Хочется прояснить несколько вопросов по указанной связке и по архитектурным вопросам в целом.
1) Во-первых DDD + REST, каким образом они вообще обьединяются? Что-то ничего нормального не нагугливается, приводятся тривиальные примеры get/post/put/delete где user/id=5 и никаких примеров из реальной жизни. Как сделать в REST что-то из рязряда GetAllUsersWhoWasBornOnMonday(), ActivateUser(int id), SelectCardsWithZeroBalance(), LoadUserDetailsPage(), AssignUserToGroup(int userID, int groupID)
2) Как производится тестирование слоя DDD и сервисов. Скажем есть у нас домейн класс Person
Person
{
public string Name {get;set}
public string Surname {get;set}
public Date DOB {get;set};
public CalculateAge()
}
и есть сервис который дергается из REST
UserWorkflow
{
public bool SendUserPromotion(int userID)
{
if (userID < 0)
throw new InvalidUserID();
User user = UserRepository.GetUser(userID);
if (user == null)
throw new InvalidUser();
if (user.CalculateAge() > 18)
{
EmailService.SendPromotionEmail(userID);
LogService.LogCommunition(userID, "Promotion was send");
UserRepository.UpdateUserLastPromotionDate(userID);
return true;
}
else
{
LogService.LogError(userID, "Promotion was not send, user is too young");
return false;
}
}
Понятно, что тут для юнит-тестирования следует замокить email service и repository, однако есть пара вопросов:
— Как проверить что EmailService, LogService и UserRepository были вызваны с нужными параметрами (юзер старше 18 лет) или не вызваны?
— Что делать собственно с домейн классом Person, если я его напрямую использую в тесте сервиса, то это вроде уже не юнит тест будет, а интеграционный, а мокить Person через интерфейс будет откровенный ужас и оверкилл
— Стоит-ли тестировать Person.CalculateAge() метод в этом случае
— Обьединяя с вопросом номер 1 — как будет SendUserPromotion() операция выглядить через интерфейс REST?
3) Вопрос по Репозиторию. Очевидно его интерфейс быстро обрастает методами UpdateUserLastPromotionDate(), GetAllUsersWhoWasBornOnMonday() и AssignUserToGroup(). Какие существуют методы по структуризации всего этого, что-бы его класс не превращался в свалку из десятков таких разношерстных методов?
Скажу сразу я знаю о существовании идеи не использовать репозиторий вообще, а прямо в методе сервиса писать соответствующие EF запросы, однако такие идеи хороши в теории, а на практике приводят к лапше из кода бизнес-логики, запросов к данным и конвертации модели данных к бизнес-моделям, а самое главное для написания юнит-тестов всего этого проходится мокить сам EF контекст, что отнимает жуткое количество времени, и позволяет тестить только простейшие запросы
Здравствуйте, Stalker., Вы писали:
S>Хочется прояснить несколько вопросов по указанной связке и по архит S>- Как проверить что EmailService, LogService и UserRepository были вызваны с нужными параметрами (юзер старше 18 лет) или не вызваны?
Нормальные либы для мокинга дают возможность провалидировать аргументы замоканных сервисов из коробки. S>- Что делать собственно с домейн классом Person, если я его напрямую использую в тесте сервиса, то это вроде уже не юнит тест будет, а интеграционный, а мокить Person через интерфейс будет откровенный ужас и оверкилл
До тех пор, пока это будет анемичный доменный класс, мокать будет по сути нечего(изменение полей можно отследить по вызовам в других методах) S>- Стоит-ли тестировать Person.CalculateAge() метод в этом случае
Стоит вынести всю бизнес логику в сервисы и тестировать ее. Впрочем хочу отметить, что Person.CalculateAge(), при наличии Person.BirthDate — это логика представления и ее выносить не надо. Отдельный юнит тест(ы) для этого можно написать безо всяких моков.
S>- Обьединяя с вопросом номер 1 — как будет SendUserPromotion() операция выглядить через интерфейс REST?
например /workflow/user/id/promotion
S>3) Вопрос по Репозиторию. Очевидно его интерфейс быстро обрастает методами UpdateUserLastPromotionDate(), GetAllUsersWhoWasBornOnMonday() и AssignUserToGroup(). Какие существуют методы по структуризации всего этого, что-бы его класс не превращался в свалку из десятков таких разношерстных методов?
В нормальных языках программирования есть linq.
Хотя его юнит тестировать — не самая приятная штука.
Здравствуйте, Stalker., Вы писали:
S>Хочется прояснить несколько вопросов по указанной связке и по архитектурным вопросам в целом.
S>1) Во-первых DDD + REST, каким образом они вообще обьединяются? Что-то ничего нормального не нагугливается, приводятся тривиальные примеры get/post/put/delete где user/id=5 и никаких примеров из реальной жизни. Как сделать в REST что-то из рязряда GetAllUsersWhoWasBornOnMonday(), ActivateUser(int id), SelectCardsWithZeroBalance(), LoadUserDetailsPage(), AssignUserToGroup(int userID, int groupID)
Гугли CQRS. Отдельно модель для команд, отдельно для запросов.
S>2) Как производится тестирование слоя DDD и сервисов. Скажем есть у нас домейн класс Person
S>и есть сервис который дергается из REST
S>Понятно, что тут для юнит-тестирования следует замокить email service и repository, однако есть пара вопросов:
S>- Как проверить что EmailService, LogService и UserRepository были вызваны с нужными параметрами (юзер старше 18 лет) или не вызваны?
Читайте доки к библиотеки мокирования. Например в мокито есть verify методы.
Здравствуйте, itslave, Вы писали:
I>Стоит вынести всю бизнес логику в сервисы и тестировать ее. Впрочем хочу отметить, что Person.CalculateAge(), при наличии Person.BirthDate — это логика представления и ее выносить не надо. Отдельный юнит тест(ы) для этого можно написать безо всяких моков.
Person.CalculateAge() это пример, там будут более сложные методы. Про существование анемичного подхода я в курсе, но во-первых нам все-же нужен обычный DDD, во-вторых даже в случае анемичного подхода проблема остается на месте — Person превратится в какой-нибудь PeopleService и каким-то образом должен будет юнит-тестится совместно с моим PersonService из примера.
По-сути вопрос можно свести к тому, что если я напишу юнит-тесты для логики Person, то тестирование PersonService возможно только в виде интеграционного теста т.к. Person нельзя замокить (не выделять-же DDD модели в интерфейсы для этого). Нормально-ли это
I>В нормальных языках программирования есть linq. I>Хотя его юнит тестировать — не самая приятная штука.
Мы используем EF, отсюда и вопрос. Даже если забыть про лапшу в коде, юнит-тестирование таких классов настоящий кошмар, у меня сейчас на совершенно базовые методы типа добавить или удалить пользователя создается moq setup юнит теста размером раз в 10 превышающий код собственно метода и польза этих тестов равна по-сути нулю т.к. можно замокить только совершенно базовые запросы.
Здравствуйте, Stalker., Вы писали:
S>Person.CalculateAge() это пример, там будут более сложные методы. Про существование анемичного подхода я в курсе, но во-первых нам все-же нужен обычный DDD, во-вторых даже в случае анемичного подхода проблема остается на месте — Person превратится в какой-нибудь PeopleService и каким-то образом должен будет юнит-тестится совместно с моим PersonService из примера. S>По-сути вопрос можно свести к тому, что если я напишу юнит-тесты для логики Person, то тестирование PersonService возможно только в виде интеграционного теста т.к. Person нельзя замокить (не выделять-же DDD модели в интерфейсы для этого). Нормально-ли это
В случае анемичного подхода у тебя будет класс Person в котором будут только данные без логики (там не будет никаких CalculateAge, Validate и т.д.) и PersonService с бизнес логикой. В данном подходе нужно мокать зависимости только PersonService, если они есть. Если их нет, то и мокать ничего не надо.
>но во-первых нам все-же нужен обычный DDD
Зачем нужен?
"For every complex problem, there is a solution that is simple, neat,
and wrong."
Здравствуйте, AndrewJD, Вы писали:
AJD>В случае анемичного подхода у тебя будет класс Person в котором будут только данные без логики (там не будет никаких CalculateAge, Validate и т.д.) и PersonService с бизнес логикой. В данном подходе нужно мокать зависимости только PersonService, если они есть. Если их нет, то и мокать ничего не надо.
Я сейчас переименовал класс в примере в UserWorkflow что-бы не путать с UserService анемичного подхода. Мой вопрос заключался в том, как будет тестироваться метод UserWorkflow.SendUserPromotion() вне зависимости анемичный это подход или нет. В случае DDD у меня существует зависимость Person.CalculateAge(), в анемичном подходе будет PersonService.CalculateAge(), т.е. тестирование становится интеграционным, т.к. замокать эти классы нельзя, они не вынесены в интерфейсы, соответственно кто как к этому подходит?
