной IO-операции неплохо "размазываются" по большой группе логических операций. Этот механизм включён в саму операционку.
V>>Про "нет копирований" булшит в обсуждаемом сценарии. V>>Сервак же не маппированные области базы данных возвращает а формирует в памяти представление твоего рекордсета. S>Ну да, всё верно. И in-proc сервер делает то же самое. Рекордсет-то точно такой же.
Разве что контекст исполнения на кажду порцию данных переключать не надо.
А, может, ты забыл, что операции записи в shared-память провоцируют исключения ОС?
Поэтому, писать в такую память "построчно" точно так же глупо.
Поэтому и было глупо насчёт "зато нет копирования".
Не всё, что написано на Stack Overflow является истинной. Даже если у поста стоит десяток плюсов. ))
V>>Можно сразу писать результат "туда". V>>Опять же, глупо возвращать ВСЕ данные сразу, их надо возвращать порциями, чтобы обрабатывать в "оперативной" манере. S>Буфер — наше всё.
Межпроцессный дорог.
А межпотоковый у меня "размазывает" одну операцию синхронизации стоимостью 1 микросекунду на сотни/тысячи сообщений в lock-free межпотоковых буферах.
V>>Я пол-года не выкатывал свою первую систему с использованием SQL-севака, потому что при обычном, принятом по-умолчанию "построчном" редактировании, т.е. с сохранением каждой строки, впечатление было ужасным после варианта с файловой базой. S>Естественно. Некурящие люди так не делали ни в какие годы.
Примерно с 2000-го года делали аж бегом. ))
Хотя тут характерно твоё согласие, хотя были возражения на это же выше.
Сам себе противоречишь.
S>Сохранение делалось "потранзакционно", а строки заказа лежали в памяти.
А когда их сотни и тут связь с серваком глюкнулась, то амба. ))
Поэтому, на MS Access и было удобно, что это и GUI-прога и локальная шустрая база одновременно.
А так-то я в период фрилансерства как раз выполнил один такой заказик для целого семейства систем на Дельфи, который был TCP проксей и "держал" TCP-связь что со стороны клиента, что со стороны сервака, пока связь восстанавливалась. Бо терять прилично наработанного времени всегда обидно, скажем, человек долго редактировать большой заказ и несколько раз его перепроверял перед сохранением.
V>>Зачем? S>Для масштабирования.
А что сначала надо масштабировать — базу или сервак приложений? ))
Просто был опыт писания сервака приложений и на нейтиве, так вот, надобность "масштабирования" волшебным образом уменьшается примерно в 10 раз. Т.е. он допускает вдесятеро большую нагрузку, чем явовские или дотнетные серваки.
И даже сложно придумать такое применение, где бы потребовалось то самое "масштабирование".
Вон ты сам писал, что RSDN работает на скромном железе для его популярности.
А популярность, действительно, нехилая.
Для нейтивной такой системы нужно было бы в 10 раз более скромное железо для того же отклика.
Здравствуйте, vdimas, Вы писали:
S>>Мы просто замеряли реальные времена исполнения запросов. По сети MS SQL отдавал данные за ~100мсек. Это в 1997 году, есличо. V>Ага, если один чел-клиент на ём работает.
Ну почему же один. Мы на боевой системе мерили.
Но даже если бы и так — напомню, что мы обсуждаем совершенно бредовое утверждение про задержки из-за in-proc vs out-of-proc.
В обоих случаях речь о локальном исполнении, поэтому никаких дополнительных "чел-клиентов" нет. V>У меня реальное боевое применение в течени нескольких лет было, если чо.
Да я уже понял. И про ресайз страниц я помню, и про то, что вставка в середину кластерного индекса медленнее, чем в хвост.
Всё это выдаёт реальный боевой опыт, отож.
S>>Полусекундные паузы из-за out-of-proc на локальной машине — беспардонное враньё. V>Смотря какая очередь запросов накопилась.
Откуда на локальной машине возьмётся очередь запросов?
V>Во фрилансерстве в 2000-е применял эти же подходы уже и на C#, задолго до всяких async — делали систему POS+учёт для торговых точек в США.
Ну, кто ж похвалит, если не сам себя.
V>Заметная разница есть у всех.
Полсекунды?
S>>На клиппере прочесть "весь набор" — это надо постараться. Я так полагаю, что вы, коллега, Клиппера своими глазами не видели, да? V>Ошибочно полагаешь.
Ну, тогда напомните мне, как именно в Клиппере можно прочесть "весь набор".
V>Тут желателен был бы пример типизированной коллекции, чтобы без copy&paste, или слил.
А, вы про коллекции. Код писать не буду — лень, но делается примерно так же, как и в случае с TListView.
То есть коллекция параметризуется типом элемента, и всё происходит в рантайме.
Да, это непригодно для value-типов, но в реальных Delphi-приложениях коллекции бывают трёх типов: TString, integer, и объектов. Вот для них всё достигается параметризацией.
V>>>4 SSD в параллель, скорость чтения 3.6 гига. S>>Неплохо, неплохо. Даже с учётом того, что реалистичная скорость, намеренная в тестах, около 2х гигов.
V>Врать не надоело? V>Полно обозоров на ютубе, народ показывает скриншоты — получают те самые 3.6 гига/с.
Я смотрел http://ssd.userbenchmark.com/SpeedTest/182182/Samsung-SSD-960-PRO-512GB
Avg. Sequential Read Speed 2,192MB/s
Max — 2,859
По двадцати тысячам замеров.
Что-то ютубовые обзорщики не выкладывают свои результаты туда. Стесняются, наверное.
V>Выйдёт. V>Скорость же удельная величина. V>Просто где-то надо не 32 гига за секунду, а 32 метра за 1ms.
Ну да. Вот только эти 32 метра разбросаны по диску, а не лежат в одной кучке.
V>Память уже давно многоканальная, особенно на серваках.
Ну, тогда мы и работать с ней будем по многим каналам. V>Обрати внимание на графике на размер очереди запросов IO самого накопителя.
Не вижу графика с размером очереди. V>А так-то есть накопители и с большим размером очереди.
V>Драйвер может помещать в очередь за раз кучу запросов к диску и за одно прерывание тоже выгребается куча же ответов. V>А в твоём варианте мы имеем от сервака приложений сотни/тысячи коннекшенов к SQL-серваку одновременно, где в каждый коннекшен серваку надо отдать данные индивидуально.
V>Судя по всему, ты не понимаешь примеры группировки операций, которые я постоянно привожу.
V>Да хотя бы почему приложение на дельфях медленнее работает с базами данных при отображении в таблицах.
Брр. Медленнее, чем что? С парадоксом дельфи работал просто прекрасно.
V>Сейчас-то это трудно заметить, а в 96-м году это было более чем очевидно, особенно при листании выборок в таблицах. V>Насчёт FoxPro аналогично — такая же точно ошибка в архитектуре и пой же самой причине тормоза, GUI морозилось, пока все данные для отображаемых строк не прочитает. ))
Непонятно, откуда внезапные тормоза в фокспре, которая работает локально и inproc. И в текстовом режиме, так что никаких windowed контролов там нету и рядом. Это ж идеал, к которому аксессу ещё стремиться и стремиться.
V>Учитывая, что мы уже выяснили, что ты не понимал, что такое ISAM, приходится объяснять, какой от него вообще толк, т.е. как именно с этим подходом можно эффективно работать.
Пока что непонятно, потому что противопоставляется тёплое и мягкое. Как можно сравнивать inproc-сервис на локальной машине с удалённым сервером? Это же совершенно разные сценарии работы.
Попытка натянуть ISAM на локальную сеть и привела к появлению нормальных клиент-серверных архитектур, в частности — SQL.
Потому что через сетку все эти идеи "драйвер может упорядочить чтение с диска и за одно прерывание обработать множество реквестов" по сети не работают никак. По сети надо отдавать запрос, выраженный как можно точнее, чтобы минимизировать трафик между клиентом и сервером.
S>>В 96м — это, наверное, ещё Delphi 1.0? 16-разрядный? Не помню, не застал. V>И в институте не программировал ни разу?
Один раз помогал знакомому делать зачёт. Во времена института я программировал исключительно под дос — под винду было не достать литературы. V>Опять какой-то детсад, сорри. V>Ключевое выделил.
V>Пока у клиента "живой" рекордсет на руках, выделенная под него shared-память будет только расти.
Это опять какой-то набор слов. Рекордсет — это же абстракция поверх какой-то реализации. Это не какая-то фиксированная структура в памяти. Это штука, которой можно делать Move, Read, и иногда Write. Внутри оно уже пользуется механизмами взаимодействия, которые, как правило, построены вокруг концепции "потока". И вот как раз эту концепцию потока можно реализовать между двумя процессами при помощи shared memory, причём вполне себе фиксированного размера.
