:
.dbschema (XML-файл такой) -> VSDBCMD.EXE (утилита командной строки)
и вызывать это всё командой
MSBuild /t:Build;Deploy MyDatabaseProject.dbproj
А где исходники от VSDBCMD.EXE ? Как то же самое в опенсорсе проделать-то?
Did you get way into doing command line deployments of your databases using vsdbcmd.exe? Well, if you are one of those developers and you’ve upgraded to the latest version of the SQL Server Database Projects, then you might be wondering just where vsdbcmd.exe went.
Answer: vsdbcmd.exe has been replaced with SqlPackage.exe.
DACPAC это zip-файл.
И чё? А на github как его хранить — в бинарном виде?
DacFx is the core technology the SQL Server Data Tools leverages for incremental database deployments, modelling and validation of database schemas and other key functionality. DacFx provides a DacServices API that supports programmatic deployment of Dacpac files.
Допустим есть некий файл "Microsoft.Data.Tools.Schema.SqlTasks.targets":
<Import Condition="'$(SQLDBExtensionsRefPath)' == ''" Project="$(MSBuildExtensionsPath)\Microsoft\VisualStudio\v$(VisualStudioVersion)\SSDT\Microsoft.Data.Tools.Schema.SqlTasks.targets" />
Так-то я бы может быть с ним и собрал бы при помощи msbuild проект .sqlproj
но где мне его взять (под опенсорсной лицензией) ?
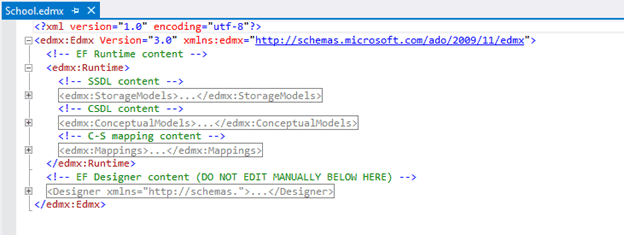
You can open an EDM designer in XML view where you can see all the three parts of the EDM: Conceptual schema (CSDL), Storage schema (SSDL) and mapping schema (MSL), together in XML view.
Здравствуйте, Arsen.Shnurkov, Вы писали:
AS>Я думаю, что переносить в базы данных не надо. AS>Там специалисты по SQL (возможно даже с Java-ой), а мне нужны советы по .Net
Может все-таки правильно вопрос задать?
Что надо то? Миграции или перенос данных?
D> Может все-таки правильно вопрос задать? D> Что надо то? Миграции или перенос данных?
Мне надо описание процесса разработки со следующими требованиями:
1) используются только опенсорсные утилиты
2) желательно, чтобы была возможность собирать стандартные "студи́йные" sqlproj-проекты
3) желательно иметь возможность сначала создать XML-файл с описанием, а потом из него SQL-скрипты,
потому что парсить SQL сложнее чем работать с Xml
И ещё нужно описание того, как все то что выше относится к Entity Framework
и всяким командам dotnet ef ...
Здравствуйте, Arsen.Shnurkov, Вы писали:
D>> Может все-таки правильно вопрос задать? D>> Что надо то? Миграции или перенос данных?
AS>Мне надо описание процесса разработки со следующими требованиями: AS>1) используются только опенсорсные утилиты AS>2) желательно, чтобы была возможность собирать стандартные "студи́йные" sqlproj-проекты AS>3) желательно иметь возможность сначала создать XML-файл с описанием, а потом из него SQL-скрипты, AS>потому что парсить SQL сложнее чем работать с Xml
AS>И ещё нужно описание того, как все то что выше относится к Entity Framework AS>и всяким командам dotnet ef ...
Значит так, если вы идете в бой с EF, то можно поиграть в рулетку с его CodeFirst. Тогда база создается из модели и скрипты миграций она также генерит.
Здравствуйте, Arsen.Shnurkov, Вы писали:
AS>Мне надо описание процесса разработки со следующими требованиями: AS>1) используются только опенсорсные утилиты
Тут SSDT наверное вообще мимо. Но тогда уж что б быть честным, то надо и sql server использовать опенсорсный. А еще лучше в что б он хранил всё в xml, так проще парсить и никаких проприетарных структур данных.
AS>2) желательно, чтобы была возможность собирать стандартные "студи́йные" sqlproj-проекты
А гуглом там вам не запрещают пользоваться? Можно хотя бы попробовать разобраться: https://erikej.github.io/efcore/2020/05/11/ssdt-dacpac-netcore.html
AS>3) желательно иметь возможность сначала создать XML-файл с описанием, а потом из него SQL-скрипты, AS>потому что парсить SQL сложнее чем работать с Xml
Зачем? Даже если писать свою утилиту мигратор то большинство потребностей покрывается примитивнейшым парсером.
AS>И ещё нужно описание того, как все то что выше относится к Entity Framework AS>и всяким командам dotnet ef ...
SSDT никак не соотносится с EF. В EF можно генерировать модельки по БД (database first). Либо code-first, но тогда SSDT тут пятое колено. Либо как сказал Danchik вообще использовать нечто иное.
То, что вы озвучили, что вам надо сочинить описание процесса разработки это хорошо. Только ни цели, ни доступных инструментов, ни хоть какого-то намека нет. Кроме того поставленные вопросы — не относятся к процессу разработки, скорее тех записки как это может работать. Ответ тут может быть один — это должно быть удобно с т.з. разработки. Остальное вообще почти без разницы. Ну разумеется процесс деплоя тоже должен быть ясным.
