Здравствуйте, Эйнсток Файр, Вы писали:
ЭФ>Мир в принципе отказывается от XML дублируя все его стандарты в комплекте технологий Json.
ЭФ>Какие идеи лежали в основе решения использовать XML?
Взяли то, что модно.
Основная проблема XML — он без нужны переусложненный. Существенная часть его возможностей никем никогда не применялась. Как только в моду вошел JSON, оказалось, что он удобнее и понятнее, поэтому он быстро вытеснил XML.
Заметим, что формат .INI-файла появился еще и до XML и до JSON, 100500 лет назад. Он простой и понятный. В нем еще и комментарии предусмотрены в удобном виде, в отличии от JSON-а. Ничто не мешало использовать именно его кроме того, что вот именно ему не повезло стать модным форматом.
ЭФ>Одной из проблем XML-файлов является их "монолитность",
Она свойственна и JSON-у, и кому угодно. Но никому не мешает положить рядом N таких файлов и договориться о том, где их искать и как их сливать. Собственно, все так и делают.
Здравствуйте, vsb, Вы писали:
R>>Отказ от XML в пользу DSL решает здесь какую-то проблему, или просто вкусовщина?
vsb>Меньше синтаксического шума, больше возможностей. Как пример крайности — XSLT, язык программирования на XML. Пользоваться им решительно невозможно. И это они ещё всё-таки ввели туда DSL (XPath).
Я несколько лет назад делал на XSLT "валидацию" referential integrity для большого XML файла, описывающего некие реляционные данные. Пришлось погуглить конечно, но ни с чем, взрывающим мозг, я не столкнулся. Засчёт этого удалось избежать программирования (и багов, к которым приводит программирование) и построения дополнительной инфраструктуры (и её падений и недоступности).
Просто не осилили к времени релиза.
Там не говорится, что они от идеи отказались совсем в любом будущем, отказались только на тот момент.
Ещё по-прежнему остаётся риск, что они всё-таки запилят Json-овые проекты до конца.
У меня картинки по ссылке не подгружаются.
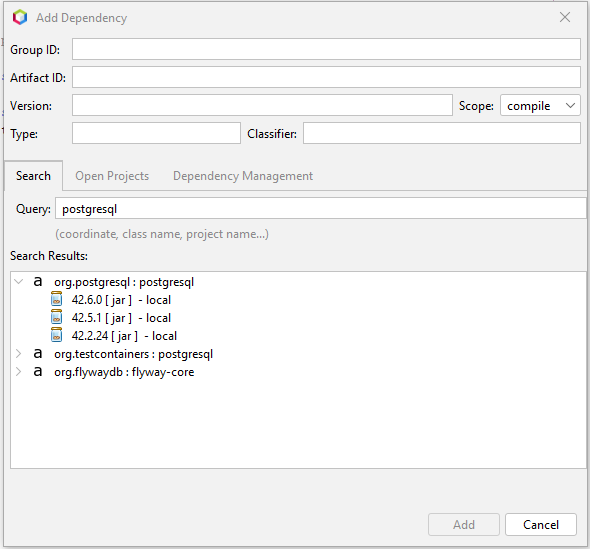
Ну, зашёл в Netbeans 19, создал новый проект, нажал Add dependencies.
Вот такое окошко добавления зависимости
И как мне через него добавить последнюю версию 42.7.0 из центрального репозитория? ·>Это всё есть в pom файле, в том числе и тулзы в IDEA для визуализации и навигации по зависимостям. ·>А для лицензий есть даже license-maven-plugin, чтобы всё само проверялось.
А в Visual Studio для Nuget всё есть из коробки, не нужны никакие плагины и тулзы. ·>Ну займись самообразованием, изучи используемые инструменты, а не тупо копипасть код со стаковерфлоу.
А с чего ты взял, что я в чём-то не разбираюсь и копипастингом занимаюсь?
Я то как раз разбираюсь в том, что делаю и мне не нравится, когда на ровном месте какие-то сложности.
