Хз в какой форум с такой темой, если что — перенесите куда правильно.
Вопрос — как правильно итерироваться по юникодному тексту? По символам я умею, как в UTF-8 (линупсы), так и по виндовому WCHAR* — UTF-16 вроде же?
Но ведь это ничего не значит, потому что один глиф (или как правильно сказать?) может состоять из нескольких codepoints, так?
В винде, допустим, должны быть какие-то функции на эту тему (кстати, какие?).
А как быть в линупсе? Я немного почитал про composition/decomposition, там про какие-то таблицы декомпозиции пишут. Самому с этим возиться неохота. Есть какое-то стандартное API, которое всегда есть или может быть легко установлено?
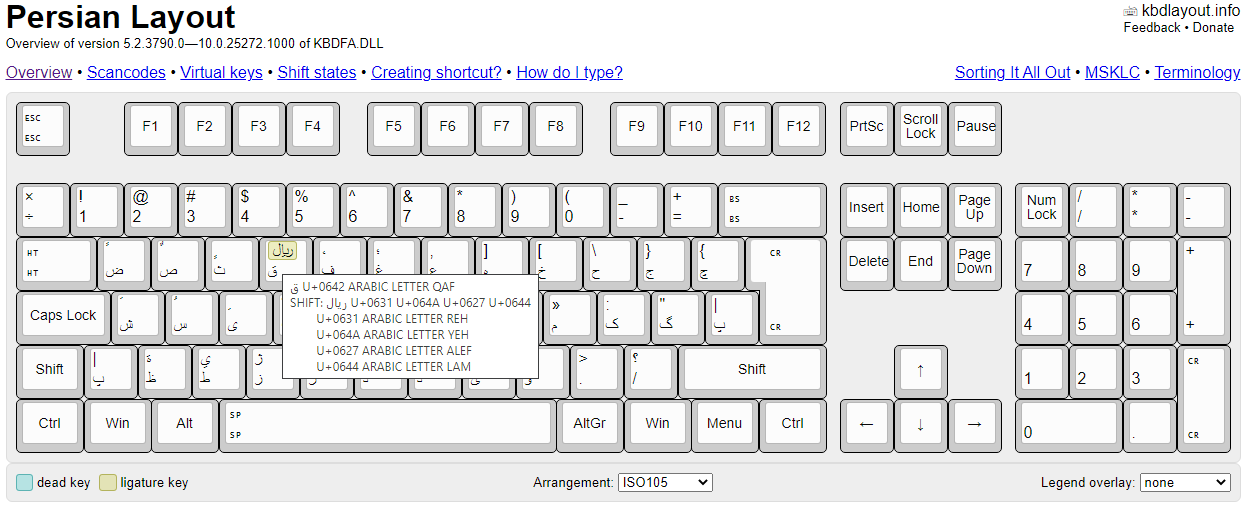
Кстати, некоторые раскладки в винде могут генерить целые пачки символов — лигатуры, например в персидском аж до 4х WCHAR может быть за одно нажатие. А отображается — как один символ. Тут явно больше одного UTF-32 codepoints. Если они могут быть подвергнуты композиции — то почему это не сделано? А если не могут, то как по ним корректно итерироваться?
П>Вопрос — как правильно итерироваться по юникодному тексту? П>один глиф (или как правильно сказать?) может состоять из нескольких codepoints, так? П>Есть какое-то стандартное API, которое всегда есть или может быть легко установлено?
Здравствуйте, σ, Вы писали:
П>>В десятку или в 11? Восьмерка, семерка, виста, XP, прости осподя, с этим как?
σ>Можно закапывать. Впрочем, венда вообще не нужна.
Здравствуйте, пффф, Вы писали:
П>Но ведь это ничего не значит, потому что один глиф (или как правильно сказать?) может состоять из нескольких codepoints, так?
АФАИК, глиф составляется из нескольких codepoints только одним способом: все, кроме первого — это combining characters.
Поэтому навигируемcя путём анализа категории уникода для каждого code point до тех пор, пока не наткнёмся на не-combining character (что-то вне категорий Mc/Mn/Me).
П>В винде, допустим, должны быть какие-то функции на эту тему (кстати, какие?).
