Здравствуйте, BlackEric, Вы писали:
BE>Книга Фаулера, как по мне, уже местами устарела. Там нет ничего про мобильные клиенты и выбора xml vs json как минимум. Есть ли что-нибудь по-новее?
А какое отношение к архитектуре имеют мобильные приложения и выбор протокола сериализации приложения?
Это все совершенно несущественные частности...
Здравствуйте, kaa.python, Вы писали:
C>>Из собственного опыта — читаем что написано у Фаулера и делаем 100% наоборот. KP>Этой книги Фаулера я вроде не читал, но мнение очень интересное. Не затруднит 1-2 примера привести? Очень заинтриговал
Например, пропаганда DTO-объектов, богатой доменной модели и мусора типа "стратегий". Совершенно не упомянуто об асинхронной модели, для долгоиграющих операций. Мелочи типа рекомендаций отделять "веб север" от "сервера приложений" можно простить, всё-таки 2006-й год был.
Что нельзя простить — совершенно бездарное описание работы удалённых сервисов, оно там в худшем стиле начала 90-х. Почти ни один из его примеров не пройдёт review у меня: нет обработки сетевых ошибок и retry, нет стратегии обеспечения идемпотентности, нет анализа на поведение при ошибках downstream-сервисов и т.д.
Нет упоминаний о трассировке и метриках для профилирования. Нет упоминаний о мониторинге и тревожных сигналах. Нет упоминаний о стратегии обеспечения безопасности межсервисных вызовов или о механизмах передачи identity вызывающего.
В общем, современная сервисная архитектура — это вообще отдельная и сложная тема. Хм. А не написать ли мне книгу про это?
Здравствуйте, vsb, Вы писали:
vsb>А какой должна быть современная архитектура? Обязательны ли микросервисы или допустим монолит? Если брать конкретно на примере Java с РСУБД, как должно работать всё от начала до конца? Вот юзер тыкнул в браузере что-то. JavaScript приложение отослало REST запрос. На бэкэнде его кто принимает, Spring MVC? Ты против DTO, т.е. мы не пишем объект, на который маппится JSON, а работаем с ним как с Map<String, ?>? Каким образом работа с базой устроена, тоже просто с Map работаем, без доменной модели? Архитектура это абстрактно, хотелось бы на более конкретных схематических примерах понять, как положено делать. Я, лично, так и не нашёл подхода, который бы меня устраивал, а свой фреймворк писать как-то странно в 2019 году.
Расскажу про свой текущий проект на Go и на Java.
Если говорить про Go, то обычно имеется выделенный контролер (это просто удобно) и бизнес модель/логика, без каких-либо четко выделенных M и V. Поэтому, пришедший через REST запрос ты так или иначе десериализуешь в свою структуру и передаешь дальше в бизнес уровни/компоненты. Сам полученных через REST объект сильно не факт что попадет в итоге базу, скорей всего он будет обработан в каком-то из бизнес компонентов и трансформирован в другую структуру, которую можно записать/считать в/из базы, а сама база k/v с объектами доменной модели. Бизнес представление содержит внутреннее состояние системы и слабо пересекающется с тем, что прилетело через REST.
Интерфейсы в купе с компонентной моделью Go позволяют получить очень чистое разделение по бизнес-компонентам и как следствие иметь легко поддерживаемый код. Скажем так, я подобный подход с Java не фак что решился бы использовать, а тут это нечто по-умолчанию и отлично работает. Ну и, конечно, фокусируешься на принципах SOLID, очень хорошо помогает в итоге и Go, в отличие от подавляющего большинства других языков, подталкивает к следованию этим практикам. Вот к примеру довольно хорошее описание де-факто стандартного подхода в Go (первый комментарий).
При этом у меня есть наглядное подтверждение правильности этого подхода. В команде довольно большая текучка, приходит и уходит как очень высококвалифицированный народ так и посредственный. При этом, проект до сих пор в великолепном, легко поддерживаемом состоянии и малейшие косяки в новых пул-реквестах просто как на ладони. В то же время в параллельной команде есть классический Spring MVC проект сделанный по Фаулеру. Я туда пару раз заглядывал починить по мелочи, и это просто АД и содомия. Нагромождение контроллеров, фабрик и прочего Java-специфического барахла делает бизнес логику совершенно не понятной и сильно размазанной. Кто-куда и зачем сказал – огромная загадка, приходится перелопачивать кучу кода что-бы понять.
Здравствуйте, Stalker., Вы писали:
C>>Именно. S>с этого и надо было начинать, анемисты известны своими экстремальными взглядами и демонстративным неприятием устоявшихся и проверенных временем подходов к разработке.
Я работал с кодовыми базами в сотни миллионов строк. С модулями/сервисами, написанными в разных стилях. В том числе и классическом фаулеровском, с rich domain objects. И вот как раз эти модули были самым АДЪ-ом, так как логика часто была размазана по всей массе кода.
Именно доменная модель провоцирует такие жутики, как скрытые удалённые вызовы в getter'ах (со скрытым контекстом вызова).
C>>К счастью, в индустрии стал общепринят стандарт SOLID, как намного более надёжный. S>все в кучу свалил, веб-сервисы это не архитектура, а технология, а про SOLID в майкрософтовской документации упоминается чуть-ли не на каждой странице.
SOLID категорически не дружит с богатой доменной моделью. Она повсеместно нарушает буквы S и D.
S>На практике, особенно когда работаешь в определенном стеке технологий, то надо не в религию ударяться, а следовать рекомендованным практикам. Эксперименты типа анемики конечно полезны, но в серьезных коммерческих проектах их нельзя применять из-за необкатанности и непопулярности в среде разработчиков.
Бред. Если стек заставляет писать в уродливом стиле — его надо менять, и не оглядываться (а legacy-код — рефакторить). Например, так был выбращен на свалку истории EJB, который как раз часто упоминается у Фаулера.
S>Я не хочу превращать топик в очередной холивар, просто отмечу что эти форумные холивары были еще 10 лет назад, и анемика дальше форумных войн никуда за это время не ушла
Большинство новых крупномасштабных систем пишутся именно в анемичной модели.
Более того, новейшие языки типа Rust или Go, фактически, вообще выбросили большую часть ООП на помойку, вместе с подпорками в виде thread-local хранилища (в Go). Так что там писать богатую доменную модель стало существенно труднее.
Здравствуйте, vsb, Вы писали:
C>>В общем, современная сервисная архитектура — это вообще отдельная и сложная тема. Хм. А не написать ли мне книгу про это? vsb>А какой должна быть современная архитектура? Обязательны ли микросервисы или допустим монолит?
Монолит однозначно возможен и желателен. Для большинства приложений это оптимальный выбор.
Я бы сказал, что именно микросервисов не существует. Так как любой микросервис при правильной реализации перестаёт быть "микро", а становится вполне себе "макро".
В целом, сервисная архитектура имеет смысл уже для достаточно больших приложений, над которыми работают десятки человек. По моему опыту, основная польза сервисов в том, что они дают удобную демаркационную линию между разными командами.
vsb>Если брать конкретно на примере Java с РСУБД, как должно работать всё от начала до конца? Вот юзер тыкнул в браузере что-то. JavaScript приложение отослало REST запрос. На бэкэнде его кто принимает, Spring MVC? Ты против DTO, т.е. мы не пишем объект, на который маппится JSON, а работаем с ним как с Map<String, ?>?
Оптимально — сразу отображаем в целевой объект, который мы потом можем записать в базу (через ORM).
Ещё у себя использую такой паттерн:
type SubtaskInfo struct {
Id String
CommandLine []string
...
}
// Структура, которая хранится в БД посредством ORM
type StoredSubtask struct {
SubtaskInfo // "Наследуемся" от SubtaskInfo
RowId string
Version int64
...
}
SubtaskInfo сгенерирован из Swagger-схемы для почти-REST-интерфейса.
Работа с базой — как обычно. В начале запроса открываем транзакцию, пишем/читаем данные через ORM или ручные запросы, в конце запроса фиксируем/откатываем. Без транзакций с NoSQL всё тоже похоже.
Здравствуйте, BlackEric, Вы писали:
BE>Книга Фаулера, как по мне, уже местами устарела. Там нет ничего про мобильные клиенты и выбора xml vs json как минимум. Есть ли что-нибудь по-новее?