Здравствуйте, Pzz, Вы писали:
Pzz>Основная проблема XML — он без нужны переусложненный. Существенная часть его возможностей никем никогда не применялась.
Достаточно простой формат. Просто люди его стали использовать где надо и не надо
Pzz>Как только в моду вошел JSON, оказалось, что он удобнее и понятнее, поэтому он быстро вытеснил XML.
Если начать пытаться на json изобразить то, что наделали в том же MSBuild, то внезапно окажется, что не так уж удобнее и понятнее.
Pzz>Заметим, что формат .INI-файла появился еще и до XML и до JSON, 100500 лет назад. Он простой и понятный. В нем еще и комментарии предусмотрены в удобном виде, в отличии от JSON-а. Ничто не мешало использовать именно его кроме того, что вот именно ему не повезло стать модным форматом.
ini не умеет иерархии и многострочные значения. Для небольших конфигов нормально, но часто народ городил костыли и страдал, потому стали активно использовать xml.
Сейчас для конфигов вместо ini и xml куда чаще используется yaml, а не убогий json.
Но у yaml свои проблемы имеются (как минимум на большом конфиге с ума сойдёшь и запутаешься во всех этих отступах).
Здравствуйте, rosencrantz, Вы писали:
R>Я несколько лет назад делал на XSLT "валидацию" referential integrity для большого XML файла, описывающего некие реляционные данные. Пришлось погуглить конечно, но ни с чем, взрывающим мозг, я не столкнулся. Засчёт этого удалось избежать программирования (и багов, к которым приводит программирование) и построения дополнительной инфраструктуры (и её падений и недоступности).
Здравствуйте, karbofos42, Вы писали: K>·>Вот уже в 2009 году было https://blog.mrhaki.com/2009/07/add-maven-dependency-in-netbeans.html K>·>Для справки: nuget появился в 2010м. K>У меня картинки по ссылке не подгружаются. K>Ну, зашёл в Netbeans 19, создал новый проект, нажал Add dependencies. K>
K>И как мне через него добавить последнюю версию 42.7.0 из центрального репозитория?
У тебя такой же диалог, что и там в картинках 2009го года. Только у тебя local источник только, нет central репы. Возможно она (ещё?) не подгрузилась. У тебя может проблемы с сетью, у тебя и картинки не подгружаются. Индекс таки большой, ибо это ведь все либы всего maven central — миллионы пакетов!
42.7.0 добавили 6 дней назад, может кеши ещё не прочистились, можно попробовать обновить индекс вручную.
Впрочем, это всё неважно. Обычно настраивают автоматический job, который проверяет наличие новых версий зависимостей и создаёт пулл-реквест, который остаётся только отревьювить и заапрувить.
Можно вручную посмотреть если есть что новенькое "mvn versions:display-dependency-updates". K>·>Это всё есть в pom файле, в том числе и тулзы в IDEA для визуализации и навигации по зависимостям. K>·>А для лицензий есть даже license-maven-plugin, чтобы всё само проверялось. K>А в Visual Studio для Nuget всё есть из коробки, не нужны никакие плагины и тулзы.
Такой функциональности как в license-maven-plugin нет. Есть только убогий аналог в виде https://github.com/tomchavakis/nuget-license K>·>Ну займись самообразованием, изучи используемые инструменты, а не тупо копипасть код со стаковерфлоу. K>А с чего ты взял, что я в чём-то не разбираюсь и копипастингом занимаюсь?
С того, что ты заявляешь, будто функциональности в maven нет. Когда она там появилась как минимум ~15 лет назад. K>Я то как раз разбираюсь в том, что делаю и мне не нравится, когда на ровном месте какие-то сложности.
Не вижу пока никаких сложностей. Вижу больше возможностей.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали: ·>У тебя такой же диалог, что и там в картинках 2009го года. Только у тебя local источник только, нет central репы. Возможно она (ещё?) не подгрузилась. У тебя может проблемы с сетью, у тебя и картинки не подгружаются.
