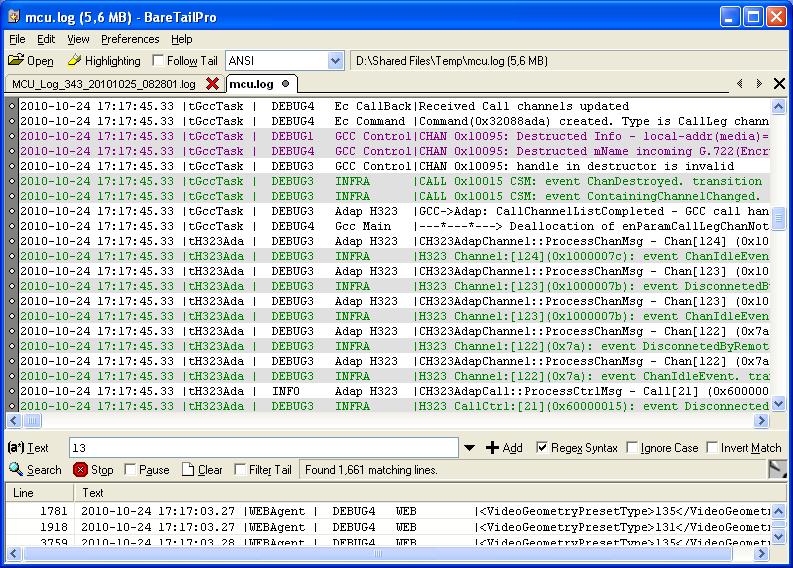
Имеется лог файл размером от 3-4 Гб.
Имеется программа BareTailPro ( честно купленная )
Требуется написать ее аналог в смысле визуального представления.
BareTailPro отличный анализатор, но нам требуется внести в анализ автоматизацию, котора поможет автоматически находить и связывать важные куски логов.
Я более или менее сносно знаю С#. Но практически нулевой опыт в создании более или менее сложных GUI.
Я не могу купить какие-либо коммерческие компоненты.
Буду очень признателен за советы о том, каким компонентом воспользоваться для реализации ( примеры/статьи были бы огромным плюсом ).
Версия .Net любая это не принципиально. Операционка WinXP & Win7 ( все x86, т.е. 32bits).
Мне нужно только графическое предствление, всячесие фильтры со и сортировки я вполне способен реализовать самостоятельно ( я так думаю ).
З.Ы. Очень желательно что бы компонент не был прожолив в смысле памяти, ибо логи бывают доходят и до 60-80Гб.
B автоматизацая сама по себе потребует значительное количество памяти.
Здравствуйте, GSL, Вы писали:
GSL>Нет это что-то типа класического ListView. имеется 2 списка: GSL>1. это полный лог GSL>2. это отфильтрованные строки по рег експ GSL>Имееющаяся прога работает с файлами любого размера, надо просто добавить специфичные функции
Здравствуйте, adontz, Вы писали:
A>Здравствуйте, GSL, Вы писали:
GSL>>Нет это что-то типа класического ListView. имеется 2 списка: GSL>>1. это полный лог GSL>>2. это отфильтрованные строки по рег експ GSL>>Имееющаяся прога работает с файлами любого размера, надо просто добавить специфичные функции
A>Я так понимаю, там десятки миллионов строк.
Вообщем иногда такое тоже бывает... обычно лог после стресса это около 8-10 Гб изредка это бывает до 50-80Гб...
если в среднем строка лога 120 символов то можно посчитать....
Вообщем нужен компоент которые загружает в память только то, что непосредственно отображает...
Здравствуйте, GSL, Вы писали:
GSL>Вообщем иногда такое тоже бывает... обычно лог после стресса это около 8-10 Гб изредка это бывает до 50-80Гб... GSL>если в среднем строка лога 120 символов то можно посчитать....
Сотни миллионов строк.
GSL>Вообщем нужен компоент которые загружает в память только то, что непосредственно отображает...
Здравствуйте, adontz, Вы писали:
A>Здравствуйте, GSL, Вы писали:
GSL>>Вообщем иногда такое тоже бывает... обычно лог после стресса это около 8-10 Гб изредка это бывает до 50-80Гб... GSL>>если в среднем строка лога 120 символов то можно посчитать....
A>Сотни миллионов строк.
GSL>>Вообщем нужен компоент которые загружает в память только то, что непосредственно отображает...
A>Увы, придётся писать самому.
т.е. нет никаких виртуальных лист вью...
адаптер я готов написать, т.е. будет по номеру строки выдавать искомое, каждый раз читая с диска...
если так то я в очень плохо ситуации, ибо писать такое я не умею и времени мне не дадут...
А продолжать в ручную анализировать это грустно...