V>А его ни in-proc не подключить, ни написать свой драйвер передачи данных для сервака, есть лишь выбор из предоставляемого. Вот и выкручивайся.
Вы его драйвер shared memory всё равно не обыграете по производительности.
V>Файл читается большими страницами. Почти всегда за раз скидывается или читается большое кол-во страниц. Т.е. затраты одной IO-операции неплохо "размазываются" по большой группе логических операций. Этот механизм включён в саму операционку.
И именно его как правило отключают взрослые СУБД. Вы посмотрите для интересу, с какими флагами открывает mdf файлы MS SQL.
А реально данные читаются экстентами, как правило по 64к.
Данные по производительности SSD при такой работе можете нагуглить сами — никаких гигабайтов в секунду там и в помине нет.
V>А, может, ты забыл, что операции записи в shared-память провоцируют исключения ОС?
Хуже — я про это даже не знал. А где прочитать про эти мифические исключения? Мне просто непонятно, для чего они могут быть нужны. Ведь shared memory ничем от обычной не отличается.
V>Примерно с 2000-го года делали аж бегом. ))
Курящие — да. Тут вопросов нет. Я и не такое видел — один крендель ухитрился в яве между двумя серверами рекордсет не по значению сериализовать, а передать как remotable object. И с умным видом рассказывал, что приложение и должно так тормозить — ну там, про размер данных, про скорость сети вещал.
V>Сам себе противоречишь.
Неа. Вы, коллега, просто всё время теряете нить беседы, отвлекаясь в разные стороны в попытках продемонстрировать свою немеренную крутизну.
Напомню, я всего лишь рассказал вам, что систем, способных делать SQL операции над локальными данными и над удалёнными, больше чем одна. Вы начали рассказывать про безумную стоимость IPC коммуникации, аргументируя это примерами с отсутствием windowless контролов в дельфи и про то, что если построчно редактировать рекордсет, открытый на удалённом перегруженном сервере, то это чревато задержками.
V>А когда их сотни и тут связь с серваком глюкнулась, то амба. ))
Не обязательно. Конкретно у нас — была амба , потому что руки не дошли написать нормальное восстановление соединения.
А точнее, нормальную синхронизацию состояния кэша. Но это опять не из-за SQL сервера, а из-за выбранной архитектуры. V>Поэтому, на MS Access и было удобно, что это и GUI-прога и локальная шустрая база одновременно.
Вот с этим — да, спорить нет смысла. Правда, всё равно она никакой магией не будет синхронизовывать заказы на сервер, надо пилить код ручной синхронизации. Но, полагаю, что сам этот код всё ещё проще, чем когда приложение вынуждено манипулировать двумя подключениями, одно из которых может в любой момент пропасть.
V>А так-то я в период фрилансерства как раз выполнил один такой заказик для целого семейства систем на Дельфи, который был TCP проксей и "держал" TCP-связь что со стороны клиента, что со стороны сервака, пока связь восстанавливалась. Бо терять прилично наработанного времени всегда обидно, скажем, человек долго редактировать большой заказ и несколько раз его перепроверял перед сохранением.
Ну вот у нас такая возможность была забесплатно, но проблема в потере связи — вовсе не в том, что мы не можем записать изменения. Тут-то мы можем просто встать в retry хоть до морковкиного заговения, т.к. заказ у нас весь уже и так висит в памяти. Проблема — в выбранном способе concurrency. Она была optimistic, но по локальному кэшу. Это означает, что пока связи не было, мы могли потерять чужие изменения, и запись транзакции потенциально откатывала их. Инициативу по переписыванию механизма коммита на более дружелюбный к разрывам связи мы начали, но в итоге так и не закончили по, скажем так, внетехническим причинам.
V>А что сначала надо масштабировать — базу или сервак приложений? ))
Если всё написано правильно, то сервак приложений.
V>Просто был опыт писания сервака приложений и на нейтиве, так вот, надобность "масштабирования" волшебным образом уменьшается примерно в 10 раз. Т.е. он допускает вдесятеро большую нагрузку, чем явовские или дотнетные серваки.
Раза 2-3 можно наиграть против нынешних технологий. С 10 — сложно. Точнее, в 3-4 можно улучить возможности масштабирования, просто переписав говнокод в рамках той же платформы.
V>И даже сложно придумать такое применение, где бы потребовалось то самое "масштабирование"
Тут вопрос в том, сколько удаётся передать в СУБД.
Современные говноподелки на говнофреймворках все, как одна, страдают одним и тем же: там, где можно обойтись одним быстрым запросом в базу, делается пачка медленных. При этом перегружена и СУБД, которая вынуждена долго удерживать локи и тормозить других клиентов, и сервер приложений, который вместо ExecuteQueryAsync занимается перемешиванием ненужных ему мегабайтов в стиле "а не изменилось ли одно из 150 неинтересных мне полей". Просто перестав это делать, мы уже снижаем и нагрузку на СУБД, и потребление памяти, и время простоя клиента. А каждый простой — это занятые ресурсы, которые тормозят входящих.
V>Вон ты сам писал, что RSDN работает на скромном железе для его популярности. V>А популярность, действительно, нехилая. V>Для нейтивной такой системы нужно было бы в 10 раз более скромное железо для того же отклика.
Вот очень, очень вряд ли. Даже если повторить прямо всю-всю функциональность с генерацией оптимального SQL, которую даёт link2db, придётся откуда-то выжать десятикратное улучшение производительности по отдаче HTML. Что там, неужто конкатенация строк в нативе даст нам десятикратный прирост? Да ну, откуда.
Там на синтетике вроде матричных вычислений и то наигрывают раза два.
А на отдаче HTML сильно много не сэкономишь. Ну, может процентов 20% за счёт более агрессивного инлайна в клинических случаях.
Экономию надо получать на асинхронщине — типа получили запрос, поняли, что делать, инициировали кверю в СУБД, и вернули поток в пул. Нефиг висеть в ожидании ответа, и тем более вступать в диалог с СУБД. Получили ответ от СУБД — отформатировали данные — вернули поток в пул.
Стандартные дотнет приложения делают совершенно не так — там обработчик реквеста, получив из поток из пула, по секунде и больше занимается онанизмом с гибернейтами, вызовами сторонних веб-сервисов и прочей содомией. Процессор при этом либо простаивает, либо перелопачивает ненужные ему данные. А остальные клиенты стоят в очереди IIS, потому что в пуле — всего по 25 потоков на CPU.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Re[53]: В России опять напишут новый объектно-ориентированны
Здравствуйте, Sinclair, Вы писали:
S>Но даже если бы и так — напомню, что мы обсуждаем совершенно бредовое утверждение про задержки из-за in-proc vs out-of-proc.
Сорри, но тогда ты мне не оппонент в споре.
С параллельными реальностями я спорить не подписывался. ))
Я всю дорогу наблюдаю эту разницу воочию, т.е. с чей-то верой бодаться банально не интересно.
Re[47]: В России опять напишут новый объектно-ориентированны
Здравствуйте, alex_public, Вы писали:
_>Кем это так позиционировалось и где?
alex_public, прям в этом топике такое писал.
_> Да и кстати сделать для себя подобные выводы в принципе может только человек очень далёкий от индустрии, т.к. язык запросов Mongo априори не может стать заменой SQL в РСУБД хотя бы потому, что РСУБД не предоставляют ни возможности MapReduce, ни произвольной структуры документа.
Смешно, весь разговор сводится к тому, что прихотится напоминать ваши же слова, возвращать в контекст и ловить при съезде с темы. Внезапно перешли с замены SQL-ю как языку запросов, на замену SQL-ю именно в РСУБД. Это не я тут предлагал язык монги в качестве лучшей альтернативы, и не я призывал посмотреть на noSQL в качестве примера "лучшего" языка запросов.
Не говоря уже о том, что если уж предлагаемый язык шире по возможностям, то это ни как не мешает выступать ему альтернативой.
_>Даже если забыть про обсуждаемые тут минусы Linq (что у нас там например с CTE или рекурсией?), то в любом случае Linq же в данный момент при работе с СУБД работает через посредника в виде SQL, так что это явно не замена, а всего лишь надстройка, полностью ограниченная возможностями SQL.
В этом утверждении либо вовсе нет логики, либо я ее не улавливаю.
Если мы ищем гипотетический язык запросов, то как линку мешает то, что у него есть реализация через SQL? Напоминаю, реализация может быть и без SQL-я, мы же гипотетический язык обсуждаем?