Вот так оно всё и работает. Вроде есть с 2009 года, а вроде проще руками xml набить, чем заставить работать окошки с кнопочками.
Забавно, что Netbeans похоже что-то почувствовал. Несколько месяцев я вручную в xml зависимости прописывал, а тут вдруг IDE при очередном запуске предложила мне разрешить ей индексы репозитория подтянуть.
Наконец-то я узнал как добавить индекс репозитория. Просто нужно дождаться, когда интеллектуальная система сама предложит (не прошло и года).
Вот такое окно настроек
Не интересно же кнопку + в окне настроек разместить, чтобы пользователь мог произвольный репозиторий указать.
Собственно, всё равно этим Add dependency неудобно пользоваться и та же 42.7.0 в индексе не появилась.
Вот и получается, что проще зайти на какой-нибудь https://mvnrepository.com/, там всё нужное искать и потом вручную в pom.xml прописывать. ·>Индекс таки большой, ибо это ведь все либы всего maven central — миллионы пакетов!
Не помню, чтобы NuGet у меня полчаса индексы скачивал.
Можно было просто в протокол добавить метод поиска, чтобы один единственный репозиторий с индексом возился, а не все его клиенты. ·>С того, что ты заявляешь, будто функциональности в maven нет. Когда она там появилась как минимум ~15 лет назад.
Функциональность, которой непонятно как пользоваться, можно сказать что отсутствует. ·>Не вижу пока никаких сложностей. Вижу больше возможностей.
Сложности в том, что даже базовые сценарии работают криво и нужно допиливать руками.
Из-за этой кривизны похоже в итоге большинство сидит и вручную всё делает, т.к. это надёжно и будет работать, а все эти окошки и кнопочки — не факт и скорее только проблем добавят.
А потом из своего мира с кривым GUI приходят и рассказывают, что окошки — это плохо и надо везде вникать в суть происходящего и делать самому.
Здравствуйте, Pzz, Вы писали:
Pzz>Заметим, что формат .INI-файла появился еще и до XML и до JSON, 100500 лет назад. Он простой и понятный. В нем еще и комментарии предусмотрены в удобном виде, в отличии от JSON-а. Ничто не мешало использовать именно его кроме того, что вот именно ему не повезло стать модным форматом.
Изначально JSON был подмножеством JS, а там свои удобство и комментарии.
Здравствуйте, karbofos42, Вы писали:
K>·>У тебя такой же диалог, что и там в картинках 2009го года. Только у тебя local источник только, нет central репы. Возможно она (ещё?) не подгрузилась. У тебя может проблемы с сетью, у тебя и картинки не подгружаются. K>Вот так оно всё и работает. Вроде есть с 2009 года, а вроде проще руками xml набить, чем заставить работать окошки с кнопочками.
Конечно, проще и быстрее. Только xml набивать не надо, он сам пишется автокомплитом.
K>Забавно, что Netbeans похоже что-то почувствовал. Несколько месяцев я вручную в xml зависимости прописывал, а тут вдруг IDE при очередном запуске предложила мне разрешить ей индексы репозитория подтянуть.
Они большие. И далеко не всем надо.
K>Не интересно же кнопку + в окне настроек разместить, чтобы пользователь мог произвольный репозиторий указать.
Это говорит о популярности данной фичи. java всё же для профессиональной разработки. Я тоже когда был маленьким диалоги любил. Помню был такой Add Class Wizard в Студии. Оно ещё живо?
А потом просто пишешь код. Ты не поверишь, но скопипастить строчку кода гораздо быстрее, чем выбирать её же из списка мышой.
K>Собственно, всё равно этим Add dependency неудобно пользоваться и та же 42.7.0 в индексе не появилась. K>Вот и получается, что проще зайти на какой-нибудь https://mvnrepository.com/, там всё нужное искать и потом вручную в pom.xml прописывать.
Проще это вообще не делать вручную.
K>·>Индекс таки большой, ибо это ведь все либы всего maven central — миллионы пакетов! K>Не помню, чтобы NuGet у меня полчаса индексы скачивал.