Думаю что для начала нужно определиться с тем, что же такое архитектура, а уже потом говорить о книгах. Архитектура, это не про мобильное приложение и не про десктопное и не про xml vs json. Арихтектура даже не про бэкенд или фронтенд. Архитектура это про программно-аппаратный комплекс, который решает бизнес задачи. Именно комплекс, который нацелен на решения задач бизнеса/пользователя.
В то же время дизайн — это как раз про xml vs json, мобильные приложения, бэкенд, фронтенд, реляционные базы VS k/v хранилища. Само собой, пересечение между архитектурой и дизайном есть и оно огромное, но акценты в обоих случаях сильно разные.
Здравствуйте, Cyberax, Вы писали:
Б>>С другой стороны, и persistance тоже не совсем слой (в "старом" понимании). Есть же и другие "слои" в инфраструктуре — слой поиска, слой нотификации, слой интеграции с какой-нибудь внешней системой и т.п. C>Тут тоже есть вопросы. "Слой" — это совершенно неправильное слово для много из этого.
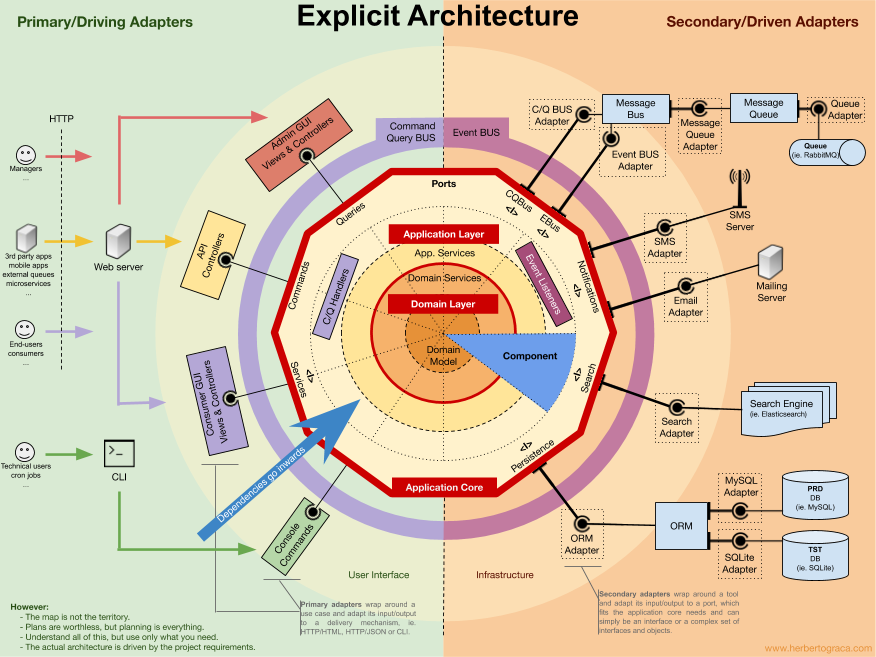
Потому что он так и не называется. В приведенной луковой/гексагональной модели слоями назваются:
— слой доменной области
— слой приложения
— слой инфраструктуры
— слой представления
(их даже видно на той страшной картинке что привел Буравчик, если продраться сквозь всю кучу слов)
в каждом из слоев те или иные части приложения. Persistance относится к слою инфраструктуры.Доменная модель про него не должна знать вообще — она должна существаовать сама по себе. Слой приложения задает требования к Persistance через определение интерфейсов которые ему будут нужны для получения/сохранения данных. В инфраструктуре делается собственно реализация этих интерфейсов и через внедрение зависимостей становится доступным в слое приложения (та самая буква D, да).
На том же слое инфраструктуры есть и например, реализация взаимодействия с какими-нибудь вненшинми сервисами. Она не выше и не ниже persistance, она "наравне", потому один слой.
P.S.
Какие-то вы со Stalker-ом категоричные.
Я всю дорогу писал в анемичном стиле, сейчас пытаюсь все же освоить нормально DDD и надо сказать, в нем что-то есть. При этом сделать его неправильно и получить полный отстой — запросто. Но по опыту могу сказать, что превратить систему на анемичной модели в неподдерживаемую кашу — так же запросто можно. Тут они вполне себе наравне. Точнее, как всегда, все сильно зависит от людей, которые реализуют
SOLID прекрасно себя чувствует и показан к применению в обоих подходах. И так же запросто нарушается разработчиками в обоих походах, в том числе и с особым цинизмом, отчего получаются монстры.
Здравствуйте, BlackEric, Вы писали:
BE>Книга Фаулера, как по мне, уже местами устарела. Там нет ничего про мобильные клиенты и выбора xml vs json как минимум. Есть ли что-нибудь по-новее?
Мне кажется что если выбор xml vs json на что-то влияет, то архитектура плохая.
А вот про мобильные клиенты и оффлайн действительно у фаулера ничего нет, тогда все было по-другому.
Что читать — About face Алана Купера (Проектирование интерфейсов), там для архитектора приложений полезных сведений гораздо больше, чем в любой книге по арихеткруте и дизайну.
Здравствуйте, Stalker., Вы писали:
C>>В том числе и классическом фаулеровском, с rich domain objects. И вот как раз эти модули были самым АДЪ-ом, так как логика часто была размазана по всей массе кода. S>как я уже писал учавствовать в холиварах на эту тему мне неинтересно, так что не будем развивать, да и странно читать на форуме, где сидят разработчики с многолетним опытом что у них в коде ад и ничего не работает. Наверно про свой код я знаю лучше
Я в детстве тоже думал, что мой код — совсем хороший.
C>>Бред. Если стек заставляет писать в уродливом стиле — его надо менять, и не оглядываться (а legacy-код — рефакторить). S>Really? Взять выбросить C#, Аzure, ASP.NET и срочно все переписать на Rust?
Нет. В анемичной модели вполне можно писать на C#/Java.
C>>Большинство новых крупномасштабных систем пишутся именно в анемичной модели. S>Ну не надо ерунду писать, поспрашивай на собеседованиях у кандидатов что такое ООП и что такое анемичная модель. Нельзя в больших коммерческих проектах применять малознакомые подходы просто потому-что так кому-то хочется, лень даже расписывать почему, очевидно-же
Малознакомые?!? С разморозкой, однако....
Здравствуйте, BlackEric, Вы писали:
BE>Книга Фаулера, как по мне, уже местами устарела. Там нет ничего про мобильные клиенты и выбора xml vs json как минимум. Есть ли что-нибудь по-новее?
Здравствуйте, Cyberax, Вы писали:
C>В общем, современная сервисная архитектура — это вообще отдельная и сложная тема. Хм. А не написать ли мне книгу про это?
На книгу редко у кого времени хватает. Хотя бы начать с серии статей — было бы здорово.
Здравствуйте, BlackEric, Вы писали:
BE>Книга Фаулера, как по мне, уже местами устарела. Там нет ничего про мобильные клиенты и выбора xml vs json как минимум. Есть ли что-нибудь по-новее?
Из собственного опыта — читаем что написано у Фаулера и делаем 100% наоборот.
C>В общем, современная сервисная архитектура — это вообще отдельная и сложная тема. Хм. А не написать ли мне книгу про это?
А напиши, серьёзно. Вангую, заработаешь ещё 1кк$
Здравствуйте, Cyberax, Вы писали:
C>Что нельзя простить — совершенно бездарное описание работы удалённых сервисов, оно там в худшем стиле начала 90-х. Почти ни один из его примеров не пройдёт review у меня: нет обработки сетевых ошибок и retry, нет стратегии обеспечения идемпотентности, нет анализа на поведение при ошибках downstream-сервисов и т.д.
C>Нет упоминаний о трассировке и метриках для профилирования. Нет упоминаний о мониторинге и тревожных сигналах. Нет упоминаний о стратегии обеспечения безопасности межсервисных вызовов или о механизмах передачи identity вызывающего.