Если мы ищем язык запросов к РСУБД — то опять же, "ограничения" SQL ему ни сколько не мешают. SQL может выразить все, что имеет отношение непосредственно к СУБД, тут все "ограничения" связаны с самой базой, а не с языком. А во всем остальном можно использовать прикладной язык, который опять-таки ограничен исключительно возможностями платформы, а не непосредственно linq-а.
Мы уже победили, просто это еще не так заметно...
Re[45]: В России опять напишут новый объектно-ориентированны
Не совсем. Мы обсуждаем чем бы таким более эффективным заменить SQL в реляционных СУБД. И в этом смысле вполне можно в качестве вдохновения полистать различные вариации реализации запросов во множестве популярных nosql СУБД.
Да и кстати сделать для себя подобные выводы в принципе может только человек очень далёкий от индустрии, т.к. язык запросов Mongo априори не может стать заменой SQL в РСУБД хотя бы потому, что РСУБД
Это в двух соседних сообщениях. Может там вас двое с одного аккаунта пишет? )
_>Любой вменяемый участник данной дискуссии отлично видел, что с какими целями я предлагал посмотреть на MongoDB.
Да тут похоже все не вменяемые. =)
Мы уже победили, просто это еще не так заметно...
Re[37]: В России опять напишут новый объектно-ориентированны
Здравствуйте, alex_public, Вы писали:
_>Я предполагаю, что рост Postgre вполне коррелирует с падением Oracle и МС SQL — люди постепенно переходят на точно такое же решение, только бесплатное. )
Не очень-то коррелирует, но дело даже не в этом. Поинт в том, что с реляционки, почему-то перерходят на другую реляционку, а не на модный NoSQL
_>А что у MySQL с этим не так? )
Чуть менее чем все.
_>Конечно. Только именно этот новый инструмент вполне себе растёт, завоёвывая всё новые прикладные области.
Да вот по этому же графику видно, что не растет и не завоевывает. Попытались было впихнуть вместо SQL-я, но что-то пошло не так.
_> В то время как про появление каких-то совершенно новых полезных применений для классических СУБД я что-то не слышал в последнее время.
Классическим СУБД и своей ниши более чем достаточно
Мы уже победили, просто это еще не так заметно...
Re[53]: В России опять напишут новый объектно-ориентированны
Здравствуйте, Sinclair, Вы писали:
S>и про то, что вставка в середину кластерного индекса медленнее, чем в хвост.
Вроде, мы же уже выяснили, что ты был не в курсе про дефрагментацию индексов и деградацию быстродействия?
S>>>Полусекундные паузы из-за out-of-proc на локальной машине — беспардонное враньё. V>>Смотря какая очередь запросов накопилась. S>Откуда на локальной машине возьмётся очередь запросов?
Мы про сценарий "склейки" сервака приложений и СУБД во всём этом топике обсуждаем.
Очередь запросов чудовищная в известных мне областях, для которых я подобную систему и предлагаю, собсно.
V>>Во фрилансерстве в 2000-е применял эти же подходы уже и на C#, задолго до всяких async — делали систему POS+учёт для торговых точек в США. S>Ну, кто ж похвалит, если не сам себя.
А ты думал оно в языке просто так появилось?
От "системщиков" и появилось.
Мы обкатали этот сценарий и показали его преимущество в GUI-приложениях.
S>>>На клиппере прочесть "весь набор" — это надо постараться. Я так полагаю, что вы, коллега, Клиппера своими глазами не видели, да? V>>Ошибочно полагаешь. S>Ну, тогда напомните мне, как именно в Клиппере можно прочесть "весь набор".
В цикле.
И речь шла обо всём отображаемом наборе, а не вообще о всех данных в таблице.
V>>Тут желателен был бы пример типизированной коллекции, чтобы без copy&paste, или слил. S>А, вы про коллекции. Код писать не буду — лень
Конечно, лень, бо сплошной copy-paste.
S>но делается примерно так же, как и в случае с TListView.
Ты мне дай типизированную коллекцию, а не абстрактную.
S>То есть коллекция параметризуется типом элемента, и всё происходит в рантайме.
Это только для случая создания элементов самой коллекцией работает.
Заметь, как много ты начинаешь не договаривать, как только дело доходит до дела...
В любом случае, коллекция выдаёт нетипизированные элементы и проверка их приведения тоже происходит в рантайм.
Поэтому, типизированные коллекции были весьма популярны.
Настоящие, статически-типизированные.
S>Да, это непригодно для value-типов, но в реальных Delphi-приложениях коллекции бывают трёх типов: TString, integer, и объектов. Вот для них всё достигается параметризацией.
В реальных Delphi-приложениях бывают произвольные коллекции.
В том числе писанные вовсе с 0-ля.
В большой системе таких коллекций больше, чем встроенных.
Я тоже посмотрел.
Показана средняя скорость НЕ самого диска, а результатов у населения.
А там не факт, что тестируемая техника имеет PCIe 3.0, в пользовательском-то сегменте самая популярная до сих пор PCIe 2.0.
Но даже по твоей ссылке видно, что у некоторых пользователей бенчмарк даёт те самые 3.6 гига/с.
S>Что-то ютубовые обзорщики не выкладывают свои результаты туда. Стесняются, наверное.
И не только ютуберы, а вообще все сколь-нибудь серьёзны бенчамрки по твоей ссылке не выкладываются, разумеется.
Покажи мне по твоей ссылке условия тестирования?
V>>Просто где-то надо не 32 гига за секунду, а 32 метра за 1ms. S>Ну да. Вот только эти 32 метра разбросаны по диску, а не лежат в одной кучке.
Продолжаем ликбез: на SSD-дисках любая относительно-длинная запись (длиннее строки хранения), даже про которую операционка рапортует как расположенную "в одной куче", де-факто "разбросана" по диску. SSD — это разновидность статической памяти, т.е. ей пофиг, насчёт в куче или не в куче, на физическом уровне там всё-равно обычный адресный доступ, как в оперативке.
V>>Обрати внимание на графике на размер очереди запросов IO самого накопителя. S>Не вижу графика с размером очереди.
Надпись DQ=128 на графике — это длина очереди.
V>>Да хотя бы почему приложение на дельфях медленнее работает с базами данных при отображении в таблицах. S>Брр. Медленнее, чем что? С парадоксом дельфи работал просто прекрасно.
Медленнее при листании страниц.
Просто взять относительно большую выборку, схватить мышой бегунок на скролл-баре и погонять туда-сюда.
V>>Насчёт FoxPro аналогично — такая же точно ошибка в архитектуре и пой же самой причине тормоза, GUI морозилось, пока все данные для отображаемых строк не прочитает. )) S>Непонятно, откуда внезапные тормоза в фокспре, которая работает локально и inproc. И в текстовом режиме, так что никаких windowed контролов там нету и рядом. Это ж идеал, к которому аксессу ещё стремиться и стремиться.
(блин, в каждом абзаце можно цокать и цокать языком)
В общем, 3-й FoxPro от 95-го года был уже графический.
А "окончательная" 5-й версия — от 97-го года.
Собсно с этой версии и пошла популярность FoxPro, на котором было разработано мильон GUI-приложух (последующие версии FoxPro от 5-го отличались не сильно).
V>>Учитывая, что мы уже выяснили, что ты не понимал, что такое ISAM, приходится объяснять, какой от него вообще толк, т.е. как именно с этим подходом можно эффективно работать. S>Пока что непонятно, потому что противопоставляется тёплое и мягкое. Как можно сравнивать inproc-сервис на локальной машине с удалённым сервером? Это же совершенно разные сценарии работы.
Это ты не на тот абзац ответил, похоже.
Это я приводил для демонстрации, что наиболее эффективным способом работы с ISAM-базами было открытие навигируемого рекордсета по индексу. В этом случае чтение данных можно было производить прямо в операции отрисовки окна, без предварительного чтения. Так вот, недостаток FoxPro был в том, что он для отображения в таблице текущей страницы сначала должен был прочитать отображаемые строки, что создавало подтормаживания GUI.
S>Попытка натянуть ISAM на локальную сеть и привела к появлению нормальных клиент-серверных архитектур, в частности — SQL.
ISAM вполне себе выбор для сервера приложений в трехзвенке.
Только не stateless псевдотрёхзвенке, как в случае HTTP-фронтенда, а настоящего stateful.
S>Потому что через сетку все эти идеи "драйвер может упорядочить чтение с диска и за одно прерывание обработать множество реквестов" по сети не работают никак. По сети надо отдавать запрос, выраженный как можно точнее, чтобы минимизировать трафик между клиентом и сервером.
