Здравствуйте, kaa.python, Вы писали:
C>>В общем, современная сервисная архитектура — это вообще отдельная и сложная тема. Хм. А не написать ли мне книгу про это? KP>Очень интересно, и если ты напишешь такую книгу, я буду одним из первых покупателей. Желательно с автографом автора
Ок
KP>Кстати, а ничего подобного уже нет? Ты очень интересные темы затронул и мне подумалось, может уже что-то, пусть и не на 100% покрывающее эти вопросы, но уже есть?
Сейчас смотрю несколько книг, но именно всего вместе не вижу.
Здравствуйте, BlackEric, Вы писали:
BE>Книга Фаулера, как по мне, уже местами устарела. Там нет ничего про мобильные клиенты и выбора xml vs json как минимум. Есть ли что-нибудь по-новее?
Из этой книги:
Термин "архитектура" пытаются трактовать все, кому не лень, и всяк на свой лад. Впрочем, можно назвать два общих варианта. Первый связан с разделением системы на наиболее крупные составные части; во втором случае имеются в виду некие конструктивные решения, которые после их принятия с трудом поддаются изменению.
Лично я считаю, что эта книга не только не устарела, просто в ней используется гораздо более высокий уровень абстракции. Например, некий программист выбирает между форматами хранения xml и json. Но зачем это делать архитектору вроде Фаулера, он предлагает шаблоны проектирования, которые позволят использовать и то, и другое, а так же расширять функционал без изменения основы, той самой части программы цена изменения которой слишком велика.
Корпоративные приложения обычно подразумевают необходимость долговременного (иногда в течение десятилетий) хранения данных. Данные зачастую способны "пережить" несколько поколений прикладных программ, предназначенных для их обработки, аппаратных средств, операционных систем и компиляторов. В продолжение этого срока структура данных может подвергаться многочисленным изменениям в целях сохранения новых порций информации без какого-либо воздействия на старые. Даже в тех случаях, когда компания осуществляет революционные изменения в парке оборудования и номенклатуре программных приложений, данные не уничтожаются, а переносятся в новую среду.
Здесь стоит понять, что формат данных это всего лишь средство. Можно одни и те же структуры данных сохранить множеством способов с помощью одного и того же формата, то есть при извлечении получать один и тот же результат. Данные можно не только хранить, но и передавать, и данные которые хранятся скорее всего будут выглядеть не так как те, которые передаются, даже если использовать один и тот же формат. Данные можно обрабатывать и для этого существует множество способов, включая управление изменениями и тому подобное.
А в целом чтобы использовать то, что написано в книге, нужно обладать очень высокой квалификацией архитектора программного обеспечения, в противном случае получится говнокод с обратными заявленным свойствами. Были времена, когда я вообще не понимал, что там написано, но со годами понял насколько там всё гениально. То что написано в этой книге можно использовать для создания приложений планетарного масштаба, я это пишу без всякой иронии или шуток.
Но тут нужно понимать, кто такой Мартин Фаулер, и кто такой Вася Пупкин. От Васи Пупкина никто особо ничего и не ждёт. От него даже не требуется читать эту книгу. Я, к примеру, читал, там есть и про расслоение системы, и про web. Но если абстрактный Вася Пупкин смотрит в книгу и этого не видит, я даже ему ничего говорить не буду. Обычный разработчик не обязан быть высокоуровневым архитектором чтобы успешно создавать программы. У Фаулера речь не просто про архитектуру, а про архитектуру корпоративных программных приложений.
Здравствуйте, Cyberax, Вы писали:
C>Ещё как можно. И даже нужно — фаулерные системы превращаются в АДЪ очень быстро.
ты похоже адепт анемичной модели, верно? Есть общепринятые подходы к разработке, и DDD с DTO в ней занимают одно из центральных мест, почитай про разработку микросервисной архитектуры от Майкрософт, у них сейчас множество хороших публикаций на эту тему, я лично именно что книжки довольно давно уже не читал т.к. базовые подходы и паттерны от того-же Фаулера прочитаны давно, а технологии и конкретные практические приемы надо брать из подобной документации т.к. книжки по ним мгновенно устаревают
Здравствуйте, Stalker., Вы писали:
C>>Ещё как можно. И даже нужно — фаулерные системы превращаются в АДЪ очень быстро. S>ты похоже адепт анемичной модели, верно?
Именно.
S>Есть общепринятые подходы к разработке, и DDD с DTO в ней занимают одно из центральных мест, почитай про разработку микросервисной архитектуры от Майкрософт
Я прекрасно знаю что пихал MS. Вся эта "орхитектура" от Microsoft провалилась целиком и полностью, в итоге. Со всеми их веб-сервисами, оркестраторами, шинами и прочими WSDL.