Здравствуйте, GSL, Вы писали:
A>>Увы, придётся писать самому. GSL>т.е. нет никаких виртуальных лист вью...
Виртуальные есть. Собственно ListView как раз поддерживает виртуальный режим. Но тут проблема в объёме ОЗУ. Даже если вы заранее проиндексируете файл и найдёте начала всех строк, то вы получите ~ 700 миллионов (80Гб) 8байтовых (больше 4Гб сдвиг) чисел. Только индекс составляет 5 с небольшим гигабайт. А обычные виртуальные контролы просят у вас данные по индексу элемента. И тут логичнее не хранить индекс и использовать относительные сдвиги. С другой тсороны индекс вам всё равно понадобится, потому что через регулярные выражения надо пропустить все строки. Да и скорость регулярных выражений на таких объёмах скорее всего будет проблемой. А как хранить отфильтрованные строки? Задача не выглядит очень уж простой.
Здравствуйте, adontz, Вы писали:
A>Здравствуйте, GSL, Вы писали:
A>>>Увы, придётся писать самому. GSL>>т.е. нет никаких виртуальных лист вью...
A>Виртуальные есть. Собственно ListView как раз поддерживает виртуальный режим. Но тут проблема в объёме ОЗУ. Даже если вы заранее проиндексируете файл и найдёте начала всех строк, то вы получите ~ 700 миллионов (80Гб) 8байтовых (больше 4Гб сдвиг) чисел. Только индекс составляет 5 с небольшим гигабайт. А обычные виртуальные контролы просят у вас данные по индексу элемента. И тут логичнее не хранить индекс и использовать относительные сдвиги. С другой тсороны индекс вам всё равно понадобится, потому что через регулярные выражения надо пропустить все строки. Да и скорость регулярных выражений на таких объёмах скорее всего будет проблемой. А как хранить отфильтрованные строки? Задача не выглядит очень уж простой.
да как-то я не задумывался про размер индекса...
дело видимо в том, что сегодня простейшим тулсом такой лог пилят на куски примерно по 4 гига и работают с ними, локализуя проблему в одной из частей.
Допустим я решил проблему того, что индекс не влазиет в память, буду банально пилить лог И работать теми же кусками по 4 гига. Все равно планируемый автоанализ ускорит/упростит нашу работу в 10-15 раз....
Здравствуйте, GSL, Вы писали:
A>>Виртуальные есть. Собственно ListView как раз поддерживает виртуальный режим. Но тут проблема в объёме ОЗУ. Даже если вы заранее проиндексируете файл и найдёте начала всех строк, то вы получите ~ 700 миллионов (80Гб) 8байтовых (больше 4Гб сдвиг) чисел. Только индекс составляет 5 с небольшим гигабайт. А обычные виртуальные контролы просят у вас данные по индексу элемента. И тут логичнее не хранить индекс и использовать относительные сдвиги. С другой тсороны индекс вам всё равно понадобится, потому что через регулярные выражения надо пропустить все строки. Да и скорость регулярных выражений на таких объёмах скорее всего будет проблемой. А как хранить отфильтрованные строки? Задача не выглядит очень уж простой. GSL>да как-то я не задумывался про размер индекса... GSL>дело видимо в том, что сегодня простейшим тулсом такой лог пилят на куски примерно по 4 гига и работают с ними, локализуя проблему в одной из частей. GSL>Допустим я решил проблему того, что индекс не влазиет в память, буду банально пилить лог И работать теми же кусками по 4 гига. Все равно планируемый автоанализ ускорит/упростит нашу работу в 10-15 раз....
Я бы посоветовал перегнать логи в БД. А ListView поддерживает виртуальный режим.
Здравствуйте, adontz, Вы писали:
A>Здравствуйте, GSL, Вы писали:
A>>>Виртуальные есть. Собственно ListView как раз поддерживает виртуальный режим. Но тут проблема в объёме ОЗУ. Даже если вы заранее проиндексируете файл и найдёте начала всех строк, то вы получите ~ 700 миллионов (80Гб) 8байтовых (больше 4Гб сдвиг) чисел. Только индекс составляет 5 с небольшим гигабайт. А обычные виртуальные контролы просят у вас данные по индексу элемента. И тут логичнее не хранить индекс и использовать относительные сдвиги. С другой тсороны индекс вам всё равно понадобится, потому что через регулярные выражения надо пропустить все строки. Да и скорость регулярных выражений на таких объёмах скорее всего будет проблемой. А как хранить отфильтрованные строки? Задача не выглядит очень уж простой. GSL>>да как-то я не задумывался про размер индекса... GSL>>дело видимо в том, что сегодня простейшим тулсом такой лог пилят на куски примерно по 4 гига и работают с ними, локализуя проблему в одной из частей. GSL>>Допустим я решил проблему того, что индекс не влазиет в память, буду банально пилить лог И работать теми же кусками по 4 гига. Все равно планируемый автоанализ ускорит/упростит нашу работу в 10-15 раз....