Обращу внимание, на разницу между UserWorkflow и бизнес-логикой в Person т.к. это возможно кого-то путает, класс UserWorkflow не содержит бизнес логику, он содержит workflow логику по манипуляции разными сервисами, типа репозитория, сервиса рассылки почты, какой-нибудь криптографии, логирования и прочего. Все это надо тоже тестировать, и все эти сервисы могут быть замокены, за исключением самого Person, т.к. он часть DDD и соответственно не мокится, откуда и вопрос
DDD используется т.к. все хотя-бы знают что это такое, анемичный подход известен только на этом форуме
Здравствуйте, Stalker., Вы писали:
S>Я сейчас переименовал класс в примере в UserWorkflow что-бы не путать с UserService анемичного подхода. Мой вопрос заключался в том, как будет тестироваться метод UserWorkflow.SendUserPromotion() вне зависимости анемичный это подход или нет. В случае DDD у меня существует зависимость Person.CalculateAge(), в анемичном подходе будет PersonService.CalculateAge(), т.е. тестирование становится интеграционным, т.к. замокать эти классы нельзя, они не вынесены в интерфейсы, соответственно кто как к этому подходит?
Какая разница называется оно формально интеграционным или юнит тестированием? Суть одна, на вход подаются входные данные сценария, на выходе проверяется результат, а также что моки соотвествующих сервисов были вызваны (email, DB, etc).
"For every complex problem, there is a solution that is simple, neat,
and wrong."
Здравствуйте, AndrewJD, Вы писали:
AJD>Какая разница называется оно формально интеграционным или юнит тестированием? Суть одна, на вход подаются входные данные сценария, на выходе проверяется результат, а также что моки соотвествующих сервисов были вызваны (email, DB, etc).
разница важная, т.к. интеграционный тест будет также завязан на логику класса DDD, у которой есть свои юнит-тесты. Но ок, ваш поинт понятен — тест становится интеграционным
Здравствуйте, Stalker., Вы писали:
S>Person.CalculateAge() это пример, там будут более сложные методы. Про существование анемичного подхода я в курсе, но во-первых нам все-же нужен обычный DDD
Обычный DDD был придуман лет эдак за 10 до юнит тестирования, и как следствие — он не юнит тестируется в общем случае.
S>во-вторых даже в случае анемичного подхода проблема остается на месте — Person превратится в какой-нибудь PeopleService и каким-то образом должен будет юнит-тестится совместно с моим PersonService из примера. S>По-сути вопрос можно свести к тому, что если я напишу юнит-тесты для логики Person, то тестирование PersonService возможно только в виде интеграционного теста т.к. Person нельзя замокить (не выделять-же DDD модели в интерфейсы для этого). Нормально-ли это
У тебя останется анемичный Person, который не мокается, и 2 сервиса — PeopleService + PersonService, которые тестируются по отдельности. И если надо — интеграционный тест на все хозяйство вместе.
S>Мы используем EF, отсюда и вопрос. Даже если забыть про лапшу в коде, юнит-тестирование таких классов настоящий кошмар, у меня сейчас на совершенно базовые методы типа добавить или удалить пользователя создается moq setup юнит теста размером раз в 10 превышающий код собственно метода и польза этих тестов равна по-сути нулю т.к. можно замокить только совершенно базовые запросы.
С CUD вообще проблем нет, а вот с селектами — да, надо помучиться. На сайте майкрососфта есть пошаговое руководство. Альтернатива — инкапсулирование селектов в неюниттестируемые репозитарии, по одному методу на селект — тоже не сказать чтобы супер.
Здравствуйте, Stalker., Вы писали:
S>Мой вопрос заключался в том, как будет тестироваться метод UserWorkflow.SendUserPromotion() вне зависимости анемичный это подход или нет.
Кэп подсказывает, что стратегия тестирования зависит от имплементации.
Здравствуйте, itslave, Вы писали:
I>У тебя останется анемичный Person, который не мокается, и 2 сервиса — PeopleService + PersonService, которые тестируются по отдельности. И если надо — интеграционный тест на все хозяйство вместе.
мокить PersonService? В результате передавать в UserWorkflow охапку интерфейсов всех сервисов обслуживающих анемичную модель? Их-же может реально много оказаться, я уже представляю чем все это закончится — вместо множества небольших сервисов разработчики начнут лепить сборные солянки из методов т.к. незахотят связываться с созданием нового сервиса для какого-то случая, мокингом и передачей его в кучу юнит-тестов. Либо просто втухушку будут лепить новый метод в неправильный сервис просто потому что тот уже замокен что-бы не заморачиваться с передачей нового сервиса в workflow.
В общем я так понимаю в случае DDD юнит тесты для классов использующих домейн-модели не пишут, а делают интеграционные тесты. Ок
I>С CUD вообще проблем нет, а вот с селектами — да, надо помучиться. На сайте майкрососфта есть пошаговое руководство. Альтернатива — инкапсулирование селектов в неюниттестируемые репозитарии, по одному методу на селект — тоже не сказать чтобы супер.
Для CUD одной записи еще ничего, но если их несколько (скажем при удалении пользователя удалить список его контактов из другой таблицы), то код уже становится монстрообразным, в Moq для проверки таких вещей надо использовать коллбэки, где вручную искать конкретную удаляемую запись в коллекции и удалять их все по-очереди т.к. Moq не позволяет удалить строку из контекста, эту операцию надо симулировать в коллбэке на своей собственной коллекции. Вообще код слоя репозитория по этой причине никто не мокит, а если-уж сильно хочется — то просто пишутся интеграционные тесты с настоящей БД, которые заодно могут тестировать куда более интересные вещи чем простые селекты или делиты, например так можно тестить проверку уникальности записи в таблице, транзакционную согласованность и кучу всего прочего, причем затраченное время будет меньше чем если-бы писался код мокинга для EF
Здравствуйте, Stalker., Вы писали:
S>мокить PersonService? В результате передавать в UserWorkflow охапку интерфейсов всех сервисов обслуживающих анемичную модель? Их-же может реально много оказаться, я уже представляю чем все это закончится — вместо множества небольших сервисов разработчики начнут лепить сборные солянки из методов т.к. незахотят связываться с созданием нового сервиса для какого-то случая, мокингом и передачей его в кучу юнит-тестов.
Да, будет какое кол-во сервисов, заинджекченные в воркфлоу или куда там еще. В самых запущенных случаях видел 20+ в параметрах конструктора. За такое надо бить линейкой по рукам на код ревью и вуаля. Также хочу отметить, что говнокод можно написать в любом случае, и я также неоднократно видел превращения aggregation roots в многотысячострочные монстры.
S>В общем я так понимаю в случае DDD юнит тесты для классов использующих домейн-модели не пишут, а делают интеграционные тесты. Ок
Да. Ведь в классике DDD даже методы Load/Save должны быть заимплеменчены частью бизнес обьекта, куда тут юнит тесты.
С интеграционными тестами все хорошо кроме 3х вещей
— необходимости наличия сконфигурированного енва для их запуска(особенно актуально в случае интеграций со всякими другими сервисами)
— достаточно приличного(как правило — нескольких часов) времени прогона полного сета тестов.
— в разы больших эфортов на написание-рефакторинг тестов
Все это неизбежно приводит к
— менее полному покрытию бизнес логики тестами
— более позднему обнаружению багов и как следствие — нестабильным билдам
Если эти риски тебя не настораживают — то почему нет.
S>Для CUD одной записи еще ничего, но если их несколько (скажем при удалении пользователя удалить список его контактов из другой таблицы), то код уже становится монстрообразным, в Moq для проверки таких вещей надо использовать коллбэки, где вручную искать конкретную удаляемую запись в коллекции и удалять их все по-очереди т.к. Moq не позволяет удалить строку из контекста, эту операцию надо симулировать в коллбэке на своей собственной коллекции. Вообще код слоя репозитория по этой причине никто не мокит, а если-уж сильно хочется — то просто пишутся интеграционные тесты с настоящей БД, которые заодно могут тестировать куда более интересные вещи чем простые селекты или делиты, например так можно тестить проверку уникальности записи в таблице, транзакционную согласованность и кучу всего прочего, причем затраченное время будет меньше чем если-бы писался код мокинга для EF
Вообщето юнит тестами рекомендуют покрывать исключительно бизнес логику, репохзитарий же к ней не относится — достаточно проверить что произошел вызов нужного метода с нужными параметрами.
И да. Юнит тесты не заменяют интеграционные, а дополняют.
Здравствуйте, itslave, Вы писали:
I>Да, будет какое кол-во сервисов, заинджекченные в воркфлоу или куда там еще. В самых запущенных случаях видел 20+ в параметрах конструктора. За такое надо бить линейкой по рукам на код ревью и вуаля. Также хочу отметить, что говнокод можно написать в любом случае, и я также неоднократно видел превращения aggregation roots в многотысячострочные монстры.