К счастью, в индустрии стал общепринят стандарт SOLID, как намного более надёжный.
Здравствуйте, BlackEric, Вы писали:
BE>Книга Фаулера, как по мне, уже местами устарела. Там нет ничего про мобильные клиенты и выбора xml vs json как минимум. Есть ли что-нибудь по-новее?
Eventually, it can be a project on its own, in its own CVS repository, and used in several projects.
...
To do this, in the PHP world we have a little tool called Deptrac (but I bet similar tools exist for other languages as well), created by Sensiolabs. We configure it using a yaml file, where we define the layers we have and the allowed dependencies between them. Then we run it through the command line, which means we can easily run it in a CI, just like we run a test suite in the CI.
с этого и надо было начинать, анемисты известны своими экстремальными взглядами и демонстративным неприятием устоявшихся и проверенных временем подходов к разработке.
C>Я прекрасно знаю что пихал MS. Вся эта "орхитектура" от Microsoft провалилась целиком и полностью, в итоге. Со всеми их веб-сервисами, оркестраторами, шинами и прочими WSDL. C>К счастью, в индустрии стал общепринят стандарт SOLID, как намного более надёжный.
все в кучу свалил, веб-сервисы это не архитектура, а технология, а про SOLID в майкрософтовской документации упоминается чуть-ли не на каждой странице. На практике, особенно когда работаешь в определенном стеке технологий, то надо не в религию ударяться, а следовать рекомендованным практикам. Эксперименты типа анемики конечно полезны, но в серьезных коммерческих проектах их нельзя применять из-за необкатанности и непопулярности в среде разработчиков. Я не хочу превращать топик в очередной холивар, просто отмечу что эти форумные холивары были еще 10 лет назад, и анемика дальше форумных войн никуда за это время не ушла
Здравствуйте, Буравчик, Вы писали:
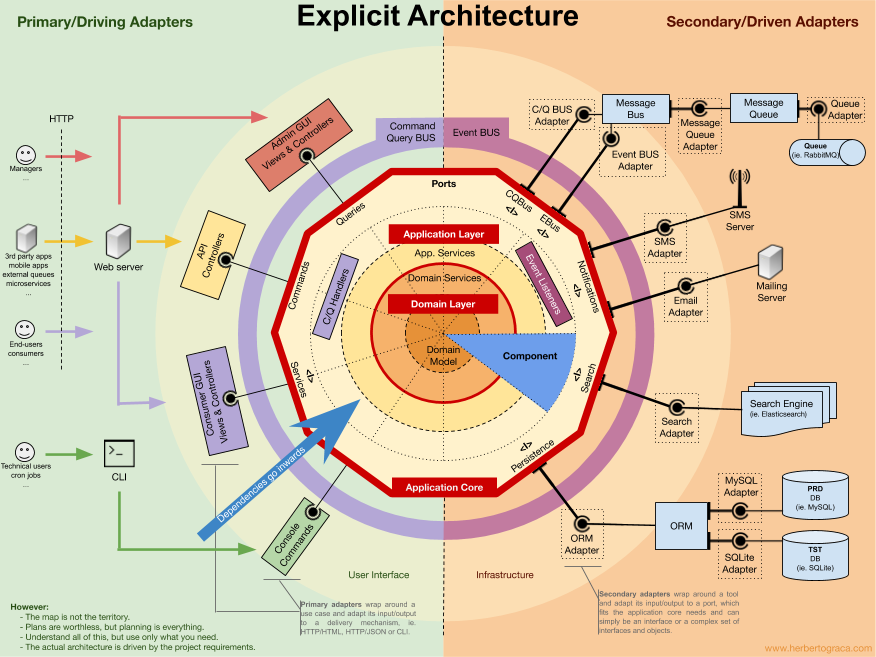
C>>CVS и PHP в 2019-м году? Что-то тут не то. Б>Это не отменяет общих принципов луковой/гексагональной архитектуры.
Какие же у неё принципы? "Наворотить, чтобы никто не догадался"?
Здравствуйте, Stalker., Вы писали:
C>>Именно. S>с этого и надо было начинать, анемисты известны своими экстремальными взглядами и демонстративным неприятием устоявшихся и проверенных временем подходов к разработке.
Я работал с кодовыми базами в сотни миллионов строк. С модулями/сервисами, написанными в разных стилях. В том числе и классическом фаулеровском, с rich domain objects. И вот как раз эти модули были самым АДЪ-ом, так как логика часто была размазана по всей массе кода.
Именно доменная модель провоцирует такие жутики, как скрытые удалённые вызовы в getter'ах (со скрытым контекстом вызова).
