Здравствуйте, MaximVK, Вы писали:
MVK>Само утверждение, что если каждый человек мыслит индивидуально => нужно создавать свой каталог знаний требует серьезного обоснования, смотри мой пример с бритвами.
Про всякую семантику и прочее помню ещё очень любили рассуждать на хабре этак в 2008-2009 году. Потом меня там забанило кармой. И где все эти разработки? В одном из обсуждений на RSDN я обернул
токенизатор из Boost.
Простейший вид парсинга:
скачать:
tokenizer.7z
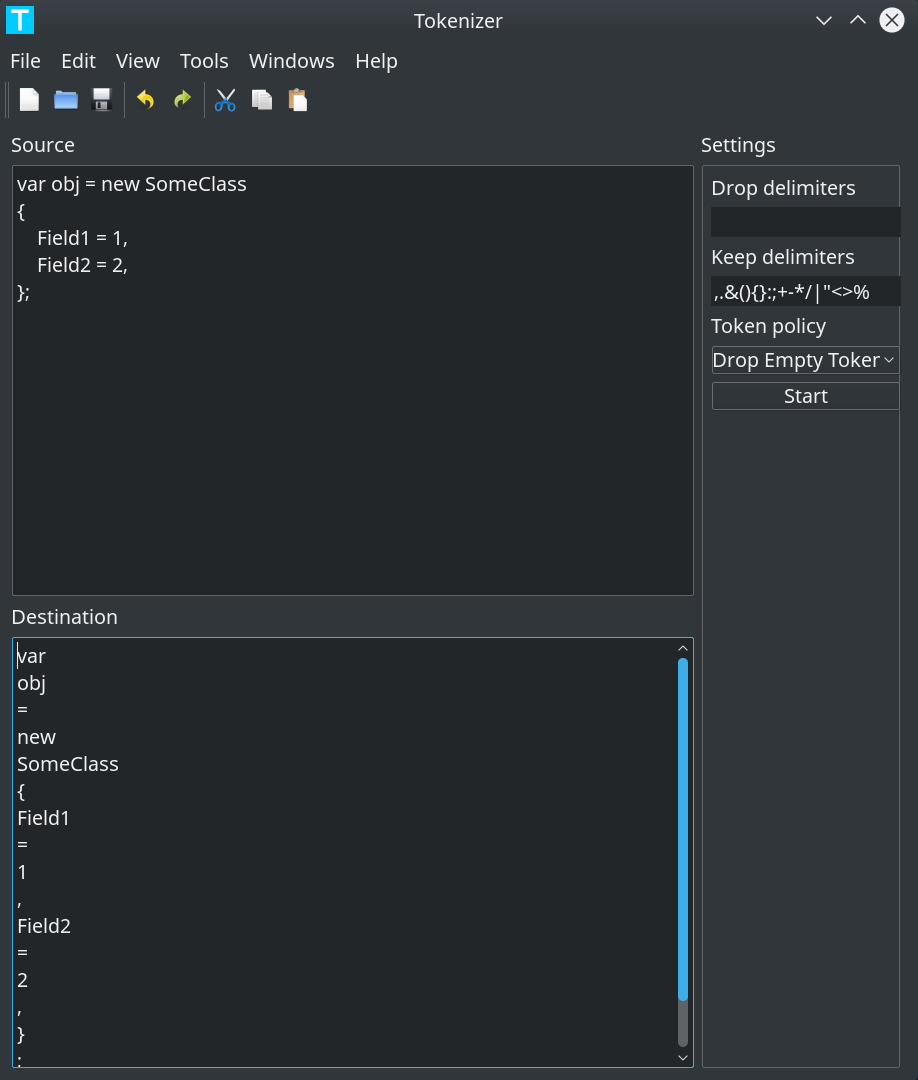
Информация существует не в абстрактном вакууме. Идея в общем-то простая, распарсить текст на токены, то есть мельчайшие не делимые элементы в данном контексте, а потом поместить их в таблицу. Справа сделать описания, или альтернативные токены, чтобы можно было перевести их на другой язык. Работа с кодировками не сделана, будет работать только ascii.
То есть первое, что нужно сделать, это получить основу. А уж каждый пользователь пусть сам описывает как он видит вот этот текст.
Беру код:
#include <iostream>
#include <cstdlib>
using namespace std;
int main()
{
cout << "Hello, world!" << endl;
system("pause");
return 0;
}
Загружаю в парсер:
#
include
<
iostream
>
#
include
<
cstdlib
>
using
namespace
std
;
int
main
(
)
{
cout
<
<
"
Hello
,
world
!
"
<
<
endl
;
system
(
"
pause
"
)
;
return
0
;
}
Но пробельные символы тоже должны быть, я придумал для них обозначения, чтобы можно было фильтровать при просмотре. А ещё на это всё навернуть
EBNF. Для файлов же в которых будет код и документация определённых версий создавать
хеш-суммы, можно сразу много, вроде MD5, SHA1 и так далее.
Я и категоризацию придумал, хотя есть альтернативные варианты, и то как это должно работать с разными пользователями. И работу одновременно в обычном текстовом редакторе и парсере одновременно. Но тут загвоздка в том, что в идеи никто не верит, нужна программа. А цель всего этого в том, чтобы разбирать и собирать тексты, код и прочее.
Что касается восприятия, то люди хорошо воспринимают списки, но работать могут лишь с небольшими объёмами данных. Потому один большой список можно поделить на множество мелких подсписков, и как ни странно это обычный древовидный список, всё уже придумали до нас.
Семантика, таксономия, давайте ещё вспомним онтологию.
MVK>А почему не теги? Почему именно иерархия?
Вообще для начала я бы хотел использовать иерархические теги. Я уже много раз расписывал это на форуме.
тег - простой тег
тег/тег - иерархический тег
тег;тег - список простых тегов
тег;тег/тег - список иерархических тегов
Вопрос здесь в фильтрах по тегам.
Если есть слой тегов:
тег1
тег1/тег2
тег1/тег3/тег4
тег1/тег3
То можно было бы отфильтровать те же токены по:
1) тег1/*,
2) тег1/тег2/*
3) тег1/тег3/*
4) тег1/тег3/тег4/*
Не обязательно делать это с начала, можно фильтровать как угодно, это уже зависит от запроса.
Другая идея в том, что я мог бы писать вот так:
тег1 - тег3 - тег4
Немного про слои, вот выше есть функция main. Но почему main? Если добавить справа несколько столбцов, то в одни можно было бы помещать теги, а в другие подмену токенов, где записать "main" как "главная", а китаец мог бы написать вот так "主要的". Я без, понятия что значит последнее, но китайцу или гугл переводчику виднее.
И код тогда мог бы существовать в параллельных состояниях причём не просто на разных разговорных языках, а отвечая именно мозгу конкретного пользователя.
#включить <потоки-ввода-вывода>
#включить <с-стандартную-библиотеку>
использовать пространство-имен стандартное;
целый главная()
{
консольный-вывод << "Привет, мир!" << конец-линии;
система("пауза");
вернуть 0;
}
Китайская версия.
#打開 <輸入/輸出流>
#打開 <標準庫>
利用 命名空間 標準;
所有的 家()
{
控制台輸出 << "你好世界!" << 行尾;
系統("暫停");
返回 0;
}
Носитель языка лишь условный носитель, а на самом деле языков столько, сколько и людей, просто в силу изучения одного и того же есть совпадения. Вот программист взял и обозвал функцию как-то, а другие давай мучайся, совмещай его каракулю с собственной нейросеткой у которой связи выстроены совершенно иначе.
Всё это я к тому, что люди изначально мыслят иначе, а компьютеру и вовсе без разницы, что там пишут на естественном языке. У него всё в машинных кодах, и имена ему подойдут абсолютно любые для компиляции. Главное чтобы были правильно расставлены, а смысл символов не важен.
Вот это условное изображения яблока контурами.