так будет либо 20+ параметров на сложные операции, либо сборные солянки, никуда при таком подходе от этого не деться
I>С интеграционными тестами все хорошо кроме 3х вещей I> — необходимости наличия сконфигурированного енва для их запуска(особенно актуально в случае интеграций со всякими другими сервисами) I> — достаточно приличного(как правило — нескольких часов) времени прогона полного сета тестов. I> — в разы больших эфортов на написание-рефакторинг тестов
в моем случае тест получается "интеграционным" только потому, что класс workflow завязан на модель DDD, все остальные сервисы (типа репозитория или почтового сервиса) там будут замокены, так что все будет быстро. Покрытие логики там тоже будет достаточным, ведь модель DDD будет покрыта своими юнит тестами. По-настоящему "интеграционным" будут только тесты кода репозитория, и то если мы вообще захотим с ними связываться, т.к. там тесты будут гонятся с настоящей базой данных.
Здравствуйте, Stalker., Вы писали:
S>Здравствуйте, itslave, Вы писали:
I>>Да, будет какое кол-во сервисов, заинджекченные в воркфлоу или куда там еще. В самых запущенных случаях видел 20+ в параметрах конструктора. За такое надо бить линейкой по рукам на код ревью и вуаля. Также хочу отметить, что говнокод можно написать в любом случае, и я также неоднократно видел превращения aggregation roots в многотысячострочные монстры.
S>так будет либо 20+ параметров на сложные операции, либо сборные солянки, никуда при таком подходе от этого не деться
Анемичная модель тяготеет к множеству мелких сервисам, православная "rich DDD model" — к god aggregation root. Жизнь — боль
S>в моем случае тест получается "интеграционным" только потому, что класс workflow завязан на модель DDD, все остальные сервисы (типа репозитория или почтового сервиса) там будут замокены, так что все будет быстро. Покрытие логики там тоже будет достаточным, ведь модель DDD будет покрыта своими юнит тестами. По-настоящему "интеграционным" будут только тесты кода репозитория, и то если мы вообще захотим с ними связываться, т.к. там тесты будут гонятся с настоящей базой данных.
Опять таки, юнит тесты придумали такими потому что так удобней. В общем случае удобней замокать зависимости, чем конфигурировать целые деревья обьектов, а если они еще и statefull, то выводить их в нужное состояние перед стартом теста. Хотя Возможно в твоем случае можно сделать проще или после первой пачки тестов задумаешься и сделаешь "как рекомендуют".
S>так будет либо 20+ параметров на сложные операции, либо сборные солянки, никуда при таком подходе от этого не деться
Если твой workflow использует эти 20+ сервисов — то этого не избежать. Но зато получаем полное покрытие сценария тестом. Как показывает практика основные ошибки возникают при взаимодействии компонентов между собой.
"For every complex problem, there is a solution that is simple, neat,
and wrong."
Здравствуйте, itslave, Вы писали:
I> — необходимости наличия сконфигурированного енва для их запуска(особенно актуально в случае интеграций со всякими другими сервисами) I> — достаточно приличного(как правило — нескольких часов) времени прогона полного сета тестов.
Это если полноценный интеграционный тест. Если же под интеграционным понимать только тестирование несколько компонентов и использованием моков и unit test инфрастуктуры — этой проблемы нет.
I> — в разы больших эфортов на написание-рефакторинг тестов
Не согласен. Если использовать blackbox подход — то как раз время сокращается при рефакторинге, т.к. внешние интерфейсы обычно гораздо стабильнее чем их реализация. В некоторых случаях можно хранить тествовые сценарии и данные во внешних XML/JSON файлах. Время подготовки тестовых данных наверное будет больше. Но такой тест покрывает весь сценарий + появляется возможность как угодно рефакторить реализацию — тест не меняется.
"For every complex problem, there is a solution that is simple, neat,
and wrong."
Здравствуйте, AndrewJD, Вы писали:
AJD>Это если полноценный интеграционный тест. Если же под интеграционным понимать только тестирование несколько компонентов и использованием моков и unit test инфрастуктуры — этой проблемы нет.
Остается необходимость очень аккуратно работать с сервисами, которые работают со внешними ресурсами, в первую очередь — с базой данных.
I>> — в разы больших эфортов на написание-рефакторинг тестов AJD>Не согласен. Если использовать blackbox подход — то как раз время сокращается при рефакторинге, т.к. внешние интерфейсы обычно гораздо стабильнее чем их реализация. В некоторых случаях можно хранить тествовые сценарии и данные во внешних XML/JSON файлах. Время подготовки тестовых данных наверное будет больше. Но такой тест покрывает весь сценарий + появляется возможность как угодно рефакторить реализацию — тест не меняется.
Даже с blackbox, все очень сильно зависит от того, насколько сервисы stateful и насколько дерево сложное. Хранение состояния во внешних файлах приводит к гемору c версионированием.
Здравствуйте, Stalker., Вы писали:
S>Хочется прояснить несколько вопросов по указанной связке и по архитектурным вопросам в целом.
S>1) Во-первых DDD + REST, каким образом они вообще обьединяются? Что-то ничего нормального не нагугливается, приводятся тривиальные примеры get/post/put/delete где user/id=5 и никаких примеров из реальной жизни. Как сделать в REST что-то из рязряда GetAllUsersWhoWasBornOnMonday(), ActivateUser(int id), SelectCardsWithZeroBalance(), LoadUserDetailsPage(), AssignUserToGroup(int userID, int groupID)
S>2) Как производится тестирование слоя DDD и сервисов. Скажем есть у нас домейн класс Person
S>- Как проверить что EmailService, LogService и UserRepository были вызваны с нужными параметрами (юзер старше 18 лет) или не вызваны? S>- Что делать собственно с домейн классом Person, если я его напрямую использую в тесте сервиса, то это вроде уже не юнит тест будет, а интеграционный, а мокить Person через интерфейс будет откровенный ужас и оверкилл S>- Стоит-ли тестировать Person.CalculateAge() метод в этом случае S>- Обьединяя с вопросом номер 1 — как будет SendUserPromotion() операция выглядить через интерфейс REST?
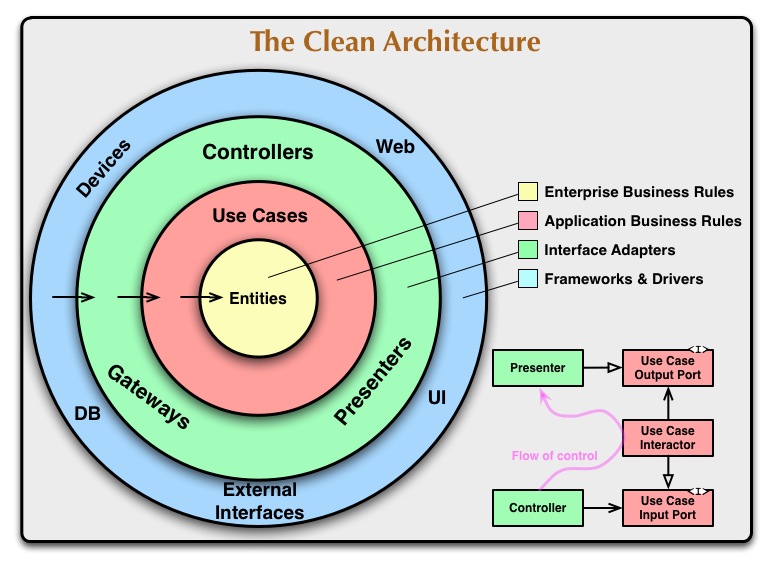
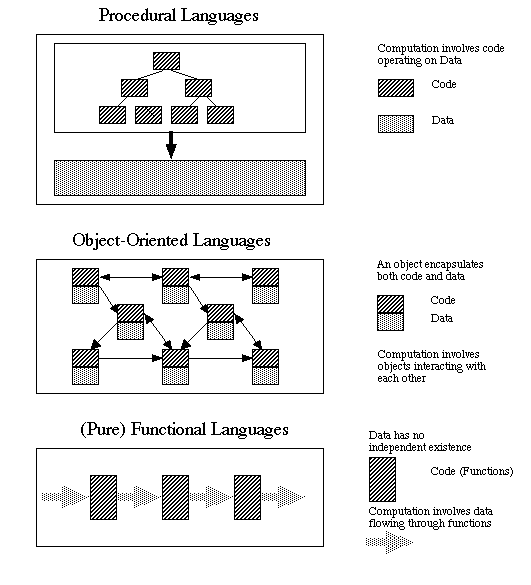
Пример кода — это не DDD, даже не ООП, это процедурное программирование. Это вызов набора процедур, оформленных в виде методов в разных классах.
S>3) Вопрос по Репозиторию. Очевидно его интерфейс быстро обрастает методами UpdateUserLastPromotionDate(), GetAllUsersWhoWasBornOnMonday() и AssignUserToGroup().
Нет, не обрастает. Репозиторий где-то хранит объекты между запусками программы и умеет их оттуда доставать. Это два-три метода Add/Remove/Find.
S>Какие существуют методы по структуризации всего этого, что-бы его класс не превращался в свалку из десятков таких разношерстных методов?