C>>К счастью, в индустрии стал общепринят стандарт SOLID, как намного более надёжный. S>все в кучу свалил, веб-сервисы это не архитектура, а технология, а про SOLID в майкрософтовской документации упоминается чуть-ли не на каждой странице.
SOLID категорически не дружит с богатой доменной моделью. Она повсеместно нарушает буквы S и D.
S>На практике, особенно когда работаешь в определенном стеке технологий, то надо не в религию ударяться, а следовать рекомендованным практикам. Эксперименты типа анемики конечно полезны, но в серьезных коммерческих проектах их нельзя применять из-за необкатанности и непопулярности в среде разработчиков.
Бред. Если стек заставляет писать в уродливом стиле — его надо менять, и не оглядываться (а legacy-код — рефакторить). Например, так был выбращен на свалку истории EJB, который как раз часто упоминается у Фаулера.
S>Я не хочу превращать топик в очередной холивар, просто отмечу что эти форумные холивары были еще 10 лет назад, и анемика дальше форумных войн никуда за это время не ушла
Большинство новых крупномасштабных систем пишутся именно в анемичной модели.
Более того, новейшие языки типа Rust или Go, фактически, вообще выбросили большую часть ООП на помойку, вместе с подпорками в виде thread-local хранилища (в Go). Так что там писать богатую доменную модель стало существенно труднее.
Здравствуйте, Cyberax, Вы писали:
C>В том числе и классическом фаулеровском, с rich domain objects. И вот как раз эти модули были самым АДЪ-ом, так как логика часто была размазана по всей массе кода.
как я уже писал учавствовать в холиварах на эту тему мне неинтересно, так что не будем развивать, да и странно читать на форуме, где сидят разработчики с многолетним опытом что у них в коде ад и ничего не работает. Наверно про свой код я знаю лучше
C>Бред. Если стек заставляет писать в уродливом стиле — его надо менять, и не оглядываться (а legacy-код — рефакторить).
Really? Взять выбросить C#, Аzure, ASP.NET и срочно все переписать на Rust?
C>Большинство новых крупномасштабных систем пишутся именно в анемичной модели.
Ну не надо ерунду писать, поспрашивай на собеседованиях у кандидатов что такое ООП и что такое анемичная модель. Нельзя в больших коммерческих проектах применять малознакомые подходы просто потому-что так кому-то хочется, лень даже расписывать почему, очевидно-же
И вообще с практической точки зрения вместо того, что-бы забивать себе голову вялотекущими холиварами 10-летней давности куда лучше направить эту энергию на что-то более полезное, в современных системах прорва мест которые надо изучать что-бы сделать хорошую систему — одна только безопасность чего стоит (токены, OAuth), а помимо нее есть микросервисы, REST, CQRS и много других интересных и реально полезных вещей
Здравствуйте, Cyberax, Вы писали:
C>Ок
Можно запустить краудфандинговую компанию для сбора средств и оценки рынка сбыта. Я бы тоже закинул 1-2 тыщи в обмен на книгу в будущем.
Здравствуйте, Буравчик, Вы писали:
C>>"Наворотить, чтобы никто не догадался"? Б>Если упомянутый тобой SOLID использовать, то получится как раз то, что на картинке. Б>Домен отдельно, сервисы отдельно, инфраструктура отдельно. Б>Не пойму, где там наворочено, что не устраивает?
Слишком много слоёв. Типа ORM и адаптера для ORM.
Здравствуйте, Stalker., Вы писали:
C>>В том числе и классическом фаулеровском, с rich domain objects. И вот как раз эти модули были самым АДЪ-ом, так как логика часто была размазана по всей массе кода. S>как я уже писал учавствовать в холиварах на эту тему мне неинтересно, так что не будем развивать, да и странно читать на форуме, где сидят разработчики с многолетним опытом что у них в коде ад и ничего не работает. Наверно про свой код я знаю лучше
Я в детстве тоже думал, что мой код — совсем хороший.
C>>Бред. Если стек заставляет писать в уродливом стиле — его надо менять, и не оглядываться (а legacy-код — рефакторить). S>Really? Взять выбросить C#, Аzure, ASP.NET и срочно все переписать на Rust?
Нет. В анемичной модели вполне можно писать на C#/Java.
C>>Большинство новых крупномасштабных систем пишутся именно в анемичной модели. S>Ну не надо ерунду писать, поспрашивай на собеседованиях у кандидатов что такое ООП и что такое анемичная модель. Нельзя в больших коммерческих проектах применять малознакомые подходы просто потому-что так кому-то хочется, лень даже расписывать почему, очевидно-же
Малознакомые?!? С разморозкой, однако....
Здравствуйте, Cyberax, Вы писали:
C>Слишком много слоёв. Типа ORM и адаптера для ORM.