Ну так он на порядок-два меньше.
K>Можно было просто в протокол добавить метод поиска, чтобы один единственный репозиторий с индексом возился, а не все его клиенты.
Основные клиенты туда не ходят. Чаще будет какой-нибудь внутренний репо с зеркалами в какой-нибудь большой организации.
K>·>С того, что ты заявляешь, будто функциональности в maven нет. Когда она там появилась как минимум ~15 лет назад. K>Функциональность, которой непонятно как пользоваться, можно сказать что отсутствует.
То что тебе непонятно — это твои личные заморочки.
K>·>Не вижу пока никаких сложностей. Вижу больше возможностей. K>Сложности в том, что даже базовые сценарии работают криво и нужно допиливать руками.
Они не базовые, они новичковые. Ява — не затачивается под новичков.
K>Из-за этой кривизны похоже в итоге большинство сидит и вручную всё делает, т.к. это надёжно и будет работать, а все эти окошки и кнопочки — не факт и скорее только проблем добавят. K>А потом из своего мира с кривым GUI приходят и рассказывают, что окошки — это плохо и надо везде вникать в суть происходящего и делать самому.
Зачем вообще гуи нужен-то? Это вообще делать самому не надо.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
·>Это говорит о популярности данной фичи. java всё же для профессиональной разработки. Я тоже когда был маленьким диалоги любил. Помню был такой Add Class Wizard в Студии. Оно ещё живо?
Тогда бы и не добавляли её, а то время потратили на окошки, а пользоваться этим невозможно.
Но зато когда я говорю, что этого нет, можно на это бесполезное нечто сослаться и сказать, что якобы есть.
·>А потом просто пишешь код. Ты не поверишь, но скопипастить строчку кода гораздо быстрее, чем выбирать её же из списка мышой.
Я никуда не спешу и копипастить не люблю.
·>Проще это вообще не делать вручную.
Ага. Надо кучу индексов выкачать к себе, чтобы типа не вручную писать в xml, а радоваться, что появился автокомплит?
Или как это не вручную?
·>Ну так он на порядок-два меньше.
Так ему индексы локальные не нужны. У каждого репозитория есть единый небольшой json, в котором указано куда можно отправить строку поиска и получить ответ.
·>Основные клиенты туда не ходят. Чаще будет какой-нибудь внутренний репо с зеркалами в какой-нибудь большой организации.
И всё это веселье будешь прописывать в pom.xml.
Когда окажется, что из дома по VPN, офисного компа и билд-сервера репозиторий доступен по разным URL, то начнётся веселье.
NuGet я просто на нужном компе настрою как надо и проект мой никак не изменится.
·>Они не базовые, они новичковые. Ява — не затачивается под новичков.
Не знаю для кого там Ява затачивалась.
Что сам язык, что всё окружение в C# сделано для человеков, а в Java-мире всё через одно место.
Ну, после C++ наверно не заметно будет, а вот после .NET как-то всё криво.
·>Зачем вообще гуи нужен-то? Это вообще делать самому не надо.
Чтобы не запоминать всякие artifactId и прочую ненужную фигню.
Здравствуйте, karbofos42, Вы писали:
K>·>Это говорит о популярности данной фичи. java всё же для профессиональной разработки. Я тоже когда был маленьким диалоги любил. Помню был такой Add Class Wizard в Студии. Оно ещё живо? K>Тогда бы и не добавляли её, а то время потратили на окошки, а пользоваться этим невозможно.
Время такое было. Раньше на добавление переменной делали визарды.
K>Но зато когда я говорю, что этого нет, можно на это бесполезное нечто сослаться и сказать, что якобы есть.
И, как оказалось, практически бесполезное, да. Т.к. пользоваться этим невозможно.
K>·>А потом просто пишешь код. Ты не поверишь, но скопипастить строчку кода гораздо быстрее, чем выбирать её же из списка мышой. K>Я никуда не спешу и копипастить не люблю.
Результирующий код ровно тот же, но с меньшими усилиями.