Классический ООП. Решение задачи проектируется в виде набора объектов, которые посылают друг другу сообщения (вызывают методы). Это модель предметной области задачи. На одну задачу их может быть много, в DDD каждую такую отдельную модель называют bounded context. И никаких следов баз данных и EF в этой модели нет. Чтобы освободиться от призрака бд, полезно представлять, что оперативная память бесконечна. Это сразу ставит бд на правильное место в твоей системе ценностей.
Пробуждать модель предметной области имеет смысл только когда нужно внести изменения в систему, выполнить операции на запись. Для чтения модель предметной области можно не использовать. Не нужно, если всё сводится к ковырянию в БД с минимумом проверок перед записью.
S>Скажу сразу я знаю о существовании идеи не использовать репозиторий вообще, а прямо в методе сервиса писать соответствующие EF запросы, однако такие идеи хороши в теории, а на практике приводят к лапше из кода бизнес-логики, запросов к данным и конвертации модели данных к бизнес-моделям, а самое главное для написания юнит-тестов всего этого проходится мокить сам EF контекст, что отнимает жуткое количество времени, и позволяет тестить только простейшие запросы
Не нужно мокать EF, не нужно тестировать способность EF обращаться к бд и заполнять структуры данными. Этим занимается команда по разработке EF и она уже выложила EF в продакшен — значит, тесты у них выполняются успешно и тебе не надо их писать. Если база данных заменяет собой модель предметной области, репозитории и юнит-тесты не нужны. Надо просто использовать EF и следить за соединением к бд. Код получится простой и короткий.
Здравствуйте, Vladek, Вы писали:
V>Пример кода — это не DDD, даже не ООП, это процедурное программирование. Это вызов набора процедур, оформленных в виде методов в разных классах.
потому-что приведенный пример кода — это сервис, не имеющий отношения к бизнес-логике и ООП
V>Нет, не обрастает. Репозиторий где-то хранит объекты между запусками программы и умеет их оттуда доставать. Это два-три метода Add/Remove/Find.
хранит, да. В базе данных. Никаких кэшей и прочих состояний т.к. речь про веб
V>Классический ООП. Решение задачи проектируется в виде набора объектов, которые посылают друг другу сообщения (вызывают методы). Это модель предметной области задачи. На одну задачу их может быть много, в DDD каждую такую отдельную модель называют bounded context. И никаких следов баз данных и EF в этой модели нет. Чтобы освободиться от призрака бд, полезно представлять, что оперативная память бесконечна. Это сразу ставит бд на правильное место в твоей системе ценностей.
Вопрос был не про ООП, а интефейс репозитория, это совершенно разные вещи
V>Не нужно мокать EF, не нужно тестировать способность EF обращаться к бд и заполнять структуры данными. Этим занимается команда по разработке EF и она уже выложила EF в продакшен — значит, тесты у них выполняются успешно и тебе не надо их писать. Если база данных заменяет собой модель предметной области, репозитории и юнит-тесты не нужны. Надо просто использовать EF и следить за соединением к бд. Код получится простой и короткий.
EF не надо мокать, а вот репозиторий надо, этот вопрос проистекал из вопроса про его интерфейс
Твой репозиторий возвращает живые сущности EF? Если да, то значит ты не стесняешься светить EF по всей системе, а следовательно лишний код в виде репозиториев или шлюзов не нужен — проще инжектить контекст EF куда надо и использовать напрямую без всяких обёрток. Нет репозиториев и шлюзов, не нужно ничего мокать и писать тесты.
С другой стороны, интерфейс шлюза, если ты его оставишь, действительно зарастёт методами. Они все собраны в одном классе потому, что скрывают за собой весь SQL. Твой шлюз будет скрывать контекст EF. Однако, опять же, если методы возвращают сущности из этого контекста, то никакого сокрытия на самом деле нет.
Здравствуйте, Vladek, Вы писали:
V>Это не репозиторий. То, что ты понимаешь под репозиторием, называется шлюзом — https://martinfowler.com/eaaCatalog/gateway.html А ещё точнее, шлюзом к табличным данным: https://martinfowler.com/eaaCatalog/tableDataGateway.html Проблемы, которую он решает (возня с SQL в коде) — у тебя нет, у тебя есть EF и запросы LINQ.
V>Твой репозиторий возвращает живые сущности EF? Если да, то значит ты не стесняешься светить EF по всей системе, а следовательно лишний код в виде репозиториев или шлюзов не нужен — проще инжектить контекст EF куда надо и использовать напрямую без всяких обёрток. Нет репозиториев и шлюзов, не нужно ничего мокать и писать тесты.
нет, это не табличный шлюз т.к. внутри репозитория работает полноценный маппер на доменную модель (EF или самописный), и нет, репозиторий возвращает не EF, а готовые доменные модели, а также может иметь некоторую дополнительную логику по управлению транзакциями, порядком сохранения или другой подобной логикой
Здравствуйте, Stalker., Вы писали:
S>нет, это не табличный шлюз т.к. внутри репозитория работает полноценный маппер на доменную модель (EF или самописный), и нет, репозиторий возвращает не EF, а готовые доменные модели, а также может иметь некоторую дополнительную логику по управлению транзакциями, порядком сохранения или другой подобной логикой
Тогда начнём сначала: с класса User (или Person). Это просто структура данных. Данные есть, поведения нет. Конечно с тестами трудности возникают — тестируют поведение, а его нет. Рефакторим — добавляем в класс метод SendPromotion(). Уже лучше, можно написать пару тестов — на отправку и сбой отправки.
Код сервиса REST упрощается до безобразия:
public bool SendUserPromotion(int userID)
{
if (userID < 0)
throw new InvalidUserID();
User user = UserRepository.GetUser(userID);
return user.SendPromotion();
}
Здесь соблюдены два важных принципа ООП:
1) В ООП лампочка сама себя вкручивает. Посылаешь объекту сообщение и он выполняет работу: user.SendPromotion().
2) В ООП ты не беспокоишься как лампочка вкрутит себя. Объект user выполнит проверку своего состояния (возраста) сам.
Куда девались остальные вызовы? Они внутри SendPromotion. Как внешние зависимости попали в объект user? Об этом позаботился UserRepository. Как это тестировать? Замокать внешние зависимости объекта user, установить нужное состояние user, вызвать метод SendPromotion, проверить изменения состояния user и моков.
Класс UserRepository не имеет лишних методов — весь код UpdateUserLastPromotionDate(userID) может быть в самом классе User или его наследнике. Главное, код сервиса REST от этих деталей не зависит. Весь конкретный код работы с User сосредоточен в самом классе User и его наследниках — прыгать по толпе файлов, чтобы выяснять детали, не приходится.
Здравствуйте, Vladek, Вы писали:
V>Тогда начнём сначала: с класса User (или Person). Это просто структура данных. Данные есть, поведения нет. Конечно с тестами трудности возникают — тестируют поведение, а его нет.
Если нет поведения — нет необходимости в тестировании. Использование структуры автоматически покрывается при написании тестов тестирующее поведение.
V>Рефакторим — добавляем в класс метод SendPromotion().
Особенно это будет криво выглядеть когда для реализации SendPromotion понадобятся еще доаолнительные домен сушности и возникнет вопрос, а чья же это собстевенно отвественность?
V>Уже лучше, можно написать пару тестов — на отправку и сбой отправки.
С таким же успехом можно написать тесты на сервис которые реализует SendPromotion.
V>Здесь соблюдены два важных принципа ООП: V>1) В ООП лампочка сама себя вкручивает. Посылаешь объекту сообщение и он выполняет работу: user.SendPromotion().
Инкапсуляция и полиморфизм не подразумевает, что ламочка сама себя вкручивает. Ты, кстати, где-то видел обратное?
V>2) В ООП ты не беспокоишься как лампочка вкрутит себя.
Никакой связи с ООП. Такой подход вообще не работает когда есть отношение многие-ко-многим.
V>Объект user выполнит проверку своего состояния (возраста) сам.
В общем случае обьект не может выполнить такую проверку, поскольку отсуствует контекст.
"For every complex problem, there is a solution that is simple, neat,
and wrong."
Здравствуйте, AndrewJD, Вы писали:
AJD>Здравствуйте, Vladek, Вы писали:
V>>Тогда начнём сначала: с класса User (или Person). Это просто структура данных. Данные есть, поведения нет. Конечно с тестами трудности возникают — тестируют поведение, а его нет. AJD>Если нет поведения — нет необходимости в тестировании. Использование структуры автоматически покрывается при написании тестов тестирующее поведение.
Полное покрытие кода тестами не нужно. Классы с полями и методами удобнее и понятнее анемичных структур данных.
V>>Рефакторим — добавляем в класс метод SendPromotion(). AJD>Особенно это будет криво выглядеть когда для реализации SendPromotion понадобятся еще доаолнительные домен сушности и возникнет вопрос, а чья же это собстевенно отвественность?
Объекты могут включать в себя другие объекты или ссылаться на них. В DDD их называют агрегатами, например.
V>>Уже лучше, можно написать пару тестов — на отправку и сбой отправки. AJD>С таким же успехом можно написать тесты на сервис которые реализует SendPromotion.