A>Я бы посоветовал перегнать логи в БД. А ListView поддерживает виртуальный режим.
перегонка такого большого лога в базу займет сама по себе более суток, потому как вставка записей при наличии индексирования черезвычайно медленная штука.
Здравствуйте, _FRED_, Вы писали:
_FR>Здравствуйте, GSL, Вы писали:
GSL>>Вообщем нужен компоент которые загружает в память только то, что непосредственно отображает...
_FR>DataGridView имеет виртуальный режим. В ListView из WinForms виртуальный режим сделан плохо
. Если хочется таки ListView можно посмотреть TreeGrid из RSDN@Home.
Прочитал, большое спасибо, позновательно.
Я попробую поиграть с обоими компонентами, хотя в детайл моде вроде там в обсуждении говорят что не тормозит.
Здравствуйте, snake, Вы писали:
S>Здравствуйте, GSL, Вы писали:
GSL>>перегонка такого большого лога в базу займет сама по себе более суток
S>Посмотрите BULK INSERT в MSSQL
Вы наверное не пробовали вставить несколько милионов записей. Не думаю что на сегодня есть что-то координально быстрее работающее чем два года назад MySql. тогда 10 милионов с одинм индексом заняло около суток, кажется...
Здравствуйте, GSL, Вы писали:
GSL>Вы наверное не пробовали вставить несколько милионов записей. Не думаю что на сегодня есть что-то координально быстрее работающее чем два года назад MySql. тогда 10 милионов с одинм индексом заняло около суток, кажется...
Несколько миллионов записей — мелочь, дело пары минут, ну разве что у тебя там тысяча колонок. CSV-файлы импортируются очень быстро.
Здравствуйте, GSL, Вы писали:
GSL>Здравствуйте, snake, Вы писали:
S>>Здравствуйте, GSL, Вы писали:
GSL>>>перегонка такого большого лога в базу займет сама по себе более суток
S>>Посмотрите BULK INSERT в MSSQL
GSL>Вы наверное не пробовали вставить несколько милионов записей. Не думаю что на сегодня есть что-то координально быстрее работающее чем два года назад MySql. тогда 10 милионов с одинм индексом заняло около суток, кажется...
Вы не имели серьезного дела с MS SQL
При Bulk Insert отключается обновление всякой статистики (в т.ч. индексов). Анализ входящих данных практически не производится. Время вставки данных в таблицу зависит фактически только от скорости файловой подсистемы. А индексы сервер потом сам обновит о всему объему данных.
Ориентировочно, это будет сравнимо с поднятием бэкапа такого же размера. На моем Xeon'е с 2 Гб данных на борту займет порядка часа-полтора.
Здравствуйте, alex_mah, Вы писали:
>Ориентировочно, это будет сравнимо с поднятием бэкапа такого же размера. На моем Xeon'е с 2 Гб данных на борту займет порядка часа-полтора.
Это я про лог 80 Гб, есличо.
Здравствуйте, alex_mah, Вы писали:
_>Здравствуйте, alex_mah, Вы писали:
>>Ориентировочно, это будет сравнимо с поднятием бэкапа такого же размера. На моем Xeon'е с 2 Гб данных на борту займет порядка часа-полтора. _>Это я про лог 80 Гб, есличо.
Дело в том, что такой анализ это рутинная работа, под нее не выделят серверов. 90% машинок в отделе это либо DualCore либо Core2Duo. Диски это обычно 250 гигов. Свободно обычно от 30-120 гигов. Еще пол года новинок не предвидется, как только исполнится 3 года компам тогда их сменят на i5 или i3.
Если честно то более 30 минут на 40 гига, уже считается неприемлемым, регексы на 40 гигах работают порядка 20 минут, после чего лог рубится на 1-2 нужных кусков по 2-5 гигов еще порядка 10 минут. Дальше анализируется.
Если неиндексированная вставка займет час, то дальше мне не помогут никакие поиски если нет индексов, кроме того формат лога текстовый, и 1 на 1000 записей битая, т.е. вообще не поддается парсингу, а в CVS лог еще перегнать надо.
Полей примерно 6, минимум 3 желательно индексировать надо индексировать ( модуль, группа, уровень ) иначе все это не будет иметь никакого смысла. Поэтому БД не рассматривается. Кроме того если я только не ошибаюсь то у MySQl, если это не настояший сервер а версия для девелопера есть ограничение на размер базы.