Все верно. Поверх ORM (библиотеки) имеется дополнительный Persistance слой.
Он:
— отвязывает приложение от схемы БД (схема БД меняется часто)
— устраняет дублирование запросов, созданных с помощью ORM
— позволяет добавить SQL запросы в обход ORM
— позволяет добавить кеширование и делать другие оптимизации
Т.е. слой нужен не для того, чтобы заменять ORM, а для того,
чтобы используя инфраструктуру (ORM) предоставить полезные функции (persistance).
Здравствуйте, Буравчик, Вы писали:
C>>Слишком много слоёв. Типа ORM и адаптера для ORM. Б>Все верно. Поверх ORM (библиотеки) имеется дополнительный Persistance слой.
Масло масляное какое-то. ORM и так является persistance-слоем.
Б>- отвязывает приложение от схемы БД (схема БД меняется часто)
Этим должна заниматься ORM и само приложение.
Б>- устраняет дублирование запросов, созданных с помощью ORM
??? Б>- позволяет добавить SQL запросы в обход ORM
???
Б>- позволяет добавить кеширование и делать другие оптимизации
Кэширование редко является полезным на уровне persistance.
В документе речь идёт об адаптерах — это таки технический термин. Означающий, что интерфейс ORM будет адаптироваться к внутреннему интерфейсу системы. От этого и возникает вопрос: нафига?
Здравствуйте, Cyberax, Вы писали:
C>Масло масляное какое-то. ORM и так является persistance-слоем.
Не. ORM является библиотекой для построения persistance-слоя.
Б>>- отвязывает приложение от схемы БД (схема БД меняется часто) C>Этим должна заниматься ORM и само приложение.
Приложение и занимается. Этот код лежит в persistance слое.
Чтобы не пришлось при небольших изменениях схемы выискивать по всему приложению запросы, которые нужно поменять.
Б>>- устраняет дублирование запросов, созданных с помощью ORM C>???
Я про повторение частей запросов, построенных с помощью ORM.
Т.е. нескольким запросам требуются одни и те же подзапросы.
Б>>- позволяет добавить SQL запросы в обход ORM C>???
Это когда надо написать запрос на голом SQL. Где такой код хранить, как не в внутри persistance?
Б>>- позволяет добавить кеширование и делать другие оптимизации C>Кэширование редко является полезным на уровне persistance.
Разные ситуации могут быть
C>В документе речь идёт об адаптерах — это таки технический термин. Означающий, что интерфейс ORM будет адаптироваться к внутреннему интерфейсу системы. От этого и возникает вопрос: нафига?
Этот адаптер — часть приложения, которая отвечает за persistance (т.е. persistance-слой). Реализует интерфейс persistance, а ORM — деталь реализации.
В некотором роде ORM адаптируется под интерфейс persistance, под требования приложения. Хотя, аддаптер может и не совсем подходящий термин.
С другой стороны, и persistance тоже не совсем слой (в "старом" понимании). Есть же и другие "слои" в инфраструктуре — слой поиска, слой нотификации, слой интеграции с какой-нибудь внешней системой и т.п.
Здравствуйте, Буравчик, Вы писали:
Б>>>- устраняет дублирование запросов, созданных с помощью ORM C>>??? Б>Я про повторение частей запросов, построенных с помощью ORM. Б>Т.е. нескольким запросам требуются одни и те же подзапросы.
"const CommonExpr = ...."
Б>>>- позволяет добавить SQL запросы в обход ORM C>>??? Б>Это когда надо написать запрос на голом SQL. Где такой код хранить, как не в внутри persistance?
Там, где оно нужно.
C>>В документе речь идёт об адаптерах — это таки технический термин. Означающий, что интерфейс ORM будет адаптироваться к внутреннему интерфейсу системы. От этого и возникает вопрос: нафига? Б>Этот адаптер — часть приложения, которая отвечает за persistance (т.е. persistance-слой). Реализует интерфейс persistance, а ORM — деталь реализации.
Ну как бы надо термины не изгибать до неузнаваемости, а так и писать: "слой доступа к данным, в котором сосредоточено управление данными". Даже термин есть: DAL (Data Access Layer).
Б>С другой стороны, и persistance тоже не совсем слой (в "старом" понимании). Есть же и другие "слои" в инфраструктуре — слой поиска, слой нотификации, слой интеграции с какой-нибудь внешней системой и т.п.
Тут тоже есть вопросы. "Слой" — это совершенно неправильное слово для много из этого.
В частности, "слой" подразумевает, что под ним (и над ним) что-то есть. Т.е. берём систему без оповещений, добавляем слой и получаем систему с оповещениями. При этом нижележащий слой не знает о системе оповещений.
Не, местами так можно делать. Но обычно это не имеет никакого смысла.