Ну, в дотнете это делается легко: https://learn.microsoft.com/en-us/dotnet/api/system.globalization.charunicodeinfo.getunicodecategory?view=net-7.0#system-globalization-charunicodeinfo-getunicodecategory(system-int32)
Внутри оно устроено не шибко сложно:https://github.com/dotnet/runtime/blob/main/src/libraries/System.Private.CoreLib/src/System/Globalization/CharUnicodeInfo.cs#L384
То есть идёт некий лукап по таблице. Полагаю, что при нежелании писать на дотнете таблицу можно выковырять из исходников и перенести в любой язык программирования.
П>Кстати, некоторые раскладки в винде могут генерить целые пачки символов — лигатуры, например в персидском аж до 4х WCHAR может быть за одно нажатие. А отображается — как один символ. Тут явно больше одного UTF-32 codepoints. Если они могут быть подвергнуты композиции — то почему это не сделано? А если не могут, то как по ним корректно итерироваться?
Я в арабских языках не силён, но насколько я знаю, там преобладают именно что лигатуры. Но если там действительно речь идёт не о визуальном соединении нескольких символов вязи, а о комбинациях — то да, значит для них в уникоде нету precomposed characters.
Итерироваться корректно — именно вот так, по базовым символам.
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Sinclair, Вы писали:
S>АФАИК, глиф составляется из нескольких codepoints только одним способом: все, кроме первого — это combining characters.
Здравствуйте, vsb, Вы писали:
vsb>Здравствуйте, Sinclair, Вы писали:
S>>АФАИК, глиф составляется из нескольких codepoints только одним способом: все, кроме первого — это combining characters.
vsb>Кажется нет.
vsb>
Здравствуйте, Sinclair, Вы писали:
П>>Но ведь это ничего не значит, потому что один глиф (или как правильно сказать?) может состоять из нескольких codepoints, так? S>АФАИК, глиф составляется из нескольких codepoints только одним способом: все, кроме первого — это combining characters. S>Поэтому навигируемcя путём анализа категории уникода для каждого code point до тех пор, пока не наткнёмся на не-combining character (что-то вне категорий Mc/Mn/Me).
Апостроф и аккут — одни из популярных символов, которые используются для составных символов. Возможно, кроме ASCII версий, есть и юникодовые код поинты для них. Окей. Как тогда мне отобразить аккут? На ум приходит только комбинация из пробела и аккута, если аккут обладает бузусловным признаком combining character.
Винда вроде и до дотнета поддерживала кучу языков, и арабский, и персидский, и кучу справа налево. Тогда в каждой аппе свои таблицы держали?
S>Я в арабских языках не силён, но насколько я знаю, там преобладают именно что лигатуры. Но если там действительно речь идёт не о визуальном соединении нескольких символов вязи, а о комбинациях — то да, значит для них в уникоде нету precomposed characters.
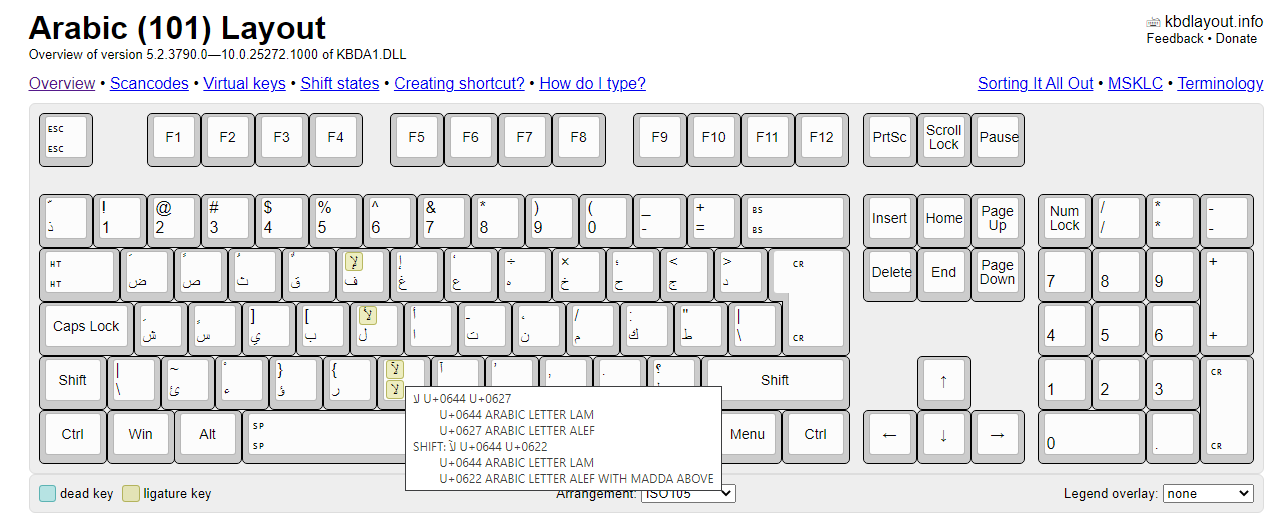
Пошерстил по раскладкам — нифига, у арабов и персов только несколько кнопок генерят лигатуры, остальные клавиши генерят вполне конкретный код. Вот, например — https://kbdlayout.info/kbda1
S>Итерироваться корректно — именно вот так, по базовым символам.