А это его письменное изображение на русском языке.

А это табличка, в которой были символы.

Казалось бы в чём разница? Разница в том, что изображение объекта поймёт носитель любого языка, а письменное изображение с текстом нет. Но табличка это тоже объект, который можно воспринимать, если и не как яблоко, то как объект.
MVK>Я не знаю, что именно ты подразумеваешь под "восприятием", поэтому тяжело прокомментировать в общем.
1) Сначала человек, видит глазами, слушает ушами, осязает. Это называется мышление восприятием.
2) Потом он запоминает и манипулирует запомненным в сознании. Это называется мышление воображением.
3) Потом человек учится воспринимать символическую информацию, которая не связана с реальными образами. Это называется мышление словами.
4) И в конце он пытается упорядочить эту символьную информацию. Это называется мышление абстракциями, или по-русски отвлечённое мышление.
Эти этапы идут постепенно по мере развития сознания. Вот моя тема, где я рассуждал подробно на эту тему, там же ссылки на материалы:
Обучение с помощью карточекАвтор: velkin
Дата: 21.11.20
.
Дальше следующий вопрос, вот у тебя ссылки на всякие термины, статьи, обучающие видео. Люди там балаболы, балаболить умеют, программировать нет. Они за свои слова не отвечают. Для чего тебе всё это, то есть что с этого получишь?
1) Если для самообразования, которое ничего не требует, то отлично.
2) Если для создания программ, то их курсы можно хоть сейчас выкидывать в мусорку.
И мы сейчас рассуждаем, рассуждаем, рассуждаем, но в итоге обмениваемся информацией посредством html. Но это так привычно, что почти никто этого не замечает. И вот я остановился и задумался.