Сервис. Список файлов *Service.cs — это просто процедурные химеры. Приносятся в жертву богу рефакторинга.
V>>Здесь соблюдены два важных принципа ООП: V>>1) В ООП лампочка сама себя вкручивает. Посылаешь объекту сообщение и он выполняет работу: user.SendPromotion(). AJD>Инкапсуляция и полиморфизм не подразумевает, что ламочка сама себя вкручивает. Ты, кстати, где-то видел обратное?
Не распарсил. https://pragprog.com/articles/tell-dont-ask
V>>2) В ООП ты не беспокоишься как лампочка вкрутит себя. AJD>Никакой связи с ООП. Такой подход вообще не работает когда есть отношение многие-ко-многим.
Не распарсил. https://pragprog.com/articles/tell-dont-ask
V>>Объект user выполнит проверку своего состояния (возраста) сам. AJD>В общем случае обьект не может выполнить такую проверку, поскольку отсуствует контекст.
У объекта есть идентичность, состояние, поведение — в общем случае. Как ни странно, но этого достаточно для проверок! Про контекст не распарсил.
Здравствуйте, Vladek, Вы писали:
V>Полное покрытие кода тестами не нужно. Классы с полями и методами удобнее и понятнее анемичных структур данных.
Полнота покрытия тут не причем. Никто не запрещает иметь классы с полями и методами — речь идет о разделении бизнес логики и доменных обьектов.
V>Объекты могут включать в себя другие объекты или ссылаться на них. В DDD их называют агрегатами, например.
Получаем на выходе либо GOD классы или искусственные сущности типа агрегатов.
AJD>>С таким же успехом можно написать тесты на сервис которые реализует SendPromotion. V>Сервис. Список файлов *Service.cs — это просто процедурные химеры. Приносятся в жертву богу рефакторинга.
Когда речь идет про религию — аргументы безполезны.
V>Не распарсил. https://pragprog.com/articles/tell-dont-ask
Где ты видел чтобы лампочка себя вкручивала
V>У объекта есть идентичность, состояние, поведение — в общем случае. Как ни странно, но этого достаточно для проверок!
Как ни странно, этого не достаточно для сценариев отличных от примитивных.
V>Про контекст не распарсил.
Обьект не знает в каком контексте(сценарии) его использует и его окружение. Это знает код который его использует. Конечно, можно использовать GOD класс который знает все — но мы вроде про хороший дизайн тут говорим.
"For every complex problem, there is a solution that is simple, neat,
and wrong."
Здравствуйте, Vladek, Вы писали:
V>Тогда начнём сначала: с класса User (или Person). Это просто структура данных. Данные есть, поведения нет.
Логика там есть — CalculateAge(), также там будет как минимум логика валидации (имя не пустое, дата рождения не в будущем итп), и другая логика связанная только с самим юзером и другими доменными классами связанными с ним. Юнит-тестирование и будет делаться для указанных методов
V>Конечно с тестами трудности возникают — тестируют поведение, а его нет. Рефакторим — добавляем в класс метод SendPromotion(). Уже лучше, можно написать пару тестов — на отправку и сбой отправки.
Откуда в доменной модели взялись вызовы почтового сервиса и логирования? Это уже не доменная модель, а гибрид с сервисом какой-то, так можно и вызовы репозитория туда-же впихнуть и класс сервиса станет вообще ненужным. И репозиторий не может ничего инджектить никуда, у него другая роль — работа с БД
V>Куда девались остальные вызовы? Они внутри SendPromotion. Как внешние зависимости попали в объект user? Об этом позаботился UserRepository. Как это тестировать? Замокать внешние зависимости объекта user, установить нужное состояние user, вызвать метод SendPromotion, проверить изменения состояния user и моков.
V>Класс UserRepository не имеет лишних методов — весь код UpdateUserLastPromotionDate(userID) может быть в самом классе User или его наследнике. Главное, код сервиса REST от этих деталей не зависит. Весь конкретный код работы с User сосредоточен в самом классе User и его наследниках — прыгать по толпе файлов, чтобы выяснять детали, не приходится.
код апдейта даты рассылки это чисто работа репозитория, у доменной модели при необходимости может быть поле с такой датой, а апдейт в БД пойдет из репозитория, который вызовет workflow сервис. По-другому это вообще не сможет работать т.к. такой апдейт может идти совместно с другими апдейтами в транзакции, и нагрузив это все в доменную модель она полностью превратится в workflow сервис с процедурным кодом внутри и кучей private методов куда и переедет собственно бизнес логика
Здравствуйте, AndrewJD, Вы писали:
AJD>Здравствуйте, Vladek, Вы писали:
V>>Полное покрытие кода тестами не нужно. Классы с полями и методами удобнее и понятнее анемичных структур данных. AJD>Полнота покрытия тут не причем. Никто не запрещает иметь классы с полями и методами — речь идет о разделении бизнес логики и доменных обьектов.
Доменные объекты — средство реализации бизнес-логики. Это одно и то же.
V>>Объекты могут включать в себя другие объекты или ссылаться на них. В DDD их называют агрегатами, например. AJD>Получаем на выходе либо GOD классы или искусственные сущности типа агрегатов.
Мы моделируем предметную область. Моделируем ровно до такой степени, чтобы решить поставленную задачу. Агрегат — это не сущность, это роль модели.
AJD>>>С таким же успехом можно написать тесты на сервис которые реализует SendPromotion. V>>Сервис. Список файлов *Service.cs — это просто процедурные химеры. Приносятся в жертву богу рефакторинга. AJD>Когда речь идет про религию — аргументы безполезны.
В ООП именно такой вывернутый наизнанку подход к моделированию позволяет создавать рабочие, простые и понятные модели. Субъект, манипулирующий объектами, отсутствует.
V>>У объекта есть идентичность, состояние, поведение — в общем случае. Как ни странно, но этого достаточно для проверок! AJD>Как ни странно, этого не достаточно для сценариев отличных от примитивных.
Talk is cheap. Show me the code.
Linus Torvalds
V>>Про контекст не распарсил. AJD>Обьект не знает в каком контексте(сценарии) его использует и его окружение. Это знает код который его использует. Конечно, можно использовать GOD класс который знает все — но мы вроде про хороший дизайн тут говорим.
Да, код должен быть независим от внешнего окружения. Именно это позволяет использовать его в разных окружениях!
Здравствуйте, Stalker., Вы писали:
S>Здравствуйте, Vladek, Вы писали:
V>>Тогда начнём сначала: с класса User (или Person). Это просто структура данных. Данные есть, поведения нет.
S>Логика там есть — CalculateAge(), также там будет как минимум логика валидации (имя не пустое, дата рождения не в будущем итп), и другая логика связанная только с самим юзером и другими доменными классами связанными с ним. Юнит-тестирование и будет делаться для указанных методов
Этот метод не меняет состояние объекта, это простой геттер.
V>>Конечно с тестами трудности возникают — тестируют поведение, а его нет. Рефакторим — добавляем в класс метод SendPromotion(). Уже лучше, можно написать пару тестов — на отправку и сбой отправки.
S>Откуда в доменной модели взялись вызовы почтового сервиса и логирования? Это уже не доменная модель, а гибрид с сервисом какой-то, так можно и вызовы репозитория туда-же впихнуть и класс сервиса станет вообще ненужным. И репозиторий не может ничего инджектить никуда, у него другая роль — работа с БД
Если есть задача рассылать письма пользователям, то логично это явно отразить в коде. А сервис — что это? Чистой воды абстракция, которая не нужна. Репозиторий достаёт из небытия нужные объекты. Бд там или нет — детали реализации.
V>>Куда девались остальные вызовы? Они внутри SendPromotion. Как внешние зависимости попали в объект user? Об этом позаботился UserRepository. Как это тестировать? Замокать внешние зависимости объекта user, установить нужное состояние user, вызвать метод SendPromotion, проверить изменения состояния user и моков. V>>Класс UserRepository не имеет лишних методов — весь код UpdateUserLastPromotionDate(userID) может быть в самом классе User или его наследнике. Главное, код сервиса REST от этих деталей не зависит. Весь конкретный код работы с User сосредоточен в самом классе User и его наследниках — прыгать по толпе файлов, чтобы выяснять детали, не приходится.
S>код апдейта даты рассылки это чисто работа репозитория, у доменной модели при необходимости может быть поле с такой датой, а апдейт в БД пойдет из репозитория, который вызовет workflow сервис. По-другому это вообще не сможет работать т.к. такой апдейт может идти совместно с другими апдейтами в транзакции, и нагрузив это все в доменную модель она полностью превратится в workflow сервис с процедурным кодом внутри и кучей private методов куда и переедет собственно бизнес логика
да, доменная модель это и есть бизнес-логика. Транзакции, workflow (что это?) — всё это модель предметной области может спокойно использовать сама. Не нужно распылять код, решающий бизнес-задачу, на совершенно абстрактные понятия типа workflow или транзакций. Это всё технические детали. Если технические детали диктуют тебе как моделировать предметную область, то никакой внятной модели не получится и понять, что же происходит можно будет лишь во время отладки, прыгая по стеку вызовов.