"пропаганда DTO-объектов и богатой доменной модели" есть везде, в том числе в whitepapers от Майкрософт т.к. без них написать современную систему невозможно. Я уже давно читал его книжки, но асинхронные методы, сетевые ошибки и прочее там вполне были. Даже про identity базовые на тот момент вещи (куки по-сути) там вроде упоминались, конечно про токены ничего не было, т.к. и самих токенов тогда еще не изобрели. Вообще сейчас сильный уклон в микросервисы, облака и SPA, которых тогда тоже не было, и про них уже достаточно много хорошей литературы. Сами по себе паттерны от Фаулера вполне актуальны
Здравствуйте, Stalker., Вы писали:
C>>Нет упоминаний о трассировке и метриках для профилирования. Нет упоминаний о мониторинге и тревожных сигналах. Нет упоминаний о стратегии обеспечения безопасности межсервисных вызовов или о механизмах передачи identity вызывающего. S>"пропаганда DTO-объектов и богатой доменной модели" есть везде, в том числе в whitepapers от Майкрософт т.к. без них написать современную систему невозможно.
Ещё как можно. И даже нужно — фаулерные системы превращаются в АДЪ очень быстро.
S>Я уже давно читал его книжки, но асинхронные методы, сетевые ошибки и прочее там вполне были.
Сейчас ещё раз просмотрел. Нету.
S>Даже про identity базовые на тот момент вещи (куки по-сути) там вроде упоминались, конечно про токены ничего не было, т.к. и самих токенов тогда еще не изобрели. Вообще сейчас сильный уклон в микросервисы, облака и SPA, которых тогда тоже не было, и про них уже достаточно много хорошей литературы.
Про identity там максимум было в разговорах про сессии.
S>Сами по себе паттерны от Фаулера вполне актуальны
Они, по большей части, антипаттерны. И да, актуальны.
Здравствуйте, Stalker., Вы писали:
C>>Ещё как можно. И даже нужно — фаулерные системы превращаются в АДЪ очень быстро. S>ты похоже адепт анемичной модели, верно?
Именно.
S>Есть общепринятые подходы к разработке, и DDD с DTO в ней занимают одно из центральных мест, почитай про разработку микросервисной архитектуры от Майкрософт
Я прекрасно знаю что пихал MS. Вся эта "орхитектура" от Microsoft провалилась целиком и полностью, в итоге. Со всеми их веб-сервисами, оркестраторами, шинами и прочими WSDL.
К счастью, в индустрии стал общепринят стандарт SOLID, как намного более надёжный.
с этого и надо было начинать, анемисты известны своими экстремальными взглядами и демонстративным неприятием устоявшихся и проверенных временем подходов к разработке.
C>Я прекрасно знаю что пихал MS. Вся эта "орхитектура" от Microsoft провалилась целиком и полностью, в итоге. Со всеми их веб-сервисами, оркестраторами, шинами и прочими WSDL. C>К счастью, в индустрии стал общепринят стандарт SOLID, как намного более надёжный.
все в кучу свалил, веб-сервисы это не архитектура, а технология, а про SOLID в майкрософтовской документации упоминается чуть-ли не на каждой странице. На практике, особенно когда работаешь в определенном стеке технологий, то надо не в религию ударяться, а следовать рекомендованным практикам. Эксперименты типа анемики конечно полезны, но в серьезных коммерческих проектах их нельзя применять из-за необкатанности и непопулярности в среде разработчиков. Я не хочу превращать топик в очередной холивар, просто отмечу что эти форумные холивары были еще 10 лет назад, и анемика дальше форумных войн никуда за это время не ушла
Здравствуйте, BlackEric, Вы писали:
BE>Книга Фаулера, как по мне, уже местами устарела. Там нет ничего про мобильные клиенты и выбора xml vs json как минимум. Есть ли что-нибудь по-новее?
А что ты хочешь прочитать, интересно, про выбор xml vs json? XML ужасен, тошнотворен и переусложнен, json просто тошнотворен. По-моему, выбор очевиден
Здравствуйте, BlackEric, Вы писали:
BE>Книга Фаулера, как по мне, уже местами устарела. Там нет ничего про мобильные клиенты и выбора xml vs json как минимум. Есть ли что-нибудь по-новее?
Дарагие ученые! В вашем учебнике по матанализу нечего не рассказываеца как считать лайки. Ни магли бы вы абнавить учебник Фихтенгольца по мат анализу и включит туда главу про лайки?
Здравствуйте, Cyberax, Вы писали:
C>Ну вот пусть эти блокировки будут в отдельной таблице, хотя бы. Которая просто недоступна через обычный REST, аналогично с паролями. Ну а номера карт вообще должны быть в отдельной БД по правилам PCIDSS. C>Если их располагать всё в одном объекте, то при одной ошибке будем иметь очередной пресс-релиз: "Компания Рога&Копыта утекла данные 100500 пользователей из-за хакерской атаки".
номера карточек должны быть зашифрованы, а не вынесены в отдельную базу, другое дело что база самих клиентов с паролями обычно в другой базе по несвязанным с секьюрными требованиями причинам
C>Ну и цепочка размышлений такая: C>1. Если делать интерфейс типа "setUserData(UserDTO userData)", то надо проверять, что только администратор может редактировать определённые поля. C>2. Но это очень плохо, так как слишком хрупко и неудобно. C>3. Почему бы тогда не выделить отдельный метод "setSensitiveUserData(SensitiveUserDTO userData)", который будет доступен только администраторам? C>4. Хм. А почему бы тогда и не выделить SensitiveUserData в отдельный объект?
и это называется "нехрупкий" подход? Есть миллион разных вариантов того кто, что и при каких обстоятельствах может править, они еще и меняться могут по ходу работы в виде добавления новых ролей и прочего, заложить это в структуре базы просто недостижимо, не говоря уже про то, какой ненормализованный монстр получится в итоге, адрес клиента например может меняться как оператором или админом, так и самим клиентом, а вот снятие блокировки только админом, эта логика не имеет отношения к структуре обьекта Клиент
C>Зачем? Пусть REST-сервис сразу проверяет на нужный формат (7343456787). Frontend'у никто не мешает телефон отформатировать заранее — он и так это обязан будет делать хотя бы для отображения, так как перевод "7343456787" в "+7 (343) 456 987" кто-то должен делать.
тогда знание о валидации и нормализации бизнес обьектов тонким слоем расползется по всем клиентам плюс будет продублировано в бизнес логике. Даже тот-же номер телефона может представлять проблему — например в интерфейсе для резидентов код страны может не указываться, а уж строка адреса и вообще перетащит половину логики валидации на клиента.
C>Аутентификация — это как раз один из примеров, где REST-интерфейс один фиг не подходит.
авторизация, не аутентификация. И делается она именно что в REST интерфейсе, а никак не в бизнес логике
Re[5]: отделять "веб север" от "сервера приложений"
Здравствуйте, Sharov, Вы писали:
C>>НМелочи типа рекомендаций отделять "веб север" от "сервера приложений" можно простить, всё-таки 2006-й год был. S>А что тут не так? Почему отделять плохо?
В 2006-м году веб-сервер был отдельной фигнёй, которая выдавала динамический HTML в ответ на запросы пользователей.
Сейчас корпоративные приложения на 90% построены в виде статических JS/HTML/CSS модулей, которые загружаются с какого-либо CDN. Затем этот JS уже просто напрямую вызывает backend'овые сервисы. Т.е. классический динамический веб-сервер как таковой часто вообще отсутствует.
Здравствуйте, Stalker., Вы писали:
C>>Если их располагать всё в одном объекте, то при одной ошибке будем иметь очередной пресс-релиз: "Компания Рога&Копыта утекла данные 100500 пользователей из-за хакерской атаки". S>номера карточек должны быть зашифрованы, а не вынесены в отдельную базу
В теории это возможно, но на практике крайне сложно, так как PCIDSS требует "need to know" уровень доступа и запрещает совмещать данные серверы уровней защиты.
C>>4. Хм. А почему бы тогда и не выделить SensitiveUserData в отдельный объект? S>и это называется "нехрупкий" подход?
Да. Всё очень просто и понятно — чувствительные объекты сразу видны, API легко выделяется и может специально мониториться (например, ставим alert на количество прочитанных объектов в секунду/за запрос).
S>Есть миллион разных вариантов того кто, что и при каких обстоятельствах может править, они еще и меняться могут по ходу работы в виде добавления новых ролей и прочего, заложить это в структуре базы просто недостижимо
Могут. Потому надо делать всё как можно проще, чтобы в случае необходимости можно было легко переписать. И как только требования появятся — смотреть что лучшее для них подходит, а не пессимизировать заранее.
И вариант с отдельным API для чувствительных данных — самый простой из тех, которые я знаю.