Т.е., в прошлый раз мне не удалось тебя устыдить, что тебя всегда заносит в одну и ту же потенциальную яму?
Ты из неё никак выбраться не можешь, смотрю. ))
Ну блин, как речь об ISAM, так ты проваливаешься в область сетевого доступа к файлам.
Это какой-то пипец.
При том, что мы даже разобрали My SQL, где в одной из его конфигураций над ISAM работает полноценный СУБД-процесс с исключительным доступом.
S>Один раз помогал знакомому делать зачёт. Во времена института я программировал исключительно под дос — под винду было не достать литературы.
При том, что любая среда программирования несла с собой справку?
Хотя, если уж по-справедливости относительно тех лет, то больше речь шла о доступе к машинному времени с нужной версией ОС.
Так-то получить машинное время под ДОС было проще, угу.
V>>Пока у клиента "живой" рекордсет на руках, выделенная под него shared-память будет только расти. S>Это опять какой-то набор слов. Рекордсет — это же абстракция поверх какой-то реализации.
А так же — курсор статический или динамический, если можно навигировать по записям туда-сюда.
S>Внутри оно уже пользуется механизмами взаимодействия, которые, как правило, построены вокруг концепции "потока". И вот как раз эту концепцию потока можно реализовать между двумя процессами при помощи shared memory, причём вполне себе фиксированного размера.
Я примерно понимаю, о чём ты, но это ходьба по-кругу.
— получается, что страницы shared-memory ты предлагаешь использовать сугубо как транспортные, то бишь аргументы "зато нет копирования" фтопку, бо копирование будет дважды — на стороне сервака на страницу и на стороне клиента из страницы;
— для рекордсетов произвольного доступа в такой системе будет больше трафик команд на сервак;
— хотя, для случая открытия рекодрдсета, когда курсор расположен на серваке, это так и есть в любом случае, т.е. любой чих (смещение курсора) провоцирует НЕСКОЛЬКО операций обмена сообщениями клиента и сервера.
Мне всё еще требуется объяснять, почему out-of-proc существенно затратней?
V>>А его ни in-proc не подключить, ни написать свой драйвер передачи данных для сервака, есть лишь выбор из предоставляемого. Вот и выкручивайся. S>Вы его драйвер shared memory всё равно не обыграете по производительности.
Я всё что угодно обыгрываю по производительности прямо замерам лабораторий Интел.
Работа у меня такая.
V>>Файл читается большими страницами. Почти всегда за раз скидывается или читается большое кол-во страниц. Т.е. затраты одной IO-операции неплохо "размазываются" по большой группе логических операций. Этот механизм включён в саму операционку. S>И именно его как правило отключают взрослые СУБД. Вы посмотрите для интересу, с какими флагами открывает mdf файлы MS SQL.
Они отключают шедуллинг ОС этого механизма, но не отключают сам механизм.
Именно под задачи СУБД из виндов торчит АПИ навроде ReadFileScatter/WriteFileGather.
S>А реально данные читаются экстентами, как правило по 64к.
Реально в нагруженных сценариях за одну операцию IO читается много страниц.
Пишется тоже.
Иначе всё-это банально не взлетит.
S>Данные по производительности SSD при такой работе можете нагуглить сами — никаких гигабайтов в секунду там и в помине нет.
Я нагуглил и данные тебе уже дал.
По данному мной графику IOPs пропускная способность НЕ зависит от размера блока, т.е. можно даже представить твою страницу 64к как 16 по 4к — пофик, получается гиг в секунду во всех конфигурациях, т.е. даже в два раза меньше, чем по ствоей ссылке бенчмарков от людей с ноутбуками на батарейках (С).
Это лишь говорит о том, что узким местом является сама БД, а не система хранения. То бишь, показанной картейки SSD по ссылке достаточны для того, чтобы на таком хранилище получить скорость примерно как от хранения таблиц на RAM-диске.
V>>А, может, ты забыл, что операции записи в shared-память провоцируют исключения ОС? S>Хуже — я про это даже не знал. А где прочитать про эти мифические исключения? Мне просто непонятно, для чего они могут быть нужны. Ведь shared memory ничем от обычной не отличается.
Shared-memory в Windows — это один из способов IO для файлов.
Самый эффективный способ для того самого IO для файлов, угу.
Литературы по отображаемым файлам — полно.
RTFM!
V>>Примерно с 2000-го года делали аж бегом. )) S>Курящие — да. Тут вопросов нет.
Вопросов стало меньше от витой пары 100 мбит и от резкого повышения производительности компов.
Для сравнения, новые Celeron-ы в 2001-м году показывали примерно впятеро лучшее быстродействие, чем мощные серваки в 1996-м.
S>Я и не такое видел — один крендель ухитрился в яве между двумя серверами рекордсет не по значению сериализовать, а передать как remotable object. И с умным видом рассказывал, что приложение и должно так тормозить — ну там, про размер данных, про скорость сети вещал.
На такой технике и таких скоростях и это прокатывало, и?
Примерно в 2001-м году на CORBA извращались — тоже вполне себе жили удалённые объекты в локалке.
Это была уже совсем другая реальность.
S>Напомню, я всего лишь рассказал вам, что систем, способных делать SQL операции над локальными данными и над удалёнными, больше чем одна. Вы начали рассказывать про безумную стоимость IPC коммуникации
Так и есть.
S>аргументируя это примерами с отсутствием windowless контролов в дельфи
Это было в другом совсем абзаце, посвящённом уже GUI.
Это относительно независимые части системы, но вместе влияющие на user experience, разумеется.
S>и про то, что если построчно редактировать рекордсет, открытый на удалённом перегруженном сервере, то это чревато задержками.
И нагрузками на сервак (пожирание памяти), если курсор на той стороне. А динамический курсор будет ТОЛЬКО на той стороне.
Или невозможности твоей схемы "буфер1 заняли, освободили буфер2 и так по-очереди" для shared memory, при локальном out-of-proc и при живом динамическом курсоре.
Просто ты или забыл уже все тонкости, или мало времени уделял разработке на стороне клиента, судя по твоим высказываниям о бодишопах.
Или просто никогда и не представлял себе происходящее, что ближе всего к истине, скорее всего.
Бо всякие тонкости/цифры и т.д. можно и подзабыть с годами, но принцип работы подзабыть всяко сложнее.
Это надо и не знать никогда.
V>>А когда их сотни и тут связь с серваком глюкнулась, то амба. )) S>Не обязательно. Конкретно у нас — была амба , потому что руки не дошли написать нормальное восстановление соединения.
Да не, у "живого" курсора именно что амба, даже если связь восстановили.
Этого хорони, неси следующего.
В общем, реально можно создать более десятка разновидностей курсоров в зависимости от параметров их открытия, я переиграл вдоволь со всеми абсолютно комбинациями и послал всё это далеко в пень еще в те далёкие года.
Просто открываешь forward-only и читаешь данные, кешируя их локально.
Всё остальное не живёт и не эффективно.
Спустя примерно 10-15 лет индустрия громко объявила, что такой способ и является единственным правилом хорошего тона.
Спасибо, знали и так, бо на своей шкуре как грится.
V>>Поэтому, на MS Access и было удобно, что это и GUI-прога и локальная шустрая база одновременно. S>Вот с этим — да, спорить нет смысла. Правда, всё равно она никакой магией не будет синхронизовывать заказы на сервер, надо пилить код ручной синхронизации.
Код синхронизации однократный для произвольных разных типов док-тов.
Всё-равно оперируемая схема строк БД зачитывается динамически.
S>Но, полагаю, что сам этот код всё ещё проще, чем когда приложение вынуждено манипулировать двумя подключениями, одно из которых может в любой момент пропасть.
Вряд ли я на пальцах объясню...
В общем, в нейтиве политика подключения к MS SQL чуть отличается от оной через ADODB.Net.
Не хочу сейчас рассматривать все за и против, скажу только, что через ADODB.Net недоступны некоторые специфические фишки сервака.
Вернее, доступны, но теряют смысл.
V>>А что сначала надо масштабировать — базу или сервак приложений? )) S>Если всё написано правильно, то сервак приложений.
Наоборот, если всё написано не правильно. ))
Серваку приложений надо делать намного меньше работы, чем серваку БД.
Масштабировать его надо только если он на PHP и прочих ASP.Net.
V>>Просто был опыт писания сервака приложений и на нейтиве, так вот, надобность "масштабирования" волшебным образом уменьшается примерно в 10 раз. Т.е. он допускает вдесятеро большую нагрузку, чем явовские или дотнетные серваки. S>Раза 2-3 можно наиграть против нынешних технологий. С 10 — сложно.