Не забывай, что этот код — часть исходного кода проекта, который надо ревьювить, мержить и т.п., поэтому его пишут для людей, а не только для автоматических тулзов.
K>·>Проще это вообще не делать вручную. K>Ага. Надо кучу индексов выкачать к себе, чтобы типа не вручную писать в xml, а радоваться, что появился автокомплит? K>Или как это не вручную?
Обновлять зависимости на последние.
K>·>Ну так он на порядок-два меньше. K>Так ему индексы локальные не нужны. У каждого репозитория есть единый небольшой json, в котором указано куда можно отправить строку поиска и получить ответ.
Нужны. Автодополнение работает в процессе набора, работает мгновенно. Тут важна latency.
K>·>Основные клиенты туда не ходят. Чаще будет какой-нибудь внутренний репо с зеркалами в какой-нибудь большой организации. K>И всё это веселье будешь прописывать в pom.xml. K>Когда окажется, что из дома по VPN, офисного компа и билд-сервера репозиторий доступен по разным URL, то начнётся веселье.
А зачем по разным урл? В любом случае, это не проблема.
K>NuGet я просто на нужном компе настрою
Не тадо такое делать. Т.к. потом внезапно окажется, что таких нужных компов сотни. И захочется вписать в pom.xml.
K>как надо и проект мой никак не изменится.
И выложишь в nuget все внутренние зависимости организации?!
K>·>Они не базовые, они новичковые. Ява — не затачивается под новичков. K>Не знаю для кого там Ява затачивалась. K>Что сам язык, что всё окружение в C# сделано для человеков, а в Java-мире всё через одно место. K>Ну, после C++ наверно не заметно будет, а вот после .NET как-то всё криво.
Потому что вендор один. Всё под контролем одной компании.
Ни в java, ни в С++ такого нет, и слава богу.
K>·>Зачем вообще гуи нужен-то? Это вообще делать самому не надо. K>Чтобы не запоминать всякие artifactId и прочую ненужную фигню.
Как это не запоминать? Ведь именно его и вводишь в этом твоём GUI.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
·>И, как оказалось, практически бесполезное, да. Т.к. пользоваться этим невозможно.
В Nuget народ прекрасно пользуется
·>Не забывай, что этот код — часть исходного кода проекта, который надо ревьювить, мержить и т.п., поэтому его пишут для людей, а не только для автоматических тулзов.
Я прекрасно в csproj вижу что там в xml добавилось и при этом ни строчки в этот xml вручную не ввожу.
Не обязательно что-то писать, чтобы потом читать.
·>Обновлять зависимости на последние.
в смысле latest вместо конкретной версии писать? Или как обновлять не вручную и в целом прописывать в файл не вручную?
·>Нужны. Автодополнение работает в процессе набора, работает мгновенно. Тут важна latency.
Мне важно, что не нужно полчаса ничего ждать и настраивать. Всё работает быстро без дополнительных телодвижений, а как этого достигли — как-то параллельно.
·>А зачем по разным урл?
Ну, вот такое бывает в крупных организациях, где у всех разный доступ.
Не говоря о том, что вполне нормально сначала разрабатывать на локальном окружении, потом это закидывать в тестовое окружение своей организации,
а дальше уже отдавать заказчику, чтобы он у себя своими билд-серверами всё собрал и развернул.
·>В любом случае, это не проблема.
Ну, придётся весь зоопарк в pom.xml прописывать или ещё чего мудрить.
По крайней мере, именно такое я видел от людей, позиционирующих себя как Java-разработчики.
Открываешь файл, а там всё подряд на все случаи жизни.
Может есть какое-то более удачное решение, но вот люди за несколько лет разработки его не нашли
(а может и не искали, т.к. и так сойдёт, зато xml сами написали, а не через какой-то GUI).
·>Не тадо такое делать. Т.к. потом внезапно окажется, что таких нужных компов сотни. И захочется вписать в pom.xml.
Ага. И логины/пароли от репозиториев тоже надо в pom.xml записать, а то слишком много компов, лень возиться.