C>>Зачем? Пусть REST-сервис сразу проверяет на нужный формат (7343456787). Frontend'у никто не мешает телефон отформатировать заранее — он и так это обязан будет делать хотя бы для отображения, так как перевод "7343456787" в "+7 (343) 456 987" кто-то должен делать. S>тогда знание о валидации и нормализации бизнес обьектов тонким слоем расползется по всем клиентам плюс будет продублировано в бизнес логике.
В REST-слое только валидация. Но она будет и в frontend'е. Тут как раз пример того, что проще всего разделять модель между фронтэндом и backend'ом.
REST тут как раз помогает — для того же Swagger'а можно достаточно богатую валидацию запихать в схему API.
C>>Аутентификация — это как раз один из примеров, где REST-интерфейс один фиг не подходит. S>авторизация, не аутентификация. И делается она именно что в REST интерфейсе, а никак не в бизнес логике
Авторизация может делаться вообще везде. В том числе и в БЛ. Которым, кстати, может быть и REST-интерфейс напрямую.
Здравствуйте, BlackEric, Вы писали:
BE>Книга Фаулера, как по мне, уже местами устарела. Там нет ничего про мобильные клиенты и выбора xml vs json как минимум. Есть ли что-нибудь по-новее?
Из этой книги:
Термин "архитектура" пытаются трактовать все, кому не лень, и всяк на свой лад. Впрочем, можно назвать два общих варианта. Первый связан с разделением системы на наиболее крупные составные части; во втором случае имеются в виду некие конструктивные решения, которые после их принятия с трудом поддаются изменению.
Лично я считаю, что эта книга не только не устарела, просто в ней используется гораздо более высокий уровень абстракции. Например, некий программист выбирает между форматами хранения xml и json. Но зачем это делать архитектору вроде Фаулера, он предлагает шаблоны проектирования, которые позволят использовать и то, и другое, а так же расширять функционал без изменения основы, той самой части программы цена изменения которой слишком велика.
Корпоративные приложения обычно подразумевают необходимость долговременного (иногда в течение десятилетий) хранения данных. Данные зачастую способны "пережить" несколько поколений прикладных программ, предназначенных для их обработки, аппаратных средств, операционных систем и компиляторов. В продолжение этого срока структура данных может подвергаться многочисленным изменениям в целях сохранения новых порций информации без какого-либо воздействия на старые. Даже в тех случаях, когда компания осуществляет революционные изменения в парке оборудования и номенклатуре программных приложений, данные не уничтожаются, а переносятся в новую среду.
Здесь стоит понять, что формат данных это всего лишь средство. Можно одни и те же структуры данных сохранить множеством способов с помощью одного и того же формата, то есть при извлечении получать один и тот же результат. Данные можно не только хранить, но и передавать, и данные которые хранятся скорее всего будут выглядеть не так как те, которые передаются, даже если использовать один и тот же формат. Данные можно обрабатывать и для этого существует множество способов, включая управление изменениями и тому подобное.
А в целом чтобы использовать то, что написано в книге, нужно обладать очень высокой квалификацией архитектора программного обеспечения, в противном случае получится говнокод с обратными заявленным свойствами. Были времена, когда я вообще не понимал, что там написано, но со годами понял насколько там всё гениально. То что написано в этой книге можно использовать для создания приложений планетарного масштаба, я это пишу без всякой иронии или шуток.
Но тут нужно понимать, кто такой Мартин Фаулер, и кто такой Вася Пупкин. От Васи Пупкина никто особо ничего и не ждёт. От него даже не требуется читать эту книгу. Я, к примеру, читал, там есть и про расслоение системы, и про web. Но если абстрактный Вася Пупкин смотрит в книгу и этого не видит, я даже ему ничего говорить не буду. Обычный разработчик не обязан быть высокоуровневым архитектором чтобы успешно создавать программы. У Фаулера речь не просто про архитектуру, а про архитектуру корпоративных программных приложений.
Здравствуйте, Cyberax, Вы писали:
Б>>Т.е. нескольким запросам требуются одни и те же подзапросы. C>"const CommonExpr = ...."
А если запросы в разных частях системы?
Б>>Это когда надо написать запрос на голом SQL. Где такой код хранить, как не в внутри persistance? C>Там, где оно нужно.
Вот я и говорю. По всей системе разбросаны. Потом ищи их...
C>Ну как бы надо термины не изгибать до неузнаваемости, а так и писать: "слой доступа к данным, в котором сосредоточено управление данными". Даже термин есть: DAL (Data Access Layer).
Это мы с тобой называем — слой, по-привычке (UI-BLL-DAL). Но на картинке слои другие — Domain, Application, Infrastructure.
Persistance — один из кусочков слоя инфрастуктуры, наравне с другими, не менее важными, кусочками.
Б>>С другой стороны, и persistance тоже не совсем слой (в "старом" понимании). Есть же и другие "слои" в инфраструктуре — слой поиска, слой нотификации, слой интеграции с какой-нибудь внешней системой и т.п. C>Тут тоже есть вопросы. "Слой" — это совершенно неправильное слово для много из этого. C>В частности, "слой" подразумевает, что под ним (и над ним) что-то есть. Т.е. берём систему без оповещений, добавляем слой и получаем систему с оповещениями. При этом нижележащий слой не знает о системе оповещений.
Вот именно. Это не слои, а адаптеры И все они — часть инфраструктуры, а не дополнительная обертка вокруг системы.
P.S. Предлагаю не спорить что есть слой, а что нет. А рассматривать вопрос по существу.
Здравствуйте, Stalker., Вы писали:
S>>>номера карточек должны быть зашифрованы, а не вынесены в отдельную базу C>>В теории это возможно, но на практике крайне сложно, так как PCIDSS требует "need to know" уровень доступа и запрещает совмещать данные серверы уровней защиты. S>не понятно что именно сложно, шифрование?
Даже зашифрованные карты нельзя просто так складировать.
Но проблема в другом. Даже при шифровании ключ для расшифровки будет в сервере приложений или веб-сервере. Иначе сервер не сможет использовать эти данные, однако. Это само по себе уже может быть нарушением запрета на множественные роли. Но ещё и у любого инженера, имеющего доступ к серверу, будет возможность данные расшифровать.
PCIDSS требует ограничивать такой доступ до "need to know". Так что реально получается необходимость внешней базы/сервиса.
ДФ>А какое отношение к архитектуре имеют мобильные приложения и выбор протокола сериализации приложения?
Протокол сериализации, да, частность, хотя такая, что потом будет влиять на все.
А обпеспечение взаимодействия с мобильным приложение — однозначно должно закладываться в архитектуре. Для него необходимо выставлять АПИ. Для обеспечения единоообразия это же апи по хорошему должен использовать и веб интерфейс.
Eventually, it can be a project on its own, in its own CVS repository, and used in several projects.
...
To do this, in the PHP world we have a little tool called Deptrac (but I bet similar tools exist for other languages as well), created by Sensiolabs. We configure it using a yaml file, where we define the layers we have and the allowed dependencies between them. Then we run it through the command line, which means we can easily run it in a CI, just like we run a test suite in the CI.
Здравствуйте, Ikemefula, Вы писали:
KP>>>Этой книги Фаулера я вроде не читал, но мнение очень интересное. Не затруднит 1-2 примера привести? Очень заинтриговал C>>Например, пропаганда DTO-объектов, I>Когда и чем плохи DTO ?
Часто это просто лишняя сущность. Хотя иногда их избежать не получается,.
Здравствуйте, Дельгядо Филипп, Вы писали:
ДФ>А какое отношение к архитектуре имеют мобильные приложения и выбор протокола сериализации приложения? ДФ>Это все совершенно несущественные частности...
С чего ты вдруг решил, что для его приложения это несущественные частности?
Здравствуйте, BlackEric, Вы писали:
BE>Вот только в названии в обоих случаях Architecture. Надо подумать где разница между дизайном и архитектурой.
Насколько я помню Architecture in Practice, там как раз есть размышления на тему отличия архитектуры от дизайна с которыми я полностью согласен и привел выше. Да и если посмотреть на вакансии архитекторов то видно, что архитектура, обычно — это про весь комплекс в целом, как минимум на уровне подразделения компании.
Здравствуйте, BlackEric, Вы писали:
BE>Протокол сериализации, да, частность, хотя такая, что потом будет влиять на все.