MA> Но тогда уж что б быть честным, то надо и sql server использовать опенсорсный.
Я-то как раз postgresql планирую. Но вы себе даже такое помыслить не можете, говорите об этом как о чем-то для вас запредельном.
Откуда столько гонора в вас?
MA> А еще лучше в что б он хранил всё в xml, так проще парсить
Зачем мне XML ? Я хочу что-то вроде "Model Driven Architecture", только модель описывать в виде XML,
потому что у меня нет графического редактора.
Дальше я собираюсь из этого XML наплодить кучу .sql-файлов при помощи T4 Template Engine
и скормить это всё в https://github.com/lecaillon/Evolve
Печалит меня то, что вышеописанный процесс не такой как "стандартный".
Если я правильно понял, стандартный основан на использовании sqlpackage.exe
MA> А гуглом там вам не запрещают пользоваться?
Но первым неясно как пользоваться (исходников утилиты sqlpackage.exe я так и не нашел
(и судя по этому проекту — https://github.com/imgen/DacpacDeployUtility не я один)
а второй не выглядел "официальным" и всё равно непонятно как он работает (может через тот же sqlpackage)
MA> большинство потребностей покрывается примитивнейшым парсером
Смотрите:
— парсеры были в 2004-м 2005-м годах. Потом в 2008 в MS зарелизили vsdbcmd.exe и .dbschema-файлы. Все кто на них не перешел — отстали от прогресса.
— дальше в 2012 от vsdbcmd.exe и .dbschema отказалиcь в пользу sqlpackage.exe и .dacpac
в 2013-2014 на собеседованиях спрашивали: а что вы знаете о юнит-тестах для SQL ?
MA> хотя бы попробовать разобраться
И теперь в 2020-м вы мне предлагаете фактически руками скрипты заливать (да там всё просто, говорите вы мне).
Это говорит только о том, что современными технологиями вы пользоваться не умеете "но там разобраться просто".
Ничего не знать и при этом пытаться глумиться, это ж надо таким быть!?!?
Здравствуйте, Arsen.Shnurkov, Вы писали:
MA>> Но тогда уж что б быть честным, то надо и sql server использовать опенсорсный. AS>Я-то как раз postgresql планирую. Но вы себе даже такое помыслить не можете, говорите об этом как о чем-то для вас запредельном. AS>Откуда столько гонора в вас?
Обидеть не хотел, извиняюсь.
Если сервер не MSSQL — то и SSDT и все связанные с ним тулзы не имеют никакого смысла / не релевантны.
AS>Зачем мне XML ? Я хочу что-то вроде "Model Driven Architecture", только модель описывать в виде XML, AS>потому что у меня нет графического редактора. AS>Дальше я собираюсь из этого XML наплодить кучу .sql-файлов при помощи T4 Template Engine
Традиционная болезнь таких подходов, в том, что они красивы на бумаге, но детали реализации БД будут и должны быть прозрачными — т.е. просвечиваться. Насколько я помню в pgsql используются генераторы, а не автогенерируемые (identity) колонки (хотя могу путать, pgsql я давно в руках не держал) как в мсскл, и это надо учитывать. Т.е. для того что бы модель было возможно использовать — нужно что бы она отражала эти детали сервера бд (ну и любые другие детали). В целом, это не проблема, если не заморачиваться универсальностью. Второй вопрос который нужно решить для себя — есть ли и понадобятся ли специальные возможности БД, которые могут не отражаться в модели. Это и вовсе не проблема для своих нужд, но может быть проблемой при использовании сторонних инструментов.
AS>Печалит меня то, что вышеописанный процесс не такой как "стандартный". AS>Если я правильно понял, стандартный основан на использовании sqlpackage.exe
Нет стандартного. В вашем контексте существование sqlpackage.exe — проще игнорировать вообще. У вас своя схема и свои утилиты.
MA>> большинство потребностей покрывается примитивнейшым парсером AS>Смотрите:
Для того что бы сделать мигратор/подыматор БД — нужны SQL скрипты, которые может потребить утилита. Единственная ее задача — поднять их в правильном порядке. Для того что бы грубо выяснить зависимости — полноценный парсинг не нужен. Проще всего выполнять эти скрипты на локальной БД — после получать схему или объекты уже из БД и уже следующим шагом — сравнение с существующей => генерация изменяющих скриптов. Как видите парсер тут не нужен. Это один из возможных наколеночных вариантов.
Очевидно, что если вы изначально имеете модель — то это и вовсе не нужно.
AS>И теперь в 2020-м вы мне предлагаете фактически руками скрипты заливать (да там всё просто, говорите вы мне). AS>Это говорит только о том, что современными технологиями вы пользоваться не умеете "но там разобраться просто".
Некоторые способы не устаревают и они просто работают, с минимальной автоматизацией. Все остальные продвинутые решения — требуют или собственных инструментов, которые известно как работают, или если берется сторонний компонент — нужно иметь на готове большой напильник для преодоления проблем (или иметь опыт с ним и таким образом известно как они работают). Брать же в слепую любой левый мигратор и вместо того что бы писать код на SQL — писать его на мета-языке или DSL, — решение совсем не без недостатков, и покрываются ли они своими достоинствами для вас лично — я не знаю.
Еще раз: SSDT силен интеграцией в студии и производимым семантическим анализом. А так же очень приличными средствами для деплоя. Если бы БД была MSSQL — выбор бы был очевиден.
Но задача: нужно вести разработку с тем что есть и задача нужно сделать средства для разработки — совершенно разного рода задачи.