Раза в 2-3 только на совсем уж синтетических тестах в одном цикле.
А как более-мнее реальность, как начинаются развесистые графы объектов в памяти, так 10 раз аж бегом разницы по потребляемой памяти и быстродействию.
S>Точнее, в 3-4 можно улучить возможности масштабирования, просто переписав говнокод в рамках той же платформы.
Не надо ставить телегу впереди лошади, коллега.
Резкий спрос на stateless-сервисы образовался в своё время как раз из-за обнаруженной надобности масштабировать явовские, а позже и дотнетные сервера.
Исторический факт, аднака.
V>>И даже сложно придумать такое применение, где бы потребовалось то самое "масштабирование" S>Тут вопрос в том, сколько удаётся передать в СУБД.
Ну я тебе давал уже реальные цифры по нейтивным системам.
Сотовые базы на узлах тоже работают аж бегом при самом жутком трафике из всех возможных.
БЕЗ всякого масштабирования, т.е. без надобности вводить дополнительные аппаратные узлы.
Потому что любое масштабирование — это дополнительные тормоза, причём, жутчайшие и невозможнейшие.
Поэтому, речь всегда о вылизанных нейтивных системах, разумеется.
V>>Вон ты сам писал, что RSDN работает на скромном железе для его популярности. V>>А популярность, действительно, нехилая. V>>Для нейтивной такой системы нужно было бы в 10 раз более скромное железо для того же отклика. S>Вот очень, очень вряд ли. Даже если повторить прямо всю-всю функциональность с генерацией оптимального SQL, которую даёт link2db, придётся откуда-то выжать десятикратное улучшение производительности по отдаче HTML. Что там, неужто конкатенация строк в нативе даст нам десятикратный прирост? Да ну, откуда.
Голая нейтивная конкатенация даёт примерно 3-5-тикратный прирост.
Но этого мало, мы же работаем через абстракции навроде StreamWriter, а там разница чудовищная по итогу выходит, более 20 раз.
Нейтивный парсинг HTTP-заголовков даёт примено столько же, в 3-5 раз и умножай это на более эффективный ввод/вывод в сравнении с дотнетными Stream.
Далее.
При применении всякой "полигональной" памяти, т.е. алгоритмов управления памятью, которые хорошо заточены именно под серверные задачи навроде вопрос-ответ — там еще +50% производительности прибавляй, т.к. управление памятью становится де-факто бесплатное от слова совсем.
Кароч, не во всех подсистемах буст до 10 раз, но по мелочи до 10 раз добегает запросто, бо где-то буст и на пару порядков аж бегом.
При этом освобождется быстродействие для других нужд, например, для той же БД.
Набор SQL-запросов у вас фиксированный, их "оптимизированные" версии можно нагенерить в офлайне, в кач-ве шага билда.
S>Там на синтетике вроде матричных вычислений и то наигрывают раза два.
Только на синтетике и можно получить 2-3 раза разницы.
А в реальной нагруженной приложухе — у-у-у.
Вот как раз периодически замеряем, стабильно примерно в 10 раз разница.
И так странно выходит, что чем больше нагрузка в нейтиве, тем он эфффективнее в пересчёте на одну операцию (по замерам разница до ~3 раз в эффективности, в зависимости от частоты запросов), а для управляемого кода — наоборот, в нагруженных сценариях он работает ХУЖЕ.
S>А на отдаче HTML сильно много не сэкономишь. Ну, может процентов 20% за счёт более агрессивного инлайна в клинических случаях.
Не так давно в местном плюсовом форуме соревновались в библиотеках форматирования текста.
Разница более 8 раз с традиционными STL-потоками iostream, а те работают быстрее дотнетных StreamWriter.
S>Экономию надо получать на асинхронщине — типа получили запрос, поняли, что делать, инициировали кверю в СУБД, и вернули поток в пул. Нефиг висеть в ожидании ответа, и тем более вступать в диалог с СУБД.
Ой, вот это даже обсуждать не охота.
Нейтив — это нейтив.
Там любое серверное приложение сразу из себя автомат представляет (или набор автоматов), т.е. прямо начиная от самой низкоуровневой архитектуры. Ничего другое на серверной стороне смысла не имеет.
S>Стандартные дотнет приложения делают совершенно не так — там обработчик реквеста, получив из поток из пула, по секунде и больше занимается онанизмом с гибернейтами, вызовами сторонних веб-сервисов и прочей содомией. Процессор при этом либо простаивает, либо перелопачивает ненужные ему данные. А остальные клиенты стоят в очереди IIS, потому что в пуле — всего по 25 потоков на CPU.
[Skip]
_>Даже если забыть про обсуждаемые тут минусы Linq (что у нас там например с CTE или рекурсией?), то в любом случае Linq же в данный момент при работе с СУБД работает через посредника в виде SQL, так что это явно не замена, а всего лишь надстройка, полностью ограниченная возможностями SQL.
Подожди чуток, заканчиваем. Поддержку CTE в полный рост можно глянуть тут — рекурсивный вариант. Еще в доводке до ума, но API уже продумано.
Re[48]: В России опять напишут новый объектно-ориентированны
Здравствуйте, IB, Вы писали:
_>>Кем это так позиционировалось и где? IB>alex_public, прям в этом топике такое писал.
В таком случае тебе конечно же будет совсем не трудно дать ссылку на соответствующую цитату... )
_>> Да и кстати сделать для себя подобные выводы в принципе может только человек очень далёкий от индустрии, т.к. язык запросов Mongo априори не может стать заменой SQL в РСУБД хотя бы потому, что РСУБД не предоставляют ни возможности MapReduce, ни произвольной структуры документа. IB>Смешно, весь разговор сводится к тому, что прихотится напоминать ваши же слова, возвращать в контекст и ловить при съезде с темы. Внезапно перешли с замены SQL-ю как языку запросов, на замену SQL-ю именно в РСУБД. Это не я тут предлагал язык монги в качестве лучшей альтернативы, и не я призывал посмотреть на noSQL в качестве примера "лучшего" языка запросов.
Пока что в данной дискуссии пытаешься съезжать в основном ты. Достаточно вспомнить тот твой нелепый тезис о том, что работа с коллекциями через Linq может быть быстрее аналогичного императивного кода. Ты очень быстро постарался замять тему, как только тебе попросили предоставить хотя бы один реальный пример...
_>>Даже если забыть про обсуждаемые тут минусы Linq (что у нас там например с CTE или рекурсией?), то в любом случае Linq же в данный момент при работе с СУБД работает через посредника в виде SQL, так что это явно не замена, а всего лишь надстройка, полностью ограниченная возможностями SQL. IB>В этом утверждении либо вовсе нет логики, либо я ее не улавливаю. IB>Если мы ищем гипотетический язык запросов, то как линку мешает то, что у него есть реализация через SQL? Напоминаю, реализация может быть и без SQL-я, мы же гипотетический язык обсуждаем?
Не улавливаешь: Linq просто не имеет прямого отношения к обсуждаемому вопросу. Для общения с СУБД в любом случае необходимо нечто (язык, протокол, api — называй как хочешь), что будет отсылаться клиентом на сервер для описания запросов. И даже если для Linq появится новый бэкенд, работающий на этом новом нечто, Linq не будет иметь никакого отношения к обсуждаемому в данной дискуссии вопросу. Потому что заменой SQL будет именно это нечто, а не Linq.
Единственным вариантом, в котором можно было бы вспомнить про Linq в данной дискуссии, является решение типа прямой пересылки linq выражений в СУБД и что я не слышал ни в нашем обсуждение, ни где-то ещё о подобных предложениях.
IB>Если мы ищем язык запросов к РСУБД — то опять же, "ограничения" SQL ему ни сколько не мешают. SQL может выразить все, что имеет отношение непосредственно к СУБД, тут все "ограничения" связаны с самой базой, а не с языком. А во всем остальном можно использовать прикладной язык, который опять-таки ограничен исключительно возможностями платформы, а не непосредственно linq-а.
Я уже давно понял, что ты относишься к тем коллегам, которые считают SQL идеалом (не смотря даже на его изначальное позиционирование как инструмент для бухгалтеров) для работы с РСУБД. И видимо с этим уже ничего не поделаешь. Однако не стоит думать, что все вокруг придерживаются тех же взглядов.
Re[46]: В России опять напишут новый объектно-ориентированны
IB>Не совсем. Мы обсуждаем чем бы таким более эффективным заменить SQL в реляционных СУБД. И в этом смысле вполне можно в качестве вдохновения полистать различные вариации реализации запросов во множестве популярных nosql СУБД.