Меня интересует что-то системное. С ICU буду разбираться, когда на линупсы захочу, а пока и на винде проблем хватает. Своё колхозить тоже как-то не особо
Здравствуйте, пффф, Вы писали:
П>Апостроф и аккут — одни из популярных символов, которые используются для составных символов. Возможно, кроме ASCII версий, есть и юникодовые код поинты для них. Окей. Как тогда мне отобразить аккут? На ум приходит только комбинация из пробела и аккута, если аккут обладает бузусловным признаком combining character.
Для комбинации пробела и аккута есть отдельный precomposed character U+00B4.
Но можно и как U+0020 U+0301. П>Спс, гляну.
Там, кстати, вроде бы ещё что-то завезли как раз для детектирования Grapheme Clusters, но я ещё не разбирался.
П>Винда вроде и до дотнета поддерживала кучу языков, и арабский, и персидский, и кучу справа налево. Тогда в каждой аппе свои таблицы держали?
Наверняка, т.к. большинство аппов ничего особенного и не поддерживали. В древних виндах всё держалось на сплошных кодировках — а там наверняка всё просто как угол дома: вот тебе байт, вот тебе его интерпретация.
Полноценную поддержку уникода со всеми этими нормализациями и декомпозициями умели только отдельные приложения, и они ессно всё таскали с собой.
П>Пошерстил по раскладкам — нифига, у арабов и персов только несколько кнопок генерят лигатуры, остальные клавиши генерят вполне конкретный код. Вот, например — https://kbdlayout.info/kbda1
А где там посмотреть, что за лигатуры генерируются?
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Sinclair, Вы писали: П>>Апостроф и аккут — одни из популярных символов, которые используются для составных символов. Возможно, кроме ASCII версий, есть и юникодовые код поинты для них. Окей. Как тогда мне отобразить аккут? На ум приходит только комбинация из пробела и аккута, если аккут обладает бузусловным признаком combining character. S>Для комбинации пробела и аккута есть отдельный precomposed character U+00B4.
Дык, вроде почти для всего есть свои отдельные precomposed chars. И аккут — просто как пример. Гипотеза, что есть отдельно условный аккут, который для composite'а и готовый precomposed аккут с пробелом — имеет право на жизнь, но с арабскими лигатурами так не проходит S>Но можно и как U+0020 U+0301. П>>Спс, гляну. S>Там, кстати, вроде бы ещё что-то завезли как раз для детектирования Grapheme Clusters, но я ещё не разбирался. П>>Винда вроде и до дотнета поддерживала кучу языков, и арабский, и персидский, и кучу справа налево. Тогда в каждой аппе свои таблицы держали? S>Наверняка, т.к. большинство аппов ничего особенного и не поддерживали. В древних виндах всё держалось на сплошных кодировках — а там наверняка всё просто как угол дома: вот тебе байт, вот тебе его интерпретация. S>Полноценную поддержку уникода со всеми этими нормализациями и декомпозициями умели только отдельные приложения, и они ессно всё таскали с собой.
NT вроде с рождения была юникодная с кодировкой UCS-2, которую сменили на UTF-16 в районе Win2K. А конвертации MultiByteToWideChar/WideCharToMultiByte c MB_COMPOSITE/MB_PRECOMPOSED были в WinAPI как минимум начиная с 95ой винды. Вероятно, с высоты нынешних позиций те реализации были кривоватыми, но работали же. Сейчас наверное работают получше. Ну так на той же базе по идее можно было бы выставить в API и итерацию по символам, и на тот момент она наверное даже была бы не кривая П>>Пошерстил по раскладкам — нифига, у арабов и персов только несколько кнопок генерят лигатуры, остальные клавиши генерят вполне конкретный код. Вот, например — https://kbdlayout.info/kbda1 S>А где там посмотреть, что за лигатуры генерируются?