Нормальная архитектура похожа на луковицу — в центре бизнес-логика, то есть модель предметной области. Это код, который делает ровно то, что просил заказчик. Все понятия, которыми оперирует заказчик, отражены в этом коде. Технические детали уходят на второй план.
Объект user отправил успешно письмо, — он же сохраняет этот факт в бд или ещё куда. Это информация, которой он владеет, его же и ответственность. Как это делается — напрямую, через наследование, через внешние зависимости — это уже детали. Дажде если они поменяеются, код, который использует user от это не поменяется.
Луковица — меняем внешние слои, внутренние не меняются; меняем внутренние слои, внешние не меняются.
Здравствуйте, Vladek, Вы писали:
V> да, доменная модель это и есть бизнес-логика. Транзакции, workflow (что это?) — всё это модель предметной области может спокойно использовать сама. Не нужно распылять код, решающий бизнес-задачу, на совершенно абстрактные понятия типа workflow или транзакций. Это всё технические детали. Если технические детали диктуют тебе как моделировать предметную область, то никакой внятной модели не получится и понять, что же происходит можно будет лишь во время отладки, прыгая по стеку вызовов.
у тебя слишком нетипичный взгляд на то, что из себя бизнес-логика представляет, дискутировать особо смысла не имеет, я придерживаюсь более стандартного подхода к разделению логики, который пропогандируется тем-же Фаулером и Майкрософт, где бизнес-логика не отвечает за вызов почтового сервера, а только генерирует условия и сообщает сервису надо-ли это делать или нет, и уж тем более не лезет в такие вещи как транзакции и порядок сохранения
еще, может кто-то прояснит какой собственно фреймворк сейчас модно юзать для RESTful сервисов, я так понимаю старый добрый WCF ушел в прошлое, вместо него пришел Web API, но сейчас смотрю уже пишут про ASP.NET Core. Кто как к этому делу подходит?
Здравствуйте, Stalker., Вы писали:
S>еще, может кто-то прояснит какой собственно фреймворк сейчас модно юзать для RESTful сервисов, я так понимаю старый добрый WCF ушел в прошлое, вместо него пришел Web API, но сейчас смотрю уже пишут про ASP.NET Core. Кто как к этому делу подходит?
Здравствуйте, Sharov, Вы писали:
S>Я NancyFx использую. web api вроде есть в wcf?
нас в основном майкрософтовские фреймворки интересуют, я так понимаю выбор для Rest сервисов в основном между WCF, Web API и каким-то новым ASP.NET Core.
WCF не содержит Web API, это разные технологии, но обе позволяют рест сервисы писать
Здравствуйте, Stalker., Вы писали:
S>нас в основном майкрософтовские фреймворки интересуют, я так понимаю выбор для Rest сервисов в основном между WCF, Web API и каким-то новым ASP.NET Core.
S>WCF не содержит Web API, это разные технологии, но обе позволяют рест сервисы писать
Есть WCF DataServices которые поддерживают OData и позволяет делать REST.
Но все WCF-based категорически не рекомендую для новых проектов потому что это ужасный легаси, который не развивается уже лет 5.
ASP.NET WebAPI — стабильный продукт, основанный на ASP.NET
ASP.NET Core WebAPI — пока еще сыроватый кроссплатформенный продукт, развитие ASP.NET WebAPI и (почти) полностью с ним же совместимый. Если аффтар любит модное-молодежное, и вероятность попасть на косяки фрйемворка его нее смущает — то не вижу причин не использовать
Здравствуйте, Vladek, Вы писали:
V>Доменные объекты — средство реализации бизнес-логики. Это одно и то же.
Если используеся жирная модель — да, если не используется то нет.
V>Мы моделируем предметную область. Моделируем ровно до такой степени, чтобы решить поставленную задачу. Агрегат — это не сущность, это роль модели.
Это все философия. На практике это вспомагательная хрень нужная для обхода кривости жирной модели данных.
AJD>>Когда речь идет про религию — аргументы безполезны. V>Объекты *Service — это карго-культ.
Где аргументы?
V>В ООП именно такой вывернутый наизнанку подход к моделированию позволяет создавать рабочие, простые и понятные модели. Субъект, манипулирующий объектами, отсутствует.
Эта можель не работает когда нужно обеспечить взаимодействие нескольких сущностей.
V>Да, код должен быть независим от внешнего окружения. Именно это позволяет использовать его в разных окружениях!
Засовываение логики в сущность гвоздями прибивает конкретный сценарий его использования.
"For every complex problem, there is a solution that is simple, neat,
and wrong."
Здравствуйте, AndrewJD, Вы писали:
AJD>Где аргументы?
Этот вопрос надо самому себе прежде всего задавать. Что ты добавил в дискуссию кроме набора догматичных и малопонятных заявлений? Читай про разницу между ПП и ООП. Я писал о ООП.
Здравствуйте, Vladek, Вы писали:
V>Объект user отправил успешно письмо, — он же сохраняет этот факт в бд или ещё куда. Это информация, которой он владеет, его же и ответственность. Как это делается — напрямую, через наследование, через внешние зависимости — это уже детали. Дажде если они поменяеются, код, который использует user от это не поменяется.
Вот в этом и проблема такого подхода. Если объект user и письмо отправляет, и в БД пишет, то код который использует user может и не поменяется, зато код отравки письма может запросто поменять логику записи в БД, причем зачастую без ведома разработчика.
Существует несколько видов связности кода. Вы пропагандируете тот, который вокруг сущности, который, как это ни парадоксально, приводит к худшей инкапсуляции, а есть функциональный, который, на самом деле, инкапсуляцию повышает.
Можно рассматривать код, который занимается только работой с БД и только отправкой писем, как сервисы, но на самом деле, это полноценные объекты. У них есть все что надо, включая состояние. А объекты типа user (без логики) как сообщения которыми они обменияваются. И тогда все становится на свои места, с точки зрения идеологии, вот и ООП в полный рост, и связность низкая, и инкапсуляция высокая. А главное поддерживать такой код существенно проще.
Здравствуйте, Vladek, Вы писали:
V>Этот вопрос надо самому себе прежде всего задавать. Что ты добавил в дискуссию кроме набора догматичных и малопонятных заявлений?
Мне лень переливать из пустого в порожнее. Почитай в этой форуме мега типики про анемик-vs-жирная модель.
V>Читай про разницу между ПП и ООП. Я писал о ООП.
Попытайся осознать простой факт, что используя один и тот же обьектно-ориентированный язык, но используя разные модели данных ты получаешь кардинально разную архитектуру.
"For every complex problem, there is a solution that is simple, neat,
and wrong."
Здравствуйте, IB, Вы писали:
IB>Здравствуйте, Vladek, Вы писали:
V>>Объект user отправил успешно письмо, — он же сохраняет этот факт в бд или ещё куда. Это информация, которой он владеет, его же и ответственность. Как это делается — напрямую, через наследование, через внешние зависимости — это уже детали. Дажде если они поменяеются, код, который использует user от это не поменяется. IB>Вот в этом и проблема такого подхода. Если объект user и письмо отправляет, и в БД пишет, то код который использует user может и не поменяется, зато код отравки письма может запросто поменять логику записи в БД, причем зачастую без ведома разработчика.
Код отправки письма меняет логику записи в БД без ведома разработчика — я что-то такое встречал в романе "Daemon" Дэниэла Суреза, но это была фантастика.
IB>Существует несколько видов связности кода. Вы пропагандируете тот, который вокруг сущности, который, как это ни парадоксально, приводит к худшей инкапсуляции, а есть функциональный, который, на самом деле, инкапсуляцию повышает. IB>Можно рассматривать код, который занимается только работой с БД и только отправкой писем, как сервисы, но на самом деле, это полноценные объекты. У них есть все что надо, включая состояние. А объекты типа user (без логики) как сообщения которыми они обменияваются. И тогда все становится на свои места, с точки зрения идеологии, вот и ООП в полный рост, и связность низкая, и инкапсуляция высокая. А главное поддерживать такой код существенно проще.
Отправка писем и запись в бд — зависимости объекта User, который обменивается с ними простыми структурами данных (готовыми письмами и заполненными сущностями EF). Отправлялка писем ничего не знает про БД, контекст БД ничего не знает про письма, оркестром управляет объект User в методе SendPromotion — название метода сразу нам говорит, зачем вообще весь этот код написан. Вся логика, касающаяся задачи, находится в нём. Эту логику можно тестировать изолированно от отправлялки писем и контекста бд.
Здравствуйте, Vladek, Вы писали:
V>Код отправки письма меняет логику записи в БД без ведома разработчика — я что-то такое встречал в романе "Daemon" Дэниэла Суреза, но это была фантастика.
А я встречаю это в каждом первом DDD проекте.
V>Отправка писем и запись в бд — зависимости объекта User, который обменивается с ними простыми структурами данных (готовыми письмами и заполненными сущностями EF). Отправлялка писем ничего не знает про БД, контекст БД ничего не знает про письма, оркестром управляет объект User в методе SendPromotion — название метода сразу нам говорит, зачем вообще весь этот код написан.