IB>
IB>Да и кстати сделать для себя подобные выводы в принципе может только человек очень далёкий от индустрии, т.к. язык запросов Mongo априори не может стать заменой SQL в РСУБД хотя бы потому, что РСУБД
IB>Это в двух соседних сообщениях. Может там вас двое с одного аккаунта пишет? )
Советую тебе прикупить словарь Даля и ознакомиться там с понятием "вдохновения". )))
Re[38]: В России опять напишут новый объектно-ориентированны
Здравствуйте, IB, Вы писали:
_>>Я предполагаю, что рост Postgre вполне коррелирует с падением Oracle и МС SQL — люди постепенно переходят на точно такое же решение, только бесплатное. ) IB>Не очень-то коррелирует, но дело даже не в этом. Поинт в том, что с реляционки, почему-то перерходят на другую реляционку, а не на модный NoSQL
Смотря где. В определённых областях естественно никогда не будет перехода, т.к. они идеально ложатся на РСУБД. А в каких-то процесс идёт...
_>>А что у MySQL с этим не так? ) IB>Чуть менее чем все.
Очень аргументированно. )))
_>>Конечно. Только именно этот новый инструмент вполне себе растёт, завоёвывая всё новые прикладные области. IB>Да вот по этому же графику видно, что не растет и не завоевывает. Попытались было впихнуть вместо SQL-я, но что-то пошло не так.
Как раз на днях встретилась в рассылке статья: https://habrahabr.ru/post/353008/. Кстати, в случае с крупнейшем банком Индонезии там указано не просто масштабное внедрение, но и как раз замена РСУБД с огромной выгодой... )))
Re[48]: В России опять напишут новый объектно-ориентированны
Здравствуйте, Danchik, Вы писали:
_>>Даже если забыть про обсуждаемые тут минусы Linq (что у нас там например с CTE или рекурсией?), то в любом случае Linq же в данный момент при работе с СУБД работает через посредника в виде SQL, так что это явно не замена, а всего лишь надстройка, полностью ограниченная возможностями SQL. D>Подожди чуток, заканчиваем. Поддержку CTE в полный рост можно глянуть тут — рекурсивный вариант. Еще в доводке до ума, но API уже продумано.
Хм, ну если говорить про использование Linq, как генератор SQL, то выглядит не плохо (сохраняет идеологию). Но если сравнивать с просто императивным кодом и держать в уме работу с коллекциями, то это конечно же весьма печально. )
В России опять напишут новый объектно-ориентированны
Здравствуйте, vdimas, Вы писали: V>Вроде, мы же уже выяснили, что ты был не в курсе про дефрагментацию индексов и деградацию быстродействия?
Неа. Мы пока что выяснили, что вы, коллега, полагали, что MyISAM в MySQL хранит индексы в том же файле, что и данные.
Про фрагментацию индексов мы ещё не разговаривали — в прошлый раз при моём уточняющем вопросе про "ресайз страницы" в MS SQL вы сослались на коллегу из курилки и сбежали из темы.
Я с удовольствием почитаю ваши очередные перлы про то, как "на самом" деле устроены B-tree индексы, и как "деградирует быстродействие" при "дефрагментации".
V>Мы про сценарий "склейки" сервака приложений и СУБД во всём этом топике обсуждаем. V>Очередь запросов чудовищная в известных мне областях, для которых я подобную систему и предлагаю, собсно.
А, просто вы мечетесь, как заяц по огороду. В этой ветке я комментировал исключительно про неспособность никаких систем, кроме Акссеса, совместно работать с локальными и удалёнными данными.
Если хотите вернуться к in-proc/out-of-proc для высоконагруженного сервера, то можно поговорить и об этом.
V>Мы обкатали этот сценарий и показали его преимущество в GUI-приложениях.
Отож. Я прямо уж не знаю, что бы было с индустрией, если бы не вы.
V>В цикле. V>И речь шла обо всём отображаемом наборе, а не вообще о всех данных в таблице.
Печалька. Ну, то есть клиппера вы всё-таки не видели. Жалко, у меня исходников не сохранилось. Дискетки столько не живут
V>Ты мне дай типизированную коллекцию, а не абстрактную.
Для чего?
V>В любом случае, коллекция выдаёт нетипизированные элементы и проверка их приведения тоже происходит в рантайм.
Конечно. И это делается ровно в одном методе. V>Поэтому, типизированные коллекции были весьма популярны. V>Настоящие, статически-типизированные. V>В реальных Delphi-приложениях бывают произвольные коллекции. V>В том числе писанные вовсе с 0-ля. V>В большой системе таких коллекций больше, чем встроенных.
Ну вот у нас в проекте на сотню тысяч строк было три таких коллекции. На дельфи же не математику писали, а бизнес приложения.
V>Показана средняя скорость НЕ самого диска, а результатов у населения. V>А там не факт, что тестируемая техника имеет PCIe 3.0, в пользовательском-то сегменте самая популярная до сих пор PCIe 2.0. V>Но даже по твоей ссылке видно, что у некоторых пользователей бенчмарк даёт те самые 3.6 гига/с.
Повторюсь: maximum: 2,859. Результатов с 3.6 гига среди 20000 результатов не зарегистрировано.
А нас, пользователей RDBMS, интересует не этот максимум, а random 4k в mixed режиме. Где мы наблюдаем значительно более реалистичные 280 мегабайт в секунду. Не гига байт, а мега байт.
Память в рандом режиме всё ещё в сорок раз быстрее.
V>Покажи мне по твоей ссылке условия тестирования? http://www.userbenchmark.com/Faq/What-is-sequential-read-speed/44
Можете скачать софтинку оттуда и проверить свою машину.
V>Продолжаем ликбез: на SSD-дисках любая относительно-длинная запись (длиннее строки хранения), даже про которую операционка рапортует как расположенную "в одной куче", де-факто "разбросана" по диску. SSD — это разновидность статической памяти, т.е. ей пофиг, насчёт в куче или не в куче, на физическом уровне там всё-равно обычный адресный доступ, как в оперативке.
Ухты! А чо ж тогда у него так различается скорость чтения в линейном режиме и покусочном? Там не всё так просто, как кажется.
V>>>Обрати внимание на графике на размер очереди запросов IO самого накопителя. S>>Не вижу графика с размером очереди. V>Надпись DQ=128 на графике — это длина очереди.
А, понятно. Ну вот, скажем, если сравнить очередь длиной в 64 с очередью длиной в 1, то ускорение всего в 4 раза. На вашей картинке при длине очереди в 128 намерили 800MB/s, но, поскольку кроме картинки, вы ничего не привели, то есть риск, что речь идёт о чистом чтении. Что в OLTP задаче не встречается.
V>>>Да хотя бы почему приложение на дельфях медленнее работает с базами данных при отображении в таблицах. S>>Брр. Медленнее, чем что? С парадоксом дельфи работал просто прекрасно.
V>Медленнее при листании страниц. V>Просто взять относительно большую выборку, схватить мышой бегунок на скролл-баре и погонять туда-сюда.
Ок, и почему же дельфи с Парадоксом будет работать медленнее, чем Access?
V>(блин, в каждом абзаце можно цокать и цокать языком) V>В общем, 3-й FoxPro от 95-го года был уже графический. V>А "окончательная" 5-й версия — от 97-го года. V>Собсно с этой версии и пошла популярность FoxPro, на котором было разработано мильон GUI-приложух (последующие версии FoxPro от 5-го отличались не сильно).
У нас популярность фокспро началась задолго до 95го года. Большинство приложений было разработано в начале 90х на фокспро для ДОС, и использовалось вплоть до перехода на полноценные клиент-серверные решения.
Вот, например, ознакомьтесь с БЭСТ-4: http://best-trade.narod.ru/bestface.htm
Выпущен в 2000 году. Всё ещё никаких Visual Foxpro — банальный дос-режим, текстовый терминал, внутри — фокспро.
Возможно, в ваших кругах фокспро 3-5 кого-то и интересовали, но у нас его никто не пользовал. Поэтому рассматривать этот продукт я смысла не вижу.
V>Это я приводил для демонстрации, что наиболее эффективным способом работы с ISAM-базами было открытие навигируемого рекордсета по индексу. В этом случае чтение данных можно было производить прямо в операции отрисовки окна, без предварительного чтения. Так вот, недостаток FoxPro был в том, что он для отображения в таблице текущей страницы сначала должен был прочитать отображаемые строки, что создавало подтормаживания GUI.
Не уверен, что недостаток — именно в этом. Потому что способа отобразить строки, не читая, я не знаю. Или имеется в виду возможность успеть дёрнуть мышкой курсор ещё до того, как отрисуются все строки, и сэкономить 250мс на ожидании подгрузки?