BE>А обпеспечение взаимодействия с мобильным приложение — однозначно должно закладываться в архитектуре. Для него необходимо выставлять АПИ. Для обеспечения единоообразия это же апи по хорошему должен использовать и веб интерфейс.
Здравствуйте, Sharov, Вы писали:
S>Здравствуйте, Cyberax, Вы писали:
C>>НМелочи типа рекомендаций отделять "веб север" от "сервера приложений" можно простить, всё-таки 2006-й год был.
S>А что тут не так? Почему отделять плохо?
Наверное, про то, что сейчас API в серверах приложений строится практически всегда с использованием HTTP. Т.е. серверы приложений являются веб-серверами.
Здравствуйте, Cyberax, Вы писали:
C>В общем, современная сервисная архитектура — это вообще отдельная и сложная тема. Хм. А не написать ли мне книгу про это?
Очень интересно, и если ты напишешь такую книгу, я буду одним из первых покупателей. Желательно с автографом автора
Кстати, а ничего подобного уже нет? Ты очень интересные темы затронул и мне подумалось, может уже что-то, пусть и не на 100% покрывающее эти вопросы, но уже есть?
Здравствуйте, kaa.python, Вы писали:
C>>В общем, современная сервисная архитектура — это вообще отдельная и сложная тема. Хм. А не написать ли мне книгу про это? KP>Очень интересно, и если ты напишешь такую книгу, я буду одним из первых покупателей. Желательно с автографом автора
Ок
KP>Кстати, а ничего подобного уже нет? Ты очень интересные темы затронул и мне подумалось, может уже что-то, пусть и не на 100% покрывающее эти вопросы, но уже есть?
Сейчас смотрю несколько книг, но именно всего вместе не вижу.
Здравствуйте, Cyberax, Вы писали:
C>Ещё как можно. И даже нужно — фаулерные системы превращаются в АДЪ очень быстро.
ты похоже адепт анемичной модели, верно? Есть общепринятые подходы к разработке, и DDD с DTO в ней занимают одно из центральных мест, почитай про разработку микросервисной архитектуры от Майкрософт, у них сейчас множество хороших публикаций на эту тему, я лично именно что книжки довольно давно уже не читал т.к. базовые подходы и паттерны от того-же Фаулера прочитаны давно, а технологии и конкретные практические приемы надо брать из подобной документации т.к. книжки по ним мгновенно устаревают
Здравствуйте, Буравчик, Вы писали:
C>>CVS и PHP в 2019-м году? Что-то тут не то. Б>Это не отменяет общих принципов луковой/гексагональной архитектуры.
Какие же у неё принципы? "Наворотить, чтобы никто не догадался"?
Здравствуйте, Cyberax, Вы писали:
C>В том числе и классическом фаулеровском, с rich domain objects. И вот как раз эти модули были самым АДЪ-ом, так как логика часто была размазана по всей массе кода.
как я уже писал учавствовать в холиварах на эту тему мне неинтересно, так что не будем развивать, да и странно читать на форуме, где сидят разработчики с многолетним опытом что у них в коде ад и ничего не работает. Наверно про свой код я знаю лучше
C>Бред. Если стек заставляет писать в уродливом стиле — его надо менять, и не оглядываться (а legacy-код — рефакторить).
Really? Взять выбросить C#, Аzure, ASP.NET и срочно все переписать на Rust?
C>Большинство новых крупномасштабных систем пишутся именно в анемичной модели.
Ну не надо ерунду писать, поспрашивай на собеседованиях у кандидатов что такое ООП и что такое анемичная модель. Нельзя в больших коммерческих проектах применять малознакомые подходы просто потому-что так кому-то хочется, лень даже расписывать почему, очевидно-же
И вообще с практической точки зрения вместо того, что-бы забивать себе голову вялотекущими холиварами 10-летней давности куда лучше направить эту энергию на что-то более полезное, в современных системах прорва мест которые надо изучать что-бы сделать хорошую систему — одна только безопасность чего стоит (токены, OAuth), а помимо нее есть микросервисы, REST, CQRS и много других интересных и реально полезных вещей
Здравствуйте, Cyberax, Вы писали:
C>Ок
Можно запустить краудфандинговую компанию для сбора средств и оценки рынка сбыта. Я бы тоже закинул 1-2 тыщи в обмен на книгу в будущем.
Здравствуйте, Буравчик, Вы писали:
C>>"Наворотить, чтобы никто не догадался"? Б>Если упомянутый тобой SOLID использовать, то получится как раз то, что на картинке. Б>Домен отдельно, сервисы отдельно, инфраструктура отдельно. Б>Не пойму, где там наворочено, что не устраивает?
Слишком много слоёв. Типа ORM и адаптера для ORM.
Здравствуйте, Cyberax, Вы писали:
C>Слишком много слоёв. Типа ORM и адаптера для ORM.
Все верно. Поверх ORM (библиотеки) имеется дополнительный Persistance слой.
Он:
— отвязывает приложение от схемы БД (схема БД меняется часто)
— устраняет дублирование запросов, созданных с помощью ORM
— позволяет добавить SQL запросы в обход ORM
— позволяет добавить кеширование и делать другие оптимизации
Т.е. слой нужен не для того, чтобы заменять ORM, а для того,
чтобы используя инфраструктуру (ORM) предоставить полезные функции (persistance).
Здравствуйте, Буравчик, Вы писали:
C>>Слишком много слоёв. Типа ORM и адаптера для ORM. Б>Все верно. Поверх ORM (библиотеки) имеется дополнительный Persistance слой.
Масло масляное какое-то. ORM и так является persistance-слоем.
Б>- отвязывает приложение от схемы БД (схема БД меняется часто)
Этим должна заниматься ORM и само приложение.
Б>- устраняет дублирование запросов, созданных с помощью ORM
??? Б>- позволяет добавить SQL запросы в обход ORM
???
Б>- позволяет добавить кеширование и делать другие оптимизации
Кэширование редко является полезным на уровне persistance.
В документе речь идёт об адаптерах — это таки технический термин. Означающий, что интерфейс ORM будет адаптироваться к внутреннему интерфейсу системы. От этого и возникает вопрос: нафига?
Здравствуйте, Cyberax, Вы писали:
C>Масло масляное какое-то. ORM и так является persistance-слоем.
Не. ORM является библиотекой для построения persistance-слоя.
Б>>- отвязывает приложение от схемы БД (схема БД меняется часто) C>Этим должна заниматься ORM и само приложение.
Приложение и занимается. Этот код лежит в persistance слое.
Чтобы не пришлось при небольших изменениях схемы выискивать по всему приложению запросы, которые нужно поменять.
Б>>- устраняет дублирование запросов, созданных с помощью ORM C>???
Я про повторение частей запросов, построенных с помощью ORM.
Т.е. нескольким запросам требуются одни и те же подзапросы.
Б>>- позволяет добавить SQL запросы в обход ORM C>???
Это когда надо написать запрос на голом SQL. Где такой код хранить, как не в внутри persistance?
Б>>- позволяет добавить кеширование и делать другие оптимизации C>Кэширование редко является полезным на уровне persistance.
Разные ситуации могут быть
C>В документе речь идёт об адаптерах — это таки технический термин. Означающий, что интерфейс ORM будет адаптироваться к внутреннему интерфейсу системы. От этого и возникает вопрос: нафига?
Этот адаптер — часть приложения, которая отвечает за persistance (т.е. persistance-слой). Реализует интерфейс persistance, а ORM — деталь реализации.
В некотором роде ORM адаптируется под интерфейс persistance, под требования приложения. Хотя, аддаптер может и не совсем подходящий термин.
С другой стороны, и persistance тоже не совсем слой (в "старом" понимании). Есть же и другие "слои" в инфраструктуре — слой поиска, слой нотификации, слой интеграции с какой-нибудь внешней системой и т.п.
Здравствуйте, Буравчик, Вы писали:
Б>>>- устраняет дублирование запросов, созданных с помощью ORM C>>??? Б>Я про повторение частей запросов, построенных с помощью ORM. Б>Т.е. нескольким запросам требуются одни и те же подзапросы.
"const CommonExpr = ...."
Б>>>- позволяет добавить SQL запросы в обход ORM C>>??? Б>Это когда надо написать запрос на голом SQL. Где такой код хранить, как не в внутри persistance?