Чтобы нагляднее проиллюстрировать мою мысль, давайте добавим еще один метод — MonthlyCharge(), в котором находится логика помесячного списания денег. Она так же хорошо изолирована от БД и отправки писем.
Проблема только в том, что по вашей логике этот метод тоже должен находиться внутри класса User, а значит он имеет доступ к внутреннему состоянию этого класса. Таким образом, логика SendPromotion() может неявно повлиять на то как списываются деньги за подписку. То есть на лицо нарушение инкапсуляции, за которую вы вроде как ратуете.
На всякий случай, ключевое слово здесь "неявно". Разработчик, совершенно без задней мысли, реализуюя логику списания денег, может поменять состояние класса User для своих нужд, и ему и в голову не придет (да и не должно), что это может отразиться на отправке промо, ну и наоборот.
If you're writing a function that can be implemented as either a member or as a non-friend non-member, you should prefer to implement it as a non-member function. That decision increases class encapsulation. When you think encapsulation, you should think non-member functions.
Здравствуйте, IB, Вы писали:
IB>Здравствуйте, Vladek, Вы писали:
V>>Код отправки письма меняет логику записи в БД без ведома разработчика — я что-то такое встречал в романе "Daemon" Дэниэла Суреза, но это была фантастика. IB>А я встречаю это в каждом первом DDD проекте.
V>>Отправка писем и запись в бд — зависимости объекта User, который обменивается с ними простыми структурами данных (готовыми письмами и заполненными сущностями EF). Отправлялка писем ничего не знает про БД, контекст БД ничего не знает про письма, оркестром управляет объект User в методе SendPromotion — название метода сразу нам говорит, зачем вообще весь этот код написан. IB>Чтобы нагляднее проиллюстрировать мою мысль, давайте добавим еще один метод — MonthlyCharge(), в котором находится логика помесячного списания денег. Она так же хорошо изолирована от БД и отправки писем. IB>Проблема только в том, что по вашей логике этот метод тоже должен находиться внутри класса User, а значит он имеет доступ к внутреннему состоянию этого класса. Таким образом, логика SendPromotion() может неявно повлиять на то как списываются деньги за подписку. То есть на лицо нарушение инкапсуляции, за которую вы вроде как ратуете.
Здесь надо разбираться с границами ответственности объекта User. Пользователи не участвуют в формировании счетов, они их только оплачивают и правила формирования счетов от них зависят только косвенно (как они воспользовались услугами или товарами). Поэтому метод ChargeUser будет использовать объект User, у которого вызовет метод — IssueInvoice, передав уже готовый счёт на оплату. Находиться метод ChargeUser будет в другом объекте — в какой-нибудь истории покупок.
Но это не так важно, важно другое — пользователя класса User не должно беспокоить как его методы реализованы и как они друг на друга влияют, контракт использования класса от этого не зависит. Если IssueInvoice ломает поведение SendPromotion, то это просто ошибка программирования, которую надо исправить. Код, который использует класс User, меняться не будет — потому что все детали скрыты внутри класса User и фикс бага не выйдет за его пределы. Вот это и есть правильная инкапсуляция.
IB>На всякий случай, ключевое слово здесь "неявно". Разработчик, совершенно без задней мысли, реализуюя логику списания денег, может поменять состояние класса User для своих нужд, и ему и в голову не придет (да и не должно), что это может отразиться на отправке промо, ну и наоборот.
Логики списания денег там быть не должно, а весь остальной код манипулирования данными пользователей будет перед глазами в одном файле. Ну а раз весь код сосредоточен в одном месте, то и юнит-тесты писать легко и соответственно ошибки можно заметить быстрее.
IB>На эту тему есть отличная статья Майерса (Effective C++), двадцати летней давности: http://www.drdobbs.com/cpp/how-non-member-functions-improve-encapsu/184401197 IB>
IB>If you're writing a function that can be implemented as either a member or as a non-friend non-member, you should prefer to implement it as a non-member function. That decision increases class encapsulation. When you think encapsulation, you should think non-member functions.
Ну вот выше ChargeUser (MonthlyCharge) мы вынесли за пределы класса User и я попытался объяснить почему ему там не место.
Здравствуйте, IB, Вы писали:
IB>Здравствуйте, Vladek, Вы писали:
IB>Вот в этом и проблема такого подхода. Если объект user и письмо отправляет, и в БД пишет, то код который использует user может и не поменяется, зато код отравки письма может запросто поменять логику записи в БД, причем зачастую без ведома разработчика.
А еще можно вспомнить про версионирование интерфейса "обьекта юзер" и поддержку чтения-записи из-в бд разных версий этого обьекта
Ну там v1 — FirstName/LastName, v2 — FirstName/SecondName/LastName — ваще весело становится
V>Если IssueInvoice ломает поведение SendPromotion, то это просто ошибка программирования, которую надо исправить. Код, который использует класс User, меняться не будет — потому что все детали скрыты внутри класса User и фикс бага не выйдет за его пределы.
Дык все эти ооп, солиды и прочие граспы они специально придуманы для того, чтобы минимизировать вероятности появления "просто ошибок".
И тебе явно показали сценарии, в каких ДДД приводит к росту вероятности появления "просто ошибок" что есть плохо вообще в принципе.
А так можно сказать что фортран-стайл рулит. Если там чот не так — ет "просто ошибка, которую надо исправить".
PS
а ваще, DDD просто устарел. Но при этом сыграл фундаментальную роль в эволюции программирования.
Здравствуйте, Vladek, Вы писали:
V>Здесь надо разбираться с границами ответственности объекта User. Пользователи не участвуют в формировании счетов, они их только оплачивают и правила формирования счетов от них зависят только косвенно (как они воспользовались услугами или товарами). Поэтому метод ChargeUser будет использовать объект User, у которого вызовет метод — IssueInvoice, передав уже готовый счёт на оплату. Находиться метод ChargeUser будет в другом объекте — в какой-нибудь истории покупок.
Это не важно, тут хоть горшком назови. Важно, что в классе User смешиваются логики, которые не имеют никакого отношения друг к другу, и все они имеют доступ к внутреннему состоянию класса. Самое интересное, что доступ к этому внутреннему состоянию не нужен ни одному ни другому методу.
V>важно другое — пользователя класса User не должно беспокоить как его методы реализованы и как они друг на друга влияют, контракт использования класса от этого не зависит.
Вот как раз это и не важно. ) Важно что внеся эти методы внутрь класса, мы дали им возможность неявно влиять друг на друга. Какую проблему мы этим решили?
V> Если IssueInvoice ломает поведение SendPromotion, то это просто ошибка программирования, которую надо исправить.
Исправить ошибку дороже чем недопустить.
V> Код, который использует класс User, меняться не будет — потому что все детали скрыты внутри класса User и фикс бага не выйдет за его пределы. Вот это и есть правильная инкапсуляция.
Еще раз. Что SendPromo, что IssueInvoice — являются внешней логикой по отношению к User, а значит внося их внутрь класса и давая доступ к приватным данным класса, мы нарушаем инкапсуляцию этих приватных данных.
V>Логики списания денег там быть не должно, а весь остальной код манипулирования данными пользователей будет перед глазами в одном файле. Ну а раз весь код сосредоточен в одном месте, то и юнит-тесты писать легко и соответственно ошибки можно заметить быстрее.
Юнит-тест, по очевидным причинам, такую ошибку не выловит — оба метода могут быть написаны совершенно корректно с точки зрения своей логики.
А тот факт, что в одном месте собран как код отправки промо, так и выставления инвойсов, скорее усложнит задачу, так как при написании логики отправки сообщений придется думать не только о сообщениях, но и вообще обо всем, что только можно сделать с пользователем.
V>Ну вот выше ChargeUser (MonthlyCharge) мы вынесли за пределы класса User и я попытался объяснить почему ему там не место.
Все не так. Методу ChargeUser не место в классе User не из-за соображений текущей бизнес-логики, которое может меняться в зависимости от погодных условий, линии партии и мнения аналитика/архитектора, а по очень простому правилу "большего пальца". Если методу не нужен доступ к приватному состоянию класса, значит это внешний метод по отношению к классу.
Здравствуйте, itslave, Вы писали:
I>Здравствуйте, Vladek, Вы писали:
V>>Если IssueInvoice ломает поведение SendPromotion, то это просто ошибка программирования, которую надо исправить. Код, который использует класс User, меняться не будет — потому что все детали скрыты внутри класса User и фикс бага не выйдет за его пределы. I> I>Дык все эти ооп, солиды и прочие граспы они специально придуманы для того, чтобы минимизировать вероятности появления "просто ошибок". I>И тебе явно показали сценарии, в каких ДДД приводит к росту вероятности появления "просто ошибок" что есть плохо вообще в принципе.
Здравствуйте, IB, Вы писали:
IB>Еще раз. Что SendPromo, что IssueInvoice — являются внешней логикой по отношению к User, а значит внося их внутрь класса и давая доступ к приватным данным класса, мы нарушаем инкапсуляцию этих приватных данных.