V>ISAM вполне себе выбор для сервера приложений в трехзвенке. V>Только не stateless псевдотрёхзвенке, как в случае HTTP-фронтенда, а настоящего stateful.
Чисто уточнить: здесь под ISAM подразумевается прямое управление курсорами? Все вот эти вот locate и seek? Вместо декларативного описания запросов, я ничего не перепутал?
V>Ну блин, как речь об ISAM, так ты проваливаешься в область сетевого доступа к файлам. V>Это какой-то пипец.
V>При том, что мы даже разобрали My SQL, где в одной из его конфигураций над ISAM работает полноценный СУБД-процесс с исключительным доступом.
Ага. И это — та самая конфигурация, в которой невозможно даже сказать rollback tran, если по пути мы нарвались на нарушение ограничения.
V>При том, что любая среда программирования несла с собой справку? Ага. Справку по форме 086-У. Вот, к примеру, с MSVS6.0 шла документация по WinAPI. По вопросу "работа с ком-портом" — ровно одно упоминание в CreateFile: что можно открыть файл с именем "COM1:" — и будет щасьте.
Как настраивать скорость передачи, биты контроля чётности — ничего. Нуль. Как проверить, пришли ли данные — угадывай. Пробовал открывать — щастья не было. Вроде даже иногда что-то читалось, но почему-то с пропусками и перебоями.
Тут справкой не отделаешься — нужна нормальная литература, с объяснением, как и что работает. А такого не было. Про ДОС были и книжки, с детальным описанием, как вешаться на прерывания, что куда писать, что откуда читать, и с примерами простейших программ. V>Хотя, если уж по-справедливости относительно тех лет, то больше речь шла о доступе к машинному времени с нужной версией ОС. V>Так-то получить машинное время под ДОС было проще, угу.
У меня было бесконечное машинное время, и ДОС, и винда. Вот только интернета не было. Поэтому приходилось пользоваться тем, что есть, и что работает.
V>Вопрос в том — можно ли делать move назад или устанавливать произвольную запись текущей. V>https://docs.microsoft.com/en-us/sql/ado/reference/ado-api/move-method-ado?view=ssdt-18vs2017 V>А так же — курсор статический или динамический, если можно навигировать по записям туда-сюда.
Под капотом — всё равно операции чтения/записи.
V>Я примерно понимаю, о чём ты, но это ходьба по-кругу. V>- получается, что страницы shared-memory ты предлагаешь использовать сугубо как транспортные, то бишь аргументы "зато нет копирования" фтопку, бо копирование будет дважды — на стороне сервака на страницу и на стороне клиента из страницы;
Ох-хо-хо. Кто-то кого-то не понимает.
Вот у нас есть кусок клиентского кода, допустим, вот такой:
rs.MoveLast()
var s = rs.ReadString(12) // reading the field #12
Это я предполагаю, что у нас есть способ читать данные типизированно, а не вытаскивать VARIANT с последующим приведением.
Что у нас будет под капотом? Ясен хрен, что у рекордсета внутри — какой-то буфер. Рекордсет не читает одну запись. Он читает сразу, скажем, полмегабайта записей, включая последнюю. Если мы говорим об in-proc сервере, то это будет буфер файла. Возможно, как в MySQL, это будет отображение файла на память; возможно, там внутри будет прямо Read() в сырой массив.
Вызов операции чтения приведёт к проверке метаданных, поиску смещения текущей записи, разбору её заголовка в поисках смещения данных запрошенного поля, и конверсии. Потому, что внутри у нас поле хранится в Win1252 или UTF-8 или ещё как-то, а читаем мы его в UCS-2. Даже если бы мы вернулись в каменный век и сказали, что мы возвращаем сырые данные прямо в формате хранения, то пришлось бы внутри ReadString() делать nstrcpy, т.к. у нас даже 0-terminatоr не хранится.
А что будет в случае с Shared Memory? Да всё то же самое, только буфер заполняется другим процессом, а не системой.
Следующее чтение случится тогда, когда позиционирование рекордсета попробует выйти за пределы буфера — тогда у нас снова подкачается буфер, т.к. гонять данные по 4 байта очень дорого — что с диском, что с соседним процессом.
В обоих случаях под капотом происходит переключение контекста.
И это мы предполагаем совершенно безумную идею, что клиенту интересно разбираться с устройством таблиц и индексов. То есть он работает прямо с теми данными, которые хранятся.
А на самом деле, клиент выполняет запрос в духе
select @docId, Commodity, case when Amount-RunQty>0 then Quantity else Amount-RunQty+Quantity end as moveQty, id from
(select oi.Commodity, oi.Amount, coalesce(RunQty, 0) as RunQty, coalesce(Quantity, 0) as Quantity, remainders.id from
OrderItems oi left join
(select id, Commodity, Quantity, (sum(Quantity) over(partition by Commodity order by ArrivalDate asc)) as RunQty from Consignments) remainders
on oi.Commodity = remainders.Commodity and remainders.RunQty - Quantity < oi.Amount) itemRemainders
И получает на выходе рекордсет, который ни к какому файлу не относится. Поэтому сервер заботливо готовит буфер на своей стороне и говорит клиенту: "готово".
Тот забирает буфер и начинает с ним работать (т.е. читать данные). Идея "биндить курсор к GUI" работает только в одном малоинтересном сценарии: "редактирование справочников", где элементарная операция волшебно совпадает со строкой таблицы.
V>Мне всё еще требуется объяснять, почему out-of-proc существенно затратней?
Конечно требуется. Пока что вы ничего не обосновали, кроме "да в девяностые все это знали".
V>Я всё что угодно обыгрываю по производительности прямо замерам лабораторий Интел. V>Работа у меня такая.
Да-да, а ещё вы очень скромный.
V>Они отключают шедуллинг ОС этого механизма, но не отключают сам механизм.
Чего? V>Именно под задачи СУБД из виндов торчит АПИ навроде ReadFileScatter/WriteFileGather.
Ухты! Как интересно. Мне вот казалось, что эти АПИ совсем для другого.
Может, проиллюстрируете мне, как эти АПИ помогут мне прочесть с диска набор из десятка страничек, разбросанных по файлу?
V>Я нагуглил и данные тебе уже дал.
Ну, приличные люди дают не только картинку, но и ссылку на статью, в которой она упомянута.
V>>>А, может, ты забыл, что операции записи в shared-память провоцируют исключения ОС? S>>Хуже — я про это даже не знал. А где прочитать про эти мифические исключения? Мне просто непонятно, для чего они могут быть нужны. Ведь shared memory ничем от обычной не отличается. V>Shared-memory в Windows — это один из способов IO для файлов. V>Самый эффективный способ для того самого IO для файлов, угу. V>Литературы по отображаемым файлам — полно. V>RTFM!
Ну вот нигде из того, что я читал, нету никаких упоминаний про то, что запись в shared-memory будет провоцировать какие-то исключения. Вот я и хочу, чтобы вы мне популярно объяснили, как это работает. Ну, вот, допустим, у меня "сервер" хочет отдать 64 килобайта данных "клиенту", и с этой целью заполняет буфер в shared memory путём банального цикла:
for(i=0;i<16384;i++)
buffer[i] = i;
Сколько у нас произойдёт "исключений ОС"?
Изменится ли это количество, если мы вместо shared-memory буфера будем использовать "обычную" память?
V>На такой технике и таких скоростях и это прокатывало, и?
Не, не прокатывало. Там практики code review не было, но ради такого случая его провели, автора — уволили.
V>Или невозможности твоей схемы "буфер1 заняли, освободили буфер2 и так по-очереди" для shared memory, при локальном out-of-proc и при живом динамическом курсоре.
V>Да не, у "живого" курсора именно что амба, даже если связь восстановили.
"Живой" курсор — это вообще фикция. Классическая дырявая абстракция.
Системы, написанные "программистами живых курсоров" в девяностых годах до сих пор масштабируют путём запуска в терминальной сессии на супермегасервере.
И считают, что двести активных пользователей — это типа ого-го как много.
V>Просто открываешь forward-only и читаешь данные, кешируя их локально.
Воот. Потому что в нормальной распределённой среде нет такого понятия, как "живой курсор". Есть запрос, есть его результат на момент времени Х.
С ним можно работать.
V>Код синхронизации однократный для произвольных разных типов док-тов. V>Всё-равно оперируемая схема строк БД зачитывается динамически.
Ну, тогда и с Аксессом разницы нет.