Там, где оно нужно.
C>>В документе речь идёт об адаптерах — это таки технический термин. Означающий, что интерфейс ORM будет адаптироваться к внутреннему интерфейсу системы. От этого и возникает вопрос: нафига? Б>Этот адаптер — часть приложения, которая отвечает за persistance (т.е. persistance-слой). Реализует интерфейс persistance, а ORM — деталь реализации.
Ну как бы надо термины не изгибать до неузнаваемости, а так и писать: "слой доступа к данным, в котором сосредоточено управление данными". Даже термин есть: DAL (Data Access Layer).
Б>С другой стороны, и persistance тоже не совсем слой (в "старом" понимании). Есть же и другие "слои" в инфраструктуре — слой поиска, слой нотификации, слой интеграции с какой-нибудь внешней системой и т.п.
Тут тоже есть вопросы. "Слой" — это совершенно неправильное слово для много из этого.
В частности, "слой" подразумевает, что под ним (и над ним) что-то есть. Т.е. берём систему без оповещений, добавляем слой и получаем систему с оповещениями. При этом нижележащий слой не знает о системе оповещений.
Не, местами так можно делать. Но обычно это не имеет никакого смысла.
Здравствуйте, Stalker., Вы писали:
S>И вообще с практической точки зрения вместо того, что-бы забивать себе голову вялотекущими холиварами 10-летней давности куда лучше направить эту энергию на что-то более полезное, в современных системах прорва мест которые надо изучать что-бы сделать хорошую систему — одна только безопасность чего стоит (токены, OAuth), а помимо нее есть микросервисы, REST, CQRS и много других интересных и реально полезных вещей
Люди регрессируют в процедурный стиль программирования, где чувствуют себя комфортно и продуктивно.
Здравствуйте, Cyberax, Вы писали:
C>>>Из собственного опыта — читаем что написано у Фаулера и делаем 100% наоборот. KP>>Этой книги Фаулера я вроде не читал, но мнение очень интересное. Не затруднит 1-2 примера привести? Очень заинтриговал C>Например, пропаганда DTO-объектов,
Здравствуйте, Cyberax, Вы писали:
C>>>Из собственного опыта — читаем что написано у Фаулера и делаем 100% наоборот. KP>>Этой книги Фаулера я вроде не читал, но мнение очень интересное. Не затруднит 1-2 примера привести? Очень заинтриговал C>Например, пропаганда DTO-объектов, богатой доменной модели и мусора типа "стратегий". Совершенно не упомянуто об асинхронной модели, для долгоиграющих операций. Мелочи типа рекомендаций отделять "веб север" от "сервера приложений" можно простить, всё-таки 2006-й год был.
C>Что нельзя простить — совершенно бездарное описание работы удалённых сервисов, оно там в худшем стиле начала 90-х. Почти ни один из его примеров не пройдёт review у меня: нет обработки сетевых ошибок и retry, нет стратегии обеспечения идемпотентности, нет анализа на поведение при ошибках downstream-сервисов и т.д.
C>Нет упоминаний о трассировке и метриках для профилирования. Нет упоминаний о мониторинге и тревожных сигналах. Нет упоминаний о стратегии обеспечения безопасности межсервисных вызовов или о механизмах передачи identity вызывающего.
C>В общем, современная сервисная архитектура — это вообще отдельная и сложная тема. Хм. А не написать ли мне книгу про это?
А какой должна быть современная архитектура? Обязательны ли микросервисы или допустим монолит? Если брать конкретно на примере Java с РСУБД, как должно работать всё от начала до конца? Вот юзер тыкнул в браузере что-то. JavaScript приложение отослало REST запрос. На бэкэнде его кто принимает, Spring MVC? Ты против DTO, т.е. мы не пишем объект, на который маппится JSON, а работаем с ним как с Map<String, ?>? Каким образом работа с базой устроена, тоже просто с Map работаем, без доменной модели? Архитектура это абстрактно, хотелось бы на более конкретных схематических примерах понять, как положено делать. Я, лично, так и не нашёл подхода, который бы меня устраивал, а свой фреймворк писать как-то странно в 2019 году.
Здравствуйте, Vladek, Вы писали:
V>Люди регрессируют в процедурный стиль программирования, где чувствуют себя комфортно и продуктивно.
Люди прогрессируют в процедурный стиль. FTFY.
Здравствуйте, Cyberax, Вы писали:
C>Оптимально — сразу отображаем в целевой объект, который мы потом можем записать в базу (через ORM).
в серьезных системах так делать ни в коем случае нельзя хотя-бы по причине mass assignment attacks — когда хакер просто дописывает в json скрытое в UI поле, а система автоматически маппит его в базу, подобный подход просто не пройдет аудит безопасности. Ну про очевидные вещи про завязанность REST интерфейса к структуре базы я уж молчу...
Здравствуйте, Stalker., Вы писали:
C>>Оптимально — сразу отображаем в целевой объект, который мы потом можем записать в базу (через ORM). S>в серьезных системах так делать ни в коем случае нельзя хотя-бы по причине mass assignment attacks — когда хакер просто дописывает в json скрытое в UI поле, а система автоматически маппит его в базу, подобный подход просто не пройдет аудит безопасности.
Ну так и пусть дописывает. Надо просто не допускать в объекте "ненужных" полей, или разделять объекты на публичную/непубличную часть. Можно так же использовать рефлексию и допускать изменение только специально аннотированных полей.
Более того, я бы вообще отделял редактируемые пользователем объекты от чувствительных для безопасности объектов. Если у объекта половина полей редактируема, а половина вызывает взрывы в безопасности — это очень плохо.
S>Ну про очевидные вещи про завязанность REST интерфейса к структуре базы я уж молчу...
А оно обычно и так привязано.
Ну и если таки требуется серьёзная развязка, то придётся использовать DTO. Никуда не деться, увы. Но я оставляю это всегда на крайний случай.
Здравствуйте, Cyberax, Вы писали:
C>Ну так и пусть дописывает. Надо просто не допускать в объекте "ненужных" полей, или разделять объекты на публичную/непубличную часть. Можно так же использовать рефлексию и допускать изменение только специально аннотированных полей. C>Более того, я бы вообще отделял редактируемые пользователем объекты от чувствительных для безопасности объектов. Если у объекта половина полей редактируема, а половина вызывает взрывы в безопасности — это очень плохо.
публичная/непубличная часть зависит от контекста, у администратора может быть право править определенное поле, а у юзера нет. Плюс DTO поля зачастую требуется чистить и приводить в нормализованный вид для последующей обработки в бизнес логике, пропускать напрямую пришедшие извне данные в любом случае нельзя, да и миллион других причин есть их использовать. Юзать рефлексию для таких вещей куда сильнее запутывает код и усложняет сопровождение
Здравствуйте, Stalker., Вы писали:
C>>Более того, я бы вообще отделял редактируемые пользователем объекты от чувствительных для безопасности объектов. Если у объекта половина полей редактируема, а половина вызывает взрывы в безопасности — это очень плохо. S>публичная/непубличная часть зависит от контекста, у администратора может быть право править определенное поле, а у юзера нет.
И вот не надо так делать, по возможности. Очень это хрупко.
S>Плюс DTO поля зачастую требуется чистить и приводить в нормализованный вид для последующей обработки в бизнес логике,
пропускать напрямую пришедшие извне данные в любом случае нельзя, да и миллион других причин есть их использовать.
Вот как раз единая валидация для бизнес-логики и REST-интерфейса — это залог умственного здоровья при сопровождении. Если у объекта есть какой-то инвариант, то что мешает его проверять одинаково везде?
Насчёт только частей объектов — нынче цветёт и пахнет GraphQL, который этим занимается. Мне он не особо нравится по идеологическим причинам, но вопросы передачи только кусков объектов он решает.
Здравствуйте, Stalker., Вы писали:
S>Здравствуйте, Cyberax, Вы писали:
C>>Оптимально — сразу отображаем в целевой объект, который мы потом можем записать в базу (через ORM).
S>в серьезных системах так делать ни в коем случае нельзя хотя-бы по причине mass assignment attacks — когда хакер просто дописывает в json скрытое в UI поле, а система автоматически маппит его в базу, подобный подход просто не пройдет аудит безопасности.
А что мешает ручками прописать что и когда можно мапить, что нет? Зачем для этого DTO создавать?