Мышкой над кнопкой с лигатурой зависаешь и смотришь
Арабская 401
Персидская 429
U+0644 LAM в арабской раскладке ведущая, в персидской — ведомая
Здравствуйте, пффф, Вы писали:
П>Дык, вроде почти для всего есть свои отдельные precomposed chars.
Я потерял нить рассуждений. Я думал, что речь о том, чтобы пилить на графемные кластеры произвольный уникодный текст.
Если достаточно просто умения изображать ограниченный набор типовых символов с умляутами, то ничего этого не надо — просто не пользуйтесь композитными последовательностями и всё.
П>И аккут — просто как пример. Гипотеза, что есть отдельно условный аккут, который для composite'а и готовый precomposed аккут с пробелом — имеет право на жизнь,
Это не гипотеза — посмотрите на страничке https://www.compart.com/en/unicode/U+00B4 раздел Based on " " (U+0020). Вот там собственно собраны все "акуты", предкомпозированные с пробелом.
П>NT вроде с рождения была юникодная с кодировкой UCS-2, которую сменили на UTF-16 в районе Win2K.
Ну, может быть. Я в те времена с уникодом не сталкивался, все наши приложения честно работали в системной кодовой странице. П>А конвертации MultiByteToWideChar/WideCharToMultiByte c MB_COMPOSITE/MB_PRECOMPOSED были в WinAPI как минимум начиная с 95ой винды. Вероятно, с высоты нынешних позиций те реализации были кривоватыми, но работали же. Сейчас наверное работают получше. Ну так на той же базе по идее можно было бы выставить в API и итерацию по символам, и на тот момент она наверное даже была бы не кривая
По идее да. Более того, если винда действительно умела в уникод, то где-то внутри такая механика должна была быть, хотя бы для собственно отображения уникодных строк.
Но это предположение неплохо бы проверить — например, попробовав отрендерить zalgo-text на какой-нибудь VM со старой версией винды.
Очень может быть, что на практике там был сделан хак, который принудительно композировал известные композиты, а на всё остальное рисовал квадратики.
П>>>Пошерстил по раскладкам — нифига, у арабов и персов только несколько кнопок генерят лигатуры, остальные клавиши генерят вполне конкретный код. Вот, например — https://kbdlayout.info/kbda1 S>>А где там посмотреть, что за лигатуры генерируются?
П>Мышкой над кнопкой с лигатурой зависаешь и смотришь
Спасибо, понял.
Короче, там всё сложно
Возьмём прямо ту кнопку с вашего скриншота, которая с шифтом отдаёт U+0644 U+0622.
Выглядит так, что при нажатии кнопки в буфер уезжает два "символа". Но при этом второй из них — это precomposed пара из ا (U+0627) и ◌ٓ (U+0653). Интересно, что для полной комбинации U+0644 U+0622 есть прекомпозиты U+FEF5 и U+FEF6.
Как я понимаю, клавиатура не порождает эти прекомпозиты потому, что непонятно, какой из них использовать — это зависит от положения буквы; она может быть либо отдельной, либо финальной (стало быть, такое сочетание не может встречаться в начале или середине слова).
И вообще, эти прекомпозиты, похоже, предназначены были как раз для тех сред, где нельзя полагаться на автокомпозицию и шрифтовые лигатуры.
То, что визуально оно выглядит как один символ, обеспечивается шрифтом. Шрифты в opentype могут лигатурить всё, что угодно, независимо от уникода. См. всякие модные шрифты, которые объединяют вполне себе ascii-шные >= в ≥.
В общем, возникает всё же вопрос о том, в чём именно состоит задача — отображение, редактирование, ещё что-то? Предыдущее обсуждение уникода на этом сайте началось с эмоджи, а закончилось выводом о необходимости добавления в стандарт кириллической буквы ё без точек
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, пффф, Вы писали:
П>Да, отображение и редактирование Произвольного unicode-текста или можно чем-то пожертвовать? Эмоджи, залго, сочетания LTR с RTL?
Что является принципиальным?
Уйдемте отсюда, Румата! У вас слишком богатые погреба.
Здравствуйте, Sinclair, Вы писали:
П>>Да, отображение и редактирование S>Произвольного unicode-текста или можно чем-то пожертвовать? Эмоджи, залго, сочетания LTR с RTL? S>Что является принципиальным?
Произвольный именно текст, эмоджи идут в жопу, LTR/RTL нужно, вперемешку — скорее да