V>Раза в 2-3 только на совсем уж синтетических тестах в одном цикле. V>А как более-мнее реальность, как начинаются развесистые графы объектов в памяти, так 10 раз аж бегом разницы по потребляемой памяти и быстродействию.
В типичных OLTP задачах нет никаких развесистых графов объектов в памяти. Если есть — то что-то не так с реализацией.
V>Ну я тебе давал уже реальные цифры по нейтивным системам. V>Сотовые базы на узлах тоже работают аж бегом при самом жутком трафике из всех возможных.
Что такое "сотовые базы"? Это случайно не про роутеры на Эрланге рассказ?
V>Голая нейтивная конкатенация даёт примерно 3-5-тикратный прирост.
Хотелось бы посмотреть на результаты реальных замеров.
V>Но этого мало, мы же работаем через абстракции навроде StreamWriter, а там разница чудовищная по итогу выходит, более 20 раз.
А тут-то откуда?
V>Нейтивный парсинг HTTP-заголовков даёт примено столько же, в 3-5 раз и умножай это на более эффективный ввод/вывод в сравнении с дотнетными Stream.
Наверное, надо всё же складывать, а не умножать.
V>При применении всякой "полигональной" памяти, т.е. алгоритмов управления памятью, которые хорошо заточены именно под серверные задачи навроде вопрос-ответ — там еще +50% производительности прибавляй, т.к. управление памятью становится де-факто бесплатное от слова совсем.
Неужто можно инкремент поинтера обогнать?
V>Набор SQL-запросов у вас фиксированный, их "оптимизированные" версии можно нагенерить в офлайне, в кач-ве шага билда.
Ну, вот до этого у меня никак руки не доходят дописать типичный OLTP запрос и посмотреть, сколько там будет вариантов плана.
Есть существенные подозрения, что надо смотреть не в сторону офлайна, а в сторону рантайм-компиляции.
Просто большинство современных движков писалось в такую эпоху, когда встроить компилятор в приложение было малореально.
Сейчас нет никакой проблемы за миллисекунды получить из плана запросов его бинарную версию, используя коробочные технологии.
Тот же Microsoft предлагает писать триггеры на C# и компилировать их статически, вместо того, чтобы сделать банальный компилятор из T-SQL в MSIL и разогнать существующие базы без вложений труда.
V>Вот как раз периодически замеряем, стабильно примерно в 10 раз разница.
Между чем и чем?
S>>А на отдаче HTML сильно много не сэкономишь. Ну, может процентов 20% за счёт более агрессивного инлайна в клинических случаях. V>Не так давно в местном плюсовом форуме соревновались в библиотеках форматирования текста. V>Разница более 8 раз с традиционными STL-потоками iostream, а те работают быстрее дотнетных StreamWriter.
Ссылка бы помогла.
V>Нейтив — это нейтив. V>Там любое серверное приложение сразу из себя автомат представляет (или набор автоматов), т.е. прямо начиная от самой низкоуровневой архитектуры. Ничего другое на серверной стороне смысла не имеет.
Для интересу можно сравнить архитектуру нативного Апача и нативного lightthpd или nginx. Чтобы понять, что не любое нативное приложение способно нормально работать. Ruki.sys никто не отменял.
V>Вот, еще и дотнет за тебя решает, как ты будешь коннекшены использовать. V>А что один и тот же коннекшен можно делить м/у разными запросами, если из одного и того же потока — этого ты через дотнет, увы, не провернёшь. Это можно было через native client или возвращённый на днях к жизни OLEDB-драйвер: V>https://blogs.msdn.microsoft.com/sqlnativeclient/2017/10/06/announcing-the-new-release-of-ole-db-driver-for-sql-server/
Это про MARS? Сомнительная фича. Для любителей "живых курсоров" и задрачивания сервера в режиме "N+1" аka master-detail.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, alex_public, Вы писали:
_>Так а где там область видимости этого самого "структурного типа"? В случае await оно вообще в куче создаётся и потом вызывается из цикла обработки сообщений или вообще другого потока. В случае yield я сам не проверял — у тебя есть точные данные, что оно размещается на стеке и при этом в области видимости вызывающего цикла? )
Сейчас — нет. Там генерируется reference type, и размещается в куче. Поэтому для агрессивной оптимизации нужен ещё и escape analysis. Всё опять упирается в инлайнинг, т.к. без него даже и со структурным типом не удалось бы сделать ничего полезного.
_>>>Ну есть обычное произвольное неотсортированное дерево и требуется найти количество узлов на кратчайшем пути между двумя заданными узлами. S>>По-прежнему непонятно. Как устроено дерево? У каждого элемента есть указатель на parent?
_>Да простейшее дерево, типа такого: _>
И как выглядит сигнатура метода, который нужно написать?
Интуитивно ожидаемая int Distance(node_t &node1, node_1 &node2) нереализуема в такой архитектуре.
_>Ээээ что? Какое ещё SortedList? Зачем нам этот жирный тормоз? Смотри, вот буквально детская задачка из самых основ работы с коллекциями: имеем простейший int[], заполненный отсортированными значениями. Надо получить его подмассив, находящийся в пределах значений от 0 и до 1000. Я могу это сделать на linq за логарифмическое, а не линейное время?
Да, конечно. Но всё равно как-то придётся объяснить инфраструктуре, что массив отсортирован. Телепатия ведь не работает.
Если вы хотите иметь возможность стрелять себе в ногу в обычной "эгей!эгей!" манере нативных программистов, то достаточно сделать тонкую обёртку типа
public static SortedArray<t> AsSorted(this T[] alreadySortedArray)
where T:IComparable<T>
{
// skip sorting, just store the reference to the original array
_array = alreadySortedArray;
}
Далее — по тексту:
var test = new int[]{1, 6, 10, -150};
var splice = from a in test.AsSorted() where a >= 0 && a <1000 select a;
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, alex_public, Вы писали:
_>В таком случае тебе конечно же будет совсем не трудно дать ссылку на соответствующую цитату... )
В соседнем же сообщении. )
_>Пока что в данной дискуссии пытаешься съезжать в основном ты. Достаточно вспомнить тот твой нелепый тезис о том, что работа с коллекциями через Linq может быть быстрее аналогичного императивного кода.
Не любого, а for, выяснили же. И опять съезд на тот же for, вместо ответа на текущее замечание )
_>Ты очень быстро постарался замять тему, как только тебе попросили предоставить хотя бы один реальный пример...
Там Антон успел раньше меня достаточно подробно все расписать, так что я не вижу смысла писать еще раз то же самое.
_>Не улавливаешь: Linq просто не имеет прямого отношения к обсуждаемому вопросу. Для общения с СУБД в любом случае необходимо нечто (язык, протокол, api — называй как хочешь), что будет отсылаться клиентом на сервер для описания запросов. И даже если для Linq появится новый бэкенд, работающий на этом новом нечто, Linq не будет иметь никакого отношения к обсуждаемому в данной дискуссии вопросу. Потому что заменой SQL будет именно это нечто, а не Linq.
Я кажется понимаю кто тут чего не улавливает... Не имеет никакого значения что именно ползает между клиентом и сервером. Важно на чем разработчик пишет свой запрос и какой результат он при этом получает.
_>Единственным вариантом, в котором можно было бы вспомнить про Linq в данной дискуссии, является решение типа прямой пересылки linq выражений в СУБД и что я не слышал ни в нашем обсуждение, ни где-то ещё о подобных предложениях.
Да ладно, как раз эта идея встречается довольно часто. Кажется есть даже в предложениях к новым версиям сиквела.
_>Я уже давно понял, что ты относишься к тем коллегам, которые считают SQL идеалом (не смотря даже на его изначальное позиционирование как инструмент для бухгалтеров) для работы с РСУБД. И видимо с этим уже ничего не поделаешь.
А это очередное ваше заблуждение. Я вижу овердохрена недостатков в SQL, но я так же считаю что вы с вдимасом ищите их совершенно не там.


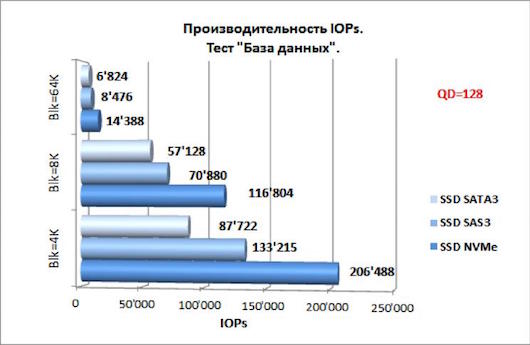





 Мы уже победили, просто это еще не так заметно...
Мы уже победили, просто это еще не так заметно...