·>И выложишь в nuget все внутренние зависимости организации?!
Я в конфиге nuget укажу какие репозитории ему нужны и с ними он будет работать.
Если завтра добавится ещё один репозиторий, то в файле проекта я не буду его добавлять и как-то что-то менять.
·>Как это не запоминать? Ведь именно его и вводишь в этом твоём GUI.
В Nuget я в поиске ввожу postgresql и получаю в списке нужный пакет Npgsql или по json получаю Newtonsoft.Json.
Запоминать какие-то идентификаторы не нужно.
Здравствуйте, karbofos42, Вы писали:
K>·>И, как оказалось, практически бесполезное, да. Т.к. пользоваться этим невозможно. K>В Nuget народ прекрасно пользуется
Отличный аргумент. Так и мавеном народ прекрасно пользуется. И не только в Студии, но и в десятке других сред.
K>·>Не забывай, что этот код — часть исходного кода проекта, который надо ревьювить, мержить и т.п., поэтому его пишут для людей, а не только для автоматических тулзов. K>Я прекрасно в csproj вижу что там в xml добавилось и при этом ни строчки в этот xml вручную не ввожу. K>Не обязательно что-то писать, чтобы потом читать.
И не обязательно визардом пользоваться, чтобы строчку кода добавить.
K>·>Обновлять зависимости на последние. K>в смысле latest вместо конкретной версии писать? Или как обновлять не вручную и в целом прописывать в файл не вручную?
"настраивают автоматический job, который проверяет наличие новых версий зависимостей и создаёт пулл-реквест, который остаётся только отревьювить и заапрувить."
K>·>Нужны. Автодополнение работает в процессе набора, работает мгновенно. Тут важна latency. K>Мне важно, что не нужно полчаса ничего ждать и настраивать. Всё работает быстро без дополнительных телодвижений, а как этого достигли — как-то параллельно.
Ну индекс это и делает. Скачивается однажды, потом всё мгновенно работает.
K>·>А зачем по разным урл? K>Ну, вот такое бывает в крупных организациях, где у всех разный доступ.
есть settings.xml для кастомных настроек, если очень надо. И профили и т.п.
K>Не говоря о том, что вполне нормально сначала разрабатывать на локальном окружении, потом это закидывать в тестовое окружение своей организации,
Так это всё и прописывается в pom.xml проекте — какой порядок, куда деплоить и как.
K>а дальше уже отдавать заказчику, чтобы он у себя своими билд-серверами всё собрал и развернул.
Обычно по-другому делается — ты билдишь у себя, а клиентам даёшь доступ к своему репо — он оттуда и тянет всё готовенькое.
K>·>В любом случае, это не проблема. K>Ну, придётся весь зоопарк в pom.xml прописывать или ещё чего мудрить. K>По крайней мере, именно такое я видел от людей, позиционирующих себя как Java-разработчики. K>Открываешь файл, а там всё подряд на все случаи жизни.
А как иначе? Предлагаешь страничку вики завести что куда жать и деплоить во всех случаях жизни? Как ты любишь — чтобы дока со скришнотами как в UI кнопочки нажимать... да?
K>·>Не тадо такое делать. Т.к. потом внезапно окажется, что таких нужных компов сотни. И захочется вписать в pom.xml. K>Ага. И логины/пароли от репозиториев тоже надо в pom.xml записать, а то слишком много компов, лень возиться.
Ээ.. Нет, конечно. Credentials это свойство клиентов, а не проектов. Идёт в локальный settings.xml, ясен пень.
K>·>И выложишь в nuget все внутренние зависимости организации?! K>Я в конфиге nuget укажу какие репозитории ему нужны и с ними он будет работать. K>Если завтра добавится ещё один репозиторий, то в файле проекта я не буду его добавлять и как-то что-то менять.
Если кто-то откроет файл проекта на другой машине — как он узнает в какую репу пойти за артефактами?