S>Ну про очевидные вещи про завязанность REST интерфейса к структуре базы я уж молчу...
Все ORM давно умеют внутри делать свой мапинг.
Здравствуйте, Cyberax, Вы писали:
C>И вот не надо так делать, по возможности. Очень это хрупко.
везде так делается, блокировка пользователя/карт/счетов, пароли и масса всего другого. Нет в этом ничего хрупкого, все как раз наоборот, по другому собственно и не получится, уровни доступа и сами данные это разные вещи
C>Вот как раз единая валидация для бизнес-логики и REST-интерфейса — это залог умственного здоровья при сопровождении. Если у объекта есть какой-то инвариант, то что мешает его проверять одинаково везде?
то, что фильтрация мусора и нормализация ввода не имеет отношения к бизнес логике, номер телефона +7 (343) 456 987, так-же как и 7343 45 69 87 допустимы на входе в сервис, но в бизнес-логику и базу пойдет 7343456787 с ограничением на длину и допустимые символы. То-же самое с авторизацией, ну не может пользователь сам себя разблокировать или сбросить пароль, к формату хранения авторизация не может иметь отношения
Здравствуйте, Stalker., Вы писали:
S>Здравствуйте, gandjustas, Вы писали:
G>>А что мешает ручками прописать что и когда можно мапить, что нет? Зачем для этого DTO создавать?
S>затем, что проще и удобнее создать DTO, чем "прописать ручками", прилепить "специальные" аннотации и рефлексию что-бы получилось "прямо как с DTO"
Это наверное зависит от инструмента. В ASP.NET можно одним атрибутом сказать что можно мапить, а что нельзя. Это гораздо проще, чем создавать DTO, которое потом еще и валидировать надо отдельно.
В целом настройка мапинга форм на объекты должна быть отдельным концептом, а не выражаться через дополнительные сущности — dto.
Здравствуйте, Stalker., Вы писали:
C>>И вот не надо так делать, по возможности. Очень это хрупко. S>везде так делается, блокировка пользователя/карт/счетов, пароли и масса всего другого. Нет в этом ничего хрупкого, все как раз наоборот, по другому собственно и не получится, уровни доступа и сами данные это разные вещи
Ну вот пусть эти блокировки будут в отдельной таблице, хотя бы. Которая просто недоступна через обычный REST, аналогично с паролями. Ну а номера карт вообще должны быть в отдельной БД по правилам PCIDSS.
Если их располагать всё в одном объекте, то при одной ошибке будем иметь очередной пресс-релиз: "Компания Рога&Копыта утекла данные 100500 пользователей из-за хакерской атаки".
Ну и цепочка размышлений такая:
1. Если делать интерфейс типа "setUserData(UserDTO userData)", то надо проверять, что только администратор может редактировать определённые поля.
2. Но это очень плохо, так как слишком хрупко и неудобно.
3. Почему бы тогда не выделить отдельный метод "setSensitiveUserData(SensitiveUserDTO userData)", который будет доступен только администраторам?
4. Хм. А почему бы тогда и не выделить SensitiveUserData в отдельный объект?
C>>Вот как раз единая валидация для бизнес-логики и REST-интерфейса — это залог умственного здоровья при сопровождении. Если у объекта есть какой-то инвариант, то что мешает его проверять одинаково везде? S>то, что фильтрация мусора и нормализация ввода не имеет отношения к бизнес логике, номер телефона +7 (343) 456 987, так-же как и 7343 45 69 87 допустимы на входе в сервис
Зачем? Пусть REST-сервис сразу проверяет на нужный формат (7343456787). Frontend'у никто не мешает телефон отформатировать заранее — он и так это обязан будет делать хотя бы для отображения, так как перевод "7343456787" в "+7 (343) 456 987" кто-то должен делать.
Если нормализацию делать ещё и в REST-слое, то будем иметь мёртвый код, который не будет использоваться и будет бомбой замедленного действия.
S>но в бизнес-логику и базу пойдет 7343456787 с ограничением на длину и допустимые символы. То-же самое с авторизацией, ну не может пользователь сам себя разблокировать или сбросить пароль, к формату хранения авторизация не может иметь отношения
Аутентификация — это как раз один из примеров, где REST-интерфейс один фиг не подходит.
Здравствуйте, gandjustas, Вы писали:
G>Это наверное зависит от инструмента. В ASP.NET можно одним атрибутом сказать что можно мапить, а что нельзя. Это гораздо проще, чем создавать DTO, которое потом еще и валидировать надо отдельно.
маппить поле блокировки можно (и нужно), но только для админа
Здравствуйте, Cyberax, Вы писали:
C>Ну вот пусть эти блокировки будут в отдельной таблице, хотя бы. Которая просто недоступна через обычный REST, аналогично с паролями. Ну а номера карт вообще должны быть в отдельной БД по правилам PCIDSS.
Я не знаю последних веяний, но раньше требовалось только шифрование. Самое главное, что оно абсолютно бесполезно по факту. Мне на сайте это тоже в шифрованном виде вводить? Какая тайна из номера карты? Это был и есть полным дибилизмом, и мне даже удивительно от тебя слышать аппеляции к PCIDSS, ведь ты человек достаточно опытен и критически мыслящий. Хотя я на это смотрю по старой памяти через призму попытки применения к не-визе этого гадкого набора рекомендаций.
Вы начали с DTO, а закончили конечными контрактами конечных сервисов/API. Имхо, именно поэтому DTO и не нужен, т.к. каждый слой, который имеет внешний/публичнвый контракт — это не DTO, а осмысленные структуры (должны быть).
PS:
Меня лично парят префиксы и суффиксы в именах, и меня парит то, что когда они есть — они пролазят везде. Более смышленные девелоперы не уподобляются хомякам, и не делают этих суффиксов/префиксов — но все равно их лепят, и пролазит это везде во всех реинкарнациях.
Если речь о слоеной вверх/низходящей архитектуре то там по определению тока контракты. Какие DTO? Что этими DTO делать? Гвозди забивать?
Если приложение простое, то можно ограничится одним наборов объектов, моделирующих ПО, но, банально расшарить транзацкию у которой есть юзерский комментарий — это уже вызовет кучу проблем.
Как вы не называйте объекты — они появляются исходя из выполняемых операций в системе. Платежная транзакция кстати очень хороший пример — ее ID в процессинге всегда не равен в клиент-банке, и выполняемые действия разные.
А ее уникальность на стороне процессинга... ну. Не такая.
Самое главное, что все отлично ложится на любые задачи, если не пытаться изобретать то, что не нужно. Нужно именно DTO — юзайте. Не нужно? Не юзайте.
Здравствуйте, Stalker., Вы писали:
G>>Это наверное зависит от инструмента. В ASP.NET можно одним атрибутом сказать что можно мапить, а что нельзя. Это гораздо проще, чем создавать DTO, которое потом еще и валидировать надо отдельно. S>маппить поле блокировки можно (и нужно), но только для админа
Маппить ничего не надо. Код сервиса или имеет право выполняться или нет. Аутентификация с помощью xxx это не все. Ещё нужно делать *авторизацию*, которая глагол. И это работа никак ни для REST-фасада.
Здравствуйте, Mystic Artifact, Вы писали:
C>>Ну вот пусть эти блокировки будут в отдельной таблице, хотя бы. Которая просто недоступна через обычный REST, аналогично с паролями. Ну а номера карт вообще должны быть в отдельной БД по правилам PCIDSS. MA> Я не знаю последних веяний, но раньше требовалось только шифрование. Самое главное, что оно абсолютно бесполезно по факту. Мне на сайте это тоже в шифрованном виде вводить?
На сайте можно показывать только последние 4 цифры и первые 2. Целиком номер выводить нельзя. Вообще нигде ("rendered unobservable"). Т.е. ни в логах, ни в отладчике, ни в дампах БД.
MA> Какая тайна из номера карты?
Возможность украсть с неё деньги. А так да, ничего.
Здравствуйте, Cyberax, Вы писали:
S>>номера карточек должны быть зашифрованы, а не вынесены в отдельную базу C>В теории это возможно, но на практике крайне сложно, так как PCIDSS требует "need to know" уровень доступа и запрещает совмещать данные серверы уровней защиты.