Ты просто не понимаешь, что такое инкапсуляция. Могу только посоветовать читать Гради Буча. Добро пожаловать в таинственный мир ООП.
Здравствуйте, Vladek, Вы писали:
V>Ты просто не понимаешь, что такое инкапсуляция. Могу только посоветовать читать Гради Буча. Добро пожаловать в таинственный мир ООП.
Буча читать вредно. Возьми только его иерархию датчиков для теплицы — это же трипл фейспалс с современной точки зрения.
Здравствуйте, Vladek, Вы писали:
V>Ты просто не понимаешь, что такое инкапсуляция. Могу только посоветовать читать Гради Буча. Добро пожаловать в таинственный мир ООП.
Друг мой, к сожалению вы, похоже, дальше Буча не пошли...
Если уж у вас такой пиитет перед классиками — ссылку на Майерса я уже давал, но мне не сложно повторить:
Since then, I've been battling programmers who've taken to heart the lesson that being object-oriented means putting functions inside the classes containing the data on which the functions operate. After all, they tell me, that's what encapsulation is all about.
They are mistaken.
Вот это mistaken и про вас тоже.
А теперь контрольные вопросы.
— Какую проблему мы решаем, добавляя метод в класс?
— Какую проблему мы решаем, добавляя метод в класс, если методу не нужен доступ к приватным данным класса?
Здравствуйте, IB, Вы писали:
IB>А теперь контрольные вопросы. IB>- Какую проблему мы решаем, добавляя метод в класс?
Реализуем поведение объекта и манипулируем его полями, чтобы изменить состояние объекта.
IB>- Какую проблему мы решаем, добавляя метод в класс, если методу не нужен доступ к приватным данным класса?
Методам SendPromo и IssueInvoice не нужен конкретный пользователь и его данные? Покажи свой код, как бы ты решил проблему.
Здравствуйте, itslave, Вы писали:
I>Здравствуйте, Vladek, Вы писали:
V>>Методам SendPromo и IssueInvoice не нужен конкретный пользователь и его приватные данные . I>Я поправил пост за тебя.
Мне надоело переливать из пустого в порожнее с приверженцами процедурного программирования.
В моём коде пользователь сам себе отправляет промоушены и выставляет счета, потому что меня не интересует как он это делает. Я просто указываю ему что делать, используя его контракт (интерфейс). Ответ на вопрос как — целиком во власти объекта и вполне может поменяться в будущем, что однако не изменит контракта. Это ООП, который служит двум главным целям, ради которых код вообще пишется — код должен работать и быть готовым к изменениям.
В случае с простыми структурами данных и процедурами код позволяет поменять у двух пользователей адреса и послать им чужие промоушены, выставить чужие счета. Структуры данных не имеют идентичности (и поведения, ведь мы не любим методы, ко-ко-ко), это просто набор полей, которые легко превратить в мусор и скормить процедуркам, получив мусор на выходе. Контракт размыт и неявен.
Здравствуйте, Vladek, Вы писали:
V>Реализуем поведение объекта и манипулируем его полями, чтобы изменить состояние объекта.
Это не проблема, это задача.
V>Методам SendPromo и IssueInvoice не нужен конкретный пользователь и его данные?
Конкретный пользователь и внутреннее состояние объекта пользователь — разные вещи.
V>Покажи свой код, как бы ты решил проблему.
Какую? ) Я же просил сначала сформулировать проблему, которую вы хотите решить добавляя метод в класс.
Здравствуйте, Vladek, Вы писали:
V>Мне надоело переливать из пустого в порожнее с приверженцами процедурного программирования.
То есть нормальные аргументы закончились? ) И полегче с эпитетами, тут в целом уже понятно кто в догмах закостенел.
V>В моём коде пользователь сам себе отправляет промоушены и выставляет счета, потому что меня не интересует как он это делает.
Это заблуждение. Как я уже показал, при таком подходе как раз и получается, что вне зависимости от желаний придется разобраться что и как делает пользователь, в противном случае не избежать побочных эффектов.
Знаете почему глобальные переменные это плохо? Вот здесь та же история. Чем больше всякого разного с пользователем можно сделать, тем выше вероятность, что одно действие неявно повлияет на другое.
V> Я просто указываю ему что делать, используя его контракт (интерфейс). Ответ на вопрос как — целиком во власти объекта и вполне может поменяться в будущем, что однако не изменит контракта.
Контракта это конечно не изменит, но вот то что произойдет внутри контракта, превратится в конкретный головняк. И чем больше методов внутрь добавляется, тем больше бардака будет, хотя снаружи контракт вроде как чистенький.
V>Это ООП, который служит двум главным целям, ради которых код вообще пишется — код должен работать и быть готовым к изменениям.
Вы все напутали На самом деле, правило OCP звучит так: "software entities should be open for extension, but closed for modification". Ваш же подход очевидным образом этому противоречит. Если нам, допустим, понадобится помимо промо предложений рассылать еще и купоны на скидки, то следуя вашей логике нужно будет поместить метод SendDiscount в класс user, то есть модифицировать его (а это означает риск неявно изменить поведение класса). Тогда как можно было бы не трогать этот класс вообще, реализовав логику снаружи.
SRP, кстати, тоже нарушается — класс user отвечает за все что можно теперь и ни о какой Single Responsibility речь даже не идет. И Interface Segregation опять же мимо... Вообщем, вам похоже надо SOLID принципы в памяти оживить. )
V>В случае с простыми структурами данных и процедурами код позволяет поменять у двух пользователей адреса и послать им чужие промоушены, выставить чужие счета.
Это каким образом? Как я уже показал, код promo.SendPromo(user) гораздо меньше подвержен наведенным эффектам, чем user.SendPromo(), если, конечно, речь не об extension methods.
V> Структуры данных не имеют идентичности (и поведения, ведь мы не любим методы, ко-ко-ко), это просто набор полей, которые легко превратить в мусор и скормить процедуркам, получив мусор на выходе. Контракт размыт и неявен.
Во-первых, все-таки не структуры, а классы, во-вторых, идентичность-таки у них есть. А в третьих, кто их будет превращать в мусор и зачем? Здесь любое изменение объекта это явное действие в рамках конкретной логики, более того, эти классы/структуры вообще можно сделать immutable и тогда будет гарантия компилятора, что их никто и никогда не поменяет. Это, к слову, еще одно преимущество такого подхода.
А что касается контракта, то он более чем явен. Просто он в другом месте, он не вокруг данных, а вокруг собственно логики, бизнес-логики, если быть точным. И это намного более правильное место для контракта.
Здравствуйте, Vladek, Вы писали:
V>Здравствуйте, itslave, Вы писали:
I>>Здравствуйте, Vladek, Вы писали:
V>>>Методам SendPromo и IssueInvoice не нужен конкретный пользователь и его приватные данные . I>>Я поправил пост за тебя.
V>Мне надоело переливать из пустого в порожнее с приверженцами процедурного программирования.
V>В моём коде пользователь сам себеразные сервисы отправляют промоушены и выставляют счета, потому что меня не интересует как он это делает. Я просто указываю ему им — сервисамчто делать, используя егоих контракт (интерфейс). Ответ на вопрос как — целиком во власти объекта и вполне может поменяться в будущем, что однако не изменит контракта. Это ООП, который служит двум главным целям, ради которых код вообще пишется — код должен работать и быть готовым к изменениям.
Здравствуйте, itslave, Вы писали:
I>ASP.NET Core WebAPI — пока еще сыроватый кроссплатформенный продукт, развитие ASP.NET WebAPI и (почти) полностью с ним же совместимый. Если аффтар любит модное-молодежное, и вероятность попасть на косяки фрйемворка его нее смущает — то не вижу причин не использовать
Немножко не так.
Сперва народ писал REST на MVC. Потом некие перцы нашли в MVC фатальный недостаток и написали свой точно такой же, но с преферансом и женщинами, назвав его WebApi.
Потом они долго и упорно пытались сделать WebApi и MVC почти совсем совместимыми, но архитектурная стройность концепций танцорам мешала.
В это время я как раз ковырялся с REST на rsdn. Поглядев на все это ..., а так же по историческим причинам, на WebApi забил, написав простенький фреймворк для MVC, и ни разу, что характерно, об этом не пожалел.
В это времяч в МС нашли фатальный недостаток в WebApi. И решили новый WebApi реализовать в виде ... ага, дополнений к MVC. В этот раз архитектурная стройность концепций почему то уже не мешала.
Но таки появились новые архитектурные концепции, и они, конечно, тут же начали танцорам мешать. Вчера прям очередной пример накопал (вот ведь бараны упоротые) — https://github.com/aspnet/Mvc/issues/5507
... << RSDN@Home 1.0.0 alpha 5 rev. 0 on Windows 8 6.2.9200.0>>








 Мы уже победили, просто это еще не так заметно...
Мы уже победили, просто это еще не так заметно...