K>·>Как это не запоминать? Ведь именно его и вводишь в этом твоём GUI. K>В Nuget я в поиске ввожу postgresql и получаю в списке нужный пакет Npgsql или по json получаю Newtonsoft.Json. K>Запоминать какие-то идентификаторы не нужно.
Ну в pom.xml вводишь postgresql он и автодополняет artifactId/groupId/version. Зачем UI, неясно. Притом зависимости ведь можно добавлять в разные места — в главный код, в тесты разных видов, во всяческие плагины и т.п. Как этим всем рулить из UI — вообще неясно.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Здравствуйте, ·, Вы писали:
·>"настраивают автоматический job, который проверяет наличие новых версий зависимостей и создаёт пулл-реквест, который остаётся только отревьювить и заапрувить."
а job сам откуда-то появится или его нужно вручную настроить? )
·>Ну индекс это и делает. Скачивается однажды, потом всё мгновенно работает.
Индекс скачивается не однажды, а периодически, иначе он ничего о новых версиях не узнает.
·>Обычно по-другому делается — ты билдишь у себя, а клиентам даёшь доступ к своему репо — он оттуда и тянет всё готовенькое.
А потом оказывается, что у клиента куча несобираемых исходников, т.к. исполнитель ему чёрт знает что присылал, а собирал всё не так, как в документации указано.
·>Если кто-то откроет файл проекта на другой машине — как он узнает в какую репу пойти за артефактами?
Оттуда же, откуда он узнает пароли и явки, чтобы их указать в локальном settings.xml
Здравствуйте, karbofos42, Вы писали:
K>·>"настраивают автоматический job, который проверяет наличие новых версий зависимостей и создаёт пулл-реквест, который остаётся только отревьювить и заапрувить." K>а job сам откуда-то появится или его нужно вручную настроить? )
Конечно, настроить нужно — указать адреса, пароли, явки. А дальше у тебя хоть каждые пол часа будут проверяться версии, зависимости, лицензии и т.п.
Ты же предлагаешь делать всё вручную, описывая в доках со скриншотами как это делать. Нет, спасибо, я слишком ленивый чтобы этим заниматься.
K>·>Ну индекс это и делает. Скачивается однажды, потом всё мгновенно работает. K>Индекс скачивается не однажды, а периодически, иначе он ничего о новых версиях не узнает.
Так он это делает сам, автоматически.
K>·>Обычно по-другому делается — ты билдишь у себя, а клиентам даёшь доступ к своему репо — он оттуда и тянет всё готовенькое. K>А потом оказывается, что у клиента куча несобираемых исходников, т.к. исполнитель ему чёрт знает что присылал, а собирал всё не так, как в документации указано.
Ты видимо не понял. pom.xml это и есть документация по сборке, которую читает и выполняет машина. Если там что-то не указано, оно просто не собирается.
K>·>Если кто-то откроет файл проекта на другой машине — как он узнает в какую репу пойти за артефактами? K>Оттуда же, откуда он узнает пароли и явки, чтобы их указать в локальном settings.xml
У меня будет ошибка "не могу скачать артефакт XXX с сервера YYY — доступ запрещён". И там уже обычно ясно куда и к кому идти и какие пароли для чего искать.
У тебя будет ошибка "Нет такого XXX". Дальше что? Куда идти?
Более того, в больших организациях будет какой-нибудь AD, где работнику дают права на сервера и это сразу доступно с его компа, settings.xml поддерживается инфраструктурой. Да и вообще обычно RO-доступ есть по умолчанию.
но это не зря, хотя, может быть, невзначай
гÅрмония мира не знает границ — сейчас мы будем пить чай
Вот я смотрю на проект .Net 6. Там только один XML это .csproj
Причем вручную, я очень редко его редактирую. Все через студию свойства проекта с уже встроенными ограничениями.
В отличие от всяких граблей в Java мне такой подход больше нравится.
То есть хошь визуально, хошь не визуально и программно
Все конфиги через json которые сливаются, в том числе и секреты пользователя.
Тот же Vix на XML.
и солнце б утром не вставало, когда бы не было меня