не понятно что именно сложно, шифрование? Шифрование в любом случае требуется, а отдельная база никак на безопасность не повлияет (юзеры находятся в отдельной базе по другим соображениям т.к. ихний аутентификационный сервис это просто отдельный сервер)
Здравствуйте, Cyberax, Вы писали:
C>Даже зашифрованные карты нельзя просто так складировать.
C>Но проблема в другом. Даже при шифровании ключ для расшифровки будет в сервере приложений или веб-сервере. Иначе сервер не сможет использовать эти данные, однако. Это само по себе уже может быть нарушением запрета на множественные роли. Но ещё и у любого инженера, имеющего доступ к серверу, будет возможность данные расшифровать.
C>PCIDSS требует ограничивать такой доступ до "need to know". Так что реально получается необходимость внешней базы/сервиса.
первый раз слышу что шифрованные карты нельзя складировать, а что с ними еще сделать-то нужно?
Шифрование в базе данных сейчас легко автоматизируется, на sql server просто включается always encrypted для требуемых полей и дб сервер сам рулит шифрованием, для клиентских систем это все прозрачно (за исключением невозможности юзать конструкции типа like). Ключ шифрования складывается в key vault, доступ только у приложений, никакие инженеры или дб админы ничего не расшифруют т.к. доступа к ключу нет
Но даже в твоем примере просто вынос куда-то (причем все равно непонятно чего — самих шифрованных номеров что-ли?) в другую базу никаких дополнительных бенефиров не даст — на другом сервере будут точно такие-же проблемы
Здравствуйте, Stalker., Вы писали:
S>Здравствуйте, gandjustas, Вы писали:
G>>Это наверное зависит от инструмента. В ASP.NET можно одним атрибутом сказать что можно мапить, а что нельзя. Это гораздо проще, чем создавать DTO, которое потом еще и валидировать надо отдельно. S>маппить поле блокировки можно (и нужно), но только для админа
Это проблема?
В конце концов можно вручную вызвать мапинг формы на модель, для этого в asp.net mvc есть TryUpdateModel(Async)
В любом случае создание DTO только для мапинга выглядит сегодня как плохая шуктка.
Здравствуйте, Stalker., Вы писали:
S>не понятно что именно сложно, шифрование? Шифрование в любом случае требуется, а отдельная база никак на безопасность не повлияет (юзеры находятся в отдельной базе по другим соображениям т.к. ихний аутентификационный сервис это просто отдельный сервер)
А вот вопрос про отдельную бд -- в микросервисной парадигме у нас изоляция по хранилищу -- 1 сервис, 1 база. И вот мне в некоем сервисе надо сохранить какие-то данные для пользователя,
я просто сохраню id пользователя полученный из другой базы? Т.е. один сервис\база отвечает за сущ. А, второй за сущ. B, соотв. инф-ия в сервисе B о сущ. А будет храниться
как некий, не факт что валидный, идентификатор? Т.е. fk constraints у нас при микросервисах идут лесом?
Здравствуйте, Ikemefula, Вы писали:
I>Когда и чем плохи DTO ?
If you regularly copy to/from DTO<=>DbEntity and the set of fields is pretty much the same in both models, then you're doing something wrong.
Здравствуйте, gandjustas, Вы писали:
G>Это проблема? G>В конце концов можно вручную вызвать мапинг формы на модель, для этого в asp.net mvc есть TryUpdateModel(Async) G>В любом случае создание DTO только для мапинга выглядит сегодня как плохая шуктка.
не проблема, но DTO это-ж не только маппинг
Здравствуйте, Sharov, Вы писали:
S>А вот вопрос про отдельную бд -- в микросервисной парадигме у нас изоляция по хранилищу -- 1 сервис, 1 база. И вот мне в некоем сервисе надо сохранить какие-то данные для пользователя, S>я просто сохраню id пользователя полученный из другой базы? Т.е. один сервис\база отвечает за сущ. А, второй за сущ. B, соотв. инф-ия в сервисе B о сущ. А будет храниться S>как некий, не факт что валидный, идентификатор? Т.е. fk constraints у нас при микросервисах идут лесом?
в микросервисах будет eventual consistency т.е. да, fk constraints, а заодно и классические транзакции действительно идут лесом. У майкрософа есть очень хорошая бесплатная книжка про имплементацию микросервисов под Azure, там все концепции и подходы описаны очень хорошо
Но в данном примере пользователи будут в другой дб и без всяких микросервисов, особенно в облаках, типа Azue, где хранилища пользователей уже есть (b2c) и писать свой велосипед нет смысла, а главное не надежно
Здравствуйте, Stalker., Вы писали:
S>Здравствуйте, gandjustas, Вы писали:
G>>Это проблема? G>>В конце концов можно вручную вызвать мапинг формы на модель, для этого в asp.net mvc есть TryUpdateModel(Async) G>>В любом случае создание DTO только для мапинга выглядит сегодня как плохая шуктка. S>не проблема, но DTO это-ж не только маппинг
А что еще?
Здравствуйте, gandjustas, Вы писали:
G>А что еще?
то, про что тут уже писали — чистка/валидация данных, отвязка от структуры бизнес обьектов, аггрегированные данные отправляемые на клиента и прочее.
Здравствуйте, alexanderfedin, Вы писали:
I>>Когда и чем плохи DTO ? A>If you regularly copy to/from DTO<=>DbEntity and the set of fields is pretty much the same in both models, then you're doing something wrong.
Подробнее — когда и чем wrong, какие проблемы и тд ?
Здравствуйте, Stalker., Вы писали:
S>Здравствуйте, gandjustas, Вы писали:
G>>А что еще? S>то, про что тут уже писали — S>- чистка/валидация данных
Простите, я по привычке валидацию входных данных и мапинг считаю одним действием. В любом случае для валидации DTO не сильно нужны.
Если мы говорим об инвариантах, то тут надо запросы в базу делать, не DTO.
S> — отвязка от структуры бизнес объектов
А зачем эта отвязка нужна? Наоборот удобнее когда приложение по-максимуму оперирует бизнес-объектами, вся идея DDD на этом построена.
S> — аггрегированные данные отправляемые на клиента и прочее.
Тут согласен, отдельные классы для viewmodel это хорошо и, зачастую полезно. Но они формируются только в слое представления и не участвуют в БЛ вообще.
REST API я бы еще и OData делал, чтобы клиент сам определял что ему надо тянуть.
Здравствуйте, Sharov, Вы писали:
S>Здравствуйте, Stalker., Вы писали:
S>>не понятно что именно сложно, шифрование? Шифрование в любом случае требуется, а отдельная база никак на безопасность не повлияет (юзеры находятся в отдельной базе по другим соображениям т.к. ихний аутентификационный сервис это просто отдельный сервер)
S>А вот вопрос про отдельную бд -- в микросервисной парадигме у нас изоляция по хранилищу -- 1 сервис, 1 база. И вот мне в некоем сервисе надо сохранить какие-то данные для пользователя, S>я просто сохраню id пользователя полученный из другой базы? Т.е. один сервис\база отвечает за сущ. А, второй за сущ. B, соотв. инф-ия в сервисе B о сущ. А будет храниться S>как некий, не факт что валидный, идентификатор? Т.е. fk constraints у нас при микросервисах идут лесом?
Какие ид-шники? сыдка на чужой datasource это плевок в священные идеалы микросервисной архитектуры
микросервисы должны быть полностью независимы — у каждого своя модель и свой датасорс. В терминах DDD — BoundedContext.
В итоге в интернет маеазине UserProfile microservice user и Order microservice user теперь живут отдельно и бользще транзакционно не апдейтятся. Теперь при попытке забанить юзера надо в одном сервисе банить а в другой бросать integration message который может обработается а может нет.
А еще там join-ы очень прикольно делать между сущностями в разных сервисах. Для reporting-a например
Одним словом — микросервисная архитектура — это психическое расстройство
Опыт — это такая вещь, которая появляется сразу после того, как была нужна...
Здравствуйте, BlackEric, Вы писали:
BE>Книга Фаулера, как по мне, уже местами устарела. Там нет ничего про мобильные клиенты и выбора xml vs json как минимум. Есть ли что-нибудь по-новее?
Жирновато на счет xml vs json, ну все достаточно очевидно. Xml более громоздкий с бОльшим набором фичей в стандарте и более многословны. JSON же более легковесный и с меньшим количеством фичей, выбор использования сугубо по месту.